
-
如何提炼性能测试点
msnshow 发布于 2011-12-24 16:03:25
没有接触过性能测试的同学会觉得性能测试很深奥,很神秘,提到性能测试让人无从下手的感觉,其实,性能测试没想象中那么复杂,简单的说,性能测试就是功能测试量变达到质变的一个过程。简言之,哪些功能可能被大量用户访问的点,就是性能测试的重点之一。
之前做过一些小项目的性能测试,经常容易出现问题的点做了一个分类,之后我们在提炼性能测试点的时候会关注这些方面:
- 前端页面上
- 页面上本身有计算内容的地方 减少运算次数
- 通过接口取其他系统数据的地方
- 页面展现内容较多时是否翻页
- iframe. 静态文件和缓存
- 页面上的静态文件,如JS,更新频率
- 读取排行榜如果不是从数据库读取可能会有性能问题
- 数据库上的
- 读取数据库
- 写入数据库
- 存储过程
- 数据库之间同步
- 数据库检索、查询
- 索引
- sql语句
- 数据类型
- 程序本身上的
- 程序与其他系统交互的
- 代码效率
业务功能,数据库及程序本身涉及到上面这些内容的,都需要注意性能问题,可以结合业务和项目实际情况,考虑把这些点作为性能测试的一个关注点。当然,性能测试上手容易,做好难,想做好性能测试,还是需要慢慢不断深入和积累的
-
接口技术和测试
msnshow 发布于 2011-12-07 21:27:04
1. 银行代收系统基本架构简介
相关名称解释:
银行代收费方式
目前广电方借由银行方进行代收费的方式包括以下三种:
1. 银行代收(也称银行柜台代收)
2. 实时划扣
3. 批量托收(也称批量扣款,批扣)
银行代收
也可称为银行柜台代收。即广电用户到银行柜台办理交费,可现金交费或转账交费。银行方向广电方发起查询、交费等交易。此方式下,银行方系统为client端,广电方系统为server端。
实时划扣
广电方系统向银行方发起交费,冲正等交易,银行方实现实时划款(扣款)。此方式下,广电方系统为client端,银行方系统为server端。
批量托收
广电方系统向银行主提供数据文件形式的批量托收文件,银行方根据数据文件,实现批量收款。
2. Web Service跨平台技术简介
Web Service主要是为了使原来各孤立的站点之间的信息能够相互通信、共享而提出的一种接口。 Web Service所使用的是Internet上统一、开放的标准,如HTTP、XML、SOAP(简单对象访问协议)、WSDL等,所以Web Service可以在任何支持这些标准的环境(Windows,Linux)中使用。注:SOAP协议(Simple Object Access Protocal,简单对象访问协议),它是一个用于分散和分布式环境下网络信息交换的基于XML的通讯协议。在此协议下,软件组件或应用程序能够通过标准的HTTP协议进行通讯。它的设计目标就是简单性和扩展性,这有助于大量异构程序和平台之间的互操作性,从而使存在的应用程序能够被广泛的用户访问。
Web Service 是一种新的web应用程序分支,他们是自包含、自描述、模块化的应用,可以发布、定位、通过web调用。Web Service可以执行从简单的请求到复杂商务处理的任何功能。一旦部署以后,其他Web Service应用程序可以发现并调用它部署的服务。
Web Service是一种应用程序,它可以使用标准的互联网协议,像超文本传输协议(HTTP)和XML,将功能纲领性地体现在互联网和企业内部网上。可将Web服务视作Web上的组件编程。
3.接口测试的英文是interface testing,接口测试测试系统组件间接口的一种测试。
接口测试的好处:
由于接口测试代码本身就是用junit(当然接口的类型不同,不一定是Junit来实现)来实现的,是属于自动化测试的范畴,因此必定也包含自动化测试所固有的优势。
1) 提高测试质量
软件开发的过程是一个持续集成和改进的过程,而每一次的改进都可能引进新bug,因此当软件的一部,或者全部修改时,都需要对软件产品重新进行测试。其目的是要验证修改后的产品是符合需求的,而当没有自动化测试代码时,往往会由于各种各样的原因,回归不充分,导致bug遗漏。
2) 提高测试效率
软件系统的规模越来越大,功能点越来越多,开发人员的自测或者测试人员的人工测试非常耗时和繁琐,势必导致测试效率的低下,而自动化测试正好解决这些耗时繁琐的任务,在对外接口功能不变的情况下,达到了一次编写,永久使用的效果。
3) 提高测试覆盖
通过手工测试很难测试到一些更深层次的异常和安全的问题,通过一些辅助的一些测试工具,能分析出代码的覆盖率,通过覆盖率的提高来提高测试的深度。
4) 更好地重现软件缺陷
由于每次执行都是相同的代码,一旦代码出错,必定回归出错
5) 更好定位错误
由于接口测试是一种自下向上的测试,因此一量出错,非常容易定位出错,不向系统测试那样了,一旦有Bug,需要几层验证之后才能确定出错位置
6) 降低修改bug的成本接口测试基本和开发人员的编码平行工作,因此发现问题会比系统测试早很多,因此减少了修改bug的成本。
7) 增进测试人员和开发人员之间的合作关系,测试工程师为了更好地开展工作,需要对开发技术有深入的理解和实践,有了与开发工程师更多的交流。
8) 降低了项目不能按时发布的风险由于接口测试很早就介入,在提交给系统测试前对项目代码的核心模块已经做了详尽的测试,必定加速系统测试的时间,由此来保证项目的按时发布。
9)提升测试人员的技能。做接口测试必须了解开发人员的开发流程和一些开发技能,也需要了解测试工具的一些使用方法和一些测试思想,提升了测试人员的技术附加值,提高了自身的竟争力。
10)促使项目开发过程的规范化
要进行接口,需要完善的文档进行保障,没有测试文档,接口测试将寸步难行,接口测试将增加开发过程规范化产出,而规范化产出也保证了项目质量。
4. Terminal AutoRunner是泽众软件公司开发的,具有自主知识产权的、面向终端系统的回归测试工具。适用于VT100、VT220等标准应用系统,支持命令行模式和窗口模式(使用Cursors编写的应用程序),支持自动录制脚本、所见即所得的资源和脚本编辑,稳定的自动同步功能。是目前国内最好的银行业务测试工具。
支持针对终端应用的自动录制。支持连续录制和单独的窗口录制。支持的窗口组件:栏位、表格、对话框、窗口等。
脚本语言采用java标准脚本:bean shell。
对录制完成的资源,可以“所见即所得”的修改,包括重新定义组件、修改组件属性、删除组件等。
对于终端设备,如:终端、密码键盘、磁卡读写器、凭证打印机等,提供虚拟设备插件支持。在测试应用系统的时候,被测试系统仍然可以使用设备,不需要修改代码。
可以单独连接到测试管理工具,也可以作为测试工具的一个插件来使用,从而广泛应用于终端测试。
-
性能测试学习线路图(建议)
msnshow 发布于 2011-10-23 14:50:39
性能测试学习线路图(建议)
1 概览
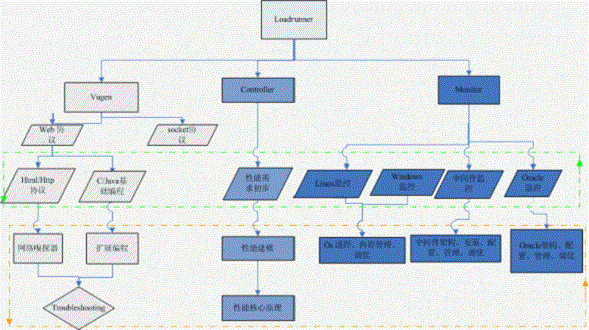
纵向划分3颗子树:vugen,controller,monitor。优先学习vugen脚本开发以及调试。
横向划分为2层:基础知识以及高级应用。
2 基础知识
2.1 Loadrunner工具使用
2.1.1 建议学习路径
Vugen开发脚本(函数使用)->controller场景设置->monitor增加计数器
http://www.cnblogs.com/jackei/archive/2006/10/20/534684.html
2.1.2 Loadrunner 认证
更多见
http://www.51testing.net/BWF_DIY/mercury/mercury_051107_1.htm
http://www.51testing.net/BWF_DIY/mercury/mercury_060104_11.htm
2.1.3 Vugen常用增强函数
增加事务:lr_start_transaction/:lr_end_transaction
检查点: web_reg_find
关联: web_reg_save_param ,web_set_max_html_param_len
日志: lr_error_message,lr_log_message, lr_output_message …
选项设置: web_set_timeout
http header: web_add_auto_header
以及更改runtime setting。
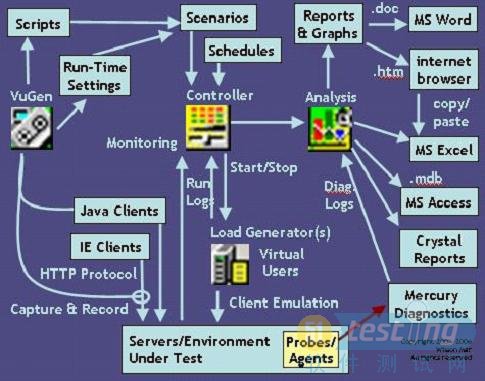
2.1.4 Loadrunner 架构图
概览图
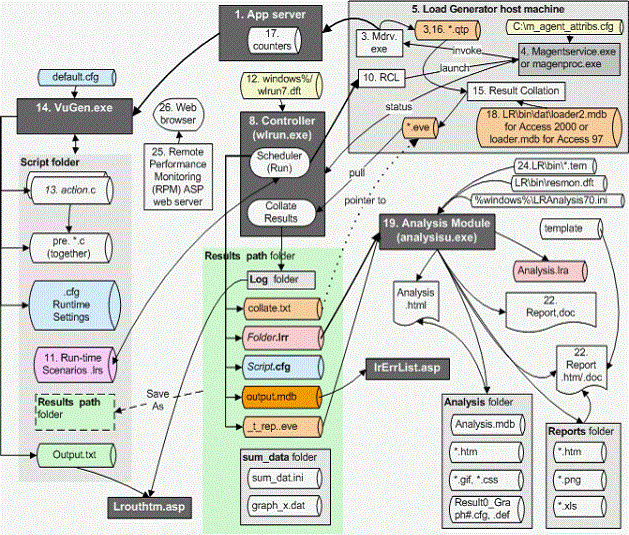
详细架构图:
2.2 Html/http协议
HTML 4.01 Specification:
http://www.eygle.com/digest/2006/12/html_xml_and_internet.html
对性能测试而言,META http-equiv控制http头、浏览器行为,故最为重要。
http协议:
http://www.faqs.org/rfcs/rfc2616.html

客户端发送请求:
服务器响应:
2.3 C 语言基础编程
Loadrunner常用的c函数主要集中在内存分配/释放、字符串操作、文件读写。
如: malloc/free
Sprintf/strcmp/strlen/
Fopen/fread/fwrite
2.4 Linux 性能分析初步
核心指令:
Top
Sar
Vmstat
Iostat
Sar -n DEV
/proc文件系统
分析经验性步骤:
首先查看 CPU 使用情况,按照诊断 CPU、内存或磁盘瓶颈的指导进行操作。对于下面的每个步骤,查找一端时间内的趋势,从中收集系统运行性能较差时的数据。另外,只有将这些数据与系统正常运行时收集的数据进行比较时才能进行准确的诊断。
步骤 1
# sar -u [interval] [iterations]
(示例: sar -u 5 30)
%idle 是否很低? 这是 CPU 未在运行任何进程的时间百分比。 在一端时间内 %idle 为零可能是 CPU 瓶颈的第一个指示。不是 -> 系统未发生 CPU 瓶颈。转至步骤 3。
是 -> 系统可能发生了 CPU、内存或 I/O 瓶颈。转至步骤 2。步骤 2
%usr 是否较高? 很多系统正常情况下花费 80% 的 CPU 时间用于用户, 20% 用于系统。其他系统通常会使用 80% 左右的用户时间。
不是 -> 系统可能遇到 CPU、内存或 I/O 瓶颈。转至步骤 3。
是 -> 系统可能由于用户进程遇到 CPU 瓶颈。转至部分 3,部分 A, 调整系统的 CPU 瓶颈。步骤 3
%wio 的值是否大于 15? (不同os有不同的阀值)
是 -> 以后记住这个值。它可能表示磁盘或磁带瓶颈。转至步骤 4。
不是 -> 转至步骤 4。步骤 4
# sar -d [interval] [iterations]
用于任何磁盘的 %busy 是否都大于 50? (请记住,50% 指示一个大概的 指南,它可能远远高于您系统的正常值。在某些系统上,甚至 %busy 值为 20 可能就表示发生了磁盘瓶颈,而其他系统正常情况下可能就为 50% busy。)对于同一个磁盘上,avwait 是否大于 avserv?不是 -> 很可能不是磁盘瓶颈,转至步骤 6。
是 -> 此设备上好像发生了 IO 瓶颈。
转至步骤 5。步骤 5
系统上存在磁盘瓶颈,发生瓶颈的磁盘上有哪些内容?
原始分区,
文件系统 -> 转至部分 3,部分 B,调整发生磁盘 IO 瓶颈的系统。
Swap -> 可能是由于内存瓶颈导致的。
转至步骤 6。步骤 6
# vmstat [interval] [iterations]
在很长的一端时间内,po 是否总是大于 0?
对于一个 s800 系统 (free * 4k) 是否小于 2 MB,
(对于 s700 系统 free * 4k 是否小于 1 MB)?
(值 2 MB 和 1 MB 指示大概的指南,真正的 LOTSFREE 值,即系统开始发生 paging 的值是在系统引导时计算的,它是基于系统内存的大小的。)不是 -> 如果步骤 1 中的 %idle 较低,系统则很可能发生了 CPU 瓶颈。
转至部分 3,部分 A,调整发生了 CPU 瓶颈的系统。
如果 %idle 不是很低,则可能不是 CPU、磁盘 IO或者内存瓶颈。
请转至部分 4,其他瓶颈。
是 -> 系统上存在内存瓶颈,转至部分 3 部分 C,调整发生内存瓶颈的系统。2.5 Windows 性能分析初步
同windows perfmon。
同样集中在 cpu,内存,io,网络上。
一般经验值:
网络
网络利用率阀值没有统一。 <30% or 80%?
冲突率: <1%
Packets Received Errors < 1%
I/O:
Disk Time % <90%
Avg. Disk Bytes/Read + Avg. Disk Bytes/Write <20K
Avg. Disk sec/Transfer <0.3 sec
队列长度:Queue Length <2
Avg. Disk sec/Transfer <18 milliseconds
内存
Available Mbytes >25%
Page in+out <20 次
内存泄露以及错误:
Pool Nonpaged Bytes : an increase of 10 percent or more from its value at system startup。
Server -> Pool Nonpaged Failures shows the number of times allocations from nonpaged pool have failed - indicates that the computer `s physical memory is too small. 应为0
Server -> Pool Paged Failures indicate that either physical memory or a paging file is near capacity. 应为0
Server -> Pool Nonpaged Peak shows the maximum number of bytes in nonpaged pool the server has had in use at any one point. Indicates how much physical memory the computer should have.
处理器
利用率 <85%
每个CPU队列长度 <2
Context Switches/sec <5000次 或者<5% of total threads
3 高级应用
3.1 性能建模
从business layer、function layer、session layer、customer layer出发,借助日志分析工具挖掘系统负载模型、用户行为模型。
<SPAN style="FONT-FAMILY: 'Arial'; COLOR: rgb(0,0,0); FONT-SI
-
【收藏】软件测试工程师的职业生涯
msnshow 发布于 2010-01-28 08:40:45
软件测试工程师作为软件质量的把关者,其职能在于保证交付到客户手中的软件可靠好用,运行畅通无阻。从产品定义到产品开发再到产品维护,都离不了软件测试。
按其级别和职位的不同,可分为三类,即:
高级软件测试工程师,熟练掌握软件测试与开发技术,且对所测试软件对口行业非常了解,能够对可能出现的问题进行分析评估;
中级软件测试工程师,编写软件测试方案、测试文档,与项目组一起制定软件测试阶段的工作计划,能够在项目运行中合理利用测试工具完成测试任务;
初级软件测试工程师,其工作通常都是按照软件测试方案和流程对产品进行功能测验,检察产品是否有缺陷。
工作职责
软件测试就是使用人工或自动手段,来运行或测试某个系统的过程。其目的在于检验它是否满足规定的需求或弄清预期结果与实际结果之间的差别。开发工作的根本是尽量实现软件用户的需求,测试工作的根本是检验软件系统是否满足软件用户的需求。
软件测试工程师简单的说是软件开发过程中的质量检测者和保障者,负责软件质量的把关工作。软件测试工程师具体工作有:
1 、使用各种测试技术和方法来测试和发现软件中存在的软件缺陷。测试技术主要分为黑盒测试和白盒测试两大类。其中黑盒测试技术主要有等价类划分法、边界值法、因果图法、状态图法、测试大纲法以及各类典型的软件故障模型等;白盒测试的主要技术有语句覆盖、分支覆盖、判定覆盖、基本路径覆盖等;
2 、测试工作需要贯穿整个软件开发生命周期。完整的软件测试工作包括单元测试、集成测试、确认测试和系统测试工作。单元测试工作主要在编码阶段完成,由开发人员和软件测试工程师共同完成,其主要依据是详细测试。集成测试的主要工作测试软件模块之间的接口是否正确实现,基本依据是软件体系结构设计。确认测试和系统测试是在软件开发完成后,验证软件的功能与需求的一致性、验证软件在相应的硬件条件下的系统功能是否满足用户需求,其主要依据是用户需求。
3 、测试人员将发现的缺陷编写成正式的缺陷报告,提交给开发人员进行缺陷的确认和修复。缺陷报告编写最主要的要求是保证缺陷的重现。要求测试人员具有很好的文字表达能力和语言组织能力。
4 、测试人员需要分析软件质量。在测试完成后,测试人员需要根据测试结果来分析软件质量,包括缺陷率、缺陷分布、缺陷修复趋势等。给出软件各种质量特性包括有功能性、可靠性、易用性、安全性、时间与资源特性等的具体度量。最后给出一个软件是否可以发布或提交用户使用的结论。
5 、测试过程中,为了更好地组织与实施测试工作,测试负责人需要制定测试计划,包括有测试资源、测试进度、测试策略、测试方法、测试工具、测试风险等。
6 、测试人员为了更好更有效地进行测试,保证测试工作质量,需要在执行测试工作之前首先需要设计测试用例,形成测试用例报告。设计测试用例是保证测试质量的核心工作,很多测试技术都可以用来指导设计用例。为了提高测试用例的设计效率,BTEST培训课程专门开设了高效设计测试用例一门课来讲授各种设计用例的技术与方法。
7 、为了提高工作效率或提高测试水平,测试工作需要引进自动化测试工具,测试人员需要学会使用自动化测试工具,编写测试脚本,进行性能测试等。
8 、测试负责人在测试工作中,还需要根据实际情况不断改进测试过程,提高测试水平,进行测试队伍的建设等。
测试组长这类测试人员通常是测试项目的负责人,既要具备较高的测试技术能力,还要具备一定的管理能力。主要职责是制定测试计划、编写测试计划、监控和管理整个测试过程。测试组长可以向上发展为测试部经理、质量经理,也可以横向发展为项目经理,而且通常待遇相对较高些。
测试分析师
主要职责是对系统的测试结果进行综合的分析,例如缺陷分析、性能分析等。测试分析师不但测试技术能力较强,还要具备数据库、操作系统等多方面的技术知识。这类职务的发展空间也不错,可以发展成系统设计师等。
自动化测试工程师、测试开发工程师
主要职责是编写测试程序、执行自动化测试任务。这类职位的测试人员至少要达到初级程序员的能力,因为经常和程序打交道。发展空间也不错,例如可以发展为程序员。
-
转:如何考核测试人员的工作绩效
msnshow 发布于 2009-10-18 12:13:56
绩效考核是一个团队的管理比较重要的一个方法和手段。合理适度公平的绩效考核对于团队的良好发展有着积极的影响作用。每个行业的团队考核和管理都会因为行业的特殊性以及公司的制度而有着很多的不同。也对于软件测试这个行业来说,也有着很多的区别。
从业四年多来,经过了日企,美企两大不同风格的公司的具体实践,对于测试团队的绩效考核,有些自己一些浅薄的认识。写在这里,留给自己深思,也希望给过路的同行一点启发。
一、绩效考核的一些片面的做法
日企和美企从很大程度上来讲,属于两种不同思想的碰撞,在各自的绩效考核上也各有一些在实践过程中,让人觉得不甚妥当的地方。在这里列举出来。
1、过分的强调了bug数量在绩效考核中的作用。
诚然,把发现bug的数量和质量作为一项重要的对测试人员的绩效考核标准是没有错误的,而且如果同时伴随着必要的奖励机制,会在一定程度上刺激测试人员对于寻找bug的热情。
但是,这个作用不可以过分的被强调。因为在实际的测试过程中,每个测试人员承担的测试模块的情况都是有区别的。比如有些人承担新开发的功能模块的测试,而有些人承担的则是旧有继承的模块的测试。bug的检出率对于新增模块来说自然要多于稳定的旧有模块。
还有,如果对bug的作用过分强调,也会使得测试人员在承担测试任务的时候挑肥拣瘦,都争着抢着去测试那些容易出问题的功能,在很大程度上会打乱测试计划和测试进度的正常进行。
一些国内的企业,包括我曾经工作过的日企,在实际的绩效考核过程中就过分的看重了bug的比重。“过犹不及”这句古语在现代的企业管理和项目管理中也发挥着它的作用。
2、只看测试用例的数量和客户对于测试的反馈而忽略了bug在绩效中的作用。
这一点在美企体现的是比较深刻的。对于很多在欧美外企工作的测试人员来说,工作量没有日企卡的那么严格,也不需要像测试leader整日的汇报动向。在既定的时间内完成测试需求的分析-测试用例的设计-测试的评审-测试的执行以及后期测试的结果汇报就可以了。如果当前测试的版本发布之后,没有其他的不良反馈,就算顺利的完成了测试任务。而也正因为这种文化的存在,在欧美企业的绩效考核中,测试case的设计质量和完成的多少以及客户的反馈成为重中之重。
这个根据应该说在很多程度上是有隐患的。可能根据这个release版本所重点关注的问题,测试员没有测试出相关的问题。但是却找到了其他的一些问题。因为绩效考核不在于考核测试人员对于bug的发现量,而且在一个跟本身release版本无关的问题上纠缠会造成一些额外的麻烦,比如说开发人员不予修改,比如说提交延迟,比如说及时你额外测试了,付出了,却没有任何的后续效果。。很多测试人员在长久的这种状态影响下,就如猫在火中取栗被烫伤了爪子一样,逐渐的把目光从全局放回了局部。及时bug就在脚边,甚至跘了自己一跤,也会因为这种影响,视为无物。那么长此以往,从这样的开发,测试团队中流出的产品的质量,可想而知。
3、对于测试人员发现的问题没有有效的评审机制。
测试人员要及早的连续的测试,要在发现问题后及早的报告。这是每一个从业人员都耳熟能详的原则。很多测试团队也在绩效考评中侧重于对测试人员发现bug量的考察。但是在实际的考评执行中,因为没有有效的bug评审机制,所以对于问题的质量的度量缺乏一定的衡量标准。
发现测试系统设计方面的缺陷和能引起测试系统出现异常的bug的意义要远远大于发现几个图形界面的小bug。所以,实际的测试中,要根据bug的严重程度和意义来给与合理的考评。
4、不重视测试人员的综合能力.
在很多测试团队中,绩效考评一般只限于两点,第一,测试用例的考察,包括书写的效率和质量;第二,测试缺陷量的考察。而对于其他,涉及很少。
测试团队的巩固和成长是一个长期的实践活动。对于测试人员的技能,素质以及其他相关的培养也是必要的。所以,在一个测试团队的绩效考核,也是需要针对综合的能力进行全面的考察。比如说,测试人员对于相关领域技能的学习能力,对于所学知识的分享能力,对于技术难题的攻克能力,外语能力,沟通能力等等。都应该是考察的一方面的内容。
二、绩效考核的几点建议
1、综合素质的考察
1)考察测试人员的职业操守,对于公司规章制度的一些遵守(如果需要)
2)考核测试人员的工作态度(是否认真,积极,努力)
3)考察测试人员的学习能力(对于边缘技术的学习能力,对于较难课题的学习和攻克能力)
2、测试成果的考察
1)考察测试人员的对于测试需求的理解
2)考察测试人员对于测试用例的设计(检查点的覆盖,业务的熟悉和掌握,测试用例的书写效率和质量)
3)考察测试人员的bug的检出率(bug的质量<严重程度,该bug的功能性影响>,确认,发行bug的工作是否到位,bug report书写的质量
4)和相关人员的沟通。包括和相关开发人员,其他人员的工作中的交流情况。
3、测试培训成功的考察
1)对于既定的测试小组的培训的学习情况。
2)对于给出的技能点的培训任务的担当和完成情况。
总结:
注意点:对于测试人员的绩效考评,要全面,公平。数据说话。也就是说,不能因为个人的亲疏远近关系而放宽或者严苛的对相关人员进行考核。不能因为个人的主观印象而要采取能拿出服众的数据给与合理的考评。
对于被考核者的评价要客观,通过考核,要让他们了解考核的意义以及对于测试人员本身使命的认知。对于被考核者的主观情绪,要把握好,并且适度的单独给与疏导,让其能够更加有效的投入到新的测试工作当中。
版权声明:本文出自tengmy的51Testing软件测试博客:http://www.51testing.com/?47068
-
功能测试常用的策略和方法
msnshow 发布于 2009-05-22 20:27:36
黑盒测试(Black-box Testing,又称为功能测试或数据驱动测试)是把测试对象看作一个黑盒子。利用黑盒测试法进行动态测试时,需要测试软件产品的功能,不需测试软件产品的内部结构和处理过程。
采用黑盒技术设计测试用例的方法有:等价类划分、边界值分析、错误推测、因果图和综合策略。
黑盒测试注重于测试软件的功能性需求,也即黑盒测试使软件工程师派生出执行程序所有功能需求的输入条件。黑盒测试并不是白盒测试的替代品,而是用于辅助白盒测试发现其他类型的错误。
黑盒测试试图发现以下类型的错误:
1)功能错误或遗漏;
2)界面错误;
3)数据结构或外部数据库访问错误;
4)性能错误;
5)初始化和终止错误。
一、黑盒测试的测试用例设计方法
· 等价类划分方法
· 边界值分析方法
· 错误推测方法
· 因果图方法
· 判定表驱动分析方法
· 正交实验设计方法
· 功能图分析方法
等价类划分:
是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的,常用的黑盒测试用例设计方法。
1) 划分等价类: 等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的。并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试。因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件,就可以用少量代表性的测试数据。取得较好的测试结果。等价类划分可有两种不同的情况:有效等价类和无效等价类。
有效等价类:是指对于程序的规格说明来说是合理的,有意义的输入数据构成的集合。利用有效等价类可检验程序是否实现了规格说明中所规定的功能和性能。
无效等价类:与有效等价类的定义恰巧相反。
设计测试用例时,要同时考虑这两种等价类。因为,软件不仅要能接收合理的数据,也要能经受意外的考验。这样的测试才能确保软件具有更高的可靠性。
2)划分等价类的方法:下面给出六条确定等价类的原则。
① 在输入条件规定了取值范围或值的个数的情况下,则可以确立一个有效等价类和两个无效等价类。
② 在输入条件规定了输入值的集合或者规定了“必须如何”的条件的情况下,可确立一个有效等价类和一个无效等价类。
③ 在输入条件是一个布尔量的情况下,可确定一个有效等价类和一个无效等价类。
④ 在规定了输入数据的一组值(假定n个),并且程序要对每一个输入值分别处理的情况下,可确立n个有效等价类和一个无效等价类。
⑤ 在规定了输入数据必须遵守的规则的情况下,可确立一个有效等价类(符合规则)和若干个无效等价类(从不同角度违反规则)。
⑥ 在确知已划分的等价类中各元素在程序处理中的方式不同的情况下,则应再将该等价类进一步的划分为更小的等价类。
3)设计测试用例:在确立了等价类后,可建立等价类表,列出所有划分出的等价类:
输入条件 有效等价类 无效等价类
然后从划分出的等价类中按以下三个原则设计测试用例:
① 为每一个等价类规定一个唯一的编号。
② 设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖地有效等价类,重复这一步。直到所有的有效等价类都被覆盖为止。
③ 设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类,重复这一步。直到所有的无效等价类都被覆盖为止。
边界值分析法
边界值分析方法是对等价类划分方法的补充。
(1)边界值分析方法的考虑:
长期的测试工作经验告诉我们,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。
使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。
(2)基于边界值分析方法选择测试用例的原则:
1)如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值,以及刚刚超越这个范围边界的值作为测试输入数据。
2)如果输入条件规定了值的个数,则用最大个数,最小个数,比最小个数少一,比最大个数多一的数作为测试数据。
3)根据规格说明的每个输出条件,使用前面的原则1)。
4)根据规格说明的每个输出条件,应用前面的原则2)。
5)如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
6)如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
7)分析规格说明,找出其它可能的边界条件。
错误推测法
错误推测法: 基于经验和直觉推测程序中所有可能存在的各种错误, 从而有针对性的设计测试用例的方法。
错误推测方法的基本思想: 列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例。 例如, 在单元测试时曾列出的许多在模块中常见的错误。 以前产品测试中曾经发现的错误等, 这些就是经验的总结。 还有, 输入数据和输出数据为0的情况。 输入表格为空格或输入表格只有一行。 这些都是容易发生错误的情况。 可选择这些情况下的例子作为测试用例。
因果图方法
前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等。 考虑输入条件之间的相互组合,可能会产生一些新的情况。 但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多。 因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例。 这就需要利用因果图(逻辑模型)。
因果图方法最终生成的就是判定表。 它适合于检查程序输入条件的各种组合情况。
利用因果图生成测试用例的基本步骤:
(1) 分析软件规格说明描述中, 那些是原因(即输入条件或输入条件的等价类),那些是结果(即输出条件), 并给每个原因和结果赋予一个标识符。
(2) 分析软件规格说明描述中的语义。找出原因与结果之间, 原因与原因之间对应的关系。 根据这些关系,画出因果图。
(3) 由于语法或环境限制, 有些原因与原因之间,原因与结果之间的组合情况不不可能出现。 为表明这些特殊情况, 在因果图上用一些记号表明约束或限制条件。
(4) 把因果图转换为判定表。
(5) 把判定表的每一列拿出来作为依据,设计测试用例。
从因果图生成的测试用例(局部,组合关系下的)包括了所有输入数据的取TRUE与取FALSE的情况,构成的测试用例数目达到最少,且测试用例数目随输入数据数目的增加而线性地增加。
前面因果图方法中已经用到了判定表。判定表(DECision Table)是分析和表达多逻辑条件下执行不同操作的情况下的工具。在程序设计发展的初期,判定表就已被当作编写程序的辅助工具了。由于它可以把复杂的逻辑关系和多种条件组合的情况表达得既具体又明确。
判定表驱动分析方法
判定表通常由四个部分组成。
条件桩(ConDItion STub):列出了问题得所有条件。通常认为列出得条件的次序无关紧要。
动作桩(Action Stub):列出了问题规定可能采取的操作。这些操作的排列顺序没有约束。
条件项(Condition Entry):列出针对它左列条件的取值。在所有可能情况下的真假值。
动作项(Action Entry):列出在条件项的各种取值情况下应该采取的动作。
规则:任何一个条件组合的特定取值及其相应要执行的操作。在判定表中贯穿条件项和动作项的一列就是一条规则。显然,判定表中列出多少组条件取值,也就有多少条规则,既条件项和动作项有多少列。
判定表的建立步骤:(根据软件规格说明)
① 确定规则的个数。假如有n个条件。每个条件有两个取值(0,1),故有 种规则。
② 列出所有的条件桩和动作桩。
③ 填入条件项。
④ 填入动作项。等到初始判定表。
⑤ 简化、合并相似规则(相同动作)。
B.Beizer 指出了适合使用判定表设计测试用例的条件:
① 规格说明以判定表形式给出,或很容易转换成判定表。
② 条件的排列顺序不会也不影响执行哪些操作。
③ 规则的排列顺序不会也不影响执行哪些操作。
④ 每当某一规则的条件已经满足,并确定要执行的操作后,不必检验别的规则。
⑤ 如果某一规则得到满足要执行多个操作,这些操作的执行顺序无关紧要。
黑盒测试的优点
1、基本上不用人管着,如果程序停止运行了一般就是被测试程序CRASh了
2、设计完测试例之后,下来的工作就是爽了,当然更苦闷的是确定crash原因
黑盒测试的缺点
1、结果取决于测试例的设计,测试例的设计部分来势来源于经验,OUSPG的东西很值得借鉴
2、没有状态转换的概念,目前一些成功的例子基本上都是针对PDU来做的,还做不到针对被测试程序的状态转换来作
3、就没有状态概念的测试来说,寻找和确定造成程序crash的测试例是个麻烦事情,必须把周围可能的测试例单独确认一遍。而就有状态的测试来说,就更麻烦了,尤其不是一个单独的tEStcase造成的问题。这些在堆的问题中表现的更为突出。
黑盒测试(功能测试)工具的选择
那么,如何高效地完成功能测试?选择一款合适的功能测试工具并培训一支高素质的工具使用队伍无疑是至关重要的。尽管现阶段存在少数不采用任何功能测试工具,从事功能测试外包项目的软件服务企业。短期来看,这类企业盈利状况尚可,但长久来看,它们极有可能被自动化程度较高的软件服务企业取代。
目前,用于功能测试的工具软件有很多,针对不同架构软件的工具也不断推陈出新。这里重点介绍的是其中一个较为典型自动化测试工具,即Mercury公司的WinRunner。
WinRunner是一种用于检验应用程序能否如期运行的企业级软件功能测试工具。通过自动捕获、检测和模拟用户交互操作,WinRunner能识别出绝大多数软件功能缺陷,从而确保那些跨越了多个功能点和数据库的应用程序在发布时尽量不出现功能性故障。
WinRunner的特点在于: 与传统的手工测试相比,它能快速、批量地完成功能点测试; 能针对相同测试脚本,执行相同的动作,从而消除人工测试所带来的理解上的误差; 此外,它还能重复执行相同动作,测试工作中最枯燥的部分可交由机器完成; 它支持程序风格的测试脚本,一个高素质的测试工程师能借助它完成流程极为复杂的测试,通过使用通配符、宏、条件语句、循环语句等,还能较好地完成测试脚本的重用; 它针对于大多数编程语言和Windows技术,提供了较好的集成、支持环境,这对基于Windows平台的应用程序实施功能测试而言带来了极大的便利。
WinRunner的工作流程大致可以分为以下六个步骤:
1.识别应用程序的GUI
在WinRunner中,我们可以使用GUI Spy来识别各种GUI对象,识别后,WinRunner会将其存储到GUI Map File中。它提供两种GUI Map File模式: Global GUI Map File和GUI Map File per Test。其最大区别是后者对每个测试脚本产生一个GUI文件,它能自动建立、存储、加载,推荐初学者选用这种模式。但是,这种模式不易于描述对象的改变,其效率比较低,因此对于一个有经验的测试人员来说前者不失为一种更好的选择,它只产生一个共享的GUI文件,这使得测试脚本更容易维护,且效率更高。
2.建立测试脚本
在建立测试脚本时,一般先进行录制,然后在录制形成的脚本中手工加入需要的TSL(与C语言类似的测试脚本语言)。录制脚本有两种模式: Context Sensitive和Analog,选择依据主要在于是否对鼠标轨迹进行模拟,在需要回放时一般选用Analog。在录制过程中这两种模式可以通过F2键相互切换。
只要看看现代软件的规模和功能点数就可以明白,功能测试早已跨越了单靠手工敲敲键盘、点点鼠标就可以完成的阶段。而性能测试则是控制系统性能的有效手段,在软件的能力验证、能力规划、性能调优、缺陷修复等方面都发挥着重要作用。
3.对测试脚本除错(debug)
在WinRunner中有专门一个Debug TOOlbar用于测试脚本除错。可以使用step、pause、breakpoint等来控制和跟踪测试脚本和查看各种变量值。
4.在新版应用程序执行测试脚本
当应用程序有新版本发布时,我们会对应用程序的各种功能包括新增功能进行测试,这时当然不可能再来重新录制和编写所有的测试脚本。我们可以使用已有的脚本,批量运行这些测试脚本测试旧的功能点是否正常工作。可以使用一个call命令来加载各测试脚本。还可在call命令中加各种TSL脚本来增加批量能力。
5.分析测试结果
分析测试结果在整个测试过程中最重要,通过分析可以发现应用程序的各种功能性缺陷。当运行完某个测试脚本后,会产生一个测试报告,从这个测试报告中我们能发现应用程序的功能性缺陷,能看到实际结果和期望结果之间的差异,以及在测试过程中产生的各类对话框等。
6.回报缺陷(defect)
在分析完测试报告后,按照测试流程要回报应用程序的各种缺陷,然后将这些缺陷发给指定人,以便进行修改和维护。
常用的功能测试方法
功能测试就是对产品的各功能进行验证,根据功能测试用例,逐项测试,检查产品是否达到用户要求的功能。常用的测试方法如下:
1、页面链接检查:每一个链接是否都有对应的页面,并且页面之间切换正确。
2、相关性检查:删除/增加一项会不会对其他项产生影响,如果产生影响,这些影响是否都正确。
3、检查按钮的功能是否正确:如update, cancel, delete, SAve等功能是否正确。
4、字符串长度检查: 输入超出需求所说明的字符串长度的内容, 看系统是否检查字符串长度,会不会出错。
5、字符类型检查: 在应该输入指定类型的内容的地方输入其他类型的内容(如在应该输入整型的地方输入其他字符类型),看系统是否检查字符类型,会否报错。
6、标点符号检查: 输入内容包括各种标点符号,特别是空格,各种引号,回车键。看系统处理是否正确。
7、中文字符处理: 在可以输入中文的系统输入中文,看会否出现乱码或出错。
8、检查带出信息的完整性: 在查看信息和update信息时,查看所填写的信息是不是全部带出。,带出信息和添加的是否一致
9、信息重复: 在一些需要命名,且名字应该唯一的信息输入重复的名字或ID,看系统有没有处理,会否报错,重名包括是否区分大小写,以及在输入内容的前后输入空格,系统是否作出正确处理。
10、检查删除功能:在一些可以一次删除多个信息的地方,不选择任何信息,按”delete”,看系统如何处理,会否出错;然后选择一个和多个信息,进行删除,看是否正确处理。
11、检查添加和修改是否一致: 检查添加和修改信息的要求是否一致,例如添加要求必填的项,修改也应该必填;添加规定为整型的项,修改也必须为整型。
12、检查修改重名:修改时把不能重名的项改为已存在的内容,看会否处理,报错。同时,也要注意,会不会报和自己重名的错。
13、重复提交表单:一条已经成功提交的纪录,back后再提交,看看系统是否做了处理。
14、检查多次使用back键的情况: 在有back的地方,back,回到原来页面,再back,重复多次,看会否出错。
15、search检查: 在有search功能的地方输入系统存在和不存在的内容,看search结果是否正确。如果可以输入多个search条件,可以同时添加合理和不合理的条件,看系统处理是否正确。
16、输入信息位置: 注意在光标停留的地方输入信息时,光标和所输入的信息会否跳到别的地方。
17、上传下载文件检查:上传下载文件的功能是否实现,上传文件是否能打开。对上传文件的格式有何规定,系统是否有解释信息,并检查系统是否能够做到。
18、必填项检查:应该填写的项没有填写时系统是否都做了处理,对必填项是否有提示信息,如在必填项前加*
19、快捷键检查:是否支持常用快捷键,如Ctrl+C Ctrl+V Backspace等,对一些不允许输入信息的字段,如选人,选日期对快捷方式是否也做了限制。
20、回车键检查: 在输入结束后直接按回车键,看系统处理如何,会否报错。
-
LoadRunner监控Linux与Windows方法
ivankaren 发布于 2013-08-14 17:25:44
LoadRunner监控Linux与Windows方法
一、监控windows系统:
1、监视连接前的准备工作
1)进入被监视windows系统,开启以下二个服务Remote Procedure Call(RPC) 和Remote Registry Service (开始—)运行 中输入services.msc,开启对应服务即可)。
2)在被监视的WINDOWS机器上:右击我的电脑,选择管理->共享文件夹->共享 在这里面要有C$这个共享文件夹 (要是没有自己手动加上)。
3)在安装LR的机器上,开始—》运行,输入 \\被监视机器IP\C$ 然后输入管理员帐号和密码,如果能看到被监视机器的C盘了,就说明你得到了那台机器的管理员权限,可以使用LR去连接了。(LR要连接WINDOWS机器进行监视要有管理员帐号和密码才行。)
问题:在执行步骤3)时,输入 \\被监视机器IP\C$,出现不能以administrator身份访问被监控系统(若采用这种方式用LR对其监控的话,会提示:“找不到网络路径”)的情况,现象就是用户名输入框是灰色的,并且默认用户是guest。
解决办法:这是安全策略的设置问题(管理工具 -> 本地安全策略 -> 安全选项 ->“网络访问:本地帐户的共享和安全模式”)。默认情况下,XP的访问方式是“仅来宾”的方式,如果你访问它,当然就固定为Guest来访问,而guest账户没有监控的权限,所以要把访问方式改为“经典”模式,这样就可以以administrator的身份登陆了。修改后,再次执行步骤3),输入管理员用户名和密码,就可以访问被监控机器C盘了。
若这样都不行的话(可能是其它问题引起的),那只好采取别的方法了。在服务器的机子上,通过windows自带的“性能日志和警报”下的“计数器日志”中新增加一个监控日志(管理工具—)性能—)性能日志和警报),配置好日志,也能监控服务器的cpu、memory、disk等计数器。当然,这种方法就不是用LR来监控了。
2、用LR监视windows的步骤
在controller 中,Windows Resources窗口中右击鼠标选择Add Measurements,添加被监控windows的IP地址,选择所属系统,然后选择需要监控的指标就可以开始监控了。
二、监控linux
1 准备工作
可以通过两种方法验证服务器上是否配置了rstatd守护程序:
①使用rup命令,它用于报告计算机的各种统计信息,其中就包括rstatd的配置信息。使用命令rup 10.130.61.203,此处10.130.61.203是要监视的linux/Unix服务器的Ip,如果该命令返回相关的统计信息。则表示已经配置并且激活了rstatd守护进程;若未返回有意义的统计信息,或者出现一条错误报告,则表示rstatd守护进程尚未被配置或有问题。
②使用find命令
#find / -name rpc.rstatd,该命令用于查找系统中是否存在rpc.rstatd文件,如果没有,说明系统没有安装rstatd守护程序。
如果服务器上没有安装rstatd程序(一般来说LINUX都没有安装),需要下载一个包才有这个服务,包名字是rpc.rstatd-4.0.1.tar.gz. 这是一个源码,需要编译,下载并安装rstatd(可以在[url]http://sourceforge.net/projects/[/url]rstatd<wbr>这个地址下载)
下载后,开始安装,安装步骤如下:
tar -xzvf rpc.rstatd-4.0.1.tar.gz
cd rpc.rstatd-4.0.1/
./configure —配置操作
make —进行编译
make install —开始安装
rpc.rstatd —启动rstatd进程
2)安装完成后配置rstatd 目标守护进程xinetd,它的主配置文件是/etc/xinetd.conf,它里面内容是一些如下的基本信息:
#
# xinetd.conf
#
# Copyright (c) 1998-2001 SuSE GmbH Nuernberg, Germany.
# Copyright (c) 2002 SuSE Linux AG, Nuernberg, Germany.
#
defaults
{
log_type = FILE /var/log/xinetd.log
log_on_success = HOST EXIT DURATION
log_on_failure = HOST ATTEMPT
#only_from = localhost
instances = 30
cps = 50 10
#
# The specification of an interface is interesting, if we are on a firewall.
# For example, if you only want to provide services from an internal
# network interface, you may specify your internal interfaces IP-Address.
#
# interface = 127.0.0.1
}
includedir /etc/xinetd.d
我们这里需要修改的是/etc/xinetd.d/下的三个conf文件 rlogin,rsh,rexec这三个配置文件,打这三个文件里的disable = yes都改成 disable = no ( disabled 用在默认的 {} 中 禁止服务)或是把# default: off都设置成 on 这个的意思就是在xinetd启动的时候默认都启动上面的三个服务!
说明:我自己在配置时,没有disable = yes这项,我就将# default: off改为:default: on,重启后(cd /etc/init.d/ ./xinetd restart)通过netstat -an |grep 514查看,没有返回。然后,我就手动在三个文件中最后一行加入disable = no,再重启xinetd,再使用netstat -an |grep 514查看,得到tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN结果,表明rsh服务器已经启动。
只要保证Linux机器上的进程里有rstatd和xinetd这二个服务就可以用LR去监视了。
两点小的技巧:
①检查是否启动: rsh server 监听的TCP 是514。
[root@mg04 root]# netstat -an |grep 514
tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN
如果能看到514在监听说明rsh服务器已经启动。
②检查是否启动: rstatd
输入命令: rpcinfo -p
如果能看到类似如下信息:
程序 版本 协议 端口
100001 5 udp 937 rstatd
100001 4 udp 937 rstatd
100001 3 udp 937 rstatd
100001 2 udp 937 rstatd
100001 1 udp 937 rstatd
那就说明rstatd服务启动了,(当然这里也可以用ps ax代替)
③重起xinetd方法:
在suse linux如下操作:
cd /etc/init.d/
./xinetd restart
看到网上有的地方说使用如下命令:
# service xinetd reload
# /sbin/service xinetd rstart
不知道是在什么系统用的。
④安装rsh,和rsh-server两个服务包方法
a. 卸载rsh
# rpm –q rsh----------查看版本号
# rpm -e 版本号---------卸载该版本。
b.安装
# rpm –ivh rsh-0.17-14.i386.rpm rsh-server-0.17-14.i386.rpm
⑤在启动rpc.rstatd时,会报错“Cannot register service: RPC: Unable to receive;errno = Ction refused”。
解决方法如下:
# /etc/init.d ./portmap start
# /etc/init.d ./nfs start
然后再次启动rpc.rstatd就好了。
最后,在controller中,将UNIX resources拖放到右边窗口里面,右击鼠标选择Add Measurements,添加被监控linux的IP地址,然后选择需要监控的指标就可以了。
三、监控UNIX
lr监控UNIX,UNIX先启动一rstatd服务
以下是在IBM AIX系统中启动rstatd服务的方法:
1、 使用telnet以root用户的身份登录入AIX系统
2、 在命令行提示符下输入:vi/etc/inetd.conf
3、 查找rstatd,找到
#rstatd sunrpc_udp udp wait root /usr/sbin/rpc.rstatd rstatd 100001 1-3
4、将#去掉
5、:wq保存修改结果
6、命令提示符下输入:refresh –s inetd 重新启动服务。
这样使用loadrunner就可以监视AIX系统的性能情况了。
注:在HP UNIX系统上编辑完inetd.conf后,重启inetd服务需要输入inetd -c
UNIX上也可以用rup命令查看rstatd程序是否被配置并激活
若rstatd程序已经运行,重启时,先查看进程ps -ef |grep inet,然后杀掉进程,再refresh –s inetd进行重启。
-
LR常用函数总结
msnshow 发布于 2011-07-02 16:47:05
事务函数:
lr_start_transaction();//标记事务的开始
lr_start_transaction();/*标记事务的结束,一般情况下,事务开始与结束联合使用*/
lr_get_trans_instance_status();//得到事务的状态
lr_get_transaction_think_time();//得到事务的指定思考时间,事务时间=整体事务时间-事务的
lr_stop_transaction();//停止事务
日志函数:
lr_debug_message();//发送调试信息到日志文件
lr_error_message();//发送错误信息到LR输入窗口或日志文件里
lr_get_debug_message();//返回当前调试的信息
lr_log_message();//发送信息到用户日志文件
lr_output_message();//发送信息到输出窗口或日志文件
lr_vuser_status_message();//发送虚拟用户的状态到LR的Controller
运行时函数:
lr_abort();//终止执行的脚本
lr_continue_on_error();//当发生错误后运行的事件
lr_exit();//从scirpt.ation.iteration中退出
lr_rendezvous_ex();//设置集合点
lr_think_time();//设置思考时间,在性能测试中为了更好模拟以后操作,可以根据实际生产环境设置思考时间。
lr_rendezous();//集合点,可以设置虚拟用户相同操作之前进行集合,通过集合点可以增加被测试应用的压力,从而达到压力测试的目的。
lr_load_dll();//调用DLL文件
例子:
lr_load_dll("user32.dll");
MessageBoxA(NULL,"This is Testing Message","message_caption",0);
return 0;
系统信息函数:
lr_get_master_host_name();//返回运行Controller主机的名称
lr_get_user_ip();//返回虚拟用户的IP地址
lr_user_data_point();//录制用户自定义的数据样例
lr_user_data_point();// 记录自己的数据来进行分析,每次要记录一个点时,请使用该函数记录采样名称和值。系统将自动记录采样的时间。执行之后,可以使用用户等义的数据,点击图形分析结果
lr_get_host_name();//返回主机名
例子;
char * host;
host=lr_get_host_name();
lr_output_message("Computer Name %s",host);
return 0;
WEB应用中常见函数
web_url();//根据函数中的URL属性加载对应的URL,不需要上下文。
web_image();//模拟鼠标在指定图片上的单击动作。此函数必须在有前置操作的上下文中使用。
Tips:在Toos—Recording Option,如果录制级别设为基于HMTL的录制方式时,web_image才会被录制到。
Web_link();//模拟鼠标在由若干个属性集合描述的链接上进行单击。此函数必须在前置动作的上下文中才可以执行。
web_submit_form. ();//函数用来提交表单。此函数可能必须在前一个操作的上下文中执行。
Tips:支持Web虚拟用户,不支持WAP虚拟用户。
web_submit_data();//函数处理无状态或者上下文无关的表单提交。它用来生成表单的GET或POST请求,这些请求与Form自动生成的请求是一样的。发送这些请求时不需要表单上下文。
web_find();//此函数的作用是在HTML页面中查找指定的字符串。当指定的HTML请求全部完成以后,开始执行搜索过程,比web_reg_find要慢。
web_find函数在C语言的脚本中已经被web_reg_find所替代,web_reg_find运行速度比较快,而且在HTML-based和URL-based的录制方式中都可以使用。 在C语言脚本中,web_find是向后兼容的。Java和Visual Basic脚本中不再支持它。
web_image_check();//检查指定的图象是否在HTML页面中出现,此函数仅仅支持基于HTML的脚本。
web_reg_add_cookie();//是注册类型的函数。它首先注册一个搜索文本字符串的请求。检查动作在后续的Action函数之后进行。如果字符串被找到,就添加到cookie中。
web_reg_find();//属于注册函数,注册一个在web页面中搜索文本字符串的请求,在接下来的Action(象web_url)类函数中执行搜索。
web_concurrent_start();//函数是并发组开始的标记。组中所有的函数是并发执行的。并发组的结束web_concurrent_end 函数。
web_reg_save_param();//关联函数,通过关联可以在测试中保持动态值,从服务器返回的数据库中查找需要关联的数据。
web_add-filter();// 过滤函数,用于对指定的URL进行过滤,分析URL加载那部分对性能有影响。界面操作Run-time Settings 下的 Internet Protocol的Download Filters。
web_custom_request();// 自定义请求函数,可以编写自定义请求格式进行接口功能测试。
FTP /IMAP方面:
ftp_logon_ex();//针对特定会话登录到FTP服务器。
ftp_put_ex();//在FTP服务器上设置工作目录及上传文件。
ftp_logout_ex();//注销当前FTP连接。
imap_create();//创建新的邮件。
imap_check();//邮件中请求检查点,实现并适用与邮箱内部的内务管理。
Tips:针对IMAP的测试,把函数中的ftp替换成imap即可。
其它常用函数:
Lr_decrypt():LR中的解密函数
实例代码: lr_output_message("解密函数测试,解密后数值:%s",lr_decrypt("4e0942869c958e3e"));
Getenv():得到定义的环境变量值
实例代码:
char *tmp,logfile[256],dlr_seperator;
logfile;
//Create an environment variable
putenv("LOGFILE_NAME=lr_xiaolintest.txt");
//
if(tmp = (char*)getenv("TEMP"))
lr_output_message("Temp Dir = %s",tmp);
else{
lr_output_message("TEMP environment variable undefined");
return -1;
}
sprintf(logfile,"%s\\%s",tmp,(char*)getenv("LOGFILE_NAME"));
System():执行操作系统的命令
char filename[1024],command[1024];
char new_dir[] = "c:\\test";
//Create a directory udder root called test and make it the current dir
if(mkdir(new_dir))
lr_output_message("Create directory :%s failed",new_dir);
else
lr_output_message("Create new directory %s",new_dir);
sprintf(filename,"%s\\%s",new_dir,"xialin.txt");
//Executr a dir /b command and directory it to a new_file
sprintf(command,"dir /b c:\\ > %s /w",filename);
system(command)
lr_output_message("Create new file %s",filename);
Rand():得到一个整型的随机值(0到32767)
srand(time(NULL));
//Generate a random number from 0-99
lr_output_message("A number between 0 and 99 is :%d\n",rand()%100);
return 0;
Getdrive()and mkdir():返回当前驱动盘的名字。
int ch,drive,curdrive;
static char path[1024];
//Save current drive letter so it can be restored later
curdrive = getdrive();
//If we can switch to the drive,it exists
lr_output_message("Available drives are:");
for(drive = 1;drive <= 26;drive++)
if (!chdrive(drive))
lr_output_message("%c:",drive + 'A' -1);
chdrive(curdrive);//Restore original drive
return 0;
Time():返回系统的时间
typedef long time_t;
time_t t;
//Get system time and display as number and string
lr_message("Time in seconds since 1/1/88: %ld\n",time(&t));
lr_message("Formatted time and date: %s",ctime(&t));
return 0;
-
LoadRunner监控Mysql和Apache进程
msnshow 发布于 2010-07-24 17:05:53
服务器端的准备工作:
1、登陆服务器,验证snmp服务能不能监控到mysql和http进程信息:
snmpwalk -Os -c public -v 1 172.16.100.28|grep mysql
snmpwalk -Os -c public -v 1 172.16.100.28|grep http
有数据即可。
如果没有数据,那么需要手工配置下文件。进入步骤 2
2、
[root@cherry root]# cd /etc/snmp/[root@cherry snmp]# vi snmpd.conf
扩大监控范围: 将 view systemview included **** 后面的数据改成更大的范围
3、运行下面命令
[root@cherry snmp]# /etc/init.d/portmap start
[root@cherry snmp]# /etc/init.d/snmpd start
4、再次验证
验证snmp服务能不能监控到mysql和http进程信息:
snmpwalk -Os -c public -v 1 172.16.100.28|grep mysql
snmpwalk -Os -c public -v 1 172.16.100.28|grep http
LunnerRunner中添加监控参数
1、控制场景-RUN-添加SNMP到监控窗口
2、在SNMP到监控窗口点击右键,添加服务器和 mysql、appache的 PID
添加PID的路径:mgmt--mib-2--host—hrswrunperf--runperftable-- hrswrunperfEnter -- hrswrunperfcpu(如果是要监控内存那么应该是***Mem)查找需要的PID
-
LoadRunner性能测试指标
msnshow 发布于 2009-06-13 11:05:47
Object
Counters
Descrīption
Reference value
Memory
Available Mbytes
可用物理内存数.如果Available Mbytes的值很小(4 MB或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
4 MB或更小,至少要有10%的物理内存值
Page/sec
(Input/Out)
为了解析硬页错误,从磁盘取出或写入的页数。一般如果Page/sec持续高于几百,那么您应该进一步研究页交换活动。有可能需要增加内存,以减少换页的需求(你可以把这个数字乘以4k就得到由此引起的硬盘数据流量)。Pages/sec的值很大不一定表明内存有问题,而可能是运行使用内存映射文件的程序所致。
推荐00-20
如果服务器没有足够的内存处理其工作负荷,此数值将一直很高。如果大于80,表示有问题(太多的读写数据操作要访问磁盘,可考虑增加内存或优化读写数据的算法)。
该系列计数器的值比较低说明响应请求比较快, 否则可能是服务器系统内存短缺引起(也可能是缓存太大, 导致系统内存太少)。
>5越低越好
Page Fault
处理器每秒处理的错误页(包括软/硬错误)。
当处理器向内存指定的位置请求一页(可能是数据或代码)出现错误时,这就构成一个Page Fault。如果该页在内存的其他位置,该错误被称为软错误(用Transition Fault/sec记数器衡量);如果该页必须从硬盘上重新读取时,被称为硬错误。许多处理器可以在有大量软错误的情况下继续操作。但是,硬错误可以导致明显的拖延。
Page Input/sec
为了解决硬错误页,从磁盘上读取的页数。
Page Output/sec
Page reads/sec
为了解决硬错误页,从磁盘上读取的次数。解析对内存的引用,必须读取页文件的次数。阈值为>5.越低越好。大数值表示磁盘读而不是缓存读。
Cache Bytes
文件系统缓存,默认情况下为50%的可用物理内存。如IIS5.0运行内存不够时,它会自动整理缓存。需要关注该计数器的趋势变化
内存泄露
如果您怀疑有内存泄露,请监视Memory\\ Available Bytes和Memory\\ Committed Bytes,以观察内存行为,并监视您认为可能在泄露内存的进程的Process\\Private Bytes、Process\\Working Set和Process\\Handle Count。如果您怀疑是内核模式进程导致了泄露,则还应该监视Memory\\Pool Nonpaged Bytes、Memory\\ Pool Nonpaged Allocs和Process(process_name)\\ Pool Nonpaged Bytes。
Process
Page Faults/sec
将进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。
Private Bytes
此进程所分配的无法与其它进程共享的当前字节数量。如果系统性能随着时间而降低,则此计数器可以是内存泄漏的最佳指示器。
Work set
处理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在工作集中,当自由内存少于一个特定的阈值时,页就会被清除出工作集。
Processor
% Processor Time
被消耗的处理器时间数量.如果服务器专用于sqlserver可接受的最大上限是80% -85%.也就是常见的CPU使用率.
ProcessorQueue Length
判断CPU瓶颈,如果processor queue length显示的队列长度保持不变(>=2)并且处理器的利用率%Processor time超过90%,那么很可能存在处理器瓶颈.如果发现processor queue length显示的队列长度超过2,而处理器的利用率却一直很低,或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈.
Physical
Disk
%DiskTime
指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。
正常值<10,此值过大表示耗费太多时间来访问磁盘,可考虑增加内存、更换更快的硬盘、优化读写数据的算法。若数值持续超过80 (此时处理器及网络连接并没有饱和),则可能是内存泄漏。
CurrentDiskQueueLength
读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。(磁盘数1.5-2倍)
Avg.Disk Queue
Length
Avg.Disk Read
QueueLength
Avg.Disk Write
QueueLength
Disk Read/sec
Disk Write/sec
读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。
磁盘瓶颈判断公式:
每磁盘的I/O数=(读次数+(4*写次数))/磁盘个数。
如果计算出来的每磁盘的I/O数大于磁盘的处理能力,那么磁盘存在瓶颈。
Avg.DiskQueue Length正常值<0.5,此值过大表示磁盘IO太慢,要更换更快的硬盘。
1. User 0 Connections (用户连接数,也就是数据库的连接数量);
2. Number of deadlocks/Sec/-Total (数据库死锁)
3. Memory\ Availalle Mbyte 内存监控 (可用内存)
4. Physicsdisk \disk time \-Total(磁盘读写总时间)(出现瓶颈时检查读磁盘的时间长还是写磁盘的时间长)
5. Butter Caile hit(数据库缓存的选取命中率)
6. 数据库的命中率不能低于92%
2、Web Server:
1. Processor \ Processon time \ Tatol cpu时间
2. Memory \ Availalle MbyteAvai 应用服务器的内存
3. Requst Quened 进入HTTP队列的时间;队列/每秒
4. Total request 总请求数时间
5. Avg Rps 平均每秒钟响应次数= 总请求时间 / 秒数
6. Avg time to last byte per terstion (mstes)平均每秒迭代次数 ; 上一个页面到下一个页面的时间是你录入角本的一个过程的执行
7. Http Error 无效请求次数
8. Send 发送请求次数字节数
Webload的压力参数:
l Load Size(压力规模大小)
l Round Time(请求时间)
l Rounds (请求数)
l Successful Rounds(成功的请求)
l Failed Rounds (失败的请求)
l Rounds Per Second (每秒请求次数)(是指你录入角本的任务在一秒中执行的次数,类似Avg time to last byte per terstion (mstes))
l Successful Rounds Per Second(每秒成功的请求次数)
l Failed Rounds Per Second(每秒失败的请求次数)
l Page Time 页面响应时间
l Pages (页面数)
l Pages Per Second (每秒页面响应数)
l H it Time(点击时间)
l Hits(点击次数,也可以是请求次数,不过有一些不一样)
l Successful Hits (成功的点击次数)
l Failed Hits (失败的点击次数)
l Hits Per Second (每秒点击数)
l Successful Hits Per Second (每秒成功的点击次数)
l Failed Hits Per Second (每秒失败的点击次数)
l Attempted Connections (尝试链接数)
l Successful Connections(成功的连接数)
l Failed Connections(失败的连接数)
l Connect Time(连接时间)
l Process Time(系统执行时间,一般用来显示CPU的运算量,服务器端与客户端都要记录)
l Receive Time(接受时间)
l Send Time(请求时间)
l Time To First Byte ()
l Throughput (Bytes Per Second)()
l Response Time(回应时间)
l Response Data Size()
l Responses()
Transactions per second(每秒处理事务数) http连接Get or Post方法的事务数
Rounds per second(每秒完成数) 每秒完全执行Agenda〔代理〕的数量
Throughput(吞吐量)(bytes per second〔每秒字节数〕) 测试服务器每秒传送的字节数
Round Time 完成一次事务所用的必要时间,单位是秒
Transaction Time是完成一次事务的必须时间。事务:包括连接时间,发送、响应和处理时间。
Connect Time 客户端到测试服务器的一个连接完成的时间,单位秒(包括建立和收到的TCP/IP时间)
Send Time 是将事务写入测试服务器的缓冲必要时间 ,单位秒
Response Time 是客户端请求接受测试服务器响应的必要时间,单位秒
Process Time 处理数据的必要时间
Load Size 负载测试时开启的虚拟客户数量〕
Rounds 在测试会话期间执行议程脚本的时间数
Attempted Connections 尝试连接测试服务器的数量
HTTP Response Status 每一个http响应被结束的时间数量
Response Data Size 由测试服务器发送的响应大小,单位字节。 -
用LoadRunner分析资源占用率
msnshow 发布于 2009-06-07 18:01:04
1. 平均事务响应时间Average Transation Response Time 优秀:<2s
良好:2-5s
及格:6-10s
不及格:>10s
2. 每秒点击率
Hits per Second
当增大系统的压力(或增加并发用户数)时,吞吐率和TPS的变化曲线呈大体一致,则系统基本稳定若压力增大时,吞吐率的曲线增加到一定程度后出现变化缓慢,甚至平坦,很可能是网络出现带宽瓶颈.同理若点击率/TPS曲线出现变化缓慢或者平坦,说明服务器开始出现.
3. 请求响应时间
Time to Last Byte
4. 每秒系统处理事务数
Transaction per second
5. 吞吐量
Throughout
6. CPU利用率
Processor / %Processor Time 好:70%
坏:85%
很差:90%+
7. 数据库操作消耗的CPU时间
Processor / %User Time 如果该值较大,可以考虑是否能通过友好算法等方法降低这个值。如果该服务器是数据库服务器, Processor\%User Time 值大的原因很可能是数据库的排序或是函数操作消耗了过多的CPU时间,此时可以考虑对数据库系统进行优化。
8. 核心态CPU平均利用率
Processor /%Privileged Time 如果该参数值和"Physical Disk"参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统
9. 处理列队中的线程数
Processor / Processor Queue Length 如果该值保持不变(>=2)个并且%Processor Time 超过90%,那么可能存在处理器瓶颈。如果发现超过2,而处理器的利用率却一直很低,那么或许更应该去解决处理器阻塞问题,这里处理器一般不是瓶颈。
10. 文件系统缓存
Memory / Cache Bytes 50%的可用物理内存
11. 剩余的可用内存
Memory / Avaiable Mbytes 至少要有10% 的物理内存值
本文出自51Testing软件测试网,感谢会员fmsbai5在每周一问(08-12-29)中的精彩回答。http://bbs.51testing.com/forum-157-1.html
12. 每秒下载页数
Memory / pages/sec 好:无页交换
坏:CPU每秒10个页交换
很差:更多的页交换
13. 页面读取操作速率
Memory / page read/sec 如果页面读取操作速率很低,同时 % Disk Time 和 Avg.Disk Queue Length的值很高,则可能有磁盘瓶径。但是,如果队列长度增加的同时页面读取速率并未降低,则内存不足。
14. 物理磁盘利用率
Physical Disk / %Disk Time 好:<30%
坏:<40%
很差:<50%+
15. 物理磁盘平均磁盘I/O队列长度
Physical Disk / Avg.Disk Queue Length 该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘
16. 网络吞吐量
Network Interface / Bytes Total/sec 判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽,结果应该小于50%
17. 数据高速缓存区命中率 命中率应大于0.90最好
18. 共享区库缓存区命中率 命中率应大于0.99
19. 监控 SGA 中字典缓冲区的命中率 命中率应大于0.85
20. 检测回滚段的争用 小于1%
21. 监控 SGA 中重做日志缓存区的命中率
应该小于1%
22. 监控内存和硬盘的排序比率 最好使它小于 10%
-
LoadRunner使用技巧- IP欺骗的使用
msnshow 发布于 2007-11-03 11:06:54
设置IP欺骗的原因
1、 当某个IP的访问过于频繁,或者访问量过大是,服务器会拒绝访问请求,这时候通过IP欺骗可以增加访问频率和访问量,以达到压力测试的效果。
2、 某些服务器配置了负载均衡,使用同一个IP不能测出系统的实际性能。LR中的IP欺骗通过调用不同的IP,可很大程度上的模拟实际使用中多IP访问和并测试服务器均衡处理的能力。
多IP地址的设置
IP地址的设置较为简单,可直接在本地连接中增加IP,或者通过LR自带的工具“IP wizard”设置,当然也可以使用其它软件设置。唯一需要注意的就是注意设置的IP的有效性。
“选项”中的IP设置
使用“选项”对话框中的“常规”选项卡,可以选择IP地址模式。只有在专家模式下操作 Controller 时,才显示该选项卡。
1. 选择“工具”>“选项”。将显示“选项”对话框。选择“常规”选项卡。
需要注意的是,这里的IP地址模式和运行时设置中的常规设置的不同,会导致IP欺骗失效。具体该怎么设置,这里就不讲了,很简单的东西。
启用IP欺骗
从 Controller 启用多个 IP 地址
定义多个 IP 地址后,您就可以设置一个选项,让 Controller 使用该功能。
要从 Controller 启用多个 IP 地址,请执行下列操作:
在 Controller“设计”视图中,选择“场景”>“启用 IP 欺骗器”。
IP欺骗功能验证
IP欺骗已经设置了,但是是不是有效呢?通常会有这样的疑问。下面我们通过一个简单的试验,来验证是否有效。
在脚本的Action()部分增加如下代码:
&nsp; char * ip=lr_get_vuser_ip();
if(ip)
lr_vuser_status_message("The ip address is %s",ip);
else
lr_vuser_status_message("IP spoofing disabled");
然后通过控制器设置并运行场景,在Controller's Vuser 窗口中,大家可以看到如下的结果:
遇到问题总结:
启动IP向导的时候出现:
---------------------------
IP Wizard
---------------------------
The IP wizard does not support DHCP-enabled network cards.Your cards are either DHCP-enabled or configured with invalid settings.
Please contact your system administrator.
Exiting...
是因为不能用动态IP
-
Web测试总结
msnshow 发布于 2011-07-10 17:26:55
一、输入框
1、字符型输入框:(1)字符型输入框:英文全角、英文半角、数字、空或者空格、特殊字符“~!@# ¥%……&*?[]{}”特别要注意单引号和&符号。禁止直接输入特殊字符时,使用“粘贴、拷贝”功能尝试输入。 (2)长度检查:最小长度、最大长度、最小长度-1、最大长度+1、输入超工字符比如把整个文章拷贝过去。 (3)空格检查:输入的字符间有空格、字符前有空格、字符后有空格、字符前后有空格 (4)多行文本框输入:允许回车换行、保存后再显示能够保存输入的格式、仅输入回车换行,检查能否正确保存(若能,检查保存结果,若不能,查看是否有正常 提示)、(5)安全性检查:输入特殊字符串 (null,NULL,
,javascript,<script>,</script>,<title>,<html>,<td>)、 输入脚本函数(<script>alert("abc")</script>)、 doucment.write("abc")、<b>hello</b>) 2、数值型输入框:(1)边界值:最大值、最小值、最大值+1、最小值-1
(2)位数:最小位数、最大位数、最小位数-1最大位数+1、输入超长值、输入整数 (3)异常值、特殊字符:输入空白(NULL)、空格或"~!@#$%^&*()_+{}|[]\:"<>?;',./?;:'-= 等可能导致系统错误的字符、禁止直接输入特殊字符时,尝试使用粘贴拷贝查看是否能正常提交、word中的特殊功能,通过剪贴板拷贝到输入框,分页符,分节 符类似公式的上下标等、数值的特殊符号如∑,㏒,㏑,∏,+,-等、 输入负整数、负小数、分数、输入字母或汉字、小数(小数前0点舍去的情况,多个小数点的情况)、首位为0的数字如01、02、科学计数法是否支持1.0E2、全角数字与半角数字、数字与字母混合、16进制,8进制数值、货币型输入(允许小数点后面几位)、(4)安全性检查:不能直接输入就copy
3、日期型输入框:(1)合法性检查:(输入0日、1日、32日)、月输入[1、3、5、7、8、10、12]、日输入[31]、月输入[4、6、9、11]、日输入[30][31]、输入非闰年,月输入[2],日期输入[28、29]、输入闰年,月输入[2]、日期输入[29、30]、月输入[0、1、12、13]
(2)异常值、特殊字符:输入空白或NULL、输入~!@#¥%……&*(){}[]等可能导致系统错误的字符 (3)安全性检查:不能直接输入,就copy 二、搜索功能
若查询条件为输入框,则参考输入框对应类型的测试方法
1、功能实现:(1)如果支持模糊查询,搜索名称中任意一个字符是否能搜索到 (2)比较长的名称是否能查到 (3)输入系统中不存在的与之匹配的条件 (4)用户进行查询操作时,一般情况是不进行查询条件的清空,除非需求特殊说明。
2、组合测试:(1)不同查询条件之间来回选择,是否出现页面错误(单选框和多选框最容易出错)(2)测试多个查询条件时,要注意查询条件的组合测试,可能不同组合的测试会报错。
三、添加、修改功能
1、特殊键:(1)是否支持Tab键 (2)是否支持回车键
2、提示信息:(1)不符合要求的地方是否有错误提示
3、唯一性:(1)字段唯一的,是否可以重复添加,添加后是否能修改为已存在的字段(字段包括区分大小写以及在输入的内容前后输入空格,保存后,数据是否真的插入到数据库中,注意保存后数据的正确性)
4、数据 正确性:(1)对编辑页的每个编辑项进行修改,点击保存,是否可以保存成功,检查想关联的数据是否得到更新。(2)进行必填项检查(即是否给出提示以及提 示后是否依然把数据存到数据库中;是否提示后出现页码错乱等)(3)是否能够连续添加(针对特殊情况)(4)在编辑的时候,注意编辑项的长度限制,有时在 添加的时候有,在编辑的时候却没有(注意要添加和修改规则是否一致)(5)对于有图片上传功能的编辑框,若不上传图片,查看编辑页面时是否显示有默认的图 片,若上传图片,查看是否显示为上传图片 (6)修改后增加数据后,特别要注意查询页面的数据是否及时更新,特别是在首页时要注意数据的更新。 (7)提交数据时,连续多次点击,查看系统会不会连续增加几条相同的数据或报错。(8)若结果列表中没有记录或者没选择某条记录,点击修改按钮,系统会抛 异常。
四、删除功能
1、特殊键:(1)是否支持Tab键 (2)是否支持回车键
2、提示信息:(1)不选择任何信息,直接点击删除按钮,是否有提示 (2)删除某条信息时,应该有确认提示
3、数据 实现:(1)是否能连续删除多个产品 (2)当只有一条数据时,是否可以删除成功 (3)删除一条数据后,是否可以添加相同的数据 (4)如系统支持批量删除,注意删除的信息是否正确 (5)如有全选,注意是否把所有的数据删除 (6)删除数据时,要注意相应查询页面的数据是否及时更新 (7)如删除的数据与其他业务数据关联,要注意其关联性(如删除部门信息时,部门下游员工,则应该给出提示) (8)如果结果列表中没有记录或没有选择任何一条记录,点击删除按钮系统会报错。
五、注册、登陆模块
1、注册功能:(1)注册时,设置密码为特殊版本号,检查登录时是否会报错 (2)注册成功后,页面应该以登陆状态跳转到首页或指定页面 (3)在注册信息中删除已输入的信息,检查是否可以注册成功。
2、登陆 功能:(1)输入正确的用户名和正确的密码 (2)输入正确的用户名和错误的密码 (3)输入错误的用户名和正确的密码 (4)输入错误的用户名和错误的密码 (5)不输入用户名和密码(均为空格)(6)只输入用户名,密码为空 (7)用户名为空,只输入密码 (8)输入正确的用户名和密码,但是不区分大小写 (8)用户名和密码包括特殊字符 (9)用户名和密码输入超长值 (10)已删除的用户名和密码 (11)登录时,当页面刷新或重新输入数据时,验证码是否更新
六、上传图片测试
1、功能 实现:(1)文件类型正确、大小合适 (2)文件类型正确,大小不合适 (3)文件类型错误,大小合适 (4)文件类型和大小都合适,上传一个正在使用中的图片 (5)文件类型大小都合适,手动输入存在的图片地址来上传 (6)文件类型和大小都合适,输入不存在的图片地址来上传 (7)文件类型和大小都合适,输入图片名称来上传 (8)不选择文件直接点击上传,查看是否给出提示 (9)连续多次选择不同的文件,查看是否上传最后一次选择的文件
七、查询结果列表
1、功能 实现:(1)列表、列宽是否合理 (2)列表数据太宽有没有提供横向滚动 (3)列表的列名有没有与内容对应 (4)列表的每列的列名是否描述的清晰 (5)列表是否把不必要的列都显示出来 (6)点击某列进行排序,是否会报错(点击查看每一页的排序是否正确)(7)双击或单击某列信息,是否会报错
八、返回键检查
1、一条已经成功提交的记录,返回后再提交,是否做了处理
2、检查多次使用返回键的情况,在有返回键的地方,返回到原来的页面多次,查看是否会出错
九、回车键检查
1、在输入结果后,直接按回车键,看系统如何处理,是否会报错
十、刷新键检查
1、在Web系统中,使用刷新键,看系统如何处理,是否会报错
十一、直接URL链接检查
1、在Web系统中,在地址栏直接输入各个功能页面的URL地址,看系统如何处理
十二、其他
1、在测试时,与网络有关的步骤必须考虑到断网的情况
2、每个页面都有相应的Title
3、在测试的时候要考虑到页面出现滚动条时,滚动条上下滚动时,页面是否正常
4、URL不区分大小写
5、某个字段是唯一的,当多个用户并发点击产生该字段时,检查系统怎么处理
6、对于电子商务网站,当用户并发购买数量大于库存的数量时,系统如何处理
7、测试数据避免单纯输入“123”、“abc“之类的,让测试数据尽量接近实际
8、进行测试时,尽量不要用超级管理员进行测试,用新建的用户进行测试。测试人员尽量不要使用同一个用户进行测试
9、做功能测试的时候,也要注意系统的性能(如操作的响应时间、内存使用情况)
十三、界面和易用性测试
1、风格、样式、颜色是否协调
2、界面布局是否整齐、协调(保证全部显示出来的,尽量不要使用滚动条
3、界面操作、标题描述是否恰当(描述有歧义、注意是否有错别字)4、操作是否符合人们的常规习惯(有没有把相似的功能的控件放在一起,方便操作)
5、提示界面是否符合规范(不应该显示英文的cancel、ok,应该显示中文的确定等)
6、界面中各个控件是否对齐
7、日期控件是否可编辑
8、日期控件的长度是否合理,以修改时可以把时间全部显示出来为准
9、查询结果列表列宽是否合理、标签描述是否合理
10、查询结果列表太宽没有横向滚动提示
11、对于信息比较长的文本,文本框有没有提供自动竖直滚动条
12、数据录入控件是否方便
13、有没有支持Tab键,键的顺序要有条理,不乱跳
14、有没有提供相关的热键
15、控件的提示语描述是否正确
16、模块调用是否统一,相同的模块是否调用同一个界面
17、用滚动条移动页面时,页面的控件是否显示正常
18、日期的正确格式应该是XXXX-XX-XX
或XXXX-XX-XX XX:XX:XX 19、页面是否有多余按钮或标签
20、窗口标题或图标是否与菜单栏的统一
21、窗口的最大化、最小化是否能正确切换
22、对于正常的功能,用户可以不必阅读用户手册就能使用
23、执行风险操作时,有确认、删除等提示吗
24、操作顺序是否合理
十四、兼容性测试
兼容性测试不只是指界面在不同操作系统或浏览器下的兼容,有些功能方面的测试,也要考虑到兼容性,比如涉及到ajax、jquery、javascript等技术的,都要考虑到不同浏览器下的兼容性问题。
十五、链接测试
主要是保证链接的可用性和正确性,它也是网站测试中比较重要的一个方面。
十六、业务流程测试
业务流程,一般会涉及到多个模块的数据,所以在对业务流程测试时,首先要保证单个模块功能的正确性,其次就要对各个模块间传递的数据进行测试,这往往是容易出现问题的地方,测试时一定要设计不同的数据进行测试。
十七、安全性测试
(1)SQL注入(登陆页面)
(2)XSS跨网站脚本攻击:程序或数据库没有对一些特殊字符进行过滤或处理,导致用户所输入的一些破坏性的脚本语句能够直接写进数据库中,浏览器会直接执行这些脚本语句,破坏网站的正常显示,或网站用户的信息被盗,构造脚本语句时,要保证脚本的完整性。
document.write("abc")
<script>alter("abc")</script>
(3)URL地址后面随便输入一些符号
(4)验证码更新问题 -
LoadRunner使用遇到的问题集锦
msnshow 发布于 2011-11-12 23:58:14
1、把HTML的内容输出到LOG中的方法
1、在脚本要记录HTML的URL前面加入函数:web_create_html_param("MyHtml", "<html>", "");;
2、在脚本要记录HTML的URL后面加入函数:lr_output_message("###the HTML is %s", lr_eval_string(" {MyHtml}"));;
3、在Controller中设置Run-Time Settings,把log设置为Always Send Message;
4、在Controller中设置Run-Time Settings,把Miscellaneous设置为在发生错误时继续运行(在这里不是必须);
5、在Controller中设置Run-Time Settings,把Preferences设置为Enable image and text check;(在这里不是必须);
6、在Controller的日志文件RES中可以查看到每个虚拟用户的LOG;
2、如何在Controller中添加系统资源检测
今天早上突然想把Windows的性能监视放到LR中,达到方便快捷的目的,下面的是具体的步骤:
1、使用192.168.0.159作为监控的对象,开通Remote Procedure Call和Remote Registry两个服务,Remote Registry一般都是给禁止的,可以改为手动并启动;
2、在159中右击我的电脑,选择管理->共享文件夹->共享 在这里面要有C$这个共享文件夹;
3、在159中使用命令netstat /ano查看445端口是否被打开;
4、输入\\192.168.0.159\c$,再输入用户名和密码,如果能进入c盘,那就说明有控制权了;
5、在Controller的Run中找到Windows Resources,对图点击右键中的Add Measurements,添加计数器;
6、需注意159机上的BlackIce;
7、对Windows Resources Graph的技巧使用,可以冻结窗体,导出HMTL,显示某个计数器等;
3、对ANALYSIS中不能导出页面细分下的子项的问题的处理方法?
1、问题描述:对ANALYSIS的导出WORD功能中只能导出树中的图表,在页面细分中点击不同的节点会有不同的图表,但是却无法把所有节点的图表一起导出;
2、如果想生成Time to First Buffer Breakdown下面Login事务和Loading事务下的图表都导出来,方法就是新建两张Time to First Buffer Breakdown图表,在不同的下面点击图表,并修改名称;
3、在导出列表中选中要导出的图表:Time to First Buffer Breakdown-All && Time to First Buffer Breakdown-Login && Time to First Buffer Breakdown-Loading;
4、总结:虽然这样做有点麻烦,但是比之前点击每个图再导出一个WORD来有用的多,但是LR可以做到在导出列表中以树的形式显示可以导出的图表,不过LR要解决图表没有名称的问题;
4、在中文版Analysis中显示系统资源图的原因与解决
1、是否可以通过修改ACCESS记录来修改这个BUG?
2、不知道它添加图表的列表是不是通过数据库LOAD的?迄今还没有找到这些记录,只找到资源图表数据;
3、解决办法1:是用VNC截图,但是这样只能看到计数器曲线,没什么意义;
4、解决办法2:在Controller中导出系统资源数据,里面有量化数据,比较真实,不过每个场景都要导出一次就很麻烦,并且不好管理,无法对数据进行帅选和合并,如果打开导出的页面有乱码,那就在编码方式选择"自动选择";
5、解决办法3:使用英文版生成的ANALYSIS,再拿到中文版下面,是可以看到系统资源这个图表的,其实我应该早想到这样的,因为在中文版下无法显示不是Analysis的错,而是Controller的错,Analysis里面是包括ACCESS和其它包含系统资源的记录的,所以在中文版是能显示的;
5、终于使用LR实现了不同虚拟用户使用不用的帐号登陆,实行不同用户并发的问题
1、在脚本设计中添加参数,参数名称为LoginUserName,选择参数类型为FILE;
2、很关键的一步就是:选者UNIQUE和EACH ITERATION/ONCE;
3、在脚本中把登陆名改为参数名;
4、使用Controller进行测试,在运行时设置LOG记录;
5、查看LOG,可以看到每个虚拟用户是使用不同的帐号登陆的;
6、总结:使用SEQUENTIAL会使得参数每次出现的地方的值都不一样;如何想使用更多用户的登陆可以使用参数数据库化;
(参考:LoadRunner参数化)
6、 LR参数数据库化(姑且这么叫,就是参数的来源于数据库)实践
1、以XQP登陆帐号为例,把bw_Users表中的UserName做为参数LoginUserName的值;
2、过程都比较简单,需要注意的是使用FILE参数类型,参数值列表中的值只有100个,其它的可以通过Edit with Notepad查看;
3、在Update Value on 中有以下几个选项:
Each Occurrence:在运行时,每遇到一次该参数,便会取一个新的值;
Each iteration:运行时,在每一次循环中都取相同的值;
Once:运行时,在每次循环中,该参数只取一次值;
可以看出,是按照从脚本小范围到大范围的选择;
4、在Select next row 有以下几种选择:
Sequential:按照顺序一行行的读取。每一个虚拟用户都会按照相同的顺序读取;
Random:在每次循环里随机的读取一个,但是在循环中一直保持不变;
Unique :唯一的数。注意:使用该类型必须注意数据表有足够多的数;
Same Line As 某个参数(比如Name):和前面定义的参数Name 取同行的记录;通常用在有关联性的数据上面;
可以看出,是和循环(迭代)很有关系的;
7、 发现可以对参数数据库化的数据进行作弊,作弊方法如下:
1、使用数据库管理器导出想要的数据为EXCEL;再保存为dat文件,再参数设置里面引用该文件;
2、在脚本文件夹中找到[参数名].dat文件;
3、对[参数名].dat文件进行编辑,把EXCEL中的数据拷贝到dat文件中;
4、进入脚本编辑,查看参数,可以见到刚刚拷贝的数据;
总结:虽然这个方法没什么很大用处,但是在无法使用VUGenerator连接数据库的时候就非常有用;
8、当在此函数中,查找的text="中文"时,LR硬是报错,换成英文字体便成功。后来,查了好久,发觉是Record-Options 中我勾选了support charset中的UTF-8,可能是录制过程中LR捕捉到的是中文,而回放过程中此函数在HTML原文件中查找到的却是乱码?总而言之,把此选项去除之后,重新录制脚本,回放能够成功了!
9、LoadRunner场景执行时出现错误:“load generator is currently running the maximum number of vuser of this type”
解决方法:
Loadruuner默认场景并发最大用户数=1000,所以需要设置load generator->Details->Vuser limits->Other Vusers更换参数值即可,如10000;当然需要你的序列号是支持,目前最大支持6.2w的序列号。
-
脚本实例:Loadrunner测试数据库、SQL语句性能
msnshow 发布于 2011-11-20 20:00:33
此代码为Loadrunner 8 通过C API类型的Vuser 测试MySQL性能,或者测试sql语句性能的脚本。
这东西很少有人用,网上资料很少,一般测试B/S的很多。
view plaincopy to clipboardprint?
Action()
{
int rc;
int db_connection; // 数据库连接
int query_result; // 查询结果集 MYSQL_RES
char** result_row; // 查询的数据衕
char *server = "localhost";
char *user = "root";
char *password = "123456";
char *database = "test";
int port = 3306;
int unix_socket = NULL;
int flags = 0;
// 找到libmysql.dll的所在位置.
rc = lr_load_dll("C:\\Program Files\\MySQL\\MySQL Server 5.1\\bin\\libmysql.dll");
if (rc != 0) {
lr_error_message("Could not load libmysql.dll");
lr_abort();
}
// 创建MySQL对象
db_connection = mysql_init(NULL);
if (db_connection == NULL) {
lr_error_message("Insufficient memory");
lr_abort();
}
// 连接到MySQL数据库
rc = mysql_real_connect(db_connection, server, user, password, database, port, unix_socket, flags);
if (rc == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 向数据库插入数据
// 此处的 {ORDER_ID} 是一个参数,简单测试时可以用一个常数代替
lr_save_string (lr_eval_string("INSERT INTO test_data (order_id) VALUES ({ORDER_ID})"),"paramInsertQuery");
rc = mysql_query(db_connection, lr_eval_string("{paramInsertQuery}"));
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
// 从数据库读取一个数据并显示
rc = mysql_query(db_connection, "SELECT order_id FROM test_data WHERE status IS FALSE LIMIT 1");
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();
}
query_result = mysql_use_result(db_connection);
if (query_result == NULL) {
lr_error_message("%s", mysql_error(db_connection));
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 如果结果集包含多行数据,需要多次调用 mysql_fetch_row 直到返回NULL
result_row = (char **)mysql_fetch_row(query_result);
if (result_row == NULL) {
lr_error_message("Did not expect the result set to be empty");
mysql_free_result(query_result);
mysql_close(db_connection);
lr_abort();
}
// 保存参数,用于删除这行数据
lr_save_string(result_row[0], "paramOrderID");
lr_output_message("Order ID is: %s", lr_eval_string("{paramOrderID}"));
mysql_free_result(query_result);
// 在事务里更新一行数据,需要用InnoDB引擎
rc = mysql_query(db_connection, "BEGIN"); //启动事务
if (rc != 0) {
lr_error_message("%s", mysql_error(db_connection));
mysql_close(db_connection);
lr_abort();