-
系统性能调优经验分享
msnshow 发布于 2011-07-02 08:59:30
性能优化的思路
首先是较为精准的定位问题,借助于相应的工具包,分析系统性能瓶颈在哪,在根据其性能指标,以及所处于层级决定选择优化的方式方法。在选择优化的方式方法时,大家可以参照以下章节调优方法,架构优化递进,进行正确的,有针对性,有步骤的优化。可能会发现部分指导思想或许有相悖嫌疑,大可不必较真,系统优化的过程本身就是一个不断分离+共享的组合拳,至于具体选择哪种优化方式,根据具体需求来定,但大型应用发展的总体思路是不断分离,在通过索引(非数据库)进行关联起来,
切记:优化一定要对系统进行细致的望闻问切,找到性能问题根源切入点,而不被表象迷糊,对症下药,发现病症所在的医生并不比操作手术刀的医生水平差。本文有工具包一章节,对于需要做优化的人员,需要熟悉,他就是我们诊断所用的CT,例如我们发现内存高了,首先想到不是内存不够用,而是为什么如此消耗内存,用工具看看内存消耗在什么地方,试想之,如在医院,病人告诉医生,他心脏不好,医生就换心脏,那样的话,每个人只要熟练掌握菜刀,都可以做医生
迭代优化
性能优化未必一次性就能满足的,可能此处瓶颈消失了,系统一旦运转快速后,在其他地方又发现新的性能瓶颈,所以性能优化是一个迭代的工作。直至满足系统需要的性能指标。
优化的成本
系统性能设计或优化是否可以一步升天,按照最好的分布式架构进行设计和优化呢,单个节点一直也运转及其健康,理论上是可以达到共产国际的,但实际实施层面不可取,必须结合实际的非功能需求进行设计和优化,一则一步到极致的话,系统的成本太过虑庞大,光是性能设计和优化的成本就高于系统本身给客户所提供的价值,也造成研发成本开销过大。二则好像能够架构这样完美系统的人还没诞生。所以一句话也同样适合架构师:有理想而不理想化,废话少扯:具体见法则
调优方法
数据库优化
很多应用,优化DB往往是最直接,最方便,见效最显著的,但并非所有的系统性能都处在瓶颈,或者DB瓶颈解决之后,可能应用层瓶颈,WEB层瓶颈,甚至架构瓶颈都会冒出来了,所以数据库优化十分重要,但往往很多人理解系统优化就是数据库优化,是不全面的。优化角色一般推荐具备较深数据知识的程序员,或者专业的DBA,而不只是会CRUD开发人员
◆ 建立正确的主键,外键,以及索引
◆ 分离原则:读写分离,业务数据分离
a) 分库
b) 分区
c) 分表
d) 分列(将大字段,不常用的隔离到他表,按需查询)
◆ 选择隔离级别:某些对数据一致性要求不高的,可以牺牲部分一致性,降低加锁阻塞
◆ 保证事务简短以及减少不必要的锁机制。
◆ 查询优化规则:
e) 避免表内的相关子查询;
f) 避免排序或为尽可能少的行排序,
g) 做大量数据排序时相关数据放在临时表中
h) .尽量在where后多传查询条件,以减少不必要返回的行
i) .尽量select只需要的字段,以减少不必要返回的列
◆ 分页存储过程:大列表的查询也可以利用分页存储过程达到优化效果。
◆ 利用数据库缓存,视图,临时表等最大程度优化系统,并对存储过程和函数进行必要的优化
◆ 如有需要,可以冗余表中字段,避免联合查询
◆ 如有需要,也可以将表内的大字段分离到单独表中,使其单独查询
◆ 必做多表关联时,尽量过滤不符条件表中数据,减少笛卡尔积计算量
◆ 复杂表表:如实时性要求不高,尽量后台任务计算,避免动态查询
应用层优化
应用层优化侧重于应用层本身的逻辑优化,算法优化,代码优化等,优化的角色可以是熟悉应用的程序员
◆ 优化算法,选择合适高效的算法,降低不必要的递归,循环、多层循环嵌套等计算
◆ 避免申请过多的不必要的内存开销
◆ 降低内存泄露(using,Dispose,弱引用,Finalize)
◆ 使用频率较低的大文件,大对象,大数组等使用完毕后,及时释放
◆ 使用频率较高的大文件,大对象,大数组尽量缓存
◆ 考虑多线程技术
◆ 选择适当的通信方式:长连接,短连接,有以下方式Socket、Remoting、Web Services(Rest,Soap)、WCF、 Named Pipes
◆ 降低应用之间通信次数,例用户认证服务,工作流服务,数据库服务
◆ 降低应用之间传输数据量,不必要传输的不传,少传
◆ 缓存机制:缓存常用的,不易变化的,偶有变化,可以考虑缓存依赖机制
◆ 支持异步计算,降低等待时间
◆ 考虑延迟加载,或者提前加载两种方式
◆ 分离原则:分离业务模块,如分离大I/O模块、分离高耗内存模块,分离高耗宽带模块
◆ 考虑分布式应用,分布式存储,如以上所有仍然搞不定的
Web优化
Web优化偏向于熟悉前端开发的技术人员
◆ 减少http请求
◆ 避免404错误
◆ 在html页面header加入缓存标签
◆ Gzip压缩网页
◆ 减少cookie体积
◆ 使用外部的js和css
◆ 消减js和css
◆ 压缩js
◆ 使用css sprites技术,众多图片合成在一起,通过CSS切分,降低图片传输的频率和数据量
◆ 可以使用静态网页的,避免使用动态网页
架构优化递进
为以示与应用层优化的区别,本文对架构的描述更侧重偏向于物理层面,再次赘述下,涉及变更架构的,需要我们的应用具有良好的拓展性,考验我们的架构师平时的功底,如何刚刚好满足需求以及两三年内业务增量,但并非架构做的越强大,越灵活,越可配置,越易水平拓展就是越好的,其一考虑此应用的投入产出比,换言之,是否值得投入这么多架构设计成本,其二架构设计也是具有一定的时效性的,IT速度太快了,今天的好东西未必是明天的好东西,年轻貌美的姑娘,总有变成老太婆那一天嘛,再者、越灵活的架构,就意味着存在更多的配置项,从某一方面,反而增加了系统的复杂度,最后、很多大型,成熟的应用,也并非一蹴而就,而是通过不断的调整优化,不断变更架构的。圣人也并非天生的,而是不断的总结,提炼,优化,重构
◆ 硬件方面使用高性能的小型机、存储设备。使用极好的网络带宽
◆ 物理分离Web Server和DB Server或者其他服务如:用户认证服务
◆ 缓存
ü 数据缓存机制
ü 页面缓存机制
◆ 物理分离业务模块,单业务单独部署一台服务器
◆ 部署多台Web Server
◆ Web负载均衡-F5
◆ 数据读写分离
◆ 使用消息队列 进行各种应用间进行同步/异步计算
◆ 应用间选择合适的通信方式,通信协议
◆ Web分布式,应用分布式,数据分布式
◆ 分布式的节点使用高性能服务器,小型机群,辅以高速网络带宽等
工具包
◆ 进程管理器,CPU,内存,I/O
◆ 日志:IIS日志,Windows日志,系统本身日志
◆ 使用dotTrace,跟踪方法执行时间,找出速度慢的方法,针对性优化
◆ Sql Profile跟踪SQL耗时情况,针对性优化
◆ HttpWatch跟踪请求耗时,以及发送和收到数据量
◆ Performance Count,使用计数器,统计相关性能指标
◆ CLRProfiler内存泄露检测工具
◆ LoadRunner,压力测试,发现性能瓶颈
其他补充

-
Loadrunner脚本开发之AJAX视频
云层 发布于 2010-01-22 13:22:29
以google搜索的提示ajax作为基础,介绍了针对这种情况下的AJAX脚本开发思路和案例
tudou地址:
http://www.tudou.com/programs/view/tB5iUma4jt0/
播放列表地址:
http://www.tudou.com/playlist/playindex.do?lid=7760429&iid=45198860&cid=25
下载地址:
ftp://user1:user1@www.atstudy.com/cloud/ajax.swf
关键技术:
ajax原理,http协议捕获,录制选项调整适应ajax,关联获得ajax,参数小应用
脚本如下:
Action()
{web_url("www.google.cn",
"URL=http://www.google.cn/",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTTP",
LAST);web_url("porridgeday10-hp.gif",
"URL=http://www.google.cn/logos/porridgeday10-hp.gif",
"Resource=1",
"RecContentType=image/gif",
"Referer=http://www.google.cn/",
"Snapshot=t2.inf",
LAST);web_url("cn_icp.gif",
"URL=http://www.google.cn/intl/zh-CN_cn/images/cn_icp.gif",
"Resource=1",
"RecContentType=image/gif",
"Referer=http://www.google.cn/",
"Snapshot=t3.inf",
LAST);
web_url("4nkMpw1Qe4k.js",
"URL=http://www.google.cn/extern_js/f/CgV6aC1DThICY24rMAo4UEACLCswDjgLLCswETgTLCswFjgXLCswFzgFLCswGDgFLCswGTgSLCswJTjJiAEsKzAmOAksKzAnOAQsKzA8OAIsKzBFOAEs/4nkMpw1Qe4k.js",
"Resource=1",
"RecContentType=text/javascript",
"Referer=http://www.google.cn/",
"Snapshot=t4.inf",
LAST);web_url("favicon.ico",
"URL=http://www.google.cn/favicon.ico",
"Resource=1",
"RecContentType=image/x-icon",
"Referer=",
"Snapshot=t5.inf",
LAST);web_url("nav_logo7.png",
"URL=http://www.google.cn/images/nav_logo7.png",
"Resource=1",
"RecContentType=image/png",
"Referer=http://www.google.cn/",
"Snapshot=t6.inf",
LAST);web_url("toolbar_animation_20090618.png",
"URL=http://www.google.cn/intl/zh-CN/images/toolbar_animation_20090618.png",
"Resource=1",
"RecContentType=image/png",
"Referer=http://www.google.cn/",
"Snapshot=t7.inf",
LAST);
web_url("csi",
"URL=http://www.google.cn/csi?v=3&s=webhp&action=&e=17259,22766,23276,23309,23337&ei=hyBZS-KsBMyTkAWDpLzrBA&rt=prt.234,xjsls.281,ol.734,xjses.734,xjsee.812,xjs.890",
"Resource=0",
"RecContentType=text/html",
"Referer=http://www.google.cn/",
"Mode=HTTP",
LAST);
//lr_save_var()
web_reg_save_param("searchid",
"LB=[\"",
"RB=\",",
"Ord=ALL",
"Search=Body",
LAST);web_url("search_7",
"URL=http://www.google.cn/complete/search?hl=zh-CN&xhr=t&q=loadrunner&cp=10",
"Resource=1",
"RecContentType=application/json",
"Referer=http://www.google.cn/",
"Snapshot=t14.inf",
LAST);lr_save_string(lr_paramarr_random("searchid"),"temp");
lr_think_time(6);
web_url("search_8",
"URL=http://www.google.cn/search?hl=zh-CN&source=hp&q={temp}&aq=2&oq=loadrunner",
"Resource=0",
"RecContentType=text/html",
"Referer=http://www.google.cn/",
"Snapshot=t15.inf",
"Mode=HTTP",
LAST);web_url("nav_logo7.png_2",
"URL=http://www.google.cn/images/nav_logo7.png",
"Resource=1",
"RecContentType=image/png",
"Referer=http://www.google.cn/search?hl=zh-CN&source=hp&q=loadrunner+%E6%98%AF%E4%BB%80%E4%B9%88&aq=2&oq=loadrunner",
"Snapshot=t16.inf",
LAST);web_url("gen_204",
"URL=http://www.google.cn/gen_204?mgmhp=shp1&ct=v&cd=false",
"Resource=0",
"RecContentType=text/html",
"Referer=http://www.google.cn/search?hl=zh-CN&source=hp&q=loadrunner+%E6%98%AF%E4%BB%80%E4%B9%88&aq=2&oq=loadrunner",
"Mode=HTTP",
LAST);web_url("csi_2",
"URL=http://www.google.cn/csi?v=3&s=web&action=&e=17259,22766,23265,23276,23309,23337&ei=kCBZS5elFM6OkQXJttj2BA&rt=prt.343,xjses.405,xjsee.452,xjsls.452,xjs.577,ol.858",
"Resource=0",
"RecContentType=text/html",
"Referer=http://www.google.cn/search?hl=zh-CN&source=hp&q=loadrunner+%E6%98%AF%E4%BB%80%E4%B9%88&aq=2&oq=loadrunner",
"Mode=HTTP",
LAST);return 0;
} -
Loadrunner学习---脚本编写(1)
zibeike 发布于 2007-12-11 17:32:16
中午看了两集《奋斗》发现越看越想看,但是想到好不容易没上班,在家还是赶紧学习下LR的知识吧。下面这个网页的文章原来也是看过的,但发现没几天就忘记了,为了加深学习的印象,特把它翻译出来。http://www.wilsonmar.com/1lrscrīpt.htm上是关于脚本编写的介绍.下面是第一部分,脚本的开发.
VuGen脚本文件的开发过程
1。定义测试项目的目标,环境,脚本,测试数据,硬件等。脚本应该符合编码规范或编码习惯。
2。创建一个版本文件夹来保存被测应用程序相关的各种不同资源,例如截获的.png/.gif图形文件,录制过程保存的html文件,录制中的所有html源文件和VuGen的录制日志。
3。列出(在表里)每一个手动操作业务过程需要的实际步骤
1)截取每一个屏幕图像(screen image )。
2)为每一个屏幕(screen)分配一个唯一的事务名称。
3)为处理的每一个步骤使用的技术组件(URL或者方法和函数)做注释。
4。创建一个版本文件夹。
注:我不喜欢使用默认位置,我喜欢把所有脚本相关的文件放到一个相同的文件夹中。不幸的是,这意味着如果我在不同的测试间互相交换录制,那我每次都得记住修改默认的设置。
注:当录制一个新的脚本时,我喜欢选择多协议而不是单个协议。。。
5。根据你的业务处理列表上指定的用户使用步骤和screen的顺序来使用VuGen录制程序,产生一系列脚本代码。在“开始录制”对话框中
* 使用COM/DCOM 协议时,选择“Win32应用程序“
* 使用Web(HTTP/HTML)时,选择“Internet Application“
6。根据改进脚本方法和脚本语言规则来修改脚本。
改进脚本的方法:
1)为每一个GUI的screen添加事务语句来获得事务时间。
2)添加显示数据来帮助调试。
3)添加验证点来验证是否期望的文本或者图片在每个脚本执行后显示。
4)通过插入新参数和动态获得整个文件的方式对硬编码的URL,用户id,用户密码和其他的变量数据进行参数化。这样脚本中的参数就可以被动态的替换,以此来模拟运行时不同数据的使用。
5)添加重试逻辑(retry logic)来处理不可见的错误。
6)添加随机函数发生器变化脚本来模拟真实的负载。
7)添加if/else逻辑来检查结果,或者来进行合适的操作,或者来在合适的时候退出脚本。
8)在一个screen中添加语句来捕获需要在其他命令中使用的数据。当使用Microsoft .NET的web form技术的时候,需要避免习惯性的“脚本超时“错误。
9)添加语句来调用外部库函数,以便保存和检索在内存Virtual Table Server中的数据。
10)处理XML.
11)添加语句来模仿客户端的Javascrīpt问题。
12)添加语句来管理超时。
13)从事务计时器中计算和减去无效的时间。
14)输出日志。
15)添加集合点。
16)添加时间(Timing)。
脚本语言规则:
把cookie代码标注出来(因为脚本运行的时候他们被再次执行)。
7。通过在VuGen中运行来调试和调整脚本(单个用户),同时运行时设置的日志能够显示如下信息:
辨别和解决脚本编辑错误。
决定timing.
设置初始运行设置的场景。
8。在控制器中使用full test Runtime Settings来运行脚本。
脚本录制和产生:
建立一个新脚本的第一步是选择一个单协议或多协议。
* 一些协议可能在多协议模式下不能用。
* 只有在多协议的GUI下你才能重新排列action
在使用Java协议之前,确保你在环境变量的路径下有JDK,否则你可能会遇到这个错误:
Error: Failed to find javac.exe Java Compiler in Path and JDK installation folder in registry. [MsgId: MERR-22981]
Error: Failed to get JRE version. Check that your PATH environment variable contains\bin directory. [MsgId: MERR-22986] 当选择Java协议的时候:
* 只有选择了“RMI Java”才能录制。
* 如果选择“Java user”,“开始录制”图标或菜单是灰色的。
当你打开一个新的脚本时,默认的脚本名称为“noname1”。下一个新的脚本名称为“noname2”,以此类推。
注:有顺序的录制多个动作(而不是录制一个动作,然后停止开始另一个动作)。这样能使你识别出在你脚本中需要关联的序列码(在例如PeopleSoft的程序中)。
注:每次修改脚本后,脚本都需要重新编译。
Java:略
脚本文件的调用:
VuGen是默认在你双击.usr后缀文件的时候被调用。
在这个文件里,Javascrīpt被指定为“Type=General-Js”。
为了避免重新编译,我使用命令行的变量和值得组合这样的批处理文件来调用控制器。例如:
 REM LoadRun from LoadRunner 8.0 default installation location:
REM LoadRun from LoadRunner 8.0 default installation location:
SET LR80=C:\Program Files\Mercury Interactive\Mercury LoadRunner\bin
cd %LR80%
wlrun.exe -TestRun c:\Temp\Scenario1.lrs -port 8080脚本文件Action
主机上的代理发送的到服务器的请求是由虚拟用户生成器创建的(VuGen.exe)action的回放实现的。
Loadrunner创建的脚本有三部分:
* vuser_init 来初始化 Vuser。执行在这部分的虚拟用户的状态是"Init"
* Action 用来重复多次迭代 执行到这部分的虚拟用户的状态是"Running"
* vuser_end 推出虚拟用户。 执行到这部分的虚拟用户的状态是"Exiting"
如果你的脚本只需要执行一次,你仍然需要把这些脚本写到Action部分,因为在其他部分(vuser_init 和vuser_end)有些命令是不合法的或者会忽略掉。
VuGen允许脚本包含多个action。所以我为每一个screen创建一个新的action。
注:如果你想使用不同的用户登陆,就不要把登陆操作放到vuser_init中,而是放到action部分。
VuGen根据选择脚本选择协议的不同来添加不用的引用到“.h”头文件。
C的.h头文件
对于Web(HTTP/HTML)协议,
创建globals.h,包含内容:
#ifndef _GLOBALS_H #define _GLOBALS_H //-------------------------- // Include Files #include "lrun.h" #include "web_api.h" #include "lrw_custom_body.h" // recorded for web_custom_request functions. //-------------------------- // Global Variables #endif // _GLOBALS_H
对于COM/DCOM协议:略
C脚本语言的格式:
LoadRunner使用的没有进行微软扩展的ANSI C语法。任意最小的action代码块如下:
#include as_web.h // from LoadRunner's include folder. Action1() { /* comment block */ // comment line return 0; }
C脚本编译/类库
当VuGen编译脚本时,产生一个"pre_cci.ci"文件,这个文件包含了所有action的代码和包含文件。这就是为什么会有语法错误“not writing pre_cci.ci”的原因。
控制器编译这些.ci文件为机器目标码。
VuGen在每一个脚本文件中自动创建一个lib文件夹,这个文件夹中包含了combined_lib.c文件。该文件包含了所有引用文件。
#include "lrun.h" 来定义 UNIX或者Windows的函数。
#include "globals.h" LoadRunner'的模版文件夹的其中一个。#include "vuser_init.c"
#include "Action.c"
#include "vuser_end.c"警告:当你使用类库中的函数却没有正确包含该类库的时候,你会收到一条错误信息:
- Error -- Unresolved symbol
C类库
LoadRunner 使用
 1994 GNU C Pre-Processor options 和 1995 LCC-win32 Retargetable C Compiler/Linker from the Free Software Foundation via Chris Fraser of AT&T and Dave Hanson of Princeton.
1994 GNU C Pre-Processor options 和 1995 LCC-win32 Retargetable C Compiler/Linker from the Free Software Foundation via Chris Fraser of AT&T and Dave Hanson of Princeton. 附加的函数定义在
 ANSI C library中。
ANSI C library中。外部的没有返回整型数的C函数需要在脚本的开头进行显式声明。例如,string函数中的 string tokenizer:
extern char* strtok(char *token, const char *delimiter);
Java语法:略
OK,先到这里,休息一下,下期接着翻译LR脚本相关知识.
-
[整理]DotNet应用程序性能计数器总结2 - System Resources\Memory
chicochen 发布于 2008-04-18 18:06:01
内存(Memory)
首先简单介绍内存相关的一些概念:
- 每个Windows进程都拥有4G的地址空间,在多任务环境下,所有进程使用的内存总和可以超过物理内存。
- 进程的一部分可能会从物理内存中删除而被暂存在硬盘的文件里(pagefile)。当进程试图访问这些被交换到pagefile里的内存的时候,系统会产生一个缺页中断(page fault),这时候Windows内存管理器会负责把对应的内存页重新从硬盘调入物理内存。
- 一个进程可以直接访问到的物理内存(不发生缺页中断)叫做这个进程的Working Set ;而一个进程从4G的地址空间当中实际分配(commit)了的、可访问的内存称为 Committed Virtual Memory 。Committed VM可能存在于Page File当中,WorkingSet则一定位于物理内存。
- 未分页池(Nonpaged Pool)是常驻内存的虚拟内存页设置,能被随时访问并且不造成分页错误。设备驱动和操作系统内核使用它存储那些必须常驻物理内存,并且不得分页存储到硬盘上的数据结构
- MDL(Memory Descrīptor List)是一个结构体,用于描述一片内存区域中的所有物理内存页。
- Memory\Available Mbytes
- 阀值:20-25%以下为可接受范围
- 含义:指示系统当前可用的内存。此处为最后采集的数据,而不是平均值。
- Memory\Page Reads/sec
- 阀值:持续大于5的值,表明内存的读请求发生了较多的缺页中断(page fault)。
- 含义:说明进程的Working Set已经不够,使用硬盘来虚拟内存。此处为读得次数,不关心读取得页数,比较大的值表明内存出现了瓶颈。1. 如果此值比较低,但Physical Disk\% Disk Time and Physical Disk\Avg. Disk Queue Length计数器很高,表明磁盘有瓶颈。2. 如果随着Physical Disk\Avg. Disk Queue Length的增加,而Memory\Page Reads/sec并没有减少,表明有内存的瓶颈。
- Memory\Pages/sec
- 阀值:持续大于5的值,说明有内存瓶颈。
- 含义:为了解决缺页中断而进行的每秒磁盘读和写的页数。将计数器Physical Disk\Avg. Disk sec/Transfer和Memory\Pages/sec的值相乘,如果得到的结果大于0.1,表明解决缺页错误的操作占到了磁盘访问时间的10%,系统出现了内存瓶颈。
- Memory\Pool Nonpaged Bytes
- 阀值:考察其自系统启动以来的增长了10%以上,如果是,表明有潜在的严重瓶颈。
- 含义:Pool Nonpaged的大小,Pool Nonpaged的具体含义参见本文顶部的概念描述。
- Server\Pool Nonpaged Failures
- 阀值:出现Nonpaged Pool分配错误的次数,一个非零值表明有瓶颈存在。
- 含义:Nonpaged Pool决定了有多少进程、内存以及其对象能够被构建,计算机的物理内存太小,会导致分配错误。当出现Nonpaged Pool分配错误,有可能是因为发生了内存泄漏。
- Server\Pool Paged Failures
- 阀值:N/A
- 含义:Paged Pool分配发生的错误次数。发生此错误,表明物理内存、分页文件不足。
- Server\Pool Nonpaged Peak
- 阀值:N/A
- 含义:服务器Nonpaged Pool的最大使用峰值,据此考察计算机的物理内存为该值的4倍为宜。
- Memory\Cache Bytes
- 阀值:N/A
- 含义:显示文件系统缓存的大小,其默认为最多使用50%的可用物理内存。由于有效内存短缺时,系统会自动调整它。
- Memory\Cache Faults/sec
- 阀值:N/A
- 含义:从文件系统缓存中查找数据,未命中的次数。这个值应该尽可能的低,较大的值表明内存出现短缺,缓存命中很低。
- Cache\MDL Read Hits %
- 阀值:值越大(接近100%),表明文件系统缓存效果越好。
- 含义:这个计数器提供了MDL(Memory Descrīptor List)成功命中文件系统缓存(而不是去磁盘读)的比率。
www.ChinaQA.com, Chico Chen, chicochen@hotmail.com
-
第一天课(4月25号)测试基础
bwg198411 发布于 2008-04-25 21:20:20
今天要掌握的知识点:
一、什么是软件测试
软件测试就是在软件投入运行前,对软件需求分析、设计规格说明书和编码的最终复查,是软件质量保证的关键步骤。
软件测试是为了发现错误而执行程序的过程。
软件测试是根据软件开发各阶段的规格说明和程序的内部结构而精心设计一批测试用例(即输入数据及预期的输出结果),并利用这些测试用例去运行程序,以发现程序错误的过程。
二、软件测试的目的
证明
1、获取系统在可接受风险范围内可用的信心
2、尝试在非正常情况和条件下的功能和特性
3、保证一个工作产品是完整的并且可用或者可被集成
检测
4、发现缺陷、错误和系统不足
5、定义系统的能力和局限性
6、提供组件、工作产品和系统的质量信息
预防
7、澄清系统的规格和性能
8、提供预防或减少可能制造错误的信息
9、在过程中尽早检测错误
10、确认问题和风险,并且提前确认解决这些问题和风险的途径
补充问题
一·如何发现问题
1·学习需求文档
2·按照需求编写测试用例
3·依照用例执行程序,发现问题。
二·如何尽早发现问题
1·把测试贯穿在整个软件研发过程中
2·从最开始参与需求分析工作,发现需求中的问题。
3·概要设计和详细设计也要参与,并发现文档中的问题。
4·对软件代码进行检查。
三·如何协助开发人员减少问题发生的概率
1·对以往项目中的测试数据及文档进行分析。
2·创建测试用例库和缺陷问题库。
3·对测试用例以及缺陷进行统计分析。
4·要提高测试用例的复用性
5·通过对已发现的缺陷的统计分析,找到软件中存在的共性问题并与相关部门协商具体的改进方案
6·在后期项目的实施和测试过程中尽量避免发生以前同样的问题
螺旋模型
在研发的每个过程,都要根据风险评估的结果,准备多套的解决方案,以应对风险/变更的发生。航天 银行应用。成本高,需要一名专业风险评估专家。对于开发人员和测试人员的技能要求较高
RUP流程:迭代增量开发模式,分阶段完成软件发研发工作,都是提高一个可运行的半成品。可以让用户在早期了解软件的进展情况,及时提出改进意见,从而进行及时变更。
IDP流程:针对软硬件集成厂商,将硬件研发,软件研发以及采购,生产,销售等环节结合在一起进行考虑。
缺陷类型:
遗漏:规定的或预期的需求未体现在产品中(可能未将规格说明全面实现,也可能需求分析阶段就遗漏了需求)
错误:未将规格说明正确实现(可能设计错误也可能编码错误)
额外的实现:需求规格并未规定的需求被纳入产品,得到实现
-
第七天课(5月12号)SQL基本语句
bwg198411 发布于 2008-05-12 21:30:47
第七天课(5月12号)
SQL Server 常见版本
* 企业版(Enterprise Edition)
* 标准版(Standard Edition)
* 个人版(Personal Edition)
* 开发者版(Developer Edition)
一、表
– 由行和列组成
– 每列又称为一个字段,每列的标题称为字段名
– 一行数据称为一个或一条记录,它表达有一定意义的信息组合
– 一个数据库表由一条或多条记录组成,没有记录的表称为空表。
– 每个表中通常都有一个主关键字(也叫主键),用于惟一地确定一条记录。主键不允许空值。不能存在具有相同的主键值的两个行二、索引
索引是根据指定的数据库表列建立起来的顺序。它提供了快速访问数 据的途径,并且可监督表的数据,使其索引所指向的列中的数据不重复。
三、视图
是一个虚拟的表,在数据库中并不实际存。 视图是由查询数据库表产生的,视图可以用来控制用户对数据的访问,并能简化数据的显示,即通过视图只显示那些需要的数据信息。四、事务
1、存储过程:事务的集合,存放在服务器中,只需在客户端发送一条调用存储过程的指令,即可以执行多条SQL命令
2、触发器:自动执行一组SQL命令,SQL内置触发器,级联更新,级联删除。五、
如果存在分组语句,则在SELECT中必须显示的查找,对应的分组字段或用聚合函数进行汇总运算。
必须有group by存在才能使用Having;
Having语句对分组后的数据进行条件筛选;
Having中可以有聚合函数;数据库的备份恢复,表的导入导出
基本语句练习
*select * from student where sname='张三'
select * from student where sname like '张%'
select * from student where sname like '张%' and shome='北京'
select * from student where shome in('北京','上海','天津')
select sno as '学号',cno as '课程号' from sc where grade between 60 and 70
select cno,avg(grade)
from sc
group by cno--统计共有多少学生信息
select count(sno)
from student--统计年龄大于20岁的学生有多少个
select count(sno)
from student
where sage>20--统计出生日期在1980年至1982年的学生人数
select count(sno)
from student
where sage between 19 and 20--统计学生的平均成绩
select avg(grade)
from sc
--统计学号为001所有课程中的最高分数
select max(grade)
from sc
where sno='20031001'--统计课程号为G001的最高分数
select min(grade)
from sc
where cno='1'--统计课程号为G001的所有课程总分
select sum(grade)
from sc
where cno='1'--统计每门课程的平均成绩
select cno, avg(grade)
from sc
group by cno--统计每门课程的平均成绩并按照从大到小显示
select cno,avg(grade)
from sc
group by cno
order by avg(grade) desc--显示有两门以上不及格的学生的学号
select sno
from sc
where grade<60
group by sno
having count(grade)>=2--查询英语课的总成绩
select sum(grade)
from sc
where cno=(select cno from course where Cname='C语言')--查询003班英语课的总成绩
select sum(grade)
from sc
where sno in(select sno from student where sclass='一班')
and cno=(select cno from course where Cname='C语言')--查询003班张三的英语成绩
select grade
from sc
where sno=(select sno from student where sclass='一班'and sname='张三')
and cno=(select cno from course where Cname='C语言')--查询003班的各门课程总成绩
select sum(grade),cno
from sc
where sno in(select sno from student where sclass='一班')
group by cno--查询003班张三的平均成绩
select avg(grade)
from sc
where sno=(select sno from student where sclass='一班'and sname='张三') -
评测网页效率的工具——YSlow
huoxingyinzi 发布于 2008-04-08 13:57:16
yslowYSlow是由Yahoo开发者团队发布的一款基于Firebug的插件。而Firebug 又是一款基于FireFox的插件。所以说YSlow是一款基于FireFox插件的插件。虽然有点绕,但是最终说明的问题是:
- 很遗憾,微软的IE系列浏览器不能使用YSlow。
- YSlow只能使用在FireFox浏览器上。
- 如果要想使用YSlow,那么你必须先安装FireFox。
- 如果要想使用YSlow,那么你就要安装FireFox上的Firebug插件。
这看上去好像有点令人沮丧,但是事实上它并不像想象中的那么麻烦,只要按照下面的步骤你将能很快的使用YSlow:
- 到http://www.mozilla.net.cn/firefox/ 下载最新版的FireFox,并安装它。当然如果你已经安装了FireFox可以跳过此步。
- 到https://addons.mozilla.org/en-US/firefox/addon/1843/ 下载最新版的Firebug,并安装它。当然如果你已经安装了Firebug可以跳过此步。
- 到https://addons.mozilla.org/en-US/firefox/addon/5369/ 下载最新版的YSlow,并安装它。当然如果你已经安装了YSlow可以跳过此步。
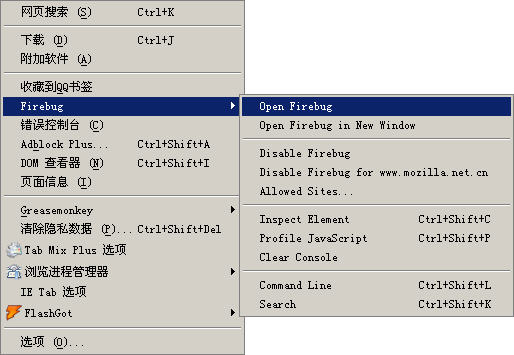
图2:在菜单中先打开Firebug插件这时候打开FireFox,你将在【工具】菜单中看到【firebug】(如图2)。打开firebug,然后在firebug中点击YSlow菜单,便看进入YSlow的主界面(如图3)。
图3:在菜单中先打开Firebug插件(点击小图查看完整大图)
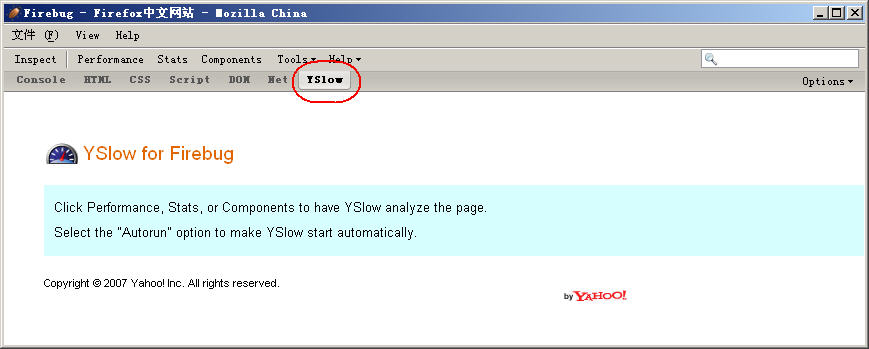
点击【Performace】菜单
YSlow便开始分析此页的效率,并从13个最影响网页效率的方面给出评估(如图4)。
图4:YSlow给出的本页面效率评估
可以看出来,YSlow评估的依据就是我们在《如何提高网页的效率(上篇)——提高网页效率的14条准则》中提到的前面13条。前面蓝色的字母表示这一条准备的得分。A最高。点击右面的三角形可以得到更多的信息和建议,有些信息里面还有“放大镜” 图标,点击也将展示更为详细的信息和建议。(如图5所示)
图5:YSlow可以给出每条准则的详细评估信息和建议
点击【Stats】菜单
这个视图会告诉你页面的总体统计信息。包括页面大小、css样式表大小、脚本文件大小、总体图片大小、flash文件大小和css中用到的图片文件大小。还会告诉你,哪些东西被缓存了,缓存了多少等等。
图6:【Stats】视图信息
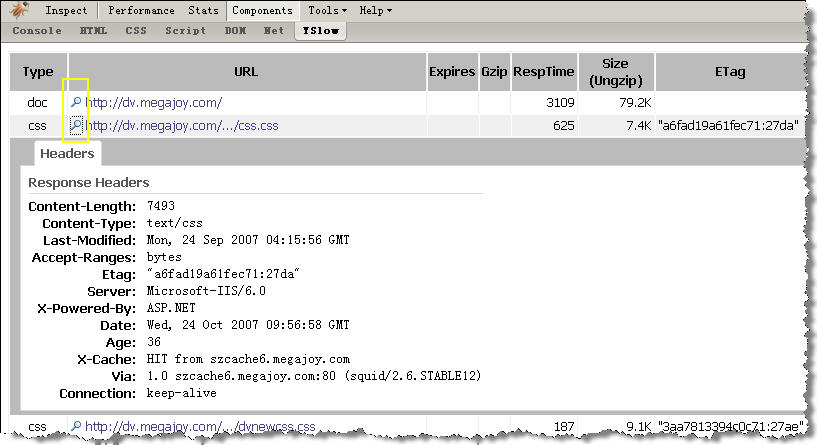
点击【Components】菜单
这个视图是一个页面所有部件的信息列表。从中我们可以得知每个部件的各种详细信息。如:类型、URL、Expires数据、状态、大小、读取时间、ETag信息等等。通过对这个列表的分析,我们就可以知道到底是什么东西最耗费我们的资源,从而有针对性的进行优化。
图7:【Components】视图信息,点击“放大镜”图标我们可以知道更详细的信息(点击小图查看完整大图)
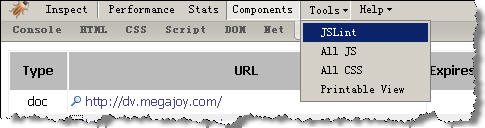
点击【Tools】菜单
【Tools】菜单包含4个子菜单,就是4个实用工具。【JSLine】工具会生成JSLine报表,报表是对本网页中JS脚本的分析报告,包含错误和建议。【ALL JS】工具,将生成本页面所有脚本代码便于阅读和打印的报表页面。【ALL CSS】工具,将生成本页面 所有CSS样式表代码便于阅读和打印的报表页面。【Printable View】将【Performance】和【Stats】视图中的信息生成一份更适合阅读和打印的报表页面。
图8:【Tools】菜单,包含了4个子菜单
点击【Help】菜单
【Help】主要是些常用的帮助途径的入口。从这里你可以很方面的访问YSlow的官方网络和博客。如果你还对YSlow的使用有什么疑惑的话,那么在这里你将获得满意的解答。
图9:【Help】菜单是些常用的帮助入口