
-
OCR(Optical Character Recognition):光学字符识别
2015-11-18 16:08:35
http://blog.csdn.net/whatday/article/details/384935511.Tesseract-OCR引擎简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
2.Tesseract-OCR的下载安装
google下载地址:http://code.google.com/p/tesseract-ocr
需要下载安装程序(tesseract-ocr-setup-3.02.02.exe)和语言库,默认有英文的语言库只能识别英文,所以还需要下载中文语言库,
由于google经常打不开,所以通过代理下载后,上传到了CSDN,
安装程序下载地址:http://download.csdn.net/detail/whatday/7740469
简体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740531
繁体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740429
安装tesseract-ocr-setup-3.02.02.exe 默认安装就可以了,
因为如果选择了其他项,安装程序会自动从网上下载,语言库和其他文件,有很大一部分是从google下载,由于不能打开所以会出错,先默认安装上,需要什么文件再下载就行。
我系统是windows8.1 默认安装好后目录如下:
其中tesseract.exe是主程序, tessdata目录是存放语言文件 和 配置文件的,下载或自己生成的语言文件放到此目录里就可以了。
3.Tesseract-OCR的命令行使用
打开DOS界面,输入tesseract:
如果出现如上输出,表示安装正常。
我准备了一张验证码1.png放在D盘根目录下,简单的执行验证码识别
其中 1.png是验证码图片 result是结果文件的名称 默认是.TXT文件 执行成功后会在验证码图片所在位置生成result.txt 打开结果为:
命令详解:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script. detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform. block of vertically aligned text.
6 = Assume a single uniform. block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
-
Tesseract-OCR引擎简介
2015-11-18 10:05:37
1.Tesseract-OCR引擎简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
2.Tesseract-OCR的下载安装
google下载地址:http://code.google.com/p/tesseract-ocr
需要下载安装程序(tesseract-ocr-setup-3.02.02.exe)和语言库,默认有英文的语言库只能识别英文,所以还需要下载中文语言库,
由于google经常打不开,所以通过代理下载后,上传到了CSDN,
安装程序下载地址:http://download.csdn.net/detail/whatday/7740469
简体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740531
繁体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740429
安装tesseract-ocr-setup-3.02.02.exe 默认安装就可以了,
因为如果选择了其他项,安装程序会自动从网上下载,语言库和其他文件,有很大一部分是从google下载,由于不能打开所以会出错,先默认安装上,需要什么文件再下载就行。
我系统是windows8.1 默认安装好后目录如下:
其中tesseract.exe是主程序, tessdata目录是存放语言文件 和 配置文件的,下载或自己生成的语言文件放到此目录里就可以了。
3.Tesseract-OCR的命令行使用
打开DOS界面,输入tesseract:
如果出现如上输出,表示安装正常。
我准备了一张验证码1.png放在D盘根目录下
其中 1.png是验证码图片 result是结果文件的名称 默认是.TXT文件 执行成功后会在验证码图片所在位置生成result.txt 打开结果为:
命令详解:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script. detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform. block of vertically aligned text.
6 = Assume a single uniform. block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
4.Tesseract-OCR的QA合集
A.ImageMagick是什么?
ImageMagick是一个用于查看、编辑位图文件以及进行图像格式转换的开放源代码软件套装
我在这里之所以提到ImageMagick是因为某些图片格式需要用这个工具来转换。
B.Leptonica 是什么?
Leptonica 是一图像处理与图像分析工具,tesseract依赖于它。而且不是所有的格式(如jpg)都能处理,所以我们需要借助imagemagick做格式转换。
Here's a summary of compression support and limitations:
- All formats except JPEG support 1 bpp binary.
- All formats support 8 bpp grayscale (GIF must have a colormap).
- All formats except GIF support 24 bpp rgb color.
- All formats except PNM support 8 bpp colormap.
- PNG and PNM support 2 and 4 bpp images.
- PNG supports 2 and 4 bpp colormap, and 16 bpp without colormap.
- PNG, JPEG, TIFF and GIF support image compression; PNM and BMP do not.
- WEBP supports 24 bpp rgb color.
C.提高图片质量?
识别成功率跟图片质量关系密切,一般拿到后的验证码都得经过灰度化,二值化,去噪,利用imgick就可以很方便的做到.
convert -monochrome foo.png bar.png #将图片二值化
D.我只想识别字符和数字?
结尾仅需要加digits
命令实例:tesseract imagename outputbase digits
E.训练你的tesseract
不得不说,tesseract英文识别率已经很不错了(现有的tesseract-data-eng),但是验证码识别还是太鸡肋了。但是请别忘记,tesseract的智能识别是需要训练的.
F.命令执行出现empty page!!错误
严格来说,这不是一个bug(tesseract 3.0),出现这个错误是因为tesseract搞不清图像的字符布局
-psm N
Set Tesseract to only run a subset of layout analysis and assume a certain form. of image. The options for N are:
0 = Orientation and script. detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR.
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform. block of vertically aligned text.
6 = Assume a single uniform. block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
对于我们的验证码a.tif排列来说,采用-psm 7(single text line)比较合适。
5.Tesseract-OCR的训练方法
A.使用jTessBoxEditor工具
1.下载地址:http://download.csdn.net/detail/whatday/7740739
这个工具是用来训练样本用的,由于该工具是用JAVA开发的,需要安装JAVA虚拟机1.6才能运行。
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
3.合并样本图像。运行jTessBoxEditor工具,在点击菜单栏中Tools--->Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张),合并成num.font.exp0.tif文件。
4.生成Box File文件。打开命令行,执行命令:
- tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
- tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
5.文字校正。 运行jTessBoxEditor工具,打开num.font.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如 下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
6.定义字体特征文件。Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties的字体特征文件。
font_properties不含有BOM头,文件内容格式如下:
- <fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang]. [fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
这里全取值为0,表示字体不是粗体、斜体等等。- font 0 0 0 0 0
7.生成语言文件。在样本图片所在目录下创建一个批处理文件,输入如下内容。- rem 执行改批处理前先要目录下创建font_properties文件
- echo Run Tesseract for Training..
- tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
- echo Compute the Character Set..
- unicharset_extractor.exe num.font.exp0.box
- mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
- echo Clustering..
- cntraining.exe num.font.exp0.tr
- echo Rename Files..
- rename normproto num.normproto
- rename inttemp num.inttemp
- rename pffmtable num.pffmtable
- rename shapetable num.shapetable
- echo Create Tessdata..
- combine_tessdata.exe num.
将批处理通过命令行执行。执行后的结果如下:
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
训练前:
1.准备一副待识别的图像,这里用画图工具随便写了一串数字,保存为number.jpg,如下图所示:
2. 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。
3. 打开Tesseract-OCR目录下的result.txt文件,看到识别的结果为7542315857,有3个字符识别错误,识别率还不是很高,那 有没有什么方法来提供识别率呢?Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。下面介绍一下具体训练样本的方法。
训练后:
用训练后的语言库识别number.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
识别结果如如图所示,可以看到识别率提高了不少。通过自定义训练样本,可以进行图形验证码、车牌号码识别等。感兴趣的朋友可以研究研究。
B.使用 CowBoxer工具
下载地址为:http://download.csdn.net/detail/whatday/7740815
第一步生成第一个 box 文件
演示中将 Tesseract 解压到了 E:\tesseract-ocr 目录。然后在该目录中建立了一个 build 目录用于存放原始数据和训练过程中生成的文件。原始图片数据一个有 3 个 (test.001.tif - test.003.tif):
首先生成第一个图片 test.001.tif 的 box 文件,这里使用官方的 eng 语言数据进行文字识别:
E:\tesseract-ocr\build>..\tesseract test.001.tif test.001 -l eng batch.nochop makebox
Tesseract Open Source OCR Engine with Leptonica
Number of found pages: 1.
执行完这个命令之后,build 目录下就生成了一个 test.001.box。使用 CowBoxer 打开这个 box 文件,CowBoxer 会自动找到同名的 tif 文件显示出来。
CowBoxer 的使用方法可以看 Help -> About 中的说明。修改完成之后 File -> Save box file 保存文件。
生成初始的 traineddata
接下来使用这一个 box 文件先生成一个 traineddata,在接下来生成其他图片的 box 文件时,使用这个 traineddata 有利于提高识别的正确率,减少修改次数。
..\tesseract test.001.tif test.001 nobatch box.train
..\training\unicharset_extractor test.001.box
..\training\mftraining -U unicharset -O test.unicharset test.001.tr
..\training\cntraining test.001.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
在 build 目录下执行完这一系列命令之后,就生成了可用的 test.traineddata。
生成其余 box 文件
将上一步生成的 test.traineddata 移动到 tesseract-ocr\tessdata 目录中,接下来生成其他 box 文件时就可以通过 -l test 参数使用它了。
..\tesseract test.002.tif test.002 -l test batch.nochop makebox
..\tesseract test.003.tif test.003 -l test batch.nochop makebox
这里仅仅是使用 3 个原始文件作为例子。实际制作训练文件时,什么时候生成一个 traineddata 根据情况而定。中途生成 traineddata 的目的只是为了提高文字识别的准确率,使后面生成的 box 文件能少做修改。
生成最终的 traineddata
在所有的 box 都制作完成后,就可以生成最终的 traineddata 了。
..\tesseract test.001.tif test.001 nobatch box.train
..\tesseract test.002.tif test.002 nobatch box.train
..\tesseract test.003.tif test.003 nobatch box.train
..\training\unicharset_extractor test.001.box test.002.box test.003.box
..\training\mftraining -U unicharset -O test.unicharset test.001.tr test.002.tr test.003.tr
..\training\cntraining test.001.tr test.002.tr test.003.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
在文件较多时可以用程序生成这种脚本执行。
未完。。。
-
Tesseract-OCR引擎简介
2015-11-18 10:00:59
http://blog.csdn.net/whatday/article/details/384935511.Tesseract-OCR引擎简介
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
2.Tesseract-OCR的下载安装
google下载地址:http://code.google.com/p/tesseract-ocr
需要下载安装程序(tesseract-ocr-setup-3.02.02.exe)和语言库,默认有英文的语言库只能识别英文,所以还需要下载中文语言库,
由于google经常打不开,所以通过代理下载后,上传到了CSDN,
安装程序下载地址:http://download.csdn.net/detail/whatday/7740469
简体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740531
繁体中文语言库下载地址:http://download.csdn.net/detail/whatday/7740429
安装tesseract-ocr-setup-3.02.02.exe 默认安装就可以了,
因为如果选择了其他项,安装程序会自动从网上下载,语言库和其他文件,有很大一部分是从google下载,由于不能打开所以会出错,先默认安装上,需要什么文件再下载就行。
我系统是windows8.1 默认安装好后目录如下:
其中tesseract.exe是主程序, tessdata目录是存放语言文件 和 配置文件的,下载或自己生成的语言文件放到此目录里就可以了。
3.Tesseract-OCR的命令行使用
打开DOS界面,输入tesseract:
如果出现如上输出,表示安装正常。
我准备了一张验证码1.png放在D盘根目录下
其中 1.png是验证码图片 result是结果文件的名称 默认是.TXT文件 执行成功后会在验证码图片所在位置生成result.txt 打开结果为:
命令详解:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script. detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform. block of vertically aligned text.
6 = Assume a single uniform. block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
4.Tesseract-OCR的QA合集
A.ImageMagick是什么?
ImageMagick是一个用于查看、编辑位图文件以及进行图像格式转换的开放源代码软件套装
我在这里之所以提到ImageMagick是因为某些图片格式需要用这个工具来转换。
B.Leptonica 是什么?
Leptonica 是一图像处理与图像分析工具,tesseract依赖于它。而且不是所有的格式(如jpg)都能处理,所以我们需要借助imagemagick做格式转换。
Here's a summary of compression support and limitations:
- All formats except JPEG support 1 bpp binary.
- All formats support 8 bpp grayscale (GIF must have a colormap).
- All formats except GIF support 24 bpp rgb color.
- All formats except PNM support 8 bpp colormap.
- PNG and PNM support 2 and 4 bpp images.
- PNG supports 2 and 4 bpp colormap, and 16 bpp without colormap.
- PNG, JPEG, TIFF and GIF support image compression; PNM and BMP do not.
- WEBP supports 24 bpp rgb color.
C.提高图片质量?
识别成功率跟图片质量关系密切,一般拿到后的验证码都得经过灰度化,二值化,去噪,利用imgick就可以很方便的做到.
convert -monochrome foo.png bar.png #将图片二值化
D.我只想识别字符和数字?
结尾仅需要加digits
命令实例:tesseract imagename outputbase digits
E.训练你的tesseract
不得不说,tesseract英文识别率已经很不错了(现有的tesseract-data-eng),但是验证码识别还是太鸡肋了。但是请别忘记,tesseract的智能识别是需要训练的.
F.命令执行出现empty page!!错误
严格来说,这不是一个bug(tesseract 3.0),出现这个错误是因为tesseract搞不清图像的字符布局
-psm N
Set Tesseract to only run a subset of layout analysis and assume a certain form. of image. The options for N are:
0 = Orientation and script. detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR.
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform. block of vertically aligned text.
6 = Assume a single uniform. block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
对于我们的验证码a.tif排列来说,采用-psm 7(single text line)比较合适。
5.Tesseract-OCR的训练方法
A.使用jTessBoxEditor工具
1.下载地址:http://download.csdn.net/detail/whatday/7740739
这个工具是用来训练样本用的,由于该工具是用JAVA开发的,需要安装JAVA虚拟机1.6才能运行。
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
3.合并样本图像。运行jTessBoxEditor工具,在点击菜单栏中Tools--->Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张),合并成num.font.exp0.tif文件。
4.生成Box File文件。打开命令行,执行命令:
- tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
- tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
5.文字校正。 运行jTessBoxEditor工具,打开num.font.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如 下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
6.定义字体特征文件。Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties的字体特征文件。
font_properties不含有BOM头,文件内容格式如下:
- <fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang]. [fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
这里全取值为0,表示字体不是粗体、斜体等等。- font 0 0 0 0 0
7.生成语言文件。在样本图片所在目录下创建一个批处理文件,输入如下内容。- rem 执行改批处理前先要目录下创建font_properties文件
- echo Run Tesseract for Training..
- tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
- echo Compute the Character Set..
- unicharset_extractor.exe num.font.exp0.box
- mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
- echo Clustering..
- cntraining.exe num.font.exp0.tr
- echo Rename Files..
- rename normproto num.normproto
- rename inttemp num.inttemp
- rename pffmtable num.pffmtable
- rename shapetable num.shapetable
- echo Create Tessdata..
- combine_tessdata.exe num.
将批处理通过命令行执行。执行后的结果如下:
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
训练前:
1.准备一副待识别的图像,这里用画图工具随便写了一串数字,保存为number.jpg,如下图所示:
2. 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。
3. 打开Tesseract-OCR目录下的result.txt文件,看到识别的结果为7542315857,有3个字符识别错误,识别率还不是很高,那 有没有什么方法来提供识别率呢?Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。下面介绍一下具体训练样本的方法。
训练后:
用训练后的语言库识别number.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
识别结果如如图所示,可以看到识别率提高了不少。通过自定义训练样本,可以进行图形验证码、车牌号码识别等。感兴趣的朋友可以研究研究。
B.使用 CowBoxer工具
下载地址为:http://download.csdn.net/detail/whatday/7740815
第一步生成第一个 box 文件
演示中将 Tesseract 解压到了 E:\tesseract-ocr 目录。然后在该目录中建立了一个 build 目录用于存放原始数据和训练过程中生成的文件。原始图片数据一个有 3 个 (test.001.tif - test.003.tif):
首先生成第一个图片 test.001.tif 的 box 文件,这里使用官方的 eng 语言数据进行文字识别:
E:\tesseract-ocr\build>..\tesseract test.001.tif test.001 -l eng batch.nochop makebox
Tesseract Open Source OCR Engine with Leptonica
Number of found pages: 1.
执行完这个命令之后,build 目录下就生成了一个 test.001.box。使用 CowBoxer 打开这个 box 文件,CowBoxer 会自动找到同名的 tif 文件显示出来。
CowBoxer 的使用方法可以看 Help -> About 中的说明。修改完成之后 File -> Save box file 保存文件。
生成初始的 traineddata
接下来使用这一个 box 文件先生成一个 traineddata,在接下来生成其他图片的 box 文件时,使用这个 traineddata 有利于提高识别的正确率,减少修改次数。
..\tesseract test.001.tif test.001 nobatch box.train
..\training\unicharset_extractor test.001.box
..\training\mftraining -U unicharset -O test.unicharset test.001.tr
..\training\cntraining test.001.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
在 build 目录下执行完这一系列命令之后,就生成了可用的 test.traineddata。
生成其余 box 文件
将上一步生成的 test.traineddata 移动到 tesseract-ocr\tessdata 目录中,接下来生成其他 box 文件时就可以通过 -l test 参数使用它了。
..\tesseract test.002.tif test.002 -l test batch.nochop makebox
..\tesseract test.003.tif test.003 -l test batch.nochop makebox
这里仅仅是使用 3 个原始文件作为例子。实际制作训练文件时,什么时候生成一个 traineddata 根据情况而定。中途生成 traineddata 的目的只是为了提高文字识别的准确率,使后面生成的 box 文件能少做修改。
生成最终的 traineddata
在所有的 box 都制作完成后,就可以生成最终的 traineddata 了。
..\tesseract test.001.tif test.001 nobatch box.train
..\tesseract test.002.tif test.002 nobatch box.train
..\tesseract test.003.tif test.003 nobatch box.train
..\training\unicharset_extractor test.001.box test.002.box test.003.box
..\training\mftraining -U unicharset -O test.unicharset test.001.tr test.002.tr test.003.tr
..\training\cntraining test.001.tr test.002.tr test.003.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
在文件较多时可以用程序生成这种脚本执行。
未完。。。
-
Selenium WebDriver 中鼠标和键盘事件分析及扩展
2015-11-16 17:39:13
http://www.ibm.com/developerworks/cn/java/j-lo-keyboard/组合键的使用以及对于 Keys 类型没有覆盖到的组合键的扩展
本文将总结 Selenium WebDriver 中的一些鼠标和键盘事件的使用,以及组合键的使用,并且将介绍 WebDriver 中没有实现的键盘事件(Keys 枚举中没有列举的按键)的扩展。举例说明扩展 Alt+PrtSc 组合键来截取当前活动窗口并将剪切板图像保存到文件。
在 IBM Bluemix 云平台上开发并部署您的下一个应用。概念
在使用 Selenium WebDriver 做自动化测试的时候,会经常模拟鼠标和键盘的一些行为。比如使用鼠标单击、双击、右击、拖拽等动作;或者键盘输入、快捷键使用、组合键使用等模拟键盘的操作。在 WebDeriver 中,有一个专门的类来负责实现这些测试场景,那就是 Actions 类,在使用该类的过程中会配合使用到 Keys 枚举以及 Mouse、 Keyboard、CompositeAction 等类。
其次,在实际测试过程中,可能会遇到某些按键没办法使用 Actions、Keys 等类来实现的情况。 比如通过使用 Alt+PrtSc 组合键来实现截取屏幕当前活动窗口的图像,在 Keys 枚举中,因为没有枚举出 PrtSc 键,所以没办法通过 Action 的 KeyDown(Keys) 来模拟按下这个动作。
再次是在自动化测试中,可能会遇到一些附件、文件上传的场景,或者是多文件上传,这些在 Selenium2.0 之后,可以直接使用 WebElement 类的 sendKeys() 方法来实现。
下面就分别介绍这些情况的具体使用。
鼠标点击操作
鼠标点击事件有以下几种类型:
清单 1. 鼠标左键点击
Actions action = new Actions(driver);action.click();// 鼠标左键在当前停留的位置做单击操作 action.click(driver.findElement(By.name(element)))// 鼠标左键点击指定的元素
清单 2. 鼠标右键点击
Actions action = new Actions(driver); action.contextClick();// 鼠标右键在当前停留的位置做单击操作 action.contextClick(driver.findElement(By.name(element)))// 鼠标右键点击指定的元素
清单 3. 鼠标双击操作
Actions action = new Actions(driver); action.doubleClick();// 鼠标在当前停留的位置做双击操作 action.doubleClick(driver.findElement(By.name(element)))// 鼠标双击指定的元素
清单 4. 鼠标拖拽动作
Actions action = new Actions(driver); // 鼠标拖拽动作,将 source 元素拖放到 target 元素的位置。 action.dragAndDrop(source,target); // 鼠标拖拽动作,将 source 元素拖放到 (xOffset, yOffset) 位置,其中 xOffset 为横坐标,yOffset 为纵坐标。 action.dragAndDrop(source,xOffset,yOffset);
在这个拖拽的过程中,已经使用到了鼠标的组合动作,首先是鼠标点击并按住 (click-and-hold) source 元素,然后执行鼠标移动动作 (mouse move),移动到 target 元素位置或者是 (xOffset, yOffset) 位置,再执行鼠标的释放动作 (mouse release)。所以上面的方法也可以拆分成以下的几个执行动作来完成:
action.clickAndHold(source).moveToElement(target).perform(); action.release();
清单 5. 鼠标悬停操作
Actions action = new Actions(driver); action.clickAndHold();// 鼠标悬停在当前位置,既点击并且不释放 action.clickAndHold(onElement);// 鼠标悬停在 onElement 元素的位置
action.clickAndHold(onElement) 这个方法实际上是执行了两个动作,首先是鼠标移动到元素 onElement,然后再 clickAndHold, 所以这个方法也可以写成 action.moveToElement(onElement).clickAndHold()。
清单 6. 鼠标移动操作
Actions action = new Actions(driver); action.moveToElement(toElement);// 将鼠标移到 toElement 元素中点 // 将鼠标移到元素 toElement 的 (xOffset, yOffset) 位置, //这里的 (xOffset, yOffset) 是以元素 toElement 的左上角为 (0,0) 开始的 (x, y) 坐标轴。 action.moveToElement(toElement,xOffset,yOffset) // 以鼠标当前位置或者 (0,0) 为中心开始移动到 (xOffset, yOffset) 坐标轴 action.moveByOffset(xOffset,yOffset);
action.moveByOffset(xOffset,yOffset) 这里需要注意,如果 xOffset 为负数,表示横坐标向左移动,yOffset 为负数表示纵坐标向上移动。而且如果这两个值大于当前屏幕的大小,鼠标只能移到屏幕最边界的位置同时抛出 MoveTargetOutOfBoundsExecption 的异常。
鼠标移动操作在测试环境中比较常用到的场景是需要获取某元素的 flyover/tips,实际应用中很多 flyover 只有当鼠标移动到这个元素之后才出现,所以这个时候通过执行 moveToElement(toElement) 操作,就能达到预期的效果。但是根据我个人的经验,这个方法对于某些特定产品的图标,图像之类的 flyover/tips 也不起作用,虽然在手动操作的时候移动鼠标到这些图标上面可以出现 flyover, 但是当使用 WebDriver 来模拟这一移动操作时,虽然方法成功执行了,但是 flyover 却出不来。所以在实际应用中,还需要对具体的产品页面做相应的处理。
清单 7. 鼠标释放操
Actions action = new Actions(driver); action.release();// 释放鼠标
键盘模拟操作
对于键盘的模拟操作,Actions 类中有提供 keyUp(theKey)、keyDown(theKey)、sendKeys(keysToSend) 等方法来实现。键盘的操作有普通键盘和修饰键盘(Modifier Keys, 下面的章节将讲到修饰键的概念)两种 :
1. 对于普通键盘,使用 sendKeys(keysToSend) 就可以实现,比如按键 TAB、Backspace 等。
清单 8. 普通键盘模拟 sendKeys(keysToSend)
Actions action = new Actions(driver); action.sendKeys(Keys.TAB);// 模拟按下并释放 TAB 键 action.sendKeys(Keys.SPACE);// 模拟按下并释放空格键 /*** 针对某个元素发出某个键盘的按键操作,或者是输入操作, 比如在 input 框中输入某个字符也可以使用这个方法。这个方法也可以拆分成: action.click(element).sendKeys(keysToSend)。 */ action.sendKeys(element,keysToSend);
注意除了 Actions 类有 sendKeys(keysToSend)方法外,WebElement 类也有一个 sendKeys(keysToSend)方法,这两个方法对于一般的输入操作基本上相同,不同点在于以下几点:
- Actions 中的 sendKeys(keysToSend) 对于修饰键 (Modifier Keys) 的调用并不会释放,也就是说当调用 actions.sendKeys(Keys.ALT); actions.sendKeys(Keys.CONTROL); action.sendKeys(Keys.SHIFT); 的时候,相当于调用 actions.keyDown(keysToSend),而如果在现实的应用中想要模拟按下并且释放这些修饰键,应该再调用 action.sendKeys(keys.NULL) 来完成这个动作。
- 其次就是当 Actions 的 sendKeys(keysToSend) 执行完之后,焦点就不在当前元素了。所以我们可以使用 sendKeys(Keys.TAB) 来切换元素的焦点,从而达到选择元素的作用,这个最常用到的场景就是在用户名和密码的输入过程中。
- 第三点,在 WebDriver 中,我们可以使用 WebElement 类的 sendKeys(keysToSend) 来上传附件,比如 element.sendKeys(“C:\\test\\uploadfile\\test.jpg”); 这个操作将 test.jpg 上传到服务器,但是使用:
Actions action = New Actions(driver); action.sendKeys(element,“C:\\test\\upload\\test.jpg”); action.click(element).sendKeys(“C:\\test\\upload\\test.jpg”);
这种方式是上传不成功的,虽然 WebDriver 在执行这条语句的时候不会出错,但是实际上并没有将文件上传。所以要上传文件,还是应该使用前面一种方式。
2.对于修饰键(Modifier keys),一般都是跟普通键组合使用的。比如 Ctrl+a、Alt+F4、 Shift+Ctrl+F 等等。
- 这里先解释一下修饰键的概念,修饰键是键盘上的一个或者一组特别的键,当它与一般按键同时使用的时候,用来临时改变一般键盘的普通行为。对于单独按下修饰 键本身一般不会触发任何键盘事件。在个人计算机上的键盘上,有以下几个修饰键:Shift、Ctrl、Alt(Option)、AltGr、 Windows logo、Command、FN(Function)。但是在 WebDriver 中,一般的修饰键指前面三个。你可以点击下面的 Wiki 链接去了解更多有关修饰键的信息,Modifier key。
- 回到上面的话题,在 WebDriver 中对于修饰键的使用需要用到 KeyDown(theKey)、keyUp(theKey) 方法来操作。
清单 9. 修饰键方法 KeyDown(theKey)、keyUp(theKey)
Actions action = new Actions(driver); action.keyDown(Keys.CONTROL);// 按下 Ctrl 键 action.keyDown(Keys.SHIFT);// 按下 Shift 键 action.keyDown(Key.ALT);// 按下 Alt 键 action.keyUp(Keys.CONTROL);// 释放 Ctrl 键 action.keyUp(Keys.SHIFT);// 释放 Shift 键 action.keyUp(Keys.ALT);// 释放 Alt 键
所以要通过 Alt+F4 来关闭当前的活动窗口,可以通过下面语句来实现:action.keyDown(Keys.ALT).keyDown(Keys.F4).keyUp(Keys.ALT).perform();
而如果是对于像键盘上面的字母键 a,b,c,d... 等的组合使用,可以通过以下语句实现 :action.keyDown(Keys.CONTROL).sednKeys(“a”).perform();
在 WebDriver API 中,KeyDown(Keys theKey)、KeyUp(Keys theKey) 方法的参数只能是修饰键:Keys.SHIFT、Keys.ALT、Keys.CONTROL, 否者将抛出 IllegalArgumentException 异常。 其次对于 action.keyDown(theKey) 方法的调用,如果没有显示的调用 action.keyUp(theKey) 或者 action.sendKeys(Keys.NULL) 来释放的话,这个按键将一直保持按住状态。
使用 Robot 类来操作 Keys 没有枚举出来的按键操作
1.在 WebDriver 中,Keys 枚举出了键盘上大多数的非字母类按键,从 F1 到 F10,NUMPAD0 到 NUMPAD9、ALT\TAB\CTRL\SHIFT 等等,你可以通过以下链接查看 Keys 枚举出来的所有按键,Enum Keys。 但是并没有列出键盘上的所有按键,比如字母键 a、b、c、d … z,一些符号键比如:‘ {}\[] ’、‘ \ ’、‘。’、‘ ? ’、‘:’、‘ + ’、‘ - ’、‘ = ’、、‘“”’,还有一些不常用到的功能键如 PrtSc、ScrLk/NmLk。对于字母键和符号键,前面我们已经提到可以直接使用 sendKeys(“a”),sendKeys(“/”) 的方式来触发这些键盘事件。而对于一些功能组合键,如 Fn + NmLk 来关闭或者打开数字键,或者 Alt+PrtSC 来抓取当前屏幕的活动窗口并保存到图片,通过 WebDriver 的 Keys 是没办法操作的。 这个时候我们就需要用到 Java 的 Robot 类来实现对这类组合键的操作了。
2.下面就以对 Alt+PrtSc 为例介绍一下 Robot 对键盘的操作。如代码清单 10。
清单 10. 通过 Robot 发出组合键动作
/** * * @Description: 这个方法用来模拟发送组合键 Alt + PrtSc, 当组合键盘事件执行之后,屏幕上的活动窗口 * 就被截取并且存储在剪切板了。 接下来就是通过读取剪切板数据转换成 Image 图像对象并保存到本地。 * @param filename : 要保存的图像的名称 */ public static void sendComposeKeys(String fileName) throws Exception { // 构建 Robot 对象,用来操作键盘 Robot robot = new Robot(); // 模拟按下键盘动作,这里通过使用 KeyEvent 类来获取对应键盘(ALT)的虚拟键码 robot.keyPress(java.awt.event.KeyEvent.VK_ALT); // 按下 PrtSC 键 robot.keyPress(java.awt.event.KeyEvent.VK_PRINTSCREEN); // 释放键盘动作,当这个动作完成之后,模拟组合键 Alt + PrtSC 的过程就已经完成, //此时屏幕活动窗口就一被截取并存入到剪切板 robot.keyRelease(java.awt.event.KeyEvent.VK_ALT); // 获取系统剪切板实例 Clipboard sysc = Toolkit.getDefaultToolkit().getSystemClipboard(); // 通过 getContents() 方法就可以将剪切板内容获取并存入 Transferable 对象中 Transferable data = sysc.getContents(null); if (data != null) { /*** 判断从剪切板获取的对象内容是否为 Java Image 类, 如果是将直接转化为 Image 对象。 到此为止,我们就从发出组合键到抓取活动窗口,再读取剪切板并存入 Image 对象的过程 就完成了,接下来要做的就是需要将 Image 对象保存到本地。 */ if (data.isDataFlavorSupported(DataFlavor.imageFlavor)) { Image image = (Image) data .getTransferData(DataFlavor.imageFlavor); writeImageToFile(image, fileName); } } }Robot 类对键盘的处理是通过 keyPress(int keycode)、keyRelease(int keycode) 方法来实现的,其中他们需要的参数是键盘按键对应的虚拟键码,虚拟键码的值可以通过 KeyEvent 类来获取。在 Java API 中对于虚拟键码的解释如下: 虚拟键码用于报告按下了键盘上的哪个键,而不是一次或多次键击组合生成的字符(如 "A" 是由 shift + "a" 生成的)。 例如,按下 Shift 键会生成 keyCode 为 VK_SHIFT 的 KEY_PRESSED 事件,而按下 'a' 键将生成 keyCode 为 VK_A 的 KEY_PRESSED 事件。释放 'a' 键后,会激发 keyCode 为 VK_A 的 KEY_RELEASED 事件。另外,还会生成一个 keyChar 值为 'A' 的 KEY_TYPED 事件。 按下和释放键盘上的键会导致(依次)生成以下键事件:
KEY_PRESSED
KEY_TYPED(只在可生成有效 Unicode 字符时产生。)
KEY_RELEASED
所以当测试中需要用到按下键盘 Alt+PrtSc 键的时候,只需要执行代码清单 10 中两个 keyPress() 和一个 keyRelease() 方法即可。
3.当这两个按键执行结束之后,屏幕上面的活动窗口已经保存到剪切板中。如果需要将其保存本地图片,只需要从剪切板读取并通过 JPEGImageEncoder 类或者 ImageIO 类将其写入本地即可。
清单 11. 使用 JPEGImageEncoder 将 Image 对象保存到本地
/** * * @Description: 这个方法用来将 Image 对象保存到本地,主要是通过 JPEGImageEncoder 类来实现图像的 * 保存 * @param image : 要保存的 Image 对象 * @param filename : 保存图片的文件名称 */ public static void writeImageToFile(Image image, String fileName) { try { // 获取 Image 对象的宽度和高度, 这里的参数为 null 表示不需要通知任何观察者 int width = image.getWidth(null); int height = image.getHeight(null); BufferedImage bi = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB); // 通过 BufferedImage 绘制图像并保存在其对象中 bi.getGraphics().drawImage(image, 0, 0, null); // 构建图像名称及保存路径 String name = Const.DIRECTORY + fileName + Const.FORMAT; File dir = new File(Const.DIRECTORY); if (!dir.exists()) { dir.mkdir(); } FileOutputStream ut = new FileOutputStream(name); @SuppressWarnings("restriction") JPEGImageEncoder encoder = JPEGCodec.createJPEGEncoder(out); encoder.encode(bi); out.flush(); out.close(); } catch (Exception e) { e.printStackTrace(); } }代码清单 11 是通过 JPEGImageEncoder 类将 Image 对象写到本地文件流,注意 Image 对象是在代码清单 10 中的如下语句获取到的:
Clipboard sysc = Toolkit.getDefaultToolkit().getSystemClipboard(); Transferable data = sysc.getContents(null); if (data != null) { if (data.isDataFlavorSupported(DataFlavor.imageFlavor)) { Image image = (Image) data .getTransferData(DataFlavor.imageFlavor); writeImageToFile(image, fileName); } }清单 12. 使用 ImageIO 将 Image 对象保存到本地
/** * * @Description: 通过使用 ImageIO 类来保存 Image 对象为本地图片 * @param image : 需要保存的 Image 对象 * @param filename : 文件名 */ public static void saveImage(Image image, String fileName) throws Exception { // 获取 Image 对象的高度和宽度 int width = image.getWidth(null); int height = image.getHeight(null); BufferedImage bi = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB); Graphics g = bi.getGraphics(); //通过 BufferedImage 绘制图像并保存在其对象中 g.drawImage(image, 0, 0, width, height, null); g.dispose(); File f = new File(fileName); // 通过 ImageIO 将图像写入到文件 ImageIO.write(bi, "jpg", f); }使用 sendKeys(keysToSend) 批量上传文件
在 Selenium2.0 之前,要上传文件是比较麻烦的一件事件,因为点击 Upload File 控件会弹出 Windows 窗口以提供用户选择文件,但是 Window 窗口已经是浏览器之外的组件,所以 Selenium 本身没办法控制, 而必须使用 Java Robot 类来模拟键盘去操作剪切板实现上传功能,而且及其不稳定。 在 Selenium 2.0 之后,WebDriver 解决了这个问题。前面已经谈到过,直接使用 WebElement 类的 sendKeys(keysToSend) 方法就可以实现文件上传了。但是如果想批量上传文件,使用 element.sendKeys(“C:\\test\\upload\\test1.txt”, “C:\\test\\upload\\test2.txt”...) 方法也是不行的,它能通过执行,但是实际上没有上传成功。这时可以通过循环的方式来实现文件的批量上传,代码清单 13 是我在百度云上面批量上传文件的测试。
清单 13. 批量上传文件
/** * * @Description: 在百度云上测试文件批量上传功能,主要是通过循环的方式去做单一 * 的上传动作 , 登陆过程已经去掉 */ @Test public void test_mutilUploadFile() throws Exception { System.out.println("upload start"); // 获取上传控件元素 WebElement uploadButton = driver.findElement(By.name("html5uploader")); // 构建上传文件路径,将需要上传的文件添加到 CharSequence 数组 CharSequence[] files = new CharSequence[5]; files[0] = "C:\\test\\test1.txt"; files[1] = "C:\\test\\test2.txt"; files[2] = "C:\\test\\test3.txt"; files[3] = "C:\\test\\test4.txt"; files[4] = "C:\\test\\test5.txt"; // 循环列出每支需要上传的文件路径,做单一上传动作 for(CharSequence file: files){ uploadButton.sendKeys(file); } Thread.sleep(2000); System.out.println("upload end"); }当执行结束后,效果如图 1。
图 1. 批量上传文件

结束语
在 Selenium WebDriver 中,有了 Actions 类和 Keys 枚举对键盘和鼠标的操作已经做的非常到位,再结合 Java 本身 Robot、KeyEvent 等类的使用,基本上可以满足工作中遇到的对鼠标键盘操作的应用了。
其次要注意的地方是 WebDriver 对浏览器的支持问题,Selenium WebDriver 支持的浏览器非常广泛,从 IE、Firefox、Chrome 到 Safari 等浏览器, WebDriver 都有相对应的实现:InterntExplorerDriver、FirefoxDriver、ChromeDriver、SafariDriver、AndroidDriver、 IPhoneDriver、HtmlUnitDriver 等。根据个人的经验,Firefox 以及 Chrome 浏览器对 WebDriver 的支持最好了,Firefox 搭上 Firebug 以及 Firepath, 在写脚本的过程中非常方便,而 ChromeDriver 是 Google 公司自己支持与维护的项目。HtmlUnitDriver 速度最快,一个纯 Java 实现的浏览器。IE 比较慢,而且对于 Xpath 等支持不是很好。更多关于 Selenium WebDriver 的知识,大家可以从下面的链接去访问 Selenium 官方文档。
-
Selenium IDE 测试
2015-11-13 11:17:26
http://www.yiibai.com/selenium/selenium_ide_debugging.html
Selenium IDE 测试
调试是为了发现和修复测试脚本,任何脚本开发的共同步骤是错误的处理。为了使这一过程更加稳固,我们可以使用Selenium IDE的一个插件叫“Power Debugger”
Step 1 : 安装Selenium IDE的Power Debugger,导航到 https://addons.mozilla.org/en-US/firefox/addon/power-debugger-selenium-ide/ 然后点击 "Add to Firefox" 链接如下所示:

Step 2 : 现在启动 'Selenium IDE' 会发新的图标, "Pause on Fail" 在录制工具栏,如下图所示。点击它为 ON。 当再次点击,将它打开为"OFF"。

Step 3 : 用户可以打开 "pause on fail" 开或关在任何时间即使测试运行
Step 4 : 一旦测试在暂停的情况下,由于步骤中有一个失败,可以使用通常的暂停/步按钮继续执行测试。如果故障是在任何测试的情况下,最后一个命令执行不会被暂停。
Step 5 : 我们还可以使用断点来了解在这过程中到底发生了什么。插入一个特定步骤一个断点,执行从上下文“右键”,选择“toggle Break Yiibai”相关菜单。

Step 6 : 插入断点则显示暂停图标,特定步骤如下所示。

Step 7 : 当我们执行该脚本,该脚本将暂停执行插入断点的地方。这将有助于计算一个元素等的值/表示在用户执行过程中。

-
功能测试工具Selenium IDE
2015-11-13 10:04:55
http://jingyan.baidu.com/article/ea24bc39bc48dada62b33139.htmlSelenium IDE
Selenium IDE:一个专门用于Firefox浏览器的插件,能够录制回放用户在Firefox中的行为,并把所记录的Selenese (Selenium Commands)转化为HTML/Java/C#/Python/Perl/Php/Ruby等语言脚本。
一.安装IDE
方法1:
打开firefox浏览器,进入官方网址:http://seleniumhq.org/download/
找到selenium IDE的下载链接,firefox会有提示安装插件,点击安装即可。
方法二:
在firefox的菜单栏中选择tools (工具)--->add-ons Manager(添加组件) 然后搜索selenium IDE 点击下载安装重启即可。
安装Firebug,tools (工具)--->add-ons Manager(添加组件) 然后搜索firebug 点击下载安装重启即可。
二.使用IDE
1.启动

2.IDE启动后,弹出如下对话框:

脚本是由Command,Target,Value组成的表格,每个脚本都是由一条一条的Action(行为)组成,而每个Action又由(Command,Target,Value)三者组成。
一.脚本语言转换
脚本语言可以转换成java,c#,pathon,ruby,HTML等。
Options->format->
若点击没有反应,则进行如下操作:
Options->options…->勾选enable experimental meatures

文件->export test case as

Selenium IDE转换的脚本可以作为Selenium-RC的脚本基础
-
Selenium IDE下载
2015-11-12 17:48:39
http://www.yiibai.com/selenium/selenium_download_ide.htmlSelenium - IDE
http://docs.seleniumhq.org/download/
步骤 1 : 启动Firefox,然后导航到URL - http://seleniumhq.org/download/。 在Selenium IDE部分,单击显示如下所示当前版本号的链接。

步骤 2 : Firefox的附加组件通知弹出了允许和禁止的选项。用户必须允许安装。
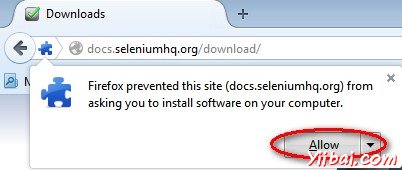
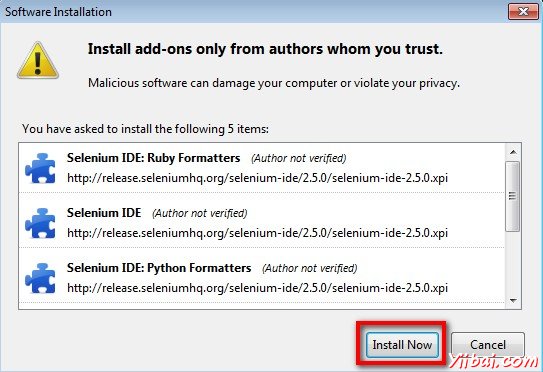
步骤3 : 加载项安装程序发出警告不可信的附加组件的用户。点击“Install Now”。
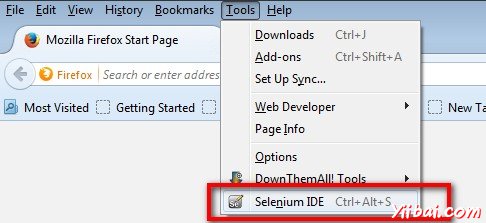
步骤 4 : Selenium IDE现在可以通过浏览访问 'Tools' >> 'Selenium IDE'。
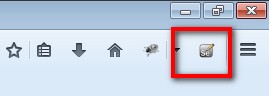
步骤 5 : 在Selenium IDE,也可以直接从快速访问菜单栏访问,如下图所示。
-
TestNG:基于注释的单元测试框架
2015-11-11 17:50:51
http://www.ibm.com/developerworks/cn/java/j-test-ng/Eclipse 3.1 中使用TestNG:基于注释的单元测试框架
这篇文章将为大家介绍TestNG这个新的测试框架的特性,以及TestNG优于Junit3.X的地方。
0
 评论:
评论:
TestNG(Test Next Generation),顾名思义,下一代的测试框架。它是基于J2SE5.0的注释特性的而构建的轻量级的单元测试框架结构。说起单元测试框架,大家都 会自然地联想到JUnit。用过JUnit3.X的程序开发人员,都会发现JUnit在提供了强大功能的同时,也存在很多令人沮丧的地方。其中一个问题就 是,JUnit3.x 在每个测试方法调用前和调用后都会调用setUp()和tearDown()的方法。如果开发人员希望在不同的测试方法中重用同一个JDBC连接或者 JNDI的Context的时候,会觉得很不方便。一般的解决这个问题的方法是使用静态方法,而这样的话,就必须小心并发控制的问题(多个线程访问共享的 静态对象)。除此之外,JUnit 3.X对于多线程测试也比较麻烦,需要其他模块的支持。
这篇文章将为大家介绍TestNG这个新的测试 框架的特性,以及TestNG优于Junit3.X的地方。众所周知,Eclipse不仅仅是功能强大的Java IDE,同时也是一个开放的应用集成平台。而Eclipse3.1提供了对J2SE5.0的支持。因此,笔者将以Eclipse为运行环境,介绍 Testng的安装,使用和运行。Eclipse3.1可以从http://www.eclipse.org/downloads/index.php下载。
关于注释
由于TestNG是基于J2SE5.0的注释特性所构建的。因此读者在阅读本文之前,必须了解注释的一些基本概念。关于J2SE的注释特性,笔者曾经在另一篇文章中详细的介绍过,详细介绍请参考"参考资料"。这里只简单的介绍一些概念。
注 释是J2SE5.0所新提供的对于元数据的支持。程序开发人员可以在不改变原有逻辑的情况下,在源文件嵌入一些补充的信息。注释都是由 @Interface annotationName 来声明的。注释可以用来修饰类定义,方法,域变量等等。使用的时候是在修饰的对象的定义前@annotationName。注释可以包含多个属性,使用的 时候为属性赋值,例如 @annotationName(prop1=value1,prop2=value2)。程序的开发人员还可以通过Java的反射特性,在运行时获得这 些注释的信息。在后面的章节中,大家会看到TestNG是如何使用它所定义的注释类型的来实现测试框架的。
安装TestNG
在 Eclipse中安装testNG很简单。和安装其他的plugin的方法相似。首先启动Eclipse3.1,在Help->Software Update->Find and Install, 在弹出的向导中,选择"Search New Features to Install", 点击"New Remote Site",如图1所示。在URL中输入 http://beust.com/eclipse,点击"OK"。如图2所示,点击"Finish",Eclipse会帮助你完成下面的安装。熟悉 Eclipse的读者对这个过程一定不会觉得陌生。
图1 新建Update Site

图2 安装TestNG

安装好TestNG后,在Eclipse中单击"Window"->Show View->Other->Java->TestNG, TestNG的视图就打开了。
图3 TestNG的视图

注意:TestNG的视图的作用时为了现实测试结果。为了显示视图的功能,图3的视图是运行了一个测试用例后的结果。读者如果是第一次打开视图,应该是空白的。
一个简单的例子
TestNG和JUnit不同,他使用注释、正则表达式和基于XML的配置文件对测试方法进行配置的。我们先来看一个简单的例子。
1) 在Eclipse中创建一个Java的项目,com.catherine.lab.testng.demo
2) 在Packet Explorer中,右键点击刚生成的项目,选择Properties。
3) 在Properties属性框中,选择"Java Build Path",点击"Add External JARs…"
4) 在文件浏览的对话框中,选择{eclipse 3.1 home directory}/plugins/com.beust.testng.eclipse_XXX/eclipse_testng.jar,以及 {eclipse 3.1 home directory}/plugins/com.beust.testng.eclipse_XXX/lib/testng-jdk14.jar/以及 testng-jdk15.jar. 点击OK
5) 在Project中创建一个package: com.catherine.lab.testng.firstTest。在package里边创建一个类:FristTestSample.
清单1 TestNG的第一个例子
package com.catherine.lab.testng.firstTest; import com.beust.testng.annotations.*; public class FirstTestSample { public FirstTestSample() { super(); } @Test public void testPass() { assert true : "This test should pass."; } @Test public void testFail() { assert false : "This test will fail"; } @Configuration(beforeTestClass = true) public void doBeforeTests() { System.out.println("invoke before test class!"); } @Configuration(afterTestClass = true) public void doAfterTests() { System.out.println("invoke after test class!"); } }6) 在Eclipse中打开Run->Run..,如图4所示。 首先在选择使用TestNG的Project,而后在选择编写了测试逻辑的Class,点击Run。测试结果就显示在TestNG的视图中了。如图5所示。
图4 配置运行TestNG的程序

图5 TestNG的运行结果

这是一个完整的测试用例。和JUnit不同,TestNG中实现测试逻辑的类不需要继承任何父类。测试方法也无需遵循testXXX的命名规则。
TestNG的类是大家所非常熟悉的普通的Java类,而在这个类中,所有的被@Test这个注释所修饰的方法都会被当作测试方法来运行。除了测试类之外,TestNG还需要了一个配置文件,用来配置测试过程。以下是一个简单的配置文件:testng.xml。
清单2 testNG的配置文件
<!DOCTYPE suite SYSTEM "http://beust.com/testng/testng-1.0.dtd" > <suite name="My First TestNG test"> <test name="Hello Test!"> <classes> <class name=" com.catherine.lab.testng.firstTest.FirstTestSample " /> </classes> </test> </suite>testng.xml可以配置测试套件<suite>,类似于JUnit的 TestSuite。而<test>类似于JUnit中的TestCase。所不同的是, TestNG中的测试套件可以包括多个测试用例,一个测试用例可以包括多个测试类,而一个测试类中可以定义多个测试方法。在下面的例子中,我们将看到这个 配置文件更复杂的应用。
在图4的运行配置中,我们也可以设置一个xml文件作为配置文件,而不是直接使用测试类。其实我们使用测试类的时 候,testNG也帮我们生成了一个缺省的xml文件。不相信的话,你可以切换到Resource Perspective,然后刷新Workspace,就会发现这个project里边生成了一个xml文件,而这个文件就是TestNG的缺省的配置文 件。
现在我们再回到清单1,大家在上面的程序清单中会发现,除了使用@Test这个注释以外,我们还使用了@Configuration这个注释。下面我们就来介绍@Configuration这个注释的用途。
在注释Configuration中,定义了以下的属性:
清单3 configuration中的属性
public boolean beforeSuite() default false; public boolean afterSuite() default false; public boolean beforeTest() default false; public boolean afterTest() default false; public boolean beforeTestClass() default false; public boolean afterTestClass() default false; public boolean beforeTestMethod() default false; public boolean afterTestMethod() default false;
- beforeSuite=true,所修饰的方法将在测试套件(也就是配置文件中的Suite Tag)中任何一个方法调用之前,调用一次
- afterSuite=true,所修饰的方法将在测试套件中所有方法都调用过后,调用一次
- beforeTest=true,在测试用例(配置文件中Test Tag)中任何一个测试方法调用之前,调用一次
- afterTest=true, 在测试用例中任何所有方法都调用之后,调用一次
- beforeTestClass=true,在测试类中任何测试方法调用之前,调用一次
- afterTestClass=true,在这个测试类中所有方法都调用过后,调用一次
- beforeTestMethod=true,在每个测试方法调用之前,调用一次
- afterTestMethod=true,在每个测试方法调用之后,调用一次
这个清单1中doBeforeTests()方法,在任何一个test方法调用之前被调用一次。doAfterTests,就是所有的test方法运行过了以后再调用一次。从Console输出的信息中,我们可以验证这一点:
图6 console输出的运行信息

更复杂的例子
上一节中我们介绍了使用testNG的一个最简单的例子,这一节中我们将介绍一些关于testNG的高级应用。 注释Test除了标志其修饰的方法为测试方法, 还提供了groups的属性。比如上面例子的两个方法testPass()和testFail(),我们可以给这两个方法加上group的属性。
清单4 测试@Test的groups属性
@Test(groups={"functional_test"}) public void testPass() { assert true : "This test should pass."; } @Test(groups={"checkin_test"}) public void testFail() { assert false : "This test will fail"; } }而后打开Run->Run…,在配置文件的Runtime配置中选择Groups,然后选择你要运行的group的名字。
图7 运行选定的测试组

这个时候我们从TestNG中看到测试结果,只有testPass运行了,而testFail因为不属于funcational_test这个组,因此并没有运行。
图8 运行结果

和第一个例子类似,虽然我们在这里并没有显示地定义配置文件,testNG已经生成了相应的配置文件了。在Resource Perspective底下可以看到这个文件:Custom_SuiteXXXX.xml.
清单5 自动生成的配置文件
<!DOCTYPE suite SYSTEM "http://beust.com/testng/testng-1.0.dtd" > <suite name="My First TestNG test"> <test name="Hello Test!"> <groups> <run> <include name="functional_test"/> </run> </groups> <classes> <class name=" com.catherine.lab.testng.firstTest.FirstTestSample " /> </classes> </test> </suite>除了groups属性以外,注释Test还支持属性dependsOnMethods和属性dependsOnGroups. 这两个属性主要用于规定测试方法的执行顺序。
TestNG并不保证按照定义的顺序执行测试方法。如果这些测试方法之间有依赖关系的话,那么我们就可以使用dependsOnXXXX的属性。我们还是看第一个例子,现在我们在这个例子里边增加了一个方法:
setupEnvforPass()。我们希望setupEnvforPass()方法在testPass方法前执行,我们修改了testPass的test注释。如清单6所示:
清单6 测试@Test的属性dependsOnMethods
@Test(groups={"functional_test"}, dependsOnMethods = { "setEnvForPass" }) public void testPass() { assert true : "This test should pass."; } @Test(groups={"checkin_test"}) public void testFail() { assert false : "This test will fail"; } @Test(groups = {"init"}) public void setEnvForPass(){ assert true: "This is dependent method" } }运行配置和配置文件都不需要改动,现在我们来运行这个例子,测试结果如图9所示。大家可以看到,虽然我们在 testPass方法之后定义了,setEnvForPass方法,但是由于我们将setEnvForPass定义为testPass的以来方 法,setEnvForPass在testPass前执行了。
同样,我们可以定义dependsOnGroups的属性,这样只有 Groups中所有的方法都被执行完,这个方法才会被执行。注意:如果depensOnGroups中制定的group在配置文件中被excluded 了,那么这个方法会依然被执行。但是如果指定的group在配置文件中被include了,而group中的方法有错误的话,那么这个方法会被skip, 不会被执行。
图9 运行结果

下面我们要介绍一个新的注释类型: @Parameter。
TestNG 的测试方法可以带有参数,参数可以通过@Parameter来声明,具体的参数值在testng.xml中定义。这是testng的一个很优越的特性。我 们还是在以前的例子上的基础上来验证这个特性。我们为setEnvForPass这个方法定义一个参数,target_server,并且在测试方法中打 印这个参数。
清单7 测试注释Parameter
@Parameters({ "target_server" }) @Test(groups = {"init"}) public void setEnvForPass(String targetServer){ assert true: "This is dependent method"; System.out.println(targetServer); } }Target_server的值在testng.xml中定义。在TestNG的运行时配置中选择Suite,然 后Browse清单8中定义好的的testng.xml。运行TestNG,我们从Console的运行结果中看到,target_server的值被打 印出来了。
清单8 自定义的配置文件
<!DOCTYPE suite SYSTEM "http://beust.com/testng/testng-1.0.dtd"> <suite name="Custom suite"> <parameter name="target_server" value="127.0.0.1"/> <test verbose="6" name="Test for 1 classes" annotations="1.5"> <groups> <run> <include name="functional_test"/> </run> </groups> <classes> <class name="com.catherine.lab.testng.firstTest.FirstTestSample"> </class> </classes> </test> </suite>测试方法的参数可以是任意多个,只要你通过配置文件传入了正确的参数,那么测试方法中就可以使用这些参数了。不过需要注意的是,参数是有作用域的,比如参数可以在配置文件的suite和test之后定义,而如果两个参数的名称一样,test中定义的参数值有较高的优先级。
testNG可以从多个线程中运行测试方法,只需要将配置文件中suite的parallel属性设为true。线程的数目在thread-count中设置。如果两个方法有依赖关系,那么他们将在一个线程中运行,除此之外,都可以在多个线程中并发的运行。
<suite name="My suite" parallel="true" thread-count="10">
除了以上介绍的特性以外,(请参阅"参考资料")
- TestNG提供了注释Factory,用来动态生成测试方法的参数。
- TestNG还提供**tTask <testng>,可以从Ant脚本中调用testNG。
- TestNG的可以调用JUnit的test cases。只需要配置文件中声明
<test name="Test1" junit="true">
<classes ..> - TestNG还可以从程序中调用:
TestNG testng = new TestNG();
testng.setTestClasses(Class[] {});
testng.run();
除了TestNG之外… 从上面的例子可以看出,TestNG这个单元测试框架的功能是很强大的,而且简单易学。开发者只需要使用TestNG所提供的注释和正确的配置文件,可以轻松地完成复杂的测试用例。
除 了TestNG之外,JTiger也是一种基于J2SE5.0的单元测试框架,其中应用了大量J2SE5.0的新特性,比如注释和静态Import。和 TestNG类似, JTiger提供了大量内建的注释类型, 比如JTiger也使用注释@Test标明测试方法, 使用注释@Category表示这个测试方法属于那一类,类似于TestNG的@Test的groups属性。和TestNG不同的是,JTiger并没 有使外部的配置文件。
总之,TestNG和JTiger都解决了JUnit3.x中存在的问题,提供了大量优于JUnit3.x的特性。而 JUnit也并没有就此止步,即将发布的JUnit4.0有了根本性的变化,JUnit4.0也将变成基于注释的测试系统。同样也将提供大量的内建注释类 型:比如@Test, @Before, @After等等。这些引入的注释类型,使得JUnit克服了以前的问题,拥有了新的活力。Justine Lee在他的文章中,详细地比较了这三种测试框架,请参阅"参考资料"。
选用何种测试框架,取决于很多的因素。虽然JUnit具有众多的拥 簇者,但是TestNG和JTiger的崛起也不可小觑的。应该说,TestNG是建立在JUnit3.x之上的,吸取了JUnit的优点,同时也摈弃和 改正了JUnit的缺点。笔者曾经在Eclipse中使用过JUnit3.x和TestNG,个人认为TestNG使用起来比JUnit3.x要更为方 便。但是JUnit提供测试插件(plug-in)的功能,TestNG目前并没有提供这种功能。不过我们有理由相信,在不久的将来TestNG会对于 eclipse插件提供更为丰富的支持。本文通过对TestNG的介绍,希望能够为大家在选择测试框架的时候提供一个新的选择。
-
Selenium之利用Excel实现参数化
2015-11-10 17:50:34
http://www.blogjava.net/qileilove/archive/2014/11/26/420620.html说明:我是通过Workbook方式来读取excel文件的,这次以登陆界面为例备注:使用Workbook读取excel文件,前提是excel需要2003版本,其他版本暂时不支持具体步骤:第一步:新建一个excel文件,并且输入数据内容第二步:在eclipse中新建一个java class,编写获取excel文件的代码CODE:package test.test2;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import jxl.Sheet;
import jxl.Workbook;
/*
* 获取Excel文件的内容,使用Workbook方式来读取excel
*/
public class ExcelWorkBook {
// 利用list集合来存放数据,其类型为String
private List<String> list = new ArrayList<String>();
// 通过Workbook方式来读取excel
Workbook book;
String username;
/*
* 获取excel文件第一列的值,这里取得值为username
*/
String sourceFile = "D:\\worktools\\workbench\\test3\\src\\test\\test2\\login.xls";;
public List<String> readUsername(String sourceString) throws IOException, Exception {
List<String> userList = new ArrayList<String>();
try {
Workbook book = Workbook.getWorkbook(new File(sourceFile));
Sheet sheet = book.getSheet(0);
// 获取文件的行数
int rows = sheet.getRows();
// 获取文件的列数
int cols = sheet.getColumns();
// 获取第一行的数据,一般第一行为属性值,所以这里可以忽略
String col1 = sheet.getCell(0, 0).getContents().trim();
String col2 = sheet.getCell(1, 0).getContents().trim();
System.out.println(col1 + "," + col2);
// 把第一列的值放在userlist中
for (int z = 1; z < rows; z++) {
String username = sheet.getCell(0, z).getContents();
userList.add(username);
}
} catch (Exception e) {
e.printStackTrace();
}
// 把获取的值放回出去,方便调用
return userList;
}
/*
* 获取excel文件第二列的值,这里取得值为password
*/
public List<String> readPassword(String sourceString) throws IOException, Exception {
List<String> passList = new ArrayList<String>();
try {
Workbook book = Workbook.getWorkbook(new File(sourceFile));
Sheet sheet = book.getSheet(0);
int rows = sheet.getRows();
for (int z = 1; z < rows; z++) {
String password = sheet.getCell(1, z).getContents();
passList.add(password);
}
} catch (Exception e) {
e.printStackTrace();
}
return passList;
}
public List<String> getList() {
return list;
}
}第三步:新建一个TestNg Class,把excel数据填写到测试界面,具体代码如下:CODE:package test.test2;
//import java.io.File;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.apache.log4j.Logger;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
//import org.openqa.selenium.firefox.FirefoxProfile;
import org.testng.annotations.BeforeClass;
import org.testng.annotations.Test;
//import File.ExcelWorkBook;
public class LoginCenter2 {
private WebDriver driver;
private String url;
String sourceFile = "D:\\worktools\\workbench\\test3\\src\\test\\test2\\login.xls";
private static Logger log = Logger.getLogger(LoginCenter2.class);
@BeforeClass
public void testBefore() {
// 设置firefox浏览器
// FirefoxProfile file=new FirefoxProfile(new
// File("C:\\Users\\qinfei\\AppData\\Roaming\\Mozilla\\Firefox\\Profiles\\t5ourl6s.selenium"));
// driver=new FirefoxDriver(file);
driver = new FirefoxDriver();
url = "http://aaaa.test.bj";
}
@Test
public void login() throws Exception {
// 初始化ExcelWorkBook Class
ExcelWorkBook excelbook = new ExcelWorkBook();
// 进入到你的测试界面
driver.get(url);
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
try {
// 把取出的username放在userlist集合里面
List<String> userList = excelbook.readUsername(sourceFile);
// 把取出的password放在passlist集合里面
List<String> passList = excelbook.readPassword(sourceFile);
// 把取出来的值,输入到界面的输入框中
int usersize = userList.size();
for (int i = 0; i < usersize; i++) {
// 通过id定位到username输入框
WebElement username = driver.findElement(By.id("username"));
// 通过id定位到password输入框
WebElement password = driver.findElement(By.id("password"));
// 通过id定位登录按钮
WebElement submit = driver.findElement(By.id("login_form_submit"));
// 清除username输入框的内容
username.clear();
// 把list中数据一个一个的取出来
String name = userList.get(i);
username.sendKeys(name);
log.info(name);
String pass = passList.get(i);
password.sendKeys(pass);
log.info(pass);
// 点击登录按钮
submit.click();
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
// 通过xpath定位登出按钮
WebElement logoutButton = driver.findElement(By.xpath(".//*[@onclick='logout()']"));
logoutButton.click();
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
driver.get(url);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
-
selenium webdriver读取excel进行数据驱动测试
2015-11-10 17:47:46
http://www.cnblogs.com/liu-ke/p/4223807.html
最近做自动化需要从文件读取数据做参数化,网上发现一个不错的解决方案。准备:新建一个excel文件,文件名为测试类名,sheet名为测试方法名excel第一行为标题,从第二行开始为测试数据build path:jxl.jarcode:

1 import java.io.FileInputStream; 2 import java.io.InputStream; 3 import java.util.HashMap; 4 import java.util.Iterator; 5 import java.util.Map; 6 7 import org.testng.Assert; 8 9 import jxl.*; 10 11 /** 12 * Excel放在Data文件夹下</p> 13 * Excel命名方式:测试类名.xls</p> 14 * Excel的sheet命名方式:测试方法名</p> 15 * Excel第一行为Map键值</p> 16 * 代码参考郑鸿志的Blog 17 * {@link www.zhenghongzhi.cn/post/42.html} 18 * @ClassName: ExcelDataProvider 19 * @Description: TODO(读取Excel数据) 20 */ 21 public class ExcelDataProvider implements Iterator<Object[]> { 22 23 private Workbook book = null; 24 private Sheet sheet = null; 25 private int rowNum = 0; 26 private int currentRowNo = 0; 27 private int columnNum = 0; 28 private String[] columnnName; 29 30 public ExcelDataProvider(String classname, String methodname) { 31 32 try { 33 34 int dotNum = classname.indexOf("."); 35 36 if (dotNum > 0) { 37 classname = classname.substring(classname.lastIndexOf(".") + 1, 38 classname.length()); 39 } 40 //从/data文件夹下读取以类名命名的excel文件 41 String path = "data/" + classname + ".xls"; 42 InputStream inputStream = new FileInputStream(path); 43 44 book = Workbook.getWorkbook(inputStream); 45 //取sheet 46 sheet = book.getSheet(methodname); 47 rowNum = sheet.getRows(); 48 Cell[] cell = sheet.getRow(0); 49 columnNum = cell.length; 50 columnnName = new String[cell.length]; 51 52 for (int i = 0; i < cell.length; i++) { 53 columnnName[i] = cell[i].getContents().toString(); 54 } 55 this.currentRowNo++; 56 57 } catch (Exception e) { 58 e.printStackTrace(); 59 Assert.fail("unable to read Excel data"); 60 } 61 } 62 63 public boolean hasNext() { 64 65 if (this.rowNum == 0 || this.currentRowNo >= this.rowNum) { 66 67 try { 68 book.close(); 69 } catch (Exception e) { 70 e.printStackTrace(); 71 } 72 return false; 73 } else { 74 // sheet下一行内容为空判定结束 75 if ((sheet.getRow(currentRowNo))[0].getContents().equals("")) 76 return false; 77 return true; 78 } 79 } 80 81 public Object[] next() { 82 83 Cell[] c = sheet.getRow(this.currentRowNo); 84 Map<String, String> data = new HashMap<String, String>(); 85 // List<String> list = new ArrayList<String>(); 86 87 for (int i = 0; i < this.columnNum; i++) { 88 89 String temp = ""; 90 91 try { 92 temp = c[i].getContents().toString(); 93 } catch (ArrayIndexOutOfBoundsException ex) { 94 temp = ""; 95 } 96 97 // if(temp != null&& !temp.equals("")) 98 // list.add(temp); 99 data.put(this.columnnName[i], temp); 100 } 101 Object object[] = new Object[1]; 102 object[0] = data; 103 this.currentRowNo++; 104 return object; 105 } 106 107 public void remove() { 108 throw new UnsupportedOperationException("remove unsupported."); 109 } 110 }
-
多浏览器测试-Selenium
2015-11-10 11:34:43
package com.gx.test;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.ie.InternetExplorerDriver;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.*;
import org.testng.annotations.*;
//http://www.yiibai.com/selenium/selenium_multi_browser_testing.html
public class MultiBrowser
{
private WebDriver driver;
// private String URL = "http://www.calculator.net";
private String URL="http://www.baidu.com";
@Parameters("browser")
@BeforeTest
public void launchapp(String browser)
{
if (browser.equalsIgnoreCase("firefox"))
{
System.out.println(" Executing on FireFox");
driver = new FirefoxDriver();
driver.get(URL);
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
driver.manage().window().maximize();
}
else if (browser.equalsIgnoreCase("chrome"))
{
System.out.println(" Executing on CHROME");
System.setProperty("webdriver.chrome.driver", "E://Sheena//liyue_Selenium2_150818//chromedriver.exe");
System.setProperty("webdriver.chrome.bin", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\Chrome.exe");
driver = new ChromeDriver();
driver.get(URL);
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
driver.manage().window().maximize();
}
else if (browser.equalsIgnoreCase("ie"))
{
System.out.println("Executing on IE");
System.setProperty("webdriver.ie.driver", "E://Sheena//liyue_Selenium2_150818//IEDriverServer.exe");
// DesiredCapabilities ieCapabilities = DesiredCapabilities.internetExplorer();
// ieCapabilities.setCapability(InternetExplorerDriver.INTRODUCE_FLAKINESS_BY_IGNORING_SECURITY_DOMAINS,true);
// driver = new InternetExplorerDriver(ieCapabilities);
driver = new InternetExplorerDriver();
driver.get(URL);
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
driver.manage().window().maximize();
}
else
{
throw new IllegalArgumentException("The Browser Type is Undefined");
}
}
@Test
public void calculatepercent()
{
// driver.findElement(By.xpath(".//*[@id='menu']/div[3]/a")).click(); // Click on Math Calculators
// driver.findElement(By.xpath(".//*[@id='menu']/div[4]/div[3]/a")).click(); // Click on Percent Calculators
// driver.findElement(By.id("cpar1")).sendKeys("10"); // Enter value 10 in the first number of the percent Calculator
// driver.findElement(By.id("cpar2")).sendKeys("50"); // Enter value 50 in the second number of the percent Calculator
// driver.findElement(By.xpath(".//*[@id='content']/table/tbody/tr/td[2]/input")).click(); // Click Calculate Button
// String result = driver.findElement(By.xpath(".//*[@id='content']/p[2]/span/font/b")).getText(); // Get the Result Text based on its xpath
String result="5";
System.out.println(" The Result is " + result); //Print a Log In message to the screen
if(result.equals("5"))
{
System.out.println(" The Result is Pass");
}
else
{
System.out.println(" The Result is Fail");
}
}
@AfterTest
public void closeBrowser()
{
driver.close();
}
}
创建一个XML这将有助于我们在参数设置浏览器的名字,不要忘记提及 parallel="tests"为了同时在所有浏览器中执行。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd" >
<suite name="Simple HTML-XML Suite">
<test name="FirefoxTest">
<parameter name="browser" value="firefox" />
<classes>
<class name="com.gx.test.MultiBrowser"/>
</classes>
</test>
<test name="ChromeTest">
<parameter name="browser" value="chrome" />
<classes>
<class name="com.gx.test.MultiBrowser"/>
</classes>
</test>
<test name="IETest">
<parameter name="browser" value="ie" />
<classes>
<class name="com.gx.test.MultiBrowser"/>
</classes>
</test>
</suite>
通过对XML文件进行右键点击执行脚本,然后选择 'Run As' >> 'TestNG' 方式,如下图所示。输出
所有的浏览器将平行展开,结果将被打印在控制台上。
注:对于我们在IE浏览器执行成功确保复选框“启用保护模式”下的“IE选项中的安全选项卡中选中或未在所有区域中未检查。
TestNG的结果以HTML格式来查看详细的分析。
-
异常处理及截图
2015-11-05 16:30:09
http://www.yiibai.com/selenium/selenium_exception_handling.html
异常处理
当我们正在开发测试中,我们要确保,即使测试失败的脚本可以继续执行。如果最坏的情况都处理不好意外的异常会被抛出。
如果发生异常,由于无法找到元素,或者预期的结果不与实际值相符,我们应该抓住这个异常并结束测试的逻辑方式,以防脚本本身突然终止。
语法
实际的代码应该放在try块和异常后的动作应该放在catch块。请注意:“finally'块就算没有问题,不管脚本是否已经被抛出的异常都会执行。
try { //Perform. Action } catch(ExceptionType1 exp1) { //Catch block 1 } catch(ExceptionType2 exp2) { //Catch block 2 } catch(ExceptionType3 exp3) { //Catch block 3 } finally { //The finally block always executes. }
示例
如果没有找到(因为任何好的理由)元素,我们应该确保走出的功能顺利。所以,总是需要有try-catch块,如果想要的跟做的是一样的。
public static WebElement lnk_percent_calc(WebDriver driver)throws Exception { try { element = driver.findElement(By.xpath(".//*[@id='menu']/div[4]/div[3]/a")); return element; } catch (Exception e1) { // Add a message to your Log File to capture the error Logger.error("Link is not found."); // Take a screenshot which will be helpful for analysis. File screenshot = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE); FileUtils.copyFile(screenshot, new File("D:\\framework\\screenshots.jpg")); throw(e1); } }
-
LR11+Win7 64bit+IE9
2015-11-02 13:52:02
LR11+Win7 64bit+IE10 一直无法录制脚本, 后来才知道LR11最高支持IE9, 卸载IE10, 安装IE9, 终于可以录制脚本了 -
LoadRunner 11 error:Cannot initialize driver dll
2015-11-02 09:55:51
这个错误很容易解决,使用win7系统时,有些程序要以管理员身份才能运行。解决方案:右键选择:“以管理员身份运行”即可。
-
Selenium IDE验证点
2015-10-30 18:07:04
http://www.yiibai.com/selenium/selenium_ide_verification_points.html
Selenium IDE验证点
我们还开发了测试用例需要检查一个Web页面的属性。这需要维护和验证命令。有两种方法可以验证点到任何脚本
插入记录模式中的任何验证点单击“右键”元素,并选择“Show all Available Commands”,如下图所示。

我们也可以通过执行“右键”,然后选择“Insert New Command”插入一个命令。

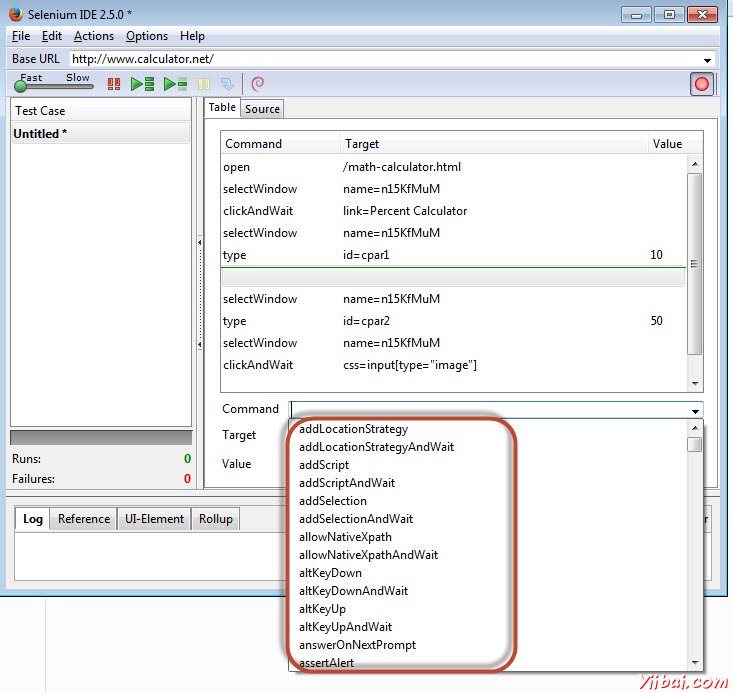
插入新的命令后,单击“Command”下拉列表,选择如下图所示的命令的列表提供适当的验证点
下面是主要用于验证的命令,这有助于我们检查一个特定步骤已通过或失败。
-
verifyElementPresent
-
assertElementPresent
-
verifyElementNotPresent
-
assertElementNotPresent
-
verifyText
-
assertText
-
verifyAttribute
-
assertAttribute
-
verifyChecked
-
assertChecked
-
verifyAlert
-
assertAlert
-
verifyTitle
-
assertTitle
同步点
在程序执行时,应用程序可能由服务器的负载情况来决定响应速度,因此,它必需要应用和脚本同步。下面是几个命令,我们可以用它来确保脚本和应用程序同步。
-
waitForAlertNotPresent
-
waitForAlertPresent
-
waitForElementPresent
-
waitForElementNotPresent
-
waitForTextPresent
-
waitForTextNotPresent
-
waitForPageToLoad
-
waitForFrameToLoad
-
-
TestNG Eclipse插件
2015-10-30 18:05:17
http://www.yiibai.com/html/testng/2013/0916311.htmlTestNG教程
TestNG是一个测试框架,其灵感来自JUnit和NUnit,但同时引入了一些新的功能,使其功能更强大,使用更方便。
TestNG设计涵盖所有类型的测试:单元,功能,端到端,集成等,它需要JDK5或更高的JDK版本。
本教程将TestNG框架需要测试的企业级应用提供健壮性和可靠性上给你带来很大的理解。
读者
本教程是专为愿意学习TestNG的框架软件专业人员。本教程帮助你理解TestNG的框架概念,并完成本教程后,将在把自己的专业知识水平较高的水平。
前提条件
在继续本教程之前,您应该了解基本的Java编程语言,文本编辑器和运行程序等,因为你要使用TestNG处理Java项目测试各级(单元,功能完善,端到端,集成等),所以如果你有软件开发和软件测试过程这些知识,那对理解和使用TestNG将是一个比大的帮助。
本站文章除注明转载外,均为本站原创或编译
欢迎任何形式的转载,但请务必注明出处,尊重他人劳动,传播学习教程;
转载请注明:文章转载自:易百教程 [http://www.yiibai.com]
本文标题:TestNG教程首页
转载请保留原文链接:http://www.yiibai.com/html/testng/2013/0913291.html
-
这种取log的方式不错
2015-10-20 15:34:30
这种取log的方式不错 -
log4j:WARN Unsupported encoding?
2015-10-20 14:47:04
运行程序时出现警告:
log4j:WARN Error initializing output writer.
log4j:WARN Unsupported encoding?
设置编码那行有空格。。。 去掉空格就OK了.
-
selenium webdriver学习------如何操作select下拉框
2015-10-15 14:57:49
http://blog.sina.com.cn/s/blog_71a536990101azot.html
下面我们来看一下selenium webdriver是如何来处理select下拉框的,以http://passport.51.com/reg2.5p这个页面为例。这个页面中有4个下拉框,下面演示4种选中下拉框选项的方法。select处理比较简单,直接看代码吧:)
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.ui.Select;public class SelectsStudy {
public static void main(String[] args) {
// TODO Auto-generated method stub
System.setProperty("webdriver.firefox.bin","D:\\Program Files\\Mozilla Firefox\\firefox.exe");
WebDriver dr = new FirefoxDriver();
dr.get("http://passport.51.com/reg2.5p");
//通过下拉列表中选项的索引选中第二项,即2011年
Select selectAge = new Select(dr.findElement(By.id("User_Age")));
selectAge.selectByIndex(2);
//通过下拉列表中的选项的value属性选中"上海"这一项
Select selectShen = new Select(dr.findElement(By.id("User_Shen")));
selectShen.selectByValue("上海");
//通过下拉列表中选项的可见文本选中"浦东"这一项
Select selectTown = new Select(dr.findElement(By.id("User_Town")));
selectTown.selectByVisibleText("浦东");
//这里只是想遍历一下下拉列表所有选项,用click进行选中选项
Select selectCity = new Select(dr.findElement(By.id("User_City")));
for(WebElement e : selectCity.getOptions())
e.click();
} }
从上面可以看出,对下拉框进行操作时首先要定位到这个下拉框,new 一个Selcet对象,然后对它进行操作。
INFO comes from :http://jarvi.iteye.com/blog/1450883
-
Android autotest - Monkey tool
2015-09-17 09:57:42
http://www.cnblogs.com/yyangblog/archive/2011/03/10/1980068.html
一、 什么是Monkey
Monkey是Android中的一个命令行工具,可以运行在模拟器里或实际设备中。它向系统发送伪随机的用户事件流(如按键输入、触摸屏输入、手势输入等),实现对正在开发的应用程序进行压力测试。Monkey测试是一种为了测试软件的稳定性、健壮性的快速有效的方法。
二、 Monkey的特征
1、测试的对象仅为应用程序包,有一定的局限性。
2、 Monky测试使用的事件流数据流是随机的,不能进行自定义。
3、可对MonkeyTest的对象,事件数量,类型,频率等进行设置。
三、Monkey的基本用法
基本语法如下:
$ adb shell monkey [options]
如果不指定options,Monkey将以无反馈模式启动,并把事件任意发送到安装在目标环境中的全部包。下面是一个更为典型的命令行示例,它启动指定的应用程序,并向其发送500个伪随机事件:
$ adb shell monkey -p your.package.name -v 500
四、Monkey测试的一个实例
通过这个实例,我们能理解Monkey测试的步骤以及如何知道哪些应用程序能够用Monkey进行测试。
Windows下(注:2—4步是为了查看我们可以测试哪些应用程序包,可省略):
1、 通过eclipse启动一个Android的emulator
2、 在命令行中输入:adb devices查看设备连接情况
C:\Documents and Settings\Administrator>adb devices
List of devices attached
emulator-5554 device
3、 在有设备连接的前提下,在命令行中输入:adb shell 进入shell界面
C:\Documents and Settings\Administrator>adb shell
#
4、 查看data/data文件夹下的应用程序包。注:我们能测试的应用程序包都在这个目录下面
C:\Documents and Settings\Administrator>adb shell
# ls data/data
ls data/data
com.google.android.btrouter
com.android.providers.telephony
com.android.mms
com.android.providers.downloads
com.android.deskclock
com.android.email
com.android.providers.media
com.android.settings
5、 以com.android.email作为对象进行MonkeyTest
#monkey -p com.android.email -v 500
其中-p表示对象包 –v 表示事件数量
运行过程中,Emulator中的应用程序在不断地切换画面。
按照选定的不同级别的反馈信息,在Monkey中还可以看到其执行过程报告和生成的事件。
五、关于Monkey测试的停止条件
Monkey Test执行过程中在下列三种情况下会自动停止:
1、如果限定了Monkey运行在一个或几个特定的包上,那么它会监测试图转到其它包的操作,并对其进行阻止。
2、如果应用程序崩溃或接收到任何失控异常,Monkey将停止并报错。
3、如果应用程序产生了应用程序不响应(application not responding)的错误,Monkey将会停止并报错。
通过多次并且不同设定下的Monkey测试才算它是一个稳定性足够的程序。
















标题搜索
我的存档
数据统计
- 访问量: 283467
- 日志数: 198
- 建立时间: 2008-08-25
- 更新时间: 2019-11-01
