
-
软件可靠性测试
2010-11-09 14:49:34
航天工业总公司二院204所 周新蕾 缪峥红
一、对软件可靠性测试的认识
1.有关术语
(1)软件可靠性 在规定条件下,在规定时间内,软件不引起系统失效的概率。该概率是系
统输入和系统使用的函数,也是软件中存在故障的函数,系统输入将确定是否会遇到存在的故
障。
(2)软件可靠性估计 应用统计技术处理在系统测试和运行期间采集、观察到的失效数据
,以评估该软件的可靠性。
(3)软件可靠性测试 在有使用代表性的环境中,为进行软件可靠性估计对该软件进行的
功能测试。
需要说明的是,"使用代表性"指的是在统计意义下该环境能反映出软件的使用环境特性
。
2.软件可靠性测试的目的
软件可靠性测试的主要目的有:
(1)通过在有使用代表性的环境中执行软件,以证实软件需求是否正确实现。
(2)为进行软件可靠性估计采集准确的数据。估计软件可靠性一般可分为四个步骤,即数
据采集、模型选择、模型拟合以及软件可靠性评估。可以认为,数据采集是整个软件可靠性
估计工作的基础,数据的准确与否关系到软件可靠性评估的准确度。
(3)通过软件可靠性测试找出所有对软件可靠性影响较大的错误。
3.软件可靠性测试的特点
软件可靠性测试不同于硬件可靠性测试,这主要是因为二者失效的原因不同。硬件失效
一般是由于元器件的老化引起的,因此硬件可靠性测试强调随机选取多个相同的产品,统计它
们的正常运行时间。正常运行的平均时间越长,则硬件就越可靠。软件失效是由设计缺陷造
成的,软件的输入决定是否会遇到软件内部存在的故障。因此,使用同样一组输入反复测试软
件并记录其失效数据是没有意义的。在软件没有改动的情况下,这种数据只是首次记录的不
断重复,不能用来估计软件可靠性。软件可靠性测试强调按实际使用的概率分布随机选择输
入,并强调测试需求的覆盖面。
软件可靠性测试也不同于一般的软件功能测试。相比之下,软件可靠性测试更强调测试
输入与典型使用环境输入统计特性的一致,强调对功能、输入、数据域及其相关概率的先期
识别。测试实例的采样策略也不同,软件可靠性测试必须按照使用的概率分布随机地选择测
试实例,这样才能得到比较准确的可靠性估计,也有利于找出对软件可靠性影响较大的故障。
此外,软件可靠性测试过程中还要求比较准确地记录软件的运行时间,它的输入覆盖一般也要
大于普通软件功能测试的要求。
对一些特殊的软件,如容错软件、实时嵌入式软件等,进行软件可靠性测试时需要有多种
测试环境。这是因为在使用环境下常常很难在软件中植入错误,以进行针对性的测试。
4.软件可靠性测试的效果
软件可靠性测试是软件可靠性保证过程中非常关键的一步。经过软件可靠性测试的软件
并不能保证该软件中残存的错误数最小,但可以保证该软件的可靠性达到较高的要求。从工
程的角度来看,一个软件的可靠性高不仅意味着该软件的失效率低,而且意味着一旦该软件失
效,由此所造成的危害也小。一个大型的工程软件没有错误是不可能的,至少理论上还不能证
明一个大型的工程软件能没有错误。因此,保证软件可靠性的关键不是确保软件没有错误,而
是要确保软件的关键部分没有错误。更确切地说,是要确保软件中没有对可靠性影响较大的
错误。这正是软件可靠性测试的目的之一。
软件可靠性测试的侧重点不同于一般的软件功能测试,其测试实例设计的出发点是寻找
对可靠性影响较大的故障。因此,要达到同样的可靠性要求,可靠性测试比一般的功能测试更
有效,所花的时间也更少。
另外,软件可靠性测试的环境是具有使用代表性的环境,这样,所获得的测试数据与软件
的实际运行数据比较接近,可用于软件可靠性估计。
总之,软件可靠性测试比一般的功能测试更加经济和有效,它可以代替一般的功能测试,
而一般的软件功能测试却不能代替软件可靠性测试,而且一般功能测试所得到的测试数据也
不宜用于软件可靠性估计。
二、软件可靠性测试中需注意的问题
软件可靠性测试一般可分为四个阶段:制定测试方案,制定测试计划,进行测试并记录测
试结果,编写测试报告。
制定测试方案时需要特别注意被测功能的识别和失效等级的定义。制定测试计划时需设
计测试实例,决定测试时要确定输入顺序,并确定程序输出的预期结果,这时也需注意测试覆
盖问题。
1.功能识别
软件可靠性测试的第一步就是进行功能识别,确定使用剖面。功能识别的目标是:识别所
有被测功能以及执行这些功能所需的相关输入,识别每一个使用需求及其相关输入的概率分
布。
为达到第一个目标,需要分析软件功能的所有集合,这些功能之间全部的约束条件,功能
之间的独立性、相互关系和相互影响,还需分析系统的不同运行模式、失效发生时系统重构
策略等对软件运行方式有较大影响的因素。
第一个目标也是一般软件功能测试需要达到的目标,但第二个目标则是软件可靠性测试
特别强调的。为了得到能够反映软件使用的有代表性的概率分布,测试人员必须和系统工程
师、系统运行分析员和顾客共同合作。需要指出的是,由于可靠性的要求,输入数据的概率分
布应包括合法数据的概率分布和非法数据的概率分布两部分。有时为了更好地反映实际使用
状况,还需给出那些影响程序运行方式的条件,如硬件配置、负荷等的概率分布。
2.定义换效等级
定义失效等级主要是为了解决下面两个问题:
·对发生概率小但失效后危害严重的功能需求的识别。
·对可不查找失效原因、并不做统计的功能需求的识别。
在制定测试计划时,失效及其等级的定义应由测试人员、设计人员和用户共同商定,达成
协议。一般的等级定义如表所示。
@@16115000.GIF;表1 失效等级定义@@
如果存在1级和2级失效可能性,那么就应该进行故障树分析,标识出所有可能造成严重失
效的功能需求和其相关的输入域、外部条件和发生的可能性。
对引起1级和2级失效的功能需求及其相关的输入域必须进行严格的强化测试。对引起3
级失效的功能可按其发生概率选择测试实例。第4级失效可不查找原因,可在以后的版本中处
理。
3.可靠性测试覆盖
可靠性测试必须保证输入覆盖和环境覆盖,这是准确估计软件可靠性的基础。
输入覆盖包括下面几个内容:
·输入域覆盖,即所有被测输入值域的发生概率之和必须大于软件可靠度的要求。
·重要输入变量值的覆盖。
·相关输入变量可能组合的覆盖,以确保相关输入变量的相互影响不会导致软件失效。
·设计输入空间与实际输入空间之间区域的覆盖,即不合法输入域的覆盖。
·各种使用功能的覆盖。
环境覆盖是指测试时必须覆盖所有可能影响程序运行方式的条件。
三、软件可靠性测试的步骤
软件可靠性测试分为四个阶段:
1.制订测试方案
本阶段的目标是识别软件功能需求,触发该功能的输入和对应的数据域,确定相关的概率
分布及需强化测试的功能。
以下是我们推荐的步骤。在一些特定的应用中,有的步骤并不是必须的。
(1)分析功能需求 分析各种功能需求,识别触发该功能的输入及相关的数据域(包括合法
与不合法的两部分)。分析时要注意下述问题:
·该软件是否存在不同的运行模式?如果存在,那么应列出所有的系统运行模式。
·是否存在影响程序运行方式的外部条件?如果存在,那么有多少?它们的影响程度如何
·各种功能需求之间是相互独立的还是相关的?如果相关,是密切相关还是部分相关?如
果两种功能密切相关,那么可将两种功能合并为一种功能。如果功能之间为部分相关,则需列
出相应输入变量的合法组合。
(2)定义失效等级 判断是否存在出现危害度较大的1级和2级失效的可能性。如果这种可
能性存在,则应进行故障树分析,标识出所有可能造成严重失效的功能需求和其相关的输入域
。
(3)确定概率分布
·确定各种不同运行方式的发生概率,判断是否需要对不同的运行方式进行分别测试。
如果需要,则应给出各种运行方式下各数据域的概率分布;否则,给出各数据域的概率分布。
·判断是否需要强化测试某些功能。
(4)整理概率分布的信息 将这些信息编码送入数据库。
2.制订测试计划
本阶段的目标是:
(1)根据前一阶段整理的概率分布信息生成相对应的测试实例集,并计算出每一测试实例
预期的软件输出结果。
本阶段需要注意:在按概率分布随机选择生成测试实例的同时,要保证测试的覆盖面。
(2)编写测试计划,确定测试顺序,分配测试资源。由于本阶段前一部分的工作需要考虑
大量的信息和数据,因此需要一个软件支持工具,建立数据库,并产生测试实例。另外,有时预
测软件输出结果也需要大量的计算,有些复杂的软件甚至要用到仿真器模拟输出结果。
总之,具体实施与被测应用软件的实际功能类型有关。
3.测试
本阶段进行软件测试。需注意的是被测软件的测试环境(包括硬件配置和软件支撑环境
)应和预期的实际使用环境尽可能一致,对某些环境要求比较严格的软件(如嵌入式软件)则应
完全一致。
测试时按测试计划和顺序对每一个测试实例进行测试,判断软件输出是否符合预期结果
。测试时应记录测试结果、运行时间和判断结果。如果软件失效,那么还应记录失效现象和
时间,以备以后核对。
4.编写测试报告
按软件可靠性估计的要求整理测试记录,并将结果写成报告。
笔者认为,软件可靠性测试的关键在于:
·对需求、输入、数据域的识别及相关概率分布的确定。
·按照概率分布随机生成测试实例,并确定测试顺序。
据国外有关文献报导,这种测试方法已成功应用于大量应用软件的可靠性测试,包括一些
商用软件和航空、航天电子设备中嵌入式软件的测试,其效果很好。因此,我们有必要投入一
定的人力、物力,针对我们的实际需要,有目的地对各类应用软件进行软件可靠性测试,从实
践中逐步积累经验。同时需要软件开发方和使用方共同合作,进行软件可靠性测试方法的研
究和有关支持工具的开发,促进我国软件可靠性水平的提高。
(计算机世界报 1997年 第16期)
-
基于UML的面向对象软件开发过程
2010-11-09 14:44:34
UML基本概念:UMl是一种标准的图形化建模语言,它是面向对象分析和设计的一种标准表示。经常用的工具有Microsoft Office Visio 2007 .
视图
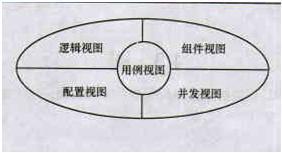
UML中的视图大致分为如下5种:
1、用例视图。用例视图强调从系统的外部参与者(主要是用户)的角度看到的或需要的系统功能。
2、逻辑视图。逻辑视图从系统的静态结构和动态行为角度显示如何实现系统的功能。
3、组件视图。组件视图显示代码组件的组织结构。
4、并发视图。并发视图显示系统的并发性,解决在并发系统中存在的通信和同步问题。
5、配置视图。配置视图显示系统的具体部署。部署是指将系统配置到由计算机和设备组成的物理结构上。
上述5种视图分别描述系统的一个方面,5种视图组合成UML完整的模型。下图显示了构成UML完整模型的5种视图间的关系
一、用例视图
用例视图描述系统应具备的功能,也就是被成为参与者的外部用户所能观察到的功能。用例是系统的一个功能单元,可以被描述为参与者与系统之间的一次交互作用。参与者可以是一个用户或者另外一个系统。客户对系统要求的功能被当作多个用例在用例视图中进行描述,一个用例就是对系统的一个用法的通用描述。用例模型的用途就是列出系统中的用例和参与者,并显示哪个参与者参与了哪个用例的执行。用例视图是其他视图的核心,它的内容直接驱动其他视图的开发。
二、逻辑视图
逻辑视图描述用例视图中提出的系统功能的实现。与用例视图相比,逻辑视图主要关注系统内部,它既描述系统的静态结构(类、对象以及他们之间的关系),也描述系统内部的动态协作关系。系统的静态结构在类图和对象图中进行描述,而动态模型则在状态图、时序图、协作图以及活动图中进行描述。逻辑视图的使用者主要是设计人员和开发人员。
三、并发视图
并发视图主要考虑资源的有效利用、代码的并行执行以及系统环境中异步事件的处理。除了将系统划分为并发执行的控制以外,并发视图还需要处理线程之间的通信和同步。并发视图的使用者是开发人员和系统集成人员。并发视图由状态图、协作图、以及活动图组成。
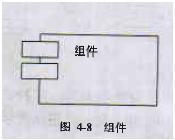
四、组件视图
组件是不同类型的代码模块,它是构造应用的软件单元。组件视图描述系统的实现模块以及它们之间的依赖关系。组件视图中也可以添加组件的其他附加信息,例如资源分配或者其他管理信息。组件视图主要由组件图构成,它的使用者主要是开发人员。
五、配置视图
配置视图显示系统的物理部署,它描述位于节点上的运行实例的部署情况。配置视图主要由配置图表示,它的使用者是开发人员、系统集成人员和测试人员。配置视图还允许评估分配结果和资源分配。
图
UML的各种图是UML模型的重要组成部分
1、 用例图(Use Case Diagram)
用例是系统中的一个可以描述参与者与系统直接交互作用的功能单元,用例图的用途是列出系统中的用例和参与者,并显示哪个参与者参与了哪个用例的执行。
2、 类图(Class Diagram)
类是对应用领域或应用解决方案中概念的描述。类图以类为中心组织,类图中国的其他元素或属于某个类,或与类相关联。
3、 对象图(Object Diagram)
对象图是类图的变体,它使用与类图相似的符号描述,不同之处在于对象图显示的是类的多个对象实例而非实际的类。可以说对象图是类图的一个例子,对象图与类图表示的不同之处在于它用带下划线的对象名称类表示对象,显示一个关系中的所有实例。
4、 状态图(State Diagram)
状态图是对类描述的补充,它用于显示类的对象可能具备的所有状态,以及引起状态改变的事件。实际建模时,并不需要为所有的类都绘制状态图,仅对那些具有多个明确状态并且这些状态会影响和改变其行为的类才有绘制状态图的必要。此外,还可以为系统绘制整体状态图。
5、 时序图(Sequence Diagram)
时序图显示多个对象间的动作协作,重点是显示对象之间发送的消息的时间顺序。
6、 协作图(Collaboration Diagram)
协作图对在一次交互中有意义的对象和对象间的链建模。除了显示消息的交互以外,协作图也显示对象以及它们之间的关系。时序图和协作图都可以表示各对象间的交互关系,但它们的侧重点不同。时序图用消息的几何排列关系来表达消息的时间顺序,各角色之间的关系是隐含的。协作图用各个角色排列来表示角色之间的关系,并用消息类说明这些关系。在实际应用中可以根据需要选用这两种图:如果需要重点强调时间或顺序,那么选择时序图;如果需要重点强调上下文,那么选择协作图。
7、 活动图(Activity Diagram)
活动图是状态图的一个变体,用来描述执行算法的工作流程中涉及的活动。活动状态代表了一个活动,即一个工作流步骤或一个操作的执行。活动图由多个动作状态组成,当一个动作完成后,动作状态将会改变,转换为一个新的状态。
8、 组件图(Component Diagram)
组件图是用代码组件来显示代码物理结构。一个组件包含它所实现的一个或多个逻辑类的相关信息。通常组件图用于实际的编程工作中。
9、 配置图(Deployment Diagram)
配置图用于显示系统中的硬件和物理结构。
模型元素
UML中的模型元素包括事物和事物之间的联系。事物是UML中重要的组成部分,它代表任何可以定义的东西。事物之间的关系能够把事物联系在一起,组成有意义的结构模型。每一个模型元素都有一个与之相对应的图形元素。
一、 事物
UML中事物可以分为结构事物、动作事物、分组事物和注释事物。
1、 结构事物
结构事物分为:类、接口、协作、用例、活动类、组件和节点
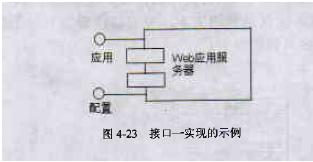
(1) 类。类是对具有相同属性、方法、关系和语义的对象的抽象,一个类可以实现一个或多个接口。类用包括类名、属性和方法的矩形表示。

(2) 接口。接口是为类或组件提供特定服务的一组操作的集合。

(3) 协作。协作定义了交互操作。一些角色和其他元素一起工作,提供一些合作的动作,这些动作比元素的总和要大。UML中协作用虚线构成的椭圆表示。

(4) 用例。用例描述系统对一个特定角色执行的一系列动作。在模型中用例通常用来组织动作事物,它是通过协作来实现的。UML中,用例用标注了用例名称的实线椭圆表示。

(5) 活动类。活动类是类对象有一个或多个进程或线程的类。在UML中活动类的表示法和类相同,只是边框用粗线条。

(6) 组件。组件是实现了一个接口集合的物理上可替换的系统部分。
(7) 节点。节点是在运行时存在的一个物理元素,它代表一个可计算的资源,通常占用一些内存和具有处理能力。一个组件集合一般来说位于一个节点,但也可以从一个节点转到另一个节点。

2、 动作事物
动作事物是UML模型中的动态部分,它们是模型的动词,代表时间和空间上的动作。交互和状态机是UML模型中最基本的两个动态事物元素。
(1) 交互。交互是一组对象在特定上下文中,为达到某种特定的目的而进行的一系列消息交换组成的动作。在交互中组成动作的对象的每个操作都要详细列出,包括消息、动作次数(消息产生的动作)、连接(对象之间的连接)。

(2) 状态机。状态机由一系列对象的状态组成。

3、 分组事物
分组事物是UML模型中组织的部分,分组事物只有一种,称为包。

4、 注释事物
注释事物是UML模型的解释部分。
二、 UML中的关系
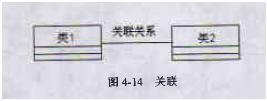
1、 关联关系
关联关系连接元素和链接实例,它用连接两个模型元素的实线表示,在关联的两端可以标注关联双方的角色和多重性标记。
2、 依赖关系
依赖关系描述一个元素对另一个元素的依附。依赖关系用源模型指向目标模型的带箭头的虚线表示。

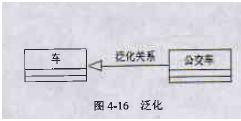
3、 泛化关系
泛化关系也称为继承关系,泛化用一条带空心三角箭头的实线表示,从子类指向父类。
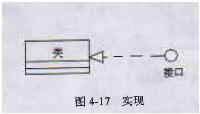
4、 实现关系
实现关系描述一个元素实现另一个元素。
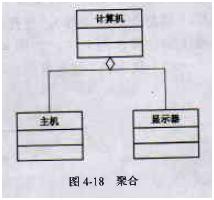
5、 聚合关系
聚合关系描述元素之间部分和整体的关系,即一个表示整体的模型元素可能由几个表示部分的模型元素聚合而成。
通用机制
一、 修饰。
在使用UML建模时,可以将图形修饰附加到UML图中的模型元素上。比如,当一个元素代表某种类型的时候,它的名称可以用粗体字形类显示;当同一元素表示该类型的实例时,该元素的名称用一条下划线修饰。

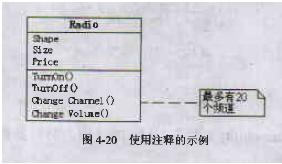
二、 注释。
UML中用一条虚线将注释连接到它为之解释的或细化的元素上。
三、 通用划分。
UML对其模型元素规定了两种类型的通用划分:型-实例(值)和接口-实现。
1、型-实例(Type-Instance):描述一个通用描述符与单个元素项之间的对应关系。实例元素使用与通用描述符相同的表示图形,但是名字的表示与通用描述符不同:实例元素名字带有下划线,而且后面还要加上冒号和通用描述符的名字。

2、接口-实现:接口声明了一个规定了服务的约定,接口的实现负责执行接口的全部语义定义并实现该项服务。
基于UML的面向对象软件开发过程:
统一过程(up)已成为一种流行的构造面向对象系统的软件开发过程,RUP是对UP的详细精化,下面介绍在业务建模、需求、设计、实现和测试这几个流程中使用UML的哪些图进行建模。
1.业务建模
采用UML的对象图和类图表示目标软件系统所基于的的应用领域中的概念和概念间的关系。这些相互关联的概念构成了领域模型。领域模型一方面可以帮助软件项目组理解业务背景,与业务专家进行有效沟通;另一方面,随着软件开发阶段的不断推进,领域模型将成为软件结构的主要基础。如果领域中含有明显的流程处理部分,可以考虑利用UML的活动图来刻画领域中的工作流,并标识业务流程中的并发、同步等特征。
2.需求
UML的的用例视图以用户为中心,对系统的功能性需求进行建模。通过识别位于系统边界之外的参与者以及参与者的目标,来确定系统要为用户提供哪些功能,并用用例进行描述。可以用文本形式或UML活动图描述用例,利用UML用例图表示参与者与用例之间、用例与用例之间的关系。采用UML顺序图图形描述参与者和系统之间的系统事件。利用系统操作契约刻画系统事件的发生引起系统内部状态的变化。如果目标系统比较庞大,用例较多,则可以用包来管理和组织这些用例,将关系密切的用例组织到同一个包里,用UML包图刻画这些包及其关系。
3.设计
把分析阶段的结果扩展成技术解决方案,包括软件体系结构设计和用力实现的设计。采用UML包图设计软件体系结构,刻画系统的分层、分块思路。采用UML协作图或顺序图寻找参与用例实现的类及其职责,这些类一部分来自领域模型,另一部分是软件实现新加入的类,它们为软件提供基础服务,如负责数据库持久化的类。用UML类图描述这些类及其关系,这些类属于体系结构的不同的包中。用UML状态图描述那些具有复杂生命周期行为的类。用UML活动图描述复杂的算法过程和有多个对象参与的业务处理过程,活动图尤其合适描述过程中的并发和同步。此外,还可以使用UML构件图描述软件代码的静态结构与管理。UML部署图描述硬件的拓扑结构以及软件和硬件的映射问题。
4.实现
把设计得到的类转换成某种面向对象程序设计语言的代码。
5.测试
不通的测试小组使用不同的UML图作为他们工作的基础:单元测试使用类图和类的规格说明,集成测试典型地使用构件图和协作图,而确认测试使用用例图和用例文本描述的来确认系统的行为是否符合这些图中的定义。
[转载 作者:aci]
-
Db2命令大全
2009-11-15 08:37:09
这篇写的好全啊,我是方便自己看,大家也可以看啊。Db2命令大全
连接数据库:
connect to [数据库名] user [操作用户名] using [密码]
创建缓冲池(8K):
create bufferpool ibmdefault8k IMMEDIATE SIZE 5000 PAGESIZE 8 K ;
创建缓冲池(16K)(OA_DIVERTASKRECORD):
create bufferpool ibmdefault16k IMMEDIATE SIZE 5000 PAGESIZE 16 K ;
创建缓冲池(32K)(OA_TASK):
create bufferpool ibmdefault32k IMMEDIATE SIZE 5000 PAGESIZE 32 K ;创建表空间:
CREATE TABLESPACE exoatbs IN DATABASE PARTITION GROUP IBMDEFAULTGROUP PAGESIZE 8K MANAGED BY SYSTEM USING ('/home/exoa2/exoacontainer') EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT8K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TABLESPACE exoatbs16k IN DATABASE PARTITION GROUP IBMDEFAULTGROUP PAGESIZE 16K MANAGED BY SYSTEM USING ('/home/exoa2/exoacontainer16k' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT16K OVERHEAD 24.1 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TABLESPACE exoatbs32k IN DATABASE PARTITION GROUP IBMDEFAULTGROUP PAGESIZE 32K MANAGED BY SYSTEM USING ('/home/exoa2/exoacontainer32k' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT32K OVERHEAD 24.1 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
GRANT USE OF TABLESPACE exoatbs TO PUBLIC;
GRANT USE OF TABLESPACE exoatbs16k TO PUBLIC;
GRANT USE OF TABLESPACE exoatbs32k TO PUBLIC;创建系统表空间:
CREATE TEMPORARY TABLESPACE exoasystmp IN DATABASE PARTITION GROUP IBMTEMPGROUP PAGESIZE 8K MANAGED BY SYSTEM USING ('/home/exoa2/exoasystmp' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT8K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TEMPORARY TABLESPACE exoasystmp16k IN DATABASE PARTITION GROUP IBMTEMPGROUP PAGESIZE 16K MANAGED BY SYSTEM USING ('/home/exoa2/exoasystmp16k' ) EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT16K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
CREATE TEMPORARY TABLESPACE exoasystmp32k IN DATABASE PARTITION GROUP IBMTEMPGROUP PAGESIZE 32K MANAGED BY SYSTEM USING ('/home/exoa2/exoasystmp32k') EXTENTSIZE 32 PREFETCHSIZE 16 BUFFERPOOL IBMDEFAULT32K OVERHEAD 24.10 TRANSFERRATE 0.90 DROPPED TABLE RECOVERY OFF;
1. 启动实例(db2inst1):
db2start
2. 停止实例(db2inst1):
db2stop
3. 列出所有实例(db2inst1)
db2ilist
5.列出当前实例:
db2 get instance
4. 察看示例配置文件:
db2 get dbm cfg|more
5. 更新数据库管理器参数信息:
db2 update dbm cfg using para_name para_value
6. 创建数据库:
db2 create db test
7. 察看数据库配置参数信息
db2 get db cfg for test|more
8. 更新数据库参数配置信息
db2 update db cfg for test using para_name para_value
10.删除数据库:
db2 drop db test
11.连接数据库
db2 connect to test
12.列出所有表空间的详细信息。
db2 list tablespaces show detail
13.查询数据:
db2 select * from tb1
14.删除数据:
db2 delete from tb1 where id=1
15.创建索引:
db2 create index idx1 on tb1(id);
16.创建视图:
db2 create view view1 as select id from tb1
17.查询视图:
db2 select * from view1
18.节点编目
db2 catalog tcp node node_name remote server_ip server server_port
19.察看端口号
db2 get dbm cfg|grep SVCENAME
20.测试节点的附接
db2 attach to node_name
21.察看本地节点
db2 list node direcotry
22.节点反编目
db2 uncatalog node node_name
23.数据库编目
db2 catalog db db_name as db_alias at node node_name
24.察看数据库的编目
db2 list db directory
25.连接数据库
db2 connect to db_alias user user_name using user_password
26.数据库反编目
db2 uncatalog db db_alias
27.导出数据
db2 export to myfile of ixf messages msg select * from tb1
28.导入数据
db2 import from myfile of ixf messages msg replace into tb1
29.导出数据库的所有表数据
db2move test export
30.生成数据库的定义
db2look -d db_alias -a -e -m -l -x -f -o db2look.sql
31.创建数据库
db2 create db test1
32.生成定义
db2 -tvf db2look.sql
33.导入数据库所有的数据
db2move db_alias import
34.重组检查
db2 reorgchk
35.重组表tb1
db2 reorg table tb1
36.更新统计信息
db2 runstats on table tb1
37.备份数据库test
db2 backup db test
38.恢复数据库test
db2 restore db test
399\.列出容器的信息
db2 list tablespace containers for tbs_id show detail
40.创建表:
db2 ceate table tb1(id integer not null,name char(10))
41.列出所有表
db2 list tables
42.插入数据:
db2 insert into tb1 values(1,’sam’);
db2 insert into tb2 values(2,’smitty’);
. 建立数据库DB2_GCB
CREATE DATABASE DB2_GCB ON G: ALIAS DB2_GCB
USING CODESET GBK TERRITORY CN COLLATE USING SYSTEM DFT_EXTENT_SZ 32
2. 连接数据库
connect to sample1 user db2admin using 8301206
3. 建立别名
create alias db2admin.tables for sysstat.tables;
CREATE ALIAS DB2ADMIN.VIEWS FOR SYSCAT.VIEWS
create alias db2admin.columns for syscat.columns;
create alias guest.columns for syscat.columns;
4. 建立表
create table zjt_tables as
(select * from tables) definition only;
create table zjt_views as
(select * from views) definition only;
5. 插入记录
insert into zjt_tables select * from tables;
insert into zjt_views select * from views;
6. 建立视图
create view V_zjt_tables as select tabschema,tabname from zjt_tables;
7. 建立触发器
CREATE TRIGGER zjt_tables_del
AFTER DELETE ON zjt_tables
REFERENCING OLD AS O
FOR EACH ROW MODE DB2SQL
Insert into zjt_tables1 values(substr(o.tabschema,1,8),substr(o.tabname,1,10))
8. 建立唯一性索引
CREATE UNIQUE INDEX I_ztables_tabname
[size=3]ON zjt_tables(tabname);
9. 查看表
select tabname from tables
where tabname='ZJT_TABLES';
10. 查看列
select SUBSTR(COLNAME,1,20) as 列名,TYPENAME as 类型,LENGTH as 长度
from columns
where tabname='ZJT_TABLES';
11. 查看表结构
db2 describe table user1.department
db2 describe select * from user.tables
12. 查看表的索引
db2 describe indexes for table user1.department
13. 查看视图
select viewname from views
where viewname='V_ZJT_TABLES';
14. 查看索引
select indname from indexes
where indname='I_ZTABLES_TABNAME';
15. 查看存贮过程
SELECT SUBSTR(PROCSCHEMA,1,15),SUBSTR(PROCNAME,1,15)
FROM SYSCAT.PROCEDURES;
16. 类型转换(cast)
ip datatype:varchar
select cast(ip as integer)+50 from log_comm_failed
17. 重新连接
connect reset
18. 中断数据库连接
disconnect db2_gcb
19. view application
LIST APPLICATION;
20. kill application
FORCE APPLICATION(0);
db2 force applications all (强迫所有应用程序从数据库断开)
21. lock table
lock table test in exclusive mode
22. 共享
lock table test in share mode
23. 显示当前用户所有表
list tables
24. 列出所有的系统表
list tables for system
25. 显示当前活动数据库
list active databases
26. 查看命令选项
list command options
27. 系统数据库目录
LIST DATABASE DIRECTORY
28. 表空间
list tablespaces
29. 表空间容器
LIST TABLESPACE CONTAINERS FOR
Example: LIST TABLESPACE CONTAINERS FOR 1
30. 显示用户数据库的存取权限
GET AUTHORIZATIONS
31. 启动实例
DB2START
32. 停止实例
db2stop
33. 表或视图特权
grant select,delete,insert,update on tables to user
grant all on tables to user WITH GRANT OPTION
34. 程序包特权
GRANT EXECUTE
ON PACKAGE PACKAGE-name
TO PUBLIC
35. 模式特权
GRANT CREATEIN ON SCHEMA SCHEMA-name TO USER
36. 数据库特权
grant connect,createtab,dbadm on database to user
37. 索引特权
grant control on index index-name to user
38. 信息帮助 (? XXXnnnnn )
例:? SQL30081
39. SQL 帮助(说明 SQL 语句的语法)
help statement
例如,help SELECT
40. SQLSTATE 帮助(说明 SQL 的状态和类别代码)
? sqlstate 或 ? class-code
41. 更改与"管理服务器"相关的口令
db2admin setid username password
42. 创建 SAMPLE 数据库
db2sampl
db2sampl F:(指定安装盘)
43. 使用操作系统命令
! dir
44. 转换数据类型 (cast)
SELECT EMPNO, CAST(RESUME AS VARCHAR(370))
FROM EMP_RESUME
WHERE RESUME_FORMAT = 'ascii'
45. UDF
要运行 DB2 Java 存储过程或 UDF,还需要更新服务器上的 DB2 数据库管理程序配置,以包括在该机器上安装 JDK 的路径
db2 update dbm cfg using JDK11_PATH d:sqllibjavajdk
TERMINATE
update dbm cfg using SPM_NAME sample
46. 检查 DB2 数据库管理程序配置
db2 get dbm cfg
47. 检索具有特权的所有授权名
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'DATABASE' FROM SYSCAT.DBAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'TABLE ' FROM SYSCAT.TABAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'PACKAGE ' FROM SYSCAT.PACKAGEAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'INDEX ' FROM SYSCAT.INDEXAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'COLUMN ' FROM SYSCAT.COLAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'SCHEMA ' FROM SYSCAT.SCHEMAAUTH
UNION
SELECT DISTINCT GRANTEE, GRANTEETYPE, 'SERVER ' FROM SYSCAT.PASSTHRUAUTH
ORDER BY GRANTEE, GRANTEETYPE, 3
create table yhdab
(id varchar(10),
password varchar(10),
ywlx varchar(10),
kh varchar(10));
create table ywlbb
(ywlbbh varchar(8),
ywmc varchar(60))
48. 修改表结构
alter table yhdab ALTER kh SET DATA TYPE varchar(13);
alter table yhdab ALTER ID SET DATA TYPE varchar(13);
alter table lst_bsi alter bsi_money set data type int;
insert into yhdab values
('20000300001','123456','user01','20000300001'),
('20000300002','123456','user02','20000300002');
49. 业务类型说明
insert into ywlbb values
('user01','业务申请'),
('user02','业务撤消'),
('user03','费用查询'),
('user04','费用自缴'),
('user05','费用预存'),
('user06','密码修改'),
('user07','发票打印'),
('gl01','改用户基本信息'),
('gl02','更改支付信息'),
('gl03','日统计功能'),
('gl04','冲帐功能'),
('gl05','对帐功能'),
('gl06','计费功能'),
('gl07','综合统计')
备份数据库:
CONNECT TO EXOA;
QUIESCE DATABASE IMMEDIATE FORCE CONNECTIONS;
CONNECT RESET;
BACKUP DATABASE EXOA TO "/home/exoa2/db2bak/" WITH 2 BUFFERS BUFFER 1024 PARALLELISM 1 WITHOUT PROMPTING;
CONNECT TO EXOA;
UNQUIESCE DATABASE;
CONNECT RESET;以下是小弟在使用db2move中的一些经验,希望对大家有所帮助。
db2 connect to YOURDB
连接数据库db2look -d YOURDB -a -e -x -o creatab.sql
导出建库表的SQLdb2move YOURDB export
用db2move将数据备份出来vi creatab.sql
如要导入的数据库名与原数据库不同,要修改creatab.sql中CONNECT 项
如相同则不用更改db2move NEWDB load
将数据导入新库中在导入中可能因为种种原因发生中断,会使数据库暂挂
db2 list tablespaces show detail
如:
详细说明:
装入暂挂
总页数 = 1652
可用页数 = 1652
已用页数 = 1652
空闲页数 = 不适用
高水位标记(页) = 不适用
页大小(字节) = 4096
盘区大小(页) = 32
预读取大小(页) = 32
容器数 = 1
状态更改表空间标识 = 2
状态更改对象标识 = 59db2 select tabname,tableid from syscat.tables where tableid=59
查看是哪张表挂起表名知道后到db2move.lst(在db2move YOURDB export的目录中)中找到相应的.ixf文件
db2 load from tab11.ixf of ixf terminate into db2admin.xxxxxxxxx
tab11.ixf对应的是xxxxxxxxx表数据库会恢复正常,可再用db2 list tablespaces show detail查看
30.不能通过GRANT授权的权限有哪种?
SYSAM
SYSCTRL
SYSMAINT
要更该述权限必须修改数据库管理器配置参数
31.表的类型有哪些?
永久表(基表)
临时表(说明表)
临时表(派生表)
32.如何知道一个用户有多少表?
SELECT * FROM SYSIBM.SYSTABLES WHERE CREATOR='USER'
33.如何知道用户下的函数?
select * from IWH.USERFUNCTION
select * from sysibm.SYSFUNCTIONS
34.如何知道用户下的VIEW数?
select * from sysibm.sysviewsWHERECREATOR='USER'
35.如何知道当前DB2的版本?
select * from sysibm.sysvERSIONS
36.如何知道用户下的TRIGGER数?
select * from sysibm.SYSTRIGGERSWHERESCHEMA='USER'
37.如何知道TABLESPACE的状况?
select * from sysibm.SYSTABLESPACES
38.如何知道SEQUENCE的状况?
select * from sysibm.SYSSEQUENCES
39.如何知道SCHEMA的状况?
select * from sysibm.SYSSCHEMATA
40.如何知道INDEX的状况?
select*fromsysibm.SYSINDEXES
41.如何知道表的字段的状况?
select*fromsysibm.SYSCOLUMNSWHERETBNAME='AAAA'
42.如何知道DB2的数据类型?
select*from sysibm.SYSDATATYPES
43.如何知道BUFFERPOOLS状况?
select*from sysibm.SYSBUFFERPOOLS
44.DB2表的字段的修改限制?
只能修改VARCHAR2类型的并且只能增加不能减少.
45.如何查看表的结构?
DESCRIBLE TABLE TABLE_NAME
OR
DESCRIBLE SELECT*FROM SCHEMA.TABLE_NAME
-
一些重要的性能计数器(转载)
2007-07-04 18:38:13
解决性能问题的时候,我往往会让客户添加下面一些计数器进行性能收集。
Process object下的所有计数器。
Processor object下的所有计数器
System object下的所有计数器
Memory object下的所有计数器
如果客户的程序是.NET程序,还会添加 .NET 开头的object下的所有技术其
如果客户使用ASP.NET,还会添加 ASP.NET 开头的object下的所有技术其
分析性能日志的时候,我会重点观察下面这些计数器
Process object
Process object中的计数器可以针对目标进程分析内存,CPU,线程数目和handle数目。首先要确定目标进程,然后分析目标进程的下面一些计数器:
% Processor Time
该计数器是该进程占用CPU资源的指标。当进程繁忙的时候,CPU平均占用率应该在80%以内。如果超过该数值,程序可以认为发生了high CPU的问题。另外一种问题是CPU波动幅度大。虽然平均占用率不高,但是上下跳动频繁。在某一个短时间段里面,会有连续高CPU的情况出现。
Handle Count
该计数器记录了当前进程使用的kernel object handle数量。Kernel object是重要的系统资源。当程序进入稳定运行状态的时候,Handle Count数量也应该维持在一个稳定的区间。如果发现Handle Count在整个程序周期内总体趋势是连续向上,可以考虑程序是否有Handle Leak
ID Process
该计数器记录了目标进程的进程ID。你可能觉得奇怪,ID有什么好观察的。进程ID是用来观察程序是否有重启发生。比如ASP.NET工作进程可能会自动回收。由于进程名都相同,只有通过进程ID来判断是否进程有重新启动现象。如果ID有变化,考虑程序是否发生崩溃或者Recycle
Private Bytes
该计数器记录了当前通过VirtualAlloc API Commit的Memory数量。无论是直接调用API申请的内存,被Heap Manager申请的内存,或者是CLR 的managed heap,都算在里面。跟Handle Count一样,如果在整个程序周期内总体趋势是连续向上,说明有Memory Leak
Virtual Bytes
该计数器记录了当前进程申请成功的用户态总内存地址,包括DLL/EXE占用的地址和通过VirtualAlloc API Reserve的Memory Space数量,所以该计数器应该总大于Private Bytes。一般来说,Virtual Bytes跟Private Bytes的变化大致一致。由于内存分片的存在, Virtual Bytes跟Private Byes一般保持一个相对稳定的比例关系。当Virtual Bytes跟Private Bytes的比例关系大于2的时候,程序往往有比较严重的内存地址分片。
Processor object
Processor object记录系统中芯片的负载情况。由于普通程序并不刻意邦定到某个具体CPU上执行,所以在多CPU机器上观察Total Instance也就足够了
% Processor Time 该计数器跟Process下的% Processor Time的意义一样,不过这里记录的是所有进程带来的芯片,而不是针对具体某一个进程。通过把这个计数器跟Process下的同名计数器一起比较,就能看出系统的高CPU问题是否是由于单一的某个进程导致的
System
System object记录系统中一个整体的统计信息。所以不区分Instance. 通过比较System object下的counter和其他counter的变化趋势,往往能看出一些线索
Context Switch/sec
Context Switch标示了系统中整体线程的调度,切换频率。线程切换是开销比较大的操作。频繁的线程切换导大量CPU周期被浪费。所以看到高CPU的时候,一定要跟Context Switch一起比较。如果两者有相同的变化趋势,高CPU往往是由于contention导致的,而不是死循环。
Exception Dispatches/sec
Exception Dispatches表示了系统中异常派发,处理的频繁程序。跟线程切换一样,异常处理也需要大量的CPU开销。分析方法跟Context Switch雷同。
File Data Operations/sec
File Data Operations记录了当前系统中磁盘文件读写的频繁程度。通过观察该计数器跟其他性能指标的变化趋势,通常能够判断磁盘文件操作是否是性能瓶颈。类似的计数器还有Network Interface\Bytes total/sec
Memory
Memory object记录了当前系统中整体内存的统计信息。
Available Mbytes
Committed Bytes
Available Mbytes记录了当前剩余的物理内存数量。Committed Bytes记录了所有进程commit的内存数量。结合两个计数器可以观察到:
1) 两者相加可以粗略估计系统总体可用内存多少,便于估计物理配置
2) 当Available Mbytes少于100MB的时候,说明系统总体内存吃紧,会影响到整个系统所有进程的性能。应该考虑增加物理内存或者监察内存泄露
3) 通过比较Process\Private Bytes跟Virtual Bytes,便于进一步确认是否有内存泄露,判断内存泄露是否是某一单个进程导致
Free System Page Table Entries,Pool Paged Bytes和Pool Paged Bytes
这三个计数器可以衡量核心态空闲内存的数量。特别是当使用/3GB开关后,核心态内存地址被压缩,容易导致核心态内存不足,继而引发一些非常妖怪的问题。可以参考以下文章:
How to use the /userva switch with the /3GB switch to tune the User-mode space to a value between 2 GB and 3 GB
http://support.microsoft.com/kb/316739/en-us
.NET CLR Memory
.NET CLR Memory object记录了CLR进程中跟CLR相关的内存信息。该类别下的所有计数器都很有意思,而且意思也非常直接。建议用一个例子程序进行测试和研究。下面是两个最常用的计数器
Bytes in all heaps
Bytes in all heaps记录了上次GC发生时候所统计到的,进程中不能被回收的所有CLR object占用的内存空间。该计数器不是实时的,每次GC发生的时候该计数器才更新。跟同一进程的Process\Private bytes比较,可以区分出managed heap和native memory的变化情况。对于memory leak,便于区分是managed heap的leak还是native memory的leak
%Time in GC
%Time in GC记录了GC发生的频繁程度。一般来说15%以内算比较正常。当超过20%说明GC发生过于频繁。由于GC不仅仅带来很高的CPU开销,还需要挂起目标进程的CLR线程,所以高频率GC是非常危险的。通过跟CPU利用率和其他性能指标比较,往往能够看出GC对性能的影响。高频率的GC往往因为
1) 负载过高
2) 不合理的架构,对内存使用效率不高
3) 内存泄露,内存分片导致内存压力
如果目标程序是ASP.NET,在ASP.NET开头的object中,下面这些计数器对于测量ASP.NET的性能非常有用。由于不少计数器存在于多个object类别中,下面只列出具体的计数器名字,而不去对应到具体的object:
Application Restarts
Application Restarts记录了ASP.NET Application Domain重启的次数。导致ASP.NET appDomain重启的原因往往是虚拟目录中被修改。比如修改了web.config文件,或者防毒程序对虚拟目录进行扫描。通过该计数器可以观察是否有异常的重启现象
Request Execution time
Request Execution time记录了请求的执行时间,是衡量ASP.NET性能的最直接参数。通过该计数器的平均值来衡量性能是否合乎预期值。需要注意的地方是由于Windows并非实时系统,所以不能用峰值来衡量整体性能。比如当GC发生的时候,请求执行时间肯定都要超过GC的时间。所以平均值才是有效的标准
Request Current
Request Current记录了当前正在处理的和等待处理的请求。最理想的情况是Request Current等于CPU的数量,这说明请求跟硬件资源能并发处理的能力恰好吻合,硬件投资正运行在最优状态。但是一般说来,当负荷比较大的时候,Request Current也随着增高。如果Request Current在一段时间内有超过10的情况,说明性能有问题。注意观察这个时候对应的CPU情况和其他的资源。如果CPU不高,很可能是程序中有blocking发生,比如等待数据库请求,导致请求无法及时完成。
Request/second
Request/second计数器记录了每秒钟到达ASP.NET的请求数。这是衡量ASP.NET负载的直接参数。注意观察Request/second是否超过程序的预期吞吐量。如果Request/Second有突发的波动,注意看是否有拒绝服务攻击。通过把Request/second,Request Current, Request Execution time和系统资源一起比较,往往能够看出来ASP.NET整体性能的变化和各个因素之间的影响
Request in Application Queue
当ASP.NET没有空余的工作线程来处理新进入的请求的时候,新的请求会被放到Application Queue中。当Application Queue堆积的请求也超过设定数值的时候,ASP.NET直接返回503 Server too busy错误,同时丢弃该请求。所以正常情况下,Request in Application Queue应该总为0,否则说明已经有请求堆积,性能问题严重
文章作者:lixiong 录入时间:
-
性能测试案例解析(四)
2007-06-18 11:50:03
4.1数据库调优策略
1.修改sql语句中影响速度的写法
2.增加或者修改索引
针对表间的连接创建索引
针对查找建立索引
使用索引时,遵守以下原则可达到更好的效果
第一:一般建立在多个字段上的一个组合索引优于针对单个字段建立的多个索引,根据值匹配条件创建的索引也需要遵循同样的原则:
第二:创建组合索引时,精确匹配的字段放在非精确匹配字段前面,取值范围大的字段放在取值范围小的字段前面,可以提高查询速度,如身份证字段应该放在性别字段前面。
第三:索引并不是越多越好,当数据库记录较多时,意味着数据库要付出的开销将会很大,从而降低数据库其他方面的性能。
3.调整相应数据库的系统参数(系统投产生的调优,通常由厂商的配合完成)
一般检查项为:复杂语句支持,大对象功能支持,并发查询性能,吞吐量,数据迁移(导出备份)。
4.2weblogic/oracle相关分析
主要监控:%processor, Avalable Mbytes(空闲内存), JVM内存,connection Delay Time(数据库连接池建立数据库连接的时间)
Oracle运行平台AIX监控(unix),cpu的使用率(cpu utilization),disk traltic(磁盘负载),page-in,page-out rate的使用情况。
以及oracle本身相关报告:相看缓冲区调整缓存,应用程序的i/o操作。
4.3性能测试用例设计要基于用户语言
即满足用户要求又相对全面的性能测试用例,设计时要基于“用户语言”,易于用户理解的、大纲形式的测试用例,这样涉及的技术语言不多,用户很容易看懂。这样使得用户在现场测试阶段能够提出很多改进建议,并同意对用例进行调整(删减近一半的用例),可以为后期执行测试节约成本。
性能测试实施的特点之一就是不会严格按照测试用例来执行,通常是在项目中对用户进行一定的调整,然后再去执行,对于测试用例进行调整,删除、修改、增加,这是很正常的,基本成本来进行设计和执行。
共计四篇,摘自<<web性能测试实战>>
备注:只为方便自已查阅,对于文中增删不全的地方,如果感兴趣建议查看原文,同时欢迎大家交流讨论!
-
WEB性能测试分析(三)
2007-06-18 11:45:29
1.随着压力的加大,吞吐率的曲线在增加到一定的时候,出现变化缓慢,甚至平坦的状态,很有可能标明网络出现带宽瓶颈。类似地,当压力加大时,点击率/TPS曲线出现变化缓慢或平坦的趋势,很有可能服务器开始出现瓶颈。
2.吞吐率与TPS具有很强的关联性:如果随着压力的加大,吞吐率和TPS的变化呈大体一致的趋势,即一起增加,说明在测试的压力下,系统没有出现显著的性能瓶颈。
3.1性能分析的步骤
1.首先从响应时间做为分析性能的起点。查看响应时间以判断是否满足用户对性能的期望。
2.考察系统的瓶颈是在网络环节还是在服务器环节。
针对服务器分析主要涉及应用程序、web服务器、数据库服务器、操作系统等。
首先应该分析业务或者用户事务的响应时间,根据测试结果来分析哪些业务真正变慢了,然后分析web资源的处理情况,最后对页面组成元素的响应时间进行分解。
1.查看结果综述图:查看事务的平均响应时间,以及事务的通过率
2.查看事务综述图和事务平均响应时间分析图:查看事务通过和失败的数值,来判断是程序算法出现问题还是服务器存在内存泄漏现象。
3.每秒通过事务数分析图:可确定系统在任何给定时刻的实际事务负载。当发现每秒通过的事务数减少时,就需要更加深入的分析,配合服务器监控数据一起分析。
4.事务性能摘要图:重点关注事务的平均和最大执行时间,如果其范围不在用户可以接受的时间范围内,需要进行原因分析。
5.事务响应时间与负载分析图:正在运行的虚拟用户和平均事务响应时间图的组合,通过它可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性能数据,为扩展应用系统提供参考,对分析具有渐变负载的测试场景比较有用。
6.事务响应时间分布情况分布图:预先定义相关事务可以接受的最小和最大事务响应时间,则可以使用此图确定服务器性能是否在可以接受的范围内。
1.点击率图:每秒点击次数,即点击率图显示在场景运行过程中虚拟用户每秒向web服务器提交的HTTP请求数,可依据点击次数来评估虚拟用户产生的负载量,还可将其与”平均事务响应时间”图进行比较,以查看点击次数对事务性能产生的影响。
系统点击率下降通常表明服务器的响应速度在变慢。
2.吞吐率图:显示场景运行过程中服务器每秒的吞吐量。度量单位是字节,表示虚拟用户在任何给定的某一秒上从服务器获得的数据量。
点击率:每秒服务器处理的HTTP申请数
吞吐率:客户端每秒从服务器获得的总数据量。
每秒HTTP响应数图还能返回其他各类状态码信息,通过分析状态码,可以判断服务器在压力下的运行情况。
常见的http状态代码:从200-505均有其含义。如202:已经接受请求,但处理尚未完成。
3.每秒连接数图:显示在运行过程中每秒新建立的TCP/IP连接数。新连接数应该是每秒点击次数的一小部分,理想情况下,很多的HTTP请求都应该使用同一连接,而不是每个请求都新打开一个连接。
通过它可深入地分析网站上那些下载很慢的图像或中断的链接等有问题的元素。
页面分解总图:可显示某一具体事务在测试过程的响应情况,进而分析相关的事务运行是否正常。
1.下载时间细分:查看静态gif图片和动态的jsp代码。
2.组件细分(随时间变化):可以选择不同的元素查看测试过程中其下载时间的变化曲线。适用于需要在客户端下载控制较多的页面,通过分析控件的响应时间,很容易就能发现哪些控件不稳定或者比较耗时。
3.下载时间细分(随时间变化):查看jsp页面主要时间花在如receive,first buffer,connection等。
下载时间细分:宏观,整个测试过程页面元素响应时间的统计分析结果
下载时间细分(随时间变化):微观,显示场景运行过程中每一秒内页面元素响应时间的统计结果。
4.第一次缓冲时间细分(随时间变化):可查看页面运行时间主要花在服务器还是网络传输上。
服务器分析通常从web服务器和数据库服务器入手。
服务器分析的第一步,分析测试工具对web服务器和数据库服务器相关计数器的监控结果,然后确定在压力下是web服务较慢还是数据处理较慢。
Web服务较慢:查看web服务器的各种参数配置,如最大连接数、最大内存等是否设置的合理。查看内存、CPU、硬盘
数据处理较慢:一般是数据库配置发生问题,或是硬件资源配置太低。如oracle,要查看内存配置、运行模式等信息。
-
性能测试实施与管理(二)
2007-06-18 11:41:23
测试计划:主要包含测试范围、测试环境、测试方案简介、风险分析等,测试计划要进行评审后方可生效。
测试报告:主要包含测试过程记录、测试分析结果、系统调整建议等。
测试经验总结:不断总结工作经验是建立学习型团队的基础,实践-总结-再实践
2.1人员之间的配合关系
客户代表:可了解一些项目的背景知识,例如客户在软件性能方面的需求,是否关注性能测试等,这些都是制定性能测试策略的依据。
需求分析员:确定哪些业务是核心业务,为后面编写核心业务模块相关的测试用例打下良好的基础,并且他们对用户群体构成以及系统的扩展目标较清楚,这些都是设计性能测试的数据来源。
架构师:了解系统的结构,使设计出的性能测试用例在“恰当”的地方施压。
2.2性能测试的范围确定
对测试项或测试需求进行打分,根据综合评分确定性能测试工作包含的测试内容,评分要素主要包含客户关注度、性能风险、测试的成本等,性能风险主要指如果不进行该项性能测试需求,投产系统可能潜在的风险。
客户关注程度或者性能风险较高的均应划分到测试范围内。
编号
测试需求
性能风险
(10分)
用户关注度(10分)
成本投入
(10分)
总分
1
系统运转一年的数据量测试
7
10
6
23
2
……
……
2.3目标系统的业务分析
确定系统的核心模块:业务比较复杂或用户使用较频繁
确定模块件的耦合关系:清晰了解核心模块间数据传输方式,通过确定模块间如何接口,可以真实地模拟多用户并发时的情况,尤其可以确定用户并发时一些算法是否正确。
分析系统压力点:多是用户使用较频繁或数据流量较大的地方。
2.4用户及场景分析
一,基于用户实际使用情况的场景测试,二,为了特殊测试目的(扩展性、稳定性)而设计的场景测试。
确定系统有多少类典型的用户,每类用户的大概数量以及在不同时间段各类用户大概按照何种比例来使用系统。较常见的用户场景有如下三种:
一天内不同时间段的使用场景
系统运行不同时期的场景
不同业务模式下的用户场景
2.5整体规划
性能测试规划的重点是时间、质量、成本等项目管理要素。
Loadrunner:是一种预测系统行为和性能的负载测试工具,目前很多公司执行性能测试的首选工具.
Rational performance: rational 系列产品之一,功能非常强大,和loadrunner竞争比较激烈.
QALoad:compu ware 公司的产品
Webload:专门用于web性能测试的工具
WAS:全称是Microsoft Web Application Stress Tool,微软提供的免费性能测试工具
Apache JMeter :开源的性能测试工具
openSTA:开源的性能测试工具
测试结果数据是分析系统瓶颈的主要依据,大量的测试结果文件要进行规范管理,统一文件的命名规范.例如:
执行性能测试尽量不要破坏用户环境,而且要预先制定相应的备份/恢复策略,以便系统发生意外时可以恢复到测试前的状态.
性能测试很有可能产生大量的垃圾数据,消除垃圾数据是测试结事后首当其冲的工作
测试时还要监控测试机的使用情况,除非保证场景消耗的资源不会超出测试机的负载能力,否则就应该认真监控测试机,因为一旦测试机发生瓶颈,所有测试结果均无实际意义.
主要关注性能测试规划与设计、测试用例设计、测试工具与技术、性能分析等方面。
性能测试用例的设计分析:可用性、执行效果、执行时间、还应该分析用例的设计方法、设计思路等。
对于瓶颈:应用系统、数据库、web服务器等有时会因配置参数不正确导致系统性能不高,可积累解决这方面问题的经验,以便于以后快速解决问题。
-
web性能测试基础(一)
2007-06-18 11:31:07
1.1基本概念
并发用户:用户并发一般发生在使用比较频繁的模块中,而且遇到异常通常都是程序的问题。
用户并发数量:在线用户数量是计算并发用户数量的主要依据之一。=使用系统的用户数量*(5%~20%)
并发主要针对WEB服务器而言,是否并发的关键是看用户的操作是否对服务器产生了影响。
吞吐量:一次性能测试过程中网络上传输的数据量的总和。
吞吐率:吞吐量/传输时间,单位时间内网络上传输的数据量,也可以指单位时间内处理的客户端请求数量。吞吐率用“请求数/秒”或者“页面数/秒”来衡量。
点击率:每秒钟用户向web服务器提交的HTTP请求数。点击率越大,对服务器的压力也越大。重要的是分析点击时产生的影响。
点击不是指鼠标的一次“单击”操作,因为在一次“单击”操作中,客户端可能向服务器发出多个HTTP请求。
1.2WEB性能测试种类
压力测试:确定一个系统的瓶颈或者不能接收用户请求的性能点,来获得系统能提供的最大服务级别的测试。
负载测试:在被测系统上不断增加压力 ,直到性能指标达到极限,响应时间超过预定指标或者某种资源已经达到饱和状态。这种测试可以找到系统的处理极限,为系统调优提供依据。
大数据量测试:针对某些系统存储、传输、统计查询等业务进行大数据量的测试。
配置测试:通过测试找到系统各资源的最优分配原则。
可靠性测试:可以施加cpu资源保持70%-90%使用率的压力,连续对系统加压运行8小时,然后根据结果分析系统是否稳定。即加载一定压力的情况下,使系统运行一段时间。
并发测试:多以发现一些算法设计上的问题。
性能测试以用户并发测试为主的测试。
性能测试主要是为了发现软件问题和硬件瓶颈。
对于性能方面给系统留有30%左右的扩展空间即可。
1.3Web全面性能测试模型
主要指需求分析和设计阶段提出的一些性能指标。
针对每个指标都要编写一个或者多个测试用例来验证系统是否达到要求。
预期指标的性能测试用例通常以单用户为主,如果涉及并发用户内容,则归并到并发用户测试用例中进行设计。
选择具有代表性、关键的业务来设计用例,并且用户的设计应该面向“模块”
用户并发性能测试分为:独立核心模块并发性能测试,组合模块并发性能测试
独立核心模块并发:完全一样功能的并发测试;完全一样操作的并发测试;相同/不同的子功能并发。
针对独立核心模块用户并发性能的测试用例设计,可发现一些核心算法或者功能方面的问题,如一些多线程、同步并发算法在单用户模式下测试是很难发现问题的,通过模拟多用户的并发操作,更容易验证其是否正确和稳定。
核心模块测试一般属于基本的性能测试,它较多地关注模拟的“功能”,一般不会对服务器进行测试。
组合模块并发:具有耦合关系的核心模块进行组合并发测试;彼此独立的、内部具有耦合关系的核心模块组的并发测试;基于用户场景的并发测试。
组合模块测试一般发现接口方面的功能问题,并尽早发现综合性能问题。
在实际中,各种类型的用户都会对应一组模块,相当于不同的业务组在并发访问系统,要充分考虑实际场景,如话费管理系统中的每月10日左右的收费高峰等场景。
在编写组合模块用户并发性能测试用例时,不但要考虑用户使用场景,还要注意并发点的运用,并发点是指一定数量的用户开始执行同一功能或者操作的时间点,一组测试场景通常包含多个并发点,从而实现了核心模块同一功能或者操作的真正并发。
独立业务实际是指一些核心业务模块对应的业务。这些模块通常具有功能比较复杂,使用比较频繁,属于核心业务等特点。主要测试这类模块和性能相关的一些算法、还要测试这类模块对并发用户的响应情况。
用户并发测试是核心业务模块的重点测试内容。
是最接近用户实际使用情况的测试,也是性能测试的核心内容。
组合并发的突出特点是根据用户使用系统的情况分成不同的用户组进行并发,每组的用户比例要根据实际情况来进行匹配。
用户并发测试是组合业务性能测试的核心内容。“组合”并发的突出特点是根据用户使用系统的情况分成不同的用户组进行并发,每组的用户比例要根据实际情况来进行匹配。
为准确展未带宽、延迟、负载和端口的变化是如何影响用户的响应时间的。主要是测试应用系统的用户数目与网络带宽的关系。
调整性能最好的办法就是软硬相结合。
主要是针对对数据库有特殊要求的系统进行的测试,主要分为三种:
1.实时大数据量:模拟用户工作时的实时大数据量,主要目的是测试用户较多或者某些业务产生较大数据量时,系统能否稳定地运行。
2.极限状态下的测试:主要是测试系统使用一段时间即系统累积一定量的数据时,能否正常地运行业务
3.前面两种的结合:测试系统已经累积较大数据量时,一些实时产生较大数据量的模块能否稳定地工作。
大数据量测试用例的设计:1,历史数据引起的大数据量测试和2运行时大数据量测试
首先确定系统数据的最长迁移周期和选择一些前面的核心模块或者组合模块的并发用户测试用例作为其主要内容即可.
性能测试的主要目的是在软件功能良好的前提下,发现系统瓶颈并解决,而软件和服务器是产生瓶颈的两大来源,因此在进行用户并发性能测试,疲劳强度与大数据量性能测试时,完成对服务器性能的监控,并对服务器性能进行评估。
服务器性能测试用例设计就是确定要采集的性能计数器,并将其与前面的测试关联起来。
可以满足预期性能指标测试用例要求的,就没有必要设计更多的内容,因为用例越多,执行的成本也越高。
一定要服从整体性能测试策略,千万不能仅从技术角度来考虑设计“全面”的测试用例,“全面”应该以是否满足自己的测试要求作为标准。
适当裁剪原则
只有根据实际项目的特点制定合理的性能测试策略、编写适当的性能测试用例,并在测试实施中灵活地变通才可以做好性能测试工作。
-
职业发展技巧二十则--转载boboli
2007-06-16 23:07:19
这是李老师的一篇博客,特喜欢这篇文章,算是对自己的警钟吧!
1.在职业生涯发展的道路上,重要的不是你现在所处的位置,而是迈出下一步的方向
2.职业生涯开发与管理:只要开始,永远不晚;只要进步,总有空间
3.职业生涯的每一次质跃发展都是以学习新知识、建立新观念为前提条件的
4.在职业生涯早期,对自己锻炼最大的工作是最好的工作;在职业生涯中期,挣钱最多的工作是最好的工作;在职业生涯后期,实现人生价值最大的工作是最好的工作
5.在职业生涯发展的进程中,什么时候你的工作热情、努力程度不为工资待遇不高、不为上级评价不公而减少,从那时起你就开始为自己打工了
6.千万不要把你的主要精力放在帮助你的上级改正缺点错误上,用同样的时间和精力,你能从他身上学到的优点,一定多于能帮他改正的缺点
7.确定你的职业锚之日,就是你的职业转变为你的事业之时
8.在职业生涯发展的道路上没有空白点;每一种环境、每一项工作都是一种锻炼,每一个困难、每一次失败都是一次机会
9.在职业生涯发展的道路上,只要不放弃目标,每一次挫折、每一次失败都是有价值的
10.在职业生涯初期,我们可能做的是自己不喜欢而且不想从事一生的工作。要分清:喜欢不喜欢这份工作是一件事,应该不应该做好这份工作、是否有能力做好这份工作是另一件事。切记:职业生涯发展是从做好本职工作开始的。当你还没有能力做好一件工作时,就没有资格说不喜欢
11.成功的人和不成功的人就差一点点:成功的人可以无数次修改方法,但绝不轻易放弃目标;不成功的人总改目标,就是不改方法
12.职业生涯没有目标不行,目标太多不行,目标总变也不行。对目标的处理方法是:选择、明确、分解、组合,加上时间坐标
12.目标分解是在现实处境与美好愿望的实现之间建立可拾级而上的阶梯,目标组合是找出不同目标之间互为因果、相互促进的内在联系
13.求知是自我实现的前提,求美是自我实现的过程
14.只有暂时没有找到解决方法的困难,没有解决不了的困难
15.自我实现让人兴奋,天人合一使人平静
16.企业不仅是挣钱谋生的场所,更是学习进步、实现人生价值的舞台
17.内职业生涯发展是外职业生涯发展的前提,内职业生涯带动外职业生涯的发展
18.外职业生涯的因素通常由别人决定、给予,也容易被别人否定、剥夺;内职业生涯的因素主要靠自己探索、获得,并且不随外职业生涯的因素改变而丧失
19.外职业生涯略超前时有动力,超前较多时有压力,超前太大时有毁灭力;内职业生涯略超前时很舒心,超前较多时很烦心,超前太大时要变心
20.正确的角色定位需要理智,及时的角色转换需要智慧 -
性能瓶颈与数据库调优
2007-05-27 23:06:55
所有的应用程序都存在一定程序的性能瓶颈,为了提高应用程序的性能,就要尽可能的减少程序的瓶颈,以下是程序中常见的性能瓶颈。
瓶颈 程序中的操作 文件的读写和网络的操作 程序等待读写数据到网络或硬盘 CPU 等待CPU空闲 内存 程序不停的分配,释放和扫描内存 异常 程序不断的处理异常消息 同步 程序等待共享资源被释放 数据库 程序等待从数据库中返回结果 具体的数据库测试主要从查询、更新、插入等方面测试,而对具体的数据库进行调优,主要从以下几个方面进行:
1.Rowre-sequencing以减少磁盘i/o
2.oracle sql调整。
3.调整oracle排序。
4.调整oracle的竞争:表和索引的参数设置对于update和insert的性能有很大的影响。
-
面向对象的分析与面向对象的设计(OOA,OOD)
2007-05-23 07:26:11
面向对象的技术追求的是软件系统对现实世界的直接模拟,它把数据和对数据的操作封装成为一个整体。
对象模型技术把信息构造在三类模型中,对象模型,状态模型和功能模型,每个模型从自己的角度对系统进行描述。
面向对象的分析分为论域分析和应用分析,面向对象的设计则分为高层设计和低层设计。
面向对象的分析主要指概念模型,按照对模型进行构造和评审的顺序分为五个层次:类和对象层,属性层,服务层,结构层和主题层。面向对象的设计,主要对系统的四个组成部分进行设计,它们是问题论域部分,用户界面部分,任务管理部分和数据管理部分。
详细内容如下:
OMT对象模型技术把分析时收集到的信息构造在三类模型中:
对象模型:对谁做
功能模型:做什么
动态模型:何时做
一.对象模型:描述系统的静态结构,包括类和对象,它们的属性和操作,以及它们之间的关系。
数据词典:用以描述类,属性和关系;
二.动态模型:着重于系统的控制逻辑,考察在任何时候对象及其关系的改变,描述这些涉及时序和改变的状态。
状态图:是一个状态和事件的网络,侧重于描述每一类对象的动态行为。
事件跟踪图:侧重于说明系统执行过程中的一个特点“场景”,也叫做脚本,是完成系统某个功能的一个事件序列。
事件:对象到对象的单个消息。
场景:在系统的一个特定的环境下发生的一系列事件。
三.功能模型:着重于系统内部数据的传送和处理。数据流图
从输入数据能得到什么样的输出数据,不考虑参加计算的数据按什么时序执行。
OOA面向对象的分析:软件开发过程中的问题定义阶段,得到对问题论域的清晰,精确的定义。
论域分析阶段:目的是使开发人员了解问题空间的组成,建立大致的系统实现环境。论域分析给出一组抽象,从高层表示论域知识,常常超出当前应用的范围,作为特定系统需求开发的参考。
领域专家和分析员,在分析过程中标识出系统的基本概念:对象,类,方法,关系等。识别论域的特征,把这些概念集成到论域的模型中。论域的模型中必须包含概念之间的关系,还有关于每个单独概念的全部信息。这里信息起一种胶合作用,把标识出的相关概念并入论域综合视图中去。
应用分析阶段:依据问题论域模型,并把问题论域模型用于当前特定的应用之中。
论域分析的视野大小直接影响到应用分析保留的信息量。
论域分析阶段不需要用基于计算机系统的程序设计语言来表示,而应用分析阶段产生的影响条件则通过基于计算机系统的程序设计语言来表示。
应用视图和类视图。在类视图中,必须对每个类的规格说明和操作进行详细化,并表示出类之间的相互作用。
OOA的任务:
完个两个任务
形式的说明所面对的应用问题,最终成为软件系统基本构成的对象,以及系统所必须亲人的,由应用环境所决定的规则和约束。
明确的规定构成系统的对象如何协同工作,完成指定的功能。
通过OOA分析建立的系统模型是以概念为中心,称为概念模型。它由一组相关的类组成。
概念模型构造和评审的顺序由五个层次构成:类和对象层,属性层,服务层,结构层,主题层。这五个层次不是构成软件系统的层次,而是分析过程中的层次。
OOA的步骤:
1. 标识对象和类。
2. 标识结构。一般与特殊(基类与派生类),整体与部分(聚合,新类)
3. 标识属性。对象所保存的信息称为它的属性。类的属性所描述的是状态信息,还要指定属性存在哪些特殊的限制(只读,属性值限定于某个范围之内等)。
4. 标识服务。对象收到消息后执行的操作称为对象提供的服务,它描述了系统需要执行的处理和功能。定义服务的目的在于定义对象的行为和对象之间的通信。
5. 标识主题。对于包含大量类和对象的概念模型往往难以掌握,标识主题则对模型进行划分,给出模型的整体框架,划分出层次结构。在标识主题时,可以采取先识别主题,而后对主题进行改进和细化,最后将主题加入到分析模型当中的步骤进行。
OOD面向对象的设计:
从分析到设计是一个逐步扩充模型的过程。
分析主要以实际问题为中心,可以不包括任何与特定计算机有关的问题,主要考虑“做什么”
设计则是面向计算机的实地开发活动,考虑“怎么做”的问题。
高层设计和低层设计:
高层设计:
窗口――人机交互界面――问题论域――系统交互界面――问题论域
报告 数据管理 物理设备
文件,RDBMS
高层设计过程中,应当使子系统的高层部件之间的通信量达到最小,把子系统中相互之间存在高度交互的类进行逻辑分组。
低层设计:
集中于类的详细设计阶段。类设计的目标是形成单一概念的模型,一个独立的类表示一个概念,以及设计的部件应该是可复用的和可靠的。
类的设计过程中需要采用信息隐蔽,高内聚低耦合等设计原则。(即存类的复用是一个很大的优点)
面向对象的设计过程:
在设计阶段中利用分析阶段中提到的五个层次(对象和类,结构,属性,服务和主题),建立系统的四个组成部分:问题论域,用户界面,任务管理和数据管理。
一.问题论域部分的设计:
主要根据需求的变化,对面向对象的分析阶段产生的模型中的类和对象,结构,属性,操作进行组合和分解,根据面向对象的设计原则,增加必要的类,属性和关系。
设计包括:复用设计;把问题论域相关的类关联起来;加入一般化的类以建立类间协议;调整继承支持级别;改进性能;加入较低层的构件。
二.用户界面部分的设计:
根据需求把交互的细节加入到用户界面的设计中,包括有效的人机交互所必须的实际显示和输入。
设计包括:用户分类,描述人及其任务的脚本;设计命令层;设计详细的交互;继续扩展用户界面原型;设计人机交互类(HIC);根据图形用户界面进行设计。
三.任务管理部分的设计
任务:进程的别称,是执行一系列活动的一段程序。当系统中有许多并发行为时,需要依照各个行为的协调和通信关系,划分各种任务。以达到简化并发行为的设计和编码的目的。
任务管理主要包括任务的选择和调整,主要工作为:识别事件驱动任务;识别时钟驱动任务;识别优先任务和关键任务;识别任务之间的协调者;对各个任务进行评审,保证它能够满足选择任务的过程标准;定义各个任务,说明它是什么任务,任务之间如何协调工作,如何通信。
四.数据管理部分的设计:
提供在数据管理系统中存储和检索对象的基本结构,包括对永久性数据的访问和管理。
数据管理的方法有三种:文件管理,关系数据库管理以及面向对象的数据库管理。
数据管理的设计包括:
1. 数据存放设计。选择数据存放的方式:
2. 设计相应的操作。为每个需要存储的对象和类增加用于存储管理的属性和操作,在类和对象的定义中加以描述。
-
c#学习笔记-对out关键字的理解
2007-05-14 13:56:14
通过out关键字明白了几点:
1.out关键字是通过引用来传递的,并且out 参数传递的变量不需要在传递之前进行初始化,否则需要先为value进行赋值,通过调用方法返回进行赋值.
2.对于静态方法,不需要进行实例化就可以直接调用.
3.int,string类型一般是值传递.
class1.cs
namespace ClassLibrary1
{
public class Class1
{
public static void Method( out int i)
{
i = 44;
}}
}form1.cs
namespace WindowsApplication7
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
int value;
ClassLibrary1.Class1.Method(out value);
Console.Write(value);}
}
} -
c#学习笔记-数据库操作
2007-05-11 09:22:39
在Dataset和datagridview中对数据进行删除、取消等操作,并将结果保存到数据库中。
Form1.cs
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Text;
using System.Windows.Forms;
namespace WindowsApplication2
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
ClassLibrary1.oracle dataaccess = new ClassLibrary1.oracle();
DataSet ds = dataaccess.getData();
dataGridView1.DataSource = ds.Tables[0];
/* 首先我们通过form1里头的load事件把数据加载到了datagridview中,dataset(数据在内存
中的缓存)已经和datagridview的datasource榜定在一起了*/
}
private void butdelete_Click(object sender, EventArgs e)
{
if (this.dataGridView1.SelectedRows.Count > 0)
{
for (int i = this.dataGridView1.SelectedRows.Count - 1; i >= 0; --i)
{
DataRowView rowview = ((DataRowView)this.dataGridView1.SelectedRows[i].DataBoundItem);
//获取用于填充行的数据绑带对象
rowview.Delete();
/*选中的行删除,但此时的被删除的数据并没有被真正的从数据库中删除,它只是
做了一个删除标记。*/
System.Windows.Forms.MessageBox.Show(rowview.Row.RowState.ToString());
/*打出行的状态查看一下。Rowstate在此非常重要,因为将涉及到对数据库的操作
系统怎么判断这一批的数据是被删除掉了
}
/*对于for循环中初始i值说明:datagridview将数据显示出来,每删除一行,
this.dataGridView1.SelectedRows.Count就会减少一行,因此初值要注意*/
}
}
private void butcancel_Click(object sender, EventArgs e)
{
((DataTable)dataGridView1.DataSource).RejectChanges();
//回滚上次更新该表的操作
}
private void btnSave_Click(object sender, EventArgs e)
{
ClassLibrary1.oracle dataaccess = new ClassLibrary1.oracle();
dataaccess.deleteData(((DataTable)dataGridView1.DataSource).DataSet);
}
}
}
Oracle.cs
using System;
using System.Collections.Generic;
using System.Text;
using System.Data .OracleClient;
using System.Data;
namespace ClassLibrary1
{
public class oracle
{
string myConnectionText = "Data Source=MYORACLE;User Id=SYSTEM;Password=SYSTEM";
string mySelectText = "SELECT * from scott.student";
public DataSet getData()
{
OracleDataAdapter custDA = new OracleDataAdapter(mySelectText, myConnectionText);
//实例化一个适配器,创建数据库的连接
OracleConnection custConn = custDA.SelectCommand.Connection;
//打开数据库的连接
DataSet ds = new DataSet();
custDA.Fill(ds);
//将对数据库的查询结果添加到DateSet中。
return ds;
}
}
}
最后的图片
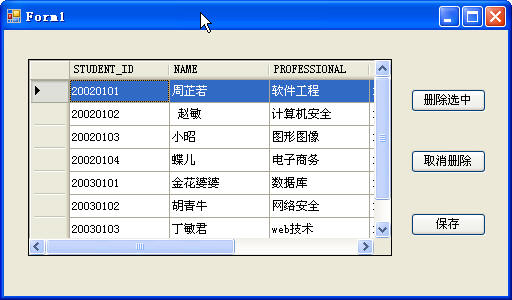

在form1.cs设计中,拖拉一个datagridview,添加三个按钮,分别将它们的name和text属性改为
butdelete.Name = "butdelete";
butdelete.Text = "删除选中";
butcancel.Name = "butcancel";
butcancel.Text = "取消删除";
butsave.Name = "butsave";
butsave.Text = "保存";
-
测试各阶段的通过标准
2007-05-08 17:23:15
单元/集成测试通过标准
⑴:各基类和存储过程的正常值测试全部通过;
⑵:联调测试各接口没有问题;
⑶:各基类和存储过程的异常值测试通过率达85%以上;
系统测试通过标准
(1)基本流程能够通畅的完成,核心功能可以体现;(不存在A,B级BUG)
(2)对具备分支的流程,确保有一种分支可以持续使用,另外几种要求可以体现设置方法和直接效果,否则就应暂时屏蔽分支功能;
(3)基本界面符合术语规范,不存在错误或明显歧义;所有可使用的流程中的界面设计工作必须完成;
(4)按照标准流程没有出现各种非正常提示;
(5)关键流程和流程中的基本数据备份恢复没有问题;
(6)所有报表能够在基本数据的基础上正确生成;
(7)非A,B级BUG的遗留数不能超过总用例数的5%
-
单元测试浅析(转载)
2007-05-06 22:54:57
一、单元测试用例的类型:
- 需求测试用例:测试是否符合需求规范
- 设计测试用例:测试是否符合系统逻辑结构
- 代码测试用例:测试代码的逻辑结构和使用的数据
需求测试用例通常是按照需求执行的功能逐条地编写输入数据和期望输出。一个好的需求用例是可以用少量的测试用例就能够覆盖所有的程序功能。
设计测试用例检测的是代码和设计是否完全相符。是对底层设计和基本结构上的测试。设计测试用例可以涉及到需求测试用例没有覆盖到的代码空间(例如界面的设计)。
代码测试用例是基于运行软件和数据结构上的。它要保证可以覆盖所有的程序分支、最小的语句和输出。
二、测试数据的种类:
- 正常数据:在测试中所用的正常数据的量是最大的,而且也是最关键的。少量的测试数据不能完全覆盖需求,但我们要从中提取出一些具有高度代表性的数据作为测试数据,以减少测试时间。
- 边缘数据:边缘测试是界于正常数据和错误数据之间的一种数据。它可以针对某一种编程语言、编程环境或特定的数据库而专门设定。例如若使用SQL Server数据库,则可把SQL Server关键字(如:';AS;Join等)设为边缘数据。其它边缘数据还有:HTML的HTML;<>等关键字以及空格、@、负数、超长字符等。边缘数据要靠测试人员的丰富经验来制定。
- 错误数据:显而易见,错误数据就是编写与程序输入规范不符的数据从而检测输入筛选、错误处理等程序的分支。
3、单元测试代码评审的检查点
- 代码风格和规则审核
- 程序设计和结构的审核
- 业务逻辑的审核
代码风格和规则的审核是在每个程序员完成一个模块或类的时候要进行编码规范的检查。
程序设计和结构的审核,对于不同的程序员所检测代码的宽度和深度也是不同的。项目经理可以根据程序员经验的不同制定被审议人员的宽度和深度。例如:年轻的程序员要审议所有代码。但有经验的就可适当减少。
业务逻辑性审议必须要在代码完成后审议。业务逻辑审议实际上是审议单元模块的功能。这些功能是以系统说明为依据的。审议人员要有开发的经验并且对系统也要熟悉。审议人员通过执行程序从而了解底层代码的状态。这阶段的审议实际也包含了前两种审议,因为审议者也可以通过最后的结果检测单元模块设计和结构的准确性。
4、代码的调试:
代码的调试是用来保证程序能按照系统需求正常运行的一种手段。但是我所提到的这种代码调试并不是简单的调试,它要包括以下两部分:
- 特征调试
- 代码覆盖调试
首先我们要先进行特征调试。它是通过运行程序找到代码中的错误,这与我们平时常进行的调试相同。到程序能运行后,我们可使用已编好的三种类型的用例并以正常数据测试用例进行测试,若不能正常运行则要用调试工具调试。在这阶段,我们要用大量正常数据去测试。测试后,该程序应可在绝大多数的正常数据中运行。
其次,我们要进行代码覆盖测试,一直要达到以下目标为至:
- 测试到每一个最小语句的代码
- 测试到所有的输出结果
我们应该通过一步步的调试去运行每个程序的所有语句和分支。如果我们想要百分之百地覆盖就应适当运用边缘数据和错误数据。测试在这个阶段的质量是难以掌握的。它基于程序员的责任心和经验。当这阶段完成后,每个程序员所测的深度也是不同的。因此,在这个测试阶段之前,项目经理(或测试工程师)应制定出测试指导和计划书。它们至少应包括以下内容:
- 测试的主要对象
- 主要调试点
- 怎样测试
- 什么时候可以完成
本文只为个人查看方便,详细可查看http://www.51testing.com/?action_viewnews_itemid_7578.html
-
全面介绍单元测试(转载)
2007-05-02 21:13:02
1。要进行充分的单元测试,应专门编写测试代码,并与产品代码隔离。比较简单的办法是为产品工程建立对应的测试工程,为每个类建立对应的测试类,为每个函数(很简单的除外)建立测试函数。
2。测试用例、输入数据及预期输出。
输入数据是测试用例的核心,它是被测试函数所读取的外部数据及这些数据的初始值。外部数据是对于被测试函数来说的,实际上就是除了局部变量以外的其他数据,共分为以下几类:参数、成员变量、全局变量、IO媒体。IO媒体是指文件、数据库或其他储存或传输数据的媒体,例如,被测试函数要从文件或数据库读取数据,那么,文件或数据库中的原始数据也属于输入数据。一个函数无论多复杂,都无非是对这几类数据的读取、计算和写入。
我们应该用一定的规则选择有代表性的数据作为输入数据,主要有三种:正常输入,边界输入,非法输入,每种输入还可以分类,也就是平常说的等价类法,每类取一个数据作为输入数据,如果测试通过,可以肯定同类的其他输入也是可以通过的。下面举例说明:
正常输入
例如字符串的Trim函数,功能是将字符串前后的空格去除,那么正常的输入可以有四类:前面有空格;后面有空格;前后均有空格;前后均无空格。
边界输入
上例中空字符串可以看作是边界输入。
再如一个表示年龄的参数,它的有效范围是0-100,那么边界输入有两个:0和100。
非法输入
非法输入是正常取值范围以外的数据,或使代码不能完成正常功能的输入,如上例中表示年龄的参数,小于0或大于100都是非法输入,再如一个进行文件操作的函数,非法输入有这么几类:文件不存在;目录不存在;文件正在被其他程序打开;权限错误。
如果函数使用了外部数据,则正常输入是肯定会有的,而边界输入和非法输入不是所有函数都有。一般情况下,即使没有设计文档,考虑以上三种输入也可以找出函数的基本功能点。实际上,单元测试与代码编写是“一体两面”的关系,编码时对上述三种输入都是必须考虑的,否则代码的健壮性就会成问题。
3。白盒测试针对程序的逻辑结构设计测试用例,用逻辑覆盖率来衡量测试的完整性。逻辑单位主要有:语句、分支、条件、条件值、条件值组合,路径。经验:发现与条件直接有关的错误主要是逻辑操作符错误,例如:||写成&&,漏了写!什么的,采用分支覆盖与条件覆盖的组合,基本上可以发现这些错误,另一方面,条件值覆盖与条件值组合覆盖往往需要大量的测试用例,因此看来,条件值覆盖和条件值组合覆盖的效费比偏低。本人认为效费比较高且完整性也足够的测试要求是这样的:完成功能测试,完成语句覆盖、条件覆盖、分支覆盖、路径覆盖。实际就是通过使用工具实现,否则人工难以完成,工作量太在。
白盒测试用例的设计,普通方法是画出程序的逻辑结构图如程序流程图或控制流图,根据逻辑结构图设计测试用例,这些是纯粹的白盒测试,推荐一类方法:先完成黑盒测试,然后统计白盒覆盖率,针对未覆盖的逻辑单位设计测试用例覆盖它,例如,先检查是否有语句未覆盖,有的话设计测试用例覆盖它,然后用同样方法完成条件覆盖、分支覆盖和路径覆盖,这样的话,既检验了黑盒测试的完整性,又避免了重复的工作,用较少的时间成本达到非常高的测试完整性。不过,这些工作可不是手工能完成的,必须借助于工具,后面会介绍可以完成这些工作的测试工具。
4。单元测试工具:针对c/c++最后介绍Visual Unit,简称VU,这是国产的单元测试工具,据说申请了多项专利,拥有一批创新的技术,如[自动生成测试代码 快速建立功能测试用例 程序行为一目了然 极高的测试完整性 高效完成白盒覆盖 快速排错 高效调试 详尽的测试报告]。[]内的文字是VU开发商的网页上摘录的,网址是:http://www.unitware.cn。前面所述测试要求:完成功能测试,完成语句覆盖、条件覆盖、分支覆盖、路径覆盖,用VU可以轻松实现,还有一点值得一提:使用VU还能提高编码的效率,总体来说,在完成单元测试的同时,编码调试的时间还能大幅度缩短。工具好不好用,合不合用,要试过才知道,还是自己去开发商的网站看吧,可以下载演示版,还有演示课件。
备注:本篇是个人剪裁过的,为了个人阅读方便,详细可查看
http://www.51testing.com/?action_viewnews_itemid_7430.html
-
单元测试-模态窗体的测试
2007-05-02 20:52:49
今天在论坛看到一篇有关单元测试文章,里面一段话:单元测试,针对业务功能进行测试,而业务功能的测试难点,就是模态窗体的测试。这个难点的罪魁祸首是Windows的消息机制决定的。每一个模态窗体都有自己的消息循环(死循环)在处理消息,当从一个模态窗体切换到另一个模态窗体的时候,测试代码就不能继续下去。针对这个问题的处理方式,就是“解铃还须系铃人”。通过Windows的消息循环就可以穿透这种切换的休克。当然了,处理方式还是比较复杂的。具体做法是什么呢?期待以后能够用一个实例来解答这个问题。如果游园的朋友知道,分享一下,谢谢!
-
静态白盒技术-通用代码审查清单
2007-05-01 07:40:42
一、数据引用错误。
定义:是指使用未经正确初始化用法和引用方式的变量、常量、数组、字符串或记录而导致的软件缺陷。
是否引用了未初始化的变量?查找遗漏之处与查找错误同等重要。
数组和字符串的下标是整数值吗?下标总是在数组和字符串大小范围之内吗?
在检索操作或者应用数组下标时是否包含“丢掉一个”这样的潜在错误?
是否在应该使用常量的地方使用了变量-例如在检查数组范围时?
变量是否被赋予不同类型的值?例如,无意中使代码为整形变量赋予一个浮点数值?
为引用的指针分配内存了吗?
一个数据结构是否在多个函数或者子程序中引用,在每一个引用中明确定义结构了吗?
二、数据声明错误。
产生的原因:不正确地声明或使用变量和常量
所有变量都赋予正确的长度、类型和存储类了吗?例如,本应声明为字符串的变量声明为字符数组了吗?
变量是否在声明的同时进行了初始化?是否正确初始化并与其类型一致?
变量有类似的名称吗?这基本上不算软件缺陷,但有可能是程序中其他地方出现名称混淆的信息。
存在声明过、但从未引用或者只引用过一次的变量吗?
在特定模块中所有变量都显式声明了吗?如果没有,是否可以理解为该变量与更高级别的模块共享?
三、计算错误。
是基本的数据逻辑问题,计算无法得到预期结果。
计算中是否使用了不同数据类型的变量,例如将整数与浮点数相加?
计算中是否使用了不同数据类型相同但不同长度的变量-例如,将字节与字相加?
计算时是否了解和考虑到编译器对类型或长度不一致的变量的转换规则?
赋值的目的变量是否小于赋值表达式的值?
在数值计算过程中是否可能出现溢出?
除数/模是否可能为零?
对于整型算术运算,某些计算,特别是除法的代码处理是否会丢失精度?
变量的值是否超过有意义的范围?例如,可能性的计算结果是否小于0%或者大于100%?
对于包含多个操作数的表达式,求值的次序是否混乱,运算优先级对吗?需要加括号使其清晰吗?
四、比较错误。
小于、大于、等于、不等于、真、假。比较和判断错误很可能是边界条件问题。
比较得正确吗?虽然听起来简单,但是比较应该是小于还是小于或等于常常发生混淆。
存在分数或者浮点值之间的比较吗?如果有,精度问题会影响比较吗?1.00000001和1.00000002极其接近,它们相等吗?
每一个逻辑表达式都正确表达了吗?逻辑计算如期进行了吗?求值次序有疑问吗?
逻辑表达式的操作数是逻辑值吗?例如,是否包含整数值的整型变量用于逻辑计算中?
五、控制流程错误。
原因:编程语言中循环等控制结构未按预期方式工作。它们通常由计算或者比较错误直接或间接造成。
如果程序包含begin..end和do...while等语句组,end是否对应?
程序、模块、子程序和循环能否终止?如果不能,可以接受吗?
可能存在永远不停的循环吗?
循环可能从不执行吗?如果是这样,可以接受吗?
如果程序包含像switch...case语句这样的多个分支,索引变量能超出可能的分支数目吗?如果超出,该情况能正确处理吗?
是否存在“丢掉一个”错误,导致意外进入循环?
六、子程序参数错误。
来源于软件子程序不正确地传递数据。
子程序接收的参数类型和大小与调用代码发送的匹配吗?次序正确吗?
如果子程序有多个入口点,引用的参数是否与当前入口点没有关联?
常量是否当作形参传递,意外在子程序中改动?
子程序是更改了仅作为输入值的参数?
每一个参数的单位是否与相应的形参匹配。
如果存在全局变量,在所有引用子程序中是否有相似的定义和属性?
七、输入/输出错误。
包括文件读取、接受键盘或者鼠标输入以及向打印机或者屏幕等输出设备写入错误。
软件是否严格遵守外部设备读写数据的专用格式?
文件或者外设不存在或者未准备好的错误情况有处理吗?
软件是否处理外部设备未连接、不可用,或者读写过程中存储空间占满等情况?
软件以预期方式处理预计的错误吗?
检查错误提示信息的准确性、正确性、语法或拼写了吗?
八、其他检查。
软件是否使用其他外语?是否处理扩展ASCII字符?是否需要用统一编码取代ASCII?
软件是否要移植到其他编译器和CPU,具有这样做的许可吗?如果没有计划或者测试,那么,移植性可能成为一个大难题。
是否考虑了兼容性,以使软件能够运行于不同数量的可用内存,不同的内部硬件,例如图形卡和显卡,不同的外设,例如打印机和调制解调器?
程序编译是否产生“警告”或者“提示”信息?这些信息通常指示进行了有疑问的处理。纯粹主义者可能认为警告信息是不可接受的。 -
动态白盒测试技术
2007-04-30 20:34:24
动态白盒测试是指利用查看代码功能和实现方式得到的信息来确定哪些要测试,哪些不要测试,如何开展测试等。
对白盒测试新的理解如下:
1.在进行白盒测试之前是需要先设计黑盒测试案例,从整体功能上去把握每一个模块功能,避免只是检查代码,走入程序员的思路范围,而忽略对功能的整体把握。
2.通过了解代码的细节,可消除冗余的测试用例,增加针对原先没有考虑到的区间的测试用例。
3.查看代码,把软件分为数据和状态(程序流程),以黑盒测试用例的角度看待软件,把得到的白盒信息映射到已写完的黑盒测试案例上。
- 数据流:观察变量,运行时的即时值(黑盒主要关注开始值和结束值)
- 次边界:有些边界在软件的内部,最终用户几乎看不到,这样的边界条件称为次边界或内部边界条件,如临近字节边界的254,255,256.ASCII码表中A~Z,a~z之外的非法区间,如@,[,{,'
- 错误强制:强制为变量赋值。不要设立现实世界中不可能出现的情况,如程序员在函数开头检查n值必须大于零,而n值仅用于该公式中,那么将n值设为零,使程序失败的测试用例就是非法的。
- 公式和等式:例如分母不能为零,考虑有没有类似的情形,什么样的程序输入会导致它出现。
- 代码范围:语句覆盖等的分析,单步执行查看(调用堆栈对话框查看);每条语句至少执行一次,路径、分支等的覆盖
技术的提升是永无止境的,要想成为一个优秀的测试人员,在掌握技术的同时,也需要在不断实践中,在恰当的时机中,来合理地运用这些基本技术。
-
c#学习笔记-基础概念
2007-04-29 13:48:24
一.基础知识篇
1.using system:表示导入名字空间,相当于c中的include语句,用于导入预定义的元素,这样在自己的程序中就可以自由地使用其中的元素.
2.public partial class form1:form 声明一个form1类,代表是system.windows.forms.form 中的部分类3.项目的创建:在vs2005中.
1.文件/新建/项目/windows应用程序/打开 (首先创建一个项目)
2.右击解决方案,添加/新项目/选择类库.打开3.在项目名称/引用/添加引用/项目/加载类库的名称/确定.(添加引用后,在程序执行过程中就可以引用类库中的相关属性)
备注:解决方案中可以包括多个类和多个项目.二、属性,事件,this关键字,静态成员等。
属性:用于定义类中的值,并对它们进行读写。
事件:用于说明发生了什么事情。
索引指示器:允许像使用数组那样为类添加路径列表。
构造函数和析构函数:分别用于对类的实例进行初始化和销毁。
保护成员:为了方便派生类的访问,又希望成员对于外界是隐藏的,这时可以使用protected修饰符,声明成员为保护成员。
内部成员:使用internal修饰符的类的成员是一种特殊的成员。这种成员对于同一包中的应用程序或库是透明的,而在包.net之外是禁止访问的。
Using System;
Class Vehicle//定义汽车类
{
Protected float weight;
Public void F(){
Weight=10;//允许访问自身成员。
}
}
Class train//定义火车类
{
Public void F(){
Vehicle v1=new Vehicle();
V1.weight=6;//错误,不允许访问V1的保护成员
}
}
Class Car:Vehicle //定义轿车类
{
Public void F(){
Vehicle v1= new Vehicle();
V1.weight=6;//正确,允许访问V1的保护成员。
}
}
This 保留字
保留字this 仅限于在构造函数、类的方法和类的实例中使用。
This做为一个值类型或变量类型,来表示对对象本身的引用、方法的对象的引用、正在构造的结构的引用、在结构的方法中它表示对调用该方法的结构的引用等。
静态成员和非静态成员
类的非静态成员属于类的实例所有,每创建一个类的实例,都在内存中为非静态成员开辟了一块区域。而类的静态成员属于类所有,为这个类的所有实例所共享。无论这个类创建了多少个副本,一个静态成员在内存中只占有一块区域。
namespace ClassLibrary1
{
public class Test
{
int x;
static int y;
void F() {
x = 1;
y = 1;
}
static void G() {
x = 1;//错误,不能访问this.x,静态成员是属于类所有的
y = 1; //正确
}
}
}
namespace WindowsApplication1
{
public partial class Form1 : System.Windows.Forms.Form
{
public Form1() //构造函数
{
InitializeComponent();
ClassLibrary1.Test t = new ClassLibrary1.Test();
t.x = 1;
t.y = 1;//不能在类的实例中访问静态成员
ClassLibrary1.Test.x = 1;//不能按类访问非静态成员
ClassLibrary1.Test.y = 1;
}
标题搜索
我的存档
数据统计
- 访问量: 19418
- 日志数: 34
- 图片数: 8
- 书签数: 11
- 建立时间: 2007-04-24
- 更新时间: 2010-11-09
