
-
[转] 学习动态性能表(五)--V$SESSION
2009-03-23 16:50:50
学习动态性能表第五篇--V$SESSION在本视图中,每一个连接到数据库实例中的session都拥有一条记录。包括用户session及后台进程如DBWR,LGWR,arcchiver等等。
V$SESSION中的常用列V$SESSION是基础信息视图,用于找寻用户SID或SADDR。不过,它也有一些列会动态的变化,可用于检查用户。如例:
SQL_HASH_VALUE,SQL_ADDRESS:这两列用于鉴别默认被session执行的SQL语句。如果为null或0,那就说明这个session没有执行任何SQL语句。PREV_HASH_VALUE和PREV_ADDRESS两列用来鉴别被session执行的上一条语句。注意:当使用SQL*Plus进行选择时,确认你重定义的列宽不小于11以便看到完整的数值。
STATUS:这列用来判断session状态是:
Achtive:正执行SQL语句(waiting for/using a resource)
Inactive:等待操作(即等待需要执行的SQL语句)
Killed:被标注为删除下列各列提供session的信息,可被用于当一个或多个combination未知时找到session。
Session信息
SID:SESSION标识,常用于连接其它列
SERIAL#:如果某个SID又被其它的session使用的话则此数值自增加(当一个 SESSION结束,另一个SESSION开始并使用了同一个SID)。
AUDSID:审查session ID唯一性,确认它通常也用于当寻找并行查询模式
USERNAME:当前session在oracle中的用户名。Client信息
数据库session被一个运行在数据库服务器上或从中间服务器甚至桌面通过SQL*Net连接到数据库的客户端进程启动,下列各列提供这个客户端的信息
OSUSER:客户端操作系统用户名
MACHINE:客户端执行的机器
TERMINAL:客户端运行的终端
PROCESS:客户端进程的ID
PROGRAM:客户端执行的客户端程序
要显示用户所连接PC的 TERMINAL、OSUSER,需在该PC的ORACLE.INI或Windows中设置关键字TERMINAL,USERNAME。Application信息
调用DBMS_APPLICATION_INFO包以设置一些信息区分用户。这将显示下列各列。
CLIENT_INFO:DBMS_APPLICATION_INFO中设置
ACTION:DBMS_APPLICATION_INFO中设置
MODULE:DBMS_APPLICATION_INFO中设置
下列V$SESSION列同样可能会被用到:
ROW_WAIT_OBJ#
ROW_WAIT_FILE#
ROW_WAIT_BLOCK#
ROW_WAIT_ROW#V$SESSION中的连接列
Column View Joined Column(s)
SID V$SESSION_WAIT,,V$SESSTAT,,V$LOCK,V$SESSION_EVENT,V$OPEN_CURSOR SID
(SQL_HASH_VALUE, SQL_ADDRESS) V$SQLTEXT, V$SQLAREA, V$SQL (HASH_VALUE, ADDRESS)
(PREV_HASH_VALUE, PREV_SQL_ADDRESS) V$SQLTEXT, V$SQLAREA, V$SQL (HASH_VALUE, ADDRESS)
TADDR V$TRANSACTION ADDR
PADDR V$PROCESS ADDR
示例:
1.查找你的session信息
SELECT SID, OSUSER, USERNAME, MACHINE, PROCESS
FROM V$SESSION WHERE audsid = userenv('SESSIONID');2.当machine已知的情况下查找session
SELECT SID, OSUSER, USERNAME, MACHINE, TERMINAL
FROM V$SESSION
WHERE terminal = 'pts/tl' AND machine = 'rgmdbs1';查找当前被某个指定session正在运行的sql语句。假设sessionID为100
select b.sql_text
from v$session a,v$sqlarea b
where a.sql_hash_value=b.hash_value and a.sid=100
寻找被指定session执行的SQL语句是一个公共需求,如果session是瓶颈的主要原因,那根据其当前在执行的语句可以查看session在做些什么。 -
学习BASH--命令别名与历史命令
2009-03-23 11:21:29
(1)alias与unalias
alias的定义规则与定义变量的规则几乎相同,使用方法:alias后加上“别名='指令 参数'”,如:
alias rm='rm -i'
取消命令别名用unalias,使用方法:unalias 变量名称,如:
unalias rm
(2)history
该指令用来查询曾经输入的指令。用法:


-
学习BASH-变量
2009-03-23 10:13:21
Linux使用的是Bourne Again SHell(简称bash),这个SHell是Bourne SHell的增强版本,是基于GNU的架构下发展而来。
(1)echo
该指令用于显示变量,如:
echo $PATH <==显示当前的PATH变量。
(2)env
该指令用于显示Linux系统中预设的变量。使用方法:直接输入env。
(3)set
该指令显示所有的变量(包含当前的环境变量和自定义变量)。使用方法:直接输入set。
(4)变量设定规则
a.变量与变量内容以等号“=”连接;
b.等号两边不能直接接空格;
c.变量名称只能是英文字母与数字,其中数字不能是开头字符;
d.若变量内容中有空格符,可以使用单引号或双引号将变量内容结合起来,需要注意:双引号内的特殊字符可以保留其特性,单引号内的特殊字符仅为一般字符;
e.可以使用跳转字符“\”将特殊符号(如Enter、$、\、空格符、'等)变成一般符号,如:name=yangmei\'s\ name(用\将'和空格转换为一般字符);
f.在一串指令中,还需要借助其他指令提供的信息,可使用quote"'command'";
g.若变量为扩增变量内容时,则需以双引号及$变量名称(如"$PATH":/home)继续累加内容;
h.若自定义变量需要在其他子程序中执行,则以export使变量可以动作,如export name;
i.通常大写字符为系统预设变量,自定义变量可以使用小写字符,方便判断;
j.取消变量的方法为:unset 变量名称。
-
VI编辑器常用指令
2009-03-18 17:02:51
基本上,vi分为3种模式,分别是“一般模式”、“编辑模式”和“命令模式”。
一般模式:以vi处理文件时,一进入该文件就是一般模式了。在这个模式中,可以使用上下左右方向键来移动光标,可以使用“删除字符”或“删除整行”来处理文件内容,也可以使用“复制”、“粘贴”来处理文件数据。
编辑模式:按i,I,o,O,a,A等字母之后才会进入编辑模式。在Linux中,按下上述字母后,在画面的左下方会出现INSERT或REPLACE字样,此时可进行写操作。按ESC键退出编辑模式回到一般模式。
命令行模式:在一般模式中,输入“:”或“/”就可将光标移动到最末一行。在该模式下,可进行搜寻数据、读取、存盘、大量字符替换、退出vi、现实行号等操作。
常用指令
(1)一般模式
Ctrl+f 屏幕向后翻一页
ctrl+b 屏幕向前翻一页
0 (数字0)移动到光标所在行的第一个字符处
$ 移动到光标所在行的最后一个字符处
G 移动到文件最后一行
n<Enter> 光标向下移动n行
/word 在光标之后查找名为“word”的字符串
:n1,n2s/word1/word2/g 在第n1行和n2行之间查找字符串word1,并将其替换为word2
:1,$s/word1/word2/g 从第一行到最后一行查找字符串word1,并将其替换为word2
:1,$s/word1/word2/gc 从第一行到最后一行查找字符串word1,并将其替换为word2,并且在替换前提示用户确认(confirm)
x,X x为向后删除一个字符,X为向前删除一个字符
dd 删除光标所在的整行
ndd 删除光标所在行的向下n行(包括光标所在行),如:20dd是删除20行
yy 复制光标所在行
nyy 复制光标所在行的向下的n行(包括光标所在行),如:20yy是复制20行
p,P p为复制的数据粘贴在光标下一行,P则为粘贴在光标上一行
u 恢复前一个动作
(2)编辑模式
i,I 在当前光标所在处插入输入的文字,已存在的字符自动后退
a,A 添加:由当前光标所在处的下一个字符开始输入,已存在的字符自动后退
o,O 插入新的一行,从光标所在行的下一行行首开始输入字符
r,R 替换:r替换光标索指的字符;R替换光标所指的字符,直到按下ESC为止
ESC 退出编辑模式,回到一般模式
(3)命令行模式
:w 将笔记的数据写入硬盘文件中
:w! 若文件属性为只读,强制写入该文件
:q 退出vi
:q! 强制退出不保存修改过的东东
:wq 保存后退出
:wq! 强制保存后退出
:w后接filename 将该文件另存为名为filename的文件(类似另存新文档)
-
[转] 中间件技术的概念与分类
2009-02-23 11:13:37
转自:
http://tech.it168.com/d/2008-04-11/200804112227497.shtml
一、为什么要中间件
计算机技术迅速发展。从硬件技术看,CPU速度越来越高,处理能力越来越强;从软件技术看,应用程序的规模不断扩大,特别是Internet及WWW的出现,使计算机的应用范围更为广阔,许多应用程序需在网络环境的异构平台上运行。这一切都对新一代的软件开发提出了新的需求。在这种分布异构环境中,通常存在多种硬件系统平台(如PC,工作站,小型机等),在这些硬件平台上又存在各种各样的系统软件(如不同的操作系统、数据库、语言编译器等),以及多种风格各异的用户界面,这些硬件系统平台还可能采用不同的网络协议和网络体系结构连接。如何把这些系统集成起来并开发新的应用是一个非常现实而困难的问题。
二、什么是中间件为解决分布异构问题,人们提出了中间件(middleware)的概念。中间件是位于平台(硬件和操作系统)和应用之间的通用服务,如图1所示,这些服务具有标准的程序接口和协议。针对不同的操作系统和硬件平台,它们可以有符合接口和协议规范的多种实现。

图1 中间件
也许很难给中间件一个严格的定义,但中间件应具有如下的一些特点:
满足大量应用的需要
运行于多种硬件和OS平台
支持分布计算,提供跨网络、硬件和OS平台的透明性的应用或服务的交互
支持标准的协议
支持标准的接口
由于标准接口对于可移植性和标准协议对于互操作性的重要性,中间件已成为许多标准化工作的主要部分。对于应用软件开发,中间件远比操作系统和网络服务更为重要,中间件提供的程序接口定义了一个相对稳定的高层应用环境,不管底层的计算机硬件和系统软件怎样更新换代,只要将中间件升级更新,并保持中间件对外的接口定义不变,应用软件几乎不需任何修改,从而保护了企业在应用软件开发和维护中的重大投资。
三、主要中间件的分类
中间件所包括的范围十分广泛,针对不同的应用需求涌现出多种各具特色的中间件产品。但至今中间件还没有一个比较精确的定义,因此,在不同的角度或不同的层次上,对中间件的分类也会有所不同。由于中间件需要屏蔽分布环境中异构的操作系统和网络协议,它必须能够提供分布环境下的通讯服务,我们将这种通讯服务称之为平台。基于目的和实现机制的不同,我们将平台分为以下主要几类:
远程过程调用(Remote Procedure Call)
面向消息的中间件(Message-Oriented Middleware)
对象请求代理(Object Request Brokers)
它们可向上提供不同形式的通讯服务,包括同步、排队、订阅发布、广播等等,在这些基本的通讯平台之上,可构筑各种框架,为应用程序提供不同领域内的服务,如事务处理监控器、分布数据访问、对象事务管理器OTM等。平台为上层应用屏蔽了异构平台的差异,而其上的框架又定义了相应领域内的应用的系统结构、标准的服务组件等,用户只需告诉框架所关心的事件,然后提供处理这些事件的代码。当事件发生时,框架则会调用用户的代码。用户代码不用调用框架,用户程序也不必关心框架结构、执行流程、对系统级API的调用等,所有这些由框架负责完成。因此,基于中间件开发的应用具有良好的可扩充性、易管理性、高可用性和可移植性。
下面,针对几类主要的中间件分别加以简要的介绍。
1、远程过程调用
远程过程调用是一种广泛使用的分布式应用程序处理方法。一个应用程序使用RPC来“远程”执行一个位于不同地址空间里的过程,并且从效果上看和执行本地调用相同。事实上,一个RPC应用分为两个部分:server和client。server提供一个或多个远程过程;client向server发出远程调用。server和client可以位于同一台计算机,也可以位于不同的计算机,甚至运行在不同的操作系统之上。它们通过网络进行通讯。相应的stub和运行支持提供数据转换和通讯服务,从而屏蔽不同的操作系统和网络协议。在这里RPC通讯是同步的。采用线程可以进行异步调用。
在RPC模型中,client和server只要具备了相应的RPC接口,并且具有RPC运行支持,就可以完成相应的互操作,而不必限制于特定的server。因此,RPC为client/server分布式计算提供了有力的支持。同时,远程过程调用RPC所提供的是基于过程的服务访问,client与server进行直接连接,没有中间机构来处理请求,因此也具有一定的局限性。比如,RPC通常需要一些网络细节以定位server;在client发出请求的同时,要求server必须是活动的等等。
2、面向消息的中间件MOM指的是利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可在分布环境下扩展进程间的通信,并支持多通讯协议、语言、应用程序、硬件和软件平台。目前流行的MOM中间件产品有IBM的MQSeries、 BEA的MessageQ等。消息传递和排队技术有以下三个主要特点:
通讯程序可在不同的时间运行:程序不在网络上直接相互通话,而是间接地将消息放入消息队列,因为程序间没有直接的联系。所以它们不必同时运行。消息放入适当的队列时,目标程序甚至根本不需要正在运行;即使目标程序在运行,也不意味着要立即处理该消息。
对应用程序的结构没有约束:在复杂的应用场合中,通讯程序之间不仅可以是一对一的关系,还可以进行一对多和多对一方式,甚至是上述多种方式的组合。多种通讯方式的构造并没有增加应用程序的复杂性。
程序与网络复杂性相隔离: 程序将消息放入消息队列或从消息队列中取出消息来进行通讯,与此关联的全部活动,比如维护消息队列、维护程序和队列之间的关系、处理网络的重新启动和在网络中移动消息等是MOM的任务,程序不直接与其它程序通话,并且它们不涉及网络通讯的复杂性。
3、对象请求代理
随着对象技术与分布式计算技术的发展,两者相互结合形成了分布对象计算,并发展为当今软件技术的主流方向。1990年底,对象管理集团OMG首次推出对象管理结构OMA(Object Management Architecture),对象请求代理(Object Request Broker)是这个模型的核心组件。它的作用在于提供一个通信框架,透明地在异构的分布计算环境中传递对象请求。CORBA规范包括了ORB的所有标准接口。1991年推出的CORBA 1.1 定义了接口描述语言OMG IDL和支持Client/Server对象在具体的ORB上进行互操作的API。CORBA 2.0 规范描述的是不同厂商提供的ORB之间的互操作。
对象请求代理(ORB)是对象总线,它在CORBA规范中处于核心地位,定义异构环境下对象透明地发送请求和接收响应的基本机制,是建立对象之间client/server关系的中间件。ORB使得对象可以透明地向其他对象发出请求或接受其他对象的响应,这些对象可以位于本地也可以位于远程机器。ORB拦截请求调用,并负责找到可以实现请求的对象、传送参数、调用相应的方法、返回结果等。client对象并不知道同server对象通讯、激活或存储server对象的机制,也不必知道server对象位于何处、它是用何种语言实现的、使用什么操作系统或其他不属于对象接口的系统成分。
值得指出的是client和server角色只是用来协调对象之间的相互作用,根据相应的场合,ORB上的对象可以是client,也可以是 server,甚至兼有两者。当对象发出一个请求时,它是处于client角色;当它在接收请求时,它就处于server角色。大部分的对象都是既扮演 client角色又扮演server角色。另外由于ORB负责对象请求的传送和server的管理,client和server之间并不直接连接,因此,与RPC所支持的单纯的Client/Server结构相比,ORB可以支持更加复杂的结构。
4、事务处理监控
事务处理监控(Transaction processing monitors)最早出现在大型机上,为其提供支持大规模事务处理的可靠运行环境。随着分布计算技术的发展,分布应用系统对大规模的事务处理提出了需求,比如商业活动中大量的关键事务处理。事务处理监控界于client和server之间,进行事务管理与协调、负载平衡、失败恢复等,以提高系统的整体性能。它可以被看作是事务处理应用程序的“操作系统”。总体上来说,事务处理监控有以下功能:
进程管理,包括启动server进程、为其分配任务、监控其执行并对负载进行平衡。
事务管理,即保证在其监控下的事务处理的原子性、一致性、独立性和持久性。
通讯管理,为client和server之间提供了多种通讯机制,包括请求响应、会话、排队、订阅发布和广播等。
事务处理监控能够为大量的client提供服务,比如飞机定票系统。如果server为每一个client都分配其所需要的资源的话,那 server将不堪重负(如图2所示)。但实际上,在同一时刻并不是所有的client都需要请求服务,而一旦某个client请求了服务,它希望得到快速的响应。事务处理监控在操作系统之上提供一组服务,对client请求进行管理并为其分配相应的服务进程,使server在有限的系统资源下能够高效地为大规模的客户提供服务。

图2 事务处理监控
四、面临的一些问题
中间件能够屏蔽操作系统和网络协议的差异,为应用程序提供多种通讯机制;并提供相应的平台以满足不同领域的需要。因此,中间件为应用程序了一个相对稳定的高层应用环境。然而,中间件服务也并非“万能药”。中间件所应遵循的一些原则离实际还有很大距离。多数流行的中间件服务使用专有的API和专有的协议,使得应用建立于单一厂家的产品,来自不同厂家的实现很难互操作。有些中间件服务只提供一些平台的实现,从而限制了应用在异构系统之间的移植。应用开发者在这些中间件服务之上建立自己的应用还要承担相当大的风险,随着技术的发展他们往往还需重写他们的系统。尽管中间件服务提高了分布计算的抽象化程度,但应用开发者还需面临许多艰难的设计选择,例如,开发者还需决定分布应用在client方和server方的功能分配。通常将表示服务放在client以方便使用显示设备,将数据服务放在server以靠近数据库,但也并非总是如此,何况其它应用功能如何分配也是不容易确定的。
-
[转] 对常见的WEB服务器和应用服务器的介绍
2009-02-23 10:30:55
转自:
http://tech.ddvip.com/2007-08/118776126332610.html
内容摘要:在选择使用WEB服务器应考虑的本身特性因素有:性能、安全性、日志和统计、虚拟主机、代理服务器、缓冲服务和集成应用程序等,下面介绍几种常用的WEB服务器。
在UNIX和LINUX平台下使用最广泛的免费HTTP 服务 器是W3C、NCSA和APACHE服务器,而Windows平台NT/2000/2003使用IIS的WEB服务器。在选择使用WEB服务器应考虑的本身特性因素有:性能、安全性、日志和统计、虚拟主机、代理服务器、缓冲服务和集成应用程序等,下面介绍几种常用的WEB服务器。
① Microsoft IIS
Microsoft的Web服务器 产品 为Internet Information Server (IIS), IIS 是允许在公共Intranet或Internet上发布信息的Web服务器。IIS是目前最流行的Web服务器产品之一,很多著名的网站都是建立在IIS的平台 上。IIS提供了一个图形界面的管理工具,称为 Internet服务管理器,可用于监视配置和控制Internet服务。IIS是一种Web服务组件,其中包括Web服务器、FTP服务器、NNTP服务器和SMTP服务器,分别用于网页浏览、文件传输、新闻服务和邮件发送等方面,它使得在网络(包括互联网和局域网)上发布信息成了一件很容易的事。它提供ISAPI(Intranet Server API)作为扩展Web服务器 功能 的编程接口;同时,它还提供一个Internet数据库连接器,可以实现对数据库的查询和更新。② IBM WebSphere
WebSphere Application Server 是 一 种功能完善、开放的Web应用程序服务器,是IBM电子商务计划的核心部分,它是基于 Java 的应用环境,用于建立、部署和 管理 Internet 和 Intranet Web 应用程序。 这一整套产品进行了扩展,以适应 Web 应用程序服务器的需要,范围从简单到高级直到企业级。WebSphere 针对以 Web 为中心的开发人员,他们都是在基本 HTTP服务器和 CGI 编程技术上成长起来的。IBM 将提供 WebSphere 产品系列,通过提供综合资源、可重复使用的组件、功能强大并易于使用的工具、以及支持 HTTP 和 IIOP 通信的可伸缩运行时环境,来帮助这些用户从简单的 Web 应用程序转移到电子商务世界。
③ BEA WebLogic
BEA WebLogic Server 是一种多功能、基于标准的web应用 服务 器,为企业构建自己的应用提供了坚实的基础。各种应用开发、部署所有关键性的任务,无论是集成各种系统和数据库,还是提交服务、跨 Internet 协作,起始点都是 BEA WebLogic Server。由于 它具有全面的功能、对开放标准的遵从性、多层架构、支持基于组件的开发,基于 Internet 的企业都选择它来开发、部署最佳的应用。BEA WebLogic Server 在使应用服务器成为企业应用架构的基础方面继续处于领先地位。BEA WebLogic Server 为构建集成化的企业级应用提供了稳固的基础,它们以 Internet 的容量和速度,在连网的企业之间共享信息、提交服务,实现协作自动化。BEA WebLogic Server 的遵从 J2EE 、面向服务的架构,以及丰富的工具集支持,便于实现业务逻辑、数据和表达的分离,提供开发和部署各种业务驱动应用所必需的底层核心功能 。④ IPlanet Application
IPlanet Application Server作为Sun与Netscape联盟产物的iPlanet公司生产的iPlanet Application Server 满足最新J2EE规范的要求。它是一种完整的WEB服务器应用解决方案,它允许企业以便捷的方式,开发、部署和 管理 关键任务 Internet 应用。该解决方案集高性能、高度可伸缩和高度可用性于一体,可以支持大量的具有多种客户机类型与数据源的事务。iPlanet Application Server的基本核心服务包括事务监控器、多负载平衡选项、对集群和故障转移全面的支持、集成的XML 解析器和可扩展格式 语言 转换(XLST)引擎以及对国际化的全面支持。iPlanet Application Server 企业版所提供的全部特性和功能,并得益于J2EE系统构架,拥有更好的商业工作流程管理工具和应用集成功能。⑤Oracle IAS
Oracle iAS的英文全称是Oracle Internet Application Server,即Internet应用服务器,Oracle iAS是基于Java的应用服务器,通过与Oracle 数据库等 产品 的结合,Oracle iAS能够满足Internet应用对可靠性、可用性和可伸缩性的要求。Oracle iAS最大的优势是其集成性和通用性,它是一个集成的、通用的中间件产品。在集成性方面,Oracle iAS将业界最流行的HTTP 服务 器Apache集成到系统中,集成了Apache的Oracle iAS通信服务层可以处理多种客户请求,包括来自Web浏览器、胖客户端和手持设备的请求,并且根据请求的具体内容,将它们分发给不同的应用服务进行处理。在通用性方面,Oracle iAS支持各种业界标准 ,包括 JavaBeans、CORBA、Servlets以及XML标准等,这种对标准的全面支持使得用户很容易将在其他系统平台上开发的应用移植到Oracle平台上。⑥ Apache
Apache源于NCSAhttpd服务器,经过多次修改,成为世界上最流行的Web服务器软件之一。Apache是自由软件,所以不断有人来为它开发新的 功能 、新的特性、修改原来的缺陷。Apache的特点是简单、速度快、性能稳定,并可做代理服务器来使用。本来它只用于小型或试验Internet网络 ,后来逐步扩充到各种Unix系统中,尤其对Linux的支持相当完美。Apache是以进程为基础的结构,进程要比线程消耗更多的系统开支,不太适合于多处理器环境,因此,在一个Apache Web站点扩容时,通常是增加服务器或扩充群集节点而不是增加处理器。到目前为止Apache仍然是世界上用的最多的Web服务器,世界上很多著名的网站都是Apache的产物,它的成功之处主要在于它的源代码开放、有一支开放的开发队伍、支持跨平台的应用(可以运行在几乎所有的Unix、Windows、Linux系统平台上)以及它的可移植性等方面。
⑦ Tomcat
Tomcat是一个开放源代码、运行servlet和JSP Web应用软件的基于Java的Web应用软件容器。Tomcat Server是根据servlet和JSP规范进行执行的,因此我们就可以说Tomcat Server也实行了Apache-Jakarta规范且比绝大多数商业应用软件服务器要好。
Tomcat是Java Servlet 2.2和JavaServer Pages 1.1技术的标准实现,是基于Apache许可证下开发的自由软件。Tomcat是完全重写的Servlet API 2.2和JSP 1.1兼容的Servlet/JSP容器。Tomcat使用了JServ的一些代码,特别是Apache服务适配器。随着Catalina Servlet引擎的出现,Tomcat第四版号的性能得到提升,使得它成为一个值得考虑的Servlet/JSP容器,因此目前许多WEB服务器都是采用Tomcat。
-
[转] 如何在Oracle中建表格时就指定主键和外键
2009-02-20 11:56:06
转自:
http://java1573.javaeye.com/blog/144959
创建表的语法
-创建表格语法:
create table 表名(
字段名1 字段类型(长度) 是否为空,
字段名2 字段类型 是否为空
);-增加主键
alter table 表名 add constraint 主键名 primary key (字段名1);-增加外键:
alter table 表名
add constraint 外键名 foreign key (字段名1)
references 关联表 (字段名2);在建立表格时就指定主键和外键
create table T_STU (
STU_ID char(5) not null,
STU_NAME varchar2(8) not null,
constraint PK_T_STU primary key (STU_ID)
);
主键和外键一起建立:
create table T_SCORE (
EXAM_SCORE number(5,2),
EXAM_DATE date,
AUTOID number(10) not null,
STU_ID char(5),
SUB_ID char(3),
constraint PK_T_SCORE primary key (AUTOID),
constraint FK_T_SCORE_REFE foreign key (STU_ID)
references T_STU (STU_ID)
) -
ORACLE中添加删除主键
2009-02-20 11:45:02
转自:
http://www.stronghearted.net/?p=10
1、创建表的同时创建主键约束
(1)无命名
create table student (
studentid int primary key not null,
studentname varchar(8),
age int);
(2)有命名
create table students (
studentid int ,
studentname varchar(8),
age int,
constraint yy primary key(studentid));
2、删除表中已有的主键约束
(1)有命名
alter table students drop constraint yy;
(2)无命名
可用 SELECT * from user_cons_columns;
查找表中主键名称得student表中的主键名为SYS_C002715
alter table student drop constraint SYS_C002715;
3、向表中添加主键约束
alter table student add constraint pk_student primary key(studentid); -
[转]oracle中的SQL语句简介(DQL,DDL,DML,DCL,TCL)
2009-02-19 16:16:52
转自:
1. 数据查询语句(data query language) DQL
这是数据库操作中最常用、最重要的一类。这类语句的作用就是将数据库中数据按自己的需求,有条理的整理出来,包含 select语句
常用的技巧还包括:SQL中在select语句中使用算术运算符
在select语句中使用连接字符串
SQL中为select语句中增加别名(Alias)
在select语句中增加提示型文字
使用like关键字
使用转义字符(换码符)
使用distinct关键字来压缩SQL语句中的select查询结果
使用in关键字来选择SQL语句中的select查询结果2. 数据定义语句(data define language) DDL
这类语句是用来建立数据库基本组件的,例如建立表,建立视图等等。包含create语句、drop语句、alter语句。
3.数据操作语句(data manipulate language)DML
这类语句的作用是根据需要写入、删除、更新数据库中的数据。主要包括Insert 语句,delete语句,update语
4.数据控制语句(data control language)DCL
这类语句主要用来实现用户的权限授予或者取消,保证数据的安全性。主要包括(
如Grant(授权)语句、Revoke(撤消)语句、Deny(拒绝)语句。
5.事物控制语句(Transaction control language)TCL
这类语句主要是用来控制事物的动作。主要包含commit语句,rollback语句,setpoint语句。
-
DML和DDL的区别
2009-02-19 15:55:28
DDL(data definition language)数据定义语言
用于改变数据库的结构,DDL语言可以完成下面的工作:
。创建(Create), 修改(Alter),删除(Drop)模式对象
。权限管理
。对表(Table),索引(Index),聚簇(Cluster)进行分析(Analyze)
。建立审计(Auditing)
。加注释(Comments)到数据字典;DDL包括以下SQL语句:
CREATE TABLE
ALTER TABLE
DROP TABLE
CREATE INDEX
DROP INDEX。。。
DML(data manipulation language)数据操纵语言用于操作数据库中的数据(改变表中的数据),DML语言不隐含COMMIT语句,因此需要用户手动提交对数据库的修改。
DDL不可以rollback,但是DML可以。
INSTER
UPDATE
DELETE
SELECT -
软件缺陷等级标准
2009-02-17 15:51:52
按照CMM5中定义的规范,BUG一般分致命,严重,一般和提示。致命是严重影响产品的BUG,比如操作手册的错误,需求的错误等。严重是产品中使功能无法实现的BUG,比如某个功能无法运行,GUI长时间僵死没有响应。一般是某个BUG的发生,只影响了一个功能,而其他功能可以正常运行。提示就是一些GUI的问题,或者友好性的问题。
更为详细的划分如下:
A类—严重错误,包括以下各种错误:
1. 由于程序所引起的死机,非法退出
2. 死循环
3. 数据库发生死锁
4. 因错误操作导致的程序中断
5. 功能错误
6. 与数据库连接错误
7. 数据通讯错误
-----------------------------------------------------------
B类—较严重错误,包括以下各种错误:
1. 程序错误
2. 程序接口错误
3. 数据库的表、业务规则、缺省值未加完整性等约束条件
-----------------------------------------------------------
C类—一般性错误,包括以下各种错误:
1. 操作界面错误(包括数据窗口内列名定义、含义是否一致)2. 打印内容、格式错误
3. 简单的输入限制未放在前台进行控制
4. 删除操作未给出提示
5. 数据库表中有过多的空字段
-----------------------------------------------------------
D类—较小错误,包括以下各种错误:
1. 界面不规范
2. 辅助说明描述不清楚
3. 输入输出不规范
4. 长操作未给用户提示
5. 提示窗口文字未采用行业术语
6. 可输入区域和只读区域没有明显的区分标志-----------------------------------------------------------
E类—测试建议 -
[转] 什么是BETA,RC,ALPHA版 - 软件命名规范
2009-02-17 15:21:23
转自:
http://aricyoung.itpub.net/post/12042/473321
发现很多网友对于软件版本命名还不是很明白,什么是Beta什么是RC?
所以特意从网络搜集了一些关于这方面的简单介绍。大家可以点击查看详细。1. 软件版本阶段说明
* Alpha版: 此版本表示该软件在此阶段主要是以实现软件功能为主,通常只在软件开发者内部交流,一般而言,该版本软件的Bug较多,需要继续修改。
* Beta版: 该版本相对于α版已有了很大的改进,消除了严重的错误,但还是存在着一些缺陷,需要经过多次测试来进一步消除,此版本主要的修改对像是软件的UI。
* RC版: 该版本已经相当成熟了,基本上不存在导致错误的BUG,与即将发行的正式版相差无几。
* Release版: 该版本意味“最终版本”,在前面版本的一系列测试版之后,终归会有一个正式版本,是最终交付用户使用的一个版本。该版本有时也称为标准版。一般情况下,Release不会以单词形式出现在软件封面上,取而代之的是符号(R)。
2. 版本命名规范
软件版本号由四部分组成,第一个1为主版本号,第二个1为子版本号,第三个1为阶段版本号,第四部分为日期版本号加希腊字母版本号,希腊字母版本号共有5种,分别为:base、alpha、beta、RC、release。例如:1.1.1.051021_beta。

3. 版本号定修改规则
* 主版本号(1):当功能模块有较大的变动,比如增加多个模块或者整体架构发生变化。此版本号由项目决定是否修改。
* 子版本号(1):当功能有一定的增加或变化,比如增加了对权限控制、增加自定义视图等功能。此版本号由项目决定是否修改。
* 阶段版本号(1):一般是 Bug 修复或是一些小的变动,要经常发布修订版,时间间隔不限,修复一个严重的bug即可发布一个修订版。此版本号由项目经理决定是否修改。
* 日期版本号(051021):用于记录修改项目的当前日期,每天对项目的修改都需要更改日期版本号。此版本号由开发人员决定是否修改。
* 希腊字母版本号(beta):此版本号用于标注当前版本的软件处于哪个开发阶段,当软件进入到另一个阶段时需要修改此版本号。此版本号由项目决定是否修改。4. 文件命名规范
文件名称由四部分组成:第一部分为项目名称,第二部分为文件的描述,第三部分为当前软件的版本号,第四部分为文件阶段标识加文件后缀,例如:项目外包平台测试报告1.1.1.051021_beta_b.xls,此文件为项目外包平台的测试报告文档,版本号为:1.1.1.051021_beta。

如果是同一版本同一阶段的文件修改过两次以上,则在阶段标识后面加以数字标识,每次修改数字加1,项目外包平台测试报告1.1.1.051021_beta_b1.xls。
当有多人同时提交同一份文件时,可以在阶段标识的后面加入人名或缩写来区别,例如:项目外包平台测试报告 1.1.1.051021_beta_b_LiuQi.xls。当此文件再次提交时也可以在人名或人名缩写的后面加入序号来区别,例如:项目外包平台测试报告1.1.1.051021_beta_b_LiuQi2.xls。
5. 版本号的阶段标识
软件的每个版本中包括11个阶段,详细阶段描述如下:
阶段名称 阶段标识
需求控制 a
设计阶段 b
编码阶段 c
单元测试 d
单元测试修改 e
集成测试 f
集成测试修改 g
系统测试 h
系统测试修改 i
验收测试 j
验收测试修改 k -
[转] 浅谈软件测试流程
2009-02-16 14:40:53
转载自:
http://www.cnblogs.com/itest/archive/2008/12/10/759215.html
【摘要】 软件测试从哪里开始到哪里结束?中间要经过哪些环节以及各环节要注意哪些事项。本文就有关问题结合个人实际工作经验进行阐述,鉴于每个环节都可以做为一个专题来进行探讨,所以受篇幅和时间限制,本文对有关问题未做深入剖析,只做一个宏观上的介绍。
【关键词】测试流程、需求分析、测试用例、测试计划、缺陷管理
一、概述
一般而言,软件测试从项目确立时就开始了,前后要经过以下一些主要环节:
需求分析→测试计划→测试设计→测试环境搭建→测试执行→测试记录→缺陷管理→软件评估→RTM.
在进行有关问题阐述前,我们先明确下分工,一般而言,需求分析、测试用例编写、测试环境搭建、测试执行等属于测试开发人员工作范畴,而测试执行以及缺陷提交等属于普通测试人员的工作范畴,测试负责人负责整个测试各个环节的跟踪、实施、管理等。
说明:
1.以上流程各环节并未包含软件测试过程的全部,如根据实际情况还可以实施一些测试计划评审、用例评审,测试培训等。在软件正式发行后,当遇到一些严重问题时,还需要进行一些后续维护测试等。
2.以上各环节并不是独立没联系的,实际工作千变万化,各环节一些交织、重叠在所难免,比如编写测试用例的同时就可以进行测试环境的搭建工作,当然也可能由于一些需求不清楚而重新进行需求分析等。这就和我们国家提出建设有中国特色的社会主义国家一样,只所以有中国特色,那是因为国情不一样。所以在实际测试过程中也要做到具体问题具体分析,具体解决。
二、测试流程

需求分析
需求分析(Requirment Analyzing)应该说是软件测试的一个重要环节,测试开发人员对这一环节的理解程度如何将直接影响到接下来有关测试工作的开展。
可能有些人认为测试需求分析无关紧要,这种想法是很不对的。需求分析不但重要,而且至关重要!
一般而言,需求分析包括软件功能需求分析、测试环境需求分析、测试资源需求分析等。
其中最基本的是软件功能需求分析,测一款软件首先要知道软件能实现哪些功能以及是怎样实现的。比如一款Smartphone包括VoIP、Wi-Fi以及Bluetooth等功能。那我们就应该知道软件是怎样来实现这些功能的,为了实现这些功能需要哪些测试设备以及如何搭建相应测试环境等,否则测试就无从谈起!
既然谈了需求分析,那么我们根据什么来分析呢?总不能凭空设想吧。
总得说来,做测试需求分析的依据有软件需求文档、软件规格书以及开发人员的设计文档等,相信管理一些规范的公司在软件开发过程中都有这些文档。
测试计划
测试计划(Test Plan)一般由测试负责人来编写。
测试计划的依据主要是项目开发计划和测试需求分析结果而制定。测试计划一般包括以下一些方面:
1. 测试背景
a. 软件项目介绍;
b. 项目涉及人员(如软硬件项目负责人等)介绍以及相应联系方式等。
2. 测试依据
a. 软件需求文档;
b. 软件规格书;
c. 软件设计文档;
d. 其他,如参考产品等。
3. 测试资源
a. 测试设备需求;
b. 测试人员需求;
c. 测试环境需求;
d. 其他。
4. 测试策略
a. 采取测试方法;
b. 搭建哪些测试环境;
d. 对测试人员进行培训等。
5. 测试日程
a. 测试需求分析;
b. 测试用例编写;
c. 测试实施,根据项目计划,测试分成哪些测试阶段(如单元测试、集成测试、系统测试阶段,α、β测试阶段等),每个阶段的工作重点以及投入资源等。
6. 其他。
测试计划还要包括测试计划编写的日期、作者等信息,计划越详细越好了。
计划赶不上变化,一份计划做的再好,当实际实施的时候就会发现往往很难按照原有计划开展。如在软件开发过程中资源匮乏、人员流动等都会对测试造成一定的影响。所以,这些就要求测试负责人能够从宏观上来调控了。在变化面前能够做到应对自如、处乱不惊那是最好不过了。
测试设计
测试设计主要包括测试用例编写和测试场景设计两方面。
一份好的测试用例对测试有很好的指导作用,能够发现很多软件问题。关于测试用例编写,请参见前面写的《也谈测试用例》一文,里面有详细阐述。
测试场景设计主要也就是测试环境问题了。
测试环境搭建
不同软件产品对测试环境有着不同的要求。如C/S及B/S架构相关的软件产品,那么对不同操作系统,如Windows系列、unix、linux甚至苹果OS等,这些测试环境都是必须的。而对于一些嵌入式软件,如手机软件,如果我们想测试一下有关功能模块的耗电情况,手机待机时间等,那么我们可能就需要搭建相应的电流测试环境了。当然测试中对于如手机网络等环境都有所要求。
测试环境很重要,符合要求的测试环境能够帮助我们准确的测出软件问题,并且做出正确的判断。
为了测试一款软件,我们可能根据不同的需求点要使用很多不同的测试环境。有些测试环境我们是可以搭建的,有些环境我们无法搭建或者搭建成本很高。不管如何,我们的目标是测试软件问题,保证软件质量。测试环境问题,还是根据具体产品以及开发者的实际情况而采取最经济的方式吧。
测试执行
测试执行过程又可以分为以下阶段:
单元测试→集成测试→系统测试→出厂测试,其中每个阶段还有回归测试等。
从测试的角度而言,测试执行包括一个量和度的问题。也就是测试范围和测试程度的问题。 比如一个版本需要测试哪些方面?每个方面要测试到什么程度?
从管理的角度而言,在有限的时间内,在人员有限甚至短缺的情况下,要考虑如何分工,如何合理地利用资源来开展测试。当然还要考虑以下问题:
1. 当测试人员测试的执行不到位、敷衍了事时该如何解决?
2. 测试效率问题,怎样提高测试效率?
3. 根据版本的不同特点是只做验证测试还是采取冒烟测试亦或是系统全面测试?
4. 当测试过程中遇到一些偶然性随机问题该怎样处理?
5. 当版本中出现很多新问题时该怎样对待?测试停止标准?
6. ……
总之,测试执行过程中会遇到很多复杂的问题,还是那句话,具体问题具体解决!本文不做过多阐述。
测试记录
缺陷记录总的说来包括两方面:由谁提交和缺陷描述。
一般而言,缺陷都是谁测试谁提交,当然有些公司可能为了保证所提交缺陷的质量,还会在提交前进行缺陷评估,以确保所提交的缺陷的准确性。
在缺陷的描述上,至少要包括以下一些方面内容:
序号
标题
预置条件
操作步骤
预期结果
实际结果
注释
严重程度
概率
版本
测试者
测试日期
以上是描述一个bug时通常所要描述的内容,当然在实际提交bug时可以根据实际情况进行补充,如附上图片、log文件等。
另外,一个版本软件测试完毕,还要根据测试情况出份测试报告,这也是所要经过的一个环节。
缺陷管理
缺陷管理方面,很多公司都采取缺陷管理工具来进行管理,常见缺陷管理工具有Test Director、Bugfree等。
下图是一个bug从提出到close所经过的一些流程,其他比如keep No action\keep spec等一些状态流程都未包含在内,在此仅做示范说明。

注:软件缺陷和bug两者在含义上有着细微差别,本文统称缺陷。
软件评估
这里评估指软件经过一轮又一轮测试后,确认软件无重大问题或者问题很少的情况下,对准备发给客户的软件进行评估,以确定是否能够发行给客户或投放市场。
软件评估小组一般由项目负责人、营销人员、部门经理等组成,也可能是由客户指定的第三方人员组成。
测试总结
每个版本有每个版本的测试总结,每个阶段有每个阶段的测试总结,当项目完成RTM后,一般要对整个项目做个回顾总结,看有哪些做的不足的地方,有哪些经验可以对今后的测试工作做借鉴使用,等等。测试总结无严格格式、字数限制。应该说,测试总结还是很总要的。
测试维护
由于测试的不完全性,当软件正式release后,客户在使用过程中,难免遇到一些问题,有的甚至是严重性的问题,这就需要修改有关问题,修改后需要再次对软件进行测试、评估、发行。
-
[转] 如果您想从一名测试员转型为测试管理人员
2009-02-13 09:48:14
转自:
http://www.51testing.com/html/200902/n106827.html
如果你是测试员或是高级测试员,有志转向管理发展,那么需要加强以下内容,至少要做到几点:
1. 测试计划的编写(要结合测试的项目,能以此来控制和确定测试所需人员,设备及时间来管理测试时间)
2. 要熟悉BUG跟踪工具及软件测试流程(如: TD, Bugzilla, CQ等)
3. 要熟悉配置管理工具(如:TestCenter ,CVS, VSS等)
4. 要熟悉自动化工具(例如:WinRunner, QTP, Robot, RFT, Automation等,能结合录制完的脚本编写代码)
5. 要熟悉压力及性能测试工具(例如: AutoRunner,LoadRunner, webload, silkperformance等,能结合相关数据,分析出性能瓶颈)
6. 要熟悉或精通一门语言 (例如: Java, C++)
7. 要熟悉数据库(例如: Oracle, DB2, SQLServer, MySQL)
8. 要熟悉主流操作系统 (例如: HP Unix, IBM AIX, Sun Solaris, Red Hat Linux, SuSE Linux, Windows)
9. 能用英文流利的和老外交流以及往来Email
10. 语言表达能力强,表达问题清晰明了
11. 沟通能力强,能和上级/开发经理很好的达成测试相关/BUG事宜
12. 学习技术的能力要强,能快速上手一个新的技术
13. 乐于与人交流 -
[转] 快速掌握重启Oracle数据库的操作步骤
2009-02-10 10:52:43
转载自:
http://oracle.chinaitlab.com/induction/743186.html
在实际的应用中,有时候工作数据库需要重新启动。本文介绍了一个特别实用的操作步骤,希望对大家有所帮助。
1. 停应用层的各种程序
2. 停Oralce的监听进程
$ lsnrctl stop
3. 在独占的系统用户下,备份控制文件:
$ sqlplus "/as sysdba"
SQL> alter database backup controlfile to trace;
4. 在独占的系统用户下,手工切换重作日志文件,确保当前已修改过的数据存入文件:
SQL> alter system switch logfile;
5. 在独占的系统用户下,运行下面SQL语句,生成杀数据库用户连接的kill_all_session.sql文件:
SQL> set head off;
SQL> set feedback off;
SQL> set newpage none;
SQL> spool ./kill_session.sql
SQL> select 'alter system kill session '''||sid||','||serial#||''';' from v$session where username is not null;
SQL> spool off;
6. 在独占的系统用户下,执行杀数据库用户连接的kill_session.sql文件
SQL> @./kill_session.sql
7. 在独占的系统用户下,用immediate方式关闭数据库:
SQL> shutdown immediate;
或者
SVRMGRL> shutdown immediate;
8. 启动oralce的监听进程
$ lsnrctl start
9. 进入独占的系统用户下,启动Oralce数据库
$ sqlplus /nolog
SQL> connect / as sysdba
SQL> startup;
或者
$ svrmgrl
SVRMGRL> connect internal;
SVRMGRL> startup;
10.启动应用层的各种程序
-
查看ORACLE企业管理器端口号
2009-02-05 17:17:49
查看E:\oracle\product\10.2.0\db_1\install\portlist.ini 文件即可。 -
[转] How to add one or more control files
2009-02-05 15:30:56
转自:
http://blog.csdn.net/dancle/archive/2006/04/07/653783.aspx
When we have one control file, now want to add one or more control files, there is many method to do it,but the better way is:
1. Shut down the database with NORMAL or IMMEDIATE options.
2. Copy the single control file to its new location. Rename it if you want or need to.
3. Modify your INIT.ORA paramter file. Change the CONTROL_FILES parameter to point to both control files.
4. Startup the database.
It is so simplely,but I think the best way is to hava more controle files that is in difficult folder.
Usually I have three control files for every database.
-
[转] Oracle 的参数文件pfile与spfile
2009-02-05 15:26:57
转自:
http://blog.csdn.net/dancle/archive/2006/03/31/645802.aspx
In Oracle Databases through 8i, parameters controling memory, processor usage, control file locations and other key parameters are kept in a pfile (short for parameter file).
The pfile is a static, plain text files which can be altered using a text editor, but it is only read at database startup. Any changes to the pfile will not be read until the database is restarted and any changes to a running database will not be written to the pfile.
Due to these limitations, in 9i Oracle introduced the spfile (server parameter file). The spfile cannot be edited by the DBA; instead it is updated by using ALTER SYSTEM commands from within Oracle. This allows parameter changes to be persistent across database restarts, but can leave you in a pinch if you need to change a parameter to get a database started but you need the database running to change the parameter.
A 9i (or later) database can have either a pfile or an spfile, or even both, but how can you tell which you have? If you have both, which one is being used? How do you go from one to the other? How do you get out of the chicken-and-the-egg quandary of a database that will not start up without you changing a parameter that’s in that file you can’t update unless the database is up?
Note: This information is based on an Oracle 9i installation on Solaris. Your mileage may vary. I have also chosen to ignore issues of RAC installation. In my example I have used ORADB as my SID.
Am I using a pfile or an spfile?
The first thing to check is if you have a pfile or spfile. They can be specified at startup or found in the default location. The default path for the pfile is
$ORACLE_HOME/dbs/init$ORACLE_SID.oraand the default for the spfile is$ORACLE_HOME/dbs/spfile$ORACLE_SID.ora.If both a pfile and an spfile exist in their default location and the database is started without a
pfile='/path/to/init.ora' then the spfile will be used.Assuming your database is running you can also check the
spfileparameter. Either the commandSHOW PARAMETER spfileorSELECT value FROM v$parameter WHERE name='spfile';will return the path to the spfile if you are using one. If the value of spfile is blank you are not using an spfile.The path to the spfile will often be represented in the database by
?/dbs/spfile@.ora. This may seem cryptic, but Oracle translates?to$ORACLE_HOMEand@to$ORACLE_SIDso this string translates to the default location of the spfile for this database.How can I create an spfile from a pfile?
As long as your pfile is in the default locations and you want your spfile in the default location, you can easily create an spfile with the command
CREATE SPFILE FROM PFILE;.If you need to be more specific about the locations you can add paths to the create command like this:
CREATE SPFILE='/u01/app/oracle/product/9.2/dbs/spfileORADB.ora'FROM PFILE=’/u01/app/oracle/product/9.2/dbs/initORADB.ora’;These commands should work even when the database is not running! This is important when you want to change a database to use an spfile before you start it.
How can I create a pfile from an spfile?
The commands for creating a pfile are almost identical to those for creating a spfile except you reverse the order of spfile and pfile:
If your pfile is in the default location and you want your spfile created there as well run
CREATE SPFILE FROM PFILE;.If you have, or want them in custom locations specify the paths like this:
CREATE PFILE='/u01/app/oracle/product/9.2/dbs/initORADB.ora'FROM SPFILE=’/u01/app/oracle/product/9.2/dbs/spfileORADB.ora’;Again, this can be done without the database running. This is useful when the database fails to start due to a parameter set in the spfile. This is also a good step to integrate into your backup procedures.
How can I see what’s in my spfile
To view the settings in the spfile we have two options: First, we can use the command above to create a pfile from the spfile. This is simple, and fairly fast, but unnecessary if the database is running.
The better way, if the database is running, is to select the parameter you want to view from the oracle view v$spparameter with a command like this:
SELECT value FROM v$spparameter WHERE name='processes';If you try to view the spfile with a text editor it may seem like it is plain text, but beware! The spfile will not behave correctly (if it works at all) if it has been edited by a text editor.
How can I update values in my spfile?
The values in spfile are updated with the
ALTER SYSTEMcommand, but to update the spfile we add an additional parameter ofSCOPE.ALTER SYSTEM SET processes=50 SCOPE=spfile;This command would update the parameter
processesin the spfile. Since this parameter can only be set at startup, we saySCOPE=spfileand the change will be reflected when the database is restarted. Other options forSCOPEarememorywhich only changes the parameter until the database is restarted, andbothwhich changes the instance immediately and will remain in effect after the database is restarted.How can I update values in my spfile when my database won’t start?
So your database won’t startup because of a problem in your spfile. You can’t edit it with a text editor and you can’t use
ALTER SYSTEMbecause your database is not running. It sounds like a problem, but really isn’t. Here’s what you do:Connect up to your database as sysdba. You should get the message
Connected to an idle instanceRun the command
CREATE pfile FROM spfile;specifying the location as above if necessary. You should now have a fresh version of the spfile.Edit the pfile to update the parameter you need to update.
Run the command
CREATE spfile FROM pfile;to move the changes you have just made back into the spfile.Startup the database normally. It should read the changed spfile and start up correctly. You can optionally delete the pfile if you are done.
-
oracle spfile和pfile小结
2009-02-05 14:38:34
简单的说:
1、pfile 文本文件 client端参数文件;不能动态修改,可以用普通的编辑器修改,修改之后需要重启。pfile可能会导致服务器启动不一致,因为可以在客户端启动。
2、spfile 二进制文件 服务器端参数文件,有了spfile,oracle可以实现动态参数在线修改,部分参数修改之后无需重启。但是,因为是二进制文件,所以不能用普通的编辑器修改,要用alter命令从sql里面来修改。spfile保证服务器每次的启动都是一致的。只有spfile而没有pfile文件时,可以通过:create pfile='位置+名字' from spfile;
如:
create pfile='E:\ORACLE\PRODUCT\10.2.0\DB_1\DBS\spfileorcl_bak.ora' from spfile;进行创建pfile文件。
同理,只有pfile而没有spfile时,可以通过:
create spfile='位置+名字' from pfile;
进行创建spfile文件。pfile和spfile二者可以互相备份。
3、通过spfile或pfile启动数据库:
(1)startup nomount启动方式,查找文件的顺序是 spfileSID.ora-〉spfile.ora-〉initSID.ora-〉init.ora(spfile优先于pfile)。
(2)startup pfile='文件目录'----通过pfile文件启动;
(3)startup spfile='文件目录'----通过spfile文件启动。以下转自:
http://www.cnblogs.com/jacktu/archive/2008/02/27/1083232.html
查看系统是以pfile还是spfile启动
Select isspecified,count(*) from v$spparameter group by isspecified;
如果isspecified里有true,表明用spfile进行了指定配置
如果全为false,则表明用pfile启动
使用SPfile的好处
Spfile改正了pfile管理混乱的问题,在多结点的环境里,pfile会有多个image
启动时候需要跟踪最新的image。这是个烦琐的过程。
用spfile以后,所有参数改变都写到spfile里面(只要定义scope=spfile或both),参数配置有个权威的来源。查看spfile location
show parameter spfile从spfile获取pfile
Create pfile='d:pfileSID.ora' from spfile;
Create pfile='d:pfileSID.ora' from spfile='spfile_location';从pfile获取spfile
Create spfile from pfile='Your_pfile_location'
Create spfile='spfile_location' from pfile='Your_pfile_location'
动态修改参数
alter system set parameter=Value scope=spfile|both|memory
Startup nomount的时候需要读去spfile或pfile,两者共存,spfile优先强制用pfile启动
SQL>startup pfile='Your_Pfile.ora'
startup spfile='/data/oracle/product/10.2.0/db_1/dbs/dbs/spfile_mqq.ora' force通过pfile连接到spfile启动
修改pfile文件
-
ORACLE实例和ORACLE_SID
2009-02-05 11:53:42
前提:同一服务器上有多个实例并且均已启动。
若登录时不指定连接串,一般是采用环境变量 ORACLE_SID,WINDOWS系统默认的ORACLE_SID值为最后所安装的实例。
1、查看实例名称和ORACLE_SID
在Unix/Linux环境可以 echo $ORACLE_SID 查看ORACLE_SID的值;
在Windows环境可以(以我自己的机器为例):
(1)开始—>运行(输入regedit),在HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\KEY_OraDb10g_home1中有ORACLE_SID的键值(系统默认值),如下图所示: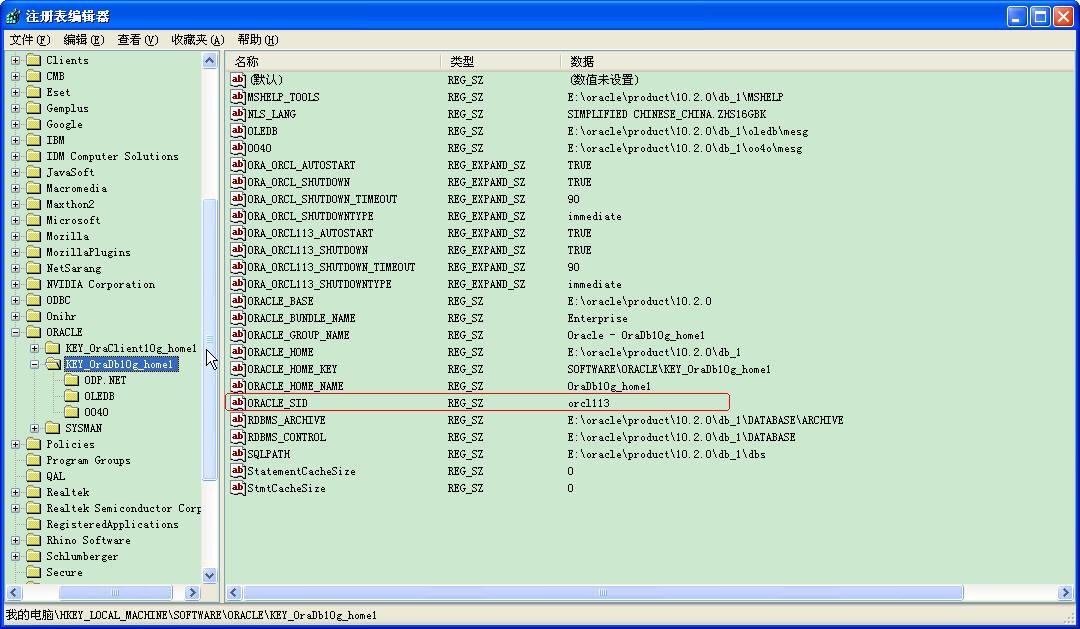
(2)登陆数据库,通过SQL语句查看(查看当前使用的数据库所对应的实例名称):
SQL>show parameter instance;
SQL>show parameter instance_name;
SQL>select * from v$instance;
2、切换实例在CMD窗口下,先修改ORACLE_SID的值(set ORACLE_SID=xxxx,该修改仅对当前CMD窗口有效),接着用同一CMD窗口访问数据库即可。
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 145482
- 日志数: 249
- 书签数: 41
- 建立时间: 2007-08-11
- 更新时间: 2013-03-28
