
-
【转】web端和移动端优秀的自动化测试工具有哪些
2016-08-13 14:55:26
作者:陈晔
来源:知乎
移动无线测试技能树- 常用IDE
- Android
- ADT
- Android Studio
- iOS
- Xcode
- Xcode
- Common
- Atom
- Sublime Text
- Vim
- Android
- 基础知识
- Android
- 掌握Android开发基础技能
- 掌握Android开发基础技能
- iOS
- 掌握iOS开发基础技能
- 掌握iOS开发基础技能
- web
- 掌握web开发基础技能
- 掌握web开发基础技能
- api
- 掌握api相关基础知识
- 掌握api相关基础知识
- 测试
- 掌握基本的测试用例设计方法和思想
- 掌握基本的测试用例设计方法和思想
- Android
- 常见应用模式
- Native
- Hybrid
- H5 App
- ReactNative
- 常用工具
- Android
- Android sdk manager
- adb
- ddms
- ant
- aapt
- emulator
- Genymotion
- hierarchyviewer
- monitor
- monkey
- monkeyrunner
- uiautomatorviewer
- iOS
- lldb
- iExplorer
- libimobiledevice 套件
- codesign
- instruments
- xcodebuild
- atos
- xcrun
- Android
- 常用UI Automation框架
- Android
- Instrumentation
- Athrun
- Robotium
- Monkey
- Monkeyrunner
- uiautomator
- Selendroid
- Calabash-Android
- monkeytalk
- Appium
- Espresso
- cafe
- iOS
- UIAutomation
- XCUITesting
- KIF
- Frank
- appium
- ios-driver
- Mechanic.js
- monkeytalk
- Calabash-iOS
- TuneupJs
- ynm3k
- Android
- 常用单元测试框架
- Android
- robolectric
- Instrumentation
- Mockito
- RxJava
- iOS
- OCUnit
- GHUnit
- XCTest
- OCMock
- OCMockito
- Expecta
- OCHamcrest
- Android
- 常用动态更新
- ReactNative
- waxpatch/wax
- ota
- 常用性能工具
- 抓包
- Charles
- fiddler
- burpsuite
- tcpdump
- anyproxy
- 弱网模拟
- iOS developer mode
- ATC
- Charles
- memory
- Android
- MAT
- ddms
- Memory Monitor
- Allocation Tracker
- LeakCanary
- dumpsys
- procrank
- top
- iOS
- Memory Leaks
- Memory Leaks
- Android
- Scan
- Android
- findbugs
- lint
- infer
- CheckStyle
- PMD
- iOS
- scan-build
- oclint
- infer
- deployment -other
- Common
- 安捷伦
- tcpdump
- wireshark
- 高速(慢速)摄像机
- 埋点
- 腾讯GT
- 网易Emmagee
- Android
- gfxinfo
- dumpsys
- traceview
- systrace
- GameBench
- battery-historian
- iOS
- Core Animation(instruments)
- Network(instruments)
- TimeProfiler(instruments)
- Zombies(instruments)
- Android
- 抓包
- 安全
- Android
- Drozer
- apktool
- dex2jar
- proguard
- 加固
- exported/permission
- AndBug
- androguard
- Xposed
- iOS
- IDB
- iRET
- DVIA
- LibiMobileDevice
- otool
- Android
- abtest
- AB Tester
- AppAdhocOptimizer
- Google Website Optimizer
- Visual Website Optimizer
- 常用灰度测试工具
- testflight
- 蒲公英
- fir
- pre
- 常用云测平台
- testin
- MQC
- MTC
- 常用持续集成平台/相关工具
- Jenkins
- Travis CI
- Android
- mvn
- gradle
- iOS
- xctool
- Cocoapods
- 多语言开发应用
- SL4A
- gomobile
- 多设备远程管理平台
- STF
- STF
- 软技能
- 知识管理/总结分享
- 沟通技巧/团队协作
- 需求管理/PM
- 交互设计/可用性/可访问性知识
- 快速的学习能力
- 常用IDE
-
TestNG doc
2012-08-21 11:11:56
http://testng.org/doc/eclipse.html
TestNG doc
-
Downloading TestNG
2012-08-21 11:10:15
Downloading TestNG
Current Release Version
The latest version of TestNG can be downloaded from Maven Central.
For the Eclipse plug-in, we suggest using the update site:
- Select Help / Software updates / Find and Install.
- Search for new features to install.
- New remote site.
- For Eclipse 3.4 and above, enter http://beust.com/eclipse.
- For Eclipse 3.3 and below, enter http://beust.com/eclipse1.
- Make sure the check box next to URL is checked and click Next.
- Eclipse will then guide you through the process.
You can also install older versions of the plug-ins here. Note that the URL's on this page are update sites as well, not direct download links.
TestNG is also hosted on GitHub, where you can download the source and build the distribution yourself:
$ git clone git://github.com/cbeust/testng.git $ cd testng $ cp ivy-2.1.0.jar ~/.ant/lib $ ant
You will then find the jar file in the target directory
Beta Version
The beta version contains changes that have been committed to the repo since the current release.
Take a look at CHANGES.txt to see if the change you want is included in the beta (listed under "Current").
You can download the beta version here.
-
java常用算法汇总
2012-03-15 10:18:55
这篇排序文章从思想 理解 到实现,然后到整理,花了我几天的时间,现把它记录于此,希望对大家有一定的帮助,写的不好的请不要见笑,写错了的,请指出来我更正。最后如果对你有一定的帮助,请回贴支持一下哦^_^ !
申明: 排序算法思想来自互联网,代码自己实现,仅供参考。
插入排序
直接插入排序、希尔排序
选择排序
简单选择排序、堆排序
交换排序
冒泡排序、快速排序
归并排序
基数排序
排序基类
Java代码
package sort;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Random;
/**
* 排序接口,所有的排序算法都要继承该抽象类,并且要求数组中的
* 元素要具有比较能力,即数组元素已实现了Comparable接口
*
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public abstract class Sort<E extends Comparable<E>> {
public final Comparator<E> DEFAULT_ORDER = new DefaultComparator();
public final Comparator<E> REVERSE_ORDER = new ReverseComparator();
/**
* 排序算法,需实现,对数组中指定的元素进行排序
* @param array 待排序数组
* @param from 从哪里
* @param end 排到哪里
* @param c
*/
public abstract void sort(E[] array, int from, int end, Comparator<E> c);
/**
* 对数组中指定部分进行排序
* @param from 从哪里
* @param len 排到哪里
* @param array 待排序数组
* @param c 比较器
*/
public void sort(int from, int len, E[] array, Comparator<E> c) {
sort(array, 0, array.length - 1, c);
}
/**
* 对整个数组进行排序,可以使用自己的排序比较器,也可使用该类提供的两个比较器
* @param array 待排序数组
* @param c 比较器
*/
public final void sort(E[] array, Comparator<E> c) {
sort(0, array.length, array, c);
}
/**
* 对整个数组进行排序,采用默认排序比较器
* @param array 待排序数组
*/
public final void sort(E[] array) {
sort(0, array.length, array, this.DEFAULT_ORDER);
}
//默认比较器(一般为升序,但是否真真是升序还得看E是怎样实现Comparable接口的)
private class DefaultComparator implements Comparator<E> {
public int compare(E o1, E o2) {
return o1.compareTo(o2);
}
}
//反序比较器,排序刚好与默认比较器相反
private class ReverseComparator implements Comparator<E> {
public int compare(E o1, E o2) {
return o2.compareTo(o1);
}
}
/**
* 交换数组中的两个元素的位置
* @param array 待交换的数组
* @param i 第一个元素
* @param j 第二个元素
*/
protected final void swap(E[] array, int i, int j) {
if (i != j) {//只有不是同一位置时才需交换
E tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
/**
* 数组元素后移
* @param array 待移动的数组
* @param startIndex 从哪个开始移
* @param endIndex 到哪个元素止
*/
protected final void move(E[] array, int startIndex, int endIndex) {
for (int i = endIndex; i >= startIndex; i--) {
array[i + 1] = array[i];
}
}
/**
* 以指定的步长将数组元素后移,步长指定每个元素间的间隔
* @param array 待排序数组
* @param startIndex 从哪里开始移
* @param endIndex 到哪个元素止
* @param step 步长
*/
protected final void move(E[] array, int startIndex, int endIndex, int step) {
for (int i = endIndex; i >= startIndex; i -= step) {
array[i + step] = array[i];
}
}
//测试方法
@SuppressWarnings("unchecked")
public static final <E extends Comparable<E>> void testSort(Sort<E> sorter, E[] array) {
if (array == null) {
array = randomArray();
}
//为了第二次排序,需拷贝一份
E[] tmpArr = (E[]) new Comparable[array.length];
System.arraycopy(array, 0, tmpArr, 0, array.length);
System.out.println("源 - " + Arrays.toString(tmpArr));
sorter.sort(array, sorter.REVERSE_ORDER);
System.out.println("降 - " + Arrays.toString(array));
sorter.sort(tmpArr, sorter.DEFAULT_ORDER);
System.out.println("升 - " + Arrays.toString(tmpArr));
}
//生成随机数组
@SuppressWarnings("unchecked")
private static <E extends Comparable<E>> E[] randomArray() {
Random r = new Random(System.currentTimeMillis());
Integer[] a = new Integer[r.nextInt(30)];
for (int i = 0; i < a.length; i++) {
a[i] = new Integer(r.nextInt(100));
}
return (E[]) a;
}
}
package sort;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Random;
/**
* 排序接口,所有的排序算法都要继承该抽象类,并且要求数组中的
* 元素要具有比较能力,即数组元素已实现了Comparable接口
*
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public abstract class Sort<E extends Comparable<E>> {
public final Comparator<E> DEFAULT_ORDER = new DefaultComparator();
public final Comparator<E> REVERSE_ORDER = new ReverseComparator();
/**
* 排序算法,需实现,对数组中指定的元素进行排序
* @param array 待排序数组
* @param from 从哪里
* @param end 排到哪里
* @param c
*/
public abstract void sort(E[] array, int from, int end, Comparator<E> c);
/**
* 对数组中指定部分进行排序
* @param from 从哪里
* @param len 排到哪里
* @param array 待排序数组
* @param c 比较器
*/
public void sort(int from, int len, E[] array, Comparator<E> c) {
sort(array, 0, array.length - 1, c);
}
/**
* 对整个数组进行排序,可以使用自己的排序比较器,也可使用该类提供的两个比较器
* @param array 待排序数组
* @param c 比较器
*/
public final void sort(E[] array, Comparator<E> c) {
sort(0, array.length, array, c);
}
/**
* 对整个数组进行排序,采用默认排序比较器
* @param array 待排序数组
*/
public final void sort(E[] array) {
sort(0, array.length, array, this.DEFAULT_ORDER);
}
//默认比较器(一般为升序,但是否真真是升序还得看E是怎样实现Comparable接口的)
private class DefaultComparator implements Comparator<E> {
public int compare(E o1, E o2) {
return o1.compareTo(o2);
}
}
//反序比较器,排序刚好与默认比较器相反
private class ReverseComparator implements Comparator<E> {
public int compare(E o1, E o2) {
return o2.compareTo(o1);
}
}
/**
* 交换数组中的两个元素的位置
* @param array 待交换的数组
* @param i 第一个元素
* @param j 第二个元素
*/
protected final void swap(E[] array, int i, int j) {
if (i != j) {//只有不是同一位置时才需交换
E tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
}
/**
* 数组元素后移
* @param array 待移动的数组
* @param startIndex 从哪个开始移
* @param endIndex 到哪个元素止
*/
protected final void move(E[] array, int startIndex, int endIndex) {
for (int i = endIndex; i >= startIndex; i--) {
array[i + 1] = array[i];
}
}
/**
* 以指定的步长将数组元素后移,步长指定每个元素间的间隔
* @param array 待排序数组
* @param startIndex 从哪里开始移
* @param endIndex 到哪个元素止
* @param step 步长
*/
protected final void move(E[] array, int startIndex, int endIndex, int step) {
for (int i = endIndex; i >= startIndex; i -= step) {
array[i + step] = array[i];
}
}
//测试方法
@SuppressWarnings("unchecked")
public static final <E extends Comparable<E>> void testSort(Sort<E> sorter, E[] array) {
if (array == null) {
array = randomArray();
}
//为了第二次排序,需拷贝一份
E[] tmpArr = (E[]) new Comparable[array.length];
System.arraycopy(array, 0, tmpArr, 0, array.length);
System.out.println("源 - " + Arrays.toString(tmpArr));
sorter.sort(array, sorter.REVERSE_ORDER);
System.out.println("降 - " + Arrays.toString(array));
sorter.sort(tmpArr, sorter.DEFAULT_ORDER);
System.out.println("升 - " + Arrays.toString(tmpArr));
}
//生成随机数组
@SuppressWarnings("unchecked")
private static <E extends Comparable<E>> E[] randomArray() {
Random r = new Random(System.currentTimeMillis());
Integer[] a = new Integer[r.nextInt(30)];
for (int i = 0; i < a.length; i++) {
a[i] = new Integer(r.nextInt(100));
}
return (E[]) a;
}
} 插入排序
直接插入排序
一般直接插入排序的时间复杂度为O ( n^2 ) ,但是当数列基本有序时,如果按照有数列顺序排时,时间复杂度将改善到O( n ),另外,因直接插入排序算法简单,如果待排序列规模不很大时效率也较高。
在已经排好序的序列中查找待插入的元素的插入位置,并将待插入元素插入到有序列表中的过程。
将数组分成两部分,初始化时,前部分数组为只有第一个元素,用来存储已排序元素,我们这里叫 arr1 ;后部分数组的元素为除第一个元素的所有元素,为待排序或待插入元素,我们这里叫 arr2 。
排序时使用二层循环:第一层对 arr2 进行循环,每次取后部分数组(待排序数组)里的第一个元素(我们称为待排序元素或称待插入元素) e1 ,然后在第二层循环中对 arr1 (已排好序的数组)从第一个元素往后进行循环,查到第一个大于待插入元素(如果是升序排列)或第一个小于待插入元素(如果是降序排列) e2 ,然后对 arr1 从 e2 元素开始往后的所有元素向后移,最后把 e1 插入到原来 e2 所在的位置。这样反复地对 arr2 进行循环,直到 arr2 中所有的待插入的元素都插入到 arr1 中。
Java代码
package sort;
import java.util.Comparator;
/**
* 直接插入排序算法
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public class InsertSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
/*
* 第一层循环:对待插入(排序)的元素进行循环
* 从待排序数组断的第二个元素开始循环,到最后一个元素(包括)止
*/
for (int i = from + 1; i <= end; i++) {
/*
* 第二层循环:对有序数组进行循环,且从有序数组最第一个元素开始向后循环
* 找到第一个大于待插入的元素
* 有序数组初始元素只有一个,且为源数组的第一个元素,一个元素数组总是有序的
*/
for (int j = 0; j < i; j++) {
E insertedElem = array[i];//待插入到有序数组的元素
//从有序数组中最一个元素开始查找第一个大于待插入的元素
if (c.compare(array[j], insertedElem) > 0) {
//找到插入点后,从插入点开始向后所有元素后移一位
move(array, j, i - 1);
//将待排序元素插入到有序数组中
array[j] = insertedElem;
break;
}
}
}
//=======以下是java.util.Arrays的插入排序算法的实现
/*
* 该算法看起来比较简洁一j点,有点像冒泡算法。
* 将数组逻辑上分成前后两个集合,前面的集合是已经排序好序的元素,而后面集合为待排序的
* 集合,每次内层循从后面集合中拿出一个元素,通过冒泡的形式,从前面集合最后一个元素开
* 始往前比较,如果发现前面元素大于后面元素,则交换,否则循环退出
*
* 总感觉这种算术有点怪怪,既然是插入排序,应该是先找到插入点,而后再将待排序的元素插
* 入到的插入点上,那么其他元素就必然向后移,感觉算法与排序名称不匹,但返过来与上面实
* 现比,其实是一样的,只是上面先找插入点,待找到后一次性将大的元素向后移,而该算法却
* 是走一步看一步,一步一步将待排序元素往前移
*/
/*
for (int i = from; i <= end; i++) {
for (int j = i; j > from && c.compare(array[j - 1], array[j]) > 0; j--) {
swap(array, j, j - 1);
}
}
*/
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 5, 9, 1, 4, 1, 2, 6, 3, 8, 0, 7 };
InsertSort<Integer> insertSort = new InsertSort<Integer>();
Sort.testSort(insertSort, intgArr);
Sort.testSort(insertSort, null);
}
}
package sort;
import java.util.Comparator;
/**
* 直接插入排序算法
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public class InsertSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
/*
* 第一层循环:对待插入(排序)的元素进行循环
* 从待排序数组断的第二个元素开始循环,到最后一个元素(包括)止
*/
for (int i = from + 1; i <= end; i++) {
/*
* 第二层循环:对有序数组进行循环,且从有序数组最第一个元素开始向后循环
* 找到第一个大于待插入的元素
* 有序数组初始元素只有一个,且为源数组的第一个元素,一个元素数组总是有序的
*/
for (int j = 0; j < i; j++) {
E insertedElem = array[i];//待插入到有序数组的元素
//从有序数组中最一个元素开始查找第一个大于待插入的元素
if (c.compare(array[j], insertedElem) > 0) {
//找到插入点后,从插入点开始向后所有元素后移一位
move(array, j, i - 1);
//将待排序元素插入到有序数组中
array[j] = insertedElem;
break;
}
}
}
//=======以下是java.util.Arrays的插入排序算法的实现
/*
* 该算法看起来比较简洁一j点,有点像冒泡算法。
* 将数组逻辑上分成前后两个集合,前面的集合是已经排序好序的元素,而后面集合为待排序的
* 集合,每次内层循从后面集合中拿出一个元素,通过冒泡的形式,从前面集合最后一个元素开
* 始往前比较,如果发现前面元素大于后面元素,则交换,否则循环退出
*
* 总感觉这种算术有点怪怪,既然是插入排序,应该是先找到插入点,而后再将待排序的元素插
* 入到的插入点上,那么其他元素就必然向后移,感觉算法与排序名称不匹,但返过来与上面实
* 现比,其实是一样的,只是上面先找插入点,待找到后一次性将大的元素向后移,而该算法却
* 是走一步看一步,一步一步将待排序元素往前移
*/
/*
for (int i = from; i <= end; i++) {
for (int j = i; j > from && c.compare(array[j - 1], array[j]) > 0; j--) {
swap(array, j, j - 1);
}
}
*/
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 5, 9, 1, 4, 1, 2, 6, 3, 8, 0, 7 };
InsertSort<Integer> insertSort = new InsertSort<Integer>();
Sort.testSort(insertSort, intgArr);
Sort.testSort(insertSort, null);
}
}插入排序算法对于大数组,这种算法非常慢。但是对于小数组,它比其他算法快。其他算法因为待的数组元素很少,反而使得效率降低。在Java集合 框架中,排序都是借助于java.util.Arrays来完成的,其中排序算法用到了插入排序、快速排序、归并排序。插入排序用于元素个数小于7的子数 组排序,通常比插入排序快的其他排序方法,由于它们强大的算法是针对大数量数组设计的,所以元素个数少时速度反而慢。
希尔排序
希尔思想介绍
希尔算法的本质是缩小增量排序,是对直接插入排序算法的改进。一般直接插入排序的时间复杂度为O ( n^2 ) ,但是当数列基本有序时,如果按照有数列顺序排时,时间复杂度将改善到O( n ),另外,因直接插入排序算法简单,如果待排序列规模不很大时效率也较高,Shell 根据这两点分析结果进行了改进,将待排记录序列以一定的增量间隔h 分割成多个子序列,对每个子序列分别进行一趟直接插入排序, 然后逐步减小分组的步长h ,对于每一个步长h 下的各个子序列进行同样方法的排序,直到步长为1 时再进行一次整体排序。
因为不管记录序列多么庞大,关键字多么混乱,在先前较大的分组步长h 下每个子序列的规模都不大,用直接插入排序效率都较高。 尽管在随后的步长h 递减分组中子序列越来越大,但由于整个序列的有序性也越来越明显,则排序效率依然较高。这种改进抓住了直接插入排序的两点本质,大大提高了它的时间效率。
希尔增量研究
综上所述:
(1) 希尔排序的核心是以某个增量h 为步长跳跃分组进行插入排序,由于分组的步长h 逐步缩小,所以也叫“缩小增量排序”插入排序。其关键是如何选取分组的步长序列ht ,. . . , hk ,. . . , h1 , h0 才能使得希尔方法的时间效率最高;
(2) 待排序列记录的个数n 、跳跃分组步长逐步减小直到为1时所进行的扫描次数T、增量的和、记录关键字比较的次数以及记录移动的次数或各子序列中的反序数等因素都影响希尔算法的时间复杂度:其中记录关键字比较的次数是重要因素,它主要取决于分组步长序列的选择;
(3) 希尔方法是一种不稳定排序算法,因为其排序过程中各趟的步长不同,在第k 遍用hk作为步长排序之后,第k +1 遍排序时可能会遇到多个逆序存在,影响排序的稳定性。
试验结果表明,SHELL 算法的时间复杂度受增量序列的影响明显大于其他因素,选取恰当的增量序列能明显提高排序的时间效率,我们认为第k 趟排序扫描的增量步长为 2^k - 1 ,即增量序列为. . . 2^k - 1 ,. . . ,15 ,7 ,3 ,1时较为理想,但它并不是唯一的最佳增量序列,这与其关联函数目前尚无确定解的理论结果是一致的。
Java代码
package sort;
import java.util.Comparator;
/**
* 希尔排序算法
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public class ShelltSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
//初始步长,实质为每轮的分组数
int step = initialStep(end - from + 1);
//第一层循环是对排序轮次进行循环。(step + 1) / 2 - 1 为下一轮步长值
for (; step >= 1; step = (step + 1) / 2 - 1) {
//对每轮里的每个分组进行循环
for (int groupIndex = 0; groupIndex < step; groupIndex++) {
//对每组进行直接插入排序
insertSort(array, groupIndex, step, end, c);
}
}
}
/**
* 直接插入排序实现
* @param array 待排序数组
* @param groupIndex 对每轮的哪一组进行排序
* @param step 步长
* @param end 整个数组要排哪个元素止
* @param c 比较器
*/
private void insertSort(E[] array, int groupIndex, int step, int end, Comparator<E> c) {
int startIndex = groupIndex;//从哪里开始排序
int endIndex = startIndex;//排到哪里
/*
* 排到哪里需要计算得到,从开始排序元素开始,以step步长,可求得下元素是否在数组范围内,
* 如果在数组范围内,则继续循环,直到索引超现数组范围
*/
while ((endIndex + step) <= end) {
endIndex += step;
}
// i为每小组里的第二个元素开始
for (int i = groupIndex + step; i <= end; i += step) {
for (int j = groupIndex; j < i; j += step) {
E insertedElem = array[i];
//从有序数组中最一个元素开始查找第一个大于待插入的元素
if (c.compare(array[j], insertedElem) >= 0) {
//找到插入点后,从插入点开始向后所有元素后移一位
move(array, j, i - step, step);
array[j] = insertedElem;
break;
}
}
}
}
/**
* 根据数组长度求初始步长
*
* 我们选择步长的公式为:2^k-1,2^(k-1)-1,...,15,7,3,1 ,其中2^k 减一即为该步长序列,k
* 为排序轮次
*
* 初始步长:step = 2^k-1
* 初始步长约束条件:step < len - 1 初始步长的值要小于数组长度还要减一的值(因
* 为第一轮分组时尽量不要分为一组,除非数组本身的长度就小于等于4)
*
* 由上面两个关系试可以得知:2^k - 1 < len - 1 关系式,其中k为轮次,如果把 2^k 表 达式
* 转换成 step 表达式,则 2^k-1 可使用 (step + 1)*2-1 替换(因为 step+1 相当于第k-1
* 轮的步长,所以在 step+1 基础上乘以 2 就相当于 2^k 了),即步长与数组长度的关系不等式为
* (step + 1)*2 - 1 < len -1
*
* @param len 数组长度
* @return
*/
private static int initialStep(int len) {
/*
* 初始值设置为步长公式中的最小步长,从最小步长推导出最长初始步长值,即按照以下公式来推:
* 1,3,7,15,...,2^(k-1)-1,2^k-1
* 如果数组长度小于等于4时,步长为1,即长度小于等于4的数组不且分组,此时直接退化为直接插
* 入排序
*/
int step = 1;
//试探下一个步长是否满足条件,如果满足条件,则步长置为下一步长
while ((step + 1) * 2 - 1 < len - 1) {
step = (step + 1) * 2 - 1;
}
System.out.println("初始步长 - " + step);
return step;
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 5, 9, 1, 4, 8, 2, 6, 3, 7, 10 };
ShelltSort<Integer> shellSort = new ShelltSort<Integer>();
Sort.testSort(shellSort, intgArr);
Sort.testSort(shellSort, null);
}
}
package sort;
import java.util.Comparator;
/**
* 希尔排序算法
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public class ShelltSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
//初始步长,实质为每轮的分组数
int step = initialStep(end - from + 1);
//第一层循环是对排序轮次进行循环。(step + 1) / 2 - 1 为下一轮步长值
for (; step >= 1; step = (step + 1) / 2 - 1) {
//对每轮里的每个分组进行循环
for (int groupIndex = 0; groupIndex < step; groupIndex++) {
//对每组进行直接插入排序
insertSort(array, groupIndex, step, end, c);
}
}
}
/**
* 直接插入排序实现
* @param array 待排序数组
* @param groupIndex 对每轮的哪一组进行排序
* @param step 步长
* @param end 整个数组要排哪个元素止
* @param c 比较器
*/
private void insertSort(E[] array, int groupIndex, int step, int end, Comparator<E> c) {
int startIndex = groupIndex;//从哪里开始排序
int endIndex = startIndex;//排到哪里
/*
* 排到哪里需要计算得到,从开始排序元素开始,以step步长,可求得下元素是否在数组范围内,
* 如果在数组范围内,则继续循环,直到索引超现数组范围
*/
while ((endIndex + step) <= end) {
endIndex += step;
}
// i为每小组里的第二个元素开始
for (int i = groupIndex + step; i <= end; i += step) {
for (int j = groupIndex; j < i; j += step) {
E insertedElem = array[i];
//从有序数组中最一个元素开始查找第一个大于待插入的元素
if (c.compare(array[j], insertedElem) >= 0) {
//找到插入点后,从插入点开始向后所有元素后移一位
move(array, j, i - step, step);
array[j] = insertedElem;
break;
}
}
}
}
/**
* 根据数组长度求初始步长
*
* 我们选择步长的公式为:2^k-1,2^(k-1)-1,...,15,7,3,1 ,其中2^k 减一即为该步长序列,k
* 为排序轮次
*
* 初始步长:step = 2^k-1
* 初始步长约束条件:step < len - 1 初始步长的值要小于数组长度还要减一的值(因
* 为第一轮分组时尽量不要分为一组,除非数组本身的长度就小于等于4)
*
* 由上面两个关系试可以得知:2^k - 1 < len - 1 关系式,其中k为轮次,如果把 2^k 表 达式
* 转换成 step 表达式,则 2^k-1 可使用 (step + 1)*2-1 替换(因为 step+1 相当于第k-1
* 轮的步长,所以在 step+1 基础上乘以 2 就相当于 2^k 了),即步长与数组长度的关系不等式为
* (step + 1)*2 - 1 < len -1
*
* @param len 数组长度
* @return
*/
private static int initialStep(int len) {
/*
* 初始值设置为步长公式中的最小步长,从最小步长推导出最长初始步长值,即按照以下公式来推:
* 1,3,7,15,...,2^(k-1)-1,2^k-1
* 如果数组长度小于等于4时,步长为1,即长度小于等于4的数组不且分组,此时直接退化为直接插
* 入排序
*/
int step = 1;
//试探下一个步长是否满足条件,如果满足条件,则步长置为下一步长
while ((step + 1) * 2 - 1 < len - 1) {
step = (step + 1) * 2 - 1;
}
System.out.println("初始步长 - " + step);
return step;
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 5, 9, 1, 4, 8, 2, 6, 3, 7, 10 };
ShelltSort<Integer> shellSort = new ShelltSort<Integer>();
Sort.testSort(shellSort, intgArr);
Sort.testSort(shellSort, null);
}
} 选择排序
简单选择排序
每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。
选择排序不像冒泡排序算法那样先并不急于调换位置,第一轮(k=1)先从array[k]开始逐个检查,看哪个数最小就记下该数所在的位置于 minlIndex中,等一轮扫描完毕,如果找到比array[k-1]更小的元素,则把array[minlIndex]和a[k-1]对调,这时 array[k]到最后一个元素中最小的元素就换到**ray[k-1]的位置。 如此反复进行第二轮、第三轮…直到循环至最后一元素
Java代码
package sort;
import java.util.Comparator;
/**
* 简单选择排序算法
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public class SelectSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
int minlIndex;//最小索引
/*
* 循环整个数组(其实这里的上界为 array.length - 1 即可,因为当 i= array.length-1
* 时,最后一个元素就已是最大的了,如果为array.length时,内层循环将不再循环),每轮假设
* 第一个元素为最小元素,如果从第一元素后能选出比第一个元素更小元素,则让让最小元素与第一
* 个元素交换
*/
for (int i = from; i <= end; i++) {
minlIndex = i;//假设每轮第一个元素为最小元素
//从假设的最小元素的下一元素开始循环
for (int j = i + 1; j <= end; j++) {
//如果发现有比当前array[smallIndex]更小元素,则记下该元素的索引于smallIndex中
if (c.compare(array[j], array[minlIndex]) < 0) {
minlIndex = j;
}
}
//先前只是记录最小元素索引,当最小元素索引确定后,再与每轮的第一个元素交换
swap(array, i, minlIndex);
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 5, 9, 1, 4, 1, 2, 6, 3, 8, 0, 7 };
SelectSort<Integer> insertSort = new SelectSort<Integer>();
Sort.testSort(insertSort, intgArr);
Sort.testSort(insertSort, null);
}
}
package sort;
import java.util.Comparator;
/**
* 简单选择排序算法
* @author jzj
* @date 2009-12-5
*
* @param <E>
*/
public class SelectSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
int minlIndex;//最小索引
/*
* 循环整个数组(其实这里的上界为 array.length - 1 即可,因为当 i= array.length-1
* 时,最后一个元素就已是最大的了,如果为array.length时,内层循环将不再循环),每轮假设
* 第一个元素为最小元素,如果从第一元素后能选出比第一个元素更小元素,则让让最小元素与第一
* 个元素交换
*/
for (int i = from; i <= end; i++) {
minlIndex = i;//假设每轮第一个元素为最小元素
//从假设的最小元素的下一元素开始循环
for (int j = i + 1; j <= end; j++) {
//如果发现有比当前array[smallIndex]更小元素,则记下该元素的索引于smallIndex中
if (c.compare(array[j], array[minlIndex]) < 0) {
minlIndex = j;
}
}
//先前只是记录最小元素索引,当最小元素索引确定后,再与每轮的第一个元素交换
swap(array, i, minlIndex);
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 5, 9, 1, 4, 1, 2, 6, 3, 8, 0, 7 };
SelectSort<Integer> insertSort = new SelectSort<Integer>();
Sort.testSort(insertSort, intgArr);
Sort.testSort(insertSort, null);
}
} 堆排序
堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),故它们均是堆,其对应的完全二叉树分别如小根堆示例和大根堆示例所示:
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小顶堆。
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大顶堆。
堆是一种完全二叉树,一般使用数组来实现。堆排序也是一种选择性的排序,每次选择第i大的元素。
另外排序过程中借助了堆结构,堆就是一种完全二叉树,所以这里先要熟悉要用的二叉树几个性质:
N(N>1)个节点的的完全二叉树从层次从左自右编号,最后一个分枝节点(非叶子节点)的编号为 N/2 取整。
且对于编号 i(1<=i<=N)有:父节点为 i/2 向下取整;若2i>N,则节点i没有左孩子,否则其左孩子为2i;若2i+1>N,则没有右孩子,否则其右孩子为2i+1。
注,这里使用完全二叉树只是为了好描述算法,它只是一种逻辑结构,真真在实现时我们还是使用数组来存储这棵二叉树的,因为完全二叉树完全可以使用数组来存储。
算法描述:
堆排序其实最主要的两个过程:第一步,创建初始堆;第二步,交换根节点与最后一个非叶子节
第一步实现 :从最后一个非叶子节点为开始向前循环每个会支节点,比较每个分支节点与他左右子节点,如果其中某个子节点比父节点大,则与父节点交换,交换后原父节点可 能还小于原子节点的子节点,所以还需对原父节点进行调整,使用原父节点继续下沉,直到没有子节点或比左右子节点都大为止,调用过程可通过递归完成。当某个 非叶子节点调整完毕后,再处理下一个非叶子节点,直到根节点也调整完成,这里初始堆就创建好了,这里我们创建的是大顶堆,即大的元素向树的根浮,这样排序 最后得到的结果为升序,因为最大的从树中去掉,并从数组最后往前存放。
第二步实现 :将树中的最后一个元素与堆顶元素进行交换,并从树中去掉最后叶子节点。交换后再按创建初始堆的算法调整根节点,如此下去直到树中只有一个节点为止。
Java代码
package sort;
import java.util.Comparator;
public class HeapSort<E extends Comparable<E>> extends Sort<E> {
/**
* 排序算法的实现,对数组中指定的元素进行排序
* @param array 待排序的数组
* @param from 从哪里开始排序
* @param end 排到哪里
* @param c 比较器
*/
public void sort(E[] array, int from, int end, Comparator<E> c) {
//创建初始堆
initialHeap(array, from, end, c);
/*
* 对初始堆进行循环,且从最后一个节点开始,直接树只有两个节点止
* 每轮循环后丢弃最后一个叶子节点,再看作一个新的树
*/
for (int i = end - from + 1; i >= 2; i--) {
//根节点与最后一个叶子节点交换位置,即数组中的第一个元素与最后一个元素互换
swap(array, from, i - 1);
//交换后需要重新调整堆
adjustNote(array, 1, i - 1, c);
}
}
/**
* 初始化堆
* 比如原序列为:7,2,4,3,12,1,9,6,8,5,10,11
* 则初始堆为:1,2,4,3,5,7,9,6,8,12,10,11
* @param arr 排序数组
* @param from 从哪
* @param end 到哪
* @param c 比较器
*/
private void initialHeap(E[] arr, int from, int end, Comparator<E> c) {
int lastBranchIndex = (end - from + 1) / 2;//最后一个非叶子节点
//对所有的非叶子节点进行循环 ,且从最一个非叶子节点开始
for (int i = lastBranchIndex; i >= 1; i--) {
adjustNote(arr, i, end - from + 1, c);
}
}
/**
* 调整节点顺序,从父、左右子节点三个节点中选择一个最大节点与父节点转换
* @param arr 待排序数组
* @param parentNodeIndex 要调整的节点,与它的子节点一起进行调整
* @param len 树的节点数
* @param c 比较器
*/
private void adjustNote(E[] arr, int parentNodeIndex, int len, Comparator<E> c) {
int minNodeIndex = parentNodeIndex;
//如果有左子树,i * 2为左子节点索引
if (parentNodeIndex * 2 <= len) {
//如果父节点小于左子树时
if (c.compare(arr[parentNodeIndex - 1], arr[parentNodeIndex * 2 - 1]) < 0) {
minNodeIndex = parentNodeIndex * 2;//记录最大索引为左子节点索引
}
// 只有在有或子树的前提下才可能有右子树,再进一步断判是否有右子树
if (parentNodeIndex * 2 + 1 <= len) {
//如果右子树比最大节点更大
if (c.compare(arr[minNodeIndex - 1], arr[(parentNodeIndex * 2 + 1) - 1]) < 0) {
minNodeIndex = parentNodeIndex * 2 + 1;//记录最大索引为右子节点索引
}
}
}
//如果在父节点、左、右子节点三都中,最大节点不是父节点时需交换,把最大的与父节点交换,创建大顶堆
if (minNodeIndex != parentNodeIndex) {
swap(arr, parentNodeIndex - 1, minNodeIndex - 1);
//交换后可能需要重建堆,原父节点可能需要继续下沉
if (minNodeIndex * 2 <= len) {//是否有子节点,注,只需判断是否有左子树即可知道
adjustNote(arr, minNodeIndex, len, c);
}
}
}
/**
* 测试
* @param args
*/
public static void main(String[] args) {
Integer[] intgArr = { 7, 2, 4, 3, 12, 1, 9, 6, 8, 5, 10, 11 };
HeapSort<Integer> sort = new HeapSort<Integer>();
HeapSort.testSort(sort, intgArr);
HeapSort.testSort(sort, null);
}
} -
cookie和session的区别
2011-09-21 12:13:03
这些都是基础知识,不过有必要做深入了解。先简单介绍一下。
二者的定义:
当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cookie 会帮你在网站上所打的文字或是一些选择,
都纪录下来。当下次你再光临同一个网站,WEB 服务器会先看看有没有它上次留下的 Cookie 资料,有的话,就会依据 Cookie
里的内容来判断使用者,送出特定的网页内容给你。 Cookie 的使用很普遍,许多有提供个人化服务的网站,都是利用 Cookie
来辨认使用者,以方便送出使用者量身定做的内容,像是 Web 接口的免费 email 网站,都要用到 Cookie。
具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案。同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制
来达到保存标识的目的,但实际上它还有其他选择。
cookie机制。正统的cookie分发是通过扩展HTTP协议来实现的,服务器通过在HTTP的响应头中加上一行特殊的指示以提示
浏览器按照指示生成相应的cookie。然而纯粹的客户端脚本如JavaScript或者VBScript也可以生成cookie。而cookie的使用
是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围
大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器。
cookie的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成cookie的作用范围。若不设置过期时间,则表示这个cookie的生命期为浏览器会话期间,关闭浏览器窗口,cookie就消失。这种生命期为浏览器会话期的cookie被称为会话cookie。
会话cookie一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。若设置了过期时间,浏览器就会把cookie
保存到硬盘上,关闭后再次打开浏览器,这些cookie仍然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏
览器进程间共享,比如两个IE窗口。而对于保存在内存里的cookie,不同的浏览器有不同的处理方式
session机制。session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。
当程序需要为某个客户端的请求创建一个session时,服务器首先检查这个客户端的请求里是否已包含了一个session标识
(称为session id),如果已包含则说明以前已经为此客户端创建过session,服务器就按照session id把这个session检索出来
使用(检索不到,会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相
关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应
中返回给客户端保存。保存这个session id的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发送给
服务器。一般这个cookie的名字都是类似于SEEESIONID。但cookie可以被人为的禁止,则必须有其他机制以便在cookie被禁止时
仍然能够把session id传递回服务器。
经常被使用的一种技术叫做URL重写,就是把session id直接附加在URL路径的后面。还有一种技术叫做表单隐藏字段。就是服务器
会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把session id传递回服务器。比如:
<form. name="testform" action="/xxx">
<input type="hidden" name="jsessionid" value="ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764">
<input type="text">
</form>
实际上这种技术可以简单的用对action应用URL重写来代替。cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE4、单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中 -
浅析Oracle语句优化规则
2011-09-20 15:33:19
1. 选用适合的ORACLE优化器
ORACLE的优化器共有3种:
a. RULE (基于规则)
b. COST (基于成本)
c. CHOOSE (选择性)
设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS . 你当然也在SQL句级或是会话(session)级对其进行覆盖。
为了使用基于成本的优化器(CBO, Cost-Based Optimizer) , 你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。
如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关。 如果table已经被analyze过, 优化器模式将自动成为CBO , 反之,数据库将采用RULE形式的优化器。
在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) , 你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。
2. 访问Table的方式ORACLE 采用两种访问表中记录的方式:
a.全表扫描
全表扫描就是顺序地访问表中每条记录。 ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。
b.通过ROWID访问表
你可以采用基于ROWID的访问方式情况,提高访问表的效率, ROWID包含了表中记录的物理位置信息……ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。 通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。
3. 共享SQL语句
为了不重复解析相同的SQL语句,在第一次解析之后, ORACLE将SQL语句存放在内存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享。 因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同, ORACLE就能很快获得已经被解析的语句以及最好的执行路径。 ORACLE的这个功能大大地提高了SQL的执行性能并节省了内存的使用。
可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering) ,这个功能并不适用于多表连接查询。
数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。
当你向ORACLE 提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句。
这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等)。
共享的语句必须满足三个条件:
A.字符级的比较:
当前被执行的语句和共享池中的语句必须完全相同。
例如:
SELECT * FROM EMP;
和下列每一个都不同
SELECT * from EMP;
Select * From Emp;
SELECT * FROM EMP;
B.两个语句所指的对象必须完全相同:
例如:
用户 对象名 如何访问
Jack sal_limit private synonym
Work_city public synonym
Plant_detail public synonym
Jill sal_limit private synonym
Work_city public synonym
Plant_detail table owner
考虑一下下列SQL语句能否在这两个用户之间共享。
SQL 能否共享 原因
select max(sal_cap) from sal_limit; 不能 每个用户都有一个private synonym - sal_limit , 它们是不同的对象
select count(*0 from work_city where sdesc like 'NEW%'; 能 两个用户访问相同的对象public synonym - work_city
select a.sdesc,b.location from work_city a , plant_detail b where a.city_id = b.city_id 不能 用户jack 通过private synonym访问plant_detail 而jill 是表的所有者,对象不同.
C.两个SQL语句中必须使用相同的名字的绑定变量(bind variables)
例如:第一组的两个SQL语句是相同的(可以共享),而第二组中的两个语句是不同的(即使在运行时,赋于不同的绑定变量相同的值)
a.
select pin , name from people where pin = :blk1.pin;
select pin , name from people where pin = :blk1.pin;
b.
select pin , name from people where pin = :blk1.ot_ind;
select pin , name from people where pin = :blk1.ov_ind;
4. 选择最有效率的表名顺序(只在基于规则的优化器中有效)
ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理。 在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。当ORACLE处理多个表时, 会运用排序及合并的方式连接它们。首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并。
例如:
表 TAB1 16,384 条记录
表 TAB2 1 条记录
选择TAB2作为基础表 (最好的方法)
select count(*) from tab1,tab2 执行时间0.96秒
选择TAB2作为基础表 (不佳的方法)
select count(*) from tab2,tab1 执行时间26.09秒
如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表。
例如:EMP表描述了LOCATION表和CATEGORY表的交集。
SELECT *
FROM LOCATION L, CATEGORY C, EMP E
WHERE E.EMP_NO BETWEEN 1000 AND 2000
AND E.CAT_NO = C.CAT_NO
AND E.LOCN = L.LOCN
将比下列SQL更有效率
SELECT *
FROM EMP E, LOCATION L, CATEGORY C
WHERE E.CAT_NO = C.CAT_NO
AND E.LOCN = L.LOCN
AND E.EMP_NO BETWEEN 1000 AND 2000
5. WHERE子句中的连接顺序。
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。
例如:
(低效,执行时间156.3秒)
SELECT *
FROM EMP E
WHERE SAL > 50000
AND JOB = 'MANAGER'
AND 25 < (SELECT COUNT(*) FROM EMP WHERE MGR = E.EMPNO);
(高效,执行时间10.6秒)
SELECT *
FROM EMP E
WHERE 25 < (SELECT COUNT(*) FROM EMP WHERE MGR = E.EMPNO)
AND SAL > 50000
AND JOB = 'MANAGER';
6. SELECT子句中避免使用 '*'
当你想在SELECT子句中列出所有的COLUMN时,使用动态SQL列引用 '*' 是一个方便的方法。不幸的是,这是一个非常低效的方法。 实际上,ORACLE在解析的过程中, 会将'*' 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间。
7. 减少访问数据库的次数
当执行每条SQL语句时, ORACLE在内部执行了许多工作: 解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等等。 由此可见, 减少访问数据库的次数 , 就能实际上减少ORACLE的工作量。
例如,以下有三种方法可以检索出雇员号等于0342或0291的职员。
方法1 (最低效)
SELECT EMP_NAME, SALARY, GRADE FROM EMP WHERE EMP_NO = 342;
SELECT EMP_NAME, SALARY, GRADE FROM EMP WHERE EMP_NO = 291;
方法2 (次低效)
DECLARE
CURSOR C1(E_NO NUMBER) IS
SELECT EMP_NAME, SALARY, GRADE FROM EMP WHERE EMP_NO = E_NO;
BEGIN
OPEN C1(342);
FETCH C1
INTO …,..,..;
OPEN C1(291);
FETCH C1
INTO …,..,..;
CLOSE C1;
END;
方法3 (高效)
SELECT A.EMP_NAME, A.SALARY, A.GRADE, B.EMP_NAME, B.SALARY, B.GRADE
FROM EMP A, EMP B
WHERE A.EMP_NO = 342
AND B.EMP_NO = 291;
注意:
在SQL*Plus , SQL*Forms和Pro*C中重新设置ARRAYSIZE参数, 可以增加每次数据库访问的检索数据量 ,建议值为200.
8. 使用DECODE函数来减少处理时间
使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表。
例如:
SELECT COUNT(*),
SUM(SAL) FROM EMP WHERE DEPT_NO = 0020 AND ENAME LIKE 'SMITH%';
SELECT COUNT(*),
SUM(SAL) FROM EMP WHERE DEPT_NO = 0030 AND ENAME LIKE 'SMITH%';
可以用DECODE函数高效地得到相同结果
SELECT COUNT(DECODE(DEPT_NO, 0020, 'X', NULL)) D0020_COUNT,
COUNT(DECODE(DEPT_NO, 0030, 'X', NULL)) D0030_COUNT,
SUM(DECODE(DEPT_NO, 0020, SAL, NULL)) D0020_SAL,
SUM(DECODE(DEPT_NO, 0030, SAL, NULL)) D0030_SAL
FROM EMP
WHERE ENAME LIKE 'SMITH%';
类似的,DECODE函数也可以运用于GROUP BY 和ORDER BY子句中。
9. 整合简单,无关联的数据库访问
如果你有几个简单的数据库查询语句,你可以把它们整合到一个查询中(即使它们之间没有关系)
例如:
SELECT NAME FROM EMP WHERE EMP_NO = 1234;
SELECT NAME FROM DPT WHERE DPT_NO = 10;
SELECT NAME FROM CAT WHERE CAT_TYPE = 'RD';
上面的3个查询可以被合并成一个:
SELECT E.NAME, D.NAME, C.NAME
FROM CAT C, DPT D, EMP E, DUAL X
WHERE NVL('X', X.DUMMY) = NVL('X', E.ROWID(+))
AND NVL('X', X.DUMMY) = NVL('X', D.ROWID(+))
AND NVL('X', X.DUMMY) = NVL('X', C.ROWID(+))
AND E.EMP_NO(+) = 1234
AND D.DEPT_NO(+) = 10
AND C.CAT_TYPE(+) = 'RD';
虽然采取这种方法,效率得到提高,但是程序的可读性大大降低,所以读者还是要权衡之间的利弊)
10. 删除重复记录
最高效的删除重复记录方法 ( 因为使用了ROWID)
DELETE FROM EMP E
WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO);11. 用TRUNCATE替代DELETE
当删除表中的记录时,在通常情况下, 回滚段(rollback segments ) 用来存放可以被恢复的信息。 如果你没有COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准确地说是恢复到执行删除命令之前的状况)
而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的信息。当命令运行后,数据不能被恢复。因此很少的资源被调用,执行时间也会很短。
TRUNCATE只在删除全表适用,TRUNCATE是DDL不是DML
12. 尽量多使用COMMIT
只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少:COMMIT所释放的资源:
a.回滚段上用于恢复数据的信息。
b.被程序语句获得的锁
c.redo log buffer 中的空间
d.ORACLE为管理上述3种资源中的内部花费
在使用COMMIT时必须要注意到事务的完整性,现实中效率和事务完整性往往是鱼和熊掌不可得兼
13. 计算记录条数
和一般的观点相反, count(*) 比count(1)稍快 , 当然如果可以通过索引检索,对索引列的计数仍旧是最快的。 例如 COUNT(EMPNO)
在CSDN论坛中,曾经对此有过相当热烈的讨论, 作者的观点并不十分准确,通过实际的测试,上述三种方法并没有显著的性能差别
14. 用Where子句替换HAVING子句
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤。 这个处理需要排序,总计等操作。 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销。
例如:
低效:
SELECT REGION, AVG(LOG_SIZE)
FROM LOCATION
GROUP BY REGION
HAVING REGION REGION != 'SYDNEY' AND REGION != 'PERTH'
高效
SELECT REGION, AVG(LOG_SIZE)
FROM LOCATION
WHERE REGION REGION != 'SYDNEY'
AND REGION != 'PERTH'
GROUP BY REGION
HAVING 中的条件一般用于对一些集合函数的比较,如COUNT() 等等。 除此而外,一般的条件应该写在WHERE子句中
15. 减少对表的查询
在含有子查询的SQL语句中,要特别注意减少对表的查询。
例如:
低效
SELECT TAB_NAME
FROM TABLES
WHERE TAB_NAME =
(SELECT TAB_NAME FROM TAB_COLUMNS WHERE VERSION = 604)
AND DB_VER =
(SELECT DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
高效
SELECT TAB_NAME
FROM TABLES
WHERE (TAB_NAME, DB_VER) = (SELECT TAB_NAME, DB_VER) FROM
TAB_COLUMNS
WHERE VERSION = 604)
Update 多个Column 例子:
低效:
UPDATE EMP
SET EMP_CAT =
(SELECT MAX(CATEGORY) FROM EMP_CATEGORIES),
SAL_RANGE =
(SELECT MAX(SAL_RANGE) FROM EMP_CATEGORIES)
WHERE EMP_DEPT = 0020;
高效:
UPDATE EMP
SET (EMP_CAT, SAL_RANGE) =
(SELECT MAX(CATEGORY), MAX(SAL_RANGE) FROM EMP_CATEGORIES)
WHERE EMP_DEPT = 0020;
16. 通过内部函数提高SQL效率。
SELECT H.EMPNO, E.ENAME, H.HIST_TYPE, T.TYPE_DESC, COUNT(*)
FROM HISTORY_TYPE T, EMP E, EMP_HISTORY H
WHERE H.EMPNO = E.EMPNO
AND H.HIST_TYPE = T.HIST_TYPE
GROUP BY H.EMPNO, E.ENAME, H.HIST_TYPE, T.TYPE_DESC;
通过调用下面的函数可以提高效率。
FUNCTION LOOKUP_HIST_TYPE(TYP IN NUMBER) RETURN VARCHAR2 AS
TDESC VARCHAR2(30);
CURSOR C1 IS
SELECT TYPE_DESC FROM HISTORY_TYPE WHERE HIST_TYPE = TYP;
BEGIN
OPEN C1;
FETCH C1
INTO TDESC;
CLOSE C1;
RETURN(NVL(TDESC, '?'));
END;
FUNCTION LOOKUP_EMP(EMP IN NUMBER) RETURN VARCHAR2 AS
ENAME VARCHAR2(30);
CURSOR C1 IS
SELECT ENAME FROM EMP WHERE EMPNO = EMP;
BEGIN
OPEN C1;
FETCH C1
INTO ENAME;
CLOSE C1;
RETURN(NVL(ENAME, '?'));
END;
SELECT H.EMPNO,
LOOKUP_EMP(H.EMPNO),
H.HIST_TYPE,
LOOKUP_HIST_TYPE(H.HIST_TYPE),
COUNT(*)
FROM EMP_HISTORY H
GROUP BY H.EMPNO, H.HIST_TYPE;
经常在论坛中看到如 '能不能用一个SQL写出…。' 的贴子, 殊不知复杂的SQL往往牺牲了执行效率。 能够掌握上面的运用函数解决问题的方法在实际工作中是非常有意义的
17. 使用表的别名(Alias)
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上。这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误。
Column歧义指的是由于SQL中不同的表具有相同的Column名,当SQL语句中出现这个Column时,SQL解析器无法判断这个Column的归属
18. 用EXISTS替代IN
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接。在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率。
低效:
SELECT *
FROM EMP(基础表)
WHERE EMPNO > 0
AND DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE LOC = 'MELB')
高效:
SELECT *
FROM EMP(基础表)
WHERE EMPNO > 0
AND EXISTS (SELECT 'X'
FROM DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
AND LOC = 'MELB')
相对来说,用NOT EXISTS替换NOT IN 将更显著地提高效率,下一节中将指出
19. 用NOT EXISTS替代NOT IN
在子查询中,NOT IN子句将执行一个内部的排序和合并。 无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历)。 为了避免使用NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS.
例如:
SELECT *
FROM EMP
WHERE DEPT_NO NOT IN (SELECT DEPT_NO FROM DEPT WHERE DEPT_CAT = 'A');
为了提高效率。改写为:
(方法一: 高效)
SELECT *
FROM EMP A, DEPT B
WHERE A.DEPT_NO = B.DEPT(+)
AND B.DEPT_NO IS NULL
AND B.DEPT_CAT(+) = 'A'
(方法二: 最高效)
SELECT *
FROM EMP E
WHERE NOT EXISTS (SELECT 'X'
FROM DEPT D
WHERE D.DEPT_NO = E.DEPT_NO
AND DEPT_CAT = 'A');
20. 用表连接替换EXISTS
通常来说 , 采用表连接的方式比EXISTS更有效率
SELECT ENAME
FROM EMP E
WHERE EXISTS (SELECT 'X'
FROM DEPT
WHERE DEPT_NO = E.DEPT_NO
AND DEPT_CAT = 'A');
(更高效)
SELECT ENAME
FROM DEPT D, EMP E
WHERE E.DEPT_NO = D.DEPT_NO
AND DEPT_CAT = 'A';
在RBO的情况下,前者的执行路径包括FILTER,后者使用NESTED LOOP
21. 用EXISTS替换DISTINCT
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT. 一般可以考虑用EXIST替换
例如:
低效:
SELECT DISTINCT DEPT_NO, DEPT_NAME
FROM DEPT D, EMP E
WHERE D.DEPT_NO = E.DEPT_NO
高效:
SELECT DEPT_NO, DEPT_NAME
FROM DEPT D
WHERE EXISTS (SELECT 'X' FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO);
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
22. 识别'低效执行'的SQL语句
用下列SQL工具找出低效SQL:
SELECT EXECUTIONS,
DISK_READS,
BUFFER_GETS,
ROUND((BUFFER_GETS - DISK_READS) / BUFFER_GETS, 2) Hit_radio,
ROUND(DISK_READS / EXECUTIONS, 2) Reads_per_run,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS > 0
AND BUFFER_GETS > 0
AND (BUFFER_GETS - DISK_READS) / BUFFER_GETS < 0.8
ORDER BY 4 DESC;
虽然目前各种关于SQL优化的图形化工具层出不穷,但是写出自己的SQL工具来解决问题始终是一个最好的方法
23. 使用TKPROF 工具来查询SQL性能状态
SQL trace 工具收集正在执行的SQL的性能状态数据并记录到一个跟踪文件中。 这个跟踪文件提供了许多有用的信息,例如解析次数。执行次数,CPU使用时间等。这些数据将可以用来优化你的系统。
设置SQL TRACE在会话级别:
有效
ALTER SESSION SET SQL_TRACE TRUE
设置SQL TRACE 在整个数据库有效仿, 你必须将SQL_TRACE参数在init.ora中设为TRUE, USER_DUMP_DEST参数说明了生成跟踪文件的目录
这一节中,作者并没有提到TKPROF的用法, 对SQL TRACE的用法也不够准确, 设置SQL TRACE首先要在init.ora中设定TIMED_STATISTICS, 这样才能得到那些重要的时间状态。 生成的trace文件是不可读的,所以要用TKPROF工具对其进行转换,TKPROF有许多执行参数。 大家可以参考ORACLE手册来了解具体的配置。
24.用EXPLAIN PLAN 分析SQL语句
EXPLAIN PLAN 是一个很好的分析SQL语句的工具,它甚至可以在不执行SQL的情况下分析语句。 通过分析,我们就可以知道ORACLE是怎么样连接表,使用什么方式扫描表(索引扫描或全表扫描)以及使用到的索引名称。
你需要按照从里到外,从上到下的次序解读分析的结果。 EXPLAIN PLAN分析的结果是用缩进的格式排列的, 最内部的操作将被最先解读, 如果两个操作处于同一层中,带有最小操作号的将被首先执行。
NESTED LOOP是少数不按照上述规则处理的操作, 正确的执行路径是检查对NESTED LOOP提供数据的操作,其中操作号最小的将被最先处理。
译者按:通过实践, 感到还是用SQLPLUS中的SET TRACE 功能比较方便。
举例:
SQL> list
1 SELECT *
2 FROM dept, emp
3* WHERE emp.deptno = dept.deptno
SQL> set autotrace traceonly /*traceonly 可以不显示执行结果*/
SQL> /
14 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 NESTED LOOPS
2 1 TABLE ACCESS (FULL) OF 'EMP'
3 1 TABLE ACCESS (BY INDEX ROWID) OF 'DEPT'
4 3 INDEX (UNIQUE SCAN) OF 'PK_DEPT' (UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
2 db block gets
30 consistent gets
0 physical reads
0 redo size
2598 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed
通过以上分析,可以得出实际的执行步骤是:
1. TABLE ACCESS (FULL) OF 'EMP'
2. INDEX (UNIQUE SCAN) OF 'PK_DEPT' (UNIQUE)
3. TABLE ACCESS (BY INDEX ROWID) OF 'DEPT'
4. NESTED LOOPS (JOINING 1 AND 3)
注: 目前许多第三方的工具如TOAD和ORACLE本身提供的工具如OMS的SQL Analyze都提供了极其方便的EXPLAIN PLAN工具。也许喜欢图形化界面的朋友们可以选用它们。
25. 用索引提高效率
索引是表的一个概念部分,用来提高检索数据的效率。 实际上,ORACLE使用了一个复杂的自平衡B-tree结构。 通常,通过索引查询数据比全表扫描要快。 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引。 同样在联结多个表时使用索引也可以提高效率。 另一个使用索引的好处是,它提供了主键(primary key)的唯一性验证。
除了那些LONG或LONG RAW数据类型, 你可以索引几乎所有的列。 通常, 在大型表中使用索引特别有效。 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率。
虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价。 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改。 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。
译者按:定期的重构索引是有必要的。
ALTER INDEX <INDEXNAME> REBUILD <TABLESPACENAME>
26. 索引的操作
ORACLE对索引有两种访问模式。
索引唯一扫描 ( INDEX UNIQUE SCAN)
大多数情况下, 优化器通过WHERE子句访问INDEX.
例如:
表LODGING有两个索引 : 建立在LODGING列上的唯一性索引LODGING_PK和建立在MANAGER列上的非唯一性索引LODGING$MANAGER.
SELECT * FROM LODGING WHERE LODGING = 'ROSE HILL';
在内部 , 上述SQL将被分成两步执行, 首先 , LODGING_PK 索引将通过索引唯一扫描的方式被访问 , 获得相对应的ROWID, 通过ROWID访问表的方式执行下一步检索。
如果被检索返回的列包括在INDEX列中,ORACLE将不执行第二步的处理(通过ROWID访问表)。 因为检索数据保存在索引中, 单单访问索引就可以完全满足查询结果。
下面SQL只需要INDEX UNIQUE SCAN 操作。
SELECT LODGING FROM LODGING WHERE LODGING = 'ROSE HILL';
索引范围查询(INDEX RANGE SCAN)
适用于两种情况:
1.基于一个范围的检索
2.基于非唯一性索引的检索
例1:
SELECT LODGING FROM LODGING WHERE LODGING LIKE 'M%';
WHERE子句条件包括一系列值, ORACLE将通过索引范围查询的方式查询LODGING_PK . 由于索引范围查询将返回一组值, 它的效率就要比索引唯一扫描低一些。
例2:
SELECT LODGING FROM LODGING WHERE MANAGER = 'BILL GATES';
这个SQL的执行分两步, LODGING$MANAGER的索引范围查询(得到所有符合条件记录的ROWID) 和下一步同过ROWID访问表得到LODGING列的值。 由于LODGING$MANAGER是一个非唯一性的索引,数据库不能对它执行索引唯一扫描。
由于SQL返回LODGING列,而它并不存在于LODGING$MANAGER索引中, 所以在索引范围查询后会执行一个通过ROWID访问表的操作。
WHERE子句中, 如果索引列所对应的值的第一个字符由通配符(WILDCARD)开始, 索引将不被采用。在这种情况下,ORACLE将使用全表扫描。
SELECT LODGING FROM LODGING WHERE MANAGER LIKE '%HANMAN';
27. 基础表的选择
基础表(Driving Table)是指被最先访问的表(通常以全表扫描的方式被访问)。 根据优化器的不同, SQL语句中基础表的选择是不一样的。
如果你使用的是CBO (COST BASED OPTIMIZER),优化器会检查SQL语句中的每个表的物理大小,索引的状态,然后选用花费最低的执行路径。
如果你用RBO (RULE BASED OPTIMIZER) , 并且所有的连接条件都有索引对应, 在这种情况下, 基础表就是FROM 子句中列在最后的那个表。
举例:
SELECT A.NAME , B.MANAGER
FROM WORKER A,
LODGING B
WHERE A.LODGING = B.LODING;
由于LODGING表的LODING列上有一个索引, 而且WORKER表中没有相比较的索引, WORKER表将被作为查询中的基础表。
28. 多个平等的索引
当SQL语句的执行路径可以使用分布在多个表上的多个索引时, ORACLE会同时使用多个索引并在运行时对它们的记录进行合并, 检索出仅对全部索引有效的记录。
在ORACLE选择执行路径时,唯一性索引的等级高于非唯一性索引。 然而这个规则只有当WHERE子句中索引列和常量比较才有效。如果索引列和其他表的索引类相比较。 这种子句在优化器中的等级是非常低的。
如果不同表中两个想同等级的索引将被引用, FROM子句中表的顺序将决定哪个会被率先使用。 FROM子句中最后的表的索引将有最高的优先级。
如果相同表中两个想同等级的索引将被引用, WHERE子句中最先被引用的索引将有最高的优先级。
举例:
DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引。
SELECT ENAME
FROM EMP
WHERE DEPT_NO = 20
AND EMP_CAT = 'A';
这里,DEPTNO索引将被最先检索,然后同EMP_CAT索引检索出的记录进行合并。 执行路径如下:
TABLE ACCESS BY ROWID ON EMP
AND-EQUAL
INDEX RANGE SCAN ON DEPT_IDX
INDEX RANGE SCAN ON CAT_IDX
29. 等式比较和范围比较
当WHERE子句中有索引列, ORACLE不能合并它们,ORACLE将用范围比较。
举例:
DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引。
SELECT ENAME
FROM EMP
WHERE DEPTNO > 20
AND EMP_CAT = 'A';
这里只有EMP_CAT索引被用到,然后所有的记录将逐条与DEPTNO条件进行比较。 执行路径如下:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON CAT_IDX
30. 不明确的索引等级
当ORACLE无法判断索引的等级高低差别,优化器将只使用一个索引,它就是在WHERE子句中被列在最前面的。
举例:
DEPTNO上有一个非唯一性索引,EMP_CAT也有一个非唯一性索引。
SELECT ENAME
FROM EMP
WHERE DEPTNO > 20
AND EMP_CAT > 'A';
这里, ORACLE只用到了DEPT_NO索引。 执行路径如下:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
我们来试一下以下这种情况:
SQL> select index_name, uniqueness from user_indexes where table_name = 'EMP';
INDEX_NAME UNIQUENES
------------------------------ ---------
EMPNO UNIQUE
EMPTYPE NONUNIQUE
SQL> select * from emp where empno >= 2 and emp_type = 'A' ;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPTYPE' (NON-UNIQUE)
虽然EMPNO是唯一性索引,但是由于它所做的是范围比较, 等级要比非唯一性索引的等式比较低!
31. 强制索引失效
如果两个或以上索引具有相同的等级,你可以强制命令ORACLE优化器使用其中的一个(通过它,检索出的记录数量少) .
举例:
SELECT ENAME
FROM EMP
WHERE EMPNO = 7935
AND DEPTNO + 0 = 10 /*DEPTNO上的索引将失效*/
AND EMP_TYPE || '' = 'A' /*EMP_TYPE上的索引将失效*/
这是一种相当直接的提高查询效率的办法。 但是你必须谨慎考虑这种策略,一般来说,只有在你希望单独优化几个SQL时才能采用它。
这里有一个例子关于何时采用这种策略,假设在EMP表的EMP_TYPE列上有一个非唯一性的索引而EMP_CLASS上没有索引。
SELECT ENAME
FROM EMP
WHERE EMP_TYPE = 'A'
AND EMP_CLASS = 'X';
优化器会注意到EMP_TYPE上的索引并使用它。 这是目前唯一的选择。 如果,一段时间以后, 另一个非唯一性建立在EMP_CLASS上,优化器必须对两个索引进行选择,在通常情况下,优化器将使用两个索引并在他们的结果集合上执行排序及合并。 然而,如果其中一个索引(EMP_TYPE)接近于唯一性而另一个索引(EMP_CLASS)上有几千个重复的值。 排序及合并就会成为一种不必要的负担。 在这种情况下,你希望使优化器屏蔽掉EMP_CLASS索引。
用下面的方案就可以解决问题。
SELECT ENAME
FROM EMP
WHERE EMP_TYPE = 'A'
AND EMP_CLASS || '' = 'X';
32. 避免在索引列上使用计算。
WHERE子句中,如果索引列是函数的一部分。优化器将不使用索引而使用全表扫描。
举例:
低效:
SELECT *
FROM DEPT
WHERE SAL * 12 > 25000;
高效:
SELECT *
FROM DEPT
WHERE SAL > 25000/12;
这是一个非常实用的规则,请务必牢记
33. 自动选择索引
如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性。
在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引。
举例:
SELECT ENAME
FROM EMP
WHERE EMPNO = 2326
AND DEPTNO = 20;
这里,只有EMPNO上的索引是唯一性的,所以EMPNO索引将用来检索记录。
TABLE ACCESS BY ROWID ON EMP
INDEX UNIQUE SCAN ON EMP_NO_IDX
34. 避免在索引列上使用NOT
通常,我们要避免在索引列上使用NOT, NOT会产生在和在索引列上使用函数相同的影响。 当ORACLE“遇到”NOT,他就会停止使用索引转而执行全表扫描。
举例:
低效:(这里,不使用索引)
SELECT * FROM DEPT WHERE DEPT_CODE NOT = 0;
高效:(这里,使用了索引)
SELECT * FROM DEPT WHERE DEPT_CODE > 0;
需要注意的是,在某些时候, ORACLE优化器会自动将NOT转化成相对应的关系操作符。
NOT > to <=
NOT >= to <
NOT < to >=
NOT <= to >
在这个例子中,作者犯了一些错误。 例子中的低效率SQL是不能被执行的。
测试:
SQL> select * from emp where NOT empno > 1;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPNO' (UNIQUE)SQL> select * from emp where empno <= 1;
no rows selected
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (RANGE SCAN) OF 'EMPNO' (UNIQUE)
两者的效率完全一样,也许这符合作者关于“ 在某些时候, ORACLE优化器会自动将NOT转化成相对应的关系操作符” 的观点。
35. 用>=替代>
如果DEPTNO上有一个索引,
高效:
SELECT *
FROM EMP
WHERE DEPTNO >= 4
低效:
SELECT * FROM EMP WHERE DEPTNO > 3
两者的区别在于, 前者DBMS将直接跳到第一个DEPT等于4的记录而后者将首先定位到DEPTNO=3的记录并且向前扫描到第一个DEPT大于3的记录。
36. 用UNION替换OR (适用于索引列)
通常情况下, 用UNION替换WHERE子句中的OR将会起到较好的效果。 对索引列使用OR将造成全表扫描。注意, 以上规则只针对多个索引列有效。 如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低。
在下面的例子中, LOC_ID 和REGION上都建有索引。
高效:
SELECT LOC_ID, LOC_DESC, REGION
FROM LOCATION
WHERE LOC_ID = 10
UNION
SELECT LOC_ID, LOC_DESC, REGION FROM LOCATION WHERE REGION = 'MELBOURNE'
低效:
SELECT LOC_ID, LOC_DESC, REGION
FROM LOCATION
WHERE LOC_ID = 10
OR REGION = 'MELBOURNE'
如果你坚持要用OR, 那就需要返回记录最少的索引列写在最前面。
注意:
WHERE KEY1 = 10 (返回最少记录)
OR KEY2 = 20 (返回最多记录)
ORACLE 内部将以上转换为
WHERE KEY1 = 10 AND((NOT KEY1 = 10) AND KEY2 = 20)
下面的测试数据仅供参考: (a = 1003 返回一条记录 , b = 1 返回1003条记录)
SQL> select * from unionvsor /*1st test*/
2 where a = 1003 or b = 1;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 CONCATENATION
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'UNIONVSOR'
3 2 INDEX (RANGE SCAN) OF 'UB' (NON-UNIQUE)
4 1 TABLE ACCESS (BY INDEX ROWID) OF 'UNIONVSOR'
5 4 INDEX (RANGE SCAN) OF 'UA' (NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
144 consistent gets
0 physical reads
0 redo size
63749 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1003 rows processed
SQL> select * from unionvsor /*2nd test*/
2 where b = 1 or a = 1003 ;
1003 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 CONCATENATION
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'UNIONVSOR'
3 2 INDEX (RANGE SCAN) OF 'UA' (NON-UNIQUE)
4 1 TABLE ACCESS (BY INDEX ROWID) OF 'UNIONVSOR'
5 4 INDEX (RANGE SCAN) OF 'UB' (NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
143 consistent gets
0 physical reads
0 redo size
63749 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client 0 sorts (memory)
0 sorts (disk)
1003 rows processedSQL> select * from unionvsor /*3rd test*/
2 where a = 1003
3 union
4 select * from unionvsor
5 where b = 1;
1003 rows selected. Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 SORT (UNIQUE)
2 1 UNION-ALL
3 2 TABLE ACCESS (BY INDEX ROWID) OF 'UNIONVSOR'
4 3 INDEX (RANGE SCAN) OF 'UA' (NON-UNIQUE)
5 2 TABLE ACCESS (BY INDEX ROWID) OF 'UNIONVSOR'
6 5 INDEX (RANGE SCAN) OF 'UB' (NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
63735 bytes sent via SQL*Net to client
7751 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client 1 sorts (memory)
0 sorts (disk)
1003 rows processed
用UNION的效果可以从consistent gets和 SQL*NET的数据交换量的减少看出
37. 用IN来替换OR
下面的查询可以被更有效率的语句替换:
低效:
SELECT *
FROM LOCATION
WHERE LOC_ID = 10
OR LOC_ID = 20
OR LOC_ID = 30
高效:
SELECT *
FROM LOCATION
WHERE LOC_IN IN (10,20,30);
这是一条简单易记的规则,但是实际的执行效果还须检验,在ORACLE8i下,两者的执行路径似乎是相同的。
38. 避免在索引列上使用IS NULL和IS NOT NULL
避免在索引中使用任何可以为空的列,ORACLE将无法使用该索引。对于单列索引,如果列包含空值,索引中将不存在此记录。 对于复合索引,如果每个列都为空,索引中同样不存在此记录。 如果至少有一个列不为空,则记录存在于索引中。
举例:
如果唯一性索引建立在表的A列和B列上, 并且表中存在一条记录的A,B值为(123,null) , ORACLE将不接受下一条具有相同A,B值(123,null)的记录(插入)。 然而如果所有的索引列都为空,ORACLE将认为整个键值为空而空不等于空。 因此你可以插入1000条具有相同键值的记录,当然它们都是空!
因为空值不存在于索引列中,所以WHERE子句中对索引列进行空值比较将使ORACLE停用该索引。
举例:
低效: (索引失效)
SELECT *
FROM DEPARTMENT
WHERE DEPT_CODE IS NOT NULL;
高效: (索引有效)
SELECT *
FROM DEPARTMENT
WHERE DEPT_CODE >=0;
39. 总是使用索引的第一个列
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引。
这也是一条简单而重要的规则。 见以下实例。
SQL> create table multiindexusage (inda number,indb number descr varchar2910));
Table created.
SQL> create index multindex on multiindexusage(inda,indb);
Index created.
SQL> set autotrace traceonly
SQL> select * from multiindexusage where inda = 1;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'MULTIINDEXUSAGE'
2 1 INDEX (RANGE SCAN) OF 'MULTINDEX' (NON-UNIQUE)
SQL> select * from multiindexusage where indb = 1;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 TABLE ACCESS (FULL) OF 'MULTIINDEXUSAGE'
很明显, 当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
40. ORACLE内部操作
当执行查询时,ORACLE采用了内部的操作。 下表显示了几种重要的内部操作。
ORACLE Clause 内部操作
ORDER BY SORT ORDER BY
UNION UNION-ALL
MINUS MINUS
INTERSECT INTERSECT
DISTINCT,MINUS,INTERSECT,UNION SORT UNIQUE
MIN,MAX,COUNT SORT AGGREGATE
GROUP BY SORT GROUP BY
ROWNUM COUNT or COUNT STOPKEY
Queries involving Joins SORT JOIN,MERGE JOIN,NESTED LOOPS
CONNECT BY CONNECT BY
41. 用UNION-ALL 替换UNION ( 如果有可能的话)
当SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并, 然后在输出最终结果前进行排序。
如果用UNION ALL替代UNION, 这样排序就不是必要了。 效率就会因此得到提高。
举例:
低效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
UNION
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31-DEC-95'
高效:
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31 - DEC - 95'
UNION ALL
SELECT ACCT_NUM, BALANCE_AMT
FROM DEBIT_TRANSACTIONS
WHERE TRAN_DATE = '31 - DEC - 95'
需要注意的是,UNION ALL 将重复输出两个结果集合中相同记录。 因此各位还是要从业务需求分析使用UNION ALL的可行性。
UNION 将对结果集合排序,这个操作会使用到SORT_AREA_SIZE这块内存。 对于这块内存的优化也是相当重要的。 下面的SQL可以用来查询排序的消耗量
Select substr(name, 1, 25) "Sort Area Name", substr(value, 1, 15) "Value"
from v$sysstat
where name like 'sort%';
42. 使用提示(Hints)
对于表的访问,可以使用两种Hints.
FULL 和 ROWID
FULL hint 告诉ORACLE使用全表扫描的方式访问指定表。
例如:
SELECT /*+ FULL(EMP) */* FROM EMP WHERE EMPNO = 7893;
ROWID hint 告诉ORACLE使用TABLE ACCESS BY ROWID的操作访问表。
通常, 你需要采用TABLE ACCESS BY ROWID的方式特别是当访问大表的时候, 使用这种方式, 你需要知道ROIWD的值或者使用索引。
如果一个大表没有被设定为缓存(CACHED)表而你希望它的数据在查询结束是仍然停留在SGA中,你就可以使用CACHE hint 来告诉优化器把数据保留在SGA中。 通常CACHE hint 和 FULL hint 一起使用。
例如:
SELECT /*+ FULL(WORKER) CACHE(WORKER)*/* FROM WORK;
索引hint 告诉ORACLE使用基于索引的扫描方式。 你不必说明具体的索引名称
例如:
SELECT /*+ INDEX(LODGING) */
LODGING
FROM LODGING
WHERE MANAGER = 'BILL GATES';
在不使用hint的情况下, 以上的查询应该也会使用索引,然而,如果该索引的重复值过多而你的优化器是CBO, 优化器就可能忽略索引。 在这种情况下, 你可以用INDEX hint强制ORACLE使用该索引。
ORACLE hints 还包括ALL_ROWS, FIRST_ROWS, RULE,USE_NL, USE_MERGE, USE_HASH 等等。
使用hint , 表示我们对ORACLE优化器缺省的执行路径不满意,需要手工修改。这是一个很有技巧性的工作。 我建议只针对特定的,少数的SQL进行hint的优化。对ORACLE的优化器还是要有信心(特别是CBO)
43. 用WHERE替代ORDER BY
ORDER BY 子句只在两种严格的条件下使用索引。
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序。
ORDER BY中所有的列必须定义为非空。
WHERE子句使用的索引和ORDER BY子句中所使用的索引不能并列。
例如:
表DEPT包含以下列:
DEPT_CODE PK NOT NULL
DEPT_DESC NOT NULL
DEPT_TYPE NULL
非唯一性的索引(DEPT_TYPE)
低效: (索引不被使用)
SELECT DEPT_CODE FROM DEPT ORDER BY DEPT_TYPE;
EXPLAIN PLAN:
SORT ORDER BY
TABLE ACCESS FULL
高效: (使用索引)
SELECT DEPT_CODE FROM DEPT WHERE DEPT_TYPE > 0
EXPLAIN PLAN:
TABLE ACCESS BY ROWID ON EMP
INDEX RANGE SCAN ON DEPT_IDX
ORDER BY 也能使用索引! 这的确是个容易被忽视的知识点。 我们来验证一下:
SQL> select * from emp order by empno;EXPLAIN PLAN
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMP'
2 1 INDEX (FULL SCAN) OF 'EMPNO' (UNIQUE)
44. 避免改变索引列的类型。
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换。
假设 EMPNO是一个数值类型的索引列。
SELECT * FROM EMP WHERE EMPNO = '123';
实际上,经过ORACLE类型转换, 语句转化为:
SELECT * FROM EMP WHERE EMPNO = TO_NUMBER('123');
幸运的是,类型转换没有发生在索引列上,索引的用途没有被改变。
现在,假设EMP_TYPE是一个字符类型的索引列。
SELECT * FROM EMP WHERE EMP_TYPE = 123
这个语句被ORACLE转换为:
SELECT * FROM EMP WHERE TO_NUMBER(EMP_TYPE) = 123
因为内部发生的类型转换, 这个索引将不会被用到!
为了避免ORACLE对你的SQL进行隐式的类型转换, 最好把类型转换用显式表现出来。 注意当字符和数值比较时, ORACLE会优先转换数值类型到字符类型。
45. 需要当心的WHERE子句
某些SELECT 语句中的WHERE子句不使用索引。 这里有一些例子。
在下面的例子里, ‘!=’ 将不使用索引。 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中。
不使用索引:
SELECT ACCOUNT_NAME FROM TRANSACTION WHERE AMOUNT != 0;
使用索引:
SELECT ACCOUNT_NAME FROM TRANSACTION WHERE AMOUNT > 0;
下面的例子中, ‘||’是字符连接函数。 就象其他函数那样, 停用了索引。
不使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME || ACCOUNT_TYPE = 'AMEXA';
使用索引:
SELECT ACCOUNT_NAME,AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME = 'AMEX'
AND ACCOUNT_TYPE = 'A';
下面的例子中, ‘+’是数学函数。 就象其他数学函数那样, 停用了索引。
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT FROM TRANSACTION WHERE AMOUNT + 3000 > 5000;
使用索引:
SELECT ACCOUNT_NAME, AMOUNT FROM TRANSACTION WHERE AMOUNT > 2000;
下面的例子中,相同的索引列不能互相比较,这将会启用全表扫描。
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME = NVL(:ACC_NAME, ACCOUNT_NAME);
使用索引:
SELECT ACCOUNT_NAME, AMOUNT
FROM TRANSACTION
WHERE ACCOUNT_NAME LIKE NVL(:ACC_NAME, '%');
如果一定要对使用函数的列启用索引, ORACLE新的功能: 基于函数的索(Function-Based Index) 也许是一个较好的方案。
CREATE INDEX EMP_I ON EMP (UPPER(ename)); /*建立基于函数的索引*/
SELECT * FROM emp WHERE UPPER(ename) = 'BLACKSNAIL'; /*将使用索引*/
46. 连接多个扫描
如果你对一个列和一组有限的值进行比较, 优化器可能执行多次扫描并对结果进行合并连接。
举例:
SELECT * FROM LODGING WHERE MANAGER IN ('BILL GATES' , 'KEN MULLER');
优化器可能将它转换成以下形式
SELECT *
FROM LODGING
WHERE MANAGER = 'BILL GATES'
OR MANAGER = 'KEN MULLER';
当选择执行路径时, 优化器可能对每个条件采用LODGING$MANAGER上的索引范围扫描。 返回的ROWID用来访问LODGING表的记录 (通过TABLE ACCESS BY ROWID 的方式)。 最后两组记录以连接(CONCATENATION)的形式被组合成一个单一的集合。
EXPLAIN PLAN:
SELECT STATEMENT ptimizer=CHOOSE
CONCATENATION
TABLE ACCESS (BY INDEX ROWID) OF LODGING
INDEX (RANGE SCAN ) OF LODGING$MANAGER (NON-UNIQUE)
TABLE ACCESS (BY INDEX ROWID) OF LODGING
INDEX (RANGE SCAN) OF LODGING$MANAGER (NON-UNIQUE)
本节和第37节似乎有矛盾之处。
47. CBO下使用更具选择性的索引
基于成本的优化器(CBO, Cost-Based Optimizer)对索引的选择性进行判断来决定索引的使用是否能提高效率。
如果索引有很高的选择性, 那就是说对于每个不重复的索引键值,只对应数量很少的记录。
比如, 表中共有100条记录而其中有80个不重复的索引键值。 这个索引的选择性就是80/100 = 0.8 . 选择性越高, 通过索引键值检索出的记录就越少。
如果索引的选择性很低, 检索数据就需要大量的索引范围查询操作和ROWID 访问表的操作。 也许会比全表扫描的效率更低。
下列经验请参阅:
a.如果检索数据量超过30%的表中记录数。使用索引将没有显著的效率提高。
b.在特定情况下, 使用索引也许会比全表扫描慢, 但这是同一个数量级上的区别。 而通常情况下,使用索引比全表扫描要快几倍乃至几千倍!
48. 避免使用耗费资源的操作
带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎执行耗费资源的排序(SORT)功能。 DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序。
例如,一个UNION查询,其中每个查询都带有GROUP BY子句, GROUP BY会触发嵌入排序(NESTED SORT) ; 这样, 每个查询需要执行一次排序, 然后在执行UNION时, 又一个唯一排序(SORT UNIQUE)操作被执行而且它只能在前面的嵌入排序结束后才能开始执行。 嵌入的排序的深度会大大影响查询的效率。
通常, 带有UNION, MINUS , INTERSECT的SQL语句都可以用其他方式重写。
如果你的数据库的SORT_AREA_SIZE调配得好, 使用UNION , MINUS, INTERSECT也是可以考虑的, 毕竟它们的可读性很强
49. 优化GROUP BY
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉。下面两个查询返回相同结果但第二个明显就快了许多。
低效:
SELECT JOB, AVG(sal)
FROM EMP
GROUP by JOB
HAVING JOB = 'PRESIDENT' OR JOB = 'MANAGER'
高效:
SELECT JOB, AVG(sal)
FROM EMP
WHERE JOB = 'PRESIDENT'
OR JOB = 'MANAGER'
GROUP by JOB
本节和14节相同。 可略过。
50. 使用日期
当使用日期时,需要注意如果有超过5位小数加到日期上, 这个日期会进到下一天!
例如:
1.
SELECT TO_DATE('01 - JAN - 93' + .99999) FROM DUAL;
Returns:“01-JAN-93 23:59:59‘
2.
SELECT TO_DATE('01 - JAN - 93' + .999999) FROM DUAL;
Returns:“02-JAN-93 00:00:00‘
虽然本节和SQL性能优化没有关系, 但是作者的功力可见一斑
51. 使用显式的游标(CURSORs)
使用隐式的游标,将会执行两次操作。 第一次检索记录, 第二次检查TOO MANY ROWS 这个exception . 而显式游标不执行第二次操作。
52. 优化EXPORT和IMPORT
使用较大的BUFFER(比如10MB , 10,240,000)可以提高EXPORT和IMPORT的速度。
ORACLE将尽可能地获取你所指定的内存大小,即使在内存不满足,也不会报错。这个值至少要和表中最大的列相当,否则列值会被截断。
可以肯定的是, 增加BUFFER会大大提高EXPORT , IMPORT的效率。 (曾经碰到过一个CASE, 增加BUFFER后,IMPORT/EXPORT快了10倍!)
可能犯了一个错误: “这个值至少要和表中最大的列相当,否则列值会被截断。 ”其中最大的列也许是指最大的记录大小。
关于EXPORT/IMPORT的优化,CSDN论坛中有一些总结性的贴子,比如关于BUFFER参数, COMMIT参数等等, 详情请查。
53. 分离表和索引
总是将你的表和索引建立在不同的表空间内(TABLESPACES)。 决不要将不属于ORACLE内部系统的对象存放到SYSTEM表空间里。 同时,确保数据表空间和索引表空间置于不同的硬盘上。
“同时,确保数据表空间和索引表空间置与不同的硬盘上。”可能改为如下更为准确 “同时,确保数据表空间和索引表空间置与不同的硬盘控制卡控制的硬盘上。” -
inner join,outer join,left join,right join的区别
2011-09-20 14:49:00
inner join,outer join,left join,right join的区别
外联接
外联接可以是左向外联接、右向外联接或完整外部联接。
在 FROM 子句中指定外联接时,可以由下列几组关键字中的一组指定:
LEFT JOIN 或 LEFT OUTER JOIN。
左向外联接的结果集包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
RIGHT JOIN 或 RIGHT OUTER JOIN。
右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
FULL JOIN 或 FULL OUTER JOIN。
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
例如:
表a
id name
1 a
2 b
3 c
表b
id store
1 15
2 10
4 67
inner join :
select * from a inner join b on a.id=b.id
结果:(只显示id匹配的选项)
id name id store
1 a 1 15
2 b 2 10
内连接还有以下写法:
select * from a inner join b where a.id=b.id
select * from a,b where a.id=b.id(连接查询的另一种写法)
select * from a as e,b as r where e.id=r.id(使用as定义别名,当表名很长时有用)
select * from a e,b r where e.id=r.id(定义别名时可以省掉as)
外连接分左外连接和右外连接
左外连接:
select * from a left outer join b on a.id=b.id
或:
select * from a left join b on a.id=b.id
结果:(除了显示匹配记录,还显示a表中所有的记录)
id name id stroe
1 a 1 15
2 b 2 10
3 c \N \N
右外连接:
select * from a right outer join b on a.id=b.id
或:
select * from a right join b on a.id=b.id
结果:(除了显示匹配的记录,还显示右表中所有的记录)
id name id store
1 a 1 15
2 b 2 10
\N \N 4 67 -
oracle利用现有表创建新表
2011-09-20 14:10:26
CREATE TABLE <newtable> AS SELECT {* | column(s)} FROM <oldtable> [WHERE <condition>];
exp:
SQL> CREATE TABLE yonghu_bak AS SELECT * FROM yonghul;
SQL> CREATE TABLE yonghu_bak AS SELECT id, name,sex FROM yonghu;
SQL> CREATE TABLE yonghu_bak AS SELECT * FROM yonghu WHERE 1=2;
当遇到一个部门有多个员工记录,需要去取出每个部门薪水最少的那笔时,就可以用到分析函数row_number()
select * from(select manager_id,employee_id,first_name,salary,row_number()
over(partition by manager_id order by salary) as currowid
from hr.employees)
where currowid = 1PS:
(1)建一个新表,架构、字段属性、约束条件、数据记录跟旧表完全一样:
Create Table print_his_0013 as Select * from print_his_0007
(2)建一个新表,架构跟旧表完全一样,但没有内容:
Create Table print_his_0013 as Select * from print_his_0007 where 1=2
-
ORACLE中添加删除主键、外键
2011-09-20 13:22:22
1、创建表的同时创建主键约束(1)无命名 create table student ( studentid int primary key not null, studentname varchar(8), age int);
(2)有命名 create table students ( studentid int , studentname varchar(8), age int, constraint yy primary key(studentid));
2、删除表中已有的主键约束
(1)无命名可用 SELECT * from user_cons_columns; 查找表中主键名称得student表中的主键名为SYS_C002715 alter table student drop constraint SYS_C002715;
(2)有命名 alter table students drop constraint yy;
3、向表中添加主键约束 alter table student add constraint pk_student primary key(studentid);
4、向表中添加外键约束 ALTER TABLE table_A ADD CONSTRAINT FK_name FOREIGN KEY(id) REFERENCES table_B(id);
5.
oracle 多表删除 同时删除多表中关联数据1、从数据表t1中把那些id值在数据表t2里有匹配的记录全删除掉
DELETE t1 FROM t1,t2 WHERE t1.id=t2.id 或DELETE FROM t1 USING t1,t2 WHERE t1.id=t2.id
2、从数据表t1里在数据表t2里没有匹配的记录查找出来并删除掉
DELETE t1 FROM t1 LEFT JOIN T2 ON t1.id=t2.id WHERE t2.id IS NULL 或
DELETE FROM t1,USING t1 LEFT JOIN T2 ON t1.id=t2.id WHERE t2.id IS NULL
3、从两个表中找出相同记录的数据并把两个表中的数据都删除掉
DELETE t1,t2 from t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t1.id=25
注意此处的delete t1,t2 from 中的t1,t2不能是别名
如:delete t1,t2 from table_name as t1 left join table2_name as t2 on t1.id=t2.id where table_name.id=25 在数据里面执行是错误的(MYSQL 版本不小于5.0在5.0中是可以的)
上述语句改写成
delete table_name,table2_name from table_name as t1 left join table2_name as t2 on t1.id=t2.id where table_name.id=25 在数据里面执行是错误的(MYSQL 版本小于5.0在5.0中是可以的)
-
oracle中"cascade"的用法总结
2011-09-20 13:20:50
级联删除,比如你删除某个表的时候后面加这个关键字,会在删除这个表的同时删除和该表有关系的其他对象1.级联删除表中的信息,当表A中的字段引用了表B中的字段时,一旦删除B中该字段的信息,表A的信息也自动删除。(当父表的信息删除,子表的信息也自动删除)
例如下面这两个表中分别存的时员工的基本信息和公司的部门信息。我们为
create table dept
(deptno number(10) not null,
deptname varchar2(30) not null,
constraint pk_dept primary key(deptno));
和
create table emp
( empno number(10) not null,
fname varchar2(20) ,
lname varchar2(20) ,
dept number(10) ,
constraint pk_emp primary key(empno));
然后我们现在增加外键试一下on delete cascadealter table emp
add constraint fk_emp_dept foreign key(dept) references dept(deptno) on delete cascade;
先增加外键。然后插入数据。
insert into dept values(1,’销售部’);
insert into dept values(2,’财务部’);
insert into emp values (2,’Mary’,'Song’,1);
insert into emp values (3,’Linda’,'Liu’,2);
insert into emp values (4,’Linlin’,'Zhang’,1);
然后现在我要删除销售部,会有什么后果呢?
delete from dept where deptno = 1;
我们发现除了dept中的一条数据被删除了,emp中两条数据也被删除了,其中emp中的两条数据是参照了销售部的这条数据的,这就很容易理解on delete cascade了。接下来我们再来看on delete set null,顾名思义了,这种方式建立的外键约束,当被参照的数据被删除是,参照该数据的那些数据的对应值将会变为空值,下面我们还是通过试验来证明on delete set null作用:
首先恢复刚才的那几条数据,然后更改约束:
alter table emp
add constraint fk_emp_dept foreign key(dept) references dept(deptno) on delete set null;
然后我们在执行删除操作:
delete from dept where deptno = 1;
你也会发现除了dept中的销售部被删除以外,emp中参照这条数据的两条数据的dept的值被自动赋空了,这就是on delete set null的作用了。使用on delete set null有一点需要注意的是,被参参照其他表的那一列必须能够被赋空,不能有not null约束,对于上面的例子来说是emp中dept列一定不能有not null约束,如果已经定义了not null约束,又使用了on delete set null来删除被参照的数据时,将会发生:ORA-01407: 无法更新 (”DD”.”EMP”.”DEPT”) 为 NULL的错误。
总的来讲on delete cascade和on delete set null的作用是用来处理级联删除问题的,如果你需要删除的数据被其他数据所参照,那么你应该决定到底希望oracle怎么处理那些参照这些即将要删除数据的数据的,你可以有三种方式:
禁止删除,这也是oracle默认的
将那些参照本值的数据的对应列赋空,这个需要使用on delete set null关键字
将那些参照本值的数据一并删除,这个需要使用on delete cascade关键字2。Oracle 删除用户时报“必须指定 CASCADE 以删除 'SE'”
这说明你要删除的oracle 用户"SE" 下面还有数据库对象,如 table, view 等,这样你删除用户时必须加选项 cascade: drop user se cascade; 表示删除用户SE,同时删除 SE 用户下的所有数据对象。还有一个办法就是先删除 se 下的所有数据对象,使 se 变成一个啥也没有的空用户,再 drop user se;3.ORACLE中Drop table cascade constraints之后果当你要drop一个table时,如果删除table的动作会造成trigger或constraint产生矛盾,系统会出现错误警告的讯息而不会允许执行.。一个极简单的例子,例如你有一个员工基本资料表,上面可能有员工编号和员工姓名等字段,另外有一个员工销售表,上面有员工编号和员工销售额两个字段,员工薪资表的员工编号字段为一个foreign key参照到员工基本资料表的员工编号:
SQL> drop table t;
Table dropped.
SQL> drop table t1;
Table dropped.
SQL> create table t (id number,name varchar2(20));
Table created.
SQL> create table t1 (id number,sal number);
Table created.
SQL> alter table t add constraint t_pk primary key (id);
Table altered.
SQL> alter table t1 add constraint t_fk foreign key (id) references t (id);
Table altered.
SQL> insert into t values (1,#39;JACK');
1 row created.
SQL> insert into t values (2,#39;MARY');
1 row created.
SQL> COMMIT;
Commit complete.
SQL> insert into t1 values (1,1000);
1 row created.
SQL> insert into t1 values (2,1500);
1 row created.
SQL> commit;
SQL> insert into t1 values (3,200);
insert into t1 values (3,200)
*
ERROR at line 1:
ORA-02291: integrity constraint (SYS.T_FK) violated - parent key not found
(違反了constraint,員工基本資料表根本沒有3號這個員工,何來的銷售紀錄。)
SQL> drop table t;
drop table t
*
ERROR at line 1:
ORA-02449: unique/primary keys in table referenced by foreign keys
(违反了constraint,员工销售表t1有參照到table t,这个reference relation不允许你drop table t)
SQL> drop table t cascade constraints;
Table dropped.
SQL> select * from t1;
ID SAL
---------- ----------
1 1000
2 1500
SQL> select CONSTRAINT_NAME,TABLE_NAME from dba_constraints where wner = #39;SYS' and TABLE_NAME = 'T1'
no rows selected
SQL>
我们可以发现利用Drop table cascade constraints可以以刪除关联table t的constraint來达成你drop table t的目的,原來属于t1的foreign key constraint已经跟随着被删除掉了,但是,储存在table t1的资料可不会被删除,也就是说Drop table cascade constraints 是不影响到存储于objec里的row data。 -
找出UNIX中最费CPU的进程
2011-09-16 15:29:59
多用户的UNIX计算机系统在运行过程中,有时会感觉到运算速度突然慢下来,有时甚至连从键盘输入字符也得过好久才会有反应。有经验的人一定会知道,这时计算机中一定在运行一个非常耗费CPU的进程。这样的进程有时是某个人在执行一个很占CPU的程序,有时则可能是系统中出了意外情况,系统本身在进行处理。无论是哪种情况,系统管理员都应及时找出这样的进程,并做出相应的处理。UNIX虽然提供了“acct”等一系列记账程序,但这些程序只能在进程结束后才能显示运行时间和占用CPU时间等信息,不能实时计算单位时间内哪一个进程占用CPU时间最多。
为此本人用shell语言编写了一段程序,利用UNIX提供的一些实用程序,实现了上述功能。
此段程序中包含ps、cut、diff等UNIX实用程序,下面先简单介绍一下这些实用程序的功能。
ps:用来显示当前系统中进程的有关信息。用-e参数则显示系统中所有进程的信息。使用-f参数则显示各进程完整的信息;
cut:用于以列为单位对文件进行剪裁。参数“-c -15,33-”表示把输入文件每行前15个字符及第33个字符以后直到行尾的所有字符放入输出文件;
echo:用于向屏幕上显示提示信息;
sleep:可以让shell程序等待若干秒,然后再执行后面的语句;
diff:用于对两个文件进行比较,不同之处则显示出来;
sort:可对文件中的各行进行排序,排序结果可显示出来;
grep:可用来找出文件中满足一定条件的行。参数“^”表示找出第一列为空格的各行;
|:为管道的符号,可实现把前面命令的输出作为后面命令输入的作用,这样就可省略生成中间文件的步骤,提高执行效率;
>:表示对输出进行重定向,把本来应显示在屏幕上的东西输出到文件中。
程序内容如下:
ps -ef|cut -c -15,33->tt1
echo Please wait a while...
sleep 20
ps -ef|cut -c -15,33->tt2
echo Attention !
echo
diff tt1 tt2|cut -c 2->tt3
sort tt3|grep ^ |cut -c -83|grep -v 0:00
echo
echo That is ok!
rm tt1 tt2 tt3
程序首先取得系统中所有进程的信息并把其中有用的字段放入临时文件tt1中。接着让程序等待20秒(时间可依具体情况进行调整)。
然后再一次取得所有进程的信息,并把所有的字段放入临时文件tt2中。
对两个临时文件进行比较,找出20秒前后信息不同的那些进程(其中就有消耗CPU时间已经发生了变化的进程)。
去掉进行比较时产生的“>”和“<”,把结果放入临时文件tt3中。
对tt3中的内容进行排序,把耗费CPU时间发生变化的同一进程的前后信息排在一起。grep“^”则是用来去掉执行此shell程序时产生的一些中间命令进程的信息。
再用cut删去每行中过长的进程信息,使输出更加清晰。而grep -v 0:00则用来去掉20秒前后只出现一次的进程。程序执行至此,在20秒前后耗费CPU时间不同的进程就显示在屏幕上了,从中可以很容易地找出所要找的进程。最后为了不在系统中留下无用的垃圾文件,还要把三个临时文件全都删去。
-
使用unix工具监控cpu、内存等系统资源占用率
2011-09-16 15:16:20
1)使用 sar -u 命令监控cpu使用
$ sar -u 5 5
12:21:15 %usr %sys %wio %idle
12:21:20 54 15 13 19
12:21:25 41 18 15 27
12:21:30 62 20 10 9
12:21:35 33 11 20 36
12:21:40 38 13 17 31
Average 45 15 15 24
%usr--运行在用户模式下cpu的使用百分比
%sys--运行在系统模式下cpu的使用百分比
%wio--进程在等待块I/O时闲置状态下cpu的使用百分比
%idle--闲置状态时cpu的使用百分比
很低的%idle说明cpu负载高,或者cpu处理能力不足,或者也可能是I/O问题。
很高的%wio,即系统I/O繁忙,进程获得cpu但在等I/O,这部分时间的比例,有可能是I/O存在问题。
2)使用top命令发现系统中最影响性能的用户
load averages: 2.83, 3.30, 3.67
143 processes: 124 sleeping, 15 running, 4 on cpu
CPU states: 45.9% idle, 24.8% user, 7.3% kernel, 22.0% iowait, 0.0% swap
Memory: 2048M real, 36M free, 2920M swap in use, 982M swap free
PID USERNAME LWP PRI NICE SIZE RES STATE TIME CPU COMMAND
23696 oracle 11 52 0 586M 536M run 279:55 7.57% oracle
19184 oracle 11 53 0 586M 536M run 166:47 2.51% oracle
11303 oracle 11 53 0 742M 698M run 25.2H 1.43% oracle
8156 oracle 11 48 0 741M 695M run 28.7H 0.96% oracle
12786 oracle 11 59 0 588M 529M run 111.8H 0.94% oracle
15222 oracle 11 49 0 741M 695M cpu/8 30.9H 0.85% oracle
2924 oracle 11 59 0 748M 688M sleep 107.5H 0.83% oracle
8178 oracle 11 59 0 741M 695M cpu/0 28.8H 0.81% oracle
15220 oracle 11 54 0 741M 697M run 31.4H 0.78% oracle
8168 oracle 11 39 0 741M 697M run 30.0H 0.77% oracle
15216 oracle 11 59 0 741M 697M cpu/9 30.1H 0.77% oracle
8164 oracle 11 39 0 741M 695M run 30.8H 0.76% oracle
11267 oracle 11 59 0 741M 697M sleep 32.3H 0.74% oracle
15214 oracle 11 59 0 741M 695M sleep 30.9H 0.70% oracle
11861 oracle 1 59 0 739M 696M sleep 16.9H 0.67% oracle
3)使用uptime命令监控cpu负载
$ uptime
12:45pm up 119 day(s), 19:01, 1 user, load average: 2.96, 2.98, 3.30
提供快速查看cpu中所有任务(包括正在运行的任务)在1分钟,5分钟,15分钟内的负载。在sun下是1,5,15分钟,在digital unix下是5,30,60分钟。
4)使用mpstat命令确定cpu瓶颈
$ mpstat 10 3
CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl
0 91 14 127 406 245 97 49 62 45 0 351 25 9 9 57
1 106 16 145 174 101 312 70 111 33 0 327 27 6 10 56
4 99 16 83 173 101 294 68 108 33 0 290 26 6 10 58
5 102 17 126 184 110 313 70 115 33 0 336 26 6 10 57
8 97 17 127 174 101 302 69 113 33 0 299 25 6 11 58
9 93 11 335 329 274 239 61 103 59 0 217 23 10 7 60
CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl
0 19 33 3504 2160 1920 791 99 116 77 0 1401 30 17 12 42
1 82 39 1908 264 101 1210 157 215 49 0 2394 39 8 18 35
4 126 45 1839 276 102 1269 167 224 51 0 2511 34 9 14 43
5 133 49 2298 293 107 1384 178 239 53 0 2840 36 8 18 39
8 95 46 2772 266 101 1266 158 214 47 0 2638 38 7 14 40
9 115 38 2961 986 847 1173 158 213 88 0 2401 34 13 13 41
CPU minf mjf xcal intr ithr csw icsw migr smtx srw syscl usr sys wt idl
0 74 30 2438 1960 1743 670 65 100 66 0 1232 25 14 14 47
1 63 40 1615 229 101 1158 123 192 47 0 2277 35 6 14 44
4 145 28 1396 249 101 1148 142 190 42 0 2397 32 8 14 47
5 73 28 1588 253 107 1213 141 202 47 0 2578 32 8 9 51
8 44 29 3181 252 101 1210 146 187 39 0 2471 30 10 9 51
9 67 24 1345 823 727 1024 105 178 83 0 2006 26 9 9 55
mpstat命令是一个sun solaris工具,以报表形式报告每个处理器的统计数据。表的每一行代表一个处理器的活动情况。第一张表显示了自启动以来各种活动情况的总结。注意 smtx项,它代表cpu尝试获取一个互斥锁定(mutex)失败的次数。mutex机制浪费cpu时间,并且降低多处理器的伸缩性能。如果stmx列的 值大于200,说明将遇到cpu瓶颈问题。
5)使用sar命令监控磁盘I/O问题
$ sar -d 5 2
12:59:00 device %busy avque r+w/s blks/s avwait avserv
12:59:05 md30 71 0.8 103 1738 0.0 7.5
md31 34 0.4 52 934 0.0 7.1
md32 39 0.4 52 925 0.0 8.6
sd10 42 0.5 57 1001 0.0 9.0
sd10,a 0 0.0 0 0 0.0 0.0
sd10,b 0 0.0 0 0 0.0 0.0
sd10,c 0 0.0 0 0 0.0 0.0
12:59:10 md30 9 0.1 5 312 0.0 27.4
md31 4 0.1 4 277 0.0 16.1
md32 7 0.1 4 289 0.0 28.2
sd10 26 0.4 36 787 0.0 11.0
sd10,a 5 0.1 7 106 0.0 7.9
sd10,b 3 0.0 1 24 0.0 28.4
sd10,c 0 0.0 0 0 0.0 0.0
Average md30 40 0.5 54 1025 0.0 8.5
md31 19 0.2 28 606 0.0 7.7
md32 23 0.3 28 607 0.0 10.0
sd10 34 0.5 47 894 0.0 9.7
sd10,a 3 0.0 3 53 0.0 7.9
sd10,b 2 0.0 1 12 0.0 28.4
sd10,c 0 0.0 0 0 0.0 0.0
-d选项监控磁盘I/O
%busy
avque--平均队列长度
r+w/s--读和写的活动
blks/s--传送的数据块的数量
avwait--平均等待时间
avserv--平均服务时间
较高的%busy和avque意味着出现了磁盘I/O瓶颈。
$ sar -b 2 5
17:08:24 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrit/s
17:08:26 0 530 100 2 2 0 0 0
17:08:28 0 536 100 3 3 0 0 0
17:08:31 0 339 100 0 1 67 0 0
17:08:33 0 332 100 1 3 67 0 0
17:08:35 0 343 100 3 57 95 0 0
Average 0 416 100 2 13 85 0 0
-b选项报告缓冲区活动,它等同于磁盘I/O活动。如果怀疑数据库I/O有问题,这个命令很有用。
bread/s--每秒钟从磁盘进行物理读入的数量
lread/s--每秒中从缓冲区读入的数量
%rcache--读入请求的缓冲区命中率
bwrit/s--每秒钟向磁盘物理写入的数量,它给dba提供了服务器上整体写入活动的指标
lwrit/s--每秒钟向缓冲区写入的数量
%wcache--写入请求的缓冲区命中率
pread/s--每秒钟从磁盘读入的数量,这个是I/O子系统上负载的极好度量
pwrit/s--每秒钟写入磁盘的数量
6)使用iostat确定磁盘I/O瓶颈
iostat可以用于报告终端和磁盘I/O活动情况,确定磁盘瓶颈。输出结果的第一行显示了自数据库启动以来各种I/O的统计数据。最常用的选项有-d,-x,-D,-c(cpu负载)。
$ iostat -d md30 md31 md32 sd10 5 5
md30 md31 md32 sd10
kps tps serv kps tps serv kps tps serv kps tps serv
9 1 13 7 0 15 7 0 14 46 6 14
112 14 11 56 7 12 56 7 10 439 46 14
24 3 8 13 2 6 11 1 10 51 6 8
3 0 12 2 0 14 2 0 9 89 10 7
3 0 25 2 0 40 2 0 10 34 19 29
-d选项可以列出每秒传送的字节数,每秒的传输次数以及平均服务时间(以毫秒计)。-d仅仅显示I/O,不区分读操作和写操作。
$ iostat -D md30 md31 md32 sd10 5 5
md30 md31 md32 sd10
rps wps util rps wps util rps wps util rps wps util
1 0 0.5 0 0 0.3 0 0 0.3 4 3 4.3
53 3 30.4 27 3 18.3 27 3 14.0 38 5 20.9
5 0 6.2 2 0 3.9 2 0 3.7 3 6 7.0
2 10 11.5 1 10 9.3 1 10 7.6 56 19 41.9
5 0 3.3 3 0 1.6 3 0 1.6 7 1 4.6
-D选项报告每秒的读操作数量,写操作数量以及磁盘使用率。
$ iostat -x 5 3
extended device statistics
device r/s w/s kr/s kw/s wait actv svc_t %w %b
md30 0.5 0.1 4.0 4.5 0.0 0.0 12.8 0 0
md31 0.3 0.1 2.0 4.5 0.0 0.0 14.6 0 0
md32 0.3 0.1 2.0 4.5 0.0 0.0 14.1 0 0
sd10 3.6 2.6 37.0 8.6 0.0 0.1 14.1 0 4
extended device statistics
device r/s w/s kr/s kw/s wait actv svc_t %w %b
md30 0.8 0.0 6.4 0.0 0.0 0.0 12.0 0 1
md31 0.4 0.0 3.2 0.0 0.0 0.0 13.0 0 1
md32 0.4 0.0 3.2 0.0 0.0 0.0 11.0 0 0
sd10 5.8 1.0 65.6 3.5 0.0 0.1 8.1 0 5
extended device statistics
device r/s w/s kr/s kw/s wait actv svc_t %w %b
md30 0.4 0.0 3.2 0.0 0.0 0.0 11.8 0 0
md31 0.2 0.0 1.6 0.0 0.0 0.0 12.7 0 0
md32 0.2 0.0 1.6 0.0 0.0 0.0 10.9 0 0
sd10 0.2 1.2 1.6 3.8 0.0 0.0 16.9 0 2
-x选项报告所有磁盘的扩展磁盘统计数据
7)使用sar命令和vmstat命令监控分页/交换
一种可以快速判定自系统启动以来是否存在任何交换活动的方法就是运行vmstat -S命令,如果swp/in和swp/out列出现非零值,就说明很可能出现了问题。另外可以使用sar命令挖掘更多的信息。
可以使用sar命令来检查系统的分页/交换活动。任何分页和交换现象都预示着将出现问题。在虚拟内存系统中,如果当前非活动用户(的进程)从内存移到磁盘 上时,就会出现分页现象(一个小问题)。而如果由于内存的不足造成当前活动用户(的进程)被移到了磁盘上,就会出现交换现象(问题很严重)。分页不像交换 那么糟糕,但是随着分页的增加,很快就会出现交换。
$ sar -p 5 5
15:15:44 atch/s pgin/s ppgin/s pflt/s vflt/s slock/s
15:15:49 109.15 302.58 351.29 154.67 680.91 0.40
15:15:54 293.25 287.50 317.86 380.95 1447.82 0.00
15:15:59 146.41 418.92 485.86 71.51 327.09 0.00
15:16:04 96.03 386.90 429.56 92.86 362.70 0.00
15:16:09 197.81 495.63 526.64 340.76 983.70 0.00
Average 168.56 378.26 422.18 208.23 760.73 0.08
-p选项报告分页活动
atch/s--每秒的分页故障数据,可通过在内存中重新声明一个页来解决故障(每秒的附件)
pgin/s--每秒换进pagein请求数
ppgin/s--每秒换进的页数
pflt/s--每秒保护错误中的分页错误数(非法访问页)或者copy-on-write(写入时拷贝)数
vflt/s--每秒翻译页错误数(不在内存中的有效页)
slock/s--每秒因软件锁请求物理I/O引起的错误数
$ sar -w 5 5
15:25:00 swpin/s bswin/s swpot/s bswot/s pswch/s
15:25:05 0.00 0.0 0.00 0.0 6520
15:25:10 0.00 0.0 0.00 0.0 6190
15:25:15 0.00 0.0 0.00 0.0 5432
15:25:20 0.00 0.0 0.00 0.0 5239
15:25:25 0.00 0.0 0.00 0.0 5620
Average 0.00 0.0 0.00 0.0 5800
-w选项报告交换和内存切换活动
swpin/s--每秒进程换入的数量
bswin/s--每秒512个字节的换入数量
swpot/s--每秒进程换出的数量
bswot/s--每秒512个字节的换出数量
pswch/s--每秒进程上下文切换的数量
$ sar -r 5 5
15:26:50 freemem freeswap
15:26:55 4544 1998060
15:27:00 4032 1995139
15:27:05 4325 1991663
15:27:10 4372 1991611
15:27:15 4522 1987298
Average 4360 1992754
-r选项报告空闲内存和空闲交换
当freemem(空闲内存--以512字节为单位列出)低于一个特定的水平时,系统就开始分页。如果它继续下降,系统就开始将一些进程交换出去。这个一个系统性能快速恶化的信号,可以查找占用过多内存的进程,或者是否存在过多的进程。
$ sar -g 5 5
15:35:46 pgout/s ppgout/s pgfree/s pgscan/s %ufs_ipf
15:35:51 43.54 58.45 57.06 0.00 0.00
15:35:56 5.95 7.94 7.54 0.00 0.00
15:36:01 105.59 132.73 224.95 1230.94 0.00
15:36:06 38.22 46.53 81.39 412.67 0.00
15:36:11 11.33 13.12 12.72 0.00 0.00
Average 40.86 51.67 76.59 327.94 0.00
-g选项报告分页活动
pgout/s--每秒换出(pageout)请求数
ppgout/s--每秒换出(pageout)的页数
pgfree/s--由分页控制程序每秒放入空闲列表的页数
pgscan/s--由分页控制程序每秒扫描的分页数
%ufs_ipf--UFS incode与由iget获取的有重用页的空闲列表的比例。这些页已被填充,无法被进程重新声明使用。这样,它就是iget造成的页面填充比例。
很高的ppgout(从内存中移出的页面数)也说明内存不足的问题。
8)使用ipcs命令确定共享内存的使用情况
ipcs命令可以用来监控sga的使用情况。它报告sga中每个共享内存段的尺寸。如果在整个sga中没有足够的内存来容纳一个连续的内存段,sga就将 建立非连续的内存段。在实例崩溃的情况下,可能就会出现内存无法释放的问题。如果发生了这样的情况,注意ipcrm命令可以清除这些段(ipcrm -m用于内存段,ipcrm -s用于信号段)。
$ ipcs -b
IPC status from as of Sat Jan 7 16:04:05 CST 2006
T ID KEY MODE OWNER GROUP QBYTES
Message Queues:
T ID KEY MODE OWNER GROUP SEGSZ
Shared Memory:
m 4608 0xdf00bc84 --rw-r----- oracle dba 708837376
m 4609 0xbd76b6f0 --rw-r----- oracle dba 541065216
T ID KEY MODE OWNER GROUP NSEMS
Semaphores:
s 65536 0xae97 --ra------- root root 129
s 1 0x100ae97 --ra------- root root 128
s 2 0x1 --ra-ra-ra- root root 1
s 3 0x73657276 --ra-ra-ra- root root 3
s 1245188 0xd8647e24 --ra-r----- oracle dba 504
s 1245189 0xbcdcaaa8 --ra-r----- oracle dba 304
这里,sga建立了2个非连续的段。通常最好是让整个sga处于一个单一的共享内存段,因为跟踪一个以上的段以及在这些段之间来回切换都需要额外的开销。可以在/etc/system文件中增加参数SHMMAX的设置,以增加一个单一的共享内存段的最大尺寸。 -
自动化测试脚本编码规范
2011-09-16 12:50:49
为了使所有的测试工程师在进行自动化设计和测试时能够使编写的脚本风格一致、步骤一致,能够把大家的设计和代码组装在一起,因此有必要对自动化测试脚本编写进行统一的规范化,下面就先来介绍整理编写的自动化脚本编写的规范。仅供参考。
1.自动化脚本编写的规范
1)基本信息
在每个脚本模块的最上面,必须写上脚本运行的软件和硬件环境(如IE版本、QTP版本、数据库版本等)、外包项目名称、脚本编写人(使用英文名或中文拼音缩写)、脚本创建时间、脚本修改时间、修改说明、输入参数、输出参数、脚本描述等。
2)常量命名规范
常量的命名应该全部用大写,使用"_"作为单词间的分隔符,单词尽量使用全名称,如,Public Const MSG_EMPTY_ROW As String = "有空行存在"。
使用Public而不是早期版本的global来声明变量。
另外,对常量的声明必须带上类型,如前面的As String。
3)变量命名规范
变量命名应该简单,应尽量使用缩写。如果是一般的值类型(如integer string),则直接使用变量用途命名。尽量使用全名,例如,Dim name As String;如果是一般的临时性变量定义,应该尽可能地简单,例如,Dim i As Integer;如果名称由多个单词组成,则取每个单词的首字母,如EntityManager缩写为em,ProcedureManager缩写为pm;如果名称由一个单词组成,则对单词进行分段取首字母,如Entity缩写为et。缩写应该控制在3个字母以内,且尽量清晰。
4)参数命名规范
参数命名的原则是全部用小写,如果参数包括两个或两个以上的单词时,首单词字母小写,其他单词首字母大写,如stepName、stepDescription。
5)函数命名规范
此处函数包括sub和function,函数表示的是一个动作,所以它的结构应该是动词+名词,动词必须小写,后面的名称首字母大写,如getMaterialCode。函数命名尽量不要使用缩写,而且它的名称应该使人一目了然,能够从名称就知道这个函数的功能,不要使用无意义的函数名称。当函数名称不足以表达其功能时,应使用在函数头部加上让调用者足够明白的注释。
6)代码注释规范
注释务必做到准确简洁,能够充分表达代码实现的功能。
7)空行
空行是区分代码块与块的间隔,在函数之间必须加上空行;而在函数内部,变量声明块和实现块(实现块指除变量声明外的其他代码)要使用空行来间隔,实现块的内部,通过空行来标识一个功能段。
8)缩进
必须严格执行缩进,变量声明块不缩进,实现块必须保证全部缩进(不可能有实现块是行首对齐的);对于基本的控制结构来说,必须要有缩进,如IF、DO、WITH、FOR、WHILE块。
9)续行
对于过长的语句来说,必须使用续行,续行位置要有明显意义,例如,sql ="SELECT [code],[name] FROM [Person]"_&"WHERE [code] LIKE'001%'"。
另外,还要通过管理对象库来提高代码的可读性,通过修改命名来达到更加易读的效果。对于使用比较频繁的代码块来说,最好将其写成函数,并尽量将功能复杂的大函数拆分成小函数。
注意:在任何地方,不要写ElseIf语句,最好转换成If…Else…Endif结构。
2.业务组件测试
BPT为Bussiness Process Testing的缩写,译为业务组件测试。
1)业务组件的简介
业务组件是组成流程测试的基本单元,组合不同的业务组件可以实现不同的业务流程测试。如将黄金交易系统的登录作为一个组件,将交割申报作为一个组件等,然后可以将这些组件按照一定的业务流程组合在一起,以满足不同业务流的测试。这里业务组件可以重复使用,从而在一定程度上提高自动化开发的效率。
2)业务组件测试的优点
业务组件测试有以下几个优点:
相关业务人员可以在没有脚本的环境下组合业务组件,实现业务流程。
对业务人员的编程能力没有要求,业务人员只需了解系统的业务流程,不用关心具体的脚本实现。这一点也实现了业务层和脚本层的分离。
一旦某个组件开发完毕,即可在不同的流程中使用该组件,实现高可复用性,从而加快业务流程测试的速度。
明确角色分工,业务人员负责流程的开发、组织;QTP工程师负责脚本的开发、维护,以及相应函数库的开发、维护。
因为实现了脚本的复用,提高了自动化开发的效率,在无形中降低了测试过程中维护的时间和成本。
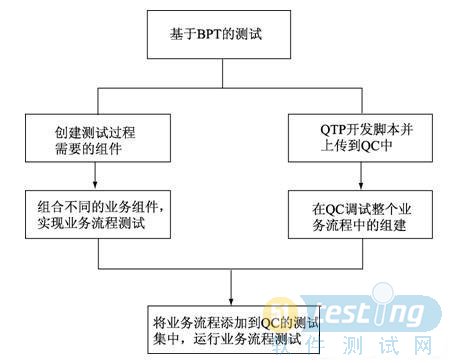
图 业务组件测试的简易流程
从图中可以看出整个过程分为两条线:第一条是由业务人员划分组件并组合不同的组件实现的不同流程测试;第二条是QTP专家负责组件的脚本的具体实现并负责调试成功,上传到QC供业务人员测试时调用。
注意:
此过程需要QC有Bussiness Process Testing组件许可的支持,也就是需要单独向HP购买。
3.整个流程的开发过程
下面我们还是以黄金外包项目为例,简单地演示一下整个流程的开发过程。
1)划分组件
个人网银交割申报业务划分为以下几部分:
登录。
递延交割申报。
递延交割当日委托查询。
递延交割当日成交查询。
递延交割历史委托查询。
历史递延交割成交查询。
注销。
2)组织业务测试流程
组织业务测试流程为:登录-递延交割申报-递延交割当日委托查询-递延交割当日成交查询-递延交割历史委托查询-历史递延交割成交查询-注销。
-
自动化测试脚本技术
2011-09-16 12:41:18
一、线性脚本线性脚本的优点:
1. 线性脚本不需要深入的工作或计划,只需坐在计算机前利用自动化测试工具录制手工测试任务即可。
2. 线性脚本可以快速开始自动化,测试工程师只需理解测试流程即可开展自动化测试工作,同时也是树立测试工程师开始对自动化感兴趣最快速的方法和技术。
3. 线性脚本对实际执行操作可以进行审计跟踪。
4. 使用线性脚本技术,用户不必是编程人员(假设不需修改脚本,用户不必关心脚本本身)。
5. 线性脚本提供良好的演示效果。
线性脚本的缺点:
1. 过程繁琐:产生可行的自动化测试(包括比较)的时间比运行手工测试要长2到10倍。
2. 一切都依赖于每次测试所捕获的内容。
3. 测试输入和比较,以及测试的数据和业务都是‘捆绑’在脚本中的,不便于修改测试数据和测试步骤。
4. 脚本不能共享和重用。
5. 由于线性脚本要求测试的对象相对比较的固定,因此容易受软件变化的影响。
6. 线性脚本修改代价大(维护成本高)。
7. 如果回放脚本时发生了录制脚本时没有发生的事情,如来自网络的意外错误消息,脚本很容易与被测试软件发生冲突,引起整个测试失败。
线性脚本的适用范围:
1. 当测试事例只使用一次时,则无需对将要丢弃的脚本花费太多的功夫,线性脚本便非常方便使用。
2. 线性脚本适合在做培训或演示时,可以回放录制好的脚本来代替击键动作。
3. 线性脚本可以用于转换。如系统的某一部分发生变化,但从用户的角度不能影响系统的工作,可以录制有用数据,替换软件或硬件,然后回放录制过程可以使新系统恢复到初始状态。
4. 线性脚本可以用自动编辑来修改自动测试,任何特定的修改只做一次,因此一次性的脚本足以满足需求。
5. 线性脚本可用于设置和清除测试,通过回放输入序列操作文件或数据库进行相应的记录的设置和清除。
二、结构化脚本
目前所有测试脚本支持三种基本控制结构如下:
顺序结构(即前面的线性脚本,依次执行每行的指令)。
选择结构:使脚本具有判断功能,即加入类似“if,switch”类型的语句来使脚本的执行具有跳跃能力,按照判断条件执行相关的指令。
叠代/循环结构:可以根据需要重复执行一个或多个指令序列如加入像“for,while”等语句。
结构化脚本类似于结构化程序设计,脚本中含有控制脚本执行的指令,这些指令或为控制结构或为调用结构。结构化脚本可以进行嵌套调用另一个脚本,执行完后在返回到当前脚本。
结构化脚本的优点:
1. 结构化脚本健壮性更好,对一些容易导致测试失败的特殊情况和测试中出现的异常情况可以进行相应的处理。
2. 结构化脚本可以像函数一样作为模块被其他脚本调用或使用。
3. 结构化脚本可以提高脚本的重用性和灵活性,使得代码易于维护,可以更好的支持自动化测试。
结构化脚本的缺点:
1. 脚本变得非常复杂,在一定程度上增加了另外的维护工作量。
2. 脚本还是在录/播的基础上实现的,因此脚本内仍然捆绑着测试的数据和逻辑,即键盘、鼠标动作表示的输入被固化在脚本中,测试修改和定制非常复杂困难。
三、共享脚本
共享脚本意味着脚本可以被多个测试事例使用,即脚本语言允许一个脚本被另一个脚本调用,这样可以节省生成脚本的时间。当重复任务发生变化时,只需修改一个脚本。共享脚本可以是在不同主机、不同系统之间共享脚本,也可以是在同一主机、同一系统之间共享脚本。此脚本开发的思路是产生一个执行某种任务的脚本,而不同的测试要重复这个任务,当要执行这个任务时只要在适当的地方调用这个脚本便可以了。
共享脚本的优点:
1. 共享脚本使得实现类似的测试花费的开销较少。
2. 共享脚本的维护开销低于线性和结构化脚本。
3. 共享脚本中删除明显的重复代码,这样代码更加简洁易懂。
4. 可以在共享脚本中增加更智能的功能,如认为的等待一定时间再次运行某个功能。
共享脚本的缺点:
1. 需要跟踪更多的脚本、文档、名字以及存储。如果管理不好,很难找出适合的脚本。
2. 对于每个测试用例仍需一个特定的测试脚本,因此维护成本比较高。
3. 共享脚本通常是针对测试软件的某一部分,不能实现真正意义上的共享。
共享脚本的编写需要更高的编程技能,提高了对测试工程师的要求数据驱动脚本是当前广泛应用的自动化测试脚本技术,它是将测试输入数据存储在数据文件里,而不是继续放在脚本本身里面。脚本里只存放控制信息,执行测试时,从文件中而不是从脚本中读取数据输入,从而使得同一个脚本可以执行不同的测试,实现了数据与脚本的分离,但测试逻辑依然与脚本捆绑在一起。
四、数据驱动脚本
数据驱动脚本的优点:
1. 在数据驱动脚本的层次上,自动化测试可以真正从中获益,可以以较小的额外开销实现很多测试事例的自动化,不需要编写更多的脚本。
2. 在数据驱动脚本中,数据文件的格式对于测试者而言非常易于处理,甚至可以在数据配置文件里添加很多方便维护的注释来增加数据的可理解性。
3. 数据驱动脚本技术使得测试工程师可以将更多的时间和精力放在自动化测试和维护测试上。
4. 数据驱动脚本技术对于测试事例的数据输入和维护带来了极大的方便。
5. 在数据驱动脚本中,甚至连期望结果都可以从脚本中提取出来,使得脚本的维护工作变得更为简单。
6. 对于一组功能强大灵活的数据驱动脚本,测试者本人甚至不需具有脚本编程技能,而只需掌握数据文件的配置方法,便可轻松的使用脚本完成自己的测试
数据驱动脚本的缺点:
1. 需要具有一定编程背景知识的人员加入到脚本编写里面。
2. 因为脚本变得逻辑性更强,引入更多的控制指令,初始脚本建立时间和开销较大。
3. 如果开发出的脚本不规范,则后期的管理和维护会带来巨大的工作量,对于测试工程本人来说需要的技能也更高。
五、关键字驱动脚本
关键字驱动脚本实际上是较复杂的数据驱动脚本的逻辑扩展。数据驱动脚
本的限制是每个测试事例执行的导航和操作必须一样,测试的逻辑知识建立在数据文件和控制脚本中。关键字驱动脚本将数据文件变为测试事例的描述,用一系列关键字指定要执行的任务。关键字驱动脚本的一个特点是它看起来更像描述一个测试事例做什么,而不是如何做。前面四种脚本是说明性方法的脚本,只有关键字驱动脚本是描述性方法,因而它更容易理解。描述性方法是将被测软件的知识建立在测试自动化环境中,相关的知识包含在支持脚本中,这些支持脚本了解被测软件,但是不需要了解测试事例。
核心思想为三个分离
1)界面元素名与测试内部对象名的分离在被测应用程序和录制生成的测试脚本之间增加一个抽象层,它可以将界面上的所有元素映射成相对应的一个逻辑对象,测试针对这些逻辑对象进行,界面元素的改变只会影响映射表,而不会影响测试。
2)测试描述与具体实现细节的分离
把测试描述和测试的具体实现细节分离开来。测试描述只说明软件测试要做什么以及期待什么样的结果,而不管怎样执行测试或怎样证实结果。这样做是因为测试的实现细节通常与特定的平台以及特定的测试执行工具有着密切的联系。这种分离使得测试描述对于应用实现细节是不敏感的,而且有利于测试在工具和平台间的移植。
3)脚本与数据的分离 最后,可以把测试执行过程中所
需的测试数据从脚本中提取出来,在运行时测试脚本再从数据存放处读取预先定制好的数据,这样脚本和数据可以独立维护。
以上这三个分离各司其职、互相独立,最大程度地减少相互之间的影响。从关键字驱动的思想可以看出,该种测试框架不仅实现了将数据和脚本相分离,而且实现了测试逻辑和数据的分离,大大提高了脚本的复用度和维护性,从而更大限度地实现了测试工具的自动化
根据测试用例得出自动化测试框架的典型要素
1)公用的环境
不同测试用例也会用到相同的测试环境,将该测试环境独立封装,在各个测试用例中灵活调用,可以增强脚本的可维护性。
2)公用的对象
成功的框架开发需要确定领域专用的“热点”(Hot spot)。所以在开发过程中必然存在大量相同的对象(如窗口、按钮、页面等)。将对象抽取出来形成一个独立的可重用强的个体,当对象的属性需要变更时做到只需修改对象属性而无需修改脚本。
3)公用的方法
将方法封装成独立的函数,通过参数的形式调用,尽量做到和数据无关。
-
[转载]敏捷测试的方法和实践 --朱少民
2011-09-01 14:01:08
有一次,当开发人员完成当前Sprint 任务的代码之后,测试人员与开发人员、产品经理一起来浏览产品、从头到尾走一边,产品经理发现了问题,认为需要对功能进行比较大的修改。这时开发人员估计需要两天时间才能完成代码,但测试人员反对这样做,我们本来只有5天测试时间,加上这次新做的功能比较多、开发代码质量不高,验收测试已经很紧张。如果再延迟两天,测试没法完成。产品经理说,你们不是在用敏捷测试方法,应该测得很快,三天应该能完成测试工作啊!
什么是敏捷测试呢?敏捷测试当然不能简单地理解测得更快,绝对不是比以前用更少时间进行测试,也不是将测试的范围缩小了或将质量降低来减少测试任务。也有人说,只有敏捷开发,没有敏捷测试。下面我们就要讨论一下:
l 究竟什么是敏捷测试?
l 敏捷测试有哪些流程改进?
l 测试人员如何面对敏捷测试的挑战?
l 在敏捷测试中如何制定相应的自动化测试策略?
等等各种问题。
1. 什么是敏捷测试
假如将过去传统的测试流程和方法硬塞入敏捷开发流程中,测试工作可能会事倍功半,测试人员可能会天天加班,而不能发挥应用的作用。敏捷测试应该是适应敏捷 方法而采用的新的测试流程、方法和实践,对传统的测试流程有所剪裁,有所不同的侧重,例如减少测试计划、测试用例设计等工作的比重,增加与产品设计人员、 开发人员的交流和协作。在敏捷测试流程中,参与单元测试,关注持续迭代的新功能,针对这些新功能进行足够的验收测试,而对原有功能的回归测试则依赖于自动 化测试。由于敏捷方法中迭代周期短,测试人员尽早开始测试,包括及时对需求、开发设计的评审,更重要的是能够及时、持续的对软件产品质量进行反馈。简单地说,敏捷测试就是持续地对软件质量问题进行及时地反馈,如图1所示。
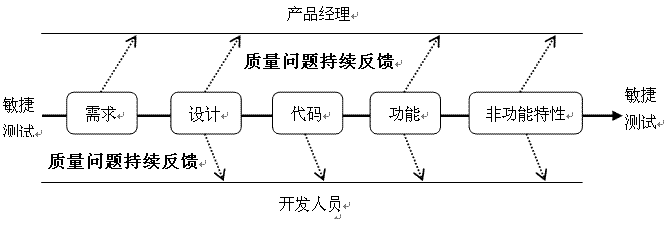
图1 敏捷测试定义的形象描述
2. 敏捷测试流程的优化
在 敏捷方法中,需求变化比较快、产品开发周期很短,我们目前采用四周时间,也就是每个月发布一个新版本。开发周期短,功能不断累加,给软件测试带来很大的挑 战,软件测试流程要做相应的调整。例如,我们原有的测试规范明确规定,首先要建立项目的主测试计划书,然后再建立每个功能任务的测试计划书,测试计划书有 严格的模板,而且需要和产品经理、开发人员讨论,并和测试团队其他人员(包括测试经理)讨论,最终得到大家的认可和签字才能通过,仅测试计划经过“起草、 评审和签发”一个完整的周期就需要一个月。在敏捷方法中,不再要求写几十页的测试计划书,而是在每个迭代周期,写出一页纸的测试计划,将测试要点(包括策 略、特定方法、重点范围等)列出来就可以了。
在原有测试规范中,要求先用Excel写出测试用例,然后进行讨论、评审,评审通过以后再导入测试用例库(在线管理系统)中。在敏捷测试中,可能不需要测试用例,而是针对use case 或user story直 接进行验证,并进行探索性测试。而节约出来的时间,用于开发原有功能的自动化测试脚本,为回归测试服务。自动化测试脚本将代替测试用例,成为软件组织的财 富。原有测试规范还要求进行两轮回归测试,在敏捷测试中,只能进行一轮回归测试。综合这些考虑,敏捷测试的流程简单有效,如下图2所示。
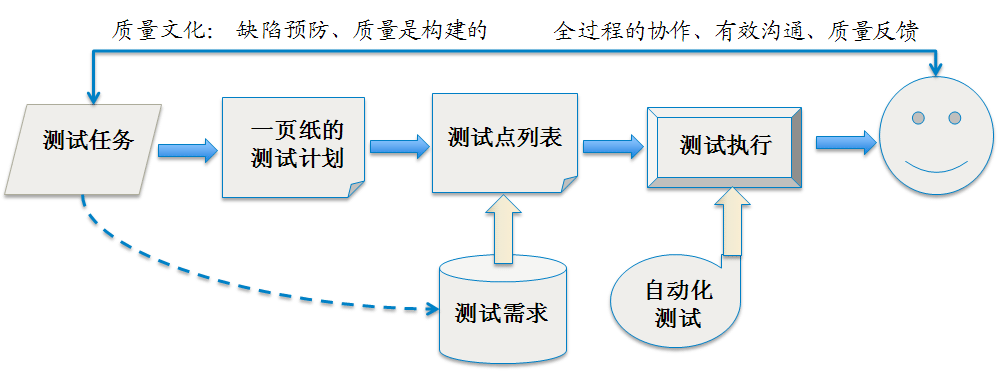
图2 敏捷测试流程简要图
在敏捷测试流程中,如前所述,测试是一个持续的质量反馈过程,测试中发现的问题及时反馈给产品经理和开发人员,而且某些关键方面也要得到我们足够的关注,主要有:
l 测试人员不仅要全程参与需求、产品功能设计等讨论,而且要面对面地、充分地讨论(包括带语言、视频的即时通讯),仅仅通过邮件是不够的。
l 参与代码复审(code review),并适当辅助开发人员进行单元测试。
l 在流程中增加一个环节“产品走查(Product work-through)”——测试人员和产品经理、开发人员等在一起,从头到尾将新功能看一遍,可直观、快速地发现问题。
3. 新功能的测试和回归测试策略
测试任务简单地可分为新功能测试和回归测试。在敏捷方法中,针对这两部分的测试建立相应的策略,以提高测试的效率,最大限度地降低质量风险。新功能测试的策略主要有:
l 不需要测试用例,直接基于用例、基于对需求的理解来完成新功能的验证。即使要写测试用例,只要保证各个功能点被覆盖,不要过于详细(大颗粒度)。
l 持续地进行验证,一旦某块新代码完成(code drop), 就开始验证,而不是等到所有代码完成后才开始测试。这也包括参与到单元测试和集成测试中。
l 实施端到端(end-to-end)的测试,确保完整的业务流程的实现,同时,也容易发现业务逻辑不够清晰、不够合理等各方面的问题。
l 阅读代码来发现问题,可以和开发人员工作保持同步,消除测试周期的压力。
l 基于经验,可以实施更多的探索性测试、组合交互性(interoperation)测试和用户场景(user scenario)测试,更有效地发现埋藏较深的缺陷。
回 归测试是敏捷测试中需要面对的难点。每次迭代都会增加新的功能,一个产品可能会经过十几次、甚至几十次迭代,回归测试范围在不断增大,而每次迭代周期没 变,可能还是一个月。这样验收测试的时间非常有限,所以回归测试很大程度上依赖于自动化测试,因为很难将回归测试控制在非常有限的范围内。当然,还是有些 办法可以帮助我们减少回归测试的范围,例如:
l 通过执行code diff来了解代码变动的所有地方,再做代码关联分析,就可以明确知道要进行哪些地方的回归测试,回归测试范围会大大缩小。
l 基于风险和操作面分析来减少回归测试的范围,例如回归测试只是保证主要功能点没有问题,而忽视一些细节的问题。
l 持续测试的过程,只要有时间,就进行测试,包括开发人员、产品设计人员都参与到日常的试用和测试中来。
4 自动化测试策略
由于开发周期短,需求、设计等方面沟通也需要花费很多时间,没有足够时间开发自动化测试脚本,至少对新功能的测试很难实现自动化测试。这时候,就需要正确的策略来提高自动化测试的效益,如图30-3所示,并说明如下。
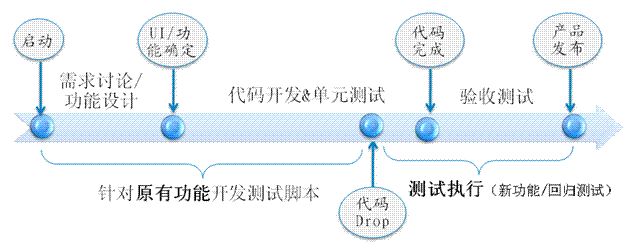
图3 自动化测试的策略
l 构建一个灵活的、开放的自动化测试框架,如基于关键字驱动的自动化框架,使测试脚本的开发简单易行,脚本维护也方便。
l 针对稳定的产品特性开发自动化测试脚本,也就是针对前期完成的已有功能开发自动化测试的脚本,而大部分新功能测试采用手工测试。
l 集中精力在单元层次上实现自动化测试,主要由开发人员实施,测试人员提供单元测试框架,并辅助完成一些所需的基础工作。
l 在产品设计、编程时就很好地考虑了自动化测试的需求,使全面的、自动化的底层测试、接口测试成为可能,尽量避免用户界面(UI)的自动化测试。
l 良好的IT基础设施,包括自动化构建软件包、自动化版本验证(BVT)、自动化部署、覆盖率自动产生等。
5 敏捷测试工具
自动化测试依赖于测试工具,所幸的是,目前已有很多敏捷测试工具。由于篇幅所限,这里只是简单地列出一些常用的敏捷测试工具,不再深入讨论了。
l 单元测试工具:TestNG、xUnit家族(如JUnit 、NUnit)、JMock、BizMock等。
l 功能测试自动化:ThoughtWorks Twist。
l Web功能测试(frontend):Selenium IDE/RC、WatiR、WatiN。
l Web service测试工具(backend):soapUI 。
l 性能测试:JMeter+BadBoy。
l 验收测试框架:Fitnesse、Tellurium。
l 敏捷测试过程管理工具:微软的Visual Studio 2010,包括TFS 2010、Scrum模板(MS VS Scrum 1.0)、Test Manager 2010、Coded UI Test等。
l 业务智能(BI)应用的测试框架:Oraylis BI.Quality (+ NUnit)。
l 其它一些协作工具等,如TestLink、BugZilla、BugFree、wiki、ant等。
6 测试人员在敏捷方法中的价值
在敏捷方法中,开发人员的主导作用更明显,系统设计、编程实现、单元测试、重构等看似关键的一些任务都落在开发人员身上,测试人员容易被边缘化。那么,在敏捷方法中,测试人员的价值又如何体现呢?
l 在需求和功能设计讨论上,测试人员可以站在客户角度上来阐述自己的观点,扮演“用户代表”角色,强调用户体验,真正体现测试人员和开发人员的互补作用。
l 测试人员不仅扮演“用户代表”角色,而且通过需求讨论、代码复审等各种活动及时地提供质量反馈,包括代码质量、接口一致性等,保证在产品构造的整个过程中质量受到足够的关注,以提高质量改进的持续性和可视性。
l 测试人员应积极参与单元测试,即使不参加单元测试,也应督促开发人员进行单元测,确保单元测试达到80%以上覆盖率,确保开发出具有良好可测试性的代码。
l 在敏捷方法中,往往将一个大的系统开发分解成多个小的子系统(模块或组件),集成测试和端到端(end-to-end)测试显得更为重要,测试人员在这些测试上能发挥更大的作用。
l 产品发布前,验收测试和回归测试依然不可缺少,这更是测试人员的用武之地。
l 一个迭代周期结束后,对缺陷根本原因进行分析、总结规律,帮助开发人员建立良好的习惯,预防缺陷,从根本上提高产品质量。
理想情况下,测试人员掌握设计模式、具有很好的编程能力,可以和开发人员进行角色互换,如在当前版本开发(/迭代周期)中担任测试人员角色,在下一个版本开发(/迭代周期)中则担任开发人员角色。这样双方对不同角色的工作有着更深刻的认识,消除沟通的障碍,开发的效率和质量会有进一步的提高。
小结
根据上面的讨论和我们的实践,最后针对敏捷测试进行一个简单的总结,就是:
l 敏捷测试就是持续测试、持续反馈,扮演“用户代表”角色,确保产品满足客户的需求。
l 敏捷功能测试 = 新特性的手工测试 (use case验证和探索性测试) + 原有功能的自动化测试 (回归测试)
l 敏捷测试人员和开发人员的区别越来越小,理想情况下,敏捷方法中,测试人员和开发人员在不同的迭代周期可以互换。
l 敏捷测试流程依据不同的团队特点、不同产品的特点而不同,因地制宜,适合才是最好。
-
ear,jar,war的区别
2011-08-02 09:40:00
Ear、Jar、War文件之间有何不同?它们分别使用在哪种环境下?
在文件结构上,三者并没有什么不同,它们都采用zip或jar档案文件压缩格式,但是它们的使用目的有所区别。
Jar文件(扩展名为. Jar)包含Java类的普通库、资源(resources)、辅助文件(auxiliary files)等
JAR 文件就是 Java Archive File,顾名思意,它的应用是与 Java 息息相关的,是 Java 的一种文档格式。JAR 文件非常类似 ZIP 文件——准确的说,它就是 ZIP 文件,所以叫它文件包。JAR 文件与 ZIP 文件唯一的区别就是在 JAR 文件的内容中,包含了一个 META-INF/MANIFEST.MF 文件,这个文件是在生成 JAR 文件的时候自动创建的。
一般通过jar命令进行打包,如果通过winrar等工具打包,包中不会生成META-INF目录。
War文件(扩展名为.War)包含全部Web应用程序。在这种情形下,一个Web应用程序被定义为单独的一组文件、类和资源,用户可以对jar文件进行封装,并把它作为小型服务程序(servlet)来访问。
打war包也是通过jar命令操作,打包后同样会生成META-INF/MANIFEST.MF文件。
如果打算将应用打成war包后做web应用发布,那么包内的内容必须符合web应用的目录结构。
Ear文件(扩展名为.Ear)包含全部企业应用程序。在这种情形下,一个企业应用程序被定义为多个jar文件、资源、类和Web应用程序的集合。
每一种文件(.jar, .war, .ear)只能由应用服务器(application servers)、小型服务程序容器(servlet containers)、EJB容器(EJB containers)等进行处理。]
EAR文件包括整个项目,内含多个ejb module(jar文件)和web module(war文件)
EAR文件的生成可以使用winrar zip压缩方式或者jar命令。jar:封装类
war:封装web站点
ear:可以封装ejb -
如何测试搜索引擎
2011-07-07 13:41:40
大家最熟悉的专业搜索引擎有yahoo!、Google、百度…………然而搜索引擎并不止这些,一些大型的网站也有自己的搜索引擎,那搜索引擎怎么测试呢?
搜索引擎的测试也分为性能与功能测试,下面依次来给大家分析下:
首先,我们把整个测试计划分为线下测试与线上测试。线下与线上测试都要分性能测试与功能测试,先说线下的测试。
一、线下性能测试也分为两个部分,一部分为直接对搜索引擎进行加压的性能测试,另一部分为通过前台应用进行加压的性能测试:
1、直接对搜索引擎进行加压,可以测试出搜索引擎本身最真实的性能状况。可以把搜索引擎的有效负荷,最大承受的压力测试出来。具体的方法是,使用工具如loadrunner使用一个web_url直接加压,加压的内容其实就是你在功能测试中,直接测试搜索引擎时使用的那些搜索关键字、属性的组合(按照搜索引擎的规则),具体的规则可以通过log来查看,也可以询问开发人员。需要注意的是,数据准备一定要海量,至少10万条以上的搜索数据(注意,就是你访问搜索引擎的那些关键字组合,至于被搜索的数据,越大越好,最少多大,看你实际需要了)。当一切都准备完毕后,就可以启动工具来进行加压了。
2、通过前台应用进行加压,主要的压力都集中在前台应用上面,对于搜索引擎本身的压力并不会很大,但是这种测试也是必须的,因为你的搜索引擎是离不开前台应用的,这种测试可以模拟最真实的终端用户使用。所以不要怕麻烦,这个才是最后真正有意义的测试结果。
二、线下功能测试分为两个部分,一部分为搜索引擎本身的功能测试,一部分为嵌套在前台应用中的功能测试:
1、搜索引擎本身的功能测试,主要就是按照用例,通过不同的搜索关键字、属性的组合(按照搜索引擎的规则)来直接访问搜索引擎,查看返回的数据、参数是不是符合原先预计的结果。可以编写脚本来批量执行,判断每一个搜索的返回结果数与内容,相对应的参数是否一致。也可以手工执行,使用浏览器或者命令行(如curl)来做,用肉眼来观察结果。
2、嵌套前台应用的功能测试,只要就是按照用例通过前台的操作,来测试搜索引擎的相关的功能,测试搜索引擎与前台的接口是否正确应用,至于如何测试,这个地球人都知道了,我就不在这里多说了。
三、线上的性能测试,这个也是使用预发布环境(记得一定要和线上一样哦,只不过是缩小的),分流线上的一部分压力到这里,观察线上与预发布环境中的各服务器的情况,如果是第一次发布,线上没有流量,那么就自己来模拟,或者靠运营来宣传了(有点想网络游戏的公测)。记录下服务器的各性能指标,如load,cpu,队列,最大并发连接数,log等等。
四、线上的功能测试,其实就是功能回归了,使用预发布环境(一套独立的缩小的线上的架构)来跑回归,手工或者自动化随便,这是不能缺少的。
特别需要注意的是,不同层次服务器之间的数据传输方式,正确率以及配置,多试试不同的配置,寻找性能最优点。
-
频繁的需求变更的应对策略
2011-06-08 16:01:29
微软的测试就是分成2个大的阶段的:当需求不稳定时,测试目的是尽量发现大的bug,帮助需求尽快稳定下来;等需求稳定了之后,再进行充分的测试。"
在需求变更频繁的时候,可以先进行使需求先稳定下来的测试,然后再进行充分的测试。对于已经稳定的部分也可以延后再做充分测试,先保证主要的功能可用即可。做之前先跟测试经理、项目经理分析清楚利弊即可,一般都会同意的(我的经验)。这样可以给测试争取更多的时间,来进行充分的测试,也避免了压力带来的负面效应和返工(需求变更后重测)造成的浪费。 -
关于testNG----转载
2011-05-26 17:17:04
TestNG是一个不错的测试框架,尤其是用于模块测试,以及大范围的测试。相对于JUnit来说,更为灵活。随着JUnit4的推出,很多功能都与TestNG相似,但相对于JUnit4,TestNG还是有很多部分是有区别的。
TestNG的IDE支持也不错,对于Eclipse,Idea,Ant都有很好的支持。
先来看一看怎么使用TestNG,当然首先需要下载TestNG包。目前的版本为5.1,下载地址如下:
http://testng.org/doc/download.html ,也可以下载相应的Eclipse插件。
运行TestNG,可以从命令行或者IDE,或者Ant中运行。
命令行:
java org.testng.TestNG -groups windows,linux -testclass org.test.MyTest
对于大型的测试,需要定义一个xml文件,一般为testng.xml。
java org.testng.TestNG testng.xml
当然如果使用Eclipse插件,就简单多了。
下面来看一下,如何来实现测试的,与JUnit4 差不多(怀疑,JUnit4是不是有抄袭TestNG的成分)。
声明测试方法如下:
@Test
public void testMethod1() {
System.out.println("in testMethod1");
}
@Test
public void testMethod2() {
System.out.println("in testMethod2");
}
基本上都是采用java5的注释实现的。
与JUnit4 不同在于,测试方法可以分组,它可以根据诸如运行时间这样的特征来对测试分类。
@Test(groups={"fun1","fun2"})
public void testMethod1() {
System.out.println("in testMethod1");
}
@Test(groups={"fun1"})
public void testMethod2() {
System.out.println("in testMethod2");
}
同JUnit4 一样,同样支持Before,After方法,如同setUp 和tearDown,不过TestNG更为灵活,支持各种签名方式,如private,protected。
@BeforeMethod
protected void beforeMethod() {
System.out.println("in beforeMethod");
}
@AfterMethod
protected void afterMethod() {
System.out.println("in afterMethod");
}
同样也支持BeforeClass 和AfterClass,只执行一次的方法,但是可以不需要使用static签名
@BeforeClass
protected void beforeClassMethod() {
System.out.println("in beforeClassMethod");
}
@AfterClass
protected void afterClassMethod() {
System.out.println("in afterClassMethod");
}
不同于JUnit4,TestNG提供了以下的特性:
依赖性测试
JUnit 框架想达到的一个目标就是测试隔离。它的缺点是:人们很难确定测试用例执行的顺序,而这对于任何类型的依赖性测试都非常重要。开发者们使用了多种技术来解决这个问题,例如,按字母顺序指定测试用例,或是更多地依靠 fixture 来适当地解决问题。
与 JUnit 不同,TestNG 利用Test注释的dependsOnMethods属性来应对测试的依赖性问题。有了这个便利的特性,就可以轻松指定依赖方法。如以下定义:testMethod2依赖于testMethod1。
当然如果testMethod1失败的话,默认testMethod2也不会执行,不过只需要设置alwaysRun = true,则可以跳过testMethod1@Test
public void testMethod1() {
System.out.println("in testMethod1");
}
@Test(dependsOnMethods="testMethod1")
public void testMethod2() {
System.out.println("in testMethod2");
}
@Test
public void testMethod1() {
System.out.println("in testMethod1");
throw new RuntimeException("failed");
}
@Test(dependsOnMethods="testMethod1",alwaysRun = true)
public void testMethod2() {
System.out.println("in testMethod2");
}
失败和重运行
在大型测试套件中,这种重新运行失败测试的能力显得尤为方便。这是 TestNG 独有的一个特性。在 JUnit 4 中,如果测试套件包括 1000 项测试,其中 3 项失败,很可能就会迫使您重新运行整个测试套件(修改错误以后)。不用说,这样的工作可能会耗费几个小时。一旦 TestNG 中出现失败,它就会创建一个 XML 配置文件,对失败的测试加以说明。如果利用这个文件执行 TestNG 运行程序,TestNG 就只 运行失败的测试。所以,在前面的例子里,您只需重新运行那三个失败的测试,而不是整个测试套件。可以看到以下的失败文件,一般命名为testng-failed.xml,以后只需要运行此文件就可以了。
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite thread-count="5" verbose="1" name="Failed suite [testng]" parallel="false" annotations="JDK5">
<test name="demo.testng.Test2(failed)" junit="false" parallel="false" annotations="JDK5">
<classes>
<class name="demo.testng.Test2">
<methods>
<include name="testMethod1"/>
<include name="testMethod2"/>
<include name="beforeClassMethod"/>
<include name="afterClassMethod"/>
<include name="beforeMethod"/>
<include name="afterMethod"/>
</methods>
</class>
</classes>
</test>
</suite>
参数化测试
TestNG 中另一个有趣的特性是参数化测试。在 JUnit 中,如果您想改变某个受测方法的参数组,就只能给每个 不同的参数组编写一个测试用例。多数情况下,这不会带来太多麻烦。然而,我们有时会碰到一些情况,对其中的业务逻辑,需要运行的测试数目变化范围很大。
在这样的情况下,使用 JUnit 的测试人员往往会转而使用 FIT 这样的框架,因为这样就可以用表格数据驱动测试。但是 TestNG 提供了开箱即用的类似特性。通过在 TestNG 的 XML 配置文件中放入参数化数据,就可以对不同的数据集重用同一个测试用例,甚至有可能会得到不同的结果。这种技术完美地避免了只能 假定一切正常的测试,或是没有对边界进行有效验证的情况。
@Parameters( { "first-name"
})
@Test(groups = { "param"
})
public void testParm(String firstName) {
System.out.println("invoked testString:" + firstName);
assertEquals(firstName, "Test");
}
在xml中设置相应的参数值,可以放入suite下面或者test下面,如果同名,一般test下面的定义覆盖suite定义。
<parameter name="first-name" value="Test"/>
高级参数化测试
尽管从一个 XML 文件中抽取数据会很方便,但偶尔会有些测试需要有复杂类型,这些类型无法用String或原语值来表示。TestNG 可以通过它的@DataProvider注释处理这样的情况。@DataProvider注释可以方便地把复杂参数类型映射到某个测试方法。例如,清单 7 中的verifyHierarchy测试中,我采用了重载的buildHierarchy方法,它可接收一个Class类型的数据, 它断言(asserting)Hierarchy的getHierarchyClassNames()方法应该返回一个适当的字符串数组:
package test.com.acme.da.ng;
import java.util.Vector;
import static org.testng.Assert.assertEquals;
import org.testng.annotations.DataProvider;
import org.testng.annotations.Test;
import com.acme.da.hierarchy.Hierarchy;
import com.acme.da.hierarchy.HierarchyBuilder;
public class HierarchyTest {
@DataProvider(name = "class-hierarchies")
public Object[][] dataValues(){
return new Object[][]{
{Vector.class, new String[] {"java.util.AbstractList",
"java.util.AbstractCollection"}},
{String.class, new String[] {}}
};
}
@Test(dataProvider = "class-hierarchies")
public void verifyHierarchy(Class clzz, String[] names)
throws Exception{
Hierarchy hier = HierarchyBuilder.buildHierarchy(clzz);
assertEquals(hier.getHierarchyClassNames(), names,
"values were not equal");
}
}
当然还有一些其他的特性,就不一一详细说明了,有兴趣可以参考相应的testNG文档。
JUnit 4 和 TestNG 在表面上是相似的。然而,设计 JUnit 的目的是为了分析代码单元,而 TestNG 的预期用途则针对高级测试。对于大型测试套件,我们不希望在某一项测试失败时就得重新运行数千项测试,TestNG 的灵活性在这里尤为有用。这两个框架都有自己的优势,您可以随意同时使用它们。 -
闲聊测试
2011-05-19 15:15:48
刚刚进入这一行业的时候,正是测试人才短缺的时期,当时高校还没有这个专业(清华,北航除外),同时各培训机构却在满天飞,各测试培训机构的标语都用“软件测试人才缺口达30万,月薪多少多少”来吸引人们的眼球。
而且当时软件测试行业进入的门槛比较低,不管你的学历是大专还是本科(研究生从事的相对少较少),行业是IT业(计算机,通信,自动化)还是非IT业只要你参加一个培训班就可以进入软件测试行业。同时这个时期总体上测试的收入和开发相比还是略逊一筹。
但是经过了短短几年,软件测试行业人才短缺的趋势就变慢了下来,当然不但软件测试是这样,其他的IT方向包括web程序员,java工程师也是这样的一个过程。原因有很多,各软件测试培训机构的学员一批批的毕业了,刚毕业的研究生们也开始从事软件测试了,国内的企业开始重视软件测试了,测试和开发的收入差距缩小了甚至有超过了。
软件测试正在慢慢的步入饱和,在这种背景下,竞争自然逐渐进入白热化的状态。测试人员开始不值钱了,做为一个测试人员,怎样在持久站中生存下来,年薪跨过10万,20万,50万,百万?是很多人考虑的问题。毕竟每个人都想让生活过的好一些在好一些。
很多文章提到了测试职业发展,技术路线和管理或者市场路线。我觉的这是从事工作初期需要考虑的事情。在你工作了好几年之后需要回头看看,是不是实现了自己预定的目标。并需要做轻微的调整。如果选错了路线,那么停下来就是进步。
测试行业技术和知识面广很重要,技术深厚的测试人员也很吃香,自然就很值钱。那么什么样的是技术大拿呢?现引用一个哥们儿得话:“掌握1-2种开发语言精通到开发的水平,能自己写些工具;自动化测试,性能测试,白盒测试,安全测试四个职业方向都比较熟悉,英语可以和老外去交流。“呵呵。这样的人的确很牛。技术全面之后,我个人认为可以向咨询域发展。当然这种人是少之又少,在一个领域做的很精通就很不错了。如果要精通这4大领域,除了要有很好的机遇和平台外,自己的加倍努力是离不开的,不过很多人工作了几年之后,学习力就下来了,也开始变的懒散,进步就会慢下来。
当然如果你是一个喜欢和人打交道的人,我认为做测试打好技术功底之后,那么就可以尝试逐渐转向管理或者市场路线,管理的发展空间我认为是很大的,它对提高自己的生活水平和技术相比应该空间更大一些。举例说明。一个技术大拿年薪30万到头了,但是如果你是管理层或者市场牛人,那么50-60万应该也是有可能的。IBM 的技术人员在中国Band 8/Band 9的级别上限大概在20-30万。
现在软件测试行业的范围比较广(汽车业,零售业,电子商务,门户网站等等),企业也比较多国内的企业和国外的企业。总体来说,外企和国有企业要好于私企 (百度除外)。国有企业主要是看工龄,越来越吃香,钱的多少主要取决于年终奖和公司的效益,例如中石油,中石化大家都知道的。现在的私人企业好多都通过期权或者股份来拉拢人心,等上市之后它就是真实存在的money了。 外企钱多,但是当你达到一个级别之后你就会受到限制。
这个时代,测试进行时。。。。
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 334540
- 日志数: 230
- 建立时间: 2007-11-19
- 更新时间: 2024-04-03
