
-
Redis服务器学习笔记(一)
2015-06-23 13:23:50
一、Redis的安装:
wget http://download.redis.io/redis-stable.tar.gz
tar xzfredis-stable.tar.gz
cd redis-stable
make
make install
二、Redis的简单介绍:
1. Redis可执行文件说明:
文件名
说明
redis-server
redis服务器
redis-cli
redis命令行客户端
redis-benchmark
redis性能测试工具
redis-check-aof
AOF文件修复工具
redis-check-dump
RDB文件检查工具
2. Redis服务器启动的两种方式:
i. 直接运行命令行:
ii. 使用初始化脚本来启动Redis。
脚本路径:redis源代码目录的utils文件夹有一个名为redis_init_script的初始化脚本
脚本内容:
#!/bin/sh
#
# Simple Redis init.d script. conceived towork on Linux systems
# as it does use of the /proc filesystem.
REDISPORT=6379
EXEC=/usr/local/bin/redis-server
CLIEXEC=/usr/local/bin/redis-cli
PIDFILE=/var/run/redis_${REDISPORT}.pid
CONF="/etc/redis/${REDISPORT}.conf"
case "$1" in
start)
if [ -f $PIDFILE ]
then
echo "$PIDFILE exists, process isalready running or crashed"
else
echo "Starting Redis server..."
$EXEC $CONF
fi
;;
stop)
if [ ! -f $PIDFILE ]
then
echo "$PIDFILE does not exist, processis not running"
else
PID=$(cat $PIDFILE)
echo "Stopping ..."
$CLIEXEC -p $REDISPORT shutdown
while [ -x /proc/${PID} ]
do
echo "Waiting for Redis to shutdown..."
sleep 1
done
echo "Redis stopped"
fi
;;
*)
echo "Please use start or stop asfirst argument"
;;
esac
配置方法:
i. 拷贝初始化脚本。
cp /{redis源码路径}/utils/redis_init_script/etc/init.d/redis_{端口号}
ii. 编辑初始化脚本。编辑脚本第6行,修改REDISPORT变量值,使得与上例中的端口号一致,例如:7777
iii. 建立必要的文件夹。
目录名
说明
/etc/redis
存放Redis的配置文件
/search/redis/端口号
存放Redis的持久化文件
iv. 复制redis源代码下redis.conf配置文件模板到/etc/redis目录下,以端口号命名。例如:7777.conf。
v. 编辑.conf配置文件。
参数
值
说明
daemonize
yes
使Redis以守护进程模式运行
pidfile
/search/redis/redis_端口号.pid
设置pid的PID文件位置
port
端口号
设置redis监听的端口号
dir
/search/redis/端口号
设置持久化文件存放位置
vi. 启动Redis。
1. Redis命令行使用命令方式:
方式一:
方式二:
三、Redis命令总结
官网命令列表:http://redis.io/commands (英文)
1、连接操作相关的命令
· quit:关闭连接(connection)
· auth:简单密码认证
2、对value操作的命令
· exists(key):确认一个key是否存在
· del(key):删除一个key
Note:DEL命令的参数不支持通配符,但是可以结合Linux的管道和xargs命令自己使用删除所有符合规则的键。
例如:删除所有以"user:"开头的键,就可以执行
redis-cli KEYS"user:*" | xargs redis-cli DEL
或者
redis-cli DEL'redis-cli KEYS "user:*"'
· type(key):返回值的类型
· keys(pattern):返回满足给定pattern的所有key
pattern通配符类型:
符号
含义
?
匹配一个字符
*
匹配任意个(包括0个)字符
[ ]
匹配括号间的任一字符,可以使用"-"符号表示一个范围,如a[b-d]可以匹配ab、ac、ad
\x
匹配字符x,用于转义符号。
· randomkey:随机返回key空间的一个key
· rename(oldname,newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
· dbsize:返回当前数据库中key的数目
· expire:设定一个key的活动时间(s)
· ttl:获得一个key的活动时间
· select(index):按索引查询
· move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
· flushdb:删除当前选择数据库中的所有key
· flushall:删除所有数据库中的所有key
3、对String操作的命令
· set(key, value):给数据库中名称为key的string赋予值value
· get(key):返回数据库中名称为key的string的value
· getset(key, value):给名称为key的string赋予上一次的value
· mget(key1, key2,…,key N):返回库中多个string(它们的名称为key1,key2…)的value
· setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
· setex(key, time,value):向库中添加string(名称为key,值为value)同时,设定过期时间time
· mset(key1, value1,key2, value2,…key N, value N):同时给多个string赋值,名称为key i的string赋值value i
· msetnx(key1,value1, key2, value2,…key N, value N):如果所有名称为key i的string都不存在,则向库中添加string,名称key i赋值为value i
· incr(key):名称为key的string增1操作
· incrby(key,integer):名称为key的string增加integer
· decr(key):名称为key的string减1操作
· decrby(key,integer):名称为key的string减少integer
· append(key, value):名称为key的string的值附加value
· substr(key, start,end):返回名称为key的string的value的子串
4、对List操作的命令
· rpush(key, value):在名称为key的list尾添加一个值为value的元素
· lpush(key, value):在名称为key的list头添加一个值为value的 元素
· llen(key):返回名称为key的list的长度
· lrange(key, start,end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
· ltrim(key, start,end):截取名称为key的list,保留start至end之间的元素
· lindex(key, index):返回名称为key的list中index位置的元素
· lset(key, index,value):给名称为key的list中index位置的元素赋值为value
· lrem(key, count,value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对keyi+1开始的list执行pop操作。
· brpop(key1, key2,…key N, timeout):rpop的block版本。参考上一命令。
· rpoplpush(srckey,dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
5、对Set操作的命令
· sadd(key, member):向名称为key的set中添加元素member
· srem(key,member) :删除名称为key的set中的元素member
· spop(key) :随机返回并删除名称为key的set中一个元素
· smove(srckey,dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
· scard(key) :返回名称为key的set的基数
· sismember(key,member) :测试member是否是名称为key的set的元素
· sinter(key1,key2,…key N) :求交集
· sinterstore(dstkey,key1, key2,…key N) :求交集并将交集保存到dstkey的集合
· sunion(key1,key2,…key N) :求并集
· sunionstore(dstkey,key1, key2,…key N) :求并集并将并集保存到dstkey的集合
· sdiff(key1,key2,…key N) :求差集
· sdiffstore(dstkey,key1, key2,…key N) :求差集并将差集保存到dstkey的集合
· smembers(key) :返回名称为key的set的所有元素
· srandmember(key) :随机返回名称为key的set的一个元素
6、对zset(sorted set)操作的命令
· zadd(key, score,member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
· zrem(key,member) :删除名称为key的zset中的元素member
· zincrby(key,increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
· zrank(key,member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
· zrevrank(key,member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
· zrange(key, start,end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
· zrevrange(key,start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
· zrangebyscore(key,min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数 zscore(key, element):返回名称为key的zset中元素element的scorezremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
· zunionstore /zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
7、对Hash操作的命令
· hset(key, field,value):向名称为key的hash中添加元素field<—>value
· hget(key, field):返回名称为key的hash中field对应的value
· hmget(key, field1,…,field N):返回名称为key的hash中field i对应的value
· hmset(key, field1,value1,…,field N, value N):向名称为key的hash中添加元素fieldi<—>value i
· hincrby(key,field, integer):将名称为key的hash中field的value增加integer
· hexists(key,field):名称为key的hash中是否存在键为field的域
· hdel(key, field):删除名称为key的hash中键为field的域
· hlen(key):返回名称为key的hash中元素个数
· hkeys(key):返回名称为key的hash中所有键
· hvals(key):返回名称为key的hash中所有键对应的value
· hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
8、持久化
· save:将数据同步保存到磁盘
· bgsave:将数据异步保存到磁盘
· lastsave:返回上次成功将数据保存到磁盘的Unix时戳
· shundown:将数据同步保存到磁盘,然后关闭服务
9、远程服务控制
· info:提供服务器的信息和统计
· monitor:实时转储收到的请求
· slaveof:改变复制策略设置
· config:在运行时配置Redis服务器
-
Nginx反向代理与负载均衡
2015-06-23 13:22:30
一、简介
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
反向代理负载均衡技术是把将来自internet上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
二、常见使用场景
1. 反向代理:(如图2-3所示)
a. Web浏览器向前端Nginx发送HTTP请求
b. 如果请求的资源是静态资源,则前端Nginx服务器直接将静态资源返回给Web浏览器;
c. 如果请求的资源是动态页面,则前端Nginx服务器通过反向代理,将请求转发给上游服务器(Tomcat\Apache等),上游服务器处理完毕动态请求后返回给前端Nginx服务器,前端Nginx服务器再转发动态页面应答给Web浏览器。
2. 负载均衡使用场景:
当Nginx前端接收到大量的HTTP请求后,通过一定的策略,尽量把请求平均地分布到每台上游服务器上,以避免单个服务器被压爆。
三、配置说明:
1. 负载均衡的基本配置
1)upstream块
语法:upstream name{...}
配置块:http
upstream块定义了一个上游服务器的集群,便于反向代理中的proxy_pass使用。例如:
Upstream backend{
Server backend1.example.com;
Server backend2.example.com;
Server backend3.example.com;
}
Server {
Location / {
Proxy_pass http://backend
}
}
2)server
语法:server name[parameters];
配置块:upstream
server配置项制定了一台上游服务器的名字,这个名字可以是域名、IP地址端口、Unix句柄等,在其后还可以跟下列参数。
· weight=number:设置向这台上游服务器转发的权值,默认为1.
· max_fails=number:该选项与fail_timeout配合使用,指在fail_timeout时间段内,如果向当前的上游服务器转发失败次数超过number,则认为在当前的fail_timeout时间段内这台上游服务器不可用。Max_fails默认为1,如果设置为0,则表示不检查失败次数。
· fail_timeout=time:表示该时间段内转发失败多少次后就认为上游服务器暂时不可用,用于优化反向代理功能。Fail_timeout默认为10秒。
· down:表示所在的上游服务器永久下线,只在使用ip_hash配置项时才有用。
· backup:在使用ip_hash配置项时它是无效的。它表示所在的上游服务器只是备份服务器,只有在所有的非备份上游服务器都失效后,才会向其转发请求。
例如:
upstream backend{
server backend1.example.com weight=5;
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;
server unix:/tmp/backend3
}
3)ip_hash
语法:ip_hash
配置块:upstream
在有些场景下,我们可能会希望来自某一个用户的请求始终落到固定的一台上游服务器上。例如:假设上游服务器会缓存一些信息,如果同一个用户的请求任意地转发到集群中的任一台上游服务器上,那么每一台上游服务器都有可能会缓存同一份信息,这既会造成资源浪费,也会难以有效地管理缓存信息。ip_hash就是用以解决上述问题的。
ip_hash与weight配置不可同时使用。如果upstream集群中有一台上游服务器暂时不可用,不能直接删除该配置,而是要down参数标识,确保转发策略的一贯性。例如:
upstream backend{
ip_hash;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com down;
server backend4.example.com;
}
4)记录日志时支持的变量
如果需要将负载均衡时的一些信息记录到access_log日志中,那么在定义日志格式时可以使用负载均衡功能提供的变量,如下表
变量名
意义
$upstream_addr
处理请求的上游服务器地址
$upstream_cache_status
表示是否命中缓存,取值范围:MISS、EXPIRED、UPDATING、STALE、HIT
$upstream_status
上游服务器返回的响应中的HTTP响应码
$upstream_response_time
上游服务器的响应时间,精确到毫秒
$upstream_http_$HEADER
HTTP的头部,如upstream_http_host
2.反向代理的基本配置
1)proxy_pass
语法:proxy_pass URL;
配置块:location、if
此配置项将当前的请求反向代理到URL参数指定的服务器上,URL可以是主机名或IP地址端口形式,例如:
proxy_pass http://localhost:8000/uri/;
还可以直接使用upstream块,例如:
upstream backend{
……
}
server {
location / {
proxy_pass http://bakend
}
}
默认情况下反向代理是不会转发请求中的host头部的。如果需要转发,那么必须加上配置:
proxy_set_headerHost $host;
2)proxy_method
语法:proxy_methodmethod
配置块:http、server、location
此配置项表示转发时的协议方法名。例如设置为:
proxy_method POST;
那么客户端发来的GET请求在转发时方法名也会改为POST。
3)proxy_hide_header
语法:proxy_hide_header the_header;
配置块:http、server、location
Nginx会将上游服务器的响应转发给客户端,但默认不会转发一下HTTP头部字段:Date、Server、X-Pad和X-Accel-*。使用proxy_hide_header后可以任意指定哪些HTTP头部字段不能被转发,例如:
proxy_hide_headerCache-Control;
proxy_hide_headerMicrosoftOfficeWebServer;
3)proxy_pass_header
语法:proxy_pass_headerthe_header;
配置块:http、server、location
与proxy_hide_header功能相反,proxy_pass_header会将原来禁止转发的header设置为允许转发。
4)proxy_pass_request_body
语法:proxy_pass_request_bodyon|off;
配置块:http、server、location
作用为确定是否向上游服务器转发HTTP包体部分。
5)proxy_pass_requst_headers
语法:proxy_pass_requst_headerson|off;
配置块:http、server、location
作用为确定是否向上游服务器转发HTTP头部。
6)proxy_redirect
语法:proxy_redirect[default|off|redirect replacement];
配置块:http、server、location
当上游服务器返回的响应是重定向或者刷新请求(如301或302),proxy_direct可以重设HTTP头部的location或refresh字段。例如:
proxy_direct http://localhost:8000/two http://frontend/one;
如果上游服务器发出的响应是302重定向请求,location字段的URL是http://localhost:8000/two/some/uri/,那么经过以上配置,实际转发给客户端的location是http://frontend/one/some/uri/。
3.反向代理和负载均衡的配置实例文件:
负载均衡:
worker_processes 1;
events {
worker_connections 1024;
}
http{
upstream lxx {//默认是80端口
server 192.168.0.62 weight=2;
server 192.168.0.161 weight=3;
}
server {
listen 80;
location / {
proxy_pass http://lxx;
}
}
}
反向代理:
worker_processes 1;
events {
worker_connections 1024;
}
http{
upstream lxx {//默认是80端口
server 192.168.0.62 weight=2;
server 192.168.0.161 weight=3;
}
server {
listen 80;
location / {
proxy_pass http://lxx;
#Proxy Settings
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream errortimeout invalid_header http_500 http_502 http_503 http_504;
proxy_max_temp_file_size 0;
proxy_connect_timeout 90;
proxy_send_timeout90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
}
}
}
-
PhpStorm+xdebug远程调试Linux机器上的代码
2015-06-23 13:21:23
一、背景介绍:
最近在了解网址导航项目,为了能够更加深入地了解被测对象,所以我选择了查看网址导航代码的方式进行,但是只是生硬地查看php源代码是比较生涩的,我希望能够通过IDE工具进行代码单步调试来了解整个网址导航的功能实现。
为了达成以上目的,我选择了phpstorm+xdebug来远程调试Linux上的代码。与之前白松分享的phpstorm+xdebug调试方法不同的是,前者调试的Webserver是在本地环境搭建了php+apache调试的,而我要面对的问题有:
1.网址导航的代码是部署在Linux虚机环境上的。
2.代码运行环境是:Linux+nginx+php-fpm+redis+superphp的环境支持
为了解决以上方法,采用了以下的方法。
二、配置方法:
1.在Linux虚机上编译配置xdebug
1)下载xdebug。访问http://xdebug.org/download.php,下载对应的xdebug源代码。
2)# tar -xvf xdebug-2.3.2.tgz
3)#cd xdebug
4)运行php目录/bin/phpize
5)配置./configure--enable-xdebug --with-php-config=/php的bin路径/php-config
6)make
7)make install
2.在Linux虚机上配置xdebug
在php.ini文件中增加如下配置:
zend_extension="/search/php5/lib/php/extensions/no-debug-non-zts-20121212/xdebug.so" //xdebug.so的路径,请根据安装的php目录来配置
[xdebug]
xdebug.idekey=PHPSTORM
xdebug.remote_connect_back = 1 //如果开启此,将忽略下面的 xdebug.remote_host 的参数
xdebug.remote_host=10.129.157.29 //注意这里是,客户端的ip<即IDE的机器的ip,不是你的web server>
xdebug.remote_enable=on
xdebug.remote_port = 9001 //注意这里是,客户端的端口<即IDE的机器的ip,不是你的web server>
xdebug.remote_handler = dbgp
xdebug.auto_trace = 1
xdebug.collect_includes = 1
xdebug.collect_params = 1
xdebug.collect_return = 1
xdebug.default_enable = 1
xdebug.collect_assignments = 1
xdebug.collect_vars = 1
xdebug.remote_autostart = 1
xdebug.show_local_vars = 1
xdebug.show_exception_trace = 0
3.下载phpstorm
4.在phpstorm中配置
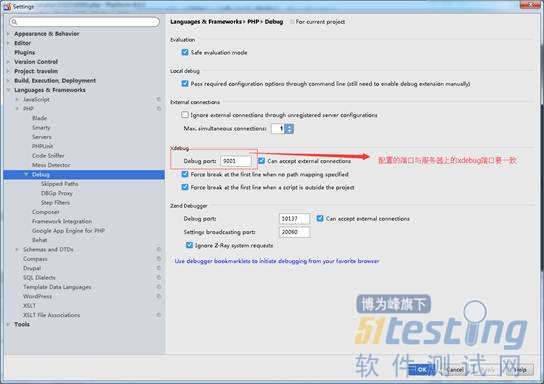
1)配置Debug项:打开file->setings->php|Debug。在右侧的xdebug配置项中,配置与服务器xdebug一样的端口号,如上例的9001。
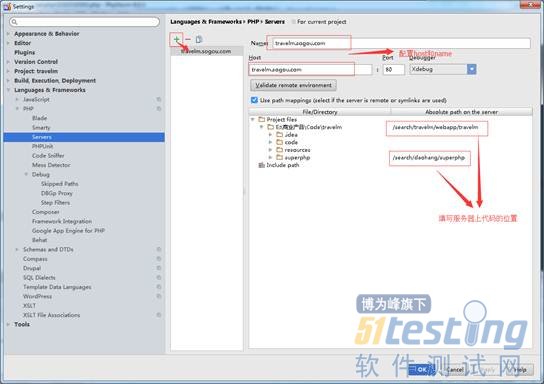
2)配置server项。
a.打开file->setings->php|Servers 在右侧点击+,添加server,host: web服务器的域名或ip ,端口一般为80。
b.勾选下面的 use pathmapping,在absolute path to the server填写服务器上代码所在的路径。这里一定要设置哦! 不然,会发生找不到文件而出错,导至调试终止 。
note:由于网址导航中还要引用superphp,所以在project中需要增加superphp,并且设置在服务器上superphp的路径。
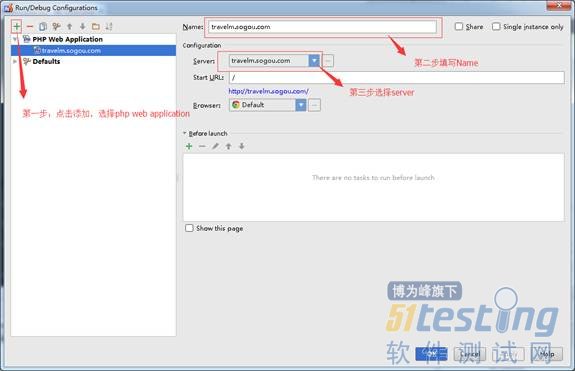
3)配置WEB Application调试点:打开Run->EditConfigurations-> 增加一个 PHP WEBAPPlication 的调试点 。
至此,配置完毕!
5.在代码中设置断点后,点击Run->Debug,浏览器被调起,同时phpstorm中的断点被中断,之后就可以F5单步调试了。
-
PhpStorm+xdebug远程调试Linux机器上的代码
2015-06-19 19:04:54
一、背景介绍:
最近在了解网址导航项目,为了能够更加深入地了解被测对象,所以我选择了查看网址导航代码的方式进行,但是只是生硬地查看php源代码是比较生涩的,我希望能够通过IDE工具进行代码单步调试来了解整个网址导航的功能实现。
为了达成以上目的,我选择了phpstorm+xdebug来远程调试Linux上的代码。与之前白松分享的phpstorm+xdebug调试方法不同的是,前者调试的Webserver是在本地环境搭建了php+apache调试的,而我要面对的问题有:
1.网址导航的代码是部署在Linux虚机环境上的。
2.代码运行环境是:Linux+nginx+php-fpm+redis+superphp的环境支持
为了解决以上方法,采用了以下的方法。
二、配置方法:
1.在Linux虚机上编译配置xdebug
1)下载xdebug。访问http://xdebug.org/download.php,下载对应的xdebug源代码。
2)# tar -xvf xdebug-2.3.2.tgz
3)#cd xdebug
4)运行php目录/bin/phpize
5)配置./configure --enable-xdebug --with-php-config=/php的bin路径/php-config
6)make
7)make install
2.在Linux虚机上配置xdebug
在php.ini文件中增加如下配置:
zend_extension="/search/php5/lib/php/extensions/no-debug-non-zts-20121212/xdebug.so" //xdebug.so的路径,请根据安装的php目录来配置
[xdebug]
xdebug.idekey=PHPSTORM
xdebug.remote_connect_back = 1 //如果开启此,将忽略下面的 xdebug.remote_host 的参数
xdebug.remote_host=10.129.157.29 //注意这里是,客户端的ip<即IDE的机器的ip,不是你的web server>
xdebug.remote_enable=on
xdebug.remote_port = 9001 //注意这里是,客户端的端口<即IDE的机器的ip,不是你的web server>
xdebug.remote_handler = dbgp
xdebug.auto_trace = 1
xdebug.collect_includes = 1
xdebug.collect_params = 1
xdebug.collect_return = 1
xdebug.default_enable = 1
xdebug.collect_assignments = 1
xdebug.collect_vars = 1
xdebug.remote_autostart = 1
xdebug.show_local_vars = 1
xdebug.show_exception_trace = 0
3.下载phpstorm
4.在phpstorm中配置
1)配置Debug项:打开file->setings->php|Debug。在右侧的xdebug配置项中,配置与服务器xdebug一样的端口号,如上例的9001。
 2)配置server项。
2)配置server项。a.打开file->setings->php|Servers 在右侧点击+,添加server,host: web服务器的域名或ip ,端口一般为80。
b.勾选下面的 use path mapping,在absolute path to the server填写服务器上代码所在的路径。这里一定要设置哦! 不然,会发生找不到文件而出错,导至调试终止 。
note:由于网址导航中还要引用superphp,所以在project中需要增加superphp,并且设置在服务器上superphp的路径。
3)配置WEB Application调试点:打开Run->Edit Configurations-> 增加一个 PHP WEB APPlication 的调试点 。
至此,配置完毕!
5.在代码中设置断点后,点击Run->Debug,浏览器被调起,同时phpstorm中的断点被中断,之后就可以F5单步调试了。

-
[测试十年]搜狗测试第一年:责任心篇
2015-05-30 12:29:41
前文回顾
小明已经入职一年多了,他先后从娜娜那里学会了细心、融入团队、主动反馈、主动学习、沟通方法等工作方法,这极大地帮助了小明,他已然从新人慢慢成长为独挡一面的顶梁柱,但是相比娜娜还是差那么一点,究竟差在哪儿呢?
本次我们将分享一个关于责任心的故事。
本期故事
再过几天就到五一劳动节了,小明提前请了四天假,想借着假期和女友去海边旅游;大熊和娜娜五一没有请假,用他们的话说,去哪儿都是人,还是在北京呆着吧。
刚好五一前要上线一个版本,为了保证项目顺利上线,大熊把小明剩余的工作交给娜娜,并且嘱咐小明把工作交接好。小明欣然地答应了,但是此刻的他,心早已经飞到阳光明媚沙滩了。
果然如大熊所料,小明只是草草地交待了下剩余的工作...
“小明,你来一下,我有话跟你讲。”大熊指了指旁边的会议室。这个会议室是一个可以容纳4人的小房间,因为大熊经常会把工作表现不好的同学请进去单聊,所以被组内同学戏称小黑屋。
小明心中大叫不好,一定是自己哪里又做得不好了,这一年他已经进去不下五次了。
两人就坐之后,大熊首先打破了沉默。
“小明,我很高兴这一年你进步了很多,不细心的毛病没了,也懂得如何去学习和沟通了,照此下去,也许有一天你会超过娜娜了。"
小明心中窃喜,一方面是因为自己的努力得到了大熊的认可,另一方面是因为自己能够与一直赶超的榜样娜娜相提并论了。
“但是,你有一点始终不及娜娜,这导致你一直追赶不上她,你知道是什么吗?”小明两眼瞪得浑圆。
“是一颗对他人、对团队负责的责任心!”
大熊继续说道:”在娜娜心中,她永远把团队的利益放在首位,时刻都想着对他人负责。同样是工作交接的事情,娜娜做得要比你出色许多,我给你看一封邮件就知道了…..”
大熊在笔记本上打开了一封邮件,那是娜娜在年前请假所发的工作交接事项,信中详细地交待了各个项目的状态、问题以及后续要做的事情。
大熊的话像根针一样直刺小明的心脏,使得他久久不能平复。他回想着自己和娜娜过去一年的工作表现,果然如大熊所说的一样,只差责任心三个字...
“大虫罗德曼并不是不想当得分王,而是他知道防守对团队有多重要,所以他会干任何需要他干的活:包办前后场篮板、满场飞奔地进行贴身防守、脏活累活一把抓、例行公事地盯住对方的大个子并在与之对位中完爆对方。”
-
[测试十年]搜狗测试第一年:主动学习篇
2015-05-11 22:04:34
前情介绍:
小明和娜娜刚工作一年,他们有一个共同的leader-大熊。
小明在这一年里,学会了主动反馈,学会了细心谨慎,学会了融入团队。
今天小明又学会了主动学习,经过是怎样的呢?且听我慢慢道来~
大熊每周三上午都会召开组内例会,娜娜发现每次例会上小明都有些心不在焉。
例会结束,大家去吃午饭,娜娜坐到小明旁边。
娜娜:“小明,你例会上看着有些心不在焉,怎么了?”
小明:“他们讲的东西我听不懂。”
娜娜:“哪里听不懂?”
小明:“他们说的那些名词,什么老板键,什么Fiddler的。”
娜娜:“那你打算怎么办?”
小明:“怎么办?凉拌呗,听不懂就算了。”
娜娜:“壳牌石油策划经理AriedeGens说过,唯一能持久的竞争优势是胜过竞争对手的学习能力。我们现在刚工作不久,会遇到很多不知道的东西,如果不主动去搞清楚,那么我们永远都学不会,只有主动学习,才能不断提升能力。”
小明仔细回想着娜娜的话…
下午娜娜看到小明在搜索Fiddler的资料,欣慰地笑了~
两周后,新来的实习生使用Fiddler时遇到一个问题。
娜娜:“小明,你之前不是查了Fiddler的资料,你帮他解决下呗。”
小明:“呃…呃……我看到过这个问题的解决方法,但是现在记不得了……”
娜娜:“有句老话说得好,好记性不如烂笔头。看到的知识,你写下来会加深印象,再实际去操作下,就不容易忘记,即使真的记不清了,也有文档可查,也容易想起怎么操作。”
小明:“我试试。”
第二天,小明发了一篇Fiddler使用方法的文章,还帮实习生解决了问题。
之后,小明发了一系列的Fiddler相关的文章,组内所有人遇到Fiddler的问题都会去找小明帮忙。
就这样,小明成了“Fiddler专家”。
-
[测试十年]搜狗测试第一年:主动反馈篇
2015-04-30 17:43:51
前文回顾:
大熊(小明的Leader)因为小明做事不细心,批评了小明。娜娜(小明的同事)一同帮助小明分析了细心的重要性以及如何做到细心。
本次我们将分享一个关于主动反馈的故事。
本期故事:
这天下午,小明正在测试一个任务时,收到了大熊的QQ留言:“老板反馈了一个浏览器下载的问题,在https的网站下载的文件损坏,你去跟一下。”
小明收到消息后,立即着手去跟进解决,发现这是一个漏测的BUG,提交给开发后就结束了。
大熊对于小明没有任何反馈很不满意,又是一顿唠叨:“你做完了为什么没有反馈?你应该多向娜娜学习。”
小明一声叹气,心想:问题解决就行了,为什么一定还要反馈呢。
他带着困惑找到娜娜:“大熊刚才又批我了,因为我跟进完毕一个问题后,没有向他反馈。”
娜娜微微一笑:“你为什么不反馈结果呢?”
小明:“没必要啊,这是一个BUG,我已经复现并且提交给开发处理了。”
娜娜顿了顿,说道:“小明,你听说过什么叫‘关键时刻’吗?”
小明摇摇头。
娜娜耐心地解释道:关键时刻(Moments of Truth,MOT) 这一理论是由北欧航空公司前总裁詹·卡尔森创造的。他认为,关键时刻就是顾客与航空公司职员面对面相互交流的时刻,这个时刻决定了企业未来的成败。放小了说,关键时刻就是人与人交流的时刻,这一时刻决定了对方对你的评价。
“举个例子:如果有人找你问路,如何去地铁,你会怎么做呢?”
小明:“指给他地铁的方向就是了。”
娜娜:“那么你在对方的心理评价是60分。”
小明:“那怎么做到100分呢?”
娜娜:“探索、提议、行动、确认。”
[plain] view plaincopy- 探索,了解对方的需求与想法。例如:进一步询问对方坐地铁是去哪里,比如去机场。
- 提议,提供适当的行动建议以符合对方期望。例如:时间不紧急而对方又不想换乘的话,可以去就近的机场大巴,如果时间紧急,最快的地铁换乘路线应该如何乘坐。
- 行动,执行先前所提议或承诺事项。例如:亲自带着他去地铁站。
- 确认,确认你达到或超越对方的期望。例如:留下对方电话,事后电话确认对方是否已经顺利到达。
“如果是这样一个过程,那么你在对方心中的评价一定很高,对吗?”小明听到娜娜的解答后,连连点头。
娜娜继续说道:以上的关键时刻同样也体现在我们的工作中。你在跟进问题时做到了行动,但是没有做到反馈。
小明继续问道:那么我该如何反馈结果呢?是口头告诉给大熊,还是写一份书面的报告?
娜娜:可以先口头告诉大熊,然后有必要的话再补一份书面的报告。
小明追问道:书面报告怎么写?是写一份BUG吗?可是我没有模板啊。
娜娜:关键时刻的核心思想是换位思考。你想想如果你是大熊的话,你希望组员如何反馈?
小明想了想,说道:我是Leader的话,如果是一个跟进问题的话,我想知道这个反馈是不是BUG,如果是BUG,有没有被处理,当前是什么状态。如果是工作汇报的话,我想知道这个问题影响不影响上线,如果影响,有没有被妥善处理了。
娜娜笑了笑,然后俏皮地一字一字强调道:“记住,换--位--思--考。”
这一刻,小明看着眼前的娜娜,回想起一年前,他们同一天入职,娜娜还只是一个不太敢说话的女生。但是一年之后,娜娜已经成长为职场精英,是大熊的左膀右臂。不甘和羡慕在小明心中交错汇集,他终于明白了自己的差距,先前对大熊叛逆的心理也释然了。
“每个人都不是完美的,都需要在失败中去总结教训,战胜困境,这样才能获得真正的力量。”
--穆里尼奥在0:5惨败皇马后,更衣室训话
-
【测试工具】Linux限流工具
2015-04-27 20:48:28
Linux下限制网卡的带宽,可用来模拟服务器带宽耗尽,从而测试服务器在此时的访问效果。
1、安装iproute
yum -y install iproute- 1
2、限制eth0网卡的带宽为50kbit:
/sbin/tc qdisc add dev eth0 root tbf rate 50kbit latency 50ms burst 1000- 1
3、限制带宽为50kbit后,在百兆局域网中wget下载一个大文件:
[root@localhost ~]# wget http://192.168.1.7/test.zip --19:40:27-- http://192.168.1.7/test.zip Connecting to 192.168.1.7:80... connected. HTTP request sent, awaiting response... 200 OK Length: 23862312 (23M) [application/zip] Saving to: ~test.zip' 37% [=======> ] 8,994,816 457K/s eta 27s 下载速度为457K/s,限制效果达到。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、解除eth0网卡的带宽限制:
/sbin/tc qdisc del dev eth0 root tbf- 1
5、对比:未作带宽限制情况下,在百兆局域网中wget下载一个大文件:
[root@localhost ~]# wget http://192.168.1.7/test.zip --19:44:33-- http://192.168.1.7/test.zip Connecting to 192.168.1.7:80... connected. HTTP request sent, awaiting response... 200 OK Length: 23862312 (23M) [application/zip] Saving to: ~test.zip' 100%[==========>] 23,862,312 6.14M/s in 3.7s 19:44:36 (6.16 MB/s) - ~test.zip' saved [23862312/23862312] 下载速度为6.16MB/s。 -
Linux下使用Squid搭建代理服务器
2015-04-27 20:47:41
背景介绍:
一般情况下大家会使用CCProxy搭建代理服务器,这种方法简单易用,但是也存在较多问题:
1.软件受注册限制只能允许3人使用;
2.CCProxy的代理请求仅支持常见的GET和POST等,对于SVN通过代理去update等请求就不支持了;
3.代理的认证方式仅有基本的Basic方式,其他的ntlm等认证方式不支持等。为了能够解决以上问题,尝试使用Squid在Linux上搭建了代理服务器,分享其中的搭建方法:
一、安装Squid:
如果系统中还没有装squid,按以下顺序输入命令后即可完成安装
1. 下载Squid安装包
# wget http://www.squid-cache.org/Versi ... 3.0.STABLE18.tar.gz- 1
2. 解压Squid安装包
# tar -zxvf squid-3.0.STABLE18.tar.gz- 1
3. 配置Squid
# cd squid-3.0.STABLE18 //配置Squid代理安装路径之类的 # ./configure --prefix=/usr/local/squid --sysconfdir=/usr/local/squid/etc --bindir=/usr/local/squid/bin --sbindir=/usr/local/squid/sbin --mandir=/usr/local/squid/share/man --enable-gnuregex --enable-carp --enable-async-io=80 --enable-removal-policies=heap,lru --enable-icmp --enable-delay-pools --enable-useragent-log --enable-referer-log --enable-kill-parent-hack --enable-snmp --enable-arp-acl --enable-htcp --enable-cache-digests --enable-default-err-language=Simplify_Chinese --enable-err-languages="Simplify_Chinese" --enable-poll --enable-linux-netfilter --disable-ident-lookups --enable-underscores --enable-auth="basic" --enable-basic-auth-helpers="NCSA" --enable-external-acl-helpers="ip_user" --enable-x-accelerator-vary- 1
- 2
- 3
4. 编译
# make- 1
5. 安装
# make install //安装Squid代理软件- 1
二、配置Squid
1. Squid的配置文件保存在/usr/local/squid/etc的squid.conf文件中
2. 配置Squid项:
a. 启动squid时如果不在squid.conf中设置主机名将无法启动,必须要设置visible_hostname这个参数值,本文中,设置的主机名是服务器的真实机器名powersite,在squid.conf中找到该项并修改:
#visible_hostname linuxserver- 1
b. 开启http_access的访问权限
#http_access allow all- 1
三、配置Squid的密码验证功能
1. 创建密码文件。
密码和用户名存放在/etc/squid/squid_passwd文件中,并需要将这个文件的权限设置为其它用户只读。
# touch /etc/squid/squid_passwd # chmod o+r /etc/squid/squid_passwd- 1
- 2
2. 使用htpasswd添加用户,并设置密码。
添加用户不需要对squid进行重启操作,我创建的用户名是setest
# htpasswd /etc/squid/squid_passwd setest New password: Re-type password for user setest- 1
- 2
- 3
3. 找到ncsa_auth命令的具体位置,后面的配置需要用到绝对路径
# which ncsa_auth /usr/sbin/ncsa_auth- 1
- 2
如果找不到ncs_auth的话,可以直接去squid的压缩包解压目录中拷贝一份到/usr/sbin/ncsa_auth,例如:
cp helpers/basic_auth/NCSA/ncsa_auth /usr/sbin/ncsa_auth- 1
4. 在squid.conf文件中定义验证程序了,创建名为ncsa_users的ACL并加入关键字REQUIRED来强制让Squid使用NCSA验证方法。
# # 在squid.conf的auth_param部分添加下列内容 # auth_param basic program /usr/sbin/ncsa_auth /etc/squid/squid_passwd # # 将以下ACL添加到squid.conf的ACL配置部分 # acl ncsa_users proxy_auth REQUIRED # # 将这些内容添加到squid.conf的http_access配置部分 # http_access allow ncsa_users- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
四、启动Squid
1. /usr/local/squid/sbin目录下的squid为运行文件。 2. 第一次运行时,先运行squid -z创建缓存文件夹。缓存文件夹在/usr/local/squid/var下创建,因此创建缓存前还需运行chmod 777 /usr/local/squid/var给该文件夹权限。 再运行squid -d 1开启squid即可。 3. 如果要关闭squid,运行squid -k shutdown则是安全关闭。 -
【调试技巧】Windbg常用调试方法
2015-04-27 20:47:06
简介:
当出现进程CPU占用率高、进程假死(不退出)、进程发生崩溃时,可以参考以下的windbg命令使用说明,进一步提供有价值的信息给开发。
1.进程CPU占用率高问题跟进方法
1)开启windbg,attach到对应的进程上
2)加载目标程序PDB和系统PDB:srv*DownstreamStore*http://msdl.microsoft.com/download/symbols
3)查看所有线程的运行时间
命令: !runaway- 1
4)切换至CPU占用较高的工作线程,如上图的6号线程命令: ~6s- 1
5)查看函数调用栈
命令: kb- 1
2.进程不退出并且不占用CPU时跟进方法
1)开启windbg,attach到对应的进程上
2)加载目标程序PDB和系统PDB:srv*DownstreamStore*http://msdl.microsoft.com/download/symbols
3)切换至0号主线程
命令: ~0s- 1
4)查看主线程的函数调用栈
命令: kb- 1
正常的调用栈一般是:
5)如果该线程拥有锁,使用!cs查看锁的拥有者命令: !cs [内存地址]- 1
以上命令会显示哪个线程拥有锁owner thread id = 0xXXXX
6)切换至拥有锁的线程命令: ~Xs X代表线程序号- 1
7)查看函数调用栈
命令: kb- 1
3.进程发生崩溃跟进方法
1)开启windbg,打开对应的dump文件
2)加载目标程序PDB和系统PDB:srv*DownstreamStore*http://msdl.microsoft.com/download/symbols
3)查看异常分析
命令: !analyze -v- 1
4)切换至崩溃现场
命令: .ecxr- 1
5)查看崩溃调用栈
命令: kb- 1
当不确定exe或者dll版本时,可以使用lm命令查看详细信息:
查看dll的版本号Lm vm xxx xxx代表dll或者exe的名称
当不确定线程崩溃或假死时,可以使用~*kb查看所有线程的函数调用栈,然后逐个分析可能崩溃或假死的线程。
查看全部线程信息~*kb
-
【测试工具】一个将Unix时间转换为通用时间的工具
2015-04-27 20:46:24
一个将Unix时间转换为通用时间的工具
演示效果:
点击转换之后变为:源代码:
function calctime2(){ var time = window.document.getElementById("inpTime").value; if ( time == "" ) { alert("时间为空,请重新输入"); return; } if ( isDigit(time) == false ) { alert("时间只能由数字组成"); return; } document.write( millisecondsStrToDate( time * 1000 )); } function isDigit(s) { var patrn=/^[0-9]{1,20}$/; if (!patrn.exec(s)) return false return true } function millisecondsStrToDate(str){ var startyear = 1970; var startmonth = 1; var startday = 1; var d , s; var sep = ":"; d = new Date(); d.setFullYear( startyear , startmonth , startday ); d.setTime(0); d.setMilliseconds(str); s = d.getYear() + "-" + (d.getMonth() + 1) + "-" + d.getDate() + " " + d.getHours() + ":" + d.getMinutes() + ":" + d.getSeconds(); //alert( d.toLocaleString()); return d.toLocaleString(); } -
快速修改win7等系统的hosts文件
2015-04-27 20:45:51
大家日常工作中经常要修改系统的hosts文件,
一般操作步骤如下:
第一步:打开C:\Windows\System32\drivers\etc目录
第二步:直接编辑hosts文件,修改内容后直接保存。
但是vista以上系统由于引入了UAC的机制,所以修改hosts文件时非常麻烦,例如:
第一步:打开C:\Windows\System32\drivers\etc目录
第二步:将hosts文件拷贝至桌面
第三步:修改桌面上的hosts文件为我们期望的内容
第四步:拷贝桌面上的hosts文件到系统原文件路径下替换原文件
现在share两种快捷的方法:
第一种:
1.在桌面上建立批处理文件,可以随便起名,例如hosts.bat,将hosts.bat的内容编辑如下:
notepad C:\Windows\System32\drivers\etc\hosts2.右键桌面上的hosts.bat,选择以管理员方式运行即可。
第二种:
1.以管理员方式启动cmd
2.在cmd中进入host的目录,即cd C:\Windows\System32\drivers\etc\
3.使用cacls命令去掉hosts的保护属性,即
cacls hosts /P Deadwalk-PC:Fnote:其中Deadwalk-PC是你当前登录的账户名称,使用以上命令是将hosts文件的属性改为Deadwalk-PC拥有F(完全控制)权限。
cacls详细用法请见help:
CACLS filename [/T] [/M] [/L] [/S[:SDDL]] [/E] [/C] [/G user:perm]
[/R user […]] [/P user:perm […]] [/D user […]]
filename 显示 ACL。
/T 更改当前目录及其所有子目录中
指定文件的 ACL。
/L 对照目标处理符号链接本身
/M 更改装载到目录的卷的 ACL
/S 显示 DACL 的 SDDL 字符串。
/S:SDDL 使用在 SDDL 字符串中指定的 ACL 替换 ACL。
(/E、/G、/R、/P 或 /D 无效)。
/E 编辑 ACL 而不替换。
/C 在出现拒绝访问错误时继续。
/G user:perm 赋予指定用户访问权限。
Perm 可以是: R 读取
W 写入
C 更改(写入)
F 完全控制
/R user 撤销指定用户的访问权限(仅在与 /E 一起使用时合法)。
/P user:perm 替换指定用户的访问权限。
Perm 可以是: N 无
R 读取
W 写入
C 更改(写入)
F 完全控制
/D user 拒绝指定用户的访问。 在命令中可以使用通配符指定多个文件。 也可以在命令中指定多个用户。缩写:
CI - 容器继承。
ACE 会由目录继承。
OI - 对象继承。
ACE 会由文件继承。
IO - 只继承。
ACE 不适用于当前文件/目录。
ID - 已继承。
ACE 从父目录的 ACL 继承。 -
【测试工具】Linux下查看指定进程的内存总和
2015-04-27 20:45:11
-
小明的故事(一) -- Json导致的事故总结
2015-04-27 20:44:16
人物简介:
小明,男,25岁,一个普通的不能再普通的大学毕业生,刚刚参加工作两年,在某互联网公司担任测试工程师一职。与其他刚毕业的同学一样,爱好看电影、听音乐、爬山……还有倒腾电子数码产品。人生格言是:”我不敢肯定,但是我和胜利有个约定”,目前最大的愿望是:挥洒青春,扎根北京。
大熊,男,32岁,资深测试工程师,在某互联网公司从事测试工作长达8年之久,是小明的Leader。为人严肃认真,平时上班总是板着脸,同事从未见他笑过。爱好不详、婚姻状况不详,因为体重180斤再加上脸比较黑,所以人送外号”大熊”。
今天的故事是这样的….
大熊:小明,今天有个测试任务你测一下。 小明:什么任务? 大熊:浏览器搜索栏推荐列表的测试任务。功能需求:当用户鼠标点击搜索栏时,搜索栏会向搜索服务器请求最热门搜索词,服务器返回内容后,浏览器将内容以下拉列表的方式展示出来。
三天后,该功能测试完毕上线了……
大熊:小明,你给我过来!(四川话口音) 小明:老大,什么事? 大熊:刚接到反馈,线上用户只要打开搜索栏就会主进程崩溃,你是怎么测的! 小明:我那天测的时候没有这个问题啊。 大熊:你当时都测试了哪些用例? 小明:不就是点击搜索栏能够弹出下拉列表嘛,另外还测试了:返回条目的个数;
点击下拉列表内容能够跳转到对应搜索结果;
切换别的搜索引擎不会有下拉列表;
服务器返回的内容是中文、英文、数字的时候,下拉列表内容也是对应的内容。
服务器返回的数据超长的情况。
大熊:服务器返回的数据格式是什么?有没有测试格式异常? 小明:服务器返回的数据格式是json格式,没有测试格式异常。格式异常这种情况测它有意义吗?怎么可能会出现返回的数据异常啊,这个服务器都是我们公司自己的服务器。
大熊什么话都没说,让小明先去查明崩溃原因。
不久之后,小明了解到了崩溃原因,原来是:
正常情况下:
出现问题时:因为搜索服务器出现了异常,返回给浏览器的数据格式不是json,而是一段html,而浏览器仍然当做json去解析,所以发生了异常崩溃了。
小明:老大,我知道错了,Json格式异常也需要测。大熊强忍胸中的怒火,在电脑上打开了一份文件,那是一份很长的事故列表,其中的内容是这样写的:
2013年10月,一款叫做桌面助手程序在获取天气预报数据时,由于服务器返回的json格式数据异常,导致桌面助手频繁崩溃。该问题造成了比较大的影响,Leader被罚1000元,测试团队上下做了深刻的反省和总结。
2012年3月,浏览器升级程序在下载一个升级策略.dll文件时
,该文件在传输过程中被江西运营商加入了一段html的广告,导致升级程序加载.dll文件时异常,造成江西一带用户无法升级。2009年5月,一款叫做音乐盒的程序在下载mp3文件时,用户环境因为拔掉网线断网,导致音乐盒崩溃。
……..看到这份列表,小明半天没有说出话来。
大熊问到:你从这件事得到了什么总结?小明思考片刻,理了理头绪,娓娓道来:
测试客户端时,要考虑服务器出现异常情况时,不会对客户端造成影响,例如服务器502挂掉了。
测试功能时要了解到网络传输过程中的数据格式,除了使用等价类、边界值考虑常见的中英文数字等数据之外,还要对数据格式异常进行测试,例如:json数据缺少{;xml数据缺少<等情况
接第2点,还要考虑返回的数据为空。
测试功能时还要考虑到网络传输过程中的异常情况,如断网、直接拔网线等。
后来,该事故的处罚结果为:大熊作为Leader连带罚款1000元,小明季度奖金取消。
年轻的小明还在路上…..
本文中部分内容为虚构,如有雷同,纯属巧合。
-
小明的故事(一) -- Json导致的事故总结
2015-04-27 20:43:04
人物简介:
小明,男,25岁,一个普通的不能再普通的大学毕业生,刚刚参加工作两年,在某互联网公司担任测试工程师一职。与其他刚毕业的同学一样,爱好看电影、听音乐、爬山……还有倒腾电子数码产品。人生格言是:”我不敢肯定,但是我和胜利有个约定”,目前最大的愿望是:挥洒青春,扎根北京。
大熊,男,32岁,资深测试工程师,在某互联网公司从事测试工作长达8年之久,是小明的Leader。为人严肃认真,平时上班总是板着脸,同事从未见他笑过。爱好不详、婚姻状况不详,因为体重180斤再加上脸比较黑,所以人送外号”大熊”。
今天的故事是这样的….
大熊:小明,今天有个测试任务你测一下。 小明:什么任务? 大熊:浏览器搜索栏推荐列表的测试任务。功能需求:当用户鼠标点击搜索栏时,搜索栏会向搜索服务器请求最热门搜索词,服务器返回内容后,浏览器将内容以下拉列表的方式展示出来。
三天后,该功能测试完毕上线了……
大熊:小明,你给我过来!(四川话口音) 小明:老大,什么事? 大熊:刚接到反馈,线上用户只要打开搜索栏就会主进程崩溃,你是怎么测的! 小明:我那天测的时候没有这个问题啊。 大熊:你当时都测试了哪些用例? 小明:不就是点击搜索栏能够弹出下拉列表嘛,另外还测试了:返回条目的个数;
点击下拉列表内容能够跳转到对应搜索结果;
切换别的搜索引擎不会有下拉列表;
服务器返回的内容是中文、英文、数字的时候,下拉列表内容也是对应的内容。
服务器返回的数据超长的情况。
大熊:服务器返回的数据格式是什么?有没有测试格式异常? 小明:服务器返回的数据格式是json格式,没有测试格式异常。格式异常这种情况测它有意义吗?怎么可能会出现返回的数据异常啊,这个服务器都是我们公司自己的服务器。
大熊什么话都没说,让小明先去查明崩溃原因。
不久之后,小明了解到了崩溃原因,原来是:
正常情况下:
出现问题时:因为搜索服务器出现了异常,返回给浏览器的数据格式不是json,而是一段html,而浏览器仍然当做json去解析,所以发生了异常崩溃了。
小明:老大,我知道错了,Json格式异常也需要测。大熊强忍胸中的怒火,在电脑上打开了一份文件,那是一份很长的事故列表,其中的内容是这样写的:
2013年10月,一款叫做桌面助手程序在获取天气预报数据时,由于服务器返回的json格式数据异常,导致桌面助手频繁崩溃。该问题造成了比较大的影响,Leader被罚1000元,测试团队上下做了深刻的反省和总结。
2012年3月,浏览器升级程序在下载一个升级策略.dll文件时
,该文件在传输过程中被江西运营商加入了一段html的广告,导致升级程序加载.dll文件时异常,造成江西一带用户无法升级。2009年5月,一款叫做音乐盒的程序在下载mp3文件时,用户环境因为拔掉网线断网,导致音乐盒崩溃。
……..看到这份列表,小明半天没有说出话来。
大熊问到:你从这件事得到了什么总结?小明思考片刻,理了理头绪,娓娓道来:
测试客户端时,要考虑服务器出现异常情况时,不会对客户端造成影响,例如服务器502挂掉了。
测试功能时要了解到网络传输过程中的数据格式,除了使用等价类、边界值考虑常见的中英文数字等数据之外,还要对数据格式异常进行测试,例如:json数据缺少{;xml数据缺少<等情况
接第2点,还要考虑返回的数据为空。
测试功能时还要考虑到网络传输过程中的异常情况,如断网、直接拔网线等。
后来,该事故的处罚结果为:大熊作为Leader连带罚款1000元,小明季度奖金取消。
年轻的小明还在路上…..
本文中部分内容为虚构,如有雷同,纯属巧合。
-
_tcscat在Debug和Release下的问题
2015-04-27 20:39:50
背景:
有如下这么一段代码,作用是获取当前程序的所在路径(C:\work\A.exe),然后将”A.exe”去掉,拼装为”C:\work\inject.dll”TCHAR szDllPath[MAX_PATH] = _T(""); TCHAR szExePath[MAX_PATH] = _T(""); GetModuleFileName(GetModuleHandle(NULL), szExePath, MAX_PATH); int nIndex = 0; int i = lstrlen(szExePath); while (i > 0) { if (szExePath[i] == _T('\\')) { nIndex = i; break; } i--; } for (i = 0; i < nIndex + 1; i++ ) { szDllPath[i] = szExePath[i]; } _tcscat(szDllPath, _T("InjectDll.dll"));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
问题:
1.Debug模式下运行,得到的结果是预期的"C:\\work\\inject.dll"。 2.Release模式下运行,得到的结果却是"C:\\work\\",也就是_tcscat函数运行不成功。结论:
1.发现使用_tcscat可能存在风险问题,换用_tcscat_s就OK了。 2.自从vc2005开始,微软力推_s安全版函数以取代不安全的标准非_s版函数,例如:strcat_s、strcopy_s、sprintf_s、_tcsnset_s、_tcsset_s、_tcstok_s...等等 3.代码静态走查是可以关注字符串运算是否使用了_s安全版函数。 -
[论坛] AQTIME整理资料
2008-07-21 23:45:06
发个AQTIME的资料,自己参照英文帮助整理的,内有AQTIME的基本使用步骤以及常用的配置方法,并且有大量实例说明。
 AQTIME资料整理.doc
AQTIME资料整理.doc
(2008-07-21 23:42:39, Size: 1.48 MB, Downloads: 0) -
[转载]Linux必学的60个命令
2008-06-05 16:58:11
inux必学的60个命令
Linux提供了大量的命令,利用它可以有效地完成大量的工
作,如磁盘操作、文件存取、目录操作、进程管理、文件权限设定等。所以,在Linux系统上工作离不开使用系统提供的命令。要想真正理解Linux系统,
就必须从Linux命令学起,通过基础的命令学习可以进一步理解Linux系统。
不同Linux发行版的命令数量不一样,但Linux发行版本最少的命令也有200多个。这里笔者把比较重要和使用频率最多的命令,按照它们在系统中的作用分成下面六个部分一一介绍。
◆ 安装和登录命令:login、shutdown、halt、reboot、install、mount、umount、chsh、exit、last;
◆ 文件处理命令:file、mkdir、grep、dd、find、mv、ls、diff、cat、ln;
◆ 系统管理相关命令:df、top、free、quota、at、lp、adduser、groupadd、kill、crontab;
◆ 网络操作命令:ifconfig、ip、ping、netstat、telnet、ftp、route、rlogin、rcp、finger、mail、 nslookup;
◆ 系统安全相关命令:passwd、su、umask、chgrp、chmod、chown、chattr、sudo ps、who;
◆ 其它命令:tar、unzip、gunzip、unarj、mtools、man、unendcode、uudecode。
本文以Mandrake Linux 9.1(Kenrel 2.4.21)为例,介绍Linux下的安装和登录命令。
immortality按:请用ctrl+f在本页中查找某一部分的内容或某一命令的用法。
Linux必学的60个命令(1)-安装与登陆命令
login
1.作用
login的作用是登录系统,它的使用权限是所有用户。
2.格式
login [name][-p ][-h 主机名称]
3.主要参数
-p:通知login保持现在的环境参数。
-h:用来向远程登录的之间传输用户名。
如果选择用命令行模式登录Linux的话,那么看到的第一个Linux命令就是login:。
一般界面是这样的:
Manddrake Linux release 9.1(Bamboo) for i586
renrel 2.4.21-0.13mdk on i686 / tty1
localhost login:root
password:
上面代码中,第一行是Linux发行版本号,第二行是内核版本号和登录的虚拟控制台,我们在第三行输入登录名,按“Enter”键在Password后输入账户密码,即可登录系统。出于安全考虑,输入账户密码时字符不会在屏幕上回显,光标也不移动。
登录后会看到下面这个界面(以超级用户为例):
[root@localhost root]#
last login:Tue ,Nov 18 10:00:55 on vc/1
上面显示的是登录星期、月、日、时间和使用的虚拟控制台。
4.应用技巧
Linux
是一个真正的多用户操作系统,可以同时接受多个用户登录,还允许一个用户进行多次登录。这是因为Linux和许多版本的Unix一样,提供了虚拟控制台的
访问方式,允许用户在同一时间从控制台(系统的控制台是与系统直接相连的监视器和键盘)进行多次登录。每个虚拟控制台可以看作是一个独立的工作站,工作台
之间可以切换。虚拟控制台的切换可以通过按下Alt键和一个功能键来实现,通常使用F1-F6 。
例如,用户登录后,按一下“Alt+
F2”键,用户就可以看到上面出现的“login:”提示符,说明用户看到了第二个虚拟控制台。然后只需按“Alt+
F1”键,就可以回到第一个虚拟控制台。一个新安装的Linux系统允许用户使用“Alt+F1”到“Alt+F6”键来访问前六个虚拟控制台。虚拟控制
台最有用的是,当一个程序出错造成系统死锁时,可以切换到其它虚拟控制台工作,关闭这个程序。
shutdown
1.作用
shutdown命令的作用是关闭计算机,它的使用权限是超级用户。
2.格式
shutdown [-h][-i][-k][-m][-t]
3.重要参数
-t:在改变到其它运行级别之前,告诉init程序多久以后关机。
-k:并不真正关机,只是送警告信号给每位登录者。
-h:关机后关闭电源。
-c:cancel current process取消目前正在执行的关机程序。所以这个选项当然没有时间参数,但是可以输入一个用来解释的讯息,而这信息将会送到每位使用者。
-F:在重启计算机时强迫fsck。
-time:设定关机前的时间。
-m: 将系统改为单用户模式。
-i:关机时显示系统信息。
4.命令说明
shutdown
命令可以安全地将系统关机。有些用户会使用直接断掉电源的方式来关闭Linux系统,这是十分危险的。因为Linux与Windows不同,其后台运行着
许多进程,所以强制关机可能会导致进程的数据丢失,使系统处于不稳定的状态,甚至在有的系统中会损坏硬件设备(硬盘)。在系统关机前使用
shutdown命令,系统管理员会通知所有登录的用户系统将要关闭,并且login指令会被冻结,即新的用户不能再登录。
halt
1.作用
halt命令的作用是关闭系统,它的使用权限是超级用户。
2.格式
halt [-n] [-w] [-d] [-f] [-i] [-p]
3.主要参数说明
-n:防止sync系统调用,它用在用fsck修补根分区之后,以阻止内核用老版本的超级块覆盖修补过的超级块。
-w:并不是真正的重启或关机,只是写wtmp(/var/log/wtmp)纪录。
-f:没有调用shutdown,而强制关机或重启。
-i:关机(或重启)前,关掉所有的网络接口。
-f:强迫关机,不呼叫shutdown这个指令。
-p: 当关机的时候顺便做关闭电源的动作。
-d:关闭系统,但不留下纪录。
4.命令说明
halt
就是调用shutdown
-h。halt执行时,杀死应用进程,执行sync(将存于buffer中的资料强制写入硬盘中)系统调用,文件系统写操作完成后就会停止内核。若系统的
运行级别为0或6,则关闭系统;否则以shutdown指令(加上-h参数)来取代。
reboot
1.作用
reboot命令的作用是重新启动计算机,它的使用权限是系统管理者。
2.格式
reboot [-n] [-w] [-d] [-f] [-i]
3.主要参数
-n: 在重开机前不做将记忆体资料写回硬盘的动作。
-w: 并不会真的重开机,只是把记录写到/var/log/wtmp文件里。
-d: 不把记录写到/var/log/wtmp文件里(-n这个参数包含了-d)。
-i: 在重开机之前先把所有与网络相关的装置停止。
install
1.作用
install命令的作用是安装或升级软件或备份数据,它的使用权限是所有用户。
2.格式
(1)install [选项]... 来源 目的地
(2)install [选项]... 来源... 目录
(3)install -d [选项]... 目录...
在
前两种格式中,会将复制至或将多个文件复制至已存在的,同时设定权
限模式及所有者/所属组。在第三种格式中,会创建所有指定的目录及它们的主目录。长选项必须用的参数在使用短选项时也是必须的。
3.主要参数
--backup[=CONTROL]:为每个已存在的目的地文件进行备份。
-b:类似 --backup,但不接受任何参数。
-c:(此选项不作处理)。
-d,--directory:所有参数都作为目录处理,而且会创建指定目录的所有主目录。
-D:创建前的所有主目录,然后将复制至 ;在第一种使用格式中有用。
-g,--group=组:自行设定所属组,而不是进程目前的所属组。
-m,--mode=模式:自行设定权限模式 (像chmod),而不是rwxr-xr-x。
-o,--owner=所有者:自行设定所有者 (只适用于超级用户)。
-p,--preserve-timestamps:以文件的访问/修改时间作为相应的目的地文件的时间属性。
-s,--strip:用strip命令删除symbol table,只适用于第一及第二种使用格式。
-S,--suffix=后缀:自行指定备份文件的。
-v,--verbose:处理每个文件/目录时印出名称。
--help:显示此帮助信息并离开。
--version:显示版本信息并离开。
mount
1.作用
mount命令的作用是加载文件系统,它的用权限是超级用户或/etc/fstab中允许的使用者。
2.格式
mount -a [-fv] [-t vfstype] [-n] [-rw] [-F] device dir
3.主要参数
-h:显示辅助信息。
-v:显示信息,通常和-f用来除错。
-a:将/etc/fstab中定义的所有文件系统挂上。
-F:这个命令通常和-a一起使用,它会为每一个mount的动作产生一个行程负责执行。在系统需要挂上大量NFS文件系统时可以加快加载的速度。
-f:通常用于除错。它会使mount不执行实际挂上的动作,而是模拟整个挂上的过程,通常会和-v一起使用。
-t vfstype:显示被加载文件系统的类型。
-n:一般而言,mount挂上后会在/etc/mtab中写入一笔资料,在系统中没有可写入文件系统的情况下,可以用这个选项取消这个动作。
4.应用技巧
在Linux
和Unix系统上,所有文件都是作为一个大型树(以/为根)的一部分访问的。要访问CD-ROM上的文件,需要将CD-ROM设备挂装在文件树中的某个挂
装点。如果发行版安装了自动挂装包,那么这个步骤可自动进行。在Linux中,如果要使用硬盘、光驱等储存设备,就得先将它加载,当储存设备挂上了之后,
就可以把它当成一个目录来访问。挂上一个设备使用mount命令。在使用mount这个指令时,至少要先知道下列三种信息:要加载对象的文件系统类型、要
加载对象的设备名称及要将设备加载到哪个目录下。
(1)Linux可以识别的文件系统
◆ Windows 95/98常用的FAT 32文件系统:vfat ;
◆ Win NT/2000 的文件系统:ntfs ;
◆ OS/2用的文件系统:hpfs;
◆ Linux用的文件系统:ext2、ext3;
◆ CD-ROM光盘用的文件系统:iso9660。
虽然vfat是指FAT 32系统,但事实上它也兼容FAT 16的文件系统类型。
(2)确定设备的名称
在Linux
中,设备名称通常都存在/dev里。这些设备名称的命名都是有规则的,可以用“推理”的方式把设备名称找出来。例如,/dev/hda1这个
IDE设备,hd是Hard Disk(硬盘)的,sd是SCSI Device,fd是Floppy Device(或是Floppy
Disk?)。a代表第一个设备,通常IDE接口可以接上4个IDE设备(比如4块硬盘)。所以要识别IDE硬盘的方法分别就是hda、hdb、hdc、
hdd。hda1中的“1”代表hda的第一个硬盘分区
(partition),hda2代表hda的第二主分区,第一个逻辑分区从hda5开始,依此类推。此外,可以直接检查
/var/log/messages文件,在该文件中可以找到计算机开机后系统已辨认出来的设备代号。
(3)查找挂接点
在决
定将设备挂接之前,先要查看一下计算机是不是有个/mnt的空目录,该目录就是专门用来当作挂载点(Mount
Point)的目录。建议在/mnt里建几个/mnt/cdrom、/mnt/floppy、/mnt/mo等目录,当作目录的专用挂载点。举例而言,如
要挂载下列5个设备,其执行指令可能如下 (假设都是Linux的ext2系统,如果是Windows XX请将ext2改成vfat):
软盘 ===>mount -t ext2 /dev/fd0 /mnt/floppy
cdrom ===>mount -t iso9660 /dev/hdc /mnt/cdrom
SCSI cdrom ===>mount -t iso9660 /dev/sdb /mnt/scdrom
SCSI cdr ===>mount -t iso9660 /dev/sdc /mnt/scdr
不过目前大多数较新的Linux发行版本(包括红旗 Linux、中软Linux、Mandrake Linux等)都可以自动挂装文件系统,但Red Hat Linux除外。
umount
1.作用
umount命令的作用是卸载一个文件系统,它的使用权限是超级用户或/etc/fstab中允许的使用者。
2.格式
unmount -a [-fFnrsvw] [-t vfstype] [-n] [-rw] [-F] device dir
3.使用说明
umount
命令是mount命令的逆操作,它的参数和使用方法和mount命令是一样的。Linux挂装CD-ROM后,会锁定CD—ROM,这样就不能用CD-
ROM面板上的Eject按钮弹出它。但是,当不再需要光盘时,如果已将/cdrom作为符号链接,请使用umount/cdrom来卸装它。仅当无用户
正在使用光盘时,该命令才会成功。该命令包括了将带有当前工作目录当作该光盘中的目录的终端窗口。
chsh
1.作用
chsh命令的作用是更改使用者shell设定,它的使用权限是所有使用者。
2.格式
chsh [ -s ] [ -list] [ --help ] [ -v ] [ username ]
3.主要参数
-l:显示系统所有Shell类型。
-v:显示Shell版本号。
4.应用技巧
前面介绍了Linux下有多种Shell,一般缺省的是Bash,如果想更换Shell类型可以使用chsh命令。先输入账户密码,然后输入新Shell类型,如果操作正确系统会显示“Shell change”。其界面一般如下:
Changing fihanging shell for cao
Password:
New shell [/bin/bash]: /bin/tcsh
上面代码中,[ ]内是目前使用的Shell。普通用户只能修改自己的Shell,超级用户可以修改全体用户的Shell。要想查询系统提供哪些Shell,可以使用chsh -l 命令,见图1所示。
图1 系统可以使用的Shell类型
从图1中可以看到,笔者系统中可以使用的Shell有bash(缺省)、csh、sh、tcsh四种。
exit
1.作用
exit命令的作用是退出系统,它的使用权限是所有用户。
2.格式
exit
3.参数
exit命令没有参数,运行后退出系统进入登录界面。
last
1.作用
last命令的作用是显示近期用户或终端的登录情况,它的使用权限是所有用户。通过last命令查看该程序的log,管理员可以获知谁曾经或企图连接系统。
2.格式
1ast[—n][-f file][-t tty] [—h 节点][-I —IP][—1][-y][1D]
3.主要参数
-n:指定输出记录的条数。
-f file:指定用文件file作为查询用的log文件。
-t tty:只显示指定的虚拟控制台上登录情况。
-h 节点:只显示指定的节点上的登录情况。
-i IP:只显示指定的IP上登录的情况。
-1:用IP来显示远端地址。
-y:显示记录的年、月、日。
-ID:知道查询的用户名。
-x:显示系统关闭、用户登录和退出的历史。
动手练习
上面介绍了Linux安装和登录命令,下面介绍几个实例,动手练习一下刚才讲过的命令。
1.一次运行多个命令
在一个命令行中可以执行多个命令,用分号将各个命令隔开即可,例如:
#last -x;halt
上面代码表示在显示系统关闭、用户登录和退出的历史后关闭计算机。
2.利用mount挂装文件系统访问Windows系统
许多Linux发行版本现在都可以自动加载Vfat分区来访问Windows系统,而Red Hat各个版本都没有自动加载Vfat分区,因此还需要进行手工操作。
mount
可以将Windows分区作为Linux的一个“文件”挂接到Linux的一个空文件夹下,从而将Windows的分区和/mnt这个目录联系起来。因
此,只要访问这个文件夹就相当于访问该分区了。首先要在/mnt下建立winc文件夹,在命令提示符下输入下面命令:
#mount -t vfat /dev/hda1 /mnt/winc
即
表示将Windows的C分区挂到Liunx的/mnt/winc目录下。这时,在/mnt/winc目录下就可以看到Windows中C盘的内容了。使
用类似的方法可以访问Windows系统的D、E盘。在Linux系统显示Windows的分区一般顺序这样的:hda1为C盘、hda5为D盘、
hda6为E盘……以此类推。上述方法可以查看Windows系统有一个很大的问题,就是Windows中的所有中文文件名或文件夹名全部显示为问号
“?”,而英文却可以正常显示。我们可以通过加入一些参数让它显示中文。还以上面的操作为例,此时输入命令:
#mount -t vfat -o iocharset=cp936 /dev/hda1 /mnt/winc
现在它就可以正常显示中文了。
3.使用mount加挂闪盘上的文件系统
在Linux下使用闪盘非常简单。Linux对USB设备有很好的支持,当插入闪盘后,闪盘被识别为一个SCSI盘,通常输入以下命令:
# mount /dev/sda1 /usb
就能够加挂闪盘上的文件系统。
小知识
Linux命令与Shell
所
谓Shell,就是命令解释程序,它提供了程序设计接口,可以使用程序来编程。学习Shell对于Linux初学者理解Linux系统是非常重要的。
Linux系统的Shell作为操作系统的外壳,为用户提供了使用操作系统的接口。Shell是命令语言、命令解释程序及程序设计语言的统称,是用户和
Linux内核之间的接口程序。如果把Linux内核想象成一个球体的中心,Shell就是围绕内核的外层。当从Shell或其它程序向Linux传递命
令时,内核会做出相应的反应。Shell在Linux系统的作用和MS DOS下的COMMAND.COM和Windows 95/98 的
explorer.exe相似。Shell虽然不是系统核心的一部分,只是系统核心的一个外延,但它能够调用系统内核的大部分功能。因此,可以说
Shell是Unux/Linux最重要的实用程序。
Linux中的Shell有多种类型,其中最常用的是Bourne
Shell(sh)、C Shell(csh)和Korn Shell(ksh)。大多数Linux发行版本缺省的Shell是Bourne
Again Shell,它是Bourne Shell的扩展,简称bash,与Bourne Shell完全向后兼容,并且在Bourne
Shell的基础上增加了很多特性。bash放在/bin/bash中,可以提供如命令补全、命令编辑和命令历史表等功能。它还包含了很多C
Shell和Korn
Shell中的优点,有灵活和强大的编程接口,同时又有很友好的用户界面。Linux系统中200多个命令中有40个是bash的内部命令,主要包括
exit、less、lp、kill、 cd、pwd、fc、fg等。
Linux必学的60个命令(2)-文件处理命令
Linux
系统信息存放在文件里,文件与普通的公务文件类似。每个文件都有自己的名字、内容、存放地址及其它一些管理信息,如文件的用户、文件的大小等。文件可以是
一封信、一个通讯录,或者是程序的源语句、程序的数据,甚至可以包括可执行的程序和其它非正文内容。
Linux文件系统具有良好的结构,系统提供了很多文件处理程序。这里主要介绍常用的文件处理命令。
file
1.作用 件内容判断文件类型,使用权限是所有用户。
2.格式
file通过探测文
file [options] 文件名
3.[options]主要参数
-v:在标准输出后显示版本信息,并且退出。
-z:探测压缩过的文件类型。
-L:允许符合连接。
-f name:从文件namefile中读取要分析的文件名列表。
4.简单说明
使用file命令可以知道某个文件究竟是二进制(ELF格式)的可执行文件, 还是Shell scrīpt文件,或者是其它的什么格式。file能识别的文件类型有目录、Shell脚本、英文文本、二进制可执行文件、C语言源文件、文本文件、DOS的可执行文件。
5.应用实例
如果我们看到一个没有后缀的文件grap,可以使用下面命令:
$ file grap
grap: English text
此时系统显示这是一个英文文本文件。需要说明的是,file命令不能探测包括图形、音频、视频等多媒体文件类型。
mkdir
1.作用
mkdir命令的作用是建立名称为dirname的子目录,与MS DOS下的md命令类似,它的使用权限是所有用户。
2.格式
mkdir [options] 目录名
3.[options]主要参数
-m, --mode=模式:设定权限,与chmod类似。
-p, --parents:需要时创建上层目录;如果目录早已存在,则不当作错误。
-v, --verbose:每次创建新目录都显示信息。
--version:显示版本信息后离开。
4.应用实例
在进行目录创建时可以设置目录的权限,此时使用的参数是“-m”。假设要创建的目录名是“tsk”,让所有用户都有rwx(即读、写、执行的权限),那么可以使用以下命令:
$ mkdir -m 777 tsk
grep
1.作用
grep命令可以指定文件中搜索特定的内容,并将含有这些内容的行标准输出。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
2.格式
grep [options]
3.主要参数
[options]主要参数:
-c:只输出匹配行的计数。
-I:不区分大小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\:忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
。:所有的单个字符。
* :有字符,长度可以为0。
正
则表达式是Linux/Unix系统中非常重要的概念。正则表达式(也称为“regex”或“regexp”)是一个可以描述一类字符串的模式
(Pattern)。如果一个字符串可以用某个正则表达式来描述,我们就说这个字符和该正则表达式匹配(Match)。这和DOS中用户可以使用通配符
“*”代表任意字符类似。在Linux系统上,正则表达式通常被用来查找文本的模式,以及对文本执行“搜索-替换”操作和其它功能。
4.应用实例
查
询DNS服务是日常工作之一,这意味着要维护覆盖不同网络的大量IP地址。有时IP地址会超过2000个。如果要查看nnn.nnn网络地址,但是却忘了
第二部分中的其余部分,只知到有两个句点,例如nnn nn..。要抽取其中所有nnn.nnn IP地址,使用[0-9 ]\{3
\}\.[0-0\{3\}\。含义是任意数字出现3次,后跟句点,接着是任意数字出现3次,后跟句点。
$grep '[0-9 ]\{3 \}\.[0-0\{3\}\' ipfile
补充说明,grep家族还包括fgrep和egrep。fgrep是fix grep,允许查找字符串而不是一个模式;egrep是扩展grep,支持基本及扩展的正则表达式,但不支持\q模式范围的应用及与之相对应的一些更加规范的模式。
dd
1.作用
dd命令用来复制文件,并根据参数将数据转换和格式化。
2.格式
dd [options]
3.[opitions]主要参数
bs=字节:强迫 ibs=及obs=。
cbs=字节:每次转换指定的。
conv=关键字:根据以逗号分隔的关键字表示的方式来转换文件。
count=块数目:只复制指定的输入数据。
ibs=字节:每次读取指定的。
if=文件:读取内容,而非标准输入的数据。
obs=字节:每次写入指定的。
of=文件:将数据写入,而不在标准输出显示。
seek=块数目:先略过以obs为单位的指定的输出数据。
skip=块数目:先略过以ibs为单位的指定的输入数据。
4.应用实例
dd命令常常用来制作Linux启动盘。先找一个可引导内核,令它的根设备指向正确的根分区,然后使用dd命令将其写入软盘:
$ rdev vmlinuz /dev/hda
$dd if=vmlinuz of=/dev/fd0
上面代码说明,使用rdev命令将可引导内核vmlinuz中的根设备指向/dev/hda,请把“hda”换成自己的根分区,接下来用dd命令将该内核写入软盘。
find
1.作用
find命令的作用是在目录中搜索文件,它的使用权限是所有用户。
2.格式
find [path][options][expression]
path指定目录路径,系统从这里开始沿着目录树向下查找文件。它是一个路径列表,相互用空格分离,如果不写path,那么默认为当前目录。
3.主要参数
[options]参数:
-depth:使用深度级别的查找过程方式,在某层指定目录中优先查找文件内容。
-maxdepth levels:表示至多查找到开始目录的第level层子目录。level是一个非负数,如果level是0的话表示仅在当前目录中查找。
-mindepth levels:表示至少查找到开始目录的第level层子目录。
-mount:不在其它文件系统(如Msdos、Vfat等)的目录和文件中查找。
-version:打印版本。
[expression]是匹配表达式,是find命令接受的表达式,find命令的所有操作都是针对表达式的。它的参数非常多,这里只介绍一些常用的参数。
—name:支持统配符*和?。
-atime n:搜索在过去n天读取过的文件。
-ctime n:搜索在过去n天修改过的文件。
-group grpoupname:搜索所有组为grpoupname的文件。
-user 用户名:搜索所有文件属主为用户名(ID或名称)的文件。
-size n:搜索文件大小是n个block的文件。
-print:输出搜索结果,并且打印。
4.应用技巧
find命令查找文件的几种方法:
(1)根据文件名查找
例如,我们想要查找一个文件名是lilo.conf的文件,可以使用如下命令:
find / -name lilo.conf
find命令后的“/”表示搜索整个硬盘。
(2)快速查找文件
根
据文件名查找文件会遇到一个实际问题,就是要花费相当长的一段时间,特别是大型Linux文件系统和大容量硬盘文件放在很深的子目录中时。如果我们知道了
这个文件存放在某个目录中,那么只要在这个目录中往下寻找就能节省很多时间。比如smb.conf文件,从它的文件后缀“.conf”可以判断这是一个配
置文件,那么它应该在/etc目录内,此时可以使用下面命令:
find /etc -name smb.conf
这样,使用“快速查找文件”方式可以缩短时间。
(3)根据部分文件名查找方法
有时我们知道只某个文件包含有abvd这4个字,那么要查找系统中所有包含有这4个字符的文件可以输入下面命令:
find / -name '*abvd*'
输入这个命令以后,Linux系统会将在/目录中查找所有的包含有abvd这4个字符的文件(其中*是通配符),比如abvdrmyz等符合条件的文件都能显示出来。
(4) 使用混合查找方式查找文件
find命令可以使用混合查找的方法,例如,我们想在/etc目录中查找大于500000字节,并且在24小时内修改的某个文件,则可以使用-and (与)把两个查找参数链接起来组合成一个混合的查找方式。
find /etc -size +500000c -and -mtime +1
mv
1.作用
mv命令用来为文件或目录改名,或者将文件由一个目录移入另一个目录中,它的使用权限是所有用户。该命令如同DOS命令中的ren和move的组合。
2.格式
mv[options] 源文件或目录 目标文件或目录
3.[options]主要参数
-i:交互方式操作。如果mv操作将导致对已存在的目标文件的覆盖,此时系统询问是否重写,要求用户回答“y”或“n”,这样可以避免误覆盖文件。
-f:禁止交互操作。mv操作要覆盖某个已有的目标文件时不给任何指示,指定此参数后i参数将不再起作用。
4.应用实例
(1)将/usr/cbu中的所有文件移到当前目录(用“.”表示)中:
$ mv /usr/cbu/ * .
(2)将文件cjh.txt重命名为wjz.txt:
$ mv cjh.txt wjz.txt
ls
1.作用
ls命令用于显示目录内容,类似DOS下的dir命令,它的使用权限是所有用户。
2.格式
ls [options][filename]
3.options主要参数
-a, --all:不隐藏任何以“.” 字符开始的项目。
-A, --almost-all:列出除了“ . ”及 “.. ”以外的任何项目。
--author:印出每个文件著作者。
-b, --escape:以八进制溢出序列表示不可打印的字符。
--block-size=大小:块以指定的字节为单位。
-B, --ignore-backups:不列出任何以 ~ 字符结束的项目。
-f:不进行排序,-aU参数生效,-lst参数失效。
-F, --classify:加上文件类型的指示符号 (*/=@| 其中一个)。
-g:like -l, but do not list owner。
-G, --no-group:inhibit display of group information。
-i, --inode:列出每个文件的inode号。
-I, --ignore=样式:不印出任何符合Shell万用字符的项目。
-k:即--block-size=1K。
-l:使用较长格式列出信息。
-L, --dereference:当显示符号链接的文件信息时,显示符号链接所指示的对象,而并非符号链接本身的信息。
-m:所有项目以逗号分隔,并填满整行行宽。
-n, --numeric-uid-gid:类似-l,但列出UID及GID号。
-N, --literal:列出未经处理的项目名称,例如不特别处理控制字符。
-p, --file-type:加上文件类型的指示符号 (/=@| 其中一个)。
-Q, --quote-name:将项目名称括上双引号。
-r, --reverse:依相反次序排列。
-R, --recursive:同时列出所有子目录层。
-s, --size:以块大小为序。
4.应用举例
ls
命令是Linux系统使用频率最多的命令,它的参数也是Linux命令中最多的。使用ls命令时会有几种不同的颜色,其中蓝色表示是目录,绿色表示是可执
行文件,红色表示是压缩文件,浅蓝色表示是链接文件,加粗的黑色表示符号链接,灰色表示是其它格式文件。ls最常使用的是ls- l,见图1所示。
图1 使用ls-l命令
文
件类型开头是由10个字符构成的字符串。其中第一个字符表示文件类型,它可以是下述类型之一:-(普通文件)、d(目录)、l(符号链接)、b(块设备文
件)、c(字符设备文件)。后面的9个字符表示文件的访问权限,分为3组,每组3位。第一组表示文件属主的权限,第二组表示同组用户的权限,第三组表示其
他用户的权限。每一组的三个字符分别表示对文件的读(r)、写(w)和执行权限(x)。对于目录,表示进入权限。s表示当文件被执行时,把该文件的UID
或GID赋予执行进程的UID(用户ID)或GID(组
ID)。t表示设置标志位(留在内存,不被换出)。如果该文件是目录,那么在该目录中的文件只能被超级用户、目录拥有者或文件属主删除。如果它是可执行文
件,那么在该文件执行后,指向其正文段的指针仍留在内存。这样再次执行它时,系统就能更快地装入该文件。接着显示的是文件大小、生成时间、文件或命令名
称。
diff
1.作用
diff命令用于两个文件之间的比较,并指出两者的不同,它的使用权限是所有用户。
2.格式
diff [options] 源文件 目标文件
3.[options]主要参数
-a:将所有文件当作文本文件来处理。
-b:忽略空格造成的不同。
-B:忽略空行造成的不同。
-c:使用纲要输出格式。
-H:利用试探法加速对大文件的搜索。
-I:忽略大小写的变化。
-n --rcs:输出RCS格式。
cmp
1.作用
cmp(“compare”的缩写)命令用来简要指出两个文件是否存在差异,它的使用权限是所有用户。
2.格式
cmp[options] 文件名
3.[options]主要参数
-l: 将字节以十进制的方式输出,并方便将两个文件中不同的以八进制的方式输出。
cat
1.作用
cat(“concatenate”的缩写)命令用于连接并显示指定的一个和多个文件的有关信息,它的使用权限是所有用户。
2.格式
cat [options] 文件1 文件2……
3.[options]主要参数
-n:由第一行开始对所有输出的行数编号。
-b:和-n相似,只不过对于空白行不编号。
-s:当遇到有连续两行以上的空白行时,就代换为一行的空白行。
4.应用举例
(1)cat命令一个最简单的用处是显示文本文件的内容。例如,我们想在命令行看一下README文件的内容,可以使用命令:
$ cat README
(2)
有时需要将几个文件处理成一个文件,并将这种处理的结果保存到一个单独的输出文件。cat命令在其输入上接受一个或多个文件,并将它们作为一个单独的文件
打印到它的输出。例如,把README和INSTALL的文件内容加上行号(空白行不加)之后,将内容附加到一个新文本文件File1 中:
$ cat README INSTALL File1
(3)cat还有一个重要的功能就是可以对行进行编号,见图2所示。这种功能对于程序文档的编制,以及法律和科学文档的编制很方便,打印在左边的行号使得参考文档的某一部分变得容易,这些在编程、科学研究、业务报告甚至是立法工作中都是非常重要的。
图2 使用cat命令/etc/named.conf文件进行编号
对行进行编号功能有-b(只能对非空白行进行编号)和-n(可以对所有行进行编号)两个参数:
$ cat -b /etc/named.conf
ln
1.作用
ln命令用来在文件之间创建链接,它的使用权限是所有用户。
2.格式
ln [options] 源文件 [链接名]
3.参数
-f:链结时先将源文件删除。
-d:允许系统管理者硬链结自己的目录。
-s:进行软链结(Symbolic Link)。
-b:将在链结时会被覆盖或删除的文件进行备份。
链接有两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link)。默认情况下,ln命令产生硬链接。
硬
连接指通过索引节点来进行的连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode
Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户
就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和
其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件才会被真正删除。
与硬连接相对应,Lnux系统中还存在另一种连接,称为符号连接(Symbilc Link),也叫软连接。软链接文件有点类似于Windows的快捷方式。它实际上是特殊文件的一种。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。
动手练习
上面我们介绍了Linux文件处理命令,下面介绍几个实例,大家可以动手练习一下刚才讲过的命令。
1.利用符号链接快速访问关键目录
符
号链接是一个非常实用的功能。假设有一些目录或文件需要频繁使用,但由于Linux的文件和目录结构等原因,这个文件或目录在很深的子目录中。比如,
Apache
Web服务器文档位于系统的/usr/local/httpd/htdocs中,并且不想每次都要从主目录进入这样一个长的路径之中(实际上,这个路径也
非常不容易记忆)。
为了解决这个问题,可以在主目录中创建一个符号链接,这样在需要进入该目录时,只需进入这个链接即可。
为了能方便地进入Web服务器(/usr/local/httpd/htdocs)文档所在的目录,在主目录下可以使用以下命令:
$ ln -s /usr/local/httpd/htdocs gg
这样每次进入gg目录就可访问Web服务器的文档,以后如果不再访问Web服务器的文档时,删除gg即可,而真正的Web服务器的文档并没有删除。
2.使用dd命令将init.rd格式的root.ram内容导入内存
dd if=/dev/fd0 ōf=floppy.fd
dd if=root.ram ōf=/dev/ram0 #
3.grep命令系统调用
grep是Linux/Unix中使用最广泛的命令之一,许多Linux系统内部都可以调用它。
(1)如果要查询目录列表中的目录,方法如下:
$ ls -l | grep '∧d'
(2)如果在一个目录中查询不包含目录的所有文件,方法如下:
$ ls -l | grep '∧[∧d]'
(3)用find命令调用grep,如所有C源代码中的“Chinput”,方法如下:
$find /ZhXwin -name *.c -exec grep -q -s Chinput {} \;-print
Linux必学的60个命令(3)-系统管理命令
Linux必学的系统管理命令
对于Linux系统来说,无论是中央处理器、内存、磁盘驱动器、键盘、鼠标,还是用户等都是文件,Linux系统管理的命令是它正常运行的核心。熟悉了Linux常用的文件处理命令以后,这一讲介绍对系统和用户进行管理的命令。
df
1.作用
df命令用来检查文件系统的磁盘空间占用情况,使用权限是所有用户。
2.格式
df [options]
3.主要参数
-s:对每个Names参数只给出占用的数据块总数。
-a:递归地显示指定目录中各文件及子目录中各文件占用的数据块数。若既不指定-s,也不指定-a,则只显示Names中的每一个目录及其中的各子目录所占的磁盘块数。
-k:以1024字节为单位列出磁盘空间使用情况。
-x:跳过在不同文件系统上的目录不予统计。
-l:计算所有的文件大小,对硬链接文件则计算多次。
-i:显示inode信息而非块使用量。
-h:以容易理解的格式印出文件系统大小,例如136KB、254MB、21GB。
-P:使用POSIX输出格式。
-T:显示文件系统类型。
4.说明
df命令被广泛地用来生成文件系统的使用统计数据,它能显示系统中所有的文件系统的信息,包括总容量、可用的空闲空间、目前的安装点等。
超
级权限用户使用df命令时会发现这样的情况:某个分区的容量超过了100%。这是因为Linux系统为超级用户保留了10%的空间,由其单独支配。也就是
说,对于超级用户而言,他所见到的硬盘容量将是110%。这样的安排对于系统管理而言是有好处的,当硬盘被使用的容量接近100%时系统管理员还可以正常
工作。
5.应用实例
Linux支持的文件系统非常多,包括JFS、ReiserFS、ext、ext2、ext3、ISO9660、XFS、Minx、vfat、MSDOS等。使用df -T命令查看磁盘空间时还可以得到文件系统的信息:
#df -T
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/hda7 reiserfs 5.2G 1.6G 3.7G 30% /
/dev/hda1 vfat 2.4G 1.6G 827M 66% /windows/C
/dev/hda5 vfat 3.0G 1.7G 1.3G 57% /windows/D
/dev/hda9 vfat 3.0G 2.4G 566M 82% /windows/E
/dev/hda10 NTFS 3.2G 573M 2.6G 18% /windows/F
/dev/hda11 vfat 1.6G 1.5G 23M 99% /windows/G
从上面除了可以看到磁盘空间的容量、使用情况外,分区的文件系统类型、挂载点等信息也一览无遗。
top
1.作用
top命令用来显示执行中的程序进程,使用权限是所有用户。
2.格式
top [-] [d delay] [q] [c] [S] [s] [n]
3.主要参数
d:指定更新的间隔,以秒计算。
q:没有任何延迟的更新。如果使用者有超级用户,则top命令将会以最高的优先序执行。
c:显示进程完整的路径与名称。
S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
s:安全模式。
i:不显示任何闲置(Idle)或无用(Zombie)的行程。
n:显示更新的次数,完成后将会退出top。
4.说明
top命令是Linux系统管理的一个主要命令,通过它可以获得许多信息。这里我们结合图1来说明它给出的信息。
图1 top命令的显示
在
图1中,第一行表示的项目依次为当前时间、系统启动时间、当前系统登录用户数目、平均负载。第二行显示的是所有启动的进程、目前运行的、挂起
(Sleeping)的和无用(Zombie)的进程。第三行显示的是目前CPU的使用情况,包括系统占用的比例、用户使用比例、闲置(Idle)比例。
第四行显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。第五行显示交换分区使用情况,包括总的交换分区、使用
的、空闲的和用于高速缓存的大小。第六行显示的项目最多,下面列出了详细解释。
PID(Process ID):进程标示号。
USER:进程所有者的用户名。
PR:进程的优先级别。
NI:进程的优先级别数值。
VIRT:进程占用的虚拟内存值。
RES:进程占用的物理内存值。
SHR:进程使用的共享内存值。
S:进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值是负数。
%CPU:该进程占用的CPU使用率。
%MEM:该进程占用的物理内存和总内存的百分比。
TIME+:该进程启动后占用的总的CPU时间。
Command:进程启动的启动命令名称,如果这一行显示不下,进程会有一个完整的命令行。
top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。这些命令是通过快捷键启动的。
:立刻刷新。
P:根据CPU使用大小进行排序。
T:根据时间、累计时间排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
可以看到,top命令是一个功能十分强大的监控系统的工具,对于系统管理员而言尤其重要。但是,它的缺点是会消耗很多系统资源。
5.应用实例
使用top命令可以监视指定用户,缺省情况是监视所有用户的进程。如果想查看指定用户的情况,在终端中按“U”键,然后输入用户名,系统就会切换为指定用户的进程运行界面,见图2所示。
图2 使用top命令监视指定用户
free
1.作用
free命令用来显示内存的使用情况,使用权限是所有用户。
2.格式
free [-b|-k|-m] [-o] [-s delay] [-t] [-V]
3.主要参数
-b -k -m:分别以字节(KB、MB)为单位显示内存使用情况。
-s delay:显示每隔多少秒数来显示一次内存使用情况。
-t:显示内存总和列。
-o:不显示缓冲区调节列。
4.应用实例
free命令是用来查看内存使用情况的主要命令。和top命令相比,它的优点是使用简单,并且只占用很少的系统资源。通过-S参数可以使用free命令不间断地监视有多少内存在使用,这样可以把它当作一个方便实时监控器。
#free -b -s5
使用这个命令后终端会连续不断地报告内存使用情况(以字节为单位),每5秒更新一次。
quota
1.作用
quota命令用来显示磁盘使用情况和限制情况,使用权限超级用户。
2.格式
quota [-g][-u][-v][-p] 用户名 组名
3.参数
-g:显示用户所在组的磁盘使用限制。
-u:显示用户的磁盘使用限制。
-v:显示没有分配空间的文件系统的分配情况。
-p:显示简化信息。
4.应用实例
在企业应用中磁盘配额非常重要,普通用户要学会看懂自己的磁盘使用情况。要查询自己的磁盘配额可以使用下面命令(下例中用户账号是caojh):
#quota caojh
Disk quotas for user caojh(uid 502):
Filesystem blocks quota limit grace files quota limit grace
/dev/hda3 58 200000 400000 41 500 1000
以上显示ID号为502的caojh账号,文件个数设置为500~1000个,硬盘空间限制设置为200MB~400MB。一旦磁盘配额要用完时,就需要删除一些垃圾文件或向系统管理员请求追加配额。
at
1.作用
at命令用来在指定时刻执行指定的命令序列。
2.格式
at [-V] [-q x] [-f file] [-m] time
3.主要参数
-V:显示标准错误输出。
-q:许多队列输出。
-f:从文件中读取作业。
-m:执行完作业后发送电子邮件到用户。
time:设定作业执行的时间。time格式有严格的要求,由小时、分钟、日期和时间的偏移量组成,其中日期的格式为MM.DD.YY,MM是分钟,DD是日期,YY是指年份。偏移量的格式为时间+偏移量,单位是minutes、hours和days。
4.应用实例
#at -f data 15:30 +2 days
上面命令表示让系统在两天后的17:30执行文件data中指明的作业。
lp
1.作用
lp是打印文件的命令,使用权限是所有用户。
2.格式
lp [-c][-d][-m][-number][-title][-p]
3.主要参数
-c:先拷贝文件再打印。
-d:打印队列文件。
-m:打印结束后发送电子邮件到用户。
-number:打印份数。
-title:打印标题。
-p:设定打印的优先级别,最高为100。
4.应用实例
(1)使用lp命令打印多个文件
#lp 2 3 4
request id is 11 (3 file(s))
其中2、3、4分别是文件名;“request id is 11 (3 file(s)) ”表示这是第11个打印命令,依次打印这三个文件。
(2)设定打印优先级别
#lp lp -d LaserJet -p 90 /etc/aliases
通过添加“-p 90”,规定了打印作业的优先级为90。它将在优先级低于90的打印作业之前打印,包括没有设置优先级的作业,缺省优先级是50
useradd
1.作用
useradd命令用来建立用户帐号和创建用户的起始目录,使用权限是超级用户。
2.格式
useradd [-d home] [-s shell] [-c comment] [-m [-k template]] [-f inactive] [-e expire ] [-p passwd] [-r] name
3.主要参数
-c:加上备注文字,备注文字保存在passwd的备注栏中。
-d:指定用户登入时的启始目录。
-D:变更预设值。
-e:指定账号的有效期限,缺省表示永久有效。
-f:指定在密码过期后多少天即关闭该账号。
-g:指定用户所属的群组。
-G:指定用户所属的附加群组。
-m:自动建立用户的登入目录。
-M:不要自动建立用户的登入目录。
-n:取消建立以用户名称为名的群组。
-r:建立系统账号。
-s:指定用户登入后所使用的shell。
-u:指定用户ID号。
4.说明
useradd可用来建立用户账号,它和adduser命令是相同的。账号建好之后,再用passwd设定账号的密码。使用useradd命令所建立的账号,实际上是保存在/etc/passwd文本文件中。
5.应用实例
建立一个新用户账户,并设置ID:
#useradd caojh -u 544
需要说明的是,设定ID值时尽量要大于500,以免冲突。因为Linux安装后会建立一些特殊用户,一般0到499之间的值留给bin、mail这样的系统账号。
groupadd
1.作用
groupadd命令用于将新组加入系统。
2.格式
groupadd [-g gid] [-o]] [-r] [-f] groupname
3.主要参数
-g gid:指定组ID号。
-o:允许组ID号,不必惟一。
-r:加入组ID号,低于499系统账号。
-f:加入已经有的组时,发展程序退出。
4.应用实例
建立一个新组,并设置组ID加入系统:
#groupadd -g 344 cjh
此时在/etc/passwd文件中产生一个组ID(GID)是344的项目。
kill
1.作用
kill命令用来中止一个进程。
2.格式
kill [ -s signal | -p ] [ -a ] pid ...
kill -l [ signal ]
3.参数
-s:指定发送的信号。
-p:模拟发送信号。
-l:指定信号的名称列表。
pid:要中止进程的ID号。
Signal:表示信号。
4.说明
进程是Linux系统中一个非常重要的概念。Linux是一个多任务的操作系统,系统上经常同时运行着多个进程。我们不关心这些进程究竟是如何分配的,或者是内核如何管理分配时间片的,所关心的是如何去控制这些进程,让它们能够很好地为用户服务。
Linux
操作系统包括三种不同类型的进程,每种进程都有自己的特点和属性。交互进程是由一个Shell启动的进程。交互进程既可以在前台运行,也可以在后台运行。
批处理进程和终端没有联系,是一个进程序列。监控进程(也称系统守护进程)时Linux系统启动时启动的进程,并在后台运行。例如,httpd是著名的
Apache服务器的监控进程。
kill命令的工作原理是,向Linux系统的内核发送一个系统操作信号
和某个程序的进程标识号,然后系统内核就可以对进程标识号指定的进程进行操作。比如在top命令中,我们看到系统运行许多进程,有时就需要使用kill中
止某些进程来提高系统资源。在讲解安装和登陆命令时,曾提到系统多个虚拟控制台的作用是当一个程序出错造成系统死锁时,可以切换到其它虚拟控制台工作关闭
这个程序。此时使用的命令就是kill,因为kill是大多数Shell内部命令可以直接调用的。
5.应用实例
(1)强行中止(经常使用杀掉)一个进程标识号为324的进程:
#kill -9 324
(2)解除Linux系统的死锁
在Linux
中有时会发生这样一种情况:一个程序崩溃,并且处于死锁的状态。此时一般不用重新启动计算机,只需要中止(或者说是关闭)这个有问题的程序即可。当
kill处于X-Window界面时,主要的程序(除了崩溃的程序之外)一般都已经正常启动了。此时打开一个终端,在那里中止有问题的程序。比如,如果
Mozilla浏览器程序出现了锁死的情况,可以使用kill命令来中止所有包含有Mozolla浏览器的程序。首先用top命令查处该程序的PID,然
后使用kill命令停止这个程序:
#kill -SIGKILL XXX
其中,XXX是包含有Mozolla浏览器的程序的进程标识号。
(3)使用命令回收内存
我们知道内存对于系统是非常重要的,回收内存可以提高系统资源。kill命令可以及时地中止一些“越轨”的程序或很长时间没有相应的程序。例如,使用top命令发现一个无用 (Zombie) 的进程,此时可以使用下面命令:
#kill -9 XXX
其中,XXX是无用的进程标识号。
然后使用下面命令:
#free
此时会发现可用内存容量增加了。
(4)killall命令
Linux下还提供了一个killall命令,可以直接使用进程的名字而不是进程标识号,例如:
# killall -HUP inetd
crontab
1.作用
使用crontab命令可以修改crontab配置文件,然后该配置由cron公用程序在适当的时间执行,该命令使用权限是所有用户。
2.格式
crontab [ -u user ] 文件
crontab [ -u user ] { -l | -r | -e }
3.主要参数
-e:执行文字编辑器来设定时程表,内定的文字编辑器是vi。
-r:删除目前的时程表。
-l:列出目前的时程表。
crontab
文件的格式为“M H D m d
cmd”。其中,M代表分钟(0~59),H代表小时(0~23),D代表天(1~31),m代表月(1~12),d代表一星期内的天(0~6,0为星期
天)。cmd表示要运行的程序,它被送入sh执行,这个Shell只有USER、HOME、SHELL三个环境变量。
4.说明
和at命令相比,crontab命令适合完成固定周期的任务。
5.应用实例
设置一个定时、定期的系统提示:
[cao @www cao]#crontab -e
此时系统会打开一个vi编辑器。
如果输入以下内容:35 17 * * 5 wall "Tomorrow is Saturday I will go CS",然后存盘退出。这时在/var/spool/cron/目录下会生产一个cao的文件,内容如下:
# DO NOT EDIT THIS FILE - edit the master and reinstall.
# (/tmp/crontab.2707 installed on Thu Jan 1 22:01:51 2004)
# (Cron version -- $Id: crontab.c,v 2.13 1994/01/17 03:20:37 vixie Exp $)
35 17 * * 5 wall "Tomorrow is Saturday I will play CS "
这样每个星期五17:35系统就会弹出一个终端,提醒星期六可以打打CS了!显示结果见图3所示。
图3 一个定时、定期的系统提示
动手练习
1.联合使用kill和top命令观察系统性能的变化
首先启动一个终端运行top命令,然后再启动一个终端使用kill命令,见图4所示。
图4 观察kill命令对top终端的影响
这时利用上面介绍的kill命令来中止一些程序:
#kill SIGKILL XXX
然后再看top命令终端的变化,包括内存容量、CPU使用率、系统负载等。注意,有些进程是不能中止的,不过学习Linux命令时可以试试,看看系统有什么反应。
2.使用at和halt命令定时关机
首先设定关机时间是17:35,输入下面代码:
#at 17:35
warning: commands will be executed using (in order) a) $SHELL b) login shell c) /bin/sh
at>halt `-i -p
at>
job 6 at 2004-01-01 17:35
此
时实际上就已经进入Linux系统的Shell,并且编写一个最简单程序:halt -i
-p。上面Shell中的文本结束符号表示按“Ctrl+D”组合键关闭命令,提交任务退出Shell。“Job 6 at 2004-01-01
17:35”表示系统接受第6个at命令,在“2004-01-01 17:35”时执行命令:先把所有网络相关的装置停止,关闭系统后关闭电源。
3.用crontab命令实现每天定时的病毒扫描
前面已经介绍了一个简单的crontab命令操作,这里看一些更重要的操作。
(1)建立一个文件,文件名称自己设定,假设为caoproject:
#crontab -e
(2)文件内容如下:
05 09 * * * antivir
用vi编辑后存盘退出。antivir是一个查杀Linux病毒的软件,当然需要时先安装在系统中。
(3)使用crontab命令添加到任务列表中:
#crontab caoproject
这样系统内所有用户在每天的9点05分会自动进行病毒扫描。
4.用kill使修改的配置文件马上生效
Windows用户一般都知道,重要配置文件修改后往往都要重新启动计算机才能使修改生效。而Linux由于采用了模块化设计,可以自己根据需要实时设定服务。这里以网络服务inetd为例介绍一些操作技巧。
inetd
是一个监听守护进程,监听与提供互联网服务进程(如rlogin、telnet、ftp、rsh)进行连接的要求,并扩展所需的服务进程。默认情况下,
inetd监听的这些daemon均列于/etc
/inetd.conf文件中。编辑/etc/inetd.conf文件,可以改变inetd启动服务器守护进程的选项,然后驱使inetd以
SIGHUP(signal 1)向当前的inetd进程发送信号,使inetd重读该文件。这一过程由kill命令来实现。
用vi或其它编辑器修改inetd.conf后,首先使用下面命令:
#ps -ef |grep inetd
上面代码表明查询inetd.conf的进程号(PID),这里假设是1426,然后使用下面命令:
# kill -1426 inetd
这样配置文件就生效了。
这一讲介绍的系统管理命令都是比较重要的,特别是crontab命令和quota命令使用起来会有一定难度,需要多做一些练习。另外,使用kill命令要注意“-9“这个参数,练习时最好不要运行一些重要的程序。
Linux必学的60个命令(4)-网络操作命令Linux必学的60个命令:网络操作命令
因
为Linux系统是在Internet上起源和发展的,它与生俱来拥有强大的网络功能和丰富的网络应用软件,尤其是TCP/IP网络协议的实现尤为成熟。
Linux的网络命令比较多,其中一些命令像ping、
ftp、telnet、route、netstat等在其它操作系统上也能看到,但也有一些Unix/Linux系统独有的命令,如ifconfig、
finger、mail等。Linux网络操作命令的一个特点是,命令参数选项和功能很多,一个命令往往还可以实现其它命令的功能。
ifconfig
1.作用
ifconfig用于查看和更改网络接口的地址和参数,包括IP地址、网络掩码、广播地址,使用权限是超级用户。
2.格式
ifconfig -interface [options] address
3.主要参数
-interface:指定的网络接口名,如eth0和eth1。
up:激活指定的网络接口卡。
down:关闭指定的网络接口。
broadcast address:设置接口的广播地址。
pointopoint:启用点对点方式。
address:设置指定接口设备的IP地址。
netmask address:设置接口的子网掩码。
4.应用说明
ifconfig是用来设置和配置网卡的命令行工具。为了手工配置网络,这是一个必须掌握的命令。使用该命令的好处是无须重新启动机器。要赋给eth0接口IP地址207.164.186.2,并且马上激活它,使用下面命令:
#fconfig eth0 210.34.6.89 netmask 255.255.255.128 broadcast 210.34.6.127
该
命令的作用是设置网卡eth0的IP地址、网络掩码和网络的本地广播地址。若运行不带任何参数的ifconfig命令,这个命令将显示机器所有激活接口的
信息。带有“-a”参数的命令则显示所有接口的信息,包括没有激活的接口。注意,用ifconfig命令配置的网络设备参数,机器重新启动以后将会丢失。
如果要暂停某个网络接口的工作,可以使用down参数:
#ifconfig eth0 down
ip
1.作用
ip是iproute2软件包里面的一个强大的网络配置工具,它能够替代一些传统的网络管理工具,例如ifconfig、route等,使用权限为超级用户。几乎所有的Linux发行版本都支持该命令。
2.格式
ip [OPTIONS] OBJECT [COMMAND [ARGUMENTS]]
3.主要参数
OPTIONS是修改ip行为或改变其输出的选项。所有的选项都是以-字符开头,分为长、短两种形式。目前,ip支持如表1所示选项。
OBJECT是要管理者获取信息的对象。目前ip认识的对象见表2所示。
表1 ip支持的选项
-V,-Version 打印ip的版本并退出。
-s,-stats,-statistics 输出更为详尽的信息。如果这个选项出现两次或多次,则输出的信息将更为详尽。
-f,-family 这个选项后面接协议种类,包括inet、inet6或link,强调使用的协议种类。如果没有足够的信息告诉ip使用的协议种类,ip就会使用默认值inet或any。link比较特殊,它表示不涉及任何网络协议。
-4 是-family inet的简写。
-6 是-family inet6的简写。
-0 是-family link的简写。
-o,-oneline 对每行记录都使用单行输出,回行用字符代替。如果需要使用wc、grep等工具处理ip的输出,则会用到这个选项。
-r,-resolve 查询域名解析系统,用获得的主机名代替主机IP地址
COMMAND
设置针对指定对象执行的操作,它和对象的类型有关。一般情况下,ip支持对象的增加(add)、删除(delete)和展示(show或list)。有些
对象不支持这些操作,或者有其它的一些命令。对于所有的对象,用户可以使用help命令获得帮助。这个命令会列出这个对象支持的命令和参数的语法。如果没
有指定对象的操作命令,ip会使用默认的命令。一般情况下,默认命令是list,如果对象不能列出,就会执行help命令。
ARGUMENTS
是命令的一些参数,它们倚赖于对象和命令。ip支持两种类型的参数:flag和parameter。flag由一个关键词组成;parameter由一个
关键词加一个数值组成。为了方便,每个命令都有一个可以忽略的默认参数。例如,参数dev是ip link命令的默认参数,因此ip link ls
eth0等于ip link ls dev eth0。我们将在后面的详细介绍每个命令的使用,命令的默认参数将使用default标出。
4.应用实例
添加IP地址192.168.2.2/24到eth0网卡上:
#ip addr add 192.168.1.1/24 dev eth0
丢弃源地址属于192.168.2.0/24网络的所有数据报:
#ip rule add from 192.168.2.0/24 prio 32777 reject
ping
1.作用
ping检测主机网络接口状态,使用权限是所有用户。
2.格式
ping [-dfnqrRv][-c][-i][-I][-l][-p][-s][-t] IP地址
3.主要参数
-d:使用Socket的SO_DEBUG功能。
-c:设置完成要求回应的次数。
-f:极限检测。
-i:指定收发信息的间隔秒数。
-I:网络界面使用指定的网络界面送出数据包。
-l:前置载入,设置在送出要求信息之前,先行发出的数据包。
-n:只输出数值。
-p:设置填满数据包的范本样式。
-q:不显示指令执行过程,开头和结尾的相关信息除外。
-r:忽略普通的Routing Table,直接将数据包送到远端主机上。
-R:记录路由过程。
-s:设置数据包的大小。
-t:设置存活数值TTL的大小。
-v:详细显示指令的执行过程。
ping
命令是使用最多的网络指令,通常我们使用它检测网络是否连通,它使用ICMP协议。但是有时会有这样的情况,我们可以浏览器查看一个网页,但是却无法
ping通,这是因为一些网站处于安全考虑安装了防火墙。另外,也可以在自己计算机上试一试,通过下面的方法使系统对ping没有反应:
# echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
netstat
1.作用
检查整个Linux网络状态。
2.格式
netstat [-acCeFghilMnNoprstuvVwx][-A][--ip]
3.主要参数
-a--all:显示所有连线中的Socket。
-A:列出该网络类型连线中的IP相关地址和网络类型。
-c--continuous:持续列出网络状态。
-C--cache:显示路由器配置的快取信息。
-e--extend:显示网络其它相关信息。
-F--fib:显示FIB。
-g--groups:显示多重广播功能群组组员名单。
-h--help:在线帮助。
-i--interfaces:显示网络界面信息表单。
-l--listening:显示监控中的服务器的Socket。
-M--masquerade:显示伪装的网络连线。
-n--numeric:直接使用IP地址,而不通过域名服务器。
-N--netlink--symbolic:显示网络硬件外围设备的符号连接名称。
-o--timers:显示计时器。
-p--programs:显示正在使用Socket的程序识别码和程序名称。
-r--route:显示Routing Table。
-s--statistice:显示网络工作信息统计表。
-t--tcp:显示TCP传输协议的连线状况。
-u--udp:显示UDP传输协议的连线状况。
-v--verbose:显示指令执行过程。
-V--version:显示版本信息。
-w--raw:显示RAW传输协议的连线状况。
-x--unix:和指定“-A unix”参数相同。
--ip--inet:和指定“-A inet”参数相同。
4.应用实例
netstat
主要用于Linux察看自身的网络状况,如开启的端口、在为哪些用户服务,以及服务的状态等。此外,它还显示系统路由表、网络接口状态等。可以说,它是一
个综合性的网络状态的察看工具。在默认情况下,netstat只显示已建立连接的端口。如果要显示处于监听状态的所有端口,使用-a参数即可:
#netstat -a
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:32768 *:* LISTEN
tcp 0 0 *:32769 *:* LISTEN
tcp 0 0 *:nfs *:* LISTEN
tcp 0 0 *:32770 *:* LISTEN
tcp 0 0 *:868 *:* LISTEN
tcp 0 0 *:617 *:* LISTEN
tcp 0 0 *:mysql *:* LISTEN
tcp 0 0 *:netbios-ssn *:* LISTEN
tcp 0 0 *:sunrpc *:* LISTEN
tcp 0 0 *:10000 *:* LISTEN
tcp 0 0 *:http *:* LISTEN
......
上面显示出,这台主机同时提供HTTP、FTP、NFS、MySQL等服务。
telnet
1.作用
telnet表示开启终端机阶段作业,并登入远端主机。telnet是一个Linux命令,同时也是一个协议(远程登陆协议)。
2.格式
telnet [-8acdEfFKLrx][-b][-e][-k][-l][-n][-S][-X][主机名称IP地址]
3.主要参数
-8:允许使用8位字符资料,包括输入与输出。
-a:尝试自动登入远端系统。
-b:使用别名指定远端主机名称。
-c:不读取用户专属目录里的.telnetrc文件。
-d:启动排错模式。
-e:设置脱离字符。
-E:滤除脱离字符。
-f:此参数的效果和指定“-F”参数相同。
-F:使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机。
-k:使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名。
-K:不自动登入远端主机。
-l:指定要登入远端主机的用户名称。
-L:允许输出8位字符资料。
-n:指定文件记录相关信息。
-r:使用类似rlogin指令的用户界面。
-S:服务类型,设置telnet连线所需的IP TOS信息。
-x:假设主机有支持数据加密的功能,就使用它。
-X:关闭指定的认证形态。
4.应用说明
用
户使用telnet命令可以进行远程登录,并在远程计算机之间进行通信。用户通过网络在远程计算机上登录,就像登录到本地机上执行命令一样。为了通过
telnet登录到远程计算机上,必须知道远程机上的合法用户名和口令。虽然有些系统确实为远程用户提供登录功能,但出于对安全的考虑,要限制来宾的操作
权限,因此,这种情况下能使用的功能是很少的。
telnet只为普通终端提供终端仿真,而不支持X-
Window等图形环境。当允许远程用户登录时,系统通常把这些用户放在一个受限制的Shell中,以防系统被怀有恶意的或不小心的用户破坏。用户还可以
使用telnet从远程站点登录到自己的计算机上,检查电子邮件、编辑文件和运行程序,就像在本地登录一样。
ftp
1.作用
ftp命令进行远程文件传输。FTP是ARPANet的标准文件传输协议,该网络就是现今Internet的前身,所以ftp既是协议又是一个命令。
2.格式
ftp [-dignv][主机名称IP地址]
3.主要参数
-d:详细显示指令执行过程,便于排错分析程序执行的情形。
-i:关闭互动模式,不询问任何问题。
-g:关闭本地主机文件名称支持特殊字符的扩充特性。
-n:不使用自动登陆。
-v:显示指令执行过程。
4.应用说明
ftp
命令是标准的文件传输协议的用户接口,是在TCP/IP网络计算机之间传输文件简单有效的方法,它允许用户传输ASCⅡ文件和二进制文件。为了使用ftp
来传输文件,用户必须知道远程计算机上的合法用户名和口令。这个用户名/口令的组合用来确认ftp会话,并用来确定用户对要传输的文件进行什么样的访问。
另外,用户需要知道对其进行ftp会话的计算机名字的IP地址。
用户可以通过使用ftp客户程序,连接到另一台计算机上;可以在目录中上下移动、列出目录内容;可以把文件从远程计算机机拷贝到本地机上;还可以把文件从本地机传输到远程系统中。ftp内部命令有72个,下面列出主要几个内部命令:
ls:列出远程机的当前目录。
cd:在远程机上改变工作目录。
lcd:在本地机上改变工作目录。
close:终止当前的ftp会话。
hash:每次传输完数据缓冲区中的数据后就显示一个#号。
get(mget):从远程机传送指定文件到本地机。
put(mput):从本地机传送指定文件到远程机。
quit:断开与远程机的连接,并退出ftp。
route
1.作用
route表示手工产生、修改和查看路由表。
2.格式
#route [-add][-net|-host] targetaddress [-netmask Nm][dev]If]
#route [-delete][-net|-host] targetaddress [gw Gw] [-netmask Nm] [dev]If]
3.主要参数
-add:增加路由。
-delete:删除路由。
-net:路由到达的是一个网络,而不是一台主机。
-host:路由到达的是一台主机。
-netmask Nm:指定路由的子网掩码。
gw:指定路由的网关。
[dev]If:强迫路由链指定接口。
4.应用实例
route命令是用来查看和设置Linux系统的路由信息,以实现与其它网络的通信。要实现两个不同的子网之间的通信,需要一台连接两个网络的路由器,或者同时位于两个网络的网关来实现。
在Linux系统中,设置路由通常是为了解决以下问题:该Linux系统在一个局域网中,局域网中有一个网关,能够让机器访问Internet,那么就需要将这台机器的IP地址设置为Linux机器的默认路由。使用下面命令可以增加一个默认路由:
route add 0.0.0.0 192.168.1.1
rlogin
1.作用
rlogin用来进行远程注册。
2.格式
rlogin [ -8EKLdx ] [ -e char ] [-k realm ] [ - l username ] host
3.主要参数
-8:此选项始终允许8位输入数据通道。该选项允许发送格式化的ANSI字符和其它的特殊代码。如果不用这个选项,除非远端的不是终止和启动字符,否则就去掉奇偶校验位。
-E:停止把任何字符当作转义字符。当和-8选项一起使用时,它提供一个完全的透明连接。
-K:关闭所有的Kerberos确认。只有与使用Kerberos 确认协议的主机连接时才使用这个选项。
-L:允许rlogin会话在litout模式中运行。要了解更多信息,请查阅tty联机帮助。
-d:打开与远程主机进行通信的TCP sockets的socket调试。要了解更多信息,请查阅setsockopt的联机帮助。
-e:为rlogin会话设置转义字符,默认的转义字符是“~”。
-k:请求rlogin获得在指定区域内远程主机的Kerberos许可,而不是获得由krb_realmofhost(3)确定的远程主机区域内的远程主机的Kerberos许可。
-x:为所有通过rlogin会话传送的数据打开DES加密。这会影响响应时间和CPU利用率,但是可以提高安全性。
4.使用说明
如果在网络中的不同系统上都有账号,或者可以访问别人在另一个系统上的账号,那么要访问别的系统中的账号,首先就要注册到系统中,接着通过网络远程注册到账号所在的系统中。rlogin可以远程注册到别的系统中,它的参数应是一个系统名。
rcp
1.作用
rcp代表远程文件拷贝,用于计算机之间文件拷贝,使用权限是所有用户。
2.格式
rcp [-px] [-k realm] file1 file2 rcp [-px] [-r] [-k realm] file
3.主要参数
-r:递归地把源目录中的所有内容拷贝到目的目录中。要使用这个选项,目的必须是一个目录。
-p:试图保留源文件的修改时间和模式,忽略umask。
-k:请求rcp获得在指定区域内的远程主机的Kerberos许可,而不是获得由krb_relmofhost(3)确定的远程主机区域内的远程主机的Kerberos许可。
-x:为传送的所有数据打开DES加密。
finger
1.作用
finger用来查询一台主机上的登录账号的信息,通常会显示用户名、主目录、停滞时间、登录时间、登录Shell等信息,使用权限为所有用户。
2.格式
finger [选项] [使用者] [用户@主机]
3.主要参数
-s:显示用户注册名、实际姓名、终端名称、写状态、停滞时间、登录时间等信息。
-l:除了用-s选项显示的信息外,还显示用户主目录、登录Shell、邮件状态等信息,以及用户主目录下的.plan、.project和.forward文件的内容。
-p:除了不显示.plan文件和.project文件以外,与-l选项相同。
4.应用实例
在计算机上使用finger:
[root@localhost root]# Finger
Login Name Tty Idle Login Time Office Office Phone
root root tty1 2 Dec 15 11
root root pts/0 1 Dec 15 11
root root *pts/1 Dec 15 11
5.应用说明
如果要查询远程机上的用户信息,需要在用户名后面接“@主机名”,采用[用户名@主机名]的格式,不过要查询的网络主机需要运行finger守护进程的支持。
mail
1.作用
mail作用是发送电子邮件,使用权限是所有用户。此外,mail还是一个电子邮件程序。
2.格式
mail [-s subject] [-c address] [-b address]
mail -f [mailbox]mail [-u user]
3.主要参数
-b address:表示输出信息的匿名收信人地址清单。
-c address:表示输出信息的抄送()收信人地址清单。
-f [mailbox]:从收件箱者指定邮箱读取邮件。
-s subject:指定输出信息的主体行。
[-u user]:端口指定优化的收件箱读取邮件。
nslookup
1.作用
nslookup命令的功能是查询一台机器的IP地址和其对应的域名。使用权限所有用户。它通常需要一台域名服务器来提供域名服务。如果用户已经设置好域名服务器,就可以用这个命令查看不同主机的IP地址对应的域名。
2.格式
nslookup [IP地址/域名]
3.应用实例
(1)在本地计算机上使用nslookup命令
$ nslookup
Default Server: name.cao.com.cn
Address: 192.168.1.9
>
在符号“>”后面输入要查询的IP地址域名,并回车即可。如果要退出该命令,输入“exit”,并回车即可。
(2)使用nslookup命令测试named
输入下面命令:
nslookup
然后就进入交换式nslookup环境。如果named正常启动,则nslookup会显示当前DNS服务器的地址和域名,否则表示named没能正常启动。
下面简单介绍一些基本的DNS诊断。
◆
检查正向DNS解析,在nslookup提示符下输入带域名的主机名,如hp712.my.com,nslookup应能显示该主机名对应的IP地址。如
果只输入hp712,nslookup会根据/etc/resolv.conf的定义,自动添加my.com域名,并回答对应的IP地址。
◆检查反向DNS解析,在nslookup提示符下输入某个IP地址,如192.22.33.20,nslookup应能回答该IP地址所对应的主机名。
◆检查MX邮件地址记录在nslookup提示符下输入:
set q=mx
然后输入某个域名,输入my.com和mail.my.com,nslookup应能够回答对应的邮件服务器地址,即support.my.com和support2.my.com。
动手练习
1.危险的网络命令
互
联网的发展使安全成为一个不能忽视的问题,finger、ftp、rcp和telnet在本质上都是不安全的,因为它们在网络上用明文传送口令和数据,嗅
探器可以非常容易地截获这些口令和数据。而且,这些服务程序的安全验证方式也是有弱点的,很容易受到“中间服务器”方式的攻击。这里笔者把一些不安全的命
令根据危险等级列出,见表3所示。
现在ftp、telnet可以被SSH命令代替绑定在端口22上,其连
接采用协商方式,使用RSA加密。身份鉴别完成之后,后面的所有流量都使用IDEA
进行加密。SSH(Secure Shell)程序可以通过网络登录到远程主机,并执行命令。rcp、rlogin等远程调用命令也逐渐被VNC软件代
替。
2.在一张网卡上绑定多个IP地址
在Linux下,可以使用ifconfig方便地绑定多个IP地址到一张网卡。例如,eth0接口的原有IP地址为192.168.0 .254,可以执行下面命令:
ifconfig eth0:0 192.168.0.253 netmask 255.255.255.0
ifconfig eth0:1 192.168.0.252 netmask 255.255.255.0
......
3.修改网卡MAC地址
首先必须关闭网卡设备,命令如下:
/sbin/ifconfig eth0 down
修改MAC地址,命令如下:
/sbin/ifconfig eth0 hw ether 00:AA:BB:CC:DD:EE
重新启用网卡:
/sbin/ifconfig eht0 up
这样网卡的MAC地址就更改完成了。每张网卡的MAC地址是惟一,但不是不能修改的,只要保证在网络中的MAC地址的惟一性就可以了。
4.初步部署IPv6
IPv4
技术在网络发展中起到了巨大的作用,不过随着时间的流逝它无论在网络地址的提供、服务质量、安全性等方面都越来越力不从心,IPv6呼之欲出。Linux
是所有操作系统中最先支持IPv6的,一般Linux基于2.4内核的Linux发行版本都可以直接使用IPv6,不过主要发行版本没有加载IPv6模
块,可以使用命令手工加载,需要超级用户的权限。
(1)加载IPv6模块
使用命令检测,其中inet6 addr: fe80::5054:abff:fe34:5b09/64,就是eth0网卡的IPv6地址。
# modprobe IPv6
#ifconfig
eth0 Link encap:Ethernet HWaddr 52:54:AB:34:5B:09
inet addr:192.168.1.2 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::5054:abff:fe34:5b09/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:21 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:100
RX bytes:0 (0.0 b) TX bytes:1360 (1.3 Kb)
Interrupt:5 Base address:0xec00
(2)使用ping命令检测网卡的IPv6地址是否有效
#ping6 -I eth0 -c 2 fe80::200:e8ff:fea0:2586
和IPv4不一样,使用ping6命令时必须指定一个网卡界面,否则系统不知道将数据包发送到哪个网络设备。I表示Interface、eth0是第一个网卡,-c表示回路,2表示ping6操作两次。结果见图1所示。
图1 IPv6网络下的ping6命令
(3)使用ip命令在IPv6下为eth0增加一个IP地址
#ip -6 addr add 3ffe:ffff:0:f101::1/64 dev eth0
使用ifconfig命令,查看网卡是否出现第二个IPv6地址。
Linux网络的主要优点是能够实现资源和信息的共享,并且用户可以远程访问信息。Linux提供了一组强有力的网络命令来为用户服务,这些工具能够帮助用户进行网络设定、检查网络状况、登录到远程计算机上、传输文件和执行远程命令等。
上面介绍了Linux中比较重要的网络命令,其实Linux还有许多命令需要学习。Linux网络操作命令的一个特点就是命令参数选项很多,并不要求全部记住,关键在于理解命令的主要用途和学会使用帮助信息。
Linux必学的60个命令(5)-网络安全命令Linux必学的60个命令:系统安全相关命令
虽然Linux和Windows NT/2000系统一样是一个多用户的系统,但是它们之间有不少重要的差别。对于很多习惯了Windows系统的管理员来讲,如何保证Linux操作系统安全、可靠将会面临许多新的挑战。本文将重点介绍Linux系统安全的命令。
passwd
1.作用
passwd命令原来修改账户的登陆密码,使用权限是所有用户。
2.格式
passwd [选项] 账户名称
3.主要参数
-l:锁定已经命名的账户名称,只有具备超级用户权限的使用者方可使用。
-u:解开账户锁定状态,只有具备超级用户权限的使用者方可使用。
-x, --maximum=DAYS:最大密码使用时间(天),只有具备超级用户权限的使用者方可使用。
-n, --minimum=DAYS:最小密码使用时间(天),只有具备超级用户权限的使用者方可使用。
-d:删除使用者的密码, 只有具备超级用户权限的使用者方可使用。
-S:检查指定使用者的密码认证种类, 只有具备超级用户权限的使用者方可使用。
4.应用实例
$ passwd
Changing password for user cao.
Changing password for cao
(current) UNIX password:
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
从上面可以看到,使用passwd命令需要输入旧的密码,然后再输入两次新密码。
su
1.作用
su的作用是变更为其它使用者的身份,超级用户除外,需要键入该使用者的密码。
2.格式
su [选项]... [-] [USER [ARG]...]
3.主要参数
-f , --fast:不必读启动文件(如 csh.cshrc 等),仅用于csh或tcsh两种Shell。
-l , --login:加了这个参数之后,就好像是重新登陆为该使用者一样,大部分环境变量(例如HOME、SHELL和USER等)都是以该使用者(USER)为主,并且工作目录也会改变。如果没有指定USER,缺省情况是root。
-m, -p ,--preserve-environment:执行su时不改变环境变数。
-c command:变更账号为USER的使用者,并执行指令(command)后再变回原来使用者。
USER:欲变更的使用者账号,ARG传入新的Shell参数。
4.应用实例
变更账号为超级用户,并在执行df命令后还原使用者。 su -c df root
umask
1.作用
umask设置用户文件和目录的文件创建缺省屏蔽值,若将此命令放入profile文件,就可控制该用户后续所建文件的存取许可。它告诉系统在创建文件时不给谁存取许可。使用权限是所有用户。
2.格式
umask [-p] [-S] [mode]
3.参数
-S:确定当前的umask设置。
-p:修改umask 设置。
[mode]:修改数值。
4.说明
传
统Unix的umask值是022,这样就可以防止同属于该组的其它用户及别的组的用户修改该用户的文件。既然每个用户都拥有并属于一个自己的私有组,那
么这种“组保护模式”就不在需要了。严密的权限设定构成了Linux安全的基础,在权限上犯错误是致命的。需要注意的是,umask命令用来设置进程所创
建的文件的读写权限,最保险的值是0077,即关闭创建文件的进程以外的所有进程的读写权限,表示为-rw-------。在
~/.bash_profile中,加上一行命令umask 0077可以保证每次启动Shell后, 进程的umask权限都可以被正确设定。
5.应用实例
umask -S
u=rwx,g=rx,o=rx
umask -p 177
umask -S
u=rw,g=,o=
上述5行命令,首先显示当前状态,然后把umask值改为177,结果只有文件所有者具有读写文件的权限,其它用户不能访问该文件。这显然是一种非常安全的设置。
chgrp
1.作用
chgrp表示修改一个或多个文件或目录所属的组。使用权限是超级用户。
2.格式
chgrp [选项]... 组 文件...
或
chgrp [选项]... --reference=参考文件 文件...
将每个的所属组设定为。
3.参数
-c, --changes :像 --verbose,但只在有更改时才显示结果。
--dereference:会影响符号链接所指示的对象,而非符号链接本身。
-h, --no-dereference:会影响符号链接本身,而非符号链接所指示的目的地(当系统支持更改符号链接的所有者,此选项才有效)。
-f, --silent, --quiet:去除大部分的错误信息。
--reference=参考文件:使用的所属组,而非指定的。
-R, --recursive:递归处理所有的文件及子目录。
-v, --verbose:处理任何文件都会显示信息。
4.应用说明
该命令改变指定指定文件所属的用户组。其中group可以是用户组ID,也可以是/etc/group文件中用户组的组名。文件名是以空格分开的要改变属组的文件列表,支持通配符。如果用户不是该文件的属主或超级用户,则不能改变该文件的组。
5.应用实例
改变/opt/local /book/及其子目录下的所有文件的属组为book,命令如下:
$ chgrp - R book /opt/local /book
chmod
1.作用
chmod命令是非常重要的,用于改变文件或目录的访问权限,用户可以用它控制文件或目录的访问权限,使用权限是超级用户。
2.格式
chmod命令有两种用法。一种是包含字母和操作符表达式的字符设定法(相对权限设定);另一种是包含数字的数字设定法(绝对权限设定)。
(1)字符设定法
chmod [who] [+ | - | =] [mode] 文件名
◆操作对象who可以是下述字母中的任一个或它们的组合
u:表示用户,即文件或目录的所有者。
g:表示同组用户,即与文件属主有相同组ID的所有用户。
o:表示其它用户。
a:表示所有用户,它是系统默认值。
◆操作符号
+:添加某个权限。
- -
[转载]浅谈软件测试流程
2008-06-03 12:29:04
浅谈软件测试流程
【摘要】 软件测试从哪里开始到哪里结束?中间要经过哪些环节以及各环节要注意哪些事项。本文就有关问题结合个人实际工作经验进行阐述,鉴于每个环节都可以做为一个专题来进行探讨,所以受篇幅和时间限制,本文对有关问题未做深入剖析,只做一个宏观上的介绍。
【关键词】测试流程、需求分析、测试用例、测试计划、缺陷管理
一、概述
一般而言,软件测试从项目确立时就开始了,前后要经过以下一些主要环节:
需求分析→测试计划→测试设计→测试环境搭建→测试执行→测试记录→缺陷管理→软件评估→RTM.
在进行有关问题阐述前,我们先明确下分工,一般而言,需求分析、测试用例编写、测试环境搭建、测试执行等属于测试开发人员工作范畴,而测试执行以及缺陷提交等属于普通测试人员的工作范畴,测试负责人负责整个测试各个环节的跟踪、实施、管理等。
说明:
1.以上流程各环节并未包含软件测试过程的全部,如根据实际情况还可以实施一些测试计划评审、用例评审,测试培训等。在软件正式发行后,当遇到一些严重问题时,还需要进行一些后续维护测试等。
2.以上各环节并不是独立没联系的,实际工作千变万化,各环节一些交织、重叠在所难免,比如编写测试用例的同时就可以进行测试环境的搭建工作,当然也可能由于一些需求不清楚而重新进行需求分析等。这就和我们国家提出建设有中国特色的社会主义国家一样,只所以有中国特色,那是因为国情不一样。所以在实际测试过程中也要做到具体问题具体分析,具体解决。
二、测试流程

需求分析
需求分析(Requirment Analyzing)应该说是软件测试的一个重要环节,测试开发人员对这一环节的理解程度如何将直接影响到接下来有关测试工作的开展。
可能有些人认为测试需求分析无关紧要,这种想法是很不对的。需求分析不但重要,而且至关重要!
一般而言,需求分析包括软件功能需求分析、测试环境需求分析、测试资源需求分析等。
其中最基本的是软件功能需求分析,测一款软件首先要知道软件能实现哪些功能以及是怎样实现的。比如一款Smartphone包括VoIP、Wi-Fi以及Bluetooth等功能。那我们就应该知道软件是怎样来实现这些功能的,为了实现这些功能需要哪些测试设备以及如何搭建相应测试环境等,否则测试就无从谈起!
既然谈了需求分析,那么我们根据什么来分析呢?总不能凭空设想吧。
总得说来,做测试需求分析的依据有软件需求文档、软件规格书以及开发人员的设计文档等,相信管理一些规范的公司在软件开发过程中都有这些文档。
测试计划
测试计划(Test Plan)一般由测试负责人来编写。
测试计划的依据主要是项目开发计划和测试需求分析结果而制定。测试计划一般包括以下一些方面:
1. 测试背景
a. 软件项目介绍;
b. 项目涉及人员(如软硬件项目负责人等)介绍以及相应联系方式等。
2. 测试依据
a. 软件需求文档;
b. 软件规格书;
c. 软件设计文档;
d. 其他,如参考产品等。
3. 测试资源
a. 测试设备需求;
b. 测试人员需求;
c. 测试环境需求;
d. 其他。
4. 测试策略
a. 采取测试方法;
b. 搭建哪些测试环境;
d. 对测试人员进行培训等。
5. 测试日程
a. 测试需求分析;
b. 测试用例编写;
c. 测试实施,根据项目计划,测试分成哪些测试阶段(如单元测试、集成测试、系统测试阶段,α、β测试阶段等),每个阶段的工作重点以及投入资源等。
6. 其他。
测试计划还要包括测试计划编写的日期、作者等信息,计划越详细越好了。
计划赶不上变化,一份计划做的再好,当实际实施的时候就会发现往往很难按照原有计划开展。如在软件开发过程中资源匮乏、人员流动等都会对测试造成一定的影响。所以,这些就要求测试负责人能够从宏观上来调控了。在变化面前能够做到应对自如、处乱不惊那是最好不过了。
测试设计
测试设计主要包括测试用例编写和测试场景设计两方面。
一份好的测试用例对测试有很好的指导作用,能够发现很多软件问题。关于测试用例编写,请参见前面写的《也谈测试用例》一文,里面有详细阐述。
测试场景设计主要也就是测试环境问题了。
测试环境搭建
不同软件产品对测试环境有着不同的要求。如C/S及B/S架构相关的软件产品,那么对不同操作系统,如Windows系列、unix、linux甚至苹果OS等,这些测试环境都是必须的。而对于一些嵌入式软件,如手机软件,如果我们想测试一下有关功能模块的耗电情况,手机待机时间等,那么我们可能就需要搭建相应的电流测试环境了。当然测试中对于如手机网络等环境都有所要求。
测试环境很重要,符合要求的测试环境能够帮助我们准确的测出软件问题,并且做出正确的判断。
为了测试一款软件,我们可能根据不同的需求点要使用很多不同的测试环境。有些测试环境我们是可以搭建的,有些环境我们无法搭建或者搭建成本很高。不管如何,我们的目标是测试软件问题,保证软件质量。测试环境问题,还是根据具体产品以及开发者的实际情况而采取最经济的方式吧。
测试执行
测试执行过程又可以分为以下阶段:
单元测试→集成测试→系统测试→出厂测试,其中每个阶段还有回归测试等。
从测试的角度而言,测试执行包括一个量和度的问题。也就是测试范围和测试程度的问题。 比如一个版本需要测试哪些方面?每个方面要测试到什么程度?
从管理的角度而言,在有限的时间内,在人员有限甚至短缺的情况下,要考虑如何分工,如何合理地利用资源来开展测试。当然还要考虑以下问题:
1. 当测试人员测试的执行不到位、敷衍了事时该如何解决?
2. 测试效率问题,怎样提高测试效率?
3. 根据版本的不同特点是只做验证测试还是采取冒烟测试亦或是系统全面测试?
4. 当测试过程中遇到一些偶然性随机问题该怎样处理?
5. 当版本中出现很多新问题时该怎样对待?测试停止标准?
6. ……
总之,测试执行过程中会遇到很多复杂的问题,还是那句话,具体问题具体解决!本文不做过多阐述。
测试记录
缺陷记录总的说来包括两方面:由谁提交和缺陷描述。
一般而言,缺陷都是谁测试谁提交,当然有些公司可能为了保证所提交缺陷的质量,还会在提交前进行缺陷评估,以确保所提交的缺陷的准确性。
在缺陷的描述上,至少要包括以下一些方面内容:
序号
标题
预置条件
操作步骤
预期结果
实际结果
注释
严重程度
概率
版本
测试者
测试日期
以上是描述一个bug时通常所要描述的内容,当然在实际提交bug时可以根据实际情况进行补充,如附上图片、log文件等。
另外,一个版本软件测试完毕,还要根据测试情况出份测试报告,这也是所要经过的一个环节。
缺陷管理
缺陷管理方面,很多公司都采取缺陷管理工具来进行管理,常见缺陷管理工具有Test Director、Bugfree等。
下图是一个bug从提出到close所经过的一些流程,其他比如keep No action\keep spec等一些状态流程都未包含在内,在此仅做示范说明。

注:软件缺陷和bug两者在含义上有着细微差别,本文统称缺陷。
软件评估
这里评估指软件经过一轮又一轮测试后,确认软件无重大问题或者问题很少的情况下,对准备发给客户的软件进行评估,以确定是否能够发行给客户或投放市场。
软件评估小组一般由项目负责人、营销人员、部门经理等组成,也可能是由客户指定的第三方人员组成。
测试总结
每个版本有每个版本的测试总结,每个阶段有每个阶段的测试总结,当项目完成RTM后,一般要对整个项目做个回顾总结,看有哪些做的不足的地方,有哪些经验可以对今后的测试工作做借鉴使用,等等。测试总结无严格格式、字数限制。应该说,测试总结还是很总要的。
测试维护
由于测试的不完全性,当软件正式release后,客户在使用过程中,难免遇到一些问题,有的甚至是严重性的问题,这就需要修改有关问题,修改后需要再次对软件进行测试、评估、发行。































标题搜索
我的存档
数据统计
- 访问量: 31305
- 日志数: 19
- 建立时间: 2008-06-03
- 更新时间: 2015-06-23
