
-
调试qtp自动化框架错误记录及总结!
2011-11-08 15:53:38
由于刚学习QTP,对其中的一些语法、规范等不是很清楚,于是常常犯错。希望我记录的这些错误可以帮助那些初学者错误一:If hadlogin Then Browser("AONE").Page("AONE").Frame("Frame").Link("注销").Click讲解:属于语法错误,QTP中似乎规定“then”后不能直接跟执行语句,必须换行。正确的表示应该是If hadlogin ThenBrowser("AONE").Page("AONE").Frame("Frame").Link("注销").Click----------------------------------------------------------------错误二:未设置前后传递的参数,报错信息如下You specified more parameters in your RunAction statement than the number of parameters defined for the action.讲解:在写第一个登录脚本时报了上面的错误,那是我一直查不到原因,后来才发现虽然在脚本上对参数传递做了描述,但在action properties内并没有任何记录。正确的做法是keyword view中选择action右击->action properties->parameters,增加input parameters----------------------------------------------------------------错误三:QTP9.2和IE7.0的兼容问题,报错信息如下This run was performed on Internet Explorer 7.x without the required 'Enable Tabbed Browsing' option cleared. Therefore, steps performed on this browser may have unexpected results. It is recommended to clear the 'Tools > Internet Options > Advanced > Enable Tabbed Browsing' option in Internet Explorer and then run this test again.讲解:可以做如下三个操作来避免1.把IE7.0设为默认浏览器2.清理IE插件(QTP录制时打开IE后,IE关闭信息提示中的插件)3.Internet选项——常规选项卡中“选项卡”的设置取消勾选“启用选项卡式浏览”----------------------------------------------------------------错误四:将action移植过来时,无法进行相对路径引用讲解:Tools->options->folders 增加D:\perth_ta路径----------------------------------------------------------------错误五:从另一个action中传值调用该function,如调用loginperth(url, login_name),出现无法打开指定URL的网页讲解:在function所在action内加url= Parameter("url")login_name= Parameter("login_name")
错误六:QTP报告自动跳出,如何设置?答:在Options>Run>View results when run session ends。七 : index的用法 !以前一直不理解为什么用index 后来看到网上一篇文章感觉很好 , 这里引用一下“有一天,一家学校的校长在典礼上叫了Tom 的名字,这时候有8 位学生都站了出来。校长事先已经记住了排队顺序中第3 个班的Tom 就是他要叫的。但
由于今天班级顺序都打乱了,校长看了,只能再次叫道,父亲是Jack,出列。幸
运的是,这个时候学生只有2 位。校长再加了个条件,爷爷叫William,父亲是Jack
的出列.最后,就只剩下一个学生出列。
在做Web 的QTP 自动化测试时候,不免会出现这样几种情况:
?? QTP 中相同属性的对象,通过添加Index 去区别;
?? 页面元素动态变化,难以通过Index 去识别; “ 有些意思哦 !那么index在那里看到值呢 ?当然是objext spy 了 !(please noted that :index means that the order that such object appeared in code ! )8.Parameter Question !1)How to parameter a drop_down list !e.g. : Browser(browser).page(".....").weblist("......").select"....."If weblist have 5 list you can use "randomNumber"indexnum=randomNumber(1,5)1 is lBound and 5 is uBoundBrowser(browser).page(".....").weblist("......").select"#"&indexnum !2) You must set a parameter in "action properties" when you call a function with some parameters !9)You can use description pragram , you can use test -object properties and method ! and you can use run-time object properties and method , when you use run-time object properties , you can use object.xx and so on , so you must learn more about dom properties and method ! -
Dictionary Object !
2011-10-31 15:17:46
1. Dictionary Object properties :
1)binarycompare : for example : a and A is different !
2)textcompare: for example :a and A is the same !
3) datebasecompre : it is useful to access so i donot want to know !
4) key : is key , it is unique !
5)items : any objects !
Method :
Add : set d=new creatobject(scrpting.dictionary)
d.add"lastname","gao"
remove: d.remove"lastname"
exists : s=exists("lastname") result is true or flase
keys: r=d.keys return all keys in Dictionary d !
items:r=d.items return all items in Dictionary d !
removeall d.removeall
count : d.count return counts in Dictionary d !
more please see
http://www.excelpx.com/home/show.aspx?id=519&cid=15
-
WSH(windown scripting host) 学习 !
2011-10-28 09:57:28
今天学习了 qtp 时候 VBscripting 然后就看到wsh了, 它是windows给各脚步提供的开发环境 ,脚本通过wsh到注册表里面来找到脚本解析器,然后脚本语言也可以直接利用wsh提供的对象去做一些事情 ! wsh 包括14个对象 !

wsh的工作原理 :

-
Qtp 和 TD 连接 !
2011-10-26 17:10:18
1. 首先要安装插件 , 它是TD 和qtp连接的一个插件 ,在TD的 ADD_in 页面
2.在QTp中设置连接 ,点击file -quality center connectiong ,输入你要连接的TD上的项目和地址 信息
3.下testplan 里面建立测试用例 ,在detail里面说明qtp脚本是做什么用的,然后在step写步骤,这个最好一个功能点写成一个步骤 , 好处 ,报bug它会自动的报上 ,而且步骤清晰 ,第二就是好划分action
4.点击“!”按钮选择“quicktest ”生成脚本
5.打开qtp 打开这个脚本 ,然后编辑脚本
6.建立 testlab , 加入testcase
7 .运行testcase 就可以了 !
-
Qtp 连接数据库 (My sql 方法 )
2011-10-26 10:28:35
’这个是建立在机器上已经安装了my sql 驱动 ,在管理工具中已经建立了数据源基础上 !
Dim Cnn
Set Cnn= CreateObject("ADODB.connection")
Cnn.open="DATABASE=databasename;DSN=数据源名称;OPTION=0;PWD=demo12;PORT=3306;SERVER=serverIp;UID=root"If Cnn.State=0 Then
Reporter.ReportEvent micFail,"testing","fail"
else
Reporter.ReportEvent micPass,"testing","successful"
End IfRS.OPEN SQL,CONN,A,B
A: ADOPENFORWARDONLY(=0) 只读,且当前数据记录只能向下移动
ADOPENSTATIC(=3) 只读,当前数据记录可自由移动
ADOPENKEYSET(=1) 可读写,当前数据记录可自由移动
ADOPENDYNAMIC(=2) 可读写,当前数据记录可自由移动,可看到新增记录
B: ADLOCKREADONLY(=1) 默认值,用来打开只读记录
ADLOCKPESSIMISTIC(=2) 悲观锁定
ADLOCKOPTIMISTIC(=3) 乐观锁定
ADLOCKBATCHOPTIMISTIC(=4) 批次乐观锁定
rs是记录集对象,open是其方法,sql是自定义的sql语句,conn是已打开的数据库连接。后面的1,3,就如楼上所说,是记录集的游标和锁类型。
ADLOCKPESSIMISTIC(=2) 悲观锁定 当记录集打开的时候将其锁定
ADLOCKOPTIMISTIC(=3) 乐观锁定 当记录集的update事件触发时锁定 -
qtp 知识拾萃!
2011-10-25 11:29:43
1.qtp多行注释 :第一种,用菜单的方式
注释:选中要注释掉的那几行代码,点击右键,选择”Comment Block”
取消注释:选中要注释掉的那几行代码,点击右键,选择”Uncomment Block”第二种,用快捷键
2.Complete word function
注释:选中要注释掉的那几行代码,按Ctrl + M
取消注释:选中要注释掉的那几行代码,按Ctrl + Shift + Mshortcut key is "ctrl+space " .if it is conflict with your input keyboard ,you have to set input keyboard shortcut key again !
3.Error : Expect the end of statment !
You must input the code again ! I donot know the reason ! hehe !
4 QTP 保留对象:
所谓qtp保留对象就是qtp本身为我们预留的一些可用对象。通俗些讲就是当打开qtp时它就已经把这些对象给实例化了,一直到我们关闭qtp后,这些保留对象的实例才会终止。
-
调用外部的dll方法 !
2011-10-24 11:25:49
1.ExternExtern.declear rettype ,"methodname", "libaryname" , "aliasname ", argtype, argtyperetype: Type of return value ;aliasname : alias name is not obligatory , if you substitue "" for the value of alias ,qtp will take the function name as alias name !argtype : parameter typeExtern.Declare micHwnd, "FindWindow", "user32.dll", "FindWindowA", micString, micString'声明 FindWindow 方法Extern.Declare micLong, "SetWindowText", "user32.dll", "SetWindowTextA", micHwnd, MicString'声明 SetWindowText 方法hwnd = Extern.FindWindow( "Notepad","新建 文本文档 (4).txt - 记事本")'获取记事本窗口的 HWNDif hwnd = 0 thenMsgBox "找不到指定窗口"elsemsgbox hwndres = Extern.SetWindowText(hwnd, "Set Title") '在此也可看出SetWindowText的用法了 '更改记事本窗口的标题end if -
Qtp有用的网站记录:
2011-10-24 11:20:16
Qtp进阶http://wenku.baidu.com/view/80cc0301bed5b9f3f90f1cdd.htmlqtp的一些实例 :http://blog.csdn.net/zzxxbb112/article/details/5111274里面有很多的实例 :vb qtp 中应用代码实例 : -
学习中Qtp的问题记录!
2011-10-21 10:51:24
1.选中qtp的activex插件后,Ie不能打开 !解决 : 在IE——internet选项——程序——管理加载项,禁用一些额外的插件,我禁用了迅雷,百度 ,和google的工具条插件 ,到底是那个插件冲突还不知道 ,通过这个可以知道,如果突然有一个软件莫名其妙的打不开,那么就是软件之间有冲突 !2.有的时候是杀毒软件的问题 ,把360关闭了就好了 ! -
(转)正则表达式学习2
2011-10-16 13:34:43
反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:
表3.常用的反义代码 代码/语法 说明 \W 匹配任意不是字母,数字,下划线,汉字的字符 \S 匹配任意不是空白符的字符 \D 匹配任意非数字的字符 \B 匹配不是单词开头或结束的位置 [^x] 匹配除了x以外的任意字符 [^aeiou] 匹配除了aeiou这几个字母以外的任意字符 例子:\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括号括起来的以a开头的字符串。
后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
呃……其实,组号分配还不像我刚说得那么简单:
- 分组0对应整个正则表达式
- 实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号
- 你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
表4.常用分组语法 分类 代码/语法 说明 捕获 (exp) 匹配exp,并捕获文本到自动命名的组里 (?<name>exp) 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) (?:exp) 匹配exp,不捕获匹配的文本,也不给此分组分配组号 零宽断言 (?=exp) 匹配exp前面的位置 (?<=exp) 匹配exp后面的位置 (?!exp) 匹配后面跟的不是exp的位置 (?<!exp) 匹配前面不是exp的位置 注释 (?#comment) 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 我们已经讨论了前两种语法。第三个(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面,也不会拥有组号。“我为什么会想要这样做?”——好问题,你觉得为什么呢?
零宽断言
地球人,是不是觉得这些术语名称太复杂,太难记了?我也有同感。知道有这么一种东西就行了,它叫什么,随它去吧!人若无名,便可专心练剑;物若无名,便可随意取舍……
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧:
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\d)\d{3})+\b,用它对1234567890进行查找时结果是234567890。
下面这个例子同时使用了这两种断言:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
负向零宽断言
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?例如,如果我们想查找这样的单词--它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:
\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的单词。但是如果多做测试(或者你思维足够敏锐,直接就观察出来了),你会发现,如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错。这是因为[^u]总要匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的\w*\b将会匹配下一个单词,于是\b\w*q[^u]\w*\b就能匹配整个Iraq fighting。负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:\b\w*q(?!u)\w*\b。
零宽度负预测先行断言(?!exp),断言此位置的后面不能匹配表达式exp。例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b匹配不包含连续字符串abc的单词。
同理,我们可以用(?<!exp),零宽度负回顾后发断言来断言此位置的前面不能匹配表达式exp:(?<![a-z])\d{7}匹配前面不是小写字母的七位数字。
请详细分析表达式(?<=<(\w+)>).*(?=<\/\1>),这个表达式最能表现零宽断言的真正用途。
一个更复杂的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(?<=<(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。
注释
小括号的另一种用途是通过语法(?#comment)来包含注释。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含注释的话,最好是启用“忽略模式里的空白符”选项,这样在编写表达式时能任意的添加空格,Tab,换行,而实际使用时这些都将被忽略。启用这个选项后,在#后面到这一行结束的所有文本都将被当成注释忽略掉。例如,我们可以前面的一个表达式写成这样:
(?<= # 断言要匹配的文本的前缀 <(\w+)> # 查找尖括号括起来的字母或数字(即HTML/XML标签) ) # 前缀结束 .* # 匹配任意文本 (?= # 断言要匹配的文本的后缀 <\/\1> # 查找尖括号括起来的内容:前面是一个"/",后面是先前捕获的标签 ) # 后缀结束贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。
表5.懒惰限定符 代码/语法 说明 *? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复 处理选项
在C#中,你可以使用Regex(String, RegexOptions)构造函数来设置正则表达式的处理选项。如:Regex regex = new Regex(@"\ba\w{6}\b", RegexOptions.IgnoreCase);
上面介绍了几个选项如忽略大小写,处理多行等,这些选项能用来改变处理正则表达式的方式。下面是.Net中常用的正则表达式选项:
表6.常用的处理选项 名称 说明 IgnoreCase(忽略大小写) 匹配时不区分大小写。 Multiline(多行模式) 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) Singleline(单行模式) 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 IgnorePatternWhitespace(忽略空白) 忽略表达式中的非转义空白并启用由#标记的注释。 ExplicitCapture(显式捕获) 仅捕获已被显式命名的组。 一个经常被问到的问题是:是不是只能同时使用多行模式和单行模式中的一种?答案是:不是。这两个选项之间没有任何关系,除了它们的名字比较相似(以至于让人感到疑惑)以外。
平衡组/递归匹配
这里介绍的平衡组语法是由.Net Framework支持的;其它语言/库不一定支持这种功能,或者支持此功能但需要使用不同的语法。
有时我们需要匹配像( 100 * ( 50 + 15 ) )这样的可嵌套的层次性结构,这时简单地使用\(.+\)则只会匹配到最左边的左括号和最右边的右括号之间的内容(这里我们讨论的是贪婪模式,懒惰模式也有下面的问题)。假如原来的字符串里的左括号和右括号出现的次数不相等,比如( 5 / ( 3 + 2 ) ) ),那我们的匹配结果里两者的个数也不会相等。有没有办法在这样的字符串里匹配到最长的,配对的括号之间的内容呢?
为了避免(和\(把你的大脑彻底搞糊涂,我们还是用尖括号代替圆括号吧。现在我们的问题变成了如何把xx <aa <bbb> <bbb> aa> yy这样的字符串里,最长的配对的尖括号内的内容捕获出来?
这里需要用到以下的语法构造:
- (?'group') 把捕获的内容命名为group,并压入堆栈(Stack)
- (?'-group') 从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败
- (?(group)yes|no) 如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分
- (?!) 零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
如果你不是一个程序员(或者你自称程序员但是不知道堆栈是什么东西),你就这样理解上面的三种语法吧:第一个就是在黑板上写一个"group",第二个就是从黑板上擦掉一个"group",第三个就是看黑板上写的还有没有"group",如果有就继续匹配yes部分,否则就匹配no部分。
我们需要做的是每碰到了左括号,就在压入一个"Open",每碰到一个右括号,就弹出一个,到了最后就看看堆栈是否为空--如果不为空那就证明左括号比右括号多,那匹配就应该失败。正则表达式引擎会进行回溯(放弃最前面或最后面的一些字符),尽量使整个表达式得到匹配。
< #最外层的左括号 [^<>]* #最外层的左括号后面的不是括号的内容 ( ( (?'Open'<) #碰到了左括号,在黑板上写一个"Open" [^<>]* #匹配左括号后面的不是括号的内容 )+ ( (?'-Open'>) #碰到了右括号,擦掉一个"Open" [^<>]* #匹配右括号后面不是括号的内容 )+ )* (?(Open)(?!)) #在遇到最外层的右括号前面,判断黑板上还有没有没擦掉的"Open";如果还有,则匹配失败 > #最外层的右括号平衡组的一个最常见的应用就是匹配HTML,下面这个例子可以匹配嵌套的<div>标签:<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
还有些什么东西没提到
上边已经描述了构造正则表达式的大量元素,但是还有很多没有提
-
转 正则表达式
2011-10-16 13:30:40
本文目标
30分钟内让你明白正则表达式是什么,并对它有一些基本的了解,让你可以在自己的程序或网页里使用它。
如何使用本教程
最重要的是——请给我30分钟,如果你没有使用正则表达式的经验,请不要试图在30秒内入门——除非你是超人 :)
别被下面那些复杂的表达式吓倒,只要跟着我一步一步来,你会发现正则表达式其实并没有你想像中的那么困难。当然,如果你看完了这篇教程之后,发现自己明白了很多,却又几乎什么都记不得,那也是很正常的——我认为,没接触过正则表达式的人在看完这篇教程后,能把提到过的语法记住80%以上的可能性为零。这里只是让你明白基本的原理,以后你还需要多练习,多使用,才能熟练掌握正则表达式。
除了作为入门教程之外,本文还试图成为可以在日常工作中使用的正则表达式语法参考手册。就作者本人的经历来说,这个目标还是完成得不错的——你看,我自己也没能把所有的东西记下来,不是吗?
清除格式 文本格式约定:专业术语 元字符/语法格式 正则表达式 正则表达式中的一部分(用于分析) 对其进行匹配的源字符串 对正则表达式或其中一部分的说明
隐藏边注 本文右边有一些注释,主要是用来提供一些相关信息,或者给没有程序员背景的读者解释一些基本概念,通常可以忽略。
正则表达式到底是什么东西?
字符是计算机软件处理文字时最基本的单位,可能是字母,数字,标点符号,空格,换行符,汉字等等。字符串是0个或更多个字符的序列。文本也就是文字,字符串。说某个字符串匹配某个正则表达式,通常是指这个字符串里有一部分(或几部分分别)能满足表达式给出的条件。
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过Windows/Dos下用于文件查找的通配符(wildcard),也就是*和?。如果你想查找某个目录下的所有的Word文档的话,你会搜索*.doc。在这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。
入门
学习正则表达式的最好方法是从例子开始,理解例子之后再自己对例子进行修改,实验。下面给出了不少简单的例子,并对它们作了详细的说明。
假设你在一篇英文小说里查找hi,你可以使用正则表达式hi。
这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是h,后一个是i。通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配hi,HI,Hi,hI这四种情况中的任意一种。
不幸的是,很多单词里包含hi这两个连续的字符,比如him,history,high等等。用hi来查找的话,这里边的hi也会被找出来。如果要精确地查找hi这个单词的话,我们应该使用\bhi\b。
\b是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
如果需要更精确的说法,\b匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在)\w。
假如你要找的是hi后面不远处跟着一个Lucy,你应该用\bhi\b.*\bLucy\b。
这里,.是另一个元字符,匹配除了换行符以外的任意字符。*同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配。因此,.*连在一起就意味着任意数量的不包含换行的字符。现在\bhi\b.*\bLucy\b的意思就很明显了:先是一个单词hi,然后是任意个任意字符(但不能是换行),最后是Lucy这个单词。
换行符就是'\n',ASCII编码为10(十六进制0x0A)的字符。
如果同时使用其它元字符,我们就能构造出功能更强大的正则表达式。比如下面这个例子:
0\d\d-\d\d\d\d\d\d\d\d匹配这样的字符串:以0开头,然后是两个数字,然后是一个连字号“-”,最后是8个数字(也就是中国的电话号码。当然,这个例子只能匹配区号为3位的情形)。
这里的\d是个新的元字符,匹配一位数字(0,或1,或2,或……)。-不是元字符,只匹配它本身——连字符(或者减号,或者中横线,或者随你怎么称呼它)。
为了避免那么多烦人的重复,我们也可以这样写这个表达式:0\d{2}-\d{8}。 这里\d后面的{2}({8})的意思是前面\d必须连续重复匹配2次(8次)。
测试正则表达式
其它可用的测试工具:
如果你不觉得正则表达式很难读写的话,要么你是一个天才,要么,你不是地球人。正则表达式的语法很令人头疼,即使对经常使用它的人来说也是如此。由于难于读写,容易出错,所以找一种工具对正则表达式进行测试是很有必要的。
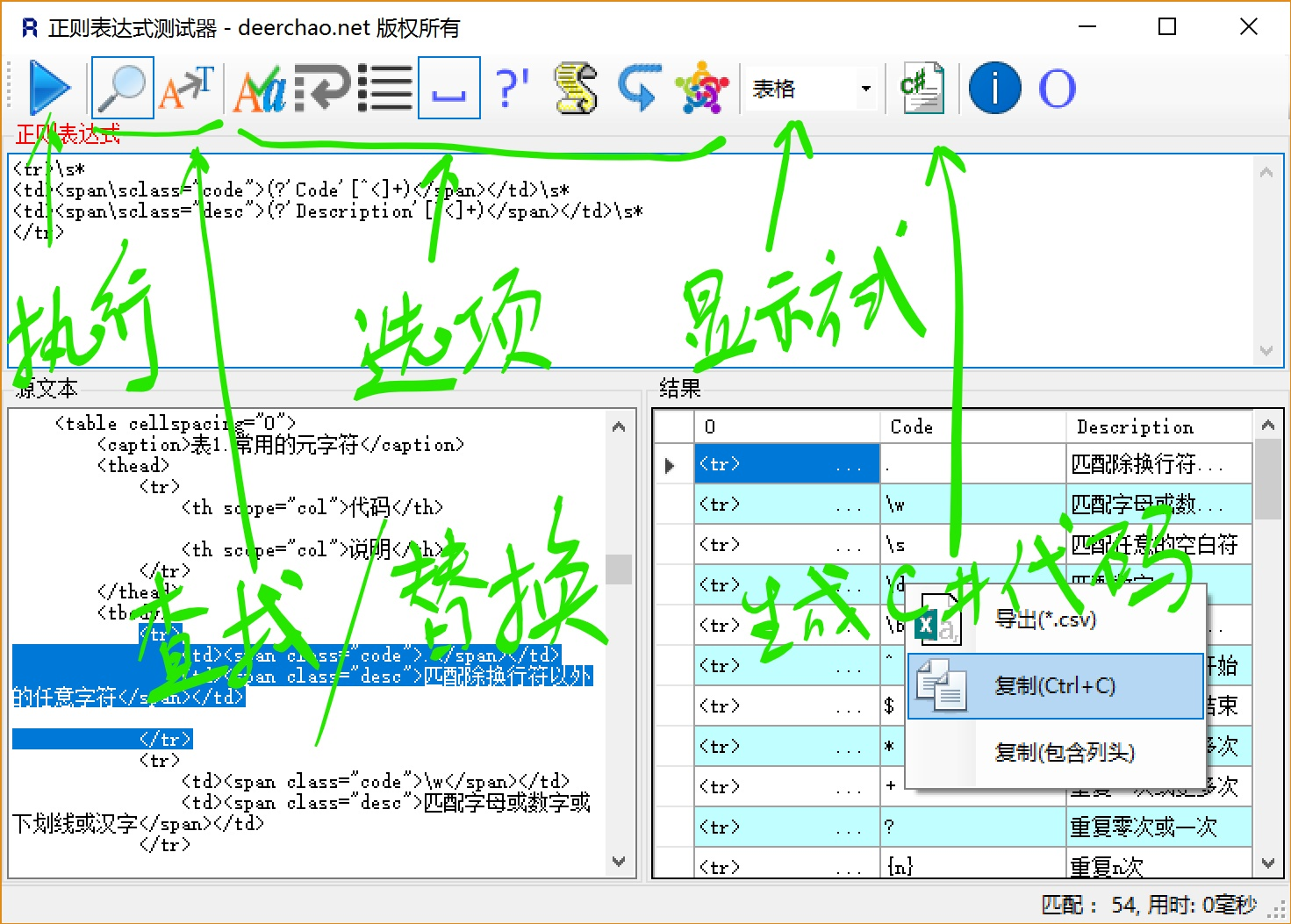
不同的环境下正则表达式的一些细节是不相同的,本教程介绍的是微软 .Net Framework 4.0 下正则表达式的行为,所以,我向你推荐我编写的.Net下的工具 正则表达式测试器。请参考该页面的说明来安装和运行该软件。
下面是Regex Tester运行时的截图:
元字符
现在你已经知道几个很有用的元字符了,如\b,.,*,还有\d.正则表达式里还有更多的元字符,比如\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。\w匹配字母或数字或下划线或汉字等。
对中文/汉字的特殊处理是由.Net提供的正则表达式引擎支持的,其它环境下的具体情况请查看相关文档。
下面来看看更多的例子:
\ba\w*\b匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。
好吧,现在我们说说正则表达式里的单词是什么意思吧:就是不少于一个的连续的\w。不错,这与学习英文时要背的成千上万个同名的东西的确关系不大 :)
\d+匹配1个或更多连续的数字。这里的+是和*类似的元字符,不同的是*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。
\b\w{6}\b 匹配刚好6个字符的单词。
表1.常用的元字符 代码 说明 . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \s 匹配任意的空白符 \d 匹配数字 \b 匹配单词的开始或结束 ^ 匹配字符串的开始 $ 匹配字符串的结束 正则表达式引擎通常会提供一个“测试指定的字符串是否匹配一个正则表达式”的方法,如JavaScript里的RegExp.test()方法或.NET里的Regex.IsMatch()方法。这里的匹配是指是字符串里有没有符合表达式规则的部分。如果不使用^和$的话,对于\d{5,12}而言,使用这样的方法就只能保证字符串里包含5到12连续位数字,而不是整个字符串就是5到12位数字。
元字符^(和数字6在同一个键位上的符号)和$都匹配一个位置,这和\b有点类似。^匹配你要用来查找的字符串的开头,$匹配结尾。这两个代码在验证输入的内容时非常有用,比如一个网站如果要求你填写的QQ号必须为5位到12位数字时,可以使用:^\d{5,12}$。
这里的{5,12}和前面介绍过的{2}是类似的,只不过{2}匹配只能不多不少重复2次,{5,12}则是重复的次数不能少于5次,不能多于12次,否则都不匹配。
因为使用了^和$,所以输入的整个字符串都要用来和\d{5,12}来匹配,也就是说整个输入必须是5到12个数字,因此如果输入的QQ号能匹配这个正则表达式的话,那就符合要求了。
和忽略大小写的选项类似,有些正则表达式处理工具还有一个处理多行的选项。如果选中了这个选项,^和$的意义就变成了匹配行的开始处和结束处。
字符转义
如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用\.和\*。当然,要查找\本身,你也得用\\.
例如:deerchao\.net匹配deerchao.net,C:\\Windows匹配C:\Windows。
重复
你已经看过了前面的*,+,{2},{5,12}这几个匹配重复的方式了。下面是正则表达式中所有的限定符(指定数量的代码,例如*,{5,12}等):
表2.常用的限定符 代码/语法 说明 * 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次 下面是一些使用重复的例子:
Windows\d+匹配Windows后面跟1个或更多数字
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
字符类
要想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)。
我们也可以轻松地指定一个字符范围,像[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话)。
下面是一个更复杂的表达式:\(?0\d{2}[) -]?\d{8}。
“(”和“)”也是元字符,后面的分组节里会提到,所以在这里需要使用转义。
这个表达式可以匹配几种格式的电话号码,像(010)88886666,或022-22334455,或02912345678等。我们对它进行一些分析吧:首先是一个转义字符\(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。
分枝条件
不幸的是,刚才那个表达式也能匹配010)12345678或(022-87654321这样的“不正确”的格式。要解决这个问题,我们需要用到分枝条件。正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。听不明白?没关系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\(?0\d{2}\)?[- ]?\d{8}|0\d{2}[- ]?\d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用分枝条件把这个表达式扩展成也支持4位区号的。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用分枝条件时,要注意各个条件的顺序。如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
分组
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作(后面会有介绍)。
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3}匹配1到3位的数字,(\d{1,3}\.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
IP地址中每个数字都不能大于255,大家千万不要被《24》第三季的编剧给忽悠了……
不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解这个表达式的关键是理解2[0-4]\d|25[0-5]|[01]?\d\d?,这里我就不细说了,你自己应该能分析得出来它的意义。
-
(转)Runtime.exec()的使用
2011-09-05 09:08:51
那就首先说点Runtime类吧,他是一个与JVM运行时环境有关的类,这个类是Singleton的。我说几个自己觉得重要的地方。
1、Runtime.getRuntime()可以取得当前JVM的运行时环境,这也是在Java中唯一一个得到运行时环境的方法。
2、Runtime上其他大部分的方法都是实例方法,也就是说每次进行运行时调用时都要用到getRuntime方法。
3、Runtime中的exit方法是退出当前JVM的方法,估计也是唯一的一个吧,因为我看到System类中的exit实际上也是通过调用Runtime.exit()来退出JVM的,这里说明一下Java对Runtime返回值的一般规则(后边也提到了),0代表正常退出,非0代表异常中止,这只是Java的规则,在各个操作系统中总会发生一些小的混淆。
4、Runtime.addShutdownHook()方法可以注册一个hook在JVM执行shutdown的过程中,方法的参数只要是一个初始化过但是没有执行的Thread实例就可以。(注意,Java中的Thread都是执行过了就不值钱的哦)
5、说到addShutdownHook这个方法就要说一下JVM运行环境是在什么情况下shutdown或者abort的。文档上是这样写的,当最后一个非精灵进程退出或者收到了一个用户中断信号、用户登出、系统shutdown、Runtime的exit方法被调用时JVM会启动shutdown的过程,在这个过程开始后,他会并行启动所有登记的shutdown hook(注意是并行启动,这就需要线程安全和防止死锁)。当shutdown过程启动后,只有通过调用halt方法才能中止shutdown的过程并退出JVM。
那什么时候JVM会abort退出那?首先说明一下,abort退出时JVM就是停止运行但并不一定进行shutdown。这只有JVM在遇到SIGKILL信号或者windows中止进程的信号、本地方法发生类似于访问非法地址一类的内部错误时会出现。这种情况下并不能保证shutdown hook是否被执行。
现在开始看这篇文章,呵呵。
首先讲的是Runtime.exec()方法的所有重载。这里要注意的有一点,就是public Process exec(String [] cmdArray, String [] envp);这个方法中cmdArray是一个执行的命令和参数的字符串数组,数组的第一个元素是要执行的命令往后依次都是命令的参数,envp我个人感觉应该和C中的execve中的环境变量是一样的,envp中使用的是name=value的方式。
1、 一个很糟糕的调用程序,代码如下,这个程序用exec调用了一个外部命令之后马上使用exitValue就对其返回值进行检查,让我们看看会出现什么问题。
import java.util.*;
import java.io.*;public class BadExecJavac
{
public static void main(String args[])
{
try
{
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("javac");
int exitVal = proc.exitValue();
System.out.println("Process exitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}A run of BadExecJavac produces:
E:classescomjavaworldjpitfallsarticle2>java BadExecJavac
java.lang.IllegalThreadStateException: process has not exited
at java.lang.Win32Process.exitValue(Native Method)
at BadExecJavac.main(BadExecJavac.java:13)
这里看原文就可以了解,这里主要的问题就是错误的调用了exitValue来取得外部命令的返回值(呵呵,这个错误我也曾经犯过),因为exitValue这个方法是不阻塞的,程序在调用这个方法时外部命令并没有返回所以造成了异常的出现,这里是由另外的方法来等待外部命令执行完毕的,就是waitFor方法,这个方法会一直阻塞直到外部命令执行结束,然后返回外部命令执行的结果,作者在这里一顿批评设计者的思路有问题,呵呵,反正我是无所谓阿,能用就可以拉。但是作者在这里有一个说明,就是exitValue也是有好多用途的。因为当你在一个Process上调用waitFor方法时,当前线程是阻塞的,如果外部命令无法执行结束,那么你的线程就会一直阻塞下去,这种意外会影响我们程序的执行。所以在我们不能判断外部命令什么时候执行完毕而我们的程序还需要继续执行的情况下,我们就应该循环的使用exitValue来取得外部命令的返回状态,并在外部命令返回时作出相应的处理。
2、对exitValue处改进了的程序import java.util.*;
import java.io.*;public class BadExecJavac2
{
public static void main(String args[])
{
try
{
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("javac");
int exitVal = proc.waitFor();
System.out.println("Process exitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}不幸的是,这个程序也无法执行完成,它没有输出但却一直悬在那里,这是为什么那?
JDK文档中对此有如此的解释:因为本地的系统对标准输入和输出所提供的缓冲池有效,所以错误的对标准输出快速的写入和从标准输入快速的读入都有可能造成子进程的锁,甚至死锁。
文档引述完了,作者又开始批评了,他说JDK仅仅说明为什么问题会发生,却并没有说明这个问题怎么解决,这的确是个问题哈。紧接着作者说出自己的做法,就是在执行完外部命令后我们要控制好Process的所有输入和输出(视情况而定),在这个例子里边因为调用的是Javac,而他在没有参数的情况下会将提示信息输出到标准出错,所以在下面的程序中我们要对此进行处理。
import java.util.*;
import java.io.*;public class MediocreExecJavac
{
public static void main(String args[])
{
try
{
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("javac");
InputStream stderr = proc.getErrorStream();
InputStreamReader isr = new InputStreamReader(stderr);
BufferedReader br = new BufferedReader(isr);
String line = null;
System.out.println("<error></error>");
while ( (line = br.readLine()) != null)
System.out.println(line);
System.out.println("");
int exitVal = proc.waitFor();
System.out.println("Process exitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}
程序的运行结果为E:classescomjavaworldjpitfallsarticle2>java MediocreExecJavac
<error></error>
Usage: javac <options></options> <source files=""></source>where <options></options> includes:
-g Generate all debugging info
-g:none Generate no debugging info
-g:{lines,vars,source} Generate only some debugging info
-O Optimize; may hinder debugging or enlarge class files
-nowarn Generate no warnings
-verbose Output messages about what the compiler is doing
-deprecation Output source locations where deprecated APIs are used
-classpathSpecify where to find user class files
-sourcepathSpecify where to find input source files
-bootclasspathOverride location of bootstrap class files
-extdirs <dirs></dirs>Override location of installed extensions
-d <directory></directory>Specify where to place generated class files
-encoding <encoding></encoding>Specify character encoding used by source files
-target <release></release>Generate class files for specific VM version
Process exitValue: 2
哎,不管怎么说还是出来了结果,作者作了一下总结,就是说,为了处理好外部命令大量输出的情况,你要确保你的程序处理好外部命令所需要的输入或者输出。
下一个题目,当我们调用一个我们认为是可执行程序的时候容易发生的错误(今天晚上我刚刚犯这个错误,没事做这个练习时候发生的)import java.util.*;
import java.io.*;public class BadExecWinDir
{
public static void main(String args[])
{
try
{
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("dir");
InputStream stdin = proc.getInputStream();
InputStreamReader isr = new InputStreamReader(stdin);
BufferedReader br = new BufferedReader(isr);
String line = null;
System.out.println("<output></output>");
while ( (line = br.readLine()) != null)
System.out.println(line);
System.out.println("");
int exitVal = proc.waitFor();
System.out.println("Process exitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}A run of BadExecWinDir produces:
E:classescomjavaworldjpitfallsarticle2>java BadExecWinDir
java.io.IOException: CreateProcess: dir error=2
at java.lang.Win32Process.create(Native Method)
at java.lang.Win32Process.<init></init>(Unknown Source)
at java.lang.Runtime.execInternal(Native Method)
at java.lang.Runtime.exec(Unknown Source)
at java.lang.Runtime.exec(Unknown Source)
at java.lang.Runtime.exec(Unknown Source)
at java.lang.Runtime.exec(Unknown Source)
at BadExecWinDir.main(BadExecWinDir.java:12)
说实在的,这个错误还真是让我摸不着头脑,我觉得在windows中返回2应该是没有找到这个文件的缘故,可能windows 2000中只有cmd命令,dir命令不是当前环境变量能够解释的吧。我也不知道了,慢慢往下看吧。嘿,果然和作者想的一样,就是因为dir命令是由windows中的解释器解释的,直接执行dir时无法找到dir.exe这个命令,所以会出现文件未找到这个2的错误。如果我们要执行这样的命令,就要先根据操作系统的不同执行不同的解释程序command.com 或者cmd.exe。
作者对上边的程序进行了修改
import java.util.*;
import java.io.*;class StreamGobbler extends Thread
{
InputStream is;
String type;StreamGobbler(InputStream is, String type)
{
this.is = is;
this.type = type;
}public void run()
{
try
{
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line=null;
while ( (line = br.readLine()) != null)
System.out.println(type + ">" + line);
} catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}public class GoodWindowsExec
{
public static void main(String args[])
{
if (args.length < 1)
{
System.out.println("USAGE: java GoodWindowsExec <cmd></cmd>");
System.exit(1);
}try
{
String sName = System.getProperty("os.name" );
String[] cmd = new String[3];if( osName.equals( "Windows NT" ) )
{
cmd[0] = "cmd.exe" ;
cmd[1] = "/C" ;
cmd[2] = args[0];
}
else if( osName.equals( "Windows 95" ) )
{
cmd[0] = "command.com" ;
cmd[1] = "/C" ;
cmd[2] = args[0];
}Runtime rt = Runtime.getRuntime();
System.out.println("Execing " + cmd[0] + " " + cmd[1]
+ " " + cmd[2]);
Process proc = rt.exec(cmd);
// any error message?
StreamGobbler errorGobbler = new
StreamGobbler(proc.getErrorStream(), "ERROR");// any output?
StreamGobbler utputGobbler = new
StreamGobbler(proc.getInputStream(), "OUTPUT");// kick them off
errorGobbler.start();
outputGobbler.start();// any error???
int exitVal = proc.waitFor();
System.out.println("ExitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}Running GoodWindowsExec with the dir command generates:
E:classescomjavaworldjpitfallsarticle2>java GoodWindowsExec "dir *.java"
Execing cmd.exe /C dir *.java
OUTPUT> Volume in drive E has no label.
OUTPUT> Volume Serial Number is 5C5F-0CC9
OUTPUT>
OUTPUT> Directory of E:classescomjavaworldjpitfallsarticle2
OUTPUT>
OUTPUT>10/23/00 09:01p 805 BadExecBrowser.java
OUTPUT>10/22/00 09:35a 770 BadExecBrowser1.java
OUTPUT>10/24/00 08:45p 488 BadExecJavac.java
OUTPUT>10/24/00 08:46p 519 BadExecJavac2.java
OUTPUT>10/24/00 09:13p 930 BadExecWinDir.java
OUTPUT>10/22/00 09:21a 2,282 BadURLPost.java
OUTPUT>10/22/00 09:20a 2,273 BadURLPost1.java
... (some output omitted for brevity)
OUTPUT>10/12/00 09:29p 151 SuperFrame.java
OUTPUT>10/24/00 09:23p 1,814 TestExec.java
OUTPUT>10/09/00 05:47p 23,543 TestStringReplace.java
OUTPUT>10/12/00 08:55p 228 TopLevel.java
OUTPUT> 22 File(s) 46,661 bytes
OUTPUT> 19,678,420,992 bytes free
ExitValue: 0这里作者教了一个windows中很有用的方法,呵呵,至少我是不知道的,就是cmd.exe /C +一个windows中注册了后缀的文档名,windows会自动地调用相关的程序来打开这个文档,我试了一下,的确很好用,但是好像文件路径中有空格的话就有点问题,我加上引号也无法解决。
这里作者强调了一下,不要假设你执行的程序是可执行的程序,要清楚自己的程序是单独可执行的还是被解释的,本章的结束作者会介绍一个命令行工具来帮助我们分析。
这里还有一点,就是得到process的输出的方式是getInputStream,这是因为我们要从Java 程序的角度来看,外部程序的输出对于Java来说就是输入,反之亦然。
最后的一个漏洞的地方就是错误的认为exec方法会接受所有你在命令行或者Shell中输入并接受的字符串。这些错误主要出现在命令作为参数的情况下,程序员错误的将所有命令行中可以输入的参数命令加入到exec中(这段翻译的不好,凑合看吧)。下面的例子中就是一个程序员想重定向一个命令的输出。
import java.util.*;
import java.io.*;// StreamGobbler omitted for brevity
public class BadWinRedirect
{
public static void main(String args[])
{
try
{
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("java jecho 'Hello World' > test.txt");
// any error message?
StreamGobbler errorGobbler = new
StreamGobbler(proc.getErrorStream(), "ERROR");// any output?
StreamGobbler utputGobbler = new
StreamGobbler(proc.getInputStream(), "OUTPUT");// kick them off
errorGobbler.start();
outputGobbler.start();// any error???
int exitVal = proc.waitFor();
System.out.println("ExitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}Running BadWinRedirect produces:
E:classescomjavaworldjpitfallsarticle2>java BadWinRedirect
OUTPUT>'Hello World' > test.txt
ExitValue: 0程序员的本意是将Hello World这个输入重订向到一个文本文件中,但是这个文件并没有生成,jecho仅仅是将命令行中的参数输出到标准输出中,用户觉得可以像dos中重定向一样将输出重定向到一个文件中,但这并不能实现,用户错误的将exec认为是一个shell解释器,但它并不是,如果你想将一个程序的输出重定向到其他的程序中,你必须用程序来实现他。可用java.io中的包。
import java.util.*;
import java.io.*;class StreamGobbler extends Thread
{
InputStream is;
String type;
OutputStream os;StreamGobbler(InputStream is, String type)
{
this(is, type, null);
}StreamGobbler(InputStream is, String type, OutputStream redirect)
{
this.is = is;
this.type = type;
this.os = redirect;
}public void run()
{
try
{
PrintWriter pw = null;
if (os != null)
pw = new PrintWriter(os);InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line=null;
while ( (line = br.readLine()) != null)
{
if (pw != null)
pw.println(line);
System.out.println(type + ">" + line);
}
if (pw != null)
pw.flush();
} catch (IOException ioe)
{
ioe.printStackTrace();
}
}
}public class GoodWinRedirect
{
public static void main(String args[])
{
if (args.length < 1)
{
System.out.println("USAGE java GoodWinRedirect <outputfile></outputfile>");
System.exit(1);
}try
{
FileOutputStream fos = new FileOutputStream(args[0]);
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("java jecho 'Hello World'");
// any error message?
StreamGobbler errorGobbler = new
StreamGobbler(proc.getErrorStream(), "ERROR");// any output?
StreamGobbler utputGobbler = new
StreamGobbler(proc.getInputStream(), "OUTPUT", fos);// kick them off
errorGobbler.start();
outputGobbler.start();// any error???
int exitVal = proc.waitFor();
System.out.println("ExitValue: " + exitVal);
fos.flush();
fos.close();
} catch (Throwable t)
{
t.printStackTrace();
}
}
}Running GoodWinRedirect produces:
E:classescomjavaworldjpitfallsarticle2>java GoodWinRedirect test.txt
OUTPUT>'Hello World'
ExitValue: 0这里就不多说了,看看就明白,紧接着作者给出了一个监测命令的小程序
import java.util.*;
import java.io.*;// class StreamGobbler omitted for brevity
public class TestExec
{
public static void main(String args[])
{
if (args.length < 1)
{
System.out.println("USAGE: java TestExec "cmd"");
System.exit(1);
}try
{
String cmd = args[0];
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec(cmd);// any error message?
StreamGobbler errorGobbler = new
StreamGobbler(proc.getErrorStream(), "ERR");// any output?
StreamGobbler utputGobbler = new
StreamGobbler(proc.getInputStream(), "OUT");// kick them off
errorGobbler.start();
outputGobbler.start();// any error???
int exitVal = proc.waitFor();
System.out.println("ExitValue: " + exitVal);
} catch (Throwable t)
{
t.printStackTrace();
}
}
}对这个程序进行运行:
E:classescomjavaworldjpitfallsarticle2>java TestExec "e:javadocsindex.html"
java.io.IOException: CreateProcess: e:javadocsindex.html error=193
at java.lang.Win32Process.create(Native Method)
at java.lang.Win32Process.<init></init>(Unknown Source)
at java.lang.Runtime.execInternal(Native Method)
at java.lang.Runtime.exec(Unknown Source)
at java.lang.Runtime.exec(Unknown Source)
at java.lang.Runtime.exec(Unknown Source)
at java.lang.Runtime.exec(Unknown Source)
at TestExec.main(TestExec.java:45)193在windows中是说这不是一个win32程序,这说明路径中找不到这个网页的关联程序,下面作者决定用一个绝对路径来试一下。
E:classescomjavaworldjpitfallsarticle2>java TestExec
"e:program filesnetscapeprogramnetscape.exe e:javadocsindex.html"
ExitValue: 0
好用了,这个我也试了一下,用的是IE。
最后,作者总结了几条规则,防止我们在进行Runtime.exec()调用时出现错误。
1、 在一个外部进程执行完之前你不能得到他的退出状态2、 在你的外部程序开始执行的时候你必须马上控制输入、输出、出错这些流。
3、 你必须用Runtime.exec()去执行程序
4、 你不能象命令行一样使用Runtime.exec()。
-
测试什么时候结束!
2011-08-25 09:32:36
刚刚测试了一个小的项目,结束了一个阶段的测试, 然后在想测试结束的标准 ,在网上收集了一下 和自己总结的基本理解如下:
首先要有测试计划,测试计划中要有软件验收的标准 ,这个标准的定义要测试经理来定一个框架,然后又软件测试组的成员,和软件利益的相关者达成一致的协议 ,就成了软件结束的标准 。
测试:
1.测试用例的通过率为98% 。 (测试用例=测试需求用例+挖掘测试用例) ;
2.bug修复率 ,一,二级bug 达到 100% ;三,四级bug80% ,五六级bug 60% ;
3.从bug发展的趋势来看 , 在最后的几天最好趋于0 ;
覆盖率 :
需求的覆盖率为100%;
测试系统的覆盖率为100% ;
信心指数 :
要项目组的每个成员负责各个的模块 , 为自己打出相应的信心指数 !
这个是目前我能总结出的项目结束的 !
-
在android开发过程中遇到的一些问题记录!
2011-08-24 09:52:48
1.R文件不识别 ? 说gen不是sourse文件夹要变成sourse文件 !
在网上找了很多的方法但是没有一个是我这种现象的 ,后来别人帮我调试一下 ,原来是开发把gen误传到svn上了,所以你在加载到eclispe的时候要把gen删除掉 !
2.报了找不到资源 ,但是我自己认为我导入的库文件是正确的
答 : 其实有的时候一定要问开发是否导入的资源库正确,我就把另一个项目的资源库没有导入正确
3.在一个工程里面导入了android2.3的库所有问题就解决了 ,所以这个还是要让开发看一下 ,要用到什么才是最重要的
总结一个调试环境的步骤 :
1.一定要看好了要那些资源文件
2.用clean的方法 ,然后再编译一下 !
3.gen的文件夹是自动生成的 ,所以可以删除掉重新编译 !
-
(转)关于LoadRunner的迭代
2011-08-09 09:27:07
通过用lr做负载压力测试过程发现,如果设定不同的action迭代次数,每次得出的结果是不同的,曲线的表现形式也是不同的。这点就使我们会感觉困惑,为什么要设置action的迭代次数?以及对于不同的应用系统应该怎样设置迭代次数呢?首先你要理解性能测试是在干什么?
性能测试是模拟系统一段时间内真实的压力情况,以考察系统的性能。
再看怎么模拟系统真实的压力情况?比如在半个小时内,用户都在进行登录操作,且平均分布在这半个小时内。我们要做的是什么?模拟这半个小时用户的行为。怎么模拟?估算出同时操作的人数,并用LoadRunner不断的发送登录请求,这就是我们为什么要迭代。
至于迭代次数,只要能够模拟出真实情况,多少次都无所谓,不过10次8次估计是模拟不出来。迭代次数至少要保证压力达到一个稳定值后再运行一段时间,这样我们得到的数据才是有效的。所以我们除非是特别要求,一般不用迭代次数,而是用运行时间。
1,迭代和并发,是完全不同的概念。没有什么关系。
比如,一个用户迭代十次,还是一个用户的压力。
10个用户执行一次,就是10个用户的压力。10个用户迭代10次,还是10个用户的压力。但他们都和参数化的数据有关系(也要看参数化是如何设置的,以及系统如何判断提交值的)。
2,你要是想知道,LR是如何实现迭代和并发:
说一个比较容易理解的层面:迭代就是不停的反复调用同一脚本,反复执行,注意,对1个用户执行10次来说,只会分配一块内存。10个用户执行一次,是调用同一脚本10次,会分配10块内存。LR调用脚本,编译后,运行,按脚本发送数据。
比如:web_url这样的函数,执行就会发HTTP request。
如果你还想知道更细节的进程和函数的实现,只能侧面验证(具体方法看各人的能力和擅长),因为我们都不是LR的开发者。
3,太显然的问题了,参数化时选择每次出现唯一,只要参数够用就OK,不够用,就设置相应的规则。
action在场景运行中iteration只对其起作用,对vuser_init和vuser_end都不起作用,action是一个可以被重复使用的最小单位其实你可以将所有脚本录制到一个action里,只是不方便管理罢了。
举个最简单的例子,像lr自带的例子——订票系统,你如果把所有脚本都录制到一个action里,那回放的时候,每个用户登录就只能买一张票,而如果想一个用户买多张票的话,这样就行不通了。那你就要设多个action,并把登录和结束各录制在一个action里,把买票录到一个action中,这样,将买票的action迭代多次,而用户登录和结束只运行一次,这不就模拟了现实中的情况了吗?
其实LoadRunner 是以客户端的角度来定义“响应时间”的,当客户端请求发出去后, LoadRunner 就开始计算响应时间,一直到它收到服务器端的响应。这个时候问题就产生了:如果此时的服务器端的排队队列已满,服务器资源正处于忙碌的状态,那么该请求会驻留在服务器的线程中,换句话说,这个新产生的请求并不会对服务器端产生真正的负载,但很遗憾的是,该请求的计时器已经启动了,因此我们很容易就可以预见到,这个请求的响应时间会变得很长,甚至可能长到使得该请求由于超时而失败。等到测试结束后,我们查看一下结果,就会发现这样一个很不幸的现象:事务平均响应时间很长,最小响应时间与最大响应时间的差距很大,而这个时候的平均响应时间,其实也就失去了它应有的意义。也就是说,由于客户端发送的请求太快而导致影响了实际的测量结果,设置步长则可以缓解这一情况,这样,应该试试设置pacing,再运行看看情况。
-
我用Jmeter的感悟!
2011-08-01 21:11:30
以前用过jmeter做过简单的测试,这次又重新捡起来居然忘了一大半,想想自己还是没有总结,哀哉了一番,呵呵 但是工作还要继续做的!看了一下使用手册,大概就能用起来了 ! 这次测试用到了相关的知识自己认为还是个皮毛,不过也要把皮毛总结一下,以免以后连皮毛都没有了 !1.jmeter的原理是线程组来组成测试,所以你要添加任何的组件必须要有一个线程组,2.然后在线程组里面添加你要设置的请求(http请求)设置ip ,端口, 编码,还有路径 ,参数比如你的url是 http://www.songtaste.com/music/catsong/cat13/2?action=spaceblogs&op=add&openwindow=1那么path=/music/catsong/cat13/2参数是action=spaceblogs&op=add&openwindow=13.然后就是添加监听器了,最有用的是:聚合报告, 以结果树显示(因为能看到返回的值),以图表显示(能看到线程运行的线路图)4.参数化,我用的是csv参数 ,在数据库里面导出一个csv数据,填好路径,然后设置好变量 ,这个变量要再参数里面的值引用 ,如果 ?{request}5.然后就是设置你的线程数 ,这个地方有很多的讲究, 线程数就不用说了,就是你要模拟的并发用户数, ramp up time ,这个是在这个时间里面启动你要设置的线程数,比如你的线程数是20 ,rampup=1 那么就是1s里面要启动20个用户 ,然后就是 在每隔1/20s启动一个用户 ,下面的循环次数也是很有讲究,开始的时候我只是设置了为1,但是后来才发现, 在取样数增加的情况下, 就在前面的1/3数出错,所以如果循环一次,得到结果就不是很客观,所以大家一定要注意,对于压力测试,本人理解一定要循环次数要多运行,我运行的是20次 !6.在线程组的下面可以设置启动时间的,这样你就可以在jmeter里面设置不同的线程组,然后设置不同的启动时间,然后在线程组的外面加上监听器 , 这样就可以在下班的时候点击一下启动 ,第二天早晨你就可以拿到报告了,最后别忘了提醒你一下,别忘了点击启动,别向我一样傻傻的设完了时间,就在那傻等着 呵呵 !7.还有就是做分布式的负载测试, 就是在你要做server的机器上 ,在jmeter的目录下,把propert下面host原来的172.0.0.1修改成你要作为负载机的ip就可以了,多台用逗号隔开,然后把负载机上的jmeter.server 打开 ,然后在server机上就可以看到远程机,设置好各个选项,启动就可以了 !总结经验,在测试前,一定要和开发谈好各个细节,比如测试的参数,测试的数据库,这个测试的时候,开始的时候偷懒没有做参数化 , 还有测试开始的时候要多试试,比如如果新的数据写入的时候如果是新的数据,那么througout就很变小,如果还是老的参数,那么throughput就不会变化,所以对于数据库的测试,1)要注意参数一定要重新写入的,不能是老的数据 !2)就是原来数据库里面有多少条数据,这个要影响数据库的写入速度 ! 所以这个很重要3)还有就是你加压的方式 ,比如我是在做 200 *20 , 然后就做 400*20 ,然后就是 600*20 这样到600就有没有响应的数据 , 然后如果你直接运行 800*20 就么有出错的,这个我想了很长时间,个人认为,这个要看你的客户真实的压力模式,所以我用不断加压的形式来运行 !4)还有这次在测试多次后,发现一个奇怪现象,就是在线程不断增加的情况下, throughout不断的下降,但是错误率并没有增加,后来分析有两个原因,就是写入数据库的数据一定要新的 ! 还有和数据库里面的数据的条数有关系。这个就是我用的jmeter的一点体会 ,不过还没有用到逻辑控制器,正则表达式,还有用命令行启动以后再仔细研究一下 ! -
(转)Run erroe R.java Android 学习笔记 !
2011-07-26 09:03:16
Problem when run
[2010-09-26 16:07:56 - Test] ERROR: Unable to open class file D:\workspace\MJAndroid\gen\com\oreilly\helloworld\R.java: No such file or directory
Solutions:
1.After creating the Project, Right click the Project Folder within the Project Explorer on the Left Tab of Eclipse.
Click on Source->Format.
The Console will say:
[2010-11-24 11:57:42 - YourProject] R.java was modified manually! Reverting to generated version!
2. just move it to another file and eclipse will auto reconfigure a new one for you. This will work as you work through your project.
3. just restart the Eclipse IDE and everything will be fine
4. 1.-Open Eclipse 2.-Open Window/Preference 3.-Expand JAVA option 4.-Select Build Path 5.-Check the option "Projec"t and uncheck "folder" options 6.-Click on OK 7.-Restart eclipse IDE
5. Go to your "workspace" folder and make sure it's not "read-only"
6. Eclipse Menu > Projects > clean
7. go to Window/Preferences/Java/Build Path,select 'Folders' and change the output folder to 'gen' (this is where Android looks for the generated java files,but the default in eclipse is 'bin').
restart Eclipse
-
佳文分享:我个人比较受用的一些习惯
2011-07-16 11:18:58
1.长期的任务,要尽早开始
一般来说,长期任务总是比较烦人,也有难度,而人心里总有逃避困难的趋势,最后的结果或者是最后干脆放弃,或者是剩下一点点时间手忙脚乱地赶工;我自己之前也有这样的教训,自欺欺人地说“要轻松生活,抛开烦扰”,到最后几天才着急办理,搞得狼狈不堪。
后来,我发现这做法其实是事与愿违的,如果调整好心理状态,尽早了解情况并不必然带来的心理压力,反而因为时间充裕,有信心把握进度,即便中间遇到突发的问题,也留有时间解决;更重要的是,尽早着手,可以充分利用边角余料的时间:比如说,接到一份文档,需要在三天后给出意见,我一定会在当天大致浏览一遍,下面的三天里,就能在坐车、走路等等零碎的时间来思考,而且效果不错,如果没有尽早了解,这些时间就浪费了,什么有意义的事情也没干(阿基米德若不是之前遇到了问题,在澡盆里泡一万年也想不出办法检测皇冠的真伪)。
电子邮件的情况也是如此,我常看到有人讨论电子邮件是马上回好还是过一段再回好,我的经验是,收了电子邮件要尽快看,至少了解邮件里说了什么,如果不是着急的,等想清楚了再回。2.时常想清楚自己正在做的事情
一般来说,我们做的工作总是有一个目的和意义的,但工作的形式又是非常具体的,忙起来往往就钻到死胡同里,忘记了真正的目的和意义,“想不清楚”自己真正要做什么了。前几天,我需要搭建一个演示环境,手上有两套方案A和B,方案A估计要半小时,方案B估计要一小时,于是我选择了方案A,可是动手之后才发现服务器缺乏一个必要的组件,于是先费劲添加好这个组件,再编译自己需要用到的软件,又发现在64位环境下会编译出错(以前我只在32位机器上编译过),上网查发现需要打一个补丁,于是又四处去寻找这个补丁……此时已经用掉一个多小时了,下面还不知道会有多少问题;我忽然想到,自己真正要做的无非是演示程序,解决打补丁、找软件之类的问题虽然很有意思,但其实从任务的角度考虑,是浪费时间,于是果断选择方案B,一小时后就顺利解决了。
据我观察,很多技术人员都热衷解决纯技术问题,温伯格称之为“hacking (神游)”;神游很好玩,容易上瘾,但我们都不是不食人间烟火的神人,要想真正做点事情,就不能放任神游。
关于这一条,还要补充一点:哪怕忙得昏天黑地,也不能没有头绪。工作的压力很大,忙得焦头烂额是常有的事情,许多人就在这种忙碌中失去了方向,往往忙了整天,下班了都不知道自己今天到底干了什么,有什么意义。我的经验是,越是这种时候,越要打起精神想想(虽然这样很难):自己究竟要干什么,目前的安排是不是可以做些调整……持续的思考,才会产生感悟,才能有改观,否则,有可能一直陷入“瞎忙”的境地而不能自拔。3.给自己设定明确的时间点
我承认自己也喜欢玩,没事的时候上Twitter、看看论坛、聊聊天,确实很有意思,信息不断更新,总有自己感兴趣的东西冒出来,可是这样守在电脑前,大量的时间就浪费了,什么有意义的事情也没有做,即便做了,效率也很低——专注才能保证效率。摸索反思之后,我觉得比较合适的做法就是,给自己设定明确的时间点:比如现在八点二十,我可以告诉自己,上网玩二十分钟,八点四十开始学英语。因为有了明确的时间界限,反而会想在这二十分钟之内,尽可能高效地把自己感兴趣的内容都看了,而不会慢慢“浏览”;到设定的时间点,一定要令行禁止,专注地做之前决定的事情。
更重要的是,从小事开始给自己设定明确的时间点,对培养执行力很有好处——如果许多小事都能做到“说做就做”,慢慢的,复杂一些大一些的任务,也能够“说做就做”了,有惯性、也有信心去完成。4.写日记
正规一点的网站,都有详细的访问日志(记录),即便不做数据挖掘,一旦网站的访问出现异常波动,就会在日志上体现出来,而且检查日志,可以发现问题所在;网站是这样,人也是这样。我从08年翻译温伯格的《技术领导之路》开始,也开始每天记日记,发现日记和网站的访问日志有相同的功能:比如我一般到公司都在8:35左右,前后误差不超过5分钟,但上周有几天都在9:00左右,检查日记,就可以发现这种变化,而且可以找出变化的原因——是早上做事的顺序改变了。而且,根据日记,我还可以观察评估这种变化的影响,是好是坏。
关于日记还要多说一点,我以前总不理解,很多记多年日记的人,他们的日记为什么那么简单?只记录哪天做了什么,加一点简单评论,而没有太多抒情。我从翻译《技术领导之路》开始到现在记了一年多的日记,逐渐明白了,持续的日记就需要这样记录:当天的主要行为,加上一点评论和反思。日记不太适合作为抒情的载体,更合适的功能是真实记录生活的痕迹,用以分析、反思,然后自己才有可能提高。5.培养预见能力
古话说“凡事,预则立,不预则废”,这是很对的。拿软件项目来说,尽管项目的开发时间很难预测,但有经验的技术人员,往往能更进行更准确的判断,这就是因为他们具有预见能力:能预见到开发中会遇到的问题,这样做出的安排,时间上更充裕(也就能保证效率),心理上也更有准备。
另一方面,我也亲眼见到许多技术人员,只管完成手上本阶段的任务就万事大吉,从来不去预见这些问题:自己的程序能够负载多大的规模和压力,超出这个负载能力,会出现怎样的问题,应该怎样解决,这个问题,照目前的发展速度,大概多久会出现……结果就是,等到问题真正出现了,手忙脚乱焦头烂额,“迭代开发”就成了“拆迁开发”——到某个时间点就要推倒全部重来过一次,质量无法保证不说,自己也累得苦不堪言。
软件行业有本名著叫《重构》,这本书的核心思想是,软件需要不停地重构,要不就会僵化(decay),如果仅仅满足于眼下没有问题,持续的重构也无从说起。6.树立大局观
前些天有个朋友与我讨论跳槽的事情,眼下有两个选择,很难决定;我听了他的详细描述说,这样吧,你暂时不看薪水、职位这些,你这样想:十年,或者五年之后,你希望自己是个怎样的人,是怎样的生活状态?拿着这个答案来衡量你现在的两个选择,看看会怎样。结果,过会儿他就很痛快地做了决定。我想,这就是大局观的作用。
我自己也会遇到许多取舍、抉择的问题,比如我总觉得自己关于计算机的基础还不够扎实,我的英语还不够好,书也读得太少,我的照片拍的还不够好……于是想去补习基础、去学英语、去读书、去看大师的照片……做其中的任何一件,都会给人成就感,但人的时间和精力都是有限的,不可能兼顾;在需要做出选择的很多时候,我都会努力摆脱一本书、一门知识、一件事的局限,跳出来想一想,宏观看来自己现在究竟在怎样的状态,重要的任务是什么,将来希望做一个怎样的人……清楚了最迫切的需求,才可以从容抉择,即便放弃了一些看来还不错的机会也不可惜——况且,正如李笑来老师说的,诱惑许多时候是伪装成机会出现的,拿着大局观的照妖镜,许多诱惑才会显出原形。
大局观不仅对个人成长有用,对工作也有用:无论手头的事情多么细小、琐碎,思维总可以跳出工作的限制,尝试从更广的角度来看待自己所做的事情,到底有怎样的价值,应该如何改进;这样,自己的工作能够做得更好,与同事的配合也会更加默契。7.在生活中细心观察
我每个周末要去麦德龙买购物一次,最开始的几周,我会选择不同的时间点去:早上八点,上午十一点,下午一点,下午四点……这样就能大概地知道,什么时候购物最省时间。这一点,光靠想是很难判断准确的,因为人多的时候有可能结帐窗口也多,人少的时候结帐窗口也少。有了这点了解,就可以妥善安排,尽量减少购物时排队的时间。此外,还可以知道停车场在不同时段的状况,下雨天,也可以选择合适的时段去购物,把车停在有遮挡的车位。
再比如,从家到公司的路不止一条,开始的时候我会尝试每一条路,看看是否拥堵,是否平坦,大概要花多少时间;如此,遇到各种情况,都可以迅速地选择相对来说最合适的路径;如果只走一条路,或者不留意观察,就不会了解这些情况,遇到情况也就没有这么多选择。8.培养分寸感
分析事物,除了定性之外,还有定量,而且定量分析往往更有意义——世界上非此即彼、非黑即白的问题太少了。可惜,许多时候我们却不自觉地在用定性的思维看待世界,往往丧失了很多机会。
举个例子吧,《把时间当作朋友》里提到了一本传记《奇特的一生》,作者详细描述了苏联科学家柳比歇夫管理时间的做法——柳比歇夫每天对时间的把握可以精确到分钟,他每天认真记录自己花多少时间做多少事情:写作35分钟,读书50分钟…虽然“精确到像一座钟”,但传记作者也承认,自认为“还充实”的生活比起柳比歇夫,确实差了太多。我读《奇特的一生》感触很深,我也深知自己虽然无法做到柳比歇夫那么精确,但至少可以偷学一招半式,让自己的生活更有条理,效率更高。但是给一些朋友推荐时,我遇到的第一反应就是:生活那么精确,都成机器人了,多可怕!潜台词就是根本不想了解,不愿意了解。但我想说的是,认真了解柳比歇夫的生活,并不要求我们都像他那样做到极致,而只是提供一个机会借鉴他人的经验和生活习惯(如果不知道,连借鉴都无从说起),至于借鉴几分,这个分寸是可以也需要自己把握的。我深以为,分寸感是非常重要的,它让我们淡定看待各种情况:看到不好的,提醒自己保持距离,看到好的,告诉自己努力借鉴,至少不要被拉大差距。这样才能坦然面对生活,找到自己所处的坐标。化用我喜欢的科学哲学家卡尔·波普的说法,我们的自我感觉良好,必须是建立在比较和判断的基础上的——越是了解这个世界,看得越多,知道的越多(当然也要把握、自我克制的越多),这种感觉才真正越“良好”(关起门来固步自封的“良好”,其实很脆弱很黯淡)。哲学家维特根斯坦在临终前说的话:“多幸福啊,我度过了美好的一生”。他说那句话,是有底气的。
-
编程获取Linux的cpu占用率和 mem使用情况
2011-06-27 10:13:44
Linux下提供top、ps命令查看当前cpu、mem使用情况,简要介绍如下:
一、使用ps查看进程的资源占用
ps -aux
查看进程信息时,第三列就是CPU占用。
[root@localhost utx86]# ps -aux | grep my_process
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.7/FAQ
root 14415 3.4 0.9 37436 20328 pts/12 SL+ 14:18 0:05 ./my_process
root 14464 0.0 0.0 3852 572 pts/3 S+ 14:20 0:00 grep my_process
每一列含义如下
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
即my_process进程当前占用cpu 3.4%, 内存0.9%
二、top动态查看系统负荷
top -n 1
显示后退出
[root@localhost utx86]# top -n 1
top - 14:23:20 up 5:14, 14 users, load average: 0.00, 0.04, 0.01
Tasks: 183 total, 1 running, 181 sleeping, 1 stopped, 0 zombie
Cpu(s): 1.8%us, 1.4%sy, 0.0%ni, 95.8%id, 0.7%wa, 0.1%hi, 0.2%si, 0.0%st
Mem: 2066240k total, 1507316k used, 558924k free, 190472k buffers
Swap: 2031608k total, 88k used, 2031520k free, 1087184k cached
1、获取cpu占用情况
[root@localhost utx86]# top -n 1 |grep Cpu
Cpu(s): 1.9%us, 1.3%sy, 0.0%ni, 95.9%id, 0.6%wa, 0.1%hi, 0.2%si, 0.0%st
解释:1.9%us是用户占用cpu情况
1.3%sy,是系统占用cpu情况
得到具体列的值:
[root@localhost utx86]# top -n 1 |grep Cpu | cut -d "," -f 1 | cut -d ":" -f 2
1.9%us
[root@localhost utx86]# top -n 1 |grep Cpu | cut -d "," -f 2
1.3%sy
2、获得内存占用情况
[root@localhost utx86]# top -n 1 |grep Mem
Mem: 2066240k total, 1515784k used, 550456k free, 195336k buffers
获得内存情况指定列
[root@localhost c++_zp]# top -n 1 |grep Mem | cut -d "," -f 1 | cut -d ":" -f 2
2066240k total
[root@localhost c++_zp]# top -n 1 |grep Mem | cut -d "," -f 2
1585676k used
三、编程实现
现在可以通过程序将cpu使用率、内存使用情况保存到文件中
// test.cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
system("top -n 1 |grep Cpu | cut -d \",\" -f 1 | cut -d \":\" -f 2 >cpu.txt");
system("top -n 1 |grep Cpu | cut -d \",\" -f 2 >>cpu.txt");
system("top -n 1 |grep Mem | cut -d \",\" -f 1 | cut -d \":\" -f 2 >>cpu.txt");
system("top -n 1 |grep Mem | cut -d \",\" -f 2 >>cpu.txt");
return 0;
}
编译、运行:
[root@localhost study]# g++ test.cpp
[root@localhost study]# ./a.out
[root@localhost study]# cat cpu.txt
2.1%us
1.5%sy
2066240k total
1619784k used四、硬盘使用率编程实现
1.硬盘使用率 命令df -lh
2.程序实现,调用statfs
int statfs(const char *path, struct statfs *buf);
int fstatfs(int fd, struct statfs *buf);
struct statfs {
long f_type; /* type of filesystem (see below) */
long f_bsize; /* optimal transfer block size */
long f_blocks; /* total data blocks in file system */
long f_bfree; /* free blocks in fs */
long f_bavail; /* free blocks avail to non-superuser */
long f_files; /* total file nodes in file system */
long f_ffree; /* free file nodes in fs */
fsid_t f_fsid; /* file system id */
long f_namelen; /* maximum length of filenames */
};
int fstatvfs(int fildes, struct statvfs *buf);
int statvfs(const char *restrict path, struct statvfs *restrict buf);struct statvfs {
unsigned long f_bsize; /* file system block size */
unsigned long f_frsize; /* fragment size */
fsblkcnt_t f_blocks; /* size of fs in f_frsize units */
fsblkcnt_t f_bfree; /* # free blocks */
fsblkcnt_t f_bavail; /* # free blocks for non-root */
fsfilcnt_t f_files; /* # inodes */
fsfilcnt_t f_ffree; /* # free inodes */
fsfilcnt_t f_favail; /* # free inodes for non-root */
unsigned long f_fsid; /* file system id */
unsigned long f_flag; /* mount flags */
unsigned long f_namemax; /* maximum filename length */
};
#include <sys/vfs.h>
#include <sys/statvfs.h>
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
int gethd(char *path);
int main()
{
char buf[256],*ptr;
FILE *file;
while(1)
{
file=fopen("/etc/fstab","r");
if(!file)return;
memset(buf,0,sizeof(buf));
while(fgets(buf,sizeof(buf),file))
{
ptr=strtok(buf," ");
if(ptr&&((strncmp(ptr,"/dev",4)==0)))
{
ptr=strtok(NULL," ");
gethd(ptr);
}
}
fclose(file);
sleep(2);
}
}int gethd(char *path)
{
struct statvfs stat1;
statvfs(path,&stat1);
if(stat1.f_flag)
printf("%s total=%dK free=%dK %0.1f%%\n",path,stat1.f_bsize*stat1.f_blocks/1024,stat1.f_bsize*stat1.f_bfree/1024,
((float)stat1.f_blocks-(float)stat1.f_bfree)/(float)stat1.f_blocks*100);
}java:
import java.io.*;
/**
* linux 下cpu 内存 磁盘 jvm的使用监控
* @author avery_leo
*
*/
public class TT {
/**
* 获取cpu使用情况
* @return
* @throws Exception
*/
public double getCpuUsage() throws Exception {
double cpuUsed = 0;Runtime rt = Runtime.getRuntime();
Process p = rt.exec("top -b -n 1");// 调用系统的“top"命令BufferedReader in = null;
try {
in = new BufferedReader(new InputStreamReader(p.getInputStream()));
String str = null;
String[] strArray = null;
while ((str = in.readLine()) != null) {
int m = 0;
if (str.indexOf(" R ") != -1) {// 只分析正在运行的进程,top进程本身除外 &&
strArray = str.split(" ");
for (String tmp : strArray) {
if (tmp.trim().length() == 0)
continue;
if (++m == 9) {// 第9列为CPU的使用百分比(RedHat
cpuUsed += Double.parseDouble(tmp);}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
in.close();
}
return cpuUsed;
}
/**
* 内存监控
* @return
* @throws Exception
*/
public double getMemUsage() throws Exception {double menUsed = 0;
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("top -b -n 1");// 调用系统的“top"命令BufferedReader in = null;
try {
in = new BufferedReader(new InputStreamReader(p.getInputStream()));
String str = null;
String[] strArray = null;
while ((str = in.readLine()) != null) {
int m = 0;
if (str.indexOf(" R ") != -1) {// 只分析正在运行的进程,top进程本身除外 &&
//
// System.out.println("------------------3-----------------");
strArray = str.split(" ");
for (String tmp : strArray) {
if (tmp.trim().length() == 0)
continue;if (++m == 10) {
// 9)--第10列为mem的使用百分比(RedHat 9)menUsed += Double.parseDouble(tmp);
}
}}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
in.close();
}
return menUsed;
}/**
* 获取磁盘空间大小
*
* @return
* @throws Exception
*/
public double getDeskUsage() throws Exception {
double totalHD = 0;
double usedHD = 0;
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("df -hl");//df -hl 查看硬盘空间BufferedReader in = null;
try {
in = new BufferedReader(new InputStreamReader(p.getInputStream()));
String str = null;
String[] strArray = null;
int flag = 0;
while ((str = in.readLine()) != null) {
int m = 0;
// if (flag > 0) {
// flag++;
strArray = str.split(" ");
for (String tmp : strArray) {
if (tmp.trim().length() == 0)
continue;
++m;
// System.out.println("----tmp----" + tmp);
if (tmp.indexOf("G") != -1) {
if (m == 2) {
// System.out.println("---G----" + tmp);
if (!tmp.equals("") && !tmp.equals("0"))
totalHD += Double.parseDouble(tmp
.substring(0, tmp.length() - 1)) * 1024;}
if (m == 3) {
// System.out.println("---G----" + tmp);
if (!tmp.equals("none") && !tmp.equals("0"))
usedHD += Double.parseDouble(tmp.substring(
0, tmp.length() - 1)) * 1024;}
}
if (tmp.indexOf("M") != -1) {
if (m == 2) {
// System.out.println("---M---" + tmp);
if (!tmp.equals("") && !tmp.equals("0"))
totalHD += Double.parseDouble(tmp
.substring(0, tmp.length() - 1));}
if (m == 3) {
// System.out.println("---M---" + tmp);
if (!tmp.equals("none") && !tmp.equals("0"))
usedHD += Double.parseDouble(tmp.substring(
0, tmp.length() - 1));
// System.out.println("----3----" + usedHD);
}
}
}// }
}
} catch (Exception e) {
e.printStackTrace();
} finally {
in.close();
}
return (usedHD / totalHD) * 100;
}public static void main(String[] args) throws Exception {
TT cpu = new TT();
System.out.println("---------------cpu used:" + cpu.getCpuUsage() + "%");
System.out.println("---------------mem used:" + cpu.getMemUsage() + "%");
System.out.println("---------------HD used:" + cpu.getDeskUsage() + "%");
System.out.println("------------jvm监控----------------------");
Runtime lRuntime = Runtime.getRuntime();
System.out.println("--------------Free Momery:" + lRuntime.freeMemory()+"K");
System.out.println("--------------Max Momery:" + lRuntime.maxMemory()+"K");
System.out.println("--------------Total Momery:" + lRuntime.totalMemory()+"K");
System.out.println("---------------Available Processors :"
+ lRuntime.availableProcessors());
}
}shell
监视磁盘hda1
#!/bin/sh
# disk_mon
# monitor the disk space
# get percent column and strip off header row from df
LOOK_OUT=0
until [ "$LOOK_OUT" -gt "90" ]
do
LOOK_OUT=`df | grep /hda1 | awk '{print $5}' | sed 's/%//g'`
echo $LOOK_OUT%
sleep 1
done
echo "Disk hda1 is nearly full!"hdtest.sh
#!/bin/ksh
#检测硬盘剩余空间并警告的shell V050921
#简单说明: 可由root用户将此脚本加入crontab,启动时间一般最好设为每天营业前,当此脚本启动时如检测到已用硬盘空间超过指定范围,则将hdwarning.sh脚本拷贝到指定用户根目录下;否则将删除指定用户的目录下的hdwarning.sh脚本.
usedhd=80 #自定义超限已用硬盘空间大小比例,默认为80%
test "$1" && userdir=$1 || userdir=/usr/scabs #前台用户的目录(默认设为统版用户),也可在调用此脚本时加上指定前台用户的目录参数
hdwarning=$(df -v |sed '1d;s/.$//;s/\/dev\///'|awk '$6>'"$usedhd"' {print $2," = ",$6"%"}')
test "$hdwarning" && { cp /usr/bin/hdwarning.sh ${userdir}/hdwarning.sh \
> ${userdir}/hdwarning.log  chmod 777 ${userdir}/hdwarning.sh ${userdir}/hdwarning.log } \
|| { rm ${userdir}/hdwarning.sh 2>/dev/null \
mv ${userdir}/hdwarning.log ${userdir}/hdwarning.log.bak 2>/dev/null }
hdwarning.sh
#!/bin/ksh
#检测硬盘剩余空间并警告的shell V050921
#增加当超标时,只在预先指定的前N位预先的指定用户登录时才显示提示信息,
#即只有这前面N位用户才有可能及时反馈,避免当超标时接到过多的前台反馈电话 V050923
#请先编辑指定用户根下的 .profile ,在最后追加一行
#  test -x hdwarning.sh &&  ./hdwarning.sh
#若.profile最后已加入了自启动专用程序命令行,则请在此行前面插入上述行
#简单说明: 当指定用户登录后,若当前目录中hdwarning.sh脚本存在(一般此
#时硬盘已用空间已经超标),则运行此脚本,并在屏幕显示警告信息,此时终端
#操作人员应该及时将此信息把馈给预先指定的部门或预先指定的管理人员,
#以便作相应的处理.若未超标或已清理磁盘文件并达标,则将删除脚本自身
#hdwarning.sh(取消登录时的检测和警告信息)
usedhd=80 #自定义超限已用硬盘空间大小比例,默认为80%
loginnum=10 #自定义最初登录反馈的用户数,默认为前 10 位
name="运维部" #接受反馈的部门或管理人员
tel="2113714 2110394" #接受反馈的部门或管理人员的联系方式或电话
test "$1" && userdir=$1 || userdir=/usr/scabs #前台用户的目录(默认设为统版用户),也可在调用此
#脚本时加上指定前台用户的目录参数
hdwaring()
{ ttyname=$(tty)
echo ${ttyname##*shell cpu====================================================================:
/proc目路下的内存文件系统映射了系统的运行时的一些信息,包括进程列表,
内存信息,CPU使用情况,还有网络等等
所以可以通过读/proc下的文件来实现统计信息的获取
但是,要注意的时不同的版本,将/proc下的每个文件中的类容会有一些差别,每一个项代表什么要自己分析,最好根据top的输出去分析
然后就可以通过shell教本或者C取得CPU使用率
比如:
我的机子是AS4(Kernel 2.6.9-5)
cat /proc/stat
cpu 1047871 11079 394341 1157538880 4909104 1945 61338
cpu0 352894 2950 157917 290318045 109839 0 49564
cpu1 234860 1978 115148 288108962 2522748 1028 6391
cpu2 106253 1674 52273 288601985 2225180 909 2839
cpu3 353863 4477 69001 290509888 51337 6 2543
intr 3021292348 2939335896 720 0 12 12 0 7 2 1 0 0 0 1951 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7217173 0 0 0 0 0 0 0 30 0 0 0 0 0 0 0 74736544 0 0 0 0 0 0 0 0 0 0 0 0 0
ctxt 379682110
btime 1158715143
processes 603543
procs_running 1
procs_blocked 0
然后就可以自己计算了复制代码- #########GetCPU.sh
- ######Author:duanjigang
- #!/bin/sh
- while true
- do
- awk '$1=="cpu"{Total=$2+$3+$4+$5+$6+$7;print "Free: " $5/Total*100"%
- " " Used: " (Total-$5)*100/Total"%"}' </proc/stat
- sleep 1
- done
#./GetCPU.sh
Free: 99.4532% Used: 0.546814%
Free: 99.4532% Used: 0.546813%
Free: 99.4532% Used: 0.546813%
Free: 99.4532% Used: 0.546813%
这样应该可以的shell cpu MEM====================================================================:
(1):取CPU使用率
机器:LinuxAS4 2.6.9-5.ELsmp (不通版本的内核会有差异的)复制代码- #cpu.sh-to get the utilization of every cpu
- #author:duanjigang<2006/12/28>
- #!/bin/sh
- awk '$0 ~/cpu[0-9]/' /proc/stat | while read line
- do
- echo "$line" | awk '{total=$2+$3+$4+$5+$6+$7+$8;free=$5;\
- print$1" Free "free/total*100"%",\
- "Used " (total-free)/total*100"%"}'
- done
#chmod +x cpu.sh
#./cpu.sh
cpu0 Free 99.7804% Used 0.219622%
cpu1 Free 99.8515% Used 0.148521%
cpu2 Free 99.6632% Used 0.336765%
cpu3 Free 99.6241% Used 0.375855%
(2)网络流量情况复制代码- #if.sh-to get the network flow of each interface
- #for my beloved ning
- #author:duanjigang<2006/12/28>
- #!/bin/sh
- echo "name ByteRec PackRec ByteTran PackTran"
- awk ' NR>2' /proc/net/dev | while read line
- do
- echo "$line" | awk -F ':' '{print " "$1" " $2}' |\
- awk '{print $1" "$2 " "$3" "$10" "$11}'
- done
#./if.sh
name ByteRec PackRec ByteTran PackTran
lo 2386061 17568 2386061 17568
eth0 1159936483 150753251 190980687 991835
eth1 0 0 0 0
sit0 0 0 0 0
(3):端口情况
http://bbs.chinaunix.net/viewthread.php?tid=864757&highlight=duanjigang
(4)至于内存
cat /proc/meminfo | grep "MemTotal"
cat /rpco/meninfo | grep "MemFree"
就可以了吧 -
查看基于Android 系统单个进程内存、CPU使用情况的几种方法(转)
2011-06-27 09:19:02
一、利用Android API函数查看
1.1 ActivityManager查看可用内存。
ActivityManager.MemoryInfo utInfo = new ActivityManager.MemoryInfo();
am.getMemoryInfo(outInfo);
outInfo.availMem即为可用空闲内存。
1.2、android.os.Debug查询PSS,VSS,USS等单个进程使用内存信息
MemoryInfo[] memoryInfoArray = am.getProcessMemoryInfo(pids);
MemoryInfo pidMemoryInfo=memoryInfoArray[0];
pidMemoryInfo.getTotalPrivateDirty();getTotalPrivateDirty()
Return total private dirty memory usage in kB. USSgetTotalPss()
Return total PSS memory usage in kB.
PSS
getTotalSharedDirty()
Return total shared dirty memory usage in kB. RSS
二、直接对Android文件进行解析查询,
/proc/cpuinfo系统CPU的类型等多种信息。
/proc/meminfo 系统内存使用信息
如
/proc/meminfo
MemTotal: 16344972 kB
MemFree: 13634064 kB
Buffers: 3656 kB
Cached: 1195708 kB
我们查看机器内存时,会发现MemFree的值很小。这主要是因为,在linux中有这么一种思想,内存不用白不用,因此它尽可能的cache和buffer一些数据,以方便下次使用。但实际上这些内存也是可以立刻拿来使用的。
所以 空闲内存=free+buffers+cached=total-used
通过读取文件/proc/meminfo的信息获取Memory的总量。
ActivityManager. getMemoryInfo(ActivityManager.MemoryInfo)获取当前的可用Memory量。三、通过Android系统提供的Runtime类,执行adb 命令(top,procrank,ps...等命令)查询
通过对执行结果的标准控制台输出进行解析。这样大大的扩展了Android查询功能.例如:
final Process m_process = Runtime.getRuntime().exec("/system/bin/top -n 1");
final StringBuilder sbread = new StringBuilder();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(m_process.getInputStream()), 8192);# procrank
Runtime.getRuntime().exec("/system/xbin/procrank");
内存耗用:VSS/RSS/PSS/USS
Terms
• VSS - Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)
• RSS - Resident Set Size 实际使用物理内存(包含共享库占用的内存)
• PSS - Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)
• USS - Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)
一般来说内存占用大小有如下规律:VSS >= RSS >= PSS >= USS
USS is the total private memory for a process, i.e. that memory that is completely unique to that process.USS is an extremely useful number because it indicates the true incremental cost of running a particular process. When a process is killed, the USS is the total memory that is actually returned to the system. USS is the best number to watch when initially suspicious of memory leaks in a process.
标题搜索
我的存档
数据统计
- 访问量: 32365
- 日志数: 56
- 建立时间: 2008-09-08
- 更新时间: 2013-03-05
