
-
测试资源归类
2010-01-15 11:02:52
bug管理
缺陷管理培训PPT
http://bbs.51testing.com/thread-130409-1-5.html
软件过程、管理和质量, 南大培训讲座ppt
http://bbs.51testing.com/thread-79978-1-6.html
软件质量保证和测试 某公司培训资料
http://bbs.51testing.com/thread-79972-1-6.html
测试管理-BUG管理
http://bbs.51testing.com/thread-42157-1-6.html
软件质量与测试效果考评标准
http://bbs.51testing.com/thread-79982-1-5.html
Bug管理的经验和实践
http://bbs.51testing.com/thread-10861-1-1.html
软件测试及Bug管理经验谈
http://bbs.51testing.com/thread-6877-1-1.html
微软bug管理
http://bbs.51testing.com/thread-112690-1-2.html
Bug管理指南
http://bbs.51testing.com/thread-115428-1-6.html
Bug管理指南,一个不错的ppt
http://bbs.51testing.com/thread-79975-1-1.html
软件测试与改错
http://bbs.51testing.com/thread-14627-1-11.html
bug分类
Bug关键字
http://bbs.51testing.com/thread-78781-1-8.html
Bug描述的常见问题
http://bbs.51testing.com/thread-3733-1-22.html
注重BUG分析的良好习惯
http://bbs.51testing.com/thread-106330-1-18.html
软件缺陷的详细整理
http://bbs.51testing.com/thread-48144-1-32.html
软件缺陷分类标准
http://bbs.51testing.com/thread-2846-1-3.html
软件缺陷分类标准
http://bbs.51testing.com/thread-10385-1-8.html
软件缺陷分类标准新版
http://bbs.51testing.com/thread-5360-1-33.html
软件缺陷分析
http://bbs.51testing.com/thread-13770-1-3.html
一份BUG记录表
http://bbs.51testing.com/thread-96894-1-6.html
bug流程
Bug管理的一般流程
http://bbs.51testing.com/thread-77663-1-8.html
BUG生命周期流程图
http://bbs.51testing.com/thread-66754-1-6.html
bug数据分析(转)
http://bbs.51testing.com/thread-35-1-3.html
【一份相当详细的】bug状态流程图+bug处理流程+角色
http://bbs.51testing.com/thread-78589-1-1.html
[原创]Bugs 的有效交流和管理[翻译]
http://bbs.51testing.com/thread-36-1-33.html
对[原创]Bugs 的有效交流和管理[翻译] 的一点点补充
http://bbs.51testing.com/thread-37-1-2.html
缺陷管理流程
http://bbs.51testing.com/thread-58612-1-6.html
缺陷管理流程图
http://bbs.51testing.com/thread-66147-1-3.html
几个流程图
http://bbs.51testing.com/thread-126388-1-4.html
缺陷状态变更流程图
BUG统计分析的几种方式
http://bbs.51testing.com/thread-4514-1-2.html
测试BUG跟踪流程
http://bbs.51testing.com/thread-6659-1-6.html
Bug收敛曲线(Gompertz曲线)自动绘制工具
http://bbs.51testing.com/thread-83930-1-8.html
结合BUGFREE新做的缺陷管理流程图
http://bbs.51testing.com/thread-71283-1-11.html
CQ的BUG管理流程[附图]
http://bbs.51testing.com/thread-16641-1-53.html
bug报告
bug报告介绍
http://bbs.51testing.com/thread-28378-1-2.html
如何写有效的bug报告
http://bbs.51testing.com/thread-125816-1-1.html
如何写bug report
http://bbs.51testing.com/thread-101389-1-1.html
一个介绍微软如何测试的ppt
http://bbs.51testing.com/thread-79976-1-1.html
(翻译)编写优秀Bug报告的艺术及案例分析
http://bbs.51testing.com/thread-17595-1-2.html
缺陷报告编写规范(个人整理)
http://bbs.51testing.com/thread-80672-1-5.html
报告软件测试错误的规范
http://bbs.51testing.com/thread-7192-1-10.html
bug工具
bug 工具
http://bbs.51testing.com/thread-2354-1-4.html
(1)Mantis
xampp成功搭建Mantis
http://bbs.51testing.com/thread-139189-1-1.html
Mantis 1.0.7 中文版本完整手册(原版英文在线完成手册翻译),欢迎下载
http://bbs.51testing.com/thread-84353-1-1.html
开源的软件缺陷跟踪工具Mantis安装使用手册1.0版本完成了,欢迎各位下载
http://bbs.51testing.com/thread-2084-1-1.html
Mantis中文使用手册(采用中文界面)
http://bbs.51testing.com/thread-8352-1-1.html
软件缺陷跟踪工具Mantis安装使用手册1.0.7版本(基于Apache,配置好图形统计),欢迎下载
http://bbs.51testing.com/thread-84372-1-10.html
Mantis中文使用教程
http://bbs.51testing.com/thread-31541-1-5.html
7步搞掂 Mantis 安装配置——有史以来最简单快捷的方法
http://bbs.51testing.com/thread-42465-1-15.html
mantis安装求告无门的进
http://bbs.51testing.com/thread-19617-1-1.html
testlink-mantis 升级宝典
http://bbs.51testing.com/thread-49291-1-16.html
请问,Mantis中的邮件服务如何配置?
http://bbs.51testing.com/thread-3354-1-26.html
mantis安装配置心得——跟大家分享:)
http://bbs.51testing.com/thread-84481-1-29.html
(2)Bugzilla
bugzilla3.0汉化包
http://bbs.51testing.com/thread-85371-1-3.html
bugzilla如何安装
http://bbs.51testing.com/thread-16653-1-1.html
Bugzilla安装攻略
http://bbs.51testing.com/thread-87274-1-3.html
Bugzilla+Apache+mysql+Perl安装手册
http://bbs.51testing.com/thread-84455-1-3.html
bugzilla安装备忘
http://bbs.51testing.com/thread-73780-1-4.html
(1 windows下
BUGZILLA在windows下的安装
http://bbs.51testing.com/thread-105958-1-6.html
Windows下Bugzilla2.20+Apache(IIS)+mysql+Perl安装
http://bbs.51testing.com/thread-22398-1-4.html
windows下安装bugzilla
http://bbs.51testing.com/thread-109541-1-22.html
bugzilla3.0+activeperl5.8.8+apache2.2.4
http://bbs.51testing.com/thread-78455-1-12.html
Bugzilla在Windows XP下的安装指南
http://bbs.51testing.com/thread-71488-1-3.html
(2 Linux下
[转] Bugzilla + Oracle + Linux 安装笔记
http://bbs.51testing.com/thread-134053-1-9.html
Linux下Bugzilla的安装
http://bbs.51testing.com/thread-77464-1-12.html
在Linux系统中bugzilla安装与配置
http://bbs.51testing.com/thread-36176-1-19.html
最新的bugzilla3.12的所有 PPM模块 物超所值
http://bbs.51testing.com/thread-113261-1-5.html
bugzilla 模块批量安装包
http://bbs.51testing.com/thread-81035-1-10.html
(3 使用说明
发一个很详细的bugzilla使用说明
http://bbs.51testing.com/thread-90881-1-1.html
bugzilla使用说明
http://bbs.51testing.com/thread-73137-1-11.html
详细的bugzilla使用指南
http://bbs.51testing.com/thread-120556-1-2.html
bugzilla使用简明手册
http://bbs.51testing.com/thread-9332-1-2.html
bugzilla实用说明
http://bbs.51testing.com/thread-7940-1-26.html
(3)ClearQuest
ClearQuest教程▼
http://bbs.51testing.com/thread-2199-1-1.html
如何搭建一套ClearQuest的测试环境
http://bbs.51testing.com/thread-75350-1-36.html
jackie的大作《ClearQuest配置手册发布版》
http://bbs.51testing.com/thread-5256-1-5.html
clearquest
http://bbs.51testing.com/thread-32671-1-27.html
sincky搜集的clearquest资料,来源网络,供大家参考
http://bbs.51testing.com/thread-20152-1-31.html
ClearQuest字段和操作权限设置的问题
http://bbs.51testing.com/thread-26003-1-31.html
(4)JIRA
JIRA中文使用手册
http://bbs.51testing.com/thread-45571-1-2.html
缺陷管理工具JIRA从入门到精通使用文档
http://bbs.51testing.com/thread-119149-1-11.html
求JIRA的详细使用说明
http://bbs.51testing.com/thread-103444-1-6.html
JIRA工作流的制定和使用
http://bbs.51testing.com/thread-116634-1-5.html
关于jira的汉化问题
http://bbs.51testing.com/thread-51733-1-11.html
一个专业的缺陷跟踪管理软件:JIRA
http://bbs.51testing.com/thread-22739-1-50.html
(5)TestLink
TestLink1.7.4中文包(全面汉化)
http://bbs.51testing.com/thread-132373-1-3.html
TestLink 1.7 安装成功 附资料
http://bbs.51testing.com/thread-94267-1-14.html
TestLink1.7正式版使用手册
http://bbs.51testing.com/thread-104475-1-4.html
(6)Test Track
Test Track Pro Client的使用手册
http://bbs.51testing.com/thread-25570-1-5.html
Test Track Pro Client的使用方法的PPT
http://bbs.51testing.com/thread-25490-1-6.html
缺陷跟踪工具Test Track配置中文文档汇总
http://bbs.51testing.com/thread-19989-1-14.html
TrackRecord 50f.pdf
http://bbs.51testing.com/thread-46405-1-15.html
关于TestTrack Pro7.5.2配置文件
http://bbs.51testing.com/thread-81643-1-20.html
推荐一个好用的BUG跟踪工具,URTracker
http://bbs.51testing.com/thread-1748-1-32.html
(7)BugFree
简单实用的BugFree
http://bbs.51testing.com/thread-77671-1-8.html
XamppForWin配置bugfree
http://bbs.51testing.com/thread-45154-1-12.html
其他资料
cq web 配置手册(转)
http://bbs.51testing.com/thread-2200-1-14.html
缺陷记录单模板
http://bbs.51testing.com/thread-91053-1-1.html
软件需求分析模板
http://bbs.51testing.com/thread-119157-1-2.html
测试要点总结
http://bbs.51testing.com/thread-106331-1-2.html
测试用例设计
http://bbs.51testing.com/thread-87484-1-6.html
测试用例评审检查单
http://bbs.51testing.com/thread-105420-1-9.html
软件工程思想PDF格式
http://bbs.51testing.com/thread-79980-1-11.html
讨论热点
大家愿意使用哪种bug管理工具(前提假设均免费)?
http://bbs.51testing.com/thread-113456-1-1.html
缺陷管理工具之三——Mantis与JIRA对比
http://bbs.51testing.com/thread-139257-1-4.html
请教,缺陷跟踪工具!
http://bbs.51testing.com/thread-156-1-67.html
如何选泽一个好BUG跟踪工具
http://bbs.51testing.com/thread-16025-1-21.html
有哪些免费又好用的缺陷跟踪系统?
http://bbs.51testing.com/thread-37503-1-25.html
Bug追踪过程中需要注意的问题
http://bbs.51testing.com/thread-31647-1-64.html
如何创建缺陷分析指标体系
http://bbs.51testing.com/thread-64682-1-2.html
Bug流程图,欢迎讨论
http://bbs.51testing.com/thread-756-1-34.html
缺陷分布曲线图是怎么绘制出来的?
http://bbs.51testing.com/thread-51293-1-2.html
BUG级别与严重程度
http://bbs.51testing.com/thread-88880-1-25.html
缺陷等级应如何划分
http://bbs.51testing.com/thread-126302-1-7.html
[转贴]软件测试书籍列表,大家补充
http://bbs.51testing.com/thread-12727-1-8.html
软件发布后,发现BUG谁负责?
http://bbs.51testing.com/thread-123408-1-14.html
问:TestDirector中的Bug优先级是如何定义的?
http://bbs.51testing.com/thread-17440-1-16.html
[请教]Mantis中的issue的status&resolution
http://bbs.51testing.com/thread-21959-1-23.html
为什么使用http://localhost/Bugzilla可以进入页面 ,但是http://IP/Bugzilla进不去
http://bbs.51testing.com/thread-57360-1-27.html -
STAF的安装和使用
2010-01-06 17:19:57
STAF 全称Software Testing Automation Framework. 作为一个软件的自动测试框架,他以各种称之为服务作为各种功能. STAF是一个开源软件.
下面就STAF/STAX的安装配置作简要的介绍.
一, Windows下的安装
1.从STAF的官网上下载STAF和STAX的安装包, 注意他们都有windows和linux平台的安装包.
2.在windows平台上,双击STAF的安装包,按照提示进行安装即可.3.在STAF的安装路径(D:\Programming\STAF)下创建一个services文件夹,将STAX的安装包介压到services文件夹下.
4.修改D:\Programming\STAF\bin中的STAF.cfg文件, 如下:
# Turn on tracing of internal errors and deprecated options
trace enable tracepoints "error deprecated"# Enable TCP/IP connections
interface tcp library STAFTCP# Set default local trust
trust machine local://local level 5# Default Service Loader Service
serviceloader library STAFDSLSSERVICE STAX LIBRARY JSTAF EXECUTE \
{STAF/Config/STAFRoot}/services/stax/STAX.jar OPTION J2=-Xmx384m
SERVICE EVENT LIBRARY JSTAF EXECUTE \
{STAF/Config/STAFRoot}/services/stax/STAFEvent.jar
SET MAXQUEUESIZE 100005.重新启动STAFProc,确认能正确启动
6.在CMD下键入下列命令来确认STAF/STAX已经安装正确:
staf local ping ping
staf local service list
staf local stax help
二, Linux下的安装
1.从STAF的官网上下载STAF和STAX的安装包, 注意他们都有windows和linux平台的安装包.
2. 先将安装包介压:
tar xzvf *^^*&.tgz
3. 介压后会出现一个STAF文件夹,进入该文件夹
./STAFInst
进行安装,默认会被安装到/usr/local/staf下.
4. 在shell提示符下键入
PATH=/usr/local/staf/bin:$PATH
export PATH
LD_LIBRARY_PATH=/usr/local/staf/lib
export LD_LIBRARY_PATH
CLASSPATH=/usr/local/staf/lib/JSTAF.jar:/usr/local/staf/samples/demo/STAFDemo.jar
export CLASSPATH
STAFCONVDIR=/usr/local/staf/codepage
export STAFCONVDIR
STAFCODEPAGE=LATIN_1
export STAFCODEPAGE
nohup /usr/local/staf/bin/STAFProc > /usr/local/staf/stafproc.out
5. 在提示符号下键入STAFProc& 确认STAFProc能正确运行6. 在STAF的安装路径(/usr/local/staf/)下创建一个services文件夹,将STAX的安装包介压到services文件夹下.
tar xvf STAX*.tar
cp -rf stax /usr/local/staf/services/
7.修改/usr/local/staf/bin中的STAF.cfg文件, 如下:
# Turn on tracing of internal errors and deprecated options
trace enable tracepoints "error deprecated"# Enable TCP/IP connections
interface tcp library STAFTCP# Set default local trust
trust machine local://local level 5# Default Service Loader Service
serviceloader library STAFDSLSSERVICE STAX LIBRARY JSTAF EXECUTE \
{STAF/Config/STAFRoot}/services/stax/STAX.jar OPTION J2=-Xmx384m
SERVICE EVENT LIBRARY JSTAF EXECUTE \
{STAF/Config/STAFRoot}/services/stax/STAFEvent.jar
SET MAXQUEUESIZE 100008.重新启动STAFProc,确认能正确启动
9.在shell提示符下键入下列命令来确认STAF/STAX已经安装正确:
staf local ping ping
staf local service list
staf local stax help
注意事项:
1.确保下载 最新的STAF/STAX
2.确保下载并安装最新的JVM(否则运行STAFMonitor会有问题)
作者曾经在LINUX上怎么也启动不了STAXMonitor, 后来从http://java.sun.com 下载了jdk-6u6-linux-i586.bin,也就是jdk LINUX版本,在shell下
sh jdk-6u6-linux-i586.bin
之后会出现jdk1.6.0_06文件夹,添加/tmp/jdk1.6.0_06/bin到PATH中
PATH=/tmp/jdk1.6.0_06/bin:$PATH
利用java -version
来确认安装配置好了JVM,然后重新启动STAFProc即可。
3.确保系统安装了Python
4.在LINUX系统下,将各个变量EXPORT出来后,会影响系统的部分功能,特别是在ESX Server上。因此,使用STAF之前,可以不用将环境变量EXPORT出来
-
Rational PureCoverage 使用和功能介绍
2009-12-23 15:15:44
Rational PureCoverage 是专门进行自动化运行分析代码覆盖信息的工具,是一个单独的产品,也是 Rational PurifyPlus 家族中的一员。可用于改善应用程序可靠性和性能。在 Linux、UNIX 和 Windows 上都可使用和集成,PureCoverage 支持 C/C++、Java、.NET、Visual Basic 和 HTML。它可以实时诊断出应用程序覆盖的函数或方法(包括调用次数)和代码行信息。
PureCoverage 产品除了有自己专门的用户界面外,也可以和 Rational ClearQuest、Rational Robot、Rational Purify、IBM WebSphere Studio、Microsoft Visual Studio .NET、Microsoft Visual Studio 6 和 Microsoft Visual Basic 等无缝的集成,还可以用强大的命令行接口。所有通过图形界面的 PureCoverage 功能都可用命令行来完成,此外 PureCoverage 还为命令行提供了更多的选项和功能。
本文分别介绍了在 Linux / UNIX 和 Windows 上如何利用 PureCoverage 图形界面和通过命令行工具分析 C/C++ 程序,对分析结果的整理和报告,以及和用户环境的集成达到自动诊断和测试的目的。
开发人员使用 PureCoverage
开发人员通常负责创建单元测试,有时负责功能测试。这些测试的目的之一是在项目中特定区域中运用所有的。您可以手工检查源代码并编写您认为可以 覆盖整个项目的测试案例,但是这并不是可靠的或者有效的开发测试的方法。您需要一个像 PureCoverage 一样的代码覆盖工具来告诉您:您确实在这个项目的特定区域运行所有的循环和条件。记住:未测试的代码很可能就是有疑问的代码!
一旦您创建了完全运行目标代码的单元测试,那不意味着您已经完成了编写测试。因为一旦下面的代码变更,您的测试就不可避免地会落后。它们不会运 行后来引进的新特征或者不同的代码路径。您可以通过利用 PureCoverage 来有规律地分析这个测试覆盖并在特定子系统的覆盖水平寻找漏洞。早一点发现比晚点发现要好得多:如果您在一个发布版本周期的晚期遇到了不充分的覆盖,您将 比其他人更晚编写测试。
当编写测试时,PureCoverage 还有另一个好处:它将告诉您何时应该停止。如果过度的测试一个功能区域或者子系统是没有好处的。如果您根据观察来编写测试,而不是利用像 PureCoverage 一样的度量工具,您将在测试创建上过分投资,并且不能得到任何额外的质量回报。PureCoverage 可以告诉您什么时候是最为合适的,帮助您节省时间和资金。
PureCoverage 对开发人员最后一个利益是,它与 Purify 的使用相结合,像一个猎手一样可以保持这个项目不受内存错误使用的影响。记住 Purify 只执行您在测试过程中实际执行的代码中的内存错误的检验。如果您的测试没有运行完所有的代码,那么您仍然不能在那些区域感受到 Purify 给您带来的好处。
测试人员使用 PureCoverage
一个测试套件只是与它所包含的测试质量有同样的性能。那看起来很明显,但是仅仅是负担着重复的操作。如果它不能真正运行这个项目,就没有必要花 费时间和资金来运行这个测试套件,即使能够通过它所有的测试。如果来自这个测试套件的结论不能真实地告诉您这个项目的质量,那么您只是在浪费时间和资源。
一种度量测试质量的方法是,了解它们所运行的这个项目的区域以及(更为重要的是)它们所错过的区域。只有了解了您的测试所覆盖的范围和漏洞,您 才能够判断出测试结论的价值。没有工具,测试中的漏洞是很难识别的――一个测试的失败或者崩溃是很显然的,然而测试中的漏洞确是隐蔽的。如果您不度量您测 试的覆盖范围,您会继续运行您的测试并看到它们都通过测试,但是从来不会知道您的覆盖水平(因此这个测试运行的价值)正在恶化。
PureCoverage 可以度量您的测试覆盖范围,并可以显示漏洞。它可以产生单线水平的报告;但是对于测试人员来说,在文档或者子目录水平通常是最容易捕捉、总结,并趋向覆盖 数据的。这样可以识别在项目整个运行时间中覆盖较少范围的区域,可以显示测试的什么位置需要按行展开有代码变更和增添新特征的区域。
Linux 或 UNIX 下用 PureCoverage 要用 purecov 命令 Build 用户程序,如果用户还想通过 PureCoverage 获得调用所有代码行的信息,那么用户程序还需要 Build 成 Debug 版本(如用 -g 选项)。用 purecov 封装 Build 就是在执行 cc 或 gcc, g++ 前加 purecov 即可,例如:
% purecov cc -g admetadata.cpp
PureCoverage 2003a.06.15 Solaris 2 (32-bit) (c) Copyright IBM Corp. 1992, 2005 All rights reserved.
Instrumenting: crti.o crt1.o values-xa.o admetadata.o libCstd.a...
libC_mtstubs.a. libcx.a... crtn.o Linking
然后运行封装好的可执行程序就可生成此程序所覆盖的数据,例如:
% ./a.out
**** PureCoverage instrumented a.out (pid 8480 at Mon Aug 31 04:25:00 2005)
* PureCoverage 2003a.06.15 Solaris 2 (32-bit) (c) Copyright IBM Corp. 1992, 2005 All rights reserved.
* For contact information type: "purecov -help"
* Options settings: -purecov \
-purecov-home=/usr/local/pure/releases/purecov.sol.2003a.06.15 \
-cache-dir=/usr/local/pure/releases/purecov.sol.2003a.06.15/cache
* License successfully checked out.
* Command-line: ./a.out
Hello, World
**** PureCoverage instrumented a.out (pid 8480) ****
* Preparing coverage data.. Please note this might take some time..
* Saving coverage data to /net/ma-homes/homes/gaowb/a.out.pcv.
* To view results type: purecov -view /net/ma-homes/homes/gaowb/a.out.pcv
运行完后 PureCoverage 会保存覆盖信息到一个扩展名为 pcv 的二进制文件,如果此文件已经存在, PureCoverage 缺省会更新合并此文件中的覆盖信息。
Windows 下用 PureCoverage 前先要 Build 好用户程序,如果用户还想通过 PureCoverage 获得调用所有函数和代码行的信息,那么用户程序需要 Build 成 Debug 版本。Build 好用户程序之后就可以用 PureCoverage 图形界面工具或 coverage 命令行工具加参数生成覆盖信息数据,PureCoverage 是一个实时诊断工具,所以在生成覆盖信息数据时它会执行用户程序。
2.2 在 Windows 下用 PureCoverage 图形界面收集覆盖信息数据
启动"Rational PureCoverage"后,在欢迎界面点击"Run"按钮或从文件菜单或工具条选择"Run"开始一个诊断程序,如图1:
图1 PureCoverage 开始运行对话框

在运行过程中 PureCoverage 会首先显示一个包含当前状态程序覆盖情况的概要窗口,如图2:
图2 PureCoverage 概要窗口

2.3 在 Windows 下用其他开发工具集成调用 PureCoverage 收集和查看覆盖信息数据
为方便用户开发和测试代码,PureCoverage 可以集成到Microsoft Visual Studio 6,Microsoft Visual Studio .NET,Microsoft Visual Basic,Rational Robot,Rational ClearQuest 和 IBM WebSphere Studio 等开发工具。要在这些集成开发环境中使用 PureCoverage 请确保安装 PureCoverage 时正确安装了和这些开发工具的集成。下面的例图3 是用 Microsoft Visual Studio 6 调用 PureCoverage 收集覆盖信息数据:
图3 在 Microsoft Visual Studio 6 中调用 PureCoverage 来收集和查看覆盖信息数据

命令行工具用法如下:
coverage [<PureCoverage options>] <exename or modulename> [<arguments to exename>]
例如:
coverage /SaveTextData="C:\pamsglib.txt" pamsglib.exe arg1 arg2 arg3
下面是生成的结果实例:
3.1 在 Linux 或 UNIX 下用 PureCoverage 查看器查看和过滤生成的覆盖信息数据
用 purecov -view 命令打开 PureCoverage 查看器可以显示覆盖信息,例如:
% purecov -view a.out.pcv
此命令将打开 PureCoverage 查看器图形窗口,如图4:
图4 PureCoverage 查看器

如果在 Build 的时候有 -g 调试选项,就可以点击 Annotated Source 按钮或从 Actions 菜单选 Show annotated source 打开源程序行覆盖信息,如图5:
图5 PureCoverage 源程序查看器

PureCoverage 会高亮度显示未调用的行。
PureCoverage 查看器还提供了几个常用的报告脚本工具,可以从菜单 File -> Run script. 来选择使用。例如:
pc_annote:生成一个源程序分析结果的文本文件
pc_below:报告低级覆盖信息
pc_build_diff:比较一个程序新旧版本的 PureCoverage 数据
pc_diff:列出新旧覆盖数据改变的文件
pc_covdiff:比较统计输出改变源代码后的覆盖信息
pc_email:给最近编辑覆盖数据的人发送邮件报告
pc_select:识别改变源代码测试的子集
pc_ssheet:生成一个数据表格式的概要
pc_summary:生成一个制表格式的全部概要
3.2 在 Linux 或 UNIX 下用导出的文本文件查看和过滤生成的覆盖信息数据
用 purecov -export 命令可以将生成的覆盖信息数据导出到一个文本文件,例如:
% purecov -export=purecov.txt a.out.pcv
下面是导出结果的结果实例:
###############################################################################
# This is a PureCoverage export file, created 23-Aug-2005 08:39:12 AM #
# Coverage data type: adjusted. #
# #
# Summary of keys and field meanings: #
# #
# to unused-blocks blocks unused-lines lines unused-funcs funcs files dirs #
# di name unused-blocks blocks unused-lines lines unused-funcs funcs files #
# fi name unused-blocks blocks unused-lines lines unused-funcs funcs sessions #
# fu name unused-blocks blocks unused-lines lines calls #
# li line_no hits #
# bl line_no hits #
# efu name #
# efi name #
# edi name #
# #
# In all of these entries, the character separating the values is a TAB, not #
# a space. #
# #
# Values for hits, calls, and sessions stop accumulating once they reach #
# 10000, so a value of 10000 should be taken as 10000 or greater. #
# #
# 'to' -- Total coverage summary. #
# 'di' -- Coverage summary for one directory, followed by the files in the #
# directory. Repeated for each directory. #
# 'edi' -- End of information for named directory. #
# 'fi' -- Coverage summary for one file, followed by the functions in the #
# file. Repeated for each file within a directory. #
# 'efi' -- End of information for named file. #
# 'fu' -- Coverage summary for one function, followed by line and block #
# coverage information for the function. Repeated for each function #
# within the file. #
# 'efu' -- End of information for named function. #
# 'li' -- Use count for the indicated line. Repeated for each line in the #
# function. If coverage adjustments are NOT applied, then the #
# hits figure is the true hits figure for the line. If coverage #
# adjustments ARE applied, then inspected and tested lines will #
# indicate INSP or TEST as appropriate, while other used and unused #
# lines will indicate their counts. Deadcode lines do not appear #
# in export format when adjustments are applied. #
# 'bl' -- Use count for the basic block. Repeated for each block in the #
# function. Note that a single line may contain multiple blocks, #
# and that a single block may span multiple lines. #
###############################################################################
to 3 9 3 8 1 3 1 1
di /net/ma-homes/homes/gaowb/ 3 9 3 8 1 3 1
fi admetadata.cpp 3 9 3 8 1 3 1
fu void display_message(char*) 2 2 2 2 0
bl 19 0
bl 20 0
li 19 0
li 20 0
efu void display_message(char*)
fu main 1 5 1 4 1
bl 6 1
bl 7 1
bl 9 0
bl 10 1
bl 10 1
li 6 1
li 7 1
li 9 0
li 10 1
efu main
fu void display_hello_world() 0 2 0 2 1
bl 14 1
bl 15 1
li 14 1
li 15 1
efu void display_hello_world()
efi admetadata.cpp
edi /net/ma-homes/homes/gaowb/
在 PureCoverage 导出的结果中,# 开头的行表示注释,包含文件描述、数据类型和结构介绍等。
to 开头的表示覆盖结果统计信息,各字段分别是未使用块、总块数、未执行行数、总行数、未调用函数或方法的个数、总函数或方法的个数、文件数和目录数。
di 开头的表示一个目录总的覆盖信息,各字段分别是目录名、未使用块、总块数、未执行行数、总行数、未调用函数或方法的个数、总函数或方法的个数和文件数。
fi 开头的表示一个文件总的覆盖信息,各字段分别是文件名、未使用块、总块数、未执行行数、总行数、未调用函数或方法的个数、总函数或方法的个数和会话数。
fu 开头的表示一个函数或方法的覆盖信息,各字段分别是函数或方法名、未使用块、总块数、未执行行数、总行数和被调用的次数。
li 开头的表示源文件中行的覆盖信息,各字段分别是行号和执行的次数。
bi 开头的表示基本块的覆盖信息,各字段分别是行号和执行的次数。
efu、efi 和 edi 分别表示该函数或方法、文件和目录信息结束。
如果用户觉得 PureCoverage 导出的结果信息太多,可以根据自己需要再过滤,如只想得到调用过的函数或方法,可以用下面的 Perl 语句:
if ( @ARGV != 1 ) { # Specify file name as command line argument
die "Usage: $0 <PureCoverageExportFileName>\n";
}
open iFH, $ARGV[0] or die "Can not open PureCoverage exported file $ARGV[0]: $!";
while ( <iFH> ) {
if ( /^fu\t.*\t0$/ ) { # Skip not calls function(s)
next;
} elsif ( /^fu\t(.*)\t\d+\t\d+\t\d+\t\d+\t\d+$/ ) { # Get called function(s)
print "$1\n";
}
}
3.3 在 Windows 下用 PureCoverage 图形界面查看和过滤数据
用 PureCoverage 运行完用户程序以后,选择 Coverage 浏览器窗口可以分等级按源文件显示覆盖信息数据,如图6:
图6 PureCoverage 浏览器窗口

选择 Coverage 函数列表窗口可以显示整个程序中函数或方法的覆盖信息数据,如图7:
图7 PureCoverage 函数列表窗口

缺省 PureCoverage 会过滤掉它认为一般用户不关心的数据,如操作系统模块,但用户也可以根据自己的实际需要定制过滤器,PureCoverage 提供了一个图形化的过滤管理器。从 View 菜单中选择 Filter Manager 或点击 Filter Manager 工具条打开过滤管理器窗口,如图8:
图8 PureCoverage 过滤管理器

PureCoverage 可以在源代码中一行一行的识别覆盖情况,双击一个函数或方法,就会打开源程序查看器窗口,如图9:
图9 PureCoverage 源程序查看器

缺省 PureCoverage 未测到的行用红色表示,已测到的行用蓝色表示,固定行用黑色表示,在多块行中部分测到用粉色表示,总报告用绿色表示。用户可根据自己的喜好定制颜色。
3.4 在 Windows 下查看和过滤用命令行工具生成的覆盖信息数据
在 PureCoverage 命令行工具生成的结果中,comment 开头的行表示注释,包含文件结构简单介绍、用户程序信息、工作路径、PureCoverage 版本信息、运行机器信息、运行时间统计、数据集大小、过滤器信息等。
CoverageData 开头的表示覆盖结果信息,CoverageData 第一行说明各字段含义,用 Tab 字符隔开;第二行是总的统计报告,包括未使用和使用的函数或方法、总函数或方法、使用函数或方法的百分比、未使用和使用的代码行数、总行数、使用行数百分 比和总调用次数等;从第三行开始是具体收集到的模块、目录、源文件和函数或方法等信息,每行都有名称、类型、父源代码、父模块、未使用和使用的函数或方 法、总函数或方法、使用函数或方法的百分比、未使用和使用的代码行数、总行数、使用行数百分比、源代码行号和总调用次数等。
SourceLines 开头的表示源程序中行号的覆盖信息。
如果用户觉得 PureCoverage 生成的结果信息太多,可以根据自己需要再过滤,如只想得到调用过的函数或方法,可以用下面的 Perl 语句:
if ( @ARGV != 1 ) { # Specify file name as command line argument
die "Usage: $0 <PureCoverageTextDataFileName>\n";
}
open iFH, $ARGV[0] or die "Can not open PureCoverage text data file $ARGV[0]: $!";
while ( <iFH> ) {
if ( /^CoverageData\t.*\t0$/ ) { # Skip not calls function(s)
next;
} elsif ( /^CoverageData\t(.*)\tFunction\t.*/ ) { # Get called function(s)
print "$1\n";
}只需要将 "purecov " 添加到编译器 cc、gcc 或 g++ 命令的前面即可。或增加一个 Build 规则在 Makefile 中,例如:
pc_relink:
admetadata.o: admetadata.cpp
purecov cc admetadata.cpp
如果用户环境中可执行程序被调用多次或指定程序不同的参数,PureCoverage 会自动合并生成的结果。
再用"purecov -export"命令将 .pcv 文件批量转换成覆盖信息数据文本文件,也可再进一步过滤得出恰当的结果。
只需要将 "coverage /SaveTextData " 添加到可执行程序的前面即可。如果用户环境中可执行程序被调用多次或指定程序不同的参数,那么用户可以用 /SaveMergeTextData 代替 /SaveTextData 选项来合并生成的结果。
可再进一步过滤得出恰当的结果。
}1) 本文所述的 Linux 或 UNIX 是指只要支持任何一个标准 cc、gcc 或 g++ 编译器的任何 Linux 或 UNIX。
2) 查看所有命令行选项可用 purecov -help(Linux/UNIX)或 coverage /help(Windows)命令。
3) PureCoverage 缺省监听级别是最详细的代码行级,也可以用-purecov-granularity=function 或者/CollectionGranularity=function 定制到函数或方法级或其他级别以收集到更精简或符合用户需要的数据。
4) 如果用户不能获得想要的函数或代码行,请确认程序是 Debug 版,即 Linux/UNIX 下 Build 的时候用了 -g 编译选项,如果用户用的是 MFC,请确认有 /ZI 编译选项。
5) 如果用户觉得缺省的 filter 不太合适,可以用 /FilterFiles 选项自己定制 filter。
6) PureCoverage 有自动调节行覆盖功能,例如在某些情况下不想统计某些行,用此功能可能更满足客户的需求。
7) Windows 下 coverage 是在 Rational/common 目录下,如果不能执行请检查此目录是否在 PATH 环境变量里。
8) 如果想在 Windows 下查看 Linux 或 UNIX 上生成的覆盖信息数据,可用 -view-file-format 选项生成 Windows PureCoverage 可识别的 .cfy 覆盖信息数据文件,但要注意 Linux 或 UNIX 下不会合并 .cfy 文件。
使用 Rational PureCoverage 进行 J2EE 代码覆盖 -
berkeley DB 详细功能介绍
2009-12-10 08:54:17
BerkeleyDB
像mysql 这类基于c/s结构的关系型数据库系统虽然代表着目前数据库应用的主流,但却并不能满足所有应用场合的需要。有时我们需要的可能只是一个简单的基于磁盘文 件的数据库系统。这样不仅可以避免安装庞大的数据库服务器,而且还可以简化数据库应用程序的设计。berkeley db正是基于这样的思想提出来的。
berkeley db是一个开放源代码的内嵌式数据库管理系统,能够为应用程序提供高性能的数据管理服务。应用它程序员只需要调用一些简单的api就可以完成对数据的访问 和管理。与常用的数据库管理系统(如mysql和oracle等)有所不同,在berkeley db中并没有数据库服务器的概念。应用程序不需要事先同数据库服务建立起网络连接,而是通过内嵌在程序中的berkeley db函数库来完成对数据的保存、查询、修改和删除等操作。berkeley db简介
berkeley db为许多编程语言提供了实用的api接口,包括c、c++、java、perl、tcl、python和php等。所有同数据库相关的操作都由 berkeley db函数库负责统一完成。这样无论是系统中的多个进程,或者是相同进程中的多个线程,都可以在同一时间调用访问数据库的函数。而底层的数据加锁、事务日志 和存储管理等都在berkeley db函数库中实现。它们对应用程序来讲是完全透明的。俗话说:“麻雀虽小五脏俱全。”berkeley db函数库本身虽然只有300kb左右,但却能够用来管理多达256tb的数据,并且在许多方面的性能还能够同商业级的数据库系统相抗衡。就拿对数据的并 发操作来说,berkeley db能够很轻松地应付几千个用户同时访问同一个数据库的情况。此外,如果想在资源受限的嵌入式系统上进行数据库管理,berkeley db可能就是惟一正确的选择了。
berkeley db作为一种嵌入式数据库系统在许多方面有着独特的优势。首先,由于其应用程序和数据库管理系统运行在相同的进程空间当中,进行数据操作时可以避免繁琐的 进程间通信,因此耗费在通信上的开销自然也就降低到了极低程度。其次,berkeley db使用简单的函数调用接口来完成所有的数据库操作,而不是在数据库系统中经常用到的sql语言。这样就避免了对结构化查询语言进行解析和处理所需的开 销。
berkeley db简化了数据库的操作模式,同时引入了一些新的基本概念,从而使得访问和管理数据库变得相对简单起来。在使用berkeley db提供的函数库编写数据库应用程序之前,有必要先了解以下这些基本概念。基本概念
关键字和数据
关 键字(key)和数据(data)是berkeley db用来进行数据库管理的基础,由这两者构成的key/data对(见表1)组成了数据库中的一个基本结构单元,而整个数据库实际上就是由许多这样的结构 单元所构成的。通过使用这种方式,开发人员在使用berkeley db提供的api来访问数据库时,只需提供关键字就能够访问到相应的数据。
key data
sport football
fruit orange
drink beer
表1 key/data对
如果想将第一行中的 “sport”和“football”保存到berkeley db数据库中,可以调用berkeley db函数库提供的数据保存接口。此时“sport”和“football”将分别当成关键字和数据来看待。之后如果需要从数据库中检索出该数据,可以用 “sport”作为关键字进行查询。此时berkeley db提供的接口函数会返回与之对应的数据“football”。
关键字和数据在berkeley db中都是用一个名为dbt的简单结构来表示的。实际上两者都可以是任意长度的二进制数据,而dbt的作用主要是保存相应的内存地址及其长度,其结构如下所示:
typedef struct {
void *data;
u_int32_t size;
u_int32_t ulen;
u_int32_t dlen;
u_int32_t doff;
u_int32_t flags;
} dbt;
在使用berkeley db进行数据管理时,缺省情况下是一个关键字对应于一个数据,但事实上也可以将数据库配置成一个关键字对应于多个数据。
在berkeley db函数库定义的大多数函数都遵循同样的调用原则:首先创建某个结构,然后再调用该结构中的某些方法。从程序设计的角度来讲,这一点同面向对象的设计原则 是非常类似的,即先创建某个对象的一个实例,然后再调用该实例的某些方法。正因如此,berkeley db引入了对象句柄的概念来表示实例化后的结构,并且将结构中的成员函数称为该句柄的方法。对象句柄
对象句柄的引入使得程序员能够完全凭借面向对象的思想,来完成对berkeley db数据库的访问和操作,即使当前使用的是像c这样的结构化语言。例如,对于打开数据库的操作来说,可以调用db的对象句柄所提供的open函数,其原型如下所示:
int db->open(db *db, db_txn *txnid, const char *file,
const char *database, dbtype type, u_int32_t flags, int mode);
对于任何一个函数库来说,如何对错误进行统一的处理都是需要考虑的问题。berkeley db提供的所有函数都遵循同样的错误处理原则,即函数成功执行后返回零,否则的话则返回非零值。错误处理
对 于系统错误(如磁盘空间不足和访问权限不够等),返回的是一个标准的值;而对于非系统错误,返回的则是一个特定的错误编码。例如,如果在数据库中没有与某 个特定关键字所对应的数据,那么在通过该关键字检索数据时就会出现错误。此时函数的返回值将是db_notfound,表示所请求的关键字并没有在数据库 中出现。所有标准的errno值都是大于零的,而由berkeley db定义的特殊错误编码则都是小于零的。
要求程序员记住所有的 错误代号既不现实也没有什么实际意义,因为berkeley db提供了相应的函数来获得错误代号所对应的错误描述。一旦有错误发生,只需首先调用db_strerror()函数来获得错误描述信息,然后再调用db ->err()或db->errx()就可以很轻松地输出格式化后的错误信息。
使用berkeley db提供的函数来进行数据库的访问和管理并不复杂,在大多数场合下只需按照统一的接口标准进行调用就可以完成最基本的操作。应用统一的编程接口
打 开数据库通常要分两步进行:首先调用db_create()函数来创建db结构的一个实例,然后再调用db->open()函数来完成真正的打开操 作。berkeley db将所有对数据库的操作都封装在名为db的结构中。db_create()函数的作用就是创建一个该结构,其原型如下所示:打开数据库
typedef struct__db db;
int db_create(db **dbp, db_env *dbenv, u_int32_t flags);
将磁盘上保存的文件作为数据库打开是由db->open()函数来完成的,其原型如下所示:
int db->open(db *db, db_txn *txnid, const char *file,
const char *database, dbtype type, u_int32_t flags, int mode);
下面这段代码示范了如何创建db对象句柄及如何打开数据库文件:
#include
#include
#include
#include
#include
#define database "demo.db"
/* 以下程序代码的程序头同此*/
int main()
{ db *dbp;
int ret;
if ((ret = db_create(&dbp, null, 0)) != 0) {
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
exit (1);
}
if ((ret = dbp->open(dbp, null, database, null, db_btree, db_create, 0664)) != 0) {
dbp->err(dbp, ret, "%s", database);
exit (1);
}
}
代 码首先调用db_create()函数来创建一个db对象句柄。变量dbp在调用成功后将成为数据库句柄,通过它可以完成对底层数据库的配置或访问。接下 去调用db->open()函数打开数据库文件,参数“database”指明对应的磁盘文件名为demo.db;参数“db_btree”表示数 据库底层使用的数据结构是b树;而参数“db_create”和“0664”则表明当数据库文件不存在时创建一个新的数据库文件,并且将该文件的属性值设 置为0664。
错误处理是在打开数据库时必须的例行检查,这可以通过调用db->err()函数来完成。其中参数“ret”是在调用berkeley db函数后返回的错误代码,其余参数则用于显示结构化的错误信息。
向berkeley db数据库中添加数据可以通过调用db->put()函数来完成,其原型如下所示:添加数据
int db->put(db *db, db_txn *txnid, dbt *key, dbt *data, u_int32_t flags);
下面这段代码示范了如何向数据库中添加新的数据:
int main()
{ db *dbp;
dbt key, data;
int ret;
if ((ret = db_create(&dbp, null, 0)) != 0) {
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
exit (1);
}
if ((ret = dbp->open(dbp,
null, database, null, db_btree, db_create, 0664)) != 0) {
dbp->err(dbp, ret, "%s", database);
exit (1);
}
memset(&key, 0, sizeof(key));
memset(&data, 0, sizeof(data));
key.data = "sport";
key.size = sizeof("sport");
data.data = "football";
data.size = sizeof("football");
if ((ret = dbp->put(dbp, null, &key, &data, 0)) == 0)
printf("db: %s: key stored.\n", (char *)key.data);
else
dbp->err(dbp, ret, "db->put");
}
代码首先声明了两个dbt结构变量,并分别用字符串“sport”和“football”进行填充。它们随后作为关键字和数据传递给用来添加数据的db->put()函数。dbt结构几乎会在所有同数据访问相关的函数中被用到。
在 向数据库中添加数据时,如果给定的关键字已经存在,大多数应用会对于已经存在的数据采用覆盖原则。也就是说,如果数据库中已经保存了一个 “sport/basketball”对,再次调用db->put()函数添加一个“sport/football”对,那么先前保存的那些数据将 会被覆盖。但berkeley db允许在调用db->put()函数时指定参数“db_nooverwrite”,声明不对数据库中已经存在的数据进行覆盖,其代码如下:
if ((ret = dbp->put(dbp, null, &key, &data, db_nooverwrite)) == 0)
printf("db: %s: key stored.\n", (char *)key.data);
else
dbp->err(dbp, ret, "db->put");
一旦给出“db_nooverwrite”标记,如果db->put()函数在执行过程中发现给出的关键字在数据库中已经存在了,就无法成功地把该key/data对添加到数据库中,于是将返回错误代号“db_keyexist”。
从berkeley db数据库中检索数据可以通过调用db->get()函数来完成,其原型如下所示:检索数据
int db->get(db *db, db_txn *txnid, dbt *key, dbt *data, u_int32_t flags);
下面这段代码示范了如何从数据库中检索出所需的数据:
int main()
{ db *dbp;
dbt key, data;
int ret;
if ((ret = db_create(&dbp, null, 0)) != 0) {
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
exit (1);
}
if ((ret = dbp->open(dbp,
null, database, null, db_btree, db_create, 0664)) != 0) {
dbp->err(dbp, ret, "%s", database);
exit (1);
}
memset(&key, 0, sizeof(key));
memset(&data, 0, sizeof(data));
key.data = "sport";
key.size = sizeof("sport");
if ((ret = dbp->get(dbp, null, &key, &data, 0)) == 0)
printf("db: %s: key retrieved: data was %s.\n",
(char *)key.data, (char *)data.data);
else
dbp->err(dbp, ret, "db->get");
}
代 码同样声明了两个dbt结构变量,并且调用memset()函数对它们的内容清空。虽然berkeley db并不强制要求在进行数据操作之前先清空它们,但出于提高代码质量考虑还是建议先进行清空操作。在进行数据检索时,对db->get()函数的返 回值进行处理是必不可少的,因为它携带着检索操作是否成功完成等信息。下面列出的是db->get()函数的返回值:
◆ 0 函数调用成功,指定的关键字被找到;
◆ db_notfound 函数调用成功,但指定的关键字未被找到;
◆大于0 函数调用失败,可能出现了系统错误。
从berkeley db数据库中删除数据可以通过调用db->del()函数来完成,其原型如下所示:删除数据
int db->del(db *db, db_txn *txnid, dbt *key, u_int32_t flags);
下面这段代码示范了如何从数据库中删除数据:
int main()
{ db *dbp;
dbt key;
int ret;
if ((ret = db_create(&dbp, null, 0)) != 0) {
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
exit (1);
}
if ((ret = dbp->open(dbp,
null, database, null, db_btree, db_create, 0664)) != 0) {
dbp->err(dbp, ret, "%s", database);
exit (1);
}
memset(&key, 0, sizeof(key));
key.data = "sport";
key.size = sizeof("sport");
if ((ret = dbp->del(dbp, null, &key, 0)) == 0)
printf("db: %s: key was deleted.\n", (char *)key.data);
else
dbp->err(dbp, ret, "db->del");
}
删除数据只需给出相应的关键字,不用指明与之对应的数据。
对 于一次完整的数据库操作过程来说,关闭数据库是不可或缺的一个环节。这是因为berkeley db需要依赖于系统底层的缓冲机制,也就是说只有在数据库正常关闭的时候,修改后的数据才有可能全部写到磁盘上,同时它所占用的资源也才能真正被全部释 放。关闭数据库的操作是通过调用db->close()函数来完成的,其原型如下所示:关闭数据库
int db->close(db *db, u_int32_t flags);
下面这段代码示范了如何在需要的时候关闭数据库:
int main()
{ db *dbp;
dbt key, data;
int ret, t_ret;
if ((ret = db_create(&dbp, null, 0)) != 0) {
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
exit (1);
}
if ((ret = dbp->open(dbp,
null, database, null, db_btree, db_create, 0664)) != 0) {
dbp->err(dbp, ret, "%s", database);
goto err;
}
memset(&key, 0, sizeof(key));
memset(&data, 0, sizeof(data));
key.data = "sport";
key.size = sizeof("sport");
if ((ret = dbp->get(dbp, null, &key, &data, 0)) == 0)
printf("db: %s: key retrieved: data was %s.\n",
(char *)key.data, (char *)data.data);
else
dbp->err(dbp, ret, "db->get");
if ((t_ret = dbp->close(dbp, 0)) != 0 && ret == 0)
ret = t_ret;
exit(ret);
}
berkeley db这个嵌入式数据库系统使用非常简单。它没有数据库服务器的概念,也不需要复杂的sql语句,所有对数据的操作和管理都可以通过函数调用来完成,非常适合于那些需要对数据进行简单管理的应用场合小结
include <db.h>
#include <string.h>
#include <stdlib.h>
#define MAXBUFFER 300
#define MAXSTRING 100
void getdata(void);
/* Declare our struct */
struct example_structure {
float myFloat;
int myInt;
char *myString;
};
typedef struct example_structure EXAMPLE_STRUCTURE;
char SAMPLE_KEY[] = "eins";
char * Database = "./sample.db";
DBT sampleKEY;
/*
* Program to illustrate marshalling and unmarshalling structures.
*
* Marshalling is the process of moving the contents of a structure's
* fields into a single contiguous memory location. This is done so that
* the structure can be stored in a Berkeley DB database.
*
* Unmarshalling is performed to take data retrieved from a Berkeley DB database
* and place it back into the structure so that it can be used by the
* application.
*/
int
main(void)
{
DBT sampleDBT; /* The Berkeley DB data structure that we use to store data
* in a database. Typically there are two of these for
* every database record, one for a key and one for the
* data. In this case, we need only one DBT for
* illustration purposes.
*/
DB *dbp;
char *SerialNumber;
int ret;
EXAMPLE_STRUCTURE myStruct; /* The structure we want to store */
int buffer_length; /* The amount of data stored in our buffer */
char buffer[MAXBUFFER]; /* The buffer itself */
char *bufferPtr; /* A pointer into the buffer */
memset(&sampleKEY, 0, sizeof(DBT));
memset(&sampleDBT, 0, sizeof(DBT));
/* First, we fill in our structure's data fields */
myStruct.myFloat = 3.04;
myStruct.myInt = 200;
/* malloc space for the string */
myStruct.myString = (char *)malloc(MAXSTRING * sizeof(char));
/* Copy a string into that space. */
strcpy(myStruct.myString, "My example string.");
/*
* In order to store the data for this structure, we must make sure that
* all its data is lined up in a single contiguous block of memory -- that
* is, in a single buffer. We also need to know how much data was put into
* that buffer. To do this, we copy the structure's data into the buffer.
* This is the actual marshalling process.
*
* Note that the order we use to copy the data is not important, except
* that we have to make sure that we unmarshall in the same order. Here
* we mix things up a bit in order to illustrate the concept.
*
* Notice that we keep track of how much data we've placed in the buffer as
* we go. Also, take care to copy each new bit of data to the end of the
* buffer, so as to not overwrite any data previously placed there.
*/
/* Initialize the buffer */
memset(&buffer, 0, MAXBUFFER);
/* Copy the struct's int into the buffer */
bufferPtr = &buffer[0];
memcpy(bufferPtr, &(myStruct.myInt), sizeof(int));
buffer_length = sizeof(int);
/* Copy the struct's string into the buffer */
bufferPtr = &buffer[buffer_length];
memcpy(bufferPtr, myStruct.myString,
strlen(myStruct.myString) + 1);
buffer_length += (strlen(myStruct.myString) + 1);
/* Copy the struct's float into the buffer */
bufferPtr = &buffer[buffer_length];
memcpy(bufferPtr, &(myStruct.myFloat), sizeof(float));
buffer_length += sizeof(float);
/*
* We now have a buffer that contains all our data. We also have the size of
* the data contained in that buffer. We can use this buffer with our DBT:
*/
sampleDBT.data = buffer;
sampleDBT.size = buffer_length;
sampleKEY.data = SAMPLE_KEY;
sampleKEY.size = sizeof(SAMPLE_KEY);
if ((ret = db_create(&dbp, NULL, 0)) != 0)
{
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
return(ret);
}
if ((ret = dbp->open(dbp,
NULL, Database, NULL, DB_BTREE, DB_CREATE, 0664)) != 0)
{
dbp->err(dbp, ret, "%s", Database);
return(ret);
}
if ((ret = dbp->put(dbp, NULL, &sampleKEY, &sampleDBT, 0)) != 0)
{
dbp->err(dbp, ret, "%s", Database);
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
return(ret);
}
//ret = dbp->close(dbp, 0);
/*
* We can now pass the data DBT to a DB->put() or DBC->c_put() call for
* storage in the database. We won't show that here.
*/
/*
* Upon retrieval from the database (again, we don't show the actual
* database get() activity), the DBT's data field is pointing to
* a void * buffer that contains exactly the data that we marshalled into
* our buffer above. We now need to only unmarshall that data. To do this,
* we have to remember the order in which we originally marshalled the
* data.
*/
/*
* Note that we're reusing the same DBT for unmarshalling process as we used
* to marshall the data. In real-world usage, the two would be different
* as they would almost certainly be declared in different scopes.
*/
/*
* Now we can print everything out to prove that the marshalling process
* worked
*/
printf("Original structure:\n");
printf("\tmyInt: %i, \tmyFloat: %f\n", myStruct.myInt, myStruct.myFloat);
printf("\tmyString: %s\n", myStruct.myString);
ret = dbp->close(dbp, 0);
getdata();
return(0);
}
void getdata(void)
{
char *bufferPtr; /* A pointer into the buffer */
EXAMPLE_STRUCTURE newStruct; /* The structure we want to place data into */
DBT sampleDBT;
DB *dbp;
int ret;
memset(&sampleDBT, 0, sizeof(DBT));
if ((ret = db_create(&dbp, NULL, 0)) != 0)
{
fprintf(stderr, "db_create: %s\n", db_strerror(ret));
}
if ((ret = dbp->open(dbp,
NULL, Database, NULL, DB_BTREE, DB_CREATE, 0664)) != 0)
{
dbp->err(dbp, ret, "%s", Database);
}
if ((ret = dbp->get(dbp, NULL, &sampleKEY, &sampleDBT, 0)) != 0)
{
dbp->err(dbp, ret, "%s", Database);
return;
}
bufferPtr = sampleDBT.data;
/* First, find the int (the first bit of data that we stored) */
newStruct.myInt = *((int *)bufferPtr);
bufferPtr += sizeof(int);
/* Next, the string */
newStruct.myString = (char *)bufferPtr;
bufferPtr += (strlen(newStruct.myString) + 1);
/* And finally, the float */
newStruct.myFloat = *((float *)bufferPtr);
printf("\nNew structure (after marshalling and unmarshalling:\n");
printf("\tmyInt: %i, \tmyFloat: %f\n", newStruct.myInt, newStruct.myFloat);
printf("\tmyString: %s\n", newStruct.myString);
/* Cleanup */
ret = dbp->close(dbp, 0);
}
output:
Original structure:
myInt: 200, myFloat: 3.040000
myString: My example string.
New structure (after marshalling and unmarshalling:
myInt: 200, myFloat: 3.040000
myString: My example string.
Press enter to continue...
I did not understand why you would us a u_int32_t for the buffer, and of course you have to either flush the output or close the database connection otherwise nothing is written.
Regards
Friedrich -
VM自动化部署
2009-11-01 17:19:57
有时,您需要同时创建和配置大量虚拟机,但是手动复制和配置大量虚拟机似乎是一件很麻烦的任务。在本文中,查看如何开发一个自动 化的 VM 部署解决方案,以使您可以快速地启动和激活批量的自配置 VM。更让人惊喜的是,您将发现一种方法,可以让您在系统启动后对各个已部署虚拟机独立运行自定义应用程序。
在软件开发和测试中,您经常需要同时创建一批虚拟机。您必须查找并复制一个模板虚拟映像,修改其显示名称和硬件设置,并解决网络接口硬件地址冲突。与此同时还需要完成网络设置、主机名和域设置的配置 — 这些工作很快就变成了体力活。
在本文中,查看如何开发一种自动化虚拟机部署解决方案,以帮助您快速自动地部署和激活一批自配置的虚拟机。这种方法还允许您在系统启动后对各个已部署虚拟机独立运行自定义应用程序。
自动化 VM 部署的架构和工作流程
我 们要提供的自动化虚拟机部署解决方案主要包含两个部分 - 虚拟机部署管理器(Virtual Machine Deployment Manager,VDM)和虚拟机配置管理器(Virtual Machine Configuration Manager,VCM)。
虚拟机部署管理器负责处理用户的 VM 部署请求,例如复制虚拟映像、配置 VM 硬件设置及在 VM 管理程序中注册 VM
虚拟机配置管理器安装在用作 VM 模板的虚拟映像中;它将在系统启动后自动配置 VM。图 1 显示了自动化 VM 部署解决方案的架构和工作流程。
图 1. 自动化 VM 部署框架的架构

正如您所见,VDM 包含三个部分:
- VDM 引擎,它是 VDM 的核心。
- VM 部署任务是特定 VM 部署任务的描述文件,在一定程度上是用户的配置文件。
- VM 模板定义(VM Template Definition,VTD)文件定义诸如 VM 模板的位置和描述之类的 VM 模板信息。VM 模板是在复制时作为源 VM 的虚拟机。
一般地,VM 部署过程包含以下步骤:
- VDM 将读入 VM 部署任务。
- VDM 将浏览包含 VTD 文件的目录以查找相应的 VM 模板,并将 VM 模板复制到部署任务文件中指定的目标位置。
- 在复制源 VM 之后,VDM 将收集所有配置数据,将其存档到 ISO 文件中,然后将该文件复制到复制的 VM 的目标位置中。
- VDM 将根据 VM 部署任务文件中定义的配置修改已复制 VM 的硬件设置;它将创建一个 CD-ROM 设备以装入在第 3 步中创建的 ISO 文件。
- 最后一个部署步骤是调用 VM 管理程序工具以在 VM 管理程序服务器中注册 VM,然后再启动该 VM。
第 5 步是可选的;用户可以通过配置 VM 部署任务文件来取消这个操作。VM 管理程序可以是 VMware 服务器、Xen 等。本文的样例实现将使用 VMware 服务器作为 VM 管理程序服务器。
VCM 是安装在 VM 模板中的。在系统启动后,它将自动启动并搜索包含配置数据的 CD,然后启动其中的配置应用程序以完成所有预定义的工作。

创建自配置的模板 VM
很明显,要让 VM 在系统启动后进行自配置,用作模板的源 VM 必须是自配置的。要创建一个自配置的 VM 模板,必须在初始创建后用 VCM 安装源 VM,如图 2 所示。
图 2. 通过安装 VCM 创建自配置的 VM 模板

VCM 的主要功能是找到标签为 VMCONIFG 的 VM 配置 CD,并在系统启动后运行其中的配置应用程序。由于源 VM 可以是 Linux®、Windows® 或其他操作系统,因此不同操作系统的 VCM 是不同的。在本文的样例代码中,提供了适用于 Linux 和 Windows 的 VCM。
适用于 Linux 的 VM 配置管理器
Linux VM 配置管理器将在安装后被注册为 Linux 服务。它将在系统第一次启动时运行。在启动时,它将执行配置,然后在配置完成时注销并将自身删除。
要安装适用于 Linux 的 VCM,请将 VCM 包复制到源 VM 中,将其解压缩到某个目录中,并运行 VCM 安装程序
install.sh。清单 1 显示了install.sh的工作原理。
清单 1. VCM 安装程序 install.sh 的样例代码片段
...
VCM_HOME=$(cd $(dirname $0);pwd)
start=`getStartNum`
stop=`getStopNum`
sed -e "s!^VCM_HOME=.*!VCM_HOME=$VCM_HOME!;\
s!^# chkconfig: 35!# chkconfig: 35 $start $stop!"\
"$VCM_HOME/vmconfigmgr" > "/etc/init.d/vmconfigmgr"
chmod +x "/etc/init.d/vmconfigmgr"
echo "Register service vmconfigmgr"
chkconfig --add vmconfigmgr
if [ $? -eq 0 ];then
echo "Install Complete Successfully!"
else
echo "Install Failed."
Fi
由于所有配置应用程序和数据都保存在 VM 配置 CD 中,因此 VCM 将首先查找 CD 并将其装入到 /media/VMCONFIG 中,然后再执行配置。清单 2 显示了 Linux VCM 在系统启动后如何查找 VM 配置 CD。
清单 2. VCM 查找并装入 VM 配置 CD 的样例代码
LABEL="VMCONFIG"
VM_CFG_DIR=/media/$LABEL
for device in `dmesg | grep "^.*:.*CD-ROM" | awk -F':' '{print $1}'`
do
volumeName=`volname "/dev/$device" | awk '{print $1}'`
PrintString "CD-ROM Drive: $device | Label: $volumeName"
if [ "$volumeName" == "$LABEL" ];then
PrintString "VM Configuration CD-ROM is: /dev/$device"
# Mount the CD-ROM
mkdir -p "$VM_CFG_DIR"
mount -t iso9660 -o ro,nosuid,nodev,utf8,uid=0 "/dev/$device" "$VM_CFG_DIR"
break
fi
done
适用于 Windows 的 VM 配置管理器
安装后,Windows VM 配置管理器将创建一项预定任务,这项任务将在系统启动后运行。像适用于 Linux 的 VCM 一样,Windows VCM 也将在第一次运行后删除预定任务。
要安装 Windows VCM,请将 Windows VCM 包复制到 Windows VM 模板中,将其解压缩到某个目录中,然后运行
install.bat。清单 3 显示了install.bat的工作原理。
清单 3. 安装 Windows VCM 的样例代码
@echo off
set VCM_HOME=%~dp0
REM Create scheduled task to run VM Configuration Manager when system boots
schtasks /create /tn "VMCONFIG" /tr %VCM_HOME%vmconfigmgr.bat /sc onstart /ru "System"
@echo on
类似于 Linux VCM,Windows VCM 也需要知道 VM 配置 CD 的盘符。Windows VCM 将使用 WMI 脚本完成此工作。清单 4 显示了 VB 脚本。
清单 4. Windows VCM 获得 VM 配置 CD 的盘符所使用的 VB 脚本样例代码
Function getDriveLetter(label)
Const wbemFlagReturnImmediately = &h10
Const wbemFlagForwardOnly = &h20
strComputer="."
driveLetter=""
Set bjWMIService = GetObject("winmgmts:\\" & strComputer & "\root\CIMV2")
Set colItems = objWMIService.ExecQuery("SELECT * FROM Win32_CDROMDrive", "WQL", _
wbemFlagReturnImmediately +
wbemFlagForwardOnly)
For Each objItem In colItems
WScript.Echo "Drive: " & objItem.Drive & " VolumeName: "
& objItem.VolumeName & " Status: " & objItem.Status
If StrComp(objItem.VolumeName, label) = 0 Then
driveLetter=objItem.Drive
WScript.Echo "driveLetter: " & driveLetter
Exit For
End If
Next
getDriveLetter=driveLetter
End Function
drive=getDriveLetter("VMCONFIG")
在将 VCM 安装到源 VM 中之后,源 VM 将变成自配置的 VM 模板。请将其关闭并保存到某个位置。
创建 VM 模板定义文件
VM 模板可以存储在不同的位置,因此 VM 部署管理器需要一种查找某个 VM 模板所在位置的机制。VM 模板定义文件是专门为此设计的;它将描述 VM 模板的属性。
单个 VTD 文件将指向单个 VM 模板。所有 VTD 文件都存储在 VDM 的 vtds 文件夹中。VDT 文件的文件名类似 OSName.vtd(其中 OSName 是用作区分 VM 模板的关键字)。例如,您可以使用 SLES10SP2.vtd 作为指向 SLES 10 SP2 VM 模板的 VTD 的文件名。清单 5 显示了 SLES10 SP2 VM 模板的样例 VTD。
清单 5. SLES 10 SP2 VM 模板的样例 VTD
# VM Template Definition File
# OS Type of the template VM, possible values are Windows, Linux.
OSType=Linux
# Description of the VM template.
Description=SuSE Linux Enterprise Server 10 SP2
# Directory where the VM template locates in.
SRCVMDIR=/local/vmware/SuSE Linux Enterprise Server 10 SP2
创建 VM 部署任务
现在所有准备工作均已完成,您可以开始创建 VM 部署任务。VM 部署任务是用 VM 部署任务文件定义的。一项 VM 部署任务将定义部署某个 VM 所需的所有配置命令。VM 部署任务的所有这些配置命令可以分为不同的类别:
- 一般 VM 配置
- 网络配置
- 自定义用户配置
- VM 注册/启动配置
清单 6、7、8 和清单 9 显示了独立于部署任务 sles10sp2vm.task 的配置设置。
清单 6. VM 部署任务文件中的一般 VM 配置设置
# Task description
TaskDescription=SLES 10 VM used for BVT
# OS name of the VM to be created, a file with the name OSName.vtd should has been
# defined in vtds directory.
OSName=SLES10SP2
# Size of the memory in MB that should be assigned to the VM
MemorySize=1300
# Disk size in GB of the first hard disk, if the number specified is not specified or
# is smaller than the disk size of template VM, it will has same disk size as
# template VM.
DiskSize=10
# Display Name of the VM.
DisplayName=SLES10SP2-143-50
# The destination directory of the VM to be created to.
Destination=/vmware/SLES10SP2-143-50
# Overwrite specifies if overwrite the existing VM.
OverwriteOnExist=Yes
这些一般设置将定义 OS 类型、内存大小、磁盘大小以及要创建的 VM 的目标位置。它还允许用户选择是否覆盖目标位置中已有的虚拟机。
清单 7. VM 部署任务文件中的网络配置设置
# Specify if to configure the network during the first boot of the VM. Yes to configure,
# or No for not configure.
# If No is specified, all properties start with ConfigNet will be ignored.
ConfigNet=yes
# Network connection type of Virtual Ethernet card eth0, possible values are Bridged,
# NAT and HostOnly. Default value is Bridged if not specified.
ConfigNet.ConnectType=NAT
# Mac address of the ethernet card, possible values are:
# 1) auto the mac will be generated automatically.
# 2) xx:xx:xx:xx:xx:xx user defined mac address. (For VMware, the valid range
# is 00:50:56:00:00:00 to 00:50:56:3F:FF:FF)
ConfigNet.MacAddress=00:50:56:3A:01:02
# Network configuration mode, dhcp or static.
ConfigNet.Mode=static
# IP address to be used for the VM.
ConfigNet.IPAddress=192.168.143.50
ConfigNet.Netmask=255.255.255.0
ConfigNet.Gateway=192.168.143.2
ConfigNet.Hostname=sles10vm-143-50
ConfigNet.Domain=ibm.com
ConfigNet.PrimaryDNS=9.181.32.72
ConfigNet.SecondDNS=9.181.2.101
在部署时,网络配置信息将由 VDM 来收集,并被保存到 VM 配置 ISO 文件中,以便在 VM 启动时可以访问这些信息。
清单 8. VM 部署任务文件中的自定义用户配置设置
# Folder holding user's configuration data. The content of this folder will be archived
# into an ISO file, with label VMCONFIG and be mounted in the VM CD-ROM.
UserConfigDataDir=/root/mydata/
# The application users want to run after system boot and network configuration.
# It will also be archive to the VMCONFIG ISO file.
UserConfigApp=/root/myapp.sh
所有用户配置数据也将被收集并保存到 VM 配置 ISO 文件中。
清单 9. VM 部署任务文件中的 VM 注册/启动配置设置
# Register VM to local vmware server or not. Yes for register, false for not register.
# Default value is No.
RegisterVM=Yes
# Parameters used to register VM. Not needed by VMware Server 1.x.
RegisterVM.HostURL=https://localhost:8333
RegisterVM.Username=root
RegisterVM.Password=password
# Power on VM after deployment or not. Yes for power on, No for not power on.
# Default value is false.
PowerOn=Yes
这些参数用于在部署后注册或启动 VM。对于 VMware Server 2.0,您必须提供服务器 URL、用户名和密码。
部署 VM
既然 VM 模板和 VM 部署任务文件已就绪,现在该进行部署了。VM 部署过程包括:
- 解析 VM 部署任务的设置
- 查找正确的 VM 模板并将其复制到目标文件夹中
- 生成包含配置数据的 ISO 文件
- 修改新 VM 的硬件配置并装入作为 CD 的 ISO 文件
- 最后,如果 VM 部署任务文件中的
RegisterVM和PowerOn属性都被设为Yes,则注册并启动 VM。
在 本文的样例代码中,VM 部署管理器被设计为解压缩后即可运行的代码,因此您不需要执行附加步骤来安装它,只需将其解压缩到便于访问的位置(例如,/opt /vmdeploymgr)。但是,要注册并启动新 VM,安装了 VDM 的服务器应当安装一些 VM 管理程序工具。VDM 应当能够调用 VM 管理程序工具来注册并启动 VM。在样例代码中,VDM 安装在 VMware 服务器所在的服务器中。
VM 部署选项
VDM 提供了三个部署选项:
- 部署单个 VM。
- 使用任务列表部署多个 VM 部署任务。
- 部署存储在文件夹中的所有 VM 部署任务。
为了支持这些选项,提供了
vmdeploymgr.sh命令的三个选项,这是 VDM 的主要应用。- 部署单个 VM 部署任务。
VDM 将允许您按照如下所示使用
-f选项来指向指定的 VM 部署任务文件:localhost:/opt/vmdeploymgr/bin # ./vmdeploymgr.sh -f ../tasks/sles10sp2.task。- 使用任务列表部署多个 VM 部署任务。
您还可以列出任务列表文件中的所有 VM 部署任务,并要求 VDM 按顺序处理该列表中的所有任务。任务列表文件是一个纯文本文件。清单 10 显示了包含三项 VM 部署任务的样例任务列表文件,VDM 将不处理最后一项任务(
win2003vm2.task),因为该任务已被注释掉。
清单 10. 样例 VM 部署任务列表文件
/opt/vmdeploymgr/tasks/sles10sp2vm.task
/opt/vmdeploymgr/tasks/rhel5u2vm.task
/opt/vmdeploymgr/tasks/win2003vm.task
#/opt/vmdeploymgr/tasks/win2003vm2.task
选项
-t用于部署 VM 部署任务列表。以下清单显示了样例命令:localhost:/opt/vmdeploymgr/bin # ./vmdeploymgr.sh -t ../tasks/vmtasklist
- 部署存储在文件夹中的所有 VM 部署任务。
VM 部署的第三个选项是部署指定文件夹中的所有任务文件。命令选项
-d用于执行此操作;如果提供-d,VDM 将在给定文件夹中搜索带有.task扩展名的所有文件,然后处理这些任务。以下清单显示了样例命令:localhost:/opt/vmdeploymgr/bin # ./vmdeploymgr.sh -d ../tasks
VM 配置 CD
VM 配置 CD 是自动化 VM 部署解决方案的最重要组件,因为它包含来自 VDM 和用户的配置数据。它使得使用同一个 VM 模板为拥有不同配置的不同操作系统创建虚拟机成为可能。换言之,对于各种操作系统,您都只需要使用一个 VM 模板 —— 这可以节省时间和磁盘空间。
该 CD 是由 VDM 所生成的 ISO 文件根据 VM 部署任务模拟的,并且将被装入虚拟光驱,这样它可以比软盘保存更多的数据。使用 VM 配置 CD 可以让您在 VM 启动后灵活地运行任何需要的应用程序。VM 配置 ISO 文件被命名为 VMCONFIG.iso 并且它的标签为 VMCONFIG。图 3 显示了适用于 Linux 的 VM 配置 CD 的文件结构。适用于 Windows 的 VM 配置 CD 的文件结构是类似的。
图 3. 适用于 Linux VM 的 VM 配置 CD 的文件结构

如 图 3 所示,vdm 文件夹主要包含 VDM 所定义的预定义配置任务(例如,网络配置),而 usr 文件夹包含 VM 部署任务文件中定义的用户自定义配置数据。run.conf 文件用于告诉 VCM 需要运行 CD 中的哪个应用程序。清单 11 显示了它的样例内容。
清单 11. run.conf 的样例内容
# Configuration application to perform. predefined VM Deployment Manager configuration,
# for example, network configuration.
VDM_CFG_APP=vdm/run.sh
# User defined configuration application that will run after system boot.
USR_CFG_APP=usr/myapp.sh
在启动已部署的 VM 时,VCM 将启动并尝试找到 VM 配置 CD。当它找到 CD 后,它将读取 run.conf 的内容,然后按顺序执行
VDM_CFG_APP和USR_CFG_APP所定义的应用程序。如果用户没有在 VM 部署任务文件中指定任何自定义配置,则 run.conf 中就不会设置USR_CFG_APP属性。将 为已复制的 VM 创建一个新 CD-ROM 以装入 VM 配置 CD,并且 VDM 将搜索 VM 的 IDE 总线(先搜索 IDE 总线,再搜索 SCSI 总线)以为 CD-ROM 查找一个空闲总线。在它找到一个空闲总线后,它将修改 VM 配置文件,创建一个新 CD-ROM,然后将 CD 装入到其中。
注册并启动 VM
要 在 VM 管理程序服务器中注册 VM 并启动该 VM,VDM 需要支持一些 VM 管理程序工具。对于 VMware Server 2.0,主要工具是 vmrun;对于 VMware Server 1.0,需要支持 vmware-cmd。安装 VMware 服务器时将默认安装这些工具。
清单 12 显示了演示如何使用 vmware-cmd 注册和启动 VM 的样例代码;清单 13 显示了演示如何使用 vmrun 注册和启动 VM 的样例代码:
清单 12. 使用 vmware-cmd 注册和启动 VM 的样例代码
vmware-cmd -s register "$vmxfile"
vmware-cmd "$vmxfile" start hard
清单 13. 使用 vmrun 注册和启动 VM 的样例代码
vmrun -T server -h "${hostURL}/sdk" -u "$username" -p "$password"\
register "[$datastoreName] $vmxfile"
vmrun -T server -h "${hostURL}/sdk" -u "$username" -p "$password"\
start "[$datastoreName] $vmxfile"
结束语
通过本文所述的自动化虚拟机部署解决方案可以看到,虚拟机的部署和初始配置已变得非常简单。您只需在 VM 部署任务文件中写下配置,然后 VM 部署管理器将为您自动部署和配置所有虚拟机。
此解决方案也是非常灵活的 —— 您可以在已部署的 VM 启动后运行您自己的应用程序。例如,您可以通过在 VM 部署任务中设置
USR_CFG_APP,要求 VM 在系统启动后运行一个应用程序以自动下载并安装新软件版本。总而言之,在部署和管理一组虚拟机时,此解决方案应当可以帮助您节省大量时间并且更高效地工作。
下载
描述 名字 大小 下载方法 Linux VM 配置管理器1 vmconfigmgr-linux.zip 5KB HTTP Windows VM 配置管理器2 vmconfigmgr-windows.zip 3KB HTTP VM 部署管理器3 vmdeploymgr.zip 14KB HTTP 关于下载方法的信息 注意:
- VM Configuration Manager, Linux 配置管理器包在 SLES 10 SP1、SP2 及 Red Hat Enterprise Linux Server(RHEL)5.2 上进行了测试。
- VM Configuration Manager, Windows 配置管理器包在 Windows Server 2003 Enterprise Edition 和 Window Server 2008 Enterprise Edition 上进行了测试。
- VM Deployment Manager 是部署管理器包;此开发平台是 SUSE Linux Enterprise Server(SLES)SP1,并且它使用 VMware Server 2.0(安装在 SLES10 SP1 中)和 VMware Server 1.0.4(安装在 SLES10 中)进行了测试。
-
linux下top命令参数解释总结
2009-10-14 11:09:21
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。
[root@bogon ~]# w
02:33:47 up 18:04, 1 user, load average: 0.40, 0.37, 0.30
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 192.168.1.165 01:47 0.00s 0.04s 0.01s w
[root@bogon ~]# top
top - 02:33:54 up 18:05, 1 user, load average: 0.37, 0.37, 0.29
Tasks: 111 total, 1 running, 110 sleeping, 0 stopped, 0 zombie
Cpu(s): 20.1%us, 2.0%sy, 0.0%ni, 77.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 904788k total, 524748k used, 380040k free, 126068k buffers
Swap: 1831400k total, 0k used, 1831400k free, 156508k cached
top - 01:06:48 up 1:22, 1 user, load average: 0.06, 0.60, 0.48
Tasks: 29 total, 1 running, 28 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.3% us, 1.0% sy, 0.0% ni, 98.7% id, 0.0% wa, 0.0% hi, 0.0% si
Mem: 191272k total, 173656k used, 17616k free, 22052k buffers
Swap: 192772k total, 0k used, 192772k free, 123988k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1379 root 16 0 7976 2456 1980 S 0.7 1.3 0:11.03 sshd
14704 root 16 0 2128 980 796 R 0.7 0.5 0:02.72 top
1 root 16 0 1992 632 544 S 0.0 0.3 0:00.90 init
2 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
统计信息区
---------------------------------------------------------
前五行是系统整体的统计信息。
第一行是任务队列信息,同uptime命令的执行结果。其内容如下:
01:06:48 当前时间
up 1:22 系统运行时间,格式为时:分
1 user 当前登录用户数
load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。三个数值分别为1分钟、5分钟、15分钟前到现在的平均值。
第二、三行为进程和CPU的信息。
当有多个CPU时,这些内容可能会超过两行。内容如下:
Tasks: 29 total 进程总数
1 running 正在运行的进程数
28 sleeping 睡眠的进程数
0 stopped 停止的进程数
0 zombie 僵尸进程数
Cpu(s): 0.3% us 用户空间占用CPU百分比
1.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0% hi
0.0% si
0.0%st
最后两行为内存信息。内容如下:
Mem: 191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存的内存量
Swap: 192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量
内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
进程信息区
统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。
D=不可中断的睡眠状态
R=运行
S=睡眠
T=跟踪/停止
Z=僵尸进程
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容
通过f键可以选择显示的内容。按f键之后会显示列的列表,按a-z即可显示或隐藏对应的列,最后按回车键确定。
按o键可以改变列的显示顺序。按小写的a- 可以将相应的列向右移动,而大写的A-Z可以将相应的列向左移动。最后按回车键确定。
按大写的F或O键,然后按a-z可以将进程按照相应的列进行排序。而大写的R键可以将当前的排序倒转。
top的使用
---------------------------------------------------------
显示系统当前的进程和其他状况;top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该 程序为止. 比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间 对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p 通过指定监控进程ID来仅仅监控某个进程的状态。
q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S 指定累计模式
s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i 使top不显示任何闲置或者僵死进程。
c 显示整个命令行而不只是显示命令名
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h/? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用 信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f/F 从当前显示中添加或者删除项目。
o/O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。 -
linux perl脚本介绍(初学者)
2009-09-07 13:02:17
http://www.fegensoft.com/fegensoft2002/seeksilence/Linux/10/10/6/12.htm (转)本章所讲的函数多数使用了UNIX操作系统的特性,在非UNIX系统中,一些函数可能没
有定义或有不同的工作方式,使用时请查看Perl联机文档。
一、文件输入/输出函数
本节讲述从文件中读取信息和向文件写入信息的内置库函数。
1、基本I/O函数
一些I/O函数在前面的章节中已有讲述,如
open:允许程序访问文件
close:终止文件访问
print:文件写入字符串
write:向文件写入格式化信息
printf:格式化字符串并输出到文件
这里简单回顾一下,再讲一些前面未提到的函数。
1)open函数
open函数将文件变量与某文件联系起来,提供访问文件的接口,例如:open(MYVAR,
"/u/file"); 如果文件打开成功,则返回非零值,否则返回零。缺省地,open打开文件用
以读取其内容,若想打开文件以写入内容,则在文件名前加个大于号:open(MYVAR, ">/u
/file"); 向已有的文件末尾添加内容用两个大于号:open(MYVAR, ">>/u/file"); 若想打
开文件作为数据导向的命令,则在命令前加上管道符(|):open(MAIL, "|mail dave");
2)用open重定向输入
可以把打开的文件句柄用作向程序输入数据的命令,方法是在命令后加管道符(|),如
:
open(CAT, "cat file*|");
对open的调用运行命令cat file* ,此命令创建一个临时文件,这个文件的内容是所
有以file打头的文件的内容连接而成,此文件看作输入文件,可用文件变量CAT访问,如:
$input = ;
下面的例子使用命令w的输出来列出当前登录的所有用户名。
1 : #!/usr/local/bin/perl
2 :
3 : open (WOUT, "w|");
4 : $time = <WOUT>;
5 : $time =~ s/^ *//;
6 : $time =~ s/ .*//;
7 : ; # skip headings line
8 : @users = ;
9 : close (WOUT);
10: foreach $user (@users) {
11: $user =~ s/ .*//;
12: }
13: print ("Current time: $time");
14: print ("Users logged on:\n");
15: $prevuser = "";
16: foreach $user (sort @users) {
17: if ($user ne $prevuser) {
18: print ("\t$user");
19: $prevuser = $user;
20: }
21: }
结果输出如下:
Current time: 4:25pm
Users logged on:
dave
kilroy
root
zarquon
w命令列出当前时间、系统负载和登录的用户,以及每个用户的作业时间和当前运行的
命令,如:
4:25pm up 1 day, 6:37, 6 users, load average: 0.79, 0.36, 0.28
User tty login@ idle JCPU PCPU what
dave ttyp0 2:26pm 27 3 w
kilroy ttyp1 9:01am 2:27 1:04 11 -csh
kilroy ttyp2 9:02am 43 1:46 27 rn
root ttyp3 4:22pm 2 -csh
zarquon ttyp4 1:26pm 4 43 16 cc myprog.c
kilroy ttyp5 9:03am 2:14 48 /usr/games/hack
上例中从w命令的输出中取出所需的信息:当前时间和登录的用户名。第3行运行w命令
,此处对open的调用指定w的输出用作程序的输入,用文件变量WOUT来访问该输入。第4行
读取第一行信息,即:
4:25pm up 1 day, 6:37, 6 users, load average: 0.79, 0.36, 0.28
接下来的两行从这行中抽取出时间。首先,第5行删除起始的空格,然后第6行删去除
时间和结尾换行符之间的所有字符,存入变量$time。
第7行从WOUT读取第二行,这行中无有用信息,故不作处理。第8行把剩下的行赋给数
组@users,然后第9行关闭WOUT,终止运行w命令的进程。
@users中的每个元素都是一行用户信息,因为本程序只需要每行的第一个单词,即用
户名,故10~12行去掉除换行符外的其它字符,这一循环结束后,@users中只剩下用户名的
列表。
第13行输出存贮在$time中的时间,注意这时print不需要加上换行符,因为$time中有
。16~21行对@users中的用户名排序并输出。因为同一个用户可以多次登录,所以用$preu
ser存贮输出的最后一个用户名,下次输出数组元素$user时,如果其与$preser相等,则不
输出。
3)文件重定向
许多UNIX shell可以把标准输出文件(STDOUT)和标准错误文件(STDERR)都重定向到同
一个文件,例如在Bourne Shell(sh)中,命令
$ foo > file1 2>&1
运行命令foo并把输出到标准输出文件和标准错误文件的内容存贮到文件file1中。下
面是用Perl实现这一功能的例子:
1: #!/usr/local/bin/perl
2:
3: open (STDOUT, ">file1") || die ("open STDOUT failed");
4: open (STDERR, ">&STDOUT") || die ("open STDERR failed");
5: print STDOUT ("line 1\n");
6: print STDERR ("line 2\n");
7: close (STDOUT);
8: close (STDERR);
运行后,文件file1中的内容为:
line 2
line 1
可以看到,这两行并未按我们想象的顺序存贮,为什么呢?我们来分析一下这段程序
。
第3行重定向标准输出文件,方法是打开文件file1将它与文件变量STDOUT关联,这也
关闭了标准输出文件。第4行重定向标准错误文件,参数>&STDOUT告诉Perl解释器使用已打
开并与STDOUT关联的文件,即文件变量STDERR指向与STDOUT相同的文件。第5、6行分别向
STDOUT和STDERR写入数据,因为这两个文件变量指向同一个文件,故两行字符串均写到文
件file1中,但顺序却是错误的,怎么回事呢?
问题在于UNIX对输出的处理上。当使用print(或其它函数)写入STDOUT等文件时,U
NIX操作系统真正所做的是把数据拷贝到一片特殊的内存即缓冲区中,接下来的输出操作继
续写入缓冲区直到写满,当缓冲区满了,就把全部数据实际输出。象这样先写入缓冲区再
把整个缓冲区的内容输出比每次都实际输出所花费的时间要少得多,因为一般来说,I/O比
内存操作慢得多。
程序结束时,任何非空的缓冲区都被输出,然而,系统为STDOUT和STDERR分别维护一
片缓冲区,并且先输出STDERR的内容,因此存贮在STDERR的缓冲区中的内容line 2出现在
存贮在STDOUT的缓冲区中的内容line 1之前。
为了解决这个问题,可以告诉Perl解释器不对文件使用缓冲,方法为:
1、用select函数选择文件
2、把值1赋给系统变量$|
系统变量$|指定文件是否进行缓冲而不管其是否应该使用缓冲。如果$|为非零值则不
使用缓冲。$|与系统变量$~和$^协同工作,当未调用select函数时,$|影响当前缺省文件
。下例保证了输出的次序:
1 : #!/usr/local/bin/perl
2 :
3 : open (STDOUT, ">file1") || die ("open STDOUT failed");
4 : open (STDERR, ">&STDOUT") || die ("open STDERR failed");
5 : $| = 1;
6 : select (STDERR);
7 : $| = 1;
8 : print STDOUT ("line 1\n");
9 : print STDERR ("line 2\n");
10: close (STDOUT);
11: close (STDERR);
程序运行后,文件file1中内容为:
line 1
line 2
第5行将$|赋成1,告诉Perl解释器当前缺省文件不进行缓冲,因为未调用select,当
前的缺省文件为重定向到文件file1的STDOUT。第6行将当前缺省文件设为STDERR,第7行又
设置$|为1,关掉了重定向到file1的标准错误文件的缓冲。由于STDOUT和STDERR的缓冲均
被关掉,向其的输出立刻被写到文件中,因此line 1出现在第一行。
4)指定读写权限
打开一个既可读又可写的文件方法是在文件名前加上"+>",如下:
open (READWRITE, "+>file1");
此语句打开既可读又可写的文件file1,即可以重写其中的内容。文件读写操作最好与
库函数seek和tell一起使用,这样可以跳到文件任何一点。
注:也可用前缀"+<"指定可读写权限。
5)close函数
用于关闭打开的文件。当用close关闭管道,即重定向的命令时,程序等待重定向的命
令结束,如:
open (MYPIPE, "cat file*|");
close (MYPIPE);
当关闭此文件变量时,程序暂停运行,直到命令cat file*运行完毕。
6)print, printf和write函数
print是这三个函数中最简单的,它向指定的文件输出,如果未指定,则输出到当前缺
省文件中,如:
print ("Hello, there!\n");
print OUTFILE ("Hello, there!\n");
第一句输出到当前缺省文件中,若未调用select,则为STDOUT。第二句输出到由文件
变量OUTFILE指定的文件中。
printf函数先格式化字符串再输出到指定文件或当前缺省文件中,如:
printf OUTFILE (“You owe me %8.2f", $owing);
此语句取出变量$owing的值并替换掉串中的%8.2f,%8.2f是域格式的例子,把$owing
的值看作浮点数。
write函数使用输出格式把信息输出到文件中,如:
select (OUTFILE);
$~ = "MYFORMAT";
write;
关于printf和write,详见《第x章 格式化输出》。
7)select函数
select函数将通过参数传递的文件变量指定为新的当前缺省文件,如:
select (MYFILE);
这样,MYFILE就成了当前缺省文件,当对print、write和printf的调用未指定文件时
,就输出到MYFILE中。
8)eof函数
eof函数查看最后一次读文件操作是否为文件最后一个记录,如果是,则返回非零值,
如果文件还有内容,返回零。
一般情况下,对eof的调用不加括号,因为eof和eof()是等效的,但与<>操作符一起使
用时,eof和eof()就不同了。现在我们来创建两个文件,分别叫做file1和file2。file1的
内容为:
This is a line from the first file.
Here is the last line of the first file.
file2的内容为:
This is a line from the second and last file.
Here is the last line of the last file.
下面就来看一下eof和eof()的区别,第一个程序为:
1: #!/usr/local/bin/perl
2:
3: while ($line = <>) {
4: print ($line);
5: if (eof) {
6: print ("-- end of current file --\n");
7: }
8: }
运行结果如下:
$ program file1 file2
This is a line from the first file.
Here is the last line of the first file.
-- end of current file --
This is a line from the second and last file.
Here is the last line of the last file.
-- end of current file --
$
下面把eof改为eof(),第二个程序为:
1: #!/usr/local/bin/perl
2:
3: while ($line = <>) {
4: print ($line);
5: if (eof()) {
6: print ("-- end of output --\n");
7: }
8: }
运行结果如下:
$ program file1 file2
This is a line from the first file.
Here is the last line of the first file.
This is a line from the second and last file.
Here is the last line of the last file.
-- end of output --$
这时,只有所有文件都读过了,eof()才返回真,如果只是多个文件中前几个的末尾,
返回值为假,因为还有要读取的输入。
9)间接文件变量
对于上述各函数open, close, print, printf, write, select和eof,都可以用简单
变量来代替文件变量,这时,简单变量中所存贮的字符串就被看作文件变量名,下面就是
这样一个例子,此例很简单,就不解释了。需要指出的是,函数open, close, write, se
lect和eof还允许用表达式来替代文件变量,表达式的值必须是字符串,被用作文件变量名
。
1: #!/usr/local/bin/perl
2:
3: &open_file("INFILE", "", "file1");
4: &open_file("OUTFILE", ">", "file2");
5: while ($line = &read_from_file("INFILE")) {
6: &print_to_file("OUTFILE", $line);
7: }
8:
9: sub open_file {
10: local ($filevar, $filemode, $filename) = @_;
11:
12: open ($filevar, $filemode . $filename) ||
13: die ("Can't open $filename");
14: }
15: sub read_from_file {
16: local ($filevar) = @_;
17:
18: <$filevar>;
19: }
20: sub print_to_file {
21: local ($filevar, $line) = @_;
22:
23: print $filevar ($line);
24: }
2、跳过和重读数据
函数名 seek
调用语法 seek (filevar, distance, relative_to);
解说 在文件中向前/后移动,有三个参数:
1、filevar,文件变量
2、distance,移动的字节数,正数向前移动,负数往回移动
3、reletive_to,值可为0、1或2。为0时,从文件头开始移动,为1时,相对于当前位置(
将要读的下一行)移动,为2时,相对于文件末尾移动。
运行成功返回真(非零值),失败则返回零,常与tell函数合用。
函数名 tell
调用语法 tell (filevar);
解说 返回从文件头到当前位置的距离。
注意:
1、seek和tell不能用于指向管道的文件变量。
2、seek和tell中文件变量参数可使用表达式。
3、系统读写函数
函数名 read
调用语法 read (filevar, result, length, skipval);
解说 read函数设计得与UNIX的fread函数等效,可以读取任意长度的字符(字节)存入一
个简单变量。其参数有四个:
1、filevar:文件变量
2、result:存贮结果的简单变量(或数组元素)
3、length:读取的字节数
4、skipval:可选项,指定读文件之前跳过的字节数。
返回值为实际读取的字节数,如果已到了文件末尾,则返回零,如果出错,则返回空串。
函数名 sysread
调用语法 sysread (filevar, result, length, skipval);
解说 更快的读取数据,与UNIX函数read等效,参数与read相同。
函数名 syswrite
调用语法 syswrite (filevar, data, length, skipval);
解说 更快的写入数据,与UNIX函数write等效,参数:
1、filevar:将要写入的文件
2、data:存贮要写入数据的变量
3、length:要写入的字节数
4、skipval写操作之前跳过的字节数。
4、用getc读取字符
函数名 getc
调用语法 $char = getc (infile);
解说 从文件中读取单个字符。
5、用binmode读取二进制文件
函数名 binmode
调用语法 binmode (filevar);
解说 当你的系统(如类DOS系统)对文本文件和二进制文件有所区别时使用。必须在打开
文件后、读取文件前使用。
二、目录处理函数
函数名 mkdir
调用语法 mkdir (dirname, permissions);
解说 创建新目录,参数为:
1、dirname:将要创建的目录名,可以为字符串或表达式
2、permissions:8进制数,指定目录的访问权限,其值和意义见下表,权限的组合方法为
将相应的值相加。
值 权限
4000 运行时设置用户ID
2000 运行时设置组ID
1000 粘贴位
0400 拥有者读权限
0200 拥有者写权限
0100 拥有者执行权限
0040 组读权限
0020 组写权限
0010 组执行权限
0004 所有人读权限
0002 所有人写权限
0001 所有人执行权限
函数名 chdir
调用语法 chdir (dirname);
解说 改变当前工作目录。参数dirname可以为字符串,也可以为表达式。
函数名 opendir
调用语法 opendir (dirvar, dirname);
解说 打开目录,与下面几个函数合用,可查看某目录中文件列表。参数为:
1、dirvar:目录变量,与文件变量类似
2、dirname:目录名,可为字符串或表达式
成功返回真值,失败返回假。
注:程序中可用同名的目录变量和文件变量,根据环境确定取成分。
函数名 closedir
调用语法 closedir (mydir);
解说 关闭打开的目录。
函数名 readdir
调用语法 readdir (mydir);
解说 赋给简单变量时,每次赋予一个文件或子目录名,对数组则赋予全部文件和子目录名
。
函数名 telldir
调用语法 location = telldir (mydir);
解说 象在文件中前后移动一样,telldir和下面的seekdir用于在目录列表中前后移动。
函数名 seekdir
调用语法 seekdir(mydir, location);
解说 location必须为telldir返回的值。
函数名 rewinddir
调用语法 rewinddir (mydir);
解说 将读取目录的位置重置回开头,从而可以重读目录列表。
函数名 rmdir
调用语法 rmdir (dirname);
解说 删除空目录。成功则返回真(非零值),失败返回假(零值)。
三、文件属性函数
1、文件重定位函数
函数名 rename
调用语法 rename (oldname, newname);
解说 改变文件名或移动到另一个目录中,参数可为字符串或表达式。
函数名 unlink
调用语法 num = unlink (filelist);
解说 删除文件。参数为文件名列表,返回值为实际删除的文件数目。
此函数之所以叫unlink而不叫delete是因为它实际所做的是删除文件的链接。
2、链接和符号链接函数
函数名 link
调用语法 link (newlink, file);
解说 创建现有文件的链接--硬链接,file是被链接的文件,newlink是被创建的链接。
成功返回真,失败返回假。
当删除这两个链接中的一个时,还可以用另一个来访问该文件。
函数名 symlink
调用语法 symlink (newlink, file);
解说 创建现有文件的符号链接,即指向文件名,而不是指向文件本身。参数和返回值同上
。
当原文件被删除(如:被unlinke函数删除),则被创建链接不可用,除非再创建一个与原
被链接的文件同名的文件。
函数名 readlink
调用语法 filename = readlink (linkname);
解说 如果linkname为符号链接文件,返回其实际指向的文件。否则返回空串。
3、文件许可权函数
函数名 chmod
调用语法 chmod (permissions, filelist);
解说 改变文件的访问权限。参数为:
1、permissions为将要设置的权限,其含义见上述mkdir中权限表
2、filelist为欲改变权限的文件列表
函数名 chown
调用语法 chown (userid, groupid, filelist);
解说 改变文件的属主,有三个参数:
1、userid:新属主的(数字)ID号
2、groupid:新的组(数字)ID号,-1为保留原组
3、filelist:欲改变属主的文件列表
函数名 umask
调用语法 ldmaskval = umask (maskval);
解说 设置文件访问权限掩码,返回值为当前掩码。
4、其它属性函数
函数名 truncate
调用语法 truncate (filename, length);
解说 将文件的长度减少到length字节。如果文件长度已经小于length,则不做任何事。其
中filename可以为文件名,也可以为文件变量
函数名 stat
调用语法 stat (file);
解说 获取文件状态。参数file可为文件名也可为文件变量。返回列表元素依次为:
文件所在设备
内部参考号(inode)
访问权限
硬链接数
属主的(数字)ID
所属组的(数字)ID
设备类型(如果file是设备的话)
文件大小(字节数)
最后访问时间
最后修改时间 最后改变状态时间
I/O操作最佳块大小
分配给该文件的块数
函数名 lstat
调用语法 lstat (file);
解说 与stat类似,区别是将file看作是符号链接。
函数名 time
调用语法 currtime = time();
解说 返回从1970年1月1日起累计秒数。
函数名 gmtime
调用语法 timelist = gmtime (timeval);
解说 将由time, stat 或 -A 和 -M 文件测试操作符返回的时间转换成格林威治时间。返
回列表元素依次为:
秒
分钟
小时,0~23
日期
月份,0~11(一月~十二月)
年份
星期,0~6(周日~周六)
一年中的日期,0~364
是否夏令时的标志
详见UNIX的gmtime帮助。
函数名 localtime
调用语法 timelist = localtime (timeval);
解说 与gmtime类似,区别为将时间值转换为本地时间。
函数名 utime
调用语法 utime (acctime, modtime, filelist);
解说 改变文件的最后访问时间和最后更改时间。例如:
$acctime = -A "file1";
$modtime = -M "file1";
@filelist = ("file2", "file3");
utime ($acctime, $modtime, @filelist);
函数名 fileno
调用语法 filedesc = fileno (filevar);
解说 返回文件的内部UNIX文件描述。参数filevar为文件变量。
函数名 fcntl
flock
调用语法 fcntl (filevar, fcntlrtn, value);
flock (filevar, flockop);
解说 详见同名UNIX函数帮助。
四、使用DBM文件
Perl中可用关联数组来访问DBM文件,所用函数为dbmopen和dbmclose,在Perl5中,已
用tie和untie代替。
函数名 dbmopen
调用语法 dbmopen (array, dbmfilename, permissions);
解说 将关联数组与DBM文件相关联。参数为:
1、array:所用关联数组
2、dbmfilename:将打开的DBM文件名
3、访问权限,详见mkdir
函数名 dbmclose
调用语法 dbmclose (array);
解说 关闭DBM文件,拆除关联数组与之的关系。
-
Linux 杀死进程和查进程方法
2009-09-01 11:15:53
Linux 下杀死进程最安全的方法是单纯使用kill命令,不加修饰符,不带标志。
首先使用ps -ef命令确定要杀死进程的PID,然后输入以下命令:
# kill -pid
注释:标准的kill命令通常都能达到目的。终止有问题的进程,并把进程的资源释放给系统。然而,如果进程启动了子进程,只杀死父进程,子进程仍在运行,因此仍消耗资源。为了防止这些所谓的“僵尸进程”,应确保在杀死父进程之前,先杀死其所有的子进程。
确定要杀死进程的PID或PPID
# ps -ef | grep httpd
以优雅平和的方式结束进程
# kill -l PID
-l选项告诉kill命令用好像启动进程的用户已注销的方式结束进程。当使用该选项时,kill命令也试图杀死所留下的子进程。但这个命令也不是总能成功–或许仍然需要先手工杀死子进程,然后再杀死父进程。
TERM信号
给父进程发送一个TERM信号,试图杀死它和它的子进程。
# kill -TERM PPID
killall命令
killall命令杀死同一进程组内的所有进程。其允许指定要终止的进程的名称,而非PID。
# killall httpd 停止和重启进程
有时候只想简单的停止和重启进程。如下:
# kill -HUP PID
该命令让Linux和缓的执行进程关闭,然后立即重启。在配置应用程序的时候,这个命令很方便,在对配置文件修改后需要重启进程时就可以执行此命令。
绝杀 kill -9 PID
同意的 kill -s SIGKILL
这个强大和危险的命令迫使进程在运行时突然终止,进程在结束后不能自我清理。危害是导致系统资源无法正常释放,一般不推荐使用,除非其他办法都无效。
当使用此命令时,一定要通过ps -ef确认没有剩下任何僵尸进程。只能通过终止父进程来消除僵尸进程。如果僵尸进程被init收养,问题就比较严重了。杀死init进程意味着关闭系统。
如果系统中有僵尸进程,并且其父进程是init,而且僵尸进程占用了大量的系统资源,那么就需要在某个时候重启机器以清除进程表了。查看Apache 连接数
因每个访问者都会在服务器上打开一个进程作提供服务查看进程数量,判断连接人数
ps -ef|grep httpd|wc -l
pstree |grep httpd查看httpd进程数(即prefork模式下Apache能够处理的并发请求数):
Linux命令:ps -ef | grep httpd | wc -l
查看Apache的并发请求数及其TCP连接状态:
Linux命令:netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果示例:
LAST_ACK 5
SYN_RECV 30
ESTABLISHED 1597
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057
说明:
SYN_RECV表示正在等待处理的请求数;
ESTABLISHED表示正常数据传输状态;
TIME_WAIT表示处理完毕,等待超时结束的请求数。服务器上的一些统计数据:1)统计80端口连接数netstat -nat|grep -i "80"|wc -l12)统计httpd协议连接数ps -ef|grep httpd|wc -l13)、统计已连接上的,状态为“established'netstat -na|grep ESTABLISHED|wc -l24)、查出哪个IP地址连接最多,将其封了.
netstat -na|grep ESTABLISHED|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -r +0n
netstat -na|grep SYN|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort -r +0nlinux做nat 服务器,我想查看穿过服务器的当前连接数
是用 more /proc/net/ip_conntrack |wc -l 统计行数还可以
more /proc/net/ip_conntrack |grep ESTABLISHED|wc -lcat /proc/slabinfo | grep ip_conn | grep -v ip_conntrack_expect | awk '{print $2}'
-
Window VNC远程控制LINUX:VNC详细配置介绍
2009-08-05 11:06:25
Window VNC远程控制LINUX:VNC详细配置介绍
//---------------------------------------vnc linux下的详细配置
1、VNC的启动/停止/重启:#service vncserver start/stop/restart
关闭具体的vncserver命令:vncserver -kill :1 vncserver -kill :22、设置密码#vncpasswd3、客户端登陆在vnc客户端中输入:服务器端IP:1或服务器端IP:24、设置登陆到KDE桌面a.[root@centos ~]# vi /etc/sysconfig/vncservers
#
# Uncomment the line below to start a VNC server on display :1
# as my 'myusername' (adjust this to your own). You will also
# need to set a VNC password; run 'man vncpasswd' to see how
# to do that.
#
# DO NOT RUN THIS SERVICE if your local area network is
# untrusted! For a secure way of using VNC, see# VNCSERVERS="1:myusername"
VNCSERVERS="1:root"# VNCSERVERARGS[1]="-geometry 800x600"
VNCSERVERARGS[1]=”-geometry 800×600 -alwaysshared -depth 24″,-alwaysshared代表允许多用户同时登录 -depth代为色深,参数有8,16,24,32。为了实现以Gnome图形化的方式登录,需配置以下两步(蓝色部分):
[root@centos .vnc]$ vi /root/.vnc/xstartup
#!/bin/sh# Uncomment the following two lines for normal desktop:
unset SESSION_MANAGER
exec /etc/X11/xinit/xinitrc[ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
vncconfig -iconic &
xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
#gnome-session蓝色部分一定要有它表示远程客户以gnome的session形式登录。这是关键步骤之1&.
打开配置文件/etc/sysconfig/vncservers,去掉下面这行的注释,实现此配置!!! "2:root"表示VNC以桌面2运行,这样可以启动root的桌面。
VNCSERVERS="2:root"
VNCSERVERARGS[1]="-geometry 800x600" 这是关键步骤之2&.
重启VNC服务和VNC程序:
#service vncserver restart
#vncserver
即可以Gnome图形化的方式远程登录。
设置VNCSERVER自动启动:
1。前题,已经配置发ROOT目录的下的.vnc/startup的配置。
2、编辑/etc/sysconfig/vncservers
添加以下:
VNCSERVERS="1:root"
VNCSERVERARGS[1]="-geometry 800x600":
3.在setup 中启动服务vnc//--------------------------------------------------------------第二部分
解决方法:
vncserver服务可以在系统引导时自动启动. 但是需要进行设置才能使之正常自动启动.
首先,编辑/etc/sysconfig/vncservers文件,把使用VNC服务的用户添加到这个文件中,添加的内容如下例所示:
VNCSERVERS="N:user"
此处N指VNC服务器所在的显示服务器编号。user指运行VNC的 用户。多个显示服务和用户之间可通过如下设置来指定:
VNCSERVERS="N:user1 Y:user2"
注意:若正在使用X Window System,那么0号显示符会被本地的X系 统使用,不能用于VNC。
对于指定的每个VNC用户,需要设置一个VNC密 码,这个密码区别于普通系统帐号密码。用户可以通过执行vncpasswd来 设置自己的VNC密 码。如:
$ vncpasswd Password: Verify:
默认配置下,VNC启动后只显示一个简易的窗口和一个终端窗口.若要显示完整红帽环境,需要创 建~username/.vnc/xstartup文件,添加以下语句:
#!/bin/bash unset SESSION_MANAGER exec /etc/X11/xinit/xinitrc
最后确保该文件可以被执行:
# chmod 755 ~username/.vnc/xstartup*
如需立即启动vncserver服务,运行以下命令:
# service vncserver start
如:
# service vncserver start Starting VNC server: 1:user1
如需引导时自动启动vncserver服务,运行以下命令:
# chkconfig vncserver on
注意:这个命令执行后不会有输出,会直接返回命令提示符,如:
# chkconfig vncserver on # chkconfig --list vncserver vncserver 0:off 1:off 2:on 3:on 4:on 5:on 6:off
//----------------------------------------------------
关于远程控制软件,给大家介绍一种免费的、小巧、实用,而且可运行在Linux、Unix和Windows平台的远程控制软件-VNC。
VNC是Virtual Network Computing的缩写,包括服务器端(被控端)和客户端(主控端)两个部分,只有服务器端软件需要安装,客户端软件直接可以运行。Linux/Unix下的服务器软件叫做VncServer,Windows下的服务器软件叫做WinVNC;客户端软件叫做VncViewer,也可以通过一般的网页浏览器来控制被控端。我这里主要介绍Linux(RedHat)下的VNC安装使用。
1. 根据需要下载VNC Server与VNC viewer。网上很多,可以google或baidu下。
2.安装。
rpm –Uvh vnc-3.3.7.i386.rpm (不管你有没有安装过,都可以用这个命令安装)
另,修改/root/.vnc/xstartup,把最后一行 twm& 改成 gnome-session& or kde&。
3.在Linux上启动VNC Server
执行vncserver命令:
[root@linux root]# vncserver
You will require a password to access your desktops.
Password: ----第一次输入密码
Verify: --第二次输入
New ‘X’ desktop is linux:1 -- 注意Linux下是登录VNC还要加这个number(例,在viewer端输入 IP:1)
(经上述步骤后,已启动VNC Server。如果想更改VNC Server密码,执行vncpasswd命令。)
4.在Windows上运行VNC Viewer
直接运行“vncviewer.exe”, 在“Connection details”对话框中的“VNC server”文本框中输入VNC Server的IP地址(或主机名及显示装置编号,(在Linux上启动VNC server的这一行,New ‘X’ desktop is linux:1 得到此信息),例如:192.168.0.1:1(冒号后面的1是上面红色标记处得到的),单击“OK”按钮后,就可以成功地打开Linux的桌面窗口。
5. 从浏览器远程遥控。
启动VNC Server 后直接打开浏览器,在地址栏中输入被控端的网址或IP地址,并在网址后加上“:5800+显示编号”的端口号即可操控该计算机。
例如:http://192.168.01.:5801 (如果显示编号为1,一般第一次设置的显示编号都是1,就用5800+1=5801。)
另:
VNCServer 配置:
1. 启动 VNC Server:
打开终端执行:vncserver
2. 默认情况下VNC Viewer只能看到 VNC Server的命令行。
要VNC Viewer上可以看到Linux桌面需要做如下设置:
在VNC Viewer所在的机器上,取消/root/.vnc/xstartup文件中下面两行的注释即可:
unset SESSION_MANAGER
exec /etc/X11/xinit/xinitrc
3. VNC端口
如果需要从外网控制内网的某台Linux,则需要打开防火墙相应的端口,并在路由器上进行端口映射。
VNC给浏览器的端口是5800+N,给vncviewer的端口是5900+N,N是设置的display号
另2:
1. 关闭相应编号的VNC服务命令:
vncserver -kill :x (X为编号)
2. 将vnc中的内容copy到之外可以下面的方法:
a. 启动vncconfig服务 在终端中输入vncconfig命令;
b. copy VNC中的内容;
c. 复制到vnc之外即可;
3. 其他增加中...
-
Linux VNC远程控制安装日记
2009-08-04 11:02:09
Linux VNC远程控制安装日记
VNC简介
网络遥控技术是指由一部计算机(主控端)去控制另一部计算机(被控端),而且当主控端在控制端时,就如同用户亲自坐在被控端前操作一样,可以执行被控端的应用程序,及使用被控端的系统资源。
VNC(Virtual Network Computing)是一套由AT&T实验室所开发的可操控远程的计算机的软件,其采用了GPL授权条款,任何人都可免费取得该软件。VNC软件 主要由两个部分组成:VNC server及VNC viewer。用户需先将VNC server安装在被控端的计算机上后,才能在主控端执行VNC viewer控制被控端。
(在windows中也由一套著名的网络遥控软件――Symantec公司推出的pcAnywhere。
VNC server与VNC viewer支持多种操作系统,如Unix系列(Unix,Linux,Solaris等),windows及MacOS,因此可将VNC server 及VNC viewer分别安装在不同的操作系统中进行控制。如果目前操作的主控端计算机没有安装VNC viewer,也可以通过一般的网页浏览器来控制被控端。
整个VNC运行的工作流程如下:
(1) VNC客户端通过浏览器或VNC Viewer连接至VNC Server。
(2) VNC Server传送一对话窗口至客户端,要求输入连接密码,以及存取的VNC Server显示装置。
(3) 在客户端输入联机密码后,VNC Server验证客户端是否具有存取权限。
(4) 若是客户端通过VNC Server的验证,客户端即要求VNC Server显示桌面环境。
(5) VNC Server通过X Protocol 要求X Server将画面显示控制权交由VNC Server负责。
(6) VNC Server将来由 X Server的桌面环境利用VNC通信协议送至客户端,并且允许客户端控制VNC Server的桌面环境及输入装置。
////////////************************/////////////////
////////////************************/////////////////
VNCserver使用
////////////************************/////////////////
////////////************************/////////////////
在Linux上启动VNC Server , 执行命令service vncserver start
[root@linux root]# vncserver :1/////////一个序号///////(第一个运行设置一个密码) vncserver <display>
You will require a password to access your desktops.
Password: ***** 为了不想任何人都可以任意操控此计算机。因此当第 1次启动VNC server时,会要求设置网络操控的密码。
Verify: *****
New ‘X’ desktop is linux:1 ////////////----一定要记住这一行稍后会用到,终端编号;
Creating default startup script. /root/.vnc/xstartup
Starting applications specified in /root/.vnc/xstartup
Log file is /root/.vnc/linux:1.log
///////////////////////////////////注意: vncpasswd 可以更改这个密码,或者添加密码
把vnc客户端 程序安装好
---客户端连接---
在Microsoft Windows上运行VNC Viewer
直接运行“vncviewer.exe”,系统会出现”Connection details”对话框。
在“Connection details”对话框中的“VNC server”文本框中输入VNC Server的IP地址(或主机名及显示装置编号,(请看3。在Linux上启动VNC server的这一行,New ‘X’ desktop is linux:1 得到此信息),例如:192.168.0.1:1(冒号后面的1是执行VNC Server生成的显示装置编号),单击“OK”按钮后,VNC Server即会开始检查所输入的信息,若是信息错误,系统会出现“Failed to connect to server”的错误信息:若是信息正确,则会接着出现“VNC Authentication”对话框。
若是在“VNC Authentication”对话框中输入的密码正确,就可以成功地打开Linux的桌面窗口。
从浏览器远程遥控。
启动VNC Server 后直接打开浏览器,在地址栏中输入被控端的网址或IP地址,并在网址后加上“:5800+显示编号”的端口号即可操控该计算机。
例如:http://192.168.1.118.:5801 (如果显示编号为1,一般第一次设置的显示编号都是1,就用5800+1=5801。)
VNC(Virtual Network Computing)虚拟网络计算工具,本质上来说是一个远程显示系统,管理员通过它不仅仅可以在运行程序的本地机上察看桌面环境,而且可以从 Internet上的任何地方察看远程机器的运行情况,而且它具有跨平台的特性。 Linux 要使用远程桌面需要安装VNC,好在Red Hat Enterprise Linux AS 5.0 已经自带了VNC,默认也已经安装了,只要配置一下就可以了。但是Windows客户端还是要安装的。
VNCServer 配置:1. 启动 VNC Server: 打开终端执行:vncserver
2. 默认情况下VNC Viewer只能看到 VNC Server的命令行。
要VNC Viewer上可以看到Linux桌面需要做如下设置: 在VNC Viewer所在的机器上,
------------------------图形化连接设置方法一 /--------------------------------
取消/root/.vnc/xstartup文件中下面两行的注释即可:
unset SESSION_MANAGER exec
/etc/X11/xinit/xinitrc或:
------------------------图形化连接设置方法二 /--------------------------------vncserver默认使用的窗口管理器是twm,这是一个很简陋的窗口管理器,你可以把你的桌面改成GNOME或KDE。
vi /home/用户名/.vnc/xstartup你可以把像上面这样把"twm &"这一行注释掉,然后在下面加入一行"gnome-session &",或者是"startkde &",分别启动GNOME桌面和KDE桌面。
------------------------------------------------------------------------------
3. Linux启动后自动运行VNCServer
1) 在 系统设置>服务器设置>服务 中把 vncserver 打勾。
2) 打开配置文件/etc/sysconfig/vncservers,去掉下面这行的注释, ////////////////////图形化连接设置
VNCSERVERS="1:root"
VNCSERVERARGS[1]="-geometry 800x600"
(这里注意一下,默认系统配置里有 –nolisten tcp 和 –nohttpd ,
这两个是阻止Xwindows登陆和HTTP方式VNC登陆的,如果需要图形界面,那就删除这部分。)
1表示VNC以桌面1运行,这样可以启动root的桌面。---------------------------多用户设置示例-----------------------------------
VNCSERVERS="1:user1 2:user2 3:user3" //序号也是和前面对应的
VNCSERVERARGS[1]="-geometry 1024x768"
VNCSERVERARGS[2]="-geometry 1024x768"
VNCSERVERARGS[3]="-geometry 800x600"
------------------------------------------------------------------------4. VNC端口 如果需要从外网控制内网的某台Linux,则需要打开防火墙相应的端口,并在路由器上进行端口映射。 VNC给浏览器的端口是5800+N,给vncviewer的端口是5900+N,N是设置的display号
---------------------Windows 客户端连接---------------------------------
Windows 客户端 VNC Viewer 的配置: 1. 从 http://www.realvnc.com/download.html 下载
VNC Free Edition for Windows Version 4.1.2 2. 打开 VNCViewer : 填入VNCServer 的IP:编号(1或2或...) 3. VNCViewer 切换全屏模式:F8
=================================防火墙设置=================================
vi /etc/sysconfig/iptables找到下面的语句:
-A RH-Firewall-1-INPUT -j REJECT ——reject-with icmp-host-prohibited
在此行之前,加上下面的内容:
-A RH-Firewall-1-INPUT -m state ——state NEW -m tcp -p tcp ——dport 5900:5903 -j ACCEPT
这句话的含义是,允许其它机器访问本机的5900到5903端口,这样,display:1, display:2, display:3的用户就可以连接到本机。
然后使用root身份重新启动防火墙:
/sbin/service iptables restart
=============================================================================1.确认VNC是否安装
默认情况下,Red Hat Enterprise Linux安装程序会将VNC服务安装在系统上。
确认是否已经安装VNC服务及查看安装的VNC版本
[root@testdb ~]# rpm -q vnc-server
vnc-server-4.1.2-9.el5
[root@testdb ~]#
若系统没有安装,可以到操作系统安装盘的Server目录下找到VNC服务的RPM安装包vnc-server-4.1.2-9.el5.x86_64.rpm,安装命令如下
rpm -ivh /mnt/Server/vnc-server-4.1.2-9.el5.x86_64.rpm
2.启动VNC服务
使用vncserver命令启动VNC服务,命令格式为“vncserver :桌面号”,其中“桌面号”用“数字”的方式表示,每个用户连个需要占用1个桌面
启动编号为1的桌面示例如下
[root@testdb ~]# vncserver :1
You will require a password to access your desktops.
Password:
Verify:
xauth: creating new authority file /root/.Xauthority
New 'testdb:1 (root)' desktop is testdb:1
Creating default startup script. /root/.vnc/xstartup
Starting applications specified in /root/.vnc/xstartup
Log file is /root/.vnc/testdb:1.log
以上命令执行的过程中,因为是第一次执行,需要输入密码,这 个密码被加密保存在用户主目录下的.vnc子目录(/root/.vnc/passwd)中;同时在用户主目录下的.vnc子目录中为用户自动建立 xstartup配置文件(/root/.vnc/xstartup),在每次启动VND服务时,都会读取该文件中的配置信息。
BTW:/root/.vnc/目录下还有一个“testdb:1.pid”文件,这个文件记录着启动VNC后对应后天操作系统的进程号,用于停止VNC服务时准确定位进程号。
3.VNC服务使用的端口号与桌面号的关系
VNC服务使用的端口号与桌面号相关,VNC使用TCP端口从5900开始,对应关系如下
桌面号为“1” ---- 端口号为5901
桌面号为“2” ---- 端口号为5902
桌面号为“3” ---- 端口号为5903
……
基于Java的VNC客户程序Web服务TCP端口从5800开始,也是与桌面号相关,对应关系如下
桌面号为“1” ---- 端口号为5801
桌面号为“2” ---- 端口号为5802
桌面号为“3” ---- 端口号为5803
……
基于上面的介绍,如果Linux开启了防火墙功能,就需要手工开启相应的端口,以开启桌面号为“1”相应的端口为例,命令如下
[root@testdb ~]# iptables -I INPUT -p tcp --dport 5901 -j ACCEPT
[root@testdb ~]# iptables -I INPUT -p tcp --dport 5801 -j ACCEPT
4.测试VNC服务
第一种方法是使用VNC Viewer软件登陆测试,操作流程如下
启动VNC Viewer软件 --> Server输入“144.194.192.183:1” --> 点击“OK” --> Password输入登陆密码 --> 点击“OK”登陆到X-Window图形桌面环境 --> 测试成功
第二种方法是使用Web浏览器(如Firefox,IE,Safari)登陆测试,操作流程如下
地址栏输入 http://144.194.192.183:5801/ --> 出现VNC viewer for Java(此工具是使用Java编写的VNC客户端程序)界面,同时跳出VNC viewer对话框,在Server处输入“144.194.192.183:1”点击“OK” --> Password输入登陆密码 --> 点击“OK”登陆到X-Window图形桌面环境 --> 测试成功
(注:VNC viewer for Java需要JRE支持,如果页面无法显示,表示没有安装JRE,可以到http://java.sun.com/javase/downloads/index_jdk5.jsp这里下载最新的JRE进行安装)
5.配置VNC图形桌面环境为KDE或GNOME桌面环境
如果您是按照我的上面方法进行的配置的,登陆到桌面后效果是非常简单的,只有一个Shell可供使用,这是为什么呢?怎么才能看到可爱并且美丽的KDE或GNOME桌面环境呢?回答如下
之所以那么的难看,是因为VNC服务默认使用的是twm图形桌面环境的,可以在VNC的配置文件xstartup中对其进行修改,先看一下这个配置文件
[root@testdb ~]# cat /root/.vnc/xstartup
#!/bin/sh
# Uncomment the following two lines for normal desktop:
# unset SESSION_MANAGER
# exec /etc/X11/xinit/xinitrc
[ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
[ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
vncconfig -iconic &
xterm -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
twm &
将这个xstartup文件的最后一行修改为“startkde &”,再重新启动vncserver服务后就可以登陆到KDE桌面环境
将这个xstartup文件的最后一行修改为“gnome-session &”,再重新启动vncserver服务后就可以登陆到GNOME桌面环境
重新启动vncserver服务的方法:
[root@testdb ~]# vncserver -kill :1
[root@testdb ~]# vncserver :1
6.配置多个桌面
可以使用如下的方法启动多个桌面的VNC
vncserver :1
vncserver :2
vncserver :3
……
但是这种手工启动的方法在服务器重新启动之后将失效,因此, 下面介绍如何让系统自动管理多个桌面的VNC,方法是将需要自动管理的信息添加到/etc/sysconfig/vncservers配置文件中,先以桌 面1为root用户桌面2为oracle用户为例进行配置如下:
格式为:VNCSERVERS="桌面号:使用的用户名 桌面号:使用的用户名"
[root@testdb ~]# vi /etc/sysconfig/vncservers
VNCSERVERS="1:root 2:oracle"
VNCSERVERARGS[1]="-geometry 1024x768"
VNCSERVERARGS[2]="-geometry 1024x768"
7.修改VNC访问的密码
使用命令vncpasswd对不同用户的VNC的密码进行修改,一定要注意,如果配置了不同用户的VNC需要分别到各自用户中进行修改,例如在我的这个实验中,root用户和oracle用户需要分别修改,修改过程如下:
[root@testdb ~]# vncpasswd
Password:
Verify:
[root@testdb ~]#
8.启动和停止VNC服务
1)启动VNC服务命令
[root@testdb ~]# /etc/init.d/vncserver start
Starting VNC server: 1:root
New 'testdb:1 (root)' desktop is testdb:1
Starting applications specified in /root/.vnc/xstartup
Log file is /root/.vnc/testdb:1.log
2:oracle
New 'testdb:2 (oracle)' desktop is testdb:2
Starting applications specified in /home/oracle/.vnc/xstartup
Log file is /home/oracle/.vnc/testdb:2.log
[ OK ]
2)停止VNC服务命令
[root@testdb ~]# /etc/init.d/vncserver stop
Shutting down VNC server: 1:root 2:oracle [ OK ]
3)重新启动VNC服务命令
[root@testdb ~]# /etc/init.d/vncserver restart
Shutting down VNC server: 1:root 2:oracle [ OK ]
Starting VNC server: 1:root
New 'testdb:1 (root)' desktop is testdb:1
Starting applications specified in /root/.vnc/xstartup
Log file is /root/.vnc/testdb:1.log
2:oracle
New 'testdb:2 (oracle)' desktop is testdb:2
Starting applications specified in /home/oracle/.vnc/xstartup
Log file is /home/oracle/.vnc/testdb:2.log
[ OK ]
4)设置VNC服务随系统启动自动加载
第一种方法:使用“ntsysv”命令启动图形化服务配置程序,在vncserver服务前加上星号,点击确定,配置完成。
第二种方法:使用“chkconfig”在命令行模式下进行操作,命令使用如下(预知chkconfig详细使用方法请自助式man一下)
[root@testdb ~]# chkconfig vncserver on
[root@testdb ~]# chkconfig --list vncserver
vncserver 0:off 1:off 2:on 3:on 4:on 5:on 6:off
终于写完了,好累,休息,休息一下~~~~~~
-- The End --
-
现在大型网站WEB架构-LVS集群配置
2009-07-31 10:22:49
ubuntu8.04下安装配置lvs-dr
一.环境
lvs-dr
eth0 192.168.1.50
eth0:1 192.168.1.55(VIP)
web1
eth0 192.168.1.51
lo:0 192.168.1.55(VIP)
web2
eth0 192.168.1.52
lo:0 192.168.1.55(VIP)注:所有真实IP必须在同一网段,VIP可以用其他网段。对于不同网段可以做IP映射。
二.lvs-dr配置
1)检查内核是否支持ipvs
modprobe -l | grep “ipvs”2)安装ipvsadm
apt-get install ipvsadm3)启用ip转发
vi /etc/sysctl.conf
net.ipv4.ip_forward = 14)配置脚本
vi bin/lvs-dr.sh
#!/bin/bash
#description:start lvs_server
#set lvs
/sbin/ipvsadm -C
/sbin/ipvsadm -A -t 192.168.1.55:80 -s rr
/sbin/ipvsadm -a -t 192.168.1.55:80 -r 192.168.1.51:80 -g -w 1
/sbin/ipvsadm -a -t 192.168.1.55:80 -r 192.168.1.52:80 -g -w 1
/etc/init.d/ipvsadm save三.WEB配置
1)配置脚本
vi bin/lvs-web.sh
#!/bin/bash
#Description : RealServer Start!
#Write by:hugwww
#Last Modefiy:2009.1.24
VIP=192.168.1.55
/sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
/sbin/route add -host $VIP dev lo:0
echo “1″ >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo “2″ >/proc/sys/net/ipv4/conf/lo/arp_announce
echo “1″ >/proc/sys/net/ipv4/conf/all/arp_ignore
echo “2″ >/proc/sys/net/ipv4/conf/all/arp_announce
sysctl -p
#endIPVS已实现了以下十种调度算法:
* 轮叫调度(Round-Robin Scheduling)
* 加权轮叫调度(Weighted Round-Robin Scheduling)
* 最小连接调度(Least-Connection Scheduling)
* 加权最小连接调度(Weighted Least-Connection Scheduling)
* 基于局部性的最少链接(Locality-Based Least Connections Scheduling)
* 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling)
* 目标地址散列调度(Destination Hashing Scheduling)
* 源地址散列调度(Source Hashing Scheduling)
* 最短预期延时调度(Shortest Expected Delay Scheduling)
* 不排队调度(Never Queue Scheduling)注:WEB服务器可以是windows 2003,windows2008,win7,linux,freeBSD,UNIX等
-
怎么学会使用RIATest(未来Flex GUI自动化测试工具)
2009-06-18 21:39:02
我们先了解RIAtest工具
RIATest是一个Flex自动化GUI测试工具,它刚刚公开发布了Beta版。InfoQ为此采访了RIATest的创造者Tigran Najaryan。Najaryan首先谈到了创造RIATest的目的:
RIATest 是一个用来对Adobe Flex 3程序进行自动化GUI测试的工具。创造RIATest的目的是为了给商业和专业开发者提供一个简单、干净的测试自动化方案,帮助他们保证产品的质量。我们在定价上非常激进,一心把测试自动化带给更多的Flex用户,而这些用户以前都负担不起其它的Flex测试自动化方案。
说到RIATest如何工作的时候,Najaryan解释说:
从技术上看,RIATest由两部分组成:Agent和IDE(或者命令行执行器)。Agent呆在浏览器一方,直接与被测程序打交道。Agent提供了组件查看器(Component Inspector),让你检查和监视被测程序的GUI组件及其属性。Agent还通过TCP连接与IDE相连。Agent与IDE在回放期间(IDE向 Agent发送指令并接收结果)以及录制期间(Agent把录下的动作通知给IDE)都经由这个TCP连接相互沟通。
测试脚本是用RIAScript语言写的。RIAScript是一个简化版的ActionScript(另有些微扩展)——因此熟悉ActionScript的开发者很容易学会编写RIATest的测试脚本。
RIATest是用什么开发的?Najaryan回答说:
RIATest从一开始就是作为Flex 3测试自动化工具来设计的,它使用了Flex的测试自动化框架。RIATest IDE是用C++和wxWidgets库写的。RIATest Agent是用Flex 3开发的。
由于现在已经可以见到不少Flex测试工具,所以InfoQ请Najaryan将RIATest与其它工具比如FlexUnit作一下比较:
RIATest作为一个自动化GUI测试工具,与单元测试等其他测试手段是相辅相成的。必须通过多种自动化测试手段才能得到最高质量的保证,自动化GUI测试和单元测试都包括在内。
谈到如何测试连通性,如HTTP请求和SOAP连接:
RIATest内建了按照指定条件自动或手动进行同步的功能,因此即使程序需要与远程数据源通信,RIATest也能完全胜任自动化测试的工作。QA工程师可以通过“'waitfor'”操作让测试脚本与被测程序的组件状态同步。
最后,Najaryan给出了一段测试脚本的例子:
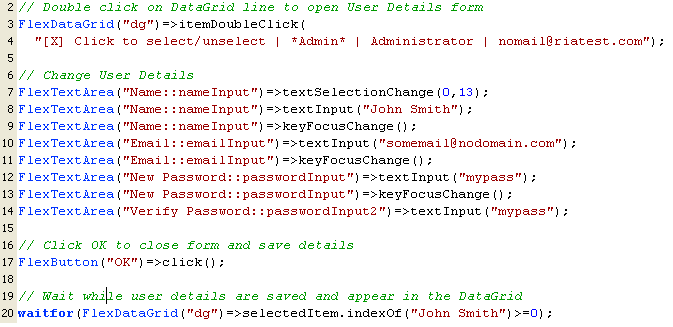
查看英文原文:RIATest for Flex Released Beta Product
http://en.wikipedia.org/wiki/RIATest
http://www.infoq.com/news/2008/03/riatest-beta-released
http://www.insideria.com/2009/02/getting-started-with-riatest-2.html
下载可以官方网站下载,要是买还算便宜,相比MI等测试工具,然后我们装好RIATest2.3那就立刻开始使用它吧。
RIATest系统需求
使用RIATest需要下面软件:
- Adobe Flex Builder 3 Professional
- Adobe Flash Player 9,0,115,0 or newer
- Microsoft Windows XP or Vista
- Mozilla Firefox 2 or Internet Explorer 6
例子
RIATest包含一个展示基于Flex类的自动操作例子的项目.
这个项目在 C:\Program Files\RIATest\samples\components.
选择应用方案
RIATest为你准备了两种方法: 使用 RIATest time Loader 或通过在编译应用程序时植入RIATest 代理.
用 RIATest Loader是一个简单的方法不需用自动操作库来编译你的应用程序.不是所有的应用程序都能用time Loader 来操作. 对于多数复杂的案例(例如当你的应用程序需要HTML页面并且不用导入无格式的SWF文件) 你需要用 RIATest 代理和自动操作库植入你的应用程序.
使用RIATest Loader
你的SWF应用文件在服务器运行的话。你可以使用本地或者远程的RIATest Loader.
使用本地RIATest Loader
如果你在本地运行你的应用程序,没有特殊要求. 在创建RIATest 项目时你可以指定该项目选项为'Use local Loader'.
使用远程RIATest Loader
如果你通过web服务器来运行你的程序,你需要上传RIATest Loader去服务器,所以RIATest Loader和你的应用程序的URLs要来自相同的域名(否则安全策略不允许Loader去访问你的应用程序). 复制下面目录下C:\Program Files\RIATest\loader 的内容去你的web服务器目录(通常和你的主SWF程序所在的目录相同). 现在打开你的浏览器访问下面地址:
http://your-server-name/your-directory/RIATestLoader.html?rtLoadURL=url-of-your-applicaiton.swf
确定服务器名,路径,应用程序名字的参数正确. 如果每个设置都正确.RIATest Loader将在你的应用程序内载入和运行. 然后关闭浏览器进入RIATest 进入项目的创建.
编译自动化库和静态代理
如果决定使用静态的自动化库和代理需要执行下面步骤:
- 在Flex Builder 3中打开你应用程序项目.
- 选择Project -> Properties -> Flex Compiler.
- 在'Additional compiler arguments' 文本中增加下面内容:
-include-libraries "C:\Program Files\RIATest\agent\RIATestAgent.swc" "C:\Program Files\Adobe\Flex Builder 3\sdks\3.0.0\frameworks\libs\automation.swc" "C:\Program Files\Adobe\Flex Builder 3\sdks\3.0.0\frameworks\libs\automation_agent.swc" "C:\Program Files\Adobe\Flex Builder 3\sdks\3.0.0\frameworks\libs\automation_dmv.swc"
你可能把Flex Builder 3和RIATest安装在其他目录,那么将需要更下面目录 C:\Program Files\Adobe\Flex Builder 3 和C:\Program Files\RIATest .
- 点击OK 保存内容关闭对话框.
- 编译你的应用程序.
RIATest代理和Flex 自动操作库现在被植入你的应用程序中. 每次你的应用程序启动,RIATest 代理为了建立自动操作的会话将去连接RIATest工具.
运行你的应用程序. 你将看到RIATest代理工具栏浮动在你的应用程序上. 工具栏标题将显示'为'RIATest Agent - Not connected'. 这是正常的,RIATest 代理没有连接到RIATest 工具.
创建RIATest工程
- 运行RIATest工具选择 File -> New Project. 一个空工程被创建.选择 File -> Save All, 选择目录来保存你的工程, 输入工程名称点击Save..
- 选择 Project -> Options. 确信所以的选择项被选中. 根据你确定的程序导入方案,你有下面选择:
A. 如果你想使用RIATest Loader 和你的SWF应用程序文件在本地,选中'Use local loader'.
B. 如果你想使用RIATest Loader 但你的应用程序在一个web服务器上,选中'Standalone or remote loader'并且在'Application URL' 输入下面内容:
http://your-server-name/your-directory/RIATestLoader.html?rtLoadURL=url-of-your-applicaiton.swf
C. 如果你有包含静态编译的RIATet 代理和自动操作库的应用文件,选中'Standalone or remote loader'并且在'Application URL' 输入你的应用程序HTML文件的地址(例如: http://localhost/myapp/bin/app.html) 或者HTML文件的路径(例如: C:\My Projects\My App\bin\app.html). - 选中 Run -> Launch Application. 默认浏览器将被启动,你的应用程序将被载入浏览器. RIATest 代理工具栏标题将显示'Connecting' 和'Ready' 信息.
- 返回RIATest tool窗口. 消息日志将显示下面内容:
Launching C:\Program Files\Internet Explorer\iexplore.exe "C:\My Projects\My App\bin\app.html"
Application launched. Waiting for connection from agent...
Agent connection accepted.
RIATest 工具标题也显示(Ready) 这样说明代理被连接和准备好,可以录制和运行action了.
录制脚本
确定RIATest 工具和代理被连接(标题都显示 'Ready'). 在RIATest 工具中选择 Project -> Add New Script. 输入新脚本的名称并保存.
选择 Run -> Start Recording (或者点击RIATest代理工具栏上的'Record'按钮). RIATest 工具和代理的标题将显示'Recording'. 切换到你的应用程序窗口来录制你想要的内容. 注意RIATest 工具录制actions声明在测试脚本窗口.
你可以按Ctrl-Shift 在你的应用程序点击任何元素来设置自动化确认和检查点. 当你按下Ctrl-Shift后鼠标点中组件将被高亮显示,用绿色半透明框来区别.
你也可以使用'Inspect' 按钮检查你应用程序的用户界面组件. RIATest 代理将用户蓝色框高亮显示鼠标指定的组件, 将显示组件的类,名称和所有可用属性. 再点击组件将结束'Inspect' 模式.
之后组件被检查你能在代理工具栏中点击'Verify'按钮. 所有的属性目录将被显示. 你可以选择任意一个你想要属性.然后点击OK一个检查点将被建立. 这个检查点将检验在选中属性中的值与当前值进行匹配.
点击RIATest 代理工具栏的'Record' 按钮 或者选择RIATest工具 Run -> Stop Recording 来停止录制. 注意你可以在任何时间停止和重新录制. 如果你录制了错误的内容, 你可以停止录制, 去RIATest 工具, 选择不正确的actions删除, 然后重新再开始录制.
当你完成录制你可以选择Run -> Terminate Application 关闭浏览器包括你的应用程序.
运行测试
在RIATest工具File -> Open Project 打开你的项目. 选择 Run -> Run Without Debugging . 浏览器将打开, 你的应用程序将被载入录制的actions和检查点将被回放.
在RIATest工具中将显示回放进程的消息日志. 检查点成功通过将显示绿色信息, 失败的actions 和检查点将显示红色信息.
回复结束后你的应用程序和浏览器将被关闭.消息日志将显示运行有多少错误和错误原因.
注意: 如果你使用Flex 3 Beta 回放将被限制为30 actions. 请去Adobe获得Flex Builder 3 Professional license .
调试测试
如果你在运行你的测试时遇到错误,你能调试你的脚本. 开始调试选择 Run -> Run Tests . 项目脚本将正常开始运行当遇到错误时(如检查点或action失败) 脚本将被暂停错误行被高亮显示. 消息日志的最后会显示错误原因 (如: 期待值与实际值不同,检查点失败). 你可以切换到你的引用程序检查组件和他们的属性. 也可以检查你的脚本变量值(如果被使用)通过鼠标移动到变量名上.
手动写测试脚本
录制为我们快速创建测试脚本提供帮助. 可是有时你需要执行更多复杂的actions,如在你的应用程序中多次重复用户界面或者执行有条件的actions.
RIATest 工具使用RIAScript. 语言来写测试脚本. RIAScript. 基于基本脚本语言. 你可以声明和赋值给变量,进行函数引用,写判断和循环方法.
RIAtest帮助对手写脚本很有帮助。
遗憾一:没有破解key
遗憾二:RIAScript和ActionScript还是有些不一样
遗憾三:对于自动化工具定义,他算是GUI加白盒自动化测试工具,上手还算容易。
-
BadBoy 简明手册
2009-05-13 17:35:40
一badboy简介
Badboy监控internet explorer的活动,提供录制/回放功能.
录制功能:badboy窗口的顶部显示当前是否处于录制状态,如果点击play按钮,badboy自动关闭录制功能,等到play结束后,可以点击recording按钮,继续录制脚本.
Remark:必须等到上一步的request处理完毕后,才能点击发送下一个request,否则下一个request会作为第一个request的子frame.
二基本操作
1创建suites,tests以及steps
测 试与网站的交互过程,可以在逻辑上划分为几个步骤.例如第一个步骤为登陆雅虎邮箱,第二步为浏览收件箱,第三步为发送邮件.每一个步骤可以包含一到多次的网站交互动作.badBoy中点击new step创建新的步骤.
 <!--[endif]-->.同理,可以创建suites以及tests.
<!--[endif]-->.同理,可以创建suites以及tests.Badboy回放时,一次执行一个step,每执行完一个step,会显示执行结果,用户必须再次点击play按钮后,执行下一个step.
2自动化测试脚本
如果不修改脚本,简单的录制回放并不能满足复杂网站的测试.
复杂网站往往有下面一些测试场景:
A页面参数唯一性要求,例如:注册页面,需要对用户的注册名进行唯一性校验.
B测试的server地址不同.
Badboy提供了易用的参数修改方法,仅仅需要双击request或者参数,在弹出窗口内修改.同时badboy提供search&replacing功能来修改脚本中的参数值.
Remark:建议选择linking variables,同一个参数,往往脚本会发送多次,选择linking variables后,badboy会查找所有的与参数有关的值.并统一替换.
三特点与技 术
1录制模式
Badboy提供两种录制模式:一request模式(默认模式)二navigation模式.点击下图N,切换模式.
<!--[endif]-->Request模式具有如下优点:如果测试的网页模版修改了,不影响脚本的回放.如果需要badboy导出脚本到jmeter进行性能测试,必须选择request模式.同时request模式的缺点如下:request模式需要添加大量的断言来检查页面上的item.
Navigation模式将会记录网站交互过程中browser中的元素的点击动作.当回放navigation模式脚本时候,不但回放http request,同时badboy会模拟brower中点击动作.navigation模式的缺点是 :无法使用navigation脚本进行性能测试,因为性能测试引擎运行时候不显示任何用户界面,所以无法执行navigation中模拟点击等动作.
总结:选择navigation模式还是request模式,取决于测试的目的,如果仅仅要求测试功能而不关心界面,则request模式无疑为首选.
2 navigation模式
Navigation录制browser的三种元素如下:
1链接点击
2按钮点击
3其 他点击,例如引发javascrīpt的操作.
3表单提交
表单提交是页面中非常重要的部分,有下面一些案例需要注意:
1如果页面表单中某些参数是依赖于某些参数的 输入,比如field B由javascrīpt根据field A的输入值计算,使用request模式将无法录制正确的参数.
2 request模式下,表单中的所有参数都将发送.包括一些预定义的元素.
自动录制form的方法:点击form中某一field,按"Ctrl-Alt-f"录制form,如果每次提交的form名字不同的话,可以使用正则表达式来表示:logonForm[0-9]{4}
4断言
断言是自动化检测的实现手段,badboy提供了两种断言:
1 content检查
检查页面中是否包含指定的text.断言可以使用正则表达式,比如要检查一个正确登陆的例子,需要检查”welcome [A-z0-9]*\.”
问题:例子,比如”tree frog”在browser中显示,在html中显示为"tree frog",因 为badboy测 试实际的html source,因此将找不到这个断言.避免这个问题的方法是在page中高亮显示text,并使用easy assertion button.如果使用复杂断言,需要精确匹配html source中的text.
5截屏
当测试失败时候,截屏是最有效的方法与开发人员沟通.在断言的属性栏中,选择失败是截屏.badboy会截取失败案例的browser屏.
6 timeout
可以为每个request设置timeout时间,右键点击à选择属性à选择play标签,设置timeout时间.
7弹出框
使用断言检查弹出框,邮件选择断言,打开"Check against Message Boxes"选项.
8 Badboy与jmeter使用注意事项:
1导出jmeter脚本的时候,jscrīpt不被导出,因为jmeter无内迁browser,jscrīpt元素无法执行.
2 data sources不被导出.
9快捷方式
快捷方式如下:
F2 Toggles Record Mode On/Off
F3 Displays the search/replace dialog, or searches if the dialog is already open.
Ctrl-Alt-Right Starts playing from the current item.
Ctrl-Alt-Space Stops Playing
Ctrl+F5 Plays entire hierarchy from the current item. (Note: if focus is inside the browser, IE will intercept as "Refresh").
F6 Single steps (plays next single item in scrīpt.)
F8 Shows/Hides scrīpt Tree
F9 Shows/Hides Summary Tab View
F12 Shows/Hides both scrīpt and Summary Views together (gives browser full window space)
Ctrl+Enter Replays the item current item in the scrīpt
Ctrl+Shift+Enter Replays the current step in the scrīpt
Ctrl+Shift+Left Rewinds the play marker to the previous step.
Ctrl+Alt+Up Moves the play marker to the previous item in scrīpt.
Ctrl+Alt+Down Moves the play marker to the previous item in scrīpt.
Ctrl+L Displays the lines Server Log File related to the most recent browsing activity.
Ctrl+K Clears all responses from the scrīpt.
Ctrl+J Attempts to find and edit the source code file for the current page and/or frame. that has focus in the browser.
Ctrl+Shift+J Attempts to find and edit the source code file for the current page and/or frame. that has focus in the browser and also adds the URL for the frame. to your scrīpt as a Monitored request.
Ctrl+Shift+M Adds URLs for all frames in the current browser as Monitored requests.
Ctrl+D Toggles DOM View On/Off for the active window.
Ctrl+Page Up While in DOM View changes to previous frame. in frame. list
Ctrl+Page Down While in DOM View changes to next frame. in frame. list
Ctrl+Alt Changes Record Mode temporarily to Navigation Mode while held down
Ctrl+Alt+N Toggles record mode between Navigation and Request mode
Ctrl+Shift+D Opens the documentation editor for the item currently selected in the scrīpt Tree.
LoadBalancer:介绍下载
http://www.stable.com.tw/index.php?option=com_content&view=article&id=124&Itemid=82&lang=zh
-
如何从LR8.0到LR9.1和安装与破解LR9.1和如何通过LR监控Linux和Unix的资源状况
2009-04-02 17:08:41
一、完全卸载LR8.0的步骤如下:
1.选择开始-控制面板-添加删除程序,选择loadrunner8.0,点击删除,卸载后重起。
2.再解压deletelicense(8.0).rar,运行deletelicense(8.0).exe,即完全卸载lr8.0
二、接下来是LR9.1的安装与破解
1、正常安装完LR9.1后,先解压lr删除注册表.rar。然后双击lr_Del_license(regedit).exe
2、然后解压替换DLL.rar,有四个mlr5lprg.dll、licensebundles.dll、lm50.dll、lm70.dll,但主要是mlr5lprg.dll、lm70.dll是关键dll,将其中的2个DLL文件拷贝到你安装目录"bin"下替换原有文件。注:lm70.dll文件的描述是with conbined license support,是一个license的支持文件;
mlr5lprg.dll应该是一个保存license的文件,其实不要替换mlr5lprg.dll也是可以的,只替换lm70.dll文件,老的license一样能注册通过,但是软件的试用的license还在3、进入LR,打开license管理器,点击添加new license输入的序列号(loadrunner 9.1 global-1000:AEACFSJI-YASEKJJKEAHJD-BCLBR)即可
在破解过程中,我还遇到一个问题,就是通过上述方法注册时,提示"License security violation",无法注册,不过没关系,你再运行lr_Del_license(regedit).exe,即可。
接下来,你就可以全新体验LR9.1带给你的刺激了。
三、如何完全卸载LR9.1
点击安装LR9.1的安装程序,提示如下

1.控制面板-添加删除程序,正常卸载LR9.1后,再解压deletelicense(8.0).rar,运行deletelicense(8.0).exe,把注册表信息删除干净;
2.运行-cmd-regedit,用注册表的查找功能,把有关把LR的注册表信息清理干净。
3.把相关HP的文件夹和子文件夹都删除。 4.重启,再运行下deletelicense(8.0).exe,OK,可以安装了! 5.破解安装lr9.1其实和lr8.1其实一样。
我们在使用LR进行性能测试的时候,经常有需要监控OS的资源使用情况的需求。对于Windows系统,这个工作进行起来很方便,直接在LR的资源 监控窗口中添加需要被监控的机器名或IP即可,但对于Linux/Unix系统,则要稍微复杂一些,我在这里简单介绍一下如何在LR中监控Linux /Unix系统的资源使用情况:
Linux对于Linux系统,要想通过LR监控Linux/Unix系统的资源使用情况,需要运行rstatd服务。如果OS没有安装rstatd(可以查找一下 系统中是否存在rpc.rstatd这个文件,如果没有,则说明系统没有安装rstatd),则需要进行安装。rstatd安装步骤如下:
获得rstatd的安装介质(rstatd.tar.gz)。rstatd可以从redhat的安装CD中获得,或者从网站上下载(给出一个下载地 址,sourceforge的:http://heanet.dl.sourceforge.net/sourceforge/rstatd)。
将rstatd.tar.gz拷贝到Linux系统中,解压,赋予可执行权限,进入rpc.rstatd目录,依次执行如下命令:
#./configure
#make
#make install
结束后,运行./rpc.rstatd命令,启动服务。这个时候,你就可以在LR中监控Linux资源了。
Unix对于Unix系统,比如Solaris,AIX或者HP UX等,它们的配置过程比较简单——在inetd.conf(在/etc目录下)文件中去掉rstatd前面的注释,然后启动rstatd服务即可。
-
HP(MI)QTP 10 下载
2009-04-01 19:40:31
HP Mercury的QTP 10已放出下载了(下面是我的用户名下载的链接,直接Copy到迅雷中就可以,有效期30天):
T6510-15063.zip 1.37G
http://h30302.www3.hp.com/prdownloads/T6510-15063.zip?ordernumber=380454070&itemid=1&downloadid=33606114&merchantId=HP_DOWNLOAD_CENTER&dlm=ON
幸运的是对License的部分没有做修改,仍就适用破解8.2~9.5的方法,或输入:
CT6M4C3XCDUTD34NNKIDXB6UIANZHNXA4ZV24UET9XQY7BHJA9Q5IJV996IC6ZKVBL3WH5HV4J
(就是lservrc文件第一行的#前面的那部分代码)New Supported Operating Systems and Environments
QuickTest Professional 10.00 now offers support for the operating systems, browsers, and development environments listed below.
For a complete list of all supported operating systems, browsers, and development environments, see the HP QuickTest Professional 10.00 Product Availability Matrix.
lMicrosoft Windows 2008 Server 32-bit Edition
lMicrosoft Windows 2008 Server 64-bit Edition
lMicrosoft Windows Vista, Service Pack 1, 32-bit Edition
lMicrosoft Windows Vista, Service Pack 1, 64-bit Edition
lMicrosoft Windows XP Professional 32-bit Edition—Service Pack 3(9.5下也可以用,不过我发现先开Foxmail,再开QTP会报错,但先开QTP,再开Foxmail没有问题)
lCitrix Presentation Server 4.5
lMicrosoft Internet Explorer 8, Beta 2
lMozilla Firefox 3.0.x (终于支持了,9.5可是不支持的)
lDelphi: IDE, versions 6, 7, and 2007 (for controls based on the Win32 VCL library)
lSAP: CRM 2007 (For controls that support test mode enhancements. Requires SAP notes: 1147166, 1066565, and 1002944. Later SAP notes related to test mode enhancements are not supported.)
lJava: IBM 32-bit JDK 1.5.x, SWT toolkit version 3.4
lJava Extensibility: Eclipse IDE 3.4
l.NET: .NET Framework 3.5—Service Pack 1
New Features
QuickTest 10.00 now offers the following new features. Click a link to view more details about the selected item.
lCentrally Manage and Share Testing Assets, Dependencies, and Versions in Quality Center 10.00
uNew resources and dependencies model for storing and managing shared assets
uSupport for asset versioning and baselines
uAsset Comparison Tool for comparing versions of individual QuickTest assets and Asset Viewer for viewing an earlier version of a QuickTest asset
uA special tool for Quality Center administrators that upgrades all QuickTest assets to use these new features.
lPerform. Single-User Local System Monitoring While Running Your Tests
The new local system monitoring feature (File > Settings > Local System Monitor) enables you to monitor the local (client-side) computer resources used by the application instance you are testing during a run session.

lImprove Portability by Saving Copies of Tests Together with Their Resource Files
You can save a standalone copy of your test and its resource files to a local drive or to another storage device using the File > Save Test with Resources command. When you save a test in this manner, QuickTest creates a copy of your test, all associated resource files, and any called actions.
lCall Actions Dynamically During the Test Run
Generally, when you insert a call to an external action, the action call becomes part of the test, and the called action is loaded each time you open the test.
In some situations, you may want to take advantage of the new LoadAndRunAction statement to load an action only when the step runs, and then run that action.
This is useful, for example, if you use many conditional statements that call external actions, and you do not want to load all of these actions each time you open the test, since these actions may not be necessary during the run session.
lDevelop Your Own Bitmap Checkpoint Comparison Algorithm
You (or a third party) can now develop custom comparers for bitmap checkpoints. A custom comparer is a COM object that performs the bitmap comparison for the checkpoint according to your testing requirements. For example, you could define a custom comparerthat allows a bitmap checkpoint to pass even if the image in the application shifts by an amount specified when the checkpoint is defined.
lCentrally Manage Your Work Items and ToDo Tasks in the To Do Pane
The new To Do pane that is now available in the QuickTest IDE, enables you to create and manage self-defined tasks, and to view a compiled set of the TODO comments from your tests, components, and associated function libraries.
For example, you can use the Tasks tab to provide instructions to someone else during a handover, or to create reminders for yourself. The Tasks tab provides check boxes in which you can mark off each task as you complete it. In the Comments tab, you can view and sort all your TODO comments. You can also jump directly to a selected TODO comment in the testing document.
You can also export your tasks and TODO comments from the To Do pane to an XLS (Excel), CSV (comma separated), or XML file.
lImprove Test Results Analysis with New Reporting Functionality
QuickTest 10.00 includes a powerful set of new reporting options that help you analyze and manage your run results more thoroughly and efficiently. These include:
uJump to step
uExport Test Results to Microsoft Word or PDF Formats
uNew Image Reporting Options
uAdditional Quality Center Details
lTest Standard and Custom Delphi Objects Using the Delphi Add-in and Delphi Add-in Extensibility
The new Delphi Add-in enables you to test Delphi controls that were created in the Delphi IDE and are based on the Win32 VCL library.
QuickTest Professional Delphi Add-in Extensibility is an SDK (Software Development Kit) package that enables you to develop support for applications that use third-party and custom Delphi controls that are not supported out-of-the-box by the QuickTest Professional Delphi Add-in. -
xml全收集|XML|XSL|W3C Schema|DTD |DOM|SAX|XPath|名称空间|RDBMS |Xlinks|
2009-03-31 12:46:34
XML 技术资料列表
文章部分:
1. XML FAQ
一份关于 XML 的非常重要的文档。
2. XML Message 教程
http://www.javaworld.com/javaworld/jw-03-2001/jw-0302-xmlmessaging.html
http://www.javaworld.com/javaworld/jw-06-2001/jw-0622-xmlmessaging2.html
JavaWorld 上两篇关于 XML Message 的教程。
3. 为什么 XML 意味着 Java
http://www.xml.com/pub/a/1999/06/fuchs/fuchs.html
介绍 XML 与 Java 的关系。
4. Perl XML 快速起步
http://www.xml.com/pub/a/2001/04/18/perlxmlqstart1.html
http://www.xml.com/pub/a/2001/05/16/perlxml.html
http://www.xml.com/pub/a/2001/06/13/perlxml.html
介绍如何使用 Perl 做 XML 开发。
5. Perl 和 XML 犯了什么错?
http://www.xml.com/pub/a/2000/10/11/perlxml/index.html
讨论了 Perl 目前在做 XML 开发中还存在哪些不足。
6. 使用 Python 处理 XML
http://www.xml.com/pub/a/1999/12/xml99/python.html
介绍如何使用 Python 做 XML 开发。
7. 使用 C++ 做 XML 编程
http://www.xml.com/pub/a/1999/11/cplus/index.html
介绍如何使用 C++ 做 XML 开发。
8. LXXXII. XML 解析器的功能
http://www.php.net/manual/en/ref.xml.php
介绍如何使用 PHP 做 XML 开发
9. W3C XML Schema 使事情变得简单
http://www.xml.com/pub/a/2001/06/06/schemasimple.html
介绍如何避免设计 XML Schema 时的一些常见缺陷。
10. 便宜的 XML
http://www.xml.com/pub/a/2001/06/27/cheapxml.html
介绍在 Web 上大量可以免费使用的 XML 软件资源。
11. 实用国际化 (i18n)
http://www.xml.com/pub/a/2001/04/18/i18n.html
关于在 XML 开发中的国际化问题对 Tim Bray 的访谈。
12. 一个 XSLT 样式单和一个用来实现国际化 (i18n) 的 XML 词典
http://www-106.ibm.com/developerworks/web/library/wa-xslt/?dwzone=web
演示了一个实现站点 Web 页面国际化的策略。
13. JAXP -- 用词不当和修正
http://www.zdnet.com/enterprise/stories/main/0,10228,2766317,00.html
对 JAXP 规范的介绍和其今后发展的预测。
14. 实体与 XSLT
http://www.xml.com/pub/a/2001/03/14/trxml10.html
介绍在 XSLT 中如何使用实体 (Entities)
15. 处理指令与 XSLT
http://www.xml.com/pub/a/2000/08/09/xslt/xslt.html
介绍在 XSLT 中如何使用处理指令 (PI)。
16. HTML 和 XSLT
http://www.xml.com/pub/a/2000/08/30/xsltandhtml/index.html
介绍如何使用 HTML 作为 XSLT 的输入和输出。
17. XSLT 外科手术
http://www.xml.com/pub/a/2001/04/25/styleqanda.html
关于 XSLT 的一些问答。
18. XT 的未来
http://www.xml.com/pub/a/2000/06/07/deviant/index.html
介绍目前最快的 XSLT 引擎 -- XT 的发展状况。
19. XSLT 测试结果
http://www.xml.com/pub/a/2001/03/28/xsltmark/index.html
http://www.xml.com/pub/a/2001/03/28/xsltmark/results.html
最近一次 XSLT 测试的结果和评论。
20. XML 技术:一个成功的故事
http://www.xml.com/pub/a/2001/05/16/wrestle.html
做 XML 开发的一个实例。
21. 几部分的集成 -- XSLT,XLink 和 SVG
http://www.xml.com/pub/a/2000/03/22/style/index.html
介绍如何集成这几种 XML 应用。
22. OpenOffice 和 XML 的冒险
http://www.xml.com/pub/a/2001/02/07/openoffice.html
介绍了在 OpenOffice 中应用 XML 技术所做的大胆实践。
23. Jetspeed 中的 XML
http://www.xml.com/pub/a/2000/05/15/jetspeed/index.html
介绍了在 Jetspeed 项目中的 XML 应用。
24. Internet 脚本:Zope 和 XML-RPC
http://www.xml.com/pub/a/2000/01/xmlrpc/index.html
介绍如何在 Zope 中做 XML-RPC 开发。
25. Semantic Web
http://www.scientificamerican.com/2001/0501issue/0501berners-lee.html
Tim Berners-Lee 关于 Semantic Web 的定义。
26. Tim Berners-Lee 关于 W3C 的 Semantic Web 活动的访谈
http://www.xml.com/pub/a/2001/03/21/timbl.html
Tim Berners-Lee 关于 W3C 的 Semantic Web 活动的访谈。
27. 创建一个 Semantic Web
http://www.xml.com/pub/a/2001/03/07/buildingsw.html
介绍如何创建一个 Semantic Web (机器可读的 Web)。
28. 荒野中的 Dublin Core
http://www.xml.com/pub/a/2000/10/25/dublincore/dc8.html
对 Dublin Core 的介绍。
29. RSS:轻量的 Web 企业联合 (Syndication)
http://www.xml.com/pub/a/2000/07/17/syndication/rss.html
介绍了 RSS 的概念。
30. 学习 RELAX
http://www.xml.com/pub/a/2000/10/16/relax/index.html
一篇介绍 RELAX 的文章。
31. XQuery 是否是在重新发明轮子?
http://www.xml.com/pub/a/2001/02/28/deviant.html
关于 XQuery 的网上大讨论。
32. 直觉和二进制的 XML
http://www.xml.com/pub/a/2001/04/18/binaryXML.html
将 XML 编码为二进制格式以加快应用程序执行效率的讨论。
33. 一篇介绍 SOAP 历史的短文
http://www.xml.com/pub/a/2001/04/04/soap.html
一篇介绍 SOAP 历史的短文。
34. 理解 ebXML,UDDI 和 XML/EDI
http://www.xml.org/feature_articles/2000_1107_dutton.shtml
介绍用于电子商务的这三种技术的体系结构。
35. ebXML:到结束时仍然没有结束
http://www.xml.com/pub/a/2001/05/16/ebxml.html
关于 ebXML 的讨论。
36. 为什么 UDDI 将会成功
http://www.stencilgroup.com/ideas_scope_200104uddi.html
关于 UDDI 的 whitepaper。
37. 数据坩埚:使用 XML 创建 B2B 应用程序
http://www-106.ibm.com/developerworks/library/xml-b2b/index.html
介绍如何使用 XML 创建 B2B 应用程序。
38. 第 10 届国际 WWW 大会的报告
http://www.xml.com/pub/a/2001/05/09/www10/index.html
第 10 届国际 WWW 大会的报告
39. XML Schema 成为 W3C 的建议
http://www-106.ibm.com/developerworks/xml/library/x-schrec.html
关于 W3C 通过 XML Schema 建议的评述。
40. XML 已经不再是旧日模样
http://www.xml.com/pub/a/2001/02/28/eightytwenty.html
介绍了 XML 在 W3C 的最新发展动态。
41. 将混乱变为有序:管理 Web 项目
http://www.webtechniques.com/archives/2000/01/desi/
介绍如何管理一个 Web 项目。
42. 建立你的 Web 团队
http://www.webtechniques.com/archives/2001/01/berry/
介绍如何建立一个 Web 团队。
43. Jabber 中的 XML 消息传递
http://www.openp2p.com/pub/a/p2p/2000/10/06/jabber_xml.html?page=1
介绍在 Jabber 中如何使用 XML 做消息传递。
44. P3P 部署指南
http://www.w3.org/TR/2001/NOTE-p3pdeployment-20010510
W3C 的 P3P 部署指南。
45. 设计 JSP 定制标记库
http://www.onjava.com/pub/a/onjava/2000/12/15/jsp_custom_tags.html
介绍如何设计 JSP 定制标记库。
46. 创建一个 Semantic Web 站点
http://www.xml.com/pub/a/2001/05/02/semanticwebsite.html
介绍如何使用 RSS 创建一个 Semantic Web 站点。
47. XML 的状态:为什么个人同样重要
http://www.xml.com/pub/a/2001/05/30/stateofxml.html
介绍过去一年中 XML 的发展,强调除了大公司以外,个人的贡献依旧关键。
48. Web Services 体系结构概述
http://www-106.ibm.com/developerworks/library/w-ovr/?dwzone=components
IBM 的 Web Services 的体系结构概述。
49. XML 和脚本语言
http://www-106.ibm.com/developerworks/library/xml-perl/
使用 Perl 和其它脚本语言处理 XML 文档的教程。
50. W3C 与 XML 有关的活动
http://www.xml.com/pub/a/2001/01/03/w3c.html
介绍在 W3C 与 XML 有关的活动。
51. 一篇 SVG 的介绍
http://www.xml.com/pub/a/2001/03/21/svg.html
一篇介绍 SVG 的文章。
52. 使用 JSP 技术开发 XML 解决方案
http://java.sun.com/products/jsp/pdf/JSPXML.pdf
Sun 的使用 JSP 做 XML 开发的 whitepaper。
53. ebXML 包围了 SOAP
http://www.xml.com/pub/a/2001/04/04/ebXML.html
介绍了 ebXML 与 SOAP 的关系。
54. 分布式的 XML
http://www.xml.com/pub/a/2000/09/06/distributed.html
介绍 XML 在下一代 Web 中所扮演的角色。
55. Infoset 调查
http://www.xml.com/pub/a/2000/08/02/deviant/infoset.html
介绍什么是 XML Infoset 和它的作用。
56. TREX 基础
http://www.xml.com/pub/a/2001/04/11/trex.html
一篇介绍 TREX 的文章。
57. 菜单上的 XML 和 Java
http://www.java-pro.com/upload/free/features/javapro/2001/04apr01/dw0104/dw0104-1.asp
介绍如何使用 Xerces 和 Java 创建 XML 分级菜单。
58. 使 SOAP 离开 Java
http://www.java-pro.com/upload/free/features/javapro/2001/04apr01/prs0104/prs0104-1.asp
一篇介绍 Apache SOAP 的 HOWTO。
59. 选择你的 Java XML 解析器
http://www.xml-zone.com/articles/pm020101/pm020101-1.asp
对 Apache,Oracle 和 Sun 的 XML 解析器的比较分析。
60. 在 Open Source 运动的中心
http://www.xmlmag.com/upload/free/features/xml/2001/01jan01/sj0101xml/sj0101xml-1.asp
详细介绍了 XML 与 Open Source 运动密不可分的关系。
61. 做 Web 开发的一种更好的方式
http://www.xmlmag.com/upload/free/features/xml/2000/04fal00/kj0004/kj0004.asp
一篇介绍 Cocoon 的 HOWTO。
62. 使用 JSP 为 XML 服务
http://www.xmlmag.com/upload/free/features/xml/2000/04fal00/ww0004/ww0004.asp
介绍如何使用 JSP 做 XML 开发。
63. XLink 可以为你的应用程序做什么
http://www.xmlmag.com/upload/free/features/xml/2000/02spr00/bdspr00/bdspr00.asp
介绍 XLink 对于开发应用程序将起到的作用。
64. 推开 Web 的樊篱
http://www.xmlmag.com/upload/free/features/xml/2001/01jan01/kc0101xml/kc0101xml.asp
介绍如何使用 XSLT 扩展 XHTML 来创建复杂的界面。
65. SOAP FAQ
http://www.develop.com/soap/soapfaq.htm
关于 SOAP 的 FAQ。
66. 使用 W3C XSLT 规范
http://www.xml.com/pub/a/2001/06/06/xsltspec.html
介绍如何阅读 W3C 的 XSLT 规范,澄清一些容易搞混的术语。
67. 从 JSP 中与 XML 交互
http://www.xml-zone.com/articles/pm050401/pm050401-1.asp
介绍使用 JSP 做 XML 开发。
68. 在关系数据库中存储 XML
http://www.xml.com/pub/a/2001/06/20/databases.html?page=1
介绍了在几种主流关系数据库 Oracle,DB2,SQL Server,Sybase 中存储和检索 XML 数据的方法。
69. 经理的 XML
http://www.arbortext.com/Think_Tank/XML_Resources/XML_for_Managers/xml_for_managers.html
为软件经理们介绍采用 XML 的众多优点。
70. 使 SOAP 和 ebXML 开始工作
http://www.advisor.com/Articles.nsf/aid/DRUMR12
一篇介绍 SOAP 和 ebXML 的文章。
71. 实现 ebXML
http://www.gca.org/papers/xmleurope2001/papers/html/s18-2a.html
关于 ebXML 如何适应 OMG 工作组的座谈。
教程部分:
1. XSLT 教程,含有大量实例
http://www.xfront.com/xsl.html
2. XML Schema 教程,含有大量实例
http://www.xfront.com/xml-schema.html
3. XML Schema 最佳实践
http://www.xfront.com/BestPracticesHomepage.html
4. XML 教程
http://www.troubleshooters.com/tpromag/200103/200103.htm
5. DOM 教程
http://developerlife.com
6. SAX 教程
http://developerlife.com
7. 使用 XML 建立 B2B 和 B2C 应用程序
http://www.redbooks.ibm.com/redbooks/SG246104.html
IBM 关于 XML 在电子商务中应用的红皮书。
8. DocBook 权威指南
http://www.docbook.org/tdg/en/html/docbook.html
一本关于 DocBook 的经典著作。 -
sar 使用
2009-03-26 12:24:59
对于sar我们可以从man sar看见很详细的解说,下面就是我看见一些有趣的和大家分享
dmesg可以直接查看cpu的主频,要查看CPU、内存的使用情况可以使用sar!
如果没有sar命令,请安装:
# yum install sysstat
sar需要带参数运行,详细使用如下:
sar 命令行的常用格式:
sar [options] [-A] [-o file] t [n]
在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有
的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式
存放在文件中,file 在此处不是关键字,是文件名。options 为命令行选项,sar命令
的选项很多,下面只列出常用选项:
-A:所有报告的总和。
-u:CPU利用率
-v:进程、I节点、文件和锁表状态。
-d:硬盘使用报告。
-r:没有使用的内存页面和硬盘块。
-g:串口I/O的情况。
-b:缓冲区使用情况。
-a:文件读写情况。
-c:系统调用情况。
-R:进程的活动情况。
-y:终端设备活动情况。
-w:系统交换活动。
下面将举例说明。
例一:使用命令行 sar -u t n
例如,每60秒采样一次,连续采样5次,观察CPU 的使用情况,并将采样结果以二进制
形式存入当前目录下的文件zhou中,需键入如下命令:
# sar -u -o zhou 60 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
14:43:50 %usr %sys %wio %idle(-u)
14:44:50 0 1 4 94
14:45:50 0 2 4 93
14:46:50 0 2 2 96
14:47:50 0 2 5 93
14:48:50 0 2 2 96
Average 0 2 4 94
在显示内容包括:
%usr:CPU处在用户模式下的时间百分比。
%sys:CPU处在系统模式下的时间百分比。
%wio:CPU等待输入输出完成时间的百分比。
%idle:CPU空闲时间百分比。
在所有的显示中,我们应主要注意%wio和%idle,%wio的值过高,表示硬盘存在I/O瓶颈,
%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,
此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表
明系统中最需要解决的资源是CPU。
如果要查看二进制文件zhou中的内容,则需键入如下sar命令:
# sar -u -f zhou
可见,sar命令即可以实时采样,又可以对以往的采样结果进行查询。
例二:使用命行sar -v t n
例如,每30秒采样一次,连续采样5次,观察核心表的状态,需键入如下命令:
# sar -v 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
10:33:23 proc-sz ov inod-sz ov file-sz ov lock-sz (-v)
10:33:53 305/ 321 0 1337/2764 0 1561/1706 0 40/ 128
10:34:23 308/ 321 0 1340/2764 0 1587/1706 0 37/ 128
10:34:53 305/ 321 0 1332/2764 0 1565/1706 0 36/ 128
10:35:23 308/ 321 0 1338/2764 0 1592/1706 0 37/ 128
10:35:53 308/ 321 0 1335/2764 0 1591/1706 0 37/ 128
显示内容包括:
proc-sz:目前核心中正在使用或分配的进程表的表项数,由核心参数MAX-PROC控制。
inod-sz:目前核心中正在使用或分配的i节点表的表项数,由核心参数
MAX-INODE控制。
file-sz: 目前核心中正在使用或分配的文件表的表项数,由核心参数MAX-FILE控
制。
ov:溢出出现的次数。
Lock-sz:目前核心中正在使用或分配的记录加锁的表项数,由核心参数MAX-FLCKRE
控制。
显示格式为
实际使用表项/可以使用的表项数
显示内容表示,核心使用完全正常,三个表没有出现溢出现象,核心参数不需调整,如
果出现溢出时,要调整相应的核心参数,将对应的表项数加大。
例三:使用命行sar -d t n
例如,每30秒采样一次,连续采样5次,报告设备使用情况,需键入如下命令:
# sar -d 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
11:06:43 device %busy avque r+w/s blks/s avwait avserv (-d)
11:07:13 wd-0 1.47 2.75 4.67 14.73 5.50 3.14
11:07:43 wd-0 0.43 18.77 3.07 8.66 25.11 1.41
11:08:13 wd-0 0.77 2.78 2.77 7.26 4.94 2.77
11:08:43 wd-0 1.10 11.18 4.10 11.26 27.32 2.68
11:09:13 wd-0 1.97 21.78 5.86 34.06 69.66 3.35
Average wd-0 1.15 12.11 4.09 15.19 31.12 2.80
显示内容包括:
device: sar命令正在监视的块设备的名字。
%busy: 设备忙时,传送请求所占时间的百分比。
avque: 队列站满时,未完成请求数量的平均值。
r+w/s: 每秒传送到设备或从设备传出的数据量。
blks/s: 每秒传送的块数,每块512字节。
avwait: 队列占满时传送请求等待队列空闲的平均时间。
avserv: 完成传送请求所需平均时间(毫秒)。
在显示的内容中,wd-0是硬盘的名字,%busy的值比较小,说明用于处理传送请求的有
效时间太少,文件系统效率不高,一般来讲,%busy值高些,avque值低些,文件系统
的效率比较高,如果%busy和avque值相对比较高,说明硬盘传输速度太慢,需调整。
例四:使用命行sar -b t n
例如,每30秒采样一次,连续采样5次,报告缓冲区的使用情况,需键入如下命令:
# sar -b 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 10/01/2001
14:54:59 bread/s lread/s %rcache bwrit/s lwrit/s %wcache pread/s pwrit/s (-b)
14:55:29 0 147 100 5 21 78 0 0
14:55:59 0 186 100 5 25 79 0 0
14:56:29 4 232 98 8 58 86 0 0
14:56:59 0 125 100 5 23 76 0 0
14:57:29 0 89 100 4 12 66 0 0
Average 1 156 99 5 28 80 0 0
显示内容包括:
bread/s: 每秒从硬盘读入系统缓冲区buffer的物理块数。
lread/s: 平均每秒从系统buffer读出的逻辑块数。
%rcache: 在buffer cache中进行逻辑读的百分比。
bwrit/s: 平均每秒从系统buffer向磁盘所写的物理块数。
lwrit/s: 平均每秒写到系统buffer逻辑块数。
%wcache: 在buffer cache中进行逻辑读的百分比。
pread/s: 平均每秒请求物理读的次数。
pwrit/s: 平均每秒请求物理写的次数。
在显示的内容中,最重要的是%cache和%wcache两列,它们的值体现着buffer的使用效
率,%rcache的值小于90或者%wcache的值低于65,应适当增加系统buffer的数量,buffer
数量由核心参数NBUF控制,使%rcache达到90左右,%wcache达到80左右。但buffer参数
值的多少影响I/O效率,增加buffer,应在较大内存的情况下,否则系统效率反而得不到
提高。
例五:使用命行sar -g t n
例如,每30秒采样一次,连续采样5次,报告串口I/O的操作情况,需键入如下命令:
# sar -g 30 5
屏幕显示:
SCO_SV scosysv 3.2v5.0.5 i80386 11/22/2001
17:07:03 ovsiohw/s ovsiodma/s ovclist/s (-g)
17:07:33 0.00 0.00 0.00
17:08:03 0.00 0.00 0.00
17:08:33 0.00 0.00 0.00
17:09:03 0.00 0.00 0.00
17:09:33 0.00 0.00 0.00
Average 0.00 0.00 0.00
显示内容包括:
ovsiohw/s:每秒在串口I/O硬件出现的溢出。
ovsiodma/s:每秒在串口I/O的直接输入输出通道高速缓存出现的溢出。
ovclist/s :每秒字符队列出现的溢出。
在显示的内容中,每一列的值都是零,表明在采样时间内,系统中没有发生串口I/O溢
出现象。
sar命令的用法很多,有时判断一个问题,需要几个sar命令结合起来使用,比如,怀疑
CPU存在瓶颈,可用sar -u 和sar -q来看,怀疑I/O存在瓶颈,可用sar -b、sar -u和 sar-d来看
-
top 详细使用说明
2009-03-26 12:22:44
功能说明:显示,管理执行中的程序。
语 法:top [bciqsS][d <间隔秒数>][n <执行次数>]
补充说明:执行top指令可显示目前正在系统中执行的程序,并通过它所提供的互动式界面,用热键加以管理。
参 数:
b 使用批处理模式。
c 列出程序时,显示每个程序的完整指令,包括指令名称,路径和参数等相关信息。
d<间隔秒数> 设置top监控程序执行状况的间隔时间,单位以秒计算。
i 执行top指令时,忽略闲置或是已成为Zombie的程序。
n<执行次数> 设置监控信息的更新次数。
q 持续监控程序执行的状况。
s 使用保密模式,消除互动模式下的潜在危机。
S 使用累计模式,其效果类似ps指令的"-S"参数。
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。top - 01:06:48 up 1:22, 1 user, load average: 0.06, 0.60, 0.48
Tasks: 29 total, 1 running, 28 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.3% us, 1.0% sy, 0.0% ni, 98.7% id, 0.0% wa, 0.0% hi, 0.0% si
Mem: 191272k total, 173656k used, 17616k free, 22052k buffers
Swap: 192772k total, 0k used, 192772k free, 123988k cachedPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1379 root 16 0 7976 2456 1980 S 0.7 1.3 0:11.03 sshd
14704 root 16 0 2128 980 796 R 0.7 0.5 0:02.72 top
1 root 16 0 1992 632 544 S 0.0 0.3 0:00.90 init
2 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0统计信息区
前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:01:06:48 当前时间
up 1:22 系统运行时间,格式为时:分
1 user 当前登录用户数
load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。
三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
Tasks: 29 total 进程总数
1 running 正在运行的进程数
28 sleeping 睡眠的进程数
0 stopped 停止的进程数
0 zombie 僵尸进程数
Cpu(s): 0.3% us 用户空间占用CPU百分比
1.0% sy 内核空间占用CPU百分比
0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比
98.7% id 空闲CPU百分比
0.0% wa 等待输入输出的CPU时间百分比
0.0% hi
0.0% si最后两行为内存信息。内容如下:
Mem: 191272k total 物理内存总量
173656k used 使用的物理内存总量
17616k free 空闲内存总量
22052k buffers 用作内核缓存的内存量
Swap: 192772k total 交换区总量
0k used 使用的交换区总量
192772k free 空闲交换区总量
123988k cached 缓冲的交换区总量。
内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,
该数值即为这些内容已存在于内存中的交换区的大小。
相应的内存再次被换出时可不必再对交换区写入。进程信息区
统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。
D=不可中断的睡眠状态
R=运行
S=睡眠
T=跟踪/停止
Z=僵尸进程
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
命令使用
1. 工具(命令)名称
top
2.工具(命令)作用
显示系统当前的进程和其他状况; top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止. 比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间 对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
3.环境设置
在Linux下使用。
4.使用方法
4.1使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
4.2参数说明
d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p 通过指定监控进程ID来仅仅监控某个进程的状态。
q该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S 指定累计模式
s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i 使top不显示任何闲置或者僵死进程。
c 显示整个命令行而不只是显示命令名
4.3其他
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F 从当前显示中添加或者删除项目。
o或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。***********************************************************************
top中按1键和F键的参数:
按1键可以等到多个cpu的情况
按F(f:当前状态,可以按相应的字母键做top的定制输出)后得参数:对F键和f键的区别:
如果进入F键区可以做显示的排序,如果进入f键区的话则可以选择显示的多个项目:
* A: PID = Process Id //进程ID
b: PPID = Parent Process Pid //父进程ID
c: RUSER = Real user name //真正的(Real)所属用户名称
d: UID = User Id //用户ID
e: USER = User Name //用户名称
f: GROUP = Group Name //组名称
g: TTY = Controlling Tty //控制
h: PR = Priority //优先权
i: NI = Nice value //优先级得值(负数代表较高的优先级,正数是较低的优先级.0标志改优先级的值是不会被调整的)
j: #C = Last used cpu (SMP) //随后使用的cpu比率
k: %CPU = CPU usage //cpu使用比率
l: TIME = CPU Time //cpu占用时间
m: TIME+ = CPU Time, hundredths //cpu%比
n: %MEM = Memory usage (RES) //内存使用率
o: VIRT = Virtual Image (kb) //虚拟镜像(VIRT = SWAP + RES:所有进程使用的虚拟内存值,包括所有的代码,数据,共享库已经被swapped out的)
p: SWAP = Swapped size (kb) //交换空间大小(所有虚拟内存中的镜像)
q: RES = Resident size (kb) //已经使用了的常驻内存(Resident size):RES = CODE + DATA
r: CODE = Code size (kb) //分配给执行代码的物理内存
s: DATA = Data+Stack size (kb) //data+stack:物理内存中非存放代码的空间,用于存放数据
t: SHR = Shared Mem size (kb) //共享内存大小.放映了一个task的潜在可以供别人使用的内存的大小
u: nFLT = Page Fault count //内存叶错误的数量
v: nDRT = Dirty Pages count //脏页的数量
w: S = Process Status //进程状态:( R )为运行或可执行的,( S )为该程序正在睡眠中,( T )正在侦测或者是停止了,( Z )僵尸程序
x: COMMAND = Command name/line //进程启动命令行参数
y: WCHAN = Sleeping in Function //在睡眠中
z: Flags = Task Flags <sched.h> //任务标志STAT 该进程的状态。其中S代表休眠状态;D代表不可中断的休眠状态;R代表运行状态;Z代表僵死状态;T代表停止或跟踪状态。
-
SVN服务器配置(svn1.4.6+apache2.2.8 )
2009-03-10 12:26:05
一、软件准备
1. Apache(apache_2.2.8-win32-x86-no_ssl.msi) http://apache.mirror.phpchina.com/httpd/binaries/win32/
2. Subversion : (1.4.6) http://subversion.tigris.org/files/documents/15/41687/svn-1.4.6-setup.exe
3. TortoiseSVN (1.4.8) http://downloads.sourceforge.net/tortoisesvn/TortoiseSVN-1.4.8.12137-win32-svn-1.4.6.msi?download
4. eclipse 客户端 site-1.2.4.zip
注意:如果要安装apache服务,一定需要对应subversion服务端的版本
Subversion(1.4.6) + Apache_2.2.8 no ssl
二、客户端安装
1> 需要site-1.2.4.zip 包,解压缩后有个site-1.2.4的文件夹。
2> Eclipse菜单<help>下面—software updates 中选择 <find and install…> ,选择第二个选项<Search for new features to install> ,点击<next>选项, New Local Site 选项添加刚解压缩的文件夹。
3>勾选几个选项后,finish 完成eclipse – SVN 客户端的安装
4> TortoiseSVN (1.4.8)的安装
三、服务端安装(只配置subversion)
1> 直接安装 svn-1.4.6-setup.exe 服务端程序
2> (eg:)在f:\下面新建文件夹svn;在svn文件夹下建立版本库svnServer 的文件夹,然后用TortoiseSVN建立版本库。
3> 如何启动svn服务(有两种方式) 1) 通过命令行方式启动 : 进subversion bin安装目录> svnserve -d -r f:\svn\svnServer
2)通过windows服务方式启动: 步骤一>需要添加服务到windows中: svnservice -install -d -r f:\svn\svnServer需要卸载windows服务使用: svnservice –remove
步骤二>需要SVNService.exe的服务程序,在命令行中加入。
3) 配置用户名,密码,权限 在新建的版本库f:\svn\svnServer中,进入conf文件夹,该文件夹下面有三个文件进行配置。 svnserve.conf 1)加anon-access = none 任何访问时使用验证 2)打开password-db = passwd 进行用户名密码验证 3)打开authz-db = authz 进行权限验证
Passwd
[users]
# harry = harryssecret
# sally = sallyssecret
admin = 123
zhangchao = 123
authz
[groups]
group_admin = admin
group_user1 = zhangchao
[/]
@group_admin = rw
[/zhangchao]
@group_user1 = rw
注意: 在TortoiseSVN 中repo-browser 查询时,在url 填写时需填入完整的目录名进行权限查看,否则无法打开.
本地查看使用url : svn://localhost/
四、服务端安装(配置subversion + apache)
1. 在架设apache 访问服务时,需要安装 apache2.2.8 no ssl 服务。
需要按一下步骤配置:
1)关于svn 的安装同上
2)安装完成apache 后使用端口80; 可以通过httpd.conf 文件进行修改(listen 8010),在右下角图标中启动apache;这时可以通过IE访问:http://localhost:8010 显示 It Works! 的字样。表示apache 启动成功,但是并不表示已经可以访问svn版本库了。如果进行apache+svn的整合,还需要以下配置.
3)第一步:将C:\Program Files\Subversion\bin(svn服务器中的安装目录)中的 mod_authz_svn.so 和 mod_dav_svn.so 复制到 Apache 安装目录 modules\目录下,再将 Subversion 安装目录下面所有的 .dll 文件复制到 Apache\Bin 目录下(注意,这一步非常重要,如果提示覆盖操作,表示版本有问题,选择否)
4)第二步: 保存, 重启 Apache 服务器
修改 httpd.conf 文件,在文件结尾加入如下语句:
#SVN configuration
LoadModule dav_module modules/mod_dav.so
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule dav_fs_module modules/mod_dav_fs.so
LoadModule authz_svn_module modules/mod_authz_svn.so
5)第三步: 再在 httpd.conf 末尾加入如下语句:
<Location /svn>
DAV svn
SVNPath f:\svn\svnServer
# 权限验证
# AuthType Basic
# AuthName "Serv8,serv99"
# AuthzSVNAccessFile C:\svn.access
# AuthUserFile C:\svn.passwd
# Require valid-user
</Location>保存,重启 Apache 服务器。在浏览器中输入 http://localhost:8010/svn/
注意:下面6行注释了,这时暂不考虑权限的问题,重启Apache服务器后,就已经与svn版本库进行整合了。 如果整合成功,会在Apache控制台的左下角显示 svn/1.4.6 字样的版本信息。
2.下面我们来进行关于apache访问的权限设置
这里说明一下:关于架设apache服务后,启动apache 后,apache不再去找SVN的svnserve.conf的相关配置信息了,会进行关于apache的权限验证认证。配置如下: # 权限验证
# AuthType Basic 打开用户验证
# AuthName "Serv8,serv99" 关于名称
# AuthzSVNAccessFile C:\svn.access 关于分组权限验证文件,与svn中authz相同,可以拷贝过来使用.
# AuthUserFile C:\svn.passwd 该文件需要用apache命令生成
命令如下:
C:\Program Files\Apache Software Foundation\Apache2.2\bin
htpasswd -c passwd zhangchao # apache 创建用户文件命令;第一次生成该文件使用
htpasswd passwd zhangchao1 # 第二次添加用户 命令
htpasswd –help # 使用该命令 查询 修改密码,删除用户等命令参数
五、安装时可能遇到的几个问题
1> svn+apache2.2架设后遇到eclipse重启的问题
解决方法:将环境变量 APR_ICONV_PATH改为APR_ICONV1_PATH 或者下载Subversion 1.4.6的zip包,将环境变量 APR_ICONV_PATH 指向解压后的 iconv文件夹。
2>可以在目录中新建一个内容为 cmd –k 命令的bat批处理文件 ,双击进入当前目录。
3>关于绑定固定域名访问:
需要安装花生壳软件,通过路由绑定端口号。指向固定的域名访问svn资源库。 -
linux下内存释放问题
2009-03-02 20:52:48
细心的朋友会注意到,当你在linux下频繁存取文件后,物理内存会很快被用光,当程序结束后,内存不会被正常释放,而是一直作为caching.这个问题,貌似有不少人在问,不过都没有看到有什么很好解决的办法.那么我来谈谈这个问题.
先来说说free命令
[root@server ~]# free -m
total used free shared buffers cached
Mem: 249 163 86 0 10 94
-/+ buffers/cache: 58 191
Swap: 511 0 511
其中:
total 内存总数
used 已经使用的内存数
free 空闲的内存数
shared 多个进程共享的内存总额
buffers Buffer Cache和cached Page Cache 磁盘缓存的大小
-buffers/cache 的内存数:used - buffers - cached
+buffers/cache 的内存数:free + buffers + cached
可用的memory=free memory+buffers+cached
有了这个基础后,可以得知,我现在used为163MB,free为86,buffer和cached分别为10,94
那么我们来看看,如果我执行复制文件,内存会发生什么变化.
[root@server ~]# cp -r /etc ~/test/
[root@server ~]# free -m
total used free shared buffers cached
Mem: 249 244 4 0 8 174
-/+ buffers/cache: 62 187
Swap: 511 0 511
在我命令执行结束后,used为244MB,free为4MB,buffers为8MB,cached为174MB,天呐都被cached吃掉了.别紧张,这是为了提高文件读取效率的做法.
引用http://www.wujianrong.com/archives/2007/09/linux_free.html"为了提高磁盘存取效率, Linux做了一些精心的设计, 除了对dentry进行缓存(用于VFS,加速文件路径名到inode的转换), 还采取了两种主要Cache方式:Buffer Cache和Page Cache。前者针对磁盘块的读写,后者针对文件inode的读写。这些Cache有效缩短了 I/O系统调用(比如read,write,getdents)的时间。"
那么有人说过段时间,linux会自动释放掉所用的内存,我们使用free再来试试,看看是否有释放>?
[root@server test]# free -m
total used free shared buffers cached
Mem: 249 244 5 0 8 174
-/+ buffers/cache: 61 188
Swap: 511 0 511
MS没有任何变化,那么我能否手动释放掉这些内存呢???回答是可以的!
/proc是一个虚拟文件系统,我们可以通过对它的读写操作做为与kernel实体间进行通信的一种手段.也就是说可以通过修改/proc中的文件,来对当前kernel的行为做出调整.那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存.操作如下:
[root@server test]# cat /proc/sys/vm/drop_caches
0
首先,/proc/sys/vm/drop_caches的值,默认为0
[root@server test]# sync
手动执行sync命令(描述:sync 命令运行 sync 子例程。如果必须停止系统,则运行 sync 命令以确保文件系统的完整性。sync 命令将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、已延迟的块 I/O 和读写映射文件)
[root@server test]# echo 3 > /proc/sys/vm/drop_caches
[root@server test]# cat /proc/sys/vm/drop_caches
3
将/proc/sys/vm/drop_caches值设为3
[root@server test]# free -m
total used free shared buffers cached
Mem: 249 66 182 0 0 11
-/+ buffers/cache: 55 194
Swap: 511 0 511
再来运行free命令,发现现在的used为66MB,free为182MB,buffers为0MB,cached为11MB.那么有效的释放了buffer和cache.
有关/proc/sys/vm/drop_caches的用法在下面进行了说明
/proc/sys/vm/drop_caches (since Linux 2.6.16)
Writing to this file causes the kernel to drop clean caches,
dentries and inodes from memory, causing that memory to become
free.
To free pagecache, use echo 1 > /proc/sys/vm/drop_caches; to
free dentries and inodes, use echo 2 > /proc/sys/vm/drop_caches;
to free pagecache, dentries and inodes, use echo 3 >/proc/sys/vm/drop_caches.
Because this is a non-destructive operation and dirty objects
are not freeable, the user should run sync(8) first.

标题搜索
我的存档
数据统计
- 访问量: 95351
- 日志数: 112
- 图片数: 1
- 文件数: 1
- 书签数: 1
- 建立时间: 2007-01-16
- 更新时间: 2010-06-28
