
-
这才是世上最全的“软件测试”思维导图!
2016-06-30 17:49:14
http://www.51testing.com/html/02/n-3710302.html -
测试开发之路—一切为了效率 (简易监控)
2016-05-24 17:57:36
http://www.51testing.com/html/28/n-3709528.html -
七年阿里老人谈新人成长
2016-05-12 14:05:03
http://www.51testing.com/html/04/n-3709104.htmlhttp://www.51testing.com/html/04/n-3709104-2.html -
测试的核心价值和能力是什么?
2016-05-10 10:01:08
http://www.51testing.com/html/57/n-3708457.html -
一种简单的数据库性能测试方法
2016-05-10 08:46:05
http://www.51testing.com/html/61/n-3709061.htmlhttp://www.51testing.com/html/61/n-3709061-2.html -
假如不是BAT,专项测试要怎样做?
2015-10-08 13:25:20
http://www.51testing.com/html/29/n-3648929.html -
做好软件测试需要具备的思维方式
2015-09-06 12:56:38
http://www.51testing.com/html/14/n-3579014.html -
日志 [2015年08月12日]
2015-08-12 16:53:43
http://www.51testing.com/html/87/n-3578287.html -
http接口自动化测试框架实现
2014-03-31 17:18:07
转载:http://blog.csdn.net/vincetest/article/details/6341658
一、测试需求描述
对服务后台一系列的http接口功能测试。
输入:根据接口描述构造不同的参数输入值
输出:XML文件
eg:http://xxx.com/xxx_product/test/content_book_list.jsp?listid=1
二、实现方法
1、选用Python脚本来驱动测试
2、采用Excel表格管理测试数据,包括用例的管理、测试数据录入、测试结果显示等等,这个需要封装一个Excel的类即可。
3、调用http接口采用Python封装好的API即可
4、测试需要的http组装字符转处理即可
5、设置2个检查点,XML文件中的返回值字段(通过解析XML得到);XML文件的正确性(文件对比)
6、首次执行测试采用半自动化的方式,即人工检查输出的XML文件是否正确,一旦正确将封存XML文件,为后续回归测试的预期结果,如果发现错误手工修正为预期文件。(注意不是每次测试都人工检查该文件,只首次测试的时候才检查)
三、Excel表格样式
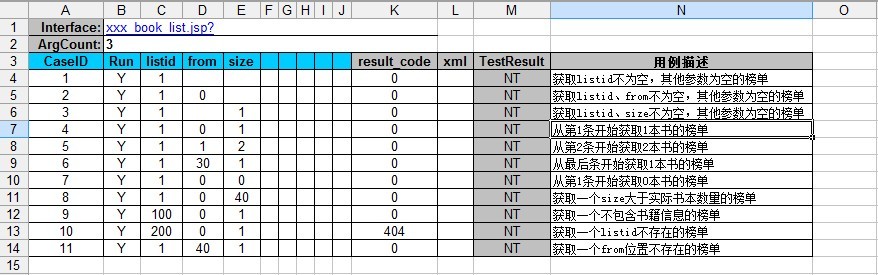
四、实现代码(代码才是王道,有注释很容易就能看明白的)
1、测试框架代码
- #****************************************************************
- # TestFrame.py
- # Author : Vince
- # Version : 1.1.2
- # Date : 2011-3-14
- # Description: 自动化测试平台
- #****************************************************************
- import os,sys, urllib, httplib, profile, datetime, time
- from xml2dict import XML2Dict
- import win32com.client
- from win32com.client import Dispatch
- import xml.etree.ElementTree as et
- #import MySQLdb
- #Excel表格中测试结果底色
- OK_COLOR=0xffffff
- NG_COLOR=0xff
- #NT_COLOR=0xffff
- NT_COLOR=0xC0C0C0
- #Excel表格中测试结果汇总显示位置
- TESTTIME=[1, 14]
- TESTRESULT=[2, 14]
- #Excel模版设置
- #self.titleindex=3 #Excel中测试用例标题行索引
- #self.casebegin =4 #Excel中测试用例开始行索引
- #self.argbegin =3 #Excel中参数开始列索引
- #self.argcount =8 #Excel中支持的参数个数
- class create_excel:
- def __init__(self, sFile, dtitleindex=3, dcasebegin=4, dargbegin=3, dargcount=8):
- self.xlApp = win32com.client.Dispatch('et.Application') #MS:Excel WPS:et
- try:
- self.book = self.xlApp.Workbooks.Open(sFile)
- except:
- print_error_info()
- print "打开文件失败"
- exit()
- self.file=sFile
- self.titleindex=dtitleindex
- self.casebegin=dcasebegin
- self.argbegin=dargbegin
- self.argcount=dargcount
- self.allresult=[]
- self.retCol=self.argbegin+self.argcount
- self.xmlCol=self.retCol+1
- self.resultCol=self.xmlCol+1
- def close(self):
- #self.book.Close(SaveChanges=0)
- self.book.Save()
- self.book.Close()
- #self.xlApp.Quit()
- del self.xlApp
- def read_data(self, iSheet, iRow, iCol):
- try:
- sht = self.book.Worksheets(iSheet)
- sValue=str(sht.Cells(iRow, iCol).Value)
- except:
- self.close()
- print('读取数据失败')
- exit()
- #去除'.0'
- if sValue[-2:]=='.0':
- sValue = sValue[0:-2]
- return sValue
- def write_data(self, iSheet, iRow, iCol, sData, color=OK_COLOR):
- try:
- sht = self.book.Worksheets(iSheet)
- sht.Cells(iRow, iCol).Value = sData.decode("utf-8")
- sht.Cells(iRow, iCol).Interior.Color=color
- self.book.Save()
- except:
- self.close()
- print('写入数据失败')
- exit()
- #获取用例个数
- def get_ncase(self, iSheet):
- try:
- return self.get_nrows(iSheet)-self.casebegin+1
- except:
- self.close()
- print('获取Case个数失败')
- exit()
- def get_nrows(self, iSheet):
- try:
- sht = self.book.Worksheets(iSheet)
- return sht.UsedRange.Rows.Count
- except:
- self.close()
- print('获取nrows失败')
- exit()
- def get_ncols(self, iSheet):
- try:
- sht = self.book.Worksheets(iSheet)
- return sht.UsedRange.Columns.Count
- except:
- self.close()
- print('获取ncols失败')
- exit()
- def del_testrecord(self, suiteid):
- try:
- #为提升性能特别从For循环提取出来
- nrows=self.get_nrows(suiteid)+1
- ncols=self.get_ncols(suiteid)+1
- begincol=self.argbegin+self.argcount
- #提升性能
- sht = self.book.Worksheets(suiteid)
- for row in range(self.casebegin, nrows):
- for col in range(begincol, ncols):
- str=self.read_data(suiteid, row, col)
- #清除实际结果[]
- startpos = str.find('[')
- if startpos>0:
- str = str[0:startpos].strip()
- self.write_data(suiteid, row, col, str, OK_COLOR)
- else:
- #提升性能
- sht.Cells(row, col).Interior.Color = OK_COLOR
- #清除TestResul列中的测试结果,设置为NT
- self.write_data(suiteid, row, self.argbegin+self.argcount+1, ' ', OK_COLOR)
- self.write_data(suiteid, row, self.resultCol, 'NT', NT_COLOR)
- except:
- self.close()
- print('清除数据失败')
- exit()
- #执行调用
- def HTTPInvoke(IPPort, url):
- conn = httplib.HTTPConnection(IPPort)
- conn.request("GET", url)
- rsps = conn.getresponse()
- data = rsps.read()
- conn.close()
- return data
- #获取用例基本信息[Interface,argcount,[ArgNameList]]
- def get_caseinfo(Data, SuiteID):
- caseinfolist=[]
- sInterface=Data.read_data(SuiteID, 1, 2)
- argcount=int(Data.read_data(SuiteID, 2, 2))
- #获取参数名存入ArgNameList
- ArgNameList=[]
- for i in range(0, argcount):
- ArgNameList.append(Data.read_data(SuiteID, Data.titleindex, Data.argbegin+i))
- caseinfolist.append(sInterface)
- caseinfolist.append(argcount)
- caseinfolist.append(ArgNameList)
- return caseinfolist
- #获取输入
- def get_input(Data, SuiteID, CaseID, caseinfolist):
- sArge=''
- #参数组合
- for j in range(0, caseinfolist[1]):
- if Data.read_data(SuiteID, Data.casebegin+CaseID, Data.argbegin+j) != "None":
- sArge=sArge+caseinfolist[2][j]+'='+Data.read_data(SuiteID, Data.casebegin+CaseID, Data.argbegin+j)+'&'
- #去掉结尾的&字符
- if sArge[-1:]=='&':
- sArge = sArge[0:-1]
- sInput=caseinfolist[0]+sArge #组合全部参数
- return sInput
- #结果判断
- def assert_result(sReal, sExpect):
- sReal=str(sReal)
- sExpect=str(sExpect)
- if sReal==sExpect:
- return 'OK'
- else:
- return 'NG'
- #将测试结果写入文件
- def write_result(Data, SuiteId, CaseId, resultcol, *result):
- if len(result)>1:
- ret='OK'
- for i in range(0, len(result)):
- if result[i]=='NG':
- ret='NG'
- break
- if ret=='NG':
- Data.write_data(SuiteId, Data.casebegin+CaseId, resultcol,ret, NG_COLOR)
- else:
- Data.write_data(SuiteId, Data.casebegin+CaseId, resultcol,ret, OK_COLOR)
- Data.allresult.append(ret)
- else:
- if result[0]=='NG':
- Data.write_data(SuiteId, Data.casebegin+CaseId, resultcol,result[0], NG_COLOR)
- elif result[0]=='OK':
- Data.write_data(SuiteId, Data.casebegin+CaseId, resultcol,result[0], OK_COLOR)
- else: #NT
- Data.write_data(SuiteId, Data.casebegin+CaseId, resultcol,result[0], NT_COLOR)
- Data.allresult.append(result[0])
- #将当前结果立即打印
- print 'case'+str(CaseId+1)+':', Data.allresult[-1]
- #打印测试结果
- def statisticresult(excelobj):
- allresultlist=excelobj.allresult
- count=[0, 0, 0]
- for i in range(0, len(allresultlist)):
- #print 'case'+str(i+1)+':', allresultlist[i]
- count=countflag(allresultlist[i],count[0], count[1], count[2])
- print 'Statistic result as follow:'
- print 'OK:', count[0]
- print 'NG:', count[1]
- print 'NT:', count[2]
- #解析XmlString返回Dict
- def get_xmlstring_dict(xml_string):
- xml = XML2Dict()
- return xml.fromstring(xml_string)
- #解析XmlFile返回Dict
- def get_xmlfile_dict(xml_file):
- xml = XML2Dict()
- return xml.parse(xml_file)
- #去除历史数据expect[real]
- def delcomment(excelobj, suiteid, iRow, iCol, str):
- startpos = str.find('[')
- if startpos>0:
- str = str[0:startpos].strip()
- excelobj.write_data(suiteid, iRow, iCol, str, OK_COLOR)
- return str
- #检查每个item (非结构体)
- def check_item(excelobj, suiteid, caseid,real_dict, checklist, begincol):
- ret='OK'
- for checkid in range(0, len(checklist)):
- real=real_dict[checklist[checkid]]['value']
- expect=excelobj.read_data(suiteid, excelobj.casebegin+caseid, begincol+checkid)
- #如果检查不一致测将实际结果写入expect字段,格式:expect[real]
- #将return NG
- result=assert_result(real, expect)
- if result=='NG':
- writestr=expect+'['+real+']'
- excelobj.write_data(suiteid, excelobj.casebegin+caseid, begincol+checkid, writestr, NG_COLOR)
- ret='NG'
- return ret
- #检查结构体类型
- def check_struct_item(excelobj, suiteid, caseid,real_struct_dict, structlist, structbegin, structcount):
- ret='OK'
- if structcount>1: #传入的是List
- for structid in range(0, structcount):
- structdict=real_struct_dict[structid]
- temp=check_item(excelobj, suiteid, caseid,structdict, structlist, structbegin+structid*len(structlist))
- if temp=='NG':
- ret='NG'
- else: #传入的是Dict
- temp=check_item(excelobj, suiteid, caseid,real_struct_dict, structlist, structbegin)
- if temp=='NG':
- ret='NG'
- return ret
- #获取异常函数及行号
- def print_error_info():
- """Return the frame. object for the caller's stack frame."""
- try:
- raise Exception
- except:
- f = sys.exc_info()[2].tb_frame.f_back
- print (f.f_code.co_name, f.f_lineno)
- #测试结果计数器,类似Switch语句实现
- def countflag(flag,ok, ng, nt):
- calculation = {'OK':lambda:[ok+1, ng, nt],
- 'NG':lambda:[ok, ng+1, nt],
- 'NT':lambda:[ok, ng, nt+1]}
- return calculation[flag]()
2、项目测试代码
- # -*- coding: utf-8 -*-
- #****************************************************************
- # xxx_server_case.py
- # Author : Vince
- # Version : 1.0
- # Date : 2011-3-10
- # Description: 内容服务系统测试代码
- #****************************************************************
- from testframe. import *
- from common_lib import *
- httpString='http://xxx.com/xxx_product/test/'
- expectXmldir=os.getcwd()+'/TestDir/expect/'
- realXmldir=os.getcwd()+'/TestDir/real/'
- def run(interface_name, suiteid):
- print '【'+interface_name+'】' + ' Test Begin,please waiting...'
- global expectXmldir, realXmldir
- #根据接口名分别创建预期结果目录和实际结果目录
- expectDir=expectXmldir+interface_name
- realDir=realXmldir+interface_name
- if os.path.exists(expectDir) == 0:
- os.makedirs(expectDir)
- if os.path.exists(realDir) == 0:
- os.makedirs(realDir)
- excelobj.del_testrecord(suiteid) #清除历史测试数据
- casecount=excelobj.get_ncase(suiteid) #获取case个数
- caseinfolist=get_caseinfo(excelobj, suiteid) #获取Case基本信息
- #遍历执行case
- for caseid in range(0, casecount):
- #检查是否执行该Case
- if excelobj.read_data(suiteid,excelobj.casebegin+caseid, 2)=='N':
- write_result(excelobj, suiteid, caseid, excelobj.resultCol, 'NT')
- continue #当前Case结束,继续执行下一个Case
- #获取测试数据
- sInput=httpString+get_input(excelobj, suiteid, caseid, caseinfolist)
- XmlString=HTTPInvoke(com_ipport, sInput) #执行调用
- #获取返回码并比较
- result_code=et.fromstring(XmlString).find("result_code").text
- ret1=check_result(excelobj, suiteid, caseid,result_code, excelobj.retCol)
- #保存预期结果文件
- expectPath=expectDir+'/'+str(caseid+1)+'.xml'
- #saveXmlfile(expectPath, XmlString)
- #保存实际结果文件
- realPath=realDir+'/'+str(caseid+1)+'.xml'
- saveXmlfile(realPath, XmlString)
- #比较预期结果和实际结果
- ret2= check_xmlfile(excelobj, suiteid, caseid,expectPath, realPath)
- #写测试结果
- write_result(excelobj, suiteid, caseid, excelobj.resultCol, ret1, ret2)
- print '【'+interface_name+'】' + ' Test End!'
3、测试入口
- # -*- coding: utf-8 -*-
- #****************************************************************
- # main.py
- # Author : Vince
- # Version : 1.0
- # Date : 2011-3-16
- # Description: 测试组装,用例执行入口
- #****************************************************************
- from testframe. import *
- from xxx_server_case import *
- import xxx_server_case
- #产品系统接口测试
- #设置测试环境
- xxx_server_case.excelobj=create_excel(os.getcwd()+'/TestDir/xxx_Testcase.xls')
- xxx_server_case.com_ipport=xxx.com'
- #Add testsuite begin
- run("xxx_book_list", 4)
- #Add other suite from here
- #Add testsuite end
- statisticresult(xxx_server_case.excelobj)
- xxx_server_case.excelobj.close()
最后感谢我的同事Roger为此做了一些优化,后续优化的东东还很多,我们一直在努力!
欢迎转载此文,转载时请注明文章来源:张元礼的博客 http://blog.csdn.net/vincetest
-
性能测试学习内容指南
2014-03-25 17:29:42
转载:http://www.51testing.com/html/64/n-859264.html
1. 性能测试理论
性能测试常用术语性能测试的应用领域性能测试工具原理2.LoardRunner基本操作及应用LoardRunner原理分析LoardRunner脚本开发流程VuGen(基本设置、检查点、参数化、关联、调试、事物)Controller(场景设计、场景监视<Windows Resources、IIS服务器、Unix/Linux Resource、Weblogic Server、数据库服务器>、集合点、IP欺骗技术、负载均衡、场景执行)Analysis(摘要报告、常见图分析、结果分析实践<分析图合并、分析图关联、页面细分、钻取技术、外部数据导入、HttpWatch分析>)3.Linux监测、分析、调优CPU监控内存监控磁盘监控网络监控4.Windows监测、分析、调优LoardRunner直接监控、Windows性能工具监控、Windows计数器5. 数据库监测、分析、调优6. 常用的服务器监测、分析、调优Apache监控Apache调优Tomcat监控7. 前端性能调优前端性能分析概要Firebug工具HttpWatchChrome自带的开发工具DynaTrace Ajax Edition工具8.网络分析9.代码分析与调优10.项目实战11.推荐书籍<<软件性能测试过程详解与案例剖析>><<性能测试进阶指南>><<深入性能测试LoardRunner>> -
性能测试工具原理
2014-03-25 17:21:04
http://www.51testing.com/html/65/n-859265.html
广义的讲,可以把性能测试过程中使用到的所有工具都称为性能测试工具,性能测试工具分为两大类,服务端性能测试工具和前端性能测试工具;服务端性能测试工具需要支持产生压力和负载,录制和生成测试脚本,设置和部署场景,产生并发用户和向系统施加持续的压力;而前端性能测试工具则不需要关系系统的压力和负载,只需要关心浏览器等客户端工具(目前的前端性能测试工具主要是Web前端性能测试工具)。
服务端性能测试工具架构1.虚拟用户脚本产生器虚拟用户脚本生成器通过Proxy方式实现,具体来说,就是由一个Proxy作为客户端和服务器之间的中间人,接收从客户端发送的数据包,记录并将其转发给服务端,接收从服务端返回的数据流,记录并返回给客户端。这样,无论是客户端还是服务端都以为自己在一个真实的运行环境中。2.压力产生器压力产生器用于根据脚本内容产生实际的负载。在性能测试工具中,压力产生器扮演者“产生负载”的角色。例如,如果一个测试场景要求产生100个虚拟用户,则压力产生器会在调度下生成100个进程或线程,每个线程对指定的脚本进行解释执行3.用户代理用户代理是运行在负载机上的进程,该进程与产生负载压力的进程或线程协作,接收调度系统的命令,调度产生负载压力的进程或线程,从这个意义上看,用户代理业可以被看作是压力产生器的组成部分4.压力调度和监控系统压力调度和监控系统是性能测试工具中直接与用户交互的主要内容。压力调度工具可以根据用户的场景要求,设置各不同脚本的VU数量、设置同步点等,而监控系统则可以对各种数据库、应用服务器、服务器的主要性能计数器进行监控5.压力结果分析工具压力结果分析工具可以用来辅助进行测试结果的分析。 -
关于软件测试的几点反思—测试工作的三个阶段
2014-03-25 09:01:47
-
计算机软件质量保证计划示例
2014-01-10 17:19:42
转载:http://www.51testing.com/html/78/n-856978.html
计划名CADCSC软件质量保证计划
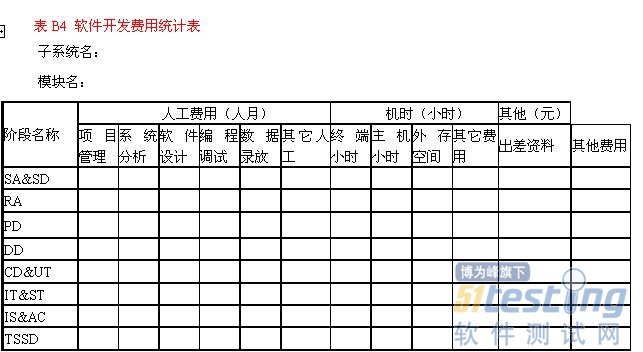
项目名中国控制系统CAD工程化软件系统项目委托单位代表签名年月日项目承办单位代表签名年月日1引言1.1目的本计划的目的在于对所开发的CADCSC软件规定各种必要的质量保证措施,以保证所交付的CADCSC软件能够满足项目委托书或合同中规定的各项需求,能够满足本项目总体组制定的且经领导小组批准的该软件系统需求规格说明书中规定的各项具体需求。软件开发单位在开发CADCSC软件系统所属的各个子系统(其中包括为本项目研制或选用的各种支持软件)时,都应该执行本计划中的有关规定,但可根据各自的情况对本计划作适当的剪裁,以满足特定的质量保证要求,剪裁后的计划必须经总体组批准。1.2定义本计划用到的一些术语的定义按GB/T11457和GB/T12505.1.3参考资料GB/T11457软件工程术语GB8566计算机软件开发规范GB8567计算机软件产品开发文件编制指南GB/T12504计算机软件质量保证计划规范GB/T12505计算机软件配置管理计划规范CADCSC软件配置管理计划2管理2.1机构在本软件系统整个开发期间,必须成立软件质量保证小组负责质量保证工作。软件质量保证小组属总体组领导,由总体组代表、项目的软件工程小组代表、项目的专职质量保证人员、项目的专职配置管理人员以及各个子系统软件质量保证人员等方面的人员组成,由项目的软件工程小组代表任组长。各子系统的软件质量保证人员在业务上受软件质量保证小组领导,在行政上受各子系统负责人领导。软件质量保证小组和软件质量保证人员必须检查和督促本计划的实施。各子系统的软件质量保证人员有权直接向软件质量保证小组报告子项目的软件质量状况。各子系统的软件质量保证人员应该根据对子项目的具体要求,制订必要的规程和规定,以确保完全遵守本计划的所有要求。2.2任务软件质量保证工作涉及软件生存周期各阶段的活动,应该贯彻到日常的软件开发活动中,而且应该特别注意软件质量的早期评审工作。因此,对新开发的或正在开发的各子系统,要按照GB8566与本计划的各项规定进行各项评审工作。软件质量保证小组要派成员参加所有的评审与检查活动。评审与检查的目的是为了确保在软件开发工作的各个阶段和各个方面都认真采取各项措施来保证与提高软件的质量。在CADCSC软件开发过程中,经总体组研究决定,要进行如下几类评审与检查工作:a.阶段评审:在软件开发过程中,要定期地或阶段性地对某一开发阶段或某几个开发阶段的阶段产品进行评审。根据总体组研究决定,在CADCSC软件及其所属各子系统的开发过程中,应该进行以下三次评审:第一次评审软件需求、概要设计、验证与确认方法;第二次评审详细设计、功能测试与演示,并对第一次评审结果复核;第三次是功能检查、物理检查和综合检查。关于这些评审工作的详细内容见第5章。阶段评审工作要组织专门的评审小组,原则上由项目总体小组成员或特邀专家担任评审组长,评审小组成员应该包括项目委托单位或用户的代表、质量保证人员、软件开发单位和上级主管部门的代表,其他参加人员视评审内容而定。每一次评审工作都应填写评审总结报告(RSR)、评审问题记录(RPL)、评审成员签字表(RMT)与软件问题报告单(SPR)等四张表格。这四张阶段评审报表的具体格式应与附录C中的规定相一致。b.日常检查:在CADCSC软件的工程化生产过程中,各子系统应该填写项目进展报表,即软件进展报表表头、软件阶段进度表、软件阶段产品完成情况表、软件开发费用表等四张表格。项目总体组杨以通过项目进展季报表发现有关软件质量的问题。项目进展季报表的具体格式应与附录B中的规定相一致。c.软件验收:必须组织专门的验收小组对CADCSC软件系统及其所属各个子系统进行验收。验收工作应按照经项目委托单位“国家自然科学基金委员会信息科学部”与CADCSC总体组双方都认可的验收规程正式履行验收手续。验收内容应包括文档验收、程序验收、演示、验收测试与测试结果评审等几项工作。具体的验收规程另行制订。2.3职责在CADCSC项目的软件质量保证小组中,其各方面人员的职责如下:a.组长全面负责有关软件质量保证的各项工作;b.总体组代表负责有关阶段评审、项目进展报表检查以及软件验收准备等三方面工作中的质量保证工作;c.项目的专职配置管理人员负责有关软件配置变动、软件媒体控制以及对供货单位的控制等三方面的质量保证活动;d.各子系统的软件质量保证人员负责测试复查和文档的规范化检查工作;e.用户代表负责反映用户的质量要求,并协助检查各类人员对软件质量保证计划的执行情况;f.项目的专职质量保证人员协助组长开展各项软件质量保证活动,负责审查所采用的质量保证工具、技术和方法,并负责汇总、维护和保存有关软件质量保证活动的各项记录。3文档本章给出了在CADCSC软件开发过程各阶段需要编制的文档名称及其要求,并且规定了评审文质量的通用的度量准则。3.1.基本文档为了确保软件的实现满足项目委托单位“国家自然科学基金委员会信息科学部”认可的需求规格说明书中规定的各项需求,CADCSC软件各开发单位至少应该编写以下八个方面内容的文档:a.软件需求规格说明书(SRS);b.软件设计说明书(SDD),对一些规模较大或复杂性较高的项目,应该把本文档分成概要设计说明书(PDD)与详细设计说明书(DDD)两个文档;c.软件测试计划(STP);d.软件测试报告(STR);e.用户手册(SUM);f.源程序清单(SCL);g.项目实施计划(PIP);h.项目开发总结(PDS)。3.2其他文档除了基本文档之外,对于尚在开发中的软件,还应该包括以下四个方面的文档:a.软件质量保证计划(SQAP);b.软件配置管理计划(SCMP);c.项目进展报表(PPR);d.阶段评审报表(PRR)。注:前面两个文档由项目软件工程小组制订,属于管理文档,各个子系统的项目承办单位与软件开发单位都应充分考虑执行计划中规定的条款。后面两类文档属于工作文档,就是本计划的2.2中提到的四张阶段评审表与四张项目进展季报表,各个子系统的项目承办单位或软件开发单位应该按照规定要求认真填写有关内容。3.3文档质量的度量准则文档是软件的重要组成部分,是软件生存周期各个不同阶段的产品描述。验证和确认就是要检查各阶段文档的合适性。评审文档质量的度量准则有以下六条:a.完备性:所有承担软件开发任务的单位,都必须按照GB8567的规定编制相应的文档,以保证在开发阶段结束时其文档是齐全的。b.正确性:在软件开发各个阶段所编写的文档的内容,必须真实地反映该阶段的工作且与该阶段的需求相一致。c.简明性:在软件开发各个阶段所编写的各种文档的语言表达应该清晰、准确简练,适合各种文档的特定读者。d.可追踪性:在软件开发各个阶段所编写的各种文档应该具有良好的可追踪性。文档的可追踪性包括纵向可追踪性与横向可追踪性两个方面。前者是指在不同文档的相关内容之间相互检索的难易程度;后者是指确定同一文档某一内容在本文档中的涉及范围的难易程度。e.自说明性:在软件开发各个阶段所编写的各种文档应该具有较好的自说明性。文档的自说明性是指在软件开发各个阶段中的不同文档能独立表达该软件其相应阶段的阶段产品的能力。f.规范性:在软件开发各个阶段所编写的各种文档应该具有良好的规范性。文档的规范性是指文档的封面、大纲、术语的含义以及图示符号等符合有关规范的规定。4标准、条例和约定在CADCSC工程化软件系统的开发过程中,还必须遵守下列标准、条例和约定:a.《CADCSC软件配置管理计划》,CADCSC软件工程小组编,1988年。b.《C语言编程格式约定》,CADCSC软件工程小组编,1988年。5评审和检查本章具体规定了应该进行的阶段评审、阶段评审的内容和评审时间要求。对新开发的或正在开发的各个子系统,都要按照GB8566的规定认真进行定期的或阶段性的各项评审工作。就整个软件开发过程而言,至少要进行软件需求评审、概要设计评审、详细设计评审、软件验证和确认评审、功能检查、物理检查、综合检查以及管理评审等八个方面的评审和检查工作。如本计划第2.2条所述,经总体组研究决定,在CADCSC软件及其所属各个子系统的开发过程中,把前七种评审分成三次进行。在每次评审之后,要对评审结果作出明确的管理决策。下面给出每次评审应该进行的工作。5.1第一次评审第一次评审会对软件需求、概要设计以及验证与确认方法进行评审。a.软件需求评审(SRR)应确保在软件需求规格说明书中规定的各项需求的合理性。b.概要设计评审(PDR)应评价软件设计说明书中的软件概要设计的技术合适性。c.软件验证和确认评审(SV&VR)应评价软件验证和确认计划中确定的验证和确认方法的合适性与完整性。5.2第二次评审第二次评审会要对详细设计、功能测试与演示进行评审,并对第一次评审结果进行复核。如果在软件开发过程中发现需要修改第一次评审结果,则应按照《CADCSC软件配置管理计划》的规定处理。a.详细设计评审(DDR)应确定软件设计说明书中的详细设计在满足软件需求规格说明书中的需求方面的可接受性。b.编程格式评审应确保所有编码采用规定的工作语言,能在规定的运行环境中运行,满足《C语言编程格式约定》,并且符合GB8566中提倡的编程风格。在满足这些要求之后,方可进行测试工作评审。c.测试工作评审应对所有的程序单元进行静态分析,检查其程序结构(即模块和函数的调用关系和调用序列)和变量使用是否正确。在通过静态分析后,再进行结构测试和功能测试。在结构测试中,所有程序单元结构测试的语句覆盖率Co必须等于100%,分支覆盖率C1必须大于或等于85%.要给出每个单元的输入和输出变量的变化范围。各个子系统只进行功能测试,不单独进行结构测试,因而要登录程序单元之间接口的变量值,力图使满足单元测试的C1和Co准则的那此测试用例在子系统功能测试时得到再现。测试工作评审要检查所进行的测试工作是否满足这些要求。特别在评审功能测试工作时,不仅要运行变量的等价值,而且要运行变量的(合法的和非法的)边界值;不仅要运行开发单位给出的测试用例,而且要允许运行任务委托单位或用户、评审人员选定的采样用例。5.3第三次评审第三次评审会要进行功能检查、物理检查和综合检查。这些评审会应在集成测试阶段结束后进行。a.功能检查(FA)应验证所开发的软件已经满足在软件需求规格说明书中规定的所有需求。b.物理检查(PA)应对软件进行物理检查,以验证程序和文档已经一致、并已做好了交付的准备。c.综合检查(CA)应验证代码和设计文档的一致性、接口规格说明之间的一致性(硬件和软件)、设计实现和功能需求的一致性、功能需求和测试描述的一致性。6软件配置管理对CADCSC工程化软件系统的各项配置进行及时、合理的管理,是确保软件质量的重要手段,也是确保该软件具有强大生命力的重要措施。有关CADCSC工程化软件的配置管理工作,可按CADCSC软件工程小组编写的《CADCSC软件配置管理计划》。在软件配置管理工作中,要特别注意规定对软件问题报告、追踪和解决的步骤,并指出实现报告、追踪和解决软件问题的机构及其职责。7工具、技术和方法在CADCSC项目所属的各个子系统(其中包括有关的支持软件)的研制与开发过程中,都应该在各自的软件质量保证活动中合理地使用软件质量活动的支持工具、技术和方法。这些工具主要有下列三种:a.C软件测试工具。它支持用C语言编写的模块的静态分析、结构测试与功能测试。主要功能为:协助测试人员判断程序结构与变量使用情况是否有错;给测试人员提供模块语句覆盖率Co和分支覆盖率C1的值,并显示未覆盖语句和未覆盖分支的号码及其分支谓词,给出不同测试用例有效性的表格;同时提出功能测试的有效情况,并协助组织最终交付给用户的有效测试用例的集合。b.软件配置管理工具。它支持用户对源代码清单的更新管理以及对重新编译与连接的代码的自动组织;支持用户在不同文档相关内容之间进行相互检索并确定同一文档某一内容在本文档中的涉及范围;同时还应支持软件配置管理小组对软件配置更改进行科学的管理。c.文档辅助生成工具与图形编辑工具。它主要协助用户绘制描述程序流程与结构的DFD图与SC图、绘制描述软件功能(输入、输出关系)的曲线以及绘制描述控制系统特性的一些其他图形,同时还可生成若干与CADCSC软件文档编制大纲相适应的文档模块板。用户利用这个工具的正文与图形编辑功能以及上述辅助功能,可以比较方便地产生清晰悦目的文档,也有利于对文档进行更改,还有助于提高文档的编制质量。8媒体控制为了保护计算机程序的物理媒体,以免非法存取、意外损坏或自然老化,CADCSC工程化软件系统的各个子系统(包括支持软件)都必须设立软件配置管理人员,并按照CADCSC软件工程小组制订的、且经CADCSC总体组批准的《CADCSC软件配置管理计划》妥善管理和存放各个子系统及其专用支持软件的媒体。9对供货单位的控制CADCSC项目所属的各个子系统开发组,如果需要从软件销售单位购买、委托其他开发单位开发、从开发单位现存软件库中选用或从项目委托单位或用户的现有软件库中选用软部件时,则在选用前应向CADCSC总体组报告,然后由CADCSC总体组组织“软件选用评审小组”进行评审、测试与检查,只有当演示成功、测试合格后才能批准选用。如果只选用其中部分内容,则按待开发软件的处理过程办理,此时CADCSC总体组不作干预。10记录收集、维护和保存在CADCSC项目及其所属的各个子系统的研制与开发期间,要进行各种软件质量保证活动,准确记录、及时分析并妥善保存有关这些活动的记录,是确保软件质量的重要条件。在软件质量保证小组中,应有专人负责收集、汇总与保存有关软件质量保证活动的记录。要收集、汇总与保存的记录名字及其保存期限见表1.表1记录名称及其保存的期限附录B项目进展报表(参考件)B1项目进展报表(月报表或季报表)由一个项目进展报表表头(表B1)和另外三个表格(表B2、表B3、表B4)组成。在表B2“软件阶段进度表中”中,要填写各个阶段的开工日期与结束日期。其中计划进度是指在项目实施计划中确定的计划进度,因此可以由管理人员事先填好,而不必由开发人员填写。实际进度是指该项目实际的开工日期与结束日期,它将随着该项目的不断进展填写。其中调整进度是指项目组长发现实际进度与计划进度不符时提出的进度修改建议;但经项目管理人员研究后,可能对此修改建议作某些更改。此外,在相继的若干次报表中,项目组长提出的建议修改日期也可能是不相同的。在此我们规定,最终的调整进度由项目经理来确定。在表B3“软件阶段产品完成情况表”中,要填写各个文档的开始编写日期与完成日期。其中关于对计划进度、调整进度与实际进度的含义的解释与上相同。表B4是关于统计软件开发费用的表格。表B1项目进展报表表头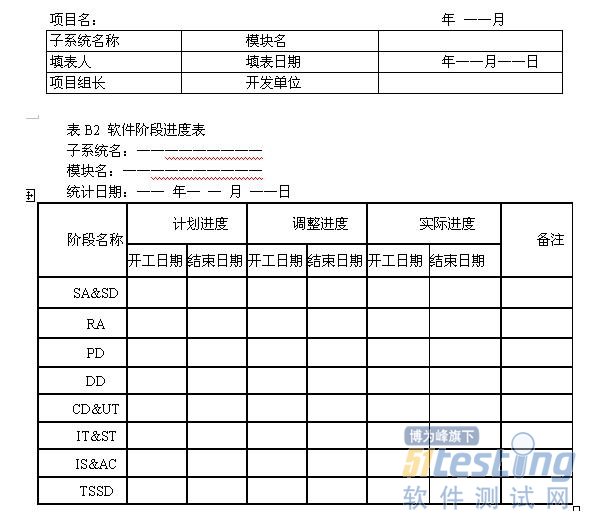 注:SA&SD(systemanalysis&softwaredefinitionphase):系统分析与软件定义阶段。——RA(requirementsanalysisphase):需求分析阶段。——PD(preliminarydesignphase):概要设计阶段。——DD(detaileddesignphase):详细设计阶段。——CD&UT(coding&unittestingphase):编码与单元测试阶段。——IT&ST(integrating&systemtestingphase):组装与系统测试阶段——IS&AC(installation&acceptancephase):安装与验收阶段。——TSSD(totalsoftwaresystemdevelopmentphase):整个软件系统的开发阶段。附录C项目阶段评审表(参考件)
注:SA&SD(systemanalysis&softwaredefinitionphase):系统分析与软件定义阶段。——RA(requirementsanalysisphase):需求分析阶段。——PD(preliminarydesignphase):概要设计阶段。——DD(detaileddesignphase):详细设计阶段。——CD&UT(coding&unittestingphase):编码与单元测试阶段。——IT&ST(integrating&systemtestingphase):组装与系统测试阶段——IS&AC(installation&acceptancephase):安装与验收阶段。——TSSD(totalsoftwaresystemdevelopmentphase):整个软件系统的开发阶段。附录C项目阶段评审表(参考件)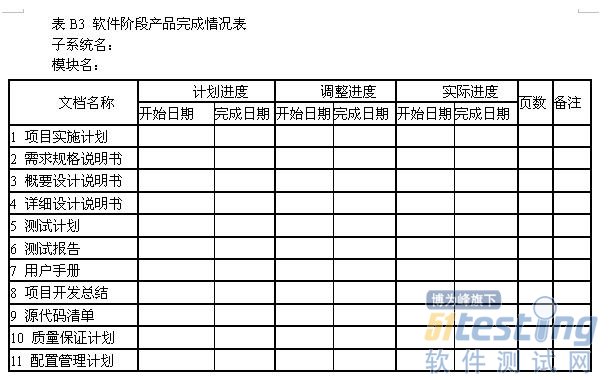
 C1在软件开发过程中的适当阶段对软件阶段产品进行评审,是确保软件产品最终质量的重要方法。阶段评审可以对某个开发阶段的阶段产品进行评审,也可以对某几个开发阶段的阶段产品进行综合评审。在每次阶段评审中,必须履行正式手续,填写必要的评审表格,以利于项目管理工作,利于产品验收时的质量检查工作。项目阶段评审表由四张子表组成。表C1是对评审中发现的问题的记录RPL(reviewproblem);表C2是评审总结报告RSR(reviewsummaryreport);表C3是对其中主要问题的详细描述SPR(softwareproblemreport);表C4是评审小组成员登记与签字表。
C1在软件开发过程中的适当阶段对软件阶段产品进行评审,是确保软件产品最终质量的重要方法。阶段评审可以对某个开发阶段的阶段产品进行评审,也可以对某几个开发阶段的阶段产品进行综合评审。在每次阶段评审中,必须履行正式手续,填写必要的评审表格,以利于项目管理工作,利于产品验收时的质量检查工作。项目阶段评审表由四张子表组成。表C1是对评审中发现的问题的记录RPL(reviewproblem);表C2是评审总结报告RSR(reviewsummaryreport);表C3是对其中主要问题的详细描述SPR(softwareproblemreport);表C4是评审小组成员登记与签字表。 -
用python做性能测试
2014-01-08 08:33:26
用python做测试实现高性能测试工具(1)—序 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/16/n-856016.html
用python做测试实现高性能测试工具(2)—优化代码 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/23/n-856023.html
用python做测试实现高性能测试工具(3)—优化系统架构 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/26/n-856026.html
用python做测试实现高性能测试工具(4)—系统架构 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/28/n-856028.html
用python做测试实现高性能测试工具(5)—多进程写log - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/42/n-856042.html
性能测试分享—LoadRunner篇 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/51/n-855951.html
性能测试分享—JMeter篇 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/50/n-855950.html
ZooKeeper的一个性能测试 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/44/n-855744.html
Loadrunner进行SOCKET并发测试遇到问题 - 51Testing软件测试网-中国软件测试人的精神家园 http://www.51testing.com/html/43/n-855743.html
-
Bug敏感度的培养
2014-01-08 08:30:50
在我们刚踏入软件测试行业时,不管你是专业的、非专业的,培训出来的还是未培训的。刚进公司时你看着身边的同时报的Bug很多并且大都是严重程度高,自己也很想提高一下,想要提高自己的bug敏感度,建议从下面几点做起,纯属个人建议。1 熟悉需求:这是最基础也是最重要的,原始需求随着项目的进度在不断地变化,这就需要你多沟通多交流清楚最新的需求是什么。毕竟书面上的需求是不完整的,隐性需求就靠你和PM沟通了,让PM听你的建议,从用户的角度考虑。2 Bug库:多看Bug库,看看别人找Bug的测试角度,可以增加自己的测试思路 ;可以避免提交重复的Bug。比如别人提了一个上边界值的问题,但下边界值也存在问题,这时候你就可以提下边界值的问题了。随着你看Bug库熟悉程度越深你的测试思路越宽阔。3 被测对象和同类产品相对比:现在市面上大部分开发的软件都有同类产品,你可以对照同类产品对自己测试的软件进行参考测试,如:功能上、建议问题。尤其是性能方面,测试的指标如CPU、内存等都不要超过同类产品。4 异常方面:断网时页面显示是否满足要求,是否有相应提示;快速切换页面是否出现异常、加载过程中进行其他操作、快速连续提交按钮是否提交多条数据、输入错误数据是否有相应处理等等5 不断总结:学到的东西要不断总结,不然会杂乱无章。可以写博客或者写日记把自己的进步记录下来,每天进步一点点,时间长了会有很大收获的,要相信上天总是眷顾勤奋的人。如果你想以后提高自己,现在就开始养成一个好习惯。以上是自己的一点拙见,希望看到这篇文章的同学,发表一下自己的意见。真正的智慧来自内心!版权声明:本文出自 liudaoweidehao 的51Testing软件测试博客:http://www.51testing.com/?425369原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。 -
用python做测试实现高性能测试工具(1)—序
2014-01-03 08:47:32
http://www.51testing.com/html/16/n-856016.html
http://www.51testing.com/html/23/n-856023.html
做过几年开发或者测试开发的人员,时常会觉得很迷茫,新功能的开发或者老功能的维护,基本是在堆代码了, 做过几年测试的朋友也会有类似的想法。性能调优或者性能测试的确很考验人分析问题、解决问题的能力,知识是否全面。本人也是第一次实现高性能的测试工具, 记录下这次diameter协议测试工具的优化过程,供大家一起学习。 有些内容涉及到具体产品,做了些改动或者单独写了测试代码演示。
Python用来开发高性能的测试工具的确有天然的缺陷,性能差还有GIL,无法利用多线程。 但办法总比困难多,那么多大的互联网公司都使用python与实际产品中,总比我们测试的性能要求搞多了。 本文主要讲述在系统设计和架构方面的性能优化,具体算法和一些小细节的优化,请参考 http://blog.csdn.net/powerccna/article/details/8020289项目背景:实现个高性能的diameter 测试工具, 接受1000+发送1000,双向要支持到2000条消息每秒。 diameter 协议的源代码是从这里下载的 http://sourceforge.net/projects/pyprotosim/, 这个开源包还支持SMPP, RADIUS, DHCP, LDAP, 而且新增加的协议字段都可以在dictionary配置属性,不需要修改代码,实在是方便。 初始阶段我们为了实现功能,没有怎么考虑性能的问题,很多地方用的是单线程,初始性能只能支持到50 消息。硬件环境: SunFire 4170, 16 核,每核2.4 GPython性能优化的几个方向:1. 换python的解析器:常见的python解析器有pysco,pypy, cython, jython, pysco已经对python 2.7不支持了,就没有测试,据说跑的很C语言一样快。对pypy, jython做了简单测试,pypy在不同机器上可以提高到5-10倍的样子,Jython虽然可以避免python GIL的问题(因为jython是跑在java虚拟机上的),但测试看来,效率提升很少。2. 优化代码3. 改变系统架构,多线程,多进程或者协程方案1: 换Python解析器如果换Python解析器能达到性能需求是最廉价的方案了,不需要对代码做任何改动。下面代码只是为了说明pypy的效果,单独写的测试代码,在windows下运行的结果。在linux下机器上运行效果会更好些。#!/usr/bin/env python#coding=utf-8import timedef check(num):a = list(str(num))b = a[::-1]if a == b:return Truereturn Falsedef test():all = xrange(1,10**7)for i in all:if check(i):if check(i**2):i**2if __name__ == '__main__':start=time.time()test()print time.time()-start分别用python和pypy的运行结果C:\Python27\python.exeD:/RCC/mp/src/test.py14.4940001965C:\pypy-2.1\pypy.exeD:/RCC/mp/src/test.py4.37800002098可以看出来pypy的运行结果效果还是明显的,虽然能提高5倍(linux机器上),50*5, 离2000还差好远。 pypy对python 多线程的支持没有明显效果,这个在后面会提到。先告一段落,太长了大家看起来累,下一篇文章中将会介绍代码优化部分。用python做测试实现高性能测试工具(2)—优化代码在上一篇中我们通过换python的解析器来优化性能。但离实际需求还很远。方案2: 优化代码工欲善其事,必先利其器。要优化代码,必须先找到代码的瓶颈所在,最土的方法是添加log, 或者print, 调试完成还需要删除,比较麻烦。python里面也提供了很多profile工具:profile, cProfile, hotshot, pystats, 但这些工具提供的结果可读性不是很好,不够直观的一眼就能看到那个函数或者那一行占用时间最多。 python line_profiler 提供了这样的功能,可以很直观的看到哪一行占用的时间最多,可谓“快准狠”,下载地址: http://pythonhosted.org/line_profiler/安装完line_profiler后,在C:\Python27\Lib\site-packages 目录下会有一个kernprof.py,在可能存在瓶颈的函数上添加 @profile, 如以下例子:@profiledef create_msg2(self,H,msg):li = msg.keys()msg_type=li[0]ULR_avps=[]ULR=HDRItem()ULR.cmd=self.dia.dictCOMMANDname2code(self.dia.MSG_TERM[msg_type])if msg_type[-1]=='A':msg=msg[msg_type]self.dia.setAVPs_by_dic(msg_type,msg,ULR_avps)ULR.appId=H.appIdULR.EndToEnd=H.EndToEndULR.HopByHop=H.HopByHopmsg=self.dia.createRes(ULR,ULR_avps)else:self.dia.setAVPs(msg_type,msg,ULR_avps)ULR.appId=self.dia.APPIDself.dia.initializeHops(ULR)msg=self.dia.createReq(ULR,ULR_avps)return msg运行此文件: kernprof.py -l -v D:\project\mp\src\protocols\libdiametermt.py, 得到如下结果。 从这图中可以很直观的看到setAVPS方法占用了96.6%的时间,再进一步定位到此函数,再次添加@proflie修饰符(可以一次在多个函数上添加Profile), 可以再进一步看到setAVPS函数中各行代码的占用时间比。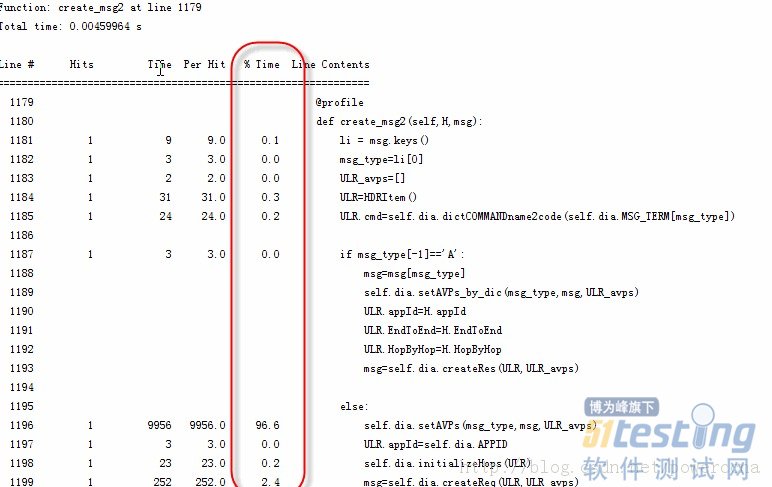 通过一步步的分析中看到,开源协议库中,setAVPS的方法中,查找avp的属性是从一个3000的循环里面查找的,每个AVP都需要循环3000次,一个diameter消息中至少10个avp,每次encoding一个avp需要循环3W次。 我们初始的解决方法是删除了很多我们性能测试中用不到的avp(没办法,测试开发资源有限,很多时候没有很好的设计,先做出满足需求的东西再说。), 但也只是提高到了150左右,离需求还差的很远。所以我们把AVP都改成了字典方式,可以根据名字快速查找到AVP的属性。除了代码的优化,同时还增加了encoding avp的线程数,后面章节将会讲到多线程和多进程,对性能的影响。
通过一步步的分析中看到,开源协议库中,setAVPS的方法中,查找avp的属性是从一个3000的循环里面查找的,每个AVP都需要循环3000次,一个diameter消息中至少10个avp,每次encoding一个avp需要循环3W次。 我们初始的解决方法是删除了很多我们性能测试中用不到的avp(没办法,测试开发资源有限,很多时候没有很好的设计,先做出满足需求的东西再说。), 但也只是提高到了150左右,离需求还差的很远。所以我们把AVP都改成了字典方式,可以根据名字快速查找到AVP的属性。除了代码的优化,同时还增加了encoding avp的线程数,后面章节将会讲到多线程和多进程,对性能的影响。 -
浏览器基准测试:IE11成绩惊人
2014-01-03 08:43:25
http://www.51testing.com/html/76/n-855976.html
一眨眼12个月过去了。不久前,微软推出了适用于Windows 7的IE11;Firefox庆祝了自己的9岁生日,而Google则发布了Chrome 31。因此我们认为这是重新测试各款浏览器最新版本的最佳时机,通过独立、苛刻的测试和评分,找出哪一款是“最好的”浏览器……
在开发基于网页且能够在这5款主要浏览器运行的应用时,我们通常会问“最好的浏览器是哪一个?去年这个时候,我们对比了Chrome 23、Firefox 16、IE9 & 10、Opera 12和Safari 5。我们对比了最新版本的各款网页浏览器,试图找出最好的一个。浏览器测试下面是所有测试的浏览器。 测试我们广泛测试了浏览器性能的4个关键指标:速度、内存使用、标准兼容程度与Javascript性能。1.速度“冷启动(Cold Start)”测试能够测量电脑重启后第一次加载浏览器所耗费的时间。从启动浏览器开始计时,待用户能够在浏览器用户界面(UI)输入文本时停止计时。
测试我们广泛测试了浏览器性能的4个关键指标:速度、内存使用、标准兼容程度与Javascript性能。1.速度“冷启动(Cold Start)”测试能够测量电脑重启后第一次加载浏览器所耗费的时间。从启动浏览器开始计时,待用户能够在浏览器用户界面(UI)输入文本时停止计时。 “冷启动”测试(数值越小越好)“热启动(Non-Cold Start)”测试能够测量电脑重启后非第一次加载浏览器所耗费时间。从启动浏览器开始计时,待用户能够在浏览器用户界面(UI)输入文本时停止计时。
“冷启动”测试(数值越小越好)“热启动(Non-Cold Start)”测试能够测量电脑重启后非第一次加载浏览器所耗费时间。从启动浏览器开始计时,待用户能够在浏览器用户界面(UI)输入文本时停止计时。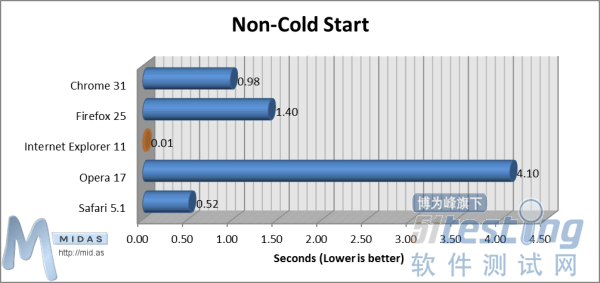 “热启动”测试(数值越小越好)在打开浏览器、清空缓存、显示空白页面(about:blank)状态下,“页面加载时间(非缓存加载)”测试能够测量浏览器完全加载复杂页面所用时间。从用户按下浏览器地址栏“确定”键开始计时,待完全加载测试页面后停止计时(测试页面将提示“加载”事件)。
“热启动”测试(数值越小越好)在打开浏览器、清空缓存、显示空白页面(about:blank)状态下,“页面加载时间(非缓存加载)”测试能够测量浏览器完全加载复杂页面所用时间。从用户按下浏览器地址栏“确定”键开始计时,待完全加载测试页面后停止计时(测试页面将提示“加载”事件)。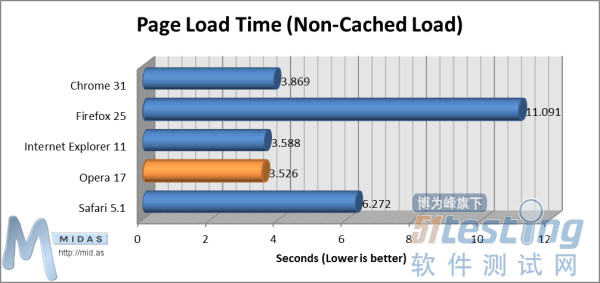 页面加载时间(非缓存加载)测试(数值越小越好)在打开浏览器、已在单一标签中加载了测试页面的状态下,“页面加载时间(从缓存加载)”测试能够测量浏览器重新加载复杂页面所用时间。从按下F5(刷新)键开始计时,待完全加载测试页面时停止计时(测试页面将提示“加载”事件)。
页面加载时间(非缓存加载)测试(数值越小越好)在打开浏览器、已在单一标签中加载了测试页面的状态下,“页面加载时间(从缓存加载)”测试能够测量浏览器重新加载复杂页面所用时间。从按下F5(刷新)键开始计时,待完全加载测试页面时停止计时(测试页面将提示“加载”事件)。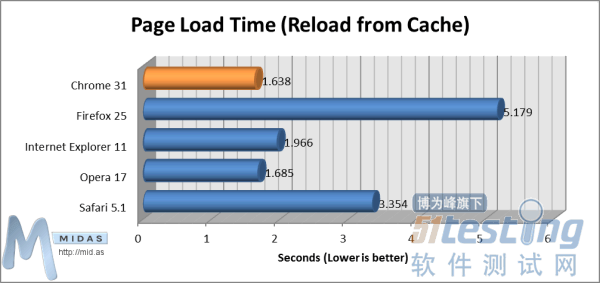 页面加载时间(从缓存加载)测试(数值越小越好)2.内存使用“基本内存使用(空白标签)”测试能够测量浏览器打开单一空白页面 (about:blank) 所使用内存。
页面加载时间(从缓存加载)测试(数值越小越好)2.内存使用“基本内存使用(空白标签)”测试能够测量浏览器打开单一空白页面 (about:blank) 所使用内存。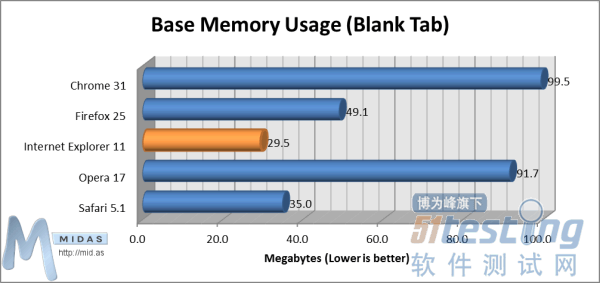 基本内存使用(空白标签)测试(数值越小越好)“内存使用(打开10个标签)”测试能够测量浏览器打开10个标签、每个标签显示主流网站主页时所使用内存。
基本内存使用(空白标签)测试(数值越小越好)“内存使用(打开10个标签)”测试能够测量浏览器打开10个标签、每个标签显示主流网站主页时所使用内存。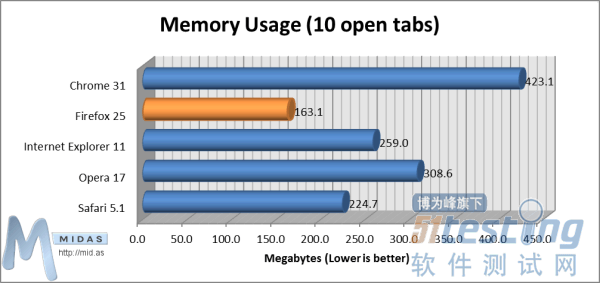 内存使用(打开10个标签)测试(数值越小越好)3.兼容性“HTML5兼容性”测试能够衡量各浏览器与当前HTML5规范的符合程度。
内存使用(打开10个标签)测试(数值越小越好)3.兼容性“HTML5兼容性”测试能够衡量各浏览器与当前HTML5规范的符合程度。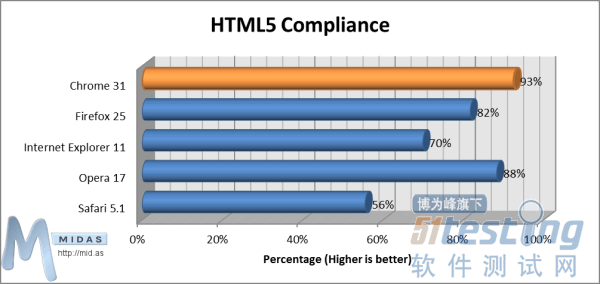 “HTML5兼容性”测试(数值越大越兼容)“CSS3兼容性”测试能够衡量各浏览器与当前CSS3规范的符合程度。
“HTML5兼容性”测试(数值越大越兼容)“CSS3兼容性”测试能够衡量各浏览器与当前CSS3规范的符合程度。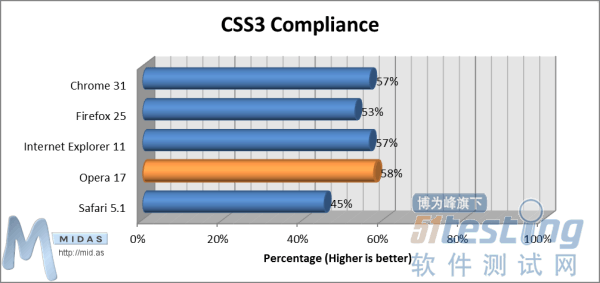 “CSS3兼容性”测试:数值越大越兼容4.JavaScript性能如今市面上许多不同的JavaScript性能测试评分软件,测试结果也各不相同。我们分析了6款最主流测试软件结果,将其结果叠加如下:
“CSS3兼容性”测试:数值越大越兼容4.JavaScript性能如今市面上许多不同的JavaScript性能测试评分软件,测试结果也各不相同。我们分析了6款最主流测试软件结果,将其结果叠加如下: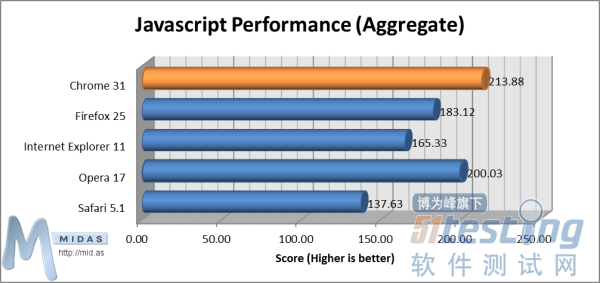 JavaScript性能测试(数值越大越好)我们在测试中叠加了6款JavaScript评分套件的得分,读者可查看/下载完整报告,了解各软件单独评分。总结
JavaScript性能测试(数值越大越好)我们在测试中叠加了6款JavaScript评分套件的得分,读者可查看/下载完整报告,了解各软件单独评分。总结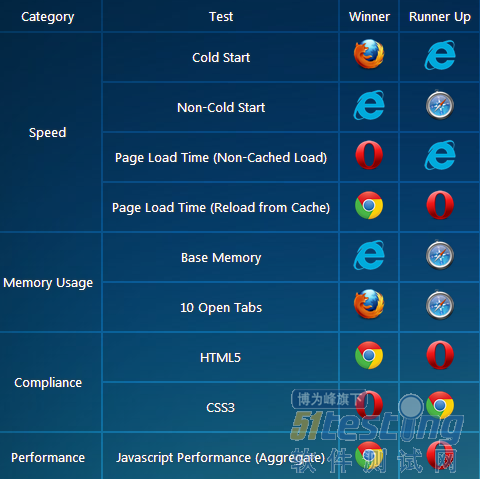 分析1.IE进步最大令我们感到惊喜的是,较之旧版本IE和其他浏览器,IE11取得了十足的进步。相较于微软其他版本浏览器,IE11最重要的改进在于缩短了页面加载时间(无论是从服务器还是缓存加载页面),以及冷启动/热启动时间。在我们的测试中,启动IE11仅用时0.01463秒!——比Opera快了280多倍。2.Chrome依旧强势在我们2012年11月份针对5款浏览器进行的13项测试中,Chrome在8个测试中位列第一,属于当之无愧的赢家。一年后,Chrome依旧强大。3.“新”Opera值得赞扬新版本的Opera与12个月前发布的Opera已有很大区别。自那时起,Opera便放弃了Chrome所使用的引擎,改为使用自有的“Presto”布局渲染器引擎。Opera用户对这一更改褒贬不一,一些人认为Opera丧失了原有特色,但我们的测试结果表明,“新”Opera值得赞扬。4.Windows平台的Safari止步不前我们是在Windows系统上测试的该款浏览器(测试详情参见报告底部)。尽管Safari的最新版本为Safari 7,但苹果在发布了Safari 5.1后便停止开发适用于Windows的Safari浏览器——在我们看来,这是一个错误的决定!因此,Windows用户能够使用的最新版本为Safari 5.1.7,这也是我们测试使用的版本。考虑到Safari 5.1.7是5款测试浏览器中最旧的一款,因此其性能不及其他竞争对手。但令人吃惊的是,它却在内存测试和热启动测试中位列第二名。结论——站在开发者角度作为基于网页的空间规划顶级解决方案开发者,我们认为在确定哪一款是“最好的”浏览器时,最重要的因素是与最新的HTML5和CSS3标准的兼容性。由于我们全身心致力于确保软件能够在所有主流浏览器上正常运行,各浏览器之间拥有通用标准就变得非常重要。理论上讲,无论你使用哪一款浏览器,只要所有浏览器100%符合标准,网页(对我们而言是网页应用)的运行状况都不应存在任何差别!Chrome 31目前最接近HTML5标准,兼容性达到了93%。但我们发现,所有浏览器在CSS3兼容性上都表现不佳,第一名(Opera 17) 的CSS3兼容性也仅有53%。对我们而言,速度(页面加载速度)和Javascript性能也同样重要,因为我们希望浏览器能够快速加载和显示网页应用。在我们的测试中,Opera 17和Chrome 25的页面加载速度非常快,IE11紧随其后。Chrome 25和Opera 17的Javascript性能叠加评分都超过了其他浏览器。若干惊喜发现:微软在IE历史版本基础上,对IE11进行了若干重大升级;Opera 17表现好于预期;Firefox 25表现不如预期,在所有测试中位列第四。
分析1.IE进步最大令我们感到惊喜的是,较之旧版本IE和其他浏览器,IE11取得了十足的进步。相较于微软其他版本浏览器,IE11最重要的改进在于缩短了页面加载时间(无论是从服务器还是缓存加载页面),以及冷启动/热启动时间。在我们的测试中,启动IE11仅用时0.01463秒!——比Opera快了280多倍。2.Chrome依旧强势在我们2012年11月份针对5款浏览器进行的13项测试中,Chrome在8个测试中位列第一,属于当之无愧的赢家。一年后,Chrome依旧强大。3.“新”Opera值得赞扬新版本的Opera与12个月前发布的Opera已有很大区别。自那时起,Opera便放弃了Chrome所使用的引擎,改为使用自有的“Presto”布局渲染器引擎。Opera用户对这一更改褒贬不一,一些人认为Opera丧失了原有特色,但我们的测试结果表明,“新”Opera值得赞扬。4.Windows平台的Safari止步不前我们是在Windows系统上测试的该款浏览器(测试详情参见报告底部)。尽管Safari的最新版本为Safari 7,但苹果在发布了Safari 5.1后便停止开发适用于Windows的Safari浏览器——在我们看来,这是一个错误的决定!因此,Windows用户能够使用的最新版本为Safari 5.1.7,这也是我们测试使用的版本。考虑到Safari 5.1.7是5款测试浏览器中最旧的一款,因此其性能不及其他竞争对手。但令人吃惊的是,它却在内存测试和热启动测试中位列第二名。结论——站在开发者角度作为基于网页的空间规划顶级解决方案开发者,我们认为在确定哪一款是“最好的”浏览器时,最重要的因素是与最新的HTML5和CSS3标准的兼容性。由于我们全身心致力于确保软件能够在所有主流浏览器上正常运行,各浏览器之间拥有通用标准就变得非常重要。理论上讲,无论你使用哪一款浏览器,只要所有浏览器100%符合标准,网页(对我们而言是网页应用)的运行状况都不应存在任何差别!Chrome 31目前最接近HTML5标准,兼容性达到了93%。但我们发现,所有浏览器在CSS3兼容性上都表现不佳,第一名(Opera 17) 的CSS3兼容性也仅有53%。对我们而言,速度(页面加载速度)和Javascript性能也同样重要,因为我们希望浏览器能够快速加载和显示网页应用。在我们的测试中,Opera 17和Chrome 25的页面加载速度非常快,IE11紧随其后。Chrome 25和Opera 17的Javascript性能叠加评分都超过了其他浏览器。若干惊喜发现:微软在IE历史版本基础上,对IE11进行了若干重大升级;Opera 17表现好于预期;Firefox 25表现不如预期,在所有测试中位列第四。 -
测试前置条件及测试点
2013-12-31 17:29:30
版权声明:本文出自 Giant321 的51Testing软件测试博客:http://www.51testing.com/?506499原创作品,转载时请务必以超链接形式标明本文原始出处、作者信息和本声明,否则将追究法律责任。一、引言
本文档根据目前公司的实际情况,规范了软件产品提交测试的前置条件以及需提交的文档资料,避免造成测试的反复和资源的浪费。另外,文档还明确了各测试阶段需要关注的一些测试点,为我们的软件测试工作明确了目的和方向。二、测试前置条件当研发部门完成了软件项目的开发任务之后,软件产品开始进入测试环节。在开发人员提交测试之前,需要遵守测试的前提条件,如果没有限定测试前的前提条件,测试人员需要花费大量的时间去完成一些简单的并且很容易发现的错误,这样会造成很大的人员浪费。因此,对于开发部门提交给测试部门的软件产品,除领导亲自特批外,均必须满足以下条件才允许提交:1、 开发部门完成软件的白盒测试。2、 开发部门完成软件的冒烟测试。3、 对于新增功能,必须提供功能列表、功能详细说明、流程明细以及关联的模块;对于修改功能,必须提供修改功能列表、具体修改内容以及影响的模块。4、 对于没有完成的功能,不能提交测试,希望在代码中注释掉。5、 对于需要与其他系统进行集成测试的软件,需要明确测试环境以及参数的配置,并且详细说明系统间具体是如何集成的。6、 对于需要进行性能测试的部分,提供详细说明以及需要达到的各项性能指标。三、测试点设计1、系统功能测试1.1 链接测试链接是Web应用系统的一个主要特征,它是在页面之间切换和指导用户去一些不知道地址的页面的主要手段。链接测试可分为三个方面。首先,测试所有链接是否按指示的那样确实链接到了该链接的页面;其次,测试所链接的页面是否存在;最后,测试web应用系统上是否有孤立的页面。1.2 表单测试当用户给Web应用系统管理员提交信息时,就需要使用表单操作,例如:用户注册、登陆、信息提交等。在这种情况下,我们必须测试提交操作的完整性,以校验提交给服务器的信息的正确性,例如:用户填写的出生日期与职业是否恰当,填写的所属省份与所在的城市是否匹配等。如果使用了默认值,还要校验默认值得正确性。如果表单只能接受指定的某些值,则也要进行测试。如:只能接受某些字符,测试时可以跳过这些字符,看系统是否会报错。1.3 cookie测试如果Web应用系统使用了Cookies,就必须检查Cookies是否能正常工作。测试的内容可包括Cookies是否起作用,是否按预定的时间进行保存,刷新对Cookies有什么影响等。1.4 数据校验测试如果系统中根据业务规则需要对用户的输入进行校验,那么就必须要保证这些校验功能正常工作。例如,省份的字段可以用一个有效列表进行校验。在这种情况下,需要验证列表完整而且程序正确调用了该列表(例如在列表中添加一个测试值,确定系统能够接受这个测试值)。1.5 应用程序特定的功能需求尝试用户的所有操作,这是用户之所以使用网站的原因,必须确保:1、功能点是否能正确使用;2、流程是否能正常运转。2、系统性能测试性能测试是测试过程中不可或缺的一个环节,它是通过自动化的测试工具模拟多种正常、峰值以及异常条件来对系统的各项性能指标进行测试。性能测试主要包含负载测试和压力测试。2.1负载测试负载测试是为了测量Web系统在某一负载级别上的性能,以保证Web系统在需求范围内能正常工作。负载级别可以是某个时刻同时访问Web系统的用户数量,也可以是在线数据处理的数量。例如:Web应用系统能允许多少个用户同时在线?如果超过了这个数量,会出现什么现象?Web应用系统能否处理大量用户对同一个页面的请求?通过负载测试,确定在各种工作负载下系统的性能,目标是测试当负载增加时,系统各项性能指标的变化情况。2.2压力测试压力测试是测试系统的限制和故障恢复能力,也就是测试Web应用系统会不会崩溃,在什么情况下会崩溃。黑客常常提供错误的数据负载,直到Web应用系统崩溃,接着当系统重新启动时获得存取权。压力测试是通过确定一个系统的瓶颈或者不能接收的性能点,来获得系统能提供的最大服务级别的测试。性能测试主要指标:(1)响应时间(RT):反映在完成某个业务所需要的时间。(2)吞吐量(TPS):反映单位时间内能够处理的事务数目。(3)服务器资源占用。3、用户界面测试3.1 站点地图和导航条确认测试的站点是否有地图。有些网络高手可以直接去自己要去的地方,而不必点击一大堆页面,另外新用户在网站中可能会迷失方向。站点地图和导航条可以引导用户进行浏览。需要验证站点地图是否正确?确认地图上的链接是否确实存在?地图有没有包括站点上的所有链接?是否每个页面都有导航条?导航条是否一致?每个页面的链接是否正常?导航条是否直观?3.2 颜色和背景由于web日益流行,很多人把它看作图形设计作品。而有些开发人员对新的背景颜色更感兴趣,以至于忽略了这种背景颜色是否易于浏览。通常来说,使用少许或尽量不使用背景是个不错的选择。如果您想用背景,那么最好使用单色的,和导航条一起放在页面的左边。否则,图案和图片可能会转移用户的注意力。3.3 图形测试在Web应用系统中,适当的图片和动画既能起到广告宣传的作用,又能起到美化页面的功能。一个Web应用系统的图形可以包括图片、动画、边框、颜色、字体、背景、按钮等。图形测试的内容有:(1)要确保图形有明确的用途,图片或动画不要胡乱地堆在一起,以免浪费传输时间。Web应用系统的图片尺寸要尽量地小,并且要能清楚地说明某件事情,一般都链接到某个具体的页面。(2)验证所有页面字体的风格是否一致。(3)背景颜色应该与字体颜色和前景颜色相搭配。(4)图片的大小和质量也是一个很重要的因素,一般采用JPG或GIF压缩。3.4 内容测试内容测试用来检验Web应用系统提供信息的正确性、准确性和相关性。信息的正确性是指信息是可靠的还是误传的。例如,在商品价格列表中,错误的价格可能引起财政问题甚至导致法律纠纷;信息的准确性是指是否有语法或拼写错误。这种测试通常使用一些文字处理软件来进行,例如使用Microsoft Word的“拼音与语法检查”功能;信息的相关性是指是否在当前页面可以找到与当前浏览信息相关的链接或入口。3.5 表格测试需要验证表格是否设置正确。用户是否需要向右滚动页面才能看见产品的价格?把价格放在左边,而把产品细节放在右边是否更有效?每一栏的宽度是否足够宽,表格里的文字是否都有折行?是否有因为某一个的内容太多,而将整行的内容拉长?3.6 整体界面测试整体界面是指整个Web应用系统的页面结构设计,是给用户的一个整体感。例如:当用户浏览Web应用系统时是否感到舒适,是否凭直觉就知道要找的信息在什么地方?整个Web应用系统的设计风格是否一致?对整体界面的测试过程,其实是一个对最终用户进行调查的过程。一般Web应用系统采取在主页上做一个调查问卷的形式,来得到最终用户的反馈信息。对所有的可用性测试来说,都需要有外部人员(与Web应用系统开发没有联系或联系很少的人员)的参与,最好是最终用户的参与。4、系统兼容性测试兼容性测试主要考虑到以下几个方面的兼容:4.1平台的兼容性需要测试在不同操作系统下(例如windows/Linux/Unix等)以及在同一操作系统不同版本下(例如winxp/win2003server/vista/win7等)的运行情况,避免软件在某一操作系统下能正常运行,但在另外的操作系统下就会运行失败。4.2浏览器的兼容性由于浏览器是web客户端的核心,而不同厂商的浏览器对Java、JavaScript、ActiveX、plug-ins或不同的HTML规格有不同的支持,所以需要对不同的浏览器进行测试,确保软件在不同浏览器下的运行都是没问题的。4.3分辨率的兼容性测试主流分辨率下的页面显示是否正常?字体大小是否合适?文本图片是否对齐等?4.4打印机的兼容性4.5组合测试5、系统安全性测试对于网站系统,安全性测试非常重要,如果用户信息被黑客泄露,客户在交易时,就不会有安全感。安全性测试主要关注以下几点:(1)现在的Web应用系统基本采用先注册,后登陆的方式。因此,必须测试有效和无效的用户名和密码,要注意到是否大小写敏感,可以试多少次的限制,是否可以不登陆而直接浏览某个页面等。(2)Web应用系统是否有超时的限制,也就是说,用户登陆后在一定时间内(例如15分钟)没有点击任何页面,是否需要重新登陆才能正常使用。(3)为了保证Web应用系统的安全性,日志文件是至关重要的。需要测试相关信息是否写进了日志文件、是否可追踪。(4)当使用了安全通信协议SSL时,还要测试加密是否正确,检查信息的完整性。(5)服务器端的脚本常常构成安全漏洞,这些漏洞又常常被黑客利用。所以,还要测试没有经过授权,就不能在服务器端放置和编辑脚本的问题。6、系统接口测试在很多情况下,系统都不是孤立的,往往会有很多外部系统与之对接。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。6.1服务器接口第一个需要测试的接口是浏览器与服务器的接口。测试人员提交事务,然后查看服务器记录,并验证在浏览器上看到的正好是服务器上发生的。测试人员还可以查询数据库,确认事务数据已正确保存。6.2外部接口有些web系统有外部接口。例如,网上商店可能要实时验证信用卡数据以减少欺诈行为的发生。测试的时候,要使用web接口发送一些事务数据,分别对有效信用卡、无效信用卡和被盗信用卡进行验证。也就是说,测试人员需要确认软件能够处理外部服务器返回的所有可能的消息。6.3错误处理接口的错误处理是最容易被忽略的地方。通常我们试图确认系统能够处理所有错误,但却无法预期系统所有可能的错误。尝试在处理过程中中断事务,尝试中断用户到服务器的网络连接,尝试中断web服务器到信用卡验证服务器的连接。在这些情况下,看看会发生什么情况?系统能否正确处理这些错误? -
sed命令详解
2013-12-25 17:27:25
1.简介sed是非交互式的编辑器。它不会修改文件,除非使用shell重定向来保存结果。默认情况下,所有的输出行都被打印到屏幕上。sed编辑器逐行处理文件(或输入),并将结果发送到屏幕。具体过程如下:首先sed把当前正在处理的行保存在一个临时缓存区中(也称为模式空间),然后处理临时缓冲区中的行,完成后把该行发送到屏幕上。sed每处理完一行就将其从临时缓冲区删除,然后将下一行读入,进行处理和显示。处理完输入文件的最后一行后,sed便结束运行。sed把每一行都存在临时缓冲区中,对这个副本进行编辑,所以不会修改原文件。2.定址定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。地址是一个数字,则表示行号;是“$"符号,则表示最后一行。例如:sed -n '3p' datafile
只打印第三行只显示指定行范围的文件内容,例如:
# 只查看文件的第100行到第200行
sed -n '100,200p' mysql_slow_query.log地址是逗号分隔的,那么需要处理的地址是这两行之间的范围(包括这两行在内)。范围可以用数字、正则表达式、或二者的组合表示。例如:
sed '2,5d' datafile
#删除第二到第五行
sed '/My/,/You/d' datafile
#删除包含"My"的行到包含"You"的行之间的行
sed '/My/,10d' datafile
#删除包含"My"的行到第十行的内容3.命令与选项
sed命令告诉sed如何处理由地址指定的各输入行,如果没有指定地址则处理所有的输入行。
3.1 sed命令
命令 功能 a\ 在当前行后添加一行或多行。多行时除最后一行外,每行末尾需用“\”续行
c\ 用此符号后的新文本替换当前行中的文本。多行时除最后一行外,每行末尾需用"\"续行 i\ 在当前行之前插入文本。多行时除最后一行外,每行末尾需用"\"续行 d 删除行 h 把模式空间里的内容复制到暂存缓冲区 H 把模式空间里的内容追加到暂存缓冲区 g 把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容 G 把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面 l 列出非打印字符 p 打印行 n 读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理 q 结束或退出sed r 从文件中读取输入行 ! 对所选行以外的所有行应用命令 s 用一个字符串替换另一个 g 在行内进行全局替换 w 将所选的行写入文件 x 交换暂存缓冲区与模式空间的内容 y 将字符替换为另一字符(不能对正则表达式使用y命令) 3.2 sed选项
选项 功能 -e 进行多项编辑,即对输入行应用多条sed命令时使用 -n 取消默认的输出 -f 指定sed脚本的文件名 4.退出状态sed不向grep一样,不管是否找到指定的模式,它的退出状态都是0。只有当命令存在语法错误时,sed的退出状态才不是0。5.正则表达式元字符与grep一样,sed也支持特殊元字符,来进行模式查找、替换。不同的是,sed使用的正则表达式是括在斜杠线"/"之间的模式。如果要把正则表达式分隔符"/"改为另一个字符,比如o,只要在这个字符前加一个反斜线,在字符后跟上正则表达式,再跟上这个字符即可。例如:sed -n '\o^Myop' datafile元字符 功能 示例 ^ 行首定位符 /^my/ 匹配所有以my开头的行 $ 行尾定位符 /my$/ 匹配所有以my结尾的行 . 匹配除换行符以外的单个字符 /m..y/ 匹配包含字母m,后跟两个任意字符,再跟字母y的行 * 匹配零个或多个前导字符 /my*/ 匹配包含字母m,后跟零个或多个y字母的行 [] 匹配指定字符组内的任一字符 /[Mm]y/ 匹配包含My或my的行 [^] 匹配不在指定字符组内的任一字符 /[^Mm]y/ 匹配包含y,但y之前的那个字符不是M或m的行 \(..\) 保存已匹配的字符 1,20s/\(you\)self/\1r/ 标记元字符之间的模式,并将其保存为标签1,之后可以使用\1来引用它。最多可以定义9个标签,从左边开始编号,最左边的是第一个。此例中,对第1到第20行进行处理,you被保存为标签1,如果发现youself,则替换为your。 & 保存查找串以便在替换串中引用 s/my/**&**/ 符号&代表查找串。my将被替换为**my** \< 词首定位符 /\<my/ 匹配包含以my开头的单词的行 \> 词尾定位符 /my\>/ 匹配包含以my结尾的单词的行 x\{m\} 连续m个x /9\{5\}/ 匹配包含连续5个9的行 x\{m,\} 至少m个x /9\{5,\}/ 匹配包含至少连续5个9的行 x\{m,n\} 至少m个,但不超过n个x /9\{5,7\}/ 匹配包含连续5到7个9的行 6.范例6.1 p命令命令p用于显示模式空间的内容。默认情况下,sed把输入行打印在屏幕上,选项-n用于取消默认的打印操作。当选项-n和命令p同时出现时,sed可打印选定的内容。sed '/my/p' datafile
#默认情况下,sed把所有输入行都打印在标准输出上。如果某行匹配模式my,p命令将把该行另外打印一遍。
sed -n '/my/p' datafile
#选项-n取消sed默认的打印,p命令把匹配模式my的行打印一遍。6.2 d命令
命令d用于删除输入行。sed先将输入行从文件复制到模式空间里,然后对该行执行sed命令,最后将模式空间里的内容显示在屏幕上。如果发出的是命令d,当前模式空间里的输入行会被删除,不被显示。
sed '$d' datafile
#删除最后一行,其余的都被显示
sed '/my/d' datafile
#删除包含my的行,其余的都被显示6.3 s命令
sed 's/^My/You/g' datafile
#命令末端的g表示在行内进行全局替换,也就是说如果某行出现多个My,所有的My都被替换为You。
sed -n '1,20s/My$/You/gp' datafile
#取消默认输出,处理1到20行里匹配以My结尾的行,把行内所有的My替换为You,并打印到屏幕上。sed 's#My#Your#g' datafile
#紧跟在s命令后的字符就是查找串和替换串之间的分隔符。分隔符默认为正斜杠,但可以改变。无论什么字符(换行符、反斜线除外),只要紧跟s命令,就成了新的串分隔符。6.4 e选项
-e是编辑命令,用于sed执行多个编辑任务的情况下。在下一行开始编辑前,所有的编辑动作将应用到模式缓冲区中的行上。
sed -e '1,10d' -e 's/My/Your/g' datafile#选项-e用于进行多重编辑。第一重编辑删除第1-3行。第二重编辑将出现的所有My替换为Your。因为是逐行进行这两项编辑(即这两个命令都在模式空间的当前行上执行),所以编辑命令的顺序会影响结果。6.5 r命令
r命令是读命令。sed使用该命令将一个文本文件中的内容加到当前文件的特定位置上。
sed '/My/r introduce.txt' datafile
#如果在文件datafile的某一行匹配到模式My,就在该行后读入文件introduce.txt的内容。如果出现My的行不止一行,则在出现My的各行后都读入introduce.txt文件的内容。6.6 w命令sed -n '/hrwang/w me.txt' datafile6.7 a\ 命令
a\ 命令是追加命令,追加将添加新文本到文件中当前行(即读入模式缓冲区中的行)的后面。所追加的文本行位于sed命令的下方另起一行。如果要追加的内容超过一行,则每一行都必须以反斜线结束,最后一行除外。最后一行将以引号和文件名结束。
sed '/^hrwang/a\
>hrwang and mjfan are husband\
>and wife' datafile
#如果在datafile文件中发现匹配以hrwang开头的行,则在该行下面追加hrwang and mjfan are husband and wife6.8 i\ 命令
i\ 命令是在当前行的前面插入新的文本。
6.9 c\ 命令
sed使用该命令将已有文本修改成新的文本。
6.10 n命令
sed使用该命令获取输入文件的下一行,并将其读入到模式缓冲区中,任何sed命令都将应用到匹配行紧接着的下一行上。
sed '/hrwang/{n;s/My/Your/;}' datafile注:如果需要使用多条命令,或者需要在某个地址范围内嵌套地址,就必须用花括号将命令括起来,每行只写一条命令,或这用分号分割同一行中的多条命令。6.11 y命令该命令与UNIX/Linux中的tr命令类似,字符按照一对一的方式从左到右进行转换。例如,y/abc/ABC/将把所有小写的a转换成A,小写的b转换成B,小写的c转换成C。sed '1,20y/hrwang12/HRWANG^$/' datafile
#将1到20行内,所有的小写hrwang转换成大写,将1转换成^,将2转换成$。
#正则表达式元字符对y命令不起作用。与s命令的分隔符一样,斜线可以被替换成其它的字符。6.12 q命令
q命令将导致sed程序退出,不再进行其它的处理。
sed '/hrwang/{s/hrwang/HRWANG/;q;}' datafile6.13 h命令和g命令
#cat datafileMy name is hrwang.Your name is mjfan.hrwang is mjfan's husband.mjfan is hrwang's wife.sed -e '/hrwang/h' -e '$G' datafilesed -e '/hrwang/H' -e '$G' datafile#通过上面两条命令,你会发现h会把原来暂存缓冲区的内容清除,只保存最近一次执行h时保存进去的模式空间的内容。而H命令则把每次匹配hrwnag的行都追加保存在暂存缓冲区。sed -e '/hrwang/H' -e '$g' datafilesed -e '/hrwang/H' -e '$G' datafile#通过上面两条命令,你会发现g把暂存缓冲区中的内容替换掉了模式空间中当前行的内容,此处即替换了最后一行。而G命令则把暂存缓冲区的内容追加到了模式空间的当前行后。此处即追加到了末尾。7. sed脚本
sed脚本就是写在文件中的一列sed命令。脚本中,要求命令的末尾不能有任何多余的空格或文本。如果在一行中有多个命令,要用分号分隔。执行脚本时,sed先将输入文件中第一行复制到模式缓冲区,然后对其执行脚本中所有的命令。每一行处理完毕后,sed再复制文件中下一行到模式缓冲区,对其执行脚本中所有命令。使用sed脚本时,不再用引号来确保sed命令不被shell解释。例如sed脚本script:
#handle datafile
3i\
~~~~~~~~~~~~~~~~~~~~~
3,$s/\(hrwang\) is\(mjfan\)/\2 is \1/
$a\
We will love eachother forever!!#sed -f script. datafile
My name is hrwang
Your name is mjfan
~~~~~~~~~~~~~~~~~~~~~
mjfan is hrwang's husband. #啦啦~~~
mjfan is hrwang's wife.
We will love eachother forever!! -
记一次磁盘性能测试
2013-12-20 17:26:25
磁盘测试的目的及概述尽管随着业界发展,处理器速度、内存大小以及I/O执行速度在快速增长,但I/O操作的吞吐量和响应时间仍然比内存访问操作要慢得多。此外,由于很多工作负载都涉及到I/O操作,磁盘I/O很容易成为系统的瓶颈。因此,磁盘读写性能往往是性能测试中一向需要考量的环节。本次测试目标本次磁盘性能测试对宿主机和各个规格云主机的磁盘性能做出加压。并重点关注云主机之间的互相影响,以及云主机与宿主机之间的影响。根据这个思路,设计以下四个测试点。测试点一:单独测试各规格云主机的性能。一来将测试结果作为基准数据,二来通过对比IOPS与磁盘空间的比例关系来验证磁盘QoS是否起作用。测试点二:设计宿主机磁盘使用率成梯度负载,测试一台云主机、多台云主机混合场景下的云主机磁盘性能变化。用于得出宿主机磁盘负载对其上云主机磁盘性能的影响。测试点三:宿主机空闲,云主机之间的互相影响。一台云主机磁盘设计成梯度负载,测试另一台云主机的磁盘变化情况。测试点四:多台云主机组合加压,使得宿主机的磁盘使用率呈现梯度,在这种场景下,测试宿主机磁盘性能。用于得出云主机磁盘压力对宿主机磁盘性能的影响。设计测试用例时,应当时刻记住测试目的。先想好要得到什么样的结果,要得到什么样的对比,然后再有针对性的设计用例。做对比时,要保证只有一个参数再变动,如此才能得出这个参数对结果的影响。工具选取与调研考虑到用例设计中的各种场景以及想要掌握的资源指标,最后选取了Fio作为本次测试的工具。Fio是一个用来对硬件I/O进行压力测试和验证的工具。支持13种不同的I/O引擎,包括:sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio 等。在Fio中,可以设置的选项有:读写方式:随机读、随机写、顺序读、顺序写、随机读写、顺序读写。文件大小:Fio进行I/O操作时使用的文件大小。运行时间:一次测试执行的时间,在该时间段内,Fio将不断执行I/O操作。混合场景读写比例:如果指定为读写操作(读与写操作都有),那么可以指定读与写占的时间比例。线程数:指定多线程同时执行相同的测试任务。Fio输出结果中含有iops、延迟时间、磁盘占用率等指标数据。在本次测试中,通过指定Fio的rate_iops参数,即限定云主机读写的负载,来达到用例中设计的组合场景。在使用Fio时,可以通过设定job文件,可以实现多条访问规则的顺序执行,进而缩减命令行中的选项长度。一个job文件可以控制产生特定数目的线程和文件。典型的job文件有global段,一个或多少job段。运行时,fio从文件读这些参数,做处理,并根据这些参数描述,启动这些仿真线程/进程。运行job的方式: fio job_filejob文件采用经典的ini文件,[]中的值表示一项job的名称。监控指标的确定磁盘I/O的性能经常基于吞吐率和延迟来评估。磁盘驱动器对大数据量顺序传输的处理常常优于小数据量随机传输操作。对于磁盘的监控指标,主要集中在以下三个方面:测试工具Fio统计的指标:iops,bps(传输速度),延迟时间。系统cpu相关的指标:%usr,%sys,%iowait,中断次数,上下文切换次数。特别关注cpu0的使用情况。系统磁盘I/O相关的指标:tps,await,svctm,%util。上述各项指标含义如下:IOPS:每秒钟处理的磁盘IO次数,由fio工具统计得出。BPS:每秒钟处理的数据量大小,由fio工具统计得出。延迟时间:%usr:在用户级别运行所使用的CPU的百分比,由mpstat命令统计得出。%sys:在系统级别(kernel)运行所使用CPU的百分比,由mpstat命令统计得出。%iowait:因IO导致的进程等待,由mpstat命令统计得出。中断:CPU中断次数,由vmstat命令统计得出。上下文切换:CPU的控制权由运行任务转移到另外一个就绪任务时所发生的事件次数,由vmstat命令统计得出。tps:每秒从物理磁盘I/O的次数,由iostat命令统计得出。await:从设备流出的平均I/O请求时间,包括请求在队列和服务时的时间,由iostat命令统计得出。svctm:平均I/O请求的服务时间,由iostat命令统计得出。磁盘util%:磁盘利用率,由iostat命令统计得出。测试过程一、测试脚本的准备与验证1.编写运行在云主机上的测试脚本该脚本主要用于触发Fio进行测试,并制定log文件的存放路径。2.将测试脚本及监控脚本拷贝至云主机为了让测试过程尽可能自动化,在宿主机上将必要的文件分发到特定云主机上执行。需要的文件有测试脚本及负责监控的脚本。3.ssh远程执行云主机上脚本宿主机上通过ssh命令使云主机上测试脚本运作,并触发监控脚本对资源使用情况进行记录。4.收集结果数据拷贝回宿主机云主机上测试结束后,统一将各个轮次结果拷贝回宿主机归档,便于后续集中处理。二、指标监控的实现使用Perfease进行资源监控。 工具介绍链接:http://doc.hz.netease.com/pages/viewpage.action?pageId=16782036三、测试结果的收集与整理使用monitor.sh会将测试过程中所有的指标数据统计并保存到文件中。而为了保证监控数据的有效性,监控的时效往往略小于真实测试时间。此外专门编写了脚本来计算各指标的平均值,但将各轮测试的结果挑选出来放进报告中颇为费时。而在整理数据的过程中,可能会遇到一些问题,例如同一用例跑两轮,两轮结果误差较大。当误差超过5%时,基本可以认定其中有一组数据无效。需要再跑一轮测试进行验证。还有可能会发现,结果数据是准确的,但与对应场景预期的结果不符。这种情况可能是脚本参数设置不对,也有可能暴露了其他问题。需要对这种情况需要找开发了解相关背景信息,进而定位原因。测试结论与总结针对四个测试点的测试目的分别对测试结果进行提炼总结,结果与测试前的预期相符:通过测试不同规格的云主机磁盘性能,各云主机iops比例与云主机磁盘空间比例相近,可以验证磁盘QoS起了作用。随着宿主机磁盘负载增加,云主机iops快速下降;await与svctm差值增大,表明IO在请求队列中的时间增加;%iowait增大,cpu等待io时间变长。宿主机磁盘空闲时,单台云主机磁盘负载增加,对其他云主机的磁盘性能影响很小。多台云主机负载增加时,其他云主机IO等待时间变长。随着云主机磁盘负载增加,宿主机iops减少,await与svctm差值增大,说明IO请求在队列中时间增加。预测试的重要性预测试是指在正式测试之前对基本功能的一个基本验证。在这个过程中进行一些探索和验证,小规模的模拟正式测试来提前暴露一些问题,最终降低测试成本与风险。这几个月下来的工作给我的体会是,性能测试过程似乎具备这样的特点:测试工具需要设置多项参数来实现业务规模、场景负载等条件,各项指标间可能需要捆绑设置。即测试条件较复杂。执行一个轮次下来往往时间很长,且大多数测试工具在执行完成后才会出具结果报告。即测试时间较漫长。测试环境要保证前后一致。测试进程尽量独占整个系统,避免测试外的因素影响最终结果。鉴于以上几点,如果因为测试脚本或测试环境的原因影响了结果,则会造成很大的时间损失。而引入预测试的目的,就是帮助我们提前检验测试脚本和测试环境,估量实际测试时间并发现需要人工介入的时刻。此外,由于预测试帮助我们快速地领略了一遍测试过程的“生命周期”,正式测试时会更加得心应手。及时发现问题即便使用预测试来提前收集测试信息,但如何能够确保测试脚本和测试环境不出一点问题呢?很多时候我们发现不了错误是因为我们根本不知道自己犯了错误。“实践是检验真理的唯一方法”,确保能发现的问题已经解决后,只好提心吊胆地开始正式测试了。测试执行过程虽然漫长,但不能掉以轻心,时刻关注新鲜出炉的结果数据。若结果表现与预期不符,要及早定位问题:是系统误差,还是测试工具设置不对,还是数据收集时统计错了目标?越早发现问题,越能节省成本。向测试自动化靠拢由于测试需要关注宿主机与云主机两方面的资源情况,监控数据需要分别收集。且测试用例设计了各种负载梯度,造成测试脚本和Fio的job文件偏多,需要对应分发到各个云主机上。这些都是繁琐但不可缺少的环节,为了防止人工操作带来的失误,在这些机械的操作尽可能地编写脚本令其自动实现。自动化除了可以用来分发测试脚本、收集测试数据,还可以对新分配的云主机进行初始化,例如安装必要的工具包、更新软件源等等操作。总而言之,自动化是一项提高效率,避免机械繁琐操作的好思路、好方法。磨刀不误砍柴工,花一点时间编写自动化工作的脚本,能为后续工作带来极大便利。
标题搜索
我的存档
数据统计
- 访问量: 24500
- 日志数: 34
- 书签数: 1
- 建立时间: 2008-07-11
- 更新时间: 2016-06-30
