celery.result.AsyncResult 对象
调用完任务工厂的 delay 方法之后,会创建一个任务并发送至队列,同时返回一个 AsyncResult 对象,基于此对象我们可以拿到任务执行时的所有信息。但是 AsyncResult 对象我们也可以手动构造,举个例子:
import time
# 我们不光要导入 task, 还要导入里面的 app
from app import app, task
# 导入 AsyncResult 这个类
from celery.result import AsyncResult
# 发送任务到队列当中
res = task.delay("古明地觉", 17)
# 传入任务的 id 和 app, 创建 AsyncResult 对象
async_result = AsyncResult(res.id, app=app)
# 此时的这个 res 和 async_result 之间是等价的
# 两者都是 AsyncResult 对象, 它们所拥有的方法也是一样的
# 下面用谁都可以
while True:
# 等价于async_result.state == "SUCCESS"
if async_result.successful():
print(async_result.get())
break
# 等价于async_result.state == "FAILURE"
elif async_result.failed():
print("任务执行失败")
elif async_result.status == "PENDING":
print("任务正在被执行")
elif async_result.status == "RETRY":
print("任务执行异常正在重试")
elif async_result.status == "REJECTED":
print("任务被拒绝接收")
elif async_result.status == "REVOKED":
print("任务被取消")
else:
print("其它的一些状态")
time.sleep(0.8)
"""
任务正在被执行
任务正在被执行
任务正在被执行
任务正在被执行
name is 古明地觉, age is 17
"""
以上就是任务可能出现的一些状态,通过轮询的方式,我们也可以查看任务是否已经执行完毕。当然 AsyncResult 还有一些别的方法,我们来看一下:
from app import task
res = task.delay("古明地觉", 17)
# 1. ready():查看任务状态,返回布尔值。
# 任务执行完成返回 True,否则为 False
# 那么问题来了,它和 successful() 有什么区别呢?
# successful() 是在任务执行成功之后返回 True, 否则返回 False
# 而 ready() 只要是任务没有处于阻塞状态就会返回 True
# 比如执行成功、执行失败、被 worker 拒收都看做是已经 ready 了
print(res.ready())
"""
False
"""
# 2. wait():和之前的 get 一样, 因为在源码中写了: wait = get
# 所以调用哪个都可以, 不过 wait 可能会被移除,建议直接用 get 就行
print(res.wait())
print(res.get())
"""
name is 古明地觉, age is 17
name is 古明地觉, age is 17
"""
# 3. trackback:如果任务抛出了一个异常,可以获取原始的回溯信息
# 执行成功就是 None
print(res.traceback)
"""
None
"""
以上就是获取任务执行结果相关的部分。
celery 的配置
celery 的配置不同,所表现出来的性能也不同,比如序列化的方式、连接队列的方式,单线程、多线程、多进程等等。那么 celery 都有那些配置呢?
·broker_url:broker 的地址,就是类 Celery 里面传入的 broker 参数。
· result_backend:存储结果地址,就是类 Celery 里面传入的 backend 参数。
· task_serializer:任务序列化方式,支持以下几种:
· binary:二进制序列化方式,pickle 模块默认的序列化方法;
· json:支持多种语言,可解决多语言的问题,但通用性不高;
· xml:标签语言,和 json 定位相似;
· msgpack:二进制的类 json 序列化,但比 json 更小、更快;
· yaml:表达能力更强、支持的类型更多,但是在
Python里面的性能不如 json;
· 根据情况,选择合适的类型。如果不是跨语言的话,直接选择 binary 即可,默认是 json。
· result_serializer:任务执行结果序列化方式,支持的方式和任务序列化方式一致。
· result_expires:任务结果的过期时间,单位是秒。
· accept_content:指定任务接受的内容序列化类型(序列化),一个列表,比如:["msgpack", "binary", "json"]。
· timezone:时区,默认是 UTC 时区。
· enable_utc:是否开启 UTC 时区,默认为 True;如果为 False,则使用本地时区。
· task_publish_retry:发送消息失败时是否重试,默认为 True。
· worker_concurrency:并发的 worker 数量。
· worker_prefetch_multiplier:每次 worker 从任务队列中获取的任务数量。
· worker_max_tasks_per_child:每个 worker 执行多少次就会被杀掉,默认是无限的。
· task_time_limit:单个任务执行的最大时间,单位是秒。
· task_default_queue :设置默认的队列名称,如果一个消息不符合其它的队列规则,就会放在默认队列里面。如果什么都不设置的话,数据都会发送到默认的队列中。
· task_queues :设置详细的队列
# 将 RabbitMQ 作为 broker 时需要使用
task_queues = {
# 这是指定的默认队列
"default": {
"exchange": "default",
"exchange_type": "direct",
"routing_key": "default"
},
# 凡是 topic 开头的 routing key
# 都会被放到这个队列
"topicqueue": {
"routing_key": "topic.#",
"exchange": "topic_exchange",
"exchange_type": "topic",
},
"task_eeg": { # 设置扇形交换机
"exchange": "tasks",
"exchange_type": "fanout",
"binding_key": "tasks",
},
}
celery 的配置非常多,不止我们上面说的那些,更多配置可以查看官网,写的比较详细。
https://docs.celeryq.dev/en/latest/userguide/configuration.html#general-settings
值得一提的是,在 5.0 之前配置项都是大写的,而从 5.0 开始配置项改成小写了。不过老的写法目前仍然支持,只是启动的时候会抛警告,并且在 6.0 的时候不再兼容老的写法。
官网也很贴心地将老版本的配置和新版本的配置罗列了出来,尽管配置有很多,但并不是每一个都要用,可以根据自身的业务合理选择。
然后下面我们就根据配置文件的方式启动 celery,当前目录结构如下:
celery_demo/config.py
broker_url = "redis://:maverick@82.157.146.194:6379/1"
result_backend = "redis://:maverick@82.157.146.194:6379"
# 写俩就完事了
celery_demo/tasks/task1.py
celery 可以支持非常多的定时任务,而不同种类的定时任务我们一般都会写在不同的模块中(当然这里目前只有一个),然后再将这些模块组织在一个单独的目录中。
当前只有一个 task1.py,我们随便往里面写点东西,当然你也可以创建更多的文件。
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x / y
celery_demo/app.py
from celery import Celery
import config
from tasks.task1 import (
add, sub, mul, div
)
# 指定一个 name 即可
app = Celery("satori")
# 其它参数通过加载配置文件的方式指定
# 和 flask 非常类似
app.config_from_object(config)
# 创建任务工厂,有了任务工厂才能创建任务
# 这种方式和装饰器的方式是等价的
add = app.task(add)
sub = app.task(sub)
mul = app.task(mul)
div = app.task(div)
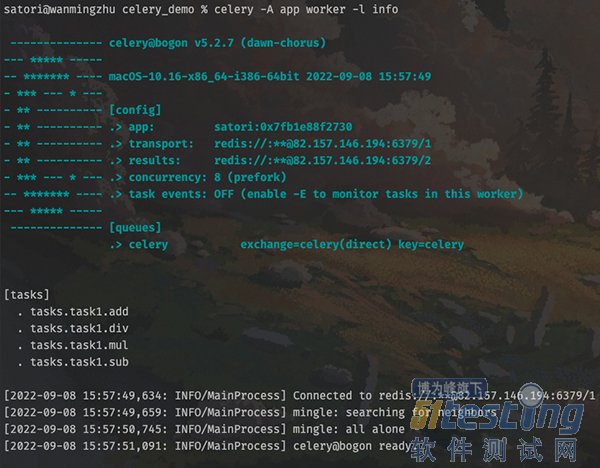
然后重新启动 worker:
输出结果显示,任务工厂都已经被加载进来了,然后我们创建任务并发送至队列。
# 在 celery_demo 目录下
# 将 app.py 里面的任务工厂导入进来
>>> from app import add, sub, mul, div
# 然后创建任务发送至队列,并等待结果
>>> add.delay(3, 4).get()
7
>>> sub.delay(3, 4).get()
-1
>>> mul.delay(3, 4).get()
12
>>> div.delay(3, 4).get()
0.75
>>>
结果正常返回了,再来看看 worker 的输出。
多个任务都被执行了。
51Testing行业调查问卷正在进行中,哪种类型的
测试更有趋势,哪种测试工具会成为主流?只要你点击下方链接参与问卷,一定能得到一些行业参考~