
-
敏捷脑图测试用例实践之路
2017-02-21 11:57:59
传统的黑盒测试用例比较繁杂,在实施敏捷的项目中会显得水土不服,让测试人员过度关注用例步骤的编写、修改,甚至同一条用例经过多人执行得到相同结果,让人想到一个呼之欲出的广告词:一次编写,多人运行相同结果,没有思考的过程,应该对用例进行改革,以便快速响应开发的交付节奏,同时形成用例评审规范,让开发、测试知己知彼,也加强开发自测的环节。本文主要讲敏捷中脑图用例的实践。不写测试用例或许测得更快,但绝不是一个测试人员的最佳素养,而现在的测试用例又过于繁杂,消耗了很多时间,怎么办呢?先看看测试用例的定义:测试用例(Test Case)是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求。还有测试用例编写的一般原则:· 测试用例要包括欲测试的功能、应输入的数据和预期的输出结果。· 测试数据应该选用少量、高效的测试数据进行尽可能完备的测试。测试用例也遇到非常多的问题:对业务不熟悉、没有测试经验的人是无法做到的(比如死机怎么处理,浏览器挂了怎么办)说实在的,每种情况不可能写的很明细,谁能保证所有可能路径都写出来呢?不懂业务的测试人员,有执行测试用例的价值吗?测试用例应当是有思考活动存在的;测试用例没有思考的过程 负责第一次编写的测试人员有思考,但负责执行的测试人员,没有再继续跟开发交互测试过程,没有更深入的思考,而是仅仅按照用例执行,那这种效果等于走过场;打开浏览器,输入账号密码登录,这些其实是不必要展示的步骤做测试就要熟悉业务,测试人员应当更加关注的是开发是否做了正确的功能,功能是否做了正确的事情,在一个测试、开发比例1:4(有些是1:10)的团队里面,测试人员的时间是有限的,不要陷入过分的步骤细节里面去深究,要把重点思路放在运用哪些测试方法、如何组合更加有效覆盖测试故事点开发人员完成任务之后,最后交付给测试人员,这种模式下,测试人员不能及早发现需求阶段的缺陷、及时编写测试用例,用例评审滞后,发现缺陷同样也会滞后。而整个过程中丢失最大的环节就是:沟通、反馈。这在《全程软件测试实践:从需求到运营》文中也曾提过。倘若要是使用传统的用例编写,把测试团队人员的思维固化,这样子下去不进则退,不利于团队发展。鉴于此,创建了敏捷脑图用例,有以下原则:1、参与需求分析、记录验收要点全程软件测试,从需求阶段开始参与,在sprint会议上对功能点进行评估,消除含混性的疑点,将明确的作为验收要点,作为脑图用例故事点的参考来源。2、编写脑图用例,要与开发人员达成一致意见开发过程中,测试人员可以根据原型图设计脑图用例(没有实际系统,测试也可以先行),与开发人员进行查漏补缺(也就是用例评审环节),主要是确认测试功能点、测试故事,以及测试数据的准备,这几个方面不可能一开始就明确下来,要不断沟通、挖掘、完善脑图用例。第一版本脑图用例要点:所见所想当时的想法很简单,以需求为思考出发点,把所有功能性、非功能性的列举出来,然后再整理故事点。第二版本的脑图用例要点:· 增加风险考虑· 增加局部决策考虑 例如:一个输入框(或者叫元素),测试人员应当针对这个元素,结合数据,考虑使用哪些测试方法进行操作· 增加全局决策考虑 例如:一个业务查询操作,在web上操作,会触发一系列元素(输入框、查询按钮),这些应当如何组合、使用什么策略· 遵循:重构->测试->重构->测试,的原则脑图的形式展现并不是最重要问题,关键问题是:思考的出发点,这个要整个团队参与讨论,达成共识,才能传承。引出思考点,大家就可以不断补充脑图,刚开始所有点可能是零散的,甚至一点关系都没有,这个时候就需要重构了,抽取相关点脑图编写不是漫无目的去思考,正如探索式测试策略,并不是指无目的去做即兴测试,有原则指引很重要。团队采用SMART原则进行脑图用例实践:· Specific(具体的):测试需要一个具体的目标(甚至原型图都可以),用来描述全景图。· Measurable(可度量的):有明确的度量可以评估目标是否达成(也就是验收条件作为测试故事点的评判标准)。· Achievable(可实现的):当前的目标应该是可实现的。这潜在地要求将一个大的目标分解为多个小目标,每个小目标也是具体的、可度量的。此外,跟踪小目标的完成情况也提供了整体进度的可度量性(一个业务操作会经过很多路径,每个路径可以单独存在或者组合存在,需要切分测试)。· Relevant(相关的):测试故事点从需求出发(包括功能性和非功能性),结合业务特性,以及相关上下文作为切入点。· Time-boxed(有时间限制的):为每一轮脑图用例的构建设定一个合理的时间窗口,例如在固定的时间窗口(一些人的专注度是45分钟,一些是60分钟,中排除不相关干扰、专注工作)。脑图用例编写流程:· 参与持续需求分析(不仅仅是需求阶段,开发阶段的变化也需要及时捕获)制定脑图用例框架· 将业务|功能测试目标分解成一系列测试任务,每个测试任务有明确的时间限制和退出条件。· 测试计划之后,优先选择一个测试任务,在一个测程内执行探索式测试,测程以45|60分钟为一轮,执行多轮。· 反思当前的测试进展,并优化测试计划。增加或删除一些测试任务,以更加准确地反应测试对象。脑图用例分析第一步:首先把业务需求分析结果填写到目标中,然后分析功能(如果没有系统,可以只看原型图),找到页面的相关元素,逐个列入脑图中,再为每个元素使用一些测试方法,例如:等价类、边界值,进行局部决策,这样子,所有元素的分析完毕,就进入第二部全局。脑图用例分析第二步:第二步继续完善,进行全局分析以及列举一些非功能性需求:全局分析:找到需求描述或者跟开发沟通代码有限制条件的地方,而不是针对某个元素;对不同元素组合有依赖关系的,也需要列出来非功能性:这个在文档中可能没有给出,需要根据经验来评估,可以参考团队积累业务的测试经验,通用的点:出错的用户体验是否ok、查询时间效率如何等等风险:尽可能琢磨需求,挖掘风险,例如需求说:根据选定频道,但是没有说这个频道不属于客户怎么办?这个就是思考的强大力量了。脑图用例分析第三步:第三步是最关键一步,产出测试故事点,根据风险、目标、要点分析得出,这里举了简单例子,可以使用关键路径组合的方法来做。当然,做完一二三步,也只是在第一个时间窗口而已(这个时候也可以直接用于测试环境探索下,验证一些关键思路,增强信心),后续还需要重构-测试,在下一个时间窗口,查漏补缺,不断完善才可以用于时间测试。允许团队成员在模板基础上进行变化,以发挥更多的思维空间,五、关于富脑图及轻脑图用例允许团队成员在模板基础上进行变化,以发挥更多的思维空间,主要有两种模式作为参考:· 富脑图用例个人认为,大脑对于图像的记忆,比文字更长久。富脑图,注重以图片、图标、图标、关联关系等记忆为主。· 轻脑图用例注重以简洁文字记忆为主团队可以在不同场景,选择合适的模板来发挥、扩散测试的思维点。不断完善用例的展现以及思考的出发点。其实,在整个开发、测试环节中,思考、沟通是最重要的环节,把产生的、达成共识的内容记录下来,汇集在脑图中展现,就可以看到整个需求点测试的全景图,然后再不断细化成测试故事点,这完全符合思维扩散以及总结的模式,大脑也容易接受,而且可以不断重构->测试->重构->测试,不断迭代下去。 -
有关大数据解说
2017-02-03 17:51:56
忽如一夜春风来,千树万树梨花开”,似乎在一夜之间,大数据就红遍了南北半球,,大数据被神化得无处不在,无所不包,无所不能。这里面有认识上的原因,也有故意忽悠的成份。笔者以为,越是在热得发烫的时候,越是需要有人在旁边吹吹冷风。在这里谈大数据的十大局限性,并非要否定其价值。相反,只有我们充分认识了大数据的特点和优劣势,才能更加有效地对其进行采集、加工、应用,充分挖掘和发挥其价值。1、数据噪声:与生俱来的不和谐大数据之所以为大数据,首先是因为其数据体量巨大。然而,在这海量的数据中,并非所有的数据都是有用的,大多数时候,有用的数据甚至只是其中的很小一部分。随着数据量的不断增加,无意义的冗余、垃圾数据也会越来越多,而且其增长的速度比数据信息更快。这样一来,我们寻求的重要数据信息或客观真理往往会被庞大数据所带来的噪声所淹没,甚至被引入歧途和陷阱,得出错误的结论。2、真实性:不得不接受的虚假“引领我们进入困局的并不是我们不知道的事物,而是我们知道、但不那么真实的事物。”真实性是一切数据价值的基础,然而这同时也是大数据的一大先天性缺陷。网络是大数据最重要的来源之一,而网络本身就充斥着大量的虚假信息。例如,网络数据中存在着大量的虚假个人注册信息、假账号、假粉丝、假交易、灌水贴及虚假的意思表示等。这种失真是由网络本身的特性决定的,比如说,绝大多数社交网站很难也不会对会员注册信息的真实性进行全面核查,电商平台也无法控制一人注册多账号,或账号与实际消费个体的非对应关系(想想你家有没有共用一个宽带或电商账号的情况)。除了网络数据,即便是通过原始方法采集的个人信息数据也无法保障其真实、准确。就拿电信运营商来说,即便推行了实名制,数据质量与期望仍有相当差距。可以预见,在相当长的时间内,即使最优秀的数据科学家、最先进的数据处理方法也无法消除或修正某些数据固有的错误和不足,对大数据真实性的追求无疑是摆在我们面前的又一挑战。3、代表性:永不可能的全样本迈尔·舍恩伯格在《大数据时代》一书中阐述的一个核心观点便是,大数据是全样本,因此不再依赖随机取样。笔者认为,这种观点是错误的。大数据来源大致可以分为两类,一类来自于物理世界的科学数据,如实验数据、传感数据、观测数据等;另一类则来自于人类社会活动,主要是互联网数据,如社交关系、商品交易、行为轨迹等个人信息。然而,这两类数据的产生、收集都存在很大的盲区和局限性。例如:很多人在网上订餐或消费的时候往往会参考其他人的推荐和点评,但经常在消费以后发现并不如意。撇开个人口味和刷评的因素,还有一个重要原因在于,网上点评的人并不具备足够的代表性。喜欢上网的本身就只是消费人群中的一部分,上网消费同时又喜欢点评的人更只是其中的一小部分,所以,由带有明显倾向的小众来代表整个群体明显是错误的。无论科学技术如何发达,来自于物理世界和网络社会的大数据永远都不可能覆盖整个自然界和人类社会;如果再考虑宗教、法律、**、道德上的诸多限制,那么大数据就更不可能成为“全样本”了。而且,被遗漏的那部分数据往往并不是随机偏差,而是系统偏差,在统计分析时不能不考虑。也正因为如此,社会学家对大数据的代表性总是保持着一份可贵的疑虑和审慎,在许多领域仍然坚持用传统的抽样方法而不是大数据来进行社会研究。4、完整性:广度与深度的缺失大数据的完整性不足主要是指单个组织所能获取的数据体量虽然巨大,但所包含的实际信息却十分有限,以致难以以此为基础进行复杂的逻辑运算或全面描述。这种不完整主要包括信息维度(决定信息广度)的缺失和维度信息(决定信息深度)的缺失。举例而言,电信运营商由于把控着数据管道,从而可以较全面地掌握用户的上网信息,有着较好的信息广度,但其掌握的信息深度却不够。运营商可以清楚地知道用户在什么时间、什么地点、以什么终端、什么网络访问了京东、亚马逊、天猫等电商,浏览了何种商品,停留了多长时间等(信息广度充分),但却不能掌握用户是否在某电商平台上购买了商品、购买了何种商品、参与了什么促销活动、以什么方式付款、支付了多少款额等(信息深度不足)。很显然,京东对用户在自己商城的浏览、消费行为了如指掌(信息深度充分),但它却无法了解用户的其他互联网行为及在其他电商平台的消费行为(信息广度不足)。在大多数情况下,对某种自然、社会现象的深入研究或者对用户的超级刻画,信息广度和信息深度缺一不可。从这个意义上讲,真正的大数据应是建立在共同的标准基础之上,融合了企业、政府、科学研究等跨领域、跨行业、跨平台数据的集合,是社会大数据。然而,当前的大数据依然以独立孤岛的形式存在,没有任何一个组织能够获取在广度和深度上都足够充分的数据。应该大力推进全社会的数据公开和共享,其中政府数据开放尤其重要。毫不夸张地讲,真正核心的数据绝大部分掌握在政府手中,没有政府参与,就没有真正的大数据。5、时效性:秒级价值存在任何数据都位于一个连续的时间轴上,都有其时间属性,即数据年龄。不同年龄的数据有着不同的价值特性,往往老数据具有总体或趋势分析价值,新数据则更具有个体应用价值。大数据时代,信息更新速度非常快,从应用的角度看,大数据的时效性往往非常短。用于探测地震和海啸的传感器所产生的数据时效往往只有几秒钟,在此之后就基本失去意义了。美国国家海洋局的超级计算机能够利用传感器传输的数据,在日本地震后9分钟内计算出海啸的可能性及强度。短短的9分钟,基本反映了当前人类计算的最高水平,但这对于瞬间消失的生命来说还是太长了。实时营销对用户状态信息的时效性也有很高的要求,试想想,如果你的目标用户在离开店面500米后才收到你所谓“量身定做”的促销信息,他(她)是不是会对此嗤之以鼻?大数据时效性的要求对数据的实时采集、实时加工、实时分发提出了极高的要求。数据处理上有一个著名的“1秒定律”,即要在秒级的时间范围内计算出分析结果并分发出去,超过这个时间,数据就失去价值了。这在许多时候还很难做到,从而在相当程度上限制了大数据的应用。6、解释性:不能没有因果关系对于舍恩伯格关于大数据的另一个核心观点,“不是因果关系,而是相关关系”,只需要了解是什么或未来会发生什么,而不是为什么和事情发生的内在原因,笔者同样不敢苟同。相关关系仅代表着过去和个案,没有解释性,有时甚至是错误的,而且不能推而广之。只有掌握了事物之间的因果关系、原因机制和科学原理,才能举一反三,迭代更新,持续推动社会进步。这是很简单的道理,不必赘言。关于相关性,一直为人津津乐道的便是啤酒与尿布的故事。然而,沃尔玛商品品种成千上万,相关关系数十亿之多,我想类似的绝妙组合尚有不少,为什么再也难见?更何况,人们仍然对啤酒与尿布的相关关系进行了合理的因果逻辑解释。试想,如果首先发现了这样的因果关系,再通过相关关系予以验证,是否可以发现更多的“啤酒和尿布”?大数据分析需要借助机器来完成,而机器从来就只能给出数据间的相关关系,而不能说明因果逻辑。因果关系需要人的思考和判断,电脑现在没有、将来也不可能完全替代人脑。玩笑一下,如此急迫地强调相关关系而不是因果关系,难道我们真的不需要脑子了吗?7、预测性:让过去决定未来大数据分析无论被赋予多么绚丽的光环,从根本上讲都只是对过去和现实的归纳和总结,其本身并不具有趋势和方向性的特征。决定趋势的是事物发展的内在因素及相互作用,在此方面大数据无能为力,这是大数据的先天性缺陷之一。舍恩伯格也坦言,与大数据同行是有一定风险的,大数据有可能会把我们锁定在以往的错误当中,使我们堕入让过去决定未来的陷阱。现在有些基金公司推出大数据指数基金,期望通过大数据对股票行情进行准确的预测。历史行情走势只是过去已经发生的影响股票市场的诸多因素共同作用的结果,以此来预测未来的市场根本不靠谱。普林斯顿大学经济学教授伯顿·麦基尔早在1973年的畅销作品《漫步华尔街》中就指出,把一只猴子蒙上双眼后让它向报纸的金融版掷飞镖而选中的投资组合,和那些专家经过大量研究而谨慎选择的投资组合相比,盈利性可能一样好。近几年甚至有研究者提出,麦基尔的这种看法低估了猴子(应该是高估了基金经理吧)。2008年,好事的俄国人更是用实验证明了这一点。俄罗斯《财经周刊》从马戏团找来一只猴子,让它从代表不同股票的牌子中选择8支进行模拟投资组合,并投入100万虚拟卢布。一年后,当金融专家再次观察猴子所选股票的表现时不由大吃一惊,其市值上涨了近3倍,跑赢了94%的基金。必须承认,我们处于一个不确定的世界里,有许多事件是无法预测的。过分依赖大数据和预测模型是危险的,因为有许多决定性的影响因素都不能纳入模型参数的覆盖范围之内。从天气预报、地震预测、足球比赛到金融危机等等,都对这一点做了很好的诠释。8、误导性:数据也会说谎与大数据的代表性、真实性、完整性、解释性等局限性相关的,对统计现象只看结果不重解释,很可能导致错误甚至危险的结论。二战时期英国与德国的空战中,工程师发现,每次战斗机回来机翼上都带有很多枪眼,因此认为机翼是最容易受到攻击的地方,需要进行特别防护。可是增加防护之后,飞机的损失率不但没有降低,反而提高了。问题究竟出在哪呢?原来工程师们被这一统计结果误导了,从而采取了错误地防护措施。对机翼枪眼的统计只针对成功返航的飞机,而那些不幸的飞机被击落的原因并没有被统计和发现。相反,机翼受损还能飞回来,说明机翼被攻击并不是飞机被击落的主要原因。至于为什么增加防护后飞机损失率反而提高了,原因很简单,因为负荷增加降低了飞机的灵活性和航程。后来,工程师们反其道而行之,在没有枪眼的部位加强防护,因为这些部位被击中的飞机都没有返航,事实证明效果良好。9、合法性:数据安全与隐私保护大数据本身及其采集、使用过程都极有可能会涉及个人隐私、商业机密、公众权益和国家信息安全。因此,安全性和合法性问题构成了大数据价值发挥的限制性因素之一。商业和技术很重要,但商业和技术背后的价值观更重要。白宫曾在2014年发表书面声明称,大数据创造的社会价值与经济价值得以遵从该国提倡的“隐私、公正、平等、自主”。中国政府在此方面虽然尚未立法,也从来没有明确的说法,但民众的基本权益和诉求理当被审慎考虑。诚然,安全性、合法性要求限制了大数据的使用和商业价值的充分发挥,但从社会价值的角度来看,是值得的,也是必须的。10、价值性:投入与收益的平衡价值密度低是被公认的大数据特征之—,这也在一定程度上限制了大数据的研究和应用。一方面,因为大数据的低密度价值特征,那么要使其价值达到可用的程度,就必须有足够规模的数据积累和有效的价值提取。以常规的监控视频为例,连续24小时的视频监控中,有用的数据可能仅有数秒。如何优化存储,并通过强大的机器能力迅速完成数据的加工处理和价值呈现,到目前为止还是大数据面临的一大难题。另一方面,大数据边际效用递增规律的存在,使许多企业、组织的数据无法达到基本的规模要求,从而也使其数据价值无法充分显现。同时,前面讲到的大数据代表性、真实性、完整性、解释性上的不足及由此引起的结论误导,不仅会降低数据的价值,甚至可能产生负面作用。除此之外,大数据的采集、存储、加工和使用所耗费的资金和时间成本都是非常高昂的。作为大数据投资主体,应该在投入和收益之间进行合理平衡。当前的确存在那么一种势力,为了某种目的极力鼓动企业进行大规模的大数据投资,如果不审慎评估,很可能得不偿失。在此讲了这么多大数据的局限性,最后再次重申,并非要以此否定大数据的价值;同时,也要再次强调,大数据代表的只是信息,而非智慧。对世界的改造仅凭有限的信息是远远不够的,更需要人类取之不尽、用之不竭的智慧。只有用好了项上这颗六斤四,才能逐步突破大数据的局限性,更好地发挥大数据价值。 -
学习性能测试需要掌握的知识面<摘自lixl99999>
2017-01-05 14:22:18
摘要:随着Internet的普及与迅速发展,企业业务量的迅速加大,数据大集中成为一种趋势,IT系统承载的负荷越来越重,系统性能的好坏严重的影响了企业对外提供的服务质量。从而对IT系统的性能进行测试和调优引起企业的重视,进而性能测试工程师成为IT市场的”香悖悖”,并且性能测试有着极高的技术挑战。于是吸引了大量的测试爱好者来学这方面的技术,而一谈到性能测试很多人便会想到鼎鼎大名的LoadRunner这款优秀的性能测试工具,然而到这里问题就产生了?
关建字:LoadRunner 性能测试 网络基础编程语言数据库操作系统
LoadRuner与性能测试的关系:LoadRunner初学者的误点:把LoadRunner神化了。很多初学LoadRunner的朋友认为掌握了使用LoadRunner这款性能测试工具,就能够做性能测试了。常在网上看到好多人在学习怎么去使用这款优秀的性能测试工具,本来学习怎么去使用LoadRunner这个工具没有错,却把LoadRunner神化了,”天真的”以为它什么都能做,以为学会了LoadRunner的使用就能做性能测试了。尽管用了大量的时间学会了如何使用LoadRunner录制脚本,如何进行关联,如何进行参数化,如何设置集合点等等?可到头来,性能测试还是不会做。为什么?对于产生的性能报告不知道怎么去分析?不知道如何利用得到的分析报告分析出系统存在的瓶颈?不知道如何进行性能调优?像这些事光会使用LoadRunner是做不到的?说白了LoadRunner只是我们做性能测试的一个工具,它并不是万能的,是死的,具体怎么做还得依靠人去操作与分析。会使用LoadRunner的人,并不一定会做性能测试,会做性能测试的人并不一定都会使用 LoadRunner。LoadRunner只是一个性能测试工具而已。我们应该意识到,测试工具只是性能测试中的一部分,仅是为达到性能测试目的而采用的一种手段
性能测试与系统性能的关系:高性能,高安全的系统,不是测试出来的,而是构架,设计,编写出来的。当然在这里我并不否认性能测试的重要性,甚至可以说没有经过性能测试的系统,一定不会是优秀的系统,软件是人开发出来的,而人总是会出错的,所谓智者千虑,必有一失……要想做好性能测试,在软件系统需求,设计,编写代码的这些阶段就应该进行性能测试,而不仅仅是系统测试这个阶段才去做性能测试,性能测试应该贯穿于整个软件开发周期中。
对初学LoadRunner朋友的建意:常看到网上一些网友发贴子问,怎么对性能测试产生的结果进行分析?测试系统时怎么去选择合适的协议?对于发这些贴子的人我想请问你?你能够详细的说下HTTP协议吗?TCP建立连接和释放连接的过程是怎样进行的?什么是协议?协议是用来做什么的?在OSI参考模型中各层的作用?数据库中产生并发的冲突的原因?不要太依赖于LoadRunner工具本身的学习,而去忽略计算机其它基础知识的学习,我们更应该去掌握一门编程语言,良好的网络基础知识,计算机原理与操作系统知识,数据库知识。这些是我们去学习怎么去使用LoadRunner前提与基础。。
1、为什么要掌握一门编程语言
其一,大家在使用LoadRunner时常会遇到一些不能录制脚本的情况发生,或者需要录制一些复杂的脚本,这时候我们就必须手动的开发脚本。其二 LoadRunner虽然强大,易于使用,可是它却属于商业软件,价格昂贵,并且代码不开源,我们无法了解LoadRunner具体的实现细节,甚至我们会怀疑LoadRunner收集的性能数据准确吗?它有是如何实现的等等,而这些我们通过LoadRunner的帮助文档无法得知。性能测试工具并不只有 LoadRunner,做性能测试还有许多优秀的性能测试工具可以选择,像JMeter,Curl- Loader等等这些非常优秀的开源工具,在全能上虽然并不上LoadRunner,但在某些方面却比LoadRunner还要强大。例如Curl- Loader这个工具,它虽然支持的协议不多,但是对于http协议它最高能产生10万的并发用户,这是LoadRunner远远所不及的。并且这些工具代码是公开的,我们能够从这些代码中去分析具体实现的细节,并且还可以自已编写代码,增强软件的功能,这也是成为性能测试高手的一条途径。LoadRunner好比我们的Windows操作系统,易于使用,功能强大,代码封闭,论全能比Linux要强大。我们的开源性能测试工具好比Linux操作系统代码开源,不易于使用,但很多方面比我们的Windows要强大。也许这个时候有人会问对于初学者学哪门语言最好最有前途C,C++,VB,JAVA,C#?其实每一种语言能够生存下来,自有其生存的道理,每一种语言都有自已优势和缺点,并且编程语言具有相通信,学好了一门,再去学另外的编程语言,非常快就能上手。对于初学者我建意学习C语言,理由有很多,例如很多优秀的开源性能测试工具就是用C语言开发的…。当然不管选择什么编程语言,或者数据库,或者操作系统,我们不要去想学哪门最好,学哪方面最有前途。我们更应该结合自身的情况,选择最合适的,而不是选择最好的。
2、为什么要掌握计算机原理和操作系统知识
论坛上常会看到这些问题?LoadRunner中线程与进程的关系?在什么时候用到它们,怎么区别用线程还是进程呢?LoadRunner录制产生了乱码怎么解决?怎么去发现内存泄漏?对那些发贴问这些问题的朋友,我依然想请问你你知道进程和线程的概念吗?知道进程有几种状态吗?知道进程间的通信是怎么进行的吗?死锁,进程与线程的区别这些概念你明白吗?如果你连内存的概念,内存的作用,内存泄露的概念都搞不清楚,你怎么去发现内存泄露?如果这些你都不知道,自然就不知道怎么去做性能测试分析?一些网友录制脚本常常会产生一些莫名奇妙的错误?还震震有词的说这是LoadRunner的原因。其实要说到底要解决这些问题就必需得有良好的计算机原理和操作系统知识。弄清了进程和线程的区别,你自然就明白了使用进程资源使用高,但安全性要强于线程,线程资源利用率少,使用线程能在一个负载生成器上运行更多的Vuser,但可能存在安全问题。LoadRunner录制产生了乱码怎么解决?为什么会产生乱码,你知道什么是字符集吗?什么是编码吗?字符串在我们内存中有是如何存放的?ASCII编码,ANSI编码,UNICODE编码它们的区别是什么?这些都是操作系统的基础基础。掌握好了这些你自然明白LoadRunner中产生乱码的原因。当然计算机原理和操作系统的基础知识还有很多得掌握的知识。像操作系统的体系架构、操作系统的重要基础概念,内存管理、存储/文件系统、驱动/硬件的管理。要做好性能测试计算机原理和操作系统知识必不可少。
3、为什么要有良好的网络基础经常在51testing论坛中看到很多人发贴子。像LoadRuner中为什么要进行关联?LoadRunner测试系统时如何选择协议?LoadRunner中的如何进行IP欺骗?等等。这些问题随便一搜就能发现大量的贴子,其实说到底这些问题和LoadRunner的关系并不是很大,要去解决这些问题并不在于你对LoadRunner这个工具使用是否熟练,而在于我们网络基础知识是否扎实。例如第一个问题LoadRunner中为什么要进行关联?相信很多朋友都知道HTTP协议知道它是超文本传输协议,但是对于一些新手往往不能够详细的说出HTTP具体的内容,像HTTP工作的原理,HTTP协议为什么要使用基于TCP的协议而不使用UDP的协议,HTTP工作在OSI参考模型的哪一层?在HTTP协议上数据是怎么传输的等等。而只有当我们明白了这一切,自然而然就会明白为什么要使用关联,到最后你会发现这些问题其实根LoadRunner关系并不是很大。HTTP协议本质上是无状态的;对页面的每个请求都将被视为新请求,而且默认情况下,来自一个请求的信息对下一个请求不可用。在传统的Web编程中,这通常意味着在每一次往返行程中,与该页及该页上的控件相关联的所有信息都会丢失。例如,如果用户将信息输入到文本框,该信息将在从浏览器或客户端设备到服务器的往返行程中丢失,为了使用浏览网页,页与页是相互联系不去丢失这些信息,于是了就从现了Cookie,Session,查询字符串等等保持状态的技术。什么是Cookie?什么是Session?Cookie 和Session 有是怎么工作的?当我们明白了这些,很多的问题就自然而然的明白了,像这些都是基础的知识和LoadRunner关系大吗?不大。
Cookie 是一些少量的数据,这些数据存储在客户端文件系统的文本文件中,或者存储在客户端浏览器会话的内存中。Cookie 包含特定于站点的信息(像用户名密码以及我们在网站一些个性化的设置等等),这些信息是随页输出一起由服务器发送到客户端的。如果浏览器使用的是 cookie,那么所有的数据都保存在浏览器端,比如我们登录以后,服务器设置了cookie用户名,那么当你再次请求服务器的时候,浏览器会将用户名一块发送给服务器,这些变量有一定的特殊标记。服务器会解释为cookie变量,所以只要不关闭浏览器,那么cookie变量一直是有效的,所以能够保证长时间不掉线。。如果设置了的有效时间,那么它会将 cookie保存在客户端的硬盘上,下次再访问该网站的时候浏览器先检查有没有 cookie,如果有的话,就读取该 cookie,然后发送给服务器。这些是Cookie的工作过程,常看到论坛上一些朋友发贴子问使用LoadRunner时录制到了一些Cookie的信息,它是用来做什么的,看起来很烦可不可以把它删除掉?明白了这些细节的知识,你自然能明白那个Cookie的信息能不能删除掉。如果web服务器端使用的是session,那么所有的数据都保存在服务器上,客户端每次请求服务器的时候会发送当前会话的SessionId,服务器根据当前 SessionId唯一地标识在服务器上包含会话数据的浏览器,以确定用户是否登录或具有某种权限。不同的用户发送请求Web服务器会随机发送一个唯一的 SessionID。而我们使用LoadRunner录制时它会把我们SessionID写死,所以导致出错。这时候就得使用关联了,这样不仅明白了 LoadRunner怎样使用关联,而且还明白了为什么要使用关联?对于LoadRunner测试系统时如何选择协议?这个问题也是网络论讨的比较多的问题。要解决这个问题同样得依靠我们的扎实的网络基础,而不是对LoadRunner使用的熟练程度,首先我们得了解LoadRunner录制时的工作原理了,LoadRunner的录制和QTP不一样,它不关心你的对象识别什么的,不关心你的什么界面之类的,不关心你使用什么语言编写的,LoadRunner有一个Agent进程,来专门监控客户端和服务器之间的通信,然后用自己的函数进行录制。LoadRunner录制的时候关心的是通信包,是客户端和服务器之间的数据包。说到这里,大家就比较清楚了,为什么有的时候不能录制呢?因为,协议不认识,导致LoadRunner截获的数据包不能解析,所以录制下来是空的。所以我们得熟悉什么是协议, 熟悉OSI参考模型,OSI参考模型中各层的作用,TCP协议栈各层的作用,熟悉TCP,UDP,ICMP等等协议。当我们明白了这些网络的基础知识后我们自然会明白应该如何去选择协议。另外关于LoadRunner中的如何进行IP欺骗?要解决这个问题同样得有良好的网络基础知识。其实当我们理解了IP 地址的格式,IP地址的分类,子网掩码的概念,以及知道怎么去进行非标准子网的划分方法 ,掌握了这些原理的东西,那么具体怎么在LoadRunner中如何进行IP欺骗,就非常简单了。 当然网络基础知识并不只是上面的而已,还包括路由器,交换机,加密技术等等这些基础的网络知识,这些远远比我们去学习怎么去使用LoadRunner更重要。
4、为什么要掌握数据库知识
数据库的重要性我想是不言而喻的,性能测试产生的一个非常大的原因是因为数据大集中的趋势,测试从某种意义来讲就是对数据测试,而我们企业的核心数据是放在数据库中的。现在大型的WEB应用程序,都采用多层结构,像典型三层,用户界面层,数据逻辑层,数据层。而数据层,而数据层对我们整个WEB应用程序的性能是非常大的,对数据库的基础知识不懂,我们怎么去进行性能测试分析?怎么知道确定性能产生的瓶颈是否是数据库的原因,如何对系统进行调优?例如数据库模型设计不合理,一条坏的SQL语句就能影响到整个WEB应用程序的性能,所以熟悉SQL语句,建表,索引,存储过程,事务,触发器,并发等这些基础知识是必需得掌握的。
路漫漫其修远兮,吾将上下而求索:性能测试难点不在于Loadrunner工具本身,难在对整个系统的全局把握,而对全局的把握你就必需得有丰富的知识面。 并不是学好了LoadRunner的使用就能做性能测试 。目前,国内性能测试领域正处于起步阶段,要做好性能测试还需学习更多的知识,技术性和非技术。性能测试这条路充满着挑战,也充满着机遇。但正如鲁迅先生所说这世上本来没有路,走的人多了,也就成了路。最后祝愿喜爱性能测试的爱好这条道路上能够不鸣则已,一鸣惊人,不飞则已,一飞冲天。
-
测试手机占用CPU,内存和流量的emmagee
2017-01-04 14:29:30
Emmagee是监控指定被测应用在使用过程中占用机器的CPU、内存、流量资源的性能测试小工具。支持SDK:Android2.2以及以上版本Emmagee功能介绍1、检测当前时间被测应用占用的CPU使用率以及总体CPU使用量2、检测当前时间被测应用占用的内存量,以及占用的总体内存百分比,剩余内存量3、检测应用从启动开始到当前时间消耗的流量数4、测试数据写入到CSV文件中,同时存储在手机中5、可以选择开启浮窗功能,浮窗中实时显示被测应用占用性能数据信息6、在浮窗中可以快速启动或者关闭手机的wifi网络操作方法:1、启动Emmagee,列表中会默认加载手机安装的所有应用2、选择你需要测试的应用,点击“开始测试”,被测应用会被启动3、测试过程中会自动记录相关性能参数4、测试完成后回到Emmagee界面,点击“结束测试”,测试结果会保存在手机指定目录的CSV文件中 -
UI测试和易用性测试
2017-01-03 14:48:10
UI测试,即测试用户界面的功能模块的布局是否合理、整体风格是否一致、各个控件的放置位置是否符合客户使用习惯,此外还要测试界面操作便 捷性、导航简单易懂性,页面元素的可用性,界面中文字是否正确,命名是否统一,页面是否美观,文字、图片组合是否完美等等。备注:只记录bug中描述措辞可能要用到的
1、检查界面操作是否友好,用户交互是否亲善2、检查界面所有的按钮、下拉框或者是导航箭头是否有反应,且是正确的反应3、不需要做成链接的地方做成了链接,并且点击不能正常跳转或是跳转错误4、检查界面中的标题或者是内容输入过多时,是否会进行换行或者是隐藏处理,而不是出现界面错位等现象;6、中英文符号的统一(开发不注意容易产生)7、检查界面中的图片是否显示正确,是否被裁减,是否被拉伸变形,是否显示完全8、图标能直观的代表要完成的操作(代表性,警示性)9、重要的对象是否用醒目的颜色表示10、措词含糊11、界面元素过多时是否提供滚动条功能(滚动条长度需要根据显示信息的长度或宽度及时变换,有利于用户了解信息的位置)12、某一操作需要时间较长,应该显示进度条或其它提示信息,并且允许进行取消操作13、提倡使用通用性词眼14、不同分辨率下显示正常 -
摘自阿雪写的功能测试的常见测试方法
2016-04-21 13:41:06
从以下三个方面来说明测试分析:· 测试分析是什么· 测试分析的重要性· 测试分析的常用方法· 测试分析是什么1.测试分析是测试人员对待测功能或待测系统在分析其测试需求后,思考如何去测试这个功能或系统,然后转化为测试点的过程。2.测试分析体现了测试人员的测试思维。通过测试分析的产出物(测试分析文档)可使项目组其他人员清楚的了解待测功能或系统是如何被测试的。3.测试分析包含两个过程:一是对待测试系统或功能的需求了解。二是思考如何去测试这个系统或功能。测试分析的重要性:1.测试分析可以帮助测试人员梳理测试功能,使测试更加充分和全面。2.测试分析为测试用例的编写提供了依据。避免了测试用例编写的随意性,可以提高用例的编写效率。3.对测试分析的产出物进行评审,可以让项目组其他成员了解待测试系统或功能是如何被测试的,项目组其他成员可以提出不同建议或指出遗漏项。使整个测试过程透明化。4.在开发人员进行代码开发之前,查看并和测试人员探讨测试分析的产出物,可以帮助开发人员自查开发逻辑是否有遗漏。测试分析的方法:目前常用的测试分析方法如下图: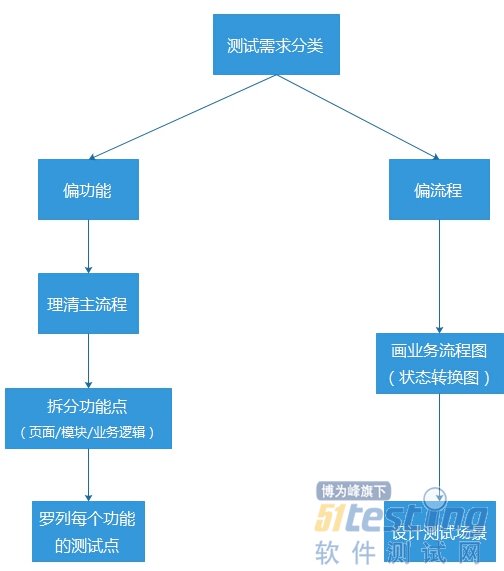 说明:1.无论是偏功能还是偏流程,测试分析的第一步首先应该理出所有的业务流程,在测试过程中,首先应该保障所有的业务流程被测试通过。2.偏功能是指业务流程很少,一般不超过三个;界面上的操作元素较多或者功能较复杂。偏流程是指业务分支较多,但页面上的操作元素较少且功能简单。3.当测试需求偏功能时:第一步:理清主业务流程第二步:从页面/模块/业务逻辑三个方面进行功能点的拆分。把功能从大化小。第三步:罗列每个功能点的测试点。第四步:对功能点的测试顺序进行不同顺序的组合。4.当测试需求偏流程时:借助工具画业务流程图(状态转换图)通过业务流程图(状态转换图)找出所有的业务分支设计测试场景,每一个测试场景代表了一个业务分支,保障所有的业务分支都被设计到。5.当测试需求较复杂时,即包含了较多的业务场景和较复杂的功能时,可以综合运用以上两种分析方法。一般,首先通过画流程图找出所有的业务分支,然后再对每一个业务分支进行功能拆分,罗列测试点。6.测试分析完后,应当产出测试分析文档。测试分析文档一般由图例和测试点组成。
说明:1.无论是偏功能还是偏流程,测试分析的第一步首先应该理出所有的业务流程,在测试过程中,首先应该保障所有的业务流程被测试通过。2.偏功能是指业务流程很少,一般不超过三个;界面上的操作元素较多或者功能较复杂。偏流程是指业务分支较多,但页面上的操作元素较少且功能简单。3.当测试需求偏功能时:第一步:理清主业务流程第二步:从页面/模块/业务逻辑三个方面进行功能点的拆分。把功能从大化小。第三步:罗列每个功能点的测试点。第四步:对功能点的测试顺序进行不同顺序的组合。4.当测试需求偏流程时:借助工具画业务流程图(状态转换图)通过业务流程图(状态转换图)找出所有的业务分支设计测试场景,每一个测试场景代表了一个业务分支,保障所有的业务分支都被设计到。5.当测试需求较复杂时,即包含了较多的业务场景和较复杂的功能时,可以综合运用以上两种分析方法。一般,首先通过画流程图找出所有的业务分支,然后再对每一个业务分支进行功能拆分,罗列测试点。6.测试分析完后,应当产出测试分析文档。测试分析文档一般由图例和测试点组成。 -
关于软件测试的几点反思—测试工作的三个阶段
2014-03-25 10:59:31
第一个阶段:发现和解决bug的阶段这个阶段的思路基本上尽可能发现更多的bug,见一个灭一个,来两个灭一双。发现bug,解决后验证bug,没有任何根源性的推动,或者推动的效果不好。这个阶段,测试工作主要集中在发现bug,要做好这个,需要多个方面的努力,比如下面这些:- 更高效的发现bug,考验测试设计的能力。这方面有非常多的方法和技巧,以及经验,这里不细说。- 发现bug之后如何清晰的描述,定级,以及跟进和验证。这个看似简单,但是你会发现很多测试工作做了几年的人这样的基本功还是不够扎实。也可能没有受到过很好的训练或者一直没有人指导。- 对业务和架构的理解能力。没有这方面的能力,很难发现一些深层次的bug。而这样的能力对于快速学习和一些技术基础也有不低的要求。- 发现bug之后如果举一反三的尽早发现更多类似的bug。大家看到的很多经典的测试书籍讲的基本都是这个阶段做的事情,比如Software Testing,How We Test Software at Microsoft,以及探索性测试相关的书籍,都是专注在如何更高效的发现缺陷。上面这些东西都是一个业务测试人员的基本功。看似简单,但是做好并不是一件容易的事情。也许这些事情一点都不cool,不sexy,甚至去做职级评审的时候不占优势,但是对于系统质量的提升,是切切实实带来很大帮助的,其工作的价值应该得到认可。但是如果一直停留在这个阶段,就陷入到上面例子中说的扫马路的阶段,因为如果没有其他方面的改变,每次都有那么多的bug。不过很多时候,我们的测试停留在这个阶段也是因为现状,考虑下这样的情况:- 开发基本不自测,甚至没有自测的环境,特别是涉及多个系统的对接。- 提测后很多基本的功能都不能正常使用- 项目管理比较混乱,但是最终的发布日期又被老大们定死,所以测试时间常常被压缩而且,而且没有对于开发人员的质量方面的考核,那么很长一段时间,我们的测试将处于这个初级阶段。我相信目前还有不少的团队是处于这样疲于应对的情况下,不只是小公司,可能一些大公司的部分项目也是如此。随着整个研发体系的发展和深入,我们应该有更高的追求。第二个阶段:质量的管理在第一个阶段中,可能有一些人会停下来想:我们一直这样下去也不是个办法?有没有更好的做法呢?最直接会想到的就是,怎么让别人少丢垃圾,让本身的bug就更少一些。如果我们做的工作只是发现bug解决bug,那么就是一个消耗战。不能形成一个良性的循环,就不能持续的优化,工作的长期累积价值就体现不出来。这个阶段核心的思路是对缺陷做分析和考核,并做研发流程中主要问题的梳理和改善。常常做的事情可以从下面几个方面来看:1. 做质量数据的统计和分析收集的数据很多,常见的有:- 外网的bug情况,包括事故,及影响的程度- 测试阶段的bug数量,分布(按系统,团队,开发个人),严重程度,bug的类别等维度- bug的横向跨团队和系统的对比,纵向的和历史情况对比- 版本发布的情况,代码变更行数的情况从这些数据的收集中就能发现很多问题,比如问题集中在哪里,哪些模块,哪些人,哪些类别等等,以及有没有改善。2. 问题的追溯和对于开发的考核这个方面也许有一些争议,但是我还是觉得这个是一个很重要的方法。光靠观念和自觉是不够的,必需要有一定的反馈机制,就好比交规一定是配合着扣分和罚款等手段,否则记录闯红灯有什么意义呢?而且现实的来说,这些方法起到约束的作用,也是一种心理暗示,要做自己做的东西负责,也便于养成好的习惯。通常的考核指标涉及这些方面:- 编译失败次数的考核- 外网事故和bug的数量- 测试阶段的bug,特别是基础功能bug和严重bug粗略的列了这么多,其实可以有很多,比如配置文件改错的情况,漏提测文件的次数等等。这里也许有很多的讨论,但是让我们看看一个实际的例子。下图是某个系统的编译失败的情况,在11月份的时候提出要统计并公开(并无惩罚条款)编译失败的情况,包含到开发的团队和个人等明显,12月份开始出现了明显的下降并稳定了。这个图隐藏了一些细节,如果剔除其他因素只看开发代码原因的编译失败则更明显,特别是后面有惩罚机制之后,进一步下降。 编译失败大幅的下降一方面是节省了大家的时间,另一方面其实也是提高了版本质量,想想如果有很多的编译失败,而且是到提交测试的阶段,这样的代码质量能好吗?是可能做过自测吗? 有了这样的机制,至少会更仔细一些。对于bug方面其实也是一样,如果开发在乎(或者被迫在乎)外网bug或者被测试发现的bug数量,他写代码的时候一定会更仔细,也会做些简单的自测,让提测的质量更高,提高了整个研发系统的效率,同时也是提升了质量,因为quality must be built in。我个人的经验,作为测试人员几乎同时面对过两个开发团队,一个有上述的考核,一个没有。表现出来的版本质量和对质量的关注完全不一样,而且前者也并没有出现开发和测试的对立,以及测试不敢提bug等负面的情况。3. 对于测试的考核除了对于开发的考核,同样也有对于测试的考核,这样也更加的公平。测试的考核通常考虑下面的指标:- 漏测:绝对数量或者漏测率- 版本的工作量和测试效率- 发布延期的情况如果测试有这样的压力,也需要不断努力去发现更多的bug。说起考核,总有人觉得这不符合智力劳动的情况,或者互联网的作风,其实不太理解为什么会这么觉得,放眼望去,有什么工作不被考核呢,sales要背quota,为什么软件开发和测试不能对自己的工作的质量负责呢?当然,具体的指标如何去定才更合理那是另一个要去考虑的。换个角度来看,适当的压力(不应该导致焦虑和扭曲的做法),其实是让一个人表现最好的状态。4. 推动开发的自测这个问题一向是个老大难问题。愿意自测的开发团队你不用太多的推动,不愿意做的推动也很难,或者你无法判断他有没有做自测。而且这方面,通常取决于开发负责人的观念和态度。如果是介于之间的,我们可以做一些事情,比如:- 统计测试阶段的bug中,属于开发可自测发现的比例。通过这个可以看有多少bug是不应该到测试阶段的,以及横行纵向的对比。当然这个标准要自己拿捏。- 给出一个自测的checklist。开发在提交前要完成这个list并正式的给出报告。这个方式我们曾经在一个项目中用过,效果不错,基本功能都通过这个保证了,前提是开发负责人认可。- 有一套自动化验收的用例,可以挂接到自动部署之后或者daily build。前提是我们的自动化要足够的问题,效果才会好。这个阶段除了业务测试的努力,也体现出了QA的价值。这里的QA是指质量管理,有的地方叫SQA,专注在质量度量和研发流程的管理上。到这个阶段,发现事情顺了很多,质量也有更大程度的提升,并有改善额趋势。第三个阶段:推动全面的质量提升到上面第二个阶段,我们发现质量有了一定的提升,但是还是有不少的问题,而且有些问题需要我们把思路和眼界拓宽来看。这里讨论的一些东西可能更适合互联网的产品。这里列一些我们可以去做的事情,受限于个人的经验,可能还很片面。1. 研发流程的梳理其实在阶段2的时候也可能有些团队已经开始做这样的事情,因为在分析质量和效率问题的时候,我们发现很多问题不单纯是代码的问题,可能还涉及研发流程的很多方面,比如:- 需求不清楚- 跨团队的配合问题- 代码版本管理- 技术方面的评审和大家的理解所以整个研发流程的规范和梳理,以及配合对应的需求和版本管理的系统也是非常的必要,实际中发现效果也是比较的明显。而且还有一点体会,在接手一个很混乱的状况时,这样角度的数量和调整比技术方案的引入更重要和切中要点,能从40分到60分,技术是往80分走的过程效果更明显。2. 提交测试前后做的一些事情- 代码的静态扫描这个方法很多的团队都在做,但是实际的效果似乎差别很多,而且ROI也很难说,不过从方法本身来说还是值得去做的,对测试人员也提出来更高的要求。- code review这个开发应该要做,特别是开发间的交叉review,非常的有帮助。不过这个也和自测一样,取决于开发负责人的态度。另外,测试也应该去做,特别是对于diff 代码的review,我们检查做了大概两个月的时间,发现还是非常的有收获。发现了一些黑盒难以发现的问题,以及开发的代码夹带,并且对于这个版本影响范围的评估也更准确。但问题是短期会花费测试更多时间,以及需要测试人员有一定的技术能力。3. 测试能力的提升测试阶段有很多的事情可以去做,觉得最主要的还是两个方面- 自动化。 越来越觉得这个是绕不开的话题,要想尽办法去做,做得更高效更全面。前面有篇blog也提到了一些轻量级的做法,业务测试的团队可以参考 http://blog.csdn.net/superqa/article/details/20644285- 辅助手段,比如代码覆盖率,特别是差异的覆盖率。这个大家都比较容易理解就不展开了。- 拓展测试的类型这个方面说起来有些泛,需要结合团队和业务的情况,比如安全测试,性能测试,兼容性测试等,去发现一些对于产品来说很重要的风险。这方面有两个前提,一是我们的基本功能质量到了一个阶段,可以让大家腾出手去拓展测试的面,另一方面我们测试人员的能力要跟得上。4. 发布环节的质量把控这个方面和传统的测试不太一样,而且了解到不同的组织做法不同,执行发布的人员可能不同,有开发,运维,专职的版本管理或者测试来做。在我们的实践中,发布后来都逐步收到测试这边,回头来看觉得还是有不少有帮助的地方。当然也不绝对的必须测试来做。- DO分离,避免了随意的发布,特别是在开发手上的时候。所有的bugfix都经过测试发布,可以更准确的度量质量(除非这个问题可以不修复,否则肯定要过发布环节)- 知道最近发了什么,可能的影响是什么,需要线上关注什么。- 灰度。 互联网产品常用的一个控制风险和节奏的手段。- 扩容的快速自动化检查,这方面也依赖于自动化的建设。- 发布过程支持灰度的控制,备份和快速的回滚。对发布系统有一定的要求,而且有可追溯性。
编译失败大幅的下降一方面是节省了大家的时间,另一方面其实也是提高了版本质量,想想如果有很多的编译失败,而且是到提交测试的阶段,这样的代码质量能好吗?是可能做过自测吗? 有了这样的机制,至少会更仔细一些。对于bug方面其实也是一样,如果开发在乎(或者被迫在乎)外网bug或者被测试发现的bug数量,他写代码的时候一定会更仔细,也会做些简单的自测,让提测的质量更高,提高了整个研发系统的效率,同时也是提升了质量,因为quality must be built in。我个人的经验,作为测试人员几乎同时面对过两个开发团队,一个有上述的考核,一个没有。表现出来的版本质量和对质量的关注完全不一样,而且前者也并没有出现开发和测试的对立,以及测试不敢提bug等负面的情况。3. 对于测试的考核除了对于开发的考核,同样也有对于测试的考核,这样也更加的公平。测试的考核通常考虑下面的指标:- 漏测:绝对数量或者漏测率- 版本的工作量和测试效率- 发布延期的情况如果测试有这样的压力,也需要不断努力去发现更多的bug。说起考核,总有人觉得这不符合智力劳动的情况,或者互联网的作风,其实不太理解为什么会这么觉得,放眼望去,有什么工作不被考核呢,sales要背quota,为什么软件开发和测试不能对自己的工作的质量负责呢?当然,具体的指标如何去定才更合理那是另一个要去考虑的。换个角度来看,适当的压力(不应该导致焦虑和扭曲的做法),其实是让一个人表现最好的状态。4. 推动开发的自测这个问题一向是个老大难问题。愿意自测的开发团队你不用太多的推动,不愿意做的推动也很难,或者你无法判断他有没有做自测。而且这方面,通常取决于开发负责人的观念和态度。如果是介于之间的,我们可以做一些事情,比如:- 统计测试阶段的bug中,属于开发可自测发现的比例。通过这个可以看有多少bug是不应该到测试阶段的,以及横行纵向的对比。当然这个标准要自己拿捏。- 给出一个自测的checklist。开发在提交前要完成这个list并正式的给出报告。这个方式我们曾经在一个项目中用过,效果不错,基本功能都通过这个保证了,前提是开发负责人认可。- 有一套自动化验收的用例,可以挂接到自动部署之后或者daily build。前提是我们的自动化要足够的问题,效果才会好。这个阶段除了业务测试的努力,也体现出了QA的价值。这里的QA是指质量管理,有的地方叫SQA,专注在质量度量和研发流程的管理上。到这个阶段,发现事情顺了很多,质量也有更大程度的提升,并有改善额趋势。第三个阶段:推动全面的质量提升到上面第二个阶段,我们发现质量有了一定的提升,但是还是有不少的问题,而且有些问题需要我们把思路和眼界拓宽来看。这里讨论的一些东西可能更适合互联网的产品。这里列一些我们可以去做的事情,受限于个人的经验,可能还很片面。1. 研发流程的梳理其实在阶段2的时候也可能有些团队已经开始做这样的事情,因为在分析质量和效率问题的时候,我们发现很多问题不单纯是代码的问题,可能还涉及研发流程的很多方面,比如:- 需求不清楚- 跨团队的配合问题- 代码版本管理- 技术方面的评审和大家的理解所以整个研发流程的规范和梳理,以及配合对应的需求和版本管理的系统也是非常的必要,实际中发现效果也是比较的明显。而且还有一点体会,在接手一个很混乱的状况时,这样角度的数量和调整比技术方案的引入更重要和切中要点,能从40分到60分,技术是往80分走的过程效果更明显。2. 提交测试前后做的一些事情- 代码的静态扫描这个方法很多的团队都在做,但是实际的效果似乎差别很多,而且ROI也很难说,不过从方法本身来说还是值得去做的,对测试人员也提出来更高的要求。- code review这个开发应该要做,特别是开发间的交叉review,非常的有帮助。不过这个也和自测一样,取决于开发负责人的态度。另外,测试也应该去做,特别是对于diff 代码的review,我们检查做了大概两个月的时间,发现还是非常的有收获。发现了一些黑盒难以发现的问题,以及开发的代码夹带,并且对于这个版本影响范围的评估也更准确。但问题是短期会花费测试更多时间,以及需要测试人员有一定的技术能力。3. 测试能力的提升测试阶段有很多的事情可以去做,觉得最主要的还是两个方面- 自动化。 越来越觉得这个是绕不开的话题,要想尽办法去做,做得更高效更全面。前面有篇blog也提到了一些轻量级的做法,业务测试的团队可以参考 http://blog.csdn.net/superqa/article/details/20644285- 辅助手段,比如代码覆盖率,特别是差异的覆盖率。这个大家都比较容易理解就不展开了。- 拓展测试的类型这个方面说起来有些泛,需要结合团队和业务的情况,比如安全测试,性能测试,兼容性测试等,去发现一些对于产品来说很重要的风险。这方面有两个前提,一是我们的基本功能质量到了一个阶段,可以让大家腾出手去拓展测试的面,另一方面我们测试人员的能力要跟得上。4. 发布环节的质量把控这个方面和传统的测试不太一样,而且了解到不同的组织做法不同,执行发布的人员可能不同,有开发,运维,专职的版本管理或者测试来做。在我们的实践中,发布后来都逐步收到测试这边,回头来看觉得还是有不少有帮助的地方。当然也不绝对的必须测试来做。- DO分离,避免了随意的发布,特别是在开发手上的时候。所有的bugfix都经过测试发布,可以更准确的度量质量(除非这个问题可以不修复,否则肯定要过发布环节)- 知道最近发了什么,可能的影响是什么,需要线上关注什么。- 灰度。 互联网产品常用的一个控制风险和节奏的手段。- 扩容的快速自动化检查,这方面也依赖于自动化的建设。- 发布过程支持灰度的控制,备份和快速的回滚。对发布系统有一定的要求,而且有可追溯性。 发布处在整个研发流程非常关键的节点,在这个点可以做很多的控制,也能发现很多的问题,对于测试团队来说,从这里可以发现很多的问题,做很多的提升,对自己和相关的合作团队。5. 外网的监控发现发布后的问题,持续运营过程中的问题,推动优化。通常监控可以分几个层面,粗浅的可以分成几类:- 运维层面的监控,比如机器,链路,资源使用,主要组件是否正常等。- 业务指标的监控,比如来自点击率,BI系统等。- 集成在产品里面的监控代码,我们称之为模块调用监控。这个是全量的,有次数,成功率,响应时间等角度。- 测试层面的自动化监控,关于在接口和功能层面。这个是采样的,但是从用户的角度来监控。
发布处在整个研发流程非常关键的节点,在这个点可以做很多的控制,也能发现很多的问题,对于测试团队来说,从这里可以发现很多的问题,做很多的提升,对自己和相关的合作团队。5. 外网的监控发现发布后的问题,持续运营过程中的问题,推动优化。通常监控可以分几个层面,粗浅的可以分成几类:- 运维层面的监控,比如机器,链路,资源使用,主要组件是否正常等。- 业务指标的监控,比如来自点击率,BI系统等。- 集成在产品里面的监控代码,我们称之为模块调用监控。这个是全量的,有次数,成功率,响应时间等角度。- 测试层面的自动化监控,关于在接口和功能层面。这个是采样的,但是从用户的角度来监控。 以上这些监控都有对应的告警机制,可以第一时间发现问题,避免造成更大的损失。为了实现上面的监控需要做大量的工作,但是这些对于整个外网运营的质量非常的重要。6. 外网事故和问题的收集,跟进和反向推动和前面的思路一样,如果只是发现问题解决问题还是稍显被动,那么对于外网事故和问题的分析,还是有很多推动性的帮助。7. 用户的问题反馈和满意度进一步的质量不只是系统本身的质量,而是从用户角度看到的质量,有时候这个可能稍微超出一些系统层面的问题,但是因为最终的质量还是用户说了算,所以我们应该扩展下思路。收集这样的问题的渠道有很多- 外网问题反馈,比如来自客服系统的,用户直接的反馈,现在很多app上都有反馈的功能。- 论坛信息的统计收集。我了解的另一个测试团队,他们还专门开发了一个自动收集外部反馈,以及过滤分析的系统来帮助他们及时的了解外包的问题反馈。写到这里,我们可以跳到整个公司或者业务的层面,来思考一些对于测试更深层次的问题:测试团队存在的价值和意义是什么?只有对业务有明确的价值,业务测试,或者说整个测试团队才有存在的意义。只要业务OK,砍掉测试团队也不是不可能。我们必须时不时的跳出我们自己的思维的圈子,站在整个事业部老大的角度来思考下测试的价值和意义。在下一篇关于测试组织方面我们可以再讨论下这方面的内容。还有一个体会:测试的水平反应整个研发体系的能力和水平。如果我们的测试还专注在第一阶段,那说明整个研发还比较初级,开发和测试都是温饱的阶段。当我们的测试人员不再趴在地上盯着最基本的功能质量的时候,才有可能抬起来看看更多有价值,有帮助和有长远意义的工作,慢慢形成一个良性的循环。摘自于http://www.51testing.com/html/62/n-859162.html
以上这些监控都有对应的告警机制,可以第一时间发现问题,避免造成更大的损失。为了实现上面的监控需要做大量的工作,但是这些对于整个外网运营的质量非常的重要。6. 外网事故和问题的收集,跟进和反向推动和前面的思路一样,如果只是发现问题解决问题还是稍显被动,那么对于外网事故和问题的分析,还是有很多推动性的帮助。7. 用户的问题反馈和满意度进一步的质量不只是系统本身的质量,而是从用户角度看到的质量,有时候这个可能稍微超出一些系统层面的问题,但是因为最终的质量还是用户说了算,所以我们应该扩展下思路。收集这样的问题的渠道有很多- 外网问题反馈,比如来自客服系统的,用户直接的反馈,现在很多app上都有反馈的功能。- 论坛信息的统计收集。我了解的另一个测试团队,他们还专门开发了一个自动收集外部反馈,以及过滤分析的系统来帮助他们及时的了解外包的问题反馈。写到这里,我们可以跳到整个公司或者业务的层面,来思考一些对于测试更深层次的问题:测试团队存在的价值和意义是什么?只有对业务有明确的价值,业务测试,或者说整个测试团队才有存在的意义。只要业务OK,砍掉测试团队也不是不可能。我们必须时不时的跳出我们自己的思维的圈子,站在整个事业部老大的角度来思考下测试的价值和意义。在下一篇关于测试组织方面我们可以再讨论下这方面的内容。还有一个体会:测试的水平反应整个研发体系的能力和水平。如果我们的测试还专注在第一阶段,那说明整个研发还比较初级,开发和测试都是温饱的阶段。当我们的测试人员不再趴在地上盯着最基本的功能质量的时候,才有可能抬起来看看更多有价值,有帮助和有长远意义的工作,慢慢形成一个良性的循环。摘自于http://www.51testing.com/html/62/n-859162.html -
软件测试工程师的“三十六变”转qingchunjun
2013-12-16 10:53:41
1. 想进入软件测试领域,还不太清楚实际的软件测试长什么样的童鞋。
2. 刚上走上测试这条路不久,接触过一些实际项目了,但还没“拧”上道的童鞋。
3. 做了一段时间测试,也明白了软件测试是怎么回事,想继续从事测试行业,但是对前途感觉很茫然的童鞋。
4. 做了一段时间测试,感觉测试不是自己所想要的职业,仍然想在IT行业发展,但想转行的童鞋。
如果您不属于这其中的某一类人,或许这篇小文并不适合您,请不要浪费你的时间了,谢谢。
职业发展是个老生常谈的问题,但一直都是一个很火的话题。随便翻翻,各个关于软件测试的坛子里,都不乏探讨软件测试工程师职业发展的帖子,为什么我还要多写这么一篇呢?好吧,先来说说这篇博文的缘起:在我将近八年的职业软件测试生涯中,遇到过不少刚刚进入测试领域的新人,也有不少做过三四年或者五六年的“老鸟”,不管做得好的还是不好的,我觉得都可以用两个字来形容大多数人的状态:“忙”与“茫”。前一个忙可能适合于大部分刚踏入测试领域的新人,他们兴趣勃勃,对一切新鲜事物都充满着好奇,总想学习更多的技术,参与更多的测试,好早点积累起属于自己的测试经验。后一个“茫”,可能更适合做了几年测试的所谓“老鸟”,他们经历了一些项目,也积累了不少的经验,不管是否领悟了测试的“真谛”,他们中的大部分人都已经习惯了目前的工作状态,成了熟练工种。或许在纠结着究竟以后的路该怎么走,究竟是学技术还是做管理?学技术的话,什么样的技术学了才会让自己在这个领域更具竞争力?做管理的话,自己具备做管理的特质吗?又或许自己根本不适合做测试?甚至于不适合做IT?可转行的话,隐藏着巨大的机会成本,风险确实很大,用什么样的职业来转行才更靠谱呢?“菜鸟”也终究有成为“老鸟“的那一天,所以这些问题是我们每个人都会遇到的,有句话说得非常好:二十岁的迷茫将导致三十岁的恐慌,而接下来面对的是四十岁的无奈。不管你现在多少岁,如果你现在还没有定下自己的目标,可能看到这句话都会有这样的感觉,迷茫、恐慌和无奈,每个词都不是什么褒义词,没人想把它们放在自己的身上。正因为有这样一些问题,这么多的无奈,才有了这篇文章。我想通过这篇文章,和大家分享一下我这么多年工作之中对测试职业生涯发展的思考,更重要的是,我同时还会给大家提供一些以后不做测试之后该如何华丽”转行“的意见供大家参考,”三十六“变究竟应该怎么变,我想这也是我这篇文章的价值所在。
本文准备分两大部分来讲不同方向的职业生涯发展之路。第一部分当然就留给那些想继续留在测试行业发展的童鞋们,讲讲如果你想在测试行业继续奋斗下去的话,为了你的“钱途”,你应该往哪方面发展。第二部分应该算是其他文章讲得较少的内容,那就是如果你干了一段时间觉得你不愿意再从事测试行业,想从一些相关的职业转行离开测试领域,那么请着重看这部分。
一、测试行业的职业发展之路
其实这部分是几乎所有关于测试的职业发展文章都会探讨的部分,相信各位看官都已经耳熟能详了。不过为了照顾本文的完整性,也便于大家比较,我也将我的经验和观点分享给大家,以作参考。如果有童鞋有更好的观点,欢迎分享和探讨。
1. 技术方向
就技术方向的职业发展之路,我非常赞同之前看过的测试大牛sincky的一篇文章里说的,如果你打定主意就想往测试技术方向去发展,做一个技术型的牛人,那摆在你面前的就只有三条路:1. 自动化测试工程/架构师 2. 性能测试工程师 3. 行业性测试专家。你几乎没有其他选择,甭管你的领导怎么忽悠你,做手动测试大量需要劳动力也好,自动化测试现在还没有大规模发展起来也罢,如果你只会手动测试,并且你所测试的软件也没有什么特别值得深究的方面的话,那么可以告诉你你的测试生涯钱途堪忧,说白了也就是没有什么核心竞争力,哪天boss们想砍人了,那你就是第一个。有些童鞋可能会说了,这个不对吧,看咱项目里不是还是80%以上的人都是做手动的嘛,为什么你却说自动化/性能测试才更具有核心竞争力呢?先说自动化吧,确实,就目前中国测试业的现状来看,80%以上的IT公司里面80%以上的测试人员都在做着黑盒的手工测试,这个假象确实麻痹了一些人,使得大家以为既然大部分人都在做着手工测试,那我也不需要去学习自动化或者性能测试了。就算很多已经实施了自动化测试的公司,也在痛苦地摸索着如何提高自动化测试的效率,如何能够真正提高系统的性能。但不管现状如何,很多公司也必须重视自动化测试,原因有二:1. 商业上的需要。很多公司,特别是测试外包公司,销售们在推销自己公司的团队和产品的时候,测试的自动化程度都是一个重要的指标,这年头说测试不说自动化都显得自己“out”了,所以自动化测试能不香吗?2. 项目需要。很多管理职位的人,如果不是做测试技术出身,都会非常迷信自动化测试的神力,把自动化测试当成测试的银弹,战无不用,用无不胜,所以相对来说,会比较重视自动化测试的人。对于性能测试和行业测试专家来说,那就是物以稀为贵了。真正能做好性能测试,并能够通过性能测试结果分析出性能瓶颈,提出性能改进方案的人,寥寥无几。行业测试专家也一样,比如电信、医疗、ERP测试,能够精通业务,真正能够利用对业务的了解改进测试效率,也是数都能数出来的,你说他们的钱途用得着担心吗?呵呵。
好了,接下来再来说说这三个职位各需要什么样的具体技能吧(可能不是很全,欢迎各位看官补充)。
1.1 自动化测试工程师/架构师
基本能力要求:
--熟悉自动化测试的理论及常用框架
--熟练使用常见的自动化测试工具并能够根据项目实际需要选择合适的工具或者开发相应的工具
--熟悉项目软件架构及层次结构,能够利用自动化测试工具或自定义的框架提高自动化测试的覆盖率和复用率
--熟悉脚本类及一到两种常用的编译型编程语言,网络协议及linux平台
1.2 性能测试工程师
基本能力要求:
--熟悉性能测试过程模型和过程
--熟悉各种常见的应用协议
--熟悉性能测试工具的原理及使用
--能够根据实际项目配置测试环境,选择合适的性能测试工具或开发性能测试工具
--能够通过对被测系统的分析,对性能测试场景进行分析和选取
--执行性能测试并根据结果分析性能瓶颈,提出性能提升改进的建议
1.3 行业测试专家
基本能力要求:
--精通某个业务性较强的行业的业务流程及关键技能,如医疗,通信,ERP等特征较明显的行业。(如果你是测一般的网站或者是手机系统之类的话,还是省省吧,这个不是这里指的行业专家)
--能够根据对本行业业务的了解和对软件测试的了解,对组织内的软件测试流程和方法做出优化,提高测试效率,节省测试成本
2. 管理方向
谈完了技术,当然就该谈谈被无数人所追崇的管理职位了。当然了,能管别人,发号施令,谁不喜欢呢?古人云:学而优则仕,就是这个道理。可职业发展这个金字塔上,能最终站上管理职位的那个塔尖的人又有多少呢?管理职位虽然看似很爽,很诱人,但绝不是每个人都适合做这个岗位的。也不是说你做了若干年的技术,成了技术大牛,你就一定能去管项目管人,毕竟管理主要是跟人打交道的活,你虽然能把电
脑弄得服服帖帖,但不一定你去管人的时候,人就会服你,所以其实谈到做管理,最关键的就不是技术了,用两个比较时髦的词来说,关键就是“沟通”和“协调”,你得会跟客户去做沟通,你得会跟其他人去做协调,这是做管理的先决条件。如果你觉得自己不善言谈,不想时时面对众人,那兄弟你还是跳过这一节,继续看看其他部分吧。
那么就从做管理来说又可以有什么样的职位选择呢?撇开高层管理什么CXO的不谈,就一般的管理而言,可以选择的管理职位有两类:
2.1 项目经理
基本能力要求:
--较高的沟通和协调能力。一方面你要能把客户哄好了,另一方面你得牢牢取得团队的支持,你要没点沟通能力和协调能力,能行吗?
--熟悉项目管理的相关知识,如果能够取得PMP证书(项目管理师认证)是最好的,因为那至少可以证明你从理论上非常专业地学习了项目管理的基本概念,熟悉了项目管理的五大过程组及九大知识领域(详细内容请参考相关PMP书籍),有一定的项目管理经验,理论上是没问题的了。
--技术方面呢,不需要你太精通技术,但作为IT行业的项目经理,我一直都认为没有任何的技术背景其实是很难胜任这个行业的管理职位的,因为技术性确实太强,人家谈论实现的时候,你啥都听不懂,是不是挺尴尬的?关键是你还得做出决策。如果打个比喻来说明究竟项目经理需要掌握技术到什么程度的话,可以用两个词:一平方公里和一米。你的知识面必须得有一平方公里宽,但这些知识的深度只有一米。什么都知道一点,什么都不精,或许对做技术的人来说不是什么好事,但如果你是做管理的,那恭喜你,兄弟,继续干吧。
2.2 测试经理
基本能力要求:
--参照项目经理的第一条,必须滴~~
--你不需要有特别多项目管理理论基础及经验,但你必须精通软件测试的方方面面,从流程、方法、工具、框架、组织等等,你都必须了解,并最好有实际的项目经验,能够随时指导测试团队的工作,对团队里面的问题提出一定的参考意见和解决方案,对团队的测试流程和方法做出改进。
二、从测试行业转行的选择
好了,看了上面的那些测试行业本身的职业发展选择,有的童鞋可能会感觉不蛋定了,压力山大了,哎呀,本人天生就是编程白痴,书看了不少,什么语言之类的人家说起来或者看着书上感觉都会,可自己一坐到电脑面前打开IDE就茫然,思路全无,硬是敲不进一行代码,我怎么可能做自动化?我怎么发展?我从事的测试就是测测手机上的游戏,我怎么做行业测试专家?说沟通和协调吧,我自己都是宅男宅女,选择性话痨,最烦跟不熟的人(客户)多说一句话,我怎么沟通?怎么做管理?得,如果您是属于这类人,其实说实话,软件测试这个职位可能并不是您的菜,您可能还需要重新考虑一下更适合你的职位。当然我们都知道,转行的机会成本是相当高的,本来做了三五年软件测试,突然让你去做医生或者建筑师,那估计谁心里都没底,除非您就是一天才。综合比较来看,比较保险的办法应该是继续从事IT行业,但不做软件测试,转到比较相关的行业,再看看自己是否适合,这样做的机会成本会低很多,风险相对较小。那么什么样的职业选择是和软件测试相关的呢?它们又应该具备什么样的技术技能呢?接下来本人会为大家一一道来。当然,这些意见都是根据我自己的一些浅薄的经验,无奈当初楼主在一些小公司被劈成几半用的时候,除了测试外,几乎软件工程里面该有的一些主要职位都做过了,如需求分析,开发,售前,售后等等,所以才会有这些结论出来,下面的内容关于能力方面的要求是最基本的,欢迎大家补充,个人见识有限,这里权当抛砖引玉了,呵呵。
1. SQA
说到SQA,其实很多公司现在都已经跟软件测试是一个概念了,测试人员既做QA又做QC的情况非常普遍,只有一些规模较大,流程确实非常正规的公司还保留有专门的SQA的职位,这里只是权当做个参考和选择之一。或许有不少童鞋会对QA和QC的区别心存疑惑,甚至有不少人根本不知道这是两个不同的职业,那么他们有什么区别呢?我这里随便解释下。如果用一个比喻来形容QA和QC的关系的话,我觉得用法官和警察的关系来形容是比较贴切的。法院的法官制定法律,但他们不亲自去抓罪犯,而警察呢,则依据法院制定的法律去判断某人是否违法,是否是应该被抓捕的罪犯,并亲自去把他们抓住。QA就如同法官,他们制定了一系列的流程,工作的输入输出,哪些文档,如何审计测试的效率,如果改进测试流程,都是他们在掌握。而QC,就是测试人员,他们则在QA的流程下,运用各种测试的方法去抓bug,尽量减少产品的缺陷,保证产品的质量。所以SQA的工作比较适合不太喜欢亲自去找bug,但喜欢从比较high level的角度去看待问题的人,说白了就是动手能力不太强,但确实对测试还比较感兴趣,对各种质量理论感兴趣的人。
基本能力要求:
--熟悉常见的质量控制体系及软件项目成熟度模型等,如CMM/CMMI,6 sigma,ISO9000,RUP等等
2. 售前工程师
为什么说测试工程师同样也适合转售前呢?因为测试工程师其实是最了解产品需求和产品功能的那个人,甚至他比模块化的开发人员还了解公司的系统或者产品。在清楚系统的功能的前提下,很容易就能够针对各种客户的需求提出相应的解决方案,再加上如果您有较好的文字功底或者是沟通技巧,那其实售前工程师是一个相当好的转行的方向。当然,这个职位也特别适合那些想做销售但又上了测试这条船的童鞋,这可是一个很好的跳板啊,呵呵。
基本能力要求:
--熟悉产品的使用及实施,能够根据客户的需求提出相应的解决方案
--较好的沟通和表达能力
--较强的文字功底和报告功底
3. 用户体验师
用户体验师或许还不是一个很火的职业,但根据当前和以后的软件业的趋势,火是必然的了。因为用户使用产品,除了功能外,越来越重视的是用户体验,功能谁都有,那当然是谁的好用就用谁的了,比如最近热得烫手的苹果产品就是最好的例子。当然用户注重用户体验了,那当然各大软件公司就必须得重视了,自然用户体验师就应运而生。其实很多大公司早已有专门的用户体验师的职位,比如苹果,乔布斯就可以说是苹果的首席用户体验师,同样国内的如百度,腾讯等大公司也都有,而且腾讯的马总也是首席体验师,任何新产品他都会亲自使用并提出改进意见,由此重要性可见一斑。那么如何又扯到跟测试这个职业相关了呢?大家想想,平时我们在做诸如易用性测试,界面UI测试等等,遇到用户体验不好的,或者给用户操作带来阻碍的东东是不是也应该算是bug呢?所以我们也可以说是对用户体验有足够的了解了,只是对用户体验师这个职位来说,还不是很专业罢了。那么要成为专业的用户体验师,我们又应该具备什么样的能力呢?
基本能力要求:
--具备较丰富的UI设计经验和较强的设计能力,并且对用户体验较为敏感。
--具备人机交互工程学,人体力学等专业知识,并且具备一定的用户体验测试经验。
4. 需求分析工程师
其实做过测试的童鞋都应该知道,在项目里面,除了客户之外,可能就是测试团队对项目需求是最了解的了。大家可以说天天都在和需求打着交道,因为需求就是我们做一些测试的依据。随着很多公司开始应用敏捷模式来进行软件开始,可能传统意义上的需求分析工程师的数量正在减少,取而代之的是测试人员在团队中担当了需求分析和功能建模的角色。但不要担心,还是有很多公司对需求分析有专门的需求的,当然,你如果是有需求分析师证书的话,那就更好了。
基本能力要求:
--了解软件项目需求分析过程,具备需求建模能力及系统用例分析及设计能力,能够使用uml建模语言建模。
--较强的沟通,交流及理解能力,要善于引导客户说出真正的需求或者理解客户真正的需求。
5. 开发工程师
这个就不说了,这个职位适合于对编码确实感兴趣的童鞋,可以考虑从测试转开发,尽管现实中一般都是开发转测试,你懂的,呵呵。
基本能力要求:
--代码编写能力较强,愿意做一个码农或者苦逼的程序猿
6. 售后及技术支持
相信每一个测试工程师测完被测系统后,你都敢拍着胸脯说,OK,我现在对这个系统的功能是最熟悉的了,哪里最容易出问题,哪里该注意什么,可能对于你来说都不在话下,甚至你还可以写出你负责测试那个模块的用户手册。没错,这就足以说明你已经胜任售后及技术工程师的角色了,如果你确实不愿意再去做测试,不妨也考虑一下这个职位。
基本能力要求:
--非常熟悉产品的各项功能及使用,并具备较强的解决问题的能力
--较强的沟通和理解能力。要跟客户打交道的岗位,必须滴的哈。。。
7. 软件测试培训及咨询
其实这个职位是比较适合资格较老的测试工程师,他们已经对软件测试烂熟于心,技术能力较强,并且可以灵活变通,了解各种测试工具及方法,升职无望或者不想再从事具体的测试工作,可以考虑这个方向,并且从现在的待遇来看,培训及咨询行业的行情还是很不错的哟,呵呵。
基本能力要求:
--精通软件测试理论及具备一定的项目实践经验,熟悉各种主流工具、流程及方法等。
--较强的沟通、表达及引导能力。这条其实非常重要,你想想,在众人面前,你讲不出来,怯场,那什么都完了。
--能够根据企业或学员的具体情况给出理想的解决方案或培训方案。
好了,我能想到的就这么多了。显然题目比较夸张了,这里给出大家的职业发展选择远远没有“三十六行”那么多,但我想应该能够给到大家一些新的idea,至少我很少看到有人写到关于非软件测试行业本身应该有哪些比较“靠谱”的职业选择的。其实早就想把这篇文章写出来,现在终于如愿了。不管怎么说,我都希望各位看官能够在看完本文后,不管你仍然选择奋战在测试战线上也好,还是准备转行也好,都能够对自己将来的职业发展有一点点的想法和方向,那么我觉得你就没有浪费这么三五分钟看完本文,我就没有浪费那么三五个小时完成本文,呵呵。当然,我也希望借由这篇短文,大家可以谈谈自己心目中理想的职业发展方向,毕竟我们都不是高帅富,有个好的职业生涯发展是每个人都希望的事。
-
Loadrunner监控内存资源snmp
2010-11-30 16:09:06
-
Loadrunner监控unix资源
2010-11-30 16:05:04
首先要有linux的守护进程rpc.rstatd
1、安装步骤
注:安装在/usr/local目录下
cd /usr/local
tar xzvf rpc.rstatd-4.0.1.tar.gz
cd rpc.rstatd-4.0.1
./configure
make
make install
安装完成后,会生成可执行文件:/usr/local/sbin/rpc.rstatd
[root@luly net-snmp-5.4.2.1]# which rpc.rstatd
/usr/local/sbin/rpc.rstatd
/usr/local/sbin/rpc.rstatd 直接执行,rpc.rstatd被启动
可能遇到的问题:
1)启动不成功,检查portmap是否有启动
ps –e | grep portmap
如果没有启动,执行:service portmap start启动程序;
另查看chkconfig确认portmap系统服务是否做成开机自启动,如果没有自启动,设置开启,以免下次重启机器后又要手动开启;
[root@luly rpc.rstatd-4.0.1]# chkconfig --list | grep portmap
portmap 0:off 1:off 2:off 3:off 4:off 5:off 6:off
//off表示开机不启动
[root@luly rpc.rstatd-4.0.1]# chkconfig portmap on
//这里设置开机启动
[root@luly rpc.rstatd-4.0.1]# chkconfig --list | grep portmap
portmap 0:off 1:off 2:on 3:on 4:on 5:on 6:off
//on表示开机启动设置成功
-
linux下安装php
2010-10-11 15:58:38
-
linux下安装mysql
2010-10-11 15:57:01
-
linux下安装apache
2010-10-11 15:42:41
-
Linux下各应用程序编译参数目录
2010-10-11 10:21:59
查看apache编译参数:cat /usr/local/apache/build/config.nice
查看mysql编译参数:cat /usr/local/mysql/bin/mysqlbug | grep CONFIGURE_LINE
查看php编译参数:/usr/local/php/bin/php -i | grep configure 或者 /usr/local/php/bin/php-config -
linux下启动各种服务
2010-10-09 11:51:35
1.启动apache
如果是装系统(linux)之前自动勾选一起装apache,也就是说系统默认安装的,那么启apache有两种方法:
a.直接用service httpd start/stop
b.直接用/etc/init.d/httpd start/stop
否则,如果是手动安装的apache,那么要到/usr/local/apache/bin下用apachectl start/stop
查看进程:ps -e |grep httpd2.启动mysql
直接用/etc/init.d/mysqld start或者进入/usr/loca/mysq/bin下用./mysqld_safe &说明:
启服务一般都可以在/etc/init.d里查到,如果有的话,都可以用这种方式启,不管当前路径在哪,都可以用这种方式,因为都是绝对路径
3.启动informix
重启informix
切换到informix用户下,su - informix
输入“oninit”重启
关闭informix
onmode -ky
4.启动rpc.rstatd
cd /usr/local/sbin/rpc.rstatd
查看进程:ps -e|grep rpc5.启动snmpd
启动snmpd:cd /usr/local/sbin/snmpd
查看进程:ps -e|grep snmp -
当虚拟机的磁盘空间不够时该如何增加一块虚拟硬盘?
2010-09-30 16:53:07
当在linux下编辑某个文件时出现file systems full时,可以用df命令查看磁盘空间使用情况
如果挂载点/的已用%占了100%了,那么就表示/目录(根目录)下已经没有空间了,解决方案:
a.可以考虑把一些.tar包之类的或者上传的压缩包删除掉
b.增加一个虚拟硬盘
操作步骤:
首先,把虚拟机关掉
其次,虚拟机-设置-硬盘sisi-点击添加,去增加硬盘空间
最后,用[root@localhost ~]# fdisk -l 去查看PV NAME(物理卷)的名称,用fdisk -l可能会出现多个pv name(如果之前有增加过虚拟硬盘),可以通过PV size,知道是哪个pv name,这里的pv size就是刚才你增加虚拟硬盘的大小
接着就按照下面的方法一步一步操作
1.查看物理卷
[root@localhost ~]# pvdisplay //Physical Volume
--- Physical volume ---
PV Name /dev/sda2
VG Name VolGroup00
PV Size 3.90 GB / not usable 24.72 MB
Allocatable yes (but full)
PE Size (KByte) 32768
Total PE 124
Free PE 0
Allocated PE 124
PV UUID jmRsdv-T0Z5-f0r6-A947-voXX-VGu0-iP60L2
2.将新的磁盘加到物理卷组里面
[root@localhost ~]# pvcreate /dev/sdb //这个就是通过fdisk -l查到的pv name
Physical volume "/dev/sdb" successfully created
[root@localhost ~]# pvdisplay
--- Physical volume ---
PV Name /dev/sda2
VG Name VolGroup00
PV Size 3.90 GB / not usable 24.72 MB
Allocatable yes (but full)
PE Size (KByte) 32768
Total PE 124
Free PE 0
Allocated PE 124
PV UUID jmRsdv-T0Z5-f0r6-A947-voXX-VGu0-iP60L2
"/dev/sdb" is a new physical volume of "3.00 GB"
--- NEW Physical volume ---
PV Name /dev/sdb
VG Name
PV Size 3.00 GB
Allocatable NO
PE Size (KByte) 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID W5ps21-bKeY-DIw0-FH1K-rVKV-ChwX-1nVzVB3.查看逻辑卷组//卷组--------VG(Volumn Group)
[root@localhost ~]# vgdisplay
--- Volume group ---
VG Name VolGroup00
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 2
Max PV 0
Cur PV 1
Act PV 1
VG Size 3.88 GB
PE Size 32.00 MB
Total PE 124
Alloc PE / Size 124 / 3.88 GB
Free PE / Size 0 / 0
VG UUID 7Ar3kU-bSbp-8yrF-3Oo3-vkSE-NDLX-10L0ZI
4.将新增的物理卷 加到卷组里面
[root@localhost ~]# vgextend VolGroup00 /dev/sdb
[root@localhost ~]# vgdisplay
--- Volume group ---
VG Name VolGroup00
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 4
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 2
Max PV 0
Cur PV 2
Act PV 2
VG Size 6.84 GB
PE Size 32.00 MB
Total PE 219
Alloc PE / Size 124 / 3.88 GB
Free PE / Size 95 / 2.97 GB
VG UUID 7Ar3kU-bSbp-8yrF-3Oo3-vkSE-NDLX-10L0ZI
这时候看到 逻辑卷组的VG size 已经变成 6.84G了5.扩展逻辑卷的大小
先df -h 看看 是哪个逻辑卷需要扩容
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/VolGroup00-LogVol00
3.3G 3.3G 0 100% /
/dev/sda1 99M 12M 82M 13% /boot
tmpfs 125M 0 125M 0% /dev/shm
/dev/hdc 3.8G 3.8G 0 100% /media/CentOS_5.4_Final“/”分区满了,对应的设备是/dev/mapper/VolGroup00-LogVol00
lvdisplay查看对应的逻辑卷名
[root@localhost ~]# lvdisplay //逻辑卷-----LV(Logical Volume)--- Logical volume ---
LV Name /dev/VolGroup00/LogVol00
VG Name VolGroup00
LV UUID ToqjmS-XzO8-Sas0-Bj5d-QCbX-9T8b-83DTNS
LV Write Access read/write
LV Status available
# open 1
LV Size 3.38 GB
Current LE 108
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
--- Logical volume ---
LV Name /dev/VolGroup00/LogVol01
VG Name VolGroup00
LV UUID gC6Qfo-BgM1-7YC0-9qvB-Z7XT-icjZ-vmFAqq
LV Write Access read/write
LV Status available
# open 1
LV Size 512.00 MB
Current LE 16
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:1需要扩容的逻辑卷是/dev/VolGroup00/LogVol00 增加1G 就是自已另外增加的虚拟硬盘大小
[root@localhost ~]# lvextend -L +1G /dev/VolGroup00/LogVol00
Rounding up size to full physical extent 1.97 GB
Extending logical volume LogVol00 to 5.34 GB让上面的扩容生效~
[root@localhost ~]# resize2fs /dev/VolGroup00/LogVol00
resize2fs 1.39 (29-May-2006)
Filesystem at /dev/VolGroup00/LogVol00 is mounted on /; on-line resizing required
Performing an on-line resize of /dev/VolGroup00/LogVol00 to 1400832 (4k) blocks.
The filesystem on /dev/VolGroup00/LogVol00 is now 1400832 blocks long.[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/VolGroup00-LogVol00
5.2G 3.3G 1.7G 66% /
/dev/sda1 99M 12M 82M 13% /boot
tmpfs 125M 0 125M 0% /dev/shm
现在看到 “/” 大小已经变成5.2G了 -
如何安全的输入mysql命令后就可以直接进入数据库?
2010-09-29 11:01:15
如果刚安装好MYSQL,超级用户root是没有密码的,故直接回车即可进入到MYSQL数据库了,(也就是说装完mysql后,不管你当前路径在哪,直接输入mysql就可以进入mysql数据库,那是因为数据库里面本身就有一个匿名的账户可以直接登录的,这样很不安全)当然这样子是可以直接进入mysql,但如果我装完mysql后,运行下面三段sql语句后,你再想用mysql直接进入数据库就不行咯~,它会提示“ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)”一定要用mysql -u root -p123456才行
//为mysql设置密码,一定要password = password('123456'),因为你会发现mysql.usr表的密码都是有加过密的,如果用password = 123456,那么密码也就成123456而不是加密的,password()是个函数,用来加密用的
mysql -u root -e "update mysql.user set password = password('123456') where user='root'"
//删除为空的记录
mysql -u root -e "delete from mysql.user where user=''"//刷新
mysql -u root -e "flush privileges",备注:上面三段mysql不需要进入数据库后再执行,不管当前在什么路径下,都可直接运行
上面这种情况,如果你想输入mysql后直接进入数据库,那么就按下面的方法来操作:
[root@localhost ~]# vi ~/.bashrc
# .bashrc
alias mysql='mysql -uroot -p123456加上alias mysql='mysql -uroot -p123456这句,退出重新登录,就可以了
-
linux下apache目录明细
2010-09-26 16:29:30
与Apache服务器相关的重要目录和文件如下:
/etc/httpd/是Apache服务器的根目录
/etc/httpd/conf/httpd.conf是Apache服务器的主配置文件
/var/www/html/是Apache服务器的文档根目录
/etc/init.d/httpd是Apache服务器启动脚本文件
/var/log/httpd/access_log是Apache服务器的访问日志文件
/var/log/httpd/error_log是Apache服务器的错误日志文件Bin目录中包括了Apache服务器运行和管理所需的执行程序,其中httpd是服务器的执行程序,apachectl是服务器的启动脚本
Lib目录中保存了Apache服务器运行所需的库文件
Conf目录用于保存Apache服务器的配置文件,其中httpd.conf是Apache服务器的主配置文件
Htdocs目录是Apache服务器的文档根目录,该目录将作为Web服务器的根目录
Manual目录中保存了Apache服务器的帮助手册文件,文件是网页格式的,可以通过访问Apache服务器中的/manual目录阅读该目录下的帮助文件内容
Man目录用于保存Apache服务器手册页文件,文件被分别保存在man1和man8两个子目录中,可用man命令阅读指定的手册页文件查询目录的帮助信息
Logs目录是用于保存Apache服务器的日志文件,其中access_log文件是访问日志文件,error_log文件是错误日志文件 -
虚拟机ping不通网关及其它IP(除本地IP)
2010-09-25 14:59:17
1.首先要查看是否有启动防火墙
2.如果防火墙关了,还是ping不通网关和其它IP,就检查下本地的杀毒软件有没有开,有一些杀毒软件很历害,如:ESET Smart,一定要关闭,这样才行
上面这两步如果都满足了,那么正常情况是可以ping通网关及其它IP的
3.上面这两种方法试过还是不行,那么有可能跟虚拟机本身的服务有关系,可以检查一下一些该启的服务有没有启,不知道哪些该启,哪些不用启,干脆全启,不过,如果全启了,开机就会有点慢哦
-
在linux下查看各个应用程序的版本
2010-09-21 15:03:57
1.查看apache版本
对于tar包,一般是放在/usr/local/apache/bin 用./apachectl -v
对于rpm包,直接用rpm -q httpd
2.查看mysql版本
进入mysql后直接用\s
3.查看linux发行版本
直接用lsb_release -a
直接用file /sbin/init 看是32位 还是64位
4.查看PHP版本
直接用php -v
如:[root@datacenter ~]# php -v
PHP 5.2.6 (cli) (built: Apr 23 2010 18:48:30)
Copyright (c) 1997-2008 The PHP Group
Zend Engine v2.2.0, Copyright (c) 1998-2008 Zend Technologies5.查看informix版本
su - informix
onstat
Informix Dynamic Server 2000 Version 9.21.UC2 //业务系统informix版本6.查看系统cpu
cat /proc/cpuinfo
model name : Dual-Core AMD Opteron(tm) Processor 2212 //业务系统CPU
model name : Intel(R) Pentium(R) Dual CPU E2160 @ 1.80GHz //邮局CPU7.查看系统内存
cat /proc/meminfo
MemTotal: 2074908 kB // [2074908/1048576=1.978G 相当于2G内存] (KB转换成G除以1048576)
我的栏目
标题搜索
我的存档
数据统计
- 访问量: 50573
- 日志数: 61
- 书签数: 1
- 建立时间: 2008-07-16
- 更新时间: 2017-05-22
