
-
windws xp 下安装 ruby on rails
2009-07-30 14:37:10

 1. 安装RadRails
1. 安装RadRails
1.1 安装JRE, 下载页面http://java.sun.com/javase/downloads/
1.2 安装Ruby One-Click Installer, 下载页面http://www.ruby-lang.org/en/downloads/这个安装比较简单,下一步就可以了,不过有一点需要注意一下,安装的时候有个“enable gem”选项建议勾上。我安装的是ruby1.8.6
1.3这一步可以选择自动安装或者手动安装,自动安装其实就是自动从网上下载安装包然后安装,建议网速好的时候再选择 这种方式(1)自动安装:安装Rails, Windows CMD(开始-->运行-->cmd) 中运行"gem install rails --include-dependencies"这里也可以不带参数输入,直接输入gem install rails ,你可以看到详细的安装过程,你可以知道都安装了些什么东东进去。不过有可能过程中需要你输入多次 Y(2)手动安装:1、分别去http://rubyforge.org/frs/?group_id=307 去下载rails (我下载的是1.1.6版本);
http://rubyforge.org/projects/activesupport 去下载activesupport(我下载的是1.3.1版本);
http://rubyforge.org/projects/activerecord/ 去下载activerecord(我下载的是1.14.4版本);
http://rubyforge.org/projects/actionpack 去下载actionpack(我下载的是1.12.5版本);
http://rubyforge.org/projects/actionmailer 去下载actionmailer(我下载的是1.2.5版本);
http://rubyforge.org/projects/aws 去下载actionwebservice(我下载的是1.1.6版本);
http://rubyforge.org/projects/rake 去下载rake(我下载的是0.7.1版本);
以上所有下载文件都包括zip和gem;
2.把第三步中下载的所有文件放到一个目录中,比如我把它放在了D:\rails中;
3.打开cmd,进入 D:\rails分别执行或者同等效果的D:\rails>gem install activesupport -v 1.3.1
D:\rails>gem install activesupport-1.3.1.gem
D:\rails>gem install activerecord-1.14.4.gem
D:\rails>gem install actionpack-1.12.5.gem
D:\rails>gem install actionmailer-1.2.5.gem
D:\rails>gem install actionwebservice-1.1.6.gem
D:\rails>gem install rake-0.7.1.gem
D:\rails>gem install rails-1.1.6.gem
到此安装过程已经结束,可以看看rails版本:C:\Documents and Settings\3238-wb>rails -vRails 2.3.31.4 下面是安装常用的IDE 推荐radrails 和 aptana(1)1、安装RadRails, 下载页面http://nchc.dl.sourceforge.net/sourceforge/radrails/radrails-0.7.1-win32.zip像Eclipse一样,直接下载下来解压缩,不用安装就可以用2、RadRails的参数配置下面是本篇文章最为重要的一个地方,也是我在开始使用RadRails时比较困扰我的一个地方,就是对它的配置,这里我也多用些笔墨介绍一下。其实主要是Interpreter Name、Ruby、Rails及Rake等几个参数的配置。先说Interpreter,在RadRails环境里
配置Interpreters
Window>Preferences>Ruby>Installed Interpreters,然后点击那个“Add”按钮,在Interpreter Name里随便输入一个名字,比如Ruby,然后在Path选择Ruby路径下的“ruby.exe”文件,比如我现在就是“C:\ruby\bin\ruby.exe”
配置Ri/rdoc
打开"Windows-->Preferences", 选择"Ruby-->Ri/rdoc"- //bin目录下面的rdoc文件,没有扩展名,不是rdoc.bat
- RDoc path: D:\ruby\bin\rdoc
- //bin目录下面的ri文件,没有扩展名,不是ri.bat
- Ri path: D:\ruby\bin\ri
配置Rails和Rake
打开"Windows-->Preferences", 选择"Rails-->Configuration"下面是Rails,在Window>Preferences>Rails>Configuration,Rails path选择目录下的rails文件(没有扩展名),特别注意不是rails.bat,如果选择了这个文件,操作无效,这一点可能是很多人易犯的一个毛病;对Rake也是,在同一个地方,点开文件选择框后,选择rake的二进制文件(没有扩展名),特别注意不是rake.bat,如果选择了这两个文件,依然是无效,
- //bin目录下面的rails文件, 没有扩展名, 不是rails.bat
- Rails Path: D:\ruby\bin\rails
- //bin目录下面的rake文件, 没有扩展名, 不是rake.bat. 如果没有rake文件,运行gem update rake(安装) 或者 gem install rake(升级)
- Rake Path: D:\ruby\bin\rake
- //bin目录下面的mongrel_rails文件, 没有扩展名. 如果没有,运行gem install mongrel 安装
- Mongrel Path: D:\ruby\bin\mongrel_rails
如果找了半天没有找到这个文件,说明你没有安装,可以用gem update rake下载。
3、初识radrails
下面让我保存好这些设置,在RadRails里面建立一个新文件。为简单起见,我们就直接在File>New下面的Rails里面点击Rails Project,建立一个名字为demo的项目,其它设置为默认。这时服务器及相关的基础代码RadRails已经帮你生成好了,在右下方的视图里有个名为“Servers”的,如果不出意外,在里面会出现一个名为“demoServer”的记录,这表示已经有了一个属于项目demo、端口号为3000、状态为停止的服务器。点击此视图右上角的绿色按钮,启动服务器,然后在你的IE浏览器,或者此绿色按钮旁边的一个蓝球,在URL框里输入http://localhost:3000。大功告成,出现了什么?很神奇吧~~~Welcome aboard
(2)Apatana:等有时间再奉上……刚接触ruby不久…… 各位大牛多多指点…… -
linux的sftp和scp
2010-05-20 12:47:44
第一个(sftp安全文件传输)是一个类ftp的客户端程序,它能够被用来在网络中传输文件。它并不使用FTP守护进程(ftpd或wu-ftpd)来进行连接,而是有意义地增强系统的安全性。实际上,通过监视一些系统中的log文件,我们可以注意到最近一个月中有80%的攻击是针对于ftpd守护进程的。
sftp避免了这些攻击从而可以停止在wu-ftpd上潜在的危险。
第二个(scp安全性复制)被用来在网络上安全地复制文件。它替代了不安全的rcp命令。Sftp和scp从连接到sshd服务器上后,不需要任何专用的守护进程。为了使用sftp和scp你必须插入以下两行在配置文件/etc/ssh2/sshd2_config中:
subsystem-sftp sftp-server
在这些修改之后,你必须重新启动sshd。然后你就可以使用sftp和scp连接到运行sshd的主机上了。
Sftp
Sftp使用在数据连接上使用ssh2,所以文件的传输是尽可能地安全。使用sftp代替ftp两个主要的的原因是:
1、Password从不用明文传输,防止sniffer(嗅探器)的攻击。
2、数据在传输时被加密,使用刺探和修改连接非常困难。
而使用sftp2是非常简单的。让我们假设你使用了你的帐户:myname通过sftp连按上了主机host1。
可以使用命令:
sftp myname@host1
一些选项能够在命令行中被指定(详细情况请查看sftp manul)
当sftp2准备好了来接受连接时,它将显示一个状态提示符 sftp>。在sftp手册中有完整的用户可以使用的命令列表;其中有:
·quit:
从这个应用程序中退出。
·cd directory:
改变当前的远程工作目录。
·lcd directory:
改变当前的本地工作目录。
·ls [ -R ] [ -l ] [ file ... ]:
列出在远地服务器上的文件名。如果是目录,则列出目录的内容。当命令行中指定了-R,则递归地显示目录树。(默认情况下,子目录并不被访问)。当命令行中指定了-l,文件与目录的权限,属主,大小和修改时间被列出。
当没有参数被指定,则.(当前目录)的内容被列出。普通情况下选项-R和-l是互相不兼容的。
·lls [ -R ] [ -l ] [ file ... ]:
与ls一样,但是是对于本地文件操作。
·get [file ...]:
从远程端传送指定的文件到本地端。目录内容被递归地复制。
·put [ file ... ]:
从本地端传送指定的文件到远地端。目录内容被递归地复制。
·mkdir dir (rmdir dir):
尝试建立或删除参数中指定的目录。
通配符对于ls,lls,get和put是支持的。格式在sshregex手册中有描述。从sftp使用加密技术以来,一直有一个障碍:连接速度慢(以我的经验有2-3倍),但是这一点对于非常好的安全性来讲只能放在一边了。在一个测试中,在我们局域网上的Sniffer可以在一个小时中捉住ftp连接上的4个password。sftp的使用可以从网络上传送文件并且除去这些安全问题。
Scp
Scp2(安全性复制)被用来从网络上安全地复制文件。它使用ssh2来进行数据传送:它使用的确认方式和提供的安全性与ssh2一样。
这可能是一种最简单的方法从远地机器上复制文件了。让我们假设你要使用你的帐户mmyname,复制在local_dir目录中的filename
文件到远地的主机host1上的remote_dir目录中。使用scp你可以输入:
scp local_dir/filename myname@host1:remote_dir
在这种方式下文件filename被复制成相同的名字。通配符可以使用(读一读sshregex手册)。命令行:
scp local_dir/* myname@host1:remote_dir
从目录local_dir复制所有文件到主机host1的目录remote_dir命令:
scp myname@host1:remote_dir/filename .
复制文件filename从host1的目录remote_dir到本地目录。
scp支持许多选项并且允许在两个远地系统之间复制文件:
scp myname@host1:remote_dir/filename myname@host2:another_dir
详情请查阅手册
显然,使用scp,你必须知道远程机器的确切目录,所以在实际上sftp经常被作为首选使用。 -
主要协议表
2009-12-11 12:31:14
主要协议表
应用层(Application Layer)
--------------------------------------------------------------------------------
BOOTP:引导协议 (BOOTP:Bootstrap Protocol)
DCAP:数据转接客户访问协议 (DCAP:Data Link Switching Client Access Protocol)
DHCP:动态主机配置协议 (DHCP:Dynamic Host Configuration Protocol)
DNS:域名系统(服务)系统 (DNS:Domain Name Systems)
Finger:用户信息协议 (Finger:User Information Protocol)
FTP:文件传输协议 (FTP:File Transfer Protocol)
HTTP:超文本传输协议 (HTTP:Hypertext Transfer Protocol)
S-HTTP:安全超文本传输协议 (S-HTTP:Secure Hypertext Transfer Protocol)
IMAP & IMAP4:信息访问协议 & 信息访问协议第4版 (IMAP & IMAP4:Internet Message Access Protocol)
IPDC:IP 设备控制 (IPDC:IP Device Control)
IRCP/IRC:因特网在线聊天协议 (IRCP/IRC:Internet Relay Chat Protocol)
LDAP:轻量级目录访问协议 (LDAP:Lightweighted Directory Access Protocol)
MIME/S-MIME/Secure MIME:多用途网际邮件扩充协议 (MIME/S-MIME/Secure MIME:Multipurpose Internet Mail Extensions)
NAT:网络地址转换 (NAT:Network Address Translation)
NNTP:网络新闻传输协议 (NNTP:Network News Transfer Protocol)NTP:网络时间协议 (NTP:Network Time Protocol)
POP&POP3:邮局协议 (POP & POP3:Post Office Protocol)
RLOGIN:远程登录命令 (RLOGIN:Remote Login in Unix)
RMON:远程监控 (RMON:Remote Monitoring MIBs in SNMP)
RWhois:远程目录访问协议 (RWhois Protocol)
SLP:服务定位协议 (SLP:Service Location Protocol)
SMTP:简单邮件传输协议 (SMTP:Simple Mail Transfer Protocol)
SNMP:简单网络管理协议 (SNMP:Simple Network Management Protocol)
SNTP:简单网络时间协议 (SNTP:Simple Network Time Protocol)
TELNET:TCP/IP 终端仿真协议 (TELNET:TCP/IP Terminal Emulation Protocol)
TFTP:简单文件传输协议 (TFTP:Trivial File Transfer Protocol)
URL:统一资源管理 (URL:Uniform. Resource Locator)
X-Window/X Protocol:X 视窗 或 X 协议(X-Window:X Window or X Protocol or X System)
表示层(Presentation Layer)
--------------------------------------------------------------------------------
LPP:轻量级表示协议 (LPP:Lightweight Presentation Protocol)
会话层(Session Layer)
--------------------------------------------------------------------------------
RPC:远程过程调用协议 (RPC:Remote Procedure Call protocol)
传输层(Transport Layer)
--------------------------------------------------------------------------------
ITOT:基于TCP/IP 的 ISO 传输协议 (ITOT:ISO Transport Over TCP/IP)
RDP:可靠数据协议 (RDP:Reliable Data Protocol)
RUDP:可靠用户数据报协议 (RUDP:Reliable UDP)
TALI:传输适配层接口 (TALI:Transport Adapter Layer Interface)
TCP:传输控制协议 (TCP:Transmission Control Protocol)
UDP:用户数据报协议 (UDP:User Datagram Protocol)
Van Jacobson:压缩 TCP 协议 (Van Jacobson:Compressed TCP)
网络层(Network Layer)
--------------------------------------------------------------------------------
路由选择(Routing)
BGP/BGP4:边界网关协议 (BGP/BGP4:Border Gateway Protocol)
EGP:外部网关协议(EGP:Exterior Gateway Protocol)
IP:网际协议 (IP:Internet Protocol)
IPv6:网际协议第6版 (IPv6:Internet Protocol version 6)
ICMP/ICMPv6:Internet 信息控制协议 (ICMP/ICMPv6:Internet Control Message Protocol)
IRDP:ICMP 路由器发现协议 (IRDP:ICMP Router Discovery Protocol)
Mobile IP: 移动 IP (Mobile IP:IP Mobility Support Protocol for IPv4 & IPv6)
NARP:NBMA 地址解析协议 (NARP:NBMA Address Resolution Protocol)
NHRP:下一跳解析协议 (NHRP:Next Hop Resolution Protocol)
OSPF:开放最短路径优先 (OSPF:Open Shortest Path First)
RIP/RIP2:路由选择信息协议 (RIP/RIP2:Routing Information Protocol)
RIPng:路由选择信息协议下一代 (RIPng:RIP for IPv6)
RSVP:资源预留协议 (RSVP:Resource ReSerVation Protocol)
VRRP:虚拟路由器冗余协议 (VRRP:Virtual Router Redundancy Protocol)
组播(Multicast)
BGMP:边界网关组播协议 (BGMP:Border Gateway Multicast Protocol)
DVMRP:距离矢量组播路由协议 (DVMRP:Distance Vector Multicast Routing Protocol)
IGMP:Internet 组管理协议 (IGMP:Internet Group Management Protocol)
MARS:组播地址解析服务 (MARS:Multicast Address Resolution Server)
MBGP:组播协议边界网关协议 (MBGP:Multiprotocol BGP)
MOSPF:组播OSPF (MOSPF:Multicast OSPF)
MSDP:组播源发现协议 (MSDP:Multicast Source Discovery Protocol)
MZAP:组播区域范围公告协议 (MZAP:Multicast Scope Zone Announcement Protocol)
PGM:实际通用组播协议 (PGM:Pragmatic General Multicast Protocol)
PIM-DM:密集模式独立组播协议 (PIM-DM:Protocol Independent Multicast - Dense Mode)
PIM-SM:稀疏模式独立组播协议 (PIM-SM:Protocol Independent Multicast - Sparse Mode)
MPLS 协议(MPLS Protocols)
CR-LDP:基于路由受限标签分发协议 (CR-LDP: Constraint-Based Label Distribution Protocol)
GMPLS:通用多协议标志交换协议 (GMPLS:Generalized Multiprotocol Label Switching)
LDP:标签分发协议 (LDP:Label Distribution Protocol)
MPLS:多协议标签交换 (MPLS:Multi-Protocol Label Switching)
RSVP-TE:基于流量工程扩展的资源预留协议 (RSVP-TE:Resource ReSerVation Protocol-Traffic Engineering)
数据链路层(Data Link Layer)
--------------------------------------------------------------------------------
ARP and InARP:地址转换协议和逆向地址转换协议 (ARP and InARP:Address Resolution Protocol and Inverse ARP)
IPCP and IPv6CP:IP控制协议和IPV6控制协议 (IPCP and IPv6CP:IP Control Protocol and IPv6 Control Protocol)
RARP:反向地址转换协议 (RARP:Reverse Address Resolution Protocol)
SLIP:串形线路 IP (SLIP:Serial Line IP) -
TCP详解
2009-12-11 12:21:51
一、TCP协议
1、TCP 通过以下方式提供可靠性:- ◆ 应用程序分割为TCP认为最合适发送的数据块。由TCP传递给IP的信息单位叫做报文段。
- ◆ 当TCP发出一个报文段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能记时收到一个确认,它 就重发这个报文段。
- ◆ 当TCP收到发自TCP连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常延迟几分之一秒。
- ◆ TCP将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化如果收到报文段的检验和有差错,TCP将丢弃这个报文段和不确认收到这个报文段。
- ◆ 既然TCP报文段作为IP数据报来传输,而IP数据报的到达可能失序,因此TCP报文段的到达也可能失序。如果必要,TCP将对收到的数据进行排序,将收到的数据以正确的顺序交给应用层。
- ◆ 既然IP数据报会发生重复,TCP连接端必须丢弃重复的数据。
- ◆ TCP还能提供流量控制,TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。
另外,TCP对字节流的内容不作任何解释。
2、TCP首部:
TCP数据被封装在一个IP数据报中,格式如下: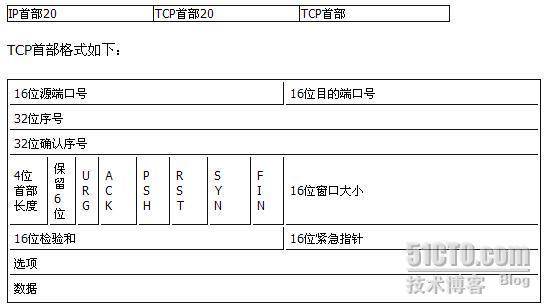 说明:
说明:
(1)每个TCP段都包括源端和目的端的端口号,用于寻找发送端和接收端的应用进程。这两个值加上IP首部的源端IP地址和目的端IP地址唯一确定一个TCP连接。
(2)序号用来标识从TCP发送端向接收端发送的数据字节流,它表示在这个报文段中的第一个数据字节。如果将字节流看作在两个应用程序间的单向流动,则TCP用序号对每个字节进行计数。
(3)当建立一个新连接时,SYN标志变1。序号字段包含由这个主机选择的该连接的初始序号ISN,该主机要发送数据的第一个字节的序号为这个ISN加1,因为SYN标志使用了一个序号。
(4)既然每个被传输的字节都被计数,确认序号包含发送确认的一端所期望收到的下一个序号。因此,确认序号应当时上次已成功收到数据字节序号加1。只有ACK标志为1时确认序号字段才有效。
(5)发送ACK无需任何代价,因为32位的确认序号字段和ACK标志一样,总是TCP首部的一部分。因此一旦一个连接建立起来,这个字段总是被设置,ACK标志也总是被设置为1。
(6)TCP为应用层提供全双工的服务。因此,连接的每一端必须保持每个方向上的传输数据序号。
(7)TCP可以表述为一个没有选择确认或否认的华东窗口协议。因此TCP首部中的确认序号表示发送方已成功收到字节,但还不包含确认序号所指的字节。当前还无法对数据流中选定的部分进行确认。
(8)首部长度需要设置,因为任选字段的长度是可变的。TCP首部最多60个字节。
(9)6个标志位中的多个可同时设置为1
◆ URG-紧急指针有效
◆ ACK-确认序号有效
◆ PSH-接收方应尽快将这个报文段交给应用层
◆ RST-重建连接
◆ SYN-同步序号用来发起一个连接
◆ FIN-发送端完成发送任务
(10)TCP的流量控制由连接的每一端通过声明的窗口大小来提供。窗口大小为字节数,起始于确认序号字段指明的值,这个值是接收端期望接收的字节数。窗口大小是一个16为的字段,因而窗口大小最大为65535字节。
(11)检验和覆盖整个TCP报文端:TCP首部和TCP数据。这是一个强制性的字段,一定是由发送端计算和存储,并由接收端进行验证。TCP检验和的计算和UDP首部检验和的计算一样,也使用伪首部。
(12)紧急指针是一个正的偏移量,黄蓉序号字段中的值相加表示紧急数据最后一个字节的序号。TCP的紧急方式是发送端向另一端发送紧急数据的一种方式。
(13)最常见的可选字段是最长报文大小MMS,每个连接方通常都在通信的第一个报文段中指明这个选项。它指明本端所能接收的最大长度的报文段。
二、TCP连接的建立和终止
1、建立连接协议
(1) 请求端发送一个SYN段指明客户打算连接的服务器的端口,隐疾初始序号(ISN),这个SYN报文段为报文段1。
(2) 服务器端发回包含服务器的初始序号的SYN报文段(报文段2)作为应答。同时将确认序号设置为客户的ISN加1以对客户的SYN报文段进行确认。一个SYN将占用一个序号。
(3) 客户必须将确认序号设置为服务器的ISN加1以对服务器的SYN报文段进行确认(报文段3)。
这3个报文段完成连接的建立,称为三次握手。发送第一个SYN的一端将执行主动打开,接收这个SYN并发回下一个SYN的另一端执行被动打开。
2、连接终止协议
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。
(3) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段6)。
(4) 客户段发回确认,并将确认序号设置为收到序号加1(报文段7)。
3、连接建立的超时
如果与服务器无法建立连接,客户端就会三次向服务器发送连接请求。在规定的时间内服务器未应答,则连接失败。
4、最大报文段长度MSS
最大报文段长度表示TCP传往另一端的最大块数据的长度。当一个连接建立时,连接的双方都要通告各自的MSS。
一般,如果没有分段发生,MSS还是越大越好。报文段越大允许每个报文段传送的数据越多,相对IP和TCP首部有更高的网络利用率。当TCP发送一个SYN时,它能将MSS值设置为外出接口的MTU长度减去IP首部和TCP首部长度。对于以太网,MSS值可达1460。
如果目的地址为非本地的,MSS值通常默认为536,是否本地主要通过网络号区分。MSS让主机限制另一端发送数据报的长度,加上主机也能控制它发送数据报的长度,这将使以较小MTU连接到一个网络上的主机避免分段。
5、 TCP的半关闭
TCP提供了连接的一端在结束它的发送后还能接收来自另一端数据的能力,这就是TCP的半关闭。
客户端发送FIN,另一端发送对这个FIN的ACK报文段。当收到半关闭的一端在完成它的数据传送后,才发送FIN关闭这个方向的连接,客户端再对这个FIN确认,这个连接才彻底关闭。
6、2MSL连接
TIME_WAIT状态也称为2MSL等待状态。每个TCP必须选择一个报文段最大生存时间(MSL)。它是任何报文段被丢弃前在网络的最长时间。
处理原则:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIME_WAIT状态停留的时间为2MSL。这样可以让TCP再次发送最后的ACK以避免这个ACK丢失(另一端超时并重发最后的FIN)。这种2MSL等待的另一个结果是这个TCP连接在2MSL等待期间,定义这个连接的插口不能被使用。
7、平静时间
TCP在重启的MSL秒内不能建立任何连接,这就是平静时间。
8、FIN_WAIT_2状态
在FIN_WAIT_2状态我们已经发出了FIN,并且另一端也对它进行了确认。只有另一端的进程完成了这个关闭,我们这端才会从FIN_WAIT_2状态进入TIME_WAIT状态。这意味着我们这端可能永远保持这个状态,另一端也将处于CLOSE_WAIT状态,并一直保持这个状态直到应用层决定进行关闭。
9、复位报文段
TCP首部的RST位是用于复位的。一般,无论合适一个报文端发往相关的连接出现错误,TCP都会发出一个复位报文段。主要情况:
(1)到不存在的端口的连接请求;
(2)异常终止一个连接。
10、同时打开
为了处理同时打开,对于同时打开它仅建立一条连接而不是两条连接。两端几乎在同时发送SYN,并进入SYN_SENT状态。当每一端收到SYN时,状态变为SYN_RCVD,同时他们都再发SYN并对收到的SYN进行确认。当双方都收到SYN及相应的ACK时,状态都变为ESTABLISHED。一个同时打开的连接需要交换4个报文段,比正常的三次握手多了一次。
11、 同时关闭
当应用层发出关闭命令,两端均从ESTABLISHED变为FIN_WAIT_1。这将导致双方各发送一个FIN,两个FIN经过网络传送后分别到达另一端。收到FIN后,状态由FIN_WAIT_1变为CLOSING,并发送最后的ACK。当收到最后的ACK,状态变为TIME_WAIT。同时关闭和正常关闭的段减缓数目相同。
12、TCP选项
每个选项的开始是1字节的kind字段,说明选项的类型。Kind=1:选项表结束(1字节) Kind=1:无操作(1字节) Kind=2:最大报文段长度(4字节) Kind=3:窗口扩大因子(4字节) Kind=8:时间戳(10字节)
三、TCP的超时和重传
对于每个TCP连接,TCP管理4个不同的定时器。
(1) 重传定时器用于当希望收到另一端的确认。
(2) 坚持定时器使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口。
(3) 保活定时器可检测到一个空闲连接的另一端何时崩溃或重启。
(4) 2MSL定时器测量一个连接处于TIME_WAIT状态的时间。
1、往返时间测量
TCP超时和重传重最重要的就是对一个给定连接的往返时间(RTT)的测量。由于路由器和网络流量均会变化,因此TCP应该跟踪这些变化并相应地改变超时时间。首先TCP必须测量在发送一个带有特别序号地字节和接收到包含该字节地确认之间的RTT。
2、拥塞避免算法
该算法假定由于分组收到损坏引起的丢失是非常少的,因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了阻塞。有两种分组丢失的指示:发生超时和收到重复的确认。拥塞避免算法需要对每个连接维持两个变量:一个拥塞窗口cwnd和一个慢启动门限ssthresh。
(1) 对一个给定的连接,初始化cwnd为1个报文段,ssthresh为65535个字节。
(2) TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制。前者是发送方感受到的网络拥塞的估计,而后者则与接收方在该连接上的可用缓存大小有关。
(3) 当拥塞发生时,ssthresh被设置为当前窗口大小的一般(cwnd和接收方通告窗口大小的最小值,但最小为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段。
(4) 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖与是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。
3、快速重传和快速恢复算法
如果我们一连串收到3个或以上的重复ACK,就非常可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出。
(1) 当收到第3个重复的ACK时,将ssthresh设置为当前拥塞窗口cwnd的一半,重传丢失的报文段,设置cwnd为ssthresh加上3倍的报文段大小。
(2) 每次收到另一个重复的ACK时,cwnd增加1个报文段大小并发送一个1个分组,如果允许的话。
(3) 当下一个确认新数据的ACK到达时,设置cwnd为ssthresh,这个ACK应该时在进行重传后的一个往返时间内对步骤1重重传的确认。另外,这个ACK也应该是对丢失的分组和收到的第一个重复的ACK之间的所有中间报文段的确认。
4、 ICMP差错
TCP如何处理一个给定的连接返回的ICMP差错。TCP能够遇到的最常见的ICMP差错就是源站抑制、主机不可达和网络不可达。
(1) 一个接收到的源站抑制引起拥塞窗口cwnd被置为1个报文段大小来发起慢启动,但是慢启动门限ssthresh没有变化,所以窗口将打开直到它开放了所有的通路或者发生了拥塞。
(2) 一个接收到的主机不可达或网络不可达实际都被忽略,因为这两个差错都被认为是短暂现象。TCP试图发送引起该差错的数据,尽管最终有可能会超时。
5、重新分组:
当TCP超时并重传时,它并不一定要重传同样的报文段,相反,TCP允许进行重新分组而发送一个较大的报文段。这是允许的,因为TCP是使用字节序号而不是报文段序号来进行识别它所要发送的数据和进行确认。
四、TCP的坚持定时器
ACK的传输并不可靠,也就是说,TCP不对ACK报文段进行确认,TCP只确认那些包含数据的ACK报文段。为了防止因为ACK报文段丢失而双方进行等待的问题,发送方用一个坚持定时器来周期性地向接收方查询。这些从发送方发出地报文段称为窗口探查。
五、TCP的保活定时器
如果一个给定的连接在2小时内没有任何动作,那么服务器就向客户发送一个探查报文段。客户主机必须处于以下4个状态之一。
(1) 客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方的正常工作的。服务器在2小时内将保活定时器复位。
(2) 客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务器将不能收到对探查的响应,并在75秒后超时。总共发送10个探查,间隔75秒。
(3) 客户主机崩溃并已经重新启动。这是服务器将收到一个对其保活探查的响应,但这个响应是一个复位,使得服务器终止这个连接。
(4) 客户主机正常运行,但是从服务器不可达。
六、TCP的一些性能
1、 路径MTU发现:
TCP的路径MTU发现按如下方式进行:在连接建立时,TCP使用输出接口或对段声明的MSS中的最下MTU作为其实的报文段大小。路径MTU发现不允许TCP超过对端声明的MSS。如果对端没有指定一个MSS,则默认为536。
一旦选定了起始的报文段大小,在该连接上的所有被TCP发送的IP数据报都将被设置DF位。如果中间路由器需要对一个设置了DF标志的数据报进行分片,它就丢弃这个数据报,并产生一个ICMP的“不能分片”差错。
如果收到这个ICMP差错,TCP就减少段大小并进行重传。如果路由器产生的是一个较新的该类ICMP差错,则报文段大小被设置位下一跳的MTU减去IP和TCP的首部长度。如果是一个较旧的该类ICMP差错,则必须尝试下一个可能的最小MTU。
2、 长肥管道
一个连接的容量=带宽X时延(RTT)。具有大的带宽时延乘积的网络称为长肥网络(LFN)。一个运行在LFN的TCP连接称为长肥管道。管道可以被水平拉长(一个长的RTT),或被垂直拉高(较高的带宽),或两个方向拉伸。
3、窗口扩大选项:
窗口扩大选项使TCP的窗口定义从16位增加到32位,这并不是通过修改TCP首部来实现的,TCP首部仍然使用16位,而是通过定义一个选项实现对16位的扩大操作来完成的。
4、时间戳选项:
时间戳选项使发送方在每个报文段中放置一个时间戳值。接收方在确认中返回这个数值,从而允许发送方为每一个收到的ACK计算RTT -
路由器NAT与路由的区别
2009-11-27 16:56:31
我来具体说下nat 我想看了你就会明白了
NAT 英文 全称是“Network Address Translation”,中文意思是“网络地址转换”,它是一个IETF(Internet Engineering Task Force, Internet工程任务组)标准,允许一个整体机构以一个公用IP(Internet Protocol)地址出现在Internet上。顾名思义,它是一种把内部私有网络地址(IP地址)翻译成合法网络IP地址的技术。简单的说,NAT就是在局域网内部网络中使用内部 地址 ,而当内部节点要与外部网络进行通讯时,就在网关(可以理解为出口,打个比方就像院子的门一样)处,将内部地址替换成公用地址,从而在外部公网(internet)上正常使用,NAT可以使多台计算机共享Internet连接,这一功能很好地解决了公共IP地址紧缺的问题。通过这种方法,您可以只申请一个合法IP地址,就把整个局域网中的计算机接入Internet中。这时,NAT屏蔽了内部网络,所有内部网计算机对于公共网络来说是不可见的,而内部网计算机用户通常不会意识到NAT的存在。如图2所示。这里提到的内部地址,是指在内部网络中分配给节点的私有IP地址,这个地址只能在内部网络中使用,不能被路由(一种网络技术,可以实现不同路径转发)。虽然内部地址可以随机挑选,但是通常使用的是下面的地址:10.0.0.0~10.255.255.255,172.16.0.0~172.16.255.255,192.168.0.0~192.168.255.255。NAT将这些无法在互联网上使用的保留IP地址翻译成可以在互联网上使用的合法IP地址。而全局地址,是指合法的IP地址,它是由NIC(网络信息中心)或者ISP(网络服务提供商)分配的地址,对外代表一个或多个内部局部地址,是全球统一的可寻址的地址。NAT功能通常被集成到路由器、防火墙、ISDN路由器或者单独的NAT设备中。比如Cisco路由器中已经加入这一功能,网络管理员只需在路由器的IOS中设置NAT功能,就可以实现对 内部网络 的屏蔽。再比如防火墙将WEB Server的内部地址192.168.1.1映射为外部地址202.96.23.11,外部访问202.96.23.11地址实际上就是访问访问192.168.1.1。另外资金有限的小型企业来说,现在通过软件也可以实现这一功能。Windows 98 SE、Windows 2000 都包含了这一功能。
NAT技术类型
NAT有三种类型:静态NAT(Static NAT)、动态地址NAT(Pooled NAT)、网络地址端口转换NAPT(Port-Level NAT)。其中静态NAT设置起来最为简单和最容易实现的一种,内部网络中的每个主机都被永久映射成 外部 网络中的某个合法的地址。而动态地址NAT则是在外部网络中定义了一系列的合法地址,采用动态分配的方法映射到内部网络。NAPT则是把内部地址映射到外部网络的一个IP地址的不同端口上。根据不同的需要,三种NAT方案各有利弊。
动态地址NAT只是转换IP地址,它为每一个内部的IP地址分配一个临时的外部IP地址,主要应用于拨号,对于频繁的远程联接也可以采用动态NAT。当远程用户联接上之后,动态地址NAT就会分配给他一个IP地址,用户断开时,这个IP地址就会被释放而留待以后使用。
网络地址端口转换NAPT(Network Address Port Translation)是人们比较熟悉的一种转换方式。NAPT普遍应用于接入设备中,它可以将中小型的网络隐藏在一个合法的IP地址后面。NAPT与动态地址NAT不同,它将内部连接映射到外部网络中的一个单独的IP地址上,同时在该地址上加上一个由NAT设备选定的TCP端口号。
在Internet中使用NAPT时,所有不同的信息流看起来好像来源于同一个IP地址。这个优点在小型办公室内非常实用,通过从ISP处申请的一个IP地址,将多个连接通过NAPT接入Internet。实际上,许多SOHO远程访问设备支持基于PPP的动态IP地址。这样,ISP甚至不需要支持NAPT,就可以做到多个内部IP地址共用一个外部IP地址上Internet,虽然这样会导致信道的一定拥塞,但考虑到节省的ISP上网费用和易管理的特点,用NAPT还是很值得的。因此我认为路由器的功能是集成了NAT与路由两项功能的.如果只配了NAT,却没有配置该路由器的路由,是上不了网的,而只配了路由而没有配NAT,路由器下面的许多台电脑是上不了网的,除非你装个wingate.
-
介绍NAT、NAPT的基本概念和工作原理及区别
2009-11-27 13:54:01
引言
近年来,随着Internet的迅猛发展,连入Internet的主机数量成倍增长。由于最初设计Internet的时候并没有考虑到需要支持这么大的规模,因而Internet使用的Ipv4协议中IP地址的长度选择了32位,它可以使IP包的格式很好地对齐;但是,目前IP地址的短缺已经成为Internet面临的最大问题之一。
为了解决IP地址短缺的问题,人们提出了许多解决方案,nternet能够支持到新一代IP协议Ipv6的出台。在众多的解决方案中,网络地址转换NAT(Network Address Translation)技术提供了一种完全将私有网和公共网隔离的方法,从而得到了广泛的应用。图1 NAT工作原理示意图1 NAT技术
NAT技术的基本功能就是,用1个或几个IP地址来实现1个私有网中的所有主机和公共网中主机的IP通信。NAT技术可为TCP、UDP以及ICMP数据包提供透明转发。
1.1 NAT工作原理
NAT的基本工作原理是,当私有网主机和公共网主机通信的IP包经过NAT网关时,将IP包中的源IP或目的IP在私有IP和NAT的公共IP之间进行转换。
如图1所示,NAT网关有2个网络端口,其中公共网络端口的IP地址是统一分配的公共IP,为202.204.65.2;私有网络端口的IP地址是保留地址,为192.168.1.1。私有网中的主机192.168.1.2向公共网中的主机166.111.80.200发送了1个IP包(Des=166.111.80.200,Src=192.168.1.2)。当IP包经过NAT网关时,NAT会将IP包的源IP转换为NAT的公共IP并转发到公共网,此时IP包(Des=166.111.80.200,Src=202.204.65.2)中已经不含任何私有网IP的信息。由于IP包的源IP已经被转换成NAT的公共IP,响应的IP包(Des=202.204.65.2,Src=166.111.80.200)将被发送到NAT。这时,NAT会将IP包的目的IP转换成私有网中主机的IP,然后将IP包(Des=192.168.1.2,Src=166.111.80.200)转发到私有网。对于通信双方而言,这种地址的转换过程是完全透明的。
1.2 NAPT技术
由于NAT实现是私有IP和NAT的公共IP之间的转换,那么,私有网中同时与公共网进行通信的主机数量就受到NAT的公共IP地址数量的限制。为了克服这种限制,NAT被进一步扩展到在进行IP地址转换的同时进行Port的转换,这就是网络地址端口转换NAPT(Network Address Port Translation)技术。
NAPT与NAT的区别在于,NAPT不仅转换IP包中的IP地址,还对IP包中TCP和UDP的Port进行转换。这使得多台私有网主机利用1个NAT公共IP就可以同时和公共网进行通信。
如图2所示,私有网主机192.168.1.2要访问公共网中的Http服务器166.111.80.200。首先,要建立TCP连接,假设分配的TCP Port是1010,发送了1个IP包(Des=166.111.80.200:80,Src=192.168.1.2:1010),当IP包经过NAT网关时,NAT会将IP包的源IP转换为NAT的公共IP,同时将源Port转换为NAT动态分配的1个Port。然后,转发到公共网,此时IP包(Des=166.111.80.200:80,Src=202.204.65.2:2010)已经不含任何私有网IP和Port的信息。由于IP包的源IP和Port已经被转换成NAT的公共IP和Port,响应的IP包(Des=202.204.65.2:,Src=2010166.111.80.200:80)将被发送到NAT。这时NAT会将IP包的目的IP转换成私有网主机的IP,同时将目的Port转换为私有网主机的Port,然后将IP包(Des=192.168.1.2:1010,Src=166.111.80.200:80)转发到私网。对于通信双方而言,这种IP地址和Port的转换是完全透明的。 -
ESMTP的三个认证方式: CRAM-MD5 PLAIN和LOGIN
2009-11-26 21:53:16
ESMTP的三个认证方式: CRAM-MD5 PLAIN和LOGIN. 下面对这三种认证方式的流程进行一个总结.
CRAM-MD5:
客户端首先向服务器端发送一个字符串: "AUTH[SPACE]CRAM-MD5[CRLF]".其中[SPACE]表示一个空格;[CRLF]表示回车换行符, 即"\r\n". 下同.
如果服务器拒绝认证方式, 则返回一个字符串: "[NUM][SPACE]str". 其中[NUM]为三位数字的服务器状态码( 下同 ).当状态码不等于334表示拒绝认证方式. str是一个服务器端定义的字符串, 用于描述错误.
如果服务器接受认证方式, 则返回一个字符串: "[NUM][SPACE]str_base64".其中str_base64是一个随机字符串经过base64编码后的字符串.
客户端收到服务器的信息后, 执行如下操作:
首先利用base64解码算法将str_base64解码. 解码后的字符串存入str
* call base64_decode
* input str_base64
* output str之后利用hmac-md5算法计算出一个摘要digest
* call hmac_md5
* input password, str
* output digest将摘要用小写字母的16进制表示, 并把字符串"username "与它合并, 成为字符串tmp
* string tmp = 'username digest'将tmp进行base64编码
* call base64_encode
* input tmp
* output tmp_base64
最后, 客户端向服务器端发送字符串: "tmp_base64[CRLF]"
根据服务器的返回判断是否认证成功PLAIN:
客户端首先做如下操作:
* string tmp = '^username^password'
* for each character in tmp
* tmp[i] = '\0' where tmp[i] == '^'
* call base64_encode
* input tmp
* output tmp_base64
最后, 客户端向服务器端发送字符串: "tmp_base64[CRLF]"
根据服务器的返回判断是否认证成功LOGIN:
客户端首先向服务器端发送一个字符串: "AUTH[SPACE]LOGIN[CRLF].
如果服务器拒绝认证方式, 则返回一个字符串: "[NUM][SPACE]str". 其中[NUM]不等于334, 表示拒绝认证方式. str是一个服务器端定义的字符串, 用于描述错误.
如果服务器接受认证方式, 则返回一个字符串: "[NUM][SPACE]user_base64". 其中user_base64是一个利用base64编码后的字符串
客户端收到服务器信息后做如下操作:
* call base64_decode
* input user_base64
* output tmp
此处仅仅对服务器返回的字符串做合法性检测. 之后的认证过程中不会用到它* call base64_encode
* input username
* output username_base64
接着, 客户端向服务器发送一个字符串: "username_base64"
服务器返回一个字符串:"[NUM][SPACE]pass_base64".其中pass_base64是一个利用base64编码后的字符串
客户端收到服务器信息后做如下操作:
* call base64_decode
* input pass_base64
* output tmp
此处也仅对服务器返回的字符串做合法性检测. 之后的认证过程中不会用到它* call base64_encode
* input password
* output password_base64
最后, 客户端向服务器发送一个字符串: "password_base64"
根据服务器的返回判断是否认证成功本文粗略介绍了ESMTP的认证方式.
所提到的三种认证方式中, CRAM-MD5的安全性最强. 而其他两种认证方式个人认为与明文传输几乎没有区别. 因为base64本身就不是一个用于加密的算法.如果采用后两者的认证方式, 任何一个攻击者都可以轻易地通过简单的嗅探获得客户端与服务器端的通信, 最终获得用户的登录名和密码.
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/monnand/archive/2006/08/17/1076581.aspx
使用smtp.163.com或smtp.qq.com时,若使用LOGIN认证,则都可以实现,用另二种时则都会出来认证失败的错误。如下图所示
smtp.163.com:
PLAIN
CRAM-MD5
smtp.qq.com:
PLAIN
CRAM-MD5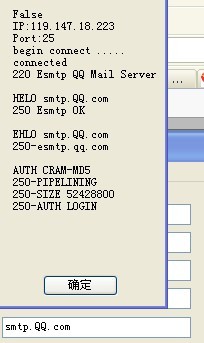
从以上图可能分析出:
一、163还用SMTP协议,而QQ用ESMTP协议。
二、163与QQ只提供LOGIN认证给我们用,其他认证未开放给用户。所以若用其他认证时,发送会失败 -
RUBY获取当前的执行文件的路径和目录
2009-11-21 15:57:59
获得当前执行文件的文件名:
__FILE__
获得当前文件的目录
File.dirname(__FILE__)
获得当前执行文件的完整路径
require ‘pathname’
Pathname.new(__FILE__).realpath获得当前执行文件的目录完整路径
require ‘pathname’
Pathname.new(File.dirname(__FILE__)).realpath如果使用$0: $0是整个ruby执行文件最顶层文件的路径。因此使用if __FILE__==$0可以判断当前ruby文件是被引用还是被执行
-
ruby 中内部变量大全
2009-11-21 15:45:18
在ruby程序中,经常会看到一些以$开头的变量,这些不是指我们自己在程序中设置的全局变量,而是指系统内部已经设置好的变量,他们代表了一些特定的意思,下面搜集了一些常用的内部变量,用一些简单的代码说明他们代表的意思:
局部域:
在某一个线程作用域内才能有效,下列也可看做是线程内的局部变量.
PS:这边讲解的几个变量都是于正则匹配相关的,正则匹配过程的代码是一样的,这里不重复输入正则表达式匹配的代码,只在第一个例子里给出完整的输入和输出,之后的例子只直接输出变量的值
$_
gets或readline最后读入的字符串.若遇到EOF则为nil.该变量的作用域是局部域.Ruby代码- irb(main):006:0> $_
- => nil
- irb(main):007:0> gets
- foobar
- => "foobar\n"
- irb(main):008:0> $_
- => "foobar\n"
$&
在当前作用域中,正则表达式最后一次匹配成功的字符串.若最后一次匹配失败,则为nil.Ruby代码- irb(main):002:0> $&
- => nil
- irb(main):010:0> /(foo)(bar)(BAZ)?/ =~ "foobarbaz"
- => 0
- irb(main):011:0> $&
- => "foobar"
$~
在当前作用域中,最后一次匹配成功的相关信息(MatchData对象-为处理与正则表达式的匹配过程相关的信息而设置的类.).
可以使用$~[n]的形式从该数据中抽取第n个匹配结果($n).相当于是$1,$2...
等同于Regexp.last_match.Ruby代码- irb(main):012:0> $~
- => #<MatchData "foobar" 1:"foo" 2:"bar" 3:nil>
- irb(main):026:0> $1
- => "foo"
- irb(main):027:0> $~[1]
- => "foo"
$`
在当前作用域中,正则表达式最后一次匹配成功的字符串前面的字符串.若最后的匹配失败则为nil.
等同于Regexp.last_match.pre_match.Ruby代码- irb(main):016:0> $`
- => "" #由于最后匹配成功的内容是foobar,输入的字符串前面没有别的字符所以是""
$'
在当前作用域中,正则表达式最后一次匹配成功的字符串后面的字符串.若最后的匹配失败则为nil.
等同于Regexp.last_match.post_match.Ruby代码- irb(main):028:0> $'
- => "baz"
$+
在当前作用域中,正则表达式最后一次匹配成功的字符串部分中,与最后一个括号相对应的那部分字符串.若最后的匹配失败则为nil.在多项选择型匹配模型中,若您无法断定是哪个部分匹配成功时,该变量将会非常有用.Ruby代码- irb(main):029:0> $+
- => "bar"
$1
$2
$3 ...
分别存储着最后一次模型匹配成功时与第n个括号相匹配的值.若没有相应的括号时,其值为nil.等同于Regexp.last_match[1], Regexp.last_match[2],...Ruby代码- irb(main):030:0> $1
- => "foo"
- irb(main):031:0> $2
- => "bar"
- irb(main):032:0> $3
- => nil
线程局部域
下列变量在一个线程内部时是全局域变量,但在不同的线程之间是彼此独立的.
$!
最近发生的异常的信息.由raise设定.Ruby代码- def exception
- begin
- raise "exception test."
- ensure
- puts $!
- end
- end
- exception
结果:引用
simple.rb:58:in `exception': exception test. (RuntimeError)
from simple.rb:64
exception test. # $!中的值
$@
以数组形式保存着发生异常时的back trace信息. 数组元素是字符串,它显示了方法调用的位置,其形式为
"filename:line"
或
"filename:line:in `methodname'"
在向$@赋值时,$!不能为nil。Ruby代码- def exception
- begin
- raise "exception test."
- ensure
- puts $@
- puts "$@ size is:#{$@.size}"
- end
- end
- exception
结果:引用
simple.rb:58:in `exception': exception test. (RuntimeError)
from simple.rb:65
simple.rb:58:in `exception' #$@中的值,是一个数组,第一个元素是错误发生的行数,第二个是异常的内容。下面打印了数组的长度
simple.rb:65
$@ size:2
全局域
这种类型的变量是整个应用中都可以访问的,而且是同一个变量的引用。是全局作用域的
$/
输入记录分隔符。默认值为"\n"。Ruby代码- irb(main):076:0> $/ #初始的输入分割符
- => "\n"
- irb(main):077:0> gets
- => "\n"
- irb(main):078:0> "test" #输入回车之后,默认插入"\n",输入结束
- => "test"
- irb(main):079:0> $/="@" #修改输入符为"@"
- => "@"
- irb(main):080:0> gets #输入回车之后没有结束读取进程,直到输入"@"之后结束
- test
- @
- => "test\n@"
$\
输出记录分隔符。print会在最后输出该字符串。
默认值为nil,此时不会输出任何字符。Ruby代码- irb(main):082:0> print "abc"
- abc=> nil
- irb(main):083:0> $\="@"
- => "@"
- irb(main):084:0> print "abc"
- abc@=> nil
$,
默认的切分字符。若Array#join中省略了参数时或在print的各个参数间将会输出它。
默认值为 nil ,等同于空字符串。Ruby代码- irb(main):087:0> ["a","b","c"].join
- => "abc"
- irb(main):088:0> $,="," #修改切分字符为","
- 查看(393) 评论(0) 收藏 分享 管理
-
TCP的2MSL等待状态对NAT的影响
2009-11-18 17:00:42
1问题症状
同一客户端只能连续打开十几张网页,之后就时而能打开时而打不开。等待几分钟后再次连续点击网页,还可以连续打开十几张网页,之后又出现相同现象。服务器为Windows 2003 Server系统,客户端为Windows 2003 Server或Windows XP时会出现上述问题,当客户端为Windows 2000 Advanced Server时上述症状消失,连续打开的网页数没有限制。
组网方式是客户端通过某型号路由器以多对一的NAT(又称为Easy IP方式的NAT)访问Web Server。
2 TCP协议简单介绍
2.1 TCP的服务及TCP报文结构
TCP和UDP都属于TCP/IP协议族中的传输层协议,尽管TCP和UDP都使用相同的网络层(IP),TCP却向应用层提供与UDP完全不同的服务。TCP提供一种面向连接的、可靠的字节流服务。面向连接意味着两个使用TCP的应用(通常是一个客户和一个服务器)在彼此交换数据之前必须先建立一个TCP连接。在一个TCP连接中,仅有两方进行彼此通信,广播和多播不能用于TCP。
TCP的报文结构如图1和图2所示。
每个TCP段都包含源端和目的端的端口号,用于寻找发端和收端应用进程。这两个值加上IP首部中的源端IP地址和目的端IP地址唯一确定一个TCP连接。有时,一个IP地址和一个端口号也称为一个套接字(Socket)。套接字对(Socket pair)(包含客户IP地址、客户端口号、服务器IP地址和服务器端口号的四元组)可唯一确定互联网中每个TCP连接的双方。
2.2 TCP连接的建立
TCP是一个面向连接的协议。无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接。为建立一条连接,需要三次握手(Three-way handshake),如图3所示。
(1)客户端发送一个SYN段指明客户打算连接的服务器的端口,以及初始序号ISN。这个SYN段为报文段1。
(2)服务器发回包含服务器的初始序号的SYN报文段(报文段2)作为应答。同时,将确认序号设置为客户的ISN加1以对客户的SYN报文段进行确认。一个SYN将占用一个序号。
(3)客户必须将确认序号设置为服务器的ISN加1以对服务器的SYN报文段进行确认(报文段3)。
发送第一个SYN的一端将执行主动打开(Active open)。接收这个SYN并发回下一个SYN的另一端执行被动打开(Passive open)。当一端为建立连接而发送它的SYN时,它为连接选择一个初始序号。ISN随时间而变化,因此每个连接都将具有不同的ISN。RFC 793 指出ISN可看作是一个32bit的计数器,每4μs加1。这样选择序号的目的在于防止在网络中被延迟的分组在以后又被传送,而导致某个连接的一方对它作错误的解释。
2.3 TCP连接的终止
建立一个连接需要三次握手,而终止一个连接要经过4次握手。既然一个TCP连接是全双工(即数据在两个方向上能同时传递),因此每个方向必须单独地进行关闭。这原则就是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向连接。当一端收到一个FIN,它必须通知应用层另一端已经终止了那个方向的数据传送。发送FIN通常是应用层进行关闭的结果。收到一个FIN只意味着在这一方向上没有数据流动。一个TCP连接在收到一个FIN后仍能发送数据。正常关闭过程如图3所示。首先进行关闭的一方(即发送第一个FIN)将执行主动关闭,而另一方(收到这个FIN)执行被动关闭。通常一方完成主动关闭而另一方完成被动关闭。图3中的报文段4发起终止连接,它将导致TCP客户端发送一个FIN,用来关闭从客户到服务器的数据传送。当服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。同时TCP服务器还向应用程序传送一个文件结束符。接着这个服务器程序就关闭它的连接,导致它的TCP端发送一个FIN(报文段6),客户必须发回一个确认,并将确认序号设置为收到序号加1(报文段7)。
2.4 2MSL等待状态
TIME_WAIT状态也称为2MSL等待状态。每个具体TCP实现必须选择一个报文段最大生存时间(MSL,Maximum Segment Lifetime)。它是任何报文段被丢弃前在网络内的最长时间。我们知道这个时间是有限的,因为TCP报文段以IP数据报在网络内传输,而IP数据报则有限制其生存时间的TTL字段。
RFC 793 指出MSL为2min。然而,实现中的常用值是30s,1min,或2min。我们知道在实际应用中,对IP数据报TTL的限制是基于跳数,而不是定时器。对一个具体实现所给定的MSL值,处理的原则是:当TCP执行一个主动关闭,并发回最后一个ACK,该连接必须在TIME_WAIT状态停留的时间为2倍的MSL。这样可让TCP再次发送最后的ACK以防这个ACK丢失(另一端超时并重发最后的FIN)。
这种2MSL等待的另一个结果是这个TCP连接在2MSL等待期间,定义这个连接的套接字对(客户的I P地址和端口号,服务器的IP地址和端口号)不能再被使用,前一替身的任何迟到报文将被丢弃,这样做的目的是防止迟到的报文被新连接曲解而干扰新的连接,所以,这个连接只能在2MSL结束后才能再被使用。这里存在的一个例外的情况,即当新连接SYN段的ISN序号大于这个连接前一个替身的最后序号时,TCP可以立即从TIME_WAIT状态恢复并开始接受这个新连接。(一个连接由一个套接字对来定义。一个连接的新的实例称为该连接的替身)。
在图3中客户执行主动关闭并进入TIME_WAIT是正常的。服务器通常执行被动关闭,不会进入TIME_WAIT状态。总之,执行主动关闭的一方总要进入TIME_WAIT状态。
3 问题分析
首先在Web Server上用Sniffer软件抓包,发现很多TCP SYN Retransmission(重传),说明当网页打不开时,SYN报文确实顺利到达了Web Server,只是Web Server没有对客户端的SYN请求做任何应答,客户端重传两次这个SYN报文试图与服务器同步,仍没有应答之后就放弃本次连接了。我们想弄清楚的是为什么Web Server没有回应客户端的SYN请求呢?是服务器本身有问题,还是客户端发来的SYN报文非法?仔细观察SYN报文的每一个字段,结构和参数都没有任何异常,是合法的SYN报文。Web Server本身似乎也没有任何问题,因为如果不经过NAT,而将客户端与服务器直连,便没有任何访问障碍。这样推论好像问题出在路由器的NAT上,可是当用一台Windows 2000 Advanced Server做客户端去访问Web Server时却又没有任何问题,并且经过同样的NAT转换,以任何操作系统的客户端去访问政务网的其他网站,也没有任何问题。
从以上现象推理,可总结为:当且仅当出现以下这种组合时,上述问题就会出现。
Windows 2000或Windows XP做客户端→该型号路由器做NAT→本台Web Server作为服务器。
通过一段时间的抓包分析,可知此问题恰恰由以上三方面的因素共同导致,即Web 应用程序、该型号路由器和客户端。
3.1 Web Server 应用程序方面的问题
在服务器上使用netstat -an命令可以看到许多从路由器NAT转换后的地址到Web Server 80 端口的连接,状态为TIME_WAIT。后得知这些连接的产生原因是:点击每个网页都会由一个引导页面跳转到一个实际的ASP页面,这样客户端就与服务器建立了两对Socket连接,那对为引导页面创建的Socket连接瞬间就被服务器关闭了。根据TCP协议的原理我们知道,主动关闭连接的一方要进入TIME_WAIT状态,其等待时间长达2MSL(Maximum Segment Lifetime)。后面综合分析的时候我会讲到这么做其实存在弊端。
3.2 该型号路由器NAT方面的问题
这两款路由器在NAT的端口分配方式上存在一种“回收再利用”的循环机制。比如说,前一次访问使用的是25024端口,当前一次的连接断开后,路由器会优先把这个端口再分配出去供新连接使用。表面上看这么做没有任何问题,既然前一连接已经关闭,为新连接重新选用此端口有什么问题吗?
3.3 Windows XP和Windows 2003做为客户端的问题
人所共知,Windows XP和Windows 2003操作系统的发布是晚于Windows 2000的,可以看作是Windows 2000的升级版,功能更强大,尤其是安全性方面更有较大的提升。为了防止黑客以猜测TCP ISN(Initial Sequence Number,初始序列号)的方式欺骗攻击TCP连接,Windows XP和Windows 2003的TCP ISN的生成算法较Windows 2000以及更早的Windows版本都更为复杂。
仔细观察我们所捕捉到的数据包,Windows2000 Advanced Server做客户端时,TCP SYN初始序列号ISN是随时间按序递增的,大致上每秒增加20几万到30几万左右,而序号的范围是0~232-1,即0~4294967295,到最大值后再从0开始,所以在几分钟的时间内序号基本上都是递增的。
而当Windows XP或Windows 2003做客户端时,我们可以看到ISN是杂乱无序的,因为系统采用了更复杂的算法来生成这些随机的ISN。尽管这样很安全,不易被黑客预测到下一个ISN的值从而遭受TCP欺骗,不过对于我们的上述应用,其实也是导致问题出现的一个因素。
3.4 综合分析
下面我们来研究客户端经过NAT转换访问Web Server的详细过程。为方便表述,我们假定客户端IP:192.168.0.2,NAT转换后IP:218.5.1.2,服务端Web Server IP:218.5.1.8。当客户端第一次打开网页的时候,它首先要和服务器建立一个TCP连接,客户端向服务器端发送SYN,源IP:192.168.0.2,并随机选择一个大于1024的端口作为源端口,这里假定为1136,目的IP:218.5.1.8,目的端口:80,经路由器NAT转换后源IP和源端口变为:218.5.1.2:25024,目的IP和端口不变。服务器收到SYN后,立即回应一个SYN ACK,经过NAT到达客户端,客户端再回应一个ACK,这样一个TCP连接就建立起来了。在服务器上运行netstat -an命令我们却可以看到有两个相关的TCP连接,其中一个状态为ESTABLISHED(这个连接是为最终的ASP页面创建的),另一个状态为TIME_WAIT(这个连接是为临时引导页面创建的)。经过测试发现这个TIME_WAIT状态在服务器上的持续时间长达133s。用户的每次点击都会产生一个TIME_WAIT状态的连接,前面讲过,这是由服务端主动关闭引导页面产生的。
我们再看路由器这边的情况。由于路由器收到服务器发来的FIN报文,知道服务器主动关闭了这个TCP连接,立即就将自己的NAT表项192.168.0.2:1136——218.5.1.2:25024——218.5.1.8:80清除,并不像服务器端那样在关闭连接后仍会进入一个长达133s的等待期,这样就形成了一种不协调,为后面的问题出现埋下了伏笔。当同一用户继续打开新网页的时候,服务器端TIME_WAIT状态的连接也越来越多。而我们观察到路由器上的NAT表项却没有明显增多,因为路由器NAT表很及时地清除了已关闭的连接,并且路由器很快(在133s内)又将已回收的端口(如25024)分配出去。注意,现在问题产生了,路由器以相同的Socket:218.5.1.2:25024连接到服务器端相同的Socket:218.5.1.8:80,但是这对Socket连接在服务器端还处在TIME_WAIT状态。根据TCP协议规范,在旧连接的实例还处于TIME_WAIT状态期间,采用相同的Socket对(客户的IP地址和端口号,服务器的IP地址和端口号)打开一个新的连接实例会被服务端拒绝,除非新连接的TCP SYN的初始序列号ISN大于旧连接实例的最后序号。当用Windows 2000 Advanced Server 的系统作客户端时之所以不会有任何问题,就是因为它的ISN序号的产生是随时间序列递增的。可是Windows XP和Windows 2003系统产生的却是大小无序的ISN序号,当新产生的ISN小于旧实例的最后序号时,客户端的SYN请求就会被拒绝,从而这个TCP连接就不能成功建立。
4 解决问题的方法
上述问题已经有了全面系统的分析,解决这个问题应该从最源头开始。我们当然不能要求用户全部改用Windows 2000系统,好的网络设备应该对应用程序提供尽可能广泛的支持,同时还要充分考虑到TCP/IP协议的固有特点,具有尽可能广泛的兼容性、适应性。
首先应从路由器着手,改进NAT端口分配“回收再利用”的机制,使端口循环使用的时间周期尽可能长(至少要大于TIME_WAIT状态的等待时间2MSL)。或者可以模仿TCP协议规范,设计一个类似TIME_WAIT的等待状态,在连接关闭时并不马上清除该NAT表项,而是进入一个等待期,在此期间该表项不允许新连接再次使用。在这两种针对路由器的改进方案中,后者会导致NAT表项数目增加,从而耗费更多的路由器内存,比较而言,前者更佳。
其次也可以考虑改进服务器端的Web应用程序。尽可能少使用或不使用引导页面,避免服务器端频繁地主动关闭TCP连接 -
计量单位 Byte,KB,MB,GB,TB,PB,EB,ZB,YB
2009-11-18 14:33:07
1GB=1024MB(理论上)
计算机存储信息的大小,最基本的单位是字节,一个汉字由两个字节组成,字母和数字由一个字节组成。
容量的单位从小到大依次是:字节(B)、KB、MB、GB、TB。它们之间的关系是。
1TB=1024GB
1GB=1024MB
1MB=1024KB
1KB=1024字节
通常人们都使用简便的叫法,把后面的“B”去掉,所以你问的1GB就是1024MB。
以上是根据教科书给出的答案,不过理论和实际是有点出入的,硬件方面,特别是硬盘,换算的方式略有差别, 既将上面公式里的1024都换成1000,24可以忽略不计。 所以现实中我们买的硬盘使用时都会发现, 实际可使用的容量和标称的是有差别的, 实际可使用的容量比标称的小,而且硬盘越大,差异越大, 硬盘厂商以1000MB为1GB, 我们的windows系统以1024MB为1GB,就是这样。
问题补充:1TB=1024GB
1GB=1024MB
1MB=1024KB
1KB=1024Byte
注:Byte就是B也就是字节
KB是千字节
MB是兆
GB是吉字节 即千兆
TB是太字节
------------------------------
1、计算机存储信息的最小单位,称之为位(bit),音译比特,二进制的一个“0”或一个“1”叫一位。
2、计算机存储容量基本单位是字节(Byte),音译为拜特,8个二进制位组成1个字节,一个标准英文字母占一个字节位置, 一个标准汉字占二个字节位置。
3、计算机存储容量大小以字节数来度量,1024进位制:
1024B=1K(千)B
1024KB=1M(兆)B
1024MB=1G(吉)B
1024GB=1T(太)B
以下还有PB、EB、ZB、YB 、NB、DB,一般人不常使用了。
KB ,2 的 10 次方 : 1024 BYTE.
MB ,2 的 20 次方 : 1048576 BYTE, 或 1024 KB.
GB ,2 的 30 次方 : 1073741824 BYTE, 或 1024 MB.
TB ,2 的 40 次方 : 1099511627776 BYTE, 或 1024 GB.
PB ,2 的 50 次方 : 1125899906842624 BYTE, 或 1024 TB.
EB ,2 的 60 次方 : 1152921504606846976 BYTE, 或 1024 PB.
ZB ,2 的 70 次方 : 1024 EB.
YB ,2 的 80 次方 : 1024 ZB -
网络状态详解
2009-11-17 17:18:25
一、Linux服务器上11种网络连接状态:

图:TCP的状态机通常情况下:一个正常的TCP连接,都会有三个阶段:1、TCP三次握手;2、数据传送;3、TCP四次挥手
注:以下说明最好能结合”图:TCP的状态机”来理解。
SYN: (同步序列编号,Synchronize Sequence Numbers)该标志仅在三次握手建立TCP连接时有效。表示一个新的TCP连接请求。
ACK: (确认编号,Acknowledgement Number)是对TCP请求的确认标志,同时提示对端系统已经成功接收所有数据。
FIN: (结束标志,FINish)用来结束一个TCP回话.但对应端口仍处于开放状态,准备接收后续数据。
1)、LISTEN:首先服务端需要打开一个socket进行监听,状态为LISTEN. /* The socket is listening for incoming connections. 侦听来自远方TCP端口的连接请求 */
2)、SYN_SENT:客户端通过应用程序调用connect进行active open.于是客户端tcp发送一个SYN以请求建立一个连接.之后状态置为SYN_SENT. /*The socket is actively attempting to establish a connection. 在发送连接请求后等待匹配的连接请求 */3)、SYN_RECV:服务端应发出ACK确认客户端的SYN,同时自己向客户端发送一个SYN. 之后状态置为SYN_RECV /* A connection request has been received from the network. 在收到和发送一个连接请求后等待对连接请求的确认 */
4)、ESTABLISHED: 代表一个打开的连接,双方可以进行或已经在数据交互了。/* The socket has an established connection. 代表一个打开的连接,数据可以传送给用户 */
5)、FIN_WAIT1:主动关闭(active close)端应用程序调用close,于是其TCP发出FIN请求主动关闭连接,之后进入FIN_WAIT1状态./* The socket is closed, and the connection is shutting down. 等待远程TCP的连接中断请求,或先前的连接中断请求的确认 */
6)、CLOSE_WAIT:被动关闭(passive close)端TCP接到FIN后,就发出ACK以回应FIN请求(它的接收也作为文件结束符传递给上层应用程序),并进入CLOSE_WAIT. /* The remote end has shut down, waiting for the socket to close. 等待从本地用户发来的连接中断请求 */
7)、FIN_WAIT2:主动关闭端接到ACK后,就进入了FIN-WAIT-2 ./* Connection is closed, and the socket is waiting for a shutdown from the remote end. 从远程TCP等待连接中断请求 */
8)、LAST_ACK:被动关闭端一段时间后,接收到文件结束符的应用程序将调用CLOSE关闭连接。这导致它的TCP也发送一个 FIN,等待对方的ACK.就进入了LAST-ACK . /* The remote end has shut down, and the socket is closed. Waiting for acknowledgement. 等待原来发向远程TCP的连接中断请求的确认 */
9)、TIME_WAIT:在主动关闭端接收到FIN后,TCP就发送ACK包,并进入TIME-WAIT状态。/* The socket is waiting after close to handle packets still in the network.等待足够的时间以确保远程TCP接收到连接中断请求的确认 */
10)、CLOSING: 比较少见./* Both sockets are shut down but we still don’t have all our data sent. 等待远程TCP对连接中断的确认 */
11)、CLOSED: 被动关闭端在接受到ACK包后,就进入了closed的状态。连接结束./* The socket is not being used. 没有任何连接状态 */
TIME_WAIT状态的形成只发生在主动关闭连接的一方。
主动关闭方在接收到被动关闭方的FIN请求后,发送成功给对方一个ACK后,将自己的状态由FIN_WAIT2修改为TIME_WAIT,而必须再等2倍 的MSL(Maximum Segment Lifetime,MSL是一个数据报在internetwork中能存在的时间)时间之后双方才能把状态 都改为CLOSED以关闭连接。目前RHEL里保持TIME_WAIT状态的时间为60秒。当然上述很多TCP状态在系统里都有对应的解释或设置,可见man tcp
二、关于长连接和短连接:
通俗点讲:短连接就是一次TCP请求得到结果后,连接马上结束.而长连接并不马上断开,而一直保持着,直到长连接TIMEOUT(具体程序都有相关参数说明).长连接可以避免不断的进行TCP三次握手和四次挥手.
长连接(keepalive)是需要靠双方不断的发送探测包来维持的,keepalive期间服务端和客户端的TCP连接状态是ESTABLISHED.目前http 1.1版本里默认都是keepalive(1.0版本默认是不keepalive的),ie6/7/8和firefox都默认用的是http 1.1版本了(如何查看当前浏览器用的是哪个版本,这里不再赘述)。Apache,java一个应用至于到底是该使用短连接还是长连接,应该视具体情况而定。一般的应用应该使用长连接。
1、Linux的相关keepalive参数
a、 tcp_keepalive_time – INTEGER
How often TCP sends out keepalive messages when keepalive is enabled.
Default: 2hours.
b、 tcp_keepalive_probes – INTEGER
How many keepalive probes TCP sends out, until it decides that the
connection is broken. Default value: 9.
c、 tcp_keepalive_intvl – INTEGER
How frequently the probes are send out. Multiplied by
tcp_keepalive_probes it is time to kill not responding connection,
after probes started. Default value: 75sec i.e. connection
will be aborted after ~11 minutes of retries.2、F5负载均衡上的相关参数说明
a、Keep Alive Interval
Specifies, when enabled, how frequently the system sends data over an idle TCP connection, to determine whether the connection is still valid.
Specify: Specifies the interval at which the system sends data over an idle connection, to determine whether the connection is still valid. The default is 1800 milliseconds.
b、Time Wait
Specifies the length of time that a TCP connection remains in the TIME-WAIT state before entering the CLOSED state.
Specify: Specifies the number of milliseconds that a TCP connection can remain in the TIME-WAIT state. The default is 2000.c、Idle Timeout
Specifies the length of time that a connection is idle (has no traffic) before the connection is eligible for deletion.
Specify: Specifies a number of seconds that the TCP connection can remain idle before the system deletes it. The default is 300 seconds.3、Apache的相关参数说明
以下是Apache/2.0.61版本的默认参数和说明a、KeepAlive:
default On.Whether or not to allow persistent connections (more than
one request per connection). Set to “Off” to deactivate.
b、MaxKeepAliveRequests:
default 100.The maximum number of requests to allow
during a persistent connection. Set to 0 to allow an unlimited amount.
We recommend you leave this number high, for maximum performance.
c、KeepAliveTimeout:
default 15. Number of seconds to wait for the next request from the
same client on the same connection.转载请注明出处。http://www.vimer.cn
-
TCP三次握手/四次挥手详解
2009-11-17 17:16:46
1、建立连接协议(三次握手)
(1)客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的报文1。
(2) 服务器端回应客户端的,这是三次握手中的第2个报文,这个报文同时带ACK标志和SYN标志。因此它表示对刚才客户端SYN报文的回应;同时又标志SYN给客户端,询问客户端是否准备好进行数据通讯。
(3) 客户必须再次回应服务段一个ACK报文,这是报文段3。
2、连接终止协议(四次挥手)
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。
(3) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段6)。
(4) 客户段发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7)。
CLOSED: 这个没什么好说的了,表示初始状态。
LISTEN: 这个也是非常容易理解的一个状态,表示服务器端的某个SOCKET处于监听状态,可以接受连接了。
SYN_RCVD: 这个状态表示接受到了SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂,基本上用netstat你是很难看到这种状态的,除非你特意写了一个客户端测试程序,故意将三次TCP握手过程中最后一个ACK报文不予发送。因此这种状态时,当收到客户端的ACK报文后,它会进入到ESTABLISHED状态。
SYN_SENT: 这个状态与SYN_RCVD遥想呼应,当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,因此也随即它会进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。
ESTABLISHED:这个容易理解了,表示连接已经建立了。
FIN_WAIT_1: 这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。
FIN_WAIT_2:上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你,稍后再关闭连接。
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
CLOSING: 这种状态比较特殊,实际情况中应该是很少见,属于一种比较罕见的例外状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?其实细想一下,也不难得出结论:那就是如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
CLOSE_WAIT: 这种状态的含义其实是表示在等待关闭。怎么理解呢?当对方close一个SOCKET后发送FIN报文给自己,你系统毫无疑问地会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,实际上你真正需要考虑的事情是察看你是否还有数据发送给对方,如果没有的话,那么你也就可以close这个SOCKET,发送FIN报文给对方,也即关闭连接。所以你在CLOSE_WAIT状态下,需要完成的事情是等待你去关闭连接。
LAST_ACK: 这个状态还是比较容易好理解的,它是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,也即可以进入到CLOSED可用状态了。
最后有2个问题的回答,我自己分析后的结论(不一定保证100%正确)
1、 为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
2、 为什么TIME_WAIT状态还需要等2MSL后才能返回到CLOSED状态?
这是因为:虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接回到CLOSED状态(就好比从SYN_SEND状态到ESTABLISH状态那样);但是因为我们必须要假想网络是不可靠的,你无法保证你最后发送的ACK报文会一定被对方收到,因此对方处于LAST_ACK状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文,所以这个TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。 -
TCP连接状态详解
2009-11-16 15:23:10
tcp状态:LISTEN:侦听来自远方的TCP端口的连接请求
SYN-SENT:再发送连接请求后等待匹配的连接请求
SYN-RECEIVED:再收到和发送一个连接请求后等待对方对连接请求的确认
ESTABLISHED:代表一个打开的连接
FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认
FIN-WAIT-2:从远程TCP等待连接中断请求
CLOSE-WAIT:等待从本地用户发来的连接中断请求
CLOSING:等待远程TCP对连接中断的确认
LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认
TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认
CLOSED:没有任何连接状态




TCP是一个面向连接的协议,所以在连接双方发送数据之前,都需要首先建立一条连接。这和前面讲到的协议完全不同。前面讲的所有协议都只是发送数据而已,大多数都不关心发送的数据是不是送到,UDP尤其明显,从编程的角度来说,UDP编程也要简单的多----UDP都不用考虑数据分片。
书中用telnet登陆退出来解释TCP协议连接的建立和中止的过程,可以看到,TCP连接的建立可以简单的称为三次握手,而连接的中止则可以叫做四次握手。
1.连接的建立
在建立连接的时候,客户端首先向服务器申请打开某一个端口(用SYN段等于1的TCP报文),然后服务器端发回一个ACK报文通知客户端请求报文收到,客户端收到确认报文以后再次发出确认报文确认刚才服务器端发出的确认报文(绕口么),至此,连接的建立完成。这就叫做三次握手。如果打算让双方都做好准备的话,一定要发送三次报文,而且只需要三次报文就可以了。
可以想见,如果再加上TCP的超时重传机制,那么TCP就完全可以保证一个数据包被送到目的地。
2.结束连接
TCP有一个特别的概念叫做half-close,这个概念是说,TCP的连接是全双工(可以同时发送和接收)连接,因此在关闭连接的时候,必须关闭传和送两个方向上的连接。客户机给服务器一个FIN为1的TCP报文,然后服务器返回给客户端一个确认ACK报文,并且发送一个FIN报文,当客户机回复ACK报文后(四次握手),连接就结束了。
3.最大报文长度
在建立连接的时候,通信的双方要互相确认对方的最大报文长度(MSS),以便通信。一般这个SYN长度是MTU减去固定IP首部和TCP首部长度。对于一个以太网,一般可以达到1460字节。当然如果对于非本地的IP,这个MSS可能就只有536字节,而且,如果中间的传输网络的MSS更佳的小的话,这个值还会变得更小。
4.TCP的状态迁移图
书P182页给出了TCP的状态图,这是一个看起来比较复杂的状态迁移图,因为它包含了两个部分---服务器的状态迁移和客户端的状态迁移,如果从某一个角度出发来看这个图,就会清晰许多,这里面的服务器和客户端都不是绝对的,发送数据的就是客户端,接受数据的就是服务器。
4.1.客户端应用程序的状态迁移图
客户端的状态可以用如下的流程来表示:
CLOSED->SYN_SENT->ESTABLISHED->FIN_WAIT_1->FIN_WAIT_2->TIME_WAIT->CLOSED
以上流程是在程序正常的情况下应该有的流程,从书中的图中可以看到,在建立连接时,当客户端收到SYN报文的ACK以后,客户端就打开了数据交互地连接。而结束连接则通常是客户端主动结束的,客户端结束应用程序以后,需要经历FIN_WAIT_1,FIN_WAIT_2等状态,这些状态的迁移就是前面提到的结束连接的四次握手。
4.2.服务器的状态迁移图
服务器的状态可以用如下的流程来表示:
CLOSED->LISTEN->SYN收到->ESTABLISHED->CLOSE_WAIT->LAST_ACK->CLOSED
在建立连接的时候,服务器端是在第三次握手之后才进入数据交互状态,而关闭连接则是在关闭连接的第二次握手以后(注意不是第四次)。而关闭以后还要等待客户端给出最后的ACK包才能进入初始的状态。
4.3.其他状态迁移
书中的图还有一些其他的状态迁移,这些状态迁移针对服务器和客户端两方面的总结如下
- LISTEN->SYN_SENT,对于这个解释就很简单了,服务器有时候也要打开连接的嘛。
- SYN_SENT->SYN收到,服务器和客户端在SYN_SENT状态下如果收到SYN数据报,则都需要发送SYN的ACK数据报并把自己的状态调整到SYN收到状态,准备进入ESTABLISHED
- SYN_SENT->CLOSED,在发送超时的情况下,会返回到CLOSED状态。
- SYN_收到->LISTEN,如果受到RST包,会返回到LISTEN状态。
- SYN_收到->FIN_WAIT_1,这个迁移是说,可以不用到ESTABLISHED状态,而可以直接跳转到FIN_WAIT_1状态并等待关闭。
4.4.2MSL等待状态
书中给的图里面,有一个TIME_WAIT等待状态,这个状态又叫做2MSL状态,说的是在TIME_WAIT2发送了最后一个ACK数据报以后,要进入TIME_WAIT状态,这个状态是防止最后一次握手的数据报没有传送到对方那里而准备的(注意这不是四次握手,这是第四次握手的保险状态)。这个状态在很大程度上保证了双方都可以正常结束,但是,问题也来了。
由于插口的2MSL状态(插口是IP和端口对的意思,socket),使得应用程序在2MSL时间内是无法再次使用同一个插口的,对于客户程序还好一些,但是对于服务程序,例如httpd,它总是要使用同一个端口来进行服务,而在2MSL时间内,启动httpd就会出现错误(插口被使用)。为了避免这个错误,服务器给出了一个平静时间的概念,这是说在2MSL时间内,虽然可以重新启动服务器,但是这个服务器还是要平静的等待2MSL时间的过去才能进行下一次连接。
4.5.FIN_WAIT_2状态
这就是著名的半关闭的状态了,这是在关闭连接时,客户端和服务器两次握手之后的状态。在这个状态下,应用程序还有接受数据的能力,但是已经无法发送数据,但是也有一种可能是,客户端一直处于FIN_WAIT_2状态,而服务器则一直处于WAIT_CLOSE状态,而直到应用层来决定关闭这个状态。
5.RST,同时打开和同时关闭
RST是另一种关闭连接的方式,应用程序应该可以判断RST包的真实性,即是否为异常中止。而同时打开和同时关闭则是两种特殊的TCP状态,发生的概率很小。
6.TCP服务器设计
前面曾经讲述过UDP的服务器设计,可以发现UDP的服务器完全不需要所谓的并发机制,它只要建立一个数据输入队列就可以。但是TCP不同,TCP服务器对于每一个连接都需要建立一个独立的进程(或者是轻量级的,线程),来保证对话的独立性。所以TCP服务器是并发的。而且TCP还需要配备一个呼入连接请求队列(UDP服务器也同样不需要),来为每一个连接请求建立对话进程,这也就是为什么各种TCP服务器都有一个最大连接数的原因。而根据源主机的IP和端口号码,服务器可以很轻松的区别出不同的会话,来进行数据的分发。
-
37个我爱Ruby的理由
2009-11-10 12:12:26
我不打算浪费时间来谈论Ruby的历史,如果你没有听说过它,你可以去它的主页看看www.ruby-lang.org,或者去它的新闻组comp.lang.ruby。如果你知道Ruby,我将讲述我为什么会喜爱它。原著:http://hypermetrics.com/ruby.html
翻译:liubin http://www.ruby-cn.org/
一切权利归原作者所有,转载请保留。
2004/12/3
我不打算浪费时间来谈论Ruby的历史,如果你没有听说过它,你可以去它的主页看看www.ruby-lang.org,或者去它的新闻组comp.lang.ruby。如果你知道Ruby,我将讲述我为什么会喜爱它。(你也可能去我的Ruby主页或者个人主页看看)
1.
它是面向对象的。 这表示什么意义呢?如果问10个程序员,你也许会得到12种结果,你有你的看法,我不会试图去改变你的看法。但是有一点,Ruby提供了对数据和方法的封装,允许类的继承,对象的多态。不像其它语言(C++,Perl等),Ruby从设计的时候开始就是一种面向对象的语言。
2.
它是纯面向对象的语言。难道是我多余?不是这样的,之所以这么说,因为Ruby中一切都是对象,包括原始数据类型(primitive data types),比如字符串,整型,都表示的是一个对象,而不需要Java那样提供包装类(wrapper classes)。另外,甚至是常量,也会被当作对象来处理,所以一个方法的接收者,可以是一个数字常量。
3.
它是动态语言。 对于只熟悉像C++,Java这样静态语言的人来说,这是一个重大的概念上的差别。动态意味着方法和变量可以在运行时候添加和重定义。它减少了像C语言那样的条件编译(#ifdef),而且容易实现反射API(reflection API)。动态性使得程序能自我感知(self-aware),比如运行时类型信息,检测丢失的方法,用来检测增加方法的钩子等。在这些方面Ruby和Lisp和Smalltalk都有一些关系。
4.
它是一种解释执行的语言。这是一个负杂的问题,值得重点解释一下,也许这个特点会因为性能的原因而引起从优点变为缺点的争论。对于此,我有几点见解:1.第一:快速开发循环是一个巨大的好处,这要得意于Ruby的解释执行。2.多慢才叫慢呢?在说它慢之前先定一个慢的基准。3.也许有人要批评我了,但我还要说:处理器每年都在变得原来越快。4.如果你真的很在意你的速度,你可以用C开发一部分你的代码。5.最后,从某种意义上说,这是一个还在争论中的问题,没有一个语言天生就是解释型的,世界上没有哪个法律进制开发一个Ruby编译器出来。
5.
它理解正则表达式。 很多年之前,正则表达式只是用在UNIX的工具如grep或者sed中,或者在vi中进行一些一定的查找-替换等。Perl的出现解决了这些问题,而现在,Ruby同样也能做到这些。越来越多得人认识到了这种字符串和文本处理技术的难以置信的能力,如果你对此表示怀疑,那么请去看一下 Jeffrey Friedl的书Mastering Regular Expressions,然后,你就应该不会有什么怀疑了。
6.
它是多平台的。 Ruby可以运行在Linux,UNIX,Windows,BeOS,甚至MS-DOS。如果我没记错,甚至还有一个Amiga 版本的
7.
它是派生来的。 这是一件好事情吗?抛去书本上的知识,它是有用的。牛顿曾说过“我如果看得比别人远,那是因为我站在巨人的肩膀上”。Ruby同样也是站在巨人的肩膀上,它借鉴了Smalltalk, CLU, Lisp, C, C++, Perl, Kornshell等的优点。在我看来它的原则包括:1.不要重复制造轮子。2.不要修补没有损坏的东西。3.最后一个也是比较特别的,它能平衡(Leverage )你已有的知识。你了解UNIX的文件和管道,没关系,你可以在Ruby中继续用,你用了两年的时间学习了printf 指示符,不必担心,Ruby中你也可以使用printf。你知道Perl的正则表达式处理,那么你也就学会了Ruby中的正则表达式。
8.
它是创新的。 是不是觉得这个和第七条矛盾了?也许是有一部分矛盾,每个硬币都有两面。一些Ruby的特点都是创新的东西,比如非常有用的Mix-in,也许这个特点会被后来的语言借鉴。(注:一位读者指出Lisp早在1979年就有mix-in了,这是我的疏忽;我应该找个更好的例子,并且能确信它。)
9.
它是非常高层次的语言。(Very High-Level Language :VHLL) 这是一个容易引起争论的话题,因为这个术语还没有广泛使用。而且它的意思比起OOP来说还是有讨论余地的。我这么说,指的是Ruby能支持复杂的结构和这些结构的负杂的操作,而需要的指令非常少,这与最小努力原则(Principle of Least Effort)一致。
10.
它有一个灵巧的垃圾收集器。 像malloc和free 这样的例程已经是昨天的恶梦了,你不需要什么回收内存的操作,甚至是调用垃圾收集器。
11.
它是脚本语言。 不要因为此就认为它不够强大,它不是一个玩具。它是完全成熟的语言,用它能轻松的完成传统的脚本操作,比如运行外部程序,检查系统资源,使用管道,捕获输出等等。
12.
它是通用的。 Kornshell做的东西它也可以做,C语言做的东西它也可以做的很好。你可以用它写一个只运行一次的只有10行的程序,或者对一些遗留程序进行包装,你想写个web server,或者一个CGI,都可以用Ruby来写。
13.
它是多线程的。 Y你可以用一些简单的API来写多线程程序,甚至在MS-DOS上都可以。
14.
它是open source的。 你想看它的源代码吗?可以,你也可以提交补丁,参加广泛的社区,包括它的创造者。
15.
它是直觉得。 Ruby的学习曲线比较低,而如果你翻过了一个坎,你开始“猜测”事情是怎么工作的,而且你的猜测很多时候都是正确的。Ruby坚持最小惊讶( Least Astonishment)的原则。
16.
它有异常机制。 像Java和 C++一样, Ruby 中也有异常机制,这意味着你不必因为返回值而将代码弄得凌乱不堪,很少的嵌套if语句,很少的意大利面条似的逻辑,更好的错误处理。
17.
它有一个高级的数组类:Array。 Ruby 中数组都是动态的,你不必像pascal那样在声明它的大小,也不必像C,C++那样为它分配内存。它们是对象,所以你不必关心它们的长度,实际上你不能"走到末尾(walk off the end)"。这个类提供了各种方法,使得你能够根据索引,根据元素来访问数组内容,也可以反向处理数组。你也可以用数作作为set,队列,堆栈等。如果你想用查找表,可以用哈希结构。
18.
它是可以扩展的。 你可以用C或者Ruby来编写外部库(external libraries),同样,你也可以修改已有的类和对象。
19.
鼓励文档编程(literate programming)。 你可以在Ruby程序中嵌入注释或者文档,这些文档可以用Ruby的文档工具提取和处理。(真正的文档编程者可能认为这是必须的基本东西吧)
20.
创造性的使用标点符号和大写字母。 比如一个方法返回一个boolean型(Ruby中并没有这种说法),那么一般这个方法最后都以问号结尾,如果一个方法要修改接收者本身,或者具有破坏性,则用一个感叹号结尾,简单,直觉。所有常量,包括类名,都以大写字母开头,所有对象属性以@符号开头。这有匈牙利命名法的实用性,但是没有视觉上的丑陋性。
21.
Reserved words aren't.It's perfectly allowable to use an identifier that is a so-called "reserved word" as long as the parser doesn't perceive an amibiguity. This is a breath of fresh air.(能用保留字作为变量吗?没看太懂。)
22.
支持迭代器。 这使得你可以给一个数组,list,tree等对象传递一个块,然后对它们的每个元素进行block调用。这个技术值得深入学习。
23.
它的安全性。 Ruby借鉴了Perl中基于$SAFE变量的分层控制机制 。这对于CGI程序来说非常有用,可以防止人们攻击web服务器。
24.
Ruby中没有指针。 像 Java一样,和C++不同,Ruby中没有指针的概念,所以免除了关于指针语法和调试的头疼。当然,这也意味着最底层的程序开发将会很困难,比如访问一个设备的控制状态寄存器;但是,我们可以用一个C库来调用。(像C语言程序员有时候要使用汇编语言一样,Ruby程序员有时候也要使用C语言来完成一定的任务)
25.
它使得人们专注于细节。 Ruby中有很多同义词和别名,你也许不记得字符串或数组的长度是size还是length,没关系,它们任何一个都可以工作。对于Range来说,你可以使用begin 和end 或者使用 first 和 last,它们也都工作。你想拼写indices,结果写成了indexes,没关系,这两个都一样。
26.
非常灵活的语法。 方法调用时候括号可以省略,参数之间只需用逗号分割。类似Perl风格的数组定义可以让你不用全部使用引号和逗号定义一个字符串的数组。关键字return可以生路。
27.
丰富的库函数。 Ruby提供了线程,socket,有限对象持久化,CGI,服务器端可执行的,数据库等其它库函数,还有对Tk的支持等。还有很多其它的库函数。
28.
本身自带调试器(debugger)。 在完美的世界中,我们才不需要调试器,但是这个世界不是完美的。
29.
交互式执行。 可以用Ruby像Kornshell那样执行。 (这可能是本页最具争论的一点,我不得不承认,Ruby真的不是一个很好的shell。但我仍然坚持,基于Ruby的shell是一个不错的主意。)
30.
它是简明的。 不像Pascal那样要求if后面跟着then,while后面跟着do 。变量不需要声明,它们不需要类型。返回类型不必指定,关键字return 可以省略,它将返回最后一个表达式的值。另一方面,它也不像Perl或者C那样复杂难懂。
31.
它是面向表达式的(expression-oriented)。 你可以轻易的使用 x = if a<0 then b else c? 这样的表达式。
32.
语法砂糖(syntax sugar)。 (像Mary Poppins解释:一勺语法的糖能使语义被接受) 。如果你想对数组x进行迭代,可以用for a in x。你也可以用a+=b代替a=a+b,这都行。很多操作符其实在Ruby中都是方法,这些方法的名字比较直观,短小,有着便利的语法。
33.
它支持操作符重载。 如果我没有记错的话,早在很久之前的SNOBOL就提供了这个功能,但是直到C++它才变得流行。虽然它可能乱用而出错,但是这仍是一个非常不错的优点。另外Ruby自动定义操作符的赋值版本,比如,如果你重定义了+,那么,你同时得到了一个+=操作符。
34.
支持无限精度的数字。 有人会关心 short, int, long吗,只需要使用 Bignum就行了,你可以轻松的实现365的阶乘。
35.
有幂操作符。 在很久以前,我们在BASIC和FORTRAN中使用它,然而当我们学习Pascal和C之后,我们才认识到这个操作符有多差劲。(我们被告知自己连它是怎么工作的都不知道-它使用了对数,迭代了吗,效率如何?),但是,我们真的关系这些吗?如果是,我们可以重写这个方法,否则,Ruby有非常好的**操作符可以用。
36.
强大的字符串处理。 If如果你想查找,判断,格式化,trim,定界(delimit),interpose,tokenize,你可以自己选择随便用哪一个来得到你想要的结果。
37.
规则很少引起异常。 Ruby的语法和语义比其它语言有条理,每种语言都有独特的一面,每条规则都会有异常发生,但是Ruby规则引起的异常就少的多了。 -
字符编码基础知识:ASCII,Unicode和UTF-8
2009-11-04 14:46:18
今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料。
结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步搞清楚。
下面就是我的笔记,主要用来整理自己的思路。但是,我尽量试图写得通俗易懂,希望能对其他朋友有用。毕竟,字符编码是计算机技术的基石,想要熟练使用计算机,就必须懂得一点字符编码的知识。
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
3.Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。
5.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx下面,还是以汉字“严”为例,演示如何实现UTF-8编码。
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
6. Unicode与UTF-8之间的转换
通过上一节的例子,可以看到“严”的Unicode码是4E25,UTF-8编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
在Windows平台下,有一个最简单的转化方法,就是使用内置的记事本小程序Notepad.exe。打开文件后,点击“文件”菜单中的“另存为”命令,会跳出一个对话框,在最底部有一个“编码”的下拉条。

里面有四个选项:ANSI,Unicode,Unicode big endian 和 UTF-8。
1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。
2)Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。
3)Unicode big endian编码与上一个选项相对应。我在下一节会解释little endian和big endian的涵义。
4)UTF-8编码,也就是上一节谈到的编码方法。
选择完”编码方式“后,点击”保存“按钮,文件的编码方式就立刻转换好了。
7. Little endian和Big endian
上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字”严“为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是”大头方式“(Big endian),第二个字节在前就是”小头方式“(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格“(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
8. 实例
下面,举一个实例。
打开”记事本“程序Notepad.exe,新建一个文本文件,内容就是一个”严“字,依次采用ANSI,Unicode,Unicode big endian 和 UTF-8编码方式保存。
然后,用文本编辑软件UltraEdit中的”十六进制功能“,观察该文件的内部编码方式。
1)ANSI:文件的编码就是两个字节“D1 CF”,这正是“严”的GB2312编码,这也暗示GB2312是采用大头方式存储的。
2)Unicode:编码是四个字节“FF FE 25 4E”,其中“FF FE”表明是小头方式存储,真正的编码是4E25。
3)Unicode big endian:编码是四个字节“FE FF 4E 25”,其中“FE FF”表明是大头方式存储。
4)UTF-8:编码是六个字节“EF BB BF E4 B8 A5”,前三个字节“EF BB BF”表示这是UTF-8编码,后三个“E4B8A5”就是“严”的具体编码,它的存储顺序与编码顺序是一致的
-
OpenSSL使用指南
2009-11-03 17:05:48
OpenSSL有两种运行模式:交互模式和批处理模式。
直接输入openssl回车进入交互模式,输入带命令选项的openssl进入批处理模式。(1) 配置文件
OpenSSL的默认配置文件位置不是很固定,可以用openssl ca命令得知。
你也可以指定自己的配置文件。
当前只有三个OpenSSL命令会使用这个配置文件:ca, req, x509。有望未来版本会有更多命令使用配置文件。(2)消息摘要算法
支持的算法包括:MD2, MD4, MD5, MDC2, SHA1(有时候叫做DSS1), RIPEMD-160。SHA1和RIPEMD-160产生160位哈西值,其他的产生128位。除非出于兼容性考虑,否则推荐使用SHA1或者RIPEMD-160。
除了RIPEMD-160需要用rmd160命令外,其他的算法都可用dgst命令来执行。
OpenSSL对于SHA1的处理有点奇怪,有时候必须把它称作DSS1来引用。
消息摘要算法除了可计算哈西值,还可用于签名和验证签名。签名的时候,对于DSA生成的私匙必须要和DSS1(即SHA1)搭配。而对于RSA生成的私匙,任何消息摘要算法都可使用。
############################################################# # 消息摘要算法应用例子 # 用SHA1算法计算文件file.txt的哈西值,输出到stdout $ openssl dgst -sha1 file.txt # 用SHA1算法计算文件file.txt的哈西值,输出到文件digest.txt $ openssl sha1 -out digest.txt file.txt # 用DSS1(SHA1)算法为文件file.txt签名,输出到文件dsasign.bin # 签名的private key必须为DSA算法产生的,保存在文件dsakey.pem中 $ openssl dgst -dss1 -sign dsakey.pem -out dsasign.bin file.txt # 用dss1算法验证file.txt的数字签名dsasign.bin, # 验证的private key为DSA算法产生的文件dsakey.pem $ openssl dgst -dss1 -prverify dsakey.pem -signature dsasign.bin file.txt # 用sha1算法为文件file.txt签名,输出到文件rsasign.bin # 签名的private key为RSA算法产生的文件rsaprivate.pem $ openssl sha1 -sign rsaprivate.pem -out rsasign.bin file.txt # 用sha1算法验证file.txt的数字签名rsasign.bin, # 验证的public key为RSA算法生成的rsapublic.pem $ openssl sha1 -verify rsapublic.pem -signature rsasign.bin file.txt
(3) 对称密码
OpenSSL支持的对称密码包括Blowfish, CAST5, DES, 3DES(Triple DES), IDEA, RC2, RC4以及RC5。OpenSSL 0.9.7还新增了AES的支持。很多对称密码支持不同的模式,包括CBC, CFB, ECB以及OFB。对于每一种密码,默认的模式总是CBC。需要特别指出的是,尽量避免使用ECB模式,要想安全地使用它难以置信地困难。
enc命令用来访问对称密码,此外还可以用密码的名字作为命令来访问。除了加解密,base64可作为命令或者enc命令选项对数据进行base64编码/解码。
当你指定口令后,命令行工具会把口令和一个8字节的salt(随机生成的)进行组合,然后计算MD5 hash值。这个hash值被切分成两部分:加密钥匙(key)和初始化向量(initialization vector)。当然加密钥匙和初始化向量也可以手工指定,但是不推荐那样,因为容易出错。
############################################################# # 对称加密应用例子 # 用DES3算法的CBC模式加密文件plaintext.doc, # 加密结果输出到文件ciphertext.bin $ openssl enc -des3 -salt -in plaintext.doc -out ciphertext.bin # 用DES3算法的OFB模式解密文件ciphertext.bin, # 提供的口令为trousers,输出到文件plaintext.doc # 注意:因为模式不同,该命令不能对以上的文件进行解密 $ openssl enc -des-ede3-ofb -d -in ciphertext.bin -out plaintext.doc -pass pass:trousers # 用Blowfish的CFB模式加密plaintext.doc,口令从环境变量PASSWORD中取 # 输出到文件ciphertext.bin $ openssl bf-cfb -salt -in plaintext.doc -out ciphertext.bin -pass env:PASSWORD # 给文件ciphertext.bin用base64编码,输出到文件base64.txt $ openssl base64 -in ciphertext.bin -out base64.txt # 用RC5算法的CBC模式加密文件plaintext.doc # 输出到文件ciphertext.bin, # salt、key和初始化向量(iv)在命令行指定 $ openssl rc5 -in plaintext.doc -out ciphertext.bin -S C62CB1D49F158ADC -iv E9EDACA1BD7090C6 -K 89D4B1678D604FAA3DBFFD030A314B29
(4)公匙密码
4.1 Diffie-Hellman
被用来做钥匙协商(key agreement),具有保密(secrecy)功能,但是不具有加密(encryption)或者认证(authentication)功能,因此在进行协商前需用别的方式对另一方进行认证。
首先,Diffie-Hellman创建一套双方都认可的参数集,包括一个随机的素数和生成因子(generator value,通常是2或者5)。基于这个参数集,双方都计算出一个公钥匙和私钥匙,公钥匙交给对方,对方的公钥匙和自己的私钥匙用来计算共享的钥匙。
OpenSSL 0.9.5 提供了dhparam命令用来生成参数集,但是生成公钥匙和私钥匙的命令dh和gendh已不推荐使用。未来版本可能会加上这个功能。
############################################################# # Diffie-Hellman应用例子 # 使用生成因子2和随机的1024-bit的素数产生D0ffie-Hellman参数 # 输出保存到文件dhparam.pem $ openssl dhparam -out dhparam.pem -2 1024 # 从dhparam.pem中读取Diffie-Hell参数,以C代码的形式 # 输出到stdout $ openssl dhparam -in dhparam.pem -noout -C
4.2 数字签名算法(Digital Signature Algorithm, DSA)
主要用来做认证,不能用来加密(encryption)或者保密(secrecy),因此它通常和Diffie-Hellman配合使用。在进行钥匙协商前先用DSA进行认证(authentication)。
有三个命令可用来完成DSA算法提供的功能。
dsaparam命令生成和检查DSA参数,还可生成DSA私钥匙。
gendsa命令用来为一套DSA参数生成私钥匙,这把私钥匙可明文保存,也可指定加密选项加密保存。可采用DES,3DES,或者IDEA进行加密。
dsa命令用来从DSA的私钥匙中生成公钥匙,还可以为私钥匙加解密,或者改变私钥匙加密的口令。############################################################# # DSA应用例子 # 生成1024位DSA参数集,并输出到文件dsaparam.pem $ openssl dsaparam -out dsaparam.pem 1024 # 使用参数文件dsaparam.pem生成DSA私钥匙, # 采用3DES加密后输出到文件dsaprivatekey.pem $ openssl gendsa -out dsaprivatekey.pem -des3 dsaparam.pem # 使用私钥匙dsaprivatekey.pem生成公钥匙, # 输出到dsapublickey.pem $ openssl dsa -in dsaprivatekey.pem -pubout -out dsapublickey.pem # 从dsaprivatekey.pem中读取私钥匙,解密并输入新口令进行加密, # 然后写回文件dsaprivatekey.pem $ openssl dsa -in dsaprivatekey.pem -out dsaprivatekey.pem -des3 -passin
4.3 RSA
RSA得名于它的三位创建者:Ron Rivest, Adi Shamir, Leonard Adleman。
目前之所以如此流行,是因为它集保密、认证、加密的功能于一体。不像Diffie-Hellman和DSA,RSA算法不需要生成参数文件,这在很大程度上简化了操作。
有三个命令可用来完成RSA提供的功能。
genrsa命令生成新的RSA私匙,推荐的私匙长度为1024位,不建议低于该值或者高于2048位。
缺省情况下私匙不被加密,但是可用DES、3DES或者IDEA加密。
rsa命令可用来添加、修改、删除私匙的加密保护,也可用来从私匙中生成RSA公匙,或者用来显示私匙或公匙信息。
rsautl命令提供RSA加密和签名功能。但是不推荐用它来加密大块数据,或者给大块数据签名,因为这种算法的速度较来慢。通常用它给对称密
匙加密,然后通过enc命令用对称密匙对大块数据加密。############################################################# # RSA应用例子 # 产生1024位RSA私匙,用3DES加密它,口令为trousers, # 输出到文件rsaprivatekey.pem $ openssl genrsa -out rsaprivatekey.pem -passout pass:trousers -des3 1024 # 从文件rsaprivatekey.pem读取私匙,用口令trousers解密, # 生成的公钥匙输出到文件rsapublickey.pem $ openssl rsa -in rsaprivatekey.pem -passin pass:trousers -pubout -out rsapubckey.pem # 用公钥匙rsapublickey.pem加密文件plain.txt, # 输出到文件cipher.txt $ openssl rsautl -encrypt -pubin -inkey rsapublickey.pem -in plain.txt -out cipher.txt # 使用私钥匙rsaprivatekey.pem解密密文cipher.txt, # 输出到文件plain.txt $ openssl rsautl -decrypt -inkey rsaprivatekey.pem -in cipher.txt -out plain.txt # 用私钥匙rsaprivatekey.pem给文件plain.txt签名, # 输出到文件signature.bin $ openssl rsautl -sign -inkey rsaprivatekey.pem -in plain.txt -out signature.bin # 用公钥匙rsapublickey.pem验证签名signature.bin, # 输出到文件plain.txt $ openssl rsautl -verify -pubin -inkey rsapublickey.pem -in signature.bin -out plain.txt
(5) S/MIME[Secure Multipurpose Internet Mail Exchange]
S/MIME应用于安全邮件交换,可用来认证和加密,是PGP的竞争对手。与PGP不同的是,它需要一套公匙体系建立信任关系,而PGP只需直接从某个地方获取对方的公匙就可以。然而正因为这样,它的扩展性比PGP要好。另一方面,S/MIME可以对多人群发安全消息,而PGP则不能。
命令smime可用来加解密、签名、验证S/MIME v2消息(对S/MIME v3的支持有限而且很可能不工作)。对于没有内置S/MIME支持的应用来说,可通过smime来处理进来(incoming)和出去(outgoing)的消息。
############################################################# # RSA应用例子 # 从X.509证书文件cert.pem中获取公钥匙, # 用3DES加密mail.txt # 输出到文件mail.enc $ openssl smime -encrypt -in mail.txt -des3 -out mail.enc cert.pem # 从X.509证书文件cert.pem中获取接收人的公钥匙, # 用私钥匙key.pem解密S/MIME消息mail.enc, # 结果输出到文件mail.txt $ openssl smime -decrypt -in mail.enc -recip cert.pem -inkey key.pem -out mail.txt # cert.pem为X.509证书文件,用私匙key,pem为mail.txt签名, # 证书被包含在S/MIME消息中,输出到文件mail.sgn $ openssl smime -sign -in mail.txt -signer cert.pem -inkey key.pem -out mail.sgn # 验证S/MIME消息mail.sgn,输出到文件mail.txt # 签名者的证书应该作为S/MIME消息的一部分包含在mail.sgn中 $ openssl smime -verify -in mail.sgn -out mail.txt
(6) 口令和口令输入(passphase)
OpenSSL口令选项名称不是很一致,通常为passin和passout。可以指定各种各样的口令输入来源,不同的来源所承担的风险取决于你的接受能力。
stdin
这种方式不同于缺省方式,它允许重定向标准输入,而缺省方式下是直接从真实的终端设备(TTY)读入口令的。pass:
直接在命令行指定口令为password。不推荐这样使用。env:
从环境变量中获取口令,比pass方式安全了些,但是进程环境仍可能被别有用心的进程读到。file:
从文件中获取,注意保护好文件的安全性。fd:
从文件描述符中读取。通常情况是父进程启动OpenSSL命令行工具,由于OpenSSL继承了父进程的文件描述符,因此可以从文件描述符中读取口令。(7) 重置伪随机数生成器(Seeding the Pseudorandom Number Generator)
对于OpenSSL,正确地重置PRNG(Pseudo Random Number Generator)很重要。
命令行工具会试图重置PRNG,当然这不是万无一失的。如果错误发生,命令行工具会生成一条警告,这意味着生成的随机数是可预料的,这时就应该采用一种更可靠的重置机制而不能是默认的。在Windows系统,重置PRNG的来源很多,比如屏幕内容。在Unix系统,通常通过设备/dev/urandom来重置PRNG。从0.9.7开始,OpenSSL还试图通过连接EGD套接字来重置PRNG。
除了基本的重置来源,命令行工具还会查找包含随机数据的文件。假如环境变量RANDFILE被设置,它的值就可以用来重置PRNG。如果没有设置,则HOME目录下的.rnd文件将会使用。
OpenSSL还提供了一个命令rand用来指定重置来源文件。来源文件之间以操作系统的文件分割字符隔开。对于Unix系统,如果来源文件是EGD套接字,则会从EGD服务器获取随机数。
EGD服务器是用Perl写成的收集重置来源的daemon,可运行在装了Perl的基于Unix的系统,见http://egd.sourceforge.net。如果没有/dev/random或者/dev/urandom,EGD是一个不错的候选。
EGD不能运行在Windows系统中。对于Windows环境,推荐使用EGADS(Entropy Gathering And Distribution System)。它可运行在Unix和Windows系统中,见http://www.securesw.com/egads。
(本文参考O’Reilly-Network Security with OpenSSL)
-
OpenSSL命令行在Linux下的运用
2009-11-03 17:03:31
1. base64编码/解码
谈到命令行下如何发送邮件附件,很多人想起了uuencode。如果没有装uuencode,也可以用base64编码代劳。以下是openssl base64编码/解码的使用:
$ openssl base64 < filename.bin > filename.txt $ openssl base64 -d < filename.txt > filename.bin
2. 校验文件的一致性
UNIX下校验文件一致性的方法很多,比如sum、cksum、md5sum、sha1sum等。sum和cksum适用于简单校验的场合,生成的校验码容易重复。md5sum有安全漏洞,当前比较推荐的是sha1sum。不过sha1sum在不同的平台用法有些不同。考虑到跨平台性,建议用openssl。
$ openssl sha1 filename SHA1(filename)= e83a42b9bc8431a6645099be50b6341a35d3dceb $ openssl md5 filename MD5(filename)= 26e9855f8ad6a5906fea121283c729c4
3. 文件加密/解密
OpenSSL支持很多加密算法,不过一些算法只是为了保持向后兼容性,现在已不推荐使用,比如DES和RC4-40。推荐使用的加密算法是bf(Blowfish)和-aes-128-cbc(运行在CBC模式的128位密匙AES加密算法),加密强度有保障。
加密示例:
$ openssl enc -aes-128-cbc < filename > filename.aes-128-cbc enter aes-128-cbc encryption password: Verifying - enter aes-128-cbc encryption password:
解密示例:
$ openssl enc -d -aes-128-cbc -in filename.aes-128-cbc > filename enter aes-128-cbc decryption password:
4. 口令生成和传递
openssl可以生成随机性很强的口令,如果你懒得去想设置什么样的口令,不妨用openssl生成。
$ openssl rand 15 -base64 s69mj+8ToN2p3Z1KESBG
以上命令要求openssl生成15个字节序列,然后用base64编码,结果产生20个字符。
在日常生活中,经常可看到这样的情况:系统管理员设置初始密码给用户,然后让用户登录去修改新密码,这给安全带来了隐患。较好的做法是用户生成口令加密后的结果发给管理员,让管理员设置到系统中。
比如对于以上我们生成的口令,UNIX口令加密方法如下:
$ openssl passwd -1 s69mj+8ToN2p3Z1KESBG $1$Rp/btEwK$qhUGFlsIpDtNT1I9MD/Gg1
管理员收集每个用户交给他的加密后的串,写到一个文件中,比如文件名为newpassword:
user_a:$1$Rp/btEwK$qhUGFlsIpDtNT1I9MD/Gg1
user_b:$1$zmUy5lry$aG45DkcaJwM/GNlpBLTDy0
…一个用户一行,用户名和密码之间用冒号分隔。
系统管理员运行如下命令导入用户密码:
$ chpasswd --encrypted < newpassword
对于老UNIX系统,生成口令密码不需要参数-1,比如:
$ openssl passwd s69mj+8ToN2p3Z1KESBG Warning: truncating password to 8 characters FS4lGulQ915WU
如果passwd命令后没有接口令,openssl会提示你输入一个:
$ openssl passwd -1 Password: Verifying - Password: $1$jACBc0.C$KR5DcpttXQoKfDiapyvav0
参考资料:
-
DES的基本流程
2009-11-02 23:18:16
DES的基本流程如下图所示:

通过56位密钥和64位明文之间的各种替换和迭代运算,最后生成64位的密文。在实际应用中通常明文和密钥都是8个字节,但是对于8个字节的密钥而言,每个字节只有前面的7位数据是有效的,第8位数据在DES计算过程中是忽略的,也就是说,如果你计算的密钥值分别为:0102030405060708,和0003020504070609,那么计算的结果应该是一样的,因为两组数据分别去掉每个字节的第8位之后是完全相同的。
其中:
IP代表初始置换(Initial Permutation),说白了就是把原来的数据按照规定的格式进行重新组合,俗话说就是倒腾数据;
PC-1:表示置换选择1(Permutation Choice 1),也是按照规定的格式倒腾;
PC-2:表示置换选择2(Permutation Choice 2),含义同上;
IP-1:表示逆初始置换,按照和IP初始置换相反的方式把数据再倒腾回来。
在实际应用中一般有单DES和三DES两种方式,我们把明文记作:P,密文记作:E,密钥记作:K,加密记为:DES(),解密记为:DES-1(),那么单DES加密可以描述为:
E=DES(P,K)
单DES解密类似可以描述为:
P=DES-1(E,K)
对于三DES而言,可以理解为用三个密钥K1,K2,K3分别进行三次加解密来求得最终的密文,可以描述为:
E=DES(DES-1(DES(P,K1),K2),K3)
实际应用中多数的三DES运算都使用16字节的密钥,分别定义为左右两个子密钥,即KL和KR,称为双长度密钥的三DES运算,加解密公式可以描述为:
E=DES(DES-1(DES(P,KL),KR),KL)
P=DES-1 (DES (DES-1 (E,KL),KR),KL)
目前多数智能卡芯片都已经集成了硬件DES引擎,可以很方便地进行DES运算,而如果使用软件实现DES的话,一个DES算法大约需要占用1K左右的代码空间,对于没有接触过DES算法的工程师来说,通常需要一周的时间可以完成一个比较完美的汇编语言DES算法。而如果采用C语言的话,时间会稍微快一点。
-
ECB CBC and 3DES
2009-11-01 21:25:36
从上一篇《DES 算法详述》文章中,已经知道了DES算法的详细过程,但上一篇文章主要解决的是一个八字节数据DES加密的问题,这一篇文章要解决数据加密——数据补位的问题、DES算法的两种模式ECB和CBC问题以及更加安全的算法——3DES算法。
一、数据补位
DES数据加解密就是将数据按照8个字节一段进行DES加密或解密得到一段8个字节的密文或者明文,最后一段不足8个字节,按照需求补足8个字节(通常补00或者FF,根据实际要求不同)进行计算,之后按照顺序将计算所得的数据连在一起即可。
这里有个问题就是为什么要进行数据补位?主要原因是DES算法加解密时要求数据必须为8个字节。
二、ECB模式
DES ECB(电子密本方式)其实非常简单,就是将数据按照8个字节一段进行DES加密或解密得到一段8个字节的密文或者明文,最后一段不足8个字节,按照需求补足8个字节进行计算,之后按照顺序将计算所得的数据连在一起即可,各段数据之间互不影响。
三、CBC模式
DES CBC(密文分组链接方式)有点麻烦,它的实现机制使加密的各段数据之间有了联系。其实现的机理如下:
加密步骤如下:
1)首先将数据按照8个字节一组进行分组得到D1D2......Dn(若数据不是8的整数倍,用指定的PADDING数据补位)
2)第一组数据D1与初始化向量I异或后的结果进行DES加密得到第一组密文C1(初始化向量I为全零)
3)第二组数据D2与第一组的加密结果C1异或以后的结果进行DES加密,得到第二组密文C2
4)之后的数据以此类推,得到Cn
5)按顺序连为C1C2C3......Cn即为加密结果。
解密是加密的逆过程,步骤如下:
1)首先将数据按照8个字节一组进行分组得到C1C2C3......Cn
2)将第一组数据进行解密后与初始化向量I进行异或得到第一组明文D1(注意:一定是先解密再异或)
3)将第二组数据C2进行解密后与第一组密文数据进行异或得到第二组数据D2
4)之后依此类推,得到Dn
5)按顺序连为D1D2D3......Dn即为解密结果。
这里注意一点,解密的结果并不一定是我们原来的加密数据,可能还含有你补得位,一定要把补位去掉才是你的原来的数据。
四、3DES 算法
3DES算法顾名思义就是3次DES算法,其算法原理如下:
设Ek()和Dk()代表DES算法的加密和解密过程,K代表DES算法使用的密钥,P代表明文,C代表密表,这样,
3DES加密过程为:C=Ek3(Dk2(Ek1(P)))
3DES解密过程为:P=Dk1((EK2(Dk3(C)))这里可以K1=K3,但不能K1=K2=K3(如果相等的话就成了DES算法了)
3DES with 2 diffrent keys(K1=K3),可以是3DES-CBC,也可以是3DES-ECB,3DES-CBC整个算法的流程和DES-CBC一样,但是在原来的加密或者解密处增加了异或运算的步骤,使用的密钥是16字节长度的密钥,将密钥分成左8字节和右8字节的两部分,即k1=左8字节,k2=右8字节,然后进行加密运算和解密运算。
3DES with 3 different keys,和3DES-CBC的流程完全一样,只是使用的密钥是24字节的,但在每个加密解密加密时候用的密钥不一样,将密钥分为3段8字节的密钥分别为密钥1、密钥2、密钥3,在3DES加密时对加密解密加密依次使用密钥1、密钥2、密钥3,在3DES解密时对解密加密解密依次使用密钥3、密钥2、密钥1。


清空Cookie - 联系我们 - 51Testing软件测试网 - 交流论坛 - 空间列表 - 站点存档 - 升级自己的空间
Powered by 51Testing
© 2003-2021
沪ICP备05003035号