
-
获取web前端性能数据
2012-06-19 23:47:48
通过Java程序获取Dynatrace数据
http://www.taobaotest.com/blogs/qa?bid=15540通过java程序获取Yslow上传数据
http://www.taobaotest.com/blogs/qa?bid=15532 -
TortoiseSVN下载
2012-02-22 11:08:14
官方下载页面:http://tortoisesvn.net/downloads.html下载1.)TortoiseSVN-1.7.5.22551-win32-svn-1.7.3.msi (TortoiseSVN安装程序)
2.)LanguagePack_1.7.5.22551-win32-zh_CN.msi (TortoiseSVN语言包)
先安装主程序(可能会重启计算机),再安装语言包。
之后点击:开始→程序→TortoiseSVN→Settings 打开设置界面,在第一项常规设置界面中,将程序语言换成:中文(简体)即可汉化。具体使用说明请参照TortoiseSVN的帮助文档。^_^ -
Java 内存泄露监控工具 -- JVM监控工具介绍jstack, jconsole, jinfo, jmap, jdb, jsta
2011-11-10 19:02:52
jstack -- 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到 当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。目前只有在Solaris和Linux的JDK版本里面才有。
jconsole – jconsole是基于Java Management Extensions (JMX)的实时图形化监测工具,这个工具利用了内建到JVM里面的JMX指令来提供实时的性能和资源的监控,包括了Java程序的内存使用,Heap size, 线程的状态,类的分配状态和空间使用等等。
jinfo – jinfo可以从core文件里面知道崩溃的Java应用程序的配置信息,目前只有在Solaris和Linux的JDK版本里面才有。
jmap – jmap 可以从core文件或进程中获得内存的具体匹配情况,包括Heap size, Perm size等等,目前只有在Solaris和Linux的JDK版本里面才有。
jdb – jdb 用来对core文件和正在运行的Java进程进行实时地调试,里面包含了丰富的命令帮助您进行调试,它的功能和Sun studio里面所带的dbx非常相似,但 jdb是专门用来针对Java应用程序的。
jstat – jstat利用了JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控等等。
jps – jps是用来查看JVM里面所有进程的具体状态, 包括进程ID,进程启动的路径等等。
推荐:
jconsole
jstat
jmap(linux下特有,也是很常用的一个命令)
观察运行中的jvm物理内存的占用情况。
参数如下:
-heap:打印jvm heap的情况
-histo:打印jvm heap的直方图。其输出信息包括类名,对象数量,对象占用大小。
-histo:live :同上,但是只答应存活对象的情况
-permstat:打印permanent generation heap情况
命令使用:
jmap -heap 2083
可以观察到New Generation(Eden Space,From Space,To Space),tenured generation,Perm Generation的内存使用情况
输出内容:

jmap -histo 2083 | jmap -histo:live 2083
可以观察heap中所有对象的情况(heap中所有生存的对象的情况)。包括对象数量和所占空间大小。
输出内容:

写个脚本,可以很快把占用heap最大的对象找出来,对付内存泄漏特别有效。
[root@tc130 bin]# jmap -heap 8208
Attaching to process ID 8208, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 19.1-b02
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 268435456 (256.0MB)
MaxNewSize = 268435456 (256.0MB)
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 5
PermSize = 21757952 (20.75MB)
MaxPermSize = 85983232 (82.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space): ========> (= Eden Space + From Space)
capacity = 230096896 (219.4375MB)
used = 97320504 (92.81206512451172MB)
free = 132776392 (126.62543487548828MB)
42.29544408978033% used
Eden Space: =======> Eden Space (heap): 内存最初从这个内存池分配给大部分对象。
capacity = 191758336 (182.875MB)
used = 86089392 (82.10124206542969MB)
free = 105668944 (100.77375793457031MB)
44.894732503310834% used
From Space: ========> Survivor Space (heap):用于保存在eden space内存池中经过垃圾回收后没有被回收的对象。
capacity = 38338560 (36.5625MB)
used = 11231112 (10.710823059082031MB)
free = 27107448 (25.85167694091797MB)
29.294558794070515% used
To Space: ========> 另一个Survivor Space (heap)
capacity = 38338560 (36.5625MB)
used = 0 (0.0MB)
free = 38338560 (36.5625MB)
0.0% used
concurrent mark-sweep generation: ========> Old/Tenured Generation (heap):用于保持已经在 survivor space内存池中存在了一段时间的对象。
capacity = 1879048192 (1792.0MB)
used = 1112082360 (1060.5643844604492MB)
free = 766965832 (731.4356155395508MB)
59.183280382837566% used
Perm Generation: ========> Permanent Generation (non-heap): 保存虚拟机自己的静态(refective)数据,例如类(class)
和方法(method)对象。 Java虚拟机共享这些类数据。这个区域被分割为只读的和只写的,
capacity = 75022336 (71.546875MB)
used = 44927840 (42.846527099609375MB)
free = 30094496 (28.700347900390625MB)
59.885951831731816% used
这里的数值和JConsole的数值做比较,是相符的,具体见JConsole的"内存"标签。
还有:
Code Cache (non-heap):HotSpot Java虚拟机包括一个用于编译和保存本地代码(native code)的内存,叫做“代码缓存区”(code cache)
全部内容详见附件: Java_内存泄露监控工具.rar(1.65 MB)
Java_内存泄露监控工具.rar(1.65 MB)
-
PHP性能监测的工具介绍 - XHProf (转载)
2011-11-10 18:42:10
PHP性能监测的工具介绍 - XHProf
http://www.cnblogs.com/cocowool/archive/2010/06/02/1750198.html
PHP性能监测的工具介绍 - XHProf
XHProf
这个软件本是Facebook内部的一个应用工具,2009年3月份开源,为PHP的性能监测提供了很好的工具。官方的介绍中提到:
XHProf is a hierarchical profiler for PHP. It reports function-level call counts and inclusive and exclusive metrics such as wall (elapsed) time, CPU time and memory usage.
XHProf's light-weight nature and aggregation capabilities make it well suited for collecting "function-level" performance statistics from production environments.
可以先来看看 XHProf 提供的图形界面的截图
XHProf的一些特性:
1、Flat Profile. 提供函数级的汇总信息,比如调用次数、执行时间、内存使用、CPU占用等。
2、Hierarchical Profile。 对每个程序,进行了父级调用和子级调用的分解。
3、Diff Reports(差异报告)。有很多种情况,我们希望能够对比,比如新版本比旧版本提升了多少速度,两个版本的差距究竟在哪里。Diff Report 就是这样的工具,接收两个输入,并且分别给出各自的 Flat Profile 和 Hierarchical Profile 报告。
4、Callgraph View(调用视图)。性能监测的数据可以绘制成调用视图,方便我们查看。
5、Memory Profile(内存监控)。这个特性帮助我们了解PHP如何分配和释放内存。值得注意的是,XHProf并不是严格的监测内存的分配和释放动作,而是计算每个函数进入和退出时的内存状况,这是一个相对简单的实现方式,但是基本上也能够满足我们日常的监控需求。
6、如何处理外部文件。XHProf将 include,require,include_once,require_once进来的文件视作是一个 function。
XHProf目前只支持一个级别的函数追踪,但是貌似也没有特别大的影响。
XHProf的安装配置
xhprof的安装配置很简单,我们首先在 PECL 的网站上下载 源码包 然后执行安装过程
% cd <xhprof_source_directory>/extension/
% phpize
% ./configure --with-php-config=<path to php-config>
% make
% make install
% make testphp.ini file: You can update your php.ini file to automatically load your extension. Add the following to your php.ini file.
[xhprof]
extension=xhprof.so
;
; directory used by default implementation of the iXHProfRuns
; interface (namely, the XHProfRuns_Default class) for storing
; XHProf runs.
;
xhprof.output_dir=<directory_for_storing_xhprof_runs>
xhprof的使用也很简单,只要将需要监控的脚本放在 xhprof_enable() 和 xhprof_disable() 中间,就可以得到相应的结果,同时也提供了一些参数可以让我们设置是否监控 Memory, CPU 的使用,是否监控PHP内置的函数,从 0.9.2 之后,还可以设置跳过一些特定的函数。
XHProf 生成的数据,可以用 XHProf UI 来进行简单的显示。
XHProf使用也很简单,下面是一个官方的例子:
<?php
function bar($x) {
if ($x > 0) {
bar($x - 1);
}
}
function foo() {
for ($idx = 0; $idx < 2; $idx++) {
bar($idx);
$x = strlen("abc");
}
}
xhprof_enable(XHPROF_FLAGS_CPU + XHPROF_FLAGS_MEMORY);
foo();
$xhprof_data = xhprof_disable();
//
// Saving the XHProf run
// using the default implementation of iXHProfRuns.
//
include_once "xhprof_lib/utils/xhprof_lib.php";
include_once "xhprof_lib/utils/xhprof_runs.php";
$xhprof_runs = new XHProfRuns_Default();
// Save the run under a namespace "xhprof_foo".
//
// **NOTE**:
// By default save_run() will automatically generate a unique
// run id for you. [You can override that behavior. by passing
// a run id (optional arg) to the save_run() method instead.]
//
$run_id = $xhprof_runs->save_run($xhprof_data, "xhprof_foo");
echo "---------------\n".
"Assuming you have set up the http based UI for \n".
"XHProf at some address, you can view run at \n".
"http://<xhprof-ui-address>/index.php?run=$run_id&source=xhprof_foo\n".
"---------------\n";
?>
我们可以持久化记录的数据,数据以文件的形式保存在指定的目录,如下图:
有了这个工具,我们可以根据其提供的数据,与相应的通知接口整合,在程序运行出现问题时,及时的发送通知信息。
xhprof画图使用的dot程序需要服务器上有libpng的环境支持,要想这部分能够正常绘图,需要安装 graphviz-2.24.0、libpng才行,具体的在参考资料4中有说。
PHP性能监控,还有两个可用的工具,一个是 XDebug,另外一个是 ZendServer。
参考文档:
1、Speed UP your php with xhprof
2、xhprof document
3、xhprof 中文文档
4、 编译xhprof的一个小意外
-
TCP/UDP Socket调试工具 V2.3_绿色简体中文免费版_支持16进制数据循环发送
2011-10-08 14:56:45
在测试socket接口前可以使用此工具进行调试,之后手动编写lr脚本就容易的多了,仅供参考。
下载地址:
http://www.xdowns.com/soft/softdown.asp?softid=34566
工具:
-
用 STAF/STAX + LAMP 实现多任务的自动化测试框架(转载)
2011-08-30 14:24:03
转自:
http://www.ibm.com/developerworks/cn/opensource/os-cn-stax-lamp/index.html简介: 本文介绍了一种基于 LAMP+STAF/STAX 的自动化测试框架,以及该框架在 WVS(WebSphere Voice Server) 产品测试中的应用。该框架具有界面友好,操作方便,多任务自动执行等特性。
STAF/STAX 是由 IBM 开发的自动化测试运行环境,由于其跨平台和扩展性强的特点,在各种测试工作中被越来越多的使用,但是它也存在流程复杂,操作不便等缺点。而 LAMP 是基于Linux,Apache,MySQL 和 PHP 的开源网络开发平台,PHP 可用 Perl 或 Python 代替。Linux+Apache+MySQL+Perl/PHP/Python 常被放在一起使用,来搭建动态网站或者服务器的开源软件,他们拥有了越来越高的兼容度,共同组成了一个强大的 Web 应用程序平台。LAMP 具有搭建快捷,界面友好等特点。为了提高测试运行效率,提供良好的使用体验,我们开发了基于LAMP+STAF/STAX 的自动化测试框架并应用在 WVS 产品的测试中。该框架中前端是 LAMP 实现的动态网站,后端是 STAF/STAX 服务及脚本。我们还利用 STAF 的参数导入特性实现了多任务的自动执行。本文将对基于 LAMP+STAF/STAX 的自动化测试框架的功能特性,体系结构,以及应用在WVS 产品测试中的拓扑结构,设计实现和配置使用进行介绍和分析。
该框架不仅利用了 STAF/STAX 的自动化功能,还利用了 LAMP 的强大 Web 应用能力,提供了丰富的自动化测试功能和可扩展特性。总体来说,主要有以下功能特性:
- 上层应用逻辑和底层自动测试实现松耦合
- 自动化测试功能可扩展性强,支持多任务执行
- 支持远程程序调用
- 方便友好提交测试任务
- 可实时监控测试任务和 STAX 运行情况
- 历史测试记录可维护
该框架符合 MVC 的三层结构,主要的功能模块都在控制层,包括提交和监控测试任务,监控 STAX 运行,支持多任务执行,维护历史测试记录等。在该框架中,表示层和控制层的功能实现是以 PHP 形式存在,采用 MySQL 作为数据容器,Apache Server 作为 Web Server,另外在控制层中关于自动化测试的功能实现是以 xml 形式存在,它是被实现层中的 STAF/STAX 所调用。它的体系结构如下图所示:
我们把该框架应用在了 WVS 产品的自动化测试中,在这个测试中,我们需要更改 WVS 的配置并对其进行重启,执行 Tester 机器上的脚本,向 Voice Enabler 所在的机器发送 Sip 请求,然后 Voice Enabler 会建立与 WVS 机器的 RTSP 连接以获取其语音识别和语音合成服务,测试结束后再从 WVS 机器拷贝日志进行分析。我们希望这一切都用 STAF/STAX 控制自动完成。因此在所有的机器上都安装了 STAF。另外我们把对测试进行前端控制的 LAMP 软件和代码也配置在了 Tester 机器上,以充分利用其系统资源。对应的,Tester 机器的 STAF 需要安装 STAX 服务来运行本地的 STAX 脚本。该系统的部署图如下所示:
关于 LAMP 的部分,这里会给出一些应用示图和代码示例,关于 STAF/STAX 中的一些功能给出代码示例,仅供参考。
该应用提供了 GUI 方式的任务提交,在提交表单中可以选择平台,版本信息,需要运行的用例类型,任务的名字等,方便快捷。如下图所示
该应用中的测试记录都被存储在了 MySQL 数据库中,可以进行浏览,查询,删除等操作,方便测试者察看以前的测试信息,辅以参考。如下图所示。
如前所述,测试任务的执行是由 STAX 模块来完成的。本框架应用中的 STAX 执行模块包括三个主要的 STAX 脚本文件,分别是 queuemgr.xml,testexecute.xml 和 funcdef.xml。其中 funcdef.xml 定义了 testexecute.xml 中要用到的功能函数,如判断操作系统类型和版本、读写文件、启动或停止应用服务器和发送HTTP请求等。testexecute.xml 里定义了测试执行的流程和各种测试变量,它执行时会首先导入记录了当前测试任务的参数的 xml 文件,然后用这些参数初始化各种测试变量并执行相应测试功能,最后在测试任务完成时将任务参数文件转移到测试日志所在目录。queuemgr.xml 定义了一个独立的 STAX 队列管理任务,它在启动后循环检查测试任务参数文件所在的目录,如果目录非空,则选择最早的任务文件名作为运行参数让 STAX 执行 testexecute.xml。此外,它还负责测试计时、错误处理和延时等待等工作。其运行流程如下图。
下面给出了 queuemgr.xml 中定义的函数 check-queue 的代码。它被 queuemgr.xml 的 main 函数在初始化各种全局变量后调用。实现自动执行任务队列的 STAX 脚本代码如下。
清单 1. queuemgr.xml 中的 check-queue 函数
代码中第一个延时等待是对空任务队列的查看周期。测试执行人员根据个人习惯有时候希望先启动任务队列执行任务,再生成测试任务参数文件。这时查看队列的循环不能在第一次遇到队列为空时就退出,而是要不断反复查看任务队列。如果在循环之间不加延时,会造成进程对 CPU 开销过大,影响其他进程。第二个延时是前后两个测试任务执行之间的延时。这是为了让刚结束的测试进程有足够时间释放各种资源和执行多个文件操作,如日志文件和测试参数文件的转移。
每次循环中获得测试任务文件列表时要判断第一个任务参数文件是否在上次循环中已经尝试执行过。若是,则上次任务肯定没有正常结束,否则应该将该任务文件转移到任务结果文件夹中。这时应该中止任务队列处理进程,提示测试执行人员查看 STAX 日志排除错误。
生成任务参数文件并启动任务队列执行的 PHP 代码如下。该部分代码在测试者提交了图 3 所示的测试任务配置表单后执行。
$isTestStarted = false; $testQueueDir=opendir("$testQueuePath"); while($fileName=readdir($testQueueDir)){ if ($fileName!="." and $fileName!="..") { $isTestStarted = true; break; } } //Here should be the code to create a parameter file for this task, using parameters set by user from the web UI. if(!$isTestStarted){ exec("STAF local STAX EXECUTE FILE /usr/local/staf/xml/queuemanager.xml CLEARLOGS"); } header('Location: / viewTestList.PHP');
在这里我们并没有去检查任务处理进程是否在系统中存在,而是根据任务文件文件夹是否为空来判断。这一判断是基于若队列中有未执行完的任务,则应该有队列处理进程在进行处理的简单假设。当然偶尔也会有测试任务出错,任务处理进程非正常中止的情况发生,使得该假设失准。因此,我们要在 PHP 代码中查询任务处理进程的日志,判断其运行状态,并在页面中向测试执行人员显示出来。如果任务文件夹中尚有文件未执行,而队列处理进程又处于停止状态,就要提示测试人员排查错误并手动重启任务队列处理进程。
STAX 任务启动后,我们也可以随时让 PHP 代码执行
exec("STAF local STAX TERMINATE JOB $JobID")来中止任务编号为 JobID 的 STAX 任务。STAX 一旦出错,意味着任务无法运行,如果能够实时监控 STAX 任务运行状态,可提高可靠性。
exec("./viewStaxLog.sh $staxJobID 2>&1", $outPut); $isStopped = false; foreach($outPut as $outputline){ $pos = strpos($outputline, "Stop JobID:"); if($pos !== false){ $isStopped = true; } } if($isStopped){ echo "<fond color=\"blue\">Stopped</font><br>"; } else{ echo "<fond color=\"red\">Running</font><br>"; }
上面清单中调用了查看 STAX 日志的 shell 脚本。STAX 日志分为两种,一种是系统对任务运行情况和错误的自动记录,另一种是测试开发人员在 STAX 任务脚本中用 <log></log> 标签主动记录的日志。可以通过 STAF 命令实时查询任何 STAX 任务的日志。在获得日志后可以根据日志中的关键字(如上面代码中的“
Stop JobID:”)判断 STAX 任务的状态。STAX 的日志可以用 STAF 命令进行查询,其代码如下。
if [ $1 = “user” ] then staf local log query machine mytest.cn.ibm.com logname STAX_Job_$2_User else staf local log query machine mytest.cn.ibm.com logname STAX_Job_$1 fi
在测试过程中,可以让 STAX 远程执行要运行的程序,这里给出实际应用中经常会调用 shell 脚本的示例,其 STAX 代码如下。
<process> <location>'local'</location> <command mode="'shell'" >'"./%" result %s %s' % (testScriptName,testParam1,testParam2)</command> <workdir>'%s' % testScriptDir</workdir> <stderr mode="'stdout'"/> <returnstdout/> </process> <if expr="RC != 0"> <log>'Error: RC=%s, STAXResult=%s, Error running test script' % (RC, STAXResult)</log> <else> <log>'Running test script. STAXResult=%s' % (STAXResult)</log> </else> </if>
STAX 使用 Python 处理其脚本中的表达式。为了便于文本分析,使用者可以在 STAX 脚本中嵌入 Python 脚本。用这种方式可以方便地利用 Python 强大的正则表达式处理能力。下面的代码示范如何从日志文件中提取相关文字并进行对比判断。
<stafcmd> <location>'%s' % logServer</location> <service>'fileman'</service> <request>'grep file "%s" machine "%s" for "%s" last CODEPAGE ascii' % (testLogName,logServer,testCaseName)</request> </stafcmd> <!—- Some other code here --> <script> import re import string result = str(STAFResult[0]) testCaseMatch = re.search("%s %s" % (testCaseName.upper(),expectedResult.upper()),result.upper()) </script>
配置这样一个自动化测试框架,需要安装 Apache Server,MySQL,PHP,如何安装该环境,这里就不赘述。我们开发的测试框架由于其功能比较多,也需要在测试中不断的更改配置,有时还要增加测试内容。为了便于其配置,我们将PHP代码中有可能需要修改的变量都放在一个单独的 PHP 文件中,而与测试用例相关的变量用 PHP 数组的形式存放在另一个 PHP 文件中。所有要用到这些配置的 PHP 文件对其进行包含。
LAMP 是功能强大的 Web 应用程序平台,STAF/STAX 具有很好的自动测试功能,把二者结合起来就可以形成更加灵活可靠,易于功能扩展的新的自动化测试框架,本文也通过在 WVS 产品测试中使用该框架从而获得了很好的测试效果。
- 在 STAF 官方网站 查看 STAF/STAX 的详细信息。
- 查看文章“利用实现程序更新包的自动部署测试”,了解 STAF(STAX) 基础知识。
- 阅读文章 “LAMP 系统性能调优,第 1 部分: 理解架构”了解 LAMP 架构。
-
自己动手创建 AIX 平台上的性能监测工具(转载)
2011-08-30 14:22:00
http://www.ibm.com/developerworks/cn/aix/library/0810_daijw_monitor/index.html
简介: 对于 AIX 平台上的系统测试人员来说 , 经常需要监测系统和应用程序的 CPU 和内存使用情况。操作系统自带的性能工具由于不具有数据分析和图形化的报表功能 , 使用起来非常不方便。本文介绍了如何利用 AIX 操作系统自带的性能工具以及 JFreeChart 图库去轻松构建一个适于自己项目需要的性能监测工具。
AIX 操作系统提供了很多性能相关的工具包,比如 perfagent.tools,bos.acct,bos.sysmgt.trace, bos.adt.samples,bos.perf.tools 以及 bos.perf.tune。它们提供了很多可以对系统性能进行监测和调优的工具。比如,监测网络活动的 netpmon,监测内存使用情况的 svmon,监测文件系统性能的 filemon,设置网络属性的 no。
JFreeChart 是一个开源的 Java lib 库,利用 JFreeChart 可以用来生成各种各样的图表,比如饼图、柱状图、线图、区域图、分布图、混合图、甘特图。
我们要创建的监测工具如下图 1 所示,可以分成两部分,一部分位于被监测的 AIX 机器 , 用来监测系统性能数据;另外一部分位于另一台机器,用来根据性能数据生成基于 WEB 的性能图表。虽然这两部分也可运行于同一台机器,但是为降低对被监测系统的性能影响,推荐将绘制图表的工作放到另一台机器上执行。
下面,我就介绍如何利用 AIX 的性能工具包和 JFreeChart 来创建一个简单易用的性能监测工具。
在开始创建性能监测工具之前,请做下列准备:
- 准备两台机器,一台是被监测的 AIX 机器 , 另外一台机器用于生成图表 ( 在文中,我们用一台 Linux 机器为例 )。
- 由于我们在采集内存和 CPU 数据时需要用到 bos.perf.tools 和 bos.acct 工具包中的命令,在使用这些命令之前,请执行下面的命令来确保 bos.perf.tools 和 bos.acct 工具包已经被正确安装在你的 AIX 机器上。
# lslpp -lI bos.perf.tools bos.acct
如果工具包已经正确安装,会有下面类似的输出:
Fileset Level State Description ---------------------------------------------------------------------------- Path: /usr/lib/objrepos bos.acct 5.3.0.30 COMMITTED Accounting Services bos.perf.tools 5.3.0.30 COMMITTED Base Performance Tools Path: /etc/objrepos bos.acct 5.3.0.30 COMMITTED Accounting Services bos.perf.tools 5.3.0.30 COMMITTED Base Performance Tools
- 通过下面的 URL 下载最新的 JFreeChart lib 到 Linux 机器上
http://www.jfree.org/jfreechart/download.html
或
http://sourceforge.net/project/showfiles.php?group_id=15494
- 由于 JFreeChart 需要 JDK1.3 或者更高版本的支持,请下载并安装 JDK 到 Linux 机器上
- 在 Linux 机器上搭建一个 WEB 服务器,这样我们就可以把生成的性能数据和图表发布到 WEB 上。
- 通过下面的 URL 下载最新的 STAF 并且安装到 AIX 和 Linux 机器上。
http://staf.sourceforge.net/getcurrent.php
为了能通过 STAF 传送数据文件,这两台机器还必须互相赋予一定的权限。因此在安装 STAF 之后,启动 STAF 之前,我们需要按照下面的方法分别修改 STAF 的配置文件。
在 Linux 机器 ( 假定 IP 地址为 9.168.0.2) 的 STAF 配置文件 /usr/local/staf/bin/STAF.cfg 里添加如下内容:
TRUST LEVEL 5 MACHINE tcp://9.168.0.1
在 AIX 机器 ( 假定 IP 地址为 9.168.0.1) 的 STAF 配置文件 /usr/local/staf/bin/STAF.cfg 里添加如下内容:
TRUST LEVEL 5 MACHINE tcp://9.168.0.2
为方便说明起见,我们假定需要监测下列性能数据:
- 系统的内存使用情况
- 系统的 CPU 使用情况
- 某个特定进程的内存使用情况 ( 比如 java)
对于系统的内存使用情况,我们可以用 svmon 命令的 -G 选项来收集数据。需要注意的是,svmon 输出的内存大小以 pages 为单位,1 page 等于 4kBytes。Svmon –G 的命令输出如下:bash-3.00# svmon -G size inuse free pin virtual memory 2031616 512534 1519082 145239 295968 pg space 2097152 1214 work pers clnt pin 145239 0 0 in use 295968 0 216566
对于系统的 CPU 使用情况,我们可以用 sar 命令的 -u 选项来收集数据。需要注意的是,-u 选项收集的是 system-wide 的 cpu 数据,如果是多 cpu 系统,命令输出的则是多个 cpu 的使用情况。如果需要某个特定 cpu 的使用情况,则需要用 -P 选项指定 CPU。Sar –u 的命令输出如下,”1”表明只采集一个时间点。
bash-3.00# sar -u 1 AIX test19 3 5 00034ADAD300 07/23/08 System configuration: lcpu=4 14:41:54 %usr %sys %wio %idle physc 14:41:55 0 0 0 100 2.00
对于特定进程的内存使用情况,我们可以用 svmon 命令的 -P 选项来收集数据。-P 选项后面要跟进程 id,所以在运行 svmon –P 之前我们必须先取得要监测的进程 id。svmon –P 的命令输出如下 :
bash-3.00# svmon -P 1450024 --------------------------------------------------------------------- Pid Command Inuse Pin Pgsp Virtual 64-bit Mthrd 16MB 1450024 java 99308 7384 0 79641 N Y N
知道如何用命令监测我们需要的性能数据后,就可以开始动手编写脚本 aixperfmonitor.sh 来分析命令的输出,把需要的数据写到相应的数据文件当中去以便于后面绘制性能图表。另外,这个脚本也包含按照设定的时间间隔持续监测性能数据的功能。
#!/bin/sh function usage { echo "Usage aixperfmonitor.sh -t <duration> -i <interval>" echo " where:" echo " -t: total monitor duration in minutes" echo " -i: monitor interval in minutes" echo "" exit } function checkProcess { # 如果有多个以 java 命名的进程,还需通过别的关键字精确选取要监测的 java 进程 ret=`ps -ef|grep java|grep WebSphere` if [ $? -ne 0 ]; then JAVARun=0 else javapid=`ps -ef|grep java|grep WebSphere|awk '{print $2}'` fi } function updatePerflog { #CPU dat file format #time %usr %sys %wio %idle sar -u 1 1|tail -1|awk '{print $1,$2,$3,$4,$5}' >> $CPUDAT #Mem dat file format #time inuse free pin virtual time=`date +%T` svmon -G|sed -e "s/memory/$time/"|sed -n '2p'|awk '{print $1,$3,$4,$5,$6}' >> $MEMDAT #Process dat file format #time inuse pin pgsp virtual if [ $JAVARun -eq 1 ]; then time=`date +%T` svmon -P $javapid | awk '($2 ~/java/){print $2,$3,$4,$5,$6}'|sed -e "s/java/$time/" >>\ $JAVADAT fi } DATDIR=/perflog CPUDAT=cpu.dat MEMDAT=mem.dat JAVADAT=java.dat duration=30 interval=30 javapid=0 running=0 JAVARun=1 while getopts ":t:i:" opt do case $opt in t) duration=$OPTARG;; i) interval=$OPTARG;; esac done #check process existence of java checkProcess rm -rf $DATDIR mkdir -p $DATDIR cd $DATDIR touch $CPUDAT touch $MEMDAT if [ $JAVARun -eq 1 ]; then touch $JAVADAT fi # 按照一定的间隔时间,在指定的时间内持续监测系统的性能数据 while [ $running -lt $duration ] do updatePerflog sleep `expr $interval \* 60` running=`expr $running + $interval` done
在 aixperfmonitor 脚本中,最重要的部分就是
updatePerflog这个函数,它对 sar 和 svmon 的命令行输出进行处理以得到我们想要的性能数据。比如,对于系统 CPU 使用情况,我们抓取了 %usr, %sys, %wio, %idle 这四个性能参数;对于系统内存使用情况 , 我们抓取了 inuse, free, pin, virtual 这四个性能参数。另外,checkpProcess函数也值得我们注意,它检查相关进程是否真的存在,如果进程不存在,则不会在updatePerflog函数中抓取相关性能数据。有了 aixperfmonitor.sh 脚本之后,我们就可以监测系统性能数据了。比如说,我们希望监测时间为 3 天,监测间隔为 10 分钟,那么我们可以通过下面的脚本完成调用:
bash-3.00# nohup ./aixperfmonitor.sh -t 4320 -i 10 2>&1 >/tmp/perfmonitor_output &
有了性能监测数据以后,我们就可以开始利用 JFreeChart 来生成图表并且把它们发布到 WEB 上了。
首先,让我们利用 JFreeChart 来编写生成图表的 Java 代码。由于下载的 JfreeChart 包中带有丰富的例程,我们不需重头开始,只要对其中的例程加以修改即可。AIXPerfChart.java 包含了生成图表的全部代码。
清单 2 AIXPerfChart.java( 只显示部分源代码 )
public class AIXPerfChart { protected final static Pattern FILE_PATTERN = Pattern.compile("([^\\/]+)\\.dat"); protected final static Pattern DATA_LINE = // 匹配数据文件的格式 , 每个 ([^\\s]+) 匹配数据文件中的一列 , 共 5 列 Pattern.compile("\\s*([^\\s]+)\\s+([^\\s]+)\\s+([^\\s]+)\\s+([^\\s]+)\\s+([^\\s]+)\\s*"); // 返回以小时为单位的监测时间 private double getTimeInDouble (String ts) { String[] hms = ts.split(":"); double t = (Double.parseDouble(hms[0]) + Double.parseDouble(hms[1]) / 60.0 + Double.parseDouble(hms[2]) / 3600.0) ; if(duration >= 0.0) { if (lastTime > t) duration += t + 24.0 - lastTime; else duration += t - lastTime; } else { duration = 0.0; } lastTime = t; return duration; //by hours } // 根据数据文件的名字来决定图表的 title, x 轴和 y 轴的标签 private void parseFileName() { String[] pathParts = dataFile.split("/"); int len = pathParts.length; Matcher m = FILE_PATTERN.matcher(pathParts[len-1]); if (m.matches()) { chartType = m.group(1); } if (chartType.equals("cpu")) { series.add(new XYSeries("User")); series.add(new XYSeries("System")); series.add(new XYSeries("WaitIO")); series.add(new XYSeries("Idle")); title = "SYSTEM CPU"; yAxisLabel = "Percentage"; } else if (chartType.equals("mem")) { series.add(new XYSeries("Inuse")); series.add(new XYSeries("Free")); series.add(new XYSeries("Pin")); series.add(new XYSeries("Virtual")); title = "SYSTEM MEMORY"; yAxisLabel = "pages"; } else { series.add(new XYSeries("Inuse")); series.add(new XYSeries("Pin")); series.add(new XYSeries("Pgsp")); series.add(new XYSeries("Virtual")); title = chartType.toUpperCase(); yAxisLabel = "pages"; } } // 创建数据集 private XYDataset createDataset() { XYSeries s1 = series.get(0); XYSeries s2 = series.get(1); XYSeries s3 = series.get(2); XYSeries s4 = series.get(3); try { if(!dataFile.startsWith("/")) { dataFile = workDir + "/" + dataFile; } BufferedReader in = new BufferedReader(new FileReader(dataFile)); String line; while((line = in.readLine()) != null) { Matcher m = DATA_LINE.matcher(line); if (m.matches()) { double x = getTimeInDouble(m.group(1)); double y1 = getYValueInDouble(m.group(2)); double y2 = getYValueInDouble(m.group(3)); double y3 = getYValueInDouble(m.group(4)); double y4 = getYValueInDouble(m.group(5)); s1.add(x, y1); s2.add(x, y2); s3.add(x, y3); s4.add(x, y4); } else { } } in.close(); } catch (Exception e) { System.err.println(e.toString()); } XYSeriesCollection dataset = new XYSeriesCollection(); dataset.addSeries(s1); dataset.addSeries(s2); dataset.addSeries(s3); dataset.addSeries(s4); return dataset; } }
在 AIXPerfChart.java 源文件当中,函数
getTimeInDouble计算每个监测时间点距开始监测时经过的时间。由于命令行输出的时间点是以二十四小时制计量并且不含日期信息,因此如果当前的监测时间点小于前一个监测时间点,就表明当前时间已经进入新的一天。在计算监测时间的时候特别需要注意到这个因素,不然会得到错误的监测时间。至于具体的计算方法,请参照清单 2 中的代码。另外,由于篇幅的关系,在清单 2 中没有列出函数
createChart和exportChart。CreateChart通过调用createDataset函数生成数据集,然后生成图表 ,exportChart则把图表按照指定的图像文件格式导出为图像文件。在createChart中还可设定图表的相关属性,比如大小,背景颜色等等。编写好 AIXPerfChart.java 后 , 让我们用下面的命令来进行编译 :
javac -cp ./jcommon-1.0.5.jar:./jfreechart-1.0.1.jar com/aix/chart/AIXPerfChart.java
编译成功后,我们今后可以通过 aixperfchart.sh 这个脚本来调用绘制图表的功能。
#!/bin/sh # 存放 AIXPerfChart.class 和 JFreeChart lib 的路径 AIX_CHART=/opt/aixperfmonitor/src java -cp ${AIX_CHART}:${AIX_CHART}/jfreechart-1.0.1.jar:${AIX_CHART}/jcommon-1.0.5.jar \ com.aix.chart.AIXPerfChart $@
最后,我们来编写脚本 htmlreport.sh,它帮助我们定期把性能数据绘制成图表并发布到 WEB 服务器上。
清单 4 htmlreport.sh( 只显示部分源代码 )
############################################################## # 通过 STAF 从 AIX 机器上获取性能数据,/perflog 为性能数据文件在 AIX 机器上的默认存放目录 # ##############################################################
ret=`staf $server process start shell command "staf local fs copy directory /perflog \
todirectory $dataDir tomachine 9.168.0.2" workdir /tmp wait returnstdout returnstderr`
########################################################## # 根据性能数据文件绘制图表 # ########################################################### aixperfchart.sh mem.dat $dataDir $imgFormat aixperfchart.sh cpu.dat $dataDir $imgFormat charts[0]="mem.$imgFormat" charts[1]="cpu.$imgFormat" index=2 cd $dataDir # 如果有多个进程的数据文件 , 逐一绘制相应的图表 images=`ls *.dat|grep -v mem|grep -v cpu` for img in $images; do aixperfchart.sh $img $dataDir $imgFormat charts[$index]="${img%%.*}.$imgFormat" let "index=$index+1" done ########################################################## # 生成包含性能图表的 html 文件 , 并发布到 WEB 上 # ########################################################## # htmlfn="${dataDir}/perfchart.html" echo "<html><head></head><body>" > $htmlfn if [ -z $server ]; then echo "<h2> Perf Charts</h2>" >> $htmlfn else echo "<h2> $server Perf Charts</h2>" >> $htmlfn fi echo "<table cellpadding=\"3\" cellspacing=\"0\">" >> $htmlfn curIndex=0 for (( curIndex=0; curIndex < $index; curIndex++ )) ; do let "i = $curIndex % 2" if [ "$i" -eq 0 ] ; then echo "<tr>" >> $htmlfn fi imageFile=${charts[$curIndex]} dataFile="${imageFile%%.*}.dat" echo "<td align="center"><img src=\"${charts[$curIndex]}\" width=600 height=320/>\ <br/><a href= \"${dataFile}\">${dataFile}</a></td>" >> $htmlfn if [ "$i" -eq 1 ] ; then echo "</tr>" >> $htmlfn fi done echo "</table></body></html>" >> $htmlfn
在脚本 htmlreport.sh 中有两个地方值得我们注意。一个是调用 STAF 的 FS service 把性能数据文件从 AIX 机器拷贝到 Linux 机器上。为方便起见,建议直接把数据文件拷贝到 web 服务器的发布目录,这样就不需要在发布性能数据及图表时再次拷贝了。另外一个是绘制图表的代码,我们把生成的图表文件名存储在 charts 数组中。考虑到读者可能需要监测多个进程,代码并没有只是简单生成 java 进程的图表,而是逐一为可能存在的进程生成图表并且存储到 charts 数组中。
有了 htmlreport.sh 脚本之后,我们就可以用下面的命令调用这个脚本让它定期绘制图表,并把图表发布到 WEB 服务器。
bash-3.00# nohup ./htmlreport.sh -t <duration> -i <interval> 2>&1 \ >/tmp/htmlreport &
假定性能数据以及图表被发布到 web 服务器的 perflog 目录,那么打开浏览器,输入下面的 URL,我们就能看到监测数据的图表了。
http://9.168.0.2/perflog/perfchart.html
在本文中,我介绍了如何利用 AIX 系统自带的性能工具包和 JFreeChart 图表库去构建一个简单易用的性能监测工具。通过简单的扩展,这个工具可以完成更多的监测功能,比如说,监测磁盘使用情况,监测 IO 使用情况,等等。
学习
- IBM 红皮书 AIX 5L Performance Tools Handbook:本红皮书深入研究了 AIX 5L 提供的系统性能优化工具的使用。
- JfreeChart 主页:在这里,你可以了解到和 JfreeChart 相关的所有资源。
- STAF 主页:在这里,您可以了解 STAF 可以做什么?
- AIX and UNIX 专区:developerWorks 的“AIX and UNIX 专区”提供了大量与 AIX 系统管理的所有方面相关的信息,您可以利用它们来扩展自己的 UNIX 技能。
- AIX and UNIX 新手入门:访问“AIX and UNIX 新手入门”页面可了解更多关于 AIX 和 UNIX 的内容。
- AIX and UNIX 专题汇总:AIX and UNIX 专区已经为您推出了很多的技术专题,为您总结了很多热门的知识点。我们在后面还会继续推出很多相关的热门专题给您,为了方便您的访问,我们在这里为你把本专区的所有专题进行汇总,让您更方便的找到你需要的内容。
- AIX Wiki:发现 AIX 相关技术信息的协作环境。
- 按主题搜索“AIX and UNIX”库:
- Safari 书店:访问此电子参考资料库可查找特定的技术资源。
- developerWorks 技术事件和网络广播:了解最新的 developerWorks 技术事件和网络广播。
- Podcasts:收听 Podcast 并与 IBM 技术专家保持同步。
获得产品和技术
- IBM 试用软件:从 developerWorks 可直接下载这些试用软件,您可以利用它们开发您的下一个项目。
讨论
- 参与 developerWorks Blog,从而加入到 developerWorks 社区中来。
- 参与“AIX and UNIX”论坛:
-
结合使用 Shell 和 STAX 实现 UAT 测试的自动化(转载)
2011-08-30 14:11:57
原文地址:http://www.ibm.com/developerworks/cn/opensource/os-cn-stafuat/index.html
2009 年 2 月 13 日
文章分析了 UAT 的特性以及在 UAT 中实现测试自动化的重要性,进而提出了一个结合应用 Shell 脚本和 STAX 语言实现的从自动化下载 Build, 安装, 执行测试用例, 生成测试报告的自动化解决方案, 对其中每一个部分进行了具体的分析和实现。
UAT 全称为 User Acceptance Test, 即用户可接受测试,是IBM产品开发周期的重要一环,
处于产品的构造和功能性测试之间,其目的是验证每天的构造(daily build)的可接受性,即能否在这个 build 上进行后续的功能性测试。由于 UAT 是测试环节的首要步骤,能够尽快给开发人员提供测试结果,所以不管采用传统的软件开发模型,还是使用今天被广泛接受的敏捷开发模式,UAT 在产品开发周期中所扮演的角色均非常重要。
传统的 UAT 测试基本都是人工完成的,如产品的安装,基本的配置,针对各个模块的功能执行测试用例等等。这种人工的测试方法会有很多问题。首先就是会存在大量的重复性劳动。在目前的软件产品开发过程当中,迭代式开发很常见。开发人员很可能会将已经完成部分功能的软件产品交付测试人员测试,而在测试人员测试的过程中根据测试人员的反馈或者用户需求的改变不断完善产品。这样一来一天可能会有3到5个版本的安装文件产生,而测试人员需要针对每个版本的安装文件执行 UAT 一系列操作,也就是说同样的测试步骤可能要被重复执行3到 5次;其次就是对于大型项目而言,UAT 操作很耗费时间,一次UAT测试的时间可能从 2,3 个小时到 7,8 个小时,每天需要多种平台和多重类型的 build,重复性的操作对测试人员来说是个很大的负担。
将 UAT 自动化,一方面无人职守的全自动化测试方案会使得 UAT 测试提供 24*7 的服务成为可能,自动检测 build 的状态,下载并进行安装、配置,执行测试用例, 最后生成测试报告,减少了等待时间,加速了产品的测试过程,缩短了开发周期。另一方面,自动化程度的提高解放了测试人员,使得UAT测试人员可以有更多的时间进行一些提高测试覆盖率,准确性方面的工作,更好的保证了测试质量。本文针对 UAT 的特点,提出了结合使用 Shell Script. 和 STAF/STAX 的 UAT 自动化测试解决方案,具有简便、轻量级、开发周期短、灵活性好等特点。结合 shell 脚本对 STAX 任务进行触发并且设计一系列的调度机制使得自动化系统可以对资源进行合理调配,从而使得无人值守的全自动化测试成为可能。另外通过该方案的实施,能够提高软件测试环节中的自动化程度和测试用例的可复用程度,很大程度上提高了测试效率,缩短了测试周期。本文提出并分析了一个一般化的用户可接受性测试包含的各个部分,提出的自动化解决方案适用于所有 web-based 的产品的下载、安装部署、配置、功能测试。作为例子,文中将使用通过此方案在 IBM WebSphere Portal 产品的 UAT 测试当中的应用来对此方案进行分析。


STAF(Software Testing Automation Framework)是开源的自动化测试框架,封装了不同平台和不同语言间通信的复杂性,提供了消息、互斥、同步、日志等可复用的服务,使用户可以在此基础上构建自动化测试解决方案。STAX(STAF Execution Engine)是运行在 STAF 之上的可解析、执行 XML 格式任务的一种服务。STAF提供了两种服务,一种是内部服务(Internal Service),即它在内部封装了一系列的常用服务供用户使用, 包括时间操作,文件系统操作,变量操作等;另外一种是外部服务(External Service),STAX 本身就是 STAF 的一种外部服务,可以通过 STAX 规定的 XML 格式来编写 STAX 脚本,实现测试人员的测试步骤。
STAX 与传统的测试脚本,如 Perl,Shell 等,相比较,存在以下优点:
- STAX 通过 STAF 的支持,能够轻松实现与其他测试机通讯的问题,对用户来说,通讯过程是完全透明的;
- STAF 本身具有跨平台的特性,可以拓展到不同的平台,而且STAF可以根据测试机的操作系统类型来定义一些在 STAX 脚本当中需要用到的变量,如文件路径分隔符(File Separator)等,这对用户来说十分方便;
- STAX 脚本具有非常好的兼容性,完全可以在 STAX 脚本当中执行 shell 或者 bat 脚本;
- STAX 脚本完全是基于 xml 格式的,脚本开发方便;
- STAX 函数之间可以相互调用,因此能够更加灵活的实现函数的复用;
下面清单所示的代码片段说明了 STAX 任务的基本结构。
<function name="listDir" scope="local"> <function-prolog>This function lists entries of specified directory on the target machine</function-prolog> <function-list-args> <function-required-arg name="target">Hostname/IP address of the target machine </function-required-arg> <function-required-arg name="targetDirectory">Target directory </function-required-arg> </function-list-args> <sequence> <script>cmd = 'LIST DIRECTORY %s' % (targetDirectory) </script> <!-- Run the staf list directory command using the supplied arguments --> <stafcmd> <location>target</location> <service>'FS'</service> <request>cmd</request> </stafcmd> <return>STAFResult</return> </sequence> </function>
根据上面的代码,我们可以大致看出 STAX 脚本的语法格式:
首先定义此功能模块的名字,在这里是“
listDir”,相当于传统语言中的函数名。然后在<function-list-args>元素里面将脚本需要定义的参数列举出来,相当于传统编程语言中仅能够在函数内部使用的局部变量。如果下面还需要用到一些变量的时候,可以通过<script>元素来定义,如“cmd”变量,这里定义为:LIST DIRECTORY %s' % (targetDirectory),LIST DIRECOTRY是STAF内部服务的一种,相当于DOS系统的dir命令或者linux系统的ls命令。“%s”是通配符,匹配的是后面括号当中的targetDirectory变量的内容,而targetDirectory是在<function-list-args>元素当中定义的。接下来有一个<stafcmd>元素,这个元素有三个子元素:<location>,<service>和<request>。其中location元素指的是这个服务应用的目标机器,service元素表示的是该服务的名称,这里“FS”,即File Service,而request元素指的是具体的服务命令字符串,这里是在前面定义过的变量cmd。
通常一个UAT的测试流程包括以下几个部分: 检测Build状态,下载Build,检测测试机状态,进行安装,进行配置,执行一些测试用例来验证各个部件的功能,生成测试报告。为了完全覆盖以上的这几个方面,基于STAF/STAX的UAT自动化测试解决方案主要包括以下几个步骤:
通常,对于一个成熟的软件产品,每天都会有一个或者多个版本的build。这些build一旦生成便会被上传到一台专门的服务器上。当生成过程结束之后,测试人员就可以下载这个版本的build进行测试,而UAT测试是整个测试流程的起点。因此,最节约时间的做法就是当文件刚刚生成结束之后就开始UAT测试,所以需要自动化的方法来不断检测build生成过程是否结束,一旦生成结束,就可以马上开始UAT操作。但是对于一个项目而言,UAT测试人员很难立即得到Build过程完成的信息,这有很多因素:
- 对于合作开发和测试,Build Team和UAT team不一定在同一地理位置,可能处于不同的时区;
- 对于大的项目,一次Build的时间可能会很长,从几小时甚至长到十几小时;
- 对于复杂项目,一个Build成功与否存在着很大的不确定因素,经常会存在构建失败的情况;
因此, 测试人员人工来检测Build生成状态有很大的难度。Build Team通常提供一些对外的服务来发布Build的信息,比如维护一个HTTP Server或者FTP Server来让远程用户能直接通过这些服务来获得Build的目录结构以便于下载Build。在UAT的自动化方案中,就可以通过Shell脚本访问这些服务来获得Build的信息。比如对于如下的目录结构。
就可以使用如下的shell脚本来获得最新的Build的版本号:
清单 2. 使用 shell 脚本获取最新 Build 的版本号
while [ ! -s "./builds.html" ] do sleep $sleeptime #将所有Build所在的目录存成一个文件待用 wget $Remote_realese_url -O ./builds.html" >> $LOG_BASEDIR/`date +%Y-%m-%d-%H`.log done #从保存的文件中提取最新的Build版本信息,这里使用AWK在文件中来获得最新版本信息 latestversion=`cat builds.html | awk -F"STARTPattern" '{print $2}' | awk -F"EndPattern" '{print $1}' | grep $VERSIONPATTERN | sort | tail -1` if [ ! -d "$BUILDS_DIR/$ latestversion " ]; then #在本地创建当前Build版本的目录 mkdir $BUILDS_DIR/$ latestversion fi
第二步,使用 Shell 下载 Build 并开始触发后续 STAX 任务
服务器端 build 生成结束之后,接下来是 build 下载的过程,这部分可以和步骤一结合在一起,一旦检测到 build 正确生成,那么马上开始下载。Build 的下载可以使用shell脚本实时访问,根据 Build 服务器提供的不同服务接口使用不同的检测 build 并下载 build 的方式,常用的有 FTP 方式,HTTP 方式或者 HTTPS 方式。在判断Build存在,创建完相关的本地目录之后,对于一个 Build 需要的所有文件,可以使用相应的命令来进行下载。最简单的有 wget,ftp。 也可以写一些相对复杂的shell脚本加强下载的稳定性,可靠性和灵活性。
检测 Build 状态和下载 Build 都是由 Unix Shell 脚本执行的,而此后的测试机状态检测以及以后的安装都由 STAX 脚本来执行。那么怎样由 Unix shell 来执行 STAX 脚本呢,STAX 的事件机制使得它的任务可以由外部触发,这个触发的方法如下:
#Trigger STAX event echo "start" while [ "$parameterFileNumber" != "0" ] do echo "start a STAX event..." echo "kick off STAX event, file number is $parameterFileNumber" let "parameterFileNumber=$parameterFileNumber-1" STAF STAXServer.cn.ibm.com SEM POST EVENT "$eventName" sleep 600 echo "a STAX event was triggered successfully!" done echo "Kick off UAT finished!"
对于一个成熟的企业及软件产品来说,测试环境往往比较复杂,而在测试环境的搭建过程当中任何一个小的问题都有可能导致测试的失败,这并不是软件本身的问题,所以在开始执行测试流程之前如何检测测试环境的正确性是十分重要的。针对这一环节,自动化解决方案如图:
- 首先,分别针对不同的测试环境制定测试任务。这些测试任务存放在一个单独的任务队列里面;
- 当第二步下载build结束之后,马上检测任务队列里面是否有等待执行的任务,如果有的话,马上执行当前测试任务,这里利用STAF的跨平台性,可以将同一个测试任务针对不同的平台分成多个任务,并发执行;
- 执行测试任务的第一步,就是检测目标测试机的环境及状态,通过 STAX 脚本在目标测试机上收集测试相关的环境信息,如操作系统的类型,版本,服务器,数据库的型号及版本等等;
- 接下来是对收集到的环境信息加以判断,如果环境符合当前的测试要求,则继续执行下一步;否则生成错误日志,发送测试报告给测试人员,中断测试流程;
- 测试环境的检测通过之后,则开始执行真正的测试任务;
在 UAT 测试流程当中,当 build 下载过程结束,环境检测通过,接下来的就是软件产品的测试,也是整个测试流程一个真正意义上的“起点”,如果在接下来的测试过程中出现问题,很有可能就是产品本身的问题。
首先,就是软件的安装,一般软件的安装往往分为静默安装和图形界面安装,针对这两种不同的安装方式,自动化测试解决方案如下:
- 静默安装:
- 静默安装的第一步是准备一个安装过程中的响应文件(response file),这个文件包括了整个安装过程当中所有需要用到的参数,比如路径信息,安装组件的选择等等。在本方案中,这个响应文件是根据用户事先配置的参数通过 STAX 脚本自动生成的,而且用户可以在提交或者修订测试任务的时候灵活的对这个响应文件进行更改;
- 接下来,STAX 脚本会自动生成一个命令文件,根据操作系统的不同会分别生成 bat 文件或者 .sh 文件,命令文件的内容为执行安装过程需要的命令;
- 然后,执行刚刚生成的命令文件,并将安装过程中一些重要的信息记录在日志文件当中,这些日志文件是以后生成测试报告的重要依据;
- 在安装的过程中,STAX 任务会不间断的监测测试机的状态和软件安装的状态,一旦安装过程出现不可逆的异常或者错误,则马上中断测试流程,发送测试报告给测试人员;
- 图形界面安装:
- 因为STAF/STAX本身并不对任何图形界面的测试提供支持,所以,在执行图形界面安装的过程中首先需要采用其他的工具进行安装脚本的录制或者编写,可以采用的工具有IBM Rational Functional Tester, Auto It等。可以针对不同的环境分别录制多个安装脚本,然后分别存放,这样的好处就是在测试过程中可以根据测试目标机的环境灵活调用安装文件,而且如果环境没有大的改动,完全可以实现安装脚本的重复使用;
- 在自动化测试过程当中,首先由STAX脚本根据目标机的环境自动拷贝相应的安装脚本到测试机上,然后执行该安装脚本;
- 同静默安装一样,在安装流程开始之后,STAX任务会不间断的进行监控并及时处理出现的问题;
安装软件的STAX脚本片段如下:
清单 4. 安装WebSphere Portal的STAX脚本片断
<stax> <function name="InstallWebSpherePortal"> <function-prolog>InstallWebSpherePortal</function-prolog> <function-list-args> </function-list-args> <sequence> <!-- Step 1. Mount build server --> <call function="'mountBuildServer'">target, mountServer, remoteMountPoint, localMountPoint</call> <!-- Step 2. Copy image and create dir--> <call function="'copyImage'">target,destinyDir,destinyFPDir,destinyFile, localMountPoint,buildPuiDir,buildPtfDir,buildPuiNum,buildPtfNum, buildZipFileName</call> <if expr="STAXResult == 0"> <call function="'writeLog'">[target, 'Success copy image files .']</call> </if> <!-- Step 3. Stop all servers--> <call function="'stopAllServers'">target,portalProfileRoot, WPSUsername,WPSPasswd, WASUsername,WASPasswd</call> <if expr="STAXResult == 0"> <call function="'writeLog'">[target, 'Stop all servers success !']</call> </else> </if> <!-- Step 4. Start to install--> <sequence> <call function="'StartInstall'">target,portalServerDir, setUpCmdLineDir,destinyDir, destinyFPDir,WPSPasswd, WASPasswd,portalConfigDir</call> <if expr="STAXResult == 0"> <call function="'writeLog'">[target, 'Fixpack install finish success !']</call> </if> </sequence> <return>0</return> </sequence> </function> </stax>
一般来说,在软件安装结束之后需要进行一些基本的配置操作,如软件调优,配置数据库数据源, 配置安全性等。基本上在 IBM 产品中这些操作都有相同的特性,即首先修改配置文件,然后执行配置命令, 中间会涉及到一些停止或者启动服务器的操作。针对不同的软件及操作系统,这些操作都可以结合事先写好的 Shell 或者 Bat 脚本,然后通过 STAX 脚本来触发这些脚本。与安装软件的过程类似,可以通过 STAX 任务实时监控整个过程的状态并及时汇报给测试人员。这一步骤成功结束之后,自动进入下一个测试环节。对于很多产品来说,两个基本的配置工作分别是进行数据库的配置和安全性的配置,例如在 WebSphere Portal 产品中,数据库迁移配置和 LDAP 的安全配置是不可缺少的两个配置步骤,实现这种配置的 STAX 示例脚本如下:
清单 5. Enable Security STAX 脚本片段
<stax> <function name="enableSecurity" scope="local"> <function-prolog>'Enable security for the portal on the target machine'</function-prolog> <function-list-args> <!-- Define arguments--> </function-list-args> <sequence> <!-- Step 1. Stop Portal. --> <call function="'retrieveWasPortalStatus'">[target, portalProfileRoot, wasUserId, wasPassword]</call> <if expr="STAXResult == 0"> <sequence> <call function="'writeLog'">[target, 'Portal is already started, begin to stop it...', 'user1']</call> <call function="'stopWasPortal'">[target, portalProfileRoot, wasUserId, wasPassword]</call> <if expr="STAXResult == 0"> <call function="'writeLog'">[target, 'Stop Portal successfully.', 'user1']</call> </if> </sequence> </if> <!-- Step 2. Run task --> <call function="'runConfigEngineTask'">[target, portalProfileRoot, 'wp-modify-ldap-security']</call> <if expr="STAXResult == 0"> <call function="'writeLog'">[target, 'Task wp-modify-ldap-security succeeded.', 'info']</call> </if> <!-- Step 3. Start portal --> <call function="'startWasPortal'">[target, portalProfileRoot]</call> <if expr="STAXResult == 0"> <sequence> <call function="'writeLog'">[target, 'Task EnableSecurity succeeded!', 'pass']</call> <return>0</return> </sequence> </if> </sequence> </function> </stax>
清单 6. DBTransfer STAX 脚本片段
<stax> <function name="DBTransfer" scope="local"> <function-prolog>'Transfer DB'</function-prolog> <function-list-args> <!-- Define arguments--> </function-list-args> <sequence> <!-- Step 1. Modify property files --> <call function="'MergeProperyFilesTool'"> [target, targetDirectory, targetFileName1, sourceFileName1, MergePropertyScript, domains1, append] </call> <call function="'MergeProperyFilesTool'"> [target, targetDirectory, targetFileName2, sourceFileName2, MergePropertyScript, domains2, append] </call> <!-- Step 2. Run task --> <call function="'runConfigEngineTask'">[target, portalProfileRoot, 'database-transfer']</call> <if expr="STAXResult == 0"> <call function="'writeLog'">[target, 'Task database-transfer succeed.', 'user1']</call> </if> <!-- Step 3. Start portal --> <call function="'startWasPortal'">[target, portalProfileRoot]</call> <if expr="STAXResult == 0"> <sequence> <call function="'writeLog'">[target, 'Task DBTranfer succeeded!', 'user1']</call> <return>0</return> </sequence> </if> </sequence> </function> </stax>
在本文的开头已经对 UAT 做了简要的介绍,UAT 是保证一个新的版本的软件或者软件补丁产生之后,其基本的各个功能模块能够正常运行的测试环节。所以,在软件安装和配置工作结束之后,执行覆盖软件基本功能的测试用例,是很有必要的。
对于基于 Web 的产品,通常用RFT针对不同软件的功能实现写好测试脚本就已经能够单独运行。为了实现 UAT 的全部过程自动化,必须将这一部分同 STAX 脚本进行连接,用 STAX 触发这些测试脚本并实时监控脚本的执行状态。通过 STAX 来触发 RFT 的 web 自动化脚本的任务示例如下:
<stax> <function name="runExampleRFTTest" scope="local"> <function-prolog>Runs a RFT testcase using LA</function-prolog> <function-list-args> <!-- Define arguments--> </function-list-args> <sequence> <!-- Run the RFT test on the RFT server --> <call function="'cafRunRFTTest'"> { 'rftServer' : target, 'properties' : mySuite, 'rftProjectArchive' : 'LWPServerGUI.zip', 'rftScript' : rftScript, 'rftScriptArgs' : rftArgs, 'maxExecutionTime': maxTime, 'browserName': browserType, 'browserPath': browserLocation, 'browserCommand': browserCmd, 'rftExecutionMode' : 'standalone' } </call> <script>(rftRunTestRC,rftRunTestCallResult) = STAXResult</script> <return>rftRunTestRC</return> </sequence> </function> </stax>
在所有的测试步骤结束之后,或者如果中途有环节出现测试错误,可以通过 STAF/STAX 生成一份测试报告并发送给测试人员,测试报告当中包括详细的测试结果,失败原因等等。试想一下,每天早上来上班的时候,一边喝咖啡一边打开邮箱,发现原来需要花费一天时间的工作已经在昨天夜里执行完毕并且有一份完整的测试报告发送到邮箱,难道不是一件很惬意的事情吗?
作为测试报告的来源,日志是自动化测试任务的重要组成部分,一方面测试任务的开发人员可以利用日志来调试脚本,另一方面,日志作为测试报告的一部分使得测试任务的使用者了解测试任务执行结果以及执行过程信息。自动化脚本开发人员通过在脚本中调用 STAF/STAX 提供的 LOG Service 来生成纯文本格式的任务日志,较为方便。但其缺点在于不直观,由于日志本身的层次结构淹没在海量的文本中,测试人员很难快速地找到自己想要了解的信息。针对这一缺点,我们把测试任务的结构自顶向下分为以下三个层次:
- 测试用例(Testcases):测试任务的顶级层次,描述此次测试任务的主要目标。一个测试任务由一个或者多个测试用例组成,同一个测试任务的多个测试用例可以串行、也可以并行执行。测试用例在任务的执行过程中,有“开始”、“成功”、“失败”等不同的状态;
- 步骤(Steps):描述了测试用例执行过程中的关键步骤,一个测试用例由多个步骤组成。步骤往往是顺序执行的,也有“开始”、“成功”、“失败”等不同的状态,步骤的执行结果决定了测试用例的结果;
- 细节(Details):组成测试任务的基本单位,由程序员在测试任务脚本中调用STAF/STAX的LOG服务自行记录,根据STAF对的LOG定义,一条日志信息可以有“
info”、“debug”、“warning”、“error”等不同的类型;
这样,在任务执行的过程当中会有一份更加友好的日志生成,包括各个步骤的执行情况,测试用例的通过情况等,日志的概述结果就可以当作测试报告发送给测试者。生成的测试报告格式如下图,这是一个基于HTML格式的报告。
下面所示的STAX代码片断提供了记录日志的函数
writeLog,它接受日志内容、日志状态、日志类型等参数,向该任务的日志目录下的日志文件中追加一条日志。<function name="writeLog" scope="local"> <function-list-args> <function-required-arg name="content"></function-required-arg> <function-optional-arg name="level" default="'info'"></function-optional-arg> <function-optional-arg name="type" default="'detail'"></function-optional-arg> <function-optional-arg name="state" default="'start'"></function-optional-arg> </function-list-args> <sequence> <script> displayLogName = 'Automation Runtime Text Output Log' #the actual name of the text log file. logFileName = '%s.txt' % STAXJobID #if content contains multiply lines, separate it from string import * lines = split(content, '\n') </script> <iterate in="lines" var="line"> <sequence> <if expr="type == 'testcase'"> <sequence> <script>line = '*TESTCASE %s:%s' % (state, line)</script> </sequence> <elseif expr="type == 'step'"> <script>line = '*STEP %s:%s' % (state, line)</script> </elseif> </if> <call function="'cafAppendJobOutputLog'">[target, 'local', line displayLogName, logFileName]</call> </sequence> </iterate> </sequence> </function>
值得注意的是,为了进一步解析生成 HTML 日志,我们把日志的类型和状态信息通过固定的标签写入了日志之中:
*TESTCASE STATE TestcaseName *STEP STATE StepName
对于一个确定的测试用例或者步骤,上述的标签总是成对出现的,这样才能保证能够正确的解析到它们的边界。
LogHelper为一个 Python 类,它封装了从文本日志中解析层次信息后生成 html 格式日志的细节,下图为LogHelper类图。下面的代码片断为
LogHelper类的核心方法parserLog方法。
清单 9. 使用 Python 构建的 LogHelper 类的 parseLog 方法
def parseLog(self, logTxtFile): """ Parse the txt log file, information of testcases and steps will be assigned to the data field of this class.Translate the common txt lines to html and assign it to the htmlContent field. """ try: self._txtLogFileName = logTxtFile fp = open(self._txtLogFileName, 'r') except IOError, e: return (1, 'Open file %s failed' % logTxtFile) #use stacks to contain the parsed entries testcases = [] steps = [] for line in fp.readlines(): #remove the timestamp logInfo = line.strip().split('\t', 1)[-1] if logInfo.startswith('*TESTCASE') or logInfo.startswith('*STEP'): #it is a tag type,name = logInfo.split(':', 1) type,state = type.split(' ', 1) if type == '*TESTCASE': if state == 'start': testcases.append(name) self.addTestcase(name) else: testcases.pop() try: self.closeTestcase(name, state) except EntryNotFoundException, e: return (1, e.msg) else: if state == 'start': steps.append(name) try: self.addTestcaseStep(name, testcases[-1]) except EntryNotFoundException, e: return (1, e.msg) else: steps.pop() try: self.closeTestcaseStep(name, testcases[-1], state) except EntryNotFoundException, e: return (1, e.msg) fp.close() return (0, '')
单击下载logHelper.py代码
通过以上的步骤描述看出,测试人员所有的工作仅仅是制定测试任务,查看测试结果,而且测试任务仅仅需要制定一次就可以通过加入任务队列的方式来重复执行,可见,这种基于STAF/STAX的UAT自动化测试解决方案极大程度上减少了测试人员的工作量,节约了测试人员宝贵的时间。
以上阐述了基于STAF/STAX并结合使用Shell Script的UAT自动化解决方案,并且结合本团队负责测试的逐个步骤进行了分析。根据UAT测试人员给予的反馈信息,这样的一套全自动测试平台可以节约测试人员约80%的测试时间,极大提高了工作效率。同样的方法结合使用shell脚本和STAX脚本可以实现很多日常工作中的自动化工作,在这方面,我们正在进行更多的尝试。
- Software Testing Automation Framework (STAF) 是一个开源的、多平台、多语言框架,详细内容请参考http://staf.sf.net。
- 更多有关 Software Testing Automation Framework (STAF) 内容,请参考软件测试自动化专题。
- 访问 developerWorks Open source 专区,获得丰富的 how-to 信息、工具和项目更新,帮助您用开放源码技术进行开发,并与 IBM 产品结合使用。
乌晓峰,IBM 中国开发中心软件工程师,曾从事WebSphere Portal 的测试工作和 UAT 的自动化开发,现在负责 WPLC 产品的软件安全测试。
肖慧斌,IBM 中国软件开发中心实习生,负责 WebSphere Portal UAT 的 automation 开发。
李夏安, IBM 中国软件开发中心实习生,负责 WebSphere Portal UAT 的 automation 开发。
原文链接: http://www.ibm.com/developerworks/cn/opensource/os-cn-stafuat/index.html
-
linux 性能监控工具dstat
2011-08-29 11:31:24
下载:dstat官方网站:
http://dag.wieers.com/home-made/dstat/解压:
# tar jxvf dstat-0.7.2.tar.bz2 && cd dstat-0.7.2执行
#dstat -tclpymsgdn执行并输出到文件
#dstat -tclpymsgdn --output status01.csv查询占用系统资源最高的东东:
dstat --top-cpu --top-mem --top-io --top-latency --top-int./dstat -tclpymsgdn --nocolor
数据图表范例: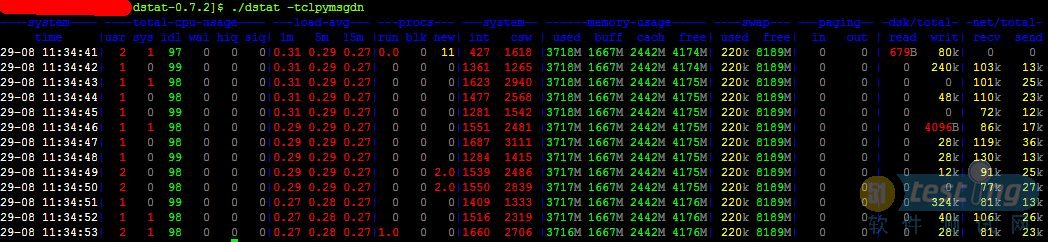
参数及使用说明参考:
dstat-0.7.2\docs\dstat.1.html
dstat-0.7.2\docs\dstat-paper.html系统调优参考:
http://people.redhat.com/alikins/system_tuning.html===========================================================
SEE ALSO
Performance tools
ifstat(1), iftop(8), iostat(1), mpstat(1), netstat(1), nfsstat(1), nstat, vmstat(1), xosview(1)
Debugging tools
htop(1), lslk(1), lsof(8), top(1)
Process tracing
ltrace(1), pmap(1), ps(1), pstack(1), strace(1)
Binary debugging
ldd(1), file(1), nm(1), objdump(1), readelf(1)
Memory usage tools
free(1), memusage, memusagestat, slabtop(1)
Accounting tools
dump-acct, dump-utmp, sa(8)
Hardware debugging tools
dmidecode, ifinfo(1), lsdev(1), lshal(1), lshw(1), lsmod(8), lspci(8), lsusb(8), smartctl(8), x86info(1)
Application debugging
mailstats(8), qshape(1)
Xorg related tools
xdpyinfo(1), xrestop(1)
Other useful info
collectl(1), proc(5), procinfo(8)
-
jconsole监控tomcat配置
2011-06-16 17:13:36
以下配置是在linux环境下进行。
1、安装jdk,推荐安装jdk6.0。
2、在tomcat的bin/catalina.sh中配置:
JAVA_OPTS="-Dcom.sun.management.jmxremote.port=10000
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false"
配置完可以试试啦。
3、使用hostname -i验证机器名,如果得到的结果为127.0.0.1则不行,需要修改linux自己的host表,将本机的IP地址放到前面,再次使用hostname -i等到的结果应该为本机的IP地址。否之jconsole无法链接。或者在catalina.sh中增加一个配置项:
-Djava.rmi.server.hostname=ip_or_hostname
例如:-Djava.rmi.server.hostname=10.10.71.39即可。
4、由于配置了上述文件,在停止tomcat的时,会由于上述配置的端口被占用而无法停掉。2种方式解决:
(1)使用killall -9 java 杀掉所有的java进程。
(2)在catalina.sh中配置CATALINA_PID=pid,这样在停止tomcat的过程中,上述被占用的端口会自动被杀掉。
然后进行连接: host:port 方式
这是最简单的不用验证用户的方式.
http://blog.sina.com.cn/s/blog_4f925fc30100tx1d.html
JProbe为Quest公司的产品(Toad 、JProbe )。JProbe是一个完全为Java设计的解析器,而且它只能用于Java。
它可以很好地完成我们所需要的任务。JProbe在简单易用的集成化套件中,为servlet、JSP和EJB应用代码提供了强大的Java性能分析、
内存纠错、代码覆盖及线程分析功能。 -
curl命令详解
2011-06-13 18:29:07
curl命令详解
一、参数详解
-M/--manual 显示全手动 -n/--netrc 从netrc文件中读取用户名和密码 --netrc-optional 使用 .netrc 或者 URL来覆盖-n --ntlm 使用 HTTP NTLM 身份验证 -N/--no-buffer 禁用缓冲输出 -o/--output 把输出写到该文件中 -O/--remote-name 把输出写到该文件中,保留远程文件的文件名 -p/--proxytunnel 使用HTTP代理 --proxy-anyauth 选择任一代理身份验证方法 --proxy-basic 在代理上使用基本身份验证 --proxy-digest 在代理上使用数字身份验证 --proxy-ntlm 在代理上使用ntlm身份验证 -P/--ftp-port <address> 使用端口地址,而不是使用PASV -Q/--quote <cmd> 文件传输前,发送命令到服务器 -r/--range <range> 检索来自HTTP/1.1或FTP服务器字节范围 --range-file 读取(SSL)的随机文件 -R/--remote-time 在本地生成文件时,保留远程文件时间 --retry <num> 传输出现问题时,重试的次数 --retry-delay <seconds> 传输出现问题时,设置重试间隔时间 --retry-max-time <seconds> 传输出现问题时,设置最大重试时间 -s/--silent 静音模式。不输出任何东西 -S/--show-error 显示错误 --socks4 <host[:port]> 用socks4代理给定主机和端口 --socks5 <host[:port]> 用socks5代理给定主机和端口 -t/--telnet-option <OPT=val> Telnet选项设置 --trace <file> 对指定文件进行debug --trace-ascii <file> Like 跟踪但没有hex输出 --trace-time 跟踪/详细输出时,添加时间戳 -T/--upload-file <file> 上传文件 --url <URL> Spet URL to work with -u/--user <user[:password]> 设置服务器的用户和密码 -U/--proxy-user <user[:password]> 设置代理用户名和密码 -V/--version 显示版本信息 -w/--write-out [format] 什么输出完成后 -x/--proxy <host[:port]> 在给定的端口上使用HTTP代理 -X/--request <command> 指定什么命令 -y/--speed-time 放弃限速所要的时间。默认为30 -Y/--speed-limit 停止传输速度的限制,速度时间'秒 -z/--time-cond 传送时间设置 -0/--http1.0 使用HTTP 1.0 -1/--tlsv1 使用TLSv1(SSL) -2/--sslv2 使用SSLv2的(SSL) -3/--sslv3 使用的SSLv3(SSL) --3p-quote like -Q for the source URL for 3rd party transfer --3p-url 使用url,进行第三方传送 --3p-user 使用用户名和密码,进行第三方传送 -4/--ipv4 使用IP4 -6/--ipv6 使用IP6 -#/--progress-bar 用进度条显示当前的传送状态 二,常用curl实例
1,抓取页面内容到一个文件中
[root@10.10.90.97 ~]# curl -o home.html http://www.sina.com.cn
2,用-O(大写的),后面的url要具体到某个文件,不然抓不下来。我们还可以用正则来抓取东西
[root@10.10.90.97 ~]# curl -O http://www.it415.com/czxt/linux/25002_3.html
3,模拟表单信息,模拟登录,保存cookie信息
[root@10.10.90.97 ~]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=****** http://blog.51yip.com/wp-login.php
4,模拟表单信息,模拟登录,保存头信息
[root@10.10.90.97 ~]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=****** http://blog.51yip.com/wp-login.php
-c(小写)产生的cookie和-D里面的cookie是不一样的。
5,使用cookie文件
[root@10.10.90.97 ~]# curl -b ./cookie_c.txt http://blog.51yip.com/wp-admin
6,断点续传,-C(大写的)
[root@10.10.90.97 ~]# curl -C -O http://www.sina.com.cn
7,传送数据,最好用登录页面测试,因为你传值过去后,curl回抓数据,你可以看到你传值有没有成功
[root@10.10.90.97 ~]# curl -d log=aaaa http://blog.51yip.com/wp-login.php
8,显示抓取错误
[root@10.10.90.97 ~]# curl -f <">http://www.sina.com.cn/asdf
curl: (22) The requested URL returned error: 404
[root@10.10.90.97 ~]# curl http://www.sina.com.cn/asdf
<HTML><HEAD><TITLE>404,not found</TITLE>
。。。。。。。。。。。。
9,伪造来源地址,有的网站会判断,请求来源地址
[root@10.10.90.97 ~]# curl -e http://localhost http://www.sina.com.cn
10,当我们经常用curl去搞人家东西的时候,人家会把你的IP给屏蔽掉的,这个时候,我们可以用代理
[root@10.10.90.97 ~]# curl -x 10.10.90.83:80 -o home.html http://www.sina.com.cn
11,比较大的东西,我们可以分段下载
[root@10.10.90.97 ~]# curl -r 0-100 -o img.part1 http://i2.f.itc.cn/thumb/180/bj/6018/b_60178154.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 101 100 101 0 0 1926 0 --:--:-- --:--:-- --:--:-- 0
[root@10.10.90.97 ~]# curl -r 100-200 -o img.part2 http://i2.f.itc.cn/thumb/180/bj/6018/b_60178154.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 101 100 101 0 0 3498 0 --:--:-- --:--:-- --:--:-- 98k
[root@10.10.90.97 ~]# curl -r 200- -o img.part3 http://i2.f.itc.cn/thumb/180/bj/6018/b_60178154.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 13515 100 13515 0 0 154k 0 --:--:-- --:--:-- --:--:-- 280k
[root@10.10.90.97 ~]# ll |grep img.part
-rw-r--r-- 1 root root 101 Jan 24 10:59 img.part1
-rw-r--r-- 1 root root 101 Jan 24 11:00 img.part2
-rw-r--r-- 1 root root 13515 Jan 24 11:00 img.part3
用的时候,把他们cat一下就OK了,cat img.part* >img.jpg
12,不显示下载进度信息
[root@10.10.90.97 ~]# curl -s -o aaa.jpg
13,显示下载进度条
[root@10.10.90.97 ~]# curl -# -O http://www.it415.com/czxt/linux/25002_3.html
######################################################################## 100.0%
14,通过ftp下载文件
[root@10.10.90.97 ~]# curl -u 用户名:密码 -O http://blog.51yip.com/demo/curtain/bbstudy_files/style.css
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者用下面的方式
[root@10.10.90.97 ~]# curl -O ftp://xukai:test@192.168.242.144:21/www/focus/enhouse/index.php
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 87518 100 87518 0 0 2312k 0 --:--:-- --:--:-- --:--:-- 11.5M
15,通过ftp上传
[root@10.10.90.97 ~]# curl -T xukai.php FONT color=#348c86 size=2 face=宋体>ftp://xukai:test@192.168.242.144:21/www/focus/enhouse/
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 87518 0 0 100 87518 0 2040k --:--:-- --:--:-- --:--:-- 8901k转自:http://xukaizijian.blog.163.com/blog/static/1704331192011024103857504/
-
Google Selenium framework
2011-06-13 18:27:05
Google Selenium framework
google selenium framework 的介绍。http://blanconet.googlepages.com/GTAC_SeleniumFramework.pdf个人觉得他们的framework还是很适合一些网站的测试的。还有一个视频有兴趣的可以去看一下。这个presentation 时间挺长的。http://www.youtube.com/swf/l.swf?swf=http://s.ytimg.com/yt/swf/cps-vfl73532.swf&video_id=hWQdCdH77NA&rel=1&eurl=http://www.henke.ws/post.cfm/Ringo---Selenium-Framework-by-Google&iurl=http://i1.ytimg.com/vi/hWQdCdH77NA/hqdefault.jpg&sk=0QGOJ7DEyc8SMs3B-zrNjTaPX3rXVXtaC&use_get_video_info=1&load_modules=1&hl=enhttp://www.henke.ws/post.cfm/Ringo---Selenium-Framework-by-Google
转自: http://www.51testing.com/?uid-111742-action-viewspace-itemid-102851
-
[java]junit4
2011-02-22 11:20:11
Junit4,与3.x有所区别
 [java]junit4 - believefym的专栏 - CSDN博客.rar(147 KB)
[java]junit4 - believefym的专栏 - CSDN博客.rar(147 KB)
1. 测试类不需要extends TestCase,代之以annotation,即测试类(不需要extends TestCase)的方法只要有@Test就可以了
2. 测试方法命名不需要一定要以test开头package junit;
public class Unit ...{
private int data;
public Unit(int data)...{
this.data = data;
}
public boolean test()...{
return true;
}
public boolean equals(Object o)...{
if(o instanceof Unit)...{
return ((Unit)o).data == data;
}
return false;
}
public void exception()...{
if (this.data==0)
throw new IndexOutOfBoundsException("exception in Unit");
}
}可以用eclipse自动生成测试类,选中要测试的类,然后new -junit test case
测试类:
package junit;import org.junit.*;
public class UnitTest ...{
private Unit unit1 = new Unit(1);
private Unit unit2 = new Unit(2);
@BeforeClass
public static void setUpBeforeClass() throws Exception ...{
System.out.println("setUpBeforeClass");
}@AfterClass
public static void tearDownAfterClass() throws Exception ...{
System.out.println("tearDownAfterClass");
}@Before
public void setUp() throws Exception ...{
System.out.println("setUp");
}@After
public void tearDown() throws Exception ...{
System.out.println("tearDown");
}@Test
public void notestTest() ...{ // 方法名不以test开头
//fail("Not yet implemented");
Assert.assertTrue(unit1.test());
}@Test
public void testEqualsObject() ...{
//fail("Not yet implemented");
Assert.assertEquals(unit1, new Unit(1));
Assert.assertEquals(unit1, unit2);
}@Test(expected = IndexOutOfBoundsException.class)
public void testException() ...{
//fail("Not yet implemented");
new Unit(0).exception();
}
}测试结果如下
为了进行TestSuit,再增加一个testcase
package junit;public class Unit2 ...{
public boolean test()...{
return true;
}
}package junit;
import org.junit.Test;public class Unit2Test ...{
@Test
public void testTest() ...{
//fail("Not yet implemented");
org.junit.Assert.assertTrue(new Unit2().test());
}}
==================================================================================
增加一个TestSuit(使用ecilpse的new -junit Test Suit只能找到3.x风格的extends TestCase的测试类,不知为何)
package junit;import org.junit.runner.RunWith;
import org.junit.runners.Suite;
import org.junit.runners.Suite.SuiteClasses;@RunWith(Suite.class)
@SuiteClasses( ...{ UnitTest.class, Unit2Test.class })
public class Suit ...{
}TestSuit测试结果
以下是控制台输出信息,跟测试类的各种annotation有关
============================================================== -
java 图形化显示,及系统状态图形化展示,监控技术
2010-12-24 17:26:38
-
shell脚本及命令使用小结及Informix监控脚本
2010-12-24 17:05:56
要求监控informix数据库,一开始是用java分析所有的onstat结果数据,因为起初不了解怎么做好,慢慢有了思路,就转为全部用shell实现。
shell脚本及命令使用小结
1. awk的使用:$ awk -F":" '{ print "username: " $1 "\t\tuid:" $3 }' /etc/passwd
说明:-F":"指定分隔符,为冒号,awk默认的分隔符是一个空格,"username: ","\t\tuid:",自定义,添加的字符串,
将awk取的值赋予变量:# echo aa bb cc | awk '{ print $3; }'
cc
# var=$(echo aa bb cc | awk '{ print $3; }')
#echo $var
cc
======================================================================================================2. sed 的使用
sed -n '2p' file
说明:输出第二行
onstat -p | sed -n '6p' | awk '{print $4 $8 }'
说明:先用sed过滤行,然后用awk过滤自己指定的列
onstat -p | sed -n '18,20p' > sed_result
说明:输出第18到第20行
sed有查找、替换、删除等功能:1) 部分行的输出与删除
注意: SED本身不改变原文件内容, 删除仅指不输出该部分,重定向输出为文件时,与原文件比为删除
sed -n '2,5p' file1 : 仅输出文件file1的2-5行
sed -e '2,5d' file1 : 将文件file1的2-5行删除
sed -e '/^#/d' file1 : 将文件file1的以#开头的行删除
sed -ne '/HELLO/p' file1 : 仅输出file1中含HELLO的行
sed -ne '/BEGIN/,/END/p' file1 : 仅输出file1中BEGIN与END间的部分
首先,匹配含BEGIN的行作为块首, 然后向后以第一次匹配的含END的行为块尾,输出该块各行
如果, 没有匹配到BEGIN,则不输出; 如果只匹配到BEGIN,则输出从该行到文件尾的各行
在匹配到BEGIN的行后面,匹配到END的前面含有的BEGIN当作一般行,仍以第一个BEGIN为块首
一个文件中, 可能有好几个这样匹配的区域块,都要输出2) 替换操作
sed -e 's/foo/bar/' file1 : 将file1中第一次出现的foo替换为bar
sed -e 's/foo/bar/g' file1 : 将file1中所有的foo替换为bar
sed -e '1,8s/foo/bar/g' file1 : 将file1的1-8行中所以的foo替换为bar
sed -e '/^$/,/^END/s/foo/bar/g' file1
首先匹配以空行为块首,END为行首的行为块尾的所有区域块,
然后将在这些区域块中出现的foo替换为bar
sed -e 's/<.*>//g' file1 : 将file1各行中,<>间的文字删除(最大)
is what meant ===> meant
sed -e 's/<[^>]*.//g' file1 : 将file1各行中,<>间的文字删除(最小)
is what meant ===> is what meant
注意: .*表示任意格式的任意字符 [^>]*表示任意个数的非>的字符
sed -e 's/girl/nice & hello/g' file1 : 将file1各行中的girl替换为nice girl hello
这里&表示前面匹配的内容,在要替换的文字里引用
更强的引用: 在匹配文字中用\(\)包含文字,在匹配文字中用\1到\9来引用
sed -e 's/\(boy\) loves \(girl\)/\2 A loves \1 B/g' file1
boy loves girl ===> girl A loves boy B'3)对同一对象执行多个sed操作时的3种方法
1). sed -e 'command1;command2;command3' file1
三个sed命令依次作用到file1的各行
2). sed -e 'command1' -e 'command2 file1
跟1)类似,比1)跟保险,1)不能用的时候可以尝试
3). sed -f script_file file1
一些复杂命令,必须写到一个script. 文件中======================================================================================================
3. while读文件: shell按行读取文件变量的递增: let num=num+1 或者 let num+=1 或者 cs=`expr $cs + 1`
#范例1:简单结构
onstat -p > status
while read line
do
echo $line
done < status#范例2:
top > status
num=1
while read line
do
if [ $num -eq 6 ];
then
#echo $num
#echo $line
fi
let num=num+1
done < status
======================================================================================================
4. until 循环; 以及读取命令行参数, $#有特殊含义,获取了传入的参数的个数,类似的特殊标识还有几个。
if [ $# -ne 3 ]
then
echo "Usage: 脚本名称 参数1 参数2 参数3, 参数1是循环次数,参数2是循环间隔时间,参数3是输出结果文件"
exit 1
fics=1
until [ $cs -gt $1 ]
do
cs=`expr $cs + 1`
sleep $2
done======================================================================================================
5. 整数比较:
-lt Less than
-gt Greater than
-le Less than or equal to
-ge Greater than or equal to
-eq Equal to
-ne Not equal to======================================================================================================
6. shell的if语句格式:
if [ $num -eq 6 ];
then
#echo $num
fi
======================================================================================================7. cut 的使用,也可以对一行的数据进行指定截取。一般都可以指定分隔符号
cut -c 1-5,10-14 file
cut -f 1,3 file我们经常会遇到需要取出分字段的文件的某些特定字段,例如 /etc/password就是通过":"分隔各个字段的。
可以通过cut命令来实现。例如,我们希望将系统账号名保存到特定的文件,就可以:
cut -d: -f 1 /etc/passwd > /tmp/users
-d用来定义分隔符,默认为tab键,-f表示需要取得哪个字段What’s cut?
子曰:cut命令可以从一个文本文件或者文本流中提取文本列。
命令用法:
cut -b list [-n] [file ...]
cut -c list [file ...]
cut -f list [-d delim][-s][file ...]
l 上面的-b、-c、-f分别表示字节、字符、字段(即byte、character、field);
l list表示-b、-c、-f操作范围,-n常常表示具体数字;
l file表示的自然是要操作的文本文件的名称;
l delim(英文全写:delimiter)表示分隔符,默认情况下为TAB;
l -s表示不包括那些不含分隔符的行(这样有利于去掉注释和标题)
上面三种方式中,表示从指定的范围中提取字节(-b)、或字符(-c)、或字段(-f)。
-c 和 -f 参数可以跟以下子参数:
m 第m个字符或字段
m- 从第m个字符或字段到文件结束
m-n 从第m个到第n个字符或字段
-n 从第1个到第n个字符或字段======================================================================================================
监控脚本原文:
if [ $# -ne 3 ]
then
echo "Usage: 脚本名称 参数1 参数2 参数3, 参数1是循环次数,参数2是循环间隔时间,参数3是输出结果文件"
exit 1
fi
echo "Time,%cached read,ovlock,%ovbuff,bufwaits,lokwaits,lockreqs,deadlks,ckpwaits,seqscans,Fg Writes,Chunk Writes,Physical Logging pages/io,Physical Logging %used,Logical Logging pages/io,Logical Logging %used,active,total,hash buckets,lock table overflows" >> informixStatus_$3.csv
cs=1
until [ $cs -gt $1 ]
dovar0=$(date | awk '{print $4}')
onstat -p > status
num=1
while read line
do
if [ $num -eq 6 ];
then
var1=$(echo $line | awk '{print $4 }' )
fi
if [ $num -eq 15 ];
then
var2=$(echo $line | awk '{print $1 }' )
var3=$(echo $line | awk '{print $3 }' )
fi
if [ $num -eq 18 ];
then
var4=$(echo $line | awk '{print $1 }' )
var5=$(echo $line | awk '{print $2 }' )
var6=$(echo $line | awk '{print $3 }' )
var7=$(echo $line | awk '{print $4 }' )
var8=$(echo $line | awk '{print $6 }' )
var9=$(echo $line | awk '{print $8 }' )
fi
let num=num+1
done < status
onstat -F > status
num=1
while read line
do
if [ $num -eq 6 ];
then
var10=$(echo $line | awk '{print $1 }' )
var11=$(echo $line | awk '{print $3 }' )
fi
let num=num+1
done < status
onstat -l > status
num=1
while read line
do
if [ $num -eq 6 ];
then
var12=$(echo $line | awk '{print $6 }' )
fi
if [ $num -eq 8 ];
then
var13=$(echo $line | awk '{print $5 }' )
fi
if [ $num -eq 12 ];
then
var14=$(echo $line | awk '{print $8 }' )
fi
if [ $num -eq 14 ];
then
var15=$(echo $line | awk '{print $4 }' )
fi
let num=num+1
done < statusonstat -k | grep active > status
num=1
while read line
do
if [ $num -eq 1 ];
then
var16=$(echo $line | awk '{print $1 }')
var17=$(echo $line | awk '{print $3 }' )
var18=$(echo $line | awk '{print $5 }' )
var19=$(echo $line | awk '{print $8 }')
fi
let num=num+1
done < statusecho "$var0,$var1,$var2,$var3,$var4,$var5,$var6,$var7,$var8,$var9,$var10,$var11,$var12,$var13,$var14,$var15,$var16,$var17,$var18,$var19" >> informixStatus_$3.csv
cs=`expr $cs + 1`
sleep $2
done
rm statusInformix监控脚本说明:
1)监控脚本名称:monitorInfx
2)监控脚本用法:monitorInfx 循环次数 循环间隔时间 结果文档名
3)监控结果命名:informixStatus_输入的结果文档名(年月日_测试类型_用户数_运行时间_开始时间)4)脚本执行范例:
nohup sh monitorInfx 600 3 20101245_HunHe_30Vuser_30Min_1401 &5)脚本执行结束后,会在当前目录下生成如下文件:
informixStatus_20101245_HunHe_30Vuser_30Min_1401.csv6)可以将此文件另存为excel文件,然后生成图表
7)注意输入的结果文档名中不要包含路径
informix监控及shell脚本.rar(404 KB) -
调整vmware虚拟机硬盘空间的方法 最简单可行
2010-11-01 21:51:25
调整vmware虚拟机硬盘空间的方法 最简单可行
在VMware中又不能直接修改虚拟机的硬盘容量大小,查找无数帖子,终于找到了解决之道,最简单傻瓜式。
其实在VMware安装目录下就有一个vmware-vdiskmanager.exe程序,它是一个命令行工具,可用来修改虚拟机硬盘的大小。方法如下:
第一步:按Win+R键调出运行对话框,输入“cmd”并按回车键启动命令提示符窗口。
第二步:进入VMware的安装目录(比如我的安装目录为:D:\ProgramFiles\VMwarelVMware Workstation),找到"vmware-vdiskmanager"文件,最简单直接拖到命令提示符窗口。第三步:在后面直接加上下面的命令: -x 20Gb "D\VMware\WinXP\Windows XP Professional.vmdk" 即 -x 需要的硬盘大小 "虚拟文件路径\虚拟系统名称.vmdk" ,如:图1

(注意;在命令提示符后输入"vmware-vdiskmanager",什么参数也不加直接按回车键,可显示这一命令的说明。参数"-X"表示要扩展虚拟机硬盘空间,紧随其后的数字是要扩展的大小(本例为扩展到20GB,这是一个磁盘总量,包含了原先的磁盘容量)。最后是指定要操作的虚拟机磁盘的具体文件,因为路径名中有空格,所以必须以双引号括起来。)第四步:按回车键开始执行,执行完毕,退出命令提示符窗口,重启VMware,会发现虚拟机硬盘空间已变成20GB了。
如果原来的虚拟机硬盘已被分成了多个分区,那么在通过vmware-vdiskmanager.exe扩大了硬盘空间后还得在盛拟机系统中安装第三方分区工具对虚拟机分区做出调整注意,请严格按图1的格式操作,否则运行不成功!
调整vmware虚拟机硬盘空间的方法 最简单可行

-
10款常用的JAVA测试工具
2010-07-30 13:29:34
10款常用的JAVA测试工具
1. 美国Segue公司的Silk系列产品
Segue公司一直专注于软件质量优化领域。在S
egue的产品套件中,拥有业内最强劲且最容易使用的、用于企业应用测试、调优和监测的自动化工具,能够帮助用户保障应用在其生命周期内的可靠性和性能。
(1) SilkPerformer——企业级性能测试工具
u 企业级自动化测试工具能够支持多种系统,如Java、.Net、Wireless、COM、CORBA、Oracle、Citrix、MetaFrame、客户机/服务器、以及各种ERP/CRM应用
u 多项专利技术精确模拟各种复杂的企业环境
u 可视化脚本记录功能及自定义工具简化了测试创建工作
u SilkPerformer的Java/.NET浏览器以及JUnit/NUnit测试输入功能简化了对并发访问情况下远程应用组件的早期负载测试工作
u 方便易用,工作流向导会逐步引导用户完成整个测试流程
(2) SilkTest International——业内唯一的Unicode功能测试工具
u SilkBean 充分利用 Java 语言的“编写一次,随处使用”的优点,让用户不必修改现有的脚本而能够在多种基于 Unix 的系统上运行
u 能够识别多种开发平台,如Java、JavaScript、HTML、ActiveX、Visual Basic 和C/C++等
u 一套脚本可供所有支持的语言使用
u 内置的错误恢复系统不仅具有自定义功能,可进行无人看守的自动测试
赛格瑞(Segue)公司是全球范围内专注于软件质量优化解决方案的领导者。2005年,赛格瑞(Segue)公司在中国设立了专门的销售服务公司,因此,赛格瑞(Segue)公司的软件测试产品在中国有了更好的技术支持。
参考网站:http://www.segue.com.cn/
推荐指数:★★★★★
2. MaxQ
MaxQ是一个免费的功能测试工具。它包括一个HTTP代理工具,可以录制测试脚本,并提供回放测试过程的命令行工具。测试结果的统计图表类似于一些较昂贵的商用测试工具。MaxQ希望能够提供一些关键的功能,比如HTTP测试录制回放功能,并支持脚本。
参考网站:http://maxq.tigris.org/
推荐指数:★★★☆☆
3. Httpunit
HttpUnit是一个开源的测试工具,是基于JUnit的一个测试框架,主要关注于测试Web应用,解决使用JUnit框架无法对远程Web内容进行测试的弊端。
HttpUnit提供的帮助类让测试者可以通过Java类和服务器进行交互,并且将服务器端的响应当作文本或者DOM对象进行处理。HttpUnit还提供了一个模拟Servlet容器,让测试者不需要发布Servlet,就可以对Servlet的内部代码进行测试。本文中作者将详细的介绍如何使用HttpUnit提供的类完成集成测试。
参考网站:http://www.httpunit.org/
推荐指数:★★★☆☆
4. Junit
是通用的测试 java 程序的测试框架JUnit可以对Java代码进行白盒测试。通过JUnitk可以用mock objects进行隔离测试;用Cactus进行容器内测试;用Ant和Maven进行自动构建;在Eclipse内进行测试;对Java应用程序、Filter、Servlet、EJB、JSP、数据库应用程序、Taglib等进行单元测试。
参考网站:http://www.junit.org/
推荐指数:★★★★★
5. Jtest
Jtest是Parasoft公司推出的一款针对java语言的自动化白盒测试工具,它通过自动实现java的单元测试和代码标准校验,来提高代码的可靠性。Jtest先分析每个java类,然后自动生成junit测试用例并执行用例,从而实现代码的最大覆盖,并将代码运行时未处理的异常暴露出来;另外,它还可以检查以DbC(Design by Contract)规范开发的代码的正确性。用户还可以通过扩展测试用例的自动生成器来添加更多的junit用例。Jtest还能按照现有的超过350个编码标准来检查并自动纠正大多数常见的编码规则上的偏差,用户可自定义这些标准,通过简单的几个点击,就能预防类似于未处理异常、函数错误、内存泄漏、性能问题、安全隐患这样的代码问题。
JTest最大的优势在于静态代码分析,至于自动生成测试代码,当然生成测试代码框架也是不错的,但要做好单元测试用户还要做大量的工作。
参考网站:http://www.parasoft.com/jsp/aep/aep.jsp
推荐指数:★★★★☆
6. Hansel
Hansel 是一个测试覆盖率的工具——与用于单元测试的 JUnit framework 相集成,很容易检查单元测试套件的覆盖情况。
参考网站:http://hansel.sourceforge.net/
推荐指数:★★☆☆☆
7. Cactus
Cactus是一个基于JUnit框架的简单测试框架,用来单元测试服务端Java代码。Cactus框架的主要目标是能够单元测试服务端的使用Servlet对象的Java方法如HttpServletRequest,HttpServletResponse,HttpSession等
针对外部可测试组件运行时,需要把JUnit测试运行为发送HTTP请求给组件的客户端进程。为了在服务器容器内部运行JUnit测试,可以用Cactus框架,它是一个免费的开源框架,是Apache Jakarta项目的一部分。Cactus 包含了关于JUnit客户端如何连接到服务器,然后使测试运行的详细信息。
参考网站:http://jakarta.apache.org/cactus/
推荐指数:★★★★☆
8. JFCUnit
JFCUnit使得你能够为Java偏移应用程序编写测试例子。它为从用代码打开的窗口上获得句柄提供了支持;为在一个部件层次定位部件提供支持;为在部件中发起事件(例如按一个按钮)以及以线程安全方式处理部件测试提供支持。
参考网站:http://jfcunit.sourceforge.net/
推荐指数:★★★☆☆
9. StrutsTestCase
StrutsTestCase(STC)框架是一个开源框架,用来测试基于 Struts 的 Web 应用程序。这个框架允许您在以下方面进行测试:
u 在 ActionForm. 类中的验证逻辑(validate() 方法)
u 在 Action 类中的业务逻辑(execute() 方法)
u 动作转发(Action Forwards)。
u 转发 JSP
STC 支持两种测试类型:
u Mock 方法 —— 在这种方法中,通过模拟容器提供的对象(HttpServletRequest、 HttpServletResponse 和 ServletContext),STC 不用把应用程序部署在应用服务器中,就可以对其进行测试。
u Cactus 方法 —— 这种方法用于集成测试阶段,在这种方法中,应用程序要部署在容器中,所以可以像运行其他 JUnit 测试用例那样运行测试用例。
参考网站:http:// strutstestcase.sourceforge.net/
推荐指数:★★★★☆
10. TestNG
TestNG是根据JUnit 和 NUnit思想而构建的一个测试框架,但是TestNG增加了许多新的功能使得它变得更加强大与容易使用比如:
u 支持JSR 175注释(JDK 1.4利用JavaDoc注释同样也支持)
u 灵活的Test配置
u 支持默认的runtime和logging JDK功能
u 强大的执行模型(不再TestSuite)
u 支持独立的测试方法
参考网站:http://testng.org/
推荐指数:★★★★☆ -
HP SiteScope Software 9[1].0 Build 911 Linux破解.rar
2009-11-05 20:10:07
HP SiteScope Software 9[1].0 Build 911 Linux破解.rar
-
测试软件清单
2009-11-05 19:39:57
测试软件清单
脚本生成及加压工具:
1)JMeter
2)Badboy
3)HP Loadrunner监控工具:
1)HP SiteScope
2)Lamda Probe
3)Quest Spotlight
4)JProfiler
辅助工具:
1.网络查看
1)Sniffer + WinCap
2)TCP_UDP_Socket调试工具
2.java相关
1)JDK 1.5 ,1.6
2)Tomcat 5 ,6
3)eclipse
3.文本编辑
1)UtraEidt
4.数据库相关
1)Oracle_10g_client
2)pl/sql dev
3)TOAD -
测试软件清单
2009-11-05 19:39:57
测试软件清单
脚本生成及加压工具:
1)JMeter
2)Badboy
3)HP Loadrunner监控工具:
1)HP SiteScope
2)Lamda Probe
3)Quest Spotlight
4)JProfiler
辅助工具:
1.网络查看
1)Sniffer + WinCap
2)TCP_UDP_Socket调试工具
2.java相关
1)JDK 1.5 ,1.6
2)Tomcat 5 ,6
3)eclipse
3.文本编辑
1)UtraEidt
4.数据库相关
1)Oracle_10g_client
2)pl/sql dev
3)TOAD












标题搜索
我的存档
数据统计
- 访问量: 713363
- 日志数: 415
- 图片数: 1
- 文件数: 3
- 建立时间: 2008-12-07
- 更新时间: 2015-07-14
