

一、什么是protobuf
Protocol Buffers(简称protobuf)是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式,用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
二、protobuf的优缺点
(1) 优点:
protobuf以高效的二进制方式存储,比XML小3到10倍,快20到100倍。
平台无关、语言无关
二进制、数据字描述
提供了完整详细的操作API
(2)缺点:
可读性差:为了提高性能,Protobuf采用了二进制格式进行编码。
对于开发同学来说,在进行程序调试时,二进制格式编码阅读比较困难。
对于测试同学来说,查看请求或者响应中的特定编码格式的protobuf数据比较困难,无法直观看到数据。
三、python如何解析
小编在测试过程中接触到的protobuf文件中以url_16_le格式编码较多,故以此编码为例进行处理,借助python的codecs库可以处理此类编码,当然codecs库中还有其他编码(utf_32_le、utf_32_be、utf_16_be、utf_7、utf_8),感兴趣的小伙伴可以去了解下。
1、命令行中实现解析

2、代码中实现解析
例:解析该protobuf文件(其中2代表url_16_le编码格式的数据) 8 { 1 { 6: 117 } 2: “\311Q\256v” 5: 1 6: 1 } |
(1) 取出url_16_le编码格式的内容,并重新转为byte类型
l2 = str(line).split('"')[1].replace('\\\\','\\') l3 =bytes(l2,encoding="utf8") |
l3输出结果为==>b’\311Q\256v’
(2) 数据处理(如图所示,l3输出结果解析后乱码,故需要进一步处理:\n\t\r禁止转义)

| l4 =codecs.escape_decode(l3, 'hex-escape')[0] |
l4输出结果为==>b’\xc9Q\xaev’(如图,处理后的数据就可以解析了哦)
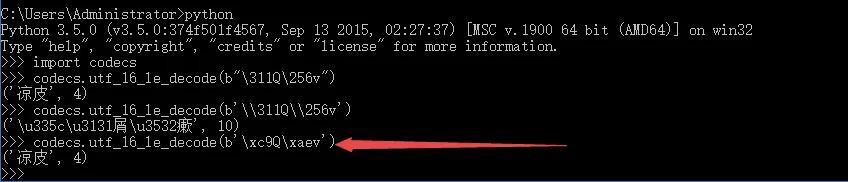
(3) 数据解码
| l5=codecs.utf_16_le_decode(l4)[0] |
l5输出结果为==>凉皮(将结果输出到某个文件就可以直观查看数据了哦)
(4) 代码总览

(5) 输出结果示例

四、小结
本文主要简单介绍了protobuf的概念及如何使用python得到可视化的数据。脚本虽简单,但在测试过程中针对每一个请求及响应,基本上都能直观的看到protobuf的数据,大大的提高了测试效率。同学们是否还有其他的可视化的方法,欢迎大家来补充~~
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












