
-
【转载】loadrunner函数web_reg_find学习记录
2013-04-08 14:49:06
先说明一下,下面的这些内容是loadrunner函数手册中的内容,今天重点学习web_reg_find/
web_find
语法:
int web_find (const char *StepName, <Attributes and Specifications list>, char *searchstring, LAST );参数:
1、StepName:步骤名称,在Tree视图中出现。2、Attributes and Specifications list:
支持的属性有:
Frame:在多Frame的情况下,定义要查找Frame的范围。
Expect:定义在什么情况下函数检查成功:找到了指定的搜索标准或者没有找到。例如说,可以检查指定的错误信息是否出现在web页面中。合法的值有2个:found和notfound。默认值是“found”。
Matchcase:指定搜索是否区分大小写。
Repeat:指定当第一次发现要查找的字符串时,搜索是否继续。当一个web页面中包含多个被查找的字符串时,此参数是非常有用的。合法的值有2个:yes,no。默认值是“yes”。
Report:指定在什么情况下,VuGen在执行日志中显示此函数的检查结果。合法的值有:success,failure,always。默认值是“always”。
Onfailure:此参数决定在函数检查失败后,Vuser是否中断。参数值是abort。如果指定了Onfailure=abort,当函数检查失败时,不论在运行时设置中的error-handling是什么,脚本都会中断。
如果没有指定Onfailure=abort,那么运行时设置中error-handling将会起作用。
支持的特性有:RightOf, LeftOf (不支持7.x及更高版本)。
RightOf:要查找的字符串右边的内容。
LeftOf:要查找的字符串左边的内容。
3、Searchstring:需要查找的字符串,格式为“What=stringxyz”。此搜索不区分大小写。
4、LAST:属性列表结束符。
返回值
整型。 成功时返回LR_PASS(0),失败时返回LR_FAIL (1)。说明
此函数的作用是在HTML页面中查找指定的字符串。此函数只能在基于HTML录制的脚本中使用。当指定的HTML请求全部完成以后,开始执行搜索过程,比web_reg_find要慢。
web_find 函数在C语言的脚本中已经被web_reg_find所替代,web_reg_find运行速度比较快,而且在HTML-based和URL-based 的录制方式中都可以使用。 在C语言脚本中,web_find是向后兼容的。Java和Visual Basic脚本中不再支持它。
运行在HTTP模式下的WAP用户都和运行在WSP回放模式下的WAP用户都不支持此函数。
web_global_verification
语法:
int web_global_verification (<List of Attributes>, LAST );参数:
List of Attributes:1、Text:此属性是一个非空的,以NULL结尾的字符串,表示要查找的内容。语法是”Text=string”。还可以使用text flags自定义字符串。
2、TextPfx:没有指定Text的情况下使用此属性。要查找的字符串的前缀。语法是” TextPfx =string”。还可以使用text flags自定义字符串。
3、TextSfx:没有指定Text的情况下使用此属性。要查找的字符串的后缀。语法是” TextSfx =string”。还可以使用text flags自定义字符串。
4、Search:可选项,在哪里查找字符串。可选的值是:Headers,Body,NORESOURCE或All。默认值是NORESOURCE。语法是“Search=value”。
5、Fail:当字符串找不到时的处理选项:Found (默认值)或NotFound。Found表示当找到对应的字符串时发生了错误(例如“Error”)。NotFound表示当找不到字符串时发生了错误。语法是“Fail=value“。
6、ID:在日志文件中标识当前函数。
LAST:属性列表结束符。
注:text flags:/IC表示忽略大小写;/BIN表示指定的是二进制数据。
返回值
整型。 成功时返回LR_PASS(0),失败时返回LR_FAIL (1)。说明
web_global_verification属于注册函数,注册一个在web页面中搜索文本字符串的请求,与web_reg_find只在下一个 Action函数中执行搜索不同的是,它是在之后所有的Action类函数中执行搜索的。可以搜索页面的body,headers,html代码或者是整 个页面。在检测一些应用程序级别(不通过http状态码来表现)的错误时,web_global_verification是非常有用的。如果要定位通过HTTP状态码表现的错误时,使用web_get_int_property。
查找范围:all:这个HTML页面;Headers:页面的头;body:页面的体,包含所有的资源但不包含头;NORESOURCE(默认选项):仅仅包含页面的体,把包括头和资源。
如果不知道要查找的精确的文本,或者要查找的多个文本不是完全相同的,可以使用前缀和后缀来表示。这时需要用到TextPfx和TextSfx属性。这2个属性必须同时指定,一旦指定了其中一个,就不能指定Text属性了。
注意:web_global_verification在WAP协议下不能运行。
web_image_check
语法:
int web_image_check(const char *CheckName, <List of Attributes>, <"Alt=alt"|| "Src=src">, LAST );参数:
1、CheckName:名称,在Tree视图中出现。2、List of Attributes:
支持的属性有:Frame(在多Frame的情况下,定义要查找Frame的范围)。
支持的选项有:expect, matchcase, repeat, report, onfailure。
Tip:选项跟属性的区别,大部分选项都只允许设置预定义的值,其他的值都是无效的。
3、Alt:检查图象的ALT标记。不允许空值。
4、Src:检查图象的SRC标记。不允许空值。
5、LAST:参数列表结束的指示符。
返回值
整型。说明
web_image_check检查指定的图象是否在HTML页面中出现。Alt或者Src两者必须有一个在参数列表中出现。如果两项都通过,那么检查成功。
此函数仅仅支持基于HTML的脚本。
web_reg_add_cookie
语法:
int web_reg_add_cookie(const char * cookie, const char * searchstring, LAST );参数:
1、Cookie:定义需要增加或修改的Cookie。Cookie的参数格式为:<name>=VALUE; (required);domain=DOMAIN_NAME;(required);expires=DATE;path=PATH;(default path is "/");secure。
此参数中的cookie元素和HTTP响应头中的Set-Cookie是相同的。例如“Session=1234;domain=sanditon.com”,在这里,“Session”是cookie的名称。
2、Searchstring:要查找的文本字符串。字符串不能为空,以null结尾。格式为“Text=string”。
3、LAST:属性列表的结束符。
返回值
整型。 成功时返回LR_PASS(0),失败时返回LR_FAIL (1)。说明
web_reg_add_cookie是注册类型的函数。它首先注册一个搜索文本字符串的请求。检查动作在后续的Action函数之后进行。如果字符串被找到,就添加到cookie中。需 要注意,尽管web_reg_add_cookie在功能上跟HTTP Set_Cookie头相似,它们还是有个明显的区别。 根据HTTP标准,domain属性在Set-Cookie头中是可选的。如果没有指定,默认的domain的值是产生cookie的服务器的host name。当使用web_reg_add_cookie函数时,服务器的hostname对于压力测试的机器来说是不可用的,所以domain属性是必选项。
此函数在HTML-based 和URL-based的脚本中都可以使用。(参照录制选项的录制标签页)。此函数是在服务器内容到达客户端之前注册搜索请求的,所以当所请求的内容一到就会执行搜索操作,脚本会比较高性。
web_reg_add_cookie是用户手动添加的,无法录制。
web_reg_find
语法:
int web_reg_find (const char *attribute_list, LAST);参数:
1、attribute_list:通过Name=Value对来传递参数。例如“Text=string”。Text,TextPfx,TextSfx三个必须有一个出现。其他的属性是可选的。
a) Text:要搜索的字符串,字符串必须非空,以NULL结尾。可以使用text flags自定义搜索字符串。
b) TextPfx:要搜索的字符串的直接前缀。
c) TextSfx:要搜索的字符串的直接后缀。
d) Search:搜索的范围。可选的值是:Headers 、Body(在请求体中搜索)、Noresource (仅仅在HTML请求体中搜索,不包括头和资源)、ALL (在请求体、头和资源中搜索),默认值是“BODY”。
e) SaveCount:匹配的个数。
f) Fail:设置函数检查在什么状态下失败。
g) ID:日志文件中标识此函数的一个字符串。
h) RelFrameId:相关联的FrameId。注意:此参数在GUI级别的脚本中不受支持。
2、LAST:属性列表结束的标记符。
返回值
整型。 成功时返回LR_PASS(0),失败时返回LR_FAIL (1)。说明
web_reg_find属于注册函数,注册一个在web页面中搜索文本字符串的请求,在接下来的Action(象web_url)类函数中执行搜索。通过查找期望的字符是否存在来验证是否返回了期望的页面。例如,通过查找“Welcome”来检查主页是否完全打开了。也可以查找“Error”检查浏览器是否发生错误。还可以使用此函数注册一个请求来统计特定字符串出现的次数。
如果检查失败,在接下来的Action类的函数中会报告错误。此函数仅仅注册请求,并不执行。函数的返回值只表明注册是否成功,并不表示检查的结果。
此函数不仅能够查找text,还能查找到围绕着text的strings。不要同时指定text和前缀后缀。
Fail,处理选项,可以是“Found或“NotFound”。默认是“NotFound”。
“Fail=Found” 指示当对应的字符找到时,函数检查失败。例如,查找单词“Error”,如果找到了,说名web请求没有成功,你想把函数检查设置为失败。
“Fail=NotFound”指示当对应的字符找不到时,函数检查失败。如果查找的是web请求成功时出现的字符串时,需要使用NotFound。
SaveCount参数指示保存到参数中的匹配的字符串的个数。使用这个属性,需要指定“SaveCount=param”。检查操作被执行后,param 的值是null结尾的数字类型的值。
如果指定了SaveCount,且没有使用Fail参数,检查不会失败,无论需要查找的字符串是否找到。通过检查SaveCount的值确定字符串是否被找到。 如果param是0,说明没有找到对应的字符串。
如果同时指定了SaveCount和Fail,指定的错误处理选项和SaveCount协同工作。 handling option specified works together with the SaveCount. Thus,如果指定了SaveCount且指定了“Fail=NotFound” ,但是字符串被找到,SaveCount被赋值为字符串出现的次数,检查成功。如果字符串找不到,SaveCount被赋值为0,检查失败(注意,参数的 0值只在运行时设置中Continue on error 选中时才有意义)。
此函数在HTML-based和URL-based的脚本中都可以使用。此函数是在所请求内容到达之前注册搜索请求的,所以当所请求内容一到达后就会执行搜索,产生的脚本比较高效。

web_reg_find和 web_find的不同之处是web_reg_find是先注册,后查找;而web_find是查找前面的请求结果。
web_find和web_reg_find函数两者是有一些差别的:
(1)web_reg_find先注册的优势是脚本能够一边接收Server的数据缓冲,一边进行查找,提高了查找的效率。
(2)web_reg_find的参数与web_find并不完全一样,其中有个参数叫做 SaveCount,它能够记录查找匹配的次数。而web_find的机制是一旦查找匹配成功,就立即返回,并不继续查找和记录匹配次数。
(3)VU run time设置中的 “enable image and text check”对 web_find有效,而对web_reg_find无效。
自己写的代码:
#include "web_api.h"
Action()
{
web_reg_find("Search=Body","Text=空间","SaveCount=abc_count",LAST);web_url("19楼",
"URL=http://www.19lou.com/",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTML",
EXTRARES,
LAST);
if(atoi(lr_eval_string("{abc_count}"))>0) //判断是否查找成功
{
lr_output_message("Log on successful."); //atoi是C语言的函数,将字符型变量转成整数型
}
else{
lr_error_message("Log on failed"); //lr_eval_message取得参数值
return(0);
}
lr_output_message(lr_eval_string("{abc_count}")); //输出统计的次数return 0;
}运行结果:
Action.c(7): Registered web_reg_find successful for "Text=空间" (count=21) [MsgId: MMSG-26364]
Action.c(7): web_url("19楼") was successful, 764227 body bytes, 23422 header bytes [MsgId: MMSG-26386]
Action.c(18): Log on successful.
Action.c(24): 21来源:http://hi.baidu.com/dcwang/blog/item/6f45aa188df4bd0e34fa412d.html
-
根据web_reg_find 页面内容查找结果,进行不同的操作
2010-10-21 18:01:54
以下代码含义:
在网页中查找一个字符串,若未找到,让页面自动循环执行刷新(即点击网页上的Refresh按钮),直到页面出现该字符串(后台操作完成后,此字符串才能显示)后,再接着执行其它操作。
aa:
//在下一个操作(即刷新)的返回页面中查找字符串“完成下载”
web_reg_find("Text=完成下载",
"SaveCount=i_Count",
LAST);web_link("Refresh",
"Text=Refresh",
"Snapshot=t23.inf",
LAST);//判断如“完成下载”字符串出现次数等于0,则再次刷新,直到此字符串出现
if(strcmp(lr_eval_string("{i_Count}"),"0")==0)
{
lr_error_message("未完成");
goto aa;
}else
{
lr_error_message("已完成批下载");
}//以下内容为字符串显示后的其它操作
......
......
-
用LoadRunner测试MMS流媒体
2010-07-01 18:16:28
步骤
内容
具体操作
1
协议选择
协议包用Global或Web都可以,选用Media Player(MMS)协议。(MMS协议无法录制,只能通过手工编写)
2
脚本编写
mms_play( "test1.wmv",
"URL=mms://202.106.xxx.xxx/1/test1.wmv",
"duration=-1",
"starttime=0",
LAST );
//lr_think_time(2000);
//mms_close();
return 0;
3
wmload.asf文件添加
拷贝至发布点根目录。比如:所发布文件的文件位于d:\media\1\和d:\media\2\两个文件夹下,则发布点的根目录为d:\media
(网上资料说应拷贝到服务器C:\wmpub\wmroot,C为系统盘。不过根据本次测试经验,应该不用这样做。)
4
并发访问
在LR的控制器里面设置并发,运行后,到服务器的流媒体服务界面(如下图),看当前已连接的客户数和当前分配带宽是否有变化。若没有变化,可尝试重新启动流媒体服务,再次运行并观察。
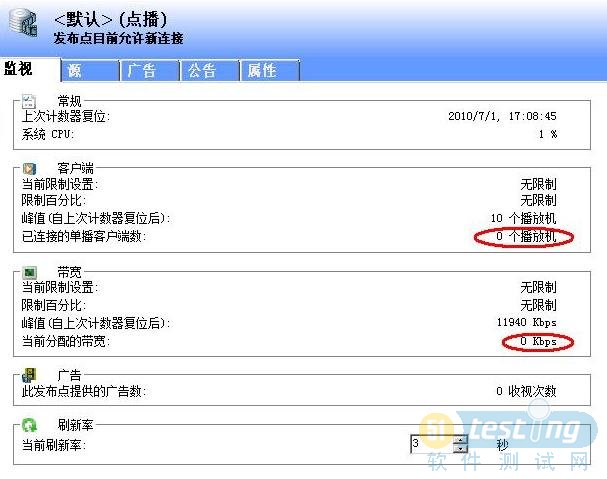
测试中发现:
1. 访问流媒体服务器时,无论是用LR的控制器并发访问,还是用IE产生单个的访问需求,只要当前程序(控制器/IE)不关闭,即使已经终止播放,上图中的“已连接的单播客户端数”也不会减少。只有当关闭当前程序(控制器/IE)时,“已连接的单播客户端数”才会响应减少或归零。但是,若当前程序(控制器/IE)中的流媒体文件已经不再播放,会从上图中的“当前分配的带宽”项的减少或归零看出来。
2. 用200个vu并发访问,发现第一次运行时,服务器端“已连接的单播客户端数”最大达到198;而第二次运行以及以后几次运行时,已连接的单播客户端数”越来越少,只有50%左右。而且,如果此时用IE直接访问mms://202.106.xxx.xxx/1/test1.wmv,服务器端“已连接的单播客户端数”根本不变化(理论上应该增加1)。怀疑由于运行次数多,视频文件已经完全在PC机内存/硬盘中,于是每次访问不再访问网络,直接从本机内存/硬盘中读取,所以服务器端的参数不变化。针对这种情况,只需清一下IE的内存即可。
-
LR运行百分比设置
2009-01-09 14:43:11
使用loadrunner时,在“运行时设置—>运行逻辑”中设置多个操作的运行百分比时,我把两个操作分别
设为40%和60%,迭代10次,运行后发现这两个操作各运行了5次;
设为20%和80%时,两个操作分别运行了3次和7次;
设为50%和50%时,两个操作分别运行了4次和6次
设为30%和70%时,两个操作分别运行了1次和9次这是怎么回事呢?为什么运行结果和设置不同呢?
咨询了刘专家,得到这样的回答:
对于运行百分比设置,只是一个随机概率的设置,所以迭代次数少的时候可能会有偏差,而且相同配置两次执行时也会不同。一般真正测试的时候都不会执行这么少的迭代的,建议迭代100次看看是否合配置相符。 -
web_find 与 web_reg_find
2008-12-25 19:57:14
使用lr中sample的订票网站,登录后,页面出现“Welcome, ww, to the Mercury Tours reservation pages.”
录制时,我在页面上选中这行字,并设置了检查点,lr自动生成的脚本语句是
web_find("Text Check", "What=Welcome, ww, to the Mercury Tours reservation pages.", "LAST");我在别的页面也设置了检查点,但lr自动生成的脚本语句是 web_reg_find(......)
我很奇怪,都是检查点,为什么生成的脚本不一样?于是就把web_find语句改成了
web_reg_find("Text=Welcome, ww, to the Mercury Tours reservation pages.",LAST);
考虑到这是reg注册函数,还把它放在了相应页面之前,但是重播时,不出意外地失败了试来试去,发现如果写成以下的样子就是成功的:
web_reg_find("Text=Welcome",LAST);
或
web_reg_find("Text=ww",LAST);我想啊想,突然发现,其实这行字的字体不完全一样,其中ww是黑体,于是改成以下语句,就重播成功啦
web_reg_find("Text=Welcome, <b>ww</b>, to the Mercury Tours reservation pages.",LAST);太开心啦!web_find函数查找目标时竟然可以忽略字体的不同
同时赞叹lr的“聪明”,当它发现选中文字的字体不同时,就用web_find函数代替web_reg_find,真不错啊! -
破解LR-安装成功
2008-11-18 14:07:28
昨天小熊在这里开了空间,今天终于装好了LR,很开心,特此纪念一下。
51testing上的好东西真多啊,小熊在这不但找到了破解版LR和中文包,还有详细的破解方法。经过两次努力,十分钟前终于搞定!打开Controller,不再有恼人的到期提醒,爽啊!
就像刘姥熊进了大观园,网上的内容让俺眼花缭乱,看着高手熊们的长篇大论,小熊心里很着急,啥时候俺也能成为一名测试高熊啊?
小熊暗下决心,一定要努力!世上无难事,只怕有心熊!fighting!
标题搜索
我的存档
数据统计
- 访问量: 146846
- 日志数: 16
- 建立时间: 2008-11-17
- 更新时间: 2013-04-08
