
-
[转] Oracle全局数据库名、环境变量和sid的区别
2009-02-05 11:23:58
转自:
http://haoxiai.net/shujuku/Oracle/111145.html
一、数据库名
什么是数据库名
数据库名就是一个数据库的标识,就像人的身份证号一样。他用参数DB_NAME表示,如果一台机器上装了多全数据库,那么每一个数据库都有一个数据库名。在数据库安装或创建完成之后,参数DB_NAME被写入参数文件之中。格式如下:
DB_NAME=myorcl
...
在创建数据库时就应考虑好数据库名,并且在创建完数据库之后,数据库名不宜修改,即使要修改也会很麻烦。因为,数据库名还被写入控制文件中,控制文件是以二进制型式存储的,用户无法修改控制文件的内容。假设用户修改了参数文件中的数据库名,即修改DB_NAME的值。但是在Oracle启动时,由于参数文件中的DB_NAME与控制文件中的数据库名不一致,导致数据库启动失败,将返回ORA-01103错误。数据库名的作用
数据库名是在安装数据库、创建新的数据库、创建数据库控制文件、修改数据结构、备份与恢复数据库时都需要使用到的。
有很多Oracle安装文件目录是与数据库名相关的,如:
winnt: d:\oracle\product\10.1.0\oradata\DB_NAME\...
Unix: /home/app/oracle/product/10.1.0/oradata/DB_NAME/...
pfile:
winnt: d:\oracle\product\10.1.0\admin\DB_NAME\pfile\ini.ora
Unix: /home/app/oracle/product/10.1.0/admin/DB_NAME/pfile/init$ORACLE_SID.ora
跟踪文件目录:
winnt: /home/app/oracle/product/10.1.0/admin/DB_NAME/bdump/...
另外,在创建数据时,careate database命令中的数据库名也要与参数文件中DB_NAME参数的值一致,否则将产生错误。
同样,修改数据库结构的语句alter database,当然也要指出要修改的数据库的名称。
如果控制文件损坏或丢失,数据库将不能加载,这时要重新创建控制文件,方法是以nomount方式启动实例,然后以create controlfile命令创建控制文件,当然这个命令中也是指指DB_NAME。
还有在备份或恢复数据库时,都需要用到数据库名。
总之,数据库名很重要,要准确理解它的作用。查询当前数据名
方法一:select name from v$database;
方法二:show parameter db
方法三:查看参数文件。修改数据库名
前面建议:应在创建数据库时就确定好数据库名,数据库名不应作修改,因为修改数据库名是一件比较复杂的事情。那么现在就来说明一下,如何在已创建数据之后,修改数据库名。步骤如下:
1.关闭数据库。
2.修改数据库参数文件中的DB_NAME参数的值为新的数据库名。
3.以NOMOUNT方式启动实例,修建控制文件(有关创建控制文件的命令语法,请参考oracle文档)二、数据库实例名
二、数据库实例名
什么是数据库实例名?
数据库实例名是用于和操作系统进行联系的标识,就是说数据库和操作系统之间的交互用的是数据库实例名。实例名也被写入参数文件中,该参数为instance_name,在winnt平台中,实例名同时也被写入注册表。
数据库名和实例名可以相同也可以不同。
在一般情况下,数据库名和实例名是一对一的关系,但如果在oracle并行服务器架构(即oracle实时应用集群)中,数据库名和实例名是一对多的关系。这一点在第一篇中已有图例说明。查询当前数据库实例名
方法一:select instance_name from v$instance;
方法二:show parameter instance
方法三:在参数文件中查询。数据库实例名与ORACLE_SID
虽然两者都表是oracle实例,但两者是有区别的。instance_name是oracle数据库参数。而ORACLE_SID是操作系统的环境变量。ORACLD_SID用于与操作系统交互,也就是说,从操作系统的角度访问实例名,必须通过ORACLE_SID。在winnt不台,ORACLE_SID还需存在于注册表中。
且ORACLE_SID必须与instance_name的值一致,否则,你将会收到一个错误,在unix平台,是“ORACLE not available”,在winnt平台,是“TNS:协议适配器错误”。数据库实例名与网络连接
数据库实例名除了与操作系统交互外,还用于网络连接的oracle服务器标识。当你配置oracle主机连接串的时候,就需要指定实例名。当然8i以后版本的网络组件要求使用的是服务名SERVICE_NAME。这个概念接下来说明。
三、数据库域名
什么是数据库域名?
在分布工数据库系统中,不同版本的数据库服务器之间,不论运行的操作系统是unix或是windows,各服务器之间都可以通过数据库链路进行远程复制,数据库域名主要用于oracle分布式环境中的复制。举例说明如:
全国交通运政系统的分布式数据库,其中:
福建节点: fj.jtyz
福建厦门节点: xm.fj.jtyz
江西: jx.jtyz
江西上饶:sr.jx.jtyz
这就是数据库域名。
数据库域名在存在于参数文件中,他的参数是db_domain.查询数据库域名
方法一:select value from v$parameter where name = 'db_domain';
方法二:show parameter domain;
方法三:在参数文件中查询。全局数据库名
全局数据库名=数据库名+数据库域名,如前述福建节点的全局数据库名是:oradb.fj.jtyz四、数据库服务名
什么是数据库服务名?
从oracle9i版本开始,引入了一个新的参数,即数据库服务名。参数名是SERVICE_NAME。
如果数据库有域名,则数据库服务名就是全局数据库名;否则,数据库服务名与数据库名相同。查询数据库服务名
方法一:select value from v$parameter where name = 'service_name';
方法二:show parameter service_name;
方法三:在参数文件中查询。数据库服务名与网络连接
从oracle8i开始的oracle网络组件,数据库与客户端的连接主机串使用数据库服务名。之前用的是ORACLE_SID,即数据库实例名。
-
[转]新手指南:彻底明白操作系统环境变量
2009-02-05 10:13:22
转自:
http://www.pconline.com.cn/pcedu/teach/empolder/system/0602/754299.html
1.环境变量的设置有几种方式?
设置环境变量有两种方式:第一种是在命令提示符运行窗口中设置;第二种是通过单击“我的电脑→属性→高级”标签的“环境变量”按钮设置。需要注意的是,第一种设置环境变量的方式只对当前运行窗口有效,关闭运行窗口后,设置就不起作用了,而第二种设置环境变量的方式则是永久有效。
2.如何在命令提示符窗口中设置环境变量?
在“开始→运行”框中输入“cmd”后按“确定”按钮,出现命令运行窗口。在命令提示符下输入“set”即可查看环境变量设置。要查看具体某个环境变量的设置,比如要查看path环境变量的设置,可以输入“set path”。要创建一个环境变量,比如要创建一个名为aa的,值为“c:”的环境变量,可以输入“set aa=c:”命令。而要删除一个环境变量,比如要删除aa环境变量,则可输入“set aa=”命令(注意=后面不能有空格)。如何更改一个环境变量的设置呢?更改环境变量有两种情况:一是追加方式,即在不改变环境变量现有设置的情况下,增加变量的值,比如要给环境变量aa增加一个值为“D:”的设置,可以输入“set aa=%path%;D:”。另一种是完全修改方式,对于这种方式,我们可以采用直接创建一个环境变量的方法来实现。
3.用户变量和系统变量的关系是什么?
点击“我的电脑→属性→高级”标签的“环境变量”按钮,出现“环境变量”对话框,如果当前是以Administrator登录系统的用户,对话框的上面为Administrator的用户变量,对话框的下面为系统变量(即相当于系统中所有用户的用户变量)。有的时候我们会看到在用户变量和系统变量中都存在某一个环境变量,比如path,那么path的值到底是用户变量中的值还是系统变量中的值,或者两者都不是呢?答案是两者都不是。path变量的值是用户变量中的值与系统变量中的值的叠加。
4.改变环境变量和环境变量中的值应该注意什么?
环境变量和环境变量的值不要含有空格,也不要用中文,切记! -
[转] Oracle9i归档日志配置指南
2009-02-04 17:12:40
转自:
http://blog.oracle.com.cn/html/62/t-58262.html
1.归档日志模式和非归档日志模式的区别
2.配置数据库的归档模式
3.启用自动归档
4.手动归档
5.归档模式和非归档模式的转换
6.配置多个归档进程
7.配置归档目标,多归档目标,远程归档目标
1.归档日志模式和非归档日志模式的区别
非归档模式只能做冷备份,并且恢复时只能做完全备份.最近一次完全备份到系统出错期间的数据不能恢复.
归档模式可以做热备份,并且可以做增量备份,可以做部分恢复.
用ARCHIVE LOG LIST 可以查看期模式状态时归档模式还是非归档模式.
2.配置数据库的归档模式
改变非归档模式到归档模式:
1)SQL>SHUTDOWN NORMAL/IMMEDIATE;
2)SQL>STARTUP MOUNT;
3)SQL>ALTER DATABASE ARCHIVELOG;
4)SQL>ALTER DATABASE OPEN;
5)SQL>做一次完全备份,因为非归档日志模式下产生的备份日志对于归档模式已经不可用了.这一步非非常重要!
改变归档模式到非归档模式:
1)SQL>SHUTDOWN NORMAL/IMMEDIATE;
2)SQL>STARTUP MOUNT;
3)SQL>ALTER DATABASE NOARCHIVELOG;
4)SQL>ALTER DATABASE OPEN;
3.启用自动归档: LOG_ARCHIVE_START=TRUE
归档模式下,日志文件组不允许被覆盖(重写),当日志文件写满之后,如果没有进行手动归档,那么系统将挂起,知道归档完成为止.
这时只能读而不能写.
运行过程中关闭和重启归档日志进程
SQL>ARCHIVE LOG STOP
SQL>ARCHIVE LOG START
4.手动归档: LOG_ARCHIVE_START=FALSE
归档当前日志文件
SQL>ALTER SYSTEM ARCHIVE LOG CURRENT;
归档序号为052的日志文件
SQL>ALTER SYSTEM ARCHIVE LOG SEQUENCE 052;
归档所有日志文件
SQL>ALTER SYSTEM ARCHIVE LOG ALL;
改变归档日志目标
SQL>ALTER SYSTEM ARCHIVE LOG CURRENT TO '& ATH';
ATH';
5.归档模式和非归档模式的转换
转换到归档日志模式
SQL>SHUTDOWN
SQL>STARTUP MOUNT
SQL>ALTER DATABASE ARCHIVELOG;
SQL>ALTER DATABASE OPEN;
转换到非归档日志模式
SQL>SHUTDOWN
SQL>STARTUP MOUNT
SQL>ALTER DATABASE NOARCHIVELOG;
SQL>ALTER DATABASE OPEN;
6.配置多个归档进程
Q:什么时候需要使用多个归档进程?
A:如果归档过程会消耗大量的时间,那么可以启动多个归档进程,这是个动态参数,可以用ALTER SYSTEM动态修改.
SQL>ALTER SYSTEM SET LOG_ARCHIVE_MAX_PROCESSES=10;
Oracle9i中最多可以指定10个归档进程
与归档进程有关的动态性能视图
v$bgprocess,v$archive_processes
7.配置归档目标,多归档目标,远程归档目标,归档日志格式
归档目标 LOG_ARCHIVE_DEST_n
本地归档目标:
SQL>LOG_ARCHIVE_DEST_1 = "LOCATION=D:\ORACLE\ARCHIVEDLOG";
远程归档目标:
SQL>LOG_ARCHIVE_DEST_2 = "SERVICE=STANDBY_DB1";
强制的归档目标,如果出错,600秒后重试:
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_4 = "LOCATION=E:\ORACLE\ARCHIVEDLOG MANDATORY REOPEN=600";
可选的归档目标,如果出错,放弃归档:
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_3 = "LOCATION=E:\ORACLE\ARCHIVEDLOG OPTIONAL";
归档目标状态:关闭归档目标和打开归档目标
关闭归档目标1
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_1 = DEFER
打开归档目标2
SQL>ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2 = ENABLE
归档日志格式
LOG_ARCHIVE_FORMAT
8.获取归档日志信息
V$ARCHVIED_LOG
V$ARCHVIE_DEST
V$LOG_HISTORY
V$DATABASE
V$ARCHIVE_PROCESSES
ARCHIVE LOG LIST; -
[转] 初识ORACLE的审计功能
2009-02-01 16:52:13
转自:
http://rake.itpub.net/post/4038/24963
顺着这样的思路去学习。
1、审计可以达到怎样的效果?我用来做什么?
2、任何概念都该有分类的吧,审计也不例外?
3、如何启用审计?数据库一级。
4、如何设定我所需要的审计?针对某个特定的监视目标了。
5、如何看审计的结果?
6、论坛上一些常见的问题,自己认为比较难理解的问题。
初识ORACLE的审计功能
顺着这样的思路去学习。
1、审计可以达到怎样的效果?我要来做什么?
2、有分类吗?
3、如何启用审计?数据库一级。
4、如何设定我所需要的审计?针对某个特定的监视目标了。
5、如何看审计的结果?
6、论坛上一些常见的问题,自己认为比较难理解的问题。一、审计可以达到怎样的效果?
可以记录对数据库对象的所有操作。什么时候,什么用户对什么对象进行了什么类型的操作。
但是无法得知操作的细节,比如到底数据更新成了1还是2?
不过现在新出现的精细审计(Fine grained Auditing),好像也可以记录DML语句了。二、审计可以分为3类。或者说,可以从3种角度去启用审计。
1、语句审计(Statement Auditing)。
对预先指定的某些SQL语句进行审计。这里从SQL语句的角度出发,进行指定。审计只关心执行的语句。
例如,audit CREATE TABLE;命令,就表明对"create table"语句的执行进行记录。
不管这语句是否是针对某个对象的操作2、权限审计(Privilege Auditing)
对涉及某些权限的操作进行审计。这里强调“涉及权限”
例如,audit CREATE TABLE;命令,又可以表明对涉及“CREATE TABLE”权限的操作进行审计。
所以说,在这种命令的情况下,既产生一个语句审计,又产生了一个权限审计。
有时候“语句审计”和“权限审计”的相互重复的。这一点可以后面证明。3、对象审计(Object Auditing)。
记录作用在指定对象上的操作。
三、如何启用审计。
通过数据库初始化参数文件中的AUDIT_TRAIL 初始化参数启用和禁用数据库审计。
DB 启用数据库审计并引导所有审计记录到数据库的审计跟踪
OS 启用数据库审计并引导所有审计记录到操作系统的审计跟踪。可以用AUDIT_FILE_DEST 初始化参数来指定审计文件存储的目录。
NONE 禁用审计这个值是默认值四、如何设定所需的审计
AUDIT语句。
例如:审计属于用户jward 的dept 表上的所有的SELECT INSERT 和DELETE 语句
AUDIT SELECT, INSERT, DELETE
ON jward.dept;五、控制何时触发审计动作。
1)By session / By Access
by session对每个session中发生的重复操作只记录一次
by access对每个session中发生的每次操作都记录,而不管是否重复。2)Whenever successful/ Whenever not successful
Whenever successful表示操作成功以后才记录下来。
Whenever not successful表示操作失败后才记录下来。六、审计实施
1、语句审计
Audit session; Audit session By;
与instance连接的每个会话生成一条审计记录。
审计记录将在连接时期插入并且在断开连接时期进行更新。
保留有关会话的信息比如连接时期断开连接时期处理的逻辑和物理I/O,
以及更多信息将存储在单独一条审计记录中
该审计记录与会话相对应
2、audit delete table
2) 权限审计
Audit DELETE ANY TABLE
by access
whenever not successful;
所有不成功的,使用DELETE ANY TABLE权限进行的操作。3) 对象审计
AUDIT SELECT, INSERT, DELETE
ON jward.dept
BY ACCESS
WHENEVER SUCCESSFUL;
七、审计结果
1)数据库初始化参数文件中AUDIT_TRAIL=OS时,审计记录存在操作系统的文件中。
UNIX系统的话,默认存在“$oracle_home/rdbms/audit/” 目录下。
If you have set AUDIT_TRAIL = OS, modify the "init.ora" file to specify
the destination for the audited records using the AUDIT_FILE_DEST parameter.
If your operating system supports AUDIT_TRAIL = OS auditing, files are
automatically created in the AUDIT_FILE_DEST for certain actions, and the
generated name contains the OS PID of the shadow process audited:
Example:
AUDIT_FILE_DEST = $ORACLE_HOME/rdbms/audit
b)windows系统的审计信息存储在事件管理器中。
你可以通过控制面板——管理工具——事件查看器——应用程序日志中找到相应的审计记录2)数据库初始化参数文件中AUDIT_TRAIL=DB时,审计记录存在数据库中。
相关表和视图:
SYS.AUD$ 是唯一保留审计结果的表。其它的都是视图。STMT_AUDIT_OPTION_MAP 包含有关审计选项类型代码的信息由SQL.BSQ 脚本在CREATEDATABASE 的时候创建
AUDIT_ACTIONS 包含对审计跟踪动作类型代码的说明
ALL_DEF_AUDIT_OPTS 包含默认对象审计选项。当创建对象时将应用这些选项DBA_STMT_AUDIT_OPTS 描述由用户设置的跨系统的当前系统审计选项
DBA_PRIV_AUDIT_OPTS 描述由用户正在审计的跨系统的当前系统权限
DBA_OBJ_AUDIT_OPTS 描述在所有对象上的审计选项
USER_OBJ_AUDIT_OPTS USER 视图描述当前用户拥有的所有对象上的审计选项以下是审计记录
DBA_AUDIT_TRAIL 列出所有审计跟踪条目
USER_AUDIT_TRAIL USER视图显示与当前用户有关的审计跟踪条目DBA_AUDIT_OBJECT 包含系统中所有对象的审计跟踪记录
USER_AUDIT_ OBJECT USER 视图列出一些审计跟踪记录而这些记录涉及当前用户可以访问的对象的语句DBA_AUDIT_SESSION 列出涉及CONNECT 和DISCONNECT 的所有审计跟踪记录
USER_AUDIT_ SESSION USER视图列出涉及当前用户的CONNECT 和DISCONNECT 的所有审计跟踪记录DBA_AUDIT_STATEMENT 列出涉及数据库全部的GRANT REVOKE AUDIT NOAUDIT 和ALTER SYSTEM 语句的审计跟踪记录
USER_ AUDIT_ STATEMENT 对于USER 视图来说这些语句应是用户发布的DBA_AUDIT_EXISTS 列出BY AUDIT NOT EXISTS 产生的审计跟踪条目
下面的视图用于细粒度审计
DBA_AUDIT_POLICIES 显示系统上的所有审计策略
DBA_FGA_AUDIT_TRAIL 列出基于值的审计的审计跟踪记录
八、一些特殊问题
1、有时候“语句审计”和“权限审计”是相互重复的。并不需要明确的区分这2种类型。
主要是考虑你对审计的需求是什么?考虑出发的角度是什么?
例如:
SQL> audit CREATE TABLE;Audit succeeded
SQL> SELECT * FROM DBA_STMT_AUDIT_OPTS;
AUDIT_OPTION SUCCESS FAILURE
---------------------------------------- ---------- ----------
CREATE TABLE BY ACCESS BY ACCESSSQL> SELECT * FROM DBA_PRIV_AUDIT_OPTS;
PRIVILEGE SUCCESS FAILURE
---------------------------------------- ---------- ----------
CREATE TABLE BY ACCESS BY ACCESS以上的一条审计设定命令,生成了两条审计规则。其实最后的结果都是一样。
就是当CREATE TABLE语句执行后,存下审计记录。2、开启某个用户下所有表的审计
audit table by user_name。据说可以。
九、参考
http://blog.itpub.net/post/468/6806http://download-west.oracle.com/docs/cd/B10501_01/server.920/a96521/audit.htm#1108
获得应用程序所执行的SQL语句
http://www.softhouse.com.cn/html/200412/2004121608315200002957.html细粒度审计(FGA)
http://www.itpub.net/showthread.php?s=&threadid=239693&highlight=%C9%F3%BC%C6 -
[转] ORACLE概要文件管理
2009-02-01 16:32:13
转自:
http://3492zhang.itpub.net/post/8531/457529
profile相关参数的单位以及参数说明。(中文)
Oracle系统为了合理分配和使用系统的资源提出了概要文件的概念。所谓概要文件,就是一份描述如何使用系统的资源(主要是CPU资源)的配置文件。将概要文件赋予某个数据库用户,在用户连接并访问数据库服务器时,系统就按照概要文件给他分配资源。在有的书中将其翻译为配置文件,其作用包括。
1、管理数据库系统资源。
利用Profile来分配资源限额,必须把初始化参数resource_limit设置为true
ALTER SYSTEM SET resource_limit=TRUE SCOPE=BOTH;
2、管理数据库口令及验证方式。
默认给用户分配的是DEFAULT概要文件,将该文件赋予了每个创建的用户。但该文件对资源没有任何限制,因此管理员常常需要根据自己数
据库系统的环境自行建立概要文件,下面介绍如何创建及管理概要文件。示例:
CREATE PROFILE pro_test
LIMIT CPU_PER_SESSION 1000
--cpu每秒会话数
任意一个会话所消耗的CPU时间量(时间量为1/100秒)
CPU_PER_CALL 1000
--cpu每秒调用数
任意一个会话中的任意一个单独数据库调用所消耗的CPU时间量(时间量为1/100秒)
CONNECT_TIME 30
--允许连接时间
任意一个会话连接时间限定在指定的分钟数内
IDLE_TIME DEFAULT
--允许空闲时间
SESSIONS_PER_USER 10
--用户最大并行会话数(指定用户的会话数量)
LOGICAL_READS_PER_SESSION 1000 --读取数/会话(单位:块)
LOGICAL_READS_PER_CALL 1000 --读取数/调用(单位:块)
PRIVATE_SGA 16K --专用sga
COMPOSITE_LIMIT 1000000 --组合限制(单位:单元)
FAILED_LOGIN_ATTEMPTS 10 --登录几次后
PASSWORD_LOCK_TIME 10 --锁定时间(单位:天)
PASSWORD_GRACE_TIME 120 --多少天后锁定
PASSWORD_LIFE_TIME 60 --口令有效期(单位:天)
PASSWORD_REUSE_MAX UNLIMITED --保留口令历史记录:保留次数(单位:次)
PASSWORD_REUSE_TIME 120 --保留口令历史记录:保留时间(单位:天)
PASSWORD_VERIFY_FUNCTION DEFAULT --启用口令复杂性函数(null或者default)
更改参数实例:alter profile pro_test LIMIT CPU_PER_SESSION 5000
删除概要文件:drop profile pro_test
为一个具体用户分配 概要文件alter user test profile pro_test;
将用户的概要文件改为默认
alter user test profile default;
查看概要文件的信息
select * from SYS.DBA_PROFILES;
select * from SYS.USER_RESOURCE_LIMITS;
-
数据库基础知识实践(七)-----创建索引、视图和序列
2009-02-01 15:35:00
oracle创建索引
适当的使用索引可以提高数据检索速度,可以给经常需要进行查询的字段创建索引
oracle的索引分为5种:唯一索引,组合索引,反向键索引,位图索引,基于函数的索引
创建索引的标准语法:
CREATE INDEX 索引名 ON 表名(列名)
TABLESPACE 表空间名;
(1)创建唯一索引:
CREATE unique INDEX 索引名 ON 表名(列名)
TABLESPACE 表空间名;
(2)创建组合索引:
CREATE INDEX 索引名 ON 表名(列名1,列名2)
TABLESPACE 表空间名;
(3)创建反向键索引:
CREATE INDEX 索引名 ON 表名(列名) reverse
TABLESPACE 表空间名;
ORACLE创建视图
create or replace view 视图名 as select * from 表 where 条件 with check option;
eg:
create or replace view view_student as
select id,name
from student with read only;
在单表视图下可以通过视图向数据表中插入数据,但前提是插入的数据要满足约束,视图查询的列不能使用系统函数,在多表视图下不能通过视图插入数据,视图实际上就是一张虚拟的表,但它不是存在于物理文件中,而是在内存中,这样的好处就是可以提高读取效率,在复杂的多表查询时可以降低开发难度。
ORACLE创建序列
create sequence 序列名称
start with 1
increment by 1
minvalue 1
maxvalue 100
nocycle;
序列创建后用
序列名.nextval得到下一个序列编号
序列名.currval得到当前序列编号
如果一个数据表的主键需要自动增长就需要创建一个序列
然后在像表中插入数据时
insert into 表名(id,name) values(序列名.nextval,'aaa');就可以了
-
数据库基础知识实践(六)-----SQL删除和更新数据
2009-01-21 14:38:54
1.用SQL删除数据
(1) 删除记录
delete from 数据表 where 条件;
(2) 整表数据删除
truncate table 数据表;
注意:truncate table 命令将快速删除数据表中的所有记录,但保留数据表结构,这种快速删除与delete from 数据表的删除全部数据表记录不一样,delete命令删除的数据将存储在系统回滚段中,需要的时候,数据可以回滚恢复,而truncate 命令删除的数据是不可以恢复的。
2.用SQL更新数据
(1) 直接赋值更新
语法:
update 数据表
set 字段名1=新的赋值,字段名2=新的赋值,......
where 条件
eg:update emp
set empno=8888,ename='TOM',hiredate='03-9月-2002'
where empno=7566;
(2) 嵌套更新
语法:
update 数据表
set 字段名1=(select 字段列表 from 数据表 where 条件),字段名2=(select 字段列表 from 数据表 where 条件),......
eg:update emp
set sal=
(
select sal+300 from emp
where empno=7599
)
where empno=7599;
-
数据库基础知识实践(五)-----SQL函数查询
2009-01-21 13:39:57
1.[ceil] 函数
用法:ceil(n),取大于等于数值n的最小整数。
eg:select mgr,mgr/100,ceil(mgr/100) from emp;
2.[floor]函数
用法:floor(n),取笑于等于数值n的最大整数。
eg:select mgr,mgr/100,floor(mgr/100) from emp;
3.[mod] 函数
用法:mod(m,n),取m整除n后的余数。
eg:select mgr,mod(mgr,1000),mod(mgr,100),mod(mgr,10) from emp;
4.[power] 函数
用法:power(m,n),取m的n次方。
eg:select mgr,power(mgr,2),power(mgr,3) from emp;
5.[round] 函数
用法:round(m,n),四舍五入,保留n位。
eg:select mgr,round(mgr/100,2),round(mgr/1000,2) from emp;
6.[sign] 函数
用法:sign(n),n>0,取1;n=0,取0;n<0,取-1。
eg:select mgr,mgr-7800,sign(mgr-7800) from emp;
7.[avg] 函数
用法:avg(字段名),求平均值。要求字段为数值型。
eg:select avg(mgr) 平均薪水 from emp;
8.[count] 函数
用法:count(字段名)或count(*),统计总数。
eg:select count(distinct job) 工作类别总数 from emp;
9.[min] 函数
用法:min(字段名),计算数值型字段最小数。
eg:select min(sal) 最少薪水 from emp;
10.[max] 函数
用法:max(字段名),计算数值型字段最大数。
eg:select max(sal) 最高薪水 from emp;
11.[sum] 函数
用法:sum(字段名),计算数值型字段总和。
eg:select sum(sal) 薪水总和 from emp;
-
数据库基础知识实践(四)-----SQL嵌套查询
2009-01-20 15:06:49
在select查询语句里可以嵌入select查询语句,称为嵌套查询。
注意:子查询可以嵌套多层,自查询操作的数据表可以是父查询不操作的数据表。子查询中不能有order by 分组语句。
1.简单嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal>=(select sal from emp where ename='小白');
2.带[in] 的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal in (select sal from emp where ename='小白') ;
3.带[any] 的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal>any(select sal from emp where job='MANAGER');
4.带[some]的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal=some(select sal from emp where job='MANAGER');
5.带[all]的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp
where sal>all(select sal from emp where job='MANAGER');
6.带exists的嵌套查询
select emp.empno,emp.ename,emp.job,emp.sal
from emp,dept
where exists
(select * from emp where emp.deptno=dept.deptno);
7.并操作的嵌套查询
(select deptno from dept)
union
(select deptno from emp);
8.交操作的嵌套查询
(select deptno from dept)
intersect
(select deptno from emp);
9.差操作的嵌套查询
(select deptno from dept)
minus
(select deptno from emp);
-
数据库基础知识实践(三)-----SQL单表查询
2009-01-19 14:04:22
用SQL进行单表查询
-
查询所有记录: select * from 数据表
-
查询所有记录的某些字段:select 字段名1,字段名2,.... from 数据表 (将显示某些特定的字段,注意这里的字段名之间的逗号是英文状态下的逗号)。
-
查询某些字段不同记录:select distinct 字段名 from 数据表
-
单条件的查询:where可以指定查询条件

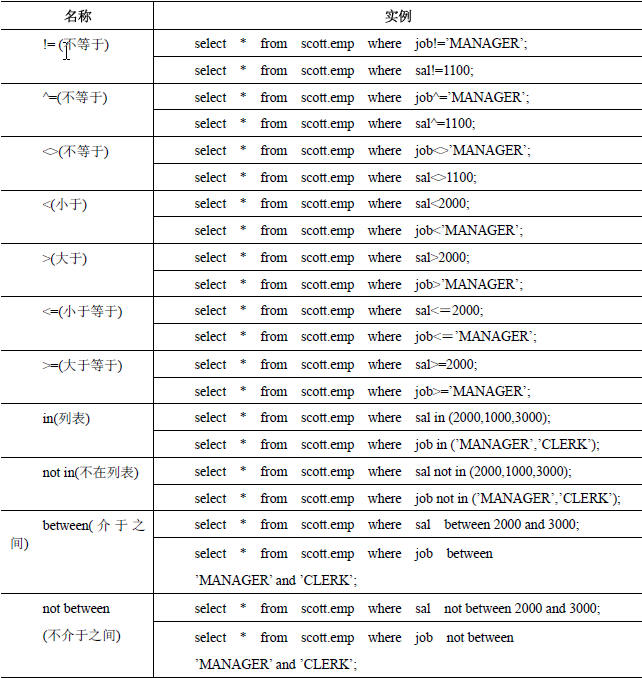

like和not like 适合字符字段的查询,%代表任意长度的字符串,_下划线代表一个任意的字符,like 'm%' 代表m开头的任意长度的字符串,like 'm__'代表m开头的长度为3的字符串。
5.组合条件查询
例如: select empno,ename,job from scott.emp where not job='CLERK'
说明:not job='CLERK' 等价于 job <> 'CLERK'。
组合条件中使用的逻辑比较符如下表所示:
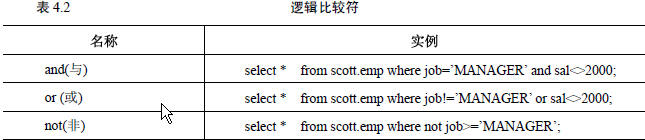
6.排序查询(order by)
例如:select empno,ename,job from scott.emp where job<='CLERK' order by job asc,sal desc;
order by 可以指定查询结果如何排序,形式为“order by 字段名 排序关键字”;asc代表升序排列,desc代表降序排列,多个排序字段通过逗号分割,若有where查询条件,order by 放在where语句之后。
7.分组查询(group by)
注意:group by 后要加所查询的所有的非聚合字段
(1)使用having字句的分组查询
select empno,ename,job,sal from scott.emp group by job,empno,ename,sal having sal<=2000;
(2)使用where字句的分组查询
select empno,ename,job,sal from scott.emp where sal<=2000 group by job,empno,ename,sal;
select job,sum(sal) from scott.emp where sal<=2000 group by job;
注意:where检查每条记录是否符合条件,having是检查分组后的各组是否满足条件。having语句只能配合group by语句使用,没有group by 时不能使用having,但可以使用where。
8.字段运算查询
可以利用集中基本的算术运算符来查询数据。常见的+,-,*,/都可以用来查询数据。
select empno,ename,sal,mgr+sal from scott.emp
注意:算术运算符仅仅适合多个数值型字段或字段与数字之间的运算。
9.变换查询显示
select empno 编号,ename 姓名,job 工作,sal 薪水 from scott.emp;
-
-
数据库基础知识实践(二)
2009-01-19 12:18:14
转自:
http://blog.chinaunix.net/u/25952/showart_207048.html
修改表
改类型、长度、是否为空:
alter table mytable modify (mycol varchar2(20) not null);
要修改类型,字段必须是空的;
要修改长度,如果字段是空的,完全可以改,如果字段不空,则只能增加长度,不能减小;
要修改是否为空,字段必须符合constraint的要求
修改列名:关于列名,没有直接的方法改变。但是可以通过其他方法达到改变列名的目的。
例如:
表A结构如下:
ID(NUMBER) NAME(VARCHAR2(20)
------------------------------------
1 TOM
2 MIKE
3 JHON
将列名NAME改变为NAME1
方法1.列复制法
1.增加一个与NAME相同结构的字段NAME1
Alter table A add(NAME1 varchar2(20));
2.将NAME中的数据复制到NAME1中
Update A Set NAME1=NAME;
3.删除NAME列
Alter table A drop column NAME;
4.修改完成
方法2.表复制法
1.将表A改名
Alter table A rename to A1
2.创建新表并复制数据
Create table A(ID,NAME1) as Select * from A1
3.删除表A1
4.修改完成
通过上面两种方法,
重新检索表A结果如下:
ID(NUMBER) NAME1(VARCHAR2(20)
------------------------------------
1 TOM
2 MIKE
3 JHON -
[转] 修改oracle 10g的字符集
2009-01-16 18:04:17
转自:
修改数据库字符集为:ZHS16GBK
查看服务器端字符集
SQL > select * from V$NLS_PARAMETERS
修改:
$sqlplus /nolog
SQL>conn / as sysdba;
若此时数据库服务器已启动,则先执行 SHUTDOWN IMMEDIATE 命
令关闭数据库服务器,然后执行以下命令:
SQL>shutdown immediate;
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE CHARACTER SET ZHS16GBK;
*
ERROR at line 1:
ORA-12721: operation cannot execute when other sessions are active
若出现上面的错误,使用下面的办法进行修改,使用INTERNAL_USE可以跳过超集的检查:
SQL>ALTER DATABASE CHARACTER SET INTERNAL_USE ZHS16GBK;
SQL>SHUTDOWN IMMEDIATE;
SQL>STARTUP -
数据库基础知识实践(一)
2009-01-16 17:30:04
创建表
创建2个有关联的表(dept和emp,之间用deptno属性产生关联):
dept表
create table dept
(
deptno number(2) NOT NULL primary key, /*设置该属性为主键非空*/
dname varchar2(14),
loc varchar2(13)
);或
create table dept
(
deptno number(2) NOT NULL ,
dname varchar2(14),
loc varchar2(13),
primary key(deptno) /*设置deptno属性为主键*/
);create table emp
(
empno number(4) NOT NULL primary key, /*设置该属性为主键非空*/
ename varchar2(10),
job varchar2(9),
ngr number(4),
hiredate date,
sal number(7,2),
comm number(7,2),
deptno number(2),
constraint fk_deptno foreign key(deptno) references dept(deptno) /*设置外键约束*/
);删除表
drop table 表名
插入数据
insert into dept values(0002,'质量管理02部','北京'); /*向dept表中插入一条数据,表的每一列均有值*/
insert into dept(deptno,loc) values(0003,'新疆'); /*向指定dept的部分列中插入一条数据*/删除数据
delete from dept t where t.deptno=0002;
-
[转载] 华为外包项目的测试流程
2009-01-08 09:45:49
转载自:
http://www.51testing.com/html/200901/n101944.html
如果竞标成功,项目就开始要启动了。
华为方会提供一份CRS(客户需求)和SOW(工作任务书),华为方派人过来进行需求培训,这时该项目的测试组长也要参与到项目需求的培训和评审,也就是测试工作应该从需求开始介入。
项目经理编写《项目计划》,开发人员产出《SRS》,这时测试组长就要根据SOW开始编写《测试计划》,其中包括人员,软件硬件资源,测试点,集成顺序,进度安排和风险识别等内容。
《测试计划》编写完成后需要进行评审,参与人员有项目经理,测试经理和华为方人员,测试组长需要根据评审意见修改《测试计划》,并上传到VSS上,由配置管理员管理。
待开发人员把《SRS》归纳好并打了基线,测试组长开始组织测试成员编写《测试方案》,测试方案要求根据《SRS》上的每个需求点设计出包括需求点简介,测试思路和详细测试方法三部分的方案。
《测试方案》编写完成后也需要进行评审,评审人员包括项目经理,开发人员,测试经理,测试组长,测试成员和华为方;如果华为方不在公司,就需要测试组长把《测试方案》发送给华为进行评审,并返回评审结果。测试组长组织测试成员修改测试方案,直到华为方评审通过后才进入下个阶段――编写测试用例。
测试用例是根据《测试方案》来编写的,通过《测试方案》阶段,测试人员对整个系统需求有了详细的理解。
这时开始编写用例才能保证用例的可执行和对需求的覆盖。测试用例需要包括测试项,用例级别,预置条件,操作步骤和预期结果。
其中操作步骤和预期结果需要编写详细和明确。测试用例应该覆盖测试方案,而测试方案又覆盖了测试需求点,这样才能保证客户需求不遗漏。
同样,测试用例也需要通过开发人员,测试人员和华为方的评审,测试组长也需要组织测试人员对测试用例进行修改,直到华为方评审通过。
在我们编写测试用例的阶段,开发人员基本完成代码的编写,同时完成单元测试。华为的外包项目一般是一次性集成,所以软件转测试部后直接进行系统测试。
测试部对刚转过来的测试版本进行预测试,如果软件未实现CheckList清单上的10%,测试部会把该版本打回。否则,软件转测试部进行系统测试。
根据《测试计划》进度安排,测试组长进行多轮次的测试,每轮测试完成后测试组长需要编写测试报告,其中包括用例执行通过情况,缺陷分布情况,缺陷产生原因,测试中的风险等等,这时测试人员就修改增加测试用例。
待到开发修改完bug并转来新的测试版本,测试部开始进行第二轮的系统测试,首先回归完问题单,再继续进行测试,编写第二轮的测试报告,如此循环下去,直到系统测试结束。
在系统测试期间,测试人员还需要编写验收手册,验收用例和资料测试用例等。
完成系统测试后,软件就开始转到华为进行验收测试,其中大概测试半个月,一般会要求测试部派人到华为方进行协助测试,并发回问题单给公司开发人员修改。
如果验收发现的缺陷率在SOW规定的范围内,那么验收成功,华为方付钱给公司,项目结束。
如果超过规定的缺陷率,那么公司可能要罚钱了,整个项目组的成员(包括开发和测试)都可能要罚了。
这种情况也会有,如果按照流程做事,概率不会很大。
测试流程的规范是很重要的,但是如果要成为优秀的测试人员只知道流程还是不够的,需要学习的东西还很多,包括熟悉相关测试业务,计算机专业知识(linux,oracle,tcp/ip等),开发的架构和语言,性能测试和系统瓶颈分析、调优等。还有性格(细心,耐心)和人际沟通能力也是很重要的决定条件。
-
[转]WebSphere环境搭建实践指南(二)
2008-12-19 14:10:26
转载自:
http://tech.it168.com/jd/2007-08-23/200708230733862.shtml
在生产环境中安装WAS完毕并创建了一个可用的概要文件之后,必须根据实际情况进行必要参数的调整,以便提高WAS性能、方便错误诊断。这些参数通常要结合运行环境的实际情况、实际的并发量和服务器的资源利用情况进行调整。完整的调优涉及操作系统、应用、应用服务器和数据库的综合调整,具体要调整的参数、含义,请参见WAS资源中提到的资源监控和性能调优章节,例如,红皮书sg246392的17.5章节中明确谈到了性能调优通常涉及的参数以及调整原则。本文提出的只是针对应用服务器本身一些重要的参数调整的指导原则和经验之谈,以便读者能够快速起步:
- Java虚拟机堆大小(JVM Heap Size): 控制JVM代码可使用的堆大小,单位M。该参数在服务器->应用程序服务器>进程定义>Java虚拟机中进行设置。JVM最大堆大小默认是256M,在生产环境中通常要根据机器物理内存情况、应用运行特性来设置,且多数情况下都要把此参数调大。根据经验,内存充足时,通常的调整在500M到1024M之间。需要注意的是,建议JVM Heap的最大值不要超过1024M,如果JVM Heap Size过大,可能会引起内存分页,或者造成JVM垃圾回收时间过长,反而影响应用服务器性能。有关Java虚拟机调优的具体信息,请参考调整JVM参数。
- Web容器线程池:该参数在“服务器 > 应用程序服务器 > server1 > 线程池”的“WebContainer”中进行设置(如图6),默认值是10到50。如果硬件资源允许,通常会把线程池的最大大小调到100。
图 6. 调整线程池
- 数据源连接池:该参数在资源->JDBC->数据源->数据源名称,选择“连接池设置”中设置,默认大小为1到10。根据资源设置的队列(Queue)原则,从Web容器线程池,到数据源连接池的参数设置,应该是从大到小的管道。前面我们列举了Web容器线程池的最大值设置100,对于数据源连接池,设置的最大值通常不超过50。多数情况下调整为30。实际运行中可以修改此参数值,观察调整对性能是否有正面影响。注意,如果把数据库连接池最大大小调得过大,JVM有限的资源都耗费在维护连接池、处理与数据库连接上,可能反而造成WAS性能的下降。
- WAS 进程日志参数:WAS进程日志常用的有SystemOut.log和SystemErr.log。这两份日志默认大小为1M,历史日志文件数为1份。在生产环境中,这样的设置通常不足以充分保存发生问题时的错误信息。我们可以通过修改日志默认大小、历史日志文件数来保存更多的信息。注意,不要把单份日志文件大小设置过大(例如,超过10M以上),否则可能影响WAS性能。另外,我们建议把应用日志与WAS日志分离开。如果应用中大量以System.out.print或者System.err.print来保存应用状态日志,也可能会影响服务器性能。
图 7. 修改WAS日志属性
- Heapdump文件:前面我们提到,Heapdump文件对磁盘空间占用很快,因此,可以设置IBM_HEAPDUMP参数把Heapdump文件存放到指定目录下。
- Web服务器的访问日志access.log:IBM Http Server的访问日志access.log默认是打开的,其中记录了经过Http服务器的请求信息。在高并发的系统中,这一日志增长非常过,当日志过大时,可能占用过多磁盘空间或引起性能下降,如果您的系统不需要这份日志,或者有其他技术手段保存用户访问信息,可以关闭该日志。具体做法为:打开IBM Http Server安装目录/conf目录下的httpd.conf文件,搜索CustomLog,把CustomLog所在行用#注释掉即可。
由于生产环境访问控制的需要,搭建WebSphere环境之后,通常可能会要求修改应用访问端口,或者更改WAS管理员密码,启用/停用管理安全性等等。
应用服务器安装完毕之后,为了避免生产环境中的端口冲突、端口访问控制,有时我们需要查看或更改应用服务器的端口。
- 查看端口
- 更改应用访问端口
默认情况下,WAS的管理控制台和应用访问是两个不同的端口。访问WAS的管理控制台或者WAS上部署的应用,所使用的端口由应用服务器端口以及虚拟主机决定。假设我们要把应用访问的端口从9080变成9082(实际工作中,如果没有Web服务器,有的环境会希望把应用访问端口变成80,方法类似),则按如下步骤进行:登陆WAS管理控制台,选择 左边菜单 服务器 - 应用服务器,点击 server1,选择“端口”,点击“WC_defaulthost”(如图8),修改端口为自己想要的任意端口(注意避免端口冲突),例如,9082。然后点击“确定”。然后“保存”。
图 8. 修改应用访问端口
然后,选择 左边菜单 环境 - 虚拟主机,点击”default_host”,选择“主机别名”(如图9),把原有端口9080改成与前面应用服务器/端口/WC_defaulthost一致的端口,例如,9082。或者点击“新建”,把在WC_defaulthost修改之后的端口号填入,点击“确定”、“保存”。
图 9. 修改虚拟主机
当然,如果你在前面应用服务器/端口/WC_defaulthost中设置的端口已经出现在虚拟主机/default_host/主机别名的列表中,则不需要做改动或者新增主机别名端口的工作。目的就是要让 应用服务器/端口/WC_defaulthost的端口出现在 虚拟主机/default_host的主机别名列表中。更改在重启WAS服务器之后生效。
- 更改WAS管理控制台端口
登陆WAS管理控制台,选择 左边菜单 服务器 - 应用服务器,点击 server1选择“端口”。然后更改WC_adminhost为自己希望的管理控制台端口。然后点击“确定”、“保存”。选择 左边菜单 环境 - 虚拟主机,点击;然后选择admin_host,选择“主机别名”。把原有端口9060改成与前面应用服务器/端口/WC_adminhost一致的端口,例如,9063。或者点击“新建”,创建一个主机别名 *, 9063。然后“确定”,“保存”。目的就是要让 应用服务器/端口/WC_adminhost的端口出现在 虚拟主机/admin_host的主机别名列表中。
-
针对生产环境要求的多变性,实际WAS环境搭建中可能涉及管理安全性的多种操作。
- 启用管理安全性
启用管理安全性将激活用于防止未经授权的用户使用服务器的设置,简单来说,进入管理控制台、更改应用服务器配置、停止应用服务器进程这些管理任务,都需要输入预先定义的用户名和密码才能完成。缺省情况下,创建概要文件时会启用管理安全性(图9)。如果在创建概要文件时没有选择“启用管理安全性”,在随后使用过程中又希望启用,则可按如下步骤进行:
首先进入控制台,例如:http://was_ip:9060/admin,注意这里登陆的用户一定要是设置安全性的用户。例如,admin。选择“安全性”>“安全管理、应用程序和基础结构”,然后点击“安全配置向导”(图10)。为了配置的简便性,在“指定保护范围”中,可以不选择“使用 Java 2 安全性来限制应用程序访问本地资源”;在“选择用户存储库”中接受默认选项,用户存储库为“联合存储库”,点击“下一步”;在配置用户存储库中填入用户名、密码。如果您是第一次启用管理安全性,则输入一个新的用户名(您登陆管理控制台的用户名)和密码。这个用户名密码是任意的,并不要求是操作系统用户,因为联合存储库默认的用户条目来自于文件;如果以前曾经使用该存储库启用过管理安全性,则使用存储库中持有管理员特权的用户名和密码。点击“下一步”、“完成”。保存之后重启应用服务器,这时登陆管理控制台等就需要提供您预定义的用户名/密码了。
图 10. 配置管理安全性
- 停用管理安全性
停用管理控制台很简单,在图10所示页面,不选择“启用管理安全性”,点击“应用”,保存并重启应用服务器即可。有一种特殊情况下,特如忘掉了管理员密码,此时我们无法登陆管理控制台,从而无法在管理控制台中停用管理安全性。这时,可从$WAS_HOME/profiles/xxx概要文件名/bin目录下,发出如下命令: wsadmin -conntype NONE 。当wsadmin的命令行窗口出现之后,发出下列命令: securityoff 。上述操作在应用服务器启动或停止的状态都能发出。再次启用WAS时,就是停用管理安全性的状态了。
- 更改管理员密码
当我们需要更改管理员密码时,可以选择“用户和组”>“管理用户”,如图11,在搜索内容为“*”时点击“搜索”,会列出该存储库中的所有用户。选中管理用户标识,可更改该用户的密码。更改即时生效。
- 停用管理安全性
停用管理控制台很简单,在图10所示页面,不选择“启用管理安全性”,点击“应用”,保存并重启应用服务器即可。有一种特殊情况下,特如忘掉了管理员密码,此时我们无法登陆管理控制台,从而无法在管理控制台中停用管理安全性。这时,可从$WAS_HOME/profiles/xxx概要文件名/bin目录下,发出如下命令: wsadmin -conntype NONE 。当wsadmin的命令行窗口出现之后,发出下列命令: securityoff 。上述操作在应用服务器启动或停止的状态都能发出。再次启用WAS时,就是停用管理安全性的状态了。
- 更改管理员密码
当我们需要更改管理员密码时,可以选择“用户和组”>“管理用户”,如图11,在搜索内容为“*”时点击“搜索”,会列出该存储库中的所有用户。选中管理用户标识,可更改该用户的密码。更改即时生效。
图 11. 管理用户
- 忘记管理员密码
如果忘记管理员密码,我们无法进入管理控制台更改密码。此时,需要先用“停用管理安全性”一节中wsadmin命令的方法,停用管理安全性,然后“更改管理员密码”,再次“启用管理安全性”即可。
- 创建更多的管理用户
使用启用管理安全性的WAS环境时,默认情况下只有一个管理员ID,这意味着同一时刻只有一个人能登陆管理控制台。这对于多人开发小组在同一WAS环境发布测试时并不方便。您可先在存储库中创建一个用户,然后为该用户ID分配相应的管理角色。具体步骤如下:1)选择“用户和组”>“管理用户”,如图24,点击“添加”,添加一个用户ID,例如,admin1。保存。 2) 选择“用户和组”>“管理用户角色”,如图25,填入用户名(必须是在存储库中已经存在的用户名),选择相应的管理角色,例如,“管理员”。点击“确定”,保存。这样,下次重启WAS时,两个用户都能同时登陆管理控制台。

生产环境、概要文件配置过于复杂或经常更改时,我们需要定期备份概要文件,以便必要时快速恢复。您可使用backupConfig 命令备份配置文件。例如,要备份概要文件AppSrv01的当前配置,可以从$WAS_HOME/profiles/AppSrv01/bin目录下,发出命令 backupConfig,它会将AppSrv01当前概要文件默认生成一个压缩包,您也可以指定该压缩包的名称,例如:backupConfig WebSphereConfig_2007_05_30.zip。恢复配置时,使用restoreConfig WebSphereConfig_2007_05_30.zip。
需要提醒的是,WAS的卸载过程不是直接删除目录,如果这样做,下次你可能无法在同一台机器上成功安装WAS。在卸载WAS之前,先停止机器上的WAS进程,用ps –ef |grep java确保没有was进程在运行。然后,执行WAS_HOME/uninstall/uninstall.sh命令卸载WAS。如果因为某些特殊原因卸载向导引导的卸载过程没有成功(例如,您直接删除了WAS安装目录),或者您希望在同一目录再次安装WAS,请参照信息中心“手工卸载”给出的建议。
- 启用管理安全性
应用部署通常会涉及如下几个任务:配置应用所需要的环境:如系统变量、虚拟主机、类路径、安全性等等;配置应用所需要的资源如JMS资源、数据源等。其中,需要注意的是:- 应用打包:部署在 WebSphere 应用服务器上的应用可以是打包的*.ear/*.war文件,也可以是未打包但符合J2EE规范要求的组件。在生产环境中,推荐使用打包的*.ear/*.war文件,便于版本控制和管理。对于复杂项目中多个J2EE组件的打包,请参见文章“关于J2EE应用开发项目包的管理”。
- 管理 Utility Jar包:大多数J2EE应用都会有一些公用的Utility Jar包,首先要强调的是:一定要避免在同一个类载入路径下存在同一个类的多个版本!这会在实际运行中带来很多莫名其妙且难以诊断的问题。其次,对于JDBC驱动这类通用等级较高的Utility Jar包,可以放置在<WAS_HOME>/lib/ext目录下;对于多个应用共享的Utility Jar,可以放在 <WAS_HOME>/lib/ext中,也可以放在shared library(共享库)中,推荐放在shared library中;对于单个应用使用的Utility Jar,可与应用打包在一起,或放入shared library中。共享库的使用能够避免Utility Jar包多个版本的混乱,以及Utility Jar包的冲突。共享库配置方法请参见红皮书sg247304 12.5.4 Step 4: Sharing utility JARs using shared libraries章节。
- Jar 包冲突:Jar包冲突问题在大型Java软件开发中经常遇到,简单的说,当不同应用使用的公用Utility Jar包、应用服务器底层的Jar包中存在同名、且版本不同的类时,我们称之为Jar包冲突。这种问题的解决办法可以参考文章如何在WebSphere中解决Jar包冲突 。
- 会话超时:针对应用场景的不同,不同应用期望的会话超时时间各不相同。WebSphere应用服务器的会话管理分为Application server、Application、Web Module三个级别。顾名思义,在每个特定级别上更改的会话管理的配置,对当前级别起作用。部署在WebSphere应用服务器上的应用,默认的会话超时时间为30分钟,默认的会话管理级别是Application Server。如果您期望更改您的应用,例如,DefaultApplication的会话超时时间,可按如下步骤进行:选择应用程序>应用程序名>会话管理(图13),选择“覆盖会话管理”,并在“设置超时”中填上期望的会话超时时间。点击“确定”保存即可。

当应用需要通过写Java环境变量的方式配置一些变量时,可在应用服务器启动脚本中用-D参数指定,也可以在应用程序服务器 > 应用程序服务器名(例如,server1) > 进程定义 > Java 虚拟机中设置“通用JVM参数” -Daaa=xxx。
当在WAS环境中遇到问题时,最方便的是利用网上资源查阅相关资料。这方面的文章已经太多,为了达到本文的目标:“为初级用户提供一个尽量完整的快速入门指南”,我不得不在这里老调重谈,请参照从何学习 WebSphere? 了解WebSphere应用服务器的常用网上资源。
了解WAS的过程是渐进式的,希望这篇文章能够在WAS安装示例文档和用户的WebSphere生产环境搭建实践之间提供一个过渡,节省您的时间。从工程师的角度看,遇到问题不是坏事,遇到问题越多,经验越多,查阅资料,并通过多种渠道获得IBM的技术支持,相信您对WAS的使用体验会更加美妙。
-
[转]WebSphere环境搭建实践指南(一)
2008-12-19 14:06:06
转载自:
http://tech.it168.com/jd/2007-08-23/200708230733862.shtml
【IT168 技术文档】
生产环境中 WebSphere 应用服务器的搭建与演示环境有很多不同,由于生产环境的多样性、应用场景的性能调优、错误诊断等严格要求,生产环境中 WebSphere 应用服务器的安装涉及到安装前系统各项检查、安装中各种参数调整,以及安装后常见的管理任务。WebSphere 应用服务器有着大量的资源可以参考,但对于很多仅仅搭建过演示或简单测试环境的用户来说,面对浩如烟海的文档很难下手。本文试图总结在搭建一个完整的 WebSphere 环境中遇到的常见问题和注意事项,为初次搭建 WebSphere 应用服务器准生产环境的人提供一个快速入门指南。与大多数商用应用服务器一样,如果您计划把WebSphere应用服务器(以下简称WAS)用于正式的生产环境或用于性能测试、生产前检验的测试环境,除了简单地安装步骤外,您还需要做一些额外的检查、规划和配置,来确保您的WebSphere应用服务器环境安全稳定运行。 WebSphere应用服务器各个版本之间安装步骤差别不大,WAS V6.x版本比以前版本的安装配置步骤中多了创建概要文件的过程,本文举例的版本为V6.1。在阅读本文之前,推荐读者先了解安装WebSphere应用服务器的大致过程或相关概念。对于WebSphere应用服务器各版本的具体安装步骤,请参照WebSphere应用服务器产品随机安装文档以及WebSphere信息中心,DeveloperWorks上也有很多关于WAS环境搭建的参考文章,如:WAS5的安装及其常见问题、在WAS6.0 ND中实现集群等,见参考资源。
在搭建准生产环境的过程中,好的准备是成功的一半,推荐逐条进行以下安装前准备工作。
WebSphere应用服务器能否顺利安装成功首先取决于目标平台是否满足安装的软件和硬件条件。WebSphere应用服务器对硬件配置的要求主要体现在待部署平台的硬件架构、CPU、内存和磁盘存储空间上,通常最低内存要求在512M以上,根据硬件平台、WebSphere应用服务器版本、组件的不同,要求的配置也会略有区别,请参考WAS详细系统需求 。磁盘空间的分配请参见“2.4 确认磁盘空间是否满足要求”。
作为一个成熟的商用应用服务器,WebSphere应用服务器会定期发布不同WAS版本(例如WAS V5.0, WAS V5.1, WAS6.0…)、组件(例如:Application Server, Edge Component)支持的操作系统版本信息。使用WebSphere服务器支持的操作系统平台,能确保应用服务器安装、使用过程中环境的正常稳定运行。尤其要注意的是,如果操作系统平台不是IBM WebSphere应用服务器官方支持的平台,在WebSphere应用环境出现问题后则无法获得WebSphere应用服务器的售后支持,更谈不上解决问题了。
例如,在笔者写这篇文章时,在x86芯片上,对于RedHat AS 4操作系统,如果要安装WebSphere应用服务器V6.1的Application Server组件,则要求的操作系统版本是Red Hat Enterprise Linux AS, Version 4 with Update 2。如果您的操作系统版本是Red Hat Enterprise Linux AS, Version 4,则还需要安装Update2,否则有可能遇到问题。
由于支持的操作系统版本是定期更新的,请在搭建WebSphere应用服务器环境前,参照系统详细需求去查看当前操作系统版本(版本要与网上列出的完全一致)是否满足WebSphere应用服务器要求。
在安装WebSphere应用服务器过程中,创建概要文件这一步骤需要用户填入机器的主机名(如图1),并且,WAS运行时也需要用到主机名(Host Name)。主机名是WAS安装节点的物理机器的网络名,它必须解析到服务器上的物理网络节点。创建概要文件中WAS使用的主机名的值可以是全限定 DNS 主机名(例如: hosta.cn.ibm.com)、短主机名(例如:hosta),或甚至是数字 IP 地址(例如:192.168.1.3),但必须是WAS所在服务器实际配置的主机名。而且,当WAS配置完毕投入使用之后,不推荐更改您设定的主机名,即使能改,过程也比较复杂。因此,根据实际经验,我们推荐用户在安装WebSphere应用服务器之前配置主机名。如果采用全限定 DNS 主机名或短主机名,可以通过hostname命令来查看当前系统的主机名。如果没有配置,则到hosts文件中添加相应的条目。
- 常见问题1:在安装WAS之后,更改了主机名,WAS无法正常启动或停止,日志报错:javax.naming.ConfigurationException: Cannot get canonical host name for server。或者报错无法找到主机名xxx。因此,在创建WAS的概要文件之前,需要根据实际情况,选择三种形式的主机名(全限定 DNS 主机名、短主机名或数字 IP 地址)中保持不变的那种主机名形式,作为WAS使用的主机名,在概要文件创建向导(图1)中填入。如果您使用 DHCP或者如果您经常更改 IP 地址,那么我们推荐在概要文件创建时使用全限定 DNS 主机名或短主机名;如果机器ip固定,而全限定 DNS 主机名或短主机名有可能更改,则在概要文件创建中使用数字ip。
- 常见问题2:如果您需要创建集群,请确保网络配置中,除了保证本机主机名配置正确外,还必须保证集群所在机器之间互相能ping通主机名。否则集群创建中add node一步可能不成功。
考虑硬盘空间分配时,在UNIX或Linux平台下可以用df –k 先查看各目录大小。如果是在生产环境上安装WebSphere应用服务器,一般要从以下几个方面来计算要预留的空间。
- WebSphere 应用服务器自身代码的占用空间。这个空间一般在1G左右,在不同的系统平台上略有差异。应在WAS安装目录下预留此空间。WebSphere应用服务器在Linux下的默认安装路径是 /opt/IBM/WebSphere/AppServer,在AIX下的默认安装路径是/usr/IBM/WebSphere/AppServer(后面我们把此路径简称为WAS_HOME)。用户可以在安装WAS时修改此安装路径。
- 概要文件所占的空间。WebSphere应用服务器V6.1创建的概要文件基本类型有3种,每个概要文件所占用的空间如下:应用程序服务器(Application Server):在WebSphere应用服务器安装没有选择安装样本程序时,这一概要文件所占磁盘空间约为200M;Deployment Manager:30M;定制概要文件(Custom,即node agent):10M。
- 如果要安装WEB服务器,则在WEB服务器所在服务器上要预留WEB服务器所占的磁盘空间。IBM HTTP服务器一般占用110M左右的空间。
- 如果安装WEB服务器,则在WEB服务器所在机器上通常也要安装Web Server Plug-in组件,该组件所占磁盘空间约为200M。
- WebSphere 应用服务器系统日志的占用空间。日志空间的估算要结合系统对日志的配置情况。WebSphere应用服务器的主要日志有SystemOut.log,SystemErr.log。我们可设置日志文件的大小和保存的历史日志文件数量,从而可以估算出其需要的空间。请参考“必要参数的调整”部分了解如何调整WebSphere应用服务器日志参数。
- 如果有WEB服务器,需考虑WEB服务器的日志空间。如果客户开启了WEB服务器的访问日志access.log(默认开启),此日志增长的速度极快,要预留足够的空间。
- 备份文件需要的空间。WebSphere应用服务器提供了一个备份命令(backupConfig.bat/sh),用来备份应用服务器的配置及其上应用。我们建议在系统稳定之后及时备份。对于一个典型生产系统,WebSphere应用服务器这个配置文件经常超过100M。可在发出backupConfig命令时,使用-logfile参数指定该备份文件的存放位置。
- 系统出错时日志,例如,JVM在发生OutOfMemory时,在大多数平台上WebSphere应用服务器会默认写javacore文件和heapdump文件,记录错误出现时的JVM Heap、线程情况,以备错误诊断使用。虽然可以调整应用服务器参数使之不产生此类文件,但为了分析问题,通常需要从此类文件入手。这类文件通常都特别大,例如heapdump文件,可能达到几百M。如果多次出现OutOfMemroy,对磁盘空间的占用很快。因此,必须考虑为此类文件预留磁盘空间。
- WAS安装程序还需要在系统的临时目录/tmp中有100M以上的空闲空间。
- 用户发布到WebSphere应用服务器上所有应用程序以及应用自身的应用日志的占用空间。这个大小与实际应用相关,而且不同应用可以差别很大。
如要了解不同平台具体的磁盘空间要求,请参考WAS V6.1信息中心“为产品安装准备操作系统”一节的内容。
前面提到WebSphere应用服务器对支持的操作系统版本有明确要求,除此之外,WAS信息中心还对特定的操作系统版本安装的包、内核参数等有特殊要求。例如,对于RHEL AS4,信息中心中说明必须安装compat-libstdc++-33-3.2.3-47.3.ppc.rpm包(这是保持 C++ 运行时兼容性所必需的,供诸如 GSKit 的组件、Java 2 软件开发包(SDK)以及 Web 服务器插件使用)以及其他一些包。对于Linux、Solaris、HP等系统,还需要调整一些相应的内核参数。请参照请WAS V6.1信息中心“为产品安装准备操作系统”一节的内容。对于Solaris系统,需要调整的参数列表列举如下:
set shmsys:shminfo_shmmax = 4294967295 set shmsys:shminfo_shmseg = 1024 set shmsys:shminfo_shmmni = 1024 set semsys:seminfo_semaem = 16384 set semsys:seminfo_semmni = 1024 set semsys:seminfo_semmap = 1026 set semsys:seminfo_semmns = 16384 set semsys:seminfo_semmsl = 100 set semsys:seminfo_semopm = 100 set semsys:seminfo_semmnu = 2048 set semsys:seminfo_semume = 256 set msgsys:msginfo_msgmap = 1026 set msgsys:msginfo_msgmax = 65535 set rlim_fd_cur=1024
WAS的安装可以使用人机交互的图形界面安装或批处理安装(称为静默安装,silent installation,预先写好响应文件,安装过程中不需要启动图形界面或者人机交互)。如果使用图形界面安装,在服务器是Linux/UNIX平台时,我们通常没有机会直接使用服务器的显示屏/控制台,而是通过自己的机器telenet到服务器上去。这种命令行直接telnet的模式下,可能不支持启动图形界面,需要用到Xmanager、X-Win32等支持X Window的工具软件。你可以在命令行下敲入命令xclock进行测试。如果出现如图2所示的图形显示,表明你能够在你的终端上启动图形界面。
图 2. 验证能够启动图形界面
2.7. 准备合适的安装介质WAS是跨平台的产品,不同的UNIX、Linux、Windows平台、32位或者64位操作系统上,安装介质都是不一样的,而且产品中包含了Application Server、Web Server、Edge Component等多种组件,当搭建WebSphere环境时,您需要从订购的WAS产品包(包括各个平台、组件的多张CD)中选择需要的安装介质。因此,安装前我们需要根据安装的WAS组件、操作系统版本、操作系统位数,选择所需要的介质。例如,如果我们要在x86架构、64位(注意,这里的64位是指操作系统是64位的)的Linux AS 4上安装WAS,就应该选择WebSphere Application Server for x86 64-bit Linux的安装介质;如果我们要安装IBM Http Server或者update installer,这两个组件都是在WebSphere Application Server Supplements CD中,同理,根据操作系统版本、位数、服务器的芯片,我们就可以选出所需要的介质了。如果WAS安装中需要打补丁,建议在安装WAS前提前下载这些补丁以备安装过程中使用。具体内容在“打补丁”一节详述。
根据实际应用场景的不同,我们需要决定WAS、Web 服务器分别装在哪些服务器上,如果需要配置集群环境,还需要考虑Deployment Manager、各个结点和集群成员都分部在哪些服务器上。例如,如果我们要配置一个集群环境,安装前,我们通常会先设计出如图3的一张拓扑结构图,以决定安装中每台服务器上实际安装、配置的组件。例如,如图3所示,图中实线是运行时的请求流,虚线是WAS各组件间的控制流。我们可以看出,在hosta机器上,应该安装WAS组件,并创建Deployment Manager、NodeA概要文件,配置集群成员C1和C2;在hostb机器上,应该安装WAS组件,创建NodeB概要文件,配置集群成员C3和C4。在machine3机器上,应该安装IBM Http Server和Plug-in组件。其中,WAS集群的配置是非常方便的,可以在创建完概要文件之后灵活调整。
其他一些常见注意事项还包括权限、端口控制等等。例如:
- WebSphere应用服务器在Unix/Linux系统上支持root用户和非root用户。但为了操作设置的简便性,通常都会在root用户下进行。
- 有的生产系统对端口访问有限制,或者系统中可以已经占用了 WAS 即将使用的默认端口,因此,需要更改WAS使用的端口(此任务将在“更改WAS使用的端口”中详述)等等。
- 如果需要创建集群,请确保参与Cell环境的各台机器之间时间一致、时区一致,建议误差控制在秒级。否则在add node过程中可能不成功。
-
安装WAS的过程非常简单,通常分为3步:安装WAS产品,为产品打补丁(如果有补丁),创建概要文件。如果您的环境很干净,没有一些特殊的限制,安装过程大多数时候是点击默认的“Next”。当然,根据环境的不同,通常会要注意以下方面:
使用图形界面方式安装WAS的过程十分简单,通常不需要做特定的修改。下面列举安装中常见的一些注意事项和提高安装速度的小窍门:
- 通常,如果您的系统曾经安装过WAS产品,安装WAS产品之前,建议停掉正在运行的WAS进程。如果安装IBM Http Server,通常最好停掉正在运行的Apache Http Server或者其他IBM Http Server进程。在Unix/Linux系统上,可以用 ps –ef |grep java 命令,去查看当前系统是否有was进程,用 ps –ef |grep httpd 命令,去查看当前系统是否有http server进程在运行。
- 安装WAS可以执行launchpad.bat/luanchpad.exe,启动“启动板”,从启动板中点击“启动WebSphere Application Server的安装向导”。如果无法成功启动“启动板”,直接到安装介质目录下的WAS目录中,执行install.exe/install.sh即可。
- 乱码:启动板或WAS安装向导显示的语言与本地操作系统语言设置有关。如果本地操作系统语言设置为中文,则 WAS安装向导就会显示中文。如果发现向导中语言显示为乱码,可以先把本地操作系统语言设置为英文,使用英文语言安装WAS。这样安装完毕的WAS仍然具有中文支持,不必担心。在Unix/Linux平台上,更改语言为英文使用下列命令: export LANG=en_US
- 安装 WAS 过程中可以选择是否安装样本应用程序(samples),为了在开发环境和生产环境中都能获得更高性能,请不要安装样本。通过省略样本,可以将应用程序服务器启动时间缩短 60% 并节省 15% 的磁盘空间;可以节省相当程度的进程占用量;并且可以节省WAS产品安装以及每次创建应用服务器概要文件的时间。
- 一个可运行的 WAS 环境至少要包含一个概要文件。因此,WAS产品安装过程中会让用户选择要创建的初始概要文件。如果在安装完WAS产品之后还要打补丁,建议此时先不要选择创建任何初始概要文件(图4),以节省打补丁所需的时间。如果在安装期间未创建概要文件,安装WAS产品结束后会显示用于启动“概要文件创建”向导的选项。基于同样原因,如果需要打补丁,我们将把创建概要文件这个工作放到打补丁之后进行,因此此处不必选择启动“概要文件创建”向导。
图 4. 安装时不选择创建初始概要文件
如果您使用的WAS版本已经推出市场一段时间,根据用户的测试和使用情况, WAS会定期公布补丁包(Fix Pack)或补丁(Fix)。建议先在测试环境中安装补丁,确认安装的补丁不会对您的运行环境带来负面影响,再将补丁安装到生产环境中。一旦您经过了适当的测试后,主动地安装预防补丁,将避免一些可能导致您系统出故障的问题。WAS V6.x的补丁升级策略 了解补丁升级策略的详情。并可以在IBM支持网站WAS补丁下载下载WAS补丁。
一般来说,WAS补丁的命名规范为:版本名-产品名-产品组件名-平台名-补丁编号名.pak。例如,6.1.0-WS-WAS-SolarisSparc64-FP0000007.pak ,这是WAS V6.1的WAS组件针对Solaris Sparc64操作系统的FP0000007补丁。如果您安装了WAS,就需要产品组件名为WASSDK和WAS的补丁;如果您安装了IBM Http Server,就需要产品组件名为IHS的补丁;如果您安装了Plugin就需要产品组件名为PLG的补丁。通常,同样补丁编号的补丁,先装WASSDK补丁,再装WAS补丁。以后,每一次打补丁的过程,都是:
1) 把补丁文件拷贝到补丁工厂安装目录的maintenance目录下;
2) 在补丁工厂的安装目录下,执行./update.sh命令启动补丁工厂;
3) 在“安装目录”中选择将要打补丁的组件的安装目录。通常,对WAS组件,补丁会自动识别出安装位置;对于IBM Http Server(简称IHS)或者Plug-in这样的组件,需要选择正确的安装位置;
4)在maintenance package selection页面中选择想要打的补丁。
概要文件是一组用于定义运行时环境的文件,每个概要文件都是一组完全隔离的运行时环境。前面我们提到了概要文件有三种基本类型。在创建概要文件的过程中,通常我们要了解以下细节:
- 概要文件创建有两种方式,图形化创建向导和命令行方式。为了操作的简便和直观,我们通常采用图形化创建向导(执行WAS_Home/ bin/ProfileManagement/pmt.sh启动该向导)。如果安装的是64位的WAS,则没有该图形化创建向导工具。这时,请直接使用./manageprofiles.sh命令。例如:在UNIX平台上创建一个Application Server类型的名为AppSrv01的profile,使用manageprofiles命令可以如下操作:
export WAS_HOME=/opt/IBM/WebSphere/AppServer echo $WAS_HOME cd $WAS_HOME/bin ./manageprofiles.sh -create -profileName AppSrv01 -profilePath $WAS_HOME/profiles/AppSrv01 -templatePath $WAS_HOME/profileTemplates/default -hostName kcgg1d7.itso.ibm.com -enableAdminSecurity true -adminUserName adminUser_ID -adminPassword adminPassword
注意,命令和参数大小写敏感的。Manageprofiles命令的语法和更多参数选项请参见红皮书sg247304.pdf或信息中心。
- 在“确认网络配置/主机名满足要求”一节中,提到了选择适当的主机名;在创建概要文件(图1)过程中,大多数情况下向导自动识别出的主机名就符合要求,否则我们需要向概要文件向导中填入适当的主机名。在同一台机器上用概要文件创建向导创建多个profile时,自动识别的主机名可能是加上域名的全限定名称例如hosta.cn.ibm.com,也可能是短名hosta。这两种形式都支持,但是不要在一个cell (Cell指WAS多个实例组成的一个受管域)中混用这两种名称方式。
- 创建应用程序服务器概要文件过程中,可以根据需要选择创建适用于开发环境或生产环境使用的应用服务器实例。例如,对于开发环境,我们可以选择使用开发模板来创建服务器,开发模板针对开发目的进行了优化的配置,减少了WAS启动时间并允许服务器在功能较少的硬件上运行。但在生产环境中,不要选择“使用开发模板”。
- 概要文件创建过程中我们可以选择“启用管理安全性”,让用户在进行登陆管理控制台、停止WAS实例等管理任务时需要输入用户名/密码。注意,如果在创建概要文件过程中没有启用管理安全性,或者启用管理安全性之后希望修改用户名或密码,都可以在概要文件创建完毕之后再次进行修改(请参见“管理安全性”)。
- 创建概要文件过程中可查看/更改该概要文件所占的port。图5显示了创建的这个概要文件实例启动时将占用的端口,我们可看到管理控制台端口是9060,Http传输端口(也就是应用访问端口)是9080。如果用命令行方式创建概要文件向导,无法通过图形化显示看到这些端口,如果希望查看端口,可以在概要文件创建完毕后查看配置得到端口值(请参见“查看/更改应用服务器端口”);如果希望修改这些端口,则可以在概要文件创建中用参数-portsFile或-startingPort指定端口。当然,所有这些端口值都可以在概要文件创建完毕之后再次修改。
图 5. 创建概要文件中显示端口
-
〔转贴〕Oracle SQL性能优化
2008-12-15 16:11:03
同事发的,具体出自哪里不清楚。

作者总结了很多具体的原则,对编写、调优sql具有指导意义。
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效):ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表.
(2) WHERE子句中的连接顺序.:ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
(3) SELECT子句中避免使用 ‘ * ‘:ORACLE在解析的过程中, 会将'*' 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间
(4) 减少访问数据库的次数:ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等;
(5) 在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200
(6) 使用DECODE函数来减少处理时间:使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表.
(7) 整合简单,无关联的数据库访问:如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
(8) 删除重复记录:最高效的删除重复记录方法 ( 因为使用了ROWID)例子:DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID)
FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
(9) 用TRUNCATE替代DELETE:当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息. 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况) 而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,执行时间也会很短. (译者按: TRUNCATE只在删除全表适用,TRUNCATE是DDL不是DML)
(10) 尽量多使用COMMIT:只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少:
COMMIT所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. ORACLE为管理上述3种资源中的内部花费
(11) 用Where子句替换HAVING子句:避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销. (非oracle中)on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后,因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,where也应该比having快点的,因为它过滤数据后才进行sum,在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里
(12) 减少对表的查询:在含有子查询的SQL语句中,要特别注意减少对表的查询.例子: SELECT TAB_NAME FROM TABLES WHERE (TAB_NAME,DB_VER) = ( SELECTTAB_NAME,DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
(13) 通过内部函数提高SQL效率.:复杂的SQL往往牺牲了执行效率. 能够掌握上面的运用函数解决问题的方法在实际工作中是非常有意义的
(14) 使用表的别名(Alias):当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误.
(15) 用EXISTS替代IN、用NOT EXISTS替代NOT IN:在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接.在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率. 在子查询中,NOT IN子句将执行一个内部的排序和合并. 无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历). 为了避免使用NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS.例子:(高效)SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND EXISTS (SELECT ‘X' FROM DEPT WHERE DEPT.DEPTNO = EMP.DEPTNO AND LOC = ‘MELB')(低效)SELECT * FROM EMP (基础表) WHERE EMPNO > 0 AND DEPTNO IN(SELECT DEPTNO FROM DEPT WHERE LOC = ‘MELB')
(16) 识别'低效执行'的SQL语句:虽然目前各种关于SQL优化的图形化工具层出不穷,但是写出自己的SQL工具来解决问题始终是一个最好的方法:SELECT EXECUTIONS , DISK_READS, BUFFER_GETS,
ROUND((BUFFER_GETS-DISK_READS)/BUFFER_GETS,2) Hit_radio,
ROUND(DISK_READS/EXECUTIONS,2) Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS>0
AND BUFFER_GETS > 0
AND (BUFFER_GETS-DISK_READS)/BUFFER_GETS < 0.8
ORDER BY 4 DESC;
(17) 用索引提高效率:索引是表的一个概念部分,用来提高检索数据的效率,ORACLE使用了一个复杂的自平衡B-tree结构. 通常,通过索引查询数据比全表扫描要快. 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引. 同样在联结多个表时使用索引也可以提高效率. 另一个使用索引的好处是,它提供了主键(primary key)的唯一性验证.。那些LONG或LONG RAW数据类型, 你可以索引几乎所有的列. 通常, 在大型表中使用索引特别有效. 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率. 虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价. 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改. 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.。定期的重构索引是有必要的.:ALTER INDEX REBUILD
(18) 用EXISTS替换DISTINCT:当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT. 一般可以考虑用EXIST替换, EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果. 例子: (低效):
SELECT DISTINCT DEPT_NO,DEPT_NAME FROM DEPT D , EMP E WHERE D.DEPT_NO = E.DEPT_NO
(高效):
SELECT DEPT_NO,DEPT_NAME FROM DEPT D WHERE EXISTS ( SELECT ‘X'
FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO);
(19) sql语句用大写的;因为oracle总是先解析sql语句,把小写的字母转换成大写的再执行
(20) 在java代码中尽量少用连接符“+”连接字符串!
(21) 避免在索引列上使用NOT 通常, 我们要避免在索引列上使用NOT, NOT会产生在和在索引列上使用函数相同的影响. 当ORACLE”遇到”NOT,他就会停止使用索引转而执行全表扫描.
(22) 避免在索引列上使用计算.
WHERE子句中,如果索引列是函数的一部分.优化器将不使用索引而使用全表扫描.
举例:
低效:
SELECT … FROM DEPT WHERE SAL * 12 > 25000;
高效:
SELECT … FROM DEPT WHERE SAL > 25000/12;
(23) 用>=替代>高效:
SELECT * FROM EMP WHERE DEPTNO >=4
低效:
SELECT * FROM EMP WHERE DEPTNO >3
两者的区别在于, 前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录.
(24) 用UNION替换OR (适用于索引列)通常情况下, 用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描. 注意, 以上规则只针对多个索引列有效. 如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低. 在下面的例子中, LOC_ID 和REGION上都建有索引.
高效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE REGION = “MELBOURNE”
低效:
SELECT LOC_ID , LOC_DESC , REGION
FROM LOCATION
WHERE LOC_ID = 10 OR REGION = “MELBOURNE”
如果你坚持要用OR, 那就需要返回记录最少的索引列写在最前面.
(25) 用IN来替换OR 这是一条简单易记的规则,但是实际的执行效果还须检验,在ORACLE8i下,两者的执行路径似乎是相同的. 低效:
SELECT…. FROM LOCATION WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30
高效
SELECT… FROM LOCATION WHERE LOC_IN IN (10,20,30);
(26) 避免在索引列上使用IS NULL和IS NOT NULL避免在索引中使用任何可以为空的列,ORACLE将无法使用该索引.对于单列索引,如果列包含空值,索引中将不存在此记录. 对于复合索引,如果每个列都为空,索引中同样不存在此记录. 如果至少有一个列不为空,则记录存在于索引中.举例: 如果唯一性索引建立在表的A列和B列上, 并且表中存在一条记录的A,B值为(123,null) , ORACLE将不接受下一条具有相同A,B值(123,null)的记录(插入). 然而如果所有的索引列都为空,ORACLE将认为整个键值为空而空不等于空. 因此你可以插入1000 条具有相同键值的记录,当然它们都是空! 因为空值不存在于索引列中,所以WHERE子句中对索引列进行空值比较将使ORACLE停用该索引.低效: (索引失效)
SELECT … FROM DEPARTMENT WHERE DEPT_CODE IS NOT NULL;
高效: (索引有效)
SELECT … FROM DEPARTMENT WHERE DEPT_CODE >=0;
(27) 总是使用索引的第一个列:如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 这也是一条简单而重要的规则,当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
(28) 用UNION-ALL 替换UNION ( 如果有可能的话):当SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并, 然后在输出最终结果前进行排序. 如果用UNION ALL替代UNION, 这样排序就不是必要了. 效率就会因此得到提高. 需要注意的是,UNION ALL 将重复输出两个结果集合中相同记录. 因此各位还是要从业务需求分析使用UNION ALL的可行性. UNION 将对结果集合排序,这个操作会使用到SORT_AREA_SIZE这块内存. 对于这块内存的优化也是相当重要的. 下面的SQL可以用来查询排序的消耗量低效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
UNION
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
高效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
UNION ALL
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
(29) 用WHERE替代ORDER BY:ORDER BY 子句只在两种严格的条件下使用索引.
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序.
ORDER BY中所有的列必须定义为非空.
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列.例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL低效: (索引不被使用)
SELECT DEPT_CODE FROM DEPT ORDER BY DEPT_TYPE
高效: (使用索引)
SELECT DEPT_CODE FROM DEPT WHERE DEPT_TYPE > 0
(30) 避免改变索引列的类型.:当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换. 假设 EMPNO是一个数值类型的索引列.
SELECT … FROM EMP WHERE EMPNO = ‘123'
实际上,经过ORACLE类型转换, 语句转化为:
SELECT … FROM EMP WHERE EMPNO = TO_NUMBER(‘123')
幸运的是,类型转换没有发生在索引列上,索引的用途没有被改变.
现在,假设EMP_TYPE是一个字符类型的索引列.
SELECT … FROM EMP WHERE EMP_TYPE = 123
这个语句被ORACLE转换为:
SELECT … FROM EMP WHERETO_NUMBER(EMP_TYPE)=123
因为内部发生的类型转换, 这个索引将不会被用到! 为了避免ORACLE对你的SQL进行隐式的类型转换, 最好把类型转换用显式表现出来. 注意当字符和数值比较时, ORACLE会优先转换数值类型到字符类型
(31) 需要当心的WHERE子句:某些SELECT 语句中的WHERE子句不使用索引. 这里有一些例子.
在下面的例子里, (1)‘!=' 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中. (2) ‘||'是字符连接函数. 就象其他函数那样, 停用了索引. (3) ‘+'是数学函数. 就象其他数学函数那样, 停用了索引. (4)相同的索引列不能互相比较,这将会启用全表扫描.
(32) a. 如果检索数据量超过30%的表中记录数.使用索引将没有显著的效率提高.
b. 在特定情况下, 使用索引也许会比全表扫描慢, 但这是同一个数量级上的区别. 而通常情况下,使用索引比全表扫描要块几倍乃至几千倍!
(33) 避免使用耗费资源的操作:带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎
执行耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序. 通常, 带有UNION, MINUS , INTERSECT的SQL语句都可以用其他方式重写. 如果你的数据库的SORT_AREA_SIZE调配得好, 使用UNION , MINUS, INTERSECT也是可以考虑的, 毕竟它们的可读性很强
(34) 优化GROUP BY:提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果但第二个明显就快了许多.低效:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP JOB
HAVING JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
高效:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
GROUP JOB -
给自己打气的(二)
2008-12-12 16:36:29
网上看来的,心情不好的时候看看挺好的。
每个人都有一套属于自我的生活理念,有的人生活的很快乐,有的人却对生活出奇的失望,归根揭底是心态的问题。
生活中总是会出现很多突如其来的灾难,会让人突然陷入一种茫然、焦急、狂躁的情绪之中,更有甚者对生命的绝望。
不难看出,随着社会的进步,竞争的激烈,让人们的各种压力增大,如果当这种压力超过了某种负荷能力的时候,就会让人出现偏激情绪,这样带来的后果是无法想象的,我个人觉得如果人能在适当的阶段给自己找一个出口,会逐渐排除这样的精神压力,让你走向更辉煌的道路。
那么我们应该怎么减轻这样的负面情绪呢?
第一:学会让自己安静,把思维沉浸下来,慢慢降低对事物的欲望。把自我经常归零,每天都是新的起点,没有年龄的限制,只要你对事物的欲望适当的降低,会赢得更多的求胜机会。(所谓退一步自然宽.)
第二:学会关爱自己,只有多关爱自己,才能有更多的能量去关爱他人,如果你有足够的能力,就要尽量帮助你能帮助的人,那样你得到的就是几份快乐,多帮助他人,善待自己,也是一种减压的方式。
第三:遇到心情烦躁的情况的时候,你喝一杯白水,放一曲舒缓的轻音乐,闭眼,回味身边的人与事,对新的未来可以慢慢的输理,即是一种休息,也是一种冷静的前进思考。
第四:多和自己竞争,没有必要嫉妒别人,也没必要羡慕别人。很多人都是由于羡慕别人,而始终把自己当成旁观者,越是这样,越是会把自己掉进一个深渊。你要相信,只要你去做,你也可以的。为自己的每一次进步而开心(事是不分大与小的,复杂的事情简单做,简单的事情认真做,认真的事情反复做,争取做到最好)
第五:广泛阅读,阅读实际就是一个吸收养料的过程,现代人面临激烈的竞争,复杂的人际关系,为了让自己不至于在某些场合尴尬,可以进行广泛的阅读,让自己的头脑充实也是一种减压的方式,人有时候是这样的,肚子里空空的时候会自然的焦急,这就对了,正是你的求知欲在呼喊你,要活着就需要这样的养分。
第六:不论在任何条件下,自己不能看不起自己,哪怕全世界都不相信你,看不起你,你一定要相信你自己,因为我相信一句话,如果你喜欢上了你自己,那么就会有更多的人喜欢你,如果你想自己是什么样的人,只要你想,努力去实现,就会的!(很多人为什么没实现,就是没毅力)
第七:学会调整情绪,尽量往好处想,很多人遇到一些事情的时候,就急的象热锅上的蚂蚁,本来可以很好解决的问题,正是因为情绪的把握不好,让简单的事情复杂化,让复杂的事情更难.其实只要把握好事情的关键,把每个细节处理的得贴就会游刃有余.遇到棘手的事情,冷静点,然后想如何才能把它做好,你越往好处想,心就越开,越往坏处想,心就越窄!
第八:珍惜身边的人,用语方面尽量不伤害,哪怕遇到你不喜欢的人,你尽量迂回,找理由离开也不要肆意伤害,这样不仅让自己心情太坏,也让场面更尴尬.珍惜现在身边的一切。
第九:热爱生命,每天吸收新的养料,每天要有不同的思维.多学会换位思考,尽量找新的事物满足对世界的新奇感,神秘感。
第十:只有用真心,用爱,用人格去面对你的生活,你的人生才会更精彩! -
给自己打气的(一)
2008-12-12 16:31:34
:) 在网上看到的,觉得不开心的时候看看挺好的
01.每天告诉自己一次,『我真的很不错』。
02.生气是拿别人做错的事来惩罚自己。
03.生活中若没有朋友,就像生活中没有阳光一样。
04.明天的希望,让我们忘了今天的痛苦。
05.生活若剥去理想、梦想、幻想,那生命便只是一堆空架子。
06.发光并非太阳的专利,你也可以发光。
07.愚者用肉体监视心灵,智者用心灵监视肉体。
08.获致幸福的不二法门是珍视你所拥有的、遗忘你所没有的。
09.贪婪是最真实的贫穷,满足是最真实的财富。
10.你可以用爱得到全世界,你也可以用恨失去全世界11.人的价值,在遭受诱惑的一瞬间被决定。
12.年轻是我们唯一拥有权利去编织梦想的时光。
13.青春一经典当即永不再赎。
14.没有了爱的语言,所有的文字都是乏味的。
15.真正的爱,应该超越生命的长度、心灵的宽度、灵魂的深度。
16.爱的力量大到可以使人忘记一切,却又小到连一粒嫉妒的沙石也不能容纳。
17.当一个人真正觉悟的一刻,他放弃追寻外在世界的财富,而开始追寻他内心世界的真正财富。
18.只要有信心,人永远不会挫败。
19.不论你在什麽时候开始,重要的是开始之後就不要停止。
20.不论你在什麽时候结束,重要的是结束之後就不要悔恨。
21.人若软弱就是自己最大的敌人。
22.人若勇敢就是自己最好的朋友。
23.『不可能』只存在於蠢人的字典里。
24.抱最大的希望,为最大的努力,做最坏的打算。
25.家!甜蜜的家!天下最美好的莫过於家。
26.游手好闲会使人心智生锈。
27.每一件事都要用多方面的角度来看它。
28.有理想在的地方,地狱就是天堂。
29.有希望在的地方,痛苦也成欢乐。
30.所有的胜利,与征服自己的胜利比起来,都是微不足道。
31.所有的失败,与失去自己的失败比起来,更是微不足道。
32.上帝从不埋怨人们的愚昧,人们却埋怨上帝的不公平。
33.美好的生命应该充满期待、惊喜和感激。
34.世上最累人的事,莫过於虚伪的过日子。
35.觉得自己做得到和做不到,其实只在一念之间。
36.第一个青春是上帝给的;第二个的青春是靠自己努力的。
37.少一点预设的期待,那份对人的关怀会更自在。
38.思想如钻子,必须集中在一点钻下去才有力量。
39.人只要不失去方向,就不会失去自己。
40.如果你曾歌颂黎明,那麽也请你拥抱黑夜。
41.问候不一定要慎重其事,但一定要真诚感人。
42.人生重要的不是所站的位置,而是所朝的方向。
43.当你能飞的时候就不要放弃飞。 最好的选择全在于您一念之间,机会总是偏爱那些时刻准备着的人!!!!
44.当你能梦的时候就不要放弃梦。
45.当你能爱的时候就不要放弃爱。
46.生命太过短暂,今天放弃了明天不一定能得到。
47.天才是百分之一的灵感加上百分之九十九的努力。
48.人总是珍惜未得到的,而遗忘了所拥有的。
49.快乐要懂得分享,才能加倍的快乐。
50.自己要先看得起自己,别人才会看得起你。
51.一个今天胜过两个明天。
52.要铭记在心;每天都是一年中最美好的日子。
53.乐观者在灾祸中看到机会;悲观者在机会中看到灾祸。
54.有勇气并不表示恐惧不存在,而是敢面对恐惧、克服恐惧。
55.肯承认错误则错已改了一半。
56.明天是世上增值最快的一块土地,因它充满了希望。
57.理想的路总是为有信心的人预备著。
58.所有欺骗中,自欺是最为严重的。
59.人生最大的错误是不断担心会犯错。
60.把你的脸迎向阳光,那就不会有阴影。
61.经验是由痛苦中粹取出来的。
62.用最少的悔恨面对过去。
63.用最少的浪费面对现在。
64.用最多的梦面对未来。
65.快乐不是因为拥有的多而是计较的少。
66.你的选择是做或不做,但不做就永远不会有机会。
67.如你想要拥有完美无暇的友谊,可能一辈子找不到朋友。
68.不如意的时候不要尽往悲伤里钻,想想有笑声的日子吧。
69.把自己当傻瓜,不懂就问,你会学的更多。
70.要纠正别人之前,先反省自己有没有犯错。
71.因害怕失败而不敢放手一搏,永远不会成功。
72.要克服生活的焦虑和沮丧,得先学会做自己的主人. -
[转] 软件测试开发人员(SDET)到底是什么职位?
2008-12-12 14:27:07
转自:
http://www.cnblogs.com/smwikipedia/archive/2008/05/14/1197309.html
软件测试开发人员(SDET)到底是什么职位?
SDET是微软三大核心技术工种之一(其它两个是PM和SDE),是任何一个产品开发团队中必不可少的一份子。SDET是产品质量和用户的代言人,主要的工作是从客观的角度去分析产品的质量以及给出系统化的反馈和建议,从而使整个开发团队能够及时地做出对正确的抉择。要做到这点,SDET需要积极的参与产品的计划、设计、和代码检验,找出并分析问题的根本原因,以及提高产品和流程质量的系统化的方案。
SDET 和SDE都有哪些区别?
SDET和SDE都需要有扎实的计算机科学基本功,包括编程能力。所不同的是,SDET的工作重点是用反向思维分析的方法找出对产品质量有负面影响的问题,带领正个团队解决这些问题,从而提高产品的质量。SDET需要掌握多种技术,用不同的方法去分析产品各个方面可能产生的种种问题。这里所强调的是对问题的系统分析能力,以及预见到常人没有想到的潜在问题。
什么样的人适合做SDET?
如果你对质量的要求很高,并且喜欢拆东西,弄明白它是怎么工作的,而且喜欢去改善它的话,那么SDET应当是你的首选。一个SDET的最基本要求就是对质量的热情:一定要找到所有的瑕疵从而达到完美。其次,喜欢钻研、分析、并改善事物是成功的SDET的又一潜质。另外,喜欢学习并掌握多种不同的技能和知识也是SDET所需的技能。
SDET都有哪些事业发展途径?
在微软,SDET有非常明确的事业发展阶段。从入门SDET开始,到与总监同级的Partner SDET,每一个阶段都有充足的挑战和机会。喜欢做技术,可以一直顺着IC的事业模型做到Partner SDET甚至Distinguished Engineer;如果你喜欢管理,可以从测试组长一直做到VP of Test。而最好的一点是,不管是做技术还是做管理,在同一级别的待遇是同等的,也就是做技术没有“顶”,不做manager也能晋升。
还可以看看内部人对这个职位的更详细的解读.
http://www.51testing.com/action_viewnews_itemid_17398.html
找到一篇不错的关于微软测试工作性质的文章,对工作角色的认识有一定的帮助,我就是SDET,属于开发和测试中间的那种,并不像自己想象的那种没有什么技术含量的黑盒测试,对SDET的要求还是挺高的,做好这种白盒测试,仍然要加紧自己在开发能力的培养,才能较快的发现代码中的问题。
1. 基本情况
测试在微软公司是一项非常重要的工作,微软公司在此方面的投入是非常巨大的。微软对测试的重视表现在工程开发队伍的人员构成上,微软的项目经理、软件开发人员和测试人员的比例基本是1:3:3或1:4:4,可以看出开发人员与测试人员的比例是1:1。对于测试的重视还表现在最后产品要发布的时候,此产品的所有相关部门都必须签字,而测试人员则具有绝对的否决权。
测试人员中分成两种职位,Software Development Engineer in Test(测试组的软件开发工程师)实际上还是属于开发人员,他们具备编写代码的能力和开发工具软件的经验,侧重于开发自动化测试工具和测试脚本,实现测试的自动化。Software Test Engineer(软件测试工程师)具体负责测试软件产品,主要完成一些手工测试以及安装配置测试。
2. 测试计划
测试计划是测试人员管理测试项目,在软件中寻找Bug的一种有效的工具。测试计划主要有两个作用,一是评判团队的测试覆盖率以及效率,让测试工作很有条理的逐步展开。二是有利于与项目经理、开发人员进行沟通。有了测试计划之后,他们就能够知道你是如何开展测试工作的,他们也会从中提出很多有益的意见,确保测试工作顺利进行。总之,有了测试计划可以更好的完成测试工作,确保用户的满意度。
测试人员在编写测试计划之前,应获得以下文档:
1)程序经理编写的产品功能说明书或产品开发计划;
2)程序经理或开发人员提供的开发进度表。
根据产品的特性及开发进度安排,测试人员制定具体的测试计划。测试计划通常包括以下内容:
1)测试目标和发布条件:
a. 给出清晰的测试目标描述;
b. 定义产品的发布条件,即在达到何种测试目标的前提下才可以发布产品的某个特定版本。
2)待测产品范围:
a. 软件主要特性/功能说明,即待测软件主要特性的列表;
b. 特性/功能测试一览,应涵盖所有特性、对话框、菜单和错误信息等待测内容,并列举每个测试范围内要重点考虑的关键功能。
3)测试方法描述:
a. 定义测试软件产品时使用的测试方法;
b. 描述每一种特定的测试方法可以覆盖哪些测试范围。
4)测试进度表:
a. 定义测试里程碑;
b. 定义当前里程碑的详细测试进度。
5)测试资源和相关的程序经理/开发工程师:
a. 定义参与测试的人员;
b. 描述每位测试人员的职责范围;
c. 给出与测试有关的程序经理/开发工程师的相关信息。
6)配置范围和测试工具:
a. 给出测试时使用的所有计算机平台列表;
b. 描述测试覆盖了哪些硬件设备;
c. 测试时使用的主要测试工具。
此外,还应列出测试中可能会面临的风险及测试的依赖性,即测试是否依赖于某个产品或某个团队。比如此项测试依赖性WindowsCE这个操作系统,而这个系统要明年2月份才能做好,那么此项测试就可能只有在明年5月份才能完成,这样就存在着依赖关系。如果那个团队的开发计划往后推,则此项测试也会被推迟。
3. 测试用例开发
一个好的测试用例就是有一个合理的概率来找到Bug,不要冗余,要有针对性,一个测试只针对一件事情。特别是功能测试的时候,如果一个测试是测了两项功能,那么如果测试结果失败的话,就不知道到底是哪项功能出了问题。
测试用例开发中主要使用的技术有等价类划分,边界值的分析,Error Guessing Testing。
等价类划分是根据输入输出条件,以及自身的一些特性分成两个或更多个子集,来减少所需要测试的用例个数,并且能用很少的测试用例来覆盖很多的情况,减少测试用例的冗余度。在等价类划分中,最基本的划分是一个为合法的类,一个为不合法的类。
边界值的分析是利用了一个规律,即程序最容易发生错误的地方就是在边界值的附近,它取决于变量的类型,以及变量的取值范围。一般对于有n个变量时,会有 6n+1个测试用例,取值分别是min-1, min, min+1, normal, max-1, max,max+1的组合。边界值的分析的缺点,是对逻辑变量和布尔型变量不起作用,还有可能会忽略掉某些输入的组合。
Error Guessing Testing完全靠的是经验,所设计的测试用例就是常说的猜测。感觉到软件在某个地方可能出错,就去设计相应的测试用例,这主要是靠实际工作中所积累的经验和知识。其优点是速度快,只要想得到,就能很快设计出测试用例。缺点就是没有系统性,无法知道覆盖率会有多少,很可能会遗漏一些测试领域。
实际上在微软是采用一些专门的软件或工具负责测试用例的管理,有一些测试信息可以被记录下来,比如测试用例的简单描述,在哪些平台执行,是手工测试还是自动测试,运行的频率是每天运行一次,还是每周运行一次。此外还有清晰的测试通过或失败的标准,以及详细记录测试的每个步骤。
4. Bug跟踪过程
在软件开发项目中,测试人员的一项最重要使命就是对所有已知Bug进行有效的跟踪和管理,保证产品中出现的所有问题都可以得到有效的解决。一般地,项目组发现、定位、处理和最终解决一个Bug的过程包括Bug报告、Bug评估和分配、Bug处理、Bug关闭等四个阶段:
1)测试工程师在测试过程中发现新的Bug后,应向项目组报告该Bug的位置、表现、当前状态等信息。项目组在Bug数据库中添加该Bug的记录。
2)开发经理对已发现的Bug进行集中讨论,根据Bug对软件产品的影响来评估Bug的优先级,制定Bug的修正策略。按照Bug的优先级顺序和开发人员的工作安排,开发经理将所有需要立即处理的Bug分配给相应的开发工程师。
3)开发工程师根据安排对特定的Bug进行处理,找出代码中的错误原因,修改代码,重新生成产品版本。
4)开发工程师处理了Bug之后,测试人员需要对处理后的结果进行验证,经过验证确认已正确处理的Bug被标记为关闭(Close)状态。测试工程师既需要验证Bug是否已经被修正,也需要确定开发人员有没有在修改代码的同时引入新的Bug。
5. Bug的不同处理方式
在某些情况下,Bug已处理并不意味着Bug已经被修正。开发工程师可以推迟Bug的修正时间,也可以在分析之后告知测试工程师这实际上不是一个真正的Bug。也就是说,某特定的Bug经开发工程师处理之后,该Bug可能包括以下几种状态。
已修正:开发工程师已经修正了相应的程序代码,该Bug不会出现了。
可推迟:该Bug的重要程度较低,不会影响当前应提交版本的主要功能,可安排在下一版本中再行处理。
设计问题:该Bug与程序实现无关,其所表现出来的行为完全符合设计要求,对此应提交给程序经理处理。
无需修正:该Bug的重要程度非常低,根本不会影响程序的功能,项目组没有必要在这些Bug上浪费时间。
五、成为优秀测试工程师的要求
要成为一名优秀的测试工程师,首先对计算机的基本知识要有很好的了解,精通一门或多门的编程语言,具备一定的程序调试技能,掌握测试工具的开发和使用技术。同时要比较细心,会按照任务的轻重缓急来安排自己的工作,要有很好的沟通能力。此外,还要善于用非常规的方式思考问题,尽可能多的参加软件测试项目,在实践中学习技能,积累经验,不断分析和总结软件开发过程中可能出错的环节。这样,一名优秀的测试工程师就从软件测试的实践中脱颖而出了。
结束语:微软的软件开发经验积淀深厚,微软工程师们的授课生动溢彩,其中有些内容是结合编程代码所作的详细讲解,较难用介绍性文字加以概括提炼,加之笔者受能力和精力所限,只能撷取部分精华内容整理成文以飨读者,因此难免是挂一漏万,甚至会有失误之处,敬请对本系列文章的关注者谅解及指正。最后对微软老师们的辛勤付出再表由衷谢意!


我的栏目
标题搜索
我的存档
数据统计
- 访问量: 146194
- 日志数: 249
- 书签数: 41
- 建立时间: 2007-08-11
- 更新时间: 2013-03-28
