

NSoup是一个开源框架,是JSoup(Java)的.NET移植版本
1、直接用起来
NSoup.Nodes.Document htmlDoc = NSoup.NSoupClient.Parse(HTMLString); //无需实例化
NSoup的强大之处在于可以用类似js的方法来获取节点元素

通过元素类型获取元素GetElementByTag("p")
NSoup.Select.Elements ele= htmlDoc.GetElementsByTag(TbTag.Text); foreach (var item in ele) { if (item.Attr("class") == "col-sm-4 col-xs-6 listtit1") //通过Attr(""href)可以获取元素的属性 { sb.AppendLine(item.Text()); //通过Text()方法可以获取元素中的文本内容 } } |
2、做了一个winform的小demo
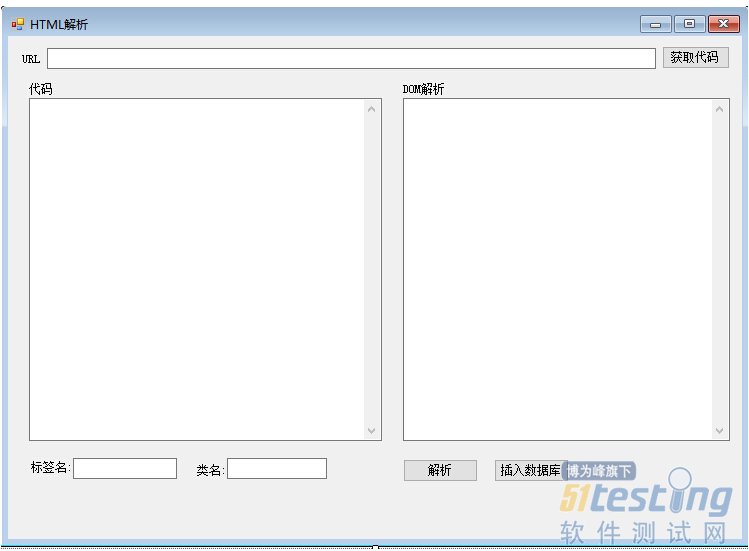
关键代码:
下面以提取一个html代码中211大学名和地点的为例:
private void GetHtml_Click(object sender, EventArgs e) { //获取指定地址的Html代码 TbCode.Text = ""; string url = TbUrl.Text.Trim(); WebClient client = new WebClient(); client.Encoding = System.Text.Encoding.UTF8; string html = client.DownloadString(url); TbCode.Text = html; } private void Analysis_Click(object sender, EventArgs e) { NSoup.Nodes.Document htmlDoc = NSoup.NSoupClient.Parse(TbCode.Text); NSoup.Select.Elements ele= htmlDoc.GetElementsByTag(TbTag.Text); System.Text.StringBuilder sb=new StringBuilder(); foreach (var item in ele) { sb.AppendLine(item.Text()); foreach (var item1 in item.NextElementSibling.Children) { if (item1.Attr("class") == "col-sm-4 col-xs-6 listtit1") { sb.AppendLine(item1.Text()); } } } TbElement.Text = sb.ToString(); } |
html代码片段(因篇幅原因未贴全):
<h4>安徽</h4>
<ul class="list-unstyled clearfix">
<li class="col-sm-4 col-xs-6 listtit1"><a href="/daxue/detail/detail3712.html">合肥工业大学</a></li>
<li class="col-sm-4 col-xs-6 listtit1"><a href="/daxue/detail/detail3715.html">中国科学技术大学</a></li>
<li class="col-sm-4 col-xs-6 listtit1"><a href="/daxue/detail/detail3716.html">安徽大学</a></li>
</ul>
效果(标签类型h4):













