
-
浅谈数据字典对分析性能的帮助
2007-03-26 17:54:06
现在普遍采用关系数据库。在用户来看,关系模型的逻辑结构是一张二维表,它由行和列组成。关系模型要求关系必须是规范化的,最基本的条件就是关系的每一个分量必须是不可再分的数据项,即不允许表中嵌套表这种结构。在关系模型中实体与实体之间的联系都是通过关系来表示即实体间的联系都是通过各个表之间的联系实现的。在数据库的物理结构中,表都是以文件形式存储的。
关于数据字典,数据字典是存储着数据库所用到的相关信息,其实也就是数据库本身所提供的一系列的表。里面存储了对象信息如表、视图、索引等信息以及内存和磁盘的运行情况、缓存区大小等的系统信息。oracle中数据字典分为静态和动态之分。静态数据字典中的表是不可以被直接访问的但是可以访问其视图,有三类视图user_、all_、dba_。而动态数据字典也包含很多表和视图,其中的数据是在数据库运行中不断更新的,比如通过查询动态数据字典我们可以监控 SGA 中字典缓冲区的命中率、监控当前数据库谁在运行什么SQL语句等信息,oracle中这些动态视图是以v$开头的,而这些数据都是只读的可以帮助我们了解系统的性能。另外数据字典中的详细的数据信息也是进行系统设计、维护的重要依据。
例如我们通过lr监控web应用系统的性能,发现应用服务器处理时间非常长,那么就需要查找是因为应用服务器的问题还是因为数据库的问题,分析应用服务器性能如果工作良好,那么就可以定位问题出在数据库中,通过SQL查看相应表或视图比如查看回滚段的争用情况、监控 SGA 中字典缓冲区等从而定位问题所在。
-
loadrunner函数实践总结-持续更新
2007-03-23 17:51:42
lr_whoami: 得到vuser的信息。
例如:
A.录制一个登录tom邮箱的脚本,当然要在脚本中首先定义
int id,scid;
char *groupname;
在脚本的的用户名、密码之后插入如下语句
lr_whoami(&id, &groupname, &scid);
lr_output_message("**********id =%d", id);
lr_output_message("**********groupname=%s", groupname);
lr_output_message("**********scid=%d", scid);
把脚本保存,命名为tomLogMail
B.运行脚本确保脚本可以成功执行,打开controller设置场景。有两点需要注意一下:
1,为了方便查找把结果文件存放在一个特定的目录下如f:\loadrunner_scrīpt\tomlogmail\res
2,在controller中的运行时设置Run-time Settings-Log中选中总是发送消息Always send messages. 此项非常重要,如果不选中该项在F:\LoadRunner_scrīpt\tomLogMail\res\log目录下将不会有任何log生成。
C.我设置3个vuser每15s增加一个。成功运行脚本
到F:\LoadRunner_scrīpt\tomLogMail\res\log目录下,看到有三个log日志文件tomLogMail_1.log、tomLogMail_2.log、tomLogMail_3.log,打开就可以看到以下信息
tomLogMail_1.log中:
Action.c(64): **********id =1 [MsgId: MMSG-17999]
Action.c(65): **********groupname=tomLogMail [MsgId: MMSG-17999]
Action.c(66): **********scid=0 [MsgId: MMSG-17999]
tomLogMail_2.log中:
Action.c(64): **********id =2 [MsgId: MMSG-17999]
Action.c(65): **********groupname=tomLogMail [MsgId: MMSG-17999]
Action.c(66): **********scid=0 [MsgId: MMSG-17999]
tomLogMail_3.log中:
Action.c(64): **********id =3 [MsgId: MMSG-17999]
Action.c(65): **********groupname=tomLogMail [MsgId: MMSG-17999]
Action.c(66): **********scid=0 [MsgId: MMSG-17999]
此log中vuser的信息就可以帮助我们了解每一个vuser的信息,尤其是当我们一次运行多个脚本的时候,清楚的了解每一个vuser的信息有时候可以帮助我们很好的解决一些问题。
例如:
登录tom邮箱,需要监控在登录成功的时候cpu的利用率是多少。
A. 写一个函数
Int cup_monitor() {} 用于监控登录成功的时候cpu的利用率返比如40%,该函数回一个int k比如40。
B. 在脚本登录用户名密码的后面插入函数
lr_user_data_point("monitorcput",k);
C.在controller中设置场景,运行,就可以看到”User Defined Data Points”是淡蓝色的,把它拖动到右边的显示区,就可以在场景运行过程中监控自定义的数据。

D.打开Analysis进行分析,也可以看到”User Defined Data Points”是淡蓝色可用的,analysis已经成功生成了数据图表,以供测试人员分析之用。

如果不设置lr_user_data_point函数,运行场景在controller和analysis中的树状菜单中”User Defined Data Points”都呈现灰色是不可用的。
-
关于终端仿真Legacy-Terminal Emulation(RTE)
2007-03-22 16:02:24
在研究lr的各种协议,发现lr的功能真是强大,传统协议Legacy中涉及到终端仿真。
终端仿真这个概念经常出现,今天仔细想了一想终端仿真?我究竟如何表达才能让别人明白呢?顿时无语!一个很简单的概念感觉上很明白,可是真的是要用语言表达出来就沉默了.....索性研究一下。
早期的计算机都是一台主机独立工作,所以当时没有终端仿真的概念。而现在的计算机则可以模拟各种终端,怎么模拟呢?举个例子

我们通过ssh等基于应用层的协议连接到远程的大型服务器上,我们可以坐在自己的电脑前面输入top,chmod.....等命令操作远程的服务器,就好像我们真正登录上到远程的服务器一样,这就叫做终端仿真。所以终端仿真就是模拟终端(UNIX/LINUX)的计算机。平时我都是用ssh就好似这样

然而lr也支持此种功能,选择Legacy-Terminal Emulation(RTE) 链接远程服务器出现如下界面

选择session type,写入host name, ip,tpye,id 就可以链接到远程服务器了,实现终端仿真

脚本中就会出现以下函数
TE_connect(
"comm-type = telnet;"
"host-name = 10.1.1.18;"
"telnet-port = 23;"
"terminal-id = 10.1.1.151;"
"set-window-size = true;"
"security-type = unsecured;"
"telnet-binary-mode = true;"
"terminal-type = linux;"
"terminal-model = vt100;"
, 60000);我们可以修改comm-type 比如说ssh。
也已修改telnet-port等等
FTP: 21 SSH:22 TELNET:23 WEB:80
也许我们会提出疑问,lr这个功能有什么用处呢?举一个简单的例子,我们对web网页录制脚本插入集合点、设置检查点、设置事务、修改脚本、设置迭代次数等等,然后在cotroller的场景中运行我们这样做的目的是什么呢?是找到系统的瓶颈、衡量服务器的性能等等。而此处我们只不过把对web网页录制改为录制登录远程服务器而已,脚本仍旧在controller场景中运行,目的同样是衡量服务器的性能等等。简单一点说就是我们录制1次登录linux,在场景中执行的时候我们可以通过增加虚拟用户数模拟多个用户同时登录服务器并进行相关操作。
-
最近
2007-03-22 10:04:21
最近很多的事情,最主要的是职业方面的。但是只有一点不变-学习是不能停止的.....有时间还会继续写测试的相关技术。也同时感谢一些朋友的关注。 -
学习loadrunner之一_事务
2007-03-14 00:20:05
Loadrunner是一款负载测试工具,它有三个核心组件分别是Virtual User Generator、Controller、Analysis。Virtual User Generator 可以通过录制脚本准确的记录下来用户的每一步操作并且可以进行集合点设置、事务设置、参数化等操作从而为在Controller中执行特定的场景做准备。Controller顾名思义,它可以控制脚本的执行,通过把脚本放置在一个特定的场景中,模拟一批真实用户的操作过程,这些模拟的真实用户就叫做虚拟用户。通过这些虚拟用户可以对系统进行负载测试。Analysis应该是测试人员极为关注的一个组件,通过Controller执行完某一个场景之后,Analysis可以自动生成测试结果并通过图形的形式显示出来,测试人员只有借助这些图表才能准确分析出系统的瓶颈并且确定性能是否达到要求。
下面介绍一下如何进行集合点、检查点以及参数化的设置:
对于集合点、检查点的设置有两种方法,一种是在录制完脚本以后,手工在脚本中添加相关的关键字例如lr_start_transaction等,这种方法对脚本语言的理解能力要求较高。另一种是直接在录制的过程中添加集合点、检查点,这样lr就会自动把集合点、检查点的关键字添加到脚本中。
事务:就是用户某一步或者某几步操作的集合。当我们需要通过某一步或是某几步操作从而衡量服务器的性能的时候,这时我们就把这些操作设置成一个事务,当事务开始执行的时候lr就开始计时当事务运行结束计时停止,执行事务的时间会在在最后的结果中显示出来。
实例:登录sina网站,把点击“天气”设置成一个事务,衡量服务器处理处理该事务的性能。
1,点击红色的录制按钮,输入URL开始录制。弹出sina的首页,点击
 设置事物的开始位置,这时弹出事务开始对话框要求输入事务的名称,一般来讲我们都会把事务名称命名为容理解的名字,此处我们命名为“天气”
设置事物的开始位置,这时弹出事务开始对话框要求输入事务的名称,一般来讲我们都会把事务名称命名为容理解的名字,此处我们命名为“天气”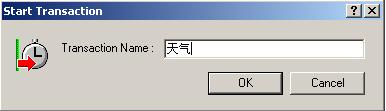
点击OK完成事务的开始点设置。
2,在sina页面上点击“天气”的连接,出现天气页面
3,点击
 设置事务的结束点,这时弹出事务结束对话框
设置事务的结束点,这时弹出事务结束对话框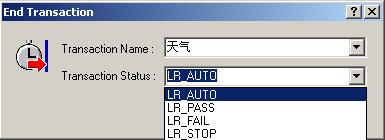
lr根据匹配原则已经自动把事务名字一栏填入“天气”,我们只需要选择事务的状态。状态有三种LR_AUTO、 LR_PASS、 LR_FAIL、 LR_STOP,
LR_AUTO:事物的状态被自动设置,如果事务执行成功,状态设置为PASS,如果执行失败,状态设置为FAIL,如果由于异常中断,状态被设置成STOP.
LR_PASS:事务如果执行成功,代码的返回状态就是PASS。
LR_FAIL:事务如果执行失败,代码的返回状态就是FAIL。
一般我们选择LR_AUTO。 那么我们会有疑问什么时候我们选择PASS或者是FAIL呢?
Lr的帮助文档中有一条例子,可以很好的帮助我们理解
lr.start_transaction("GetStocks");
try {String stocks[];
stocks = orStockServer1.getStockList();
if (stocks.length == 0)throw new Exception("No stocks returned/available");
lr.end_transaction("GetStocks", lr.PASS);
}lr.end_transaction("GetStocks", lr.FAIL);
lr.message(" An exception occurred : " + e1.toString() );
代码说明:这时一个得到stock list的例子,程序中设置了异常检查来确保getStockList()方法返回非零的长度。
同时我也进行了如下的脚本修改
………………
lr_start_transaction("天气");
lr_think_time( 3 );
web_add_cookie("mysinal=ai_erica; DOMAIN=weather.news.sina.com.cn");
web_add_cookie("SINAGLOBAL=221.219.31.58.924471172571904604; DOMAIN=weather.news.sina.com.cn");
………………
lr_end_transaction("天气", LR_FAIL);
在最后我把该事物的结束状态设置为FAIL,然后运行该脚本,其实该事物的运行是没有任何错误的,完全可以运行成功,只是在最后我把事务的状态手工设置为FAIL。当脚本执行完后,查看Ececution Log看到这样一条log语句:
Action.c(297): Notify: Transaction "天气" ended with "Fail" status (Duration: 5.1436).
那么这样做的意义是什么呢?为什么要设置事务结束状态呢?原因就是在Analysis中生成结果图表的时候我们就能看到这个名为“天气”的事务执行是失败的。如果语句是这样:
Action.c(297): Notify: Transaction "天气" ended with "Pass" status (Duration: 5.1436).
Analysis中生成结果图表的时候我们就能看到这个名为“天气”的事务执行是成功的。
设置事务结束状态的用途就在这里。试想Lr为什么能自动生成结果图表?无非就是Analysis通过一些定义好的API获取执行脚本过程中的返回值,从而显示出事务执行的正确还是错误,或是显示出响应时间等信息,然后调用GUI使我们很直观的看到测试结果。
-
发送HTTP请求的简易过程
2007-03-13 16:22:19

我个人理解:欢迎拍砖
当我们点击一个网页的链接URL的时候比如sina. 客户端(我们自己的机器)就向sina的服务器发送一个标准的HTTP请求,其中客户端发送的链接URL请求被包含在HTTP中,TCP/IP承载HTTP在网络中进行传输,最终找到sina的服务器,sina服务器中包含三个层次(表示层、控制层、模型层),通过控制层查找相应的模型(模型层主要涉及的是一些业务的实现,我们最熟悉的jsp+structs 中的action就是属于模型层)或是数据库执行相应的数据操作,比如通过模型层找到用户想看的那个URL页面信息,然后把结果返回给表示层,表示层就会向客户端返回一篇html文档,数据又经过7层模型传回到客户端,ie浏览器进行html文档的解析,把页面显示出来。
HTTP请求包括三部分:Request Line请求行,header头部,body
其中Request Line中包含了用户请求的URL其次还有请求的方法、协议等一些其他信息。
-
几种服务器简述
2007-03-13 11:52:47
现在我们常接触到的有以下几种服务器:
IIS: 在windows下首选此web服务器,它支持HTML、ASP
Apache: 它是一种web服务器,它支持HTML、PHP, ,但若要支持ASP,必须下载plug in
Tomcat: 它也是一种web服务器,它支持HTML、JSP、servlet
BEA的WebLogic、IBM的WebSphere: 他们是j2ee应用服务器, 不仅支持HTML、JSP、servlet, 主要用来部署基于j2ee的企业应用程序 如EJB,(EJB通常用来处理更为复杂的业务逻辑),所以WebLogic和WebSphere的功能相比tomcat更加强大是企业级的应用服务器。
现在大多数应用服务器都包含了web服务器,也就是说web服务器是应用服务器的子集。但是基于性能考虑一般不把应用服务器和web服务器配置在一起。
JBOSS: 也是一种j2ee服务器,和WebLogic、WebSphere属于同一类。它是开源的,具有良好的运行效率和可靠性,所以也得到越来越多的j2ee应用开发者的青睐。
有一篇文章是讲述web服务器和应用服务器的区别的
http://blog.csdn.net/ndscyanfly/archive/2006/11/30/1422137.aspx
其实简单来讲,就是应用服务器为企业提供了更强大的功能以及可以处理更为复杂的业务逻辑,它通过各种协议,把商业逻辑暴露给客户端应用程序,应用程序使用此商业逻辑就象调用对象的一个方法一样。而这些方法都遵循一定的规定与格式,就如同我们必须明确的定义每个齿轮的半径大小、体积、齿轮宽度,把许多这样按规定制作的齿轮对接在一起才能提供动力。
-
SQL语法详解
2007-03-13 10:06:01
一些基本的SQL命令有一段时间不用了,就会有些忘记了,周六的时候找了一些,今天贴出来共享。(忘记了是从那个网站找到的了:))
**********
SQL语法详解
Select用途:
从指定表中取出指定的列的数据
语法:
SELECT column_name(s) FROM table_name
解释:
从数据库中选取资料列,并允许从一或多个资料表中,选取一或多个资料列或资料行。SELECT 陈述式的完整语法相当复杂,但主要子句可摘要为:
SELECT select_list
[ INTO new_table ]
FROM table_source
[ WHERE search_condition ]
[ GROUP BY group_by_expression ]
[ HAVING search_condition ]
[ ORDER BY order_expression [ ASC | DESC ] ]
例:
“Persons” 表中的数据有
LastName
FirstName
Address
City
Hansen
Ola
Timoteivn 10
Sandnes
Svendson
Tove
Borgvn 23
Sandnes
Pettersen
Kari
Storgt 20
Stavanger
选出字段名” LastName”、” FirstName” 的数据
SELECT LastName,FirstName FROM Persons
返回结果:
LastName
FirstName
Hansen
Ola
Svendson
Tove
Pettersen
Kari
选出所有字段的数据
SELECT * FROM Persons
返回结果:
LastName
FirstName
Address
City
Hansen
Ola
Timoteivn 10
Sandnes
Svendson
Tove
Borgvn 23
Sandnes
Pettersen
Kari
Storgt 20
Stavanger
Where
用途:
被用来规定一种选择查询的标准
语法:
SELECT column FROM table WHERE column condition value
下面的操作符能被使用在WHERE中:
=,<>,>,<,>=,<=,BETWEEN,LIKE
注意: 在某些SQL的版本中不等号< >能被写作为!=
解释:
SELECT语句返回WHERE子句中条件为true的数据
例:
从” Persons”表中选出生活在” Sandnes” 的人
SELECT * FROM Persons WHERE City='Sandnes'
Persons 表中的数据有:
LastName
FirstName
Address
City
Year
Hansen
Ola
Timoteivn 10
Sandnes
1951
Svendson
Tove
Borgvn 23
Sandnes
1978
Svendson
Stale
Kaivn 18
Sandnes
1980
Pettersen
Kari
Storgt 20
Stavanger
1960
返回结果:
LastName
FirstName
Address
City
Year
Hansen
Ola
Timoteivn 10
Sandnes
1951
Svendson
Tove
Borgvn 23
Sandnes
1978
Svendson
Stale
Kaivn 18
Sandnes
1980
And & Or
用途:
在WHERE子句中AND和OR被用来连接两个或者更多的条件
解释:
AND在结合两个布尔表达式时,只有在两个表达式都为 TRUE 时才传回 TRUE
OR在结合两个布尔表达式时,只要其中一个条件为 TRUE 时,OR便传回 TRUE
例:
Persons 表中的原始数据:
LastName
FirstName
Address
City
Hansen
Ola
Timoteivn 10
Sandnes
Svendson
Tove
Borgvn 23
Sandnes
Svendson
Stephen
Kaivn 18
Sandnes
用AND运算子来查找Persons 表中FirstName为”Tove”而且LastName为” Svendson”的数据
SELECT * FROM Persons
WHERE FirstName='Tove'
AND LastName='Svendson'
返回结果:
LastName
FirstName
Address
City
Svendson
Tove
Borgvn 23
Sandnes
用OR运算子来查找Persons 表中FirstName为”Tove”或者LastName为” Svendson”的数据
SELECT * FROM Persons
WHERE firstname='Tove'
OR lastname='Svendson'
返回结果:
LastName
FirstName
Address
City
Svendson
Tove
Borgvn 23
Sandnes
Svendson
Stephen
Kaivn 18
Sandnes
你也能结合AND和OR (使用括号形成复杂的表达式),如:
SELECT * FROM Persons WHERE
(FirstName='Tove' OR FirstName='Stephen')
AND LastName='Svendson'
返回结果:
LastName
FirstName
Address
City
Svendson
Tove
Borgvn 23
Sandnes
Svendson
Stephen
Kaivn 18
Sandnes
Between…And
用途:
指定需返回数据的范围
语法:
SELECT column_name FROM table_name
WHERE column_name
BETWEEN &#118;alue1 AND &#118;alue2
例:
“Persons”表中的原始数据
LastName
FirstName
Address
City
Hansen
Ola
Timoteivn 10
Sandnes
Nordmann
Anna
Neset 18
Sandnes
Pettersen
Kari
Storgt 20
Stavanger
Svendson
Tove
Borgvn 23
Sandnes
用BETWEEN…AND返回LastName为从”Hansen”到”Pettersen”的数据:
SELECT * FROM Persons WHERE LastName
BETWEEN 'Hansen' AND 'Pettersen'
返回结果:
LastName
FirstName
Address
City
Hansen
Ola
Timoteivn 10
Sandnes
Nordmann
Anna
Neset 18
Sandnes
Pettersen
Kari
Storgt 20
Stavanger
为了显示指定范围之外的数据,也可以用NOT操作符:
SELECT * FROM Persons WHERE LastName
NOT BETWEEN 'Hansen' AND 'Pettersen'
返回结果:
LastName
FirstName
Address
City
Svendson
Tove
Borgvn 23
Sandnes
Distinct
用途:
DISTINCT关键字被用作返回唯一的值
语法:
SELECT DISTINCT column-name(s) FROM table-name
解释:
当column-name(s)中存在重复的值时,返回结果仅留下一个
例:
“Orders”表中的原始数据
Company
OrderNumber
Sega
3412
W3Schools
2312
Trio
4678
W3Schools
6798
用DISTINCT关键字返回Company字段中唯一的值:
SELECT DISTINCT Company FROM Orders
返回结果:
Company
Sega
W3Schools
Trio
Order by
用途:
指定结果集的排序
语法:
SELECT column-name(s) FROM table-name ORDER BY { order_by_expression [ ASC | DESC ] }
解释:
指定结果集的排序,可以按照ASC(递增方式排序,从最低值到最高值)或者DESC(递减方式排序,从最高值到最低值)的方式进行排序,默认的方式是ASC
例:
“Orders”表中的原始数据:
Company
OrderNumber
Sega
3412
ABC Shop
5678
W3Schools
2312
W3Schools
6798
按照Company字段的升序方式返回结果集:
SELECT Company, OrderNumber FROM Orders
ORDER BY Company
返回结果:
Company
OrderNumber
ABC Shop
5678
Sega
3412
W3Schools
6798
W3Schools
2312
按照Company字段的降序方式返回结果集:
SELECT Company, OrderNumber FROM Orders
ORDER BY Company DESC
返回结果:
Company
OrderNumber
W3Schools
6798
W3Schools
2312
Sega
3412
ABC Shop
5678
Group by
用途:
对结果集进行分组,常与汇总函数一起使用。
语法:
SELECT column,SUM(column) FROM table GROUP BY column
例:
“Sales”表中的原始数据:
Company
Amount
W3Schools
5500
IBM
4500
W3Schools
7100
按照Company字段进行分组,求出每个Company的Amout的合计:
SELECT Company,SUM(Amount) FROM Sales
GROUP BY Company
返回结果:
Company
SUM(Amount)
W3Schools
12600
IBM
4500
Having
用途:
指定群组或汇总的搜寻条件。
语法:
SELECT column,SUM(column) FROM table
GROUP BY column
HAVING SUM(column) condition &#118;alue
解释:
HAVING 通常与 GROUP BY 子句同时使用。不使用 GROUP BY 时,HAVING 则与 WHERE 子句功能相似。
例:
“Sales”表中的原始数据:
Company
Amount
W3Schools
5500
IBM
4500
W3Schools
7100
按照Company字段进行分组,求出每个Company的Amout的合计在10000以上的数据:
SELECT Company,SUM(Amount) FROM Sales
GROUP BY Company HAVING SUM(Amount)>10000
返回结果:
Company
SUM(Amount)
W3Schools
12600
Join
用途:
当你要从两个或者以上的表中选取结果集时,你就会用到JOIN。
例:
“Employees”表中的数据如下,(其中ID为主键):
ID
Name
01
Hansen, Ola
02
Svendson, Tove
03
Svendson, Stephen
04
Pettersen, Kari
“Orders”表中的数据如下:
ID
Product
01
Printer
03
Table
03
Chair
用Employees的ID和Orders的ID相关联选取数据:
SELECT Employees.Name, Orders.Product
FROM Employees, Orders
WHERE Employees.ID = Orders.ID
返回结果:
Name
Product
Hansen, Ola
Printer
Svendson, Stephen
Table
Svendson, Stephen
Chair
或者你也可以用JOIN关键字来完成上面的操作:
SELECT Employees.Name, Orders.Product
FROM Employees
INNER JOIN Orders
ON Employees.ID = Orders.ID
INNER JOIN的语法:
SELECT field1, field2, field3
FROM first_table
INNER JOIN second_table
ON first_table.keyfield = second_table.foreign_keyfield
解释:
INNER JOIN返回的结果集是两个表中所有相匹配的数据。
LEFT JOIN的语法:
SELECT field1, field2, field3
FROM first_table
LEFT JOIN second_table
ON first_table.keyfield = second_table.foreign_keyfield
用”Employees”表去左外联结”Orders”表去找出相关数据:
SELECT Employees.Name, Orders.Product
FROM Employees
LEFT JOIN Orders
ON Employees.ID = Orders.ID
返回结果:
Name
Product
Hansen, Ola
Printer
Svendson, Tove
Svendson, Stephen
Table
Svendson, Stephen
Chair
Pettersen, Kari
解释:
LEFT JOIN返回”first_table”中所有的行尽管在” second_table”中没有相匹配的数据。
RIGHT JOIN的语法:
SELECT field1, field2, field3
FROM first_table
RIGHT JOIN second_table
ON first_table.keyfield = second_table.foreign_keyfield
用”Employees”表去右外联结”Orders”表去找出相关数据:
SELECT Employees.Name, Orders.Product
FROM Employees
RIGHT JOIN Orders
ON Employees.ID = Orders.ID
返回结果:
Name
Product
Hansen, Ola
Printer
Svendson, Stephen
Table
Svendson, Stephen
Chair
解释:
RIGHT JOIN返回” second_table”中所有的行尽管在”first_table”中没有相匹配的数据。
Alias
用途:
可用在表、结果集或者列上,为它们取一个逻辑名称
语法:
给列取别名:
SELECT column AS column_alias FROM table
给表取别名:
SELECT column FROM table AS table_alias
例:
“Persons”表中的原始数据:
LastName
FirstName
Address
City
Hansen
Ola
Timoteivn 10
Sandnes
Svendson
Tove
Borgvn 23
Sandnes
Pettersen
Kari
Storgt 20
Stavanger
运行下面的SQL:
SELECT LastName AS Family, FirstName AS Name
FROM Persons
返回结果:
Family
Name
Hansen
Ola
Svendson
Tove
Pettersen
Kari
运行下面的SQL:
SELECT LastName, FirstName
FROM Persons AS Employees
返回结果:
Employees中的数据有:
LastName
FirstName
Hansen
Ola
Svendson
Tove
Pettersen
Kari
Insert Into
用途:
在表中插入新行
语法:
插入一行数据
INSERT INTO table_name
&#118;alueS (&#118;alue1, &#118;alue2,....)
插入一行数据在指定的字段上
INSERT INTO table_name (column1, column2,...)
&#118;alueS (&#118;alue1, &#118;alue2,....)
例:
“Persons”表中的原始数据:
LastName
FirstName
Address
City
Pettersen
Kari
Storgt 20
Stavanger
运行下面的SQL插入一行数据:
INSERT INTO Persons
&#118;alueS ('Hetland', 'Camilla', 'Hagabakka 24', 'Sandnes')
插入后”Persons”表中的数据为:
LastName
FirstName
Address
City
Pettersen
Kari
Storgt 20
Stavanger
Hetland
Camilla
Hagabakka 24
Sandnes
运行下面的SQL插入一行数据在指定的字段上:
INSERT INTO Persons (LastName, Address)
&#118;alueS ('Rasmussen', 'Storgt 67')
插入后”Persons”表中的数据为:
LastName
FirstName
Address
City
Pettersen
Kari
Storgt 20
Stavanger
Hetland
Camilla
Hagabakka 24
Sandnes
Rasmussen
Storgt 67
Update
用途:
更新表中原有数据
语法:
UPDATE table_name SET column_name = new_&#118;alue
WHERE column_name = some_&#118;alue
例:
“Person”表中的原始数据:
LastName
FirstName
Address
City
Nilsen
Fred
Kirkegt 56
Stavanger
Rasmussen
Storgt 67
运行下面的SQL将Person表中LastName字段为”Rasmussen”的FirstName更新为”Nina”:
UPDATE Person SET FirstName = 'Nina'
WHERE LastName = 'Rasmussen'
更新后”Person”表中的数据为:
LastName
FirstName
Address
City
Nilsen
Fred
Kirkegt 56
Stavanger
Rasmussen
Nina
Storgt 67
同样的,用UPDATE语句也可以同时更新多个字段:
UPDATE Person
SET Address = 'Stien 12', City = 'Stavanger'
WHERE LastName = 'Rasmussen'
更新后”Person”表中的数据为:
LastName
FirstName
Address
City
Nilsen
Fred
Kirkegt 56
Stavanger
Rasmussen
Nina
Stien 12
Stavanger
Delete
用途:
删除表中的数据
语法:
DELETE FROM table_name WHERE column_name = some_&#118;alue
例:
“Person”表中的原始数据:
LastName
FirstName
Address
City
Nilsen
Fred
Kirkegt 56
Stavanger
Rasmussen
Nina
Stien 12
Stavanger
删除Person表中LastName为”Rasmussen”的数据:
DELETE FROM Person WHERE LastName = 'Rasmussen'
执行删除语句后”Person”表中的数据为:
LastName
FirstName
Address
City
Nilsen
Fred
Kirkegt 56
Stavanger
Create Table
用途:
建立新的资料表。
语法:
CREATE TABLE table_name
(
column_name1 data_type,
column_name2 data_type,
.......
)
例:
创建一张叫“Person”的表,该表有4个字段LastName, FirstName, Address, Age:
CREATE TABLE Person
(
LastName varchar,
FirstName varchar,
Address varchar,
Age int
)
如果想指定字段的最大存储长度,你可以这样:
CREATE TABLE Person
(
LastName varchar(30),
FirstName varchar(30),
Address varchar(120),
Age int(3)
)
下表中列出了在SQL的一些数据类型:
Data Type
Descrīption
integer(size)
int(size)
smallint(size)
tinyint(size)
Hold integers only. The maximum number of digits are specified in parenthesis.
decimal(size,d)
numeric(size,d)
Hold numbers with fractions. The maximum number of digits are specified in size. The maximum number of digits to the right of the decimal is specified in d.
char(size)
Holds a fixed length string (can contain letters, numbers, and special characters). The fixed size is specified in parenthesis.
varchar(size)
Holds a variable length string (can contain letters, numbers, and special characters). The maximum size is specified in parenthesis.
date(yyyymmdd)
Holds a date
Alter Table
用途:
在已经存在的表中增加后者移除字段
语法:
ALTER TABLE table_name
ADD column_name datatype
ALTER TABLE table_name
DROP COLUMN column_name
注意:某些数据库管理系统不允许移除表中的字段
例:
“Person”表中的原始数据:
LastName
FirstName
Address
Pettersen
Kari
Storgt 20
在Person表中增加一个名为City的字段:
ALTER TABLE Person ADD City varchar(30)
增加后表中数据如下:
LastName
FirstName
Address
City
Pettersen
Kari
Storgt 20
移除Person表中原有的Address字段:
ALTER TABLE Person DROP COLUMN Address
移除后表中数据如下:
LastName
FirstName
City
Pettersen
Kari
Drop Table
用途:
在数据库中移除一个数据表定义及该数据表中的所有资料、索引、触发程序、条件约束及权限指定。
语法:
DROP TABLE table_name
Create Database
用途:
建立新的数据库.
语法:
CREATE DATABASE database_name
Drop Database
用途:
移除原有的数据库
语法:
DROP DATABASE database_name
聚集函数
count
用途:
传回选取的结果集中行的数目。
语法:
SELECT COUNT(column_name) FROM table_name
例:
“Persons”表中原始数据如下:
Name
Age
Hansen, Ola
34
Svendson, Tove
45
Pettersen, Kari
19
选取记录总数:
SELECT COUNT(Name) FROM Persons
执行结果:
3
sum
用途:
以表达式传回所有值的总和,或仅 DISTINCT 值。SUM 仅可用于数值资料行。已忽略 Null 值。
语法:
SELECT SUM(column_name) FROM table_name
例:
“Persons”表中原始数据如下:
Name
Age
Hansen, Ola
34
Svendson, Tove
45
Pettersen, Kari
19
选取”Persons”表中所有人的年龄总和:
SELECT SUM(Age) FROM Persons
执行结果:
98
选取”Persons”表中年龄超过20岁的人的年龄总和:
SELECT SUM(Age) FROM Persons WHERE Age>20
执行结果:
79
avg
用途:
传回选取的结果集中值的平均值。已忽略 Null 值。
语法:
SELECT AVG(column_name) FROM table_name
例:
“Persons”表中原始数据如下:
Name
Age
Hansen, Ola
34
Svendson, Tove
45
Pettersen, Kari
19
选取”Persons”表中所有人的平均年龄:
SELECT AVG(Age) FROM Persons
执行结果:
32.67
选取”Persons”表中年龄超过20岁的人的平均年龄:
SELECT AVG(Age) FROM Persons WHERE Age>20
执行结果:
39.5
max
用途:
传回选取的结果集中值的最大值。已忽略 Null 值。
语法:
SELECT MAX(column_name) FROM table_name
例:
“Persons”表中原始数据如下:
Name
Age
Hansen, Ola
34
Svendson, Tove
45
Pettersen, Kari
19
选取”Persons”表中的最大年龄:
SELECT MAX(Age) FROM Persons
执行结果:
45
min
用途:
传回选取的结果集中值的最小值。已忽略 Null 值。
语法:
SELECT MIN(column_name) FROM table_name
例:
“Persons”表中原始数据如下:
Name
Age
Hansen, Ola
34
Svendson, Tove
45
Pettersen, Kari
19
选取”Persons”表中的最小年龄:
SELECT MIN(Age) FROM Persons
执行结果:
19
算术函数
abs
用途:
传回指定数值表达式 (Numeric Expression) 的绝对正值。
语法:
ABS(numeric_expression)
例:
ABS(-1.0) ABS(0.0) ABS(1.0)
执行结果:
1.0 0.0 1.0
ceil
用途:
传回大于等于给定数值表达式的最小整数。
语法:
CEIL(numeric_expression)
例:
CEIL(123.45) CEIL(-123.45)
执行结果:
124.00 -123.00
floor
用途:
传回小于或等于给定数值表达式的最大整数。
语法:
FLOOR(numeric_expression)
例:
FLOOR(123.45) FLOOR(-123.45)
执行结果:
123.00 -124.00
cos
用途:
在指定表达式中传回指定角度 (以弪度为单位) 的三角余弦值的数学函数。
语法:
COS(numeric_expression)
例:
COS(14.7
执行结果:
-0.599465
cosh
用途:
传回以弧度为单位的角度值,其余弦为指定的 float 表达式,也称为反余弦。
语法:
COSH(numeric_expression)
例:
COSH(-1)
执行结果:
3.14159
sin
用途:
以近似的数值 (float) 表达式传回给定角度 (以弧度) 之三角正弦函数 (Trigonometric Sine)。
语法:
SIN(numeric_expression)
例:
SIN(45.175643)
执行结果:
0.929607
sinh
用途:
传回以弪度为单位的角度,其正弦为指定的 float 表达式 (也称为反正弦)。
语法:
SINH(numeric_expression)
例:
SINH(-1.00)
执行结果:
-1.5708
tan
用途:
传回输入表达式的正切函数。
语法:
TAN(numeric_expression)
例:
TAN(3.14159265358979/2)
执行结果:
1.6331778728383844E+16
tanh
用途:
传回以弪度为单位的角度,其正切为指定的 float 表达式 (也称为反正切)。
语法:
TANH(numeric_expression)
例:
TANH(-45.01)
执行结果:
-1.54858
exp
用途:
传回给定的 float 表达式的指数 (Exponential) 值。
语法:
EXP(numeric_expression)
例:
EXP(378.615345498)
执行结果:
2.69498e+164
log
用途:
传回给定的 float 表达式之自然对数。
语法:
LOG(numeric_expression)
例:
LOG(5.175643)
执行结果:
1.64396
power
用途:
传回给定表达式指定乘幂的值。
语法:
POWER(numeric_expression,v)
例:
POWER(2,6)
执行结果:
64
sign
用途:
传回给定的表达式之正 (+1)、零 (0) 或负 (-1) 号。
语法:
SIGN(numeric_expression)
例:
SIGN(123) SIGN(0) SIGN(-456)
执行结果:
1 0 -1
sqrt
用途:
传回给定表达式的平方。
语法:
SQRT(numeric_expression)
例:
SQRT(10)
执行结果:
100 -
负载测试、压力测试
2007-03-10 17:37:29
今天下午在研究loadrunner中的事务图后,觉得应该自己根据以前测试过的系统写一个性能测试用力。
首先应该明确一些基本的概念:
负载测试:通常运行时间比较短,在系统上逐渐加压,直到性能指标达到饱和状态(比如相应时间超出预期要求、系统资源占用率居高不下等),从而验证系统预期的性能目标、相应时间等。
压力测试:长时间运行,逐渐增加超负荷(并发、循环、多用户等),直到系统产生异常以及对异常的处理能力,从而验证系统可靠性、找到系统的瓶颈。 **微软压力测试的经验值为72小时。**
-
2007.3.9
2007-03-09 23:23:09
软件测试是我的职业,我想我会一直沿着这个道路发展下去。做事情要专业,也许口号有点大~但是我希望自己能做的更好,也希望能更好的和其他朋友交流。
记录下点点滴滴,记录下我的职业成长道路……这是我所希望的.....
