
-
Selenium学习笔记
2013-04-18 17:24:41
Selenium介绍:Selenium-IDE是firefox的查件,用来录制和回放自动测试脚本。适合用于简单的测试和演示。Selenium-WebDriver属于Selenium2.0,取代Selenium-RC,WebDriver API基于不同浏览器native对自动化的支持,不同浏览器有不同的Driver。Selenium-RC是采用javascript注入技术,对所有浏览器都一样。用Javascript脚本来驱动自动化。如果只是使用WebDriver API并且在本地执行,就不需要Selenium Server,当如下情况的时候要使用Selenium Server。- 使用 Selenium-Grid在多台电脑并行运行测试。
- 在远程机器上执行测试。
- 没有使用Java binding但是要使用HtmlUnitDriver。
Selenium-IDE:Tips: 1. 在录制过程中要产生type命令,也许需要点击页面的其他部分。2. 建议使用clickAndWait方法,等待页面load成功。3. 使用Base URL,有利于在不同Domain之间运行case,这样open语句可以用相对url,系统会和base url进行拼接。Selenium Command的分类:1. Actions命令用于操作被测软件,一旦出错或者失败,当前运行的测试就停止。2. Accessors用于检测应用的状态并存储在变量中。也用来自动产生断言(Assertion)3. Assertions类似于Accessors,并且能确认应用状态是否符合预期。Assertions命令又有3个使用模式:“assert”,“verify”和“waitFor”,如:“assertText”, “verifyText” and “waitForText”如果assert失败,测试就停止,如果verify失败测试会继续,在结果中记录这次失败。通常assert用来确定页面是否正确,之后用verify来测试各种控件。waitFor会等待某个条件为真,当在timeout的时限内还没有消息的话测试会失败或者挂起。Selenium的命令简单,由命令本身和2个参数组成,参数通常是一个定位器,或者text pattern,或者一个变量。
在Selenium-IDE中测试用例以HTML的格式存储,是一个表格,有三列(command,target,value),每一行代表一个命令。verifyText //div//a[2] Login Test Suite同样用HTML描述包含多个test case。常用的命令有:open, click/clickAndWait, verifyTitle/assertTitle, verifyTextPresent,verifyElementPresent,verifyText,verifyTable,waitForPageToLoad,waitForElementPresent命令的Target参数通常是一个locator,用来指定某个控件 -
ClearCase的一些基本概念
2011-01-30 15:37:20
公司采用的代码管理工具是ClearCase,在使用过程中,经历了从最初的比较迷惑到基本熟悉的过程。说实话并不是怎么易用。里面的概念也比较难于理解。这里我就介绍一下ClearCase的一些基本概念,这些都是使用ClearCase所必需知道的:
1. VOB--Versioned Object Base, ClearCase将所有管理的文件的各种版本都存储在这个VOB中,VOB可以看作是整个ClearCase SCM系统的中心数据库。
2. View--View分为SnapShot View和Dynamic View,Snapshot view是clearcase在服务器上存储的文件和目录的一个本地镜像,用户可以在本地进行修改,然后进行同步,要经常Update View保持最新的版本,Dynamic View是动态试图,他并不在本地存储任何文件,始终和服务器保持一致。
3. Reserved checkout vs unreserved checkout -- 一个文件可以被多个用户的多个view来unreserved checkout,但是同时只能有一个用户reserved checkout。当一个用户reserved checkout的时候,其他unreserved checkout的文件,不能checkin,只能等reserved checkout的文件被checkin之后才能够checkin。
4. hijacked文件--当用户创建Snapshot View的时候,本地的文件属性都是只读的,如果用户没有check out的情况下就对文件进行了修改,这个文件就为hijacked文件,此时这个文件已经脱离的ClearCase的控制,所以最好不要Hijacked 文件。
5. mastership--很多情况下,ClearCase都被部署为MultiSite的形式,特别是跨地域开发的时候,每个地方的开发人员都在本地的一个VOB副本上工作,叫做replica, ClearCase负责同步这些不同的VOB。为了避免冲突,ClearCase提供了一个排他修改的属性,叫做mastership。所有的VOB对象都有一个master replica。master replica 对这个对象有排他的修改操作权限,因此对于一个VOB对象只有master replica才能对他进行修改或删除。所以在你把新的文件或目录Add to source control的时候,最好要选择 “Make current replica the master of all newly created branches”。
6. merge文件--当一个用户check out一个文件进行了修改,在check in的时候如果clearcase发现这个文件和最新的版本有冲突的时候(可能是其他用户也对该文件进行了修改并已经check in),会提示要merge文件,这时候就可能需要手工的merge了。
-
Rational Functional Tester经验总结(2)
2011-01-18 13:48:57
接着上一篇继续说说:)
4. 使用Public Object Map还是Private Object Map?在RFT中,录制的对象都保存在Object Map中,分为公有的和私有的,对于每个单独的测试脚本我建议都使用Private Object Map,这样各个脚本比较独立,不易出错。但公有的也有好处就是共享,统一管理。不过在通常的测试中,每一个独立的测试用例都是测试界面的某一部分功能,某一个UI对象的调用只是在相应的测试脚本中,因此很少有在多个测试脚本里调用同一个对象。除非对于某些系统,可能有些对象被很多脚本调用,这时候可以考虑用Public Object Map,这样就可以在对象出现变化的时候统一的改动而不必对每个脚本调整,但是这又多了要维护这个公用 Object Map的工作。而且要保证Public Object Map不要冗余和不断将对象merge进去不是件简单的事。大家要根据实际情况衡量利弊。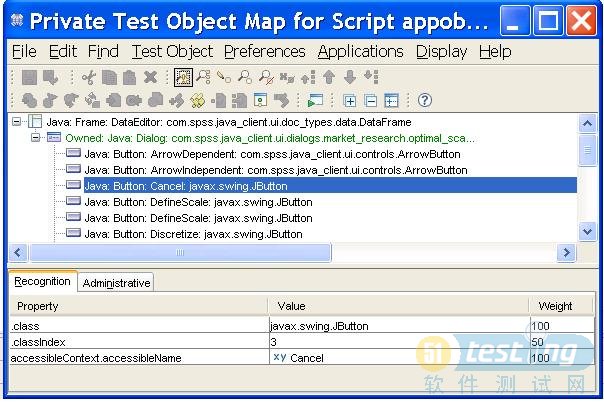
5. 是用Record/Play的方式开发吗?
大部分的测试自动化工具都是Record/Play的方式,并且给的例子也是采用这种方式。但实际开发中,我想没有人会使用这种方式,采用这种方式生成的脚本和被测软件和环境有着太多的关联,测试用例是会不断细化和改变的,当用例变化时需要重新录制,而且很难debug,维护成本太高。除非只是给用户做个demo可以用这种方式。所以我建议自己来写不要录制,采取的做法如下(以购物系统为例):
第一,生成Object Map,将需要调用的对象识别出来并存入Object Map。如:登录按钮,注册按钮各种输入框,导航键等等。
第二,写一些通用的task,这些task组成testcase,比如登录过程是一个task,注册也是,挑选一件商品,结算等等。
第三,写testcase,testcase就调用不同的task,如:用户登录--挑选一件商品--去结算。这就是个完整的测试用例,可以调用实现准备好的task来完成。
6. 能不能不用Object Map,在运行过程中动态识别对象?
这是可以的,有些时候对象是运行时动态生成并且每次可能都不同,这样你就无法事先识别它,或者应用程序不是很稳定变动很频繁,这样生成Object Map就很不划算,因为我们要不断的去修改它。这时候我们选择动态识别对象采用find()方法如下,但是性能是要牺牲的动态识别的速度要比事先录制在识别慢:
Test Object [] bj = find(atDescendant(".class", "Html.BUTTON",
".text", "OK"));
这样在运行时会找到类型为Html.BUTTON,文本为"OK"的对象。使用完一定要释放,否则当有大量对象的时候会有内存问题。
obj.unregister();
7. 灵活运用正则表达式,在录制对象的时候,对象的属性被记录下来,你可以将属性值转换成正则表达式,这样当属性稍有变化时依然可以匹配,又或者可以同时匹配多个对象,对于运行时才按照某种格式生成的某些属性值,采用正则表达式可以很好的解决。右键点击对象属性值,选择转换为 正则表达式。
正则表达式。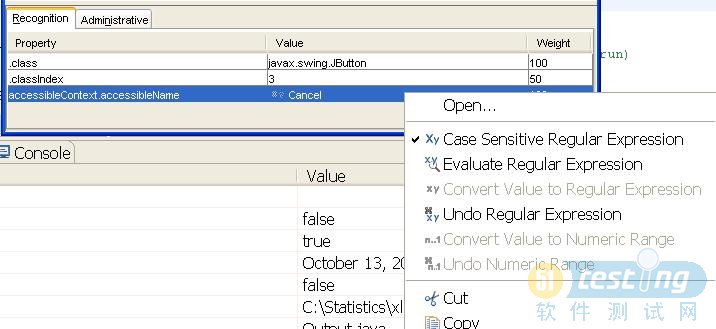
8.在RFT的log中插入信息,RFT支持多种日志格式,txt, html, TPTP, xml等等,前面说了,开发过程主要是采用自己编程的方法,但我们如何把程序的信息,警告或者错误也写到RFT的log中呢?很简单RFT提供了接口,
static void logTestResult(java.lang.String headline, boolean passed, java.lang.String additionalInfo)
就先总结这么多吧,以后有了继续更新,希望对您有帮助。
-
Rational Functional Tester经验总结(1)
2011-01-18 11:04:02
Rational Functional Tester 是IBM Rational 测试工具集的新一代应用于功能自动化测试的工具。相比于早期的Rational robot在易用性和稳定性上都有了很大提高。我们最近也在使用,感觉并不比QTP差。许多新功能都设计的好用。这里我并不是像傻瓜书一样介绍RFT的使用,因为这些大家都可以自己安装根据软件自带的实例都可以自学完成。我要说的是一些我们使用过程中的经验总结,希望对大家有所帮助。
1. 为了很好的支持多种语言,特别是亚太地区的语言,在开始使用RFT的时候将文本文件的编码方式设置为UTF-8,如下
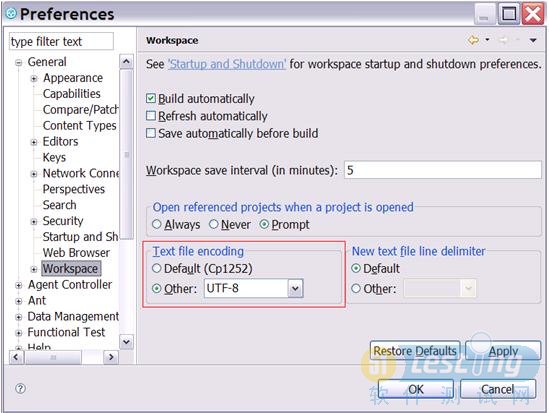
2. RFT的发现对象的机制是匹配事先录制好的或者实现的对象属性,不是鼠标的操作,每一个属性都有一个权重值在0到100之间。在RFT匹配对象的时候会计算出一个识别分数,识别分数等于所有不匹配属性权值之和乘以100.如果所有属性都匹配,最后的识别分数为0.如果某一个属性不匹配,比如这个属性的权值是50,那么匹配分数为50×100等于5000.(这个值越大说明对象越不和我们的baseline匹配)。
因此在RFT我们可以设置一些冗余度来控制对象匹配的精确性,这点非常有用,比如说开发人员修改了UI对象的某一个属性,但是我们记录了这个对象的多个属性来匹配,这时候我们通过设置冗余度,使得即使UI对象的某个属性发生改变,RFT依然可以识别该属性,我们不用重新录制或者修改脚本。如下图:
通过上面积个参数可设置识别阀值,具体意义请参考帮助文档。
3. 到底用不用Simplified Scripting? RFT 默认使用这个选项,Simplified scripting用语句来记录用户的操作,用户可以很容易的理解和编辑,背后对应的是Java或VB代码(真正后台执行)。但是在实际的测试自动化中我建议不要用此选项,因为这样有多了一层维护的成本而且Simplified Scripting容易出错。我们建议直接生成编辑Java代码,这样给测试开发人员很大的灵活性可以进行扩展和查错。省去了Simplified Scripting也减少测试出错的可能。

-
Silk Performer基本概念
2008-04-15 18:03:07
Silk Performer是Borland公司生产的一款性能测试工具,和Load Runner是竞争对手。Silk Performer采用work flow的概念将性能测试的步骤制作成一个工作流,这让初学者很容易上手,十分方便。其中包括baseline的测试。 另一点好的方面是,它将一个测试作为一个整体工程来看待,所有的相关文件都整合在某一个工程文件内。
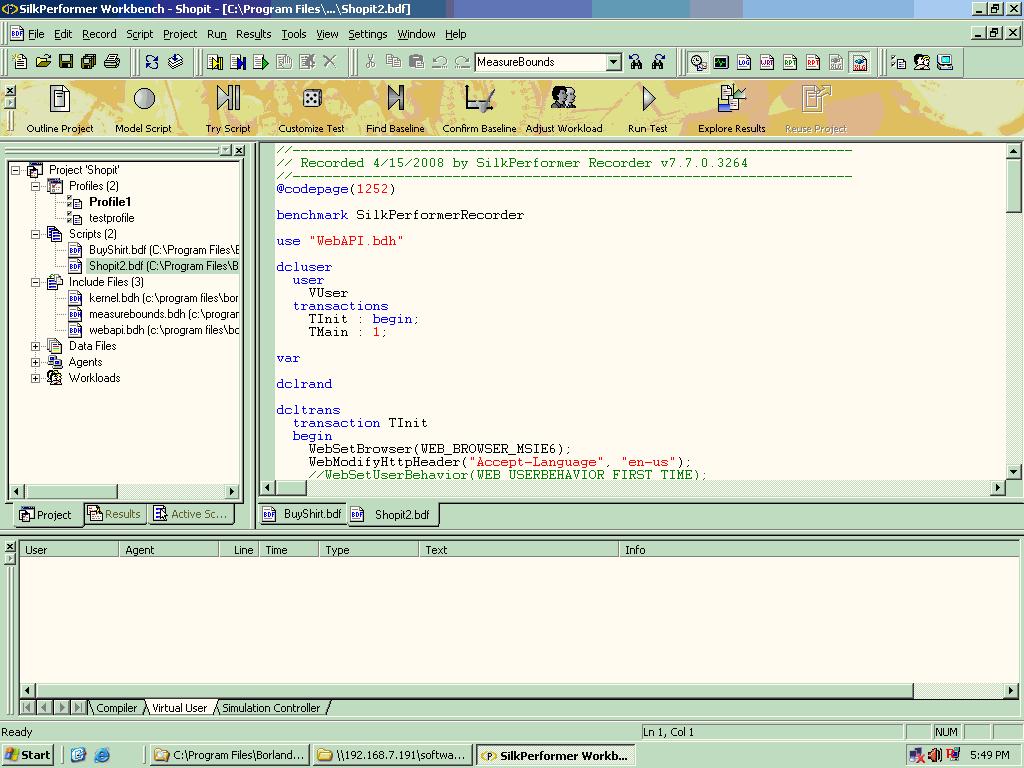
这里介绍一些基本概念:
Project: 一个Project是配置文件(Profiles)、教本文件(scrīpts)、包含文件(Include files)、数据文件(Data files)、客户端(Agents)以及Work Loads文件的组合,其中Include file是Silk Performer教本运行时需要的库文件系统会根据脚本自行添加。
Profile文件:这个文件是录制脚本和播放教本的基本设置,经常用到的是设置不同的浏览器类型和网络连接类型。
scrīpt文件就是录制下来的用户操作文件,在测试的时候由Virtual user运行。
Data file包含一些测试数据,比如用户登录名和密码。
Work load文件是定义测试的行为,里面定义了压力的类型,有多少虚拟用户,执行多长时间等等一系列的参数。
User Type是一个scrīpt,一个User Group和一个Profile的组合,顾名思义就是一组什么样的用户在什么配置下执行什么操作。其中User Group中可以定义执行哪些Transaction以及执行多少次,一个User Group特定于一个scrīpt。
Baseline通过采用一个虚拟用户执行每一种User Type的方法得到一些初始数据作为今后计算虚拟用户数的标准,计算公式是:Vusers = Session Time[s] * Sessions Per Peak Hour / 3600. 同时可以定义一些Timer的上限和下限。要注意的是每一个BaseLine是和一个WorkLoad相关的,如果你改变了相应的WorkLoad那么也需要重新制作BaseLine。
-
在Windows Server Cluster中安装非cluster程序
2008-02-25 18:27:03
在最近的一个项目中,我们的服务器程序需要提供Failover的功能。我们通过在部署环境中建立Windows Server Cluster并在CLuster的节点上安装服务器端程序来达到此目的。
首先介绍一下Windows Cluster这个名词,提起Windows Cluster容易让人混淆。他有三个不同的延伸:
1. Windows NLB cluster是Windows本身提供的网络负载均衡的集群服务。属于active/active模式,即多个节点可以运行相同的程序或服务。
2. Windows Server Cluster是Windows本身提供的支持Failover的集群服务。属于active/passive模式,即某一个程序或者服务(cluster resource)在任意时刻只能在一个节点中运行。
3. Windows Compute Cluster Server用于高性能计算,是微软推出的特殊的服务器。
这里我们主要讨论第2种,支持Failover的Windows Server Cluster.许多服务器程序本身就支持Cluster,如Microsoft Exchange, SQL Server等。但是如果我们自己的服务器程序本身在开发的时候没有对Windows Server Cluster做特别的开发,是否就不能利用Windows Server Cluster的failover功能吗?答案是否定的,我们可以通过cluster Administrator进行配置来利用Windows Server Cluster的failover功能来让我们的服务更加稳定。但是并不是所有的程序都可以通过配置来实现failover。
部署非Cluster程序到Cluster环境中的主要步骤是:
1. 搭建Windows Server Cluster环境,参考微软文档。
2. 在每个节点上安装应用程序。
3. 打开Cluster Administrator。新建一个Virtual Server,也可以用默认的Virtual Server即"Cluster Group"
4. 添加相应的资源到特定的Group中,这里的Group就是你的virtual server。添加何种资源就要看你的程序需要那种资源,详细的资源类型介绍可以参考微软的网站。
5. 配置资源的属性比如依赖性,以及failover方案。
我们采用2个节点的cluster来支持failover,将服务器所需资源加入其中。配置结果如下:
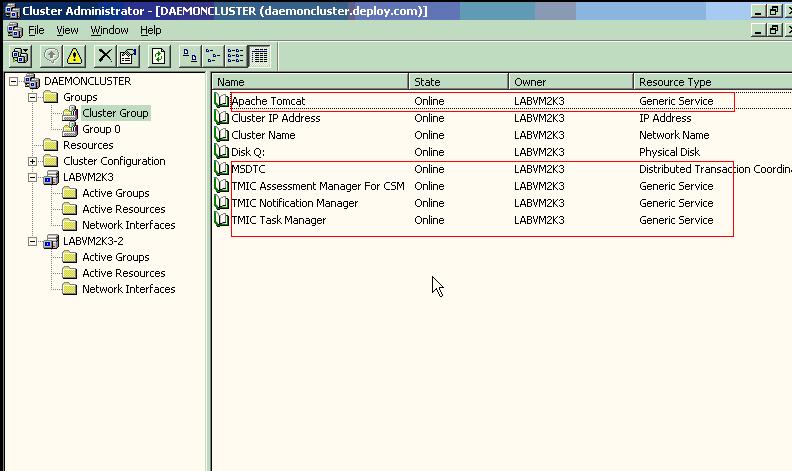
图中红色的资源就是服务器程序所需的资源,通过手工加入。这个时候我们看到"Cluster Group"在第一个节点上运行,测试服务一切正常。然后关闭服务器LABVM2K3。我们会看到整个Group切换到了LABVM2K3-2上运行,测试服务一切正常。实现了服务器的Failover。
-
Exchange server 2003安装中error code 0xc0070714问题的解决
2008-02-21 17:15:04
在安装Exchange server 2003的时候遇见错误如下:
Setup failed while installing sub-component System attendant service with error code 0xc0070714
导致安装失败。
我的安装平台是Windows 2003 Server Enterprise SP1.解决方法: 升级系统Windows 2003 Server到SP2,此问题得以解决。但微软的安装程序文档只要求系统Windows 2003 Server Enterprise,提醒大家升级到SP2来安装Exchange server 2003.
另外在安装过程中会出现“平台兼容性问题的提示”可以忽略,继续安装即可。
-
推荐Badboy进行WebUI自动化
2007-12-07 16:49:21
最近用了badboy软件做了一些自动化测试,总体感觉还是很不错的。它的一个优点是可以支持2种录制方式,一种是只录制http请求,一种是录制真正的UI操作如QTP。另外一个好处是它可以将Http请求形式的脚本存成Jmeter的jmx格式,这样JMeter中就可以直接使用。这点对于测试Https协议很有用,因为JMeter并不能录制Https连接中的内容。当然其他UI自动化所必须的基本功能它也具备,如参数化,断言等。另外它还可以给出一些性能方面的数据Response Time。
当然也有缺点。如只支持IE浏览器,但最大的缺点就是没有办法手工编辑录制的脚本,不像robot和QTP可以直接用支持的语言来修改录制好的脚本。有兴趣的话可以去badboy网站下载玩玩:
-
JMeter进行POP3协议测试
2007-11-30 18:17:59
JMeter也支持POP3邮件协议的测试(通过Mail Reader Sampler),但默认的发行版没有包含JavaMail包,所以要进行POP3测试之前先要下载JavaMail,目前最新版本为1.4.1.否则将会出现图1所示的错误.下载地址:
http://java.sun.com/products/javamail/index.jsp.
下载完成后将lib中的jar包(smtp.jar,pop3.jar等)放入JMeter_Home\lib下. 然后重新启动JMeter.

图 1
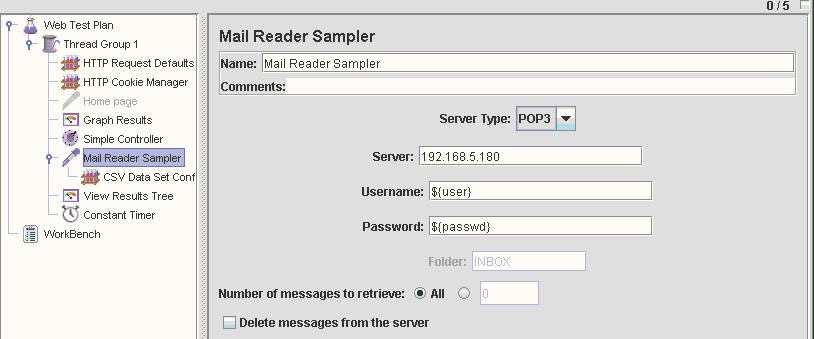
接下来用5个thread从邮件服务器收信(设置Thread Group的User数为5),当一个用户登录POP3服务器之后,帐户就被lock.因此同一账户不能再次登录.我们需要参数化登录的用户,使每个Thread用不同的帐号来登录.否则就会出现用户登录错误的异常. 通过在Mail Reader Sampler下加入CSV date set config来实现.我定义了2个变量一个user,一个passwd,代表了POP3登录所要求的用户名和密码.在user.txt中有5行记录,分别是5个用户的用户名和密码.如图2:
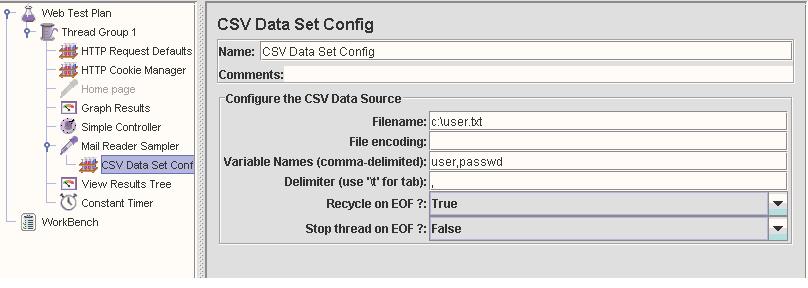
图 2
这个时候,每一个thread就会读取user.txt文件中的一行.因此5个thread模拟5个不同的用户收信.当测试计划的loop count大于1的时候,JMeter的thread会多次登录用户邮箱,还需要加入一个Constant Timer来防止在用户邮箱还没unlock的情况下,紧接着就进行下一轮测试进而产生用户帐户锁定的异常.
设置Mail Reader Sampler的参数如图3:
图 3
运行测试计划,通过View Results Tree来观察结果.测试全部成功.如图4:

图 4
-
JMeter的录制和远程执行
2007-11-29 20:42:46
对于Web的性能测试,我们可以选择JMeter的Sampler(Http Request)来实现发送请求.但是在大多数时候,我们并不十分清楚测试用例所包含的所有http请求.在这种情况下,我们可以用Http Proxy Server来录制测试步骤中的Http请求.
1. 加入Http Proxy Server(右键WorkBench,选择Add->Non-Test Elements-Http Proxy Server)
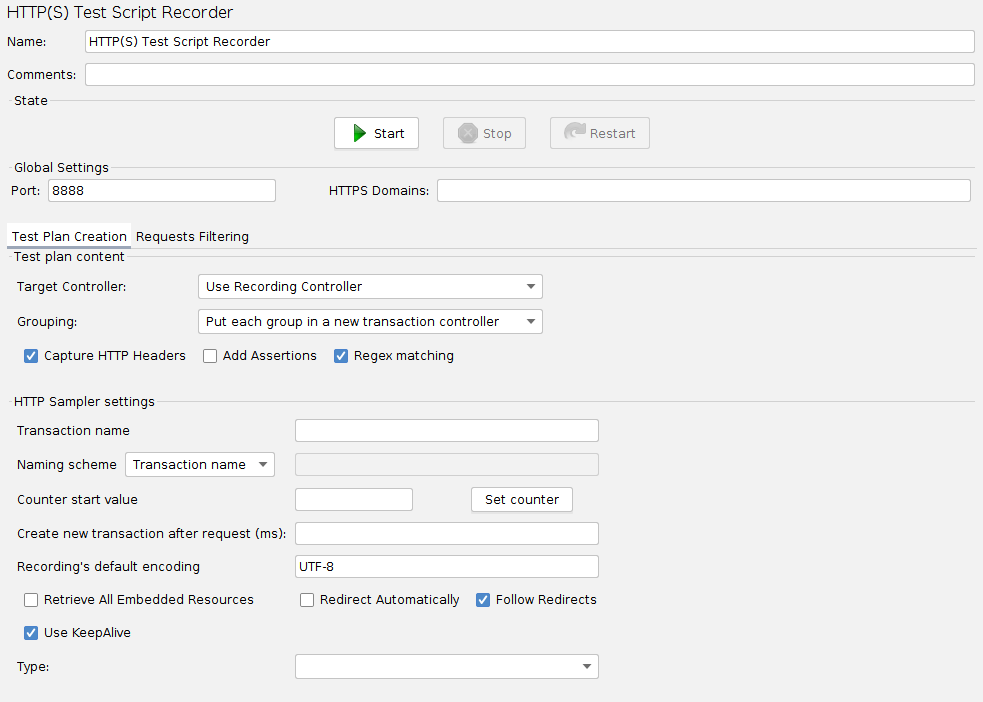
2. 进行相应配置,如录制的请求的存放地点(Target Controller),默认的时候会查找Recording Controller,将请求放在它的下面.还需要设置Grouping来确定是否对请求进行分组.Patterns to Include和Patterns to Exclude用来过滤请求,进而只录制我们需要的请求类型,如"*.\.html"只记录html请求.
3. 设置浏览器的proxy server指向JMeter的机器,端口为8080.
4. 点击Http Proxy Server上的Start按钮,操作浏览器进行测试,点击Stop按钮停止录制.
你将会看到一系列的http请求加入到测试计划中.
如果在Target Controller或它的父Controller中存在 HTTP Request Defaults,那么在录制好的Http请求中,所有HTTP Request Defaults中定义的元素将会以空白代替,比如 HTTP Request Defaults中定义了Server Name or IP,那么所有 HTTP Request中的此项都为空.
如果在Target Controller或它的父Controller中存在User Defined Variables,并且定义了一些变量,那么录制的请求中的任何符合次变量值的内容都会被变量代替.如,定义server为www.google.cn,那么所有请求中的google地址都会替换为${server}.
通过加入 View Results Tree可以看到实际的请求和对应的相应.加入Save Responses to a file可以将相应存到文件中.
-
JMeter做性能测试
2007-11-28 15:48:26
JMeter是一款开源免费的性能测试工具,可以支持多种协议如http,https,ftp,LDAP,JDBC,JUnit等.大家可以去http://jakarta.apache.org/jmeter查找有关信息.
安装JMeter首先要安装JRE(Java runtime environment)1.4以上版本,为了支持其他协议的测试我们可以下载相应的jar包把它放在Jmeter的classpath下:
- JMETER_HOME/lib - used for utility jars
- JMETER_HOME/lib/ext - used for JMeter components and add-ons
例如我们要支持Mail的功能就要下载JavaMail.
在JMeter中,Test Plan由thread group组成, Thread Group代表了一组虚拟的用户.在Thread Group中定义用户的行为,我们可以加入其他任何元素,Samplers,Controllers,Listener,Timers,Assertions,Configure elements,Pre-Processors,Post-Processors.
Samplers用来产生各种请求如,Http sampler,ftp sampler. Controller和Logic Controller用来控制测试的顺序和逻辑.Listener用来显示测试结果.Timers用来产生延时.Assertion用来测试结果是否符合预期.Pre-Processor执行需要在sampler产生request之前进行的操作.Post-Processors执行需要在sampler产生request之后进行的操作. Timer比较特殊,当一个Thread Group中出现多个Timer的时候,JMeter会将所有的时间相加来做为sampler发送request之前的延时时间.
Samplers和Controllers是按顺序执行的,如下图

执行顺序是One, Two,Three,Four
其它元素的作用区域就是它本身所在的区域和它的子区域.例如一个Assertion应用于某一个请求,它就只对该请求生效,如果应用于Controller就会影响controller下的所有请求.
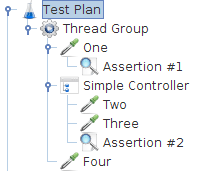
Assertion#1应用于One, Assertion应用鱼Two和Three所有这些元素的执行顺序如下:
1. Pre-Processors
2. Timers
3. Sampler
4. Post-Processors (unless SampleResult is null)
5. Assertions (unless SampleResult is null)
6. Listeners (unless SampleResult is null)
例如一个test plan如下
- Controller
- Post-Processor 1
- Sampler 1
- Sampler 2
- Timer 1
- Assertion 1
- Pre-Processor 1
- Timer 2
- Post-Processor 2
执行顺序是:
Pre-Processor 1
Timer 1
Timer 2
Sampler 1
Post-Processor 1
Post-Processor 2
Assertion 1
Pre-Processor 1
Timer 1
Timer 2
Sampler 2
Post-Processor 1
Post-Processor 2
Assertion 1 -
TCPDump使用方法小结(1)
2007-11-26 11:56:15
在进行网络测试的时候,我们经常需要进行抓包的工作,当然有许多测试工具可以使用,比如sniffer, ethreal等.但最为方便和简单得就非TCPDump莫属. Linux的发行版里基本都包括了这个工具. TCPDump将网络接口设置成混杂模式以便捕获到达的每一个数据包.下面给出TCPDump的部分常用选项:
-i <interface> 指定监听的网络接口
-v 指定详细模式输出详细的报文信息
-vv 指定更详细模式输出更详细的报文信息
-x 指定以16进制数格式显示数据包
-X 规定以ASCII码格式显示输出
-n 规定在捕获过程中不需向DNS查询IP地址
-F <file> 从指定文件中读取表达式
-D 显示可用网络接口
-s <length> 设置捕获数据包的长度
TCPDump的表达式:
默认情况下TCPDump将捕获所有到达网络的数据包.这并不是我们想要的,因此就必须通过表达式来限制不必要的流量,只输出我们需要监听的数据包.
1. 类型限定词
类型限定词有: host, port和net. host用来指定主机或目的地址,port指定端口,net可以用来指定某一子网. 如:
tcpdump 'port 80' 监听80端口
tcpdump 'net 192.168.1' 监听子网192.168.1.0
tcpdump 'net 192.168.1.0/24'
2. 逻辑运算符
逻辑运算符有AND,OR和NOT. ()可将多个表达式组合起来.
tcpdump 'port 80 and (host 192.168.1.10 or host 192.168.1.11)'
监听主机192.168.1.10 或 192.168.1.11的80端口.
3. 传输方向限定词
关键词src指定源地址,dst指定目的地址
tcpdump 'port 80 and (src 192.168.1.10 or src 192.168.1.11)'
tcpdump 'dst port 25'
4. 协议限定词
用来捕获特定协议的数据包有: ether(Ethernet), TCP,UDP,ICMP,IP,ip6(IPv6),ARP,rarp(reverse ARP)等.
5. 原语
原语主要有: 算术运算符(+,-,*,/,>,<,>=,<=,!=等), broadcast, gateway, greater, less.
broadcast捕获广播数据包, greater和less相当于>=和<=.
标题搜索
我的存档
数据统计
- 访问量: 63482
- 日志数: 41
- 文件数: 7
- 建立时间: 2007-04-16
- 更新时间: 2013-04-18
