
-
【转贴】WEB自动化测试中针对验证码的解决方案
2007-12-12 15:40:53
作者:guanhe 来源:cnblogs目前,不少网站在用户登录、用户提交信息等登录和输入的页面上使用了验证码技术。验证码技术可以有效防止恶意用户对网站的滥用,使得网站可以有效避免用户信息失窃、广告SPAM等问题。但与此同时,验证码技术的使用却使得WEB自动化测试面临了较大的困难——由于验证码的存在,传统的“录制”-“回放”工具由于不能识别验证码而失效。在各大软件测试的论坛中,经常能看到测试工程师在焦急地发问:“自动化测试时如何处理页面上的验证码?”,可见,该问题确实是一个对相当多的测试工程师造成严重困扰的问题。其实,验证码并不像它表面上看起来那么神秘,也并不像一些测试工程师认为的那样坚不可摧,通过一些技术和非技术性的手段,测试工程师完全可以把这个阻碍测试的绊脚石踢开。
下面,本文就从验证码的实现手段说起,向各位饱受验证码困扰的测试工程师说明,如何通过我们的聪明才智,成功地解决验证码带来的自动化测试方面的问题。
1 验证码及其为自动化测试带来的困扰
验证码一般应用在WEB系统涉及登录和输入的页面上,其实现的一般方法是在页面上显示一幅图片,要求用户肉眼识别图片中的信息并将该信息作为输入的一部分进行提交。页面上显示的这幅图片一般是一串随机产生的数字或符号,并且被添加了用于防止识别的背景。验证码的主要目的是为了防止恶意用户利用自动工具(机器人)对用户口令进行暴力破解、恶意注册用户,或是向网站发布令人厌烦的广告信息等。
验证码具有随机性和不易被自动工具识别的特点,当用户访问某个使用验证码的页面时,每次对该相同页面的访问都会得到一个随机产生的不同的验证码,并且,这些验证码具有能够被人工识别,但很难被自动工具识别的特点,这样,自动工具就很难适应使用验证码的页面,从而达到保护网站不被恶意使用的目的。
当然,不同网站使用的验证码在表现形式上会有所不同。例如,常用的一些论坛程序、小型网站等使用相对较简单的数字验证码;而Hotmail和Gmail等则使用较为复杂的数字、字符等混排的验证码,并通过变形等手段对验证码图片进行处理;还有一些网站使用动物图片作为验证码。
图1给出了几个典型网站的验证码表现。
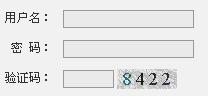

ITPub的验证码 Gmail的验证码 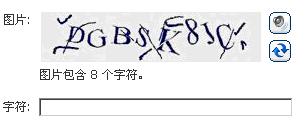
Hotmail的验证码 图1 几个典型网站的验证码
辨证唯物主义告诉我们,任何事务都可以从正反两个方面来看待,验证码也不例外。验证码在保护网站不受到恶意注册和垃圾信息困扰方面发挥了有效的作用,但对于需要使用自动化测试工具进行测试的自动化测试来说,验证码则带来了相当的困扰。因为验证码在本质上是一种为了防止自动工具对网站进行操作的手段,而自动化测试工具也不幸属于自动工具之列,因此,在软件测试的过程中,验证码同样成为了自动化测试的障碍。
自动化测试工具基本的原理是“录制”-“回放”,也就是使用测试工具“录制”用户的操作形成脚本,并在后续测试过程中通过“回放”该脚本来重复用户的操作。设想我们使用自动化测试工具对某个使用了验证码的网站进行测试,由于验证码的存在,录制得到的脚本就不能直接回放成功。
在各大软件测试论坛中,“如何处理WEB验证码”是一个被经常问到的问题,可见,该问题确实是一个对相当多的测试工程师造成严重困扰的问题。解决验证码的问题并不容易,但也并不是不能解决,本文拟从生成验证码的方法、测试的不同类型和阶段提出针对WEB验证码的自动化测试解决方案,分析各种方案的优缺点,并结合具体的测试工具说明各种方法的应用。
验证码的主要实现方法
要解决验证码的问题,我们首先来看看在不同类型的网站上,验证码究竟是如何实现的。
从实现方式上来说,验证码分为“读取式”和“生成式”两种。
“读取式”是指从服务器上指定的目录下随机读取预先制作好的图片文件,将图片文件显示在页面上要求用户识别。粗看起来,这种方式的安全性应该比较好,因为网站制作者可以通过精心制作非常难于自动识别的图片,将自动工具自动识别的风险降到最低,但实际上,这种方式存在一个致命的缺点:容易在页面文件中泄漏图片文件的URL,而恶意用户正好可以利用这一点,通过反复尝试访问使用验证码的页面,获得大部分预先制作好的图片文件URL和需要输入的验证码之间的关系,然后通过该对应关系跳过验证码的验证,使验证码失效。
另外,由于该方法需要预先制作大量的图片文件,前期的工作量比较大,因此,目前已经很少有网站完全采用该方式实现验证码技术。
“生成式”则是指在程序中通过代码的方式,随机生成一个串,并将该串用图形的方式显示在页面上要求用户识别。这种方式由于实现较为方便,因此目前主要的网站均采用该方法实现验证码。当然,“生成式”也有一定的缺点,例如,由于“生成式”一般利用某种网站开发语言提供的图形函数生成图形,每个字符生成的位图是完全相同的,恶意用户可以利用这一点,使用OCR的方式将位图“翻译”成对应的字符串内容。因此,“生成式”一般还会在生成的图片上叠加背景噪音,增加识别的难度。Hotmail和Gmail等网站更是利用变形、改变颜色等方法让验证码的自动识别变得几乎不可能。
总体来说,“生成式”是依靠程序中的代码在运行时动态生成起到验证作用的图片的,但从其具体实现上来看,这种实现方式依赖于具体的编程语言,以及生成图片的格式。
1.1 Xbm图片格式及其动态生成
x-xbitmap格式的图片(以下简称为Xbm格式)由于其特殊性,是一种广泛被用于验证码的图片格式。该图片格式之所以特殊,在于它并不跟gif,jpg等图片格式一样,是一个二进制图片格式,而是采用ASCII码来表示图形——换句话说,它是一个纯文本文件,必须由操作系统对其进行解释才能显示出相应的图片。
以下是一个xbm文件的内容:
#define counter_width 32
#define counter_height 10
static unsigned char counter_bits[] = { 0x
初看起来,这个文件和图形并没有什么关联,但如果我们新建一个文件,将以上内容复制到文件内并将其保存为test.xbm,然后打开IE窗口,并将该文件直接拖拽到它上面后,我们会惊奇地发现,仿佛变魔术一样,显示出来的并不是这个文件的内容,而是一副图片(见图2)。
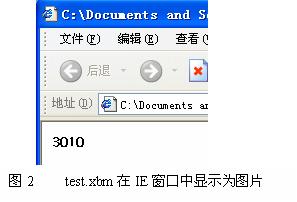
熟悉C语言的读者肯定一眼就能看出,上面给出的xbm文件的内容完全就是C代码中的一个数组定义。没错,xbm文件就是采用了一个数组来表示一幅图片的。
在上面的文件内容中,#define counter_width 32 定义的是图片的以象素表示的宽度,一般来说,8个象素的宽度可以用来表示一个字符,因此这里的32可以用来表示本图片显示4个字符。
#define counter_height 10定义了图片的高度,表示该图片中每个字符的高度为10象素。而接下来的数组表示的就是图片显示内容的16进制代码了。
一个16进制的字节可以表示为8位二进制数据,xbm文件用二进制的1表示一个黑色的象素,用二进制的0表示一个白色的象素,因此,一个字节可以表示8个象素。以上面的xbm文件为例,一个32×10象素的图片就需要40个字节来表示。xbm文件是按行描述的,对上面的例子来说,每4个字节表示了一行。
因此,如果我们把上述的数组按照4个字节分组进行排列,就会发现字符和数字之间的对应关系。从图3可以看到,由于一个字节能够表示8个象素,而一个图片上的字符宽度也正好是8个象素,因此,对本例来说,按照4个一组的方式排列,很容易得到数组和图片上显示字符的对应关系。

xbm文件可以表示任意的黑白两色图形,而且非常易于生成,因此不少的asp论坛/聊天室的登陆验证码都是采用这样的方法在asp中动态生成的。不过由于攻击者可以利用这种图形格式的处理过程中的漏洞,制造一个超大的图片而导致系统资源耗尽的情况,在Windows XP的SP2以后,就取消了对该图片格式的默认支持,用户必须通过修改注册表才能获得对该图片格式的支持。
1.2 其他图片格式的验证码图形的动态生成
xbm图片文件格式简单,易于生成,但也存在明显的不足——因为图片只能为黑白两色,因此较为容易被自动工具识别。有鉴于此,目前大部分JSP、PHP和ASP.NET网站都利用这些语言本身提供的图形函数在运行时生成图形。
典型的生成图形的过程包括以下几个步骤:
- 生成图形对象;
- 用背景色填充图形对象;
- 随机生成字符串,随机选择前景颜色,利用程序语言的图形库函数以图形方式向图形对象中写入该字符串;
- 向图形对象中增加随机产生的点或者线;
- 输出图片文件头,输出图片文件内容。
下面是一段使用PHP编写可以用来产生验证码的代码:
 //生成验证码图片 Header("Content-type: image/PNG"); session_start(); $auth_num=""; session_register('auth_num'); srand((double)microtime()*1000000); $auth_num_k = md5(rand(0,9999)); $auth_num = substr($auth_num_k,17,5); $im = imagecreate(58,28); $black = ImageColorAllocate($im, 0,0,0); $white = ImageColorAllocate($im, 255,255,255); $gray = ImageColorAllocate($im, 200,200,200); imagefill($im,68,30,$gray); //将四位整数验证码绘入图片 imagestring($im, 5, 10, 8, $auth_num, $black); for($i=0;$i<50;$i++) //加入干扰象素 { imagesetpixel($im, rand()%70 , rand()%30 , $black); } ImagePNG($im); ImageDestroy($im);
//生成验证码图片 Header("Content-type: image/PNG"); session_start(); $auth_num=""; session_register('auth_num'); srand((double)microtime()*1000000); $auth_num_k = md5(rand(0,9999)); $auth_num = substr($auth_num_k,17,5); $im = imagecreate(58,28); $black = ImageColorAllocate($im, 0,0,0); $white = ImageColorAllocate($im, 255,255,255); $gray = ImageColorAllocate($im, 200,200,200); imagefill($im,68,30,$gray); //将四位整数验证码绘入图片 imagestring($im, 5, 10, 8, $auth_num, $black); for($i=0;$i<50;$i++) //加入干扰象素 { imagesetpixel($im, rand()%70 , rand()%30 , $black); } ImagePNG($im); ImageDestroy($im); 当然,在具体采用该方法生成验证码时,还可以在代码中通过图形变形等手段让图形变得更难以被自动工具识别。
另外,注意在上面的代码中,我们将随机生成的用于生成验证码图片的实际数据保存到了Session中,这一步对于验证码的实现非常关键,网上广泛流传的一篇用PHP实现验证码的文章将验证码对应的实际数据存放在页面的hidden Field中,从安全性的角度来说,这种方式将导致验证码对应的实际数据在客户端可见,只需要通过简单的页面分析即可获得,这就完全失去了验证码抵抗恶意攻击的作用。
1.3 验证码是否正确的验证过程
产生验证码图片只是验证码技术实现的一个步骤,验证码图片在页面上正确显示后,用户需要识别验证码并提交了相应的内容,验证码技术应该能够判断用户的输入与验证码对应的实际数据是否一致。
在具体的实现中,一般是将验证码对应的实际数据存放在服务端的Session中,在验证用户输入的代码中通过比较用户的输入和验证码对应的实际数据是否一致来判断用户输入的验证码是否正确。
仍然以用PHP实现验证码为例,验证用户输入是否正确的代码如下:
session_start(); $num=trim($num); if($auth_num==$num && $num<>""){ echo "验证成功"; }else{ echo "验证失败"; }<!--[if !supportLists]-->4 自动测试中
图4 验证码实现的大致原理图
从图4中可以看到,从技术的角度来看,至少设计两种不同的方法来实现自动测试工具对验证码的处理:
<!--[if !supportLists]-->1、 <!--[endif]-->完全从客户端角度考虑,靠模式识别的方法识别出验证码图片对应的字符串;
<!--[if !supportLists]-->2、 <!--[endif]-->从服务端角度考虑,如果自动测试工具可以获取Session中存储的随机数,也就能正确处理验证码了。
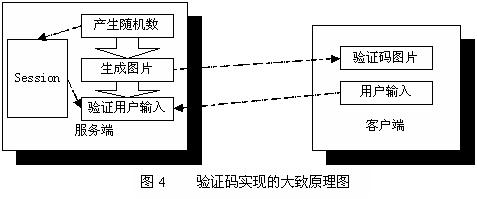
这两种方法是解决自动化测试中验证码问题的主要方法,我们分别称其为识别法和服务端插入法。这两种方法在实现方法上侧重点不同,适用的场合也不同。
识别法完全不用考虑服务端应用的实现,通过各种技术方法对显示的验证码图片进行“破译”,这样,即使完全不能接触到服务端代码,也能让自动化测试在有验证码的情况下进行下去;但这种方法当然也有其致命的缺点:只能对简单的验证码进行识别,对复杂的验证码,根本就无法识别。
而服务端插入法则从服务端入手,通过提供一个额外的客户端接口,向客户端只需要知道该接口的调用方法,就能通过该接口来获取该页面的验证码图片对应的实际数据,并使用该数据继续测试。
另一方面,除了技术角度解决问题的方法以外,还可以通过一些非技术的方法来解决验证码问题。
<!--[if !supportLists]-->4.1 <!--[endif]-->识别法的实现
识别法适用于不能获得和改变服务器端代码的情况下,在这种情况下,由于服务端代码本身不可获得,或是不能对其进行修改,测试者只能完全从客户端的角度想办法解决验证码的问题。
识别法的核心是对验证码图片的模式识别算法,该算法的可实现性基本取决于图片本身的复杂程度。以本文前面列举的验证码示例来说,类似Gmail和Hotmail的验证码基本上是无法通过程序来识别的。而最简单的验证码实现,例如ASP下用xbm技术生成的图片,就可以很容易地通过算法来识别;在PHP、dotNET等平台上完全使用图形库函数生成的图片,同样可以通过对某个区域内的图片分析,识别出图片对应的实际数字或是字母。
下面以处理xbm格式的验证码为例,介绍对其进行识别的算法。
本文的2.1节对xbm文件格式进行了深入的探讨,用xbm实现验证码的方法在ASP和dotNET平台上非常常见,由于xbm文件格式的规则性,因此很容易通过程序对其进行识别。一般的识别过程如下:
- <!--[if !supportLists]-->多次访问带有验证码的页面,分析每次获得的xbm文件和显示的图片之间的对应关系,获得验证码中所有符号对应的十六进制串;
- <!--[if !supportLists]-->编写识别验证码的代码,识别代码根据获得的xbm文件,将其按照编码方式分组,然后与上一步骤中获得的对应的十六进制串进行比较,这样就可以识别出该xbm文件对应的验证码的实际数据。
下面这段代码是用于将xbm图片文件识别为相应的验证码内容的C语言代码:
int getDigital(char dig[10])
{
const char orgdig[10][10] = {
{0x3c,0x66,0xc3,0xc3,0xc3,0xc3,0xc3,0xc3,0x66,0x7e}, //0
{0x18,0x1c,0x18,0x18,0x18,0x18,0x18,0x18,0x18,0x00}, //1
{0x3c,0x66,0x60,0x60,0x30,0x18,0x0c,0x06,0x06,0x7e}, //2
{0x3c,0x66,0xc0,0x60,0x1c,0x60,0xc0,0xc0,0x66,0x38}, //3
{0x38,0x3c,0x36,0x33,0x33,0x33,0xff,0x30,0x30,0xfe}, //4
{0xfe,0xfe,0x06,0x06,0x3e,0x60,0xc0,0xc3,0x66,0x3c}, //5
{0x60,0x30,0x18,0x0c,0x3e,0x63,0xc3,0xc3,0x66,0x3c}, //6
{0xff,0xc0,0x60,0x30,0x18,0x18,0x18,0x18,0x18,0x18}, //7
{0x3c,0x66,0xc3,0x66,0x3c,0x66,0xc3,0xc3,0x66,0x3c}, //8
{0x3c,0x66,0xc3,0xc3,0x66,0x3c,0x18,0x0c,0x06,0x03} //9
};
int i=0, j=0;
int ret = 1;
for(i=0; i<10; i++)
{
ret = 1;
for(j=0; j<10; j++)
{
if(orgdig[i][j]!= dig[j])
{
ret = 0;
break;
}
}
if(ret)
return i;
}
return -1;
}
主函数:
char picc[500], t[40], od[10];
char separators[] = ",";
char *token, *endstr;
int i=0, j=0;
//获取需要识别的图片中的数据描述部分,内容为
//0x3c, 0x3c, 0x18, 0x3c, 0x66 …
//将其存放在字符串picc中
…………
//分解获得的串
token = (char *)strtok(picc, separators); /* Get the first token */
if(!token)
{
return( -1 );
}
while( token != NULL )
{
if(!strcmp(token , "")) //处理为“空”的内容,将其替换成0x00
t[i] = 0x00;
else
t[i] = strtol(token, &endstr, 16);
i++;
token = (char *)strtok(NULL, separators);
}
for(i=0; i<4; i++) //一共4个数字,分别调用getDigital函数进行处理
{
for(j=0; j<10; j++)
{
od[j] = t[j*4+i];
}
lr_output_message("%d", getDigital(od));
}其他通过服务器代码绘图方式实现的识别码识别相对麻烦一些,但原理上都差不多,无非是将获取到的图片进行分析,通过识别方法判断其对应的符号。
<!--[if !supportLists]-->1.2 <!--[endif]-->服务端插入法
如果可以控制和修改服务端代码,就可以使用服务端插入法。该方法在服务端提供一个可被客户端使用的接口,只要客户端传递过来自己的SessionID,该接口就返回此时正确的Session,这种方法就可以很容易地让自动测试工具直接获取到正确的应该提交的验证码内容。从测试的角度来说,这种方法就等于是在系统上增加了一个测试接口,从而提高了系统的可测试性。
服务端插入法的实现并不复杂,在任何一个平台上都能很容易实现,在此就不再赘述了。服务端插入法可以针对任何类型的应用使用,但这种方法也有明显的不足:
<!--[if !supportLists]-->1、 <!--[endif]-->如果是已经上线的应用,网站不太可能会允许保留一个这样的接口,因此,该方法一般用于还未上线的WEB系统,如果要在已上线的WEB系统上使用该方法,则必须通过管理上的方法提高该方面的安全性;
<!--[if !supportLists]-->2、 <!--[endif]-->采用这种方法,在性能测试时,由于该方法需要额外请求一次才能获得实际的验证码,相对于实际的用户操作来说,访问带有验证码页面的请求会多一次,因此在获得的测试结果上会有些许的差异。
<!--[if !supportLists]-->1.3 <!--[endif]-->解决自动测试中验证码问题的非技术方法
其实,测试并不只是单单的技术问题,除了上面给出的识别法和服务端插入法,其实,通过非技术的方式也能让自动化测试在具有验证码的系统上成功应用。当然,这些非技术方法应用的前提是,测试团队必须具有足够的能力和机会影响系统的实现。如果完全没有方法接触到服务端代码或是完全不能修改服务端代码,以下的方法就都不能应用了。
下面,让我们跳出技术的范围,换个角度来看看如何解决验证码的问题:
<!--[if !supportLists]-->1、 <!--[endif]-->屏蔽法
屏蔽法是最容易想到的一种方法,方法的核心就是:在被测系统中暂时屏蔽验证功能。这种方法最容易实现,对测试结果也不会有太大的影响(当然,这种方式去掉了“验证验证码”这个环节,如果该环节本身存在功能上的问题,或是本身就是性能的瓶颈,那就一定会对测试结果造成影响了)。但这种方法也有一个问题:如果被测系统是一个实际已上线的系统,屏蔽验证功能会对已经在运行的业务造成非常大的安全性的风险,因此,对于已上线的系统来说,用这种方式就不合适了。
<!--[if !supportLists]-->2、 <!--[endif]-->后门法
后门法不屏蔽验证码,但在其中留一个后门,在代码中设定一个所谓的“万能验证码”,只要用户输入这个“万能验证码”,就能通过验证,否则,还是按照正常的验证方式进行验证。这种方式仍然存在安全性的问题,但由于我们可以通过管理手段将“万能验证码”控制在一个小的范围内,而且只在测试期间保留这个小小的后门,相对第一种方法来说,在安全性方面有了较大的提高。
<!--[if !supportLists]-->1.4 <!--[endif]-->各种方法的比较
本文提供了多种用于解决具有验证码的WEB系统在自动测试时遇到问题的方法,这些方法既包含技术性的方法,也包含非技术性的方法。但由于每种方法的出发点不同,因此这些方法也就具有各自不同的优缺点和适用场合。本节我们对本文提到的各种方法进行比较,分别给出其优缺点和适用的场合。
技术性方法
非技术性方法
识别法
服务端插入法
屏蔽法
后门法
优点 不需要修改代码,也不需要在代码中增加额外的接口和后门,在服务端代码不可接触到的情况下,是唯一的选择
理论上来说可以解决任何验证码的问题,而且不需要修改已有的服务端代码
简单修改现有代码就能让自动测试顺利进行,开销小
实现方式不复杂,对现有代码改动小,安全性相对有保证
缺点 存在技术限制,只能对相对简单的验证码图片进行分析识别,对复杂的图片无法进行识别
存在一定的安全隐患,如果被攻击者获知测试接口,验证码就会失去作用
存在很大的安全问题,对于未上线应用还可应用,对于已上线的实际应用,该方法不可行;况且,由于该方法需要对代码修改的内容太多,导致发布时可能发生某些验证码被不正确屏蔽的情况
如果被攻击者探测得到万能验证码,则验证码会失去作用
适用场合 <!--[if !supportLists]-->1、 <!--[endif]-->服务端代码不可接触到或是不可进行任何修改
<!--[if !supportLists]-->2、 <!--[endif]-->验证码采用xbm等较简单的方式实现
未上线系统,或是在测试条件下安全性要求不是特别高的系统;
开发阶段,未实际上线的系统
可在实际应用系统上应用
应用建议 纯粹的客户端识别解决方案成本较高,建议主要采用服务端方式实现
在管理上需要增加对测试接口的管理,系统在发布时需要保证去掉测试接口
在发布管理时,一定要有合理的方案保证发布时所有被屏蔽的验证码能够得到恢复
为了保证上线系统的安全,该方法一般需要结合密码管理方法使用,通过定期更换万能验证码、控制其知晓范围等手段保证安全
<!--[if !supportLists]-->2 <!--[endif]-->小结
针对WEB系统的验证码对自动化测试带来的挑战,本文详细分析了WEB验证码常见的实现方法,并根据分析提出了几种不同的解决方案:识别法、服务端插入法、屏蔽法和后门法。这几种方法各有其优缺点和适用场合,因此本文也给出了这几种方法之间的对比,并给出了各种方法的应用建议。
当然,本文的重点是介绍解决WEB系统的验证码对自动化测试带来问题的方法,在实际的自动化测试过程中,除了需要了解本文所介绍的方法外,还需要了解相应的自动化测试工具的具体应用方法,虽然不同的测试工具在提供的功能上大同小异,但在具体的使用层面上,不同的工具还是有较大差异性的,请读者自行查阅相应的测试工具文档,从工具的文档中获取相应信息。
-
自动化测试最优体会—来自微软
2007-09-30 10:34:41
1。在做任何事情之前先编写详细的测试计划-自动战略会非常清楚,并获得管理人员和同仁的支持;
2。将测试事例管理架构放到一起,这样每个测试人员都按相同的标准编写,所有测试也都易于维护和理解;
3。减少维护-编写公共的功能和模块,这样可在任何地方重复使用它们;
4。编写有意义的测试日志,并对所有通过和失败的结果产生总结报告,记录任何事情;
5。实现测试运行的无人看管,并具有从失败中恢复的能力;
6。使测试能够跨多种语言,平台和配置;
7。在测试中引入随机性;
8。启动小的每天运行的测试,例如构造验证测试,指望成功;
9。通过发现错误的数量和比率度量自动化的有效性;
10。在冲击测试中实现自动化-在产品中连续运行测试直至系统失败;--------
以上是我在一本叫做“软件测试自动化测试技术与实例详解”书上摘录下来的精华,电子工业出版社的。这些点,我在实际操作中都有体会。不过,我都不记得这本书是谁借给我的了,赫赫。

-
自动测试技术小记----QTP描述性对象识别
2007-08-15 16:28:49
今天发现在某种情况下,不得不用描述性方式来定义对象。
情况是这样的:比如我要新增一个记录,记录信息包含A/B两个信息项,其中A是具有唯一性的。所以测试脚本除了Check正常情况还要check重复性(违反唯一性的)情况。我把两个Check合并在一个Action里面了,我是对象驱动的方式,先抓对象存储到对象库再编脚本的。check是check记录提交出去后系统反馈的提示信息,所以我要先抓取提示信息框对象,因为正反两种情况提示信息是不一样的,我抓取的时候发现两个提示信息框不能生成两个不同的对象,在抓第二个时候的QTP不会生成一个新的对象,而是依附在第一个对象上,且同时第一个对象的某些关键属性会由原先的一个常量值变成[complex value]。
所以以后如果再遇到此种情况就不得不用描述性来定义对象了哦。
标题搜索
我的存档
数据统计
- 访问量: 33863
- 日志数: 40
- 建立时间: 2007-02-01
- 更新时间: 2010-07-29
