
-
数据库迁移测试(存储过程)
2010-05-10 18:02:33
讲到SP,那真是痛苦中的痛苦啊,调试困难,测试困难;因为它不仅受到本身代码准确性的影响,也受到被执行数据的正确性、数据量、数据库特性等的诸多影响,所以在数据库迁移的过程中复杂SP改写和测试就是重中之重了。
很有幸,最近工作中碰到了一次大规模的数据库迁移测试,虽然耗掉了半条老命,但总算项目成功收尾,总算也有些闲暇来写点总结感受。
开始,单步调试
和程序调试一样,单步的调试肯定是最有效的,所以单步执行存储过程中的逻辑是基础。橙子也是这么做的,橙子挑取了部分测试数据,小数据量的,只为验证逻辑。将Update操作改写为Select,因为Update操作比较耗费资源,并且破坏原数据。为了测试效率,橙子需要尽快知道逻辑正确性,不过这个也为后续的测试错误埋下了伏笔。
臭虫,MySQL的表别名
单步调试开始,第一段逻辑就发现了BUG。由于项目是从SqlServer迁移至Mysql,SqlServer对于表别名是不区分大小写的,而Mysql则区分大小写,结果造成了表别名书写的大量错误。上百个复杂SP,发动程序,DBA一起修改,也算是顺利修改完成,测试继续
麻烦,数据导入错误
橙子继续测试,但总是逻辑错误,代码Review之后,确定应该是数据问题,随后开始检查数据。这下傻眼了,发现从SqlServer迁移过来的数据有大量错误,主要是datetime,bit这类。随后查原因,原来SqlServer中有默认值的字段,到MySQL后由于没有默认值,都成了null了;而使用文本导出导入的方式,又将SqlServer中大量的空字段转变成了/0。这下DBA也傻眼了,重做数据吧。之后橙子提议,在导出数据后要做必要的Check,以确保导入。这里也给橙子自己一个提醒,测试开始前应先确保被测数据的正确性,这样更方便Cause的确定
注意,MySQL不会自动取整
解决了数据问题,橙子又发现了一个Bug,原来SqlServer在除运算后是会自动取整的,但是Mysql不会。如果你在除运算后,有case操作,那就要特别注意了。小数据量的单步调式顺利完成,橙子和同事们都对本次迁移充满信心,因为复杂逻辑没有问题,SP的集成调用也OK,事先最担心的逻辑验证看来很顺利。事实证明麻烦真的就是会在你盲目乐观的时候找上门的。
狗屎,MySQL的查询优化
随后导入了海量数据,开始仿真测试。也许SqlServer还算可以的查询优化,把我们的程序员和DBA都养懒了。大段大段的子查询,大量的join操作迁移到MySQL后,原先几10秒完成的Select,10分钟都完成不了。看来MySQL的查询优化还真是不行。这下麻烦了,连测试结果都得不到,咋整?没辙,大家打回原始社会吧,工具不行,只能靠人了。于是开始解耦,靠人来优化查询。最后我们花了大量的时间,使用内存零时表的方式,解耦了大部分join查询,使SP中的每个Select都尽量简单,也算人为解决了查询优化的问题。这个过程耗费了整个迁移工作量的绝大部分,并且导致了所有逻辑测试必须返工重做。因此橙子对于之前没有预估海量数据和查询优化造成的影响而急功近利的做法懊悔不已。
未完待续 -
WEB测试新说
2009-10-27 22:30:02
WEB应用的发展真是太迅猛了,搜索引擎,WEB2.0,SNS,MiniBlog真是一个接一个,随之带来开发技术,测试技术的变革也是日新月异。曾经坊间流传的各类WEB测试总结文章显然已经不适应这样的发展了,什么链接测试啊,表单测试啊,cookie测试啊,这些对于大多数测试人来说已经是小巫见大巫了,写此文的用意,也是想通过自己的总结,对原先WEB测试的技术做一个补充,将WEB测试放置到一个更高的位置。
1. Track测试
Track是什么,其实很简单,对于互联网的应用,点击率就是命门,那就是说每个应用都需要记录自己的点击率,说细致了,就是重要的链接都需要有自己的点击记录,无论你用的是哪种Track技术,作为测试人员,对于这么重要的测试点怎么能够放过呢。这里需要注意的是Track是否有效:很好理解,是否正确计数嘛;Track是否有合理的区分机制:不同的链接起码要能区别Track;Track的实际意义:毕竟Track本身也是有消耗的,并不是所有链接都Track就可以了
2. Ajax注入测试
现在的网站都大量的使用JS和Ajax技术,当然这里就需要加强注入的测试了,其实这是一个后台处理程序对输入参数的校验严谨性的问题。但是由于Ajax是异步提交的过程,而一般通过页面的黑盒测试又比较难发现此类的BUG,所以对于那些有安全性要求的应用,应当提高这类的测试力度,幸好,我们还有firebug之类好用的工具,来帮助我们完成测试
3. Cache机制的测试
由于对于性能的追求,以及各类缓存架构的层出不穷,缓存机制成为了每个WEB应用不可缺少的架构组成部分。对于缓存的测试无非是有效性的测试,缓存过期的测试,缓存更新的测试等
4. 分布式架构的测试
这个测试范畴就有点大了,对于现在的互联网应用,分布式的架构是解决性能和存储最有效的解决之道,诸如静态文件存储,缓存服务,甚至数据库都有可能是分布式的。对于测试的要求当然也需要涉及到性能,备份,读取等的测试,以保证分布式系统中的同步与离散存储的有效性
5. 爬虫的测试
做互联网,当然是希望google,百度收录的多多益善,而那些盗窃内容的爬虫则被挡在门外了。所以这也是一种新型的安全性测试,可能涉及到系统防火墙的测试,白名单爬虫稳定率的测试等。当然其实像google webmaster这类工具,还能反过来对我们的测试提供有效的测试数据,像外链的质量和链接有效性等
6. 搜索引擎的测试
对于有搜索服务的网站而言,这是避不开的一个测试点。比如索引建立的测试,索引更新的测试,搜索结果,纠错词,提示词这些都不能忽视。并且搜索服务又往往和缓存机制有千丝万缕的联系,所以对于测试的要求也是复核性的
7. API的测试
对于互联网提供的各种API,除了功能的测试外,特别需要注意安全性和性能的测试
-
Android应用程式的剖析(转)
2009-10-23 11:44:22
Android應用程式基本上是由下面四個區塊組合而成:
1. Activity
2. Broadcast Intent Receiver
3. Service
4. Content Provider
並非所有的應用程式都需要有這四種區塊來組成,依開發人員的應用程式可能用到其中幾個區塊來組合。
一旦開發人員決定在應用程式中使用那些區塊來組成,開發人員應該在AndroidManifest.xml文件中列出來。這是一個XML文件,開發人員可以在其中聲明應用程式用到的區塊組件以及此區塊提供的功能和必要的條件。在Android Manifest File Document有完整的細節描述。(請參考下述網址:http://code.google.com/android/devel/bblocks-manifest.html )
首先,我們先來看第一個區塊Activity
Activity
Activities是Android四個區塊中最常用的一種。在應用程式中,一個Activity通常就是一個單獨的畫面。每一個Activity通過一個繼承了Activity基本類別來實現。這個類別將會顯示一個或有多個View物件的界面。並且回應一些事件功能。
大部份的應用程式都會由多個畫面來組成。例如:一個文字訊息傳送程式會有一個畫面是用來顯示要發送訊息的聯絡人清單,另一個畫面用來輸入要傳送的訊息內容,最後一個畫面用來查閱舊的訊息內容或是改變程式的設定畫面。
每一個畫面都會實作在一個Activity裡。切換到另一個畫面就是去啟動另一個Activity起來。在某些情況下,Activity可以回傳一個數值給之前的一個Activity,例如:一個Activity讓使用者選取一張照片,然後告知上一個Activity使用者選取了那張照片。
當一個新的畫面打開時,之前的畫面會暫停並且系統會將它放進歷史堆疊中。使用者可以向後導航到之前打開的歷史畫面。畫面也可以在不適合繼續保存時,從歷史堆疊中移除。Android為每一個以主畫面(Home)打開的應用程式保持其歷史堆疊。
Intent and Intent Filters:
Android使用一個特殊的類別叫做Intent,來在畫面之間做移動的動作,Intent是用來描述一個應用程式想要做什麼事情。在Intent資料結構中兩個最重要的部份,一個是動作及對資料產生什麼樣的反應。
動作主要的內容有MAIN(程式的進入點),View,Pick,Edit等動作。而資料則是用URI的形式來表示。
例如:想要查看一個聯絡人的訊息,開發人員需要建立一個Intent,包含了View的動作及指向該聯絡人資料的URI描述句。
另一個相關的類別是Intent Filter。當Intent要求去做某些事情時,Intent Filter被用來描述這個activity能夠做些什麼事情。例如:一個activity要能夠顯示聯絡人資料,就必需要在Intent Filter說明要如何處理聯絡人資料並且用ACTION_VIEW來呈現出來。Intent Filter都會宣告在AndroidManifest.xml檔案中。
而畫面的切換則是由resolving intent來實現。當使用者想要產生新的畫面時,現行的activity就使用startActivity(myIntent)方法。然後系統會根據所有已安裝的應用程式所定義的intent filter來看那個應用程式是最適合myIntent。當startActivity方法被呼叫時,resolving Intents的處理過程是伴隨而來的。
而resolving Intent提供開發人員有兩個好處:
A. 讓Activities可以很容易的利用Intent的機制去使用其他應用程式的功能。
B. 讓Activities可以很容易的在任何情況下,由新的Activity來取代。
接下來是Broadcast Intent Receiver
Broadcast Intent Receiver:
當開發人員希望應用程式來對外部的事件做一些處理時,可以使用Broadcast Intent Receiver。例如:當電話響時,或是網路資料可以使用時,或是時間到了午夜時。Broadcast Intent Receiver並不能拿來顯示出使用者介面,它必需利用Notification Manager來通知使用者所設定的事件已經觸發。
Broadcast Intent Receiver同樣可以在AndrodiManifest.xml檔案中宣告,也可以在撰寫程式碼,利用 Context.registerReceiver()方法來宣告Broadcast Intent Receiver。
應用程式並不會因為Broadcast Receivers被呼叫而被它執行起來。而且當Broadcast Receivers被觸發時,系統會依宣告的需求來執行相對應的應用程式。應用程式可以利用 Context.sendBroadcast()方法來發出他們自己的intent broadcast給其他的應程式。
接下來是Service
Service:
Service是沒有使用者介面,而且是可以長時間運作的程式碼。例如:像多媒體播放器,再播放列表中的歌曲。對於一個多媒體播放器的應用程式,可能會有一個或多個Activities在運行,使用者選擇歌曲並播放,然而,並不會有一個Activity來處理播放音樂,因為使用者可能開啟不同的應用程式時,音樂還是要繼續播放。
此時,多媒體播放器的Activity就會使用 Content.startService()方法來讓音樂持續播放。系統會一直播放音樂,直到音樂結束。
當應用程式進入背景狀態時,開發人員可以利用 Content.bindService()方法來跟Service進行連結的動作。當連接到一個Service時,開發人員就可以透過該Service開放出來的介面跟應用程式進行溝通。以剛才播放音樂的Service來看,Service可能允許使用者進行音樂的暫停、倒轉、快轉等動作。
最後我們介紹Content Provider
Content Provider:
應用程式可以將應用程式的資料儲存到檔案、SQLite資料庫或其他的機制儲存起來。當開發人員希望應用程式的資料可以被其他應用程式共享時,Content Provider就會非常有用。Content Provider實現了讓應用程式之間互相分享資料的機制。在Accessing Content Providers有完整的細節描述。(請參考下述網址:http://code.google.com/android/devel/data/contentproviders.html )。 -
android
2009-10-21 12:18:57
最近入手了G2,玩起了android系统
现在android还是在一个起步的阶段,有实际意义的软件还是比较少,虽然market上东东不少,但是多数还是娱乐为主,真正能称为互联网应用的还是屈指可数,不过玩玩Twitter什么的还是不错的
本身从android开发来说,完全和iphone两个调调,苹果还是那样封闭,google就好多了,本身android的思想就是:你的应用告诉系统要做什么,系统找人帮你搞定。这样的设计理念真是很充分地发挥了大众的力量,将不同的应用之间架起了桥梁,又方便了开发者,真是很好的构想
最近也在介入一个android平台的地图应用,这里聊android人还不是很多,希望大家多多交流
-
Spider概念在测试中的应用(二)
2009-09-27 17:19:55
首先,我们要统一一个概念,被测试的页面是由HTML、CSS和JS所组成的。而Spider的应用,是可以用来快速的进行HTML的检查和遍历,但是对于CSS和JS就有其局限性了
通过Spider其实很容易的获取到了所需要测试的页面的HTML,然后采用正则表达式的方式去获取所需的页面对象。因为HTML是标准的标签格式的,所以,获取起来也是比较方便的,然后根据标签的属性,比如ID,Class可以对对象进行区分,这就有些类似于一般的自动化测试对象,对GUI的SPY了。既然有了对象,然后对对象的内容或属性进行检查也是很方便的。
这样做的好处是将HTML整个作为文本来处理,操作简单。
以下是C#的示例,以获取页面上所有的链接对象:
//获取页面HTML并保存到Page
Regex regex = new Regex("<a[^>]+>");
MatchCollection mc = regex.Matches(page);
//mc中包含了结果对象,可以分别进行处理
利用同样的方式,我们还可以获取页面上Div、Button、Text的对象,并且对其内容进行进一步的检查
有人会说,看上去和QTP,Selenium等有异曲同工之处,而且,似乎要去搭建这样一个Framework还是比较麻烦的,为什么要这么做呢。其实这里有一个很大的优点是其他自动化工具不能做到的,即Spider可以多线程进行工作。我们是不是经常会碰到QTP,Selenium工作时,占用了当前进程,以致我们只能等待,并且一旦测试的内容海量,我们还得等很长的时间呢?Spider多线程的优势就在这里了
在下认为,对于WEB的测试,利用Spider的方式,能够很大的提高测试效率的
-
互联网QA之Q&A
2009-08-25 22:30:34
先解释一下标题,这里的Q&A就是问题与答案,不是解释QA这个名词的这里想和大家一起分享一下到底怎么去做互联网的QA。很多朋友,同事都和在下探讨过到底QA是干什么的,怎么做才能叫QA了。就现在业界内的普遍说法是,将tester和QA划分开,QA就是更注重于流程的管理,质量的保证。这样说确实不错,在那些推崇RUP,CMMI的传统软件公司内,利用各种QA的策略,流程和方法,能有效的控制开发的成本和质量;但是换到互联网行业看看呢,我们推崇的是XP,TDD,SCRUM,我们追求的是敏捷,或许死板繁琐的流程反而成了效率的枷锁。那好了,QA不能拘泥于流程了,完蛋了,那这个职位要干嘛?恐怖很多互联网的同仁们都多少遇到这样的问题,严重一点也许真的影响到仕途的发展哦。OK,这是我们的Question!下面Answer来了!先说一段往事,在下年轻的时候做过一阵子WOW的QA,没错,魔兽世界,想当年咱也是一游戏青年啊。当时也是糊里糊涂的用QTP写了一段测试游戏中对帐号在线时间计时扣点收费的自动化测试,起初是没觉得这个东东有太大用处,倒是公司领导硬是申请了12台PC,7×24小时的去执行这个测试,目的是为了监控检测整个游戏扣点收费的正确性。顿悟啊!QAQA原来真正要Assurance的Quality在这里呢。这里有个Keyword — 监控检测(当然这里指的是业务逻辑上的)。是的,对于互联网来说连续的不出错运行时间就是一个重要的质量指标;出错后能第一时间获悉错误,解决问题,又是一个不能忽视的重要的质量指标;在下觉得互联网QA的职责比较重要的一方面就是监控,通过监控的手段来达到质量的提升。其实互联网的监控又岂是一句两句可以说清楚的。不过作为一名QA,如果你能帮助你的团队快速发现问题,快速解决问题,你难道不是一名优秀的QA吗?你做的就是QA嘛!让我们把QA头上那沉重的紧箍咒拿下来吧,从实际出发,才是做好QA的根本。P.S.在下可不是说流程不重要啊,不过这些都是后话了,等咱也混迹在上市公司,等咱也背靠着500墙的时候,咱也需要写写文档,统计下数据的,:) -
Spider概念在测试中的应用(一)
2009-08-24 23:30:25
Spider,其实就是抓取网页的爬虫,大部分搜索引擎都会使用Spider来做数据源的收集。这真是一个很好的设计,那么好的设计我们是不是也能拿来在测试中使用一下呢。
其实,目前还是有很多检查链接有效性的工具,诸如LinkBot等都是采用了Spider的概念来达到测试的目的的
那么我们就将这个思想再扩展一下。在互联网网的应用中,页面的数量一向是超级繁多的,我们在平时的测试中也很难做到各个页面都去检查,特别是一些小逻辑或UI的改动,我们一般是利用等价类的方法论来做一些抽样的测试,但是这样的测试其实是不充分的,碍于成本和产出的失比,我们不会去测试过多的等价类。
但是利用Spider的概念就可以很好的解决这种GET的问题了(当然POST的测试解决起来比较困难,还是建议采用“半自动化”),而且Spider可以进行多种行为控制,也是一种很灵活的应用。对于结果的分析,最简单的无非对于HTTP.STATUS的检查,那样很容易发现一些由于数据或者配置造成的异常。如果更进阶一步,可以Parse Spider获取到的Stream以精确地检查结果
-
续“半自动化测试”
2009-08-24 22:48:33
今天正巧,公司正巧在51testing上挂了招聘启事,正巧被一个许久未联系的老同事看见,就顺便正巧找在下聊下天,又正巧的聊到了我那篇烂作“半自动化测试”。
发现当初写博文的时候确实考虑不周,东拉西扯的没个正词儿,似乎也没把问题说清楚,到底该怎么做呢,故今日补上此文。总结一下,之前说的“半自动化”测试,目的当然是简化日新月异的互联网更新过程中的测试过程,提高相应的测试效率。其核心内容就是通过测试工具来简化输入过程,而由人工来处理结果的判断(其实你真要自动化去检查,也是完全可以的,只是考虑到互谅网应用UI的不确定性,至少我是不愿意早早地去抓UI检查的)举个例子说,论坛发帖的测试,一直是繁琐的事情,特别是关系到积分的变化,等级的判断等。好,现在来分析,传其实发帖的过程就是一个POST的过程,作为测试人员,我们完全是有机会接触到暴露的接口的,没有接口?那好吧,源程序你总可以拿到吧,什么?拿不到?OK,你们公司也太OUT了吧.好了好了,言归正传.我们完全可以通过代码模拟一个将用户ID和发帖内容作为参数的简单的POST程序,这个小程序只需要两个输入框,一个按钮,就完成了发帖子.当然根据业务逻辑的复杂程度,你还可以传入更多的参数,如帖子类型啊;甚至可以输入循环值以达到重复发帖的效果.这样一个简单的小程序应该费不了多少时间,但是对于反复的测试工作来说就简化了很多了,起码不用打开页面...跳转...输入...发帖;如果你希望这样的小程序能更通用,更灵活,那就再抽象一点,将POST的URL也参数化了这里只是举了一个简单的例子,根据不同的情况,和各自公司的需求,相信会有不少的简化方法.其实这样的方法很多人都想得到,只是一个付诸实践的过程测试绝不是一种只是点鼠标敲键盘的工作,我们是属于技术部的,我们是技术人员,我们需要的是以技术的眼光来看待工作,以技术的方式来发现和解决问题 -
服务器的TIME_WAIT连接
2009-03-24 17:34:36
平时做压力测试的时候,经常会发现在服务器端产生大量的TIME_WAIT状态的TCP连接,到底这玩意儿会不会对性能产生影响呢?解答这个问题之前,看来需要先分析一下TIME_WAIT产生的具体原因。
TIME_WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认。这个好像是官方说法了,不是太理解,那好再详细一点。
从以上的图可以看出,TIME_WAIT只出现在主动关闭的那个阶段,也就是说只有主动关闭方才会出现这个状态,OK,这样解决了一个大问题咯。那针对我们的case,就是因为服务器端主动关闭连接咯。不过这样又会有两种可能性:1.服务器主动关闭,客户端被动关闭; 2. 服务器、客户端都主动关闭
第一种:
第二种: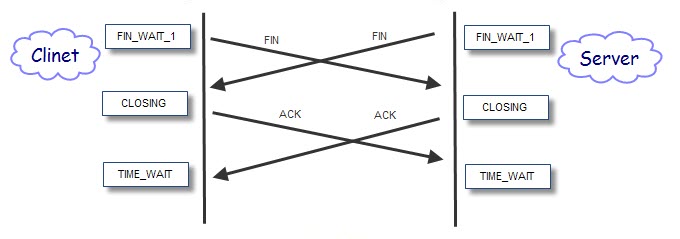
这样看来只要服务器主动关闭连接,TIME_WAIT就不可避免,因此应该可以忽略其对性能的影响了,因为如果应用逻辑如此,其无可避免。并且通过在下的测试,TIME_WAIT的连接在等待2MSL后,会由系统释放关闭,此时会占用一些CPU的资源,但占用率几乎可以忽略。
看一下造成服务器端主动关闭的一些方法,主要是针对HTTP的访问:- HTTP服务关闭KeepAlive
- 客户端Header中的Connection定义为Close
-
谈一下搜索服务的质量管理
2009-03-16 14:56:05
搜索引擎作为当下互联网最为热门的应用,被各大各小的互联网站点所运用,而各个互联网站点又不尽相同地提供着各自不同的搜索服务,特别是垂直搜索的出现,更告诉我们搜索质量的重要性。
作为互联网公司的QA、Tester,我们自然要关心自己公司的搜索质量。这里和以下要谈的应该被在下归结为质量的命题,在这里我们就不谈如何实施测试了,因为在下更希望和大家分享一些质量的思路而非实施的细节,所以这里的功能和性能。。。也许有机会再写吧(其实自己比较懒,嘻嘻)。
这里的搜索质量更多的被定义为适合自己公司的,适合自己应用的结果质量。怎么理解呢?先列举几个质量控制点吧
有一个核心观点,能搜到想搜的东东才是最好的。垂直搜索就是发扬了这样的一个核心观点,比如我在google上搜索“橙子”,会列出很多和橙子有关的结果,但是我要的是我这个blog,也许google并不认为“橙子”这个关键字和我这个blog有关系;但是我到51testing来搜“橙子”,也许我的blog就应该出现了,至少应该排名再前些,对吧。OK,这是一个明显的质量点了
再来一个,我的blog名字是“贪吃的橙子”,但是也许我的好友不是太记得,他们会搜索“贪吃橙子”、“贪吃橙”、“吃橙子” and so on,其实就是找我的blog嘛(臭美下,估计没什么人要找的)。那这里就带出一个搜索服务的专用名词了,“纠错词”,也就是这些错误的词汇,作为一个良好的搜索服务,应该明确地给其定义,等同于那个正确的关键词。OK,这是又一个明显的质量点
看看还有没有哦,恩~遥想哪一天我的这个blog出名了,大家都开始搜了,“贪吃的橙子”因为搜的人太多了,现在因为太出名了,成了一个特殊的分词了,那作为搜索服务,原先搜索“贪吃的橙子”从语法上将,应该会将“贪吃”和“橙子”作为分词来进行搜索,但是现在这是一个独一无二的分词了。应该更严格地匹配了。OK,这可也是直接影响搜索结果的质量点哦
最后再来一个,再过NN年,老子天下闻名了,功成身退,写个回忆录,出本书,还叫“贪吃的橙子”(发觉自己真不要脸啊)。这时候这个词可就不单单是blog,还是书名,高质量的搜索服务应该可以区分出两者的不同,并且予以不同的处理对待。0K,又一个质量点。
哎,谈到质量管理,真是无止尽啊,因为人的要求无止尽嘛。所以这里也就只列了几个质量点而已,对待不同的业务、应用应该还有更多的质量点需要关注。
-
对于多线程同步避免Lock(String)的补充
2009-02-20 17:30:10
最近由于测试需要,用.NET写了不少多线程同步的应用,期间的学习过程中经常看到很多同志提及,避免对string的lock,其主要的出发点是:针对字符串,根据string的恒定性,.NET有个拘留池,用来提高性能。
公共语言运行库通过维护一个表来存放字符串,该表称为拘留池,它包含程序中以编程方式声明或创建的每个唯一的字符串的一个引用。因此,具有特定值的字符串的实例在系统中只有一个。
例如,如果将同一字符串分配给几个变量,运行库就会从拘留池中检索对该字符串的相同引用,并将它分配给各个变量。由于这个原因,假如你lock的字符串对象在拘留池中(通常是编译时显式声明的用引号引起来的字符串),那么,这个对象也有可能被分配到另外一个变 量,如果这个变量也使用了lock,那么,两个lock语句表面上lock的不同对象,但实质上却是同一个对象,这将造成不必要的阻塞,甚至可能造成死 锁。且不亦发现问题。
其实,实际中还有一点非常重要的原因:
String有一个不可破坏的特性(immutable),或者简单叫做只读特性,这意味任何改变String的操作其实都没有改变原本那个String,而是创建了一个新的String实例同时让变量的引用(指针)指向了新String。哇靠,这个特性可NB啦,这就意味着即使string可以被看作引用类型被lock,但实际不可变更对象的值,否则lock就失效了!
-
存储过程测试中binary_checksum的应用
2009-01-15 15:44:00
内建的SQL binary_checksum()函数返回SQL表里某一行的校验和,即以一个整数值来表示某一行的字符数据。
日常的测试工作中我们可能会遇到这样的测试需求:一个存储过程返回一个结果行集,这个行集可能包含海量数据或多个字段,测试这样一个存储过程的方法其实也很直白————预设结果集,进行比较。但是由于需要严格校验结果行集的正确,以至于我们需要对整个行集进行校验,如何做呢?
select checksum_agg(binary_checksum(*)) from test_table
对就是如此简单了,返回整个行集的整数值,加以比较。这也是建议自动化测试脚本在测试存储过程时采用的方式。
由于最近几天有个以前的同事在问,以上的这个需求如何实现结果校验,是否需要循环校验?在下认为这样校验整数值就已经可以达到必要的效果了。在下自认为是个极懒之人,所以不自觉地又贯彻了一次在下的测试准则。
-
所谓“半自动化”测试
2008-12-24 17:43:07
对于测试人员,特别是.com的测试人员来说,提起“自动化测试”,那真是爱恨交加。个中缘由这里就不累述了,大家同道中人自然是体会深刻。时常会想,既然我们有“灰盒测试”的概念,为何不能有“半自动化测试”呢?
其实此处讲的“半自动化”的概念,归根结底就是:测试步骤自动化,结果检查人工完成。
目前比较流行的自动化测试框架也好,工具也好,在下觉得都未提供一种足够强大、灵活的结果检查方式。而测试人员在编写自动化测试脚本的时候往往需要把绝大多数精力投入到如何去判断测试结果的正确性上,特别是web的自动化测试,几乎无法面面俱到,甚至会遇到需要编写复杂的算法来验证结果的情况。反之通过手工肉眼去判断测试结果就来得方便的多,也直观的多。
再回过头去看测试框架和工具,本身自动化测试的宗旨就是大大减少繁复而枯燥的人为操作,岂不就是输入、点击等测试步骤嘛。通过获取操作对象,利用测试数据驱动,来完成自动化过程。这个过程就是自动化工具的长处了,脚本的编写也相对简单很多。利用这些特性,很方便的就能完成测试输入的自动化了。
当然这只是我们“半自动化”的一半,嘿嘿,四分之一自动化。利用测试框架的特性,我们大可以将一些测试输入封装,测试对象抽象。这样在对待同类型对象时又方便了很多,实例化就OK啦。由此我们已经基本解决了大部分对象的测试输入自动化的问题。设计好测试数据,数据——对象——输入,中断——检查——报告,done,半自动化了。
PS.开博第一篇,提供一些在下实际工作中的体会,与同道们分享,工具框架其实都是自动化测试的表象,好的适合自己的方法才是自动化测试的精髓。我们的目标是:用最简单的方法,做最复杂的测试。
