
-
EXPDP,IMPDP中的exclude使用
2015-04-23 18:04:58
由于系统上线前需要在一个准生产环境进行发布验证,因此需要进行生产环境数据库的镜像还原操作。最近每两周都要执行一次数据库的导入导出操作,使用的是expdp和impdp,最近一周内生产环境数据量每天增长1G,今天看有个表有6K多万条数据。同时在impdp导入的过程中,需要生成索引,结果生成索引消耗了1个半小时仍然没有完成,但是该表的数据又不是具体需要的业务数据,因此考虑将表剔除,不进行导入操作。一般剔除操作使用的是exclude,在剔除表时,使用的命令为:exclude=table:"in('table_name1','table_name2')"在使用过程中报语法错误,百度发现需要对",',(,)分别进行转意,命令修改为exclude=table:\"in\(\'table_name1\',\'table_name2\'\)\"后执行成功,操作时间缩短为半小时。参考了网上的一片文章《【EXPDP】使用EXPDP工具的 EXCLUDE选项过滤掉不关心的数据库对象》 -
XAMPP安装配置
2012-06-27 18:57:41
公司在发展过程中需要一个开源的测试管理系统,最终确定为Mantis + Testlink,其中运行环境选用的是XAMPP集成运行环境。XAMPP的安装配置方式见http://www.apachefriends.org/zh_cn/xampp-windows.html
-
loadrunner使用-提高篇 转
2012-06-27 18:53:19
1. 概述
在山东BOSS性能压力测试过程中,发现脚本对于整个压力测试过程的重要性,一个压力测试脚本录制和编辑修改得怎么样直接影响后面压力测试的执行。通常情况下,脚本应尽可能的精简,就像写代码一样。针对BOSS系统的特点, 个人 认为把单一业务录制成一个Action,并在脚本中添加Transaction,Find检查(可以采用URL-based scrīpt 方式录制并事先设定),Rendezvous,参数化等基本元素,然而有时我们会发现光有这些基本元素还不能满足我们的要求。比如在Controller 中运行我们的脚本时,一旦压力过大或某种原因导致某一业务失败,而此时我们很想尽快地找出错误的原因。当然此时我们第一想到的是,查找 日志 ,但是有时发现查找日志很不方便,因此我们希望寻求一种更快捷的方式,希望能直接从Controller的Errors错误中找到出错的服务号码、在第几次Iteration的哪个Transaction出错。实现的方式,当然是通过简单的编程来调用错误日志里的信息,另外本文中还简单介绍了关于LoadRunner 工具使用的一些常用注意事项、脚本处理技巧和一些常用性能参数的分析及 性能测试 中机器瓶颈的定义和查看机器瓶颈的相关命令。
下面再具体的一一介绍。2.性能测试脚本说明
一个规范的性能测试脚本就像一段规范的程序代码一样,需要基本的说明信息:
在下面要介绍的脚本中,我把这些信息以注释的形式放在vuser_init最前面:
/*
@corporation:Copyright By *** Technologies CO.,LTD. All Rights Reserved.
@Athour:XuLinLin
@Date:2005-09-18
@Name:异地缴费压力测试脚本
@Parameter:BOSSURL,LogName,PhoneNum,iteration,FanHui
@Data:BOSSURL:BOSSURL.dat; //由于BOSS压力测试前台展现环境多,故将地址也参数化。
LogName:LogName.dat; //登录用操作员,选择具备异地缴费权限的操作员,这里选择的是德州操作员300个。
PhoneNum:PhoneNum.dat; //用于异地缴费的服务号码,这里选择的是烟台的正常在用的标准全球通号码3000个。
iteration:iteration.dat; //用于压力测试出错时,打印出错所在的循环次数。
@Descrīption:此脚本用于测试异地缴费的性能及稳定性,选用德州的操作员对烟台的标准全球通号码进行异地缴费,目标是
通过vuser模仿真实操作员进行异地缴费,达到验证或测试系统性能和稳定性的目的。
@Notes:脚本的录制使用的是LoadRunner8.0的VU,采用的是URL-based scrīpt方式,需要特别注意的是Recording Options(按Ctrl+F7)
的Advanced 选项里的Surport Charset一般情况默认为不选,除非字符集合采用的是国际标准才选中UTF-8选项,否则会出现汉字乱码现象。
*/3.登陆成功与否判断
通常情况下,任何业务必须在登陆成功后才能做,所以有必要对登陆成功与否进行判断:
下面我从脚本中取出相关部分进行简单介绍:
vuser_init()
{
int status; //定义变量用于判断登陆是否成功
web_reg_find("Text="山东移动BOSS"",
LAST);
…….
…….
web_submit_data("reguserAction.do", //登陆提交数据Action。
"Action="http://{BOSSURL}/boss/reguserAction.do"",
"Method="POST"",
"RecContentType="text/html"",
"Referer="http://{BOSSURL}/boss/index.jsp"",
"Snapshot="t12.inf"",
"Mode="HTTP"",
ITEMDATA,
"Name="logname"", "Value="{LogName}"", ENDITEM,
"Name="password"", "Value=", ENDITEM,
LAST);
status = web_submit_data("reguserAction.do", // 取成功与否标志
"Action="http://{BOSSURL}/boss/reguserAction.do"",
"Method="POST"",
"RecContentType="text/html"",
"Referer="http://{BOSSURL}/boss/index.jsp"",
"Snapshot="t12.inf"",
"Mode="HTTP"",
ITEMDATA,
"Name="logname"", "Value="{LogName}"", ENDITEM,
"Name="password"", "Value=", ENDITEM,
LAST);
if (status ="=" LR_FAIL) //一旦登陆失败,脚本给出提示报错信息。
{
lr_error_message("错误信息: %s", "不能正常登陆!");
return -1;
}
}4.定义事务
事务的定义,很简单,也很有必要,尽量是每个定义的事物符合逻辑和小。
在下面的脚本中,在异地缴费这一业务中定义了两个Transaction:准备异地缴费数据和提交异地缴费,见如下脚本代码:
lr_start_transaction("准备异地缴费数据");
web_set_max_html_param_len("4096");
……….
web_submit_data("chargeacc.do",
"Action="http://{BOSSURL}/boss/charge/commonbusiness/acccharge/chargeacc.do?act=queryaccount"",
"Method="POST"",
"RecContentType="text/html"",
"Referer="http://{BOSSURL}/boss/charge/commonbusiness/acccharge/acccharge.jsp?act=first"",
"Snapshot="t74.inf"",
"Mode="HTTP"",
ITEMDATA,
"Name="isconfirm"", "Value="no"", ENDITEM,
"Name="chargetype"", "Value="telnumber"", ENDITEM,
"Name="telnumber"", "Value="{PhoneNum}"", ENDITEM,
"Name="nowfee"", "Value="0.0"", ENDITEM,
"Name="factfee"", "Value=", ENDITEM,
"Name="totalfee"", "Value="0.0"", ENDITEM,
LAST);
lr_end_transaction("准备异地缴费数据", LR_AUTO);5.增强脚本,脚本编程
增强脚本,对脚本进行简单的编程,为性能或压力测试提供方便,这也是写
本文的宗旨,下面对此做简单的介绍:
5.1定义成功与否的判断标志或字符串。
在此,我把判断成功与否的标志定义在异地缴费Action 最前面,具体定义如下:char fanhuiflag[30]="操作业务数据成功!";
但是大家可能会问,字符串"操作业务数据成功!"从何处而来,可以肯定的不能凭空想象,成功标志可从两三种方式来取得:
第一种:也是最简单的一种,直接从脚本中取得,具体操作是以View Tree 方式找到相关的界面,然后从Server Response的Snapshot的Body里去取。见下面的 图片 :
注:Snapshot在录制前要将Recording Options>Advanced里的Save snapshot resources locally 选项选中。
第二种方式,从脚本代码中去取,即取find函数中相关字符串,具体做法是,找到在提交事件前的web_reg_find函数,然后从中取相关字符串。
web_reg_find("Text="---------操作业务数据成功!--------"",
LAST);
值得注意的是要有web_reg_find函数,可以在录制前选中Recording Options>Advanced里的Generate web_reg_find functions for page titles 选项。
第三种方式,从本地的snapshot里去取,具体操作,首先找到提交数据事件相关脚本,找到snapshot文件的名称,然后从本地的data文件里去找这个snapshot文件,然后丛中找到我们需要的字符串。
web_reg_find("Text="---------操作业务数据成功!--------"",
LAST);
…….
web_submit_data("chargeacc.do_3",
"Action="http://{BOSSURL}/boss/charge/commonbusiness/acccharge/chargeacc.do?act=submit&atype=commitdata"",
"Method="POST"",
"RecContentType="text/html"",
"Referer="http://{BOSSURL}/boss/charge/commonbusiness/acccharge/chargeacc.do?act=querycustomer"",
"Snapshot="t129.inf"",
"Mode="HTTP"",
ITEMDATA,
"Name="isconfirm"", "Value="no"", ENDITEM,
"Name="chargetype"", "Value="telnumber"", ENDITEM,
"Name="telnumber"", "Value=", ENDITEM,
"Name="nowfee"", "Value="8.8"", ENDITEM,
"Name="factfee"", "Value="0.00"", ENDITEM,
"Name="totalfee"", "Value="8.8"", ENDITEM,
"Name="accountno"", "Value="{WCSParam_Diff1}"", ENDITEM,
"Name="factpay"", "Value="8.8"", ENDITEM,
"Name="grantpercent"", "Value=", ENDITEM,
"Name="grantfee"", "Value="0"", ENDITEM,
"Name="takecash"", "Value="8.8"", ENDITEM,
"Name="zero"", "Value="0"", ENDITEM,
"Name="paytype"", "Value="Cash"", ENDITEM,
"Name="remark"", "Value=", ENDITEM,
"Name="invoice"", "Value="joininvoice"", ENDITEM,
LAST);
5.2设置和保存判断成功与否的参数
有一点大家都很清楚,业务成功返回的字符串和失败返回的字符串是不同的,我们所要做的是将返回的字符串做为参数保存下来,然后拿这个参数和我们事先定义好的成功的标志做比较,有两种方式可以设置和保存这一参数,下面简单介绍:
第一种方式也是最准确的方式,是以View Tree 方式找到相关的界面,然后从Server Response的Snapshot的Body里的成功的返回标志,然后对其进行Create Parameter,这样LoadRunner会自动在脚本中添加web_reg_save_param函数,具体如下:
// [WCSPARAM WCSParam_Text2 24 操作业务数据成功!_Text2] Parameter {WCSParam_Text2} created by Correlation Studio
web_reg_save_param("WCSParam_Text2",
"LB="---------"",
"RB="-"",
"Ord="1"",
"RelFrameId="1"",
"Search="Body"",
LAST);
第二种方式是在提交事件前添加web_reg_save_param函数,具体操作是在提交事件前右击鼠标选择Insert Before 选项,然后在弹出的对话框中选择Services里的web_reg_save_param选项,单击OK按纽,然后在弹出的对话框中输入相关的数据。
5.3 编写相关判断代码段
在已经定义好判断字符串和设置和保存好成功与否的标志字符串参数后,编写相关判断代码段,这也是最关键的地方,具体代码段如下:
if (strcmp(fanhuiflag,lr_eval_string("{WCSParam_Text2}"))!="0)
{
lr_error_message("消息: %s,在第 %s 次循环时出错,出错号码:%s", "提交异地缴费数据失败!", lr_eval_string("{iteration}"), lr_eval_string("{PhoneNum}"));
}
简单解释如下:
fanhuiflag:前面已经定义好的成功标志字符串的数组名,当然前面也可以用指针来实现,这里不做介绍。
WCSParam_Text2:为实现设置和保存好的成功与否返回的字符串的参数;
PhoneNum:服务号码的参数化,具体为电话号码。关于参数化,这里不做分析和解释部分。
Iteration:为了定位具体的循环而设置的参数。
Strcmp函数:LoadRunner自带的字符串比较函数,相等时返回0
lr_eval_string函数:LoadRunner自带求字符串函数,函数格式为
char * lr_eval_string (const char * instring );
(另一种判断方式:先事先定义好int rc="1;" char *fanhuiflag="操作业务数据成功!";然后在定义事务的结尾进行判断: rc="strcmp(str_tip,lr_eval_string(""{re_str_tip}"));
if(rc="=0)"
{
lr_end_transaction("异地缴费_提交", LR_PASS);
}
else
{
lr_error_message("异地缴费_提交失败,号码为:%s",lr_eval_string("{msisdn}"));
lr_end_transaction("异地缴费_提交", LR_FAIL);
}
//lr_end_transaction("异地缴费_提交",LR_AUTO);)
5.4 验证需求是否实现
下面简单介绍,整个验证过程,在确保脚本正确和测试环境正常的情况下,我们先在VU里验证下是否真正实现了我们想要的功能,为了方便,我特地将判断条件该为="=而不是!=,通过查看日志来检查。
首先,选中菜单栏里的Run-time Settings子菜单,设置里面的Log选项,选中Enable Logging 和Always send messages 和Extended log 及Parameter substitution。
设置Run Logic 里的Number of Iterations 为2,然后运行,并查看日志。可以得到如下的日志(只取了关键部分的):
第一次循环关键部分:
YiDiJiaoFei.c(598): Notify: Transaction "提交异地缴费数据" ended with "Fail" status (Duration: 4.8459 Wasted Time: 0.0060).
YiDiJiaoFei.c(605): Notify: Parameter Substitution: parameter "WCSParam_Text2" = "操作业务数据成功!"
YiDiJiaoFei.c(607): Notify: Next row for parameter iteration = 1 [table = iteration].
YiDiJiaoFei.c(607): Notify: Parameter Substitution: parameter "iteration" = "1"
YiDiJiaoFei.c(607): Notify: Parameter Substitution: parameter "PhoneNum" = "13953555588"
YiDiJiaoFei.c(607): Error: 消息: 提交异地缴费数据失败!,在第 1 次循环时出错,出错号码:13953555588
第二次循环关键部分:
YiDiJiaoFei.c(598): Notify: Transaction "提交异地缴费数据" ended with "Fail" status (Duration: 4.2347 Wasted Time: 0.0064).
YiDiJiaoFei.c(605): Notify: Parameter Substitution: parameter "WCSParam_Text2" = "操作业务数据成功!"
YiDiJiaoFei.c(607): Notify: Next row for parameter iteration = 2 [table = iteration].
YiDiJiaoFei.c(607): Notify: Parameter Substitution: parameter "iteration" = "2"
YiDiJiaoFei.c(607): Notify: Parameter Substitution: parameter "PhoneNum" = "13953572390"
YiDiJiaoFei.c(607): Error: 消息: 提交异地缴费数据失败!,在第 2 次循环时出错,出错号码:13953572390
下面验证执行时,能正确找到出错的号码信息,将脚本加入到场景后,同样设置好Run-time Settings。
设置结果保存路径等相关信息,按Start Scenario 执行场景,等出错是单击右上角的Errors,然后选中错误信息再按Details按纽查看错误信息。6.多机均匀对被测系统施压编辑本段回目录
怎么样使多台产生vuser的测试机均匀地对被测试的系统施加压力?
在测试的过程中,为了尽可能减少或者避免本身的测试机成为测试过程中的瓶颈,需要使用多台测试机产生vuser对被测试系统施加压力,下面对操作步骤做简单介绍:
在默认模式下使用controller添加多台Generators机器时,不管你怎么加,最终能真正起作用的只有一台(10.19.180.2/3/4或localhost):
为了让10.19.180.2/3/4机器同时能真正被添加进去,我们需要做以下几步工作:
改变场景模式,将组模式()改变为百分比模式(percentage mode),具体做法是,选择Scenario菜单下的Convert Scenario to the Percentage Mode;
然后,在已经添加好的Load Generators机器列表中同时选择你想选择的机器;
最后,点OK按钮就可以得到我们所要的结果了。
当然,如有必要我们还可以把场景模式改为Vuser Group Mode,具体做法如下:
选择Scenario菜单下的Convert Scenario to the Vuser Group Mode;
然后在弹出的对话框中,单击Yes按钮可以得到如下结果,
到此为止,添加多台Load Generators测试机整个过程就完成了,其实很简单,关键是你发现了没有。7. 怎么样在关联时取列表的最后一个值
在压力测试脚本的关联过程中,我们有时可能需要关联最新的值(如最新的流水号,通常情况下,最新的流水号放在列表的最下方),所以找最新的流水号就是最列表最下方,如果保存在数组里,那就是找index值最大的那个元素。下面以重打发票(注:具体流程为先缴费,然后查询缴费历史,然后从缴费历史里找到最新的流水号,然后使用此流水号进行重打发票)为例对整个过程做详细的介绍:
首先,在缴费历史里找到需要关联的流水号并关联之,具体做法如下,
7.1以Tree View方式打开脚本并在对应事件的Page View里找到最新的流水号
找到我们需要关联的流水号(这里为536dxwf0200051031000000)后,需要把它给关联,(因为返回的值是事后才知道的,且对于不同的电话号码,对应的返回值不同,所以对于这样的值是需要关联的。)具体做法是打开Server Response 页面并在Body里找到需要关联的流水号,然后选中此流水号并在右键弹出的菜单中使用Create Parameter关联之。
7.2单击是(Y)按钮,对应的脚本中会增加如下内容。
单击View scrīpt 图标以scrīpt模式查看关联情况。
7.3到此为止脚本中多出如下代码段,下面对它做一定的分析:
web_reg_find("Text="缴费历史查询"",
LAST);
// [WCSPARAM WCSParam_Text1 23 536dxwf0200051031000000] Parameter {WCSParam_Text1} created by Correlation Studio
web_reg_save_param("WCSParam_Text1",
"LB="formnum="",
"RB=\"",
"Ord=8",
"RelFrameId=1",
"Search=Body",
LAST);
//后面的内容为注释部分,说明流水号536dxwf0200051031000000已经关联并保存到WCSParam_Text1参数中。
web_reg_save_param()为LoadRunner的保存参数所用的函数,其作用是将返回流水号保存到WCSParam_Text1参数中,以便使用不同的号码进行缴费历史查询出来的流水号能随着时间的变化流水号也跟着变化,而不是录制脚本时的 536dxwf0200051031000000,这样可以避免在重打发票时不会报诸如此流水号不存在等类似错误信息。然而现在的问题是怎么将此流水号对应到重打发票对应的地方。另一个问题是,不是所有的号码缴费后查询到的流水号数量都和录制脚本时查询到的流水号相同,事实上每做一笔除查询类的操作都会有一个流水号。而我们关注的是怎么取到最新的缴费的流水号,下面详细介绍相关步骤。
5.1 修改web_reg_save_param()函数相关部分,很简单,把"Ord="8"",改为"Ord=ALL",目的是找最TOP的那个参数值。
5.2 光保存和取参数还不够,我们需要把参数能正确传递到重打发票对应的地方,为此我采取的做法如下:
在缴费历史事件脚本最前面定义两个变量,目的是为了将流水号以字符串的形式保存在变量里(因为LoadRunner不支持在web_submit_data()函数里直接使用变量):具体做法是:
char WCSParam_Text1Pram[50]; //保存取到的流水号
char WCSParam_Text1PramVal[50]; //保存以"Value="流水号""取到的流水号。
将关联好的流水号存到变量里,在此的做法是在对应的web_submit_data()函数后添加如下代码段:
lr_message("WCSParam_text1:%s",lr_eval_string("{WCSParam_Text1}"));
//打印出关联的参数WCSParam_Text1的值。
sprintf(WCSParam_Text1Pram,"{WCSParam_Text1_%s}",lr_eval_string("{WCSParam_Text1_count}"));
//把取到流水号保存到WCSParam_Text1Pram里,具体形式为
sprintf(WCSParam_Text1PramVal,"Value="%s"",lr_eval_string(WCSParam_Text1Pram));
//组合流水号和”Value=”并保存到WCSParam_Text1PramVal变量中。
lr_message("The value argument is : %s", WCSParam_Text1PramVal);
//打印出字符串变量WCSParam_Text1PramVal的值。
5.3 找到重打发票中响应的流水号,并把其中的"Value="536dxwf0200051031000000""替换成WCSParam_Text1PramVal,在这里总共有两处。
到此为止,流水号的关联已经基本上处理完毕,下面我们执行脚本,来验证我们想要的是不是真的有效。(注,参数化的问题在本文中不做具体介绍)为了看到明显的效果,我们需要将日志的处理做简单设置。
然后执行脚本,查看相关执行日志,可以得到类似下面得消息。8.使用LoadRunner一些常用的注意事项
Note1:VuGen仅能录制 Windows平台上的会话,但是,录制的Vuser脚本既可以在Windows 平台上运行,也可以在 UNIX 平台上运行。
通用 Vuser 函数和特定于协议的函数,它们共同构成了 LoadRunner API,并使Vuser能够直接与服务器通信。
Note2:用于运行Vuser脚本的C解释器仅支持ANSI C语言。它不支持 Microsoft对ANSI C的任何扩展。
通常情况下,可以将登录到服务器的活动录制到vuser_init部分中、将客户端活动录制到Actions部分中,并将注销过程录制到vuser_end部分中。
Note3:只能向Action部分(而不是init或end 部分)添加集合。
Note:不要从事务内部发送消息,因为这可能使事务执行时间变长,并扭曲事务结果。
Note4:如果使用日志运行时设置修改脚本的调试级别,则 lr_message、lr_output_message 和 lr_log_message 函数的行为将不会更改,它们将继续发送消息。
Note5:录制 Java Vuser 脚本时, Vuser 脚本中将不生成 lr_think_time 语句。
Note6:VuGen 新建参数,但不会自动替换任何在脚本中选定的字符串。
Note7:不要将参数命名为 unique,因为该名已被 VuGen 使用。
Note8:如果在常规运行时设置文件夹中将“错误处理”设置为“出现错误时仍继续”,则错误消息仍将被发送到输出窗口。
Note9:因为生成的服务器消息很长,而且日志记录会降低系统的运行速度,所以请仅为脚本中特定的代码块激活服务器消息日志记录功能。
Note10:启用“出现错误时仍继续”功能时,将覆盖 0 严重级别;即使发生数据库错误,也将继续执行脚本。然而,如果禁用了“出现错误时仍继续”功能,但将严重级别指定为 1,则当发生数据库错误时仍将继续执行脚本。
Note11:下列协议不是线程安全协议:Sybase-Ctlib、Sybase-Dblib、Informix、Tuxedo 和 PeopleSoft-Tuxedo。
Note12:对于支持树视图的协议(如“视图”菜单所示),在树视图中运行 Vuser脚本时, VuGen 将从 Vuser 脚本中的第一个图标开始运行该脚本。
Note13:要显示运行时查看器,必须安装 Microsoft Internet Explorer 4.0 或更高版本。
Note:Vuser 生成“结果摘要”报告时,事务时间可能会增加。Vuser 可以仅在从 VuGen 运行时才生成“结果摘要”报告。使用 Controller 运行 Web Vuser 脚本时, Vuser 不能生成报告。
Note14:当使用 Javascrīpt 和 VBscrīpt Vuser 时,在脚本中用到的 COM 对象必须完全的兼容。这使下列情况成为了可能:一个应用程序操纵另一个应用程序中的对象,或者公开对象以便操纵它们。9.性能参数解析
WEB资源参数
每秒点击次数:中Vuser每秒向Web服务器提交的HTTP请求数,依据点击次数来评估Vuser产生的负载量。
吞吐量:案运行过程中服务器上每秒的吞吐量。吞吐量的度量单位是字节,表示Vuser在任何给定的某一秒上从服务器获得的数据量,依据服务器吞吐量来评估Vuser产生的负载量。
每秒HTTP响应数:中每秒从Web服务器返回的HTTP状态代码号(表示HTTP请求的状态,例如“the request was successful”、“the page was not found”)
每秒下载页面数:每秒钟从服务器下载的网页数,依据下载的页面数来评估Vuser产生的负载量。
每秒重试次数:中每秒钟内服务器尝试的连接次数,在下列情况下将重试服务器连接:初始连接未经授权、要求代理服务器身份验证、服务器关闭了初始连接、初始连接无法连接到服务器或者服务器最初无法解析负载生成者的IP地址。
连接数:每个时间点上打开的TCP/IP连接数。
每秒SSL连接数:每秒打开的新的以及重新使用的SSL连接数。当对安全服务器打开TCP/IP连接后,浏览器将打开SSL连接,因为新建SSL连接需要消耗大量的资源,所以应该尽量少地打开新的SSL连接。网页细分图
注意:由于要从客户端测定服务器时间,因此,如果发送初始HTTP请求到发送第一次缓冲这一段时间内网络性能发生变化,则网络时间可能会影响此测定。因此,所显示的服务器时间是一个估计值,可能不太精确。
DNS解析:显示使用最近的DNS服务器将DNS名称解析为IP地址所需的时间。“DNS 查找”度量是指示DNS解析问题或DNS服务器问题的一个很好的指示器。
连接:显示与包含指定URL的Web服务器建立初始连接所需的时间。连接度量是一个很好的网络问题指示器。此外,它还可表明服务器是否对请求作出响应。
第一次缓冲:显示从初始HTTP请求(通常为 GET)到成功收回来自Web服务器的第一次缓冲时为止所经过的时间。第一次缓冲度量是很好的Web服务器延迟和网络滞后指示器。注意:由于缓冲区大小最大为 8K,因此第一次缓冲时间可能也就是完成元素下载所需的时间。
SSL握手:显示建立SSL连接(包括客户端 hello、服务器hello、客户端公用密钥传输、服务器证书传输和其他部分可选阶段)所用的时间,自此点之后,客户端与服务器之间的所有通信都将被加密。SSL握手度量仅适用于HTTPS通信。
接收:显示从服务器收到最后一个字节并完成下载之前经过的时间。“接收”度量是很好的网络质量指示器(查看用来计算接收速率的时间/ 大小比率)。
FTP验证:显示验证客户端所用的时间。如果使用FTP,则服务器在开始处理客户端命令之前,必须验证该客户端。“FTP 验证”度量仅适用于 FTP 协议通信。
客户端时间:显示因浏览器思考时间或其他与客户端有关的延迟而使客户机上的请求发生延迟时,所经过的平均时间。
错误时间:显示从发出HTTP请求到返回错误消息(仅限于HTTP错误)这期间经过的平均时间。系统资源(UNIX资源参数)
CPU utilization :CPU的使用时间百分比
Disk rate :磁盘传输速率
Paging rate :每秒钟读入物理内存或写入页面文件中的页数
Page-in rate :每秒钟读入到物理内存中的页数
Page-out rate :每秒钟写入页面文件和从物理内存中删除的页数
Collision rate :每秒钟在以太网上检测到的冲突数
Context switches rate :每秒钟在进程或线程之间的切换次数
Average load :上一分钟同时处于“就绪”状态的平均进程数
Swap-in rate :正在交换的进程数
System mode CPU utilization :在系统模式下使用CPU的时间百分比
User mode CPU utilization :在用户模式下使用CPU的时间百分比网络监视参数
网络延迟时间:源计算机与目标计算机(例如,数据库服务器和Vuser负载生成器)之间的整个路径的延迟。
网络子路径时间:从源计算机到路径上每个节点的延迟。注意:从源计算机到每个节点的延迟是同时而又独立地度量的。因此,从源计算机到其中一个节点的延迟可能大于源计算机与目标计算机之间的整个路径上的延迟。
网络段延:路径上每个段的延迟。
验证网络是否是瓶颈:可以合并各种图来确定网络是否是瓶颈。例如,通过使用网络延迟时间图和运行Vuser图,可以确定Vuser的数量如何影响网络延迟。网络延迟时间图指示在方案运行期间的网络延迟。数据库服务器
User Calls :在每次登录、解析或执行时, Oracle 会分配资源(Call State 对象)以记录相关的用户调用数据结构。在确定活动时,用户调用与RPI调用的比指明了,因用户发往Oracle的请求类型而生成的内部工作量
Total file opens :由实例执行的文件打开总数。每个进程需要许多文件(控制文件、日志文件、数据库文件)以便针对数据库进行工作
Opened cursors current :当前打开的光标总数
DB block changes :由于与一致更改的关系非常密切,此统计计算对SGA中所有块执行的、作为更新或删除操作一部分的更改总数。这些更改将生成重做日志项,如果事务被提交,将是对数据库的永久性更改。此统计是一个全部数据库作业的粗略指示,并且指出(可能在每事务级上)弄脏缓冲区的速率。
10.AIX操作系统机器性能瓶颈定义
瓶颈定义
CPU bound : vmstat : when %user+%sys greater than 80%;
Disk I/O bound : vmstat : when %iowait greater than 40%(AIX4.3.3 or later);
Application disk bound :vmstat : when %tm_act greater than 70%;
Paging space low : lsps -a : when used paging space greater than 70% active;
Paging bound : iostat vmstat : paging logical volumes %tm_act greater than 30% of the I/O(iostat) and paging activity greater than 10* the number of CPUs(vmstat);
Thrashing : vmstat sar :rising page outs, CPU wait and run queue;11.系统性能分析命令
cpu : vmstat,iostat,topas,nmon,ps,sar,time,timex,netpmon,trace,trcrpt;
内存:vmstat,topas,nmon,ps,svmon,lsps,filemon,trace,trcrpt;
磁盘:iostat,topas,nmon,lvmstat,iostat -d, lvmstat, lsps,filemon,lsattr,lsdev;
网络:netstat,topas,nmon,entstat,nfsstat,ifconfig,iptrace,ipreport,trace,trcrpt;
监视CPU使用情况:vmstat 2 ; iostat -t 2 6;sar -P ALL 2 3;
监视内存使用情况: vmstat 2 10;ps aux;svmon -G;svmon -Pau 10;
监视I/O使用情况: iostat 5;sar -d 3 3;
监视网络使用情况: netstat -i ;netstat -m;netstat -v; -
<转>:理解Load Average做压力测试
2012-06-27 18:51:19
SIP的第四期结束了,因为控制策略的丰富,早先的的压力测试结果已经无法反映在高并发和高压力下SIP的运行状况,因此需要重新作压力测试。跟在测试人员后面做了快一周的压力测试,压力测试的报告也正式出炉,本来也就算是告一段落,但第二天测试人员说要修改报告,由于这次作压力测试的同学是第一次作,有一个指标没有注意,因此需要修改几个测试结果。那个没有注意的指标就是load average,他和我一样开始只是注意了CPU,内存的使用状况,而没有太注意这个指标,这个指标与他们通常的限制(10左右)有差别。重新测试的结果由于这个指标被要求压低,最后的报告显然不如原来的好看。自己也没有深入过压力测试,但是觉得不搞明白对将来机器配置和扩容都会有影响,因此去问了DBA和SA,得到的结果相差很大,看来不得不自己去找找问题的根本所在了。
通过下面的几个部分的了解,可以一步一步的找出Load Average在压力测试中真正的作用。
CPU时间片
为了提高程序执行效率,大家在很多应用中都采用了多线程模式,这样可以将原来的序列化执行变为并行执行,任务的分解以及并行执行能够极大地提高程序的运行效率。但这都是代码级别的表现,而硬件是如何支持的呢?那就要靠CPU的时间片模式来说明这一切。程序的任何指令的执行往往都会要竞争CPU这个最宝贵的资源,不论你的程序分成了多少个线程去执行不同的任务,他们都必须排队等待获取这个资源来计算和处理命令。先看看单CPU的情况。下面两图描述了时间片模式和非时间片模式下的线程执行的情况:
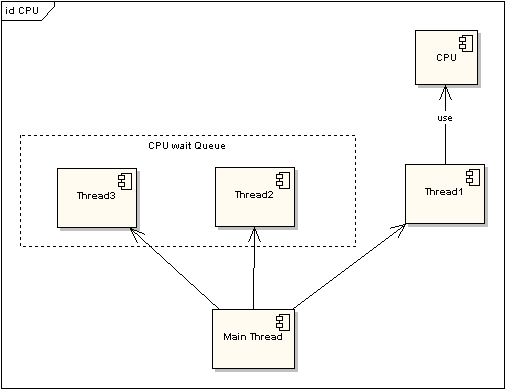
图 1 非时间片线程执行情况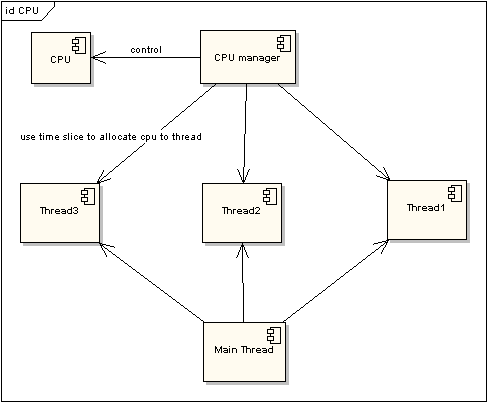
图 2 非时间片线程执行情况在图一中可以看到,任何线程如果都排队等待CPU资源的获取,那么所谓的多线程就没有任何实际意义。图二中的CPU Manager只是我虚拟的一个角色,由它来分配和管理CPU的使用状况,此时多线程将会在运行过程中都有机会得到CPU资源,也真正实现了在单CPU的情况下实现多线程并行处理。
多CPU的情况只是单CPU的扩展,当所有的CPU都满负荷运作的时候,就会对每一个CPU采用时间片的方式来提高效率。
在Linux的内核处理过程中,每一个进程默认会有一个固定的时间片来执行命令(默认为1/100秒),这段时间内进程被分配到CPU,然后独占使用。如果使用完,同时未到时间片的规定时间,那么就主动放弃CPU的占用,如果到时间片尚未完成工作,那么CPU的使用权也会被收回,进程将会被中断挂起等待下一个时间片。
CPU利用率和Load Average的区别
压力测试不仅需要对业务场景的并发用户等压力参数作模拟,同时也需要在压力测试过程中随时关注机器的性能情况,来确保压力测试的有效性。当服务器长期处于一种超负荷的情况下运行,所能接收的压力并不是我们所认为的可接受的压力。就好比项目经理在给一个人估工作量的时候,每天都让这个人工作12个小时,那么所制定的项目计划就不是一个合理的计划,那个人迟早会垮掉,而影响整体的项目进度。
CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准,看到50%-60%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
Load Average是CPU的Load,它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。为什么要统计这个信息,这个信息的对于压力测试的影响究竟是怎么样的,那就通过一个类比来解释CPU利用率和Load Average的区别以及对于压力测试的指导意义。
我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在一共有4个电话亭(就好比我们的机器有4核),有10个人需要打电话。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以立刻将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。
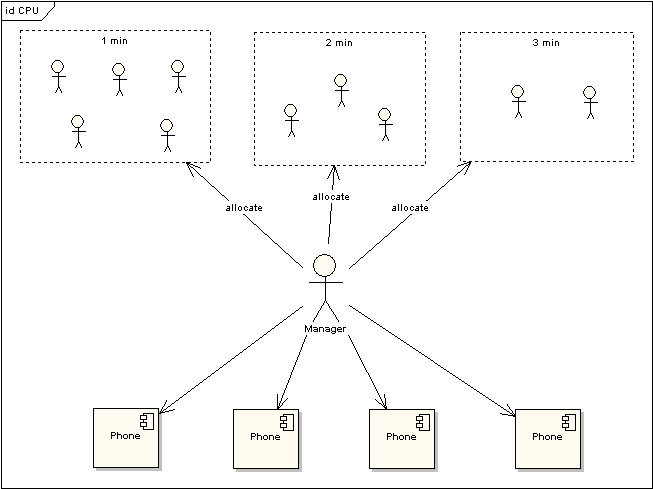
图 3 电话使用场景上图中对于使用电话的用户又作了一次分类,1min的代表这些使用者占用电话时间小于等于1min,2min表示使用者占用电话时间小于等于2min,以此类推。根据电话使用规则,1min的用户只需要得到一次分配即可完成通话,而其他两类用户需要排队两次到三次。
电话的利用率 = sum (active use cpu time)/period
每一个分配到电话的使用者使用电话时间的总和去除以统计的时间段。这里需要注意的是是使用电话的时间总和(sum(active use cpu time)),这与占用时间的总和(sum(occupy cpu time))是有区别的。(例如一个用户得到了一分钟的使用权,在10秒钟内打了电话,然后去查询号码本花了20秒钟,再用剩下的30秒打了另一个电话,那么占用了电话1分钟,实际只是使用了40秒)
电话的Average Load体现的是在某一统计时间段内,所有使用电话的人加上等待电话分配的人一个平均统计。
电话利用率的统计能够反映的是电话被使用的情况,当电话长期处于被使用而没有的到足够的时间休息间歇,那么对于电话硬件来说是一种超负荷的运作,需要调整使用频度。而电话Average Load却从另一个角度来展现对于电话使用状态的描述,Average Load越高说明对于电话资源的竞争越激烈,电话资源比较短缺。对于资源的申请和维护其实也是需要很大的成本,所以在这种高Average Load的情况下电话资源的长期“热竞争”也是对于硬件的一种损害。
低利用率的情况下是否会有高Load Average的情况产生呢?理解占有时间和使用时间就可以知道,当分配时间片以后,是否使用完全取决于使用者,因此完全可能出现低利用率高Load Average的情况。由此来看,仅仅从CPU的使用率来判断CPU是否处于一种超负荷的工作状态还是不够的,必须结合Load Average来全局的看CPU的使用情况和申请情况。
所以回过头来再看测试部对于Load Average的要求,在我们机器为8个CPU的情况下,控制在10 Load左右,也就是每一个CPU正在处理一个请求,同时还有2个在等待处理。看了看网上很多人的介绍一般来说Load简单的计算就是2* CPU个数减去1-2左右(这个只是网上看来的,未必是一个标准)。
补充几点:
1.对于CPU利用率和CPU Load Average的结果来判断性能问题。首先低CPU利用率不表明CPU不是瓶颈,竞争CPU的队列长期保持较长也是CPU超负荷的一种表现。对于应用来说可能会去花时间在I/O,Socket等方面,那么可以考虑是否后这些硬件的速度影响了整体的效率。
这里最好的样板范例就是我在测试中发现的一个现象:SIP当前在处理过程中,为了提高处理效率,将控制策略以及计数信息都放置在Memcached Cache里面,当我将Memcached Cache配置扩容一倍以后,CPU的利用率以及Load都有所下降,其实也就是在处理任务的过程中,等待Socket的返回对于CPU的竞争也产生了影响。
2.未来多CPU编程的重要性。现在服务器的CPU都是多CPU了,我们的服务器处理能力已经不再按照摩尔定律来发展。就我上面提到的电话亭场景来看,对于三种不同时间需求的用户来说,采用不同的分配顺序,我们可看到的Load Average就会有不同。假设我们统计Load的时间段为2分钟,如果将电话分配的顺序按照:1min的用户,2min的用户,3min的用户来分配,那么我们的Load Average将会最低,采用其他顺序将会有不同的结果。所以未来的多CPU编程可以更好的提高CPU的利用率,让程序跑的更快。
以上所提到的内容未必都是很准确或者正确,如果有任何的偏差也请大家指出,可以纠正一些不清楚的概念。
文章来自:http://www.blogjava.net/cenwenchu/archive/2008/06/30/211712.html
-
推荐一个性能测试的博客
2012-06-27 18:49:32
推荐一个性能测试的博客,对很多相关的东西有比较细的说明http://www.performancecompetence.com/ -
new start
2012-05-23 14:41:25
上次写日志是四年前,这四年经历了很多事情。今天重新开始写日志,记录整理工作中的点点滴滴目前需要整理的东西1. 测试基本理论,方法,工作中的相关体会2. 测试工具的使用,QTP,Loadrunner3. 测试管理工具的使用,Mantis,TestLink,QC4. 编程语言,VB,JAVA5. 测试管理6. 数据库,Oracle,SQLServer7. 自动化测试8. 性能测试 -
我的测试生涯
2008-07-15 14:59:14
今天就从这里开始吧
标题搜索
我的存档
数据统计
- 访问量: 152419
- 日志数: 7
- 建立时间: 2008-07-15
- 更新时间: 2015-04-23
