

大语言模型在端侧的规模化应用对计算性能、能效比需求的“提拽式”牵引,在算法与芯片之间,撕开了一道充分的推理竞争场。
面对想象中的终端场景,基于 GPU 和 FPGA 的推理方案的应用潜力需要被重新审视。
近日,无问芯穹、清华大学和上海交通大学联合提出了一种面向 FPGA 的大模型轻量化部署流程,首次在单块 Xilinx U280 FPGA 上实现了 LLaMA2-7B 的高效推理。
相关工作现已被可重构计算领域顶级会议 FPGA’24 接收。

随着 FPGA 在高性能计算领域的应用潜力被不断挖掘,震动从学术界传导到产业界,引发了一轮半导体领域的 FPGA 公司收购热。
在几乎所有可能对未来世界产生重大影响的产、研趋势中,高性能计算都处于关键位置。虽然设备的核心计算部件仍是 CPU 和 GPU ,但在一个人工智能算法不断进步、新标准不断涌现的时代里,加速这些日新月异的算法推理工作至关重要。
在软硬件协同优化趋势下,FPGA 在灵活构建高效的大模型推理系统中将发挥越来越重要的作用。它被认为是通往 5G 通信、数据中心、无人驾驶等诸多千亿美元级别市场的钥匙。
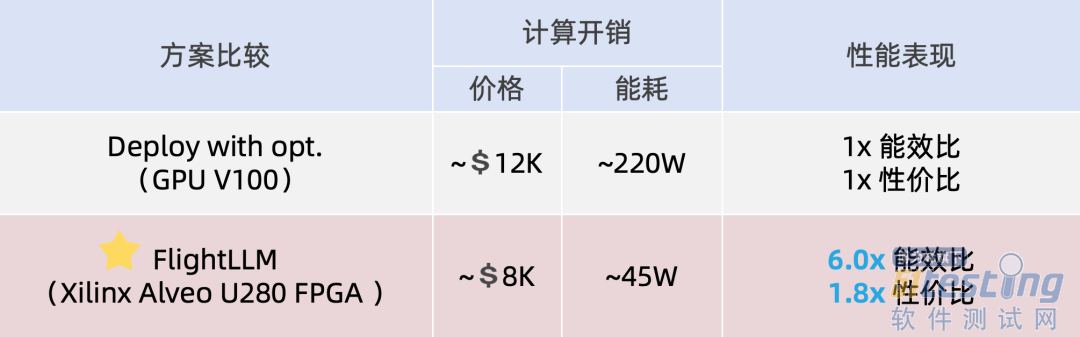
被 FPGA’24 接收的新成果名为 FlightLLM。在单 batch 场景下相比在同等工艺 V100S GPU 上使用 vLLM 推理框架和 SmoothQuant 量化库,FlightLLM 可实现 6.0 倍的能效比提升和 1.8 倍的性价比提升。
放眼未来 1 至 2 年,大模型可能将在代码补全、实时聊天机器人、售后支持等延时敏感应用场景中落地。在这些场景中,延时低、功耗小对于用户的交互体验至关重要。
然而,目前大模型的计算量和存储量相比传统神经网络呈现数量级增加,这导致其推理速度和能效很难满足这些需要快速反馈、能耗敏感场景的需求。
为解决上述问题,行业内通常采用如稀疏化、量化的方法来压缩大模型。但是 GPU 硬件平台仅能支持部分粗粒度的模型压缩方法,对于定制化的模型压缩方法的计算效率很低。
作者认为,FPGA 具有低成本、可配置、低功耗的特性,可成为加速大模型推理的潜在解决方案。但要想用好,仍需要解决以下挑战:
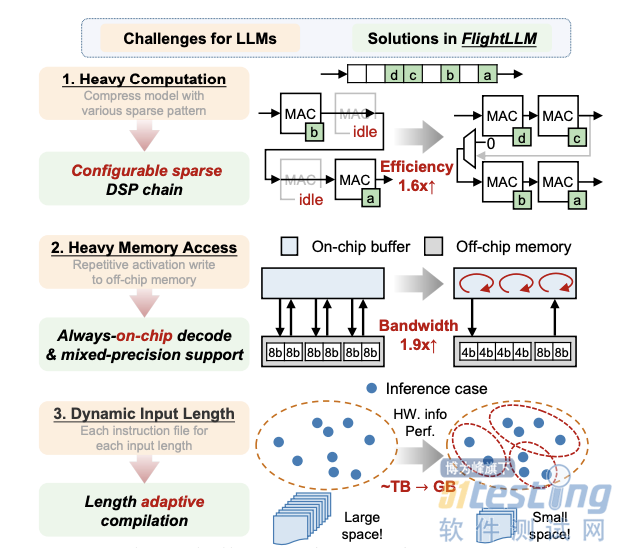
·计算效率低下:大模型中灵活的稀疏模式(例如块稀疏、N:M 稀疏等)导致计算效率低下。
· 内存带宽利用率低:大模型的 decode 阶段反复从片外存储器中读写细粒度的数据,导致较低的带宽利用率(29%-43%)。
· 编译开销大:大模型的动态稀疏模式和可变输入长度构成了一个庞大的指令空间。例如,为 2048 种输入 token 长度生成指令将导致在 FPGA 上约 TB 量级的存储开销。
FlightLLM 的核心思想是利用 FPGA 上特定的资源(如 DSP48 和异构存储层次结构)来解决大模型的计算和存储开销问题。

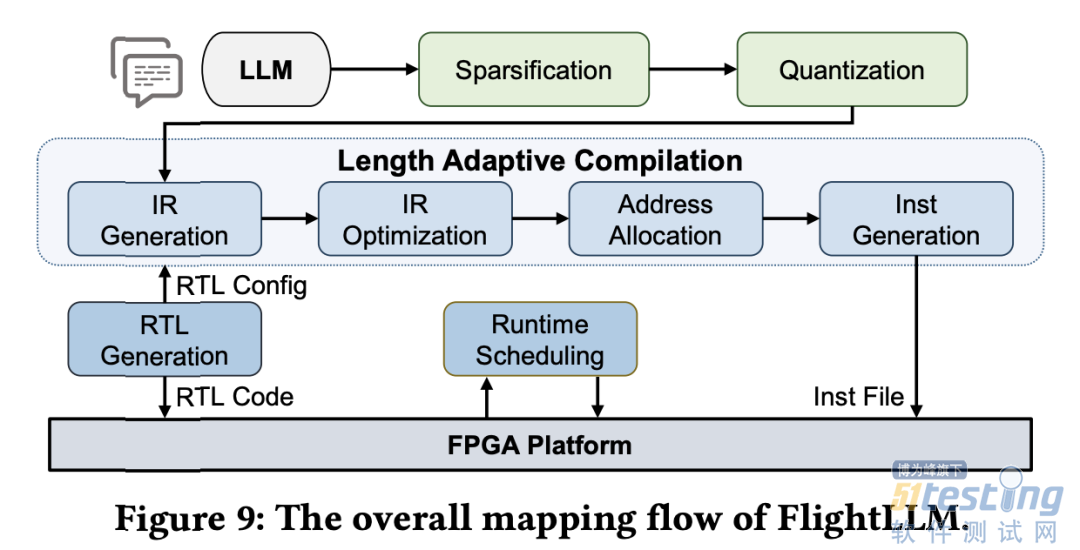
FlightLLM的整体架构
尽管在理论上,稀疏可以为大模型推理带来性能提升,但它们不能直接在现有硬件架构上实现。在基于 Transformer 的大模型中,大多采用稀疏注意力和剪枝等稀疏化方法来加速推理。
然而,稀疏化所生成的稀疏矩阵,其密度和稀疏模式并不确定。这给硬件设计带来了很大的挑战,特别是对于 FPGA 这种基于固定 DSP48 乘法单元的架构。此前的工作引入了大量额外的硬件架构来支持稀疏计算,但这会导致硬件资源显著增加。根据估算,需要多消耗近 5 倍的硬件资源。
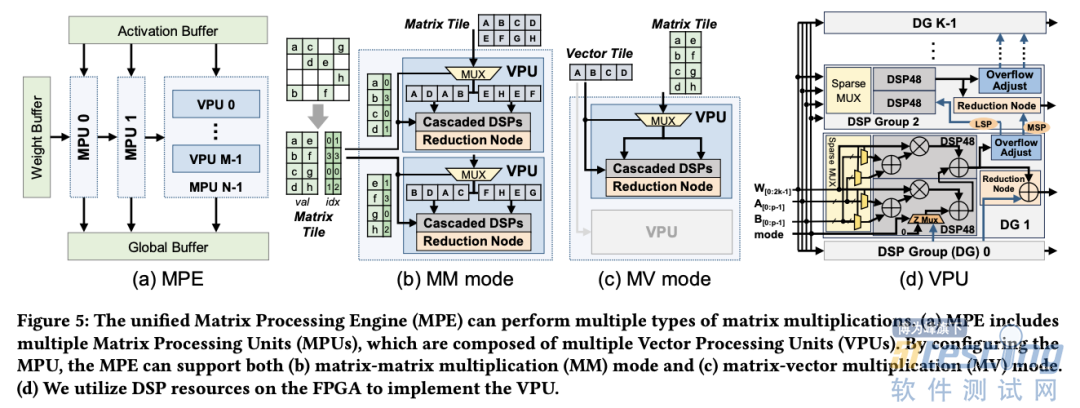
(a) 统一矩阵处理引擎(Matrix Processing Engine, MPE),可灵活支持(b)矩阵-矩阵乘(Matrix-Matrix multiplication, MMMult)和(c)矩阵-向量乘(Matrix-Vector multiplication, MVMult)计算模式。(d)每个MPE由多个基于稀疏DSP48链的向量处理引擎(Vector Processing Engine, VPE)组成。
为此,FlightLLM 采用了软硬件协同设计来克服低计算效率的挑战。研究者设计了统一的矩阵处理引擎(MPE),以处理与矩阵计算相关的所有操作(见上图)。
此前的工作均通过级联 DSP 来充分利用 DSP48 的硬件资源来减少硬件开销。然而,由于级联链的路径是固定的,因此完全级联的 DSP 架构对稀疏计算不友好。
FlightLLM 在这一问题上提出了针对性的解决方案。FlightLLM 利用 FPGA 上的 DSP48 计算单元,设计了一个可配置的稀疏 DSP 链。稀疏 DSP 链支持多种的稀疏模式,其计算效率(即运行时 DSP 利用率)提升了 1.6 倍。
此外,在解码阶段,作者发现大模型推理的主要效率限制来自于频繁访问片外存储器的小数据量激活向量。
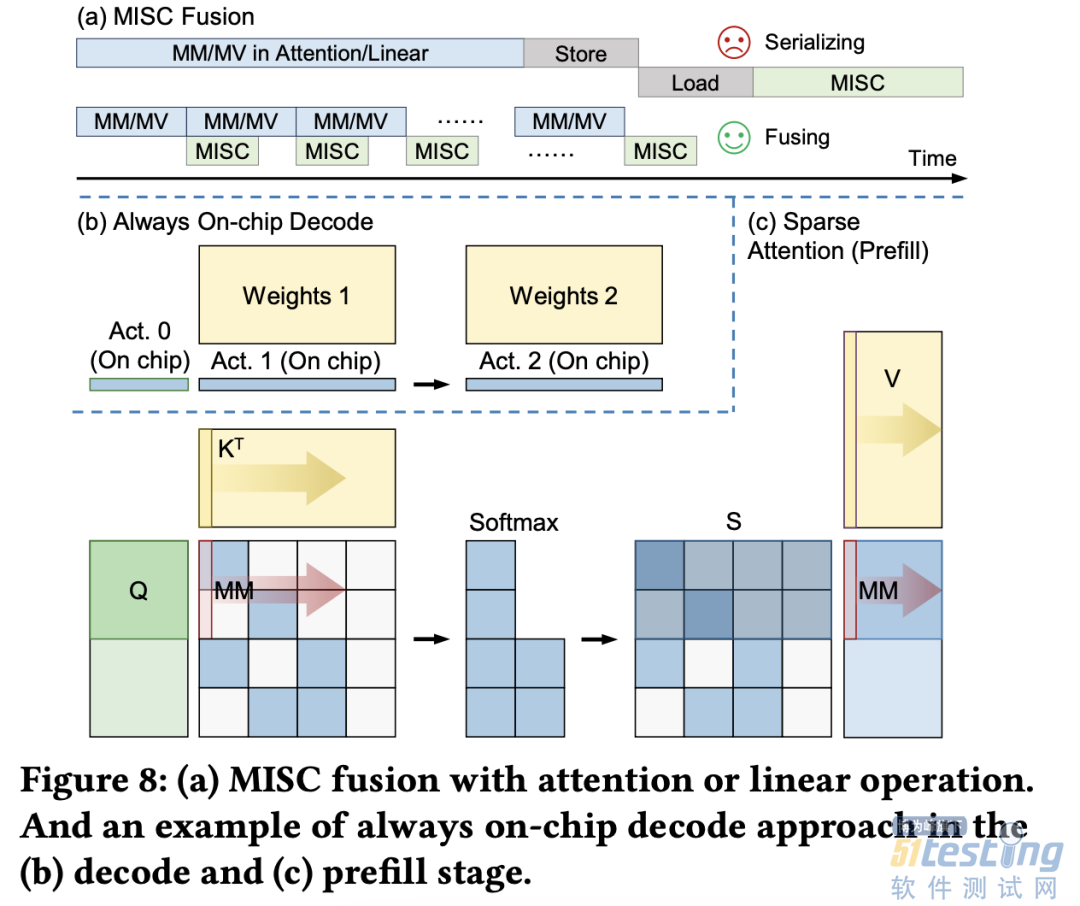
(a)大模型推理阶段的注意力层/线性层与非线性激活操作(MISC)的算子融合实现;全片上解码在(b)预取(Prefill)阶段和(c)解码(Decode)阶段的示意图:利用算子融合和FPGA的高片上存储,使得大模型推理解码阶段的激活值无须写到片外。
为了减少激活向量的片外存储器访问,解决访存带宽利用率低的挑战,FlightLLM 使用了算子融合技术,将解码阶段每次推断中的计算进行融合,提出了 always-on-chip decode 的数据流。通过混合精度量化和算子融合的设计,将 decode 阶段的激活值最大程度在片上缓存中复用。
最后,由于大模型每次推理过程 token 长度都会增加,因此需要不同的指令。而大模型有大量计算和存储需求,即使使用粗粒度指令,指令数量仍然非常庞大。
通过在不同输入 token 长度下推理性能的测量,作者观察到 prefill 和 decode 的延时和输入 token 长度之间的关系存在着 「阶梯」增长的特征,并且 prefill 阶段延时随输入 token 长度增加得更快。
这是因为 prefill 阶段是计算瓶颈,计算量随 token 长度显著增加;而 decode 阶段是访存瓶颈,因此延时增加不明显。阶梯状增长的原因则主要是粗粒度指令集。由于矩阵 - 矩阵乘指令的输出并行度是 128,矩阵 - 向量乘的输出并行度是 16,因此 prefill 和 decode 的 「阶梯」 的宽度分别为 128 和 16。
基于这些发现,FlightLLM 提出了一种 token 长度自适应的编译方法,通过复用 prefill 阶段和 decode 阶段的指令来减少编译指令的存储开销,进而对每个 「阶梯」输入 token 长度的指令分组,以 「阶梯」 宽度复用指令序列。这种设计显著减少了指令的总存储开销。
目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上实现了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的实验结果表明,FlightLLM 的端到端延迟优于 NVIDIA V100S GPU。
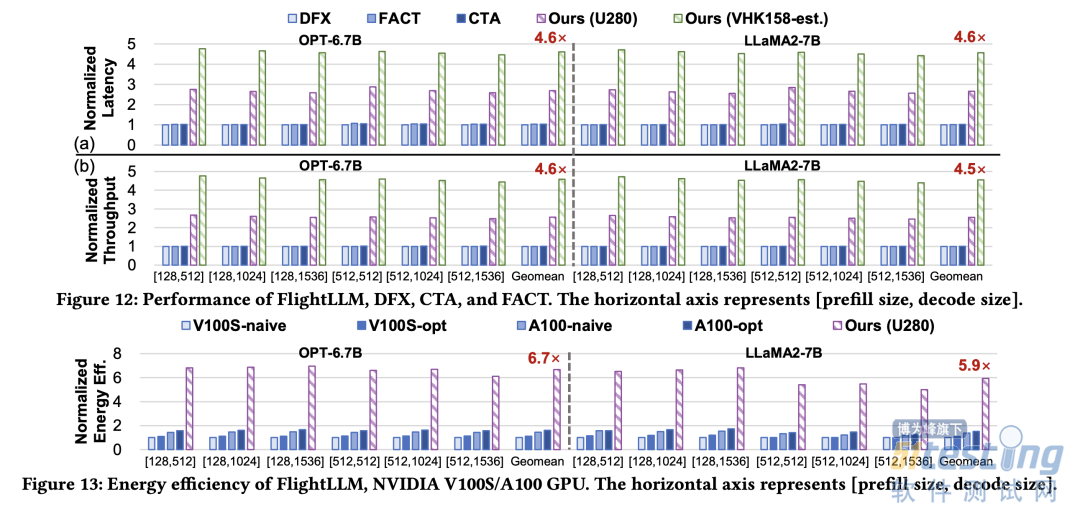
此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超过了 NVIDIA V100S 和 A100 GPU,分别提高了 6.0× 和 4.2×,在性价比上提高了 1.8× 和 1.5×。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












