

2.1.4 XPath与CSS选择器的对比
XPath与CSS选择器孰优孰劣一直是Selenium社区中讨论较激烈的话题之一,CSS选择器的热衷者们认为其可读性高、速度快;而XPath的热衷者们则认为,它可以随意穿越整个页面上的任意元素(即穿越识别模式),而CSS选择器却做不到。
此处有必要解释一下什么是“穿越识别模式”,通常在编写XPath或者CSS选择器的定位器时会使用两种策略:第一种策略是直接通过类似id或者name的控件属性进行唯一识别,如input[name=UserName];第二种策略就是用“穿越识别模式”,通俗地讲就是从父对象到子对象一层一层识别,如//div/div[1]/input。
虽然不推荐使用这类方式来进行对象识别,但是有些时候不得不使用,例如,采用相对定位法处理没有id和name的对象的例子就是特例。
接下来通过对比,巩固上面所学的知识。
实验一:基本网页且嵌套层数不多
每年Selenium大会的组织者及Selenium项目组成员之一的Dave Haeffner会在他的技术博客上详细比较CSS选择器与XPath在不同浏览器上的表现。在其中一篇文章中,他尝试比较了CSS选择器与XPath在不同浏览器上的运行时间,在测试过程中运行两套脚本:第一套脚本只是简单地通过id和class查找元素;第二套脚本采用自顶向下穿越嵌套元素的方式查找元素。通俗一点讲,第一套脚本是直接通过id与class属性查找元素的,第二套脚本是一层一层地往下查找元素的;其中每一套脚本都会尝试利用 CSS 选择器与XPath这两种不同的识别方式进行对比。下面是最终的脚本执行结果。
通过id与class查找元素的脚本执行结果如下。
Browser | CSS | XPath Internet Explorer 8 | 23 seconds | 22 seconds Chrome 31 | 17 seconds | 16 seconds Firefox 26 | 22 seconds | 22 seconds Opera 12 | 17 seconds | 20 seconds Safari 5 | 18 seconds | 18 seconds |
通过穿越元素的方式查找元素的脚本执行结果如下。
Browser | CSS | XPath Internet Explorer 8 | not supported | 29 seconds Chrome 31 | 24 seconds | 26 seconds Firefox 26 | 27 seconds | 27 seconds Opera 12 | 25 seconds | 25 seconds Safari 5 | 23 seconds | 22 seconds |
从以上数据可以看到,不管是通过id与class查找元素还是通过穿越元素的方式查找元素,XPath与CSS选择器在性能上没有明显差距。当然,以上只是一个最基本的实验,这个实验所测试的只是一个基本网页。对于部分真实Web项目来说,HTML的嵌套深度要远远大于这个基本网页,那么我们再来看一下后面的实验。
实验二:大型网页且深层嵌套
紧接着Dave Haeffner又做了第二个实验,这次的实验更贴近多数实际项目,Dave Haeffner测试中用了各种不同组合类型的识别方式,并对比了CSS选择器与XPath在各类浏览器上的表现。图2.8是其最终的对比结果。
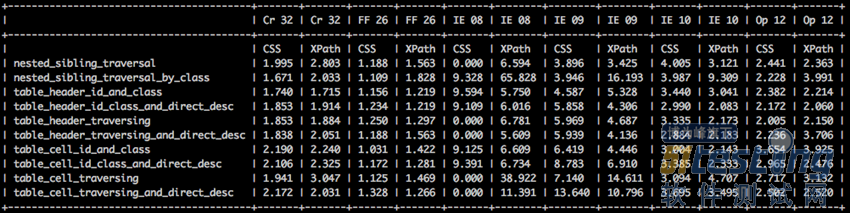
图2.8 CSS选择器与XPath的对比结果
图2.8虽然给出了一连串数字,但要一个个对其进行对比估计很困难,因此,Dave Haeffner把这些数据导入Excel中,并以更加直观的图表方式进行了展示。生成图表后,针对各个不同浏览器的对比结果,如图2.9~图2.12所示。

图2.9 CSS选择器和XPath在Chrome上的表现
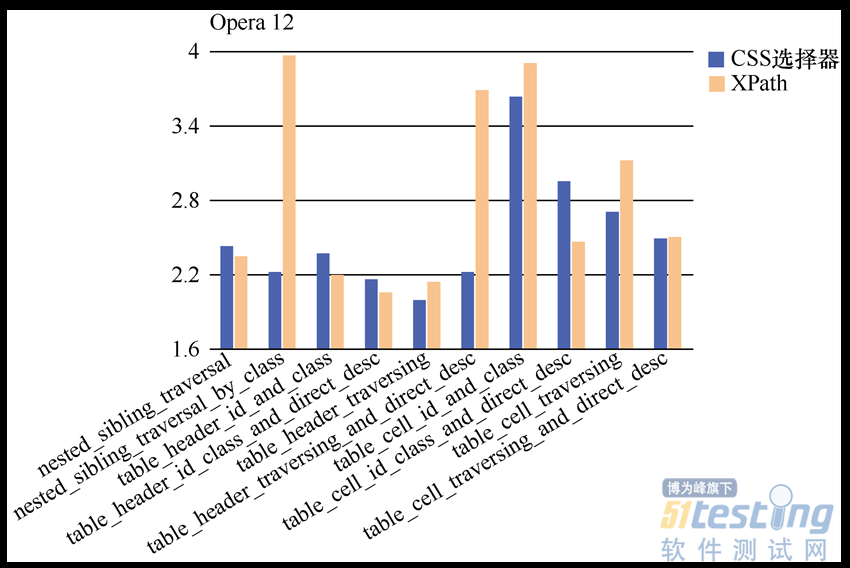
图2.10 CSS选择器和XPath在Firefox上的表现
Dave Haeffner给出的结论如下。
(1)XPath 可以在网页中从上往下穿越查找(从父对象到子对象),也可以从下往上穿越查找(从子对象到父对象),而CSS选择器仅支持向下穿越查找。
(2)在对两大主流浏览器Chrome与Firefox进行对比后发现,两者性能差距不大,CSS选择器的速度稍快。在页面内容丰富、嵌套层次有一定深度的情况下,CSS选择器的速度更快。
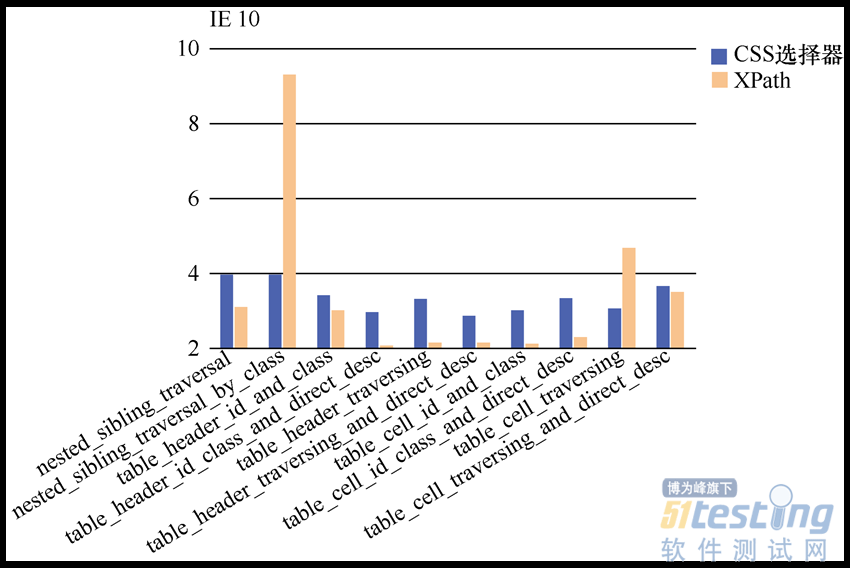
图2.11 CSS选择器和XPath在IE上的表现
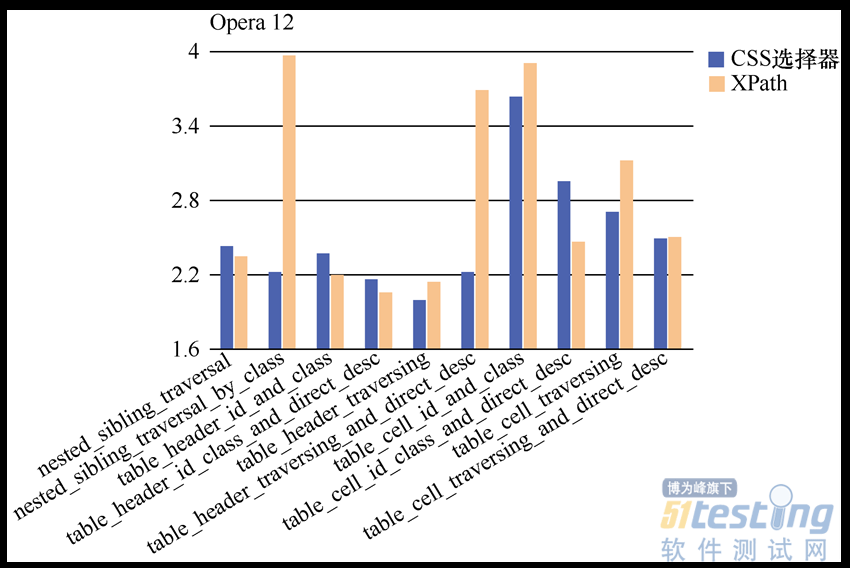
图2.12 CSS选择器和XPath在Opera上的表现
(3)在IE浏览器上,XPath总体上会比CSS选择器速度快一些。
(4)当需要穿越嵌套节点或者处理表格时,XPath会相对比较慢。
以上两个实验都出自Dave Haeffner的Elemental Selenium。
那么,究竟是选择CSS选择器还是XPath呢?以下是作者的建议。
建议一
在两者中选择用哪一个是一个非常困难的决定,以作者的经验来看,当自动化项目只支持IE浏览器时,建议使用XPath作为查找方式,因为它在各IE浏览器版本上的表现还是非常出众的;在非IE浏览器的情况下,建议使用CSS选择器代替XPath来作为对象查找方式。
建议二
假设项目中的主要元素都包含id和class属性,无论使用哪一种查找方式,尽量使用id进行查找,并避免使用穿越方式获取对象。首先,从性能上来说,用id查找的方式会快很多。其次,id方式会比穿越方式更加稳定,通常开发工程师不会改动id,但是他们会经常改动元素的层级和位置,这样经常导致穿越查找方式失效。最后,无论用XPath还是CSS选择器,在编写效率及易读性上,通过id查找的方式要远高于穿越方式。
建议三
在大多数实际项目测试中,都会面对主流浏览器,如Chrome、Firefox和IE等。那么这里又可以有两种选择。
第一种情况,使用CSS选择器与XPath混合方式进行,在脚本中使用两套对象库,一套用XPath,一套用CSS选择器,当脚本运行时可根据各自的优点选择使用。例如,当运行IE浏览器时,自动切换XPath对象库;当运行非IE浏览器时,自动切换CSS选择器对象库。当然,这种方式也有它的缺点,即需要维护两套不同查找方式的对象库。
第二种情况,只选用XPath或者CSS选择器其中一种查找方式,只维护一套对象库,这类情况适用于项目中的主要元素都包含了id与class的情形,原因是当两种查找方式在使用id时,其速度上的差距并不是非常明显,具体选择哪个还要具体情况具体分析。例如,若项目中有很多表格,那么就需要避开XPath选择CSS选择器;如果项目重心在IE上且很少有表格,那么最好选择XPath。
2.1.5 FindElement与FindElements各显“神通”
还记得第 1 章讲解的经典实例吗?我们当时通过 find_element_by_name 这个方法查找指定对象,但在实际项目中,find_element_by_name并不是最常用的,真正常用的是find_element方法,为什么?下面先来看一下find_element方法与find_element_by_name有哪些不同。
方法find_element_by_name的功能参数和用法如下。
功能:通过name属性查找元素。
参数:所要查找的元素的name值。
用法:driver.find_element_by_name("UserName")。
方法find_element的功能参数和用法如下。
功能:通过多种方式查找元素。
参数:第一个参数by指定查找方式,如根据id、name、XPath、CSS选择器等;第二个参数针对第一个参数的查找方式给出相应的查找字符串。
用法:driver.find_element(By.ID, "UserName")。
分析
一些读者可能已经发现了,其实find_element方法比find_element_by_name更灵活,灵活在哪里?灵活在识别方式上,读者可以想象一下,假如开发人员突然把name属性去掉,那么在测试中也需要把find_element_by_name这个方法也一起替换,这样就增加了很多维护工作。相比之下,find_element把具体的识别方式抽离出来作为一个参数,这样就可以很轻松地把识别方式及识别字符串一起抽离出来单独放在对象库中。假设开发人员把name去掉了,那么我们只需要把对象库中的By.name改成By.XXX(其他识别方式)即可,这样就不用再修改脚本层的内容了,只需要集中关注对象库这一层的维护即可。
进一步分析
如果读者看过Selenium的源代码,就会发现其实所有的find_element_by_*方法均直接调用了find_element方法。下面是一段示例代码。
def find_element_by_id(self, id_): """Finds an element by id. :Args: - id\_ - The id of the element to be found. :Usage: driver.find_element_by_id('foo') """ return self.find_element(by=By.ID, value=id_) |
在上面的程序中,3个双引号里的内容是Python的注释,可以忽略,主要看return语句,所有find_element_by_*方法内返回的都是find_element()方法的返回值。也就是说,find_element方法才是核心方法,其他所有的find_element_by_*方法是在其基础上实现的。
接下来,又到了实例环节了。
1)关于find_element方法的实例
此处我们还使用第1章的经典实例,改写find_element_by_name方法,具体代码如下。
import unittest from selenium import webdriver from selenium.webdriver.common.by import By class BookFlight(unittest.TestCase): username_textbox = (By.NAME, "UserName") password_textbox = (By.CSS_SELECTOR, "input[name=password]") login_button = (By.XPATH, "//input[@name='login']") def setUp(self): self.driver = webdriver.Firefox() def test_login(self): driver = self.driver driver.get("Mercury Tours登录页面") assert "Mercury Tours" in driver.title username_edit = driver.find_element(*self.username_textbox) password_edit = driver.find_element(*self.password_textbox) login_button = driver.find_element(*self.login_button) username_edit.send_keys("mercury") password_edit.send_keys("mercury") login_button.click() assert "Find a Flight" in driver.title def tearDown(self): self.driver.close() if __name__ == "__main__": unittest.main() |
细心的读者一定已经注意到,上面这个脚本除了替换find_element_by_name方法为find_element外,还抽离了UserName、password和login这3个元素的查找方式,以及查找字符串,代码如下。
username_textbox = (By.NAME, "UserName") password_textbox = (By.CSS_SELECTOR, "input[name=password]") login_button = (By.XPATH, "//input[@name='login']") |
脚本一共使用到了3种不同的查找方式:第一种方式是直接通过name属性查找,紧跟着name属性值;第二种方式是通过CSS选择器查找,紧跟着CSS选择器查找字符串;第三种方式是通过XPath查找,紧跟着XPath查找字符串。那么,如何使用这3个抽离出来的对象呢?请看如下代码。
username_edit = driver.find_element(*self.username_textbox) password_edit = driver.find_element(*self.password_textbox) login_button = driver.find_element(*self.login_button) |
这里只需要把每一个对象变量传入find_element方法即可,但是细心的读者一定又发现,每一个变量之前多了一个“*”号,为什么呢?仔细想想find_element有几个参数,是不是有两个参数?那么此时我们传入的只有一个参数,其实“*”号在此处的作用就是把(By.XXX,“XXX”)拆开,然后分别传入函数的两个参数中,而之前的3个带“*”号的参数称为“打包参数”。在实际自动化测试项目中,你会发现,这样管理测试对象是非常方便的。通常的做法是把所有的打包参数分离到一个Locators文件或者外部对象数据文件,一旦对象属性或者结构发生了变更,测试脚本无须任何改动,只要更改Locators或者外部数据对象文件的内容,就可以进行测试了。
2)关于find_elements方法的实例
find_elements方法虽然没有find_element那么常用,但是很多时候find_elements可以做find_element无法完成的事情,如下面这段代码。
import unittest from selenium import webdriver from selenium.webdriver.common.by import By class BookFlight(unittest.TestCase): all_links = (By.TAG_NAME, "a") def setUp(self): self.driver = webdriver.Firefox() def test_login(self): driver = self.driver driver.get("Mercury Tours登录页面") links = driver.find_elements(*self.all_links) print("link count is " + str(len(links))) for link in links: print("link name is " + link.text) def tearDown(self): self.driver.close() if __name__ == "__main__": unittest.main() |
这个例子的主要流程为获取登录页面上的所有链接对象,并输出所有链接个数,以及每一个链接的文本内容,find_elements方法的参数与find_element一样,只是返回的是一个WebElement类型的列表。请看下面这行代码。
| links = driver.find_elements(*self.all_links) |
下面是输出所有链接个数的代码。
| print("link count is " + str(len(links))) |
len()方法可以获取列表的个数。别忘了还要把str转化成int类型。接着通过for循环遍历所有的link,并调用每一个link对象的text属性,获取文本内容并输出。
for link in links: print("link name is " + link.text) |
关于find_element方法查找匹配对象后的返回信息,通常会有3种情况。
找到唯一一个对象。
没有找到匹配的对象。
找到一个以上的对象。
对于第一种情况—找到唯一一个对象,即返回唯一的一个对象;对于第二种情况—没有找到匹配的对象,方法会自动返回一个NoSuchElementException异常;对于第三种情况—找到一个以上的对象,也就是多个对象,find_element只会返回第一个找到的对象,如果需要获取到所有的对象,就要使用find_elements方法。
关于find_elements方法同样也会有这3种情况,但两者还是有一定差别,无论是3种情况中的哪一种情况,find_elements返回的都是一个列表。当找到唯一一个对象时,返回带有一个元素的列表;当没有找到时,返回一个空的列表;当找到多个对象时,返回包含所有元素的列表。
表2-1总结了这3种情况。
表2-1 find_element和find_elements方法在3种情况下的对比

版权声明:51Testing软件测试网获得人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












