
-
Selenium学习笔记
2013-04-18 17:24:41
Selenium介绍:Selenium-IDE是firefox的查件,用来录制和回放自动测试脚本。适合用于简单的测试和演示。Selenium-WebDriver属于Selenium2.0,取代Selenium-RC,WebDriver API基于不同浏览器native对自动化的支持,不同浏览器有不同的Driver。Selenium-RC是采用javascript注入技术,对所有浏览器都一样。用Javascript脚本来驱动自动化。如果只是使用WebDriver API并且在本地执行,就不需要Selenium Server,当如下情况的时候要使用Selenium Server。- 使用 Selenium-Grid在多台电脑并行运行测试。
- 在远程机器上执行测试。
- 没有使用Java binding但是要使用HtmlUnitDriver。
Selenium-IDE:Tips: 1. 在录制过程中要产生type命令,也许需要点击页面的其他部分。2. 建议使用clickAndWait方法,等待页面load成功。3. 使用Base URL,有利于在不同Domain之间运行case,这样open语句可以用相对url,系统会和base url进行拼接。Selenium Command的分类:1. Actions命令用于操作被测软件,一旦出错或者失败,当前运行的测试就停止。2. Accessors用于检测应用的状态并存储在变量中。也用来自动产生断言(Assertion)3. Assertions类似于Accessors,并且能确认应用状态是否符合预期。Assertions命令又有3个使用模式:“assert”,“verify”和“waitFor”,如:“assertText”, “verifyText” and “waitForText”如果assert失败,测试就停止,如果verify失败测试会继续,在结果中记录这次失败。通常assert用来确定页面是否正确,之后用verify来测试各种控件。waitFor会等待某个条件为真,当在timeout的时限内还没有消息的话测试会失败或者挂起。Selenium的命令简单,由命令本身和2个参数组成,参数通常是一个定位器,或者text pattern,或者一个变量。
在Selenium-IDE中测试用例以HTML的格式存储,是一个表格,有三列(command,target,value),每一行代表一个命令。verifyText //div//a[2] Login Test Suite同样用HTML描述包含多个test case。常用的命令有:open, click/clickAndWait, verifyTitle/assertTitle, verifyTextPresent,verifyElementPresent,verifyText,verifyTable,waitForPageToLoad,waitForElementPresent命令的Target参数通常是一个locator,用来指定某个控件 -
ClearCase的一些基本概念
2011-01-30 15:37:20
公司采用的代码管理工具是ClearCase,在使用过程中,经历了从最初的比较迷惑到基本熟悉的过程。说实话并不是怎么易用。里面的概念也比较难于理解。这里我就介绍一下ClearCase的一些基本概念,这些都是使用ClearCase所必需知道的:
1. VOB--Versioned Object Base, ClearCase将所有管理的文件的各种版本都存储在这个VOB中,VOB可以看作是整个ClearCase SCM系统的中心数据库。
2. View--View分为SnapShot View和Dynamic View,Snapshot view是clearcase在服务器上存储的文件和目录的一个本地镜像,用户可以在本地进行修改,然后进行同步,要经常Update View保持最新的版本,Dynamic View是动态试图,他并不在本地存储任何文件,始终和服务器保持一致。
3. Reserved checkout vs unreserved checkout -- 一个文件可以被多个用户的多个view来unreserved checkout,但是同时只能有一个用户reserved checkout。当一个用户reserved checkout的时候,其他unreserved checkout的文件,不能checkin,只能等reserved checkout的文件被checkin之后才能够checkin。
4. hijacked文件--当用户创建Snapshot View的时候,本地的文件属性都是只读的,如果用户没有check out的情况下就对文件进行了修改,这个文件就为hijacked文件,此时这个文件已经脱离的ClearCase的控制,所以最好不要Hijacked 文件。
5. mastership--很多情况下,ClearCase都被部署为MultiSite的形式,特别是跨地域开发的时候,每个地方的开发人员都在本地的一个VOB副本上工作,叫做replica, ClearCase负责同步这些不同的VOB。为了避免冲突,ClearCase提供了一个排他修改的属性,叫做mastership。所有的VOB对象都有一个master replica。master replica 对这个对象有排他的修改操作权限,因此对于一个VOB对象只有master replica才能对他进行修改或删除。所以在你把新的文件或目录Add to source control的时候,最好要选择 “Make current replica the master of all newly created branches”。
6. merge文件--当一个用户check out一个文件进行了修改,在check in的时候如果clearcase发现这个文件和最新的版本有冲突的时候(可能是其他用户也对该文件进行了修改并已经check in),会提示要merge文件,这时候就可能需要手工的merge了。
-
Rational Functional Tester经验总结(2)
2011-01-18 13:48:57
接着上一篇继续说说:)
4. 使用Public Object Map还是Private Object Map?在RFT中,录制的对象都保存在Object Map中,分为公有的和私有的,对于每个单独的测试脚本我建议都使用Private Object Map,这样各个脚本比较独立,不易出错。但公有的也有好处就是共享,统一管理。不过在通常的测试中,每一个独立的测试用例都是测试界面的某一部分功能,某一个UI对象的调用只是在相应的测试脚本中,因此很少有在多个测试脚本里调用同一个对象。除非对于某些系统,可能有些对象被很多脚本调用,这时候可以考虑用Public Object Map,这样就可以在对象出现变化的时候统一的改动而不必对每个脚本调整,但是这又多了要维护这个公用 Object Map的工作。而且要保证Public Object Map不要冗余和不断将对象merge进去不是件简单的事。大家要根据实际情况衡量利弊。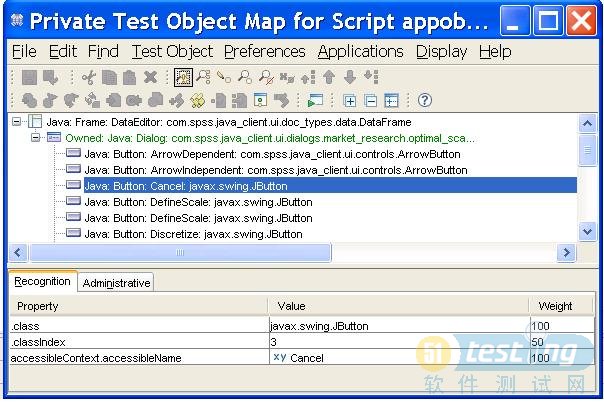
5. 是用Record/Play的方式开发吗?
大部分的测试自动化工具都是Record/Play的方式,并且给的例子也是采用这种方式。但实际开发中,我想没有人会使用这种方式,采用这种方式生成的脚本和被测软件和环境有着太多的关联,测试用例是会不断细化和改变的,当用例变化时需要重新录制,而且很难debug,维护成本太高。除非只是给用户做个demo可以用这种方式。所以我建议自己来写不要录制,采取的做法如下(以购物系统为例):
第一,生成Object Map,将需要调用的对象识别出来并存入Object Map。如:登录按钮,注册按钮各种输入框,导航键等等。
第二,写一些通用的task,这些task组成testcase,比如登录过程是一个task,注册也是,挑选一件商品,结算等等。
第三,写testcase,testcase就调用不同的task,如:用户登录--挑选一件商品--去结算。这就是个完整的测试用例,可以调用实现准备好的task来完成。
6. 能不能不用Object Map,在运行过程中动态识别对象?
这是可以的,有些时候对象是运行时动态生成并且每次可能都不同,这样你就无法事先识别它,或者应用程序不是很稳定变动很频繁,这样生成Object Map就很不划算,因为我们要不断的去修改它。这时候我们选择动态识别对象采用find()方法如下,但是性能是要牺牲的动态识别的速度要比事先录制在识别慢:
Test Object [] bj = find(atDescendant(".class", "Html.BUTTON",
".text", "OK"));
这样在运行时会找到类型为Html.BUTTON,文本为"OK"的对象。使用完一定要释放,否则当有大量对象的时候会有内存问题。
obj.unregister();
7. 灵活运用正则表达式,在录制对象的时候,对象的属性被记录下来,你可以将属性值转换成正则表达式,这样当属性稍有变化时依然可以匹配,又或者可以同时匹配多个对象,对于运行时才按照某种格式生成的某些属性值,采用正则表达式可以很好的解决。右键点击对象属性值,选择转换为 正则表达式。
正则表达式。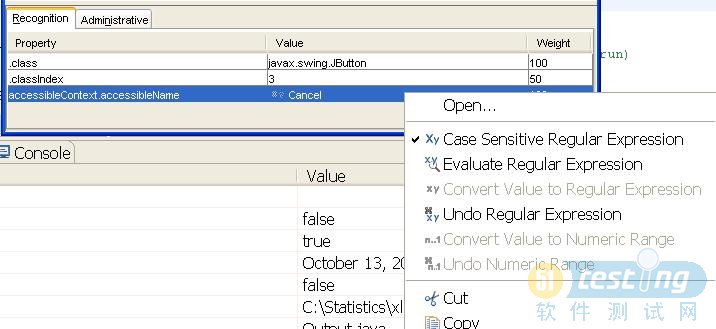
8.在RFT的log中插入信息,RFT支持多种日志格式,txt, html, TPTP, xml等等,前面说了,开发过程主要是采用自己编程的方法,但我们如何把程序的信息,警告或者错误也写到RFT的log中呢?很简单RFT提供了接口,
static void logTestResult(java.lang.String headline, boolean passed, java.lang.String additionalInfo)
就先总结这么多吧,以后有了继续更新,希望对您有帮助。
-
Rational Functional Tester经验总结(1)
2011-01-18 11:04:02
Rational Functional Tester 是IBM Rational 测试工具集的新一代应用于功能自动化测试的工具。相比于早期的Rational robot在易用性和稳定性上都有了很大提高。我们最近也在使用,感觉并不比QTP差。许多新功能都设计的好用。这里我并不是像傻瓜书一样介绍RFT的使用,因为这些大家都可以自己安装根据软件自带的实例都可以自学完成。我要说的是一些我们使用过程中的经验总结,希望对大家有所帮助。
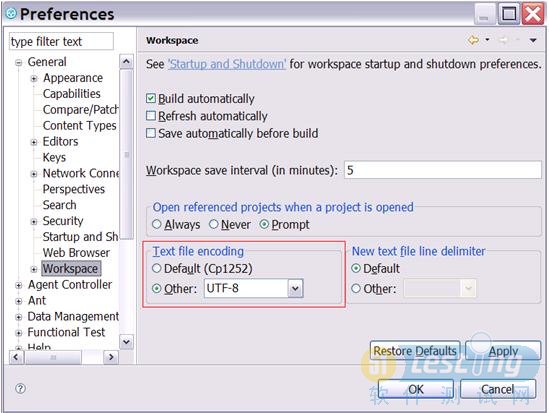
1. 为了很好的支持多种语言,特别是亚太地区的语言,在开始使用RFT的时候将文本文件的编码方式设置为UTF-8,如下
2. RFT的发现对象的机制是匹配事先录制好的或者实现的对象属性,不是鼠标的操作,每一个属性都有一个权重值在0到100之间。在RFT匹配对象的时候会计算出一个识别分数,识别分数等于所有不匹配属性权值之和乘以100.如果所有属性都匹配,最后的识别分数为0.如果某一个属性不匹配,比如这个属性的权值是50,那么匹配分数为50×100等于5000.(这个值越大说明对象越不和我们的baseline匹配)。
因此在RFT我们可以设置一些冗余度来控制对象匹配的精确性,这点非常有用,比如说开发人员修改了UI对象的某一个属性,但是我们记录了这个对象的多个属性来匹配,这时候我们通过设置冗余度,使得即使UI对象的某个属性发生改变,RFT依然可以识别该属性,我们不用重新录制或者修改脚本。如下图:
通过上面积个参数可设置识别阀值,具体意义请参考帮助文档。
3. 到底用不用Simplified Scripting? RFT 默认使用这个选项,Simplified scripting用语句来记录用户的操作,用户可以很容易的理解和编辑,背后对应的是Java或VB代码(真正后台执行)。但是在实际的测试自动化中我建议不要用此选项,因为这样有多了一层维护的成本而且Simplified Scripting容易出错。我们建议直接生成编辑Java代码,这样给测试开发人员很大的灵活性可以进行扩展和查错。省去了Simplified Scripting也减少测试出错的可能。

-
如何在Linux系统下添加硬盘
2010-06-17 11:05:47
要在Linux下添加硬盘有以下几个步骤:
1. 在计算机上安装硬盘,电脑会自动识别到该硬盘。
2. 开机运行命令fdisk -l查看硬盘分区情况,如下
Disk /dev/hda: 21.4 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 89 610470 82 Linux swap / Solaris
/dev/hda3 90 2610 20249932+ 83 Linux
Disk /dev/hdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk /dev/hdb doesn't contain a valid partition table
hda是应景分区好的第一块IDE硬盘,我们看到有三个分区分别为hda1,hda2,hda3. /dev/hdb就是我们新安装的硬盘,可以看到“/dev/hdb doesn't contain a valid partition table”说明该硬盘还没被分区。另外如果硬盘为sda,sdb...说明硬盘是SCSI硬盘。
3. 对硬盘进行分区,运行fdisk -u /dev/hdb。m可显示帮助,一般我们用命令a来添加新分区。可以是主分区,也可以是扩展分区。最后输入w,保存退出。运行fdisk -l,部分显示如下:
Disk /dev/hdb: 10.7 GB, 10737418240 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hdb1 1 1305 10482381 83 Linux
4. 对分区进行格式化,mkfs.ext3 /dev/hdb1
5. 挂载硬盘,
root@g11-64-1 ~]# mkdir /mnt/hdb1
[root@g11-64-1 ~]# mount /dev/hdb1 /mnt/hdb1
[root@g11-64-1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hda3 19G 8.2G 9.7G 46% /
/dev/hda1 99M 16M 79M 17% /boot
tmpfs 250M 0 250M 0% /dev/shm
/dev/hdb1 9.9G 151M 9.2G 2% /mnt/hdb1
6. 修改文件/etc/fstab, 使得开机自动加载该硬盘分区。加入一行如:
/dev/hdb1 /mnt/hdb1 ext3 defaults 0 0
-
最近学习笔记上传
2009-10-28 11:30:34
最近,学习了白盒测试中的代码覆盖率和silk test 自动化测试工具,并且在工作中应用工具BullseyeCoverage和Rational PureCoverage进行代码覆盖率测试。用SilkTest实现产品的UI自动测试。
我将学习笔记以上传至我的文件中,有兴趣的朋友可以下载学习。 -
ANT十五大最佳实践(转)
2009-03-02 16:52:24
ANT十五大最佳实践
作者:Eric M. Burke, coauthor of Java Extreme Programming Cookbook
原文:http://www.onjava.com/pub/a/onjava/2003/12/17/ant_bestpractices.html
在 Ant出现之前,构建和部署Java应用需要使用包括特定平台的脚本、Make文件、各种版本的IDE甚至手工操作的“大杂烩”。现在,几乎所有的开源 Java项目都在使用Ant,大多数公司的内部项目也在使用Ant。Ant在这些项目中的广泛使用自然导致了读者对一整套Ant最佳实践的迫切需求。
本文总结了我喜爱的Ant技巧或最佳实践,多数是从我亲身经历的项目错误或我听说的其他人经历的 “恐怖”故事中得到灵感的。比如,有人告诉我有个项目把XDoclet 生成的代码放入带有锁定文件功能的版本控制工具中。当开发者修改源代码时,他必须记住手工检出(Check out)并锁定所有将要重新生成的文件。然后,手工运行代码生成器,只到这时他才能够让Ant编译代码,这一方法还存在如下一些问题:
- 生成的代码无法存储在版本控制系统中。
- Ant(本案例中是Xdoclet)应该自动确定下一次构建涉及的源文件,而不应由程序员手工确定。
- Ant的构建文件应该定义好正确的任务依赖关系,这样程序员就不必为了完成构建而不得不按照特定顺序调用任务。
当 我开始一个新项目时,我首先编写Ant构建文件。Ant文件明确地定义构建的过程,并被团队中的每个程序员使用。本文所列的技巧基于这样的假定:Ant构 建文件是一个必须仔细编写的重要文件,它应在版本控制系统中得到维护,并被定期进行重构。下面是我的十五大Ant最佳实践。
1. 采用一致的编码规范
Ant用户有的喜欢有的痛恨其构建文件的XML语法。与其跳进这一令人迷惑的争论中,不如让我们先看一些能保持XML构建文件简洁的方法。
首 先也是最重要的,花费时间格式化你的XML让它看上去很清晰。不论XML是否美观,Ant都可以工作。但是丑陋的XML很难令人读懂。倘若你在任务之间留 出空行,有规则的缩进,每行文字不超过90列左右,那么XML令人惊讶地易读。再加上使用能够高亮XML语法的优秀编辑器或IDE工具,你就不会有阅读的 麻烦。
同样,精选含意明确、容易读懂的词汇来命名任务和属性。比如,dir.reports就比rpts好。特定的编码规范并不重要,只要拿出一套规范并坚持使用就行。
2. 将build.xml放在项目根目录中
Ant构建文件build.xml可以放在任何位置,但是放在项目顶级目录中可以保持项目简洁。这是最常用的规范,开发者能够在顶级目录中找到预期的build.xml。把构建文件放在根目录中,也能够使人容易了解项目目录树中不同目录之间的逻辑关系。以下是一个典型的项目目录层次:
[root dir]
| build.xml
+--src
+--lib (包含第三方 JAR包)
+--build (由 build任务生成)
+--dist (由 build任务生成)当build.xml在顶级目录时,假设你处于项目某个子目录中,只要输入:ant -find compile 命令,不需要改变工作目录就能够以命令行方式编译代码。参数-find告诉Ant寻找存在于上级目录中的build.xml并执行。
3. 使用单一的构建文件
有人喜欢将一个大项目分解成几个小的构建文件,每个构建文件分担整个构建过程的一小部分工作。这确实是看法不同的问题,但是应该认识到,将构建文件分割会 增加对整体构建过程的理解难度。要注意在单一构建文件能够清楚表现构建层次的情况下不要过工程化(over-engineer)。
即使你把项目划分为多个构建文件,也应使程序员能够在项目根目录下找到核心build.xml。尽管该文件只是将实际构建工作委派给下级构建文件,也应保证该文件可用。
4. 提供良好的帮助说明
应尽量使构建文件自文档化。增加任务描述是最简单的方法。当你输入ant -projecthelp时,你就可以看到带有描述的任务清单。比如,你可以这样定义任务:
<target name="compile"
description="Compiles code, output goes to the build dir.">最简单的规则是把所有你想让程序员通过命令行就可以调用的任务都加上描述。对于一般用来执行中间处理过程的内部任务,比如生成代码或建立输出目录等,就无法使用描述属性。
这时,可以通过在构建文件中加入XML注释来处理。或者专门定义一个help任务,当程序员输入ant help时来显示详细的使用说明。
<target name="help" description="Display detailed usage information">
<echo>Detailed help...</echo></target>5. 提供清除任务
每个构建文件都应包含一个清除任务,用来删除所有生成的文件和目录,使系统回到构建文件执行前的初始状态。执行清空任务后还存在的文件都应处在版本控制系统的管理之下。比如:
<target name="clean"
description="Destroys all generated files and dirs.">
<delete dir="${dir.build}"/>
<delete dir="${dir.dist}"/>
</target>除非是在产生整个系统版本的特殊任务中,否则不要自动调用clean任务。当程序员仅仅执行编译任务或其他任务时,他们不需要构建文件事先执行既令人讨厌又没有必要的清空任务。要相信程序员能够确定何时需要清空所有文件。
6. 使用ANT管理任务从属关系
假 设你的应用由Swing GUI组件、Web界面、EJB层和公共应用代码组成。在大型系统中,你需要清晰地定义每个Java包属于系统的哪一层。否则任何一点修改都要被迫重新编 译成百上千个文件。糟糕的任务从属关系管理会导致过度复杂而脆弱的系统。改变GUI面板的设计不应造成Servlet和EJB的重编译。
当系统变得庞大后,稍不注意就可能将依赖于客户端的代码引入到服务端。这是因为典型的IDE项目文件编译任何文件都使用单一的classpath。而Ant能让你更有效地控制构建活动。
设计你的Ant构建文件编译大型项目的步骤:首先,编译公共应用代码,将编译结果打成JAR包文件。然后,编译上一层的项目代码,编译时依靠第一步产生的JAR文件。不断重复这一过程,直到最高层的代码编译完成。
分步构建强化了任务从属关系管理。如果你工作在底层Java框架上,偶然引用到高层的GUI模板组件,这时代码不需要编译。这是由于构建文件在编译底层框架时在源路径中没有包含高层GUI面板组件的代码。
7. 定义并重用文件路径
如果文件路径在一个地方一次性集中定义,并在整个构建文件中得到重用,那么构建文件更易于理解。以下是这样做的一个例子:
<project name="sample" default="compile" basedir=".">
<path id="classpath.common">
<pathelement location="${jdom.jar.withpath}"/>
...etc </path>
<path id="classpath.client">
<pathelement location="${guistuff.jar.withpath}"/>
<pathelement location="${another.jar.withpath}"/>
<!-- reuse the common classpath -->
<path refid="classpath.common"/>
</path>
<target name="compile.common" depends="prepare">
<javac destdir="${dir.build}" srcdir="${dir.src}">
<classpath refid="classpath.common"/>
<include name="com/oreilly/common/**"/>
</javac>
</target>
</project>当项目不断增长构建日益复杂时,这一技术越发体现出其价值。你可能需要为编译不同层次的应用定义各自的文件路径,比如运行单元测试的、运行应用程序的、运 行Xdoclet的、生成JavaDocs的等等不同路径。这种组件化路径定义的方法比为每个任务单独定义路径要优越得多。否则,很容易丢失任务从属关系 的轨迹。
8. 定义恰当的任务从属关系
假设dist任务从属于jar任务,那么哪个任务从属于compile任务哪个任务从属于prepare任务呢?Ant构建文件最终定义了任务的从属关系图,它必须被仔细地定义和维护。
应该定期检查任务的从属关系以保证构建工作得到正确执行。大的构建文件随着时间推移趋向于增加更多的任务,所以到最后可能由于不必要的从属关系导致构建工作非常困难。比如,你可能发现在程序员只需编译一些没有使用EJB的GUI代码时又重新生成了EJB代码。
以“优化”的名义忽略任务的从属关系是另一种常见的错误。这种错误迫使程序员为了得到恰当的结果必须记住并按照特定的顺序调用一串任务。更好的做法是:提 供描述清晰的公共任务,这些任务包含正确的任务从属关系;另外提供一套“专家”任务让你能够手工执行个别的构建步骤,这些任务不提供完整的构建过程,但是 让那些专家用户在快速而恼人的编码期间能够跳过某些步骤。
9.使用属性
任何需要配置或可能发生变化的信息都应作为Ant属性定义下来。对于在构建文件中多次出现的值也同样处理。属性既可以在构建文件头部定义,也可以为了更好的灵活性而在单独的属性文件中定义。以下是在构建文件中定义属性的样式:
<project name="sample" default="compile" basedir=".">
<property name="dir.build" value="build"/>
<property name="dir.src" value="src"/>
<property name="jdom.home" value="../java-tools/jdom-b8"/>
<property name="jdom.jar" value="jdom.jar"/>
<property name="jdom.jar.withpath"
value="${jdom.home}/build/${jdom.jar}"/>
etc...
</project>或者你可以使用属性文件:
<project name="sample" default="compile" basedir=".">
<property file="sample.properties"/>
etc...
</project>在属性文件 sample.properties中:
dir.build=build
dir.src=src
jdom.home=../java-tools/jdom-b8
jdom.jar=jdom.jarjdom.jar.withpath=${jdom.home}/build/${jdom.jar}用一个独立的文件定义属性是有好处的,它可以清晰地定义构建中的可配置部分。另外,在开发者工作在不同操作系统的情况下,你可以在不同的平台上提供该文件的不同版本。
10. 保持构建过程独立
为了最大限度的扩展性,不要应用外部路径和库文件。最重要的是不要依赖于程序员的CLASSPATH设置。取而代之的是,在构建文件中使用相对路径并定义自己的路径。如果你引用了绝对路径如C:\java\tools,其他开发者未必使用与你相同的目录结构,所以就无法使用你的构建文件。
如果你部署开放源码项目,应该提供包含编译代码所需的所有JAR文件的发行版本。当然,这是在遵守许可协议的基础上。对于内部项目,相关的JAR文件都应在版本控制系统的管理中,并捡出(check out)到大家都知道的位置。
当你必须引用外部路径时,应将路径定义为属性。使程序员能够用适合他们自己的机器环境的参数重载这些属性。你也可以使用以下语法引用环境变量:
<property environment="env"/>
<property name="dir.jboss" value="${env.JBOSS_HOME}"/>11. 使用版本控制系统
构建文件是一个重要的制品,应该像代码一样进行版本控制。当你标记你的代码时,也应用同样的标签标记构建文件。这样当你需要回溯到旧版本并进行构建时,能够使用相应版本的构建文件。
除构建文件之外,你还应在版本控制中维护第三方JAR文件。同样,这使你能够重新构建旧版本的软件。这也能够更容易保证所有开发者拥有一致的JAR文件,因为他们都是同构建文件一起从版本控制系统中捡出的。
通常应避免在版本控制系统中存放构建成果。倘若你的源代码很好地得到了版本控制,那么通过构建过程你能够重新生成任何版本的产品。
12. 把Ant作为“最小公分母”
假设你的开发团队使用IDE工具,当程序员通过点击图标就能够构建整个应用时为什么还要为Ant而烦恼呢?
IDE的问题是一个关于团队一致性和重现性的问题。几乎所有的IDE设计初衷都是为了提高程序员的个人生产率,而不是开发团队的持续构建。典型的IDE要 求每个程序员定义自己的项目文件。程序员可能拥有不同的目录结构,可能使用不同版本的库文件,还可能工作在不同的平台上。这将导致出现这种情况:在Bob 那里运行良好的代码,到Sally那里就无法运行。
不管你的开发团队使用何种IDE,一定要建立所有程序员都能够使用的Ant构建文件。要建立一个程序员在将新代码提交版本控制系统前必须执行Ant构建文 件的规则。这将确保代码是经过同一个Ant构建文件构建的。当出现问题时,要使用项目标准的Ant构建文件,而不是通过某个IDE来执行一个干净的构建。
程序员可以自由选择任何他们习惯使用的IDE工具或编辑器。但是Ant应作为公共基线以保证代码永远是可构建的。
13. 使用zipfileset属性
人们经常使用Ant产生WAR、JAR、ZIP和 EAR文件。这些文件通常都要求有一个特定的内部目录结构,但其往往与你的源代码和编译环境的目录结构不匹配。
一个最常用的方法是写一个Ant任务,按照期望的目录结构把一大堆文件拷贝到临时目录中,然后生成压缩文件。这不是最有效的方法。使用zipfileset属性是更好的解决方案。它让你从任何位置选择文件,然后把它们按照不同目录结构放进压缩文件中。以下是一个例子:
<ear earfile="${dir.dist.server}/payroll.ear"
appxml="${dir.resources}/application.xml">
<fileset dir="${dir.build}" includes="commonServer.jar"/>
<fileset dir="${dir.build}">
<include name="payroll-ejb.jar"/>
</fileset>
<zipfileset dir="${dir.build}" prefix="lib">
<include name="hr.jar"/>
<include name="billing.jar"/>
</zipfileset>
<fileset dir=".">
<include name="lib/jdom.jar"/>
<include name="lib/log4j.jar"/>
<include name="lib/ojdbc14.jar"/>
</fileset>
<zipfileset dir="${dir.generated.src}" prefix="META-INF">
<include name="jboss-app.xml"/>
</zipfileset>
</ear>在这个例子中,所有JAR文件都放在EAR文件包的lib目录中。hr.jar和billing.jar是从构建目录拷贝过来的。因此我们使用zipfileset属性把它们移动到EAR文件包内部的lib目录。prefix属性指定了其在EAR文件中的目标路径。
14. 测试Clean任务
假设你的构建文件中有clean和compile的任务,执行以下的测试。第一步,执行ant clean;第二步,执行ant compile;第三步,再执行ant compile。第三步应该不作任何事情。如果文件再次被编译,说明你的构建文件有问题。
构建文件应该只在与输出文件相关联的输入文件发生变化时执行任务。一个构建文件在不必执行诸如编译、拷贝或其他工作任务的时候执行这些任务是低效的。当项目规模增长时,即使是小的低效工作也会成为大的问题。
15. 避免特定平台的Ant封装
不管什么原因,有人喜欢用简单的、名称叫做compile之类的批文件或脚本装载他们的产品。当你去看脚本的内容你会发现以下内容:
ant compile
其实开发人员都很熟悉Ant,并且完全能够自己键入ant compile。请不要仅仅为了调用Ant而使用特定平台的脚本。这只会使其他人在首次使用你的脚本时增加学习和理解的烦扰。除此之外,你不可能提供适用于每个操作系统的脚本,这是真正烦扰其他用户的地方。
总结
太多的公司依靠手工方法和特别程序来编译代码和生成软件发布版本。那些不使用Ant或类似工具定义构建过程的开发团队,花费了太多的时间来捕捉代码编译过程中出现的问题:在某些开发者那里编译成功的代码,到另一些开发者那里却失败了。
生成并维护构建脚本不是一项富有魅力的工作,但却是一项必需的工作。一个好的Ant构建文件将使你能够集中到更喜欢的工作——写代码中去!
-
Python代码覆盖率测试
2009-01-14 15:34:19
最近在做python的白盒测试,其中要测试testcase的代码覆盖率。我采用了coverage模块来做此项测试,在这里把coverage模块的使用方法做个简单的介绍,见我的文件(Python代码覆盖率测试)。但是这个模块只提供了基本的语句覆盖,并没有条件覆盖,分支覆盖的支持。 -
UI测试指南和自动化工具介绍
2009-01-08 10:55:19
我新上传了文件,界面测试指南和界面自动化测试工具介绍,这是我做用户界面自动化测试的一些总结。希望对大家有所帮助。请从我的文件中下载:
http://www.51testing.com/?39769/action_viewspace_itemid_102042.html
http://www.51testing.com/?39769/action_viewspace_itemid_102043.html
-
如何在Debian中设置locale
2008-10-20 10:40:52
在Linux中通过locale来设置程序运行的不同语言环境,locale由ANSI C提供支持。locale的命名规则为<语言>_<地区>.<字符集编码>,如zh_CN.UTF-8,zh代表中文,CN代表大陆地区,UTF-8表示字符集。在locale环境中,有一组变量,代表国际化环境中的不同设置:
1. LC_COLLATE
定义该环境的排序和比较规则2. LC_CTYPE
用于字符分类和字符串处理,控制所有字符的处理方式,包括字符编码,字符是单字节还是多字节,如何打印等。是最重要的一个环境变量。3. LC_MONETARY
货币格式4. LC_NUMERIC
非货币的数字显示格式5. LC_TIME
时间和日期格式6. LC_MESSAGES
提示信息的语言。另外还有一个LANGUAGE参数,它与LC_MESSAGES相似,但如果该参数一旦设置,则LC_MESSAGES参数就会失效。LANGUAGE参数可同时设置多种语言信息,如LANGUANE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"。7. LANG
LC_*的默认值,是最低级别的设置,如果LC_*没有设置,则使用该值。类似于 LC_ALL。8. LC_ALL
它是一个宏,如果该值设置了,则该值会覆盖所有LC_*的设置值。注意,LANG的值不受该宏影响。一个例子:
设置前,使用默认locale:
debian:~# locale
LANG="POSIX"
LC_CTYPE="POSIX"
LC_NUMERIC="POSIX"
LC_TIME="POSIX"
LC_COLLATE="POSIX"
LC_MONETARY="POSIX"
LC_MESSAGES="POSIX"
LC_PAPER="POSIX"
LC_NAME="POSIX"
LC_ADDRESS="POSIX"
LC_TELEPHONE="POSIX"
LC_MEASUREMENT="POSIX"
LC_IDENTIFICATION="POSIX"
LC_ALL=设置后,使用zh_CN.GDK中文locale:debian:~# export LC_ALL=zh_CN.GBK
debian:~# locale
LANG=zh_CN.UTF-8
LC_CTYPE="zh_CN.GBK"
LC_NUMERIC="zh_CN.GBK"
LC_TIME="zh_CN.GBK"
LC_COLLATE="zh_CN.GBK"
LC_MONETARY="zh_CN.GBK"
LC_MESSAGES="zh_CN.GBK"
LC_PAPER="zh_CN.GBK"
LC_NAME="zh_CN.GBK"
LC_ADDRESS="zh_CN.GBK"
LC_TELEPHONE="zh_CN.GBK"
LC_MEASUREMENT="zh_CN.GBK"
LC_IDENTIFICATION="zh_CN.GBK"
LC_ALL=zh_CN.GBK"C"是系统默认的locale,"POSIX"是"C"的别名。所以当我们新安装完一个系统时,默认的locale就是C或POSIX。
在Debian中安装locales的方法如下:
· 通过apt-get install locales命令安装locales包
· 安装完成locales包后,系统会自动进行locale配置,你只要选择所需的locale,可以多选。最后指定一个系统默认的locale。这样系统就会帮你自动生成相应的locale和配置好系统的locale。· 增加新的locale也很简单,用dpkg-reconfigure locales重新配置locale即可。
· 我们也可手动增加locale,只要把新的locale增加到/etc/locale.gen文件中,再运行locale-gen命令即可生成新的locale。再通过设置上面介绍的LC_*变量就可设置系统的locale了。下是一个locale.gen文件的样例。
· # This file lists locales that you wish to have built. You can find a list
· # of valid supported locales at /usr/share/i18n/SUPPORTED. Other
· # combinations are possible, but may not be well tested. If you change
· # this file, you need to rerun locale-gen.
· #
·zh_CN.GBK GBK
·zh_CN.UTF-8 UTF-8 -
在Debian 4.0上安装Vmware tools
2008-10-16 14:00:11
介绍一下如何在Debian 4.0虚拟机中安装vnware tools。在测试过程中我们经常会用到虚拟机,在虚拟机中安装vmware tools后可以很方便的和主机传递文件。
1. 选择VM->Install VMware Tools...
2. 用uname -r检测linux内核版本
如:2.6.18-6-686
3. 安装gcc-4.1和linux-headers-2.6.18-6-686(根据你的系统版本)
apt-get install gcc-4.1
apt-get install linux-headers-2.6.18-6-686
4. 从CDROM中拷贝VMwareTools-6.0.2-59824.tar.gz到/tmp
这个文件就是VMware tools的安装包。如果在第一步执行后没有在cdrom中找到此文件,则需要从网上下载或者在其他的Linux虚拟机(如redhat)中执行第一步,并将此文件拷贝到debian上。
5. 建立连接
ln -s /usr/src/linux-headers-2.6.18-4-486 /usr/src/linux
6.设置环境变量
export CC=/usr/bin/gcc-4.1
7. 解压缩:tar zxvf VMwareTools-6.0.2-59824.tar.gz
8. 进入目录运行 ./vmware-install.pl接受所有默认设置,选择分辨率为1024*768安装成功。 -
在IIS上配置SSL服务
2008-05-16 14:00:49
在测试web应用的时候经常会测试HTTPs的联接情况。这是就需要自己搭建HTTPS服务器,这里讲述如何用IIS6.0搭建HTTPS服务。创建一个服务器证书是简单的,IIS的向导就可以完成这个功能。但是创建出的证书并没有经过CA认证,所以Brower在访问的时候,首先会出现警告。要模拟正常工作的情况,最好自己创建一个CA,然后再用这个CA去签名服务器证书,这样就可以了。 主要步骤是:
1. 下载并安装openssl windows版本。
2. 创建CA。
openssl req -x509 -newkey rsa:1024 -keyout cakey.pem -out cacert.pem
然后将cakey.pem放在apps\demoCA\private\下,把cacert.pem放在apps\demoCA\下。
3. 用IIS的certificate向导产生一个证书申请,certreq.txt. 注意证书申请时的Country要与生成CA时候选择的相同,同时Common name选项就是你的服务器DNS name。
4. 用第2步生成的CA来签名证书
openssl ca -in certreq.txt -out server.pem
5. 把pem格式转换为X509格式
openssl x509 -in server.pem -out server.cer
6. 在IIS server中继续完成证书配置。
7. 将CA的证书转换为x509格式:
openssl x509 -in cacert.pem -out cacert.cer
8. 将cacert.cer导入Browser中。
现在就可以用https访问服务器了,并且不会出现警告窗口。
-
Windows NLB cluster配置要点
2008-04-21 17:59:48
在Web测试过程中,往往需要对服务器进行负载平衡,Windows Server本身就提供了一种负载平衡的机制。关于Windows NLB的配置网上也有许多现成的教程,这里我只说明一些重要的参数配置以及它们的含义。通过打开本地连接的属性选择“网络负载均衡”,并单击属性按钮就可以打开NLB的配置窗口。如下:

在Cluster IP configuration中填入必要的信息,如IP,掩码,DNS名称。Cluster有两种工作模式,unicast和multicast。首先说明一下,在Windows NLB中客户端的包会传递给每一个Cluster节点,然后每个节点根据特定的规则进行过滤。
当选择unicast的时候,cluster使用一个虚拟的IP地址和Mac地址,一般在L2的switch上,会记录固定的MAC地址和端口的对应关系,这样防止数据包发向每个交换机端口。但在unicast的时候系统根据一个注册表中的值(MaskSourceMAC)来决定是否隐藏MAC地址,如果值为1,交换机就无法记录对应关系,所以发个cluster的数据包会在交换机的每个端口进行发送,这样就造成了switch flooding。但如果设置为0,那么MAC地址就会与特定端口绑定,所有数据包都发送至一台服务器,所以就无法进行Load Balance。这时候就需要其他技术来让switch不要记录Cluster Mac地址。选择unicast,所有节点共享相同的IP和MAC地址,所以节点之间不能通信。
当选择multicast时候,给cluster分配了一个多播地址而不是改变它的静态地址,所以允许节点之间进行通信。但是对于节点ARP的请求,返回的response中的IP地址会被多播地址取代,这种ARP请求会被一些路由器拒绝,因此需要管理员自己在router中加入静态的ARP记录。
接下来需要定义主机参数如下:
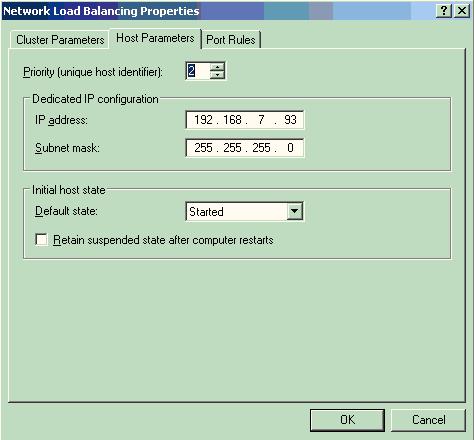
Priority选择1-32之间的数字,每个节点应该不相同,Dedicated IP是本机IP地址。
最后添加port rules如下:
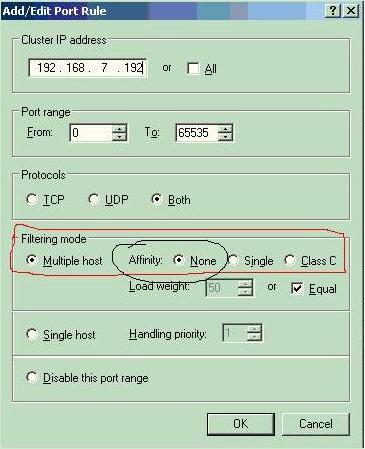
“Filtering mode(筛选模式)”:在此选项设置中,选择以何种方式提供服务有“Multiple host(多主机)”和“single host”。选择多主机之间进行负载平衡时,“Affinity(相似性)”可以选择“None”、“Single”、 “Class C”三种。相似性在此是设置在多主机负载平衡时,对客户端的IP做出的相应反应。选择“None”表示所有节点都是等价的,所有请求根据Load Weight的配置进行分配。选择“Single(单一)”,表示第一次用户端访问VIP分配到实际的物理主机后,以后从该客户端的所有请求都由这台主机提供处理;若选择“Class C”模式,则表示一个C类地址的客户端请求将全部由第一次处理请求的主机负责。当请求为有状态的时候,应该选择Single或者Class C,当请求是无状态的时候选择None。不过当某个节点发生故障重新加入cluster后所有的状态都会丢失。
“Single Host(单一主机)”:若选择此选项,该端口范围内的所有请求都将由一台主机来进行处理,此选项将配合后面的主机优先级来进行主机判定。 -
Silk Performer基本概念
2008-04-15 18:03:07
Silk Performer是Borland公司生产的一款性能测试工具,和Load Runner是竞争对手。Silk Performer采用work flow的概念将性能测试的步骤制作成一个工作流,这让初学者很容易上手,十分方便。其中包括baseline的测试。 另一点好的方面是,它将一个测试作为一个整体工程来看待,所有的相关文件都整合在某一个工程文件内。
这里介绍一些基本概念:
Project: 一个Project是配置文件(Profiles)、教本文件(scrīpts)、包含文件(Include files)、数据文件(Data files)、客户端(Agents)以及Work Loads文件的组合,其中Include file是Silk Performer教本运行时需要的库文件系统会根据脚本自行添加。
Profile文件:这个文件是录制脚本和播放教本的基本设置,经常用到的是设置不同的浏览器类型和网络连接类型。
scrīpt文件就是录制下来的用户操作文件,在测试的时候由Virtual user运行。
Data file包含一些测试数据,比如用户登录名和密码。
Work load文件是定义测试的行为,里面定义了压力的类型,有多少虚拟用户,执行多长时间等等一系列的参数。
User Type是一个scrīpt,一个User Group和一个Profile的组合,顾名思义就是一组什么样的用户在什么配置下执行什么操作。其中User Group中可以定义执行哪些Transaction以及执行多少次,一个User Group特定于一个scrīpt。
Baseline通过采用一个虚拟用户执行每一种User Type的方法得到一些初始数据作为今后计算虚拟用户数的标准,计算公式是:Vusers = Session Time[s] * Sessions Per Peak Hour / 3600. 同时可以定义一些Timer的上限和下限。要注意的是每一个BaseLine是和一个WorkLoad相关的,如果你改变了相应的WorkLoad那么也需要重新制作BaseLine。
-
浅析Windows内存计数器
2008-03-24 20:36:17
最近测试中发现Windows服务器的速度很慢,发现是内存造成瓶颈,现在将Windows内存检测的一些方法总结一下。Windows内存中有三个数据很重要,Pages/sec, Available Bytes和Committed Bytes.
在测试中内存的缺少会造成频繁的页错误,导致系统不停在磁盘和内存中交换数据,有可能表现出IO瓶颈的现象,实则内存不足。在页错误中,有分为硬件错误和软件错误,硬件错误是指程序需要的数据不在内存中需要从硬盘读取,软件错误是指数据还在内存的缓存中但已不再程序的驻留内存里,需要从内存的其他地方读取。访问硬盘比内存要慢几个数量级,所以当系统出现很多硬件页错误时候,系统就会慢的很多,成为系统产生抖动。
如何发现硬件页错误呢?通过在性能监视器里监控一下指标:
Memory\Pages/sec, Process(All_process)\Working Set, Memory\Pages Input/sec
Memory\Pages Output/sec
同时可以通过一下计数器看到内存和磁盘之间的频繁交换:
Memory\Page Reads/sec, PhysicalDisk\Disk Reads/sec,
PhysicalDisk\Avg.Disk Read Bytes/sec
其中,Pages/sec是指由于硬件页错误而引起的页交换数量等于Pages Input/sec和Pages Output/sec的总和。Page Faults/sec是页错误的数量包括硬件的和软件的。
因此总结下来,当Pages/sec大于10的时候就表明系统存在抖动(thrashing),当Available Bytes小于4MB时就说明系统内存不足,Committed Bytes的数值明显大于内存总量的时候,系统就应该增加内存。
有一点值得注意的是,如果某个程序连续的读取内存映像文件(Memory Mapping file)的时候也会造成Pages/sec变的很大,但此时不能认定系统出现抖动,我们还要参考其他数值来确定是否内存出现瓶颈。
-
【转】数据库设计三大范式应用实例剖析
2008-03-14 15:57:04
引言
数据 库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
设计范式是不是很难懂呢?非也,大学教材上给我们一堆数学公式我们当然看不懂,也记不住。所以我们很多人就根本不按照范式来设计数据库。
实质上,设计范式用很形象、很简洁的话语就能说清楚,道明白。本文将对范式进行通俗地说明,并以笔者曾经设计的一个简单论坛的数据库为例来讲解怎样将这些范式应用于实际工程。
范式说明
第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
例如,如下的数据库表是符合第一范式的:
字段1 字段2 字段3 字段4
而这样的数据库表是不符合第一范式的:
字段1 字段2 字段3 字段4 字段3.1 字段3.2
很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。
假定选课关系表为SelectCourse(学号, 姓名, 年龄,课程 名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系:
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
这个数据库表不满足第二范式,因为存在如下决定关系:
(课程名称) → (学分)
(学号) → (姓名, 年龄)
即存在组合关键字中的字段决定非关键字的情况。
由于不符合2NF,这个选课关系表会存在如下问题:
(1) 数据冗余:
同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
(2) 更新异常:
若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
(3) 插入异常:
假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。
(4) 删除异常:
假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
把选课关系表SelectCourse改为如下三个表:
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。
这样的数据库表是符合第二范式的,消除了数据冗余、更新异常、插入异常和删除异常。
另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。
第三范式(3NF):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:
关键字段 → 非关键字段x → 非关键字段y
假定学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号) → (姓名, 年龄, 所在学院, 学院地点, 学院电话)
这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况,读者可自行分析得知。
把学生关系表分为如下两个表:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。
这样的数据库表是符合第三范式的,消除了数据冗余、更新异常、插入异常和删除异常。
鲍依斯-科得范式(BCNF):在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合第三范式。假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。它会出现如下异常情况:
(1) 删除异常:
当仓库被清空后,所有"存储物品ID"和"数量"信息被删除的同时,"仓库ID"和"管理员ID"信息也被删除了。
(2) 插入异常:
当仓库没有存储任何物品时,无法给仓库分配管理员。
(3) 更新异常:
如果仓库换了管理员,则表中所有行的管理员ID都要修改。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 数量)。
这样的数据库表是符合BCNF范式的,消除了删除异常、插入异常和更新异常。范式应用
我们来逐步搞定一个论坛的数据库,有如下信息:
(1) 用户:用户名,email,主页,电话,联系地址
(2) 帖子:发帖标题,发帖内容,回复标题,回复内容
第一次我们将数据库设计为仅仅存在表:
用户名 email 主页 电话 联系地址 发帖标题 发帖内容 回复标题 回复内容
这个数据库表符合第一范式,但是没有任何一组候选关键字能决定数据库表的整行,唯一的关键字段用户名也不能完全决定整个元组。我们需要增加"发帖ID"、"回复ID"字段,即将表修改为:
用户名 email 主页 电话 联系地址 发帖ID 发帖标题 发帖内容 回复ID 回复标题 回复内容
这样数据表中的关键字(用户名,发帖ID,回复ID)能决定整行:
(用户名,发帖ID,回复ID) → (email,主页,电话,联系地址,发帖标题,发帖内容,回复标题,回复内容)
但是,这样的设计不符合第二范式,因为存在如下决定关系:
(用户名) → (email,主页,电话,联系地址)
(发帖ID) → (发帖标题,发帖内容)
(回复ID) → (回复标题,回复内容)
即非关键字段部分函数依赖于候选关键字段,很明显,这个设计会导致大量的数据冗余和操作异常。
我们将数据库表分解为(带下划线的为关键字):
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:发帖ID,标题,内容
(3) 回复信息:回复ID,标题,内容
(4) 发贴:用户名,发帖ID
(5) 回复:发帖ID,回复ID
这样的设计是满足第1、2、3范式和BCNF范式要求的,但是这样的设计是不是最好的呢?
不一定。
观察可知,第4项"发帖"中的"用户名"和"发帖ID"之间是1:N的关系,因此我们可以把"发帖"合并到第2项的"帖子信息"中;第5项"回复"中的"发帖ID"和"回复ID"之间也是1:N的关系,因此我们可以把"回复"合并到第3项的"回复信息"中。这样可以一定量地减少数据冗余,新的设计为:
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:用户名,发帖ID,标题,内容
(3) 回复信息:发帖ID,回复ID,标题,内容
数据库表1显然满足所有范式的要求;
数据库表2中存在非关键字段"标题"、"内容"对关键字段"发帖ID"的部分函数依赖,即不满足第二范式的要求,但是这一设计并不会导致数据冗余和操作异常;
数据库表3中也存在非关键字段"标题"、"内容"对关键字段"回复ID"的部分函数依赖,也不满足第二范式的要求,但是与数据库表2相似,这一设计也不会导致数据冗余和操作异常。
由此可以看出,并不一定要强行满足范式的要求,对于1:N关系,当1的一边合并到N的那边后,N的那边就不再满足第二范式了,但是这种设计反而比较好!
对于M:N的关系,不能将M一边或N一边合并到另一边去,这样会导致不符合范式要求,同时导致操作异常和数据冗余。
对于1:1的关系,我们可以将左边的1或者右边的1合并到另一边去,设计导致不符合范式要求,但是并不会导致操作异常和数据冗余。
结论
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常。这并意味着不符合范式要求的设计一定是错误的,在数据库表中存在1:1或1:N关系这种较特殊的情况下,合并导致的不符合范式要求反而是合理的。
在我们设计数据库的时候,一定要时刻考虑范式的要求。转自CSDN新闻频道
-
如何升级Windows Server 2003到Windows Server 2003 R2
2008-03-03 17:06:24
Windows Server 2003 R2 是微软为了扩展 Windows Server 2003 系统的功能而推出的一项功能软件包,目前已经有很多用户将 Windows Server 2003 升级到了 R2 版。
Windows Server 2003 R2 的程序文件是在 Windows Server 2003 SP1 的基础上开发的,因此在将 Windows Server 2003 升级到 R2 版之前,我们必须首先安装 SP1 或 SP2(至少安装 SP1)。在升级到 R2 版后,SP1 将无法卸载。Windows Server 2003 R2 的安装程序由两张 CD 组成,第一张 CD 是 Windows Server 2003 with SP1 的安装程序、第二张就是 R2 组件的安装程序。如果我们已经有安装好的 Windows Server 2003 系统(已安装 SP1 或 SP2,至少安装有 SP1),只要直接运行第二张光盘中的安装程序,即可将 Windows Server 2003 升级到 R2 版了。
但是当Server本身是域控制器的时候,升级过程中将会产生如下错误:
“The Active Directory installation wizard cannot continue because the forest is not prepared for installing windows server 2003 ,use the adprep command-line tool to prepare both the forest and the domain for more information about using the ADprep ,see active directory Help。。。”
产生的原因是由于域中的Schema没有扩展到最新的匹配windows 2003 server R2 的SCHEMA。解决方法是:将R2的第二张光盘放入光驱,然后运行以下命令:
光驱盘符:\CMPNENTS\R2\ADPREP\adprep.exe /forestprep最好先对AD进行备份以防止意外发生。
-
在Windows Server Cluster中安装非cluster程序
2008-02-25 18:27:03
在最近的一个项目中,我们的服务器程序需要提供Failover的功能。我们通过在部署环境中建立Windows Server Cluster并在CLuster的节点上安装服务器端程序来达到此目的。
首先介绍一下Windows Cluster这个名词,提起Windows Cluster容易让人混淆。他有三个不同的延伸:
1. Windows NLB cluster是Windows本身提供的网络负载均衡的集群服务。属于active/active模式,即多个节点可以运行相同的程序或服务。
2. Windows Server Cluster是Windows本身提供的支持Failover的集群服务。属于active/passive模式,即某一个程序或者服务(cluster resource)在任意时刻只能在一个节点中运行。
3. Windows Compute Cluster Server用于高性能计算,是微软推出的特殊的服务器。
这里我们主要讨论第2种,支持Failover的Windows Server Cluster.许多服务器程序本身就支持Cluster,如Microsoft Exchange, SQL Server等。但是如果我们自己的服务器程序本身在开发的时候没有对Windows Server Cluster做特别的开发,是否就不能利用Windows Server Cluster的failover功能吗?答案是否定的,我们可以通过cluster Administrator进行配置来利用Windows Server Cluster的failover功能来让我们的服务更加稳定。但是并不是所有的程序都可以通过配置来实现failover。
部署非Cluster程序到Cluster环境中的主要步骤是:
1. 搭建Windows Server Cluster环境,参考微软文档。
2. 在每个节点上安装应用程序。
3. 打开Cluster Administrator。新建一个Virtual Server,也可以用默认的Virtual Server即"Cluster Group"
4. 添加相应的资源到特定的Group中,这里的Group就是你的virtual server。添加何种资源就要看你的程序需要那种资源,详细的资源类型介绍可以参考微软的网站。
5. 配置资源的属性比如依赖性,以及failover方案。
我们采用2个节点的cluster来支持failover,将服务器所需资源加入其中。配置结果如下:
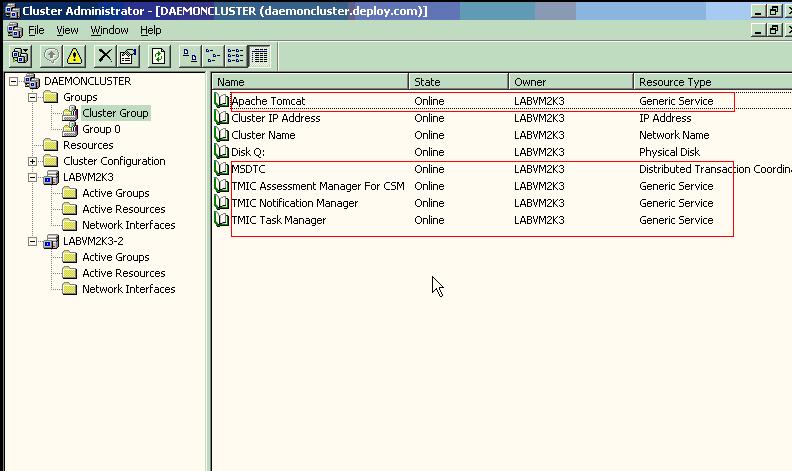
图中红色的资源就是服务器程序所需的资源,通过手工加入。这个时候我们看到"Cluster Group"在第一个节点上运行,测试服务一切正常。然后关闭服务器LABVM2K3。我们会看到整个Group切换到了LABVM2K3-2上运行,测试服务一切正常。实现了服务器的Failover。
-
Exchange server 2003安装中error code 0xc0070714问题的解决
2008-02-21 17:15:04
在安装Exchange server 2003的时候遇见错误如下:
Setup failed while installing sub-component System attendant service with error code 0xc0070714
导致安装失败。
我的安装平台是Windows 2003 Server Enterprise SP1.解决方法: 升级系统Windows 2003 Server到SP2,此问题得以解决。但微软的安装程序文档只要求系统Windows 2003 Server Enterprise,提醒大家升级到SP2来安装Exchange server 2003.
另外在安装过程中会出现“平台兼容性问题的提示”可以忽略,继续安装即可。
-
sscanf函数的高级用法
2007-12-15 21:38:48
转载时请注明出处:http://blog.csdn.net/absurd/
大家都知道sscanf是一个很好用的函数,利用它可以从字符串中取出整数、浮点数和字符串等等。它的使用方法简单,特别对于整数和浮点数来说。但新手可能并不知道处理字符串时的一些高级用法,这里做个简要说明吧。
1. 常见用法。
char str[512] = {0};
sscanf("123456 ", "%s", str);
printf("str=%s\n", str);
2. 取指定长度的字符串。如在下例中,取最大长度为4字节的字符串。
sscanf("123456 ", "%4s", str);
printf("str=%s\n", str);
3. 取到指定字符为止的字符串。如在下例中,取遇到空格为止字符串。
sscanf("123456 abcdedf", "%[^ ]", str);
printf("str=%s\n", str);
4. 取仅包含指定字符集的字符串。如在下例中,取仅包含1到9和小写字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", str);
printf("str=%s\n", str);
5. 取到指定字符集为止的字符串。如在下例中,取遇到大写字母为止的字符串。
sscanf("123456abcdedfBCDEF", "%[^A-Z]", str);
printf("str=%s\n", str);
标题搜索
我的存档
数据统计
- 访问量: 63330
- 日志数: 41
- 文件数: 7
- 建立时间: 2007-04-16
- 更新时间: 2013-04-18
