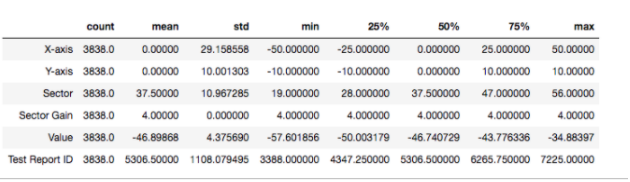
import pandas as pd import numpy as np import plotly.graph_objects as go excel_data = pd.read_csv('11adtoolsingle.csv') result_test = excel_data.pivot_table(values="Value",index=["X-axis","Y-axis","sector"],aggfunc=[np.sum,np.mean]) result_test.head(20) |

import pandas as pd import plotly.graph_objects as go excel_data = pd.pd.read_csv('11adtoolsingle.csv') result_test =excel_data.groupby(['X-axis','Y-axis'])['Value'].mean() result_test |
X-axis Y-axis -40 10 -50.424603 -39 10 -50.371553 -38 10 -49.581362 -37 10 -48.765840 -36 10 -46.163199 -35 10 -46.299201 -34 10 -46.773487 -33 10 -47.197108 -32 10 -47.969916 -31 10 -48.574481 -30 10 -49.738138 -29 10 -50.811379 -28 10 -50.846868 -27 10 -51.398935 -26 10 -51.578865 -25 10 -51.576730 Name: Value, dtype: float64 |
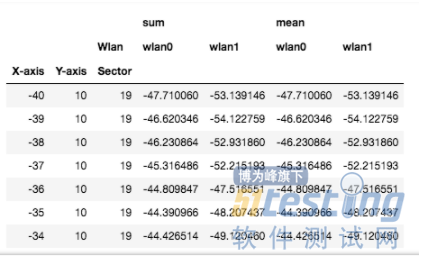
import pandas as pd import numpy as np import plotly.graph_objects as go excel_data = pd.read_excel('data.xlsx',sheet_name='Sheet2') excel_data.head(5) result_test = excel_data.pivot_table(index=["X-axis","Y-axis","Sector"],columns = ["Wlan"],values="Value",aggfunc=[np.sum,np.mean]) result_test.head(20) |
import pandas as pd import numpy as np import plotly.graph_objects as go excel_data = pd.read_csv('11adtoolsingle.csv') result_test = excel_data.pivot_table(index = ["X-axis","Y-axis","Sector"],values="Value",aggfunc="mean").reset_index().sort_values(by = "Value",ascending =False).head(10) result_test |

import pandas as pd import plotly.graph_objects as go excel_data = pd.read_csv('11adtoolsingle.csv') excel_data.info() |
<class 'pandas.core.frame.DataFrame'> |
import pandas as pd |
Wlan 0 |
import pandas as pd |
0 |
import pandas as pd |