
-
什么是测试框架
架构师Jack 发布于 2011-03-01 21:13:04
测试框架总体而言可以参考软件开发框架来构建,下面是从软件开发框架原则中对应提取的测试框架的属性:1、测试框架是测试开发过程中提取特定领域测试方法共性部分形成的体系结构;(软件框架是软件开发过程中提取特定领域软件的共性部分形成的体系结构)2、测试框架的作用:在其基础上重用测试设计原则和测试经验,调整部分内容便可满足需求,可提高测试用例设计开发质量,降低成本,缩短时间;3、不同测试技术领域有不同的测试框架类型;4、测试框架不是一个现成可用的系统,是一个半成品,需要测试工程师基于它结合自己的测试对象知识转化成自己的测试用例;5、测试框架是提供给测试人员开发相应领域测试用例的测试分析设计工具;6、测试框架不是测试用例集,而是通用的,具有一般性的系统主体部分。测试人员像做填空一样,根据具体业务完成特定应用系统中与众不同的特殊部分;7、测试设计模式的思想(等价类/边界值)在测试框架中进行应用。以上为个人总结体会,不一定正确,但我开发的测试框架却是的确满足了以上7个属性来实现的。 -
IBM RFT 框架
evergreen_wang 发布于 2009-07-10 17:53:28
在进行 IBMRational Functional Tester(RFT)自动化测试脚本开发时,我们往往需要首先创建一个测试框架,然后基于此进行测试脚本的开发。一个设计良好的测试框架会给以后的脚本开发带来很多便利。在这篇文章里,我们结合一个实际的 Windows .Net 应用程序的测试框架。项目 来介绍一下如何使用 RFT 构建一个结构合理、可扩展的,用于测试
测试框架设计的几点原则
一个好的测试框架需要具备哪些元素呢?虽然对不同的项目而言,答案可能有所不同。但总的来说,一个好的测试框架通常具有以下的共同特点:分层结构
关注分离
代码重用
结构清晰
易于维护
方便调试
可扩展性好除了以上所述的几点外,一个好的框架还应该提供相应的通用服务,以使得脚本开发者可以很容易而且快速地基于它来开发脚本。比如象错误处理,本地化版本支持,日志服务等。
定义良好的层次结构
如何定义一个良好的层次结构,是我们在构建测试框架首先需要考虑的问题。通常我们会把最基本的一些原子 操作 放在最底层,而在较上层封装这些操作,并开放相应的接口供最终的脚本开发者进行调用。这样往往会使得 Case 更加简洁易读。根据面向对象基本理论,我们首先要定义一些基础的控件类,用来代表那些需要在测试中进行操作的基本界面元素,象按钮,输入框等。如果你使用 RFT 测试 Java 或 Web 应用,那么你可以直接使用 IBM Package,在这个包里封装了所有的在 Java 和 Web 这两个 Domain 下的基本控件。通过在你的脚本中调用这些类,你就可以很方便地实现对被测应用的操纵。但是,我们所测试的应用是基于 Windows .Net 的,在这个包里没有对应的控件类可以利用,因此,第一步,我们要开发自己的控件类。
其实,我们也可以不定义基础类,而直接使用 GUITestObject 来操纵每一个界面对象,但这样做的代价是显而易见的,会有很多重复且不易读的代码充斥在我们的脚本中。这显然不是我们所想要的。好在虽然各种控件的种类繁多,但对于每一个控件而言,需要封装的主要是一些我们在测试中经常需要调用的简单方法,比如说 Click(),或 SetText(),因此工作量并不太大。
在实现了这一层之后,理论上说,我们可以直接在 Case 脚本里调用这些方法来实现对测试对象的操作。但这样做也有一个问题是,如果以后你对这些方法的名称进行了修改,或者因为程序实现的改变,原来的 A 类控件被 B 类代替,这时,势必会对所有已经编写好的 Case 脚本造成很大的影响,带来很大的代码维护量。因此为了隔离下层代码对上层 Case 的影响,我们在其中又加入了新的一层。最后的层次结构如下:

图 1. 层次结构
以下是对每一层的具体解释:
NetWidgets:这一层封装了所有的基本 Windows 控件,它与具体的应用无关,可以看作是测试 .Net 应用的基础类库。对应于 Windows 的每一个控件,在这一层里,都有一个对应的 Class,其中包括对该控件的基本操作,以及一些在测试过程需要使用的验证方法,比如验证某个属性的值。
AppLib:所有与当前测试应用相关的方法及对象在这一层定义。它包括 2 部分:
Dialogs:正如名称所示,在这一部分中,主要保存所有的对话框或其他窗口对象,以及对这些窗口上控件的 操作 方法。他们通过调用下一层的基本控件函数来实现。与 NetWidgets 不同,在这一层定义的方法,是与应用中具体的控件名称所绑定的,具有明确的含义,如 SetPassword();而在 NetWidgets 层中,仅仅是某一类控件的一个通用的方法而已,如 SetText()。除了窗口对象外,一些其他的经常需要乃至的对象,如应用中的菜单,工具栏等,也在这一部分定义。Wizards:在这一部分所定义的方法,他们包含是一些基本操作的组合,用来完成某项具体的功能,如 Login()。这些功能都是大部分 Cases 需要经常调用,或者是特定的测试步骤组合。通过将它们纳入这一层统一管理,可以很方便地起到代码重用的目的。通常这些 Wizard 是对同一个 Dialog 上的操作组合,但这并不是必须的。有时候跨多个 Dialog 的组合操作在测试用例中也是很常见的,因此也需要归纳从而提高重用性。
TestCases:很明显,这是最上一层,也就是保存所有测试脚本的地方。通过调用中间 AppLib 层的方法来实现所有测试功能,包括执行操作,检查状态并记录测试结果。
在描述完整个框架的大致结构后,我们来看看这种结构的优点:代码隔离。通过引入 AppLib 中间层,对最上层 TestCases 屏蔽最底层实现,也就是将测试逻辑与具体功能实现逻辑分开。TestCasse 层只关注具体的测试步骤,而 NetWidgets 完成最终的功能实现。通过这种方式,使得 TestCases 层的代码简单明了,可读性好;另外未来对 NetWidgets 的改变将不会对 TestCases 层造成任何影响,也就是提高的程序的可维护性。
结构清晰。各层所定义的方法及功能也十分明确。每一层仅通过调用其直接下层来实现功能,禁止跨层调用保证代码之间的多重依赖。这对编码调试或测试运行时对问题的快速定位很有帮忙。
可扩展性好。软件产品总是在不断地发展,新功能不断地引入。在使用这种三层结构的框架以后,当需要增加新的 Cases 时,只需先加入对应的对话框及窗口对象到 AppLib,然后再通过调用它们来完成代码编写。新加的 AppLib 对象不会对原有的对象造成任何影响,因为每个对象都有仅属于自己的代码文件。而原有的 AppLib 对象则可以简单地在新的 Case 中重用。
采用这样的框架,只开放相应的接口供最终的脚本开发者进行调用,会使 Case 更加简洁易读。在 GUI 界面发生变化时,也不需要对 TestCase 做任何修改,大大提高了程序的可维护性和可扩展性。
在 RFT 里的具体实现
在定义完整个测试架构以后,接下来是在测试工具
中用代码加以实现。在本 项目 中,我们使用的是 RFT,现在,让我们来看看在 RFT 里的具体实现。
图 2. 在 RFT 里的实现
从上图可以看到,我们使用 3 个 Project 来对应 3 个不同的层,而不是象通常的项目一样,将所有的代码放在一起,层次结构通过不同的包结构来体现。这样做的主要原因是让各层之间更加独立,而且更易于管理。另一个好处是,多个 Project 的设计可以让复制和共享更加灵活。例如,当其他 Team 也想要利用 NetWidgets 时,只需要简单地将对应的 Project 共享给他们即可;而另一个 Team 如果需要某一个 Suite 来验证某项具体功能,则可以将 3 层所对应的 Project 都共享给他。
Dialogs 和 Wizards 目录中定义了所有与具体被测应用相关的方法,而位于 Suite Project 中的 Test Case 则调用他们来进行测试。在这里我们列出一些代码以便大家能够更清楚地了解它们之间的调用关系。
这是一段摘自 LoginDlg. java 的代码(Dialog):
图 3. LoginDlg.java 代码片断(Dialog)这是一段摘自 Login.
java 的代码(Wizard):
图 4. Login.java 代码片断 (wizard)
从上面的代码可以看出,在 Dialog 对象中,所定义的方法都是对该 Dialog 中控件的基本 操作 方法,象点击一个按钮,在编辑框里输入字串等。但在 Wizard 中,则通过将这些 Dialog 中的基本操作串联起来完成一个简单任务,如登录。相类似的功能则放入同一个 Wizard。框架中的其他公用服务
通过在框架中提供一些公用 服务 ,可以使得该框架更加易于使用,并且功能强大。在前面的图 2 中,可以看到在 Utils 目录下有 3 个 Class。它们分别提供不同的功能,让我们做一下简单的介绍。对于自动化测试而言,有一个很重要的环节是用一种统一的方式来记录测试的结果,从而可以方便地进行统计或生成报表。所以第一个要提到的是 TestResult。
TestResult
这个 Class 用来记录每个 Case 的名称和执行结果。它读取一个 Xml 模板文件,这个文件定义了哪些内容需要在测试结果中显示。在自动执行完成后,包括 Suite 名称,测试环境,Case 信息,测试结果等这些数据将会被写入,生成结果文件。最后通过一个事先定义好的样式表文件进行格式化,用网页的形式呈现。
另外,对于失败的 Case,最主要的错误信息及屏幕截图也会一并记录下来,以方便进行分析查错。
LibException
这个 Class 作为所有运行时异常的基类。这个父类里增加了以下功能:
当有错误发生时,抓取屏幕截图,保存到本地文件,同时将文件路径写入一字符串属性中。
当有错误发生时,保存错误的 Stack trace 到文件中,同时将文件路径写入一字符串属性中。
通过这些功能,结合使用上述的 TestResult 类,就可以很方便地保存每个错误发生时的详细信息,而不仅仅是一个简单的错误消息。ObjectFinder
一般来说,在 RFT 测试中,通常使用 Object Map 来在回放中定位界面对象。Object Map 是在测试脚本录制中自动生成的,因此使用起来较为方便。但它有一个缺点是,它记录了所有对象的层次结构,并据此进行查找。一旦对象的关键属性或层次发生改变,则必须重新录制以更新 Object Map。当项目里 Case 比较多的时候,这就变成了一项费时费力的工作。因此,RFT 还提供了另一种动态查找的方法 TestObject.Find(),在编写脚本时可以即时地调用该函数,通过给定的属性值进行查找定位。目前它的效率已经与通过 Object Map 定位不相上下。
ObjectFinder 类是一个用来动态查找对象的工具类,它通过调用 TestObject.Find() 来实现,并提供多种不同的查找方法。最常见的是指定对象的 .class 和 .text 属性来在某个窗口中进行查找。这个类主要在 AppLib 层中的 Dialog 对象中使用,在那些对窗口中对象进行操作的函数中,第一条语句很可能就是调用 ObjectFinder.getObject(className, captionText, parent) 来找到所要操作的界面对象。
另一个使用动态查找的好处是,可以将那些用于识别界面元素的关键属性保存到一个配置文件中。当有属性值变化时,就可以很简单地通过修改配置文件实现,而无需修改脚本。同时,如果需要进行其他 资源文件中提取界面上的文本资源,自动生成我们所需的属性识别配置文件中,从而大大简化了手工编写的工作量,同时也可以轻松应对因界面文本改变而带来的查找修改的困扰。语言 版本的测试,也可以直接将配置文件替换为其他语言版本的文件来实现对多语言版本测试的支持。在我们这个项目中,我们还有另外一个工具可以直接从源码的结束语
开发一个适合自己项目的 RFT 自动化框架,需要了解架构设计方面的基础知识,以及清楚地知道一个好的测试框架所需要提供的功能。但这并不很困难,因为有很多这方面的文章和经验可供参考,同时也有很多成熟的框架可资借鉴。
除了结构清晰,关注分离,易于扩展之外,一些通用服务也是一个好的测试框架不可或缺的部分。通过利用这些服务,RFT 的脚本开发人员可以更方便、快捷地开发出自动化脚本,同时保证使用统一的方法,生成格式一致的测试结果。这些也是使用框架的意义所在。
-
QTP与RFT比较
chenyb85 发布于 2009-03-11 18:53:53
注明:QTP选用9.2版本;
RFT选用7.0.1版本。 一.QTP介绍
是Mercury QuickTest Professional的简称,HP自动化测试工具;
是一种针对功能测试和回归测试自动化提供的测试软件,通过加载不同插件来支持主要的软件应用程序和环境,默认只支持标准windows控件,VB,和ActiveX;
是关键字驱动测试方法。(不绝对,主要看如何使用工具)
二.RFT介绍
是Rational Functional Tester的简称,IBM自动化测试工具;
是一个面向对象的自动测试工具,默认支持大多数的应用程序,而其他的非默认支持的应用程序可以通过加载不同的支持Jar包或自定义对象识别进行操作;
是数据驱动的测试方法。(不绝对,主要看如何使用工具)
比较项
QTP
RFT
说明
学习难度
工具的图形化操作功能比较简单;
脚本编写比较简单;
可以通过简单的描述性编程实现手动识别对象。
工具的图形化操作功能比较简单;
脚本编写比较难;
通过find方法实现手动识别对象,使用难席比较大点。
RFT比QTP难说一些。
帮助文档
帮助文档挺系统,还对各类控件进行归类,方便查找;也提供了内置对象和内置函数的查找文档;还提供了对外接口说明文档;整个帮助有不少例子。
帮助文档和教程很少,很不系统。
而提供的API接口只有说明文档,未提供如何使用该文档;提供的例子很少。
QTP比RFT更全、更人性化。
环境要求
环境要求较低,有512M内容就能比较顺畅的使用了。
环境要求比较高,至少得1G内存才能比较顺畅使用,512M内存时比较卡,速度慢。
RFT要求比较高。
脚本语言
VBS
Java、VB.NET
支持应用程序
默认支持windows控件,VB,和ActiveX;
可以加插件来支持其他常用的应用程序。不过插件都是要单买的,价格很高。
默认支持大部分常用的应用程序。
其他应用程序可以通过加载相应的识别Jar包进行识别,可惜,这些Jar包没有现成的。
都差不多,就看钱的问题了。
录制脚本
支持图形化的操作录制脚本;
支持图形化的操作添加验证点;
支持图形化的操作应用正则表达式。
支持图形化的操作录制脚本;
支持图形化的操作添加验证点;
支持图形化的操作应用正则表达式。
(有一个比较怪的做法,默认情况下,在一个文本框中输入值,是先获取此文本框的对象,然后点击文本框范围内的点,然后通过键盘输入方式输入值;下拉框对象也是点击下拉框的值。但是RFT可以手工修改脚本,改成直接赋值的方法)
RFT功能更强一些,不过QTP更易用一些。
参数化
支持图形化的数据表格式数据操作;
使用的是Excel文件来作为测试数据存储介质;
可以直接打开Excel数据文件修改数据;
支持指参数化数据;
支持图形化的数据表格式数据操作;
使用的是Xml格式文件来存储测试数据;
Xml测试数据只支持在RFT软件中使用格式化方式显示和修改;
Xml测试数据使用标准的数据格式,通用性更好。
QTP更容易用一些,RFT更标准化一些。
测试数据加载
测试数据加载简单,使用内置函数能方便实现。
可以用封装的方法来动态加载数据,不过比较复杂,而且还得修改脚本中参数化的地方。
QTP简单些
对象识别能力
有内置识别的比较标准的控件识别强;
组合的控件识别较弱;
默认支持dom,可以直接操作。
有内置识别的比较标准的控件识别强;
自定义的控件识别较弱;
可以自定义非标准控件的识别;
当然,通过Jar包的加载,理论上可以操作任何想操作的对象。
差不太多,RFT的定制能力更强,但难度也比较大。
手动添加对象
提供树形的对象选取方式,可以选择当前节点,也可以选择父节点或子节点,使用挺方便。
提供节点直接选择和对象遍历选择,
不大实用。
首先,节点直接选择不能选择父节点或子节点,很多情况是直接选择不到要选的节点的;
其次,遍历节点更是不可能,因为页面经常一遍历就有好几百个对象,很是不好找。
QTP更好一些,也更人性化。
控件在页面中情况
提供了Active Screen,即页面的缓存,方便在编写脚本时查看页面情况。
未提供相应功能。
QTP更人性化一些。
脚本编辑
提供步骤编辑界面,方便不会不会编程的人员使用;
脚本编辑器的功能比较弱。
只有脚本编辑器,没有步骤编辑器;
脚本编辑器的功能比较强,跟操作Eclipse差不太多。
RFT强些。
脚本调试
HP为QTP加入了VBS调试功能;
调试功能比较弱。
直接使用Eclipse调试Java的强大功能。
RFT强些。
回放速度
速度比较快。
速度较慢。
QTP快些。
结果报告
树形显示各个步骤的执行情况。
可以在代码中向报告写内容。
提供多种形式的结果显示。
可以在代码中向报告写内容。
差不太多。
扩展性
除了加插件,扩展的东西不多。
有Jar包,几乎就可以扩展。
RFT强些。
结合性
提供了与其他程序结合的接口,对C#、VB和VBS结合性比较好。
可以通过C#、VB和VBS等编写程序方便的调用和操作QTP。
这个不太清楚,暂未用到,后期补充。
暂不清楚。
-
利用分类树方法设计测试用例
陈能技 发布于 2007-10-21 20:49:00
陈能技
2007-10-21什么是分类树?
什么是分类树?设想你希望设计出一个系统用于把一堆的美金硬币分成不同的类别(例如:一分币、五分币、一角币、二角五分币)。假设通过一些测量手段可以区别这些硬币,例如可以用直径来分类。你可以把硬币倒入一个槽,槽的直径恰好能让一角的硬币通过,如果能通过,那么它就被划分为一角的硬币;否则就继续倒入另外一个槽,槽的直径恰好能让一分币的硬币通过,如果能通过,则被分类成一分币;否则又继续下一个槽,这个槽的直径只容五分币大小的通过,如此类推。这样的过程实际上就是在构造一棵分类树。用于构造分类树的判断过程提供了一种有效的方法用于把一堆的硬币归类,而这种方式可以用于更广泛的各种各样的分类问题。
分类树被广泛应用于各种学科,例如医疗诊断、计算机数据结构、植物分类、心理学的决策论等。我们现在要讨论的是分类树在测试用例的设计方面的应用。
分类树方法用于测试用例的设计
测试用例的设计是对测试质量而言非常关键的软件测试活动,因为测试用例集合的选择对测试的深度和测试范围的影响非常大。
分类树方法是由Grochtmann和Grimm在1993年提出的,是在软件功能测试方面一种有效的测试方法,通过分类树把测试对象的整个输入域分割成独立的类。
按照分类树方法,测试对象的输入域被认为是由各种不同的方面组成并且都与测试相关。对于每个方面,分离和组成各种类别,而分类结果的各类又可能再进一步地被分类。这种通过对输入域进行层梯式的分类表现为树状结构。随后,通过组合各种不同分类的结果来形成测试用例。
使用分类树方法,对于测试人员来说最重要的信息来源是测试对象的功能规格说明书。使用分类树方法的一个重要的好处是:它把测试用例设计转变成一个组合若干结构化和系统化的测试对象组成部分的过程 - 使其容易把握,易于理解,当然也易于文档化。
如何使用分类树方法设计测试用例?
分类树方法的基本原理是:首先把测试对象的可能输入按照不同的分类方式进行分类,每一种分类要考虑的是测试对象的不同的方面。然后把各种分开的输入组合在一起产生不冗余的测试用例,同时又能覆盖测试对象的整个输入域。
因此,可以把使用分类树方法设计测试用例的过程分为3大步骤:
1、 识别出测试对象并分析输入空间。
2、 对测试对象的输入空间进行分类。
3、 画出分类树、组合成测试用例。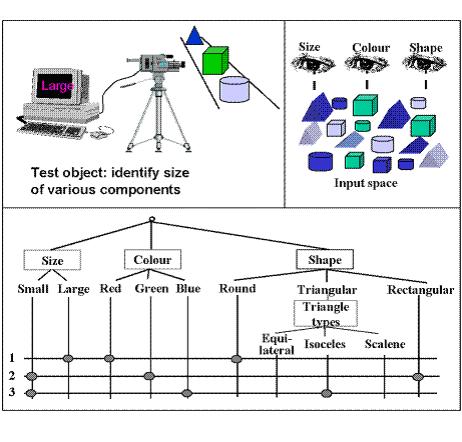
在第一个步骤中,测试人员需要确定与测试相关的方面。每个方面应该有精确的限制,从而可以清晰地区别测试对象的可能输入。例如,上图中的大小(Size)、颜色(Colour)、形状(Shape)共同组成了测试对象的可能输入的方面。
在接下来的步骤,依据测试对象的每个方面对可能的输入进行划分,这个划分就是数学上说的"分类"。分类的结果就形成了各种"类"。因此一个"分类"的结果代表了测试对象的某个方面的输入。例如,大小(Size)方面的可能输入是大(Large)或者小(Small);颜色(Colour)方面的可能输入是红色(Red)、绿色(Green)、蓝色(Blue)等。
最后一个步骤是形成测试用例。测试用例是由不同分类的类组合形成,在组合类的时候需要注意逻辑兼容性,也就是说交集不能为空。测试人员组合类形成需要的测试用例,以便覆盖测试对象的所有方面并充分考虑它们的组合。例如,测试用例1就考虑了大尺寸、红颜色、圆形的输入。
分类树方法测试用例设计的工具
如果测试用例是依据软件功能规格来设计的,那么我们叫这种类型的测试为功能测试。虽然功能测试对于验证系统非常重要并且广泛应用在测试中,但是只有很少的方法和工具可以系统地产生相应的测试用例。
而CTE XL(Classification Tree Editor eXtended Logics)是为数不多的工具之一。它是一个语法控制的、图形化的编辑器。帮助我们更加有效地使用分类树方法进行测试用例的设计。
工具的使用方法比较简单,下面作简要的介绍。
1、首先创建测试对象,如下图所示,创建一个测试对象Block,并开始进行分类。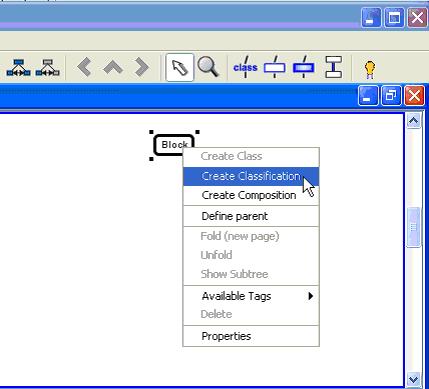
2、对测试对象进行分类:添加类别元素Size、Colour、Form,如下图所示。
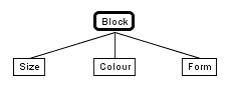
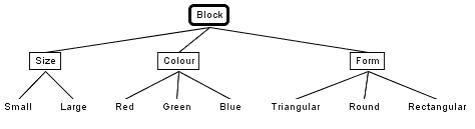
3、向各种类别添加类,形成分类树,如下图所示。
4、添加测试用例,如下图所示。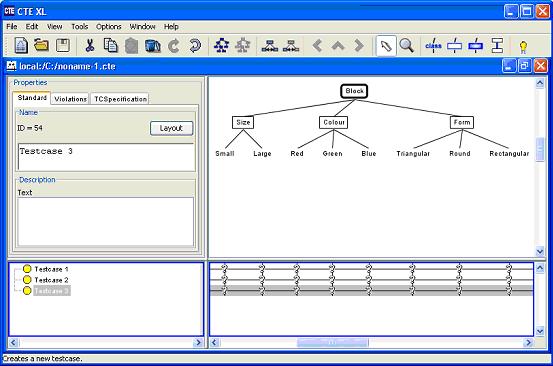
5、对于添加的每个测试用例,通过选择并标注各类的组合,形成需要的测试用例,如下图所示。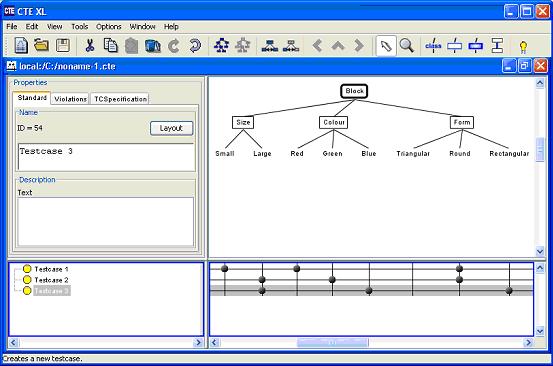
6、最后把测试用例输出到文档,以便将来测试人员按照测试用例文档执行测试。
分类树方法测试用例设计工具的扩展思路
虽然CTE XL在应用分类树方法进行测试用例设计方面已经很出色,而且考虑到了与测试用例管理、需求管理的整合,考虑到了测试用例组合的自动化,也考虑到了测试用例组合的规则问题。但是我认为在分类树方法的测试用例设计工具的开发上还可以考虑实现更多有用的功能特性。
首先,可以考虑分类树与软件设计的整合。目前大部分软件企业在软件设计方面都遵循了UML的方式进行设计,能对系统进行详细和深入的分析。而测试用例的设计也是一个由粗到细的设计过程,有些细节不能在需求阶段考虑清楚的,可以在设计阶段借鉴详细设计的结果来指导测试用例的设计。因此如何把UML类图、顶层用例图等直接转换成分类树是一个值得我们考虑的方向。
其次,在测试用例的自动产生方面可以把正交表设计和均匀表设计考虑进去。正交表和均匀表也是很多测试人员使用的测试用例设计方法。正交表的整齐可比性、均匀表的均匀分散性为测试用例的选择筛选提供了有效的途径。它们能使测试用例的设计既不失完整覆盖性,又能有效控制和减少测试用例个数,从而使测试用例的可执行性更强。 -
JVM参数设置详解
smile665 发布于 2010-05-10 23:56:34

 JVM 参数设置详细说明
JVM 参数设置详细说明
1: heap size
a: -Xmx<n>
指定 jvm 的最大 heap 大小 , 如 :-Xmx=2g
b: -Xms<n>
指定 jvm 的最小 heap 大小 , 如 :-Xms=2g , 高并发应用, 建议和-Xmx一样, 防止因为内存收缩/突然增大带来的性能影响。
c: -Xmn<n>
指定 jvm 中 New Generation 的大小 , 如 :-Xmn256m。 这个参数很影响性能, 如果你的程序需要比较多的临时内存, 建议设置到512M, 如果用的少, 尽量降低这个数值, 一般来说128/256足以使用了。
d: -XX:PermSize=<n>
指定 jvm 中 Perm Generation 的最小值 , 如 :-XX:PermSize=32m。 这个参数需要看你的实际情况,。 可以通过jmap 命令看看到底需要多少。
e: -XX:MaxPermSize=<n>
指定 Perm Generation 的最大值 , 如 :-XX:MaxPermSize=64m
f: -Xss<n>
指定线程桟大小 , 如 :-Xss128k, 一般来说,webx框架下的应用需要256K。 如果你的程序有大规模的递归行为, 请考虑设置到512K/1M。 这个需要全面的测试才能知道。 不过, 256K已经很大了。 这个参数对性能的影响比较大的。
g: -XX:NewRatio=<n>
指定 jvm 中 Old Generation heap size 与 New Generation 的比例 , 在使用 CMS GC 的情况下此参数失效 , 如 :-XX:NewRatio=2
h: -XX:SurvivorRatio=<n>
指定 New Generation 中 Eden Space 与一个 Survivor Space 的 heap size 比例 ,-XX:SurvivorRatio=8, 那么在总共 New Generation 为 10m 的情况下 ,Eden Space 为 8m
i: -XX:MinHeapFreeRatio=<n>
指定 jvm heap 在使用率小于 n 的情况下 ,heap 进行收缩 ,Xmx==Xms 的情况下无效 , 如 :-XX:MinHeapFreeRatio=30
j: -XX:MaxHeapFreeRatio=<n>
指定 jvm heap 在使用率大于 n 的情况下 ,heap 进行扩张 ,Xmx==Xms 的情况下无效 , 如 :-XX:MaxHeapFreeRatio=70
k: -XX:LargePageSizeInBytes=<n>
指定 Java heap 的分页页面大小 , 如 :-XX:LargePageSizeInBytes=128m
2: garbage collector
a: -XX:+UseParallelGC
指定在 New Generation 使用 parallel collector, 并行收集 , 暂停 app threads, 同时启动多个垃圾回收 thread, 不能和 CMS gc 一起使用 . 系统吨吐量优先 , 但是会有较长长时间的 app pause, 后台系统任务可以使用此 gc
b: -XX:ParallelGCThreads=<n>
指定 parallel collection 时启动的 thread 个数 , 默认是物理 processor 的个数 ,
c: -XX:+UseParallelOldGC
指定在 Old Generation 使用 parallel collector
d: -XX:+UseParNewGC
指定在 New Generation 使用 parallel collector, 是 UseParallelGC 的 gc 的升级版本 , 有更好的性能或者优点 , 可以和 CMS gc 一起使用
e: -XX:+CMSParallelRemarkEnabled
在使用 UseParNewGC 的情况下 , 尽量减少 mark 的时间
f: -XX:+UseConcMarkSweepGC
指定在 Old Generation 使用 concurrent cmark sweep gc,gc thread 和 app thread 并行 ( 在 init-mark 和 remark 时 pause app thread). app pause 时间较短 , 适合交互性强的系统 , 如 web server
g: -XX:+UseCMSCompactAtFullCollection
在使用 concurrent gc 的情况下 , 防止 memory fragmention, 对 live object 进行整理 , 使 memory 碎片减少
h: -XX:CMSInitiatingOccupancyFraction=<n>
指示在 old generation 在使用了 n% 的比例后 , 启动 concurrent collector, 默认值是 68, 如 :-XX:CMSInitiatingOccupancyFraction=70
有个 bug, 在低版本(1.5.09 and early)的 jvm 上出现 , http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6486089
i: -XX:+UseCMSInitiatingOccupancyOnly
指示只有在 old generation 在使用了初始化的比例后 concurrent collector 启动收集
3:others
a: -XX:MaxTenuringThreshold=<n>
指定一个 object 在经历了 n 次 young gc 后转移到 old generation 区 , 在 linux64 的 java6 下默认值是 15, 此参数对于 throughput collector 无效 , 如 :-XX:MaxTenuringThreshold=31
b: -XX:+DisableExplicitGC
禁止 java 程序中的 full gc, 如 System.gc() 的调用. 最好加上么, 防止程序在代码里误用了。对性能造成冲击。
c: -XX:+UseFastAccessorMethods
get,set 方法转成本地代码
d: -XX:+PrintGCDetails
打应垃圾收集的情况如 :
[GC 15610.466: [ParNew: 229689K->20221K(235968K), 0.0194460 secs] 1159829K->953935K(2070976K), 0.0196420 secs]
e: -XX:+PrintGCTimeStamps
打应垃圾收集的时间情况 , 如 :
[Times: user=0.09 sys=0.00, real=0.02 secs]
f: -XX:+PrintGCApplicationStoppedTime
打应垃圾收集时 , 系统的停顿时间 , 如 :
Total time for which application threads were stopped: 0.0225920 seconds
4: a web server product sample and process
JAVA_OPTS=" -server -Xmx2g -Xms2g -Xmn256m -XX:PermSize=128m -Xss256k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 "
最初的时候我们用 UseParallelGC 和 UseParallelOldGC,heap 开了 3G,NewRatio 设成 1. 这样的配置下 young gc 发生频率约 12,3 秒一次 , 平均每次花费 80ms 左右 ,full gc 发生的频率极低 , 每次消耗 1s 左右 . 从所有 gc 消耗系统时间看 , 系统使用率还是满高的 , 但是不论是 young gc 还是 old gc,applicaton thread pause 的时间比较长 , 不合适 web 应用 . 我们也调小 New Generation 的 , 但是这样会使 full gc 时间加长 .
后来我们就用 CMS gc(-XX:+UseConcMarkSweepGC), 当时的总 heap 还是 3g, 新生代 1.5g 后 , 观察不是很理想 , 改为 jvm heap 为 2g 新生代设置 -Xmn1g, 在这样的情况下 young gc 发生的频率变成 ,7,8 妙一次 , 平均每次时间 40~50 毫秒左右 ,CMS gc 很少发生 , 每次时间在 init-mark 和 remark(two steps stop all app thread) 总共平均花费 80~90ms 左右 .
在这里我们曾经 New Generation 调大到 1400m, 总共 2g 的 jvm heap, 平均每次 ygc 花费时间 60~70ms 左右 ,CMS gc 的 init-mark 和 remark 之和平均在 50ms 左右 , 这里我们意识到错误的方向 , 或者说 CMS 的作用 , 所以进行了修改
最后我们调小 New Generation 为 256m,young gc 2,3 秒发生一次 , 平均停顿时间在 25 毫秒左右 ,CMS gc 的 init-mark 和 remark 之和平均在 50ms 左右 , 这样使系统比较平滑 , 经压力测试 , 这个配置下系统性能是比较高的
在使用 CMS gc 的时候他有两种触发 gc 的方式 :gc 估算触发和 heap 占用触发 . 我们的 1.5.0.09 环境下有次 old 区 heap 占用再 30% 左右 , 她就频繁 gc, 个人感觉系统估算触发这种方式不靠谱 , 还是用 heap 使用比率触发比较稳妥 .
这些数据都来自 64 位测试机 , 过程中的数据都是我在 jboss log 找的 , 当时没有记下来 , 可能存在一点点偏差 , 但不会很大 , 基本过程就是这样 .
5: 总结
web server 作为交互性要求较高的应用 , 我们应该使用 Parallel+CMS,UseParNewGC 这个在 jdk6 -server 上是默认的 ,new generation gc, 新生代不能太大 , 这样每次 pause 会短一些 .CMS mark-sweep generation 可以大一些 , 可以根据 pause time 实际情况控制
参考资料:
http://17studio.javaeye.com/blog/443439
-
QTP10破解方法,插件延长使用时间方法,及mgn-mqt82.exe下载
ljonathan 发布于 2009-03-19 16:00:00
注意:一定要手动创建文件夹,在相应文件夹下进行操作,否则无法成功生成注册码
破解步骤:
1.安装qtp,一路默认下来,到要求输入License的界面
2.拷贝mgn-mqt82.exe(下载)到C:\Program Files\Mercury Interactive(自己手动创建)文件夹下
3.自己手动创建C:\Program Files\Common Files\Mercury Interactive\License Manager文件夹
4.执行自己刚才创建的C:\Program Files\Mercury Interactive文件夹下的破解工具mgn-mqt82.exe,会提示lservrc文件生成。
5.在C:\Program Files\Common Files\Mercury Interactive\License Manager\下找到文件lservrc,用记事本打开,复制文件LSERVRC中#之前的字符串,那个就是注册码, 如: 3QVWCPPOS5NGGFM6KPX64EQFSH6INFRJIVMC5WZ4XIIFIXX86UCPIP4M686DZKV9NANA9BUP# "QuickTestPro" version "6.0", no expiration date, exclusiveJZ7F79F6YQQFVUWNG2V7AW22K537DOELQYNX6VSCNCZ9J8M2QW9OXO5DSEQKUZA46X5BO# "FT-Unified" version "1.0", no expiration date, exclusive 就拷贝#号前的 3QVWCPPOS5NGGFM6KPX64EQFSH6INFRJIVMC5WZ4XIIFIXX86UCPIP4M686DZKV9NANA9BUP
然后粘贴到license向导中的license输入的地方,点击确定,可以看到信息为无限制使用,也可以打开qtp,在help-about qtp--License对话框中可以看到该qtp已经显示为无限制使用了以上部分亲自验证过,以下部分未亲自验证过:
插件延长使用时间方法:(试用于任何情况,包括插件已过期)
已试成功的插件有JAVA\NET\ORACLE\POWERBUILDER\WEBSERVICE\DELPHI(其余的插件类似)
控制面板-添加删除程序中删除所有附加插件,使用REGCLEAN注册表软件清理一下注册表,打开QTP一次, 再安装QTP95所需插件,打开QTP95,熟悉的13天又回来了.
独立DELPHI插件延长使用方法 不管在任何时候安装DELPHI插件,其使用时间是由QTP95中已安装插件所能使用的时间来决定的.所以要延长使用时间的话,需要将所有插件全部卸载然后再重新安装 延长使用方法同上面一样.
PS:千万注意不要随便修改系统时间,往后调即使插件过期还有办法让它继续使用,要是往前调系统时间那就怎么都没有办法再使用插件了.这个是注册码生成工具: mgn-mqt82.rar(235 KB)
-
HTTP协议
mklodoss 发布于 2010-04-23 09:13:44
HTTP协议2007年03月03日 星期六 16:05计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求信息和服务,HTTP目前协议的版本是1.1.HTTP是一种无状态的协议,无状态是指Web浏览器和Web服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后Web服务器返回响应(response),连接就被关闭了,在服务器端不保留连接的有关信息.HTTP遵循请求(Request)/应答(Response)模型。(2) Web浏览器向Web服务器发送请求命令。HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则。计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求信息和服务,HTTP目前协议的版本是1.1.HTTP是一种无状态的协议,无状态是指Web浏览器和Web服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后Web服务器返回响应(response),连接就被关闭了,在服务器端不保留连接的有关信息.HTTP遵循请求(Request)/应答(Response)模型。Web浏览器向Web服务器发送请求,Web服务器处理请求并返回适当的应答。所有HTTP连接都被构造成一套请求和应答。HTTP使用内容类型,是指Web服务器向Web浏览器返回的文件都有与之相关的类型。所有这些类型在MIME Internet邮件协议上模型化,即Web服务器告诉Web浏览器该文件所具有的种类,是HTML文档、GIF格式图像、声音文件还是独立的应用程序。大多数Web浏览器都拥有一系列的可配置的辅助应用程序,它们告诉浏览器应该如何处理Web服务器发送过来的各种内容类型。HTTP通信机制是在一次完整的HTTP通信过程中,Web浏览器与Web服务器之间将完成下列7个步骤:(1) 建立TCP连接在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80(2) Web浏览器向Web服务器发送请求命令一旦建立了TCP连接,Web浏览器就会向Web服务器发送请求命令例如:GET/sample/hello.jsp HTTP/1.1(3) Web浏览器发送请求头信息浏览器发送其请求命令之后,还要以头信息的形式向Web服务器发送一些别的信息,之后浏览器发送了一空白行来通知服务器,它已经结束了该头信息的发送。(4) Web服务器应答客户机向服务器发出请求后,服务器会客户机回送应答,HTTP/1.1 200 OK应答的第一部分是协议的版本号和应答状态码(5) Web服务器发送应答头信息正如客户端会随同请求发送关于自身的信息一样,服务器也会随同应答向用户发送关于它自己的数据及被请求的文档。(6) Web服务器向浏览器发送数据Web服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据(7) Web服务器关闭TCP连接一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码Connection:keep-aliveTCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。HTTP请求格式当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息,HTTP请求信息由3部分组成:l 请求方法URI协议/版本l 请求头(Request Header)l 请求正文下面是一个HTTP请求的例子:GET/sample.jspHTTP/1.1Accept:image/gif.image/jpeg,*/*Accept-Language:zh-cnConnection:Keep-AliveHost:localhostUser-Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0)Accept-Encoding:gzip,deflateusername=jinqiao&password=1234(1) 请求方法URI协议/版本请求的第一行是“方法URL议/版本”:GET/sample.jsp HTTP/1.1以上代码中“GET”代表请求方法,“/sample.jsp”表示URI,“HTTP/1.1代表协议和协议的版本。根据HTTP标准,HTTP请求可以使用多种请求方法。例如:HTTP1.1支持7种请求方法:GET、POST、HEAD、OPTIONS、PUT、DELETE和TARCE。在Internet应用中,最常用的方法是GET和POST。URL完整地指定了要访问的网络资源,通常只要给出相对于服务器 -
并发用户数的计算方法
Jon 发布于 2009-03-30 23:12:35
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是2000个,那么这个数量,就是系统用户数
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量
平均并发用户数的计算:
C=nL /T
其中C是平均的并发用户数,n是平均每天访问用户数,L是一天内用户从登录到退出的平均时间(操作平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:
C^约等于C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论
-
JVM参数调优[整理收藏]
Jon 发布于 2009-03-30 22:50:39
JVM参数调优是一个很头痛的问题,可能和应用有关系,别人说可以的对自己不一定管用。下面是本人一些调优的实践经验,希望对读者能有帮助,环境LinuxAS4,resin2.1.17,JDK6.0,2CPU,4G内存,dell2950服务器,网站是舍得网,http://shedewang.com
一:串行垃圾回收,也就是默认配置,完成10万request用时153秒,JVM参数配置如下
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps ";
这种配置一般在resin启动24小时内似乎没有大问题,网站可以正常访问,但查看日志发现,在接近24小时时,Full GC执行越来越频繁,大约每隔3分钟就有一次Full GC,每次Full GC系统会停顿6秒左右,作为一个网站来说,用户等待6秒恐怕太长了,所以这种方式有待改善。MaxTenuringThreshold=7表示一个对象如果在救助空间移动7次还没有被回收就放入年老代,GCTimeRatio=19表示java可以用5%的时间来做垃圾回收,1/(1+19)=1/20=5%。
二:并行回收,完成10万request用时117秒,配置如下:
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xmx2048M -Xms2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=500 -XX:+UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 ";
并行回收我尝试过多种组合配置,似乎都没什么用,resin启动3小时左右就会停顿,时间超过10秒。也有可能是参数设置不够好的原因,MaxGCPauseMillis表示GC最大停顿时间,在resin刚启动还没有执行Full GC时系统是正常的,但一旦执行Full GC,MaxGCPauseMillis根本没有用,停顿时间可能超过20秒,之后会发生什么我也不再关心了,赶紧重启resin,尝试其他回收策略。
三:并发回收,完成10万request用时60秒,比并行回收差不多快一倍,是默认回收策略性能的2.5倍,配置如下:
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 ";
这个配置虽然不会出现10秒连不上的情况,但系统重启3个小时左右,每隔几分钟就会有5秒连不上的情况,查看gc.log,发现在执行ParNewGC时有个promotion failed错误,从而转向执行Full GC,造成系统停顿,而且会很频繁,每隔几分钟就有一次,所以还得改善。UseCMSCompactAtFullCollection是表是执行Full GC后对内存进行整理压缩,免得产生内存碎片,CMSFullGCsBeforeCompaction=N表示执行N次Full GC后执行内存压缩。
四:增量回收,完成10万request用时171秒,太慢了,配置如下
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xincgc ";
似乎回收得也不太干净,而且也对性能有较大影响,不值得试。
五:并发回收的I-CMS模式,和增量回收差不多,完成10万request用时170秒。
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:+CMSIncrementalPacing -XX:CMSIncrementalDutyCycleMin=0 -XX:CMSIncrementalDutyCycle=10 -XX:-TraceClassUnloading ";
采用了sun推荐的参数,回收效果不好,照样有停顿,数小时之内就会频繁出现停顿,什么sun推荐的参数,照样不好使。
六:递增式低暂停收集器,还叫什么火车式回收,不知道属于哪个系,完成10万request用时153秒
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseTrainGC ";
该配置效果也不好,影响性能,所以没试。
七:相比之下,还是并发回收比较好,性能比较高,只要能解决ParNewGC(并行回收年轻代)时的promotion failed错误就一切好办了,查了很多文章,发现引起promotion failed错误的原因是CMS来不及回收(CMS默认在年老代占到90%左右才会执行),年老代又没有足够的空间供GC把一些活的对象从年轻代移到年老代,所以执行Full GC。CMSInitiatingOccupancyFraction=70表示年老代占到约70%时就开始执行CMS,这样就不会出现Full GC了。SoftRefLRUPolicyMSPerMB这个参数也是我认为比较有用的,官方解释是softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap,我觉得没必要等1秒,所以设置成0。配置如下
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -XX:+DisableExplicitGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSPermGenSweepingEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -Xloggc:log/gc.log ";
上面这个配置内存上升的很慢,24小时之内几乎没有停顿现象,最长的只停滞了0.8s,ParNew GC每30秒左右才执行一次,每次回收约0.2秒,看来问题应该暂时解决了。
参数不明白的可以上网查,本人认为比较重要的几个参数是:-Xms -Xmx -Xmn MaxTenuringThreshold GCTimeRatio UseConcMarkSweepGC CMSInitiatingOccupancyFraction SoftRefLRUPolicyMSPerMB -
In Search of Speed 学习笔记[收藏]
Jon 发布于 2009-11-19 09:58:31
原雅虎首席性能官、现任 Google Web 性能专家 Steve Souders,近期在 LA 隆重举行的 SpeedGeeks 会议上发表重要讲话:In Search of Speed(slides, video),以下为学习笔记:
1. 以 iGoogle 为例,前端页面组件渲染的时间占了整个页面打开时间的 91%,前端优化的重要性不言而喻。
2. 前端优化十四条原则,是个人都知道,不必多说了。
3. 如果想要更快一点,可以参考新书 Even Faster Web Sites。
4. Google 页面延时增加 0.4 秒,搜索量会下降 0.6%;雅虎页面延时增加 0.4 秒,访问量会下降 5-9%;Bing 页面延时增加 2 秒,收入会下降 4.3%。
5. 高性能 = 更好的用户体验 + 更多访问量 + 更多收入 + 成本节约
6. 为什么没有那么多人来做 性 能 优 化 这么有前途的事呢?因为这他妈的太难了!
7. 当然,如果这事没那么难的话,是个人都能做了!
8. 我们今年的口号是:本来就快!(Fast by Default)
9. Aptimize 公司的性能优化神油:整合 JS、整合 CSS、Sprites、Data: URIs、更长的过期时间、精简 JS 和 CSS、automatically in real time。
10. 在 http://sharepoint.microsoft.com 上抹了点神油,果然有奇效:Empty Cache 的 requests 从 96 降到 35,Primed Cache 的 requests 从 50 降到 9。JS 减少了 7 个,CSS 减少了 12 个,图片减少了 25 张。页面性能提升:Empty Cache - 46-64%;Primed Cache - 15-53%。 详见: http://blogs.msdn.com/sharepoint/archive/2009/09/28/how-we-did-it-speeding-up-sharepoint-microsoft-com.aspx
11. 有家“典型电子商务网站”,名叫 StrangeLoop Networks,自打抹了神油:每次访问页面数由 11 提升到 16,浏览网站平均时间由 24 分钟提升到 30 分钟,转化率上升了 16%,订单价值上升了 5.5%。
12. 为啥某些网站比较慢?“某些”包括但不限于:Google Mail、Google Docs、AOL、Twitter、ESPN、Best Buy、IKEA、CNN...(这些网站钱多人傻,快去推销优化服务!)
13. 原因是由于缺乏 Progressive Rendering(渐进渲染)!
14. 对比五家搜索引擎:Google Search、Yahoo Search、Bing、Ask 和 AOL Search,页面打开 0.5 秒时,没有一个显示内容,等到 1 秒时,Google Search 和 Bing 显示了主要内容,直到 2 秒时,Ask 还是没有显示任何内容。
15. 快使用双截棍: WebPagetest.org
16. 对比六家新闻网站:Yahoo News、CNN、CNET、Google News、NY Times 和 MSNBC,页面打开 1 秒时,Google News 率先显示了 Logo,直到 4 秒时,CNN 还是空白一片。
17. Progressive Enhancement:deliver HTML、defer JS、avoid DOM、decorate later。
18. 先做 Progressive Enhancement,再做 Progressive Rendering。
19. 最近新闻:http://spriteme.org 帮助优化 sprites,http://www.browserscope.org 用于对比不同的浏览器访问,HTTP Watch Studio 支持 HTTP 存档格式(HAR),@font-face 标记如果放在SCRIPT. 标签下方则将导致 IE 浏览器阻止渲染。
20. 讲话要点,必须掌握:关注前端!使用 YSlow 和 PageSpeed 工具! Progressive enhancement -> progressive rendering!
21. 最后感言:网页速度是下一个竞争激烈的目标,必须在别人动手之前先优化自己!(否则会死得很难看,信不信?)--转B2BPOOD-冯亮记录
-
YSlow的强大动能实例演示
Jon 发布于 2009-11-19 14:05:44
前面我们简单介绍了YSlow测试前端性能工具,现在把该工具集成到Firefox中来综合运用,结合Firefox强大的插件功能,我们通过测试实践发现本工具有非常强大的作用,通过访问web页面,并运行YSlow插件就能一目了然看到页面请求发送到页面完全显示所利用的时间和过程访问的server及过程脚本实现逻辑。下面举例说明
YSlow主要有四部分显示分别是 Grade,Components,Statistics和Tools(下面以访问http://china.alibaba.com为例子说明)
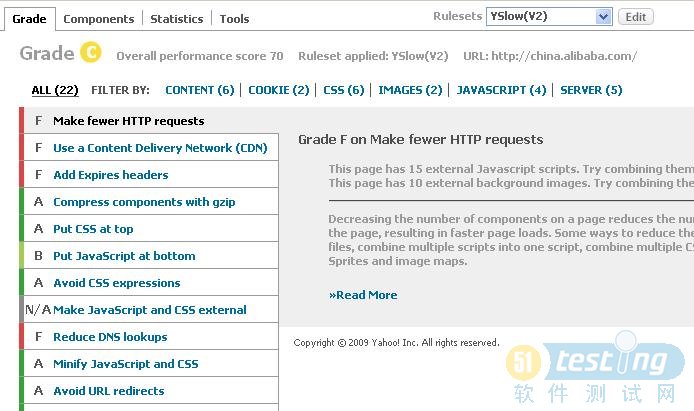
1.Grade
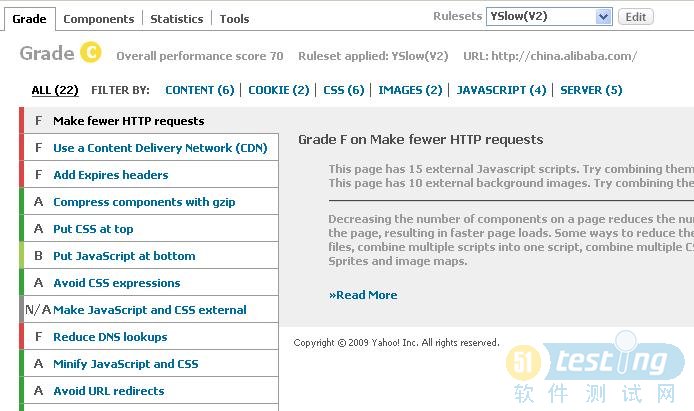
(1)content检查:一共有6个,有HTTP请求,DNS、URL、AJAX缓存、DOM、还有对HTTP404检查
(2)Cookie检查
(3)CSS检查:主要检查页面前端css交互,js
(4)images:图片检查
(5)JavaScript检查:如found 4 处js请求
There are 4 Javacript scripts found in the head of the document
- http://style.china.alibaba.com/js/homepage/index0906/merge/index-top-v1.js
- http://smart.china.alibaba.com/offer/rec_offer.do?...
- http://amos.im.alisoft.com/muliuserstatus.aw?...
- http://china.alibaba.com/shtml/top-source/aliservice.html?...
(6)SERVER:请求服务器检查,含图片server,应用server,css/js服务器
2.Components
来分析请求访问主要包含什么内容,有哪些组成部分,见截图

通过这个图我们不难看出请求后的文件大小和请求花的时间,我们以css和flash两项为例子说明
(1)css 大小是38.1K,对应url也给出,它的response time是121ms
(2)flash 大小25.4k,它的response time是279ms
通过对比我们就能发现那些消耗的时间比较多,显示flash消耗时间较css长,并且我们可以通过HEADS查看详细过程信息,我们来看一下flash的HEADS信息
Response Header 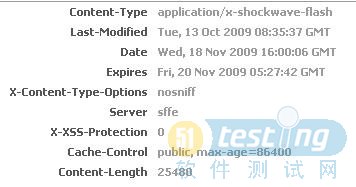
通过HEADERS信息查看是不是很详细呢。
3.Statistics
我们再来看工具的统计功能,其实我最喜欢也就是它的统计,2个饼图很形象(见下如)
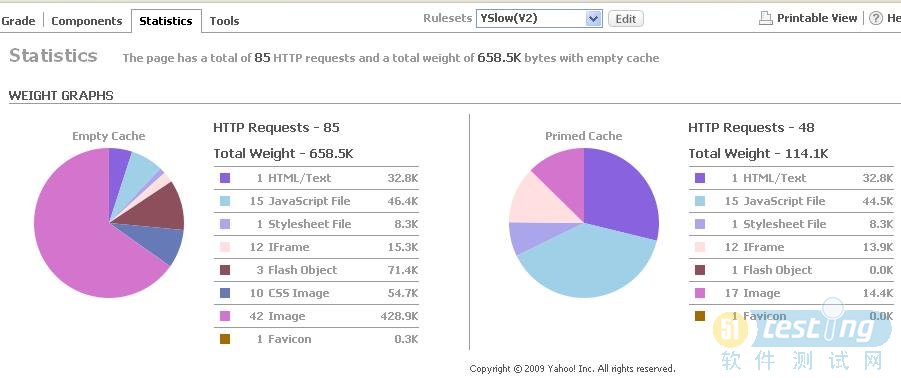
是不是很清晰呢
YSlow针对网站速度体验上的优化,将其总结为很多条,分别用F到A的指标来对你的网站速度做出评价并给出数据,F代表最差,A代表最好。
我们可以通过分析得到的数据对自己的网站和服务器做相应的优化。
25480 -
YSlow工具介绍
Jon 发布于 2009-11-19 15:05:29
工具介绍在网络google下很多内容的,有些都是大同小异的,我觉得我整理的这部分还是比较好的,建议看看。
YSlow是Yahoo开发的一个用于测试分析网站优化的Firefox工具插件,使用时您必须先安装有Firefox。YSlow针对网站速度体验上的优化,将其总结为13条,分别用F到A的指标来对你的网站速度做出评价并给出数据,F代表最差,A代表最好。我们可以通过分析得到的数据对自己的网站和服务器做相应的优化。
这只是一样评测分析,改进还是要靠自己,这里要谈的就是实实在在的如何针对每一条进行优化:1. Make fewer HTTP requests ( 减少Http请求数)
一个网页不可避免的要引入大量的外部文件:Javascript、css、背景图片……由于Http协议的无状态性,用户的每一次访问,都会重新向服务器请求所有文件,而大量Http请求的累加,正是影响网站速度的最主要原因。
所以这里的解决方法只有一个:合并。最理想的情况莫过于一个网页只包含一个css,一个js,一张背景图。
合并Js和Css文件很好理解,背景图片要怎么合并?这里采用的主要方法是CSS Sprites,简单说就是把所有的图片拼接成一张大图,在不同的Css里指定背景图坐标来显示不同图片。具体可以参考Dave Shea的Image Slicing’s Kiss of Death一文,还有网站提供了在线的CSS Sprites服务,只需要上传小图片,就可以获得拼接后的大图以及相应坐标。
不过在当前越来越多动辄包含10余个文件的开发框架面前,减少 Http请求数也变得越来越难。一直都认为所谓框架,给出的应该是一整套完善的开发思想,从服务器配置到数据库设计甚至是到UI体验乃至SEO,但现在很多Framework总是各自为战,后台与前端脱节,只在自己的一片领域里提供一定程度上的方便,没有考虑到最终产品的统合,甚至连基本的代码侵入性问题没有处理好(这里点名批评dojo,恨不得在所有的html标签上印上dojo的章子),不能不说是一种遗憾。
所以如果网站中采用框架的话,在框架的选择面前,建议多采用轻量级,侵入性低的框架,也是为了日后产品的优化维护着想。2. Use a CDN (使用CDN,可以略过,不是能力范围)
CDN(Content delivery network)内容分发网络,能够智能根据网络节点情况选择服务节点,大型网站部署时尤为重要。不过这属于硬件级别的解决方案,我们没有条件配置CDN的时候,可以自行设置忽略这一项评测。
在Firefox地址栏键入about:config,然后新建一个字符串,名称为extensions.firebug.yslow.cdnHostnames,值为所要评测网站的域名,多个设置用逗号分隔。例如我的设置就是artwc.com,localhost3. Add an Expires header (为文件头指定Expires,文件缓存)
Expires是浏览器Cache机制的一部分,浏览器的缓存取决于Header中的四个值: Cache-Control, Expires, Last-Modified, ETag。这个项目的考评主要针对Cache-Control和Expires。
具体的Cache原理不是本文所涉及的,有兴趣的同学可以看看Caching Tutorial一文。为了优化这个选项,我们所要做的是对站内所有的文件有针对性的设置Cache-Control和Expires,这里基于Apache主机举例:首先开启mod_header模块,在httpd.conf中取消
- LoadModule headers_module modules/mod_headers.so
一行的注释。然后对于图片,文件等不会经常更新的文件设置一个比较长的过期时间
-
< FilesMatch "\.(ico|pdf|flv|jpg|jpeg|png|gif|js|css|swf)$" >
-
Header set Expires "Thu, 15 Apr 2010 20:00:00 GMT"
-
<!-- < SPAN-->FilesMatch >
对于Cache-Control可以设置的更加细致一些,这里对图片,文件设置了7天,对XML,对html、php设置了2小时。
-
< FilesMatch "\.(ico|pdf|flv|jpg|jpeg|png|gif|js|css|swf)$" >
-
Header set Cache-Control " max-age = 604800 , public"
-
<!-- < SPAN-->FilesMatch >
-
< FilesMatch "\.(html|htm|php)$" >
-
Header set Cache-Control " max-age = 7200 , must-revalidate"
-
<!-- < SPAN-->FilesMatch >
Expires也可以通过开启mod_expires来实现
4. Gzip components / 启用Gzip压缩
HTTP/1.1支持接收服务器端经过Gzip压缩的数据,在Apache2中,可以开启mod_deflate实现。
同样去掉注释- LoadModule deflate_module modules/mod_deflate.so
然后对所有文本类文件添加Gzip处理
- DeflateCompressionLevel 3
- < FilesMatch "\.(php|htm|html|js|css)$" >
- SetOutputFilter DEFLATE
- <!-- < SPAN-->FilesMatch >
5. Put CSS at the top (将Css文件放在头部)
很好理解的一条,主要是为了避免最后加载Css引起的浏览器白屏,改善用户体验。6. Put JS at the bottom (将Js文件放在底部)
同样很容易理解,为了让DOM先行加载。7. Avoid CSS expressions (避免CSS expressions)
CSS expressions可以轻易的引起浏览器假死,也不在W3C规范内,不只是避免,最好完全不要用。8. Make JS and CSS external (将Js和Css文件独立)
将Js和Css文件单独做成外部文件加载,一则可以功能复用,二则可以生成缓存,当然这一条和第一条要互相参照找出最好的解决方案才是。9. Reduce DNS lookups (减少DNS查询)
外部文件分散于多个服务器,连接每台服务器都会做一次DNS查询,这一条是针对多服务器的部署。10. Minify JS (压缩Js文件)
压缩Js文件,Yahoo!官方推荐的工具是JSMin和YUI Compressor。本站也可以进行js压缩http://artwc.com/tools.html11. Avoid redirects (避免重定向)
每一次的重定向都会重新发送Header请求。所以在Apache下,无比强大的mod_rewrite是必须要学的。12. Remove duplicate scripts (移除重复的脚本)
开发中没有规划好,会出现页面中重复引用一个文件的情况,IE中即便是重复引用也会重新向服务器发送一次请求。13. Configure ETags (配置ETags)
在第三条中已经对浏览器缓存机制中的Cache-Control和Expires进行了配置,这一条评测的是另外两个:Last-Modified和ETag
简单的说,即使设置了文件的期限,浏览器在访问资源时往往会因为Last-Modified和ETag而重新下载整个资源,所以简单的做法是关闭Last-Modified和ETag, 在Apache中做如下配置- FileETag None
- < FilesMatch "\.(ico|pdf|flv|jpg|jpeg|png|gif|js|css)$" >
- < p > Header unset Last-Modified</ <!-- < SPAN-->p >
- </<!-- < SPAN-->FilesMatch >
-
外企英语面试问题和口语技巧
frontgirl 发布于 2010-03-22 00:00:07
外企英语面试问题和口语技巧
上一篇 / 下一篇 2010-03-16 12:58:56 / 个人分类:求职应聘
如何在外企英语面试中脱颖而出?如何有效的运用英语在外企英文面试中打动面试官?在外企口语面试中应该避免哪些内容?外企面试看种什么样的英语证书?……我们请到了上海外教网的英语外教William Hill先生(美国)为我们简要谈谈外企英语面试竞争力的问题。
William Hill先生曾任某知名外企上海分公司人力资源经理。1、流利而准确的英语表达能力将成为你的职场竞争力。
外企英语面试和雅思托福等出国考试不一样。前者是竞争型测试,后者是通过型测试。也就是说,参加出国考试的通过人数没有名额限制,你只要能力足够高,发挥得足够好,就能够pass。然而外企招聘却是有名额限制的,只有优于他人的应聘者才可能在外企英文面试中脱颖而出。
专业而熟练的职业技能结合流利的口语表达、清晰的英语思维、地道的英语发音、准确而恰当的俚语运用、跨文化沟通技巧等将成为你应聘外企的主要竞争力。外教William Hill先生告诉我们:“I interviewed a lot of candidates in Shanghai, a few of which did impress me deeply with veteran skills. I was surprised at their spokenEnglishbecause they appeared to be a Chinese American. I just couldn't decline them.”
在多人竞争某一职位时,简单的“可以理解的”初级英语层次显然不能够凸显个人实力。William Hill先生建议应聘者不妨关注一下自己的英语表达和发音,中国式英语是应该避免的,多了解你即将应聘的外企的国家文化,因为每个国家的文化不同会使面试过程的氛围也不同。相对来讲美国企业的面试比较relaxing,有点像一般的聊天,只不过聊的内容不是普通的“闲聊”。如果在外企英文面试中能准确地融入一些该国的俚语,则你的面试过程将会非常的愉快。
2、外企招聘时看重哪些英语证书?
如果外企的面试官是老外的话,那么国内的一些英语考试如CET4、CET6、TEM4、TEM8等可能作用并不明显,除了老外不了解这些考试外更多的在于这些考试并没有对考生的口语能力进行测试。关于这个问题William Hill说:“I don't think candidates with those certificates are up to par, because what we focus on is the communicating ability. And, as is known, CET and TEM don't seem totestone's speaking skills. But he who owns an IELTS or TOEFL certificate may be preferred.”可见雅思、托福等出国英语证书可能在一定程度上增强应聘者的竞争力。
常见典型问题拆招:
3、关于介绍自己的:Could you say something about yourself? Could you sell yourself within a few minutes?
这个问题可以说是大众问题了,通过这个问题,面试官一方面大致把握一下你的英语水平,一方面找到和你交流的突破点,探寻本质,打破沙锅是人力资源经理的一惯作风,因此回答这个问题时务必事实求是,否则后面很可能无法自圆其说。不过这个问题其实也不复杂,外教William Hill告诉我们说与其说这个是测试应聘者的问题,不如说是应聘者卖弄自己英语的大好机会,So don't miss the boat!
你可以从以下几个方面突出自己:职业技能强项,该技能的深入程度,该技能完成过的项目以及自己其他相关方面的深入研究和学习、探索,注意突出个性。请不要在自己的姓名、年龄、毕业学校、兴趣爱好等方面浪费时间,也不用再把你的简历背诵一遍,因为老外已经看过你的CV了。时间可以根据情况控制在 2-3分钟的样子。注意外企英语面试是口头表达的过程,建议在随后的互动过程中多多使用口语化的表达,尽量让自己融入整个对话(Conversation),而不是在教条式的背诵文章。
4、关于应聘动机的:Why do you wanna work for us? What makes you come here today?
面试官想了解一下你的求职动机,看看你对公司是否有所了解。显然这个功课是你来面试之前就应该做好的,所以千万别说开始面试了还不知道这个公司是做什么的。请在回答这个问题的时候充满信心,不要说是来试试的(you really wanna take a try?),如果能事先将公司信息整理好并梳理一下和自己的职业技能相结合来介绍,则可谓Perfect Response。
5、关于你的弱点:What do you think is your greatest weakness? May I know it?
注意后面那句是客气的,千万别说No,也别说"I don't think I have any weakness"。客观地评价一下自己确实存在但对工作并不重要的缺点是一个不错的办法,当然别忘了要提一下你将采取什么样的办法来克服或弥补自己的缺点。
6、关于你过去的工作:How do you like your last job? Why did ya leave your last job?
面试官想通过你对过去的工作的看法,了解你对今后的工作态度。如果你说你不喜欢你过去的工作,那么你将面临“既然不喜欢为什么却会选择”这样的难题,最终结果是“缺乏判断力或者没有主见”。事实上你既然做过以前的工作,那么应该多少还是比较喜欢的,不妨谈谈过去的工作特点和你所负责的主要任务,但要突出过去的工作趋于平淡且失去挑战性,你可以在更艰巨的任务和岗位中发挥能力。同时面试官极有可能问你以前的同事和上司的一些问题,切记不要把责任归咎到别人身上。
7、关于你将来的打算:How long do you propose to work here?
这个问题对职场老手来说简直就是a piece of cake。简洁的几句话表达出你希望在这个公司一直工作下去即可,同时要体现出你的上进心,渴望与公司一起发展和进步,不断提升自己。
8、反问的机会:Ok, now if you have any questions, please feel free to ask me.
“Nope, I have none, thanks!”这样的回答就完全错了。抓住这个机会,把事先准备好的问题和盘托出,多了解一些关于公司发展、职位要求、员工培训、员工晋升、员工福利等方面的问题。
其实外企英语面试并没有什么特别之处,话题内容上也跳不出中文面试的框框,无非是用英语来表达而已。在某些特定职位的招聘上,可能外企更看重的是个人的职业能力而对英语表达要求甚低;或者在某些特定的条件下没有太多的竞争者,应聘者不需要具备非常好的英语听说能力就可拿到offer。但这些情况并不影响我们对自身竞争力的提升,卓越的英语听说能力必将为你的职场生涯带来裨益。
一些可能用得上的俚语表达:
注意:
1、up to par 达到标准。
2、I won't let the cat out of the bag. 我会严守秘密。
3、get on the ball 开始(做事)
4、a piece of cake 形容非常容易
5、face the music 勇于承担责任
-
[转]Selenium 若干个具体的API入门
kakamissyou 发布于 2010-03-22 23:47:56
Selenium 是 thoughtworks公司的一个集成测试的强大工具。最近参与了一个系统移植的项目,正好用到这个工具,
把一些使用心得分享给大家,希望大家能多多使用这样的强大的,免费的工具,来保证我们的质量。
Selenium 的文档现存的不少,不过都太简单了。使用Selenium的时候,我更多的是直接去看API文档,好在API不错,
一个一个看,就能找到所需要的 :-) 官方网站:http://www.openqa.org/selenium/
好,下面进入正题!
一、Selenium 的版本
Selenium 现在存在2个版本,一个叫 selenium-core, 一个叫selenium-rc 。
selenium-core 是使用HTML的方式来编写测试脚本,你也可以使用 Selenium-IDE来录制脚本,但是目前Selenium-IDE
只有 FireFox 版本。Selenium-RC 是 selenium-remote control 缩写,是使用具体的语言来编写测试类。
selenium-rc 支持的语言非常多,这里我们着重关注java的方式。这里讲的也主要是 selenium-rc,因为个人还是喜欢这种
方式 :-)二、一些准备工作
1、当然是下载 selenium 了,到 http://www.openqa.org/selenium/ 下载就可以了,记得选择selenium-rc 的版本。
2、学习一下 xpath 的知识。有个教程:http://www.zvon.org/xxl/XPathTutorial/General_chi/examples.html
一定要学习这个,不然你根本看不懂下面的内容!3、安装 jdk1.5
三、selenium-rc 一些使用方法
在 selenium-remote-control-0.9.0\server 目录里,我们运行 java -jar selenium-server.jar
之后你就会看到一些启动信息。要使用 selenium-rc ,启动这个server 是必须的。当然,启动的时候有许多参数,这些用法可以在网站里看看教程,不过不加参数也已经足够了。
selenium server 启动完毕了,那么我们就可以开始编写测试类了!
我们先有个概念,selenium 是模仿浏览器的行为的,当你运行测试类的时候,你就会发现selenium 会打开一个
浏览器,然后浏览器执行你的操作。
好吧,首先生成我们的测试类:
java 代码- public class TestPage2 extends TestCase {
- private Selenium selenium;
- protected void setUp() throws Exception {
- String url = “http://xxx.xxx.xxx.xxx/yyy”;
- selenium = new DefaultSelenium("localhost", SeleniumServer.getDefaultPort
- (), "*iexplore", url);
- selenium.start();
- super.setUp();
- }
- protected void tearDown() throws Exception {
- selenium.stop();
- super.tearDown();
- }
- }
代码十分简单,作用就是初始化一个 Selenium 对象。其中:
url : 就是你要测试的网站
localhost: 可以不是localhost,但是必须是 selenium server 启动的地址
*iexplore : 可以是其它浏览器类型,可以在网站上看都支持哪些。下面我就要讲讲怎么使用selenium 这个对象来进行测试。
1、测试文本输入框
假设页面上有一个文本输入框,我们要测试的内容是 在其中输入一些内容,然后点击一个按钮,看看页面的是否跳转
到需要的页面。- public void test1() {
- selenium.open("http://xxx.xxx.xxx/yyy");
- selenium.type("xpath=//input[@name='userID']", "test-user");
- selenium.click("xpath=//input[@type='button']");
- selenium.waitForPageToLoad("2000");
- assertEquals(selenium.getTitle(), "Welcome");
- }
上面的代码是这个意思:
1、调用 selenium.open 方法,浏览器会打开相应的页面
2、使用 type 方法来给输入框输入文字
3、等待页面载入
4、看看新的页面标题是不是我们想要的。2、测试下拉框
java 代码- public void test1() {
- selenium.open("http://xxx.xxx.xxx/yyy");
- selenium.select("xpath=//SELECT[@name='SBBUSYO']", "index=1");
- selenium.click("xpath=//input[@type='button']");
- selenium.waitForPageToLoad("2000");
- assertEquals(selenium.getTitle(), "Welcome");
- }
可以看到,我们可以使用 select 方法来确定选择下拉框中的哪个选项。
select 方法还有很多用法,具体去看看文档吧。3、测试check box
java 代码
- public void test1() {
- selenium.open("http://xxx.xxx.xxx/yyy");
- selenium.check("xpath=//input[@name='MEICK_000']");
- selenium.click("xpath=//input[@type='button']");
- selenium.waitForPageToLoad("2000");
- assertEquals(selenium.getTitle(), "Welcome");
- }
我们可以使用 check 方法来确定选择哪个radio button
4、得到文本框里的文字
java 代码- assertEquals(selenium.getValue("xpath=//input[@name='WNO']"), "1");
getValue 方法就是得到文本框里的数值,可不是 getText 方法,用错了可就郁闷了。
5、判断页面是否存在一个元素
java 代码- assertTrue(selenium.isElementPresent("xpath=//input[@name='MEICK_000']"));
一般这个是用来测试当删除一些数据后,页面上有些东西就不会显示的情况。
6、判断下拉框里选择了哪个选项
java 代码- assertEquals(selenium.getSelectedIndex("xpath=//SELECT[@name='HATIMING']"), "1");
这个可以用来判断下拉框显示的选项是否是期望的选项。
7、如果有 alert 弹出对话框怎么办?
这个问题弄了挺长时间,可以这样来关闭弹出的对跨框:
java 代码- if(selenium.isAlertPresent()) {
- selenium.getAlert();
- }
其实当调用 selenium.getAlert() 时,就会关闭 alert 弹出的对话框。
也可以使用 System.out.println(selenium.getAlert()) 来查看对跨框显示的信息。在测试的时候,有的人会显示许多alert 来查看运行时的数据,那么我们可以用下面的方式来关闭那些 alert:
java 代码- while(selenium.isAlertPresent()) {
- selenium.getAlert();
- }
8、如何测试一些错误消息的显示?
java 代码- assertTrue(selenium.getBodyText().indexOf("错误消息")>=0);
切记: getBodyText 返回的时浏览器页面上的文字,不回包含html 代码的,如果要显示html 代码,用下面这个:
java 代码- System.out.println(selenium.getHtmlSource());
以上就是最常用的几个方法了,例如 click, type, getValue 等等。
还有就是一定要学习 xpath, 其实xpath 也可以有“与、或、非”的操作:java 代码- selenium.check("xpath=//input[(@name='KNYKBN')and(@value='Y')]");
四、其他
selenium 还有更多的用法,例如弹出页面等等。当面对没见过的测试要求时,我最笨的方法就是按照api文档一个一个找,
好在不多,肯定能找到。
Source URL: http://www.javaeye.com/topic/107276 -
【转载】遇到问题为什么应该自己动手
lamuda 发布于 2010-03-16 23:11:43
1. 遇到问题寻找捷径为什么是很聪明的做法
我们在生活中总是在不停地试图做最优经济决策,只不过很多时候我们为适应远古社会而进化的大脑未必适用于现代工业社会(《Mean Genes》,《进化心理学》,《How We Decide》),所以很多时候我们可以在超市为选择哪一卷卫生纸斟酌半天(《Predictably Irrational》),却在面对生活中重大抉择的时候轻易就随波逐流(《Paradox Of Choice》)。
我们的很多决策依赖于情绪系统的输出(从进化时间上比较“旧”的大脑部分)(《How We Decide》,《Synaptic Self》),这部分大脑属于典型的经过了漫长进化时间所雕琢过的,决策机制严重适应远古社会的模块(《Mean Genes》),比如在物质贫乏的远古时期,不管什么时候遇到富含热量的食物是必吃无误的,所以我们的情绪大脑只要闻到美食是绝对不去克制诱惑的,长出脂肪又如何?有的是饥寒交迫的时候去燃烧这些脂肪。然而这条规则到了现代这个物质充裕的社会却成了灾难(去查一下美国的肥胖比例?),可谓成也萧何败萧何。这样的例子在《Mean Genes》中还有不少。
我们在学习新东西,遇到困难的时候,为什么会放弃?因为我们下意识中会对所面临的困难以及成功后所得的收益作一个评估(经典的cost/return分析),这里特别重要的是对面临的困难的评估:我们都知道学习任何一门技能,一开始可能还兴趣浓厚,捋袖子上阵,过了一阵子便会遇到一个典型的分水岭,你会发现未知的东西比你想象得要多,困难重重,似乎一眼看过去没法确信什么时候才能掌握,甚至觉得有点Mission Impossible,当觉知到的困难到一定程度之后,我们的大脑便会想:既然很大可能最终失败,甚至看不到成功的可能,为什么要白费力气去学一通呢?还不如省省呢。这是一个聪明的经济决策,去权衡性价比应该是每个经济个体的原则。然而,这个决策笨就笨在,它把困难评估得过高了,因此决策的前提就弄错了。为什么这么说呢?现代社会很多新东西是知识密集型的,而不像我们祖先生活的远古社会可能绝大部分是体力活。对体力活的评估我们很在行,大约能知道困难有多大,需要耗时多久,有没有可能完成。然而对学习新知识的困难程度的评估,我们却很不在行,因为大部分知识都是需要等你掌握了之后才会“豁然开朗”、“柳暗花明的”,而在这之前你会觉得这东西太难了,完全没有头绪,摸不着门道,觉得山重水复疑无路,你会想“既然无路,就别去碰得满头是包了吧?何苦呢?”。
有一个很不错的概念叫做“Unknown Unknown”,大意是如果你不知道一个东西的话,你也不会知道你自己不知道它。很多时候新知识就有这个特性——掌握了之后觉得很明白,掌握之前却觉得“不可能啊”、“这简直没有解嘛”。在这样的认知之下,你自然会高估前方的困难、风险和不确定性,因为你不知道什么样的知识才能解决你的困惑。然而事实上呢?只要智商没有根本的差别,别人的大脑能够掌握的知识,你的大脑也能掌握,你所感觉到的巨大困难只不过是因为Unknown Unknown,你所需要的只是耐心地踏遍这块知识版图,当你掌握了那些你该掌握的知识之后自然会柳暗花明。
2. 遇到问题寻找捷径为什么只是小聪明
我们在遇到困难的时候会试图去寻找捷径,心里的想法大概是:既然我自己解决可能需要耗费极大的精力,甚至连最终能否解决都无法判断,那么为什么要冒风险花费大量的时间去尝试呢?还不如想想其他法子。比如绕过问题,或者将问题外包给别人。
这很聪明,很经济:用最小的代价解决手头的问题。看上去是一个寻求经济上最优解的法子。
不过到底是局部最优还是全局最优呢?
“用最小的代价解决手头的问题”——这里的问题在于,难道我们计算收益的时候仅仅考虑是否解决了手头的问题吗?如果解决的过程中得到了其他的收益呢?

(图片注:荣耀属于indexed)
为了解决一个技术问题,你踏遍互联网,翻了若干教程、网站、书籍,最终解决了这个问题的同时还知道了以后遇到类似的问题该到哪儿最快最有效地找到参考,你还知道了哪些网站是寻找这个领域最有价值信息的地方,你还知道了哪些书是领域内最经典的书,说不定你在到处乱撞的过程中还会遇到其他若干意想不到的收益。
为了解决一个内存泄漏的bug,你学习了一堆底层知识、了解了一堆调试工具、学习了若干wikipedia页面,表面上看来,仅仅为了解决这一个小bug你的时间花销未免太大了点,然而关键就在于,它的收益远远不止于解决了这一个小bug,下次你遇到任何类似的bug的时候就能够哐当两下就解决之了。
生活或工作中,很大程度上你遇到的每个问题都不是孤立的,既然你遇到了某问题,那么很大的可能性你以后还会遇到类似的问题。当然,这个说法的另一面是,也有一些问题是一锤子买卖,即以后不会遇到类似的问题,因此只求速解决。不过按照我的经验这样的问题实在太少了,此外,你觉得你真的能够分辨你面对的问题是否属于这类问题吗?底线是,就算是这样的问题,你自己动手解决也能培养学习能力和思考能力。如果你判断它是一锤子问题,外包给别人解决,那么你就永远没机会发现这个问题背后蕴藏着哪些知识,这就成了一个自我实现的预言。
如果选择总是问别人的话,下次你还得继续问别人,每次直接问到问题的答案的同时意味着你永远都要靠别人的大脑来获得答案。
困难的路越走越容易,容易的路越走越难。
-
testlink 故障处理
MichaelChou111 发布于 2009-05-07 12:13:37
1. apache 服务无法启动~~很诡异,不知为何,apache服务启动不成功,提示:the request operation has failed !
解决办法: 怀疑是80端口被占用的问题,用netstat查看端口,但是没有发现被占用(netstat命令不太会用,回头还要好好研究研究,很有用的命令) ,从网上查看解决办法,如下:在dos命令行中进入apache安装的bin 目录下,运行 httpd.exe -w -n "apache2" -k start (其中apache2 为本机真是的服务名,又是很诡异我的bin目录下没有httpd.exe 这个可执行程序,所以不能用这个名利来查看 http.conf 文件中具体是哪一行出错了),无奈之下,修改apache 的端口 ,修改如下:listen 80----->linsten 192.168.0.112:800,保存重启服务,居然成功~~~,apache服务算是启动起来了~~
2. 访问路径出错:提示404错误
错误的原因:前段时间安装了mantis,修改了apache的httpd.conf文件,修改了directory 的设置,导致页面直接跳转至mantis的页面,而mantis还没有安装成功,导致页面出现404错误。
解决办法:修改 documentroot "E:/WWWROOT"
<directory "E:/WWWROOT">
至此:可爱的testlink页面又出现了!哈哈
-
如何使用Loadrunner进行资源占用率分析?(拷贝的)
huaxiang0208 发布于 2009-05-14 14:39:21
1. 平均事务响应时间
Average Transation Response Time 优秀:<2s
良好:2-5s
及格:6-10s
不及格:>10s
2. 每秒点击率
Hits per Second
当增大系统的压力(或增加并发用户数)时,吞吐率和TPS的变化曲线呈大体一致,则系统基本稳定若压力增大时,吞吐率的曲线增加到一定程度后出现变化缓慢,甚至平坦,很可能是网络出现带宽瓶颈.同理若点击率/TPS曲线出现变化缓慢或者平坦,说明服务器开始出现.
3. 请求响应时间
Time to Last Byte
4. 每秒系统处理事务数
Transaction per second
5. 吞吐量
Throughout
6. CPU利用率
Processor / %Processor Time 好:70%
坏:85%
很差:90%+
7. 数据库操作消耗的CPU时间
Processor / %User Time 如果该值较大,可以考虑是否能通过友好算法等方法降低这个值。如果该服务器是数据库服务器, Processor\%User Time 值大的原因很可能是数据库的排序或是函数操作消耗了过多的CPU时间,此时可以考虑对数据库系统进行优化。
8. 核心态CPU平均利用率
Processor /%Privileged Time 如果该参数值和"Physical Disk"参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统
9. 处理列队中的线程数
Processor / Processor Queue Length 如果该值保持不变(>=2)个并且%Processor Time 超过90%,那么可能存在处理器瓶颈。如果发现超过2,而处理器的利用率却一直很低,那么或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈。
10. 文件系统缓存
Memory / Cache Bytes 50%的可用物理内存
11. 剩余的可用内存
Memory / Avaiable Mbytes 至少要有10% 的物理内存值
12. 每秒下载页数
Memory / pages/sec 好:无页交换
坏:CPU每秒10个页交换
很差:更多的页交换
13. 页面读取操作速率
Memory / page read/sec 如果页面读取操作速率很低,同时 % Disk Time 和 Avg.Disk Queue Length的值很高,则可能有磁盘瓶径。但是,如果队列长度增加的同时页面读取速率并未降低,则内存不足。
14. 物理磁盘利用率
Physical Disk / %Disk Time 好:<30%
坏:<40%
很差:<50%+
15. 物理磁盘平均磁盘I/O队列长度
Physical Disk / Avg.Disk Queue Length 该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘
16. 网络吞吐量
Network Interface / Bytes Total/sec 判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽,结果应该小于50%
17. 数据高速缓存区命中率 命中率应大于0.90最好
18. 共享区库缓存区命中率 命中率应大于0.99
19. 监控 SGA 中字典缓冲区的命中率 命中率应大于0.85
20. 检测回滚段的争用 小于1%
21. 监控 SGA 中重做日志缓存区的命中率
应该小于1%
22. 监控内存和硬盘的排序比率 最好使它小于 10%
 mgn-mqt82.rar(235 KB)
mgn-mqt82.rar(235 KB)
标题搜索
我的存档
数据统计
- 访问量: 16194
- 日志数: 23
- 建立时间: 2008-10-31
- 更新时间: 2013-06-26
