

Scrapy爬虫开发流程一般包括如下步骤:
1)确定项目需求。
2)创建Scrapy项目。
3)定义页面提取的Item。
4)分析被爬对象页面。
5)编写爬取网站的Spider并提取Item。
6)编写Item Pipeline来存储提取到的Item(即数据)。
7)运行爬虫。
一、确定项目需求

图17-1
该专题中,每页10条数据,总共的页数在10以上,因为它是上拉加载下一页数据,暂时无法得知总页数是多少。假设我们的项目需求就是爬取最近10页的文章信息,包括文章标题,文章URL和文章的作者名称。
二、创建Scrapy项目
在开始爬取之前,必须先创建一个Scrapy项目。 进入存储代码的目录中,在shell中使用scrapy startproject命令运行:
scrapy startproject jianshu_spider
其中jianshu_spider为项目名称。
该命令将会创建包含下列内容的jianshu_spider目录:
jianshu_spider/ ----scrapy.cfg ----jianshu_spider/ --------__init__.py --------items.py --------middlewares.py --------pipelines.py --------settings.py --------spiders/ ------------__init__.py |
这些文件分别是:
●scrapy.cfg: 项目的配置文件
●jianshu_spider/: 该项目的python模块。
●jianshu_spider/items.py: 项目中的item文件。
●jianshu_spider/middlewares.py: 项目中的middlewares文件。
●jianshu_spider/pipelines.py: 项目中的pipelines文件。
●jianshu_spider/settings.py: 项目的设置文件。
●jianshu_spider/spiders/: 放置spider代码的目录。
三、定义页面提取的Item
Item是保存爬取到的数据的容器,它的使用方法和Python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
可以通过创建一个 scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一个Item。
首先根据需要从jianshu.com获取到的数据对Item进行建模。 前面项目需求中得知我们需要获取文章标题,文章URL和文章的作者名称。对此,在Item中定义相应的字段。编辑jianshu_spider目录中的items.py文件:
import scrapy class JianshuItem(scrapy.Item): ----title = scrapy.Field() ----url = scrapy.Field() ----author_name = scrapy.Field() |
四、分析被爬对象页面
编写爬虫程序之前,首先需要对被爬的页面进行分析,主流的浏览器都带有分析页面的工具或插件,比如Chrome浏览器的开发者工具(Tools->Developer->tools)分析页面。
1、数据信息
在Chrome浏览器中打开https://www.jianshu.com/c/V2CqjW,选中第一个文章列表并右击,选择“检查”,查看其HTML代码,如图17-2所示。

图17-2
可以右边红框所示,每篇文章的信息包含在<li>元素中:
<li id="note-25476707" data-note-id="25476707" class=""> ... </li> |
文章标题和文章URL在<a class="title"></a>元素中:
<a class="title" target="_blank" href="/p/b74107b6464d">走向架构之路之某个类重载方法很多该如何优化</a>
文章的作者名称在<a class="nickname"></a>元素中:
<a class="nickname" target="_blank" href="/u/f408bdadacce">AWeiLoveAndroid</a>
2、链接信息
上面列出的但是第一页元素的数据,我们要采集它的1-10页的信息,那么就要获取到下一页的链接。有些网站的下一页是通过点击“next”或者“下一页”触发的,简书网站是通过上拉加载。
我们可以点击到在Chrome浏览器的审查页面中选中Network和XHR,再页面上拉加载下一页的文章信息,如图17-3所示。
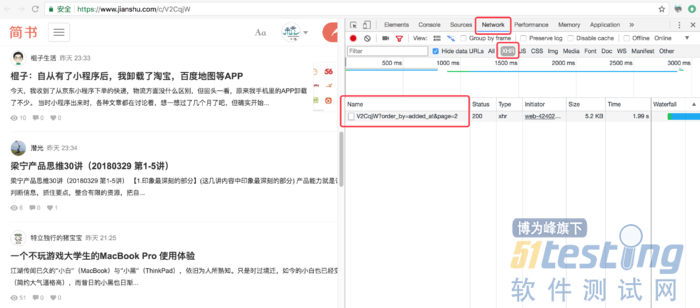
图17-3
可以发现,在下拉的过程中,XHR下方出现了一个https://www.jianshu.com/c/V2CqjW?order_by=added_at&page=2地址,里面有一个参数为page=2,同时验证发现当page=3时就是第三页的文章信息。
五、编写爬取网站的Spider并提取Item
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成item的方法。
创建一个Spider,必须继承scrapy.Spider类, 且定义以下三个属性:
●name:用于区别Spider。该名字必须是唯一的,不可以为不同的Spider设定相同的名字。
●start_urls:包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
●parse()方法。它是spider的一个方法。被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
以下为我们的第一个Spider的伪代码,保存在jianshu_spider/spiders 目录下的jianshu_spider.py文件中:
#-*-coding:utf-8-*- import scrapy class JianshuSpider(scrapy.Spider): # 每一个爬虫的唯一标识 ----name="jianshu_spider" # 定义爬虫爬取的起始点,起始点可以是多个,这里只有一个 ----start_urls=[ --------"https://www.jianshu.com/c/V2CqjW" ----] ----def parse(self,response): # 提取数据信息的代码 ...... # 提取链接信息的代码 ...... |
如果上面的代码有上面不明白的,没关系,后面的章节我会详细讲解,现在只需要知道是这么一个大概的流程即可。
从Spider的角度来看,爬取的运行流程如下循环:
1)以初始的URL初始化Request,并设置回调函数。 当该Request下载完毕并返回时,将生成Response,并作为参数传给该回调函数。
2)在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
3)在回调函数内,可以使用选择器(Selectors) 来分析网页内容,并根据分析的数据生成Item。
4)最后,由Spider返回的Item将被存到数据库或存入到文件中。
六、编写Item Pipeline来存储提取到的Item(即数据)
略
七、运行爬虫
进入项目的根目录,执行下列命令启动spider:
scrapy crawl jianshu_spider crawl jianshu_spider启动用于爬取jianshu.com的spider,将得到类似的输出: [scrapy] INFO:Scrapy started(bot:tutorial) [scrapy] INFO:Optional features available:... [scrapy] INFO:Overridden settings:{} [scrapy] INFO:Enabledextensions:... [scrapy] INFO:Enabled downloader middlewares:... [scrapy] INFO:Enabled spider middlewares:... [scrapy] INFO:Enabled item pipelines:... [jianshu_spider] INFO:Spider opened [jianshu_spider] DEBUG:Crawled(200) <GET https://www.jianshu.com/c/V2CqjW> (referer:None) [jianshu_spider] DEBUG:Crawled(200)(referer:None) [jianshu_spider] INFO:Closing spider(finished) |
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












