
-
windws xp 下安装 ruby on rails
2009-07-30 14:37:10

 1. 安装RadRails
1. 安装RadRails
1.1 安装JRE, 下载页面http://java.sun.com/javase/downloads/
1.2 安装Ruby One-Click Installer, 下载页面http://www.ruby-lang.org/en/downloads/这个安装比较简单,下一步就可以了,不过有一点需要注意一下,安装的时候有个“enable gem”选项建议勾上。我安装的是ruby1.8.6
1.3这一步可以选择自动安装或者手动安装,自动安装其实就是自动从网上下载安装包然后安装,建议网速好的时候再选择 这种方式(1)自动安装:安装Rails, Windows CMD(开始-->运行-->cmd) 中运行"gem install rails --include-dependencies"这里也可以不带参数输入,直接输入gem install rails ,你可以看到详细的安装过程,你可以知道都安装了些什么东东进去。不过有可能过程中需要你输入多次 Y(2)手动安装:1、分别去http://rubyforge.org/frs/?group_id=307 去下载rails (我下载的是1.1.6版本);
http://rubyforge.org/projects/activesupport 去下载activesupport(我下载的是1.3.1版本);
http://rubyforge.org/projects/activerecord/ 去下载activerecord(我下载的是1.14.4版本);
http://rubyforge.org/projects/actionpack 去下载actionpack(我下载的是1.12.5版本);
http://rubyforge.org/projects/actionmailer 去下载actionmailer(我下载的是1.2.5版本);
http://rubyforge.org/projects/aws 去下载actionwebservice(我下载的是1.1.6版本);
http://rubyforge.org/projects/rake 去下载rake(我下载的是0.7.1版本);
以上所有下载文件都包括zip和gem;
2.把第三步中下载的所有文件放到一个目录中,比如我把它放在了D:\rails中;
3.打开cmd,进入 D:\rails分别执行或者同等效果的D:\rails>gem install activesupport -v 1.3.1
D:\rails>gem install activesupport-1.3.1.gem
D:\rails>gem install activerecord-1.14.4.gem
D:\rails>gem install actionpack-1.12.5.gem
D:\rails>gem install actionmailer-1.2.5.gem
D:\rails>gem install actionwebservice-1.1.6.gem
D:\rails>gem install rake-0.7.1.gem
D:\rails>gem install rails-1.1.6.gem
到此安装过程已经结束,可以看看rails版本:C:\Documents and Settings\3238-wb>rails -vRails 2.3.31.4 下面是安装常用的IDE 推荐radrails 和 aptana(1)1、安装RadRails, 下载页面http://nchc.dl.sourceforge.net/sourceforge/radrails/radrails-0.7.1-win32.zip像Eclipse一样,直接下载下来解压缩,不用安装就可以用2、RadRails的参数配置下面是本篇文章最为重要的一个地方,也是我在开始使用RadRails时比较困扰我的一个地方,就是对它的配置,这里我也多用些笔墨介绍一下。其实主要是Interpreter Name、Ruby、Rails及Rake等几个参数的配置。先说Interpreter,在RadRails环境里
配置Interpreters
Window>Preferences>Ruby>Installed Interpreters,然后点击那个“Add”按钮,在Interpreter Name里随便输入一个名字,比如Ruby,然后在Path选择Ruby路径下的“ruby.exe”文件,比如我现在就是“C:\ruby\bin\ruby.exe”
配置Ri/rdoc
打开"Windows-->Preferences", 选择"Ruby-->Ri/rdoc"- //bin目录下面的rdoc文件,没有扩展名,不是rdoc.bat
- RDoc path: D:\ruby\bin\rdoc
- //bin目录下面的ri文件,没有扩展名,不是ri.bat
- Ri path: D:\ruby\bin\ri
配置Rails和Rake
打开"Windows-->Preferences", 选择"Rails-->Configuration"下面是Rails,在Window>Preferences>Rails>Configuration,Rails path选择目录下的rails文件(没有扩展名),特别注意不是rails.bat,如果选择了这个文件,操作无效,这一点可能是很多人易犯的一个毛病;对Rake也是,在同一个地方,点开文件选择框后,选择rake的二进制文件(没有扩展名),特别注意不是rake.bat,如果选择了这两个文件,依然是无效,
- //bin目录下面的rails文件, 没有扩展名, 不是rails.bat
- Rails Path: D:\ruby\bin\rails
- //bin目录下面的rake文件, 没有扩展名, 不是rake.bat. 如果没有rake文件,运行gem update rake(安装) 或者 gem install rake(升级)
- Rake Path: D:\ruby\bin\rake
- //bin目录下面的mongrel_rails文件, 没有扩展名. 如果没有,运行gem install mongrel 安装
- Mongrel Path: D:\ruby\bin\mongrel_rails
如果找了半天没有找到这个文件,说明你没有安装,可以用gem update rake下载。
3、初识radrails
下面让我保存好这些设置,在RadRails里面建立一个新文件。为简单起见,我们就直接在File>New下面的Rails里面点击Rails Project,建立一个名字为demo的项目,其它设置为默认。这时服务器及相关的基础代码RadRails已经帮你生成好了,在右下方的视图里有个名为“Servers”的,如果不出意外,在里面会出现一个名为“demoServer”的记录,这表示已经有了一个属于项目demo、端口号为3000、状态为停止的服务器。点击此视图右上角的绿色按钮,启动服务器,然后在你的IE浏览器,或者此绿色按钮旁边的一个蓝球,在URL框里输入http://localhost:3000。大功告成,出现了什么?很神奇吧~~~Welcome aboard
(2)Apatana:等有时间再奉上……刚接触ruby不久…… 各位大牛多多指点…… -
RUBY获取当前的执行文件的路径和目录
2009-11-21 15:57:59
获得当前执行文件的文件名:
__FILE__
获得当前文件的目录
File.dirname(__FILE__)
获得当前执行文件的完整路径
require ‘pathname’
Pathname.new(__FILE__).realpath获得当前执行文件的目录完整路径
require ‘pathname’
Pathname.new(File.dirname(__FILE__)).realpath如果使用$0: $0是整个ruby执行文件最顶层文件的路径。因此使用if __FILE__==$0可以判断当前ruby文件是被引用还是被执行
-
ruby 中内部变量大全
2009-11-21 15:45:18
在ruby程序中,经常会看到一些以$开头的变量,这些不是指我们自己在程序中设置的全局变量,而是指系统内部已经设置好的变量,他们代表了一些特定的意思,下面搜集了一些常用的内部变量,用一些简单的代码说明他们代表的意思:
局部域:
在某一个线程作用域内才能有效,下列也可看做是线程内的局部变量.
PS:这边讲解的几个变量都是于正则匹配相关的,正则匹配过程的代码是一样的,这里不重复输入正则表达式匹配的代码,只在第一个例子里给出完整的输入和输出,之后的例子只直接输出变量的值
$_
gets或readline最后读入的字符串.若遇到EOF则为nil.该变量的作用域是局部域.Ruby代码- irb(main):006:0> $_
- => nil
- irb(main):007:0> gets
- foobar
- => "foobar\n"
- irb(main):008:0> $_
- => "foobar\n"
$&
在当前作用域中,正则表达式最后一次匹配成功的字符串.若最后一次匹配失败,则为nil.Ruby代码- irb(main):002:0> $&
- => nil
- irb(main):010:0> /(foo)(bar)(BAZ)?/ =~ "foobarbaz"
- => 0
- irb(main):011:0> $&
- => "foobar"
$~
在当前作用域中,最后一次匹配成功的相关信息(MatchData对象-为处理与正则表达式的匹配过程相关的信息而设置的类.).
可以使用$~[n]的形式从该数据中抽取第n个匹配结果($n).相当于是$1,$2...
等同于Regexp.last_match.Ruby代码- irb(main):012:0> $~
- => #<MatchData "foobar" 1:"foo" 2:"bar" 3:nil>
- irb(main):026:0> $1
- => "foo"
- irb(main):027:0> $~[1]
- => "foo"
$`
在当前作用域中,正则表达式最后一次匹配成功的字符串前面的字符串.若最后的匹配失败则为nil.
等同于Regexp.last_match.pre_match.Ruby代码- irb(main):016:0> $`
- => "" #由于最后匹配成功的内容是foobar,输入的字符串前面没有别的字符所以是""
$'
在当前作用域中,正则表达式最后一次匹配成功的字符串后面的字符串.若最后的匹配失败则为nil.
等同于Regexp.last_match.post_match.Ruby代码- irb(main):028:0> $'
- => "baz"
$+
在当前作用域中,正则表达式最后一次匹配成功的字符串部分中,与最后一个括号相对应的那部分字符串.若最后的匹配失败则为nil.在多项选择型匹配模型中,若您无法断定是哪个部分匹配成功时,该变量将会非常有用.Ruby代码- irb(main):029:0> $+
- => "bar"
$1
$2
$3 ...
分别存储着最后一次模型匹配成功时与第n个括号相匹配的值.若没有相应的括号时,其值为nil.等同于Regexp.last_match[1], Regexp.last_match[2],...Ruby代码- irb(main):030:0> $1
- => "foo"
- irb(main):031:0> $2
- => "bar"
- irb(main):032:0> $3
- => nil
线程局部域
下列变量在一个线程内部时是全局域变量,但在不同的线程之间是彼此独立的.
$!
最近发生的异常的信息.由raise设定.Ruby代码- def exception
- begin
- raise "exception test."
- ensure
- puts $!
- end
- end
- exception
结果:引用
simple.rb:58:in `exception': exception test. (RuntimeError)
from simple.rb:64
exception test. # $!中的值
$@
以数组形式保存着发生异常时的back trace信息. 数组元素是字符串,它显示了方法调用的位置,其形式为
"filename:line"
或
"filename:line:in `methodname'"
在向$@赋值时,$!不能为nil。Ruby代码- def exception
- begin
- raise "exception test."
- ensure
- puts $@
- puts "$@ size is:#{$@.size}"
- end
- end
- exception
结果:引用
simple.rb:58:in `exception': exception test. (RuntimeError)
from simple.rb:65
simple.rb:58:in `exception' #$@中的值,是一个数组,第一个元素是错误发生的行数,第二个是异常的内容。下面打印了数组的长度
simple.rb:65
$@ size:2
全局域
这种类型的变量是整个应用中都可以访问的,而且是同一个变量的引用。是全局作用域的
$/
输入记录分隔符。默认值为"\n"。Ruby代码- irb(main):076:0> $/ #初始的输入分割符
- => "\n"
- irb(main):077:0> gets
- => "\n"
- irb(main):078:0> "test" #输入回车之后,默认插入"\n",输入结束
- => "test"
- irb(main):079:0> $/="@" #修改输入符为"@"
- => "@"
- irb(main):080:0> gets #输入回车之后没有结束读取进程,直到输入"@"之后结束
- test
- @
- => "test\n@"
$\
输出记录分隔符。print会在最后输出该字符串。
默认值为nil,此时不会输出任何字符。Ruby代码- irb(main):082:0> print "abc"
- abc=> nil
- irb(main):083:0> $\="@"
- => "@"
- irb(main):084:0> print "abc"
- abc@=> nil
$,
默认的切分字符。若Array#join中省略了参数时或在print的各个参数间将会输出它。
默认值为 nil ,等同于空字符串。Ruby代码- irb(main):087:0> ["a","b","c"].join
- => "abc"
- irb(main):088:0> $,="," #修改切分字符为","
- 查看(399) 评论(0) 收藏 分享 管理
-
37个我爱Ruby的理由
2009-11-10 12:12:26
我不打算浪费时间来谈论Ruby的历史,如果你没有听说过它,你可以去它的主页看看www.ruby-lang.org,或者去它的新闻组comp.lang.ruby。如果你知道Ruby,我将讲述我为什么会喜爱它。原著:http://hypermetrics.com/ruby.html
翻译:liubin http://www.ruby-cn.org/
一切权利归原作者所有,转载请保留。
2004/12/3
我不打算浪费时间来谈论Ruby的历史,如果你没有听说过它,你可以去它的主页看看www.ruby-lang.org,或者去它的新闻组comp.lang.ruby。如果你知道Ruby,我将讲述我为什么会喜爱它。(你也可能去我的Ruby主页或者个人主页看看)
1.
它是面向对象的。 这表示什么意义呢?如果问10个程序员,你也许会得到12种结果,你有你的看法,我不会试图去改变你的看法。但是有一点,Ruby提供了对数据和方法的封装,允许类的继承,对象的多态。不像其它语言(C++,Perl等),Ruby从设计的时候开始就是一种面向对象的语言。
2.
它是纯面向对象的语言。难道是我多余?不是这样的,之所以这么说,因为Ruby中一切都是对象,包括原始数据类型(primitive data types),比如字符串,整型,都表示的是一个对象,而不需要Java那样提供包装类(wrapper classes)。另外,甚至是常量,也会被当作对象来处理,所以一个方法的接收者,可以是一个数字常量。
3.
它是动态语言。 对于只熟悉像C++,Java这样静态语言的人来说,这是一个重大的概念上的差别。动态意味着方法和变量可以在运行时候添加和重定义。它减少了像C语言那样的条件编译(#ifdef),而且容易实现反射API(reflection API)。动态性使得程序能自我感知(self-aware),比如运行时类型信息,检测丢失的方法,用来检测增加方法的钩子等。在这些方面Ruby和Lisp和Smalltalk都有一些关系。
4.
它是一种解释执行的语言。这是一个负杂的问题,值得重点解释一下,也许这个特点会因为性能的原因而引起从优点变为缺点的争论。对于此,我有几点见解:1.第一:快速开发循环是一个巨大的好处,这要得意于Ruby的解释执行。2.多慢才叫慢呢?在说它慢之前先定一个慢的基准。3.也许有人要批评我了,但我还要说:处理器每年都在变得原来越快。4.如果你真的很在意你的速度,你可以用C开发一部分你的代码。5.最后,从某种意义上说,这是一个还在争论中的问题,没有一个语言天生就是解释型的,世界上没有哪个法律进制开发一个Ruby编译器出来。
5.
它理解正则表达式。 很多年之前,正则表达式只是用在UNIX的工具如grep或者sed中,或者在vi中进行一些一定的查找-替换等。Perl的出现解决了这些问题,而现在,Ruby同样也能做到这些。越来越多得人认识到了这种字符串和文本处理技术的难以置信的能力,如果你对此表示怀疑,那么请去看一下 Jeffrey Friedl的书Mastering Regular Expressions,然后,你就应该不会有什么怀疑了。
6.
它是多平台的。 Ruby可以运行在Linux,UNIX,Windows,BeOS,甚至MS-DOS。如果我没记错,甚至还有一个Amiga 版本的
7.
它是派生来的。 这是一件好事情吗?抛去书本上的知识,它是有用的。牛顿曾说过“我如果看得比别人远,那是因为我站在巨人的肩膀上”。Ruby同样也是站在巨人的肩膀上,它借鉴了Smalltalk, CLU, Lisp, C, C++, Perl, Kornshell等的优点。在我看来它的原则包括:1.不要重复制造轮子。2.不要修补没有损坏的东西。3.最后一个也是比较特别的,它能平衡(Leverage )你已有的知识。你了解UNIX的文件和管道,没关系,你可以在Ruby中继续用,你用了两年的时间学习了printf 指示符,不必担心,Ruby中你也可以使用printf。你知道Perl的正则表达式处理,那么你也就学会了Ruby中的正则表达式。
8.
它是创新的。 是不是觉得这个和第七条矛盾了?也许是有一部分矛盾,每个硬币都有两面。一些Ruby的特点都是创新的东西,比如非常有用的Mix-in,也许这个特点会被后来的语言借鉴。(注:一位读者指出Lisp早在1979年就有mix-in了,这是我的疏忽;我应该找个更好的例子,并且能确信它。)
9.
它是非常高层次的语言。(Very High-Level Language :VHLL) 这是一个容易引起争论的话题,因为这个术语还没有广泛使用。而且它的意思比起OOP来说还是有讨论余地的。我这么说,指的是Ruby能支持复杂的结构和这些结构的负杂的操作,而需要的指令非常少,这与最小努力原则(Principle of Least Effort)一致。
10.
它有一个灵巧的垃圾收集器。 像malloc和free 这样的例程已经是昨天的恶梦了,你不需要什么回收内存的操作,甚至是调用垃圾收集器。
11.
它是脚本语言。 不要因为此就认为它不够强大,它不是一个玩具。它是完全成熟的语言,用它能轻松的完成传统的脚本操作,比如运行外部程序,检查系统资源,使用管道,捕获输出等等。
12.
它是通用的。 Kornshell做的东西它也可以做,C语言做的东西它也可以做的很好。你可以用它写一个只运行一次的只有10行的程序,或者对一些遗留程序进行包装,你想写个web server,或者一个CGI,都可以用Ruby来写。
13.
它是多线程的。 Y你可以用一些简单的API来写多线程程序,甚至在MS-DOS上都可以。
14.
它是open source的。 你想看它的源代码吗?可以,你也可以提交补丁,参加广泛的社区,包括它的创造者。
15.
它是直觉得。 Ruby的学习曲线比较低,而如果你翻过了一个坎,你开始“猜测”事情是怎么工作的,而且你的猜测很多时候都是正确的。Ruby坚持最小惊讶( Least Astonishment)的原则。
16.
它有异常机制。 像Java和 C++一样, Ruby 中也有异常机制,这意味着你不必因为返回值而将代码弄得凌乱不堪,很少的嵌套if语句,很少的意大利面条似的逻辑,更好的错误处理。
17.
它有一个高级的数组类:Array。 Ruby 中数组都是动态的,你不必像pascal那样在声明它的大小,也不必像C,C++那样为它分配内存。它们是对象,所以你不必关心它们的长度,实际上你不能"走到末尾(walk off the end)"。这个类提供了各种方法,使得你能够根据索引,根据元素来访问数组内容,也可以反向处理数组。你也可以用数作作为set,队列,堆栈等。如果你想用查找表,可以用哈希结构。
18.
它是可以扩展的。 你可以用C或者Ruby来编写外部库(external libraries),同样,你也可以修改已有的类和对象。
19.
鼓励文档编程(literate programming)。 你可以在Ruby程序中嵌入注释或者文档,这些文档可以用Ruby的文档工具提取和处理。(真正的文档编程者可能认为这是必须的基本东西吧)
20.
创造性的使用标点符号和大写字母。 比如一个方法返回一个boolean型(Ruby中并没有这种说法),那么一般这个方法最后都以问号结尾,如果一个方法要修改接收者本身,或者具有破坏性,则用一个感叹号结尾,简单,直觉。所有常量,包括类名,都以大写字母开头,所有对象属性以@符号开头。这有匈牙利命名法的实用性,但是没有视觉上的丑陋性。
21.
Reserved words aren't.It's perfectly allowable to use an identifier that is a so-called "reserved word" as long as the parser doesn't perceive an amibiguity. This is a breath of fresh air.(能用保留字作为变量吗?没看太懂。)
22.
支持迭代器。 这使得你可以给一个数组,list,tree等对象传递一个块,然后对它们的每个元素进行block调用。这个技术值得深入学习。
23.
它的安全性。 Ruby借鉴了Perl中基于$SAFE变量的分层控制机制 。这对于CGI程序来说非常有用,可以防止人们攻击web服务器。
24.
Ruby中没有指针。 像 Java一样,和C++不同,Ruby中没有指针的概念,所以免除了关于指针语法和调试的头疼。当然,这也意味着最底层的程序开发将会很困难,比如访问一个设备的控制状态寄存器;但是,我们可以用一个C库来调用。(像C语言程序员有时候要使用汇编语言一样,Ruby程序员有时候也要使用C语言来完成一定的任务)
25.
它使得人们专注于细节。 Ruby中有很多同义词和别名,你也许不记得字符串或数组的长度是size还是length,没关系,它们任何一个都可以工作。对于Range来说,你可以使用begin 和end 或者使用 first 和 last,它们也都工作。你想拼写indices,结果写成了indexes,没关系,这两个都一样。
26.
非常灵活的语法。 方法调用时候括号可以省略,参数之间只需用逗号分割。类似Perl风格的数组定义可以让你不用全部使用引号和逗号定义一个字符串的数组。关键字return可以生路。
27.
丰富的库函数。 Ruby提供了线程,socket,有限对象持久化,CGI,服务器端可执行的,数据库等其它库函数,还有对Tk的支持等。还有很多其它的库函数。
28.
本身自带调试器(debugger)。 在完美的世界中,我们才不需要调试器,但是这个世界不是完美的。
29.
交互式执行。 可以用Ruby像Kornshell那样执行。 (这可能是本页最具争论的一点,我不得不承认,Ruby真的不是一个很好的shell。但我仍然坚持,基于Ruby的shell是一个不错的主意。)
30.
它是简明的。 不像Pascal那样要求if后面跟着then,while后面跟着do 。变量不需要声明,它们不需要类型。返回类型不必指定,关键字return 可以省略,它将返回最后一个表达式的值。另一方面,它也不像Perl或者C那样复杂难懂。
31.
它是面向表达式的(expression-oriented)。 你可以轻易的使用 x = if a<0 then b else c? 这样的表达式。
32.
语法砂糖(syntax sugar)。 (像Mary Poppins解释:一勺语法的糖能使语义被接受) 。如果你想对数组x进行迭代,可以用for a in x。你也可以用a+=b代替a=a+b,这都行。很多操作符其实在Ruby中都是方法,这些方法的名字比较直观,短小,有着便利的语法。
33.
它支持操作符重载。 如果我没有记错的话,早在很久之前的SNOBOL就提供了这个功能,但是直到C++它才变得流行。虽然它可能乱用而出错,但是这仍是一个非常不错的优点。另外Ruby自动定义操作符的赋值版本,比如,如果你重定义了+,那么,你同时得到了一个+=操作符。
34.
支持无限精度的数字。 有人会关心 short, int, long吗,只需要使用 Bignum就行了,你可以轻松的实现365的阶乘。
35.
有幂操作符。 在很久以前,我们在BASIC和FORTRAN中使用它,然而当我们学习Pascal和C之后,我们才认识到这个操作符有多差劲。(我们被告知自己连它是怎么工作的都不知道-它使用了对数,迭代了吗,效率如何?),但是,我们真的关系这些吗?如果是,我们可以重写这个方法,否则,Ruby有非常好的**操作符可以用。
36.
强大的字符串处理。 If如果你想查找,判断,格式化,trim,定界(delimit),interpose,tokenize,你可以自己选择随便用哪一个来得到你想要的结果。
37.
规则很少引起异常。 Ruby的语法和语义比其它语言有条理,每种语言都有独特的一面,每条规则都会有异常发生,但是Ruby规则引起的异常就少的多了。 -
DES的基本流程
2009-11-02 23:18:16
DES的基本流程如下图所示:

通过56位密钥和64位明文之间的各种替换和迭代运算,最后生成64位的密文。在实际应用中通常明文和密钥都是8个字节,但是对于8个字节的密钥而言,每个字节只有前面的7位数据是有效的,第8位数据在DES计算过程中是忽略的,也就是说,如果你计算的密钥值分别为:0102030405060708,和0003020504070609,那么计算的结果应该是一样的,因为两组数据分别去掉每个字节的第8位之后是完全相同的。
其中:
IP代表初始置换(Initial Permutation),说白了就是把原来的数据按照规定的格式进行重新组合,俗话说就是倒腾数据;
PC-1:表示置换选择1(Permutation Choice 1),也是按照规定的格式倒腾;
PC-2:表示置换选择2(Permutation Choice 2),含义同上;
IP-1:表示逆初始置换,按照和IP初始置换相反的方式把数据再倒腾回来。
在实际应用中一般有单DES和三DES两种方式,我们把明文记作:P,密文记作:E,密钥记作:K,加密记为:DES(),解密记为:DES-1(),那么单DES加密可以描述为:
E=DES(P,K)
单DES解密类似可以描述为:
P=DES-1(E,K)
对于三DES而言,可以理解为用三个密钥K1,K2,K3分别进行三次加解密来求得最终的密文,可以描述为:
E=DES(DES-1(DES(P,K1),K2),K3)
实际应用中多数的三DES运算都使用16字节的密钥,分别定义为左右两个子密钥,即KL和KR,称为双长度密钥的三DES运算,加解密公式可以描述为:
E=DES(DES-1(DES(P,KL),KR),KL)
P=DES-1 (DES (DES-1 (E,KL),KR),KL)
目前多数智能卡芯片都已经集成了硬件DES引擎,可以很方便地进行DES运算,而如果使用软件实现DES的话,一个DES算法大约需要占用1K左右的代码空间,对于没有接触过DES算法的工程师来说,通常需要一周的时间可以完成一个比较完美的汇编语言DES算法。而如果采用C语言的话,时间会稍微快一点。
-
ECB CBC and 3DES
2009-11-01 21:25:36
从上一篇《DES 算法详述》文章中,已经知道了DES算法的详细过程,但上一篇文章主要解决的是一个八字节数据DES加密的问题,这一篇文章要解决数据加密——数据补位的问题、DES算法的两种模式ECB和CBC问题以及更加安全的算法——3DES算法。
一、数据补位
DES数据加解密就是将数据按照8个字节一段进行DES加密或解密得到一段8个字节的密文或者明文,最后一段不足8个字节,按照需求补足8个字节(通常补00或者FF,根据实际要求不同)进行计算,之后按照顺序将计算所得的数据连在一起即可。
这里有个问题就是为什么要进行数据补位?主要原因是DES算法加解密时要求数据必须为8个字节。
二、ECB模式
DES ECB(电子密本方式)其实非常简单,就是将数据按照8个字节一段进行DES加密或解密得到一段8个字节的密文或者明文,最后一段不足8个字节,按照需求补足8个字节进行计算,之后按照顺序将计算所得的数据连在一起即可,各段数据之间互不影响。
三、CBC模式
DES CBC(密文分组链接方式)有点麻烦,它的实现机制使加密的各段数据之间有了联系。其实现的机理如下:
加密步骤如下:
1)首先将数据按照8个字节一组进行分组得到D1D2......Dn(若数据不是8的整数倍,用指定的PADDING数据补位)
2)第一组数据D1与初始化向量I异或后的结果进行DES加密得到第一组密文C1(初始化向量I为全零)
3)第二组数据D2与第一组的加密结果C1异或以后的结果进行DES加密,得到第二组密文C2
4)之后的数据以此类推,得到Cn
5)按顺序连为C1C2C3......Cn即为加密结果。
解密是加密的逆过程,步骤如下:
1)首先将数据按照8个字节一组进行分组得到C1C2C3......Cn
2)将第一组数据进行解密后与初始化向量I进行异或得到第一组明文D1(注意:一定是先解密再异或)
3)将第二组数据C2进行解密后与第一组密文数据进行异或得到第二组数据D2
4)之后依此类推,得到Dn
5)按顺序连为D1D2D3......Dn即为解密结果。
这里注意一点,解密的结果并不一定是我们原来的加密数据,可能还含有你补得位,一定要把补位去掉才是你的原来的数据。
四、3DES 算法
3DES算法顾名思义就是3次DES算法,其算法原理如下:
设Ek()和Dk()代表DES算法的加密和解密过程,K代表DES算法使用的密钥,P代表明文,C代表密表,这样,
3DES加密过程为:C=Ek3(Dk2(Ek1(P)))
3DES解密过程为:P=Dk1((EK2(Dk3(C)))这里可以K1=K3,但不能K1=K2=K3(如果相等的话就成了DES算法了)
3DES with 2 diffrent keys(K1=K3),可以是3DES-CBC,也可以是3DES-ECB,3DES-CBC整个算法的流程和DES-CBC一样,但是在原来的加密或者解密处增加了异或运算的步骤,使用的密钥是16字节长度的密钥,将密钥分成左8字节和右8字节的两部分,即k1=左8字节,k2=右8字节,然后进行加密运算和解密运算。
3DES with 3 different keys,和3DES-CBC的流程完全一样,只是使用的密钥是24字节的,但在每个加密解密加密时候用的密钥不一样,将密钥分为3段8字节的密钥分别为密钥1、密钥2、密钥3,在3DES加密时对加密解密加密依次使用密钥1、密钥2、密钥3,在3DES解密时对解密加密解密依次使用密钥3、密钥2、密钥1。
-
DES 算法详述
2009-11-01 21:23:41
DES算法总的说来可以两部分组成:
一、对密钥的处理。这一部分是把我们用的64位密钥(实际用的56位,去掉了8个奇偶校验位)分散成16个48位的子密钥。
二、对数据的加密。通过第一步生成的子密钥来加密我们所要加密的数据,最终生成密文。
下面就通过这两部分分别介绍DES算法的实现原理。
一.密钥分散——子密钥的生成
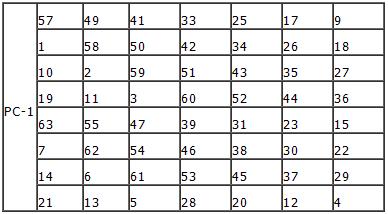
64比特的密钥生成16个48比特的子密钥。其生成过程见图:
64比特的密钥K,经过PC-1后,生成56比特的串。其下标如表所示:

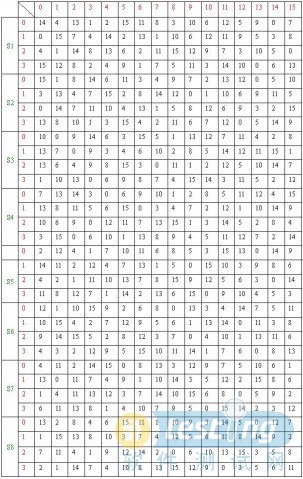
该比特串分为长度相等的比特串C0和D0(分别为28比特)。然后C0和D0分别循环左移1位,得到C1和D1。C1和D1合并起来生成C1D1。C1D1经过PC-2变换后即生成48比特的K1。K1的下标列表为:
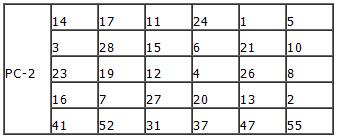
C1、D1分别循环左移LS2位,再合并,经过PC-2,生成子密钥K2……依次类推直至生成子密钥K16。
注意:Lsi (I =1,2,….16)的数值是不同的。具体见下表:

注:PC-1 和 PC-2是密钥的指定为置换。
至此,我们已成功的生成了16个48位的子密钥。
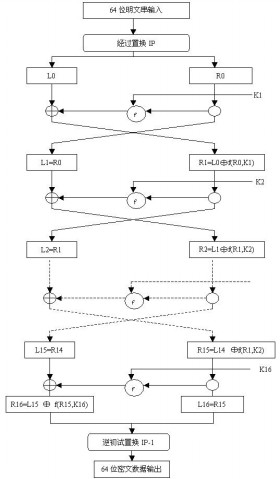
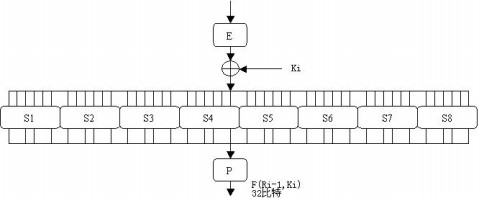
二.加密流程图
DES算法处理的数据对象是一组64比特的明文串。设该明文串为m=m1m2…m64 (mi=0或1)。明文串经过64比特的密钥K来加密,最后生成长度为64比特的密文E。其加密过程图示如下:
二. DES算法加密过程
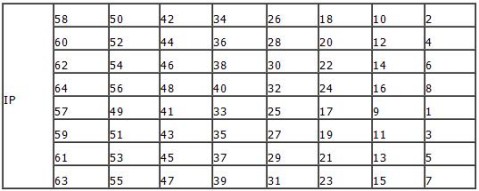
对DES算法加密过程图示的说明如下:待加密的64比特明文串m,经过IP置换后,得到的比特串的下标列表如下:
该比特串被分为32位的L0和32位的R0两部分。R0子密钥K1经过变换f(R0,K1)(f变换算法见下)输出32位的比特串f1,f1与L0做异或运算。
f1与L0做异或运算后的结果赋给R1,R0则原封不动的赋给L1。L1与R0又做与以上完全相同的运算,生成L2,R2…… 一共经过16次运算。最后生成R16和L16。其中R16为L15与f(R15,K16)做不进位二进制加法运算的结果,L16是R15的直接赋值。R16与L16合并成64位的比特串。值得注意的是R16一定要排在L16前面。R16与L16合并后成的比特串,经过置换IP-1后所得比特串的下标列表如下:
经过置换IP-1后生成的比特串就是密文e.。
f 算法
变换f(Ri-1,Ki)的功能是将32比特的输入再转化为32比特的输出。其过程如图所示:
首先、输入Ri-1(32比特)经过变换E后,膨胀为48比特。膨胀后的比特串的下标列表如下:

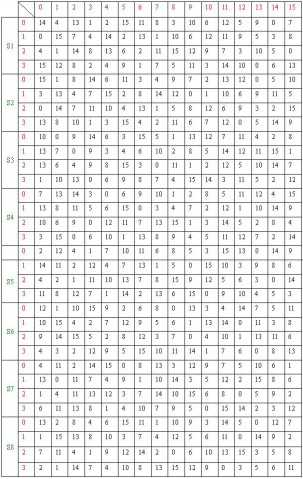
其次、膨胀后的E和Ki异或的结果分为8组,每组6比特。各组经过各自的S盒后,变为4比特,
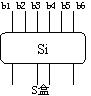
S盒的算法为:输入b1,b2,b3,b4,b5,b6,计算x=b1*2+b6, y=b5+b4*2+b3*4+b2*8,再从Si表(见下表)中查出x 行,y 列的值Sxy。将Sxy化为二进制,即得Si盒的输出。
最后、合并8组S盒输出成为32比特。该32比特经过P变换后,其下标列表如下:

经过P变换后输出的比特串才是32比特的f (Ri-1,Ki)。
以上介绍了DES算法的加密过程。DES算法的解密过程是一样的,区别仅仅在于第一次迭代时用子密钥K16,第二次K15、......,最后一次用K1,算法本身并没有任何变化。
-
Erlang开发环境Windows + Emacs + Distel的配置 Z
2009-10-16 14:59:02
Emacs + Distel是目前为止开发Erlang工程最好的组合(我也是听说的,请选择性接受)。光用Editplus + Erlang Syntax Highlight Plugin实在痛苦,在窗口之间不停地切来切去,调试起来也很成问题。google了一把,决定配一个Emacs + Distel的环境。配好后,基本功能试了试,挺好用,高级功能还没有用到,以后再说。
我的环境:
WinXP Pro SP2 + Erlang R12B-5 + Emacs 22.3 + Distel 4.03
首先安装Erlang和Emacs,安装过程和一般应用软件差不多,这里略过。为避免路径中空格带来麻烦,Erlang的安装路径不要带空格(如E:\erl5.6.5)。
然后配置环境变量:
ERL_HOME=E:\erl5.6.5
PATH加入%ERL_HOME%\bin
HOME=E:\erlang(这个路径配置为erlang工程的目录)
解压缩Distel到E:\erl5.6.5\lib\distel-4.03(这个路径随意,便于管理,将它放到erlang的lib下面)
在E:\erlang(环境变量HOME)创建一个名为“.emacs”的文本文件,内容如下:
;; Erlang mode
(setq load-path (cons "E:/erl5.6.5/lib/tools-2.6.2/emacs" load-path))
(setq erlang-root-dir "E:/erl5.6.5")
(setq exec-path (cons "E:/erl5.6.5/bin" exec-path))
(require 'erlang-start)
;; Distel
(let ((distel-dir "E:/erl5.6.5/lib/distel-4.03/elisp"))
(unless (member distel-dir load-path)
(setq load-path (append load-path (list distel-dir)))))
(require 'distel)
(distel-setup);; Some Erlang customizations
(add-hook 'erlang-mode-hook
(lambda ()
;; when starting an Erlang shell in Emacs, default in the node name
(setq inferior-erlang-machine-options '("-sname" "emacs"))
;; add Erlang functions to an imenu menu
(imenu-add-to-menubar "imenu")))
;; A number of the erlang-extended-mode key bindings are useful in the shell too
(defconst distel-shell-keys
'(("\C-\M-i" erl-complete)
("\M-?" erl-complete)
("\M-." erl-find-source-under-point)
("\M-," erl-find-source-unwind)
("\M-*" erl-find-source-unwind)
)
"Additional keys to bind when in Erlang shell.")
(add-hook 'erlang-shell-mode-hook
(lambda ()
;; add some Distel bindings to the Erlang shell
(dolist (spec distel-shell-keys)
(define-key erlang-shell-mode-map (car spec) (cadr spec)))))
别忘记将以上路径更换为自己实际的路径。注意路径分隔符是正斜杠“/”而不是反斜杠“\”。这样emacs启动时可以自动加载erlang mode和distel的配置文件。
再在E:\erlang(环境变量HOME)建立一个名为“.erlang.cookie”的文本文件,内容随意,例如:
it_is_a_secret_file
这个文件是Erlang的Magic Cookie文件。由于Distel需要和运行的erlang节点进行通信,因此这一步不可少。
最后创建一坨Emacs的快捷方式,放在桌面或者任务栏快速启动,右击快捷方式选“属性”,将“起始位置”设为E:\erlang(HOME环境变量)。这样Emacs启动后可以直接定位到erlang工程的目录。
启动Emacs,打开一个erl文件,应该能看到多了一个“Erlang”菜单,菜单下有一个Distel的子菜单,如图:
至此,环境全部配置完成。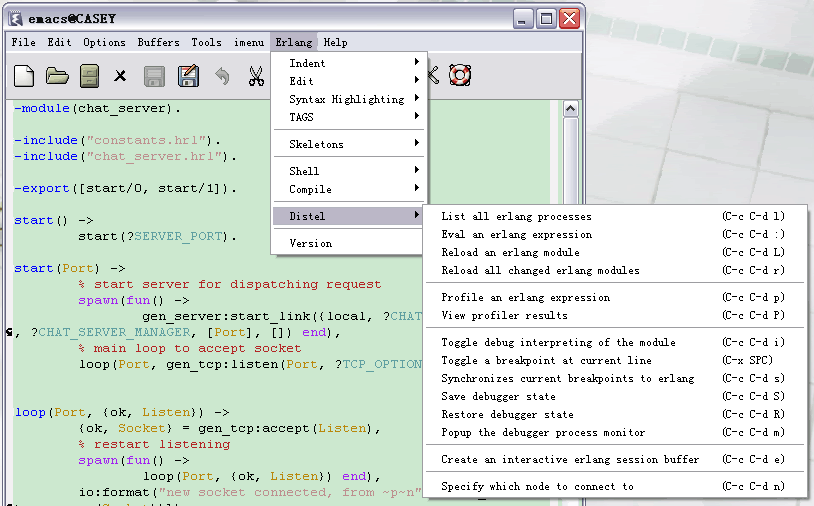
-
ruby--推荐序
2009-09-04 09:57:48
如果你想掌握Ruby,这本书是最好的起点。如果你想运用Ruby,这本书也是案头必备。所以,如果你已经决定要走入Ruby的世界,那么这本书是必经之路,而本不需要一篇“推荐序”。
问题在于,我们为什么还要学习一种新的语言?特别是当Ruby整体上仍然是一个没有完全成熟的“小语种”的时候,为什么要把宝贵的精力投入到Ruby中?这才是我想讨论的问题。
跟很多人一样,我学习程序设计是从Basic语言开始的。然而在初步了解了程序设计的基本概念之后,我便迅速地转向了C语言,并且在上面下了一番苦功夫。是C语言帮助我逐步理解了计算机系统以及算法、数据结构等基础知识,从而迈入程序设计的大门之中的。C语言出色地实现了真实计算机系统的抽象,从而表现出极佳的适应性和强大的系统操控能力。直到今天,我仍认为认真理解和实践C语言是深入理解计算机系统的捷径。然而,当我尝试着用C语言来干点实事的时候,立刻发现一些问题:C的抽象机制过于简单,容易犯错,开发效率低下,质量难以稳定。这时,有一位老师向我介绍了Visual Basic,他盛赞VB是“最高级的开发语言”,代表未来的发展方向。正好当时有一个学校的项目摆在我面前,我几乎没有学习,凭着自己那点Quick Basic的底子,借助在线帮助,迅速地将项目完成,并且获得了好评。
通过这些初级的实践,我体会到VB在开发应用程序方面所具有的惊人的高效率,进而意识到,C与VB是两类设计目标完全不同的语言。以C语言为代表的系统编程语言的优势在于能够充分发挥机器的性能,而像VB这样的语言的优势则是充分提高人的效率。事实上,执行性能与开发效率是软件开发中的一对矛盾,所有的程序设计语言都必须面对这个矛盾,作出自己的选择。
在当时,大多数新语言的选择是上下通吃。它们一方面提供了丰富多彩的高级抽象,另一方面又提供了强有力的底层操作能力,希望由此实现高性能与高效率的统一。C++、Java、C#和Delphi都是走的这条路线,甚至VB从5.0开始也强化了底层操作机制,并提供了编译模型,不落人后。
我当时选择了C++。对于熟悉C语言的我来说,这是一个自然而然的选择。深入学习C++是一个漫长而艰苦的过程,不但要理解伴随面向对象和泛型而来的大量概念,牢记各种奇怪的语法规则,还要了解实践应用中大量存在的陷阱,掌握一系列“模式”、“惯用法”和“条例”。在克服这种种困难的过程中,我对程序设计的认识确实得到了强有力的提升,但是C++真的实现了执行性能和开发效率的双丰收了吗?很遗憾,答案是“否”。我自己的体会是,使用C++要花费大量精力来进行试探性设计,还可能要投入巨大精力来消除代码缺陷,因此开发效率不高。一些权威的调查显示,在新项目的执行中,C++的开发效率甚至低于C,这不得不发人深思。C++提供了大量的语言机制,又存在一些陷阱,想要实现良好的运行性能,就必须遵守一系列清规戒律,这就带来了思想上的不自由,其结果往往是效率的低下。
随后流行的Java和C#等语言,有效地消除了C++中存在的一些陷阱和缺陷,并且提供了很好的基础设施和开发环境,大大提高了开发效率。但是它们都设定了严整的结构和规则,进行严格的编译期检查,强调规范、纪律和计划。这些语言的拥护者们骨子里都认为,构造大规模软件是一个严肃的工程,必须施加强有力的约束和规范,时时刻刻预防和纠正开发者可能犯下的错误。当然,这样必然会导致对开发者思维的束缚和思考效率的限制,从而导致宏观上的低效。但他们认为,这是构造大型高质量软件所必须付出的代价。
然而,世界上另外有一些人的想法完全不同。他们认为,一种“可上九天揽月,可下五洋捉鳖”的终极语言即使能够实现,也注定是低效的。既然这个世界本身就是丰富多彩的,为什么不保留编程语言的多样性,各取所需,各得其所,彼此协同合作,不亦乐乎?既然C语言在充分发挥机器性能方面已经登峰造极,那么就应该尽力创造能够充分发挥人脑效能的程序设计语言。当人的效率充分提高的时候,所有的问题都会迎刃而解,或者至少大为简化。
1998年,我读到一本薄薄的小书,叫做《Perl入门》。这本书介绍了一种完全陌生的语言,不但看上去稀奇古怪,而且骨子里透露出来一股与C++、Java等完全不同的气质:狂放、不羁、乖张、散漫,无法无天。对于当时的我来说,这一切令人诧异,难以接受。而Perl的拥护者似乎也懒得挑战“主流意识形态”,他们自嘲地说,Perl就是骆驼,样子不好看,气味也不好闻,但就是能干活。随后进入视野的Python外表温文尔雅,简朴工整,但其实质与Perl一样,也是崇尚自由灵活,追求简单直接。伴随着Web走来的JavaScript和PHP,虽然外表上差别很大,但是总体上看,与Perl、Python一样,都是把自由放在结构之上,把人放在机器之上的语言。人们称它们为“动态语言”或者“脚本语言”。这些语言的出现和流行,强有力地挑战了过去20年来人们深信不疑的传统观念。传统认为编译阶段的类型检查至关重要,可是动态语言却把这类检查推迟到执行阶段的最后一刻才进行;传统认为严整的结构和严肃的开发过程是必不可少的,可是动态语言却能够用一种看上去随意自由的风格去“堆砌”系统;传统把精致的模型和多层次的设计视为最佳实践,而动态语言却往往是蛮不讲理地直来直去;传统把频繁的变化和修改视为不良过程的标志,而动态语言却将此视为自然而然的工作方式;传统认为必须在机器性能与人的效率之间取得折中,动态语言却偏执地强调人的效率,而把机器性能这档子事情抛到九霄云外。动态语言离经叛道,却又大获成功,不由分说地把人们好不容易搭建起来的那个严谨的、精致的圣殿冲击得摇摇欲坠。人们怀着复杂的心情观察着动态语言的发展,猜度着它的方向和影响。
这时候我发现了Ruby。
很多转向Ruby的人,在谈论这种语言的时候,都提到“乐趣”这个字眼,我也不例外。使用Ruby编程,你会体验到一种难以名状的趣味,这种感觉,就好像是突然掌握了十倍于从前的力量,同时又挣脱了长久以来一直束缚在身上的枷锁一般。“白日放歌须纵酒,青春作伴好还乡”,当年临摹“Hello World”时的淳朴热情仿佛又回到了身上。Ruby实现了最纯粹意义上的面向对象,让Smalltalk、Perl和Lisp的灵魂在新的躯壳里高歌。相比于Python,Ruby的思想更加清晰一致,形式更加灵活;相比于Perl,Ruby更简单质朴,绝少光怪陆离之举;相比于Smalltalk和Lisp,Ruby更富有现代感和实干气质;相比于庙堂之上的“工业语言”,Ruby自由挥洒、轻快锐利;而相比于JavaScript和PHP,Ruby从Smalltalk继承而来的深厚底蕴又大占优势。面对执行性能与开发效率的谜题,Ruby毫不犹豫地选择了开发效率,选择了对人脑的友好。Ruby的基本思想非常简单淳朴,对于基本原则的坚持非常彻底,毫不打折扣,而在具体应用中又集各家所长,实现了巧妙的平衡。从我自己的体验来讲,使用Ruby写程序,与使用C++等主流语言感觉完全不同,没有战战兢兢的规划和设计,没有紧绷的神经,没有一大堆清规戒律,有的是一种闲庭信步的悠然,有的是时不时灵光一闪的洋洋自得,有的是抓住问题要害之后猛冲猛打的快感。我的水平还不高,还不能够设计更精妙的框架和DSL(领域语言),但我相信我已经初步体会到了Ruby的乐趣。
自从这本书的第1版出版以来,Ruby的发展越来越快。最初人们用Ruby来完成一些临时的任务,然后就迅速被它迷住了,越来越多有用和有趣的东西被开发出来,越来越多有才华的人加入了Ruby的阵营,从而形成了一股潜流。这潜流在2003年以后就已经出现了,只是还没有引起外部世界的注意。然而自2005年以后,潜流变成了潮流,越来越多的人被卷进来。整个社群围绕着Ruby的质朴与自由,创造了大量的珍宝(gems)。有人用200行Ruby代码写了一个飞快的全文搜索引擎,有人把(X)HTML的解析变成了CSS Selector的有趣复用,有人用13行Ruby代码完成了一个P2P文件共享程序,有人把Google引以为豪的MapReduce算法轻巧地实现在一个小小的Ruby程序库中。当然,最为人津津乐道的还是Ruby on Rails在Web开发领域掀起的风暴。所有这一切,都令人对Ruby报以越来越热烈的掌声。
今天,Ruby已经成为世界上发展最快的程序设计语言之一,一个充满热情和创造力的社群围绕着它,开展着种种激动人心的工作。在这里没有什么豪言壮语,但是所有的工作都在扎扎实实地推进,人们被自己内心的力量驱动着,而这种力量来自于Ruby质朴和自由的乐趣,它是近于纯粹的。
我深深地知道,Ruby今天还不是“主流”,其前景究竟如何,也不是没有争论。在今天这个时代,选择技术路线是一件关乎生计和名利的事情,是不纯粹也不能纯粹的事情。在各种场合,年轻的或是年长的程序员们头头是道地分析着IT大局,掰着指头计算着技术的“钱”途,这些都无可厚非,甚至非常必要。但是,作为一个把程序设计当成自己的事业,或者至少是职业的人,总应该在自己的内心中留下那么一小片空间,在那里抛开一切功利,回归质朴,追求纯粹的编程的乐趣。如果你跟我一样,希望体会这样一种内心的乐趣,我热情地邀请你翻开这本书,加入Ruby社群。也请你相信,当越来越多的人为着自己的乐趣而共同努力的时候,我们就能创造历史。
-
判断字段中是否包含中文
2009-08-25 17:30:22
SQL> create table test(a varchar2(10));
Table created.
SQL> insert into test values('鸟');
1 row created.
SQL> commit;
Commit complete.
SQL> insert into test values('深刻');
1 row created.
SQL> commit;
Commit complete.
SQL> insert into test values('aaa');
1 row created.
SQL> insert into test values('bbb');
1 row created.
SQL> commit;
Commit complete.
SQL> select a from test;
A
----------
鸟
深刻
aaa
bbb
SQL> select a from test where asciistr(a) like '%\%';
A
----------
鸟
深刻
SQL> select a from test where asciistr(a) not like '%\%';
A
----------
aaa
bbb -
sed命令使用详解
2009-08-19 15:21:31
sed 编辑器是 Linux 系统管理员的工具包中最有用的资产之一,
因此,有必要彻底地了解其应用
Linux 操作系统最大的一个好处是它带有各种各样的实用工具。存在如此之多不同的实用工具,几乎不可能知道并了解所有这些工具。可以简化关键情况下操作的一个实用 工具是 sed。它是任何管理员的工具包中最强大的工具之一,并且可以证明它自己在关键情况下非常有价值。
sed 实用工具是一个“编辑器”,但它与其它大多数编辑器不同。除了不面向屏幕之外,它还是非交互式的。这意味着您必须将要对数据执行的命令插入到命令行或要处 理的脚本中。当显示它时,请忘记您在使用 Microsoft Word 或其它大多数编辑器时拥有的交互式编辑文件功能。sed 在一个文件(或文件集)中非交互式、并且不加询问地接收一系列的命令并执行它们。因而,它流经文本就如同水流经溪流一样,因而 sed 恰当地代表了流编辑器。它可以用来将所有出现的 "Mr. Smyth" 修改为 "Mr. Smith",或将 "tiger cub" 修改为 "wolf cub"。流编辑器非常适合于执行重复的编辑,这种重复编辑如果由人工完成将花费大量的时间。其参数可能和一次性使用一个简单的操作所需的参数一样有限, 或者和一个具有成千上万行要进行编辑修改的脚本文件一样复杂。sed 是 Linux 和 UNIX 工具箱中最有用的工具之一,且使用的参数非常少。
sed 的工作方式
sed 实用工具按顺序逐行将文件读入到内存中。然后,它执行为该行指定的所有操作,并在完成请求的修改之后将该行放回到内存中,以将其转储至终端。完成了这一行 上的所有操作之后,它读取文件的下一行,然后重复该过程直到它完成该文件。如同前面所提到的,默认输出是将每一行的内容输出到屏幕上。在这里,开始涉及到 两个重要的因素—首先,输出可以被重定向到另一文件中,以保存变化;第二,源文件(默认地)保持不被修改。sed 默认读取整个文件并对其中的每一行进行修改。不过,可以按需要将操作限制在指定的行上。
该实用工具的语法为:
sed [options] '{command}' [filename]
在这篇文章中,我们将浏览最常用的命令和选项,并演示它们如何工作,以及它们适于在何处使用。
替换命令
sed 实用工具以及其它任何类似的编辑器的最常用的命令之一是用一个值替换另一个值。用来实现这一目的的操作的命令部分语法是:
's/{old value}/{new value}/'
因而,下面演示了如何非常简单地将 "tiger" 修改为 "wolf":
$ echo The tiger cubs will meet on Tuesday after school | sed
's/tiger/wolf/'
The wolf cubs will meet on Tuesday after school
$
注意如果输入是源自之前的命令输出,则不需要指定文件名—同样的原则也适用于 awk、sort 和其它大多数 LinuxUNIX 命令行实用工具程序。
多次修改
如果需要对同一文件或行作多次修改,可以有三种方法来实现它。第一种是使用 "-e" 选项,它通知程序使用了多条编辑命令。例如:
$ echo The tiger cubs will meet on Tuesday after school | sed -e '
s/tiger/wolf/' -e 's/after/before/'
The wolf cubs will meet on Tuesday before school
$
这是实现它的非常复杂的方法,因此 "-e" 选项不常被大范围使用。更好的方法是用分号来分隔命令:
$ echo The tiger cubs will meet on Tuesday after school | sed '
s/tiger/wolf/; s/after/before/'
The wolf cubs will meet on Tuesday before school
$
注 意分号必须是紧跟斜线之后的下一个字符。如果两者之间有一个空格,操作将不能成功完成,并返回一条错误消息。这两种方法都很好,但许多管理员更喜欢另一种 方法。要注意的一个关键问题是,两个撇号 (' ') 之间的全部内容都被解释为 sed 命令。直到您输入了第二个撇号,读入这些命令的 shell 程序才会认为您完成了输入。这意味着可以在多行上输入命令—同时 Linux 将提示符从 PS1 变为一个延续提示符(通常为 ">")—直到输入了第二个撇号。一旦输入了第二个撇号,并且按下了 Enter 键,则处理就进行并产生相同的结果,如下所示:
$ echo The tiger cubs will meet on Tuesday after school | sed '
> s/tiger/wolf/
> s/after/before/'
The wolf cubs will meet on Tuesday before school
$
全局修改
让我们开始一次看似简单的编辑。假定在要修改的消息中出现了多次要修改的项目。默认方式下,结果可能和预期的有所不同,如下所示:
$ echo The tiger cubs will meet this Tuesday at the same time
as the meeting last Tuesday | sed 's/Tuesday/Thursday/'
The tiger cubs will meet this Thursday at the same time
as the meeting last Tuesday
$
与 将出现的每个 "Tuesday" 修改为 "Thursday" 相反,sed 编辑器在找到一个要修改的项目并作了修改之后继续处理下一行,而不读整行。sed 命令功能大体上类似于替换命令,这意味着它们都处理每一行中出现的第一个选定序列。为了替换出现的每一个项目,在同一行中出现多个要替换的项目的情况下, 您必须指定在全局进行该操作:
$ echo The tiger cubs will meet this Tuesday at the same time
as the meeting last Tuesday | sed 's/Tuesday/Thursday/g'
The tiger cubs will meet this Thursday at the same time
as the meeting last Thursday
$
请记住不管您要查找的序列是否仅包含一个字符或词组,这种对全局化的要求都是必需的。
sed 还可以用来修改记录字段分隔符。例如,以下命令将把所有的 tab 修改为空格:
sed 's// /g'
其 中,第一组斜线之间的项目是一个 tab,而第二组斜线之间的项目是一个空格。作为一条通用的规则,sed 可以用来将任意的可打印字符修改为任意其它的可打印字符。如果您想将不可打印字符修改为可打印字符—例如,铃铛修改为单词 "bell"—sed 不是适于完成这项工作的工具(但 tr 是)。
有时,您不想修改在一个文件中出现的所有指定项目。有时,您只想在满足某些条件时才作修改—例如,在与其它一些数据匹配之后才作修改。为了说明这一点,请考虑以下文本文件:
$ cat sample_one
one 1
two 1
three 1
one 1
two 1
two 1
three 1
$
假定希望用 "2" 来替换 "1",但仅在单词 "two" 之后才作替换,而不是每一行的所有位置。通过指定在给出替换命令之前必须存在一次匹配,可以实现这一点:
$ sed '/two/ s/1/2/' sample_one
one 1
two 2
three 1
one 1
two 2
two 2
three 1
$
现在,使其更加准确:
$ sed '
> /two/ s/1/2/
> /three/ s/1/3/' sample_one
one 1
two 2
three 3
one 1
two 2
two 2
three 3
$
请 再次记住唯一改变了的是显示。如果您查看源文件,您将发现它始终保持不变。您必须将输出保存至另一个文件,以实现永久保存。值得重复的是,不对源文件作修 改实际是祸中有福—它让您能够对文件进行试验而不会造成任何实际的损害,直到让正确命令以您预期和希望的方式进行工作。
以下命令将修改后的输出保存至一个新的文件:
$ sed '
> /two/ s/1/2/
> /three/ s/1/3/' sample_one > sample_two
该输出文件将所有修改合并在其中,并且这些修改通常将在屏幕上显示。现在可以用 head、cat 或任意其它类似的实用工具来进行查看。
脚本文件
sed 工具允许您创建一个脚本文件,其中包含从该文件而不是在命令行进行处理的命令,并且 sed 工具通过 "-f" 选项来引用。通过创建一个脚本文件,您能够一次又一次地重复运行相同的操作,并指定比每次希望从命令行进行处理的操作详细得多的操作。
考虑以下脚本文件:
$ cat sedlist
/two/ s/1/2/
/three/ s/1/3/
$
现在可以在数据文件上使用脚本文件,获得和我们之前看到的相同的结果:
$ sed -f sedlist sample_one
one 1
two 2
three 3
one 1
two 2
two 2
three 3
$
注意当调用 "-f" 选项时,在源文件内或命令行中不使用撇号。脚本文件,也称为源文件,对于想重复多次的操作和从命令行运行可能出错的复杂命令很有价值。编辑源文件并修改一个字符比在命令行中重新输入一条多行的项目要容易得多。
限制行
编辑器默认查看输入到流编辑器中的每一行,且默认在输入到流编辑器中的每一行上进行编辑。这可以通过在发出命令之前指定约束条件来进行修改。例如,只在此示例文件的输出的第 5 和第 6 行中用 "2" 来替换 "1",命令将为:
$ sed '5,6 s/1/2/' sample_one
one 1
two 1
three 1
one 1
two 2
two 2
three 1
$
在这种情况下,因为要修改的行是专门指定的,所以不需要替换命令。因此,您可以灵活地根据匹配准则(可以是行号或一种匹配模式)来选择要修改哪些行(从根本上限制修改)。
禁止显示
sed 默认将来自源文件的每一行显示到屏幕上(或重定向到一个文件中),而无论该行是否受到编辑操作的影响,"-n" 参数覆盖了这一操作。"-n" 覆盖了所有的显示,并且不显示任何一行,而无论它们是否被编辑操作修改。例如:
$ sed -n -f sedlist sample_one
$
$ sed -n -f sedlist sample_one > sample_two
$ cat sample_two
$
在 第一个示例中,屏幕上不显示任何东西。在第二个示例中,不修改任何东西,因此不将任何东西写到新的文件中—它最后是空的。这不是否定了编辑的全部目的吗? 为什么这是有用的?它是有用的仅因为 "-n" 选项能够被一条显示命令 (-p) 覆盖。为了说明这一点,假定现在像下面这样对脚本文件进行了修改:
$ cat sedlist
/two/ s/1/2/p
/three/ s/1/3/p
$
然后下面是运行它的结果:
$ sed -n -f sedlist sample_one
two 2
three 3
two 2
two 2
three 3
$
保持不变的行全部不被显示。只有受到编辑操作影响的行被显示了。在这种方式下,可以仅取出这些行,进行修改,然后把它们放到一个单独的文件中:
$ sed -n -f sedlist sample_one > sample_two
$
$ cat sample_two
two 2
three 3
two 2
two 2
three 3
$
利用它的另一种方法是只显示一定数量的行。例如,只显示 2-6 行,同时不做其它的编辑修改:
$ sed -n '2,6p' sample_one
two 1
three 1
one 1
two 1
two 1
$
其它所有的行被忽略,只有 2-6 行作为输出显示。这是一项出色的功能,其它任何工具都不能容易地实现。Head 将显示一个文件的顶部,而 tail 将显示一个文件的底部,但 sed 允许从任意位置取出想要的任意内容。
删除行
用一个值替换另一个值远非流编辑器可以执行的唯一功能。它还具有许多的潜在功能,在我看来第二种最常用的功能是删除。删除与替换的工作方式相同,只是它删除指定的行(如果您想要删除一个单词而不是一行,不要考虑删除,而应考虑用空的内容来替换它—s/cat//)。
该命令的语法是:
'{what to find} d'
从 sample_one 文件中删除包含 "two" 的所有行:
$ sed '/two/ d' sample_one
one 1
three 1
one 1
three 1
$
从显示屏中删除前三行,而不管它们的内容是什么:
$ sed '1,3 d' sample_one
one 1
two 1
two 1
three 1
$
只显示剩下的行,前三行不在显示屏中出现。对于流编辑器,一般当它们涉及到全局表达式时,特别是应用于删除操作时,有几点要记住:
上三角号 (^) 表示一行的开始,因此,如果 "two" 是该行的头三个字符,则
sed '/^two/ d' sample_one
将只删除该行。
美元符号 ($) 代表文件的结尾,或一行的结尾,因此,如果 "two" 是该行的最后三个字符,则
sed '/two$/ d' sample_one
将只删除该行。
将这两者结合在一起的结果:
sed '/^$/ d' {filename}
删除文件中的所有空白行。例如,以下命令将 "1" 替换为 "2",以及将 "1" 替换为 "3",并删除文件中所有尾随的空行:
$ sed '/two/ s/1/2/; /three/ s/1/3/; /^$/ d' sample_one
one 1
two 1
three 1
one 1
two 2
two 2
three 1
$
其通常的用途是删除一个标题。以下命令将删除文件中所有的行,从第一行直到第一个空行:
sed '1,/^$/ d' {filename}
添加和插入文本
可以结合使用 sed 和 "a" 选项将文本添加到一个文件的末尾。实现方法如下:
$ sed '$a
> This is where we stop
> the test' sample_one
one 1
two 1
three 1
one 1
two 1
two 1
three 1
This is where we stop
the test
$
在该命令中,美元符号 ($) 表示文本将被添加到文件的末尾。反斜线 () 是必需的,它表示将插入一个回车符。如果它们被遗漏了,则将导致一个错误,显示该命令是错乱的;在任何要输入回车的地方您必须使用反斜线。
要将这些行添加到第 4 和第 5 个位置而不是末尾,则命令变为:
$ sed '3a
> This is where we stop
> the test' sample_one
one 1
two 1
three 1
This is where we stop
the test
one 1
two 1
two 1
three 1
$
这将文本添加到第 3 行之后。和几乎所有的编辑器一样,您可以选择插入而不是添加(如果您希望这样的话)。这两者的区别是添加跟在指定的行之后,而插入从指定的行开始。当用插入来代替添加时,只需用 "i" 来代替 "a",如下所示:
$ sed '3i
> This is where we stop
> the test' sample_one
one 1
two 1
This is where we stop
the test
three 1
one 1
two 1
two 1
three 1
$
新的文本出现在输出的中间位置,而处理通常在指定的操作执行以后继续进行。
读写文件
重定向输出的功能已经演示过了,但需要指出的是,在编辑命令运行期间可以同步地读入和写出文件。例如,执行替换,并将 1-3 行写到名称为 sample_three 的文件中:
$ sed '
> /two/ s/1/2/
> /three/ s/1/3/
> 1,3 w sample_three' sample_one
one 1
two 2
three 3
one 1
two 2
two 2
three 3
$
$ cat sample_three
one 1
two 2
three 3
$
由于为 w (write) 命令指定了 "1,3",所以只有指定的行被写到了新文件中。无论被写的是哪些行,所有的行都在默认输出中显示。
修改命令
除了替换项目之外,还可以将行从一个值修改为另一个值。要记住的是,替换是对字符逐个进行,而修改功能与删除类似,它影响整行:
$ sed '/two/ c
> We are no longer using two' sample_one
one 1
We are no longer using two
three 1
one 1
We are no longer using two
We are no longer using two
three 1
$
修 改命令与替换的工作方式很相似,但在范围上要更大些—将一个项目完全替换为另一个项目,而无论字符内容或上下文。夸张一点讲,当使用替换时,只有字符 "1" 被字符 "2" 替换,而当使用修改时,原来的整行将被修改。在两种情况下,要寻找的匹配条件都仅为 "two"。
修改全部但……
对于大多数 sed 命令,详细说明各种功能要进行何种修改。利用感叹号,可以在除指定位置之外的任何地方执行修改—与默认的操作完全相反。
例如,要删除包含单词 "two" 的所有行,操作为:
$ sed '/two/ d' sample_one
one 1
three 1
one 1
three 1
$
而要删除除包含单词 "two" 的行之外的所有行,则语法变为:
$ sed '/two/ !d' sample_one
two 1
two 1
two 1
$
如果您有一个文件包含一系列项目,并且想对文件中的每个项目执行一个操作,那么首先对那些项目进行一次智能扫描并考虑将要做什么是很重要的。为了使事情变得更简单,您可以将 sed 与任意迭代例程(for、while、until)结合来实现这一目的。
比如说,假定您有一个名为 "animals" 的文件,其中包含以下项目:
pig
horse
elephant
cow
dog
cat
您希望运行以下例程:
#mcd.ksh
for I in $*
do
echo Old McDonald had a $I
echo E-I, E-I-O
done
结 果将为,每一行都显示在 "Old McDonald has a" 的末尾。虽然对于这些项目的大部分这是正确的,但对于 "elephant" 项目,它有语法错误,因为结果应当为 "an elephant" 而不是 "a elephant"。利用 sed,您可以在来自 shell 文件的输出中检查这种语法错误,并通过首先创建一个命令文件来即时地更正它们:
#sublist
/ a a/ s/ a / an /
/ a e/ s/ a / an /
/a i/ s / a / an /
/a o/ s/ a / an /
/a u/ s/ a / an /
然后执行以下过程:
$ sh mcd.ksh 'cat animals' | sed -f sublist
现 在,在运行了 mcd 脚本之后,sed 将在输出中搜索单个字母 a (空格,"a",空格)之后紧跟了一个元音的任意位置。如果这种位置存在,它将把该序列修改为空格,"an",空格。这样就使问题更正后才显示在屏幕上, 并确保各处的编辑人员在晚上可以更容易地入睡。结果是:
Old McDonald had a pig
E-I, E-I-O
Old McDonald had a horse
E-I, E-I-O
Old McDonald had an elephant
E-I, E-I-O
Old McDonald had a cow
E-I, E-I-O
Old McDonald had a dog
E-I, E-I-O
Old McDonald had a cat
E-I, E-I-O
提前退出
sed 默认读取整个文件,并只在到达末尾时才停止。不过,您可以使用退出命令提前停止处理。只能指定一条退出命令,而处理将一直持续直到满足调用退出命令的条件。
例如,仅在文件的前五行上执行替换,然后退出:
$ sed '
> /two/ s/1/2/
> /three/ s/1/3/
> 5q' sample_one
one 1
two 2
three 3
one 1
two 2
$
在退出命令之前的项目可以是一个行号(如上所示),或者一条查找/匹配命令:
$ sed '
> /two/ s/1/2/
> /three/ s/1/3/
> /three/q' sample_one
one 1
two 2
three 3
$
您 还可以使用退出命令来查看超过一定标准数目的行,并增加比 head 中的功能更强的功能。例如,head 命令允许您指定您想要查看一个文件的前多少行—默认数为 10,但可以使用从 1 到 99 的任意一个数字。如果您想查看一个文件的前 110 行,您用 head 不能实现这一目的,但用 sed 可以:
sed 110q filename
处理问题
当使用 sed 时,要记住的重要事项是它的工作方式。它的工作方式是:读入一行,在该行上执行它已知要执行的所有任务,然后继续处理下一行。每一行都受给定的每一个编辑命令的影响。
如果您的操作顺序没有十分彻底地考虑清楚,那么这可能会很麻烦。例如,假定您需要将所有的 "two" 项目修改为 "three",然后将所有的 "three" 修改为 "four":
$ sed '
> /two/ s/two/three/
> /three/ s/three/four/' sample_one
one 1
four 1
four 1
one 1
four 1
four 1
four 1
$
最初读取的 "two" 被修改为 "three"。然后它满足为下一次编辑建立的准则,从而变为 "four"。最终的结果不是想要的结果—现在除了 "four" 没有别的项目了,而本来应该有 "three" 和 "four"。
当执行这种操作时,您必须非常用心地注意指定操作的方式,并按某种顺序来安排它们,使得操作之间不会互相影响。例如:
$ sed '
> /three/ s/three/four/
> /two/ s/two/three/' sample_one
one 1
three 1
four 1
one 1
three 1
three 1
four 1
$
这非常有效,因为 "three" 值在 "two" 变成 "three" 之前得到修改。
标签和注释
可以在 sed 脚本文件中放置标签,这样一旦文件变得庞大,可以更容易地说明正在发生的事情。存在各种各样与这些标签相关的命令,它们包括:
接下来的步骤
访问并收藏 Linux 技术中心
阅读 Dale Dougherty 和 Arnold Robbins 的著作 sed & awk, 2nd Edition (O'Reilly & Associates 出版社)。
: 冒号表示一个标签名称。例如:
:HERE
以冒号开始的标签可以由 "b" 和 "t" 命令处理。
b {label} 充当 "goto" 语句的作用,将处理发送至前面有一个冒号的标签。例如,
b HERE
将处理发送给行
:HERE
如果紧跟 b 之后没有指定任何标签,则处理转至脚本文件的末尾。
t {label} 只要自上次输入行或执行一次 "t" 命令以来进行了替换操作,就转至该标签。和 "b" 一样,如果没有给定标签名,则处理转至脚本文件的末尾。
# 符号作为一行的第一个字符将使整行被当作注释处理。注释行与标签不同,不能使用 b 或 t 命令来转到注释行上。 -
数据类型和Json格式
2009-08-04 20:57:45
1.
前几天,我才知道有一种简化的数据交换格式,叫做yaml。
我翻了一遍它的文档,看懂的地方不多,但是有一句话令我茅塞顿开。。
它说,从结构上看,所有的数据最终都可以分成三种类型:
第一种类型是scalar(标量),也就是一个单独的string(字符串)或数字(numbers),比如“北京”这个单独的词。
第二种类型是sequence(序列),也就是若干个相关的数据按照一定顺序并列在一起,又叫做array(数组)或List(列表),比如“北京,东京”。
第三种类型是mapping(映射),也就是一个名/值对(Name/value),即数据有一个名称,还有一个与之相对应的值,这又称作hash(散列)或dictionary(字典),比如“首都:北京”。
我恍然大悟,数据构成的最小单位原来如此简单!难怪在编程语言中,只要有了数组(array)和对象(object)就能够储存一切数据了。
2.
我马上想到了json。
21世纪初,Douglas Crockford寻找一种简便的数据交换格式,能够在服务器之间交换数据。这其实需要二步,第一步是将各种数据转化为一个字符串,也就是数据的串行化(serialization),第二步才是交换这个字符串。
当时通用的数据交换语言是XML,但是Douglas Crockford觉得XML的生成和解析都太麻烦,所以他提出了一种简化格式,也就是Json。
Json的规格非常简单,只用一个页面、几百个字就能说清楚,而且Douglas Crockford声称这个规格永远不必升级,因为该规定的都规定了。
1) 并列的数据之间用逗号(“,”)分隔。
2) 映射用冒号(“:”)表示。
3) 并列数据的集合(数组)用方括号("[]")表示。
4) 映射的集合(对象)用大括号(“{}”)表示。
上面四条规则,就是Json格式的所有内容。
比如,下面这句话:
“北京市的面积为16800平方公里,常住人口1600万人。上海市的面积为6400平方公里,常住人口1800万。”
写成json格式就是这样:
如果事先知道数据的结构,上面的写法还可以进一步简化:[
{"城市":"北京","面积":16800,"人口":1600},
{"城市":"上海","面积":6400,"人口":1800}
][
["北京",16800,1600],
["上海",6400,1800]
]由此可以看到,json非常易学易用。所以,在短短几年中,它就取代xml,成为了互联网上最受欢迎的数据交换格式。
我猜想,Douglas Crockford一定事先就知道,数据结构可以简化成三种形式,否则怎么可能将json定义得如此精炼呢!
3.
我还记得,在学习javascript的时候,我一度搞不清楚“数组”(array)和“对象”(object)的根本区别在哪里,两者都可以用来表示数据的集合。
比如有一个数组a=[1,2,3,4],还有一个对象a={0:1,1:2,2:3,3:4},然后你运行alert(a[1]),两种情况下的运行结果是相同的!这就是说,数据集合既可以用数组表示,也可以用对象表示,那么我到底该用哪一种呢?
我后来才知道,数组表示有序数据的集合,而对象表示无序数据的集合。如果数据的顺序很重要,就用数组,否则就用对象。
4.
当然,数组和对象的另一个区别是,数组中的数据没有“名称”(name),对象中的数据有“名称”(name)。
但是问题是,很多编程语言中,都有一种叫做“关联数组”(associative array)的东西。这种数组中的数据是有名称的。
比如在javascript中,可以这样定义一个对象:
var a={"城市":"北京","面积":16800,"人口":1600};
但是,也可以定义成一个关联数组:
a["城市"]="北京";
a["面积"]=16800;
a["人口"]=1600;这起初也加剧了我对数组和对象的混淆,后来才明白,在Javascript语言中,关联数组就是对象,对象就是关联数组。这一点与php语言完全不同,在php中,关联数组也是数组。
比如运行下面这段javascript:
var a=[1,2,3,4];
a['foo']='Hello World';
alert(a.length);
最后的结果是4,也就是说,数组a的元素个数是4个。
但是,运行同样内容的php代码就不一样了:
$a=array(1,2,3,4);
$a["foo"]="Hello world";
echo count($a);
最后的结果是5,也就是说,数组a的元素个数是5个。
(完)
-
验证数字的正则表达式集
2009-07-30 18:09:16
验证数字:^[0-9]*$
验证n位的数字:^\d{n}$
验证至少n位数字:^\d{n,}$
验证m-n位的数字:^\d{m,n}$
验证零和非零开头的数字:^(0|[1-9][0-9]*)$
验证有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
验证有1-3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
验证非零的正整数:^\+?[1-9][0-9]*$
验证非零的负整数:^\-[1-9][0-9]*$
验证非负整数(正整数 + 0) ^\d+$
验证非正整数(负整数 + 0) ^((-\d+)|(0+))$
验证长度为3的字符:^.{3}$
验证由26个英文字母组成的字符串:^[A-Za-z]+$
验证由26个大写英文字母组成的字符串:^[A-Z]+$
验证由26个小写英文字母组成的字符串:^[a-z]+$
验证由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
验证由数字、26个英文字母或者下划线组成的字符串:^\w+$
验证用户密码:^[a-zA-Z]\w{5,17}$ 正确格式为:以字母开头,长度在6-18之间,只能包含字符、数字和下划线。
验证是否含有 ^%&',;=?$\" 等字符:[^%&',;=?$\x22]+
验证汉字:^[\u4e00-\u9fa5],{0,}$
验证Email地址:^\w+[-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
验证InternetURL:^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ ;^[a-zA-z]+://(w+(-w+)*)(.(w+(-w+)*))*(?S*)?$
验证电话号码:^(\(\d{3,4}\)|\d{3,4}-)?\d{7,8}$:--正确格式为:XXXX-XXXXXXX,XXXX-XXXXXXXX,XXX-XXXXXXX,XXX-XXXXXXXX,XXXXXXX,XXXXXXXX。
验证身份证号(15位或18位数字):^\d{15}|\d{}18$
验证一年的12个月:^(0?[1-9]|1[0-2])$ 正确格式为:“01”-“09”和“1”“12”
验证一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 正确格式为:01、09和1、31。
整数:^-?\d+$
非负浮点数(正浮点数 + 0):^\d+(\.\d+)?$
正浮点数 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
非正浮点数(负浮点数 + 0) ^((-\d+(\.\d+)?)|(0+(\.0+)?))$
负浮点数 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数 ^(-?\d+)(\.\d+)?$

清空Cookie - 联系我们 - 51Testing软件测试网 - 交流论坛 - 空间列表 - 站点存档 - 升级自己的空间
Powered by 51Testing
© 2003-2021
沪ICP备05003035号