
-
Liunx������װ���ļ����乤��RZSZ�������İ�װ
2008-12-16 15:16:52
Linuxϵͳ���ļ����乤��RZSZ
RZSZ���
һ����˵��linux�����������ͨ��ssh�ͻ���������Զ�̵ĵ�½�����ģ�ʹ��ssh��½linux�����Ժ�����ܹ����ٵĺͱ��ػ��������ļ��Ľ����أ�Ҳ�����ϴ��������ļ����������ͱ��أ�
��ssh�йص�������������ṩ�ܷ���IJ�����
sz����ѡ�����ļ����ͣ�send�������ػ���
rz�����и�����ᵯ��һ���ļ�ѡ�ڣ��ӱ���ѡ���ļ��ϴ���Linux������
rz��sz��Linux/UnixͬWindows����ZModem�ļ�����������й��ߣ�windows����Ҫ֧��ZModem��telnet/ssh�ͻ��ˣ����磺SecureCRT����SecureCRT��½��Unix/Linux������telnet��ssh���ɣ�����������rz�����ǽ����ļ���SecureCRT�ͻᵯ���ļ�ѡ��Ի���ѡ���ļ�֮��رնԻ����ļ��ͻ��ϴ�����ǰĿ¼��Ĭ��ʹ�ö����Ʒ�ʽ���ͣ�����������sz <file1name> <file2name>��������ͬʱ���Ͷ���ļ������Ƿ��ļ���windows�ϣ������λ���ǿ������ã��Ժ���������
�ŵ㣺 ��ftp����㣬���ҷ��������ô�FTP����
��װrzsz������
һ����˵����װLinuxϵͳʱ�ᰲװrzsz������������Щ���ư�װ��linux����û�а�rzsz����װ��ϵͳ�������SecureCRT������windows���ߴ����ļ��ر��㣬�����ڰ�װLiunx���ֶ���װrzsz��������
1.��ȡrzsz������
��ʽ1����¼linux��
������wget http://freeware.sgi.com/source/rzsz/rzsz-3.48.tar.gz���ء�
��ʽ2����windows�·���http://freeware.sgi.com/source/rzsz/rzsz-3.48.tar.gz
����rzsz-3.48.tar.gz��������ʹ��ftp�������ļ����乤���ϴ���Linux���������а�װ
2����ѹ������
# tar zxvf rzsz-3.48.tar.gz

��ͼ������ѹ��һ����Ϊsrc��Ŀ¼��
3����װrzsz��������ʹ��make posix��
ע�⣺һ��Ҫ���뵽rzsz��������ѹ��Ŀ¼�У���������/home/srcĿ¼
# cd src
# ls
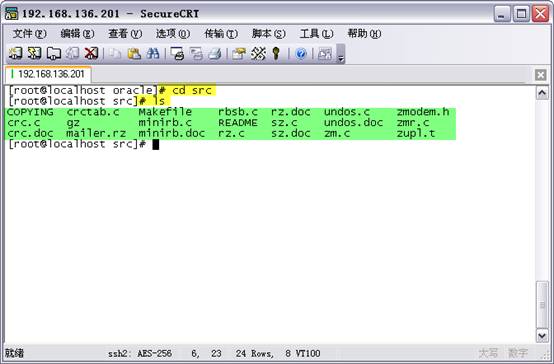
��ͼ��ʾ��rzsz����������װ�볣���GNU������ͬ��û��configure(����)��make install (��װ����)�ļ���
ִ������make,�鿴�����ʾ��Ϣ
# make
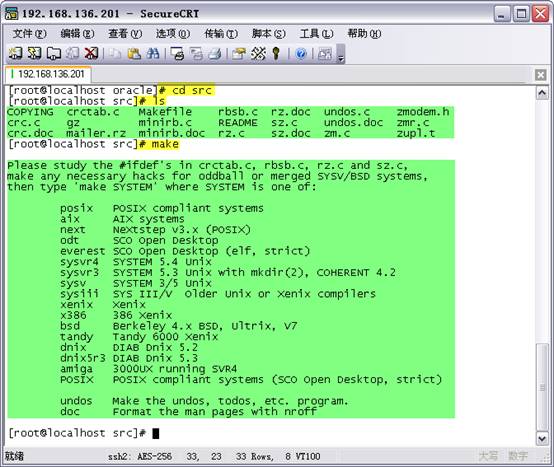
�����Լ���ϵͳѡ��make��λ�ò�����һ������£�ѡposix��linux�Ϳ����ˣ���ѡ��posix����ִ�����£�
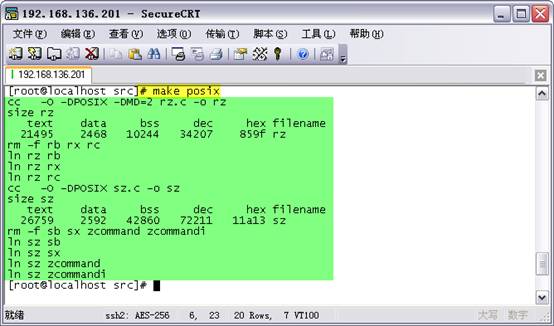
# make posix
��������ֿ��Կ�make�����еĹ���������ͼ��
4����rz��sz�ű����Ƶ�Ŀ¼/usr/bin���棬�Ա���ʹ�á�������д���û�$PATH���������У�
# cp rz sz /usr/bin
5�����û�������
# export RZSZLINE=/dev/modem
����������������������ִ������rz��ʱ����������ʾ��
��Warning: Missing environment variable 'RZSZLINE' (Linux)
rz ready. Type "sz file ..." to your modem program����
ע�����ַ������õĻ�������ֻ�ڵ�ǰ��shell����Ч�������Ҫ������Ч���μ��ҵ���һƪ���¡�Linux���û�������С�ᡷ
6����֤��װ
����1��rz�����windows�е��ļ��ϴ���Liunx��������
ʹ��SecureCRT���ӵ�linux��������Ȼ��ִ������rz���ᵯ��ѡ����windows���ļ��ĶԻ���
# rz

ѡ����Ҫ�ϴ����ļ������ȷ������ť�Ϳɰ�windows�����ϵ��ļ�ͨ��sshЭ���ϴ���Linux��������
�ϴ��ļ�����λ�ã�ִ��rz����ʱ���ڵ�Ŀ¼��
���磺��������[root@localhost root]# rz //��/rootĿ¼��ִ�е�rz����
���ϴ���jdk��װ����洢��/rootĿ¼��
���ɣ�ͨ����Shifs������Ctrl��������ʵ�ֶ���ļ��Ĵ��䡣
����2��sz�����Linux�µ��ļ����ص�windows��
# sz <file1name> <file2name> ��
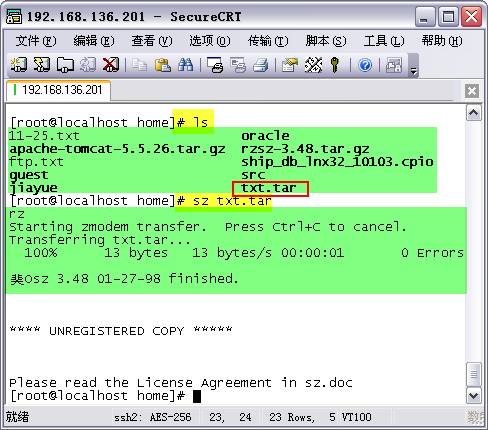
���سɹ���
�����ļ�����λ�ã�
�ļ������سɹ��ˣ�������һ�����⣺�ļ����ص�windows��ʲôλ�ã�
�ܼ��ļ�����λ�õ�������ͨ��SecureCRT���õģ�����ͼ��ʾ��
�����ѡ�-���Ựѡ�
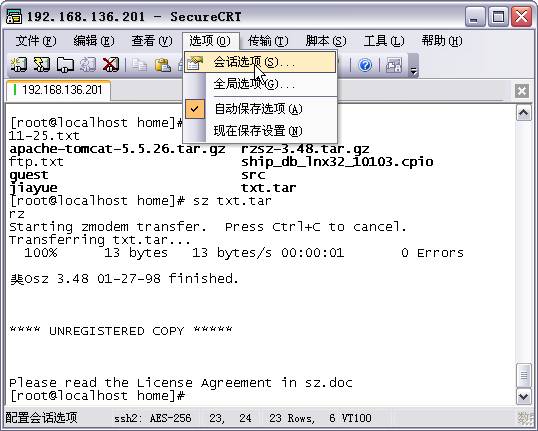
���á�X/Y/Zmodem����
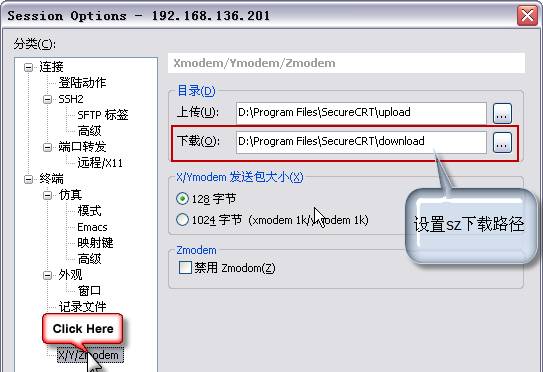
������ͼ��ʾ������Ŀ¼D:\Program Files\SecureCRT\download�鿴�ļ��Ƿ���ȷ���ء�
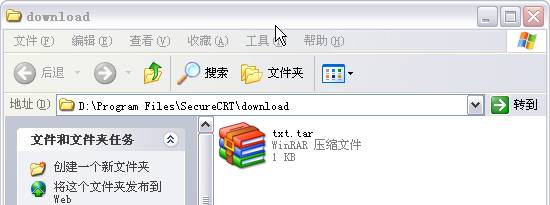
OK��һ��������rzsz��������װ�ɹ���
-
���ܲ���ʹ�õ�һЩ������ ��2��
2008-12-16 14:55:10
���ܲ���ʹ�õ�һЩ������ ��2��
Memory object
Memory object��¼�˵�ǰϵͳ�������ڴ��ͳ����Ϣ��
Available Mbytes ��Committed Bytes
Available Mbytes��¼�˵�ǰʣ��������ڴ�������Committed Bytes��¼�����н���commit���ڴ�����������������������Թ۲쵽��
1) ������ӿ��Դ��Թ���ϵͳ��������ڴ���٣����ڹ�����������
2) ��Available Mbytes����100MB��ʱ��˵��ϵͳ�����ڴ�Խ�����Ӱ�쵽����ϵͳ���н��̵����ܡ�Ӧ�ÿ������������ڴ������ڴ�й¶
3) ͨ���Ƚ�Process\Private Bytes��Virtual Bytes�����ڽ�һ��ȷ���Ƿ����ڴ�й¶���ж��ڴ�й¶�Ƿ���ijһ�������̵���
Free System Page Table Entries��Pool Paged Bytes��Pool Paged Bytes
���������������Ժ�������̬�����ڴ���������ر��ǵ�ʹ��/3GB���غ���̬�ڴ��ַ��ѹ���������º���̬�ڴ治�㣬�̶�����һЩ�dz���ֵ����⡣���Բο�ǰ���ᵽ�����£�
.NET CLR Memory object
.NET CLR Memory object��¼��CLR�����и�CLR��ص��ڴ���Ϣ��������µ����м�������������˼��������˼Ҳ�dz�ֱ�ӡ�������һ�����ӳ�����в��Ժ��о���������������õļ�����
Bytes in all heaps
Bytes in all heaps��¼���ϴ�GC����ʱ����ͳ�Ƶ��ģ������в��ܱ����յ�����CLR objectռ�õ��ڴ�ռ䡣�ü���������ʵʱ�ģ�ÿ��GC������ʱ��ü������Ÿ��¡���ͬһ���̵�Process\Private bytes�Ƚϣ��������ֳ�managed heap��native memory�ı仯���������memory leak������������managed heap��leak����native memory��leak
%Time in GC
%Time in GC��¼��GC������Ƶ���̶ȡ�һ����˵15%������Ƚ�������������20%˵��GC��������Ƶ��������GC�����������ܸߵ�CPU����������Ҫ����Ŀ����̵�CLR�̣߳����Ը�Ƶ��GC�Ƿdz�Σ�յġ�ͨ����CPU�����ʺ���������ָ��Ƚϣ������ܹ�����GC�����ܵ�Ӱ�졣��Ƶ�ʵ�GC������Ϊ
1) ���ع���
2) �������ļܹ������ڴ�ʹ��Ч�ʲ���
3) �ڴ�й¶���ڴ��Ƭ�����ڴ�ѹ��
���Ŀ�������ASP.NET����ASP.NET��ͷ��object�У�������Щ���������ڲ���ASP.NET�����ܷdz����á����ڲ��ټ����������ڶ��object����У�����ֻ�г�����ļ��������֣�����ȥ��Ӧ�������object:
Application Restarts
Application Restarts��¼��ASP.NET Application Domain�����Ĵ���������ASP.NET appDomain������ԭ������������Ŀ¼�б��ġ���������web.config�ļ������߷������������Ŀ¼����ɨ�衣ͨ���ü��������Թ۲��Ƿ����쳣����������
Request Execution time
Request Execution time��¼�������ִ��ʱ�䣬�Ǻ���ASP.NET���ܵ���ֱ�Ӳ�����ͨ���ü�������ƽ��ֵ�����������Ƿ�Ϻ�Ԥ��ֵ����Ҫע��ĵط�������Windows����ʵʱϵͳ�����Բ����÷�ֵ�������������ܡ����統GC������ʱ������ִ��ʱ��϶���Ҫ����GC��ʱ�䡣����ƽ��ֵ������Ч�ı�
Request Current
Request Current��¼�˵�ǰ���ڴ����ĺ͵ȴ�����������������������Request Current����CPU����������˵�������Ӳ����Դ�ܲ�������������ǡ���Ǻϣ�Ӳ��Ͷ��������������״̬������һ��˵���������ɱȽϴ��ʱ��Request CurrentҲ�������ߡ����Request Current��һ��ʱ�����г���10�������˵�����������⡣ע��۲����ʱ���Ӧ��CPU�������������Դ�����CPU���ߣ��ܿ����dz�������blocking����������ȴ����ݿ���������������ʱ��ɡ�
Request/second
Request/second��������¼��ÿ���ӵ���ASP.NET�������������Ǻ���ASP.NET���ص�ֱ�Ӳ�����ע��۲�Request/second�Ƿ������Ԥ�������������Request/Second��ͻ���IJ�����ע�⿴�Ƿ��оܾ�������ͨ����Request/second,Request Current, Request Execution time��ϵͳ��Դһ��Ƚϣ������ܹ�������ASP.NET�������ܵı仯��������֮���Ӱ��
Request in Application Queue
��ASP.NETû�п���Ĺ����߳��������½���������ʱ���µ�����ᱻ�ŵ�Application Queue�С���Application Queue�ѻ�������Ҳ�����趨��ֵ��ʱ��ASP.NETֱ�ӷ���503 Server too busy����ͬʱ����������������������£�Request in Application QueueӦ����Ϊ0������˵���Ѿ�������ѻ���������������
-
���ܲ���ʹ�õ�һЩ��������1��
2008-12-16 14:42:25
���ܲ���ʹ�õ�һЩ������ ��1��
l Process object�µ����м�����
l Processor object�µ����м�����
l System object�µ����м�����
l Memory object�µ����м�����
l �����.NET���۲� .NET ��ͷ��object�µ����м�����
l �����ASP.NET���۲� ASP.NET ��ͷ��object�µ����м�����
�������ܼ�������������
Process object
Process object�еļ������������Ŀ����̷����ڴ棬CPU,�߳���Ŀ��handle��Ŀ������Ҫȷ��Ŀ����̣�Ȼ�����Ŀ����̵�����һЩ��������
% Processor Time
�ü������Ǹý���ռ��CPU��Դ��ָ�ꡣ�����̷�æ��ʱ��CPUƽ��ռ����Ӧ����80%���ڡ������������ֵ�����������Ϊ������high CPU�����⡣����һ��������CPU�������ȴ���Ȼƽ��ռ���ʲ��ߣ�������������Ƶ������ijһ����ʱ������棬����������CPU��������֡�
Handle Count
�ü�������¼�˵�ǰ����ʹ�õ�kernel object handle������Kernel object����Ҫ��ϵͳ��Դ������������ȶ�����״̬��ʱ��Handle Count����ҲӦ��ά����һ���ȶ������䡣�������Handle Count���������������������������������ϣ����Կ��dz����Ƿ���Handle Leak
ID Process
�ü�������¼��Ŀ����̵Ľ���ID������ܾ�����֣�ID��ʲô�ù۲�ġ�����ID�������۲�����Ƿ�����������������ASP.NET�������̿��ܻ��Զ����ա����ڽ���������ͬ��ֻ��ͨ������ID���ж��Ƿ���������������������ID�б仯�����dz����Ƿ�����������Recycle
Private Bytes
�ü�������¼�˵�ǰͨ��VirtualAlloc API Commit��Memory������������ֱ�ӵ���API������ڴ棬��Heap Manager������ڴ棬������CLR ��managed heap�����������档��Handle Countһ����������������������������������������ϣ�˵����Memory Leak
Virtual Bytes
�ü�������¼�˵�ǰ��������ɹ����û�̬���ڴ��ַ������DLL/EXEռ�õĵ�ַ��ͨ��VirtualAlloc API Reserve��Memory Space���������Ըü�����Ӧ���ܴ���Private Bytes��һ����˵��Virtual Bytes��Private Bytes�ı仯����һ�¡������ڴ��Ƭ�Ĵ��ڣ� Virtual Bytes��Private Byesһ�㱣��һ������ȶ��ı�����ϵ����Virtual Bytes��Private Bytes�ı�����ϵ����2��ʱ���������бȽ����ص��ڴ��ַ��Ƭ��
Processor object
Processor object��¼ϵͳ��оƬ�ĸ��������������ͨ����������ij������CPU��ִ�У������ڶ�CPU�����Ϲ۲�Total InstanceҲ���㹻��
% Processor Time
�ü�������Process�µ�% Processor Time������һ�������������¼�������н��̴�����оƬ����������Ծ���ijһ�����̡�ͨ���������������Process�µ�ͬ��������һ��Ƚϣ����ܿ���ϵͳ�ĸ�CPU�����Ƿ������ڵ�һ��ij�����̵��µ�
System object
System object��¼ϵͳ��һ�������ͳ����Ϣ�����Բ�����Instance. ͨ���Ƚ�System object�µ�counter������counter�ı仯���ƣ������ܿ���һЩ����
Context Switch/sec
Context Switch��ʾ��ϵͳ�������̵߳ĵ��ȣ��л�Ƶ�ʡ��߳��л��ǿ����Ƚϴ�IJ�����Ƶ�����߳��л�������CPU���ڱ��˷ѡ����Կ�����CPU��ʱ��һ��Ҫ��Context Switchһ��Ƚϡ������������ͬ�ı仯���ƣ���CPU����������contention���µģ���������ѭ����
Exception Dispatches/sec
Exception Dispatches��ʾ��ϵͳ���쳣�ɷ���������Ƶ�������߳��л�һ�����쳣����Ҳ��Ҫ������CPU����������������Context Switch��ͬ��
File Data Operations/sec
File Data Operations��¼�˵�ǰϵͳ�д����ļ���д��Ƶ���̶ȡ�ͨ���۲�ü���������������ָ��ı仯���ƣ�ͨ���ܹ��жϴ����ļ������Ƿ�������ƿ�������Ƶļ���������Network Interface\Bytes total/sec
-
Windows���ܼ�������ʹ��
2008-12-16 14:40:43
Windows���ܼ�������ʹ��
һ Windows���ܼ�����
������Winxp�еġ�Windows���ܼ�������Ϊ��˵����
�������->��������->����->������־�;���������ͼ��ʾ��

����1����̬����
����Ҽ���ѡ�����Ӽ�����������ͼ��ʾ��
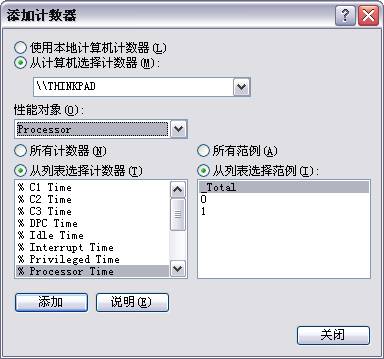
�������Ӽ������������У�ѡ�����ܶ���Ϊ��Processor���� ��������ΪĬ�����ã�������ϣ��������������ť���رմ��ڣ�����ʵʱ����ѡ�еIJ�����
����2����������־����
�������->��������->����->������־�;���->��������־->�½���־����
�����½���־����Test_guok����
������־���ӵĶ���ͼ����������������ܶ���Processor�����б�ѡ���������% Processor Time��
��ע����% Processor Time�� ָ����������ִ�з������߳�ʱ��İٷֱȡ����㷽���ǣ�������������ڷ������̻߳��ʱ�䣬�÷��������ȥ��ֵ��(ÿ̨��������һ�������̣߳����߳���û�������߳̿�������ʱ��������)������������Ǵ����������Ҫ˵��������ʾ�ڷ������ʱ���۲�ķ�æʱ��ƽ���ٷֱȡ����ֵ���� 100% ��ȥ�÷����ʱ���������ġ�
������־�ļ����硰��־�ļ����͡���ѡ���ı��ļ�(���ŷָ�)����
��ע����������־�;������Զ��ŷָ����Ʊ����ָ��ĸ�ʽ�ռ����ݣ��Ա���������ӱ������Ϊ��������ݷ����������������ô˷�ʽ��
���üƻ�����ʱ�䰴�������г�
���óɹ���ȷ�Ϻ�����ͼ��ʾ��
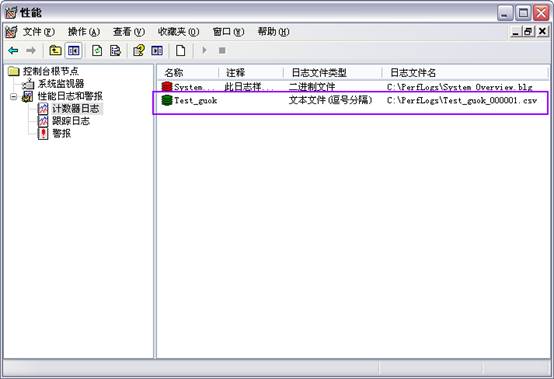
�� ���ݷ���
��C:/ PerfLogsĿ¼�´���־��Test_guok_000001.csv��
ѡ��Excel�еġ����롱->��ͼ����->������ͼ��������ͼ��ʾ
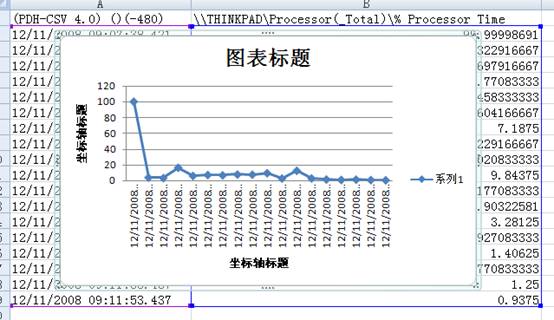
-
ʹ��DEBUGDIAG�ֶ�ץȡDUMP�ļ�
2008-12-16 14:35:09
ʹ��DebugDiag�ֶ�ץȡdump�ļ�
l �ֶ�ץȡIIS dump�ļ�
l �鿴dump�ļ���Ĭ�ϴ洢λ��
l ��dump�ļ��Ĵ洢λ��
l ץȡdump�ļ���ʱ��
�ֶ�ץȡIIS dump�ļ�
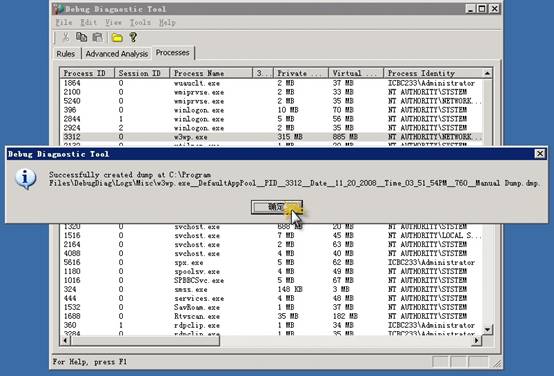
1������DebugDiag 1.1 (x86)������ѡ��������͡������еġ�ȡ������ť���Processes��ҳ��
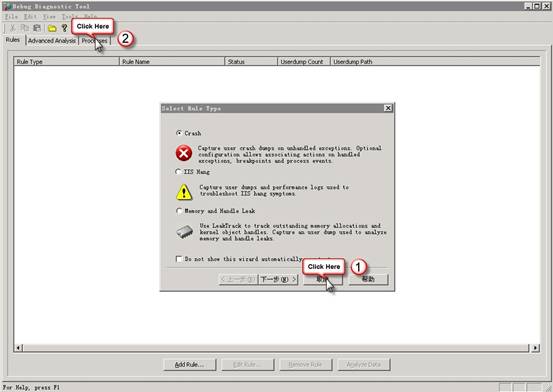
2���Ҽ�����w3wp���̣���ѡ��Create Full Userdump
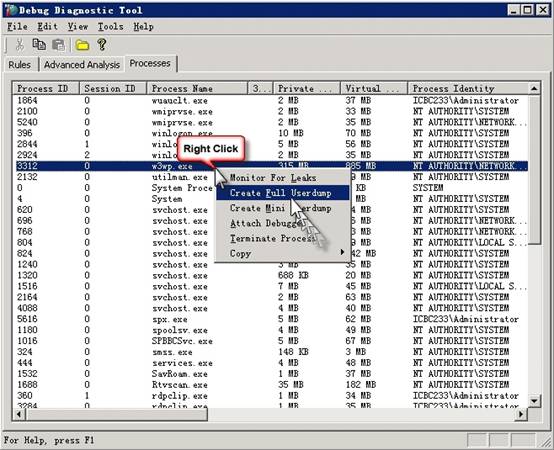
�ȴ�һ��ʱ�����ֳɹ�����dump�ļ����Լ�dump���ļ����ʹ洢·���ĶԻ����ȷ�����ɡ�
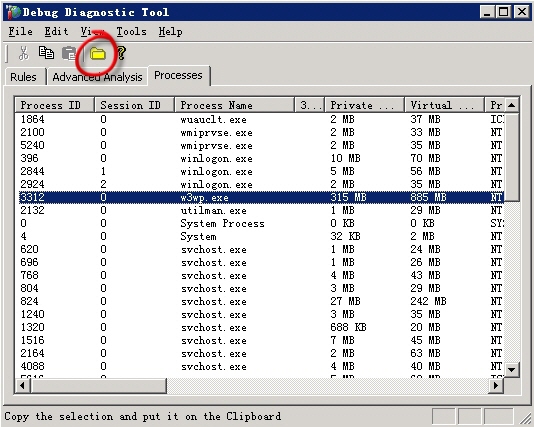
�鿴dump�ļ���Ĭ�ϴ洢λ��
1�����DebugDiag 1.1 (x86)���������ڹ������еġ��ļ��С�ͼ��
�鿴�����Ĵ���
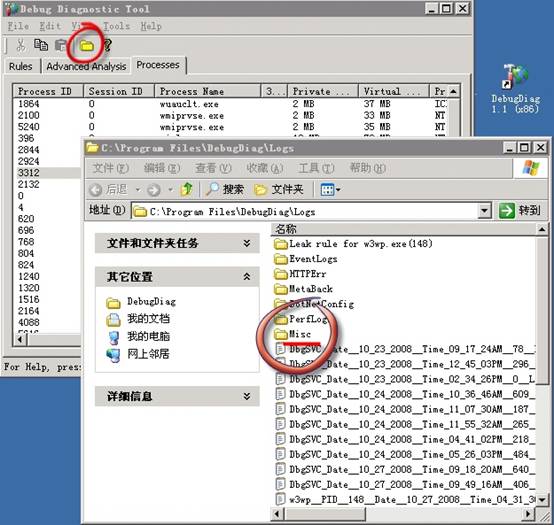
�����е�misc�ļ��У��ղ���ץȡ��dump�ļ��ʹ�������С�

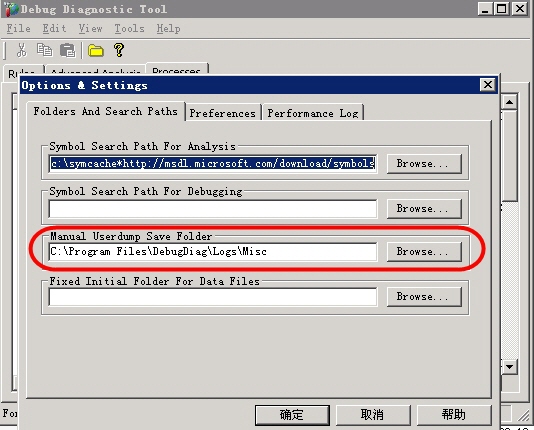
��dump�ļ��Ĵ洢λ��
���DebugDiag 1.1 (x86)���߲˵����еġ�Tools��->��Options and Settings������Manual Userdump Save Folder�е�·��Ϊ��Ҫ�ĵ�·�����ɡ�
ץȡdump�ļ���ʱ��
1��Ӧ�ó����ʼ����ϣ�����ִ��ǰ����Ҫץȡһ��dump�ļ�
2��ʹ�����ܼ������۲�����е��ڴ�ʹ���������IIS����ǰ���۲�Prvite��#time in GC�ı仯��ץȡdump�ļ��Ա��ڿ�������
3������ѡ�������ܼ������й۲�gen2��large object heap��bytes in all heaps�ѵ�ʹ�ú��ͷ�������ڶѵ�ʹ�ü����ﵽһ���߷�ֵ�����ֵ��ǰץȡdump����ͬʱץȡ���ͷŵ�һ���ͷ�ֵ�����ȣ�ǰץȡһ��dump�����㿪���Աȷ�����
-
�����Ч��չ���ܲ��ԣ�2��
2008-12-16 14:24:08
�����Ч��չ���ܲ��ԣ�2��
3.2 ���ò��Ի���
���ò��Ի����Dz���ʵʩ��һ����Ҫ���ڣ����Ի����ʺ���������Ӱ����Խ������ʵ�Ժ���ȷ�ԡ����Ի�������Ӳ������������������Ӳ������ָ���Ա���ķ��������ͻ��ˡ����������豸���Լ���ӡ��/ɨ���ǵȸ���Ӳ���豸�����ɵĻ�������������ָ������������ʱ�IJ���ϵͳ�����ݿ⼰����Ӧ���������ɵĻ��������ǵ��������أ��������������١���ʾ�ֱ��ʣ����ݿ�Ȩ�ޡ������ȶԲ��Խ����Ӱ�졣������������������������ü��鲻ͬ�IJ��Ի�����
����Ի������裺
1) ���Ի����滮
���Ի����Ĺ滮����Ӳ�������������й������Ի����������Դ�Ĺ滮����������Checklist���Dz��Ի����������ķ�ʽ��ɣ�
���Ի�������checklist
���Ի���˵��
�Բ��Ի����ļ��
��Ŀ����
������Ŀ����
��Ŀ���
����Ŀ�ļ��
��������ͼ
���Ի�������������ͼ
Ӳ������
�������û���Ӳ��������Ϣ
���磺
CPU����ǿ3.0
�ڴ棺4GB
Ӳ�̣�200G
������ǧ��
��������
���Ի�������ʹ�õ������������ã�Ҫ����ϸ�汾��
���磺
����ϵͳ��Windows Server 2003 SP2
ϵͳ����AD����Ϣ���С�MSDTC����
Ӧ��ƽ̨��Microsoft .Net Framework2.0 SP1
Ӧ��������MCMS 2002 SP1
���ݿ⣺SQL Server 2005 SP1
����IIS6.0
�������IE7.0
ɱ��������ŵ��SEP
��������ǽ��windows����ǽ
����Ҫ��
����������������ϸ���ã�
���磺
����ϵͳ��Ҫ����/3G��֧��
��Ҫ��windows����ǽ
IISӦ�����ӳص���ϸ����
IE��Ҫ��Ӧ����ַ���ӵ�����վ��
�����ͺ�
�������Ի����������ͺ���Ϣ��ϸ
���磺
Intel PRO/100 NIC
Intel(R) 82567V-2 Gigabit Network Connection
������Ϣ
��������ľ���������
���磺
������������
IP��ַ
��������
Ĭ������
DNS������
���Թ���
������������Ҫ��װ�IJ��Թ���
���Թ�������
���Թ��߰汾
���Թ����
�û�Ȩ��
�������Ի����е��û�Ȩ��
Ӧ�������б�
�����Ե��������汾����
�磺
�Ż���վ��̨���������
��̬ץȡ�����
�������ݵ���Ӧ��
Ӧ������Ҫ��
����Ӧ����������ϸ����
Dao.config���ݿ����ӵ�����
Webconfig����
�������ݵ�������
2) ���Ի�������
����checklist�е��������ˡ�Ӳ�����á������ͺŵ�Ҫ�����Ի�����Ӳ�������绷�������Ϻ�ÿ���豸��PC���������Ҫ��������Ӳ�����ñ������Ա���ά��
3) ���Ի�������
����checklist�е��������á�����Ҫ��������Ϣ���û�Ȩ�����ò��Ի�����PC�ͷ�����������������������Ϻ�ÿ���豸��PC���������Ҫ�����������������ĵ������Ա��ں��ڵĻ���ά����
4) Ӧ�ó�����
����checklist�е�Ӧ�������б���Ӧ������Ҫ��Ӧ�ó������Ի����У�������Ϻ�ÿ��Ӧ�ó���IJ���Ҫ��������Ӧ�����������ĵ������Ա��ں��ڵ�����ά����
5) ���Ի�����ʹ��
��ʹ�ù����п��ܻ�Բ��Ի�����һ���ĵ�����ÿ�ε�����Ҫ����Ӧ���ĵ������Ի�������checklist������Ӳ�����ñ�������Ӧ�����������ĵ����͡�Ӧ�����������ĵ��������ģ��Ա��ֻ������ĵ���һ�¡�
6) ���Ի�������
��Ŀ��������Ҫ����Ŀ��ʹ�õ���Դ����������������ʹ�õ���Դ�����ͷš�
Ӳ����Դ��PC���������������̿ռ䡢��������
������Դ��IP��ַ
3.3 �������ݵĻ�ȡ�ʹ���
���ܲ��Ե����ݻ�ȡ��Ҫ��������ʽ
1) ���������ݣ��������ҵ���쳣������߽�����ȹ����������ݣ�����������������Ļ������ݣ����磺�û���Ȩ�ޡ����á��������롢ԭ���ݵȣ�������ϵͳ��ҵ�����ݣ�
2) ���������ݣ����Ѿ����������������е����ݻ��ϰ汾�е����ݵ������ڴ˻����Ͻ������ݵ�������ӹ�Ϊ�������ݣ�
3) �����ۡ����ݣ�ʹ����ʵ��ҵ�����̽����еķǵ��ӻ�ҵ�������ֹ�¼��ϵͳ������֤ҵ���ͬʱҲ����˲������ݵĻ��ۣ����߲��Ա������ݡ���������������۵�����������һ�������ԣ���Ϊ�Ѿ�������ҵ�����ݻ�������ȷ�ġ�һ�µģ����ҿ���ȱ��ijЩ�ض�ҵ������ݣ����������ķ�֧ҵ����������Ҫ���ݶԲ�������ķ��������µIJ������ݣ��Ա�����������ҵ�����͡�
���ܲ���ʹ�õ����ݺ��ܲ�����һ�����������������ݵIJ��ص㲻ͬ�����ܲ���ʹ�õ����ݲ��ÿ������ȥУ�鹦�ܡ����ܲ�������Ҫע�����¼��㣺
1) �������ݵ�Ψһ����
���ܲ�������ʹ���Զ������Թ��߽��в��ԣ���ʹ����ͬ�ĽŲ����������������в��ԣ������ڲ��Թ�����һ��Ҫע��ű��в������ظ����⣬��Ʋ�������ʱҪ���Dz����û����Լ�ÿ���û����ܵ����Ĵ����������������������������ʹ���ظ����ݣ����յ��²���ʧ�ܡ�
2) �������ݵ���������
���ܲ�����������ϵͳ�����Ӵ��������ݣ����ӵ����������ԴﵽӰ��ϵͳ���ܵij̶ȣ����磺���ݿ������100�����ݺͱ�����100W�����ݵ���Ӧʱ��һ���Dz�ͬ�ģ������Ա��뼰ʱ�Ķ����ӵIJ������ݽ����������Ա�֤���Ի����Ĺ�ƽ�ԣ�������֤���Խ������ʵ�ԡ�
3) ����������������������������
���ܲ�������Ҫʹ�á��������������в��ԣ�����������������ָ�����Ķ��٣���Ҫ���ǵ����������Ĵ�С�����磺�������µIJ��ԣ�����Ҫ���㷢������������Ҫ��Ҫ���ǵ��������ݵĴ�С��Ҳ����˵����Ҫ���Ƿ���10W��1K��С�����µ����ܻ�Ҫ���Ƿ���10W��10M��С�����µ����ܡ�
4) ������������������
�������ݼ������ԣ���������ָ�����ȵ��ַ�������Ȼ�������ִ�е�Ҫ���ǶԺ�������������ܶ��Ӱ�죬���磺����֤���ݵ�Ψһ�ԣ���������������м��ʲ����ظ����ݣ��ռ��IJ��Խ��������Ա�����������ܲ����еĿ�����Ա������Ҫ�����ڴ��Dump�ļ�����������ġ�û�й�����ַ��������ڿ�����Ա��dump�ļ��ķ�����
4. ��ο�չ���ܲ���
��������ǰ�ڵ������������ӣ����ò�������������������˲��Թ�����һ��룬��Ҫ����һ�ݾ���˵�����IJ��Ա��棬��Ӧ��ȷ���ղ��Ե�ǿ�ȣ����ֲ��Ե�һ���ԣ���߲��Եľ��ȡ�
�ж������ĺû���Ҫ���������ʵ��Ӧ�õ�������ֻ����һ���IJ���ǿ���£����ܲ��Գ�����������Դ�������ʣ��������е��ٶȣ��������ȶ��ԡ�ͨ���Ա��ڲ�ͬ�IJ���ǿ���£���ͬ����ÿһ������ģ����ʵ��������������������е�Ч�ʣ����Dzſ����жϳ���ͬ������ÿһ��ģ���ǿ�����������������������ӡ�
���ܲ��Կ�ʼ�����в��������붼Ӧ��ѭͳһ�ı�����������һ�����ڣ�������һ���ƫ���Ӧ�����������������Ĵ���ҡ�Ҫ�ر�ע���ⲿ�����Բ��Խ����Ӱ�죬������������Թ����У��ⲿ������һ�£������١������ڴ�ʹ���ʲ�һ�������п��ܵ��²��Խ����ʵ������г��롣
ʵ��1��XX��Ŀʹ���ն�PC��A1����Loadrunner ����15Сʱ��17��00-�ڶ�����8��00����ѹ�����ԣ��ڶ���鿴�������������PC��A1���ڴ治�㣬����Loadrunner���賿3��00 �鿴(674) ����(0) �ղ� ���� ����
�����Ч��չ���ܲ��ԣ�1��
2008-12-16 13:57:05
�����Ч��չ���ܲ��ԣ�1��
һ�� ���ܲ�������
���ܲ�����һ�ֹ����ϵ�˵�������������¸��ֲ�ͬ�����ܲ������ͣ�ÿ�ֲ������Ͷ�������ȷ�IJ���Ŀ�ġ�
1.���ܲ��ԣ�Performance Testing��
���ܲ��Եķ�����ͨ��ģ���������е�ҵ��ѹ������ʹ�ó�����ϣ�����ϵͳ�������Ƿ���������������Ҫ�����ض���������������֤ϵͳ������״����
��Ҫǿ�����ض�����Ӳ���������ض��IJ���ҵ���£����ϵͳ�ĸ�������ָ�ꡣ
2.���ز��ԣ�Load Testing��
�ڸ����IJ��Ի����£�ͨ���ڱ���ϵͳ�ϲ�������ѹ����ֱ������ָ�곬��Ԥ��ָ���ij����Դʹ���Ѿ��ﵽ����״̬��Ŀ�����˽�ϵͳ���������ʹ����������ޡ����ز��Ե���Ҫ��;�Ƿ���ϵͳ���ܵĹյ㣬Ѱ��ϵͳ�ܹ�֧�ֵ�����û���ҵ��ȴ���������Լ����
���ز������ڹ̶����Ի��������������ԽǶȣ����ط��棩���������£��仯һ�����ԽǶȲ���������ѹ�����鿴ϵͳ���������ߺʹ������ޣ��Լ��Ƿ�������ƿ�����ڣ��յ㣩����Ҫ�����ǴӶ����ͬ�IJ��ԽǶ�ȥ̽�����ϵͳ�����ܱ仯�����������ܵ��š����ԽǶȿ����Dz����û�����ҵ�������������Ȳ�ͬ����ĸ��ء�
3.ѹ�����ԣ�Stress Testing��
����ϵͳ��һ������״̬��ϵͳ�ܹ������ĻỰ�������Լ��Ƿ���ִ���һ�������ȶ��Բ��ԡ�
��������Ϊ��Դ�ļ����ԡ����Թ�ע����Դ���ڱ��ͻ��ɵ�����£�ϵͳ�ܷ��������У���һ���ڼ���ѹ���µ��ȶ��Բ��ԡ�����Ҫ������ͨ�����ԡ����ű�֤ϵͳ��ʹ���û��ļ���ѹ����Ҳ�����������ϵͳ������
ѹ�����Ե�Ŀ���ǵ���ϵͳ������Դ�����ɵ�����µı��֣������Ƕ�ϵͳ�Ĵ���ʱ����ʲôӰ�졣���������һ����Ҫ�ڷ���������Ƶ�ʻ���Դ�ķ�ʽ��ִ��ϵͳ��Ŀ����ͨ�������Է���������ϵͳ�ڼ�����ӻ��������ұ�����������Ҫ��֤ϵͳ�Ŀɿ��ԡ�
4.���ò��ԣ�Configuration Testing��
ͨ���Ա���ϵͳ����Ӳ�������ĵ������˽���ֲ�ͬ����������Ӱ��ij̶ȣ��Ӷ��ҵ�ϵͳ������Դ�����з���ԭ��
��Ҫ�������ܵ��ţ��ھ������Ի���˻��������ݺ��л�������������Ӳ�����á����硢����ϵͳ��Ӧ�÷����������ݿ��ȣ����ٽ����Խ��������ݽ��жԱȣ��жϵ����Ƿ�ﵽ���״̬��
5.�������ԣ�Concurrency Testing��
ģ�Ⲣ�����ʣ����Զ��û���������ͬһ��Ӧ�á�ģ�顢����ʱ�Ƿ�������صIJ������⣬���ڴ�й©���߳�������Դ�������⡣
6.�ɿ��Բ��ԣ�Reliability Testing��
ͨ����ϵͳ����һ����ҵ��ѹ��������£���Ӧ�ó�������һ��ʱ�䣬����ϵͳ�������������Ƿ��ܹ��ȶ����С�
��Ҫ��ѹ���������ֿ������ߵIJ��Ի����Ͳ���Ŀ�IJ�һ����ѹ������ǿ������Դ���������ϵͳ�Ƿ�������ɿ��Բ���ǿ���� һ����ҵ��ѹ���³�ʱ�䣨��24��7������ϵͳ����עϵͳ���������������Դʹ�����Ƿ������ӡ���Ӧʱ���Ƿ�Խ��Խ�������Ƿ��в��ȶ����ס�
���������Ч��չ���ܲ���
1.����
������Ϊ���۲�Ʒ���ܵ���Ҫ�ֶΣ����ܲ������������Թ�����ռ�ı���һֱ�ܴ�Ҫ�����ṩһ��ȷ��Ȩ���IJ��Ա��棬������Ա��Ŭ��������Ȼ���ɻ�ȱ��������Ҫ���Dz�����Ա�����Ĺ���˼·�����IJ������̺����õIJ��Է�����
2.Ŀǰ���ܲ��Դ��ڵ�����
�����ܽ��������е����ܲ��ԣ���Ȼ������Ա��ʼ���նԲ��Թ��������������渺�𣬵����Ա����¯����ܾ������в��㣬�Բ��Խ�����Ĵ����ǣ���������Щʱ���Ƚϳ�����Բ�ͬ�IJ��Զ�������ܶԱȲ����У������ٶ��������¼�����������⣺
1. ����������֣�����Ŀ�겻��ȷ�����Լƻ�����ϸ��
2. ȱ�������Լ���Բ��Զ���ļ���������
3. ���Ի������ȶ��Լ�ǰ��һ���Բ��㣻
4. �������ݾ�ȷ�Ժʹ����Բ��㣻
5. ����������������
���棬���Ǿ��������������ͬʱ��̽��һ����ν����Щ���⡣
3. ���ܲ�����
��������һ�����������ԵĻ��ڣ��ڽӵ���ѹ������������������صĿ��ǣ�������Ա�������ڽ��ȣ�����Ͷ�뵽����IJ��Թ���ȥ�ˣ����ԡ���¼��������æ�IJ����ֺ�������������һ��ŷ��֣�����Ӳ�����ò�����Ҫ�������绷�������룬���������汾���ԣ�һʱŪ���ﻢ���£��ⶼ��û�����ò������ǵĻ���
������ô����Ӧ������������ܲ��Ե��������أ�
������������Ŀ��������顢��Ҫ����������������Ҳһ�������õ����������������Ҫ��������Ƿ������������ڿ�ʼ����ǰ����������ҪŪ�����¼������⣺
1. Ҫ����ʲô����ԵĶ�����˭��
2. Ҫ����ʲô�����������ҪŪ���������֤����ʲô���⣿
3. ��Щ���ػ�Ӱ����Խ����
4. ��Ҫ�����IJ��Ի�����������Ӳ�������绷������
5. Ӧ���������ԣ�
����ֻ���������������������ϸ��������������п���Ū������һϵ�е����⣬ֻ�жԲ�������dz����������Ŀ�꼫����ȷ��ǰ���£����Dzſ����ƶ�����ʵ���еIJ��Լƻ�����ȷ����Ŀ��,�꾡���Լƻ��ڶԲ����������˽�Ļ����ϣ��ƶ���������ϸ�IJ��Լƻ����Բ��Ե�ʵʩ�Ǵ�������ġ�
3.1 ���Լ�����
��Ŀǰ�Ĵ��£�Ҫ�������Ա�ڶ�ʱ��������е�����Ӳ��֪ʶ�Dz�̫��ʵ�ģ���ƽʱ������ԱӦץ���Բ��Թ��ߺͲ������۵��о����ڲ��Լƻ��У�Ӧ���о����Զ���Ͳ��Թ��߷�������ѧϰʱ�䣬ֻ���ڳ�ֳ��ղ��Թ��ߣ���ȫ�˽���Զ����ǰ���£����Dz��ܹ�ʵʩ���ԡ������ڴ������ʶ�ϵIJ��ԣ���ʹ����Ŭ�������Ҳ�DZ������ۣ�Ҳ����֤�����⣬������˵�������IJ��Ա���ȥ˵���û���
���������
1) ��ʵ�ļ����רҵ����֪ʶ��
2) ������ʵ�����ܲ��Լ��Ż����飻
3) ���ܲ�����ع��ߵ�ʹ�ã�
4) ����ϵͳ��ԭ������Ϥ����ϵͳ����ϵ�ܹ�������ϵͳ����Ҫ��������Լ��ڴ�������洢/�ļ�ϵͳ������/Ӳ���Ĺ���������Э���ʵ�ּ����ɡ����ܵļ�ط�����ԭ������Ϥ���õ����ܼ�������
5) ���ݿ�ԭ�����ܽ���һ������ݿ������������ϤSQL�ű���ʹ�ã���Ϥ���õ����ݵ��Ź��ߺͳ��õ����ܼ�������
6) webӦ�÷�����ԭ�����˽�һ������ã���Ϥ���õķ��������ܼ�ط�����ԭ������Ϥ���õ����ܼ�������
7) ���������ԭ����������ϤTCP/IPЭ�飬��ϤHTTPЭ�飬���ټ������˽����㡢�IJ㽻������·������ʹ�ú����á��˽ⳣ�õ�������������ص����ܼ�������
��ҵ֪ʶ����Ϥר����ҵ��ҵ��֪ʶ���û�����������������վ��̨����ϵͳ���漰��ҵ��֪ʶ���û�������֤ȯ����ϵͳ���漰��ҵ��֪ʶ���û�������
32λ windows2003 IIS����������3GB֧��
2008-12-16 13:12:24
32λ windows2003 IIS����������3GB֧��
32λWindows Ĭ���ܹ�Ѱַ4G�ռ䣬����32λ�汾����ϵͳ�����ơ�ͨ�������2GΪ����ϵͳ���ģ���Ȩģʽ������������2GΪӦ�ó����û�ģʽ��������
Windows�ṩ��һ��BOOT.INI�ļ���/3GB�IJ��������·���3GB�ڴ���û�ģʽӦ�ó�����ϵͳ���ĵ��ڴ浽1GB������Ӧ�ó���������û�ģʽ�Ľ��̿�Ѱַ�ռ����Ӷ��������ܡ�
�������裺
1.�༭BOOT.INI�ļ�������Ӧ�ı�
1) ��������е�ϵͳ
2) ѡ���
3) �������ͻָ�ҳ��������ð�ť
4) ����༭�����±����༭BOOT.INI�ļ�
5) �༭[operating systems]���������/3GB�������£�
multi(0)....."windows server 2003, Enterprise Edition" /fastdetect switch��/3GB
��ͼһ��

��ͼһ��
2.����IIS��/3GB֧��
1) �����������������
2) ˫��������̨��Ŀ¼�еġ��������
3) ˫�����������
4) ˫�����ҵĵ��ԡ�
5) ˫��COM+Ӧ�ó���
6) �Ҽ�������IIS Out-Of-Process Pooled Applications����ѡ�����ԡ�
7) ѡ���ҳ
8) ѡ�С�����3GB֧�֡�����ȷ����ť��
��ͼ����
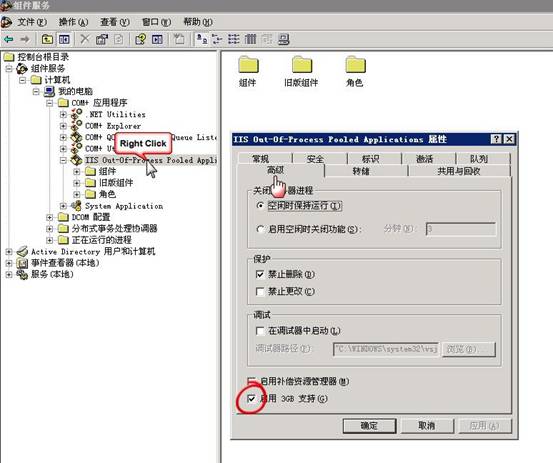
��ͼ����
3.����������ʹ������Ч
SQL Sever 2005 �¼�����������������ͼ�Σ�ͼ�ģ�
2008-12-16 13:02:59
l ʹ�� SQL Server 2005 �¼������� ���� Deadlock Graph �¼�
l Deadlock Graph �¼��� XML �ļ���ʽ���档
1�������ļ����˵��ϣ��������½��������� ���ӵ� SQL Server ʵ����
�������������������Ի���

ע�⣺���ѡ�������������Ӻ�������ʼ��������������������������Ի�����ֱ�ӿ�ʼ���١���Ҫ�رմ����ã��������������˵��ϣ�������ѡ��������������������Ӻ�������ʼ��������ѡ��
2�����������������Ի�������������������У�������ٵ����ơ�
3������ʹ��ģ�����б��У�Ϊ�˸���ѡ��һ������ģ�壻�������ʹ��ģ�壬��ѡ�����հ�����
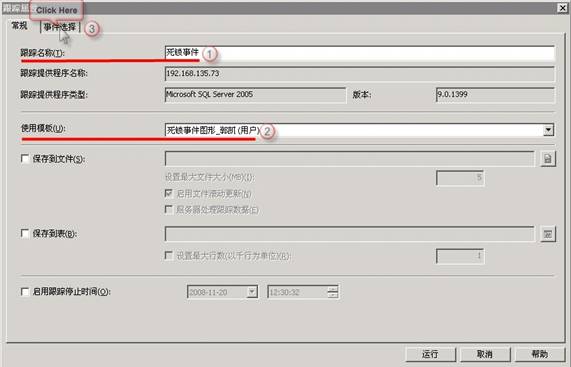
4���������¼�ѡ����ѡ���
�����¼����������У�չ����Locks���¼����Ȼ��ѡ����Deadlock Graph����ѡ�����û����ʾ��Locks���¼������ѡ������ʾ�����¼�������ʾ�����
���¼���ȡ������ѡ������ӵ��������������Ի����С�
ע�⣺���ʹ��ģ�彫������� ���¼���ȡ������ѡ�����Ҫȡ�����ٴ�ѡ��Deadlock Graph �¼����Ż�������¼���ȡ������ѡ�
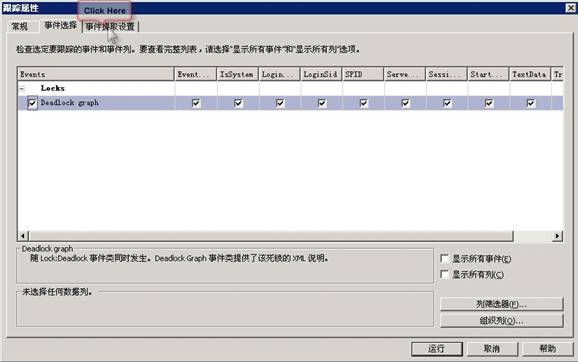
Deadlock Graph �¼��� XML �ļ���ʽ����
5�������¼���ȡ������ѡ��ϣ��������ֱ𱣴����� XML �¼�����
6����������Ϊ���Ի����У�����Ҫ�洢 Deadlock Graph �¼����ļ������ơ�
7�������������ļ��е��������� XML �����Խ����� Deadlock Graph �¼����浽���� XML �ļ��У�������ͬ�ļ��е�ÿ������ XML ������Ϊÿ�� Deadlock Graph �¼������µ� XML �ļ���
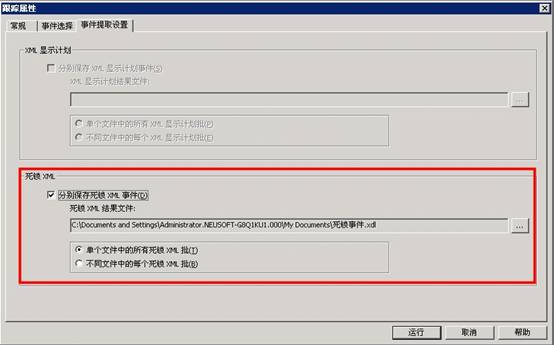
���������ļ����������� SQL Server Management Studio �д鿴���ļ�
ע�⣺�������ϲ������ã��ڲ��Խ�������Ҫ�ֶ��ı���Deadlock Graph �¼��ĸ��ټ�¼��Ϊ���������ڵ�3����û�����ñ����ļ���ѡ�
Linux���û�������С��
2008-12-12 15:50:27
1���ܽᱳ��
��linuxϵͳ�£���������ز���װ��Ӧ�ó����п����ڼ�����������ʱ������command not found������ʾ���ݡ����ÿ�ζ�����װĿ���ļ����ڣ��ҵ���ִ���ļ������в�����̫�����ˡ����漰����������PATH���������⣬��PATH������Ҳ����linux�¶��ƻ���������һ����ɲ��֡�����������RedHat AS4������������Ƶ����⡣
2���������
Linux��һ�����û��IJ���ϵͳ��ÿ���û���¼ϵͳ������һ��ר�õ����л�����ͨ��ÿ���û�Ĭ�ϵĻ���������ͬ�ģ����Ĭ�ϻ���ʵ���Ͼ���һ�黷�������Ķ��塣�û����Զ��Լ������л������ж��ƣ��䷽����������Ӧ��ϵͳ����������
3�����ƻ�������
���������Ǻ�Shell������صģ��û���¼ϵͳ���������һ��Shell������Linux��˵һ����bash����Ҳ���������趨���л���������Shell��ʹ��chsh�����
���ݷ��а汾�������bash������������ϵͳ�������ļ���/etc/bashrc��/etc/profile����Щ�����ļ��������鲻ͬ�ı�����shell�����ͻ���������ǰ��ֻ�����ض���shell�й̶�����bash���������ڲ�ͬshell�й̶��������ԣ�shell�����Ǿֲ��ģ�������������ȫ�ֵġ�����������ͨ��Shell���������õģ����úõĻ��������ֿ��Ա����е�ǰ�û������еij�����ʹ�á�����bash���Shell������˵������ͨ����������������Ӧ�Ļ���������ͨ��export�����û���������
ע��Linux�Ļ�����������һ��ʹ�ô�д��ĸ
4��������������ʵ��
1.ʹ������echo��ʾ��������
����ʹ��echo��ʾ�����ı���HOME
$ echo $HOME
/home/kevin
2.����һ���µĻ�������
$ export MYNAME=��my name is kevin��
$ echo $ MYNAME
my name is Kevin
3.���Ѵ��ڵĻ�������
���ϸ�ʾ��
$ MYNAME=��change name to jack��
$ echo $MYNAME
change name to jack
4.ʹ��env������ʾ���еĻ�������
$ env
HOSTNAME=localhost.localdomain
SHELL=/bin/bash
TERM=xterm
HISTSIZE=1000
SSH_CLIENT=192.168.136.151 1740 22
QTDIR=/usr/lib/qt-3.1
SSH_TTY=/dev/pts/0
����
5.ʹ��set������ʾ���б��ض����Shell����
$ set
BASH=/bin/bash
BASH_ENV=/root/.bashrc
����
6.ʹ��unset�����������������
$ export TEMP_KEVIN=��kevin�� #����һ����������TEMP_KEVIN
$ env | grep TEMP_KEVIN #�鿴��������TEMP_KEVIN�Ƿ���Ч�����ڼ���Ч��
TEMP_KEVIN=kevin #֤����������TEMP_KEVIN�Ѿ�����
$ unset TEMP_KEVIN #ɾ����������TEMP_KEVIN
$ env | grep TEMP_KEVIN #�鿴��������TEMP_KEVIN�Ƿ�ɾ����û�������ʾ��֤��TEMP_KEVIN������ˡ�
7.ʹ��readonly��������ֻ������
ע�����ʹ����readonly����Ļ��������Ͳ����Ա��Ļ�����ˡ�
$ export TEMP_KEVIN ="kevin" #����һ����������TEMP_KEVIN
$ readonly TEMP_KEVIN #����������TEMP_KEVIN��Ϊֻ��
$ env | grep TEMP_KEVIN #�鿴��������TEMP_KEVIN�Ƿ���Ч
TEMP_KEVIN=kevin #֤����������TEMP_KEVIN�Ѿ�����
$ unset TEMP_KEVIN #����ʾ�˱���ֻ�����ܱ�ɾ��
-bash: unset: TEMP_KEVIN: cannot unset: readonly variable
$ TEMP_KEVIN ="tom" #�ı���ֵΪtom����ʾ�˱���ֻ�����ܱ���
-bash: TEMP_KEVIN: readonly variable
8.ͨ���Ļ������������ļ����Ļ���������
��Ҫע����ǣ�һ������£�������ͨ�û��������������ļ��������ĸ��û��Ļ��������ļ�����Ϊ�������ܻ����DZ�ڵ�Σ�ա�
$ cd ~ #���û���Ŀ¼��
$ ls -a #�鿴�����ļ����������ص��ļ�
$ vi .bash_profile #���û����������ļ�
���磺
�༭���PATH���������ʽΪ��
PATH=$PATH:<PATH 1>:<PATH 2>:<PATH 3>:------:<PATH N>
������Լ�����ָ����·�����м���ð�Ÿ�����
�����������ĺ����û��´ε�½ʱ��Ч��
�����������Ч�����ִ���������䣺$source .bash_profile
��Ҫע����ǣ���ò�Ҫ�ѵ�ǰ·����./���ŵ�PATH��������ܻ��ܵ����벻���Ĺ�����
��ɺ���ͨ��$ echo $PATH�鿴��ǰ������·�����������ƺͿ��Ա���Ƶ��������λ��shell������·��֮��ij����ˡ�
5��ѧϰ�ܽ�
1.Linux�ı�������
���������������������֣�Linux�����ɷ�Ϊ���ࣺ
1. ���õģ���Ҫ�������ļ�������������Ч��
2. ��ʱ�ģ�ʹ��export�������������ɣ������ڹر�shellʱʧЧ��
2.���ñ��������ַ���
1. ��/etc/profile�ļ������ӱ������������û���Ч�����õģ���
��VI���ļ�/etc/profile�ļ������ӱ������ñ��������Linux�������û���Ч�������ǡ����õġ���
���磺�༭/etc/profile�ļ�������CLASSPATH����
# vi /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
ע�����ļ���Ҫ��������Ч��Ҫ����# source /etc/profile��Ȼֻ�����´��ؽ����û�ʱ��Ч��
2. ���û�Ŀ¼�µ�.bash_profile�ļ������ӱ������Ե�һ�û���Ч�����õģ���
��VI���û�Ŀ¼�µ�.bash_profile�ļ������ӱ������ı�������Ե�ǰ�û���Ч�������ǡ����õġ���
���磺�༭guok�û�Ŀ¼��/home/guok���µ�.bash_profile
$ vi /home/guok/.bash.profile
�����������ݣ�
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
ע�����ļ���Ҫ��������Ч��Ҫ����$ source /home/guok/.bash_profile��Ȼֻ�����´��ؽ����û�ʱ��Ч��
3. ֱ������export�������������ֻ�Ե�ǰshell��BASH����Ч����ʱ�ģ���
��shell����������ֱ��ʹ��[export ������=����ֵ] ����������ñ���ֻ�ڵ�ǰ��shell��BASH��������shell��BASH��������Ч�ģ�shell�ر��ˣ�����Ҳ��ʧЧ�ˣ��ٴ���shellʱ��û�������������Ҫʹ�õĻ�����Ҫ���¶��塣
Linux������װ����С�ᣨ����rpm��⣩
2008-12-12 12:44:28
��ʹ��Linuxϵͳ�Ĺ����У��������İ�װ�DZ��ⲻ�˵ģ���Linux�£�������װ���������ܶ࣬��װ����Ҳ��ʽ����������������Ȼ�Ȳ���windows :-)���������dz����������������֣�
1������������Դ�����ѹ��������ѹ����Ҫ�ֶ����롣����������װ��ͨ������gzipѹ������tar������Ϊ.tar.gz����
./configure �����ã�
make �����룩
make install ����װ��
make clean ��ж�أ�
ע�����͵�Դ���������������װ������������������webmin
Ҫִ����Ŀ¼��./setup.sh���뽻��ʽ���ð�װ
���uninstall����
��������������Ҫ��װ�İ��µ�README�ļ�2�������Ŀ�ִ�г�����ֻҪ��װ���Ϳ����ˣ�ϰ��windows��װ�����ѵ������������������װ������RPM����RedhatLinuxPacketManager������Redhat�İ���������������.rpm��
��Ȼ����������rpm��ʽ�����Դ���룻��gzipѹ�����Ŀ�ִ�г������
����ֻҪ���������µİ�װ˼·����������ʽ�İ�װ��Ҳ���ڻ����ˡ����棬���ǽ��в�ͬ��������װ����ϸ����
��һ���֣���װ.tar.gz������
1.���ȣ�ʹ��tar -xzvf�����������磺
# tar -xzvf apache_1_3_6_tar.gz
*******************************************
tar����������ͣ�
x �ӵ����ļ����ͷ��ļ���
z ��gzip��ѹ��/��ѹ���ļ������ϸ�ѡ�����Խ������ļ�����ѹ��������ԭʱҲһ��Ҫʹ�ø�ѡ����н�ѹ����
v ��ϸ����tar�������ļ���Ϣ������ѡ�tar�������ļ���Ϣ��
f ʹ�õ����ļ����豸�����ѡ��ͨ���DZ�ѡ�ġ�
�����Ҫ��ϸ�˽�tar��ʹ�òμ������ĵ�
*******************************************�����ͻ��ڵ�ǰĿ¼�д�����һ����Ŀ¼(Ŀ¼����.tat.gz�����ļ������ƣ���������Ž�ѹ�˵����ݡ��籾���о���apache_1.3.6
2.�������Ŀ¼������ls����鿴һ�����������ļ����������£�
# cd apache_1.3.6
# ls��۲�һ�����Ŀ¼�а�����������һ���ļ���configure��Makefile����Imake��
1�������configure�ļ�,��ִ�У�
# ./configure
# make
# make install2�������Makefile�ļ�,��ִ�У�
# make
# make install3�������Imake�ļ�,��ִ�У�
# xmkmf
# make
# make install4�����û��itstall����װ���̣��ļ�����rzsz����������ִ��
# make posix
��
# make linux
3.���û�г���ʲô������ʾ�Ļ���tar���Ͱ�װ����ˡ�������װ��ʲôλ�ã�ͨ�����ڰ�װʱ���֡����û�п��Բ���һ��README��
tar����װ�����еij������⣺1��û�а�װC��C++������
ȷ�﷽����ִ������gcc��C++��Ϊg++������ʾ�Ҳ���������
�����������Linux��װ����mount������Ȼ�����RPMSĿ¼��ִ�����
# rpm -ivh gcc*��C��C++��������RPM���������ὲ����2��û�а�װmake����
ȷ�﷽����ִ������make����ʾ�Ҳ���������
�����������Linux��װ����mount������Ȼ�����RPMSĿ¼��ִ�����
# rpm -ivh make*3��û�а�װautoconf���ߣ�
ȷ�﷽����ִ������make����ʾ�Ҳ���������
�����������Linux��װ����mount������Ȼ�����RPMSĿ¼��ִ�����
# rpm -ivh autoconf*4��ȱ��ijЩ���ӿ⣻
ȷ�﷽������makeʱ����ʾ��ҪijЩ�ļ���
�����������װ��������ļ��İ����ڶ����֣���װ.rpm������
RPM��RedHat��˾��RedhatLinux�Ƴ���һ����������������ͨ�����ܹ�������������ʵ�������İ�װ����windows�°�װ����һ������
1.��װ������ִ��rpm -ivh rpm�������磺
# rpm -ivh apache-1.3.6.i386.rpm
*******************************************
rpm �������ͣ�
i ��װ������
v ��ʾ������Ϣ
h ��װʱ�����ϣ���(``#'')
�����Ҫ��ϸ�˽�rpm��ʹ�òμ���¼
*******************************************2.����������
# rpm -Uvh rpm����
��
3.���������
# rpm -e rpm����4.��ѯ����������ϸ��Ϣ��
# rpm -qpi rpm����5.��ѯij���ļ��������Ǹ�rpm���ģ�
# rpm -qf rpm����6.�������������ϵͳ����д����Щ�ļ���
# rpm -qpl rpm����
*****************************************��¼��
��rpm��⡷
һ����װ������
�����ʽ��
rpm -i ( or --install) options file1.rpm ... fileN.rpm
������
file1.rpm ... fileN.rpm ��Ҫ��װ��RPM�����ļ���
��ϸѡ�
-h (or --hash) ��װʱ���hash�Ǻ� (``#'')
--test ֻ��װ���в��ԣ�����ʵ�ʰ�װ��
--percent �ٷֱȵ���ʽ�����װ�Ľ��ȡ�
--excludedocs ����װ�������е��ĵ��ļ�
--includedocs ��װ�ĵ�
--replacepkgs ǿ�����°�װ�Ѿ���װ��������
--replacefiles �滻�����������������ļ�--force �������������ļ��ij�ͻ
--noscr��pts ������Ԥ��װ�ͺ�װ�ű�
--prefix ����������װ���� ָ����·����
--ignorearch ��У���������Ľṹ
--ignoreos ��������������еIJ���ϵͳ
--nodeps ����������Թ�ϵ
--ftpproxy �� ��Ϊ FTP����
--ftpport ָ��FTP�Ķ˿ں�Ϊ
ͨ��ѡ��
-v ��ʾ������Ϣ
-vv ��ʾ������Ϣ
--root ��RPM��ָ����·����Ϊ"��Ŀ¼"������Ԥ��װ����ͺ�װ���ᰲװ�����Ŀ¼��
--rcfile ����rpmrc�ļ�Ϊ
--dbpath ����RPM ���Ͽ�����ڵ�·��Ϊ
���ӣ�
1.��װ����
rpm -ivh *.rpm
��ϵͳ��ʾ�������Ѱ�װ����������ԭ����������װ����������ȷʵ��ִ�а�װ��������� -ivh���һ������-replacepkgs����
2.���߰�װ
rpm -i ftp��//ftp.* *.rpm
ftp��//ftp.*�ǵ�ַ *.rpm������
������������ɾ��ж��
�����ʽ��
rpm -e ( or --erase) options pkg1 ... pkgN
����
pkg1 ... pkgN ��Ҫɾ����������
��ϸѡ��
--test ִֻ��ɾ���IJ���
--noscr��pts ������Ԥ��װ�ͺ�װ�ű�����
--nodeps �����������
ͨ��ѡ��
-vv ��ʾ������Ϣ
--root ��RPM��ָ����·����Ϊ"��Ŀ¼"������Ԥ��װ����ͺ�װ���ᰲװ�����Ŀ¼��
--rcfile ����rpmrc�ļ�Ϊ
--dbpath ����RPM ���Ͽ�����ڵ�·��Ϊ
���ӣ�
1.�����
rpm-e *.rpm
������������
�����ʽ
rpm -U ( or --upgrade) options file1.rpm ... fileN.rpm
����
file1.rpm ... fileN.rpm ������������
��ϸѡ��
-h (or --hash) ��װʱ���hash�Ǻ� (``#'')
--oldpackage ����"����"��һ���ϰ汾
--test ֻ������������
--excludedocs ����װ�������е��ĵ��ļ�
--includedocs ��װ�ĵ�
--replacepkgs ǿ�����°�װ�Ѿ���װ��������
--replacefiles �滻�����������������ļ�
--force �������������ļ��ij�ͻ
--percent �ٷֱȵ���ʽ�����װ�Ľ��ȡ�
--noscr��pts ������Ԥ��װ�ͺ�װ�ű�
--prefix ����������װ���� ָ����·����
--ignorearch ��У���������Ľṹ
--ignoreos ��������������еIJ���ϵͳ
--nodeps ����������Թ�ϵ
--ftpproxy �� ��Ϊ FTP����
--ftpport ָ��FTP�Ķ˿ں�Ϊ
ͨ��ѡ��
-v ��ʾ������Ϣ
-vv ��ʾ������Ϣ
--root ��RPM��ָ����·����Ϊ"��Ŀ¼"������Ԥ��װ����ͺ�װ���ᰲװ�����Ŀ¼��
--rcfile ����rpmrc�ļ�Ϊ
--dbpath ����RPM ���Ͽ�����ڵ�·��Ϊ
���ӣ�
1.��������
rpm -uvh *.rpm
ע�⣺��ʱ���ļ���������Ҫ������������������
�ġ���ѯ
�����ʽ��
rpm -q ( or --query) options
������
pkg1 ... pkgN ����ѯ�Ѱ�װ��������
��ϸѡ��
-p (or ``-'') ��ѯ���������ļ�
-f ��ѯ�����ĸ�������
-a ��ѯ���а�װ��������
--whatprovides ��ѯ�ṩ�� ���ܵ�������
-g ��ѯ���� ���������
--whatrequires ��ѯ������Ҫ ���ܵ�������
��Ϣѡ��
��ʾ��������ȫ����ʶ
-i ��ʾ�������ĸ�Ҫ��Ϣ
-l ��ʾ�������е��ļ��б�
-c ��ʾ�����ļ��б�
-d ��ʾ�ĵ��ļ��б�
-s ��ʾ���������ļ��б�����ʾÿ���ļ���״̬
--scr��pts ��ʾ��װ��ж�ء�У��ű�
--queryformat (or --qf) ���û�ָ���ķ�ʽ��ʾ��ѯ��Ϣ
--dump ��ʾÿ���ļ���������У����Ϣ
--provides ��ʾ�������ṩ�Ĺ���
--requires (or -R) ��ʾ����������Ĺ���
ͨ��ѡ��
-v ��ʾ������Ϣ
-vv ��ʾ������Ϣ
--root ��RPM��ָ����·����Ϊ"��Ŀ¼"������Ԥ��װ����ͺ�װ���ᰲװ�����Ŀ¼��
--rcfile ����rpmrc�ļ�Ϊ
--dbpath ����RPM ���Ͽ�����ڵ�·��Ϊ
1.��ѯһ�����Ƿ�װ
rpm -q *.rpm
2. �鿴�������������
rpm -qpi *.rpm
3.�鿴�������ѻ���ϵͳ�ﰲװ��Щ����
rpm -qpl *.rpm
4.�����ж�ij���ļ������ĸ�������
rpm -qf *.rpm
5.�г����б���װ��rpm ������
rpm �Cqa
�塢У���Ѱ�װ��������
�����ʽ��
rpm -V ( or --verify, or -y) options
����
pkg1 ... pkgN ��ҪУ�����������
������ѡ��
-p Verify against package file
-f ��������������
-a Verify �����������
-g ������������ ��������
��ϸѡ��
--noscr��pts ������У��ű�
--nodeps ����������
--nofiles ��У���ļ�����
ͨ��ѡ��
-v ��ʾ������Ϣ
-vv ��ʾ������Ϣ
--root ��RPM��ָ����·����Ϊ"��Ŀ¼"������Ԥ��װ����ͺ�װ���ᰲװ�����Ŀ¼��
--rcfile ����rpmrc�ļ�Ϊ
--dbpath ����RPM ���Ͽ�����ڵ�·��Ϊ
���ӣ�
1.�г��������ļ�
rpm -Va *.rpm
����У���������е��ļ�
���
rpm -K ( or --checksig) options file1.rpm ... fileN.rpm
������
file1.rpm ... fileN.rpm ���������ļ���
Checksig--��ϸѡ��
--nopgp ��У��PGPǩ��
ͨ��ѡ��
-v ��ʾ������Ϣ
-vv ��ʾ������Ϣ
--rcfile ����rpmrc�ļ�Ϊ
�ߡ�����RPMѡ��
--rebuilddb �ؽ�RPM���Ͽ�
--initdb ����һ���µ�RPM���Ͽ�
--quiet �����ܵļ������
--help ��ʾ�����ļ�
--version ��ʾRPM�ĵ�ǰ�汾
����������ϣ�
��ivh����װ��ʾ��װ����--install--verbose--hash
��Uvh������������--Update��
��qpl���г�RPM�������ڵ��ļ���Ϣ[Query Package list]��
��qpi���г�RPM��������������Ϣ[Query Package install package(s)]��
��qf������ָ���ļ������ĸ�RPM������[Query File]��
��Va��У�����е�RPM�����������Ҷ�ʧ���ļ�[View Lost]��
��e��ɾ����
rpm -q samba //��ѯ�����Ƿ�װ
rpm -ivh /media/cdrom/RedHat/RPMS/samba-3.0.10-1.4E.i386.rpm ����·����װ����ʾ����
rpm -ivh --relocate /=/opt/gaim gaim-1.3.0-1.fc4.i386.rpm ��ָ����װĿ¼
rpm -ivh --test gaim-1.3.0-1.fc4.i386.rpm������ ���������������ϵ�������������İ�װ��
rpm -Uvh --oldpackage gaim-1.3.0-1.fc4.i386.rpm ���°汾����Ϊ�ɰ汾
rpm -qa | grep httpd�������� �� ��[����ָ��rpm���Ƿ�װ]--all����*httpd*
rpm -ql httpd�������������� ���� ��[����rpm��]--list�����ļ���װĿ¼
rpm -qpi Linux-1.4-6.i368.rpm�� ��[�鿴rpm��]--query--package--install package��Ϣ
rpm -qpf Linux-1.4-6.i368.rpm�� ��[�鿴rpm��]--file
rpm -qpR file.rpm�������� �� ������[�鿴��]������ϵ
rpm2cpio file.rpm |cpio -div ��[����ļ�]
rpm -ivh file.rpm �� ��[��װ�µ�rpm]--install--verbose--hash
rpm -ivh http://mirrors.kernel.org/fedora/core/4/i386/os/Fedora/RPMS/gaim-1.3.0-1.fc4.i386.rpm
rpm -Uvh file.rpm ��[����һ��rpm]--upgrade
rpm -e file.rpm ��[ɾ��һ��rpm��]--erase
rpm������⼯��
1.��β���װ���ǻ�ȡrpm���е��ļ���
ʹ�ù���rpm2cpio��cpio
rpm2cpio xxx.rpm | cpio -vi
rpm2cpio xxx.rpm | cpio -idmv
rpm2cpio xxx.rpm | cpio --extract --make-directories
����i��extract��ͬ����ʾ��ȡ�ļ���v��ʾָʾִ�н���
d��make-directory��ͬ����ʾ���ݰ����ļ�ԭ����·������Ŀ¼
m��ʾ�����ļ��ĸ���ʱ�䡣
2.��β鿴��rpm����ص��ļ���������Ϣ��
�������е����Ӷ�����ʹ��������mysql-3.23.54a-11
1.�ҵ�ϵͳ�а�װ����Щrpm������
rpm -qa ���г����а�װ���İ�
���Ҫ�������а�װ���İ���ij���ַ���sql��������
rpm -qa |grep sql
3.��λ��ij�����������ļ�ȫ����
rpm -q mysql ���Ի��ϵͳ�а�װ��mysql������ȫ�������п��Ի��
��ǰ�������İ汾����Ϣ����������п��Եõ���Ϣmysql-3.23.54a-11
4.һ��rpm���е��ļ���װ������ȥ�ˣ�
rpm -ql ����
ע��������Dz�����.rpm����������������
Ҳ����˵ֻ����mysql����mysql-3.23.54a-11������mysql-3.23.54a-11.rpm��
���ֻ����֪����ִ�г���ŵ�����ȥ�ˣ�Ҳ������which������
which mysql
5.һ��rpm���а�����Щ�ļ���
һ��û�а�װ������������ʹ��rpm -qlp ****.rpm
һ���Ѿ���װ������������������ʹ��rpm -ql ****.rpm
6.��λ�ȡ����һ���������İ汾����;�������Ϣ��
һ��û�а�װ������������ʹ��rpm -qip ****.rpm
һ���Ѿ���װ������������������ʹ��rpm -qi ****.rpm
7.ij���������ĸ���������װ�ģ������ĸ������������������
rpm -qf `which ������` ������������ȫ��
rpm -qif `which ������` �������������й���Ϣ
rpm -qlf `which ������` �������������ļ��б�
ע�⣬���ﲻ�����ţ�����`�����Ǽ������Ͻǵ��Ǹ�����
Ҳ����ʹ��rpm -qilf��ͬʱ�����������Ϣ���ļ��б�
8.ij���ļ����ĸ���������װ�ģ������ĸ���������������ļ���
ע�⣬ǰһ�������еķ�����ֻ�������ִ�еij�������ķ�������������
���ڿ�ִ�г���Ҳ����������ͨ���κ��ļ���ǰ����֪������ļ�����
���Ȼ��������������·����������whereis����which��Ȼ��ʹ��rpm -qf���磺
# whereis ftptop
ftptop: /usr/bin/ftptop /usr/share/man/man1/ftptop.1.gz
# rpm -qf /usr/bin/ftptop
proftpd-1.2.8-1
# rpm -qf /usr/share/doc/proftpd-1.2.8/rfc/rfc0959.txt
proftpd-1.2.8-1
�ܽ
�����������ص���Ϣ��rpm -q��q��ʾ��ѯquery��������Ը�����ѡ�����
i ��ʾinfo���������������Ϣ��
l ��ʾlist������ļ��б���
a ��ʾall�������а���ִ�в�ѯ��
f ��ʾfile�������ļ�������صIJ�ѯ��
p ��ʾpackage���������������в�ѯ
��Ҫ�IJ�ѯ��������ʹ��grep���������ߴ�"` `"�е������в���
9.ʲô��rpm��
rpm ��RedHat Package Management����RedHat�ķ���֮һ
10.Ϊʲô��Ҫrpm��
��һ������ϵͳ�£���Ҫ��װʵ�ָ��ֹ��ܵ�����������Щ������һ�㶼�и��Ե�
������ͬʱҲ�д��۸��ӵ�������ϵ��ͬʱ����Ҫ����������İ汾���Լ���װ��
���ã�ж�ص��Զ������⡣Ϊ�˽����Щ���⣬RedHat����Լ���ϵͳ�����һ��
�Ϻõİ취��������ǧ�ϰٵ������������RPM����ϵͳ����ϵͳ�а�װ��rpm����ϵͳ
�Ժ�ֻҪ�Ƿ���rpm�ļ����Ĵ���ij����Է���İ�װ��������ж��
11.�Dz������е�linux��ʹ��rpm ��
�κ�ϵͳ����Ҫ������ϵͳ����˺ܶ�linux��ʹ��rpmϵͳ����rpmϵͳ��ΪRHר��
����TL,Mandrake��ϵͳҲ��ʹ��rpm������rpm��Դ��������ڱ��ϵͳ�Ͻ��б��룬
�����п����ڱ��ϵͳ��Ҳʹ��rpm
����rpm������һЩϵͳҲ���Լ���������������������debian��deb����
slakwareҲ�����Լ��İ�����ϵͳ
12.rpm�����ļ���Ϊʲô��ô����
rpm�����ļ����а���������������İ汾��Ϣ������ϵͳ��Ϣ��Ӳ��Ҫ��ȵȡ�
����mypackage-1.1-2TL.i386.rpm������mypackage����ϵͳ�еǼǵ�������������
1.1�������İ汾�ţ�2�Ƿ��кţ�TL��ʾ����TL����ϵͳ����������RH�ȡ�i386��ʾ
����intel x86ƽ̨����������sparc�ȡ�
13.�������ļ����е�i386,i686��ʲô��˼��
rpm���������ļ����У������������������ƣ��汾��Ϣ�������������õ�Ӳ���ܹ�
����Ϣ��
i386ָ���������������intel 80386���ϵ�x86�ܹ��ļ����(AI32)
i686ָ���������������intel 80686����(����pro����)��x86�ܹ��ļ����(IA32)
noarchָ�����������Ӳ���ܹ��أ�����ͨ�á�
i686�������ij���ͨ�����CPU�������Ż������ԣ������ݱȽ����ԣ�i386�İ���
x86�����϶������á���ǰһ�㲻���ݡ��������ڵļ����������pro���µ�CPU�Ѿ�����
�ã�ͨ�����õĻ���������ʹ��i686������
14.��ͬ����ϵͳ���е�rpm���ɷ���ã�
�����Ѿ�����ɶ����Ƶ�rpm�������ڲ���ϵͳ������ͬ��һ�㲻�ܻ��á�
������src.rpm���е���������������Ҫ��װʱ���б��ر��룬����ͨ�������ڲ�ͬ
ϵͳ�°�װ��
15.ʹ��rpmʱ������һЩ��������
Q ����rpm -e **.rpm��ɾ��rpm��
A ������Ҫ����rpm��
rpm -e �������������汾�ŵ���Ϣ�����Dz������к�.rpm
Q ��MS��ϵͳ����û�ж�RPM�ļ��Ĺ��ߣ�
A wincmd with rpm plugins.....
Q �Ƿ����ͨ��ftp��װ��װ����rpm����
A ���ԡ�rpm -ivh ftp://xxxxxxxx/PATH2SomeRPM
Q rpm��װʱ���еİ��汾������ô�죿
A ��ʱ���ڰ�װ��������̫�ϣ���ϵͳ����ص��������汾�Ƚ��£����Կ�����Ҫ��װ�İ�������һЩ�ļ����Ҳ�������ʱ�����ֽ���취��
��һ����ϵͳ�ļ����ҵ�����Ҫ���ļ�������ͬ�����Ƶ��ļ�����һ���������ӵ� ��Ҫ��Ŀ¼�¡�
�ڶ������ذ�װ�°汾����������Linux ���ã���Xmanager����Linuxͼ�ν���
2008-12-11 16:43:30
��Ҫ��Զ���ն�ʹ����ͼ�ν����������Ϳ���Linux������������windows����ʹ��MSTSCһ����linuxͨ��XDMCP���ṩ����֧�֣�����ֻҪ��һ���ն˷��������磺xmanager�Ϳ���ʵ�֣�����װ��Xmanager���Dz���ֱ��Զ������Linux��������Xwindow����ģ���Ҫ��Linux������Ӧ�����ã���ϸ�������¡�
ǰ�
��װlinuxʱһ��Ҫѡ��xwindow�������������ǰ�ᣬ����װ�����Ǿ���û��ͼ�ν���ġ�**********************************************************
����������������˵����
XDMCP(X Display Manager Control Protocol),X��ʾ���Э�飻
xdm(manages a collection of X displays),��ʾ��������·���ڣ�/etc/X11/xdm�¼����ļ���
����Xaccess ���ʿ����ļ���
����Xservices ��������ʾ��Զ����ʾ�����ļ���
����xdm-config xdm����Ҫ�����ļ���
**********************************************************����Linux��
ʹ��root�û���¼ϵͳ������������
Step1��
�༭/etc/X11/xdm/Xaccess����������У�
#* # any host can get a login window �ĵ�һ��"#"��ȥ��
����
* # any host can get a login windowStep2:
��/etc/X11/gdm/gdm.conf���ҵ��������Ϣ��
[xdmcp]
Enable=0 ��Enable=false
����
[xdmcp]
Enable=1 ��Enable=true
��ȷ��������Ϣ���ڣ�
Port=177Step3:
��/etc/inittab����
id:3:initdefault:
����
id:5:initdefault:Step4:
# chmod 444 /etc/X11/xdm/Xservers
# chmod 755 /etc/X11/xdm/Xsetup_0
ȷ��/etc/X11/xdm/Xservers������Ϊ444��/etc/X11/xdm/Xsetup_0������Ϊ755Step5:
#vi /etc/X11/xdm/xdm-config
�����һ�У� DisplayManager.requestPort: 0 ǰ��ӣ���ע�͵����С�Step6:
#vi /etc/X11/xdm/Xservers
�����һ�У�:0 local /usr/X11R6/bin/X ǰ���#��ע�͵���һ�С�Step7:
# xdm
����xdm�ű�������ʹ��xmanager�ȹ��߾Ϳ�������Linux�ˡ�Step8:
�����Ҫÿ�������Զ�����xdm����ô����/etc/rc.d/rc.local�ļ�β������./etc/X11R6/bin/xdm
ע�����ǵ�xdm�ű�·�����ܻ���ҵIJ�һ������which xdm���Ҽ��ɣ��������ʹ��mstsc /console���ӿ���̨������
2008-12-08 11:25:36
�������ʹ��mstsc /console���ӿ���̨������
���⣺windows xp ������sp3����ʹ��MSTSC /console���ӵ�����̨
windows xp������sp3�������mstsc /admin����ʵ��Xp2��MSTSC /console�Ĺ��ܡ�sp3��mstsc����ϸ�������£�
MSTSC [<connection file>] [/v:<server[:port]>] [/admin] [/f[ullscreen]]
[/w:<width> /h:<height>] [/public] | [/span] [/edit "connection file"] [/migrate]
"connection file" -- ָ�����ӵ� .rdp �ļ������ơ�
/v:<server[:port]> -- ָ��Ҫ���ӵ�Զ�̼������
/admin -- �������ӵ��Ự�Թ�����������
/f -- ��ȫ��ģʽ����Զ�����档
/w:<width> -- ָ��Զ�����洰�ڵĿ��ȡ�
/h:<height> -- ָ��Զ�����洰�ڵĸ߶ȡ�
/public -- �ڹ���ģʽ������Զ�����档
/span -- ʹԶ������Ŀ��Ⱥ߶��뱾������������ƥ�䣬���б�Ҫ����չ�����
��ʾ������Ҫ��չ�������ʾ����������ʾ�������������ͬ�ĸ߶Ȳ���
ֱ���С�
/edit -- ��ָ���� .rdp �����ļ����б༭��
/migrate -- ��ʹ�ÿͻ������ӹ����������ľ������ļ�Ǩ�Ƶ��µ� .rdp �����ļ���
���ӣ�winXP_Sp2��win2003_sp2��Dos��MSTSC���÷�MSTSC [<Connection File>] [/v:<server[:port]>] [/console] [/f[ullscreen]]
[/w:<width> /h:<height>] | /Edit"ConnectionFile" | /Migrate | /?<Connection File> -- ָ�����ӵ� .rdp �ļ������ơ�
/v:<server[:port]> -- ָ��Ҫ���ӵ����ն˷�������
/console -- ���ӵ��������Ŀ���̨�Ự��
/f -- ��ȫ��ģʽ�����ͻ��ˡ�
/w:<width> -- ָ��Զ��������Ļ�Ŀ��ȡ�
/h:<height> -- ָ��Զ��������Ļ�ĸ߶ȡ�
/edit -- ��ָ���� .rdp �ļ����༭��
/migrate -- ���ͻ������ӹ����������ľɰ�
�����ļ�Ǩ�Ƶ��µ� .rdp �����ļ���/? -- ��ʾ���÷���Ϣ��
DOSԶ�������������mstsc /v: 192.168.136.250 /console
LoadRunner�����������⼰����������ۻ���
2008-12-03 12:51:05
����1��LoadRunner¼�ƽű�ʱ�������Զ����������
�����ʩ������IE->Internetѡ��->�������������õ������������չ����Ҫ����������->������������VuGen¼�ƽű�������2����װLoadRunner�����������ɹ���ͣ����99%��װ����
�����ʩ��1��LoadRunner���������ķ���·���в��������ģ�
2��LoadRunner�����������õ�Ŀ¼����̫�����ᰲװ���ɹ���(���齫���������������̵ĸ�Ŀ¼�½��а�װ������ D��\)Linux����ļ�������� Whereis��find��locate+updatedb
2008-12-01 22:49:36
�ļ��������Whereis��find��locate+updatedb
������
�����ƣ�whereis
���ܣ���λ�ļ����ڵ�Ŀ¼
ʹ��whereis������Զ�λ���������λ�ã�
[root@yanghsia root]#whereis ls ��# ��λls�����λ�ã�
ls��/bin/ls ��# lsλ��/usr/blnĿ¼�£�
whereis�����ͨ�����Ҵ����ϵ������ļ���ʵ�ֶ�λ�ģ���������ָ��һ����ִ���ļ�������whereis���Ҳ�����������Ϊwhereis�Ǹ��ݻ�������PATH�������ļ��ģ���PATHͨ�����óɴ���������Щ·������ /bin��/usr/bin�ȣ����whereis����;�����ڶ�λshell�������ڵ�λ�á�
�����ƣ�find
���ܣ������ļ�
find�������������ָ����Ŀ¼��ʼ�����ļ��������ٶ���Ȳ���whereis�����û���κ����ƣ����ҹ���Ҫ��whereis����ǿ��
[root@yanghsia root]#find -name student.txt
/tmp/student.txt ��# ���ҽ���������ƣ�locate
���ܣ������ļ���Ŀ¼
��find�����⣬locateҲ����ϵͳ�в����ļ��ij��÷�����
[root@yanghsia root]#locate student.txt ��# ����student.txt�ļ���
��locate������ҵ��ļ���findһ��û���κ����ƣ���ִ���ٶ�ȴ��findҪ�첻�٣�����Ҫԭ�����ڣ�locate���ǴӴ�����ʵʱ�����ļ������ǵ���updatedb�����������Ϣ���в�����Ӧ���ļ���Ŀ¼������һ���ٶȵ�Ȼ���ˡ�
[root@yanghsia root]#updatedb
ע�⣺���locate�Ҳ���ij���ļ���������ȷ�Ÿ��ļ��϶����ڣ���һ����updatedb���ɵ���Ϣ���Ѿ���ʱ�ˡ���ʱ��Ҫ���ľ�����root���ݵ�¼��Ȼ��ִ��updatedb������½�������ϵͳ�����ļ���Ŀ¼�����Ͽ⣬��Ȼ������̿��ܻ��˷�һ��ʱ�䣬���Ժ��ٲ����ļ�ʱ�ͷ�����ˡ��������
���ƣ�Fing
ǰ�ԣ�����find����
����find����ǿ��Ĺ��ܣ���������ѡ��Ҳ�ܶ࣬���д�ѡ�ֵ�����ǻ�ʱ�����˽�һ�¡���ʹϵͳ�к��������ļ�ϵͳ( NFS)��find�����ڸ��ļ�ϵͳ��ͬ����Ч��ֻ�������Ӧ��Ȩ�ޡ�
������һ���dz�������Դ��find����ʱ���ܶ��˶������ڰ������ں�ִ̨�У���Ϊ����һ������ļ�ϵͳ���ܻỨ�Ѻܳ���ʱ��(������ָ30G�ֽ����ϵ��ļ�ϵͳ)��
һ��find �����ʽ
1��find�����һ����ʽΪ��
find pathname -options [-print -exec -ok ...]
2��find����IJ�����
pathname: find���������ҵ�Ŀ¼·����������.����ʾ��ǰĿ¼����/����ʾϵͳ��Ŀ¼��
-print�� find���ƥ����ļ�������������
-exec�� find�����ƥ����ļ�ִ�иò�����������shell�����Ӧ�������ʽΪ'command' { } \;��ע��{ }��\��֮��Ŀո�
-ok�� ��-exec��������ͬ��ֻ������һ�ָ�Ϊ��ȫ��ģʽ��ִ�иò�����������shell�����ִ��ÿһ������֮ǰ�����������ʾ�����û���ȷ���Ƿ�ִ�С�
3��find����ѡ��
-name
�����ļ��������ļ���
-perm
�����ļ�Ȩ���������ļ���
-prune
ʹ����һѡ�����ʹfind����ڵ�ǰָ����Ŀ¼�в��ң����ͬʱʹ��-depthѡ���ô-prune����find������ԡ�
-user
�����ļ������������ļ���
-group
�����ļ����������������ļ���
-mtime -n +n
�����ļ��ĸ���ʱ���������ļ��� - n��ʾ�ļ�����ʱ�������n�����ڣ�+ n��ʾ�ļ�����ʱ�������n����ǰ��find�����-atime��-ctime ѡ������Ƕ���-m timeѡ�
-nogroup
��������Ч��������ļ��������ļ�����������/etc/groups�в����ڡ�
-nouser
��������Ч�������ļ��������ļ���������/etc/passwd�в����ڡ�
-newer file1 ! file2
���Ҹ���ʱ����ļ�file1�µ����ļ�file2�ɵ��ļ���
-type
����ijһ���͵��ļ������磺
b - ���豸�ļ���
d - Ŀ¼��
c - �ַ��豸�ļ���
p - �ܵ��ļ���
l - ���������ļ���
f - ��ͨ�ļ���
-size n��[c] �����ļ�����Ϊn����ļ�������cʱ��ʾ�ļ��������ֽڼơ�
-depth���ڲ����ļ�ʱ�����Ȳ��ҵ�ǰĿ¼�е��ļ���Ȼ����������Ŀ¼�в��ҡ�
-fstype������λ��ijһ�����ļ�ϵͳ�е��ļ�����Щ�ļ�ϵͳ����ͨ�������������ļ�/etc/fstab���ҵ����������ļ��а����˱�ϵͳ���й��ļ�ϵͳ����Ϣ��
-mount���ڲ����ļ�ʱ����Խ�ļ�ϵͳmount�㡣
-follow�����find�����������������ļ���������������ָ����ļ���
-cpio����ƥ����ļ�ʹ��cpio�������Щ�ļ����ݵ��Ŵ��豸�С�
����,��������������:
-amin n
��������ϵͳ�����N���ӷ��ʵ��ļ�
����-atime n
��������ϵͳ�����n*24Сʱ���ʵ��ļ�
����-cmin n
��������ϵͳ�����N���ӱ��ı��ļ�״̬���ļ�
����-ctime n
��������ϵͳ�����n*24Сʱ���ı��ļ�״̬���ļ�
-mmin n
��������ϵͳ�����N���ӱ��ı��ļ����ݵ��ļ�
����-mtime n
��������ϵͳ�����n*24Сʱ���ı��ļ����ݵ��ļ�
4��ʹ��exec��ok��ִ��shell����
ʹ��findʱ��ֻҪ����Ҫ�IJ���д��һ���ļ���Ϳ�����exec�����find���ң��ܷ����
����Щ����ϵͳ��ֻ����-execѡ��ִ������l s��ls -l���������������û�ʹ����һѡ����Ϊ�˲��Ҿ��ļ���ɾ�����ǡ�����������ִ��rm����ɾ���ļ�֮ǰ���������ls���һ�£�ȷ����������Ҫɾ�����ļ���
execѡ������������Ҫִ�е������ű���Ȼ����һ�Զ�{ }��һ���ո��һ��\�������һ���ֺš�Ϊ��ʹ��execѡ�����Ҫͬʱʹ��printѡ������֤һ��find����ᷢ�ָ�����ֻ����ӵ�ǰ·��������·�����ļ�����
���磺Ϊ����ls -l�����г���ƥ�䵽���ļ�������ls -l�������find�����-execѡ����
# find . -type f -exec ls -l { } \;
-rw-r--r-- 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r--r-- 1 root root 12959 2003-02-25 ./conf/magic
-rw-r--r-- 1 root root 180 2003-02-25 ./conf.d/README
����������У�find����ƥ�䵽�˵�ǰĿ¼�µ�������ͨ�ļ�������-execѡ����ʹ��ls -l��������г���
��/logsĿ¼�в��Ҹ���ʱ����5����ǰ���ļ���ɾ�����ǣ�
$ find logs -type f -mtime +5 -exec rm { } \;
��ס����shell�����κη�ʽɾ���ļ�֮ǰ��Ӧ���Ȳ鿴��Ӧ���ļ���һ��ҪС�ģ���ʹ������mv��rm����ʱ������ʹ��-execѡ��İ�ȫģʽ�������ڶ�ÿ��ƥ�䵽���ļ����в���֮ǰ��ʾ�㡣
������������У� find�����ڵ�ǰĿ¼�в��������ļ�����.LOG��β������ʱ����5�����ϵ��ļ�����ɾ�����ǣ�ֻ������ɾ��֮ǰ�ȸ�����ʾ��
$ find . -name "*.conf" -mtime +5 -ok rm { } \;
< rm ... ./conf/httpd.conf > ? n
��y��ɾ���ļ�����n����ɾ����
�κ���ʽ�����������-execѡ����ʹ�á�
�����������������ʹ��grep���find��������ƥ�������ļ���Ϊ�� passwd*�����ļ�������passwd��passwd.old��passwd.bak��Ȼ��ִ��grep���������Щ�ļ����Ƿ����һ��sam�û���
# find /etc -name "passwd*" -exec grep "sam" { } \;
sam:x:501:501::/usr/sam:/bin/bash
����find��������ӣ�
1�����ҵ�ǰ�û���Ŀ¼�µ������ļ���
�������ַ���������ʹ��
$ find $HOME -print
$ find ~ -print
2���õ�ǰĿ¼���ļ��������ж���дȨ�ޣ������ļ���������û��������û����ж�Ȩ���ļ���
$ find . -type f -perm 644 -exec ls -l { } \;
3��Ϊ�˲���ϵͳ�������ļ�����Ϊ0����ͨ�ļ������г����ǵ�����·����
$ find / -type f -size 0 -exec ls -l { } \;
4������/var/logsĿ¼�и���ʱ����7����ǰ����ͨ�ļ�������ɾ��֮ǰѯ�����ǣ�
$ find /var/logs -type f -mtime +7 -ok rm { } \;
5��Ϊ�˲���ϵͳ����������root����ļ���
$find . -group root -exec ls -l { } \;
-rw-r--r-- 1 root root 595 10�� 31 01:09 ./fie1
6��find���ɾ����Ŀ¼�з���ʱ����7���������������ֺ���admin.log�ļ���
������ֻ�����λ���֣�������Ӧ�ļ��ĺ���Ҫ����999���Ƚ�����admin.log*���ļ� ������ʹ�������������
$ find . -name "admin.log[0-9][0-9][0-9]" -atime -7 -ok
rm { } \;
< rm ... ./admin.log001 > ? n
< rm ... ./admin.log002 > ? n
< rm ... ./admin.log042 > ? n
< rm ... ./admin.log942 > ? n
7��Ϊ�˲��ҵ�ǰ�ļ�ϵͳ�е�����Ŀ¼������
$ find . -type d | sort
8��Ϊ�˲���ϵͳ�����е�rmt�Ŵ��豸��
$ find /dev/rmt -print
����xargs
xargs - build and execute command lines from standard input
��ʹ��find�����-execѡ���ƥ�䵽���ļ�ʱ�� find�������ƥ�䵽���ļ�һ�ݸ�execִ�С�����Щϵͳ���ܹ����ݸ�exec������������ƣ�������find�������м�����֮�ͻ���������������Ϣͨ���ǡ�������̫����������������������xargs������ô����ڣ��ر�����find����һ��ʹ�á�
find�����ƥ�䵽���ļ����ݸ�xargs�����xargs����ÿ��ֻ��ȡһ�����ļ�������ȫ��������-execѡ�������������������ȴ������Ȼ�ȡ��һ�����ļ���Ȼ������һ��������˼�����ȥ��
����Щϵͳ�У�ʹ��-execѡ���Ϊ����ÿһ��ƥ�䵽���ļ�������һ����Ӧ�Ľ��̣����ǽ�ƥ�䵽���ļ�ȫ����Ϊ����һ��ִ�У���������Щ����¾ͻ���ֽ��̹��࣬ϵͳ�����½������⣬���Ч�ʲ��ߣ�
��ʹ��xargs������ֻ��һ�����̡����⣬��ʹ��xargs����ʱ��������һ�λ�ȡ���еIJ��������Ƿ���ȡ�ò������Լ�ÿһ�λ�ȡ��������Ŀ������ݸ������ѡ�ϵͳ�ں�����Ӧ�Ŀɵ�������ȷ����
������xargs���������ͬfind����һ��ʹ�õģ�������һЩ���ӡ�
��������Ӳ���ϵͳ�е�ÿһ����ͨ�ļ���Ȼ��ʹ��xargs�������������Ƿֱ����������ļ�
#find . -type f -print | xargs file
./.kde/Autostart/Autorun.desktop: UTF-8 Unicode English text
./.kde/Autostart/.directory: ISO-8859 text\
......
������ϵͳ�в����ڴ���Ϣת���ļ�(core dump) ��Ȼ��ѽ�����浽/tmp/core.log �ļ��У�
$ find / -name "core" -print | xargs echo "" >/tmp/core.log
�������ִ��̫�����Ҹij��ڵ�ǰĿ¼�²���
#find . -name "file*" -print | xargs echo "" > /temp/core.log
# cat /temp/core.log
./file6
�ڵ�ǰĿ¼�²��������û����ж���д��ִ��Ȩ���ļ������ջ���Ӧ��дȨ�ޣ�
# ls -l
drwxrwxrwx 2 sam adm 4096 10�� 30 20:14 file6
-rwxrwxrwx 2 sam adm 0 10�� 31 01:01 http3.conf
-rwxrwxrwx 2 sam adm 0 10�� 31 01:01 httpd.conf
# find . -perm -7 -print | xargs chmod o-w
# ls -l
drwxrwxr-x 2 sam adm 4096 10�� 30 20:14 file6
-rwxrwxr-x 2 sam adm 0 10�� 31 01:01 http3.conf
-rwxrwxr-x 2 sam adm 0 10�� 31 01:01 httpd.conf
��grep���������е���ͨ�ļ�������hostname����ʣ�
# find . -type f -print | xargs grep "hostname"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your
��grep�����ڵ�ǰĿ¼�µ�������ͨ�ļ�������hostnames����ʣ�
# find . -name \* -type f -print | xargs grep "hostnames"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your
ע�⣬������������У� \����ȡ��find�����е�*��shell�е����⺬�塣
find�������ʹ��exec��xargs����ʹ�û�����ƥ�䵽���ļ�ִ�м������е����
�ġ�find ����IJ���
������findһЩ���ò��������ӣ����õ���ʱ��������ˣ�������ǰ�������ӣ����õ������еĵ�һЩ������Ҳ������man��鿴��̳������������find�������ֲ�
1��ʹ��nameѡ��
�ļ���ѡ����find������õ�ѡ�Ҫô����ʹ�ø�ѡ�Ҫô������ѡ��һ��ʹ�á�
����ʹ��ij���ļ���ģʽ��ƥ���ļ�����סҪ�����Ž��ļ���ģʽ��������
���ܵ�ǰ·����ʲô�������Ҫ���Լ��ĸ�Ŀ¼$HOME�в����ļ�������*.txt���ļ���ʹ��~��Ϊ 'pathname'���������˺�~���������$HOMEĿ¼��
$ find ~ -name "*.txt" -print
��Ҫ�ڵ�ǰĿ¼����Ŀ¼�в������еġ� *.txt���ļ��������ã�
$ find . -name "*.txt" -print
��Ҫ�ĵ�ǰĿ¼����Ŀ¼�в����ļ�����һ����д��ĸ��ͷ���ļ��������ã�
$ find . -name "[A-Z]*" -print
��Ҫ��/etcĿ¼�в����ļ�����host��ͷ���ļ��������ã�
$ find /etc -name "host*" -print
��Ҫ����$HOMEĿ¼�е��ļ��������ã�
$ find ~ -name "*" -print ��find . -print
Ҫ����ϵͳ�߸������У��ʹӸ�Ŀ¼��ʼ�������е��ļ���
$ find / -name "*" -print
������ڵ�ǰĿ¼�����ļ���������Сд��ĸ��ͷ���������������֣������.txt���ļ��������������ܹ�������Ϊax37.txt���ļ���
$find . -name "[a-z][a-z][0--9][0--9].txt" -print
2����permѡ��
�����ļ�Ȩ��ģʽ��-permѡ��,���ļ�Ȩ��ģʽ�������ļ��Ļ������ʹ�ð˽��Ƶ�Ȩ�ޱ�ʾ����
���ڵ�ǰĿ¼�²����ļ�Ȩ��λΪ755���ļ������ļ��������Զ���д��ִ�У������û����Զ���ִ�е��ļ��������ã�
$ find . -perm 755 -print
����һ�ֱ��﷽�����ڰ˽�������ǰ��Ҫ��һ�����-����ʾ��ƥ�䣬��-007���൱��777��-006�൱��666
# ls -l
-rwxrwxr-x 2 sam adm 0 10�� 31 01:01 http3.conf
-rw-rw-rw- 1 sam adm 34890 10�� 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10�� 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10�� 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10�� 31 20:19 temp
# find . -perm 006
# find . -perm -006
./sam
./httpd1.conf
./temp
-perm mode:�ļ��������÷���mode
-perm +mode:�ļ����ɲ��ַ���mode
-perm -mode: �ļ�������ȫ����mode
3������ij��Ŀ¼
����ڲ����ļ�ʱϣ������ij��Ŀ¼����Ϊ��֪���Ǹ�Ŀ¼��û������Ҫ���ҵ��ļ�����ô����ʹ��-pruneѡ����ָ����Ҫ���Ե�Ŀ¼����ʹ��-pruneѡ��ʱҪ���ģ���Ϊ�����ͬʱʹ����-depthѡ���ô-pruneѡ��ͻᱻfind������ԡ�
���ϣ����/appsĿ¼�²����ļ�������ϣ����/apps/binĿ¼�²��ң������ã�
$ find /apps -path "/apps/bin" -prune -o -print
4��ʹ��find�����ļ���ʱ����ô�ܿ�ij���ļ�Ŀ¼
����Ҫ��/usr/samĿ¼�²��Ҳ���dir1��Ŀ¼֮�ڵ������ļ�
find /usr/sam -path "/usr/sam/dir1" -prune -o -print
find [-path ..] [expression] ��·���б��ĺ�����DZ���ʽ
-path "/usr/sam" -prune -o -print �� -path "/usr/sam" -a -prune -o
-print �ļ�д����ʽ��˳����ֵ, -a �� -o ���Ƕ�·��ֵ���� shell �� && �� || ������� -path "/usr/sam" Ϊ�棬����ֵ -prune , -prune �����棬��������ʽΪ�棻������ֵ -prune����������ʽΪ�١���� -path "/usr/sam" -a -prune Ϊ�٣�����ֵ -print ��-print�����棬��������ʽΪ�棻������ֵ -print����������ʽΪ�档
�������ʽ�������������α��дΪ
if -path "/usr/sam" then
-prune
else
-print
�ܿ�����ļ���
find /usr/sam \( -path /usr/sam/dir1 -o -path /usr/sam/file1 \) -prune -o -print
Բ���ű�ʾ����ʽ�Ľ�ϡ�
\ ��ʾ���ã���ָʾ shell ���Ժ�����ַ���������ͣ������� find ����ȥ���������塣
����ijһȷ���ļ���-name��ѡ�����-o ֮��
#find /usr/sam \(-path /usr/sam/dir1 -o -path /usr/sam/file1 \) -prune -o -name "temp" -print
5��ʹ��user��nouserѡ��
���ļ����������ļ�������$HOMEĿ¼�в����ļ�����Ϊsam���ļ��������ã�
$ find ~ -user sam -print
��/etcĿ¼�²����ļ�����Ϊuucp���ļ���
$ find /etc -user uucp -print
Ϊ�˲��������ʻ��Ѿ���ɾ�����ļ�������ʹ��-nouserѡ��������ܹ��ҵ���Щ������/etc/passwd�ļ���û����Ч�ʻ����ļ�����ʹ��-nouserѡ��ʱ�����ظ����û����� find�����ܹ�Ϊ�������Ӧ�Ĺ�����
���磬ϣ����/homeĿ¼�²������е������ļ��������ã�
$ find /home -nouser -print
6��ʹ��group��nogroupѡ��
����user��nouserѡ��һ��������ļ������ڵ��û��飬 find����Ҳ����ͬ����ѡ�Ϊ����/appsĿ¼�²�������gem�û�����ļ��������ã�
$ find /apps -group gem -print
Ҫ����û����Ч�����û���������ļ�������ʹ��nogroupѡ������find������ļ�ϵͳ�ĸ�Ŀ¼�������������ļ�
$ find / -nogroup-print
7�����ո���ʱ������ʱ��Ȳ����ļ�
���ϣ�����ո���ʱ���������ļ�������ʹ��mtime,atime��ctimeѡ����ϵͳͻȻû�п��ÿռ��ˣ����п���ijһ���ļ��ij����ڴ��ڼ�����Ѹ�٣���ʱ�Ϳ�����mtimeѡ���������������ļ���
�ü���-��������ʱ���ھ��n�����ڵ��ļ������üӺ�+��������ʱ���ھ��n����ǰ���ļ���
ϣ����ϵͳ��Ŀ¼�²��Ҹ���ʱ����5�����ڵ��ļ��������ã�
$ find / -mtime -5 -print
Ϊ����/var/admĿ¼�²��Ҹ���ʱ����3����ǰ���ļ��������ã�
$ find /var/adm -mtime +3 -print
8�����ұ�ij���ļ��»�ɵ��ļ�
���ϣ�����Ҹ���ʱ���ij���ļ��µ�����һ���ļ��ɵ������ļ�������ʹ��-newerѡ�����һ����ʽΪ��
newest_file_name ! oldest_file_name
���У��������Ƿ��š�
���Ҹ���ʱ����ļ�sam�µ����ļ�temp�ɵ��ļ���
�����������ļ�
-rw-r--r-- 1 sam adm 0 10�� 31 01:07 fiel
-rw-rw-rw- 1 sam adm 34890 10�� 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10�� 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10�� 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10�� 31 20:19 temp
# find -newer httpd1.conf ! -newer temp -ls
1077669 0 -rwxrwxr-x 2 sam adm 0 10�� 31 01:01 ./httpd.conf
1077671 4 -rw-rw-rw- 1 root root 2792 10�� 31 20:19 ./temp
1077673 0 -rw-r--r-- 1 sam adm 0 10�� 31 01:07 ./fiel
���Ҹ���ʱ���ڱ�temp�ļ��µ��ļ���
$ find . -newer temp -print
9��ʹ��typeѡ��
��/etcĿ¼�²������е�Ŀ¼�������ã�
$ find /etc -type d -print
�ڵ�ǰĿ¼�²��ҳ�Ŀ¼������������͵��ļ��������ã�
$ find . ! -type d -print
��/etcĿ¼�²������еķ��������ļ���������
$ find /etc -type l -print
10��ʹ��sizeѡ��
�������ļ������������ļ���������ָ���ļ����ȼȿ����ÿ飨block����������Ҳ�������ֽ������������ֽڼ����ļ����ȵı�����ʽΪN c���Կ�����ļ�����ֻ�����ֱ�ʾ���ɡ�
�ڰ����ļ����Ȳ����ļ�ʱ��һ��ʹ���������ֽڱ�ʾ���ļ����ȣ��ڲ鿴�ļ�ϵͳ�Ĵ�С����Ϊ��ʱʹ�ÿ�������������ת����
�ڵ�ǰĿ¼�²����ļ����ȴ���1 M�ֽڵ��ļ���
$ find . -size +1000000c -print
��/home/apacheĿ¼�²����ļ�����ǡ��Ϊ100�ֽڵ��ļ���
$ find /home/apache -size 100c -print
�ڵ�ǰĿ¼�²��ҳ��ȳ���10����ļ���һ�����512�ֽڣ���
$ find . -size +10 -print
11��ʹ��depthѡ��
��ʹ��find����ʱ������ϣ����ƥ�����е��ļ���������Ŀ¼�в��ҡ�ʹ��depthѡ��Ϳ���ʹfind��������������������һ��ԭ����ǣ�����ʹ��find������Ŵ��ϱ����ļ�ϵͳʱ��ϣ�����ȱ������е��ļ�������ٱ�����Ŀ¼�е��ļ���
������������У� find������ļ�ϵͳ�ĸ�Ŀ¼��ʼ������һ����ΪCON.FILE���ļ���
��������ƥ�����е��ļ�Ȼ���ٽ�����Ŀ¼�в��ҡ�
$ find / -name "CON.FILE" -depth -print
12��ʹ��mountѡ��
�ڵ�ǰ���ļ�ϵͳ�в����ļ��������������ļ�ϵͳ��������ʹ��find�����mountѡ�
�ӵ�ǰĿ¼��ʼ����λ�ڱ��ļ�ϵͳ���ļ�����XC��β���ļ���
$ find . -name "*.XC" -mount -printFind��������
ÿһ�ֲ���ϵͳ�����ɳ�ǧ�������ͬ������ļ�����ɵġ�������ϵͳ�����Դ����ļ����û��Լ����ļ������й����ļ��ȵȡ�������ʱ������ij���ļ�����Ӳ���е��ĸ��ط���������WINDOWS����ϵͳ��Ҫ����һ���ļ����൱�����飬ֻҪ�������ϵ������ʼ�������������о��ܰ��ո��ַ�ʽ�ڱ���Ӳ���ϣ��������磬������INTERNET�ϲ��Ҹ����ļ����ĵ���
����ʹ��Linux���û���û����ô�����ˣ���Linux�ϲ���ij���ļ�ȷʵ��һ���Ƚ��鷳�����顣�Ͼ���Linux����Ҫ����ʹ��ר�õġ����ҡ�������Ѱ����Ӳ���ϵ��ļ���Linux�µ��ļ������ʽ�dz����ӣ�����WINDOWS,DOS�¶���ͳһ��AAAAAAA.BBB��ʽ��ô������ң���WINDOWS�У�ֻҪ֪��Ҫ���ҵ��ļ����ļ������ߺ��ͷdz����ײ��ҵ���Linux�в����ļ�������ͨ��Ϊ��find�������find�������ܰ���������ʹ��,����Linux���ճ������з���IJ��ҳ�������Ҫ���ļ�������Linux������˵����find������Ҳ���˽��ѧϰLinux�ļ��ص�ķ�������ΪLinux���а汾���࣬�汾�����ܿ죬��Linux�鼮������д��ij�������ļ�������λ�ã�����Linux���ְ�ͼ�������Dz����ҵ�������˵REDHAT Linux 7.O��REDHAT Linux 7.1����Щ��Ҫ�������ļ����ڵ�Ӳ��λ�ú��ļ�Ŀ¼�����˺ܴ�ĸı䣬�����ѧ��ʹ�á�find�������ô�ڳ�ǧ�����Linux�ļ���Ҫ�ҵ����е�һ�������ļ����൱���ѵģ�������û�о�ͨ��find������֮ǰ�ͳԹ������Ŀ�ͷ���ã��������ϸΪ��ҽ���ǿ��ġ�find�������ȫ��ʹ�÷�������;��
����ͨ���ļ������ҷ���
�����������˵�����ͺ���WINDOWS�²����ļ�һ�����������ˡ�����������ļ����ڵ������ļ������棬ֻҪʹ�ó����ġ�ls"������ܷ���IJ��ҳ�������ôʹ�á�find���������������Ͳ��ܸ���������̵�ӡ�Ͼ���find�������ǿ���ܲ�ֹ��������֪����ij���ļ����ļ���������֪������ļ��ŵ��ĸ��ļ��У������Dz����Ƕ���ļ��������˵����������������httpd.conf����ļ���ϵͳ���ĸ�Ŀ¼�£�������ϵͳ��ij���ط�Ҳ��֪���������ǿ���ʹ���������
����find / -name httpd.conf
�����������������������������ˣ�����ֱ����find����д�� -name������Ҫ��ϵͳ�����ļ������ң����д��httpd.conf���Ŀ���ļ������ɡ��Ե�һ��ϵͳ���ڼ������Ļ����ʾ�����ҽ���б���
etc/httpd/conf/httpd.conf
���������httpd.conf����ļ���Linuxϵͳ�е�����·�������ҳɹ���
��������������ϲ��������ϵͳ��û����ʾ���������ô��Ҫ��Ϊϵͳû��ִ��find/ -name httpd.conf��������������ϵͳ��û�а�װApache����������ʱֻҪ�㰲װ��Apache Web��������Ȼ����ʹ��find / -name httpd.conf�����ҵ���������ļ��ˡ�
����������Ҽ��ɣ�
������Linuxϵͳ�С�find�������Ǵ����ϵͳ�û�������ʹ�õ����������ROOTϵͳ����Ա��ר����������ͨ�û�ʹ�á�find������ʱҲ�п����������������⣬�Ǿ���Linuxϵͳ��ϵͳ����ԱROOT����ijЩ�ļ�Ŀ¼���óɽ�ֹ����ģʽ��������ͨ�û���û��Ȩ���á�find����������ѯ��ЩĿ¼�����ļ�������ͨ�û�ʹ�á�find����������ѯ��Щ�ļ�Ŀ¼�ǣ����������"Permissiondenied."����ֹ���ʣ�������ϵͳ������ѯ������Ҫ���ļ���Ϊ�˱��������Ĵ������ǿ���ʹ��ת�ƴ�����ʾ�ķ��������Ų����ļ�������
find / -name access_log 2>/dev/null
������������ǰѲ��Ҵ�����ʾת�Ƶ��ض���Ŀ¼��ȥ��ϵͳִ���������������������Ϣ��ֱ�����͵�stderrstream 2 �У�access_log 2���DZ���ϵͳ���Ѵ�����Ϣ���͵�stderrstream 2�У�/dev/null��һ��������ļ��������յĻ��ߴ������Ϣ��������ѯ���Ĵ�����Ϣ����ת���ˣ���������ʾ�ˡ�
����Linuxϵͳ�����ļ�Ҳ����������һ��ʵ�����⡣�������������Ӳ�̣����ϵͳ�в���ij���ļ���Ҫ�����൱����һ��ʱ�䣬�ر��Ǵ���Linuxϵͳ�������ϴ��Ӳ�̣��ļ�������Ƕ�����Ŀ¼�е�ʱ���������֪��������ļ������ij�����Ŀ¼�У���ôֻҪ�����Ŀ¼�������Ҿ��ܽ�ʡ�ܶ�ʱ���ˡ�ʹ��find /etc -name httpd.conf �Ϳ��Խ��������⡣�����������DZ�ʾ��etcĿ¼�в�ѯhttpd.conf����ļ���������˵��һ�¡�/ ������������ŵĺ��壬������� ��find/ �����DZ�ʾҪ��Linuxϵͳ������ROOTĿ¼�²����ļ���Ҳ����������Ӳ���ϲ����ļ�������find/etc������ֻ�� etcĿ¼�²����ļ�����Ϊ��find/etc����ʾֻ��etcĿ¼�²����ļ������Բ��ҵ��ٶȾ���ӦҪ��ܶ��ˡ�
�������ݲ����ļ������ҷ�����
���������������WINDOWS�в�����֪���ļ���������һ���ġ�������Linux�и��ݲ����ļ��������ļ��ķ���Ҫ����WINDOWS�е�ͬ����ҷ���Ҫǿ��öࡣ��������֪��ij���ļ�������srm��3����ĸ����ôҪ�ҵ�ϵͳ�����а�������3����ĸ���ļ��ǿ���ʵ�ֵģ����룺
����find /etc -name '*srm*'
����������������Linuxϵͳ����/etc����Ŀ¼�в������еİ�����srm��3����ĸ���ļ������� absrmyz�� tibc.srm�ȵȷ����������ļ�������ʾ����������㻹֪������ļ�����srm ��3����ĸ��ͷ�ģ���ô���ǻ�����ʡ����ǰ����Ǻţ��������£�
����find/etc -name 'srm*'
��������ֻ����srmyz �������ļ��ű����ҳ�������absrmyz���� absrm�������ļ���������Ҫ������ʾ�����������ļ���Ч�ʺͿɿ��Ծʹ����ǿ�ˡ�
���������ļ���������ѯ������
�������ֻ֪��ij���ļ��Ĵ�С�������ڵ�����Ҳ����ʹ�á�find��������ҳ��������WINDOWSϵͳ�е�"����"�����ǻ�����ͬ�ġ�������"����"��WINDOWS�е�"��������"ʹ�������ļ����ļ��С���ӡ�����û��Լ������е�����������������ס�������ʹ��Internet �������������ס�"��������"������һ���������÷���ά���˼�����������ļ���������ʹ�������ٶȸ��졣ʹ��"��������"ʱ���û�����ָ����������������磬�û��������ơ����ͼ���С�����ļ����ļ��С��û������������������ض��ı����ļ�������û���ʹ�� Active Directory����ʱ���������������ض����ƻ�λ�õĴ�ӡ����
������������֪��һ��Linux�ļ���СΪ1,500 bytes����ô���ǿ���ʹ��������������ѯfind / -size 1500c���ַ� c �������Ҫ���ҵ��ļ��Ĵ�С����bytesΪ��λ���������������ļ��ľ����С����֪������ô��Linux�л����Խ���ģ�����ҷ�ʽ�������������������find/ -size +10000000c ���������������ָ��ϵͳ�ڸ�Ŀ¼�в��ҳ�����10000000�ֽڵ��ļ�����ʾ�����������еġ������DZ�ʾҪ��ϵͳֻ�г�����ָ����С���ļ�����ʹ�á�-�����ʾҪ��ϵͳ�г�С��ָ����С���ļ���������б�������Linuxʹ�ò�ͬ�� find"�����ϵͳ��Ҫ�����IJ��Ҷ������������Ǻ���������Linux��ʹ�á�find"����ķ�ʽ�Ǻܶ�ģ��� find"��������ļ�ֻҪ���Ӧ�ã�˿��������WINDOWS�в��������
����find / -amin -10 # ������ϵͳ�����10���ӷ��ʵ��ļ�
����find / -atime -2 # ������ϵͳ�����48Сʱ���ʵ��ļ�
����find / -empty # ������ϵͳ��Ϊ�յ��ļ������ļ���
����find / -group cat # ������ϵͳ������ groupcat���ļ�
����find / -mmin -5 # ������ϵͳ�����5�������Ĺ����ļ�
����find / -mtime -1 #������ϵͳ�����24Сʱ���Ĺ����ļ�
����find / -nouser #������ϵͳ�����������û����ļ�
����find / -user fred #������ϵͳ������FRED����û����ļ�
����������б����Ƕ�find����������ָ���ļ����������в��ҵIJ��������������ﲢû���о����еIJ����������ο��й�Linux�й��鼮����֪������find����IJ��Һ�����
����-amin n
��������ϵͳ�����N���ӷ��ʵ��ļ�
����-atime n
��������ϵͳ�����n*24Сʱ���ʵ��ļ�
����-cmin n
��������ϵͳ�����N���ӱ��ı�״̬���ļ�
����-ctime n
��������ϵͳ�����n*24Сʱ���ı�״̬���ļ�
����-empty
��������ϵͳ�пհ��ļ�����հ��ļ�Ŀ¼����Ŀ¼��û����Ŀ¼���ļ���
����-false
��������ϵͳ�����Ǵ�����ļ�
����-fstype type
��������ϵͳ�д�����ָ���ļ�ϵͳ���ļ������磺ext2 .
����-gid n
��������ϵͳ���ļ������� ID Ϊ n���ļ�
����-group gname
��������ϵͳ���ļ�����gnam�ļ��飬����ָ�����ID���ļ�
��Find����Ŀ���ѡ��˵����
����Find����Ҳ�ṩ���û�һЩ���е�ѡ�������Ʋ��Ҳ������±����������ܽ�������������õ�find����Ŀ���ѡ����÷���
����ѡ��
������;����
����-daystart
����.����ϵͳ�ӽ��쿪ʼ24Сʱ���ڵ��ļ����÷�����-amin
����-depth
����ʹ����ȼ���IJ��ҹ��̷�ʽ,��ij��ָ��Ŀ¼�����Ȳ����ļ�����
����-follow
������ѭͨ������ӷ�ʽ����; ���⣬Ҳ�ɺ���ͨ������ӷ�ʽ��ѯ
����-help
������ʾ����ժҪ
����-maxdepth levels
������ij����ε�Ŀ¼�а��յݼ���������
����-mount
���������ļ�ϵͳĿ¼�в��ң� �÷����� -xdev.
����-noleaf
������ֹ�ڷ�UNUX�ļ�ϵͳ��MS-DOSϵͳ��CD-ROM�ļ�ϵͳ�н������Ż�����
����-version
������ӡ�汾����
����ʹ��-followѡ���find��������ѭͨ������ӷ�ʽ���в��ң�������ָ�����ѡ�����һ�������find�������ͨ������ӷ�ʽ�����ļ����ҡ�
����-maxdepthѡ������þ�������find������Ŀ¼�а��յݼ���ʽ�����ļ���ʱ�������ļ�����ij������������������Ŀ¼���������²����ٶȱ��������һ��ѵ�ʱ����ࡣ���磬����Ҫ�ڵ�ǰ(.)Ŀ¼������Ŀ¼�в���һ������fred���ļ������ǿ���ʹ����������
����find . -maxdepth 2 -name fred
�����������fred�ļ���./sub1/fredĿ¼�У���ô�������ͻ�ֱ�Ӷ�λ����ļ������Һ����׳ɹ������磬����ļ���./sub1/sub2/fredĿ¼�У���ô�������������ҵ�����Ϊǰ���Ѿ���find������Ŀ¼�����IJ�ѯĿ¼����Ϊ2��ֻ�ܲ���2��Ŀ¼�µ��ļ�����������Ŀ�ľ���Ϊ����find������Ӿ�ȷ�Ķ�λ�ļ���������Ѿ�֪����ij���ļ�������ڵ��ļ�Ŀ¼��������ô����-maxdepth n �ͺܿ������ָ��Ŀ¼�в��ҳɹ���
����ʹ�û�ϲ��ҷ�ʽ�����ļ�
����find�������ʹ�û�ϲ��ҵķ�����������������/tmpĿ¼�в��Ҵ���100000000�ֽڲ�����48Сʱ���ĵ�ij���ļ������ǿ���ʹ��-and ������������ѡ������������ϳ�һ����ϵIJ��ҷ�ʽ��
����find /tmp -size +10000000c -and -mtime +2
����ѧϰ����������Ե����Ѷ�֪�����ڼ���������ʹ��and ,or �ֱ��ʾ���롱�͡��Ĺ�ϵ����Linuxϵͳ�IJ���������һ��ͨ�á�
�����������������ӣ�
����find / -user fred -or -user george
�������ǿ��Խ���Ϊ��/tmpĿ¼�в�������fred����george�������û����ļ���
������find�����л�����ʹ�á��ǡ��Ĺ�ϵ�������ļ����������Ҫ��/tmpĿ¼�в������в�����panda���ļ���ʹ��һ����
����find /tmp ! -user panda
��������Ϳ��Խ���ˡ��ܼ�
�������Ҳ���ʾ�ļ��ķ���
�������ҵ�ij���ļ������ǵ�Ŀ�ģ����Ǹ���֪�����ҵ����ļ�����ϸ��Ϣ�����ԣ�������Dz�ȡ�ֲ����ļ�����ʹ��LS�������鿴�ļ���Ϣ���൱�����ģ���������Ҳ��������������������ʹ�á�
����find / -name "httpd.conf" -ls
����ϵͳ���ҵ�httpd.conf�ļ�����������Ļ����ʾhttpd.conf�ļ���Ϣ��
����12063 34 -rw-r--r-- 1 root root 33545 Dec 30 15:36 /etc/httpd/conf/httpd.conf
��������ı������һЩ���õIJ����ļ�����ʾ�ļ���Ϣ�IJ�����ʹ�÷���
����ѡ��
������;����
����-exec command;
�������Ҳ�ִ������
����-fprint file
������ӡ�ļ������ļ���
����-fprint0 file
������ӡ�ļ������ļ��������յ��ļ�
����-fprintf file format
������ӡ�ļ���ʽ
����-ok command;
�������û�����ִ�в����������û���Y ȷ������ִ��
����-printf format
������ӡ�ļ���ʽ
����-ls
������ӡͬ���ļ���ʽ���ļ�.
****************************************************************************************************************************************���ƣ�locate ���
����ʹ��Ȩ�ޣ�����ʹ����
����ʹ�÷�ʽ�� locate [-q] [-d ] [--database=]
����locate [-r ] [--regexp=]
����locate [-qv] [-o ] [--output=]
����locate [-e ] [-f ] <[-l ] [-c]
����<[-U ] [-u]>
����locate [-Vh] [--version] [--help]
����˵����
����locate ��ʹ���߿��Ժܿ��ٵ���Ѱ����ϵͳ���Ƿ���ָ���ĵ������䷽�����Ƚ���(ʹ��updatedb����)һ������ϵͳ�����е������Ƽ�·�������ݿ⣬֮��Ѱ��ʱ��ֻ���ѯ������ݿ⣬������ʵ�����뵵��ϵͳ֮���ˡ�
����
������һ��� distribution ֮�У����ݿ�Ľ����������� contab ���Զ�ִ�С�һ��ʹ������ʹ��ʱֻҪ��
����# locate your_file_name
��������ʽ�Ϳ����ˡ�
����˵����
����-u
����-U
�����������ݿ⣬-u ���ɸ�Ŀ¼��ʼ��-U �����ָ����ʼ��λ�á�
����-e
������Ŀ¼�ų���Ѱ�ҵķ�Χ֮�⡣
����-l
������� �� 1����������ȫģʽ���ڰ�ȫģʽ�£�ʹ���߲��ῴ��Ȩ���������ĵ��������ʼ�ٶȼ�������Ϊ locate ������ʵ�ʵĵ���ϵͳ��ȡ�õ�����Ȩ�����ϡ�
����-f
�������ض��ĵ���ϵͳ�ų����⣬��������û�е���Ҫ�� proc ����ϵͳ�еĵ����������ݿ��С�
����-q
��������ģʽ��������ʾ�κδ���ѶϢ��
����-n
����������ʾ �������
����-r
����ʹ����������ʽ ��Ѱ�ҵ�������
����-o
����ָ�����ݿ������ơ�
����-d
����ָ�����ݿ��·��
����-h
������ʾ����ѶϢ
����-v
������ʾ�����ѶϢ
����-V
������ʾ����İ汾ѶϢ
������
����locate chdrv : Ѱ�����н� chdrv �ĵ���
����locate -n 100 a.out : Ѱ�����н� a.out �ĵ����������ֻ��ʾ 100 ��
����locate -u : �������ݿ�
����locate�����������Ѱ���ݿ�ʱ�����ҵ����������ݿ���updatedb���������£�updatedb����cron daemon�����Խ����ģ�locate��������Ѱ���ݿ�ʱ����������Ӳ����������Ѱ�������ÿ죬���ϲ����locate���ҵ��ĵ�����������Ž�����ո����ģ����ܻ��Ҳ��������ڶ�ֵ�У�updatedbÿ�����һ�Σ���������crontab�������趨ֵ��(etc/crontab)
����locateָ��������Ѱ���������ĵ���������ȥ���浵����Ŀ¼���Ƶ����ݿ��ڣ�Ѱ�ҺϺ�������ʽ�����ĵ�����Ŀ¼¼������ʹ��������Ԫ���硱*����?���ȣ���ָ��������ʽ����ָ������Ϊkcpa*ner, locate���ҳ�������ʼ�ִ�Ϊkcpa�ҽ�βΪner�ĵ�����Ŀ¼��������Ϊkcpartner��Ŀ¼¼����Ϊkcpa_ner����г���Ŀ¼�°�����Ŀ¼���ڵ����е�����
����locateָ���find��Ѱ�����Ĺ������ƣ���locate����update����Ӳ���е����е�����Ŀ¼�����Ƚ���һ���������ݿ⣬��ִ��loacteʱֱ���Ҹ���������ѯ�ٶȻ�Ͽ죬�������ݿ�һ�����ɲ���ϵͳ��������Ҳ����ֱ���´�updateǿ��ϵͳ�������������ݿ⡣
����������һ����ִ��update����ʹ��locateѰ�ҵ�������ʧ�ܣ���ʱ��Ҫִ��slocate ��u�����Ҳ��ִ��updatedbָ���Ч����ͬ��������slocate���ݿ⣬���������/usr/sbin�²���slocateִ�е�������locate�������ݿ�Ѱ����Ҫ�ҵ����ϡ�
ע��Updatedb������
ijЩʱ����ᷢ�����Linuxϵͳ��Ӳ���ڷ���ת������ϵͳ�����ٶȱ仺��
ʹ��[top]����鿴��Դռ�á�
#top
����ܻᷢ��һ����updatedb�Ľ����ڷ������У�ռ������dz����ϵͳ��Դ����ô���������[cron]�Զ����еĸ���ϵͳ���ݵĽű���
����������Ϊ��ϵͳ������ļ������������Ա���locate��whereis�Ȳ�ѯ������ܹ�����ִ�С��Ż�������
ʹ��root��½
#ls /etc/cron*
���ܿ���cron.daily��cron.weekly���ļ��У�������cron.daily����Ӧ����slocate�Ƚű�������ÿ��ִ��һ�Σ�
���ö�ʱ���µĹ���Ƶ�ʴ�ÿ��һ�ν��͵�ÿ��ִ��һ�Σ��������£�����slocate�ű����е�cron.weeklyĿ¼���ɣ�
#mv /etc/cron.daily/slocate /etc/cron.weekly/
�༭�����ļ�updatedb.conf�����ò���Ҫ����������Ŀ¼���磺��Ĺ����������ƶ��洢�豸
#vi /etc/updatedb.conf
�ҵ�PRUNEPATHS���ں����������㲻�������updatedb����������Ŀ¼������/mnt/winD�������������Ҫ���������������̡�
linux����ϵͳ������swap�ռ䣨��ʱ+���ã�
2008-11-24 15:46:49
��ʱ����swap�ռ�
�������£�
���µIJ�����Ҫ��root�û��½��У�
�����Ƚ���һ������������dd���
step 1:#dd if=/dev/zero ��f=/home/swap bs=1024 count=512000
�����ͻᴴ��/home/swap��ôһ�������ļ����ļ��Ĵ�С��512000��block��һ�������1��blockΪ1K����������ռ���512M���ܹ��ռ�=bs*count=512M����
�����ٰ�����������swap������
step 2:# mkswap /home/swap
ע�ͣ��Ѹղſռ��ʽ����swap��ʽ
�ٽ���ʹ�����swap������ʹ���Ϊ��Ч״̬��
step 3:#swapon /home/swap
ע�ͣ�ʹ�øղŴ�����swap�ռ�
���Ҫ�رոտ��ٵ�swap�ռ䣬ֻ�����#swapoff
ʵ�����£�
--------------------------------------------------------------------------------
1.�鿴ϵͳSwap�ռ�ʹ��[root@guok usr]# free
total used free shared buffers cached
Mem: 513980 493640 20340 0 143808 271780
-/+ buffers/cache: 78052 435928
Swap: 1052248 21256 10309922.�ڿռ���ʴ�����swap�ļ�
[root@guok usr]# mkdir swap
[root@guok usr]# cd swap
[root@guok swap]# dd if=/dev/zero ��f=swapfile bs=1024 count=10000
10000+0 records in
10000+0 records out
[root@guok swap]# ls -al
total 10024
drwxr-xr-x 2 root root 4096 7�� 28 14:58 .
drwxr-xr-x 19 root root 4096 7�� 28 14:57 ..
-rw-r--r-- 1 root root 10240000 7�� 28 14:58 swapfile
[root@guok swap]# mkswap swapfile
Setting up swapspace version 1, size = 9996 KiB
3.����swap�ļ�
[root@guok swap]# swapon swapfile
[root@guok swap]# ls -l
total 10016
-rw-r--r-- 1 root root 10240000 7�� 28 14:58 swapfile
[root@guok swap]# free
total used free shared buffers cached
Mem: 513980 505052 8928 0 143900 282288
-/+ buffers/cache: 78864 435116
Swap: 1062240 21256 1040984
[root@guok swap]#
--------------------------------------------------------------------------------��������Swap�ռ�
��������free -m����鿴һ���ڴ��swap������С���ͷ���������512M�Ŀռ��ˡ�������������������Ժ���swap����ԭ����ô���µ�swapû���Զ���������Ҫ�ֶ���������������Ҫ��/etc/fstab�ļ�����������һ��
/home/swap swap swap defaults 0 0
��ͻᷢ����Ļ����Զ������Ժ�swap�ռ�Ҳ�����ˡ�
Linux ����root����Ľ��������ȫ��
2008-11-23 19:02:51
Linux�����û�rootӵ��ϵͳ�����Ȩ�ޡ��������û��������������root ���룬����ϵͳ�ܵ��ڿ͵����֣�����root �˺ŵ�¼ϵͳʱ�����ǿ���ͨ�����а취���ָ�root �����롣
һ�����뵥�û�ģʽ
����1.ʹ��Linux ϵͳ��������
����������Ѵ�����Linux ϵͳ���������̣��������ü����ϵͳ����������������ʾboot ��ʾ�������룺
����boot: linux single
����ϵͳ��������ʾ��Ϊ��#���ĵ��û�ģʽ����������������м���Ϊ1�������ļ�ϵͳ�����أ��ܶ�ϵͳ����û�����У���������ϵͳ��֤����һ��ϵͳ����Աʹ���ض��Ļ������� root �ļ�ϵͳ��Ϊ��д����ʱ�����ʹ�ã�
����(1)passwd ����������root��������
����# passwd root
����# reboot
��������ϵͳ��root �����ѱ����¡�
����(2)ͨ���� /etc/shadow �ļ���ɾ��root ������
����# cd /etc
����# vi shadow
��������root ��ͷ��һ���С�root���������һ���� ����ǰ������ɾ����
������һ�н������ڡ�root ����⋯⋯�������������ϵͳ��root ������Ϊ�ա�
����2.��LILO ��ϵͳ������������
������ϵͳ��LILO ������������ʱ���ڳ���LILO ��ʾ��ʱ���룺
����LILO: linux single
�������뵥�û�����password �ķ���ͬ1��
����3.��GRUB ��ϵͳ������������
������GRUB����ϵͳ���뵥�û����裺
����(1) ����GRUB��ѡ��Red Hat Linux��ѡ�Ȼ����� e ���༭��
����(2) ѡ����kernel��ͷ��һ�У��ٰ�e �����ڴ��е�ĩβ�����ո��������single���Իس������˳��༭ģʽ��
����(3) �ص��� GRUB ��Ļ���� b ���������뵥�û�ģʽ��
�������뵥�û�����password �ķ���ͬ1��
����ʹ��Linux ϵͳ��װ��
����������û��ϵͳ�������̣�ͬʱ��ϵͳ������LILO ��GRUB �ֱ�ɾ��(����װ��Windows ϵͳ��)����ôֻ��ʹ��Linux ϵͳ��װ�����ָ�root �����롣
�����õ�һ��Linux ϵͳ��װ������������boot ��ʾ�������룺
���boot: linux rescue
������ʱϵͳ�����Ԯģʽ��Ȼ�������ʾ��ɣ�
����1.ѡ�����Ժͼ��̸�ʽ��
����2.ѡ���Ƿ�����������һ��ϵͳ�����粻��Ҫ�����Կ���ѡ��������������ã�
����3 . ѡ���Ƿ���ϵͳ����Ӳ���ϵ�Redhat Linux ϵͳ��ѡ�������
����4.ϵͳ��ʾӲ���ϵ�ϵͳ�Ѿ����ҵ�����������/mnt/sysimage �£�
����5.��������״̬������������root �����룺
����# chroot/mnt/sysimage (��ϵͳ��Ϊ������)
����# cd /mnt/sysimage
����# passwd root
Linux ����root����Ľ��������ͼ�⣩
2008-11-23 18:49:31
���Linux����ϵͳ��root����,����ô����?�����ࣺܶ
����һ
��1�� �������»������e��ť������༭ģʽ��

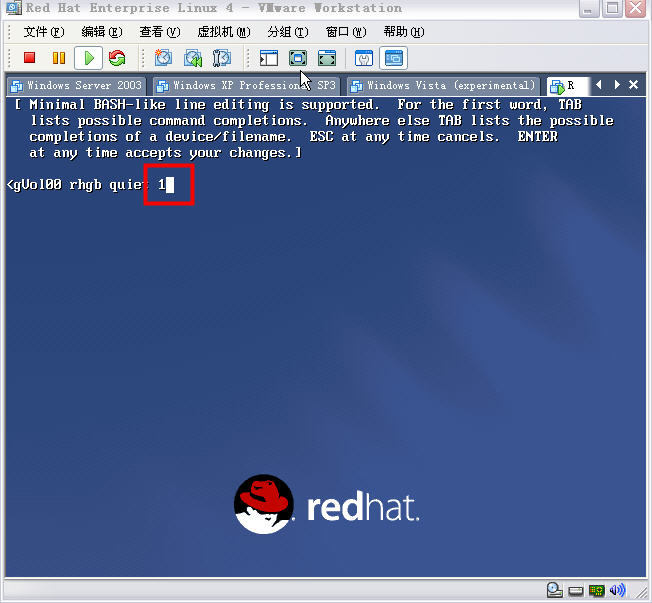
��2���������µĻ����ѡ��������ʾ��ѡ��ٴΰ���e��ť��
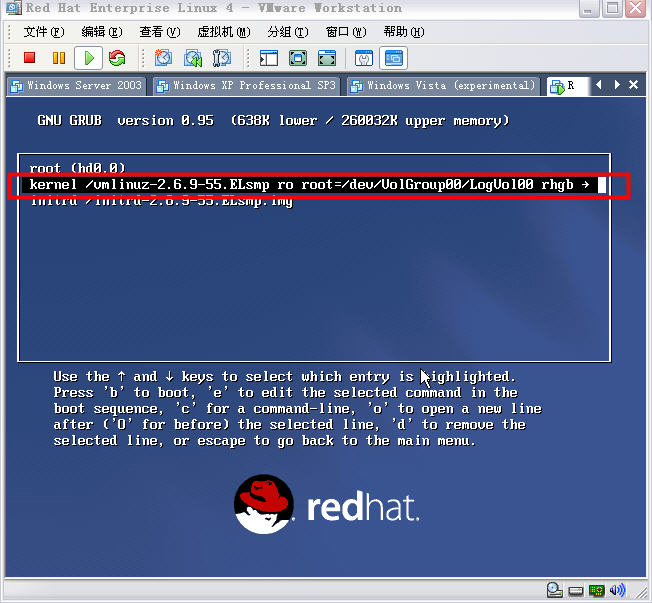
Ȼ��������ʾ��ҳ������ո��1������Enter��ť������ͼ��
��3�����ص�����ҳ����b��ť��linux��
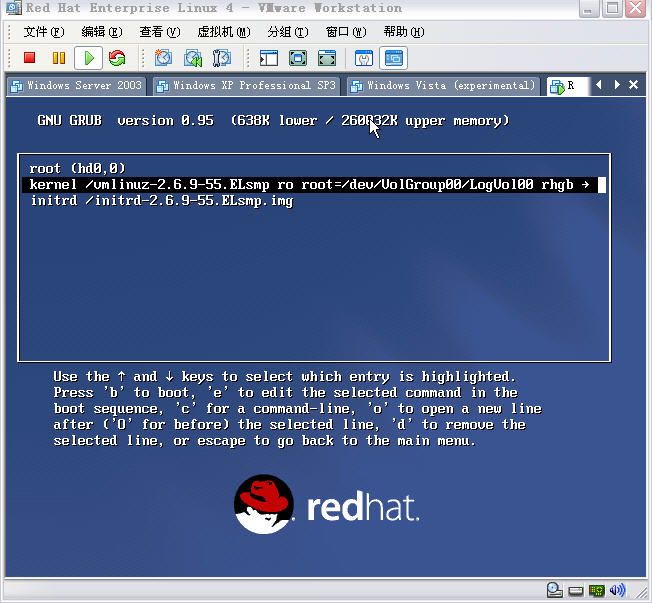
����������ͼ��ʾ��

��4����passwd������root�û����룻
��5������reboot����shutdown -r now��������linux����������ϣ�����ͼ��

OK��ϵͳ������������ʹ���������½ϵͳ��
�������� ��
����1����ϵͳ���̵ĵ�һ�Ų����������������ϵͳ���ӹ����ɹ���������boot: ������linux rescue�س��� ��
����2�������������������ߣ������������硣�������Ƿ�����������ϵͳ����ʱѡ���ǡ���ϵͳ���롰������ʾ���¡� ����
����3��ִ������chroot /mnt/sysimage/ ��Ĭ�ϵ�ϵͳ�����/mnt/sysimage/Ŀ¼�£� ��
����4��ִ������/usr/bin/passwd����root��� ��
����5��ִ������exit; ��ȡ�����̣���������ϵͳ�� ��
����Ȼ�����µĿ����¼ϵͳ�� ��
�����������root��������LoadRunner ����QC���⼰�������
2008-11-18 13:36:52
ʹ��Loadrunner->����->qc���ӣ�����http://qc������IP���˿�/qcbin��
���ִ�����Ϣ
��1����Failed to create list of projects on current Quality Center server.��
��2����Failed to Get Domain List.��
��3����Server has been disconnected while performing GetDomainList action����ϣ�This error may occur with previous version of QuickTest Professional, WinRunner, or LoadRunner, which do not support the new authentication procedure that TestDirector for Quality Center 9.0 uses. This can also happen when using the QC OTA API to create any utilities to connect to QC projects.
���������Define BACKWARD_SUPPORT_ALL_DOMAINS_PROJECTS as "Y" in the Site Administrator
This parameter enables the use of DomainList and ProjectsList properties for the purposes of backward compatiblity. If this parameter is set to "Y," the DomainList and ProjectsList properties are supported.�������裺
1. Launch the Site Administrator.
2. Select the Site Configuration tab.
3. Set the value for BACKWARD_SUPPORT_ALL_DOMAINS_PROJECTS to Y.����˵����
If the parameter does not exist, you will need to add it.
��������
�ҵĴ浵
����ͳ��
- ������: 48962
- ��־��: 19
- ����ʱ��: 2008-11-13
- ����ʱ��: 2008-12-16
