
-
性能测试(并发负载压力)测试分析-简要篇(转)
2007-01-25 13:07:55
在论坛混了多日,发现越来越多的性能测试工程师基本上都能够掌握利用测试工具来作负载压力测试,但多数人对怎样去分析工具收集到的测试结果感到无从下手,下面我就把个人工作中的体会和收集到的有关资料整理出来,希望能对大家分析测试结果有所帮助。
分析原则:
• 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
• 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
• 分段排除法 很有效
分析的信息来源:
•1 根据场景运行过程中的错误提示信息
•2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 •Error: Failed to connect to server "10.10.10.30:8080": [10060] Connection
•Error: timed out Error: Server "10.10.10.30" has shut down the connection prematurely
分析:
•A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
•B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
•C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired
分析:可能是以下原因造成
•A、应用服务参数设置太大导致服务器的瓶颈
•B、页面中图片太多
•C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
• 分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
• 细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
• 如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题
3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低。
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;
内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)
4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in ('db block gets’,
'consistent gets','physical reads') ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = 'redo log space requests' ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name='sorts (disk)' and b.name='sorts (memory)'
注:上述SQL Server和Oracle数据库分析,只是一些简单、基本的分析,特别是Oracle数据库的分析和优化,是一门专门的技术,进一步的分析可查相关资料。
说明:
以上只是个人的体会和部分资料的整理,并不代表专家之言。算抛砖引玉,有不同看法和更深入的分析的,希望大家勇要发言,以推动我们国内的性能测试工作。 -
开发出高性能的网站,(三):压缩和其他服务器端的技术
2007-01-08 14:04:04
在第一部分 , 我们讲了代码优化的20个技巧,这些代码优化都是针对开发者源代码的;在第二部分 , 我们谈了缓冲控制。我们在此第三部分中,将来和大家一起看看其他的服务器端的技术,来提升网站的速度,我们先来看看HTTP压缩。
什么是HTTP压缩?
HTTP压缩(或叫HTTP内容编码)作为一种网站和网页相关的标准,存在已久了,只是最近几年才引起大家的注意。HTTP压缩的基本概念就是采用标准的gzip压缩或者deflate编码方法,来处理HTTP响应,在网页内容发送到网络上之前对源数据进行压缩。有趣的是,在版本4的IE和NetScape中就早已支持这个技术,但是很少有网站真正使用它。Port80软件公司做的一项调查显示,财富1000强中少于5%的企业网站在服务器端采用了HTTP压缩技术。不过,在具有领导地位的网站,如Google、Amazon、和Yahoo!等,HTTP内容编码技术却是普遍被使用的。考虑到这种技术会给大型的网站们带来带宽上的极大节省,用于突破传统的系统管理员都会积极探索并家以使用HTTP压缩技术。
我们可以在浏览器发出的Accept请求的头部看到HTTP内容编码的键值。我们来看看Mozilla Firefox浏览器的这个请求,如下,我们特别注意一下Accept,Accept-Language,Accept-Encoding,和Accept-Charset的头(header):GET / HTTP/1.1
Host: www.port80software.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.6) Gecko/20040206 Firefox/0.8
Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9, text/plain;q=0.8,video/x-mng,image/png,image/jpeg,image/gif;q=0.2,*/*;q=0.1
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
这些个"Accept"值会被服务器用到,进而决定将适当的内容通过内容协商(Content Negotiation)发回来—这是非常有用的功能,它可以让网站服务器返回不同的语言、字符集、甚至还可以根据使用者的习惯返回不同的技术。关于内容协商的讨论很多,我们这就不再多讲。我们主要来看看和服务器端压缩有关的一些东西。Accept-Encoding表明了浏览器可接受的除了纯文本之外的内容编码的类型,比如gzip压缩还是deflate压缩内容。
我们下面来看看IE发出的请求headers,我们可以看到类似的Accept-Encoding值:GET / HTTP/1.1
Host: www.google.com
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; .NET CLR 1.1.4322)
Accept: image/gif,image/x-xbitmap,image/jpeg,image/pjpeg, application/vnd.ms-excel,application/vnd.ms-powerpoint,application/msword, application/x-shockwave-flash,*/*
Accept-Encoding: gzip,deflate
Accept-Language: en-us
Connection: keep-alive
假设当今主流的每种浏览器都支持gzip和deflate编码(那些不支持的也不会发出Accept-Encoding),我们可以简单的修改一下网站服务器,从而返回压缩内容到这些浏览器上,并返回标准(也就是没有压缩的)内容到其他的浏览器上。在下例中,如果我们的浏览器告诉Google它不接受内容编码,我们会取回3,358字节的数据;如果我们发出Accept-Encoding,再加上应答header告诉我们Content-Encoding: gzip,我们则会取回仅仅1,213字节 。用浏览器的查看源代码功能来看源代码,我们看不出什么差异,但如果使用网络跟踪的话,我们就会发现其响应是不同的。
图一: Google压缩 / 非压缩对比
上例中,虽然文件不大,但是效果依然很明显—压缩后比原来小了74%。再加上我们前面两部分谈到的HTML、CSS、和Javascrīpt代码优化,Google在提升网站性能上的成果非常惊人—它的一个网页居然可以放在一个TCP响应包里。
虽然Google在带宽上的考虑也远远超出其他一般的网站,HTTP内容编码进一步让HTML、CSS、和Javascrīpt等瘦身50%甚至更多。不好的地方是,HTTP内容编码(词语‘压缩’和‘内容编码’在本文中基本上是一个意思) 基本上针对文本内容很有效,对于图像和其他二进制文件的压缩效果就一般了,有时可能根本没有效果,但总的来说,即使有很多二进制文件的时候,整体上可以瘦身15%到30%那么多。
HTTP内容编码的服务器端支持
如果你现在认同HTTP压缩的价值,下一个大问题是:你如何来实施?在Apache网站服务器上,可以使用mod_deflate来进行HTTP内容的编码。在微软的IIS上,就有些麻烦了。虽然IIS 5可以支持gzip的编码压缩,但实施起来还是超级麻烦,尤其考虑到因为各种浏览器中细微差异来进行各种细致参数调整的时候。所以在IIS 5上,还是要考虑第三方的采用ISAPI过滤器的压缩插件,比如httpZip 就是最好的一种。IIS 6上集成了压缩功能,也更快更灵活,但是还是配置起来比较复杂。ZipEnable 带给我们第一个专为IIS 6集成压缩细致管理的工具—并且还有浏览器兼容情况监测功能。
服务器内容编码的实质
当实施HTTP压缩时,要平衡考虑一些因素;如果将服务器配置成‘输出’的内容压缩方式,虽然可以降低带宽的使用,但同时却增加了CPU的开销。多数情况下,这不是什么大问题,尤其当网站服务器所作工作很少的时候。不过,在网络浏览很繁重的网站服务器上,运行相当多的动态内容就可能会达到CPU工作的极限,这时再进而进行压缩的话,CPU可能会超负荷运行了。通过添加而外的服务器硬件资源,当然可能会减轻这种问题,并让我们享受通过压缩而节省下来的带宽, 但最后带宽和CPU的问题还是要看哪个成本更高。
说到底,系统管理员和网站开发者是否对HTTP的压缩有兴趣,还是要看最后的效果如何。当我们明显的发现带宽的负载下来了,那么访问者也可能会明显感觉转载网页的速度慢了。因为,压缩产生和解压缩会带来的CPU负载, TTFB (time to first byte)也通常会增加,这样浏览器渲染网页的速度也会降下来,但这还算是很好的平衡,因为数据压缩后传输的包变小了、变少了,提交的速度会变快,这个快速回补偿网页渲染的慢速。然而,对于宽带用户来说,这样的改善可能就不明显了。不过,这两种情况下,对于网站建设者来说,都可以节省一些网络上的投资。当然,如果可感知的反应时间对某网站来说是主要目标,并且网站的访问者很多都还使用拨号上网,那么本文的第二部分钟所讲的缓冲控制就是比较好的性能提高策略。
最后,HTTP内容编码的另一个潜在问题是和由脚本产生的网页带来的服务器负载有关的,比如PHP和ASP。在此种情况下,主要的问题是,网页内容每次请求可能会被再压缩,这样就会给服务器增加更多的负载(相对压缩静态内容来说)。如果,网站中所有的网页都是在请求时生成的话,那么使用HTTP内容编码就得格外小心了。还好,很多商业上使用的压缩插件,直到如何对内容进行缓冲,但业余(较便宜的)的压缩工具可能就没有这些特性了。
动态网页:立即生成,还是稍后生成?
有趣的是,很多的开发者都是在网站被访问时开始动态的生成很多甚至全部他们网站的网页。比如,http://www.domain.com/article.php?id=5就是一个通用的URL,它暗示了某个网页是由数据库查询时或填充模版生成的。这种常用方法的问题是,在很多情况下,在请求时间生成一个网页是pointless的,因为很多时候这个主要的静态的(所谓的静态的动态网页、或脚本网页),其内容很长时间也不变化,这显然对于提高网页装载速度没有什么帮助。实际上,在一个高负荷的网站这种方式会严重的降低服务期的性能。
要避免不必要的动态网页的生成,有一个方法是,每次有变化时,则预先生成有内容的静态.html网页。如果这些生成的.html网页,还是经过了代码优化(在本文第一部分中过这些描述方法),则更好。这不仅会让服务器交付这些网页更快变得更容易,而且这些技术还会使搜索引擎更友好。
不幸的是,在很多情况下,简单的生成动态的HTML网页并不太容易,也为很多网页只有在网页被访问时才能够正确的生成动态内容。在这种情况下,你最好是对网页进行‘烘焙’生成快速执行的形式。在ASP .NET的情况下,这种形式则是二进制代码,在服务器端执行的特别快。不好的地方是,在用户访问之前,服务器需要先执行这些网页强制执行这些字节代码。还好,在ASP .NET 2.0中,这些问题将得到改善。在PHP中,一些诸如Zend等的优化软件是不错的投资。
对于提交静态和动态网页、或者HTML和图像的不同需要来说,考虑一下针对物理服务器或其他的硬件上的加速可能,也是比较明智的选择。为了网页加速而加强硬件方面的投入的另一个方法是专业化—不同的部件进行不同的工作,这样产生出最大的效率。虽然,本文是从代码和网站服务器校对来说明如何提高网站的性能的,我们也不妨讨论讨论其他相关的元素。
对网站服务器进行涡轮增压
加速网站要考虑的一个重点是服务器软件和服务器硬件。先谈软件,网站系统管理员不太可能来回因为易用性问题、性能问题、安全问题等在Apache和IIS之间切换来切换去。简言之,网站服务器和其底层的操作系统之间的关系错综复杂、互相影响,再进行系统或服务迁移则更是繁重且有风险的工作。所以,你如果真的考虑放弃一种网站服务器而使用另一种的话,你必须严肃认真的好好考虑这个问题;而如果速度是考虑的第一要素的话,建议你考虑一下Zeus。
再谈硬件,如果要考虑升级硬件,则先仔细分析一下服务器上的主要任务。在静态网站上,主要的工作是调整网络连接和把文件从磁盘拷贝到网络上。要加速这样类型的网站,你得把注意力放在高速硬盘子系统和高速网络子系统上,另外还得有足够多的内存来处理并发请求。实际上,你可能得给服务器添加大量的内存,从而为经常使用的对象尽可能的增加内存缓冲来减轻磁盘的存取。有趣的是,CPU的速度在这里却不是十分关键。虽然不能否认CPU对网站的整体性能有影响,但瓶颈主要发生在磁盘上。但是,当网站处理动态网页和静态网页差不多一样多的时候,处理器就显得很关键了,但即便如此高速磁盘或双网卡还是更有效一些。另一种情况下,除了要处理动态网页,还要处理其他占用CPU的操作(比如SSL和HTTP压缩等)的时候,CPU就显得十分关键了。换句话说,要加速网站服务时,服务器具体所作的工作决定着什么类型的硬件资源更需要增强。
当你没有那么多增加服务器硬件或软件的预算时,还有一些物美价廉的解决方法。比如,你可以对服务器的TCP/IP设置进行优化,这样依赖TCP/IP网络的HTTP便可以最优运行。TCP/IP的设置优化里,有一项是TCP的接受窗口,可以把它调整成最适合应用或者最适合网络连接的,或者是针对确保TCP连接的一些参数(如ACK或TCP_NODELAY等)进行调整,根据具体情况设置成使用或不使用。还有一些参数,比如TIME_WAIT时间等,也是可以进行调整的。但要记住,不管怎么调整这些网站服务或操作系统的参数,都必须进行真实的加载试验以验证你的调整会不会反而减慢用户访问的服务或带来新的问题。此外,一定要弄懂这些参数之后,再进行调整。
通过分工进行加速
网站加速还可以考虑的一个出发点是,不同的网站内容可能会拥有不同的提交特性。考虑到不同的内容,其特性也不同,我们可以用多个服务器,每个服务器来执行不同的内容处理,这样可能比用服务器池(server farm)中的每一个服务来处理同样的任务要好得多。
我们来看一个分工进行加速的简单例子。当你的商务网站给购物车或外部网使用SSL加密的时候,你会发现当有多个用户同时访问的时候,SSL加密带来HTTPS段的明显负载会使你的服务器的性能会急剧下降。这种情况下,把流量分配给另一台服务器,其意义就十分明显了。比如,把你的主站点放在www.domain.com上,把结账的处理部分放在shop.domain.com上。这个shop.domain.com就是一个专门处理SSL流量的服务器,可能会用到SSL加速卡。采取分工的方式,可以让你专心处理结账的用户的SSL流量,而不至于像以往SSL的处理会导致服务器整体性能的下降。对于图像和其他重量级的二进制的比如PDF文档或.exe文档,服务器处理其下载可能要花些力气,这些连接通常持续的时间比一般的连接都长,会消耗大量宝贵的TCP/IP资源。进而,对于这些媒体资源(PDF、.exe、图像等)的处理,我们也并不需要把它们和文本资源(HTML、CSS和Javascrīpt等)等同对待处理。在这种情况下,让处理文本资源的服务器有高性能的CPU,让处理媒体资源的服务器有大带宽,是有的放矢的解决之道。
分工还可以进一步应用到网页的生成上。我们可以考虑把生成网页的工作单独放在一个服务器上,把处理静态内容的工作放在另一个服务器上。现在已然有很多网站是采取这样的模式了,这其中很多网站会使用一个叫做Squid的反向代理(reverse proxy)。在设置过程中,代理服务器专门提供静态的内容,速度很快;而后台的服务器则可以专心处理在访问时才会产生的动态内容。缓冲控制策略和规则,我们在第二部分中谈到过,在这时的设置过程中就显得十分重要了;我们得确保代理服务器的缓冲中储存的内容在共享缓冲中是安全的。
为了争夺市场而提速
我们刚才谈的那些东西主要是一些低成本的加速技术,在我们本文即将结束的时候,我们来看看一些需要软硬件成本很高但收益可观的方法。目前市场上提供有一些需要花些钱的独特加速设备,它们可以进行比如网络连接分流、压缩、缓冲、和其他等技术,从而达到加速的目的。 如果你不在乎投资高带宽的话,这些解决方案就十分有效,但是大多数的网站还是更喜欢我们先前介绍过的物美价廉的方法,比如代码优化、缓冲、和HTTP编码等。
就算你有很多资金,可以投资一个服务器池(server farm)、并添加最高档的加速设备,也使用压缩和缓冲技术等,但你还是会最后达到一个极限。要想进一步再提速,还有最后一招:把内容放在离访问者最近的地方,有可能的话,在那个地方再实施上述各类技术(如压缩、缓冲等)。你肯定注意过,有些网站提供镜像服务器等,这样世界各地的访问者就可以就近访问所需内容。不过,还有比这个更有地理分布意义的方法,并且可以透明的让访问者使用。内容分发网络(Content Distribution Network – CDN),比如Akamai,就可以让我们把重型内容(如图象和其他二进制内容等)搬移到离访问者更近的地方,这样通过内容分发网站在世界各地的边缘缓冲,访问者访问起来就会更快。这种方式带来了性能上极大提高,目前世界级的一些大网站都在使用。虽然这算不上是经济实用的方法,但作为这些方法的最后补充,放在这里以飨读者。 -
开发出高性能的网站 (二) — 最佳缓冲控制
2007-01-08 14:01:35
本文的第一部分 (二月份)介绍了如何通过优化代码来尽可能少的传输数据,在本文的第二部分中,我们将着重介绍如何利用Web端的缓冲技术(caching)来尽可能降低传输的频繁度。一旦您开始注意进行有效的缓冲设置,您便可以极大地减少网页加载的次数,尤其对于经常访问您网站的常客和忠诚的访问者来说更是如此,而且还可以降低您整体带宽的消耗,并减少您有限的服务器资源的占用。
Web缓冲的种类缓冲技术的原理很简单。为防止每次都重复地加载同一内容而带来的各种资源消耗和浪费,我们保留一份内容的本地副本,并且只要它还有效就可以反复使用它。最常见的网页缓冲是浏览器缓冲,浏览器缓冲在最终用户的本地硬盘上储存了图像和其他网页对象的副本,以供重复使用。除此之外,还有别的缓冲,比如web服务器上的,还有网络路径上的,甚至最终用户本地的网络上都有—不过,这些不同的缓冲其目的是基本一致的。从本地浏览器的缓冲上开始,往外有本地网络的代理(proxy)缓冲,这样如果代理缓冲中有相同的内容,本地网络中其它的用户便不必跑到远端的web服务器上去索取内容了,他们直接使用代理缓冲里这些相同的东西就可以了。再往外,你的ISP和再往外的各个ISP们可能都有一个类似的代理缓冲。最后,在web服务器上还会使用一个叫做‘reverse proxy cache’的缓冲来保持住最后生成的网页,准备提交,这样可以减轻服务器重复生成和提交被请求的内容的负担。我们可以把上述各种网页缓存分成两类:私有的(private)和公共的(public)。私有缓冲,基本上就是浏览器缓冲,对于一个单个的用户代理(user agent)来说是独一无二的,也就是说只有拥有它的某个最终用户才可以使用。其他的缓冲,比如proxy和reverse proxy缓冲都是公共缓冲。它们是共享资源,其中存储的东西可以被不止一个最终用户使用。图一展示了网页主要常见的缓冲类型:
图一:网页中的缓冲上述图示说明了我们讨论的一个关键问题:网页缓冲存在于网站和网页服务的各个地方,它们尽可能的保存您要访问的网站内容。一方面,从网站性能的角度来讲,我们要让缓冲能够自行发挥作用;另一方面对其能够进行有目的的控制也很关键,比如我们必须可以规定哪些对象可以放入缓冲中、哪些不可以,以及对象保留多长时间等。
新鲜程度和有效性为了更好的使用缓冲,包括更有效的使用浏览器缓冲,我们需要对某一个资源的有效性提供指示,以表明这个资源是否还可以放在缓冲中。更具体的说,我们需要对网页对象提供一系列的缓冲规则,比如设置失效期,达到失效期的对象就不能再保存在缓冲中了。幸运的是,对于依据缓冲控制规则失效的东西,我们有一些工具来处理它们。有两个概念控制着缓冲如何工作:新鲜程度(freshness)和验证(validation)。新鲜程度指的是某个放在缓冲的对象是否是新的,换成更技术化的术语来说,就是这个在缓冲中的对象的状态是否和其相对应的在web服务器上的资源的状态一致。如果浏览器缓冲或者其他的缓冲没有足够的信息表明其是新鲜的,则系统就会产生警告错误并把这个对象当作过期的或者是不新鲜的(stale)。验证则是某个缓冲检查原始服务器来确认是否有潜在不新鲜的对象的过程。如果服务器确认某个缓冲对象仍是新鲜的,则浏览器继续使用本地的资源,否则服务器就会送出一份新鲜的拷贝。
一个简单的缓冲例子我们举一个例子来说新鲜和验证的概念。在此我们使用浏览器缓冲为例,别的公共缓冲的核心原理和浏览器缓冲是一样的。第一步:远程站点有一个网页叫做page1.html。这个网页引用了image1.gif、image2.gif和image3.gif,并且有一个到page2.html的链接。当我们第一次访问这个网页的时候,HTML和相关的GIF图像就会被一个接一个的被下载到本地的浏览器缓冲中
图二:第一次缓冲加载一旦数据被下载到缓冲中,这些数据就会被加上‘邮戳’,这个邮戳就标示了它们从哪里来、何时被访问过。邮戳中也有可能包含有第三条信息:何时需要被重新下载。但是,大多数的网站都不会给它们的数据加上这第三条信息,所以我们也假设我们的例子中也不涉及到这第三条信息。第二步:用户点击了page2.html的链接,这个网页以往从未被访问过,这个网页引用了image1.gif、image3.gif和image4.gif。此时,浏览器下载了这个网页的标示代码,但问题来了:还需要重新下载image1.gif和image3.gif吗,既然它们已经存在于缓冲中了?这个问题的答案显然是不必重新下载。不过,我们如何保证这两个图像自打上次存到缓冲中后,从来没有修改过呢?如果没有缓冲控制信息,可能我们没法保证。所以,浏览器会给服务器发送请求来能够重新验证这些图像是否被修改过。如果没有被修改过,服务器就会快速返回一个304Not Modified回复,告诉浏览器可以放心的使用缓冲中的图像。然而,如果图像被修改过,浏览器就需要下载这个图像的新鲜的拷贝了。这个常见的请求-回复的循环是这样的:
图三:检查缓冲从这个简单的例子中可以很明显地看出来,,即使当CSS、图像、和Javascrīpt是新鲜的,我们也不一定能够享受到缓冲带来的好处,因为浏览器访问一个对象前都要先到服务器那里兜个圈子。IE 浏览器中缺省的设置是‘自动’,这个设置可以在单次浏览器会话中跳过对缓冲对象再验证的过程,这在一定程度上减少了浏览器和服务器之间的持续的来回通信。您可能注意过在同一次的浏览会话中,一般来说重复访问同一个网页的加载速度都比较快。您如果在浏览器设置中选择‘每次访问网页’这个选项,则您就会发现性能上的下降,这是很多个304Not Modified回复造成的。
图四:IE的缓冲控制对话框注意:尽管IE的‘智能缓冲’可以有效地减少不必要的验证请求,它也是IE不断提醒用户若要看到新内容请清除缓冲的罪魁祸首。所以,使用缓冲,必须折中考虑很多事情。
设置缓冲控制策略通过最小化来回通信的次数可以对浏览器加载次数产生巨大的变化。这种变化最显著的情况出现在下述情况下:经过了第一次访问后,用户再次光顾这个网页。这种情况下,所有的网页对象都得再验证,每次都会消耗宝贵的时间,更不用说消耗的带宽和服务器资源。另一方面,恰当的使用缓冲控制可以让浏览器直接从缓冲中加载原来加载过的对象,而不必‘长途跋涉’再次造访服务器。添加缓冲控制规则的效果,可以在网页的加载时间上看得出来,即使用户使用的是宽带,也可以感觉得到网页渲染的速度变快了。除了用户确实感觉得到的变化外,web服务器也可以从处理大量的缓冲再验证请求的负担重稍事解脱一些,这样进而可以更好的提供服务。不过,为了更充分的享受到缓冲带来的好处,程序员需要花些时间精心制作一些缓冲控制策略,来按照网站对象可能的生命周期对其进行分类。这里有一个例子,说的是某简单的电子商务网站的一整套缓冲控制策略:
在这个表中,从缓冲控制的角度来看,共有六类不同类型的对象。既然和公司标识及其他品牌标示有关的东西不太可能变化,这些导航和公司标识的图片就可以看作是基本上永久不变的。CSS和Javascrīpt文件一般来说也是至少半年才会变化。因为网站内容对于搜索引擎优化和用户体验来说至关重要,因此主要的页眉图像可以设置成变化稍微频繁一些。每月的‘特价商品’图像,当然它的保鲜期也就设置成一个月了。还有一些针对个人的特价商品,它们的图象保存在用户的缓冲中,其保鲜期设置成两周,也就是从首次访问开始算起的过期时限是两周。注意,这个类别被标注成‘私有’,以表示这种缓冲不能存在于共享或代理缓冲中。最后,除上述之外其他所有别的内容,它们的缺省都是不能作为缓冲内容的,依次来保证这些文本和动态的内容每次访问请求都是新鲜送出的。对于缓冲HTML网页,你必须得小心谨慎,不管它们是不是静态生成的,除非你很清楚其中的玄机,如果你不清楚的话,就最好保证这些网页不要缓冲。如果某用户缓冲了你的HTML网页,你设置了一定长度的过期时间,则在过期之前,无论你的网页做了多少更新,该用户都不会看到这些变化。另一方面,如果你只是对于独立的对象进行缓冲的话,比如图像、Flash文件、Javascrīpt、和样式表单等,简单的进行重命名就可以替换掉这些缓冲内容。打个比方,您设定了一个策略,想要每年更新您站点的标识文件,但只过了半年的时候,您的公司要做品牌形象改变,并且需要对网站进行相应的修改。幸运的是,如果您没有设定HTML网页要做缓冲,您只消改变标识文件的名称(比如logo.gif变成newlogo.gif)并更改相应HTML文件中的Object Type Duration Navigational, logo images One year CSS, Javascrīpt Six months Main header images Three months Monthly special offer image One month Personalized special offer image (private) Two weeks from first access All other content (HTML, ASP, etc.) Do not cache 引用部分即可。当这个HTML文件被解析时,浏览器就会意识到在它的缓冲中并没有这个新的标示文件,浏览器就会去服务器上下载它。当然了,老的标示文件虽然仍存在于用户的缓冲中相当长的一段时间,但是再也不会被用到了。在慎重的考虑过哪些对象可以或者不可以被存入缓冲中,下一步就是要部署这些策略。
管理缓冲有三种方法来设置缓冲控制规则:- 通过编程序来设置HTTP的headers
- 通过
- 通过配置web服务器来设置HTTP的headers
通过Expires这个header被打上时间戳,所以浏览器在这个时间没有到来之前不会重新向服务器请求这个网页,而是直接从缓冲调出,或者除非用户修改了浏览器中缓冲的设置,或手动的清除了缓冲。当然了,缓冲网页虽然可以带来好处,但如上面所述有时我们并不想缓冲它们,这时您可以把Expires的值设置成过去的某个时间,比如:Expires。除此之外,还有两个Pragma标签被用来和HTTP1.0浏览器的缓冲控制中,而Cache-Control标签则是针对HTTP1.1客户端的。无论何种浏览器,也不管浏览器的版本是多少,只要您是要保证某个网页不被存入缓冲中,这两个标签就很有用:
编程的缓冲控制多数的服务器端的编程环境,如:PHP,ASP,和ColdFusion都可以让你修改HTTP Headers来实现一些特殊的功能。比如,在ASP中,你可以在网页的上面加上一些代码,来调用一些现成的Response对象属性:<% Response.Expires = "1440"Response.CacheControl = "max-age=86400,private"%>在此你通过ASP来生成适合HTTP1.0的Expires header和适合HTTP1.1的Cache-Controlheader。同时在此你还未这个缓冲对象指定了保鲜时间(freshness lifetime)为24小时(注意:Expires值的单位是分钟,而Cache-Control值是秒。)。所以在HTTP响应时,下列header就被加上了(这里我们假设‘现在’是二月十三日、星期五的8:46 PM,格林威治标准时。):Expires: Sat, 14 Feb 2004 20:46:04 GMTCache-control: max-age=86400,private这个机制或类似的其他主流服务器端编程环境下的机制比单单使用
编程缓冲控制Apache和Microsoft IIS都提供一系列的缓冲控制机制。麻烦的是,这两种常用的web服务器使用不同的方法来缓冲,并且缓冲控制策略的授权也不完全掌握在对网站资源非常熟悉的开发者手中。
Apache上的缓冲控制就设定缓冲策略而言,在Apache模块正常安装的情况下,Apache比IIS要容易一些。Apache的服务器管理员,可以通过在服务器的配置文件中(一般来说是httpd.conf)设定mod_expires值来给不同的对象设定保鲜期。在Apache中,Virtual Host和Directory容器可以用来为不同站点指定不同的指示(directive),也可以为同一站点内不同的目录指定不同的指示。这一点,比起metabase脚本对象或图形界面的IIS来说要方便许多。mod_expires的ExpiresByType指示就更好用了,通过它只要一行代码,您就可以设定好某给定MIME类型的所有文件的保鲜期。这个指示可以让您轻松的给站点内的所有的脚本、样式表单、以及图像文件设定缓冲策略。当然,基于对象类型或目录,您还可以制定更为精细的策略。在此情况下,通过给某个特定目录及其子目录的某个.htaccess文件中使用指示(directive),在主配置文件中的设置就可以不考虑了(需要服务器管理员的审慎决定)。通过这种方法,开发人员就可以编写和维护自己的缓冲控制指示,而不需要拥有系统管理员的权限,即使在共享的主机托管环境下也是如此。若您的Apache服务器起初没有mod_expires这一项,我们可以生成它,最好方法就是把它制作成一个共享对象(最简单的方法是使用aspx),之后再在httpd.conf文件中加上这样一行:LoadModule expires_module modules/mod_expires.so如上述,您可以把您配置的指示直接放在httpd.conf文件中。不过,不少管理员更倾向于在外部配置文件中来使用这些东西,这样可以让配置文件干净利落。在我们的例子中,我们也遵循这样的方法,在httpd.conf中使用Apache的Include指示(其中的IfModule容器不必一定使用,它是可选的,使用它比较经典、也比较安全):之后,我们可以在具体的模块配置文件(expires.conf)中来找到这些控制mod_expires行为的各种指示。下面是一些指示的例子: ExpiresActive OnExpiresDefault "access 1 month"ExpiresByType image/png "access 3 months"ExpiresActive指示的作用是让mod_expires生效,ExpiresDefault指示的作用是设定缺省的保鲜期,当有些文件中没有指定保鲜期时,则使用这个缺省的保鲜期。注意其中设定保鲜期的语法;时间单位用什么都可以,可以用秒、也可以用年,基本单位在modification和access中指定。 我们来看看刚才说过的非常有用的ExpiresByType指示,我们在此的例子中要设定服务上所有的.png文件:AllowOverride IndexesExpiresDefault "access 6 months" /static下所有的内容。这个目录拥有自己的ExpiresDefault指示,以及AllowOverride指示,AllowOverride指示的作用是允许为自己及其子目录进行设置,该设置将忽略.htaccess文件中的有关设置。.htaccess文件,则是这个样子的:ExpiresByType text/html "access 1 week"注意这将忽略所有的指示,否则这些指示会对/static目录及其子目录中的所有带有text/hmtl的MIME类型文件起作用。通过使用配置文件中的指示组合,以及通过.htaccess来忽略这些指示,我们基本上可以制定出各种各样的缓冲控制策略,不管该策略有多么复杂,都可以通过管理员或得到合理授权的开发人员来生成。
IIS上的缓冲控制如果您使用微软的Internet Information Service (IIS),设置缓冲控制规则时,您必须有权限使用IIS的Metabase,而IIS Metabase一般是通过Internet Service Manager (ISM)来管理的,ISM是微软管理控制台,通过ISM我们可以控制管理设置。在IIS中设定失效时间,操作比较简单,先运行ISM,之后找到那个你要设定失效时间的目录或文件的属性菜单,之后点击‘HTTP Headers’标签。接下来,选中’Enable Content Expiraction’的复选框;然后,再点击单选钮进行下一步的选择。您可以选择让某个内容立即失效,或设定相对失效期(单位:分、时、或天),或绝对失效期。注意在此之后,Expires和Cache-Control就会被加上了。基本上是下面的样子: 图五:IIS中缓冲控制尽管它的GUI相对友好,但是给IIS上不同类型文件设定不同的缓冲控制策略却显得比较笨拙。如果IIS上站点的文件不按照保鲜期来组织的话,那就更麻烦了。但如果您恰巧是心中牢记缓冲策略来设计网站的话,并且你把不同类型的文件放在不同的目录下,比如
图五:IIS中缓冲控制尽管它的GUI相对友好,但是给IIS上不同类型文件设定不同的缓冲控制策略却显得比较笨拙。如果IIS上站点的文件不按照保鲜期来组织的话,那就更麻烦了。但如果您恰巧是心中牢记缓冲策略来设计网站的话,并且你把不同类型的文件放在不同的目录下,比如 /images/dynamic,/images/static,/images/navigation等,那么通过MMC设置缓冲策略就容易的多了。不过,若您不是这样,或是您正打算优化现有的网站,那您基本上就不得不一个一个文件、一个一个目录的来设置策略了,这绝对是超级麻烦。比起Apache更麻烦的是,在IIS中给开发人员授权让他们来设定缓冲策略,也没什么好的方法,因为修改相应的设定需要访问MMC。不过还好,有第三方软件工具—Port80软件公司提供的CacheRight 可以进行较为方便的设定。和mod_expires的工作原理类似,CacheRight软件创立一个简单的、基于文本的规则文件,它存在于每个网站的文件根(document root),通过它管理员和开发员可以来给整个网站设定失效指示。而且,CacheRight在ExpiresByType指示之外,还添加了ExpiresByPath指示,使前者更完善,这一点超越了mod_expires。有了这一功能,在IIS上为不同文件类型设定策略、或者让一些指定的文件或子文件集忽略某些策略,就相当的容易了。我们看看下面的例子:ExpiresByType image/* : 6 months after access publicExpiresByPath /navimgs/*, /logos/* : 1 year after modification public这里,所有的图像文件的保鲜期都是六个月,只有在navimgs和logos目录下的文件除外。和mod_expires一样,CacheRight可以帮助您设定相对于文件修改时间的失效时间,也可以设定成相对于用户第一次访问的时间。这样的灵活性对于发布或更新的时间安排可能有变化的情况非常有用,而发布和更新计划常常变化是非常普遍的。无论您使用什么样的web服务器,您都值得花些时间来了解如何在服务器端来管理缓冲控制。在编程的缓冲控制中,有规律的中间缓冲和浏览器缓冲都可以很好的运用指示(directive);而在
缓冲的好处至此为止,对于复杂的缓冲问题,我们也只是简单介绍了一些皮毛,希望我们能够给提升网站性能的一个潜在道路指明方向。我们特别希望您通过本文,能了解为什么制定一套综合性的网站缓冲控制策略很重要,我们也希望您现在已经掌握了一些有效地实施这些策略的方法。正确合理的运用这些方法,带来的效果是显著的—能够极大地加快网页加载的速度,尤其对于您网站的老顾客更是如此。此外,缓冲的使用还可以更有效的利用网络带宽,并能减轻服务器的负载。只要您稍稍有意识的修改一下HTTP headers就可以取得上述效果,或者用最少的软件投资即可制订好有效的、基于失效时间的缓冲控制—最省钱省力实现网站性能优化的方法之一。 -
开发出高性能的网站 (一) 20个客户端代码优化技巧
2007-01-08 13:33:05
这个分为三部分的文章概述了一个直观的、省时省力的方法来提升访问网站的速度,这是基于网站性能有关的两个简单法则:
- 尽可能的减少数据的传输量
- 尽可能的减少数据的传输频率
若使用得当,此两条法则会:
- 提高网页的加载速度
- 降低服务器使用的资源
- 提高网络带宽利用率
使用这些技巧来开发网站,不仅能够提高用户对一个网站或者是基于web的一个应用的满意度,更可以节约网站数据传输的成本。这篇文章所讲述的技术细节可帮助我们写出很好很实用的代码,从更广泛的角度来讲,这也将会给网站打造出良好的可用性基础。
第一部分 – 20个客户端代码优化技巧
为自己写代码,为使用而编译
任何一个程序员都很清楚地知道,之所以不把自己所使用的代码作为最终的代码来交付是有它合理的原因的。写代码时最好要尽可能多写些注释,通过编排格式在最大程度上提高代码的可阅读性,同时避免过分的简洁不让晦涩的代码给日后的维护带来困难。之后,我们再使用编译器等把源代码转化成其他格式,一方面达到最优执行,另一方面可以防止反编译,以免造成源代码被剽窃。上述的这种模式其实也适用于网站的开发。具体做法是:先制作好网站和网页的源代码,再利用一些简单的技术(比如:减少空白区域,进行图片和脚本的优化,文件重命名等)把源代码减肥然后你就可以将准备好的网站和网页交付使用了。
希望这种概念对于你来说并不突兀,因为起码你很有可能正是在您站点的副本上操作,而不是直接在正在运行的站点上作修改更新。如果你不是这样做的,那么请马上停止阅读本文,赶紧去给你的站点做个副本吧!无论您的网站的内容是静态的手册还是非常复杂的使用内容管理系统来驱动(CMS-driven)的应用,这都是唯一正确的开发网站的方式。你要是现在还不相信的话,那么我敢说很快的等到你损毁了网站的一些文件却发现难以恢复的时候你就信了。
在建造网站时,您可能会把注意力放在导致下载速度降低的最大元凶—图片、二进制文件(如Flash等)上。减少GIF图片文件的颜色数、压缩JPEG图片文件的大小、优化SWF文件固然颇有裨益,其他大有帮助的方法也不能小觑。要记得网站性能法则中的第一条,我们得不断的努力以尽可能少地传输数据,不论它是markup文件、图片还是脚本。把精力放在减少(X)HTML、CSS和Javascrīpt文件的字节数上似乎是瞎忙乎,可是,这可能恰恰就是最应该注意的地方。
在一个典型的网页加载过程中,(X)HTML文件是最先被浏览器读到的。既然这个文件决定了其他文件的关系,我们可以管这个文件叫主文件(host document)。浏览器一旦接收到这个主文件,便开始解析各种markup;一般在解析的同时,也会触发一系列对相关对象的请求,例如外部脚本、关联的样式表单、图片、或嵌入式Flash等等。这些CSS和Javascrīpt文件有可能继续触发一些对相关图片或脚本等的请求。这些对相关文件的请求排成队列的速度越快,它们到达浏览器的速度也就越快,从而越早的开始显示出页面来。了解了主文件的重要性,我们便知道把它尽快地传给浏览器并加以解析的重要性,因为尽管主文件本身相对来说整个传输量来说只是一小部分,它却能够严重地阻碍网页的加载速度。要明白,用户才不在乎你使用的字节数的多少,用户在乎的是时间!
那么您具体需要怎么做才能作到最优传输的万全准备呢?一个基本的方法是减少空白区域,精简CSS和Javascrīpt,更改文件名,以及对要提交的代码也采用前述相同的策略,使之越简洁越好(Google 就是一个例子). 这些目前大家都熟知的通用技巧,在很多网站和一些书中比如Andy King的 《Speed up Your Site: Website Optimisation 》都能找到。本文则列出我们认为最有效的优化markup和代码的二十大技巧。当然,您可以手动来做部分优化,或者使用网页编辑器及工具来完成一些优化,当然还可以开发出您自己的精简工具。我们要向你介绍一个由Port80软件公司开发的工具w3compiler. 它几乎实现了下面将要提到的所有技巧,而且它也反映出在“真实”世界里代码优化任务的商业价值。接下来,我们来谈谈这些技巧!
Markup优化
典型的markup要么是手工编辑出来的,在非常紧凑,注重标准的格式基础上加入注释和空白区域(white space)的文件;要么是编辑器生成的,非常之肥胖,带有过分的格式编排及编辑器特有的通常用来控制结构的注释,甚至还会有不少重复的和没有用修饰或者代码。这两者都不是最优传输的情况。下列技巧既安全又容易,是减小文件尺寸的好方法:
1、尽可能的除去空白区域
一般而言,空白区域字符(空格、制表符、换行符等)都可以安全删除,但要避免修改pre,textarea, 及受CSS属性中white-space影响的标签。
2、除去注释
除了在客户端给IE和doctype声明的条件注释外,几乎所有的注释都可以安全去除掉。
3、使用最短格式的颜色表示
使用颜色时,不要一股脑的使用十六进制或全颜色名称(full color name),要尽可能根据实际情况使用最短格式的颜色表示。比如,一个为#ff0000的颜色属性可以直接用red</code来说明,而lightgoldenrodyellow可以换成 #FAFAD2#FAFAD2。
4、 使用最短格式的字符表示
和最短颜色表示一样,一些名称可以用最短字符来表示,我们可以用较短的数字来代替某些长长的字母。比如:È 可以变成È。或者,偶尔这个方法反过来也行,比如:ð如果变成ð则可以省一个字节。不过,这个方法不太安全,而且成效有限。
5、 除去无用的标签
有些‘垃圾’markup,比如使用了多次的重复标签或者某些编辑器里用作广告的meta标签,都可以安全地被删除。
CSS优化
CSS也有一套成熟而又简单的优化方法。实际上,时下大多数的CSS都较 (X)HTML更容易压缩。下面所列的技巧除了最后一条都是安全的。最后一条涉及到客户端的网页技术,可能会变得比较复杂。
6、除去CSS中的空白区域
相比起(X)HTML来,CSS对于空白区域没有那么敏感,所以除去空白区域便可以极大地减少CSS文件和style样式表区域的大小。
7、 除去CSS注释
如同除去markup代码中的注释一样,由于CSS中的注释对普通的最终用户来说并没有什么实用价值,所以也应该被除去。不过,如果考虑到较低级的浏览器,则在CSS中的style标签中的屏蔽注释信息不可以被除去。
8. 使用最短格式来表示颜色值
和HTML一样,CSS颜色也可以用词语或十六进制格式表示。注意,在CSS中这样做的效果会稍微明显一些。主要是因为CSS中支持3位的十六进制色值,例如对白色可用#fff来表示。
9、对CSS的规则进行合并、减少或删除
CSS中的诸如字体大小、字体重量等规则往往可以使用一种单属性字体的速记注释方式来表示。使用得当的话,这个技巧可以让您把如下的规则:p {font-size: 36pt;
font-family: Arial;
line-height: 48pt;
font-weight: bold;}
改写成下面简短的形式:p{font:bold 36pt/48pt Arial;}
如果继承方法使用得当的话,您还会发现在样式表单中的一些规则可以显著的减少或干脆删掉。到目前为止尚没有能自动移除规则的工具,所以只能通过手工调整CSS向导(Wizard)来进行这些工作。不过即将推出的w2compiler 2.0会有这个功能。
10、对类和ID值进行重命名
在CSS优化中最危险的动作可能是重命名类或ID值了。看看如下规则:.superSpecial {color: red; font-size: 36pt;}
可将其更名为sS。而对ID值一样可以遵循这样的原则,例如对于:#firstParagraph {background-color: yellow;}
则可将原来的 ”#firstParagraph” 重命名为 ”#fp”,并在整个文档中重复这一动作 。诚然,这样做可能会涉及到“标识-样式-脚本”互相依赖的问题:如果一个“tag”有一个ID值,而这个值又可能不但用于样式表,还可能用于脚本参考,甚至可能是一个链接目标地址。在这种情况下,您一旦修改了这个值,您就必须得保证对所有相关的脚本和链接参考都进行了相应的修改,包括其他文件中的这个值,所以千万要小心细致。
改变类的值相对改变ID值来说,危险性小一些。因为经验告诉我们,比较起ID值来说,大多数Javascrīpt程序员都不太经常处理类的值。然而,改变类的名称来缩减CSS的尺寸也面临着和改变ID名称同样的问题,所以再次强调,要小心谨慎。
请注意:最好不要更改名称属性,尤其是表单区域中的名称属性。因为这些数值也会被服务器端程序所操作。虽然不是不可能,但对多数的网站来讲,要计算好这些相互依赖关系是困难的。
Javascrīpt优化
越来越多的网站都依赖于Javascrīpt来生成导航菜单、表格确认和其他各种各样实用的东西。不足为奇,大多数这些代码都非常笨重,亟待优化。对Javascrīpt代码的很多优化技术同那些用于markup代码和CSS的技术很相似。不过,对Javascrīpt的优化必须更加小心翼翼,因为一旦操作有误,其后果可能不仅仅是显示变形,并且可能导致网页残缺不全。下面我们先来看看一些最简单明了的方法,然后再探讨那些需要小心操作的技巧。
11. 除去Javascrīpt注释
除了 注释,其他所有的 // or /* */ 注释都可以安全删除,因为 它们对于最终使用者来说没有任何意义(除非有人想了解您的脚本是如何工作的)。
12.除去Javascrīpt中的空白区域
有意思的是,除去Javascrīpt中的空白区域并不象想象的那么有用。一方面,像如下代码:x = x + 1;
显然可以简短得写成x=x+1;
然而,很多随便的Javascrīpt程序员会忘记在两行之间加上分号,这时空白区域的除去就会带来问题。比如,下面合法的Javascrīpt使用了暗示的(implied)分号:x=x+1
y=y+1
草率地删除了空白区域则会产生如下表达式:x=x+1y=y+1
显然,错误就产生了。但如果您加上必需的分号,如下:x=x+1;y=y+1;
则在字节数上并没有减少。然而在此,我们仍然鼓励这种格式的变化,因为对w3compiler Beta版的测试反馈中,很多人对‘看起来压缩了的’脚本非常满意(也许这是因为视觉上确认了对原始代码的格式转变)。他们也喜欢这种处理方法产生的另一个效果,那就是让交付的代码变得更难读。
13.进行代码优化
简单的方法如除去暗示的(implied)分号,某些情形下的变量声明或者空回车语句都可以进一步减少脚本代码。一些简略的表达方式也会产生很好的优化,例如:x=x+1;
可以写成:x++;
不过得小心谨慎,不然代码很容易出错。
14.重命名用户自定义的变量和函数
为了阅读方便,我们都知道在脚本中应该使用象sumTotal这样的变量而不是s。不过,考虑到下载的速度,sumTotal这个变量就显得冗长了。这个长度对于最终使用者来说没有意义,但对浏览器下载则是个负担。这个时候s就成为较好的选择了。先写好方便阅读的代码,然后再使用一些工具来处理以供交付。这种处理方式在这里再一次展示了其价值所在。将所有的名称都重新用一个或两个字母来命名将带来显著的改善。
15.改写内建(built-in)对象
长长用户变量名会造成Javascrīpt代码过长,除此之外,内建(built-in)对象(比如Window、Document、Navigator等)也是原因之一。例如:alert(window.navigator.appName);
alert(window.navigator.appVersion);
alert(window.navigator.userAgent);
可以改写成如下简短的代码:w=window;n=w.navigator;a=alert;
a(n.appName);
a(n.appVersion);
a(n.userAgent);
如果这几个对象使用频繁的话,这样改写带来的好处就不言而喻了。事实上这些对象也的确经常被调用。然而我要提醒的是,如果Window或Navigator对象仅仅被使用了一次的话,这样的替换反而使代码变得更长。所以手工进行这种优化时要格外小心,不过好在目前市面的常用的Javascrīpt代码优化工具都已经考虑到这个因素了。
这个技巧带来一个对象更名后脚本执行效率的问题:除了代码长短上带来的好处,这种改写更名实际上还会稍微的提高一点脚本执行的速度,因为这些对象将会被放在所有被调用对象中比较靠前的位置。Javascrīpt游戏开发程序员使用这个技巧已经有多年了,下载和执行速度都会有所提高,并且对本地浏览器的内存花销也会降低,可谓一石三鸟。
文件方面的优化
最后一类的优化技巧与文件和站点的组织有关。下面谈及的一些技巧可能会牵扯到服务器的调整和站点的重构。
16.重命名用户访问不到的独立文件和目录
一些站点往往包含有诸如SubHeaderAbout.gif或rollover.js等是用户无法通过URL来访问的文件。它们通常都保存在一个标准名称的目录中,比如/images,因此我们常常会在markup代码中看到这样的句子:<img src="/images/SubHeaderAbout.gif">
或者更糟糕的象<img src="../../../images/SubHeaderAbout.gif">
既然这些文件从来都不会被访问到,对于最终使用者而言,方便不方便阅读便无关紧要。考虑下载速度的因素,上述句子改成下列形式更有意义:<img src="/0/a.gif">
然而手工的文件和目录的修改工作量太大了,我们可以借助一些内容管理系统来完成相关的工作,比如将内容重命名成简短格式等。前面提到的w3compiler就有自动复制并且检查相互依赖关系的功能。如果使用得当,这个技巧会给引用这些文件的(X)HTML文件减肥不少,并且也让那些剽窃(X)HTML的人重新使用这些文件设置了重重障碍。
17.使用URL rewriter来缩短所有的网页URL
注意在刚才提到的技巧中并不建议对网页的文件名(例如products.html)进行重命名。那样的话,则下面的标示:<a href="products.html">Products</a>
就会变成<a href="p.html">Products</a>
这背后的主要原因是读者会看到一个这样的URL:http://www.sitename.com/p.html相比起http://www.sitename.com/products.html来,后者比前者要来的更有意义、更好用的多。
不过,在不牺牲网页URL原义的前提下,假如我们结合更名技巧和修改服务器配置的话,我们还是有可能从缩短文件名中得到收获。譬如,在源代码中把products.html用p.htmll替换掉,之后再设立一个URL复写(rewrite)规则,由服务器端的一个类似复写模块的过滤器比如 来使用这个规则,从而再把这个URL扩展成一个较为用户友好的值。注意这个窍门,如果这个复写规则只执行‘外部’(external)重定向的话,新的URL仅仅会写在使用者浏览器的地址条处,因而会强迫浏览器重新请求该页。在此种情况下,文件本身没有被重命名,仅仅是在源代码中URL里使用了重命名的简短的文件名。
由于这个技巧依赖于URL的复写,并且缺少对服务器端工具(如复写模块)的广泛接触渠道和理解,即使是象w3compiler之类的高级工具在目前也不推崇使用这个技巧。然而, 考虑到像Yahoo!这样的大型网站通过积极使用该技巧得到了显著的获益,这个技巧是不能够被忽视的,毕竟它给目录及文件名称都是非常具描述性的站点提供了明显的减肥(X)HTML文件的效果。
18.除去或缩短文件扩展名
想想看,其实有些情况下文件的扩展名并没有多大用处,比如.gif, .jpg, .js等。浏览器不会依赖这些扩展名来显示页面,而是在处理时使用MIME类的头信息(header)。了解了这一点,我们就可以把:<img src="images/SubHeaderAbout.gif">
简化为:<img src="images/SubHeaderAbout">
或是结合文件名目录名重命名,我们可以得到:<img src="/0/sA">.
您可别乍一看这个结果就吓跑了,.sA.gif仍然是.sA.gif文件,只不过网页的访问者不知道罢了。
不过,为了使用这个相对高级的技巧,您还需要对服务器来做一下修改。主要要做的工作是启用一个叫做“内容协商”(content negotiation)的东西。它可能是服务器自带的,也可能需要一个扩展(比如象Apache的mod_negotation 模块或者IIS里Port80的PageXchanger )来支持。这样做会有一个负面的影响,它可能会造成服务器性能的一点损失。然而,内容协商的功能所带来的好处远大于所付出的。干净利落的URL可让您的网站即安全又轻便,甚至还使得自适应的内容传递变成可能:根据访问者浏览器的功能和系统的设置来向他传输不同类型的图片或语言!更多的说明请参看同作者所著的 Towards Next Generation URLs 一文。
注意:少了扩展名的URL不会降低您网站在搜索引擎上的排名。Port80软件和其他知名网站(如W3C网站)都使用此技术而没有负面效果。
19. 重构<scrīpt>和<style>调用方式来优化请求次数
我们常常在一个HTML文件头中看到这样标记代码:<scrīpt src="/scrīpts/rollovers.js"></scrīpt>
<scrīpt src="/scrīpts/validation.js"></scrīpt>
<scrīpt src="/scrīpts/tracking.js"></scrīpt>
大多数情况下,上述代码应该被简化成:<scrīpt src="/0/g.js"></scrīpt>
其中g.js包含了所有供全局使用的函数。虽然把脚本文件分成三份对于维护来说是有道理的,但对于代码的传输则没有意义。单个的脚本下载要比三个分离的请求高效的多,并且这也同时简化了markup代码的长度。有趣的是,这个方法模仿了传统编程语言编译器的连接概念
20.考虑代码级的cache能力
提高网站性能中最重要的方法之一是提高缓冲能力(cacheability)。网页开发者对使用<meta>标签来设置缓冲控制都很熟悉,可是撇开meta对代理的缓冲毫无用处不说,缓冲能力的真正价值是其对相关对象(比如图片或脚本)方面的应用。为了提高缓冲能力,您要考虑根据改变频率对相关对象进行分段,把更适合缓冲处理的东西放在某个目录中(比如:/cache或者/images/cache。一旦您按照这个方法来组织您的网站,添加缓冲控制规则就很容易了,这样你的网站就会向经常来的访问者“跳”出来。
现在,您已经了解了20条有用的优化技巧来使您的网站变得更快。从单条来看它们可能没有很大的作用。可是把它们合起来使用的话,网站的传输能力便会有明显的提高。在下一篇文章中,我们将重点放在缓冲处理上。我们会解释缓冲如何经常会被错误使用,以及如何通过一些小小的改动来取得性能的显著提高。 - 尽可能的减少数据的传输量
-
VMI出现错误,解决办法二
2006-12-30 00:18:48
事件查看器-应用程序 PerfNet/WinMgmt错误——解决实例
-
VMI出现错误,解决办法一
2006-12-30 00:13:25
单击开始,然后右键单击我的电脑。
在快捷菜单上,单击管理。
在计算机管理控制台的左窗格中,双击“服务和应用程序”。
在“服务和应用程序”下,单击服务。
在计算机管理控制台的右窗格中,找到然后右键单击 Windows Management Instrumentation。
在快捷菜单上,单击停止。
启动 Windows 资源管理器,然后找到 %SystemRoot%System32WbemRepository 文件夹。
删除 %SystemRoot%\System32\WbemR\epository 文件夹中的所有文件。
重新启动计算机。当计算机重新启动时,删除的文件会重新创建出来。
注意:当重新启动计算机时,Windows Management Instrumentation 服务会自动启动。
-
如何测试web网站?
2006-12-15 16:00:38
译文
web网站本质上带有web服务器和客户端浏览器的C/S结构的应用程序。主要考虑web页面、TCP/IP通讯、Internet链接、防火墙和运行在web页面上的一些程序(例如,applet、javascrīpt、应用程序插件),以及运行在服务器端的应用程序(例如,CGI脚本、数据库接口、日志程序、动态页面产生器,asp等)。另外,因为服务器和浏览器类型很多,不同版本差别很小,但是表现出现的结果却不同,连接速度以及日益迅速的技术和多种标准、协议。使得web测试成为一项正在不断研究的课题。其它要考虑的如下:1、服务器上期望的负载是多少(例如,每单位时间内的点击量),在这些负载下应该具有什么样的性能(例如,服务器反应时间,数据库查询时间)。性能测试需要什么样的测试工具呢(例如,web负载测试工具,其它已经被采用的测试工具,web 自动下载工具,等等)?
2、系统用户是谁?他们使用什么样的浏览器?使用什么类型的连接速度?他们是在公司内部(这样可能有比较快的连接速度和相似的浏览器)或者外部(这可能有使用多种浏览器和连接速度)?
3、在客户端希望有什么样的性能(例如,页面显示速度?动画、applets的速度等?如何引导和运行)?
4、允许网站维护或升级吗?投入多少?
5、需要考虑安全方面(防火墙,加密、密码等)是否需要,如何做?怎么能被测试?需要连接的Internet网站可靠性有多高?对备份系统或冗余链接请求如何处理和测试?web网站管理、升级时需要考虑哪些步骤?需求、跟踪、控制页面内容、图形、链接等有什么需求?
6、需要考虑哪种HTML规范?多么严格?允许终端用户浏览器有哪些变化?
7、页面显示和/或图片占据整个页面或页面一部分有标准或需求吗?
8、内部和外部的链接能够被验证和升级吗?多久一次?
9、产品系统上能被测试吗?或者需要一个单独的测试系统?浏览器的缓存、浏览器操作设置改变、拨号上网连接以及Internet中产生的“交通堵塞”问题在测试中是否解决,这些考虑了吗?10、服务器日志和报告内容能定制吗?它们是否被认为是系统测试的主要部分并需要测试吗?
11、CGI程序、applets、javascrīpts、ActiveX 组件等能被维护、跟踪、控制和测试吗?
原文:How can World Wide Web sites be tested?
Web sites are essentially client/server applications - with web servers and 'browser' clients. Consideration should be given to the interactions between html pages, TCP/IP communications, Internet connections, firewalls, applications that run in web pages (such as applets, javascrīpt, plug-in applications), and applications that run on the server side (such as cgi scrīpts, database interfaces, logging applications, dynamic page generators, asp, etc.). Additionally, there are a wide variety of servers and browsers, various versions of each, small but sometimes significant differences between them, variations in connection speeds, rapidly changing technologies, and multiple standards and protocols. The end result is that testing for web sites can become a major ongoing effort. Other considerations might include:- What are the expected loads on the server (e.g., number of hits per unit time?), and what kind of performance is required under such loads (such as web server response time, database query response times). What kinds of tools will be needed for performance testing (such as web load testing tools, other tools already in house that can be adapted, web robot downloading tools, etc.)?
- Who is the target audience? What kind of browsers will they be using? What kind of connection speeds will they by using? Are they intra- organization (thus with likely high connection speeds and similar browsers) or Internet-wide (thus with a wide variety of connection speeds and browser types)?
- What kind of performance is expected on the client side (e.g., how fast should pages appear, how fast should animations, applets, etc. load and run)?
- Will down time for server and content maintenance/upgrades be allowed? how much?
- What kinds of security (firewalls, encryptions, passwords, etc.) will be required and what is it expected to do? How can it be tested?
- How reliable are the site's Internet connections required to be? And how does that affect backup system or redundant connection requirements and testing?
- What processes will be required to manage updates to the web site's content, and what are the requirements for maintaining, tracking, and controlling page content, graphics, links, etc.?
- Which HTML specification will be adhered to? How strictly? What variations will be allowed for targeted browsers?
- Will there be any standards or requirements for page appearance and/or graphics throughout a site or parts of a site??
- How will internal and external links be validated and updated? how often?
- Can testing be done on the production system, or will a separate test system be required? How are browser caching, variations in browser option settings, dial-up connection variabilities, and real-world internet 'traffic congestion' problems to be accounted for in testing?
- How extensive or customized are the server logging and reporting requirements; are they considered an integral part of the system and do they require testing?
- How are cgi programs, applets, javascrīpts, ActiveX components, etc. to be maintained, tracked, controlled, and tested?
-
软件测试分析报告应该包括哪些内容?
2006-12-15 15:39:22
1.1编写目的
说明这份测试分析报告的具体编写目的,指出预期的阅读范围。1.2背景
说明:a.被测试软件系统的名称;
b.该软件的任务提出者、开发者、用户及安装此软件的计算中心,指出测试环境与实际运行环境 之间可能存在的差异以及这些差异对测试结果的影响。
1.3定义
列出本文件中用到的专问术语的定义和外文首字母组词的原词组。1.4参考资料
列出要用到的参考资料,如:a.本项目的经核准的计划任务书或合同、上级机关的批文;
b.属于本项目的其他已发表的文件;
c.本文件中各处引用的文件、资料,包括所要用到的软件开发标准。列出这些文件的标题、文件编号、发表日期和出版单位,说明能够得到这些文件资料的来源。
2测试概要
用表格的形式列出每一项测试的标识符及其测试内容,并指明实际进行的测试工作内容与测试计划中预先设计的内容之间的差别,说明作出这种改变的原因。3测试结果及发现
3.1测试1(标识符)
把本项测试中实际得到的动态输出(包括内部生成数据输出)结果同对于动态输出的要求进行比较,陈述其中的各项发现。3.2测试2(标识符)
用类似本报告3.1条的方式给出第 2项及其后各项测试内容的测试结果和发现。4对软件功能的结论
4.1功能1(标识符)
4.1.1能力
简述该项功能,说明为满足此项功能而设计的软件能力以及经过一项或多项测试已证实的能力。4.1.2限制
说明测试数据值的范围(包括动态数据和静态数据),列出就这项功能而言,测试期间在该软件中查出的缺陷、局限性。4.2功能2(标识符)
用类似本报告4.l的方式给出第2项及其后各项功能的测试结论。......
5分析摘要
5.1能力
陈述经测试证实了的本软件的能力。如果所进行的测试是为了验证一项或几项特定性能要求的实现,应提供这方面的测试结果与要求之间的比较,并确定测试环境与实际运行环境之间可能存在的差异 对能力的测试所带来的影响。5.2缺陷和限制
陈述经测试证实的软件缺陷和限制,说明每项缺陷和限制对软件性能的影响,并说明全部测得的性能缺陷的累积影响和总影响。5.3建议
对每项缺陷提出改进建议,如:a. 各项修改可采用的修改方法;
b. 各项修改的紧迫程度;
c. 各项修改预计的工作量;
d. 各项修改的负责人。
5.4评价
说明该项软件的开发是否已达到预定目标,能否交付使用。6测试资源消耗
总结测试工作的资源消耗数据,如工作人员的水平级别数量、机时消耗等。 -
性能测试原理及性能测试实例分析
2006-12-15 15:32:45
【摘要】 在大型软件系统投入生产之前进行性能测试已经成为趋势,本文结合一个性能测试案例对性能测试的过程和原理进行了介绍。
【关键字】 性能测试 并发测试 负载测试
• 软件测试中的性能测试
软件测试是保证软件质量的重要手段,也是软件过程中一个必不可少的环节。而性能测试则隶属于软件测试中的系统级测试,它对软件在集成系统中运行的性能行为进行测试,旨在及早确定和消除软件中与构架有关的性能瓶颈。
• 性能测试的含义
目前对性能测试没有明确的定义,一般地,它主要是针对系统的性能指标制定性能测试方案,执行测试用例,得出测试结果来验证系统的性能指标是否满足既定值。性能指标里可能包括系统各个方面的能力,如系统并发处理能力,批量业务处理能力等。
• 性能测试的分解
在性能测试的执行中,可以根据具体的性能指标,分解为几种测试,根据其关系,可以在不同的时间和空间内执行。这些子测试通常包括以下几种:
并发测试:验证系统的并发处理能力。一般是和服务器端建立大量的并发连接,通过客户端的响应时间和服务器端的性能监测情况来判断系统是否达到了既定的并发能力指标。
负载测试:验证系统的负载工作能力。系统配置不变的条件下,在一定时间内,服务器端在高负载情况下的性能行为表现。这里的负载可以是用户数,交易数,事务数等。
配置测试:核实在操作条件保持不变的情况下,系统在使用不同配置时其性能行为的可接受性。
健壮性测试:核实被测系统的性能行为在异常或极端条件之下的可接受性。这里的异常或极端条件指的是资源过少,用户数过多,突发故障等。
随着软件系统的规模日益庞大,结构日趋复杂,对软件系统的性能测试已经成为必须和趋势。尤其大型的分布式软件系统更要在正式运行前进行性能测试,因为这样的系统在投入生产之后,往往要接受大批量的业务量,这对应用程序本身,操作系统, 中心数据库服务器,中间件服务器,网络设备的承受力都是一个严峻的考验。在其中任意一个环节出现的问题都可能给用户带来巨大的商业损失。预见软件系统的并发承受能力以避免商业风险,这是在软件测试阶段就应该解决的。例如中国人民银行的现代化支付系统和上海外汇交易中心的本币交易系统都在投入生产之前进行了多轮的第三方性能测试,起到了很好的作用。
下面我就介绍一个性能测试案例。
• 一个性能测试实例
• 被测系统
1)被测系统介绍
本系统应我国金融信息化发展设计,采用当今比较先进和流行的技术,是运行在城域网上的大型分布式应用系统。
本系统遵循J2EE规范,采用B/S体系结构进行设计和开发。业务主要分为交易业务和查询业务,查询业务采用J2EE规范,交易业务以J2EE体系架构为基础,进行进一步的处理,采用了TCP的四层结构。系统体系结构图如下:
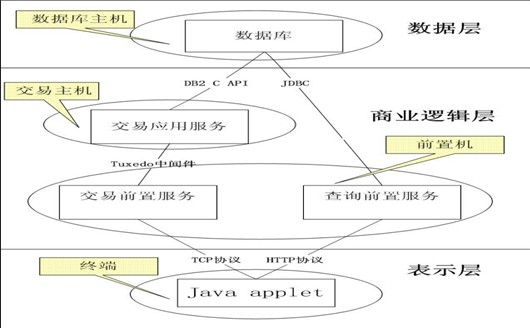
图表 1被测系统体系结构设计图
- 表示层:
运行在终端上。运行java applet程序,提供协议控制和用户界面,与系统最终用户实现直接交互,通过TCP/HTTP与前置系统通讯。向前置系统发送请求报文,并接收前置系统返回的回应报文。
- 商业逻辑层:
作为中间层实现核心业务逻辑服务。
交易应用服务:运行在交易主机上。在tuxedo中间件上运行业务处理程序,按交易规则处理前置机发来的交易指令,通过tuxedo jolt与前置机连接,通过DB2 C API与数据库连接。
交易前置服务和查询前置服务:运行在前置机上。交易前置服务运行服务程序接收终端请求报文并通过tuxedo jolt客户端将其转发给交易主机,再通过轮询和同步反馈接收交易主机返回的报文,将其转发给业务终端;查询前置服务运行在weblogic应用服务器上并调用Jreport组件,通过JDBC完成对查询流指令的发送并接受数据库返回的结果给业务终端。
- 数据层:
运行在数据库主机上。负责整个系统中数据信息的存储、访问及其优化。运行DB2数据库服务程序。通过DB2 C API与交易主机通讯,JDBC与查询前置服务通讯。
数据库主机和交易主机运行在交易中心城市,前置机运行在各个分中心城市,终端是各个城市参加交易的单位,整个系统覆盖城域网。2) 被测系统的性能要求和性能指标
金融系统是业务处理十分频繁、数据交换吞吐量很大的系统,业务处理的速度直接关系到公司的经济效益和客户对公司的评价。在客观条件下,整个广域网系统必须在大业务量的情况下同时保持快速的实时响应能力,以保证整个业务系统的通畅运行。用户对此提出如下性能指标:

表格1用户要求性能指标表
下面我们会根据此系统和给定的性能指标来进行性能测试:
性能测试的目的是最大程度地模拟真实业务场景,来验证系统的性能指标,并发现可能存在的性能瓶颈。
1)对被测系统进行系统分析
我们可以看到本系统大体上由终端、前置机、交易主机、数据库主机节点组成。
在整个业务流程中,业务终端→前置机→交易主机→数据库主机形成了一个压力流串,每个节点在压力下能够正常工作是整个系统正常运转的基础。也就是说,如果其中任意一个节点在业务压力下发生了拥塞、处理不力等不正常情况,那整个系统都无法正常运转。
我们来看一下业务流程。
首先,从终端到前置机,终端产生业务报文发送至前置机,前置机上运行查询前置服务和交易前置服务,查询前置服务向下通过HTTP协议以WEB服务形式和终端连接,向上通过JDBC直接与数据库系统相连。交易前置服务向下通过基于TCP协议的socket连接和终端通讯,向上通过tuxedo jolt客户端和交易应用服务连接。交易应用服务进行业务逻辑计算,并操作数据库系统。
由以上分析,我们可以整理出整个系统的两条压力流程线来,之所以我们把其分为两条流程线,是因为交易前置服务和查询前置服务的工作原理完全不同,下与终端的连接,上与交易主机的连接也完全是独立的两个通路。
终端→交易前置机→交易主机→数据库系统
终端→查询前置机→数据库系统
下面我们先独立分析两条流程线,之后我们将再次综合分析,以考虑二者之间的相互影响作用。
第一条路线上主要运行的是登陆指令和交易指令信息。
当系统运作时,多个交易终端与交易前置服务建立socket连接,完成登陆,之后发送交易指令,造成对交易前置服务的压力。交易前置服务通过运行服务程序接收到交易指令,并检验其合法性,然后通过交易中间件tuxedo的客户端把业务的压力传递给交易主机进行处理。交易主机进行必要的金融计算和业务逻辑运行,得出反馈结果,生成消息,一方面顺原路返回到各个终端上去,一方面记录入数据库。
在本条流程线上的加压主要考验交易前置服务程序的socket多连接建立能力,tuxedo交易中间件的即时响应能力,交易主机的计算能力,以及DB2数据库的DML语句加锁机制。
第二条路线上主要运行的是查询指令信息。
查询指令产生时,通过http协议访问weblogic上的web服务器和应用服务器上的相应组件,以JDBC接口访问后台的DB2数据库,并把数据库返回的结果发送至终端界面。
在本条流程线上的加压主要验证weblogic处理能力,数据库中索引是否创建合理。
两条流程线相对独立,但又是互相依赖的。由于是对同一个数据库系统进行读操作和写操作,查询流程的结果依赖于交易流程数据的产生,交易流程的产生的数据又通过查询流程得到验证。在进行压力测试时,两者的协同会对数据库形成压力的冲击。
鉴于以上分析,结合用户性能指标,我们决定把本次性能测试分解为如下几个子测试来进行。A: 并发登陆测试:750个终端一分钟内并发登陆系统,并且响应时间在30秒之内。
B: 业务负载测试
此下又有三个子测试。
- 交易流程测试:多个终端发起交易请求,逐渐加压,以达到300笔/秒的压力为限。
- 查询流程测试:多个终端进行查询,逐渐加压,以达到400笔/秒的压力为限。查询成功与否以所请求的web页面完全展现为标准。(查询响应能力其实和数据库中的数据量有关系,后来和用户进一步确认,基础数据为30万条)
- 综合测试:
在上面两种测试都通过的情况下,进行综合测试。
2)性能测试的执行过程,性能测试依照下面的步骤来进行:
本次压力测试采用MI公司的loadrunner工具,脚本编辑和编译工作在VU Generator(脚本作坊)中进行。
理想的脚本是对现实世界的业务行为进行了完全无误的模拟,这其实是不可能的。我们的目标是使模拟的误差在我们认可的范围之内,并能有方法加以控制。
针对并发登陆测试和交易流程测试,由于两者运行机理相同,都是终端调用socket client,和交易前置的socket server建立连接,将请求消息发送至交易前置机。我们考虑采用将此部分java socket程序编入测试脚本程序,生成登陆和交易业务脚本,通过loadrunner来执行。这样做的好处是绕过终端IE界面复杂的处理逻辑,直接施压在前置机上(这种方式同时也带来了偏差,在执行测试场景时通过其它方法得到了一定的弥补)。
脚本除了要实现与前置机的socket连接,业务发送等功能,还要建立用户信息数据池,设置检测点、异常退出点,为脚本执行后的结果统计和分析提供正确的依据。
交易业务脚本内容略。部分如下:
public class Actions {/*登陆变量初始化*/ProtocolManager protocol;//ProtocolManager为实现socket连接的类 ServiceName service; //ServiceName对服务端的信息进行了封装,包括IP地址和端口号。LoginMessage login;//LoginMessage为登陆时需要向服务器发送的消息,待服务器确认并返回回应消息时,登陆成功。protocol = new ProtocolManager(); //创建ProtocolManager类的protocol对象service = ServiceName.getInstance();//获得ServiceName的实例login=new LoginMessage();//创建LoginMessage类的login对象service.setIP("200.31.10.18");//设置服务端的IP地址service.setPort(17777);//设置服务端的端口号/*设置登陆消息*/ login.serUserName(lr.eval.string(“{loginName}”));//从数据池里读出用户名,设置在login成员变量里login.setPasswd(“1234”);//数据库中添加的用户密码都为1234/*发送登陆消息*/protocol.login(login);//发送登陆消息lr_start_transaction("trade");//交易开始点TradeMessage trademessage;//生成交易消息/*设置交易消息*/………………………….
………………………….
/*发送交易消息*/………………………….
………………………….
if(sendfail)lr_end_transaction("trade", LR_FAIL);//如果发送交易消息失败,交易结束,返回。/*循环回收主机返回的处理信息*/…………………………
…………………………
if(recievefail)lr_end_transaction("trade", LR_FAIL);//如果不能接收到主机处理回应消息,交易结束,返回。if(recievesuccess)lr_end_transaction("trade", LR_PASS);//如果接收到主机成功处理的回应消息,交易结束,返回。…………………………..
}在上面的例子中,我们主要对每笔交易进行了transaction化。在交易开始时设置开始检测点,交易结束时设置结束检测点,并给loadrunner报出交易状态。实际的脚本中在回收交易响应消息时还进行了拆包,在应用层上对交易状态进行识别,并非例子中只在socket层加以判断。
针对查询流程测试,由于loadrunner工具支持基于http的web访问录制功能,我们将考虑采用以录制脚本为主,手工编写脚本为辅的方法,生成查询业务脚本,通过loadrunner来执行。由于查询脚本基本由录制生成http请求和应答,不同的压力测试工具录制会有差别,这里就不再写出查询脚本样例。
在本次性能测试中,用户提出的性能指标不够细致和确切,通过对用户调查和实际业务分析,我们把性能指标的实现方式进行了明确的定位。A:并发登陆测试场景
并发登陆750用户/分钟,登陆响应时间在30秒之内。仔细考虑一下,这里的并发登陆750用户/分钟指的是系统能够在1分钟内接受750个用户的登陆请求,而处理的效果如何则在交易终端体现,即登陆响应时间。基于这样的理解,我们把用户性能指标转化为如下的测试场景:
从第一秒钟开始,用loadrunner每秒钟登陆13个用户,并保持socket连接,直到1分钟结束,从终端向系统一共发送750个左右的用户登陆请求,系统在一分钟内建立了750个连接。在终端观察并统计登陆响应时间。如果系统不能响应持续增加的登陆请求或平均登陆响应时间大于30秒,并发登陆测试场景都不能算通过。
为了帮助用户更加深入了解系统的能力,我们对系统的瞬时并发能力进行测试,即测试系统所能承受的最大的瞬时并发用户登陆连接请求个数。这个场景通过loadrunner在登陆前设置同步点来实现,这个结果将结合上一个结果一同反映系统的登陆处理能力。B:交易流程测试和查询流程测试:
在这里我们只对系统的业务负载能力做测试(并发处理能力在登陆测试中已经得到考证)。测试场景如下:
在loadrunner中,建立goal-orented的测试场景,以400笔/秒为目标,将调度权交给loadrunner来试图达到这个指标。
C: 综合测试:
交易流程测试和查询流程测试同时进行。
以上的测试场景要求均可在loadrunner中的Controller进行设置完成。
测试场景的创建之后,我们的测试任务更加具体化和清晰化。
在loadrunner中的controller中开启unix系统资源计数器,weblogic计数器,DB2计数器,检测系统资源消耗情况,并最终和测试结果数据合并,成为分析图表。
测试结果可在测试执行完毕后,通过loadrunner工具中的Analysis(分析器)获得。
A: 并发登陆测试
依照设计好的测试场景,用loadrunner工具在一分钟内渐增向系统发送登陆请求。分别进行三次,结果如下
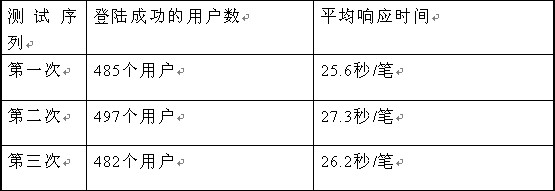
表格 2登陆测试结果数据表
注:这里的登陆成功用户指的是系统接受了登陆请求,并建立了连接。平均响应时间在登陆脚本里设置检测点,由loadrunner工具自动获得。
考察系统的瞬时并发处理能力:在完成上一步测试的前提下,逐步增加瞬时并发登陆用户数,直到系统极限。
测试执行结果如下:

B: 负载测试
- 交易流程测试:
测试结果如下:
对于通过网络接口发送的批量业务请求,均在性能指标所指定的时间范围内得到请求成功的反馈消息,说明主机已经处理成功。
在通过网络接口发送业务请求的同时,开启IE,通过实际终端界面进行登陆和交易,系统响应时间延长,界面显示和刷新明显变慢,到业务量高峰时期,界面已经不能显示任何信息,处于不可工作的状态。
需求说明的是系统正常工作时,每个界面终端不仅应该能够展示己方的交易信息,还要展示其他交易单位的交易信息和系统信息。因此当交易量大的时候,界面需要展示的信息量是巨大的,这本身对终端界面是一个性能考验。
- 查询流程测试:
本流程测试在交易流程测试之后进行,以利用其生成的数据。
测试结果基本满足性能指标。
- 综合测试
由于交易流程测试的未通过,本测试已经不能执行。
A:并发测试结果分析
根据上述的并发测试响应时间表,我们可以得出以下的结论:
被测系统在一分钟内并不能接受750个用户的登陆请求,其可接受的登陆请求用户数大概为490个左右。在这样的条件下,登陆响应时间在用户要求范围之内。
被测系统的瞬时并发处理能力约为122个用户。
B: 交易流程测试结果分析及性能评价
根据交易流程测试结果可知,通过脚本程序进行业务行为,发送业务请求消息到回收主机处理回应消息,这段时间系统是顺畅的,反应也是迅速的,但是在终端界面却不能即时展现消息。这说明信息的回馈通路在终端界面出现了性能瓶颈。当界面需要在短时间内展示大量交易信息时,已经不能承受负荷。这与终端采用java applet技术有关。
C: 查询流程测试结果分析
查询流程基本符合性能指标。
需要说明的是,实际中,以上每个场景的测试都执行了多次,中间件参数进行了多次的调优。从以上测试的结果分析也可以看出,我们的性能测试瓶颈不是出现在中间件产品上,而是在自身开发的程序上。
• 总结
由以上的实例过程我们可以看出性能测试基本由以下几个步骤进行
- 系统分析
将系统的性能指标转化为性能测试的具体目标。通常在这一步骤里,要分析被测系统结构,结合性能指标,制定具体的性能测试实施方案。这要求测试人员对被测系统结构和实施业务的全面掌握。
2. 建立虚拟用户脚本
将业务流程转化为测试脚本,通常指的是虚拟用户脚本或虚拟用户。虚拟用户通过驱动一个真正的客户程序来模拟真实用户。在这一步骤里,要将各类被测业务流程从头至尾进行确认和记录,弄清这些交易过程可以帮助分析到每步操作的细节和时间,并能精确地转化为脚本。此过程类似制造一个能够模仿人的行为和动作的机器人过程。这个步骤非常重要,在这里将现实世界中的单个用户行为比较精确地转化为计算机程序语言。如果对现实世界的行为模仿失真,不能反映真实世界,性能测试的有效性和必要性也就失去了意义。
3. 根据用户性能指标创建测试场景
根据真实业务场景,将单个用户的行为进行复制和控制,转化为多个用户的行为。在这个步骤里,对脚本的执行制定规则和约束关系。具体涉及到交易量,并发时序等参数的设置。这好比是指挥脚本运行的司令部。这个步骤十分关键,往往需要结合用户性能指标进行细致地分析。
4. 运行测试场景,同步监测应用性能
在性能测试运行中,实时监测能让测试人员在测试过程中的任何时刻都可以了解应用程序的性能优劣。系统的每一部件都需要监测:客户端,网络,web服务器,应用服务器,数据库和所有服务器硬件。实时监测可以在测试执行中及早发现性能瓶颈。
5. 性能测试的结果分析和性能评价
结合测试结果数据,分析出系统性能行为表现的规律,并准确定位系统的性能瓶颈所在。在这个步骤里,可以利用数学手段对大批量数据进行计算和统计,使结果更加具有客观性。在性能测试中,需要注意的是,能够执行的性能测试方案并不一定是成功的,成败的关键在于其是否精确地对真实世界进行了模拟。
在整个性能测试过程中,自动化测试工具的选择只能影响性能测试执行的复杂程度,简便一些或繁杂一些;但人的分析和思考却会直接导致性能测试的成败。所以本篇着重于对性能测试思路的整理。测试工具的介绍可以参看有关压力测试工具的资料。
注1:在本次性能测试案例中,还涉及到健壮性测试和可恢复性测试,限于篇幅,只介绍了并发测试和负载测试。
注2:loadrunner脚本样例并非实际运行脚本,只是为了表示其流程。
• 参考文献
Roger S. Pressman:软件工程实践者的研究方法黄柏素梅宏译机械工业出版社
文章出处:www.51testing.com 作者:柳胜
-
性能测试(并发负载压力)测试分析-简要篇
2006-12-15 15:15:24
在论坛混了多日,发现越来越多的性能测试工程师基本上都能够掌握利用测试工具来作负载压力测试,但多数人对怎样去分析工具收集到的测试结果感到无从下手,下面我就把个人工作中的体会和收集到的有关资料整理出来,希望能对大家分析测试结果有所帮助。
分析原则:
• 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
• 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
• 分段排除法 很有效
分析的信息来源:
•1 根据场景运行过程中的错误提示信息
•2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 •Error: Failed to connect to server “10.10.10.30:8080″: [10060] Connection
•Error: timed out Error: Server “10.10.10.30″ has shut down the connection prematurely
分析:
•A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
•B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
•C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired
分析:可能是以下原因造成
•A、应用服务参数设置太大导致服务器的瓶颈
•B、页面中图片太多
•C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
• 分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
• 细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
• 如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题
3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低。
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;
内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)
4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in (’db block gets’,
‘consistent gets’,'physical reads’) ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = ‘redo log space requests’ ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name=’sorts (disk)’ and b.name=’sorts (memory)’
注:上述SQL Server和Oracle数据库分析,只是一些简单、基本的分析,特别是Oracle数据库的分析和优化,是一门专门的技术,进一步的分析可查相关资料。
原始链接:http://blog.51testing.com/?49159/action_viewspace_itemid_869.html
-
集合点疑问
2006-12-05 23:05:20
刚开始做性能测试的工作,现在主要学习使用LoadRunner,在实际工作的使用过程中,有很多不是太理解的地方。
比如:现在要通过一个网站首页,测试该网站服务器的性能参数,总共用户数是600个,每分钟10个,如果采用集合点的话,哪种方式比较符合实际?
如果选择当所有正在运行的 Vuser 中的 100% 到达集合点时释放,那么能算出多少用户的时候才释放么?
希望自己能够早日强起来。


