
-
【转】缺陷管理之缺陷收敛趋势分析续
2010-02-22 09:53:50
转自:
http://www.51testing.com/?uid-249369-action-viewspace-itemid-207652
上篇文章对收敛趋势的一些基本概念做了讲解,本文就不再罗嗦了,没看过的同学请先看上一篇文章《缺 陷管理之缺陷收敛趋势分析,如果不看,我不保证你能看懂。本文将缺陷收敛趋势分析另外一种计算和表现方法,比上一种简单。看图说话: 当前发现:在一个测试周期内发现的缺陷数目,也可以说是新增缺陷数目。累计发现:截止到一个测试周期结束,所有发现的缺陷数目。当前解决:在一个测试周期内,经过测试人员验证并关闭的缺陷数目。累计解决:戒子到一个测试周期技术,多有关闭的缺陷数目。如果用N1,N2...Nn表示每个测试周期发现的缺陷数目,那么N1表示第一个“当前发现”的数目,Nn表示第n个“当前发现”数目。于是:累计发现n = N1 + N2 + ... + Nn如果用C1,C2...Cn表示每个测试周期关闭的缺陷数目,那么C1表示第一个“当前解决”的数目,Cn表示第n个“当前解决”数目。于是:累计解决n = C1 + C2 + ... + CN统计都比较简单,累计发现和累计解决两天曲线表现出来是一致上扬。如果累计解决曲线越接近累计曲线,说明缺陷收敛情况比较好。理论上,当所有缺陷都关闭的时候,累计发现和累计解决就重合,但在实际情况中较少。
当前发现:在一个测试周期内发现的缺陷数目,也可以说是新增缺陷数目。累计发现:截止到一个测试周期结束,所有发现的缺陷数目。当前解决:在一个测试周期内,经过测试人员验证并关闭的缺陷数目。累计解决:戒子到一个测试周期技术,多有关闭的缺陷数目。如果用N1,N2...Nn表示每个测试周期发现的缺陷数目,那么N1表示第一个“当前发现”的数目,Nn表示第n个“当前发现”数目。于是:累计发现n = N1 + N2 + ... + Nn如果用C1,C2...Cn表示每个测试周期关闭的缺陷数目,那么C1表示第一个“当前解决”的数目,Cn表示第n个“当前解决”数目。于是:累计解决n = C1 + C2 + ... + CN统计都比较简单,累计发现和累计解决两天曲线表现出来是一致上扬。如果累计解决曲线越接近累计曲线,说明缺陷收敛情况比较好。理论上,当所有缺陷都关闭的时候,累计发现和累计解决就重合,但在实际情况中较少。
-
【转】缺陷管理之缺陷收敛趋势分析
2010-02-22 09:51:56
转自:
http://www.51testing.com/?uid-249369-action-viewspace-itemid-206131
之前在别处写过一篇的一篇博文,忘了同步过来了,发现被很过网站抄袭(连个转字都不写,晕),分享给各位测友吧 (*^__^*) 嘻嘻……
版权声明:本文可以被转载,但是在未经本人许可前,不得用于任何商业用途或其他以盈利为目的的用途。本人保留对本文的一切权利。如需转载,请在转载是保留此版权声明,并保证本文的完整性。缺陷趋势,个人的理解是在一定周期时间或者一定阶段内,缺陷的按照一个或者多个维度的动态分布。周期可以是天,周,月。阶段可以是版本,例如1.2,1.3,1.3。先来张图,有个直观的认识。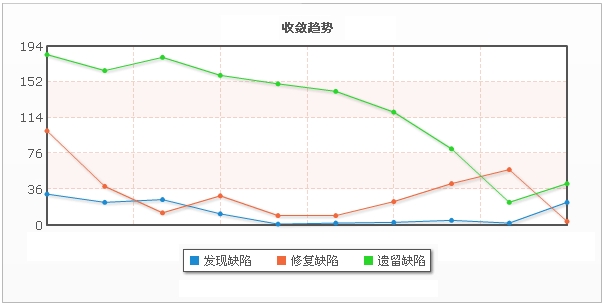 先对上图中出现的术语解释一下。发现缺陷:测试人员在某一测试周期内新发现的缺陷总数。修复缺陷:测试人员在某一测试周期内,对开发人员修复的缺陷验证并通过并缺陷总数。遗留缺陷:在某一测试周期结束时刻,未关闭的缺陷总数。收敛趋势:表示在一定周期内,遗留缺陷的变化情况。收敛趋势曲线走势能反映被测试目标的质量变化情况,可以辅助管理人员决策,也可以做为产品的发布的一个重要参考。收敛趋势曲线往下跌的时候,表示产品质量在持续改善。收敛趋势曲线往上扬,表示产品质量在持续恶化,如果在开发阶段前期,这种情况也正常;如果在开发阶段的后期或者临近发布点,那么这种情况要引起注意了。收敛趋势曲线越趋近于水平(横轴),产品质量越好。
先对上图中出现的术语解释一下。发现缺陷:测试人员在某一测试周期内新发现的缺陷总数。修复缺陷:测试人员在某一测试周期内,对开发人员修复的缺陷验证并通过并缺陷总数。遗留缺陷:在某一测试周期结束时刻,未关闭的缺陷总数。收敛趋势:表示在一定周期内,遗留缺陷的变化情况。收敛趋势曲线走势能反映被测试目标的质量变化情况,可以辅助管理人员决策,也可以做为产品的发布的一个重要参考。收敛趋势曲线往下跌的时候,表示产品质量在持续改善。收敛趋势曲线往上扬,表示产品质量在持续恶化,如果在开发阶段前期,这种情况也正常;如果在开发阶段的后期或者临近发布点,那么这种情况要引起注意了。收敛趋势曲线越趋近于水平(横轴),产品质量越好。蓝色缺陷越趋近于近于水平(横轴),表示产品质量比较稳定,但不代表质量好。另外,蓝色和红色两条曲线可以辅助分析收敛趋势的变化情况,如果发现缺陷数目大于修复缺陷数,那么收敛趋势曲线就上扬,反之则下跌。
-
【转】权威《测试工作规范》文档
2010-02-04 11:37:29
转自:
http://www.51testing.com/?uid-100917-action-viewspace-itemid-207656
来源:网络
版本记录:
文件状态: [√] 草稿 [ ] 正式发布 [ ] 正在修改 当前版本: **** 作 者: ******* 完成日期: ****.**.** 签 收 人: 签收日期: 目录
3.2.1实施测试用例... 43.2.2提交报告... 4
1.编写目的
本文档是测试团队的日常工作规范,主要侧重测试工作流程的控制,明确软件工程的各阶段测试团队应完成的工作。测试技术和策略等问题不在本文档描述范围内。
2.测试团队构成
2.1职责
测试是软件开发过程中的重要组成部分,肩负着如下责任:
A、在项目的前景、需求文档确立基线前对文档进行测试,从用户体验和测试的角度提出自己的看法。
B、编写合理的测试计划,并与项目整体计划有机地整合在一起。
C、编写覆盖率高的测试用例。
D、针对测试需求进行相关测试技术的研究。
E、认真仔细地实施测试工作,并提交测试报告以供项目组参考。
F、进行缺陷跟踪与分析。
2.2角色划分
在人力资源有限的情况下,一个团队成员可能会同时承担多个角色。
角色名称 相关主要责任 测试负责人 组建测试组 协调测试组内部的沟通 代表测试组与其它角色组进行沟通 编写测试计划q 测试报告分析 测试用例设计工程师 编写测试用例{可以由测试负责人兼任} 测试实施工程师 实施测试用例,执行测试 技术支持工程师 为测试工作提供技术支持 3.工作流程及规范
3.1计划与设计阶段
3.1.1成立测试团队在项目组成立的同时,测试组也将同时成立。团队成立的工作与责任如下:
过程要点 详细说明 输入条件 项目组成立(参与《项目计划书》的评审) 工作内容 为测试组任命一名测试负责人,同时确定测试组的构成人选。 退出标准 测试组成立 责任人 测试负责人 图表 1
3.1.2测试预通知
在正式测试任务下达前,开发团队应提前一周左右向测试团队下达预通知,告之较为确切的测试日期,提供当前最新的相关资料。测试负责人可视具体情况决定是否需要调整人力。测试人员可预先熟悉必要的背景资料,协助测试负责人编写《测试计划》初稿。
过程要点 详细说明 输入条件 项目进入软件实现阶段(编码) 工作内容 项目/产品经理邮件通知测试负责人正式测试交接时间,测试规模预估等 退出标准 预先通知得到测试负责人确认,并提交《测试计划》初稿 责任人 产品经理,测试负责人 图表 2
3.1.3召开测试启动会议
过程要点 详细说明 输入条件 测试负责人完成测试计划初稿 工作内容 开发团队与测试团队交接测试内容,对测试目标达成一致,商讨测试计划初稿的可行性,统一项目组的目标和测试的工作重点。 退出标准 明确测试内容与重点,项目方提交《测试任务书》,测试方提交《测试计划》正稿。 责任人 产品经理,测试负责人 图表 3
3.1.4编写测试计划文档
需求分析文档确立后,测试组需要编写测试计划文档,为后续的测试工作提供直接的指导
过程要点 详细说明 输入条件 项目需求文档建立 工作内容 根据项目的需求文档,按照测试计划文档模板编写测试计划。测试计划中应该至少包括以下关键内容: a .测试需求——需要测试组测试的范围,估算出测试所花费的人力资源和各个测试需求的测试优先级 b.测试方案——整体测试的测试方法和每个测试需求的测试方法 c.测试资源——本次测试所需要用到的人力、硬件、软件、技术的资源 d.测试组角色——明确测试组内各个成员的角色和相关责任 e.里程碑——明确标准项目过程中测试组该关注的里程碑 a.可交付工件——在测试组的工作中必须向项目组提交的产物,包括测试计划、测试报告等等 b.风险管理——列举出测试工作所可能出现的风险 测试计划编写完毕后,必须提交给项目组全体成员,并由项目组组中各个角色组联合评审。 退出标准 a.测试计划由项目组评审通过. b.在项目开发过程中,要适时的对测试计划进行跟踪,以供评估此次计划的完整性、可行性,在项目结束时还要最后评估一下测试计划的质量 责任人 测试负责人 图表 4
3.1.5设计测试用例
在需求分析文档确立基线以后,测试组需要针对项目的测试需求编写测试用例,在实际的测试中,测试用例将是唯一实施标准。在用例的编写过程中,具体的任务和责任人如下:
过程要点 详细说明 输入条件 测试需求明确,测试计划明确 工作内容 根据每一步测试计划编写全部的测试用例 退出标准 测试用例需要覆盖所有的测试需求 责任人 测试用例设计工程师(可由测试实施工程师或测试负责人兼做) 图表 5
3.2实施测试阶段
3.2.1实施测试用例
实施测试用例将花费测试组绝大部分时间,这些工作都是建立在前期很多计划工作的基础上。
过程要点 详细描述 输入条件 测试负责人之前一个工作日定出当日的测试计划,确定可用的测试用例。 工作内容 测试实施工程师根据测试计划中分配给自己的测试任务和提供的测试用例,实施相应的测试用例,并将记录实施用例的结果 退出标准 测试用例中的所有任务被执行,结果被记录。 责任人 测试实施工程师 图表 6
3.2.2提交报告
在约定的测试周期完成之后,测试负责人需要总结此次测试的结果,编写测试报告
过程要点 详细描述 输入条件 测试组完成了预定周期的测试任务 工作内容 测试负责人根据此轮测试的结果,编写测试报告,主要应包含以下内容: a.测试报告的版本 b.测试的人员和时间 c.测试所覆盖的缺陷——测试组在这轮测试中所有处理的缺陷,报告了测试负责人处理的缺陷和实施工程师验证的缺陷。不仅要写出覆盖缺陷的总数,还要写明这些缺陷的去向 d.测试新发现的缺陷数量 e.上一版本活动缺陷的数量 f.经过此轮测试,所有活动缺陷的数量及其状态分类 g.测试评估——写明在这一版本中,那些功能被实现了,那些还没有实现,这里只需写明和上一版本不同之处即可 h.急待解决的问题——写明当前项目组中面临的最优先的问题,可以重复提出 退出标准 在每轮测试结束之后应尽快将符合标准的测试报告发给全项目组 责任人 测试负责人 图表7
3.2.3回归测试
在每轮测试结束之后,由测试组重新拷贝修改后的最新版本,进行回归测试。
过程要点 详细描述 输入条件 在每轮测试中,按照现有的测试用例没有新的缺陷被发现,测试报告中全部的活动缺陷都被解决。 工作内容 测试组将按照测试计划中对于回归测试的策略对产品进行回归测试,回归测试的用例属于测试用例的一部分或者是全部测试用例,但不能超出原先预定的测试用例的范围。 退出标准 回归测试所运行的用例全部通过。 责任人 测试实施工程师 (可由测试实施工程师或测试负责人兼做) 图表 2
3.3总结阶段
测试工作结束或即将结束时,测试组就要开始着手准备进行总结的工作。
3.3.1编写测试报告
在回归测试结束之后,测试负责人将要编写测试总结报告,对测试进行总结,并且提交给全体项目组,为产品的后续工作提供重要的信息支持。
过程要点 详细描述 输入条件 测试组完成了所有的测试实施工作 工作内容 测试负责人根据测试的结果,按照测试报告的文档模板编写测试报告,测试报告必须包含以下重要内容: a.测试资源概述——多少人、多长时间 b.测试结果摘要——分别描述各个测试需求的测试结果,产品实现了哪些功能点,哪些还没有实现 c.缺陷分析——按照缺陷的属性分类进行分析 d.测试需求覆盖率——原先列举的测试需求的测试覆盖率,可能一部分测试需求因为资源和优先级的因素没有进行测试,那么在这里要进行说明 e.测试评估——从总体对项目质量进行评估 f.测试组建议——从测试组的角度为项目组提出工作建议 退出标准 测试负责人完成了符合标准的测试报告,发送给全项目组。 责任人 测试负责人 3.3.2测试工作总结
测试总结工作是在以上的工作全部结束以后,它的目的是评估本次测试工作,总结经验,使下一次的工作做得更好。
过程要点 详细描述 输入条件 测试负责人完成了符合标准的测试报告,发送给全项目组 工作内容 测试负责人根据测试的结果,按照测试总结的文档模板编写测试总结, 退出标准 测试负责人完成了符合标准的测试总结,发送给全测试组。 责任人 测试负责人 3.3.3测试验收
测试验收工作是在以上工作全部结束后,对测试的过程,效果进行验收,宣布测试结束。
过程要点 详细描述 输入条件 测试组完成了所有的测试实施工作,测试负责人完成符合标准的测试总结文档 工作内容 由测试发起会上约定的验收组成员,对本测试进行验收,验收内容包括: a.测试效果验收——测试是否达到预期目的 b.测试文档验收——测试过程文档是否齐全,可信,符合标准 c.测试评估——从总体对测试的质量进行评估 d.测试建议——对本次测试工作指出不足,需要在以后工作中改进的地方 e.宣布测试结束——测试验收组成员签字宣布本次测试结束 退出标准 签发测试验收报告 责任人 产品经理 3.3.4测试归档
测试归档是在测试验收结束宣布测试有效,结束测试后,对测试过程中涉及到各种标准文档进行归类,存档。
过程要点 详细描述 输入条件 测试验收通过 工作内容 归类,存档测试过程涉及到的文档,主要包括以下文档(必须) a.测试任务 b.测试计划 c.测试用例 d.测试报告 e.测试总结报告 f.测试验收报告 退出标准 全部文档归类完毕,版本号封存 责任人 测试负责人 3.4缺陷跟踪
测试验收结束后,跟踪产品在试运行阶段暴露出来的新缺陷,以及已提交的缺陷是否再次发生。
过程要点 详细描述 输入条件 测试组完成了所有的测试实施工作,测试验收通过,产品试运行、运行。 工作内容 a.已发现缺陷是否再次发生 b.是否有新发现的在测试中未发现的缺陷 c.是否有新发现的在测试中已发现但未修改的缺陷 定义: A类:新发现的缺陷 B类:已发现的缺陷 C类:已发现未修改的缺陷 退出标准 缺陷跟踪报告 责任人 产品经理、项目实施经理 4.缺陷类型定义
本规范定义以下五类缺陷
A类——严重错误,包括:
1. 由于程序所引起的死机,非法退出
2. 死循环
3. 导致数据库发生死锁
4. 数据通讯错误
5 严重的数值计算错误
B类——较严重错误,包括:
1. 功能不符
2. 数据流错误
3. 程序接口错误
4. 轻微的数值计算错误
C类——一般性错误,包括:
1. 界面错误(详细文档)
2. 打印内容、格式错误
3. 简单的输入限制未放在前台进行控制
4. 删除操作未给出提示
D类——较小错误,包括:
1. 辅助说明描述不清楚
2. 显示格式不规范
3. 长时间操作未给用户进度提示
4. 提示窗口文字未采用行业术语
5. 可输入区域和只读区域没有明显的区分标志
6. 系统处理未优化 E类——测试建议(非缺陷)
5.测试标准
软件测试合格须符合以下标准。
A类错误 B类错误 C类错误 D类错误 E类建议 无 无 ≤2% ≤4% 暂不作要求 以上比例为错误占总测试模块的比例。软件产品未经测试合格,不允许投运。
6.问题争议处理
如开发团队对测试结论有争议,由PM和成员会议协调解决。测试团队和开发团队应无条件服从仲裁结果。
7.测试标准文档
1. 《测试任务说明书》
2. 《测试计划》
3. 《测试用例》
4. 《测试报告》
5. 《测试总结报告》
6. 《测试验收报告》
7. 《缺陷跟踪报告》
-
【转】七个关于有效沟通的哲理故事
2010-01-29 12:02:13
原创作者:Jerry
转载请注明:来自Sawin系统分析之窗
最后修改时间:2005-8-25
有效沟通是企业经营管理和我们个人在社会生活经常需要遇到的基本问题。人与人之间要达成真正的沟通并不是一件易事。以下一些简洁而寓意深刻的故事,可能比我和其他沟通专家所著的专业文章对你更直接,更具有震憾作用和启发意义。
1 有一个秀才去买柴,他对卖柴的人说:“荷薪者过来!”卖柴的人听不懂“荷薪者”(担柴的人)三个字,但是听得懂“过来”两个字,于是把柴担到秀才前面。
秀才问他:“其价如何?”卖柴的人听不太懂这句话,但是听得懂“价”这个字,于是就告诉秀才价钱。 秀才接着说:“外实而内虚,烟多而焰少,请损之。(你的木材外表是干的,里头却是湿的,燃烧起来,会浓烟多而火焰小,请减些价钱吧。)”卖柴的人因为听不懂秀才的话,于是担着柴就走了。
管理者平时最好用简单的语言、易懂的言词来传达讯息,而且对于说话的对象、时机要有所掌握,有时过分的修饰反而达不到想要完成的目的。
2 美国知名主持人林克莱特一天访问一名小朋友,问他说:“你长大后想要当甚么呀?”小朋友天真的回答:“嗯…我要当飞机的驾驶员!”林克莱特接着问:“如果有一天,你的飞机飞到太平洋上空所有引擎都熄火了,你会怎么办?”小朋友想了想:“我会先告诉坐在飞机上的人绑好安全带,然后我挂上我的降落伞跳出去。”当在现场的观众笑的东倒西歪时,林克莱特继续着注视这孩子,想看他是不是自作聪明的家伙。没想到,接着孩子的两行热泪夺眶而出,这才使的林克莱特发觉这孩子的悲悯之情远非笔墨所能形容。于是林克莱特问他说:“为甚么要这么做?”小孩的答案透露出一个孩子真挚的想法: “我要去拿燃料,我还要回来!!
你听到别人说话时……你真的听懂他说的意思吗?你懂吗?如果不懂,就请听别人说完吧,这就是“听的艺术”:1. 听话不要听一半。2. 不要把自己的意思,投射到别人所说的话上头。
3 A对B说:"我要离开这个公司。我恨这个公司!"B建议道:"我举双手赞成你报复!!破公司一定要给它点颜色看看。不过你现在离开,还不是最好的时机。" A问:为什么?B说:"如果你现在走,公司的损失并不大。你应该趁着在公司的机会,拼命去为自己拉一些客户,成为公司独挡一面的人物,然后带着这些客户突然离开公司,公司才会受到重大损失,非常被动。"A觉得B说的非常在理。于是努力工作,事遂所愿,半年多的努力工作后,他有了许多的忠实客户。再见面时B问A:“现在是时机了,要跳赶快行动哦!”A淡然笑道:“老总跟我长谈过,准备升我做总经理助理,我暂时没有离开的打算了。”
其实这也正是B的初衷。一个人的工作,只有付出大于得到,让老板真正看到你的能力大于位置,才会给你更多的机会替他创造更多利润。
4 曾经有个小国的人到中国来,进贡了三个一模一样的金人,把皇帝高兴坏了。可是这小国的人不厚道,同时出一道题目:这三个金人哪个最有价值?皇帝想了许多办法,请来珠宝匠检查,称重量,看做工,都是一模一样的。
怎么办?使者还等着回去汇报呢。泱泱大国,不会连这个小事都不懂吧?最后,有一位退位的老大臣说他有办法。皇帝将使者请到大殿,老臣胸有成足地拿着三根稻草,插入第一个金人的耳朵里,这稻草从另一边耳朵出来了。第二个金人的稻草从嘴巴里直接掉出来,而第三个金人,稻草进去后掉进了肚子,什么响动也没有。老臣说:第三个金人最有价值!使者默默无语,答案正确。 最有价值的人,不一定是最能说的人。老天给我们两只耳朵一个嘴巴,本来就是让我们多听少说的。善于倾听,才是成熟的人最基本的素质。
5 有一位表演大师上场前,他的弟子告诉他鞋带松了。大师点头致谢,蹲下来仔细系好。等到弟子转身后,又蹲下来将鞋带解松。有个旁观者看到了这一切,不解地问:“大师,您为什么又要将鞋带解松呢?”大师回答道:“因为我饰演的是一位劳累的旅者,长途跋涉让他的鞋带松开,可以通过这个细节表现他的劳累憔悴。” “那你为什么不直接告诉你的弟子呢?”“他能细心地发现我的鞋带松了,并且热心地告诉我,我一定要保护他这种热情的积极性,及时地给他鼓励,至于为什么要将鞋带解开,将来会有更多的机会教他表演,可以下一次再说啊。”
6 一个女儿对父亲抱怨她的生活,抱怨事事都那么艰难。她不知该如何应付生活,想要自暴自弃了。她已厌倦抗争和奋斗,好象一个问题刚解决,新的问题就又出现了。
她的父亲是位厨师,他把她带进厨房。他先往三只锅里倒入一些水,然后把它们放在旺火上烧。不久锅里的水烧开了。他往一只锅里放些胡萝卜,第二只锅里放只鸡蛋,最后一只锅里放入碾成粉末状的咖啡豆。他将它们侵入开水中煮,一句话也没有说。
女儿咂咂嘴,不耐烦地等待着,纳闷父亲在做什么。大约20分钟后,他把火闭了,把胡萝卜捞出来放入一个碗内,把鸡蛋捞出来放入另一个碗内,然后又把咖啡舀到一个杯子里。做完这些后,他才转过身问女儿,“亲爱的,你看见什么了?”“胡萝卜、鸡蛋、咖啡”,她回答。
他让她靠近些并让她用手摸摸胡萝卜。她摸了摸,注意到他们变软了。父亲又让女儿拿一只鸡蛋并打破它。将壳剥掉后,他看到了是只煮熟的鸡蛋。最后,他让她喝了咖啡。品尝到香浓的咖啡,女儿笑了。她怯生问到:“父亲,这意味着什么?”
他解释说,这三样东西面临同样的逆境——煮沸的开水,但其反应各不相同。胡萝卜入锅之前是强壮的,结实的,毫不示弱;但进入开水之后,它变软了,变弱了。鸡蛋原来是易碎的,它薄薄的外壳保护着它呈液体的内脏。但是经开水一煮,它的内脏变硬了。而粉状咖啡豆则很独特,进入沸水之后,它们倒改变了水。“哪个是你呢?”他问女儿。“当逆境找上门来时,你该如何反应?你是胡萝卜,是鸡蛋,还是咖啡豆?”
7 有一个人因为生意失败,逼不得已变卖了新购的住宅,而且连他心爱的小跑车也脱了手,改以电单车代步。有一日,他和太太一起,相约了几对私交甚笃的夫妻出外游玩,其中一位朋友的新婚妻子因为不知详情,见到他们夫妇共乘一辆电单车来到约定地点,便冲口而出地问:「为甚么你们骑电单车来?」众人一时错愕,场面变得很尴尬,但这位妻子不急不缓地回应答:「我们骑电单车,因为我想抱着他。」 -
【转】对初学LoadRunner朋友的建议
2010-01-28 14:07:34
随着Internet的普及与迅速发展,企业业务量的迅速加大,数据大集中成为一种趋势,IT系统承载的负荷越来越重,系统性能的好坏严重的影响了企业对外提供的服务质量.从而对IT系统的性能进行测试和调优引起企业的重视,进而性能测试工程师成为IT市场的”香悖悖”,并且性能测试有着极高的技术挑战.于是吸引了大量的测试爱好者来学这方面的技术,而一谈到性能测试很多人便会想到鼎鼎大名的LoadRunner这款优秀的性能测试工具,然而到这里问题就产生了?
关建字:LoadRunner 性能测试 网络基础 编程语言 数据库 操作系统
LoadRuner与性能测试的关系:LoadRunner初学者的误点:把LoadRunner神化了.很多初学LoadRunner的朋友认为掌握了使用LoadRunner这款性能测试工具,就能够做性能测试了.常在网上看到好多人在学习怎么去使用这款优秀的性能测试工具,本来学习怎么去使用LoadRunner这个工具没有错,却把LoadRunner神化了,”天真的”以为它什么都能做,以为学会了LoadRunner的使用就能做性能测试了.尽管用了大量的时间学会了如何使用LoadRunner录制脚本,如何进行关联,如何进行参数化,如何设置集合点等等?可到头来,性能测试还是不会做.为什么? 对于产生的性能报告不知道怎么去分析?不知道如何利用得到的分析报告分析出系统存在的瓶颈?不知道如何进行性能调优?像这些事光会使用LoadRunner是做不到的?说白了LoadRunner只是我们做性能测试的一个工具,它并不是万能的,是死的,具体怎么做还得依靠人去操作与分析.会使用LoadRunner的人,并不一定会做性能测试,会做性能测试的人并不一定都会使用LoadRunner.LoadRunner只是一个性能测试工具而已.我们应该意识到,测试工具只是性能测试中的一部分,仅是为达到性能测试目的而采用的一种手段
性能测试与系统性能的关系:高性能,高安全的系统,不是测试出来的,而是构架,设计,编写出来的.当然在这里我并不否认性能测试的重要性,甚至可以说没有经过性能测试的系统,一定不会是优秀的系统,软件是人开发出来的,而人总是会出错的,所谓智者千虑,必有一失……要想做好性能测试,在软件系统需求,设计,编写代码的这些阶段就应该进行性能测试,而不仅仅是系统测试这个阶段才去做性能测试,性能测试应该贯穿于整个软件开发周期中.
对初学LoadRunner朋友的建意:常看到网上一些网友发贴子问,怎么对性能测试产生的结果进行分析?测试系统时怎么去选择合适的协议?对于发这些贴子的人我想请问你?你能够详细的说下HTTP协议吗?TCP建立连接和释放连接的过程是怎样进行的?什么是协议?协议是用来做什么的?在OSI参考模型中各层的作用?数据库中产生并发的冲突的原因?不要太依赖于LoadRunner工具本身的学习,而去忽略计算机其它基础知识的学习,我们更应该去掌握一门编程语言,良好的网络基础知识,计算机原理与操作系统知识,数据库知识.这些是我们去学习怎么去使用LoadRunner前提与基础。.
1为什么要掌握一门编程语言其一,大家在使用LoadRunner时常会遇到一些不能录制脚本的情况发生,或者需要录制一些复杂的脚本,这时候我们就必须手动的开发脚本.其二LoadRunner虽然强大,易于使用,可是它却属于商业软件,价格昂贵,并且代码不开源,我们无法了解LoadRunner具体的实现细节,甚至我们会怀疑LoadRunner收集的性能数据准确吗?它有是如何实现的等等,而这些我们通过LoadRunner的帮助文档无法得知.性能测试工具并不只有LoadRunner,做性能测试还有许多优秀的性能测试工具可以选择,像JMeter,Curl-Loader等等这些非常优秀的开源工具,在全能上虽然并不上LoadRunner,但在某些方面却比LoadRunner还要强大.例如Curl-Loader这个工具,它虽然支持的协议不多,但是对于http协议它最高能产生10万的并发用户,这是LoadRunner远远所不及的.并且这些工具代码是公开的,我们能够从这些代码中去分析具体实现的细节,并且还可以自已编写代码,增强软件的功能,这也是成为性能测试高手的一条途径.LoadRunner好比我们的Windows操作系统,易于使用,功能强大,代码封闭,论全能比Linux要强大.我们的开源性能测试工具好比Linux操作系统代码开源,不易于使用,但很多方面比我们的Windows要强大.也许这个时候有人会问对于初学者学哪门语言最好最有前途C,C++,VB,JAVA,C#?其实每一种语言能够生存下来,自有其生存的道理,每一种语言都有自已优势和缺点,并且编程语言具有相通信,学好了一门,再去学另外的编程语言,非常快就能上手.对于初学者我建意学习C语言,理由有很多,例如很多优秀的开源性能测试工具就是用C语言开发的….当然不管选择什么编程语言,或者数据库,或者操作系统,我们不要去想学哪门最好,学哪方面最有前途.我们更应该结合自身的情况,选择最合适的,而不是选择最好的.
2为什么要掌握计算机原理和操作系统知识
论坛上常会看到这些问题?LoadRunner中线程与进程的关系?在什么时候用到它们,怎么区别用线程还是进程呢?LoadRunner录制产生了乱码怎么解决?怎么去发现内存泄漏?对那些发贴问这些问题的朋友,我依然想请问你你知道进程和线程的概念吗?知道进程有几种状态吗?知道进程间的通信是怎么进行的吗?死锁,进程与线程的区别这些概念你明白吗?如果你连内存的概念,内存的作用,内存泄露的概念都搞不清楚,你怎么去发现内存泄露?如果这些你都不知道,自然就不知道怎么去做性能测试分析?一些网友录制脚本常常会产生一些莫名奇妙的错误?还震震有词的说这是LoadRunner的原因.其实要说到底要解决这些问题就必需得有良好的计算机原理和操作系统知识.弄清了进程和线程的区别,你自然就明白了使用进程资源使用高,但安全性要强于线程,线程资源利用率少,使用线程能在一个负载生成器上运行更多的Vuser,但可能存在安全问题.LoadRunner录制产生了乱码怎么解决?为什么会产生乱码,你知道什么是字符集吗?什么是编码吗?字符串在我们内存中有是如何存放的?ASCII编码,ANSI编码,UNICODE编码它们的区别是什么?这些都是操作系统的基础基础.掌握好了这些你自然明白LoadRunner中产生乱码的原因.当然计算机原理和操作系统的基础知识还有很多得掌握的知识.像操作系统的体系架构、操作系统的重要基础概念,内存管理、存储/文件系统、驱动/硬件的管理.要做好性能测试计算机原理和操作系统知识必不可少.
3为什么要有良好的网络基础
经常在51testing论坛中看到很多人发贴子.像LoadRuner中为什么要进行关联?,LoadRunner测试系统时如何选择协议?LoadRunner中的如何进行IP欺骗?等等.这些问题随便一搜就能发现大量的贴子,其实说到底这些问题和LoadRunner的关系并不是很大,要去解决这些问题并不在于你对LoadRunner这个工具使用是否熟练,而在于我们网络基础知识是否扎实.例如第一个问题LoadRunner中为什么要进行关联?相信很多朋友都知道HTTP协议知道它是超文本传输协议,但是对于一些新手往往不能够详细的说出HTTP具体的内容,像HTTP工作的原理,HTTP协议为什么要使用基于TCP的协议而不使用UDP的协议,HTTP工作在OSI参考模型的哪一层?在HTTP协议上数据是怎么传输的等等.而只有当我们明白了这一切,自然而然就会明白为什么要使用关联,到最后你会发现这些问题其实根LoadRunner关系并不是很大.HTTP协议本质上是无状态的;对页面的每个请求都将被视为新请求,而且默认情况下,来自一个请求的信息对下一个请求不可用.在传统的 Web 编程中,这通常意味着在每一次往返行程中,与该页及该页上的控件相关联的所有信息都会丢失.例如,如果用户将信息输入到文本框,该信息将在从浏览器或客户端设备到服务器的往返行程中丢失,为了使用浏览网页,页与页是相互联系不去丢失这些信息,于是了就从现了Cookie,Session,查询字符串等等保持状态的技术.什么是Cookie?什么是Session?Cookie 和Session 有是怎么工作的?当我们明白了这些,很多的问题就自然而然的明白了,像这些都是基础的知识和LoadRunner关系大吗?不大.Cookie 是一些少量的数据,这些数据存储在客户端文件系统的文本文件中,或者存储在客户端浏览器会话的内存中.Cookie 包含特定于站点的信息(像用户名密码以及我们在网站一些个性化的设置等等),这些信息是随页输出一起由服务器发送到客户端的.如果浏览器使用的是cookie,那么所有的数据都保存在浏览器端,比如我们登录以后,服务器设置了cookie用户名,那么当你再次请求服务器的时候,浏览器会将用户名一块发送给服务器,这些变量有一定的特殊标记.服务器会解释为cookie变量,所以只要不关闭浏览器,那么cookie变量一直是有效的,所以能够保证长时间不掉线..如果设置了的有效时间,那么它会将 cookie保存在客户端的硬盘上,下次再访问该网站的时候浏览器先检查有没有 cookie,如果有的话,就读取该 cookie,然后发送给服务器.这些是Cookie的工作过程,常看到论坛上一些朋友发贴子问使用LoadRunner时录制到了一些Cookie的信息,它是用来做什么的,看起来很烦可不可以把它删除掉?明白了这些细节的知识,你自然能明白那个Cookie的信息能不能删除掉.如果web服务器端使用的是session,那么所有的数据都保存在服务器上,客户端每次请求服务器的时候会发送当前会话的SessionId,服务器根据当前SessionId唯一地标识在服务器上包含会话数据的浏览器,以确定用户是否登录或具有某种权限.不同的用户发送请求Web服务器会随机发送一个唯一的SessionID.而我们使用LoadRunner录制时它会把我们SessionID写死,所以导致出错.这时候就得使用关联了,这样不仅明白了LoadRunner怎样使用关联,而且还明白了为什么要使用关联?对于LoadRunner测试系统时如何选择协议?这个问题也是网络论讨的比较多的问题.要解决这个问题同样得依靠我们的扎实的网络基础,而不是对LoadRunner使用的熟练程度,首先我们得了解LoadRunner录制时的工作原理了,LoadRunner的录制和QTP不一样,它不关心你的对象识别什么的,不关心你的什么界面之类的,不关心你使用什么语言编写的,LoadRunner有一个Agent进程,来专门监控客户端和服务器之间的通信,然后用自己的函数进行录制.LoadRunner录制的时候关心的是通信包,是客户端和服务器之间的数据包.说到这里,大家就比较清楚了,为什么有的时候不能录制呢?因为,协议不认识,导致LoadRunner截获的数据包不能解析,所以录制下来是空的.所以我们得熟悉什么是协议,熟悉OSI参考模型,OSI参考模型中各层的作用,TCP协议栈各层的作用,熟悉TCP,UDP,ICMP等等协议.当我们明白了这些网络的基础知识后我们自然会明白应该如何去选择协议.另外关于LoadRunner中的如何进行IP欺骗?要解决这个问题同样得有良好的网络基础知识.其实当我们理解了IP地址的格式,IP地址的分类,子网掩码的概念,以及知道怎么去进行非标准子网的划分方法 ,掌握了这些原理的东西,那么具体怎么在LoadRunner中如何进行IP欺骗,就非常简单了. 当然网络基础知识并不只是上面的而已,还包括路由器,交换机,加密技术等等这些基础的网络知识,这些远远比我们去学习怎么去使用LoadRunner更重要.
4为什么要掌握数据库知识
数据库的重要性我想是不言而喻的,性能测试产生的一个非常大的原因是因为数据大集中的趋势,测试从某种意义来讲就是对数据测试,而我们企业的核心数据是放在数据库中的.现在大型的WEB应用程序,都采用多层结构,像典型三层,用户界面层,数据逻辑层,数据层.而数据层,而数据层对我们整个WEB应用程序的性能是非常大的,对数据库的基础知识不懂,我们怎么去进行性能测试分析?怎么知道确定性能产生的瓶颈是否是数据库的原因,如何对系统进行调优?例如数据库模型设计不合理,一条坏的SQL语句就能影响到整个WEB应用程序的性能,所以熟悉SQL语句,建表,索引,存储过程,事务,触发器,并发等这些基础知识是必需得掌握的.
路漫漫其修远兮,吾将上下而求索:性能测试难点不在于Loadrunner工具本身,难在对整个系统的全局把握,而对全局的把握你就必需得有丰富的知识面.并不是学好了LoadRunner的使用就能做性能测试 .目前,国内性能测试领域正处于起步阶段,要做好性能测试还需学习更多的知识,技术性和非技术.性能测试这条路充满着挑战,也充满着机遇.但正如鲁迅先生所说这世上本来没有路,走的人多了,也就成了路.最后祝愿喜爱性能测试的爱好这条道路上能够不鸣则已,一鸣惊人,不飞则已,一飞冲天. -
【转】详解IE浏览器的缓存
2010-01-27 15:16:19
转自:
http://www.51testing.com/?uid-183791-action-viewspace-itemid-130503
我们在上网浏览信息时经常会用到IE里的“前进”、“后退”按钮,来调用阅读过的页面。你会发现,这时的显示速度比较快。其实这些刚调出来的内容就存放在电脑的缓存中,而不需再次从网上重新传输数据。这就引出了一个概念——缓存,你对它是否了解呢?让我们一起来了解一下这方面的知识吧!
缓存的概念
缓存是指在本地使用的电脑中开辟一个空间,作为数据传输的缓冲区。IE里的缓存主要就是用来暂时保存用户以前访问过的信息。既然缓存存在于硬盘之中,那么它肯定是以文件夹的形式出现的。各个不同类型的浏览器都有各个不同的文件夹作为缓存使用。在系统缺省状态下,IE 5.0的缓存文件夹为“WINDOWSTemporary Internet Files”。当用户在浏览器中设置一定量的磁盘缓存后,浏览器上网工作时会把从网上读出的网页、图像以及其他数据存放在磁盘缓存之中,并建立相应的文档索引。然后检查磁盘缓冲区中是否存在相应的数据。如果有,则直接从本地磁盘上读出。缓存按照信息存放的位置可分成内存缓存和硬盘缓存两种。内存缓存是用于暂时存储本次上网所调用的数据资料的,从Internet上传来的每一个网页信息,在内存缓存中都相应地给予保存一个备份,“前进”和“后退”实际上是将以前的页面从内存缓存中调出来并显示在用户的浏览器窗口中,在内存缓存中存放的网页信息量和内存缓存的大小有关,内存缓存越大,保存的网页信息量就越多。硬盘缓存是用于保存用户前几次上网时所调用的信息资料,用户从“历史记录”中调出的内容其实就是保存在硬盘缓存中,只要用户开辟的硬盘缓存足够大,就可保存用户前几个星期甚至几个月前调用过的信息资料。
缓存的正确设置
如果缓存容量设置的太小,所能存放的数据信息量就很小,大部分数据还是需要从网上重新下载,并且系统还要花费一定的系统资源来频繁清除缓存中的数据,最终结果会使浏览速度明显下降。
如果浏览器的缓存设置太大,磁盘缓存中存放的数据信息量将很大,以后每次需要重新访问这些信息时,浏览器将不得不在庞大的缓存信息中搜索需要的文档,这样会使硬盘频繁工作,所需时间将长于从网上下载数据的时间。另外,如果缓存容量设置得太大,在硬盘容量一定的情况下,其他系统程序占用的资源将变得相对较少,从而会降低电脑本身的运行速度,磁盘缓存就失去了应有的作用。如果你经常要访问的信息量很大,而且电脑中的硬盘有较多闲置空间,那么你可以把硬盘缓存的数值设置成100MB~300MB。
用户无论使用哪一种浏览器,正确设置浏览器的缓存参数将大大地提高浏览效率,并在一定程度上改善浏览器的工作性能。我们以IE 5.0浏览器为例:
打开IE 5.0操作窗口,单击“工具”菜单中的“Internet选项”,屏幕上将出现“Internet选项”对话框。单击“常规”标签下的“Internet临时文件”设置栏,单击“设置”按钮,程序将会打开一个标题为“设置”对话框。如果用户想节省硬盘的空间,也可选取“删除文件”按钮,以便释放出更多缓存空间。
在“设置”对话框上有4个单选项:
1、每次访问此页时检查:表示浏览器将发送一个信息给所要访问的页面的Web服务器,查询当前访问的信息是否有变动,如无变动,就从硬盘缓存中直接调用,而且每次访问都要发送信息给Web服务器进行验证。
2、每次启动Internet Explorer时检查:表示本次上网浏览器将只发送一次信息给Web服务器进行验证,以后无论信息是否发生变动,都从硬盘缓存中直接调用所要访问的页面的信息。
3、自动:表示浏览器将自动检查所要访问的信息最近是否发生变动,如有变动,则从Internet上重新下载网页;相反,则直接从硬盘中读取数据。
4、不检查:表示对要调用的页面信息不进行校验,直接从硬盘中调用。
弄清楚了以上4个选项后,用户就可根据自己的实际情况进行设定,浏览器默认选择“自动”这一单选项。
在“使用的磁盘空间处”用鼠标直接拖动滑动杆来改变缓存的大小,或者直接在后面的文本框中输入具体的数值。如果用户想改变浏览器缓存的位置,如C盘空间小或为使用方便,用户只需将缓存移到其他分区或者把缓存放到一个易操作的地方,就可通过另外选择一个文件夹来作为缓存。在这里用户只要按下“移动文件夹”并指定要新建的文件夹名称即可。参数设定后,单击“确定”按钮,退出选项对话框。
注意事项
1、磁盘缓存如果使用不当或使用时间较长时,有时会导致浏览器降低工作效率或停止工作。具体表现在:一是打开一个网页时硬盘不停地工作,需很长的时间才有反应。这是因为缓存太大、缓存中数据太多造成的;二是浏览器不工作,无法打开任何网页。这是因为缓存中的数据文档混乱或者已经破坏造成的。解决此类问题的方法是适当减小缓存容量或者定期及时清理缓存中的数据。
2、使用缓存后网页不能自动更新,虽然在设置缓存时可自动检测网页是否更新,但实际工作中常出现读出旧网页内容。解决上述故障的方法是随时按下浏览器的“刷新”或“Reload”按钮。
-
【转】敏捷开发&敏捷测试
2010-01-27 14:12:15
转自:
http://www.51testing.com/?uid-301297-action-viewspace-itemid-205288
首先敏捷测试是敏捷的一种,原有测试定义中通过执行被测系统发现问题,通过测试这种活动能够提供对被测系统提供度量等概念还是适用的。在传统的测试定义上,还需要添加
敏捷测试是遵循敏捷宣言的一种测试实践:
强调从客户的角度,即使用系统的用户的角度,来测试系统
重点关注持续迭代的测试新开发的功能,而不再强调传统测试过程中严格的测试阶段。
建议尽早开始测试,一旦系统某个层面可测,比如提供了模块功能,就要开始模块层面的单元测试,同时随着测试深入,持续进行回归测试保证之前测试过内容的正确性。
敏捷开发
人与人之间的交互是复杂的,并且其效果从来都是难以预期的,但却是工作中最重要的方面。-- Tom DeMacro和Timothy Lister
敏捷软件开发宣言:
● 个体和交互 胜过 过程和工具
● 可以工作的软件 胜过 面面俱到的文档
● 客户合作 胜过 合同谈判
● 响应变化 胜过 遵循计划
虽然右项也有价值,但是我们认为左项具有更大的价值。
敏捷宣言遵循的原则:
● 我们最优先要做的是通过尽早的、持续的交付有价值的软件来使客户满意。
● 即使到了开发的后期,也欢迎改变需求。敏捷过程利用变化来为客户创造竞争优势。
● 经常性地交付可以工作的软件,交付的间隔可以从几个星期到几个月,交付的时间间隔越短越好。
● 在整个项目开发期间,业务人员和开发人员必须天天都在一起工作。
● 围绕被激励起来的个体来构建项目。给他们提供所需的环境和支持,并且信任他们能够完成工作。
● 在团队内部,最具有效果并富有效率的传递信息的方法,就是面对面的交谈。
● 工作的软件是首要的进度度量标准。
● 敏捷过程提倡可持续的开发速度。责任人、开发者和用户应该能够保持一个长期的、恒定的开发速度。
● 不断地关注优秀的技能和好的设计会增强敏捷能力。
● 简单是最根本的。
● 最好的构架、需求和设计出于自组织团队。
● 每隔一定时间,团队会在如何才能更有效地工作方面进行反省,然后相应地对自己的行为进行调整
-
【转】最常用的网络命令精萃
2010-01-27 13:57:53
转自:
http://blog.csdn.net/bladewing/archive/2004/07/13/40599.aspx
最常用的网络命令精萃
作者:佚名
一、ping
它是用来检查网络是否通畅或者网络连接速度的命令。作为一个生活在网络上的管理员或者黑客来说,ping命令是第一个必须掌握的DOS命令,它所利用的原理是这样的:网络上的机器都有唯一确定的IP地址,我们给目标IP地址发送一个数据包,对方就要返回一个同样大小的数据包,根据返回的数据包我们可以确定目标主机的存在,可以初步判断目标主机的操作系统等。下面就来看看它的一些常用的操作。先看看帮助吧,在DOS窗口中键入:ping /? 回车,出现如图1。所示的帮助画面。在此,我们只掌握一些基本的很有用的参数就可以了(下同)。-t 表示将不间断向目标IP发送数据包,直到我们强迫其停止。试想,如果你使用100M的宽带接入,而目标IP是56K的小猫,那么要不了多久,目标IP就因为承受不了这么多的数据而掉线,呵呵,一次攻击就这么简单的实现了。
-l 定义发送数据包的大小,默认为32字节,我们利用它可以最大定义到65500字节。结合上面介绍的-t参数一起使用,会有更好的效果哦。
-n 定义向目标IP发送数据包的次数,默认为3次。如果网络速度比较慢,3次对我们来说也浪费了不少时间,因为现在我们的目的仅仅是判断目标IP是否存在,那么就定义为一次吧。
说明一下,如果-t 参数和 -n参数一起使用,ping命令就以放在后面的参数为标准,比如“ping IP -t -n 3”,虽然使用了-t参数,但并不是一直ping下去,而是只ping 3次。另外,ping命令不一定非得ping IP,也可以直接ping主机域名,这样就可以得到主机的IP。
下面我们举个例子来说明一下具体用法。
这里time=2表示从发出数据包到接受到返回数据包所用的时间是2秒,从这里可以判断网络连接速度的大小 。从TTL的返回值可以初步判断被ping主机的操作系统,之所以说“初步判断”是因为这个值是可以修改的。这里TTL=32表示操作系统可能是win98。
(小知识:如果TTL=128,则表示目标主机可能是Win2000;如果TTL=250,则目标主机可能是Unix)
至于利用ping命令可以快速查找局域网故障,可以快速搜索最快的QQ服务器,可以对别人进行ping攻击……这些就靠大家自己发挥了。
二、nbtstat
该命令使用TCP/IP上的NetBIOS显示协议统计和当前TCP/IP连接,使用这个命令你可以得到远程主机的NETBIOS信息,比如用户名、所属的工作组、网卡的MAC地址等。在此我们就有必要了解几个基本的参数。
-a 使用这个参数,只要你知道了远程主机的机器名称,就可以得到它的NETBIOS信息如图3(下同)。
-A 这个参数也可以得到远程主机的NETBIOS信息,但需要你知道它的IP。
-n 列出本地机器的NETBIOS信息。
当得到了对方的IP或者机器名的时候,就可以使用nbtstat命令来进一步得到对方的信息了,这又增加了我们入侵的保险系数。
三、netstat
这是一个用来查看网络状态的命令,操作简便功能强大。
-a 查看本地机器的所有开放端口,可以有效发现和预防木马,可以知道机器所开的服务等信息,如图4。
这里可以看出本地机器开放有FTP服务、Telnet服务、邮件服务、WEB服务等。用法:netstat -a IP。
-r 列出当前的路由信息,告诉我们本地机器的网关、子网掩码等信息。用法:netstat -r IP。
以下转自:http://blog.csdn.net/mi_mang/archive/2009/07/04/4318271.aspx
1 、命令介绍
显示活动的 TCP 连接、计算机侦听的端口、以太网统计信息、IP 路由表、IPv4 统计信息(对于 IP、ICMP、TCP 和 UDP 协议)以及 IPv6 统计信息(对于 IPv6、ICMPv6、通过 IPv6 的 TCP 以及通过 IPv6 的 UDP 协议)。使用时如果不带参数,netstat 显示活动的 TCP 连接。
2、命令参数netstat -a 显示所有活动的 TCP 连接以及计算机侦听的 TCP 和 UDP 端口。
-e 显示以太网统计信息,如发送和接收的字节数、数据包数。该参数可以与 -s 结合使用。
-n 显示活动的 TCP 连接,不过,只以数字形式表现地址和端口号,却不尝试确定名称。
-o 显示活动的 TCP 连接并包括每个连接的进程 ID (PID)。
-p 显示 Protocol 所指定的协议的连接。在这种情况下,Protocol 可以是 tcp、udp、tcpv6 或 udpv6。如果该参数与 -s 一起使用按协议显示统计信息
-s 按协议显示统计信息
-r 显示 IP 路由表的内容
sec 每隔 Interval 秒重新显示一次选定的信息。
3、使用举例要想显示以太网统计信息和所有协议的统计信息,请键入下列命令:
netstat -e -s
要想仅显示 TCP 和 UDP 协议的统计信息,请键入下列命令:
netstat -s -p tcp udp
要想每 5 秒钟显示一次活动的 TCP 连接和进程 ID,请键入下列命令:netstat -o 5
四、tracert
跟踪路由信息,使用此命令可以查出数据从本地机器传输到目标主机所经过的所有途径,这对我们了解网络布局和结构很有帮助。
这里说明数据从本地机器传输到192.168.0.1的机器上,中间没有经过任何中转,说明这两台机器是在同一段局域网内。用法:tracert IP。
五、net
这个命令是网络命令中最重要的一个,必须透彻掌握它的每一个子命令的用法,因为它的功能实在是太强大了,这简直就是微软为我们提供的最好的入侵工具。首先让我们来看一看它都有那些子命令,键入net /?回车。
在这里,我们重点掌握几个入侵常用的子命令。
net view
使用此命令查看远程主机的所以共享资源。命令格式为net view \\IP。
net use
把远程主机的某个共享资源影射为本地盘符,图形界面方便使用,呵呵。命令格式为net use x: \\IP\sharename。上面一个表示把192.168.0.5IP的共享名为magic的目录影射为本地的Z盘。下面表示和192.168.0.7建立IPC$连接(net use \\IP\IPC$ "password" /user:"name")。
建立了IPC$连接后,呵呵,就可以上传文件了:copy nc.exe \\192.168.0.7\admin$,表示把本地目录下的nc.exe传到远程主机,结合后面要介绍到的其他DOS命令就可以实现入侵了。
net start
使用它来启动远程主机上的服务。当你和远程主机建立连接后,如果发现它的什么服务没有启动,而你又想利用此服务怎么办?就使用这个命令来启动吧。用法:net start servername,如图9,成功启动了telnet服务。
net stop
入侵后发现远程主机的某个服务碍手碍脚,怎么办?利用这个命令停掉就ok了,用法和net start同。
net user
查看和帐户有关的情况,包括新建帐户、删除帐户、查看特定帐户、激活帐户、帐户禁用等。这对我们入侵是很有利的,最重要的,它为我们克隆帐户提供了前提。键入不带参数的net user,可以查看所有用户,包括已经禁用的。下面分别讲解。
1,net user abcd 1234 /add,新建一个用户名为abcd,密码为1234的帐户,默认为user组成员。
2,net user abcd /del,将用户名为abcd的用户删除。
3,net user abcd /active:no,将用户名为abcd的用户禁用。
4,net user abcd /active:yes,激活用户名为abcd的用户。
5,net user abcd,查看用户名为abcd的用户的情况。
net localgroup
查看所有和用户组有关的信息和进行相关操作。键入不带参数的net localgroup即列出当前所有的用户组。在入侵过程中,我们一般利用它来把某个帐户提升为administrator组帐户,这样我们利用这个帐户就可以控制整个远程主机了。用法:net localgroup groupname username /add。
现在我们把刚才新建的用户abcd加到administrator组里去了,这时候abcd用户已经是超级管理员了,呵呵,你可以再使用net user abcd来查看他的状态,和图10进行比较就可以看出来。但这样太明显了,网管一看用户情况就能漏出破绽,所以这种方法只能对付菜鸟网管,但我们还得知道。现在的手段都是利用其他工具和手段克隆一个让网管看不出来的超级管理员,这是后话。有兴趣的朋友可以参照《黑客防线》第30期上的《由浅入深解析隆帐户》一文。
net time
这个命令可以查看远程主机当前的时间。如果你的目标只是进入到远程主机里面,那么也许就用不到这个命令了。但简单的入侵成功了,难道只是看看吗?我们需要进一步渗透。这就连远程主机当前的时间都需要知道,因为利用时间和其他手段(后面会讲到)可以实现某个命令和程序的定时启动,为我们进一步入侵打好基础。用法:net time \\IP。
六、at
这个命令的作用是安排在特定日期或时间执行某个特定的命令和程序(知道net time的重要了吧?)。当我们知道了远程主机的当前时间,就可以利用此命令让其在以后的某个时间(比如2分钟后)执行某个程序和命令。用法:at time command \\computer。
表示在6点55分时,让名称为a-01的计算机开启telnet服务(这里net start telnet即为开启telnet服务的命令)。
七、ftp
大家对这个命令应该比较熟悉了吧?网络上开放的ftp的主机很多,其中很大一部分是匿名的,也就是说任何人都可以登陆上去。现在如果你扫到了一台开放ftp服务的主机(一般都是开了21端口的机器),如果你还不会使用ftp的命令怎么办?下面就给出基本的ftp命令使用方法。
首先在命令行键入ftp回车,出现ftp的提示符,这时候可以键入“help”来查看帮助(任何DOS命令都可以使用此方法查看其帮助)。
大家可能看到了,这么多命令该怎么用?其实也用不到那么多,掌握几个基本的就够了。
首先是登陆过程,这就要用到open了,直接在ftp的提示符下输入“open 主机IP ftp端口”回车即可,一般端口默认都是21,可以不写。接着就是输入合法的用户名和密码进行登陆了,这里以匿名ftp为例介绍。
用户名和密码都是ftp,密码是不显示的。当提示**** logged in时,就说明登陆成功。这里因为是匿名登陆,所以用户显示为Anonymous。
接下来就要介绍具体命令的使用方法了。dir 跟DOS命令一样,用于查看服务器的文件,直接敲上dir回车,就可以看到此ftp服务器上的文件。
cd 进入某个文件夹。
get 下载文件到本地机器。
put 上传文件到远程服务器。这就要看远程ftp服务器是否给了你可写的权限了,如果可以,呵呵,该怎么 利用就不多说了,大家就自由发挥去吧。
delete 删除远程ftp服务器上的文件。这也必须保证你有可写的权限。
bye 退出当前连接。
quit 同上。
八、telnet
功能强大的远程登陆命令,几乎所有的入侵者都喜欢用它,屡试不爽。为什么?它操作简单,如同使用自己的机器一样,只要你熟悉DOS命令,在成功以administrator身份连接了远程机器后,就可以用它来干你想干的一切了。下面介绍一下使用方法,首先键入telnet回车,再键入help查看其帮助信息。
然后在提示符下键入open IP回车,这时就出现了登陆窗口,让你输入合法的用户名和密码,这里输入任何密码都是不显示的。
当输入用户名和密码都正确后就成功建立了telnet连接,这时候你就在远程主机上具有了和此用户一样的权限,利用DOS命令就可以实现你想干的事情了,如图19。这里我使用的超级管理员权限登陆的。
到这里为止,网络DOS命令的介绍就告一段落了,这里介绍的目的只是给菜鸟网管一个印象,让其知道熟悉和掌握网络DOS命令的重要性。其实和网络有关的DOS命令还远不止这些,这里只是抛砖引玉,希望能对广大菜鸟网管有所帮助。学好DOS对当好网管有很大的帮助,特别的熟练掌握了一些网络的DOS命令。
另外大家应该清楚,任何人要想进入系统,必须得有一个合法的用户名和密码(输入法漏洞差不多绝迹了吧),哪怕你拿到帐户的只有一个很小的权限,你也可以利用它来达到最后的目的。所以坚决消灭空口令,给自己的帐户加上一个强壮的密码,是最好的防御弱口令入侵的方法。
最后,由衷的说一句,培养良好的安全意识才是最重要的。
-
【转】netstat -an 命令端口状态详解
2010-01-27 13:32:33
netstat -an命令能看到所有和本地计算机建立连接的IP,它包含四个部分:proto(连接方式)、local address(本地连接地址)、foreign address(和本地建立连接的地址)、state(当前端口状态)。通过这个命令的详细信息可以完全监控自己的计算机上的连接。
netstat -an命令显示的state(当前端口状态)有以下几种状态:
LISTEN:侦听来自远方的TCP端口的连接请求
SYN-SENT:在发送连接请求后等待匹配的连接请求
SYN-RECEIVED:在收到和发送一个连接请求后等待对方对连接请求的确认
ESTABLISHED:代表一个打开的连接
FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认
FIN-WAIT-2:从远程TCP等待连接中断请求
CLOSE-WAIT:等待从本地用户发来的连接中断请求
CLOSING:等待远程TCP对连接中断的确认
LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认
TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认
CLOSED:没有任何连接状态 -
windows-运行窗口常用命令
2010-01-26 17:27:54
explorer--资源管理器
logoff--注销
lusrmgr.msc--本地用户和组
services.msc--本地服务设置
notepad--记事本
devmgmt.msc--设备管理器
winver--windows版本
compmgmt.msc--计算机管理
taskmgr--任务管理器
mmc--控制台
gpedit.msc--组策略
secpol.msc--本地安全设置
regedit--注册表编辑器
-
【转】计算机常用端口
2010-01-26 10:49:18
计算机常用端口
HTTP:80:www服务。
DHCP:服务器端的端口号是67
DHCP:客户机端的端口号是68
POP3:POP3仅仅是接收协议,POP3客户端使用SMTP向服务器发送邮件。POP3所用的端口号是110。
SMTP:端口号是25。SMTP真正关心的不是邮件如何被传送,而只关心邮件是否能顺利到达目的地。SMTP具有健壮的邮件处理特性,这种特性允许邮件依据一定标准自动路由,SMTP具有当邮件地址不存在时立即通知用户的能力,并且具有在一定时间内将不可传输的邮件返回发送方的特点。
Telnet:端口号是23。Telnet是一种最老的Internet应用,起源于ARPNET。它的名字是“电信网络协议(Telecommunication Network Protocol)”的缩写。
FTP:FTP使用的端口有20和21。20端口用于数据传输,21端口用于控制信令的传输,控制信息和数据能够同时传输,这是FTP的特殊这处。FTP采用的是TCP连接。
TFTP:端口号69,使用的是UDP的连接。
DNS:53,名称服务
NetBIOS:137,138,139,其中137、138是UDP端口,当通过网上邻居传输文件时用这个端口。而139端口:通过这个端口进入的连接试图获得NetBIOS/SMB服务。这个协议被用于windows文件和打印机共享和SAMBA。还有WINS Regisrtation也用它。
NNTP 网络新闻传输协议:119
SNMP(简单网络管理协议):161端口
RPC(远程过程调用)服务:135端口
QQ:使用8000(服务端)和4000端口(客户端)
21 端口:21 端口主要用于FTP(File Transfer Protocol,文件传输协议)服务。
23 端口:23 端口主要用于Telnet(远程登录)服务,是Internet上普遍采用的登录和仿真程序。
25 端口:25 端口为SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)服务器所开放,主要用于发送邮件,如今绝大多数邮件服务器都使用该协议。
53 端口:53 端口为DNS(Domain Name Server,域名服务器)服务器所开放,主要用于域名解析,DNS 服务在NT 系统中使用的最为广泛。
67、68 端口:67、68 端口分别是为Bootp 服务的Bootstrap Protocol Server(引导程序协议服务端)和Bootstrap Protocol Client(引导程序协议客户端)开放的端口。
69 端口:TFTP 是Cisco 公司开发的一个简单文件传输协议,类似于FTP。
79 端口:79 端口是为Finger 服务开放的,主要用于查询远程主机在线用户、操作系统类型以及是否缓冲区溢出等用户的详细信息。
80 端口:80 端口是为HTTP(HyperText Transport Protocol,超文本传输协议)开放的,这是上网冲浪使用最多的协议,主要用于在WWW(World Wide Web,万维网)服务上传输信息的协议。
99 端口:99 端口是用于一个名为“Metagram Relay”(亚对策延时)的服务该服务比较少见,一般是用不到的。
109、110 端口:109 端口是为POP2(Post Office Protocol Version2,邮局协议2)服务开放的,110 端口是为POP3(邮件协议3)服务开放的,POP2、POP3 都是主要用于接收邮件的。
111 端口:111 端口是SUN 公司的RPC(Remote Procedure Call,远程过程调用)服务所开放的端口,主要用于分布式系统中不同计算机的内部进程通信,RPC 在多种网络服务中都是很重要的组件。
113 端口:113 端口主要用于Windows 的“Authentication Service”(验证服务)。
119 端口:119 端口是为“Network News Transfer Protocol”(网络新闻组传输协议,简称NNTP)开放的。
135 端口:135 端口主要用于使用RPC(Remote Procedure Call,远程过程调用)协议并提供DCOM(分布式组件对象模型)服务。
137 端口:137 端口主要用于“NetBIOS Name Service”(NetBIOS名称服务)。
139 端口:139 端口是为“NetBIOS Session Service”提供的,主要用于提供Windows 文件和打印机共享以及Unix 中的Samba 服务。
143 端口:143 端口主要是用于“Internet Message Access Protocol”v2(Internet 消息访问协议,简称IMAP)。
161 端口:161 端口是用于“Simple Network Management Protocol”(简单网络管理协议,简称SNMP)。
443 端口:443 端口即网页浏览端口,主要是用于HTTPS 服务,是提供加密和通过安全端口传输的另一种HTTP。
554 端口:554 端口默认情况下用于“Real Time Streaming Protocol”(实时流协议,简称RTSP)。
1024 端口:1024 端口一般不固定分配给某个服务,在英文中的解释是“Reserved”(保留)。
1080 端口:1080 端口是Socks 代理服务使用的端口,大家平时上网使用的WWW 服务使用的是HTTP 协议的代理服务。
1755 端口:1755 端口默认情况下用于“Microsoft Media Server”(微软媒体服务器,简称MMS)。
3389端口:远程桌面网络层---数据包的包格式里面有个很重要的字段叫做协议号。比如在传输层如果是TCP连接,那么在网络层IP包里面的协议号就将会有个值是6,如果是UDP的话那个值就是17---传输层。
传输层---通过接口关联(端口的字段叫做端口)---应用层。用netstat –an 可以查看本机开放的端口号。代理服务器常用以下端口:(1). HTTP协议代理服务器常用端口号:80/8080/3128/8081/9080(2). SOCKS代理协议服务器常用端口号:1080(3). FTP(文件传输)协议代理服务器常用端口号:21(4). Telnet(远程登录)协议代理服务器常用端口:23HTTP服务器,默认的端口号为80/tcp(木马Executor开放此端口);HTTPS(securely transferring web pages)服务器,默认的端口号为443/tcp 443/udp;Telnet(不安全的文本传送),默认端口号为23/tcp(木马Tiny Telnet Server所开放的端口);FTP,默认的端口号为21/tcp(木马Doly Trojan、Fore、Invisible FTP、WebEx、WinCrash和Blade Runner所开放的端口);TFTP(Trivial File Transfer Protocol ),默认的端口号为69/udp;SSH(安全登录)、SCP(文件传输)、端口重定向,默认的端口号为22/tcp;SMTP Simple Mail Transfer Protocol (E-mail),默认的端口号为25/tcp(木马Antigen、Email Password Sender、Haebu Coceda、Shtrilitz Stealth、WinPC、WinSpy都开放这个端口);POP3 Post Office Protocol (E-mail) ,默认的端口号为110/tcp;WebLogic,默认的端口号为7001;Webshpere应用程序,默认的端口号为9080;webshpere管理工具,默认的端口号为9090;JBOSS,默认的端口号为8080;TOMCAT,默认的端口号为8080;WIN2003远程登陆,默认的端口号为3389;Symantec AV/Filter for MSE ,默认端口号为 8081;Oracle 数据库,默认的端口号为1521;ORACLE EMCTL,默认的端口号为1158;Oracle XDB( XML 数据库),默认的端口号为8080;Oracle XDB FTP服务,默认的端口号为2100;MS SQL*SERVER数据库server,默认的端口号为1433/tcp 1433/udp;MS SQL*SERVER数据库monitor,默认的端口号为1434/tcp 1434/udp;QQ,默认的端口号为1080/udp -
正则表达式全部符号解释
2010-01-22 15:39:14
字符 描述 \ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 ^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 $ 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 * 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 + 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 ? 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 中的"do" 。? 等价于 {0,1}。 {n} n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 {n,} n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 {n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 ? 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 . 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 (pattern) 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript. 中使用 SubMatches 集合,在JScript. 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 '\(' 或 '\)'。 (?:pattern) 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 (?=pattern) 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 (?!pattern) 负向预查,在任何不匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 x|y 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 [xyz] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 [^xyz] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 [a-z] 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 [^a-z] 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 \b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 \B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 \cx 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 \d 匹配一个数字字符。等价于 [0-9]。 \D 匹配一个非数字字符。等价于 [^0-9]。 \f 匹配一个换页符。等价于 \x0c 和 \cL。 \n 匹配一个换行符。等价于 \x0a 和 \cJ。 \r 匹配一个回车符。等价于 \x0d 和 \cM。 \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 \S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 \t 匹配一个制表符。等价于 \x09 和 \cI。 \v 匹配一个垂直制表符。等价于 \x0b 和 \cK。 \w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 \W 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 \xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。. \num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 \n 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 \nm 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 \nml 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 \un 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 转自:
http:/ /yirlin.cnblogs.com/archive/2006/04/12/373222.html
-
网络设备相关术语
2010-01-22 13:48:07
SNMP陷阱(SNMP Trap)
自1998以来,SNMP已经被广泛被接受和支持。SNMP依赖的模式是管理站与代理(即是Management and Agent Model)。SNMP Trap是SNMP的一部分,当被监控段出现特定事件,可能是性能问题,甚至是网络设备接口宕掉等,代理端会给管理站发告警事件。通过告警事件,管理站可以通过定义好的方法来处理告警。SNMP陷阱(SNMP Trap)是由一个SNMP代理发送的信息给管理员,其使一个代理通知管理站的重要事件,通过一个未被请求的SNMP信息。在SNMP自陷的通知后面的观点是这样的:如果一个管理员是负责大量的设备,每个设备有大量的目标,这对他是不切实际的或请求信息来自每个设备中的每个目标。每个在管理设备上的代理的解决方案在没有请求的情况下通知管理员。它通过发送信息叫做这个事件的陷阱。在接收到这个事件之后,管理员配置它和可能选择基于这个事件的行动。举例来说,管理员能够直接轮询这个代理,或轮询其它相关设备代理来获得对这个事件更好的理解。
SNMP MIB
管理信息数据库(MIB)是一个信息存储库,它包含管理代理中的有关配置和性能的数据,有组织体系和公共结构,其中包含分属不同组的多个数据对象。SNMP管理信息数据库(MIB)是一个用于存储定义在SNMP系统中的数据库。它包括一个在虚拟数据库中目标的收集,用于的管理在网络中实体(例如路由器和交换机)。在MIB中的对象使用一个抽象语法标记(ASN.1) 叫做“管理信息结构版本2” (SMIv2)。MIB-I是指最初的MIB定义;MIB-II是指稍后的定义。SNMPv2包括MIB-II和添加了一些新的对象。SNMP OID
SNMP对象标识符(OID)是定义在特定MIB模式中的值,来定义一个特定的在MIB数据库中SNMP目标。SNMP OID是划界序列数字组成a.b.c...x.y.z的周期。它对信息的一个项目是一个独特的标识符,其是一个MIB的一部分。典型的OIDs能够有与它们相关的名字。OIDs在自然中是分等级的。因此1.2.3出现在1.3之前但是在1.2之后。SNMP共同体(SNMP Communities)
SNMP共同体(SNMP Communities)是使一个智能网络设备来验证SNMP请求的鉴定方案。SNMP代理(SNMP Agent)
简单网络管理(SNMP)架构假定管理员和代理的存在。SNMP代理在管理网络设备上是一个软件模型,负责维护本地管理信息和分发那个信息通过SNMP协议到一个SNMP管理员。一个管理信息交换能够被一个管理员管理(通过轮询)或通过代理(通过陷阱)。代理功能作为集合和发送关于管理反馈给一个来自管理员的请求资源搜集设备。SNMP管理员(SNMP Manager)
SNMP管理员(SNMP)架构设定了管理员和代理的存在。一个SNMP管理员,也叫做SNMP控制台,是一个负责为了网络管理应用和用户管理部分或全部配置的软件模型。一个代理是一个软件模型,在一个管理设备中负责维护本地管理信息和分发那个信息给一个通过SNMP的管理员。一个管理信息交换能够被这个管理员发起(通过轮询)或由代理(通过陷阱)。 -
【转】成为测试主管第一步--制定测试流程
2010-01-22 10:38:02
作者:陈卫俊 文章来源:CSDN
刚接到这个题目的时候也有一些犯难,:测试流程在不同的公司都会有微小的差异,而这些差异就有可能会决定测试流程是否是真正适用。在不同公司,不同的现状情况引入适合的测试流程,就好像如同在《寻秦记》中提到的剑圣,他的三个徒弟剑法的风格类型完全不一样同,这一点上,因材施教是非常重要的。其实在动笔撰写本文的时候之前,我一直觉的感受到很大压力很大,这其中最重要的原因莫过于怕误人子弟了,。测试流程的制定不是一门科学,而有时看起来,它更像一门艺术,一个好的测试管理者其实在面对不同的公司,不同的研发阶段,会采用不同的测试流程, 。或是而同样的测试流程,为了真正达到执行的效果,执行的方法也可能不一样。
实施测试流程一般都是有两个原因,:一是软件质量出现的了问题,虽然在某种程度上已经得到解决,但仍需要通过测试,把预防措施的方法找到并固化下来;还有另一个原因则种是软件研发的规模壮大,要求做的在流程上更加清晰,可靠更好。我个人从我自己的角度出发最怕以下一某些情况是让人非常头疼的,:一种情况是,是今天刚看了一本书,被告知说这样做是规范应该这样制定的,而明天就要引入进来,完全不考虑公司的实际情况;另一种情况是“苏联模式”,二是那种即某某大公司的测试流程如此制定是这样做的,我们也要采用相同的方法这样。其实流程没有最好的,只有适合自己的,规范的测试流程不一定会帮助研发成功,反而在某些情况下会弄不好羁绊到自己自己的工作。
- 现在大多数测试人会犯一个共同的错误,往往——把流程设计的得很完美,但没有可操作性很差,无法帮助对于软件公司真正的目的——研发,并没有起到应有的作用成功,久而久之测试的重要性就无从谈起,测试团队也渐渐在公司变成次要部门,成为打杂的得不到应有的重视。
- 在流程的设计过程中,最重要的问题在于是目当前项目的特点是什么,产品经常出什么样的哪些问题,需要做什么怎样的调整,现有测试团队能不能做这样的能否做作出调整,研发团队是不是会不会能接收接受?
首先谈谈项目特点,按照项目特点,大致可以一般来说分成两类,:
- 一种是长期进行的项目,这种项目有基本的框架,有核心的技术,应用比较稳定,这种项目要注重测试用例的积累与复用,同时也适合做单元测试,自动化测试的积累;
- 另一种是变更频度更高,灵活,规模不大的项目,如果做自动化测试则会出现二次开发的时间大于手工测试的时间,而且项目结束后测试用例在长期中也没有任何复用,在自动化测试人员普遍成本比较高的情况下,所以反而更适做功能测试。
- 虽然这两者可能在长远的目标上并不一致,但是引入测试管理平台,从测试需求,、测试设计,、缺陷管理等方面入手则是测试团队必备的技能。一个好的测试流程必需要有好的系统平台的支撑,如果你把测试流程设计的得很完美,跟如同小学语文教科书一样,但执行这样的流程在起来现有的资源的情况下是未免不现实,倒并非说详细的流程是洪水猛兽,只是对于一家软件公司来说,资源的限制仍然是瓶颈所在的。,那流程也就没有意义,一般来说一个执行的得好的测试流程必然会有好的平台,就像我以前所在国内的几家很有声名的软件公司,其测试平台要不是么是采购的,就要么是自己开发的,但最主要是要适合自己一套适合自身特点的流程平台起了非常积极的作用。在这里也给大家建议一些好的测试平台,比如Mercury Interactive的Test Director,、IBM的TestManager,、Silk的一些缺陷管理平台,这些平台大多都能充分满足测试团队的要求其实都能满足大家的要求。,当然,还有一些免费的开源工具也是可用的。但从长远的角度看,我还是更建议大家读者使用那些不仅仅只是满足缺陷管理的工具,而是要应该选择能集成测试需求,、测试设计,、测试用例,、缺陷管理的工具,最好也能满足自动化的集成的,什么样的产品能满足就不多说了,免得有打广告之嫌J,而商业软件,如MI或IBM的产品在这些方面都有较好的表现。
- 项目特点决定流程的长期目标,但对于不同产品类型的公司,可能出现的问题往往会不一样同。,比如说在金蝶的EAS-BossBOSS,、或是在金山做的游戏软件,、亦或还是在阿里巴巴做电子商务,作为测试管理者,就要具体的问题都应该区别对待。
对于EAS-Boss这样大型的软件产品,团队的规模比较大,核心技术比较稳定。但对于这样的这样的产品有以下一些特点:
- 由于产品比较大,手工测试时重复的工作量特别大;
- 引擎与产品框架比较稳定;
- 编译与发布的流程比较固化;
- 由于团队的规模比较大,接口特别多,集成测试风险特别高;。
这样种产品的测试,主要是把大量的重复频度比较高的功能测试转化为自动化测试角本脚本,在开发过程中要注意,核心引擎与稳定的产品部分,尽可能使用测试框架形成单元测试集,;同时由于编译与发布固化,适合做每日编译, ,自动化的执行单元测试集与自动化的测试角本。在做这种测试流程时,同时还要注意引入强大的分析统计工具,比如代码覆盖与评审工具,内存检查与性能函数分析工具,出错表统计模块,达到发布,、测试执行与评估自动化、一体化。由于进行每日集成,接口的问题可以尽早的暴露出来,避免了后期集成的风险,。
- 这一点每日集成对于大型项目非常重要。同时,由于测试的自动化,大部分的自动化测试角本在空闲的时间运行,测试组可以在进入手工测试时得到比较稳定的版本,及大极大的提升了团队开发与测试的执行效率,。但然而在这样的情况下,缺陷点是整个团队对研发,、测试体系的技术要求特别高,其本上不亚于有时甚至难过做一个大型的项目。这样的测试流程在,在中小团队比较难以实现比较困难,而关键就在于无法降低的成本比较高。下图就是一个稳定项目的测试流程图。

- 游戏软件产品的测试流程又有不同。当你去带领这个测试团队一个游戏团队时,可能游戏核心引擎应该是比较相对稳定的,而游戏内部的故事情节可能会不断的变化,。这时你可把一些更加稳定的程序做成比较稳定的自动化回归测试,同时加强对不断变化的游戏情节的功能测试,同时注意这些功能是不是否会影响到其它相关的模块。同时在因此,游戏测试的过程中还有一些比较有其特殊性,主要表现以下几点:
- 服务器的稳定性,网络流量,与安全是游戏最至关重要的,(往往有很多游戏不是不好玩,而是太不稳定);
- 游戏由于有及时的即时更新,会经常在同时修改缺陷的时候,还在同一模块下增加新功能;
- 好的网络游戏开发,其的功能必然会是迎合玩家的需求(游戏性
分析)。
对于游戏软件产品来说,这些需要特别注意重点控制的点关键,要求测试团队必需要加强以下几个方面,性能测试,代码的融合、相关性影响面的判断、版本的变更与控制,还有游戏性的分析与测试。性能测试主要加强以下几点,则需要注意在并发下服务器的稳定性监控,、网络流量与游戏客户端在大场面下的表现。;而版本控制在游戏软件的过程中,其意义更多——则会避免已经改了的问题重复出现,或是改了更新上去问题还是存在,如何高效的合并代码,、合成游戏资源、图片与角本脚本还是一个比较难度很高的事情,尤其涉及到多个部门。;而游戏性测试主要是避免那种些与游戏风格相背的情况,或是开发团队累死累活拼命完成得功能性任务做出的功能没有可延续性。
- 性能测试与版本控制,在大多数软件的测试流程中都会涉及,但是在不同的软件产品/项目中都有其特点。一般属于通用软件测试流程的部分,但而游戏性测试则需要对游戏感觉很好有比较深刻的了解,并由真正懂懂得的玩家的人来担任,。某些时候,他甚至可以不是一个很好的软件测试人员,但他一定是一个真正懂游戏的人,这里有一些扯远,但这里,本文稍后一节,将我会在后面会强调人的因素也决定了流程的实施。
- 下图是游戏迭代开发模型图

- 如果你去做电子商务,或是做门户,这些项目的适时性,高性能,复杂的功能会给你更高的技术要求,更高强的时间性效率挑战,对测试的设计,、执行,、与性能测试提出更高的要求。其实在大多数互联网公司经常会出现这样的情况:刚出去的功能又撤下来修改,或是性能达不到要求仍需要又要调优。许多一些人都会犯这样一个错,认为测试的时间不够,就只要测试执行,而忽略了其他几个环节就可以了,不做细致的分析与设计,为后续工作带来很大压力。其实,一个充分测试过的有质量保证的产品,可以减轻客服,、市场,、等各方面很多的压力。产品在用户和研发之间,反复,几次不如晚一些上提供给用户。从另外一方面看,这还需要测试主管能顶住某些压力。时间紧迫当然这不是理由,如何在流程上保证测试的需求分析,、用例的设计与研发在开发时同步进行是最重要的,这时你要加强早期的测试介入,明确卡住需求确认这一部分,。这样,在研发进入开发阶段时,测试团队也能进入测试设计,。当研发开发完成时,你测试团队事实上已经其本基本上完成了大部分的测试设计,并准备进入测试执行,。不要在开发提交后再去想如何测测试,抱怨之声也就不绝于耳了。这样才可能测试好一个时间比较紧的项目不管在用于测试的时间上,还是测试的质量上都无法满足要求。
- ,同时测试设计的很好,不仅可以节约测试执行的时间,也可以在反复提交的过程中,由于用例执行的一致性,保证了测试在多次的执行中的质量,;。同时也有发布的标准,一是缺陷的情况,二是用例的执行与覆盖。同时由于研发给的测试时间比较紧,所以有两件事情就必需作做好,:一是明确产品提交测试时间,并在研发延迟时给自己争取时间;二是在质量达不到要求的情况下,时间及时的做出反应,不要到最后在研发不了解项目质量的情况下建议研发延迟项目。为了达到上面的要求你必需要一个很好的测试平台,把设计,测试用例管理,执行与用例的联动,缺陷管理与报表统计打通,尽可能的利用平台解决事务性工作,降低流程执行的成本,。也就是说,既让测试人员可以集中精力去测试,同时又能够让研发管理人员随时获取正在进行测试的进度与质量,。当这些工作做到透明化时以后,就算让研发延迟发布,研发部门也会接收接受,。下图是这一阶段的大致流程

- 在这里可以跟大家说一下,我就曾经在产品发布权限不在测试这里部门的情况下,成功的让研发决定推迟发布了大约一半以上的项目,。大多数的测试部门主管,很难顶住来自项目/技术经理的压力是有理由的,因为他们根本不了解你做了哪些工作。有时候一些情况下,看似不可能的事情任务要想做成完成,关键要看在于事情的技巧,。流程表示了只是一个大方向的东西,而且,你永远也无法将责任推卸给流程也许是对的,更多情况下,作为测试主管,需要但将做事的方法与风格可以影响到推广到测试流程的推广中。
- 在测试互联网项目时,还有一个更重要的就是如何保证性能,。
- 也许大家会说不就是性能测试并不是单独存在的。其实不是完全正确,如果有充足的优秀高手人力资源做性能测试当然很好,但性能测试也不能完全保证所有的项目完全没有性能问题都完美无缺,因此,项目投入期间,同时性能测试是一个这个费时费力的工作,所以往往都是一般在资源不足的情况下开展的。作为测试主管,更应该,要学会判断那些相对更加重要的问题项目影响面会更广,需要集中做性能测试。这时你也许会问,那么会有人问其它相对不太重要的项目与问题怎么办,?其实做过性能调优的人都知道,大部分的性能问题都是由于一两个弱智的SQL语句导致的,所以可以从流程上加强对SQL查询语句在I/O问题的跟踪与评审,,从而避免大部分性能问题。
- 上面分析了不同公司根据上文的分析,不同类型的产品在测试流程上的是有很大差异的。这时,也许大家你也许可以把握测试流程大的方向了,但真正是否适合现有的测试团队与研发团队,则仍需要精心的调整,。当我遇到问题的时候,第一时间往往有时候不是去寻找流程不对的问题,而是通过现有资源与执行的方法可能需要着手来微调一下你的测试流程,直到发现问题的所在,并纪录下来,最后整合到原来设定的流程中。
- 这样的情况大概常常发生:比如说在需求上的处理,可能会有很多的测试人员会经常指责需求人员撰写的文档非常粗糙不详细,无法进行测试,。好像在我的记忆中,需求人员常常就是被骂的得灰头土脸,但是经过这些年在测试岗位上的工作,我才渐渐发现,其实有时候需求人员更需要鼓励鼓励是比职责更加有效的工作方式。这可能是一个放之四海皆准的工作态度。,指责只能加深对立,。其实在验收需求时,由于当时大家也只是知道一个大概我们的需求人员也只能从大致上把握核了解,可能大多数情况下是:原则上没有问题就通过了,。但然而,这种不负责任的态度却是给我们在做的测试工作带来相当多的麻烦。也只有在这样的时候,这些问题才能真正暴露出来,从而使测试设计时就会发现很多问题并没有写清楚,。一般情况下,很多测试人员这时就多半会放弃手边的工作,并消极地认为认为无法做工作无法继续下去。,等东西出来,并将问题最终归结到是需求给的不详细,而大加指责。
- 从我对测试主管工作的记事以来,就在印象中保留了这样的一幕。记的刚进一家公司时,我团队中的人员就开始经常会有下属跟我说抱怨,公司的需求工程师让我们太失望了。需求如何如何不好,然而,多少有些经验的我,当时我是把几家国内我服务过的顶尖公司情况作了一个简单的对比,的需求跟公司的需求人员的需求做了比较这时才发现,发现,原来我们公司的需求人员还是做的得不错的,。让测试人员把心态调整过来是测试主管的另外一件事。试问,,如果是你做需求作为需求工程师,是否会比他们做的好吗得更好??有了这样的基调,就可以让然后建议测试人员去总结不清楚的地方,给需求人员一个相对比较具体和明确的意见,这样顺利的了解了需求。
- 其实有时候不是流程不对流程在这其中并没有太多值得指责的地方,而是相互的理解与支持,换位思考而对流程的执行态度,却是更加关键的。我们不得不学会如何换位思考,并更多地从他人的角度来看待这些问题。
- 同样的问题还出现在还有需求变更上,很多测试人过不了这一关,。总是他们指责研发人员,让研发那些本来就已经恼火的软件工程师更加火冒三丈。换位思考一番,其实不难了解,,其实需求变更对研发工程师来说是更大的麻烦,。他们需要修改设计,、代码,相较而测试只要需改测试用例,他们的工作确实更加麻烦。简单来说,就ok了,其实大家要分析什么样的需求变更最可怕,而不是眉毛胡子一把抓,其实测试对需求变更并不可怕,怕的是只有在提交时才发现,导致测试时间不够,才会真正让测试人员心慌。这时需要从研发流程上保证变更及时的通知到测试就可以了行,。也许有人会说你也需要说:,说的倒很容易,如果研发不按照你的要求做怎么办!其实这里你只要用我所采用的方法是用数据说话,在项目进行时统计发生过多少次这样的事情,让研发管理层知道,让项目组之间有一个比较,。一方面,如果是一家公司重视质量的公司,必然会引起重视;另一方面,从质量管理部门角度本身出发,也应该推动公司重视质量。,随着时间的增加,需求变更给测试人员的反馈一定会有下降的趋势,。关键是测试不能抓住鸡毛就一直揪着不放宽容一些来看待身边的同事,要允许别人他们犯错,对于解决问题本身来说会大有裨益。只要趋势是好的就可以了。同时如果出现这样的情况并且极大影响到了测试进度,则要与研发部门沟通清楚,,如果研发不认可的情况下还可以请上级进行评估一下。
- 上面说的是不同态度在同样流程下的实现不同结果,下面主要讲一下关于自身资源是否胜任做流程上规定的事情,某些工作,也许并不一定是测试部门的优势,而另外一些,则需要根据测试团队的基本能力和资源进行评估。比如像性能测试、SQL的trace、自动化功能测试、单元测试集成、游戏性测试。其实这些流程上的关键点,可能大多数从功能测试上来一路走来的测试人员是无法做的到,这时要善于利用资源,不一定要测试做,可以从通过流程上保正有人来做积极调动其它部门的同事。,或是找有能力的人来做,测试可以进行监控。其实这种技术含量高一点的测试,对人的因素要求更大高,可以借助研发团队一起来做会有更好的效果,。记的第一次做Oracle数据库性能监控时,就是请的Oracle的DBA专家帮助设计了性能参数,成功的地进行了关于Oracle应用的性能测试。现在国内的测试人员普遍的技术水平不高,严重的v如果你对开发很精通,、同时又精通对测试颇有研究,、善于诊断性能与架构上的问题,、经常会帮助研发部门解决一些他们无法解决的事情,、同时又还懂的如何做测试管理,并了解研发人员的心态,那就真得的找不出你还有不成功的理由了任何理由让人不对你刮目相看了。
-
【转】如何写好测试报告
2010-01-22 10:29:32
作者:蒲冬梅 文章来源:CSDN
最近读Cem Kaner,James Bach,Bret Pettichord合著的《软件测试经验与教训》受益颇多,因此根据文中的部份内容总结出来与大家共享,希望能达到知识交流与共享的目的。如果感兴趣,也可以阅读原书。
测试报告是产品部与技术部进行沟通的主要手段,测试报告的好坏直接影响BUG的修改速度和程序员的心情。如果下苦功夫研究并写好报告,则所有阅读这些报告的人都会受益。因此我整理并撰写此文,希望对于能修直产品部与技术部的桥梁有所帮助。
一、 缺陷报告的原则
1、 有些错误永远也不会改正。测试员的责任不是保证所有错误都得到改正,而是准确报告问题,使程序员能够理解问题的影响。而深入研究并写出好的报告,常常对错误改正的可能性产生巨大的影响。
2、 及时报告缺陷。不要等到第二天或是下周才报告程序错误,不要等到忘记了一些关键细节才报告。拖延的时间越长,程序错误被解决的可能性就越小。
3、 每个程序错误都需要单独报告。不要努力把不同的程序错误合并到同一份报告,来减轻项目经理或程序员对重复错误报告的不断抱怨。如果多个程序错误写到一份报告中,有些错误就可能得不到修改。
4、 小缺陷也值得报告。小错误会使客户感到困惑,并降低客户对产品其他部份的信心。被认为是很小的缺陷可能包括拼写错误、小的屏幕格式问题,鼠标遗迹、小的计算错误,图形比例不准、在线帮助错误、不适当的灰掉了的菜单选项、不起作用的快捷键、不正确的错误信息,以及其它程序员认为不值得花精力去修改的缺陷。
5、 努力使错误报告有更高的价值。由于有很多人都要阅读并依赖错误报告,因此要下功夫丰富每个错误报告的信息。提高报告的可理解性。如:A、清楚列出错误报告的前置条件与实现的每一个步骤,避免前后语言混乱,它应该只需要描述现象,不要在产生错误的步骤中试图给出程序员的解决办法。这样会使错误报告看来冗长而难于理解。如果有好的解决办法或建议可以附在错误报告描述之后。B、要始终保持中立语气。C、不要开玩笑,否则有可能造成误解。
6、 永远都要报告不可重现的错误,这样的错误可能是时间炸弹。不可重现的错误可能会是公司能够支付的最昂贵的缺陷。有时错误无法重现。看到程序错误一次,但不知道如何使其再次出现。如果产品交付客户还出现这种情况,会影响客户对产品的信心,如果技术支持人员需要很长时间评估客户的数据或环境,客户则会更加厌烦。如果测试员清晰地报告错误征兆,程序员通过研究测试员怎么得到特定消息,或当测试员查看对话框或点击特定控件时可能会出现的情况。从而能够跟踪代码,相信程序员能够改正报告中“不可重现”缺陷中的20%。但在报告此类BUG时,一定要明确说明自己不能重现这个程序错误。
二、 缺陷报告的注意事项
1、 引用别人的错误报告要小心。如果没有得到错误报告的提交者的允许,可以补充评论,但不能编辑别人的材料。对于其他测试员的错误报告即使很糟糕也不要擅自修改。任何时候需要在错误报告中做补充,都要注明自己的姓名和日期。
2、 看似极端的缺陷可能是潜在的安全漏洞。如在一个在预期接受一个1~99的字段中,输入65536个9会导致程序崩溃。会有人真的这么干吗?是的,有人当然要这样做。有人会认为“如果有人愚蠢到这样做,程序崩溃会教训他“而忽略该错误,但实际上白痴不是惟一滥用程序的人。任何会产生严重后果的问题都应该解决,不管其多么“不可能”发生,当熟练的攻击者利用程序中的缺陷得手后,会写下这个消息并广为传播,使得其所有生手都可以使用脚本。
3、 立即对程序错误延迟决定上诉,如果决定据理力争,就一定要赢。如果测试员对某个BUG的处理有意见,确实需要上诉,不要依赖自己最初错误报告中的语言和信息,报告是不可更改的,但是测试员需要列举更有效的例子,测试员需要与其他产品项目相关人员沟通,补充做一些后续测试,寻找该程序错误可能存在的更严重的错误。程序员所做的每个上诉都必须是有说服力的。即使不能赢得所有上诉(当然不可能赢得所有上诉)也应该得到自己的所有上诉理应获胜的好名声。
至此,上面罗列的条款都与我们实际工作有着密切的关联,希望能借助此篇文章,让你能有兴趣读完本书的全部内容,相信一定能让你获益匪浅。
回复:如何写好测试报告 曾盛开(技术部)
我看完了,总是觉得程序员和测试员之间在问题分歧上存在很多不同之处,其中包括个人专业知识的深度,对软件理解的能力,对业务、程序的理解能力,产品开发成本、周期与bug之间的协调。
诸多方面加起来,使我的脾气在沟通协调bug问题上变得很容易激昂,或者说发火,头脑发热。程序员多少都有些自大,不甘屈服的情绪,而且确实很多东西由于变得和以前写好、定好的需求有出入,导致做好的东西可能又被推翻。。。心里那种滋味很不好受的。。。毕竟每个地方和环节都是自己努力去想过的,有时候一个问题可能是花去几天时间确保那样做没有漏洞和正确。
我感觉到两个部门之间协调缺少更多互动,比如产品部在测试之前或者有空时候可以培训一下技术部,一般会测试哪些东西,如何测试的,这样子程序员心里多少有更多的底,在写程序的时候会有一种警惕性,从而产品部也会轻松一些,双方有利,应该是三方有利,公司最有利。。产品部也要考虑如何帮助程序员快速有利地处理bug,而不是一味为了bug而找bug,这根本背离了两个部门合作的基调;技术部也同样有责任去帮助产品部理解好系统运行的流程,找出隐藏的bug 。
另外,我想说的是在文档细节上面不要过分苛求,否则一方面是开发进度和成本,另一方面是使Xp轻量级文档开发流程又变成重量级文档开发,程序员为了文档忙于疲命。。我深有体会的,文档花去的时间几乎占用了1/4-1/3。
我觉得在测试的同事面前谈测试,有些班门弄斧,关公卖刀,但有些话不得不说,那就开诚布公拿出来,就算贻笑大方也好吧~~~
回复:回复:如何写好测试报告 李鹏
文档花去的时间几乎占用了1/4-1/3:这个时间我不觉得多,我觉得不够。花在需求定义,开发文档方面的时间应该是1/2以上
我觉得XP编程不适合我们,理由有三:
1、我们的8.0项目跨度有近2年,可以说是个中型项目,xp编程比较适合小项目(2-3个月)。
2、xp编程理论中基本上没有提到如何对程序进行系统的测试,而我们公司非常重视软件测试,程序员和测试员的比例近1:1。
3、xp中对文档的定义是“够用就好”,而在众多的工程理论(rup、cmm)中都建议要有详尽得需求和开发文档。花在需求定义,开发文档方面的时间应该是1/2以上。回复:回复:如何写好测试报告 黄为东
技术部和产品部的斗争性,有它的积极作用,但确实存在两个部门目标不一致性的问题,既存在内部损耗,又存在被共同忽视的中间地带。
大胆设想一下,假设把技术部和产品部合并为一个大部,每个小组都配2个测试员,是否会更好呢?这样测试人员对本组开发人员的配合密切程度也许会更高。问题是,测试的专业性、分工性是否会下降?
该怎么组织,是一个大问题。回复:回复:如何写好测试报告 蒲冬梅
产品只有足够人性化,用户才会乐意使用此功能,而不是买回去就将其束之高阁。文档只有足够详细化,才能为产品部测试提供准确的依据。因此就需要产品部与技术部能够有更多沟通,更充分的文档准备,更大的耐心。
因为最终目标我们只有一个,做出来的产品要对得起用户。因此我们需要彼此体谅,理解与尊重。
如果技术部有时间或是计划能够安排接受产品部的测试培训,我想我们部门每个同事都会举双手双脚赞成的。这样应该能减少很大部份测试的工作量。
关于为了找BUG而找BUG的说法,我觉得是很有必要就此申明一两句的。现在产品部最终提交到技术部的BUG都是有人负责审核的(BUG的定位是否准确,BUG的描述是否清晰等)。由于BUG的数量,这项工作其实是相当费时与费力的,因此曾停过一段的时间,但是为了提高BUG的质量和减少为了BUG而需要与产品部沟通的时间,这部份工作我们依然坚持在做。但是难免会有部份BUG在产品部进行准确定位是很困难的,而如果改为由技术部来定位则仅仅只是几分钟的事情,因此我们并未严格控制每个BUG都会精确定位,但是我们的目标是尽可能减少技术部为了BUG的描述或定位而进行多次反复的沟通。
因此就BUG本身的问题,也欢迎技术部能多多提意见,我们一定坚绝改正。
-
【sql】总结sql数据库性能优化相关的注意事项
2010-01-22 10:08:55
近期因工作需要,希望比较全面的总结下SQL SERVER数据库性能优化相关的注意事项,在网上搜索了一下,发现很多文章,有的都列出了上百条,但是仔细看发现,有很多似是而非或者过时(可能对SQL SERVER6.5以前的版本或者ORACLE是适用的)的信息,只好自己根据以前的经验和测试结果进行总结了。我始终认为,一个系统的性能的提高,不单单是试运行或者维护阶段的性能调优的任务,也不单单是开发阶段的事情,而是在整个软件生命周期都需要注意,进行有效工作才能达到的。所以我希望按照软件生命周期的不同阶段来总结数据库性能优化相关的注意事项。
一、分析阶段
一般来说,在系统分析阶段往往有太多需要关注的地方,系统各种功能性、可用性、可靠性、安全性需求往往吸引了我们大部分的注意力,但是,我们必须注意,性能是很重要的非功能性需求,必须根据系统的特点确定其实时性需求、响应时间的需求、硬件的配置等。最好能有各种需求的量化的指标。
另一方面,在分析阶段应该根据各种需求区分出系统的类型,大的方面,区分是OLTP(联机事务处理系统)和OLAP(联机分析处理系统)。
二、设计阶段
设计阶段可以说是以后系统性能的关键阶段,在这个阶段,有一个关系到以后几乎所有性能调优的过程—数据库设计。
在数据库设计完成后,可以进行初步的索引设计,好的索引设计可以指导编码阶段写出高效率的代码,为整个系统的性能打下良好的基础。
以下是性能要求设计阶段需要注意的:
1、 数据库逻辑设计的规范化
数据库逻辑设计的规范化就是我们一般所说的范式,我们可以这样来简单理解范式:
第1规范:没有重复的组或多值的列,这是数据库设计的最低要求。
第2规范: 每个非关键字段必须依赖于主关键字,不能依赖于一个组合式主关键字的某些组成部分。消除部分依赖,大部分情况下,数据库设计都应该达到第二范式。
第3规范: 一个非关键字段不能依赖于另一个非关键字段。消除传递依赖,达到第三范式应该是系统中大部分表的要求,除非一些特殊作用的表。
更高的范式要求这里就不再作介绍了,个人认为,如果全部达到第二范式,大部分达到第三范式,系统会产生较少的列和较多的表,因而减少了数据冗余,也利于性能的提高。
2、 合理的冗余
完全按照规范化设计的系统几乎是不可能的,除非系统特别的小,在规范化设计后,有计划地加入冗余是必要的。
冗余可以是冗余数据库、冗余表或者冗余字段,不同粒度的冗余可以起到不同的作用。
冗余可以是为了编程方便而增加,也可以是为了性能的提高而增加。从性能角度来说,冗余数据库可以分散数据库压力,冗余表可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
3、 主键的设计
主键是必要的,SQL SERVER的主键同时是一个唯一索引,而且在实际应用中,我们往往选择最小的键组合作为主键,所以主键往往适合作为表的聚集索引。聚集索引对查询的影响是比较大的,这个在下面索引的叙述。
在有多个键的表,主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。
主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前面。
4、 外键的设计
外键作为数据库对象,很多人认为麻烦而不用,实际上,外键在大部分情况下是很有用的,理由是:
外键是最高效的一致性维护方法,数据库的一致性要求,依次可以用外键、CHECK约束、规则约束、触发器、客户端程序,一般认为,离数据越近的方法效率越高。
谨慎使用级联删除和级联更新,级联删除和级联更新作为SQL SERVER 2000当年的新功能,在2005作了保留,应该有其可用之处。我这里说的谨慎,是因为级联删除和级联更新有些突破了传统的关于外键的定义,功能有点太过强大,使用前必须确定自己已经把握好其功能范围,否则,级联删除和级联更新可能让你的数据莫名其妙的被修改或者丢失。从性能看级联删除和级联更新是比其他方法更高效的方法。
5、 字段的设计
字段是数据库最基本的单位,其设计对性能的影响是很大的。需要注意如下:
A、数据类型尽量用数字型,数字型的比较比字符型的快很多。
B、 数据类型尽量小,这里的尽量小是指在满足可以预见的未来需求的前提下的。
C、 尽量不要允许NULL,除非必要,可以用NOT NULL+DEFAULT代替。
D、少用TEXT和IMAGE,二进制字段的读写是比较慢的,而且,读取的方法也不多,大部分情况下最好不用。
E、 自增字段要慎用,不利于数据迁移。
6、 数据库物理存储和环境的设计
在设计阶段,可以对数据库的物理存储、操作系统环境、网络环境进行必要的设计,使得我们的系统在将来能适应比较多的用户并发和比较大的数据量。
这里需要注意文件组的作用,适用文件组可以有效把I/O操作分散到不同的物理硬盘,提高并发能力。
7、 系统设计
整个系统的设计特别是系统结构设计对性能是有很大影响的,对于一般的OLTP系统,可以选择C/S结构、三层的C/S结构等,不同的系统结构其性能的关键也有所不同。
系统设计阶段应该归纳一些业务逻辑放在数据库编程实现,数据库编程包括数据库存储过程、触发器和函数。用数据库编程实现业务逻辑的好处是减少网络流量并可更充分利用数据库的预编译和缓存功能。
8、 索引的设计
在设计阶段,可以根据功能和性能的需求进行初步的索引设计,这里需要根据预计的数据量和查询来设计索引,可能与将来实际使用的时候会有所区别。
关于索引的选择,应改主意:
A、根据数据量决定哪些表需要增加索引,数据量小的可以只有主键。
B、根据使用频率决定哪些字段需要建立索引,选择经常作为连接条件、筛选条件、聚合查询、排序的字段作为索引的候选字段。
C、把经常一起出现的字段组合在一起,组成组合索引,组合索引的字段顺序与主键一样,也需要把最常用的字段放在前面,把重复率低的字段放在前面。
D、一个表不要加太多索引,因为索引影响插入和更新的速度。
三、编码阶段
编码阶段是本文的重点,因为在设计确定的情况下,编码的质量几乎决定了整个系统的质量。
编码阶段首先是需要所有程序员有性能意识,也就是在实现功能同时有考虑性能的思想,数据库是能进行集合运算的工具,我们应该尽量的利用这个工具,所谓集合运算实际是批量运算,就是尽量减少在客户端进行大数据量的循环操作,而用SQL语句或者存储过程代替。关于思想和意识,很难说得很清楚,需要在编程过程中来体会。
下面罗列一些编程阶段需要注意的事项:
1、 只返回需要的数据
返回数据到客户端至少需要数据库提取数据、网络传输数据、客户端接收数据以及客户端处理数据等环节,如果返回不需要的数据,就会增加服务器、网络和客户端的无效劳动,其害处是显而易见的,避免这类事件需要注意:
A、横向来看,不要写SELECT *的语句,而是选择你需要的字段。
B、纵向来看,合理写WHERE子句,不要写没有WHERE的SQL语句。
C、 注意SELECT INTO后的WHERE子句,因为SELECT INTO把数据插入到临时表,这个过程会锁定一些系统表,如果这个WHERE子句返回的数据过多或者速度太慢,会造成系统表长期锁定,诸塞其他进程。
D、对于聚合查询,可以用HAVING子句进一步限定返回的行。
2、尽量少做重复的工作
这一点和上一点的目的是一样的,就是尽量减少无效工作,但是这一点的侧重点在客户端程序,需要注意的如下:
A、控制同一语句的多次执行,特别是一些基础数据的多次执行是很多程序员很少注意的。
B、减少多次的数据转换,也许需要数据转换是设计的问题,但是减少次数是程序员可以做到的。
C、杜绝不必要的子查询和连接表,子查询在执行计划一般解释成外连接,多余的连接表带来额外的开销。
D、合并对同一表同一条件的多次UPDATE,比如
1. UPDATE EMPLOYEE SET FNAME=’HAIWER’ WHERE EMP_ID=’ VPA30890F’
2. UPDATE EMPLOYEE SET LNAME=’YANG’ WHERE EMP_ID=’ VPA30890F’
这两个语句应该合并成以下一个语句
1. UPDATE EMPLOYEE SET FNAME=’HAIWER’,LNAME=’YANG’
2. WHERE EMP_ID=’ VPA30890F’
E、 UPDATE操作不要拆成DELETE操作+INSERT操作的形式,虽然功能相同,但是性能差别是很大的。
F、 不要写一些没有意义的查询,比如
SELECT * FROM EMPLOYEE WHERE 1=2
3、 注意事务和锁
事务是数据库应用中和重要的工具,它有原子性、一致性、隔离性、持久性这四个属性,很多操作我们都需要利用事务来保证数据的正确性。在使用事务中我们需要做到尽量避免死锁、尽量减少阻塞。具体以下方面需要特别注意:
A、事务操作过程要尽量小,能拆分的事务要拆分开来。
B、 事务操作过程不应该有交互,因为交互等待的时候,事务并未结束,可能锁定了很多资源。
C、 事务操作过程要按同一顺序访问对象。
D、提高事务中每个语句的效率,利用索引和其他方法提高每个语句的效率可以有效地减少整个事务的执行时间。
E、 尽量不要指定锁类型和索引,SQL SERVER允许我们自己指定语句使用的锁类型和索引,但是一般情况下,SQL SERVER优化器选择的锁类型和索引是在当前数据量和查询条件下是最优的,我们指定的可能只是在目前情况下更有,但是数据量和数据分布在将来是会变化的。
F、 查询时可以用较低的隔离级别,特别是报表查询的时候,可以选择最低的隔离级别(未提交读)。
4、 注意临时表和表变量的用法
在复杂系统中,临时表和表变量很难避免,关于临时表和表变量的用法,需要注意:
A、如果语句很复杂,连接太多,可以考虑用临时表和表变量分步完成。
B、 如果需要多次用到一个大表的同一部分数据,考虑用临时表和表变量暂存这部分数据。
C、 如果需要综合多个表的数据,形成一个结果,可以考虑用临时表和表变量分步汇总这多个表的数据。
D、其他情况下,应该控制临时表和表变量的使用。
E、 关于临时表和表变量的选择,很多说法是表变量在内存,速度快,应该首选表变量,但是在实际使用中发现,这个选择主要考虑需要放在临时表的数据量,在数据量较多的情况下,临时表的速度反而更快。
F、 关于临时表产生使用SELECT INTO和CREATE TABLE + INSERT INTO的选择,我们做过测试,一般情况下,SELECT INTO会比CREATE TABLE + INSERT INTO的方法快很多,但是SELECT INTO会锁定TEMPDB的系统表SYSOBJECTS、SYSINDEXES、SYSCOLUMNS,在多用户并发环境下,容易阻塞其他进程,所以我的建议是,在并发系统中,尽量使用CREATE TABLE + INSERT INTO,而大数据量的单个语句使用中,使用SELECT INTO。
G、 注意排序规则,用CREATE TABLE建立的临时表,如果不指定字段的排序规则,会选择TEMPDB的默认排序规则,而不是当前数据库的排序规则。如果当前数据库的排序规则和TEMPDB的排序规则不同,连接的时候就会出现排序规则的冲突错误。一般可以在CREATE TABLE建立临时表时指定字段的排序规则为DATABASE_DEFAULT来避免上述问题。
5、 子查询的用法
子查询是一个 SELECT 查询,它嵌套在 SELECT、INSERT、UPDATE、DELETE 语句或其它子查询中。任何允许使用表达式的地方都可以使用子查询。
子查询可以使我们的编程灵活多样,可以用来实现一些特殊的功能。但是在性能上,往往一个不合适的子查询用法会形成一个性能瓶颈。
如果子查询的条件中使用了其外层的表的字段,这种子查询就叫作相关子查询。相关子查询可以用IN、NOT IN、EXISTS、NOT EXISTS引入。
关于相关子查询,应该注意:
A、NOT IN、NOT EXISTS的相关子查询可以改用LEFT JOIN代替写法。比如:
1. SELECT PUB_NAME
2. FROM PUBLISHERS
3. WHERE PUB_ID NOT IN
4. (SELECT PUB_ID
5. FROM TITLES
6. WHERE TYPE = 'BUSINESS')
可以改写成:
1. SELECT A.PUB_NAME
2. FROM PUBLISHERS A LEFT JOIN TITLES B
3. ON B.TYPE = 'BUSINESS' AND
4. A.PUB_ID=B. PUB_ID
5. WHERE B.PUB_ID IS NULL
1. SELECT TITLE
2. FROM TITLES
3. WHERE NOT EXISTS
4. (SELECT TITLE_ID
5. FROM SALES
6. WHERE TITLE_ID = TITLES.TITLE_ID)
可以改写成:
1. SELECT TITLE
2. FROM TITLES LEFT JOIN SALES
3. ON SALES.TITLE_ID = TITLES.TITLE_ID
4. WHERE SALES.TITLE_ID IS NULL
B、 如果保证子查询没有重复 ,IN、EXISTS的相关子查询可以用INNER JOIN 代替。比如:
1. SELECT PUB_NAME
2. FROM PUBLISHERS
3. WHERE PUB_ID IN
4. (SELECT PUB_ID
5. FROM TITLES
6. WHERE TYPE = 'BUSINESS')
可以改写成:
1. SELECT DISTINCT A.PUB_NAME
2. FROM PUBLISHERS A INNER JOIN TITLES B
3. ON B.TYPE = 'BUSINESS' AND
4. A.PUB_ID=B. PUB_ID
C、 IN的相关子查询用EXISTS代替,比如
1. SELECT PUB_NAME
2. FROM PUBLISHERS
3. WHERE PUB_ID IN
4. (SELECT PUB_ID
5. FROM TITLES
6. WHERE TYPE = 'BUSINESS')
可以用下面语句代替:
1. SELECT PUB_NAME
2. FROM PUBLISHERS
3. WHERE EXISTS
4. (SELECT 1
5. FROM TITLES
6. WHERE TYPE = 'BUSINESS' AND
7. PUB_ID= PUBLISHERS.PUB_ID)
D、不要用COUNT(*)的子查询判断是否存在记录,最好用LEFT JOIN或者EXISTS,比如有人写这样的语句:
1. SELECT JOB_DESC FROM JOBS
2. WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)=0
应该改成:
1. SELECT JOBS.JOB_DESC FROM JOBS LEFT JOIN EMPLOYEE
2. ON EMPLOYEE.JOB_ID=JOBS.JOB_ID
3. WHERE EMPLOYEE.EMP_ID IS NULL
1. SELECT JOB_DESC FROM JOBS
2. WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)<>0
应该改成:
1. SELECT JOB_DESC FROM JOBS
2. WHERE EXISTS (SELECT 1 FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)
6、 慎用游标
数据库一般的操作是集合操作,也就是对由WHERE子句和选择列确定的结果集作集合操作,游标是提供的一个非集合操作的途径。一般情况下,游标实现的功能往往相当于客户端的一个循环实现的功能,所以,大部分情况下,我们把游标功能搬到客户端。
游标是把结果集放在服务器内存,并通过循环一条一条处理记录,对数据库资源(特别是内存和锁资源)的消耗是非常大的,所以,我们应该只有在没有其他方法的情况下才使用游标。
另外,我们可以用SQL SERVER的一些特性来代替游标,达到提高速度的目的。
A、字符串连接的例子
这是论坛经常有的例子,就是把一个表符合条件的记录的某个字符串字段连接成一个变量。比如需要把JOB_ID=10的EMPLOYEE的FNAME连接在一起,用逗号连接,可能最容易想到的是用游标:
3. DECLARENAME_CURSORCURSORFOR
4. SELECTFNAMEFROMEMPLOYEEWHEREJOB_ID=10ORDERBYEMP_ID
5. OPENNAME_CURSOR
6. FETCHNEXTFROMRNAME_CURSORINTO@NAME
8. BEGIN
9. SET@NAMES=ISNULL(@NAMES+’,’,’’)+@NAME
10. FETCHNEXTFROMNAME_CURSORINTO@NAME
11. END
12. CLOSENAME_CURSOR
13. DEALLOCATENAME_CURSOR
可以如下修改,功能相同:
1. DECLARE @NAME VARCHAR(1000)
2. SELECT @NAMES = ISNULL(@NAMES+’,’,’’)+FNAME
3. FROM EMPLOYEE WHERE JOB_ID=10 ORDER BY EMP_ID
B、 用CASE WHEN 实现转换的例子
很多使用游标的原因是因为有些处理需要根据记录的各种情况需要作不同的处理,实际上这种情况,我们可以用CASE WHEN语句进行必要的判断处理,而且CASE WHEN是可以嵌套的。比如:
表结构:
1. CREATE TABLE 料件表(
2. 料号 VARCHAR(30),
3. 名称 VARCHAR(100),
4. 主单位 VARCHAR(20),
5. 单位1 VARCHAR(20),
6. 单位1参数 NUMERIC(18,4),
7. 单位2 VARCHAR(20),
8. 单位2参数 NUMERIC(18,4)
9. )
10.
11. GO
12.
13. CREATE TABLE 入库表(
14. 时间 DATETIME,
15. 料号 VARCHAR(30),
16. 单位 INT,
17. 入库数量 NUMERIC(18,4),
18. 损坏数量 NUMERIC(18,4)
19. )
20.
21. GO
其中,单位字段可以是0,1,2,分别代表主单位、单位1、单位2,很多计算需要统一单位,统一单位可以用游标实现:
1. DECLARE @料号 VARCHAR(30),
2. @单位 INT,
3. @参数 NUMERIC(18,4),
4.
5. DECLARE CUR CURSOR FOR
6. SELECT 料号,单位 FROM 入库表 WHERE 单位 <>0
7. OPEN CUR
8. FETCH NEXT FROM CUR INTO @料号,@单位
9. WHILE @@FETCH_STATUS<>-1
10. BEGIN
11. IF @单位=1
12. BEGIN
13. SET @参数=(SELECT 单位1参数 FROM 料件表 WHERE 料号 =@料号)
14. UPDATE 入库表 SET 数量=数量*@参数,损坏数量=损坏数量*@参数,单位=1 WHERE CURRENT OF CUR
15. END
16. IF @单位=2
17. BEGIN
18. SET @参数=(SELECT 单位1参数 FROM 料件表 WHERE 料号 =@料号)
19. UPDATE 入库表 SET 数量=数量*@参数,损坏数量=损坏数量*@参数,单位=1 WHERE CURRENT OF CUR
20. END
21. FETCH NEXT FROM CUR INTO @料号,@单位
22. END
23. CLOSE CUR
24. DEALLOCATE CUR
可以改写成:
1. UPDATE A SET
2. 数量=CASE A.单位 WHEN 1 THEN A.数量*B. 单位1参数
3. WHEN 2 THEN A.数量*B. 单位2参数
4. ELSE A.数量
5. END,
6. 损坏数量= CASE A.单位 WHEN 1 THEN A. 损坏数量*B. 单位1参数
7. WHEN 2 THEN A. 损坏数量*B. 单位2参数
8. ELSE A. 损坏数量
9. END,
10. 单位=1
11. FROM入库表 A, 料件表 B
12. WHERE A.单位<>1 AND
13. A.料号=B.料号
C、 变量参与的UPDATE语句的例子
SQL ERVER的语句比较灵活,变量参与的UPDATE语句可以实现一些游标一样的功能,比如:
在
1. SELECT A,B,C,CAST(NULL AS INT) AS 序号
2. INTO #T
3. FROM 表
4. ORDER BY A ,NEWID()
产生临时表后,已经按照A字段排序,但是在A相同的情况下是乱序的,这时如果需要更改序号字段为按照A字段分组的记录序号,就只有游标和变量参与的UPDATE语句可以实现了,这个变量参与的UPDATE语句如下:
1. DECLARE @A INT
2. DECLARE @序号 INT
3. UPDATE #T SET
4. @序号=CASE WHEN A=@A THEN @序号+1 ELSE 1 END,
5. @A=A,
6. 序号=@序号
D、如果必须使用游标,注意选择游标的类型,如果只是循环取数据,那就应该用只进游标(选项FAST_FORWARD),一般只需要静态游标(选项STATIC)。
E、 注意动态游标的不确定性,动态游标查询的记录集数据如果被修改,会自动刷新游标,这样使得动态游标有了不确定性,因为在多用户环境下,如果其他进程或者本身更改了纪录,就可能刷新游标的记录集。
7、 尽量使用索引
建立索引后,并不是每个查询都会使用索引,在使用索引的情况下,索引的使用效率也会有很大的差别。只要我们在查询语句中没有强制指定索引,索引的选择和使用方法是SQLSERVER的优化器自动作的选择,而它选择的根据是查询语句的条件以及相关表的统计信息,这就要求我们在写SQL语句的时候尽量使得优化器可以使用索引。
为了使得优化器能高效使用索引,写语句的时候应该注意:
A、不要对索引字段进行运算,而要想办法做变换,比如
SELECT ID FROM T WHERE NUM/2=100
应改为:
SELECT ID FROM T WHERE NUM=100*2
SELECT ID FROM T WHERE NUM/2=NUM1
如果NUM有索引应改为:
SELECT ID FROM T WHERE NUM=NUM1*2
如果NUM1有索引则不应该改。
发现过这样的语句:
1. SELECT 年,月,金额 FROM 结余表
2. WHERE 100*年+月=2007*100+10
应该改为:
1. SELECT 年,月,金额 FROM 结余表
2. WHERE 年=2007 AND
3. 月=10
B、 不要对索引字段进行格式转换
日期字段的例子:
WHERE CONVERT(VARCHAR(10), 日期字段,120)=’2008-08-15’
应该改为
WHERE日期字段〉=’2008-08-15’ AND 日期字段<’2008-08-16’
ISNULL转换的例子:
WHERE ISNULL(字段,’’)<>’’应改为:WHERE字段<>’’
WHERE ISNULL(字段,’’)=’’不应修改
WHERE ISNULL(字段,’F’) =’T’应改为: WHERE字段=’T’
WHERE ISNULL(字段,’F’)<>’T’不应修改
C、 不要对索引字段使用函数
WHERE LEFT(NAME, 3)='ABC' 或者WHERE SUBSTRING(NAME,1, 3)='ABC'
应改为:
WHERE NAME LIKE 'ABC%'
日期查询的例子:
WHERE DATEDIFF(DAY, 日期,'2005-11-30')=0应改为:WHERE 日期 >='2005-11-30' AND 日期 <'2005-12-1‘
WHERE DATEDIFF(DAY, 日期,'2005-11-30')>0应改为:WHERE 日期 <'2005-11-30‘
WHERE DATEDIFF(DAY, 日期,'2005-11-30')>=0应改为:WHERE 日期 <'2005-12-01‘
WHERE DATEDIFF(DAY, 日期,'2005-11-30')<0应改为:WHERE 日期>='2005-12-01‘
WHERE DATEDIFF(DAY, 日期,'2005-11-30')<=0应改为:WHERE 日期>='2005-11-30‘
D、不要对索引字段进行多字段连接
比如:
WHERE FAME+ ’.’+LNAME=‘HAIWEI.YANG’
应改为:
WHERE FNAME=‘HAIWEI’ AND LNAME=‘YANG’
8、 注意连接条件的写法
多表连接的连接条件对索引的选择有着重要的意义,所以我们在写连接条件条件的时候需要特别的注意。
A、多表连接的时候,连接条件必须写全,宁可重复,不要缺漏。
B、 连接条件尽量使用聚集索引
C、 注意ON部分条件和WHERE部分条件的区别
9、 其他需要注意的地方
经验表明,问题发现的越早解决的成本越低,很多性能问题可以在编码阶段就发现,为了提早发现性能问题,需要注意:
A、程序员注意、关心各表的数据量。
B、 编码过程和单元测试过程尽量用数据量较大的数据库测试,最好能用实际数据测试。
C、 每个SQL语句尽量简单
D、不要频繁更新有触发器的表的数据
E、 注意数据库函数的限制以及其性能
10、学会分辩SQL语句的优劣
自己分辨SQL语句的优劣非常重要,只有自己能分辨优劣才能写出高效的语句。
A、 查看SQL语句的执行计划,可以在查询分析其使用CTRL+L图形化的显示执行计划,一般应该注意百分比最大的几个图形的属性,把鼠标移动到其上面会显示这个图形的属性,需要注意预计成本的数据,也要注意其标题,一般都是CLUSTERED INDEX SEEK 、INDEX SEEK 、CLUSTERED INDEX SCAN 、INDEX SCAN 、TABLE SCAN等,其中出现SCAN说明语句有油画的余地。也可以用语句
SET SHOWPLAN_ALL ON
要执行的语句
SET SHOWPLAN_ALL OFF
查看执行计划的文本详细信息。
B、用事件探查器跟踪系统的运行,可疑跟踪到执行的语句,以及所用的时间,CPU用量以及I/O数据,从而分析语句的效率。
C、可以用WINDOWS的系统性能检测器,关注CPU、I/O参数
四、测试、试运行、维护阶段
测试的主要任务是发现并修改系统的问题,其中性能问题也是一个重要的方面。重点应该放在发现有性能问题的地方,并进行必要的优化。主要进行语句优化、索引优化等。
试运行和维护阶段是在实际的环境下运行系统,发现的问题范围更广,可能涉及操作系统、网络以及多用户并发环境出现的问题,其优化也扩展到操作系统、网络以及数据库物理存储的优化。
这个阶段的优花方法在这里不再展开,只说明下索引维护的方法:
A、 可以用DBCC DBREINDEX语句或者SQL SERVER维护计划设定定时进行索引重建,索引重建的目的是提高索引的效能。
B、 可以用语句UPDATE STATISTICS或者SQL SERVER维护计划设定定时进行索引统计信息的更新,其目的是使得统计信息更能反映实际情况,从而使得优化器选择更合适的索引。
C、 可以用DBCC CHECKDB或者DBCC CHECKTABLE语句检查数据库表和索引是否有问题,这两个语句也能修复一般的问题。
D、
五、 网上资料中一些说法的个人理解
1、 “应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
SELECT ID FROM T WHERE NUM IS NULL
可以在NUM上设置默认值0,确保表中NUM列没有NULL值,然后这样查询:
SELECT ID FROM T WHERE NUM=0”
个人意见:经过测试,IS NULL也是可以用INDEX SEEK查找的,0和NULL是不同概念的,以上说法的两个查询的意义和记录数是不同的。
2、 “应尽量避免在 WHERE 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。”
个人意见:经过测试,<>也是可以用INDEX SEEK查找的。
3、 “应尽量避免在 WHERE 子句中使用 OR 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
SELECT ID FROM T WHERE NUM=10 OR NUM=20
可以这样查询:
SELECT ID FROM T WHERE NUM=10
UNION ALL
SELECT ID FROM T WHERE NUM=20”
个人意见:主要对全表扫描的说法不赞同。
4、 “IN 和 NOT IN 也要慎用,否则会导致全表扫描,如:
SELECT ID FROM T WHERE NUM IN(1,2,3)
对于连续的数值,能用 BETWEEN 就不要用 IN 了:
SELECT ID FROM T WHERE NUM BETWEEN 1 AND 3”
个人意见:主要对全表扫描的说法不赞同。
5、 “如果在 WHERE 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
SELECT ID FROM T WHERE NUM=@NUM
可以改为强制查询使用索引:
SELECT ID FROM T WITH(INDEX(索引名)) WHERE NUM=@NUM”
个人意见:关于局部变量的解释比较奇怪,使用参数如果会影响性能,那存储过程就该校除了,我坚持我上面对于强制索引的看法。
6、 “尽可能的使用 VARCHAR/NVARCHAR 代替 CHAR/NCHAR ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。”
个人意见:“在一个相对较小的字段内搜索效率显然要高些”显然是对的,但是字段的长短似乎不是由变不变长决定,而是业务本身决定。在SQLSERVER6.5或者之前版本,不定长字符串字段的比较速度比定长的字符串字段的比较速度慢很多,所以对于那些版本,我们都是推荐使用定长字段存储一些关键字段。而在2000版本,修改了不定长字符串字段的比较方法,与定长字段的比较速度差别不大了,这样为了方便,我们大量使用不定长字段。
7、 关于连接表的顺序或者条件的顺序的说法,经过测试,在SQL SERVER,这些顺序都是不影响性能的,这些说法可能是对ORACLE有效。
出处忘了:作者见谅
-
【转】Web应用程序的整体测试
2010-01-22 09:58:03
随着Internet的日益普及,现在基于B/S结构的大型应用越来越多,可如何对这些应用进行测试成为日益迫切的问题。有许多测试人员来信问我B/S的测试如何做,由于工作较繁忙,对大家提出的问题也是头痛医头脚痛医脚,没有对WEB的测试过程做一个整体的概述。希望通过本篇能够让大家了解大型Web应用是如何来进行测试的。B/S下的功能测试比较简单,关键是如何做好性能测试。目前大多数的测试人员认为只要跑一些测试工具证明我的产品是可以达到性能的就ok了,为了证明而去测试是没有任何价值的,关键是要发现产品性能上的缺陷,定位问题,解决问题,这才是测试要做的。
首先我们从两个方面分析如何进行WEB测试,从技术实现上来讲一般的B/S结构,无论是.NET还是J2EE,都是多层构架,有界面层,业务逻辑层,数据层。而从测试的流程上来说,首先是发现问题,分析问题,定位问题,再由开发人员解决问题。那么B/S的结构的测试如何来做?
如何发现问题是我首先要介绍的,在做WEB测试之前你需要一些资料,比如产品功能说明书,性能需求说明书,不一定很完善,但一定要有,明确测试目标,这是基本的常识,可是我往往看到的是已经开始动手测了,但还不知自己的系统要达到的性能指标是什么。这里我简单讲一下测试的性能指标:
l 通用指标(指Web应用服务器、数据库服务器必需测试项):
* ProcessorTime: 指服务器CPU占用率,一般 平均达到70%时,服务就接近饱和;
* Memory Available Mbyte : 可用内存数,如果测试时发现内存有变化情况也要注意,如果是内存泄露则比较严重;
* Physicsdisk Time : 物理磁盘读写时间情况;
l Web服务器指标:
* Avg Rps: 平均每秒钟响应次数=总请求时间 / 秒数;
* Avg time to last byte per terstion (mstes):平均每秒业务角本的迭代次数 ,有人会把这两者混淆;
* Successful Rounds:成功的请求;
* Failed Rounds :失败的请求;
* Successful Hits :成功的点击次数;
* Failed Hits :失败的点击次数;
* Hits Per Second :每秒点击次数;
* Successful Hits Per Second :每秒成功的点击次数;
* Failed Hits Per Second :每秒失败的点击次数;
* Attempted Connections :尝试链接数;
l 数据库服务器指标:
* User 0 Connections :用户连接数,也就是数据库的连接数量;
* Number of deadlocks:数据库死锁;
* Butter Cache hit :数据库Cache的命中情况;
上面的指标只是一些通用的指标,起到抛砖引玉的作用,对于不同的应用你还必需作相应的调整,比如程序使用的是.NET技术的,则必需加入一些针对性的测试指标。对于这些指标的详细了解,你可以参考Windows 下面的 SystemMonitor的帮助与LoadRunner、ACT的帮助。对于发现问题,指标的设置非常重要,它会帮你定性的发现一些错误。对于定性的压力测试我就不做过多的分析,工具很多,流行的主要有LoadRunner,ACT,WAS,WebLoad,各个工具有它的使用范围,其中我各个认为LoadRunner 最全面,它提供了多种协议的支持,对复杂的压力测试都可以胜任,WAS与ACT则对微软的技术支持的比较好,其中WAS支持分布式机群测试,ACT则是与.NET集成比较好,支持ViewState (.NET 下控件缓存的支持) 的测试,当时我用时,其它测试工具还不支持,现在应该支持了吧,呵呵。在这一阶段测试你要不断的跟据系数的测试目标进行变化,一开始由于系统过于庞大,所以我们要分成若干个子系统,各个子系统的性能目标必需明确,主要是并发指标定一个阀值,同时设定一些与系统相关的测试参数,应用服务器,数据库服务器都要有,对达不到阀值的与一些通用参数有问题的子系统进行深入分析。比如它的并发达不到你的要求,证明子系统性能有问题,或是数据库用户连接过高,程序没有释放用户连接等等。这个我们要对子系统进行详细测试,由于B/S 结构下,图片的请求对性能的影响较大,所以我们对子系统测试时要分两个部分进行,一、非程序部分,即图片等等;二、应用程序本身。通过事务或函数的分离,可以把这两块实现单独的测试,具体做法参考各个工具的手册,我这里就不做说明。对子系统的测试参数的设置要求则更高,它有助你后面精确的定位问题,比如对异常,死锁,网络流量等等前面没有注意到的情况的增加,同时你要注意增加测试参数的收集对系统的性能影响比较大,所以一般不要超过10个,刚刚介绍的整体的性能测试指标也不要增加很多,这样影响会小一点。最后在这一阶段要说明的是数据库的数据量会很大程度的影响性能,所以要根据前面的性能需求说明书向数据库中模拟相应的数据量,来进行测试,这样才有更高的可信度。
上面所说的是对问题的发现,下面就是分析问题原因,这一步的要求比较高,一般由测试人员与程序员配合完成,当然如果你有相当的开发经验,再做这方面的测试,就更为难得。下面我们说说如何精确定位问题,出现问题的可能性可能有很多种,大致分以下几种,一、性能达不到目标;二、性能达到目标,但有一些其它的问题,比如异常,死锁,缓存命中过低,网络流量较大;三、服务器稳定性的问题,比如内存泄漏……。要发现这些问题起马的要求要有一款使用的比较称心的性能分析与优化工具,比如微软的.NET下就有自己开发的工具,对Borland的Java开发工具中也有类似的工具,但我个人认为更好的工具是Rose下的Purify与Quantify,主要是他对.net 与java ,C++都有支持,而且分析效果特别专业,我们先了解一下Rational Purify, Rational Purify 能自动找出Visual C/C++ 和Java 代码中与内存有关的错误,确保整个应用程序的质量和可靠性。在查找典型的Visual C/C++ 程序中的传统内存访问错误,以及Java,C# 代码中与垃圾内存收集相关的错误方面;Rational Quantity 则是一款针对函数级的性能分析利器,使用它你可以从图形化的界面中得到函数调用的时间,百分比与次数,以及子函数所占时间,使你可以更快的定位性能瓶颈。
我们先说性能优化与异常的处理,性能优化有一个原则,即用时间比例最大的进行优化,效果才最明显,比如有个函数它的执行时间为30秒,如果你优化了一百倍则执行时间为0.3秒,提升了29.7秒,而如果它的执行时间为0.3秒,优化后为0.003秒,实际提升了0.297秒,提升的效果并不明显,而且写过程序的人都知道,后者性能优化的代价更大。在性能优化的过程中,一般是先数据库,后程序,因为数据库的优化不需要修改程序,修改的风险很小。但如何才能确定是数据库的问题,这就需要技巧,在使用Quantity时,你一路分析下去,大多数最终会发现,是数据库查询函数占用时间比较大,比如什么,SqlCmd.ExecuteNoQuery等等数据库执行函数,这时你就需要分析数据库,呵呵。数据库的分析原则是先索引,后存储过程,最后表结构视图的优化,索引的优化是最简单也是通常最有效的方法,如果合理的使用会带来意想不到不到的效果。在这里我要给大家简单的介绍一下我的最爱,SQLProfile,SQL查询分析器,Precise,SQLProfile是一个SQL语句跟踪器,可以跟踪程序流程使用的SQL语句与存储过程,结合查询分析器对SQL的分析,可以对索引的优化做出很好的判断,但索引也不是万能的,在增删改较多的表,索引过多会引起这些操作的性能下降,所以判断还是需要一定的经验。同时针对用户使用频度最高的SQL进行优化也是最行之有效的,这时我则需要Precise,它可以观测某一个较长时间内的SQL语句的执行情况。数据库优化的潜能挖光后,如果还是达不到性能要求或是还有问题,则要从程序来进行优化,这是程序员做的事,测试人员要做的,就是告诉他们,哪个函数执行过多引起了性能下降,比如异常过多,某个循环过多,或是DCOM调用过多等等,但说服程序员也是一件不容易的事,你要在这一阶段做的出色一定要有几年的编程经验,并且要让程序员感到听你的性能会有提升,这是一件很不容易的事情哦。
内存的分析,一般是一个长期分析的过程,要做好不容易,首先要有长期奋战的准备,其次内存泄漏的分析最好是放在单元测试之中同步进行,而不是要等到最后再去发现问题,当然出了问题也只好面对,一般这类问题都是在服务器运行了很久才暴露出来,一旦发现问题后,则需要定位问题,分析的原则采用子系统相互独立运行,找到最小问题的系统集,或是借助内存分析工具观察内存对象情况,初步定位问题,再用Purify进行运行时分析,通常C++ 内存问题比较多,Java与.NET比较少,一般由GC不合理引起。C++的内存错误就比较多了,主要常见的有:
1、 Array Bounds Read (ABR) :数组越界读
2、 Array Bounds Write (ABW):数组越界写
3、 Beyond stack Read (BSR):堆栈越界读
4、 Free Memory Read(FMR):空闲内存读
5、 Invalid pointer Read(IPR):非法指针阅读
6、 Null Pointer Read(NPR): 空指针阅读
7、 Uninitialized Memory Read(UMR):未初始化内存读写
8、 Memory Leak:内存泄漏
注:如果需要更多的信息,可以参见Purify的帮助信息。
顺便提一句,为什么我要说单元测试时做这个比较好,由于单元测试针对的是单一功能,这时结合单元测试案例做内存分析会更快的定位问题,同时由于问题较早的发现,则后期的风险则会减少,当然如果结合代码覆盖工具PureCoverage 来做就更完美了,呵呵。
完成此文,已经是凌晨了,也算是回答了前一段时间提出要进行B/S结构测试又无从下手的朋友的要求,在这里要向大家表达一下歉意,由于工作比较忙,难免对大家的来信有所疏漏,请大家原谅。此文的要求的读者,对测试工具有所了解,希望进入更深测试的同仁,希望我的文章给大家带来帮助,同时也借此文表达一些曾经帮助过我的朋友与同事。
注:本篇只是对B/S应用的测试过程作一个整体的描述,对某一个阶段使用的工具只是作大概的介绍,你也可使用你比较熟悉的工具达到相同的目标。
-
【转】用Syslog 记录UNIX和Windows日志的方法
2010-01-21 15:37:07
在比较大规模的网络应用或者对安全有一定要求的应用中,通常需要对系统的日志进行记录分类并审核,默认情况下,每个系统会在本地硬盘上记录自己的日志,这样虽然也能有日志记录,但是有很多缺点:首先是管理不便,当服务器数量比较多的时候,登陆每台服务器去管理分析日志会十分不便,其次是安全问题,一旦有入侵者登陆系统,他可以轻松的删除所有日志,系统安全分析人员不能得到任何入侵信息。因此,在网络中安排一台专用的日志服务器来记录系统日志是一个比较理想的方案。本文以FreeBSD下的syslog为例,介绍如何利用freebsd的syslogd来记录来自UNIX和windows的log信息。
一、记录UNIX类主机的log信息
首先需要对Freebsd的syslog进行配置,使它允许接收来自其他服务器的log信息。
在/etc/rc.conf中加入:
syslogd_flags="-4 -a 0/0:*"
说明:freebsd的syslogd参数设置放在/etc/rc.conf文件的syslogd_flags变量中
Freebsd对syslogd的默认设置参数是syslogd_flags="-s",(可以在/etc/defaults/rc.conf中看到)
默认的参数-s表示打开UDP端口监听,但是只监听本机的UDP端口,拒绝接收来自其他主机的log信息。如果是两个ss,即-ss,表示不打开任何UDP端口,只在本机用/dev/log设备来记录log.
修改后的参数说明:
-4 只监听IPv4端口,如果你的网络是IPv6协议,可以换成-6
-a 0/0:* 接受来自所有网段所有端口发送过来的log信息。
如果只希望syslogd接收来自某特定网段的log信息可以这样写:-a 192.168.1.0/24:*
-a 192.168.1.0/24:514或者-a 192.168.1.0/24表示仅接收来自该网段514端口的log信息,这也是freebsd的syslogd进程默认设置,也就是说freebsd在接收来自其他主机的log信息的时候会判断对方发送信息的端口,如果对方不是用514端口发送的信息,那么freebsd的syslogd会拒绝接收信息。即,在默认情况下必须:远程IP的514端口 发送到本地IP的514,
在参数中加入*,表示允许接收来自任何端口的log信息。这点,在记录UNIX类主机信息的时候感觉不到加不加有什么区别,因为UNIX类主机都是用514端口发送和接收syslog信息的。但是在接收windows信息的时候就非常重要了。因为windows的syslog软件不用514端口发送信息,这会让默认配置的syslogd拒绝接收信息。笔者同样在linux系统下用linux的syslogd来配置log服务器,发现linux下的syslogd就没有那么多限制,只要给syslogd加上-r参数,就可以接收来自任何主机任何端口的syslog信息,在这方面来说freebsd的默认配置安全性要比linux稍微高一点。
修改好syslogd参数后,我们需要修改一下/etc/syslog.conf文件,指定log信息的存放路径,
比如你要记录其他系统的远程登陆登出信息并指定日志存放路径,则需要修改以下行:
authpriv.* /var/log/testlog
这表示把系统的登入登出日志(包括本机系统登陆登出日志)存放到/var/log/testlog文件中。
当然,这是最简陋的做法,因为这样会把所有服务器的登陆登出信息存放在一个文件中,察看的时候很不方便,通常的做法是用一个脚本,对接收到的信息进行简单的分拣,再发送到不同的文件。
如下设置:
authpriv.* |/var/log/filter_log.sh
在记录目标前面加上“|”表示把接收到的信息交给后面的程序处理,这个程序可以是一个专门的日志处理软件,也可以是一个自己编写的小的脚本,举例:
#!/bin/sh
read stuff
SERVER=`echo $stuff |awk ‘{print $4}’`
echo $stuff >> /var/log/login_log/$SERVER.log
这个简单的脚本以IP作为分类依据,先用read读取log信息,用awk取出第四字段(即IP地址或者主机名所在的字段),以该字段为文件名存放该主机的日志。
这样一来,来自192.168.1.1的log会记录到192.168.1.1.log文件中,来自192.168.1.2的log会被记录在192.168.1.2.log文件中,分析和归类就比较方便了。当然这是一个最简单的例子,读者可以根据自己的需求写出更好的脚本,甚至把log信息分类后插入数据库中,这样日志的管理和分析就更方便了。
最后重启一下syslogd服务,让配置生效:
/etc/rc.d/syslogd restart
OK,服务端的配置完成。现在配置一下客户端:
这里所说的客户端,就是发送自己的日志到远程日志服务器上的主机。
修改/etc/syslog.conf文件:
我们举例你只要记录系统登入登出日志到远程日志服务器上,那么只需要修改以下一行:
authpriv.* @192.168.10.100
这里的192.168.10.100就是log服务器的IP,“@”符号表示发送到远程主机。
OK,重启一下syslog服务:
Linux: /etc/init.d/syslogd restart
BSD: /etc/rc.d/syslogd restart
用logger测试一下是否配置成功:
logger –p authpriv.notice “Hello,this is a test”
到log服务器上去看看,“Hello,this is a test”应该已经被记录下了。最后在客户机上登陆登出几次,看看真实的authpriv信息是否也被成功的记录下。
二、Windows日志的记录
对于UNIX类主机之间记录日志,由于协议、软件和日志信息格式等都大同小异,因此实现起来比较简单,但是windows的系统日志格式不同,日志记录软件,方式等都不同。因此,我们需要第三方的软件来将windows的日志转换成syslog类型的日志后,转发给syslog服务器。
介绍第三方软件evtsys (全称是evntlog to syslog)
下载地址:http://code.google.com/p/eventlog-to-syslog/
文件才几十K大小,非常小巧,解压后是两个文件evtsys.dll和evtsys.exe
把这两个文件拷贝到 c:\windows\system32目录下。
打开Windows命令提示符(开始->运行 输入CMD)
C:\>evtsys –i –h 192.168.10.100
-i 表示安装成系统服务
-h 指定log服务器的IP地址
如果要卸载evtsys,则:
net stop evtsys
evtsys -u
启动该服务:
C:\>net start evtsys
打开windows组策略编辑器 (开始->运行 输入 gpedit.msc)
在windows设置-> 安全设置 -> 本地策略 ->审核策略 中,打开你需要记录的windows日志。evtsys会实时的判断是否有新的windows日志产生,然后把新产生的日志转换成syslogd可识别的格式,通过UDP 3072端口发送给syslogd服务器。
OK,所有的配置windows端配置完成,现在配置一下syslogd的配置文件,
参数的配置和上面相同,所不同的是evtsys是以daemon设备的方式发送给 syslogd log信息的。因此,需要在/etc/syslog.conf中加入:
daemon.notice |/var/log/filter_log.sh
关于syslog 记录设备和记录等级方面的知识可以参考syslog文档。
OK,所有配置设置完成。
Linux 、BSD和windows上的系统日志都可以统一记录到一台日志服务器上轻松管理了。
-
Syslog
2010-01-21 14:26:55
Syslog常被称为系统日志或系统记录,是一种用来在互联网协定(TCP/IP)的网络中传递记录档讯息的标准。这个词汇常用来指涉实际的syslog 协定,或者那些送出syslog讯息的应用程式或数据库。
syslog协定属于一种主从式协定:syslog发送端会传送出一个小的文字讯息(小于1024字节)到syslog接收端。接收端通常名为“syslogd”、“syslog daemon”或syslog服务器。系统日志讯息可以被以UDP协定及╱或TCP协定来传送。这些资料是以明码型态被传送。不过由于SSL加密外套(例如Stunnel、sslio或sslwrap等)并非syslog协定本身的一部分,因此可以被用来透过SSL/TLS方式提供一层加密。
syslog通常被用于资讯系统管理及资安稽核。虽然它有不少缺陷,但仍获得相当多的装置及各种平台的接收端支援。因此syslog能被用来将来自许多不同类型系统的日志记录整合到集中的储存库中。
-
ORACLE-LOB字段
2010-01-21 13:48:52
在ORACLE数据库中,LOB(Large Objects—大对象)是用来存储大量的二进制和文本数据的一种数据类型(一个LOB字段可存储可多达4GB的数据)。目前,它又分为两种类型:内部LOB和外部LOB。内部LOB将数据以字节流的形式存储在数据库的内部。因而,内部LOB的许多操作都可以参与事务,也可以像处理普通数据一样对其进行备份和恢复操作。Oracle8i支持三种类型的内部LOB:BLOB(二进制数据)、CLOB(单字节字符数据)、NCLOB(多字节国家字符数据)。其中CLOB和NCLOB类型适用于存储超长的文本数据,BLOB字段适用于存储大量的二进制数据,如图像、视频、音频等。
可通过以下语句可查看clob字段的信息:select dbms_lob.substr(col_lob) from table_name
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 146028
- 日志数: 249
- 书签数: 41
- 建立时间: 2007-08-11
- 更新时间: 2013-03-28
