
-
Android vnc server 安装
liyun100 发布于 2010-04-06 14:38:22
想通过PC来控制G1 phone(android), 在 MARKET找了半天,没有找到VNC server,只有VNC viewer,在网上搜索了一下,发现了一个叫做ANDROIDVNCSERVER的东东。以下是安装过程。
转自:http://blog.csdn.net/stevenliyong/archive/2010/03/10/5365148.aspx
名称:Android VNC Server on G1 (PC 远程控制 Android 手机) I found a vnc server for G1.1. Original vnc project
http://code.google.com/p/android-vnc/
This one could not be used on G1, because it need build a special keyboard driver into kernel
2. Forked vnc server
http://code.google.com/p/android-vnc-server/
Forked from android-vnc project on google code.
The original android-vnc need build a special keyboard driver into kernel. It's not necessary. Also the touch event support is added in this version.
First download and install the binary
http://code.google.com/p/android-vnc-server/downloads/list
If you have adb on server:
#adb push androidvncserver /data
#adb shell /data/androidvncserverOr you can just copy the downloaded file androidvncserver to the /sdcard,
Then umount the sdcard and launch the terminal from your G1, then type
# su <- I have root access, I'm not sure whether the following steps work without root access.
# cp /sdcard/androidvncserver /data/
# chmod a+x /data/androidvncserver
# /data/androidvncserver &
And finally:
Run vnc viewer from hose PC.
Here I use
http://downloads.sourceforge.net/vnc...3.10-setup.exe
make sure the connection address with port 5901 : 192.168.0.101:5901
Now, I can remote control my phone from host pc.
在安装的过程上,遇到了以下问题, 在使用chmod命令时,总是提示,permission denied,在chmod 命令后添加了权限 777(即可执行又可读写的权限) 就可以了。
另附图:通过 ADB启动VNC SERVER时的图
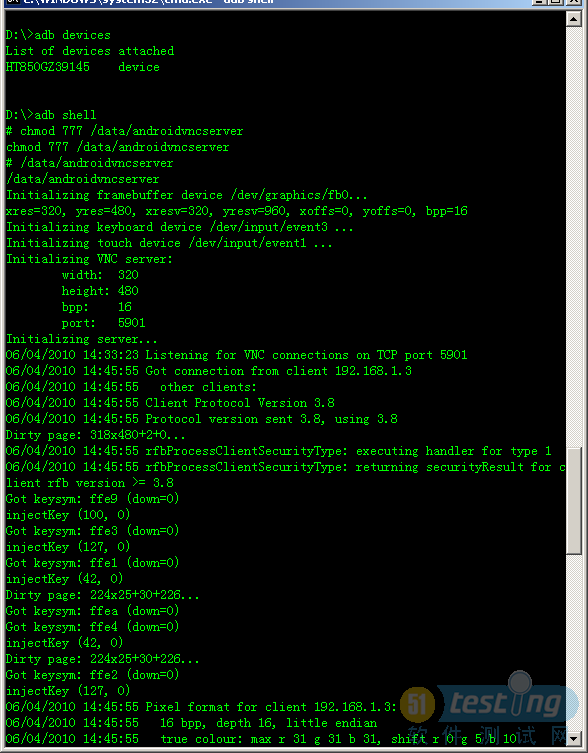


-
导入联系人至Android 手机中.
liyun100 发布于 2010-04-11 09:30:42
一、 把 *.csv 文件的打开方式选择为 记事本 打开,然后 保存为 *.txt 文件,
二、 打开 windows 自带的 Outlook Express 软件,选择 联系人---打开通讯簿
三、 在通讯簿中选择 文件---导入----其它通讯簿....----文本文件(以逗号分隔)----在 浏览处选择刚才保存好的 *.txt 文件,注意调整对应的号码等选项,可以打开 *.csv 文件参考对应的项。
四、 导入完成后,在 编辑---全选 之后,用右键复制,在随意地方建新文件夹将之粘贴 进去,此时的文件就变成为 .vcf 格式了。
五、 将。VCF格式的文件拷贝到你的SDCARD中。
六、 在CONTACT APP中 Menu - Import/Export - 从SDCARD中导入。 -
测试构想
yc800 发布于 2010-10-04 13:33:50
一般来说,大多数人做事之前先打个“草稿”。同样,在测试实践中,我们有这样的经验:喜欢在做事之前,预想一些案例,这些案例很“杂乱”,是凭着测试者的先期经验或者感觉,进行编写。做这个工作,应该在测试计划之前,有点像部队推演“沙盘”。对于没有测试经验的测试者,也会根据一些所学,进行这类活动的。在平时,或多或少对新手和老手,或者水平高的对水平低的测试者观察了一番,觉得这“打草稿”,还真的有些学问。
先不妨引入一个叫“测试构想”的词语,关于“测试构想”,可以这样认为:就是你用它来找出BUG的测试要点,是你编写测试用例的基础,或者就是测试用例的一种升华或抽象。是测试中的一种感性概念,实例化可以举画画中画轮廓类比,主要是一种测试感觉。
有“测试构想”这个东西,还是好好研究一下。意图是形成测试构架观。测试时,先做一种预处理工作,将测试“经验”、“灵感”变成一种针对具体项目的“简构架”,这个构架可以很方便的去让事情畅快运行,你在过程中就可以轻松的做好事情。主要目的还是想通过整理,有效的指导工作。
曾经编写过一些测试案例指导测试员测试,在编写之前,脑子中就会有相关的测试项目出现的问题,还有一些相关的经典案例。这些东西,并不是较全面案例,但是,一旦组入案例中,这些东西,往往有一些效果,特别是做衍生机型。
如何去走这样的路?
1、有效的进行积累工作。
凡是在工作实践中的事情,有些事潜移默化的,你自然记住,这些东西一般来说,就是工作感觉。对于这类感觉,个人比较赞成,进行阶段性总结,做好思想笔记。还有一类是,突发事件,对于项目中的某些很特殊很有“味道”的问题,最好也是做好工作笔记。其实,整个工作的过程,就是积累过程,但是这个积累,必须要有好的方法去消化,记住。否则,时间久了,也就忘记了,积累也就没有了,那如果做一个类似项目,你有得重新做起。
这个好像跟“测试构想”没有多大关系吧?不是。测试构想是没有积累就可以有,但是这个构想有用与否,是否可以产生作用,是跟积累有很大的关系。同样的一个测试项目,有些工程师考虑的周全一些,有些就粗糙一些,跟测试积累有很大关系。这里强调积累,有助于产生高效的构想。
2、尽量形成一个“测试构想目录”。
引用一篇文章中提到的一个定义和实例,如下:
定义:测试构想目录就是列出了最有可能发现大多数可能存在的软件故障的测试构想列表。
如一个查询功能,你的测试构想是什么?
设有以下几点:1)、无条件;2)、一个或者几个查询条件;3)、是否支持模糊查询;4)、是否可用OR ,ADN等连接;5)、结果是否导出;6)、结果是否支持排序……
那么,这个构想,你记录了吗?抽象了吗?在以后的测试编写中使用了吗?完善了吗?如果答案是肯定的。那么你的测试构想积累的多了,形成了目录了,那么你的经验也就是慢慢积累了。之后,就是具体化工作了。
3、如何能做成一本好的目录呢?
首先:它包含好测试构想(这是针对于测试的深度和广度来说),这时,需要继承一些积累,预估一些问题,还可以有自己内心中的一个与类似东西的差分表。
其次:易于快速阅读(略读)、好查、好用,可以很容易地找到你想到的,忽略你不要的。
最后:只包含你要的。
不同的领域做不同的构想。就象你编程时,不同的业务构建不同的模块一样。
当然,通用的,可以创建通用的目录。
目录的内容涉及,需要你的经验积累,甚至包含一些自己对测试对象的了解,有句话“了解有多深测试有多深”。
4、将目录草图进行沟通
预则立不预则废,这里的“预”不是一个人在做。
形成自己的目录后,和你的工作伙伴沟通,彼此再构想一下。因为是构想,所以其中的每一个点是很抽象的,他代表了一大片东西。一般来说,构想中存在差异,具体执行中也许就是一大片存在的差异。
每个人的测试思维都是独立的,覆盖面也是不一样。大家在一起,互补一下,可以扩大有效抽象面,减少无效面。对于执行团队来说,是少做了一些无用功。
同时,做好差异化分析,取长补短,总结积累。
测试构想之后,就应该形成具体一点的东西,可以是测试计划,案例草案等等。
-
【转载】LoadRunner的学习资源
xinqidian123 发布于 2010-10-19 09:24:51
Read First
What is Load Testing (10 Pages)
C:\Program Files\HP\LoadRunner\help\Learn_More_Testing.pdfHP LoadRunner Quick Start (30 Pages)
C:\Program Files\HP\LoadRunner\tutorial\LR_QuickStart.pdfTutorial (150 Pages)
C:\Program Files\HP\LoadRunner\tutorial\Tutorial.pdfUser Guides
Virtual User Generator (1420 Pages)
C:\Program Files\HP\LoadRunner\help\vugen.pdfController (552 Pages)
C:\Program Files\HP\LoadRunner\help\Cntrl_pc.pdfAnalysis (676 Pages)
C:\Program Files\HP\LoadRunner\help\analysis.pdfOnline Monitoring Reference (402 Pages)
C:\Program Files\HP\LoadRunner\help\online.pdfAdditional Reading
Installation Guide (80 Pages)
C:\Program Files\HP\LoadRunner\help\install.pdfMonitoring Best Practices (248 Pages)
C:\Program Files\HP\LoadRunner\help\Monitoring_BP.pdfFlex Protocol Enhancements (12 Pages)
C:\Program Files\HP\LoadRunner\dat\Flex.pdfThats 3580 Pages of information on LR – How many pages have you gone through? (I probably did less than 1500)
The above can also be found in Compiled Help Files. A couple like the Automation and Function reference are not found in the PDFs above, so it makes sense to list out the locations of these.
CHM Files
Everything from the above PDF listing
C:\Program Files\HP\LoadRunner\bin\online.chmFunction Reference
C:\Program Files\HP\LoadRunner\bin\FuncRef.chmC Language function ref
C:\Program Files\HP\LoadRunner\bin\c_language_FuncRef.chmAutomation Reference (dont even go there)
C:\Program Files\HP\LoadRunner\bin\automation.chmWell thats with the Documentation on your PC.
————————————————————-
Now for the online stuff. Remember, many of your queries can be solved by using the search functionality at any of the following sites. Make it a habit to devote time every week to go through the latest posts, and it will make quite a good difference in your learning path.
Email Lists:
http://tech.groups.yahoo.com/group/loadrunner/
http://groups.google.com/group/LR-LoadRunner
http://tech.groups.yahoo.com/group/Advanced-LoadRunner/(very little activity there – only for experienced users)
Discussion Boards:
http://www.sqaforums.com/postlist.php?Cat=0&Board=UBB6(ofcourse!)
http://forums13.itrc.hp.com/service/forums/categoryhome.do?categoryId=915(HP Perf Center Forum)
http://www.bish.co.uk/forum/index.php?board=2.0(Richard Bishop)
White Papers / Presentations:
HP LoadRunner tips and tricks
https://h10078.www1.hp.com/bto/download/loadrunner-configuration.pdf
Performance Center New Features:
http://hpbroadband.com/(S(vlbj3h3h2ej4qane0gsonc55))/program.aspx?key=5831MtEPC7May2009
LR Compiler
http://www.loadtester.com/under-hood-loadrunner-compiler
Blogs:
Official HP Blog:http://www.communities.hp.com/online/blogs/loadrunner/default.aspx
Scott Moore, Tim Chase et alhttp://www.loadtester.com/blog
Alexander Podelkohttp://www.testingreflections.com/blog/67
Stuart Moncrieffhttp://www.myloadtest.com/&http://www.jds.net.au/tag/loadrunner/
Dmitry Motevichhttp://motevich.blogspot.com/(includes video tutorials)
papayamilkshake/Hwee Seong Tanhttp://www.loadrunnertnt.com/tag/loadrunner/
Kim Sandellhttp://ptfrontline.wordpress.com/category/loadrunner/
Richard Bishophttp://www.bish.co.uk/index.php?option=com_content&view=category&id=34:recent&Itemid=1
Wilson Mar: (deserves a seperate heading of his own – not a blog – but additional reading)
LoadRunner Architecturehttp://www.wilsonmar.com/1loadrun.htm
VUScriptinghttp://www.wilsonmar.com/1lrscript.htm
VTShttp://www.wilsonmar.com/1mercvts.htm
AJAX RIA web app load testing using LoadRunnerhttp://www.wilsonmar.com/ajax_rec.htm
Results Explorerhttp://www.wilsonmar.com/lrexplore.htm
Twitter Feeds
Coming Soon
Protocol & Application Specific Resources
AJAX c & s
http://www.wilsonmar.com/ajax_rec.htm
Flex, AMF
http://hpbroadband.com/(S(3uelw04503pkjo55saxzlofd))/program.aspx?key=5831LoadRunner24March10
CITRIX
CITRIX document (for LR7.51)
http://www.ccaheaven.com/wps/Mercury%20Interactive’s%20LoadRunner%20for%20Citrix.pdf
Tim Chase CITRIX Scripting Best Practices
http://www.loadtester.com/whitepapers/Citrix_LoadRunner.pdf
Scott Moore’s CITRIX Scripting Tips
http://www.loadtester.com/citrix-tips-2007-part-1
Remedy ARS
From JDShttp://www.jds.net.au/tech-tips/vugen-scripting-for-remedy/
Misc stuff
LoadRunner VuGen to JMeter conversion
http://www.performanceengineer.com/blog/lr2jm-convert-loadrunner-scripts-to-jmeter/
Various Links :http://loadtester.tumblr.com/
Certification Information:
http://h20546.www2.hp.com/main/americas/certification/?sitepick=PT(General Info)
http://www.hp.com/partnerlearning/learner_id.html(HP Learner ID)
https://ibt1.prometric.com/index.asp?ibt=9710657000&(Prometric Id)
-
头脑风暴法介绍
qiuteng258 发布于 2010-10-13 10:52:24
1 头脑风暴法介绍
头脑风暴法出自“头脑风暴”一词。所谓头脑风暴(Brain-storming) 最早是精神病理学上的用语,指精神病患者的精神错乱状态而言的,现在转而为无限制的自由联想和讨论,其目的在于产生新观念或激发创新设想。
头脑风暴法又称智力激励法、BS法、自由思考法,是由美国创造学家A·F·奥斯本于1939年首次提出、1953年正式发表的一种激发性思维的方法。此法经各国创造学研究者的实践和发展,至今已经形成了一个发明技法群,如奥斯本智力激励法、默写式智力激励法、卡片式智力激励法等等。
在群体决策中,由于群体成员心理相互作用影响,易屈于权威或大多数人意见,形成所谓的“群体思维”。群体思维削弱了群体的批判精神和创造力,损害了决策的质量。为了保证群体决策的创造性,提高决策质量,管理上发展了一系列改善群体决策的方法,头脑风暴法是较为典型的一个。
头脑风暴法有可分为直接头脑风暴法(通常简称为头脑风暴法)和质疑头脑风暴法(也称反头脑风暴法)。前者是在专家群体决策尽可能激发创造性,产生尽可能多的设想的方法,后者则是对前者提出的设想、方案逐一质疑,分析其现实可行性的方法。
采用头脑风暴法组织群体决策时,要集中有关专家召开专题会议,主持者以明确的方式向所有参与者阐明问题,说明会议的规则,尽力创造在融洽轻松的会议气氛。一般不发表意见,以免影响会议的自由气氛。由专家们“自由”提出尽可能多的方案。
2 头脑风暴法的基本程序
头脑风暴法力图通过一定的讨论程序与规则来保证创造性讨论的有效性,由此,讨论程序构成了头脑风暴法能否有效实施的关键因素,从程序来说,组织头脑风暴法关键在于以下几个环节:
2.1.1 确定议题
一个好的头脑风暴法一般从对问题的准确阐明开始。因此,必须在会前确定一个目标,使与会者明确通过这次会议需要解决什么问题,同时不要限制可能的解决方案的范围。一般而言,比较具体的议题能使与会者较快产生设想,主持人也较容易掌握;比较抽象和宏观的议题引发设想的时间较长,但设想的创造性也可能较强。
2.1.2 会前准备
为了使头脑风暴畅谈会的效率较高,效果较好,可在会前做一点准备工作。如收集一些资料预先给大家参考,以便与会者了解与议题有关的背景材料和外界动态。就参与者而言,在开会之前,对于要解决的问题一定要有所了解。会场可作适当布置,座位排成圆环形的环境往往比教室式的环境更为有利。此外,在头脑风暴会正式开始前还可以出一些创造力测验题供大家思考,以便活跃气氛,促进思维。
2.1.3 确定人选
一般以8人~12人为宜,也可略有增减(5~15人)。与会者人数太少不利于交流信息,激发思维;而人数太多则不容易掌握,并且每个人发言的机会相对减少,也会影响会场气氛。只有在特殊情况下,与会者的人数可不受上述限制。
2.1.4 明确分工
要推定一名主持人,1~2名记录员(秘书)。主持人的作用是在头脑风暴畅谈会开始时重申讨论的议题和纪律,在会议进程中启发引导,掌握进程。如通报会议进展情况,归纳某些发言的核心内容,提出自己的设想,活跃会场气氛,或者让大家静下来认真思索片刻再组织下一个发言高潮等。记录员应将与会者的所有设想都及时编号,简要记录,最好写在黑板等醒目处,让与会者能够看清。记录员也应随时提出自己的设想,切忌持旁观态度。
2.1.5 规定纪律
根据头脑风暴法的原则,可规定几条纪律,要求与会者遵守。如要集中注意力积极投入,不消极旁观;不要私下议论,以免影响他人的思考;发言要针对目标,开门见山,不要客套,也不必做过多的解释;与会之间相互尊重,平等相待,切忌相互褒贬等等。
2.1.6 掌握时间
会议时间由主持人掌握,不宜在会前定死。一般来说,以几十分钟为宜。时间太短与会者难以畅所欲言,太长则容易产生疲劳感,影响会议效果。经验表明,创造性较强的设想一般要在会议开始10分钟~15分钟后逐渐产生。美国创造学家帕内斯指出,会议时间最好安排在30~45分钟之间。徜若需要更长时间,就应把议题分解成几个小问题分别进行专题讨论。
3 会后的设想处理
通过组织头脑风暴畅谈会,往往能获得大量与议题有关的设想。至此任务只完成了一半。更重要的是对已获得的设想进行整理,分析,以便选出有价值的创造性设想来加以开发实施。这个工作就是设想处理。
头脑风暴法的设想处理通常安排在头脑风暴畅谈会的次日进行。在此以前,主持人或记录员(秘书)应设法收集与会者在会后产生的新设想,以便一并进行评价处理。设想处理的方式有两种。一种是专家评审,可聘请有关专家及畅谈会与会者代表若干人(5人左右为宜)承担这项工作。另一种是二次会议评审,即由头脑风暴畅谈会的参加者共同举行第二次会议,集体进行设想的评价处理工作。
4 避免误区
头脑风暴是一种技能,一种艺术,头脑风暴的技能需要不断提高。如果想使头脑风暴保持高的绩效,必须每个月进行不止一次的头脑风暴。有活力的头脑风暴会议倾向于遵循一系列陡峭的"智能"曲线,开始动量缓慢地积聚,然后非常快,接着又开始进入平缓的时期。头脑风暴主持人应该懂得通过小心地提及并培育一个正在出现的话题,让创意在陡峭的"智能"曲线阶段自由形成。
头脑风暴提供了一种有效的就特定主题集中注意力与思想进行创造性沟通的方式,无论是对于学术主题探讨或日常事务的解决,都不失为一种可资借鉴的途径。惟需谨记的是使用者切不可拘泥于特定的形式,因为头脑风暴法是一种生动灵活的技法,应用这一技法的时候,完全可以并且应该根据与会者情况以及时间、地点、条件和主题的变化而有所变化,有所创新。
参与头脑风暴的好处
(1) 极易操作执行,具有很强的实用价值。
(2) 非常具体地体现了集思广益,体现团队合作的智慧。
(3) 每一个人思维都能得到最大限度的开拓,能有效开阔思路,激发灵感。
(4) 在最短的时间内可以批量生产灵感,会有大量意想不到的收获。
(5) 几乎不再有任何难题。
(6) 面对任何难题,举重若轻。对于熟练掌握“头脑风暴法”的人来讲,再也不必一个人冥思苦想,孤独“求索”了。
(7) 因为头脑越来越好用,可以有效锻炼一个人及团队的创造力。
(8) 使参加者更加自信,因为,他会发现自己居然能如此有“创意”。
(9) 可以发现并培养思路开阔、有创造力的人才。
(10) 创造良好的平台,提供了一个能激发灵感、开阔思路的环境。
(11) 因为良好的沟通氛围,有利于增加团队凝聚力,增强团队精神。
(12) 可以提高工作效率,能够更快更高效解决问题。
(13) 使参加者更加有责任心,因为人们一般都乐意对自己的主张承担责任。
4.1 头脑风暴法的激发机理
头脑风暴何以能激发创新思维?根据A·F·奥斯本本人及其他研究者的看法,主要有以下几点:
Ø 第一,联想反应。联想是产生新观念的基本过程。在集体讨论问题的过程中,每提出一个新的观念,都能引发他人的联想。相继产生一连串的新观念,产生连锁反应,形成新观念堆,为创造性地解决问题提供了更多的可能性。
Ø 第二,热情感染。在不受任何限制的情况下,集体讨论问题能激发人的热情。人人自由发言、相互影响、相互感染,能形成热潮,突破固有观念的束缚,最大限度地发挥创造性地思维能力。
Ø 第三,竞争意识。在有竞争意识情况下,人人争先恐后,竞相发言,不断地开动思维机器,力求有独到见解,新奇观念。心理学的原理告诉我们,人类有争强好胜心理,在有竞争意识的情况下,人的心理活动效率可增加50%或更多。
Ø 第四,个人欲望。在集体讨论解决问题过程中,个人的欲望自由,不受任何干扰和控制,是非常重要的。头脑风暴法有一条原则,不得批评仓促的发言,甚至不许有任何怀疑的表情、动作、神色。这就能使每个人畅所欲言,提出大量的新观念。
5 头脑风暴法的要求
5.1.1 组织形式
参加人数一般为5~10人(课堂教学也可以班为单位),最好由不同专业或不同岗位者组成;
会议时间控制在1小时左右;
设主持人一名,主持人只主持会议,对设想不作评论。设记录员1~2人,要求认真将与会者每一设想不论好坏都完整地记录下来。
5.1.2 会议类型
设想开发型:这是为获取大量的设想、为课题寻找多种解题思路而召开的会议,因此,要求参与者要善于想象,语言表达能力要强。
设想论证型;这是为将众多的设想归纳转换成实用型方案召开的会议。要求与会者善于归纳、善于分析判断。
5.1.3 会前准备工作
会议要明确主题。会议主题提前通报给与会人员,让与会者有一定准备;
选好主持人。主持人要熟悉并掌握该技法的要点和操作要素,摸清主题现状和发展趋势;
参与者要有一定的训练基础,懂得该会议提倡的原则和方法;
会前可进行柔化训练,即对缺乏创新锻炼者进行打破常规思考,转变思维角度的训练活动,以减少思维惯性,从单调的紧张工作环境中解放出来,以饱满的创造热情投入激励设想活动。
5.1.4 会议原则
为使与会者畅所欲言,互相启发和激励,达到较高效率,必须严格遵守下列原则:
——禁止批评和评论,也不要自谦。对别人提出的任何想法都不能批判、不得阻拦。即使自己认为是幼稚的、错误的,甚至是荒诞离奇的设想,亦不得予以驳斥;同时也不允许自我批判,在心理上调动每一个与会者的积极性,彻底防止出现一些“扼杀性语句”和“自我扼杀语句”。诸如“这根本行不通”、“你这想法太陈旧了”、“这是不可能的”、“这不符合某某定律”以及“我提一个不成熟的看法”、“我有一个不一定行得通的想法”等语句,禁止在会议上出现。只有这样,与会者才可能在充分放松的心境下,在别人设想的激励下,集中全部精力开拓自己的思路。
——目标集中,追求设想数量,越多越好。在智力激励法实施会上,只强制大家提设想,越多越好。会议以谋取设想的数量为目标。
——鼓励巧妙地利用和改善他人的设想。这是激励的关键所在。每个与会者都要从他人的设想中激励自己,从中得到启示,或补充他人的设想,或将他人的若干设想综合起来提出新的设想等。
——与会人员一律平等,各种设想全部记录下来。与会人员,不论是该方面的专家、员工,还是其他领域的学者,以及该领域的外行,一律平等;各种设想,不论大小,甚至是最荒诞的设想,记录人员也要求认真地将其完整地记录下来。
——主张独立思考,不允许私下交谈,以免干扰别人思维;
——提倡自由发言,畅所欲言,任意思考。会议提倡自由奔放、随便思考、任意想象、尽量发挥,主意越新、越怪越好,因为它能启发人推导出好的观念。
——不强调个人的成绩,应以小组的整体利益为重,注意和理解别人的贡献,人人创造民主环境,不以多数人的意见阻碍个人新的观点的产生,激发个人追求更多更好的主意。
5.1.5 会议实施步骤
会前准备:参与人、主持人和课题任务三落实,必要时可进行柔性训练。
设想开发:由主持人公布会议主题并介绍与主题相关的参考情况;突破思维惯性,大胆进行联想;主持人控制好时间,力争在有限的时间内获得尽可能多的创意性设想。
设想的分类与整理:一般分为实用型和幻想型两类。前者是指目前技术工艺可以实现的设想,后者指目前的技术工艺还不能完成的设想。
完善实用型设想:对实用型设想,再用脑力激荡法去进行论证、进行二次开发,进一步扩大设想的实现范围。
幻想型设想再开发:对幻想型设想,再用脑力激荡法进行开发,通过进一步开发,就有可能将创意的萌芽转化为成熟的实用型设想。这是脑力激荡法的一个关键步骤,也是该方法质量高低的明显标志。
5.1.6 主持人技巧
主持人应懂得各种创造思维和技法,会前要向与会者重申会议应严守的原则和纪律,善于激发成员思考,使场面轻松活跃而又不失脑力激荡的规则;
可轮流发言,每轮每人简明扼要地说清楚创意设想一个,避免形成辩论会和发言不均;
要以赏识激励的词句语气和微笑点头的行为语言,鼓励与会者多出设想,如说:“对,就是这样! 太棒了!好主意!这一点对开阔思路很有好处!”等等;
禁止使用下面的话语:“这点别人已说过了!”“实际情况会怎样呢?”“请解释一下你的意思。”“就这一点有用”“我不赞赏那种观点。”等等;
经常强调设想的数量,比如平均3分钟内要发表10个设想;
遇到人人皆才穷计短出现暂时停滞时,可采取一些措施,如休息几分钟,自选休息方法,散步、唱歌、喝水等,再进行几轮脑力激荡。或发给每人一张与问题无关的图画,要求讲出从图画中所获得的灵感。
根据课题和实际情况需要,引导大家掀起一次又一次脑力激荡的“激波”。如课题是某产品的进一步开发,可以从产品改进配方思考作为第一激波、从降低成本思考作为第二激波、从扩大销售思考作为第三激波等。又如,对某一问题解决方案的讨论,引导大家掀起“设想开发”的激波,及时抓住“拐点”,适时引导进入“设想论证”的激波。
要掌握好时间,会议持续1小时左右,形成的设想应不少于100种。但最好的设想往往是会议要结束时提出的,因此,预定结束的时间到了可以根据情况再延长5分钟,这是人们容易提出好的设想的时候。在1分钟时间里再没有新主意、新观点出现时,智力激励会议可宣布结束或告一段落。<
-
nokia手机暗码
qiuteng258 发布于 2010-10-13 10:59:06
暗 码 用 途 备 注
*#06# 查询IMEI号码 所有手机通用
*#7370# 格式化手机 Series 60手机专用
*#7780# 恢复出厂设置 Series 60和Series 40手机通用
*#0000# 查询当前软件版本号 所有手机通用
*#7760# 查询生产线号码 Series 40手机专用
*#2820# 查询蓝牙设备地址 Series 60和Series 40手机通用
*3370# 激活EFR 部分型号的手机可用
#3370# 关闭EFR 部分型号的手机可用
*4720# 激活HFR 部分型号的手机可用
#4720# 关闭HFR 部分型号的手机可用
*#92702689# 查询总通话时间 仅限6630
*#92702689# 进入数据模式 Series 40手机专用
*#7370925538# 为手机上锁 Series 60手机专用 -
手机系统出错代码
qiuteng258 发布于 2010-10-13 11:00:11
以下是一些出错的代码,你可以轻松了解到出错的原因
KErrNotFound-1 找不到指定文件
KErrGeneral-2 一般错误
KErrCancel-3 操作被取消
KErrNoMemory-4 内存不足
KErrNotSupported-5 不支持所要求的操作
KErrAgument-6 错误要求
KErrTotalLossOfprecision-7 精确的失去总和
KErrBadHandle-8 错误的物件
KErrOverflow-9 超出限定的界限
KErrUderflow-10 少于限定的界限
KErrAlreadyExsits-11 已经存在了
KErrPathNotFound-12 找不到指定的目录
KErrDided-13 程序关闭
KErrLnUse-14 指定的物件正被其他程序使用中
KErrServerTerminated-15 服务器已关闭
KErrServerBusy-16 服务器正忙
KErrCompletion-17 完成的过程中出现错误计世
KErrNotReady-18 还没准备好
KErrUnknow-19 不知名的错误
KErrCorrupt-20 错误
KErrAccessDenied-21 拒绝接受
KErrLocked-22 锁闭
KErrWrite-23 读写失败
KErrDisMounted-24 错误的磁盘
KErrEof-25 出乎预料的文件到了尾端
KErrDiskFull-26 磁盘已满
KErrBadDiver-27 驱动损坏
KErrBadName-28 不允许的名称
KErrCommsLineFail-29 Comms线失败
KErrCommsFrame-30 Comms线框框错误
KErrCommsOverrun-31 Comms线超频错误
KErrCommsParity-32 Comms同位错误
KErrTimeOut-33 时间到了
KErrCouldNotConect-34 连接失败
KErrCouldNotDisconect-35 断连接失败
KErrDisconnected-36 断了
KErrBadLibraryEntryPoint-37 损坏的资料库接入点 -
手机软件测试的经验总结
qiuteng258 发布于 2010-10-13 10:43:23
1.在提交高通前务必要检查文档与实际程序的功能表现是否相同,比如说,客户端新增了快捷键,等操作必须在相应的帮助性文档中详细描述其使用的方便之处,引导用户形成预定的操作习惯。这样做可以增强程序的易用性。
2.在模拟器上视频的处理速度较快,所以不会出现画面移动的图像变模糊的现象,但是由于手机的分辨率相对低,处理速度也远比不上计算机的处理速度,所以一般在模拟器显示正常的速度,到了手机就应该让开发人员适当调慢,否则将会出现移动物体变模糊不能清晰辨认的情况。3.有些系统中使用了很多的图片资源,当在两个界面之间(例如在主菜单界面和帮助界面之间,主界面菜单是由许多图片组成的,帮助界面是一个html文件的浏览显示),连续按若干次使其在两个界面之间连续切换,会出现图像重叠现象,其原因是手机的CPU处理速度跟不上刷新速度,而且主界面的图片资源一直没有释放,导致图像的残留。一般可模拟Grinder把这些类似的问题测出来。
4.是否正确处理来电。如果没有适当正确的来电处理,有些来电会使播放器画面变乱,有些直接退出,甚至死机。Brew程序员往往会在来电处理后的恢复中忘了对音乐的处理,比如说原先选择了关闭音乐的,来电处理后音乐又自动开始播放了。有时候需要模拟两个或以上的连续的来电以发掘程序深层的逻辑错误,这些错误大多是来电处理后的恢复过程的错误。另外短信,电量不足等一些事件警告的出现也有可能导致程序出错,也要作出相应的处理。
5.注意确保系统的说明和帮助的完整清晰,检查系统提示信息,确保在系统中出现的文字的正确拼写,没有错别字。要尽量用敬称“您”而不用“你”。
6.标题,菜单等的文字显示要尽量用小字体,尽量缩短文字,能用简短文字说明清楚的就不要用长句,例如“按2,4键可以左右移动图片”就可改成“按2,4键左右移动图片”,或者甚至改成“按2,4键移动图片”。因为不同的手机显示屏幕宽度不一样,在一款手机上显示正确不代表在其他款式都能正确显示,然而用小字体,短句子就能适应大多数手机的屏幕宽度。
7.线程的处理,有些系统设有多个线程,如果没有处理好线程的调用释放问题的话,就很可能出现线程争用的问题。例如一个宠物系统,宠物死亡后,会调用一个新的线程循环播放哀吊音乐,有些程序员由于粗心大意忘记了释放这个线程,当重新开始系统时,就会出现这个线程播放的音乐与系统过程的背景音乐交替播放的情况。
8.文件处理。当涉及文件读写操作的时候,要特别注意测试文件操作带来的内存问题。比如说,有些系统需要用文件记录系统最高分或分值等,要注意测试第一次运行程序时的退出操作(此时没有最高分记录或其他分值记录),程序是否申请了文件指针或文件资源而没有释放。如果是的话,则会导致退出时的内存错误。另外对于Brew,应用程序的文件包中不得包含零字节的文件,每个文件至少有一个字节,同时还要求不能包含无用的文件或文件夹,目的是节省手机上有限的存储资源。
9.颜色的搭配,有些背景色跟文字或图片的颜色搭配在模拟器可以较清晰的显示出来,但是到了手机由于其分辨率问题就不那么明显了。颜色搭配要以清晰美观为基础,还要适当考虑系统的种类,用户心理等问题。
10.用模拟器模拟网络不通的情况。目的是测试软件的网络连接,网络资源请求,缓冲区存储等模块的性能,看看内存是否有正确释放等。可以通过断开网络连接的方法模拟手机网络不通的情况,具体就是把本地连接的状态设成禁用或者直接拔掉网络连接线。11.数据请求或传输等需时较多的过程要确保有提示界面,最好有动画显示数据在传输过程中,请用户耐心等待。另外要注意在这个过程中对重复按键予以忽略,因为等待时间过长或响应迟钝时,用户趋向于重复按手机按钮。
12.不要忽略了对后台数据正确性的测试。输入特殊字符或异常字符,看后台有没有相应的容错处理(当然这些也可由手机端处理)。多个客户端同时发出请求,测试后台的多线程处理能力,看能同时处理多少用户的同时请求,平均响应时间是多少,是否在可接受范围内。
13.来电,短信,电量不足等一些事件警告的出现也有可能导致程序出错,也要作出相应的处理。有些网络程序由于设置了数据通讯时不处理来电,这时候就要在低电量情况下测试,用电量不足的警告事件来触发程序的suspend和resume处理事件,看是否做了恰当的处理。
-
用户名密码的测试方法(别小看哦)
movestar 发布于 2010-08-20 10:27:18
别小看了这个用户名密码这么简单的输入框。可测试的内容还是很多的,并且引发的问题也有很多种类。下面就说一说他的测试方法。
一、用户注册
只从用户名和密码角度写了几个要考虑的测试点,如果需求中明确规定了安全问题,Email,出生日期,地址,性别等等一系列的格式和字符要求,那就都要写用例测了~
以等价类划分和边界值法来分析
1.填写符合要求的数据注册: 用户名字和密码都为最大长度(边界值分析,取上点)
2.填写符合要求的数据注册 :用户名字和密码都为最小长度(边界值分析,取上点)
3.填写符合要求的数据注册:用户名字和密码都是非最大和最小长度的数据(边界值分析,取内点)
4.必填项分别为空注册
5.用户名长度大于要求注册1位(边界值分析,取离点)
6.用户名长度小于要求注册1位(边界值分析,取离点)
7.密码长度大于要求注册1位(边界值分析,取离点)
8.密码长度小于要求注册1位(边界值分析,取离点)
9.用户名是不符合要求的字符注册(这个可以划分几个无效的等价类,一般写一两个就行了,如含有空格,#等,看需求是否允许吧~)
10.密码是不符合要求的字符注册(这个可以划分几个无效的等价类,一般写一两个就行了)
11.两次输入密码不一致(如果注册时候要输入两次密码,那么这个是必须的)
12.重新注册存在的用户
13.改变存在的用户的用户名和密码的大小写,来注册。(有的需求是区分大小写,有的不区分)
14.看是否支持tap和enter键等;密码是否可以复制粘贴;密码是否以* 之类的加秘符号显示
备注:边界值的上点、内点和离点大家应该都知道吧,呵呵,这里我就不细说了~~
二、修改密码
当然具体情况具体分析哈~不能一概而论~
实际测试中可能只用到其中几条而已,比如银行卡密码的修改,就不用考虑英文和非法字符,更不用考虑那些TAP之类的快捷键。而有的需要根据需求具体分析了,比如连续出错多少次出现的提示,和一些软件修改密码要求一定时间内有一定的修改次数限制等等。
1.不输入旧密码,直接改密码
2.输入错误旧密码
3.不输入确认新密码
4.不输入新密码
5.新密码和确认新密码不一致
6.新密码中有空格
7.新密码为空
8.新密码为符合要求的最多字符
9.新密码为符合要求的最少字符
10.新密码为符合要求的非最多和最少字符
11.新密码为最多字符-1
12.新密码为最少字符+1
13.新密码为最多字符+1
14.新密码为最少字符-1
15.新密码为非允许字符(如有的密码要求必须是英文和数字组成,那么要试汉字和符号等)
16.看是否支持tap和enter键等;密码是否可以复制粘贴;密码是否以* 之类的加秘符号
17.看密码是否区分大小写,新密码中英文小写,确认密码中英文大写
18.新密码与旧密码一样能否修改成功
另外一些其他的想法如下:
1 要测试所有规约中约定可以输入的特殊字符,字母,和数字,要求都可以正常输入、显示正常和添加成功
2 关注规约中的各种限制,比如长度,大否支持大小写。
3 考虑各种特殊情况,比如添加同名用户,系统是否正确校验给出提示信息,管理员帐户是否可以删除,因为有些系统管理员拥有最大权限,一旦删除管理员帐户,就不能在前台添加,这给最终用户会带来很多麻烦。比较特殊的是,当用户名中包括了特殊字符,那么对这类用户名的添加同名,修改,删除,系统是否能够正确实现,我就遇到了一个系统,添加同名用户时,如果以前的用户名没有特殊字符,系统可以给出提示信息,如果以前的用户名包含特殊字符,就不校验在插入数据库的时候报错。后来查到原因了,原来是在java中拼SQL语句的时候,因为有"_",所以就调用了一个方法在“_”,前面加了一个转义字符,后来发现不该调用这个方法。所以去掉就好了。所以对待输入框中的特殊字符要多关注。
4 数值上的长度 之类的,包括出错信息是否合理
5 特殊字符:比如。 / ' " \ </html> 这些是否会造成系统崩溃
6 注入式bug:比如密码输入个or 1=1
7 登录后是否会用明文传递参数
8 访问控制(不知道这个算不算):登录后保存里面的链接,关了浏览器直接复制链接看能不能访问。 -
Android系统
enjoyspace 发布于 2010-08-04 19:06:36
Android是google公司针对手机开发的一个平台,并公布了其中大部分代码,其大部分应用程序都是用JAVA开发的,毕竟它是商业性的产品嘛,有所保留也是理所当然的。对于搞嵌入式linux开发的人来说我们可以从中学习其长处,也算得上是未来的一个发展方向和趋势吧。
我们先来看看Android它的体系结构吧。下面是一张公开的Android体系结构图。

android的系统架构和其操作系统一样,采用了分层的架构。从架构图看,android分为四个层,从高层到低层分别是应用程序层、应用程序框架层、系统运行库层和linux核心层。蓝色的代表java程序,黄色的代码为运行JAVA程序而实现的虚拟机,绿色部分为C/C++语言编写的程序库,红色的代码内核(linux内核+drvier)
1.应用程序
Android会同一系列核心应用程序包一起发布,该应用程序包包括email客户端,SMS短消息程序,日历,地图,浏览器,联系人管理程序等。所有的应用程序都是使用JAVA语言编写的。
2.应用程序框架
开发人员也可以完全访问核心应用程序所使用的API框架。该应用程序的架构设计简化了组件的重用;任何一个应用程序都可以发布它的功能块并且任何其它的应用程序都可以使用其所发布的功能块(不过得遵循框架的安全性限制)。同样,该应用程序重用机制也使用户可以方便的替换程序组件。
隐藏在每个应用后面的是一系列的服务和系统, 其中包括;
* 丰富而又可扩展的视图(Views),可以用来构建应用程序, 它包括列表(lists),网格(grids),文本框(text boxes),按钮(buttons), 甚至可嵌入的web浏览器。
* 内容提供器(Content Providers)使得应用程序可以访问另一个应用程序的数据(如联系人数据库), 或者共享它们自己的数据
* 资源管理器(Resource Manager)提供 非代码资源的访问,如本地字符串,图形,和布局文件( layout files )。
* 通知管理器 (Notification Manager) 使得应用程序可以在状态栏中显示自定义的提示信息。
* 活动管理器( Activity Manager) 用来管理应用程序生命周期并提供常用的导航回退功能。有关更多的细节和怎样从头写一个应用程序,请参考 如何编写一个 Android 应用程序.
3.系统运行库
1)程序库
Android 包含一些C/C++库,这些库能被Android系统中不同的组件使用。它们通过 Android 应用程序框架为开发者提供服务。以下是一些核心库:
* Bionic系统 C 库 - 一个从 BSD 继承来的标准 C 系统函数库( libc ), 它是专门为基于 embedded linux 的设备定制的。
* 媒体库 - 基于 PacketVideo OpenCORE;该库支持多种常用的音频、视频格式回放和录制,同时支持静态图像文件。编码格式包括MPEG4, H.264, MP3, AAC, AMR, JPG, PNG 。
* Surface Manager - 对显示子系统的管理,并且为多个应用程序提 供了2D和3D图层的无缝融合。这部分代码
* Webkit,LibWebCore - 一个最新的web浏览器引擎用,支持Android浏览器和一个可嵌入的web视图。鼎鼎大名的 Apple Safari背后的引擎就是Webkit
* SGL - 底层的2D图形引擎
* 3D libraries - 基于OpenGL ES 1.0 APIs实现;该库可以使用硬件 3D加速(如果可用)或者使用高度优化的3D软加速。
* FreeType -位图(bitmap)和矢量(vector)字体显示。
* SQLite - 一个对于所有应用程序可用,功能强劲的轻型关系型数据库引擎。*还有部分上面没有显示出来的就是硬件抽象层。其实Android并非讲所有的设备驱动都放在linux内核里面,而是实现在userspace空间,这么做的主要原因是GPL协议,Linux是遵循该协议来发布的,也就意味着对 linux内核的任何修改,都必须发布其源代码。而现在这么做就可以避开而无需发布其源代码,毕竟它是用来赚钱的。而在linux内核中为这些userspace驱动代码开一个后门,就可以让本来userspace驱动不可以直接控制的硬件可以被访问。而只需要公布这个后门代码即可。一般情况下如果要将Android移植到其他硬件去运行,只需要实现这部分代码即可。包括:显示器驱动,声音,相机,GPS,GSM等等
2)Android 运行库
Android 包括了一个核心库,该核心库提供了JAVA编程语言核心库的大多数功能。
每一个Android应用程序都在它自己的进程中运行,都拥有一个独立的Dalvik虚拟机实例。Dalvik被设计成一个设备可以同时高效地运行多个虚拟系统。 Dalvik虚拟机执行(.dex)的Dalvik可执行文件,该格式文件针对小内存使用做了优化。同时虚拟机是基于寄存器的,所有的类都经由JAVA编译器编译,然后通过SDK中 的 "dx" 工具转化成.dex格式由虚拟机执行。
Dalvik虚拟机依赖于linux内核的一些功能,比如线程机制和底层内存管理机制。
4.Linux 内核
Android 的核心系统服务依赖于 Linux 2.6 内核,如安全性,内存管理,进程管理, 网络协议栈和驱动模型。 Linux 内核也同时作为硬件和软件栈之间的抽象层。其外还对其做了部分修改,主要涉及两部分修改:
1).Binder (IPC):提供有效的进程间通信,虽然linux内核本身已经提供了这些功能,但Android系统很多服务都需要用到该功能,为了某种原因其实现了自己的一套。
2).电源管理:主要是为了省电,毕竟是手持设备嘛,低耗电才是我们的追求。
最后在谈谈Android所采用的语言,其应用开发采用java语言,我们所说的java一般包含三个部分:
1)java语言:即其语法,其写代码的程式
2).java虚拟机:为了实现一次编译到处可以运行的原则,java在编译连接以后并没有产生目标机器语言,而是采用了Java bytecode这种Java共用指令,这时就需要一个虚拟机来执行改指令。
3).库:跟我们常用的C语言一样提供一些常用的库
后两者结合就是Java Runtime Environment。
Android使用的虚拟机叫 Dalvik,最初并是不为Java设计的,它并不能运行Java bytecode指令,而是运行叫Dalvik executable,简称dx。为止Android提供了dx工具,用来将Java bytecode转换为dx。
Android源代码结构:
Google提供的Android包含了原始Android的目标机代码,主机编译工具、仿真环境,代码包经过解压缩后,第一级别的目录和文件如下所示:
.
|-- Makefile (全局的Makefile)
|-- bionic (Bionic含义为仿生,这里面是一些基础的库的源代码)
|-- bootloader (引导加载器)
|-- build (build目录中的内容不是目标所用的代码,而是编译和配置所需要的脚本和工具)
|-- dalvik (JAVA虚拟机)
|-- development (程序开发所需要的模板和工具)
|-- external (目标机器使用的一些库)
|-- frameworks (应用程序的框架层)
|-- hardware (与硬件相关的库)
|-- kernel (Linux2.6的源代码)
|-- packages (Android的各种应用程序)
|-- prebuilt (Android在各种平台下编译的预置脚本)
|-- recovery (与目标的恢复功能相关)
`-- system (Android的底层的一些库)
bionic目录展开一个级别的目录如下所示:
bionic/
|-- Android.mk
|-- libc
|-- libdl
|-- libm
|-- libstdc++
|-- libthread_db
`-- linker
bootloader目录展开的两个级别目录:
bootloader/
`-- legacy
|-- Android.mk
|-- README
|-- arch_armv6
|-- arch_msm7k
|-- fastboot_protocol.txt
|-- include
|-- libboot
|-- libc
|-- nandwrite
`-- usbloader
build目录展开的一个级别的目录如下所示:
build/
|-- buildspec.mk.default
|-- cleanspec.mk
|-- core (各种以mk为结尾的文件,它门是编译所需要的Makefile)
|-- envsetup.sh
|-- libs
|-- target (包含board和product两个目录,为目标所需要文件)
`-- tools (编译过程中主机所需要的工具,一些需要经过编译生成)
其中,core中的Makefile是整个Android编译所需要的真正的Makefile,它被顶层目录的Makefile引用。
envsetup.sh是一个在使用仿真器运行的时候,用于设置环境的脚本。
dalvik目录用于提供Android JAVA应用程序运行的基础————JAVA虚拟机。
development目录展开的一个级别的目录如下所示:
development
|-- apps (Android应用程序的模板)
|-- build (编译脚本模板)
|-- cmds
|-- data
|-- docs
|-- emulator (仿真相关)
|-- host (包含windows平台的一些工具)
|-- ide
|-- pdk
|-- samples (一些示例程序)
|-- simulator (大多是目标机器的一些工具)
`-- tools
在emulator目录中qemud是使用QEMU仿真时目标机器运行的后台程序,skins是仿真时手机的界面。
samples中包含了很多Android简单工程,这些工程为开发者学习开发Android程序提供了很大便利,可以作为模板使用。
external目录展开的一个级别的目录如下所示:
external/
|-- aes
|-- apache-http
|-- bluez
|-- clearsilver
|-- dbus
|-- dhcpcd
|-- dropbear
|-- elfcopy
|-- elfutils
|-- emma
|-- esd
|-- expat
|-- fdlibm
|-- freetype
|-- gdata
|-- giflib
|-- googleclient
|-- icu4c
|-- iptables
|-- jdiff
|-- jhead
|-- jpeg
|-- libffi
|-- libpcap
|-- libpng
|-- libxml2
|-- netcat
|-- netperf
|-- neven
|-- opencore
|-- openssl
|-- oprofile
|-- ping
|-- ppp
|-- protobuf
|-- qemu
|-- safe-iop
|-- skia
|-- sonivox
|-- sqlite
|-- srec
|-- strace
|-- tagsoup
|-- tcpdump
|-- tinyxml
|-- tremor
|-- webkit
|-- wpa_supplicant
|-- yaffs2
`-- zlib
在external中,每个目录表示Android目标系统中的一个模块,可能有一个或者若干个库构成。其中:
opencore为PV(PacketVideo),它是Android多媒体框架的核心。
webkit是Android网络浏览器的核心。
sqlite是Android数据库系统的核心。
openssl是Secure Socket Layer,一个网络协议层,用于为数据通讯提供安全支持。
frameworks目录展开的一个级别的目录如下所示:
frameworks/
|-- base
|-- opt
`-- policies
frameworks是Android应用程序的框架。
hardware是一些与硬件相关的库
kernel是Linux2.6的源代码
packages目录展开的两个级别的目录如下所示:
packages/
|-- apps
| |-- AlarmClock
| |-- Browser
| |-- Calculator
| |-- Calendar
| |-- Camera
| |-- Contacts
| |-- Email
| |-- GoogleSearch
| |-- HTMLViewer
| |-- IM
| |-- Launcher
| |-- Mms
| |-- Music
| |-- PackageInstaller
| |-- Phone
| |-- Settings
| |-- SoundRecorder
| |-- Stk
| |-- Sync
| |-- Updater
| `-- VoiceDialer
`-- providers
|-- CalendarProvider
|-- ContactsProvider
|-- DownloadProvider
|-- DrmProvider
|-- GoogleContactsProvider
|-- GoogleSubscribedFeedsProvider
|-- ImProvider
|-- MediaProvider
`-- TelephonyProvider
packages中包含两个目录,其中apps中是Android中的各种应用程序,providers是一些内容提供者(在Android中的一个数据源)。
packages中两个目录的内容大都是使用JAVA编写的程序,各个文件夹的层次结构是类似的。
prebuilt目录展开的一个级别的目录如下所示:
prebuilt/
|-- Android.mk
|-- android-arm
|-- common
|-- darwin-x86
|-- linux-x86
`-- windows
system目录展开的两个级别的目录如下所示:
system/
|-- bluetooth
| |-- bluedroid
| `-- brfpatch
|-- core
| |-- Android.mk
| |-- README
| |-- adb
| |-- cpio
| |-- debuggerd
| |-- fastboot
| |-- include (各个库接口的头文件)
| |-- init
| |-- libctest
| |-- libcutils
| |-- liblog
| |-- libmincrypt
| |-- libnetutils
| |-- libpixelflinger
| |-- libzipfile
| |-- logcat
| |-- logwrapper
| |-- mkbootimg
| |-- mountd
| |-- netcfg
| |-- rootdir
| |-- sh
| `-- toolbox
|-- extras
| |-- Android.mk
| |-- latencytop
| |-- libpagemap
| |-- librank
| |-- procmem
| |-- procrank
| |-- showmap
| |-- showslab
| |-- sound
| |-- su
| |-- tests
| `-- timeinfo
`-- wlan
`-- ti -
Android模拟器的基本操作
inking 发布于 2010-01-12 15:03:45
运行环境:1、安装JDK
2、安装Android SDK
建议:添加JDK、SDK的环境变量,将路径添加到path环境变量中。
配置步骤:
1、进入cmd命令行模式下,判断JDK和Android是否安装和配置成功
(判断JDK是否安装好,请输入java -version,如果能返回java的版本信息,则安装成功)
(判断Android是否安装好,请输入Android -h,如果能返回Android的版本信息,则安装成功)
2、创建AVD、SDcard
2.1创建AVD,cmd命令行模式下,输入
>android create avd --name sdk_1_5_avd --target 2
(sdk_1_5_avd 为创建的AVD的名字,可以取任意名字)
2.2创建SDcard,cmd命令行模式下,输入
>mksdcard 1024M c:\\\\sdcard.img
(c:\\\\sdcard.img 为创建的SDcard的名字和路径,可以取任意名字)
3、从android-sdk\\\\tools目录下的emulator.exe发送个快捷方式到桌面上,然后查看emulator.exe快捷方式的属性,在“目标”后面添加 -avd sdk_1_5_avd -sdcard c:\\\\sdcard.img的参数
(sdk_1_5_avd为AVD文件
c:\\\\sdcard.img为创建的SD卡文件)
修改为C:\\\\android-sdk-windows-1.5_r2\\\\tools\\\\emulator.exe -avd test -sdcard c:\\\\sdcard.img
4、双击运行桌面的emulator.exe快捷方式,则可以启动带SD卡的emulator.exe模拟器
5、安装apk文件
例如有个apk文件在E:\\\\software\\\\android\\\\Mine.apk
在cmd命令行模式下,输入
>adb install E:\\\\software\\\\android\\\\Mine.apk
则会提示如下信息 pkg: /data/local/tmp/Mine.apk success
6、在模拟器的Menu菜单栏里已经添加了刚才安装软件的快捷方式,点击即可运行该软件。
7、上传文件到指定目录
在cmd命令行模式下,输入
>adb push E:\\\\music\\\\hello.mp3 /sdcard/
(查看目录方法
>adb shell 进入she\\\’ll命令模式下
#ls 查看即可)
-
测试职业发展(转载)
amyaxl 发布于 2010-09-16 13:21:20
From 谢颖怡的日志 测试窝
以下这个发展计划是在《软件评测师教程》看到的,以为会在网上找得到,可是居然没搜索到,所以只有逐字打上来了。自入行以来,非常关心测试职位的职业发展,而这个发展计划,比较权威,也比较实用,可行性高。
国际推荐的软件测试职业发展计划如下:
1~2年,测试技能:熟悉整个测试过程及产品业务领域,学习和掌握自动测试工具,学习测试自动化编程技术;开发和执行测试脚本,承担系统测试实施任务;学习编程语言、操作系统、网络与数据库方面的技能。
3~4年,测试过程:深入了解测试过程,掌握测试过程设计及改进,参与软件工作产品的同行评审;进一步了解产品业务领域,改进测试自动化编程技术,能指导初级测试工程师;加强编程语言、操作系统、网络与数据库方面的技能。
4~5年,测试组织工作:管理1~3名测试工程师,担任任务估算、管理及进度控制;进一步培养在软件项目管理及支持工具方面的技能。
5~6年,技术管理:管理4~8名测试工程师,提高任务估算、管理及进度控制能力,完成测试规划冰制定测试计划;研究测试的技术手段,保持使用项目指导及支持工具的技能;用大量的时间为其他测试工程师提供技术及过程方面的指导;开始与客户打交道并做演示推介。
6~12年,测试管理:管理8名以上测试工程师,负责一个或多个项目的测试工作,与客户打交道并做演示推介;保持使用项目管理及支持工具的技能。
无论在哪个年龄,无论在哪个公司,你都要专注于发掘或者发展自己的“利用价值”,我们可以把利用价值分成三个档次:第一个档次,忍别人不能忍的。第二个档次,做别人不能做的。第三个档次,想别人不能想的。
-
不要透支你的"知识积累" (转载)
amyaxl 发布于 2010-09-16 11:00:55
ZZ FROM 金鑫的日志 测试窝
(一)长期游走各类测试论坛,当然包括测试窝啰。同时工作实践中,带过的测试新人朋友也不少了。给我一个较为普遍的感受,作为一个新人,想要尽快掌握被测产品业务,尽快提升
测试相关技能。是否具备知识积累的能力?与此同时,是否具备一套行之有效的积累方法。显得格外重要了身处软件这一行,在这个资讯爆炸的时代,大家单凭脑袋要记住所有的信息,几乎是不可能的。(除非有记忆面包可以吃) 。而在工作、学习的过程中,我们通常不会要求自己或
别人一定要具备怎样的理论或技能之后,方能开展某种具体的工作。实际上大家都是先碰到问题,再开始有针对性学起来,经过一系列的搜索资料,学习、实践直至处理完手头的问题之后。很多朋友往往是如释重负、“挥挥衣袖”,倘若很长时间之
后又遇到类似问题。不得不再一次的搜集你的记忆神经,不好彩!!!自离破碎的记忆不足以支撑问题的处理,试想又一次的检索、学习、实践的 Action(貌似回放脚本时,还得
稍上int&end)只怕在所难免。甚者,往往不惜透支自己的"知识积累",处处寻求高人解围、或是发帖求助等诸如此类的做法,比比皆是起来...当然本文的初衷并不是摒弃“勤学好问”的优良传统,只是寄语更多测试新人、或是工作经历不长的朋友:软件测试行业与其他的IT行业岗位一样,需要持续充实大量的计算机、互
联网、工具使用、各种理论等,量级庞大的信息。掌握好一套适合自己知识积累方法,可以帮组大家少走弯路。所以,有机会去interview新人的时候,我一定会问的问题,就是“请问你常在哪些网站搜集,跟学习,而又通过过怎样的方式记录下来”。身为一个靠IT 吃饭的人,如果他的回答
是“我会用纸笔记下来”,或是“用Word、笔记本记下来”,我接着就会问,那你遇到重复的问题,怎么找。如果答不出来这两个相关的问题,除非他是白纸一张新人,不然我会对他
简历上的"积极好学、学以致用..."大打折扣啰。那么如何做到的知识积累有效性呢?分享我自己的习惯,具备一些特性:
1、要能操作便利以便迅速的纪录下我要记的东西;
2、要能具备检索功能(大言不惭的说,有些文章,还能让搜索引擎收录了),以便我可以在最短时间通过关键字找到我想找的内容;
3、要能容易分享,通过过分享才能与其他人讨论,或是接受别人的拍砖、批评,或是可以解决了人家的问题;
4、要能跨机器,跨地域。也就是这些信息可以网路存储的 ;(二)
接着上篇,本文介绍一下个人觉得适合整理知识的一些常用工具,供大家参考:
A、写博客,身为一个软件测试工程师,又或软件从业人员,每每碰到问题后,解决问题的方法,就如同测试过程发现缺陷时的信息,是最佳的Test Case一样,这么有价值的资讯,
一定要想办法记录下来,因为你会碰到这问题,一定会有其他人也会碰到。如同每次测试完成更新用例一样,记录下来,可以让自己经过知识管理内化、外显的过程,更深深的了
解这问题的本质, 可以让其他碰到问题的人快速找到解决方式,可以让下次自己在碰到这问题时,马上有sample code可以用,可以 证明自己学习是有方法的,可以证明自己是
有分享的热忱的。有着很多热心助人的博客前辈们,我们没必要害怕自己的文章没有价值,不要害怕人家的指导或是指正,因为最后的受益者,还是自己。关于博客站点,很多了,
想必不用我说大家应该知道的比我多吧?有条件的朋友还可以使用 WordPress 或 GoogleSite搭建功能强大的个性化的博客或站点B、FreeMind,FreeMind是一款跨平台的、基于GPL协议的自由软件,用Java编写,是一个用来绘制思维导图的软件。其产生的文件格式后缀为.mm 。可用来做笔记,脑图记录,脑力
激汤等。个人常用来,对于多头绪的工作任务安排,可以非常有效梳理。类似的还有Xmind : http://www.xmind.net/ 拿来随手记录想法,或是整理读书心得、会议记录、
Roadmap跟task清单相当不错的工具。格式可转换相当多,包括转成freemind的格式、HTML、图档、Open Office格式。而Freemind可以额外转成pdf,以及可互动式的XHTML,还有
提供xslt的自订导出格式,以及一些wiki的格式。C、书签,习惯用Firefox的Xmark,除了把记录都记在server端以外,还会有同步书签的功能,建立自己的帐号后,还可以在Xmark的网站上通过网页搜寻、整理、分享和预览。请
见:http://www.xmarks.com/ (目前本人觉得chrome的Google书签,也不错,可以随时随地通过网络同步最新的个人收藏)D、文件同步,之前很长一段时间使用Google文档 功能,可以很有效的同步、编辑与分享各类常用文档、表格、PPT等。而且通过Google表格自带的表单功能,设计表单,还可以作
为部门内部一些日常工作的记录与入库(非数据库,指的是在线表格),不过目前Google的产品使用起来很麻烦。至于如何能顺利使用,FQ的功夫,大家比我熟练吧,呵呵E、RSS,RSS客户端工具有很多,目前个人认为还是Google Reader最为靠谱,强大的同步功能,可以选择喜爱或是分享。实现了知识共享的集群效应。个人认为这也是Google中国
离开后,仍然没有yan割这个功能的原因吧!不过maybe你常见到,现在的Google Reader有时无法打开你之前的某些订阅吧,不妨试着更改一下协议试试,哈哈
最近看到一款工具Feedly(http://www.feedly.com/)还没试用,不过据说,提供很强大的介面跟user experience,UI很好用。当然除了UI好用之外,提供了Firefox的plug-in,
可以随时在浏览网页的时候,都可以把相关的信息submit回去feedly或其他方式share出来。另外,feedly也会根据你订阅网站的内容,提供一些相关你可能也有兴趣的网站供你
订阅。而每一篇文章,又可以通过很多不同的方式在上面直接share,例如Gmail, Facebook,Twitter等一堆在当下很是杯具接口中发布,而且这款工具目前还有了支持chrome的插
件下载,值得大家尝试。F、另外,习惯经常阅读PDF资料的朋友,可以使用PDF-XChange Viewer工具,这是一款我用过最好用的PDF reader,重点是可以额外在上面加注记的功能,简直快可以媲美word里
面的批注了,同时PDF-XChange Viewer搭配DropBox,还可以实现何时何地都可以继续阅读同一份PDF啦!结论
每次发现了不错的文章,有用的资料,或是从问题中学到了技巧,没有纪录下来,就错失了增加知识积累极高价值的机会。千万千万不要相信自己的记忆力,通过最近的两篇短文,希望能帮组大家寻找适合自己的学习方式,这条路上,不仅自己会很有成就感,还且也会有很多贵人相助。试想一下,
这样的习惯外加一段时间的积累,不成专家,你都难哦!!!抛砖引玉一下,如果你还常常为不知如何积累知识而苦恼,不知道该如何记录、分享、搜寻知识,也算是我的建议了。
-
一套比较完整的软件测试人员面试题(包括技术和人力资源方面)
超越自我 发布于 2010-07-05 09:00:27
一套比较完整的软件测试人员面试题(包括技术和人力资源方面)
你为什么选择软件测试行业
因为之前有了解软件测试这个行业,觉得他的发展前景很好。也对根据你以前的工作经验描述一下软件开发、测试过程,由那些角色负责,你做什么
要有架构师、开发经理、测试经理、程序员、测试员我在里面主要是负责所分到的模块执行测试用例。
结合你以前的学习和工作经验,你认为如何做好测试。
根据我以前的工作经验,我认为做好工作首先要有一个好的沟通,只有沟通无障碍了,才会有好的协作,才会有跟好的效率,再一个就是技术一定要过关,做测试要有足够的耐心,和一个良好的工作习惯,不懂的就问,实时与同事沟通这样的话才能做好测试工作。你觉得测试最重要的是什么
尽可能的找出软件的错误
怎样看待加班问题
加班的话我没有太多的意见,但是我还是觉得如果能够合理的安排时间的话,不会有太多时候会加班的。
如果一个很有个性的程序员认为自己的BUG不是BUG,怎么解决?
首先我要确定我所提的在我认为是不是bug,如果我认为是的话我会在他面前重现这个bug和他讲这是个bug,和他沟通,或者我会找到我的直系领导让他解决。
为什么在团队中要有测试
因为软件有错误,如果没有专业的测试人员很难发现软件的一些错误。在测试时代学习自己最大的收获是什么?
在测试时代我除了学习了测试的知识外,还看到了老师们对待测试的一种态度,明白了做任何工作都要有沟通,做测试的也要有很好的沟通才可以做好。知道自己在项目组中的位置,和开发的关系。你对未来的规划
我想在工作中慢慢的积累经验,使自己强大起来,能够担任更重要的职务。
自己优势及缺点
我的优点是有足够的耐心对待每一件事情,善于观察事物,承受压力的能力很强。缺点可能就是我不是很爱说话,习惯做不习惯说,但是和人沟通还是没有问题的。
你为什么选择测试时代不选择51testing
因为相对比来看测试时代价钱相对公道,师资也不错,还有一个原因就是在网上查了一下测试时代的口碑不错,也是网放心过来的原因。
13.请谈谈您对测试工作的理解
我认为测试工作是找出软件产品的错误,
14.你认为测试人员需要具备哪些素质?
我认为做测试的应该要有一定的协调能力,因为测试人员要经常与开发接触处理一些问题,如果处理不好的话会引起一些冲突这样的话工作上就会做不好。还有测试人员要有一定的耐心,有的时候做的测试很枯燥乏味的。除了要有耐心之外还要细心,不放过每一个可能的错误。
15.你为什么能够做测试这一行。
虽然说我的测试技术还不是很纯熟,但是我觉得我还是可以胜任软件测试这个工作的,因为做软件测试不仅是要求技术好,还要有一定的沟通能力,耐心、细心等外在的因素。综合起来看我认为我是胜任这个工作的。
1测试的目的是什么?
测试的目的是找出软件产品中的错误,是软件尽可能的符合用户的要求。
当软件测试是不可能能够找出全部的错误的。
2. 测试分为那几个阶段?
一般来说测试大体分为5个阶段:
单元测试、集成测试、确认测试、系统测试、验收测试
在测试过程中如果有需要还要进行回归测试。
3. 单元测试的测试对象,目的、测试依据、测试方法?
测试对象是模块内部的程序错误;目的是消除局部模块逻辑和功能上的错误和缺陷;
测试依据是模块的详细设计;测试方法采用白盒测试。
4. 集成测试的测试对象,目的、测试依据、测试方法?
集成测试的测试对象是模块间的组装和调用关系;
目的是找出与软件设计相关的程序结构模块调用关系,模块间接口方面问题;
测试依据是概要设计;测试方法采用灰盒测试。
5. 系统测试的测试对象,目的、测试依据、测试方法?
系统测试的测试对象是整个系统;测试的目的是对整个系统进行测试;
测试的依据是需求规格说明书;测试方法黑盒测试。
6. 测试覆盖的类型
测试覆盖的类型有:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、条件组合覆盖、路径覆盖
7. 性能测试的分类
分为:性能测试、负载测试、压力测试、容量测试
负载测试与压力测试可以结合进行。
8. 列举您熟悉的主流自动化测试工具
我熟悉的自动化测试工具有:基于web的测试管理工具TestDirector、配置管理工具VSS、
QTP以及性能测试工具LoadRunner
9. 编辑sql语句时,年月日型时间字段如何表达
加引号
13. c/s和b/s结构的软件进行测试时有何不同
C/S又称Client/Server或客户/服务器模式。服务器通常采用高性能的PC、工作站或小型机,并采用大型数据库系统。客户端需要安装专用的客户端软件。
B/S是Brower/Server的缩写,客户机上只要安装一个浏览器(Browser)。浏览器通过Web Server 同数据库进行数据交互。
$o;~k V*O
lTestAge 中国软件测试时代$I siX_ k14. 安全测试的后台是什么
17. 页面中有一个输入日期的输入框和一个输入身份证号的输入框,如何进行用例设计?
输入日期的输入框要考虑边界值、输入非法数据、非数字等
省份证输入框要考虑18位省份证、16位身份证、非18、16位的数据、汉字、字母、非法数据、
18. 测试和质量保证有什么区别 你的看法
质量保证是对软件制作过程的制作质量进行管理,看是否符合公司的规定。
软件测试是对软件产品的质量本身进行测试,是从技术方面出发测试软件质量
19. 用过什么缺陷管理工具? 流程是什么 有什么能改进的
我所熟悉的是TD
流程是讲测试计划、方案、测试用例录入TD,在TD上执行测试用例记录缺陷,并对bug进行跟踪。
20. 你有没有用过QTP做项目,QTP的工作原理
我有用QTP做过项目
QTP的工作原理是执行重复的手动测试,
首先制定测试计划再根据测试计划创建测试脚本,然后对脚本进行优化增强测试脚本的能接下来运行脚本分析测试的结果
21. 什么是白盒测试?白盒测试的工具有哪些?
白盒测试是测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有的逻辑路径进行测试。
工具有:Rational Purify 、Rational Quantify 、Rational Purecoveage
22. 路由器,集线器,交换机的区别?
路由器的作用是用于连接不同网段并且找到网络中数据传输最合适的路径。
集线器的作用是将一些pc机连起来组成一个局域网。
交换机的作用与集线器的相似,区别在于集线器采用的是共享带宽的方式,交换机是独享带宽。
24. 我手上这支笔,请你根据这支笔设计测试用例
首先我要测它的外观、颜色是否符合要求、她所占的空间是多大、是否环保、接下来测它的质量、这支笔是否能够写字流畅、写出的自得颜色是否符合要求、能使用多长时间等
25. BUG报告包括那些内容
Bug出现的位置、可重现的步骤、所使用的数据、bug的截图、发现人及日期。
26. 请列举一些Oracle数据库中的SID语句
27. W和H模型的区别
W模型强调的是测试伴随整个软件开发周期,而且测试的对象不仅是程序,需求也需要进行测试,测试与开发是同步进行的。
H模型是讲测试活动玩却的独立出来,形成了完全独立的流程,可以实现迭代而W模型不支持迭代这是两者最打的区别。
28. 没有任何说明书,如何进行测试?
首先是通过对软件测使用来熟悉整个软件,接着是与开发沟通掌握软件的特性并一一记录下来,作为测试的依据。
29. 测试计划包括那些内容那些重要?
测试计划包括
-
性能测试人员面试经典技术问题(汇总)----果然经典
ljonathan 发布于 2010-09-02 10:06:34
第一篇:性能测试人员面试经典技术问题
1.请问什么是性能测试、负载测试、压力测试?
原参考答案:
性能测试:对一个软件系统而言,包括执行效率、资源占用、系统稳定性、安全性兼容性、可扩展性等。
负载测试:通过逐步加压的方式来确定系统的处理能力,确定系统能承受的各项阀值。
压力测试:逐步增加负载,使系统某些资源达到饱和甚至失效的测试。
个人理解:
经典的问题,答案打算参考段念的书:
性能测试(Performance Testing):是通过模拟系统实际运行的压力和使用场景组合,测试系统的性能是否满足实际生产的性能要求。
特点:1.主要目的是验证系统是否具备其宣称的能力
2.需要事先了解被测系统的典型场景,并具有确定的性能目标
3.要求在已确定的环境下运行
负载测试(Load Testing):通过在被测系统上不断增加压力,直到某个性能指标超过预定指标或者某种资源使用已经达到饱和状态
特点:1. 主要目的是找到系统处理能力的极限,为系统调优提供数据。测试形式/手段:"检测--加压--知道性能指标超过预期"
2.在给定的测试环境下进行,考虑被测系统的业务压力量和典型场景
3. 一般用来了解系统的性能容量,或是配合性能调优
压力测试(Stress Testing):测试系统在一定饱和状态下(CPU/MEMORY),
特点:1. 主要目的是检查系统处于压力情况下时,应用的表现
2. 一般用于测试系统的稳定性
2.请分别针对性能测试、负载测试和压力测试试举一个简单的例子?
原参考答案:
性能测试例子:公司开发了一个小型项目管理系统,上线前需要做负载、压力、大数据量、强度测试等。
负载测试:逐步加压,从而得到“响应时间不超过10秒”,“服务器平均CPU利用率低于85%”等指标阀值。
压力测试:逐步加压,从而使“响应时间超过10秒”,“服务器平均CPU利用率高于90%”等指标来确定系统能承受的最大负载量。
3.请例举出常用的性能测试工具,并指出这些工具的优缺点?
LoadRunner,录制脚本快捷操作简便,需要一定的学习时间,有采购成本。
4.请问您是如何得到性能测试需求?怎样针对需求设计、分析是否达到需求?
在查看需求文档,从中提取性能测试需求,与用户交流,了解实际使用情况。
结合业务信息设计操作场景总结出需测试的性能关键指标。
执行用例后根据提取关键性能指标来分析是否满足性能需求。
5.什么时候可以开始执行性能测试?
在产品相对比较稳定,功能测试结束后。灵活性比较强。
6.什么是集合点?设置集合点有什么意义?LoadRunner中设置集合点的函数是哪个?
集合点可以控制各个Vuser以便在同一时刻执行任务。
借助集合点,可以再LoadRunner中实现真正意义上的并发。
lr_rendezvous()
7.性能测试时,是不是必须进行参数化?为什么要创建参数?LoadRunner中如何创建参数?
8是。
模拟用户真实的业务操作。
创建参数列表,用参数替换固定的文本。
8.您了解关联吗?如何找出哪里需要关联?请给一些您所在项目的实例。
了解。
使用LoadRunner自动关联功能。手动关联:录制两份相同操作步骤的脚本,找出不同的部分进行判断。
一个项目管理系统,每次登录后服务器都自动分配一个sessionID以便之后每次表单提交后验证。
9.您如何调试LoadRunner脚本?
设置断点、增加log。
10.在LoadRunner中如何编写自定义函数?请给出一个您在以前项目中编写的函数。
11.请问您是如何理解LoadRunner中集合点、事务以及检查点等概念?
集合点:可以控制各个Vuser以便在同一时刻执行任务,可实现真正意义上的并发。
事务:事务是用来度量服务器响应时间的操作集。
检查点:在回放脚本期间搜索特定内容,从而验证服务器响应内容的正确性。
12.如何应用LoadRunner进行性能测试?
使用虚拟用户生成器创建脚本,使用控制器设定场景、运行脚本,使用分析器分析运行后得到的数据。
13.LoadRunner中思考时间有什么作用?
用户执行两个连续操作期间等待的时间。模拟用户真实的使用情况。
14.LoadRunner中如何实现多用户并发操作,需要进行哪些设置?
设置集合点来实现,在脚本中加入lr_rendezvous(),然后可以在控制器中设定集结百分比。
15.LoadRunner中有基于目标和手动两种场景设计方式,他们分别适用于什么情况?
手动场景可按照要求来配置场景,能够更加精确的满足测试需要。
目标场景要先制定希望实现的测试目标,然后由控制器惊醒自动测试评估。
16.LoadRunner中有几种并发执行策略,它们的含义是什么?
三种。1.当所有虚拟用户中的x%到达集合点时释放。2.当所有正在运行的虚拟用户中的x%到达集合点时释放。3.当x个虚拟用户到达集合点时释放。
17.有5台配置为处理器:Intel Pentium 4 1.6G,内存容量 512MB,硬盘容量 40GB的机器,如何较好的利用这些机器完成一次并发用户数为1000人的性能测试工作?
1台做应用服务器,1台做数据库服务器,1台运行控制器并承担一部分负载生成任务,2台负载生成器。
18.平时大家在注册邮箱等关联操作时,经常会遇到需要输入验证码的情况,请问,如果我们公司也开发了一套带验证码的应用软件,需要警醒性能测试,您会如何处理?
留一个后门,我们设定一个所谓的“万能验证码”,只要用户输入这个“万能验证码”,系统就验证通过。测试完成后补上后门。
============================================================================================================================================
第二篇:性能测试面试题(参考第四篇的英文题目及答案)
1.什么是负载测试?什么是性能测试?
2.性能测试包含了哪些测试(至少举出3种)
3.简述性能测试的步骤
4.简述使用Loadrunner的步骤
5.什么时候可以开始执行性能测试?
6.LoadRunner由哪些部件组成?
7.你使用LoadRunner的哪个部件来录制脚本?
8.LoadRunner的哪个部件可以模拟多用户并发下回放脚本?
9.什么是集合点?设置集合点有什么意义?Loadrunner中设置集合点的函数是哪个?
10.什么是场景?场景的重要性有哪些?如何设置场景?
11.请解释一下如何录制web脚本?
12.为什么要创建参数?如何创建参数?
13.什么是关联?请解释一下自动关联和手动关联的不同。
14.你如何找出哪里需要关联?请给一些你所在项目的实例。
15.你在哪里设置自动关联选项?
16.哪个函数是用来截取虚拟用户脚本中的动态值?(手工管联)
17.你在VUGen中何时选择关闭日志?何时选择标准和扩展日志?
18.你如何调试LoadRunner脚本?
19你在LR中如何编写自定义函数?请给出一些你在以前进行的项目中编写的函数。
20.在运行设置下你能更改那些设置?
21.你在不同的环境下如何设置迭代?
22.你如何在负载测试模式下执行功能测试?
23.什么是逐步递增?你如何来设置?
24.以线程方式运行的虚拟用户有哪些优点?
25.当你需要在出错时停止执行脚本,你怎么做?
26.响应时间和吞吐量之间的关系是什么?
27.说明一下如何在LR中配置系统计数器?
28.你如何识别性能瓶颈?
29.如果web服务器、数据库以及网络都正常,问题会出在哪里?
30.如何发现web服务器的相关问题?
31.如何发现数据库的相关问题?
32.解释所有web录制配置?
33.解释一下覆盖图和关联图的区别?
34.你如何设计负载?标准是什么?
35.Vuser_init中包括什么内容?
36. Vuser_end中包括什么内容?
37.什么是think time?think_time有什么用?
38.标准日志和扩展日志的区别是什么?
39.解释以下函数及他们的不同之处。
Lr_debug_message
Lr_output_message
Lr_error_message
Lrd_stmt
Lrd_fetch
40.什么是吞吐量?
41.场景设置有哪几种方法
============================================================================================================================================
第三篇:性能测试面试题
1、 【测试理论】描述不同的角色(用户、产品开发人员、系统管理员)各自关注的软件性能要点。
2、 【测试理论】解释5个常用的性能指标的名称与具体含义。
3、 【测试流程】简述性能测试流程与各阶段的工作内容。
4、 【LR工具】web系统中,username参数表为file类型,表中有12个值,分别A、B、C、D、E、F、G、H、I、J、K、L。
测试场景中虚拟并发用户数设为4,迭代次数设为3,
参数中Select next row与Update value on分别为(Sequential, Each Iteration)与(Unique, Once)时,
写出迭代3次的取值情况。
(Select next row, Update value on) 虚拟用户取值(VUi:迭代时取值)
(Sequential, Each Iteration)
VU1:
VU2:
VU3:
VU4:
(Unique, Once)
VU1:
VU2:
VU3:
VU4:
5、【LR工具】web系统脚本录制过程中,两次录制同一功能点,在View Tree的Server Response中产生的字符串分别为:
Server Response:name="_id_Node " value=" RSDP0013425" />", ENDITEM,
Server Response:name="_id_Node " value=" RSDP1203655" />", ENDITEM,
为脚本回放成功,需要对字符串中某些字符做一定处理,写出详细实现方法。
6、 【数据库应用】现有Customers表和Sales表的数据如下:
Customers表:
CustID Name ShpCity Discount
449320 Adapto PortLand 0.05
890003 AA PortLand 0.05
888402 Seaworth Albany 0.04
Sales表:
SaleID CustID SaleMount
234112 499320 8000
234113 888402 6500
234114 499320 5900
234115 890003 4500
要求:
1) 给出查询语句,描述:在Customers表中查询名字为AA或Bolt的查询语句;
2) 给出删除操作,描述:在Sales表中删除SaleID为234115的语句。
3) 根据以下结果表给出多表查询语句。
SaleID CustID Name Discount SaleMount
234112 499320 Adapto 0.05 8000
234113 888402 Seaworth 0.04 6500
234114 499320 Adapto 0.05 5900
234115 890003 AA 0.05 4500
7、 【数据库应用】为了尽可能避免大表全表扫描,最常见的方法有哪些?
8、 【中间件】WebLogic参数调整中,列举三项影响并发性能的参数项并简述其含义。
9、 【Unix命令】HP-UX与AIX操作系统中,监控CPU、内存、磁盘I/O的命令分别是什么?
10、 【Unix命令】用命令实现:
1) 对文件FileA添加读、写、执行权限;
2) 列出当前系统与java相关的活动进程;
3) 搜索当前文件夹中所有的.sh文件。
11、 【网络】服务器ip地址为128.64.96.100,HP-UX操作系统,ftp服务开启,用户名与密码分别为username/password, /home目录下有一个monitor.svc文件,现需要将monitor.svc文件取到客户机192.168.2.100,服务器与客户机二者之间网络互通,描述在192.168.2.100上操作过程
============================================================================================================================================
第四篇: 45道性能测试的面试题及答案(In English)
1. What is load testing?
- Load testing is to test that if the application works fine with the loads that result from large number of simultaneous users, transactions and to determine weather it can handle peak usage periods.
2. What is Performance testing?
- Timing for both read and update transactions should be gathered to determine whether system functions are being performed in an acceptable timeframe. This should be done standalone and then in a multi user environment to determine the effect of multiple transactions on the timing of a single transaction.
3. Did u use LoadRunner? What version?
- Yes. Version x.x .
4. Explain the Load testing process? -
Step 1: Planning the test. Here, we develop a clearly defined test plan to ensure the test scenarios we develop will accomplish load-testing objectives.
Step 2: Creating Vusers. Here, we create Vuser scripts that contain tasks performed by each Vuser, tasks performed by Vusers as a whole, and tasks measured as transactions.
Step 3: Creating the scenario. A scenario describes the events that occur during a testing session. It includes a list of machines, scripts, and Vusers that run during the scenario. We create scenarios using LoadRunner Controller. We can create manual scenarios as well as goal-oriented scenarios. In manual scenarios, we define the number of Vusers, the load generator machines, and percentage of Vusers to be assigned to each script. For web tests, we may create a goal-oriented scenario where we define the goal that our test has to achieve. LoadRunner automatically builds a scenario for us.
Step 4: Running the scenario.We emulate load on the server by instructing multiple Vusers to perform. tasks simultaneously. Before the testing, we set the scenario configuration and scheduling. We can run the entire scenario, Vuser groups, or individual Vusers.
Step 5: Monitoring the scenario.We monitor scenario execution using the LoadRunner online runtime, transaction, system resource, Web resource, Web server resource, Web application server resource, database server resource, network delay, streaming media resource, firewall server resource, ERP server resource, and Java performance monitors.
Step 6: Analyzing test results. During scenario execution, LoadRunner records the performance of the application under different loads. We use LoadRunner’s graphs and reports to analyze the application’s performance.
5. When do you do load and performance Testing?
- We perform. load testing once we are done with interface (GUI) testing. Modern system architectures are large and complex. Whereas single user testing primarily on functionality and user interface of a system component, application testing focuses on performance and reliability of an entire system. For example, a typical application-testing scenario might depict 1000 users logging in simultaneously to a system. This gives rise to issues such as what is the response time of the system, does it crash, will it go with different software applications and platforms, can it hold so many hundreds and thousands of users, etc. This is when we set do load and performance testing.
6. What are the components of LoadRunner?
- The components of LoadRunner are The Virtual User Generator, Controller, and the Agent process, LoadRunner Analysis and Monitoring, LoadRunner Books Online.
7. What Component of LoadRunner would you use to record a Script?
- The Virtual User Generator (VuGen) component is used to record a script. It enables you to develop Vuser scripts for a variety of application types and communication protocols.
8. What Component of LoadRunner would you use to play Back the script. in multi user mode?
- The Controller component is used to playback the script. in multi-user mode. This is done during a scenario run where a vuser script. is executed by a number of vusers in a group.
9. What is a rendezvous point?
- You insert rendezvous points into Vuser scripts to emulate heavy user load on the server. Rendezvous points instruct Vusers to wait during test execution for multiple Vusers to arrive at a certain point, in order that they may simultaneously perform. a task. For example, to emulate peak load on the bank server, you can insert a rendezvous point instructing 100 Vusers to deposit cash into their accounts at the same time.
10. What is a scenario?
- A scenario defines the events that occur during each testing session. For example, a scenario defines and controls the number of users to emulate, the actions to be performed, and the machines on which the virtual users run their emulations.
11. Explain the recording mode for web Vuser script?
- We use VuGen to develop a Vuser script. by recording a user performing typical business processes on a client application. VuGen creates the script. by recording the activity between the client and the server. For example, in web based applications, VuGen monitors the client end of the database and traces all the requests sent to, and received from, the database server. We use VuGen to: Monitor the communication between the application and the server; Generate the required function calls; and Insert the generated function calls into a Vuser script.
12. Why do you create parameters?
- Parameters are like script. variables. They are used to vary input to the server and to emulate real users. Different sets of data are sent to the server each time the script. is run. Better simulate the usage model for more accurate testing from the Controller; one script. can emulate many different users on the system.
13. What is correlation?
Explain the difference between automatic correlation and manual correlation? - Correlation is used to obtain data which are unique for each run of the script. and which are generated by nested queries. Correlation provides the value to avoid errors arising out of duplicate values and also optimizing the code (to avoid nested queries). Automatic correlation is where we set some rules for correlation. It can be application server specific. Here values are replaced by data which are created by these rules. In manual correlation, the value we want to correlate is scanned and create correlation is used to correlate.
14. How do you find out where correlation is required? Give few examples from your projects?
- Two ways: First we can scan for correlations, and see the list of values which can be correlated. From this we can pick a value to be correlated. Secondly, we can record two scripts and compare them. We can look up the difference file to see for the values which needed to be correlated. In my project, there was a unique id developed for each customer, it was nothing but Insurance Number, it was generated automatically and it was sequential and this value was unique. I had to correlate this value, in order to avoid errors while running my script. I did using scan for correlation.
15. Where do you set automatic correlation options?
- Automatic correlation from web point of view can be set in recording options and correlation tab. Here we can enable correlation for the entire script. and choose either issue online messages or offline actions, where we can define rules for that correlation. Automatic correlation for database can be done using show output window and scan for correlation and picking the correlate query tab and choose which query value we want to correlate. If we know the specific value to be correlated, we just do create correlation for the value and specify how the value to be created.
16. What is a function to capture dynamic values in the web Vuser script?
- Web_reg_save_param function saves dynamic data information to a parameter.
17. When do you disable log in Virtual User Generator, When do you choose standard and extended logs?
- Once we debug our script. and verify that it is functional, we can enable logging for errors only. When we add a script. to a scenario, logging is automatically disabled. Standard Log Option: When you selectStandard log, it creates a standard log of functions and messages sent during script. execution to use for debugging. Disable this option for large load testing scenarios. When you copy a script. to a scenario, logging is automatically disabled Extended Log Option: Selectextended log to create an extended log, including warnings and other messages. Disable this option for large load testing scenarios. When you copy a script. to a scenario, logging is automatically disabled. We can specify which additional information should be added to the extended log using the Extended log options.
18. How do you debug a LoadRunner script?
- VuGen contains two options to help debug Vuser scripts-the Run Step by Step command and breakpoints. The Debug settings in the Options dialog box allow us to determine the extent of the trace to be performed during scenario execution. The debug information is written to the Output window. We can manually set the message class within your script. using the lr_set_debug_message function. This is useful if we want to receive debug information about a small section of the script. only.
19. How do you write user defined functions in LR?
Give me few functions you wrote in your previous project? - Before we create the User Defined functions we need to create the external library (DLL) with the function. We add this library to VuGen bin directory. Once the library is added then we assign user defined function as a parameter. The function should have the following format: __declspec (dllexport) char* (char*, char*)Examples of user defined functions are as follows:GetVersion, GetCurrentTime, GetPltform. are some of the user defined functions used in my earlier project.
20. What are the changes you can make in run-time settings?
- The Run Time Settings that we make are: a) Pacing - It has iteration count. b) Log - Under this we have Disable Logging Standard Log and c) Extended Think Time - In think time we have two options like Ignore think time and Replay think time. d) General - Under general tab we can set the vusers as process or as multithreading and whether each step as a transaction.
21. Where do you set Iteration for Vuser testing?
- We set Iterations in the Run Time Settings of the VuGen. The navigation for this is Run time settings, Pacing tab, set number of iterations.
22. How do you perform. functional testing under load?
- Functionality under load can be tested by running several Vusers concurrently. By increasing the amount of Vusers, we can determine how much load the server can sustain.
23. What is Ramp up? How do you set this?
- This option is used to gradually increase the amount of Vusers/load on the server. An initial value is set and a value to wait between intervals can bespecified. To set Ramp Up, go to ‘Scenario Scheduling Options’
24. What is the advantage of running the Vuser as thread?
- VuGen provides the facility to use multithreading. This enables more Vusers to be run per generator. If the Vuser is run as a process, the same driver program is loaded into memory for each Vuser, thus taking up a large amount of memory. This limits the number of Vusers that can be run on a single generator. If the Vuser is run as a thread, only one instance of the driver program is loaded into memory for the given number of Vusers (say 100). Each thread shares the memory of the parent driver program, thus enabling more Vusers to be run per generator.
25. If you want to stop the execution of your script. on error, how do you do that?
- The lr_abort function aborts the execution of a Vuser script. It instructs the Vuser to stop executing the Actions section, execute the vuser_end section and end the execution. This function is useful when you need to manually abort a script. execution as a result of a specific error condition. When you end a script. using this function, the Vuser is assigned the status “Stopped”. For this to take effect, we have to first uncheck the “Continue on error” option in Run-Time Settings.
26. What is the relation between Response Time and Throughput?
- The Throughput graph shows the amount of data in bytes that the Vusers received from the server in a second. When we compare this with the transaction response time, we will notice that as throughput decreased, the response time also decreased. Similarly, the peak throughput and highest response time would occur approximately at the same time.
27. Explain the Configuration of your systems?
- The configuration of our systems refers to that of the client machines on which we run the Vusers. The configuration of any client machine includes its hardware settings, memory, operating system, software applications, development tools, etc. This system component configuration should match with the overall system configuration that would include the network infrastructure, the web server, the database server, and any other components that go with this larger system so as to achieve the load testing objectives.
28. How do you identify the performance bottlenecks?
- Performance Bottlenecks can be detected by using monitors. These monitors might be application server monitors, web server monitors, database server monitors and network monitors. They help in finding out the troubled area in our scenario which causes increased response time. The measurements made are usually performance response time, throughput, hits/sec, network delay graphs, etc.
29. If web server, database and Network are all fine where could be the problem?
- The problem could be in the system itself or in the application server or in the code written for the application.
30. How did you find web server related issues?
- Using Web resource monitors we can find the performance of web servers. Using these monitors we can analyze throughput on the web server, number of hits per second that occurred during scenario, the number of http responses per second, the number of downloaded pages per second.
31. How did you find database related issues?
- By running “Database” monitor and help of “Data Resource Graph” we can find database related issues. E.g. You can specify the resource you want to measure on before running the controller and than you can see database related issues
32. Explain all the web recording options?
33. What is the difference between Overlay graph and Correlate graph?
- Overlay Graph: It overlay the content of two graphs that shares a common x-axis. Left Y-axis on the merged graph show’s the current graph’s value & Right Y-axis show the value of Y-axis of the graph that was merged. Correlate Graph: Plot the Y-axis of two graphs against each other. The active graph’s Y-axis becomes X-axis of merged graph. Y-axis of the graph that was merged becomes merged graph’s Y-axis.
34. How did you plan the Load? What are the Criteria?
- Load test is planned to decide the number of users, what kind of machines we are going to use and from where they are run. It is based on 2 important documents, Task Distribution Diagram and Transaction profile. Task Distribution Diagram gives us the information on number of users for a particular transaction and the time of the load. The peak usage and off-usage are decided from this Diagram. Transaction profile gives us the information about the transactions name and their priority levels with regard to the scenario we are deciding.
35. What does vuser_init action contain?
- Vuser_init action contains procedures to login to a server.
36. What does vuser_end action contain?
- Vuser_end section contains log off procedures.
37. What is think time? How do you change the threshold?
- Think time is the time that a real user waits between actions. Example: When a user receives data from a server, the user may wait several seconds to review the data before responding. This delay is known as the think time. Changing the Threshold: Threshold level is the level below which the recorded think time will be ignored. The default value is five (5) seconds. We can change the think time threshold in the Recording options of the Vugen.
38. What is the difference between standard log and extended log?
- The standard log sends a subset of functions and messages sent during script. execution to a log. The subset depends on the Vuser type Extended log sends a detailed script. execution messages to the output log. This is mainly used during debugging when we want information about: Parameter substitution. Data returned by the server. Advanced trace.
39. Explain the following functions:
- lr_debug_message - The lr_debug_message function sends a debug message to the output log when the specified message class is set. lr_output_message - The lr_output_message function sends notifications to the Controller Output window and the Vuser log file. lr_error_message - The lr_error_message function sends an error message to the LoadRunner Output window. lrd_stmt - The lrd_stmt function associates a character string (usually a SQL statement) with a cursor. This function sets a SQL statement to be processed. lrd_fetch - The lrd_fetch function fetches the next row from the result set.
40. Throughput
- If the throughput scales upward as time progresses and the number of Vusers increase, this indicates that the bandwidth is sufficient. If the graph were to remain relatively flat as the number of Vusers increased, it would be reasonable to conclude that the bandwidth is constraining the volume of data delivered.
41. Types of Goals in Goal-Oriented Scenario
- Load Runner provides you with five different types of goals in a goal oriented scenario:
* The number of concurrent Vusers
* The number of hits per second
* The number of transactions per second
* The number of pages per minute
* The transaction response time that you want your scenario
42. Analysis Scenario (Bottlenecks):
In Running Vuser graph correlated with the response time graph you can see that as the number of Vusers increases, the average response time of the check itinerary transaction very gradually increases. In other words, the average response time steadily increases as the load increases. At 56 Vusers, there is a sudden, sharp increase in the average response time. We say that the test broke the server. That is the mean time before failure (MTBF). The response time clearly began to degrade when there were more than 56 Vusers running simultaneously.
43. What is correlation?
Explain the difference between automatic correlation and manual correlation? - Correlation is used to obtain data which are unique for each run of the script. and which are generated by nested queries. Correlation provides the value to avoid errors arising out of duplicate values and also optimizing the code (to avoid nested queries). Automatic correlation is where we set some rules for correlation. It can be application server specific. Here values are replaced by data which are created by these rules. In manual correlation, the value we want to correlate is scanned and create correlation is used to correlate.
44. Where do you set automatic correlation options?
- Automatic correlation from web point of view, can be set in recording options and correlation tab. Here we can enable correlation for the entire script. and choose either issue online messages or offline actions, where we can define rules for that correlation. Automatic correlation for database, can be done using show output window and scan for correlation and picking the correlate query tab and choose which query value we want to correlate. If we know the specific value to be correlated, we just do create correlation for the value and specify how the value to be created.
45. What is a function to capture dynamic values in the web vuser script?
- Web_reg_save_param function saves dynamic data information to a parameter.
============================================================================================================================================
-
RAID的入门
dazhijn_China 发布于 2008-09-20 17:21:38
做项目过程中接触到了存储的一些知识,从网上查了点关于RAID的资料,希望对同样刚入门的朋友有点用吧。
一、什么是RAID?
RAID(Redundant Array of Inexpensive Disks)的概念源自1975年由Patterson、Gibson和Katz这三位工程师发表的题为《A Case of Redundant Array of Inexpensive Disks(廉价磁盘冗余阵列方案)》的论文。其基本思想就将多个容量较小的、相对廉价的硬盘驱动器进行有机结合,使其性能超过一只昂贵的大硬盘。二、RAID技术规范简介
RAID技术主要包括RAID0~RAID7,它们的侧重点各不相同,现一一列举如下:1)RAID 0
连续以位或字节为单位分割数据,并行读写于多个磁盘上,具有较高的读写传输率,但没有数据冗余,还不能算是真正的RAID结构。RAID0只是单纯的提高性能,没有数据的可靠性保证,其中一块儿磁盘出现问题会影响到所有的数据,因此,RAID0不适用于对数据安全性要求比较高的应用。2)RAID 1
它通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID1可提高数据读写性能。但是单位成本最高,而具有较高的安全性和可用性。当一块磁盘失效时,系统可以自动切换到另一块磁盘上进行读写,而不用重组失效的数据。3)RAID 0+1
也称为RAID 10标准,即RAID 0和RAID 1标准结合的产物,在连续地以位或字节为单位分割数据并且并行读/写多个磁盘的同时,为每一块磁盘作磁盘镜像进行冗余。它的优点是同时拥有RAID 0的超凡速度和RAID 1的数据高可靠性,但是CPU占用率同样也更高,而且磁盘的利用率比较低。4)RAID 2
将数据条块化地分布于不同的硬盘上,条块单位为位或字节,并使用称为“加重平均纠错码(海明码)”的编码技术来提供错误检查及恢复。这种编码技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施更复杂,因此在商业环境中很少使用。5)RAID 3
它同RAID 2非常类似,都是将数据条块化分布于不同的硬盘上,区别在于RAID 3使用简单的奇偶校验,并用单块磁盘存放奇偶校验信息。如果一块磁盘失效,奇偶盘及其他数据盘可以重新产生数据;如果奇偶盘失效则不影响数据使用。RAID 3对于大量的连续数据可提供很好的传输率,但对于随机数据来说,奇偶盘会成为写操作的瓶颈。6)RAID 4
RAID 4同样也将数据条块化并分布于不同的磁盘上,但条块单位为块或记录。RAID 4使用一块磁盘作为奇偶校验盘,每次写操作都需要访问奇偶盘,这时奇偶校验盘会成为写操作的瓶颈,因此RAID 4在商业环境中也很少使用。7)RAID 5
RAID 5不单独指定的奇偶盘,而是在所有磁盘上交叉地存取数据及奇偶校验信息。在RAID 5上,读/写指针可同时对阵列设备进行操作,提供了更高的数据流量。RAID 5更适合于小数据块和随机读写的数据。RAID 3与RAID 5相比,最主要的区别在于RAID 3每进行一次数据传输就需涉及到所有的阵列盘;而对于RAID 5来说,大部分数据传输只对一块磁盘操作,并可进行并行操作。在RAID 5中有“写损失”,即每一次写操作将产生四个实际的读/写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。8)RAID 6
与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。较差的性能和复杂的实施方式使得RAID 6很少得到实际应用。9)RAID 7
这是一种新的RAID标准,其自身带有智能化实时操作系统和用于存储管理的软件工具,可完全独立于主机运行,不占用主机CPU资源。RAID 7可以看作是一种存储计算机(Storage Computer),它与其他RAID标准有明显区别。除了以上的各种标准(如表1),我们可以如RAID 0+1那样结合多种RAID规范来构筑所需的RAID阵列,例如RAID 5+3(RAID 53)就是一种应用较为广泛的阵列形式。用户一般可以通过灵活配置磁盘阵列来获得更加符合其要求的磁盘存储系统。 -
Linux操作系统在NAS中的典型应用
ainux 发布于 2008-08-24 15:27:20
大多数NAS最显著的特点之一,就是它所采用的操作系统或应用系统能够提供特殊存储功能。这些特殊的操作系统也叫微内核(Micro Kerne1)操作系统。一个微内核操作系统一般只有通信和存储功能,旨在充分利用全部的硬件资源提供专门的存储应用服务。也就是说,它不支持桌面或服务器系统所具有的大多数功能。另外,专门性的存储服务要求所采用的操作系统具有很好的弹性和可定制性。一方面,Linux几乎支持所有主流的网络硬件和网络协议,另一方面,Linux有很好的文件系统支持。因此它可以为NAS提供一个很好的系统平台,通过它可以很方便地进行数据备份、同步和复制等。此外,Linux良好的开放特性使得Linux NAS产品对于各种存储客户端的支持都没有问题,包括Windows产品、Mac系统、Netware服务器或客户端,以及各种类型的Unix/Linux系统。这种开放的特性对于整合比较复杂的局域网络、完成数据集中一致的存储是至关重要的。典型的局域网Linux存储应用如图1所示。
1.Unix 、Linux客户端访问NAS方法要从安装Unix/ Linux操作系统的计算机或服务器来使用NAS,必须启用Unix/ Linux NFS服务。NAS支持NFS版本2.0及3.0的协议,要正确地使用NFS服务,必须指定用户联机的UID及IP地址,请由「用户管理.用户」的NFS设定,选项进行设定。在您设定完成后,请用root身分登入,执行mount指令连接到NAS。之后,在个别的用户登入后,将可以根据之前所做的NFS设定对NAS进行存取。
2.Windows 客户端
在微软窗口操作系统下,可透过下列步骤存取NAS:
1. 在局域网络上寻找并连接到NAS,可利用以下几种方法:
开启网上邻居,找出所属工作群组。如果无法找到,请浏览整个网络。在您的工作群组上连续按两下鼠标,找出NAS,再连续按两下鼠标来连接NAS。 透过窗口的寻找计算机功能来找出NAS。例如,在Windows XP下,请依照以下的步骤:
开启「网上邻居」。
请在工具列上按一下「搜寻」。
在「计算机名称」中输入NAS名称。
按一下[立即搜寻]。
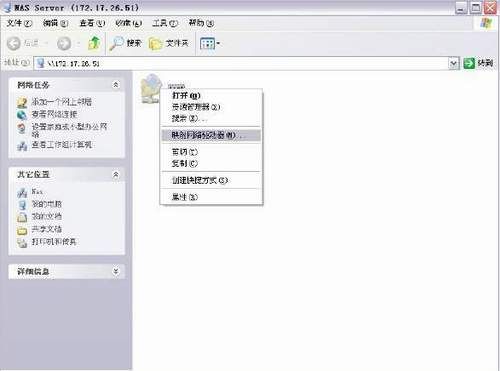
找到服务器后,请连续按两下鼠标来连接NAS。2. 成功地连接NAS后,应可看到所有可用之网络磁盘清单。点选所要使用的网络磁盘,按鼠标右键,此时会出现一个选单。按「映射网络驱动器」后会出现另一个窗口,供选择联机的服务器代码。如果您会常常使用这个网络磁盘,请选取「登陆时重新连接」。最后,按「确定」便可将该网络磁盘联机成您计算机中的一部磁盘驱动器。 如图2 。
3. 联机成功后,此时网络磁盘便成为计算机中的一部磁盘驱动器。您可以在「我的计算机」当中找到这台网络磁盘,并且使用标准的文件操作方式来建立或存取其上的资料。
集中式网络服务领域的Linux NAS
集中式网络服务领域Linux NAS也有着大显身手的舞台, 图3就是一个典型的服务器网络集中存储案例。Linux NAS设备正逐步替代磁带机及磁盘阵列柜,成为服务器数据存储和数据备份应用领域的新宠。通过进一步整责合开源的或第三方的管理软件,Linux NAS将为用户提供高可用的复制文件系统、服务器镜像和备份、流式内容分发、数据库备份技术、Linux快照存储和多版本文件系统等完整的服务器端数据存储解决方案。

图3一个典型的服务器网络集中存储结构图
Linux操作系统在NAS应用中的不足
1 工具缺乏
Linux用于存储方案的平台时,一个主要缺陷在于Linux下的存储管理软件缺少一些重要的特征。虽然文件共享、磁盘镜像和备份软件可从许多厂商那里获得,但是,同时具有卷管理、磁盘管理、用户和策略管理、集群存储管理、分级存储管理和复制功能的软件还很少。尽管在一些开放源代码及商业实现中的Linux上已经具有部分上述特征,但是来自顶级厂商的企业级软件产品几乎没有。诸如Veritas、Legato、NovaStor和EMC等厂商能很容易地为磁带和其它持久存储设备提供脱机备份产品,但是对数据库至关重要的在线备份工具还很缺乏。
2 NAS 池问题
对于 Linux 集中式网络服务给存储带来的主要难题,究其根源可归结于多种存储设备的使用。通常,集群中各服务器都在本地有一些直接连接的存储设备 (DAS)。对于更大的外部存储池,则可通过存储区域网络 (SAN) 来提供。大多数应用还要求在多个节点之间共享某些数据。这可通过网络连接的存储设备 (NAS) 来实现。结果,在一个集群中将形成两个甚至三个截然不同的存储池。NAS 池和 SAN 池分别部署在由不同供应商提供的不同存储平台上,而且各自都有自己独特的管理工具。结果,不仅增加了系统的复杂程度和系统管理员的负担,而且增加了费用。
3 Linux文件服务器不能进行NAS的镜像级备
到目前为止,文件服务器的所有备份和恢复选项都是基于文件的,这意味着备份和恢复软件仍然要通过文件系统进行。有一些应用程序会创建上百万个小文件。恢复上百万个小文件恐怕是备份和恢复系统最困难的任务。用来创建inode的时间,比实际恢复数据的时间还要多。这就是为什么大部分主要备份/恢复软件厂商已经能够使用原始设备来备份文件系统,却仍然是文件级的恢复的原因。不幸的是,今天的文件服务器对这个问题还没有解决方
4 上限比SAN低
虽然大部分应用程序将永远不会超出文件服务器的能力限度去传输数据,但是值得一提的是,理论上SAN可以比NAS传输更多的数据。如果应用程序需要数量大得难以置信的吞吐量,就可以量化地测试一下它们。对于某些环境来说,NAS提供了更快更便宜的SAN替代品。但是,对于其他环境来说,SAN可能是惟一的选择。虽然某些NAS厂商提供的快照和离站复制软件可以提供某种良好的恢复可能性,但是仍然难以达到SAN的水平。文件服务器在某些时候必须备份到磁带上,然而将文件服务器备份到磁带上却是个挑战。原因之一是由于进行完整备份到磁带通常将比其他任何应用程序更加占用I/O系统。这意味着将一个大型文件服务器备份到磁带上将在系统上形成沉重的负载。虽然许多文件服务器已经明显地提高了备份和恢复速度,但在写入磁带时SAN仍然要快得多。
总结:
由于大众的呼吁,Linux硬件驱动程序推出的速度越来越快比其它操作系统的驱动程序要迅速得多。Linux支持的存储设备也越来越多, 同样Linux存储管理软件的功能也会得到增加。
Sistina公司的全球软件系统将多个服务器磁盘和SANs综合进了卷管理中,使得用户可以方便地通过NFS、SM B、FTP和HTTP等进行访问。更重要的是,该工具提供了容错和负荷分配特性。McDATA公司的SANavigator软件支持sAN镜像、配置和Linux平台规划等。通过使用专业厂商提供的交换机和主机总线适配器(H B A S),SANavigator软件还具备了数据搜集和分析工具、SAN映射和物理路径跟踪工具, 以及时间日志和通告等特性。
面对网络存储技术的不断更新,开放源码形式给Linux带来的生机远远超过人们的想象。新技术在Linux中的应用远比一些商业系统要快速和顺利许多, 比如,iSCSI技术在Linux平台上就是最先得到实质性应用的。Linux在大规模存储平台方面也取得了稳定的进步,Linux同仁们正致力于使其成为第一个使用Infiniband的操作系统,Infiniband将赋予Linux大型主机的功能。
NAS作为网络存储的主要形式之一,在使用了Linux系统作为服务平台以后,可以为用户提供更高性价比的解决方案。这是因为Linux能使用公共的、现成的组件创建功能强大的高端机器,可以在大多数低价PC服务器上稳定运行,并且性能良好,可以长时间运行却很少出现故障和停机。Linux不仅在系统性能和开放性上体现出独特的优势,而且在商务方面由于本身价格比较便宜,没有高的授权费用,而更具竞争力。
-
RAID配置全程
ainux 发布于 2008-08-09 19:57:33
一、RAID介绍
RAID是Redundent Array of Inexpensive Disks的缩写,直译为“廉价冗余磁盘阵列”,也简称为“磁盘阵列”。后来RAID中的字母I被改作了Independent,RAID就成了“独立冗余磁盘阵列”,但这只是名称的变化,实质性的内容并没有改变。
可以把RAID理解成一种使用磁盘驱动器的方法,它将一组磁盘驱动器用某种逻辑方式联系起来,作为逻辑上的一个磁盘驱动器来使用。RAID的优点
1. 传输速率高。在部分RAID模式中,可以让很多磁盘驱动器同时传输数据,而这些磁盘驱动器在逻辑上又是一个磁盘驱动器,所以使用RAID可以达到单个的磁盘驱动器几倍的速率。因为CPU
的速度增长很快,而磁盘驱动器的数据传输速率无法大幅提高,所以需要有一种 方案 解决二者之间的矛盾。2. 更高的安全性。相较于普通磁盘驱动器很多RAID模式都提供了多种数据修复功能,当RAID中的某一磁盘驱动器出现 严重 故障无法使用时,可以通过RAID中的其他磁盘驱动器来恢复此驱动器中的数据,而普通磁盘驱动器无法实现,这是使用RAID的第二个原因。RAID的分类
RAID 0,无冗余无校验的磁盘阵列。数据同时分布在各个磁盘上,没有容错能力,读写速度在RAID中最快,但因为任何一个磁盘损坏都会使整个RAID系统失效,所以安全系数反倒比单个的磁盘还要低。一般用在对数据安全要求不高,但对速度要求很高的场合,如:大型游戏、图形图像编辑等。此种RAID模式至少需要2个磁盘,而更多的磁盘则能提供更高效的数据传输。

RAID 1,镜象磁盘阵列。每一个磁盘都有一个镜像磁盘,镜像磁盘随时保持与原磁盘的内容一致。RAID1具有最高的安全性,但只有一半的磁盘空间被用来存储数据。主要用在对数据安全性要求很高,而且要求能够快速恢复被损坏的数据的场合。此种RAID模式每组仅需要2个磁盘。

RAID 0+1,从其名称上就可以看出,它把RAID0和RAID1 技术 结合起来,数据除分布在多个磁盘上外,每个磁盘都有其物理镜像盘,提供全冗余能力,允许一个以下磁盘故障,而不影响数据可用性,并具有快速读写能力。但是RAID0+1至少需要4个磁盘才能组建。
RAID 5, 无独立校验盘的奇偶校验磁盘阵列。同样采用奇偶校验来检查错误,但没有独立的校验盘,而是使用了一种特殊的算法,可以计算出任何一个带区校验块的存放位置。这样就可以确保任何对校验块进行的读写操作都会在所有的RAID磁盘中进行均衡,既提高了系统可靠性也消除了产生瓶颈的可能,对大小数据量的读写都有很好的性能。为了能跨越数组里的所有磁盘来写入数据及校验码信息,RAID 5设定最少需要三个磁盘,因此在这种情况下,会有1/3的磁盘容量会被备份校验码占用而无法使用,当有四个磁盘时,则需要1/4的容量作为备份,才能让最坏情况的发生率降到最低。当磁盘的数目增多时,每个磁盘上被备份校验码占用的磁盘容量就会降低,但是磁盘故障的 数据恢复。风险 率也同时增加了,一但同时有两个磁盘故障,则无法进行
JBOD,JBOD(Just Bundle Of Disks)既简单磁盘捆绑。JBOD是在逻辑上把几个物理磁盘一个接一个串联到一起,从而提供一个大的逻辑磁盘。JBOD上的数据简单的从第一个磁盘开始存储, 当第一个磁盘的存储空间用完后, 再依次从后面的磁盘开始存储数据。JBOD存取性能完全等同于对单一磁盘的存取操作,也不提供数据安全保障。它只是简单的提供一种利用磁盘空间的方法,JBOD的存储容量等于组成JBOD的所有磁盘的容量的总和。

Matrix RAID,矩阵磁盘阵列。是Intel 新近创立的一种针对SATA接口的专利RAID模式,特点是能在2个磁盘上同时实现RAID 0与RAID 1两种模式,其工作原理是将2个磁盘中的每个磁盘的部分磁盘空间划分出来组成RAID 0或1,而将剩余空间组成RAID1或0。Matrix RAID还有一个功能:支持RAID 1阵列分区的“热备份”硬盘。通常支持Matrix RAID功能的主板具有四个SATA接口,而建立一组Matrix RAID只需要两块硬盘,使用两个SATA接口。另外两个闲置的SATA接口就可以插上硬盘,启动“热备份”功能。当Matrix RAID系统中的一块硬盘出现故障时,“热备份”硬盘便会立刻接替它的工作,以保证RAID 1阵列分区中数据的安全。由于RAID 0阵列分区中的数据在一块硬盘崩溃的时候就已经损毁了,所以“热备份”硬盘对RAID 0阵列是无效的。

以上是 服务器及工作站上使用,此处便不做介绍了。目前 主流升技主板上搭载的RAID控制器所能支持的全部RAID模式,并且由于RAID控制器厂商和产品型号的不同,所能支持的RAID模式种类也各不相同,只有极少数主板能够全部支持上述的RAID模式,而每块主板具体所支持的RAID模式种类请至http://www.abit.com.cn 升技官方主页的产品介绍当中核对查找。另有一些其他 RAID 模式基本用于专业RAID 模式下磁盘空间的使用
针对不同RAID 模式在实际运用中可以使用的磁盘空间分别有多少,在用列表举例说明:

* Matrix RAID由于其特殊的磁盘分配概念,所以在此单独举例说明:
例如,使用2 块 120G 的磁盘组成RAID 其总容量是240G,先建立一个RAID 0,并手动指定一个1至238G之间的RAID 0模式的磁盘容量,然后利用剩余磁盘空间建立一个RAID 1模式。如:
100G(RAID 0)+ 70G(RAID 1)或
50G (RAID 0)+ 95G(RAID 1)等等
具体如何分配RAID 0与RAID 1的磁盘大小可按使用需求决定。
二、RAID 制作
如何制作RAID呢?
第一步:一般板载RAID控制器在主板BIOS中都会有控制器的开启与关闭选项,以及制作RAID所 数据恢复必备 的 RAID BIOS的开关选项,将他们设置开启并保存BIOS后,在开机自检时,在IDE设备检测结束后,会有RAID BIOS自检界面出现,按提示按特殊键进入RAID BIOS 进行创建、删除、等操作。设置Block Size(区块大小),一般选64K至128K即可,区块大对于大文件的读取和大型游戏或 程序 的运行有益,而区块小,对于小文件读取或建立Web、BBS服务器等有益。然后保存RAID,要注意的是一担磁盘被组建成RAID后磁盘上原有的数据将全部被抹除;
第二步:在安装操作系统时要让操作系统能够正确识别已创建的RAID,并能在其上进行系统的安装,Windows 2000以前的操作系统由于架构关系在此及以下步骤就没有相关设置了,而Windows 2000 / XP / 2003等操作系统在安装一始就需要按提示按F6键告知安装程序,有RAID设备需要手动安装驱动程序。

第三步:按下F6后,系统没有任何提示,也不会中断系统的硬件检测过程,而是在全部自检完毕后,会进入手动驱动安装界面。此时,将主板附件中的软盘驱动程序放入软驱内,按S键开始手动驱动安装;

提示软驱内插入软盘,按回车键确认;

安装程序会读取软盘内的驱动,并以列表形式列出。

由于受到安装程序的限制,列表中的驱动最多只能显示四项,如驱动大于四项的,可按上下键移动显示框,来显示列表中的全部驱动。


加载完成后,继续操作系统安装过程时就能正确识别RAID和正确的磁盘容量,利用Windows安装程序自带的分区及格式化工具可进行分区及格式化并在RAID上安装操作系统。
注意:在Windows全部安装尚未完成时,切勿将软盘从软驱内取出,因为在安装过程中还要多次读取软盘上的驱动。
另外,如果出现以下画面是请不要紧张,按确定即可,这是由于某些旧版本的驱动程序尚未通过微软的徽标认证,但是不会对使用造成任何影响的。

等到操作系统安装全部完成并成功进入Windows后,检查磁盘盘符是否与分区设置时相符,相符即告成功。大部分RAID控制器在Windows 下可以通过该厂商推出的相应软件程序,可以在Windows中对RAID进行 Windows操作系统得大体步骤,而由于板载RAID控制器的厂牌不尽相同,所以在具体设置的项目名称和设置上有略微的差异。管理 。以上就是制作RAID并在RAID上安装目前 升技主板上板载的RAID控制器的厂牌主要有HighPoint、SiliconImage、intel、VIA、nVIDIA、ULi、SiS等,下面就按照不同厂牌的常用型号对RAID制作过程中的相关细节作介绍。HighPoint 374
使用的主板型号有AT7、IT7、AT7-MAX2、IT7-MAX2。
首先,将BIOS中的RAID开关项开启并保存

随后在RAID BIOS自荐画面时按Ctrl+H键,进入RAID BIOS设置:
选Create Array创建RAID;

进入创建界面;

设置RAID 模式;

设置RAID 的名字(按自己喜好或RAID用户随便啦);

设置区块大小,然后保存设置;

RAID 组建后按操作系统对应加载驱动程序

操作系统成功安装完成即制作完成。
SiliconImage
升技主板使用过3112、3114、3132三种型号的控制器,对应型号如下:

虽然是三种不同的型号,但是BIOS设定和RAID BIOS界面大致相同,只是所支持的RAID 模式稍有不同,所以就一起来介绍了。
BIOS设定;

按Ctrl+S键进入RAID BIOS主界面;

创建RAID;

自动配置;

手动配置,配置区块大小;

选取磁盘;

确认磁盘容量;

保存退出;

驱动加载
3112、3114的加载

3132 驱动加载

操作系统成功安装完成即制作完成。
intel
目前升技主板使用的intel RAID 控制器 分别是 intel ICH5R、ICH6R、ICH7R南桥芯片中集成的SATA RAID 控制器。主板型号对应有以下几种:

它们的BIOS设定和RAID BIOS界面也大致相同,只是所支持的RAID 模式稍有不同,所以也一起来介绍了。
BIOS设定;

将On-Chip SATA 模式设定为 Enhanced Mode;

将On-Chip SATA Mode 设定为 RAID;

保存BIOS充启后,按Ctrl+I 进入RAID BIOS

创建RAID ;

确认创建;

RAID 0模式下磁盘信息;

Matrix RAID 模式下的磁盘信息(只有ICH6R、ICH7R能够组建Matrix RAID);
ICH5R(82801ER)与ICH6R(82801FR)软盘驱动加载;

ICH7R 软盘驱动加载;

组建成功Matrix RAID后,在安装程序中识别出的磁盘容量;

操作系统成功安装完成即制作完成。
VIA
由于VIA的8237及8237R南桥芯片集成了SATA RAID控制器,只要使用这两种南桥芯片的主板都是支持SATA RAID的,型号如下:
Socket 478 平台的 VI7、VT7;
Socket 462 平台的 KV7、KV7-V、KW7,VA-20;
Socket 754 平台的 KV8-MAX3、KV8、KV8PRO、KV8PRO-3rdEye、KV-80、KV-81、KV-85;
Socket 939 平台的AV8、AV8-3rdEye、RocketBoy AV8、RocketBoy AV8-3rdEye、AX8、AX8-V、AX8 V2.0、AX8-3rdEye。
由于都是使用的8237及8237R南桥,所以设置基本相同,只是由于RAID BIOS版本不同会稍有变化。
BIOS中的OnChip IDE Device下将OnChip SATA MODE Select设定为RAID,有的主板BIOS选项为OnChip SATA RAID ROOM,将其设为Enabled,保存重启即可;

按Tab键进入RAID BIOS,选则Create Array创建RAID;

进入RAID创建菜单;

选择RAID 模式;

在选取磁盘和区块大小后,选Start Create Process 进行创建动作,当提示Create New Array OK!时,表示创建成功;

退出RAID BIOS后,即可安装操作系统,安装时加载软盘驱动,绝大部分型号主板附带的软盘驱动都是ABIT整合驱动软盘,在进行下拉菜单项后即可选取VIA 的RAID 驱动;

但也有如AX8系列主板附带的软盘驱动稍有不同;

系统安装成功后即告组建RAID成功。
nVIDIA
目前板载RAID主要有nForce2 MCP-RAID南桥与nForce3、nForce4系列单芯片中集成,对应主板如下:

它们的BIOS设定和RAID BIOS界面也大致相同,只是所支持的RAID 模式稍有差异,所以也一起来介绍。
BIOS设定:
将RAID Function设置为Enabled,然后将接有准备组建RAID的磁盘的端口RAID模式设置为Enabled,保存即可;

保存BIOS并重启之后,按F10进入RAID BIOS,设置RAID 模式;

设置区块大小;

选取磁盘;

按F7结束,确认并保存后,按Ctrl+X退出;
加载驱动;

在这里要注意的是nVIDIA系列的RAID控制器在加载软盘驱动时需要连续加载同系列的NVIDIA RAID CLASS DRIVER与NVIDIA nForce Storage Controller两项驱动,只加载其中任意一项都会导致磁盘无法正确识别,而无法完成操作系统安装。
操作系统成功安装完成即制作完成。
ULi
升技目前所使用的ULi RAID 控制器只有M1689单芯片中所集成的SATA RAID控制器,对应的主板有KU8和UL8两款,RAID BIOS也完全相同。
BIOS设定;

保存BIOS重启后,按Ctrl+A进入RAID BIOS;

RAID BIOS相当简洁明了,几乎没有二、三级子菜单,前三项分别是组建不同的RAID模式,然后设定区块大小;

用左右方向键进行选择,然后保存退出,并在安装操作系统时加载软盘驱动;
操作系统成功安装完成即制作完成。
SiS
目前升技板载有SiS SATA RAID 控制器的型号有SG-80一款。
BIOS设定开启RAID;

保存重启后按Ctrl+S进入RAID BIOS
按 R 键开始编辑RAID;

按 A 键建立RAID;

按1 2 3 键选择RAID模式;

选择自动创建与手动创建;

设置区块大小;

选取磁盘;

此处提示的意思是:“您是否要将源盘数据保存到其他硬盘?”
选 Y 保存的话所要占用的时间会相当长,且如果是两个新硬盘的话也没有必要保存数据,所以一般不推荐用此种方法保存。而选 N 则可跳过此处。

通过以上步骤后创建操作已经完成,按 Q 键退出,此时会弹出提示是否保存此次操作,按 Y 键保存即可。
加载软盘驱动

成功安装操作系统后,安装Windows下的软件制作即告完成。
以上就是主流的带有RAID功能的升技主板基本的RAID创建过程的介绍,希望能够给对RAID有兴趣的升技主板用户有所帮助。
-
SMI-S: The Storage Management Initiative Specification
ainux 发布于 2008-09-20 22:48:49
The Storage Management Initiative-Specification (SMI-S) is a standard that has been developed by the SNIA Storage Management Initiative (SMI), its “Member Companies,” and the SNIA’s Technical Working Groups in association with additional standards and technical bodies who are strategically aligned with the SNIA. The specification was designed with the purpose of standardizing and streamlining storage management functions and features into a common set of tools that address the day-to-day tasks of the IT environment.
All activities, programs, and development of SMI-S are supervised and guided by the Storage Management Initiative (SMI), its Governing Board, and its Committees together with the 12 SNIA Technical Working Groups (TWGs) and the support and oversight of the SNIA Board of Directors and the SNIA Technical Council.
The SMI-S effort began in 1997 as an idea built on the Distributed Management Task Force’s (DMTF) Common Information Model (CIM); it further incorporated the work and technology of many industry experts and companies. The spec was adopted formally by the SNIA, becoming "SMI-S" in 2002, and has grown considerably since that time. It has been implemented in over 500 products. SMI is currently developing an online vendor showcase of these products.
SMI-S is now in development on v1.4. and is currently starting specification work on v1.5. It has incorporated the work of over 50 companies and hundreds of engineers and v1.0 was designated as a standard by ISO/IEC in January 2007. The specification process starts with the TWGs and is reviewed by no less then 20 individuals who work through several different revisions before it is voted on for adoption by the participants of the TWG, TSG, and Technical Council. After it is adopted, it moves to the development phase through the SMI Lab program and then goes to the SMI-S Conformance Testing Program (SMI-S CTP) beginning with the Provider tests and followed by client testing approximately 6 months later. Not all SMI-S participants go through the SMI-S CTP. CTP ensures that certain baseline requirements are adhered to and conform to the specification.
Storage Management Features and Functionality
SMI-S presently includes work with: Hardware Devices: SMI-S Providers
- Switches
- Arrays (FC and iSCSI)
- Servers
- NAS Devices
- Tape Libraries
- Host Profiles
- HBAs
SMI-S Clients (software)
- Configuration Discovery
- Provisioning and Trending
- Security
- Asset Management
- Compliance and Cost Management
- Event Management
- Data Protection
-
Virtualization(虚拟化)技术简介
zeus 发布于 2007-12-11 23:20:12
一 背景
有些时候我们希望在一台机器上同时运行不同操作系统下的应用程序,这种需求可以有三种实现方式(需要强调,这里是指运行不同操作系统的应用,而不是运行另一种体系的应用,比如在X86上运行Apple Mac上的应用)
1. 纯仿真方式,比如bochs,缺点是运行速度太慢
2. OS/API仿真方式,比如wine,
3. virtualization方式,对于一般的应用,有时可以达到”natively”。
二 Virtualization
Virtualization并不是一个新技术,早在60/70年代,IBM就已经在360/67,370等硬件体系实现上Virtualization。Virtualization通过VMM(Virtual Machine Monitor)把一个硬件虚拟成多个硬件(VM,Virtual Machine),各VM之间可以认为是完全隔离的。这个隔离不同于各进程之间的地址空间隔离。无论是内存,设备,还是处理器等对各VM来讲,都被认为是自已独一套的。在VM上可以运行”任何”的操作系统(称为Guest OS)而不会对其它的VM产生影响。
1.内存
通过MMU已经可以将用户地址空间与系统进址空间完全分离了,VM也是通过同样的方法将真实的物理内存与VM中的“物理内存”分开,VM上运行的操作系统对MMU的操作将被VMM捕获,经过变换后替代VM进行真正的MMU操作。
2.外设
a)VMM用假的设备“欺骗”VM。
VM对该设备的操作被VMM捕获并解释执行
b)该外设被某个VM独占,VMM捕获方式
VM对该设备的操作被VMM捕获,VMM将这个操作传递给真正的外设
c)该外设被某个VM独占,直接使用方式
VM对该设备的操作不需要通过VMM,直接传给真正的外设
3. 处理器
VMM需要对处理器监控,从而达到在不能让VM的指令影响系统的情况下,又要确保指令对VM的正确性。
比如执行如下指令(X86)
cli
pushfl
popl %eax
对VMM来讲,是不允许VM的关闭中断指令使真正的CPU关闭中断的,但之后push/pop结果,必需确保(%eax中)对应的位被清零。
因此VMM需要捕获cli, pushfl等指令的执行,相应的cli只是关闭该VM对中断的响应,而pushfl则需要将EFLAGS和对应该VM的中断屏蔽位(实际上还有其它一些特殊标志位)结合后的数据压栈。
三 Sensitive Instruction(敏感指令)和内存/IO保护
从上面可以看到,要想实现virtualization,系统必需能做到:
1. 在内存读写操作时,能够进行地址变换.
2. 对某些特殊内存(比如MMU使用的页表内存)和一些IO口的操作不能被直接执行,而是被VMM捕获
3. 一些处理器指令不能直接执行,而需要被VMM捕获。
在Virtualization中,如果某个指令不能被VM直接执行,必需被VMM捕获,那么称这个指令为sensitive-instruction。为了能够实现VM,要求任何一个sensitive-instruction指令都要产生TRAP,从而被VMM捕获得。
不过,对内存/IO操作需要特殊考虑,限制某些内存的读写一般是通过MMU提供的页R/W保护机制实现的(当访问禁止读写的地址时,也需要产生TRAP,而不是忽略),因此不把读写内存操作看成是sensitive-instruction。
对于IO操作,有些IO地址直接占用的物理地址,可通过MMU的保护机制实现,有些IO地址是独立的,一种方式是把这种IO归类到sensitive-instruction,另一种情况,比如X86系统,可以使用IO操作允许BITMAP,起到MMU类似的保护机制。
四 Privleged (特权)
现在大多数处理器为了防止应用程序的错误代码破坏整个系统,把处理器分成了两种或多种状态,某些指令只有在高级别的状态(内核态,RING0等)下才能正确执行,操作系统的代码通常运行在该状态下;而一般的应用程序运行在低级别的状态(用户态),某些指令是禁止执行的。对于指令,通常可分为三类:
1.普通指令,在各种状态下的执行效果是一样的,Non-Privileged Instruction,(MMU的内存保护不属于指令体系范围,所以读写内存也是普通指令)
2.特殊指令,在不同状态下,指令的结果不一样,但程序不会产生TRAP,而是继续执行。(Privileged Instruction??? Non- Privileged Instruction)
3.特殊指令,在低级别状态下,执行该指令会产生TRAP,中止当前程序的执行,Privileged Instruction。
五 Virtualizable(可虚拟化)
对照sensitive的定义,指令可以分成:
a)non-sensitive/non-privileged instruction
b)sensitive/non-privileged instruction
c)sensitive/privileged instruction
(non-sensitive/privileged的指令好象很少见)
如果一个系统支持特权指令,并且不存在(b)类型的的指令,那么我们称之为”NATURALLY VIRTUALIZABLE”(当然,MMU的保护机制也是必需的)。通常这种系统的处理器在设计时就考虑到了VM机制,因而还会为Virtualization提供一些硬件指令级的支持,以提高性能。
对于每个VM,只会运行在低级别状态(用户态)下,这样所有的sensitive指令会被VMM捕获,并由VMM分析指令后返回给VM一个”虚假”的结果,从而把自已看成是一个完整的硬件系统。
如果处理器含有(b)类指令,也可以实现Virtualization,但需要某种技术使(b)类指令产生TRAP。
六 Dynamic Scan-Before-Execute
很多处理器,包括X86,属于不幸的那种,这些处理器存在(b)类指令(X86有17个指令),所以实现虚拟化需要其它的方法,通常采用的方法就是SCAN-BEFORE-EXECUTE。
对于要执行的指令,先进行扫描,如果找到(b)类指令,就会用特殊的陷阱指令(比如X86的brk)替换或设置成硬件调试地址,通过这种方式将处理器转交到VMM手中。
静态的SBE几乎是不现实的,而是采用动态扫描法,而且也不会大范围的扫描,通常扫描到一个(b)类指令或扫描到一个跳转指令(扫描到跳转的行为在实际实现上因为性能等考虑会复杂一些,通常是在分支跳转指令时设置断点)或指令会跨页时设置陷阱,把执行权交给VMM,另外,扫描结果通常会有记录,可以在重复调用时起到加速作用。 为了对付SEC,SMC,以及在有代码扫描记录时,还需要将正在执行的(或扫描过的)代码空间进行读写保护。
七 VMM
VMM是一段监控代码,运行在最高级别状态下,用来实现以下功能:
1.替VM“执行”所有的sensitive指令。
2.在VM地址和真实地址之间进行变换,并实现Guest OS的PAGE TABLES功能。
3.Virtualization各VM的中断向量表,并实现VM中的中断
4.Virtualization被VMM(各低层HOST OS)占用的各种处理器资源(比如LDT,GDT,IDT,TSS等)
5.提供”真实的”Timing.
6.Virtualization 各种设备/硬件接口
7.BIOS(?)
8.其它等等
VMM一般分成VMM over HW或VMM over HOST OS两种。
1.VMM over HW: 在硬件上的核心只有VMM,VMM本身就是一个多任务(分时)系统,但不会直接运行应用程序,或者说每个应用程序都是一个VM。
2.VMM over HOST OS,比如VMWare, VirtualPC,这时候VMM也只是一个应用(或内核功能模块),VMM运行(加载)后,会载获各种sensitive指令导致的TRAP向量,如果产生TRAP的不属于VM,再传递给原来的处理函数。
八 Full System Virtualization vs Paravirtualization
Full System Virtualization就是指完全的虚拟化,但对于通常的情况(比如各VM都运行LINUX),完全虚拟化性能不够理想,以下面的代码为例:
unsigned int back_flags;
save_flags(back_flags);
cli();
*bitsp |= value;
restore_flags(back_flags);
译成汇编码(X86)是
(假设back_flags分配到寄存器ecx,,value存在eax中,bisp地址存放在edx中)
pushfl(*)
popl %ecx
cli(*)
orl %eax, (%edx)
pushl %ecx
popfl(*)
六条指令(如果用汇编写是四条指令)就会产生三次TRAP,性能可想很知。
对于通常的使用情况,导致性能下降的代码都是操作系统的代码。而操作系统恰恰可以认为是安全的(可信任的)。因此通过适当修改操作系统(Guest OS)的代码,提高Guest OS代码运行时的级别等手段,可以让VM的性能再次提高。
在这种情况下,各VM在OS级别并不是完全的隔离,但对应Guest OS上的应用来讲,表现的结果还是完全隔离的。这种方式被称为paravirtualization。Paravirtualization的局限性就是只能运行通用的操作系统。范围受到很大限制。


标题搜索
我的存档
数据统计
- 访问量: 11376
- 日志数: 27
- 建立时间: 2008-07-15
- 更新时间: 2015-03-18
