
对规则进行处理以简化匹配过程
样式规则有几个来源:
· 外部样式表或style标签内的css规则
· 行内样式属性
· html可视化属性(映射为相应的样式规则)
后面两个很容易匹配到元素,因为它们所拥有的样式属性和html属性可以将元素作为key进行映射。
就像前面问题2所提到的,css的规则匹配可能很狡猾,为了解决这个问题,可以先对规则进行处理,以使其更容易被访问。
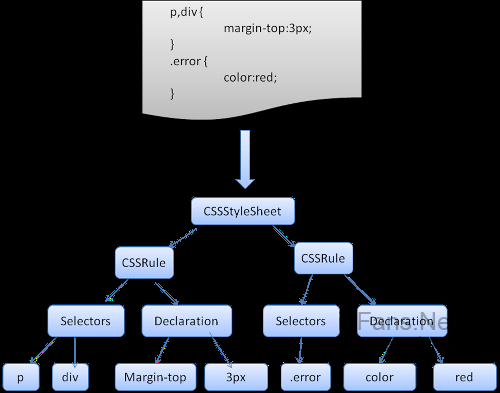
解析完样式表之后,规则会根据选择符添加一些hash映射,映射可以是根据id、class、标签名或是任何不属于这些分类的综合映射。如果选择符为id,规则将被添加到id映射,如果是class,则被添加到class映射,等等。
这个处理是匹配规则更容易,不需要查看每个声明,我们能从映射中找到一个元素的相关规则,这个优化使在进行规则匹配时减少了95+%的工作量。
来看下面的样式规则:
p.error {color:red}
#messageDiv {height:50px}
div {margin:5px}
第一条规则将被插入class映射,第二条插入id映射,第三条是标签映射。
下面这个html片段:
<p class=”error”>an error occurred </p>
<div id=” messageDiv”>this is a message</div>
我们首先找到p元素对应的规则,class映射将包含一个“error”的key,找到p.error的规则,div在id映射和标签映射中都有相关的规则,剩下的工作就是找出这些由key对应的规则中哪些确实是正确匹配的。
例如,如果div的规则是
table div {margin:5px}
这也是标签映射产生的,因为key是最右边的选择符,但它并不匹配这里的div元素,因为这里的div没有table祖先。
Webkit和Firefox都会做这个处理。
以正确的级联顺序应用规则
样式对象拥有对应所有可见属性的属性,如果特性没有被任何匹配的规则所定义,那么一些特性可以从parent的样式对象中继承,另外一些使用默认值。
这个问题的产生是因为存在不止一处的定义,这里用级联顺序解决这个问题。
样式表的级联顺序
一个样式属性的声明可能在几个样式表中出现,或是在一个样式表中出现多次,因此,应用规则的顺序至关重要,这个顺序就是级联顺序。根据css2的规范,级联顺序为(从低到高):
1. 浏览器声明
2. 用户声明
3. 作者的一般声明
4. 作者的important声明
5. 用户important声明
浏览器声明是最不重要的,用户只有在声明被标记为important时才会覆盖作者的声明。具有同等级别的声明将根据specifity以及它们被定义时的顺序进行排序。Html可视化属性将被转换为匹配的css声明,它们被视为最低优先级的作者规则。
Specifity
Css2规范中定义的选择符specifity如下:
· 如果声明来自style属性,而不是一个选择器的规则,则计1,否则计0(=a)
· 计算选择器中id属性的数量(=b)
· 计算选择器中class及伪类的数量(=c)
· 计算选择器中元素名及伪元素的数量(=d)
连接a-b-c-d四个数量(用一个大基数的计算系统)将得到specifity。这里使用的基数由分类中最高的基数定义。例如,如果a为14,可以使用16进制。不同情况下,a为17时,则需要使用阿拉伯数字17作为基数,这种情况可能在这个选择符时发生html body div div …(选择符中有17个标签,一般不太可能)。
一些例子:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style=”” /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
规则排序
规则匹配后,需要根据级联顺序对规则进行排序,webkit先将小列表用冒泡排序,再将它们合并为一个大列表,webkit通过为规则复写“>”操作来执行排序:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
逐步处理 Gradual process
webkit使用一个标志位标识所有顶层样式表都已加载,如果在attch时样式没有完全加载,则放置占位符,并在文档中标记,一旦样式表完成加载就重新进行计算。
布局 Layout
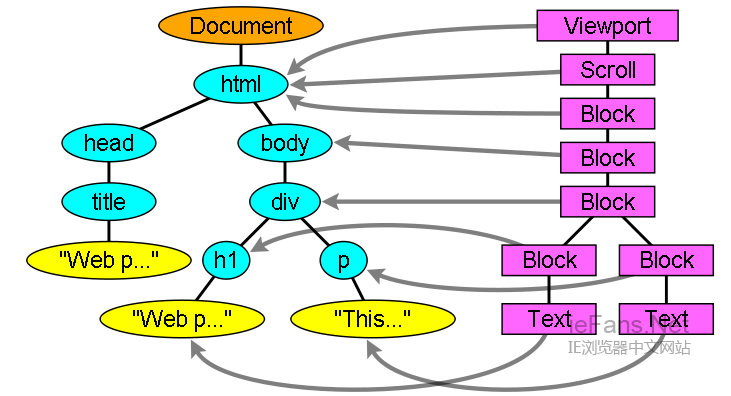
当渲染对象被创建并添加到树中,它们并没有位置和大小,计算这些值的过程称为layout或reflow。
Html使用基于流的布局模型,意味着大部分时间,可以以单一的途径进行几何计算。流中靠后的元素并不会影响前面元素的几何特性,所以布局可以在文档中从右向左、自上而下的进行。也存在一些例外,比如html tables。
坐标系统相对于根frame,使用top和left坐标。
布局是一个递归的过程,由根渲染对象开始,它对应html文档元素,布局继续递归的通过一些或所有的frame层级,为每个需要几何信息的渲染对象进行计算。
根渲染对象的位置是0,0,它的大小是viewport-浏览器窗口的可见部分。
所有的渲染对象都有一个layout或reflow方法,每个渲染对象调用需要布局的children的layout方法。
Dirty bit 系统
为了不因为每个小变化都全部重新布局,浏览器使用一个dirty bit系统,一个渲染对象发生了变化或是被添加了,就标记它及它的children为dirty-需要layout。存在两个标识-dirty及children are dirty,children are dirty说明即使这个渲染对象可能没问题,但它至少有一个child需要layout。
全局和增量 layout
当layout在整棵渲染树触发时,称为全局layout,这可能在下面这些情况下发生:
1. 一个全局的样式改变影响所有的渲染对象,比如字号的改变
2. 窗口resize
layout也可以是增量的,这样只有标志为dirty的渲染对象会重新布局(也将导致一些额外的布局)。增量 layout会在渲染对象dirty时异步触发,例如,当网络接收到新的内容并添加到Dom树后,新的渲染对象会添加到渲染树中。
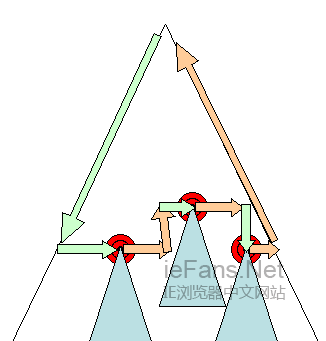
图20:增量 layout
异步和同步layout
增量layout的过程是异步的,Firefox为增量layout生成了reflow队列,以及一个调度执行这些批处理命令。Webkit也有一个计时器用来执行增量layout-遍历树,为dirty状态的渲染对象重新布局。
另外,当脚本请求样式信息时,例如“offsetHeight”,会同步的触发增量布局。
全局的layout一般都是同步触发。
有些时候,layout会被作为一个初始layout之后的回调,比如滑动条的滑动。
优化
当一个layout因为resize或是渲染位置改变(并不是大小改变)而触发时,渲染对象的大小将会从缓存中读取,而不会重新计算。
一般情况下,如果只有子树发生改变,则layout并不从根开始。这种情况发生在,变化发生在元素自身并且不影响它周围元素,例如,将文本插入文本域(否则,每次击键都将触发从根开始的重排)。
layout过程
layout一般有下面这几个部分:
1. parent渲染对象决定它的宽度
2. parent渲染对象读取chilidren,并:
1. 放置child渲染对象(设置它的x和y)
2. 在需要时(它们当前为dirty或是处于全局layout或者其他原因)调用child渲染对象的layout,这将计算child的高度
3. parent渲染对象使用child渲染对象的累积高度,以及margin和padding的高度来设置自己的高度-这将被parent渲染对象的parent使用
4. 将dirty标识设置为false
Firefox使用一个“state”对象(nsHTMLReflowState)做为参数去布局(firefox称为reflow),state包含parent的宽度及其他内容。
Firefox布局的输出是一个“metrics”对象(nsHTMLReflowMetrics)。它包括渲染对象计算出的高度。
宽度计算
渲染对象的宽度使用容器的宽度、渲染对象样式中的宽度及margin、border进行计算。例如,下面这个div的宽度:
<div style=”width:30%”/>
webkit中宽度的计算过程是(RenderBox类的calcWidth方法):
· 容器的宽度是容器的可用宽度和0中的最大值,这里的可用宽度为:contentWidth=clientWidth()-paddingLeft()-paddingRight(),clientWidth和clientHeight代表一个对象内部的不包括border和滑动条的大小
· 元素的宽度指样式属性width的值,它可以通过计算容器的百分比得到一个绝对值
· 加上水平方向上的border和padding
到这里是最佳宽度的计算过程,现在计算宽度的最大值和最小值,如果最佳宽度大于最大宽度则使用最大宽度,如果小于最小宽度则使用最小宽度。最后缓存这个值,当需要layout但宽度未改变时使用。
Line breaking
当一个渲染对象在布局过程中需要折行时,则暂停并告诉它的parent它需要折行,parent将创建额外的渲染对象并调用它们的layout。
绘制 Painting
绘制阶段,遍历渲染树并调用渲染对象的paint方法将它们的内容显示在屏幕上,绘制使用UI基础组件,这在UI的章节有更多的介绍。
全局和增量
和布局一样,绘制也可以是全局的-绘制完整的树-或增量的。在增量的绘制过程中,一些渲染对象以不影响整棵树的方式改变,改变的渲染对象使其在屏幕上的矩形区域失效,这将导致操作系统将其看作dirty区域,并产生一个paint事件,操作系统很巧妙的处理这个过程,并将多个区域合并为一个。Chrome中,这个过程更复杂些,因为渲染对象在不同的进程中,而不是在主进程中。Chrome在一定程度上模拟操作系统的行为,表现为监听事件并派发消息给渲染根,在树中查找到相关的渲染对象,重绘这个对象(往往还包括它的children)。
绘制顺序
css2定义了绘制过程的顺序-http://www.w3.org/TR/CSS21/zindex.html。这个就是元素压入堆栈的顺序,这个顺序影响着绘制,堆栈从后向前进行绘制。
一个块渲染对象的堆栈顺序是:
1. 背景色
2. 背景图
3. border
4. children
5. outline
Firefox显示列表
Firefox读取渲染树并为绘制的矩形创建一个显示列表,该列表以正确的绘制顺序包含这个矩形相关的渲染对象。
用这样的方法,可以使重绘时只需查找一次树,而不需要多次查找——绘制所有的背景、所有的图片、所有的border等等。
Firefox优化了这个过程,它不添加会被隐藏的元素,比如元素完全在其他不透明元素下面。
Webkit矩形存储
重绘前,webkit将旧的矩形保存为位图,然后只绘制新旧矩形的差集。
动态变化
浏览器总是试着以最小的动作响应一个变化,所以一个元素颜色的变化将只导致该元素的重绘,元素位置的变化将大致元素的布局和重绘,添加一个Dom节点,也会大致这个元素的布局和重绘。一些主要的变化,比如增加html元素的字号,将会导致缓存失效,从而引起整数的布局和重绘。
渲染引擎的线程
渲染引擎是单线程的,除了网络操作以外,几乎所有的事情都在单一的线程中处理,在Firefox和Safari中,这是浏览器的主线程,Chrome中这是tab的主线程。
网络操作由几个并行线程执行,并行连接的个数是受限的(通常是2-6个)。
事件循环
浏览器主线程是一个事件循环,它被设计为无限循环以保持执行过程的可用,等待事件(例如layout和paint事件)并执行它们。下面是Firefox的主要事件循环代码。
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 可视模型 CSS2 visual module
画布 The Canvas
根据CSS2规范,术语canvas用来描述格式化的结构所渲染的空间——浏览器绘制内容的地方。画布对每个维度空间都是无限大的,但浏览器基于viewport的大小选择了一个初始宽度。
根据http://www.w3.org/TR/CSS2/zindex.html的定义,画布如果是包含在其他画布内则是透明的,否则浏览器会指定一个颜色。
CSS盒模型
CSS盒模型描述了矩形盒,这些矩形盒是为文档树中的元素生成的,并根据可视的格式化模型进行布局。每个box包括内容区域(如图片、文本等)及可选的四周padding、border和margin区域。
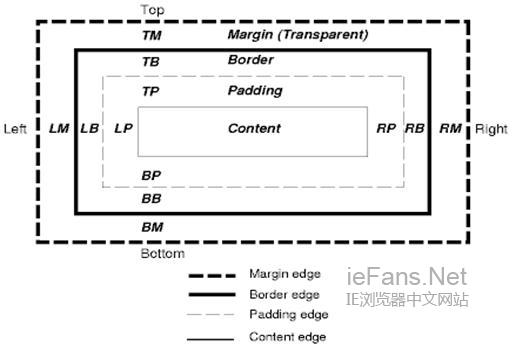
每个节点生成0-n个这样的box。
所有的元素都有一个display属性,用来决定它们生成box的类型,例如:
block-生成块状box
inline-生成一个或多个行内box
none-不生成box
默认的是inline,但浏览器样式表设置了其他默认值,例如,div元素默认为block。可以访问http://www.w3.org/TR/CSS2/sample.html查看更多的默认样式表示例。
定位策略 Position scheme
这里有三种策略:
1. normal-对象根据它在文档的中位置定位,这意味着它在渲染树和在Dom树中位置一致,并根据它的盒模型和大小进行布局
2. float-对象先像普通流一样布局,然后尽可能的向左或是向右移动
3. absolute-对象在渲染树中的位置和Dom树中位置无关
static和relative是normal,absolute和fixed属于absolute。
在static定位中,不定义位置而使用默认的位置。其他策略中,作者指定位置——top、bottom、left、right。
Box布局的方式由这几项决定:box的类型、box的大小、定位策略及扩展信息(比如图片大小和屏幕尺寸)。
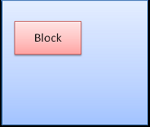
Box类型
Block box:构成一个块,即在浏览器窗口上有自己的矩形
Inline box:并没有自己的块状区域,但包含在一个块状区域内
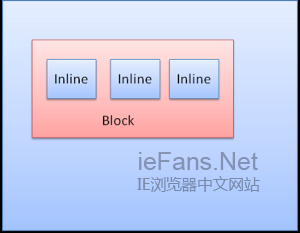
block一个挨着一个垂直格式化,inline则在水平方向上格式化。
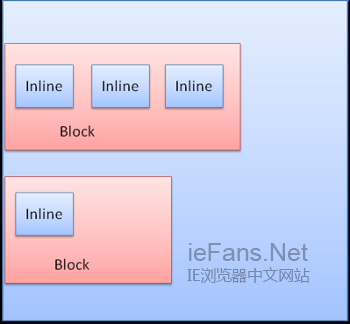
Inline盒模型放置在行内或是line box中,每行至少和最高的box一样高,当box以baseline对齐时——即一个元素的底部和另一个box上除底部以外的某点对齐,行高可以比最高的box高。当容器宽度不够时,行内元素将被放到多行中,这在一个p元素中经常发生。
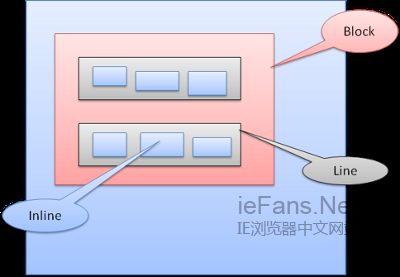
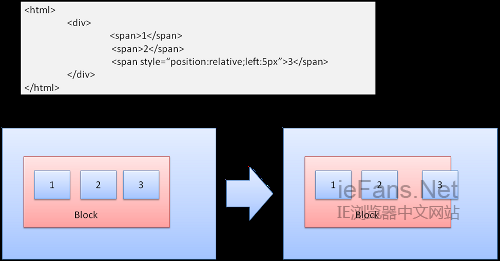
定位 Position
Relative
相对定位——先按照一般的定位,然后按所要求的差值移动。
Floats
一个浮动的box移动到一行的最左边或是最右边,其余的box围绕在它周围。下面这段html:
<p>
<img style=”float:right” src=”images/image.gif” width=”100″ height=”100″>Lorem ipsum dolor sit amet, consectetuer…
</p>
将显示为:

Absolute和Fixed
这种情况下的布局完全不顾普通的文档流,元素不属于文档流的一部分,大小取决于容器。Fixed时,容器为viewport(可视区域)。
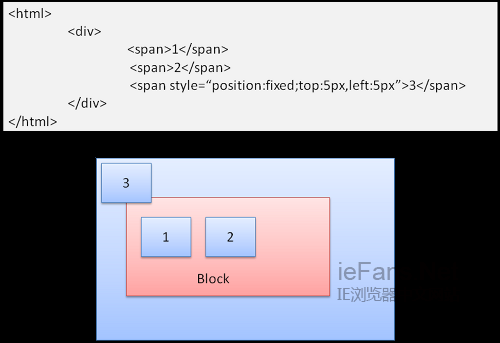
图17:fixed
注意-fixed即使在文档流滚动时也不会移动。
Layered representation
这个由CSS属性中的z-index指定,表示盒模型的第三个大小,即在z轴上的位置。Box分发到堆栈中(称为堆栈上下文),每个堆栈中靠后的元素将被较早绘制,栈顶靠前的元素离用户最近,当发生交叠时,将隐藏靠后的元素。堆栈根据z-index属性排序,拥有z-index属性的box形成了一个局部堆栈,viewport有外部堆栈,例如:
<STYLE. type=”text/css”>
div {
position: absolute;
left: 2in;
top: 2in;
}
</STYLE>
<P>
<DIV
style=”z-index: 3;background-color:red; width: 1in; height: 1in; “>
</DIV>
<DIV
style=”z-index: 1;background-color:green;width: 2in; height: 2in;”>
</DIV>
</p>
结果是:

虽然绿色div排在红色div后面,可能在正常流中也已经被绘制在后面,但z-index有更高优先级,所以在根box的堆栈中更靠前。
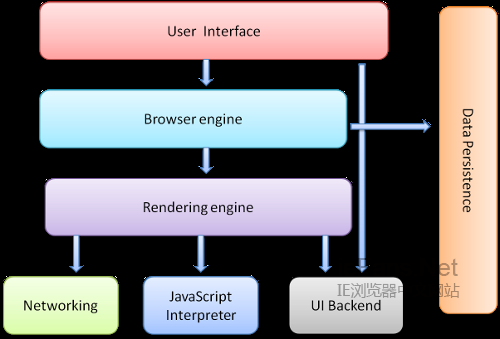
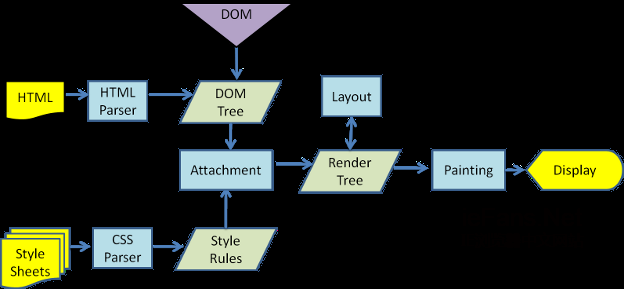
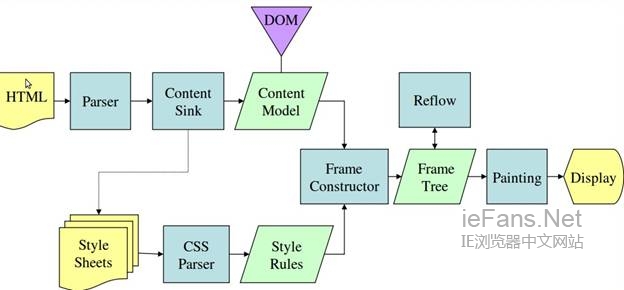
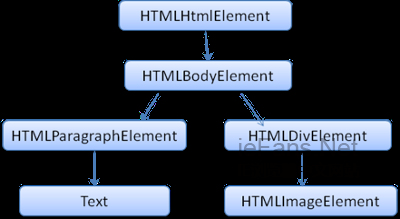
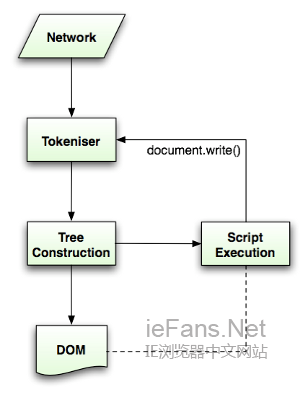
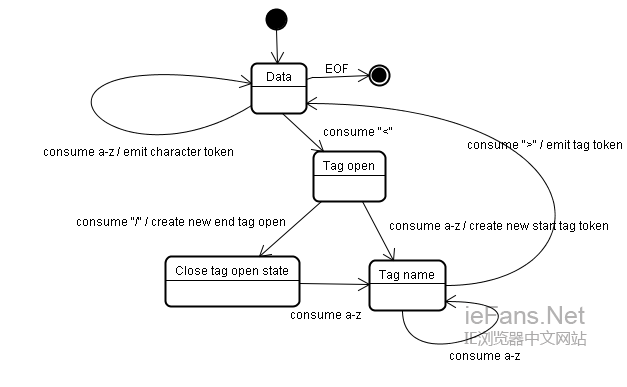
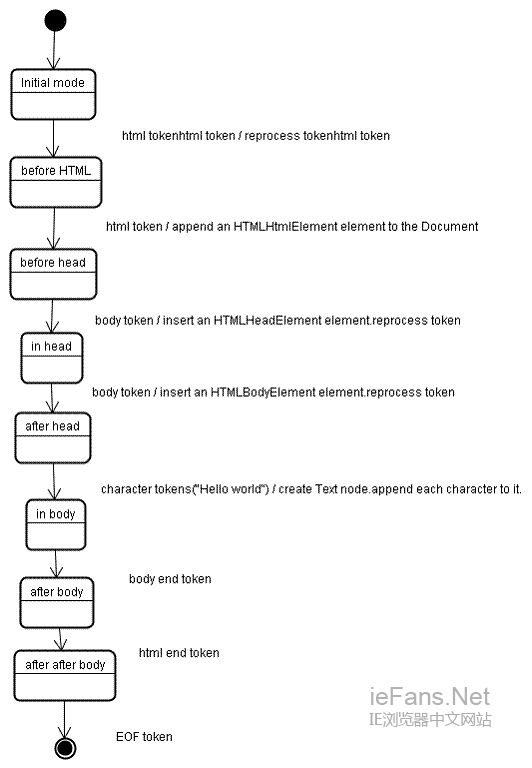
国外也有网友根据浏览器的工作原理绘制了几张工作流程图,方便大家通过简易的图片来了解这个辛苦的过程:

原文:http://taligarsiel.com/Projects/howbrowserswork1.htm
编译:zzzaquarius


 http_get_post.rar(981 KB)
http_get_post.rar(981 KB)
