
-
Tomcat参数配置与简单的性能验证(转)
2011-05-17 16:37:39
最近在对Tomcat服务器的web应用进行性能测试的过程中,有时LoadRunner中总会报错:
Action.c(71): Error -27791: Server "localhost" has shut down the connection prematurely
但是这个错误并不是每次测试都会出现,通常在长时间的测试之后才偶尔出现,而奇怪的是在Tomcat的日志中并没有相应的错误。从出错信息的字面信息来看,应该是服务器由于某些原因关闭了连接,而Tomcat并不认为这是一个错误,因此没有在日志中记录下来。在网上的搜索中看到,这个错误在其他的服务器如WebLogic、IIS等均有发生,看来是一个通用的问题。在诊断的过程中,发现Tomcat运行界面有时会提示:“严重: All threads (10) are currently busy, waiting. Increase maxThreads (10) or check the servlet status”,根据这一线索对Tomcat的server.xml中的maxThreads、connectionTimeout参数进行配置,解决了这个问题。
试验
为了验证这两个参数对测试结果的影响,我做了一些试验。
测试场景:一个测试脚本、20个虚拟用户、10次迭代
参数设置及相应运行结果:maxThreads
connectionTimeout(豪秒)
错误个数
5
1000
16
10
1000
13
15
1000
7
20
1000
0
5
10000
1
10
10000
0
15
10000
0
20
10000
0
试验结论
当最大线程数较少、超时时间较短时,出现这个错误的次数就越多;随着最大线程数逐步接近并发用户数,该错误逐渐减少。另外,延长超时时间也能够减少错误的出现,但这时由于请求在处于排队状态,因此会增加响应时间。引申
将该结果应用于性能调优中,在一定的负载压力下,增加最大线程数能够有效的提高服务器的并发处理能力,但前提是系统资源如CPU、内存等不会成为系统瓶颈,在不能再提高最大线程数时,也可以用增加超时时间的方法,但这会造成响应时间的增加。参数最佳设置根据具体应用和测试结果而定。在有条件的情况下,最好就是集群了。
附:
当以上错误出现在用到web_reg_save_param函数的响应中时,会伴随着其他错误:
Action.c(248): Error -26377: No match found for the requested parameter "ClientID". Check whether the requested boundaries exist in the response data. Also, if the data you want to save exceeds 10240 bytes, use web_set_max_html_param_len to increase the parameter size
Action.c(248): Error -26374: The above "not found" error(s) may be explained by header and body byte counts being 0 and 0, respectively. -
软件测试工具LR通用性能分析流程(转)
2011-05-16 16:12:29
第一步:从分析Summary的事务执行情况入手Summary主要是判定事务的响应时间与执行情况是否合理。如果发现问题,则需要做进一步分析。通常情况下,如果事务执行情况失败或响应时间过长等,都需要做深入分析。
下面是查看分析概要时的一些原则:
(1):用户是否全部运行,最大运行并发用户数(Maximum Running Vusers)是否与场景设计的最大运行并发用户数一致。如果没有,则需要打开与虚拟用户相关的分析图,进一步分析虚拟用户不能正常运行的详细原因;
(2):事务的平均响应时间、90%事务最大响应时间用户是否可以接受。如果事务响应时间过长,则要打开与事务相关的各类分析图,深入地分析事务的执行情况;
(3):查看事务是否全部通过。如果有事务失败,则需要深入分析原因。很多时候,事务不能正常执行意味着系统出现了瓶颈;
(4):如果一切正常,则本次测试没有必要进行深入分析,可以进行加大压力测试;
(5):如果事务失败过多,则应该降低压力继续进行测试,使结果分析更容易进行;
......
上面这些原则都是分析Summary的一些常见方法,大家应该灵活使用并不断地进行总结与完善,尤其要主要结合实际情况,不能墨守成规。
第二步:查看负载生成器和服务器的系统资源情况。
查看分析概要后,接下来要查看负载生成器和待测服务器的系统资源使用情况:查看CPU的利用率和内存使用情况,尤其要注意查看是否存在内存泄露问题。这样做是由于很多时候系统出现瓶颈的直接表现是CPU利用率过高或内存不足。应该保证负载生成器在整个测试过程中其CPU、内存、带宽没有出现瓶颈,否则测试结果无效。而待测试服务器,则重点分析测试过程中CPU和内存是否出现了瓶颈:CPU需要查看其利用率是否经常达到100%或平均利用率一直高居95%以上;内存需要查看是否够用以及测试过程是否存在溢出现象(对于一些中间件服务器要查看其分配的内存是否够用)。
第三步:查看虚拟用户与事务的详细执行情况。
在前两步确定了测试场景的执行情况基本正常后,接下来就要查看虚拟用户与事务的执行情况。对于虚拟用户,主要查看在整个测试过程中是否运行正常,如果有较多用户不能正常运行,则需要重新设计场景或调整用户加载与退出方式再次进行测试。对于事务,重点关注整个过程的事务响应时间是否逐渐变长以及是否存在不能正常执行的事务。总之,对每个用户或事务的执行细节都应该认真分析不可轻易忽略;
example1:一个性能逐步下降的服务器,需要进一步分析其性能下降的原因【可以查找是否存在内存泄露问题】;
example2:一个性能相对稳定的服务器,但是响应时间偏大,这时需要分析程序算法是否存在缺陷或服务器参数的配置是否合理。
第四步:查看错误发生情况。
整个测试过程中错误的发生情况也应该是分析的重点。下面是查看错误发生情况的常用准则:
(1)查看错误发生曲线在整个测试过程中是否是有规律变化的,如果有规律通常意味着程序在并发处理方面存在一定的缺陷。图5-9所示的每秒缺陷数量曲线十分有规律,这是因为服务器定期生成缓存文件导致用户不能正常访问而产生的错误;
(2)查看错误分类统计,作为优化系统的参考。例如对于Web性能测试,当出现瓶颈时往往需要查看服务器的错误统计信息结果:如果“超时错误”占到90%以上,可能需要提高硬件配置;如果较多的“内部服务器错误”,则可能是程序方面存在问题。
第五步:查看Web资源与细分网页。
本步骤仅适用于Web性能测试。查看Web资源图时,往往结合前面对虚拟用户以及事务响应时间的分析结果,重点分析服务器的稳定性。对于网页细分功能则遵循如下原则:首先分析从用户发出请求到收到第一个缓冲为止,哪些环节比较耗时;其次找出页面哪些组成部分对用户响应时间影响较大;当对页面的性能问题定位后,就可以采取相关的解决方案。
-
90%请求的响应时间可以作为测试结果的相应时间(转)
2011-05-11 11:02:49
今天看了人家写的 描述性统计与性能结果分析-LoadRunner,学到了平均相应时间和90%事务相应时间的关系,其中平均响应时间满足了但是未必符合性能要求,有时候还要看90%事务相应时间。具体参看以下内容:
LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。
为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求?
假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想?
假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?
为了解答上面的疑问,我们先来看一张表:

在上面这个表中包含了几个不同的列,其含义如下:
CmdID 测试时被请求的页面
NUM 响应成功的请求数量
MEAN 所有成功的请求的响应时间的平均值
STD DEV 标准差(这个值的作用将在下一篇文章中重点介绍)
MIN 响应时间的最小值
50 th(60/70/80/90/95 th) 如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义
MAX 响应时间的最大值
我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。我把结论性的东西整理一下:
1. 90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%;
2. 对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户请求的响应时间分布情况;
3. 从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。也就是说假如我们确定Home Page的响应时间应该在5秒内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的响应时间是大于这个值的;对于Page 1也是一样,假如我们确定对于Page 1 的请求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有20-30%的用户请求的响应时间是超过了我们的要求的;
4. 你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的;
5. 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲线就越接近真实情况;
6. 在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用90%或95%用户响应时间来作为度量标准,它们并不冲突。实际上,在定义某些系统的性能需求时,一定范围内的请求失败也是可以被接受的;
7. 上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。
事实上,在性能测试领域中还有更多的东西是目前的商业测试工具或者开源测试工具都没有专门讲述的——换句话说,性能测试仅仅有工具是不够的。我们还需要更多其他领域的知识,例如数学和统计学,来帮助我们更好的分析性能数据,找到隐藏在那些数据之下的真相。
数据统计分析的思路与分析结果的展示方式是同样重要的,有了好的分析思路,但是却不懂得如何更好的展示分析结果和数据来印证自己的分析,就像一个人满腹经纶却不知该如何一展雄才
一图胜千言,所以这次我会用两张图表来说明“描述性统计”在性能测试结果分析中的其他应用。
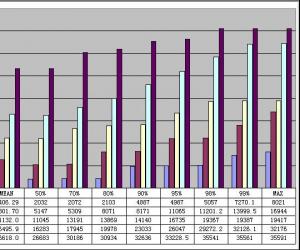
在这张图中,我们继续使用了上一篇文章——《描述性统计与结果分析》一文中的方法,对响应时间的分布情况来进行分析。上面这张图所使用的数据是通过对
Google.com 首页进行测试得来的,在测试中分别使用10/25/50/75/100 几个不同级别的并发用户数量。通过这张图表,我们可以通过横向比较和纵向比较,更清晰的了解到被测应用在不同级别的负载下的响应能力。
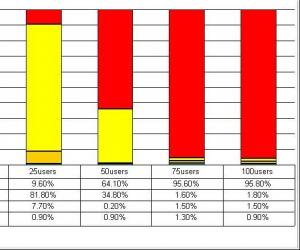
这张图所使用的数据与第一张图一样,但是我们使用了另外一个视角来对数据进行展示。表中最左侧的2000/5000/10000/50000的单位是毫秒,分别表示了在整个测试过程中,响应时间在0-2000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在2001-5000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在5001-10000毫秒范围内的事务数量占成功的事务总数的百分比,以及响应时间在10001-50000毫秒范围内的事务数量占成功的事务总数的百分比。
这几个时间范围的确定是参考了业内比较通行的“2-5-10原则”——当然你也可以为自己的测试制定其他标准,只要得到企业内的承认就可以。所谓的 “2-5-10原则”,简单说,就是当用户能够在2秒以内得到响应时,会感觉系统的响应很快;当用户在2-5秒之间得到响应时,会感觉系统的响应速度还可以;当用户在5-10秒以内得到响应时,会感觉系统的响应速度很慢,但是还可以接受;而当用户在超过10秒后仍然无法得到响应时,会感觉系统糟透了,或者认为系统已经失去响应,而选择离开这个Web站点,或者发起第二次请求。
那么从上面的图表中可以看到,当并发用户数量为10时,超过95%的用户都可以在5秒内得到响应;当并发用户数量达到25时,已经有80%的事务的响应时间处在危险的临界值,而且有相当数量的事务的响应时间超过了用户可以容忍的限度;随着并发用户数量的进一步增加,超过用户容忍限度的事务越来越多,当并发用户数到达75时,系统几乎已经无法为任何用户提供响应了。
这张图表也同样可以用于对不同负载下事务的成功、失败比例的比较分析。
Note:上面两个图表中的数据,主要通过Excel 中提供的FREQUENCY,AVERAGE,MAX,MIN和PERCENTILE几个统计函数获得,具体的使用方法请参考Excel帮助手册。
-
LoadRunner进程和线程设置(转)
2011-05-09 11:21:59
虚拟用户已线程还是进程的方式运行,对被测服务器的压力是完全不同的,首先我们要知道在loadrunner中有3个地方涉及到虚拟用户的运行方式,分别是:1、在Vug->run-time settings->miscellane->multithreading中可以设置虚拟用户是已线程还是进程的方式运行
2、在controller中设置场景时,是已单场景模式运行还是已场景组方式运行,在这两种不同的运行方式下,虚拟用户的运行方式也是不同的
3、在controller中使用IP欺骗时,在专家模式下的tools->options->general->multiple IP address mode中也可以选择每个IP是已线程还是进程方式运行
下面我们介绍一下这三个设置线程和进程之间的关系:
首先说一下run-time settings中的设置与controller中单场景和场景组的关系:
要记住虚拟用户是以线程还是进程方式运行是在Vug->run-time settings中设置的,其次在controller中如果使用单场景运行,那么该场景中无论有多少个脚本、多少个负载生成器,运行这些脚本的虚拟用户均依照Vug->run-time settings中设置的线程还是进程方式运行,但是如果在controller中如果以场景组方式运行时,每个场景组均会作为一个进程被启动,而每个组中的用户又是按照Vug->run-time settings中设置的线程还是进程方式运行。
再说一下在controller中使用IP欺骗时,在专家模式下的tools->options->general->multiple IP address mode中的设置:
如果选择的是进程方式:
1、如果这个ip是在单场景中,那么有几个不同的ip的负载生成器就会启动几个进程,每个负载生成器的虚拟用户的运行方式仍然按照Vug->run-time settings中设置的线程还是进程方式运行
2、如果是在场景组中运行,这就要看场景组是如何设置的了,有两种情况:
a、每个场景组中添加一个虚拟ip,这时运行每个场景组时只启动一个进程
b、每个场景组中添加多个虚拟ip,这时运行每个场景组时,每个场景组启动一个进程,每个ip启动一个进程,每个ip的虚拟用户的运行方式按照Vug->run-time settings中设置的线程还是进程方式运行。
如果在controller中使用IP欺骗时,在专家模式下的tools->options->general->multiple IP address mode中选择的线程方式:
1、如果这个ip是在单场景中,那么对于不同的ip的负载生成器只会启动一个进程,每个负载生成器的虚拟用户的运行方式仍然按照Vug->run-time settings中设置的线程还是进程方式运行。
2、如果是在场景组中运行,每个场景组启动一个进程,所有ip已线程的方式在组进程中运行,每个ip的虚拟用户的运行方式按照Vug->run-time settings中设置的线程还是进程方式运行。
-
LoadRunner设置检查点的几种方法介绍
2011-05-04 10:49:21
前段时间在群里跟大家讨论一个关于性能测试的问题,谈到如何评估测试结果,有一个朋友谈到规范问题,让我颇有感触,他说他们公司每次执行压力测试的时候,都要求脚本中必须有检查点存在,不然测试结果将不被认可,这是他们公司的规范。其实,在做压力测试过程,我们很容易忽略很多东西,而且随着自身的技术演变,我们很容易去丢失掉一些很好的习惯,当我们再碰到这些问题的时候,我们才发现其实是我们太粗心大意了,所以说好的习惯要保持。这次我刚好也要接手一些性能工作,因此就如何规范设置检查点来谈谈一些基本的流程和方法。使用LoadRunner做压力测试,大致如下几个流程:
1、明确测试目标
2、录制测试脚本
3、脚本优化、调试
4、场景运行
5、分析测试结果
当然这里都是概况性的标题,但从这里我们可以明确的是测试脚本是整个压力测试过程中的重点步骤,如果测试脚本都不能确保正确与否,后面的测试过程就无从说起了。很多时候我们把脚本调试就简单的认为是脚本回放没有错误就认为脚本是没有问题的,这当然不能这么肯定,脚本调试是一个非常严谨的过程,我大致归纳如下几步:
1、明确每一行脚本的作用,也就是说每一行脚本执行的功能是什么;
2、删减不需要的脚本语句,比如在录制过程由于LR默认设置导致录制之后出现很多冗余的脚本,这些个脚本对我们的测试过程没有用途的应该删除掉,至于哪些是冗余就要具体分析了,所以说脚本录制完之后要分析脚本运行的过程,方能理解脚本执行的用途,不然在后面施压时运行错误,就会开始到处找问题,而又找不出问题;
3、查找存在的关联并进行相关设置
4、设置检查点,设置检查点的目的就是为了验证页面每次运行之后是否正确,设置检查点的过程总要通过不能的回放来进行验证检查点设置是否正确。
5、通过测试目标明确脚本执行的目标事务,并添加事务;
6、对需要进行并打操作的功能设置集合点
7、根据实际情况设置ThinkTime
8、在以上所有脚本调试步骤完成之后,设置迭代次数,通过在Vuser中设置多次迭代来验证脚本在多次循环运行时是否存在错误
注意:在Vuser中运行和回放脚本的过程,要密切关注replay log,也就是回放日志,很多问题通常都暴露在回放日志中,只不过我们没有认真去检查,所以没发觉。因为大多数情况是我们在回放脚本之后只观察回放日志中有没有红色的错误提示信息,如果没有我们就认为我们的脚本是ok的,其实不然,很多时候一些隐藏的错误就在回放日志中可以被发现,比如回放日志中的Warning信息,也就是警告信息,这些信息一旦你不去理会它,它将在场景运行过程中开始频繁暴露出来,而在场景中报错之后我们就认为可能是系统有问题或者是测试过程存在其他问题等等,而很难去考虑到是脚本的问题,是脚本在Vuser中调试就存在的问题。还有的时候一些问题在一次脚本回放中就不能被发现,他需要通过Vuser中设置多次迭代才能在回放日志暴露出问题来,所以说我们通常的思维就是一旦测试脚本没有一次回放没有出现错误,就去场景中运行,结果在场景中哪怕是运行10个用户都还会报错,这就是问题的根源所在。
下面还是重点说说检查点吧,三种常用的文本检查web_reg_find的方法:
1、 将脚本切换到树结构,在page view页面上找到你要check的文本内容, 并执行鼠标右键,选择Add a text check.
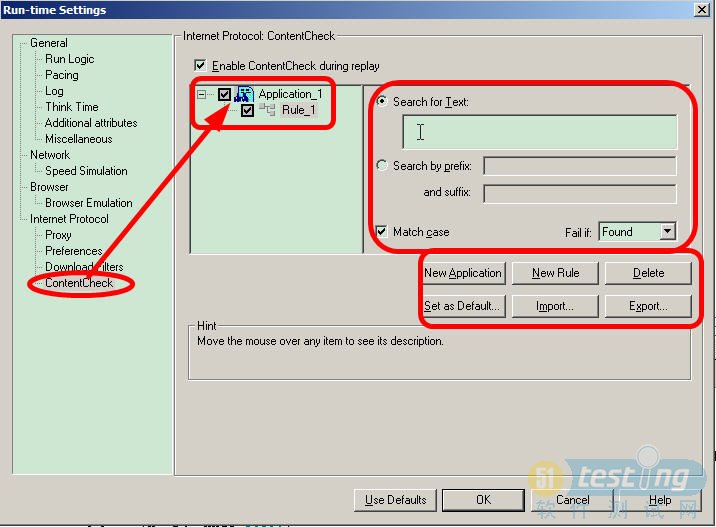
2、 通过Vuesr界面去设置检查点,如图所示:
3、将脚本切换回代码界面, 在光标闪烁的上行,添加如下的代码:
添加的代码根据你检查的方式不同而不同, 你可以选择其中之一即可。
代码一:
web_reg_find("Text=Payment Details",LAST);
注:“Payment Details” 为你要检查的文本;
脚本执行到此处,若在页面上找到了这几个字符串,那脚本继续执行下去;若没有找到,脚本将在此报错并且结束。
代码二:
web_reg_find("Text=Payment Details", "SaveCount=para_count", LAST); //check 的函数
这里是要运行的页面脚本
if (atoi(lr_eval_string("{para_count}"))>0) //验证是否找到了页面上的要检查的字符串
lr_output_message("Pass!");
else
lr_output_message("Failed!");
注意:
“Payment Details” 为你要检查的文本;
脚本执行到此处,不管页面上是否存在你要检查的字符串,脚本都不会报错,而是执行下去。
此段代码将找到的你要检查的字符串的个数,存为一个参数。 然后在页面代码的后面,通过检查这个参数的值是否大于0,来判断是否找到了你所要检查的字符串。
注意:这里的测试结果均以200状态码返回,其失败的结果将在分析报告中进行分类标识。
代码三:
web_reg_find("Text=Payment Detdils", "Fail=NotFound",LAST);或者
web_reg_find("Text=Payment Detdils", "Fail=Found",LAST);
以上两段脚本就比较简洁,通过查询文本内容来决定此次运行的测试结果是否失败。
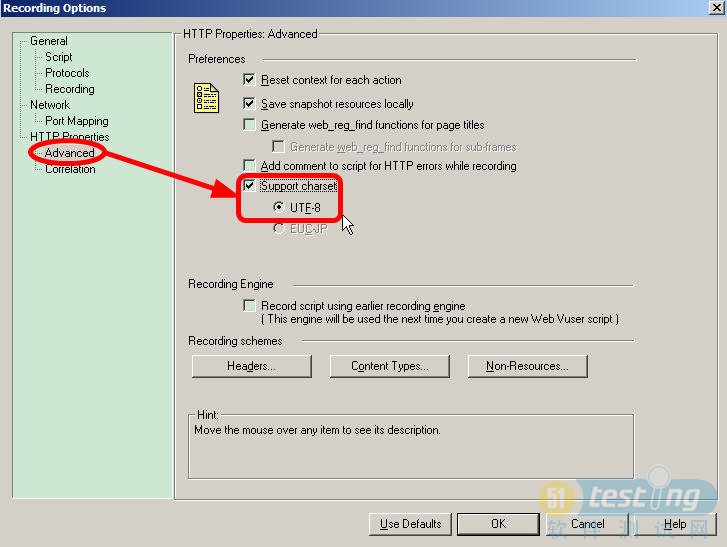
注意:在使用检查点的时候我们还需要注意一些问题,通常我们都要设置一些中文检查点,但是LR默认不支持,如果你设置了中文检查点而报错,那你就应该注意了,在录制脚本的时候去掉默认设置的UTF-8选择,如下图所示:
并且还设置启用图片和文本检查点,如下图所示:
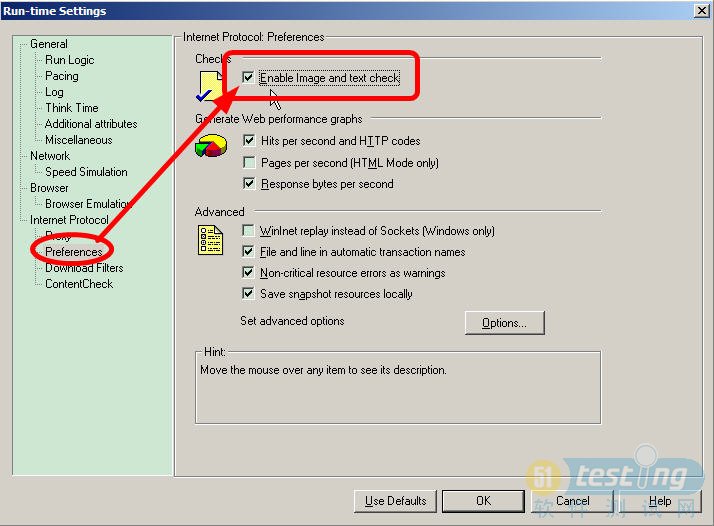
以上就是设置检查点的全过程,设置检查点的目的不只是为了验证我们的脚本没有错误,而更重要的是一个规范问题,如何使得测试结果更具有说服力,那就所有的测试脚本中都添加检查点设置
-
汇总(转载)
2009-12-23 16:07:16
-
LoadRunner案例分析之六(转)
2009-12-22 19:38:16
这个案例起源于不久前在51testing上的一个帖子,其实我这里的绝大多数的案例都是来源于51testing论坛,正所谓来源于生活,高于生活嘛(怎么感觉在说艺术,嘿嘿)。其实应该是来源于51,服务于51。 这个问题大概是这样的:LoadRunner对服务器进行压力测试的时候需要设置检查点,需要检查的内容是从服务器端返回的值,检查的方法是跟一个Excel文件中的内容进行比对。 从服务器端取值利用关联函数这个当然不用多说,关键是进行比对的方法,如何从Excel中取内容呢?QTP对Excel的支持非常好,QTP的数据都是集成在Excel中的,而且QTP的语言也是VBScript,利用QTP从Excel中取内容当时非常容易。但是LoadRunner对Excel的支持就没有那么好了,而且LoadRunner主要支持C,Java等语言。 当然我们也可以利用其他的方法解决问题,比如把Excel文件中的内容copy到文本文件,利用LoadRunner本身支持的参数文件进行对照,这样读取的时候就变的非常容易了。当然这里我们是针对C读取Excel文件的问题,所以如何利用C语言读取Excel文件的内容就是问题的关键了,下面就介绍一个利用VC读取Excel文件的方法。 在开发软件时,经常要将数据输出到Excel 2000中,在Excel 2000中对该数据进行进一步地格式化处理或进行计算处理。在Visual Basic中处理起来较简单,Excel 2000的VB编程帮助中有较为详细的介绍。在Visual C++中如何进行处理了?利用Excel 2000的ActiveX Automate功能,处理起来同VB中类似。但要注意以下几点:
对于对象的属性值的读取或赋值,需要用GetProperty()或SetProperty(NewValue)函数,不能象VB中直接通过属性名称取值或赋值。例如:Worksheet.GetCount(), Worksheet.SetName(“Sheet1”)。
对集合对象中的成员对象的引用,必须使用集合对象的GetItem()函数。例如:Worksheets.GetItem(ColeVariant ((long)1))或Worksheets.GetItem(ColeVariant(“Sheet1”))取得第一个工作表。
在COM接口中,时常用到Variant,BSTR,SafeArray数据类型。Variant数据类型是一个联合,可表示几乎所有的类型的数据,具体用法见MSDN中的相关介绍,类_variant_t是对VARIANT数据类型的封装。在Excel 2000的VB编程帮助中,如果提到某函数或属性需要一个值,该值的数据类型通常是Variant,在封装Excel 2000对象的类定义中,说明了具体需要的数据类型。BSTR是一个包括了字符串和字符串长度的数据结构,类_bstr_t是对BSTR数据类型的封装。在Excel 2000的VB编程帮助中提到的字符串通常指BSTR。具体函数参数或属性的数据类型,见封装该对象的类的定义。SafeArray是一个包括数组和数组边界的结构,数组边界外的内容不允许访问。在Excel 2000的VB编程帮助中提到的数组是指SafeArray。关于SafeArray的处理,请见MSDN的相关帮助。
对于缺省参数和缺省值。在VB中,函数的参数可以空缺,在VC++中不允许,必须将所有的参数填写完全。如果你希望指定某个参数为缺省值,根据参数数据类型的不同,可指定不同的缺省值。当参数数据类型为字符串时,可以用长度为0的字符串。如果参数是Variant类型,可用常量vtMissing,该常量在comdef.h中定义。也可用_variant_t(DISP_E_PARAMNOTFOUND, VT_ERROR)产生一个Variant对象。
Excel对象中的集合对象有时包括的子对象是不一定的,例如:Range对象,可以表示Cell的集合,也可以表示Column的集合或Row的集合,Range.GetItem(1)可以返回Cell或Column或Row对象。
对对象的引用或传递对象,使用IDispatch类对象,有时利用Variant对IDispatch进行包装。
以下是一段源程序,演示如何启动Excel 2000,利用一个模板文件产生一个新文档,在该文档的”Sheet1”工作表的第一个单元中填写一段文字,设置第一列的列宽,然后调用一个模板中的宏,执行一段程序,最后打印预览该Excel文档。模板文件名称:MyTemplate.xlt。程序在Visual C++ 6.0 sp4,Windows 2000 Professional sp-1下调试通过。
首先利用Visual C++ 6.0,建立一个MFC基于对话框的工程项目,共享DLL,Win32平台。工程名称ExcelTest。在主对话框中加入一个按钮,
ID IDC_EXCELTEST
Caption Test Excel
双击该按钮,增加成员函数void CExcelTestDlg::OnExceltest()。
在BOOL CExcelTestApp::InitInstance()中,dlg.DoModal();之前增加代码:
if (CoInitialize(NULL)!=0)
{
AfxMessageBox(”初始化COM支持库失败!”);
exit(1);
}
在return FALSE; 语句前,加入:
CoUninitialize();
选择Menu->View->ClassWizade,打开ClassWizade窗口,选择Add Class->From a type library,选择D:\Program Files\Microsoft Office\office\Excel9.OLB(D:\Program Files\Microsoft Office\是本机上Microsoft Office 2000的安装目录,可根据个人机器上的实际安装目录修改)。选择_Application、Workbooks、_Workbook、Worksheets、_Worksheet、 Range,加入新类,分别为_Application、Workbooks、_Workbook、Worksheets、_Worksheet、 Range,头文件Excel9.h,源文件Excel9.cpp。
在ExcelTestDlg.cpp文件的头部,#include “ExcelTestDlg.h”语句之下,增加 :
#include “comdef.h”
#include “Excel9.h”
在void CExcelTestDlg::OnExceltest() 函数中增加如下代码:
void CExcelTestDlg::OnExceltest()
{
_Application ExcelApp;
Workbooks wbsMyBooks;
_Workbook wbMyBook;
Worksheets wssMysheets;
_Worksheet wsMysheet;
Range rgMyRge;
//创建Excel 2000服务器(启动Excel)
if (!ExcelApp.CreateDispatch(”Excel.Application”,NULL))
{
AfxMessageBox(”创建Excel服务失败!”);
exit(1);
}
//利用模板文件建立新文档
wbsMyBooks.AttachDispatch(ExcelApp.GetWorkbooks(),true);
wbMyBook.AttachDispatch(wbsMyBooks.Add(_variant_t(”g:\\exceltest\\MyTemplate.xlt”)));
//得到Worksheets
wssMysheets.AttachDispatch(wbMyBook.GetWorksheets(),true);
//得到sheet1
wsMysheet.AttachDispatch(wssMysheets.GetItem(_variant_t(”sheet1″)),true);
//得到全部Cells,此时,rgMyRge是cells的集合
rgMyRge.AttachDispatch(wsMysheet.GetCells(),true);
//设置1行1列的单元的值
rgMyRge.SetItem(_variant_t((long)1),_variant_t((long)1),_variant_t(”This Is A Excel Test Program!”));
//得到所有的列
rgMyRge.AttachDispatch(wsMysheet.GetColumns(),true);
//得到第一列
rgMyRge.AttachDispatch(rgMyRge.GetItem(_variant_t((long)1),vtMissing).pdispVal,true);
//设置列宽
rgMyRge.SetColumnWidth(_variant_t((long)200));
//调用模板中预先存放的宏
ExcelApp.Run(_variant_t(”CopyRow”),_variant_t((long)10),vtMissing,vtMissing,
vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,
vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,
vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,
vtMissing,vtMissing,vtMissing,vtMissing,vtMissing,vtMissing);
//打印预览
wbMyBook.SetSaved(true);
ExcelApp.SetVisible(true);
wbMyBook.PrintPreview(_variant_t(false));
//释放对象
rgMyRge.ReleaseDispatch();
wsMysheet.ReleaseDispatch();
wssMysheets.ReleaseDispatch();
wbMyBook.ReleaseDispatch();
wbsMyBooks.ReleaseDispatch();
ExcelApp.ReleaseDispatch();
}
添加完以上程序后,可运行看结果。 -
LoadRunner案例分析之五(转)
2009-12-22 19:36:41
问题源于51testing的一个帖子,一个朋友想要把从服务器端利用关联取回来的值跟预定的值进行对比,以此判断是否执行成功。关联函数当然用的是web_reg_save_param。预定的期望值存储在Excel文件的固定一列。 我首先想到的就是利用方法读取Excel文件,然后在LoadRunner中利用c函数进行对比。其实Excel提供的接口相当强大,以前我们经常利用一些VBscript提供的API进行编程,解析Excel中的内容。而且Mercury的功能测试工具Quick Test Professinal提供了对Excel的强大支持。测试数据直接就是保存在Excel中,而且编程语言就是VBScript。不过LoadRunner就没有那么幸运,用的是更加通用的C语言。接下来很多朋友就给出了自己的看法。 后来作者自己给出了一个利用VBScript读取文件并写入文本文件的宏,如下:
Sub QuoteCommaExport() Dim DestFile As String
Dim FileNum As Integer
Dim ColumnCount As Integer
Dim RowCount As Integer
‘ 提示用户指定目标文件名。
DestFile = InputBox(”Enter the destination filename” & Chr(10) & “(with complete path and extension):”, “Quote-Comma Exporter”)
‘ 获取下一个可用的文件句柄编号。
FileNum = FreeFile()
‘ 关闭错误检查功能。
On Error Resume Next
‘ 尝试打开目标文件以供输出。
Open DestFile For Output As #FileNum
‘ 如果出现错误,则报告错误并结束程序。
If Err <> 0 Then MsgBox “Cannot open filename ” & DestFileEnd
‘ End If
‘ 打开错误检查功能。
On Error GoTo 0
‘ 循环选择的每一行。
For RowCount = 1 To Selection.Rows.Count
‘ 循环选择的每一列。
For ColumnCount = 1 To Selection.Columns.Count
‘ 将当前单元格中的文本写入到文件中,文本用引号括起来。
Print #FileNum, “”"” & Selection.Cells(RowCount, ColumnCount).Text & “”"”;
‘ 检查单元格是否位于最后一列。
If ColumnCount = Selection.Columns.Count Then
‘ 如果是,则写入一个空行。
Print #FileNum,
Else
‘ 否则,则写入一个逗号。
Print #FileNum, “,”;
End If
‘ 开始 ColumnCount 循环的下一个迭代。
Next ColumnCount
‘ 开始 RowCount 循环的下一个迭代。
Next RowCount
‘ 关闭目标文件。
Close #FileNum End Sub
但是这个并不能解决问题。
后来,这位仁兄又不辞劳苦,找来一篇利用dll访问的例子,下面就是详细内容。 如果使用DLL不知道可否实现,将查到的一篇比较好的介绍加载DLL的帖子转载过来,供大家研究
“LoadRunner下DLL的调用”
原帖地址http://www.softqa.net/bbs/index.php?showtopic=100
具体内容如下:
LoadRunner下DLL的调用
场景介绍
最近在做类似于QQ的通信工具的性能测试时发现了一些问题,现总结出来与大家分享一下。希望大家在使用LoadRunner时不仅仅停在只是录制/播放角本,而全面提升角本的编程技术,解决复杂场景。
本次测试中碰到的问题是这样的,在消息的传送过程中遇到了DEC加密的过程,LoadRunner录制到的全是加密的消息,比如我录制了某一个用户的登陆,发送消息,退出,但由于是加密的,只能单个用户使用,但如果我想并发多少个用户就存在很多问题,最直接的一个问题就是用户名是加密的,密码是加密的,当然你可以说让程序那里注掉加密的代码进行明码的测试,当然也是一种办法。但程序组提出了要使用更真实的方法来模拟,这时就必需使用下面介绍的方法。
一开始是直接把API移植到LoadRunner中来,不过由于加密算法异常复杂,有几层循环,而角本是解释执行的,进行一次加密运算可能需要好几分钟,当然在角本里可以把角本本身运行的时间去掉,但这样做显然没有直接调用DLL来的效率高。由于程序组比较忙,所以无法提供DLL给测试,所以测试完成了DLL的编写,并在LoadRunner中调用成功,高效的完成了用户信息加密,参数关联,成功的完成了测试。
动态链接库的编写
在Visual C++6.0开发环境下,打开FileNewProject选项,可以选择Win32 Dynamic-Link Library建立一个空的DLL工程。
1. Win32 Dynamic-Link Library方式创建Non-MFC DLL动态链接库 每一个DLL必须有一个入口点,这就象我们用C编写的应用程序一样,必须有一个WINMAIN函数一样。在Non-MFC DLL中DllMain是一个缺省的入口函数,你不需要编写自己的DLL入口函数,用这个缺省的入口函数就能使动态链接库被调用时得到正确的初始化。如果应用程序的DLL需要分配额外的内存或资源时,或者说需要对每个进程或线程初始化和清除操作时,需要在相应的DLL工程的.CPP文件中对DllMain()函数按照下面的格式书写。
BOOL APIENTRY DllMain(HANDLE hModule,DWORD ul_reason_for_call,LPVOID lpReserved)
{
switch( ul_reason_for_call )
{
case DLL_PROCESS_ATTACH:
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
case DLL_PROCESS_DETACH:
break;
default:
break;
}
return TRUE;
}
参数中,hMoudle是动态库被调用时所传递来的一个指向自己的句柄(实际上,它是指向_DGROUP段的一个选择符);ul_reason_for_call是一个说明动态库被调原因的标志,当进程或线程装入或卸载动态链接库的时候,操作系统调用入口函数,并说明动态链接库被调用的原因,它所有的可能值为:DLL_PROCESS_ATTACH: 进程被调用、DLL_THREAD_ATTACH: 线程被调用、DLL_PROCESS_DETACH: 进程被停止、DLL_THREAD_DETACH: 线程被停止;lpReserved为保留参数。到此为止,DLL的入口函数已经写了,剩下部分的实现也不难,你可以在DLL工程中加入你所想要输出的函数或变量了。 我们已经知道DLL是包含若干个函数的库文件,应用程序使用DLL中的函数之前,应该先导出这些函数,以便供给应用程序使用。要导出这些函数有两种方法,一是在定义函数时使用导出关键字_declspec(dllexport),另外一种方法是在创建DLL文件时使用模块定义文件.Def。需要读者注意的是在使用第一种方法的时候,不能使用DEF文件。下面通过两个例子来说明如何使用这两种方法创建DLL文件。 1)使用导出函数关键字_declspec(dllexport)创建MyDll.dll,该动态链接库中有两个函数,分别用来实现得到两个数的最大和最小数。在MyDll.h和MyDLL.cpp文件中分别输入如下原代码:
//MyDLL.h
extern “C” _declspec(dllexport) int desinit(int mode); 更新为 extern “C” _declspec(dllexport) int desinit(int ,int);
extern “C” _declspec(dllexport) void desdone(void); 更新为 extern “C” _declspec(dllexport) void desdone(int ,int);
extern “C” _declspec(dllexport) void des_setkey(char *subkey, char *key);
extern “C” _declspec(dllexport) void endes(char *block, char *subkey);
extern “C” _declspec(dllexport) void dedes(char *block, char *subkey);
//MyDll.cpp
#include”MyDll.h”
//这里我用了比较大小的函数代替了我要实现的函数
int desinit(int a, int b)
{
if(a>=b)return a;
else
return b;
}
int desdone(int a, int b)
{
if(a>=b)return b;
else
return a;
}
该动态链接库编译成功后,打开MyDll工程中的debug目录,可以看到MyDll.dll、MyDll.lib两个文件。LIB文件中包含DLL文件名和DLL文件中的函数名等,该LIB文件只是对应该DLL文件的”映像文件”,与DLL文件中,LIB文件的长度要小的多,在进行隐式链接DLL时要用到它。读者可能已经注意到在MyDll.h中有关键字”extern C”,它可以使其他编程语言访问你编写的DLL中的函数。
LoadRunner调用动态链接库
上面完成动态链接库开发后,下面就介绍动态链接库如何被LoadRunner进行调用,其实也是很简单的。在LoadRunner中的DLL调用有局部调用与全局调用,下面介绍局部调用。
首先把你编译的DLL放在角本路径下面,这里是MyDll.dll,MyDll.lib.然后在Action中使用
lr_load_dll(”MYDll.dll”),此函数可以把DLL加载进来,让你调用DLL里面的函数,而DLL中的运算是编译级的,所以效率极高,代码样例如下:
#include “lrs.h”
Action()
{
//
int nRet = 6;
char srckey[129];
memset(srckey, ‘a’, 128);
lr_message(lr_eval_string(srckey));
lr_load_dll(”MyDLL.dll”);
nRet = desinit(5,8);
lr_message(”比较的结果为%d”,nRet);
return 0;
}
运行结果
比较的结果为8 全局的动态链接库的调用则需要修改mdrv.dat,路径在LoadRunner的安装目录下面(LoadRunner/dat directory);在里面修改如例:
[WinSock]
ExtPriorityType=protocol
WINNT_EXT_LIBS=wsrun32.dll
WIN95_EXT_LIBS=wsrun32.dll
LINUX_EXT_LIBS=liblrs.so
SOLARIS_EXT_LIBS=liblrs.so
HPUX_EXT_LIBS=liblrs.sl
AIX_EXT_LIBS=liblrs.so
LibCfgFunc=winsock_exten_conf
UtilityExt=lrun_api
ExtMessageQueue=0
ExtCmdLineOverwrite=-WinInet No
ExtCmdLineConc=-UsingWinInet No
WINNT_DLLS=user_dll1.dll, user_dll2.dll, …
//最后一行是加载你需要的DLL
这样你就可以在LR中随意的调用程序员写的API函数,进行一些复杂的数据加密,准备的一些操作,进行复杂的测试。同时如果你觉的有大量高复杂的运算也可以放在DLL中进行封装,以提高效率。 -
LoadRunner案例分析之四(转)
2009-12-22 19:34:53
最近在论坛上看到几次这样的问题,今天突然想起来,觉得比较典型,有必要分析一下。 这个问题的具体描述大概是这样的:在web应用下,模拟十个用户并发进行数据的添加,结果每次执行全部成功,但是数据却不是十条,每次数据不一样,但是都比十小。 乍一看,可能是数据参数化的问题,其实仔细想想,道理其实很简单。是数据库的问题。
大多数的数据库都有记录锁的问题,第一次的数据操作没有commit之前,第二次对同样表进行的操作可能就没有办法成功。所以每次数据的条数都达不到十条。但是为什么每次都不一样呢?这个问题也容易解释,因为每次的操作服务器的响应时间是不同的,所以不同虚拟用户的提交时间也不是不同的,这样一来,就导致每次提交成功的数据量不一致。导致每次结果的条数可能是不同的。 其实这个问题,跟LoadRunner的使用并没多大关系,而主要是对数据库的了解和应用执行机制的了解。如何解决这个问题,我现在还没有好的思路,是否对应用程序写数据库的过程作一些改进?大家可以一起探讨。 -
LoadRunner案例分析之三(转)
2009-12-22 19:33:52
以前一直没有解决的问题,利用LoadRunner测试一个应用的时候,需要验证域用户,所以即使录制成功,每次回放的时候都提示错误,用户名和密码不对,对此耿耿于怀了很久。今天居然解决了。解决方法就是一个简单的函数调用: web_set_user,此函数的解释和用法如下: The web_set_user function is a Service function that specifies a login string and password for a Web server or proxy server. It can be called more than once if several proxy servers require authentication. web_set_user overrides the run-time proxy authentication settings for user name and password. When you log onto a server that requires user and password validation, VuGen records a web_set_user statement containing the login details. However, there are some more stringent, authentication methods for which VuGen is unable to insert web_set_user statements. See User Authentication for more detail. In such cases, you can add web_set_user into your script. manually. When you run the script, LoadRunner automatically submits the user authorization along with every subsequent request to that server. At the end of the script, LoadRunner resets the authorization. This function is supported for all Web Vusers, and for WAP Vusers running in HTTP mode only. It is not supported for WAP Vusers running in Wireless Session Protocol (WSP) replay mode. Example 3
The following example was inserted manually by the user into the script. as the Web server “mansfield” uses NTLM authentication. VuGen cannot record NTLM or Digest authentication. Note that for NTLM authentication the domain name “mansfield” followed by a double backslash must be prepended to the user name: web_set_user(”mansfield\\freddy”, “XYZ”, “mansfield:80″); 原来一直没有想到域的设置,结果一直不行,现在可以了。
另外一个问题跟之前这个有关系,那就是验证码的问题,之前曾经看过段念(关河大侠)的关于验证码的是三个解决方案,这里是第四种解决方案。对于一些比较简单有规律的验证码可以搞定。对于复杂的比如有干扰的,或者没有规律的则参考关大侠的其他解决方案。 这个应用经过源代码分析,发现每次客户端请求过来的验证码都可以取到,格式如下固定,是四个数字的组合。经过多次尝试发现如下规律:
验证码如下: 52|52|52|51|46|47|49|55|
对应界面的验证码是: 6039
规律是第2,5,8,9位的值减去46对应的即是验证码。
有了这个规律,就可以通过关联提前取得服务器的验证码,然后通过简单的计算,得到结果。详细代码如下:
#include “web_api.h” Action()
{ // char* str = “52|52|52|51|46|47|49|55|”;
char result[64];
int num1;
int num2;
int num3;
int num4; int temp1;
int temp2;
int temp3;
int temp4; web_set_user(”XXXXDomain\\szXXXX”,
lr_decrypt(”46246a2633f042c67758b9ddc2b863038aa063c03d7e”),
“XXXX.XXXX.com.cn:8080″); web_reg_save_param(”check”, “LB=Image=”, “RB=\\”, LAST); web_url(”Register”,
“URL=http://XXXX.XXXX.com.cn:8080/xx/main/Register”,
“Resource=0″,
“RecContentType=text/html”,
“Referer=”,
“Snapshot=t1.inf”,
“Mode=HTML”,
LAST); lr_think_time( 6 ); sscanf(lr_eval_string(”{check}”), “%d|%d|%d|%d|%d|%d|%d|%d”, &temp1, &num1, &temp2, &temp3, &num2, &temp4, &num3, &num4); num1 -= 46;
num2 -= 46;
num3 -= 46;
num4 -= 46; sprintf(result, “%d%d%d%d”, num1, num2, num3, num4); lr_log_message(”getvalue : %s”, result); web_submit_form(”Register;jsessionid=6726009A7D21963602B166D91C883413″,
“Snapshot=t2.inf”,
ITEMDATA,
“Name=Register.reason”, “Value= “, ENDITEM,
“Name=set_attach”, “Value=result”, ENDITEM,
LAST); return 0;
} -
LoadRunner案例分析之二(转)
2009-12-19 16:42:24
一个朋友问起这样一个问题:他们公司的系统上线以后,用户分布在各个不同的地区,而且接入系统的方式和带宽也不同,这种情况下进行性能测试,如何保证更加真实的模拟用户行为?用LoadRunner可以做到吗?回答当然是肯定的,其实这些都是简单问题的组合,这样的问题考察的也是你对工具的熟悉和掌握程度。在VUGen里面,是可以通过RTS (runTimeSetting)来模拟一个单个用户更加真实的行为,比如思考时间,网络带宽,是否清除cache等等。同样的设置也可以在场景中进行设置。而且LoadRunner提供设置不同用户组不同RunTimeSetting的功能。以达到模拟不同用户行为的更加真实组合。
假设有三种不同带宽的用户,而且上传和下载的带宽也有所不同,那么可以录制两个脚本,分别模拟上传和下载的用户行为,再Controller里面,建立六个不同的脚本组,脚本组的用户数可以按照绝对或者百比分的方法分布。比如100,50,200用户或者20%,40%,40%等,这取决于你的业务模型。然后设置不同的带宽和分布情况。这样不同用户组的虚拟用户模拟出来的就是不同带宽的用户实际接入情况。就可以满足之前的问题的要求。参考下图:
-
LoadRunner案例分析之一(转)
2009-12-19 16:27:38
第一个问题:是如何利用LoadRunner判断HTTP服务器的返回状态. 两种方法,第一种方法是利用LR的内置函数web_get_int_property, 如下是一个简单的例子:
Action.c
{
int HttpRetCode;
web_url(”my_home”, “URL=http://my_home”, “TargetFrame=_TOP”, LAST);
HttpRetCode = web_get_int_property(HTTP_INFO_RETURN_CODE);
if (HttpRetCode == 200)
lr_log_message(”The script. successfully accessed the My_home home page”);
else
lr_log_message(”The script. failed to access the My_home home page “);
}另外一种就是最原始的办法,也是Zee兄这种高手才最先想到的,自己取HTTP服务器的数据,然后利用关联函数分析啊. (果然是高啊). 其实所有的东西都可以从服务器的返回取,然后自己动手解析,呵呵. 举个不太恰当的例子: 你需要一套家具,可以去家具市场挑,当然也可以自己买木材原料和工具,动手加工. 那才是最合乎自己需要的. 这样一比喻, Zee兄弟似乎成了木匠了,嘻嘻~~
第二个问题:动态数据参数化的问题.
其实第一次看到这个问题,我没有马上反应过来,后来仔细想想, 明白了. 就是需要参数化的数据不是静态的,是动态的. 比如从数据库中选出来的.
针对这个问题,我跟Zee兄弟的看法一致,应该提前从数据源(比如数据库)把数据选取出来,然后在执行的时候直接进行参数化的选取. 反之,如果在程序执行期间,进行数据的选取,将可能带来数据库服务器的强大压力,因为参加并发执行的每个虚拟用户都去数据库搜刮一下,对数据库将是多么严峻的考验啊.
朋友或者同事之间的探讨是加深对问题理解和增加知识面,扩展视野最直接的途径和方法,加强沟通,keep in touch.
-
性能测试概念和术语解释(转)
2009-12-19 16:13:33
响应时间(response time)
响应时间,是指系统对用户操作的反馈时间。我们可以举一个163邮箱登录的例子:
我们如何来测试邮箱的登录响应时间呢?我们首先进入mail.163.com网页,输入合法的用户名和密码,点击“登录”,直到登录后的邮箱界面完全显示出来为止。那么响应时间从什么时候开始计算呢?是我们输入用户名的时候,还是点击“登录”的时候?
显然,我们应该从按下“登录”按钮的那一瞬间开始计时,到登录后页面完全显示出来为止,这才是真正的用户登录时间,而不包括用户输入用户名和密码的时间以及思考停顿的时间(think time)登录响应时间其实包括3个部分:网络传输时间,服务器处理时间,浏览器显示时间
即登录响应时间=网络传输时间*2+服务器处理时间+客户端显示时间
网络传输是双向的,所以要乘以2。网络传输时间又可以包括接入网的传输时间和互联网中的传输时间,它的大小和你所使用的上网方式有关,比如光纤一般要比adsl要快。
服务器包括web服务器和数据库服务器,服务器处理时间是我们测试的重点,也是我们能够控制的部分,因为最终用户用什么机器上网,什么接入方式上网我们是控制不了的。我们要重点测试服务器的处理速度如何,以及能否承受较大的压力,我们可以用工具(比如LoadRunner)来模拟大量用户同时登录访问服务器,来查看服务器的承载能力。
客户端显示时间,如何将服务器传过来的页面尽快地显示到浏览器上,是开发人员需要考虑的问题,这里面涉及到算法优化的问题,这也是开发人员容易忽略的地方。
由此可见,响应时间是可以分解成若干个时间段的,任何一个环节出问题都会影响到最终的响应时间,这就需要我们在实际工作中结合具体情况加以分析。
最后再说明一点,响应时间的快慢是一个相对的概念,没有绝对的标准,比如对于163邮箱登录来说,用户可以接受的时间可以在10秒以内,而对于一个实时的军工软件来说,相应时间要精确到毫米级别甚至更低。
对于普通的web网站来说,一个普遍被接受的响应时间标准是2/5/10,即用户对2秒钟以内的的响应时间非常满意,对于5秒钟以内的响应时间基本满意,对于10秒钟以上的响应时间则无法接受.吞吐量(throughput)
吞吐量,是指单位时间内流经被测系统的数据流量,一般单位为b/s,即每秒钟流经的字节数。
吞吐量是大型门户网站以及各种电子商务网站衡量自身负载能力的一个很重要的指标,一般吞吐量越大,系统单位时间内处理的数据越多,系统的负载能力也越强。
吞吐量和很多因素有关,比如服务器的硬件配置,网络的拓扑结构,软件的技术架构等。实际工作中,我们往往对升级客户的硬件配置无能为力,大多数情况下,我们还是在软件的技术架构上做文章:
比如后台数据库装oracle还是装sql server,显然前者的处理能力更强;
web服务器是用weblogic还是iis,要看服务器端的语言是jsp还是asp…
测试的时候多跟项目经理,系统架构师以及用户沟通,来获取系统架构的第一手材料。并发(concurrency)
并发,是指多个同时发生的操作。比如有10个用户同时点击“登录”按钮(注意是同时),来登录163邮箱,我们就说此次登录163邮箱的并发数为10。
需要注意的是,并发和并行不是一个概念,并发是同时发生,并行是同步运行。10个用户并发登录163邮箱,只是在点击“登录”按钮那一瞬间是并行的,而登录后各个用户的操作则不同步。稳定性测试(reliability testing)
稳定性测试,也叫可靠性测试(reliability testing),是指连续运行被测系统,检查系统运行时的稳定程度。
我们通常用mtbf(mean time between failure,即错误发生的平均时间间隔)来衡量系统的稳定性,mtbf越大,系统的稳定性越强
稳定性测试的方法也很简单,即采用24*7(24小时*7天)的方式让系统不间断运行,至于具体运行多少天,是一周还是一个月,视项目的实际情况而定。
负载测试(load testing)
负载测试,是性能测试的一种,通常是指让被测系统在其能忍受的压力的极限范围之内连续运行,来测试系统的稳定性。
可以看出负载测试和稳定性测试比较相似,都是让被测系统连续运行,区别就在于负载测试需要给被测系统施加其刚好能承受的压力,比如我们还是测试163邮箱系统的登录模块,我们先用1个用户登录,再用两个用户并发登录,再用5个,10个…在这个过程中,我们每次都需要观察并记录服务器的资源消耗情况(可以通过任务管理器中的性能监视器或者控制面板中的性能监视器),当发现服务器的资源消耗快要达到临界值时(比如cpu的利用率90%以上,内存的占有率达到80%以上),停止增加用户,假如现在的并发用户数为20,我们就用这20个用户同时多次重复登录,直到系统出现故障为止。
负载测试为我们测试系统在临界状态下运行是否稳定提供了一种办法。压力测试(stress testing)
压力测试,是性能测试的一种,通常是指持续不断的给被测系统增加压力,直到将被测系统压垮为止,用来测试系统所能承受的最大压力。
比如我们不断增加并发的登录用户数,20,30,50…比如,当增加到70个用户并发登录时,系统崩溃了,我们就可以知道163邮箱所能承载的最大登录并发数为70个左右。我们把上面的思路整理一下,编写一下163邮箱登录模块性能测试用例,供大家参考(假设163邮箱要求登录的时间最多不超过10秒,测试环境略)
关于性能测试的分类,可以举一个比较通俗的例子方便大家理解:
假设一个人很轻松就能背1袋米,背2袋米很吃力,最多就能背3袋米
稳定性测试–我让他背1袋米,但是让他去操场上跑圈,看多久累倒。
负载测试–我让他背2袋米去操场上跑圈,看多久累倒。
压力测试–我让他背2袋米,3袋米,4袋米…发现他最多就能背3袋 -
LoadRunner出现error问题及解决方法总结(转)
2009-11-27 14:57:58
一、Step download timeout (120 seconds)这是一个经常会遇到的问题,解决得办法走以下步骤:
1、 修改run time setting中的请求超时时间,增加到600s,其中有三项的参数可以一次都修改了,HTTP-request connect timeout,HTTP-request receieve timeout,Step download timeout,分别建议修改为600、600、5000;run time setting设置完了后记住还需要在control组件的option的run time setting中设置相应的参数;
2、 办法一不能解决的情况下,解决办法如下:
设置runt time setting中的internet protocol-preferences中的advaced区域有一个winlnet replay instead of sockets选项,选项后再回放就成功了。切记此法只对windows系统起作用,此法来自zee的资料。
二、问题描述Connection reset by peer
这个问题不多遇见,一般是由于下载的速度慢,导致超时,所以,需要调整一下超时时间。
解决办法:Run-time setting窗口中的‘Internet Protocol’-‘Preferences’设置set advanced options(设置高级选项),重新设置一下“HTTP-request connect timeout(sec),可以稍微设大一些”;
三、问题描述connection refused
这个的错误的原因比较复杂,也可能很简单也可能需要查看好几个地方,解决起来不同的操作系统方式也不同;
1、 首先检查是不是连接weblogic服务过大部分被拒绝,需要监控weblogic的连接等待情况,此时需要增加acceptBacklog,每次增加 25%来提高看是否解决,同时还需要增加连接池和调整执行线程数,(连接池数*Statement Cache Size)的值应该小于等于oracle数据库连接数最大值;
2、 如果方法一操作后没有变化,此时需要去查看服务器操作系统中是否对连接数做了限制,AIX下可以直接vi文件limits修改其中的连接限制数,还有 tcp连接等待时间间隔大小,wiodows类似,只不过wendows修改注册表,具体修改方法查手册,注册表中有TcpDelayTime项;
四、问题描述open many files
问题一般都在压力较大的时候出现,由于服务器或者应用中间件本身对于打开的文件数有最大值限制造成,解决办法:
1、 修改操作系统的文件数限制,aix下面修改limits下的nofiles限制条件,增大或者设置为没有限制,尽量对涉及到的服务器都作修改;
2、 方法一解决不了情况下再去查看应用服务器weblogic的commonEnv.sh文件,修改其中的nofiles文件max-nofiles数增大,应该就可以通过了,具体就是查找到nofiles方法,修改其中else条件的执行体,把文件打开数调大;修改前记住备份此文件,防止修改出错;
五、问题描述has shut down the connection prematurely
一般是在访问应用服务器时出现,大用户量和小用户量均会出现;
来自网上的解释:
1> 应用访问死掉
小用户时:程序上的问题。程序上存在数据库的问题
2> 应用服务没有死
应用服务参数设置问题
例如:
在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
Java连接池的大小设置,或JVM的设置等
3> 数据库的连接
在应用服务的性能参数可能太小了
数据库启动的最大连接数(跟硬件的内存有关)
以上信息有一定的参考价值,实际情况可以参考此类调试。
如果是以上所说的小用户时:程序上的问题。程序上存在数据库的问题,那就必须采用更加专业的工具来抓取出现问题的程序,主要是程序中执行效率很低的sql语句,weblogic可以采用introscope定位,期间可以注意观察一下jvm的垃圾回收情况看是否正常,我在实践中并发500用户和600用户时曾出现过jvm锯齿型的变化,上升下降都很快,这应该是不太正常的;
六、问题描述Failed to connect to server
这个问题一般是客户端链接到服务失败,原因有两个客户端连接限制(也就是压力负载机器),一个网络延迟严重,解决办法:
1、 修改负载机器的tcpdelaytime注册表键值,改小;
2、 检查网络延迟情况,看问题出在什么环节;
建议为了减少这种情况,办法一最好测试前就完成了,保证干净的网络环境,每个负载机器的压力测试用户数不易过大,尽量平均每台负载器的用户数,这样以上问题出现的概率就很小了。
-
场景设置(转自论坛)
2009-11-14 09:59:26
VuGen建立的第一个脚本 TestFirst的action脚本如下
char *filename = "c:\\test.txt";
Action() {
long file;
int id;
char *groupname;
/* Create a new file */
if ((file = fopen(filename, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
/* Write the Vuser id and group to the log file */
id = 1;
groupname = "one";
fprintf(file, "logfile of virtual user id: %d group: %s\n", id, groupname);
fclose(file);
return 0;
}
vu_End脚本如下
char *filepath = "c:\\test.txt";
vuser_end()
{
long file;
int id;
/* Create a new file */
if ((file = fopen(filepath, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
id = 1;
fprintf(file, "%d End ", id);
fclose(file);
return 0;
}
VuGen建立的第二个脚本TestSecond的Action脚本如下
char *filename = "c:\\test.txt";
Action() {
long file;
int id;
char *groupname;
/* Create a new file */
if ((file = fopen(filename, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
/* Write the Vuser id and group to the log file */
id = 2;
groupname = "two";
fprintf(file, "logfile of virtual user id: %d group: %s\n", id, groupname);
fclose(file);
return 0;
}
vu_End脚本如下:
#include "as_web.h"
char *filepath = "c:\\test.txt";
vuser_end()
{
long file;
int id;
/* Create a new file */
if ((file = fopen(filepath, "a" )) == NULL) {
lr_output_message("Unable to create %s", filename);
return -1;
}
id = 2;
fprintf(file, "%d End ", id);
fclose(file);
return 0;
}
上边的脚本其实很相类似只不过每个脚本中用one,two来标示每个用户(为了看到测试效果),我们这样做只是为了检测Controller如何调用脚本。
还有一点我在vu_end()加入代码,这是因为我们知道vuGen设置iteration的数值,实质是设置action的运行次数,也就是说只有运行action的iteration后才会运行vu_end。
一.设置iteration为1,在Controller中添加运行testfirst,testSecond脚本用户各一,运行结果如下:
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
2 End
二.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各一,运行结果如下:
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
三.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各一,每隔1分钟加载1个用户,运行结果如下:
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
四.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各2,每隔1分
钟加载1个用户,运行结果如下:
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 2 group: two
2 End
五.设置iteration为2,在Controller中添加运行testfirst,testSecond脚本用户各2,设置每隔10秒加载1个用户并设置duration为40秒,运行结果如下:
logfile of virtual user id: 1 group: one
logfile of virtual user id: 1 group: one
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx’省略
logfile of virtual user id: 1 group: one
2 End
logfile of virtual user id: 2 group: two
logfile of virtual user id: 1 group: one
1 End
logfile of virtual user id: 2 group: two
2 End
logfile of virtual user id: 1 group: one
1 End
以上对loadrunner的研究说明用户对应脚本,而不管他当前运行到什么状态。在第四中设置中很容易清晰的看出运行次序,可以说是从头运行到尾。(这么做只是为了研究,实际操作中情况千变万化,我只是为了测试结果清晰化)
你的三个问题从上边的试验可以得出结论,脚本影响实际程序的状态通过action脚本中运行的状态(如果你没有录制关闭页面脚本那么当前状态仍然是打开状态)。其实你设置的情况比较复杂了,我把几种不同的设置,所得出的运行结果都列举出来了。你可以自行研究。
你第一个问题 状态仍然是打开状态
你第二个问题 你的设置情况与我第五种试验设置一致,结论是仍然打开页面
你第三个问题 虚拟用户是针对loadrunner来说的,虚拟用户试和运行的机器有关系,你设置虚拟用户是为了把虚拟用户分布到不同的机器上,模拟现实世界,实际登陆用户是对你的测试软件来说的, 这是有区别的,要弄清楚概念。工具只是实现你测试目的的辅助手段,你所开发的脚本都是根据你的测试用例,在这个案例中你这么做有没有意义取决你选择的压力测试策略。如果现实中有这么做的,你就可以模拟!
我想这些测试试验可以帮助你了解iteration和虚拟用户设置对脚本调用的作用! -
LoadRunner使用虚拟IP测试流程(转)
2009-10-31 16:57:24
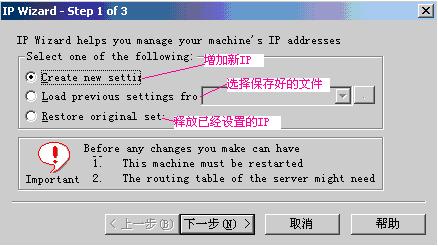
说明:增加新IP选择第一项;使用保存的文件增加IP选择第二项;释放已经设置的IP选择第三项。
点“下一步”,如图
此步让输入web server的IP地址(尚不清楚有何意义),不输入,直接点‘下一步’,如图:
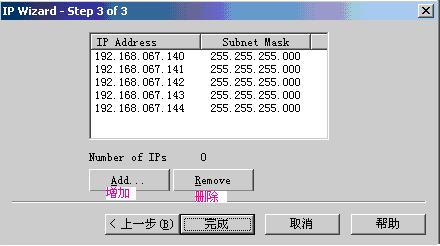
说明:使用remove按钮可以删除选定的虚拟IP。
点add按钮,如图:
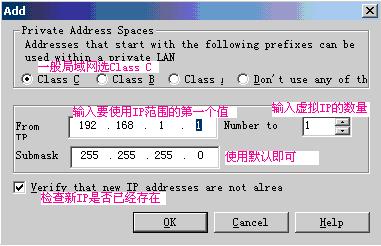
说明:‘检查新IP是否已经存在’选项并没有起作用;根据输入的IP的第一个值和数量,自动添加到虚拟IP列表中,例如:192.168.67.140 4,则增加的虚拟IP是:192.168.67.140、192.168.67.141、192.168.67.142、192.168.67.143。
点ok按钮,如图:
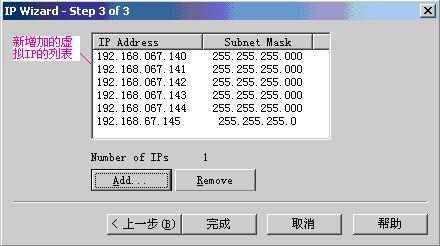
点“完成”按钮,如图:
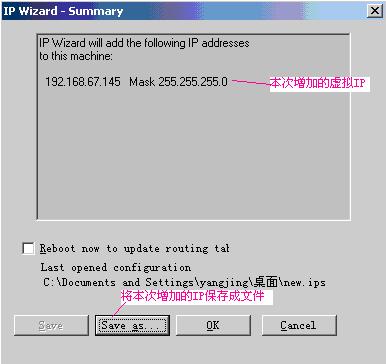
说明:使用Save as…可以将本次增加的IP保存成.ips文件,下次再使用时就可以直接选择此文件了。
点‘OK’按钮即可。
现在需要重启计算机。
(重新启动计算机后,设置的虚拟IP都生效了,此时使用ping会发现都能ping通,并且本机的IP也被改成了第一个虚拟IP地址。确认虚拟IP是否都生效的方法:在运行中输入cmd,在命令窗口录入ipconfig/all,然后就能看到已经生效的所有IP。)
在controller中,选择 Scenario-〉Enable IP Spoofer,此项设置允许使用IP欺骗。
按Generators按钮,设置虚拟用户生成器,将虚拟IP地址都添加进去,并连通。如图:
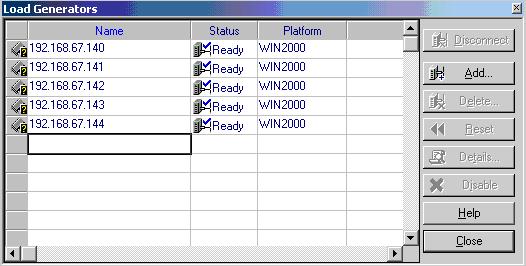
连接成功的虚拟用户生成器会在工具栏中显示,如图:

然后设计方案,如下图例子:

运行方案。
打开IP Wizard,释放所有虚拟IP。
重新启动计算机
-
常见系统资源Monitor问题
2009-10-20 13:54:48
常见系统资源Monitor问题
最近老是看见有tx对在Controller中添加系统资源Monitor连接不上的问题,为此查了Controller的说明,上面对以下情况作了解释,同学们看看,应该大部分问题都能解决了。反正还是建议大家要多看看帮助,呵呵
监控windows配置:
一 windows1 监视连接前的准备工作
首先保证被监视的windows系统开启以下二个服务Remote Procedure Call(RPC) 和Remote Registry Service (这里具体在那里开起服务就不说了)
被监视的WINDOWS机器:右击我的电脑,选择管理->共享文件夹->共享 在这里面要有C$这个共享文件夹,(要是没有自己手动加)
然后保证在安装LR的机器上使用运行.输入\\被监视机器IP\C$ 然后输入管理员帐号和密码,如果能看到被监视机器的C盘了,就说明你得到了那台机器的管理员权限,可以使用LR去连接了
说明: LR要连接WINDOWS机器进行监视貌似要有管理员帐号和密码才行,
2 用LR监视windows的步骤(这里就不详细说明了,只要在窗口中右击鼠标选择Add Measurements就可以了)
Q1:无法Monitor在另一个domain的Windows主机或者报错"Access Denied"
A1:获取远程主机的管理员权限,在命令行模式下运行如下命令
Net use \\<主机名>
在弹出的用户名提示后输入远程主机的用户名,在弹出的密码提示后输入远程主机密码Q2:无法Monitor一个NT/2000的主机,报错"computer name not found"或"connot connect to the host"
A2:远程主机只允许具有管理员权限的用户Monitor资源,若需要非管理员也能够获得资源信息,需要手工授权"Read"权限给某些文件和注册表项。具体步骤如下:
1、 授权给用户以下文件的读权限
a) %windir%\system32\PERFCxxx.DAT
b) %windir%\system32\PERFHxxx.DAT
其中xxx是系统的基础语言id,如英语就是009,如果找不到文件,最好从安装光盘中copy出来
2、 在注册表中查找以下表项并授予读权限
HKEY_LOCAL_MACHINE\Software\Microsoft\WindowsNT\CurrentVersion\Perflib以及其子项
3、 在注册表中查找以下表项并授予读权限
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\SecurePipeServers\winregQ3:从WinNT主机上无法获得一些Win2000下的计数器
A3:在Win2000主机上运行Controller或TuningQ4:一些Windows的默认计数器报错
A4:把报错的计数器删除并添加更合适的计数器Q5:无法获得目标主机上SQL Server(version 6.5)的性能计数器
A5:这是6.5版本的SQL Server的一个bug,需要手工在被监控主机的注册表中赋予以下表项读权限
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQLServer\MSSQLServerQ6:选中的measurement参数没有显示在图表中
A6:确定display file和online.exe已经被注册。运行loadrunner\bin下的set_mon.bat文件Q7:在Monitor Windows主机时,在图表中没有出现任何参数
A7:查看Windows主机中的Windows Performance Monitor,如果没有出错,则查看通讯设置Q8:在Monitor Unix主机时,在图表中没有出现任何参数
A8:确保Unix主机上rstated进程已经运行Q9:无法监控如下的Web服务器:Web IIS、MS ASP、ColdFusion
A9:同Q7Q10:无法监控WebLogic(JMX)服务器
A10:打开LoadRunner\dat\monitors\WebLogicMon.ini文件,查找以下字符串:
[WebLogicMonitor]
JVM=javaw.exe
把javaw.exe替换成java.exe -
Weblogic常用监控指标(转)
2009-10-20 13:48:59
JMSRuntime JMSServersCurrentCount 返回当前JMS服务的连接数
ConnectionsCurrentCount 返回本JMS服务器上当前的连接数
JMSServersHighCount 返回自服务器启动后JMS服务的最大连接数
ConnectionsHighCount 返回本JMS服务器自上次重置后的最大连接数
JVMRuntime HeapSizeCurrent 返回当前JVM堆中内存数,单位时字节
HeapFreeCurrent 返回当前JVM堆中空闲内存数,单位时字节
ExecuteQueueRuntime ExecuteThreadCurrentIdleCount 返回队列中当前空闲线程数
PendingRequestOldestTime 返回队列中最长的等待时间
PendingRequestCurrentCount 返回队列中等待的请求数
Queue Length 队列长度
JDBCConnectionPoolRuntime WaitingForConnectionHighCount
返回本JDBCConnectionPoolRuntimeMBean 上最大等待连接数
WaitingForConnectionCurrentCount 返回当前等待连接的总数
MaxCapacity 返回JDBC池的最大能力
WaitSecondsHighCount 返回等待连接中的最长时间等待者的秒数
ActiveConnectionsCurrentCount 返回当前活动连接总数
ActiveConnectionsHighCount 返回本JDBCConnectionPoolRuntimeMBean 上最大活动连接数注:weblogic通常监控JVM和执行队列,JDBC连接池,其中执行队列最关键的指标是Queue Length 队列长度
weblogic一般来说监控jvm的使用、执行线程队列情况、和连接池的变化情况,还有一个很重要的检查weblogic的console日志这里经常能反映一些很重要到情况。
监控weblogic的jvm有一个很好的自带工具,由于weblogic使用自己的jrockit作为jvm,自带一个工具通过在启动参数加-Xmanagement,然后进入到jrockit的bin路径下命令行console启动,可以看到更加细微的jvm的情况,对jvm的调优很好。
这里还是建议一定对jvm的工作原理做一个深入的理解会对你很有帮助,同时了解不同的jrockit的jvm垃圾回收器各自的特点,这些都对weblogic的调优大有帮助。 -
Loadrunner Analysis之Web Page Diagnostics(转自论坛)
2009-10-20 13:45:41
简单介绍一下Loadrunner Analysis中的Web Page Diagnostics模块的使用,很多人对于测试之后的结果数据分析摸不着头脑,其实loadrunner Analysis给你提供了很好的文档,大家没事可以多翻翻,多翻几遍对于性能测试你就入门了 ;)
Web Page Diagnostics (以下简称WPD),这是LR Analysis中非常重要的一块,搞清楚这部分的内容会让你少走很多弯路,很多环境问题都可以通过它来定位,比如客户端,网络。通过它可以你可以比较好的来定位是环境的问题还是应用本身的问题,当然更重要的是Web页面本身的问题。
WPD包括下面几个图表:
Web Page Diagnostics 这是张总图,包括下面几张Over Time图的内容
Page Component Breakdown 页面中每个元素的平均响应时间占整个页面响应时间的百分比
Page Component Breakdown(Over Time) 在整个测试过程中,任意一秒内页面中每个元素的响应时间(例如在runtime中设置了browser cache,页面中的资源文件就只会在第一次下载,后面的页面响应时间也就不包括这些元素的时间,这在Page Component Breakdown中是看不出来的,因为Page Component Breakdown是整个测试期间内的平均时间。当然,是否启用了cache,通过over time图就能看出来)
Page Download Time Breakdown 页面中每个元素的响应时间分割图,响应时间被分割为以下几个部分:DNS Resolution,Connection,First Buffer,SSL Handshaking,Receive,FTP Authentication,Client,Error
Page Download Time Breakdown(Over Time) 在整个测试过程中,任意一秒内页面中每个元素的响应时间分割图
Time to First Buffer Breakdown First Buffer Time时间分割为Network Time和Server Time,客户端http请求发送到接收到服务器端的应答包(ACK)为Network Time,从接收到ACK到完成First Buffer接受为Server Time
Time to First Buffer Breakdown(Over Time) 基本同上,任意一秒内的
Downloaded Component Size(KB) 页面中每个元素的大小(KB)
介绍了这么多,具体如何分析呢?
首先打开Web Page Diagnostics图,来看看下面一个例子Download Time图: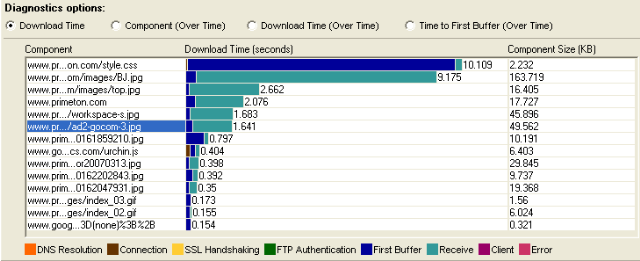
上图存在两个问题:
1、receive时间很长
这个一般是网络问题,当然如果你确认网络不存在问题,那么你就要看看是不是客户端的问题(客户端也可能会造成Receive过长,这个千万要注意)
2、页面问题
页面上包括了非常多的图片,而且图片似乎都没有优化,最大的竟然有163K,记下来,这可是罪证哦 ;)
很多时候,你可以根据DNS,Connection,Receive来看出是否存在网络问题,根据Client来判断是否存在客户端问题。
看看,挺简单的吧! ^_^
换个图看看,Page Component Breakdown(Over Time)
很清楚吧,页面元素都被cache了,说明场景启用了browser cache,页面的响应时间只包括红线和蓝线。
Time to First Buffer Breakdown(Over Time) ,图就不贴了,这个图非常重要,也最复杂,这里的值不绝对,当网络状况不好的时候,server time很可能包括网络时间,因为很多页面元素比较小(小于4k的样子),在First Buffer就完成传输,所以一定要注意分析。 -
性能测试(并发负载压力)测试分析-简要篇(转自论坛)
2009-10-20 12:10:04
分析原则:
• 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
• 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
• 分段排除法 很有效
分析的信息来源:
•1 根据场景运行过程中的错误提示信息
•2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 •Error: Failed to connect to server "10.10.10.30:8080": [10060] Connection
•Error: timed out Error: Server "10.10.10.30" has shut down the connection prematurely
分析:
•A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
•B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
•C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired
分析:可能是以下原因造成
•A、应用服务参数设置太大导致服务器的瓶颈
•B、页面中图片太多
•C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
• 分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
• 细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
• 如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题
3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低,还要考虑页面错误的情况;
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;
内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)
4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in ('db block gets’,
'consistent gets','physical reads') ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = 'redo log space requests' ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name='sorts (disk)' and b.name='sorts (memory)'
注:上述SQL Server和Oracle数据库分析,只是一些简单、基本的分析,特别是Oracle数据库的分析和优化,是一门专门的技术,进一步的分析可查相关资料,在Unix/linux 操作系统,当CPU利用率低,但是事务响应时间仍然较长时,还需要观察 I/O Wait 的变化,以鉴别是否因为 I/O 导致 CPU 利用率低
标题搜索
我的存档
数据统计
- 访问量: 166788
- 日志数: 260
- 书签数: 81
- 建立时间: 2007-08-28
- 更新时间: 2012-06-13
