
-
Web测试需要了解的知识(转)
2013-06-17 17:56:57
这里只是介绍Web测试相对于其他类型软件的测试额外需要了解的内容,关于测试方法不是本文的重点,里面谈到的每一项在以后的文章中再说明。大家看到这些内容可能都不陌生,我晒出的内容也许不对或有误导,请大家指正。1. HTTP/HTTPS协议
· 你应该去了解什么是http协议
· 什么是GET, POST, session, cookie等
· Get与Post的区别是什么?
· session与cookie的区别是什么?
· 什么是无状态?
2. 浏览器机制
· 理解浏览器在处理javascript及渲染CSS的机制
· 了解IE与其他浏览器的差异
· 为什么兼容性测试时需要特别关注IE
· 浏览器在加载javascript,CSS有时在前面有时在后面,为什么?
· 加载顺序会对视觉和使用上有什么影响呢?
· 各种浏览器使用的内核分别是什么?
3. web架构
也许你会说这是架构师的事儿,没错,基本是他们的活儿,但是理解了web架构能让我们测试的更深入。你要知道:
· 软件出错时怎么个报警法?是否有详尽的log记录?
· 服务器缓存机制如何?
· 数据库如何主从同步,如何备份的?
· 集群如何处理session的?
4. 安全
因为web应用的特殊性,你需要掌握的安全技能:
· 如何进行SQL注入测试?如何防止SQL注入?
· 什么是跨站脚本攻击(XSS)?如何开展此类测试,应该如何防范XSS?
· 什么是DOS,DDOS?开发人员如何coding来避免?
· 传输哪些重要数据时需要加密
· 哪些页面需要使用SSL/https来加密传输
· 什么是跨站伪造请求攻击 cross site request forgeries (XSRF),如何避免?
· 安全证书的意义,浏览器在证书失效时提示是怎样的?
5. web性能
你应该知道的web性能知识:
· web前端的性能极大影响了用户,如何观察这些数据?CSS和图片的合并压缩的意义
· 了解浏览器cache及服务端cache
· 对于图片请求过多的网站,为何要把图片放置在不同的域名下,最好使用CDN?
· 确 认你的网站有一个 favicon.ico 文件放在网站的根下,如 /favicon.ico.每当有用户收藏网站/网页时,浏览器会自动请求这个文 件,就算这个图标文件没有在你的网页中明显说明,浏览器也会请求。如果你没有这个文件,就会出大量的404错误,这会消耗你的服务器带宽,服务器返回 404页面会比这个ico文件可能还大
· 知道单个页面的http请求数越少越好
· 顺序加载和异步加载的优劣,何时需要使用AJAX?懒加载的意义,用于何处?
· 如何使用性能测试工具Jmeter/LR等开展性能测试?
6. SEO
只要是WEB应用,都会有SEO,因为它是种免费的搜索引擎推广方式,否则在百度搜索你们网站,是没有结果的。所以,你需要知道:
· XML sitemap的意义,可以让搜索引擎了解你的网站地图
· 了解 robots.txt 和搜索引擎爬虫是如何工作的
· 搜索引擎喜欢什么样的URL?
· 重定向301和302对于搜索引擎的意义?
· 网页Meta信息中title,description等的重要性
7. 用户体验
网站的功能只是说实现了什么,而用户体验则诠释了做的有多好,用户使用起来是否有难度,是否会爱上这个网站(当然12306除外,咯咯)
· 访问网站的用户操作行为是怎么样的?页面的访问频率占比如何?因为测试的精力和侧重点也要根据这个数据而定
· 网站部署时是否会影响到用户使用,如何避免?
· 不要直接显示不友好的错误提示,是否有友好的提示信息?
· web应用不能泄漏用户的隐私信息
· 页面是在当前页打开还是另开一个tab?
· 页面元素的布局如何影响到用户体验的?
8. 使用工具
· HttpWatch,基于IE的网络数据分析工具,包括网页摘要,Cookies管理,缓存管理,消息头发送/接受,字符查询,POST 数据和目录管理功能等
· FireBug,用途同上,基于firefox的
· Yslow,前端网站性能工具,显示测试结果的分析,分为等级、组件、统计信息
· Fiddler,强大的web前端调试工具,它能记录/拦截所有客户端和服务器的http和https请求,允许你监视,设置断点,甚至修改输入输出数据,也可用于安全测试
· Chrome扩展程序:浏览器兼容性检测工具,分析网站的兼容性情况
· ShowIP:显示访问网站的IP,web测试中你是否经常因为访问的网站IP不对,而被开发人员BS呢?它能帮助到你。
谈到的内容很多,囊括了诸多内容,也有些没有罗列出来,因为都太细节了,不是此文的范围。本来只是做了个Overview,抛砖引玉罢了,因为里面每一子项都可以成为一个专题。 -
Session对性能测试的影响
2013-04-10 13:19:27
Session介绍Cookie是Web产品测试过程中不可缺少的一部分,我们需要通过Cookie信息辨别用户,得到属于自己的结果数据,例如DWR接口测试过程中,需要在请求头信息中传入测试用户的cookie信息,才可以得到该用户学习的课程,发表的博客,或者关注的用户等。Cookie信息通过模拟登陆操作就可以获得。但是,你有没有注意到你获得的Cookie是由什么组成的?是否包含NTES_SESS信息,是否包含SessionID信息?
NTES_SESS是URS返回的Cookie信息,NTESSTUDYSI是云课堂返回的Session信息,NTESSTUDYSI存储SessionID信息,不同的产品会配置不同的变量名。这个信息对于接口测试来说并不是必须的,但是却会在性能测试过程中起到很关键的作用。Cookie和Session有什么区别,为什么性能测试过程中必须需要Session信息?下面,我们一一阐述:
Cookie是什么:
cookie是小甜饼、小型文本文件,因为HTTP协议是无状态的,浏览器无法区分这次请求来自于哪个浏览器,因此产生了随着HTTP请求一起被传递给 服务器的Cookie信息。Cookie是保存在客户端的,存在内存中的cookie,浏览器关闭后就消失了,存在时间是短暂的;存在硬盘中的 Cookie,但存储时间长度超过过期时间或者用户手动清除时,cookie信息会消失。
Session是什么:
Session是会话,当用户第一次对网站服务器发生请求时,服务器会创建Session信息,生成SessionID用来唯一标识用户,并会把该 SessionID返回给客户端浏览器(只存在内存,并不存在硬盘中),在会话结束之前的每次请求,浏览器会自动将该SessionID附加在请求头信息 中,服务端接受请求时,检测是否存在SessionID(不存在或者Session过期都会重新生成Session),并通过该SessionID以键值 对的方式查询用户信息。服务端的Session使用类似散列表的结构存储用户信息。
Session的常见实现形式是会话 Cookie(Session Cookie),即未设置过期时间的Cookie,这个Cookie的默认生命周期为浏览器会话期间,只要关闭浏览器窗口,Cookie就消失了,这种形 式的Session是和Cookie绑定在一起的。而平常所说的Cookie主要指的是另一类Cookie——持久Cookie(Persistent Cookies)。持久Cookie是指存放于客户端硬盘中的Cookie信息(设置了一定的有效期限)。持久Cookie一般会保存用户的用户ID,该 信息在用户注册或第一次登录的时候由服务器生成包含域名及相关信息的Cookie发送并存放到客户端的硬盘文件上,并设置Cookie的过期时间,以便于 实现用户的自动登录和网站内容自定义。
我们在执行接口测试之前,首先会通过URS得到用户Cookie信息,这份Cookie信息中至 少会得到NTES_SESS字段对应的Values值,如果在获取Cookie时,我们同时跳转到产品页面,向该产品服务器发送请求(例如云课堂),那么 在我们得到的Cookie信息中同样存在NTESSTUDYSI字段,该字段就是该产品的Tomcat服务器产生的32位的SessionID +jvmRoute设置的后缀名。在做接口测试时,如果请求头中没有传入SessionID信息,那么每次执行时,Tomcat都会重新生成一份 Session;即便你传入该SessionID信息,如果SessionID过了超时时间设置,Tomcat还是会重新生成一份,Tomcat默认的 Session过期时间为30Min。
性能影响
虽然只是一个小小的SessionID,却会对性能测试的产生很大的影响:
1、Session缺失:
在做Lofter产品的性能测试时,测试getHomePage接口,发现响应时间比较慢,JVM内存在测试过程中一直增长,Young GC收集不过来,Old区内存不断增长,最终会导致频繁Full GC,使用Jmap定位到堆内存中java.util.concurrent.ConcurrentHashMap$Segment 对象不断增加,但是并不知道这个对象时谁在什么时候产生的。我们Dump出来此时的堆内存,使用MAT (Memory Analyzer Tool)工具进一步分析,到底是什么操作产生了大量的ConcurrentHashMap$Segment。
由上图可以看到这个对象是由org.apache.catalina.session.StandardManager产生的,session.StandardManager就是存储Session的容器。
通过了解Session的原理得知,我们在测试过程中,只是传入了Cookie信息,在Cookie中没有包含SessionID信息,所以每次请 求时,Tomcat都会检查是否存在该标识信息,如果没有则会创建。如果我们测试过程中有几十万次请求,那么Tomcat会创建几十万个Session信 息,假设一条Session需要2K的数据,那几十万的Session可能会使得Session容器占用上百兆的空间。同时需要注意,因为我们每个请求都 会创建Session,这个Session是创建了以后不会被使用的(下次请求中依然没有携带SessionID),即垃圾Session,但是垃圾 Session在过期之前是会一直存在内存中的,默认的Session保存时间是30Min,这样的垃圾Session会在内存中保存至少30Min,如 果在这30Min中内我们不停的发送请求,Session容器占用的内容空间会 不断扩大,最终会影响我们的测试结果。
2、Session过期
即便我们在请求中加入了SessionID,但是还可能会产生不停的创建Session问题,这是为什么?因为Session是存在过期时间 的,默认的Tomcat中web.xml中设置的session过期时间为30Min,如果我们得到的SessionID在30Min后使用,依据 Tomcat的Session机制,首先会检查是否存在SessionID,如果有的话,检测是否过期,如果传入的SessionID已经过 期,Tomcat还是会每次都自动生成Session信息。
Mark,Session的过期时间有三种设置方式:一种是Tomcat的配置文件web.xml中设置,一种是webroot项目代码中的配 置文件web.xml中设置,一种是代码中设置session.setMaxInactiveInterval(15*60),所以我们在测试中要记得检 测和确认这三个地方。
3、SessionID后缀不匹配
在测试云课堂项目中,我明明已经修改了每个地方的Session过期时间,请求中传入了没有过期的SessionID,可是为什么还是会不停的创建Session?
一般我们的产品架构是Nginx+Tomcat方式,静态请求走Nginx,动态请求通过Nginx访问到Tomcat。Nginx处理 Session采用了session sticky方案,需用到第三方模块jvm_route,需要在Nginx的配置文件中upstream.conf中设置:
upstream study {
server 10.120.36.68:8010 srun_id=qa18-8010;
server 10.120.36.97:8010 srun_id=qa19-8010;
jvm_route $cookie_NTESSTUDYSI reverse;
keepalive 100;
}该配置文件中配置了一个Nginx连接两个Tomcat,当请求过来时,会依据SessionID中的后缀来查找请求发送到哪个Tomcat, 例如NTESSTUDYSI=1816E5ECBC052F6ABA420FEE7B06DA86.qa18-8010;就会把带这个SessionID 的请求发送到 10.120.36.68(qa18)这台机器上去。
在qa18这台机器的Tomcat配置文件server.xml中,会设置jvmRoute="qa18-8010",这样保证生成的SessionID的后缀是qa18-8010,如果这个两个后缀不一致的话,同样会出现问题。
例如如果Nginx配置文件中upstream.conf中设置的srun_id=qa18-8010,而tomcat配置文件中设置的 jvmRoute="qatest18-8010",那么获取Cookie得到的SessionID后缀则为qatest18-8010,当发送请求到 Nginx时,检测到SessionID的后缀和设置的server服务器无法匹配,则会丢失session,使得发送到Tomcat的动态请求依旧是没 有Session信息的请求,造成session丢失,测试过程中还会有session不断的创建。
-
页面性能测试(转)
2012-03-06 11:09:04
一、页面性能测试概述页面性能测试则是针对于页面性能优化而开展的一种性能测试,目的是对Web系统的页面进行测试以确认系统页面是否会影响系统的性能并为页面的优化提供依据与建议,最终提升系统的整体性能表现,提高用户体验满意度。可见,Web系统页面性能测试是相对Web系统后台测试的另外一种性能测试,是Web系统性能测试的一个重要部分。
二、页面性能测试必要性
相对于C/S架构的应用系统,Web应用系统所有数据都需要从服务器端下载,虽然浏览器有缓存机制,但客户每次访问仍然需要下载大量的数据。特别是用户 对系统要求越来越高,除了要求功能完备,对界面的美观、易用性也提出了更高的要求,越炫的页面也就意味着页面中要包含更多的脚本、样式表、图片和 Flash,页面的数据量也就越大,这对Web系统的性能提出了极大的挑战。
曾经有个在线打印服务的应用提供商说他们的系统不需要关注 系统性能问题,没有必要进行性能测试,因为他们可以购买足够多的服务器来支撑系统;不少业界同行也认为只要有足够多的服务器资源,性能就不会存在问题。其 实不然,他们都只关注到了应用系统的后台性能表现,而忽略了页面对系统整体性能的影响。举个例子,当一个页面中包含几百个请求,页面中没有经过优化的 javaScript文件、CSS 文件与图片件大小达到10MB,即使当前只有一个用户在访问该系统,页面的访问速度也会慢得惊人,纵使增加再多的服务器也不见得会有明显的性能提升。
可见,对Web应用系统的页面进行性能测试和优化是非常有必要的。只有通过对页面的性能测试,发现页面存在的性能问题并根据性能测试结果进行页面优化以 提升页面的加载性能,从而提升系统的整体性能。在应用系统高并发访问时,更能体现出Web页面优化后所带来的系统整体性能提升效果。
2种方式来提升你的web 应用程序的速度:
● 减少请求和响应的往返次数
● 减少请求和响应的往返字节大小。
减少请求和响应的往返次数:
HTTP缓存是最好的减少客户端服务器端往返次数的办法。缓存提供了提供一种机制来保证客户端或者代理能够存储一些东西,而这些东西将会在稍后的 HTTP 响应中用到的。(即第一次请求了,到了客户端,缓存起来,下次如果页面还要这个JS文件或者CSS文件啥的,就不要到服务器端去取下来了,但是还是要去服 务器上去访问一次,因为请求要对比ETAG值,关于这个值,我将会在下次翻译中介绍其作用)这样,就不用让文件再次跨越整个网络了。
缓存相关的请求头
为了提高性能,微软的IE和其他的web客户端总是想尽办法来维持从远程服务器上下载下来的本地的缓存。
当客户端需要一个资源(html,css.js…),他们有3种可能的动作:
1、发送一个一般的HTTP请求到远程服务器端,请求这个资源。
2、发送一个有条件的HTTP请求到服务器,条件就是如果它不同于本地的缓存版本。
3、如果缓存的拷贝可用,就使用本地的缓存资源。
当发送一个请求,客户也许会使用如下的几个HEADER
减少请求肯响应往返的字节大小:
1、使用更少的图画
2、将所有的CSS浓缩到一个CSS文件中
3、将所有的脚本浓缩到一个JS文件中
4、简化你的页时间
5、使用HTTP压缩
三、页面性能测试工具介绍第一种是通过HTTP代理的方式来截取客户与服务器之间的通讯。
此类的工具非常的多,如:
charles是一个HTTP代理/ HTTP监视器/使开发人员可以查看所有的计算机和互联网之间的HTTP和SSL/ HTTPS流量的反向代理。这包括请求,响应和HTTP标头(其中包含的cookies和缓存信息)。
charles界面清爽,采用中国的瓷器为logo,给人的感觉简洁高雅。而且使用也非常简单。进入下载页面,选择你适合你的版本,安装也非常简单,一路“next”就OK了。

点击工具栏上的“红色”按钮,就自动的记录你浏览器访问的所有网站。
Fiddler是一个Web调试代理,记录所有的HTTP(S)之间的计算机和互联网的交通。提琴手允许您检查交通,设置断点,和“捣鼓”传入或传出数据。菲德勒包括一个强大的基于事件的脚本子系统,并可以使用任何。NET语言扩展。
Fiddler是免费软件,可以调试,从几乎任何应用程序,支持代理,包括IE浏览器,谷歌Chrome,苹果Safari,Mozilla Firefox中,歌剧,还有数千交通。您也可以像Windows电话,iPod/ iPad和其他流行的设备调试的交通。

Fiddler2相比Charles功能要更强大一些。当然了,如果单单把他们理解成页面性能测试工具有此片面,尤其Fiddlers2功能强大,当然了,我也没有深究,在此就不过多评论了。
-
性能测试分析之带宽瓶颈的疑惑(转)
2012-03-05 16:32:26
第一部分, 测试执行先看一图,再看下文
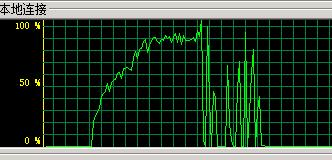
这个当然就是压力过程中带宽的使用率了,我们的带宽是1Gbps的,合计传输速率为128MB/s,也正因为这个就让我越来越疑惑了,不过通过压力过程中的各项数据我又不得不相信。
在看看测试页面的大小和请求,如下图所示:

这是通过httpwatch检测得出来的,页面传输内容的大小为652154Byte,请求数为149次,也就是说加载一次页面就大概需要请求这么多次请求,传输这么大的内容,当然这里剔除缓存机制来分析的。
场景设计:
1、并发用户200
2、每20秒加载10个用户
3、全部用户加载完成之后,持续运行10分钟
监控目标:TPS、响应时间、点击率、吞吐率、内存、CPU和网络带宽
测试分析结果如下图:

这里的可以得出平均点击率为11952.139次/s,而吞吐率为73178737byte,大约为73MB/s,TPS:720/s,这里的错误后面再说。

这里的响应时间很显然没有上去,说明压力没有传到页面上,而上面的错误也同时可以证实,报错基本都是请求被拒绝,也就说后面没有请求导致页面没有压力,响应时间就无效了。
通过监控得到系统资源占用率数据有:
CPU:25~30%
内存:20%
网络带宽:70~95%
通过Httpwatch在压力过程监控的页面响应时间为:6.454s
通过结合虚拟用户、点击率、吞吐率和响应时间的曲线图分析得出如下总结:
当虚拟用户加载到150的时候,点击率和吞吐率此时处于峰值,且网络带宽达到90%以上,当虚拟用户继续加载的时候,点击率和吞吐率均都开始下 降,此时场景运行开始报错,提示信息为服务器连接被拒绝。通过分析,处于峰值只有网络带宽,为90%以上,而对比此处的吞吐率值恰为95MB/s左 右,1Gbps的网络带宽传输速率为128MB/s,从而表明由于吞吐量过大,占用了大量的带宽资源,导致后续的虚拟用户无法得到服务器的资源,而致使请 求被拒绝。从最后的页面响应时间来看,系统的压力并没有被承接到页面上,而是由于过大的吞吐量吞噬了网络带宽,导致最终无法有效地完成测试任务。
第二部分,测试分析
如上的结果确实是证实了网络带宽不够用,抱着这个不大相信的疑问,我在群里跟大家讨论了一番,当然大家的给出结论也都是一致,也有建议修改系统 的参数,释放所有的带宽等;还有就是分析页面,当然这个我个人认为是比较切实的路径,毕竟1Gbps的带宽,如果再扩从的话也不大现实,所以还是要靠优化 程序着手。
我又继续通过httpwatch工具对其他门户网站首页进行检测,发现页面容量差不多,但是从请求上来讲,腾讯和同花顺的首页请求都只有80左 右,而我们的却有149个请求,这里的请求数就直接决定于点击率的多少,从这里我们就可以发觉,并不是对所有的压力测试来说,每秒钟的点击率越高,对应的 吞吐率越大就说明系统的性能越好,必须相对请求数而言来进行分析。从另一个层面上来说点击率越高是说明程序效率好,但是从本身来讲,如果一个页面本身的请 求就很多,那最后的点击率必然会大,大到最后的结果就是页面内容累计容量就越大,导致传输带宽的不断放大,当然就带宽不够用了。如果一定程序上降低了单个 页面的请求数量,那页面的执行效率必然会越高,而需要结合整体页面的容量大小来衡量。
最后,我给开发提出的建议,还是需要对程序、页面等进行优化,优化硬件还有待考量,优化建议如下:
1、降低页面的请求次数
2、优化页面中各个元素的容量大小,结合Page Speed和YSlow工具进行优化测试
3、多方面结合缓存机制
不知道以上的分析结果是否准确,但让我从性能分析的思路上又走出了一个绝地,不要放过每一个细节,也许那就是拐点。
-
[原创]HttpWatch工具简介及使用技巧(转)
2012-02-22 17:08:24
一 概述:
HttpWatch强大的网页数据分析工具.集成在Internet Explorer工具栏.包括网页摘要.Cookies管理.缓存管理.消息头发送/接受.字符查询.POST 数据和目录管理功能.报告输出 HttpWatch 是一款能够收集并显示页页深层信息的软件。它不用代理服务器或一些复杂的网络监控工具,就能够在显示网页同时显示网页请求和回应的日志信息。甚至可以显示浏览器缓存和IE之间的交换信息。集成在Internet Explorer工具栏。
二 安装HttpWatch
略过^_^
三 基本功能介绍
启动Httpwatch
从IE的“查看”—“浏览器栏”—“HttpWatch”启动HttpWatch。如下图所示:
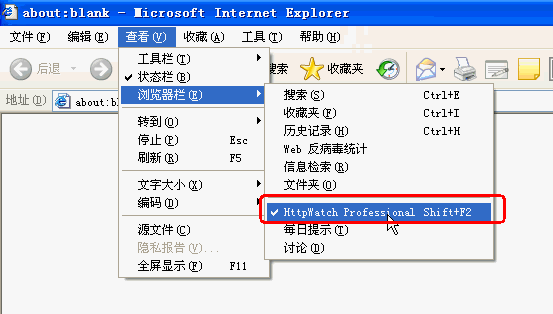
以下是HttpWatch程序界面
以下用登录我的邮箱mail.163.com例子来展示Httpwatch:
点击“Record”后,在IE打开需要录制的网址,mail.163.com,输入用户名,密码后完成登录操作
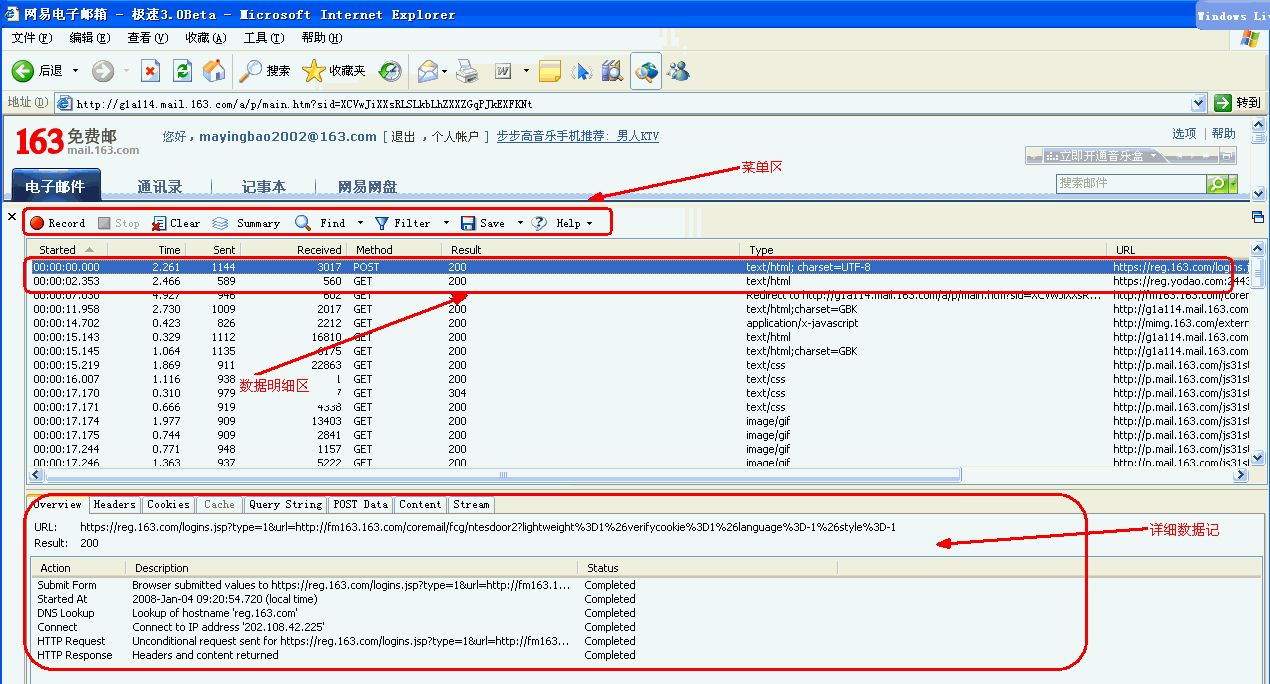
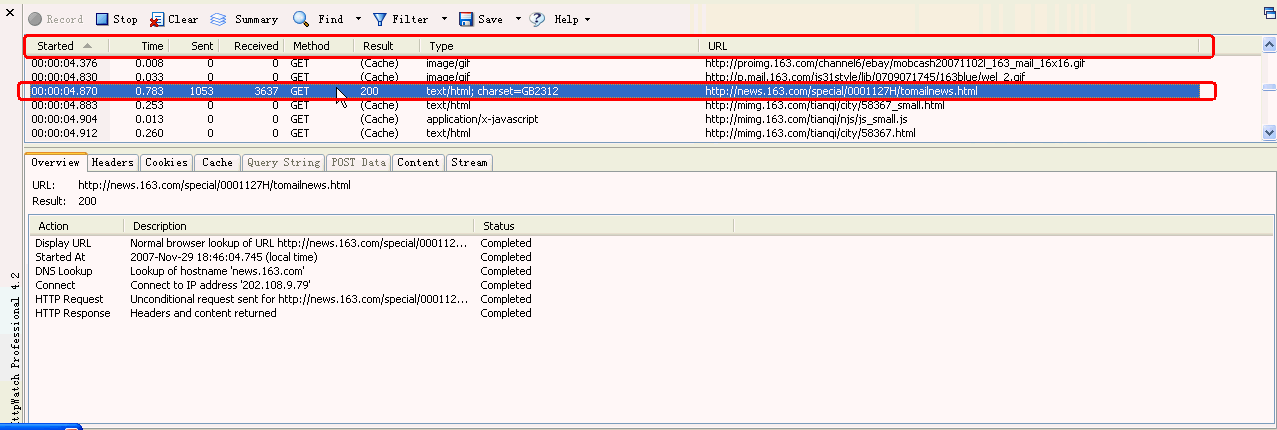
1. 3.1 Overview(概要)
表示选定某个信息显示其概要信息
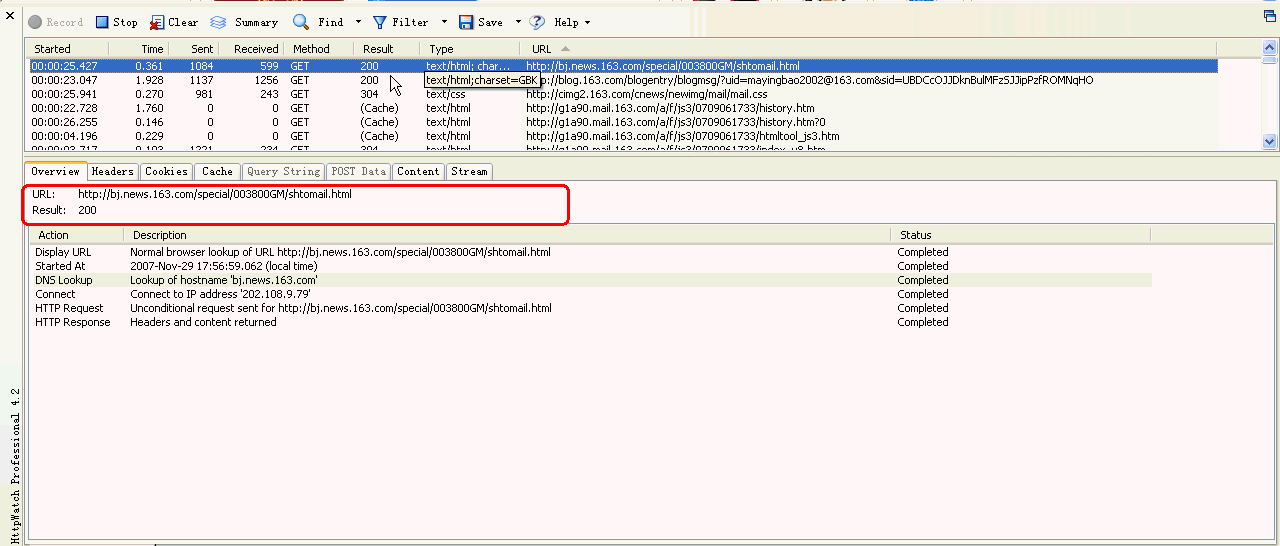
如上图红框所示:
URL: http://mimg.163.com/external/closea_d.js
Result:200
请求的URL是http://mimg.163.com/external/closea_d.js ,返回的Htpp状态代码结果200,表示成功;
Resync URL Browser requested refresh if changed - http://mimg.163.com/external/closea_d.js
浏览器请求的URL
Started At 2008-Jan-04 09:21:09.422 (local time)
请求开始时间(实际记录的是本机的时间)
Connect Connect to IP address '218.107.55.86'
请求的网址的IP地址
Http Request Unconditional request sent for http://mimg.163.com/external/closea_d.js
Http请求,当浏览器向Web服务器发出请求时,它向服务器传递了一个数据块,也就是请求信息
Http Response Headers and content returned
Http响应,当浏览器接受到web服务器返回的信息时
2. 3.2 Header(报头)
表示从Web服务器发送和接受的报头信息;
http://g1a90.mail.163.com/a/p/main.htm?sid=UBDCcOJJDknBulMFzSJJipPzfROMNqHO
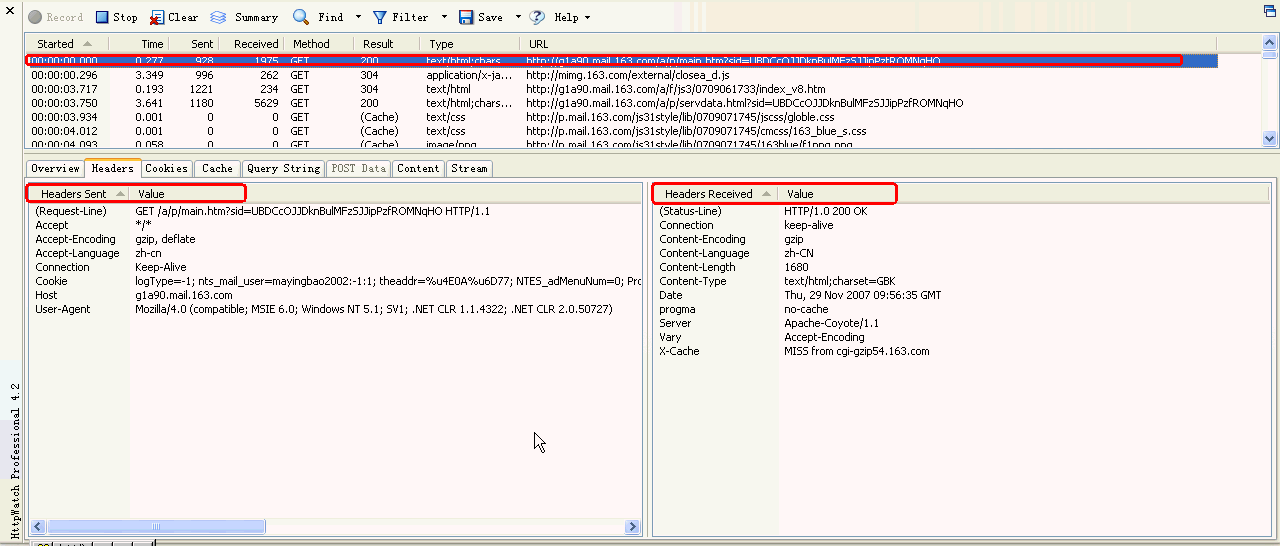
如上图红框所示:
Http请求头发送信息
Headers Sent value
Request-Line GET /external/closea_d.js HTTP/1.1
以上代码中“GET”代表请求方法,“closea_d.js”表示URI,“HTTP/1.1代表协议和协议的版本。
Accept */*
指示能够接受的返回数据的范围, */*表示所有
Accept-Encoding gzip, deflate
Accept-Encoding表明了浏览器可接受的除了纯文本之外的内容编码的类型,比如gzip压缩还是deflate压缩内容。
Accept-Language zh-cn
表示能够接受的返回数据的语言
Connection Keep-Alive
保持Tcp请求连接
备注:在HTTP工作开始之前,Web浏览器首先要通过网络与Web服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80
Cookie vjuids=-1b9063da8.1173d33f879.0.9aab8b85a459d; vjlast=1199406314; _ntes_nnid=a1e69963f40453af8a9ad171cc4cd8da,0|tech|; NTES_UFC=3000000100000000000000000000000000000000000000000000000000000000; Province=021; City=021; ntes_mail_firstpage=normal; NTES_SESS=68LUOUH9ewcCBFyN5OXZ_0qf._IOMCkFscaGYrooXpjtVF7r8Vx7jAzg7HGdWo00GQEn1ZmrZcX7FMAXnb052r8XOFZZYk.hN; NETEASE_SSN=mayingbao2002; NETEASE_ADV=11&23&1199409658752;
Coremail=VDeAMrrrDFaTa%XCVwJiXXsRLSLkbLhZXXZGqPJkEXFKNt
Cookie没什么说的就是客户端记录相关信息
Host mimg.163.com
请求连接的主机名称’
Referer Http://g1a114.mail.163.com/a/p/main.htm?sid=XCVwJiXXsRLSLkbLhZXXZGqPJkEXFKNt
包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
User-Agent Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
客户端标识浏览器类型
Http请求头返回信息
Headers Received Value
Status-Line Http/1.0 200 ok
表示Http服务端响应返回200
Accept-Ranges bytes
Http请求范围的度量单位
Age 117
表示Http接受到请求操作响应后的缓存时间
Cache-Control max-age=3600
一个用于定义缓存指令的通用头标
Connection keep-alive
保持Tcp请求连接
Content-Type application/x-javascript
标明发送或者接收的实体的MIME类型
Date Fri, 04 Jan 2008 01:12:26 GMT
发送HTTP消息的日期
Etag "10f470-734-b32eb00"
一种实体头标,它向被发送的资源分派一个唯一的标识符
Expires Fri, 04 Jan 2008 02:12:26 GMT
指定实体的有效期
Last-Modified Fri, 04 Jan 2008 01:01:00 GMT
指定被请求资源上次被修改的日期和时间
Server Apache
一种标明Web服务器软件及其版本号的头标
X-Cache HIT from mimg68.nets.com
表示你的 http request 是由 proxy server 回的
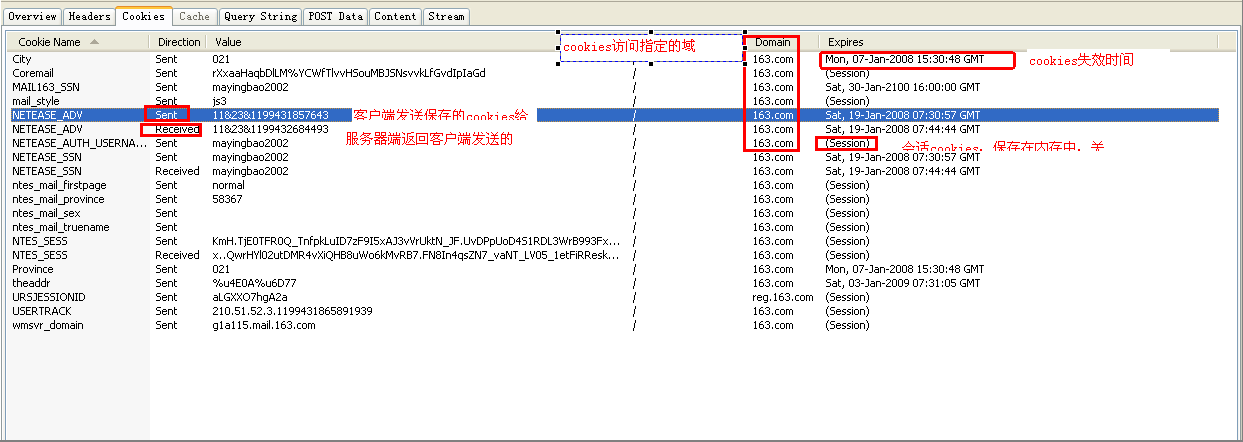
3. 3.3 Cookies
显示Cookies信息
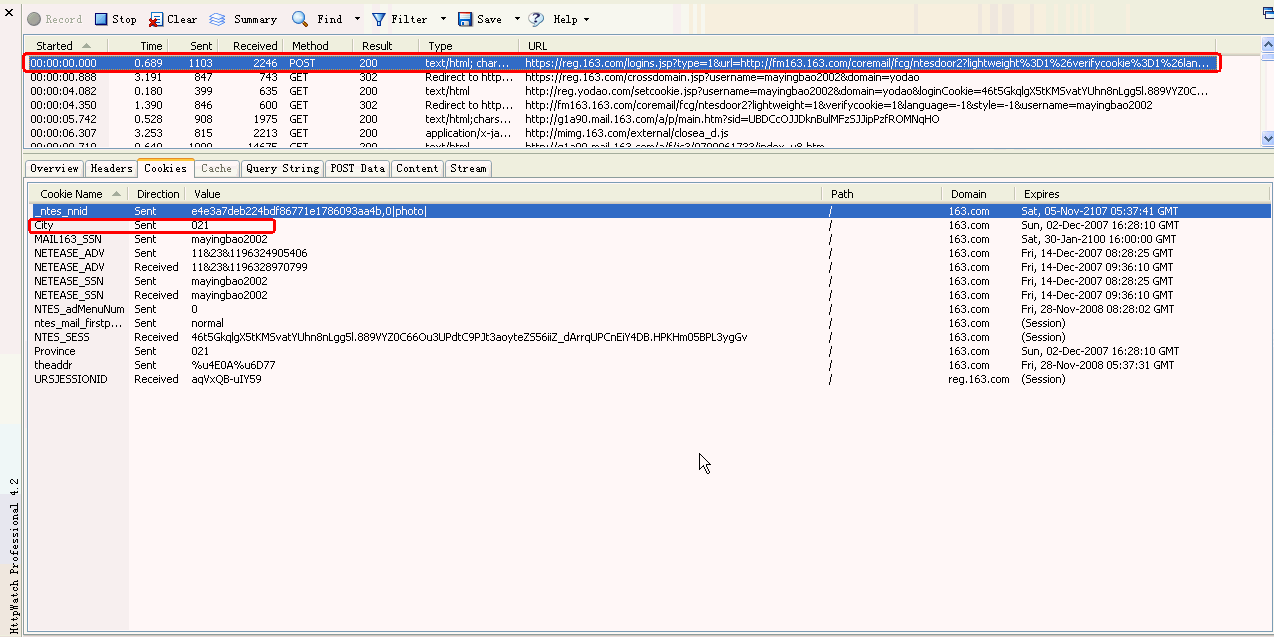
如上图所示City=021,其实是我163邮箱中设置城市信息值,在Cookies中记录为021(代表上海这个城市)
备注:
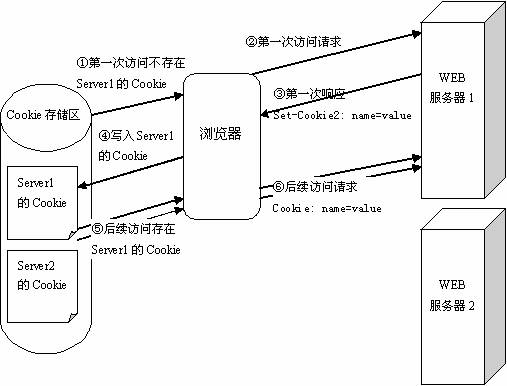
什么是cookie?Cookie是一种在客户端保持HTTP状态信息的技术,Cookie是在浏览器访问WEB服务器的某个资源时,由WEB服务器在HTTP响应消息头中附带传送给浏览器的一片数据,WEB服务器传送给各个客户端浏览器的数据是可以各不相同的。
浏览器可以决定是否保存这片数据,一旦WEB浏览器保存了这片数据,那么它在以后每次访问该WEB服务器时,都应在HTTP请求头中将这片数据回传给WEB服务器。
显然,Cookie最先是由WEB服务器发出的,是否发送Cookie和发送的Cookie的具体内容,完全是由WEB服务器决定的。
Cookie在浏览器与WEB服务器之间传送的过程如图7.1所示。
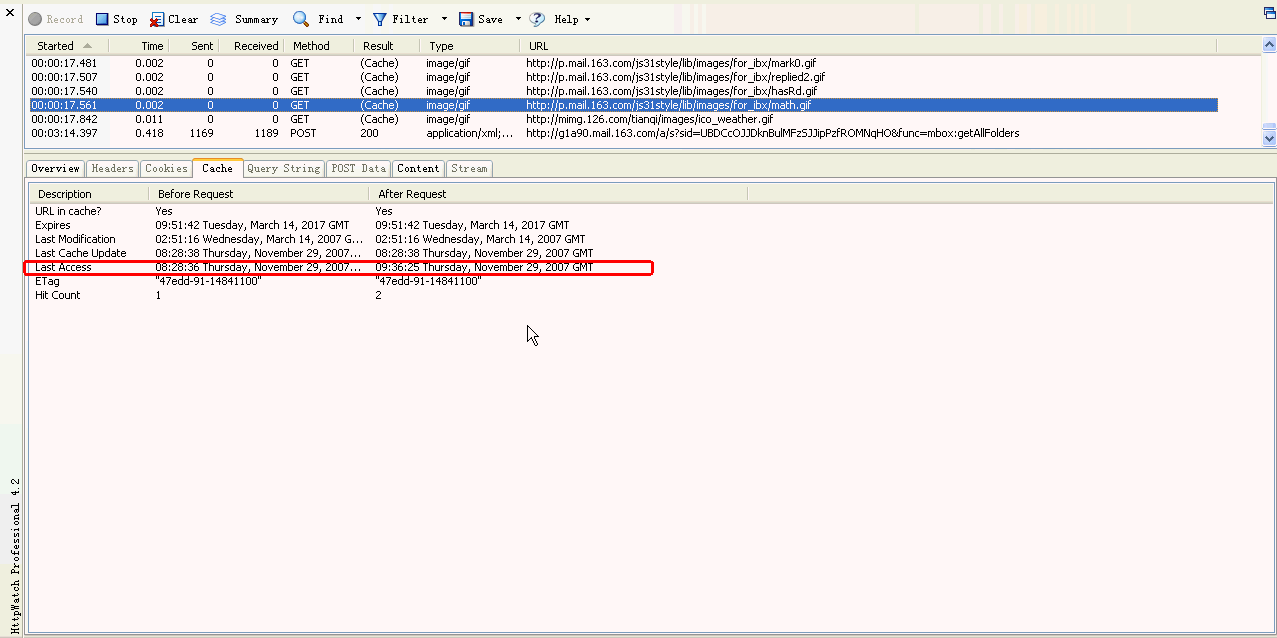
4. 3.4 Cache(缓存)
显示在请求完成前后的浏览器缓存里URL地址栏里的详细信息
5. 3.5 Query String(查询字符串)
显示查询字符串被用在是传递参数url中
如下图所示:
http://reg.yodao.com/setcookie.jsp?username=mayingbao2002&domain=yodao.com&loginCookie=uaLr3t2p5wKi_ku90vYy04gK1MamttMzYGFxdsppqrz3ZhjsWZ8jzDlVjmxEIpSSx2hn__w3ZsoBSFu6gKRZyRUdIgZYzVciX&clearPersistCookie=
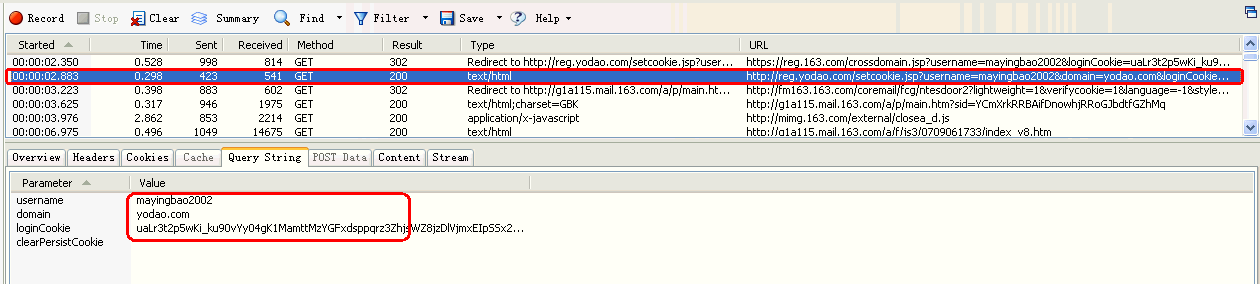
如上面的红框中显示的mayingbao2002字符串,是存在于请求的URL传递的参6. 3.6 POST Data
显示通过Post方式数据信息
以下是mail.163.com登录过程中POST Data,如下图所示:
https://reg.163.com/logins.jsp?type=1&url=http://fm163.163.com/coremail/fcg/ntesdoor2?lightweight%3D1%26verifycookie%3D1%26language%3D-1%26style%3D-1
上面的红框:application/x-www-form-urlencoded表示,post方式默认提交数据编码
备注:以下为Post方式提交数据编码几种方式:
text/plain
以纯文本的形式传送
application/x-www-form-urlencoded
默认的编码形式,即URL编码形式
multipart/form-data
MIME编码,上传文件的表单必须选择该
Mime Type指的是如text/html,text/xml等类型
MIME(Multipurpose Internet Email Extension),意为多用途Internet邮件扩展,它是一种多用途网际邮件扩充协议,在1992年最早应用于电子邮件系统,但后来也应用到浏览器。服务器会将它们发送的多媒体数据的类型告诉浏览器,而通知手段就是说明该多媒体数据的MIME类型,从而让浏览器知道接收到的信息哪些是MP3文件,哪些是JPEG文件等等。当服务器把把输出结果传送到浏览器上的时候,浏览器必须启动适当的应用程序来处理这个输出文档。在HTTP中,MIME类型被定义在<head>、</head>部分的Content-Type中。
数据类型
MIME类型
超文本标记语言文本 .htm,.html文件
text/html(数据类别是text,种类是html,下同)
纯文本,.txt文件
text/plain
RTF文本,.rtf文件
application/rtf
GIF图形,.gif文件
image/gif
JPEG图形,.jpeg, .jpg文件
image/jpeg
au声音,.au文件
audio/basic
MIDI音乐,mid,.midi文件
audio/midi,audio/x-midi
RealAudio音乐,.ra, .ram文件
audio/x-pn-realaudio
MPEG,.mpg,.mpeg文件
video/mpeg
AVI,.avi文件
video/x-msvideo
GZIP,.gz文件
application/x-gzip
TAR,.tar文件
application/x-tar
如上图红圈所表示,可以看到POST Data 中的password和username数据;
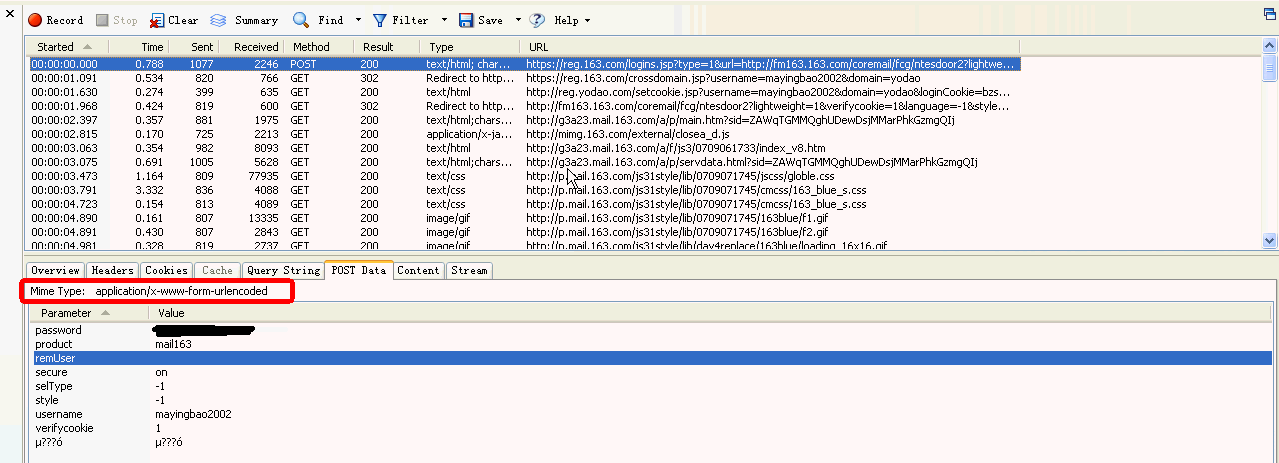
备注:get方法和Post方法区别
GET方法
GET方法是默认的HTTP请求方法,我们日常用GET方法来提交表单数据,然而用GET方法提交的表单数据只经过了简单的编码,同时它将作为URL的一部分向Web服务器发送,因此,如果使用GET方法来提交表单数据就存在着安全隐患上。例如
Http://127.0.0.1/login.jsp?Name=zhangshi&Age=30&Submit=%cc%E+%BD%BB
从上面的URL请求中,很容易就可以辩认出表单提交的内容。(?之后的内容)另外由于GET方法提交的数据是作为URL请求的一部分所以提交的数据量不能太大
POST方法
POST方法是GET方法的一个替代方法,它主要是向Web服务器提交表单数据,尤其是大批量的数据。POST方法克服了GET方法的一些缺点。通过POST方法提交表单数据时,数据不是作为URL请求的一部分而是作为标准数据传送给Web服务器,这就克服了GET方法中的信息无法保密和数据量太小的缺点。因此,出于安全的考虑以及对用户隐私的尊重,通常表单提交时采用POST方法。
7. 3.7 Content
统计显示收到的Http响应信息
如下图所示:可以查看
页响应具体内容:
8. 3.8 Stream
显示客户端发送的数据,然后服务器端返回的数据
客户端发送总数据:901 bytes sent to 218.107.55.86:80
客户端接受到服务器端返回总数据:247 bytes received by 192.168.52.188.10720
以下用请求一个mail.163.com中的Logo图标为例说明:

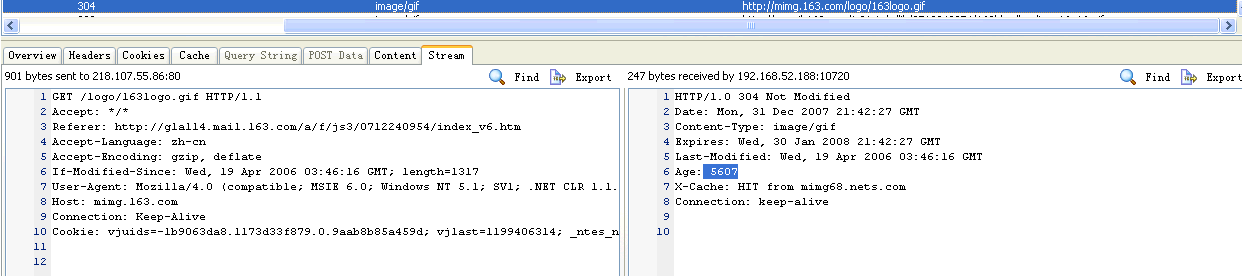
http://mimg.163.com/logo/163logo.gif
左边:客户端向服务器端发送数据流
1 GET /logo/163logo.gif HTTP/1.1
以上代码中“GET”代表请求方法,“closea_d.js”表示URI,“HTTP/1.1代表协议和协议的版本。
2 Accept: */*
指示能够接受的返回数据的范围, */*表示所有
3 Referer: http://g1a114.mail.163.com/a/f/js3/0712240954/index_v6.htm
包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
4 Accept-Language: zh-cn
表示能够接受的返回数据的语言
5 Accept-Encoding: gzip, deflate
Accept-Encoding表明了浏览器可接受的除了纯文本之外的内容编码的类型,比如gzip压缩还是deflate压缩内容。
6 User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
客户端标识浏览器类型
7 Host: mimg.163.com
访问地址主机标识地址
8 Connection: Keep-Alive
保持Tcp连接(前台已有备注,这里不做说明)
9Cookie: vjuids=-1b9063da8.1173d33f879.0.9aab8b85a459d; vjlast=1199406314; _ntes_nnid=a1e69963f40453af8a9ad171cc4cd8da,0|tech|; NTES_UFC=3000000100000000000000000000000000000000000000000000000000000000; Province=021; City=021; ntes_mail_firstpage=normal; NTES_SESS=68LUOUH9ewcCBFyN5OXZ_0qf._IOMCkFscaGYrooXpjtVF7r8Vx7jAzg7HGdWo00GQEn1ZmrZcX7FMAXnb052r8XOFZZYk.hN; NETEASE_SSN=mayingbao2002; NETEASE_ADV=11&23&1199409658752; Coremail=VDeAMrrrDFaTa%XCVwJiXXsRLSLkbLhZXXZGqPJkEXFKNt; wmsvr_domain=g1a114.mail.163.com
Cookies没什么说的,前面已列举了
右边:服务器端向客户端返回数据流
1 HTTP/1.0 304 Not Modified
服务器告诉客户,原来缓冲的文档还可以继续使用。
2 Date: Mon, 31 Dec 2007 21:42:27 GMT
发送HTTP消息的日期
3 Content-Type: image/gif
服务器返回请求类型是image/gif
4 Expires: Wed, 30 Jan 2008 21:42:27 GMT
指定实体的有效期
5 Last-Modified: Wed, 19 Apr 2006 03:46:16 GMT
指定被请求资源上次被修改的日期和时间
6 Age: 5607
表示Http接受到请求操作响应后的缓存时间
7 X-Cache: HIT from mimg68.nets.com
表示你的 http request 是由 proxy server 回的
8 Connection: keep-alive
保持Tcp请求连接状态
9. 3.9 HttpWatch请求信息框
菜单区如上图红框所示:
Started: 表示开始记录请求一个URL时间
Time: 表示记录请求耗费的时间
Sent: 表示客户端向服务器端发送请求字节大小
Reveived:表示客户端收到服务端发送请求字节大小
Method: 表示请求URL方式
Result: 表示服务器返回到客户端结果
以下是Httpwatch中http状态码列表
-
Tomcat内存溢出解决办法
2012-02-17 17:17:39
使用Java程序从数据库中查询大量的数据时出现异常:
java.lang.OutOfMemoryError: Java heap space
在JVM中如果98%的时间是用于GC且可用的 Heap size 不足2%的时候将抛出此异常信息。
JVM堆的设置是指java程序运行过程中JVM可以调配使用的内存空间的设置.JVM在启动的时候会自动设置Heap size的值,其初始空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1/4。可以利用JVM提供的-Xmn -Xms -Xmx等选项可进行设置。
解决办法:
理方法是
在myeclipse中设置TOMCAT的内存大小
Tomcat是目前应用十分广泛的一个Java servlet container与web服务器,但java.lang.OutOfMemoryError与java.lang.OutOfMemoryError: PermGen space的异常相信真正用过tomcat的人都遇到过(用户量大,应用使用频繁等),这个异常和JVM默认划分的内存上限是128M有关,如果你的业务足够繁忙,128M是远远不够的,所以你可以给JVM分配上1G甚至更多,这样就可以避免内存溢出。
分配方法:
1)linux下
编辑tomcat的catalina.sh文件,在第一行的后面增加一句:
JAVA_OPTS='-server -Xms256m -Xmx512m -XX:PermSize=128M -XX:MaxPermSize=256M'
注意:单引号不能少,-server表示以server模式运行(运行效率比默认的client高很多,自己云去测试),-Xms256m是最小内存,-Xmx512m是最大内存,其中的256与512可根据你自己的内存做相应调整,PermSize/MaxPermSize最小/最大堆大小.一般报内存不足时,都是说这个太小,堆空间剩余小于5%就会警告,建议把这个稍微设大一点,不过要视自己机器内存大小来设置,我自己的文件如下:
#!/bin/sh
JAVA_OPTS='-server -Xms1024m -Xmx1024m XX:PermSize=128M -XX:MaxPermSize=256M'
# -----------------------------
2)windows下
编辑tomcat的catalina.bat文件,在第一行的后面增加一句:
set JAVA_OPTS=-server -Xms256m -Xmx512m -XX:PermSize=128M -XX:MaxPermSize=256M
注意:没有单引号
2.1)如果windows下tomcat被作为一种服务安装了,可通过tomcat monitor的java页进行配置
注:Java Options中每一行的最后不能有空格。
上面配置的catalina.bat中-server选项对应:Java Virtual Matchine
D:\Java\jdk1.6.0_03\jre\bin\server\jvm.dll
这里的jvm.dll不是jre\bin\client\jvm.dll而是\jre\bin\server\jvm.dll(要安装JDK不是JRE)
如果你不想提高tomcat的执行效率,你可以按默认的配置
现在说明一个各个配置参数
提示中给出了设置的参数:
-vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M MyEclipse内存不足之JVM内存浅谈的几个问题:
1. 各个参数的含义什么?
2. 为什么有的机器我将-Xmx和-XX:MaxPermSize都设置为512M之后Eclipse可以启动,而有些机器无法启动?
3. 为何将上面的参数写入到eclipse.ini文件Eclipse没有执行对应的设置?
下面我们就MyEclipse内存不足之JVM内存一一对一些概念进行回答
1. 各个参数的含义什么?
参数中-vmargs的意思是设置JVM参数,所以后面的其实都是JVM的参数了,我们首先了解一下JVM内存管理的机制,然后再解释每个参数代表的含义。
◆堆(Heap)和非堆(Non-heap)内存
按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在 Java 虚拟机启动时创建的。”“在JVM中堆之外的内存称为非堆内存(Non-heap memory)”。可以看出JVM主要管理两种类型的内存:堆和非堆。简单来说堆就是Java代码可及的内存,是留给开发人员使用的;非堆就是JVM留给自己用的,所以方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码都在非堆内存中。
◆堆内存分配
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、-Xmx相等以避免在每次GC 后调整堆的大小。
◆非堆内存分配
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
◆JVM内存限制(最大值)
首先JVM内存限制于实际的最大物理内存(废话!呵呵),假设物理内存无限大的话,JVM内存的最大值跟操作系统有很大的关系。简单的说就32位处理器虽然可控内存空间有4GB,但是具体的操作系统会给一个限制,这个限制一般是2GB-3GB(一般来说Windows系统下为1.5G-2G,Linux系统下为2G-3G),而64bit以上的处理器就不会有限制了。
2. 为什么有的机器我将-Xmx和-XX:MaxPermSize都设置为512M之后Eclipse可以启动,而有些机器无法启动?
通过上面对JVM内存管理的介绍我们已经了解到JVM内存包含两种:堆内存和非堆内存,另外JVM最大内存首先取决于实际的物理内存和操作系统。所以说设置VM参数导致程序无法启动主要有以下几种原因:
1) 参数中-Xms的值大于-Xmx,或者-XX:PermSize的值大于-XX:MaxPermSize;
2) -Xmx的值和-XX:MaxPermSize的总和超过了JVM内存的最大限制,比如当前操作系统最大内存限制,或者实际的物理内存等等。说到实际物理内存这里需要说明一点的是,如果你的内存是1024MB,但实际系统中用到的并不可能是1024MB,因为有一部分被硬件占用了。
3. 为何将上面的参数写入到eclipse.ini文件Eclipse没有执行对应的设置?
那为什么同样的参数在快捷方式或者命令行中有效而在eclipse.ini文件中是无效的呢?这是因为我们没有遵守eclipse.ini文件的设置规则:
参数形如“项 值”这种形式,中间有空格的需要换行书写,如果值中有空格的需要用双引号包括起来。比如我们使用-vm C:\Java\jre1.6.0\bin\javaw.exe参数设置虚拟机,在eclipse.ini文件中要写成这样:
-vm C:\Java\jre1.6.0\bin\javaw.exe 按照上面所说的,最后参数在eclipse.ini中可以写成这个样子:
-vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M 实际运行的结果可以通过Eclipse中“Help”-“About Eclipse SDK”窗口里面的“Configuration Details”按钮进行查看。
另外需要说明的是,Eclipse压缩包中自带的eclipse.ini文件内容是这样的:
-showsplash org.eclipse.platform --launcher.XXMaxPermSize 256m -vmargs -Xms40m -Xmx256m 其中–launcher.XXMaxPermSize(注意最前面是两个连接线)跟-XX:MaxPermSize参数的含义基本是一样的,我觉得唯一的区别就是前者是eclipse.exe启动的时候设置的参数,而后者是eclipse所使用的JVM中的参数。其实二者设置一个就可以了,所以这里可以把–launcher.XXMaxPermSize和下一行使用#注释掉。 -
项目性能检测新工具学习
2012-02-17 15:36:14
1.JAVA自带的性能检测工具JAVA-VM,是在C:\Program Files\Java\jdk1.6.0_10\bin的路径中,这个工具可以检测堆内存、非堆内存等其他数据
2.JPROFILE的使用,主要是环境配置问题,配置好后,可以查看堆\线程\对象被调用的情况等.
-
JAVA内存溢出分为两种情况
2012-02-17 12:36:02
JAVA内存溢出分为两种情况:
一种是内存足够时
JVM堆内存是足够的,但只是没有连续的内存空间导致,比如申请连续内存空间的数组:
Java代码
String[] array = new String[10000]。
String[] array = new String[10000]。
还有一种是某种原因导致的内存不足而产出内出溢出。
比如,内存泄露导致的内存溢出。内存泄露时指存在无用的对象不能被GC回收,一般情况下不会出现问题。但是如果存在大量GC不能回收的无用对象后,会导致堆内存严重不足,而产生内存泄露。
这里详细讲述第二种内存溢出的情况。
一、内存溢出类型
1、java.lang.OutOfMemoryError: PermGen space
JVM管理两种类型的内存,堆和非堆。堆是给开发人员用的上面说的就是,是在JVM启动时创建;非堆是留给JVM自己用的,用来存放类的信息的。 它和堆不同,运行期内GC不会释放空间。如果web app用了大量的第三方jar或者应用有太多的class文件而恰好MaxPermSize设置较小,超出了也会导致这块内存的占用过多造成溢出,或者 tomcat热部署时侯不会清理前面加载的环境,只会将context更改为新部署的,非堆存的内容就会越来越多。
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域,这块内存主要是被JVM存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中,它和存放类实例(Instance)的Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的应用中有很CLASS的话,就很可能出现PermGen space错误,这种错误常见在web服务器对JSP进行pre compile的时候。如果你的WEB APP下都用了大量的第三方jar, 其大小超过了jvm默认的大小(4M)那么就会产生此错误信息了。
一个最佳的配置例子:(经过本人验证,自从用此配置之后,再未出现过tomcat死掉的情况)
set JAVA_OPTS=-Xms800m -Xmx800m -XX:PermSize=128M -XX:MaxNewSize=256m -XX:MaxPermSize=256m
2、java.lang.OutOfMemoryError: Java heap space
第一种情况是个补充,主要存在问题就是出现在这个情况中。其默认空间(即-Xms)是物理内存的1/64,最大空间(-Xmx)是物理内存的1 /4。如果内存剩余不到40%,JVM就会增大堆到Xmx设置的值,内存剩余超过70%,JVM就会减小堆到Xms设置的值。所以服务器的Xmx和Xms 设置一般应该设置相同避免每次GC后都要调整虚拟机堆的大小。假设物理内存无限大,那么JVM内存的最大值跟操作系统有关,一般32位机是1.5g到3g 之间,而64位的就不会有限制了。
注意:如果Xms超过了Xmx值,或者堆最大值和非堆最大值的总和超过了物理内存或者操作系统的最大限制都会引起服务器启动不起来。
垃圾回收GC的角色
JVM调用GC的频度还是很高的,主要两种情况下进行垃圾回收:
当应用程序线程空闲;另一个是java内存堆不足时,会不断调用GC,若连续回收都解决不了内存堆不足的问题时,就会报out of memory错误。因为这个异常根据系统运行环境决定,所以无法预期它何时出现。
根据GC的机制,程序的运行会引起系统运行环境的变化,增加GC的触发机会。
为了避免这些问题,程序的设计和编写就应避免垃圾对象的内存占用和GC的开销。显示调用System.GC()只能建议JVM需要在内存中对垃圾对象进行回收,但不是必须马上回收,
一个是并不能解决内存资源耗空的局面,另外也会增加GC的消耗。
二、JVM内存区域组成
简单的说java中的堆和栈
java把内存分两种:一种是栈内存,另一种是堆内存
1。在函数中定义的基本类型变量和对象的引用变量都在函数的栈内存中分配;
2。堆内存用来存放由new创建的对象和数组
在函数(代码块)中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量所分配的内存空间;在堆中分配的内存由java虚拟机的自动垃圾回收器来管理
堆的优势是可以动态分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的。缺点就是要在运行时动态分配内存,存取速度较慢;
栈的优势是存取速度比堆要快,缺点是存在栈中的数据大小与生存期必须是确定的无灵活性。
java堆分为三个区:New、Old和Permanent
GC有两个线程:
新创建的对象被分配到New区,当该区被填满时会被GC辅助线程移到Old区,当Old区也填满了会触发GC主线程遍历堆内存里的所有对象。Old区的大小等于Xmx减去-Xmn
java栈存放
栈调整:参数有+UseDefaultStackSize -Xss256K,表示每个线程可申请256k的栈空间
每个线程都有他自己的Stack
三、JVM如何设置虚拟内存
提示:在JVM中如果98%的时间是用于GC且可用的Heap size 不足2%的时候将抛出此异常信息。
提示:Heap Size 最大不要超过可用物理内存的80%,一般的要将-Xms和-Xmx选项设置为相同,而-Xmn为1/4的-Xmx值。
提示:JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4。
默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、-Xmx相等以避免在每次GC 后调整堆的大小。
提示:假设物理内存无限大的话,JVM内存的最大值跟操作系统有很大的关系。
简单的说就32位处理器虽然可控内存空间有4GB,但是具体的操作系统会给一个限制,
这个限制一般是2GB-3GB(一般来说Windows系统下为1.5G-2G,Linux系统下为2G-3G),而64bit以上的处理器就不会有限制了
提示:注意:如果Xms超过了Xmx值,或者堆最大值和非堆最大值的总和超过了物理内存或者操作系统的最大限制都会引起服务器启动不起来。
提示:设置NewSize、MaxNewSize相等,"new"的大小最好不要大于"old"的一半,原因是old区如果不够大会频繁的触发"主" GC ,大大降低了性能
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;
由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
解决方法:手动设置Heap size
修改TOMCAT_HOME/bin/catalina.bat
在“echo "Using CATALINA_BASE: $CATALINA_BASE"”上面加入以下行:
JAVA_OPTS="-server -Xms800m -Xmx800m -XX:MaxNewSize=256m"
四、性能检查工具使用
定位内存泄漏:
JProfiler工具主要用于检查和跟踪系统(限于Java开发的)的性能。JProfiler可以通过时时的监控系统的内存使用情况,随时监视垃圾回收,线程运行状况等手段,从而很好的监视JVM运行情况及其性能。
1. 应用服务器内存长期不合理占用,内存经常处于高位占用,很难回收到低位;
2. 应用服务器极为不稳定,几乎每两天重新启动一次,有时甚至每天重新启动一次;
3. 应用服务器经常做Full GC(Garbage Collection),而且时间很长,大约需要30-40秒,应用服务器在做Full GC的时候是不响应客户的交易请求的,非常影响系统性能。
因为开发环境和产品环境会有不同,导致该问题发生有时会在产品环境中发生,通常可以使用工具跟踪系统的内存使用情况,在有些个别情况下或许某个时刻确实是使用了大量内存导致out of memory,这时应继续跟踪看接下来是否会有下降,
如果一直居高不下这肯定就因为程序的原因导致内存泄漏。
五、不健壮代码的特征及解决办法
1、尽早释放无用对象的引用。好的办法是使用临时变量的时候,让引用变量在退出活动域后,自动设置为null,暗示垃圾收集器来收集该对象,防止发生内存泄露。
对于仍然有指针指向的实例,jvm就不会回收该资源,因为垃圾回收会将值为null的对象作为垃圾,提高GC回收机制效率;
2、我们的程序里不可避免大量使用字符串处理,避免使用String,应大量使用StringBuffer,每一个String对象都得独立占用内存一块区域;
String str = "aaa";
String str2 = "bbb";
String str3 = str + str2;//假如执行此次之后str ,str2以后再不被调用,那它就会被放在内存中等待Java的gc去回收,程序内过多的出现这样的情况就会报上面的那个错误,建议在使用字符串时能使用 StringBuffer就不要用String,这样可以省不少开销;
3、尽量少用静态变量,因为静态变量是全局的,GC不会回收的;
4、避免集中创建对象尤其是大对象,JVM会突然需要大量内存,这时必然会触发GC优化系统内存环境;显示的声明数组空间,而且申请数量还极大。
这是一个案例想定供大家警戒
使用jspsmartUpload作文件上传,运行过程中经常出现java.outofMemoryError的错误,
检查之后发现问题:组件里的代码
m_totalBytes = m_request.getContentLength();
m_binArray = new byte[m_totalBytes];
问题原因是totalBytes这个变量得到的数极大,导致该数组分配了很多内存空间,而且该数组不能及时释放。解决办法只能换一种更合适的办 法,至少是不会引发outofMemoryError的方式解决。参考:http://bbs.xml.org.cn/blog /more.asp?name=hongrui&id=3747
5、尽量运用对象池技术以提高系统性能;生命周期长的对象拥有生命周期短的对象时容易引发内存泄漏,例如大集合对象拥有大数据量的业务对象的时候,可以考虑分块进行处理,然后解决一块释放一块的策略。
6、不要在经常调用的方法中创建对象,尤其是忌讳在循环中创建对象。可以适当的使用hashtable,vector 创建一组对象容器,然后从容器中去取那些对象,而不用每次new之后又丢弃
7、一般都是发生在开启大型文件或跟数据库一次拿了太多的数据,造成 Out Of Memory Error 的状况,这时就大概要计算一下数据量的最大值是多少,并且设定所需最小及最大的内存空间值。
-
JProfiler学习笔记(转二)
2012-01-13 17:30:03
选择Web容器是否和Jprofiler一起运行:
默认即可

配置提示:
在“远程控制”的时侯要仔细阅读一下。

然后选择立即起动,开始运行。

点击“OK”,我们可以看到另外一个小窗口出来了:

Jprofiler的窗口为:

这样我们就可以进行监控了!
(五) 开始测试
1. 在IE地址栏中输入:http://localhost/test/init1.jsp,执行一次,我们可以在内存视图中看到cn.test.TestBean对象被创建了10000次:

2.标记现在的状态,然后再执行init1.jsp和,init2.jsp可以让我们找到哪些类在调用后没有被释放(很重要!!!)

查看哪些类被发生了变化:

红色的变成是发生变化的对象及其数量。
我刚才执行了4次init1.jsp和1次init2.jsp,正好产生了50000个TestBean对象,和图示显示的一样。
3. 过一会后,按F4键进行垃圾回收。但回收完成后,这些对象依然存在,说明某些地方对这个类的引用没有被释放!
4. 找出是哪些地方使用了TestBean类,并且没有释放它们
在cn.test.TestBean对象上点击右键选择“Take Heap Snapshot for Selection”,观察它的heap

下一步:

点击“OK”:

在该类中点击右键,在出现的菜单中选择“Use Selected Objects”:

出现如下窗口:

选择”Allocations”,点击“OK”,然后我们要的结果就出来了

图中显示调用此类的地方是init1.jsp和init2.jsp,并且各自占用的比率都列出来了。
既然问题的所在找出来了,接下来就该去解决问题了!
(五)总结
其实,我们在测试内存占用时还可以另外写一个释放内存的JSP文件来配合测试,会更清楚一些:
Free.sjp
<%@pagelanguage="java"import="java.util.*,cn.test.*"pageEncoding="ISO-8859-1"%>
<!DOCTYPEHTMLPUBLIC"-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>init</title>
</head>
<body>
<%TestMain.list.clear();%> collection OK!
</body>
</html>
在点击完init1.jsp或init2.jsp后,可以看到内存是TestBean对象的数量增加了,然后执行free.sjp,接着再执行F4进行垃圾回收,立刻可以看到TestBean对象被释放掉了。
-
JProfiler学习笔记(转一)
2012-01-13 17:28:24
JProfiler学习笔记
一、安装JProfiler
从http://www.ej-technologies.com/下载5.1.2并申请试用序列号
二、主要功能简介
1.内存剖析Memory profiler
JProfiler的内存视图部分可以提供动态的内存使用状况更新视图和显示关于内存分配状况信息的视图。所有的视图都有几个聚集层并且能够显示现有存在的对象和作为垃圾回收的对象。
- 所有对象
显示类或在状况统计和尺码信息堆上所有对象的包。你可以标记当前值并显示差异值。 - 记录对象Record objects
显示类或所有已记录对象的包。你可以标记出当前值并且显示差异值。 - 分配访问树Allocation call tree
显示一棵请求树或者方法、类、包或对已选择类有带注释的分配信息的J2EE组件。 - 分配热点Allocation hot spots
显示一个列表,包括方法、类、包或分配已选类的J2EE组件。你可以标注当前值并且显示差异值。对于每个热点都可以显示它的跟踪记录树。
2.堆遍历Heap walker
在JProfiler的堆遍历器(Heap walker)中,你可以对堆的状况进行快照并且可以通过选择步骤下寻找感兴趣的对象。堆遍历器有五个视图:
- 类Classes
显示所有类和它们的实例。 - 分配Allocations
为所有记录对象显示分配树和分配热点。 - 索引References
为单个对象和“显示到垃圾回收根目录的路径”提供索引图的显示功能。还能提供合并输入视图和输出视图的功能。 - 数据Data
为单个对象显示实例和类数据。 - 时间Time
显示一个对已记录对象的解决时间的柱状图。
3.CPU剖析CPU profiler
JProfiler提供不同的方法来记录访问树以优化性能和细节。线程或者线程组以及线程状况可以被所有的视图选择。所有的视图都可以聚集到方法、类、包或J2EE组件等不同层上。CPU视图部分包括:
- 访问树Call tree
显示一个积累的自顶向下的树,树中包含所有在JVM中已记录的访问队列。JDBC,JMS和JNDI服务请求都被注释在请求树中。请求树可以根据Servlet和JSP对URL的不同需要进行拆分。 - 热点Hot spots
显示消耗时间最多的方法的列表。对每个热点都能够显示回溯树。该热点可以按照方法请求,JDBC,JMS和JNDI服务请求以及按照URL请求来进行计算。 - 访问图Call graph
显示一个从已选方法、类、包或J2EE组件开始的访问队列的图。
4.线程剖析Thread profiler
对线程剖析,JProfiler提供以下视图:
- 线程历史Thread history
显示一个与线程活动和线程状态在一起的活动时间表。 - 线程监控Thread monitor
显示一个列表,包括所有的活动线程以及它们目前的活动状况。 - 死锁探测图表Deadlock Detection
显示一个包含了所有在JVM里的死锁图表。 - 目前使用的监测器Current monitor useage
显示目前使用的监测器并且包括它们的关联线程。 - 历史检测记录History usage history
显示重大的等待事件和阻塞事件的历史记录。 - 监测使用状态Monitor usage statistics
显示分组监测,线程和监测类的统计监测数据。
5.VM遥感勘测技术VM telemetry
观察JVM的内部状态,JProfiler提供了不同的遥感勘测视图,如下所示:
- 堆Heap
显示一个堆的使用状况和堆尺寸大小活动时间表。 - 记录的对象Recorded objects
显示一张关于活动对象与数组的图表的活动时间表。 - 垃圾回收Garbage collector
显示一张关于垃圾回收活动的活动时间表。 - 类Classes
显示一个与已装载类的图表的活动时间表。 - 线程Threads
显示一个与动态线程图表的活动时间表。
三、实战
(一)任务目标
找出项目中内存增大的原因
(二)配置说明
操作系统:Windows2003
Web容器:Tomcat5.0.23
JDK版本:sun1.4.2
监控类型:本地
Jprofiler安装路径:D:/jprofiler5
Tomcat安装路径:D:/Tomcat5
(三) 测试项目
1. 新建WEB项目test
2. 建包cn.test
3. 在该包下建类文件TestMain.java和TestBean.java
package cn.test;
public class TestBean {
String name = "";
}
packagecn.test;
importjava.util.ArrayList;
publicclassTestMain {
publicstaticArrayListlist=newArrayList(); //存放对象的容器
public static int counter = 0; //作统计用
}
4.建测试用的JSP文件init1.jsp、init2.jsp
Init1.jsp(每次执行都创建1万个TestBean对象)
<%@pagelanguage="java"import="cn.test.*"pageEncoding="ISO-8859-1"%>
<!DOCTYPEHTMLPUBLIC"-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>init</title>
</head>
<body><%
for(inti=0;i<10000;i++){
TestBean b =newTestBean();
TestMain.list.add(b);
}
%>
SIZE:<%=TestMain.list.size()%><br/>
counter:<%=TestMain.counter++%>
</body>
</html>
Init2.jsp和init1.jsp一模一样即可(后面有用)。
(四) 配置测试用例
1. 点击d:/jprofiler5/bin/jprofiler.exe
2. 执行菜单SessionàIntegration WizardsàNew ServerIntegration


选择是本地测试还是远程测试:

选择tomcat运行的脚本文件:

选择虚拟机的类型:

选择监控端口:
用默认的即可

选择Web容器是否和Jprofiler一起运行:
默认即可
- 所有对象
-
数据库查询优化原则(转)
2011-12-07 10:07:04
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引。
2.应尽量避免在where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在where子句中使用or来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=205.in和not in也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用between就不要用in了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
若要提高效率,可以考虑全文检索。
7.如果在where子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t wherenum=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) wherenum=@num
8.应尽量避免在where子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
select id from t where datediff(day,createdate,'2005-11-30')=0--‘2005-11-30’生成的id应改为:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'10.不要在where子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
13.很多时候用exists代替in是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15.索引并不是越多越好,索引固然可以提高相应的select的效率,但同时也降低了insert及update的效率,因为insert或update时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
16.应尽可能的避免更新clustered索引数据列,因为clustered索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新clustered索引数据列,那么需要考虑是否应将该索引建为clustered索引。
17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18.尽可能的使用varchar/nvarchar代替char/nchar,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要使用select * from t,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21.避免频繁创建和删除临时表,以减少系统表资源的消耗。
22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用select into代替create table,避免造成大量log,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先truncate table,然后drop table,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用FAST_FORWARD游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置SET NOCOUNT ON,在结束时设置SET NOCOUNT OFF。无需在执行存储过程和触发器的每个语句后向客户端发送DONE_IN_PROC消息。
29.尽量避免大事务操作,提高系统并发能力。
30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。 -
转多核平台下的Java优化(2)
2011-11-15 11:44:30
启用 NUMAnuma 是一个 CPU 的特性。SMP 架构下,CPU 的核是对称,但是他们共享一条系统总线。所以 CPU 多了,总线就会成为瓶颈。在 NUMA 架构下,若干 CPU 组成一个组,组之间有点对点的通讯,相互独立。启动它可以提高性能。
NUMA 需要硬件,操作系统,JVM 同时启用,才能启用。Linux 可以用 numactl 来配置 numa,JVM 通过-XX:+UseNUMA 来启用。
激进优化特性
在 Java1.6 中,激进优化(AggressiveOpts)是默认开启的。激进优化是一般有一些下一个版本才会发布的优化选项。但是有可能造成不稳定。前段时间以讹传讹的 JDK7的 Bug,就是开启这个选项后测到的。
逃逸分析
让一个对象在一个方法内创建后,如果他传递出去,就可以称为方法逃逸;如果传递到别的线程,成为线程逃逸。如果能知道一个对象没有逃逸,就可以把它分配在栈而不是堆上,节约 GC 的时间。同时可以将这个对象拆散,直接使用其成员变量,有利于利用高速缓存。如果一个对象没有线程逃逸,就可以取消其中一切同步操作,很大的提高性能。
但是逃逸分析是很有难度的,因为花了 cpu 去对一个对象去分析,要是他不逃逸,就无法优化,之前的分析血本无归。所以不能使用复杂的算法,同时现在的 JVM 也没有实现栈上分配。所以开启之后,性能也可能下降。
可以使用-XX:+DoEscapeAnalysis 来开启逃逸分析。
高吞吐量 GC 配置
对于高吞吐量,在年轻态可以使用 Parallel Scavenge,年老态可以使用 Parallel Old 垃圾收集器。
使用-XX:+UseParallelOldGC 开启
可以将-XX:ParallelGCThreads 根据 CPU 的个数进行调整。可以是 CPU 数的1/2或者5/8
低延迟 GC 配置
对于低延迟的应用,在年轻态可以使用 ParNew,年老态可以使用 CMS 垃圾收集器。
可以使用-XX:+UseConcMarkSweepGC 和-XX:+UseParNewGC 打开。
可以将-XX:ParallelGCThreads 根据 CPU 的个数进行调整。可以是 CPU 数的1/2或者5/8
可以调整-XX:MaxTenuringThreshold (晋升年老代年龄)调高,默认是15.这样可以减少年老代 GC 的压力
可以-XX:TargetSurvivorRatio,调整 Survivor 的占用比率。默认50%.调高可以提供 Survivor 区的利用率
可以调整-XX:SurvivorRatio,调整 Eden 和 Survivor 的比重。默认是8。这个比重越小,Survivor 越大,对象可以在年轻态呆更多时间。
-
转多核平台下的Java优化
2011-11-15 11:42:45
现在多核 CPU 是主流。利用多核技术,可以有效发挥硬件的能力,提升吞吐量,对于 Java 程序,可以实现并发垃圾收集。但是 Java 利用多核技术也带来了一些问题,主要是多线程共享内存引起了。目前内存和 CPU 之间的带宽是一个主要瓶颈,每个核可以独享一部分高速缓存,可以提高性能。JVM 是利用操作系统的”轻量级进程”实现线程,所以线程每操作一次共享内存,都无法在高速缓存中命中,是一次开销较大的系统调用。所以区别于普通的优化,针对多核平台,需要进行一些特殊的优化。代码优化
线程数要大于等于核数
如果使用多线程,只有运行的线程数比核数大,才有可能榨干 CPU 资源,否则会有若干核闲置。要注意的是,如果线程数目太多,就会占用过多内存,导致性能不升反降。JVM 的垃圾回收也是需要线程的,所以这里的线程数包含 JVM 自己的线程
尽量减少共享数据写操作
每个线程有自己的工作内存,在这个区域内,系统可以毫无顾忌的优化,如果去读共享内存区域,性能也不会下降。但是一旦线程想写共享内存(使用 volatile 关键字),就会插入很多内存屏障操作(Memory Barrier 或者 Memory Fence)指令,保证处理器不乱序执行。相比写本地线程自有的变量,性能下降很多。处理方法是尽量减少共享数据,这样也符合”数据耦合”的设计原则。
使用 synchronize 关键字
在 Java1.5 中,synchronize 是性能低效的。因为这是一个重量级操作,需要调用操作接口,导致有可能加锁消耗的系统时间比加锁以外的操作还多。相比之下使用 Java 提供的 Lock 对象,性能更高一些。但是到了 Java1.6,发生了变化。synchronize 在语义上很清晰,可以进行很多优化,有适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在 Java1.6 上 synchronize 的性能并不比 Lock 差。官方也表示,他们也更支持 synchronize,在未来的版本中还有优化余地。
使用乐观策略
传统的同步并发策略是悲观的。表现语义为:多线程操作一个对象的时候,总觉得会有两个线程在同时操作,所以需要锁起来。乐观策略是,假设平时就一个线程访问,当出现了冲突的时候,再重试。这样更高效一些。Java 的 AtomicInteger 就是使用了这个策略。
使用线程本地变量(ThreadLocal)
使用 ThreadLocal 可以生成线程本地对象的副本,不会和其他线程共享。当该线程终止的时候,其本地变量可以全部回收。
类中 Field 的排序
可以将一个类会频繁访问到的几个 field 放在一起,这样他们就有更多的可能性被一起加入高速缓存。同时最好把他们放在头部。基本变量和引用变量不要交错排放。
批量处理数组
现在处理器可以用一条指令来处理一个数组中的多条记录,例如可以同时向一个 byte 数组中读或者写 store 记录。所以要尽量使用 System.arraycopy ()这样的批量接口,而不是自己操作数组。
JVM 优化
启用大内存页
现在一个操作系统默认页是4K。如果你的 heap 是4GB,就意味着要执行1024*1024次分配操作。所以最好能把页调大。这个配额设计操作系统,单改 Jvm 是不行的。Linux 上的配置有点复杂,不详述。
在 Java1.6 中 UseLargePages 是默认开启的,LasrgePageSzieInBytes 被设置成了4M。笔者看到一些情况下配置成了128MB,在官方的性能测试中更是配置到256MB。
启用压缩指针
Java 的64的性能比32慢,原因是因为其指针由32位扩展到64位,虽然寻址空间从4GB 扩大到 256 TB,但导致性能的下降,并占用了更多的内存。所以对指针进行压缩。压缩后的指针最多支持32GB 内存,并且可以获得32位 JVM 的性能。
在 JDK6 update 23 默认开启了,之前的版本可以使用-XX:+UseCompressedOops 来启动配置。
性能可以看这个评测,性能的提升是很可观。
-
转载:配置IIS及进程回收
2011-09-29 16:56:16
如何配置回收
要点只有在工作进程隔离模式下运行时才能使用这个 IIS 6.0 功能。
在工作进程隔离模式中,可以将 IIS 配置为定期重新启动分配给应用程序池的工作进程,从而允许您回收有问题的 Web 应用程序。回收可以使存在问题的应用程序保持顺利运行,尤其是在无法修改应用程序代码时。这确保这些应用程序池保持正常运行,且可以恢复系统资源。
您可以将工作进程配置为基于经过的时间、服务的请求数、计划的时间或内存利用率来重新启动,也可以将它们配置为按需启动。
要点您 必须是本地计算机上 Administrators 组的成员或者必须被委派了相应的权限,才能执行下列步骤。作为安全性的最佳操作,请使用不属于 Administrators 组的帐户登录计算机,然后使用运行方式命令以管理员身份运行 IIS 管理器。在命令提示符下,键入 runas /user:administrative_accountname "mmc %systemroot%\system32\inetsrv\iis.msc"。
配置要在经过一定时间后回收的工作进程
1.在 IIS 管理器中,展开本地计算机,展开“应用程序池”,右键单击该应用程序池,然后单击“属性”。
2.在“回收”选项卡上,选中“回收工作进程(分钟)”复选框。
3.单击向上或向下箭头,设置在经过多少分钟后回收工作进程。
4.单击“确定”。配置要在处理一定数量的请求后回收的工作进程
1.在 IIS 管理器中,展开本地计算机,展开“应用程序池”,右键单击该应用程序池,然后单击“属性”。
2.在“回收”选项卡上,选中“回收工作进程(请求数目)”复选框。
3.单击向上或向下箭头,设置在处理多少请求后回收工作进程。
4.单击“确定”。配置要在计划的时间回收的工作进程
1.在 IIS 管理器中,展开本地计算机,展开“应用程序池”,右键单击该应用程序池,然后单击“属性”。
2.在“回收”选项卡上,选中“在下列时间回收工作进程”复选框。
3.单击“添加”向列表中添加一个时间,单击“删除”从列表中删除一个时间,或者单击“编辑”更改将回收工作进程的现有时间。
4.单击“确定”。注意如果将回收设置为在计划的时间进行,则在系统时间发生变化时,回收可能不按计划进行。为了避免无意更改计划的回收时间,请在系统时间更改之后立即回收计划的工作进程。
配置要在消耗一定内存量之后回收的工作进程
1.在 IIS 管理器中,展开本地计算机,展开“应用程序池”,右键单击该应用程序池,然后单击“属性”。
2.在“回收”选项卡上,在“内存回收”下,选中“最大虚拟内存(兆)”或“最大使用的内存(兆)”复选框。
3.单击向上或向下箭头,设置内存限制。
4.单击“确定”。================================================================================================================================
附上几个不错的IIS配置的链接:
http://www.ip126.com/Article/2009/200907/7338.html
http://www.ithov.com/server/website/web/77393.shtml
http://www.jb51.net/article/27982.htm
-
建高性能网站(转)
2011-07-19 15:38:20
原则1 减少HTTP请求数
构造请求、等待响应需要时间,因此请求数量越少越好。减少请求的总体思路就是合并资源,减少显示一个页面需要的文件数。
1. Image Map
通过设置<img>标签的usemap属性与使用<map>标签可以在一幅图片上切分出多个区域,指向不同的链接。比起使用多幅图片分别构造链接减少了请求数。
2. CSS Sprite(CSS贴图整合/贴图拼合/贴图定位)
通过设置元素的background-position样式做到。一般用于界面图标。典型的可以参考TinyMCE编辑器上方的那些小按钮。多个小图实质是从一个统一的大图通过不同的偏移量裁剪而来,这样加载界面上的众多按钮实际上只要请求一次(请求大图一次),从而减少HTTP请求数。
3. Inline Image(内联图片)
在<img>的src中不指定外部图片文件的URL,而是直接将图片信息放入。例如src="data:image/gif;base64,R0lGODlhDAAMAL..."某些特殊情况下有用(例如一个不大的图片仅在当前页面用到)。
原则2 利用多线路CDN
为你的站点提供多种线路(例如国内电信、联通、移动)、多个地理位置(北方、南方、西部)的访问,使得所有用户都能够快速访问。
原则3 利用HTTP Cache
给不频繁更新的资源(例如静态图)加较长的Expires头信息,这些资源一经缓存,未来很长时间都可以不再重复传输了。
原则4 使用Gzip压缩
使用Gzip压缩HTTP报文,减小体积,减少传输时间。
原则5 将样式表置于页面前部
先加载样式表,这样页面渲染得以较早开始,给用户页面加载较快的感觉。
原则6 将脚本置于页面尾部
原因同5,先处理页面显示,页面渲染较早完成,而脚本逻辑稍后执行,这样给用户页面加载较快的感觉。
原则7 避免使用CSS表达式
过于复杂的JavaScript脚本逻辑、DOM查找、选择操作将会降低页面处理效率。
原则8 将JavaScript与CSS作为外联资源
这似乎与原则1中的合并思想相悖,但其实不然:考虑每个页面都引入了一个公共的JavaScript资源(例如jQuery或是ExtJS这样的JavaScript库),单就一个页面的表现来看,内联(即将JavaScript嵌入HTML)页面将比外联(使用<script>标签引入)页面加载更快(因为其较少的HTTP请求数)。但如果有很多页面都引入了这个公共JavaScript资源,那么内联方案会造成重复传输(因为这个资源内嵌在每个页面中了,所以每次打开一个页面都要将这部分资源传输一遍,从而造成网络传输资源的浪费)。而将这种资源独立出来外联引用可以解决这个问题。
由于JavaScript和CSS相对稳定,我们可以对其对应的资源设置较长的失效期(参考原则3)。
原则9 减少DNS查找
作者给出的建议是:
1. 使用Keep-Alive保持连接
如果连接断开,那么下次连接又要执行DNS查找,即使对应的域名-IP映射已被缓存,查找也是要消耗一些时间的
2. 减少域名
每次请求新域名都需要进行通过DNS查找不同的域名,且DNS缓存无法发挥作用。因此应该尽量将站点组织在一个统一域名下,避免使用过多子域名
原则10 压缩你的JavaScript
使用JS压缩工具压缩你的JavaScript吧,很有效哦。看看jQuery的两个不同的发行版本就知道区别了:
http://code.jquery.com/jquery-1.6.2.js 阅读版jQuery代码,230KB
http://code.jquery.com/jquery-1.6.2.min.js 压缩版jQuery代码(用于实际部署),89.4KB
原则11 尽量避免重定向
一次重定向意味着在你真正访问到想要看到的页面前加入了一轮额外的HTTP请求(客户端发起HTTP请求→HTTP服务器返回重定向响应→客户端对新URL发起请求→HTTP服务器返回内容,下划线部分为额外的请求),因此消耗更多的时间(也就给人反应更慢的感觉)。因此除非必要,不要随意使用重定向。几个“必要”的情况:
1. 避免URL失效
旧站点迁移后,为了避免旧的URL失效,通常将对旧URL的请求重定向至新系统的对应地址。
2. URL美化
在可读性好的URL与实际资源URL之间转换,例如对于Google Toolbar,用户记得住http://toolbar.google.com这个对人类富有语义的地址,却很难记住http://www.google.com/tools/firefox/toolbar/FT3/intl/en/index.html这个真正的资源地址。因此有必要保留前者,并且将对前者的请求重定向至后者。
原则12 移除重复的脚本
不要在一个页面中重复引入相同的脚本。例如脚本B和C都依赖于A,那么在使用了B和C的页面中就有可能存在对A的重复引用。解决方法,对于简单的站点手动检查依赖性,消去重复引入;对于复杂的站点则需要构建自己的依赖管理/版本控制机制。
原则13 小心处理ETag
ETag是除Last-Modified之外的另一种HTTP Cache手段。通过hash的办法辨识资源是否被修改。但ETag存在一些问题,例如:
1. 不一致:不同Web服务器(Apache, IIS等)定义的ETag格式不同
2. ETag的计算是不稳定的(由于考虑过多因素),例如:
1) 相同资源在不同服务器上计算出来的ETag不一样,而大型Web应用通常由不止一台服务器提供服务,这就导致客户端在服务器A缓存好的资源明明仍然有效,而在下次请求B时由于ETag不同而被认定为失效,导致相同资源的重复传输。
2) 资源不变,而由于一些其他因素的变化,例如配置文件更改,导致ETag变化。直接后果是系统更新后客户端大规模发生Cache失效,导致传输量大增,站点性能下降。
作者给出的建议是:要么根据你的应用特点改进已有的ETag计算方法,要么干脆就不用ETag,而改用最简单的Last-Modified。
原则14 在Ajax中利用HTTP Cache
Ajax是异步请求,异步请求不会阻塞你现在的操作,而且当请求完成时,你马上就可以看到结果。但异步不代表能够瞬时完成,也不代表能够容忍它花无限多的时间完成。因此对于Ajax请求的性能也需要重视。有很多Ajax请求访问的是一些相对稳定的资源,因此别忘了对Ajax请求利用好HTTP Cache机制,具体参见原则3、13。
-
新语言的学习
2011-07-19 09:28:44
从客户现场回公司了,有时间学习了下日语,唉,日本人真的不怕麻烦,几个简单的词,要说一大串,呵呵,好拗口呀!
标题搜索
我的存档
数据统计
- 访问量: 16209
- 日志数: 21
- 建立时间: 2008-12-10
- 更新时间: 2017-02-10

{kind=link}