
-
测试角色以及工作任务分解
qiuteng258 发布于 2010-12-13 14:25:29
按照目前现有的测试项目特性对测试人员的工作任务内容进行了详细的划分,主要目的是让不同角色的测试人员能够明白自己在整个项目中的角色是什么?该做什么样的工作?这样分解能够使得项目能够有条不紊的进行。(此工作任务工作分解针对的是敏捷型的项目。SIT,SVT过程被裁减)
TM测试经理
- 定义可测试性需求
- 制定产品包验证主计划
- 接收并评审产品测试工作任务书
- 申请测试ID和创建测试环境
- 制定"测试分析与测试计划"活动的计划
- 组织测试开工会
- 参加产品测试的需求分析(系统)
- 评审测试规格
- 制定产品总体测试策略
- 评审总体测试策略
- 组织测试估计
- 制定测试与验证计划
- 评审测试与验证计划
- 组织产品测试开工会
- 组织测试方案设计开工会
- 制定SDV测试策略
- 组织评审SDV测试策略
- 度量分析
- 组织测试重估计
- 更新测试与验证计划
- 准备阶段结束报告
- 组织阶段结束会议
- 准备SDV测试报告
- 评审SDV测试报告
- SDV测试总结
- 优化测试策略
- 转验收测试评估
- 测试结束申请
- 组织过程度量分析
- 准备测试关闭报告
- 组织产品测试关闭会议
- 归档测试管理文件夹
- 规划下一版本测试任务
TL测试小组组长
- 测试规格分解分配
- 进行需求跟踪
- 组织自动化测试方案设计
- 组织缺陷分析
- 组织SDV缺陷分析
- 协助测试TL组织测试实施
- 风险问题评估与分析
- 制定项目组培训计划
- 转测试评估
- 优化测试过程
- 测试方案设计(系统)
- 测试方案设计
- 组织测试方案、用例设计
- 进行需求跟踪
- 组织评审测试方案
- 组织测试用例实现
- 组织用例内部检视
- 提取版本测试基础用例
- 制定转story测试标准
- 组织story测试环境准备
- 制定story结束标准
- 组织SDV测试环境准备
- 组织SDV测试执行
- 缺陷跟踪汇总
- 组织回归验证问题
- 审核使用手册
- 审核验收手册
- 准备验收交付件
- 验收问题跟踪
- 版本回溯总结
- 配合其他部件进行联调测试
- 编写SDV测试报告
TE 测试工程师
- 产品测试的需求分析(系统)
- 优化测试方案
- 协助编写测试用例
- 准备story测试环境
- 准备SDV测试环境
- 执行测试用例
- 回归验证问题单
- 编写使用手册
- 编写验收手册
- 个人阶段总结
-
<LR性能测试实战>摘录:监控Linux/Unix系统资源(部分语言自己组织)
阅微草人 发布于 2007-11-19 10:30:40
监控Linux/Unix系统资源(部分语言自己组织)
下面介绍两种在性能测试过程中监控linux/unix系统资源的方法。
1 在Controller中监控linux/unix系统资源
在LoadRunner的Controller中可以直接监控系统资源。监视前需要做的准备工作是配置
rstatd守护程序。后续工作和监控windows资源基本一致。
下面介绍配置rstatd守护程序的过程。
第一步,验证服务器上是否已经配置了rstatd守护程序,有以下两种方法。
使用rup命令 rup命令用于报告计算机的各种统计信息。在监视的linux/unix服务器上运行下面格式的rup命令:
# rup 10.20.5.213
Rup后面是要监视服务器的IP,如果该命令返回相关的统计信息,则表示已经配置并且激活了rstatd守护程序;若未返回有意义的统计信息,或者出现一条报错消息,则表示rstatd尚未被配置。
使用find命令 使用#find /-name rpc.rstatd命令查找系统中是否存在rpc.rstatd文件,如果没有,则说明系统没有安装rstatd.
第二步,如果服务器上没有安装 rstatd,则需要安装。下面以linux服务器介绍rstatd的安装步骤。
首先需要获得rstatd的安装介质(文件名可能是rstatd***.tar.gz),可以从安装cd中获得,或者网上下载。
将rstatd***.tar.gz文件拷贝到linux系统中,在该文件路径下执行解压缩:
# tar xzvf rstatd***.tar.gz
进入解压后的目录,依次执行如下命令来进行编译安装:
# ./configure
# make
# make install
安装结束后,运行rpc.rstatd,启动rstatd服务。
再次运行上面的rup命令,验证rstatd正确被配置并且被激活了。
第三步,如果系统安装了rstatd但是没有启动,则需要重新启动。启动步骤如下:
运行该命令:su root,输入密码,以系统管理员来登录。
打开“/etc/inetd.conf”文件,查找包含rstatd的行(以rstatd开始)。如果该行被注释掉了(使用#标识),则删除注释符,然后保存文件。
在命令行运行kill -1 inet_pid,其中inet_pid为inetd进程的PID。(在HP Unix编辑完inetd.conf后,重启inet服务需要输入“inetd -c”;在IBM AIX上编辑完inetd.conf后,重启inet需要输入“refresh s inetd”.)
再次运行rup命令可以看到rstatd已经配置且被激活了。
在controller中添加计数器和windows差不多。常见性能计数器参考帮助文档analysis.pdf。
2 使用top命令监控linux/unix系统资源
监控linux/unix资源可能会碰到不稳定的情况。遇到这种情况可以使用资源监控命令top
来记录服务其的性能指标,并将结果记录到指定文档中以便分析。由于linux和unix中的top命令参数和使用方法略有不同,下面分开介绍。
A linux下的top命令
Top命令是系统管理的一个主要命令。在linux中top命令参数的详细说明可以通过在终端输入“man top”来查看。Top命令的格式如下:
Top [-] [d delay] [q] [c] [S] [s] [i] [n]
-d:指定更新的间隔,以秒计算。
-q:没有任何延迟的更新。如果使用者是超级用户,则top命令将以最高的优先序执行。
-c:显示完整的进程路径与名称。
-S:累积模式,会将已完成或消失的子进程的CPU时间累积起来。
-s:安全模式。
-i:不显示任何闲置(Idle)或无用(zombie)的进程。
-n:显示更新的次数,完成后将会退出top。
在输入top命令后,动态显示系统资源占有情况时,还可以使用快捷键来对显示内容和方式进行实时调整。部分常用的快捷键及功能如下:
P:根据CPU使用时间多少进行排序。
T:根据时间/累计时间进行排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
i:切换闲置和无用进程的显示。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中(top配置文件的推荐写法)。
在性能测试中,较常见的是通过linux的输入重定向将top命令本应显示在终端上的系统资源信息输出到当前目录的指定文件中。例如“top –d 180 –I > test.txt”命令语句就会根据top命令中的设置,将测试人员所关注的系统资源信息按照每180s一次的频率写入当前目录下的test.txt文件中。
B unix下的top命令
在unix中,top命令的格式跟linux中一样,参数要比linux下简单一些。主要有以下几个参数(注意相同参数名所代表的意义有所变化):
-s time:设置屏幕刷新的时间间隔time,默认为5秒。
-d count:屏幕刷新count次后,退出top命令。
-b:使用“batch”模式显示系统的执行状态。此时,所有的功能键均没有任何作用。
-i:使用“interactive”模式显示系统的执行状态。
-I:显示系统程序的执行状态,不显示空闲进程及僵尸进程(defunct process).
-n:使用“no-interactive”模式显示系统的执行状态。
-q:仅在root下用,重置top优先级到-20。
-u:不显示用户UID。
-v:显示版本号。
-U username:仅显示username拥有的进程。
-f file:将top命令本应显示在终端上的系统资源信息输出当前目录的file文件中。
例如,“top –s 120 –d 300 –I –f test.txt”命令语句就会根据top命令中的设置,将所有非空闲或僵尸进程的信息每隔120秒输入到test.txt文件中一次,共输入300次。
-
关于场景测试
ice00snow 发布于 2010-08-13 12:24:16
场景测试
场景从用户的角度来描述系统的行为,反映系统的期望运行方式。它是由一系列相关活动组成,它就像一个剧本,是演绎系统未来预期的使用过程。场景可以看作是用户需求的内容,完全站在用户的视角来描述用户与系统的交互,之后的功能需求说明,则是用户需求分解的结果,定义了必须实现的软件功能。
针对用户需求内容的测试,我们称之为场景测试;而用户需求分解的结果,也就是功能特征的测试,对应系统功能测试;
功能测试主要关注系统提供的功能特征是否满足需求,测试功能的不同处理流程(正常或异常处理);理论上,一个功能测试用例仅用于测试一个功能,一个功能可能需要多个功能测试用例来覆盖。
场景测试关注于不同场景、事务、业务流程等跨功能,仅用到各个功能的一部分处理流程;一个场景测试用例仅测试一个场景、事务或业务流程。场景测试首先在系统测试阶段测试通过,然后在用户确认阶段,由用户执行场景测试来进行产品验收。
功能测试是场景测试的先决条件,只有功能测试已经完成并且其发现的问题得到解决,场景测试才可能有效的实施。然而面对庞大的系统,并不能苛求所有的功能测试都完毕之后,才能执行场景测试。实际上,在迭代式开发模型下,测试是以场景为目标进行迭代测试,先测试某个场景上用到的功能是正确可用的,然后确认该场景测试通过,然后再执行下一个场景所用到的功能。如此循环往复,根据场景优先级逐步完成系统测试。
全面的系统测试在理论上是不可行的,因为庞大的功能特征使得投入的人时将是个天文数字。而采取以结果为导向的场景测试,将会得到最大的投入产出比。所以说,测试场景的主要价值在于使用用户典型的应用场景,按用户需要的紧急重要程度进行测试,使得测试工作高效。但是,有一个残酷的现实,那就是凡是提供给用户的功能,用户就可能用到,就需要做到全面测试。所以场景的概念实际上是需要延伸到开发阶段的,在开发阶段,可以根据场景优先级开发需要的功能,那些场景用不到的功能就先不做,从而在源头上规避不必要的投入。然而,开发并不是真正的源,真正的源头是需求分析设计。用户的需求,用户的实际应用最有发言权,所以直接与用户沟通的人是最有发言权的,也就是他们可以设计出最高效的场景。需求是直接研究用户需求,研究用户应用场景的人,然后需求建立在研究的基础之上,设计出产品的真实需求来。所以需求最有应用场景的发言权,最应该首先提出来用户典型应用场景,然后再设计出这些场景需要用到的功能特征。所以要做到场景测试,实际上需要从需求开始做起,需求与用户沟通,确认用户的实际场景,然后分析这些场景,并据此设计出产品的解决方案,得到用户使用产品的应用场景,并排列出优先级;然后开发根据场景优先级开发出产品;最后测试根据场景优先级进行测试,并结合软件实际情况,给出拓展场景,给出使用说明,推荐给用户使用。
至此,场景测试的探讨告一段落,这也印证了一个概念,那就是工作的高效源自规划,规划越充分,最后实践的越顺利。 -
如何判断是否需要对一个软件进行性能测试?(本人原创)
godn_1981 发布于 2008-05-15 21:48:49
这个问题是51testing在0425的一个有奖问答题目,下面是本人的回答,呵呵,居然获得第一名~~

回答正文:
关于性能测试的看法
关于楼主的问题:有的软件没做性能测试,客户反馈了很多性能问题;有的软件没做性能测试,客户从没抱怨性能有问题;有的软件做了性能测试,客户依然反馈了很多性能问题;有的软件做了性能测试,客户从没抱怨性能有问题……
这确实是个问题。
其实我倒觉得问题不是要不要做的问题,而是怎么做,做多少的问题!
请注意,没有任何一个软件不需要做性能测试,而是说需要程度到底有多高,这个需求程度决定了花多少精力去做,并且怎么做的问题。
就算一个只有1000行代码的小程序,你怎么能保证它不需性能测试?你怎么知道它里面就没有内存溢出?你怎么知道它有没有耗费了不必要的资源?
所以问题不是做不做的问题,而是花多少代价,怎么做的问题。
一般性能测试有几个层次,或者说两个需求。
a.为了找出性能问题
b.为了给出性能指标
c.为了给出需要的配置
而我们国内现在常做的软件无非有几种:1.单机版应用程序 2.C/S或者B/S的项目(一般是外包项目或者政府软件,银行,医疗证券类软件)
对于单机版应用程序来说,一般作性能测试是比较简单的,一般需求是两个,
第一,你要测试一下有没有内存泻漏,或者深情况下内存溢出,或者有没有申请一些没必要的资源。这个一般要用一些分析工具
第二,一般一个单机版应用程序,你总要给出,最低配置或者建议配置什么的,那么你给客户这个东西 就需要性能测试,测试一下在各种配置下面的运行情况,给出理想的建议值
对于C/S或者B/S结构的软件就比较复杂了,一般是必须要做性能测试的。这个性能测试一般从以下方面考虑:
第一,优化
这个还是去考虑性能有没有问题,这个是起码的要求。特别是B/S系统,有没有多余请求,资源有没有释放之类的问题,要先考虑的。这类的问题,一般用网络分析工具就可以搞定。
第二,时间
这个是一般性能测试的重点。一般是用性能测试工具LR或WAS之类的做,这个叫负载测试。一般你测试一个软件,总要给老大一个结论,500人并发时,响应时间大概是几秒,300人并发时,是几秒。这个是每个客户都会要的。
第三,配置
这个也是性能测试的重点。这个一般叫压力测试。譬如一般客户会向你要一个数据:我想500人同时并发,响应时间在3秒之内,那么我的服务器要求最低配置是多少?这个嘛,你就只管压吧!压垮了,升级服务器,再压,又垮了,继续升级,到客户要求的性能指标达到为止,呵呵~~~~~~~~~~~~
总结一下,不是要不要做的问题,而是怎么做,按照客户要求哪些需求,哪些指标做的问题!51testing地址:http://bbs.51testing.com/thread-113138-2-1.html
-
白盒测试中的六种覆盖方法
87117899 发布于 2007-05-15 11:08:39
摘要:白盒测试作为测试人员常用的一种测试方法,越来越受到测试工程师的重视。白盒测试并不是简单的按照代码设计用例,而是需要根据不同的测试需求,结合不同的测试对象,使用适合的方法进行测试。因为对于不同复杂度的代码逻辑,可以衍生出许多种执行路径,只有适当的测试方法,才能帮助我们从代码的迷雾森林中找到正确的方向。本文介绍六种白盒子测试方法:语句覆盖、判定覆盖、条件覆盖、判定条件覆盖、条件组合覆盖、路径覆盖。
白盒测试的概述
由于逻辑错误和不正确假设与一条程序路径被运行的可能性成反比。由于我们经常相信某逻辑路径不可能被执行, 而事实上,它可能在正常的情况下被执行。由于代码中的笔误是随机且无法杜绝的,因此我们要进行白盒测试。
白盒测试又称结构测试,透明盒测试、逻辑驱动测试或基于代码的测试。白盒测试是一种测试用例设计方法,盒子指的是被测试的软件,白盒指的是盒子是可视的,你清楚盒子内部的东西以及里面是如何运作的。
白盒的测试用例需要做到:
·保证一个模块中的所有独立路径至少 被使用一次
·对所有逻辑值均需测试 true 和 false
·在上下边界及可操作范围内运行所有循环
·检查内部数据结构以确保其有效性白盒测试的目的:通过检查软件内部的逻辑结构,对软件中的逻辑路径进行覆盖测试;在程序不同地方设立检查点,检查程序的状态,以确定实际运行状态与预期状态是否一致。
白盒测试的特点:依据软件设计说明书进行测试、对程序内部细节的严密检验、针对特定条件设计测试用例、对软件的逻辑路径进行覆盖测试。
白盒测试的实施步骤:
1.测试计划阶段:根据需求说明书,制定测试进度。
2.测试设计阶段:依据程序设计说明书,按照一定规范化的方法进行软件结构划分和设计测试用例。
3.测试执行阶段:输入测试用例,得到测试结果。
4.测试总结阶段:对比测试的结果和代码的预期结果,分析错误原因,找到并解决错误。白盒测试的方法:总体上分为静态方法和动态方法两大类。
静态分析是一种不通过执行程序而进行测试的技术。静态分析的关键功能是检查软件的表示和描述是否一致,没有冲突或者没有歧义。
动态分析的主要特点是当软件系统在模拟的或真实的环境中执行之前、之中和之后 , 对软件系统行为的分析。动态分析包含了程序在受控的环境下使用特定的期望结果进行正式的运行。它显示了一个系统在检查状态下是正确还是不正确。在动态分析技术中,最重要的技术是路径和分支测试。下面要介绍的六种覆盖测试方法属于动态分析方法。
白盒测试的优缺点
1. 优点
·迫使测试人员去仔细思考软件的实现
·可以检测代码中的每条分支和路径
·揭示隐藏在代码中的错误
·对代码的测试比较彻底
·最优化2. 缺点
·昂贵
·无法检测代码中遗漏的路径和数据敏感性错误
·不验证规格的正确性六种覆盖方法
首先为了下文的举例描述方便,这里先给出一张程序流程图。(本文以1995年软件设计师考试的一道考试题目为例,图中红色字母代表程序执行路径)。
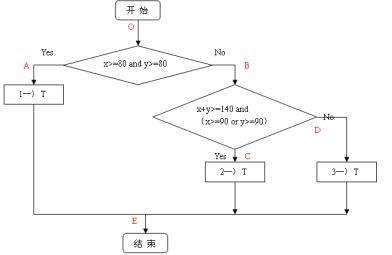
1、语句覆盖
1)主要特点:语句覆盖是最起码的结构覆盖要求,语句覆盖要求设计足够多的测试用例,使得程序中每条语句至少被执行一次。
2)用例设计:(如果此时将A路径上的语句1—〉T去掉,那么用例如下)
XY路径15050OBDE29070OBCE3)优点:可以很直观地从源代码得到测试用例,无须细分每条判定表达式。
4)缺点:由于这种测试方法仅仅针对程序逻辑中显式存在的语句,但对于隐藏的条件和可能到达的隐式逻辑分支,是无法测试的。在本例中去掉了语句1—〉T去掉,那么就少了一条测试路径。在if结构中若源代码没有给出else后面的执行分支,那么语句覆盖测试就不会考虑这种情况。但是我们不能排除这种以外的分支不会被执行,而往往这种错误会经常出现。再如,在Do-While结构中,语句覆盖执行其中某一个条件分支。那么显然,语句覆盖对于多分支的逻辑运算是无法全面反映的,它只在乎运行一次,而不考虑其他情况。
2、判定覆盖
1)主要特点:判定覆盖又称为分支覆盖,它要求设计足够多的测试用例,使得程序中每个判定至少有一次为真值,有一次为假值,即:程序中的每个分支至少执行一次。每个判断的取真、取假至少执行一次。
2)用例设计:
XY路径19090OAE25050OBDE39070OBCE3)优点:判定覆盖比语句覆盖要多几乎一倍的测试路径,当然也就具有比语句覆盖更强的测试能力。同样判定覆盖也具有和语句覆盖一样的简单性,无须细分每个判定就可以得到测试用例。
4)缺点:往往大部分的判定语句是由多个逻辑条件组合而成(如,判定语句中包含AND、OR、CASE),若仅仅判断其整个最终结果,而忽略每个条件的取值情况,必然会遗漏部分测试路径。
3、条件覆盖
1)主要特点:条件覆盖要求设计足够多的测试用例,使得判定中的每个条件获得各种可能的结果,即每个条件至少有一次为真值,有一次为假值。
2)用例设计:
XY路径19070OBC240OBD3)优点:显然条件覆盖比判定覆盖,增加了对符合判定情况的测试,增加了测试路径。
4)缺点:要达到条件覆盖,需要足够多的测试用例,但条件覆盖并不能保证判定覆盖。条件覆盖只能保证每个条件至少有一次为真,而不考虑所有的判定结果。
4、判定/条件覆盖
1)主要特点:设计足够多的测试用例,使得判定中每个条件的所有可能结果至少出现一次,每个判定本身所有可能结果也至少出现一次。
2)用例设计:
XY路径19090OAE25050OBDE39070OBCE47090OBCE3)优点:判定/条件覆盖满足判定覆盖准则和条件覆盖准则,弥补了二者的不足。
4)缺点:判定/条件覆盖准则的缺点是未考虑条件的组合情况。
5、组合覆盖
1)主要特点:要求设计足够多的测试用例,使得每个判定中条件结果的所有可能组合至少出现一次。
2)用例设计:
XY路径19090OAE29070OBCE39030OBDE47090OBCE53090OBDE67070OBDE75050OBDE3)优点:多重条件覆盖准则满足判定覆盖、条件覆盖和判定/条件覆盖准则。更改的判定/条件覆盖要求设计足够多的测试用例,使得判定中每个条件的所有可能结果至少出现一次,每个判定本身的所有可能结果也至少出现一次。并且每个条件都显示能单独影响判定结果。
4)缺点:线性地增加了测试用例的数量。
6、路径覆盖
1)主要特点:设计足够的测试用例,覆盖程序中所有可能的路径。
2)用例设计:
XY路径19090OAE25050OBDE39070OBCE47090OBCE3)优点:这种测试方法可以对程序进行彻底的测试,比前面五种的覆盖面都广。
4)缺点:由于路径覆盖需要对所有可能的路径进行测试(包括循环、条件组合、分支选择等),那么需要设计大量、复杂的测试用例,使得工作量呈指数级增长。而在有些情况下,一些执行路径是不可能被执行的,如:
If (!A)B++;
If (!A)D--;这两个语句实际只包括了2条执行路径,即A为真或假时候对B和D的处理,真或假不可能都存在,而路径覆盖测试则认为是包含了真与假的4条执行路径。这样不仅降低了测试效率,而且大量的测试结果的累积,也为排错带来麻烦。
总结
白盒测试是一种被广泛使用的逻辑测试方法,是由程序内部逻辑驱动的一种单元测试方法。只有对程序内部十分了解才能进行适度有效的白盒测试。但是贯穿在程序内部的逻辑存在着不确定性和无穷性,尤其对于大规模复杂软件。因此我们不能穷举所有的逻辑路径,即使穷举也未必会带来好运(穷举不能查出程序逻辑规则错误,不能查出数据相关错误,不能查出程序遗漏的路径)。
那么正确使用白盒测试,就要先从代码分析入手,根据不同的代码逻辑规则、语句执行情况,选用适合的覆盖方法。任何一个高效的测试用例,都是针对具体测试场景的。逻辑测试不是片面的测试正确的结果或是测试错误的结果,而是尽可能全面地覆盖每一个逻辑路径。
-
白盒测试实例1~10(转)
lc1119 发布于 2009-03-02 11:25:47
白盒测试实例之一——需求说明
三角形的问题在很多软件测试的书籍中都出现过,问题虽小,五脏俱全,是个很不错的软件测试的教学例子。本文借助这个例子结合教学经验,从更高的视角来探讨需求分析、软件设计、软件开发与软件测试之间的关系与作用。
题目:根据下面给出的三角形的需求完成程序并完成测试:
一、输入条件:
1、 条件1:a+b>c
2、 条件2:a+c>b
3、 条件3:b+c>a
4、 条件4:0<a<200
5、 条件5:0<b<200
6、 条件6:0<c<200
7、 条件7:a==b
8、 条件8:a==c
9、 条件9:b==c
10、条件10:a2+b2==c2
11、条件11:a2+ c2== b2
12、条件12:c2+b2== a2
二、输出结果:
1、不能组成三角形
2、等边三角形
3、等腰三角形
4、直角三角形
5、一般三角形
6、某些边不满足限制
白盒测试实例之二——答案
很多初学者一看到这个需求(详见白盒测试实例之一——需求说明收藏),都觉得很简单,然后立刻就开始动手写代码了,这并不是一个很好的习惯。如果你的第一直觉也是这样的,不妨耐心看到文章的最后。
大部分人的思路:
1、首先建立一个main函数, main函数第一件事是提示用户输入三角形的三边,然后获取用户的输入(假设用户的输入都是整数的情况),用C语言来写,这一步基本上不是问题(printf和scanf),但是要求用java来写的话,很多学生就马上遇到问题了,java5.0及之前的版本不容易获取用户的输入。
点评:这样的思路做出来的程序只能通过手工方式来测试所有业务逻辑,而且这个程序只能是DOS界面版本了,要是想使用图形化界面来做输入,就得全部写过代码。
2、业务处理流程的思路用流程图表示如下:

3、C语言代码:
1. #include<stdio.h>
2. void main()
3. {
4. int a, b, c;
5. printf("please enter three integer:");
6. scanf("%d%d%d", &a, &b, &c);
7. if(0<a && a<200 && 0<b && b<200 && 0<c && c<200)
8. {
9. if(a+b>c && a+c>b && c+b>a)
10. {
11. if(a==b && b==c && a==c) //这里可以省掉一个判断
12. {
13. printf("1是等边三角形");
14. }
15. else
16. {
17. if(a==b || b==c || a==c)
18. {
19. printf("2是等腰三角形");
20. }
21. else
22. {
23. if(a*a+b*b==c*c || a*a+c*c==b*b || b*b+c*c==a*a)
24. {
25. printf("3是直角三角形");
26. }
27. else
28. {
29. printf("4是一般三角形");
30. }
31. }
32. }
33. }
34. else
35. {
36. printf("5不能组成三角形");
37. }
38. }
39. else
40. {
41. printf("6某些边不满足限制");
42. }
43. }点评:这样的思路做出来的程序只能通过手工方式来测试所有业务逻辑,而且这个程序只能是DOS界面版本了,要是想使用web或图形化界面来做输入,就得全部写过代码。
相关阅读:
白盒测试实例之三——需求分析
关键字:白盒测试、需求分析
需求分析是后续工作的基石,如果分析思路有问题,后续工作可能就会走向不正确的方向,比如:代码重用性差、难于测试、难于扩展和难于维护等。反而,如果需求分析做的好,对设计、开发和测试来说,都可能是很大的帮助。
看到题目给出的条件达12个之多,粗粗一看,好像很复杂,但仔细分析之后,发现可以把它们分成4组来讨论:
1、 条件1:a+b>c; 条件2:a+c>b; 条件3:b+c>a
这三个表达式有什么特点呢?实际上它们的逻辑是一样的:两个数之和大于第三个数。那么,前面程序的写法就存在逻辑重复的地方,应该把这个逻辑提取到一个函数中。
2、 条件4:0<a<200; 条件5:0<b<200; 条件6:0<c<200
这三个表达式也是同一个逻辑:判断一个数的范围是否在(0, 200)区间内,也应该把这个逻辑提取到一个函数中,去掉重复的逻辑,提高代码的可重用性。
可重用性的好处:比如,现在用户的需求改为了三条边的取值范围要改为[100,400],那么,按前面的思路来说,需要改3个地方,而现在只需要在一个函数里改1个地方,这就是代码重用的好处。
3、条件7:a==b; 条件8:a==c; 条件9:b==c
这三个表达式的逻辑:判断两个数是否相等。也应该把它提取到一个函数中。
我们进一步来分析一下判断是否是等边三角形或等腰三角形的条件:
(1)前面程序的判断是从最直观的方式(a==b && b==c && a==c)(实际上只需要两个表达式成立即可)三条边都相等来判定是等边三角形;(a==b || b==c || a==c)只有两条边相等来判定是等腰三角形。
(2)转变一下思路:给定三个整数,然后用一个函数来判断这三个整数有几个相等,返回相等的个数,如果返回值等于3,那么它是等边三角形,如果返回值是2,那么它是等腰三角形,否则,它是一般三角形(如果不是直角三角形的话)。
4、条件10:a2+b2==c2 条件11:a2+ c2== b2 条件12:c2+b2== a2
这三个条件的处理方式有两种:
(1)跟前面三组分析一样,把相同的逻辑提取到一个函数中,然后三次调用。
(2)根据直角三角形的特点:斜边是最长的,所以我们可以事先写一个函数来找到最长的边,然后把它赋值给c,这样处理之后,只需要一次调用判定(a2+b2==c2)的函数了。
相关阅读:
白盒测试实例之四——程序设计
关键字:白盒测试
程序设计对于软件的质量和软件实施过程的难易程度起着至关重要的作用。好的设计,即使聘用没什么经验的开发人员都很容易产生出高质量的代码出来;而差的设计,即使是经验很丰富的开发人员也很容易产生缺陷,特别是可重用性、可测试性、可维护性、可扩展性等方面的缺陷。
经过以上的分析,下面来看一下如何设计。在下图中,每个方框都使用一个函数来实现,为了跟用户界面分开,最顶上的函数不要写在main函数中。
把思路用流程图的方式表达出来,不用停留在脑袋里:

具体的函数的调用关系图:

复杂模块triangleType的流程图:

相关阅读:
白盒测试实例之五——编码
1、Triangle.h
1. /*
2. * Copyright (c) 2008, 胡添发(hutianfa@163.com)
3. *
4. * 三角形类型判断
5. *
6. */
7.
8. #include<stdio.h>
9. #include<String.h>
10.
11. /*
12. * 判断一个整数是否在(0, 200)区间内
13. * 返回值:true-否; false-是
14. */
15. bool isOutOfRange(int i);
16.
17. /*
18. * 判断三条边是否合法(即:判断三条边都在合法的范围内)
19. * 返回值:true-是; false-否
20. */
21. bool isLegal(int a, int b, int c);
22.
23. /*
24. * 判断两条边之和是否大于第三边
25. * 返回值:true-是; false-否
26. */
27. bool isSumBiger(int a, int b, int c);
28.
29. /*
30. * 判断三条边是否能够组成三角形
31. * 返回值:true-是; false-否
32. */
33. bool isTriangle(int a, int b, int c);
34.
35. /*
36. * 判断两条边是否相等
37. * 返回值:true-是; false-否
38. */
39. bool isEquals(int a, int b);
40.
41. /*
42. * 求三角形有几条边相等
43. * 返回值:相等边的数量
44. */
45. int howManyEquals(int a, int b, int c);
46.
47. /*
48. * 判断是否满足两边平方之和是否等于第三边的平方
49. *
50. */
51. bool isPowerSumEquals(int a, int b, int c);
52.
53. /*
54. * 判断第一个数是否比第二个数大
55. */
56. bool isGreaterThan(int a, int b);
57.
58. /*
59. * 判断是否是直角三角形
60. *
61. */
62. bool isRightRriangle(int a, int b, int c);
63.
64. /*
65. * 判断三角形的类型,返回值:
66. * 1、不能组成三角形
67. * 2、等边三角形
68. * 3、等腰三角形
69. * 4、直角三角形
70. * 5、一般三角形
71. * 6、某些边不满足限制
72. */
73. int triangleType(int a, int b, int c);
白盒测试实例之六——单元测试的步骤
单元测试的步骤:
1、 理解需求和设计
理解设计是很重要的,特别是要搞清楚被测试模块在整个软件中所处的位置,这对测试的内容将会有很大的影响。需要记住的一个原则就是:好的设计,各模块只负责完成自己的事情,层次与分工是很明确的。在单元测试的时候,可以不用测试不属于被测试模块所负责的功能,以减少测试用例的冗余,集成测试的时候会有机会测试到的。
举例:
1. /*
2.
3. * 判断三条边是否能够组成三角形
4.
5. * 返回值:true-是; false-否
6.
7. */
8.
9. bool isTriangle(int a, int b, int c);
测试该函数的时候,只需要测试三条边(在合法的取值范围内的整数)是否能够满足两边之和是否大于第三边的功能,而不需要测试三条边是否在合法的范围(0, 200)之间的整数,因为调用该函数之前,一定要先通过下面函数的检查,要是检查不通过,就不会执行isTriangle函数。
1. /*
2.
3. * 判断三条边是否合法(即:判断三条边都在合法的范围内)
4.
5. * 返回值:true-是; false-否
6.
7. */
8.
9. bool isLegal(int a, int b, int c);
所以,单元测试主要是关注本单元的内部逻辑,而不用关注整个业务的逻辑,因为会有别的模块去完成相关的功能。
白盒测试实例之七——单元测试的尝试
以测试isOutOfRange函数为例,首先知道该函数在整个软件架构中处于最底层(叶子),所以对它进行测试并不需要写桩模块,只需要写驱动模块。要注意的问题是:对于测试结果是否通过测试不要使用printf方式打印被测试函数的返回结果值,否则就需要人工去检查结果了。
使用边界值的方法可以得到5个测试用例,写的驱动模块代码如下:
TestTriangle.cpp:
1. /*
2. * Copyright (c) 2008, 胡添发(hutianfa@163.com)
3. *
4. * 单元测试与集成测试
5. *
6. */
7. #include "Triangle.h"
8. /*
9. * 测试isOutOfRange函数,使用边界值的方法(0,1,5,199,200)
10. *
11. */
12. void testIsOutOfRange_try()
13. {
14. if(isOutOfRange(0) == true)
15. {
16. printf("pass!\n");
17. }
18. else
19. {
20. printf("fail!\n");
21. }
22.
23. if(isOutOfRange(1) == false)
24. {
25. printf("pass!\n");
26. }
27. else
28. {
29. printf("fail!\n");
30. }
31.
32. }
33.
34.
35. void main()
36. {
37. testIsOutOfRange_try();
38. }
小知识:做单元测试的时候,一般不直接在main函数中写所有的测试代码,否则的话,main函数将会非常庞大。正确的做法:针对每个函数分别创建一个或若干个(函数比较复杂时)测试函数,测试函数的名称习惯以test开头。
写到这里发现重复的代码太多了,而且如果测试用例数量很多的话,对于测试结果的检查也将是很大的工作量。在测试有错误的时候,这样的单元测试结果也很难获得更多关于错误的信息。
解决问题的途径可以采用cppUnit单元测试框架。不过这里为了让学生能够对单元测试和单元测试框架有进一步的理解,我决定自己写一个类似cppUnit的简单的测试框架。
相关阅读:
白盒测试实例之八——构建自己的单元测试框架(上)
在上一讲“单元测试的尝试”里我们遇到了几个问题:
1、代码重复的问题太多
2、测试结果需要人工去检查
3、对测试的总体信息也无从得知
本讲将构建一个简单的单元测试框架来解决以上的问题:
1、代码重复的问题太多
这个问题很容易解决,只需要把判断预期结果和实际结果的逻辑提取到某个函数中即可。从整个代码来看,有两种类型的结果的函数:
(1)返回布尔型
(2)返回整数
因此,需要两个类型的判断预期结果和实际结果是否相符的函数:
1. /*
2. * 判断是否取值为真
3. */
4. void assertTrue(char *msg, bool actual)
5. {
6. if(actual)
7. {
8. printf(".");
9. }
10. else
11. {
12. printf("F");
13. }
14. }
15.
16. /*
17. * 判断预期结果和实际结果是否相符
18. */
19. void assertEquals(char *msg, int expect, int actual)
20. {
21. if(expect == actual)
22. {
23. printf(".");
24. }
25. else
26. {
27. printf("F");
28. }
29. }
小知识:XUnit系列的框架的习惯使用assert*的命名来定义判断函数,对于通过的测试习惯打印一个“.”号,而对于失败的测试习惯打印一个“F”。
2、测试结果需要人工去检查
对于测试结果不要使用printf方式打印被测试函数的返回结果值就可以避免这个问题。
3、对测试的总体信息也无从得知
除了问题1的解决办法里使用“.”表示测试通过和“F”表示测试失败可以提高对测试结果的信息的直观性之外,做单元测试的人还希望能够得到以下的信息:
(1)执行的测试用例总数、通过的数量和失败的数量
(2)测试执行的时间
(3)如果测试用例执行失败了,希望知道是哪个测试用例失败,从而去分析失败的原因。
白盒测试实例之九——构建自己的单元测试框架(下)
完整的源代码如下:
1、UnitTest.h
1. /*
2. * Copyright (c) 2008, 胡添发
3. *
4. * 简单的单元测试框架
5. *
6. */
7.
8. #include<stdio.h>
9. #include<string.h>
10. #include<time.h>
11. #include<stdlib.h>
12.
13. /*
14. * VC中没有sleep函数,自己写一个
15. * wait单位是毫秒
16. */
17. extern void sleep(clock_t wait);
18.
19.
20. /*
21. * 判断是否取值为真
22. */
23. void assertTrue(char *msg, bool actual);
24.
25. /*
26. * 判断预期结果和实际结果是否相符
27. */
28. void assertEquals(char *msg, int expect, int actual);
29.
30. /*
31. * 初始化测试,开始计时
32. */
33. void init();
34.
35. /*
36. * 结束测试,结束计时,打印报告
37. */
38. void end();
白盒测试实例之十——集成测试的概念
测一、桩模块和驱动模块(以C语言为例):
很多人对桩模块和驱动模块的概念会搞不清楚,下面先介绍这两个概念:
模块结构实例图:

假设现在项目组把任务分给了7个人,每个人负责实现一个模块。你负责的是B模块,你很优秀,第一个完成了编码工作,现在需要开展单元测试工作,先分析结构图:
1、由于B模块不是最顶层模块,所以它一定不包含main函数(A模块包含main函数),也就不能独立运行。
2、B模块调用了D模块和E模块,而目前D模块和E模块都还没有开发好,那么想让B模块通过编译器的编译也是不可能的。
那么怎样才能测试B模块呢?需要做:
1、写两个模块Sd和Se分别代替D模块和E模块(函数名、返回值、传递的参数相同),这样B模块就可以通过编译了。Sd模块和Se模块就是桩模块。
2、写一个模块Da用来代替A模块,里面包含main函数,可以在main函数中调用B模块,让B模块运行起来。Da模块就是驱动模块。
知识点:
桩模块的使命除了使得程序能够编译通过之外,还需要模拟返回被代替的模块的各种可能返回值(什么时候返回什么值需要根据测试用例的情况来决定)。
驱动模块的使命就是根据测试用例的设计去调用被测试模块,并且判断被测试模块的返回值是否与测试用例的预期结果相符。
二、集成测试策略:
1、 非增式集成测试
各个单元模块经过单元测试之后,一次性组装成完整的系统。
优点:集成过程很简单。
缺点:出现集成问题时,查找问题比较麻烦,而且测试容易遗漏。
范例:

2、 增式集成测试
(1)自顶向下
A、 纵向优先
从最顶层开始测试,需要写桩模块。测试的顺序:从跟节点开始,每次顺着某枝干到该枝干的叶子节点添加一个节点到已测试好的子系统中,接着再加入另一枝干的节点,直到所有节点集成到系统中。
B、 横向优先
跟纵向优先的区别在于:每次并不是顺着枝干走到叶子,而是逐一加入它的直属子节点。
纵向优先的范例:

(2)自底向上
每次从叶子节点开始测试,测试过的节点摘掉,然后把树上的叶子节点摘下来加入到已经测试好的子系统之中。优点:不需要写桩模块,但需要写驱动模块。
范例:

相关阅读:
-
如何在 LoadRunner 脚本中做关联 (Correlation)(转)
zhong51test 发布于 2008-11-26 14:53:41
如何在 LoadRunner 脚本中做关联 (Correlation)
当录制脚本时,VuGen会拦截client端(浏览器)与server端(网站服务器)之间的对话,并且通通记录下来,产生脚本。在VuGen 的Recording Log中,您可以找到浏览器与服务器之间所有的对话,包含通讯内容、日期、时间、浏览器的请求、服务器的响应内容等等。脚本和Recording Log最大的差别在于,脚本只记录了client端要对server端所说的话,而Recording Log则是完整纪录二者的对话。
当执行脚本时,您可以把VuGen想象成是一个演员,它伪装成浏览器,然后根据脚本,把当初真的浏览器所说过的话,再对网站伺服器重新说一遍,VuGen企图骗过服务器,让服务器以为它就是当初的浏览器,然后把网站内容传送给VuGen。
所以纪录在脚本中要跟服务器所说的话,完全与当初录制时所说的一样,是写死的(hard-coded)。这样的作法在遇到有些比较聪明的服务器时,还是会失效。这时就需要透过「关联(correlation)」的做法来让VuGen可以再次成功地骗过服务器。
何谓关联(correlation)?
所谓的关联(correlation)就是把脚本中某些写死的(hard-coded)数据,转变成是撷取自服务器所送的、动态的、每次都不一样的数据。
举一个常见的例子,刚刚提到有些比较聪明的服务器,这些服务器在每个浏览器第一次跟它要数据时,都会在数据中夹带一个唯一的辨识码,接下来就会利用这个辨识码来辨识跟它要数据的是不是同一个浏览器。一般称这个辨识码为Session ID。对于每个新的交易,服务器都会产生新的Session ID给浏览器。这也就是为什么执行脚本会失败的原因,因为VuGen还是用旧的Session ID向服务器要数据,服务器会发现这个Session ID是失效的或是它根本不认识这个Session ID,当然就不会传送正确的网页数据给VuGen了。
下面的图示说明了这样的情形:
当录制脚本时,浏览器送出网页A的请求,服务器将网页A的内容传送给浏览器,并且夹带了一个ID=123的数据,当浏览器再送出网页B的情求时,这时就要用到ID=123的数据,服务器才会认为这是合法的请求,并且把网页B的内容送回给浏览器。
在执行脚本时会发生什么状况?浏览器再送出网页B的请求时,用的还是当初录制的ID=123的数据,而不是用服务器新给的ID=456,整个脚本的执行就会失败。
要对付这种服务器,我们必须想办法找出这个Session ID到底是什么、位于何处,然后把它撷取下来,放到某个参数中,并且取代掉脚本中有用到Session ID的部份,这样就可以成功骗过服务器,正确地完成整个交易了。
哪些错误代表着我应该做关联(correlation)?
假如脚本需要关联(correlation),在还没做之前是不会执行通过的,也就是说会有错误讯息发生。不过,很不幸地,并没有任何特定的错误讯息是和关联(correlation)有关系的。会出现什么错误讯息,与系统实做的错误处理机制有关。错误讯息有可能会提醒您要重新登入,但是也有可能直接就显示HTTP 404的错误讯息。
要如何做关联(correlation)?
关联(correlation)函数
关联(correlation)会用到下列的函数:
• web_reg_save_param:这是最新版,也是最常用来做关联(correlation)的函数。
语法:
web_reg_save_param ( “Parameter Name” , < list of Attributes >, LAST );
• web_create_html_param、web_create_html_param_ex:这二个函数主要是保留作为向前兼容的目的的。建议使用 web_reg_save_param 函数。
详细用法请参考使用手册。在VuGen中点选【Help】>【Function reference】>【Contexts】>【Web and Wireless Vuser Functions】>【Correlation Functions】。
如何找出要关联(correlation)数据
简单的说,每一次执行时都会变动的值,就有可能需要做关联(correlation)。
VuGen提供二种方式帮助您找出需要做关联(correlation)的值:
1. 自动关联
2. 手动关联
自动关联
VuGen内建自动关联引擎(auto-correlation engine),可以自动找出需要关联的值,并且自动使用关联函数建立关联。
自动关联提供下列二种机制:
• Rules Correlation:在录制过程中VuGen会根据订定的规则,实时自动找出要关联的值。规则来源有两种:
o 内建(Built-in Correlation):
VuGen已经针对常用的一些应用系统,如AribaBuyer、BlueMartini、BroadVision、InterStage、 mySAP、NetDynamics、Oracle、PeopleSoft、Siebel、SilverJRunner等,内建关联规则,这些应用系统可能会有一种以上的关联规则。您可以在【Recording Options】>【Internet Protocol】>【Correlation】中启用关联规则,则当录制这些应用系统的脚本时,VuGen会在脚本中自动建立关联。
您也可以在【Recording Options】>【Internet Protocol】>【Correlation】检视每个关联规则的定义。
o 使用者自订(User-defined Rules Correlation):
除了内建的关联规则之外,使用者也可以自订关联规则。您可以在【Recording Options】>【Internet Protocol】>【Correlation】建立新的关联规则。
• Correlation Studio:有别于Rules Correlation,Correlation Studio则是在执行脚本后才会建立关联,也就是说当录制完脚本后,脚本至少须被执行过一次,Correlation Studio才会作用。Correlation Studio会尝试找出录制时与执行时,服务器响应内容的差异部分,藉以找出需要关联的数据,并建立关联。
Rule Correlation
请依照以下步骤使用Rule Correlation:
1. 启用auto-correlation
1. 点选VuGen的【Tools】>【Recording Options】,开启【Recording Options】对话窗口,选取【Internet Protocol】>【Correlation】,勾选【Enable correlation during recording】,以启用自动关联。
2. 假如录制的应用系统属于内建关联规则的系统,如AribaBuyer、BlueMartini、BroadVision、InterStage、 mySAP、NetDynamics、Oracle、PeopleSoft、Siebel、SilverJRunner等,请勾选相对应的应用系统。
3. 或者也可以针对录制的应用系统加入新的关联规则,此即为使用者自订的关联规则。
4. 设定当VuGen侦测到符合关联规则的数据时,要如何处理:
【Issue a pop-up message and let me decide online】:跳出一个讯息对话窗口,询问您是否要建立关联。
【Perform correlation in sceipt】:直接自动建立关联
2. 录制脚本
开始录制脚本,在录制过程中,当VuGen侦测到符合关联规则的数据时,会依照设定建立关联,您会在脚本中看到类似以下的脚本,此为BroadVision应用系统建立关联的例子,在脚本批注部分可以看到关联前的数据为何。
3. 执行脚本验证关联是OK的。
Correlation Studio
当录制的应用系统不属于VuGen预设支持的应用系统时,Rule Correlation可能既无法发挥作用,这时可以利用Correlation Studio来做关联。
Correlation Studio会尝试找出录制时与执行时,服务器响应内容的差异部分,藉以找出需要关联的数据,并建立关联。
使用Correlation Studio的步骤如下:
1. 录制脚本并执行
2. 执行完毕后,VuGen会跳出下面的【Scan Action for Correlation】窗口,询问您是否要扫描脚本并建立关联,按下【Yes】按钮。
3. 扫描完后,可以在脚本下方的【Correlation Results】中看到扫描的结果。
4. 检查一下扫瞄的结果后,选择要做关联的数据,然后按下【Correlate】按钮,一笔一笔做,或是按下【Correlate All】让VuGen一次就对所有的数据建立关联。
注意:由于Correlation Studio会找出所有有变动的数据,但是并不是所有的数据都需要做关联,所以不建议您直接用【Correlate All】。
5. 一般来说,您必须一直重复步骤1~4直到所有需要做关联的数据都找出来为止。因为有时前面的关联还没做好之前,将无法执行到后面需要做关联的部份。
有可能有些需要做关联的动态数据,连Correlation Studio都无法侦测出来,这时您就需要自行做手动关联了。
手动关联
手动关联的执行过程大致如下:
1. 使用相同的业务流程与数据,录制二份脚本
2. 使用WinDiff工具协助找出需要关联的数据
3. 使用web_reg_save_param函数手动建立关联
4. 将脚本中有用到关联的数据,以参数取代
接下来将详细的说明如何执行每个步骤
使用相同的业务流程与数据,录制二份脚本
1. 先录制一份脚本并存档。
2. 依照相同的操作步骤与数据录制第二份脚本并存盘。注意,所有的步骤和输入的数据一定都要一样,这样才能找出由服务器端产生的动态数据。
有时候会遇到真的无法使用相同的输入数据,那您也要记住您使用的输入数据,到时才能判断是您输入的数据,还是变动的数据。
使用WinDiff工具协助找出需要关联的数据
1. 在第二份脚本中,点选VuGen的【Tools】>【Compare with Vuser…】,并选择第一份脚本。
2. 接着WinDiff会开启,同时显示二份脚本,并显示有差异的地方。WinDiff会以一整行黄色标示有差异的脚本,并且以红色的字体显示真正差异的文字。(假如没看到红色字体,请点选【Options】>【View】>【Show Inline Differences】)。
3. 逐一检视二份脚本中差异的部份,每一个差异都可能是需要做关联的地方。选取差异的脚本,然后复制。
在复制时,有时并不需要取整行脚本,可能只会选取脚本中的一部分。
注意:请忽略lr_thik_time的差异部份,因为lr_thik_time是用来模拟每个步骤之间使用者思考延迟的时间。
4. 接着要在Recording Log(单一protocol)或是Generation Log(多重protocol)中找这个值。将鼠标光标点到Recording Log的第一行开头,按下Ctrl+F,开启【Find】窗口,贴上刚刚复制的脚本,找出在Recording Log第一次出现的位置。
结果会有二种:
o 在Recording Log中找不到要找的数据,这时请先确认您找对了脚本,毕竟现在开启了二个几乎一样的脚本,很容易弄错。
o 在Recording Log中找到了要找的数据,这时要确认数据是从服务器端传送过来的。首先可以先检查数据的标头,从标头的Receiving response可以知道数据是从服务器端传送到client端的。假如此数据第一次出现是在Sending request中,则表示此数据是由client端产生,不需要做关联,但是有可能需要做参数化(parameterized)。
您要找的标头格式如下:
*** [tid=b9 Action1 2] Receiving response from host astra.merc-int.com:80 ( 25/11/2002 12:04:00 )
5. 现在您已经找到录制二次都不一样,而且是由服务器所产生的动态数据了,而此数据极有可能需要做关联。
使用web_reg_save_param函数手动建立关联
在找到是由服务器所产生的动态数据之后,接下来要做的就是找出适当的位置,使用web_reg_save_param函数,将这个动态数据撷取到某个参数中。
1. 要在哪里使用web_reg_save_param函数?
在之前的步骤,我们已经在Execution Log找到可能需要关联的动态数据。在Execution Log中选取动态数据前的文字然后复制,我们将会利用这段文字,来帮助我们找出要关联的动态数据。
不过在这之前我们要先找出使用web_reg_save_param函数的正确位置,所以我们要再重新执行一遍脚本,而且这次会开启所有的Log。
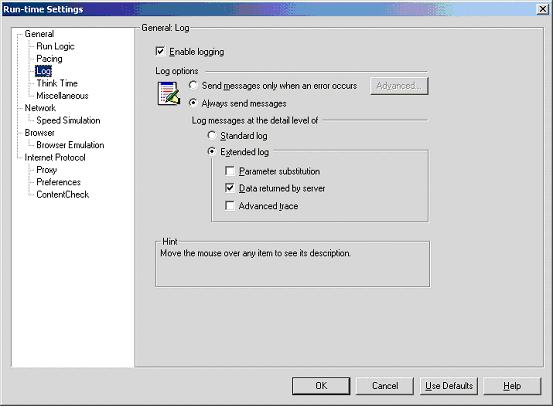
1. 在VuGen中点选【Vuser】>【Run-Time Settings】。
2. 点选【General】>【Log】。
3. 勾选【Enable logging】、【Always sends messages】、【Extended log】,以及【Extended log】下的所有选项。
4. 按下【OK】就可以执行脚本了。
执行完脚本之后,在Execution Log中搜寻刚刚复制的字符串。找到字符串后,在字符串前面会有A.tion1.c(7),这个7就是到时候要插入web_reg_save_param函数的位置,也就是要插入到脚本的第7行。
在脚本的第7行前插入一行空白行,然后输入
web_reg_save_param(“UserSession”,
“UserSession” 这个 “UserSession” 就是到时要使用的参数名称,建议给个有意义的名字。
注意:到这里整个web_reg_save_param函数还没完成。
2. 找出web_reg_save_param中要用到的边界
web_reg_save_param函数主要是透过动态数据的前面和后面的固定字符串,来辨识要撷取的动态数据的,所以我们还需要找出动态数据的边界字符串。
找出左边界字符串
再回到Execution Log中,选取动态数据前的字符串并且复制它。
这时会有个问题,到底要选取多少字符串才足以唯一识别要找的动态数据呢?建议是越多越好,但是尽量不要包含到特殊字符。
在这边我们选取「input type=hidden name=userSession value=」字符串。选好之后,还要再确认一次这段字符串真的是可以唯一识别的,所以我们在Execution Log中透过Ctrl+F的搜寻,找找看这段字符串是否可以找到要找的动态数据。假如找不到,web_reg_save_param函数还有个ORD参数可以使用,ORD参数可以设定出现在第几次的字符串才是要找的字符串。
将这个边界字符串加到未完成的web_reg_save_param函数中:
web_reg_save_param(“UserSession”, “LB= input type=hidden name=userSession value=”,
找出右边界字符串
接下来要找出动态数据的右边界字符串,这个字符串就比较好找了,从动态数据的最后一个字符开始,通常就是我们要找的右边界字符串了。
以这个例子来看,就是「>」,所以再把右边界字符串加入,web_reg_save_param函数中,这时web_reg_save_param函数已经快完成了。最后再加上「LAST);」就完成整个web_reg_save_param函数了。
web_reg_save_param(“UserSession”, “LB= input type=hidden name=userSession value=”, “RB=>”, LAST);
将脚本中有用到关联的数据,以参数取代
当使用web_reg_save_param建立参数后,接下来就是用“UserSession”参数去取代脚本中写死的(hard-coded)资料。
范例:
将
“Name=userSession”, “Value=75893.0884568651DQADHfApHDHfcDtccpfAttcf”, ENDITEM,
换成
“Name=userSession”, “Value={UserSession}”, ENDITEM,
到这里您已经完成了一个关联了,接下来就是执行脚本,是否能成功运行,假如还是有问题,就要检查看看是否还需要再做另一个关联。
关于 web_reg_save_param 函数
对于关联(correlation)来说,web_reg_save_param是最重要的一个函数,其功能是在下载的网页内容中,透过设定的边界字符串,找出特定的数据并将其储存在一个参数中,以供后续脚本使用。
接下来将针对web_reg_save_param做比较详细的说明。
Service and registration type function
web_reg_save_param是一个Service function。service function主要是用来完成一些特殊的工作的,如关联、设定proxy、提供认证信息等,当其作用时,不会对网页的内容做任何的修改。
web_reg_save_param同时也是一个registration type function (只要函数名称中包含_reg_的字眼,表示其为registration type function)。registration type function意味着其真正作用的时机是在下一个action function完成时执行的。举例来说,当某个web_url执行时所接收到的网页内容中包含了要做关联的动态数据,则必须将 web_reg_save_param放在此web_url之前,则web_reg_save_param会在web_url执行完毕后,也就是网页内容都下载完后,再执行web_reg_save_param找寻要做关联的动态数据并建立参数。
所以要记住一点,要使用registration type function时,要注意其放置的位置必须在要作用的action function之前。
语法
int web_reg_save_param(const char *ParamName, <list of Attributes>, LAST);
参数说明
ParamName:存放动态数据的参数名称
list of Attributes:其它属性,包含 Notfound, LB, RB, RelFrameID, Search, ORD, SaveOffset, Convert, 以及 SaveLen。属性值不分大小写,例如 Search=all。以下将详细说明每个属性值的意义:
• Notfound:指定当找不到要找的动态数据时该怎么处置。
o Notfound=error:当找不到动态数据时,发出一个错误讯息。假如没设定此属性,此为LoadRunner的默认值。
o Notfound=warning:当找不到动态数据时,不发出错误讯息,只发出警告,脚本也会继续执行下去不会中断。在对角本除错时,可以使用此属性值。
• LB:动态数据的左边界字符串。此属性质是必须要有的,而且区分大小写。
• RB:动态数据的右边界字符串。此属性质是必须要有的,而且区分大小写。
• RelFrameID:相对于URL而言,欲搜寻的网页的Frame。此属性质可以是All或是数字,而且可有可无。
• Search:搜寻的范围。可以是Headers(只搜寻headers)、Body(只搜寻body部分,不搜寻header)、Noresource (只搜寻body部分,不搜寻header与resource)或是All(搜寻全部范围,此为默认值)。此属性质可有可无。
• ORD:指明从第几次出现的左边界开始才是要撷取的数据。此属性质可有可无,默认值是1。假如值为All,则所有找到符合的数据会储存在数组中。
• SaveOffset:当找到符合的动态数据时,从第几个字符开始才开始储存到参数中。此属性质不可为负数,其默认值为0。
• Convert:可能的值有二种:
o HTML_TO_URL: 将HTML-encoded数据转成URL-encoded数据格式
o HTML_TO_TEXT:将HTML-encoded数据转成纯文字数据格式
• SaveLen:从offect开始算起,到指定的长度内的字符串,才储存到参数中。此参数可有可无,默认值是-1,表示储存到结尾整个字符串。
范例
web_reg_save_param("A", "LB/ic=<a href=", "RB='>", "Ord=All", LAST);nner会搜寻网页中所有以 「<a href=」 开头,且以 「’>」结束,当中包含的字符串,并且储存在「A」参数中。
Tips and Tricks
以下提供一些关联的常见问题:
• 如何打印出参数值?
lr_output_message这二个函数来做到。例如:
lr_output_message(“Value Captured = %s”, lr_eval_string(“{ParameterName}”));
lr_eval_string与lr_output_message函数的使用说明请参考LoadRunner Online Function Reference。
• 在脚本的data目录下找不到路制时的快照(snapshot)
造成在脚本的data目录下找不到路制时的快照(snapshot)的可能原因如下:
o 脚本是由VuGen 6.02或更早的版本所录制的
o 汇入的Action不会包含快照(snapshot)的档案
o 脚本是储存在只读的目录下,早成VuGen无法储存执行时撷取的快照(snapshot)
o 某些步骤并不会产生快照(snapshot),如浏览某个资源
o 快照(snapshot)功能被取消
【Tools】>【General options】>【Correlation】tab >【Save correlation information during replay】
• 开启WinDiff时出现「File no longer available」的错误讯息
WinDiff这个工具有些限制,无法开启包含空格符的目录或是脚本,所以建议命名时不要使用空格符,并且尽可能将名称取短一点。
• 录制时突然跳出【Correlation warning】对话窗口
当你有勾选自动关联的【Issue a popup message and let me decide online】选项,当VuGen发现有可能要做关联的数据时,就会跳出【Correlation warning】的窗口,询问你要做关联(Correlation in scrīpt)还是要忽略(Ignore)。
另外你也可以勾选【Perform correlation in scrīpt】,让VuGen自动作关联,不会再跳出询问窗口。
或是勾选【Disable correlation engine】,关闭自动关联的功能。
• 如何手动启动「Scan action for correlation」的功能
要手动启动「Scan action for correlation」的功能,请先执行脚本一次后,点选【Vuser】>【Scan Action for Correlation】。
• 执行完脚本后并未出现【Scan Action for Correlation】窗口
要启用【Scan Action for Correlation】功能,请点选【Tools】>【General options】>【Correlation】tab,勾选【Show Scan for correlation popup after replay of Vuser】选项 -
Loadrunner中web_reg_save_param的使用详解(转)
zhong51test 发布于 2008-11-26 15:40:31
应用范围
在使用Loadrunner进行性能测试时,经常遇到一种情况,需要通过web页面修改某事务的状态。于是需要首先读出当前的事务的状态,再进行修改,此时便可以使用到web_reg_save_param了。可以通过它先将事务的状态读出写入一个自定义的变量中,根据变量的值来决定下一步的动作。简要说明
语法:int web_reg_save_param(const char *ParamName, <list of Attributes>, LAST);参数说明:
ParamName: 存放得到的动态内容的参数名称
list of Attributes: 其它属性,包括:Notfound, LB, RB, RelFrameID, Search, ORD, SaveOffset, Convert, SaveLen。属性值不分大小写
Notfound: 当在返回信息中找不到要找的内容时应该怎么处理
Notfound=error: 当在返回信息中找不到要找的内容时,发出一个错误讯息。这是缺省值。
Notfound=warning: 当在返回信息中找不到要找的内容时,只发出警告,脚本也会继续执行下去不会中断。
LB( Left Boundary ) : 返回信息的左边界字串。该属性必须有,并且区分大小写。
RB( Right Boundary ): 返回信息的右边界字串。该属性必须有,并且区分大小写。
RelFrameID: 相对于URL而言,欲查找的网页的Frame。此属性质可以是All或是数字,该属性可有可无。
Search : 返回信息的查找范围。可以是Headers,Body,Noresource,All(缺省)。该属性质可有可无。
ORD : 说明第几次出现的左边界子串的匹配项才是需要的内容。该属性可有可无,缺省值是1。如为All,则将所有找到的内容储存起来。
SaveOffset : 当找到匹配项后,从第几个字元开始存储到参数中。该属性不能为负数,缺省值为0。
SaveLen :当找到匹配项后,偏移量之后的几个字元存储到参数中。缺省值是-1,表示一直到结尾的整个字串都存入参数。
Convert : 可取的值有以下两种:
HTML_TO_URL : 将 HTML-encoded 资料转成 URL-encoded 资料格式
HTML_TO_TEXT : 将 HTML-encoded 资料转成纯文字资料格式实例讲解
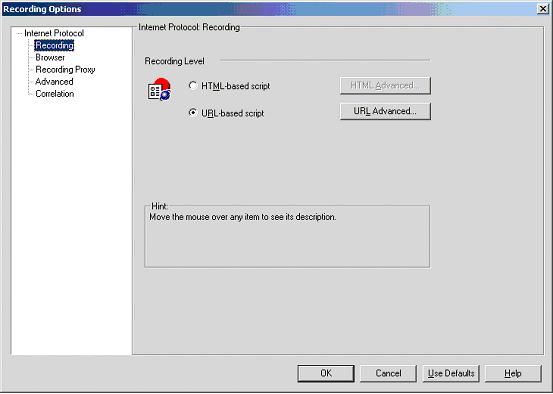
目的:取得页面中的商品状态,如果状态是正常态就改为注销态,否则改为正常态。录制脚本使用的是URL based scrīpt
将返回的数据记录到日志
直接手工访问页面,检查URL
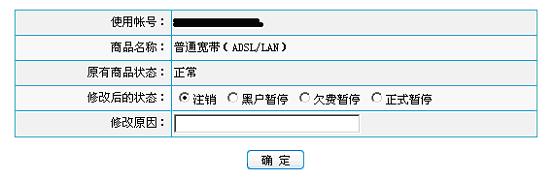
该页面上点击右键,选择属性
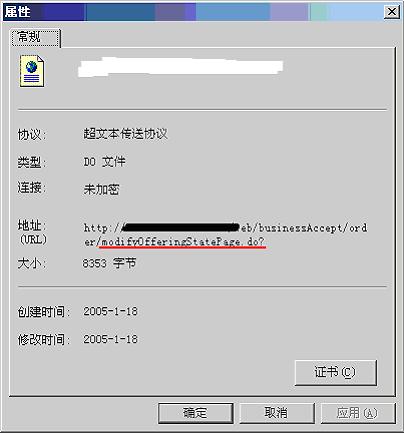
看到URL,对照录制下的脚本中有:web_url("modifyOfferingStatePage.do",
"URL={url}/web/businessAccept/order/modifyOfferingStatePage.do?offeringId=
282172&offeringSpecId=1&offeringSpecName=普通宽带(ADSL/LAN)&customerName=
{clientname}&nodeId=260000&pos1=定购管理&pos2=修改商品状态",
"Resource=0",
"RecContentType=text/html",
"Referer={url}/web/businessAccept/order/orderMenu.do",
"Snapshot=t23.inf",
"Mode=HTTP",
LAST);于是在这段代码前添加注册函数:
web_reg_save_param("oldstate",
"LB/IC=原有商品状态:</td>",
"RB/IC=</td>",
"Search=body",
"Ord=1",
"RelFrameId=1",
"SaveOffset=57",
"SaveLen=4",
LAST);
web_url("modifyOfferingStatePage.do",
"URL={url}/web/businessAccept/order/modifyOfferingStatePage.do?offeringId=
282172&offeringSpecId=1&offeringSpecName=
普通宽带(ADSL/LAN)&customerName={clientname}&nodeId=
260000&pos1=定购管理&pos2=修改商品状态",
"Resource=0",
"RecContentType=text/html",
"Referer={url}/web/businessAccept/order/orderMenu.do",
"Snapshot=t23.inf",
"Mode=HTTP",
LAST);
...............
//将得到的内容存入日志用于检查
lr_log_message("getvalue : %s",lr_eval_string ("{oldstate}"));
if ( lr_eval_string ("{oldstate}") == "正常"){
web_submit_data("modifyOfferingState.do",
"Action={url}/web/businessAccept/order/modifyOfferingState.do",
"Method=POST",
"RecContentType=text/html",
"Referer={url}/web/businessAccept/order/modifyOfferingStatePage.do?offeringId=
282172&offeringSpecId=1&offeringSpecName=普通宽带(ADSL/LAN)&customerName=
{clientname}&nodeId=260000&pos1=定购管理&pos2=修改商品状态",
"Snapshot=t24.inf",
"Mode=HTTP",
ITEMDATA,
"Name=offering.state", "Value=1", ENDITEM,
"Name=offering.recentModifyReason", "Value=修改原因", ENDITEM,
"Name=offering.customerId", "Value=281218", ENDITEM,
"Name=offering.offeringId", "Value=282172", ENDITEM,
"Name=offering.offeringSpecId", "Value=1", ENDITEM,
"Name=offering.recentMender", "Value=root", ENDITEM,
"Name=offering.recentModifyDatetime", "Value=2005-01-16", ENDITEM,
"Name=nodeId", "Value=260000", ENDITEM,
"Name=customerName", "Value={clientname}", ENDITEM,
"Name=offeringSpecName", "Value=普通宽带(ADSL/LAN)", ENDITEM,
"Name=submit.x", "Value=33", ENDITEM,
"Name=submit.y", "Value=13", ENDITEM,
LAST);
}
Else
{
web_submit_data("modifyOfferingState.do",
"Action={url}/web/businessAccept/order/modifyOfferingState.do",
"Method=POST",
"RecContentType=text/html",
"Referer={url}/web/businessAccept/order/modifyOfferingStatePage.do?offeringId=
282172&offeringSpecId=1&offeringSpecName=普通宽带(ADSL/LAN)&customerName=
{clientname}&nodeId=260000&pos1=定购管理&pos2=修改商品状态",
"Snapshot=t24.inf",
"Mode=HTTP",
ITEMDATA,
"Name=offering.state", "Value=0", ENDITEM,
"Name=offering.recentModifyReason", "Value=修改原因", ENDITEM,
"Name=offering.customerId", "Value=281218", ENDITEM,
"Name=offering.offeringId", "Value=282172", ENDITEM,
"Name=offering.offeringSpecId", "Value=1", ENDITEM,
"Name=offering.recentMender", "Value=root", ENDITEM,
"Name=offering.recentModifyDatetime", "Value=2005-01-16", ENDITEM,
"Name=nodeId", "Value=260000", ENDITEM,
"Name=customerName", "Value={clientname}", ENDITEM,
"Name=offeringSpecName", "Value=普通宽带(ADSL/LAN)", ENDITEM,
"Name=submit.x", "Value=33", ENDITEM,
"Name=submit.y", "Value=13", ENDITEM,
LAST);
}
从日志中截取的真实的返回内容为:
vuser_init.c(689): <tr bgcolor="#F6F6F6">\r\n
vuser_init.c(689): <td width="30%" height="23" align="right">\r\n
vuser_init.c(689): 原有商品状态:</td>\r\n
vuser_init.c(689): <td width="70%" height="23"> 正常 </td>\r\n
vuser_init.c(689): </tr>\r\n
vuser_init.c(689): <tr bgcolor="#F4FBFE">\r\n
vuser_init.c(689): <td width="30%" height="23" align="right">\r\n
vuser_init.c(689): 修改后的状态:</td>\r\n
vuser_init.c(689): <td width="70%" height="23">\r\n
vuser_init.c(689): \r\n
vuser_init.c(689): \r\n
vuser_init.c(689): \r\n
vuser_init.c(689): <input type="radio" name='offering.state' value='4' checked>
可以看到左边界是:原有商品状态:</td>,
右边界是:</td>,偏移量为:57(包括了空格),
长度为:4(因为一个汉字长度为2),最后存入变量的值是:正常4.经验总结
1)为了便于脚本的调试,将返回的数据都写入日志是个好办法;
2)为了验证取得的数据是否是自己期望的,可以将取得的数据写入日志中进行验证,
例:lr_log_message("getvalue : %s",lr_eval_string ("{oldstate}"));
3)因为它是一个注册函数,必须在返回信息前使用,所以注册的位置必须正确,否则很可能得到类似如下错误:
4)vuser_init.c(734): Error -27190: No match found for the requested parameter "oldstate".
Check whether the requested boundaries exist in the response data. Also,
if the data you want to save exceeds 1024 bytes,
use web_set_max_html_param_len to increase the parameter size [MsgId: MERR-27190]
5)vuser_init.c(734): Error -27187: The above "not found"
error(s) may be explained by header and body byte counts being 0 and 0,
respectively. [MsgId: MERR-27187]
6)vuser_init.c(734):
web_concurrent_end highest severity level was "ERROR" [MsgId: MMSG-27181]
7)所以使用手工方法,右键页面确定在代码中哪个位置之前注册函数至关重要
8)如果脚本中中文为乱码,可能是因为源文件的字符集和操作系统字符集不匹配。试试:
-
负载压力测试动态参数关联详解(网络转载)
zhong51test 发布于 2008-12-10 11:33:08
1.为什么需要动态参数关联之所以需要动态关联的原因是在系统交互过程中,服务器会动态的生成一些动态的信息给客户端,客户端需要将接受到的动态信息原封不动或者经过相应的处理再次返回给服务器,通过这样的交互,服务器可以认定客户端的可靠性或者适应业务的需要。比如session的动态信息;OA系统中发布新的公文产生的新的流水号;C/S应用中服务器可能动态的给客户端分配新的端口号。
2.LR中动态关联的原理
在HTTP的LR脚本中,LR实现动态关联的机制是在服务器返回的信息中匹配查找一些特征串信息,然后将找到的特征串保存在变量中,在后续的业务操作中,LR将保存的变量值提交给服务器,从而实现了动态信息的关联,联动,保证LR的脚本回放过程中使用的是新的动态参数,而不是历史的脏数据信息。
在C/S的LR脚本中,LR提供相关的函数,可以将从服务器接收到的buffer中的部分内容保存在变量中,替换后续的变量信息,就可以实现动态参数的关联了。
3.B/S动态关联的方法
B/S动态关联的方法可以分为自动关联和手动关联两种。
自动关联就是LR中已经默认的定义了一系列的动态参数查找匹配的规则,录制的脚本回放后,LR会自动的识别一些动态参数,自动的修改脚本,添加相关的脚本关联函数,实现动态参数的关联;
手动的关联是在LR不能自动关联的情况下被迫进行的相关的手动修改脚本的方式,同样实现自动关联的效果。
4.自动关联的实现
自动关联在回放脚本后,LR会自动弹出提示对话框,询问是否进行correlation(自动关联),确认后LR会自动比对,查找出脚本中需要自动关联的参数位置,供测试人员选择确认参数是否需要自动关联;
5.手动脚本的关联实现
明确脚本中需要关联的参数,观察的细节一般是脚本中频繁出现的一些变量,比如脚本中的web_submit_data提交的客户端请求中包含的一些参数,比较两次录制的脚本,可能会发现里面的某些变量的参数值发生变化,这种情况一般需要引起关注,是否存在动态参数的关联。另一种方式可能需要和开发人员交流,在业务的交互中,是否存在某些动态的验证参数数据。
动态参数的查找位置一般是提交动态参数前的web交互中的服务器响应中查找,可以将LR的视图切换到TREEVIEW视图下,测试人员可以看到每一个web交互过程中的服务器响应的详细数据信息以及客户端提交的web请求信息。点击查看示意图
定位到要找的动态参数的服务器响应位置后,下面的操作是进行手动的关联,将动态参数值保存在变量中。首先在返回动态参数值的web请求前注册一个变量,使用web_reg_save_param注册一个变量,可以详细的查看一下该函数的帮助信息。在LR的TREEVIEW视图下,用户可以使用GUI交互的方式很方便的注册一个变量,用来保存动态参数。步骤如下:
在返回参数的web请求上点右键:insertbefore–》service->web_reg_save_param,填写相应的参数特征信息,解释一下,左右边界(左右边界是动态参数值的左边和右边的特征串,LR就是通过左右边界来唯一的找到web请求的服务器响应数据中的动态参数的。)另外一个比较重要的地方就是部分特殊字符的转义问题,如果在左右边界中出现了特殊字符,如引号,在出现问题是需要考虑这个环节。
确认以后,测试人员可以在scrīpteview视图中看到LR自动添加的参数注册函数。
测试人员可以使用lr_error_message函数来打印调试信息,检查是否正确的捕获了动态参数;方式如下:
lr_error_message(“theparamvalueis%s”,lr_eval_string(“{变量名}”)); 这样,在脚本的回放中,用户可以看到红色的打印输出信息。
最后的步骤就是将脚本中的历史动态参数信息替换成已经注册的变量,这样LR就可以自动的提交动态参数值了,而不是提交不进行修改的历史数据信息。替换方法是将以前的值替换成{变量名}的方式即可。
-
负载压力测试动态参数关联详解(网络转载)
zhong51test 发布于 2008-12-10 11:33:09
1.为什么需要动态参数关联之所以需要动态关联的原因是在系统交互过程中,服务器会动态的生成一些动态的信息给客户端,客户端需要将接受到的动态信息原封不动或者经过相应的处理再次返回给服务器,通过这样的交互,服务器可以认定客户端的可靠性或者适应业务的需要。比如session的动态信息;OA系统中发布新的公文产生的新的流水号;C/S应用中服务器可能动态的给客户端分配新的端口号。
2.LR中动态关联的原理
在HTTP的LR脚本中,LR实现动态关联的机制是在服务器返回的信息中匹配查找一些特征串信息,然后将找到的特征串保存在变量中,在后续的业务操作中,LR将保存的变量值提交给服务器,从而实现了动态信息的关联,联动,保证LR的脚本回放过程中使用的是新的动态参数,而不是历史的脏数据信息。
在C/S的LR脚本中,LR提供相关的函数,可以将从服务器接收到的buffer中的部分内容保存在变量中,替换后续的变量信息,就可以实现动态参数的关联了。
3.B/S动态关联的方法
B/S动态关联的方法可以分为自动关联和手动关联两种。
自动关联就是LR中已经默认的定义了一系列的动态参数查找匹配的规则,录制的脚本回放后,LR会自动的识别一些动态参数,自动的修改脚本,添加相关的脚本关联函数,实现动态参数的关联;
手动的关联是在LR不能自动关联的情况下被迫进行的相关的手动修改脚本的方式,同样实现自动关联的效果。
4.自动关联的实现
自动关联在回放脚本后,LR会自动弹出提示对话框,询问是否进行correlation(自动关联),确认后LR会自动比对,查找出脚本中需要自动关联的参数位置,供测试人员选择确认参数是否需要自动关联;
5.手动脚本的关联实现
明确脚本中需要关联的参数,观察的细节一般是脚本中频繁出现的一些变量,比如脚本中的web_submit_data提交的客户端请求中包含的一些参数,比较两次录制的脚本,可能会发现里面的某些变量的参数值发生变化,这种情况一般需要引起关注,是否存在动态参数的关联。另一种方式可能需要和开发人员交流,在业务的交互中,是否存在某些动态的验证参数数据。
动态参数的查找位置一般是提交动态参数前的web交互中的服务器响应中查找,可以将LR的视图切换到TREEVIEW视图下,测试人员可以看到每一个web交互过程中的服务器响应的详细数据信息以及客户端提交的web请求信息。点击查看示意图
定位到要找的动态参数的服务器响应位置后,下面的操作是进行手动的关联,将动态参数值保存在变量中。首先在返回动态参数值的web请求前注册一个变量,使用web_reg_save_param注册一个变量,可以详细的查看一下该函数的帮助信息。在LR的TREEVIEW视图下,用户可以使用GUI交互的方式很方便的注册一个变量,用来保存动态参数。步骤如下:
在返回参数的web请求上点右键:insertbefore–》service->web_reg_save_param,填写相应的参数特征信息,解释一下,左右边界(左右边界是动态参数值的左边和右边的特征串,LR就是通过左右边界来唯一的找到web请求的服务器响应数据中的动态参数的。)另外一个比较重要的地方就是部分特殊字符的转义问题,如果在左右边界中出现了特殊字符,如引号,在出现问题是需要考虑这个环节。
确认以后,测试人员可以在scrīpteview视图中看到LR自动添加的参数注册函数。
测试人员可以使用lr_error_message函数来打印调试信息,检查是否正确的捕获了动态参数;方式如下:
lr_error_message(“theparamvalueis%s”,lr_eval_string(“{变量名}”)); 这样,在脚本的回放中,用户可以看到红色的打印输出信息。
最后的步骤就是将脚本中的历史动态参数信息替换成已经注册的变量,这样LR就可以自动的提交动态参数值了,而不是提交不进行修改的历史数据信息。替换方法是将以前的值替换成{变量名}的方式即可。
-
谈谈LoadRunner中Pacing的设置[转]
zhong51test 发布于 2009-08-13 14:02:33
在 LoadRunner 的运行场景中,有一个不大起眼的设置,可能经常会被很多人忽略,它就是 Pacing 。具体设置方式为: Run-Time settings à General à Pacing ,这个设置的功能从字面上就很容易理解,即在场景的两次迭代 (iteration) 之间,加入一个时间间隔(步进)。设置方法也很简单,这里就不赘述了,我在这里想说明的是,这个设置到底有什么作用?为什么要进行这个设置?说实话,虽然我在以前做过的一些性能测试中,偶尔会对这个步进值进行一些设置,但其实对它的真正含义和作用,我还并不十分清楚。
前段时间,我在对X银行招聘信息系统进行性能测试的时候,发现这个值的设置对于测试的结果有着很大的影响,很遗憾当时没有深入研究这个问题,而只是简单地认为它同脚本中的 thinktime 一样只是为了更真实地模拟实际情况而已。最近在网络上看到一篇题为《调整压力测试工具》的文章,读完之后,再用之前我的测试经历加以印证,真有种豁然开朗的感觉。以下就将我的一些体会与大家分享:
通常我们在谈到一个软件的“性能”的时候,首先想到的就是“响应时间”和“并发用户数”这两个概念。我们看到的性能需求经常都是这样定义的:
“要求系统支持 100 个并发用户”
看到这样的性能需求,我们往往会不假思索地就在测试场景中设置 100 个用户,让它们同时执行某一个测试脚本,然后观察其操作的响应时间,我们都是这样做的,不是吗?我在实际实施性能测试的过程中,也往往都是这样做的。可惜的是,我们中的大多数人很少去更深入地思考一下其中的奥妙,包括我自己。
事实上,评价一个软件系统的性能,可以从两个不同的视角去看待:客户端视角和服务器视角(也有人把它叫做用户视角和系统视角),与此相对应的,又可以引出两个让初学者很容易混淆的两个概念:“并发用户数”和“每秒请求数”。“并发用户数”是从客户端视角去定义的,而“每秒请求数”则是从服务器视角去定义的。
因此,上面所描述的做法的局限性就是,它反映的仅仅是客户端的视角。
对于这个世界上的很多事情,变换不同的角度去看它,往往可以有助于我们得到更正确的结论。现在,我们就转换一下角度,以服务器的视角来看看性能需求应该怎么样定义: “要求系统的事务处理能力达到 100 个 / 秒” ( 这里为了理解的方便,假定在测试脚本中的一个事务仅仅包含一次请求 )
面对以这样方式提出的性能需求,在 LoadRunner 中,我们又该如何去设置它的并发用户数呢?千万不要想当然地以为设置了 100 个并发用户数,它就会每秒向服务器提交 100 个请求,这是两个不同的概念,因为 LoadRunner 模拟客户端向服务器发出请求,必须等待服务器对这个请求做出响应,并且客户端收到这个响应之后,才会重新发出新的请求,而服务器对请求的处理是需要一个时间的。我们换个说法,对于每个虚拟用户来说,它对服务器发出请求的频率将依赖于服务器对这个请求的处理时间。而服务器对请求的处理时间是不可控的,如果我们想要在测试过程中维持一个稳定的每秒请求数( RPS ),只有一个方法,那就是通过增加并发用户数的数量来达到这个目的。这个方法看起来似乎没有什么问题,如果我们在测试场景中只执行一次迭代的话。然而有经验的朋友都会知道,实际情况并不是这样,我们通常会对场景设置一个持续运行时间(即多次迭代),通过多个事务 (transaction) 的取样平均值来保证测试结果的准确性。测试场景以迭代的方式进行,如果不设置步进值的话,那么对于每个虚拟用户来说,每一个发到服务器的请求得到响应之后,会马上发送下一次请求。同时,我们知道, LoadRunner 是以客户端的角度来定义“响应时间”的 ,当客户端请求发出去后, LoadRunner 就开始计算响应时间,一直到它收到服务器端的响应。这个时候问题就产生了:如果此时的服务器端的排队队列已满,服务器资源正处于忙碌的状态,那么该请求会驻留在服务器的线程中,换句话说,这个新产生的请求并不会对服务器端产生真正的负载,但很遗憾的是,该请求的计时器已经启动了,因此我们很容易就可以预见到,这个请求的响应时间会变得很长,甚至可能长到使得该请求由于超时而失败。等到测试结束后,我们查看一下结果,就会发现这样一个很不幸的现象:事务平均响应时间很长,最小响应时间与最大响应时间的差距很大,而这个时候的平均响应时间,其实也就失去了它应有的意义。也就是说,由于客户端发送的请求太快而导致影响了实际的测量结果。
因此,为了解决这个问题,我们可以在每两个请求之间插入一个间隔时间,这将会降低单个用户启动请求的速度。间歇会减少请求在线程中驻留的时间,从而提供更符合现实的响应时间。这就是我在文章开头所提到的 Pacing 这个值的作用。
最后再补充一句话:虽然性能测试通常都是从客户端活动的角度定义的,但是它们应该以服务器为中心的视角来看待。请注意这句话,理解它很重要,只有真正理解了这句话,你才会明白为什么我们一直强调做性能测试的时候要保证一个独立、干净的测试环境,以及一个稳定的网络,因为我们希望评价的是软件系统真正的性能,所以必须排除其它一切因素对系统性能造成的影响。
花了几天的时间才完成这篇文章,如果它能够帮助大家对性能测试多一些理解或者多一些思考,那就是我的荣幸了。 -
软件企业质量保证的基石―QA、QC的良性协作(转贴)
yexu 发布于 2007-01-29 11:40:03
作者:贺忻 来源:测试时代 2006年10月13日
国内的软件产业发展了20多年的时间,已经由个人英雄时代步入到中、小团队协作时代。相信不久的将来,国内一定会出现航
母级的软件企业,那时候我们会迎来集团军作战的时代。不同的时代表明软件规模的不同,也标志着软件质量管理的复杂度急剧上升,同时对软件质量的保障方法也提出了更高的要求。
本文并不打算系统的阐述软件企业的质量保证体系,而是想从另一个侧面同大家分享软件企业在软件开发过程中两个重要角色之间的协作关系,以两个角色之间高效的互动来说明在开发过程中,我们如何来有效的保障软件产品的质量。
1.软件企业的质量保证体系我们知道质量保证体系的建设是一个系统工程,质量的保障不是某些人或者某些部门的工作,而是整个企业的文化,理念的贯彻。如果一个企业在进行质量保证体系的建设和推广过程中,只是在强调方法,强调规范,而不是把质量意识,企业文化贯穿其中,那质量保证体系是否能持续的发挥作用,并形成为企业的核心竞争力就值得怀疑了。
一般软件企业在规划质量保证体系的时候都会选择一个模型,目前比较流行的模型有:ISO9000:2000、CMMI、RUP、XP等,具体选用那种模型,还需要看企业的实际情况,并且能充分的协调:人、技术、过程三者之间的关系,使之能充分的发挥作用,促进生产力的发展。
在软件企业的质量保证体系建设过程中,一般需要独立完成以下几个流程:
项目管理流程、软件开发流程、软件测试流程、质量保证流程、配置管理流程
以上这些流程需要相辅相成,各自之间都有相应的接口,通过项目管理流程将所有的活动贯穿起来,共同来保证软件产品的质量。
整个软件质量保证体系中,所有的流程围绕软件开发流程展开,唯一的目标就是保证软件开发的质量,所以在众多的流程中,软件开发流程为质量保证体系中的主流程,其它的流程为辅助流程。之所以我们需要建立众多的辅助流程,就是为了让软件开发过程透明、可控,通过多角色之间的互动,来有效的降低软件开发过程中的风险,持续不断的提高软件产品的质量。2.QA、QC的职责
在我们开始讨论QA、QC的职责之前,我们先假定一个前提条件,即:企业内部的质量保证体系已经建设完毕,即上述的五个流程已经编写完毕,并且通过了试运行,目前正在按部就班的执行。
QA的英文为:Quality Assurance 我们翻译为“质量保证”。QC的英文为:Quality Control 我们翻译为“质量控制”。
我们将这两个角色之间进行一下职责划分,以方便我们后续的讨论
QA:监控公司质量保证体系的运行状况,审计项目的实际执行情况和公司规范之间的差异,并出具改进建议和统计分析报告,对公司的质量保证体系的质量负责。
QC:对每一个阶段或者关键点的产出物(工件)进行检测,评估产出物是否符合预计的质量要求,对产出物的质量负责。
通过上面的职责划分,我们发现,如果我们将软件的生产比喻成一条产品加工生产线的话,那QA只负责生产线本身的质量保证,而不管生产线中单个产品的实际质量情况。QA通过保证生产线的质量来间接保证软件产品的质量。而QC不管生产线本身的质量,而只关注生产线中生产的产品在每一个阶段的质量是否符合预期的要求,如果我们生产的是杯子,那QC只关注:生产的材料是否是预期的,每个杯子瓶口的直径是否符合要求,杯子把手是否符合设计要求等等具体的、可量化的点。
针对软件企业的软件开发过程而言:QA可以进一步明确为SQA,即:软件质量保证,只负责软件开发流程的质量,企业内相对应的角色为:软件质量保证人员,有的企业就直接称之为SQA。
QC可以进一步明确为SQC,即:软件质量控制,只负责软件开发过程中各个阶段产出的工件的质量,产出的工件可能是相关的文档或者代码等,企业内相对应的角色为:软件测试人员。
由于各个企业采用的开发流程和测试流程不一样,在各个阶段SQC的对应人员不一定都为测试人员,如在需求阶段,产生的工件为《需求规格说明书》,对该文档的主要质量控制手段为评审,这时候在此阶段担任SQC职责的就是评审小组的成员。3.QA、QC的良性协作
通过以上分析发现,SQA和SQC虽然主要的工作都是为了保证软件的质量,但是着眼点不尽相同。
SQA通过控制过程来保证软件产品的质量,而SQC是通过控制每个阶段的“结果”来保证软件产品的质量。
如果在软件开发过程中我们只要SQA或者SQC是否可以保证软件产品的质量那?答案一定是不可以的,通过下面的分析我们看看原因到底是什么。
软件企业中只有SQA的角色如果企业中只有SQA的角色而没有SQC,我们假设企业对SQA的投入力度很大,于是企业得到了一个很好的流程(生产线),但是这个时候软件的产品是否就没有问题了那?如果我们的生产源头没有得到有效的控制,进入生产线的材料是残次品,那不管我们的流程控制的多好,那最终的产品的质量都不会高。
可能有朋友会说,如果我进行了很好的流程控制,对原材料的控制方法当然也纳入到了我们的流程之中,原材料没有了问题,那这件事情是不会发生的。
如果是制造业,这件事情可能会存在,但是在软件产业中,这件事情几乎不会发生。因为在软件产品的开发过程当中,几乎所有的原材料都是自己生产的,如需求规格说明书、概要设计、详细设计等,单靠过程的控制无法得到无缺陷的“原材料”。由于软件开发的固有特性,我们在每一步的生产加工过程中,都会引入新的缺陷,不管我们的流程规划的多么完美。所以,在每一阶段完成后,都需要对上一阶段的工作产品进行检验,评估这个阶段的工作产品是否符合预定的质量要求,只有这样才能保证最终软件产品的质量。
软件企业中只有SQC的角色如果企业当中只有SQC而没有SQA的角色,我们也假设企业对SQC的投入力度很大,在每一个阶段SQC都找出了相应的缺陷,这时候企业的质量保证是否就没有问题了那?
如果纯从质量保证的观点来看,在理想情况下,上述的软件企业的质量的确是没有问题,因为在每一个阶段,通过大量专业SQC(测试)的努力工作,找出了软件产品中的“全部”缺陷,这样的产品的质量当然没有问题了。
但是我们从另外一个角度看一下这个问题:首先软件中的缺陷在理论上是不可能被全部找出来的,由于软件测试的不可遍历性。其次,如果我们维护一个上述的软件测试团队,成本是相当高的,目前国际上还没有那个商业性的公司能够维护的起(微软的产品还会有大量的缺陷),也就是说在实际操作过程中几乎没有公司会同意上述的做法。另外,如果我们在软件生产的过程中,只单一的强调对结果的检验环节,而忽视过程控制,会造成持续的返工、极大的推迟交付产品的日期,最终造成软件开发的失败。这样的做法就像我们想减肥,不是去节食、多做运动,而是去不断的称体重想达到减肥的目的一样可笑。所以,我们想提高软件的质量,不是持续不断的进行测试,而是要改变软件开发的方式,改变我们的流程,在过程中保证软件产品的质量。
通过以上分析发现,如果想有效的保证软件产品的质量,SQA和SQC缺一不可,两种角色必须相互配合,在“过程”和“结果”都正确的基础上,才能有效改善软件产品的质量。4.质量的持续改进
软件质量的提高,过程的改进是一个循序渐进的过程,不可能一蹴而就。针对软件企业而言,如何调配有限的资源,针对质量保证的短板,来有针对性的做出质量改进的规划才是企业迫切需要解决的问题。
首先,企业必须对软件质量的保证提出切实的目标,质量保证的目标绝对不是为了过级,拿到认证,这些只是附带的结果。企业质量保证的目标应该是提高产品的竞争力,重塑企业的文化。
其次,在质量保证的技术层面,SQA人员和SQC人员的互动,会为企业选择质量保证的短板提出建设性的意见。
SQC(测试)人员在工作过程中会产生出大量的过程数据,SQA人员通过对这些数据的统计分析,发现企业的问题所在,进而反馈到流程的改进活动中,再通过SQC人员搜集的大量数据来验证流程改进的有效性,最终达到质量的持续改进。
质量是企业的根本,不管我们现在的产品销售情况如何,企业之间的竞争早晚会过渡到质量的竞争上来,所以只有我们自己练好内功,才有希望打造出我们自己的百年老店。 -
测试报告文档
nicklyl 发布于 2008-02-26 21:38:08
**系统测试报告
1.引言
本文档为**的系统测试活动给出一个总结报告,该报告用于评估系统测试活动的质量和产品的质量,并且决定是否把产品发布给最终用户。
2.测试时间,地点和人员
测试时间:
地点:
测试人员:
3.测试环境描述
(测试系统的软硬件配置)
4.测试数据度量
4.1测试用例执行度量
测试对象 用例总数 执行总数 OK项 POK项 NG项 NT项 发现缺陷数 系统功能 系统性能 系统GUI规范 系统可安装姓 合计 4.2 测试进度和工作量度量
1.进度度量
进度度量参考表22.3
表22.3进度度量
任务 计划开始时间 计划结束时间 实际开始时间 实际结束时间 环境准备 系统测试执行及 回归 系统测试报告 系统测试报告评审 2.工作量度量
工作量度量参考表22.4
表22.4工作量度量
执行任务 开始时间 结束时间 工作量/时 4.3 缺陷数据度量
缺陷数据度量参考表22.5
表22.5 缺陷数据度量
(饼图显示缺陷的比例情况)被测对象 总数 致命 严重 一般 提示 设计错误 赋值错误 算法错误 接口错误 功能错误 其他 系统功能 系统性能 系统GUI规范 合计 -
Bug生命周期
testhome 发布于 2008-10-18 20:45:44
首先测试发现Bug并提交bug(bug状态为new/Active),然后分配bug(bug状态为assigned),开发人员接收并修改bug(bug状态为fixed/Resolved),最后测试人员验证bug(bug状态为Closed)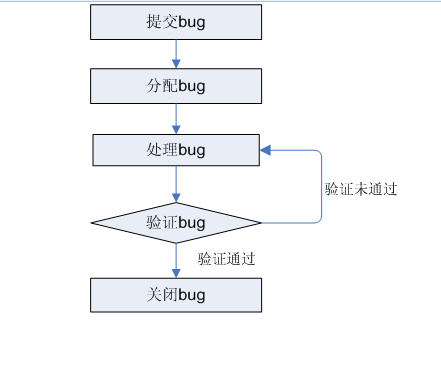
此时肯定有人会发现问题,这么简单的流程图是太理想化了,无法满足实际。这是当然,Bug是可以‘死而复生’的,也许在下个版本问题有再次出现,又或许从测试人员角度讲,问题验证不通过怎么办?从管理及开发角度想,这不是bug又怎么办。带着这些疑问,我们进一步完善流程图。
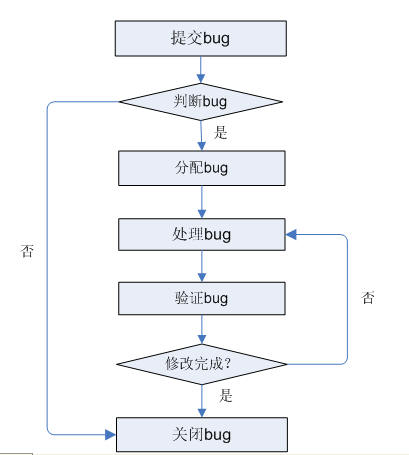
基本可以满足一般的使用。但是我们忽略了一点,bug是有分类的“严重程度(Severity)和优先级别(Priority)”。在实际的应用中,很多项目的bug都比较多,而此时由于bug只在非极端条件下产生或者修改需要牵动这个框架,会造成更多的潜在缺陷,在悲观点就是面对市场压力需要尽快发布的情况等。Bug是否被修改?什么时候修改?就是需要定夺的了。又想到一点,如果此项目是多个测试人员同时测试,那是否bug会提交重复呢?理清楚思路后,就可以在进一步完善我们的流程图啦!
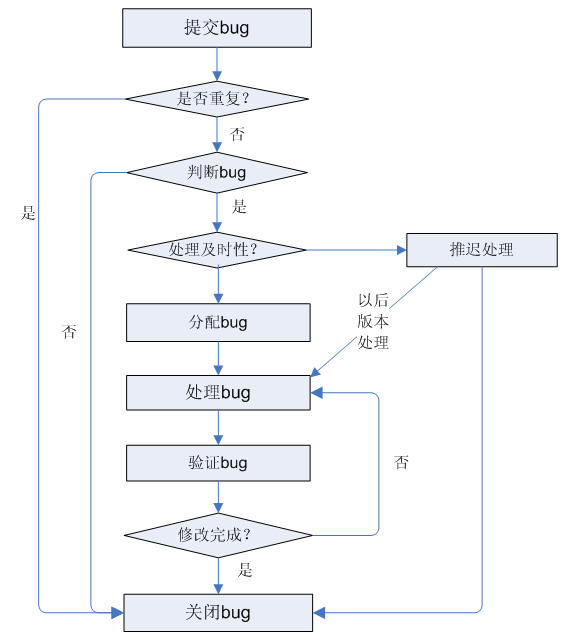
-
操作系统监控(1)
xiaohanjiang 发布于 2010-07-19 10:18:01
性能测试,必须从os级别了解系统运行情况。
判断系统是存在问题。
1 系统运行状况
1.1 系统负载情况
1.1.1 uptime
uptime
1、能够统计系统当前时间
2、主机运行的时间
3、当前用户的连接数
4、load average统平均负载
是指在特定时间间隔内运行队列中的平均进程数。如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的。如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
load average<=3×内核个数 表示性能优良
load average<=5×内核个数 表示性能问题严重
[linux @ localhost]$ uptime
显示结果为:
10:19:04 up 257 days, 18:56, 12 users, load average: 2.10, 2.10,2.09
显示内容说明:
10:19:04 //系统当前时间
up 257 days, 18:56 //主机已运行时间,时间越大,说明你的机器越稳定。
12 user //用户连接数,是总连接数而不是用户数
load average // 系统平均负载,统计最近1,5,15分钟的系统平均负载
1.2 系统mem情况
1.2.1 空闲内存情况vmstat
vmstat
可以查看空闲内存情况
可以查看swap空闲情况,如果空闲小于20%说明交换区不够
如果pi,po 长期不等于0,表示内存不足。
bash-2.03# vmstat 2
procs memory page disk faults cpu
r b w swap free re mf pi po fr de sr s6 sd sd -- in sy cs us sy id
0 0 0 6093120 4373312 1 13 2 0 0 0 0 0 2 0 0 151 156 134 1 1 98
0 0 0 5916512 4650168 0 3 0 0 0 0 0 0 2 0 0 148 59 126 0 0 100
0 0 0 5916512 4650168 0 0 0 0 0 0 0 0 1 0 0 138 90 105 0 2 98
0 0 0 5916512 4650168 0 0 0 0 0 0 0 0 0 0 0 183 95 146 0 0 99
有关内存的参数
memoy
swap-->现时可用的交换内存(k表示)
free-->空闲的内存(k表示)
buff : the amount of memory consumed by buffers (in KB by default)
inact : the amount of memory on the inactive list (in KB by default)
active: the amount of memory on the active list (in KB by default)
pages
re--》回收的页面
mf--》非严重错误的页面
pi--》进入页面数(k表示)
po--》出页面数(k表示)
fr--》空余的页面数(k表示)
de--》提前读入的页面中的未命中数
sr--》通过时钟算法扫描的页面
1.2.2 当前内存的使用情况top
top 也列出当前内存的情况,已经使用的,空闲的。
如:
load averages: 0.02, 0.02, 0.01 15:53:38
79 processes: 78 sleeping, 1 on cpu
CPU states: 98.8% idle, 0.4% user, 0.8% kernel, 0.0% iowait, 0.0% swap
Memory:
PID USERNAME THR PRI NICE SIZE
28388 root 1 59 0 2568K 1760K cpu0 0:00 0.17% top
17754 oracle 11 59 0 0K 0K sleep 15:21 0.10% oracle
1.3 系统swap情况
1.3.1 查看交换区的使用情况vmstat 2
vmstat 2
显示的swap列为空闲的交换区大小
如:
bash-3.00# vmstat 2
kthr memory page disk faults cpu
r b w swap free re mf pi po fr de sr s6 sd sd -- in sy cs us sy id
0 0 0 5486728 3810320 1 4 2 0 0 0 0 0 0 0 0 373 42 110 0 0 100
0 0 0 4453840 2701304 1 14 0 0 0 0 0 0 0 1 0 435 446 208 1 0 99
0 0 0 4453840 2701304 0 0 0 0 0 0 0 0 0 3 0 449 103 217 0 0 100
0 0 0 4453840 2701304 0 0 0 0 0 0 0 0 0 5 0 465 290 233 0 4 96
0 0 0 4453840 2701304 0 0 0 0 0 0 0 0 0 0 0 420 73 199 0 0 99
swap 列表示空闲的交换区的大小,单位是k
1.3.2 查看交换区的使用情况top
top 也会列出交换区的情况,已经使用的,空闲的。
如:
load averages: 0.02, 0.02, 0.01 15:53:38
79 processes: 78 sleeping, 1 on cpu
CPU states: 98.8% idle, 0.4% user, 0.8% kernel, 0.0% iowait, 0.0% swap
Memory:
PID USERNAME THR PRI NICE SIZE
28388 root 1 59 0 2568K 1760K cpu0 0:00 0.17% top
17754 oracle 11 59 0 0K 0K sleep 15:21 0.10% oracle
-
【转】如何估算测试时间
紫梦 发布于 2010-07-12 11:02:05
测试时间在什么阶段要评估出来?个人认为:最迟在申请测试资源时要评估出来,测试资源包括时间、人力、工具等。
而测试时间体现在什么文档中以便作为测试依据呢?
个人认为在测试计划中需要阐明。测试计划中至少要写明,要测试什么(即范围),谁来测试(即测试中的人力资源),怎么测试(测试策略),什么时间测试(测试中的时间资源),风险评估,然后就是一些约定和术语解释避免歧义。
测试资源中用多少人力和时间资源是互相牵制的,都是依据这个项目或者产品按单位人需要的时间来计算的。
测试时间如何估算呢?
经验所得:开发的coding的时间和项目环境下测试的时间是1:1,前提是开发和测试的比例是3:1。
那麽这个时间的估算有些受到开发估算coding时间的牵制,那麽最好再结合:项目需要测试的范围来评估,根据测试范围大概会有多少用例产出,以及有多少牵扯到的用例需要回归,测试的平均执行效率来大概估算测试时间。
在上面大的估算时间上,个人认为还要综合以下几点来保证测试时间比较靠谱:
1、测试中由于需求与代码实现差异而产生的用例维护时间,以及和开发沟通,和需求方确认的时间。
2、测试环境的稳定性,有时候测试环境宕掉,影响测试进度。
3、开发人员的编码质量
4、开发人员修复bug的速率
5、开发人员中新人的比例,一般新人对业务不熟悉,编码考虑会欠周到。
6、测试人员对执行测试用例的效率
7、测试用例的复杂度,可能一个case里面有很多的step。
8、测试数据对项目的影响,如果项目本身测试过程中对数据的依赖很大,而数据的重用性不好
9、测试中因为bug和开发人员的沟通时间,以及不断帮助开发人员重现bug的时间。
10、项目中如果需要UI和UED等其他部门资源的支持,这些资源的配合沟通时间。
-
面试题--10年金山WPS Office系统测试
bobo45123 发布于 2010-07-06 21:49:28
一、
问答题(共20分)(1)以下循环执行次数是? (5分)
#include
main()
{
int i;
for(i=2;i==0;)printf("%d\n",i--)
printf("%d\n",i);
}
(2)一个程序,实现了图片转文本的功能,可以将任意图片转换成文本内容,并输出,请说明你的测试重点。 (5分)
(3)产品的测试通常涉及以下几个方面:单元测试、集成测试、系统测试。
请简述系统测试相关的测试点,并举实例说明。 (5分)
4-6题中,可以选择任意一题作答,共5分
(4)请简述,哪些操作系统分别支持哪些文件系统格式?
(5)给你一个软件产品,如何预估完成测试任务所需的时间?
(6)Windows XP多用户下"注销"与"切换"的区别?
二、测试设计题(共40分)
(1)请写出以下功能的测试思路及关键用例 (20分)
功能说明:下图是一个便签软件,点击+可以增加多个便签,下图是新建了两个便签。
(注意,测试不要要只局限在便签的增删)
(2)如图所示,是一个PDF书籍阅读软件。假设功能已开发完成,要进行测试,请写出测试思路。(20分)
三、分析题(共10分)
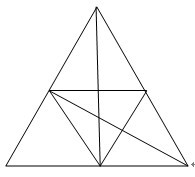
(1)请数出下图中三角形的个数,并给出简要的分析思路 (5分)
(2)一只叫小快的蜗牛从井底爬到井口,白天小快要睡觉,晚上才出来活动,每个晚上小快可以向上爬6尺,但是白天睡觉的时候会下滑5尺,井深20尺,问几天小快可以爬出来?请写出分析思路。 (5分)
四、程序题(共30分)
(1)用你熟悉的开发语言:实现输入一个仅包含英文字母和空格的字符串,找出该字符串中没有出现过的字母(不区分大小写)。请写出思路及代码(可用伪代码实现)。 (15分)
(2)用你熟悉的开发语言:实现输入一个正整数,求它是几位数。请写出思路及代码(可用伪代码实现)。 (15分)
(注意:不允许将正整数转换为字符串来用strlen处理)
-
缺陷严重级别问题说明
wfl51 发布于 2010-06-30 23:48:44
致命(critical):导致运行中断(应用程序崩溃),预期的功能没有得到实现,测试工作无法继续进行等。具体现象包括:
? 由于程序所引起的死机,非法退出;
? 死循环;
? 数据库错误、丢失数据、造成资料被破坏、数据库发生死锁;
? 数据通讯错误;
? 严重的数值计算错误;
? 页面不存在、服务器错误;
严重(Major):主要功能未能实现或者产品规格没有准确实现,产品功能没有正确执行、系统性能下降等问题。具体现象包括:
? 菜单或按钮没有实现其本来的作用,不能进入相关联的下级功能域,影响其它功能的实现;
? 影响下一个流程的操作。如不能保存数据;
? 按钮实现了不属于自己本身的功能。如确定按钮实现了保存功能;
? 遗漏了功能或者功能不符;
? 数据出错,如数据导入导出错误;
? 内存泄露数据流错误;
? 程序接口错误;
? 轻微的数值计算错误;
一般(Normal):不太严重的错误,这样的缺陷虽然不影响系统的基本使用,但没有很好的实现功能,没有达到预期的效果。具体现象包括:
? 界面错误(详细文档);
? 打印内容、格式错误;
? 简单的输入限制未放在前台进行控制;
? 删除操作未给出提示等;
? 次要功能丧失,提示信息不太正确;
? 用户界面太差,操作时间长等;
提示(Minor):主要是界面方面问题,如错别字、画面误显示或误动作,提示信息有误。具体现象包括:
? 辅助说明描述不清楚;
? 显示格式不规范;
? 长时间操作未给用户进度提示;
? 提示窗口文字未采用行业术语;
? 可输入区域和只读区域没有明显的区分标志;
? 系统处理未优化; -
[转载]敏捷软件开发模型-SCRUM
chicochen 发布于 2008-07-12 17:27:45
一 什么是Scrum?
Scrum (英式橄榄球争球队), 软件开发模型是敏捷开发的一种,在最近的一两年内逐渐流行起来。
Scrum的基本假设是:
开发软件就像开发新产品,无法一开始就能定义软件产品最终的规程,过程中需要研发、创意、尝试错误,所以没有一种固定的流程可以保证专案成功。Scrum 将软件开发团队比拟成橄榄球队,有明确的最高目标,熟悉开发流程中所需具备的最佳典范与技术,具有高度自主权,紧密地沟通合作,以高度弹性解决各种挑战,确保每天、每个阶段都朝向目标有明确的推进。Scrum 开发流程通常以 30 天(或者更短的一段时间)为一个阶段,由客户提供新产品的需求规格开始,开发团队与客户于每一个阶段开始时挑选该完成的规格部分,开发团队必须尽力于 30 天后交付成果,团队每天用 15 分钟开会检查每个成员的进度与计划,了解所遭遇的困难并设法排除。
二 Scrum较传统开发模型的优点
Scrum模型的一个显著特点就是响应变化,它能够尽快地响应变化。下面的图片使用传统的软件开发模型(瀑布模型、螺旋模型或迭代模型)。随着系统因素(内部和外部因素)的复杂度增加,项目成功的可能性就迅速降低。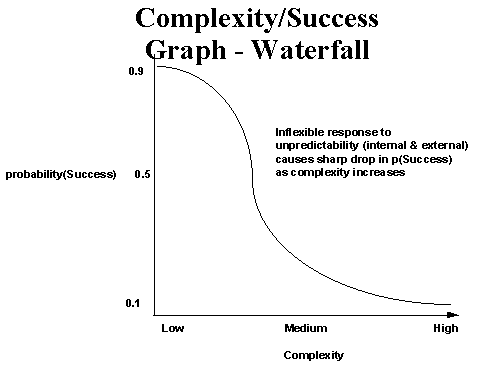
下图是Scrum模型和传统模型的对比: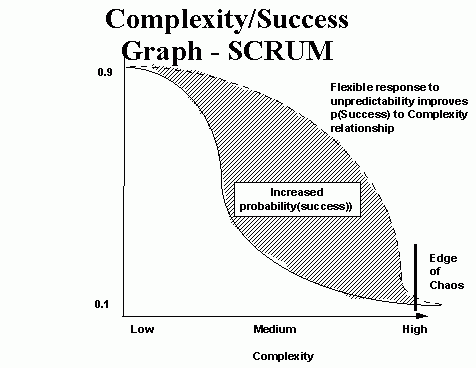
三 Scrum模型
一) 有关Scrum的几个名词backlog: 可以预知的所有任务, 包括功能性的和非功能性的所有任务。
sprint:一次跌代开发的时间周期,一般最多以30天为一个周期.在这段时间内,开发团队需要完成一个制定的backlog,并且最终成果是一个增量的,可以交付的产品。
sprint backlog:一个sprint周期内所需要完成的任务。
scrumMaster: 负责监督整个Scrum进程,修订计划的一个团队成员。
time-box: 一个用于开会时间段。比如每个daily scrum meeting的time-box为15分钟。
sprint planning meeting: 在启动每个sprint前召开。一般为一天时间(8小时)。该会议需要制定的任务是:产品Owner和团队成员将backlog分解成小的功能模块, 决定在即将进行的sprint里需要完成多少小功能模块,确定好这个Product Backlog的任务优先级。另外,该会议还需详细地讨论如何能够按照需求完成这些小功能模块。制定的这些模块的工作量以小时计算。Daily Scrum meeting:开发团队成员召开,一般为15分钟。每个开发成员需要向ScrumMaster汇报三个项目:今天完成了什么? 是否遇到了障碍? 即将要做什么?通过该会议,团队成员可以相互了解项目进度。
Sprint review meeting:在每个Sprint结束后,这个Team将这个Sprint的工作成果演示给Product Owner和其他相关的人员。一般该会议为4小时。
Sprint retrospective meeting:对刚结束的Sprint进行总结。会议的参与人员为团队开发的内部人员。一般该会议为3小时。
二)实施Scrum的过程简单介绍
1) 将整个产品的backlog分解成Sprint Backlog,这个Sprint Backlog是按照目前的人力物力条件可以完成的。
2) 召开sprint planning meeting,划分,确定这个Sprint内需要完成的任务,标注任务的优先级并分配给每个成员。注意这里的任务是以小时计算的,并不是按人天计算。
3) 进入sprint开发周期,在这个周期内,每天需要召开Daily Scrum meeting。
4) 整个sprint周期结束,召开Sprint review meeting,将成果演示给Product Owner.
5) 团队成员最后召开Sprint retrospective meeting,总结问题和经验。
6) 这样周而复始,按照同样的步骤进行下一次Sprint.
整个过程如下图所示: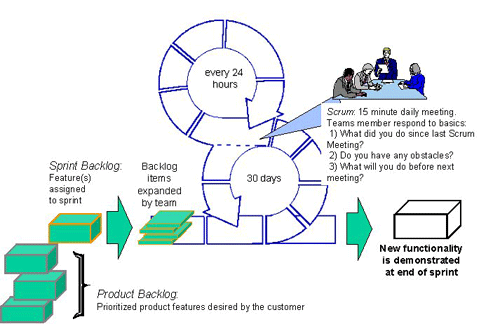
-
软件开发模型
jejo 发布于 2009-11-18 18:25:39
软件开发模型(Software Development Model)是指软件开发全部过程、活动和任务的结构框架。软件开发包括需求、设计、编码和测试等阶段,有时也包括维护阶段。
典型的开发模型有:①瀑布模型(waterfall model);②渐增模型/演化/迭代(incremental model);③原型模型(prototype model);④螺旋模型(spiral model);⑤喷泉模型(fountain model);⑥智能模型(intelligent model) ; 7. 混合模型(hybrid model)
1. 边做边改模型(Build-and-Fix Model)
遗憾的是,许多产品都是使用"边做边改"模型来开发的。在这种模型中,既没有规格说明,也没有经过设计,软件随着客户的需要一次又一次地不断被修改.
在这个模型中,开发人员拿到项目立即根据需求编写程序,调试通过后生成软件的第一个版本。在提供给用户使用后,如果程序出现错误,或者用户提出新的要求,开发人员重新修改代码,直到用户满意为止。
这是一种类似作坊的开发方式,对编写几百行的小程序来说还不错,但这种方法对任何规模的开发来说都是不能令人满意的,其主要问题在于:
(1) 缺少规划和设计环节,软件的结构随着不断的修改越来越糟,导致无法继续修改;
(2) 忽略需求环节,给软件开发带来很大的风险;
(3) 没有考虑测试和程序的可维护性,也没有任何文档,软件的维护十分困难。
2. 瀑布模型(Waterfall Model)
1970年Winston Royce提出了著名的"瀑布模型",直到80年代早期,它一直是唯一被广泛采用的软件开发模型。
瀑布模型将软件生命周期划分为制定计划、需求分析、软件设计、程序编写、软件测试和运行维护等六个基本活动,并且规定了它们自上而下、相互衔接的固定次序,如同瀑布流水,逐级下落。
在瀑布模型中,软件开发的各项活动严格按照线性方式进行,当前活动接受上一项活动的工作结果,实施完成所需的工作内容。当前活动的工作结果需要进行验证,如果验证通过,则该结果作为下一项活动的输入,继续进行下一项活动,否则返回修改。
瀑布模型强调文档的作用,并要求每个阶段都要仔细验证。但是,这种模型的线性过程太理想化,已不再适合现代的软件开发模式,几乎被业界抛弃,其主要问题在于:
(1) 各个阶段的划分完全固定,阶段之间产生大量的文档,极大地增加了工作量;
(2) 由于开发模型是线性的,用户只有等到整个过程的末期才能见到开发成果,从而增加了开发的风险;
(3) 早期的错误可能要等到开发后期的测试阶段才能发现,进而带来严重的后果。
我们应该认识到,"线性"是人们最容易掌握并能熟练应用的思想方法。当人们碰到一个复杂的"非线性"问题时,总是千方百计地将其分解或转化为一系列简单的线性问题,然后逐个解决。一个软件系统的整体可能是复杂的,而单个子程序总是简单的,可以用线性的方式来实现,否则干活就太累了。线性是一种简洁,简洁就是美。当我们领会了线性的精神,就不要再呆板地套用线性模型的外表,而应该用活它。例如增量模型实质就是分段的线性模型,螺旋模型则是接连的弯曲了的线性模型,在其它模型中也能够找到线性模型的影子。
3. 快速原型模型(Rapid Prototype Model)
快速原型模型的第一步是建造一个快速原型,实现客户或未来的用户与系统的交互,用户或客户对原型进行评价,进一步细化待开发软件的需求。通过逐步调整原型使其满足客户的要求,开发人员可以确定客户的真正需求是什么;第二步则在第一步的基础上开发客户满意的软件产品。
显然,快速原型方法可以克服瀑布模型的缺点,减少由于软件需求不明确带来的开发风险,具有显著的效果。
快速原型的关键在于尽可能快速地建造出软件原型,一旦确定了客户的真正需求,所建造的原型将被丢弃。因此,原型系统的内部结构并不重要,重要的是必须迅速建立原型,随之迅速修改原型,以反映客户的需求。
4. 增量模型(Incremental Model)
与建造大厦相同,软件也是一步一步建造起来的。在增量模型中,软件被作为一系列的增量构件来设计、实现、集成和测试,每一个构件是由多种相互作用的模块所形成的提供特定功能的代码片段构成.
增量模型在各个阶段并不交付一个可运行的完整产品,而是交付满足客户需求的一个子集的可运行产品。整个产品被分解成若干个构件,开发人员逐个构件地交付产品,这样做的好处是软件开发可以较好地适应变化,客户可以不断地看到所开发的软件,从而降低开发风险。但是,增量模型也存在以下缺陷:
(1) 由于各个构件是逐渐并入已有的软件体系结构中的,所以加入构件必须不破坏已构造好的系统部分,这需要软件具备开放式的体系结构。
(2) 在开发过程中,需求的变化是不可避免的。增量模型的灵活性可以使其适应这种变化的能力大大优于瀑布模型和快速原型模型,但也很容易退化为边做边改模型,从而是软件过程的控制失去整体性。
在使用增量模型时,第一个增量往往是实现基本需求的核心产品。核心产品交付用户使用后,经过评价形成下一个增量的开发计划,它包括对核心产品的修改和一些新功能的发布。这个过程在每个增量发布后不断重复,直到产生最终的完善产品。
例如,使用增量模型开发字处理软件。可以考虑,第一个增量发布基本的文件管理、编辑和文档生成功能,第二个增量发布更加完善的编辑和文档生成功能,第三个增量实现拼写和文法检查功能,第四个增量完成高级的页面布局功能。
5.螺旋模型(Spiral Model)
1988年,Barry Boehm正式发表了软件系统开发的"螺旋模型",它将瀑布模型和快速原型模型结合起来,强调了其他模型所忽视的风险分析,特别适合于大型复杂的系统。
螺旋模型沿着螺线进行若干次迭代,图中的四个象限代表了以下活动:
(1) 制定计划:确定软件目标,选定实施方案,弄清项目开发的限制条件;
(2) 风险分析:分析评估所选方案,考虑如何识别和消除风险;
(3) 实施工程:实施软件开发和验证;
(4) 客户评估:评价开发工作,提出修正建议,制定下一步计划。
螺旋模型由风险驱动,强调可选方案和约束条件从而支持软件的重用,有助于将软件质量作为特殊目标融入产品开发之中。但是,螺旋模型也有一定的限制条件,具体如下:
(1) 螺旋模型强调风险分析,但要求许多客户接受和相信这种分析,并做出相关反应是不容易的,因此,这种模型往往适应于内部的大规模软件开发。
(2) 如果执行风险分析将大大影响项目的利润,那么进行风险分析毫无意义,因此,螺旋模型只适合于大规模软件项目。
(3) 软件开发人员应该擅长寻找可能的风险,准确地分析风险,否则将会带来更大的风险
一个阶段首先是确定该阶段的目标,完成这些目标的选择方案及其约束条件,然后从风险角度分析方案的开发策略,努力排除各种潜在的风险,有时需要通过建造原型来完成。如果某些风险不能排除,该方案立即终止,否则启动下一个开发步骤。最后,评价该阶段的结果,并设计下一个阶段。
6.演化模型(incremental model)
主要针对事先不能完整定义需求的软件开发。用户可以给出待开发系统的核心需求,并且当看到核心需求实现后,能够有效地提出反馈,以支持系统的最终设计和实现。软件开发人员根据用户的需求,首先开发核心系统。当该核心系统投入运行后,用户试用之,完成他们的工作,并提出精化系统、增强系统能力的需求。软件开发人员根据用户的反馈,实施开发的迭代过程。第一迭代过程均由需求、设计、编码、测试、集成等阶段组成,为整个系统增加一个可定义的、可管理的子集。
在开发模式上采取分批循环开发的办法,每循环开发一部分的功能,它们成为这个产品的原型的新增功能。于是,设计就不断地演化出新的系统。 实际上,这个模型可看作是重复执行的多个“瀑布模型”。
“演化模型”要求开发人员有能力把项目的产品需求分解为不同组,以便分批循环开发。这种分组并不是绝对随意性的,而是要根据功能的重要性及对总体设计的基础结构的影响而作出判断。有经验指出,每个开发循环以六周到八周为适当的长度。
7.喷泉模型(fountain model, (面向对象的生存期模型, OO模型))
喷泉模型与传统的结构化生存期比较,具有更多的增量和迭代性质,生存期的各个阶段可以相互重叠和多次反复,而且在项目的整个生存期中还可以嵌入子生存期。就像水喷上去又可以落下来,可以落在中间,也可以落在最底部。
8.智能模型(四代技术(4GL))
智能模型拥有一组工具(如数据查询、报表生成、数据处理、屏幕定义、代码生成、高层图形功能及电子表格等),每个工具都能使开发人员在高层次上定义软件的某些特性,并把开发人员定义的这些软件自动地生成为源代码。这种方法需要四代语言(4GL)的支持。4GL不同于三代语言,其主要特征是用户界面极端友好,即使没有受过训练的非专业程序员,也能用它编写程序;它是一种声明式、交互式和非过程性编程语言。4GL还具有高效的程序代码、智能缺省假设、完备的数据库和应用程序生成器。目前市场上流行的4GL(如Foxpro等)都不同程度地具有上述特征。但4GL目前主要限于事务信息系统的中、小型应用程序的开发。
9.混合模型(hybrid model)
过程开发模型又叫混合模型(hybrid model),或元模型(meta-model),把几种不同模型组合成一种混合模型,它允许一个项目能沿着最有效的路径发展,这就是过程开发模型(或混合模型)。实际上,一些软件开发单位都是使用几种不同的开发方法组成他们自己的混合模型。
各种模型的比较
每个软件开发组织应该选择适合于该组织的软件开发模型,并且应该随着当前正在开发的特定产品特性而变化,以减小所选模型的缺点,充分利用其优点,下表列出了几种常见模型的优缺点。
模型 优点 缺点
瀑布模型 文档驱动 系统可能不满足客户的需求
快速原型模型 关注满足客户需求 可能导致系统设计差、效率低,难于维护
增量模型 开发早期反馈及时,易于维护 需要开放式体系结构,可能会设计差、效率低
螺旋模型 风险驱动 风险分析人员需要有经验且经过充分训练
标题搜索
我的存档
数据统计
- 访问量: 22471
- 日志数: 55
- 书签数: 1
- 建立时间: 2007-08-22
- 更新时间: 2010-02-27
