
-
.VuGen会修改录制浏览器中的代理服务器设置吗?
2016-08-04 23:18:46
.VuGen会修改录制浏览器中的代理服务器设置吗?- 会修改。在开始录制 基于浏览器的Web Vuser脚本时,VuGen首先会启动指定的浏览器。然后,VuGen会指示浏览器访问VuGen代理服务器。为此,VuGen会修改录制浏览器上的代 理服务器设置。默认情况下,VuGen会立即将代理服务器设置更改为Localhost:7777。录制之后,VuGen会将原始代理服务器设置还原到该 录制浏览器中。因此,在VuGen进行录制的过程中,不可以更改代理服务器设置,否则将无法正常进行。
-
敢于否定自己 摈弃偏见
2016-03-22 17:59:04
敢于否定自己 摈弃偏见经过朱迪和尼克的生死拼搏,动物失踪案,最终“告破”,然而案子结束后,一切看起来都那么让人痛苦压抑,因为朱迪自己潜意识的偏见,在答记者问的环节失去了自己的搭档和朋友尼克,之前繁荣和谐的动物城变得充满捩气,种族偏见上扬,肉食草食动物间的关系日益紧张。事情的演变日益超出朱迪的掌控,这只最初充满美好憧憬的兔子回到了兔窝镇,心灰意懒,直到发现父母摈弃偏见,与另一只狐狸愉快合作,才深觉自己的错误, 并经过父母无意识地对话意识到自己犯了一个更严重的错误——“动物失踪案”是一场人为导演的事件,事件的真正主谋正在逍遥法外。 至此,朱迪再次回到动物城,请求尼克谅解,再次联手追查真相……最后的结局大家都知道,动物城又恢复了原来的样子,不,是比原来更美好,兔子朱迪也真正实现了自己的人生和职业梦想。做错事儿,自己打脸本身不是什么值得炫耀的事情,但非常需要勇气,一个错误被无视或遮掩会像雪球一样压在心里,越滚越大,以至无法自拔。工作中的失误, 推脱责任或者专注于寻找借口是大忌,其结果比承认错误设法补救严重得多。设想,朱迪如果不主动纠错,不像尼克道歉,她和尼克的感情,甚至动物城的结局是不 是都不堪设想?职场不是乌托邦,有偏见、有不公正很常见,还是那句话,你左右不了大环境,但是你可以主导自己的人生。当朱迪想 要做一个真正的警察,让她所在的城市更美好时,却发现所有人都在告诉她不行,因为她是一只“兔子”,整个世界都在阻挠她,然而,她做到了。所以,改变,从 自己开始,去行动,不放弃,你一定会成为那个实现自我的人,你也会看到更美的世界。像兔子朱迪一样,在职场里快跑,你也可以的。
至此,朱迪再次回到动物城,请求尼克谅解,再次联手追查真相……最后的结局大家都知道,动物城又恢复了原来的样子,不,是比原来更美好,兔子朱迪也真正实现了自己的人生和职业梦想。做错事儿,自己打脸本身不是什么值得炫耀的事情,但非常需要勇气,一个错误被无视或遮掩会像雪球一样压在心里,越滚越大,以至无法自拔。工作中的失误, 推脱责任或者专注于寻找借口是大忌,其结果比承认错误设法补救严重得多。设想,朱迪如果不主动纠错,不像尼克道歉,她和尼克的感情,甚至动物城的结局是不 是都不堪设想?职场不是乌托邦,有偏见、有不公正很常见,还是那句话,你左右不了大环境,但是你可以主导自己的人生。当朱迪想 要做一个真正的警察,让她所在的城市更美好时,却发现所有人都在告诉她不行,因为她是一只“兔子”,整个世界都在阻挠她,然而,她做到了。所以,改变,从 自己开始,去行动,不放弃,你一定会成为那个实现自我的人,你也会看到更美的世界。像兔子朱迪一样,在职场里快跑,你也可以的。 -
存储过程
2015-12-12 16:01:16
枯燥杂乱的网文不给你转了,用我自己的词汇给你组织一下这个概念吧:
你可以把存储过程当做:把一系列语句合并到一起的这么一个整体
我觉得举例说明比较好,给你个例子:
先将【表1】中ID号为50—2000的记录删除、
再将【表2】中的这些记录的状态(STATUS)改为“已解除”:
delete 表1 where ID > 50 and ID < 2000
update 表2 set STATUS = '已解除' where ID > 50 and ID < 2000
正常情况下,以上两条语句分步执行就可以了,如果要用存储过程呢?
先建立存储过程(以下的语法为Sybase数据库的,其他数据库类同):
create procedure PRC_TEST (@start_ID int, @end_ID int)
as
begin
delete 表1 where ID > @start_ID and ID < @end_ID
update 表2 set STATUS = '已解除' where ID > @start_ID and ID < @end_ID
end
好了,执行这个语句,就将存储过程PRC_TEST提交到数据库里了,它有两个参数:start_ID int 和 end_ID,代表起始和终止ID号,类型为整数型int
怎么用这个存储过程呢? 这样执行:exc PRC_TEST 50, 2000
执行时,它先得到了两个参数,50、2000,分别赋值给start_ID int 和 end_ID,然后按照这两个参数分步执行封装在存储过程里的那两条语句了。
如果你这样执行:exc PRC_TEST 220, 8660
就是处理两个表中ID介于220—8660之间的记录了。
----------------------------------------------------------------------------
你也许会问了,既然可以分步执行的几句SQL,为什么要费力的写成存储过程啊?
主要是(我的经验和认识):
1、使数据处理参数化,对经常使用的一系列SQL进行封装,使其成为一个存储过程的整体,在每次执行时只要更换执行参数即可,不用去改里面每句SQL的where子句
2、★★这个很重要★★,假设你要循环处理某些数据,例如需要使用“游标”、“Do...while...语句”…………时,就要用到存储过程(或触发器)
=====================================================================
最后给你转一个短文吧,这是书面上的概念:
将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来, 那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令。
那么存储过程与一般的SQL语句有什么区别呢?
存储过程的优点:
1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量
4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权
存储过程的种类:
1.系统存储过程:以prc_(或sp_)开头,用来进行系统的各项设定.取得信息.相关管理工作,
如 sp_help就是取得指定对象的相关信息
2.扩展存储过程 以XP_开头,用来调用操作系统提供的功能
exec master..xp_cmdshell 'ping 10.8.16.1'
3.用户自定义的存储过程,这是我们所指的存储过程 -
存储过程
2015-12-12 16:01:16
枯燥杂乱的网文不给你转了,用我自己的词汇给你组织一下这个概念吧:
你可以把存储过程当做:把一系列语句合并到一起的这么一个整体
我觉得举例说明比较好,给你个例子:
先将【表1】中ID号为50—2000的记录删除、
再将【表2】中的这些记录的状态(STATUS)改为“已解除”:
delete 表1 where ID > 50 and ID < 2000
update 表2 set STATUS = '已解除' where ID > 50 and ID < 2000
正常情况下,以上两条语句分步执行就可以了,如果要用存储过程呢?
先建立存储过程(以下的语法为Sybase数据库的,其他数据库类同):
create procedure PRC_TEST (@start_ID int, @end_ID int)
as
begin
delete 表1 where ID > @start_ID and ID < @end_ID
update 表2 set STATUS = '已解除' where ID > @start_ID and ID < @end_ID
end
好了,执行这个语句,就将存储过程PRC_TEST提交到数据库里了,它有两个参数:start_ID int 和 end_ID,代表起始和终止ID号,类型为整数型int
怎么用这个存储过程呢? 这样执行:exc PRC_TEST 50, 2000
执行时,它先得到了两个参数,50、2000,分别赋值给start_ID int 和 end_ID,然后按照这两个参数分步执行封装在存储过程里的那两条语句了。
如果你这样执行:exc PRC_TEST 220, 8660
就是处理两个表中ID介于220—8660之间的记录了。
----------------------------------------------------------------------------
你也许会问了,既然可以分步执行的几句SQL,为什么要费力的写成存储过程啊?
主要是(我的经验和认识):
1、使数据处理参数化,对经常使用的一系列SQL进行封装,使其成为一个存储过程的整体,在每次执行时只要更换执行参数即可,不用去改里面每句SQL的where子句
2、★★这个很重要★★,假设你要循环处理某些数据,例如需要使用“游标”、“Do...while...语句”…………时,就要用到存储过程(或触发器)
=====================================================================
最后给你转一个短文吧,这是书面上的概念:
将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来, 那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令。
那么存储过程与一般的SQL语句有什么区别呢?
存储过程的优点:
1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量
4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权
存储过程的种类:
1.系统存储过程:以prc_(或sp_)开头,用来进行系统的各项设定.取得信息.相关管理工作,
如 sp_help就是取得指定对象的相关信息
2.扩展存储过程 以XP_开头,用来调用操作系统提供的功能
exec master..xp_cmdshell 'ping 10.8.16.1'
3.用户自定义的存储过程,这是我们所指的存储过程 -
存储过程
2015-12-12 16:01:16
枯燥杂乱的网文不给你转了,用我自己的词汇给你组织一下这个概念吧:
你可以把存储过程当做:把一系列语句合并到一起的这么一个整体
我觉得举例说明比较好,给你个例子:
先将【表1】中ID号为50—2000的记录删除、
再将【表2】中的这些记录的状态(STATUS)改为“已解除”:
delete 表1 where ID > 50 and ID < 2000
update 表2 set STATUS = '已解除' where ID > 50 and ID < 2000
正常情况下,以上两条语句分步执行就可以了,如果要用存储过程呢?
先建立存储过程(以下的语法为Sybase数据库的,其他数据库类同):
create procedure PRC_TEST (@start_ID int, @end_ID int)
as
begin
delete 表1 where ID > @start_ID and ID < @end_ID
update 表2 set STATUS = '已解除' where ID > @start_ID and ID < @end_ID
end
好了,执行这个语句,就将存储过程PRC_TEST提交到数据库里了,它有两个参数:start_ID int 和 end_ID,代表起始和终止ID号,类型为整数型int
怎么用这个存储过程呢? 这样执行:exc PRC_TEST 50, 2000
执行时,它先得到了两个参数,50、2000,分别赋值给start_ID int 和 end_ID,然后按照这两个参数分步执行封装在存储过程里的那两条语句了。
如果你这样执行:exc PRC_TEST 220, 8660
就是处理两个表中ID介于220—8660之间的记录了。
----------------------------------------------------------------------------
你也许会问了,既然可以分步执行的几句SQL,为什么要费力的写成存储过程啊?
主要是(我的经验和认识):
1、使数据处理参数化,对经常使用的一系列SQL进行封装,使其成为一个存储过程的整体,在每次执行时只要更换执行参数即可,不用去改里面每句SQL的where子句
2、★★这个很重要★★,假设你要循环处理某些数据,例如需要使用“游标”、“Do...while...语句”…………时,就要用到存储过程(或触发器)
=====================================================================
最后给你转一个短文吧,这是书面上的概念:
将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来, 那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令。
那么存储过程与一般的SQL语句有什么区别呢?
存储过程的优点:
1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量
4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权
存储过程的种类:
1.系统存储过程:以prc_(或sp_)开头,用来进行系统的各项设定.取得信息.相关管理工作,
如 sp_help就是取得指定对象的相关信息
2.扩展存储过程 以XP_开头,用来调用操作系统提供的功能
exec master..xp_cmdshell 'ping 10.8.16.1'
3.用户自定义的存储过程,这是我们所指的存储过程 -
memcache 存储 session
2015-10-02 11:14:57
http://blog.csdn.net/weilee2009/article/details/7658260http://blog.163.com/wz_pk007/blog/static/170627050201324114448269/ -
程序流程图-控制流程图
2015-09-28 17:50:24
 查看(2459)
评论(0)
收藏
分享
管理
查看(2459)
评论(0)
收藏
分享
管理
程序流程图-控制流程图
2015-09-28 17:46:34


用例相关图--因果图
2015-09-28 15:21:56
测试用例设计--因果图
http://www.cnblogs.com/nzyjlr/archive/2010/12/01/1893230.html
http://wenku.baidu.com/link?url=6qk7oIPOm_JytPigyBTcJWMsoxhjKJq_XpBSkpv6PhDbhtUCEGGApaxHobF2tgaKj__461xvKmbh9auDYlD60w9KwWkR_ULtQfRKhEEMsVK
1.
分割功能说明书
对于规模比较大的程序来说,
由于输入条件的组合数太大,
所以很难整体上
使用一个因果图。
我们可以把它划分为若干部分,
然后分别对每个部分使用因果
图。例如,测试编译程序时,可以把每个语句作为一个部分。
2.
识别出“原因”和“结果”,并加以编号
所谓原因,
是指输入条件或输入条件的等价类;
而结果则是指输出条件或输
出条件的等价类。
每个原因或结果都对应于因果图中的一个节点。
当原因或结果
成立(或出现)时,相应的节点取值为
1
,否则为
0
。
例如,有一个饮料自动售货机(处理单价为
5
角钱)的控制处理软件,它的
软件规格说明如下:
若投入
5
角钱的硬币,按下“
橙汁
”或“
啤酒
”的按钮,则相应的饮料就送
出来。若投入
1
元钱的硬币,同样也是按“
橙汁
”或“
啤酒
”的按钮,则自动售
货机在送出相应饮料的同时退回
5
角钱的硬币。
用例相关图--因果图
2015-09-28 15:21:56
测试用例设计--因果图
http://www.cnblogs.com/nzyjlr/archive/2010/12/01/1893230.html
http://wenku.baidu.com/link?url=6qk7oIPOm_JytPigyBTcJWMsoxhjKJq_XpBSkpv6PhDbhtUCEGGApaxHobF2tgaKj__461xvKmbh9auDYlD60w9KwWkR_ULtQfRKhEEMsVK1.
分割功能说明书
对于规模比较大的程序来说,
由于输入条件的组合数太大,
所以很难整体上
使用一个因果图。
我们可以把它划分为若干部分,
然后分别对每个部分使用因果
图。例如,测试编译程序时,可以把每个语句作为一个部分。
2.
识别出“原因”和“结果”,并加以编号
所谓原因,
是指输入条件或输入条件的等价类;
而结果则是指输出条件或输
出条件的等价类。
每个原因或结果都对应于因果图中的一个节点。
当原因或结果
成立(或出现)时,相应的节点取值为
1
,否则为
0
。
例如,有一个饮料自动售货机(处理单价为
5
角钱)的控制处理软件,它的
软件规格说明如下:
若投入
5
角钱的硬币,按下“
橙汁
”或“
啤酒
”的按钮,则相应的饮料就送
出来。若投入
1
元钱的硬币,同样也是按“
橙汁
”或“
啤酒
”的按钮,则自动售
货机在送出相应饮料的同时退回
5
角钱的硬币。
loadrunner流媒体压力测试
2015-09-04 10:53:58
最近用loadrunner9.5体验了一下它的流媒体压力测试功能。使用中一大感觉是文档不够详尽,找了半天资料,加上自己的摸索,终于学会简单的使用流媒体压力测试功能。下面把经验教训和大家分享一下:这次准备测试的是dss的rtsp并发能力。1. 在CentOS 5.4环境下搭建一个dss 6.0.3的流媒体服务器。2. 编写Vuser的script。文档提到loadrunner支持real和media player两种流媒体协议,怎么测rtsp呢?
针对media player协议的文档说明只支持mms, mmst或mmsu协议,那么只有试试real协议的相关函数了。(Real协议相关文档信息量是在太少,支持哪些网络协议,音视频标准,文件格式居然都没提...) 编写如下action代码: Action()
{
lreal_open_player(1); lreal_open_url(1,"rtsp://192.168.1.200:554/sample_300kbit.mp4"); lreal_play(1, 10000); lreal_stop(1); lreal_close_player(1); return 0;
}3. 创建场景,测试1。1个Vuser,测试正常。
2个或以上Vuser,绝大部分失败。同时看dss服务器状态,同一时段只有两个正常连接。 4. 测试2。
把runtime setting里面的multithreading关闭。
10个Vuser,全部成功。看来这种情况下使用real协议相关函数,不能使用多线程模式。(文档啊.. http://blog.sina.com.cn/s/blog_652176440100h30a.html用LoadRunner测试MMS流媒体
上一篇 / 下一篇 2010-07-01 18:16:28 / 个人分类:成功的喜悦
步骤
内容
具体操作
1
协议选择
协议包用Global或Web都可以,选用Media Player(MMS)协议。(MMS协议无法录制,只能通过手工编写)
2
脚本编写
mms_play( "test1.wmv",
"URL=mms://202.106.xxx.xxx/1/test1.wmv",
"duration=-1",
"starttime=0",
LAST );
//lr_think_time(2000);
//mms_close();
return 0;
3
wmload.asf文件添加
拷贝至发布点根目录。比如:所发布文件的文件位于d:\media\1\和d:\media\2\两个文件夹下,则发布点的根目录为d:\media
(网上资料说应拷贝到服务器C:\wmpub\wmroot,C为系统盘。不过根据本次测试经验,应该不用这样做。)
4
并发访问
在LR的控制器里面设置并发,运行后,到服务器的流媒体服务界面(如下图),看当前已连接的客户数和当前分配带宽是否有变化。若没有变化,可尝试重新启动流媒体服务,再次运行并观察。
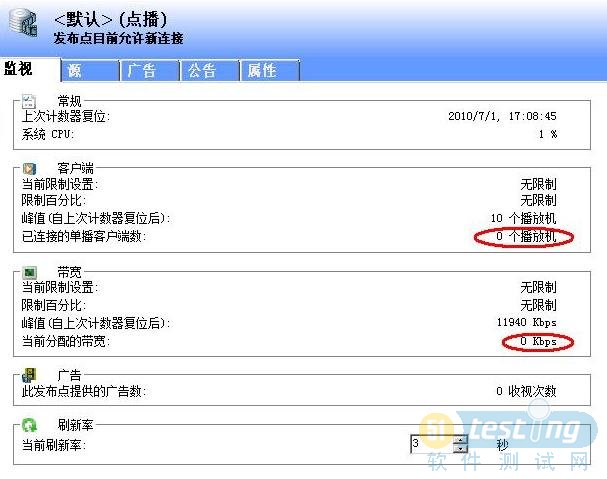
测试中发现:
1. 访问流媒体服务器时,无论是用LR的控制器并发访问,还是用IE产生单个的访问需求,只要当前程序(控制器/IE)不关闭,即使已经终止播放,上图中的“已连接的单播客户端数”也不会减少。只有当关闭当前程序(控制器/IE)时,“已连接的单播客户端数”才会响应减少或归零。但是,若当前程序(控制器/IE)中的流媒体文件已经不再播放,会从上图中的“当前分配的带宽”项的减少或归零看出来。
2. 用200个vu并发访问,发现第一次运行时,服务器端“已连接的单播客户端数”最大达到198;而第二次运行以及以后几次运行时,已连接的单播客户端数”越来越少,只有50%左右。而且,如果此时用IE直接访问mms://202.106.xxx.xxx/1/test1.wmv,服务器端“已连接的单播客户端数”根本不变化(理论上应该增加1)。怀疑由于运行次数多,视频文件已经完全在PC机内存/硬盘中,于是每次访问不再访问网络,直接从本机内存/硬盘中读取,所以服务器端的参数不变化。针对这种情况,只需清一下IE的内存即可。
http://www.51testing.com/html/05/228105-216432.html
使用LoadRunner测试WMS
LoadRunner是一款非常强大的测试工具,本文为笔者在对LoadRunner有了初步了解后对WMS的压力测试过程,因为接触时间比较短,不对之处欢迎大家指出。由于Licence的原因,对WMS的测试只支持最多100个虚拟用户。下面就开始测试了。
1 要有一个可用的WMS的地址,可以在本机的流媒体服务中创建,也可以使用远程的。
2 打开LoadRunner8.1,并运行窗口中点击Create/Edit Srcirpts ,如下图:
2 在弹出的窗口中点击New VUser Scripts,如下图:

3 点击New VUser Script后,会弹出一个窗口让选择脚本协议,在这里我们选择Streaming下面的WMS,如下图:

4 确定后会在窗口中新开一个Lab页,该页面的左边为导航栏,标明了完成测试的5个步骤,如下图:

5 首先执行第一项创建脚本,在WMS中不能录制脚本所以只能手动来写了,有关WMS脚本的写法可以参考LoarRunner自带的帮助文档。点击Create Script,如下图:

6 在右边出现的界面中点击Script. View ,如下图:

7 点击Srcipt View后就会出现脚本编辑区域,选择Action,在代码中添加启动WMS的代码,如下图:

8 脚本写好之后就需要执行第二步来验证下脚本是否正确,或是是否能和指定的WMS地址相连接。点击左边的Verify Replay,在右侧的界面中点击Start Replay,如下图:

9 通常会出现如下的错误,原因是在WMS的根目录(C:\wmpub\wmroot)下缺少wmload.asf文件,至于这个文件是做什么用的大家可以网上搜一下。随便找一个asf文件将名称改为wmload然后放在WMS的根目录即可。
有可能添加wmload.asf文件后仍然不成功,有两个可能的原因:
a 流媒体服务器没有默认的点播发布点,如果没有添加默认点播发布点,路径只想WMS根目录。
b 默认点播发布点“拒绝新连接”了,选中“允许新连接”即可。

10 这些都搞定后,重新验证会出现成功的界面。

11 点击上图中出现的Run-Time Settings 设置脚本的运行迭代次数等信息。

12 设置好迭代次数后,就可以执行第三步了,不过第三步主要是设置事务和参数的,在本例中用不上,所以直接执行第四步,点击Concurrent User 出现如下界面:

13 点击上图中Create Controller Scenario ,创建一个控制场景,在这之前会提示保存脚本信息,这里我们将脚本信息命名为TestWMS ,如下图:

13 保存好脚本信息后,会弹出一个场景设置框,可以设置虚拟用户的个数,我们设置虚拟用户为100,如下图:

14 点击确定后会弹出运行测试的窗口,在此窗口中点击 Edit Schedule 可以设置多用户是以什么形式并发的,如下图:

15 点击上图中的 Edit Schedule 出现设置窗口,如下图:

16 设置完成后,可以点击窗口右侧的Start Scenairo按钮开始运行测试,如下图:

16 测试运行完成后,点击窗口上方的分析结果按钮来查看测试结果,如下图:

17 最后就可以根据结果来编写相应的测试报告了

http://www.cnblogs.com/oec2003/archive/2010/05/21/1740625.html
Virtual Bytes Working set Private bytes
2015-09-04 09:55:54
Working set和Private bytes区别
在Performance monitor中可以通过private bytes和Virtual bytes来衡量程序的内存使用. 在task manager中, 也有Memory Usage和VM Size两项. 但是仔细比较后会发现Memory Usage并不是对应private bytes, VM Size也不是对应Virtual Bytes.
其实,
task manager中的Memory Usage对应的是working set, VM Size对应的是private bytes. 因此如果使用task manager观察内存使用, 应该注意到这个差别. Working Set和Private Bytes
==============
一个有趣的问题是, working set指目前程序所消耗的物理内存, private bytes值commit的内存, 那么为什么有些进程的working set比private bytes还大? 要回答这个问题, 需要仔细看看两者的定义:
- "Working Set refers to the numbers of pages of virtual memory committed to a given process, both shared and private."
- "Private Bytes is the current size, in bytes, of memory that this process has allocated that cannot be shared with other processes."
所以, Working Set包含了可能被其他程序共享的内存, 而Private Bytes只包括被当前进程使用的内存.
DLL是一个典型的可能被其他程序共享的资源. DLL的加载使用文件映像, 因此包含DLL的物理内存可以被同时映像到多个进程上. 所以在进程中加载DLL的内存只能算到working set上, 而不能被算到private bytes上.
2010年4月15日更新:
在解决内存问题的时候Shared的部分一般可以不用考虑.
一个进程使用内存的时候, 它占用的内存会被分为两部分, 一部分是working set, 另一部分是private byte减去working set. 其中working set是贮存在物理内存中的, 而另一部分是paging file, 存在磁盘上.
一般来说把所有进程的working set加起来会比你机器上所拥有的物理内存要大, 这是因为有Shared的资源(比如DLL)的缘故.
在windows系统上,关于内存泄漏我们通常会听到这么两句话:
1. 借助性能监视器,Private Bytes和Virtual Bytes至少有一个是一条斜向上曲线,大多数泄漏是这种情况;
2. 如果Private Byte和Virtual Bytes一起上升,但是后者比前者上升得快或者比例超过3:1,说明不仅仅有内存泄漏,而且泄漏导致了内存碎片
但关键的是,这些指标到底是什么意思,这几个指标的这些变化趋势真的就能反映出进程有内存泄漏问题?如果能为什么能等等问题,其实没有多少人能够真正说得清楚,本文就试图通过这些指标入手,谈谈windows内存相关技术知识,但也不准备深入到内核层次深谈内存管理机制,只是会涉及我们平时涉及最多概念背后的故事。
首先还是要普及一下老生常谈:“在Windows系统中,任何一个进程都被赋予其自己的虚拟地址空间,该虚拟地址空间覆盖了一个相当大的范围,对于32位进程,其地址空间为232=4,294,967,296 Byte (4G),这使得一个指针可以使用从0x00000000到0xFFFFFFFF的4GB范围之内的任何一个值。虽然每一个32位进程可使用4GB的地址空间,但并不意味着每一个进程实际拥有4GB的物理地址空间,该地址空间仅仅是一个虚拟地址空间,此虚拟地址空间只是内存地址的一个范围。进程的虚拟地址空间是为每个进程所私有的,在进程内运行的线程对内存空间的访问都被限制在调用进程之内,而不能访问属于其他进程的内存空间。这样,在不同的进程中可以使用相同地址的指针来指向属于各自调用进程的内容而不会由此引起混乱。”
每个进程看到得虚拟地址空间有大量准确定义的区(area)构成,每个区都有专门的功能。从最低的地址看起:
• 程序代码和数据:代码是从同一固定地址开始,紧接着的是和C全局变量相对应的数据区。
• 堆:代码和数据区后紧随着的是运行时堆。作为调用malloc和free这样的C标准库函数,堆可以在运行时动态的扩展和收缩。
• 共享库:在地址空间的中间附近是一块用来存放像C标准库和数学库这样共享库的代码和数据的区域。
• 栈:位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数调用。和堆一样每次我们从函数返回时,栈就会收缩。
• 内核虚拟存储器:内核是操作系统总是驻留在存储器中的部分。地址空间顶部的四分之一部分是为内核预留的。(对用户的程序来说是禁止访问的,操作系统的代码在此。内核对象也驻留在此)
最容易和上面所谓虚拟地址搞混的一个词就是“虚拟内存”,今天的windows操作系统能够使得磁盘空间看上去就像内存一样,磁盘上的文件通常称为页文件(pagefile),从应用程序的角度来看,页文件透明地增加了应用程序能够使用的内存的数量(突破物理内存大小的限制)。如果计算机拥有1G的RAM(物理内存),同时在硬盘上有一个1G的页文件,那么运行的应用程序就认为计算机总共拥有2G的RAM。
实际上并不是真正拥有2GB的RAM(微软不准备砸内存厂商的饭碗)。它的大致原理是将进程在物理内存中的各个部分保存到页文件中,当运行的应用程序需要时,再将页文件的各个部分重新加载到RAM中。举例:某进程试图访问的数据是在RAM中。在这种情况下,CPU将数据的虚拟地址映射到内存的物理地址中,然后执行需要的访问。线程试图访问的数据不在RAM中,而是存放在pagefile中的某个地方。这时,试图访问就称为页错误(page fault),CPU将把试图进行的访问通知操作系统。这时操作系统就寻找RAM中的一个内存空页。如果找不到空页,系统必须释放一个空页。如果一个页面尚未被修改,系统就可以释放该页面。但是,如果系统需要释放一个已经修改的页面,那么它必须首先将该页面从RAM拷贝到页交换文件中,然后系统进入该页文件,找出需要访问的数据块,并将数据加载到空闲的内存页面。然后,操作系统更新它的用于指明数据的虚拟内存地址现在已经映射到RAM中的相应的物理存储器地址中的表。这时CPU重新运行生成初始页面失效的指令,但是这次CPU能够将虚拟内存地址映射到一个物理RAM地址,并访问该数据块。
接下来分析一下进程中申请内存使用然后释放(或者不释放==!)是个什么情况:
为进程“分配内存”,这个概念可以细化:“预定一坨地址空间”,“提交一坨内存空间”,“将内存空间映射到主存”。而在程序中我们通常所访问的地址都必须是进程地址空间中被保留和提交的那段地址空间。
•预定地址空间Reserve:即从进程的4GB地址空间中保留一段地址空间,这个过程通过VirtualAlloc函数完成,并把分配类型参数设置为MEM_RESERVE。这段空间的起始地址必须是系统分配粒度的整数倍,大小必须是系统页面大小的整数倍。
•提交内存空间Commit:即为进程已保留的地址空间映射机器的内存,这里要特别注意,所谓内存一般并不是机器的主存RAM,而只是机器的pagefile。这个过程同样又VirtualAlloc完成,只是把分配类型参数设置为MEM_COMMIT。这段空间的起始地址和大小都必须是页面大小的整数倍。这样进程的对应被提交的区域就被映射到机器的虚拟内存上。
•将内存空间映射到主存:这点很重要,操作系统总是只有在进程提交的页面被访问时才将相应的页面加载到主存中,同时修改进程对应页面的地址空间映射。这时,进程的地址空间中的对应区域才和机器上的主存对应起来。
解释了这些终于可以回过头来看看关于windows内存常常提及的几个指标了:
Working Set:“Working Set is the current size, in bytes, of the Working Set of this process. The Working Set is the set of memory pages touched recently by the threads in the process. If free memory in the computer is above a threshold, pages are left in the Working Set of a process even if they are not in use. When free memory falls below a threshold, pages are trimmed from Working Sets. If they are needed they will then be soft-faulted back into the Working Set before leaving main memory.”此为官方解释,实际上该指标记录了所有映射到进程虚拟地址空间的物理内存RAM的大小(即:Task Manager中的Mem Usage),它不仅仅是用户方式分区部分的映射,而是整个进程地址空间的映射。即它同时包括内核方式分区中映射到RAM的部分。在用户方式分区部分只有在进程提交的页面被访问时才将相应的页面加载到主存中,而对于该部分的大小总是系统页面大小的整数倍。随着进程的不断运行,影响“Working Set”的因素包括:(1) 机器可用主存的大小 (2) 进程本身“Working Set”的大小范围。当机器的可用主存小于一定值(阙值)时,系统会释放一些老的最近没有被访问的页面,把这些页面通过交换文件交换到机器的虚拟内存中;当Working Set的大小大于该进程所设置的最大值时,同样会把一些老的页面交换到机器的虚拟内存中。当这些页面下次再被访问时,它们才加载到主存。
Private Bytes:“Private Bytes is the current size, in bytes, of memory that this process has allocated that cannot be shared with other processes.”该指标记录了进程用户方式分区地址空间中已提交的总的空间大小。无论是直接调用API申请的内存,被Heap Manager申请的内存,或者是CLR 的managed heap,都算在里面。
Virtual Bytes:“Virtual Bytes is the current size, in bytes, of the virtual address space the process is using. Use of virtual address space does not necessarily imply corresponding use of either disk or main memory pages. Virtual space is finite, and the process can limit its ability to load libraries.”该指标记录了当前进程申请成功的其虚拟地址空间的总的空间大小,包括DLL/EXE占用的地址和通过VirtualAlloc API Reserve(即不管有没有commit)的Memory Space数量。
补充一点:如两个进程都需要同一个DLL的支持,所以在进程运行过程中,这个DLL被映射到了两个进程的地址空间中,如果这个DLL的大小为4K,在两个进程中都要提交4K的虚拟地址空间来映射这个DLL。当第一个进程访问了这个DLL时,这个DLL被加载到机器主存中,这时,第二个进程也要访问该DLL,这时,系统就不会再加载一遍该DLL了,因为这个DLL已经在主存中了。当然上面所说的访问仅仅是读取的操作,如果这时候某个进程要修改DLL对应这段地址中的某个单元时,这时,系统必须为第二个进程分配另外的新页面,并把要修改位置对应的页面拷贝的这个新页面,同时,第二个进程中的这个DLL被映射到这个新页面上,这就是传说中的写时拷贝(Copy on Write)。
其实光是定义了、解释了这些概念,还是弄不清楚他们分别是对进程运行时哪些具体状态的写照、到底什么指标能够更准确的描述进程内存状况。
•Private Bytes are what your app has actually allocated, but include pagefile usage;
•Working Set is the non-paged Private Bytes plus memory-mapped files;
•Virtual Bytes are the Working Set plus paged Private Bytes and standby list.
通过上面的描述,首先Working Set不是进程内存消耗的全部,该指标是动态的,在测量的过程中会不断变化。(变化的最小单位为4K)所以Working Set指标强调的是进程对机器主存的消耗,不是进程内存的全部信息。
Private Bytes包含所有为进程提交的内存,包括机器主存和虚拟内存,可以认为它是进程对物理内存消耗,且该指标相对来说更加稳定。在程序产生内存泄漏时,该值一定是不断上涨的。所以一般更倾向于使用Private Bytes来定量进程的内存消耗和分析进程的内存泄漏。内存泄露时表现的现象是私有虚拟内存的递增,而不是工作集大小的递增。因为在某个点上,内存管理器会阻止一个进程继续增加物理内存大小,但它可以继续增大它的虚拟内存大小。source:http://bbs.pediy.com/showthread.php?t=156036
Linux下查看CPU信息[/proc/cpuinfo]
2015-08-29 11:11:29
http://blog.csdn.net/sycflash/article/details/6643492http://blog.csdn.net/qianlong4526888/article/details/20051931http://www.cnblogs.com/dongzhiquan/archive/2012/02/16/2354977.htmlhttp://www.blogjava.net/fjzag/articles/317773.htmlweb_custom_request应用示例
2015-01-26 17:26:55
web_custom_request应用示例
LoadRunner提供的web_custom_request函数可以用于实现参数的动态生成。在LoadRunner中,web_reg_save_param和custom_request都常于处理参数的动态生成。
web_reg_save_param函数是大家都已经熟悉的了,它的主要作用是从一个response中获得后续的request需要使用的数据,然后将其作为一个参数保存下来,供后续步骤使用。该方法在LoadRunner中被称为Correlation(关联)。
而web_custom_request函数则可以用于完全自定义向服务端发送的request。
接下来我们用一个实际的例子说明一下web_custom_request的具体应用:
以Mercury自带的MercuryWebTours例子为例,假设我们希望在登录进入后将用户的前两条记录删除,我们来看看用web_custom_request如何实现这个目标。
首先,我们尝试用HTML方式对该操作进行录制。录制后的脚本中与删除相关的部分大致如下:
 web_url("welcome.pl", "URL=http://localhost/MercuryWebTours/welcome.pl?page=itinerary", "Resource=0", "RecContentType=text/html", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=home", "Snapshot=t3.inf", "Mode=HTML", EXTRARES, "URL=images/in_itinerary.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, "URL=images/home.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, LAST);lr_think_time(2);web_submit_form("itinerary.pl", "Snapshot=t4.inf", ITEMDATA, "Name=1", "Value=on", ENDITEM, "Name=2", "Value=on", ENDITEM, "Name=removeFlights.x", "Value=116", ENDITEM, "Name=removeFlights.y", "Value=8", ENDITEM, LAST);
web_url("welcome.pl", "URL=http://localhost/MercuryWebTours/welcome.pl?page=itinerary", "Resource=0", "RecContentType=text/html", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=home", "Snapshot=t3.inf", "Mode=HTML", EXTRARES, "URL=images/in_itinerary.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, "URL=images/home.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, LAST);lr_think_time(2);web_submit_form("itinerary.pl", "Snapshot=t4.inf", ITEMDATA, "Name=1", "Value=on", ENDITEM, "Name=2", "Value=on", ENDITEM, "Name=removeFlights.x", "Value=116", ENDITEM, "Name=removeFlights.y", "Value=8", ENDITEM, LAST);我们通过树型模式查看一下在submit form的时候实际向服务器发出的请求的内容:
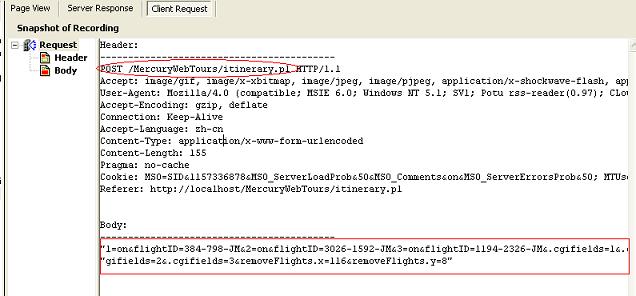
从请求内容中可以看到,我们通过POST方法发出了请求,请求发送的目的URL是/MercuryWebTours/itinerary.pl,发送的内容是:
"1=on&flightID=384-798-JM&2=on&flightID=3026-1592-JM&3=on&flightID=1194-2326-JM&.cgifields=1&.c"
"gifields=2&.cgifields=3&removeFlights.x=116&removeFlights.y=8"从发送的内容中可以很明显的分析得出,1=on表示第一个checkbox是被选中的,flightID=384-798-JM表示的是第一条记录 所对应的flightID。因此,如果我们需要自己组成这个发送的request的话,必须首先通过关联的方式获得前两条记录的flightID,然后再 组成request的内容。
web_custom_request方法的原型是:
int web_custom_request (const char *RequestName, <List of Attributes>,[EXTRARES, <List of Resource Attributes>,] LAST );其中List of Attributes的主要项目是Method,URL和BODY等。对这个例子来说,我们可以很容易构造出我们需要的request的BODY内容。
……
strcpy(creq, "Body=1=on&flightID=");
strcat(creq, lr_eval_string("{fID1}"));
strcat(creq, "&2=on&flightID=");
strcat(creq, lr_eval_string("{fID2}"));
strcat(creq, "&.cgifields=1&.cgifields=2");
strcat(creq, "&removeFlights.x=116&removeFlights.y=8");
……其中{fID1}、{fID2}等都是通过关联获得的flightID的数据。
因此,我们可以根据图中的数据编写custom_request语句:
web_custom_request("itinerary.pl","Method=POST", "URL=http://localhost/MercuryWebTours/itinerary.pl", "RecContentType=text/xml", creq, "Snapshot=t4.inf", LAST);
较为完整的代码如下:Action() {
{ char creq[500]; web_reg_save_param("fID1", "LB=INPUT TYPE=\"hidden\" NAME=\"flightID\" VALUE=\"", "RB=\"", "ORD=1", "SEARCH=BODY", LAST); web_reg_save_param("fID2", "LB=INPUT TYPE=\"hidden\" NAME=\"flightID\" VALUE=\"", "RB=\"", "ORD=2", "SEARCH=BODY", LAST); web_url("welcome.pl", "URL=http://localhost/MercuryWebTours/welcome.pl?page=itinerary", "Resource=0", "RecContentType=text/html", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=home", "Snapshot=t3.inf", "Mode=HTML", EXTRARES, "URL=images/in_itinerary.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, "URL=images/home.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, LAST); lr_think_time(2); strcpy(creq, "Body=1=on&flightID="); strcat(creq, lr_eval_string("{fID1}")); strcat(creq, "&2=on&flightID="); strcat(creq, lr_eval_string("{fID2}")); strcat(creq, "&.cgifields=1&.cgifields=2"); strcat(creq, "&removeFlights.x=116&removeFlights.y=8"); lr_output_message(creq); web_custom_request("itinerary.pl","Method=POST", "URL=http://localhost/MercuryWebTours/itinerary.pl", "RecContentType=text/xml", creq, "Snapshot=t4.inf", LAST); return 0;
char creq[500]; web_reg_save_param("fID1", "LB=INPUT TYPE=\"hidden\" NAME=\"flightID\" VALUE=\"", "RB=\"", "ORD=1", "SEARCH=BODY", LAST); web_reg_save_param("fID2", "LB=INPUT TYPE=\"hidden\" NAME=\"flightID\" VALUE=\"", "RB=\"", "ORD=2", "SEARCH=BODY", LAST); web_url("welcome.pl", "URL=http://localhost/MercuryWebTours/welcome.pl?page=itinerary", "Resource=0", "RecContentType=text/html", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=home", "Snapshot=t3.inf", "Mode=HTML", EXTRARES, "URL=images/in_itinerary.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, "URL=images/home.gif", "Referer=http://localhost/MercuryWebTours/nav.pl?page=menu&in=itinerary", ENDITEM, LAST); lr_think_time(2); strcpy(creq, "Body=1=on&flightID="); strcat(creq, lr_eval_string("{fID1}")); strcat(creq, "&2=on&flightID="); strcat(creq, lr_eval_string("{fID2}")); strcat(creq, "&.cgifields=1&.cgifields=2"); strcat(creq, "&removeFlights.x=116&removeFlights.y=8"); lr_output_message(creq); web_custom_request("itinerary.pl","Method=POST", "URL=http://localhost/MercuryWebTours/itinerary.pl", "RecContentType=text/xml", creq, "Snapshot=t4.inf", LAST); return 0; }
}
拼接
2015-01-22 20:08:55
http://wenku.baidu.com/link?url=28A4mkpEX3SLqNW_1dIDaDTxzhJVza5wUVSi__A47JfVCM2JXryj2hYWqnt9Q_Ss_SgKl7sz_urWCHN0zI6Pp0dhbUtztT_j-eISRMG7HNy拼接
2015-01-22 20:05:52
lr_save_string(lr_eval_string("{row_idA}"),str);
然后再连上命令
拼接
2015-01-22 05:31:59
char
str[1000];
strcpy(str,"SNSID=7999&UserID=1&CommentsTypeID=1&CommentsID=1&AuthorID=1&CommentsContent=1
");
web_custom_request("Publish",
"Url=
http://116.211.23.123/SNS/Publish.htm",
"Method=POST",
"Referer=http://116.211.23.123/SNS/Publish.htm
",
"Mode=HTTP",
str,
LAST);
http://wenku.baidu.com/link?url=exqZJolr_JC4EWMVoh56wSMnm7GHUSnxBg6_Sm9ziwzubtjqNddMCoyrk1Ml4ggAM1PvFrVpdYEenE2xs3UDSg-d7KLA_czV57MDJwanoyO
strtok
2015-01-22 05:01:32
http://www.spasvo.com/news/html/2013925164536.html脚本:
Action()
{
char *username;
lr_output_message("参数值为:%s",lr_eval_string("{NewParam}"));
username=lr_eval_string("{NewParam}");
lr_output_message("username的值是:%s",username);
lr_output_message("截取后的值:%s",strtok(lr_eval_string("{NewParam}"),"kibon"));
//strtok 返回特殊标记分割的字符
lr_save_string((char*)strtok(lr_eval_string("{NewParam}"),"kibon"),"temp");
lr_output_message("变量的值为:%s",lr_eval_string("{temp}"));
return 0;
}家庭和生活一样,吃了快餐面
2014-12-19 21:14:48
我的家庭和我的工作一样,由于急于求成导致现在事业家庭都是像吃了快餐面。一时的高潮之后是无法上扬的疲惫和无奈;看红日有感
2014-11-14 10:35:33
通过看红日。沈军长和黎青的爱情。黎青的选择他的倔强。她很成熟。她的选择,她的命运。我理解了一些道理。她结婚后不和军长在一起生活,有她的生存道理。在一起她就不会好。她的人生也不是她愿意的选择~她就不本份了,她们不在一起,她有她的发展空间;她很成熟。很有思想;那时军长找她,还有谁敢找她呢。谁敢和军长竞争?~



















标题搜索
我的存档
数据统计
- 访问量: 29777
- 日志数: 57
- 图片数: 1
- 建立时间: 2007-06-22
- 更新时间: 2016-08-04
