什么是 celery
这次我们来介绍一下
Python 的一个第三方模块 celery,那么 celery 是什么呢?
· celery 是一个灵活且可靠的,处理大量消息的分布式系统,可以在多个节点之间处理某个任务;
· celery 是一个专注于实时处理的任务队列,支持任务调度;
· celery 是开源的,有很多的使用者;
· celery 完全基于 Python 语言编写;
所以 celery 本质上就是一个任务调度框架,类似于 Apache 的 airflow,当然 airflow 也是基于 Python 语言编写。
不过有一点需要注意,celery 是用来调度任务的,但它本身并不具备存储任务的功能,而调度任务的时候肯定是要把任务存起来的。因此要使用 celery 的话,还需要搭配一些具备存储、访问功能的工具,比如:消息队列、Redis缓存、
数据库等等。官方推荐的是消息队列 RabbitMQ,个人认为有些时候使用 Redis 也是不错的选择,当然我们都会介绍。
那么 celery 都可以在哪些场景中使用呢?
· 异步任务:一些耗时的操作可以交给celery异步执行,而不用等着程序处理完才知道结果。比如:视频转码、邮件发送、消息推送等等;
· 定时任务:比如定时推送消息、定时爬取数据、定时统计数据等等;
celery 的架构
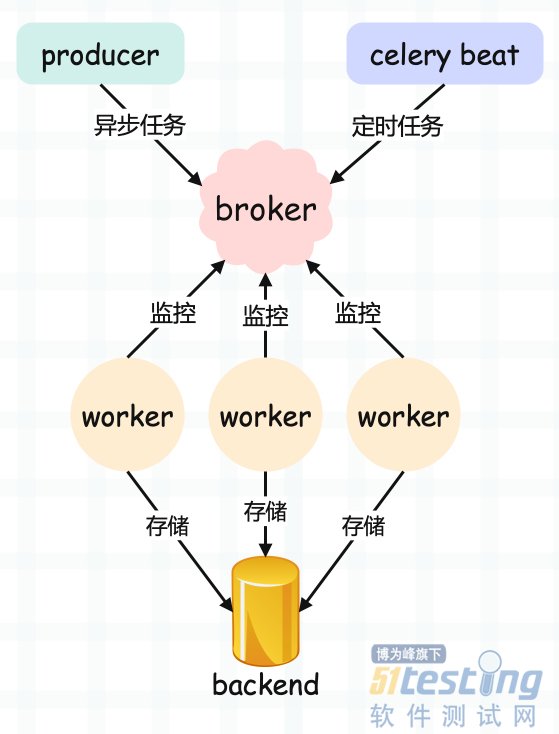
我们看一下 celery 的架构:
· producer:生产者,专门用来生产任务(task);
· celery beat:任务调度器,调度器进程会读取配置文件的内容,周期性地将配置文件里面到期需要执行的任务发送给消息队列,说白了就是生产定时任务;
· broker:任务队列,用于存放生产者和调度器生产的任务。一般使用消息队列或者 Redis 来存储,当然具有存储功能的数据库也是可以的。这一部分是 celery 所不提供的,需要依赖第三方。作用就是接收任务,存进队列;
· worker:任务的执行单元,会将任务从队列中顺序取出并执行;
· backend:用于在任务结束之后保存状态信息和结果,以便查询,一般是数据库,当然只要具备存储功能都可以作为 backend;
下面我们来安装 celery,安装比较简单,直接 pip install celery 即可。这里我本地的 celery 版本是 5.2.7,Python 版本是 3.8.10。
另外,由于 celery 本身不提供任务存储的功能,所以这里我们使用 Redis 作为消息队列,负责存储任务。因此你还要在机器上安装 Redis,我这里有一台云服务器,已经安装好了。
后续 celery 就会将任务存到 broker 里面,当然要想实现这一点,就必须还要有能够操作相应 broker 的驱动。Python 操作 Redis 的驱动也叫 redis,操作 RabbitMQ 的驱动叫 pika,直接 pip install ... 安装即可。
celery 实现异步任务
我们新建一个工程,就叫 celery_demo,然后在里面新建一个 app.py 文件。
# 文件名:app.py
import time
# 这个 Celery 就类似于 flask.Flask
# 然后实例化得到一个app
from celery import Celery
# 指定一个 name、以及 broker 的地址、backend 的地址
app = Celery(
"satori",
# 这里使用我服务器上的 Redis
# broker 用 1 号库, backend 用 2 号库
broker="redis://:maverick@82.157.146.194:6379/1",
backend="redis://:maverick@82.157.146.194:6379/2")
# 这里通过 @app.task 对函数进行装饰
# 那么之后我们便可调用 task.delay 创建一个任务
@app.task
def task(name, age):
print("准备执行任务啦")
time.sleep(3)
return f"name is {name}, age is {age}"
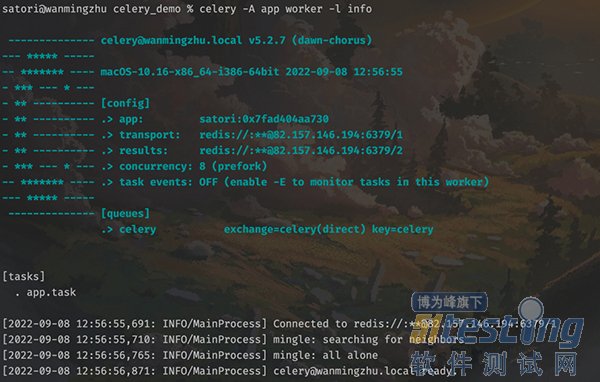
我们说执行任务的对象是 worker,那么我们是不是需要创建一个 worker 呢?显然是需要的,而创建 worker 可以使用如下命令创建:
注意:在 5.0 之前我们可以写成 celery worker -A app ...,也就是把所有的参数都放在子命令 celery worker 的后面。但从 5.0 开始这种做法就不允许了,必须写成 celery -A app worker ...,因为 -A 变成了一个全局参数,所以它不应该放在 worker 的后面,而是要放在 worker 的前面。
下面执行该命令:
以上就前台启动了一个 worker,正在等待从队列中获取任务,图中也显示了相应的信息。然而此时队列中并没有任务,所以我们需要在另一个文件中创建任务并发送到队列里面去。
import time
from app import task
# 从 app 导入 task, 创建任务, 但是注意: 不要直接调用 task
# 因为那样的话就在本地执行了, 我们的目的是将任务发送到队列里面去
# 然后让监听队列的 worker 从队列里面取任务并执行
# 而 task 被 @app.task 装饰, 所以它不再是原来的 task 了
# 我们需要调用它的 delay 方法
# 调用 delay 之后, 就会创建一个任务
# 然后发送到队列里面去, 也就是我们这里的 Redis
# 至于参数, 普通调用的时候怎么传, 在 delay 里面依旧怎么传
start = time.perf_counter()
task.delay("古明地觉", 17)
print(
time.perf_counter() - start
) # 0.11716766700000003
然后执行该文件,发现只用了 0.12 秒,而 task 里面明明 sleep 了 3 秒。所以说明这一步是不会阻塞的,调用 task.delay 只是创建一个任务并发送至队列。我们再看一下 worker 的输出信息:
可以看到任务已经被消费者接收并且消费了,而且调用 delay 方法是不会阻塞的,花费的那 0.12 秒是用在了其它地方,比如连接 Redis 发送任务等等。
另外需要注意,函数被 @app.task 装饰之后,可以理解为它就变成了一个任务工厂,因为被装饰了嘛,然后调用任务工厂的 delay 方法即可创建任务并发送到队列里面。我们也可以创建很多个任务工厂,但是这些任务工厂必须要让 worker 知道,否则不会生效。所以如果修改了某个任务工厂、或者添加、删除了某个任务工厂,那么一定要让 worker 知道,而做法就是先停止 celery worker 进程,然后再重新启动。
如果我们新建了一个任务工厂,然后在没有重启 worker 的情况下,就用调用它的 delay 方法创建任务、并发送到队列的话,那么会抛出一个 KeyError,提示找不到相应的任务工厂。
其实很好理解,因为代码已经加载到内存里面了,光修改了源文件而不重启是没用的。因为加载到内存里面的还是原来的代码,不是修改过后的。
然后我们再来看看 Redis 中存储的信息,1 号库用作 broker,负责存储任务;2 号库用作 backend,负责存储执行结果。我们来看 2 号库:
以上我们就启动了一个 worker 并成功消费了队列中的任务,并且还从 Redis 里面拿到了执行信息。当然啦,如果只能通过查询 backend 才能拿到信息的话,那 celery 就太不智能了。我们也可以直接从程序中获取。
直接查询任务执行信息
Redis(backend)里面存储了很多关于任务的信息,这些信息我们可以直接在程序中获取。
from app import task
res = task.delay("古明地觉", 17)
print(type(res))
"""
<class 'celery.result.AsyncResult'>
"""
# 直接打印,显示任务的 id
print(res)
"""
4bd48a6d-1f0e-45d6-a225-6884067253c3
"""
# 获取状态, 显然此刻没有执行完
# 因此结果是PENDING, 表示等待状态
print(res.status)
"""
PENDING
"""
# 获取 id,两种方式均可
print(res.task_id)
print(res.id)
"""
4bd48a6d-1f0e-45d6-a225-6884067253c3
4bd48a6d-1f0e-45d6-a225-6884067253c3
"""
# 获取任务执行结束时的时间
# 任务还没有结束, 所以返回None
print(res.date_done)
"""
None
"""
# 获取任务的返回值, 可以通过 result 或者 get()
# 注意: 如果是 result, 那么任务还没有执行完的话会直接返回 None
# 如果是 get(), 那么会阻塞直到任务完成
print(res.result)
print(res.get())
"""
None
name is 古明地觉, age is 17
"""
# 再次查看状态和执行结束时的时间
# 发现 status 变成SUCCESS
# date_done 变成了执行结束时的时间
print(res.status)
# 但显示的是 UTC 时间
print(res.date_done)
"""
SUCCESS
2022-09-08 06:40:34.525492
"""
另外我们说结果需要存储在 backend 中,如果没有配置 backend,那么获取结果的时候会报错。至于 backend,因为它是存储结果的,所以一般会保存在数据库中,因为要持久化。我这里为了方便,就还是保存在 Redis 中。
51Testing行业调查问卷正在进行中,哪种类型的
测试更有趋势,哪种测试工具会成为主流?只要你点击下方链接参与问卷,一定能得到一些行业参考~