
-
[转]查找文件中的文字xp中使用无效的解决办法
2007-09-23 15:56:14
我们可能会常用到windows系统的搜索功能,就是在一大堆文件中查找含有某个单词的文件。这个功能在windows2000中使用正常,可在windowsxp中使用无效,系统装模做样地查了半天,硬是说没找到。现在原因找到了:
xp的注册表问题
运行regedit,编辑注册表
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\ContentIndex
右侧FilterFilesWithUnknownExtensions子键(REG_DEWORD类型)的键值改为1。另:如果你熟悉Windows2000及以前版本的搜索方式,对WindowsXP的动画搜索助手和分类别的搜索方式不习惯,那么你可以通过改变搜索属性来找回你熟悉的搜索模式。
搜索里有个“改变首选项”,单击后,将“改变文件和文件夹搜索行为”设置为“高级”即可。
-
[转]和各位谈谈release testing
2007-08-21 22:28:48
这个阶段平时处理的好的,比较细心的人在这边正常情况下是不会发生什么问题。但是也难免。所以这个release testing也是非常重要的一个步骤。不要小看之。
这个阶段正常会发生什么情况呢:
开发人员少放了一个文件,或者多放了一个文件,没影响功能。(你说是不是问题?)
开发人员放错了文件。
还有的开发人员可能会把以前的版本放进来了。
程序的名字写错了。在微软,有一次错的比较厉害的是:Window Live Hotmail 写成了 Window Live Hotmal,这个问题就比较大啦。
原来我在一家软件公司,开发人员会把自己的公司名字也错过。
有些很明显的地方的标题是不是错了。
还有一些问题,开发人员说已经改好了,但还是错的。(在规范的软件的过程中,正常不会出现这样的问题。但一些不是很规范的公司,还是会出现这样的问题。)
有的时候,在自己的机器上,一点问题都没有,但到了客户那边问题就是100%出现。(我原来就出现过这样的问题,调一个函数中有一点错误,在自己的机器上怎么也不出现,清空在build,还是没问题,但是到了canon,问题就是出现。后来还是直接在客户那边调试的。真怪啊。)
会不会有不一致的地方。
产品安装,不是多了东西,就是少了东西。(安装程序哦)
调试版本。(这个我出现过的,有次不小心把调试的版本发上去了,搞得安装包特大,不说了,脸红了。)
客户可能会要求做一些修改的地方,是不是都修改了。(这肯定要达标啊,不然客户怎么给你钱?)
你的环境很好,但客户的机器就不同了。(是不是再确认一下在各个环境下的测试呢?)
你的版本是不是13或者250。(也许,你觉得无所谓,但是客户可能不这么考虑。)
安全漏洞测试。(这块我接触不多。如果您有这方面的经验,我们可以讨论一下。)
病毒测试。(呵呵,这是最呕心的。你的安装包里携带病毒。别觉得自己的机器没问题啊。我一朋友就发生过这样的问题。)
这么多问题,release testing 重要吧?
评论:
Release流程当然重要,而且需要做的很细。
尝试考虑以下问题:
1、Release test 由谁来负责?Release过程由谁来负责?
2、文件缺失或是版本不对,谁来做版本控制的?有没有一个Release file list?有没有Release check list?
3、Release测试是在什么环境下完成的?开发环境还是客户环境?
4、Release测试时,测试人员应当接受什么样的版本?是否测试人员也要参与Build过程?
5、有没有一个严格的Release测试流程?哪些是在Release之前必须要验证的?
既然楼主已经意识到“在规范的软件的过程中,正常不会出现这样的问题。但一些不是很规范的公司,还是会出现这样的问题。”,那么提最后一个问题
6、规范的软件过程是什么?有没有这样的一个过程?有没有按这样的一个流程执行?
-
测试外包中测试活动的分配
2007-08-04 14:30:48
在测试外包的情况下,发包方与接包方在测试活动方面的任务分配,可以参照以下的分配:
发包方 接包方
测试的统一管理 √
创建系统测试计划 √
创建高层次的测试设计 √
审核和批准高层次测试设计 √
创建测试脚本 √
审核和批准测试脚本 √
执行测试脚本 √
每日/每周测试报告 √
撰写测试总结报告 √
批准测试总结报告 √
定义过程、更新模板、 √
测试工具管理(含许可管理) √
创建和维护测试自动化框架 √
创建自动化测试脚本 √
执行自动化测试脚本 √ √
维护自动化测试脚本 √ √
-
测试报告的内容
2007-08-04 11:33:09
测试总结报告包含了测试过程中获得的测试结果的一个概述,它包括:
- 管理总结
- 测试度量
- 目前仍为open状态的issue的总结以及解决的计划(如在下一版本修复或者在被要求的情况下修复)
- 已解决的测试issue的总结
- 执行的测试脚本/用例的结果
- 图形和度量表格
图形提供了对于测试度量结果的一个易于理解的形式的表现。测试总结报告中需要包含以下图表:
- Inflow/outflow
显示了在随着时间发展发现的issue的绝对数值、随着时间发展open的issue的数量、随着时间发展被关闭的issue的数量。它显示了测试团队发现缺陷的效力以及开发团队修复缺陷的效力。
- 按严重程度和状态分类的outstanding issue
- 根本原因分析(需求,设计,开发、测试、环境或者其他)
- 对于测试退出准则是否满足的分析
-
估算测试工作量时几个考虑的因素
2007-08-04 11:17:44
从客户文档中摘录的:
- 受影响的最终用户数
- solution的复杂程度(包括子系统)
- 需要的业务/IT知识
- 临时性的约束
- 环境约束
- 测试团队的经验
- 历史性的数据
- 提交给测试团队的项目交付物的质量和特性
-
公司的笔记本终于可以在家上网了
2007-07-29 13:50:01
这周拿到了新的笔记本,系统都是公司IT配置好的,可是拿回家却发现上不了网。家里之前是两台机器通过无线路由器共享ADSL上网的,可是公司笔记本却连不上网,ping得到路由器地址192.168.0.1,却访问不了路由器管理页面http://192.168.0.1,无论无线有线都不行。无奈之下把ADSL连路由器的网线拔下,直接连到公司笔记本上,可以上网,在换成通过路由器,还是不能上网。
今天又重新试了一下,经过多次尝试,发现是虚拟机IP地址和路由器冲突了。安装了虚拟机软件后,多了两个VMWARE网络适配器,其中一个被设置成了192.168.0.1,和路由器的冲突了,于是把它改掉,重试,可以上网了。可是换成无线上网还是不成功。一个比较奇怪的地方是系统启动的时候总是会提示network adapter没有安装驱动程序,但其实无线网卡是可以连接的,于是点进去重新修改了驱动程序安装,可是装完后提示驱动程序软件没有找到适合的网络适配器。过了很久才想起来可能是这个冲突了,于是上网查了一下DELL 630使用的网卡1505 MiniCard所用的程序,发现不应该是Intel PRO,于是把它卸掉重启,OK,终于可以无线上网了。
-
将Domain Controller降级为普通工作站后的问题
2007-07-22 21:59:53
这周的工作过程中遇到这样的问题:一套安装了SQL Server 2005的服务器,一开始打算在上面安装Domain controller,于是安装了,后来因为其他的原因需要把它降级为普通的工作站,于是卸载Domain controller,在安装和卸载活动目录的过程中,可以看到提示有一些security设置被改变了。卸载完成后,SQL Server服务无法启动了,重启机器也是如此。Error Number是17113。
在网上搜索了一下,发现仅有的针对这个问题的一个可能的解决方案是在SQL Server的SQL Configuration Manager里把VIA network protocol禁掉,可是尝试了一下,还是不行。不知道还有没有其他的解决方案,目前看起来只能重装SQL Server了,:(。看来以后要改变计算机的属性,尤其是和security设置相关的,要当心了。
-
[转]Why some start-ups finish badly (from Financial Times)
2007-07-15 11:31:31
今天从别人的博客上看到的,觉得还是比较说明问题的。
KEY REASONS FOR FAILING TO MAKE IT
■ Poor credit management practices, such as paying bills before the last date that they need to be settled.
■ Lack of access to finance to fund expansion.
■ Lack of cash in the bank to support the business when the unexpected happens, such as a key customer going out of business.
■ Relying too much on a single supplier or customer.
■ Lack of focus on selling a product or service.
■ Failure to bring key people in from the start: namely, experts in finance, sales, operations and technical innovation. A good mentor can often make the difference between success and failure.
-
[转]Windows Mobile程序的自动化测试简介
2007-07-08 22:30:52
作者: 未知 来源: eNet硅谷动力
随手打开MEDC 2007的课程列表页面,看到了一个课程的标题《使用Windows Mobile Test Framework进行自动化测试》,突然想起来新的Windows Mobile 6 SDK中似乎包含这个叫做什么Windows Mobile Test Framework的东东,于是乎打开WM6的安装目录下的Tools\Windows Mobile Test Framework\Windows Mobile Test Framework.zip这个zip包瞅一瞅。
真是不看不知道,一看吓一跳。。。微软居然把这个框架单独发布出来了。其实这套东西貌似在Windows CE 5的CE Tool Kit中就包含,不过现在貌似把它单独提出来进行推广了。那么,我也来写一个关于它的系列和大家来研究研究这套Windows Mobile Test Framework吧。
一、微软Windows Mobile Test Framework简介
Windows Mobile Test Framework(以后简称为WMTF)是微软内部使用的一套Windows CE/Windows Mobile上的自动化测试框架。使用这套框架,我们可以很方便的用它来模拟用户来对您的程序进行操作,来进行功能/UI/本地化等多种测试。
此框架的整体结构如下图所示:
绿色部分为微软在这个Windows Mobile Test Framework中所提供的。
橙色的UIAL,为我们需要使用微软在Windows Mobile Test Framework中的工具来自己生产且做少量修改工作的。
蓝色部分为需要我们大家自己来完成的部分。
二、Windows Mobile Test Framework各层次介绍
1) Utils.Net:
这一层提供了很多在其他各个层次中经常需要用到的公共对象或者是一些在.NET Fx中有而在.NET CF中被省略了的对象,例如进程/设备信息/内存/注册表等。
2) Logging:
这一层顾名思义,当然是封装了日志记录的功能,用来记录测试中的过程和结果。当然,这套Logging机制非常不错,不但在这里可以用,您甚至可以把它用于开发过程中甚至是桌面程序开发中。3) DATK:
DATK的全称是Device Automation ToolKit。它是一套影射了所有的Windows CE上的标准控件的一套类库。例如文本框,列表框,按钮等等。同时,在这一层还有一个主要的对象叫做WindowsFinder,它几乎可以说是DATK甚至是WMTF的核心部分。您可以通过它来制定条件(例如类型,文本,进程等等)来寻找到某一个控件,然后把这个控件绑定到一个DATK控件上,然后您的代码来操作这个DATK 控件就可以实现对实际的控件的调用。这其实就是Windows Mobile Test Framework的核心部分。
4)Mobility ToolKit:
以后我们将它简称为MTK。MTK里面主要在DATK的基础上增添了许多针对移动设备特有的对象。可以认为它是DATK的一个扩展。
5)UIAL:
UIAL(UI Abstraction Layer),它是您要测试的应用程序的界面的一个影射。您必须为您的需要测试的每一个界面建立对应的UIAL层代码(借助微软提供的工具),这样才可以对程序进行测试。一个典型的UIAL层代码通常包含4部分。
A. 对话框类:它是你要测试的那个对话框的一个影射,同时这个类里面也应该包含该界面上面所有控件地应的DATK控件。
B. 应用程序类:用来启动该对话框。
C. IdnHolder类:用来查找对话框中的本地化资源文字。
D. 自测试代码:赫赫。。。从这一层起,就需要做测试了。
6) Area Libraries:
在这一层我们通常来封装一些可以复用的步骤。举例来说,您的测试程序中需要打开某一个对话框,而这个步骤显然是可以复用的(也许为了测试不同的地方我们需要反复的打开这个对话框)。那么我们就可以把这个打开程序,然后再打开该对话框的步骤封装到Area Libraries便于以后复用。
7)Test Cases & Test Suites:
这一层我们通常简称为Tests层,显然,在这一层我们用来编写我们的测试代码。和NUnit之类的很相似。使用Suite来把一些Test Cases组织到一起。
最终,测试引擎Tux.NET将调用Tests层中的测试代码,按照您的测试脚本来测试程序。 -
[转]Oracle中自增字段的两种方法的比较(Trigger和Sequence)
2007-07-01 16:28:14
在ORACLE中,没有象MS-SQLSERVER中那样子有自增字段,但是如果我们要实现这个功能,有2种方法
1 Trigger
sql语句如下:
create or replace trigger trigger_name
before insert on your_sid.tablename
for each row
begindeclare
i number;
cursor cur is select max(id) from your_sid.tablename;BEGIN
open cur;FETCH cur INTO i;
if i is NULL then
:new.id := 0; //可以根据实际需要来定初始值
else
:new.id := i + 1; //这里以1递增
end if;Close cur;
END;END;
/其中:your_sid为数据库的当前用户SID,tablename为表名,id为列名,
2 Sequence
sql语句如下:
create sequence your_sid.sequence_name
increment by 1 //指定序列以1递增,如果没指定,默认值1会使用
start with 1 //由1开始计数
nomaxvalue //不设置最大值
minvalue 1 //设置最小值1
cache 20 //预分配缓存大小为20
order二者的区别在于,Sequence的效率要比Trigger的高,因为Trigger每次都要遍历表中所有记录以寻找ID最大值,而Sequence每次执行后,都会保留最大值;
-
自动化软件测试成熟度等级——译自《自动化软件测试——入门、管理和实现》一书
2007-06-30 15:19:13
个人觉得这本书的书名翻译的不太准确,我认为书名译作《自动化软件测试——引入、管理和实施》更为准确。这不是一本讲具体的自动化测试实现的书,所以“入门”、“实现”一词有些误导。主要的原因可能是这本书目前出的是影印版,并不是中译本,因此图书编辑可能没有仔细的阅读过书的内容就粗略的翻译了一下书名。
作者把自动化测试成熟度划分为五个等级,实际上与CMM5中的等级一一关联。
自动化软件测试Level 1:
这个等级的自动化软件测试被称作“随机的自动化”(accidental automation)。在这个阶段,自动化测试没有实施或者只是基于临时性的(ad hoc)。可能会试验性地使用自动化测试工具。通过捕获/回放工具,自动化测试脚本被记录和回放,只有工具产生的脚本被使用。脚本不会为了可复用性或可维护性的目的而进行修改。没有遵循一个自动化脚本设计或开发的标准。产生的脚本不可复用并且难于维护,并且在每一个软件build都需要重新创建。这种自动化实际上在每一个测试周期可能会比手工测试增加125%或者更多的测试花费。
自动化软件测试Level 2:
这个级别的自动化软件测试被称作“伴随性的自动化”(incidental automation)。在第二个等级,自动化测试脚本被修改,但是没有文档化的标准或可重复性。在这个阶段使用的工具包括项目计划工具、捕获/回放工具、模拟器和仿真器、语法和语义分析器、调试工具等。
新项目中自动化测试工具的引入没有经过计划、没有遵循一个流程。没有测试设计和开发的标准。没有考虑测试进度和测试需求的问题,或者在构思自动化测试工具的使用时没有参考测试进度和测试需求。和等级1一样,这种类型的自动化没有提供多少投资回报,或者说实际上增加了测试的工作量。
自动化软件测试Level 3:
这个级别的自动化软件测试被称作“有意识的自动化”(intentional automation)。在第三个等级,自动化测试是明确定义的,并且得到了很好的管理。测试需求和测试脚本来自于软件需求规约和设计文档。
自动化脚本的创建基于测试设计和开发规范,但是测试团队不评审自动化测试过程。自动化测试成为可重用以及可维护的。在这个级别的自动化测试中,投资开始有回报,收支平衡的点可以在第二次回归测试周期中获得。这个阶段的工具类型包括需求管理工具、项目计划工具、捕获/回放工具、模拟仿真工具、语法语义分析器、调试工具等。
自动化软件测试Level 4:
这个级别的自动化软件测试被称作“高级自动化”(advanced automation)。这个等级代表了对于等级3的一个实践了的和完善了的版本,同时加上一条主要的改进——发布后的缺陷跟踪。在修改、测试创建和回归测试的整个流程中,缺陷被捕获和提交。软件测试团队成为产品开发的一个完整的部分,测试工程师和应用程序开发者协同工作来创建一个满足测试需求的产品。任何的缺陷都很早的被发现,从而降低修复的成本。除了上面等级提到的工具,缺陷和变更跟踪工具、测试过程产生工具和代码评审工具在这个阶段得到应用。
自动化软件测试Level 5:
这个阶段应用的工具,除了上面等级用到的工具之外,还包括测试数据产生工具、度量采集工具(例如复杂度度量等)、覆盖率和频度分析工具、缺陷分析和缺陷预防的数据工具。
-
在虚拟机上安装LINUX鼠标不能识别的问题
2007-06-30 11:04:33
今天在虚拟机上安装LINUX,在选择鼠标类型的时候选了带滚轮的USB鼠标(我的笔记本的鼠标是这种),可是发现选了之后鼠标就不能识别了,后续的步骤都靠键盘操作。后来GOOGLE了一下,发现应该选择PS/2鼠标,因为选的实际上应该是虚拟机的鼠标类型(PS/2),而不是宿主机的真实鼠标类型。 -
HEAD IN DESIGN PATTERNS读书笔记——DECORATOR 模式
2007-06-26 21:36:59
第三个PATTERN——DECORATOR
StarBuzz Coffee最近发展的非常迅速,他们决定更新他们的饮料订单系统。
他们开始提出的类图是这样的:
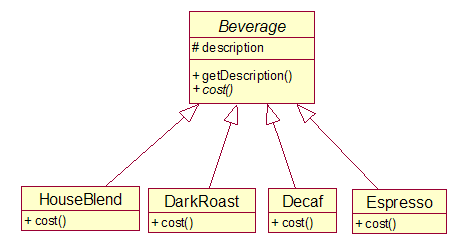
然而除了咖啡之外,你可能还会要一些调料,比如牛奶、豆汁、摩卡等等,StarBuzz Coffee会对这些收取一点费用。而订单系统需要根据没一种需求指定项目并计算总价。于是按照上面的方案最终导致了类的数量的爆炸。
也许你会说,为什么需要那么多的类,可以把调料作为成员变量加到基类中,子类继承得到这些调料的信息。那么试试看:
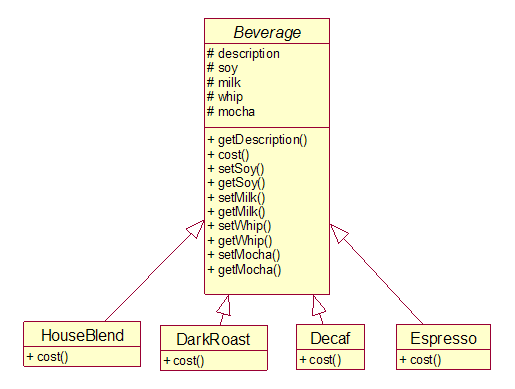
现在我们在Beverage类里实现cost()方法(而不是让它作为抽象方法),这样它可以计算一个具体的饮料实例的调料的花费。子类仍然会重写cost(),但它们依然会调用超类的版本,这样它们就可以计算基本的饮料加上调料的总花费。
但是有一系列因素的变化会影响这个设计:
调料价格的变化会迫使我们修改现有的代码
新的调料会迫使我们在超类中增加新方法以及修改cost()方法。
我们可能会有一些新的饮料类型,对于其中的一些饮料,可能使用调料是不恰当的,但是它们还是会继承hasWhip()这样的方法(就像第一章开始的例子中橡皮鸭继承fly()方法一样)。
如果客户要求双份的牛奶怎么办?
下面是我们改变的设计:我们将由一个饮料开始,在运行时用调料来“装饰”它。例如,客户需要一个有摩卡和蛋奶的Dark Roast,我们的步骤将是:
1. 得到DarkRoast对象

2. 用Mocha对象来装饰它
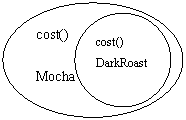
Mocha对象是一个decorator,它的类型镜像了它所装饰的类型——Beverage(此处的“镜像”指它们是同一种类型)。因此,Mocha也有一个cost()方法。
3. 用Whip对象来装饰它
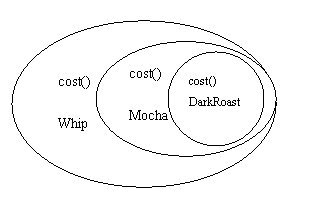
4. 调用cost()方法,依靠委派来增加调料的花费
首先调用最外层Whip对象的cost()方法,它调用Mocha对象的cost()方法,Mocha对象调用DarkRoast对象的cost()方法。
DarkRoast对象返回它的花费,99美分,Mocha对象加上它的花费20美分,返回总值共1.19美元,Whip对象加上它的花费10美分,返回总值1.29美元
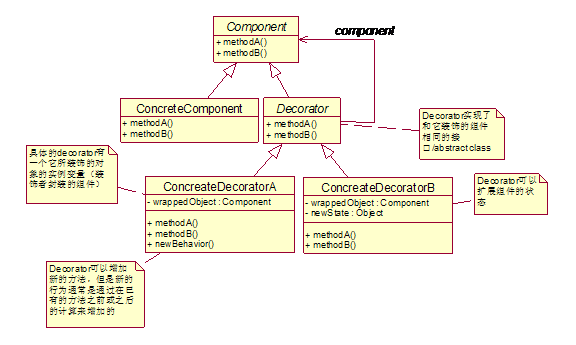
l Decorator和被它装饰的对象有着同样的超类。
l 可以使用一个或多个decorator来包装一个对象
l 既然decorator和被它装饰的对象有着同样的超类,在使用一个原始(被包装的)对象的地方,我们可以传递一个装饰了的对象。
l Decorator在把方法委派给它装饰的对象之前或者之后,把它自己的行为加上去来完成剩余的工作(这一点很关键!)
l 对象可以在任何时候被装饰,因此我们可以在运行时用任意多个decorator来装饰它。
现在我们来看DECORATOR PATTERN的描述:
Decorator Pattern动态地为一个对象附加额外的职责。Decorators提供了区别于通过子类化来扩展功能的另一种解决方案。
现在我们的Starbuzz饮料系统变成下面的框架:
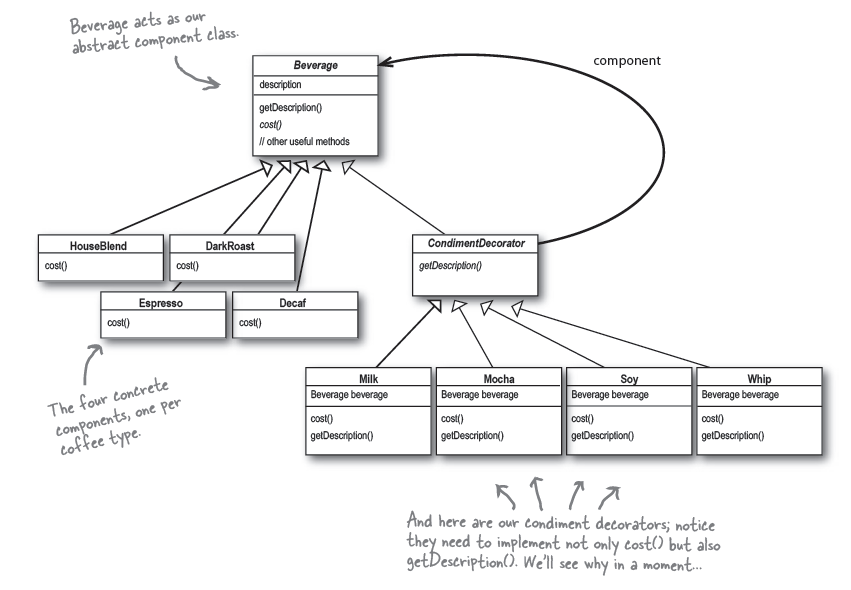
这里CondimentDecorator继承Beverage类是为了获得类型的匹配,而不是通过继承来获得行为(behavīor)。行为是通过其中包含的基本的component以及其他decorator的组合来获得的。
如果依靠继承,我们的行为只能在编译时静态地决定。通过composition,我们可以在运行时任意地混合使用decorators。
Decorator模式的一个实例是Java中的I/O类。FileInputStream, BufferedInputStream, LineNumberInputStream——看着眼熟吧。
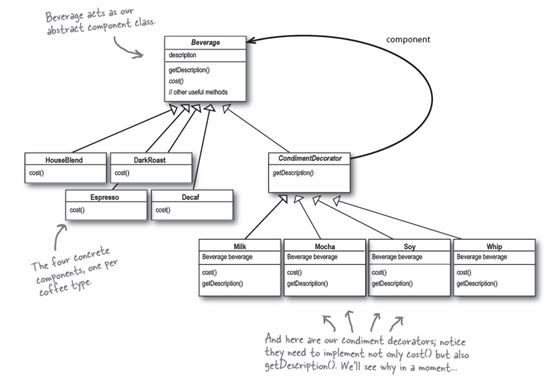
-
[转]自动化测试策略
2007-06-24 16:10:26
作者:老徐 新闻来源:STTE 更新时间:2007-4-3 18:10:56
工作周期及阶段确定:组长初步确定工作周期,并定义自动化测试的阶段,例如需求分析/设计阶段,开发实现阶段,运行阶段,而运行阶段中要根据所属系统所处软件生命周期的不同阶段来定义自动化测试的运行周期,例如当前处于所属系统的运营维护阶段(上线之后),其每3个月进行一次新版本的发布,则自动化测试亦为每三个月执行一次。或其每周进行一次Build的发布,则自动化测试亦为每周执行一次。
分析自动化测试风险:根据所属系统的开发平台、界面特性、测试环境搭建维护的难易程度、测试工具的适用性等方面的分析结果进行自动化测试风险的分析。主要从战略层面进行风险的分析,不要分析某个具体的自定义控件的可测试性。
手工测试现状复审:依据手工测试现状分析报告中提供的已有业务测试过程进行业务需求覆盖度的分析,判断已有业务测试过程是否完整,若不完整则需要向测试管理部提出反馈:被测系统的手工测试现状尚不符合自动化测试的需求,请求是否延期并委托手工测试方完善业务测试过程。
测试方法及工具确定:根据所属系统的特点和当前自动化测试组织的实施能力,确定自动化测试的方法,例如业务驱动方法、关键字驱动方法、数据驱动方法;另外要结合现有的软件自动化测试专用工具,判断采用何种自动化测试管理工具搭建自动化测试的管理平台、运行平台,或者是新开发一种框架来实现自动化测试。
编写文档:自动化测试分析师编制《自动化测试工作策略》
内部评审:组长组织自动化测试工作小组的内部评审
外部评审:组长向自动化测试管理组的计划控制经理提出评审申请,计划控制经理组织自动化测试管理组的外部评审,评审《自动化测试策略》,需要项目组、自动化测试小组和质量控制经理共同参与评审。
组长将评审通过的《自动化测试策略》纳入配置管理库。
-
[转]自动化测试计划
2007-06-24 16:06:07
作者:老徐 新闻来源:STTE 更新时间:2007-4-3 18:13:15
- 设定测试运行模式:根据《自动化测试需求分析说明书》中的描述,针对所有业务测试过程之间的关系,设计所有业务测试过程的执行顺序、前后关联关系等
-
设定测试运行计划:根据《自动化测试需求分析说明书》中对于自动化测试执行应用的描述,例如在每次Build,或者在每次新版本发布时执行自动化测试,设计自动化测试将来的执行计划
-
确定自动化测试缺陷生命周期模式:在自动化测试的运行过程中,业务组件在验证过程中将会遇到验证失败的情况,应在计划中定义自动化测试缺陷定义标准、自动化测试缺陷处理方案,则在自动化测试实现活动中要开发相应的缺陷提交组件供每个业务组件调用,以在测试发现可能的缺陷时判断是否是真正的缺陷并自动向缺陷管理子系统中提交缺陷报告。
-
设定开发计划:根据所有业务测试过程之间的关系以及将来的执行计划,同时考虑每个业务测试过程的优先级,确定所有业务测试过程的开发时间计划、开发责任人等
-
确定所需开发资源:依据开发计划确定在开发业务测试过程中所需的自动化测试工程师资源、自动化测试工具资源、开发环境资源等
-
确定所需运行资源:依据测试运行计划确定在自动化测试运行过程中所需的自动化测试环境资源、自动化测试工具资源等
-
编制测试计划:自动化测试分析师编制《自动化测试计划》,组长组织测试管理部的内部评审
-
组长向自动化测试管理组的计划控制经理提出申请,由计划控制经理组织自动化测试管理组的外部评审,评审《自动化测试计划》,需要项目组、自动化测试小组和质量控制经理共同参与评审。
-
外部评审结束后,若通过则由计划控制经理依据《自动化测试计划》中提出的资源需求提供各种资源。
-
组长将评审通过的《自动化测试计划》纳入配置管理库。
- 设定测试运行模式:根据《自动化测试需求分析说明书》中的描述,针对所有业务测试过程之间的关系,设计所有业务测试过程的执行顺序、前后关联关系等
-
[转]自动化测试需求分析
2007-06-24 16:02:32
作者:老徐 新闻来源:STTE 更新时间:2007-4-3 18:12:45
-
自动化优先级标定:自动化测试分析师获得所有的测试需求及测试案例,依据“测试需求可自动化判断标准”,使用《自动化测试_测试需求优先级计算模版》进行每个测试需求的自动化优先级的标定。
-
确定自动化测试范围:依据测试需求的自动化优先级标定结果,配合自动化率的目标确定将要对哪些测试需求进行自动化,从而达到确定自动化测试范围的目的。
-
文档编制:自动化测试分析师编制《自动化测试需求分析说明书》
-
内部评审:组长组织自动化测试小组的内部评审
-
外部评审:组长向自动化测试管理组的计划控制经理提出申请,由计划控制经理组织测试管理组的外部评审,评审《自动化测试需求分析说明书》,需要项目组、自动化测试小组和质量控制经理共同参与评审。
-
组长将评审通过的《自动化测试需求分析说明书》纳入配置管理库。
-
自动化测试分析师将《自动化测试需求分析说明书》中规定的所有自动化测试需求和测试案例纳入自动化测试技术平台的测试需求管理子系统。
-
-
HEAD IN DESIGN PATTERNS读书笔记——STRATEGY模式
2007-06-24 10:06:05
应用程序:小鸭模拟程序(MiniDuckSimulator)
问题的提出:
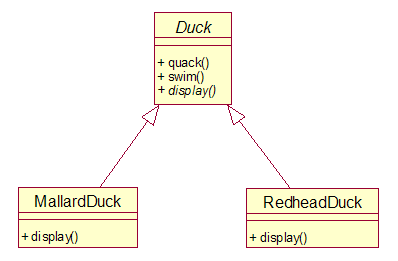
初始的情况是这样的:Duck类中包含了quack()和swim()方法,以及一个抽象方法display()(Duck实际上为抽象类)。MallardDuck,RedheadDuck以及其他许多鸭子类都继承了Duck类。
之后增加了一个新的需求,就是在这个鸭子模拟系统中需要增加会飞的鸭子。程序员Joe认为只要在Duck类中增加一个fly()方法就可以了。

但事实并不是这么简单。上面代码的直接结果是橡皮鸭也开始在屏幕上飞来飞去了,而这是不合逻辑的。事实上上面代码等于把fly()方法赋予了所有Duck类的子类,而其中许多都是不会飞的鸭子。
一种解决方式是在子类中修改fly()的行为,将橡皮鸭的fly()方法改成什么也不做。但同时存在另一些情况比如木头鸭既不会呷呷叫也不会飞。同时Joe知道接下来每半年要更新一次产品加入一些新的变更,他需要不断的为每一个新加入的子类修改fly()和quack()的实现……
于是Joe想到了使用接口,把fly()方法和quack()方法从Duck类中分离出来,抽象成两个接口Flyable和Quackable:
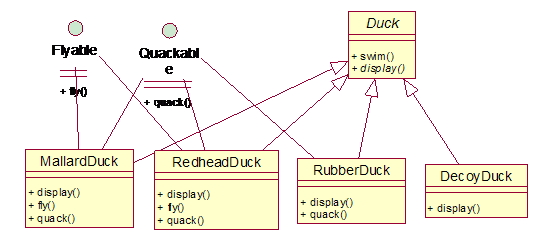
但是这样的代码可重用性很差,因为即便是能飞的鸭子,飞行的行为也可能不只一种。
解决方案:
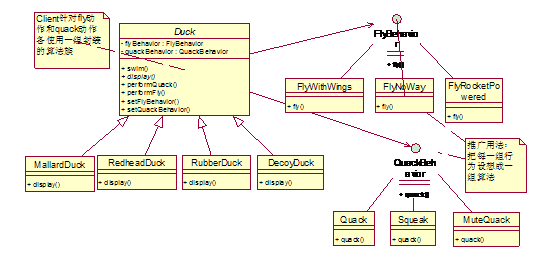
这里Duck类通过performQuack()和performFly()方法把quack()和fly()代理给了两个接口类,可以在运行时为Duck的子类设置具体的行为类,此时根据子类中包含的具体行为类对象决定具体的fly(),quack()行为。
使用HAS-A的组成来创建系统提供了很大的灵活性。不仅可以把封装一组算法封装进自身的一组类,而且可以在运行时改变行为,只要用来组成系统的对象实现了正确的行为类。
-
[转]C++如何实现虚函数的动态联编
2007-06-23 20:38:29
编译器是如何针对虚函数产生可以再运行时刻确定被调用函数的代码呢?也就是说,虚函数实际上是如何被编译器处理的呢?Lippman在深度探索C++对象模型[1]中的不同章节讲到了几种方式,这里把“标准的”方式简单介绍一下。
我所说的“标准”方式,也就是所谓的“VTABLE”机制。编译器发现一个类中有被声明为virtual的函数,就会为其搞一个虚函数表,也就是VTABLE。VTABLE实际上是一个函数指针的数组,每个虚函数占用这个数组的一个slot。一个类只有一个VTABLE,不管它有多少个实例。派生类有自己的VTABLE,但是派生类的VTABLE与基类的VTABLE有相同的函数排列顺序,同名的虚函数被放在两个数组的相同位置上。在创建类实例的时候,编译器还会在每个实例的内存布局中增加一个vptr字段,该字段指向本类的VTABLE。通过这些手段,编译器在看到一个虚函数调用的时候,就会将这个调用改写,针对1.1中的例子:
void bar(A * a)
{
a->foo();
}
会被改写为:
void bar(A * a)
{
(a->vptr[1])();
}
因为派生类和基类的foo()函数具有相同的VTABLE索引,而他们的vptr又指向不同的VTABLE,因此通过这样的方法可以在运行时刻决定调用哪个foo()函数。
虽然实际情况远非这么简单,但是基本原理大致如此。 -
[转]面向对象的设计原则-类设计原则
2007-06-23 09:43:12
作者:中国系统分析员顾问团高级顾问 张华 来自:CSAI.cn
在面向对象设计中,如何通过很小的设计改变就可以应对设计需求的变化,这是令设计者极为关注的问题。为此不少OO先驱提出了很多有关面向对象的设计原则用于指导OO的设计和开发。下面是几条与类设计相关的设计原则。
1. 开闭原则(the Open Closed Principle OCP)
一个模块在扩展性方面应该是开放的而在更改性方面应该是封闭的。因此在进行面向对象设计时要尽量考虑接口封装机制、抽象机制和多态技术。该原则同样适合于非面向对象设计的方法,是软件工程设计方法的重要原则之一。
我们以收音机的例子为例,讲述面向对象的开闭原则。我们收听节目时需要打开收音机电源,对准电台频率和进行音量调节。但是对于不同的收音机,实现这三个步骤的细节往往有所不同。比如自动收缩电台的收音机和按钮式收缩在操作细节上并不相同。因此,我们不太可能针对每种不同类型的收音机通过一个收音机类来实现(通过重载)这些不同的操作方式。但是我们可以定义一个收音机接口,提供开机、关机、增加频率、降低频率、增加音量、降低音量六个抽象方法。不同的收音机继承并实现这六个抽象方法。这样新增收音机类型不会影响其它原有的收音机类型,收音机类型扩展极为方便。此外,已存在的收音机类型在修改其操作方法时也不会影响到其它类型的收音机。
图1是一个应用OCP生成的收音机类图的例子:
图1 OCP应用(收音机)2. 替换原则 (the Liskov Substitution Principle LSP)
子类应当可以替换父类并出现在父类能够出现的任何地方。这个原则是Liskov于1987年提出的设计原则。它同样可以从Bertrand Meyer 的DBC (Design by Contract) 的概念推出。
我们以学生为例,夜校生为学生的子类,因此在任何学生可以出现的地方,夜校生均可出现。这个例子有些牵强,一个能够反映这个原则的例子时圆和椭圆,圆是椭圆的一个特殊子类。因此任何出现椭圆的地方,圆均可以出现。但反过来就可能行不通。
Liskov的相关图示见图2:

图2 Liskov 原则运用替换原则时,我们尽量把类B设计为抽象类或者接口,让C类继承类B(接口B)并实现操作A和操作B,运行时,类C实例替换B,这样我们即可进行新类的扩展(继承类B或接口B),同时无须对类A进行修改。
3. 依赖原则 (the Dependency Inversion Principle DIP)
在进行业务设计时,与特定业务有关的依赖关系应该尽量依赖接口和抽象类,而不是依赖于具体类。具体类只负责相关业务的实现,修改具体类不影响与特定业务有关的依赖关系。
在结构化设计中,我们可以看到底层的模块是对高层抽象模块的实现(高层抽象模块通过调用底层模块),这说明,抽象的模块要依赖具体实现相关的模块,底层模块的具体实现发生变动时将会严重影响高层抽象的模块,显然这是结构化方法的一个"硬伤"。
面向对象方法的依赖关系刚好相反,具体实现类依赖于抽象类和接口(见图-3)。
为此,我们在进行业务设计时,应尽量在接口或抽象类中定义业务方法的原型,并通过具体的实现类(子类)来实现该业务方法,业务方法内容的修改将不会影响到运行时业务方法的调用。

图3依赖原则图示4. 接口分离原则(the Interface Segregation Principle ISP)
采用多个与特定客户类有关的接口比采用一个通用的涵盖多个业务方法的接口要好。
ISP原则是另外一个支持诸如COM等组件化的使能技术。缺少ISP,组件、类的可用性和移植性将大打折扣。
这个原则的本质相当简单。如果你拥有一个针对多个客户的类,为每一个客户创建特定业务接口,然后使该客户类继承多个特定业务接口将比直接加载客户所需所有方法有效。
图4展示了一个拥有多个客户的类。它通过一个巨大的接口来服务所有的客户。只要针对客户A的方法发生改变,客户B和客户C就会受到影响。因此可能需要进行重新编译和发布。这是一种不幸的做法。

图4 带有集成接口的服务类我们再看图-5中所展示的技术。每个特定客户所需的方法被置于特定的接口中,这些接口被Service类所继承并实现。

图5 使用接口分离的服务类设计
如果针对客户A的方法发生改变,客户B和客户C并不会受到任何影响,也不需要进行再次编译和重新发布。
以上四个原则是面向对象中常常用到的原则。此外,除上述四原则外,还有一些常用的经验诸如类结构层次以三到四层为宜、类的职责明确化(一个类对应一个具体职责)等可供我们在进行面向对象设计参考。但就上面的几个原则看来,我们看到这些类在几何分布上呈现树型拓扑的关系,这是一种良好、开放式的线性关系、具有较低的设计复杂度。一般说来,在软件设计中我们应当尽量避免出现带有闭包、循环的设计关系,它们反映的是较大的耦合度和设计复杂化。
-
[转]ruby实现抽象类和抽象方法
2007-06-22 18:38:43
ruby语言本身并没有提供abstract class和abstract method机制。这是ruby的spirit所决定的。但如果我们真的需要定义一个公共抽象类(或者抽象方法)来让子类来实现,又该如何做呢?
我们可以通过在调用方法时抛出NotImplementedError来防止方法被调用。如(来自《ruby cookbook》的例子):
class Shape2D
def area
raise NotImplementedError.new("#{self.class.name}#area是抽象方法")
end
end
class Square < Shape2D
def initialize(length)
@length = length
end
def area
@length ** 2
end
end
父类Shape2D的方法area就是我们所需要的“抽象方法”了。你不能直接调用:
s1=Shape2D.new
s1.area
这样调用将抛出错误:Shape2D#area是抽象方法 (NotImplementedError)
Shape2D的子类Square覆写了此方法。由此我们模拟实现了抽象方法。那么抽象类该如何实现呢?自然而然,我们想到如果把类的initialize方法这样处理,那么这样的类将没办法被new生成,不正是我们所需要的抽象类?说干就干:
class Shape2D
def initialize
raise NotImplementedError.new("#{self.class.name}#area是抽象类")
end
def area
raise NotImplementedError.new("#{self.class.name}#area是抽象方法")
end
end
当你调用Shape2D.new时,解释器将提示你:Shape2D是抽象类(NotImplementedError)
我们已经实现了抽象方法和抽象类,感觉还是不够好,对每一个需要实现抽象类的类来说,我们都需要去写一句:raise NotImplementedError.new...实在不够爽。ruby鼓励我们去修改类的行为,甚至是标准库,那好,我们修改Class类吧,提供类似attr_reader的声明式服务:
class Class
def
abstract(*args)
args.each do |method_name|
define_method(method_name) do |*args|
if method_name == :initialize
msg = "#{self.class.name}是抽象类"
else
msg = "#{self.class.name}##{method_name}是抽象方法"
end
raise NotImplementedError.new(msg)
end
end
end
end
OK,如此一来,我们的Shape2D可以写成:
class Shape2D
abstract:initialize,:area #initialize和area是抽象方法
end
尽管在ruby中,抽象类和抽象方法是否有用存在怀疑,不过知道这样的办法总是不错的主意。
