
-
常用的Python库
2009-11-26 21:12:43
Tkinter———— Python默认的图形界面接口。
Tkinter是一个和Tk接口的Python模块,Tkinter库提供了对Tk API的接口,它属于Tcl/Tk的GUI工具组。Tcl/Tk是由John Ousterhout发展的书写和图形设备。Tcl(工具命令语言)是个宏语言,用于简化shell下复杂程序的开发,Tk工具包是和Tcl一起开发的,目的是为了简化用户接口的设计过程。Tk工具包由许多不同的小部件,如一个按钮、一个滚动条等。通过Tk提供的这些小部件,我们就可快速地进行GUI开发。Perl、Scheme等语言也利用Tk库进行GUI开发。Tkinter是跨平台,在各种平台下都能使用。
Python Imaging Library(PIL)————python提供强大的图形处理的能力,并提供广泛的图形文件格式支持,该库能进行图形格式的转换、打印和显示。还能进行一些图形效果的处理,如图形的放大、缩小和旋转等。是Python用户进行图象处理的强有力工具。
Pmw(Python megawidgets)Python超级GUI组件集————一个在python中利用Tkinter模块构建的高级GUI组件,每个Pmw都合并了一个或多个Tkinter组件,以实现更有用和更复杂的功能。
PyXML———— 用Python解析和处理XML文档的工具包,包中的4DOM是完全相容于W3C DOM规范的。它包含以下内容:
xmlproc: 一个符合规范的XML解析器。
Expat: 一个快速的,非验证的XML解析器。 还有其他
和他同级别的还有 PyHtml PySGML
PyGame———— 用于多媒体开发和游戏软件开发的模块。
PyOpenGL———— 模块封装了“OpenGL应用程序编程接口”,通过该模块python程序员可在程序中集成2D和3D的图形。
NumPy、NumArray和SAGE———— NumArray是Python的一个扩展库,主要用于处理任意维数的固定类型数组,简单说就是一个矩阵库。它的低层代码使用C来编写,所以速度的优势很明显。NumPy是Numarray的后继者,用来代替NumArray。SAGE是基于NumPy和其他几个工具所整合成的数学软件包,目标是取代 Magma, Maple, Mathematica和Matlab 这类工具。
MySQLdb模块———— 用于连接MySQL数据库。还有用于zope的ZMySQLDA模块,通过它就可在zope中连接mysql数据库。
PyGTK ———— 用于python GUI程序开发的GTK+库。GTK就是用来实现GIMP和Gnome的那个库。有了它,你完全可以自信的尝试自己制造Photoshop
PyQt ———— 用于python的Qt开发库。QT就是实现了KDE环境的那个库,由一系列的模块组成,有qt, qtcanvas, qtgl, qtnetwork, qtsql, qttable, qtui and qtxml,包含有300个类和超过5750个的函数和方法。PyQt还支持一个叫qtext的模块,它包含一个QScintilla库。该库是 Scintillar编辑器类的Qt接口。
PyMedia ———— 用于多媒体操作的python模块。它提供了丰富而简单的接口用于多媒体处理(wav, mp3, ogg, avi, divx, dvd, cdda etc)。可在Windows和Linux平台下使用。
Psyco ———— 一个Python代码加速度器,可使Python代码的执行速度提高到与编译语言一样的水平。
Python-ldap ———— 提供一组面向对象的API,可方便地在python中访问ldap目录服务,它基于OpenLDAP2.x。
smtplib模块 ———— 发送电子邮件。
ftplib模块 ———— 定义了FTP类和一些方法,用以进行客户端的ftp编程。我们可用python编写一个自己的ftp客户端程序,用于下载文件或镜像站点。如果想了解ftp协议的详细内容,请参考RFC959。
xmpppy模块 ———— Jabber服务器采用开发的XMPP协议,Google Talk也是采用XMPP协议的IM系统。在Python中有一个xmpppy模块支持该协议。也就是说,我们可以通过该模块与Jabber服务器通信,是不是很Cool。
下面这些就不详细介绍,只列出名字和功能
adodb ———— ADO数据库连接组件
bsddb3 ———— BerkeleyDB的连接组件
chardet ———— 编码检测
Cheetah ———— 构建和扩充任何种类的基于文本的内容
cherrypy ———— 一个WEB framework
ctypes ———— 用来调用动态链接库
Cx-oracle ———— 连接oracle的工具
DBUtils ———— 数据库连接池
django ———— 一个WEB framework
DPKT ———— raw-scoket网络编程
docutils ———— 用来写文档的
dpkt ———— 数据包的解包和组包
feedparser ———— rss解析
Kodos ———— 正则表达式调试工具
Mechanize ———— 爬虫连接网站常用
pefile ———— windows pe文件解析器
py2exe ———— 用来生成windows可执行文件
pycurl ———— URL处理工具
pydot ———— 画图的,graphiz
pyevent ———— Python的事件支持
pylint ———— 培养良好的编码习惯
Pylons ———— 又一个web framework
pypcap ———— 抓包的
pysqlite2 ———— SQLite的连接组件
python-dnet ———— 控制网络安全的其他设备
pythonwin ———— Python的Windows扩展
pywmi ———— 省了好多折腾功夫
reportlab ———— Python操作PDF的Libary。
scapy ———— 网络包构建分析框架,可编程的wireshark,有兴趣的google “Silver Needle in the Skype”
scons ———— 项目构建工具,写好了模板用起来还是很方便的
sendpkt ———— Python发包
setuptools ———— 一套python包管理机制
simplejson ———— JSON的支持
sqlalchemy ———— SQL数据库连接池
SQLObject ———— 数据库连接池
twisted ———— 巨无霸的网络编程框架
winpdb ———— 自己的程序或者用别的库不太明白的时候就靠它了
wxPython ———— GUI编程框架,熟悉MFC的人会非常喜欢,简直是同一架构 -
QTP对象库管理
2009-11-25 16:26:11
在QTP中,如果不能有效的管理对象,将大大加大后期脚本的维护成本。我们需要的是一个干净整洁的对象库,但由于QTP本身对于对象的管理操作的局限性,我们只有运用有限的方法,来应对无限的可能发生的情况。
在录制过程中,QTP将抓取大量的WEB对象(包括Button、Link、text等),有些对象是重复出现的,可以重复利用。但如果不及时清理这些冗余的对象,势必造成对象库臃肿和复杂。
下面,我们制定了一系列规范,来管理我们的对象库
在QTP通过执行脚本中的语句来识别WEB页面中的对象,脚本语句包括Browser(Main、Sub_O、Sub_T)、Page、***(控件类型:如WebEdit、WebButton等)我们规定:
1)Browser只允许出现3种,即主页面(Main),次页面(Sub_O)、第三页(Sub_T),其中主页面Main没有creatontime标记,次页面Sub_O的creatontime标记值为1,第三页面Sub_T的Sub_Ocreatontime标记值为22)Page页的名称需和页面的Title对应
3)出现重复的对象,需要合并到(运用MI公司提供的QuickTest Plus中的插件Repositories Merge Utility合并)
实现步骤: a、设置环境变量:“Test settings”->"Environment"
b、Variable type:User-defined
c、Click “New”
d、input “name”、“Value”
(such as->name:ObjectPath_Product)
e、save
f、QTP脚本中写语句读取环境变量:
( Such as->ObjectPath = Environment.Value ("ObjectPath_Product")
Call SetObjectRepository(ObjectPath)
)
g、用VB写函数,用于调用对象库
(见如下代码),VB函数可以写在后缀名为VBS的文件中
h、在QTP中加载对象库文件:
“Test settings”->"Resources"
在"Object repository type"中加载对象库文件
点击“Set as Default”
i、 h、在QTP中加载VB函数:
“Test settings”->"Resources"
在"Associated library files"中加载VBS函数文件
点击“Set as Default”注:1)这里的Value我们可以输入对象库的存放地址,用于把文件地址传到QTP脚本中
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/xiaohe119/archive/2007/04/27/1587163.aspx
-
JConsole的使用手册
2009-11-18 12:06:54
JConsole毕竟是JDK自带的东西,功能虽然没有一些商业软件那么强大,但是稳定性好,在大压力情况下也不会发生什么问题。而且,提供了相对全面的系统监控功能,还是值得一用的。
JConsole
JConsole是一个基于JMX的GUI工具,用于连接正在运行的JVM,不过此JVM需要使用可管理的模式启动。如果要把一个应用以可管理的形式启动,可以在启动是设置
com.sun.management.jmxremote。例如,启动一个可以在本地监控的J2SE的应用Java2Demo ,需输入以下命令:一、本地方式
1、方法1:
JDK_HOME\bin\java -Dcom.sun.management.jmxremote jarJDK_HOME\demo\jfc\Java2D\Java2Demo.jarJDK_HOME需要是一个含有JDK5.0的目录。
例如:测试例子Java2Demo.jar在D:\Computer\Java\jdk1.5.0_05\demo\jfc\Java2D因此命令可以写为:
D:\Computer\Java\jdk1.5.0_05\bin\java -Dcom.sun.management.jmxremote -jar D:\Computer\Java\jdk1.5.0_05\demo\jfc\Java2D\Java2Demo.jar方法2:
cmd进入dos下,进入到应用程序所在目录,执行语句如下
java -Dcom.sun.management.jmxremote -jar Java2Demo.jar2、启动jdk_home\bin目录下的Jconsole.exe就可以看到有一个本地的连接在里面。点击连接就可以进入相应的监视界面了。
-
TD中工作流的应用(转)
2009-11-14 11:08:43
我使用TD时间也不是非常长,和牛人相比那是天壤之别!只是我有幸配置TD。相信不是哪么多测试人员有这种锻炼的机会!在我配置的过程中,发现关于工作流(workflow)的资料非常之少,给我配置起来带来了很大时间上的浪费。可是工作流却是TD功能宽度和自定义级别最大的,如果不学会来使用,TD很多应该能实现的功能都可能大打折扣或者不能使用。当然,本着对初学者和不太懂的人以借鉴的思想,我尽量写的简便通俗易懂点
一、基础篇:
为了能够更好的开始讲解工作流,我先说明些东西。这些内容是基础。请耐心看,如果你已经知道可以跳过。
1.作流其实就是TD中提供的一种可以达到编程效果的一个编辑器。我们可以直接编辑脚本,不用单独编译。
2.工作流脚本是使用VB语言编写的,所以它支持如msgbox类的输入输出函数。
3.您需要明确知道你想在什么时候执行你的脚本。比如Defects_Bug_New里面的语句只在你新建缺陷的时候执行,其他时候是不执行的。
再比如Defects_Bug_FieldChange就是在缺陷内容发生改变了的时候执行的语句。
4.一般默认的东西我们不要乱作修改。如:
Sub Defects_Bug_FieldChange(FieldName)
On Error GoTo 0
End Sub这些内容我们就要保留。
5.同样的Sub可以存在多个,也就是说如Sub Defects_Bug_FieldChange(FieldName)这样的函数我们可以编写几个,不必要修改系统原来的Sub Defects_Bug_FieldChange(FieldName)
6.文中提到的,TD数据库中使用的字段(如BG_BUG_ID)。是那里来的?
它是在你需要输入USER ID和Password那个页面(/start_a.htm),右上角有个叫CUSTOMIZE的链接,点击下,用admin用户登陆,在“Customize Project Entities” -> “DEFECT”里面的System Fields或者User Fields里面随便选择一个字段,右边查看里面“Field Name”后面的就是数据库中使用的字段了的名字了。比如你选择Subject,对应的Field Name就是BG_SUBJECT.
7.工作流中的GoTo语句不能像VB里面那样使用。因为标签是无效的。
8.理论上来讲,TD中的大部分功能东西都能通过这里编辑,比如按钮。事件。当然前提是你够熟悉。
9.如果要脚本起作用,只要退出再登陆进TD.脚本就会立刻起作用。
二、工作流的实践一 ——新建缺陷时候的默认值
需求说明:我们在打开添加缺陷的页面的时候(特别是使用了自定义字段的时候)我们最希望的就是给这些不是非常重要的,但是又不希望没有内容的字段,有些默认值。哪么我们第一个来做的就是这个需求。请先看代码。
Sub Defects_Bug_New
On Error Resume Next
Bug_Fields("BG_DETECTION_VERSION").Value = "Ehome 2.0"
On Error GoTo 0
End Sub这段代码,你只要复制到工作流脚本中去,哪么你在添加缺陷的时候,版本这个字段里面就会自动有一个内容Ehome 2.0。这段代码中的Defects_Bug_New代表新建缺陷的时候执行的脚本,Bug_Fields("BG_DETECTION_VERSION")具体缺陷字段。这是最简单的工作流脚本了。你明白了没有?
三、工作流的实践二 ——记录修改人和修改时间
需求说明:我们希望在开发修改了一个缺陷的状态为“修改完成“的时候,记录下修改他的人,和修改时间。方便我们管理。同样,请先看代码:
Sub Defects_Bug_FieldChange(FieldName)
On Error Resume Next
if FieldName = "BG_STATUS" Then
if Bug_Fields("BG_STATUS").Value = "P1-修改完成待验证" then
Bug_Fields("BG_RESPONSIBLE").Value = User.UserName
Bug_Fields("BG_USER_02").Value = now()
end if
end if
On Error GoTo 0
End Sub这段代码内容就多了几行,里面Defects_Bug_FieldChange(FieldName)代表的是缺陷字段发生改变的时候执行的语句。里面的BG_STATUS代表缺陷状态,BG_RESPONSIBLE代表负责人(Syestem Fields表里的),BG_USER_02代表用户自定义字段(User Fields里的)。User.UserName代表当前操作的用户名,now()代表当前时间。剩下的东西就很容易看懂了吧。
三、工作流的实践三 ——不修改我的缺陷必须说理由
需求说明:有时候开发很懒,不喜欢写说明,哪么对我们测试来说,没有任何说明就返回我们。使我们很不好处理问题。哪么我们希望当程序员如果修改缺陷状态为”不修改””遗留”的时候,让程序员必须输入说明。
Sub Defects_Bug_FieldChange(FieldName)
On Error Resume Nextdim i
i=""
msg1 ="遗留或不修改此缺陷需要输入说明!"
title1 ="输入说明"If FieldName = "BG_STATUS" Then
if (Bug_Fields("BG_STATUS").Value = "P2-待遗留" or Bug_Fields("BG_STATUS").Value = "P3-暂时不修改") and Bug_Fields("BG_DEV_COMMENTS").Value = "" then
do
i= InputBox(msg1,title1)
if i="" then
msgbox"必须输入说明"
else exit do
end if
loop
Bug_Fields("BG_DEV_COMMENTS").Value = i
end if
end if
On Error GoTo 0
End Sub这段代码内容就稍微多了点点,并且使用了VB的函数。我就简单的说下思路吧,具体解释,只要你看懂了上面的工作流。相信这个里面的代码也不是很复杂。
1.开始声明和定义一些需要使用的变量。和内容。
2.判断修改的字段是不是缺陷状态(BG_STATUS)
3.再判断修改成的内容是不是遗留或者不修改
4.最后判断说明(BG_DEV_COMMENTS)里面是不是没有内容
5.如果是的话,就打开输入函数输入说明(InputBox(msg1,title1))
6.做个循环,如果没有输入说明,就提示必须输入说明(msgbox"必须输入说明")
7.最后吧输入的内容赋值给保存说明的字段(BG_DEV_COMMENTS)
本文出自onlonely的51Testing软件测试博客:http://www.51testing.com/?154467
-
场景设置(转自论坛)
2009-11-14 09:59:26
VuGen建立的第一个脚本 TestFirst的action脚本如下
char *filename = "c:\\test.txt";
Action() {
long file;
int id;
char *groupname;
/* Create a new file */
if ((file = fopen(filename, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
/* Write the Vuser id and group to the log file */
id = 1;
groupname = "one";
fprintf(file, "logfile of virtual user id: %d group: %s\n", id, groupname);
fclose(file);
return 0;
}
vu_End脚本如下
char *filepath = "c:\\test.txt";
vuser_end()
{
long file;
int id;
/* Create a new file */
if ((file = fopen(filepath, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
id = 1;
fprintf(file, "%d End ", id);
fclose(file);
return 0;
}
VuGen建立的第二个脚本TestSecond的Action脚本如下
char *filename = "c:\\test.txt";
Action() {
long file;
int id;
char *groupname;
/* Create a new file */
if ((file = fopen(filename, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
/* Write the Vuser id and group to the log file */
id = 2;
groupname = "two";
fprintf(file, "logfile of virtual user id: %d group: %s\n", id, groupname);
fclose(file);
return 0;
}
vu_End脚本如下:
#include "as_web.h"
char *filepath = "c:\\test.txt";
vuser_end()
{
long file;
int id;
/* Create a new file */
if ((file = fopen(filepath, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
id = 2;
fprintf(file, "%d End ", id);
fclose(file);
return 0;
}
上边的脚本其实很相类似只不过每个脚本中用one,two来标示每个用户(为了看到测试效果),我们这样做只是为了检测Controller如何调用脚本。
还有一点我在vu_end()加入代码,这是因为我们知道vuGen设置iteration的数值,实质是设置action的运行次数,也就是说只有运行action的iteration后才会运行vu_end。
一.设置iteration为1,在Controller中添加运行testfirst,testSecond脚本用户各一,运行结果如下:
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
2 End
二.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各一,运行结果如下:
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
三.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各一,每隔1分钟加载1个用户,运行结果如下:
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
四.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各2,每隔1分
钟加载1个用户,运行结果如下:
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
五.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各2,设置每隔10秒加载1个用户并设置duration为40秒,运行结果如下:
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx’省略
logfile of virtual user id: 1 group: one
2 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
2 End
logfile of virtual user id: 1 group: one
1 End
以上对loadrunner的研究说明用户对应脚本,而不管他当前运行到什么状态。在第四中设置中很容易清晰的看出运行次序,可以说是从头运行到尾。(这么做只是为了研究,实际操作中情况千变万化,我只是为了测试结果清晰化)
你的三个问题从上边的试验可以得出结论,脚本影响实际程序的状态通过action脚本中运行的状态(如果你没有录制关闭页面脚本那么当前状态仍然是打开状态)。其实你设置的情况比较复杂了,我把几种不同的设置,所得出的运行结果都列举出来了。你可以自行研究。
你第一个问题 状态仍然是打开状态
你第二个问题 你的设置情况与我第五种试验设置一致,结论是仍然打开页面
你第三个问题 虚拟用户是针对loadrunner来说的,虚拟用户试和运行的机器有关系,你设置虚拟用户是为了把虚拟用户分布到不同的机器上,模拟现实世界,实际登陆用户是对你的测试软件来说的, 这是有区别的,要弄清楚概念。工具只是实现你测试目的的辅助手段,你所开发的脚本都是根据你的测试用例,在这个案例中你这么做有没有意义取决你选择的压力测试策略。如果现实中有这么做的,你就可以模拟!
我想这些测试试验可以帮助你了解iteration和虚拟用户设置对脚本调用的作用! -
JProfiler连接Weblogic使用说明
2009-11-11 17:19:41
1. 本地连接
1.1 环境说明
本地安装JProfiler,Weblogic相关工具
1.2 步骤说明
1. 打开工具JProfiler后,在Session菜单下选择New windows,弹出Quickstart窗口界面,在该界面选择第三项An application server,locally or remotely, 然后点击Next.
2. 进入Integration wizard界面,选择应用服务的类型和版本.此处,我们选择BEA Weblogic 9.2, 然后点击Next.
3. 选择连接的类型,是本地还是远程,这里我们选择本地(on this computer), 然后点击Next.
4. 选择第一个,启动weblogic时,试图去连接本次建立的连接,一直会等待到成功连接,而选择第二个,若是发现weblogic没有启动,将不做等待;这里我们选择第一项.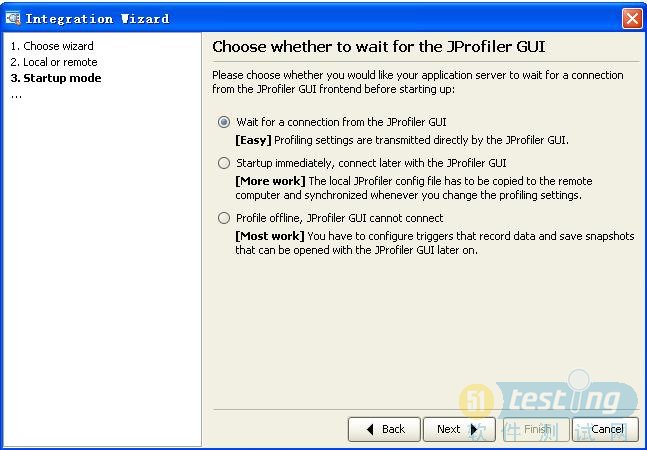
5. 选择Weblogic的启动文件Startweblogic.cmd(如:E:\bea\user_projects\domains\powerbid_test_domain\bin文件夹下), 然后点击Next.
6. 选择JDK的提供厂商和其版本. 这里我们选择了Sun Microsystems 的1.5版, 然后点击Next.
7. 选择两种处理模式,这里选择第一种,符合应用服务(JIT/hotspot complation enabled)
8. 选择JProfiler的使用端口,对于本地连接来说,此处作用不大,用默认即可
9. 对前面设置的内容统一展现,若是检查没有问题,则点击Next,进行下一步操作.
10. 点击Finish, 完成了本次连接的配置,若是选择了马上连接,则下一步开始连接.
11. 这里对配置好的连接进行设置,根据需要可以进行过虑等设置,完成后点击OK.
12. 开始连接本地的weblogic应用,连接成功后,可以得到相关的信息
2. 远程连接
2.1环境说明
本地安装JProfiler
监控机器上安装JProfiler
两台机器能够ping通,且在本地映射监控机器上的Weblogic的安装目录(本文档把监控机器的bea815映射到本地的F盘),该目录必须是可写的.
把远程监控机上的Weblogic启动文件Startweblogic.cmd拷贝到本地2.2步骤说明
1.打开工具JProfiler后,在Session菜单下选择New windows,弹出Quickstart窗口界面,在该界面选择第三项An application server, locally or remotely, 然后点击Next.
2. 进入Integration wizard界面,选择应用服务的类型和版本.此处,我们选择BEA Weblogic 9.2,然后点击Next.
3. 选择连接的类型,是本地还是远程,这里我们选择远程(on a remote computer), 再选择远程计算机的操作系统,然后点击Next.
4. 选择第一个,启动weblogic时,试图去连接本次建立的连接,一直会等待到成功连接,而选择第二个,若是发现weblogic没有启动,将不做等待;这里我们选择第一项.
5. 选择远程监控机器的IP地址或服务器名,如:192.168.0.9
6. 这里的路径为远程监控机器安装JProfiler的路径.如:C:\Program Files\jprofiler5
7. 选择远程监控机器的Weblogic的启动文件,startWeblogic.cmd(先把远程监控机的weblogic的启动文件的路径映射成本地路径),拷贝到本地,然后选择该启动文件。
8. 选择JDK的提供厂商和其版本. 这里我们选择了Sun Microsystems 的1.4版.
9. 选择两种处理模式,这里选择第一种,符合应用服务(JIT/hotspot complation enabled)
10. 选择JProfiler的使用端口,要求本地安装的JProfiler和远程监控机的JProfiler保持一致,才能够保证连接,此处都用默认的8849.
11.对前面设置的内容统一展现,若是检查没有问题,则点击Next,进行下一步操.
12. 点击Finish, 完成了本次连接的配置,若是选择了马上连接,则下一步开始连接,在开始连接之前,要求先启动远程监控机上Weblogic目录下的JProfiler配置连接时产生的startWebLogic_jprofiler.cmd文件.
(该文件和远程监控机中的startWebLogic.cmd文件在同一目录下)
13. 这里对配置好的连接进行设置,根据需要可以进行过虑等设置,完成后点击OK.
14. 开始连接本地的weblogic应用,连接成功后,可以得到相关的信息.note:在本地监控时总会出现如下图错误提示
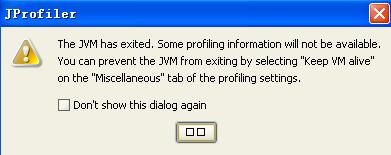
1.点击Start Center,对监控时新建的session进行修改
2.点击profiling Settings后,点击Customize profiling Settings按钮,设置,如图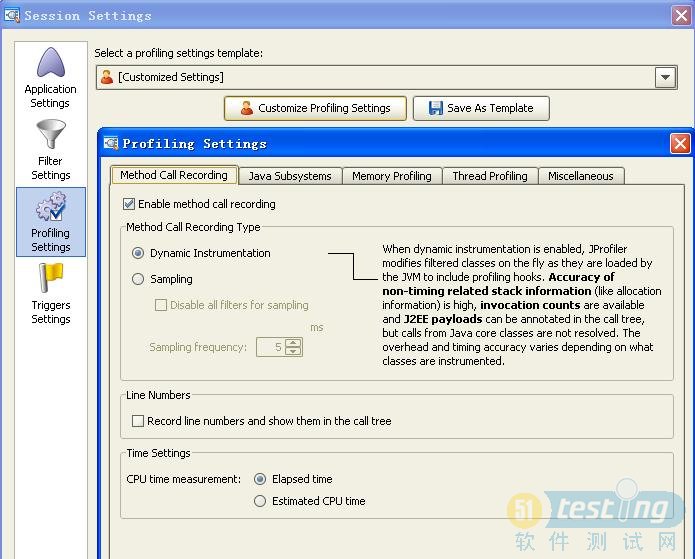
3.点击Miscellaneous标签,勾选keep vm alive -
python遍历文件夹和文件
2009-10-31 16:58:46
这个也许是最常用的功能,如下:
复制代码 代码如下:
import os
import os.path
rootdir = "D:\\programmer\\training"
for parent, dirnames, filenames in os.walk(rootdir):
#case 1:
for dirname in dirnames:
print "parent is:" + parent
print "dirname is:" + dirname
#case 2
for filename in filenames:
print "parent is:" + parent
print "filename with full path :" + os.path.join(parent, filename)解释说明:
1.os.walk返回一个三元组.其中dirnames是所有文件夹名字(不包含路径),filenames是所有文件的名字(不包含路径).parent表示父目录.
2.case1 演示了如何遍历所有目录.
3.case2 演示了如何遍历所有文件.
4.os.path.join(dirname,filename) : 将形如"/a/b/c"和"d.java"变成/a/b/c/d.java".perl分割路径和文件名
常用函数有三种:分隔路径,找出文件名.找出盘符(windows系统),找出文件的扩展名.
复制代码 代码如下:
import os.path
spath="D:/download/flight/flighthtml.txt"
# case 1:
p,f=os.path.split(spath);
print "dir is:"+p
print "file is:"+f
# case 2:
drv,left=os.path.splitdrive(spath);
print "driver is:"+drv
print "left is:"+left
# case 3:
f,ext=os.path.splitext(spath);
print "f is:"+f
print "ext is:"+ext这三个函数都返回二元组.
1.case1 分隔目录和文件名
2.case2 分隔盘符和文件名
3.case3 分隔文件和扩展名 -
LoadRunner使用虚拟IP测试流程(转)
2009-10-31 16:57:24
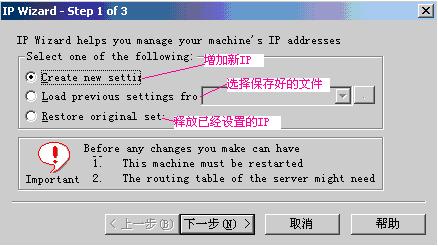
说明:增加新IP选择第一项;使用保存的文件增加IP选择第二项;释放已经设置的IP选择第三项。
点“下一步”,如图
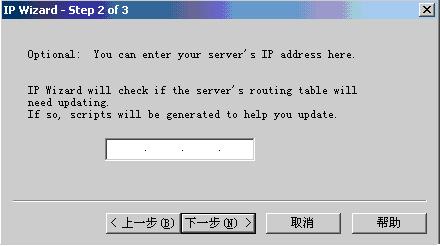
此步让输入web server的IP地址(尚不清楚有何意义),不输入,直接点‘下一步’,如图:
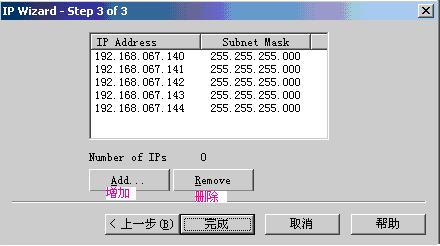
说明:使用remove按钮可以删除选定的虚拟IP。
点add按钮,如图:
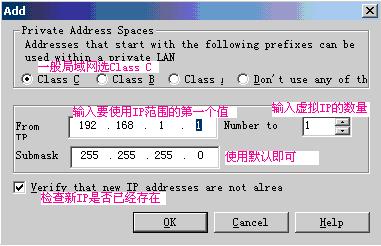
说明:‘检查新IP是否已经存在’选项并没有起作用;根据输入的IP的第一个值和数量,自动添加到虚拟IP列表中,例如:192.168.67.140 4,则增加的虚拟IP是:192.168.67.140、192.168.67.141、192.168.67.142、192.168.67.143。
点ok按钮,如图:
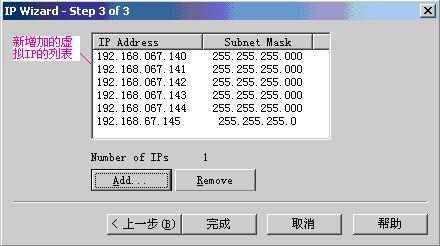
点“完成”按钮,如图:
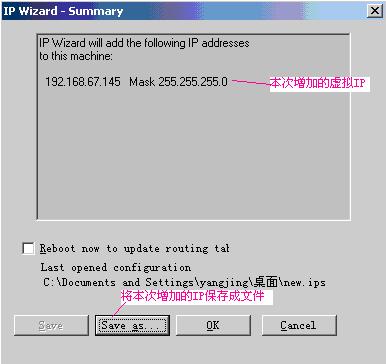
说明:使用Save as…可以将本次增加的IP保存成.ips文件,下次再使用时就可以直接选择此文件了。
点‘OK’按钮即可。
现在需要重启计算机。
(重新启动计算机后,设置的虚拟IP都生效了,此时使用ping会发现都能ping通,并且本机的IP也被改成了第一个虚拟IP地址。确认虚拟IP是否都生效的方法:在运行中输入cmd,在命令窗口录入ipconfig/all,然后就能看到已经生效的所有IP。)
在controller中,选择 Scenario-〉Enable IP Spoofer,此项设置允许使用IP欺骗。
按Generators按钮,设置虚拟用户生成器,将虚拟IP地址都添加进去,并连通。如图:
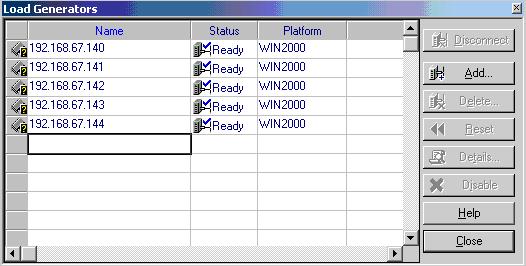
连接成功的虚拟用户生成器会在工具栏中显示,如图:

然后设计方案,如下图例子:

运行方案。
打开IP Wizard,释放所有虚拟IP。
重新启动计算机
-
python urllib2 (转)
2009-10-31 16:53:24
当处理HTTP链接的时候,链接如果有中文的话,那么发起HTTP链接的时候,一定要先把URL编码,否则就会出现问题。而在python中,用 urllib2.quote(URL)进入编码和urllib2.unquote(URL)解码的时候,有一点需要注意,就是URL字符串不能是 unicode编码,此时必须把URL编码转换成适当的编码,如utf-8或gb2312等而python处理编码转换的机制如下:原来编码》内部编码》目的编码 python的内部编码是使用unicode来处理的 gb=”中国”#此处为原本gb2312编码 uni=unicode(gb,’gb2312′)#把gb2312编码转换成unicode的内部编码 utf=uni.encode(’utf-8′)#把unicode编码转换成utf-8目的编码在处理wxpython文本框的时候要注意,默认的编码是unicode编码,利用urllib.quote编码时候,可以通过如下方面转换后,再进行 URL编码 URL=wxpython文本框原本的unicode编码 URL=URL.encode(’utf-8′)#把unicode编码转换成utf-8编码 URL=urllib2.quote(URL)#进入URL编码,以便HTTP链接
对我来说,Python里面哪个模块用的最多,恐怕urllib2这个不是第一也得算前三了。先看下下面最常用的代码
Python语言:
import urllib2
req = urllib2.Request("http://www.g.cn")
res = urllib2.urlopen( req )
html = res.read()
res.close()
这里可以通过urllib2进行抓取页面 。也可以直接使用urllib2.urlopen( http://www.g.cn),通过Reques对象打开的好处是,我们可以很方便的为Reques 添加HTTP 请求的头部信息。
Python语言:
import urllib2
req = urllib2.Request("http://www.g.cn")
req.add_header( "Cookie" , "aaa=bbbb" ) # 这里通过add_header方法很容易添加的请求头
req.add_header( "Referer", "http://www.fayaa.com/code/new/" )
res = urllib2.urlopen( req )
html = res.read()
res.close()
headers 初始化为{} ,所有如果连续执行两次req.add_header( "Cookie" , "aaa=bbbb" ) , 则后面的值会把前面的覆盖掉
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False):
当执行 res = urllib2.urlopen( req ) 时
_opener = None
def urlopen(url, data=None):
global _opener
if _opener is None:
_opener = build_opener()
return _opener.open(url, data)
_opener = build_opener() 这里_opener 是一个全局变量。第一次使用时,通过build_opener() 得到一个值,以后再次使用就是保存到这个全局变量中值。
def build_opener(*handlers):
"""Create an opener object from a list of handlers.
The opener will use several default handlers, including support
for HTTP and FTP.
If any of the handlers passed as arguments are subclasses of the
default handlers, the default handlers will not be used.
"""
import types
def isclass(obj):
return isinstance(obj, types.ClassType) or hasattr(obj, "__bases__")
pener = OpenerDirector()
default_classes = [ProxyHandler, UnknownHandler, HTTPHandler,
HTTPDefaultErrorHandler, HTTPRedirectHandler,
FTPHandler, FileHandler, HTTPErrorProcessor]
if hasattr(httplib, 'HTTPS'):
default_classes.append(HTTPSHandler)
skip = []
for klass in default_classes:
for check in handlers:
if isclass(check):
if issubclass(check, klass):
skip.append(klass)
elif isinstance(check, klass):
skip.append(klass)
for klass in skip:
default_classes.remove(klass)
for klass in default_classes:
opener.add_handler(klass())
for h in handlers:
if isclass(h):
h = h()
opener.add_handler(h)
return opener
这里就可以看到 默认的处理程序有 ProxyHandler, 代理服务器处理 UnknownHandler, HTTPHandler, http协议的处理 HTTPDefaultErrorHandler, HTTPRedirectHandler, http的重定向处理 FTPHandler, FTP处理 FileHandler, 文件处理 HTTPErrorProcessor
我们也可以添加自己处理程序
cookie = cookielib.CookieJar()
urllib2.HTTPCookieProcessor(cookie) 这个就是对cookie的处理程序
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
添加后就可以对每次收到响应中的Set-Cookie 记录到cookie 对象中,下次发送请求的时候就可以把这些Cookies附加到请求中
urllib2.install_opener(opener) 用我们生成的opener 替换掉urllib2中的全局变量
比如第一次请求:
connect: (www.google.cn, 80)
send: 'GET /webhp?source=g_cn HTTP/1.1\r\nAccept-Encoding: identity\r\nHost: www.google.cn\r\nConnection: close\r\nUser-Agent: Python-urllib/2.5\r\n\r\n'
reply: 'HTTP/1.1 200 OK\r\n'
header: Cache-Control: private, max-age=0
header: Date: Sun, 21 Dec 2008 13:47:39 GMT
header: Expires: -1
header: Content-Type: text/html; charset=GB2312
header: Set-Cookie: PREF=ID=5d750b6ffc3d7d04:NW=1:TM=1229867259:LM=1229867259:S=XKoaKmsjYO_-CsHE; expires=Tue, 21-Dec-2010 13:47:39 GMT; path=/; domain=.google.cn
header: Server: gws
header: Transfer-Encoding: chunked
header: Connection: Close
第二次请求中就会附加
Cookie: PREF=ID=5d750b6ffc3d7d04:NW=1:TM=1229867259:LM=1229867259:S=XKoaKmsjYO_-CsHE等Cookie
connect: (www.google.cn, 80)
send: 'GET /webhp?source=g_cn HTTP/1.1\r\nAccept-Encoding: identity\r\nHost: www.google.cn\r\nCookie: PREF=ID=5d750b6ffc3d7d04:NW=1:TM=1229867259:LM=1229867259:S=XKoaKmsjYO_-CsHE\r\nConnection: close\r\nUser-Agent: Python-urllib/2.5\r\n\r\n'
reply: 'HTTP/1.1 200 OK\r\n'
header: Cache-Control: private, max-age=0
header: Date: Sun, 21 Dec 2008 13:47:41 GMT
header: Expires: -1
header: Content-Type: text/html; charset=GB2312
header: Server: gws
header: Transfer-Encoding: chunked
header: Connection: Close
如果想要在urllib中启用调试,可以用
>>> import httplib
>>> httplib.HTTPConnection.debuglevel = 1
>>> import urllib
但是在urllib2中无效,urllib2中没有发现很好的启用方法因为,
class AbstractHTTPHandler(BaseHandler):
def __init__(self, debuglevel=0):
self._debuglevel = debuglevel
会默认把调试级别改成0
我是这样用实现的,
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
opener.handle_open["http"][0].set_http_debuglevel(1) -
Jprofiler 安装--远程监控(转)
2009-10-31 16:50:08
WEB服务总是莫名其妙的运行一段时间后JVM直接OutOfMemory错误,这个问题一直困扰着程序的正常运行。大概半个月时间一次,上网查了些资料,也做了不少优化,什么weblogic环境变量Xms,Xmx,MaxPermSize参数调整,可问题依旧,况且这也是治标不治本,问题也许发生在程序中,可能存在内存泄露,或spring和hibernate框架相关的问题。
在网上找到个大家说很好的工具叫Jprofiler,学着弄弄,down下来个最新版本。软件需要注册,注册后有十天的试用期。现在把安装过程记下来。
由于我要监控的程序是在远程的linux系统下的weblogic服务,所以这里记录的是远程监控的配置过程。
先介绍下环境:
系统服务器:
操作系统:linux redhat
web服务器:weblogic 8.1
java虚拟机版本:1.4.2
jprofiler版本:jprofiler_linux_5_1_2.tar.gz(安装包共三个版本 sh,exe,tar.gz)
客户端:
操作系统:Windows Xp SP2
jprofiler5.1.2 for windows(安装包:jprofiler_windows_5_1_2.zip)
安装:
一.客户端安装:
1 windows下直接解压zip包,运行jprofiler5.1.2的exe安装即可。
2 运行jprofiler并进行配置
1)Quick Start:
选择 An application on a remote computer
->Next
2)Local or remote:
The profiled application s located 选择 On a remote computer,
Platform. of the remote computer 下拉菜单选择“Linux X86/AMD64”
->Next
3)Remote address :填写被监控应用程序所在远程计算机的IP
4)Installation directory:解压路径:/var/jprofiler5
5) choose JVM :
JVM Vendor: Sun jvm提供商
Version:1.4.2 版本
Mode:hotspot 系统默认
6)jprofile port :8849
7)startup mode:
Wait for …… 为了在开发环境中获取监控的信息,它将等待远程计算机上的Jprofile GUI 启动,并和本机建立连接,这种方式比较便于修改jprofiler的配置信息。
Don't wait for …… 不必等待远程计算机的Jprofile GUI 先启动和建立连接,立即启动。但在启动远程应用程序前必须校验当前所配置会话的配置文件。虚拟机参数将参考Jprofile 的config 文件的路径。
这里选择Don't wait for ……
->Next
8) Config synchronization:
Directory for config file in the remote computer:/opt (远程config文件的路径)
同步方式:
Manual synchronization;copy to diretory;execute command:
提供三种同步方式,这里我选择的是第一个手工同步。
->Next
9)Perform. modifications:
Integration type: [Generic application]
Selected JVM: Sun 1.4.2 (hotspot)
Startup mode: Don't wait for JProfiler GUI, startup immediatelyImportant: The local config file C:\Documents and Settings\Jan\.jprofiler5\config.xml must be copied manually to /opt on the remote computer when the profiling settings are changed.
(1) Please insert-Xrunjprofiler:port=8849,nowait,id=115,config=/opt/config.xml -Xbootclasspath/a:/var/jprofiler5/bin/agent.jar
into the start command of your remote application right after the java command.
(2) Please add
/var/jprofiler5/bin/linux-x86
to the environment variable LD_LIBRARY_PATH.
A remote session named Remote application on 10.5.31.49 will be created that connects to a running instance of the remote application that is started with the modified start command.
这里的黑体文字部分要保存下来,在服务器端安装时会用到。
->Next
10) Finished:
选No,I will start the session later
因为我们还没有配置服务器端。二.服务器端安装
1 将jprofiler_linux_5_1_2.tar.gz上传到服务器上,/var/下建立jprofiler5目录,并将程序解压到/opt/jprofiler5下即可
2 修改用户环境变量.bash_profile。
加入export LD_LIBRARY_PATH=/var/jprofiler5/bin/linux-x86。如果是 64 位服务器,则选择linux-x64。
运行source .bash_profile 使环境变量立即生效
3 添加weblogic启动参数
将一.9).(1)中黑体的部分加到weblogic的启动文件startWebLogic.sh的参数中如:
${JAVA_HOME}/bin/java ${JAVA_VM} ${MEM_ARGS} ${JAVA_OPTIONS} -verbosegc
-Xrunjprofiler:port=8849,nowait,id=115,config=/opt/config.xml -Xbootclasspath/a:/var/jprofiler5/bin/agent.jar
-Dweblogic.Name=${SERVER_NAME} -Dweblogic.ProductionModeEnabled=${PRODUCTION_MODE} -Djava.security.policy="${WL_HOME}/server/lib/weblogic.policy" weblogic.Server
尽量让它在一行中。
4 把 C:\Documents and Settings\Jan\.jprofiler5\ 下的config.xml上传到服务器上,路径为一.8)中配置的Directory for config file in the remote computer:/opt
因为这里选择的同步方式是Manual synchronization,所以以后配置发生改变时,需要手工再次上传新的config.xml到这个路径。
三.启动weblogic服务:**************************************************
* To start WebLogic Server, use a username and *
* password assigned to an admin-level user. For *
* server administration, use the WebLogic Server *
* console at http://[hostname]:[port]/console *
***************************************************
JProfiler> Protocol version 25
JProfiler> Using JVMPI
JProfiler> 32-bit library
JProfiler> Don't wait for frontend to connect.
JProfiler> Using config file /opt/config.xml (id: 114)
JProfiler> Listening on port: 8849.
[Full GC 114K->84K(520256K), 0.0063330 secs]
JProfiler> Native library initialized
JProfiler> If output stops here, please remove -Xdebug from the command line
JProfiler> Using dynamic instrumentation
JProfiler> Time measurement: elapsed time
JProfiler> CPU profiling enabled
JProfiler> Hotspot compiler enabled
JProfiler> Starting weblogic/Server ...<Feb 5, 2008 11:41:31 AM CST> <Info> <WebLogicServer> <BEA-000377> <Starting WebLogic Server with Java HotSpot(TM) Client VM Version 1.4.2_09-b05 from Sun Microsystems Inc.>
<Feb 5, 2008 11:41:31 AM CST> <Info> <Configuration Management> <BEA-150016> <This server is being started as the administration server.>启动本机的刚才配置好的Session,开始连接……进入监控界面。
-
使用自定义请求向服务器发送请求的方法(转自论坛)
2009-10-28 22:43:46
在LR中,web_submit_data中字符串的拼接有个问题,就是不能使用C中的字符串类型去直接替换,就算使用了lr_save_string函数,仍然可能会存在问题,以下举例说明。
脚本背景如下:
web_submit_data(classicustomermaterial_significanteventinfo.jsf")返回的页面上可能存在多条记录,同时记录数不确定,因此需要设定一个循环,来重复关联,并执行后续的操作,如:
web_submit_data("creditReviewClassiLoanMaterial.jsf",
ITEMDATA,
"Name=body:frm2:classiAssetsVOTable_0:check", "Value=true", ENDITEM,
"Name=body:frm2:classiAssetsVOTable_1:check", "Value=true", ENDITEM,
"Name=body:frm2:_id148", "Value=填写债项级分类信息", ENDITEM,
"Name=body:frm2_SUBMIT", "Value=1", ENDITEM,
"Name=autoScroll", "Value=0,102", ENDITEM,
"Name=body:frm2:_link_hidden_", "Value=", ENDITEM,
LAST);
假定黑体部分的脚本classiAssetsVOTable_0:check、classiAssetsVOTable_1:check是需要循环进行关联的。如果有实际操作过的朋友就不难发现,0、1这些数字很难在函数中用变量替换。这个时候有一个简便的方法,就是使用LR中提供的自定义请求函数来向服务器提交请求,即使用web_custom_request函数。该函数的使用方法很简单,最主要的是在Body部分把ITEMDATA之后的“Name”和“Value”通过{Name}={Value}的形式组合起来,并且在多组值之间用“&”分隔。如:
web_custom_request("creditReviewClassiLoanMaterial.jsf",
"Method=POST",
"RecContentType=text/html",
"Snapshot=t19.inf",
"Mode=HTML",
"Body=body:frm2:classiAssetsVOTable_1:check=true&
body:frm2:classiAssetsVOTable_%2:check=true&
body:frm2:_id148=填写债项级分类信息&
body:frm2_SUBMIT=1&
autoScroll=0,102&
body:frm2:_link_hidden_="
LAST);
关于该函数更详细的信息可以参考LR的帮助文档。
回放脚本,成功!通过执行结果我们可以看到,使用web_custom_request向服务器发送请求和使用web_submit_data发送请求起到的效果是完全一样的。不过看到这里,可能大家会有一个疑问:为什么要使用自定义请求报文来代替原有的web_submit_data呢?用原来的这个不是好好的吗?主要是因为在有些时候,我们需要使用自定义的字符串来对脚本进行一些特殊处理,例如在本例中,我们就遇到了这样的问题。由于我们需要将
"Name=body:frm2:classiAssetsVOTable_0:check", "Value=true", ENDITEM,
"Name=body:frm2:classiAssetsVOTable_1:check", "Value=true", ENDITEM,
这部分脚本放进循环体中,因此我们希望可以通过字符串拼接的方式,组装出这一整串字符,放进请求函数中,而在web_submit_data中很难达到这样看似简单的目的(我一直觉得应该还是有办法的,但我试了很久一直不成功。),所以只好另找出路。
以下是脚本的示例:
1、 利用字符串操作函数组装所需的字符串
strcpy(str,"BODY=");
for(i=0;i<count;i++)
{
sprintf(tmp,"body:frm2:classiAssetsVOTable_%d:check=true&",i);
strcat(str, tmp);
}
strcat(str,"body:frm2:_id148=填写债项级分类信息&body:frm2_SUBMIT=1&autoScroll=0,102&body:frm2:_link_hidden_=");
2、 在自定义请求函数中使用组装好的字符串。
web_custom_request("creditReviewClassiLoanMaterial.jsf",
"URL={url}",
"Method=POST",
"RecContentType=text/html",
"Referer={url}",
"Snapshot=t19.inf",
"Mode=HTML",
str,
LAST);
可能大家会有一个疑问:为什么要使用自定义请求报文来代替原有的web_submit_data呢?用原来的这个不是好好的吗?主要是因为在有些时候,我们需要使用自定义的字符串来对脚本进行一些特殊处理,例如在本例中,我们就遇到了这样的问题。由于我们需要将
"Name=body:frm2:classiAssetsVOTable_0:check", "Value=true", ENDITEM,
"Name=body:frm2:classiAssetsVOTable_1:check", "Value=true", ENDITEM,
这部分脚本放进循环体中,因此我们希望可以通过字符串拼接的方式,组装出这一整串字符,放进请求函数中,而在web_submit_data中很难达到这样看似简单的目的 -
QTP与QC的完美结合实现自动化测试框架-业务组件测试(转)
2009-10-28 22:40:37
摘要:利用QTP和QC相结合搭建功能自动化测试框架关键词:自动化测试 测试框架 组件
做功能自动化测试都会不约而同的遇到一个比较棘手的问题-测试框架的搭建。这也是直接影响功能自动化测试成功与否的关键。框架做的好可以使测试事半功倍,反之轻则很难看到工作的成果重则会使整个测试失败。目前网上有很多关于测试框架的讨论,其中也有成型的测试框架,其中有很多好的思想在里边,很值得借鉴。但今天要讨论的不是网上已有的,而是HP已经为我们设计好的一个测试体系,业务组件测试。他是利用QTP与QC的完美结合组成的一个体系架构。它可以轻易实现目前比较流行的三层测试架构:脚本层,业务层,数据层相分离,为开展功能自动化测试提供一个高效、稳定、容易的测试实现。
一.概述
1.1业务组件(Bussiness Process Testing)简介
业务组件是组成流程测试的基本单元,组合不同的业务组件可以实现不同的业务流程测试。如将fligt系统的登录最为一个组件,选择航班最为一个组件等。这样可以实现组件的复用,提高开发效率。
1.2 Bussiness Process Testing的优点
1) 相关业务人员可以在没有脚本的环境下组合业务组件,实现业务流程。
2) 对业务人员的编程能力没有要求,业务人员只需了解系统的业务流程,不用关心具体的脚本实现。这一点也实现了业务层和脚本层的分离。
3) 一旦某个组件开发完毕,即可在不同的流程中使用该组件,实现高可复用性,从而加快业务流程测试的速度。
4) 明确的角色分工,业务人员负责流程的开发、组织;QTP工程师负责脚本的开发、维护以及相应函数库的开发、维护。
5) 因为实现了脚本的复用,提高了自动化开发的效率,无形中就降低了测试过程中维护的时间和成本。
1.3 Bussiness Process Testing的简易流程

如图所示,整个过程分为2条线:第一个是由业务测试人员划分组件并组合不同的组件实现不同的流程测试;其次QTP专家负责组件的脚本具体实现并负责调试成功,上传到QC供业务测试人员调用。
注:测试数据的组织后边介绍,以便实现三层的测试架构;此过程需要QC有Bussiness Process Testing组件许可的支持,也就是需要单独向HP购买。
下边以QTP自带的示例程序演示整个流程的开发过程
2.1划分组件
本次将系统划分为:登录;选择航班并插入;打开订单;更新订单;删除订单;注销。这样划分仅为演示之用,不用在实际的测试之中。
2.2组织业务测试流程
本次只是用于演示,所以流程不会100%覆盖,在实际的测试过程中要达到100%的流程覆盖。本次测试流程如下:
流程1:登录-选择航班并插入-注销
流程2:登录-选择航班并插入-更新订单-注销
流程3:登录-选择航班并插入-更新订单-删除订单-注销
流程4:登录-打开订单-更新订单-删除订单-注销
下边需要根据划分的组件来实现组件脚本的实现。
2.3创建应用程序区域
在开发脚本之前首先要做的是要创建一个应用程序区域。应用程序区域提供创建业务组件所需的所有资源和设置,每个业务组建都居于一个应用程序区域,并从这些应用程序区域集成这些资源和设置。在此创建一个名为“订票系统流程测试”的区域,如图所示。
创建过程:依次选择:file-New-Function library。保存后自动上传至QC默认目录。

在此也可以加载自己的函数库,对象库,恢复场景等,这样以后创建的组建都可以共享该应用程序区域的资源。同时也方便维护,这也是一个优点所在,例如一旦函数库改变在此从新加载新的函数库即可,不用在脚本理修改。总之这个应用程序区域很重要,以后所有的脚本均是基于这个区域。应用程序路径一定要加载正确,否则录制时不能生成脚本。
2.4创建脚本
在创建脚本之前最好在QC中组织好目录树,方便保存及调用。关于脚本的开发过程,每个人、每个公司都有自己的方法。在此源代码也没法一一贴出。所以在此只列出输入参数和输出参数,方便后边的参数化以及数据组织。本次也采用最通用的方式即对象库解决对象识别问题。脚本的开发规范以及参数命名也以我自己惯用方式。

注:“-”为无相应参数。
在QTP中创建组件脚本有2中模式:Bussiness Component和Scripted Component。区别:Bussiness Component只能见关键字视图,QC中亦可见关键字视图;Scripted Component可以看见专家视图,在QC中脚本代码不可见。一般创建后者,本次也是采用后者,方便编辑脚本,控制脚本结构。
注意:参数一定要合理设置并对代码中的输入项做参数化与参数关联,否则测试数据传不到脚本,导致脚本运行失败。参数可以在QTP中创建,也可以在QC中创建,效果等同。
脚本开发完保存至QC,如图:

至此脚本开发完毕。也实现了脚本和业务层、数据层的脱离,现在单个组件脚本实现业务流程中的某一个功能且脚本中不会涉及具体的测试数据,从而为实现三层结构打下基础。接下来的工作就是在QC中组织需要测试的业务流程以及需要的测试数据。
这里有一个需要注意的地方,就是在QTP创建脚本如果选择Bussiness Component类型,在“设计步骤”选项卡可以看到QTP中的关键字视图,相关人员可以像在QTP操作一样,但是看不到代码。这也是为何上边为何创建脚本组件的原因。
2.5业务流程的组织
业务流程的组织主要是在“测试计划”模块中实现。这的主要工作是由业务测试人员完成。规划好目录结构以后,根据需要测试的业务流程拖拽需要的组件即可。这一步和在“测试计划”中拖拽测试用例很相似,区别就是这个是组合业务流程,而且可以自动执行。组织好后的效果如图:

需要注意的是,创建用例是请选择“BUSINESS-PROCESS”测试类型,否则组件脚本拖拽不过来。拖拽脚本是在“测试脚本”选项卡中进行,如上图。限于篇幅,在此创建目录和拖拽等动作不再详述,请参见QC的用户手册。另外,根据实际的系统,可以把组件分组,以组的形式控制流程。例如,选择如图的2到4的组件,然后选择工具栏叉号旁边的图标,即可把组件分成一组。这样可以更好的控制流程。
至此,所有的业务流程均以实现。可以在QC中选择运行(绿色箭头),进行相关的调试。
这里实现的是三层结构中的业务层。这里进行的业务流程组织和脚本没有任何关系,相关人员不用关心脚本如何实现,只要保证所有的流程均已覆盖即可。
接下来就是要实现数据层的工作了,从而实现三层的测试架构。
2.6测试数据的组织
测试数据的组织也是在“测试计划”模块中实现。选择某一个流程,在“测试脚本”选项卡中右击要设计数据的组件,在弹出窗口中选择“迭代”,弹出组件迭代设置窗口,如图:
在此可以根据测试需求设置组件要迭代的次数,以及每次迭代的参数值。如上图,设置了3次迭代每次迭代输入的订单信息均不相同。同时可以设置输入参数选择上一个组件的输出参数(在复选框中打勾,按提示操作即可),如下图。是流程4中的“打开订单”组件,orderNo参数使用的是“选择航班并插入”组件的输出参数。注意,此流程的“选择航班并插入”设置了三次迭代,所以“打开订单”也要对应三次迭代,否则会提示错误。

在组织数据时,可以在单个组件中设置每次迭代的数据,由于组件的重用次数很多,所以这样做还是有些麻烦。解决方法就是在外部组织好数据后,批量导入。QC默认是txt文本文件,格式可以把现有参数导出,参照它给的格式设计自己数据即可。
至此,数据层的设计也已完毕。同时也实现了测试数据和具体的业务流程相分离。
其实,这里的数据和业务层的分离并不是很彻底,不能根据自己的想法去设计,所以还有很大的改进空间,还需要进一步研究。
通过以上几个步骤,开发工作基本结束。以后就是需要相关的维护即可。当然,最后还是要执行测试。2.7执行测试
测试的执行是在“测试实验室”中进行的。这里和操作QC执行用例很相似。也是组织目录,拖拽相应的测试流程即可,这里也不在累述。可参见用户手册执行测试用例部分。当然执行测试可以选择本机执行,也可以选择在远程机器上执行测试,但要注意要安装相应组件和设置主机。执行效果如下图:
QC会记录每次执行的结果,包括流程中每个组件的执行状态,执行时间等信息。这也是QC的强大之处,它会给出一个很人性化的结果,方便我们后续的分析工作,以及对系统给出一个量化的指标。这一点QC做的相当完善,从需求开始到最后的缺陷分析以及测试报告,都会有一个图形的界面供我们参考,这对我们写测试报告提供了极大的方便,给我们提供了强有力的,可靠的数据支持。
注:以上全部工作在WinXP(sp3)+QTP9.5+QC9.0环境下完成。
三.总结
本文只是针对业务组件测试给出了一个简单叙述,QTP以及QC的强大之处远不及这些。对于QTP和QC的其他功能本文没有提及,其他功能在自动化测试中起到的作用,是有些工具不能代替的,也许这也是现在很多公司、很多人都在学习、使用的原因之一吧!前一段时间51的调查文件就是一个很好的证明,HP(Mercury)的所有产品都是遥遥领先其他工具。当然有很多公司也有自己的测试框架,也有自己开发的测试工具。但不可否认QTP确实是一个很好的测试工具,虽然它很贵。
需要提到的是,QTP和QC是一个开放式的架构,HP(也就是以前的MERCURY)为我们提供了很多接口,我们完全可以利用这些接口开发出自己的框架,实现三层乃至更高的框架结构。这些接口以及函数说明都能在QTP的帮助文档中找到。
最后希望国内的测试发展越来越好,中国的软件越做越好。 -
搭建jprofiler环境(转自论坛)
2009-10-28 22:39:07
前言:因需要用jprofiler监控内存泄漏问题。我开始着手研究。遇到了问题。先到一个软件测试群中问了两遍。都没有回答。大家却为一些闲事讨论的热闹。哎。难道你们真的认为工作就是闲聊吗。求人不如求己。一切靠自己。而且我自己也有能力搞定。不到半天把windows下和linux下监控都搞定了。现简单记录下:
1:搭建redhat linux as 5 + tomcat 5.5 + jprofiler 5环境
(1)下载jprofiler的windows和linux安装包
(2)安装jprofiler的windows版本
(3)安装linux的rpm包 rpm -ivh jprofiler.rpm 系统默认安装到了/opt目录下
(4)配置tomcat的catalina.sh文件:把代码粘贴到如图的位置:复制内容到剪贴板(5)配置linux系统变量:vi /etc/profile代码:
CATALINA_OPTS="$CATALINA_OPTS -Xms128m -Xmx128m $JPDA_OPTS -agentlib:jprofilerti=port=8849 -Xbootclasspath/a:/opt/jprofiler4/bin/agent.jar"复制内容到剪贴板(6)启动windows下jprofile客户端一步步设置下来就连接成功了。代码:
export LD_LIBRARY_PATH=/opt/jprofiler4/bin/linux-x86
2:搭建了windows下:jdk 1.5+ tomcat 5.0+ jprofiler 5.1环境
(1)分别安装jdk tomcat jprofiler
(2)设置环境变量:JAVA_HOME JAVA_PATH CLASSPATH TOMCAT_HOME CATALIN_HOME CATALINA_BASE
(3)在tomcat的startup.bat文件中添加:复制内容到剪贴板备注:把C:\Documents and Settings\your_name\.jprofiler5\config.xml和D:\Program Files\jprofiler4\bin\agent.jar路径下的config.xml和agent.jar文件分别拷贝到c:\usr目录下。代码:
set JAVA_OPTS=%JAVA_OPTS% -agentlib:jprofilerti=port=8849,nowait,id=102,config=c:\usr\config.xml -Xbootclasspath/a:c:\usr\agent.jar
(4)启动jprofiler,根据提示步骤一步步的设置就可以了。 -
常见系统资源Monitor问题
2009-10-20 13:54:48
常见系统资源Monitor问题
最近老是看见有tx对在Controller中添加系统资源Monitor连接不上的问题,为此查了Controller的说明,上面对以下情况作了解释,同学们看看,应该大部分问题都能解决了。反正还是建议大家要多看看帮助,呵呵
监控windows配置:
一 windows1 监视连接前的准备工作
首先保证被监视的windows系统开启以下二个服务Remote Procedure Call(RPC) 和Remote Registry Service (这里具体在那里开起服务就不说了)
被监视的WINDOWS机器:右击我的电脑,选择管理->共享文件夹->共享 在这里面要有C$这个共享文件夹,(要是没有自己手动加)
然后保证在安装LR的机器上使用运行.输入\\被监视机器IP\C$ 然后输入管理员帐号和密码,如果能看到被监视机器的C盘了,就说明你得到了那台机器的管理员权限,可以使用LR去连接了
说明: LR要连接WINDOWS机器进行监视貌似要有管理员帐号和密码才行,
2 用LR监视windows的步骤(这里就不详细说明了,只要在窗口中右击鼠标选择Add Measurements就可以了)
Q1:无法Monitor在另一个domain的Windows主机或者报错"Access Denied"
A1:获取远程主机的管理员权限,在命令行模式下运行如下命令
Net use \\<主机名>
在弹出的用户名提示后输入远程主机的用户名,在弹出的密码提示后输入远程主机密码Q2:无法Monitor一个NT/2000的主机,报错"computer name not found"或"connot connect to the host"
A2:远程主机只允许具有管理员权限的用户Monitor资源,若需要非管理员也能够获得资源信息,需要手工授权"Read"权限给某些文件和注册表项。具体步骤如下:
1、 授权给用户以下文件的读权限
a) %windir%\system32\PERFCxxx.DAT
b) %windir%\system32\PERFHxxx.DAT
其中xxx是系统的基础语言id,如英语就是009,如果找不到文件,最好从安装光盘中copy出来
2、 在注册表中查找以下表项并授予读权限
HKEY_LOCAL_MACHINE\Software\Microsoft\WindowsNT\CurrentVersion\Perflib以及其子项
3、 在注册表中查找以下表项并授予读权限
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\SecurePipeServers\winregQ3:从WinNT主机上无法获得一些Win2000下的计数器
A3:在Win2000主机上运行Controller或TuningQ4:一些Windows的默认计数器报错
A4:把报错的计数器删除并添加更合适的计数器Q5:无法获得目标主机上SQL Server(version 6.5)的性能计数器
A5:这是6.5版本的SQL Server的一个bug,需要手工在被监控主机的注册表中赋予以下表项读权限
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer\MSSQLServerQ6:选中的measurement参数没有显示在图表中
A6:确定display file和online.exe已经被注册。运行loadrunner\bin下的set_mon.bat文件Q7:在Monitor Windows主机时,在图表中没有出现任何参数
A7:查看Windows主机中的Windows Performance Monitor,如果没有出错,则查看通讯设置Q8:在Monitor Unix主机时,在图表中没有出现任何参数
A8:确保Unix主机上rstated进程已经运行Q9:无法监控如下的Web服务器:Web IIS、MS ASP、ColdFusion
A9:同Q7Q10:无法监控WebLogic(JMX)服务器
A10:打开LoadRunner\dat\monitors\WebLogicMon.ini文件,查找以下字符串:
[WebLogicMonitor]
JVM=javaw.exe
把javaw.exe替换成java.exe -
Weblogic常用监控指标(转)
2009-10-20 13:48:59
JMSRuntime JMSServersCurrentCount 返回当前JMS服务的连接数
ConnectionsCurrentCount 返回本JMS服务器上当前的连接数
JMSServersHighCount 返回自服务器启动后JMS服务的最大连接数
ConnectionsHighCount 返回本JMS服务器自上次重置后的最大连接数
JVMRuntime HeapSizeCurrent 返回当前JVM堆中内存数,单位时字节
HeapFreeCurrent 返回当前JVM堆中空闲内存数,单位时字节
ExecuteQueueRuntime ExecuteThreadCurrentIdleCount 返回队列中当前空闲线程数
PendingRequestOldestTime 返回队列中最长的等待时间
PendingRequestCurrentCount 返回队列中等待的请求数
Queue Length 队列长度
JDBCConnectionPoolRuntime WaitingForConnectionHighCount
返回本JDBCConnectionPoolRuntimeMBean 上最大等待连接数
WaitingForConnectionCurrentCount 返回当前等待连接的总数
MaxCapacity 返回JDBC池的最大能力
WaitSecondsHighCount 返回等待连接中的最长时间等待者的秒数
ActiveConnectionsCurrentCount 返回当前活动连接总数
ActiveConnectionsHighCount 返回本JDBCConnectionPoolRuntimeMBean 上最大活动连接数注:weblogic通常监控JVM和执行队列,JDBC连接池,其中执行队列最关键的指标是Queue Length 队列长度
weblogic一般来说监控jvm的使用、执行线程队列情况、和连接池的变化情况,还有一个很重要的检查weblogic的console日志这里经常能反映一些很重要到情况。
监控weblogic的jvm有一个很好的自带工具,由于weblogic使用自己的jrockit作为jvm,自带一个工具通过在启动参数加-Xmanagement,然后进入到jrockit的bin路径下命令行console启动,可以看到更加细微的jvm的情况,对jvm的调优很好。
这里还是建议一定对jvm的工作原理做一个深入的理解会对你很有帮助,同时了解不同的jrockit的jvm垃圾回收器各自的特点,这些都对weblogic的调优大有帮助。 -
Loadrunner Analysis之Web Page Diagnostics(转自论坛)
2009-10-20 13:45:41
简单介绍一下Loadrunner Analysis中的Web Page Diagnostics模块的使用,很多人对于测试之后的结果数据分析摸不着头脑,其实loadrunner Analysis给你提供了很好的文档,大家没事可以多翻翻,多翻几遍对于性能测试你就入门了 ;)
Web Page Diagnostics (以下简称WPD),这是LR Analysis中非常重要的一块,搞清楚这部分的内容会让你少走很多弯路,很多环境问题都可以通过它来定位,比如客户端,网络。通过它可以你可以比较好的来定位是环境的问题还是应用本身的问题,当然更重要的是Web页面本身的问题。
WPD包括下面几个图表:
Web Page Diagnostics 这是张总图,包括下面几张Over Time图的内容
Page Component Breakdown 页面中每个元素的平均响应时间占整个页面响应时间的百分比
Page Component Breakdown(Over Time) 在整个测试过程中,任意一秒内页面中每个元素的响应时间(例如在runtime中设置了browser cache,页面中的资源文件就只会在第一次下载,后面的页面响应时间也就不包括这些元素的时间,这在Page Component Breakdown中是看不出来的,因为Page Component Breakdown是整个测试期间内的平均时间。当然,是否启用了cache,通过over time图就能看出来)
Page Download Time Breakdown 页面中每个元素的响应时间分割图,响应时间被分割为以下几个部分:DNS Resolution,Connection,First Buffer,SSL Handshaking,Receive,FTP Authentication,Client,Error
Page Download Time Breakdown(Over Time) 在整个测试过程中,任意一秒内页面中每个元素的响应时间分割图
Time to First Buffer Breakdown First Buffer Time时间分割为Network Time和Server Time,客户端http请求发送到接收到服务器端的应答包(ACK)为Network Time,从接收到ACK到完成First Buffer接受为Server Time
Time to First Buffer Breakdown(Over Time) 基本同上,任意一秒内的
Downloaded Component Size(KB) 页面中每个元素的大小(KB)
介绍了这么多,具体如何分析呢?
首先打开Web Page Diagnostics图,来看看下面一个例子Download Time图: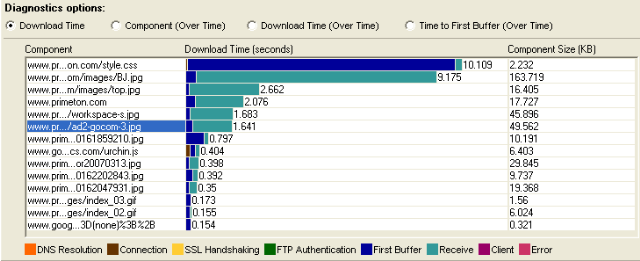
上图存在两个问题:
1、receive时间很长
这个一般是网络问题,当然如果你确认网络不存在问题,那么你就要看看是不是客户端的问题(客户端也可能会造成Receive过长,这个千万要注意)
2、页面问题
页面上包括了非常多的图片,而且图片似乎都没有优化,最大的竟然有163K,记下来,这可是罪证哦 ;)
很多时候,你可以根据DNS,Connection,Receive来看出是否存在网络问题,根据Client来判断是否存在客户端问题。
看看,挺简单的吧! ^_^
换个图看看,Page Component Breakdown(Over Time)
很清楚吧,页面元素都被cache了,说明场景启用了browser cache,页面的响应时间只包括红线和蓝线。
Time to First Buffer Breakdown(Over Time) ,图就不贴了,这个图非常重要,也最复杂,这里的值不绝对,当网络状况不好的时候,server time很可能包括网络时间,因为很多页面元素比较小(小于4k的样子),在First Buffer就完成传输,所以一定要注意分析。 -
内存泄漏(转自论坛)
2009-10-20 13:42:10
定义:
一般我们常说的内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显示释放的内存。应用程序一般使用malloc,realloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用,我们就说这块内存泄漏了
广义的说,内存泄漏不仅仅包含堆内存的泄漏,还包含系统资源的泄漏(resource leak),比如核心态HANDLE,GDI Object,SOCKET, Interface等,从根本上说这些由操作系统分配的对象也消耗内存,如果这些对象发生泄漏最终也会导致内存的泄漏。而且,某些对象消耗的是核心态内存,这些对象严重泄漏时会导致整个操作系统不稳定。所以相比之下,系统资源的泄漏比堆内存的泄漏更为严重。
泄漏的分类:
以发生的方式来分类,内存泄漏可以分为4类:
1. 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
2. 偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
3. 一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
4. 隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较之于常发性和偶发性内存泄漏它更难被检测到。
从测试方面来讲:
如果Process\Private Bytes计数器和Process\Working Set计数器的值持续升高,
同时Memory\Available bytes计数器的值缺却持续降低的话,说明很有可能是存在内存泄漏
内存泄漏检测工具:
1.ccmalloc-Linux和Solaris下对C和C++程序的简单的使用内存泄漏和malloc调试库。
2.Dmalloc-Debug Malloc Library.
3.Electric Fence-Linux分发版中由Bruce Perens编写的malloc()调试库。
4.Leaky-Linux下检测内存泄漏的程序。
5.LeakTracer-Linux、Solaris和HP-UX下跟踪和分析C++程序中的内存泄漏。
6.MEMWATCH-由Johan Lindh编写,是一个开放源代码C语言内存错误检测工具,主要是通过gcc的precessor来进行。
7.Valgrind-Debugging and profiling Linux programs, aiming at programs written in C and C++.
8.KCachegrind-A visualization tool for the profiling data generated by Cachegrind and Calltree.
9.IBM Rational PurifyPlus-帮助开发人员查明C/C++、托管.NET、Java和VB6代码中的性能和可靠性错误。PurifyPlus 将内存错误和泄漏检测、应用程序性能描述、代码覆盖分析等功能组合在一个单一、完整的工具包中。
10.Parasoft Insure++-针对C/C++应用的运行时错误自动检测工具,它能够自动监测C/C++程序,发现其中存在着的内存破坏、内存泄漏、指针错误和I/O等错误。并通过使用一系列独特的技术(SCI技术和变异测试等),彻底的检查和测试我们的代码,精确定位错误的准确位置并给出详细的诊断信息。能作为Microsoft Visual C++的一个插件运行。
11.Compuware DevPartner for Visual C++ BoundsChecker Suite-为C++开发者设计的运行错误检测和调试工具软件。作为Microsoft Visual Studio和C++ 6.0的一个插件运行。
12.Electric Software GlowCode-包括内存泄漏检查,code profiler,函数调用跟踪等功能。给C++和.Net开发者提供完整的错误诊断,和运行时性能分析工具包。
13.Compuware DevPartner Java Edition-包含Java内存检测,代码覆盖率测试,代码性能测试,线程死锁,分布式应用等几大功能模块。
14.Quest JProbe-分析Java的内存泄漏。
15.ej-technologies JProfiler-一个全功能的Java剖析工具,专用于分析J2SE和J2EE应用程序。它把CPU、执行绪和内存的剖析组合在一个强大的应用中。JProfiler可提供许多IDE整合和应用服务器整合用途。JProfiler直觉式的GUI让你可以找到效能瓶颈、抓出内存泄漏、并解决执行绪的问题。4.3.2注册码:A-G666#76114F-1olm9mv1i5uuly#0126
16.BEA JRockit-用来诊断Java内存泄漏并指出根本原因,专门针对Intel平台并得到优化,能在Intel硬件上获得最高的性能。 -
性能测试(并发负载压力)测试分析-简要篇(转自论坛)
2009-10-20 12:10:04
分析原则:
• 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
• 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
• 分段排除法 很有效
分析的信息来源:
•1 根据场景运行过程中的错误提示信息
•2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 •Error: Failed to connect to server "10.10.10.30:8080": [10060] Connection
•Error: timed out Error: Server "10.10.10.30" has shut down the connection prematurely
分析:
•A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
•B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
•C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired
分析:可能是以下原因造成
•A、应用服务参数设置太大导致服务器的瓶颈
•B、页面中图片太多
•C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
• 分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
• 细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
• 如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题
3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低,还要考虑页面错误的情况;
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;
内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)
4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in ('db block gets’,
'consistent gets','physical reads') ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = 'redo log space requests' ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name='sorts (disk)' and b.name='sorts (memory)'
注:上述SQL Server和Oracle数据库分析,只是一些简单、基本的分析,特别是Oracle数据库的分析和优化,是一门专门的技术,进一步的分析可查相关资料,在Unix/linux 操作系统,当CPU利用率低,但是事务响应时间仍然较长时,还需要观察 I/O Wait 的变化,以鉴别是否因为 I/O 导致 CPU 利用率低 -
每秒事务数和点击率(转)
2009-10-20 11:46:45
事务是在脚本中定义的某个操作,而点击是在测试中产生的http请求。
例如,我定义了一个提交form的事务,我关心的也就是这个提交操作的数量与分值及响应时间的关系。而实际上这个form提交可能产生多个http请求。首先提交form本身有一次http请求,如果此请求被服务器端接受,则要转向到结果页面的第一个页面,又是一次http请求,如果这个页面中含有图片的话,那么每个图片都需要通过一个http连接来下载。
所以:
平均每个事务产生的点击数
= 事务的数量+事务的数量×事务成功概率+事务的数量×事务成功概率×平均每个页面中含有的图片数
= 事务的数量×(1+平均事务成功概率×(1+平均每个页面含有的图片数))
一个事务中有多个请求,如果一个事务中的某个请求失败,事务就失败了,所以说errors应该是请求的失败次数 -
QTP学习
2009-10-18 20:52:14
DOM技术的应用
1.最普通的方法
Browser("百度一下,你就知道").Page("百度一下,你就知道").WebEdit("wd").Set "helloworld"2.描述性编程
Browser("百度一下,你就知道").Page("百度一下,你就知道").webedit("name:=wd").Set "123"3.对象自身接口
Browser("百度一下,你就知道").Page("百度一下,你就知道").WebEdit("wd").Object.value="helloworld"4.DOM技术
Browser("百度一下,你就知道").Page("百度一下,你就知道").Object.getElementById("kw").value="helloworld"5.childobject结合描述性编程循环遍历获取对象
'描述对象
Set Desc = Description.Create()
oDesc("micclass").Value = "WebEdit"
'获取webedit的数量
edit_count=Browser("百度一下,你就知道").Page("百度一下,你就知道").ChildObjects(oDesc).count
'获取子对象集合
set editobjects=Browser("百度一下,你就知道").Page("百度一下,你就知道").ChildObjects(oDesc)
For i=0 to edit_count-1
If editobjects(i).GetROProperty("name")="wd" then
editobjects(i).set "helloworld"
End If
Next6.getElementsByName和getElementsByTagName返回的都是一个集合对象
getElementsByName:
'*****************************
Set pageOjbect=Browser("百度一下,你就知道").Page("百度一下,你就知道")
set editObjs= pageOjbect.Object.getElementsByName("wd")
For each obj in editObjs
obj.value="helloworld"
Next
'*****************************getElementsByTagName:
'*****************************
Set pageOjbect=Browser("百度一下,你就知道").Page("百度一下,你就知道")
set editObjs= pageOjbect.Object.getElementsByTagName("input")
For i=0 to editObjs.length
If editObjs.item(i).name="wd" Then
editObjs.item(i).value="helloworld"
Exit for
End If
Next
Set editObjs=nothing
Set pageObject=nothing
'*****************************对象库
DESCRIPTION PROPERTIES:用于对象识别时对比的属性
ordinal indentifier :是针对出现相同对象时可以自动给对象进行编号,也就是INDEX
Additional details:qtp的智能识别,意思就是如果打开了智能识别之后,QTP如果在页面上找不到对象之后,他会找最接近的一个对象进行匹配,,但是如果关闭了这个功能之后,只要有一个属性不匹配,QTP就会找不到对象的


标题搜索
我的存档
数据统计
- 访问量: 166056
- 日志数: 260
- 书签数: 81
- 建立时间: 2007-08-28
- 更新时间: 2012-06-13
