

什么是Trie树

图示就表示5个字符串,radd、ram、rthe、rtfink、rgood,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到最后节点的一条路径表示一个字符串。Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
如何实现一个Trie树
如何存储
Trie树是一棵多叉树,一个节点有多个子节点,这时可以借助散列表的思想,通过一个下标与字符一一映射的数组来存储子节点的指针。
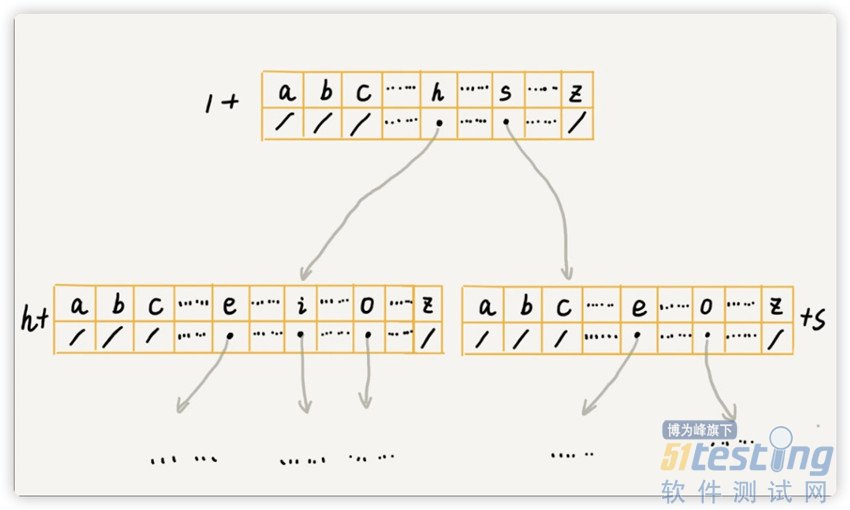
假设我们的字符串中只有从 a 到 z 这 26 个小写字母,我们在数组中下标为 0 的位置,存储指向子节点 a 的指针,下标为 1 的位置存储指向子节点 b 的指针,以此类推,下标为 25 的位置,存储的是指向的子节点 z 的指针。如果某个字符的子节点不存在,对应的下标的位置存储 null。
数组是一个Node数组,根据索引就可以获取到子节点
代码实现
public class TrieNode { public char data; public TrieNode[] children = new TrieNode[26]; // 标记字符是不是最后一个字符 public boolean isEndingChar = false; public TrieNode(char data){ this.data = data; } } public class Trie { private TrieNode root = new TrieNode('/'); public void insert(char[] text) { TrieNode p = root; for (char c : text) { // 确定字符该存的位置 int index = c - 'a'; if (p.children[index] == null) { TrieNode node = new TrieNode(c); p.children[index] = node; } // 如果已经存在节点了,就指向下一个节点 p = p.children[index]; } p.isEndingChar = true; } public boolean find(char[] pattern){ TrieNode p = root; for (char c : pattern) { int index = c - 'a'; // 如果一条路径都到达叶子节点了,还没有匹配到,就说明不存在这个pattern if (p.children[index] == null) { return false; } p = p.children[index]; } // 如果是尾部字符,就说明匹配到了,如果不是说明pattern只是一个前缀 return p.isEndingChar; } } |
复杂度分析
时间复杂度
构建Trie树的过程需要扫描所有的字符,需要O(n)的时间复杂度,n表示所有的字符数,如果要查询的字符串的长度是m,那么只需要m次比较就能确定是否存在这个字符串,需要O(m)的时间复杂度。
空间复杂度
Trie树用数组来存储一个节点的子节点的指针,在上面的例子中,假设的字符范围知识小写字符,如果还包含大写字母、数字、符号等等,那数组的空间就需要更大了,而且在存储节点的时候,每个数组并不能充分利用,只是存储了不多几个,有很大一部分的浪费。所以Trie 树是比较耗内存的,用的是一种空间换时间的思路。
这个问题的解决思路是可以用其他数据结构代替数组,但是会降低查找的效率,后面再说用什么数据结构替换。
Trie 树与其他动态数据结构比较
Trie 树在处理字符串匹配的时候,是对字符集有要求的,不然是无法发挥它的高效查找的优势:
字符串中包含的字符集不能太大。我们前面讲到,如果字符集太大,那存储空间可能就会浪费很多。即便可以优化,但也要付出牺牲查询、插入效率的代价。
要求字符串的前缀重合比较多,不然空间消耗会变大很多。
如果要用 Trie 树解决问题,那我们就要自己从零开始实现一个 Trie 树,还要保证没有 bug,这个在工程上是将简单问题复杂化,除非必须,一般不建议这样做。
我们知道,通过指针串起来的数据块是不连续的,而 Trie 树中用到了指针,所以,对缓存并不友好,性能上会打个折扣
针对在一组字符串中查找字符串的问题,我们在工程中,更倾向于用散列表或者红黑树。因为这两种数据结构,我们都不需要自己去实现,直接利用编程语言中提供的现成类库就行了。Trie 树比较适合的是查找前缀匹配的字符串,类似于搜索引擎的关键词提示功能、自动输入补全,都可以根据trie树来找到公共前缀。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












