
-
LoadRunner监视的性能计数器
2008-06-25 11:23:47
Memory:内存使用情况可能是系统性能中最重要的因素。如果系统“页交换”频繁,说明内存不足。“页交换”是使用称为“页面”的单位,将固定大小的代码和数据块从RAM 移动到磁盘的过程,其目的是为了释放内存空间。尽管某些页交换使Windows 2000 能够使用比实际更多的内存,也是可以接受的,但频繁的页交换将降低系统性能。减少页交换将显著提高系统响应速度。要监视内存不足的状况,请从以下的对象计数器开始:
Available Mbytes:可用物理内存数. 如果Available Mbytes的值很小(4 MB 或更小),则说明计算机上总的内存可能不足,或某程序没有释放内存。
page/sec:表明由于硬件页面错误而从磁盘取出的页面数,或由于页面错误而写入磁盘以释放工作集空间的页面数。一般如果pages/sec持续高于几百,那么您应该进一步研究页交换活动。有可能需要增加内存,以减少换页的需求(你可以把这个数字乘以4k就得到由此引起的硬盘数据流量)。Pages/sec 的值很大不一定表明内存有问题,而可能是运行使用内存映射文件的程序所致。
page read/sec:页的硬故障,page/sec的子集,为了解析对内存的引用,必须读取页文件的次数。阈值为>5. 越低越好。大数值表示磁盘读而不是缓存读。由于过多的页交换要使用大量的硬盘空间,因此有可能将导致将页交换内存不足与导致页交换的磁盘瓶径混淆。因此,在研究内存不足不太明显的页交换的原因时,您必须跟踪如下的磁盘使用情况计数器和内存计数器:
Physical Disk\ % Disk Time
例如,包括 Page Reads/sec 和 % Disk Time 及 Avg.Disk Queue Length。如果页面读取操作速率很低,同时 % Disk Time 和 Avg.Disk Queue Length的值很高,则可能有磁盘瓶径。但是,如果队列长度增加的同时页面读取速率并未降低,则内存不足。
要确定过多的页交换对磁盘活动的影响,请将 Physical Disk\ Avg.Disk sec/Transfer 和 Memory\ Pages/sec 计数器的值增大数倍。如果这些计数器的计数结果超过了 0.1,那么页交换将花费百分之十以上的磁盘访问时间。如果长时间发生这种情况,那么您可能需要更多的内存。
Page Faults/sec:每秒软性页面失效的数目(包括有些可以直接在内存中满足而有些需要从硬盘读取)较page/sec只表明数据不能在内存的指定工作集中立即使用。Cache Bytes:文件系统缓存(File System Cache),默认情况下为50%的可用物理内存。如IIS5.0 运行内存不够时,它会自动整理缓存。需要关注该计数器的趋势变化
如果您怀疑有内存泄露,请监视 Memory\ Available Bytes 和 Memory\ Committed Bytes,以观察内存行为,并监视您认为可能在泄露内存的进程的 Process\Private Bytes、Process\Working Set 和Process\Handle Count。如果您怀疑是内核模式进程导致了泄露,则还应该监视 Memory\Pool Nonpaged Bytes、Memory\ Pool Nonpaged Allocs 和 Process(process_name)\ Pool Nonpaged Bytes。Pages per second :每秒钟检索的页数。该数字应少于每秒一页。
Process:
Processor Time: 被处理器消耗的处理器时间数量。如果服务器专用于sql server,可接受的最大上限是80-85%
Page Faults/sec:将进程产生的页故障与系统产生的相比较,以判断这个进程对系统页故障产生的影响。Work set: 处理线程最近使用的内存页,反映了每一个进程使用的内存页的数量。如果服务器有足够的空闲内存,页就会被留在工作集中,当自由内存少于一个特定的阈值时,页就会被清除出工作集。
Inetinfo:Private Bytes:此进程所分配的无法与其它进程共享的当前字节数量。如果系统性能随着时间而降低,则此计数器可以是内存泄漏的最佳指示器。Processor:监视“处理器”和“系统”对象计数器可以提供关于处理器使用的有价值的信息,帮助您决定是否存在瓶颈。
Processor Time:如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。
User Time:表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。%Privileged Time:(CPU内核时间)是在特权模式下处理线程执行代码所花时间的百分比。如果该参数值和"Physical Disk"参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。另外设置Tempdb in RAM,减低"max async IO","max lazy writer IO"等措施都会降低该值。
此外,跟踪计算机的服务器工作队列当前长度的 Server Work Queues\ Queue Length 计数器会显示出处理器瓶颈。队列长度持续大于 4 则表示可能出现处理器拥塞。此计数器是特定时间的值,而不是一段时间的平均值。
DPC Time:越低越好。在多处理器系统中,如果这个值大于50%并且Processor:% Processor Time非常高,加入一个网卡可能会提高性能,提供的网络已经不饱和。Thread
ContextSwitches/sec: (实例化inetinfo 和dllhost 进程) 如果你决定要增加线程字节池的大小,你应该监视这三个计数器(包括上面的一个)。增加线程数可能会增加上下文切换次数,这样性能不会上升反而会下降。如果十个实例的上下文切换值非常高,就应该减小线程字节池的大小。Physical Disk:
%Disk Time %:指所选磁盘驱动器忙于为读或写入请求提供服务所用的时间的百分比。如果三个计数器都比较大,那么硬盘不是瓶颈。如果只有%Disk Time比较大,另外两个都比较适中,硬盘可能会是瓶颈。在记录该计数器之前,请在Windows 2000 的命令行窗口中运行diskperf -yD。若数值持续超过80%,则可能是内存泄漏。Avg.Disk Queue Length:指读取和写入请求(为所选磁盘在实例间隔中列队的)的平均数。该值应不超过磁盘数的1.5~2 倍。要提高性能,可增加磁盘。注意:一个Raid Disk实际有多个磁盘。
Average Disk Read/Write Queue Length:指读取(写入)请求(列队)的平均数。Disk Reads(Writes)/s: 物理磁盘上每秒钟磁盘读、写的次数。两者相加,应小于磁盘设备最大容量。
Average Disksec/Read: 指以秒计算的在此盘上读取数据的所需平均时间。Average Disk sec/Transfer:指以秒计算的在此盘上写入数据的所需平均时间。
Network Interface:Bytes Total/sec :为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较
SQLServer性能计数器:
Access Methods(访问方法) 用于监视访问数据库中的逻辑页的方法。. Full Scans/sec(全表扫描/秒) 每秒不受限的完全扫描数。可以是基本表扫描或全索引扫描。如果这个计数器显示的值比1或2高,应该分析你的查询以确定是否确实需要全表扫描,以及S Q L查询是否可以被优化。
. Page splits/sec(页分割/秒)由于数据更新操作引起的每秒页分割的数量。
Buffer Manager(缓冲器管理器):监视 Microsoft® SQL Server? 如何使用:内存存储数据页、内部数据结构和过程高速缓存;计数器在 SQL Server 从磁盘读取数据库页和将数据库页写入磁盘时监视物理 I/O。 监视 SQL Server 所使用的内存和计数器有助于确定:是否由于缺少可用物理内存存储高速缓存中经常访问的数据而导致瓶颈存在。如果是这样,SQL Server 必须从磁盘检索数据。是否可通过添加更多内存或使更多内存可用于数据高速缓存或 SQL Server 内部结构来提高查询性能。
SQL Server 需要从磁盘读取数据的频率。与其它操作相比,例如内存访问,物理 I/O 会耗费大量时间。尽可能减少物理 I/O 可以提高查询性能。
Page Reads/sec:每秒发出的物理数据库页读取数。这一统计信息显示的是在所有数据库间的物理页读取总数。由于物理 I/O 的开销大,可以通过使用更大的数据高速缓存、智能索引、更高效的查询或者改变数据库设计等方法,使开销减到最小。.Page Writes/sec (.写的页/秒) 每秒执行的物理数据库写的页数。
Buffer Cache Hit Ratio. 在“缓冲池”(Buffer Cache/Buffer Pool)中没有被读过的页占整个缓冲池中所有页的比率。可在高速缓存中找到而不需要从磁盘中读取的页的百分比。这一比率是高速缓存命中总数除以自 SQL Server 实例启动后对高速缓存的查找总数。经过很长时间后,这一比率的变化很小。由于从高速缓存中读数据比从磁盘中读数据的开销要小得多,一般希望这一数值高一些。通常,可以通过增加 SQL Server 可用的内存数量来提高高速缓存命中率。计数器值依应用程序而定,但比率最好为90% 或更高。增加内存直到这一数值持续高于90%,表示90% 以上的数据请求可以从数据缓冲区中获得所需数据。
. Lazy Writes/sec(惰性写/秒)惰性写进程每秒写的缓冲区的数量。值最好为0。
Cache Manager(高速缓存管理器) 对象提供计数器,用于监视 Microsoft® SQL Server? 如何使用内存存储对象,如存储过程、特殊和准备好的 Transact-SQL 语句以及触发器。
. Cache Hit Ratio(高速缓存命中率,所有Cache”的命中率。在SQL Server中,Cache可以包括Log Cache,Buffer Cache以及Procedure Cache,是一个总体的比率。) 高速缓存命中次数和查找次数的比率。对于查看SQL Server高速缓存对于你的系统如何有效,这是一个非常好的计数器。如果这个值很低,持续低于80%,就需要增加更多的内存。
Latches(闩) 用于监视称为闩锁的内部 SQL Server 资源锁。监视闩锁以明确用户活动和资源使用情况,有助于查明性能瓶颈。. Average Latch Wait Ti m e ( m s ) (平均闩等待时间(毫秒)) 一个SQL Server线程必须等待一个闩的平均时间,以毫秒为单位。如果这个值很高,你可能正经历严重的竞争问题。
Latch Waits/sec (闩等待/秒) 在闩上每秒的等待数量。如果这个值很高,表明你正经历对资源的大量竞争。
Locks(锁) 提供有关个别资源类型上的 SQL Server 锁的信息。锁加在 SQL Server 资源上(如在一个事务中进行的行读取或修改),以防止多个事务并发使用资源。例如,如果一个排它 (X) 锁被一个事务加在某一表的某一行上,在这个锁被释放前,其它事务都不可以修改这一行。尽可能少使用锁可提高并发性,从而改善性能。可以同时监视 Locks 对象的多个实例,每个实例代表一个资源类型上的一个锁。. Number of Deadlocks/sec(死锁的数量/秒) 导致死锁的锁请求的数量
Average Wait Time(ms) (平均等待时间(毫秒)) 线程等待某种类型的锁的平均等待时间
Lock Requests/sec(锁请求/秒) 每秒钟某种类型的锁请求的数量。
Memory manager:用于监视总体的服务器内存使用情况,以估计用户活动和资源使用,有助于查明性能瓶颈。监视 SQL Server 实例所使用的内存有助于确定:
是否由于缺少可用物理内存存储高速缓存中经常访问的数据而导致瓶颈存在。如果是这样,SQL Server 必须从磁盘检索数据。
是否可以通过添加更多内存或使更多内存可用于数据高速缓存或 SQL Server 内部结构来提高查询性能。Lock blocks:服务器上锁定块的数量,锁是在页、行或者表这样的资源上。不希望看到一个增长的值。
Total server memory:sql server服务器当前正在使用的动态内存总量.监视IIS需要的一些计数器
File Cache Hits %、File CacheFlushes、File Cache Hits
File Cache Hits %是全部缓存请求中缓存命中次数所占的比例,反映了IIS 的文件缓存设置的工作情况。对于一个大部分是静态网页组成的网站,该值应该保持在80%左右。而File Cache Hits是文件缓存命中的具体值,File CacheFlushes 是自服务器启动之后文件缓存刷新次数,如果刷新太慢,会浪费内存;如果刷新太快,缓存中的对象会太频繁的丢弃生成,起不到缓存的作用。通过比较File Cache Hits 和File Cache Flushes 可得出缓存命中率对缓存清空率的比率。通过观察它两个的值,可以得到一个适当的刷新值(参考IIS 的设置ObjectTTL 、MemCacheSize 、MaxCacheFileSize)
Web Service:
Bytes Total/sec:显示Web服务器发送和接受的总字节数。低数值表明该IIS正在以较低的速度进行数据传输。
Connection Refused:数值越低越好。高数值表明网络适配器或处理器存在瓶颈。
Not Found Errors:显示由于被请求文件无法找到而无法由服务器满足的请求数(HTTP状态代码404) -
性能测试(并发负载压力)测试分析
2008-06-25 11:12:29
分析原则:
• 具体问题具体分析(这是由于不同的应用系统,不同的测试目的,不同的性能关注点)
• 查找瓶颈时按以下顺序,由易到难。
服务器硬件瓶颈-〉网络瓶颈(对局域网,可以不考虑)-〉服务器操作系统瓶颈(参数配置)-〉中间件瓶颈(参数配置,数据库,web服务器等)-〉应用瓶颈(SQL语句、数据库设计、业务逻辑、算法等)
注:以上过程并不是每个分析中都需要的,要根据测试目的和要求来确定分析的深度。对一些要求低的,我们分析到应用系统在将来大的负载压力(并发用户数、数据量)下,系统的硬件瓶颈在哪儿就够了。
• 分段排除法 很有效
分析的信息来源:
•1 根据场景运行过程中的错误提示信息
•2 根据测试结果收集到的监控指标数据
一.错误提示分析
分析实例:
1 •Error: Failed to connect to server "10.10.10.30:8080": [10060] Connection
•Error: timed out Error: Server "10.10.10.30" has shut down the connection prematurely
分析:
•A、应用服务死掉。
(小用户时:程序上的问题。程序上处理数据库的问题)
•B、应用服务没有死
(应用服务参数设置问题)
例:在许多客户端连接Weblogic应用服务器被拒绝,而在服务器端没有错误显示,则有可能是Weblogic中的server元素的AcceptBacklog属性值设得过低。如果连接时收到connection refused消息,说明应提高该值,每次增加25%
•C、数据库的连接
(1、在应用服务的性能参数可能太小了 2、数据库启动的最大连接数(跟硬件的内存有关))
2 Error: Page download timeout (120 seconds) has expired分析:可能是以下原因造成
•A、应用服务参数设置太大导致服务器的瓶颈
•B、页面中图片太多
•C、在程序处理表的时候检查字段太大多
二.监控指标数据分析
1.最大并发用户数:
应用系统在当前环境(硬件环境、网络环境、软件环境(参数配置))下能承受的最大并发用户数。
在方案运行中,如果出现了大于3个用户的业务操作失败,或出现了服务器shutdown的情况,则说明在当前环境下,系统承受不了当前并发用户的负载压力,那么最大并发用户数就是前一个没有出现这种现象的并发用户数。
如果测得的最大并发用户数到达了性能要求,且各服务器资源情况良好,业务操作响应时间也达到了用户要求,那么OK。否则,再根据各服务器的资源情况和业务操作响应时间进一步分析原因所在。
2.业务操作响应时间:
• 分析方案运行情况应从平均事务响应时间图和事务性能摘要图开始。使用“事务性能摘要”图,可以确定在方案执行期间响应时间过长的事务。
• 细分事务并分析每个页面组件的性能。查看过长的事务响应时间是由哪些页面组件引起的?问题是否与网络或服务器有关?
• 如果服务器耗时过长,请使用相应的服务器图确定有问题的服务器度量并查明服务器性能下降的原因。如果网络耗时过长,请使用“网络监视器”图确定导致性能瓶颈的网络问题
3.服务器资源监控指标:
内存:
1 UNIX资源监控中指标内存页交换速率(Paging rate),如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。也可能是内存访问命中率低。
2 Windows资源监控中,如果Process\Private Bytes计数器和Process\Working Set计数器的值在长时间内持续升高,同时Memory\Available bytes计数器的值持续降低,则很可能存在内存泄漏。
内存资源成为系统性能的瓶颈的征兆:
很高的换页率(high pageout rate);
进程进入不活动状态;
交换区所有磁盘的活动次数可高;
可高的全局系统CPU利用率;内存不够出错(out of memory errors)
处理器:
1 UNIX资源监控(Windows操作系统同理)中指标CPU占用率(CPU utilization),如果该值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。如果服务器专用于SQL Server,可接受的最大上限是80-85%
合理使用的范围在60%至70%。
2 Windows资源监控中,如果System\Processor Queue Length大于2,而处理器利用率(Processor Time)一直很低,则存在着处理器阻塞。
CPU资源成为系统性能的瓶颈的征兆:
很慢的响应时间(slow response time)
CPU空闲时间为零(zero percent idle CPU)
过高的用户占用CPU时间(high percent user CPU)
过高的系统占用CPU时间(high percent system CPU)
长时间的有很长的运行进程队列(large run queue size sustained over time)
磁盘I/O:
1 UNIX资源监控(Windows操作系统同理)中指标磁盘交换率(Disk rate),如果该参数值一直很高,表明I/O有问题。可考虑更换更快的硬盘系统。
2 Windows资源监控中,如果 Disk Time和Avg.Disk Queue Length的值很高,而Page Reads/sec页面读取操作速率很低,则可能存在磁盘瓶径。
I/O资源成为系统性能的瓶颈的征兆 :
过高的磁盘利用率(high disk utilization)
太长的磁盘等待队列(large disk queue length)
等待磁盘I/O的时间所占的百分率太高(large percentage of time waiting for disk I/O)
太高的物理I/O速率:large physical I/O rate(not sufficient in itself)
过低的缓存命中率(low buffer cache hit ratio(not sufficient in itself))
太长的运行进程队列,但CPU却空闲(large run queue with idle CPU)4.数据库服务器:
SQL Server数据库:
1 SQLServer资源监控中指标缓存点击率(Cache Hit Ratio),该值越高越好。如果持续低于80%,应考虑增加内存。
2 如果Full Scans/sec(全表扫描/秒)计数器显示的值比1或2高,则应分析你的查询以确定是否确实需要全表扫描,以及SQL查询是否可以被优化。
3 Number of Deadlocks/sec(死锁的数量/秒):死锁对应用程序的可伸缩性非常有害,并且会导致恶劣的用户体验。该计数器的值必须为0。
4 Lock Requests/sec(锁请求/秒),通过优化查询来减少读取次数,可以减少该计数器的值。
Oracle数据库:
1 如果自由内存接近于0而且库快存或数据字典快存的命中率小于0.90,那么需要增加SHARED_POOL_SIZE的大小。
快存(共享SQL区)和数据字典快存的命中率:
select(sum(pins-reloads))/sum(pins) from v$librarycache;
select(sum(gets-getmisses))/sum(gets) from v$rowcache;
自由内存: select * from v$sgastat where name=’free memory’;
2 如果数据的缓存命中率小于0.90,那么需要加大DB_BLOCK_BUFFERS参数的值(单位:块)。
缓冲区高速缓存命中率:
select name,value from v$sysstat where name in ('db block gets’,
'consistent gets','physical reads') ;
Hit Ratio = 1-(physical reads / ( db block gets + consistent gets))
3 如果日志缓冲区申请的值较大,则应加大LOG_BUFFER参数的值。
日志缓冲区的申请情况 :
select name,value from v$sysstat where name = 'redo log space requests' ;
4 如果内存排序命中率小于0.95,则应加大SORT_AREA_SIZE以避免磁盘排序 。
内存排序命中率 :
select round((100*b.value)/decode((a.value+b.value), 0, 1, (a.value+b.value)), 2)from v$sysstat a, v$sysstat b where a.name='sorts (disk)' and b.name='sorts (memory)' -
关于边界值分析方法
2008-06-24 16:27:34
一.方法简介
1.定义:边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法。通常边界值分析法是作为对等价类划分法的补充,这种情况下,其测试用例来自等价类的边界。2.与等价划分的区别
1)边界值分析不是从某等价类中随便挑一个作为代表,而是使这个等价类的每个边界都要作为测试条件。
2)边界值分析不仅考虑输入条件,还要考虑输出空间产生的测试情况。3.边界值分析方法的考虑:
长期的测试工作经验告诉我们,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。
使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。4.常见的边界值
1)对16-bit 的整数而言 32767 和 -32768 是边界
2)屏幕上光标在最左上、最右下位置
3)报表的第一行和最后一行
4)数组元素的第一个和最后一个
5)循环的第 0 次、第 1 次和倒数第 2 次、最后一次5.边界值分析
1)边界值分析使用与等价类划分法相同的划分,只是边界值分析假定错误更多地存在于划分的边界上,因此在等价类的边界上以及两侧的情况设计测试用例。
例:测试计算平方根的函数
--输入:实数
--输出:实数
--规格说明:当输入一个0或比0大的数的时候,返回其正平方根;当输入一个小于0的数时,显示错误信息"平方根非法-输入值小于0"并返回0;库函数Print-Line可以用来输出错误信息。
2)等价类划分:
I.可以考虑作出如下划分:
a、输入 (i)<0 和 (ii)>=0
b、输出 (a)>=0 和 (b) Error
II.测试用例有两个:
a、输入4,输出2。对应于 (ii) 和 (a) 。
b、输入-10,输出0和错误提示。对应于 (i) 和 (b) 。3)边界值分析:
划分(ii)的边界为0和最大正实数;划分(i)的边界为最小负实数和0。由此得到以下测试用例:
a、输入 {最小负实数}
b、输入 {绝对值很小的负数}
c、输入 0
d、输入 {绝对值很小的正数}
e、输入 {最大正实数}
4)通常情况下,软件测试所包含的边界检验有几种类型:数字、字符、位置、重量、大小、速度、方位、尺寸、空间等。
5)相应地,以上类型的边界值应该在:最大/最小、首位/末位、上/下、最快/最慢、最高/最低、 最短/最长、 空/满等情况下。
6)利用边界值作为测试数据项
边界值
测试用例的设计思路
字符
起始-1个字符/结束+1个字符
假设一个文本输入区域允许输入1个到255个 字符,输入1个和255个字符作为有效等价类;输入0个和256个字符作为无效等价类,这几个数值都属于边界条件值。
数值
最小值-1/最大值+1
假设某软件的数据输入域要求输入5位的数据值,可以使用10000作为最小值、99999作为最大值;然后使用刚好小于5位和大于5位的 数值来作为边界条件。
空间
小于空余空间一点/大于满空间一点
例如在用U盘存储数据时,使用比剩余磁盘空间大一点(几KB)的文件作为边界条件。
7)内部边界值分析:
在多数情况下,边界值条件是基于应用程序的功能设计而需要考虑的因素,可以从软件的规格说明或常识中得到,也是最终用户可以很容易发现问题的。然而,在测试用例设计过程中,某些边界值条件是不需要呈现给用户的,或者说用户是很难注意到的,但同时确实属于检验范畴内的边界条件,称为内部边界值条件或子边界值条件。
内部边界值条件主要有下面几种:
a)数值的边界值检验:计算机是基于二进制进行工作的,因此,软件的任何数值运算都有一定的范围限制。项
范围或值
位(bit)
0或者1
字节(byte)
0——225
字(word)
0~65535(单字)或 0~4294967295(双字)
千(K)
1024
兆(M)
1048576
吉(G)
1073741824
b)字符的边界值检验:在计算机软件中,字符也是很重要的表示元素,其中ASCII和Unicode是常见的编码方式。下表中列出了一些常用字符对应的ASCII码值。
字符
ASCII码值
字符
ASCII码值
空 (null)
0
A
65
空格 (space)
32
a
97
斜杠 ( / )
47
Z
90
0
48
z
122
冒号 ( : )
58
单引号 ( ‘ )
96
@
64
c)其它边界值检验
6.基于边界值分析方法选择测试用例的原则
1)如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值,以及刚刚超越这个范围边界的值作为测试输入数据。
例如,如果程序的规格说明中规定:"重量在10公斤至50公斤范围内的邮件,其邮费计算公式为……"。作为测试用例,我们应取10及50,还应取10.01,49.99,9.99及50.01等。
2)如果输入条件规定了值的个数,则用最大个数,最小个数,比最小个数少一,比最大个数多一的数作为测试数据。
比如,一个输入文件应包括1~255个记录,则测试用例可取1和255,还应取0及256等。
3)将规则1)和2)应用于输出条件,即设计测试用例使输出值达到边界值及其左右的值。
例如,某程序的规格说明要求计算出"每月保险金扣除额为0至1165.25元",其测试用例可取0.00及1165.24、还可取一0.01及1165.26等。
再如一程序属于情报检索系统,要求每次"最少显示1条、最多显示4条情报摘要",这时我们应考虑的测试用例包括1和4,还应包括0和5等。
4)如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
5)如果程序中使用了一个内部数据结构,则应当选择这个内部数据结构的边界上的值作为测试用例。
6)分析规格说明,找出其它可能的边界条件。二.实战演习
1.现有一个学生标准化考试批阅试卷,产生成绩报告的程序。其规格说明如下:程序的输入文件由一些有80个字符的记录组成,如右图所示,所有记录分为3组:
①标题:这一组只有一个记录,其内容为输出成绩报告的名字。
②试卷各题标准答案记录:每个记录均在第80个字符处标以数字"2"。该组的第一个记录的第1至第3个字符为题目编号(取值为1一999)。第10至第59个字符给出第1至第50题的答案(每个合法字符表示一个答案)。该组的第2,第3……个记录相应为第51至第100,第101至第150,…题的答案。
③每个学生的答卷描述:该组中每个记录的第80个字符均为数字"3"。每个学生的答卷在若干个记录中给出。如甲的首记录第1至第9字符给出学生姓名及学号,第10至第59字符列出的是甲所做的第1至第50题的答案。若试题数超过50,则第2,第3……纪录分别给出他的第51至第100,第101至第150……题的解答。然后是学生乙的答卷记录。
④学生人数不超过200,试题数不超过999。
⑤程序的输出有4个报告:
a)按学号排列的成绩单,列出每个学生的成绩、名次。
b)按学生成绩排序的成绩单。
c)平均分数及标准偏差的报告。
d)试题分析报告。按试题号排序,列出各题学生答对的百分比。
解答:分别考虑输入条件和输出条件,以及边界条件。给出下表所示的输入条件及相应的测试用例。
输出条件及相应的测试用例表。
2.三角形问题的边界值分析测试用例
在三角形问题描述中,除了要求边长是整数外,没有给出其它的限制条件。在此,我们将三角形每边边长的取范围值设值为[1, 100] 。
3.NextDate函数的边界值分析测试用例
在NextDate函数中,隐含规定了变量mouth和变量day的取值范围为1≤mouth≤12和1≤day≤31,并设定变量year的取值范围为1912≤year≤2050 。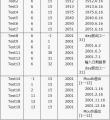
(本文节选自开拖拉机上班《史上最全的测试用例设计方法总结》)
-
软件测试
2008-06-23 10:49:52
-
性能分析的步骤
2008-06-19 11:17:16
3.1性能分析的步骤1.首先从响应时间做为分析性能的起点。查看响应时间以判断是否满足用户对性能的期望。2.考察系统的瓶颈是在网络环节还是在服务器环节。针对服务器分析主要涉及应用程序、web服务器、数据库服务器、操作系统等。首先应该分析业务或者用户事务的响应时间,根据测试结果来分析哪些业务真正变慢了,然后分析web资源的处理情况,最后对页面组成元素的响应时间进行分解。3.1.1用户事务分析1.查看结果综述图:查看事务的平均响应时间,以及事务的通过率2.查看事务综述图和事务平均响应时间分析图:查看事务通过和失败的数值,来判断是程序算法出现问题还是服务器存在内存泄漏现象。3.每秒通过事务数分析图:可确定系统在任何给定时刻的实际事务负载。当发现每秒通过的事务数减少时,就需要更加深入的分析,配合服务器监控数据一起分析。4.事务性能摘要图:重点关注事务的平均和最大执行时间,如果其范围不在用户可以接受的时间范围内,需要进行原因分析。5.事务响应时间与负载分析图:正在运行的虚拟用户和平均事务响应时间图的组合,通过它可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性能数据,为扩展应用系统提供参考,对分析具有渐变负载的测试场景比较有用。6.事务响应时间分布情况分布图:预先定义相关事务可以接受的最小和最大事务响应时间,则可以使用此图确定服务器性能是否在可以接受的范围内。3.1.2web资源分析1.点击率图:每秒点击次数,即点击率图显示在场景运行过程中虚拟用户每秒向web服务器提交的HTTP请求数,可依据点击次数来评估虚拟用户产生的负载量,还可将其与”平均事务响应时间”图进行比较,以查看点击次数对事务性能产生的影响。系统点击率下降通常表明服务器的响应速度在变慢。2.吞吐率图:显示场景运行过程中服务器每秒的吞吐量。度量单位是字节,表示虚拟用户在任何给定的某一秒上从服务器获得的数据量。点击率:每秒服务器处理的HTTP申请数吞吐率:客户端每秒从服务器获得的总数据量。每秒HTTP响应数图还能返回其他各类状态码信息,通过分析状态码,可以判断服务器在压力下的运行情况。常见的http状态代码:从200-505均有其含义。如202:已经接受请求,但处理尚未完成。3.每秒连接数图:显示在运行过程中每秒新建立的TCP/IP连接数。新连接数应该是每秒点击次数的一小部分,理想情况下,很多的HTTP请求都应该使用同一连接,而不是每个请求都新打开一个连接。3.1.3网页元素细分通过它可深入地分析网站上那些下载很慢的图像或中断的链接等有问题的元素。页面分解总图:可显示某一具体事务在测试过程的响应情况,进而分析相关的事务运行是否正常。1.下载时间细分:查看静态gif图片和动态的jsp代码。2.组件细分(随时间变化):可以选择不同的元素查看测试过程中其下载时间的变化曲线。适用于需要在客户端下载控制较多的页面,通过分析控件的响应时间,很容易就能发现哪些控件不稳定或者比较耗时。3.下载时间细分(随时间变化):查看jsp页面主要时间花在如receive,first buffer,connection等。下载时间细分:宏观,整个测试过程页面元素响应时间的统计分析结果下载时间细分(随时间变化):微观,显示场景运行过程中每一秒内页面元素响应时间的统计结果。4.第一次缓冲时间细分(随时间变化):可查看页面运行时间主要花在服务器还是网络传输上。服务器分析通常从web服务器和数据库服务器入手。服务器分析的第一步,分析测试工具对web服务器和数据库服务器相关计数器的监控结果,然后确定在压力下是web服务较慢还是数据处理较慢。Web服务较慢:查看web服务器的各种参数配置,如最大连接数、最大内存等是否设置的合理。查看内存、CPU、硬盘数据处理较慢:一般是数据库配置发生问题,或是硬件资源配置太低。如oracle,要查看内存配置、运行模式等信息。4.1数据库调优策略1.修改sql语句中影响速度的写法2.增加或者修改索引针对表间的连接创建索引针对查找建立索引使用索引时,遵守以下原则可达到更好的效果第一:一般建立在多个字段上的一个组合索引优于针对单个字段建立的多个索引,根据值匹配条件创建的索引也需要遵循同样的原则:第二:创建组合索引时,精确匹配的字段放在非精确匹配字段前面,取值范围大的字段放在取值范围小的字段前面,可以提高查询速度,如身份证字段应该放在性别字段前面。第三:索引并不是越多越好,当数据库记录较多时,意味着数据库要付出的开销将会很大,从而降低数据库其他方面的性能。3.调整相应数据库的系统参数(系统投产生的调优,通常由厂商的配合完成)一般检查项为:复杂语句支持,大对象功能支持,并发查询性能,吞吐量,数据迁移(导出备份)。4.2weblogic/oracle相关分析主要监控:%processor, Avalable Mbytes(空闲内存), JVM内存,connection Delay Time(数据库连接池建立数据库连接的时间)Oracle运行平台AIX监控(unix),cpu的使用率(cpu utilization),disk traltic(磁盘负载),page-in,page-out rate的使用情况。以及oracle本身相关报告:相看缓冲区调整缓存,应用程序的i/o操作。4.3性能测试用例设计要基于用户语言即满足用户要求又相对全面的性能测试用例,设计时要基于“用户语言”,易于用户理解的、大纲形式的测试用例,这样涉及的技术语言不多,用户很容易看懂。这样使得用户在现场测试阶段能够提出很多改进建议,并同意对用例进行调整(删减近一半的用例),可以为后期执行测试节约成本。性能测试实施的特点之一就是不会严格按照测试用例来执行,通常是在项目中对用户进行一定的调整,然后再去执行,对于测试用例进行调整,删除、修改、增加,这是很正常的,基本成本来进行设计和执行。 -
场景选项
2008-06-03 11:04:09
如果需要测试多少人可以同时运行Web 应用,那么推荐定义Virtual Users Goal。运行定
义该目标类型的场景和运行Manual 类型的场景类似如果想测试Web Server 的真正实力,推荐定义目标类型为:Hits per Second、Pages per
Minute 或者Transactions per Second,这些类型都需要指定一个虚拟用户的最小值和最大值。如果想知道在多少用户并发访问网站时,事务的响应时间达到性能指标说明书中规定响
应时间的最大值,那么推荐使用Transactions Response Time 类型。指定需要测试的事务的名
称,虚拟用户数量的最小值和最大值,还有预先定义好的事务的响应时间。如果你定义的类型是Pages per Minute、Hits/Transactions per Second,Controller 首先用
最小用户数除以定义的目标,得到一个值,然后确定每个用户应该达到的hits/transactions
或者pages per minute,然后controller 开始按照以下的策略加载用户:
l 如果选择的是自动的加载虚拟用户,LoadRunner 会首先加载50 个用户。如果定义的最
大用户数小于50,LoadRunner 就会一次加载所有的虚拟用户。
l 如果选择的是在场景运行一段时间后达到目标,LoadRunner 就会尝试在定义的这段时
间内达到目标,根据时间限制和计算出的每个用户的hits、transactions 或者pages,
LoadRunner 确定第一批加载多少用户。
l 如果选择的是按照一定的阶段达到目标(也就是先在x 长时间内达到y pages/hits,然后
再达到下一个目标),LoadRunner 计算每个用户应该达到的数字后,再确定第一批加载
多少用户。
每加载一批用户后,LoadRunner 会判断是否达到这批用户的目标。如果这批用户的目
标没有达到,LoadRunner 重新计算每一个用户应该达到的目标数字后,重新调整下一批加
载用户的数量。默认情况下,LoadRunner 每两分钟加载一批用户。
如果Controller 加载了最多数量的用户还没有达到预定的目标,LoadRunner 会重新计算
每个用户的目标,然后同时运行最大数量的用户,尝试达到预定的目标。
如果出现以下情况,Pages per Minute、Hits/Transactions per Second 类型的场景会置于
“Failed”状态:
l Controller 使用了指定的最大数量的用户,并且两次都没有达到目标
l 所有的用户运行都失败
l 没有足够的Load Generators 机器(现有的机器已经超载运行的情况下)
l Controller 增加了几批用户后,pages per minute 或者hits/transactions per second 没有
增加
l Controlller 加载第一批用户后,定义的目标没有被捕捉到 -
WIN SOCKET API 函数
2008-05-30 11:00:46
-
loadrunner 相关知识
2008-05-27 13:23:54
-
loadrunner 相关知识
2008-05-27 13:23:53
-
函数解释
2008-05-27 12:01:27
脚本里面有2个函数,解释一下:1.几个函数的解释:
1)int web_url (const char *Name, const char * url, <List of Attributes>,
[EXTRARES, <List of Resource Attributes>,] LAST );
这个函数load 指定的web页面 .
*Name:页面的name;
l url:页面的url,Resource:指示the URL是否是一个资源。0,不是,1,是。
l RecContentType:录制脚本过程中,Header响应的类型,e.g. text/html, application/x- javascrīpt
l Referer – 参考web页的the URL
l Snapshot - snapshot 文件名(扩展名inf), correlation的时候要的。
l Mode – 录制的级别: HTML or HTTP
l Last- 属性列表的结束标志。
2) int web_submit_data ( const char *StepName,//页面文件名, <List of attributes>,
ITEMDATA,//Item数据
<List of data>,
[ EXTRARES, <List of Resource Attributes>,]
LAST );
这个函数以GET and POST requests方式发送form。
*StepName:
这里有个例子, the web_submit_data function submits a form using the POST method:
web_submit_data("customerinfo.asp",
"Action=http://lazarus/webflight/customerinfo.asp",
"Method=POST",
"TargetFrame=",
"EncType=multipart/www-urlencoded"
"RecContentType=text/html"
ITEMDATA,
"name=flight", "value=6593", ENDITEM,
"name=reserveFlight", "value=Next >",ENDITEM,
LAST);
-
IP Spoofer
2008-05-27 11:42:33
当运行场景时,虚拟用户使用它们所在的Load Generator 的固定的IP 地址。每个Load Generator 上(同时)运行大量的虚拟用户(*不明白),这样就造成了大量的用户使用同一IP 同时访问一个网站的情况,这种情况和实际运行的情况不符,并且有一些网站会限制同一个IP 的登陆。为了更加真实的模拟实际情况,LoadRunner允许运行的虚拟用户使用不同的IP 访问同一网站,这种技术称为“IP 欺骗”。启用该选项后,场景中运行的虚拟用户将模拟从不同的IP 地址发送请求。该选项非常
的有用。注意:IP Spoofer 在连接Load Generators 之前启用。要使用IP 欺骗,各个Load Generator 机器必须使用固定的IP,不能使用动态IP(即DHCP)。
IP Wizard工具就提供了生成多个ip的功能,IP Wizard是一个单独的程序,我们可以在开始菜单里面找到,你可以添加一个局域网内的IP段。添加后重启,在Win2k下使用Ipconfig/all查看到很多虚拟的IP,最后要在Controller里面选择enable ip spoofer.
-
接上文
2008-05-26 12:02:13
LR支持的协议和应用非常广泛,很少有人能用完这么多协议,我们就常见的大多数人用的加以讨论:
B/S系统:选择Web(Http/Html),
C/S系统:根据C/S结构所用到的后台数据库来选择不同的协议,如果后台数据库是Sybase,则采用sybaseCTlib协议,如果是Sql server,则使用MS Sql server的协议,至于oracle 数据库系统,当然就使用oracle 2-tier协议。
对于没有数据库的c/s(ftp, SMTP)这些可以选择windows sockets协议。
至于其他的ERP,EJB(需要ejbdetector.jar),选择相应的协议即可.下列协议不是线程安全协议:Sybase-Ctlib、Sybase-Dblib、Informix、Tuxedo 和 PeopleSoft-Tuxedo -
使用LoadRunner录制脚本时如何选择合适的协议?
2008-05-26 11:56:58
