
-
WEB测试(转载)
2007-02-15 08:56:05
1. 功能测试
1.1.链接测试
链接是 Web 应用系统的一个主要特征,它是在页面之间切换和指导用户去一些不知道地址的页面的主要手段。链接测试可分为三个方面。首先,测试所有链接是否按指示的那样确实链接到了该链接的页面;其次,测试所链接的页面是否存在;最后,保证 Web 应用系统上没有孤立的页面,所谓孤立页面是指没有链接指向该页面,只有知道正确的 URL 地址才能访问。
链接测试可以自动进行,现在已经有许多工具可以采用。链接测试必须在集成测试阶段完成,也就是说,在整个 Web 应用系统的所有页面开发完成之后进行链接测试。
1.2. 表单测试
当用户给 Web 应用系统管理员提交信息时,就需要使用表单操作,例如用户注册、登陆、信息提交等。在这种情况下,我们必须测试提交操作的完整性,以校验提交给服务器的信息的正确性。例如:用户填写的出生日期与职业是否恰当,填写的所属省份与所在城市是否匹配等。如果使用了默认值,还要检验默认值的正确性。如果表单只能接受指定的某些值,则也要进行测试。例如:只能接受某些字符,测试时可以跳过这些字符,看系统是否会报错。
1.3.Cookies测试
Cookies 通常用来存储用户信息和用户在某应用系统的操作,当一个用户使用 Cookies 访问了某一个应用系统时, Web 服务器将发送关于用户的信息,把该信息以 Cookies 的形式存储在客户端计算机上,这可用来创建动态和自定义页面或者存储登陆等信息。
如果 Web 应用系统使用了 Cookies ,就必须检查 Cookies 是否能正常工作。测试的内容可包括 Cookies 是否起作用,是否按预定的时间进行保存,刷新对 Cookies 有什么影响等。
1.4.设计语言测试
Web 设计语言版本的差异可以引起客户端或服务器端严重的问题,例如使用哪种版本的 HTML 等。当在分布式环境中开发时,开发人员都不在一起,这个问题就显得尤为重要。除了 HTML 的版本问题外,不同的脚本语言,例如 Java 、 Javascrīpt 、 ActiveX 、 VBscrīpt 或 Perl 等也要进行验证。
1.5.数据库测试
在 Web 应用技术中,数据库起着重要的作用,数据库为 Web 应用系统的管理、运行、查询和实现用户对数据存储的请求等提供空间。在 Web 应用中,最常用的数据库类型是关系型数据库,可以使用 SQL 对信息进行处理。在使用了数据库的 Web 应用系统中,一般情况下,可能发生两种错误,分别是数据一致性错误和输出错误。数据一致性错误主要是由于用户提交的表单信息不正确而造成的,而输出错误主要是由于网络速度或程序设计问题等引起的,针对这两种情况,可分别进行测试。
2. 性能测试
2.1.连接速度测试
用户连接到 Web 应用系统的速度根据上网方式的变化而变化,他们或许是电话拨号,或是宽带上网。当下载一个程序时,用户可以等较长的时间,但如果仅仅访问一个页面就不会这样。如果 Web 系统响应时间太长(例如超过 5 秒钟),用户就会因没有耐心等待而离开。
另外,有些页面有超时的限制,如果响应速度太慢,用户可能还没来得及浏览内容,就需要重新登陆了。而且,连接速度太慢,还可能引起数据丢失,使用户得不到真实的页面。
2.2.负载测试
负载测试是为了测量 Web 系统在某一负载级别上的性能,以保证 Web 系统在需求范围内能正常工作。负载级别可以是某个时刻同时访问 Web 系统的用户数量,也可以是在线数据处理的数量。例如: Web 应用系统能允许多少个用户同时在线?如果超过了这个数量,会出现什么现象? Web 应用系统能否处理大量用户对同一个页面的请求?
2.3.压力测试
负载测试应该安排在 Web 系统发布以后,在实际的网络环境中进行测试。因为一个企业内部员工,特别是项目组人员总是有限的,而一个 Web 系统能同时处理的请求数量将远远超出这个限度,所以,只有放在 Internet 上,接受负载测试,其结果才是正确可信的。
进行压力测试是指实际破坏一个 Web 应用系统,测试系统的反映。压力测试是测试系统的限制和故障恢复能力,也就是测试 Web 应用系统会不会崩溃,在什么情况下会崩溃。黑客常常提供错误的数据负载,直到 Web 应用系统崩溃,接着当系统重新启动时获得存取权。
压力测试的区域包括表单、登陆和其他信息传输页面等。
3. 可用性测试
3.1.导航测试
导航描述了用户在一个页面内操作的方式,在不同的用户接口控制之间,例如按钮、对话框、列表和窗口等;或在不同的连接页面之间。通过考虑下列问题,可以决定一个 Web 应用系统是否易于导航:导航是否直观? Web 系统的主要部分是否可通过主页存取? Web 系统是否需要站点地图、搜索引擎或其他的导航帮助?
在一个页面上放太多的信息往往起到与预期相反的效果。 Web 应用系统的用户趋向于目的驱动,很快地扫描一个 Web 应用系统,看是否有满足自己需要的信息,如果没有,就会很快地离开。很少有用户愿意花时间去熟悉 Web 应用系统的结构,因此, Web 应用系统导航帮助要尽可能地准确。
导航的另一个重要方面是 Web 应用系统的页面结构、导航、菜单、连接的风格是否一致。确保用户凭直觉就知道 Web 应用系统里面是否还有内容,内容在什么地方。
Web 应用系统的层次一旦决定,就要着手测试用户导航功能,让最终用户参与这种测试,效果将更加明显。
3.2.图形测试
在 Web 应用系统中,适当的图片和动画既能起到广告宣传的作用,又能起到美化页面的功能。一个 Web 应用系统的图形可以包括图片、动画、边框、颜色、字体、背景、按钮等。图形测试的内容有:
( 1 )要确保图形有明确的用途,图片或动画不要胡乱地堆在一起,以免浪费传输时间。 Web 应用系统的图片尺寸要尽量地小,并且要能清楚地说明某件事情,一般都链接到某个具体的页面。
( 2 )验证所有页面字体的风格是否一致。
( 3 )背景颜色应该与字体颜色和前景颜色相搭配。
( 4 )图片的大小和质量也是一个很重要的因素,一般采用 JPG 或 GIF 压缩。
3.3.内容测试
内容测试用来检验 Web 应用系统提供信息的正确性、准确性和相关性。
信息的正确性是指信息是可靠的还是误传的。例如,在商品价格列表中,错误的价格可能引起财政问题甚至导致法律纠纷;信息的准确性是指是否有语法或拼写错误。这种测试通常使用一些文字处理软件来进行,例如使用 Microsoft Word 的 " 拼音与语法检查 " 功能;信息的相关性是指是否在当前页面可以找到与当前浏览信息相关的信息列表或入口,也就是一般 Web 站点中的所谓 " 相关文章列表 " 。
3.4.整体界面测试
整体界面是指整个 Web 应用系统的页面结构设计,是给用户的一个整体感。例如:当用户浏览 Web 应用系统时是否感到舒适,是否凭直觉就知道要找的信息在什么地方?整个 Web 应用系统的设计风格是否一致?
对整体界面的测试过程,其实是一个对最终用户进行调查的过程。一般 Web 应用系统采取在主页上做一个调查问卷的形式,来得到最终用户的反馈信息。
对所有的可用性测试来说,都需要有外部人员(与 Web 应用系统开发没有联系或联系很少的人员)的参与,最好是最终用户的参与。
4. 客户端兼容性测试
4.1.平台测试
市场上有很多不同的操作系统类型,最常见的有 Windows 、 Unix 、 Macintosh 、 Linux 等。 Web 应用系统的最终用户究竟使用哪一种操作系统,取决于用户系统的配置。这样,就可能会发生兼容性问题,同一个应用可能在某些操作系统下能正常运行,但在另外的操作系统下可能会运行失败。
因此,在 Web 系统发布之前,需要在各种操作系统下对 Web 系统进行兼容性测试。
4.2.浏览器测试
浏览器是 Web 客户端最核心的构件,来自不同厂商的浏览器对 Java ,、 Javascrīpt 、 ActiveX 、 plug-ins 或不同的 HTML 规格有不同的支持。例如, ActiveX 是 Microsoft 的产品,是为 Internet Explorer 而设计的, Javascrīpt 是 Netscape 的产品, Java 是 Sun 的产品等等。另外,框架和层次结构风格在不同的浏览器中也有不同的显示,甚至根本不显示。不同的浏览器对安全性和 Java 的设置也不一样。
测试浏览器兼容性的一个方法是创建一个兼容性矩阵。在这个矩阵中,测试不同厂商、不同版本的浏览器对某些构件和设置的适应性。
5. 安全性测试
Web 应用系统的安全性测试区域主要有:
( 1 )现在的 Web 应用系统基本采用先注册,后登陆的方式。因此,必须测试有效和无效的用户名和密码,要注意到是否大小写敏感,可以试多少次的限制,是否可以不登陆而直接浏览某个页面等。
( 2 ) Web 应用系统是否有超时的限制,也就是说,用户登陆后在一定时间内(例如 15 分钟)没有点击任何页面,是否需要重新登陆才能正常使用。
( 3 )为了保证 Web 应用系统的安全性,日志文件是至关重要的。需要测试相关信息是否写进了日志文件、是否可追踪。
( 4 )当使用了安全套接字时,还要测试加密是否正确,检查信息的完整性。
( 5 )服务器端的脚本常常构成安全漏洞,这些漏洞又常常被黑客利用。所以,还要测试没有经过授权,就不能在服务器端放置和编辑脚本的问题。
6. 总结
本文从功能、性能、可用性、客户端兼容性、安全性等方面讨论了基于 Web 的系统测试方法。
基于 Web 的系统测试与传统的软件测试既有相同之处,也有不同的地方,对软件测试提出了新的挑战。基于 Web 的系统测试不但需要检查和验证是否按照设计的要求运行,而且还要评价系统在不同用户的浏览器端的显示是否合适。重要的是,还要从最终用户的角度进行安全性和可用性测试。
-
LoadRunner完全卸载方法
2007-02-15 08:53:21
如何重新安装LoadRunner:
如果安装LoadRunner最新版本失败,相信很多朋友都会遇到重新安装不成功的烦恼。原因可能是多种情况,可能是早期的LoadRunner版本兼容性问题导致安装失败,也可能安装过程中弹出组件注册失败的各种错误。如果正常重新安装,只能先让LoadRunner充分卸载。
可以按以下的步骤操作:
1.保证所有LoadRunner的相关进程(包括Controller、VuGen、Analysis和Agent Process)全部关闭。
2.备份好LoadRunner安装目录下测试脚本,这些脚本一般存放在LoadRunner安装目录下的“scrīpts”子目录里。
3.在操作系统控制面板的“删除与添加程序”中运行LoadRunner的卸载程序。如果弹出提示信息关于共享文件的,都选择全部删除。
4.卸载向导完成后,按照要求重新启动电脑。完成整个LoadRunner卸载过程。
5.删除整个LoadRunner目录。(包括Agent Process)
6.在操作中查找下列文件,并且删除它们
1) wlrun.*
2) vugen.*
7.运行注册表程序(开始- 运行- regedit)
8.删除下列键值:
如果只安装了MI公司的LoadRunner这一个产品,请删除:
HKEY_LOCAL_MACHINESOFTWAREMercury Interactive.
HKEY_CURRENT_USERSOFTWAREMercury Interactive.
否则请删除:
HKEY_LOCAL_MACHINESOFTWAREMercury InteractiveLoadRunner.
HKEY_CURRENT_USERSOFTWAREMercury InteractiveLoadRunner.
9.最后清空回收站
如果你完成了以上操作,你就可以正常的重新安装LoadRunner。最好保证安装LoadRunner时关闭所有的杀毒程序。因为以往在安装LoadRunner时同时运行杀毒程序会出现不可预知的问题。
-
什么是测试用例的设计粒度?
2007-02-09 14:29:28
测试用例的设计粒度一直是个引起争论的话题,有主张详细到具体的操作步骤,也有主张写成测试要点即可。实际上测试用例的粒度主要考虑下面几个因素:
复用情况:如果随着产品不停得升级,需要设计的详细些,追求一劳永逸,反之仅使用一两次,则没有必要设计的过于详细;
项目进度:项目时间如果允许可以设计的详细些,反之则能执行即可;
使用对象:测试用例如果供多人使用,尤其让后参加测试的工程师来执行,则需要设计的详细些。如何划分测试用例的粒度?
我们是不太可能在一个测试用例包含所有测试需求的,因为众多的功能以及不同的路径组合将使这样一个测试用例像巨无霸一般,完全不具有可操作性。——除非您的软件所包含的功能真的又少又简单,不过如果真的有这么一个软件,恐怕也没有测试和发布的必要了。
当然,这也并不是要您走向另一个极端,为需求中定义的每个特性或功能都提供一个甚至多个测试用例。这里的关键,是要寻找一个合适的度。推荐的方法是:关注有效功能。
有效功能:就是指在被测应用所涉及的实际业务中,当用户在手工状态下进行工作时,整个业务流程中对用户来说,具有实际意义那些功能。这个功能的特征是当我们把这个功能单独从计算机软件还原到用户的原始手工状态时,它的完成可以作为用户实际业务的一个阶段性结束的标志,而不是一旦从这个业务流程中独立出来就失去了意义。而该业务完成后,可以为其他用户或业务提供所需要的信息。
这里区分“有效功能”的关键有如下两个:
1. 这个功能是可以还原到用户原始的手工业务流程中去的。我们的计算机和软件,都是为了帮助用户解决手工业务中一些烦琐和低效的问题,而提出的一些忠实于原始工作方法或略有变通的解决方案,并不是要改变用户全部的业务流程。所以,应该从用户实际业务的角度来判断功能是否有效。
2. 这个功能是否可以标志着用户实际业务的一个阶段性结束?并且这项业务完成之后,被完成的业务实体是否可以交付给其他用户或业务以供完成下面的工作?
为了方便理解,我们可以先看一下下面的例子。
拿我们常见的财务软件来说,当添加一张会计凭证时,通常是需要填写会计科目,在使用计算机完成工作时,我们可以利用软件的功能,从很多备选科目中选择一个自己需要的科目,或者通过科目代码来输入科目。这项功能很有可能会作为一个特性要求出现在软件需求规格说明书中,那么这个科目的选择或输入是不是一个有效功能呢?让我们试着用上面规则来衡量一下。
首先,这个功能在用户手工业务处理过程中是存在的,不同的是这项功能是在用户填写凭证时,在自己的大脑中完成的——用户会根据需要,在自己记忆的科目中选择合适的填写上去,这项功能节省了用户在记忆大量会计科目时付出的额外劳动。我们可以认为这个功能是为用户原来的工作提供了一种简便的、变通的方法。
那么这项功能的完成对于用户来说意味着什么呢?我们从上面的描述中可以看到,用户希望软件提供的是可以添加一张完整的凭证这样的功能,而不仅仅是方便填写会计科目。填写会计科目只是用户在添加凭证时的一个步骤,单独把这个功能提取出来对用户来说没有任何实际意义。对于业务流程下游的用户,需要的也不仅仅只是一个会计科目的信息,而是一张包含了会计科目以及其他会计信息的完整的会计凭证,否则就无法进行下面的工作。这样看来,这个功能并不是一个有效的功能,我们可以把它最为需要测试的特性在测试需求中进行描述,却不应该作为一个单独的测试用例出现在我们的测试用例集中。而我们在测试用例中真正关注的,应该是添加会计凭证这个具有实际意义的功能。
另外,我们还需要关注如何将多个相互之间存在依赖关系的功能区分为单个的有效功能。例如,现在有A、B、C三个功能,其中B功能的开始必须依赖于A功能的完成,而且A功能如果出现不同的完成状态,B功能也会做出不同的反应;C功能对B功能的依赖也是如此。那么这时候,我们是否应当将三个相互依赖的功能包含在一个测试用例中呢?这样的做法也不是不可以,但是我们也可以先判断一下,这三个功能是否都是有效功能(您可以使用前面提到的方法来试着评判一下)?如果A、B、C都是独立的有效功能,那么我们可以从上面的描述中发现,它们之间存在的依赖性,可以理解为是一种状态或者说数据的依赖性。后一个功能关心的,是前一个功能最终提供给它的是什么样的“输入”,而不是前一个功能到底作了些什么。这样看来,我们完全可以将它们分别包含在几个独立的测试用例中,而在每个测试用例的开始,把不同的输入作为不同前置条件来描述。
那么怎样才能把握好测试用例的设计粒度的尺度呢,这就需要在实践中不断的摸索总结经验了。
-
JAVA内存泄漏原因和内存泄漏检测工具
2007-02-07 14:12:40
摘要
虽然Java虚拟机(JVM)及其垃圾收集器(garbage collector,GC)负责管理大多数的内存任务,Java软件程序中还是有可能出现内存泄漏。实际上,这在大型项目中是一个常见的问题。避免内存泄漏的第一步是要弄清楚它是如何发生的。本文介绍了编写Java代码的一些常见的内存泄漏陷阱,以及编写不泄漏代码的一些最佳实践。一旦发生了内存泄漏,要指出造成泄漏的代码是非常困难的。因此本文还介绍了一种新工具,用来诊断泄漏并指出根本原因。该工具的开销非常小,因此可以使用它来寻找处于生产中的系统的内存泄漏。垃圾收集器的作用
虽然垃圾收集器处理了大多数内存管理问题,从而使编程人员的生活变得更轻松了,但是编程人员还是可能犯错而导致出现内存问题。简单地说,GC循环地跟踪所有来自“根”对象(堆栈对象、静态对象、JNI句柄指向的对象,诸如此类)的引用,并将所有它所能到达的对象标记为活动的。程序只可以操纵这些对象;其他的对象都被删除了。因为GC使程序不可能到达已被删除的对象,这么做就是安全的。
虽然内存管理可以说是自动化的,但是这并不能使编程人员免受思考内存管理问题之苦。例如,分配(以及释放)内存总会有开销,虽然这种开销对编程人员来说是不可见的。创建了太多对象的程序将会比完成同样的功能而创建的对象却比较少的程序更慢一些(在其他条件相同的情况下)。
而且,与本文更为密切相关的是,如果忘记“释放”先前分配的内存,就可能造成内存泄漏。如果程序保留对永远不再使用的对象的引用,这些对象将会占用并耗尽内存,这是因为自动化的垃圾收集器无法证明这些对象将不再使用。正如我们先前所说的,如果存在一个对对象的引用,对象就被定义为活动的,因此不能删除。为了确保能回收对象占用的内存,编程人员必须确保该对象不能到达。这通常是通过将对象字段设置为null或者从集合(collection)中移除对象而完成的。但是,注意,当局部变量不再使用时,没有必要将其显式地设置为null。对这些变量的引用将随着方法的退出而自动清除。
概括地说,这就是内存托管语言中的内存泄漏产生的主要原因:保留下来却永远不再使用的对象引用。
典型泄漏
既然我们知道了在Java中确实有可能发生内存泄漏,就让我们来看一些典型的内存泄漏及其原因。
全局集合
在大的应用程序中有某种全局的数据储存库是很常见的,例如一个JNDI树或一个会话表。在这些情况下,必须注意管理储存库的大小。必须有某种机制从储存库中移除不再需要的数据。
这可能有多种方法,但是最常见的一种是周期性运行的某种清除任务。该任务将验证储存库中的数据,并移除任何不再需要的数据。
另一种管理储存库的方法是使用反向链接(referrer)计数。然后集合负责统计集合中每个入口的反向链接的数目。这要求反向链接告诉集合何时会退出入口。当反向链接数目为零时,该元素就可以从集合中移除了。
缓存
缓存是一种数据结构,用于快速查找已经执行的操作的结果。因此,如果一个操作执行起来很慢,对于常用的输入数据,就可以将操作的结果缓存,并在下次调用该操作时使用缓存的数据。
缓存通常都是以动态方式实现的,其中新的结果是在执行时添加到缓存中的。典型的算法是:
检查结果是否在缓存中,如果在,就返回结果。
如果结果不在缓存中,就进行计算。
将计算出来的结果添加到缓存中,以便以后对该操作的调用可以使用。
该算法的问题(或者说是潜在的内存泄漏)出在最后一步。如果调用该操作时有相当多的不同输入,就将有相当多的结果存储在缓存中。很明显这不是正确的方法。为了预防这种具有潜在破坏性的设计,程序必须确保对于缓存所使用的内存容量有一个上限。因此,更好的算法是:
检查结果是否在缓存中,如果在,就返回结果。
如果结果不在缓存中,就进行计算。
如果缓存所占的空间过大,就移除缓存最久的结果。
将计算出来的结果添加到缓存中,以便以后对该操作的调用可以使用。
通过始终移除缓存最久的结果,我们实际上进行了这样的假设:在将来,比起缓存最久的数据,最近输入的数据更有可能用到。这通常是一个不错的假设。新算法将确保缓存的容量处于预定义的内存范围之内。确切的范围可能很难计算,因为缓存中的对象在不断变化,而且它们的引用包罗万象。为缓存设置正确的大小是一项非常复杂的任务,需要将所使用的内存容量与检索数据的速度加以平衡。
解决这个问题的另一种方法是使用java.lang.ref.SoftReference类跟踪缓存中的对象。这种方法保证这些引用能够被移除,如果虚拟机的内存用尽而需要更多堆的话。
ClassLoader
Java ClassLoader结构的使用为内存泄漏提供了许多可乘之机。正是该结构本身的复杂性使ClassLoader在内存泄漏方面存在如此多的问题。ClassLoader的特别之处在于它不仅涉及“常规”的对象引用,还涉及元对象引用,比如:字段、方法和类。这意味着只要有对字段、方法、类或ClassLoader的对象的引用,ClassLoader就会驻留在JVM中。因为ClassLoader本身可以关联许多类及其静态字段,所以就有许多内存被泄漏了。
确定泄漏的位置
通常发生内存泄漏的第一个迹象是:在应用程序中出现了OutOfMemoryError。这通常发生在您最不愿意它发生的生产环境中,此时几乎不能进行调试。有可能是因为测试环境运行应用程序的方式与生产系统不完全相同,因而导致泄漏只出现在生产中。在这种情况下,需要使用一些开销较低的工具来监控和查找内存泄漏。还需要能够无需重启系统或修改代码就可以将这些工具连接到正在运行的系统上。可能最重要的是,当进行分析时,需要能够断开工具而保持系统不受干扰。
虽然OutOfMemoryError通常都是内存泄漏的信号,但是也有可能应用程序确实正在使用这么多的内存;对于后者,或者必须增加JVM可用的堆的数量,或者对应用程序进行某种更改,使它使用较少的内存。但是,在许多情况下,OutOfMemoryError都是内存泄漏的信号。一种查明方法是不间断地监控GC的活动,确定内存使用量是否随着时间增加。如果确实如此,就可能发生了内存泄漏。
详细输出
有许多监控垃圾收集器活动的方法。而其中使用最广泛的可能是使用-Xverbose:gc选项启动JVM,并观察输出。
[memory ] 10.109-10.235: GC 65536K->16788K (65536K), 126.000 ms
箭头后面的值(本例中是16788K)是垃圾收集所使用的堆的容量。控制台
查看连续不断的GC的详细统计信息的输出将是非常乏味的。幸好有这方面的工具。JRockit Management Console可以显示堆使用量的图示。借助于该图,可以很容易地看出堆使用量是否随时间增加。

Figure 1. The JRockit Management Console甚至可以配置该管理控制台,以便如果发生堆使用量过大的情况(或基于其他的事件),控制台能够向您发送电子邮件。这明显使内存泄漏的查看变得更容易了。
内存泄漏检测工具
还有其他的专门进行内存泄漏检测的工具。JRockit Memory Leak Detector可以用来查看内存泄漏,并可以更深入地查出泄漏的根源。这个强大的工具是紧密集成到JRockit JVM中的,其开销非常小,对虚拟机的堆的访问也很容易。
专业工具的优点
一旦知道确实发生了内存泄漏,就需要更专业的工具来查明为什么会发生泄漏。JVM自己是不会告诉您的。这些专业工具从JVM获得内存系统信息的方法基本上有两种:JVMTI和字节码技术(byte code instrumentation)。Java虚拟机工具接口(Java Virtual Machine Tools Interface,JVMTI)及其前身Java虚拟机监视程序接口(Java Virtual Machine Profiling Interface,JVMPI)是外部工具与JVM通信并从JVM收集信息的标准化接口。字节码技术是指使用探测器处理字节码以获得工具所需的信息的技术。
对于内存泄漏检测来说,这两种技术有两个缺点,这使它们不太适合用于生产环境。首先,它们在内存占用和性能降低方面的开销不可忽略。有关堆使用量的信息必须以某种方式从JVM导出,并收集到工具中进行处理。这意味着要为工具分配内存。信息的导出也影响了JVM的性能。例如,当收集信息时,垃圾收集器将运行得比较慢。另外一个缺点是需要始终将工具连在JVM上。这是不可能的:将工具连在一个已经启动的JVM上,进行分析,断开工具,并保持JVM运行。
因为JRockit Memory Leak Detector是集成到JVM中的,就没有这两个缺点了。首先,许多处理和分析工作是在JVM内部进行的,所以没有必要转换或重新创建任何数据。处理还可以背负(piggyback)在垃圾收集器本身上而进行,这意味着提高了速度。其次,只要JVM是使用-Xmanagement选项(允许通过远程JMX接口监控和管理JVM)启动的,Memory Leak Detector就可以与运行中的JVM进行连接或断开。当该工具断开时,没有任何东西遗留在JVM中,JVM又将以全速运行代码,正如工具连接之前一样。
趋势分析
让我们深入地研究一下该工具以及它是如何用来跟踪内存泄漏的。在知道发生内存泄漏之后,第一步是要弄清楚泄漏了什么数据--哪个类的对象引起了泄漏?JRockit Memory Leak Detector是通过在每次垃圾收集时计算每个类的现有对象的数目来实现这一步的。如果特定类的对象数目随时间而增长(“增长率”),就可能发生了内存泄漏。

图2. Memory Leak Detector的趋势分析视图因为泄漏可能像细流一样非常小,所以趋势分析必须运行很长一段时间。在短时间内,可能会发生一些类的局部增长,而之后它们又会跌落。但是趋势分析的开销很小(最大开销也不过是在每次垃圾收集时将数据包由JRockit发送到Memory Leak Detector)。开销不应该成为任何系统的问题——即使是一个全速运行的生产中的系统。
起初数目会跳跃不停,但是一段时间之后它们就会稳定下来,并显示出哪些类的数目在增长。
找出根本原因
有时候知道是哪些类的对象在泄漏就足以说明问题了。这些类可能只用于代码中的非常有限的部分,对代码进行一次快速检查就可以显示出问题所在。遗憾地是,很有可能只有这类信息还并不够。例如,常见到泄漏出在类java.lang.String的对象上,但是因为字符串在整个程序中都使用,所以这并没有多大帮助。
我们想知道的是,另外还有哪些对象与泄漏对象关联?在本例中是String。为什么泄漏的对象还存在?哪些对象保留了对这些对象的引用?但是能列出的所有保留对String的引用的对象将会非常多,以至于没有什么实际用处。为了限制数据的数量,可以将数据按类分组,以便可以看出其他哪些对象的类与泄漏对象(String)关联。例如,String在Hashtable中是很常见的,因此我们可能会看到与String关联的Hashtable数据项对象。由Hashtable数据项倒推,我们最终可以找到与这些数据项有关的Hashtable对象以及String(如图3所示)。

图3. 在工具中看到的类型图的示例视图倒推
因为我们仍然是以类的对象而不是单独的对象来看待对象,所以我们不知道是哪个Hashtable在泄漏。如果我们可以弄清楚系统中所有的Hashtable都有多大,我们就可以假定最大的Hashtable就是正在泄漏的那一个(因为随着时间的流逝它会累积泄漏而增长得相当大)。因此,一份有关所有Hashtable对象以及它们引用了多少数据的列表,将会帮助我们指出造成泄漏的确切Hashtabl。

图4. 界面:Hashtable对象以及它们所引用数据的数量的列表对对象引用数据数目的计算开销非常大(需要以该对象作为根遍历引用图),如果必须对许多对象都这么做,将会花很多时间。如果了解一点Hashtable的内部实现原理就可以找到一条捷径。Hashtable的内部有一个Hashtable数据项的数组。该数组随着Hashtable中对象数目的增长而增长。因此,为找出最大的Hashtable,我们只需找出引用Hashtable数据项的最大数组。这样要快很多。

图5. 界面:最大的Hashtable数据项数组及其大小的清单更进一步
当找到发生泄漏的Hashtable实例时,我们可以看到其他哪些实例在引用该Hashtable,并倒推回去看看是哪个Hashtable在泄漏。

图 6. 这就是工具中的实例图例如,该Hashtable可能是由MyServer类型的对象在名为activeSessions的字段中引用的。这种信息通常就足以查找源代码以定位问题所在了。

图7. 检查对象以及它对其他对象的引用找出分配位置
当跟踪内存泄漏问题时,查看对象分配到哪里是很有用的。只知道它们如何与其他对象相关联(即哪些对象引用了它们)是不够的,关于它们在何处创建的信息也很有用。当然了,您并不想创建应用程序的辅助构件,以打印每次分配的堆栈跟踪(stack trace)。您也不想仅仅为了跟踪内存泄漏而在运行应用程序时将一个分析程序连接到生产环境中。
借助于JRockit Memory Leak Detector,应用程序中的代码可以在分配时进行动态添加,以创建堆栈跟踪。这些堆栈跟踪可以在工具中进行累积和分析。只要不启用就不会因该功能而产生成本,这意味着随时可以进行分配跟踪。当请求分配跟踪时,JRockit 编译器动态插入代码以监控分配,但是只针对所请求的特定类。更好的是,在进行数据分析时,添加的代码全部被移除,代码中没有留下任何会引起应用程序性能降低的更改。

图8. 示例程序执行期间String的分配的堆栈跟踪结束语
内存泄漏是难以发现的。本文重点介绍了几种避免内存泄漏的最佳实践,包括要始终记住在数据结构中所放置的内容,以及密切监控内存使用量以发现突然的增长。
我们都已经看到了JRockit Memory Leak Detector是如何用于生产中的系统以跟踪内存泄漏的。该工具使用一种三步式的方法来找出泄漏。首先,进行趋势分析,找出是哪个类的对象在泄漏。接下来,看看有哪些其他的类与泄漏的类的对象相关联。最后,进一步研究单个对象,看看它们是如何互相关联的。也有可能对系统中所有对象分配进行动态的堆栈跟踪。这些功能以及该工具紧密集成到JVM中的特性使您可以以一种安全而强大的方式跟踪内存泄漏并进行修复。
-
读书笔记—《WEB性能测试实战》之WEB性能测试分析(一)
2007-02-06 13:57:15
性能测试的结果分析是性能测试的重中之重。在实际工作中,由于测试的结果分析比较复
杂、需要具备很多相关的专业知识,因此常常会感觉拿到数据不知从何下手。这也是我学习性能
测试过程中感觉比较尴尬和棘手的事,为此我在研读了《WEB性能测试实战》后特作了以下笔
记,这里只是书中第4章WEB应用程序性能分析的一
部分,贴出来希望和大家共同讨论:
一:性能分析的基础知识:
1.几个重要的性能指标:相应时间、吞吐量、吞吐率、TPS(每秒钟处理的交易数)、点
击率等。
2.系统的瓶颈分为两类:网络的和服务器的。服务器瓶颈主要涉及:应用程序、WEB服务
器、数据库服务器、操作系统四个方面。
3.常规、粗略的性能分析方法:
当增大系统的压力(或增加并发用户数)时,吞吐率和TPS的变化曲线呈大体一致,则系统
基本稳定;若压力增大时,吞吐率的曲线增加到一定程度后出现变化缓慢,甚至平坦,很可能是
网络出现带宽瓶颈,同理若点击率/TPS曲线出现变化缓慢或者平坦,说明服务器开始出现颈。
4.作者提出了如下的性能分析基本原则,此原则本人十分赞同:
——由外而内、由表及里、层层深入
应用此原则,分析步骤具体可以分为以下三步:
第一步:将得到的响应时间和用户对性能的期望值比较确定是否存在瓶颈;
第二步:比较Tn(网络响应时间)和Ts(服务器响应时间)可以确定瓶颈发生在网络还是服
务器;
第三步:进一步分析,确定更细组件的响应时间,直到找出发生性能瓶颈的根本原因。
二:以WEB应用程序为例来看下具体的分析方法:
1.用户事务分析:
a.事务综述图(Transaction Summary ):以柱状图的形式表现了用户事务执行的成功与
失败。通过分析成功与失败的数据可以直接判断出系统是否运行正常。若失败的事务非常多,则
说明系统发生了瓶颈或者程序在执行过程中发生了问题。
b.事务平均响应时间分析图(Average Transaction Response Time): 该图显示在
测试场景运行期间的每一秒内事务执行所用的平均时间,还显示了测试场景运行时间内各个事务
的最大值、最小值和平均值。通过它可以分析系统的性能走向。若所有事务响应时间基本成一条
曲线,则说明系统性能基本稳定;否则如果平均事务响应时间逐渐变慢,说明性能有下降趋势,
造成性能下降的原因有可能是由于内存泄漏导致。
c.每秒通过事务数分析图(Transaction per Second即TPS):显示在场景运行的每一
秒中,每个事 务通过、失败以及停止的数量。通过它可以确定系统在任何给定时刻的实际事务
负载。若随着测试的进展,应用系统在单位时间内通过的事务数目在减少,则说明服务器出现瓶
颈。
d.每秒通过事务总数分析图(Total Transactions per Second):显示场景运行的
每一秒中,通过、失败以及停止的事务总数。若在同等压力下,曲线接近直线,则性能基本趋于
稳定;若在单位时间内通过的事务总量越来越少,即整体性能下降。原因可能是内存泄漏或者程
序中的缺陷。
e.事务性能摘要图(Transaction Performance Summary):显示方案中所有事务的
最小、最大平均执行时间,可以直接判断响应时间是否符合客户要求(重点关注事务平均、最大
执行时间)。
f.事务响应时间与负载分析图(Transaction Response Time Under load):通过
该图可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性
能数据。
g.事务响应时间(百分比)图(Transaction Response Time(percentile)):该
图是根据测试结果进行分析而得到的综合分析图。分析该图应从整体出发,若可能事务的最大响
应时间很长,但如果大多数事务具有可接受的响应时间,则系统的性能是符合。
h.事务响应时间分布情况图(Transaction Response Time (Distribution)):该
图显示了测试过程中不同响应时间的事务数量。若系统预先定义了相关事务可以接受的最小和最
大事务响应时间,则可以使用此图确定系统性能是否在接受范围内。
分析到这一步,只能大概判断出瓶颈可能会出在那,要具体定位瓶颈还需要更深入
的分析。没有贴图,看起来有点费劲,如果你对这些图都比较了解,应该是比较简单的,这
篇只是对于用户事务的分析,欢迎大家跟贴讨论。未完待续
-
你有没有听说过“可伸缩性测试”(转载)
2007-02-05 13:50:25
提到性能测试,大家马上脑海里会出现负载测试、压力测试、容量测试等概念,那么大家知不知道还有可伸缩性测试。可伸缩性测试可以看成性能测试的一个扩展,关注系统本身的可伸缩性,下面给大家具体介绍。
系统的可伸缩性可以从硬件和软件两个方面来理解:
1、硬件的可伸缩性
是不是可以通过硬件设备的增加来支持更多的用户,比如通过增加cpu个数或者存储器空间大小等。
2、软件的可伸缩性
是不是可以通过运行更多的实例或者采用分布式处理来支持更多的用户。
那么再具体一点就是一个可伸缩的系统必须具有随负荷增加响应时间也线性增加的特点。这样就可以通过线性的增加硬件设备、实例个数或者分布式处理点来处理更多的数据量。也就能更好的在不增加响应时间的前提下支持更多的用户。
可伸缩性测试具体的测试过程为:进行负载测试,记录不同负载下的平均响应时间,然后查看平均响应时间是否线性增加。如线性增加,说明系统具有可伸缩性,否则则说明系统可伸缩性较差或者没有。 -
性能测试技术(转载)
2007-02-05 13:47:20
对于企业应用程序,有许多进行性能测试的方法,其中一些方法实行起来要比其他方法困难。所要进行的性能测试的类型取决于想要达到的结果。例如,对于可再现性,基准测试是最好的方法。而要从当前用户负载的角度测试系统的上限,则应该使用容量规划测试。本文将介绍几种设置和运行性能测试的方法,并讨论这些方法的区别。简介
如果不进行合理的规划,对J2EE应用程序进行性能测试将会是一项令人望而生畏且有些混乱的任务。因为对于任何的软件开发流程,都必须收集需求、理解业务需要,并在进行实际测试之前设计出正式的进度表。性能测试的需求由业务需要驱动,并由一组用例阐明。这些用例可以基于历史数据(例如,服务器一周的负载模式)或预测的近似值。弄清楚需要测试的内容之后,就需要知道如何进行测试了。
在开发阶段前期,应该使用基准测试来确定应用程序中是否出现性能倒退。基准测试可以在一个相对短的时间内收集可重复的结果。进行基准测试的最好方法是,每次测试改变一个且只改变一个参数。例如,如果想知道增加JVM内存是否会影响应用程序的性能,就逐次递增JVM内存(例如,从1024 MB增至1224 MB,然后是1524 MB,最后是2024 MB),在每个阶段收集结果和环境数据,记录信息,然后转到下一阶段。这样在分析测试结果时就有迹可循。下一小节我将介绍什么是基准测试,以及运行基准测试的最佳参数。
开发阶段后期,在应用程序中的bug已经被解决,应用程序达到一种稳定状态之后,可以运行更为复杂的测试,确定系统在不同的负载模式下的表现。这些测试被称为容量规划测试、渗入测试(soak test)、峰谷测试(peak-rest test),它们旨在通过测试应用程序的可靠性、健壮性和可伸缩性来测试接近于现实世界的场景。对于下面的描述应该从抽象的意义上理解,因为每个应用程序的使用模式都是不同的。例如,容量规划测试通常都使用较缓慢的ramp-up(下文有定义),但是如果应用程序在一天之中的某个时段中有快速突发的流量,那么自然应该修改测试以反映这种情况。但是,要记住,因为更改了测试参数(比如ramp-up周期或用户的考虑时间(think-time)),测试的结果肯定也会改变。一个不错的方法是,运行一系列的基准测试,确立一个已知的可控环境,然后再对变化进行比较。
基准测试
基准测试的关键是要获得一致的、可再现的结果。可再现的结果有两个好处:减少重新运行测试的次数;对测试的产品和产生的数字更为确信。使用的性能测试工具可能会对测试结果产生很大影响。假定测试的两个指标是服务器的响应时间和吞吐量,它们会受到服务器上的负载的影响。服务器上的负载受两个因素影响:同时与服务器通信的连接(或虚拟用户)的数目,以及每个虚拟用户请求之间的考虑时间的长短。很明显,与服务器通信的用户越多,负载就越大。同样,请求之间的考虑时间越短,负载也越大。这两个因素的不同组合会产生不同的服务器负载等级。记住,随着服务器上负载的增加,吞吐量会不断攀升,直到到达一个点。

图1.随着负载的增加,系统吞吐量的曲线(单位:页面/秒)注意,吞吐量以稳定的速度增长,然后在某一个点上稳定下来。
在某一点上,执行队列开始增长,因为服务器上所有的线程都已投入使用,传入的请求不再被立即处理,而是放入队列中,当线程空闲时再处理。

图2. 随着负载的增加,系统执行队列长度的曲线注意,最初的一段时间,执行队列的长度为零,然后就开始以稳定的速度增长。这是因为系统中的负载在稳定增长,虽然最初系统有足够的空闲线程去处理增加的负载,最终它还是不能承受,而必须将其排入队列。
当系统达到饱和点,服务器吞吐量保持稳定后,就达到了给定条件下的系统上限。但是,随着服务器负载的继续增长,系统的响应时间也随之延长,虽然吞吐量保持稳定。

图3. 随着负载的增加,系统中两个事务的响应时间曲线注意,在执行队列(图2)开始增长的同时,响应时间也开始以递增的速度增长。这是因为请求不能被及时处理。
为了获得真正可再现的结果,应该将系统置于相同的高负载下。为此,与服务器通信的虚拟用户应该将请求之间的考虑时间设为零。这样服务器会立即超载,并开始构建执行队列。如果请求(虚拟用户)数保持一致,基准测试的结果应该会非常精确,完全可以再现。
您可能要问的一个问题是:“如何度量结果?”对于一次给定的测试,应该取响应时间和吞吐量的平均值。精确地获得这些值的唯一方法是一次加载所有的用户,然后在预定的时间段内持续运行。这称为“flat”测试。

图4. flat测试的情况(所有的用户都是同时加载的)与此相对应的是“ramp-up”测试。

图5. ramp-up测试的情况(在测试期间,用户以稳定速度(每秒x个)增加)ramp-up测试中的用户是交错上升的(每几秒增加一些新用户)。ramp-up测试不能产生精确和可重现的平均值,这是因为由于用户的增加是每次一部分,系统的负载在不断地变化。因此,flat运行是获得基准测试数据的理想模式。
这不是在贬低ramp-up测试的价值。实际上,ramp-up测试对找出以后要运行的flat测试的范围非常有用。ramp-up测试的优点是,可以看出随着系统负载的改变,测量值是如何改变的。然后可以据此选择以后要运行的flat测试的范围。
Flat测试的问题是系统会遇到“波动”效果。
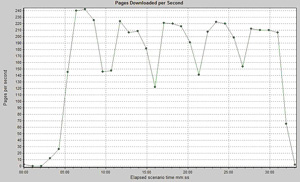
图6. 一次flat测试中所测得的系统吞吐量的曲线(单位:页面/秒)注意波动的出现,吞吐量不再是平滑的。
这在系统的各个方面都有所体现,包括CPU的使用量。

图7. 一次flat测试中所测得的系统CPU使用量随时间变化的曲线注意,每隔一段时间就会出现一个波形。CPU使用量不再是平滑的,而是有了像吞吐量图那样的尖峰。
此外,执行队列也承受着不稳定的负载,因此可以看到,随着系统负载的增加和减少,执行队列也在增长和缩减。
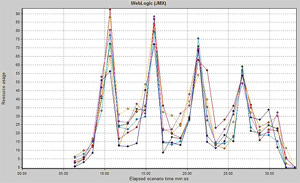
图8. 一次flat测试中所测得的系统执行队列的曲线注意,每隔一段时间就会出现一个波形。执行队列曲线与上面的CPU使用量图非常相似。
最后,系统中事务的响应时间也遵循着这个波动模式。

图9. 一次flat测试中所测得的系统事务的响应时间注意,每隔一段时间就会出现一个波形。事务的响应时间也与上面的图类似,只不过其效果随着时间的推移逐渐减弱。
当测试中所有的用户都同时执行几乎相同的操作时,就会发生这种现象。这将会产生非常不可靠和不精确的结果,所以必须采取一些措施防止这种情况的出现。有两种方法可以从这种类型的结果中获得精确的测量值。如果测试可以运行相当长的时间(有时是几个小时,取决于用户的操作持续的时间),最后由于随机事件的本性使然,服务器的吞吐量会被“拉平”。或者,可以只选取波形中两个平息点之间的测量值。该方法的缺点是可以捕获数据的时间非常短。
性能规划测试
对于性能规划类型的测试来说,其目标是找出,在特定的环境下,给定应用程序的性能可以达到何种程度。此时可重现性就不如在基准测试中那么重要了,因为测试中通常都会有随机因子。引入随机因子的目的是为了尽量模拟具有真实用户负载的现实世界应用程序。通常,具体的目标是找出系统在特定的服务器响应时间下支持的当前用户的最大数。例如,您可能想知道:如果要以5秒或更少的响应时间支持8,000个当前用户,需要多少个服务器?要回答这个问题,需要知道系统的更多信息。
要确定系统的容量,需要考虑几个因素。通常,服务器的用户总数非常大(以十万计),但是实际上,这个数字并不能说明什么。真正需要知道的是,这些用户中有多少是并发与服务器通信的。其次要知道的是,每个用户的“考虑时间”即请求间时间是多少。这非常重要,因为考虑时间越短,系统所能支持的并发用户越少。例如,如果用户的考虑时间是1秒,那么系统可能只能支持数百个这样的并发用户。但是,如果用户的考虑时间是30秒,那么系统则可能支持数万个这样的并发用户(假定硬件和应用程序都是相同的)。在现实世界中,通常难以确定用户的确切考虑时间。还要注意,在现实世界中,用户不会精确地按照间隔时间发出请求。
于是就引入了随机性。如果知道普通用户的考虑时间是5秒,误差为20%,那么在设计负载测试时,就要确保请求间的时间为5×(1 +/- 20%)秒。此外,可以利用“调步”的理念向负载场景中引入更多的随机性。它是这样的:在一个虚拟用户完成一整套的请求后,该用户暂停一个设定的时间段,或者一个小的随机时间段(例如,2×(1 +/- 25%)秒),然后再继续执行下一套请求。将这两种随机化方法运用到测试中,可以提供更接近于现实世界的场景。
现在该进行实际的容量规划测试了。接下来的问题是:如何加载用户以模拟负载状态?最好的方法是模拟高峰时间用户与服务器通信的状况。这种用户负载状态是在一段时间内逐步达到的吗?如果是,应该使用ramp-up类型的测试,每隔几秒增加x个用户。或者,所有用户是在一个非常短的时间内同时与系统通信?如果是这样,就应该使用flat类型的测试,将所有的用户同时加载到服务器。两种不同类型的测试会产生没有可比性的不同测试。例如,如果进行ramp-up类型的测试,系统可以以4秒或更短的响应时间支持5,000个用户。而执行flat测试,您会发现,对于5,000个用户,系统的平均响应时间要大于4秒。这是由于ramp-up测试固有的不准确性使其不能显示系统可以支持的并发用户的精确数字。以门户应用程序为例,随着门户规模的扩大和集群规模的扩大,这种不确定性就会随之显现。
这不是说不应该使用ramp-up测试。对于系统负载在一段比较长的时间内缓慢增加的情况,ramp-up测试效果还是不错的。这是因为系统能够随着时间不断调整。如果使用快速ramp-up测试,系统就会滞后,从而报告一个较相同用户负载的flat测试低的响应时间。那么,什么是确定容量的最好方法?结合两种负载类型的优点,并运行一系列的测试,就会产生最好的结果。例如,首先使用ramp-up测试确定系统可以支持的用户范围。确定了范围之后,以该范围内不同的并发用户负载进行一系列的flat测试,更精确地确定系统的容量。
渗入测试
渗入测试是一种比较简单的性能测试。渗入测试所需时间较长,它使用固定数目的并发用户测试系统的总体健壮性。这些测试将会通过内存泄漏、增加的垃圾收集(GC)或系统的其他问题,显示因长时间运行而出现的任何性能降低。测试运行的时间越久,您对系统就越了解。运行两次测试是一个好主意——一次使用较低的用户负载(要在系统容量之下,以便不会出现执行队列),一次使用较高的负载(以便出现积极的执行队列)。
测试应该运行几天的时间,以便真正了解应用程序的长期健康状况。要确保测试的应用程序尽可能接近现实世界的情况,用户场景也要逼真(虚拟用户通过应用程序导航的方式要与现实世界一致),从而测试应用程序的全部特性。确保运行了所有必需的监控工具,以便精确地监测并跟踪问题。
峰谷测试
峰谷测试兼有容量规划ramp-up类型测试和渗入测试的特征。其目标是确定从高负载(例如系统高峰时间的负载)恢复、转为几乎空闲、然后再攀升到高负载、再降低的能力。
实现这种测试的最好方法就是,进行一系列的快速ramp-up测试,继之以一段时间的平稳状态(取决于业务需求),然后急剧降低负载,此时可以令系统平息一下,然后再进行快速的ramp-up;反复重复这个过程。这样可以确定以下事项:第二次高峰是否重现第一次的峰值?其后的每次高峰是等于还是大于第一次的峰值?在测试过程中,系统是否显示了内存或GC性能降低的有关迹象?测试运行(不停地重复“峰值/空闲”周期)的时间越长,您对系统的长期健康状况就越了解。
结束语
本文介绍了进行性能测试的几种方法。取决于业务需求、开发周期和应用程序的生命周期,对于特定的企业,某些测试会比其他的更适合。但是,对于任何情况,在决定进行某一种测试前,都应该问自己一些基本问题。这些问题的答案将会决定哪种测试方法是最好的。
这些问题包括:
- 结果的可重复性需要有多高?
- 测试需要运行和重新运行几次?
- 您处于开放周期的哪个阶段?
- 您的业务需求是什么?
- 您的用户需求是什么?
- 您希望生产中的系统在维护停机时间中可以持续多久?
- 在一个正常的业务日,预期的用户负载是多少?
将这些问题的答案与上述性能测试类型相对照,应该就可以制定出测试应用程序的总体性能的完美计划。
-
我来谈谈WinRunner和QTP的区别
2007-02-05 12:23:15
WinRunner Compared to QuickTest Pro
 Common environments shared by both WinRunner and QuickTest Pro:
Common environments shared by both WinRunner and QuickTest Pro:Web-Related Environments
IE, Netscape, AOL
JDK, Java Foundation Classes, AWT
Symantec Visual Café
ActiveX Controls
ERP/CRM
Oracle: Jinitiator, 11i, NCA
Custom Client Server
Windows
C++/C
Visual Basic
Operating Systems
Windows 98, 2000, NT, ME, XP
Legacy
3270, 5250 Emulators
VT100
WinRunner Only Environments:Custom Client/Server
PowerBuilder
Forte
Centura
Stingray
SmallTalk
ERP/CRM
Baan
PeopleSoft Windows
Siebel 5, 6 GUI Clients
Oracle GUI Forms
QuickTest Pro Only Environments:ERP/CRM
SAP
Siebel 7.x
PeopleSoft 8.x
.Net
WinForms
WebForms
.Net controls
Web Services
XML, HTTP
WSDL, SOAP
J2EE, .Net
Multimedia
RealAudio/Video
Flash
Common features found in both WinRunner and QuickTest Pro:Record/Replay
ODBC & Excel Connectivity
Code Editor & Debugger
Recovery Manager
Shared Object Repository
Rapid Object Import
Numerous Checkpoints
Analog
scrīpt & Function Libraries
WinRunner Only Environments:Function Generator
Database Integration
Run Wizard
TSL
MDI
QuickTest Pro Only Environments:ActiveScreen
TestGuard
Tree View
scrīptFusion
Data Table
VBscrīpt
Function Generator*
(coming in v7.0)
Run Wizard*
(coming in v7.0)
WinRunner和Quick Test Professional(简称QTP)都是MERCURY公司开发的非常强大功能自动化测试工具,从时间上来看,WinRunner在1995年便已经推出,而QTP直到2002年才正式推出。
我想从以下几点来谈谈我个人的看法,这里只列出它们两者的不同点:
1.从界面来看:WinRunner只有一个显示脚本的界面,而QTP的Kyword View 、Expert View、Data Table、Active Screen四个界面可以显示在同一个窗口,在脚本回放时让人可以时时刻刻了解到脚本运行的情况,虽然这些功能WinRunner都可以实现,但相比较下QTP更直观、更好;
2.从支持的语言来看:如上表列出的,两者有所不同,在这我就不再列出;
3.从生成的脚本来看:WinRunner生成的是TSL脚本,这是MI公司独有的语言,是一种类C语言,而QTP生成的是VBscrīpt,从编程能力上,WinRunner更胜一筹,因为它拥有相当丰富的C语言函数库,相对而言QTP则更显得大众化,它面向的是没有太多技术背景和编程经验的测试人员;
4.从适用范围来看:WinRunner比较适用于C/S架构软件,而QTP虽然对于C/S架构的也适用,但对于B/S架构的适用性更剩一筹;
5.QTP8.0具有的一大特性:关键字驱动测试(keyword-driven testing)其原理和特点如下:
a. 关键字驱动测试是数据驱动测试的一种改进类型
b. 主要关键字包括三类:被操作对象(Item)、操作(Operation)和值(value),用面向对象形式可将其表现为 Item.Operation(Value)
c. 将测试逻辑按照这些关键字进行分解,形成数据文件。
d. 用关键字的形式将测试逻辑封装在数据文件中,测试工具只要能够解释这些关键字即可对其应用自动化
具体选用那种工具,应该根据公司自身的情况来定。这些只是个人理解,如果有不完整或者不对的地方,欢迎大家跟帖讨论!
-
我们公司对于BUG严重性级别的划分
2007-02-01 10:45:16
在测试过程中,为了便于对发现的缺陷的管理和有利于缺陷的修改等后期工作,我们常常会将缺陷按照严重程度划分成不同的级别。
比较常见的是很多公司将缺陷划分成如下4个等级:
1. 非常严重的缺陷,例如,软件的意外退出甚至操作系统崩溃,造成数据丢失。
2. 较严重的缺陷,例如,软件的某个菜单不起作用或者产生错误的结果;
3. 软件一般缺陷,例如,本地化软件的某些字符没有翻译或者翻译不准确;
4. 软件界面的细微缺陷,例如,某个控件没有对齐,某个标点符号丢失等;我们公司对于缺陷的划分如下:
A.操作系统崩溃;样机死机;
B.任何方式操作造成应用程序崩溃或非法退出;
整个功能无法实现;
看门狗不断复位;
C.局部功能实现错误或不能实现;
任何方式操作造成乱数、数据丢失、不能读取数据;
允许非法用户对系统进行操作;
查询结果与查询条件不符;
数据窗口的TAB顺序混乱;
标题栏与模块名称不一致;
数据的单位不一致;
D.冗错失败;
删除或重大更改数据时没有提示信息;
下拉列表中不能显示所有设计要求的数据;
系统中有错别字;
窗口的最小化、还原、最大化功能不能实现;
E.表达不清楚或令人困惑的消息框、弹出的窗口;
整个系统中控件的名称或快捷键不统一;
数据格式不统一;
数据窗口中的数据显示不完整;
报表的表格线未对齐或预览、打印的内部不全;
F.操作不方便
G.建议性修改
在软件发版之前规定不能出现D类以上bug,允许出现少量D类以下的bug。部
门质量目标:1.对于软件产品每千行代码出现的bug数不能大于0.7个(D类以
上);2.每个项目的测试周期的平均延迟时间不超过一天。
-
一个好的测试工程师应该具备的素质
2007-01-30 09:55:00
人是测试工作中最有价值也是最重要的资源,没有一个合格的、积极的测试小组,测试就不可能实现。然而,在软件开发产业中有一种非常普遍习惯,那就是让那些经验最少的新手、没有效率的开发者或不适合干其他工作的人去做测试工作。这绝对是一种目光短浅的行为,对一个系统进行有效的测试所需要的技能绝对不比进行软件开发需要的少,事实上,测试者将获得极其广泛的经验,他们将遇到许多开发者不可能遇到的问题。
①、沟通能力
一名理想的测试者必须能够同测试涉及到的所有人进行沟通,具有与技术(开发者)和非技术人员(客户,管理人员)的交流能力。既要可以和用户谈得来,又能同开发人员说得上话,不幸的是这两类人没有共同语言。和用户谈话的重点必须放在系统可以正确地处理什么和不可以处理什么上。而和开发者谈相同的信息时,就必须将这些活重新组织以另一种方式表达出来,测试小组的成员必须能够同等地同用户和开发者沟通。
②、移情能力
和系统开发有关的所有人员都处在一种既关心又担心的状态之中。用户担心将来使用一个不符合自己要求的系统,开发者则担心由于系统要求不正确而使他不得不重新开发整个系统,管理部门则担心这个系统突然崩溃而使它的声誉受损。测试者必须和每一类人打交道,因此需要测试小组的成员对他们每个人都具有足够的理解和同情,具备了这种能力可以将测试人员与相关人员之间的冲突和对抗减少到最低程度。
③、技术能力
就总体言,开发人员对那些不懂技术的人持一种轻视的态度。一旦测试小组的某个成员作出了一个错误的断定,那么他们的可信度就会立刻被传扬了出去。一个测试者必须既明白被测软件系统的概念又要会使用工程中的那些工具。要做到这一点需要有几年以上的编程经验,前期的开发经验可以帮助对软件开发过程有较深入的理解,从开发人员的角度正确的评价测试者,简化自动测试工具编程的学习曲线。
④、自信心
开发者指责测试者出了错是常有的事,测试者必须对自己的观点有足够的自信心。如果容许别人对自己指东指西,就不能完成什么更多的事情了。
⑤、外交能力
当你告诉某人他出了错时,就必须使用一些外交方法。机智老练和外交手法有助于维护与开发人员的协作关系,测试者在告诉开发者他的软件有错误时,也同样需要一定的外交手腕。如果采取的方法过于强硬,对测试者来说,在以后和开发部门的合作方面就相当于“赢了战争却输了战役”。
⑥、幽默感
在遇到狡辩的情况下,一个幽默的批评将是很有帮助的。
⑦、很强的记忆力
一个理想的测试者应该有能力将以前曾经遇到过的类似的错误从记忆深处挖掘出来,这一能力在测试过程中的价值是无法衡量的。因为许多新出现的问题和我们已经发现的问题相差无几。
⑧、耐心
一些质量保证工作需要难以置信的耐心。有时你需要花费惊人的时间去分离、识别和分派一个错误。这个工作是那些坐不住的人无法完成的。
⑨、怀疑精神
可以预料,开发者会尽他们最大的努力将所有的错误解释过去。测式者必须听每个人的说明,但他必须保持怀疑直到他自己看过以后。
⑩、自我督促
干测试工作很容易使你变得懒散。只有那些具有自我督促能力的人才能够使自己每天正常地工作。
11、洞察力
一个好的测试工程师具有“测试是为了破坏”的观点,捕获用户观点的能力,强烈的质量追求,对细节的关注能力。应用的高风险区的判断能力以便将有限的测试针对重点环节。 -
软件测试要点小结
2007-01-30 08:58:12
一、 环境配置测试
(1) 网络连接是否正常
(2) 网络流量负担是否过重
(3) 软件测试平台是否可选
(4) 如果(3),是否在不同的软件测试平台进行软件测试
(5) 所选软件测试平台的版本(包括Service Pack)是否正确
(6) 所选软件测试平台的参数设置是否正确
(7) 所选软件测试平台上正在运行的其它程序是否会影响测试结果
(8) 画面的分辨率和色彩设定是否正确
二、 代码测试
A. 静态测试
(1) 同一程序内的代码书写是否为同一风格
(2) 代码布局是否合理、美观
(3) 程序中函数、子程序块分界是否明显
(4) 注释是否符合既定格式
(5) 注释是否正确反映代码的功能
(6) 变量定义是否正确(长度、类型、存储类型)
(7) 是否引用了未初始化变量
(8) 数组和字符串的下标是否为整数
(9) 数组和字符串的下标是否在范围内(不“越界”)
(10) 进行数组的检索及其它操作中,是否会出现“漏掉一个这种情况”
(11) 是否在应该使用常量的地方使用了变量(例:数组范围检查)
(12) 是否为变量赋予不同类型的值
(13) (12)的情况下,赋值是否符合数据类型的转换规则
(14) 变量的命名是否相似
(15) 是否存在声明过,但从未引用或者只引用过一次的变量
(16) 在特定模块中所有的变量是否都显式声明过
(17) 非(16)的情况下,是否可以理解为该变量具有更高的共享级别
(18) 是否为引用的指针分配内存
(19) 数据结构在函数和子程序中的引用是否明确定义了其结构
(20) 计算中是否使用了不同数据类型的变量
(21) 计算中是否使用了不同的数据类型相同但长度不同的变量
(22) 赋值的目的变量是否小于赋值表达式的值
(23) 数值计算是否会出现溢出(向上)的情况
(24) 数值计算是否会出现溢出(向下)的情况
(25) 除数是否可能为零
(26) 某些计算是否会丢失计算精度
(27) 变量的值是否超过有意义的值
(28) 计算式的求值的顺序是否容易让人感到混乱
(29) 比较是否正确
(30) 是否存在分数和浮点数的比较
(31) 如果(30),精度问题是否会影响比较
(32) 每一个逻辑表达式是否都得到了正确表达
(33) 逻辑表达式的操作数是否均为逻辑值
(34) 程序中的Begin…End和Do…While等语句中,End是否对应
(35) 程序、模块、子程序和循环是否能够终止
(36) 是否存在永不执行的循环
(37) 是否存在多循环一次或少循环一次的情况
(38) 循环变量是否在循环内被错误地修改
(39) 多分支选择中,索引变量是否能超过可能的分支数
(40) 如果(39),该情况是否能够得到正确处理
(41) 子程序接受的参数类型、大小、次序是否和调用模块相匹配
(42) 全局变量定义和用法在各个模块中是否一致
(43) 是否修改了只作为输入用的参数
(44) 常量是否被做为形式参数进行传递
B 动态测试
(1) 测试数据是否具有一定的代表性
(2) 测试数据是否包含测试所用的各个等价类(边界条件、次边界条件、空白、无效)
(3) 是否可能从客户那边得到测试数据
(4) 非(3)的情况下,所用的测试数据是否具有实际的意义
(5) 是否每一组测试数据都得到了执行
(6) 每一组测试数据的测试结果是否与预期结果一致
(7) 文件的属性是否正确
(8) 打开文件语句是否正确
(9) 输入/输出语句是否与格式说明书所记述的一致
(10) 缓冲区大小与记录长度是否匹配
(11) 使用文件前是否已打开了文件
(12) 文件结束条件是否存在
(13) 产生输入/输出错误时,系统是否进行检测并处理
(14) 输出信息中是否存在文字书写错误和语法错误
(15) 控件尺寸是否大小适宜
(16) 控件颜色是否符合规约
(17) 控件布局是否合理、美观
(18) 控件TAB顺序是否从左到右,从上到下
(19) 数字输入框是否接受数字输入
(20) (19)的情况下、数字是否按既定格式显示
(21) 数字输入框是否拒绝字符串和“非法”数字的输入
(22) 组合框是否的能够进行下拉选择
(23) 组合框是否能够进行下拉多项选择
(24) 对于可添加数据组合框,添加数据后数据是否能够得到正确显示和进行选择
(25) 列表框是否能够进行选择
(26) 多项列表框是否能够进行多数据项选择
(27) 日期输入框是否接受正确的日期输入
(28) 日期输入框是否拒绝错误的日期输入
(29) 日期输入框在日期输入后是否按既定的日期格式显示日期
(30) 单选组内是否有且只有一个单选钮可选
(31) 如果单选组内无单选钮可选,这种情况是否允许存在
(32) 复选框组内是否允许多个复选框(包括全部可选)可选
(33) 如果复选框组内无复选框可选,这种情况是否允许存在
(34) 文本框及某些控件拒绝输入和选择时显示区域是否变灰或按既定规约处理
(35) 密码输入框是否按掩码的方式显示
(36) Cancel之类的按钮按下后,控件中的数据是否清空复原或按既定规约处理
(37) Submit之类的按钮按下后,数据是否得到提交或按既定规约处理
(38) 异常信息表述是否正确
(39) 软件是否按预期方式处理错误
(40) 文件或外设不存在的情况下是否存在相应的错误处理
(41) 软件是否严格的遵循外设的读写格式
(42) 画面文字(全、半角、格式、拼写)是否正确
(43) 产生的文件和数据表的格式是否正确
(44) 产生的文件和数据表的计算结果是否正确
(45) 打印的报表是否符合既定的格式
(46) 错误日志的表述是否正确
(47) 错误日志的格式是否正确 -
黑盒测试的测试用例设计方法〔转载〕
2007-01-29 17:08:02
黑盒测试的测试用例设计方法
一、黑盒测试的测试用例设计方法
1. 等价类划分方法
2. 边界值分析方法
3. 错误推测方法
4. 因果图方法
5. 判定表驱动分析方法
6. 正交实验设计方法
7. 功能图分析方法二、等价类划分
等价类划分方法是把所有可能的输入数据,即程序的输入域划分成若干部分(子集),然后从每一个子集中选取少数具有代表性的数据作为测试用例。该方法是一种重要的、常用的黑盒测试用例设计方法。
1. 等价类的概念
等价类:等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的。并合理地假定,测试某等价类的代表值就等于对这一类其它值的测试。因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件,就可以用少量代表性的测试数据。取得较好的测试结果。等价类划分可有两种不同的情况:有效等价类和无效等价类。
有效等价类:是指对于程序的规格说明来说是合理的,有意义的输入数据构成的集合。利用有效等价类可检验程序是否实现了规格说明中所规定的功能和性能。
无效等价类:与有效等价类的定义恰巧相反。
设计测试用例时,要同时考虑这两种等价类。因为,软件不仅要能接收合理的数据,也要能经受意外的考验。这样的测试才能确保软件具有更高的可靠性。
2. 划分等价类的方法
下面给出六条确定等价类的原则:
1) 在输入条件规定了取值范围或值的个数的情况下,则可以确立一个有效等价类和两个无效等价类。
2) 在输入条件规定了输入值的集合或者规定了“必须如何”的条件的情况下,可确立一个有效等价类和一个无效等价类。
3) 在输入条件是一个布尔量的情况下,可确定一个有效等价类和一个无效等价类。
4) 在规定了输入数据的一组值(假定n个),并且程序要对每一个输入值分别处理的情况下,可确立n个有效等价类和一个无效等价类。
5) 在规定了输入数据必须遵守的规则的情况下,可确立一个有效等价类(符合规则)和若干个无效等价类(从不同角度违反规则)。
6) 在确知已划分的等价类中各元素在程序处理中的方式不同的情况下,则应再将该等价类进一步的划分为更小的等价类。
3. 设计测试用例
在确立了等价类后,可建立等价类表,列出所有划分出的等价类:
输入条件 有效等价类 无效等价类
。。。。。。。。。
。。。。。。。。。
然后从划分出的等价类中按以下三个原则设计测试用例:
1) 为每一个等价类规定一个唯一的编号。
2) 设计一个新的测试用例,使其尽可能多地覆盖尚未被覆盖地有效等价类,重复这一步。直到所有的有效等价类都被覆盖为止。
3) 设计一个新的测试用例,使其仅覆盖一个尚未被覆盖的无效等价类,重复这一步。直到所有的无效等价类都被覆盖为止。三、边界值分析法
边界值分析方法是对等价类划分方法的补充。
边界值分析方法的考虑:
长期的测试工作经验告诉我们,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。
使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。
基于边界值分析方法选择测试用例的原则:
1) 如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值,以及刚刚超越这个范围边界的值作为测试输入数据。
2) 如果输入条件规定了值的个数,则用最大个数,最小个数,比最小个数少一,比最大个数多一的数作为测试数据。
3) 根据规格说明的每个输出条件,使用前面的原则1)。
4) 根据规格说明的每个输出条件,应用前面的原则2)。
5) 如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
6) 如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
7) 分析规格说明,找出其它可能的边界条件。四、错误推测法
错误推测法:基于经验和直觉推测程序中所有可能存在的各种错误,从而有针对性的设计测试用例的方法。
错误推测方法的基本思想:列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例。例如,在单元测试时曾列出的许多在模块中常见的错误。以前产品测试中曾经发现的错误等,这些就是经验的总结。还有,输入数据和输出数据为0的情况。输入表格为空格或输入表格只有一行。这些都是容易发生错误的情况。可选择这些情况下的例子作为测试用例。
五、因果图方法
前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系,相互组合等。考虑输入条件之间的相互组合,可能会产生一些新的情况。但要检查输入条件的组合不是一件容易的事情,即使把所有输入条件划分成等价类,他们之间的组合情况也相当多。因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例。这就需要利用因果图(逻辑模型)。
因果图方法最终生成的就是判定表。它适合于检查程序输入条件的各种组合情况。
利用因果图生成测试用例的基本步骤:
1) 分析软件规格说明描述中,那些是原因(即输入条件或输入条件的等价类),那些是结果(即输出条件),并给每个原因和结果赋予一个标识符。
2) 分析软件规格说明描述中的语义。找出原因与结果之间,原因与原因之间对应的关系。根据这些关系,画出因果图。
3) 由于语法或环境限制,有些原因与原因之间,原因与结果之间的组合情况不不可能出现。为表明这些特殊情况,在因果图上用一些记号表明约束或限制条件。
4) 把因果图转换为判定表。
5) 把判定表的每一列拿出来作为依据,设计测试用例。
从因果图生成的测试用例(局部,组合关系下的)包括了所有输入数据的取TRUE与取FALSE的情况,构成的测试用例数目达到最少,且测试用例数目随输入数据数目的增加而线性地增加。
六、判定表驱动分析方法
前面因果图方法中已经用到了判定表。判定表(Decision Table)是分析和表达多逻辑条件下执行不同操作的情况下的工具。在程序设计发展的初期,判定表就已被当作编写程序的辅助工具了。由于它可以把复杂的逻辑关系和多种条件组合的情况表达得既具体又明确。
1.判定表通常由四个部分组成。
条件桩(Condition Stub):列出了问题得所有条件。通常认为列出得条件的次序无关紧要。
动作桩(Action Stub):列出了问题规定可能采取的操作。这些操作的排列顺序没有约束。
条件项(Condition Entry):列出针对它左列条件的取值。在所有可能情况下的真假值。
动作项(Action Entry):列出在条件项的各种取值情况下应该采取的动作。
规则:任何一个条件组合的特定取值及其相应要执行的操作。在判定表中贯穿条件项和动作项的一列就是一条规则。显然,判定表中列出多少组条件取值,也就有多少条规则,既条件项和动作项有多少列。
2.判定表的建立步骤(根据软件规格说明):
1) 确定规则的个数。假如有n个条件,每个条件有两个取值(0,1),故有n2种规则。
2) 列出所有的条件桩和动作桩。
3) 填入条件项。
4) 填入动作项。等到初始判定表。
5) 简化。合并相似规则(相同动作)。
3.适合使用判定表设计测试用例的条件:
1) 规格说明以判定表形式给出,或很容易转换成判定表。
2) 条件的排列顺序不会也不影响执行哪些操作。
3) 规则的排列顺序不会也不影响执行哪些操作。
4) 每当某一规则的条件已经满足,并确定要执行的操作后,不必检验别的规则。
5) 如果某一规则得到满足要执行多个操作,这些操作的执行顺序无关紧要。 -
软件测试模型
2007-01-26 20:07:53

V模型
V模型最早是由Paul Rook在20世纪80年代后期提出的,旨在改进软件开发的效率和效果。V模型反映出了测试活动与分析设计活动的关系。从左到右描述了基本的开发过程和测试行为,非常明确的标注了测试过程中存在的不同类型的测试,并且清楚的描述了这些测试阶段和开发过程期间各阶段的对应关系。
V模型指出,单元和集成测试应检测程序的执行是否满足软件设计的要求;系统测试应检测系统功能、性能的质量特性是否达到系统要求的指标;验收测试确定软件的实现是否满足用户需要或合同的要求。
但V模型存在一定的局限性,它仅仅把测试作为在编码之后的一个阶段,是针对程序进行的寻找错误的活动,而忽视了测试活动对需求分析、系统设计等活动的验证和确认的功能。

W模型(也叫双V模型)
W模型由Evolutif公司公司提出,相对于V模型,W模型增加了软件各开发阶段中应同步进行的验证和确认活动。W模型由两个V字型模型组成,分别代表测试与开发过程,图中明确表示出了测试与开发的并行关系。
W模型强调:测试伴随着整个软件开发周期,而且测试的对象不仅仅是程序,需求、设计等同样要测试,也就是说,测试与开发是同步进行的。W模型有利于尽早地全面的发现问题。例如,需求分析完成后,测试人员就应该参与到对需求的验证和确认活动中,以尽早地找出缺陷所在。同时,对需求的测试也有利于及时了解项目难度和测试风险,及早制定应对措施,这将显著减少总体测试时间,加快项目进度。
但W模型也存在局限性。在W模型中,需求、设计、编码等活动被视为串行的,同时,测试和开发活动也保持着一种线性的前后关系,上一阶段完全结束,才可正式开始下一个阶段工作。这样就无法支持迭代的开发模型。对于当前软件开发复杂多变的情况,W模型并不能解除测试管理面临着困惑。

X模型
X模型是由Marick提出的,他的目标是弥补V模型的一些缺陷,例如:交接、经常性的集成等问题。
X模型的左边描述的是针对单独程序片段所进行的相互分离的编码和测试,此后将进行频繁的交接,通过集成最终合成为可执行的程序。右上半部分,这些可执行程序还需要进行测试。已通过集成测试的成品可以进行封版并提交给用户,也可以作为更大规模和范围内集成的一部分。多根并行的曲线表示变更可以在各个部分发生。
X模型还定位了探索性测试(右下方)。这是不进行事先计划的特殊类型的测试,诸如“我这么测一下结果会怎么样?”,这一方式往往能帮助有经验的测试人员在测试计划之外发现更多的软件错误。
但V模型的一个强项是它明确的需求角色的确认,而X模型没有这么做,这大概是X模型的一个不足之处。 而且由于X模型从没有被文档化,其内容一开始需要从V模型的相关内容中进行推断,因为它还没有完全从文字上成为V模型的全面扩展。

H模型
V模型和W模型均存在一些不妥之处。如前所述,它们都把软件的开发视为需求、设计、编码等一系列串行的活动,而事实上,这些活动在大部分时间内是可以交叉进行的,所以,相应的测试之间也不存在严格的次序关系。同时,各层次的测试(单元测试、集成测试、系统测试等)也存在反复触发、迭代的关系。
为了解决以上问题,有专家提出了H模型。它将测试活动完全独立出来,形成了一个完全独立的流程,将测试准备活动和测试执行活动清晰地体现出来。









标题搜索
我的存档
数据统计
- 访问量: 67953
- 日志数: 52
- 书签数: 24
- 建立时间: 2007-01-26
- 更新时间: 2009-09-29
