
-
How many virtual users do I need? 计算需要的vuser
2015-05-06 12:01:24
基本公式:
--------
English:
Total Transations = TPS * Vuser
==>
Vuser = Total Transations / TPS
=====================================
中文:
高峰时段的访问量 = Vuser数量 * 访问频率(由平均访问时长计算)
==>
Vuser数量 = 高峰时段的访问量 / 访问频率(由平均访问时长计算)
------------------------------------
说明:访问频率是平均访问时长的倒数
------------------------------------
比如:
Peak visit rate (visits/hour) : 20000
Average visit length (minutes/visit) : 3
计算 Virtual Users required ?
----------------------------------
访问频率 = 1 / (3 minutes/visit) = 1/3 visit/minutes = 20 visits/hour
Vuser = (20000 visits/hour ) / (20 visits/hour) = 1000
----------------------------------
参考:
http://www.webperformance.com/library/tutorials/CalculateNumberOfLoadtestUsers/
-
淘宝测试blog推荐_02
2011-07-29 18:21:03
1. 性能测试瓶颈分析
在性能测试过程中,瓶颈犹如功能测试的bug,瓶颈的分析犹如bug的定位。性能测试工程师好比医生,看到病象,定位病因。性能瓶颈的定位更像庖丁解牛,层层解剖,最后定位问题之所在。下面分享一个内存泄漏的瓶颈分析。
病象:TPS波动非常大;狂打超时日志;偶尔有500错误。
看到这个现象,其实说明不了什么问题,就象人咳嗽,不一定是感冒,可能是上火,嗓子发炎。但是看到这个现象至少说明系统是有性能问题存在,我们就要进一步进行分析,看看问题到底在哪?用jconsole监控内存,发现内存使用如图1

图1:内存使用情况图
从图1中,我们可以很清晰的看到内存使用不正常,FGC非常频繁,差不多5分钟进行一次,而且内存回收不彻底,每次回收在1G左右徘徊。到这里我们已经可以定位是内存问题,导致了我们看到的TPS波动大,FGC频繁,超时严重等等一系列现象。
那么是谁吃了我的内存???
用简单的jstat命令查看系统GC情况,看到情况如图2所示

图2
在图2的绿色框标注,我们可以很清晰的看到进行一次FGC,内存只回收12%左右,回收很不彻底,而且FGC的时间持续5秒。内存回收不彻底,肯定是有些方法霸占了内存不释放,导致系统频繁FGC来进行回收。
那么谁是真正的凶手呢??
用jmap 命令对内存使用进行分析,发现情况如图3所示

图3
通过FGC前后的内存使用进行比对,发现这三个方法快速占用内存从最少到最多,而且回收不掉,始终霸占着前几位。再通过其他工具分析,看看这三个是不是真正的凶手。
用MAT分析工具进行分析,图4所示

图4
这三个方法各占了内存使用的14%,那么问题就很清晰明朗了。这三个方法就是真正的凶手,调优就从这三个方法入手。
性能瓶颈的分析,犹如庖丁解牛,层层剖析。最终定位问题之所在。
VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=8641
2. JAVA-OPTS引发的思考
我们在性能测试过程中,经常要修改应用的JAVA-OPTS参数。修改这些参数,不单单是修改这些数字,本着知其所以然的态度,我们要知道这些参数背后的意义。
常见的JAVA-OPTS的配置项。
JAVA_OPTS=”-server -Xms1536m -Xmx1536m -XX:NewSize=320m -XX:MaxNewSize=320m -XX:PermSize=96m -XX:MaxPermSize=256m -Xmn500m -XX:MaxTenuringThreshold=5″
-Xms:设置堆内存池的最小值
-Xmx:设置堆内存池的最大值
-XX:NewSize:设置新对象生产堆内存
-XX:MaxNewSize:设置最大新对象生产堆内存
-XX:PermSize:设置Perm区的大小
XX:MaxPermSize:设置Perm区的最大值
-Xmn:设置Young区的大小
-XX:MaxTenuringThreshold:设置垃圾最大年龄。
更加详细的说明,请参考图1

图1
看到这里,或许你会迷糊什么是堆内存,什么Perm区?这样就引出了第二个思考:JAVA内存模型。
JAVA内存模型如图2所示。

图2
JAVA的内存模型可以分为3个代:Young、Tenured、Perm。有的版本又叫:New、Old、Perm。中文叫:年轻代、终生代、永久代。或许中文还有其他的叫法,但是表示的意思是一样的。
Young和Tenured共同组成了堆内存(heap)。
Young(年轻代)还可以分为Eden区和两个Survivor区(from和to,这两个Survivor区大小严格一至)。新的对象实例总是首先放在Eden区,Survivor区作为Eden区和 Tenured(终生代)的缓冲,可以向 Tenure(终生代)转移活动的对象实例。如图3所示。

图3
在明白了JAVA内存模型后,就引出了第三个思考:Jconsole在性能测试中的使用。Jconsole是我们在性能测试中常用的工具,打开Jconsole后,可以看到很多监控图表。当你明白JAVA内存模型后,也就很容易明白Jconsole的监控图表了。如图4所示。

图4
在Jconsole图中,我们可以很明显看到内存可以分为堆内存和非堆在堆内存。在堆的上面有三个柱子,分别代别的是:Eden、Survivor、Old。Old区就是Tenured区。
在了解上述知识后,我们在使用Jconsole来监控应用的内存时,会更加清晰。
VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=6621
3. 谈一谈JVM内存JAVA_OPTS参数
最近几个月,做的性能测试项目中,发现了一些内存方面的问题,其中有涉及到对JBOSS里的JAVA_OPTS配置,例如一下所示;
JAVA_OPTS=”-server -Xms1536m -Xmx1536m -XX:NewSize=320m -XX:MaxNewSize=320m -XX:PermSize=96m -XX:MaxPermSize=256m -Xmn500m -XX:MaxTenuringThreshold=5″
JAVA_OPTS并不是已成不变的,不同的应用、软硬件环境下,要想充分发挥应用的性能,这些参数里边的设置可是非常有技巧和具有经验积累的。
经过查找资料,先看下JAVA_OPTS参数表示的意义。-server:一定要作为第一个参数,在多个CPU时性能佳
-Xms:初始Heap大小,使用的最小内存,cpu性能高时此值应设的大一些
-Xmx:java heap最大值,使用的最大内存
上面两个值是分配JVM的最小和最大内存,取决于硬件物理内存的大小,建议均设为物理内存的一半。-XX:PermSize:设定内存的永久保存区域
-XX:MaxPermSize:设定最大内存的永久保存区域
-XX:MaxNewSize:
-Xss 15120 这使得JBoss每增加一个线程(thread)就会立即消耗15M内存,而最佳值应该是128K,默认值好像是512k.
+XX:AggressiveHeap 会使得 Xms没有意义。这个参数让jvm忽略Xmx参数,疯狂地吃完一个G物理内存,再吃尽一个G的swap。
-Xss:每个线程的Stack大小
-verbose:gc 现实垃圾收集信息
-Xloggc:gc.log 指定垃圾收集日志文件
-Xmn:young generation的heap大小,一般设置为Xmx的3、4分之一
-XX:+UseParNewGC :缩短minor收集的时间
-XX:+UseConcMarkSweepGC :缩短major收集的时间
提示:此选项在Heap Size 比较大而且Major收集时间较长的情况下使用更合适。稳定的开发架构环境下,建议出一份有实践、经验论证的JAVA_OPTS配置,能够非常切合实际的服务于当前开发、测试的软件流程。
VN:F [1.9.7_1111]谈一谈JVM内存JAVA_OPTS参数, 9.0 out of 10 based on 5 ratings 转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=3395
4. JAVA内存泄露
最近在写性能宝典,正好内存泄露是其中非常重要的主题,记录下来,欢迎大家参与讨论,给出建议,谢谢!
内存溢出就是你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
JAVA中的内存溢出的导致原因很多,最主要的可能有以下几种:
A. 由于JVM堆内存设置过小,可以通过-Xms -Xmm设置。
B. JVM堆内存是足够的,但只是没有连续的内存空间导致,比如申请连续内存空间的数组:String[] array = new String[10000]。
C.由于导入较多的依赖jar包以及项目本身引用的class太多。
D. 测试过程中生成太多的对象。
E. 缓存池载入太多的等待队列。
F. 还有可能是不断的内存泄露导致最后内存不足溢出内存泄漏的慨念
1.c/c++是程序员自己治理内存,Java内存是由GC自动回收的。
我虽然不是很熟悉C++,不过这个应该没有犯常识性错误吧。
2.什么是内存泄露?
内存泄露是指系统中存在无法回收的内存,有时候会造成内存不足或系统崩溃。
在C/C++中分配了内存不释放的情况就是内存泄露。
3.Java存在内存泄露
我们必须先承认这个,才可以接着讨论。虽然Java存在内存泄露,但是基本上不用很关心它,非凡是那些对代码本身就不讲究的就更不要去关心这个了。
Java中的内存泄露当然是指:存在无用但是垃圾回收器无法回收的对象。而且即使有内存泄露问题存在,也不一定会表现出来。
4.Java中参数都是传值的。
对于基本类型,大家基本上没有异议,但是对于引用类型我们也不能有异议。
Java内存泄露情况
JVM回收算法是很复杂的,我也不知道他们怎么实现的,但是我只知道他们要实现的就是:对于没有被引用的对象是可以回收的。所以你要造成内存泄露就要做到:
持有对无用对象的引用!
不要以为这个很轻易做到,既然无用,你怎么还会持有它的引用? 既然你还持有它,它怎么会是无用的呢?
以下以堆栈更经典这个经典的例子来剖析。
public class Stack {
private Object[] elements=new Object[10];
private int size = 0;public void push(Object e){
ensureCapacity();
elements[size++] = e;
}public Object pop(){
if( size == 0)
throw new EmptyStackException();
return elements[--size];
}private void ensureCapacity(){
if(elements.length == size){
Object[] ldElements = elements;
elements = new Object[2 * elements.length+1];
System.arraycopy(oldElements,0, elements, 0, size);
}
}
}
上面的原理应该很简单,假如堆栈加了10个元素,然后全部弹出来,虽然堆栈是空的,没有我们要的东西,但是这是个对象是无法回收的,这个才符合了内存泄露的两个条件:无用,无法回收。但是就是存在这样的东西也不一定会导致什么样的后果,假如这个堆栈用的比较少,也就浪费了几个K内存而已,反正我们的内存都上G了,哪里会有什么影响,再说这个东西很快就会被回收的,有什么关系。下面看两个例子。
例子1
public class Bad{
public static Stack s=Stack();
static{
s.push(new Object());
s.pop(); //这里有一个对象发生内存泄露
s.push(new Object()); //上面的对象可以被回收了,等于是自愈了
}
}
因为是static,就一直存在到程序退出,但是我们也可以看到它有自愈功能,就是说假如你的Stack最多有100个对象,那么最多也就只有100个对象无法被回收其实这个应该很轻易理解,Stack内部持有100个引用,最坏的情况就是他们都是无用的,因为我们一旦放新的进取,以前的引用自然消失!例子2
public class NotTooBad{
public void doSomething(){
Stack s=new Stack();
s.push(new Object());
//other code
s.pop();//这里同样导致对象无法回收,内存泄露.
}//退出方法,s自动无效,s可以被回收,Stack内部的引用自然没了,所以
//这里也可以自愈,而且可以说这个方法不存在内存泄露问题,不过是晚一点
//交给GC而已,因为它是封闭的,对外不开放,可以说上面的代码99.9999%的
//情况是不会造成任何影响的,当然你写这样的代码不会有什么坏的影响,但是
//绝对可以说是垃圾代码!没有矛盾吧,我在里面加一个空的for循环也不会有
//什么太大的影响吧,你会这么做吗?
}VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=3625
5. jmap -dump:live为啥会触发Full GC
昨天组里的新人小朋友问是不是每次执行jmap -dump:live都会触发一次Full GC,因为当时他在做性能测试时某应用已经好几个小时没有一次FGC了,结果他执行了下dump就增加了次FGC。
我当时模糊回答应该会,以前看过哪篇文章好像提过^-^,不过本着严谨不误导新人小朋友的原则,还是找时间抽空验证实践了把:
测试环境:linux , sun jdk 1.6.07 , 32位
测试结果: jmap -dump:live 以及 jmap -histo:live都会触发Full GC,即使加上JVM参数-XX:+DisableExplicitGC也不影响结果
那么为什么呢? 其实大概猜也能知道,live选项的,如果FGC后,看到的活的对象比没有FGC的自然更精确。
我们来通过源码验证学习一下:
入口自然是 $j2se/src/share/classes/sun/tools/JMap.java
关键点是
VirtualMachine vm = attach(pid);
InputStream in = ((HotSpotVirtualMachine)vm).
heapHisto(live ? LIVE_OBJECTS_OPTION : ALL_OBJECTS_OPTION);以及
InputStream in = ((HotSpotVirtualMachine)vm).
dumpHeap((Object)filename,
(live ? LIVE_OBJECTS_OPTION : ALL_OBJECTS_OPTION));于是找到这里
HotSpotVirtualMachine.java:
public InputStream dumpHeap(Object … args) throws IOException {
return executeCommand(“dumpheap”, args);}
和
public InputStream heapHisto(Object … args) throws IOException {
return executeCommand(“inspectheap”, args);
}接着看到
LinuxVirtualMachine.java:
先是创建UNIX socket,然后连到target VM,把dumpheap或inspectheap命令通过socket发过去。
那么具体的inspectheap在sun hotspot核心代码里是如何处理的呢?
看这里 $hotspot/src/share/vm/services/attachListener.cpp
heap_inspection函数有如下关键代码:
VM_GC_HeapInspection heapop(out, live_objects_only /* request full gc */, true /* need_prologue */);
同样dumpheap在hotspot里也是这个文件里处理的:
jint dump_heap(AttachOperation* op, outputStream* out) {
…
// Request a full GC before heap dump if live_objects_only = true
// This helps reduces the amount of unreachable objects in the dump
// and makes it easier to browse.
HeapDumper dumper(live_objects_only /* request GC */);
int res = dumper.dump(op->arg(0));…
这下我们就可以明白了,与实验结果也对上号了
参考资料: http://forums.java.net/jive/message.jspa?messageID=115907
VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=10010
-
淘宝测试blog推荐_01
2011-07-29 16:25:43
1. 我眼中的性能测试工程师
许久以前就答应悟石要分享一下我眼中的性能测试工程师,结果托来托去快托过年了,囧…
想想来杭州有半年了,也对目前主站的性能评测团队工作模式有些许了解了,再加上以前在上家雇主也做过几年自认还算很有技术含量的性能测试工作,我想我还算有点资格说的吧:)
性能测试说的装B点儿,其实没啥,就是和Response Time(或者说latency)、throughput(也可以说capacity)以及scalability打交道。弄懂了这三个要素,应该就算是一个合格的性能测试工程师了。
当然,我不会装B,只是一介武夫,所以我接下来只想从偏技术层面聊聊我心目中真正的主站性能测试工程师是啥样的:
- 大局观。性能测试工程师一定要有系统化的思维,要站在整个系统测试的角度看问题。一个优秀的性能工程师必须要有相当的知识广度。否则在测试期间,你必须依赖外界援助(比如DBA,Dev或OPS)来协助,效率不高,更关键的是可能会被误导,漏掉很多性能BUG。我常常看到组里的童鞋们在压测时一看到TPS降了,就死盯着应用,就着急的去分析线程或做CPU Profiling。找不到原因后有时问到我时,我习惯的第一句总是 你看过DB么?确认DB端正常么?看过压测客户端么?确认压测端正常么? 我个人意见:不要老凭经验,一有重复症状就思维定式;一定要坚持先从全局看问题,隔离到是应用层面、DB层面抑或是压测客户端层面后再进一步深入定位问题。
- 技能深度。在性能测试工具方面有自己独特的理解;同时也应该在操作系统、数据库、应用程序等方向的配置管理与调优方向上非常的熟悉。
- 敏感。这个一方面是天赋,一方面是经验积累吧, 很多隐蔽的性能问题确实是需要丰富的经验才能发现,极容易漏掉:)
- 兴趣。 其实这条才是最重要的^-^
如果说具体些通俗些,我眼里主站真正的性能工程师是这样的:
- 熟悉Java(包括JVM内在机理)/c/c++。理由很简单,主站大部分的外围应用和中间件都是JAVA写的,底层核心系统是c/c++写的。
- 精通linux管理和shell编程。理由更简单,我一直觉得,shell熟练与否非常大程度决定了一个工程师的工作效率。
- 对数据库管理和性能优化有自己的实践和心得(数据库永远是个性能要点)
- 精通某一个性能测试工具。不止是使用,更包括原理,如何改造扩展。
- 熟悉linux kernel的实现(比如内存管理、文件系统、系统调用… )。 这条感触在最近两个月特别深,可能是受到褚霸、子团等大侠们的影响吧,如果不熟悉kernel,确实很难在底层系统的性能测试上有所真正建树。其实这块也算是整个质量保证部的技术短板吧,现在淘宝的linux内核组都是自测+他人review的形式,如果。。。^-^
- 了解常见硬件,特别是存储相关。这块主要是受国外Percona公司的Peter和Vadim影响,他们能成为世界公认的mysql性能专家,他们熟悉mysql源码当然很重要,但也与他们那非常渊博的底层硬件知识是分不开的。
当然以上都是我个人意见,从我自己的角度出发看的问题。其实性能测试还有很多领域,比如前端性能测试这块,我是小白,就不发表任何相关意见了^-^ 但说到底,做性能这块关键一是经验积累二是掌握相关底层技术
至今还记得百淘65期让我最为难忘的细节,达人青云在分享他的牛P经历时总结到的:
- 结合优势,做别人做不了的
- 发现问题,做别人没做过的
- 主动出击,做别人不爱做的
希望自己能一直铭记这三句话,有天能成为一个真正的性能工程师
VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=8308
2. 项目性能测试体验感想二
最近有幸和云帅参与了新江湖的性能测试, 这个项目中,由于测试时间紧,性能点多,我们从开发提交测试后就进行性能测试。提早介入测试导致我们后来遇到很多问题。我主要的工作是协助云帅,申请性能测试服务器,验证搭建好的性能测试环境和功能,准备性能测试数据,后期我参与了好友最近更新的相册这个性能点的执行,下面说下具体是怎么做上面的事情的:
(1)申请性能测试服务器:
先找总的开发负责人给出本阶段性能点所需要信息,包括 性能点,服务名,Hsf版本号,数据源,data-pool设置,jdk版本号,apache版本号,jboss版本号,jvm设置,代码库路径,压测页面链接,依赖系统和该性能点对应的开发负责人。收集完这些信息后我们可以向悟石他们申请机器啦。申请时除了上面最后三点,其他内容都需要提供。这样做是为了之后让scm参照上面的信息部署环境。(2)验证搭建的环境/功能:
1、验证jdk、apache、jboss的版本:可以通过拷贝文件valid-env,执行check.sh来快速验证jdk、apache、jboss的版本。或者通过如下的方法来依次验证。
a、jdk版本查看 先通过jbosscle文件查找到使用的JAVA_HOME地址,然后根据目录查找 /opt/taobao/java/bin/java -version 或者 /opt/taobao/java/bin/java1 -version;
b、apache版本查看 /opt/taobao/install/httpd/bin/httpd -version;
c、jboss版本查看 jboss启动日志jboss_stdout.log中有,只要看前面几行就能查找到。
2、证数据库配置:数据库的配置,一般存放在应用下的conf目录下,orcle-***-ds.xml/mysql-***-ds.xml文件里。检查它是否连接了正确的数据库schema,连接数是否正确。
3、查看apache的访问日志是否屏蔽掉。查看conf目录下,httpd.conf文件里——CustomLog这个配置项。
4、验证功能:需要确保所要测试的性能点的功能及相关功能正确。执行几个主流程查看或者跑一下接口是否通。(3)准备测试数据:
1.向DBA讨教了如何快速准备大量的性能测试数据。两种方法。写存储或者设置autoincrement。我这次主要用的是后者。将表的主键设置autoincrement,这样可以通过insert into 表(字段1,字段2…) select value1,value2… from 表 执行一次可以成倍增长当前的数据。这种方法简单快捷,如果只是为了纯粹增加表的数据流这个方法还是比较好的。当然除了数据库的方法还可以通过接口去插数据,在lr中执行下也是不错的选择。
2.性能测试环境下什么数据也没有,所以通过导入功能测试环境的数据来充当,mysql工具中有一个很好的功能:可以将功能测试数据库库的表结构和数据复制到性能测试数据库,如果性能测试数据库中已经存在该表,就drop掉该表,执行速度很快,大大方便我们准备数据。推荐大家用SQLyog Enterprise这个工具,真的不错。方法如下:打开mysql的数据库,连接到功能测试库上,点击File——New Conections,连接到性能测试库上,选择你要操作的表,右击选择第二项——Copy Table To Diffierent Host/Database,在界面中左边是源数据库,也就是我们的功能测试数据库,选择你要复制的表,支持多选,右边选择目标数据库,也就是我们的性能测试数据库及对应的用户,如果表已经存在,勾选选项:Drop table if exists in target ,具体要拷贝表结构和数据或者只是表结构都可以自己选择,最后点击copy,数据库表结构和数据很快可以复制完。(4)录制脚本:
淘江湖二期很多页面是采用了异步方式调用,所以录制完一个页面后,通过抽取每个请求作为一个脚本。接口测试这块采用http的方式去模拟测试,这样方式最大的好处是脚本准备比较方便。(5)测试执行:
1、一个页面通过加载该页面所有的异步请求,逐步增加各个脚本的并发用户数,调整并发用户数,查看是否满足预期的tps。
2、测试过程中时刻关注lr的运行情况,曲线有没有波动很大,几个日志信息,debug日志,超时日志和velocity日志,是否有大量日志出现。监控java虚拟内存是否正常释放,曲线是否平稳,而不是往上的趋势。一般如果有问题的话,刚开始运行脚本就会出现频繁报错,这时需要马上停下来查看问题原因。排查原因有很多,由于我们介入较早,有一些是因为数据库表结构没有建索引,或者是应用的版本没更新导致(初期bug比较多,版本经常更新),所以经过这次测试,深刻体会到性能测试的前提需要在sql审核通过,索引加好,功能比较稳定的前提下进行,也就是功能测试第二阶段开始,此时功能相对稳定,表结构也不会怎么变化,会少走很多弯路。
3.由于这次页面性能测试依赖的应用比较多,最多有用到13台应用服务器,当测试某个性能点的时候,需要查看与该应用交互的应用的情况,可以用netstat -nal命令。查出来后,监控这些相关的服务器,cpu,load,日志情况等。
4.用lr监控cpu这些数据时发现有一台服务器监控到的cpu有问题,空闲状态cpu就已经达到60%了,具体原因也不清楚,所以换了方式采用我们这边的一个监控cpu和load的shell脚本来做。(6)关于性能测试计划:这次测试有11个性能点,6个接口和5个页面,计划中根据测试优先级高低分三个阶段进行,分阶段搭建测试环境和准备数据和脚本,先接口后页面的顺序执行。
(7)关于性能测试日报:日报中主要记录目前所处的测试阶段,当天的测试工作,测试结果和结果分析,BugList,问题和风险,以及明天的计划。
最后非常非常感谢云帅,像老师一样,非常细心和耐心,教我很多很多,让我受益很多很多,更让我体会到了一个优秀的性能测工程师认真严谨的工作态度。
VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=3676
3. TPS真的重要吗
TPS 每秒成功事务数,做过性能测试的人都知道这个词,那么TPS真的重要么,除了它我们就不需要关注其它的指标了吗?
带着疑问,我们一起看一下这次的性能测试我们的过程,我们先是通过线上的访问统计整理出高峰时段的访问量,然后经过算出每台机器的访问量,把这个访问量作为目标TPS,测试过程就是验证系统能否达到这个目标。
然而,线下测试达到目标后,系统上线却出现了性能问题,而 TPS并没有线下测试的高,认真分析后,发现问题在于,我们测试的场景还是与线上有很大的差异,线上是很多Client请求造成的压力,而线下测试Client数量去只有一台,虽然并发请求的量可能相同,可对系统造成的压力去有很大的不同,为什么压力不同,线上的情况就是一个有力的证明,探究原因,应有不少,比如线上测试时,单台client自身压力比较大,对服务器压力有影响,1台Client并发40个请求与10台Client并发4个请求对服务器进行施压的效果一定是不同的。
总结起来,我感觉性能测试并不是那么简单,简单的只关注TPS这一个指标,应做到的是尽可能符合现实的场景,综合考虑各个关键指标。VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=3784
4. 性能测试总结
加入底层平台测试大概有一年了,接触了比较多的项目,做了各种测试,其中觉得最难做得就是性能测试。曾经迷茫过、曾经犯过错、曾经失败返工过,尽管底层平台系统的测试产品业务很如此的单纯。深知性能测试的博大,把自己的一点小小经验整理下,让自己和别人以后少走些弯路。
要做好性能测试首先要明确性能测试的目标。性能测试主要目标是发现系统的瓶颈,找出系统的性能基线,对系统进行调优,确认所测系统是否满足需求方的性能要求。有了准确的目标,性能测试才能测试准确。
产品性能测试通常粗的分,我会将性能测试分为两类:可靠性测试(压力测试、负载测试等)和性能测试。这两种测试有很多的不同点:
1)可靠性测试往往模拟的用户的使用情况,强调的为时间的延续性,要求产品没有不可接受的失败。
2)性能测试往往需要和硬件条件联系在一起,寻找性能的最好发挥以及最优的方案
通常性能测试需要在产品设计时就要进行简单性能测试,以对产品进行性能初期评估和调优,早于可靠性测试。同时在系统稳定时,常常还需要做详细的性能测试,以给应用方以数据参考。
那如何做性能测试那?
1) 性能测试应该早期就积极介入。介入代码审查和分析性能目标,多提出疑问,早期发现潜在的性能问题
2) 性能测试考虑全局,他是一个系统的测试。需要在产品的每个部件都做了一个测试,并全部成功后才开始系统测试执行。需要考虑多种因素:环境的、硬件的、软件的等等。
3) 测试前一定要检查确认配置。参数一定要配置对,否则测试无效。最好对于每个测试都有一个checklist,每次检查前都一一检查。这一步骤一定不可以省略,并需要被开发review。
4) 数据预热和数据准备很关键。一开始系统并不是一个干净的环境。我们需要在性能测试开始前预存一定的数据,并且让其有个增量。而且也要考虑到哪些方面数据多少(要更具实际情况)。
5) 准备测试脚本和工具要考虑实际情况。比如人的思考时间,场景的设计,不同操作的比例,数据的随机性等都要仔细设计,最和可以开发以及应用方进行讨论和确认。
6) 测试执行前一定要确保服务器独占,执行中如果是5-7天的测试,最好拿出一天先跑一个一天压力不高的测试,潜在一天发现可发现的问题。
7) 多种测试结果的分析发现问题。
a) Log日志的分析
b) 系统状态的分析
c) 数据一致性的分析
性能测试需要长时间的经验积累,我知道的只是些皮毛,后面还会继续探索,喜欢性能测试并将会在实践中不断积累和成长VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=9339
5. 服务器性能测试典型工具介绍 性能测试工具
服务器性能测试典型工具介绍 性能测试工具
众所周知,服务器是整个网络系统和计算平台的核心,许多重要的数据都保存在服务器上,很多网络服务都在服务器上运行,因此服务器性能的好坏决定了整个应用系统的性能。
现在市面上不同品牌、不同种类的服务器有很多种,用户在选购时,怎样从纷繁的型号中选择出所需要的,适合于自己应用的服务器产品,仅仅从配置上判别是不 够的,最好能够通过实际测试来筛选。而各种的评测软件有很多种,你应该选择哪个软件测试?下面就介绍一些较典型的测试工具:
(一)服务器整机系统性能测试工具
一台服务器系统的性能可以按照处理器、内存、存储、网络几部分来划分,而针对不同的应用,可能会对某些部分的性能要求高一些。
Iometer(www.iometer.org):存储子系统读写性能测试
Iometer是Windows系统下对存储子系统的读写性能进行测试的软件。可以显示磁盘系统的最大IO能力、磁盘系统的最大吞吐量、CPU使用率、错误信息等。用户可以通过设置不同的测试的参数,有存取类型(如sequential ,random)、读写块大小(如64K、256K),队列深度等,来模拟实际应用的读写环境进行测试。
Iometer操作简单,可以录制测试脚本,可以准确有效的反映存储系统的读写性能,为各大服务器和存储厂商所广泛采用。
Sisoft Sandra(www.sisoftware.co.uk):WINDOWS下基准评测
SiSoft发行的Sandra系列测试软件是Windows系统下的基准评测软件。此软件有超过三十种以上的测试项目,能够查看系统所有配件的信息,而且能够对部分配件(如CPU、内存、硬盘等)进行打分(benchmark),并且可以与其它型号硬件的得分进行对比。另外,该软件还有系统稳定性综合测试、性能调整向导等附加功能。
Sisoft Sandra软件在最近发布的Intel bensley平台上测试的内存带宽性能并不理想,不知道采用该软件测试的FBD内存性能是否还有参考价值,或许软件应该针对FBD内存带宽的测试项目做一个升级。
Iozone(www.iozone.org):linux下I/O性能测试
现在有很多的服务器系统都是采用linux操作系统,在linux平台下测试I/O性能可以采用iozone。
iozone是一个文件系统的benchmark工具,可以测试不同的操作系统中文件系统的读写性能。可以测试Read, write, re-read, re-write, read backwards, read strided, fread, fwrite, random read, pread ,mmap, aio_read, aio_write 等等不同的模式下的硬盘的性能。测试所有这些方面,生成excel文件,另外, iozone还附带了用gnuplot画图的脚本。
该软件用在大规模机群系统上测试NFS的性能,更加具有说服力。
Netperf(www.netperf.org):网络性能测试
Netperf可以测试服务器网络性能,主要针对基于TCP或UDP的传输。Netperf根据应用的不同,可以进行不同模式的网络性能测试,即批量数 据传输(bulk data transfer)模式和请求/应答(request/reponse)模式。Netperf测试结果所反映的是一个系统能够以多快的速度向另外一个系统发送数据,以及另外一个系统能够以多块的速度接收数据。
Netperf工具以client/server方式工作。server 端是netserver,用来侦听来自client端的连接,client端是 netperf,用来向server发起网络测试。在client与server之间,首先建立一个控制连接,传递有关测试配置的信息,以及测试的结果;在控制连接建立并传递了测试配置信息以后,client与server之间会再建立一个测试连接,用来来回传递着特殊的流量模式,以测试网络的性能。
对于服务器系统来说,网络性能显得尤其重要,有些服务器上为了节省成本,采用了桌面级的网络芯片,性能怎样,用这个软件一测便知了。
以上介绍的这几款测试工具都是可以免费从网上下载的非商业软件,但是其测试结果和认可程度均是为大多数使用者所认同的。你可以根据自己的应用需求选择不同的软件进行测试。
(二)针对应用的测试工具
随着web应用的增多,服务器应用解决方案中以Web为核心的应用也越来越多,很多公司各种应用的架构都以web应用为主。一般的web测试和以往的应 用程序的测试的侧重点不完全相同,在基本功能已经通过测试后,就要进行重要的系统性能测试了。系统的性能是一个很大的概念,覆盖面非常广泛,对一个软件系 统而言包括执行效率、资源占用率、稳定性、安全性、兼容性、可靠性等等,以下重点从负载压力方面来介绍服务器系统性能的测试。系统的负载和压力需要采用负载测试工具进行,虚拟一定数量的用户来测试系统的表现,看是否满足预期的设计指标要求。负载测试的目标是测试当负载逐渐增加时,系统组成部分的相应输出项,例如通过量、响应时间、CPU负载、内存使用等如何决定系统的性能,例如稳定性和响应等。
负载测试一般使用工具完成,有LoadRunner,Webload,QALoad等,主要的内容都是编写出测试脚本,脚本中一般包括用户常用的功能,然后运行,得出报告。
使用压力测试工具对web服务器进行压力测试。测试可以帮助找到一些大型的问题,如死机、崩损、内存泄漏等,因为有些存在内存泄漏问题的程序,在运行一两次时可能不会出现问题,但是如果运行了成千上万次,内存泄漏得越来越多,就会导致系统崩滑。
Loadrunner:预测系统行为和性能的负载测试工具
目前,业界中有不少能够做性能和压力测试的工具,Mercury(美科利)Interactive公司的LoadRunner是其中的佼佼者,也已经成为了行业的规范,目前最新的版本8.1。
LoadRunner 是一种预测系统行为和性能的负载测试工具,通过模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner 能够对整个企业架构进行测试,LoadRunner 适用于各种体系架构,能支持广范的协议和技术(如Web、Ftp、Database等),能预测系统行为并优化系统性能。它通过模拟实际用户的操作行为和实行实时性能监测,来帮助您更快的查找和发现问题。Loadrunner是一个强大有力的压力测试工具,它的脚本可以录制生成,自动关联。测试场景面向指标,实现了多方监控。而且测试结果采用图表显示,可以自由拆分组合。
文章来源于领测软件测试网 http://www.ltesting.net/
VN:F [1.9.7_1111]转载务必注明出处Taobao QA Team,原文地址:http://qa.taobao.com/?p=4091
-
性能测试人员面试经典技术问题(汇总)----果然经典
2010-09-02 10:06:34
第一篇:性能测试人员面试经典技术问题
1.请问什么是性能测试、负载测试、压力测试?
原参考答案:
性能测试:对一个软件系统而言,包括执行效率、资源占用、系统稳定性、安全性兼容性、可扩展性等。
负载测试:通过逐步加压的方式来确定系统的处理能力,确定系统能承受的各项阀值。
压力测试:逐步增加负载,使系统某些资源达到饱和甚至失效的测试。
个人理解:
经典的问题,答案打算参考段念的书:
性能测试(Performance Testing):是通过模拟系统实际运行的压力和使用场景组合,测试系统的性能是否满足实际生产的性能要求。
特点:1.主要目的是验证系统是否具备其宣称的能力
2.需要事先了解被测系统的典型场景,并具有确定的性能目标
3.要求在已确定的环境下运行
负载测试(Load Testing):通过在被测系统上不断增加压力,直到某个性能指标超过预定指标或者某种资源使用已经达到饱和状态
特点:1. 主要目的是找到系统处理能力的极限,为系统调优提供数据。测试形式/手段:"检测--加压--知道性能指标超过预期"
2.在给定的测试环境下进行,考虑被测系统的业务压力量和典型场景
3. 一般用来了解系统的性能容量,或是配合性能调优
压力测试(Stress Testing):测试系统在一定饱和状态下(CPU/MEMORY),
特点:1. 主要目的是检查系统处于压力情况下时,应用的表现
2. 一般用于测试系统的稳定性
2.请分别针对性能测试、负载测试和压力测试试举一个简单的例子?
原参考答案:
性能测试例子:公司开发了一个小型项目管理系统,上线前需要做负载、压力、大数据量、强度测试等。
负载测试:逐步加压,从而得到“响应时间不超过10秒”,“服务器平均CPU利用率低于85%”等指标阀值。
压力测试:逐步加压,从而使“响应时间超过10秒”,“服务器平均CPU利用率高于90%”等指标来确定系统能承受的最大负载量。
3.请例举出常用的性能测试工具,并指出这些工具的优缺点?
LoadRunner,录制脚本快捷操作简便,需要一定的学习时间,有采购成本。
4.请问您是如何得到性能测试需求?怎样针对需求设计、分析是否达到需求?
在查看需求文档,从中提取性能测试需求,与用户交流,了解实际使用情况。
结合业务信息设计操作场景总结出需测试的性能关键指标。
执行用例后根据提取关键性能指标来分析是否满足性能需求。
5.什么时候可以开始执行性能测试?
在产品相对比较稳定,功能测试结束后。灵活性比较强。
6.什么是集合点?设置集合点有什么意义?LoadRunner中设置集合点的函数是哪个?
集合点可以控制各个Vuser以便在同一时刻执行任务。
借助集合点,可以再LoadRunner中实现真正意义上的并发。
lr_rendezvous()
7.性能测试时,是不是必须进行参数化?为什么要创建参数?LoadRunner中如何创建参数?
8是。
模拟用户真实的业务操作。
创建参数列表,用参数替换固定的文本。
8.您了解关联吗?如何找出哪里需要关联?请给一些您所在项目的实例。
了解。
使用LoadRunner自动关联功能。手动关联:录制两份相同操作步骤的脚本,找出不同的部分进行判断。
一个项目管理系统,每次登录后服务器都自动分配一个sessionID以便之后每次表单提交后验证。
9.您如何调试LoadRunner脚本?
设置断点、增加log。
10.在LoadRunner中如何编写自定义函数?请给出一个您在以前项目中编写的函数。
11.请问您是如何理解LoadRunner中集合点、事务以及检查点等概念?
集合点:可以控制各个Vuser以便在同一时刻执行任务,可实现真正意义上的并发。
事务:事务是用来度量服务器响应时间的操作集。
检查点:在回放脚本期间搜索特定内容,从而验证服务器响应内容的正确性。
12.如何应用LoadRunner进行性能测试?
使用虚拟用户生成器创建脚本,使用控制器设定场景、运行脚本,使用分析器分析运行后得到的数据。
13.LoadRunner中思考时间有什么作用?
用户执行两个连续操作期间等待的时间。模拟用户真实的使用情况。
14.LoadRunner中如何实现多用户并发操作,需要进行哪些设置?
设置集合点来实现,在脚本中加入lr_rendezvous(),然后可以在控制器中设定集结百分比。
15.LoadRunner中有基于目标和手动两种场景设计方式,他们分别适用于什么情况?
手动场景可按照要求来配置场景,能够更加精确的满足测试需要。
目标场景要先制定希望实现的测试目标,然后由控制器惊醒自动测试评估。
16.LoadRunner中有几种并发执行策略,它们的含义是什么?
三种。1.当所有虚拟用户中的x%到达集合点时释放。2.当所有正在运行的虚拟用户中的x%到达集合点时释放。3.当x个虚拟用户到达集合点时释放。
17.有5台配置为处理器:Intel Pentium 4 1.6G,内存容量 512MB,硬盘容量 40GB的机器,如何较好的利用这些机器完成一次并发用户数为1000人的性能测试工作?
1台做应用服务器,1台做数据库服务器,1台运行控制器并承担一部分负载生成任务,2台负载生成器。
18.平时大家在注册邮箱等关联操作时,经常会遇到需要输入验证码的情况,请问,如果我们公司也开发了一套带验证码的应用软件,需要警醒性能测试,您会如何处理?
留一个后门,我们设定一个所谓的“万能验证码”,只要用户输入这个“万能验证码”,系统就验证通过。测试完成后补上后门。
============================================================================================================================================
第二篇:性能测试面试题(参考第四篇的英文题目及答案)
1.什么是负载测试?什么是性能测试?
2.性能测试包含了哪些测试(至少举出3种)
3.简述性能测试的步骤
4.简述使用Loadrunner的步骤
5.什么时候可以开始执行性能测试?
6.LoadRunner由哪些部件组成?
7.你使用LoadRunner的哪个部件来录制脚本?
8.LoadRunner的哪个部件可以模拟多用户并发下回放脚本?
9.什么是集合点?设置集合点有什么意义?Loadrunner中设置集合点的函数是哪个?
10.什么是场景?场景的重要性有哪些?如何设置场景?
11.请解释一下如何录制web脚本?
12.为什么要创建参数?如何创建参数?
13.什么是关联?请解释一下自动关联和手动关联的不同。
14.你如何找出哪里需要关联?请给一些你所在项目的实例。
15.你在哪里设置自动关联选项?
16.哪个函数是用来截取虚拟用户脚本中的动态值?(手工管联)
17.你在VUGen中何时选择关闭日志?何时选择标准和扩展日志?
18.你如何调试LoadRunner脚本?
19你在LR中如何编写自定义函数?请给出一些你在以前进行的项目中编写的函数。
20.在运行设置下你能更改那些设置?
21.你在不同的环境下如何设置迭代?
22.你如何在负载测试模式下执行功能测试?
23.什么是逐步递增?你如何来设置?
24.以线程方式运行的虚拟用户有哪些优点?
25.当你需要在出错时停止执行脚本,你怎么做?
26.响应时间和吞吐量之间的关系是什么?
27.说明一下如何在LR中配置系统计数器?
28.你如何识别性能瓶颈?
29.如果web服务器、数据库以及网络都正常,问题会出在哪里?
30.如何发现web服务器的相关问题?
31.如何发现数据库的相关问题?
32.解释所有web录制配置?
33.解释一下覆盖图和关联图的区别?
34.你如何设计负载?标准是什么?
35.Vuser_init中包括什么内容?
36. Vuser_end中包括什么内容?
37.什么是think time?think_time有什么用?
38.标准日志和扩展日志的区别是什么?
39.解释以下函数及他们的不同之处。
Lr_debug_message
Lr_output_message
Lr_error_message
Lrd_stmt
Lrd_fetch
40.什么是吞吐量?
41.场景设置有哪几种方法
============================================================================================================================================
第三篇:性能测试面试题
1、 【测试理论】描述不同的角色(用户、产品开发人员、系统管理员)各自关注的软件性能要点。
2、 【测试理论】解释5个常用的性能指标的名称与具体含义。
3、 【测试流程】简述性能测试流程与各阶段的工作内容。
4、 【LR工具】web系统中,username参数表为file类型,表中有12个值,分别A、B、C、D、E、F、G、H、I、J、K、L。
测试场景中虚拟并发用户数设为4,迭代次数设为3,
参数中Select next row与Update value on分别为(Sequential, Each Iteration)与(Unique, Once)时,
写出迭代3次的取值情况。
(Select next row, Update value on) 虚拟用户取值(VUi:迭代时取值)
(Sequential, Each Iteration)
VU1:
VU2:
VU3:
VU4:
(Unique, Once)
VU1:
VU2:
VU3:
VU4:
5、【LR工具】web系统脚本录制过程中,两次录制同一功能点,在View Tree的Server Response中产生的字符串分别为:
Server Response:name="_id_Node " value=" RSDP0013425" />", ENDITEM,
Server Response:name="_id_Node " value=" RSDP1203655" />", ENDITEM,
为脚本回放成功,需要对字符串中某些字符做一定处理,写出详细实现方法。
6、 【数据库应用】现有Customers表和Sales表的数据如下:
Customers表:
CustID Name ShpCity Discount
449320 Adapto PortLand 0.05
890003 AA PortLand 0.05
888402 Seaworth Albany 0.04
Sales表:
SaleID CustID SaleMount
234112 499320 8000
234113 888402 6500
234114 499320 5900
234115 890003 4500
要求:
1) 给出查询语句,描述:在Customers表中查询名字为AA或Bolt的查询语句;
2) 给出删除操作,描述:在Sales表中删除SaleID为234115的语句。
3) 根据以下结果表给出多表查询语句。
SaleID CustID Name Discount SaleMount
234112 499320 Adapto 0.05 8000
234113 888402 Seaworth 0.04 6500
234114 499320 Adapto 0.05 5900
234115 890003 AA 0.05 4500
7、 【数据库应用】为了尽可能避免大表全表扫描,最常见的方法有哪些?
8、 【中间件】WebLogic参数调整中,列举三项影响并发性能的参数项并简述其含义。
9、 【Unix命令】HP-UX与AIX操作系统中,监控CPU、内存、磁盘I/O的命令分别是什么?
10、 【Unix命令】用命令实现:
1) 对文件FileA添加读、写、执行权限;
2) 列出当前系统与java相关的活动进程;
3) 搜索当前文件夹中所有的.sh文件。
11、 【网络】服务器ip地址为128.64.96.100,HP-UX操作系统,ftp服务开启,用户名与密码分别为username/password, /home目录下有一个monitor.svc文件,现需要将monitor.svc文件取到客户机192.168.2.100,服务器与客户机二者之间网络互通,描述在192.168.2.100上操作过程
============================================================================================================================================
第四篇: 45道性能测试的面试题及答案(In English)
1. What is load testing?
- Load testing is to test that if the application works fine with the loads that result from large number of simultaneous users, transactions and to determine weather it can handle peak usage periods.
2. What is Performance testing?
- Timing for both read and update transactions should be gathered to determine whether system functions are being performed in an acceptable timeframe. This should be done standalone and then in a multi user environment to determine the effect of multiple transactions on the timing of a single transaction.
3. Did u use LoadRunner? What version?
- Yes. Version x.x .
4. Explain the Load testing process? -
Step 1: Planning the test. Here, we develop a clearly defined test plan to ensure the test scenarios we develop will accomplish load-testing objectives.
Step 2: Creating Vusers. Here, we create Vuser scripts that contain tasks performed by each Vuser, tasks performed by Vusers as a whole, and tasks measured as transactions.
Step 3: Creating the scenario. A scenario describes the events that occur during a testing session. It includes a list of machines, scripts, and Vusers that run during the scenario. We create scenarios using LoadRunner Controller. We can create manual scenarios as well as goal-oriented scenarios. In manual scenarios, we define the number of Vusers, the load generator machines, and percentage of Vusers to be assigned to each script. For web tests, we may create a goal-oriented scenario where we define the goal that our test has to achieve. LoadRunner automatically builds a scenario for us.
Step 4: Running the scenario.We emulate load on the server by instructing multiple Vusers to perform. tasks simultaneously. Before the testing, we set the scenario configuration and scheduling. We can run the entire scenario, Vuser groups, or individual Vusers.
Step 5: Monitoring the scenario.We monitor scenario execution using the LoadRunner online runtime, transaction, system resource, Web resource, Web server resource, Web application server resource, database server resource, network delay, streaming media resource, firewall server resource, ERP server resource, and Java performance monitors.
Step 6: Analyzing test results. During scenario execution, LoadRunner records the performance of the application under different loads. We use LoadRunner’s graphs and reports to analyze the application’s performance.
5. When do you do load and performance Testing?
- We perform. load testing once we are done with interface (GUI) testing. Modern system architectures are large and complex. Whereas single user testing primarily on functionality and user interface of a system component, application testing focuses on performance and reliability of an entire system. For example, a typical application-testing scenario might depict 1000 users logging in simultaneously to a system. This gives rise to issues such as what is the response time of the system, does it crash, will it go with different software applications and platforms, can it hold so many hundreds and thousands of users, etc. This is when we set do load and performance testing.
6. What are the components of LoadRunner?
- The components of LoadRunner are The Virtual User Generator, Controller, and the Agent process, LoadRunner Analysis and Monitoring, LoadRunner Books Online.
7. What Component of LoadRunner would you use to record a Script?
- The Virtual User Generator (VuGen) component is used to record a script. It enables you to develop Vuser scripts for a variety of application types and communication protocols.
8. What Component of LoadRunner would you use to play Back the script. in multi user mode?
- The Controller component is used to playback the script. in multi-user mode. This is done during a scenario run where a vuser script. is executed by a number of vusers in a group.
9. What is a rendezvous point?
- You insert rendezvous points into Vuser scripts to emulate heavy user load on the server. Rendezvous points instruct Vusers to wait during test execution for multiple Vusers to arrive at a certain point, in order that they may simultaneously perform. a task. For example, to emulate peak load on the bank server, you can insert a rendezvous point instructing 100 Vusers to deposit cash into their accounts at the same time.
10. What is a scenario?
- A scenario defines the events that occur during each testing session. For example, a scenario defines and controls the number of users to emulate, the actions to be performed, and the machines on which the virtual users run their emulations.
11. Explain the recording mode for web Vuser script?
- We use VuGen to develop a Vuser script. by recording a user performing typical business processes on a client application. VuGen creates the script. by recording the activity between the client and the server. For example, in web based applications, VuGen monitors the client end of the database and traces all the requests sent to, and received from, the database server. We use VuGen to: Monitor the communication between the application and the server; Generate the required function calls; and Insert the generated function calls into a Vuser script.
12. Why do you create parameters?
- Parameters are like script. variables. They are used to vary input to the server and to emulate real users. Different sets of data are sent to the server each time the script. is run. Better simulate the usage model for more accurate testing from the Controller; one script. can emulate many different users on the system.
13. What is correlation?
Explain the difference between automatic correlation and manual correlation? - Correlation is used to obtain data which are unique for each run of the script. and which are generated by nested queries. Correlation provides the value to avoid errors arising out of duplicate values and also optimizing the code (to avoid nested queries). Automatic correlation is where we set some rules for correlation. It can be application server specific. Here values are replaced by data which are created by these rules. In manual correlation, the value we want to correlate is scanned and create correlation is used to correlate.
14. How do you find out where correlation is required? Give few examples from your projects?
- Two ways: First we can scan for correlations, and see the list of values which can be correlated. From this we can pick a value to be correlated. Secondly, we can record two scripts and compare them. We can look up the difference file to see for the values which needed to be correlated. In my project, there was a unique id developed for each customer, it was nothing but Insurance Number, it was generated automatically and it was sequential and this value was unique. I had to correlate this value, in order to avoid errors while running my script. I did using scan for correlation.
15. Where do you set automatic correlation options?
- Automatic correlation from web point of view can be set in recording options and correlation tab. Here we can enable correlation for the entire script. and choose either issue online messages or offline actions, where we can define rules for that correlation. Automatic correlation for database can be done using show output window and scan for correlation and picking the correlate query tab and choose which query value we want to correlate. If we know the specific value to be correlated, we just do create correlation for the value and specify how the value to be created.
16. What is a function to capture dynamic values in the web Vuser script?
- Web_reg_save_param function saves dynamic data information to a parameter.
17. When do you disable log in Virtual User Generator, When do you choose standard and extended logs?
- Once we debug our script. and verify that it is functional, we can enable logging for errors only. When we add a script. to a scenario, logging is automatically disabled. Standard Log Option: When you selectStandard log, it creates a standard log of functions and messages sent during script. execution to use for debugging. Disable this option for large load testing scenarios. When you copy a script. to a scenario, logging is automatically disabled Extended Log Option: Selectextended log to create an extended log, including warnings and other messages. Disable this option for large load testing scenarios. When you copy a script. to a scenario, logging is automatically disabled. We can specify which additional information should be added to the extended log using the Extended log options.
18. How do you debug a LoadRunner script?
- VuGen contains two options to help debug Vuser scripts-the Run Step by Step command and breakpoints. The Debug settings in the Options dialog box allow us to determine the extent of the trace to be performed during scenario execution. The debug information is written to the Output window. We can manually set the message class within your script. using the lr_set_debug_message function. This is useful if we want to receive debug information about a small section of the script. only.
19. How do you write user defined functions in LR?
Give me few functions you wrote in your previous project? - Before we create the User Defined functions we need to create the external library (DLL) with the function. We add this library to VuGen bin directory. Once the library is added then we assign user defined function as a parameter. The function should have the following format: __declspec (dllexport) char* (char*, char*)Examples of user defined functions are as follows:GetVersion, GetCurrentTime, GetPltform. are some of the user defined functions used in my earlier project.
20. What are the changes you can make in run-time settings?
- The Run Time Settings that we make are: a) Pacing - It has iteration count. b) Log - Under this we have Disable Logging Standard Log and c) Extended Think Time - In think time we have two options like Ignore think time and Replay think time. d) General - Under general tab we can set the vusers as process or as multithreading and whether each step as a transaction.
21. Where do you set Iteration for Vuser testing?
- We set Iterations in the Run Time Settings of the VuGen. The navigation for this is Run time settings, Pacing tab, set number of iterations.
22. How do you perform. functional testing under load?
- Functionality under load can be tested by running several Vusers concurrently. By increasing the amount of Vusers, we can determine how much load the server can sustain.
23. What is Ramp up? How do you set this?
- This option is used to gradually increase the amount of Vusers/load on the server. An initial value is set and a value to wait between intervals can bespecified. To set Ramp Up, go to ‘Scenario Scheduling Options’
24. What is the advantage of running the Vuser as thread?
- VuGen provides the facility to use multithreading. This enables more Vusers to be run per generator. If the Vuser is run as a process, the same driver program is loaded into memory for each Vuser, thus taking up a large amount of memory. This limits the number of Vusers that can be run on a single generator. If the Vuser is run as a thread, only one instance of the driver program is loaded into memory for the given number of Vusers (say 100). Each thread shares the memory of the parent driver program, thus enabling more Vusers to be run per generator.
25. If you want to stop the execution of your script. on error, how do you do that?
- The lr_abort function aborts the execution of a Vuser script. It instructs the Vuser to stop executing the Actions section, execute the vuser_end section and end the execution. This function is useful when you need to manually abort a script. execution as a result of a specific error condition. When you end a script. using this function, the Vuser is assigned the status “Stopped”. For this to take effect, we have to first uncheck the “Continue on error” option in Run-Time Settings.
26. What is the relation between Response Time and Throughput?
- The Throughput graph shows the amount of data in bytes that the Vusers received from the server in a second. When we compare this with the transaction response time, we will notice that as throughput decreased, the response time also decreased. Similarly, the peak throughput and highest response time would occur approximately at the same time.
27. Explain the Configuration of your systems?
- The configuration of our systems refers to that of the client machines on which we run the Vusers. The configuration of any client machine includes its hardware settings, memory, operating system, software applications, development tools, etc. This system component configuration should match with the overall system configuration that would include the network infrastructure, the web server, the database server, and any other components that go with this larger system so as to achieve the load testing objectives.
28. How do you identify the performance bottlenecks?
- Performance Bottlenecks can be detected by using monitors. These monitors might be application server monitors, web server monitors, database server monitors and network monitors. They help in finding out the troubled area in our scenario which causes increased response time. The measurements made are usually performance response time, throughput, hits/sec, network delay graphs, etc.
29. If web server, database and Network are all fine where could be the problem?
- The problem could be in the system itself or in the application server or in the code written for the application.
30. How did you find web server related issues?
- Using Web resource monitors we can find the performance of web servers. Using these monitors we can analyze throughput on the web server, number of hits per second that occurred during scenario, the number of http responses per second, the number of downloaded pages per second.
31. How did you find database related issues?
- By running “Database” monitor and help of “Data Resource Graph” we can find database related issues. E.g. You can specify the resource you want to measure on before running the controller and than you can see database related issues
32. Explain all the web recording options?
33. What is the difference between Overlay graph and Correlate graph?
- Overlay Graph: It overlay the content of two graphs that shares a common x-axis. Left Y-axis on the merged graph show’s the current graph’s value & Right Y-axis show the value of Y-axis of the graph that was merged. Correlate Graph: Plot the Y-axis of two graphs against each other. The active graph’s Y-axis becomes X-axis of merged graph. Y-axis of the graph that was merged becomes merged graph’s Y-axis.
34. How did you plan the Load? What are the Criteria?
- Load test is planned to decide the number of users, what kind of machines we are going to use and from where they are run. It is based on 2 important documents, Task Distribution Diagram and Transaction profile. Task Distribution Diagram gives us the information on number of users for a particular transaction and the time of the load. The peak usage and off-usage are decided from this Diagram. Transaction profile gives us the information about the transactions name and their priority levels with regard to the scenario we are deciding.
35. What does vuser_init action contain?
- Vuser_init action contains procedures to login to a server.
36. What does vuser_end action contain?
- Vuser_end section contains log off procedures.
37. What is think time? How do you change the threshold?
- Think time is the time that a real user waits between actions. Example: When a user receives data from a server, the user may wait several seconds to review the data before responding. This delay is known as the think time. Changing the Threshold: Threshold level is the level below which the recorded think time will be ignored. The default value is five (5) seconds. We can change the think time threshold in the Recording options of the Vugen.
38. What is the difference between standard log and extended log?
- The standard log sends a subset of functions and messages sent during script. execution to a log. The subset depends on the Vuser type Extended log sends a detailed script. execution messages to the output log. This is mainly used during debugging when we want information about: Parameter substitution. Data returned by the server. Advanced trace.
39. Explain the following functions:
- lr_debug_message - The lr_debug_message function sends a debug message to the output log when the specified message class is set. lr_output_message - The lr_output_message function sends notifications to the Controller Output window and the Vuser log file. lr_error_message - The lr_error_message function sends an error message to the LoadRunner Output window. lrd_stmt - The lrd_stmt function associates a character string (usually a SQL statement) with a cursor. This function sets a SQL statement to be processed. lrd_fetch - The lrd_fetch function fetches the next row from the result set.
40. Throughput
- If the throughput scales upward as time progresses and the number of Vusers increase, this indicates that the bandwidth is sufficient. If the graph were to remain relatively flat as the number of Vusers increased, it would be reasonable to conclude that the bandwidth is constraining the volume of data delivered.
41. Types of Goals in Goal-Oriented Scenario
- Load Runner provides you with five different types of goals in a goal oriented scenario:
* The number of concurrent Vusers
* The number of hits per second
* The number of transactions per second
* The number of pages per minute
* The transaction response time that you want your scenario
42. Analysis Scenario (Bottlenecks):
In Running Vuser graph correlated with the response time graph you can see that as the number of Vusers increases, the average response time of the check itinerary transaction very gradually increases. In other words, the average response time steadily increases as the load increases. At 56 Vusers, there is a sudden, sharp increase in the average response time. We say that the test broke the server. That is the mean time before failure (MTBF). The response time clearly began to degrade when there were more than 56 Vusers running simultaneously.
43. What is correlation?
Explain the difference between automatic correlation and manual correlation? - Correlation is used to obtain data which are unique for each run of the script. and which are generated by nested queries. Correlation provides the value to avoid errors arising out of duplicate values and also optimizing the code (to avoid nested queries). Automatic correlation is where we set some rules for correlation. It can be application server specific. Here values are replaced by data which are created by these rules. In manual correlation, the value we want to correlate is scanned and create correlation is used to correlate.
44. Where do you set automatic correlation options?
- Automatic correlation from web point of view, can be set in recording options and correlation tab. Here we can enable correlation for the entire script. and choose either issue online messages or offline actions, where we can define rules for that correlation. Automatic correlation for database, can be done using show output window and scan for correlation and picking the correlate query tab and choose which query value we want to correlate. If we know the specific value to be correlated, we just do create correlation for the value and specify how the value to be created.
45. What is a function to capture dynamic values in the web vuser script?
- Web_reg_save_param function saves dynamic data information to a parameter.
============================================================================================================================================
-
性能测试从零开始--读书笔记(转载)
2010-09-01 11:40:19
author: selfimpr
blog: http://blog.csdn.net/lgg201
mail: lgg860911@yahoo.com.cn
感谢51testing 的柳胜前辈精彩的讲解
以下是我的读书笔记, 在公司是程序员, 工作需要, 简单学习一下, 分享出来, 不足之处, 请邮件指点, 谢谢.
Vuser 脚本语言基础
1 脚本结构 :1.1 vuser_init: 脚本初始化操作 , 一般放置登录操作 , 分配内存等 , 在播放 vuser_init 时 , Controller 的 Vuser 状态区域会显示 initialize 状态
1.2 Action: 虚拟用户要做的业务操作 .
1.3 vuser_end: 与 vuser_init 对应 , 做收尾工作 .
2 脚本中使用的三种函数
2.1 VU 通用函数 : lr_ 系列函数
2.2 协议相关函数 : 一般以协议名开头 , 比如 web 协议就是 web_ 系列
2.3 语言相关函数 : 由 VU 脚本的生成语言决定 . 多用于用户自定义函数进行脚本扩展 .
3 以 C 语言的 VU 脚本为例 , 实际上是隐式的存在 main 函数的 , 然后在 main 中去依次调用了 vuser_init, Action, vuser_end 几个函数 .
4 录制 HTTP 协议的 web 系统测试脚本时 , 会生成一个 globals.h 文件 , 这个文件用来负责 vuser_init, Action, vuser_end 三个脚本都可用的全局变量的声明 .
5 lr_whoami(*userid, char **groupname, int *sceneid) 可以用来获取当前运行 vuser 的 vuserid, 组名 , 场景 id, 在动态参数化的时候 , 可以使用这些值来构建动态参数 .
6 自定义函数 :
6.1 直接引用 : 以 C 语言产生的脚本 , 可以直接在 Action 外部定义函数 , 然后在 Action 内使用 .
6.2 本地加载 : 使用 lr_load_dll(char *dll_file_name); 加载动态链接库 , 然后调用库中的函数 .
6.3 include 模式 : 把多个函数写在一个文件中 , 在 vuser_init, Action, vuser_end 中的 include 并调用
6.4 全局加载 (dll) 模式 : 在 LoadRunnder/data 目录下的 mdrv.dat 文件中 , 查找对应协议 , 然后在下面按照已有内容格式配置链接库即可
7 通用 vu 函数 : 构建在 C 语言基础上的脚本框架函数 , 以 lr 开头 , 分为以下几类
7.1 事务和事务控制函数 :
7.1.1 lr_end_sub_transaction: 标记子事务的结束以便进行性能分析
7.1.2 lr_end_transaction: 标记 LoadRunner 事务的结束
7.1.3 lr_end_transaction_instance: 标记事务实例的结束以便进行性能分析
7.1.4 lr_fail_trans_with_error: 打开事务的状态设置为 LR_FAIL 并发送错误消息 .
7.1.5 lr_get_trans_instance_duration: 获取事务实例的持续时间
7.1.6 lr_get_trans_instance_wasted_time: 获取事务实例浪费的时间
7.1.7 lr_get_transaction_duration: 获取事务的持续事件 ( 按事务名称 )
7.1.8 lr_get_transaction_think_time: 获取事务的思考时间 ( 按事务名称 )
7.1.9 lr_get_transaction_wasted_time: 获取事务浪费的时间 ( 按事务的名称 )
7.1.10 lr_resume_transaction: 继续收集事务数据以便进行性能分析
7.1.11 lr_resume_transaction_instance: 继续收集事务实例数据以便进行性能分析
7.1.12 lr_set_transaction_instance_status: 设置事务实例的状态
7.1.13 lr_set_transaction_status: 设置打开事务的状态
7.1.14 lr_set_transaction_status_by_name: 设置事务的状态
7.1.15 lr_start_sub_transaction: 标记子事务的开始
7.1.16 lr_start_transaction: 标记事务的开始
7.1.17 lr_start_transaction_instance: 启动嵌套事务 ( 由它的父事务的句柄指定 )
7.1.18 lr_stop_transaction: 停止事务数据的收集
7.1.19 lr_stop_transaction_instance: 停止事务实例的数据收集
7.1.20 lr_wasted_time: 消除所有打开事务浪费的时间 .
7.2 命令行分析函数 : 当 LoadRunner 以命令行方式启动和运行时 , 以下函数用来分析命令行
7.2.1 lr_get_attrib_double: 检索脚本命令行中使用的 double 类型变量
7.2.2 lr_get_attrib_long: 检索脚本命令行中使用的 long 行变量
7.2.3 lr_get_attrib_string: 检索脚本命令行中使用的字符串
7.3 系统信息函数 : 获取 VU 的系统信息
7.3.1 lr_user_data_point: 记录用户定义的数据采集点
7.3.2 lr_whoami: 将有关 vuser 的信息返回给 vuser 脚本
7.3.3 lr_get_host_name: 返回执行 vuser 脚本的主机名
7.3.4 lr_get_master_host_name: 返回运行 LoadRunner Controller 的计算机名
7.4 字符串函数 :
7.4.1 lr_eval_string: 返回参数的当前值
7.4.2 lr_save_string: 将以 NULL 结尾的字符串保存到参数中
7.4.3 lr_save_var: 将变长字符串保存到参数中
7.4.4 lr_save_datetime: 将当前日期和时间保存到参数中
7.4.5 lr_advance_param: 前进到下一个可用参数
7.4.6 lr_decrypt: 解密已编码的字符串
7.4.7 lr_eval_string_ext: lr_eval_string 的扩展 , 为指向包含参数数据的缓冲区的指针
7.4.8 lr_eval_string_ext_free: 释放由 lr_eval_string_ext 分配的指针
7.4.9 lr_save_searched_string: 在缓冲区中搜索字符串实例 , 并将该字符串实例保存到参数中 .
7.5 消息函数 :
7.5.1 lr_debug_message: 将调试信息发送到输出窗口
7.5.2 lr_error_message: 将错误消息发送到输出窗口
7.5.3 lr_get_debug_message: 得到当前的消息类
7.5.4 lr_log_message: 将输出消息直接发送到 output.txt 文件 , 此文件位于 vuser 脚本目录
7.5.5 lr_output_message: 将消息发送到输出窗口中
7.5.6 lr_set_debug_message: 为输出消息设置消息类
7.5.7 lr_vuser_status_message: 生成格式化输出并将其打印到 Controller Vuser 状态区域
7.5.8 lr_message: 将消息发送到 vuser 日志和输出窗口 .
7.6 运行时函数 :
7.6.1 lr_load_dll: 加载外部 dll
7.6.2 lr_think_time: 暂停脚本的执行 , 以模拟思考时间
7.6.3 lr_continue_on_error: 指定脚本如何处理错误场景 , 是继续还是退出
7.6.4 lr_rendezvous: 在 vuser 脚本中设置集合点
8 HTTP 协议函数 :
8.1 HTTP 协议 :
8.1.1 header 设置 :
8.1.1.1 web_add_header
8.1.1.2 web_clean_heander
8.1.2 点击链接 :
8.1.2.1 web_link( 文字链接 )
8.1.2.2 web_image( 点击图片链接 )
8.1.3 提交表单 :
8.1.3.1 web_submit_data
8.1.3.2 web_submit_form.
8.2 web 系统设置
8.2.1 cache 设置 :
8.2.1.1 web_cache_leanup
8.2.1.2 web_load_cache
8.2.2 cookie 设置
8.2.2.1 web_add_cookie
8.2.2.2 web_cleanup_cookies
8.2.3 proxy 设置
8.2.3.1 web_set_proxy
8.2.3.2 web_set_secure_proxy
8.3 LoadRunner 框架支持
8.3.1 检查点 :
8.3.1.1 web_find
8.3.1.2 web_image_check
8.3.2 关联
8.3.2.1 web_create_html_param
8.3.2.2 web_create_html_param_ex
8.3.2.3 web_reg_save_param
8.3.2.4 web_set_max_html_param_len
8.3.3 控制
8.3.3.1 lr_start_transaction
8.3.3.2 lr_rendezvous
8.3.3.3 lr_think_time
用户行为模拟器 —VUSER
1 录制 HTTP 协议的脚本时 , 录制方式的选择原则 :1.1 基于浏览器的应用程序使用 HTML-basedScript.
1.2 不是浏览器的应用使用 URL-based Script.
1.3 如果基于浏览器的应用程序中包含了 Javascript. 并且该脚本向服务器产生了请求 , 比如 DataGrid 的分页按钮等 , 也要使用 URL-based 方式录制
1.4 给予浏览器的应用程序中使用了 HTTPS 安全协议 , 使用 URL-based 方式录制 .
2 几种有用的日志 : 脚本能够正常运行后 , 应当禁用日志以降低消耗 .
2.1 执行日志 :
2.1.1 脚本运行时产生 .
2.1.2 描述 Vuser 运行时执行的操作
2.1.3 黑色表示标准输出消息 , 红色表示标准错误消息 , 绿色用引号括起来的文字字符串 ( 例如 URL), 蓝色表示事务信息 ( 开始 , 结束 , 状态 , 持续时间 );
2.2 录制日志 : 在脚本录制过程中产生 , 详细描述录制过程中客户端与服务器之间的各种交互动作 .
2.3 产生日志 : 记录了脚本录制的设置 , 网络实践到脚本函数的转换过程 .
3 Tools/General Options/Display/Show browser during replay 选中后可以在 VU 运行时查看浏览器活动 , 不过这只是一个不完整的解释器而不是浏览器 , 因此一些脚本可能会加载不完全 . 打开运行时查看器后在运行脚本时就会实时播放动作 .
4 关联 : 对于一些请求 , 需要以前面某次请求服务器响应的数据去作为请求参数 , 因此 , 不能把这些数据硬编码 , 而是以参数的方式提供 , 同样 , 要使用的前面某次请求响应的数据也要写入到变量中以便使用 .
5 录制前自动关联 : 在录制脚本之前 , 已知寻找需要关联数据和关联的规则 , 就可以通过为 VU 设置规则来让其自动关联 .
5.1 内建关联规则 : 对于一些常用系统 , VU 有内建的关联规则 , 通过 Recording Options/HTTP Properties/Correlation 中启用关联规则 , 然后选择相应的关联规则 , 则在录制对应的系统时 , 就会自动建立关联 .
5.2 自定义关联规则 : Recording Options/HTTP Properties/Correlation 中建立新的关联规则 ( 也需要启用关联 )
6 录制后自动关联 : 录制完成后 , 脚本至少需要执行一次 , 在执行中 , 录制后关联会试图找出录制时和执行时服务器响应内容的差异部分 , 藉以找出需要关联的数据并建立关联 .
7 手动关联 :
7.1 找出需要关联的数据
7.1.1 使用相同的业务流程和数据 , 录制两份脚本
7.1.2 使用 WinDiff 工具找出不同点 : Tools/Compare with Vuser
7.2 使用 web_reg_save_param 函数手动建立关联
7.3 web_reg_save_param 函数放在要检查内容的请求之前
7.4 原理 : 捕获第一个操作的输出 à 保存为参数 à 将参数作为另一个操作的输入
8 关联的用户和意义 :
8.1 简化和优化脚本代码
8.2 动态生成数据 : session 等服务器端返回数据的利用
8.3 支持唯一数据
9 除了显式的以 lr_start_transaction 控制事务外 , 还可以在 vuser 的运行时设置中的 miscellaneous 选项中定义自动事务 .
10 集合点 ( 同步点 ): 为了模拟较重的用户负载 , 需要模拟多个 vuser 同时向服务器发送请求 , 此时 , 就可以在 vuser 脚本中通过 lr_rendezvous 来创建集合点 , Controller 在遇到集合点时会暂停脚本 , 等待其他 vuser 到达后 , 一起释放 vuser 运行 . 需要注意的是只能在 action 中添加集合点 , 而不能在 vuser_init 和 vuser_end 中创建 .
11 思考时间 : 为了模拟用户在操作过程中的停顿 , 可以用 lr_think_time 来设置思考时间 , 思考时间的单位是秒 . 有时测试不需要思考时间 , 这时就可以通过 Run-time Settings/Think time 中设置忽略思考时间 .
12 由于集合点和思考时间在 Controller 运行中都会产生等待 , 因此如果在事务中有这两项操作 , 就可能会对事务的响应时间产生影响导致结果不准确 .
13 参数化的过程 :
13.1 在脚本中用参数取代常量值
13.2 设置参数的属性以及数据源 .
14 参数数据源类型 : 参数的信息在脚本目录下的 ” 脚本名 .prm” 文件中
14.1 Data Files: 数据保存在文件中
14.2 User-Defined Functions: 调用外部 dll 函数生成数据
14.3 Internal Data: 虚拟用户内部产生的数据
14.3.1 Date/Time: 用当前日期 / 时间替换参数 , 需要指定 Date/Time 格式 .
14.3.2 Group Name: 用虚拟用户组名称替换参数
14.3.3 Load Generator Name: 用脚本负载生成器的名称替换参数 , 负载生成器是虚拟用户在运行的计算机
14.3.4 Iteration Number: 用当前迭代数目替换参数
14.3.5 Random Number: 用一个随机数替换参数
14.3.6 Unique Number: 用一个唯一的数字来替换参数 .
14.3.7 Vuser Id: 用运行时分配给 Vuser 的 id 替换参数
15 Tools/General Options/Parameterization 可以定义参数的括号类型 .
16 直接的参数化 , 只有在其作为函数参数时才能够使用 , 而且 , 有些函数的有些参数是不能被参数化的 , 在这种情况下 , 如果想要参数化 , 可以使用 lr_eval_string() 来代替要参数化的内容 , 而我们去参数化 lr_eval_string() 的参数 .
17 由于 lr_eval_string 返回的是一个指向参数值的指针 , 内容在每次 Iteration 后自动释放 , 因此 , 对于一个大的 Iteration, 如果使用 lr_eval_string 做参数化可能导致内存迟迟不能释放 , 此时可以使用 lr_eval_string_ext 和 lr_eval_string_ext_free 配对使用来自己做清理工作 .
18 Vuser/Parameter List 中可以统一管理当前脚本中所有参数的属性 .
19 参数的 update value on 意义
19.1 each occurrence: 每发生一次换一个
19.2 each iteration: 每次迭代换一个
19.3 once: 所有循环中都使用同一个值
20 参数的 when out of values 的意义
20.1 Abort Vuser: 中止
20.2 Continue in a cyclick manner: 继续循环取值
20.3 Continue with last value: 取最后一个值
21 从数据库导入参数
21.1 利用 Microsoft Query 从已存在的数据库中导入参数数据 (Microsoft Query 是 Office 的套件之一 , 没有安装开始菜单中的快捷方式 , 可以在 Office 安装目录下找 MSQRY32.EXE, 如果没有 , 可能是安装 Office 时没有安装 , 运行安装程序添加组件即可 )
21.2 指定数据库连接或 SQL: 在设置参数的界面如下顺序操作
21.2.1 点击 Data wizard
21.2.2 选择 Specify SQL statement manually
21.2.3 Creat
21.2.4 新建数据源 , 导入数据即可
22 检查点 : 对于 web 应用 , vuser 中的请求执行成功并不能代表业务流程是成功的 , 比如用户名密码错误也会返回 200 响应 , 所以 , 需要检查服务器的响应内容来判断业务流程是否执行成功 , 这个判断的点就是检查点 .
22.1 全局检查点 : 运行时设置中设置 ContentCheck, 这种检查点对于有统一出错处理页面的系统是有效的 .
22.2 检查函数 : 在一个请求完成后 , 运行检查函数 , 然后作出期望的处理返回 .
22.2.1 web_find: 检查文本
22.2.2 web_image_check: 检查图片
22.2.3 web_reg_find: 与 web_find 类似 , 不过 , 这个函数是先注册 ( 在请求之前 ), 然后查找 , 并且 , 这个函数可以查找多次 , 通过 SaveCount 保存查找到的次数 . 另外 , 通过运行时设置设置的 enable image and text check 对 web_find 有效 , 而对 web_reg_find 无效 , 即 web_reg_find 只要写了就会查找 .
23 Action/Import Action into vuser 可以将其他 Action 引入进来
24 在 Run-time settings 中可以设置脚本的全局错误处理机制 ( 是否继续执行 ), 但是 , 对于某些特殊段的脚本如果期望得到特殊的效果 , 可以通过 lr_continue_on_error 函数来控制 , 该函数接受参数 0 或 1, 0 表示以下代码在发生错误时退出 , 反之则继续执行 .
25 动态运行 : Tools/General Options/Replay 中设置动态运行的延时 , 然后在 view 菜单内选择 Animated run 即可以进入动态运行状态 , 此时运行脚本每运行一句都会暂停设定的毫秒数 .
26 扩展日志选项的意义 :
26.1 参数替换 : 记录指定给脚本的所有参数及其相应的值
26.2 服务器返回的数据 : 记录服务器返回的所有数据
26.3 高级跟踪 : 记录 vuser 在会话期间发送的所有函数和消息 .
27 由于扩展日志内容较大 , 因此可以选择性的开启 , 以自定义函数方式 , 调用处理时同错误处理一样 .
void ud_log_extend(int switch) {
lr_set_debug_message(LR_MSG_CLASS_EXTENDED_LOG, switch); // 设置扩展日志
lr_set_debug_message(LR_MSG_CLASS_PARAMETERS_LOG, switch); // 设置参数替换日志
lr_set_debug_message(LR_MSG_CLASS_RESULT_LOG, switch); // 设置服务器返回数据日志
lr_set_debug_message(LR_MSG_CLASS_FULL_LOG, switch); // 设置高级跟踪日志
}
Action_test{
ud_log_extend(1); /* 开启扩展日志 */
web_link(“test”, “Text=test”, LAST);
ud_log_extend(0); /* 关闭扩展日志 */
return 0;
}
28 验证测试脚本的通常流程 :
28.1 录制或开发脚本
28.2 单用户单迭代 : 解决可能存在的关联问题
28.3 单用户多迭代 : 验证参数化问题
28.4 多用户单迭代 : 验证可能存在的多线程问题
28.5 多用户多线程 : 实际就是真正的性能测试开始 .
29 Tools/Create Controller Scenario 根据当前脚本创建场景
性能测试指挥中心 —Controller
1 手工场景 : 负载测试通常使用手工场景 , 首先设置虚拟用户数目 , 脚本 , 以及它们运行的方式 , 然后运行得出服务器的响应时间等指标 .2 面向目标的场景 : 首先定义测试要达到的目标 , 然后 LoadRunner 自动基于这些目标创建场景 , 运行过程中 , 不断把结果和目标相比较决定下一步走向 .
3 虚拟用户组 : 一组用户指的就是针对同一个脚本的多个虚拟用户 , 在同一个场景中 , 可以用多个用户组使用同一个脚本 .
4 集合点 ( 同步点 ): 如果当前场景中的脚本中包含集合点 (rendezvous), 那么可以通过 Scenario/Rendezvous 打开集合点信息面板来设置集合点信息
4.1 点击 Policy 按钮 : 这里设置集合点的策略 . 三个 Release 选项用来设置释放集合点的策略 , timeout 表明第一个 vuser 等待一定时间后就不再等待 , 释放等待用户 , 继续执行场景 .
5 负载生成器 : 网内安装了负载生成器的机器都可以被同一个 Controller 控制用来生成负载 .
6 在 Controller 中可以对 vuser 组进行运行时设置 , 这里可以设置网络带宽来模拟真实的情况 .
7 在 schedule( 调度栏 ) 内可以设置 vuser 加载及卸载的方式等调度策略 .
8 Scenario/Convert scenario to the percentage mode 可以将场景转换为百分比模式 . 百分比模式的场景只是对场景内的 vuser group 中的 vuser 数量进行了百分比分配
9 面向场景的目标类型 : 一次只能设置一个目标 .
9.1 virtual users: 虚拟用户数量 , 如果测试服务器的并发处理能力 , 使用这个目标 .
9.2 hits per second: 每秒点击数 , 测试 web 的真正响应处理能力 .
9.3 transaction per second: 每秒事务数 , 这种目标需要选择事务名 .transaction response time: 事务响应时间 , 需要选择事务名 , 测试 web 的真正响应处理能力 .
9.4 pages per minute: 每分钟页面响应数
10 Controller 的加载策略 :
10.1 在使用 pages per minute, hits/transaction per second 这几种目标时 , 加载时首先用最小用户数除以定义的目标 , 得到一个值 , 然后确定每个用户应该达到的数据 , 然后 Controller 开始按照以下策略加载用户 :
10.1.1 如果选择的是自动加载 vuser, controller 会首先记载 50 个 vuser, 如果定义的最大用户数小于 50, 会一次加载所有的 vuser.
10.1.2 如果选择的是在场景运行一段时间后达到目标 , LoadRunner 会尝试在定义的这段时间内达到目标 , 根据时间限制和计算出的单用户数据确定第一批加载多少 vuser.
10.1.3 如果选择的是按照一定的阶段达到目标 ( 也就是 x 长时间内达到 y 数据 , 然后达到下一目标 ), LoadRunner 计算每个用户应该达到的数字后 , 再确定第一批加载多少用户 .
10.2 每加载一批用户 , LoadRunner 会判断是否达到这批用户的目标 , 如果这批用户目标没有达到 , LoadRunner 重新计算每一个用户应该达到的目标数字后 , 重新调整下一批加载用户数量 .
10.3 如果 Controller 加载了最多数量的用户还没有达到预订目标 , 会重新计算每个用户的目标 , 然后同时运行最大数量的用户 , 尝试达到预订目标
10.4 如果出现以下情况 , pages per minute, hits/transaction per second 三种类型的面向目标场景会置于 ”Failed” 状态 :
10.4.1 Controller 使用了指定的最大数量用户 , 并且两次都没有达到目标
10.4.2 所有的用户运行都失败
10.4.3 没有足够的 LoadGenerator 机器
10.4.4 Controller 增加了几批用户后 , pages per minute, hits/transaction per second 数据没有增加 .
11 IP 欺骗设置 : 应对某些服务器要求不允许单 IP 多登的测试 .
11.1 在负载生成器机器上 ( 必须使用固定 IP), “Windows 开始 ”/LoadRunner/Tools/Ip wizard 打开 IP 向导 , 根据向导配置 IP 列表 .
11.2 在 Controller 中 , Scenario/Enable IP spoofer 打开 IP 欺骗
12 场景的运行时控制
12.1 场景开始运行后 , 可以通过 stop 按钮停止 , 但是停止的方式需要在运行之前通过 Tools/Options/Run-time settings 中设置好
12.2 场景开始运行后的 reset 按钮用来将方案中的所有 vuser 组重置为其方案前的关闭状态
12.3 Vusers 用来查看 vuser 组内每个 vuser 的详细状态
12.4 Run/Stop Vusers 打开 ” 运行 / 停止 vuser” 对话框 , 在场景运行时决定是继续执行还是停止某个用户组 .
12.5 运行时释放集合点用户 : Scenario/Rendezvous 然后选定用户 disable vuser
13 如果系统提供的数据采集点不能满足需求 , 可以在脚本中用 lr_user_data_point 自定义数据采集点 .
14 判断磁盘瓶颈的方法 : 每磁盘 I/O 数 = [ 读次数 +(4* 写次数 )]/ 磁盘个数 , 如果每磁盘的 I/O 数大于磁盘的处理能力 , 那么磁盘存在瓶颈 .
寻找系统瓶颈的得力助手 —Analysis
1 Analysis 功能 :1.1 Analysis 图有助于确定系统性能瓶颈 .
1.2 “ 图数据 ” 视图和 ” 原始数据 ” 视图以电子表格格式显示用于生成图的实际数据 .
1.3 “ 报告 ” 功能可以使用户查看每个图的摘要 , HTML 报告或各种性能和活动报告 .
2 摘要报告 (summary):
2.1 Analysis summary( 统计摘要 ):
2.1.1 Maximum Running vusers: 最大同时运行用户数
2.1.2 Total Throughput(bytes): 吞吐量
2.1.3 Average Thoughput(bytes/second): 吞吐率
2.1.4 Total Hits: 总点击数
2.1.5 Average Hits per Second: 每秒点击数
2.1.6 View HTTP Responses Summary: 查看 HTTP 响应的摘要
3 Trasaction summary( 事务摘要 ):
3.1 Minimum: 事务最小时间
3.2 Average: 平均事务时间
3.3 Maximum: 事务最大时间
3.4 Std.Deviation: 标准方差 . 值越大数据越离散也就说明不稳定 .
3.5 90 Percent: 90% 的事务消耗的时间 , 通常这个值比总平均时间个更可靠 .
3.6 Pass/Fail/Stop: 通过 / 失败 / 中途停止的事务数
4 在 Average Transaction Response Time 图中 , 可以选择某个事务曲线 , 右键 ”Web Page Breakdown for login” 将事务进行分解 , 查看事务过程中每个请求的每一步是怎么样完成的 .
5 Time to first buffer breakdown(Over Time) 图中可以对比页面响应时间中的服务器时间和网络时间 , 从而分析是网络还是服务器造成的耗时 .
6 Page Download Time Breakdown(Over Time) 图中可以看出每次请求详细分解的请求时间 ( 包括客户端时间 , 连接时间 , DNS 解析时间 , 错误时间 , 首次缓存时间 , FTP 鉴权时间 , 接收时间 , SSL 处理时间等等 ).
7 图的合并 :
7.1 叠加 : 重叠共用一个 x 轴的两个图的内容 , 合并图使用左右两个不同的 y 轴
7.2 平铺 : 共用同一个 x 轴的数据 , 但显示上上下分离 , 合并图仍然是左右两个不同的 y 轴
7.3 关联 : 当前图的 y 轴成为合并图的 x 轴 , 被合并图的 y 轴是合并图的 y 轴
8 可以使用 Reports 生成报告 .
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/lgg201/archive/2010/08/15/5812928.aspx
-
上周测试rmi接口,写了简单的swing客户端和测试性能的java多线程脚本,有兴趣的研究
2010-07-29 13:53:24
上周测试rmi接口,写了简单的swing客户端和测试性能的java多线程脚本,有兴趣的研究
因为lib下jar包太大已删除,有截图说明使用到了哪些jar包
一个教训:
关于多线程中平均响应时间的计算方法,最开始的时候有点想当然了,后来被别人review出来。
应该是 分别计算每个线程的平均响应时间,然后 求和之后取平均值。
而不是之前的简单的用 运行时间/总次数
但是,平均每秒处理的请求数,还是之前的,简单的 总次数/运行时间
也可以这样计算: 每个线程的平均每秒处理的请求数 求和
其他想法:
脚本运行期间,已经随时打出了,每个线程的响应时间等信息,最后也做了统计,
但是没有整体情况的图表可以查看,
可以将数据写入文本,然后用excel处理,生成比较直观的图表,这样性能报告更好些。
这是脚本project :
 testClient.rar(48.3 KB)
testClient.rar(48.3 KB) -
一个不错的博客:卖烧烤的鱼测试博客
2009-07-21 18:01:53
以下均为转载:
地址:
http://www.cnblogs.com/mayingbao/archive/2006/04/17/376800.html
[原创]性能测试之“Windows性能监视器”
[原创]性能测试之“Windows性能监视器”
一 Windows性能监视器
以下用Winxp中的“Windows性能监视器”为例说明:
打开控制面板->管理工具->性能->性能日志和警报,如下图所示:
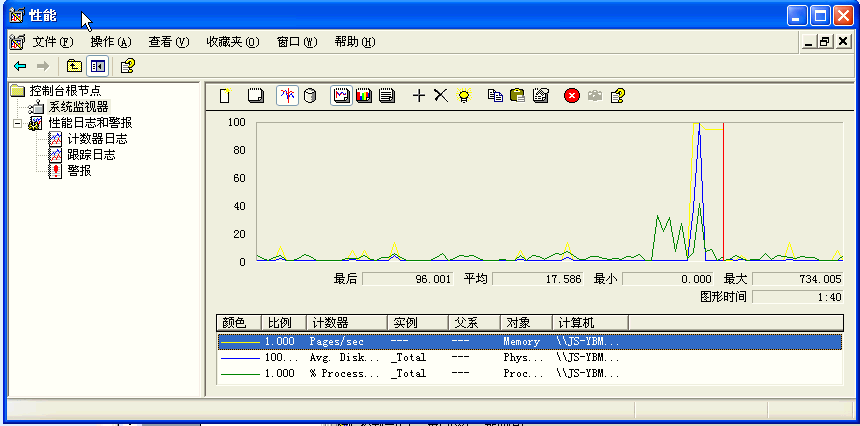
方法1:动态监视
点击右键后,选择“添加计数器”如下图所示:
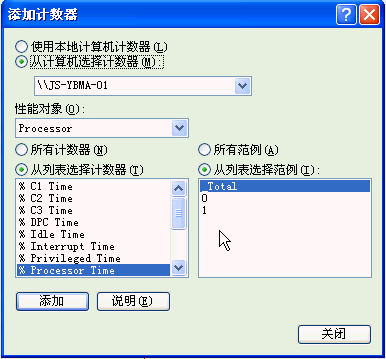
从“添加计数器”窗口中,选择性能对象为“Process”; 其它设置为默认设置;设置完毕,点击“添加”按钮,关闭窗口,即可实时监视选中的参数。
方法2:计数器日志跟踪
打开控制面板->管理工具->性能->性能日志和警报->计数器日志->新建日志设置
设置新建日志名“TopView_V1.0.0.0_PerLog_20060215”;
设置日志监视的对像和计数器,如设置性能对像“Processor”,列表选择计数器“% Processor Time”
备注:“% Processor Time” 指处理器用来执行非闲置线程时间的百分比。计算方法是,测量范例间隔内非闲置线程活动的时间,用范例间隔减去该值。(每台处理器有一个闲置线程,该线程在没有其他线程可以运行时消耗周期)。这个计数器是处理器活动的主要说明器,显示在范例间隔时所观察的繁忙时间平均百分比。这个值是用 100% 减去该服务不活动的时间计算出来的。
设置日志文件,如“日志文件类型”,选择“文本文件(逗号分隔)”;
备注:“性能日志和警报”以逗号分隔或制表符分隔的格式收集数据,以便容易导入电子表格程序,为面准备数据分析准备,所以启用此方式!
设置计划,如时间按下面所列出
设置成功,确认后如下图所示:

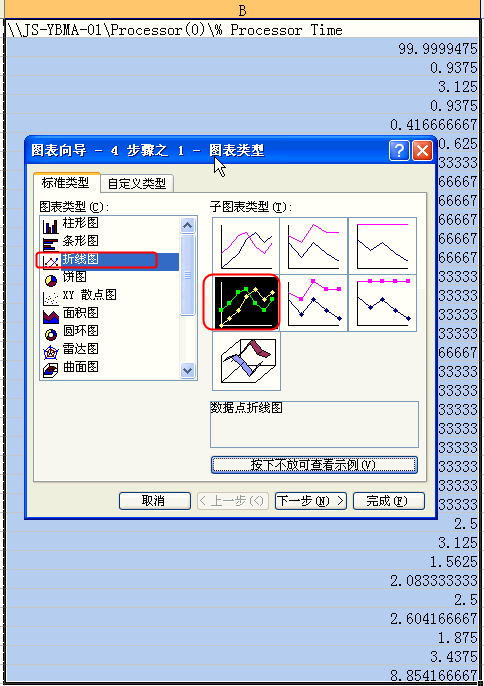
二 数据分析
在C:"PerfLogs打开日志”TopView_V1.0.0.0_PerLog_20060215_000001.csv”
选择Excel中的“插入”->“图表”->“折线图”,如下图所示
[原创]什么是性能测试?
[原创]什么是性能测试?
以下是Wikipedia中的解释:
Performance testing
From Wikipedia, the free encyclopediaJump to: navigation, search
http://en.wikipedia.org/wiki/Performance_testing
Performance Testing covers a broad range of engineering or functional evaluations where a material, product, system, or person is not specified by detailed material or component specifications: rather, emphasis is on the final measurable performance characteristics.
Performance testing can refer to the assessment of the performance of a human examinee. For example, a behind-the-wheel driving test is a performance test of whether a person is able to perform. the functions of a competent driver of an automobile.
In the computer industry, software performance testing is used to determine the speed or effectiveness of a computer, network, software program or device. This process can involve quantitative tests done in a lab, such as measuring the response time or the number of MIPS (millions of instructions per second) at which a system functions. Qualitative attributes such as reliability, scalability and interoperability may also be evaluated. Performance testing is often done in conjunction with stress testing.
为什么要进行性能测试呢?
性能测试的目的是验证软件系统是否能够达到用户提出的性能指标,并发现应用程序中中存在的性能瓶颈,如:如资源争用或运行速度慢的代码。然后通过性能调优,达到优化系统的目的。
性能测试的目标是什么?
以下是Robert W. Buchanan, Jr 的《The Art of Testing Network Systems》(John Wiley & Sons, Inc., 1996) 中对此有详细描述。
性能测试目标
度量最终用户的响应时间
定义最佳硬件配置
检查可靠性
查看硬件或软件升级
评估新产品
度量系统容量
确定瓶颈
在实施性能测试过程中,应制定性能测试目标来。为了提供评估基准,应明确区分可接受和不可接受测试结果的标准。
例如:
比较模糊的性能测试目标:新产品要上线,请选择web服务器的硬件。
明确的性能测试目标:新产品要上线,在一台 HP 服务器和一台 NEC 服务器上运行同一个300 个虚拟用户。当 300 个用户同时浏览 Web 应用程序页面时,确定哪一种硬件的响应时间更短。
性能测试应贯穿于整个软件产品生命周期中,以下是与各阶段相关联的关系:
产品计划和设计
评估新产品
如果你明确了具体的性能目标后,可以开始进行测试,确定应用程序是否满足这些要求。通常性能测试假定这些应用程序稳定、可靠地运行。因此,在性能测试中应最大限度的减少影响性能测试的条件。例如,代码中的错误可以导致出现性能问题,甚至掩盖性能问题。所以要精确地比较不同性能测试的结果,应用程序必须正确地工作。如果调整过程修改了组件的实现,则重新测试应用程序的功能尤其重要。应用程序必须通过功能性测试后才可以测试性能。除了应用程序更改外,硬件、网络通信量、软件配置、系统服务等诸多方面也会发生意外的更改。控制应用程序更改很重要。
还有一个测试过程改进的文章也很好。。。。
-
如何测试socket服务器的性能?
2009-04-03 16:27:47
问题内容:如何测试socket服务器的性能?(请各位高手提供思路及方法)我想测试用SOCKET实现的一个服务器的性能,如并发数,速度等,现在不知道如何下手,希望有高手指点一下,提供思路、方法、所使用的工具,以及需测试那些性能指标。- 原讨论链接:http://community.csdn.net/expert/topicview1.asp?id=1558818
- 所属论坛:网络通信 审核组:其他
- 提问者:kk_liwei 解决者:LuYang
- 感谢:SharpKing515、lm07082000、Oversense、leisureful、flywind999999、danbo、52cgi、keen_9
- 关键字:
- 答案:
---------------------------------------------------------------
可以通过对网络中的TCP状况进行统计,通过分析连接的成功和失败的统计数据便可以判断出该网络运行的性能。借此也可以间接的看出你的服务器的情况了,编程SNMP可以达到这个要求
---------------------------------------------------------------
首先声明我不是高手,只是曾经用过TTCP测试过网络性能.
地址是:
http://quox.org/install/benchmarks/ttcp-1.12.html
---------------------------------------------------------------
用RationalSuiteTestStudioforWindows有专门的工具,
可以在www.rational.com上下一个,装上之后在robot里面找,
专门作c/s测试的。可以先分析client,然后帮你测试,或者自己写点脚本测
还可以得到很多图表
---------------------------------------------------------------
用Rational中一个工具,具体忘记了,比较好用,不过我用起来感觉其只能测并发数!
我一般用CommView这个工具,个人觉得非常好用,功能超级强大,但是监视的机子必须比较牛不过现在TracePlus做得更好,能全部以图形方式把所有这些东西表现出来,这是一套工具!
---------------------------------------------------------------
可以编写专门的测试软件来模拟你需要的性能项目,如同时模拟几万个SOCKET访问等等,同时传输指定大小文件的速率等等 ----leisureful
---------------------------------------------------------------
我在unix上用expect模拟过400个用户同时访问服务器的情况。你要学会expect编程,并且编写一个可以被expect控制的用户端程序。但我只是测试服务器是否可以支持400用户并发操作,测试速率可能要复杂写。 ----flywind999999
---------------------------------------------------------------
Compuware QALOAD
可以监控服务器的性能CPU MEM Disk I/O TCP/IP Packet network......
www.compuware-china.com
www.compuware.com
在QALOAD里,你可以直接将你的代码嵌入到QALOAD的框架中,当然建议用QALOAD来录制过程,以便自动生成测试代码。
因为,QALOAD生成的代码是标准C/C++的,现在的版本用的编译器是VC++6.0,你可以用到任何WIN32 API,甚至MFC的东西、自己写的...,只要你把头文件加进去就可以了
----smilefox
---------------------------------------------------------------
自已动手写一个client吧, 动态的生成一些模拟数据,根据回应来做统计。
主要测试以下性能:
响应时间
并发访问最大限度、良性限度
平均处理无故障数
错误数据处理
平均处理无故障时间
平均接收数据包丢失数
多协议环境兼容性 ------LuYang
---------------------------------------------------------------
谁用过 VS.NET 的 ACT 工程?
那个不就是测试服务器性能的吗?...
---------------------------------------------------------------
可以用SNMP
也就事Simple Network Manage Protocol
是一套专用于系统管理之类的协议 -
介绍一下Web服务器和APP服务器
2009-04-02 12:43:32
介绍一下Web服务器和APP服务器
通俗的讲,Web服务器传送(serves)页面使浏览器可以浏览,然而应用程序服务器提供的是客户端应用程序可以调用(call)的方法(methods)。
确切一点,你可以说:Web服务器专门处理HTTP请求(request),但是应用程序服务器是通过很多协议来为应用程序提供(serves)商业逻辑(business logic)。
一、Web服务器(Web Server)
Web服务器可以解析(handles)HTTP协议。当Web服务器接收到一个HTTP请求(request),会返回一个HTTP响应(response),例如送回一个HTML页面。为了处理一个请求(request),Web服务器可以响应(response)一个静态页面或图片,进行页面跳转(redirect),或者把动态响应(dynamic response)的产生委托(delegate)给一些其它的程序例如CGI脚本,JSP(JavaServer Pages)脚本,servlets,ASP(Active Server Pages)脚本,服务器端(server-side)JavaScript,或者一些其它的服务器端(server-side)技术。无论它们(译者注:脚本)的目的如何,这些服务器端(server-side)的程序通常产生一个HTML的响应(response)来让浏览器可以浏览。
要知道,Web服务器的代理模型(delegation model)非常简单。当一个请求(request)被送到Web服务器里来时,它只单纯的把请求(request)传递给可以很好的处理请求(request)的程序(译者注:服务器端脚本)。Web服务器仅仅提供一个可以执行服务器端(server-side)程序和返回(程序所产生的)响应(response)的环境,而不会超出职能范围。服务器端(server-side)程序通常具有事务处理(transaction processing),数据库连接(database connectivity)和消息(messaging)等功能。
虽然Web服务器不支持事务处理或数据库连接池,但它可以配置(employ)各种策略(strategies)来实现容错性(fault tolerance)和可扩展性(scalability),例如负载平衡(load balancing),缓冲(caching)。集群特征(clustering—features)经常被误认为仅仅是应用程序服务器专有的特征。
二、应用程序服务器(The Application Server)
根据我们的定义,作为应用程序服务器,它通过各种协议,可以包括HTTP,把商业逻辑暴露给(expose)客户端应用程序。Web服务器主要是处理向浏览器发送HTML以供浏览,而应用程序服务器提供访问商业逻辑的途径以供客户端应用程序使用。应用程序使用此商业逻辑就象你调用对象的一个方法(或过程语言中的一个函数)一样。
应用程序服务器的客户端(包含有图形用户界面(GUI)的)可能会运行在一台PC、一个Web服务器或者甚至是其它的应用程序服务器上。在应用程序服务器与其客户端之间来回穿梭(traveling)的信息不仅仅局限于简单的显示标记。相反,这种信息就是程序逻辑(program logic)。 正是由于这种逻辑取得了(takes)数据和方法调用(calls)的形式而不是静态HTML,所以客户端才可以随心所欲的使用这种被暴露的商业逻辑。
在大多数情形下,应用程序服务器是通过组件(component)的应用程序接口(API)把商业逻辑暴露(expose)(给客户端应用程序)的,例如基于J2EE(Java 2 Platform, Enterprise Edition)应用程序服务器的EJB(Enterprise JavaBean)组件模型。此外,应用程序服务器可以管理自己的资源,例如看大门的工作(gate-keeping duties)包括安全(security),事务处理(transaction processing),资源池(resource pooling), 和消息(messaging)。就象Web服务器一样,应用程序服务器配置了多种可扩展(scalability)和容错(fault tolerance)技术。
三、 举例例如,设想一个在线商店(网站)提供实时定价(real-time pricing)和有效性(availability)信息。这个站点(site)很可能会提供一个表单(form)让你来选择产品。当你提交查询(query)后,网站会进行查找(lookup)并把结果内嵌在HTML页面中返回。网站可以有很多种方式来实现这种功能。我要介绍一个不使用应用程序服务器的情景和一个使用应用程序服务器的情景。观察一下这两中情景的不同会有助于你了解应用程序服务器的功能。
情景1:不带应用程序服务器的Web服务器
在此种情景下,一个Web服务器独立提供在线商店的功能。Web服务器获得你的请求(request),然后发送给服务器端(server-side)可以处理请求(request)的程序。此程序从数据库或文本文件(flat file,译者注:flat file是指没有特殊格式的非二进制的文件,如properties和XML文件等)中查找定价信息。一旦找到,服务器端(server-side)程序把结果信息表示成(formulate)HTML形式,最后Web服务器把会它发送到你的Web浏览器。
简而言之,Web服务器只是简单的通过响应(response)HTML页面来处理HTTP请求(request)。
情景2:带应用程序服务器的Web服务器
情景2和情景1相同的是Web服务器还是把响应(response)的产生委托(delegates)给脚本(译者注:服务器端(server-side)程序)。然而,你可以把查找定价的商业逻辑(business logic)放到应用程序服务器上。由于这种变化,此脚本只是简单的调用应用程序服务器的查找服务(lookup service),而不是已经知道如何查找数据然后表示为(formulate)一个响应(response)。 这时当该脚本程序产生HTML响应(response)时就可以使用该服务的返回结果了。
在此情景中,应用程序服务器提供(serves)了用于查询产品的定价信息的商业逻辑。(服务器的)这种功能(functionality)没有指出有关显示和客户端如何使用此信息的细节,相反客户端和应用程序服务器只是来回传送数据。当有客户端调用应用程序服务器的查找服务(lookup service)时,此服务只是简单的查找并返回结果给客户端。
通过从响应产生(response-generating)HTML的代码中分离出来,在应用程序之中该定价(查找)逻辑的可重用性更强了。其他的客户端,例如收款机,也可以调用同样的服务(service)来作为一个店员给客户结帐。相反,在情景1中的定价查找服务是不可重用的因为信息内嵌在HTML页中了。
总而言之,在情景2的模型中,在Web服务器通过回应HTML页面来处理HTTP请求(request),而应用程序服务器则是通过处理定价和有效性(availability)请求(request)来提供应用程序逻辑的。
四、警告(Caveats)
现在,XML Web Services已经使应用程序服务器和Web服务器的界线混淆了。通过传送一个XML有效载荷(payload)给服务器,Web服务器现在可以处理数据和响应(response)的能力与以前的应用程序服务器同样多了。
另外,现在大多数应用程序服务器也包含了Web服务器,这就意味着可以把Web服务器当作是应用程序服务器的一个子集(subset)。虽然应用程序服务器包含了Web服务器的功能,但是开发者很少把应用程序服务器部署(deploy)成这种功能(capacity)(译者注:这种功能是指既有应用程序服务器的功能又有Web服务器的功能)。相反,如果需要,他们通常会把Web服务器独立配置,和应用程序服务器一前一后。这种功能的分离有助于提高性能(简单的Web请求(request)就不会影响应用程序服务器了),分开配置(专门的Web服务器,集群(clustering)等等),而且给最佳产品的选取留有余地。
标题搜索
我的存档
数据统计
- 访问量: 714612
- 日志数: 415
- 图片数: 1
- 文件数: 3
- 建立时间: 2008-12-07
- 更新时间: 2015-07-14
