
-
WebDriver+python+chrome
2012-06-13 09:47:43
1、将chromedriver_win_20.0.1133.0.zip文件解压后放在chrome安装路径下,如:C:\Program Files\Google\Chrome\Application,并且将该路径配置到环境变量path中
2、安装python2.7
3、配置webdriver
-
“测试”测试人员在工作中的沟通能力
2011-08-26 16:01:53
众所周知,沟通能力作为一项特别重要的软技能(soft skill),在工作中起着举足轻重的作用。作为一名测试人员,我的沟通能力究竟怎么样?让我们通过一次简单的test case review和其前后的工作为你把把脉,测试一下你的沟通能力怎么样。
问题1:请问,在test case review会议上你能够把test case的结构和里面的逻辑都清晰准确地表达出来么?
如果答案是肯定的,那么恭喜你,你已经具有非常重要的基础沟通能力“能把一个你已经弄懂的事情说清楚”。
问题2:请问,在test case review会前,你是否找了开发人员去了解他们在design review会议后是否有了新的发现?比如,某个改动的复杂度超出了design时的设想?
如果答案是肯定的,那么恭喜你,你已经具有比较难得的沟通能力“能够在合适的时间找合适的人去获取信息”。这些沟通看似不必须,因此也容易被很多人忽略,因为即使不做这样的沟通你的工作也能按部就班地进行(等待版本,完全按照你的理解和计划去测试。。。)。但就是这些看似不必须的工作往往是重要的、能够产生价值的。设想,得到这些信息是否可能提醒你此处的质量值得更多的关注?或者甚至这个CR可能没有办法及时提交测试,进而影响测试的安排?即使开发人员确认没有什么surprise,那么你是否更有信心,因为当开始测试的时候,你了解的信息都是最终的结论。有时,通过主动去获取更多看似只是间接和你相关的信息,其实会让你和你团队的工作直接受益,从而更高效紧密地合作。
问题3:请问,在test case review会后,对于需要进一步跟踪的问题,你是否写了会议记录,并在其中把每个问题分配到具体的人,设定deadline去及时解决?
如果答案是肯定的,那么恭喜你!你具有了不多见的沟通能力“主动、及时、有效地发布信息给需要的人”。如果说找别人要信息还是比较自然的事情,那么能够换位思考,知道什么人希望从你这里获取什么样的信息,并主动把信息清晰完整准确地传递给他们,这样的能力一点都不常见。
至此,诊断结束,总结如下:工作中的沟通能力并不仅仅指能否把一个想要说明的问题说清楚;它还包括:能够在合适的时间找合适的人去获取信息,并主动及时地发布信息给需要的人。在工作中,我们更应该锻炼的是后面这个意义上的沟通能力的提高。 -
Eclipse使用ANT
2011-05-27 18:13:10
Ant是Java平台下非常棒的批处理命令执行程序,能非常方便地自动完成编译,测试,打包,部署等等一系列任务,大大提高开发效率。如果你现在还没有开始使用Ant,那就要赶快开始学习使用,使自己的开发水平上一个新台阶。
Eclipse中已经集成了Ant,我们可以直接在Eclipse中运行Ant。
以前面建立的Hello工程为例,创建以下目录结构:

新建一个build.xml,放在工程根目录下。build.xml定义了Ant要执行的批处理命令。虽然Ant也可以使用其它文件名,但是遵循标准能更使开发更规范,同时易于与别人交流。
通常,src存放Java源文件,classes存放编译后的class文件,lib存放编译和运行用到的所有jar文件,web存放JSP等web文件,dist存放打包后的jar文件,doc存放API文档。
然后在根目录下创建build.xml文件,输入以下内容:
<?xml version="1.0"?>
<project name="Hello world" default="doc">
<!-- properies -->
<property name="src.dir" value="src" />
<property name="report.dir" value="report" />
<property name="classes.dir" value="classes" />
<property name="lib.dir" value="lib" />
<property name="dist.dir" value="dist" />
<property name="doc.dir" value="doc"/>
<!-- 定义classpath -->
<path id="master-classpath">
<fileset file="${lib.dir}/*.jar" />
<pathelement path="${classes.dir}"/>
</path>
<!-- 初始化任务 -->
<target name="init">
</target>
<!-- 编译 -->
<target name="compile" depends="init" description="compile the source files">
<mkdir dir="${classes.dir}"/>
<javac srcdir="${src.dir}" destdir="${classes.dir}" target="1.4">
<classpath refid="master-classpath"/>
</javac>
</target>
<!-- 测试 -->
<target name="test" depends="compile" description="run junit test">
<mkdir dir="${report.dir}"/>
<junit printsummary="on"
haltonfailure="false"
failureproperty="tests.failed"
showoutput="true">
<classpath refid="master-classpath" />
<formatter type="plain"/>
<batchtest todir="${report.dir}">
<fileset dir="${classes.dir}">
<include name="**/*Test.*"/>
</fileset>
</batchtest>
</junit>
<fail if="tests.failed">
***********************************************************
**** One or more tests failed! Check the output ... ****
***********************************************************
</fail>
</target>
<!-- 打包成jar -->
<target name="pack" depends="test" description="make .jar file">
<mkdir dir="${dist.dir}" />
<jar destfile="${dist.dir}/hello.jar" basedir="${classes.dir}">
<exclude name="**/*Test.*" />
<exclude name="**/Test*.*" />
</jar>
</target>
<!-- 输出api文档 -->
<target name="doc" depends="pack" description="create api doc">
<mkdir dir="${doc.dir}" />
<javadoc destdir="${doc.dir}"
author="true"
version="true"
use="true"
windowtitle="Test API">
<packageset dir="${src.dir}" defaultexcludes="yes">
<include name="example/**" />
</packageset>
<doctitle><![CDATA[<h1>Hello, test</h1>]]></doctitle>
<bottom><![CDATA[<i>All Rights Reserved.</i>]]></bottom>
<tag name="todo" scope="all" description="To do:" />
</javadoc>
</target>
</project>
以上xml依次定义了init(初始化),compile(编译),test(测试),doc(生成文档),pack(打包)任务,可以作为模板。
选中Hello工程,然后选择“Project”,“Properties”,“Builders”,“New…”,选择“Ant Build”:

填入Name:Ant_Builder;Buildfile:build.xml;Base Directory:${workspace_loc:/Hello}(按“Browse Workspace”选择工程根目录),由于用到了junit.jar包,搜索Eclipse目录,找到junit.jar,把它复制到Hello/lib目录下,并添加到Ant的Classpath中:(选择User Entries)加入架包

然后在Builder面板中钩上Ant_Build,去掉Java Builder:

再次编译,即可在控制台看到Ant的输出:
Buildfile: F:\eclipse-projects\Hello\build.xml
init:
compile:
[mkdir] Created dir: F:\eclipse-projects\Hello\classes
[javac] Compiling 2 source files to F:\eclipse-projects\Hello\classes
test:
[mkdir] Created dir: F:\eclipse-projects\Hello\report
[junit] Running example.HelloTest
[junit] Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0.02 sec
pack:
[mkdir] Created dir: F:\eclipse-projects\Hello\dist
[jar] Building jar: F:\eclipse-projects\Hello\dist\hello.jar
doc:
[mkdir] Created dir: F:\eclipse-projects\Hello\doc
[javadoc] Generating Javadoc
[javadoc] Javadoc execution
[javadoc] Loading source files for package example...
[javadoc] Constructing Javadoc information...
[javadoc] Standard Doclet version 1.4.2_04
[javadoc] Building tree for all the packages and classes...
[javadoc] Building index for all the packages and classes...
[javadoc] Building index for all classes...
[javadoc] Generating F:\eclipse-projects\Hello\doc\stylesheet.css...
[javadoc] Note: Custom tags that could override future standard tags: @todo. To avoid potential overrides, use at least one period character (.) in custom tag names.
[javadoc] Note: Custom tags that were not seen: @todo
BUILD SUCCESSFUL
Total time: 11 seconds
Ant依次执行初始化,编译,测试,打包,生成API文档一系列任务,极大地提高了开发效率。将来开发J2EE项目时,还可加入部署等任务。并且,即使脱离了Eclipse环境,只要正确安装了Ant,配置好环境变量ANT_HOME=<Ant解压目录>,Path=…;%ANT_HOME%\bin,在命令行提示符下切换到Hello目录,简单地键入ant即可。 -
Tomcat参数配置与简单的性能验证(转)
2011-05-17 16:37:39
最近在对Tomcat服务器的web应用进行性能测试的过程中,有时LoadRunner中总会报错:
Action.c(71): Error -27791: Server "localhost" has shut down the connection prematurely
但是这个错误并不是每次测试都会出现,通常在长时间的测试之后才偶尔出现,而奇怪的是在Tomcat的日志中并没有相应的错误。从出错信息的字面信息来看,应该是服务器由于某些原因关闭了连接,而Tomcat并不认为这是一个错误,因此没有在日志中记录下来。在网上的搜索中看到,这个错误在其他的服务器如WebLogic、IIS等均有发生,看来是一个通用的问题。在诊断的过程中,发现Tomcat运行界面有时会提示:“严重: All threads (10) are currently busy, waiting. Increase maxThreads (10) or check the servlet status”,根据这一线索对Tomcat的server.xml中的maxThreads、connectionTimeout参数进行配置,解决了这个问题。
试验
为了验证这两个参数对测试结果的影响,我做了一些试验。
测试场景:一个测试脚本、20个虚拟用户、10次迭代
参数设置及相应运行结果:maxThreads
connectionTimeout(豪秒)
错误个数
5
1000
16
10
1000
13
15
1000
7
20
1000
0
5
10000
1
10
10000
0
15
10000
0
20
10000
0
试验结论
当最大线程数较少、超时时间较短时,出现这个错误的次数就越多;随着最大线程数逐步接近并发用户数,该错误逐渐减少。另外,延长超时时间也能够减少错误的出现,但这时由于请求在处于排队状态,因此会增加响应时间。引申
将该结果应用于性能调优中,在一定的负载压力下,增加最大线程数能够有效的提高服务器的并发处理能力,但前提是系统资源如CPU、内存等不会成为系统瓶颈,在不能再提高最大线程数时,也可以用增加超时时间的方法,但这会造成响应时间的增加。参数最佳设置根据具体应用和测试结果而定。在有条件的情况下,最好就是集群了。
附:
当以上错误出现在用到web_reg_save_param函数的响应中时,会伴随着其他错误:
Action.c(248): Error -26377: No match found for the requested parameter "ClientID". Check whether the requested boundaries exist in the response data. Also, if the data you want to save exceeds 10240 bytes, use web_set_max_html_param_len to increase the parameter size
Action.c(248): Error -26374: The above "not found" error(s) may be explained by header and body byte counts being 0 and 0, respectively. -
软件测试工具LR通用性能分析流程(转)
2011-05-16 16:12:29
第一步:从分析Summary的事务执行情况入手Summary主要是判定事务的响应时间与执行情况是否合理。如果发现问题,则需要做进一步分析。通常情况下,如果事务执行情况失败或响应时间过长等,都需要做深入分析。
下面是查看分析概要时的一些原则:
(1):用户是否全部运行,最大运行并发用户数(Maximum Running Vusers)是否与场景设计的最大运行并发用户数一致。如果没有,则需要打开与虚拟用户相关的分析图,进一步分析虚拟用户不能正常运行的详细原因;
(2):事务的平均响应时间、90%事务最大响应时间用户是否可以接受。如果事务响应时间过长,则要打开与事务相关的各类分析图,深入地分析事务的执行情况;
(3):查看事务是否全部通过。如果有事务失败,则需要深入分析原因。很多时候,事务不能正常执行意味着系统出现了瓶颈;
(4):如果一切正常,则本次测试没有必要进行深入分析,可以进行加大压力测试;
(5):如果事务失败过多,则应该降低压力继续进行测试,使结果分析更容易进行;
......
上面这些原则都是分析Summary的一些常见方法,大家应该灵活使用并不断地进行总结与完善,尤其要主要结合实际情况,不能墨守成规。
第二步:查看负载生成器和服务器的系统资源情况。
查看分析概要后,接下来要查看负载生成器和待测服务器的系统资源使用情况:查看CPU的利用率和内存使用情况,尤其要注意查看是否存在内存泄露问题。这样做是由于很多时候系统出现瓶颈的直接表现是CPU利用率过高或内存不足。应该保证负载生成器在整个测试过程中其CPU、内存、带宽没有出现瓶颈,否则测试结果无效。而待测试服务器,则重点分析测试过程中CPU和内存是否出现了瓶颈:CPU需要查看其利用率是否经常达到100%或平均利用率一直高居95%以上;内存需要查看是否够用以及测试过程是否存在溢出现象(对于一些中间件服务器要查看其分配的内存是否够用)。
第三步:查看虚拟用户与事务的详细执行情况。
在前两步确定了测试场景的执行情况基本正常后,接下来就要查看虚拟用户与事务的执行情况。对于虚拟用户,主要查看在整个测试过程中是否运行正常,如果有较多用户不能正常运行,则需要重新设计场景或调整用户加载与退出方式再次进行测试。对于事务,重点关注整个过程的事务响应时间是否逐渐变长以及是否存在不能正常执行的事务。总之,对每个用户或事务的执行细节都应该认真分析不可轻易忽略;
example1:一个性能逐步下降的服务器,需要进一步分析其性能下降的原因【可以查找是否存在内存泄露问题】;
example2:一个性能相对稳定的服务器,但是响应时间偏大,这时需要分析程序算法是否存在缺陷或服务器参数的配置是否合理。
第四步:查看错误发生情况。
整个测试过程中错误的发生情况也应该是分析的重点。下面是查看错误发生情况的常用准则:
(1)查看错误发生曲线在整个测试过程中是否是有规律变化的,如果有规律通常意味着程序在并发处理方面存在一定的缺陷。图5-9所示的每秒缺陷数量曲线十分有规律,这是因为服务器定期生成缓存文件导致用户不能正常访问而产生的错误;
(2)查看错误分类统计,作为优化系统的参考。例如对于Web性能测试,当出现瓶颈时往往需要查看服务器的错误统计信息结果:如果“超时错误”占到90%以上,可能需要提高硬件配置;如果较多的“内部服务器错误”,则可能是程序方面存在问题。
第五步:查看Web资源与细分网页。
本步骤仅适用于Web性能测试。查看Web资源图时,往往结合前面对虚拟用户以及事务响应时间的分析结果,重点分析服务器的稳定性。对于网页细分功能则遵循如下原则:首先分析从用户发出请求到收到第一个缓冲为止,哪些环节比较耗时;其次找出页面哪些组成部分对用户响应时间影响较大;当对页面的性能问题定位后,就可以采取相关的解决方案。
-
QTP自动化测试工程师需要掌握的DOM(转)
2011-05-13 17:06:59
在使用QTP测试WEB页面时,经常需要利用测试对象中的Object属性来访问和操作DOM,因此,QTP自动化测试工程师非常有必要掌握一些常用的DOM知识。 下面就列举了一些常用的DOM属性、方法和集合:常用DOM 属性
● className.同一样式规则的元素用相同的类名。可以通过className快速过滤出一组类似的元素。
● document.用于指向包含当前元素的文档对象。
● id.当前元素的标识。如果文档中包含多个相同id的元素,则返回一个数组。
● innerHTML.用于指向当前元素的开始标记和结束标记之间的所有文本和HTML标签。
● innerText.用于指向当前元素的开始标记和结束标记之间的所有文本和HTML标签。
● offsetHeight, offsetWidth.元素的高度和宽度。
● offsetLeft, offsetTop.当前元素相同对于父亲元素的左边位置和顶部位置。
● outerHTML.当前元素的开始标记和结束标记之间的所有文本和HTML标签。
● outerText.当前元素的开始标记和结束标记之间的所有文本,但不包括HTML标签。
● parentElement.当前元素的父亲元素。
● sourceIndex.元素在document.all集合中的索引(index)。
● style.元素的样式表单属性。
● tagName.当前元素的标签名。
● title.在IE中,代表元素的tool tip文本。
常用DOM 方法
● click().模拟用户对当前元素的鼠标点击。
● contains(element).用于判断当前元素是否包含指定的元素。
● getAttribute(attributeName, caseSensitive).返回当前元素所包含的某个属性,参数attributeName为属性名、caseSensitive表示是否大小写敏感。
● setAttribute(attributeName, value, caseSenstive). 设置当前元素的属性。
常用DOM 集合
● All[].当前元素中包含的所有HTML元素的数组。
● children[].当前元素包含的孩子元素。
-
QTP & DOM (转)
2011-05-13 17:04:48
要想用QTP做好WEB自动化测试,需要熟悉DOM 。
通过 DOM ( Document Object Model ,文档对象模型),可以操纵页面的每个 HTML 元素。
常用 DOM 属性和方法
Every HTML element in a Web page is a scriptable object in the object model, with its own set of properties, methods, and events. To enable access to these objects, Internet Explorer creates a top-level document object for each HTML document it displays. When you use the .Object property on a Web page object in your test or component, you actually get a reference to this DOM object. This document object represents the entire page. From this document object, you can access the rest of the object hierarchy by using properties and collections.
Following are the most useful document properties and methods available through the Web .Object property: (通过.Object 可以访问以下属性、集合和方法)
Properties 属性
· activeElement Property - Retrieves the object that has the focus when the parent document has focus.
· cookie Property - Sets or retrieves the string value of a cookie.
· documentElement Property - Retrieves a reference to the root node of the document.
· readyState Property - Retrieves a value that indicates the current state of the object.
· URL Property - Sets or retrieves the URL for the current document.
· URLUnencoded Property - Retrieves the URL for the document, stripped of any character encoding.
Collections 集合
· all - Returns a reference to the collection of elements contained by the object.
· frames - Retrieves a collection of all window objects defined by the given document or defined by the document associated with the given window.
· images - Retrieves a collection, in source order, of img objects in the document.
· links - Retrieves a collection of all objects that specify the HREF property and all area objects in the document.
Methods 方法
· getElementById Method - Returns a reference to the first object with the specified value of the ID attribute.
· getElementsByName Method - Retrieves a collection of objects based on the value of the NAME attribute.
· getElementsByTagName Method - Retrieves a collection of objects based on the specified element name.
Note that some of these properties are also provided by QuickTest Test Objects. For example, it is possible to access the cookies set by a Web page both through the cookie property in the DOM, and through the GetCookies method provided by the Browser Test Object.
activeElement
Retrieves the object that has the focus when the parent document has focus.
You can get the source index of the active element (object that has focus) on the page by doing the following:
CurrentSourceInd = Browser("Browser"). Page("Page").Object.activeElement.sourceIndex
Now you can query the source index of any object on the page by doing the following:
SrcIdx = Browser("Browser").Page("Page").WebEdit("q").GetROProperty("source_index")
You can then compare the two values to see if the WebEdit is the active element on the page that has focus. If the source index of the WebEdit is the same as the source index of the activeElement , then the WebEdit is the object that has focus.
activeElement 代表当前获得焦点的对象
例子:
' 当前获得焦点的页面元素的 sourceIndex
CurrentSourceInd = Browser("Web Tours").Page("Web Tours").Object.activeElement.sourceIndex
Print CurrentSourceInd
' 获取 username 输入框的 sourceIndex 属性
SrcIdx = Browser("Web Tours").Page("Web Tours").Frame("navbar").WebEdit("username").GetROProperty("source_index")
Print SrcIdx
If CurrentSourceInd<>SrcIdx Then
Reporter.ReportEvent micFail," 默认焦点错误 "," 默认焦点未置于 UserName 输入框上! "
End If
' 把焦点置于 username 输入框上
Browser("Web Tours").Page("Web Tours").Frame("navbar").WebEdit("username").Object.focus
SrcIdx = Browser("Web Tours").Page("Web Tours").Frame("navbar").WebEdit("username").GetROProperty("source_index")
Print SrcIdx
cookie
A cookie is a small piece of information stored by the browser that applies to a Web page. Each cookie can store up to 20 name=value; pairs called crumbs, and the cookie is always returned as a string of all the cookies that apply to the page. This means that you must parse the string returned to find the values of individual cookies.
The following is an example which retrieves the value of the cookie for a specified Web page.
strCookie = Browser("Browser").Page("Page").Object.cookie
Note: You can also use the Browser Test Object's GetCookies method to retrieve cookies for a specific URL. For example:
msgbox Browser("Yahoo").GetCookies("http://finance.yahoo.com")
使用 Object.cookie 来获取指定页面上的 Cookie
例子:
strCookie = Browser("Web Tours").Page("Web Tours").Object.cookie
Print strCookie
' 也可这样获取 Cookie
Print Browser("Web Tours").GetCookies("http://127.0.0.1:1080/WebTours/")
documentElement
The documentElement property is a reference to the root node of the document. It is read-only, and has no default value. The root node of a typical HTML document is the html object.
documentElement 属性指向DOM 的根节点,通常就是HTML 节点对象
This example uses the documentElement property to retrieve the innerHTML property of the entire document.
msgbox Browser("Browser").Page("Page").Object.documentElement.innerHTML
可以通过 Object.documentElement 访问 innerHTML 属性取得整个文档的 HTML 文本
例子:
Print Browser("Web Tours").Page("Web Tours").Object.documentElement.innerHTML
取到页面的 HTML 文本如下:
<HEAD><TITLE>Web Tours</TITLE></HEAD><FRAMESET border=1 frameSpacing=4 borderColor=#e0e7f1 rows=65,* frameBorder=0><FRAME. name=header marginWidth=2 marginHeight=2 src="header.html" noResize scrolling=no><FRAME. name=body marginWidth=2 marginHeight=2 src="welcome.pl?signOff=true" noResize></FRAMESET>
readyState
The readyState property is a string value a string value that indicates the current state of the object.
用readyState 属性来标识指定对象当前的状态,这个属性对于所有DOM 元素都适用。
Note that the readyState property is applicable to any DOM element. Both examples below are equally valid, and both will display the readyState of the object to which they belong
msgbox Browser("Browser").Page("Page").Object.readyState
and
msgbox Browser("Browser").Page("Page").Link("Link").Object.readyState
An object's state is initially set to uninitialized, and then to loading. When data loading is complete, the state of the link object passes through the loaded and interactive states to reach the complete state.
对象状态的一般变化过程:
uninitialized -> loading -> loaded -> interactive -> complete
URL
The URL property sets or retrieves the URL for the current document. This property is valid for Page and Frame. objects.
The following example displays the URL for the Web page that is currently open in the browser:
msgbox Browser("Browser").Page("Page").Object.URL
URL 属性对于 Page 和 Frame. 对象都适用
例子:
Print Browser("Web Tours").Page("Web Tours").Object.URL
Print Browser("Web Tours").Page("Web Tours").Frame("body").Object.URL
Print Browser("Web Tours").Page("Web Tours").Frame("header").Object.URL
Print Browser("Web Tours").Page("Web Tours").Frame("info").Object.URL
Print Browser("Web Tours").Page("Web Tours").Frame("navbar").Object.URL
输出页面对象以及各个 Frame. 对象的 URL 属性:
http://127.0.0.1:1080/WebTours/
http://127.0.0.1:1080/WebTours/welcome.pl?signOff=true
http://127.0.0.1:1080/WebTours/header.html
http://127.0.0.1:1080/WebTours/home.html
http://127.0.0.1:1080/WebTours/nav.pl?in=home
URLUnencoded
The only difference between the URL property and the URLUnencoded property is that the URLUnencoded property strips the URL of any character codings (such as %20 for spaces, and so forth.)
For more information about URL character encoding issues, see RFC-1738 on Uniform. Resource Locators (URL) .
URL 与 URLUnencoded 的区别在于 URLUnencoded 属性去掉了 URL 中的格式编码,例如代表空格的 %20
all, frames, images, 和 links 集合
Return a reference to the collection of elements contained by the object.
The all collection contains all the elements in the specified object. 指定对象中的所有元素。
The frames property contains objects of type window (frame).
Frame. 类型的对象中的所有元素。
The images property contains objects of type of img (image).
Image 类型的对象中的所有元素。
The links collections contains objects of types HREF and area.
HREF 、area 类型的对象中的所有元素。
length property - Sets or retrieves the number of objects in a collection.
item method - Retrieves an object from the all collection or various other collections.
namedItem method - Retrieves an object or a collection from the specified collection.
There are additional methods available for accessing some of the collections. For example, the images collection provides the tags method, which can be used to retrieve a collection of objects with a specified tag name. For more information, see http://msdn.microsoft.com/en-us/library/ms535862(VS.85).aspx .
The following example loops through all the INPUT tags, and displays a message indicating the number of tags checked:
Set inputs = Browser("Browser").Page("Page").Object.all.tags("INPUT")
'Loop over all inputs in this collection and get the 'checked' value:
For Each inputBtn In inputs
If inputBtn.checked Then
checkedCount = checkedCount + 1
End If
Next
MsgBox checkedCount & " checkboxes are checked."
The following example displays a message indicating the number of frames in the specified Web page:
msgbox Browser("Yahoo").Page("Yahoo!").Object.frames.length
从 all 、 frames 、 images 、 links 等集合中可以方便地获取到同一类型的所有对象。
例子:
' 取得 Frame. 的个数
Print Browser("Web Tours").Page("Web Tours").Object.frames.length
Browser("Web Tours").Page("Web Tours").Frame("navbar").WebEdit("username").Set "jojo"
Browser("Web Tours").Page("Web Tours").Frame("navbar").WebEdit("password").SetSecure "4b4735162198024e11994f954660"
Browser("Web Tours").Page("Web Tours").Frame("navbar").Image("Login").Click 55,14
Browser("Web Tours").Page("Web Tours").Frame("navbar").Image("Itinerary Button").Click
Browser("Web Tours").Page("Web Tours").Frame("info").WebCheckBox("1").Set "ON"
Browser("Web Tours").Page("Web Tours").Frame("info").WebCheckBox("2").Set "ON"
' 取得标签为 INPUT 的所有对象
Set inputs = Browser("Web Tours").Page("Web Tours").Frame("info").Object.all.tags("INPUT")
For Each inputBtn In inputs
If inputBtn.checked Then
checkedCount = checkedCount + 1
End If
Next
Print checkedCount & " checkboxes are checked."
getElementById
The getElementById method returns a reference to the first object with the specified value of the ID attribute.
The following example sets the value of obj to the first element in the page that has an ID of "mark":
Set bj = Browser("Browser").Page("Yahoo!").Object.getElementByID("mark")
通过对象的 ID 来查找对象
例子:
Set bj = Browser("Google").Page("Google").Object.getElementById("tb")
msgbox obj.innerText
getElementsByName 和 getElementsByTagName
The getElementsByName and getElementsByTagName methods can be used just like getElementById except that they return a collection of objects (as opposed to getElementById , which returns only the first matching object it finds.)
For example, the following script. line will display a message indicating the number of images on the page - image objects have an "IMG" tag.
msgbox Browser("Yahoo").Page("Yahoo!").Object.getElementsByTagName "IMG").length
getElementById 只查找并返回第一个匹配的对象,而 getElementsByName 和 getElementsByTagName 则返回一个包含匹配对象的集合。
例:
set imags = Browser("Google").Page("Google").Object.getElementsByTagName("IMG")
For i=0 to imags.length -1
Print imags(i).src
Next
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/testing_is_believing/archive/2010/01/08/5161739.aspx -
QTP提供的两种对象接口(转)
2011-05-13 16:07:32
QTP为用户提供了两种操作对象的接口,一种就是对象的封装接口,另一种是对象的自身接口。
对象的自身接口是对象控件本身的接口,只要做过软件开发,使用过控件的人应该很清楚。
对象的封装接口是QTP为对象封装的另一层接口,它是QTP通过调用对象的自身接口来实现的。两种接口的脚本书写格式的差别在于:
自身接口需要在对象名后面加object再加属性名或方法名,
封装接口就不用在对象名后面加object。具体格式如下:
对实际对象的操作:
对象.object.自身属性
对象.object.自身方法()
对象.GetROProperty("封装属性")
对象.封装方法()对仓库对象的操作:
对象.GetTOProperty("封装属性")
对象.GetTOProperties() ’获取所有封装属性的值
对象.SetTOProperty("封装属性", "封装属性值")比如操作JavaEdit对象,通过QTP封装的封装接口,脚本如下:
设置JavaEdit的内容:
JavaDialog("Add NE").JavaEdit("NE Name").Set "NE1"
读取JavaEdit的内容:
msgbox JavaDialog("Add NE").JavaEdit("NE Name").GetROProperty("value")如果通过JavaEdit的自身接口,脚本如下:
设置JavaEdit的内容:
JavaDialog("Add NE").JavaEdit("NE Name").object.setText("NE1")
读取JavaEdit的内容:
Msgbox JavaDialog("Add NE").JavaEdit("NE Name").object.getText()QTP执行JavaEdit().Set语句时,是通过执行JavaEdit().object.setText()来实现的。
QTP执行JavaEdit().GetROProperty("value"),是通过执行JavaEdit().object.getText()来实现的。
JavaEdit对象的封装接口Set()和GetROProperty("value"),是QTP封装JavaEdit对象的自身接口setText()和getText()而得来的。对象的封装接口是QTP使用的缺省接口,我们录制出来的脚本都是使用封装接口,大家用的也都是封装接口。
但是封装接口不如自身接口丰富,因为QTP只是封装了部分常用的自身接口嘛。
所以我们在需要时,可以绕过封装接口,直接调用对象的自身接口。
不过有些自身接口不够稳定,在实践中偶尔会出现问题,但是概率很少。
封装接口有相应功能的话,就尽量用封装接口吧!理解了封装接口和自身接口的原理,我们就可以更加灵活的操作对象了。
但是我们怎么知道对象都有哪些封装接口和自身接口呢?
其实很简单,用对象查看器(Object Spy)查看对象,在查看窗口里有列出这些接口,包括属性和方法。
窗口中间有选择栏让你选择Native Properties和Identification Properties或者Native Operations 和Test Object Operations (QTP10.0是这样)
当选择Native Properties和Native Operations,它显示的就是对象的自身接口(自身的属性和方法)
当选择Identification Properties和Test Object Operations时,它显示的就是对象的封装接口(封装的属性和方法) -
编写图片空间QTP脚本时的一点经验(转)
2011-05-13 15:09:54
我录制QTP脚本的思路是让能跑起来的都跑起来,不能跑起来的暂时不管,同时先采取固化脚本的思路写脚本(详细),完成后再加入参数化,让脚本灵活起来!呵呵!以下是我编写图片空间时的一点经验!
经验1:用FireEvent方法处理TOP菜单中弹出的子菜单
Browser(”淘宝网-店铺管理平台“).Page(”淘宝网-店铺管理平台“).Link(”素材管理(1)”).Click
Browser(”淘宝网-店铺管理平台“).Page(”淘宝网-店铺管理平台“).Link(”图片空间“).Click
我在编辑用鼠标点击TOP菜单时,发现脚本在运行时,不稳定,有时能捕捉到子菜单,有时又不能捕捉到子菜单,后加上FireEvent方法:
browser(”淘宝网-店铺管理平台“).Page(”淘宝网-店铺管理平台“).Link(”素材管理(1)”).FireEvent “onmouseup”
Browser(”淘宝网-店铺管理平台“).Page(”淘宝网-店铺管理平台“).Link(”图片空间“).Click
这时每次运行脚本时,都能捕捉到子菜单了。
经验2:通过对象唯一性确认页面访问对象
需要校验图片分类下图片的数量,思路是将页面显示的数目与数据库中查询的数据进行对比,但此时不能直接读取有图片数量的对象,因为此对象不具有“唯一性”,它属于动态生成的对象。改变校验思路是先取得页面中具有“唯一性”对象图片分类DESC对象(系统中图片分类是具有唯一性),然后通过DOM对象取得图片数量的INFO对象。
set my_obj=browser(”图片空间“).Page(”图片空间“).Link(”宝贝图片“).Object
set my_b_info=my_obj.parentnode.nextSibling
然后取得有图片分类下图片数据:
经验3:通过CURRENTSYTLE判别LINK对象可用性tx=my_b_info.outertext
‘msgbox “a” + tx + “b” 用来校验是否有空格
text=left(tx,len(tx)-4)
‘text=text+0
‘msgbox IsNumeric(text)
提供两种思路:
第一种方式:
V=strcomp(browser(”图片空间“).Page(”图片空间“).Link(”name:=下移“,”index:=5″).GetROProperty(”class”), “move-down J_TagMoveDown no-move-down”,1)
If v=0 Then
reporter.ReportEvent micPass,”pass”,”提示成功“
else
reporter.ReportEvent micFail,”fail”,”提示失败“
End If
第二种方式:
set my_obj =browser(”图片空间“).Page(”图片空间“).Link(”name:=下移“,”index:=5″).object
x= my_obj.currentstyle.getattribute(”cursor”)
y=”not-allowed”
v=strcomp(x,y,1)
If v=0 Then
reporter.ReportEvent micPass,”pass”,”提示成功“
else
reporter.ReportEvent micFail,”fail”,”提示失败“
End If
经验4:通过DESCRIPTION访问对象库中同一对象运行时动态对象中静态提示文本
在页面中经常出现的DIALOG对象,在同一页面中可能会出现很多不同的DIALOG,但是读取对象时只有一个对象,但是其中静态文本,却是动态生成的,不同的操作对应不同的提示,此时通过:Static(”text:=图片标题不能超过50字符“).Exist语句判断系统是否成功操作!
Set MyDescription = Description.Create()
MyDescription(”text”).Value = “此分类为系统分类,不可删除。"
在这里的VALUE我们可以根据不同的对话框设置不同的静态文本:
If browser(”图片空间“).Dialog(”Windows Internet Explorer”).Static(MyDescription).Exist then
reporter.ReportEvent micPass,”pass”,”删除系统分类时提示成功“
browser(”图片空间“).Dialog(”Windows Internet Explorer”).WinButton(”确定“).Click
else
reporter.ReportEvent micFail,”fail”,”删除系统分类时提示失败“
End If
Set MyDescription = Nothing
也可以采取这种方式:
If browser(”图片空间“).Dialog(”Windows Internet Explorer”).Static(”text:=图片标题不能超过50字符“).Exist Then
reporter.ReportEvent micPass,”pass”,”图片标题不能超过50字符提示成功“
browser(”图片空间“).Dialog(”Windows Internet Explorer”).WinButton(”确定“).Click
else
reporter.ReportEvent micFail,”fail”,”图片标题不能超过50字符提示失败“
End If
-
Junit4 新断言语法介绍(转)
2011-05-12 15:34:43
1. 引言
JUnit4提供的新断言语法具有很多优点且使用简单,这已经不再是新鲜事了,可发现在实际测试代码中仍未被普及应用,特发此文,以期更多的人能掌握运用。
2. assertThat基本语法
Hamcrest 是一个测试辅助工具,提供了一套通用的匹配符 Matcher,灵活使用这些匹配符定义的规则,程序员可以更加精确的表达自己的测试思想,指定所想设定的测试条件。
Junit4结合Hamcrest提供了新的断言语句-assertThat,只需一个assertThat语句,结合Hamcrest提供的匹配符,就可以表达全部的测试思想。
assertThat的基本语法如下:assertThat(T actual, Matcher matcher)
assertThat(String reason, T actual, Matcher matcher)actual 是接下来想要验证的值;
matcher是使用 Hamcrest 匹配符来表达的对前面变量所期望的值的声明,如果 actual值与 matcher 所表达的期望值相符,则断言成功,否则断言失败。
reason是自定义的断言失败时显示的信息。
一个简单的例子:// 如果测试的字符串testedString包含子字符串"taobao"则断言成功
assertThat( testedString, containsString( "taobao" ) );
3. assertThat优点- 统一
只需一条assertThat语句即可替代旧有的其他语句(如assertEquals,assertNotSame,assertFalse,assertTrue,assertNotNull,assertNull等),使断言变得简单、代码风格统一,增强测试代码的可读性和可维护性。
- 语法直观易懂
assertThat 不再像 assertEquals 那样,使用比较难懂的“谓宾主”语法模式(如:assertEquals(3, x);)。相反,assertThat 使用了类似于“主谓宾”的易读语法模式(如:assertThat(x,is(3));),使得代码更加直观、易读,符合人类思维习惯。
- 错误信息更具描述性
旧的断言语法如果断言失败,默认不会有额外的提示信息,如
assertTrue(testedString.indexOf(“taobao”) > -1);
如果该断言失败,只会抛出无用的错误信息,如java.lang.AssertionError: ,除此之外不会有更多的提示信息。
新的断言语法会默认自动提供一些可读的描述信息,如
assertThat(testedString, containsString(“taobao”));
如果该断言失败,抛出的错误提示信息如下:
java.lang.AssertionError:
Expected: a string containing “taobao”
got: “taoba”
- 跟Matcher匹配符联合使用更灵活强大
Matcher提供了功能丰富的匹配符,assertThat结合这些匹配符使用可更灵活更准确的表达测试思想。
// 验证字符串 s是否含有子字符串 "taobao" 或 "qa" 中间的一个
// 旧的断言,不直观,需要分析代码逻辑明白验证意图
assertTrue(s.indexOf("taobao")>-1||s.indexOf("qa")>-1);
// 新的断言,直观易懂,准确表达测试思想
assertThat(s,anyOf(containsString("taobao"),containsString("qa")));
// anyOf满足条件之一即成立,containsString包含字符串则成立
4. assertThat使用
要想发挥assetThat的威力,必须跟Hamcrest联合使用,JUnit4本身包含了一些自带了一些 Hamcrest 的匹配符 Matcher,但是只有有限的几个。因此建议你将Hamcrest包加入项目。
在pom里加入Hamcrest依赖。<dependency>
<groupId>org.hamcrest</groupId>
<artifactId>hamcrest-all</artifactId>
<version>1.1</version>
</dependency>
在测试类里导入包import static org.junit.Assert.*;
import static org.hamcrest.Matchers.*;
通过例子学习是有效的学习方式之一,下面通过常用的示例演示如何使用assertThat,更详细的用法请参考Hamcrest相关文档。- 字符相关匹配符
/**equalTo匹配符断言被测的testedValue等于expectedValue,
* equalTo可以断言数值之间,字符串之间和对象之间是否相等,相当于Object的equals方法
*/
assertThat(testedValue, equalTo(expectedValue));/**equalToIgnoringCase匹配符断言被测的字符串testedString
*在忽略大小写的情况下等于expectedString
*/
assertThat(testedString, equalToIgnoringCase(expectedString));/**equalToIgnoringWhiteSpace匹配符断言被测的字符串testedString
*在忽略头尾的任意个空格的情况下等于expectedString,
*注意:字符串中的空格不能被忽略
*/
assertThat(testedString, equalToIgnoringWhiteSpace(expectedString);/**containsString匹配符断言被测的字符串testedString包含子字符串subString**/
assertThat(testedString, containsString(subString) );/**endsWith匹配符断言被测的字符串testedString以子字符串suffix结尾*/
assertThat(testedString, endsWith(suffix));/**startsWith匹配符断言被测的字符串testedString以子字符串prefix开始*/
assertThat(testedString, startsWith(prefix));- 一般匹配符
/**nullValue()匹配符断言被测object的值为null*/
assertThat(object,nullValue());/**notNullValue()匹配符断言被测object的值不为null*/
assertThat(object,notNullValue());/**is匹配符断言被测的object等于后面给出匹配表达式*/
assertThat(testedString, is(equalTo(expectedValue)));/**is匹配符简写应用之一,is(equalTo(x))的简写,断言testedValue等于expectedValue*/
assertThat(testedValue, is(expectedValue));/**is匹配符简写应用之二,is(instanceOf(SomeClass.class))的简写,
*断言testedObject为Cheddar的实例
*/
assertThat(testedObject, is(Cheddar.class));/**not匹配符和is匹配符正好相反,断言被测的object不等于后面给出的object*/
assertThat(testedString, not(expectedString));/**allOf匹配符断言符合所有条件,相当于“与”(&&)*/
assertThat(testedNumber, allOf( greaterThan(8), lessThan(16) ) );/**anyOf匹配符断言符合条件之一,相当于“或”(||)*/
assertThat(testedNumber, anyOf( greaterThan(16), lessThan(8) ) );- 数值相关匹配符
/**closeTo匹配符断言被测的浮点型数testedDouble在20.0¡À0.5范围之内*/
assertThat(testedDouble, closeTo( 20.0, 0.5 ));/**greaterThan匹配符断言被测的数值testedNumber大于16.0*/
assertThat(testedNumber, greaterThan(16.0));/** lessThan匹配符断言被测的数值testedNumber小于16.0*/
assertThat(testedNumber, lessThan (16.0));/** greaterThanOrEqualTo匹配符断言被测的数值testedNumber大于等于16.0*/
assertThat(testedNumber, greaterThanOrEqualTo (16.0));/** lessThanOrEqualTo匹配符断言被测的testedNumber小于等于16.0*/
assertThat(testedNumber, lessThanOrEqualTo (16.0));- 集合相关匹配符
/**hasEntry匹配符断言被测的Map对象mapObject含有一个键值为"key"对应元素值为"value"的Entry项*/
assertThat(mapObject, hasEntry("key", "value" ) );/**hasItem匹配符表明被测的迭代对象iterableObject含有元素element项则测试通过*/
assertThat(iterableObject, hasItem (element));/** hasKey匹配符断言被测的Map对象mapObject含有键值“key”*/
assertThat(mapObject, hasKey ("key"));/** hasValue匹配符断言被测的Map对象mapObject含有元素值value*/
assertThat(mapObject, hasValue(value)); - 统一
-
90%请求的响应时间可以作为测试结果的相应时间(转)
2011-05-11 11:02:49
今天看了人家写的 描述性统计与性能结果分析-LoadRunner,学到了平均相应时间和90%事务相应时间的关系,其中平均响应时间满足了但是未必符合性能要求,有时候还要看90%事务相应时间。具体参看以下内容:
LoadRunner中的90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。
为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求?
假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想?
假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?
为了解答上面的疑问,我们先来看一张表:

在上面这个表中包含了几个不同的列,其含义如下:
CmdID 测试时被请求的页面
NUM 响应成功的请求数量
MEAN 所有成功的请求的响应时间的平均值
STD DEV 标准差(这个值的作用将在下一篇文章中重点介绍)
MIN 响应时间的最小值
50 th(60/70/80/90/95 th) 如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义
MAX 响应时间的最大值
我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。我把结论性的东西整理一下:
1. 90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%;
2. 对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE 函数很简单的算出不同百分比用户请求的响应时间分布情况;
3. 从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。也就是说假如我们确定Home Page的响应时间应该在5秒内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的响应时间是大于这个值的;对于Page 1也是一样,假如我们确定对于Page 1 的请求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有20-30%的用户请求的响应时间是超过了我们的要求的;
4. 你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的;
5. 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲线就越接近真实情况;
6. 在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用90%或95%用户响应时间来作为度量标准,它们并不冲突。实际上,在定义某些系统的性能需求时,一定范围内的请求失败也是可以被接受的;
7. 上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。
事实上,在性能测试领域中还有更多的东西是目前的商业测试工具或者开源测试工具都没有专门讲述的——换句话说,性能测试仅仅有工具是不够的。我们还需要更多其他领域的知识,例如数学和统计学,来帮助我们更好的分析性能数据,找到隐藏在那些数据之下的真相。
数据统计分析的思路与分析结果的展示方式是同样重要的,有了好的分析思路,但是却不懂得如何更好的展示分析结果和数据来印证自己的分析,就像一个人满腹经纶却不知该如何一展雄才
一图胜千言,所以这次我会用两张图表来说明“描述性统计”在性能测试结果分析中的其他应用。
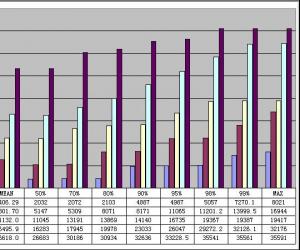
在这张图中,我们继续使用了上一篇文章——《描述性统计与结果分析》一文中的方法,对响应时间的分布情况来进行分析。上面这张图所使用的数据是通过对
Google.com 首页进行测试得来的,在测试中分别使用10/25/50/75/100 几个不同级别的并发用户数量。通过这张图表,我们可以通过横向比较和纵向比较,更清晰的了解到被测应用在不同级别的负载下的响应能力。
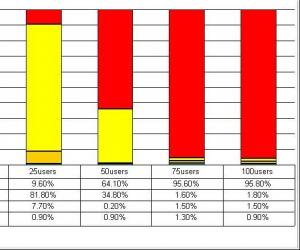
这张图所使用的数据与第一张图一样,但是我们使用了另外一个视角来对数据进行展示。表中最左侧的2000/5000/10000/50000的单位是毫秒,分别表示了在整个测试过程中,响应时间在0-2000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在2001-5000毫秒范围内的事务数量占成功的事务总数的百分比,响应时间在5001-10000毫秒范围内的事务数量占成功的事务总数的百分比,以及响应时间在10001-50000毫秒范围内的事务数量占成功的事务总数的百分比。
这几个时间范围的确定是参考了业内比较通行的“2-5-10原则”——当然你也可以为自己的测试制定其他标准,只要得到企业内的承认就可以。所谓的 “2-5-10原则”,简单说,就是当用户能够在2秒以内得到响应时,会感觉系统的响应很快;当用户在2-5秒之间得到响应时,会感觉系统的响应速度还可以;当用户在5-10秒以内得到响应时,会感觉系统的响应速度很慢,但是还可以接受;而当用户在超过10秒后仍然无法得到响应时,会感觉系统糟透了,或者认为系统已经失去响应,而选择离开这个Web站点,或者发起第二次请求。
那么从上面的图表中可以看到,当并发用户数量为10时,超过95%的用户都可以在5秒内得到响应;当并发用户数量达到25时,已经有80%的事务的响应时间处在危险的临界值,而且有相当数量的事务的响应时间超过了用户可以容忍的限度;随着并发用户数量的进一步增加,超过用户容忍限度的事务越来越多,当并发用户数到达75时,系统几乎已经无法为任何用户提供响应了。
这张图表也同样可以用于对不同负载下事务的成功、失败比例的比较分析。
Note:上面两个图表中的数据,主要通过Excel 中提供的FREQUENCY,AVERAGE,MAX,MIN和PERCENTILE几个统计函数获得,具体的使用方法请参考Excel帮助手册。
-
QTP调用外部.vbs函数的方法比较(转)
2011-05-09 17:30:11
方式1:Executefile方式2:加到QTP的Resorece
方式3:ExecuteGlobal方法
在比较之前先简明叙述一下使用方法,以给初学者由浅入深的理解
比如我们有一个函数Wally.vbs放在了C:盘下,其中有如下函数(获取本机的IP地址):
FunctionGetIPAddr()
SetobjWMI=GetObject("winmgmts://./root/cimv2")
SetcolIP=objWMI.ExecQuery("Select*fromWin32_NetworkAdapterConfigurationwhereIPEnabled=TRUE")
ForEachIPIncolIP
temp=IP.IPAddress(0)
ExitFor
Next
GetIPAddr=temp
EndFunction
方式1的使用方法:直接在QTP中打:
Executefile"c:\wally.vbs"
随后就可以引用wally.vbs中的任意函数了,如msgboxGetIPAddr()
方式2的使用方法:
点击QTP菜单的File->Settings->Resources,之后添加wally.vbs到QTP的resource中
随后就可以引用wally.vbs中的任意函数了,如msgboxGetIPAddr()
方式3的使用方式:
ExecuteGlobal是VBS的函数而非QTP特有的函数,ExecuteGlobal的功能可以引入其它vbs文件的函数,就和C++的include,Java的import一样。使用范例:
dimfso:setfso=createobject("scripting.filesystemobject")
executeglobalfso.opentextfile("c:\wally.vbs",1).readall
setfso=nothing大家可以看到其实它是把wally.vbs全部读入内存中
随后就可以引用wally.vbs中的任意函数了,如msgboxGetIPAddr()
下面是一些我使用中的心得:
方式1:Executefile的好处:
QTP可以使用这个函数方便了自己写语句来引入函数,灵活性非常高
方式1:Executefile的缺点和解决方案:
1.会使得QTP的语句执行的黄色指针工作异常,狂跳
2.Debug很头疼。我以前的上周有一段经历,一个很小的Bug,调试的时候Stepinto不进正确的函数体,竟然跳到了一行空行。后来这个小Bug竟然足足花了我3整天的时间。这个应该是QTP的Bug,希望它后续的版本可以改进
3.会莫名其妙的执行一些本不应该有的操作,大大降低QTP执行时间效率,之间屏幕在闪,但是不知道在执行些什么。我曾经遇到过这样的情况:任其自然执行,屏幕狂闪,执行了半小时;我单步执行,只花了5分钟执行完毕。可见这会使得原本就受质疑的QTP的Performance更受谴责
解决方案:
以上三点我找不出解决方案,属于Hp的严重Bug还是需要HP来完善
方式2:加到QTP的Resorece的好处:
毕竟是QTP自带的引用外部VBS函数的,非常稳定
方式2:加到QTP的Resorece的缺点和解决方案:
灵活程度大打折扣,经常的情况是使用同一个测试框架对于不同的项目需要引入不同的VBS文件,非常不灵活
解决方案:
不过这也是有方法可以解决的:在外部调用AOM的函数中添加:
Setobj=CreateObject("QuickTest.Application")
SetqtLibraries=obj.Test.Settings.Resources.Libraries'Getthelibrariescollectionobject
IfqtLibraries.Find("C:\wally.vbs")=-1Then
qtLibraries.Add"C:\wally.vbs",1
EndIf
这样子就可以通过外部文件调用QTP对象模型来加载指定的VBS,也可以非常灵活。
方式3:ExecuteGlobal方法的优势:1.自己写代码,非常灵活
2.外部函数由于从内存中读取,避免了I/O,执行速度加快,而且通过这个方法调用其它文件函数非常稳定
方式3:ExecuteGlobal方法的缺点:
1.一下子把可能需要用到的VBS文件全部读入内存,势必会增加内存开销
2.Debug时候Stepinto不到指定的函数,调试不方便
解决方案:
对于1的解决方案的答案是没有解决方案,因为采取了ExecuteGlobal方法后内存开销增大是不可避免的。但是这点内存对于运行QTP来说并不是个不可承受的内存,微不足道
对于2的解决方案其实可以在需要调试的时候手工加入到QTP专家视图窗口,调试完毕后再采用ExecuteFile调用
事实上如果要我排个序的话我的优先顺序是:
方式2:加到QTP的Resorece>>方式3:ExecuteGlobal>>方法方式1:Executefile
-
LoadRunner进程和线程设置(转)
2011-05-09 11:21:59
虚拟用户已线程还是进程的方式运行,对被测服务器的压力是完全不同的,首先我们要知道在loadrunner中有3个地方涉及到虚拟用户的运行方式,分别是:1、在Vug->run-time settings->miscellane->multithreading中可以设置虚拟用户是已线程还是进程的方式运行
2、在controller中设置场景时,是已单场景模式运行还是已场景组方式运行,在这两种不同的运行方式下,虚拟用户的运行方式也是不同的
3、在controller中使用IP欺骗时,在专家模式下的tools->options->general->multiple IP address mode中也可以选择每个IP是已线程还是进程方式运行
下面我们介绍一下这三个设置线程和进程之间的关系:
首先说一下run-time settings中的设置与controller中单场景和场景组的关系:
要记住虚拟用户是以线程还是进程方式运行是在Vug->run-time settings中设置的,其次在controller中如果使用单场景运行,那么该场景中无论有多少个脚本、多少个负载生成器,运行这些脚本的虚拟用户均依照Vug->run-time settings中设置的线程还是进程方式运行,但是如果在controller中如果以场景组方式运行时,每个场景组均会作为一个进程被启动,而每个组中的用户又是按照Vug->run-time settings中设置的线程还是进程方式运行。
再说一下在controller中使用IP欺骗时,在专家模式下的tools->options->general->multiple IP address mode中的设置:
如果选择的是进程方式:
1、如果这个ip是在单场景中,那么有几个不同的ip的负载生成器就会启动几个进程,每个负载生成器的虚拟用户的运行方式仍然按照Vug->run-time settings中设置的线程还是进程方式运行
2、如果是在场景组中运行,这就要看场景组是如何设置的了,有两种情况:
a、每个场景组中添加一个虚拟ip,这时运行每个场景组时只启动一个进程
b、每个场景组中添加多个虚拟ip,这时运行每个场景组时,每个场景组启动一个进程,每个ip启动一个进程,每个ip的虚拟用户的运行方式按照Vug->run-time settings中设置的线程还是进程方式运行。
如果在controller中使用IP欺骗时,在专家模式下的tools->options->general->multiple IP address mode中选择的线程方式:
1、如果这个ip是在单场景中,那么对于不同的ip的负载生成器只会启动一个进程,每个负载生成器的虚拟用户的运行方式仍然按照Vug->run-time settings中设置的线程还是进程方式运行。
2、如果是在场景组中运行,每个场景组启动一个进程,所有ip已线程的方式在组进程中运行,每个ip的虚拟用户的运行方式按照Vug->run-time settings中设置的线程还是进程方式运行。
-
LoadRunner设置检查点的几种方法介绍
2011-05-04 10:49:21
前段时间在群里跟大家讨论一个关于性能测试的问题,谈到如何评估测试结果,有一个朋友谈到规范问题,让我颇有感触,他说他们公司每次执行压力测试的时候,都要求脚本中必须有检查点存在,不然测试结果将不被认可,这是他们公司的规范。其实,在做压力测试过程,我们很容易忽略很多东西,而且随着自身的技术演变,我们很容易去丢失掉一些很好的习惯,当我们再碰到这些问题的时候,我们才发现其实是我们太粗心大意了,所以说好的习惯要保持。这次我刚好也要接手一些性能工作,因此就如何规范设置检查点来谈谈一些基本的流程和方法。使用LoadRunner做压力测试,大致如下几个流程:
1、明确测试目标
2、录制测试脚本
3、脚本优化、调试
4、场景运行
5、分析测试结果
当然这里都是概况性的标题,但从这里我们可以明确的是测试脚本是整个压力测试过程中的重点步骤,如果测试脚本都不能确保正确与否,后面的测试过程就无从说起了。很多时候我们把脚本调试就简单的认为是脚本回放没有错误就认为脚本是没有问题的,这当然不能这么肯定,脚本调试是一个非常严谨的过程,我大致归纳如下几步:
1、明确每一行脚本的作用,也就是说每一行脚本执行的功能是什么;
2、删减不需要的脚本语句,比如在录制过程由于LR默认设置导致录制之后出现很多冗余的脚本,这些个脚本对我们的测试过程没有用途的应该删除掉,至于哪些是冗余就要具体分析了,所以说脚本录制完之后要分析脚本运行的过程,方能理解脚本执行的用途,不然在后面施压时运行错误,就会开始到处找问题,而又找不出问题;
3、查找存在的关联并进行相关设置
4、设置检查点,设置检查点的目的就是为了验证页面每次运行之后是否正确,设置检查点的过程总要通过不能的回放来进行验证检查点设置是否正确。
5、通过测试目标明确脚本执行的目标事务,并添加事务;
6、对需要进行并打操作的功能设置集合点
7、根据实际情况设置ThinkTime
8、在以上所有脚本调试步骤完成之后,设置迭代次数,通过在Vuser中设置多次迭代来验证脚本在多次循环运行时是否存在错误
注意:在Vuser中运行和回放脚本的过程,要密切关注replay log,也就是回放日志,很多问题通常都暴露在回放日志中,只不过我们没有认真去检查,所以没发觉。因为大多数情况是我们在回放脚本之后只观察回放日志中有没有红色的错误提示信息,如果没有我们就认为我们的脚本是ok的,其实不然,很多时候一些隐藏的错误就在回放日志中可以被发现,比如回放日志中的Warning信息,也就是警告信息,这些信息一旦你不去理会它,它将在场景运行过程中开始频繁暴露出来,而在场景中报错之后我们就认为可能是系统有问题或者是测试过程存在其他问题等等,而很难去考虑到是脚本的问题,是脚本在Vuser中调试就存在的问题。还有的时候一些问题在一次脚本回放中就不能被发现,他需要通过Vuser中设置多次迭代才能在回放日志暴露出问题来,所以说我们通常的思维就是一旦测试脚本没有一次回放没有出现错误,就去场景中运行,结果在场景中哪怕是运行10个用户都还会报错,这就是问题的根源所在。
下面还是重点说说检查点吧,三种常用的文本检查web_reg_find的方法:
1、 将脚本切换到树结构,在page view页面上找到你要check的文本内容, 并执行鼠标右键,选择Add a text check.
2、 通过Vuesr界面去设置检查点,如图所示:
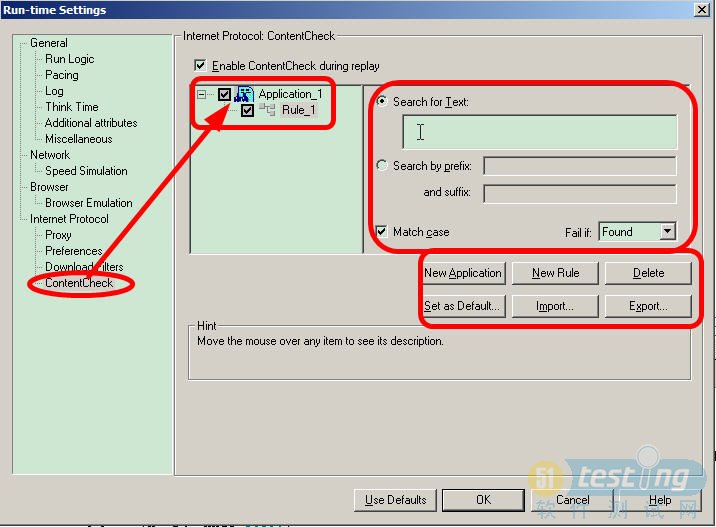
3、将脚本切换回代码界面, 在光标闪烁的上行,添加如下的代码:
添加的代码根据你检查的方式不同而不同, 你可以选择其中之一即可。
代码一:
web_reg_find("Text=Payment Details",LAST);
注:“Payment Details” 为你要检查的文本;
脚本执行到此处,若在页面上找到了这几个字符串,那脚本继续执行下去;若没有找到,脚本将在此报错并且结束。
代码二:
web_reg_find("Text=Payment Details", "SaveCount=para_count", LAST); //check 的函数
这里是要运行的页面脚本
if (atoi(lr_eval_string("{para_count}"))>0) //验证是否找到了页面上的要检查的字符串
lr_output_message("Pass!");
else
lr_output_message("Failed!");
注意:
“Payment Details” 为你要检查的文本;
脚本执行到此处,不管页面上是否存在你要检查的字符串,脚本都不会报错,而是执行下去。
此段代码将找到的你要检查的字符串的个数,存为一个参数。 然后在页面代码的后面,通过检查这个参数的值是否大于0,来判断是否找到了你所要检查的字符串。
注意:这里的测试结果均以200状态码返回,其失败的结果将在分析报告中进行分类标识。
代码三:
web_reg_find("Text=Payment Detdils", "Fail=NotFound",LAST);或者
web_reg_find("Text=Payment Detdils", "Fail=Found",LAST);
以上两段脚本就比较简洁,通过查询文本内容来决定此次运行的测试结果是否失败。
注意:在使用检查点的时候我们还需要注意一些问题,通常我们都要设置一些中文检查点,但是LR默认不支持,如果你设置了中文检查点而报错,那你就应该注意了,在录制脚本的时候去掉默认设置的UTF-8选择,如下图所示:
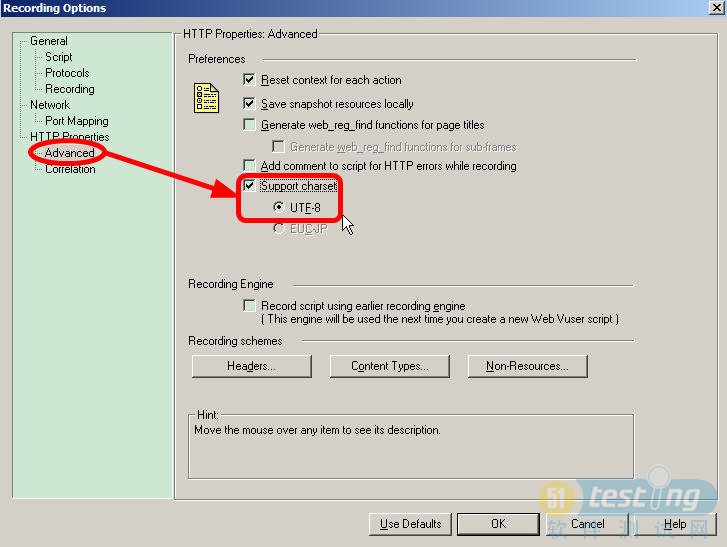
并且还设置启用图片和文本检查点,如下图所示:
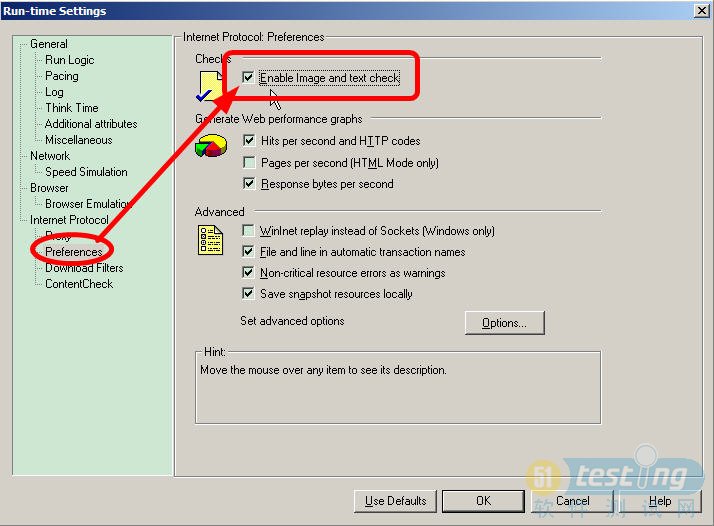
以上就是设置检查点的全过程,设置检查点的目的不只是为了验证我们的脚本没有错误,而更重要的是一个规范问题,如何使得测试结果更具有说服力,那就所有的测试脚本中都添加检查点设置
-
TOMCAT启动一闪而过解决办法
2011-03-25 11:18:41
TOMCAT启动一闪而过可能原因有
1. 没有设置环境变量
步骤:
(1)把JDK解压放到C:\jdk1.5.0下,把Tomcat解压放到C:\Tomcat-5.5.27下[Tomcat是解压版的]
(2)添加系统环境变量:
JAVA_HOME=C:\jdk1.5.0 只配置这一个也可以。
CLASSPATH=.;%JAVA_HOME%\LIB
TOMCAT_HOME=C:\Tomcat-5.5.27(3)修改系统环境变量PATH,在它的最前面加入:
%JAVA_HOME%\BIN;2. tomacat\conf\server.xml 中的端口与其他软件的冲突
步骤:
<!-- Define a non-SSL HTTP/1.1 Connector on port 8080 -->
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />修改以上代码段中的port
-
QTP全局和局部的错误处理模式(转)
2011-03-25 10:35:00
局和局部的错误处理模式上一篇 / 下一篇 2011-03-17 13:55:55 / 个人分类:QuickTestProfessional
以下内容转载自http://makar.javaeye.com/blog/280272
QTP提供全局错误处理模式,有Popup message box,Process next action iteration,Stop run,Process next step这四种。
QTP也提供On Error Resumt Next/On Error goto 0的局部错误处理模式。可以在局部范围内实现Process next step的效果,忽略错误继续执行后续步骤。这个局部错误处理模式,象局部变量优先于全局变量并且只在本函数内有效一样,优先级高于全局错误处理模式,同时只在本函数局部范围(Action本身也可以看成是个函数)内生效。它不会影响外层函数的错误处理模式,但会改变局部范围内调用的子孙函数,将子孙函数的错误处理模式改为Stop Run!
四种全局错误处理模式的区别在于:
1、Process next step
这种模式忽略错误继续往下执行,可以通过Err.Number来判断是否发生了错误。
因为Case函数的每个步骤都是密切相关的,不可能忽略错误继续往下执行下一步骤
也不可能在每个步骤每个语句后面都加错误检查,这样错误处理代码太多了
在很多个步骤后再检查也是不严谨的,会错上加错,并因此失去第一个错误的信息
所以,这种模式不可取
2、Stop run
这种模式发生错误后,就抛出异常(可用Err对象得到异常里的错误信息),中止本函数,并一层一层的返回到上一层函数,最后到达Action函数后(Action本身也可以看成是个函数),就停止整个Test的执行。
在一层一层的返回上层函数的过程中,如果某个中间函数有On Error Resumt Next/On Error goto 0,就会把错误拦截下来,这个中间函数会继续往下执行,不会中止函数并返回上一层函数。
3、Popup message box
这种模式在发生错误时,弹出对话框让用户选择Stop、Retry、Skip、Debug。
主控Test要全自动执行,不能要求人工干预,所以这种模式不可取
4、Process next action iteration
这种模式跟Stop run类似,但是它只是退出本次Action循环,还会继续下一个Action循环。
主控Test没有继续下一个Action循环的需求,所以这种模式不可取。
经过上述分析,我们可以得到结果,我们的主控Test,全局错误处理模式使用Stop run模式,同时在主控函数里使用On Error Resumt Next/On Error goto 0的局部错误处理模式来调用Case函数。这样使得Case函数和其子函数里发生错误时,会停止执行,并层层返回到主控函数这里,并由主控函数来拦截错误,记录错误。然后主控函数就可以正常的继续执行下一个Case函数了,不用担心会导致整个Test停止执行。
主控函数调用Case函数的详细过程如下:
Err.Clear
On Error Resume Next
call CaseFunctionName
If Err.Number <> 0 Then
WriteLog Err.Number '错误码
WriteLog Err.Description '错误描述
WriteLog Err.Source '错误来源对象,不过好像没啥用
End
Err.Clear
On Error goto 0 -
老王python
2011-02-19 12:18:11
亲爱的朋友:欢迎你!很高兴能在这里见到你,你能来到这里说明你真的很喜欢python,很想把python给学好!我觉的你很幸运,开始我学python的时候比较少资料,学起来也比较头疼,现在随着python越来越流行,资料也越来越多,大家以后学起来应该会轻松很多了。我前段时间花了很多时间整理了一些python教程,我觉的对初学python的朋友来说是个很好的引路人,我相信通过它你可以快速的上手python的。不信可以试试哦!最近索取资料的朋友比较多,让老王python感到欣慰!为了让更多的朋友了解python,学习python,喜欢python!我做出了一个艰难的决定:如果你想要得到这份资料的话:只要做下面列举的5件事情中的2件事,对你来说轻而易举!- 如果你有一些python相关群的话,除我的群:跟着老王学python外,将这篇文章的链接发到群里,分享给想学python的朋友
- 如果你有QQ而且有微博的话,将这篇文章的链接发到在微博里面,分享给想学python的朋友
- 如果你有个人的技术博客的话,将这篇文章转发到你的博客里,分享给想学python的朋友
- 如果你有技术论坛的账户的话,把这篇文章转发到论坛的文章里,分享给想学python的朋友
- 如果你有QQ空间的话,把这篇文章转发到QQ空间里并且分享这篇文章,把信息分享给想学python的朋友
如果你做了上面5件事情的2件事情,请你把做的相关链接或者信息截图整理好后通过邮箱发给我,我的邮箱是:老王python 提供简单实用的python 教程。本文地址:http://www.cnpythoner.com/pythonshop 转载请保留280026798@qq.com
我会把教程的地址发到你的邮箱里先分享先学习哦!希望你不要错过这个和python亲密接触的机会!
-
QTP自动化感悟
2010-07-03 10:07:04
最近换了一家公司,开始专职做QTP自动化工作,公司做的事医疗软件行业的项目,用的是PowerBuilder开发的CS架构程序,在选择测试工具方面,当时考虑使用QTP或者Robot,后来考虑到易用性及如何更方便的在技术质量管理部进行推广等因素的考虑,决定使用QTP,总所周知,在QTP9.5之前是没有PB插件的,最后使用QTP10进行测试脚本的编写。刚开始学习QTP的人,都习惯于如果解决技术上面的问题,想想自己刚开始学习的时候也是如此,总能为学会读取Excel、连接数据库而感到高兴,认为自己只要学会解决技术方面的问题就算是学好QTP。慢慢地,QTP做久了之后,想法开始改变了,想的多的问题变成脚本的粒度、脚本的复用性、脚本的结构这些问题了。技术上问题也许自己并不能解决,呵呵,但是总有人能解决的,google、help这些里面都是学习的地方。也学每个学习QTP得人都会经历这个过程吧。话说回来,在我做C/S方面的自动化测试之前,是做B/S web方面的,说实在的觉得web方面可能技术上有更高要求,不过大同小异,只是对不同程序所用的插件不同,识别出的对象不同而已,思想还是一样的。因为医疗方面的业务流程是比较复杂的,目前都是按照业务流程上面的功能模块进行QTP脚本的分割的,因为每个功能模块在其他业务流程中也有被使用的可能性,按照单个功能模块提供了脚本的复用性,例如:
-
sqlserver2005(转)
2010-06-17 17:30:20
'用户 'sa' 登录失败。该用户与可信 SQL Server 连接无关联
问题一、忘记了登录Microsoft SQL Server 2005 的sa的登录密码
解决方法:先用windows身份验证的方式登录进去,然后在‘安全性’-‘登录’-右键单击‘sa’-‘属性’,修改密码点击确定就可以了。
问题二、已成功与服务器建立连接,但是在登录过程中发生错取。(provider:共享内存提供程序,error:0-管道的另一端上无任何进程。)(Microsoft SQL Server,错误:233)
解决方法:打开‘程序’-‘所有程序’-‘Microsoft SQL Server 2005 ’-‘配置工具’-‘SQL Server 配置管理器’,在弹出的窗体中,找到‘SQL Server 2005 网络配置’,把‘MSSQLSERVER的协议’下的“Named Pipes”和“TCP/IP”启动,然后重新启动Microsoft SQL Server 2005就可以了。
问题三、无法打开用户默认数据库。登录失败。用户‘sa’登录失败。(Microsoft SQL Server, 错误:4064)
解决方法:先用windows身份验证的方式登录进去,然后在‘安全性’-‘登录’-右键单击‘sa’-‘属性’,将默认数据库设置成master,点击确定就可以了。
问题四、sql server 2005 错误 18452
无法连接到服务器
服务器:消息18452, 级别16,状态1
[Microsoft][ODBC SQL Server Driver][SQL Server]用户‘sa’登陆失败。原因:未与信任SQL Server连接相关联
该错误产生的原因是由于SQL Server使用了"仅 Windows"的身份验证方式,因此用户无法使用SQL Server的登录帐户(例如 sa )进行连接,解决方法如下设置允许SQL Server身份登录 (基本上这个很有用)
操作步骤:
1。在企业管理器中,展开"SQL Server组",鼠标右键点击SQL Server服务器的名称
2。选择"属性"
3。再选择"安全性"选项卡
4。在"身份验证"下,选择"SQL Server和 Windows"
5。确定,并重新启动SQL Server服务
问题五、用户 'sa' 登录失败。该用户与可信 SQL Server 连接无关联。
解决方法:检查你的数据库的认证模式,windows 和 混合模式,需要SA登陆的请选择混合模式。
检查计算机1433连接端口,1434数据端口是否打开针对sql 2005 进入管理器中“安全”==》“用户”==》双击用户(弹出属性对话框)==》“状态”把状态改成enable,退出管理器重新登录(用户验证模式)
即:右键数据库属性对话框,选择“安全性”选项卡,服务器身份验证模式选择“SQL Server和Windows身份验证模式 。然后重新配置sa的登陆信息即可。SQL SERVER 2005使用sa 登录失败-提示该用户与可信 SQL Server 连接无关联
错误提示:
sa 登录失败,提示该用户与可信 SQL Server 连接无关联
解决方法:
打开SQL Server Management Studio Express,
右键点击服务器,选择Properties(属性),在弹出窗口中点击Security(安全)切换到安全面板,
将server authentication服务器认证从windows authentication mode(windows用户认证模式)
修改为Sql Server and Windows Authentication mode(Sql server和windows认证模式),ok。
打开security(安全性) -- logins(登录名) ,右键选中sa,选择properties(属性),点击Status(状态)切换到状态面板,将Login(登录)设置为Enabled(启用)。
切记:一定要把SQL2005服务重启才生效。 -
崩溃中
2010-03-10 14:48:54
崩溃中,想跳槽,这几天忙完就去投简历。。。。
标题搜索
我的存档
数据统计
- 访问量: 165143
- 日志数: 260
- 书签数: 81
- 建立时间: 2007-08-28
- 更新时间: 2012-06-13
