用python做测试实现高性能测试工具(1)—序
上一篇 /
下一篇 2014-01-03 08:47:32
用python做测试实现高性能测试工具(1)—序
http://www.51testing.com/html/16/n-856016.html
http://www.51testing.com/html/23/n-856023.html
做过几年开发或者测试开发的人员,时常会觉得很迷茫,新功能的开发或者老功能的维护,基本是在堆代码了, 做过几年测试的朋友也会有类似的想法。性能调优或者性能测试的确很考验人分析问题、解决问题的能力,知识是否全面。本人也是第一次实现高性能的测试工具, 记录下这次diameter协议测试工具的优化过程,供大家一起学习。 有些内容涉及到具体产品,做了些改动或者单独写了测试代码演示。
Python用来开发高性能的测试工具的确有天然的缺陷,性能差还有GIL,无法利用多线程。 但办法总比困难多,那么多大的
互联网公司都使用python与实际产品中,总比我们测试的性能要求搞多了。 本文主要讲述在系统设计和架构方面的性能优化,具体算法和一些小细节的优化,请参考 http://blog.csdn.net/powerccna/article/details/8020289
项目背景:
实现个高性能的diameter 测试工具, 接受1000+发送1000,双向要支持到2000条消息每秒。 diameter 协议的源代码是从这里下载的 http://sourceforge.net/projects/pyprotosim/, 这个开源包还支持SMPP, RADIUS, DHCP, LDAP, 而且新增加的协议字段都可以在dictionary配置属性,不需要修改代码,实在是方便。 初始阶段我们为了实现功能,没有怎么考虑性能的问题,很多地方用的是单线程,初始性能只能支持到50 消息。硬件环境: SunFire 4170, 16 核,每核2.4 G
Python性能优化的几个方向:
1. 换python的解析器:常见的python解析器有pysco,pypy, cython, jython, pysco已经对python 2.7不支持了,就没有测试,据说跑的很C语言一样快。对pypy, jython做了简单测试,pypy在不同机器上可以提高到5-10倍的样子,Jython虽然可以避免python GIL的问题(因为jython是跑在
java虚拟机上的),但测试看来,效率提升很少。
2. 优化代码
3. 改变系统架构,多线程,多进程或者协程
方案1: 换Python解析器
如果换Python解析器能达到性能需求是最廉价的方案了,不需要对代码做任何改动。下面代码只是为了说明pypy的效果,单独写的测试代码,在windows下运行的结果。在linux下机器上运行效果会更好些。
#!/usr/bin/env python #coding=utf-8 import time def check(num): a = list(str(num)) b = a[::-1] if a == b: return True return False all = xrange(1,10**7) for i in all: if check(i): if check(i**2): i**2 if __name__ == '__main__': start=time.time() test() print time.time()-start 分别用python和pypy的运行结果 C:\Python27\python.exeD:/RCC/mp/src/test.py 14.4940001965 C:\pypy-2.1\pypy.exeD:/RCC/mp/src/test.py 4.37800002098 |
可以看出来pypy的运行结果效果还是明显的,虽然能提高5倍(linux机器上),50*5, 离2000还差好远。 pypy对python 多线程的支持没有明显效果,这个在后面会提到。
先告一段落,太长了大家看起来累,下一篇
文章中将会介绍代码优化部分。
用python做测试实现高性能测试工具(2)—优化代码
在上一篇中我们通过换
python的解析器来优化性能。但离实际需求还很远。
方案2: 优化代码
工欲善其事,必先利其器。要优化代码,必须先找到代码的瓶颈所在,最土的方法是添加log, 或者print, 调试完成还需要删除,比较麻烦。python里面也提供了很多profile工具:profile, cProfile, hotshot, pystats, 但这些工具提供的结果可读性不是很好,不够直观的一眼就能看到那个函数或者那一行占用时间最多。 python line_profiler 提供了这样的功能,可以很直观的看到哪一行占用的时间最多,可谓“快准狠”,下载地址: http://pythonhosted.org/line_profiler/
安装完line_profiler后,在C:\Python27\Lib\site-packages 目录下会有一个kernprof.py,在可能存在瓶颈的函数上添加 @profile, 如以下例子:
@profile def create_msg2(self,H,msg): li = msg.keys() msg_type=li[0] ULR_avps=[] ULR=HDRItem() ULR.cmd=self.dia.dictCOMMANDname2code(self.dia.MSG_TERM[msg_type]) if msg_type[-1]=='A': msg=msg[msg_type] self.dia.setAVPs_by_dic(msg_type,msg,ULR_avps) ULR.appId=H.appId ULR.EndToEnd=H.EndToEnd ULR.HopByHop=H.HopByHop msg=self.dia.createRes(ULR,ULR_avps) else: self.dia.setAVPs(msg_type,msg,ULR_avps) ULR.appId=self.dia.APPID self.dia.initializeHops(ULR) msg=self.dia.createReq(ULR,ULR_avps) return msg |
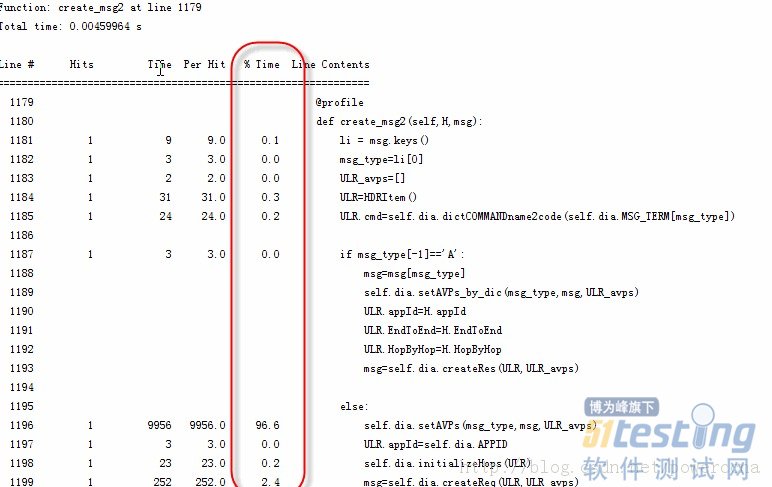
运行此文件: kernprof.py -l -v D:\project\mp\src\protocols\libdiametermt.py, 得到如下结果。 从这图中可以很直观的看到setAVPS方法占用了96.6%的时间,再进一步定位到此函数,再次添加@proflie修饰符(可以一次在多个函数上添加Profile), 可以再进一步看到setAVPS函数中各行代码的占用时间比。
通过一步步的分析中看到,开源协议库中,setAVPS的方法中,查找avp的属性是从一个3000的循环里面查找的,每个AVP都需要循环3000次,一个diameter消息中至少10个avp,每次encoding一个avp需要循环3W次。 我们初始的解决方法是删除了很多我们
性能测试中用不到的avp(没办法,测试开发资源有限,很多时候没有很好的设计,先做出满足需求的东西再说。), 但也只是提高到了150左右,离需求还差的很远。所以我们把AVP都改成了字典方式,可以根据名字快速查找到AVP的属性。
除了代码的优化,同时还增加了encoding avp的线程数,后面章节将会讲到多线程和多进程,对性能的影响。
收藏
举报
TAG: