

背景:
接口测试用例运行在Jenkins节点上,在某些情况下,比如网络波动等原因,会导致用例运行失败,此时会触发邮件和钉钉预警,通知给到责任人,按照现有策略,当本次构建失败时,会立马触发第二次构建活动,若第二次构建仍然失败,则会再次触发预警信息。
在这种策略下,会导致相关责任人收到一些额外的无意义预警信息(如第一次构建超时,而第二次构建成功),所以就多写了一个脚本,在Jenkins中作为Robotframework用例的运行入口,当有用例执行失败时,在所有cases执行完成后,会选择本次运行失败的cases再重试一次,然后合并两次的测试报告文件。
脚本内容很简单,可拓展性很强:
#!/usr/bin/env python
# -*- coding:utf8 -*-
import getopt
import os
import sys
from pathlib import Path
from robot.api import ExecutionResult
def parse_args() -> tuple:
"""解析命令行传入的参数"""
opts, args = getopt.getopt(sys.argv[1:], '-i:-e:-F:-E:', ["includeTag=", "excludeTag=", "format=", "env="])
try:
target = args[0]
except IndexError:
target = "./"
def _parse(option, default_value=None):
if isinstance(option, tuple):
temp = [opt_value for (opt_name, opt_value) in opts if opt_name in option]
else:
temp = [opt_value for (opt_name, opt_value) in opts if opt_name == option]
return temp[0] if len(temp) > 0 else default_value
include_tag = _parse(("-i", "--includeTag")) # 包含用例标签
exclude_tag = _parse(("-e", "--excludeTag")) # 排除用例标签
env = _parse(("-E", "--env"), 'm') # 用例运行环境
fm = _parse(("-F", "--format"), 'robot') # 用例文件后缀名
return include_tag, exclude_tag, env, fm, targetdef first_run(target, env, include_tag, exclude_tag, fm): """首次运行用例
项目的基本目录结构是固定的, 在命令行中写死了变量文件的相对路径.
"""
if include_tag:
cmd = f"robot -F {fm} -i {include_tag} --output output_origin.xml --log NONE --report NONE -V variables.py:{env} -V ../Common/Variables/commonVars.py:{env} {target}"
elif exclude_tag is not None:
cmd = f"robot -F {fm} -e {exclude_tag} --output output_origin.xml --log NONE --report NONE -V variables.py:{env} -V ../Common/Variables/commonVars.py:{env} {target}"
else:
cmd = f"robot -F {fm} --output output_origin.xml --log NONE --report NONE -V variables.py:{env} -V ../Common/Variables/commonVars.py:{env} {target}"
print(f'First run cmd >>>> {cmd}')
os.system(cmd)def parse_robot_result(xml_path) -> bool:
"""解析用例运行结果"""
suite = ExecutionResult(xml_path).suite
fail = {}
for test in suite.tests:
if test.status == "FAIL":
fail.update({test.name: test.status})
all_tests = suite.statistics.critical print("*" * 50)
print("当前运行目录为: ", os.getcwd())
print("总测试条数:{0}, 初次运行时,通过的用例数: {1}, 失败的用例数: {2}".format(all_tests.total, all_tests.passed, all_tests.failed))
if all_tests.failed > 0:
print("其中失败的用例信息为: %s" % str(fail))
print("*" * 50)
return all_tests.failed > 0def rerun_fail_case(target, env, include_tag, exclude_tag, fm): """ # TODO
如果要重新运行整个套件,需要使用`rerunfailedsuites`, 如果只想重新运行失败的测试用例而不是套件中已通过的测试,则使用`rerunfailed`(必须保证case是独立的)
-R, --rerunfailed <file>
Selects failed tests from an earlier output file to be re-executed.
-S, --rerunfailedsuites <file>
Selects failed test suites from an earlier output file to be re-executed.
""" if include_tag:
cmd = f"robot -F {fm} -i {include_tag} -V variables.py:{env} -V ../Common/Variables/commonVars.py:{env} --rerunfailed output_origin.xml --output output_rerun.xml {target}"
elif exclude_tag is not None:
cmd = f"robot -F {fm} -e {exclude_tag} -V variables.py:{env} -V ../Common/Variables/commonVars.py:{env} --rerunfailed output_origin.xml --output output_rerun.xml {target}"
else:
cmd = f"robot -F {fm} -V variables.py:{env} -V ../Common/Variables/commonVars.py:{env} --rerunfailed output_origin.xml --output output_rerun.xml {target}"
print(f'重复运行失败的用例: {cmd}')
os.system(cmd)
"""再次运行失败的用例"""def merge_output():
"""合并xml文件,并生成测试报告
注意集成到jenkins中时,需要指定 Output xml name为merge.xml
"""
os.system("rebot --merge --output merge.xml *.xml")def main():
include_tag, exclude_tag, env, fm, target = parse_args() # 切换到output目录
if Path(target).is_dir():
os.chdir(Path(target))
else:
os.chdir(Path(target).parent)
for xml in Path.cwd().glob("*.xml"):
os.remove(xml)
first_run(target, env, include_tag, exclude_tag, fm)
failed = parse_robot_result("output_origin.xml")
if failed:
rerun_fail_case(target, env, include_tag, exclude_tag, fm)
# 不论是否存在失败的用例, 都会合并测试报告
merge_output()if __name__ == '__main__':
main()
除-E参数外,其他都是robot提供的的命令行参数,在项目中使用了变量文件,来使得用例支持切换运行环境,-E参数需要传入用例运行的环境,-i 或-e参数用来传入标签,过滤本次要运行的测试用例,可以传入多个标签,如:H5ANDP1、H5ORMini、NotPaid等。
在Jenkins项目配置中,构建操作配置的 Execute Windows Batch Cmd 如下:
cd %WORKSPACE%/ParkTest/interface
python runrobot.py --env=%Env% -F robot -i %Tag% ./
exit 0
Env和Tag都是在参数化构建时传入的,并且设有默认值。
在构建后操作中,使用Robot Framework插件收集构建结果,由于上面在脚本中修改了默认的输出文件名,这里要对应进行配置,如下:
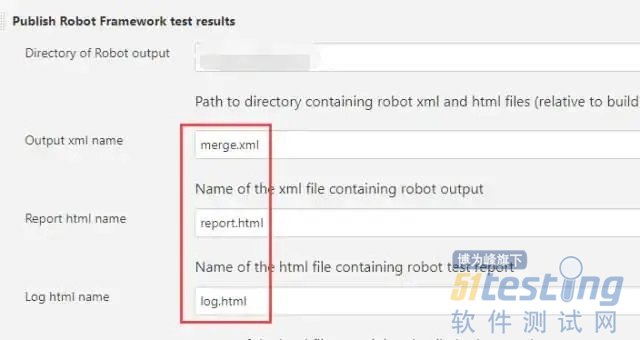
当项目第一次构建失败时,第二次构建只会运行之前失败的测试用例,并合并两次生成的测试报告,在测试报告中展示如下:


这样就可以减少一些无效的报错邮件了。
关于以上方案,有一点还要进行特别说明,那就是项目中测试用例之前必须是相互独立的。保持Case独立性我认为是很有必要的,每一个 Test Case 应该只测试一种场景,根据case复杂程度,不同场景同样可大可小,但不能相互影响。当我们有随机的跑其中某个Case或乱序的跑这些Cases时,测试的结果都应该是准确的。Suite level和Directory level同样要注意独立性的问题。保持Case的独立性,这一点应当作为自动化用例编写规范,严格要求组内其他成员。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












