
-
Monkey测试策略--包的指定
rarity0310 发布于 2014-04-28 10:43:11
Monkey的测试策略
来自: http://www.douban.com/note/257030159/
一. 分类
Monkey测试针对不同的对象和不同的目的采用不同的测试方案,首先测试的对象、目的及类型如下:
测试的类型分为:应用程序的稳定性测试和压力测试
测试对象分为:单一apk和apk集合
测试的目的分为:解决问题的测试(忽略异常的测试)和验收测试(不忽略异常的测试)
二. 应用程序的稳定性测试:约束限制
-p<allowed-package-name>
如果用此参数指定了一个或几个包,Monkey 将只允许系统启动这些包里的Activity。如果你的应用程序还需要访问其它包里的Activity(如选择取一个联系人),那些包也需要在此同时指 定。如果不指定任何包,Monkey将允许系统启动全部包里的Activity。要指定多个包,需要使用多个 -p选项,每个-p选项只能用于一个包。
* 指定一个包: adb shell monkey -p com.htc.Weather 100
说明:com.htc.Weather为包名,100是事件计数(即让Monkey程序模拟100次随机用户事件)。
* 指定多个包:adb shell monkey -p com.htc.Weather –pcom.htc.pdfreader -p com.htc.photo.widgets 100
* 不指定包:adb shell monkey 100
说明:Monkey随机启动APP并发送100个随机事件。
* 要查看设备中所有的包,在CMD窗口中执行以下命令:
>adb shell
#cd data/data
#ls
1. 针对单个apk
(1) 不忽略异常
在进行单个apk的验收测试时,则使用单一apk且不忽略异常的命令执行。
例如:
monkey -p com.android.mms --throttle 1000 -s 100-v -v -v 15000 > /mnt/sdcard/monkey_test.txt &
(2) 忽略异常
在进行单个apk的解决问题的测试时,则使用单一apk且忽略异常的命令执行,这样可以在一次执行的过程中发现应用程序中的多个问题。
例如:
monkey -p com.android.mms --throttle 1000 -s 100--ignore-crashes --ignore-timeouts --ignore-security-exceptions--ignore-native-carshes --monitor-native-crashes -v -v -v 15000 >/mnt/sdcard/monkey_test.txt &
2. 针对多个apk
(1) 不忽略异常
例如:
monkey --pkg-whitelist-file /data/whitelist.txt--throttle 1000 -s 100 -v -v -v 15000 > /mnt/sdcard/monkey_test.txt &
(2) 忽略异常
例如:
monkey --pkg-whitelist-file /data/whitelist.txt--throttle 1000 -s 100 --ignore-crashes --ignore-timeouts--ignore-security-exceptions --ignore-native-carshes --monitor-native-crashes-v -v -v 15000 > /mnt/sdcard/monkey_test.txt &
三. 应用程序的压力/健壮性测试
应用程序的压力 /健壮性测试,其主要是缩短monkey测试中事件与事件之间的延迟时间,验证在快速的事件响应的过程中,程序是否能正常运行。这种压力/健壮性测试主要 是针对单一apk来执行;我们可以将--throttle的值设定为500或者更小,一般都使用500毫秒的延迟事件。
在进行apk的集合测试时,对于高频率使用的apk、长时间使用的apk都要包含在执行的应用程序中间。
APK分类具体:
高频率使用的apk如:Phone、Contacts、Message、Settings、File Manager、Gallery、Input Method
长时间使用的apk如:Phone、Browser、Music player、Camera、Video player、Email、Chat
其他的apk如:Calendar、Notepad、Calculator、FM Radio、Google Search-v
命令行的每一个-v将增加反馈信息的级别。
Level 0(缺省值)除启动提示、测试完成和最终结果之外,提供较少信息。
Level 1提供较为详细的测试信息,如逐个发送到Activity的事件。
Level 2提供更加详细的设置信息,如测试中被选中的或未被选中的Activity。
日志级别 Level 0
*示例 adbshell monkey -p com.htc.Weather –v 100
说明缺省值,仅提供启动提示、测试完成和最终结果等少量信息
日志级别 Level 1
*示例 adbshell monkey -p com.htc.Weather –v -v 100
说明 提供较为详细的日志,包括每个发送到Activity的事件信息
日志级别 Level 2
*示例 adbshell monkey -p com.htc.Weather –v -v –v 100
说明 最详细的日志,包括了测试中选中/未选中的Activity信息
事件
-s <seed>
用于指定伪随机数生成器的seed值,如果seed相同,则两次Monkey测试所产生的事件序列也相同的。
* 示例:
Monkey测试1:adb shellmonkey -p com.htc.Weather –s 10 100
Monkey 测试2:adb shellmonkey -p com.htc.Weather –s 10 100
两 次测试的效果是相同的,因为模拟的用户操作序列(每次操作按照一定的先后顺序所组成的一系列操作,即一个序列)是一样的。操作序列虽 然是随机生成的,但是只要我们指定了相同的Seed值,就可以保证两次测试产生的随机操作序列是完全相同的,所以这个操作序列伪随机的; -
接口测试方法
agatha1113 发布于 2013-06-05 17:08:48
其实无论用那种测试方法,接口测试的原理是通过测试程序模拟客户端向服务器发送请求报文,服务器接收请求报文后对相应的报文做出处理然后再把应答报文发送给客户端,客户端接收应答报文这一个过程。
方法一、用LoadRunner实现接口测试
大家都知道LoadRunner是一种性能测试工具,但它也可以用在我们做接口测试的时候。开发人员开发出来的接口,提供给测试人员详细的接口使用说明书,该说明书最基本的要求如下:
接口测试地址:/SNS/Publish
请求报文参数说明:
参数名称
参数描述
字符类型
字符值
SNSID
社区ID
String
6
UserID
用户ID
String
10
CommentsTypeID
评论类型ID
String
2
CommentsID
评论ID
String
10
AuthorID
作者ID
String
10
CommentsContent
评论内容
String
50
请求报文格式:
<?xml version="1.0" encoding="ISO-8859-1"?>
< Publish >
<SNSID>123</SNSID>
<UserID>456</ UserID >
<CommentsTypeID>2</ CommentsTypeID >
<CommentsID>123</CommentsID>
<AuthorID>456</AuthorID>
<CommentsContent>Don't forget the meeting!</CommentsContent >
</Publish>应答报文的参数接口说明:
参数名称
参数描述
字符类型
字符值
UserID
用户ID
String
10
CommentsTypeID
评论类型ID
String
2
CommentsID
评论ID
String
10
CommentsContent
评论内容
String
50
StatusCode
返回值
Int
0代表pass,非0代表fail
StatusText
返回信息描述
String
<?xml version="1.0" encoding="ISO-8859-1"?>
< Publish >
<UserID>456</ UserID >
<CommentsTypeID>2</ CommentsTypeID >
<CommentsID>123</CommentsID>
<CommentsContent>Don't forget the meeting!</CommentsContent >
<StatusCode>0</StatusCode>
<StatusText>发送成功一条评论</StatusText>
</Publish>有了上述的说明书之后,测试人员可以根据文档的描述在LoadRunner书写相应的接口测试脚本。
LoadRunner中涉及到向服务器发送请求的API方法包括:web_url(),web_submit_form(),web_submit_data(),web_custom_request()。下面介绍两种我常用的方法:
方法一:使用web_submit_data()
web_submit_data("insert",
"Action=http://116.211.23.123/SNS/Publish.htm ",
"Method=POST",
"Referer=http://116.211.23.123/SNS/Publish.htm ",
"Mode=HTML",
ITEMDATA,
"Name= SNSID ","Value=6601",ENDITEM,
"Name= UserID ","Value=123",ENDITEM,
"Name= CommentsTypeID ","Value=1",ENDITEM,
"Name= CommentsID ","Value=456",ENDITEM,
"Name= AuthorID","Value=789",ENDITEM,
"Name= CommentsContent ","Value=Just for testing",ENDITEM,
LAST);方法二:使用web_custom_request()
char str[1000];
strcpy(str,"SNSID=7999&UserID=1&CommentsTypeID=1&CommentsID=1&AuthorID=1&CommentsContent=1");
web_custom_request("Publish",
"Url= http://116.211.23.123/SNS/Publish.htm",
"Method=POST",
"Referer=http://116.211.23.123/SNS/Publish.htm ",
"Mode=HTTP",
str,
LAST);这也是一种写法,可以跟web_submit_data互换。这种写法更利于拼接参数。
方法一适合一些xml结构的根元素下的子元素同处于根元素下面,且子元素数目较少的情况下,如果xml结构比较复杂,比如说根元素下面有多级子元素,或者xml树结构分叉较多的时候,我们可以先把xml拼接成一个字符串然后通过web_custom_request()向服务器发送请求。
我们在做接口功能测试的时候会很注意接口的应答报文的信息,这时候我们可以通过LoadRunner的日志信息查看或者可以通过web_reg_find()或者web_find()这样的API函数来统计接口的运行结果,推荐使用web_reg_find(),web_reg_find()和web_find()区别请大家百度一下,详细信息太多,在这里不便叙述。
因为web_reg_find()是注册型函数,所以应该放在web_submit_data()或者web_custom_request()的前面。
如:
web_reg_find("Text=<StatusCode>0</StatusCode>",//应答报文里边的信息
"SaveCount= StatusCodeCount", //统计查询字段的信息,如果找到值为1,如果未找到值为0
LAST);在脚本的最后我们可以对查询字段的信息进行统计
// Check result
if (atoi(lr_eval_string("{StatusCodeCount }")) > 0){ //判断如果Welcome字符串出现次//数大于0
lr_output_message("Send out the comment successfully."); }//在日志中输出Send out //the comment successfully
else{ //如果出现次数小于等于
lr_error_message("Send out the comment unsuccessfully."); //在日志中输出Send out //the comment successfully
return(0);
}总结:用LoadRunner做接口测试无法做到把接口参数和程序分理,接口的参数可以通过参数化的方法来实现对同一个参数多个数据的测试。参数化后的测试数据保存在此脚本的保存位置下。
方法二、通过Java + Fitnesse实现接口功能测试
什么是Fitnesse?
FitNesse是一套软件开发协作工具 FitNesse是帮助大家加强软件开发过程中的协作的工具。能够让客户、测试人员和开发人员了解软件要做成什么样,帮助建议软件最终是否达到了设计初衷。
FitNesse是一套软件测试工具 从另外一个角度看,FitNesse是一个轻量级的、开源的框架,能够帮助开发团队方便的定义验收测试(Acceptance Tests),通过在web页面上简单的输出和预计输出的表格就可实现,并且可以运行这些测试以确定是否通过。
FitNesse是wiki可以很方便的创建和编辑页面 FitNesse是一个web服务器不用过多的安装配置,很方便使用。
我习惯使用Eclipse集成开发工具写测试代码,用fitnesse准备接口的测试数据,由此实现接口的测试数据和测试程序的分离。
关于Fitnesse的使用大家可以参考官方网址。Fitnesse的四种常见表格是:
ColumnFixture,ActionFixture,Decision Table,ScriptTable。在工作中ColumnFixture用的最多。
下面的程序使用的是ColumnFixture表格。
// Java fixtures
package info.fitnesse.fixturegallery;
import fit.ColumnFixture;
public class PublishTest extends ColumnFixture {
//通过url向服务器发送请求的程序段省略
public StringSNSID; //对应列名|first part|
public StringUserID; //对应列名|second part|
private StringCommentsTypeID;
private StringAuthorID;
private StringCommentsContent;
private StringUserID;
//对参数的set和get方法省略
}
ColumnFixture表格里边的测试数据是:
//省略设置表格的存储位置信息总结:上述两种方法都是对接口做功能测试的方法,使用LoadRunner做接口测试的时候可以不用让开发人员提供测试人员相应的UI测试页面,直接调用接口做测试,但是测试程序和数据的依赖性太强;使用Fitnesse做接口测试的时候可以实现测试程序和数据的分离,只用点击Fitnesse界面的Test按钮就可以实现测试,测试消耗时间比使用LoadRunner做接口测试少。
以上纯属个人见解,敬请拍砖!
-
Web测试不再纠结,robot framework三驾马车之Autoit+selenium
dingheng9546 发布于 2013-05-14 15:35:55

AutoIt 是一个使用类似BASIC脚本语言的免费软件,它设计用于Windows GUI中进行自动化操作.它利用模拟键盘按键,鼠标移动和窗口/控件的组合来实现自动化任务.而这是其它语言不可能做到或无可靠方法实现的。在web测试中,许多控件selenium完成起来有难度的。此时结合Autoit可以达到事半功倍的效果。比如上传下载,activex,web上遇到大部分的windows控件都可以搞定了。RF+selenium+autoit的强大自己体会去吧。废话不多说,直接上安装教程和简单例子。剩下的各位自己,去摸索。
1,准备安装包,群共享中Autoitlibrary.zip
2,安装pywin32.exe,此为autoit的依赖库,在群GX能找到。
3,cmd到Autoitlibrary的解压目录,敲命令python setup.py install 如果你第二步没跳过去,应该能安装成功。此时在C盘会有一个robotframework的文件夹,里面有很多例子。
4、启动ride, addlibrary AutoItLibrary 不是红色的,恭喜你成功了。
如果想要测试C/S程序,Autoit+sikuli可以解决绝大多数问题了。那就需要你深入研究Autoit,祝大家开心测试。
下面附送上传文件的例子,大家试试,群GX也会有的。
*** Settings ***
Library Selenium2Library
Library AutoItLibrary
*** Variables ***
${path} e:\\boot.ini
${url} http://www.rayfile.com/zh-cn/option/
${browser} gc
*** Test Cases ***
Login To Rayfile And Upload
[Tags] up
打开浏览器
上传
*** Keywords ***
打开浏览器
open browser ${url} ${browser}
上传
click element upload0
Win Wait Active 打开
Control Set Text 打开 \ [CLASS:Edit; INSTANCE:1] ${path}
Control Click 打开 \ [CLASS:Button; INSTANCE:2]
-
Web测试不再纠结,robot framework三驾马车之sikuli+selenium
dingheng9546 发布于 2013-05-12 20:07:41
模态对话框、activex、flash等各种自定义控件处理起来是不是很头疼。Sikuli是一个根据图形匹配的测试工具,尤其是结合了selenium,基本上可以解决web测试上所有的技术问题。不知道sikuli的可以下载了先体验一下,IDE很简单,用截图也能做测试,但是这也不是本文介绍的重点。本文介绍在RF下sikuli+selenium协同工作互补不足。所以本文仅针对在RF下selenium不能满足需求的使用者。如果你不懂sikuli,可以先了解一下,一种截图测试工具。
Sikuli与robotframework集成
Sikuli只能jython调用,而在RF中,selenium库是python写的。所以要把sikuli当成一个远程库调用。jython没安装的,请参考前一篇日志http://www.51testing.com/index.php?uid-424226-action-viewspace-itemid-845458。
Sikuli远程环境
1、 下载sikuli,并安装。这个不用说太多了吧。ps:sikuli只能在32位jdk6跑
2、 创建一个测试文件夹[C:\robot] [C:\robot\data] [C:\robot\libs] [C:\robot\suites]
3、 下载文件http://robotframework.googlecode.com/hg/tools/remoteserver/robotremoteserver.py另存在[C:\robot\libs]文件夹内
4、 复制sikuli的安装目录下的C:\Program Files (x86)\Sikuli X\sikuli-script.jar到[C:\robot\libs]文件夹内
5、 加上环境变量到class_path (C:\robot\libs\sikuli-script.jar).
6、 新建一个文件SikuliRemoteLibrary.py到[C:\robot\libs]文件夹内(此文件在群GX可以下载Rf+sikuli+selenium例子.rar,)
7、 运行sikuli远程库,如果你前面的环境是完全按照我的教程能运行jybot,那现在应该在命令行敲 jython.bat C:\robot\libs\ SikuliRemoteLibrary.py 如果出现robot framework remote server starting at localhost:8270 那就成功启动了sikuli远程库了。反之,好好检查环境变量吧,或者把sikuli-script.jar拖到 class_path 所在的目录。
Robot framrwork 调用sikuli远程库,拿百度来说事吧。
很简答的例子,一个是调用selenium在百度输入selenium并搜索,另一个case是调用sikuli在百度输入selenium并搜索。
文档粘贴在本文最后,请复制并保存在[C:\robot\suites]。图片截图很简单,input.png是输入框的,请尽量截图让sikuli知道是唯一的。Submit.png是百度一下的按钮,截图放在[C:\robot\data]。以上内容均可以加入群247870083去群共享取Rf+sikuli+selenium例子.rar
。
*** Settings ***
Documentation Integrating Selenium, Sikuli into Robot Framework
Test Setup
Test Teardown Run Keyword If Test Failed Take Screenshot
Library Selenium2Library 15 # Selenium library
Library Remote http://localhost:${port} # Sikuli
Library Screenshot # Taking screenshots when a test fails
*** Variables ***
${url} http://www.baidu.com # 百度网站
${browser} ff # Browser
${port} 8270 # Default port number for the remote server
${data_path} c:\\robot\\data # Sikuli images
${similarity} 0.90 # Used in Sikuli image comparison
${timeout} 10 # Time to wait for objects
*** Testcases ***
login To Baidu And Serch With Selenium
[Tags] selenium
登录百度首页
用slenium的方式输入并点击搜索
[Teardown] close all browsers
login To Baidu And Serch With Sikuli
[Tags] sikuli
登录百度首页
用sikuli的方式输入并点击搜索
*** Keywords ***
登录百度首页
open browser ${url} ${browser}
maximize browser window
用slenium的方式输入并点击搜索
input text wd selenium
click button kw
用sikuli的方式输入并点击搜索
Object Exists ${data_path}\\input.png \ ${similarity} ${timeout}
type at object ${data_path}\\input.png \ selenium ${timeout} ${similarity}
Object Exists ${data_path}\\submit.png \ ${similarity} ${timeout}
click object ${data_path}\\submit.png \ ${timeout} ${similarity}
-
诊断 CPU、内存或磁盘瓶颈的流程图(zt)
liangjz 发布于 2007-03-29 13:31:34
从步骤 1 开始,首先查看 CPU 使用情况,按照诊断 CPU、内存或磁盘瓶颈的指导进行操作。对于下面的每个步骤,查找一端时间内的趋势,从中收集系统运行性能较差时的数据。另外,只有将这些数据与系统正常运行时收集的数据进行比较时才能进行准确的诊断。
步骤 1
# sar -u [interval] [iterations]
(示例: sar -u 5 30)
%idle 是否很低? 这是 CPU 未在运行任何进程的时间百分比。在一端时间内 %idle 为零可能是 CPU 瓶颈的第一个指示。不是 -> 系统未发生 CPU 瓶颈。转至步骤 3。
是 -> 系统可能发生了 CPU、内存或 I/O 瓶颈。转至步骤 2。步骤 2
%usr 是否较高? 很多系统正常情况下花费 80% 的 CPU 时间用于用户, 20% 用于系统。其他系统通常会使用 80% 左右的用户时间。
不是 -> 系统可能遇到 CPU、内存或 I/O 瓶颈。转至步骤 3。
是 -> 系统可能由于用户进程遇到 CPU 瓶颈。转至部分 3,部分 A, 调整系统的 CPU 瓶颈。步骤 3
%wio 的值是否大于 15?
是 -> 以后记住这个值。它可能表示磁盘或磁带瓶颈。转至步骤 4。
不是 -> 转至步骤 4。步骤 4
# sar -d [interval] [iterations]
用于任何磁盘的 %busy 是否都大于 50? (请记住,50% 指示一个大概的 指南,它可能远远高于您系统的正常值。在某些系统上,甚至 %busy 值为 20 可能就表示发生了磁盘瓶颈,而其他系统正常情况下可能就为 50% busy。)对于同一个磁盘上,avwait 是否大于 avserv?不是 -> 很可能不是磁盘瓶颈,转至步骤 6。
是 -> 此设备上好像发生了 IO 瓶颈。
转至步骤 5。步骤 5
系统上存在磁盘瓶颈,发生瓶颈的磁盘上有哪些内容?
原始分区,
文件系统 -> 转至部分 3,部分 B,调整发生磁盘 IO 瓶颈的系统。
Swap -> 可能是由于内存瓶颈导致的。
转至步骤 6。步骤 6
# vmstat [interval] [iterations]
在很长的一端时间内,po 是否总是大于 0?
对于一个 s800 系统 (free * 4k) 是否小于 2 MB,
(对于 s700 系统 free * 4k 是否小于 1 MB)?
(值 2 MB 和 1 MB 指示大概的指南,真正的 LOTSFREE 值,即系统开始发生 paging 的值是在系统引导时计算的,它是基于系统内存的大小的。)不是 -> 如果步骤 1 中的 %idle 较低,系统则很可能发生了 CPU 瓶颈。
转至部分 3,部分 A,调整发生了 CPU 瓶颈的系统。
如果 %idle 不是很低,则可能不是 CPU、磁盘 IO或者内存瓶颈。
请转至部分 4,其他瓶颈。
是 -> 系统上存在内存瓶颈,转至部分 3 部分 C,调整发生内存瓶颈的系统。 -
哪些自动化测试工具支持AJAX (转)
peterz 发布于 2009-03-02 20:07:17
原文引用于:http://www.cnblogs.com/oscarxie/archive/2008/01/17/1042670.html
由于AJAX的流行,目前越来越多的Website或是WebApp都或多或少的会加入AJAX的特性,例如Google的搜索,新浪的自选股票等,但是自动化测试工具可能升级不及时暂时还不支持AJAX,最近做的一次压力测试使用LoadRunner 8.0(由于VSTS中的Webtest不支持Ajax,操作都录制不下来,所以放弃)虽然能录制下操作,但是到参数化时才发现,所有的Ajax信息被参数化后存到Body中,整个Body包含全部的请求信息,同时没有很好的页面视图,见下图:
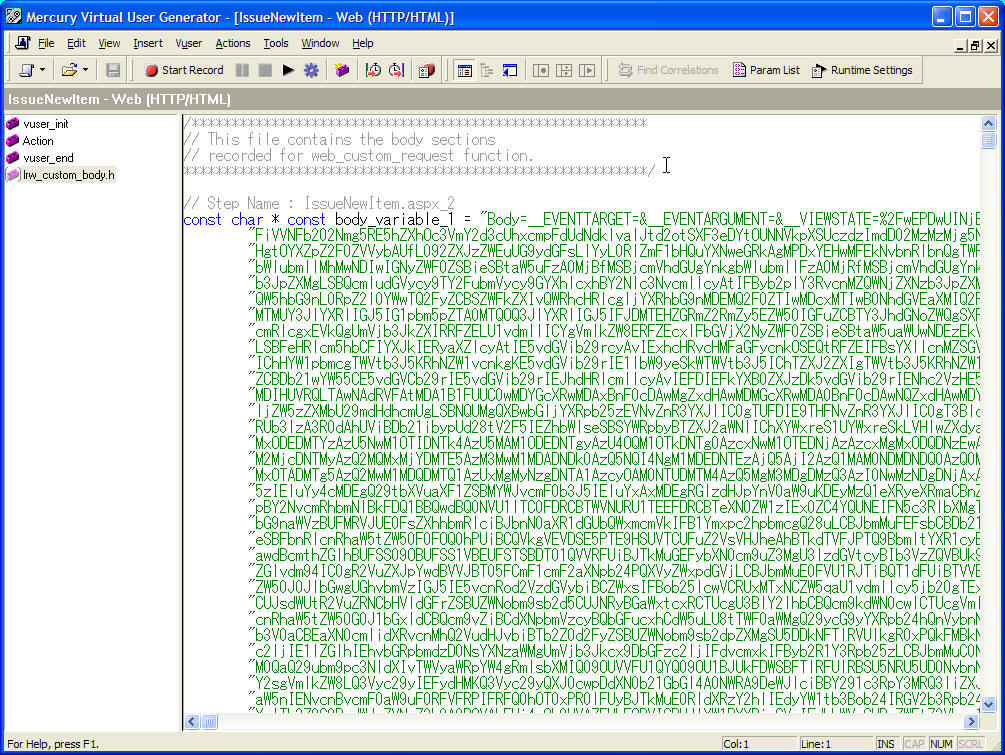
那么要做某个输入框或下拉选项的参数化将非常困难,要从Body中找到对应的字段,没有可视化的效果,使用View Tree模式,看不到页面。在这种情况下,促发我去查找有哪些自动化测试工具能支持AJAX的。不支持的工具有:
Ø QTP 9.1 及其以下版本,
但能够录制,如果有Div画出来的控件无法录制的问题,可以通过依次点击 Tools --> Web Event Recording Configuration, 把Event configuration level 的设置从默认的Basic改为Medium ,然后 关闭QTP,重新录制你的脚本就可以了。
Ø LoadRunner 8.0 及其以下版本
Ø VSTS WebTest,即使是新发布的VS2008中的Webtest也不支持,这个好像微软没有跟上
支持AJAX的工具:
Ø Mercury LR 9.0 及LR8.1加补丁,在LR9.0中,AJAX作为一个单独的协议可供选择
大家都熟悉就不介绍了Ø RadView WebLoad 8.1
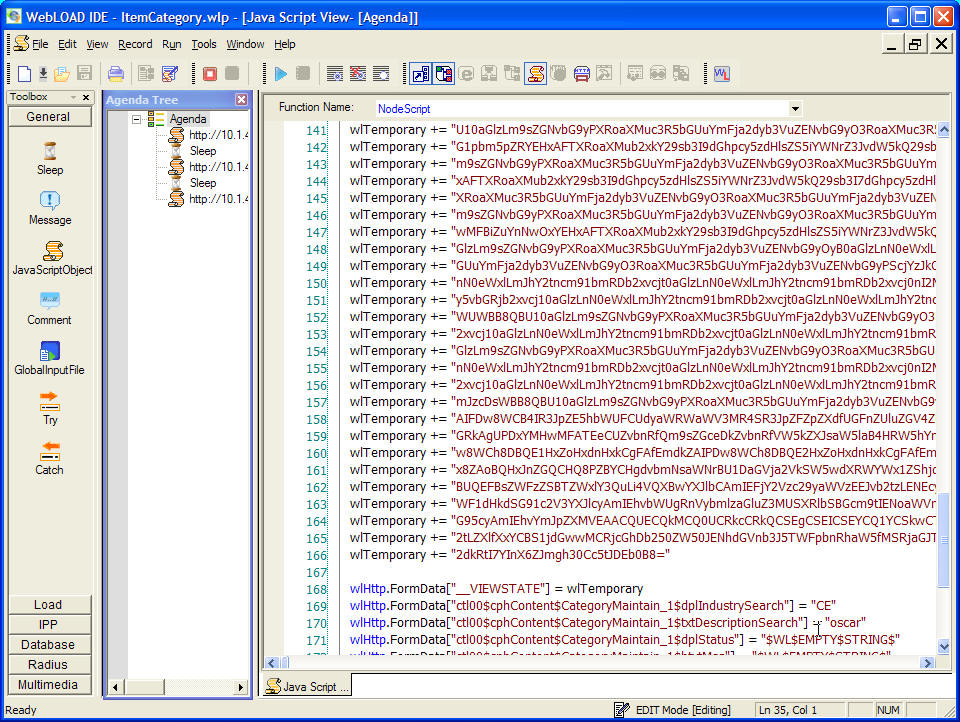
WebLoad中有专门的[wlHttp.FormData]来标识每一个操作。WebLoad是一个开源的压力测试工具,其中的很多源码都已公开。
WebLOAD是来自Radview软件的负载测试工具,它可被用以测试性能和伸缩性,也可被用于正确性验证(验证返回结果的正确性)。其测试脚本是用Javascript(和集成的COM/Java对象)编写的,并支持多种协议,如Web(包括AJAX在内的REST/HTTP)、SOAP/XML及其他可从脚本调用的协议如FTP、SMTP等,因而可从所有层面对应用程序进行测试。Radview声称拥有超过1600个客户和12年的开发WebLOAD的经验,他们在今年二月发布了WebLOAD专业版的v8版本。而在四月,Radview则以GPL协议发布了WebLOAD的开源社区版本,该版本可从webload.org下载。
Ø Parasoft WebKing 6.0

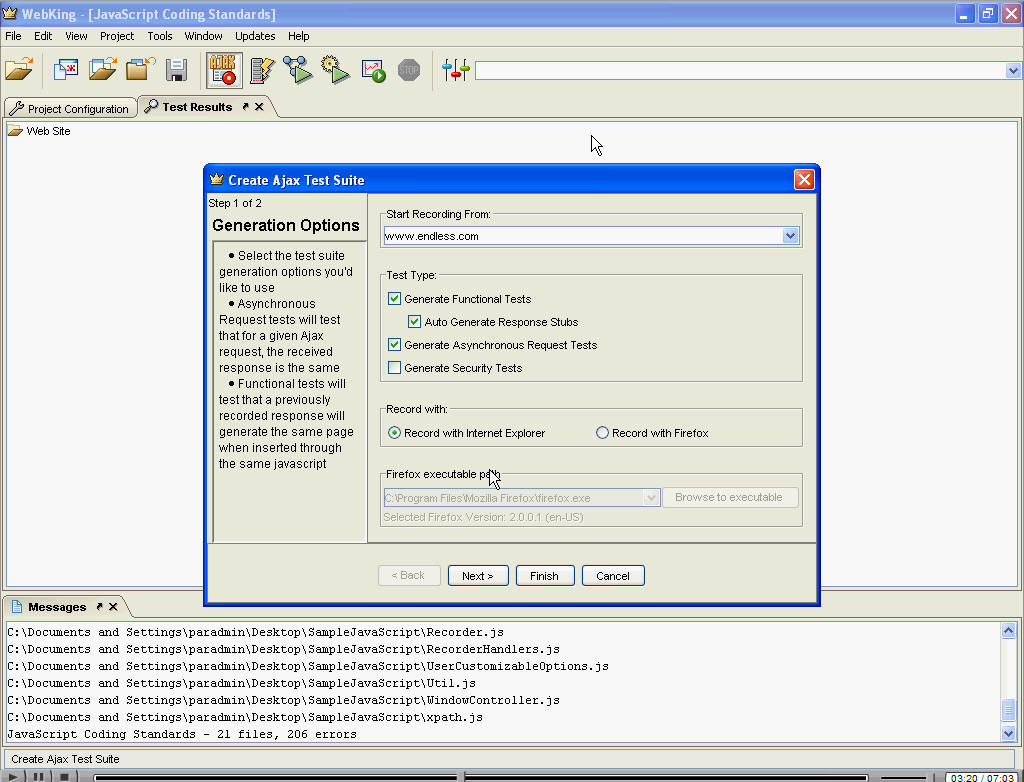
引用:支持AJAX应用的测试工具WebKing 6.0Parasoft WebKing提供先进的自动化测试解决方案,涵盖功能和回归测试套件的创建、执行和管理等,并能很好支持AJAX 开发模式,完成对AJAX应用的测试。
借助WebKing 6.0 可以发现JavaScript. 代码中存在的、手工不容易发现的缺陷. WebKing 6.0 提供空前的支持以发布正确无误的、一致的JavaScript应用. 在构建AJAX 应用中,许多开发人员对JavaScript还不够熟悉。因为JavaScript不会被编译,开发人员很容易引入错误,这些错误只有到运行时才被发现。通过政策和规则的建立和强制实施,WebKing 6.0可以在编程时帮助开发人员预防错误。
现在,WebKing 6.0可以测试象Google地图那样的AJAX应用,提供自动化的功能测试。WebKing可以隔离和测试单个应用的组件,无需额外的脚本就可以支持不同的浏览器. 除此之外,动态数据被转换为稳定的数据,以减少测试噪音。如同在HTTP消息层上,WebKing可以在页面对象(page object)层次上完成验证。无论什么样的条件,WebKing 可以通过异步HTTP消息来验证客户端JavaScript引擎. 测试用例灵活,并容易被复用和共享。
WebKing 6.0能消除因Web应用变化而需要重写脚本所带来的痛苦。短暂的发布周期会要求开发团队和测试团队之间更紧密的协作。更少的技术用户能通过直观的、易用的界面创建测试用例,并能将这些测试用例转换为开发人员易理解的、基于source-code的单元测试,这些单元测试可再现软件行为。这可以显著降低重复劳动,这些自动产生的单元测试采用开源的HttpUnit库来加强AJAX应用。
特性
功能测试
AJAX 应用测试
负载、性能测试
可存取性分析
客户可定制的增强
Intranet标准执行
自动产生开发人员友好的JUnit 测试用例
在不同浏览器运行已录制测试
组织和实施测试的轻型框架支持的平台
Windows XP (Professional or Server Edition)
Windows Server 2003
Windows 2000
Linux
Solaris
JavaScript. Coding Standards
Overview
BeforeUnload.rule
BrowserDetect.rule
BrowserSpecificEventRegistration.rule
CheckAnonDec1.rule and CheckAnonDec2.rule
CheckClosures1.rule, CheckClosures2.rule and CheckClosures3.rule
CurrentTarget.rule
DocEditInnerHtml.rule
DoubleClick.rule
DoWhileAssign.rule
EmptyForBody.rule
EmptyFunctBody.rule
EnforcePrototype.rule
ForConditions1.rule
ForConditions2.rule
ForLoopVarAssign.rule
FunctionReturn.rule
GlobalHttpRequest1.rule and GlobalHttpRequest2.rule
IfAssign.rule
IfWithoutBlock.rule
IllegalIdentifier.rule
IncrementAssign.rule
KeyModifiers.rule
ManyCases.rule
MouseEnterLeave.rule
MouseEventXY.rule
NamingConvention.rule
NestedReferences.rule
NullComparison.rule
RelatedTarget.rule
SetAttribute_Class.rule
SrcElement.rule
SynchronousRequest.rule
TextRangeFromBookmark1.rule and TextRangeFromBookmark1.rule
Timers1.rule and Timers2.rule
UnusedLocalVar1.rule and UnusedLocalVar2.rule
UnWatchMethod.rule
WatchMethod.rule
WhileAssign.rule
XMLHttpRequestCalls.rule
了解更多信息:
http://www.parasoft.com/jsp/products/home.jsp?product=WebKing&itemId=86
WebKing Data Sheet
WebKing Technical Papers
WebKing Reviews
JAVA Technology Solutions
Web Application Technology Solutions
-
MySQL查询优化技术之使用索引
xiaoningln 发布于 2007-02-07 14:50:06
MySQL查询优化技术系列讲座之使用索引索引是提高查询速度的最重要的工具。当然还有其它的一些技术可供使用,但是一般来说引起最大性能差异的都是索引的正确使用。在MySQL邮件列表中,人们经常询问那些让查询运行得更快的方法。在大多数情况下,我们应该怀疑数据表上有没有索引,并且通常在添加索引之后立即解决了问题。当然,并不总是这样简单就可以解决问题的,因为优化技术本来就并非总是简单的。然而,如果没有使用索引,在很多情况下,你试图使用其它的方法来提高性能都是在浪费时间。首先使用索引来获取最大的性能提高,接着再看其它的技术是否有用。
这一部分讲述了索引是什么以及索引是怎么样提高查询性能的。它还讨论了在某些环境中索引可能降低性能,并为你明智地选择数据表的索引提供了一些指导方针。在下一部分中我们将讨论MySQL查询优化器,它试图找到执行查询的效率最高的方法。了解一些优化器的知识,作为对如何建立索引的补充,对我们是有好处的,因为这样你才能更好地利用自己所建立的索引。某些编写查询的方法实际上让索引不起作用,在一般情况下你应该避免这种情形的发生。
索引的优点
让我们开始了解索引是如何工作的,首先有一个不带索引的数据表。不带索引的表仅仅是一个无序的数据行集合。例如,图1显示的ad表就是不带索引的表,因此如果需要查找某个特定的公司,就必须检查表中的每个数据行看它是否与目标值相匹配。这会导致一次完全的数据表扫描,这个过程会很慢,如果这个表很大,但是只包含少量的符合条件的记录,那么效率会非常低。
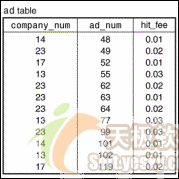
图1:无索引的ad表
图2是同样的一张数据表,但是增加了对ad表的company_num数据列的索引。这个索引包含了ad表中的每个数据行的条目,但是索引的条目是按照company_num值排序的。现在,我们不是逐行查看以搜寻匹配的数据项,而是使用索引。假设我们查找公司13的所有数据行。我们开始扫描索引并找到了该公司的三个值。接着我们碰到了公司14的索引值,它比我们正在搜寻的值大。索引值是排过序的,因此当我们读取了包含14的索引记录的时候,我们就知道再也不会有更多的匹配记录,可以结束查询操作了。因此使用索引获得的功效是:我们找到了匹配的数据行在哪儿终止,并能够忽略其它的数据行。另一个功效来自使用定位算法查找第一条匹配的条目,而不需要从索引头开始执行线性扫描(例如,二分搜索就比线性扫描要快一些)。通过使用这种方法,我们可以快速地定位第一个匹配的值,节省了大量的搜索时间。数据库使用了多种技术来快速地定位索引值,但是在本文中我们不关心这些技术。重点是它们能够实现,并且索引是个好东西。
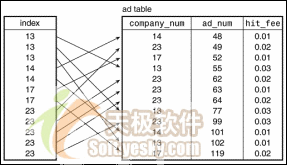
图2:索引后的ad表
你可能要问,我们为什么不对数据行进行排序从而省掉索引?这样不是也能实现同样的搜索速度的改善吗?是的,如果表只有一个索引,这样做也可能达到相同的效果。但是你可能添加第二个索引,那么就无法一次使用两种不同方法对数据行进行排序了(例如,你可能希望在顾客名称上建立一个索引,在顾客ID号或电话号码上建立另外一个索引)。把与数据行相分离的条目作为索引解决了这个问题,允许我们创建多个索引。此外,索引中的行一般也比数据行短一些。当你插入或删除新的值的时候,移动较短的索引值比移动较长数据行的排序次序更加容易。
不同的MySQL存储引擎的索引实现的具体细节信息是不同的。例如,对于MyISAM数据表,该表的数据行保存在一个数据文件中,索引值保存在索引文件中。一个数据表上可能有多个索引,但是它们都被存储在同一个索引文件中。索引文件中的每个索引都包含一个排序的键记录(它用于快速地访问数据文件)数组。
与此形成对照的是,BDB和InnoDB存储引擎没有使用这种方法来分离数据行和索引值,尽管它们也把索引作为排序后的值集合进行操作。在默认情况下,BDB引擎使用单个文件存储数据和索引值。InnoDB使用单个数据表空间(tablespace),在表空间中管理所有InnoDB表的数据和索引存储。我们可以把InnoDB配置为每个表都在自己的表空间中创建,但是即使是这样,数据表的数据和索引也存储在同一个表空间文件中。
前面的讨论描述了单个表查询环境下的索引的优点,在这种情况下,通过减少对整个表的扫描,使用索引明显地提高了搜索的速度。当你运行涉及多表联结(jion)查询的时候,索引的价值就更高了。在单表查询中,你需要在每个数据列上检查的值的数量是表中数据行的数量。在多表查询中,这个数量可能大幅度上升,因为这个数量是这些表中数据行的数量所产生的。
假设你拥有三个未索引的表t1、t2和t3,每个表都分别包含数据列i1、i2和i3,并且每个表都包含了1000条数据行,其序号从1到1000。查找某些值匹配的数据行组合的查询可能如下所示:
SELECT t1.i1, t2.i2, t3.i3
FROM t1, t2, t3
WHERE t1.i1 = t2.i2 AND t2.i1 = t3.i3;
这个查询的结果应该是1000行,每个数据行包含三个相等的值。如果在没有索引的情况下处理这个查询,那么如果我们不对这些表进行全部地扫描,我们是没有办法知道哪些数据行含有哪些值的。因此你必须尝试所有的组合来查找符合WHERE条件的记录。可能的组合的数量是1000 x 1000 x 1000(10亿!),它是匹配记录的数量的一百万倍。这就浪费了大量的工作。这个例子显示,如果没有使用索引,随着表的记录不断增长,处理这些表的联结所花费的时间增长得更快,导致性能很差。我们可以通过索引这些数据表来显著地提高速度,因为索引让查询采用如下所示的方式来处理:
1.选择表t1中的第一行并查看该数据行的值。
2.使用表t2上的索引,直接定位到与t1的值匹配的数据行。类似地,使用表t3上的索引,直接定位到与表t2的值匹配的数据行。
3.处理表t1的下一行并重复前面的过程。执行这样的操作直到t1中的所有数据行都被检查过。
在这种情况下,我们仍然对表t1执行了完整的扫描,但是我们可以在t2和t3上执行索引查找,从这些表中直接地获取数据行。理论上采用这种方式运行上面的查询会快一百万倍。当然这个例子是为了得出结论来人为建立的。然而,它解决的问题却是现实的,给没有索引的表添加索引通常会获得惊人的性能提高。
MySQL有几种使用索引的方式:
· 如上所述,索引被用于提高WHERE条件的数据行匹配或者执行联结操作时匹配其它表的数据行的搜索速度。
· 对于使用了MIN()或MAX()函数的查询,索引数据列中最小或最大值可以很快地找到,不用检查每个数据行。
· MySQL利用索引来快速地执行ORDER BY和GROUP BY语句的排序和分组操作。
· 有时候MySQL会利用索引来读取查询得到的所有信息。假设你选择了MyISAM表中的被索引的数值列,那么就不需要从该数据表中选择其它的数据列。在这种情况下,MySQL从索引文件中读取索引值,它所得到的值与读取数据文件得到的值是相同的。没有必要两次读取相同的值,因此没有必要考虑数据文件。索引的代价
一般来说,如果MySQL能够找到方法,利用索引来更快地处理查询,它就会这样做。这意味着,对于大多数情况,如果你没有对表进行索引,就会使性能受到损害。这就是我所描绘的索引优点的美景。但是它有缺点吗?有的,它在时间和空间上都有开销。在实践中,索引的优点的价值一般会超过这些缺点,但是你也应该知道到底有一些什么缺点。
首先,索引加快了检索的速度,但是减慢了插入和删除的速度,同时还减慢了更新被索引的数据列中的值的速度。也就是说,索引减慢了大多数涉及写操作的速度。发生这种现象的原因在于写入一条记录的时候不但需要写入数据行,还需要改变所有的索引。数据表带有的索引越多,需要做出的修改就越多,平均性能的降低程度也就越大。在本文的"高效率载入数据"部分中,我们将更细致地了解这些现象并找出处理方法。
其次,索引会花费磁盘空间,多个索引相应地花费更多的磁盘空间。这可能导致更快地到达数据表的大小限制:
· 对于MyISAM表,频繁地索引可能引起索引文件比数据文件更快地达到最大限制。
· 对于BDB表,它把数据和索引值一起存储在同一个文件中,添加索引引起这种表更快地达到最大文件限制。
· 在InnoDB的共享表空间中分配的所有表都竞争使用相同的公共空间池,因此添加索引会更快地耗尽表空间中的存储。但是,与MyISAM和BDB表使用的文件不同,InnoDB共享表空间并不受操作系统的文件大小限制,因为我们可以把它配置成使用多个文件。只要有额外的磁盘空间,你就可以通过添加新组件来扩展表空间。
使用单独表空间的InnoDB表与BDB表受到的约束是一样的,因为它的数据和索引值都存储在单个文件中。
这些要素的实际含义是:如果你不需要使用特殊的索引帮助查询执行得更快,就不要建立索引。
选择索引
假设你已经知道了建立索引的语法,但是语法不会告诉你数据表应该如何索引。这要求我们考虑数据表的使用方式。这一部分指导你如何识别出用于索引的备选数据列,以及如何最好地建立索引:
用于搜索、排序和分组的索引数据列并不仅仅是用于输出显示的。换句话说,用于索引的最好的备选数据列是那些出现在WHERE子句、join子句、ORDER BY或GROUP BY子句中的列。仅仅出现在SELECT关键字后面的输出数据列列表中的数据列不是很好的备选列:SELECT
col_a <- 不是备选列
FROM
tbl1 LEFT JOIN tbl2
ON tbl1.col_b = tbl2.col_c <- 备选列
WHERE
col_d = expr; <- 备选列
当然,显示的数据列与WHERE子句中使用的数据列也可能相同。我们的观点是输出列表中的数据列本质上不是用于索引的很好的备选列。
Join子句或WHERE子句中类似col1 = col2形式的表达式中的数据列都是特别好的索引备选列。前面显示的查询中的col_b和col_c就是这样的例子。如果MySQL能够利用联结列来优化查询,它一定会通过减少整表扫描来大幅度减少潜在的表-行组合。
考虑数据列的基数(cardinality)。基数是数据列所包含的不同值的数量。例如,某个数据列包含值1、3、7、4、7、3,那么它的基数就是4。索引的基数相对于数据表行数较高(也就是说,列中包含很多不同的值,重复的值很少)的时候,它的工作效果最好。如果某数据列含有很多不同的年龄,索引会很快地分辨数据行。如果某个数据列用于记录性别(只有"M"和"F"两种值),那么索引的用处就不大。如果值出现的几率几乎相等,那么无论搜索哪个值都可能得到一半的数据行。在这些情况下,最好根本不要使用索引,因为查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。惯用的百分比界线是"30%"。现在查询优化器更加复杂,把其它一些因素也考虑进去了,因此这个百分比并不是MySQL决定选择使用扫描还是索引的唯一因素。
索引较短的值。尽可能地使用较小的数据类型。例如,如果MEDIUMINT足够保存你需要存储的值,就不要使用BIGINT数据列。如果你的值不会长于25个字符,就不要使用CHAR(100)。较小的值通过几个方面改善了索引的处理速度:
· 较短的值可以更快地进行比较,因此索引的查找速度更快了。
· 较小的值导致较小的索引,需要更少的磁盘I/O。
· 使用较短的键值的时候,键缓存中的索引块(block)可以保存更多的键值。MySQL可以在内存中一次保持更多的键,在不需要从磁盘读取额外的索引块的情况下,提高键值定位的可能性。
对于InnoDB和BDB等使用聚簇索引(clustered index)的存储引擎来说,保持主键(primary key)短小的优势更突出。聚簇索引中数据行和主键值存储在一起(聚簇在一起)。其它的索引都是次级索引;它们存储主键值和次级索引值。次级索引屈从主键值,它们被用于定位数据行。这暗示主键值都被复制到每个次级索引中,因此如果主键值很长,每个次级索引就需要更多的额外空间。
索引字符串值的前缀(prefixe)。如果你需要索引一个字符串数据列,那么最好在任何适当的情况下都应该指定前缀长度。例如,如果有CHAR(200)数据列,如果前面10个或20个字符都不同,就不要索引整个数据列。索引前面10个或20个字符会节省大量的空间,并且可能使你的查询速度更快。通过索引较短的值,你可以获得那些与比较速度和磁盘I/O节省相关的好处。当然你也需要利用常识。仅仅索引某个数据列的第一个字符串可能用处不大,因为如果这样操作,那么在索引中不会有太多的唯一值。
你可以索引CHAR、VARCHAR、BINARY、VARBINARY、BLOB和TEXT数据列的前缀。
使用最左(leftmost)前缀。建立多列复合索引的时候,你实际上建立了MySQL可以使用的多个索引。复合索引可以作为多个索引使用,因为索引中最左边的列集合都可以用于匹配数据行。这种列集合被称为"最左前缀"(它与索引某个列的前缀不同,那种索引把某个列的前面几个字符作为索引值)。
假设你在表的state、city和zip数据列上建立了复合索引。索引中的数据行按照state/city/zip次序排列,因此它们也会自动地按照state/city和state次序排列。这意味着,即使你在查询中只指定了state值,或者指定state和city值,MySQL也可以使用这个索引。因此,这个索引可以被用于搜索如下所示的数据列组合:
state, city, zip
state, city
state
MySQL不能利用这个索引来搜索没有包含在最左前缀的内容。例如,如果你按照city或zip来搜索,就不会使用到这个索引。如果你搜索给定的state和具体的ZIP代码(索引的1和3列),该索引也是不能用于这种组合值的,尽管MySQL可以利用索引来查找匹配的state从而缩小搜索的范围。
不要过多地索引。不要认为"索引越多,性能越高",不要对每个数据列都进行索引。我们在前面提到过,每个额外的索引都会花费更多的磁盘空间,并降低写操作的性能。当你修改表的内容的时候,索引就必须被更新,甚至可能重新整理。如果你的索引很少使用或永不使用,你就没有必要减小表的修改操作的速度。此外,为检索操作生成执行计划的时候,MySQL会考虑索引。建立额外的索引会给查询优化器增加更多的工作量。如果索引太多,有可能(未必)出现MySQL选择最优索引失败的情况。维护自己必须的索引可以帮助查询优化器来避免这类错误。
如果你考虑给已经索引过的表添加索引,那么就要考虑你将增加的索引是否是已有的多列索引的最左前缀。如果是这样的,不用增加索引,因为已经有了(例如,如果你在state、city和zip上建立了索引,那么没有必要再增加state的索引)。
让索引类型与你所执行的比较的类型相匹配。在你建立索引的时候,大多数存储引擎会选择它们将使用的索引实现。例如,InnoDB通常使用B树索引。MySQL也使用B树索引,它只在三维数据类型上使用R树索引。但是,MEMORY存储引擎支持散列索引和B树索引,并允许你选择使用哪种索引。为了选择索引类型,需要考虑在索引数据列上将执行的比较操作类型:
· 对于散列(hash)索引,会在每个数据列值上应用散列函数。生成的结果散列值存储在索引中,并用于执行查询。散列函数实现的算法类似于为不同的输入值生成不同的散列值。使用散列值的好处是散列值比原始值的比较效率更高。散列索引用于执行=或<=>操作等精确匹配的时候速度非常快。但是对于查询一个值的范围效果就非常差了:
id < 30
weight BETWEEN 100 AND 150
· B树索引可以用于高效率地执行精确的或者基于范围(使用操作<、<=、=、>=、>、<>、!=和BETWEEN)的比较。B树索引也可以用于LIKE模式匹配,前提是该模式以文字串而不是通配符开头。
如果你使用的MEMORY数据表只进行精确值查询,散列索引是很好的选择。这是MEMORY表使用的默认的索引类型,因此你不需要特意指定。如果你希望在MEMORY表上执行基于范围的比较,应该使用B树索引。为了指定这种索引类型,需要给索引定义添加USING BTREE。例如:
CREATE TABLE lookup
(
id INT NOT NULL,
name CHAR(20),
PRIMARY KEY USING BTREE (id)
) ENGINE = MEMORY;
如果你希望执行的语句的类型允许,单个MEMORY表可以同时拥有散列索引和B树索引,即使在同一个数据列上。
有些类型的比较不能使用索引。如果你只是通过把值传递到函数(例如STRCMP())中来执行比较操作,那么对它进行索引就没有价值。服务器必须计算出每个数据行的函数值,它会排除数据列上索引的使用。
使用慢查询(slow-query)日志来识别执行情况较差的查询。这个日志可以帮助你找出从索引中受益的查询。你可以直接查看日志(它是文本文件),或者使用mysqldumpslow工具来统计它的内容。如果某个给定的查询多次出现在"慢查询"日志中,这就是一个线索,某个查询可能没有优化编写。你可以重新编写它,使它运行得更快。你要记住,在评估"慢查询"日志的时候,"慢"是根据实际时间测定的,在负载较大的服务器上"慢查询"日志中出现的查询会多一些。 -
性能测试如何定位性能瓶颈
另一种蓝 发布于 2011-06-13 11:08:40
接触性能测试不深,更非专家,自己的理解,瓶颈产生在以下几方面:- 1、网络瓶颈,如带宽,流量等形成的网络环境
- 2、应用服务瓶颈,如中间件的基本配置,CACHE等
- 3、系统瓶颈,这个比较常用:应用服务器,数据库服务器以及客户机的CPU,内存,硬盘等配置
- 4、数据库瓶颈,以ORACLE为例,SYS中默认的一些参数设置
- 5、应用程序本身瓶颈,
针对网络瓶颈,现在冒似很少,不过也不是没有,首先想一下如果有网络的阻塞,断网,带宽被其他资源占用,限速等情况,应用程序或系统会是什么情况,针对WEB,无非是超时,HTTP400,500之类的错,针对一些客户端程序,可能也是超时,掉线,服务器下发的,需要服务器返回的信息获取不到还有一种更明显的情况,应该就是事务提交慢,如果封装事务的代码再不完善,一般造成的错误,无非就是数据提交不完整,或者因为网终原因+代码缺陷造成重复性提交。如此综合下来,肯定是考虑网络有瓶颈,然后考虑网络有问题时,怎样去优化,是需要优化交互的一些代码,还是接口之类的。
应用服务的瓶颈的定位,比较复杂,学习中,不过网上有很多资料可以参考的。一般像tomcat,weblogic之类的,有默认的设置,也有经过架构和维护人员进行试验调试的一些值,这些值一般可以满足程序发布的需要,不必进行太多的设置,可能我们认识的最基本的就是JAVA_OPTS的设置,maxThreads,time_out之类的参数我们做借助LR,Jemeter或webload之类的工具,执行性能测试,尤其是对应用服务造成了压力,如果应用服务有瓶颈,一般我们设置的log4j.properties,日志都会记录下来。然后根据日志,去进一步确定应用服务的问题
系统瓶颈,这个定位虽说比较复杂,但是有很多前辈的经验值参考,不作说明,相信用LR的同行,也可以从性能记数器中得出一些指标值,加上nagios,cacti,可以很明显的看出系统哪些资源够用,哪些资源明显不够用。不过,一般系统瓶颈的造成,是因为应用程序本身造成的。关于这点儿的分析和定位,就需要归入应用程序本身瓶颈分析和定位了。
现在基本所有的东东,都离不开数据库这个后台,数据库的瓶颈实在是不知道是什么概念,数据库管理员的工作,数据库管理员日常做的工作,可能就是有瓶颈定位的工作,比如:查询一下V$sys_event,V$sysstat,v$syssql之类的表,比对一下日常正常情况下的监控数据,看一下有没有异常等。其他方面,我也不是太了解。
应用程序瓶颈,这个是测试过程中最需要去关注的,需要测试人员和开发人员配合执行,然后定位,我这儿做的大都是执行性的,比如会有脚本去运行,开发人员会结合jprofiler之类的工具,去看一下堆遍历,线程剖析的情况确定哪儿有问题。大致是这样,没有实际操作过
逐步细化分析,先可以监控一些常见衡量CPU,内存,磁盘的性能指标,进行综合分析,然后根据所测系统具体情况,进行初步问题定位,然后确定更详细的监控指标来分析。
怀疑内存不足时:
方法1:
【监控指标】:Memory Available MBytes ,Memory的Pages/sec, page read/sec, Page Faults/sec
【参考值】:
如果 Page Reads/Sec 比率持续保持为 5,表示可能内存不足。
Page/sec 推荐00-20(如果服务器没有足够的内存处理其工作负荷,此数值将一直很高。如果大于80,表示有问题)。
方法2:根据Physical Disk 值分析性能瓶颈
【监控指标】:Memory Available MBytes ,Pages read/sec,%Disk Time 和 Avg.Disk Queue Length
【参考值】:%Disk Time建议阈值90%
当内存不足时,有点进程会转移到硬盘上去运行,造成性能急剧下降,而且一个缺少内存的系统常常表现出很高的CPU利用率,因为它需要不断的扫描内存,将内存中的页面移到硬盘上。
怀疑内存泄漏时
【监控指标】:Memory Available MBytes ,Process\Private Bytes和Process\Working Set,PhysicalDisk/%Disk Time
【说明】:
Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。内存泄漏应该通过一个长时间的,用来研究分析当所有内存都耗尽时,应用程序反应情况的测试来检验。
CPU分析
【监控指标】:
System %Processor Time CPU,Processor %Processor Time CPU
Processor%user time 和Processor%Privileged Time
system\Processor Queue Length
Context Switches/sec 和%Privileged Time
【参考值】:
System\%Total processor time不持续超过90%,如果服务器专用于SQL Server,可接受的最大上限是80-85% ,合理使用的范围在60%至70%。
Processor %Processor Time小于75%
system\Processor Queue Length值,小于CPU数量的总数+1
CPU瓶颈问题
1、System\%Total processor time如果该值持续超过90%,且伴随处理器阻塞,则说明整个系统面临着处理器方面的瓶颈.
注:在某些多CPU系统中,该数据虽然本身并不大,但CPU之间的负载状况极不均衡,此时也应该视作系统产生了处理器方面的瓶颈.
2、排除内存因素,如果Processor %Processor Time计数器的值比较大,而同时网卡和硬盘的值比较低,那么可以确定CPU 瓶颈。(内存不足时,有点进程会转移到硬盘上去运行,造成性能急剧下降,而且一个缺少内存的系统常常表现出很高的CPU利用率,因为它需要不断的扫描内存,将内存中的页面移到硬盘上。)
造成高CPU使用率的原因:
频繁执行程序,复杂运算操作,消耗CPU严重
数据库查询语句复杂,大量的 where 子句,order by, group by 排序等,CPU容易出现瓶颈
内存不足,IO磁盘问题使得CPU的开销增加
磁盘I/O分析
【监控指标】:PhysicalDisk/%Disk time,PhysicalDisk/%Idle Time,Physical Disk\ Avg.Disk Queue Length, Disk sec/Transfer
【参考值】:%Disk Time建议阈值90%
Windows资源监控中,如果% Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
Processor%Privileged Time该参数值一直很高,且如果在 Physical Disk 计数器中,只有%Disk time 比较大,其他值都比较适中,硬盘可能会是瓶颈。若几个值都比较大, 那么硬盘不是瓶颈。若数值持续超过80%,则可能是内存泄露。如果 Physical Disk 计数器的值很高时该计数器的值(Processor%Privileged Time)也一直很高, 则考虑使用速度更快或效率更高的磁盘子系统。
Disk sec/Transfer 一般来说,该数值小于15ms为最好,介于15-30ms之间为良好,30-60ms之间为可以接受,超过60ms则需要考虑更换硬盘或是硬盘的RAID方式了.
Average Transaciton Response Time(事务平均响应时间)随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应用系统随着投产时间的变化,整体性能将会有下降的趋势
Transactions per Second(每秒通过事务数/TPS)当压力加大时,点击率/TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈
Hits per Second(每秒点击次数)通过对查看“每秒点击次数”,可以判断系统是否稳定。系统点击率下降通常表明服务器的响应速度在变慢,需进一步分析,发现系统瓶颈所在。
Throughput(吞吐率)可以依据服务器的吞吐量来评估虚拟用户产生的负载量,以及看出服务器在流量方面的处理能力以及是否存在瓶颈。
Connections(连接数)当连接数到达稳定状态而事务响应时间迅速增大时,添加连接可以使性能得到极大提高(事务响应时间将降低)
Time to First Buffer Breakdown(Over Time)(第一次缓冲时间细分(随时间变化))可以使用该图确定场景或会话步骤运行期间服务器或网络出现问题的时间。
碰到过的性能问题:
- 1. 在高并发的情况下,产生的处理失败(比如:数据库连接池过低,服务器连接数超过上限,数据库锁控制考虑不足等)
- 2. 内存泄露(比如:在长时间运行下,内存没有正常释放,发生宕机等)
- 3. CPU使用偏离(比如:高并发导致CPU使用率过高)
- 4. 日志打印过多,服务器无硬盘空间
如何定位这些性能问题:
1. 查看系统日志,日志是定位问题的不二法宝,如果日志记录的全面,很容易通过日志发现问题。
比如,系统宕机时,系统日志打印了某方法执行时抛出out of memory的错误,我们就可以顺藤摸瓜,很快定位到导致内存溢出的问题在哪里。
2. 利用性能监控工具,比如:JAVA开发B/S结构的项目,可以通过JDK自带的Jconsole,或者JProfiler,来监控服务器性能,Jconsole可以远程监控服务器的CPU,内存,线程等状态,并绘制变化曲线图。
利用Spotlight可以监控数据库使用情况。
我们需要关注的性能点有:CPU负载,内存使用率,网络I/O等
3. 工具和日志只是手段,除此之外,还需要设计合理的性能测试场景
具体场景有:性能测试,负载测试,压力测试,稳定性测试,浪涌测试等
好的测试场景,能更加快速的发现瓶颈,定位瓶颈
4. 了解系统参数配置,可以进行后期的性能调优
除此以外,还想说个题外话,就是关于性能测试工具的使用问题
在刚开始用Loadrunner和JMeter的时候,做高并发测试时,都出现过没有把服务器压垮,这两个程序自己先倒下的情况。
如果遇到这个问题,可以通过远程调用多个客户端的服务,分散性能测试工具客户端的压力来解决。
说这个的目的是想说,做性能测试的时候,我们一定要确保瓶颈不要发生在我们自己的测试脚本和测试工具上。
-
LoadRunner监控Linux与Windows方法
ring12345 发布于 2011-06-15 17:20:32
一、监控windows系统:
1、监视连接前的准备工作
1)进入被监视windows系统,开启以下二个服务Remote Procedure Call(RPC) 和Remote Registry Service (开始—)运行 中输入services.msc,开启对应服务即可)。
2)在被监视的WINDOWS机器上:右击我的电脑,选择管理->共享文件夹->共享 在这里面要有C$这个共享文件夹 (要是没有自己手动加上)。
3)在安装LR的机器上,开始—》运行,输入 \\被监视机器IP\C$ 然后输入管理员帐号和密码,如果能看到被监视机器的C盘了,就说明你得到了那台机器的管理员权限,可以使用LR去连接了。(LR要连接WINDOWS机器进行监视要有管理员帐号和密码才行。)
问题:在执行步骤3)时,输入 \\被监视机器IP\C$,出现不能以administrator身份访问被监控系统(若采用这种方式用LR对其监控的话,会提示:“找不到网络路径”)的情况,现象就是用户名输入框是灰色的,并且默认用户是guest。
解决办法:这是安全策略的设置问题(管理工具 -> 本地安全策略 -> 安全选项 ->“网络访问:本地帐户的共享和安全模式”)。默认情况下,XP的访问方式是“仅来宾”的方式,如果你访问它,当然就固定为Guest来访问,而guest账户没有监控的权限,所以要把访问方式改为“经典”模式,这样就可以以administrator的身份登陆了。修改后,再次执行步骤3),输入管理员用户名和密码,就可以访问被监控机器C盘了。
若这样都不行的话(可能是其它问题引起的),那只好采取别的方法了。在服务器的机子上,通过windows自带的“性能日志和警报”下的“计数器日志”中新增加一个监控日志(管理工具—)性能—)性能日志和警报),配置好日志,也能监控服务器的cpu、memory、disk等计数器。当然,这种方法就不是用LR来监控了。
2、用LR监视windows的步骤
在controller 中,Windows Resources窗口中右击鼠标选择Add Measurements,添加被监控windows的IP地址,选择所属系统,然后选择需要监控的指标就可以开始监控了。
二、监控linux
1 准备工作
可以通过两种方法验证服务器上是否配置了rstatd守护程序:
①使用rup命令,它用于报告计算机的各种统计信息,其中就包括rstatd的配置信息。使用命令rup 10.130.61.203,此处10.130.61.203是要监视的linux/Unix服务器的Ip,如果该命令返回相关的统计信息。则表示已经配置并且激活了rstatd守护进程;若未返回有意义的统计信息,或者出现一条错误报告,则表示rstatd守护进程尚未被配置或有问题。
②使用find命令
#find / -name rpc.rstatd,该命令用于查找系统中是否存在rpc.rstatd文件,如果没有,说明系统没有安装rstatd守护程序。
如果服务器上没有安装rstatd程序(一般来说LINUX都没有安装),需要下载一个包才有这个服务,包名字是rpc.rstatd-4.0.1.tar.gz. 这是一个源码,需要编译,下载并安装rstatd(可以在[url]http://sourceforge.net/projects/[/url]rstatd<wbr>这个地址下载)
下载后,开始安装,安装步骤如下:
tar -xzvf rpc.rstatd-4.0.1.tar.gz
cd rpc.rstatd-4.0.1/
./configure —配置操作
make —进行编译
make install —开始安装
rpc.rstatd —启动rstatd进程
2)安装完成后配置rstatd 目标守护进程xinetd,它的主配置文件是/etc/xinetd.conf,它里面内容是一些如下的基本信息:
#
# xinetd.conf
#
# Copyright (c) 1998-2001 SuSE GmbH Nuernberg, Germany.
# Copyright (c) 2002 SuSE Linux AG, Nuernberg, Germany.
#
defaults
{
log_type = FILE /var/log/xinetd.log
log_on_success = HOST EXIT DURATION
log_on_failure = HOST ATTEMPT
#only_from = localhost
instances = 30
cps = 50 10
#
# The specification of an interface is interesting, if we are on a firewall.
# For example, if you only want to provide services from an internal
# network interface, you may specify your internal interfaces IP-Address.
#
# interface = 127.0.0.1
}
includedir /etc/xinetd.d
我们这里需要修改的是/etc/xinetd.d/下的三个conf文件 rlogin,rsh,rexec这三个配置文件,打这三个文件里的disable = yes都改成 disable = no ( disabled 用在默认的 {} 中 禁止服务)或是把# default: off都设置成 on 这个的意思就是在xinetd启动的时候默认都启动上面的三个服务!
说明:我自己在配置时,没有disable = yes这项,我就将# default: off改为:default: on,重启后(cd /etc/init.d/ ./xinetd restart)通过netstat -an |grep 514查看,没有返回。然后,我就手动在三个文件中最后一行加入disable = no,再重启xinetd,再使用netstat -an |grep 514查看,得到tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN结果,表明rsh服务器已经启动。
只要保证L
-
XPATH表达式
800716 发布于 2010-12-21 15:08:29
xpath常用路径表达式如下://从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置.选取当前节点..选取当前节点的父节点@指定属性示例一:使用属性定位识别元素//div[@id=’categories’]选 取id为categories的div,返回所有符合条件节点Watir代码:@ie.div(:xpath,”//div[@id='categories']“)示 例二:使用tag以及数组位置定位元素//a返回所有a子元素,无论它们在文档中的位置Watir代码:@ie.link(:xpath,”//a”)注:watir中使用该xpath自动返回元素集中的第一个元素,该代 码与@ie.link(:xpath,”//a[1]”)效果相同。若需要识别其他位置元素,可使用数组方式定位识别, 如:@ie.link(:xpath,”//a[2]”).click点击第二个tag为a的元素,@ie.link(:xpath,” //a[last()]”)点击最后一个tag为a的元素示例三:使用相对路径识别元素//a[1]/../../../../../../div[2]/input首 先找到第一个a元素,一层层定位到根节点下第二个div,再选取input节点Watir代码:@ie.text_field(:xpath,”//a[1]/../../../../../../div[2]/input”).set ‘test’注:使用相对路径可以去除对id,name等属性的依赖,当页面元素缺乏类似属性来定位识别时,可以使用该方法进行控件操作示 例四:根据模糊属性定位元素//a[contains(@href , ' crafts ')]定位到href属性值中含有crafts的a元素Watir代码@ie.link(:xpath,”//a[contains(@href,'crafts')]“).click示 例五:属性不被Watir支持,但可通过xpath识别//select[@foo='bar')]当遇 到有属性名为foo的情况,watir并不支持通过该属性来定位查询元素,但可通过xpath查询识别Watir代码:@ie.select_list(:xpath,”//select[@foo='bar')]“).select ‘Art’示例五:使用element_by_xpath扩展Watir不支持的控件Watir代码:puts @ie.element_by_xpath(”//object”).name注:某些页面标签并不被Watir所支持,比如object,可以通过这种方法获取元素附表一:Watir识别HTML元 素的方法(From Wiki)
How?
HTML源码
Watir代码
注
:action
<form. action=”page.htm”>
ie.form(:action, /page/).click
只可用于form元素, 通过指定form提交的url来识别
:after?
<a>one</a> <a>two</a> <a>one</a>
ie.link(:after?, ie.link(:text, “two”)).click
定位到指定元素之后的页面控件
:class
<a>
ie.link(:class, “header”).click
当元素有class属性时可以使用其进行定位、识别
:for
<label for=”header”>
ie.label(:for, “header”).click
只可用于定位label元素
:href
<a href=”page.htm”>
ie.link(:href, /page/).click
可使用href属性定位超链接
:id
<a>
ie.link(:id, “header”).click
用于通过id识别控件,由于xhtml说明中定义 了id唯一,推荐使用这种最为可靠的识别方式
:index
<button>
ie.button(:index, 1).click
用 于定位页面指定类别第N个元素。目前的Watir版本中从index为1开始计数,但以后可能会从0开始计数。
:method
<form. method=”get”>
ie.form(:method, “get”).click
仅可用于定位form元素,form的method属 性值可以是get或post
:name
<a>
ie.link(:name, “header”).click
:src
<img src=”photo.png”>
ie.image(:src, /photo/).click
当需要通过URL来识别一个图片元素时使用
:text
<a>click me</a>
ie.link(:text, “click me”).click
可用于识别包含文本的页面元素,如link,span,div等
:title
<a title=”header”>
ie.link(:title, “header”).click
识别含有title属性的元素
:value
<input value=”text”>
ie.text_field(:value, “text”).click
用于识别含有默认值的text field元素或button元素
:url
<a href=”page.htm”>
ie.link(:url, /page/).click
url属性和href属性相同
 path
path<a href=”page.htm”>
ie.link(:xpath,”//a[@href='page.htm']“).click
使用xpath定位元素
multiple attribute
<a>click me</a> <a>click me</a>
ie.link(:text => “click me”, :index => 2).click
可以使用多个属性联合定位识别,如本例所示,将点击文本 为”click me”的第二个链接
-
扩展RFT的对象识别技术
lilb01505 发布于 2008-06-02 17:53:39
长期困扰 Rational Functional Tester (RFT) 自动化测试的一个问题就是如何有效地识别 GUI 元素,以适应 GUI 的不断变化,这在敏捷开发日益成为主流开发模式的情况下显得更加重要。本文通过大量的实例向您介绍了针对不同的 GUI 元素,选择不同的对象识别技术,以提高 RFT 自动化测试的效率。
从开发的角度看,GUI 通常都是基于某一 GUI 开发库(SWT/SWING/AWT),这些库通常是按照面向对象的方式进行建模的,它将每一个 GUI 元素映射成该库中某一个类的对象。
从测试的角度看,所有的 GUI 元素,无论基于何种 GUI 库,都被 RFT 映射成对象,RFT 提供一个对象模型框架管理各种 GUI 元素。
图 1 是一个典型的基于 SWT 开发的 GUI,对于其中的一个按钮,在开发者看来,它就是 SWT 库中 Button 类的一个对象;但是 RFT 并不区分这是 SWT 库中的按钮,或者是其他 GUI 库的按钮,它都被映射成 RFT 对象模型中 GuiTestObject 对象。
在用 RFT 提供的 Inspector 工具获取 GUI 元素时,需要用到开发模型。而进行 RFT 脚本开发时,又需要用到 RFT 对象模型。熟练掌握两种对象模型,对提高 RFT 自动化测试效率非常有帮助。
图 1. RFT 对象模型示例
基于 RFT 的自动化测试,都会采用 IBM 推荐的 ITCL 框架。在这个框架下,所有的脚本被划分为三个层次:对象层,任务层,用例层。对象识别就是在 RFT 的对象模型框架下,得到被测程序的 GUI 对象。它是对象层开发中最核心的任务。
常用的 RFT 的对象识别技术可以分为两大类:静态识别与动态识别。动态和静态方法各有优缺点,静态方法识别效率高、开发成本比较低,但是脚本的可维护性比较差;而动态方法刚好相反。


采用常用的对象识别技术,可以识别出大部分的 GUI 元素,但有时也会遇到 RFT 无法识别的 GUI 元素,事实上识别这类用常用对象识别技术无法识别的 GUI 元素占用了 RFT 脚本开发的大部分时间。
RFT 中一个非常重要的根接口是 IGraphical 接口,它定义了针对 GUI 元素的所有标准操作(click,doubleclick,drag 等)。另外一个非常重要的根类是 GuiTestObject,它继承自 TestObject 并实现了 IGraphical 接口。常用对象识别技术中 GUI 元素都是被映射为 GuiTestObject 对象。它们在 RFT 对象模型中的位置如图 2 所示。灵活运用这些类、接口及其方法,能够极大地扩展 RFT 对象识别的功能。
图 2. RFT 对象模型类图
- 问题描述
使用 RFT 经常听到的一个谬论就是 RFT 只能测试基于 java 的 GUI 程序,对于 C/C++ 或者 windows 标准控件,RFT 无法识别。事实上,RFT 提供了 IWindow 接口用于识别平台相关的控件。
- IWindow 接口介绍
从图 2 中可以看出,IWindow 接口也继承自 IGraphical 接口,从这点看,IWindow 接口具有与 GuiTestObject 类似的功能。
使用 IWindow 接口能够识别平台相关的 GUI 控件,但是其接口函数的具体实现与平台相关,windows 与 linux 上的实现就不一样,可以通过下述方法判断具体的平台,本文将主要分析 windows 上的应用。
清单 1
- 典型应用
图 3 是记事本的“页面设置”对话框,是一个 windows 原始窗体。如何识别这个窗体,并点击“确定”按钮呢?基于 RFT 的实现方法如下:
图 3. 被测试程序 GUI
确定对象识别的起始点。通常选取最上层窗体作为对象识别的起始点,具体方法如下所示:
清单 2
这些方法都返回一个 IWindow 接口的数组,每一个数组元素代表一个顶层窗口,并且这些窗口之间是互相独立的。
识别符合要求的顶层窗口,即“页面设置”对话框。IWindow 接口提供了两个方法:getText() 与 getWindowClassName() 来实现。对于窗体,getText() 返回窗体的标题;对于控件,getText() 返回控件的文本。getWindowClassName() 返回 win32 标准控件名。如何知道被测程序的标准控件名呢?在 windows 上有许多工具,例如下文中将提到的 AutoIt 以及 Visual Studio 提供的 Spy++。图 4 是用 AutoIt 得到的 GUI 元素的属性。
图 4. 利用 AutoIt 得到 GUI 元素的属性
对顶层窗体数组根据文本值和标准控件名进行匹配,则可以识别出符合要求的顶层窗体。这两个方法均返回字符串,为了提高识别的效率,通常对这些字符串进行正则表达式匹配。具体用法如下,参数 sCaption 表示窗体的标题,sWindowClassName 表示窗体的 Win32 标准类名。
清单 3
识别窗体内的控件,即“确定”按钮。以顶层窗口为起点,通过 IWindow 提供的 getChildren() 函数可以得到内嵌在顶层窗体的 GUI 控件(如 button,label 等),该方法返回 IWindow 接口的数组,对数组元素根据文本值和标准控件名进行匹配,即可识别出内嵌的控件。识别内嵌控件的方法如下,参数 iTopwin 表示顶层窗体,sCtrlText 表示控件的文本值,sCtrlClassName 表示控件的 Win32 标准类名。
清单 4
IWindow 还提供了 getOwned() 方法,可以得到出顶层窗体拥有的子窗体(如模式对话框等)。
完成点击“页面设置”窗体中“确定”按钮的 RFT 脚本如下。
清单 5
- 问题描述
在进行 GUI 自动化测试时,一个经常遇到的问题就是如何测试开发者定制的控件?通常一组定制的控件,是作为一个整体被 RFT 识别出来,你可以对这个整体作一些操作,但是如何识别出每一个具体的定制控件呢?可以使用 TestObject 类提供的方法:Invoke 函数。
- Invoke 方法介绍
Invoke 方法类似于 java 中的反射机制,它可以在运行时而不是编译时调用函数。通俗地说,在 RFT 中,它可以根据字符串来调用相应的函数。这使得不仅可以调用某些确定的方法(如 GuiTestObject 的方法),还可以主动查询定制控件本身提供的方法,大大加强了对象识别能力。
- 典型应用
使用 Invoke 函数的一个典型例子就是测试 Notes 8 的 tab 项。Notes 8 的 tab 项是一个定制的 java 控件。RFT 会将多个 tab 项识别为一个 GuiTestObject 对象,如何识别出每一个 tab 项呢?并执行关闭 tab 项的操作呢?
首先采用 Object map 方法识别出 RFT 能够识别出的最小的定制控件的集合。如下图 2 红色方框所示的 GUI 元素是 RFT 所能识别出的最小的对象。在本例中它被识别为 GuiTestObject 的对象:sTabFolderObject。
图 5. Notes 8 中定制控件
图 5 Notes 8 中定制控件
确定需要调用的方法。调用 Invoke 方法需要事先知道方法的名称,TestObject 提供了另外一个方法:getMethods 它能够返回控件所有的方法,你可以按照如下的方式调用它。
清单 6
按照这种方式,能够在控制台打印该控件所有可用的方法,从中分析出需要的方法。在本例中发现 getItems 能够返回所有的 tab 项。
调用 Invoke 方法识别出具体的定制控件。完整的用法如下所示,参数 name 表示希望识别的 tab 项的文本值,sTabFolderObject 为上述红色方框表示的对象。
清单 7
完成关闭 tab 项操作。利用 Invoke 可以很便捷的操作 GUI 对象,但是一定要避免使用用户所不能操作的方式来操作控件,因为这违背了测试的原则。从 getMethods 返回的方法中发现 dispose 方法也可以关闭 tab 项,但很显然用户不能这样操作,而用户关闭 tab 项的操作就是点击 tab 项的“X”。因此在 RFT 脚本中,可以首先得到“X”的坐标,然后在该点执行单击操作。具体的方法如下所示。
清单 8
- 问题描述
使用 RFT 进行自动化测试时,经常遇到这样的尴尬,一方面 RFT 在识别某些对象时遇到一些问题,比如无法识别,识别效率低,开发识别脚本代价很高。另一方面又有大量的第三方 GUI 自动化工具对某些特定的领域有很好的性能。如果能够结合 RFT 与其他自动化工具,就能够极大地提高自动化测试的效率,更加适应敏捷开发与测试。
- AutoIt 介绍
AutoIt 是一种在 windows 平台上,针对 C/C++ 以及 windows 标准控件的,免费、开源的自动化管理工具。AutoIt 本身有一种非常简单的脚本语言,这种脚本语言类于 Basic,并且其脚本可以直接转化为可执行程序且不依赖于任何库。事实上,AutoIt 的这些功能,RFT 提供的 IWindow 接口也能够完成,但 AutoIt 具有更高的效率。
- 典型应用一
仍然以 IWindow 接口中点击“页面设置”对话框中的“确定”按钮为例。介绍如何结合 RFT 与 AutoIt 完成上述操作。
- 开发 AutoIt 脚本。AutoIt 对 GUI 对象的识别区分 windows 和 controls。对于 windows 是通过 title/text 方式进行对象识别;对于 controls 是通过 title/text/controlID 方式进行识别。ControlID 是 AutoIt 中特有的概念,它不是一个特定的值,可以是:内部 ID,text,class,instance,classmn 以及它们的组合。在本例中,最终需要识别的对象是“确定”按钮,同时它又位于“页面设置”窗体中。具体的 AutoIt 脚本如下。
清单 9
- 在 RFT 中调用 AutoIt 脚本。RFT 提供了多种启动其它进程的方法,其中类 RationalTestscrīpt 提供的 startApp 和 Run 方法比较常用。使用 startApp 需要事先在 IDE 中进行配置,而 Run 方法具有更多的普遍性,具体的调用方法如下。
清单 10
- 典型应用二
在 RFT 中一类经常遇到的问题就是如何处理那些非预期的活动窗体。例如,点击安全网页上的 link,而这个 link 所指向的却是一个非安全的网页,如果浏览器对安全性要求较高的话,就会弹出一个对话框询问你是否仍然打开这个页面,如果选择“是”则下次重复这样的操作将不再会弹出对话框进行询问,否则下次仍然会询问。因此是否会出现这个窗体取决于是否建立了信任关系,而在脚本开发时是无法预见的。
采用常用的对象识别技术,其典型的处理方法如下所示。
清单 11
上述处理方法采用了常用的对象识别技术识别那些非预期的窗体,如果这些窗体无法用常用方法识别,如何来处理这类问题呢?
图 6. 非预期的对话框
图 6 是打开网页前,系统弹出的一个对话框,它是一个 windows 原始窗体,无法采用常用方法识别(当然可以用 IWindow 来识别),以下结合 RFT 和 AutoIt 来处理。
- 开发 AutoIt 脚本。AutoIt 脚本的任务是点击“Security Alert”对话框中的“Yes”按钮。这可以分为两步,第一步判断对话框是否已经存在;第二步点击“Yes”按钮。具体的 AutoIt 脚本如下所示。
清单 12
- 开发 RFT 脚本。RFT 脚本有三个任务,第一是点击安全网页上的 link 使得“Security Alert”对话框出现。第二是调用 AutoIt 脚本关闭弹出的对话框。第三是判断非安全网页是否已经打开。具体的 RFT 脚本如下所示。
清单 13
从以上可以看出,相比单纯使用 RFT,基于 RFT 与 AutoIt 的混合解决方案需要的脚本显著减少,大大提高了脚本开发效率。当然这种混合解决方案需要你对 AutoIt 有一定的了解,增加了学习的负担,但是一旦掌握,对于提高自动化测试效率是很明显的。
本文阐述了各种不同的对象识别技术,其中 IWindow 接口用于识别 windows 标准控件;Invoke 方法用于识别应用程序定制的 GUI 控件;此外还介绍了 windows 平台上一款优秀的自动化工具 AutoIt 以及如何与 RFT 结合进行自动化测试。将 RFT 常用的对象识别技术与这些特定条件下的对象识别技术相结合,能够使得 GUI 自动化测试更加敏捷。
-
RFT实现可复用的测试框架
lilb01505 发布于 2008-06-02 17:22:06
IBM Rational Functional Tester 6.1 可以使测试人员创建现代的、基于模式的、可复用的测试框架。此篇优秀的文章将告诉您如何进行。
由 John D. McGregor 博士创建的测试设计模式, 为面向对象的组件测试设计一个架构,规定了以下内容:“测试软件的基础体系结构常常被设计成有益于跨许多应用程序和测试解决方案。一般的功能是作为测试许多不同类型组件的基础并作为标准工具的接口。” 同许多测试设计模式一样,该模式立即说明了常常模糊的测试问题,也就是测试代码的重复,并阐明了可能的解决方案:创建了一个可复用的测试框架。
要创建一个可复用的测试框架您都需要什么呢?最核心的,您需要一个组成测试方法学的对象(如各种测试设计模式中描述的)和被测对象(如各种 GUI 控件所表明的)之间的抽象层。此种抽象会要求具备完全面向对象程序设计语言的功能,它是一个具有健壮的映射方法的语言。您当然会需要一种识别 GUI 控件并以面向对象方式显露出其属性的技术。还需要的是一个知道所有控件及验证 GUI 控件对象方法的集成开发环境。最后,一个允许包含多种辅助工具的足够开放的环境会帮助创建最有效的框架。
包含所有这些特性的工具使用起来会足够简单,并且它能够使测试专业人员便于管理,这种工具可以被当作一种框架。当你想节省测试所有被测试应用的时间时,花费时间创建一个可重用的测试框架会导致整体时间的节约。在 Eclipse 集成开发环境中运行的 IBM® Rational® Functional Tester 6.1(参见图 1)提供所有这些功能。Functional Tester 有两种版本:VB.NET 脚本(在 Visual Studio .NET 集成开发环境中运行)和 Java™脚本版本(在 Eclipse 环境中运行的)。本文中考虑 Java 脚本版本。因为现在已经有一个可以创建可复用测试框架的产品了,所以没理由不开始。
图 1. IBM Rational Functional Tester 6.1版本(功能测试透视图)
一旦您拿到了 Functional Tester 工具,就可以开始创建可复用的框架了。但您从哪里开始?您如何进行?有指导吗?幸运的是,在您之前已经进行了一些工作。在其他类型的软件设计模式中,已经创建了许多测试设计模式。当然,它们并没有包括所有需要的东西以创建可复用的测试框架,但值得进行参考。重复了使用模式的好处:
- 它们为问题解决者提供一个词汇表。“嘿,你知道吗,我们应该使用一个 Null Object。”
- 它们关注问题背后的力量。其使设计者更好地理解何时以及为什么应用解决方案。
- 它们鼓励迭代思考。每个解决方案创建一个新的在其中可以解决新问题的环境。
现在我们有了工具(Functional Tester)并且我们有了设计方法。是时候回顾一下需求了。我们将看到许多 Functional Tester 能够直接满足的需求,同时也要专注于我们必须添加的以创建可复用框架的一般功能。目的是设计具有以下新功能的测试框架:
- 自动的测试输入生成
- 自动的预期结果生成
- 自动的比较器
这些功能出自 Robert V. Binder 的 测试面向对象的系统模型、模式和工具 。书中列出许多更多的需求,然而,剩下的要么是由 Functional Tester 自动处理的,要么对一般解决方案不是必要的。
在 Functional Tester 提供的功能中,脚本被记录,并且测试人员执行以下工作:将脚本模块化、数据驱动想得到的输入、创建想得到的验证点,并回放脚本。然而,如果测试用例的数量很大的话,问题会出现。在此情况下,需要记录所有测试用例步骤的时间可能不能实行。当联系到许多测试工程上时,该问题扩大了。解决方案是提供用于生成可在所有测试工程中复用的测试输入的一般框架。
自动生成测试输入有三个主要的方法:
- Functional Tester 数据池(可以由 IBM® Rational® TestManager 数据库导入)
- 简单地,通过编程方法控制的 XML 或关系数据库的获取和设置
- 由算法的生成和过滤作为参数的,通过编程方法控制的 XML 或关系数据库的获取和设置
每个方法在一般测试框架中都有一个有效的角色。
方法一:使用: Functional Tester 数据池输入信息
Functional Tester 数据池用于生成不需要由复杂算法(例如 Address,或 Phone 字段)衍生而来的可变数据。您可以利用 IBM Rational TestManager 数据库池创建的自动格式化特性来创建简单的模式,如社会安全码、名和姓、地址和邮政区码。然后,Functional Tester 可以导入这些数据池(参见图 2)。
图 2. 导入数据池
在导入之后,您使用 Functional Tester 关联数据库和您的脚本。Functional Tester 允许您选择哪一项用数据池值来替代。您可以通过索引或脚本中的名称查阅到数据池字段。在引用创建之后,如果需要,这些值可以通过编程的方式改变。下载必要的代码,以插入到文中底部的数据池值中。
简单的说,当只需要一般算法时,通过编程方法控制的 XML 或关系数据库的获取和设置是有用的,但数据模式对于生成的数据池输入仍旧是太复杂。一个实例是自动生成持续的帐户或一般的分类帐户,在其中嵌入了一些语义,并且希望在那样的测试数据中维持真实性,特别是数据涉及非常大的必须在测试程序执行之间保持顺序的数字。此处最有利的解决方案是创建测试数据库并通过编程的方式从那些行中获取输入数据,执行任意需要的语法分析,在 Functional Tester 中按需要使用数据,在 Functional Tester 中从一个脚本到另一个脚本进行数据更新,并更新或将带有在下一个测试程序执行中使用的数据的行插入到测试数据库中。
您需要为您使用的数据库安装数据库驱动。对于本文中描述的测试框架,创建 SQL Server 测试数据库。要想加强 Functional Tester 类的内聚力,您可能想要将代码与实际的和测试数据库的交互隔离开来,并只是将 SQL 语句作为这些方法的参数进行传递
如果您想要为测试框架提供来自 Functional Tester 脚本的基于 SQL 的数据库调用的最大化的抽象,您可以实现设计模式 Mapper 和 Query Object,其允许您对 Functional Tester 脚本中的信息进行一般化的请求,以服从具体数据库 SQL 语法到其他类的构造。
通过算法从 XML 或关系数据库中检索数据来有计划地生成输入数据是一般测试框架的核心引擎。本文介绍了一个方法三的版本,其中实现了设计模式 Combinational Function Test。在此模式中,由每个输入值组合生成的操作被评估。
一种用于存储一组 GUI 控件的可能输入值的有效方法是将控件及其可能的值放入 XML 文件中。随着当前这种应用开发中的动态的、执行时决定显示哪个控件的趋势,现在有一个好的机会,您项目的开发团队已经在 XML 配置文件中定义了控件和其可能的值。但如果他们没有,您就可以在几分钟之内做出那样一个 XML 文件。(在本文的底部下载 GUI 控件和其可能值的示例 XML 描述)。您可能想要通过任意组合框的下拉列表提交值。对于文本框,您可以提交导致各类业务规则的结果值的具体实例(比如,提交 1 和 12,如果业务规则规定 0 和 10 之间的值会导致一个结果,而 11 和 20 之间的值会导致另一个结果)。
提交条件式来代替值是可能的(例如 "< 20)。这需要一些额外的编码来分析条件式,这可能会十分复杂(参阅 可重用的面向对象软件的设计模式元素 中的 Interpreter 设计模式)。
要访问 XML 文件,我们将利用文档对象模型(Document Object Model,DOM)。此方法需要比其他方法更少的编程并在将所有 XML 访问代码保留在 Functional Tester 类中方面占有优势。使用 DOM 的通常劣势是需要许多内存,但当需要为应用程序定义 GUI 控件的 XML 文件很小时是不成问题的。如果您测试经常变化的应用程序,可以考虑更简单的维护,来为每一屏创建单个的 XML 文档,或一些其他的逻辑分割。一旦您理解了文档遍历方法,对包含 GUI 控件和对于这些控件可能的值的 XML 文件的 DOM 分析就相当的简单了。基本上,您创建类来设置 DOM 使其与 XML 文档一起工作,过滤 XML 节点,并处理过滤器的结果。下载本文底部的代码进行所有这三个动作。
如这三个类所描述的,本文中的策略是通过指定以下内容来检索节点的:
- 期望节点的根
- 期望节点的父节点
- 期望节点的名称
过滤器还指定达到对照节点所必要的兄弟节点的数量。为了便于使测试框架一般化,您应该使用变量对应那些值作为这些过滤节点的名称,并在中央位置设置这些变量的值。这使得配置下一个在测应用程序的测试框架更加简单。使用像 Functional Tester 这样的现代工具的一个意义是使得将强大的应用程序,如 DOM 引入到复杂的任务中(如创建一般化的测试框架)来进行辅助成为可能。
使用 Functional Tester 的另一个意义是,根据其对 Java 的支持,它对 Collection(创建任何种类的框架所绝对必要的)提供很强的支持。在此处描述的测试框架中,所有 Combinational Function Test 模式实现所涉及到的 GUI 控件的名称和可能的输入值存储在一个Vectors的Vector中。此超级Vector索引为 0 的Vector包含了每个参与实现的 GUI 控件的名称。每个余下部分的Vector包含了每一个参与GUI 实现的控件的可能输入值。创建框架时必须完成的一项任务是构造一个等同于每个 GUI 控件可能拥有的三个名称的映射:XML 文件、被测应用程序代码和 Functional Tester Test Object Map。您可以生成一个使用正规表达的类,或者如果您企业中的命名标准严格限定,您可以进行简单的编辑。
既然我们将所有参与的输入值存储到Vectors中,那我们就可以开始生成所有可能组合的工作了。此处使用的方法是递归形成存储在每个 GUI 控件可能值Vectors 中的值的积(我们称这些Vectors为“置换群(Permutation Group)”)。我们开始形成包含一组 ArrayLists 的 ArrayList,在其中,每个构成的 ArrayLists 正好包含第一个置换群的一个元素。然后,创建一个新的 ArrayList,它包含每个(超级 ArrayList 的)构成的 ArrayLists 的内容和第二个置换群的所有单元的向量积。伴随每个递归步骤,会形成带有一个额外置换群的向量积。
在过程的最后,我们有一组 ArrayLists(测试用例),每个都包含对应参与的 GUI 控件的有效值(下载本文底部的代码。)。ArrayLists 中值的顺序与 XML 文件中的 GUI 控件的顺序是一致的(回去参考 XML 文件配置的代码)。您的框架应该为每个测试用例分配一个数,为了简单地再次运行失败的测试用例。
当然,处理测试输入的所有可能的全排列输出很快就行不通了(依据在测的应用程序)。例如,如果您有十个参与的 GUI 控件,并且如果每个控件只取三个可能的值,您将生成 59,049 个测试用例!有许多方法限制该数量。最简单的方法是在 XML 文件中加入标志,使得只考虑临界的 GUI 控件和值。另一种方法是让框架生成所有的测试用例,但只处理第一个 n,或者只处理随机选择的(可以在一个单个的,全世界都容易接受的类中定义这些选择标准的参数,以简化对每个在测应用程序的变量配置)。其他方法还涉及在代码中调用生成测试用例的业务规则(就是说,“如果 GUI 控件 A 的值小于 20,但 GUI 控件 B 的值大于 12,那么删掉该测试用例”)。
一旦创建了用于自动生成测试输入的类,您就可以创建使用这些输入的 Functional Tester 脚本了。此处的整个方案是遵循由 John D. McGregor 博士创建的一个版本的测试设计模式:利用测试脚本的顺序测试用例,及 Robert V. Binder 创建的测试设计模式:Test Case/Test Suite Method。我们的测试框架的整个结构是具有一个单个控制器的测试脚本,它执行两个功能:1) 在先前的测试脚本之后进行清除,并设置后续脚本,及 2)调用其它模块化的测试脚本。这些模块化脚本越是紧密,就越能更好地促进脚本的复用性。用于调用其它脚本的 Functional Tester Java 语法是:
callscrīpt ("OtherModularizedscrīptName");。有所帮助的是将控制器脚本中的callscrīpt语句用System.out.println语句(在控制台中书写注释,指示在处理控制器脚本过程中发生的事件的顺序)进行分离。假设被测的应用程序有大量的测试用例,我们承认记录每个测试用例以创建模块化的测试脚本必须预先有利于一个更一般化的解决方案。Functional Tester 工具使我们实现 Prototype 设计模式(Design Patterns Elements of Reusable Object-Oriented)以在执行时选择期望的功能测试方法。这可以通过利用反射在 Functional Tester 助手类中参数化地调用方法来完成(下载本文底部的代码)。在记录脚本时,Functional Tester 会自动生成这些助手类。
Functional Tester 助手类中包含了到被测应用程序中的 GUI 对象的索引。Functional Tester 的向 Test Object Map 中添加 GUI 控件的概念(可由多个测试脚本使用)有效地实现了 Fowler 的 Identity Map 设计模式。Functional Tester 通过测试人员执行的两步骤的过程获得了这些 GUI 对象的属性:
- 使用 Functional Tester GUI 控件识别工具。更确切地说,将“手”图标(参见图 3)拖到控件上,释放以向 Functional Tester Test Object Map 中输入对象。
- 将 Test Object Map 添加到需要访问该控件的测试脚本中(在 Functional Test Perspective 顶部菜单栏:选择scrīpt > Open Test Object Map > select an object > Add to scrīpt)。
图 3. Drag Hand Selection 方法
利用上面概括的过程,您应该能够创建模块化的、可复用的,由您所创建的测试脚本控制器调用的脚本。然而一个错过的内容是动态控制测试程序的方法。对此,您的测试框架可以使用一个 GUI 接口,通过它测试团队可以控制运行时参数(当然,在您的测试控制器脚本启动时,Functional Tester 也允许您输入命令行参数)。幸运的是,Functional Tester 允许您访问任何您要用 Standard Widget Toolkit((SWT)来创建的 GUI。
首先,您需要将 SWT 安装到 Functional Tester(Eclipse)环境中(查阅书籍 SWT A Developer's Notebook 中的逐步的指导)。假如我们想要一个可以输入某些运行时参数的简单对话框窗口。然后您需要生成一个 SWT 外壳类和对话框窗口本身的类(下载本文底部的代码)。完成了的测试框架执行时的对话框窗口如图 4 显示。
图 4. SWT 输入对话框窗口的运行时显示
既然您的测试框架中包含了输入测试用例数据和执行测试用例的一般化机制,那么您就需要一个自动验证结果的方法。存在许多比较基线数据和实际结果的可用选择。Functional Tester 提供三种类型的验证:静态、手动和动态(在 Functional Tester Help 中搜索主题
IftVerificationPoint,以得到完整的描述)。要创建一个一般的测试框架,您最好的选择可能是手动,因为其考虑最大化的编程控制和有效的、高容量的验证。当然,您也可以书写自己的代码,但 Functional Tester 方法已经将结果写到 Playback 日志中。因此,您的测试框架会包含脚本,如:vpManual("vpResultChecker1", strExpectedResult, strActualResult).performTest();然后,您会从 XML 文件或关系数据库表格中读到预期的结果。您会想将每个测试用例 ID 与一致的期望结果关联起来。在大容量的测试环境中,您也许还想创建 GUI 来显示所有的验证失败(参见图 5)。
图 5. 显示验证差异的 GUI 示例
现在您拥有了一般测试框架的核心。Functional Tester 提供其两个自身直接的支持,以及通过其开放的体系结构对其他辅助产品的支持。与您曾想要实现的其他更简单的测试设计模式要做的事情相比,本文中的实例相当复杂。当然,如早些时候陈述的,Functional Tester 本身已经实现了很多简单的满足可重用测试框架的需求。其他的需求你也可以在 Functional Tester 中很容易实现。具备了这样一种通用的测试框架,您可以在将来的测试工程中大大地减少测试时间。
-
RFT 助您轻松完成自动化功能测试
lilb01505 发布于 2008-06-02 17:17:05
本文将向读者介绍 IBM Rational Functional Tester 的强大的功能和良好的易用性,以及如何帮助测试人员轻松的完成自动化的功能测试。
在软件工程领域,如果说有一种工作让人在痛苦中感受它的价值、在无休止的加班中体会它的苦涩、在技术的进步中体验它的快乐的话,那它一定是软件测试。计算机技术发展到今天,自动化测试工具的广泛应用使人们重新认识到测试的源动力:最优的质量成本,软件开发过程中的测试及各种质量保证活动,无疑是在追求软件质量成本和收益间的最佳平衡点。
谈到自动化测试,首先我们要明确什么情况下需要自动化。自动化测试的目的是通过自动执行测试脚本,使测试人员在更短的时间内能够更快地完成更多的软件测试,并提供以更高的频率执行测试的能力,从而有效降低测试成本、提高测试效率。从软件测试的成本来看,使用测试工具进行软件自动化测试的成本可以以下公式表示:
自动化测试的成本=测试工具成本+测试脚本的创建成本+测试脚本的维护成本
既然自动化测试的目的在于降低测试成本、提高测试效率,因此,测试团队在选择自动化测试工具时,必须在提高测试效率的同时,尽量做到自动化测试的总体成本小于手工测试成本。因此,自动化测试工具的脚本自动化创建能力和可维护性,就成了衡量自动化测试工具的重要因素。
在实际的测试工作中,一般说来,我们选择自动化的功能测试工具无外乎要解决以下三个问题:
- 自动化的功能回归测试
- 大批量数据驱动的软件测试
- 整个软件测试生命周期的管理
在选择自动化测试工具解决这些问题的过程中,人们主要关心的问题是使用自动化测试工具创建测试脚本的能力、工具的易用性、测试脚本的编程和扩展能力、测试脚本的参数化技术以及作为软件开发重要环节的测试工作和其它软件生命周期管理工具的集成能力。
因此,摆脱自动化测试困惑的根本途径,就是理解自动化测试的本质,明确自己的自动化测试需求,选择合适的自动化测试工具,帮助测试团队提高效率、降低成本,最终实现软件开发过程的全过程质量保证。
2 IBM最新自动化功能测试解决方案:Rational Functional Tester
IBM Rational Functional Tester(简称RFT)是一款先进的、自动化的功能和回归测试工具,它适用于测试人员和GUI开发人员。使用它,测试新手可以简化复杂的测试任务,很快上手;测试专家能够通过选择工业标准化的脚本语言,实现各种高级定制功能。通过IBM的最新专利技术,例如基于Wizard的智能数据驱动的软件测试技术、提高测试脚本重用的scrīptAssurance技术等等,大大提高了脚本的易用性和可维护能力。同时,它第一次为Java和Web测试人员,提供了和开发人员同样的操作平台(Eclipse),并通过提供与IBM Rational整个测试生命周期软件的完美集成,真正实现了一个平台统一整个软件开发团队的能力。
IBM RFT的最大特色就是基于开发人员的同一开发平台(Eclipse),为Java和Web测试人员提供了自动化测试能力。如图一所示,使用RFT进行软件测试时,我们只要在开发人员工作的Eclipse环境中打开Functional Test透视图,就会马上拥有专业的自动化功能测试工具所拥有的全部功能。
图一、IBM Rational Functional Test工作界面
在RFT中实现测试脚本的过程和大部分的自动化测试工具一样,是基于录制的脚本生成技术。当我们完成测试用例后,只要在功能测试工具条上选择测试脚本录制按钮,就会启动测试用例的脚本实现过程。
如图二所示,在脚本录制的"选择脚本资产"对话框中,用户可以选择预定义好的公用测试对象图和公用测试数据池,也可以选择在脚本录制过程中生成私有测试对象图和数据池。测试对象图是IBM用来解决测试脚本在不同被测版本间,成功回放的关键技术,它为测试脚本的重用提供了重要保证;而测试数据池是IBM用来实现数据驱动的自动化功能测试的重要手段,使用智能化的数据驱动测试向导,测试脚本的参数化几乎变得易如反掌。
图二、"选择脚本资产"对话框
如图三所示,在功能测试的录制监视窗口,测试员可以根据提示启动被测应用系统,执行测试用例中规定的测试步骤,实现测试脚本的录制。在测试脚本录制过程中,测试员可以根据需要插入验证点和数据驱动的测试脚本,验证点是在指令中比较实际结果和预期结果的测试点,自动化功能测试工具正是通过它实现对被测系统功能需求的验证。
图三、测试脚本录制窗口
完成脚本录制过程以后,RFT会自动生成用工业标准语言Java描述的测试脚本,如下所示:
import resources.ThirdwithDatapoolHelper; import com.rational.test.ft.*; import com.rational.test.ft.object.interfaces.*; import com.rational.test.ft.scrīpt.*; import com.rational.test.ft.value.*; import com.rational.test.ft.vp.*; /** * Descrīption : Functional Test scrīpt * @author ndejun */ public class ThirdwithDatapool extends ThirdwithDatapoolHelper { /** * scrīpt Name : <b>ThirdwithDatapool</b> * Generated : <b>2005-4-17 15:22:36</b> * Descrīption : Functional Test scrīpt * Original Host : WinNT Version 5.1 Build 2600 (S) * * @since 2005/04/17 * @author ndejun */ public void testMain(Object[] args) { startApp("ClassicsJavaB"); // Frame: ClassicsCD classicsJava(ANY,MAY_EXIT).close(); } }
基于Java的测试脚本,为高级测试软员提高了更强大的编程和定制能力,测试员甚至可以通过在Helper类中加入各种客户化脚本,实现各种高级测试功能。
RFT具有基于向导(Wizards)的数据驱动的功能测试能力。在功能测试脚本的录制过程中,如图四所示,我们可以方便选择被测应用图形界面上的各种被测对象,进行参数化,通过生成新的数据池字段或从数据池中选择已存在数据字段,实现数据驱动的功能回归测试。
图四、数据驱动的功能测试
在生成测试脚本的同时,RFT还能够帮助测试员在验证点中使用正则表达式或使用数据驱动的方法建立动态验证点。动态验证点用来处理普通验证点的期望值随着输入参数不同而发生变化的情况。在下面的例子中,如图五所示,订单总金额会随着购买商品数量的不同而变化,通过数据驱动的功能测试方法,测试员首先要对购买的商品数量和订单总金额进行参数化,然后编辑验证点中的期望值,将其用数据池中的对应订单总金额代替,这样验证点中的总金额就随着购买商品数量的不同而得出正确的总金额。通过简单操作、无需任何编程,测试员就可以很方便地实现动态验证点的功能。
图五、生成动态验证点
此外,测试员还可以通过在验证点中使用正则表达式,建立更加灵活的验证点,保证测试脚本的重用性。
图六、正则表达式在验证点中的应用
使用IBM Rational Functional Test工具进行Java和Web应用系统测试时,标准Java的测试脚本语言,为测试脚本的可重用性和脚本能力提供了第一层保证。此外,通过维护"测试对象图",IBM为测试员提供了不用任何编程就可以实现测试脚本在不同的被测系统版本间的重用能力。"测试对象图"分为两种,一种是公用"测试对象图",它可以为项目中的所有测试脚本使用;另一种是私有"测试对象图",它只被某一个管理的测试脚本所使用。在软件开发的不同版本间,开发员会跟据系统需求的变化,修改被测系统和用于构建被测系统的各种对象,所以测试脚本在不同的版本间进行回归测试时经常会失败。因此,通过维护公用"测试对象图",如图七所示,测试员可以根据被测应用系统中对象的改变,更新测试对象的属性值及对应权重,这样在不修改测试脚本的前提下,就能使原本会失败的测试脚本回放成功。同时,为了方便测试员对测试对象图的修改和维护能力,RFT还提供了强大的查询和查询定制能力,帮助测试脚本维护人员快速找到变化的测试对象,进行修改和维护工作。
图七、测试对象图的维护
其次,IBM提供的scrīptAssurance专利技术,使测试员能够从总体上改变工具对测试对象变更的容忍度,在很大程度上提高了脚本的可重用性。scrīptAssurance技术主要使用以下两个参数:脚本回放时,工具所容忍被测对象差异的最大门值和用于识别被测对象的属性权重。使用这种技术,测试员可以通过Eclipse的首选项设定脚本回放的容错级别,即门值,如图八和图九所示:
图八、IBM专利技术:scrīptAssurance容错级别设定
点击高级,能够看到各种具体的可接受的识别门值。
图八、scrīptAssurance门值设定
其次,测试员可以根据被测对象实际更改情况,在测试对象图中(如图七所示)修改用于回放时识别被测对象的属性及其权重。在测试脚本回访时,测试对象的识别分数将由以下公式计算得出:
int score = 0; for ( int i = 0; i < property.length; ++i ) score += (100 - match(property[i])) * weight;
其中,match()将根据属性的符合程度返回0~100之间的值,完全符合返回100,完全不符合返回0。
测试脚本回放成功与否则取决于:识别得分 < 识别门值。通过这一技术,如图十所示,通过设置恰当的scrīptAssurance门值和为用于识别对象的属性设置合适的权重,即使在两个回归测试的版本间测试对象有多个属性不同,对象仍有可能被正确识别,脚本仍有可能回放成功。这为测试脚本的重用提供了最大程度的灵活性。
图十、scrīptAssrance技术保证脚本的重用
IBM Rational的自动化功能测试工具基于Eclipse平台,提供了和需求管理工具(RequisitePro)、建模工具、代码级测试工具和变更及配置管理工具(ClearQuest和ClearCase)的完美集成,这使得系统测试人员能够和整个软件开发团队在同一个软件平台上,实现系统功能测试,完成测试脚本的配置管理和缺陷追踪。
如果一种软件工具能够在提供强健的自动化测试脚本录制和自动化测试能力的同时,很好地解决测试脚本的可维护性、大批量数据驱动的软件测试和整个软件开发生命周期的集成问题,它无疑为降低软件测试的质量成本提供了重要保证,而IBM Rational Functional Tester正是这样的工具,它的出现必将使我们的测试生活变得更加美好!
-
Rational Robot 的自动化功能测试框架
lilb01505 发布于 2008-06-02 17:10:58
本文介绍了构建在 IBM Rational Robot 基础之上的自动化功能测试框架,来帮助组织更好的进行自动化的功能测试。
测试本身就是一项异常艰苦的工作,而成功的进行自动化的功能测试,对很多软件开发组织来讲,更是困难重重。本文介绍了构建在IBM Rational Robot基础之上的自动化功能测试框架,来帮助组织更好的进行自动化的功能测试。
随着业务的变化,软件产品的种类越来越多,软件产品的升级越来越快,在很多的软件开发组织中,测试部门承受着巨大的压力,他们一方面要测试越来越多的软件产品,一方面要应对越来越短的测试时间,同时,还要面对捉襟见肘的测试资源。
每个版本发布都包括新增加的功能和已有的功能,已有的功能已经在以前的版本中进行过测试,但是还需要在此版本中执行回归测试。在这种情况下,测试部门往往会考虑到,既然回归测试的测试用例都已经存在并且已经在上一个版本中执行过,那么在新版本中能否自动的执行这些测试?如果能这样的话,将极大的节省时间和资源,将有限的资源投入到新功能的测试上,缓解测试的压力。
通常情况下,软件开发组织会使用自动化测试工具,使用录制回放方式来进行功能测试的自动化。但是录制回放方式并不能解决全部问题。
业界的经验表明,虽然录制回放方式能够快速的生成测试,但是仅仅单纯的使用录制回放是不够的。
首先,也是最主要的原因,就是使用录制回放方式,往往需要耗费时间和资源来调试、维护脚本。这些工作量随着脚本数量的增加,可能会增大到几乎不可能再对脚本进行有效维护的地步;其次,使用录制回放方式,要求应用已经开发完成并且在录制中不出现错误,但是往往当应用达到此条件时已经没有足够的时间进行测试;最后,使用录制回放方式,要求每个测试人员均会使用测试脚本语言“编程”,而当前大多数软件开发组织测试人员专注于业务,往往没有兴趣和精力来“编程”。
所以,录制回放方式并不能解决所有的问题,在自动化的功能测试上,需要有测试框架的支持。
IBM Rational Robot是一款优秀的自动化测试工具,自动化功能测试框架是基于Robot之上构建的。如下图:
业务测试人员类似于当前软件开发组织中使用手工执行测试的测试人员。可以看到,在解决方案中,除传统的业务测试人员外,增加了技术测试人员角色。技术测试人员偏重于自动化测试相关技术,实际上并不直接执行测试。
解决方案的核心是使用Robot的SQABasic脚本开发的Robot测试技术框架。此Robot测试技术框架以表驱动为指导思想,读入动态结构,解释并执行动态结构中的每一项,是自动化测试的引擎。同时,为了提高Robot测试技术框架的易用性,在解决方案中还包括测试设计工具,它是使用其它编程语言,比如JAVA、Dephi等开发的应用程序。在测试设计工具中,测试技术人员首先建立和待测试应用一一对应的静态结构,此静态结构以页面为单位,随后业务测试人员从静态结构中选择不同的页面,组成测试动态结构,即测试用例,随后,此动态结构被Robot测试技术框架读入并解释执行。
3.2.1 表驱动介绍
Robot测试技术框架是基于表驱动测试思想。表驱动测试就是预先在表中定义清楚代表每一步执行操作的关键字,然后由脚本读入表中的每一行,根据关键字来执行对应的动作。以CQ Web登录界面为例:
当要自动执行“登录”按钮时,可以如下图来定义此表:
登录 然后在Robot的脚本中,打开表,读入此行并执行。这样的话,Robot便去点击界面上的“登录”按钮了。
'打开文件 Dim sData() as string InFileName = getExcelFileName ReadExcelData InFileName, sData() =============================== ‘解释并执行 Select Case (sKeyWord) Case "登录" Window SetContext, "currentwindow", "" PushButton Click, "Text=登录", ""
以上是表驱动的简单示例。在自动化测试中,基于表驱动,还需要解决以下问题:对象识别、验证点、数据池、分支执行、数据关联、日志记录、调用其它脚本、脚本结束。本节将分别展示其在Robot测试技术框架中的实现方式。
3.2.2 对象识别
根据IBM Rational Robot识别对象并执行操作的要求,如果要让Robot找到界面上的对象并执行相关动作,需要给Robot指定每个对象的对象类型、对象标志、执行动作和数据,如下图所示。
图 3. 为Robot指定每个对象的对象类型、对象标志、执行动作和数据
以按钮举例来讲,如果要让Robot自动点击某个按钮,那么首先要告诉Robot需要在“Button”这种类型的对象上进行操作;其次要告诉Robot,在此类型的对象上要执行什么操作,比如click;第三要告诉Robot要click那个具体的按钮上,比如要click“登录”按钮。
表 2:对象识别表 动作类型 对象类型 对象标志 执行动作 数据 G Button 确定 Click G EditBox 姓名 Click Jack G ComboBox 角色列表 Click 系统管理员 G RadioButton 区域 Click
在Robot测试技术框架中,相应的处理为:
'打开文件 Dim sData() as string InFileName = getExcelFileName ReadExcelData InFileName, sData() =============================== ‘对文件中每一行 Select Case (sObjType) Case "Button" ProcessButton(sObjAction, sObjData, sData) Case “EditBox” ProcessEditBox(sObjAction, sObjData, sData) Case “ComboBox” ProcessComboBox(sObjAction, sObjData, sData) Case “RadioButton” ProcessRadioButton(sObjAction, sObjData, sData) =============================== ‘对按钮执行的动作 Select Case(sObjAction) Case “Click” Window SetContext, "currentwindow", "" PushButton Click, "Text=" & sObjData, "" =============================== ‘对文本框执行的动作 Select Case(sObjAction) Case “Click” EditBox Click, "Name=" & sObjData, "" InputKeys "^+{HOME}{DELETE}" InputKeys sData =============================== ‘对组合框执行的动作 Select Case(sObjAction) Case “Click” ComboBox Click, "Name=" & sObjData, "" ComboListBox Click, "Name=" & sObjData, "Text=" & sData =============================== ‘对单选按钮执行的动作 Select Case(sObjAction) Case “Click” RadioButton Click, "Name=" & sObjData
要强调的是,以按钮为例,虽然在表中需要为界面上每一个具体的按钮定义一行,但是在测试技术框架中,所有按钮处理的代码都是一样的。
3.2.3 验证点
没有验证点的自动化测试就不能称之为测试。从这句话中就可以看到验证点在自动化测试中的重要性。对于验证点来讲,因为不同的测试、不同的应用验证点都不相同,所以Robot测试技术框架仅仅提供了扩展的机制,不同的验证点可以通过扩展机制加入到测试技术框架中。
加入验证点之后,表的定义如下:
表 3:对象识别表 动作类型 对象类型 对象标志 执行动作 数据 G Button 确定 Click G HTMLLink 链接 Click G ComboBox 角色列表 Click 系统管理员 G RadioButton 区域 Click V VP VP_SUM VP_SUM 24
最后一行是加入的验证点。所有的验证点其对象类型均为VP,不同的验证点有不同的对象标志,上表中的验证点是VP_SUM,验证点的基线数据为24。
在Robot测试技术框架中,处理如下:
‘对文件中每一行 Select Case (sObjType) Case …… Process…… Case “VP” ProcessVP(sObjAction, sData) =============================== ‘对验证点执行的动作 g_VP_SUM_Baseline = sData Callscrīpt sObjAction =============================== ‘验证点脚本的处理 sData = g_VP_SUM_Baseline SQAGetProperty “”, “”, sActual if sData = sActual then …… else …… end if
将验证点的基线数据放入全局变量g_VP_SUM_Baseline中,然后使用Callscrīpt函数来调用验证点的脚本。对每一个验证点单独的创建一个脚本文件,脚本文件的名字和验证点的标志相同,都是VP_SUM。虽然各个验证点脚本的内容都不相同,但是一般的步骤是首先从全局变量g_VP_SUM_Baseline中取出基线数据,然后使用SQAGetProperty函数从界面上取实际的数据,再比较实际数据和基线数据。
3.2.4 数据池
往往需要使用不同的数据来运行同一个测试,在自动化测试中是使用数据池来实现的。数据池的增加比较简单,就是往表中增加表示数据的列,每一列代表一次测试执行所需要的数据。如下表:
表 4:数据池表a 动作类型 对象类型 对象标志 执行动作 数据1 G Button 确定 Click G HTMLLink 链接 Click G ComboBox 角色列表 Click 系统管理员 普通管理员 G RadioButton 区域 Click V VP VP_SUM VP_SUM 24 24
从上表中看到,“数据1”这一列代表一次测试的执行所需要的数据,“数据2”代表另外一次测试的执行所需要的数据。
在Robot测试技术框架中,加入循环,按照数据列的数量来进行循环,每一个循环均从第一行执行到最后一行。
3.2.5 执行分支
在测试中,往往是同一个业务或者功能,但是因为输入的数据、选择的条件不同,而具有不同的执行流程。执行分支的处理比较简单,就是在相应的数据列的位置上,填写代表忽略的特殊标志,比如“IGNORE”,当测试执行到此动作时,判断其数据是否是“IGNORE”,如果是,就不执行此动作而到下一个动作。对应的表如下:
表 5:数据池表b 动作类型 对象类型 对象标志 执行动作 数据1 G Button 确定 Click G HTMLLink 链接 Click G ComboBox 角色列表 Click 系统管理员 普通管理员 G RadioButton 区域 Click V VP VP_SUM VP_SUM 24 IGNORE
从上表中看到,第一次执行会执行VP_SUM验证点,但是第二次执行,因为验证点相应的数据是“IGNORE”,所以就不会执行VP_SUM验证点。
在Robot测试技术框架中,在每次执行动作时,先判断其数据是否是“IGNORE”即可。
3.2.6 数据关联
在测试中,需要处理数据关联这种情况。数据关联是指前一个动作执行完成后,应用产生新的数据,此数据在随后的动作中需要用到。因为这些数据是在执行的过程中由程序产生的,所以没有办法预先在表中准备。在这种情况下对应的表如下:
表 6:数据池表c 动作类型 对象类型 对象标志 执行动作 数据1 G Button 确定 Click G HTMLLink 链接 Click G ComboBox 角色列表 Click 系统管理员 普通管理员 G RadioButton 区域 Click V VP VP_SUM VP_SUM 24 IGNORE G DC DC_GETID DC_GETID G EditBox 交易号 Click DC_GETID DC_GETID
从上表可以看到,首先使用DC_GETID来将要关联的数据取出来,然后在需要使用此数据的地方,再使用DC_SETID赋值回去。
在Robot测试技术框架中,取数据的处理如下:
‘对文件中每一行 Select Case (sObjType) Case …… Process…… Case “DC” ProcessDC(sData) =============================== ‘对数据关联执行的动作 Callscrīpt sData =============================== ‘数据关联中,获取数据脚本的处理 SQAGetProperty “”, “”, g_DC_ID
对每一个数据关联,取数据单独的创建一个脚本文件,脚本文件的名字和数据关联的名字相同,都比如说都叫DC_GETID。虽然数据关联取数据脚本的内容各不相同,但是一般的步骤是使用SQAGetProperty函数从界面上取得数据,放入全局变量g_DC_ID中。
在Robot测试技术框架中,赋值回去的处理如下:
‘对文件中每一行 Select Case (sObjType) Case …… Process…… Case “EditBox” ProcessEditBox(sObjAction, sObjData, sData) =============================== ‘对文本框执行的动作 Select Case(sObjAction) Case “Click” EditBox Click, "Name=" & sObjData, "" InputKeys "^+{HOME}{DELETE}" InputKeys g_DC_ID
即从全局变量g_DC_ID中取出数据,再输入到文本框中。
3.2.7 其它处理
其它处理包括日志记录、调用其它脚本以及脚本结束,相应的表如下:
表 7:数据池表d 动作类型 对象类型 对象标志 执行动作 数据1 G Button 确定 Click G HTMLLink 链接 Click G ComboBox 角色列表 Click 系统管理员 普通管理员 G RadioButton 区域 Click V VP VP_SUM VP_SUM 24 IGNORE G DC DC_GETID DC_GETID G EditBox 交易号 Click DC_GETID DC_GETID L 输入交易号 输入交易号 S Order Order X
可以看到,在动作类型这一列,使用使用“L”代表记录日志,日志的内容存放在这一行的数据列中,比如上表中的“输入交易号”;使用标志“S”代码调用其它脚本,要调用的脚本名称存放在这一行的数据列中,比如上表中的“Order”;使用标志“X”代表脚本结束。
在Robot测试技术框架中,相应的处理如下:
‘对文件中每一行 Select Case (sActType) Case “G” Process…… Case “L” Log(sData) Case “S” Callscrīpt sData Case “X” Exit
测试设计工具的最主要的目的就是为了提高Robot测试技术框架的易用性,帮助测试人员生成表驱动所需要的表。另外,测试设计工具通过使用数据库,能够在工具级别为测试重用提供支持。测试设计工具主要包括两方面的功能:供技术测试人员创建测试的静态结构;供业务测试人员创建测试的动态结构。
测试的静态结构要求和应用保持一致,以页面为单位。即应用中各个功能的层次结构是如何来安排的,就相应的在测试设计工具中按照这种安排来建立静态结构,直到每个页面为止。这样来设计的好处是:首先,静态结构和应用保持一致,将来应用发生变化,比较容易定位到静态结构中需要修改的地方;其次,建立静态结构,应用是什么样子,就建立成什么样子,照搬即可,不需要很多的业务知识,比较适合于技术测试人员;最后,静态结构和应用保持一致,将来业务测试人员设计测试的动态结构时,能够方便的根据应用在静态结构中找到相应的页面。
以下是已经建好的静态结构的示例:
可以看到,左边是和应用功能组织保持一致的树形结构。点开“集团理财”节点,可以在右边的上半部分看到此页面中的元素,页面上每一个元素都按照Robot技术框架的要求输入必要的信息,比如对象类型、对象标志、执行动作等。这些内容是由技术测试人员根据页面来输入的。如果不希望人工输入的话,那么也可以开发相应的工具去解析页面,来自动的生成每个页面的元素,或者是使用IBM Rational Functional Tester(简称RFT)的对象映射功能,由RFT去页面上抓取对象来生成。
测试的动态结构和测试的要求有关。在创建测试用例的过程中,测试用例的每一个步骤,均是选自静态结构中的一个页面,将页面加入到测试用例中之后,还可以指定此次测试用例要测试页面上那些元素。另外,在测试的动态结构中,还可以指定测试数据、验证点、数据关联等操作。当设计完成后就直接生成真正可以被Robot测试技术框架所执行的表。
以下是已经建好的动态结构的示例:
可以看到,左边是和按照测试的要求组织起来的测试用例。点开“票据托管”这个测试用例,可以在右边的上半部分看到此测试用例的执行步骤,比如第一步是“登录”,第二步是“票据托管导航”,依次下来是“票据托管”和“退出”,这些步骤都是从静态结构中选出来的。当点击测试步骤中“票据托管”这个页面,在下方将此页面的元素显示出来,业务测试人员可以为每一个测试元素输入数据、指定数据关联、添加验证点等。
当业务测试人员设计好测试用例后,就可以将测试用例传递给Robot测试技术框架,又测试技术框架解释并执行。

回页首
可以看到,使用IBM Rational Robot提供的强大功能所搭建起来的自动化功能测试框架,能够帮助软件开发组织成功的实施自动化的功能测试。
1. 通过重用已有的静态结构和动态结构,能够有效的促进测试的重用,并且在IBM Rational Robot的支持下,可以自动的执行这些测试
2. 通过使用测试设计工具来生成动态配置,可以看到除测试技术框架的SQABasic脚本外,不需要再维护任何其它的脚本,降低了脚本调试、维护的工作量。并且将来的维护是基于测试设计工具来进行,也降低了自动化测试整体的维护工作量
3. 通过使用测试设计工具来生成静态配置,能够做到根据界面的设计来进行配置,而不需要等到待测试应用完全可用,就使得及早测试成为可能
4. 通过支持业务、技术测试人员的分工,在测试技术框架中封装自动化测试技术细节,使得业务测试人员不需要自动化测试技术的相关知识,只需要通过测试设计工具,就能够简单、直观的进行测试的设计和执行,降低了自动化测试的实施难度
另外,在实施自动化功能测试框架中,还发现两个有趣的现象。第一,因为可以去自动化的执行测试,所以业务测试人员更多的在使用测试设计工具,从而导致测试设计在整个测试中所占的比重有显著的提高,有效的提升测试的质量;第二,因为统一、一致的界面操作方式、提示方式和表达方式有利于自动化测试的进行,所以也间接的促使开发团队在设计、开发过程中更加注重界面的规范性以及界面控件的可测试性。
-
LR函数小全(转载)
lsf4662872 发布于 2007-10-08 16:36:13
LR函数:
lr_start_transaction
为性能分析标记事务的开始
lr_end_transaction
为性能分析标记事务的结束
lr_rendezvous
在 Vuser 脚本中设置集合点
lr_think_time
暂停 Vuser 脚本中命令之间的执行
lr_end_sub_transaction
标记子事务的结束以便进行性能分析
lr_end_transaction
标记 LoadRunner 事务的结束
Lr_end_transaction("trans1",Lr_auto);
lr_end_transaction_instance
标记事务实例的结束以便进行性能分析
lr_fail_trans_with_error
将打开事务的状态设置为 LR_FAIL 并发送错误消息
lr_get_trans_instance_duration
获取事务实例的持续时间(由它的句柄指定)
lr_get_trans_instance_wasted_time
获取事务实例浪费的时间(由它的句柄指定)
lr_get_transaction_duration
获取事务的持续时间(按事务的名称)
lr_get_transaction_think_time
获取事务的思考时间(按事务的名称)
lr_get_transaction_wasted_time
获取事务浪费的时间(按事务的名称)
lr_resume_transaction
继续收集事务数据以便进行性能分析
lr_resume_transaction_instance
继续收集事务实例数据以便进行性能分析
lr_set_transaction_instance_status
设置事务实例的状态
lr_set_transaction_status
设置打开事务的状态
lr_set_transaction_status_by_name
设置事务的状态
lr_start_sub_transaction
标记子事务的开始
lr_start_transaction
标记事务的开始
Lr_start_transaction("trans1");
lr_start_transaction_instance
启动嵌套事务(由它的父事务的句柄指定)
lr_stop_transaction
停止事务数据的收集
lr_stop_transaction_instance
停止事务(由它的句柄指定)数据的收集
lr_wasted_time
消除所有打开事务浪费的时间
lr_get_attrib_double
检索脚本命令行中使用的 double 类型变量
lr_get_attrib_long
检索脚本命令行中使用的 long 类型变量
lr_get_attrib_string
检索脚本命令行中使用的字符串
lr_user_data_point
记录用户定义的数据示例
lr_whoami
将有关 Vuser 脚本的信息返回给 Vuser 脚本
lr_get_host_name
返回执行 Vuser 脚本的主机名
lr_get_master_host_name
返回运行 LoadRunner Controller 的计算机名
lr_eval_string
用参数的当前值替换参数
lr_save_string
将以 NULL 结尾的字符串保存到参数中
lr_save_var
将变长字符串保存到参数中
lr_save_datetime
将当前日期和时间保存到参数中
lr _advance_param
前进到下一个可用参数
lr _decrypt
解密已编码的字符串
lr_eval_string_ext
检索指向包含参数数据的缓冲区的指针
lr_eval_string_ext_free
释放由 lr_eval_string_ext 分配的指针
lr_save_searched_string
在缓冲区中搜索字符串实例,并相对于该字符串实例,将该缓冲区的一部分保存到参数中
lr_debug_message
将调试信息发送到输出窗口
lr_error_message
将错误消息发送到输出窗口
lr_get_debug_message
检索当前消息类
lr_log_message
将消息发送到日志文件
lr_output_message
将消息发送到输出窗口
lr_set_debug_message
设置调试消息类
lr_vuser_status_message
生成带格式的输出,并将其写到 ControllerVuser 状态区域
lr_message
将消息发送到 Vuser 日志和输出窗口
lr_load_dll
加载外部 DLL
lr_peek_events
指明可以暂停 Vuser 脚本执行的位置
lr_think_time
暂停脚本的执行,以模拟思考时间(实际用户在操作之间暂停以进行思考的时间)
lr_continue_on_error
指定处理错误的方法
lr_continue_on_error (0);lr_continue_on_error (1);lr_rendezvous
在 Vuser 脚本中设置集合点
TE_wait_cursor
等待光标出现在终端窗口的指定位置
TE_wait_silent
等待客户端应用程序在指定秒数内处于静默状态
TE_wait_sync
等待系统从 X-SYSTEM 或输入禁止模式返回
TE_wait_text
等待字符串出现在指定位置
TE_wait_sync_transaction
记录系统在最近的 X SYSTEM 模式下保持的时间
WEB函数列表:
web_custom_request
允许您使用 HTTP 支持的任何方法来创建自定义 HTTP 请求
web_image
在定义的图像上模拟鼠标单击
web_link
在定义的文本链接上模拟鼠标单击
web_submit_data
执行“无条件”或“无上下文”的表单
web_submit_form
模拟表单的提交
web_url
加载由“URL”属性指定的 URL
web_set_certificate
使 Vuser 使用在 Internet Explorer 注册表中列出的特定证书
web_set_certificate_ex
指定证书和密钥文件的位置和格式信息
web_set_user
指定 Web 服务器的登录字符串和密码,用于 Web 服务器上已验证用户身份的区域
web_cache_cleanup
清除缓存模拟程序的内容
web_find
在 HTML 页内搜索指定的文本字符串
web_global_verification
在所有后面的 HTTP 请求中搜索文本字符串
web_image_check
验证指定的图像是否存在于 HTML页内
web_reg_find
在后面的 HTTP 请求中注册对 HTML源或原始缓冲区中文本字符串的搜索
web_disable_keep_alive
禁用 Keep-Alive HTTP 连接
web_enable_keep_alive
启用 Keep-Alive HTTP 连接
web_set_connections_limit
设置 Vuser 在运行脚本时可以同时打开连接的最大数目
web_concurrent_end
标记并发组的结束
web_concurrent_start
标记并发组的开始
web_add_cookie
添加新的 Cookie 或修改现有的 Cookie
web_cleanup_cookies
删除当前由 Vuser 存储的所有 Cookie
web_remove_cookie
删除指定的 Cookie
web_create_html_param
将 HTML 页上的动态信息保存到参数中。(LR 6.5 及更低版本)
web_create_html_param_ex
基于包含在 HTML 页内的动态信息创建参数(使用嵌入边界)(LR 6.5 及更低版本)。
web_reg_save_param
基于包含在 HTML 页内的动态信息创建参数(不使用嵌入边界)
web_set_max_html_param_len
设置已检索的动态 HTML 信息的最大长度
web_add_filter
设置在下载时包括或排除 URL 的条件
web_add_auto_filter
设置在下载时包括或排除 URL 的条件
web_remove_auto_filter
禁用对下载内容的筛选
web_add_auto_header
向所有后面的 HTTP 请求中添加自定义标头
web_add_header
向下一个 HTTP 请求中添加自定义标头
web_cleanup_auto_headers
停止向后面的 HTTP 请求中添加自定义标头
web_remove_auto_header
停止向后面的 HTTP 请求中添加特定的标头
web_revert_auto_header
停止向后面的 HTTP 请求中添加特定的标头,但是生成隐性标头
web_save_header
将请求和响应标头保存到变量中
web_set_proxy
指定将所有后面的 HTTP 请求定向到指定的代理服务器
web_set_proxy_bypass
指定 Vuser 直接访问(即不通过指定的代理服务器访问)的服务器列表
web_set_proxy_bypass_local
指定 Vuser 对于本地 (Intranet) 地址是否应该避开代理服务器
web_set_secure_proxy
指定将所有后面的 HTTP 请求定向到服务器web_set_max_retries
设置操作步骤的最大重试次数
web_set_timeout
指定 Vuser 等待执行指定任务的最长时间
web_convert_param
将 HTML 参数转换成 URL 或纯文本
web_get_int_property
返回有关上一个 HTTP 请求的特定信息
web_report_data_point
指定数据点并将其添加到测试结果中
web_set_option
在非 HTML 资源的编码、重定向和下载区域中设置 Web 选项
web_set_sockets_option
设置套接字的选项 -
一个安全测试的checklist(转)
fz_alinmo 发布于 2008-12-01 10:04:43
1. 不登录系统,直接输入登录后的页面的url是否可以访问2. 不登录系统,直接输入下载文件的url是否可以下载,如输入http://url/download?name=file是否可以下载文件file
3. 退出登录后按后退按钮能否访问之前的页面
4. ID/密码验证方式中能否使用简单密码。如密码标准为6位以上,字母和数字混合,不能包含ID,连续的字母或数字不能超过n位
5. 重要信息(如密码,身份证号码,信用卡号等)在输入或查询时是否用明文显示;在浏览器地址栏里输入命令javascrīpt:alert(doucument.cookie)时是否有重要信息;在html源码中能否看到重要信息
6. 手动更改URL中的参数值能否访问没有权限访问的页面。如普通用户对应的url中的参数为l=e,高级用户对应的url中的参数为l=s,以普通用户的身份登录系统后将url中的参数e改为s来访问本没有权限访问的页面
7. url里不可修改的参数是否可以被修改
8. 上传与服务器端语言(jsp、asp、php)一样扩展名的文件或exe等可执行文件后,确认在服务器端是否可直接运行
9. 注册用户时是否可以以'--,' or 1=1 --等做为用户名
10. 传送给服务器的参数(如查询关键字、url中的参数等)中包含特殊字符(','and 1=1 --,' and 1=0 --,'or 1=0 --)时是否可以正常处理
11. 执行新增操作时,在所有的输入框中输入脚本标签(<scrīpt>alert("")</scrīpt>)后能否保存
12. 在url中输入下面的地址是否可以下载:http://url/download.jsp?file=C:\windows\system32\drivers\etc\hosts,http://url/download.jsp?file=/etc/passwd
13. 是否对session的有效期进行处理
14. 错误信息中是否含有sql语句、sql错误信息以及web服务器的绝对路径等
15. ID/密码验证方式中,同一个账号在不同的机器上不能同时登录
16. ID/密码验证方式中,连续数次输入错误密码后该账户是否被锁定
17. 新增或修改重要信息(密码、身份证号码、信用卡号等)时是否有自动完成功能(在form标签中使用autocomplete=off来关闭自动完成功能
-
安全测试学习笔记二(对于top 10 漏洞的分析)(转贴)
yexu 发布于 2007-01-17 08:41:02
1, 问题:没有被验证的输入
测试方法:
数据类型(字符串,整型,实数,等)
允许的字符集
最小和最大的长度
是否允许空输入
参数是否是必须的
重复是否允许
数值范围
特定的值(枚举型)
特定的模式(正则表达式)2, 问题:有问题的访问控制
测试方法:
主要用于需要验证用户身份以及权限的页面,复制该页面的url地址,关闭该页面以后,查看是否可以直接进入该复制好的地址
例:从一个页面链到另一个页面的间隙可以看到URL地址
直接输入该地址,可以看到自己没有权限的页面信息,3 错误的认证和会话管理
分析:帐号列表:系统不应该允许用户浏览到网站所有的帐号,如果必须要一个用户列表,推荐使用某种形式的假名(屏幕名)来指向实际的帐号。
浏览器缓存:认证和会话数据不应该作为GET的一部分来发送,应该使用POST,
4 问题:跨站脚本(XSS)
分析:攻击者使用跨站脚本来发送恶意代码给没有发觉的用户,窃取他机器上的任意资料
测试方法:
• HTML标签:<…>…</…>
• 转义字符:&(&);<(<);>(>); (空格) ;
• 脚本语言:
<scrīpt language=‘javascrīpt’>
…Alert(‘’)
</scrīpt>
• 特殊字符:‘ ’ < > /
• 最小和最大的长度
• 是否允许空输入
例:对Grid、Label、Tree view类的输入框未作验证,输入的内容会按照html语法解析出来
5,缓冲区溢出
分析:用户使用缓冲区溢出来破坏web应用程序的栈,通过发送特别编写的代码到web程序中,攻击者可以让web应用程序来执行任意代码。
6,注入式漏洞。
例:一个验证用户登陆的页面,如果使用的sql语句为:
Select * from table A where username=’’ + username+’’ and pass word …..
Sql 输入 ‘ or 1=1 ―― 就可以不输入任何password进行攻击
7,不恰当的异常处理
分析:程序在抛出异常的时候给出了比较详细的内部错误信息,暴露了不应该显示的执行细节,网站存在潜在漏洞,
8,不安全的存储
没有加密关键数据
例:view-source:http地址可以查看源代码
在页面输入密码,页面显示的是 *****, 右键,查看源文件就可以看见刚才输入的密码,
9,拒绝服务
分析:攻击者可以从一个主机产生足够多的流量来耗尽狠多应用程序,最终使程序陷入瘫痪。需要做负载均衡来对付。
10,不安全的配置管理
分析:Config中的链接字符串以及用户信息,邮件,数据存储信息都需要加以保护
程序员应该作的: 配置所有的安全机制,关掉所有不使用的服务,设置角色权限帐号,使用日志和警报。
-
需求跟踪矩阵
annayin 发布于 2007-03-06 15:36:05
首先,需求项同测试用例之间应当尽量避免多对多的情况,而是一条需求或者一个用例对应多个测试用例;
另外,对于需求的覆盖率,通常只是看是否有测试用例覆盖,而不会统计用多少个测试用例覆盖。通常是用已经关联测试用例的需求数量除以全部的需求数量来获得需求的覆盖率。
对于需求跟踪矩阵,最大的作用还是在于变更控制——当需求发生变化时,可以方便的定位到哪些测试用例可能需要重新维护。像IBM Rational套件中的RequisitePro就提供类似的功能。 -
正确对待需求的变更
longhate 发布于 2008-04-24 16:47:33
1.对于需求和需求变更的理解
软件需求是整个软件项目的最关键的一个输入,和传统的生产企业相比较,软件的需求具有模糊性、不确定性、变化性和主观性的特点,它不像生产汽车、电脑等硬件的需求,是有形的、客观的、可描述的、可检测的。软件需求是软件项目最难把握的问题,同时又是关系项目成败的关键因素,因此对于需求分析和需求变更的处理十分重要。
软件需求变更会给项目带来巨大的风险,会导致项目的成本费用增加、开发周期延长、产品质量下降及团队工作效率下降等不良后果,因而需求变更在软件开发项目中应该尽量避免。然而由于政府对特定软件的相关要求、用户部门市场战略的调整、工业界的发展等因素都可能带来需求的变更,而这些因素往往不可避免。在软件开发过程中如果只有一条真理的话,那一定是:需求的变化是永恒的,需求不可能是完备的。因而,对于需求变更应该正确的对待,尽量将其负面影响降低到最低。
2。减少需求变更
正如前文所说,需求变更往往是不可避免的。通常是项目负责人员花费了大量的气力避免需求变更,可最后需求变更总是会出现。但是这并不意味着项目开发人员不应该做这方面的工作,项目开发人员对于需求变更的正确态度应该和软件测试的态度一样,在需求并更发生之前尽量减少需求变更,以将需求变更带来的风险降低到最低。项目开发人员切忌在项目设计之前试图消除需求变更,这样做往往费力不讨好。
相比于需求开发人员而言,客户可能对需求变更认识不足,认为他们出钱,程序员或软件开发公司就要为它服务,因此客户对需求变更往往将需求变更视为儿戏,随个人喜好随意变更需求。因此,在需求人员同用户代表或用户部门主管人员接触时,就应该向他们挑明态度,和他们协商好,特别是应该让他们清楚软件的定价应该与软件的功能相关,以及需求随意变更所带来的风险的承担者应该由客户和项目开发者共同承担。通过这样做,让客户在需求分析之前就尽量对他们所需要的功能有个整体的了解和确定的思路,而不是等到程序员开始编码了,才提出以前原本在需求分析时就可以提出的需求。
让客户明白减少需求变更的重要性后,需求分析人员应该采取合适的方法同客户交流,帮助他们明确他们的需求。需求分析人员和客户的关系不应该仅仅是记录人员和需求提供者,他们的关系应该更多的是战略合作伙伴关系。虽然需求分析人员和客户存在着服务商和顾客的关系,但是他们有着一个共同的目标:开发出适合客户需求的软件,因此需求分析人员除了记录客户提出的需求以外,还应和用户讨论,提出一些建议,使用合适的工具帮助客户提出需求。在需求分析时,尽量多的召集需求研讨会,邀请开发人员和客户共同协商探讨,在研讨会上允许任意的提出需求,并将这些需求整理成档后由客户代表和需求分析人员共同商议可选的功能,这样能够尽量使得需求完备。在需求开发时,开发人员采用原型的方法启发客户思考功能需求也不失为一个好办法。
虽然需求不可能是完备的,但是在项目开始设计时尽量使得需求完备还是应该的,也是值得的。
3。规范文档
需求文档作为客户和开发人员的接口在整个项目开发过程中起着举足轻重的作用。需求文档应该按照一定的格式和规范书写,而且应该具备完整性、一致性、基线控制、历史记录等特性。文档书写完毕以后应该交给客户审阅,在客户满意的基础上确定基线。一个完整规范的需求文档不仅能够有助于设计人员和编码人员完成项目开发,更重要的是它作为一个阶段性的成果可以供软件需求变更时参考。
需求变更发生后,也应该生成相应的文档,并且这些文档的书写也应该采用规范的形式书写。需求变更文档也应该包含基线以供下一次修改参考,还应包含历史记录以供开发人员和客户清楚当前的文档内容的新旧以及历史文档的情况,以备以后查看。
4。设计良好的体系结构
开发软件就如同建造一座房屋,软件体系结构则如同建房屋时的规划。两层高的家庭住宅和几十层高的商业大厦建造时的规划必然不同,同样,大型软件和小软件采用的体系结构也必然有所区别。因此,设计一个合理的体系结构对于项目的成败也是十分关键的。
体系结构的建立一般位于需求分析结束之后,软件设计之前。软件体系结构的设计是从结构的角度对整个系统进行分析,选择合适的构件,安排构件间的相互作用以及他们之间的约束,形成一个系统框架以满足用户需求。在设计软件体系结构时,不仅应该想到如何完成满足现在已经提出的用户需求,同时也应适当地考虑到需求的变更。
采用有弹性和可扩展的软件体系结构设计可以有效地降低需求变更引起的风险和维护代价,能够在项目范围未发生变化的前提下很好地适应需求的变化。体系结构的灵活和可扩展性设计使得开发者可以在这种体系结构上面进行各个功能层的组合和分离,也可以将各个功能层分布在各个不同的服务器上共同提供服务,因而能够快速的对需求变更作出响应,并且对已经开发好的系统产生尽可能少的影响。
体系结构的设计除了考虑到体系结构的灵活性和可扩展性以外,还应尽量采用松散耦合的结构,使得结构中的各个构件之间的关联程度尽可能的少,这样就能在需求发生变更时一个构件的变化对另一个构件产生尽可能少的影响。
现有的软件体系结构很多,包括管道-过滤器结构、B/S结构(含C/S结构)、解释器/虚拟机结构、黑板系统以及基于中间件技术的体系结构。在设计体系结构时,首先应该选出适合项目需求的系统结构,然后在从中挑选出那些扩展性比较好,构件之间耦合性比较小的体系结构。基于中间件技术的体系结构就是扩展性比较好的体系结构。采用中间件技术,中间件作为用户界面和操作系统以及网络的连接点,向上为用户提供服务,向下屏蔽操作系统和网络的细节。这种分层的思想能够很好的适应操作系统和网络的变化,可扩展性十分的好。同时,可以在中间件中给出容易改变的接口或是为系统将来改变预留接口来实现功能上的需求变更。当然可扩展性比较好的体系结构远不止基于中间件技术的体系结构这一种,具体的选择和运用应该由设计人员根据实际需要考虑。
5。采用面向对象思想
需求是不稳定的,因而没有不变的需求,然而需求之中却有稳定的东西,这就是对象。世界都是由对象组成的,而对象都是持久的,例如动物、植物已经有相当长的时间。虽然对象也在变化,动物、植物也在不断的进化。但对象在一个相当长的时期内都存在,动植物的存在时间肯定比任何一家企业长久。面向对象的开发方法的精髓就是从企业的不稳定需求中分析出企业的稳定对象,以企业对象为基础来组织需求、构架系统。这样得出的系统就会比传统的系统要稳定得多,因为企业的模式一旦变化,只需要将稳定的企业对象重新组织就行了。
面向对象(OO)技术的三大特征保证了采用OO技术可以建立易于改变和加强可重用性的软件系统。封装可以把问题影响的范围缩小,外部的变化要求对系统的影响可以限定到某个类层次或某些类层次中,从而改变系统的一部分相对简单;继承可以使改变基于原有技术基础,很大程度上减少重复开发工作;多态的应用可以使开发和设计人员在相对统一的接口下更改系统的实现细节,从而改变系统的行为。
显然,OO技术是一种增强软件可维护性、健壮性以及保持设计稳定性的一种分析和设计方法,可以在一定程度上快速对需求变更进行反应,并可相对减少需求变更需要的成本。因此,在系统开发过程中应该尽量的采用面向对象的思维方式来构建系统和开发系统。
6。需求变更控制
正如前文所言,需求变更不可避免的会发生,那么当需求变更发生后项目开发人员应该如何应对呢?
一般来讲,需求的变更通常意味着需求的增加,需求的减少相对很少,而且处理也比较容易。当客户提出新需求的时候,项目开发人员应该分析这些新需求对项目现阶段带来的风险,得出双方实现变更需求的需要的成本,包括时间、人力、资源等等方面,再与客户商讨是否有必要进行变更和如何在最小代价下实现变更。
当客户确实希望进行需求变更时,可以让开发人员开发一个快速原型,让用户体验一下,以确保客户确确实实的希望添加这些需求。在客户和项目开发人员共同确定了需求变更后,项目开发人员应该与客户签订一份新的合同。
当客户提出需求变更并且签订了合同后或是开发人员根据市场和国家政策作出的需求变更得到确证后,项目开发人员应该决定何时实施这些变更。对于那些对系统影响不大和一些优先权十分高的需求变更可以立即在项目中实施,而对于那些对于整个系统现阶段的开发影响很大,而且又不是十分紧急的需求可以放在下一个版本中进行。无论是立即实施还是放在下一个版本中,都应该给新的需求一个充足的开发和测试时间,保证产品质量。
结论
在面对需求变更时,除了通过减少需求变更和规范文档,从分析和设计的角度通过采用合理的分析和设计方法适应需求变更以外,还应该改变我们设计的意识和对需求变更的理解,做好对需求变更的控制和管理,做到对需求变更的灵活应对,在一定程度上降低维护代价和提高用户满意度 -
全球化,国际化,本地化的关系
laika1234 发布于 2011-05-25 21:03:04
看到有人在问全球化和国际化的关系,国际化和本地话的关系,我们今天就简单说说这三者之间的关系。
我们所说的全球化,国际化,本地化都是针对软件来说的。简单的来说全球化=国际化+本地化。
所谓的全球化,就是软件的目标市场并不是一个国家,而是多个国家或区域,我这里借用一下
全球化软件是为全球用户设计,面向全球市场发布的具有一致的界面,风格和功能的软件,他的核心特征和代码设计并不仅仅局限于某一种语言和区域用户,可以支持不同目标市场的语言和数据的输入,输出,显示和存储。全球化软件也称为国际化软件,全球化对应的英文是Globalization,缩写为G11N.G是首字母,N是尾字母。11表示在首字母G和尾字母N之间省略了11个字母。
其实全球化软件按照字面意思理解的话也可以叫国际化软件。全球就是针对多个国家的意思,国际化也是针对多个国家的意思,但是全球化软件在开发过程中又可以分为两个大的部分,一般叫做国际化和本地化,为了将此国际化和彼国际化分开,所以叫做全球化。 所以全球化=国际化+本地化
这块主要是定义的问题,如果把一个面向全球用户的软件叫做国际化软件也可以,但是如果在做这个软件的公司内部就不好区分这个大的国际化和他下面细分出来的国际化,所以一般就叫做全球化。所以如果你是给公司外部的人来说,不关注技术细节的话,说你的产品是全球化软件或国际化软件都可以。但是公司内部具体去做这个软件的话最好还是将全球化和国际化定义严格分开。
下面我们来说说国际化和本地化的关系,其实我和项目组里的人合作了很长时间,他们有时候也是分不清楚国际化和本地化,大家对本地化可能了解的比较多,因为这个也比较好理解,就是要做不同语言的本地化版本。但是国际化具体做什么他们就不是特别清楚,所以两个老是搞错。
我们还是来引用
软件国际化就是在软件设计和文档开发过程中,使得功能和代码设计能处理多种语言和文化习俗,能够在创建不同语言版本时,不需要重新设计源程序代码的软件工程方法。国际化的英文单词是Internationalization,所写为I18N,其中I是首字母,N是尾字母。18表示在首字母的I和尾字母N之间省略了18个字母
软件本地化是将一个软件产品按照特定国家/地区或语言市场的需要进行加工,使之满足特定市场上的用户对语言和文化的特殊要求的软件生产活动。本地化的英文对应Localization,缩写为L10N,其中L为首字母,N是尾字母,10表示在首字母的L和尾字母的N之间省略了10个字母。
我们从上面的描述上去分析,国际化需要保证功能和代码设计能处理多种语言和文化习俗,在创建不同语言版本时,不需要重新设计源程序代码,这个说明国际化实际上是为本地化服务的,其实在软件开发过程中加入国际化的设计就是为了更好,更快的出本地化版本。国际化并不针对某一特定语言来做,国际化做好了的话,你的软件就可以处理多种语言和文化习俗,语言也就是各种国家的文字显示,输入输出,各种语言的操作系统上运行,习俗通常指的是区域相关的,比如日期时间显示格式,数字,货币符号,姓名显示顺序等。当你的软件如果国际化做的比较好时,在做本地化时就不需要重新设计或修改源代码,只需要进行资源文件的翻译,然后出本地化的build.而本地化是针对特定语言的,特定市场的,如果该语言和该市场没有特殊要求,那么简单的说就是一个将资源文件进行翻译,然后出一个本地化的build,然后测试该本地化build上本地化问题,比如字符串没有翻译等,这个是全球化软件最理想的情况,但是往往个别国家或区域对软件在基础功能上又有些特殊的要求,本地化组需要在基于已经发布的英文版上增加特色功能然后自己发布。
我们简单的总结一下本地化测试和国际化测试,基于比较理想的全球化软件开发模式,各个国家没有自己特殊的需求
1测试需要用的操作系统:
国际化测试人员一般会基于多个语言的操作系统进行测试,因为国际化测试需要负责软件对各个不同国家操作系统的支持。一般至少选择两个,亚洲为代表的比如日语,和欧洲为代表的,比如德语。
本地化测试人员一般只在某一个特定语言的操作系统进行测试。除非该测试人员要负责多个语言的本地化。
2测试的build
国际化测试一般用英文build和伪本地化build进行测试,英文build一般主要用来发现国际化第一级和第二级的问题,伪本地化build主要用来测试国际化第三级的问题。
本地化测试一般用已经翻译过的本地化build.
3 bug的处理方式
国际化的bug一般都是需要通过修改代码才行修改好
本地化的bug一般都是通过修改翻译,修改资源文件来修复,不需要修改代码(这个是理想情况。)
4测试的核心关注点不同
国际化测试关注针对各种语言的支持,概括来说就是对DBCS,Hi-ASCII的支持,包括显示,输入,输出等,还有对于不同国家的时间日期格式,货币符号显示等
本地化测试主要关注自己测试的语言上的输入,输出,显示,所测语言上一些特殊性等。
5测试进入项目的时间不同
国际化测试一般很早就开始进入项目,基本上是项目开始不久,需求基本确定后。
本地化测试一般进入项目时间较晚,一般是国际化测试进入到中期或快结束时进入。
从以上可以看出国际化和本地化的关系,概括来说就是好的国际化设计可以使软件更容易的本地化,减少本地化过程所需要的时间和精力,缩短发布时间。同理,国际化测试人员做的好了,本地化测试人员的工作就比较容易了。



我的栏目
标题搜索
我的存档
数据统计
- 访问量: 334143
- 日志数: 230
- 建立时间: 2007-11-19
- 更新时间: 2024-04-03
